

Googleの新技術TurboQuantが検索とAIの未来を変える
Googleがベクトル検索技術の新たな突破口となるTurboQuantを発表した。この技術はAI処理に必要なサイズとメモリ要件を劇的に削減し、検索エンジンの仕組みを根本から変える可能性がある。
TurboQuantは高度なアルゴリズムの集合体で、ベクトルデータベースの構築時間を「ほぼゼロ」に短縮する。従来の検索システムではコストが高く限定的だった大規模な意味検索が、低コストで瞬時に行えるようになる。これは検索結果の質、AI概要の増加、パーソナライズされた検索体験に直接影響を与える技術革新だ。
TurboQuantが解決するベクトル検索の課題

TurboQuantの重要性を理解するには、まずベクトル検索の基本とその課題を知る必要がある。従来のキーワードマッチングとは異なるアプローチで、検索エンジンはより深い意味理解を実現しようとしている。
ベクトル埋め込み:言葉を数値に変換する技術
ベクトル埋め込みは、テキストや画像、動画を一連の数値に変換する技術だ。これらの数値は単語や概念の意味的関係をエンコードする。例えば「王様」から「男性」を引き、「女性」を足すと「女王」に近いベクトルが得られる。言葉の数学的操作が可能になるのは、各単語が文脈に基づいてベクトル空間にマッピングされるためだ。
この技術はGoogleが2013年に発表したWord2Vecの研究から発展した。当時から、単語の意味を学習するベクトル表現の可能性は認識されていた。現在の検索エンジンは、この技術をさらに発展させてユーザーの検索意図を深く理解しようとしている。
ベクトル検索とメモリのボトルネック
ベクトル検索は、ベクトル空間内で互いに近い点を見つけるプロセスだ。ユーザーの検索クエリをベクトル空間に埋め込み、意味的に類似したコンテンツを近傍から探し出す。従来のキーワード完全一致ではなく、概念的な関連性に基づく検索が可能になる。
しかし課題があった。多次元空間でのベクトル検索は膨大なメモリを消費する。メモリは近傍探索のボトルネックとなり、大規模なデータセットでの実用的な応用を制限していた。GoogleのエンジニアPandu Nayak氏がDOJ対Google裁判で証言したように、RankBrainのようなシステムでもコストの高い処理であるため、上位20〜30件の結果に限定して適用されていた。
ベクトル量子化の限界とTurboQuantの解決策
メモリ問題に対処するため、ベクトル量子化という技術が開発された。これは巨大なデータポイントのサイズを縮小する数学的手法で、超効率的なzipファイルのようなものだ。しかしデータを圧縮すると結果の品質が低下し、さらに圧縮データに追加されるビットがメモリ負荷を増やすという逆説的な問題があった。
TurboQuantはこの問題を根本から解決する。大きなデータベクトルを回転させて幾何学的に単純化し、JPEG圧縮のように各部分を個別に小さな離散集合にマッピングする。これにより元のベクトルの主要概念を保持しながら、メモリ使用量を大幅に削減できる。隠れたエラーはQJLと呼ばれる数学的手法で1ビットのメモリを使用して検証・修正され、精度を維持したまま高速処理を実現する。
検索エンジンへの具体的な影響

TurboQuantの実用化は、検索エンジンの動作とユーザー体験に具体的な変化をもたらす。従来の技術的制約によって実現できなかった機能が、現実的なコストで提供可能になる。
大規模な意味検索の実現とAI概要の増加
TurboQuantにより、Googleは大規模な意味検索を実行できるようになる。従来はコストが高すぎて上位20〜30件の結果に限定されていたベクトル検索が、数百件の候補に対して瞬時に行える。これによりAI概要(AI Overviews)の質と量が向上し、複雑な質問にも即座にAI生成の回答を提供できるようになる。
Search Engine Journalの記事では、TurboQuantが検索結果の多様性と関連性を高める可能性が指摘されている。ユーザーの特定のニーズと意図に合致した、真に役立つコンテンツがより容易に表面化する仕組みだ。
高度にパーソナライズされた検索体験
Googleが導入したパーソナルインテリジェンスは、TurboQuantによってさらに強化される見込みだ。個人の検索履歴、ドキュメント、メール、好みを瞬時に検索可能なベクトル空間に格納し、リアルタイムのAIアシスタントとして機能する。DeepMind CEOのDemis Hassabis氏が描くユニバーサルAIアシスタントの構想に近づく一歩となる。
視覚データをベクトル空間に変換する技術も進化する。AIグラスやGemini Liveを通じて取得した大量の視覚情報が検索可能になり、「鍵をどこに置いたか」といった日常的な質問にも視覚的記憶に基づいて回答できるようになる。
エージェントシステムとロボティクスの進化
エージェントシステムの能力向上
AIエージェントは従来、コンテキストウィンドウの制限と情報取得の遅さに制約されていた。TurboQuantにより、AIエージェントは無限の完全に想起可能な長期記憶を持つことができる。あらゆるインタラクション、ドキュメント、メール、好みをミリ秒単位で瞬時に検索し、他のエージェントと大量の情報を通信できるようになる。
ロボティクスの実用化加速
ロボットが現実世界で動作する際、周囲の物体の意味的文脈を理解するのは複雑な課題だ。TurboQuantはロボットが環境内の物体を意味的に分類し、適切な行動を判断する能力を大幅に向上させる。Google DeepMindとBoston Dynamicsのパートナーシップも、この技術進化の文脈で捉えることができる。ロボットの知能化と実用化が加速する見込みだ。
SEO担当者への実践的影響

TurboQuantのような技術進化は、SEOの実践方法に具体的な変化を要求する。単なる技術的最適化から、ユーザー意図の本質的理解へと重心が移行する。
コンテンツ戦略の再考が必要な理由
TurboQuantがもたらす最大の変化は、AI概要がより多くの検索クエリでユーザーを満足させるようになる点だ。世界の情報を整理するだけのコンテンツは、AI回答によって代替される可能性が高まる。一方で、人々がAI回答よりも関わりたいと思うようなコンテンツは、より高い価値を持つようになる。
Search Engine Journalの著者Marie Haynes氏は、自身のコミュニティ「The Search Bar」での議論を紹介している。そこで指摘されているのは、ユーザー意図を徹底的に理解し満たすことに焦点を当てたSEO担当者にとって、基本的なアプローチは変わらないという点だ。しかしビジネスモデルによって影響は異なる。
従来のSEO要素の相対的重要性変化
TurboQuantがGoogleのランキングシステムに導入されれば、意味検索の精度と範囲が拡大する。その結果、従来のSEO要素である被リンクやSEOに特化したコピーの重要性が相対的に低下する可能性がある。Googleは数百件の可能な結果に対して意味検索を行い、ユーザーに瞬時に正確で役立つ情報を提供できるようになる。
技術的な観点から見ると、TurboQuantの研究論文は2025年4月に公開されており、Googleは約1年間かけて改善を重ねてきた。このタイムラインは、2025年6月のコアアップデートで観測された変化の背景にMUVERAというベクトル検索の突破があったとする同氏の以前の推測と一致する。技術の研究公開から実装までには時間的余裕があり、突然の変化ではなく計画的に進化が進んでいる。
AIと検索の未来像

TurboQuantは単なる技術的改善ではなく、AIと検索の関係性を再定義する転換点となる。Demis Hassabis氏が予測する5〜10年以内のAGI(人工汎用知能)実現に向けた、重要なブレークスルーの一つと位置付けられる。
エージェント型AIの普及とウェブサイトの最適化
エージェント型AIの普及に伴い、ウェブサイトは人間だけでなく機械に対しても情報を伝達できるように最適化する必要が生じる。これは従来のSEOやCRO(コンバージョン最適化)から、AAIO(エージェント型AI最適化)への移行を意味する。コンテンツは構造化され、意味的に明確に記述され、AIエージェントが容易に理解・処理できる形式であることが重要になる。
回答エンジン最適化(Answer Engine Optimization)という概念も注目を集めている。AI応答にコンテンツが採用されるための最適化手法で、従来の検索エンジン最適化とは異なるアプローチが求められる。
技術進化に対応するビジネスモデルの変革
TurboQuantのような技術進化は、一部のビジネスモデルに根本的な変革を迫る。情報のキュレーションを主要な価値提案とするサービスは、AI概要によって需要が減少する可能性がある。一方で、深い専門性、独自の洞察、人間ならではの創造性を提供するコンテンツは、より高い差別化要因となる。
重要なのは、現在のビジネスモデルがAIの進化によってどのような影響を受けるかを客観的に評価し、必要に応じて適応することだ。Marie Haynes氏が提供するGemini Gemは、この評価プロセスを支援するツールとして機能する。複数のドキュメントを知識ベースに入力し、AIの世界でのビジネスの将来についてブレインストーミングを行うことができる。
この記事のポイント
- GoogleのTurboQuantはベクトル検索のインデックス作成時間を「ほぼゼロ」に短縮し、AI処理のメモリ要件を大幅に削減する技術だ。
- 従来はコストが高く限定的だった大規模な意味検索が可能になり、AI概要の質と量が向上する見込みである。
- パーソナライズされた検索体験が強化され、ユニバーサルAIアシスタントの実現に近づく。
- SEOにおいては、ユーザー意図の本質的理解と真に役立つコンテンツの提供が従来以上に重要になる。
- エージェント型AIの普及に伴い、ウェブサイトは機械に対しても情報を伝達できる最適化(AAIO)が必要となる。

・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Cloudflare Client-Side Securityが全ユーザーに開放。GNNとLLMを融合した最新の検知技術を解説
Cloudflareは、ウェブサイトの閲覧者側で実行される悪意のあるスクリプトを検知・遮断する「Client-Side Security」の大幅なアップデートを発表した。これまでエンタープライズ向けに提供されていた高度なセキュリティ機能が、セルフサービスを利用するすべてのユーザーに開放される。1日あたり35億ものスクリプトを評価する同社のネットワークが、より広範なウェブサイトを保護する体制を整えた。
今回の更新で最も注目すべきは、AIを用いた新しい検知システムの導入だ。グラフニューラルネットワーク(GNN)と大規模言語モデル(LLM)を組み合わせることで、誤検知を劇的に減らしつつ、未知の攻撃を高い精度で特定できるようになった。従来のシグネチャベースの防御では防ぎきれない、高度に難読化された攻撃への対策が強化されている。
クライアントサイドを標的とした攻撃は、サイトの表示を崩すことなくデータを盗み出すため、運営者が気づきにくいという特徴がある。Cloudflareはこの課題に対し、最新のAI技術を統合することで、運用の手間を最小限に抑えながら強固な防御を提供することを目指している。本記事では、その技術的な仕組みと実戦での成果について詳しく解説する。
Cloudflare Client-Side Securityの進化と新展開

Cloudflareは、強力なセキュリティ機能を営業担当者との交渉なしに利用可能にすることを基本原則として掲げている。その一環として、これまで「Page Shieldアドオン」と呼ばれていた機能を「Client-Side Security Advanced」へと統合し、セルフサービスプランのユーザーでも即座に導入できるようにした。
全ユーザーへの門戸開放と無料化の意義
今回のアップデートにより、ドメインベースの脅威インテリジェンスがすべての顧客に無料で提供される。2025年には、Magentoなどのプラットフォームを利用する中小規模のECサイトが、クライアントサイドからの攻撃により数週間にわたって被害を受け続ける事例が多数報告された。こうしたリソースの限られたサイト運営者でも、ダッシュボード上のトグルを切り替えるだけで、既知の悪意のあるドメインとの通信を可視化できるようになった。
PCI DSS v4への対応とコンプライアンス
Client-Side Security Advancedには、コードの変更を継続的に監視する機能が含まれている。これは、クレジットカード業界のセキュリティ基準である「PCI DSS v4」の要件11.6.1を満たすために不可欠な要素だ。EC事業者はこのツールを導入することで、法規制や業界基準への準拠を容易に進めることができる。また、コンテンツセキュリティポリシー(CSP)に基づいたプロアクティブなブロックルールの運用も可能となっている。
攻撃をあぶり出す仕組み:ASTとブラウザレポーティング

クライアントサイドのセキュリティ管理は、膨大なデータを扱う極めて困難な課題だ。一般的なエンタープライズサイトでは、平均して2,200もの固有のスクリプトが動作している。さらに、これらのスクリプトの約3分の1は30日以内に更新される。これらを手動で承認していては、開発パイプラインが停止してしまうため、自動化された高度な分析が必要となる。
レイテンシゼロで監視するアーキテクチャ
Cloudflareのシステムは、ブラウザレポーティング(Content Security Policyなど)を利用して信号を収集する。これにより、サイトにスキャナーを導入したり、アプリケーションに特別なコードを埋め込んだりする必要がない。ユーザーのブラウザからの報告をCloudflareのプロキシ経由で受け取る仕組みのため、ウェブアプリケーションの表示速度に一切の影響を与えないのが大きな強みだ。
難読化を突破するAST解析の威力
攻撃者は検知を逃れるために、コードの変数を意味のない文字列に書き換えたり、構造を複雑にしたりする「難読化」を行う。Cloudflareはこれに対抗するため、スクリプトを「AST(Abstract Syntax Tree / 抽象構文木)」に分解して解析する。ASTとは、プログラムの構造を樹状図のような形式で表現したものだ。コードの見かけ上の書き方が変わっても、論理的な構造や挙動(インテント)を抽出できるため、悪意のある意図を正確に特定できる。
以下のデモは、難読化されたコードがどのようにAST的な構造として捉えられるかを視覚化したイメージだ。
var _0x1a2b = ["\x63\x6F\x6F\x6B\x69\x65"];
function _0x3c4d(){
send(_0x1a2b[0]);
} このデモは難読化されたコードが解析され、データの持ち出しという構造が特定される過程を視覚化したイメージである。
GNNとLLMを組み合わせた「二段構え」の検知システム

Cloudflareが導入した最新の検知システムは、2つの異なるAIモデルを連携させる「カスケード型」のアーキテクチャを採用している。これにより、広大なインターネット上に存在する無限に近いバリエーションのスクリプトを、効率的かつ正確に処理することが可能になった。
構造を捉えるGNNの役割と限界
第1段階として、すべてのスクリプトはグラフニューラルネットワーク(GNN)によって評価される。GNNはASTの構造を学習し、変数の名前が変更されていても、実行パターンの特徴から悪意のある挙動を検知する。GNNは処理が高速であり、未知の脅威(ゼロデイ攻撃)を見逃さない「高い再現率」を持っている。しかし、その一方で、複雑な広告用スクリプトや難読化された正当なライブラリを誤って「攻撃」と判定してしまう「偽陽性」が課題となっていた。
Workers AIによるLLMの「セカンドオピニオン」
GNNが「疑わしい」と判定したスクリプトのみ、第2段階として大規模言語モデル(LLM)に送られる。ここで使用されるのは、Cloudflareの「Workers AI」上で動作するオープンソースのLLMだ。LLMはコードの意味的な文脈を深く理解しており、開発者がよく使う記述パターンやフレームワーク特有の動作を識別できる。LLMが「これは怪しいが見た目は無害なコードだ」と判断すれば、GNNの判定を上書きして誤検知を防ぐ。この二段構えにより、独自の評価では偽陽性を約3分の1にまで削減することに成功した。
実戦での成果:ルーターを標的にした「core.js」の検知事例

この新しい検知システムは、すでに実際の攻撃を特定する成果を上げている。最近検知された「core.js」という悪意のあるスクリプトの事例は、AIによる構造・意味解析の有効性を証明するものとなった。
高度な難読化とゼロデイ攻撃の正体
「core.js」は、特定の地域でXiaomi製のOpenWrtベースのホームルーターを乗っ取ることを目的としたスクリプトだった。このスクリプトは、ルーターのWAN設定(DHCP、スタティックIP、PPPoEなど)を動的に照会し、DNS設定を書き換えてトラフィックをハイジャックしようとする。さらに、管理パスワードを密かに変更して、正当な所有者を締め出す機能まで備えていた。この攻撃はウェブサイトを直接改ざんするのではなく、侵害されたブラウザ拡張機能を通じてユーザーのセッションに注入されていた。
偽陽性を劇的に減らす精度の向上
このスクリプトは高度に圧縮・難読化されており、従来のシグネチャベースの防御システムでは検知が困難だった。しかし、CloudflareのGNNは難読化の奥にある悪意のある構造を暴き出し、Workers AI上のLLMがその意図を「ルーターのAPIを悪用する攻撃である」と確信を持って判定した。全体的なトラフィックにおける偽陽性率は約0.3%から0.1%へと低下し、固有のスクリプト単位では、偽陽性率が1.39%から0.007%へと約200倍も改善されたという。これにより、運用担当者はアラート疲れに陥ることなく、真の脅威に集中できるようになった。
独自の分析:クライアントサイドセキュリティが不可欠になる理由

今日のウェブ制作において、サードパーティ製スクリプトの利用は避けて通れない。広告、アクセス解析、チャットボット、SNS連携など、1つのサイトで数十の外部サービスが読み込まれることは珍しくない。しかし、これは「サプライチェーン攻撃」のリスクを常に抱えていることを意味する。自社のサーバーをどれだけ堅牢に守っても、読み込んでいる外部のJavaScriptが侵害されれば、ユーザーの個人情報や決済データは簡単に盗まれてしまう。
Cloudflareの今回の取り組みが画期的なのは、AIを「検知の高速化」だけでなく「運用の現実化」に活用した点だ。これまでのクライアントサイドセキュリティは、厳格に設定すれば誤検知が増えてビジネスを阻害し、緩く設定すれば攻撃を見逃すというジレンマがあった。GNNで広く網を張り、LLMで賢く精査するというアプローチは、膨大かつ変化の激しい現代のウェブエコシステムにおける現実的な解といえる。
特に、Workers AIを活用して自社ネットワーク内でLLMを完結させている点は、プライバシーとレイテンシの両面で合理的だ。セキュリティ製品が「導入するとサイトが重くなる」というこれまでの常識を覆し、パフォーマンスを維持したまま高度なAI防御を適用できるようになった意義は大きい。今後は、さらにLLMの判定基準を最適化することで、よりアグレッシブな検知設定が可能になり、未知の攻撃に対する防御力はさらに高まっていくと指摘されている。
この記事のポイント
- Cloudflare Client-Side Security Advancedがセルフサービスプランの全ユーザーに開放された
- ドメインベースの脅威インテリジェンスが無料化され、中小規模のサイトでも導入が容易になった
- GNNによる構造解析とLLMによる意味解析を組み合わせた二段構えの検知システムを導入した
- Workers AIを活用することで、サイトの表示速度に影響を与えずに高度なスクリプト解析を実現した
- ルーターを標的とした「core.js」のような、従来のシステムでは見逃されやすいゼロデイ攻撃の検知に成功した
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

フォーム自動化の実践テクニック——フロントエンドから始める業務効率化
フォームが正常に送信されても、業務がうまく回らないことがある。CSS-Tricksの記事では、フォーム送信後のワークフローに注目した設計の重要性が指摘されている。フロントエンド開発者がデータの行方を追うことで、業務の効率化が実現できる。
具体的な例として、週末に届いた問い合わせメールが月曜まで放置され、商機を逃したケースが紹介されている。フォームそのものは完璧に動作していたが、データを受け取る側のプロセスに問題があった。このような「フォームは動くが業務は止まる」状況を防ぐには、フロントエンドの設計段階から自動化を意識する必要がある。
「送信完了」では終わらないフォーム設計

従来のフォーム実装は、データをAPIエンドポイントにPOSTし、メールを送信して終了するパターンが多かった。しかしこの方法には限界がある。重複送信による混乱、CRM(顧客関係管理システム)へのインポート時のフォーマット不一致、週末の問い合わせの見落としなど、実際の業務では多くの問題が発生する。
Litmusの2025年メールマーケティングレポートによると、受信箱ベースのワークフローではフォローアップの遅れが生じやすく、特にリード生成に依存するセールスチームに影響が大きい。メールは単なる通知ではなく、業務を引き継ぐ「ハンドオフ」の手段として捉える必要がある。
フロントエンドの選択が自動化を左右する
HubSpotの調査では、フロントエンド段階(ユーザー操作時)のデータ品質が、その後のプロセス全体の成否を決定づけることが明らかになっている。フォーム設計における実践的な判断基準を見ていく。
必須項目と任意項目の再定義
「ビジネスがデータに何を求めているか」から逆算して項目を設計する。電話でのフォローアップが主要な方法なら、電話番号フィールドを必須にする。役職情報がフォローアップの重要な文脈でないなら、任意項目とする。この判断には、コーディング前の関係者間での協力が不可欠だ。
実際の事例として、電話番号フィールドを任意としたが、CRM側で必須項目として扱われていたため、送信データが無効化され、CRMがデータを拒否する事態が発生した。ユーザー体験の仮定ではなく、業務プロセスの観点からコーディング判断を下す必要がある。
データ品質を高めるフロントエンド処理

送信後のデータ処理を楽にするには、フロントエンド段階で可能な限りデータを整えることが効果的だ。下流のツールは融通が利かない。「John Wick」と「john wick」が同じ人物の送信であることを関連付けられない。
早期のデータ正規化
電話番号のような特定の形式でフォーマットが必要なデータは、送信前に一貫性を持たせる。余分な空白の削除、タイトルケース(各単語の先頭を大文字)への統一も同様だ。
あるクライアントは、大文字小文字の不一致によって作成された重複レコードを手動で整理するために、200件のCRMエントリをクリーニングする作業を強いられた。このような手間は、5分のフロントエンドコードで防げる。
フロントエンドでの重複送信防止
クリック時に送信ボタンを無効にするだけでも、重複送信による頭痛の種を防げる。処理中であることを示すローディングインジケーターを表示する、送信処理中のフラグを保存するなどの明確な「送信状態」を示すことが重要だ。
重複したCRMエントリは、クリーニングに実費がかかる。低速ネットワーク上の忍耐強くないユーザーは、機会さえあれば何度もボタンをクリックする。
意味のある成功・エラー状態
フォーム送信後、ユーザーに何を知らせるべきか。デフォルトの「ありがとう!」メッセージは一般的だが、実際にどの程度の文脈を提供しているだろうか。送信データはどこに行くのか。チームはいつフォローアップするのか。待っている間にチェックできるリソースはあるか。これらはリードの期待値を設定するだけでなく、フォローアップ時のチームの助けにもなる貴重な文脈情報だ。
エラーメッセージもビジネスを助けるべきだ。重複送信を扱う場合、「このメールアドレスはすでにシステムに登録されています」というメッセージは、一般的な「問題が発生しました」よりもはるかに役立つ。
自動化対応フォームの実装テクニック

次回のフォーム実装で確実に実施すべき、具体的な技術的アプローチを紹介する。
送信前の高度なバリデーション
単にフィールドが存在するかどうかをチェックするのではなく、実際に使用可能かどうかを検証する。
function validateForAutomation(data) {
return {
email: /^[^\s@]+@[^\s@]+\.[^\s@]+$/.test(data.email),
name: data.name.trim().length >= 2,
phone: !data.phone || /^\d{10,}$/.test(data.phone.replace(/\D/g, ''))
};
}このバリデーションが重要な理由は、CRMが不正な形式のメールアドレスを拒否するからだ。エラー処理は、ユーザーが送信をクリックする前、サーバー応答を2秒待った後ではなく、事前に捕捉すべきだ。
ただし、この電話番号バリデーションは一般的なケースをカバーするが、国際フォーマットなどに対応するには不十分な場合がある。本番環境では、包括的な検証のためにlibphonenumberのようなライブラリの使用を検討する価値がある。
一貫性のあるフォーマット処理
バックエンドで処理されると想定するのではなく、送信前にデータを整形する。
function normalizeFormData(data) {
return {
name: data.name.trim()
.split(' ')
.map(word => word.charAt(0).toUpperCase() + word.slice(1).toLowerCase())
.join(' '),
email: data.email.trim().toLowerCase(),
phone: data.phone.replace(/\D/g, ''), // 数字のみに変換
message: data.message.trim()
};
}この処理を行う理由は、「JOHN SMITH」と「john smith」が重複レコードを作成し、クライアントが200件以上のCRMエントリを手動で修正する事態を防ぐためだ。この修正には5分のコーディングで済み、下流での時間を節約できる。
ただし、この名前分割ロジックには注意点がある。単一の名前、ハイフン付きの姓、「McDonald」のような特殊なケース、複数のスペースを含む名前では問題が発生する可能性がある。堅牢な名前処理が必要な場合は、代わりに名前と姓を別々のフィールドとして要求することを検討する。
二重送信の防止実装
クリック時に送信ボタンを無効にする方法で実現できる。
let submitting = false;
async function handleSubmit(e) {
e.preventDefault();
if (submitting) return;
submitting = true;
const button = e.target.querySelector('button[type="submit"]');
button.disabled = true;
button.textContent = '送信中...';
try {
await sendFormData();
// 成功時の処理
} catch (error) {
submitting = false; // エラー時に再試行を許可
button.disabled = false;
button.textContent = 'メッセージを送信';
}
}このパターンが機能する理由は、せっかちなユーザーはダブルクリックし、低速ネットワークでは再度クリックするからだ。このガードがないと、クリーニングに実費がかかる重複リードが作成される。
自動化のためのデータ構造化
平坦なFormDataオブジェクトを送信するのではなく、データを構造化する。
const structuredData = {
contact: {
firstName: formData.get('name').split(' ')[0],
lastName: formData.get('name').split(' ').slice(1).join(' '),
email: formData.get('email'),
phone: formData.get('phone')
},
inquiry: {
message: formData.get('message'),
source: 'website_contact_form',
timestamp: new Date().toISOString(),
urgency: formData.get('urgent') ? 'high' : 'normal'
}
};構造化データが重要な理由は、Zapier、Make、カスタムWebhookなどのツールがそれを期待するからだ。平坦なオブジェクトを送信すると、誰かがそれを解析するロジックを書く必要がある。事前に構造化して送信すれば、自動化は「そのまま動作する」。これは、脆弱な単一ステップの「シンプルなZap」ではなく、より信頼性が高く保守可能なワークフローを構築するためのZapier自身の推奨事項を反映している。
送信後のワークフローを意識した設計

理想的なフローは次のようになる。ユーザーがフォームを送信、データがエンドポイント(またはフォームサービス)に到着、自動的にCRM連絡先を作成、セールスチームにSlack/Discord通知を送信、フォローアップシーケンスをトリガー、レポート用にスプレッドシートにデータを記録。
フロントエンドの選択がこれを可能にする。フォーマットの一貫性はCRMへのインポート成功、構造化データは自動化ツールによる自動入力、重複排除は煩雑なクリーニングタスクの不要、バリデーションは「無効なエントリ」エラーの減少につながる。
実際の経験として、見積もりフォームを再構築した後、クライアントの自動見積もり成功率が60%から98%に向上した。変更点は、{ "amount": "$1,500.00"}を送信する代わりに、{ "amount": 1500}を送信するようにしたことだ。Zapier連携は通貨記号を解析できなかった。
フォーム送信のベストプラクティス
これらの教訓から、フォーム設計に関する以下のベストプラクティスが導き出される。
ワークフローについて早期に質問する。「誰かがこれを記入した後、何が起こるか」が最初の質問になるべきだ。これにより、どこに何が必要か、どのデータが特定の形式で入ってくる必要があるか、どの統合を使用するかが明確になる。
実際のデータでテストする。余分なスペースや奇妙な文字列、携帯電話番号、不適切な大文字小文字の文字列など、独自の入力でフォームに記入する。「John Smith」ではなく「JOHN SMITH 」を入力すると、驚くほどのエッジケースが発生する可能性がある。
タイムスタンプとソースを追加する。必ずしも必要ではないように思えても、システムに設計として組み込むことは理にかなっている。半年後には、いつ受信したかを知ることが役立つ。
冗長性を持たせる。メールとWebhookの両方をトリガーする。メールで送信すると、誰かが「あのメッセージ届きましたか」と尋ねるまで、沈黙することが多い。
成功を過剰に伝える。リードの期待値を設定することは、より楽しい体験につながる。「メッセージが送信されました。営業のサラが24時間以内に回答します」は、単なる「成功しました!」よりもはるかに優れている。
この記事のポイント
- フォームの「送信完了」は業務のスタート地点であり、フロントエンド設計がバックエンドの自動化効率を決定する
- データの正規化はフロントエンド段階で行うことで、CRMなどの下流システムでの手作業を大幅に削減できる
- 構造化されたデータ形式はZapierなどの自動化ツールとの連携を容易にし、ワークフローの信頼性を高める
- 重複送信防止や詳細なバリデーションは、ユーザー体験の向上だけでなく、業務コストの削減にも直結する
- フォーム設計時には「このデータが手元を離れた後、何が起こるか」を常に問い続けることが重要だ
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

生成AI時代のSEO戦略——ChatGPT・Geminiに選ばれるECサイトの作り方
生成AIが検索エンジンの代わりに使われる時代が来つつある。ChatGPTやGemini、Perplexityといった大規模言語モデル(LLM)は、ユーザーの質問に答えるためにGoogleを検索し、情報を収集している。検索結果で上位に表示されない、あるいは全くランキングされていないページは、これらのAIプラットフォームからもほぼ見えない状態だ。
つまり、従来の検索エンジン最適化(SEO)は、生成AIプラットフォーム上での可視性を確保するための基盤技術として、その重要性を増している。ECサイト運営者は、人間の顧客だけでなく、AIエージェントにも発見され、引用されるための新しいSEO戦略を考える必要がある。
生成AIが検索エンジンをどう使うか
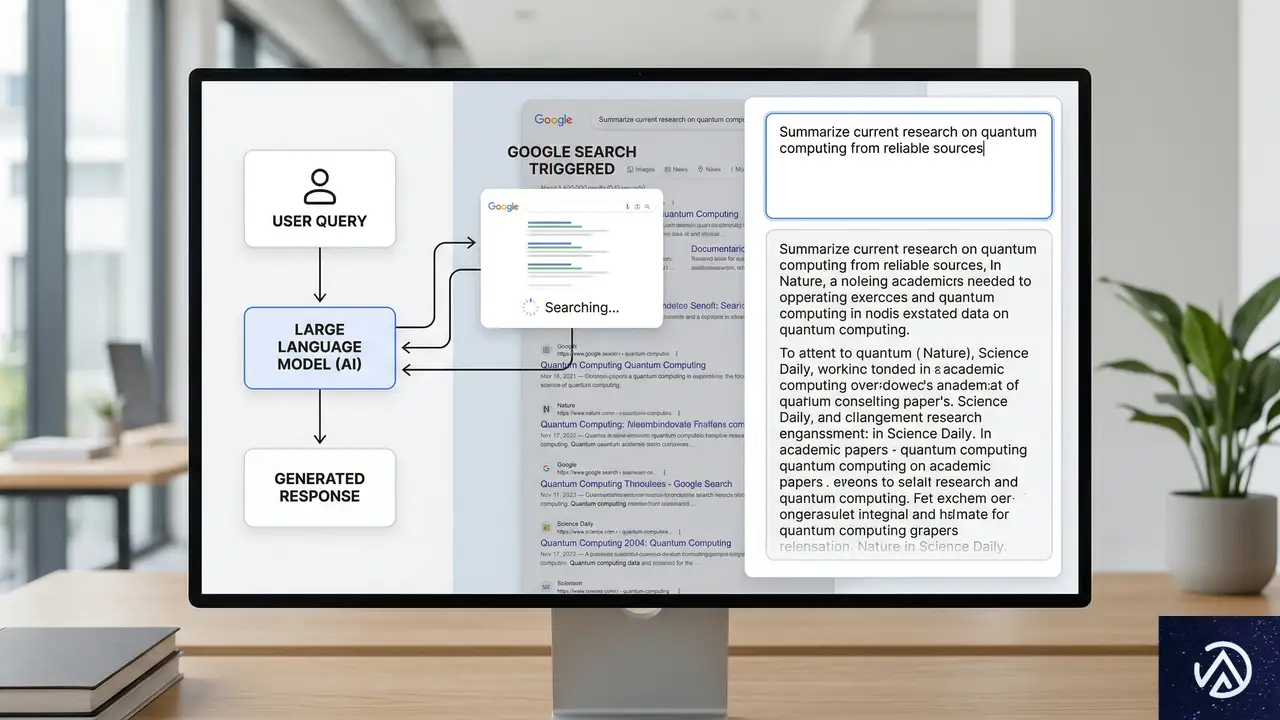
Practical Ecommerceの記事によると、ChatGPTなどの大規模言語モデルは、ユーザーの質問に答える際、内部でGoogle検索を実行して情報を収集している。この事実は、AI時代のSEOを考える上で決定的に重要だ。
AIが参照するのは、あくまでGoogleの検索インデックスだ。したがって、Googleで上位にランキングされていないページは、AIの回答にも引用されにくい。逆に言えば、従来のSEO対策でGoogleからの評価を高めることが、AIからの可視性を高める最も確実な近道となる。
AIの回答生成と引用のメカニズム
AIがユーザーに回答を提供する際、必ずしも情報源のサイト名を明示するとは限らない。内容を要約し、独自の言葉で回答を構成する場合が多い。しかし、その回答の根拠となる情報があなたのサイトから引用されていれば、それは間接的なブランド認知と信頼の構築に繋がる。
さらに、AIが特定の分野で繰り返しあなたのサイトの情報を参照するようになれば、将来的には「信頼できる情報源」として、より積極的な推薦を行う可能性も生まれる。この段階に至るためには、まずAIに「発見される」ことが不可欠だ。
AI時代のキーワードリサーチ

生成AIプラットフォームは、ユーザーがどのようなプロンプト(質問)を入力しているかのデータを公開していない。このため、従来の検索エンジン向けのキーワードリサーチ手法が、AI時代においても主要な情報源となる。
検索意図の深掘りがカギ
ユーザーが商品を購入するに至るまでの道筋(カスタマージャーニー)を理解することが重要だ。第三者のキーワードツールを活用し、キーワードを「情報収集」「比較検討」「購入」といった検索意図別に分類する。これにより、研究段階のユーザーから購入直前のユーザーまで、あらゆる段階でターゲットを捕捉するコンテンツ戦略が立てられる。
キーワードギャップ分析も有効だ。これは、競合サイトが獲得しているが自社サイトが獲得できていないキーワードを特定する手法である。これらのキーワードをターゲットにしたコンテンツを作成することで、見込み客を取り込む機会を増やせる。
長く、予測不能なプロンプトへの備え
AIへのプロンプトは、従来の検索クエリよりも長く、会話調である傾向がある。また、その内容は多様で予測が難しい。しかし、高レベルのキーワード最適化を行い、ユーザーの根本的なニーズ(問題解決、欲求充足)に応えるコンテンツを用意しておくことが、あらゆる形式の問い合わせに対する最良の備えとなる。
AIと人間の両方に最適化されたコンテンツ
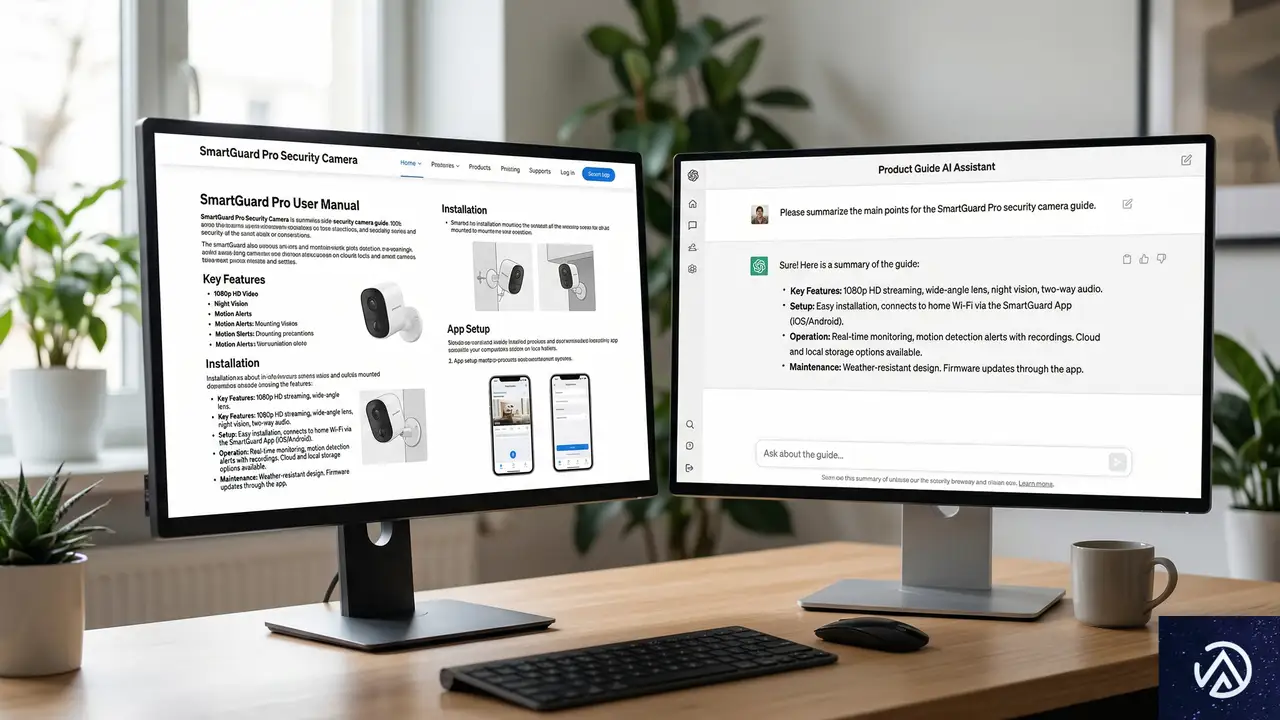
最高のECコンテンツとは、自社の商品が消費者のニーズに対応し、問題を解決する方法を説明するものだ。トラフィックの絶対量は数年前より減少しているかもしれないが、商品発見のための基盤としての重要性は変わらない。
ファネル全体をカバーするコンテンツ戦略
「購入直前」(ボトムオブザファネル)のクエリのみに焦点を当てるのは短絡的だ。確かにコンバージョンに直結しやすいが、新規顧客の発見という観点では機会を狭めてしまう。認知段階や検討段階のユーザーを惹きつけるトップ・ミドルファネルのコンテンツも充実させることで、AIが幅広い質問に対してあなたのサイトを情報源として参照する可能性が高まる。
要約されても価値がある
AIがあなたのコンテンツを要約し、会社名を明示せずに回答に組み込むこともある。一見するとブランド露出の機会を失っているように思える。しかし、あなたの情報が「信頼できるLLMソリューションの一部」として回答に含まれることは、将来的な直接的な推薦への布石となり得る。まずは質の高い情報を提供し、AIの学習データの一部になることが第一歩だ。
AIエージェントが理解しやすいサイト構造
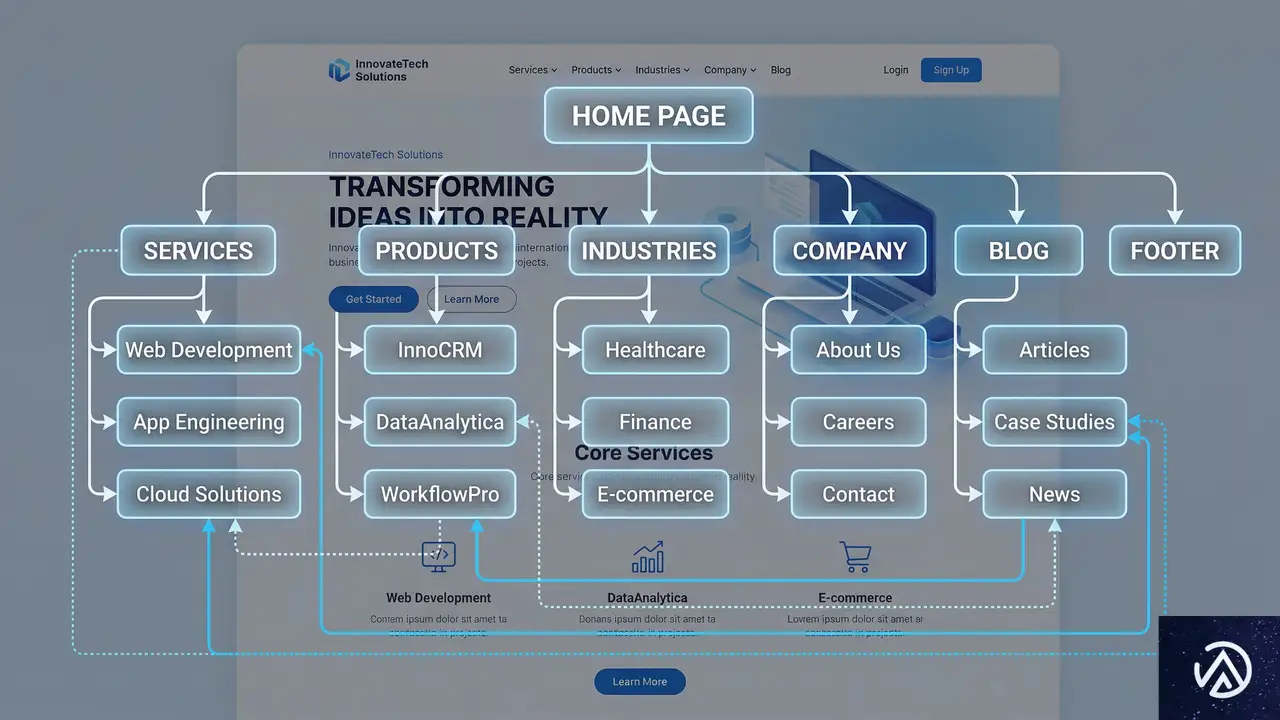
サイトのアーキテクチャ(構造)は、人間のユーザーだけでなく、AIボットがサイトを理解する上でも極めて重要だ。水平型のサイトアーキテクチャ(ページが深く埋もれていない構造)と適切な内部リンクは、ボットの巡回性を高め、ロングテールキーワードでのランキング機会を増やす。
明確な構造がAIの理解を助ける
整理されたサイト構造は、AIがあなたのビジネスを理解し、その商品やサービスをトレーニングデータ内で正しく位置づける手助けをする。これは、関連する質問に対してあなたのサイトが候補として挙がりやすくなることを意味する。
最適化されたナビゲーションの条件
AIエージェントにも対応した最適化されたサイトナビゲーションは、以下の条件を満たしている。
- 人間とAIエージェントの両方が、素早く必要なものを見つけられる構造である。
- JavaScriptが無効でも利用可能で、あらゆるウェブブラウザでアクセスできる。
- サイトの最も重要なセクションと、提供する主なベネフィットに焦点が当てられている。
このような堅牢な構造は、あらゆるクローラー(Googleボット、AIボット)に対して、サイトの価値を明確に伝える基盤となる。
リンク構築と権威性の信号
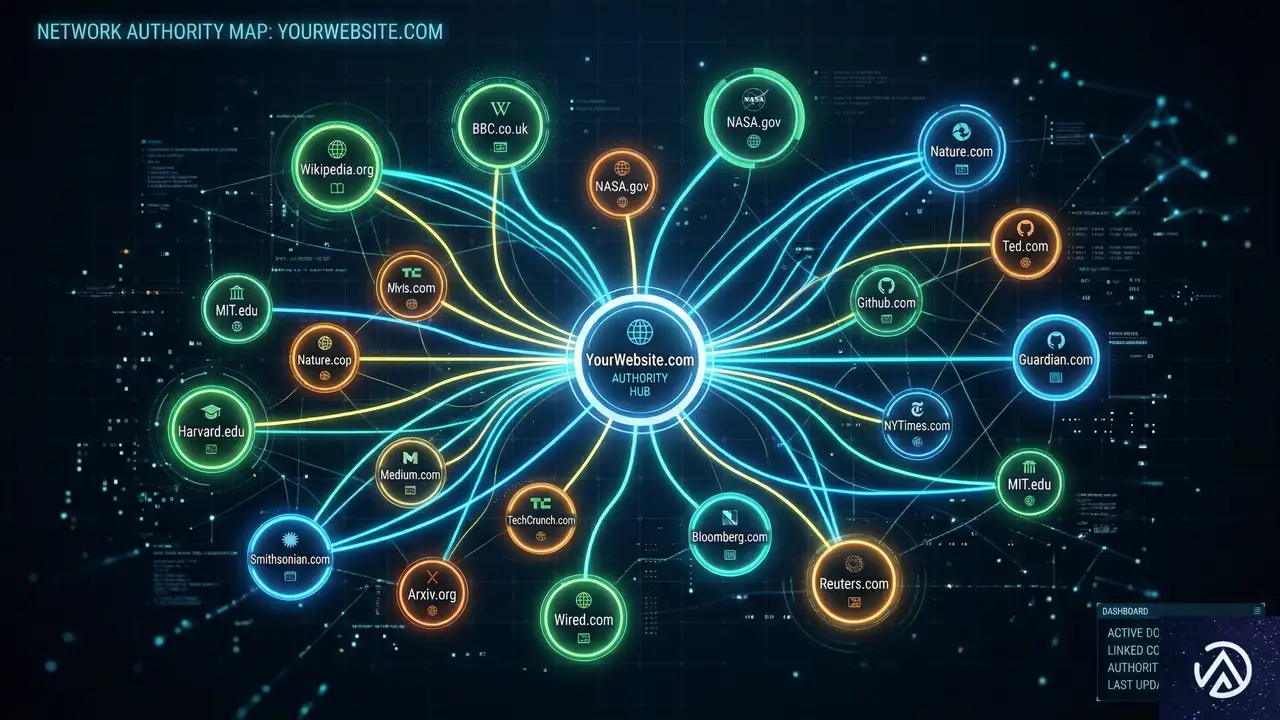
バックリンクなどの権威性の信号が、生成AIの可視性にどの程度影響するかは、現時点では完全には解明されていない。しかし、間接的な証拠や専門家の推察から、従来のSEOと同様に重要な役割を果たしていると考えられる。
間接的だが無視できないシグナル
高い有機検索順位は、そのままAIによる発見を促進する。さらに、権威ある競合他社と共に言及・リンクされる「エンティティ関連性」は、検索順位を押し上げる。自社サイトから権威ある出版物への一貫した言及やリンクは、AIがあなたのビジネスを信頼する材料を提供する。
これらの間接的なAIシグナルは、従来のリンク構築手法を通じて獲得できる。ジャーナリストへのアウトリーチ、専門家としてメディアに引用されること、ソーシャルメディア上での関係構築などがその具体策だ。
可視性が第一歩
生成AI検索最適化(GEO)における成功の第一定義は、実際の売上ではなく「可視性」である。AIの回答に引用され、ユーザーの目に触れる機会を増やすことが初期目標だ。そして、従来のSEO対策を怠ったサイトがAIに見いだされる可能性は、限りなくゼロに近い。
この記事のポイント
- ChatGPTなどの生成AIは、回答生成のためにGoogleを検索している。したがって、Google SEOはAI可視性の基礎となる。
- AI向けのキーワードリサーチでは、検索意図を深掘りし、カスタマージャーニーの全段階をカバーすることが重要だ。
- コンテンツは、商品が問題を解決する方法を説明するものに注力する。AIに要約されても、信頼できる情報源としての地位を築く第一歩となる。
- 水平型のサイト構造と明確なナビゲーションは、AIボットがサイトを理解し、情報を正しく処理するために不可欠だ。
- バックリンクやブランド言及は、AIがサイトの権威性を判断する間接的なシグナルとして機能する可能性が高い。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AI時代のEC集客戦略:高品質コンテンツを生む12ステップのフレームワーク
AIによってコンテンツ制作のコストが劇的に下がった一方で、インターネット上には似たような質の低い記事が溢れかえっている。2026年の現在、ECサイトが検索エンジンやSNSのフィードで生き残るためには、単にAIで文章を生成するだけでは不十分だ。
検索結果のクリック率低下や、AIチャットによるユーザー行動の変化に対応するためには、AIを活用しながらも「人間が書いた以上の価値」を提供できるプロセスが求められている。Practical Ecommerceの記事では、この課題を打破するための具体的なフレームワークが提示された。
この記事では、AIを強力な武器に変え、オーガニックトラフィックを確実に獲得するための「12ステップのフレームワーク」を詳しく解説する。量産型の「AIスロップ(AI製のゴミコンテンツ)」から脱却し、真に顧客を惹きつけるコンテンツ作りのヒントを探っていこう。
2026年のAIコンテンツ市場が直面する負のスパイラル

現在、コンテンツマーケティングの世界では大きな地殻変動が起きている。かつては記事を書き、検索順位を上げれば自然とトラフィックが流入してきたが、その「当たり前」が通用しなくなっているのだ。
ゼロクリック検索とAIチャットの台頭
ゼロクリック検索とは、ユーザーが検索エンジンで検索を行った際、結果画面に表示される情報だけで満足し、どのサイトもクリックせずに離脱する現象を指す。2026年、この割合はさらに増加している。Googleの検索結果画面にはAIによる回答(AI Overviews)が鎮座し、ユーザーが個別の記事を訪れる必要性は薄れつつある。
さらに、多くの消費者が検索の入り口としてChatGPTやPerplexityのようなAIチャットを使い始めている。検索の「始まりから終わりまで」をAIとの対話で完結させてしまうため、従来のSEO(検索エンジン最適化)だけでは顧客との接点を持つことが難しくなっているのが現状だ。
アルゴリズム更新によるトラフィックの激変
2026年2月に実施されたGoogleのアルゴリズムアップデートは、多くの大手メディアに衝撃を与えた。特に、スマートフォンなどのフィードに表示される「Google Discover」への影響が大きかった。DiscoverSnoopの調査によれば、Yahooのような巨大サイトですら、このアップデートによってコンテンツの露出が約50%減少し、オーディエンスが6割以上も激減したという。
こうした状況下で、多くのマーケターは「トラフィックが減った分を、AIによる大量生産で補おう」という誘惑に駆られる。しかし、これが負のスパイラルの始まりだ。安易なAI生成コンテンツはどれも似たようなトーンになり、結果として競争力を失い、さらにパフォーマンスが悪化するという悪循環に陥ってしまう。
なぜ「量」ではなく「質」が差別化要因になるのか

1年前まで、AIを活用する最大のメリットは「スピード」や「コスト」だった。しかし、誰もがAIを使えるようになった現在、そのアドバンテージは消失した。今、他社と差をつけるために必要なのは、AIをどう使いこなして「質」を担保するかという実行力の差である。
AIスロップからの脱却
AIスロップ(AI Slop)とは、AIによって生成された、価値の低い、あるいは不正確なコンテンツを指す。読者は直感的に「これはAIが書いた中身のない記事だ」と見抜くようになっている。検索エンジンもまた、こうした低品質な情報の氾濫を食い止めるべく、より専門性(Expertise)、体験(Experience)、権威性(Authoritativeness)、信頼性(Trustworthiness)の「E-E-A-T」を重視するようになっている。
単に「プロンプト(AIへの指示文)」を工夫するだけでは、この壁を越えることはできない。必要なのは、AIの出力を厳密に管理し、検証し、洗練させるための「プロセス」そのものの構築だ。
人間を超えるAIライティングの可能性
一方で、適切に管理されたAIコンテンツは、人間が書いたものと同等、あるいはそれ以上の評価を受けることもある。ニューヨーク・タイムズが行ったクイズ形式の調査では、人間が書いた文章と、それをAIがリライトした文章を比較した際、約半数の読者がAI版を好むという結果が出た。
これは「AIの文章は冷たい」「人間味がない」という先入観を捨てるべきであることを示唆している。AIは構造化、論理の整理、多角的な視点の提供において非常に優れている。その強みを引き出しつつ、人間が最終的な品質を保証する体制こそが、2026年の勝ちパターンだ。
高品質なAIコンテンツを生む12ステップ・フレームワーク

Practical Ecommerceが提唱する「12ステップ・フレームワーク」は、コンテンツ制作を細分化し、各工程でAIと人間が協力することで品質を極限まで高める手法だ。このプロセスを自動化のワークフローに組み込むことで、安定して高い成果を出すことが可能になる。
企画から検証までの初期段階
最初のステップは、具体的なトピックと記事の目的を明確にすることだ(ステップ1:アイデア)。次に、信頼できる情報源(ソース)を収集し、記事のトーンやスタイルを定義する(ステップ2:ソースとブリーフ)。ここで重要なのは「どの情報をAIに与えるか」を人間が厳選することである。
続いて、入力した情報の信頼性をチェックする(ステップ3:検証)。AIが誤った情報を元に文章を作らないよう、ソースの信憑性を確認する工程だ。その後、各ソースから重要な事実やデータ、主張を抽出して要約し(ステップ4:要約)、記事の骨組みとなる構成案を作成する(ステップ5:構成)。
執筆・校正・最適化のプロセス
構成案に基づき、AIにフルバージョンの記事を書かせる(ステップ6:草案)。ここからが品質を分ける重要な工程だ。生成された草案をブリーフや構成案と照らし合わせ、AI自身に批判的に添削させる(ステップ7:校正)。さらに、ソースとの類似性をチェックし、意図しない盗用を防ぐ(ステップ8:盗用チェック)。
また、AI特有の言い回しや不自然な表現を排除し(ステップ9:AI臭の排除)、検索エンジンだけでなく、AIチャット(回答エンジン)やGoogle Discoverに最適化させる(ステップ10:最適化)。最後に、これまでの工程をクリアしているかをAIに採点させ、高得点のものだけを人間が最終チェックする(ステップ11:評価)。最後に、情報の鮮度を保つための更新予定日を設定して完了だ(ステップ12:更新トリガー)。
【独自分析】ECサイトにおけるAIコンテンツの活用戦略

このフレームワークを実際のECサイト、例えばWooCommerce(ウーコマース)を運用しているショップにどう適用すべきか。単なる商品説明にとどまらない、戦略的なアプローチが必要だ。
Google Discoverへの最適化とクリック率予測
ECサイトにとって、Google Discoverは爆発的なトラフィックをもたらす宝庫だ。Discoverに掲載されるためには、ユーザーの興味を強く惹きつけるタイトルと画像が欠かせない。12ステップの「最適化」段階では、AIを使って複数のタイトル案を生成し、それぞれのクリック率を予測するツール(Discover click-through predictorなど)を活用するのが有効だ。
また、Discoverは「新しさ」だけでなく「関連性」を重視する。過去に売れた商品の活用事例や、季節ごとの悩み解決記事などを、このフレームワークに沿って高品質に仕上げることで、フィードへの露出機会を最大化できる。
AIスロップと高品質コンテンツの視覚的比較
ここで、単にAIに書かせただけの「AIスロップ」と、フレームワークを経て構造化された「高品質コンテンツ」の違いを視覚的に見てみよう。ECサイトのブログ記事を想定したデモだ。
<!-- 高品質なコンテンツの構造例 -->
<div class="content-comparison">
<div class="slop-example">
<h4>AIスロップ(NG例)</h4>
<p>商品は良いです。多くの人が買っています。特徴は3つあります。1つ目は安さ、2つ目は速さ、3つ目は便利さです。ぜひ買ってください。</p>
</div>
<div class="quality-example">
<h4>高品質コンテンツ(OK例)</h4>
<p>最新の調査データによれば、ユーザーの8割が「時短」を重視しています。本製品は独自の技術により、従来比30%の効率化を実現しました。</p>
</div>
</div>※このデモは、具体性の欠ける一般的な記述(左)と、データとベネフィットを構造化した記事(右)の対比を視覚化したイメージである。
左側の例は、AIに「おすすめの靴について記事を書いて」と丸投げした際によく見られるパターンだ。一方、右側は「具体的なデータ(2026年の歩行解析)」や「具体的なターゲットの悩み(立ち仕事の疲れ)」をソースとして与え、フレームワークに沿って出力させた結果を想定している。どちらがユーザーに刺さり、検索エンジンに評価されるかは明白だ。
この記事のポイント
- 2026年はゼロクリック検索やAIチャットの普及により、単純なSEO記事では流入が稼げない。
- Google Discoverなどのフィードで生き残るには、アルゴリズムの変動に耐えうる「質の高いコンテンツ」が必須となる。
- AIによる量産は「負のスパイラル」を招くため、量ではなくプロセスによる差別化を目指すべきだ。
- 12ステップのフレームワークを活用し、検証・校正・最適化をシステム化することで、AIスロップを回避できる。
- ECサイトでは、具体的なデータや顧客のベネフィットに基づいた「構造化された情報」の提供が勝敗を分ける。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AIマーケティングの勝機はコンテキスト・エンジニアリングにあり:プロンプトの限界を超えるデータ設計術
AIをマーケティングに導入する際、多くの担当者は「どのツールを買うか」や「いかに優れたプロンプト(指示文)を書くか」に腐心する。しかし、AIから真の価値を引き出し、信頼に足る成果物を得られるかどうかを決定づけるのは、ツールの性能でもプロンプトの巧拙でもない。その正体は「コンテキスト(文脈)」の設計にある。
2024年から2025年にかけて、マーケティング業界ではプロンプト・エンジニアリングの習得がブームとなったが、その技術には明確な限界が見え始めている。MarTechの記事において、著者のAna Mourão(アナ・モウラン)氏は、AIのパフォーマンスは「どう尋ねるか」ではなく「AIが何を知っているか」に依存すると指摘した。この「AIに何を知らせるか」を設計する技術こそが、コンテキスト・エンジニアリングだ。
本記事では、プロンプトの壁を突破し、ビジネスに直結するAI出力を得るための「コンテキスト・エンジニアリング」の概念と実践方法を掘り下げる。特にデータが命となるECサイト運営やマーケティング担当者にとって、この視点の有無が競合との決定的な差を生むことになるだろう。
プロンプト・エンジニアリングからコンテキスト・エンジニアリングへの転換

プロンプト・エンジニアリングは、AIに対してより具体的で構造化された指示を出す技術だ。確かに、曖昧な指示よりも詳細なプロンプトの方が質の高い回答を得られる。しかし、どれほどプロンプトを磨き上げても、AIが参照できる情報が不足していれば、その出力はどこかで見かけたような「ありきたりな内容」に終始してしまう。
例えば、同じAIツールを使い、同じプロンプトを入力する2人のマーケターを比較してみよう。一方はプロンプトだけを入力し、もう一方はプロンプトに加えて「整理された顧客セグメントデータ」「過去のキャンペーン成果」「ブランド独自のトーン&マナー」「法的制約」をAIに読み込ませている。この場合、後者が圧倒的に優れた、実戦的な出力を得ることは火を見るより明らかだ。
成果を分ける「コンテキスト・アーキテクチャ」の差
MarTechのAna Mourão氏は、同じ企業の2つのチームが同じコンテンツ推薦エンジンを使った場合の例を挙げている。チームAはCDP(Customer Data Platform / 顧客データプラットフォーム)をツールに接続し、購入履歴や商品への関心度、過去のエンゲージメントデータを統合した。一方でチームBは、ツールのデフォルト設定のまま、導入時に作成された標準的なプロンプトのみを使用した。
両チームが休眠顧客への再アプローチ(ウィンバック・キャンペーン)を実施した結果、チームAのAIは「顧客が以前購入した具体的なカテゴリー」に触れ、すでにカートに入っている商品を避け、過去の反応パターンに基づいたトーンでメッセージを生成した。対してチームBの出力は、どのブランドにも当てはまるような表面的なパーソナライズにとどまった。この差を生んだのが、コンテキスト・アーキテクチャ(文脈の構造)の質だ。
コンテキスト・エンジニアリングの定義
コンテキスト・エンジニアリングとは、AIが特定のタスクを実行する際に、どのようなデータ、知識、ツール、記憶、そして構造を利用できるかを意図的に設計する実践を指す。開発者の視点で言えば、AIとのやり取りが発生する前に、適切な情報をAIのワーキングメモリ(一時的な記憶領域)にロードするパイプラインを構築することだ。
マーケティングの現場においては、AIがキャンペーン案を練ったりコピーを書いたりする際に、その判断の根拠となる「ビジネス固有の文脈」にアクセスできる状態を整えることを意味する。これにより、ボトルネックは個人のプロンプト作成スキルから、組織としてのデータ・プロセス基盤へと移行する。これは個人のスキルの問題ではなく、システムの設計問題なのだ。
マーケターはすでに「コンテキスト・エンジニア」である

コンテキスト・エンジニアリングという言葉は新しく聞こえるかもしれないが、実は多くの熟練マーケターが日常的に行っている業務と重なる部分が多い。顧客データの戦略を立て、ツール間のデータ連携を設計し、情報の流れを管理してきた経験は、そのままAI時代のコンテキスト設計に転用できる。
MarTechの記事によれば、マーケティング・テクノロジー(MarTech / マーテック)の管理に必要な中核能力は、コンテキスト・エンジニアリングの機能と密接に関連している。それらをAI活用の文脈で捉え直すと、以下のような役割が見えてくる。
システム理解とアーキテクチャの構想
まず必要になるのが、どのデータシステムが存在し、それらがどう繋がっているかを把握する「システム理解」だ。AIエージェント(特定の目的のために自律的に動作するAIプログラム)に対して、どの情報源を供給すべきか、逆にどのデータがノイズになるかを判断する能力が求められる。
次に、システム間でデータがどのように流れるかを設計する「アーキテクチャの構想」だ。これは、適切なタイミングで顧客データやビジネスルール、過去のパフォーマンス履歴をAIツールに届けるためのパイプラインを構築することを意味する。データが古ければ、AIが生成する回答も「過去の現実」を反映したものになってしまうため、常に新鮮なコンテキストを供給する仕組みが不可欠だ。
ガバナンスと組織管理
ツール管理の側面では、プラットフォームへのアクセス権限やデータプライバシーの制御が重要になる。AIエージェントに「何を見せてよいか」「何を決して見せてはいけないか」を決定するのはマーケターの仕事だ。また、組織管理においては、誰がどのコンテキスト層を維持する責任を持つかを明確にする必要がある。責任の所在が曖昧になると、コンテキストの質は音もなく低下していくからだ。
コンテキスト・エンジニアリングを実践するためのチェックリスト

コンテキスト・エンジニアリングを具体的に進めるためには、自社のAIツールが「何を知っているか」「何を知るべきか」を問い直す必要がある。Ana Mourão氏が提唱する実践的なチェックリストを基に、そのステップを確認していこう。
1.AIがアクセス可能なデータ層をマッピングする
現在利用している各AIツールに、どのような情報源が接続されているかを書き出してみよう。顧客プロフィール、カスタマージャーニーの履歴、商品カタログ、過去のキャンペーン結果、ブランドガイドライン、コンプライアンス規則などだ。多くのチームでは、AIがプロンプトと一般的な学習データのみに頼っており、独自のビジネスコンテキストが欠落していることに気づくはずだ。
2.コンテキストの「ギャップ」を特定する
コンテンツ生成、リードスコアリング、キャンペーンの最適化など、用途ごとに必要なデータが揃っているかを確認する。ブランドの声(Brand Voice)のガイドラインがないAIは、文法は正しくても「どこにでもあるブランド」のようなコピーしか書けない。正確なセグメントデータがないパーソナライズエンジンは、根拠のない推測に基づいて動くことになる。
3.コンテキスト層の所有者を明確にする
企業内では、顧客データはCRMチーム、成果データは分析チーム、ブランド指針はクリエイティブチームというように、データが分散していることが多い。これらをAIが利用できる形で統合し、維持する責任者を決める必要がある。所有者が不明確なデータは、更新が滞り、AIの判断を狂わせる原因となる。
4.コンテキストの品質を監査する
AIの出力が劣化している場合、その原因はプロンプトではなく、供給されているデータの劣化(コンテキスト・ロット)にあることが多い。AIは間違ったデータに基づいても、自信満々に回答を生成する。そのため、AIに流れ込むデータが最新かつ正確であるかを定期的にレビューするプロセスが不可欠だ。
「統治」と「知識」:ガバナンスとの違いを理解する

コンテキスト・エンジニアリングを語る上で避けて通れないのが「ガバナンス(統治)」との違いだ。これらは混同されやすいが、役割は明確に異なる。ガバナンスが「AIは何を許されるか」というルールを定めるのに対し、コンテキスト・エンジニアリングは「AIがうまくタスクを遂行するために何を知る必要があるか」という知識の基盤を整えるものだ。
コンテキストのないガバナンスは、ルールは守るが役に立たないAIを生む。出力は安全だが、ビジネス固有の情報が欠けているため、実用性に乏しい。逆に、ガバナンスのないコンテキストは、豊かな顧客データを利用しつつも、プライバシーやコンプライアンスを無視した危険なAIを生み出してしまう。
McKinsey(マッキンゼー)の2025年10月のレポートによれば、MarTechの購入者の34%が「スキルの不足」をテクノロジーから価値を引き出す上での障害として挙げている。コンテキスト・エンジニアリングは、まさにその欠けているスキルのひとつであり、マーケターが自ら獲得すべき領域だと言えるだろう。
独自の分析:ECサイトにおけるコンテキスト活用の重要性

コンテキスト・エンジニアリングの考え方は、特にデータ密度が高いEC・WooCommerceサイトの運営において極めて強力な武器になる。中小規模のECサイトがAIを活用して大手に対抗するためには、プロンプトの工夫以上に、自社が持つ「顧客との関係性」という文脈をいかにAIに組み込むかが重要だ。
WooCommerceデータのコンテキスト化
WooCommerceを利用している場合、注文履歴、レビュー、商品の属性、在庫状況といった膨大なデータがデータベースに蓄積されている。これらをAIに「コンテキスト」として与えることで、単なる商品説明の要約ではなく、「この商品の購入者は、次にこれを欲しがる傾向がある」「この顧客は価格よりも品質を重視する」といった深い洞察に基づいた施策が可能になる。
筆者の見解としては、今後のEC制作においては「AIチャットボットを設置する」といった表面的な実装よりも、ボットの裏側にある「知識ベース(ナレッジベース)」をいかに最新の状態に保ち、ブランドの哲学を反映させるかという設計業務が主流になると予測している。これはまさに、コンテキスト・エンジニアリングそのものだ。
「データが語ること」と「真実」の橋渡し
AIはコンテキスト・グラフ(データ間の関係図)を読み取ることはできるが、データの裏にある「意味」までは理解できない。例えば、「数値上は割引対象だが、ブランドイメージ維持のために今は割引すべきではないセグメント」や「データには現れていないが、現場で感じている顧客の行動変化」などは、人間にしか判断できない文脈だ。
Ana Mourão氏が述べているように、マーケターは「コンテキストの代理人」として、何が重要で、何がデータから漏れているのかを判断し続けなければならない。AIに良質な文脈を与え、その出力が現実と乖離していないかを監督すること。これが、AI時代のマーケターに求められる新たな専門性である。
この記事のポイント
- AIの成果を左右するのはプロンプトのスキルではなく、提供される「コンテキスト(文脈)」の質である。
- コンテキスト・エンジニアリングとは、AIが参照するデータ、知識、構造を意図的に設計する技術を指す。
- マーケターが持つシステム理解やアーキテクチャ構想のスキルは、そのままAI活用に転用できる。
- ガバナンス(ルール)とコンテキスト(知識)の両輪を揃えることで、安全かつ実用的なAI運用が可能になる。
- ECサイト運営においては、独自の顧客データやブランド哲学をAIに組み込むことが競合優位性につながる。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Google-Agent登場でSEO激変?エージェント・ウェブの到来とWebMCPの衝撃
Googleが新しいユーザーエージェント「Google-Agent」を発表した。これは単なる情報の収集だけでなく、AIエージェントが人間に代わってウェブサイト上で「行動」することを前提とした仕組みだ。従来の「人間がブラウザでページを閲覧する」というウェブのあり方が、根本から覆されようとしている。
この変化は、SEO(検索エンジン最適化)の歴史において最も大きなパラダイムシフトになると予測されている。これまではキーワードで検索結果の上位を狙い、ユーザーのクリックを誘発することがゴールだった。しかし、これからは「AIエージェントがいかにスムーズにサイトの機能を利用できるか」が重要になる。
本記事では、Googleが推進する「エージェント・ウェブ」の正体と、それを支える技術プロトコル、そして今後のウェブ運営者が取るべき対策について深掘りしていく。検索の未来は、単なる情報の提示から「タスクの完了」へと急速にシフトしているのだ。
Google-Agentとは何か?新しいクローラーが示唆する未来

Googleが新たに導入した「Google-Agent」は、特定のAIエージェントがユーザーの指示を受けてウェブサイトにアクセスする際に使用される識別子だ。Google DeepMindが開発した「Project Mariner」のような、ブラウザを操作するAIモデルがこれを利用する。従来のGooglebotが検索インデックス作成のために巡回するのに対し、Google-Agentは「実務の代行」のためにサイトを訪れる点が異なる。
ユーザーに代わって「行動」するAIエージェント
AIエージェントとは、ユーザーの意図を汲み取り、自律的にタスクを実行するソフトウェアのことだ。例えば「来週の出張のために、予算3万円以内で東京駅近くのホテルを予約してほしい」と頼めば、エージェントが複数のサイトを巡回し、条件に合うプランを見つけ、予約フォームの入力まで済ませてくれる。この一連の動作において、人間は一度もサイトの画面を見る必要がない。
Googleの検索部門責任者であるLiz Reid氏は、将来的に「多くのエージェント同士が会話する世界」が来ると予測している。ユーザーのエージェントがホテルの予約システム(エージェント)と直接交渉し、最適な取引を成立させる。これが、Googleが描く「エージェント・ウェブ」の姿だ。
Google-Agentの識別とサイト側の対応
Google-Agentは、HTTPリクエストのUser-Agentヘッダーに含まれる。これにより、ウェブサイトの運営者は「今アクセスしているのは人間か、それともGoogleのAIエージェントか」を判別できる。Search Engine Journalの記事によれば、モバイル版とデスクトップ版の両方でこの新しいタグが使用されることが確認されている。
現在、多くのSEO担当者が「AIによるクローリングを拒否すべきか」を議論している。しかし、Google-Agentをブロックすることは、AIエージェント経由で訪れる「購買意欲の高いユーザー」を門前払いすることと同義だ。これからのウェブサイトは、AIが読みやすく、かつ操作しやすい構造を持つことが生き残りの条件となる。
「エージェント・ウェブ」を支える5つの主要プロトコル
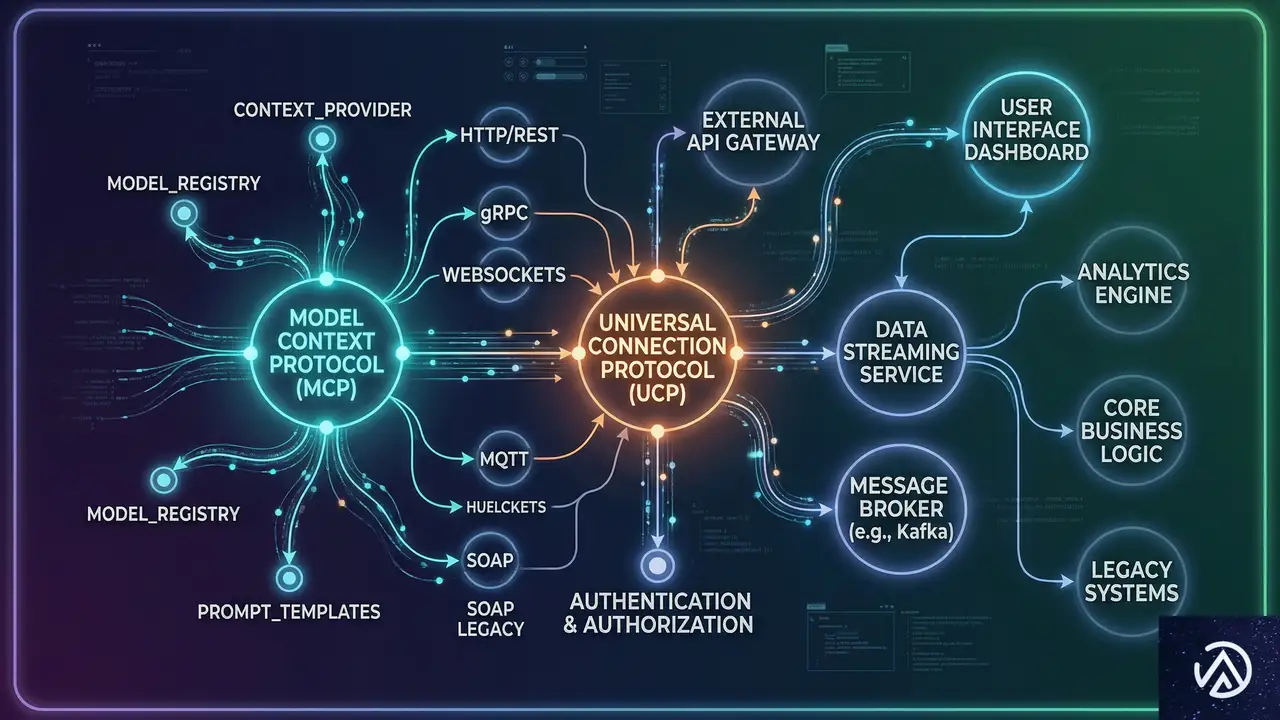
AIエージェントがウェブサイトを効率的に利用するためには、人間向けの視覚的なUI(ユーザーインターフェース)だけでは不十分だ。Googleは、マシン同士がデータをやり取りし、機能を実行するための複数のプロトコルを提唱している。これらは、今後のウェブ開発における共通言語となる可能性が高い。
WebMCP:サイトの機能をネイティブに操作する
WebMCP(Model Context Protocol)は、AIエージェントがウェブサイトのバックエンドデータや機能に安全にアクセスするための仕組みだ。従来のブラウザ操作では、AIは画面上のピクセルを解析してボタンの場所を探す必要があり、処理が遅くエラーも起きやすかった。WebMCPを使えば、エージェントはサイトが提供する「ツール」を直接呼び出せるようになる。
例えば、問い合わせフォームを埋める際、エージェントはHTMLの構造を解析するのではなく、WebMCP経由で必要なデータ項目を直接受け取り、正確な値を流し込む。これにより、人間が操作するよりも遥かに高速かつ正確なタスク実行が可能になる。これは、ウェブサイトが「閲覧される文書」から「呼び出し可能なAPIの集合体」に変わることを意味している。
UCPとA2A:AI同士が商談し決済する世界
ECサイトにとって特に重要なのが、UCP(Universal Commerce Protocol)だ。これは、検索結果画面(SERPs)から直接、AIが商品の購入手続きを行えるようにするプロトコルだ。ユーザーは商品詳細ページに遷移することなく、AIアシスタントに「これを買って」と伝えるだけで注文が完了する。
また、A2A(Agent to Agent)は、異なるサービスのエージェント同士が通信するための規格だ。Marie Haynes氏によれば、将来的には「私のSEOエージェントが、あなたの提供するツールのエージェントと価格交渉を行う」といったシナリオも現実味を帯びている。ビジネスの接点が、人間対人間から、プログラム対プログラムへと移行していくのだ。
このデモは、従来の人間主体のウェブ閲覧と、AIエージェントが直接システムと対話する次世代のウェブ構造の違いを視覚化したイメージだ。
検索の概念が変わる。AI Searchへの完全移行

GoogleのNick Fox氏は「検索はAI Search(AI検索)になりつつあり、Geminiアプリはあなたのパーソナルアシスタントである」と述べている。これは、従来の「10本の青いリンク」が並ぶ検索結果ページが、最終的にはAIとの対話インターフェースに吸収されることを示唆している。Googleは「AIモード」と「AI Overviews(AIによる概要回答)」を一体のものとして捉え始めている。
「検索結果」から「パーソナルアシスタント」へ
これまでの検索エンジンは、ユーザーが入力したクエリに対して「関連する可能性が高いページ」を提示する場所だった。しかし、これからのGoogleは、ユーザーの代わりに問題を解決する「アシスタント」へと進化する。ユーザーが情報を探す手間を省き、答えを直接提示したり、アクションを実行したりすることが主目的となる。
この変化により、ウェブサイトへの流入(クリック数)は減少する可能性がある。AIが検索結果画面でユーザーの疑問を解決してしまえば、サイトを訪れる必要がなくなるからだ。しかし、Marie Haynes氏は、これを「摩擦のない商取引(フリクションレス・コマース)」のチャンスだと捉えている。クリックを稼ぐのではなく、AIを通じて直接コンバージョン(成果)を得るモデルへの転換が求められている。
コンテンツ制作者とプラットフォームの新たな関係
1998年の創業以来、Googleとコンテンツ制作者の間には「コンテンツを提供すれば、代わりにトラフィックと広告収益を還元する」という暗黙の了解があった。しかし、AIがコンテンツを学習し、その要約をユーザーに提供する現在のモデルでは、このパートナーシップは崩壊しつつあるとの見方もある。
これからのクリエイターや企業は、単に情報を発信するだけでなく、AIエージェントが「利用できる価値」を提供する必要がある。それは独自のデータであったり、AIが実行可能な特定のサービス機能であったりする。情報の「量」ではなく、エージェントにとっての「有用性」が、新しい評価軸となるだろう。
実務者が今すぐ取り組むべき3つのアクション

エージェント・ウェブの全貌はまだ不透明だが、今から準備を始めることは可能だ。技術の進化をただ待つのではなく、AIが好むサイト構造へと段階的にシフトしていくことが推奨される。ここでは、具体的な3つのステップを挙げる。
構造化データを超えた「機能の公開」
これまでのSEOでは、Schema.orgなどの構造化データを用いて、情報の意味を検索エンジンに伝えてきた。これからはさらに一歩進んで、サイトの「機能」をAIが利用できるように整備する必要がある。具体的には、WebMCPのようなプロトコルの動向を注視し、将来的にAPIやエージェント専用のインターフェースを提供できる準備をしておくことだ。
特にECサイトを運営している場合は、UCP(Universal Commerce Protocol)について学ぶことが不可欠だ。Googleのショッピング機能と連携し、AIが商品を正しく認識し、決済フローを理解できるようにデータを整えておくことが、将来の売上に直結する。
「バイブ・コーディング」による開発スピードの向上
Marie Haynes氏は、AIツールを活用して直感的に開発を行う「バイブ・コーディング(Vibe Coding)」の重要性を説いている。Claude CodeやGoogle AI Studioなどのツールを使い、自然言語で指示を出しながら、AIエージェントに対応した機能を素早く実装していく手法だ。
技術的な詳細をすべて手書きするのではなく、AIと対話しながら「エージェントが使いやすい構造」をプロトタイピングしていく。このスピード感が、変化の激しいAI時代には武器になる。開発者だけでなく、マーケターもこれらのツールに触れ、AIがどのようにコードやデータを解釈するのかを肌感覚で理解しておくべきだ。
独自分析:SEO担当者は「エージェント最適化」へ舵を切るべきか
筆者の見解として、今後のSEOは「Search Engine Optimization」から「Agentic Ecosystem Optimization(エージェント・エコシステム最適化)」へと変質していくだろう。これまでは「人間にどう見せるか」というUX(ユーザーエクスペリエンス)が重視されてきたが、今後はそれに加えて「AIエージェントにとっての使い勝手」を考慮したAX(エージェントエクスペリエンス)が重要になる。
これは、小規模なサイト運営者にとっては大きなチャンスかもしれない。巨大なドメインパワーを持つサイトが検索結果を独占する時代から、特定のタスクを最も効率的に解決できるエージェントを持つサイトが選ばれる時代になる可能性があるからだ。ユーザーの「悩み」を解決する具体的な「機能」を提供できれば、検索順位に関わらずAIエージェントがあなたのサイトを指名してくれるようになるだろう。
一方で、単なる情報のまとめサイトや、独自の価値がないコンテンツは、AI Overviewsによって完全に代替され、存在意義を失うリスクが高い。これからのウェブサイトは、単なる「情報の置き場所」ではなく、特定の目的を遂行するための「道具」として再定義される必要がある。Google-Agentの登場は、その長い旅の始まりに過ぎない。
この記事のポイント
- Google-Agentは、AIエージェントがユーザーに代わってサイトを操作するための新しい識別子だ。
- WebMCPやUCPといった新プロトコルにより、AIがサイトの機能をネイティブに利用可能になる。
- 検索は「情報の提示」から「タスクの実行(パーソナルアシスタント)」へと進化している。
- 今後のSEOは、クリックを稼ぐことよりも、AIエージェントを通じた直接的なアクションの完了を目指すべきだ。
- 「バイブ・コーディング」などのAI開発ツールを活用し、変化に即応できる体制を整えることが重要だ。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AEO(回答エンジン最適化)の新戦略:AI検索でコンテンツを引用させるための構造化手法
検索エンジンの役割が「リンクの羅列」から「直接的な回答」へと劇的に変化している。GoogleのAI OverviewsやMicrosoft Copilot、PerplexityといったAI検索エンジンの普及により、Webサイトの運営者は従来のSEO(検索エンジン最適化)に加えて、AEO(Answer Engine Optimization:回答エンジン最適化)への対応を迫られている状況だ。
最新の調査データによれば、AI検索からのトラフィックは月間約1%のペースで成長を続けており、特定の業界では無視できない規模に達している。AIにコンテンツを引用させ、自社の認知度を高めるためには、これまでの「ページ単位の評価」という考え方を捨てる必要がある。
この記事では、AIがどのようにコンテンツを解析し、どの断片を回答として採用するのかを、最新の研究結果と技術的な視点から詳しく解説する。AI時代に生き残るためのコンテンツ構造の作り方を、具体的なステップと共に見ていこう。
AIは「ページ」ではなく「断片」でコンテンツを評価する

従来の検索エンジンは、キーワードの関連性やリンクの強さを基に「Webページ全体」をランク付けしてきた。しかし、AI検索エンジンは全く異なるアプローチを取る。AIはページを読み込む際、内容を細かな「断片(フラグメント)」に分解して理解しようとする。このプロセスは「パージング(解析)」と呼ばれ、AIが回答を生成するための基礎となる。
パージング(解析)というプロセスの理解
MicrosoftのBingチームでプリンシパル・プロダクトマネージャーを務めるKrishna Madhavan氏によれば、AIアシスタントはコンテンツを構造化された小さな断片に分解し、それぞれの権威性と関連性を評価する。そして、複数のソースから抽出した最適な断片を組み合わせて、一つの首尾一貫した回答を作り出すのだ。
これは、たとえGoogleで検索順位が1位だったとしても、コンテンツの構造がAIにとって抽出困難であれば、AIの回答には引用されない可能性があることを示している。AIは「最も優れたページ」を探しているのではなく、「質問に対する最も適切な回答の断片」を探しているからだ。
AIトラフィックの現状と成長率
2026年1月のConductor AEO/GEOベンチマークレポートによると、AI経由のトラフィックはWebサイト全体のセッションの約1.08%を占めている。数字だけ見れば小さく感じるかもしれないが、前年比で357%もの急増を見せたケースもあり、その成長速度は驚異的だ。
特に医療分野では、Google検索の約2回に1回がAIによる概要表示(AI Overviews)を伴うというデータもある。ユーザーが検索結果のリンクをクリックする前にAIの回答で満足してしまう「ゼロクリック検索」が増える中で、AIの回答内に自社サイトが「出典」として引用されることは、新たな流入経路を確保するための生命線となる。
研究結果から判明した「引用されやすいコンテンツ」の条件

どのようなコンテンツがAIに好まれるのかについては、すでに複数の大学や研究機関が実証実験を行っている。その中でも、プリンストン大学やジョージア工科大学などが発表した「GEO(Generative Engine Optimization:生成エンジン最適化)」に関する論文は、非常に示唆に富んでいる。
GEO(生成エンジン最適化)の有効な手法
この研究では、9つの最適化戦略をテストした結果、特定のテクニックによってAI回答での視認性が最大40%向上することが確認された。最も効果的だったのは「信頼できる情報源の引用」だ。統計データや専門家の発言を適切に引用しているサイトは、そうでないサイトに比べて視認性が115.1%も増加したという。
一方で、意外な事実も判明している。文章を「説得力のあるトーン」や「権威を感じさせる文体」で書くことは、AIの引用率向上にはほとんど寄与しなかった。AIはレトリック(修辞学)に惑わされることはなく、検証可能な事実と論理的な構造を重視している。マーケティング的な装飾よりも、裏付けのある情報提供が優先される環境だ。
第三者メディア(アーンドメディア)の圧倒的な影響力
トロント大学が2025年9月に行った調査では、ChatGPTやPerplexityなどの主要AIエンジンが、自社サイトよりも「第三者による評価」を圧倒的に信頼していることが明らかになった。例えば家電分野では、AIが引用するソースの92.1%が第三者の専門メディアやレビューサイトであり、メーカー公式サイトの引用率は極めて低かった。
これは、自社サイト内でのSEOだけでは不十分であることを意味している。業界紙への寄稿、プレスリリース、信頼性の高い比較サイトへの掲載といった「アーンドメディア(獲得メディア)」での露出が、間接的にAI検索での視認性を高める鍵となる。AIはインターネット全体を俯瞰し、多くの場所で言及されている情報を「真実」として採用する傾向があるからだ。
AIに選ばれるための具体的な構造化テクニック

AIがコンテンツを「断片」として抽出する以上、制作者側も「抽出されやすい形」で情報を提供しなければならない。ここでは、MicrosoftやGoogleのガイドライン、および最新の研究に基づいた具体的な構成案を提示する。
見出しの役割とQ&A形式の採用
見出し(H2やH3タグ)は、AIにとって「ここから新しい概念が始まる」という強力なシグナルになる。「概要」や「詳細はこちら」といった曖昧な見出しは避け、そのセクションの内容を正確に記述した見出しを付けるべきだ。例えば「AIによるコンテンツ解析の仕組み」といった具体的な表現が望ましい。
また、ユーザーの質問をそのまま見出しにし、その直後で端的に回答する「Q&A形式」はAIとの相性が抜群だ。AIアシスタントは、この質問と回答のペアをそのままコピーしてユーザーに提示することが多いため、引用される確率が飛躍的に高まる。結論を先に述べ、その後に詳細な解説を続ける「逆ピラミッド型」の記述を徹底しよう。
「スニッパブル(切り出し可能)」なレイアウト設計
AIは長い段落よりも、箇条書き、番号付きリスト、比較表といった構造化されたデータを好む。これらは「スニッパブル(Snippable)」、つまり簡単に切り出せる形式だからだ。情報を整理して提示することで、AIは人間と同じように「このサイトは情報が整理されていて分かりやすい」と判断する。
以下のデモは、AIが情報を抽出しやすい「構造化された比較」のイメージだ。このように明確な境界線とラベルを持つ構成は、AIによるパージングを助ける効果がある。
<!-- 構造化された情報の例 -->
<div class="comparison-box">
<h4>SEOとAEOの違い</h4>
<ul>
<li>SEO:検索順位を上げ、サイトへの流入を最大化する</li>
<li>AEO:AIの回答に採用され、情報の正確性を担保する</li>
</ul>
</div>対象:ページ全体の評価
指標:クリック率(CTR)
対象:情報の断片(フラグメント)
指標:引用シェア・ブランド認知
このデモのように、情報を対比させて整理することで、AIは「SEOとAEOの違い」という文脈を即座に理解できる。
権威性のシグナルとスキーママークアップの活用
AIに「この情報は正しい」と確信させるためには、技術的な裏付けが必要だ。ここで重要になるのが、Googleも重視しているE-E-A-T(経験・専門性・権威性・信頼性)の概念と、それを機械に伝えるための「構造化データ」である。
E-E-A-Tと情報の鮮度
Microsoftのガイドラインでは、成功するコンテンツの条件として「新鮮で、権威があり、構造化され、意味的に明確であること」を挙げている。特に「意味的な明確さ」についてはシビアだ。「革新的な」「最先端の」といった曖昧な形容詞は、AIにとっては評価の対象にならない。それよりも「従来比で処理速度が30%向上した」といった、測定可能な事実に基づいた記述が求められる。
また、情報の鮮度(フレッシュネス)も重要なシグナルだ。古いデータや更新が止まったコンテンツは、AIに「不正確な可能性がある」と判断され、引用候補から外されやすい。定期的なリライトと、公開日・更新日の明示は必須と言える。
AIの理解を助ける構造化データの種類
スキーママークアップ(構造化データ)は、人間向けのテキストを「機械が理解できるデータ」に変換する翻訳機の役割を果たす。Microsoftは、スキーマを利用することでAIがコンテンツの内容を推測する必要がなくなり、自信を持って回答に採用できるようになると指摘している。
特にAEOにおいて優先順位が高いスキーマは以下の通りだ。
- FAQPage:質問と回答のペアを定義する。AIが最も引用しやすい形式だ。
- HowTo:手順やステップを定義する。ハウツー系の回答に採用されやすくなる。
- Product:価格、在庫、レビューを定義する。ECサイトのAI検索対応には必須だ。
- Article / BlogPosting:著者情報や公開日を定義し、情報の信頼性を高める。
これに加えて、サイトの更新を検索エンジンに即座に通知する「IndexNow」を併用することで、情報の鮮度と正確性を高いレベルで維持することが可能になる。
クローラー制御と計測の進め方

AI検索エンジンに対応するためには、どのクローラーを許可し、どのクローラーを制限するかという戦略も重要になる。また、施策の結果をどのように計測するかも、従来のSEOとは異なる視点が必要だ。
robots.txtによる学習と検索の切り分け
主要なAIプラットフォームは、クローラーを「検索用」と「モデル学習用」で分けていることが多い。例えばOpenAIの場合、OAI-SearchBot はChatGPTの検索機能(回答への引用)に使用されるが、GPTBot は将来のモデル学習に使用される。
自社のコンテンツをAIの回答に引用させたいが、AIモデルの学習に無償で使われるのは避けたいという場合は、robots.txt で個別に制御することが可能だ。検索用ボットを許可し、学習用ボットを拒否することで、著作権を保護しつつ検索流入を確保するバランスが取れる。
AI経由の流入を可視化する方法
AEOの成果を測る最も手軽な方法は、Bing Webmaster Toolsを活用することだ。ここには「AIパフォーマンスレポート」があり、Microsoft Copilotでの引用状況やクリック数を確認できる。Googleについては、Search Consoleの検索パフォーマンスから「検索タイプ:AI Overview(またはそれに類するフィルタ)」で動向を追うことになる。
また、ChatGPTからの流入は、アクセス解析ツールで utm_source=chatgpt.com というパラメータが付与される仕様になっている。これをモニタリングすることで、AI検索がどの程度自社サイトへのトラフィックに貢献しているかを具体的に把握できる。従来の「キーワード順位」だけでなく、「AI回答内でのシェア」を新たな指標として設定すべきだ。
この記事のポイント
- AIはページ全体ではなく、構造化された「断片(フラグメント)」を抽出して回答を生成する。
- 信頼できるソースの引用や統計データは、AI回答での視認性を100%以上向上させる可能性がある。
- 自社サイトの改善だけでなく、第三者メディアでの露出(アーンドメディア)がAIの信頼獲得に直結する。
- Q&A形式、箇条書き、スキーママークアップを活用し、AIが解析しやすい「スニッパブル」な構造を作る。
- Googleは「質の高いコンテンツ」と抽象的に述べるが、Microsoftは具体的な構造化の手法を公開しており、後者のガイドラインがAEOの指針となる。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AIを実務のパートナーへ:Model Context Protocol(MCP)が変えるEC運用の未来
AIはチャットの枠を超え、実務をこなす「オペレーター」へと進化している。これまでAIとの対話はブラウザ上のチャット画面で完結することが多かったが、その境界線が消えようとしているのだ。
2024年にAnthropic(アンソロピック)が発表した「MCP(Model Context Protocol / モデル・コンテキスト・プロトコル)」が、この変革の中核を担う。メール配信プラットフォームのBeehiiv(ビーハイブ)が最近このMCP統合を発表したことで、EC周辺のソフトウェア業界でも大きな注目を集めている。
このプロトコルにより、EC事業者はAIを自社のデータやツールと直接連携させ、高度な自動化の恩恵を享受できるようになる。本記事では、MCPがどのようにビジネスの現場を変えるのか、具体的な事例とともに詳しく解説する。
MCPとは何か:AIとデータを繋ぐ新しい「標準規格」
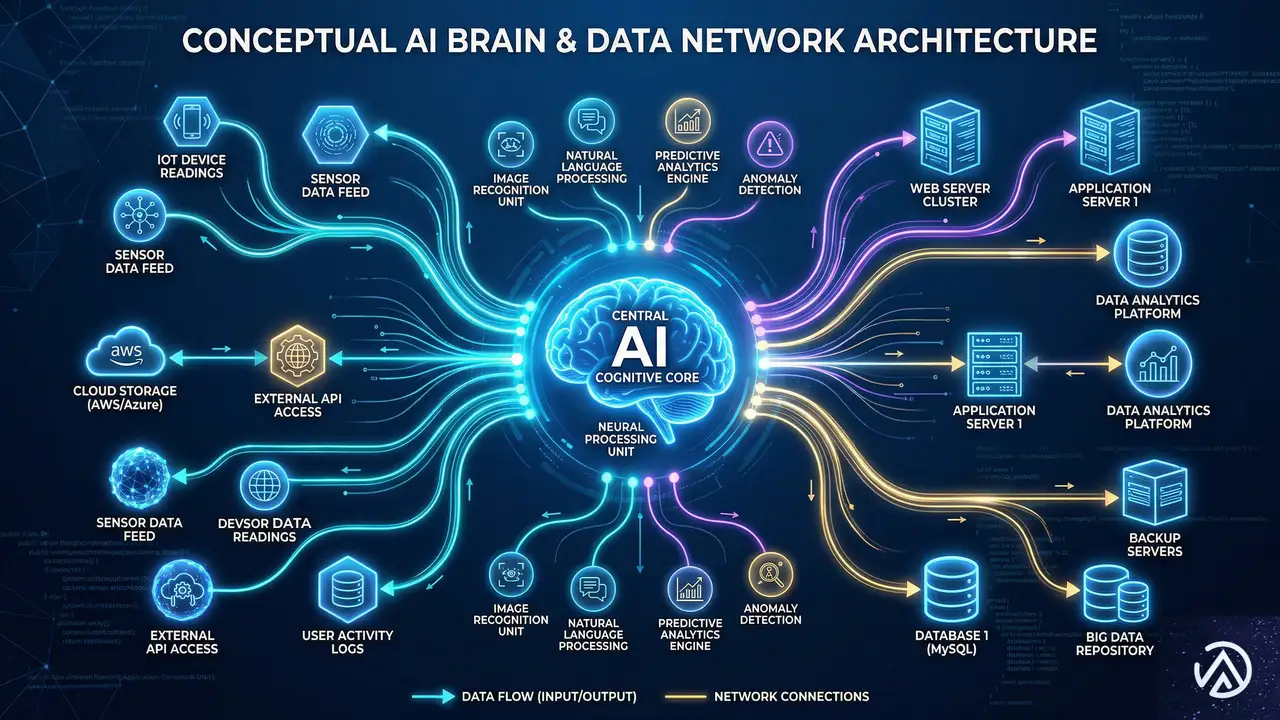
MCP(Model Context Protocol)は、AIアシスタントをデータソースやビジネスツールに安全に接続するためのオープンな標準規格だ。AnthropicのClaude(クロード)などの大規模言語モデル(LLM)が、企業の内部データや開発環境に直接アクセスできるように設計されている。
情報の架け橋としての役割
従来、AIに特定のデータ(例えば最新の在庫状況や顧客リスト)を読み込ませるには、個別のAPI連携を構築するか、手動でデータをアップロードする必要があった。MCPはこの手間を大幅に削減する。MCPに対応したソフトウェアであれば、AIがそのツール内のデータを自らクエリ(問い合わせ)し、アクションを実行できるようになる。
Practical Ecommerceの記事によると、MCPは「AIインフラ」として機能し、AIとビジネスを動かすシステムの間に位置する。これにより、AIはより正確で、文脈に沿った回答や行動が可能になるという。
APIとの違いと補完関係
MCPは既存のAPIを置き換えるものではなく、補完するものだ。APIは厳密で安定した処理(注文処理や決済など)に適している。一方でMCPは柔軟性が高く、AIが複数のツールをまたいで情報を探索し、状況に応じた判断を下す際に力を発揮する。
将来的なECのシステムスタック(技術構成)は、信頼性のためのAPIと、適応性のためのMCPという二段構えになると予測されている。これにより、定型業務はAPIで、複雑な判断を伴う業務はAIエージェントで自動化するという役割分担が進むだろう。
EC業界での導入事例:ShopifyやShippoの動向
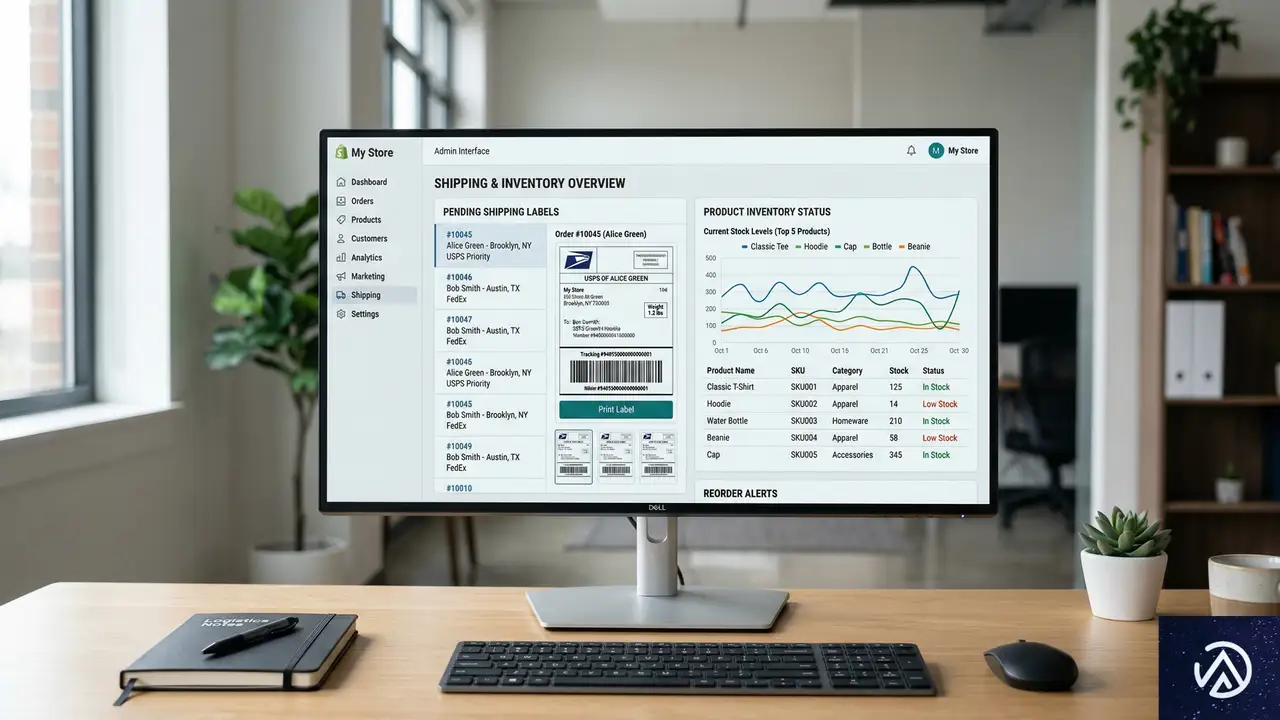
すでに多くのEC関連ツールがAIとの直接的な連携を開始している。ShopifyやShippo(シッポ)といった主要なプラットフォームでの活用例を見てみよう。
ShopifyのStorefront MCP
Shopifyは「Hydrogen」のアップデートを通じて、Storefront MCPへのAI対応を導入した。これにより、AIエージェントが自律的に商品を閲覧し、カートを管理し、チェックアウトを支援することが可能になる。
単にチャットボットが質問に答えるだけでなく、AIがストアの構造を理解し、ユーザーに代わって「買い物を進める」環境が整いつつある。これは、従来の検索窓に代わる、新しい購買体験の入り口となる可能性を秘めている。
Shippoによる物流プロセスのAI化
配送管理プラットフォームのShippoは、MCPサーバーを公開し、配送ワークフローをAIシステムに開放している。AIアシスタントは、運送業者の料金を比較し、ラベルを生成し、荷物を追跡し、住所の妥当性を確認することができる。
例えば、複数の出荷に遅延が発生していることをAIが検知した場合、代替の運送業者を確認し、フルフィルメントルールを更新して、影響を受ける顧客に通知するといった一連の作業を、人間の直接的な監視なしに(設定されたガイドライン内で)実行できるのだ。
Beehiivによるマーケティング分析
メールマガジン配信サービスのBeehiivは、アカウントをChatGPTやClaudeなどのAIツールとリンクさせるMCP統合を発表した。現在は分析に重点を置いており、AIが件名の効果測定や購読者の成長率、解約率(チャーンレート)を評価する。
これにより、メールマーケティングが実際のEC売上にどのように貢献しているかをAIが分析し、次のコンテンツ制作や収益化の判断を支援する。マーケターは複雑なスプレッドシートを読み解く代わりに、AIに直接「どのメールが最も成約に繋がったか」を尋ねるだけで済むようになる。
「チャット」から「オペレーター」へのパラダイムシフト

MCPがもたらす最大の変化は、AIの役割が「相談相手」から「実務の実行者」へと変わることだ。このパラダイムシフトがEC運用にどのような影響を与えるのか、具体的なイメージで捉えてみよう。
意思決定から実行までをAIが担う
これまでのAI活用は、レポートの要約やメールの下書き作成といった「思考の補助」が中心だった。しかし、MCPスタイルの統合が進むと、AIは自らデータを取得し、ツールを操作して「行動」を起こすようになる。
以下のデモは、MCPによってAIが「在庫不足」を検知し、自律的に「発注案」を作成して管理者に提案するワークフローの概念を視覚化したものだ。
※このデモは、MCPによるAIエージェントの動作概念を視覚化したイメージである。
このように、AIが自ら「次のステップ」を考え、ツールを操作して準備を整えてくれる。人間は最終的な「承認」ボタンを押すだけで済むようになるのが、MCP後の世界だ。
エージェント型コマースの台頭:OpenAIやGoogleの動き

MCPはAIが「ビジネスの裏側」にアクセスするための規格だが、一方で「消費者がAIの中で買い物をする」ための規格も登場している。これを「エージェント型コマース(Agentic Commerce)」と呼ぶ。
OpenAIのAgentic Commerce Protocol
OpenAIは、ChatGPTなどのAI環境内で商品の発見や取引を可能にする「Agentic Commerce Protocol」の開発を進めている。Googleも同様に、GeminiなどのAIインターフェースを通じてショッピングを完結させる手法を模索中だ。
これらのプロトコルは、消費者がどのように商品を見つけ、購入するかを定義する。対してMCPは、事業者がどのようにその注文を処理し、管理するかというバックエンドの運用を定義する。この両輪が揃うことで、ECのあり方は根本から再構築されることになる。
独自の分析:中小EC事業者が受ける恩恵
筆者の分析によれば、MCPの真の価値は「自動化の民主化」にある。これまで、複数のシステムを連携させた高度な自動化ワークフローを構築するには、多額の予算と専任のエンジニアが必要だった。
しかし、主要なツールがMCPに対応すれば、非エンジニアの担当者でもAIを通じて「ツール同士を会話させる」ことができるようになる。これは、リソースの限られた中小規模のECサイトにとって、大手企業と競合するための強力な武器になるはずだ。もはや、APIの仕様書を読み解く必要はなく、AIに「このツールとあのツールを使って、こういう処理をして」と指示するだけで済む時代が近づいている。
EC事業者が今準備すべきこと

MCPのような新しい技術が登場した際、すぐに飛びつく必要はないが、備えをしておくことは重要だ。Practical Ecommerceの著者Armando Roggio氏は、特定のプロトコルそのものよりも、AIを活用するための「準備」に焦点を当てるべきだと指摘している。
データのクリーンアップと構造化
AIが自律的に動くためには、その判断材料となるデータが整理されている必要がある。在庫データ、顧客情報、商品属性などが正確かつ構造化されていなければ、AIは正しい判断を下せない。まずは自社のデータを「AIが読み取りやすい状態」に整えることが、最も確実な投資となる。
柔軟なシステムスタックの検討
今後、新しいツールを導入する際は、そのサービスがMCPやAPI連携にどの程度積極的かを確認することが望ましい。外部のAIシステムと柔軟に繋がる「オープンな設計」のツールを選んでおくことで、将来的なAIエージェントの導入がスムーズになるだろう。
AIはもはや、話し相手ではなく「働くスタッフ」だ。そのスタッフが能力を最大限に発揮できる環境を整えることが、これからのEC運営者に求められる役割といえる。
この記事のポイント
- MCP(Model Context Protocol)はAIとビジネスデータを安全に繋ぐ新しい標準規格である
- ShopifyやShippoなどが導入を開始しており、AIが自律的に実務をこなす環境が整いつつある
- AIの役割は「チャットによる相談」から「ワークフローの実行」へと劇的に変化している
- 事業者はデータの整理と構造化を進めることで、将来的なAI統合の恩恵を最大化できる
- APIの信頼性とMCPの柔軟性を組み合わせた、新しいシステムスタックが主流になる見込みだ
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Cloudflare Gen13サーバーの設計思想 192コアAMD EPYCで2倍のスループットを実現
Cloudflareが第13世代サーバー「Gen13」の設計詳細を公開した。192コアのAMD EPYC Turin 9965プロセッサを搭載し、前世代比で最大2倍のスループットを実現している。
Gen13は768GBのDDR5-6400メモリ、24TBのPCIe 5.0 NVMeストレージ、デュアル100GbEネットワークインターフェースを備える。特に注目すべきは、Rustで書き直された新リクエスト処理層「FL2」への移行により、大容量L3キャッシュへの依存を解消した点だ。これによりコア数を2倍に増やしながら、レイテンシの増加を抑えることに成功した。
この記事では、Cloudflare Blogの記事を基に、Gen13サーバーの各コンポーネント選択の背景と設計思想を解説する。
CPU設計の転換:キャッシュからコアへ

Gen13の最大の特徴は、AMD EPYC Turin 9965プロセッサの採用だ。192コア/384スレッドを備え、前世代のGen12(96コア)からコア数を2倍に増やしている。
L3キャッシュ依存からの脱却
興味深いのは、コア数が2倍になった一方で、コアあたりのL3キャッシュ容量が83.3%減少している点だ。Gen12のAMD EPYC Genoa-X 9684Xはコアあたり12MBのL3キャッシュを持っていたが、Gen13のTurin 9965はコアあたり2MBしかない。
この一見逆行するような選択の背景には、Cloudflareのソフトウェアスタックの根本的な変化がある。Cloudflareはリクエスト処理層をFL1からFL2へ移行した。FL2はRustで書き直された新アーキテクチャで、大容量L3キャッシュへの依存度が大幅に低減されている。
Cloudflare Blogの記事によると、FL2ワークロードはコア数に対してほぼ線形にスケールする特性を持つ。このため、コア数を増やすことが直接的なスループット向上につながる。L3キャッシュ容量の減少による潜在的なパフォーマンス低下は、FL2の効率的なメモリ使用によって相殺された。
3つの候補から9965を選んだ理由
Cloudflareのエンジニアチームは、Gen13のCPU候補として3つのAMD Turinプロセッサを評価した。128コアの9755、160コアの9845、そして192コアの9965だ。
評価の結果、9965が選ばれた理由は明確だ。生産環境でのテストにおいて、9965の192コアは最高の総合リクエスト処理性能を示した。さらに、500WのTDP(熱設計電力)における性能/ワット効率も優れており、ラックレベルでの総所有コスト(TCO)が最も低くなると判断された。
運用面でも、192コアという高密度構成はメリットがある。同じ計算能力を提供するために必要なサーバー台数が減るため、プロビジョニング、パッチ適用、監視にかかる運用オーバーヘッドを削減できる。
メモリとストレージの拡張

12チャネルDDR5-6400で帯域幅33%向上
CPUコア数が2倍になったことで、メモリサブシステムにもより高い要求が課せられた。Gen13は12個のDDR5-6400メモリチャネルすべてを活用する構成を採用している。
各チャネルに64GB DIMMを1枚ずつ配置する「1DIMM per channel」構成で、合計768GBのメモリ容量を実現。ピークメモリ帯域幅はソケットあたり614GB/sに達し、Gen12から33.3%向上した。
すべてのチャネルを均等に使用する構成は、メモリインターリーブの観点から重要だ。AMD Turinプロセッサは、同じDIMMタイプ、同じ容量、同じランク構成のメモリチャネル間でインターリーブを行う。インターリーブにより、連続したメモリアクセスが単一のチャネルではなくすべてのチャネルに分散され、実効的なメモリ帯域幅が向上する。
コアあたり4GBの「適正容量」を維持
メモリ容量の決定において、Cloudflareは「コアあたり4GB」という比率を維持することを選択した。Gen12でも同じ比率が採用されており、実績のあるバランスだ。
設計初期には、コアあたり4GBから6GBの範囲が検討された。192コアの場合、768GBから1152GBに相当する。実際のDIMM容量の粒度を考慮すると、選択肢は12x48GB(576GB)、12x64GB(768GB)、12x96GB(1152GB)の3つだった。
12x48GB構成は容量が不足し、メモリを多く消費するワークロードを飢餓状態にするリスクがある。一方、12x96GB構成はコアあたり50%の容量増加となるが、電力消費の増加とコストの大幅な上昇(現在のメモリ価格は1年前の10倍)が問題だ。
12x64GBの768GB構成は、コアあたり4GBという実績のある比率を維持しつつ、サーバーあたりの総容量をGen12の2倍に拡大する。FL2はFL1と比べてメモリ使用効率が大幅に向上しており、ソフトウェアスタックの移行によって生じた余剰容量が、今後数年間のCloudflareの成長を支えるヘッドルームとなる。
ストレージ:PCIe 5.0と容量50%増
ストレージサブシステムも大幅に強化された。Gen13はPCIe Gen 5.0 NVMeドライブを採用し、レイテンシの改善と増大するストレージ帯域幅要求に対応する。
物理的なストレージ容量も、3台のNVMeドライブにより24TBに拡張された。Gen12サーバーは4つのE1.Sストレージスロットを備えていたが、実際に使用されていたのは2スロットのみだった。Gen13では同じ4スロット設計を維持しつつ、3スロットに8TBドライブを実装している。
3台目のドライブ追加により、サーバーあたりのストレージ容量は16TBから24TBへ50%増加した。これはCDNキャッシュ性能の維持・向上に加え、Durable Objects、Containers、Quicksilverサービスなどの成長予測を支えるためだ。
さらにGen13シャーシには、最大10台のU.2 PCIe Gen 5.0 NVMeドライブを収容できるフロントドライブベイが追加された。この設計により、同じシャーシをコンピュートプラットフォームとストレージプラットフォームの両方で使用できる柔軟性が生まれる。必要に応じてコンピュートSKUをストレージSKUに変換することも可能だ。
ネットワークと電源の刷新

8年ぶりのネットワークアップグレード:25GbEから100GbEへ
Gen13で最も大きな変化の一つが、ネットワークインターフェースの刷新だ。8年以上にわたりCloudflareフリートの基盤となってきたデュアル25GbEから、デュアル100GbEへと移行する。
この変更の必要性は明白だ。192コアという高性能CPUがより多くのリクエストを処理できるようになると、ネットワーク帯域幅がボトルネックになる。実際、世界中のコロケーション施設から収集した1週間分の本番データによると、Gen12ではポートあたりのP95帯域幅が利用可能帯域幅の50%を一貫して超えていた。
Gen13ではサーバーあたりのスループットが2倍になるため、NIC帯域幅が飽和するリスクが高まる。100GbEへの移行は、このボトルネックを解消するための必然的な選択だ。
50GbEではなく100GbEを選んだ理由は、産業界の経済性にある。50GbEトランシーバーの市場規模は依然として小さく、サプライチェーン上のリスクが高い。デュアル100GbEポートによりサーバーあたり200Gb/sの集約帯域幅を実現し、今後数年間のトラフィック成長に対応できる将来性も確保した。
電源:800Wから1300Wへ拡張
コンピュート能力とネットワーク能力の向上に伴い、サーバーの電力エンベロープも自然に拡大した。Gen13は必要な電力を供給するため、より大型の電源装置を搭載する。
Gen12ノードは800W 80 PLUS Titanium CRPS(共通冗長電源装置)で十分に動作していたが、Gen13では1300W 80 PLUS Titanium CRPSを選択した。
Gen13の通常動作時の電力消費は850Wに達する。Gen12の600Wから250Wの増加だ。主な要因は、TDPが400Wから500Wに上がったCPU、メモリ容量の2倍化、追加のNVMeドライブである。
1000Wではなく1300Wを選んだ理由は、現在のPSUエコシステムに1000Wの高効率オプションがほとんどないためだ。サプライチェーンの信頼性を確保するために、産業界標準の次の階層である1300Wに移行した。
EU Lot 9規制は、欧州連合に展開するサーバーが、負荷10%、20%、50%、100%において規制で指定された効率率閾値を満たす電源装置を備えることを要求する。この閾値は80 PLUS Power Supply認証プログラムのチタニウムグレードPSU要件と一致する。Gen13ではEU Lot 9に完全準拠するためチタニウムグレードPSUを選択し、欧州のデータセンターをはじめとする全世界での展開を可能にした。
セキュリティと管理の継続性

Project Argus DC-SCM 2.0の継承
Gen13では、Gen12で導入された管理機能とセキュリティ関連コンポーネントをマザーボードから分離するアーキテクチャを維持する。これらは「Project Argus」データセンターセキュアコントロールモジュール2.0(DC-SCM 2.0)に集約されている。
DC-SCMモジュールには、サーバーのセキュリティの中枢となる重要なコンポーネントが収められている。
- 基本入出力システム(BIOS)
- ベースボード管理コントローラ(BMC)
- ハードウェアルートオブトラスト(HRoT)とTPM
- 冗長性のためのデュアルBMC/BIOSフラッシュチップ
このアーキテクチャをGen13でも継続する決定は、前世代で実証されたセキュリティ上の利点に基づく。管理機能を専用モジュールにオフロードすることで、以下のメリットを維持できる。
迅速な回復機能は、デュアルイメージ冗長性により、偶発的な破損や悪意のある更新が検出された場合にBIOS/UEFIおよびBMCファームウェアをほぼ瞬時に復元できる。
物理的耐性については、Gen13シャーシでは侵入検知メカニズムをシャーシの平坦な端からさらに遠ざけ、物理的な傍受を難しくしている。
PCIe暗号化は、Gen10プラットフォームから有効化されていたCPUとメモリ間の暗号化(TSME)に加え、AMD Turin 9965プロセッサがPCIeトラフィックにも暗号化を拡張する。これにより、システム内のすべてのバスを通過するデータが転送中も保護される。
運用的一貫性も重要だ。Gen12管理スタックを維持することで、セキュリティ監査、展開、プロビジョニング、運用標準手順が完全に互換性を保つ。
ドロップインアクセラレータサポートの強化
フリートのモジュール性維持は、Cloudflareのサーバー設計における中核的な要件だ。この要件により、Cloudflareは2024年にGPUを世界中の100以上の都市に迅速に改造・展開できた。
Gen13では、高性能PCIeアドインカードのサポートを継続する。Gen13の2Uシャーシレイアウトは更新され、より要求の厳しい電力と熱要件をサポートするように構成されている。Gen12がシングル幅GPU1枚に制限されていたのに対し、Gen13アーキテクチャはダブル幅PCIeカード2枚をサポートする。
この記事のポイント
- Cloudflare Gen13サーバーは192コアAMD EPYC Turin 9965を採用し、前世代比最大2倍のスループットを実現
- FL2(Rust製新リクエスト処理層)への移行により、大容量L3キャッシュへの依存を解消。コア数増加による性能向上を可能にした
- メモリは12チャネルDDR5-6400構成で768GBを実装。帯域幅33%向上とコアあたり4GBの適正容量を維持
- ネットワークは8年ぶりに刷新。デュアル25GbEからデュアル100GbEへ移行し、帯域幅ボトルネックを解消
- セキュリティはProject Argus DC-SCM 2.0アーキテクチャを継承。PCIe暗号化を追加し、データ転送中の保護を強化
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験