

Action Scheduler 4.0.0の変更点、WooCommerceのテーブル肥大化を抑制
WooCommerceの裏側で動くAction Schedulerは、多くのデータベースの中でも特に負荷の高いテーブルを持つ。高トラフィックのストアでは、完了した処理を削除する仕組みが追いつかず、失敗したアクションは一切消えないまま蓄積し続けることが問題になっていた。4.0.0はその根本に手を入れたメジャーアップデートだ。失敗アクションの保持期間をデフォルトで3か月に制限し、クリーンアップを専用のデイリージョブとして分離した。これにより、アクションとログのテーブルサイズが際限なく肥大化する状態を防げる。
本バージョンは7月28日リリース予定のWooCommerce 11.0にバンドルされ、すでにWordPress.orgで単独でも入手可能だ。互換性を壊す変更が複数含まれているため、拡張機能を開発している人や大規模ストアを運用している人は、4.0.0での動作検証を早めに始める必要がある。
4.0.0が狙う根本的なテーブル肥大化の抑制
Action SchedulerはWordPress管理画面での注文処理やメール送信など、WooCommerceの非同期ジョブを支えるコアライブラリだ。これまでは小さなバグフィックスが中心で、3.9.x台を刻んでいた。しかし今回、互換性を壊す複数の変更をまとめて投入するため、バージョン番号が4.0.0にジャンプした。WordPress形式のバージョン付けでは3.9.3の次は3.10ではなく4.0だから、意図的な動きといえる。
失敗アクション 無期限で保持
クリーンアップ キュー処理のついでに小分け
専用ジョブ 毎日3時に一括処理
バッチサイズ 最低250件、最大まで連続
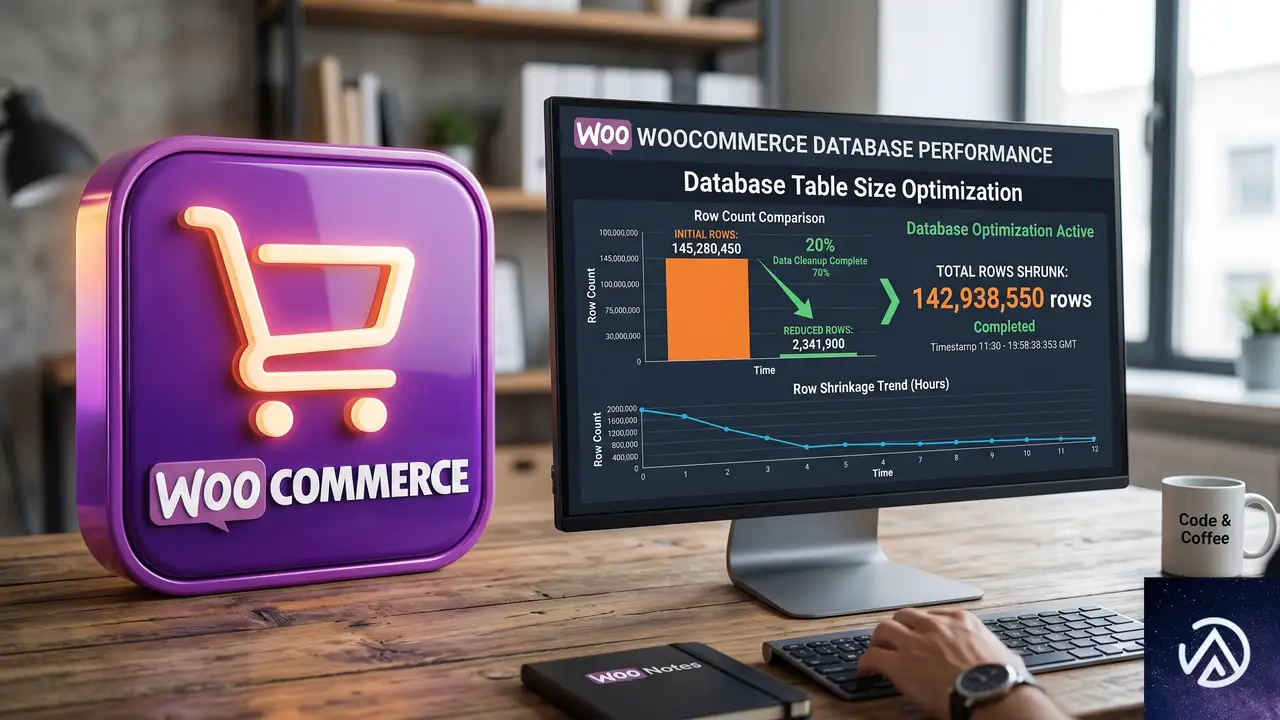
このデモが示すように、クリーンアップの仕組みが根本から見直された。特に失敗アクションが自動削除の対象になった点と、削除処理が専用ジョブとして分離された点が、テーブル肥大化を抑える大きな柱だ。
互換性の壁を越えるメジャーバージョンアップ
4.0.0ではWordPress 6.8以上の動作要件が課せられ、WordPress 7.0との互換性も明示された。これは今後のWooCommerceエコシステムにとって、基盤環境を一段上げる布石でもある。また、後述するユニークアクションの判定変更は、同じフックでも引数が異なれば別物として生成されるようになり、既存コードの重複防止ロジックに影響を与える可能性がある。
失敗アクションの保持期間を3か月に制限

これまでAction Schedulerは、完了とキャンセルのアクションだけを削除していた。失敗ステータスのアクションは、自らフィルターで追加しない限り永久に残り続けた。多忙なストアではこれが原因でアクションテーブルとログテーブルが無制限に成長し、自力で回復できない状況に陥っていた。4.0.0では、失敗アクションが発生から3か月を超えると自動的に削除される専用のクリーンアップパスがデフォルトで有効化された。
3か月という期間は、典型的な四半期会計サイクルに合わせつつ、障害調査のための十分な猶予を残す設計だ。より厳格なデータ保持ポリシーを持つストアでは、action_scheduler_retention_period_for_failedフィルターで秒単位の期間を変更できる。あるいはaction_scheduler_enable_failed_action_cleanupに__return_falseを渡せば、4.0.0以前と同じく無期限保持に戻せる。
注目すべき点は、既にaction_scheduler_default_cleaner_statusesフィルターで失敗ステータスを追加していた場合、そちらの設定が優先されることだ。その場合は、4.0.0の新しい失敗専用パスではなく、既存のクリーンアップサイクルに統合されるため、動作が変わることはない。
クリーンアップを専用のデイリージョブに分離

旧バージョンでは、古いアクションの削除はキューの各バッチ処理にインラインで埋め込まれ、一度に少量しか処理されなかった。そのため、処理量の多いストアではクリーンアップが追いつかず、テーブルが大きくなる一方だった。4.0.0では、クリーンアップを独立したタスクとし、サイト時刻で毎日午前3時に一度だけ実行する方式に変更された。
この方式により、削除処理が通常のキュー処理のパフォーマンスに影響を与えなくなり、大規模テーブルでも遅延なく追いつけるようになった。バッチサイズはaction_scheduler_cleanup_batch_sizeフィルターで変更可能で、デフォルトの250件より少なくも多くもできる。もし従来のインライン方式に戻したい場合は、カスタムキュークリーナーを実装すれば自動的にそちらが使われるが、ほとんどのサイトではその必要はないだろう。
ユニークアクションの判定に引数が加わった
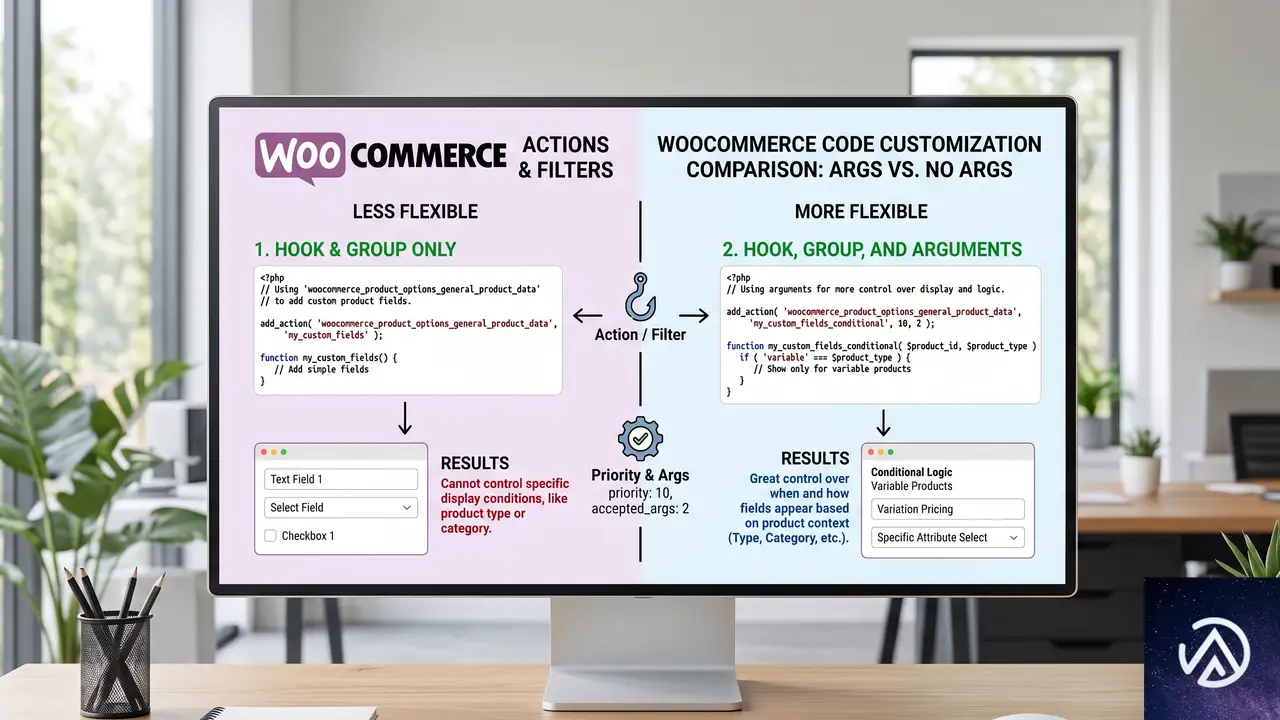
as_enqueue_async_action()やスケジュール系関数の$uniqueパラメータは、同じアクションが重複して生成されるのを防ぐためのものだ。従来はフック名とグループだけを比較していたため、引数が異なる2つのアクションでも同一とみなされ、後のほうが黙って破棄される挙動だった。これが4.0.0では、引数の内容まで含めて同一性を判定するように変更された。
この変更は互換性を壊すため、特に注意が必要だ。旧来のフックとグループだけの重複防止に依存していたコードでは、これまでよりも多くのアクションが生成されるようになる。意図しない大量のジョブがキューに積まれないよう、$uniqueを使っている箇所は必ず見直してほしい。
WooCommerceサイトへの実務的な影響と移行のポイント
4.0.0はWooCommerce 11.0のバンドルに先立って単独テストが可能だ。大規模ストアや独自の拡張機能でAction Schedulerを利用している開発者は、以下の3点を中心にステージング環境で動作検証を行うことを推奨する。
- 失敗アクションの保持ポリシー
3か月のデフォルトが自社のデータ保持要件に合致するか確認し、必要ならフィルターで調整する。 - ユニークアクションの重複防止ロジック
$unique=trueを使用している全箇所を洗い出し、引数が異なるアクションが正しく生成されるかテストする。 - クリーンアップの実行タイミング
デイリージョブへの移行により、削除がバッチ処理から外れたことで、期待していたリアルタイム性が失われていないか確認する。必要に応じてカスタムクリーナーを実装する。
開発元のWooCommerceチームはGitHubでフィードバックを募集しており、予期しない動作があれば早期に報告するよう呼びかけている。WooCommerce 11.0の正式リリースまで1か月あまり。致命的なトラブルを回避するために、今のうちに4.0.0との互換性テストを済ませておくことが賢明だ。
この記事のポイント
- Action Scheduler 4.0.0はテーブル肥大化を防ぐため、クリーンアップの仕組みを根本から見直したメジャーアップデート
- 失敗アクションがデフォルトで3か月後に自動削除されるようになり、保持期間のカスタマイズも可能
- クリーンアップが専用のデイリージョブとして実行され、キュー処理のパフォーマンスに影響しなくなった
- ユニークアクションの重複チェックに引数が含まれるようになり、既存の重複防止ロジックへの影響に注意が必要
- WooCommerce 11.0へのバンドル前に単体テストを行い、互換性の問題を早期に発見することが重要

・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Trustindexプラグインの脆弱性、認証なしでトークンが漏洩する問題と対策
Trustindexプラグインのトラブルシューティング用RESTエンドポイントが認証なしでアクセス可能になっていると、Instagram Graph APIのアクセストークンを含む全オプションが外部に漏洩する。HMAC署名のキーに公開情報を使っている設計上の欠陥が原因であり、修正パッチが配布されるまでの間はエンドポイント自体を遮断する応急処置が必要になる。
何が起きているのか 〜 脆弱性の全体像
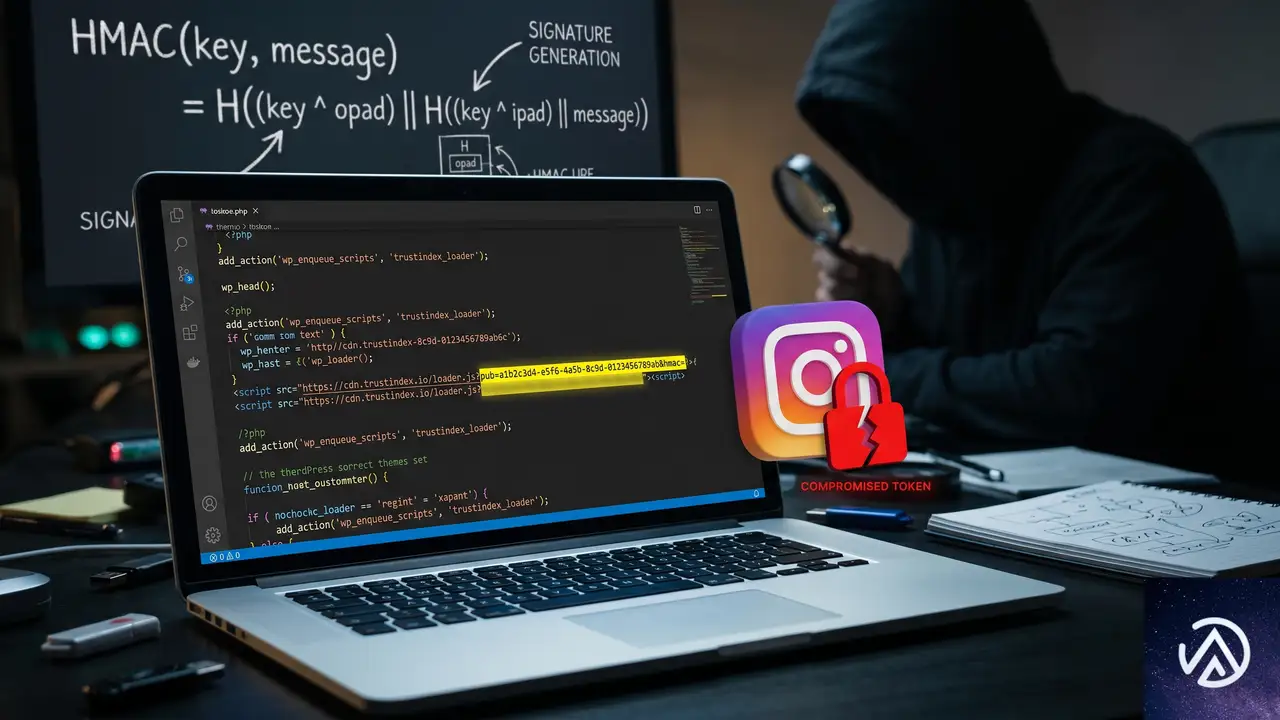
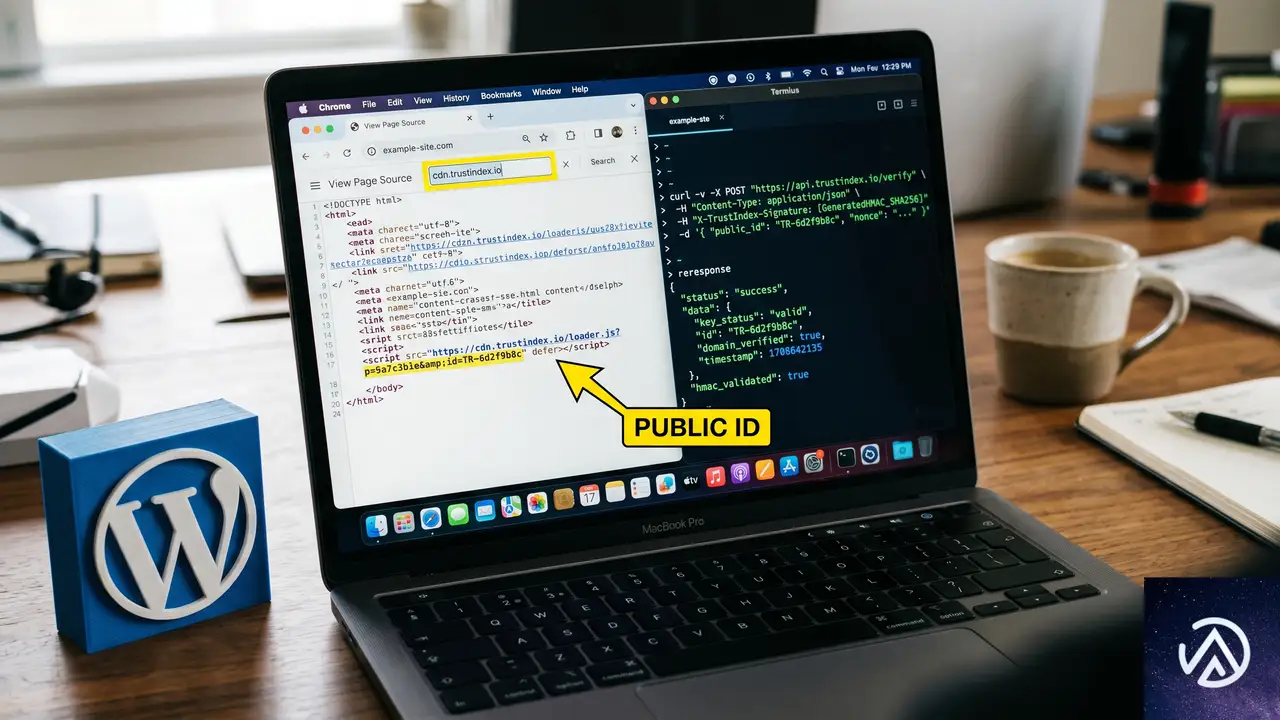
この問題は、Trustindexの「Instagram Feed」ウィジェットを設置したWordPressサイトで発生する。プラグインは管理画面のトラブルシューティング用に /wp-json/trustindex_feed_hook_instagram/troubleshooting というRESTエンドポイントを用意している。このエンドポイントに正しい署名付きリクエストを送ると、プラグインが保存している全オプション、つまりInstagramのアクセストークンや各種設定をJSON形式で返してしまう。
認証にはHMAC-SHA256による署名検証が使われているが、その署名用の秘密鍵(キー)がサイトごとに公開されている「パブリックID」になっている。このIDは、プラグインが生成するCDNのURL(https://cdn.trustindex.io/wp-feeds/XX/パブリックID/data.json)に含まれ、ページのソースコードやネットワークリクエストを覗けば誰でも取得できる。つまり署名の計算に必要な材料がすべて攻撃者の手に渡ってしまうため、認証がまったく機能していない状態だ。
影響は深刻だ。漏洩したInstagramアクセストークンを使えば、サイト運営者になりすましてInstagram Graph APIを呼び出し、プロフィール情報の取得やメディア投稿の操作が可能になる。トークンの有効期限が切れるか運営者が手動で失効させるまで、不正利用のリスクが続く。
自分のサイトが影響を受けるかどうかの確認方法
まず、TrustindexプラグインをインストールしてInstagramフィードを表示しているサイトが対象だ。それ以外のフィード(FacebookやGoogleレビューなど)を使っているだけの場合は、今回のエンドポイントとは関係がない。確認手順は次の3ステップで行える。
STEP 3の詳細は、UNIXのターミナルで以下のようなリクエストを投げる。HMACの計算にはパブリックIDと現在のUNIXタイムスタンプを使うため、スクリプトを組むか手動で計算する必要がある。
# PUBLIC_ID と TIMESTAMP は各自の値に置き換える
PUBLIC_ID="取得したパブリックID"
TIMESTAMP=$(date +%s)
SIGNATURE=$(echo -n "$TIMESTAMP" | openssl dgst -sha256 -hmac "$PUBLIC_ID" | awk '{print $2}')
curl -H "X-Signature: $SIGNATURE" -H "X-Timestamp: $TIMESTAMP" \
"https://あなたのサイトドメイン/wp-json/trustindex_feed_hook_instagram/troubleshooting"レスポンスに source.access_token や access_token といった文字列が含まれていれば、情報が丸見えの状態だと判断できる。この確認はあくまで自己診断用であり、他者のサイトに対して行ってはならない。
修正パッチが配布されるまでに取るべき応急措置
プラグイン開発者から公式のアップデートが提供されるまでは、以下のいずれかの方法で該当エンドポイントへの外部アクセスを完全に遮断する。
.htaccessでエンドポイントをブロックする
サーバーがApacheを使っている場合、WordPressのインストールディレクトリにある.htaccessファイルに以下の記述を追加する。これにより、該当URLへのリクエストは403 Forbiddenで弾かれる。
<IfModule mod_rewrite.c>
RewriteEngine On
RewriteRule ^wp-json/trustindex_feed_hook_instagram/troubleshooting - [F]
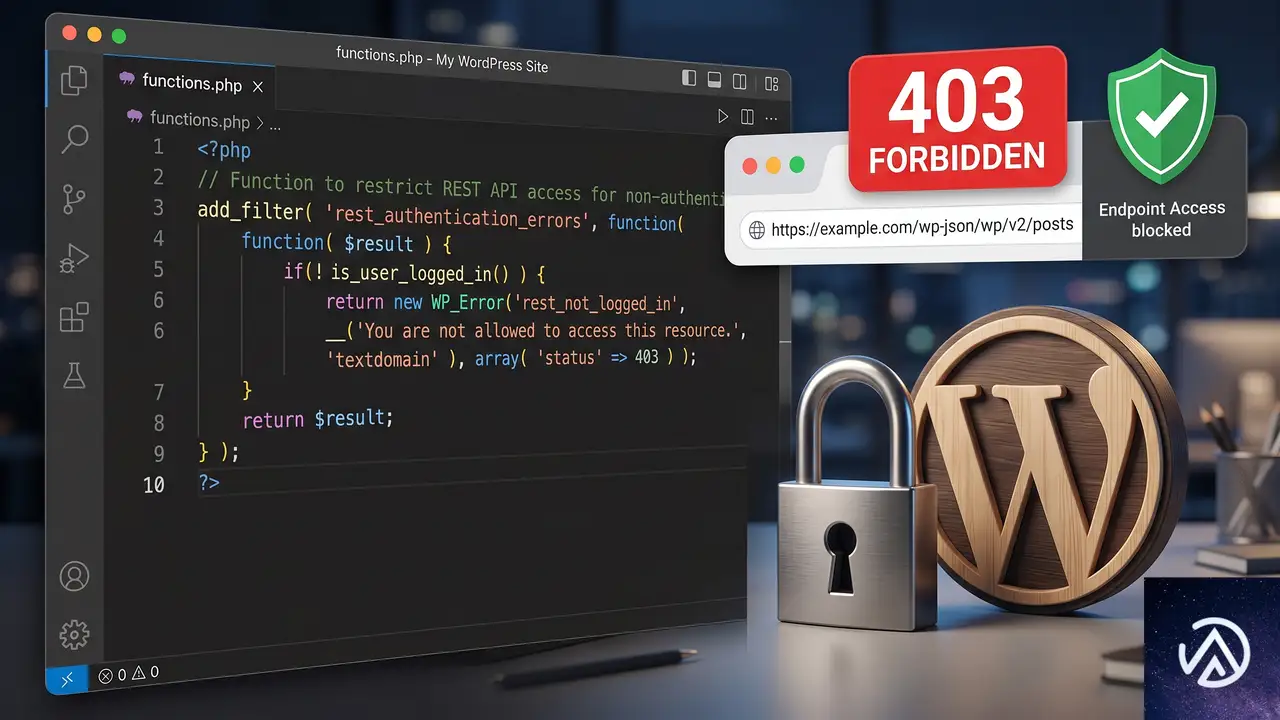
</IfModule>functions.phpでREST APIアクセスを制限する
テーマのfunctions.php(子テーマ推奨)に下記のコードを追加すると、未ログインユーザーからの該当エンドポイントへのアクセスを拒否できる。管理画面にログインしているユーザーは引き続き利用できるため、サポートが必要になった際にも支障がない。
add_filter( 'rest_authentication_errors', function( $result ) {
if ( ! empty( $result ) ) {
return $result;
}
$current_route = $GLOBALS['wp']->query_vars['rest_route'] ?? '';
if ( strpos( $current_route, '/trustindex_feed_hook_instagram/troubleshooting' ) !== false && ! is_user_logged_in() ) {
return new WP_Error(
'rest_forbidden',
'このエンドポイントへのアクセスにはログインが必要です。',
array( 'status' => 403 )
);
}
return $result;
} );プラグインを一時停止する判断
Instagramフィードの表示が必須でないなら、脆弱性が修正されるまでプラグイン自体を無効化するのが最も確実だ。フィードが表示されなくなる影響が許容できるビジネスであれば、この選択肢も検討しよう。
すでにトークンが漏洩した可能性がある場合の対処
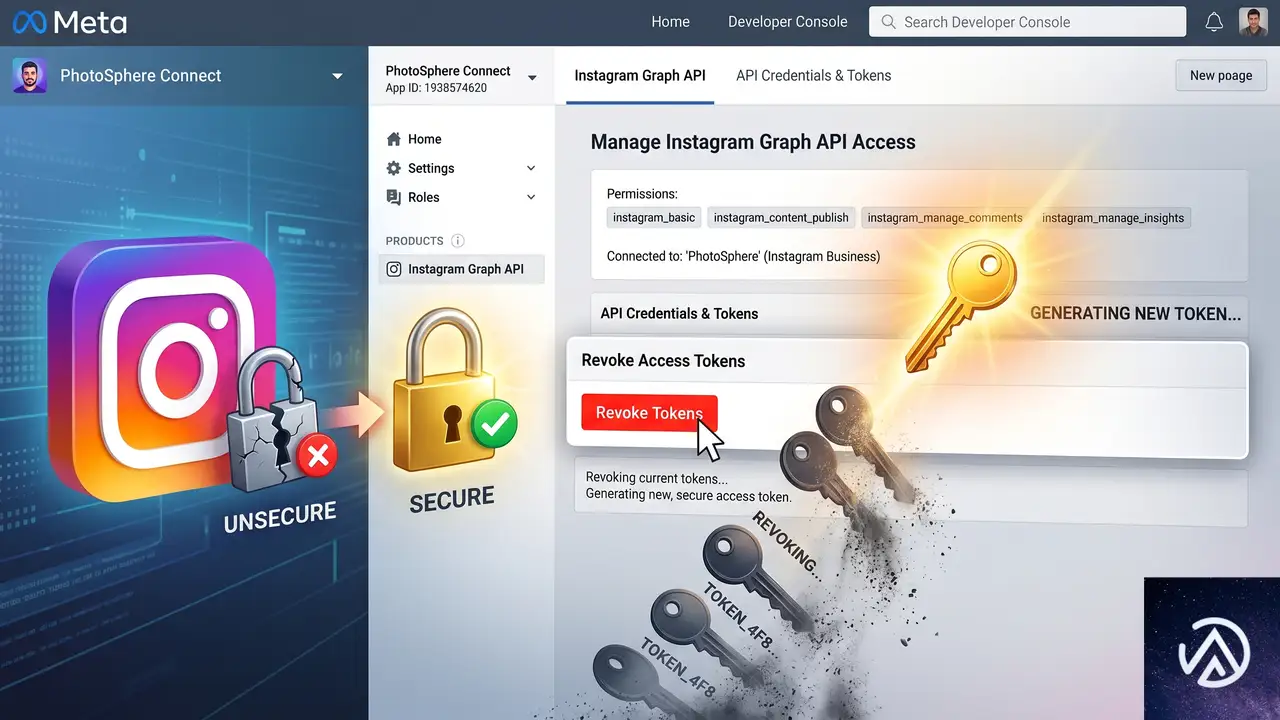
アクセスログを精査して不審なリクエストがなかったか確認するのが先決だが、ログが十分に残っていないケースも多い。疑わしい場合は、以下の手順でトークンを強制的に無効化し、新しいトークンを再発行する。
特にInstagram Graph APIのアクセストークンは長期トークン(Long-Lived Token)で運用していることが多く、一度漏洩すると数カ月単位で悪用されるリスクがある。トークン失効後は、フィードが一時的に表示されなくなるが、再設定すればすぐに復旧する。
根本的な原因と再発防止の考え方
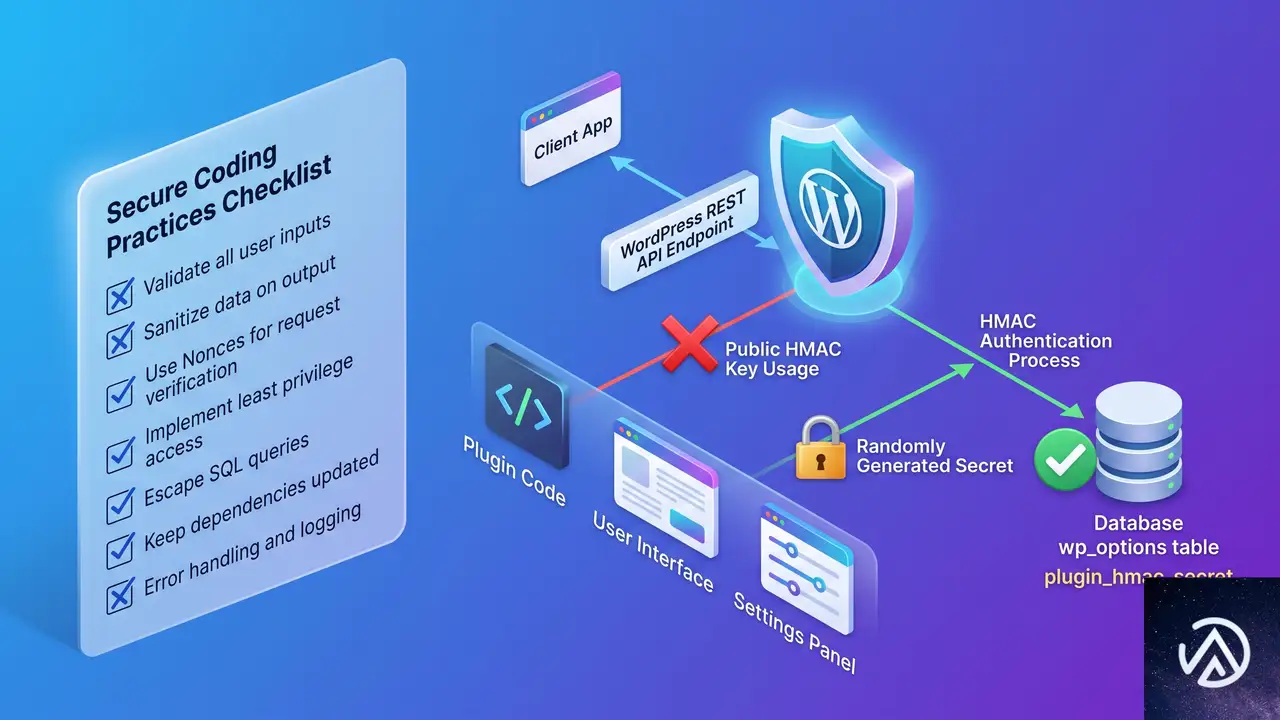
今回の脆弱性の本質は、認証用の秘密情報が公開前提の値になっている設計ミスにある。HMAC署名を使うこと自体は正しいが、秘密鍵が「誰でも見られるURLの一部」にある時点でセキュリティは成り立たない。
プラグイン開発者側が取るべき修正は、プラグイン有効化時にランダムなシークレットを wp_options テーブルに保存し、その値を署名キーに使う方式へ変更することだ。さらに、トラブルシューティングという目的を考えれば、current_user_can('manage_options') で管理者権限を要求するだけでも十分な防御になる。このエンドポイントはあくまでサポートスタッフ向けであり、未認証ユーザーに開放する理由は一切ない。
サイト運営者としても、すべてのプラグインを無条件に信頼するのではなく、導入後に「どんなRESTエンドポイントが増えたか」「公開される情報はないか」をセキュリティプラグインや手動チェックで確認する習慣が身を守る。WordPressのサイトヘルス機能やQuery Monitorのようなツールを普段から使い、異常なAPIリクエストがないか注視しておくことが再発防止につながる。
よくある質問
プラグインのどのバージョンから修正されますか
2026年6月17日時点では、開発者は調査中と回答しており修正バージョンは未発表だ。Trustindexの公式チェンジログとWordPress管理画面の更新通知を定期的に確認し、セキュリティアップデートが配信され次第ただちに適用する必要がある。
応急処置としてプラグインを無効化すると、フィードはどうなりますか
プラグインを無効化すると、Instagramフィードは表示されなくなる。ただ、表示崩れが起こるだけでサイト全体がダウンするわけではない。トークン漏洩のリスクと天秤にかけて、ビジネス上の重要性が高い場合は上記の.htaccessやfunctions.phpによる遮断を選ぶほうが現実的だ。
Instagramのトークンを変えたあと、再度漏洩することはありますか
アプリやサーバー側の脆弱性が修正されていない限り、新しいトークンも同じエンドポイントから再び漏洩する可能性がある。必ず、アクセス制限の応急措置を先に施したうえでトークンを再発行する順序を守ってほしい。
FacebookやGoogleのフィードにも同じ問題はありますか
今回確認されたのは trustindex_feed_hook_instagram のエンドポイントのみだが、同じ認証設計を他のフィード用エンドポイントにも流用している可能性は否定できない。不安があれば、trustindex_feed_hook_facebook や trustindex_feed_hook_google といった類似のエンドポイントが存在しないか、REST APIのルート一覧で確認しておくと安心できる。
自分のサイトがすでに攻撃されたかどうか確かめる方法はありますか
サーバーのアクセスログに /wp-json/trustindex_feed_hook_instagram/troubleshooting へのリクエストが記録されていれば、それが正規のサポート用途か攻撃かを判別する必要がある。あわせて、Instagram Graph APIの使用状況をFacebook開発者コンソールの「アプリのインサイト」で確認し、見覚えのないAPIコールや異常なリクエスト数がないかを調査するのが確実だ。
この記事のポイント
- Trustindexプラグインのトラブルシューティング用RESTエンドポイントが認証不備によりInstagramアクセストークンを露出させている
- 原因はHMAC署名の秘密鍵として、誰でも取得できるパブリックIDを使用している設計ミス
- 修正パッチが配布されるまでは、.htaccessかfunctions.phpでエンドポイントへの外部アクセスを遮断する
- トークン漏洩が疑われる場合はInstagram側でトークンを即時失効させ再発行する
- 常にプラグインのREST APIエンドポイントを定期的に監視し、不要な露出がないか確認する習慣が再発防止の鍵

・ Reddit、Stack Overflow、WordPress.org フォーラムを日々巡回し、現場の悩みを拾い上げて記事化
・ WordPress、WooCommerce、Next.js などモダンWeb制作領域のトラブルシューティングが専門
・ 「検索しても答えが見つからなかった」を一つでも減らすことが目標
・ エラーメッセージから根本原因にたどり着く粘り強い調査が得意
・ 初心者がつまずきやすい箇所を先回りで解決する記事作りを心がけている

WordPress 7.0リリース後の開発者情報まとめ(2026年6月版)
2026年5月20日にWordPress 7.0が正式リリースされた。その後1ヵ月の間に、メディア編集の刷新やクライアントサイドでの画像処理、テーマ向けスタイル機能の強化など、開発者にとって見逃せないアップデートが続いている。
本記事では、Developer WordPress News の「What’s new for developers? (June 2026)」を読み解きながら、6月に登場した主要トピックを整理する。プラグイン開発者、テーマ制作者、そしてサイト運営者が押さえておきたいポイントを中心に、実務への影響をわかりやすく解説する。
メディア編集モーダルがデフォルトに、画像処理の進化
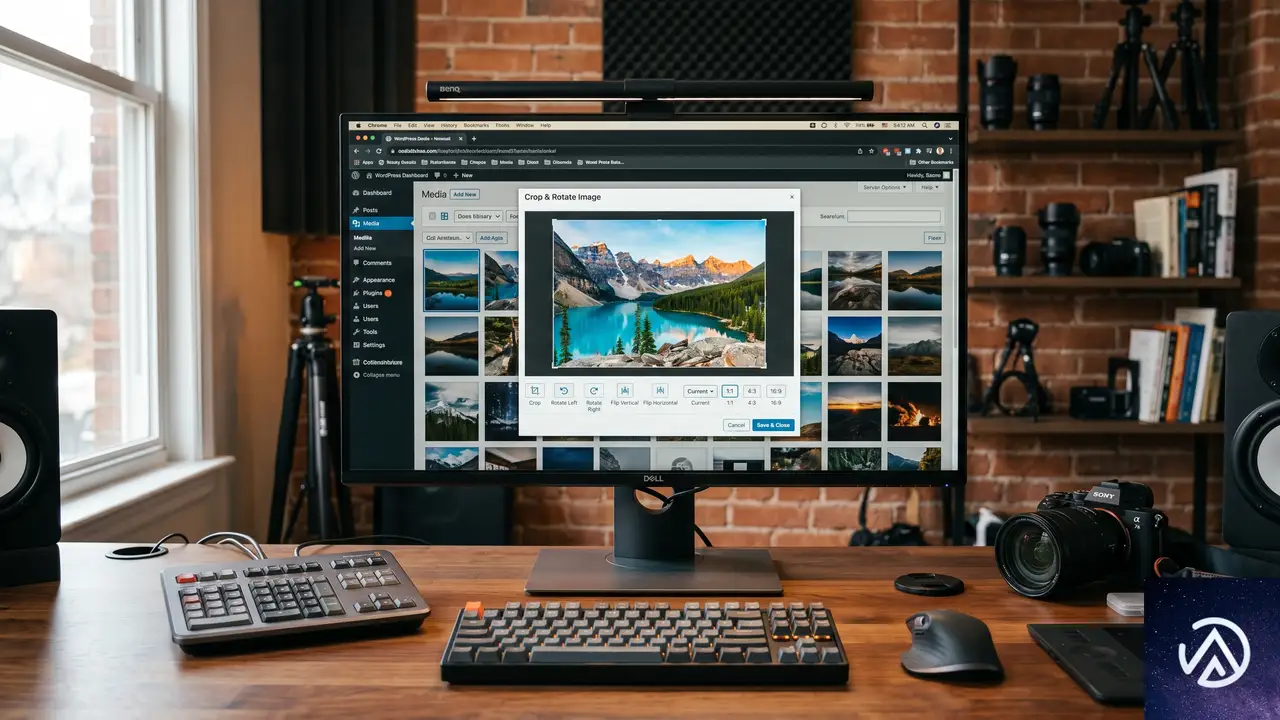
画像の切り抜きがより直感的に
Gutenberg 23.3では、画像の切り抜き操作が専用のモーダルウィンドウで行われるようになった。これまでは編集画面内で直接操作していたが、今回の変更により、縦横比の指定や回転、反転、ズーム、メタデータの編集までひとつのモーダルに集約されている。
操作の入り口はこれまで通り「切り抜き」ボタンだが、編集体験は格段に整理された。プラグインで画像編集機能を独自に拡張している場合や、画像メタデータに依存する処理を組んでいる場合は、実際の画像を使ったキーボード操作やタッチ操作のテストが必要だ。
ブラウザ上で画像リサイズを行うクライアントサイド処理
もうひとつ注目したいのが、クライアントサイドメディア処理のテスト呼びかけだ。これは、可能な場合にはブラウザ上で VIPS/WASM パイプラインを使って画像のサブサイズを生成し、必要に応じてサーバーサイド処理にフォールバックする仕組みである。
対応形式はAVIFやWebP、HEIC、Ultra HDR、JPEG XL、GIFから動画への変換など多岐にわたる。ただし、現時点ではChromiumブラウザと最新のGutenbergプラグインの組み合わせに限られ、FirefoxやSafariでは無効、メモリが2GB以下のデバイスではスキップされる。通信速度が遅い場合やContent Security Policyの worker-src が制限的な場合も利用できない。
このデモでは、従来のようにサーバーがすべてのリサイズを担当する方法から、可能なときはブラウザが先に処理を引き受ける流れへの変化を示している。サーバーの負荷軽減とユーザー体験の向上が期待されるが、環境による制限があるため、フォールバックを含めたテストが欠かせない。
プラグインとツールを取り巻く重要な更新
React 19への移行は一時的に巻き戻されたが準備は続く
WordPress 7.0ではReact 19へのアップグレードが計画されていたが、Gutenbergでは一時的にこの変更が巻き戻された。理由は、複数のプラグインがReact 18のJSXランタイムヘルパーをバンドルしており、React 19と同時に読み込むとクラッシュする問題が発生したためだ。
コアチームはWordPress 7.1でのReact 19導入を目指し、より段階的な戦略で進める方針を示している。コンパイル済みのJSXを同梱しているプラグインや、@wordpress/element を使っている場合、またはエディターのプライベートAPIに触れている場合は、引き続きテスト環境で最新のGutenbergを試すことをおすすめする。
Abilities APIの拡充が進行中
Abilities APIはこれまでのラウンドアップでも取り上げられてきたが、6月も継続的に改良が進んだ。ライフサイクルフィルターや入出力のバリデーションフィルター、wp_get_abilities() へのフィルタリングサポート、サイトやユーザー、環境情報のレスポンス拡張、RESTスキーマの堅牢化などが行われている。
能力(アビリティ)を使った実験を始めている開発者は、以前の想定に頼りすぎず、トランクの最新の挙動を確認しておくとよい。
PHPサポートの明確化とUnicodeメールアドレス対応の提案
WordPress 6.9および7.0では、PHP 8.5を完全にサポートすることが正式に明文化された。これにより、古い「ベータサポート」ラベルは廃止され、WordPress 7.0時点での最低動作バージョンはPHP 7.4、推奨はPHP 8.3に整理されている。
一方で、メールアドレスやユーザー名、スラッグにおけるUnicode対応を拡張する提案も公開され、フィードバックが募られている。この提案は is_email() や sanitize_email() などの関数、フィルター、データベース格納、文字の正規化などに影響を及ぼす可能性があり、メールアドレスを扱うプラグインは早めに内容を確認しておく価値がある。
AI Clientを使った画像生成プラグインのチュートリアル
4月・5月のラウンドアップで紹介されたAI ClientとConnectors APIに関する実践的なチュートリアルが登場した。ここでは、画像生成プラグインを構築する方法が解説されており、特に機能検出パターンが参考になる。プラグインは、プロバイダーが設定済みかどうか、そして必要な機能をサポートしているかを確認したうえでUIを表示すべきであり、チュートリアルではメディアライブラリから画像を生成し、添付ファイルとして保存する一連の流れが実装されている。
テーマ開発者向けのスタイルとブロックの改善

単一ブロックインスタンスへの擬似状態スタイルの適用
Gutenberg 23.3では、個別のブロックインスタンスに対して :hover や :focus、:visited といった擬似状態のスタイルを設定できるようになった。これまではサイト全体のブロックすべてに影響するスタイルしか設定できなかったが、この変更により、特定のボタンだけホバー時の色を変えるといった細やかな制御が可能になる。
この機能は、Add supports for pseudo states on single block instances というPRで実装されており、長年課題となっていたインタラクティブな状態の標準化に向けた動きとして注目されている。ボタンやリンク、ナビゲーションのデザインにこだわるテーマ制作者は、Gutenbergでテストしてみるとよい。
レスポンシブ対応のスタイル状態がさらに拡張
レスポンシブかつ状態を考慮したスタイル設定は、Gutenberg 23.2と23.3で大きく前進した。23.2ではグローバルなブロックスタイルに状態付きのレスポンシブ設定が導入され、23.3ではレイアウトのレスポンシブスタイルや、状態選択時に一部のコントロールを隠すUI調整が加えられている。
まだGutenbergプラグインでのテスト段階だが、theme.jsonのプリセットや設定、レイアウトプリセット、ブロックサポート、カスタムレスポンシブコントロールに依存しているテーマにとっては影響が大きいため、Responsive style states for blocks 、 iteration for WP 7.1 のIssueを追いかけておくとよい。
その他テーマ向けのブロックアップデート
細かいが実務に効く変更もいくつか入った。グローバルスタイルのカラーパネルでスラッグベースの色選択が統合され、ホームリンクブロックに不足していたコントロールが追加された。パンくずブロックでは視覚的な区切り文字がスクリーンリーダー向けに非表示となり、ナビゲーションでは非推奨化された block_core_navigation_submenu_render_submenu_icon() 関数のシムが復活している。画像ブロックでは幅か高さの片方だけが設定された場合に出力が崩れる問題も修正された。
また、WordPress 7.0では著者アーカイブリンクのデフォルトの title 属性(「Posts by Author」)が削除されている。マークアップのわずかな変更だが、テーマの表示テストやスナップショットテストに影響する可能性があるため注意しておきたい。
WordPress Playgroundの最新動向
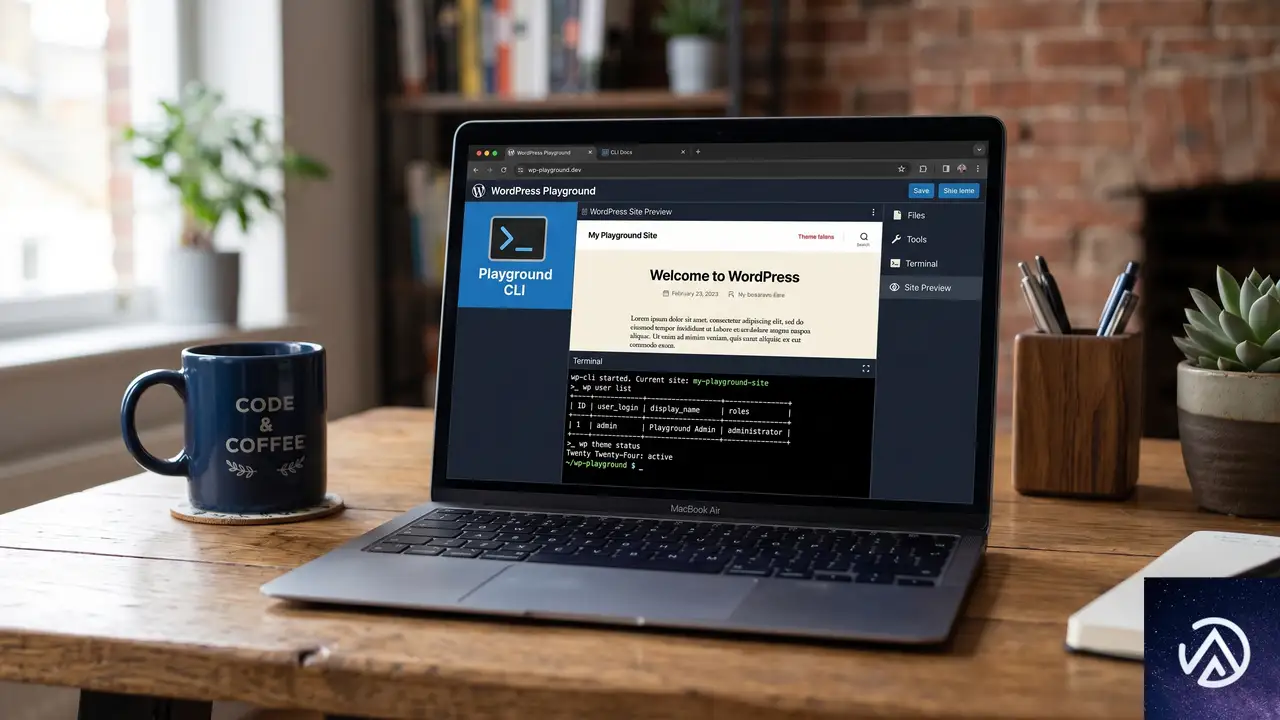
wp-nowが非推奨に、Playground CLIへの移行を
ローカル環境を手早く立ち上げるために wp-now を使っていた開発者は、Playground CLIへの移行が必要になる。Developer WordPress Newsの記事によると、2026年6月8日付でwp-nowが非推奨となり、今後の推奨パスはPlayground CLIに一本化された。
移行は比較的スムーズに行えるよう設計されており、テスト用サイトを素早く立ち上げたいプラグイン開発者やテーマ制作者は、早めに切り替えておくとよいだろう。
PRプレビューとPHPスニペットの公式ガイド
Playground関連では、2つの役立つガイドも公開された。ひとつは「PR Preview with WordPress Playground: What changes in version 3 of the GitHub Action」で、プルリクエストのプレビューを自動化するGitHub Actionの最新バージョンについて解説している。プロジェクトでPlaygroundプレビューを利用しているなら、一度目を通しておきたい内容だ。
もうひとつは「Run PHP examples anywhere with WordPress Playground」で、WordPressの開発者向けドキュメントやチュートリアルに、ブラウザ上で実行可能なPHPサンプルを埋め込む方法を紹介している。技術記事を書く立場の開発者にとって、この手法は読者の理解を大きく助ける強力な武器になる。
保存型Playgroundと古いWordPressバージョンの復元
Playground v3.1.35およびv3.1.36では、サイトの保存とSites APIの機能が大きく進んだ。保存したブラウザ上のWordPressサイトに何度も戻れる永続化の仕組み、自動保存からの復元UX、埋め込みPlaygroundでの不要な保存プロンプト回避などが実装されている。
さらに、WordPress 0.7 のような過去のバージョンを丸ごとロードできるようになり、Virtual WordPress Museum のようなデモも登場した。デモやテスト、教育目的の用途が一層広がる変更といえる。
PHP.wasmによる高度なデモやフレームワーク対応
PHP.wasm周辺の開発も活発だ。新しい「Running PHP Frameworks in Playground」ガイドでは、WordPress以外のPHPフレームワークをPlayground上で動かす方法が示されており、ブラウザベースのツール構築の可能性を大きく広げている。また、@php-wasm/compile-extension ワークフローにより、PHP拡張のコンパイルも以前より容易になった。高度なデモやドキュメント用のサンプルを作る開発者には、これらの進歩も見逃せない。
ユーザーインターフェースとアクセシビリティの改良

実験的なダッシュボードのカスタマイズ機能がウィジェットを追加
カスタマイズ可能なダッシュボードはまだ実験段階だが、Gutenberg 23.3では新たに5つのウィジェット(サイトヘルス、ニュース、イベント、クイックドラフト、サイトプレビュー/URLバー)が追加され、レイアウトの調整も進んだ。ゴーストウィジェットやサイズプリセット、コンテナブレークポイントによるグリッドカラムなど、徐々に実用性が高まっている。
管理者画面の拡張やプラグイン独自の管理パネルを開発しているなら、この実験がどこに向かっているのかを customizable dashboard overview issue で追いかけておくことをおすすめする。
エディターと管理画面でのアクセシビリティの磨き込み
GutenbergとCoreの両方でアクセシビリティ関連の改善が続いている。Gutenberg 23.3ではリビジョン機能が改善され、フォントライブラリのフォーカスナビゲーションも修正された。Core側では、管理画面のカラースキームのコントラスト強化、フロントエンドツールバーのフォーカスアウトライン修正、ハイコントラストモード時のボタンアクティブ状態の不具合対応などが行われている。
カスタム管理画面やエディターパネル、メディア操作UIを提供している場合は、キーボード操作、ハイコントラストモード、文字サイズの拡大設定、標準以外の管理画面カラースキームを組み合わせたテストを定期的に実施することが重要だ。
この記事のポイント
- メディア編集はモーダルに集約され、クライアントサイド画像処理の実験的テストも始まった。サーバー負荷の低減とUX向上が見込まれる
- React 19移行は一時停止中だが、WordPress 7.1に向けた準備は継続。プラグイン開発者は互換性を確認しておく
- テーマ開発では、単一ブロックへの擬似状態スタイル適用やレスポンシブスタイルの拡張など、表現力が高まる変更が多い
- PlaygroundはCLIへの一本化、保存型サイトの強化、過去バージョン対応などで開発者の実験環境が飛躍的に便利になった
- アクセシビリティの改良も着実に進行。カスタムUIを作るならテストにキーボード操作やハイコントラストモードを含める
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

OptinMonsterなど4プラグインのサプライチェーン攻撃、不正管理者を確認する手順
OptinMonster、TrustPulse、PushEngage、Uncanny Automator のいずれかのプラグインを導入している場合、ただちに管理画面の全ユーザー一覧を確認し、身に覚えのない管理者アカウントが作成されていないか点検する必要がある。これらのプラグインに使用されている CDN スクリプトが改ざんされ、悪意ある管理者を自動生成するサプライチェーン攻撃が 2026 年 6 月に確認された。
何が起きたのか 今回のサプライチェーン攻撃の仕組み

攻撃者はプラグインのソースコードそのものを改変したわけではなく、各プラグインが配信に利用している外部 CDN 上のスクリプトファイルに細工を施した。このため、プラグイン自体のバージョンアップや通常のマルウェアスキャンでは異常を検知しにくいのが特徴だ。
改ざんされたスクリプトは、サイトのフロントエンドに読み込まれる形で実行され、裏側で WordPress のユーザー登録 API を突いて新規の管理者アカウントを作成する。攻撃者がすでに管理者権限を取得している場合、サイトの改ざんや情報の窃取が自由に行える極めて危険な状態となる。
国内の WordPress サイトでも、マーケティングツールとして該当プラグインを導入しているケースは少なくない。攻撃が表面化した時点で、該当プラグインの開発元はすでに CDN 側の改ざんを修正し、侵害された可能性のある顧客への通知を進めているが、すべてのサイト運営者が自らチェックを行うことが被害の深刻化を防ぐうえで決定的に重要だ。
サイトに悪意ある管理者は存在しない。
サイト訪問時に不正スクリプトが実行され、未知の管理者アカウントが自動生成される。
自分は対象か 影響を受けるプラグインを導入していないか確認する
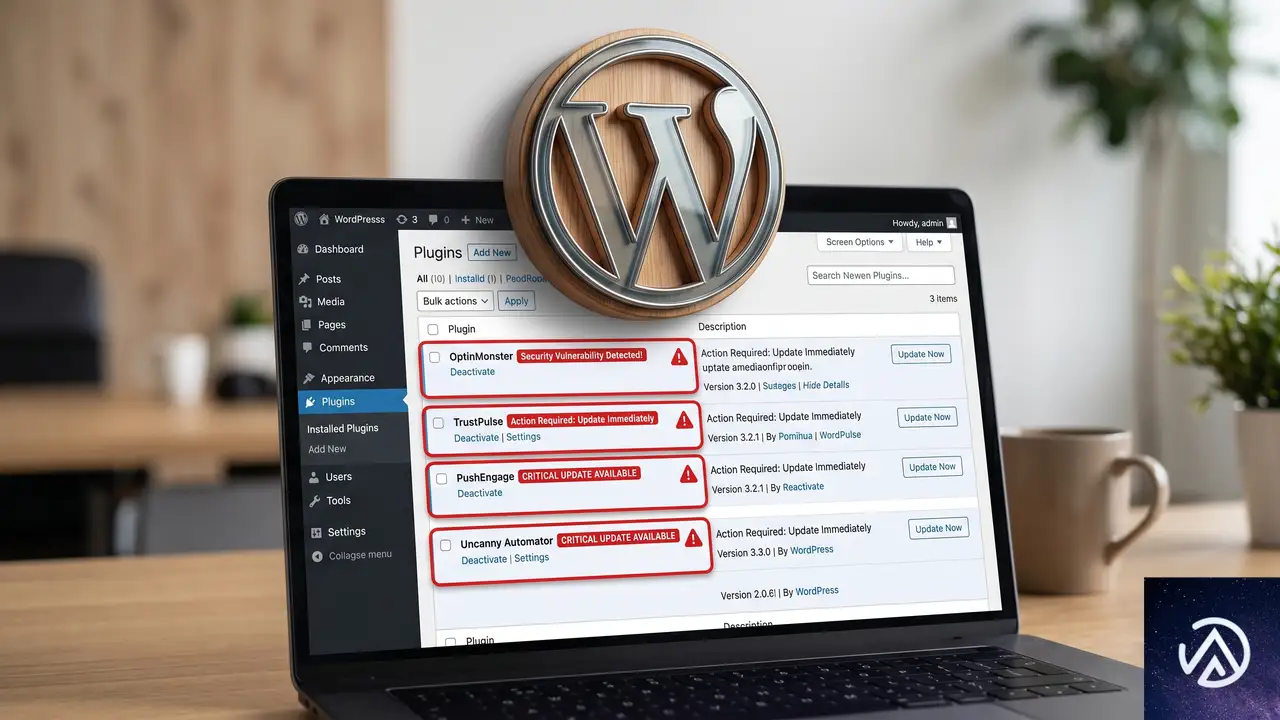
今回のサプライチェーン攻撃の対象として報告されたのは次の 4 製品だ。いずれか 1 つでも導入している場合は、影響を受けた可能性を前提に全手順を実行する必要がある。
- OptinMonster(オプティンモンスター)
- TrustPulse(トラストパルス)
- PushEngage(プッシュエンゲージ)
- Uncanny Automator(アンキャニーオートメーター)
プラグイン一覧ページでこれらの名称を検索すれば、導入の有無はすぐに判別できる。ただし、テーマの functions.php に直接コードを埋め込んでいる場合や、カスタム実装で CDN スクリプトを読み込んでいる場合はプラグイン管理画面では発見できないため、サイトのソースコードやタグマネージャーの設定も併せて確認するとより確実だ。
不正な管理者アカウントを特定して削除する手順
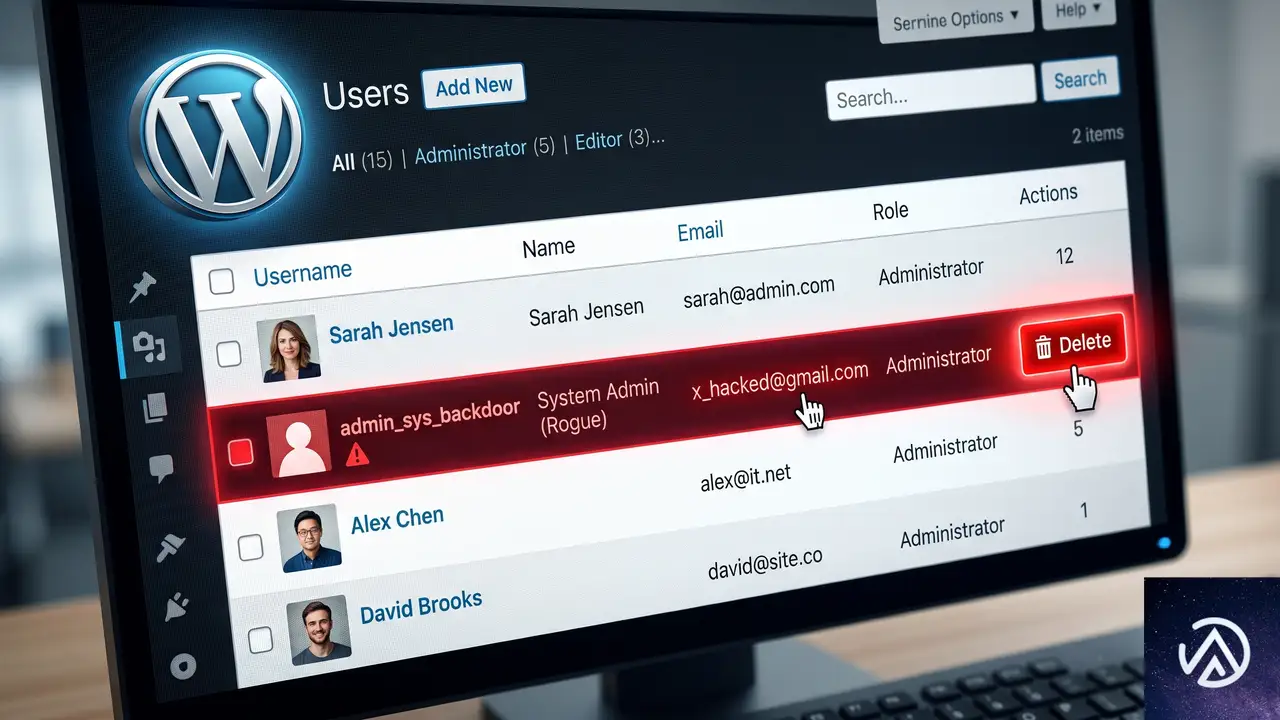
まず管理画面の「ユーザー」→「ユーザー一覧」を開き、管理者権限を持つアカウントをすべて確認する。身に覚えのない管理者アカウントが存在する場合は、そのアカウントが攻撃によって作成された可能性が極めて高い。
削除時に「投稿の所有権」をどうするか
不正な管理者を削除する際、WordPress はそのユーザーが作成した投稿の帰属先を尋ねてくる。該当ユーザーが攻撃者である場合、そのアカウントが作成した投稿そのものも悪意あるコンテンツであることが多いため、すべて「削除」を選択して問題ない。もし誤って残す必要がある場合のみ、正当な管理者に帰属を変更する。
不正な管理者アカウントがゼロでも油断できない理由
攻撃スクリプトは任意のタイミングで管理者を作成する仕組みになっている。現在のユーザー一覧に不審点がなくても、改ざんされた CDN スクリプトが過去に読み込まれたことがあれば、攻撃者がすでにアクセストークンや認証情報を窃取している可能性を排除できない。必ず後述の予防措置まで実行する必要がある。
感染後のサイトを安全な状態に戻すために今すぐやるべきこと
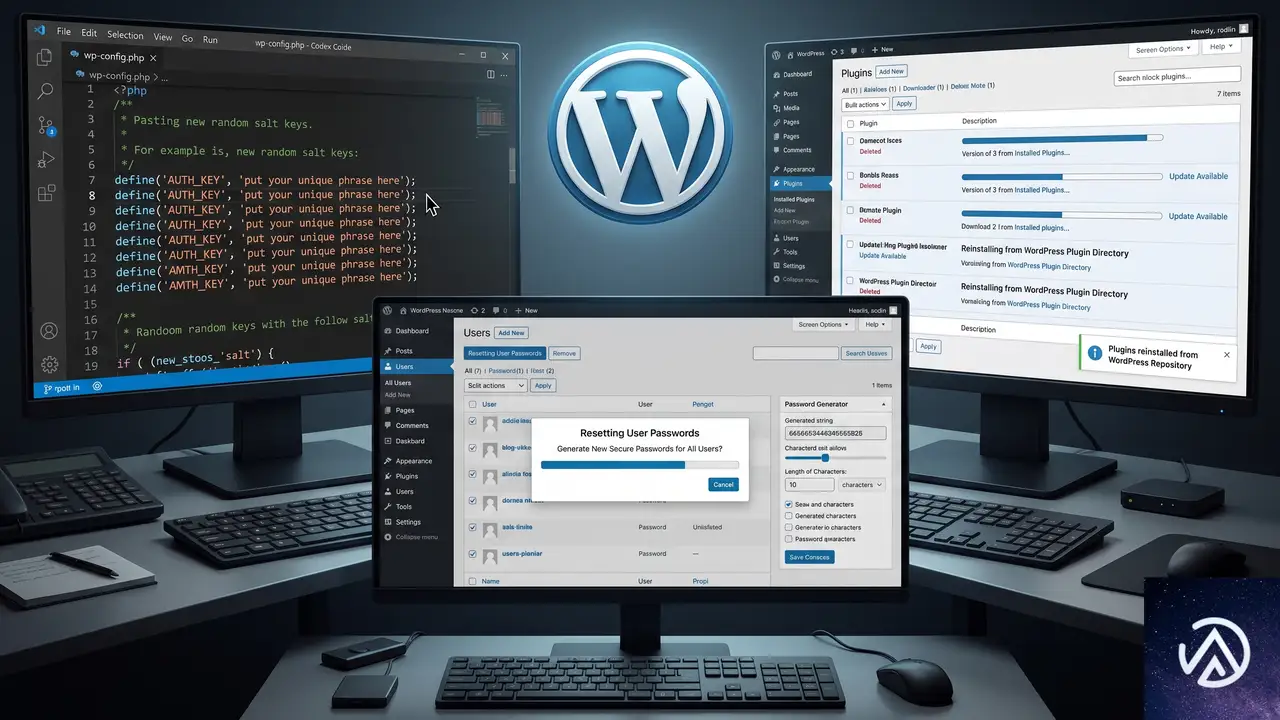
該当プラグインを完全に削除して再インストールする
単なる無効化では不十分だ。該当プラグインを一度完全に削除し、公式リポジトリまたは開発元から最新版をダウンロードして再インストールする。これにより、仮に攻撃者がプラグインの管理画面内に保存していた設定値や隠しコードを仕込んでいたとしても、完全に除去できる。
全ユーザーのパスワードをリセットし多要素認証を有効にする
攻撃者がすでに正当なユーザーのログイン情報を盗んでいる可能性を想定し、サイトの全ユーザー(特に管理者・編集者権限)のパスワードを変更する。加えて多要素認証(二段階認証)をただちに有効にし、パスワード単体ではログインできない設定に切り替えることが再侵入の防止に直結する。
WP ソルトキーを強制的に無効化する
wp-config.php に定義されている認証用のソルトキー(AUTH_KEY、SECURE_AUTH_KEY、LOGGED_IN_KEY、NONCE_KEY とそれぞれの SALT)をすべて新しい値に置き換える。これで既存のすべてのログインセッションが即座に無効になり、攻撃者が盗んだクッキーではアクセスできなくなる。WordPress の公式ソルト生成ツールを使えば、ランダムな値がすぐに発行できる。
.htaccess や wp-config.php に仕込まれたバックドアを点検する
管理者権限を取得した攻撃者は、テーマファイルやプラグインファイルを編集してバックドアを仕込むことが多い。特に functions.php や wp-config.php、.htaccess に不自然なコードが追記されていないかを FTP またはサーバー管理画面のファイルマネージャーで直接確認する。見慣れない base64 デコード処理や eval 関数を含むコード、不明な外部 URL へのリクエストがあれば攻撃の痕跡だ。
なぜ通常のウイルススキャンでは検知されなかったのか

一般的なセキュリティプラグインは、サーバー上の PHP ファイルやデータベースの不審なパターンをスキャンする。しかし今回の攻撃は、問題のあるコードがサイト外部の CDN 上にあり、ブラウザの JavaScript 実行を通じて攻撃が成立する仕組みだった。サーバー側のファイルに痕跡が残らないため、従来型のマルウェアスキャンでは検出が困難だった。
この手口が示しているのは、外部リソースに依存するプラグインは、その配信網が侵害された場合にプラグイン本体の安全性とは無関係に危険になりうるという現実だ。CDN から読み込まれるスクリプトに対しては、Subresource Integrity(SRI)属性による改ざん検知が有効だが、これを実装しているプラグインは現状ほとんど存在しないことも今回の問題を深刻にした。
再発を防ぐために導入すべき具体的な対策
外部 CDN スクリプトを監視する仕組みを整える
すべての外部スクリプトをやみくもに拒否するのは現実的ではないが、コンテンツセキュリティポリシー(CSP)ヘッダーを適切に設定することで、どの CDN からのスクリプト実行を許可するかを明示的に制御できる。許可リストにないドメインからのスクリプトはブラウザ側でブロックされるため、未知の改ざんが発生した場合の被害を抑える障壁になる。
管理者ユーザーの監査ログを定期的に確認する
新しい管理者の追加や権限変更を記録する監査ログプラグインを導入しておけば、今回のように見知らぬアカウントが作成されたときに即座に気づける。攻撃が CDN 経由で行われたとしても、サーバー側でユーザーが作成される瞬間をログに残すことができるため、異常検知の有効な補助線になる。
利用プラグインの外部依存関係を定期的に見直す
導入済みのすべてのプラグインが、どの外部ドメインに対してリクエストを送っているかを定期的に棚卸しする習慣をつけると、今回のようなサプライチェーンリスクの芽を早期に見つけやすくなる。プラグインがバックグラウンドで読み込んでいる CDN スクリプトや API エンドポイントを把握していれば、問題発生時に影響範囲を素早く特定できる。
よくある質問
該当プラグインを無効にしただけで安全といえるか
安全とはいえない。改ざんされたスクリプトが過去に読み込まれた時点ですでに不正な管理者が作成されている可能性がある。無効化では既存の被害は解消されず、削除と再インストール、およびユーザー一覧の精査が必須になる。
不正な管理者が見つからなかった場合でも何かすべきことはあるか
全ユーザーのパスワードリセットとソルトキーの変更は必ず実行する。改ざんスクリプトが認証クッキーやアクセストークンを窃取していた場合、攻撃者は管理者アカウントを作らずとも正当なユーザーとしてログインできる可能性があるためだ。
これらのプラグインは今後も使い続けても大丈夫か
各開発元はすでに CDN の改ざんを修正し、再発防止策を強化している。しかしどのプラグインでも外部依存がある以上、同様のリスクをゼロにすることは不可能だ。使用を継続する場合は、この記事で述べた監視と予防の仕組みを併せて導入することが前提になる。
WordPress 本体や他の無関係なプラグインまで影響を受けるのか
今回の攻撃は対象プラグインの CDN スクリプト経由でのみ実行された。ただし管理者権限を奪取された後は、WordPress 本体や他のプラグインを含め、サイト全体が改ざん対象になりうる。該当プラグインを使用していた場合は、サイト全体のファイル整合性チェックを併せて行うとよい。
この記事のポイント
- OptinMonster、TrustPulse、PushEngage、Uncanny Automator 利用者は要緊急対応
- 不正な管理者アカウントの有無を「ユーザー一覧」で即座に確認する
- 該当プラグインの完全削除と再インストールで痕跡を除去する
- 全ユーザーパスワードのリセットとソルトキー変更が防御の基本線
- CSP 設定と管理者監査ログで将来の類似攻撃に備える
・ Reddit、Stack Overflow、WordPress.org フォーラムを日々巡回し、現場の悩みを拾い上げて記事化
・ WordPress、WooCommerce、Next.js などモダンWeb制作領域のトラブルシューティングが専門
・ 「検索しても答えが見つからなかった」を一つでも減らすことが目標
・ エラーメッセージから根本原因にたどり着く粘り強い調査が得意
・ 初心者がつまずきやすい箇所を先回りで解決する記事作りを心がけている

ShinyHuntersが教育機関を標的に、Oracle PeopleSoft脆弱性を悪用
CVE-2026-35273を悪用した大規模攻撃、教育機関が標的に

2026年5月下旬から6月上旬にかけて、Oracle PeopleSoftの重大な脆弱性を悪用するサイバー攻撃が発生した。MandiantとGoogle Threat Intelligence Group(GTIG)の調査により、攻撃者はShinyHunters(UNC6240)として知られるグループであり、標的となったのは主に高等教育機関を含む世界中の組織だった。
攻撃の起点となったのはCVE-2026-35273だ。PeopleSoftのEnvironment Managementコンポーネントに存在するリモートコード実行の脆弱性で、CVSSスコアは最高レベルの9.8。この脆弱性は6月10日にOracleからセキュリティアラートが発表されるまでゼロデイとして悪用されていた。
この記事では、本攻撃キャンペーンの技術的な分析、攻撃者の手口、そして組織が今すぐ取るべき具体的な防御策について、技術に詳しい同僚のようにわかりやすく解説する。
グローバル通知の試みと被害の実態
GTIGはスキャン活動と悪用を検知した後、潜在的に脆弱なエンドポイントを持つ100以上の組織に通知を行った。通知対象の大半は米国に拠点を置き、その68%が高等教育機関だった。一部の組織は脆弱性の修正に成功したが、多くの組織で侵害が確認され、窃取されたデータがShinyHuntersのデータリークサイトに公開される事態に至った。
攻撃の起点となったゼロデイ脆弱性
問題のCVE-2026-35273は、PeopleSoftのEnvironment Management Hub(EMHub)における重大な欠陥だ。この機能は管理者やシステム間コンポーネント向けであり、エンドユーザーが直接利用するものではない。しかし、認証なしでリモートからのコード実行が可能であることが攻撃成立の決定的な要因となった。
攻撃基盤の構築から内部偵察までの技術分析
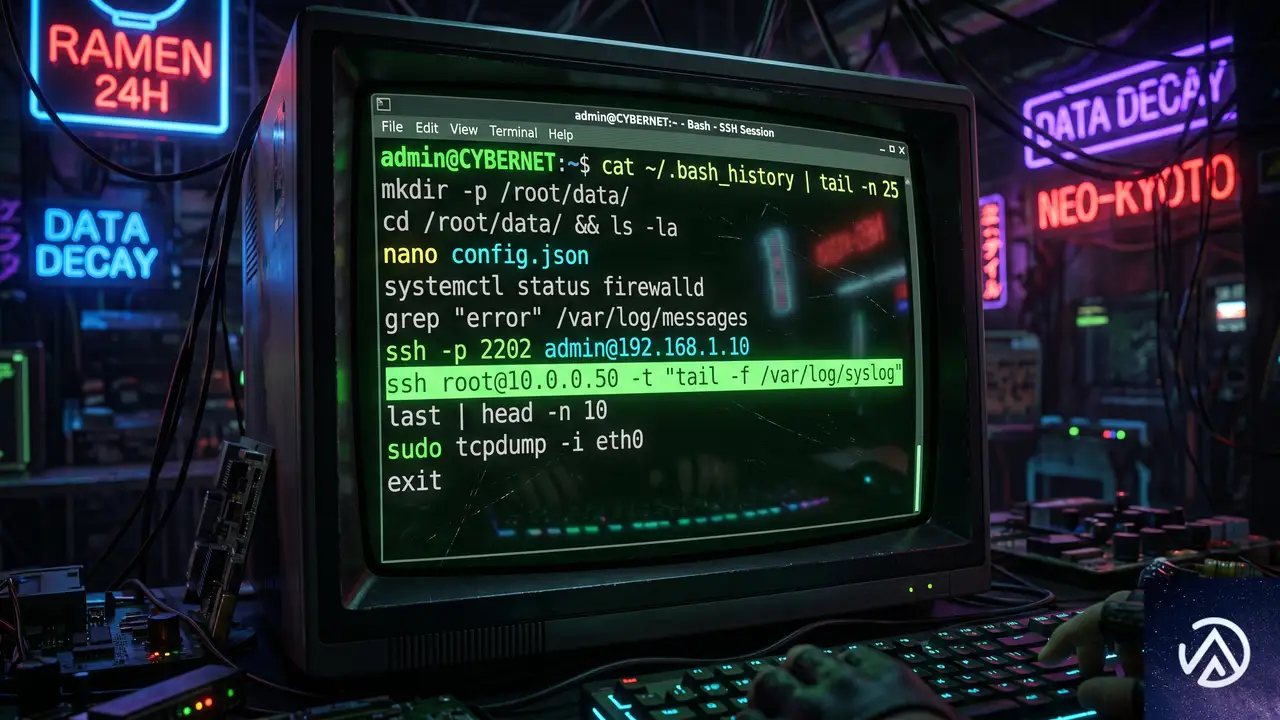
攻撃者の手口は、ステージングサーバーの構築から始まった。2026年5月27日、攻撃者はオープンソースのリモート管理ツールであるMeshCentralをインストールし、C2(コマンド&コントロール)環境を整えた。その際、正規のMicrosoft Azureサービスを装うドメイン「azurenetfiles.net」を取得し、SSL証明書まで自動化する念の入れようだ。
ステージングサーバーには、MeshCentralエージェントが配置された。エージェントのファイル名は「meshagent32-azure-ops.exe」など、正規のAzure運用エージェントに見せかけられていた。これらのエージェントは、攻撃者が自由に遠隔操作を行うためのバックドアとして機能する。
内部ネットワークの探索と情報収集
ステージングサーバーのコマンド履歴(.bash_history)からは、侵入後の詳細な偵察活動が明らかになった。攻撃者はmeshctrl.jsというMeshCentralのCLIツールを使い、侵害したマシン上で以下のようなコマンドを実行し、内部ネットワークの地図を作り出していた。
- システムのホスト名やユーザーIDの確認
- PeopleSoftのプロセススケジューラ設定ファイル(psappsrv.cfg)の解析による、マシン名とIPアドレスの抽出
- ネットワークマウントの確認とPeopleSoft関連領域の特定
- ローカルホストテーブル(/etc/hosts)を精査し、内部の全ノードをマッピング
- WebLogicサーバーのXML設定ファイルからのアプリケーションサーバー情報の収集
これらの偵察は、後の水平展開を効率的に行うための下準備だ。まずは地図を描き、その後に攻撃を拡大するという、組織的な手口が浮かび上がる。
水平展開の自動化スクリプトとデータ窃取の仕組み
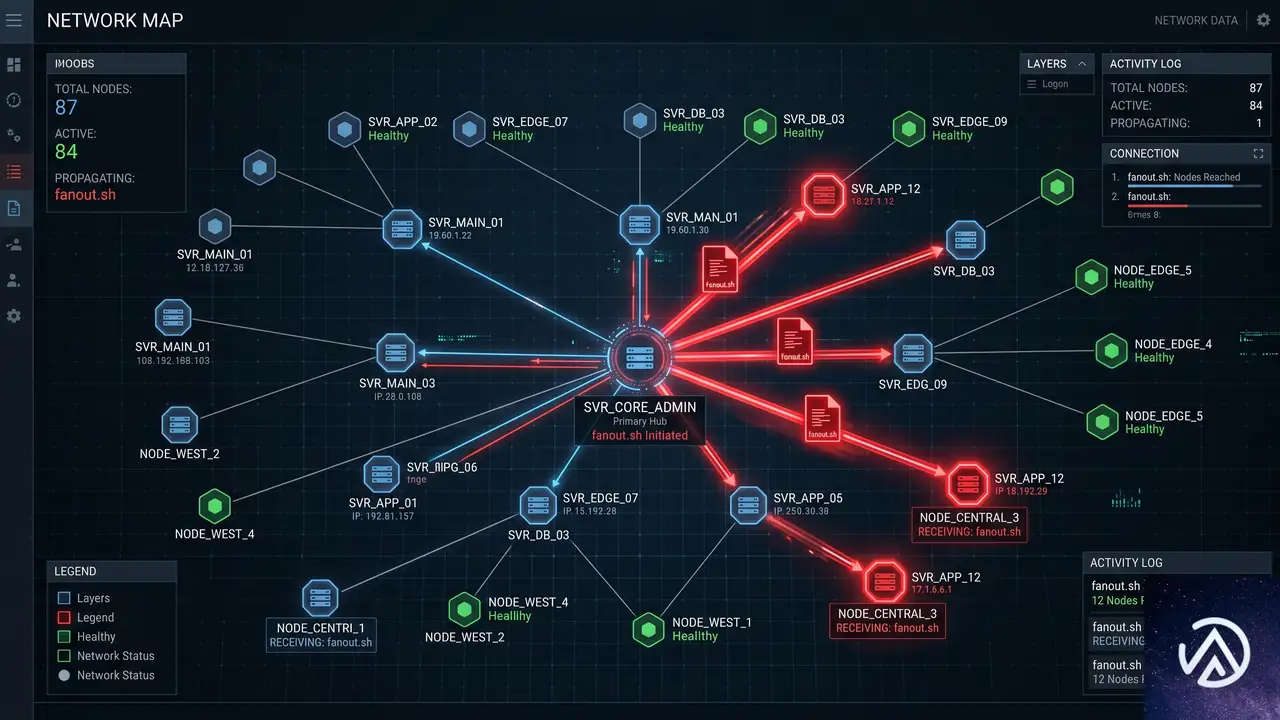
攻撃の核心は、自走式の水平展開スクリプト「[victim_abbreviation]_fanout.sh」にある。このスクリプトは、偵察フェーズで収集した内部ホスト情報を基に、SSHの認証情報を総当たりで試行し、侵害範囲を一気に拡大するよう設計されている。
スクリプトは、特定の命名規則を持つホスト名を/etc/hostsから抽出し、事前にハードコードされた複数のユーザー名とパスワードのリストを使ってSSH接続を試みる。この手法はSSHクレデンシャル・スプレー攻撃と呼ばれるものだ。
攻撃が成功すると、スクリプトはPayloadとして「README-IF-YOU-SEE-THIS-YOUVE-BEEN-HACKED.TXT」というファイルを、WebLogicやプロセススケジューラのディレクトリに書き込む。これは単なる嫌がらせの証跡ではなく、被害組織に対する恐喝のマーカーとして機能した。
データの流出とリークサイトへの接続
水平展開が完了した後、攻撃者は窃取したデータをzstdという高圧縮率のツールでアーカイブし、ステージングサーバー経由で外部へ持ち出した。一連のコマンド履歴の最後には、攻撃者のステージングサーバーから、ShinyHuntersのデータリークサイト公開ミラーをホストするIPアドレス「176.120.22.24」へのSSH接続が記録されていた。
この接続が、侵害された組織のデータが最終的にリークサイトで公開されるまでの一連の流れを決定づけた。実際に2026年6月9日には、複数の被害組織のデータが同サイト上に公開されている。
今すぐ取るべき具体的な防御策

この脅威に対抗するため、GoogleとOracleの両方は、PeopleSoftを運用する組織に対し、以下の即時対応を強く推奨している。対策は、ネットワークの遮断、ログ監視、そしてホストレベルの監査という3つのレイヤーに分類できる。
ネットワークレベルでの緊急対応
最も即効性が高いのは、エンドポイントそのものへの外部からのアクセスを遮断することだ。具体的には、ファイアウォールや境界ネットワークで「/PSEMHUB/hub」と「/PSIGW/HttpListeningConnector」へのHTTP POSTリクエストを遮断する。これらのエンドポイントは一般ユーザー向けの機能ではないため、遮断による業務への影響はない。
WAF(Webアプリケーションファイアウォール)だけに頼るのは危険だ。ルールをすり抜けられる可能性があるため、あくまで補助的な対策と考えるべきだろう。
ログとエンドポイントの徹底監視
次に重要なのが、侵入口と内部活動の痕跡をログから探し出すことだ。WebLogicのアクセスログで「/PSEMHUB/hub」や「/PSIGW/HttpListeningConnector」へのPOSTリクエストを調査する。送信元が外部IPや信頼できないアドレスであれば要注意だ。
特に「/PSIGW/HttpListeningConnector」へのリクエストでは、SSRF(サーバーサイドリクエストフォージェリ)攻撃の兆候を探す。リクエストパラメータに「127.0.0.1」や「localhost」などのループバックアドレス、内部IPレンジが含まれていないか確認する必要がある。
さらに、ネットワークレベルでは、PeopleSoftサーバーから外部の不審な宛先へのSMB通信(TCPポート445)を監視する。これは攻撃チェーンの一環として、WindowsマシンのNetNTLMハッシュを窃取するために悪用される可能性があるためだ。
ホストレベルでのフォレンジック監査
最後に、侵害の有無を確定させるためのファイルシステム調査を行う。以下のディレクトリに、通常存在しないファイルやフォルダがないかを重点的にチェックする。
- WebLogicのアプリケーションディレクトリ内の「PSEMHUB.war」配下に、未知のJSPファイル(WebShell)が生成されていないか
- 「envmetadata/transactions/」ディレクトリに、不審なフォルダや攻撃者のツールがドロップされていないか
- 「envmetadata/data/environment/」配下に、最近更新された怪しいXMLファイルがないか(XMLDecoderを介した永続化の可能性)
これらの調査により、攻撃者が仕掛けたバックドアや永続化の仕組みを特定し、再起動後も安全な状態を確保できる。
この記事のポイント
- ShinyHuntersはCVE-2026-35273をゼロデイとして悪用し、100以上の組織を攻撃した。標的の68%は高等教育機関だった
- 攻撃者は正規クラウドサービスを装う高度なC2インフラを構築し、MeshCentralを悪用して遠隔操作と水平展開を自動化した
- スクリプトによるSSHスプレー攻撃で内部ネットワークに拡散し、最終的にデータを窃取。盗まれた情報はリークサイトで公開された
- 防御の最優先事項は、使用していない管理用エンドポイントをネットワーク境界で遮断すること。これによりWAFバイパスのリスクを根本的に排除できる
- 遮断と並行して、アクセスログの調査、SMB通信の監視、ファイルシステムのフォレンジック監査を速やかに実施する必要がある
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

JavaScriptがログアウト時に動かない原因と直し方
管理画面にログインしているときだけ JavaScript が動き、ログアウトすると止まる。この現象の原因は、ほぼ「スクリプトの読み込み順序」と「キャッシュ・最適化プラグインの挙動」のどちらか、あるいは両方の組み合わせだ。ログイン時は管理バー用のスクリプト等が読み込まれるため依存関係が偶然成立し、ログアウト時にそれが外れてエラーになるケースが多い。
ログアウト時だけ JavaScript が動かなくなる仕組み
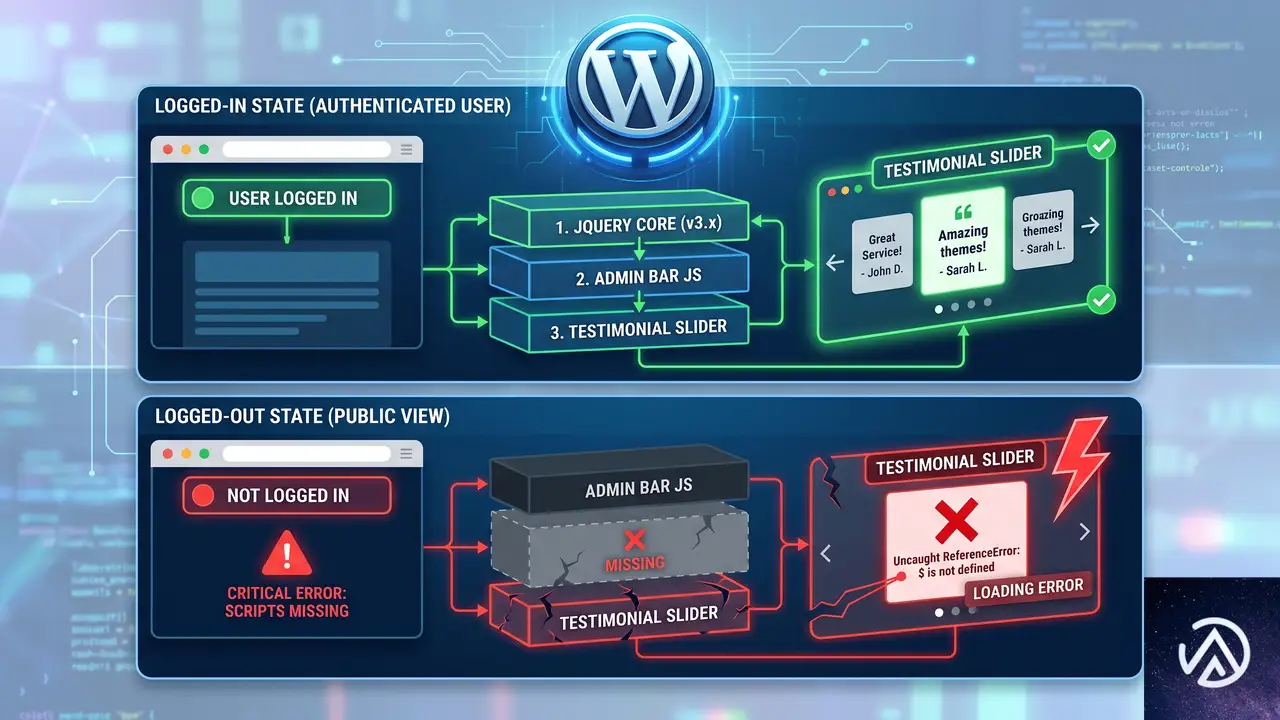
このデモは典型的な依存関係の崩れを示している。ログイン中は WordPress が管理バーやフッターに jQuery を読み込むため、その後に記述されたスクリプトが偶然動く。ログアウトすると jQuery が存在せず、$ is not defined や jQuery is not defined といったエラーで止まる。
HTML ブロックに直接書いた JavaScript が招く問題
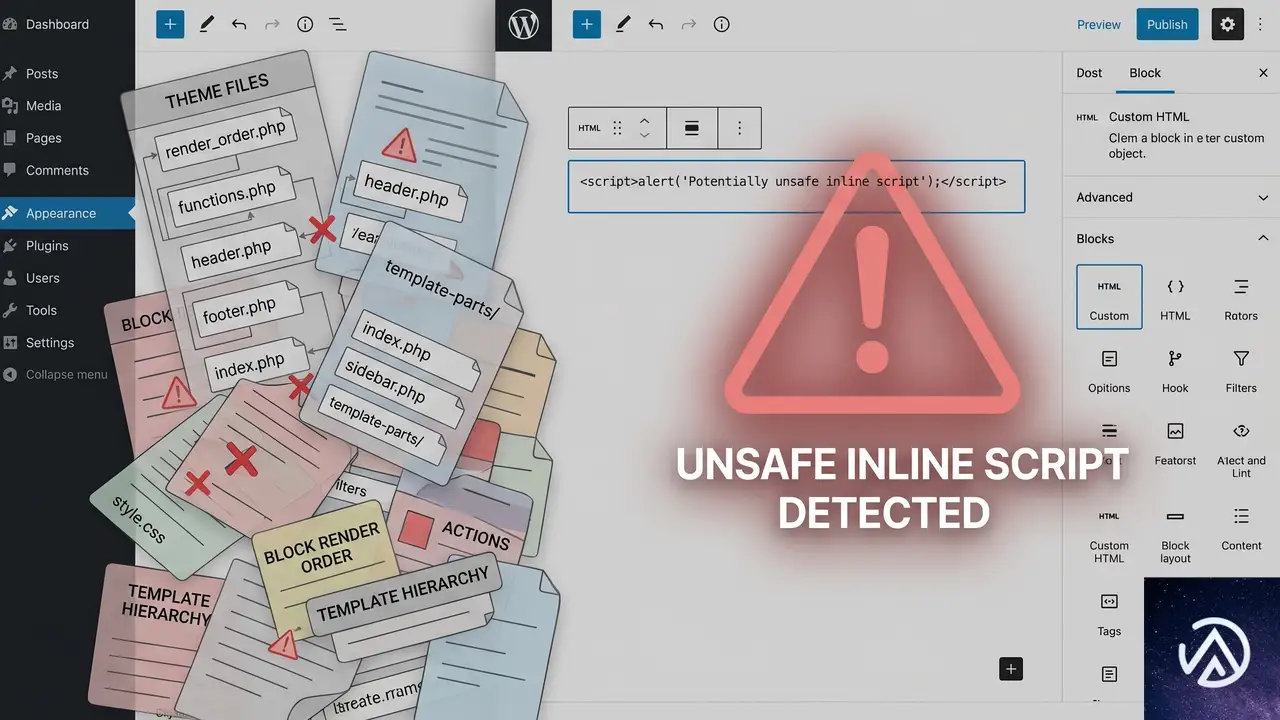
WordPress の「カスタム HTML」ブロックに <script> タグを直書きする方法は、一見手軽だが制御が難しい。出力される位置がテーマやブロック配置に依存し、jQuery などのライブラリより前に実行されれば必ず失敗する。さらにインラインスクリプトは多くのキャッシュプラグインで最適化対象から外されたり、結合・遅延読み込みの対象にならず、ログアウト時だけ二重に不利な状況を生む。
HTML ブロック直書きスクリプトの3つの弱点
- 読み込み順序を制御できない(テーマの render 順に依存する)
- jQuery の依存関係を WordPress に伝えられない
- キャッシュ・圧縮プラグインがスクリプトとして認識しない場合がある
ログアウト時でも動くようにする正しい組み込み手順

原則は「JavaScript は HTML ブロックに直書きせず、WordPress の仕組み(wp_enqueue_script)で読み込む」ことだ。すでに直書きで動いているものを移行するには、以下の手順で進める。
STEP 1 既存の script タグを外部ファイルに移す
HTML ブロック内の <script>〜</script> 部分だけを抜き出し、子テーマのフォルダ内に testimonial-slider.js のような名前で保存する。<script> タグそのものは不要で、中身のコードだけを移す。HTML ブロックにはスライダーの構造(ul や div のマークアップ)だけを残す。
STEP 2 functions.php で安全に読み込む
子テーマの functions.php に以下のコードを追加する。管理画面ではなくフロントエンドだけに読み込ませるために wp_enqueue_scripts フックを使う。依存関係として jquery を指定すれば、WordPress 本体の jQuery が先に読み込まれてから実行される。
function my_testimonial_slider_script() {
wp_enqueue_script(
'testimonial-slider',
get_stylesheet_directory_uri() . '/testimonial-slider.js',
array('jquery'),
'1.0.0',
true
);
}
add_action('wp_enqueue_scripts', 'my_testimonial_slider_script');最後の引数 true はフッターで読み込む指定だ。スライダーの DOM 要素が本文中に存在する場合はフッター読み込みで問題ない。もしスライダーを本文より前に実行する必要があるなら false にしてヘッダーで読ませるが、多くのケースではフッターで十分だ。
STEP 3 $ の衝突を防ぐ
WordPress の jQuery は noConflict モードで動作しているため、$ がそのまま使えない環境がある。古いコードを流用している場合は $ is not a function エラーが起きやすい。回避策として、外部ファイル全体を即時実行関数で囲み、引数で $ を受け取る記法が安全だ。
(function($) {
$(document).ready(function() {
// ここにスライダーのコード
});
})(jQuery);STEP 4 キャッシュプラグインでスクリプトを除外する
ここまで対応しても直らない場合、キャッシュや最適化プラグインが原因の可能性が高い。ログアウト時はページキャッシュが有効になり、スクリプトの遅延読み込みや結合が適用される。自前の testimonial-slider.js をこれらの処理から除外する必要がある。
プラグインの設定画面で「スクリプトの除外」「遅延読み込みの除外」といった項目を探し、testimonial-slider(ハンドル名)または testimonial-slider.js(ファイル名の一部)を指定する。除外後は必ずキャッシュを全削除してからログアウト状態で確認する。
Elementor のフックやテーマのアクションフックを使った場合の注意点
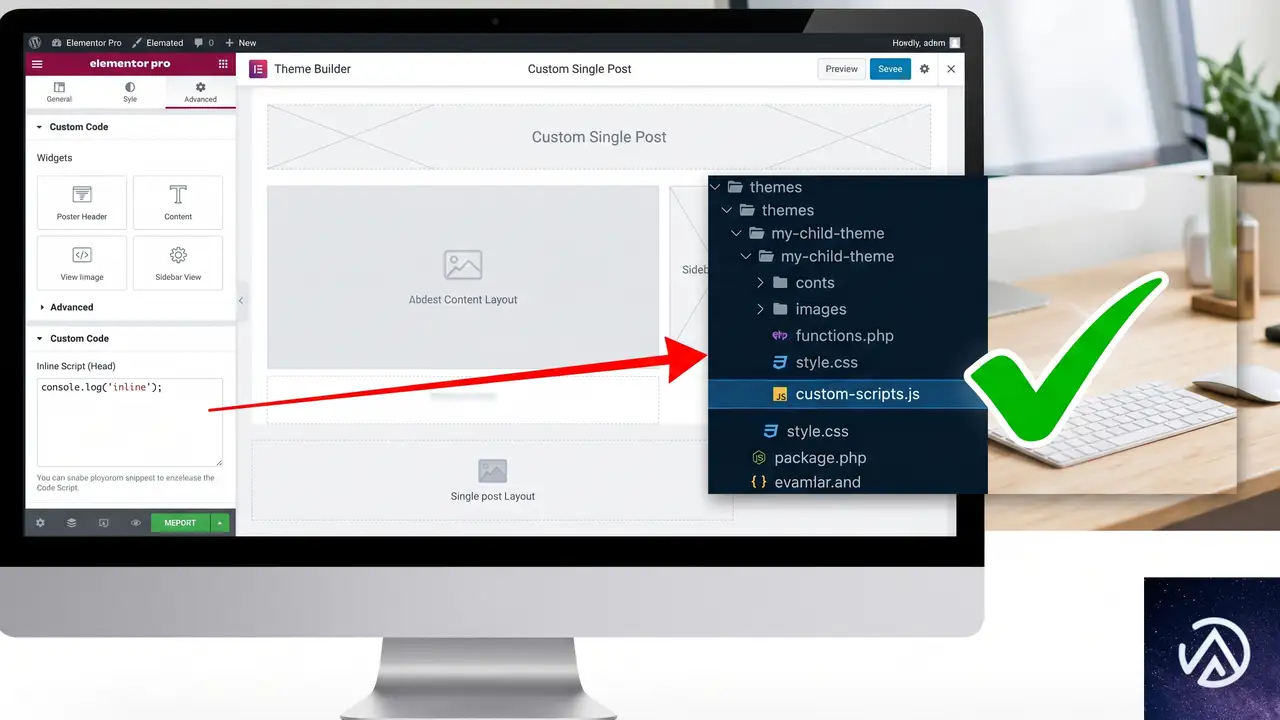
テーマ付属のフック(GeneratePress の Element など)に HTML ブロックごと差し込む方法も考えられるが、根本的にはスクリプトの読み込み順序問題は同じだ。フックで出力する位置を変えても、jQuery より前に呼ばれるリスクは残る。フックを使う場合でも、スクリプト部分は wp_enqueue_script に任せ、フックにはマークアップだけを出力する形が堅実だ。
Elementor Pro の「カスタムコード」機能を使っているなら、その中に script タグを書くのではなく、同様に子テーマのファイルとして切り出してハンドル登録するほうが制御できる。どうしても直書きが必要なら、カスタムコードの「場所」設定を「本文の終了タグ直前」にし、さらにコード内で jQuery を明示的に使う($ を使わない)ことでエラーを減らせる。
よくある質問
コンソールに「$ is not defined」と出るがどう直せばいいか
jQuery が読み込まれる前に $ を使っているか、noConflict モードで $ が無効になっている。即時関数で (function($) { ... })(jQuery); とラップし、すべての $ をこのスコープ内に収めれば解決する。
functions.php を編集せずに直す方法はあるか
「WPCode」などのコードスニペット管理プラグインを使えば、管理画面から wp_enqueue_script のコードを登録できる。functions.php を直接触りたくない場合の現実的な代替手段だ。スニペットの実行場所を「フロントエンドのみ」に設定するのを忘れないようにする。
キャッシュを削除しても直らないのはなぜか
ブラウザキャッシュだけを消していて、サーバー側のページキャッシュや CDN キャッシュが残っているケースが多い。WordPress のキャッシュプラグインの「すべてのキャッシュを削除」を実行し、さらに CDN を使っている場合はその管理画面からもパージする。シークレットウィンドウで確認するとブラウザキャッシュの影響を除外できる。
スライダーのマークアップだけ残して script を外したら表示が消えた
新しく作った JS ファイルが正しく読み込まれていない。ブラウザの開発者ツールの「ネットワーク」タブで testimonial-slider.js が 200 番で返っているか確認する。404 ならパスが間違っている。読み込まれているのに動かない場合は、コンソールに別のエラーが出ていないか調べる。
この記事のポイント
- ログアウト時だけ JavaScript が動かない原因は、jQuery の依存切れとキャッシュ最適化の複合
- HTML ブロックへの script 直書きは読み込み順序を制御できず、根本対策にならない
- wp_enqueue_script で jQuery 依存を明示し、外部ファイルとして切り出すのが正攻法
- 即時関数で $ の衝突を防ぎ、キャッシュプラグインでは独自スクリプトを除外対象に追加する
- Elementor やテーマフックを使う場合も、スクリプトだけは enqueue に任せる設計が堅実
・ Reddit、Stack Overflow、WordPress.org フォーラムを日々巡回し、現場の悩みを拾い上げて記事化
・ WordPress、WooCommerce、Next.js などモダンWeb制作領域のトラブルシューティングが専門
・ 「検索しても答えが見つからなかった」を一つでも減らすことが目標
・ エラーメッセージから根本原因にたどり着く粘り強い調査が得意
・ 初心者がつまずきやすい箇所を先回りで解決する記事作りを心がけている
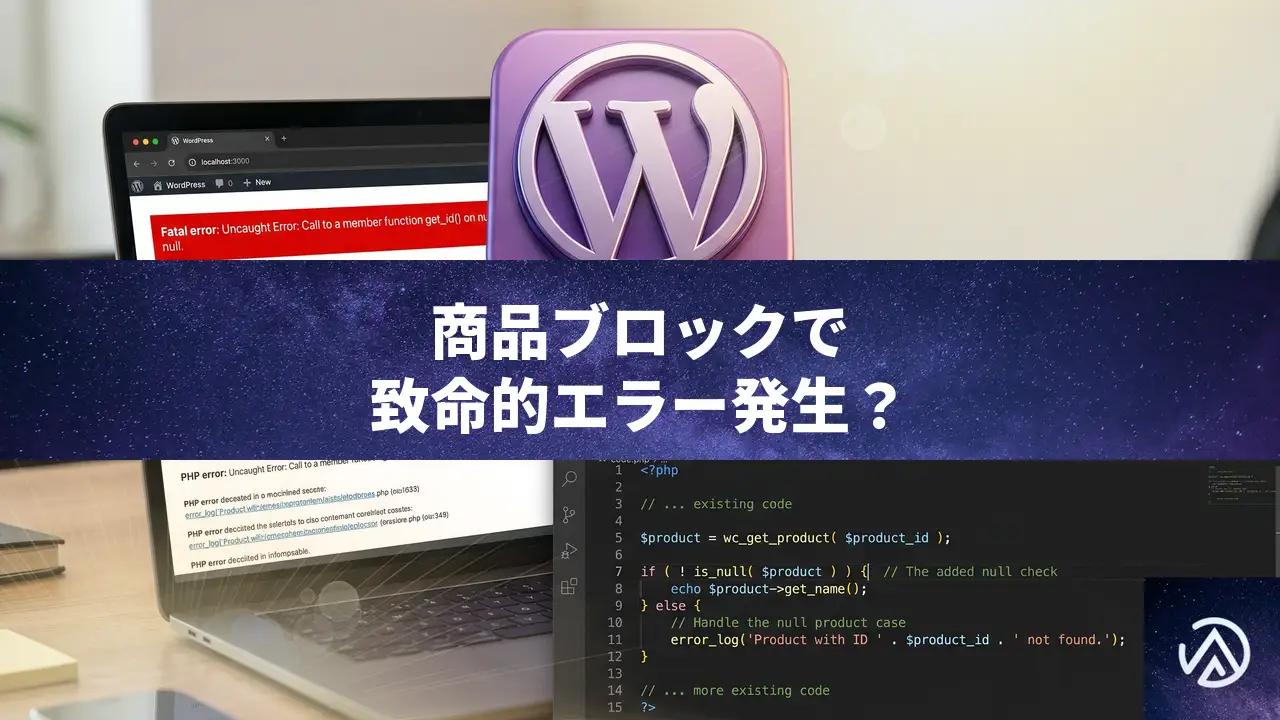
特定商品ブロックを設置した固定ページでfatal errorが発生する問題の直し方
特定商品ブロックを固定ページに配置したときに「Uncaught Error Call to a member function get_id() on null」というfatal errorが表示されるのは、PreCart for WooCommerce のバグが原因だ。プラグインを最新バージョンへ更新するか、functions.php へ一時的な修正コードを追加すれば直る。
なぜ固定ページ上の商品ブロックで fatal error が起こるのか

PreCart は WooCommerce の商品情報を扱うフィルターフック(woocommerce_product_add_to_cart_text など)にコールバック関数を登録し、その中で global $product から商品オブジェクトを取得して $product->get_id() を呼び出している。しかし、ブロックエディタで「特定商品」ブロックを通常の固定ページに配置すると、WooCommerce のブロック表示パイプラインではグローバル変数 $product が null のままフィルターが走るケースがある。PreCart のコードには null チェックがないため、null に対して get_id() を呼び出してしまい、致命的なエラーでページ全体が落ちる。
$product が null のままコールバックが実行される$product->get_id() で致命的エラー発生(画面が真っ白になる)影響を受けるメソッドは change_add_to_cart_text()、display_pre_order_messgae()、display_pre_order_badge() など、いずれも保護コードがない。WooCommerce の商品ブロックを店舗ページ以外で使っているサイトはすべてこの問題に遭遇し得る。
PreCart を更新してエラーを解消する手順
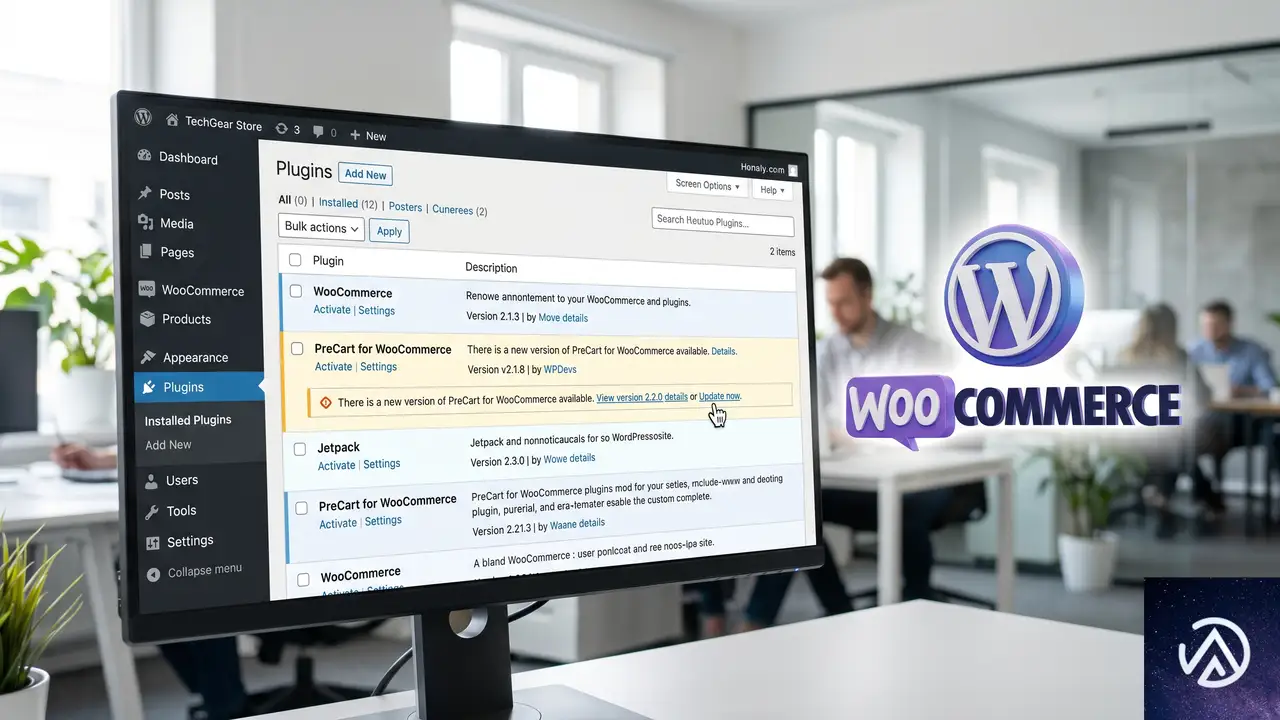
開発元はこの問題を認識しており、すでに修正アップデートがリリースされている。まずは管理画面からプラグインを最新版に上げるのが最も安全で確実な対処法だ。
更新通知が表示されない場合
「ダッシュボード」→「更新」から更新の再確認を行うか、PreCart のプラグインページで一度「プラグインを削除」→ 公式リポジトリから再インストールする方法もある。ただしこの場合、設定がリセットされる可能性があるため、事前に PreCart の設定をメモしておくかエクスポート機能があれば使っておくと安心だ。
functions.php で null チェックを追加して一時的に対処する方法

どうしてもすぐにプラグインを更新できない場合や、何らかの理由で更新後に問題が残る場合は、テーマの functions.php にフックを追加して一時的にエラーを回避できる。
/**
* PreCart の null チェック不足による fatal error を回避(一時的対応)
*/
add_filter( 'woocommerce_product_add_to_cart_text', function( $text, $product ) {
if ( ! $product || ! is_a( $product, 'WC_Product' ) ) {
return $text;
}
// 以下は原本の処理が走るが、早期リターンで保護
return $text;
}, 1, 2 );
add_filter( 'woocommerce_single_product_summary', function() {
global $product;
if ( ! $product || ! is_a( $product, 'WC_Product' ) ) {
return;
}
// 同様に早期リターン
}, 1 );上記のコードは PreCart が使っているのと同じフックに、より優先度の高いコールバック(優先度 1)で null チェックを追加し、商品オブジェクトが存在しないときは処理を打ち切る仕組みだ。PreCart のフィルターよりも先に実行されるため、致命的エラーに至る前に関数を抜けられる。
$product->get_id();
$product->get_id();
functions.php 編集時の注意点
子テーマを使っていない場合、テーマ更新で修正が上書きされるリスクがある。必ず子テーマの functions.php にコードを追加するか、Code Snippets プラグインでコードを管理するのが望ましい。また、この一時対応はあくまで応急処置であり、PreCart の他の機能が正常に動作しない可能性もゼロではない。早めに公式アップデートを適用して、追加コードは削除する。
手動修正後に確認しておきたいポイント
- 一時的なコードを追加した後、サイトの表示速度やエラーログに変化がないか定期的にチェックする
- PreCart の機能(カート追加テキストの変更や予約注文バッジなど)が期待どおり動作しているかテストする
- PHP のエラーログを確認し、別の箇所で同様の null 参照エラーが隠れていないか調べる
- サイト全体のキャッシュをクリアし、CDN を利用している場合は CDN キャッシュも破棄する
- PreCart の更新が確認できたら必ずプラグインを最新版に上げ、追加コードを削除する
よくある質問
PreCart 以外のプラグインでも同じように商品ブロックでエラーが出ることはありますか
ある。WooCommerce のブロックを通常ページで使うと、$product グローバルを正しく取り扱っていない他の拡張プラグインでも同様の null 参照エラーが起きるケースが報告されている。エラーの文面に別のプラグイン名が含まれている場合は、そちらの開発元へ報告しつつ、同じように functions.php で早期リターンを追加すれば応急回避できることが多い。
WooCommerce の商品ブロックを固定ページで使うこと自体は問題ないのでしょうか
WooCommerce のブロックは基本的に店舗ページや商品ページで使うことを想定しているが、WordPress の標準ブロックとして技術的にはどの投稿タイプでも利用できる。プラグインがグローバル変数の有無を適切にハンドリングしていれば固定ページで使っても問題は起きない。ただ、テーマやプラグインが認めるまで、動作確認は入念に行ったほうがよい。
エラーメッセージが表示されずに画面が真っ白になる場合はどうすればよいですか
WordPress が致命的エラーを表示しない設定(WP_DEBUG が false)のときは、管理画面のメールに送られる復旧モード用のリンクを探すか、サーバーの PHP エラーログを確認する。wp-config.php で define('WP_DEBUG', true); を一時的に有効にすれば、画面上にエラー詳細が表示され、原因を特定しやすくなる。なお、本番環境ではデバッグモードをすぐに無効に戻すこと。
管理画面にも入れなくなってしまった場合はどうすれば直りますか
FTP またはレンタルサーバーのファイルマネージャーで /wp-content/plugins/precart/ ディレクトリの名前を一時的に変更(例:precart_deactivated)すれば、プラグインが無効化されて管理画面に再ログインできる。その後、前述の更新や一時コードで対処し、ディレクトリ名を元に戻す。
この記事のポイント
- 固定ページに WooCommerce 商品ブロックを配置したときの fatal error は PreCart の null チェック不足が原因
- 解決策は PreCart プラグインの最新版への更新が最も安全で確実
- すぐに更新できない場合は、functions.php にフックで早期リターンを追加すれば応急回避できる
- functions.php 編集は子テーマで行い、アップデート後は必ず追加コードを削除する
- 管理画面に入れなくなったら FTP でプラグインフォルダ名を変更し無効化する
・ Reddit、Stack Overflow、WordPress.org フォーラムを日々巡回し、現場の悩みを拾い上げて記事化
・ WordPress、WooCommerce、Next.js などモダンWeb制作領域のトラブルシューティングが専門
・ 「検索しても答えが見つからなかった」を一つでも減らすことが目標
・ エラーメッセージから根本原因にたどり着く粘り強い調査が得意
・ 初心者がつまずきやすい箇所を先回りで解決する記事作りを心がけている

AWS WAFがAIボット収益化機能を追加、コンテンツ所有者が課金可能に
AWSは2026年6月15日、AWS WAFにAIトラフィック収益化機能を追加した。コンテンツ所有者やパブリッシャーが、自社のWebコンテンツにアクセスするAIボットやAIエージェントに対して、ネットワークエッジで直接課金できるようになる。
AIボットによるWebトラフィックは、多くのコンテンツプロバイダーで全体の50%を超え、AI専用クローラーは前年比300%以上増加している。従来の検索エンジンクローラーはリンクを返すことで参照トラフィックをもたらすが、AIボットはコンテンツを要約してAIインターフェイス上で表示するため、元のサイトにはほとんどトラフィックが還元されない。その結果、コンテンツ提供者はインフラコストだけを負担し、広告収入や購読コンバージョンといった従来の収益源が得られない状況が続いていた。
今回の新機能は、このギャップを埋めるものだ。AWS WAF Bot Controlの仕組みを拡張し、コンテンツパスごと、ボットカテゴリごと、検証ティアごとにリクエスト単価を設定できる。また、ステーブルコインによる支払いをウォレットで受け取り、単一のダッシュボードで収益とボットアクティビティを追跡可能にする。
AIボット収益化の新機能がAWS WAFに追加された背景

AIトラフィックの爆発的な増加
GPTBotやClaude-Web、Perplexity-BotといったAIクローラーは、学習用データやリアルタイム情報の収集のためにWebサイトを大量にクロールする。こうしたトラフィックは増加の一途をたどり、一部のコンテンツプロバイダーではAIボットが全リクエストの50%を超えるまでになっている。検索エンジンのクローラーとは異なり、AIボットはインデックスを生成する代わりにテキストを直接消費し、要約をAIチャット画面に表示する。そのため、元記事を読むための流入はほとんど発生しない。
従来のBot Controlでは限界があった理由
AWS WAF Bot Controlはこれまで、650種類以上のAIボットを検出し、ブロックまたはレート制限をかけることができた。しかし、ボットのトラフィックを完全に遮断するのではなく、課金して収益化したいというニーズは強く存在していた。コンテンツを無料で提供し続ければインフラコストがかさむ一方、単純にブロックすればAIサービスへの露出が途絶えてしまう。そこで、ボットにコンテンツ利用の対価を支払わせる仕組みが求められていた。
AIトラフィック収益化の仕組み

x402プロトコルとHTTP 402 Payment Required
今回の収益化機能の核は、x402というマシンツーマシン決済のオープンプロトコルだ。ルールに合致したAIボットからのリクエストに対し、AWS WAFはHTTP 402 Payment Requiredレスポンスを返す。このレスポンスボディには、コンテンツの価格(USDC建て)、受け入れ可能なブロックチェーンネットワーク(BaseやSolanaなど)、送金先ウォレットアドレス、支払いタイムアウトを含むJSON形式のプライスマニフェストが含まれる。これを受け取ったx402対応のエージェントランタイムは、自律的に署名付き支払い承認を提出し、AWS WAFがそれを検証したうえでコンテンツを提供するという流れだ。
ステーブルコイン決済の流れ
決済はステーブルコイン(USDC)で行われ、サードパーティのファシリテーターサービス(現在はCoinbaseのx402 Facilitator)がオンチェーン上の決済処理を支援する。Stripeによる直接アカウント決済やMachine Payments Protocol(MPP)への対応も近日中に予定されている。コンテンツ所有者は、AWS WAFの設定パネルでウォレットアドレスを指定するだけでよく、独自の決済インフラを構築する必要はない。また、AWS自体は決済手数料を徴収しない。
上記のように、収益化を有効にするとAIボットのアクセスが自動的に402レスポンスに切り替わり、支払いが完了したリクエストだけがコンテンツに到達する。コンテンツ所有者はアクセスを遮断する代わりに料金を設定し、ボットトラフィックを収益源に変えることができる。
収益化の設定手順
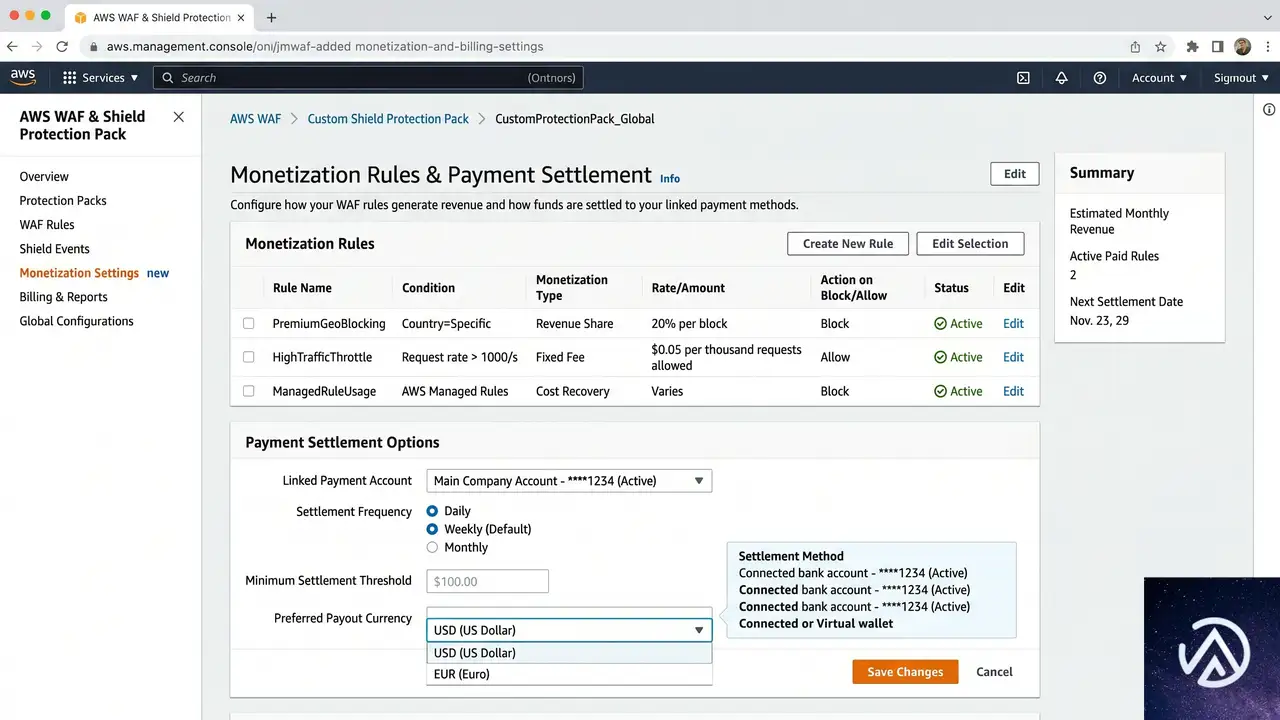
プロテクションパックの作成
AIトラフィック収益化を使うには、まずAWS WAF Bot ControlをCommonまたはTargetedレベルで有効にしたうえで、プロテクションパック(Protection Pack)を作成する。プロテクションパックとは、どのコンテンツパスを収益化するか、各検証ティアにいくら課金するか、どの支払い方法を受け入れるかといったポリシーをまとめた設定単位だ。AWSマネジメントコンソールで「WAF & Shield」を開き、「Protection packs (web ACLs)」から作成を開始する。
作成時にアプリカテゴリ(コンテンツ・パブリッシングシステム、Eコマースなど)を選択し、保護対象のリソース(CloudFrontディストリビューション)をひも付ける。推奨ルールパッケージが提示されるが、個別のルールを選ぶことも可能だ。プロテクションパックを作成したら、必要に応じて価格帯や支払い方法、コンテンツ範囲、ライセンス条項をカスタマイズする。
収益化ルールの設定
プロテクションパックを選び、「Configure AI monetization」から検証ティアごとにアクションを割り当てる。アクションは6種類ある。Monetize(402を返し課金)、Allow(無料アクセス許可)、Block(完全遮断)、Count(課金せずログだけ記録)、CAPTCHA(人間の確認)、Challenge(ブラウザかどうかのサイレントチェック)だ。Monetizeを選択すると、支払い決済用のブロックチェーンネットワーク(BaseやSolanaなど)を指定し、ウォレットアドレスとUSDC建てのページ単価を設定する。
Monetizeアクションは、Amazon CloudFrontディストリビューションに関連付けられたWeb ACLでのみサポートされる。リージョナルWeb ACLでは使えない点に注意が必要だ。また、本番投入前にテストモード(Currency modeをTestに切り替え)で、テストネット(Base SepoliaやSolana Devnet)を使った検証が可能となっている。テストモードでも実際の402レスポンスと支払いフローが再現され、すべてのイベントにCurrencyMode: TESTのログが付与される。
この一連の流れは、サイトのオリジンサーバーに一切手を加えることなく、AWS WAFのエッジで完結する。コンテンツ提供者はアプリケーションコードを修正する必要がないため、既存のWebサイトに迅速に収益化機能を追加できる。
AIトラフィック分析ダッシュボードと収益トラッキング
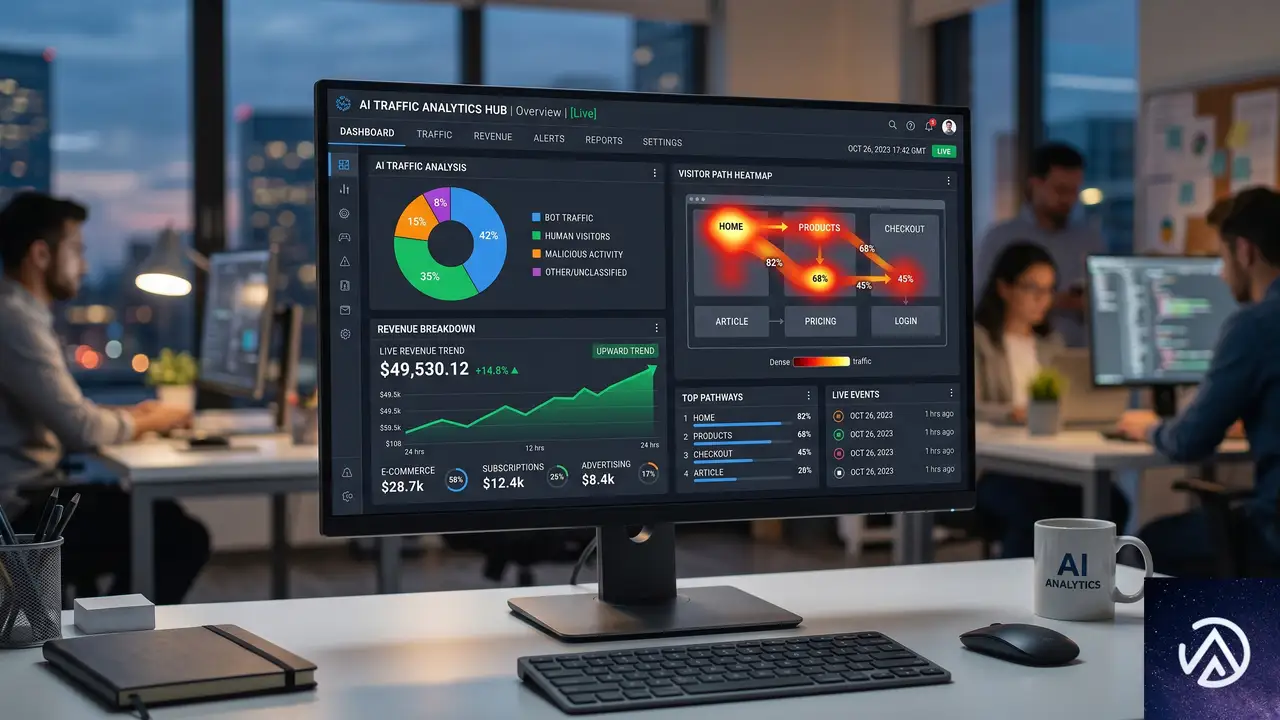
価格設定を最適化するためのAIトラフィック分析ダッシュボードも提供される。プロテクションパックを選択すると、ボットリクエスト全体、AIボットリクエスト、検証済みAIトラフィック、未検証AIトラフィックの4カテゴリに分けてトラフィックを可視化する。帯域幅の消費量、推定月間コスト、ピークリクエストレートといったインフラ影響指標も表示され、パスごとのヒートマップで時間帯別のAIボット集中度がわかる。
Currency modeをRealに切り替えると、「AI access monetization」ダッシュボードで実際の収益をリアルタイムに追跡可能だ。総収益、検証済みボットと未検証ボットの内訳、リクエストあたりの平均単価が表示され、上位の収益ソースやコンテンツパス別の収益ランキングも確認できる。Settlementsタブでは決済プロバイダーごとの精算状況や支払い失敗の分析も行える。
導入のポイントと今後の展望
この機能は、CloudFrontを利用するすべてのAWS WAFユーザーに対して追加料金なしで提供される。ただし、Monetizeを適用できるのはCloudFrontディストリビューションに関連付けたWeb ACLのみである点は押さえておきたい。また、テストモードを活用して本番適用前に価格設定やウォレット設定、x402フローを十分に検証することが推奨される。
今後、Stripeの直接アカウント決済やMPPに対応することで、より多様な支払い手段が利用可能になる見通しだ。AIボットのトラフィックが増え続ける中、コンテンツの価値を適切に回収する仕組みとして、この収益化機能は重要な選択肢となる。自社サイトへのAIクローラーの影響を分析している企業は、まずBot Controlのダッシュボードでトラフィックの可視化から始め、段階的に収益化を検討するのが良いだろう。
この記事のポイント
- AWS WAFにAIボット向け課金機能が追加され、HTTP 402とx402プロトコルでマシンツーマシン決済を実現
- コンテンツパスや検証ティアごとにリクエスト単価を設定でき、ステーブルコインで収益を受け取れる
- 設定はプロテクションパック単位で行い、CloudFront環境のエッジで自律的に課金とコンテンツ配信が完結
- AIトラフィック分析ダッシュボードでコストと収益を可視化し、価格設定を最適化できる
- テストネットを使った検証モードがあり、本番適用前にリスクを評価可能
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験
AI EngineとJetpackが衝突してGeminiが使えない時の解決策
AI Engine プラグインをバージョン 3.5.5 以降にアップデートすれば、この問題は即座に解決する。根本原因は Jetpack が REST API に追加する整数型 enum フィールドを、Google Gemini がツール定義で拒否していたことにある。AI Engine の開発者がこのスキーマ生成ロジックを修正し、文字列型以外の enum を自動除去するようになった。
どのようなエラーが発生するのか
Desktop Commander で AI Engine を MCP サーバーとして管理モードで接続し、AI モデルに Google Gemini を指定すると、次のようなエラーで通信が失敗する。
「GenerateContentRequest.tools[0].function_declarations[30].parameters.properties[jetpack_publicize_connections].items.properties[status].enum: only allowed for STRING type」という趣旨のエラーが返る。翻訳すると「enum は STRING 型にしか使えない」という厳格な制約に違反した形だ。
管理画面では具体的に「AI Engine が Gemini API からの応答に失敗しました」といった形で表示され、チャットが開始できないか、途中で止まる。管理モードでなければ発生しないエラーだ。
なぜ Jetpack と AI Engine が衝突するのか

核心は Google Gemini API の「ツール定義」に対する極めて厳格なバリデーションにある。Gemini は利用可能な関数のパラメータをスキーマで受け取るが、enum(許容値の固定リスト)を使う場合、そのデータ型を必ず文字列にしなければならない。
一方 Jetpack は、WordPress の投稿作成や更新時に使われる REST API エンドポイントへ、ソーシャルメディア連携用のフィールドを動的に追加している。その中の jetpack_publicize_connections フィールドには status というパラメータがあり、Jetpack はこれを整数型の enum([0, 1])として定義している。
AI Engine が WordPress のスキーマ全体を走査して Gemini 向けのツールリストを組み立てる際、この整数型 enum をそのまま継承してしまう。その結果、Gemini API がリクエスト全体を「400 Bad Request」ではねつける流れだ。
読み取り専用モードならば投稿作成系のツールが含まれないため、このエラーは発生しない。管理モードで書き込み権限を付与する場合に限って表面化する。
AI Engine 3.5.5 以降へのアップデートで恒久修正する
AI Engine の開発者によって、バージョン 3.5.5 で根本的な修正が加えられた。ツールスキーマを作成する際、文字列型以外の enum 定義を自動的に除去する処理が追加されている。
スキーマキャッシュのバージョンも同時に引き上げられているため、更新後に手動でキャッシュをクリアする必要はない。自動的に再生成され、Jetpack の整数型 enum は除去された状態でツールリストが構築される。
どうしてもアップデートできない場合の手動修正
何らかの理由で AI Engine を最新版にできない場合、子テーマの functions.php または Code Snippets プラグインに以下のコードを追加し、Jetpack の整数型 enum フィールドを強制的に文字列型へ変換できる。
<?php
/**
* Jetpack と AI Engine、Google Gemini の競合を修正する。
* Jetpack の status enum フィールドを文字列型に変換する。
*/
add_action( 'wp_enqueue_scripts', 'enqueue_parent_styles' );
function enqueue_parent_styles() {
wp_enqueue_style( 'parent-style', get_template_directory_uri() . '/style.css' );
}
add_action( 'rest_api_init', 'fix_jetpack_enum_for_gemini', 9999 );
function fix_jetpack_enum_for_gemini() {
global $wp_rest_additional_fields;
if ( ! empty( $wp_rest_additional_fields ) ) {
foreach ( $wp_rest_additional_fields as $post_type => $fields ) {
if ( isset( $wp_rest_additional_fields[$post_type]['jetpack_publicize_connections'] ) ) {
if ( isset( $wp_rest_additional_fields[$post_type]['jetpack_publicize_connections']['schema']['items']['properties']['status'] ) ) {
// 問題を起こす整数 enum を除去
unset( $wp_rest_additional_fields[$post_type]['jetpack_publicize_connections']['schema']['items']['properties']['status']['enum'] );
// データ型を文字列に明示
$wp_rest_additional_fields[$post_type]['jetpack_publicize_connections']['schema']['items']['properties']['status']['type'] = 'string';
}
}
}
}
}
?>コード追加だけでは修正されないケースがある。AI Engine はツールリストをデータベースに強力にキャッシュしているため、キャッシュを強制的に再生成させる必要がある。
Jetpack を無効化した状態でチャットを実行することで、AI Engine は Jetpack 関連フィールドのないスキーマを新規に作成する。Jetpack を再有効化した後は上記のフィルタが働き、問題の enum がスキーマに混入することはなくなる。
よくある質問
Jetpack を使っていなければこの問題は起こらないのか
Jetpack の jetpack_publicize_connections フィールドが原因であるため、Jetpack を導入していなければ発生しない。ただし、他のプラグインも整数型 enum を REST API に追加している場合は似たエラーが出る可能性がある。その場合も AI Engine 3.5.5 以降であれば同様に自動除去される。
読み取り専用モードではなぜ問題ないのか
読み取り専用モードでは、投稿の作成や更新といった書き込み系のツールが Gemini に送信されない。問題の jetpack_publicize_connections フィールドは投稿作成時に登場するため、ツールリストから除外される。管理モードだけが影響を受ける。
AI モデルが Gemini 以外でも同じエラーは出るか
このエラーは Gemini のツール定義バリデーションが特に厳格なために発生する。OpenAI の GPT シリーズなど、他の AI モデルでは整数型 enum を許容するものもあるが、根本原因はスキーマにあるため、どのモデルでも潜在的な問題になりうる。AI Engine 3.5.5 の修正で全モデルに対応できる。
AI Engine 3.5.5 にアップデートした後、スキーマキャッシュは本当に自動クリアされるのか
開発者によれば、スキーマキャッシュのバージョンナンバーが引き上げられているため、更新後の初回リクエスト時に自動的に再生成される。手動でキャッシュを削除する操作は不要。もし不安があれば、AI Engine の設定画面からキャッシュを手動クリアしても問題ない。
この記事のポイント
- AI Engine 3.5.5 以降のアップデートで根本解決する
- 原因は Jetpack の整数型 enum を Gemini が拒否するため
- 読み取り専用モードでは書き込み系ツールが送信されず問題は出ない
- 手動修正する場合は Jetpack 一時無効化によるキャッシュ再生成が必須
- 修正後は文字列型以外の enum が自動除去され、あらゆる AI モデルで安定する
・ Reddit、Stack Overflow、WordPress.org フォーラムを日々巡回し、現場の悩みを拾い上げて記事化
・ WordPress、WooCommerce、Next.js などモダンWeb制作領域のトラブルシューティングが専門
・ 「検索しても答えが見つからなかった」を一つでも減らすことが目標
・ エラーメッセージから根本原因にたどり着く粘り強い調査が得意
・ 初心者がつまずきやすい箇所を先回りで解決する記事作りを心がけている

Googleのノンコモディティ方針、ECサイトが取るべきコンテンツ戦略
Googleが2026年5月、AI検索時代を見据えた新しい可視性ガイドラインを公開した。その中核にあるのが「ノンコモディティ・コンテンツ(Non-Commodity Content)」という概念だ。誰にでも書ける凡庸な情報ではなく、書き手自身の経験や独自の視点がにじむコンテンツを評価するという方針である。
Practical Ecommerceの記事によると、この考え方自体は目新しいものではない。Googleは長年にわたりEEAT(経験・専門性・権威性・信頼性)を重視してきた。しかしAIによるゼロクリック検索が急速に台頭する中で、改めて「人間にしか書けないコンテンツ」の重要性が言語化された形だ。
この記事では、Googleの「ノンコモディティ」方針の具体的な内容を整理する。あわせて、ECサイトを運営する事業者やWooCommerceユーザーがこの変化をどう受け止め、どんなコンテンツ戦略を取るべきかを実務目線で解説する。
Googleが定義する「コモディティコンテンツ」とは何か

GoogleのAI可視性ガイドラインは、検索上位を目指すコンテンツを2つに大別している。「コモディティコンテンツ」と「ノンコモディティコンテンツ」だ。まず前者の定義から確認しよう。
誰が書いても同じになる情報
コモディティコンテンツとは、いわゆる「一般的な知識」に基づいて書かれた情報のことだ。具体例としてGoogleが挙げているのが「初めて住宅を購入する人への7つのヒント」といった記事である。この手の内容は、どの書き手が担当しても似たような仕上がりになる。
実務的にいえば、競合他社の記事を参考に構成し、公開データだけを元にまとめた商品比較記事や、製品スペックを並べただけの紹介ページが該当する。生成AIを使えば数分で量産できるタイプのコンテンツだ。
検索におけるコモディティコンテンツの限界
Google検索のインハウスリエゾンであるダニー・サリバン氏は、2026年4月のSearch Central Live Torontoでこのテーマを取り上げている。同氏が示した業界別の対比表を見ると、コモディティコンテンツの問題点がより明確になる。
- ランニングシューズ販売店の場合「ランニングシューズ購入時に考慮すべき10のポイント」
- インテリアデザイナーの場合「2024年に見逃せないキッチントレンド」
これらは情報として誤りではない。しかし、検索エンジンから見れば「どのサイトを上位表示してもユーザー体験に大差がない」と判断されるリスクをはらむ。AIによる回答生成が進むほど、この傾向は強まるだろう。
ノンコモディティコンテンツが評価される理由

一方のノンコモディティコンテンツは、書き手固有の経験や専門知識に裏打ちされた情報を指す。生成AIが簡単に要約したり、出典なしで再利用したりしにくい性質を持つ。
Googleが示した具体例
先のダニー・サリバン氏による業界別の対比表では、ノンコモディティに該当する例として以下が挙げられている。
- ランニングシューズ販売店「なぜこの顧客のシューズは400マイルで壊れたのか、摩耗パターンの分析」
- インテリアデザイナー「大理石 vs ブドウジュース、5人家族に石材を勧めなかった理由」
どちらも実際の顧客対応や施工現場で起きた具体的なエピソードだ。競合が簡単に真似できる内容ではなく、読み手に「この店で買いたい」「このデザイナーに依頼したい」と思わせる力がある。
EEATとの関係性
ノンコモディティという用語は新しいが、背景にある考え方はGoogleが長年重視してきたEEATと重なる。EEATとは「Experience(経験)」「Expertise(専門性)」「Authoritativeness(権威性)」「Trustworthiness(信頼性)」の頭文字を取った評価基準だ。
Practical Ecommerceの記事では、Googleが以前から人間の評価者に対してEEATに基づくサイト評価を指示しており、ランキングアルゴリズムにもヘルプフルコンテンツシステムの一部としてEEATに似た要素が組み込まれている可能性が高いと指摘している。要するに、新しい概念が登場したというより、AI時代に合わせて既存の評価軸を再定義したと見るのが自然だ。
上図の対比からわかるように、ノンコモディティコンテンツは「そのサイトでなければ読めない情報」を提供する。この一点がAI時代の検索評価において決定的な差となる。
ECサイトが取り組むべきコンテンツ戦略

では、WooCommerceをはじめとするECサイト運営者は、この方針転換にどう対応すればよいのか。具体的な打ち手を3つの軸で整理する。
独自データに基づく分析記事
顧客の購買データや問い合わせ履歴を分析し、傾向を記事化する手法はノンコモディティコンテンツの典型例だ。「昨年と比べて20代女性の購入単価が15%上昇した理由」「雨の日に売れる商品トップ5とその背景」といった内容である。
WooCommerceのレポート機能やGoogleアナリティクスのデータを活用すれば、小規模店舗でも十分に独自性のある分析が可能だ。数字と具体的な事例をセットにすることで、読み手の信頼を得やすくなる。
実際の使用例や顧客ストーリー
商品紹介ページに顧客の使用シーンを詳細に盛り込むことも効果的だ。「30代男性がキャンプで3日間使用した感想」「子育て中の女性が選んだ理由と1カ月後の変化」といった具体的なエピソードは、スペック表では伝わらない価値を読者に届ける。
重要なのは、単なるレビュー評価の転載ではなく、店舗スタッフが直接ヒアリングした内容や観察した気づきを文章化することだ。この一手間が、生成AIでは代替できない独自性を生む。
専門家としての見解や実験結果
自社で取り扱う商材について、スタッフが実際に検証した結果を公開する方法もある。「3種類の防水スプレーを実際に試して効果を比較した」「同価格帯の Bluetooth イヤホン5製品を音質測定器でテストした」といった記事だ。
これらは手間とコストがかかるが、検索エンジンからの評価だけでなく、ブランドの信頼構築やリピーター獲得にも直結する。YouTube動画と組み合わせれば、さらに効果は高まるだろう。
コモディティコンテンツが無価値というわけではない

ここまでノンコモディティの重要性を強調してきたが、誤解してはいけない点がある。商品リリース情報や価格改定のお知らせ、採用情報といった「コモディティ的」なコンテンツにも確かな価値は存在する。
読者が求めるなら迷わず発信する
Practical Ecommerceの記事はこの点を明確に指摘している。読者が知りたい情報であれば、それがコモディティコンテンツであっても積極的に発信すべきだ。自社ブランドのファンは新製品の発表を待っているし、既存顧客はメンテナンス情報を必要としている。
直接流入の強化は、結局のところ最も確実なSEO対策である。コモディティかノンコモディティかという区分に過度に縛られるより、まずは目の前の顧客が何を求めているかに集中する姿勢が大切だ。
バランスの取れたコンテンツ設計を
理想的なのは、両方のタイプをバランスよく配置することだ。商品ページはコモディティ的な基本情報をしっかり押さえつつ、ブログ記事ではノンコモディティ的な独自コンテンツで差別化する。この二層構造が、AI検索時代のECサイトに求められるコンテンツ戦略の基本線となる。
WooCommerceサイト運営者が今すぐ始めるべき3つの施策

ここまでの内容を踏まえ、WooCommerceでECサイトを運営する事業者が今日から取り組める具体的なアクションを3つに絞って提案する。
1. 商品説明文に実体験を注入する
メーカー提供のスペック情報をそのまま転載している商品説明ページがあるなら、すぐに手を入れるべきだ。スタッフが実際に商品を使った感想や、想定外の使い方の発見、競合品との微妙な違いなどを追記するだけで、コンテンツの独自性は格段に高まる。
2. 社内ブログに顧客事例カテゴリを新設する
WooCommerceサイトにブログ機能を追加するのは難しくない。そこに「お客様事例」というカテゴリを作り、月1本のペースで実際の顧客ストーリーを掲載していく。許可を得た上で、購入のきっかけや使用後の変化を具体的に聞き取って記事化する。
3. アクセス解析から問いの種を探す
Googleサーチコンソールで自社サイトに流入している検索クエリを確認し、まだ十分に回答できていない質問を特定する。「〇〇 比較」「〇〇 口コミ」「〇〇 使い方」といったクエリに対して、自社の実体験やデータに基づいた回答記事を用意すれば、それがそのままノンコモディティコンテンツになる。
この記事のポイント
- GoogleはAI検索時代に対応するため「ノンコモディティコンテンツ」の重要性を正式に打ち出した
- ノンコモディティとは、書き手固有の経験や専門知識に裏打ちされた、生成AIでは簡単に再現できない情報を指す
- ECサイトでは顧客データ分析、使用事例の詳細な紹介、自社検証記事の公開が有効な差別化策となる
- 読者が求める情報であれば、コモディティ的なコンテンツにも価値はある、バランスが肝心
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験