

Google 2026年3月コアアップデート開始——2026年最初の広範な更新とサイト運営者の対策
2026年3月27日、Googleは検索ランキングシステムの広範な変更を伴う「2026年3月コアアップデート」のリリースを公表した。Google検索ステータスダッシュボードによれば、展開の開始は太平洋標準時の午前2時である。今回のアップデートは、2026年に入ってから初めての広範なコアアップデートとなる。
このアップデートは、完了までに最大2週間を要する見込みだ。Googleは公式なブログ記事や具体的な目的の詳細については現時点で発表していない。しかし、コアアップデートの性質上、検索結果の信頼性と有用性を高めるための包括的な調整が行われていると考えられる。
サイト運営者やSEO担当者にとって、この2週間は検索順位の動向を注視すべき期間となる。ランキングの変動は一過性のものである可能性も高いため、展開が完全に終了するまでは冷静な対応が求められる。この記事では、アップデートの概要と、私たちが取るべき具体的なアクションについて解説する。
2026年3月コアアップデートの概要とスケジュール

今回のアップデートは、Googleが定期的に実施するランキングアルゴリズムの抜本的な見直しの一環だ。特定のサイトやページを狙い撃ちにするものではなく、ウェブ全体のコンテンツ評価を再定義することを目的としている。
展開期間と影響の範囲
Googleの発表によれば、ロールアウト(展開)には約2週間かかる見通しだ。つまり、4月上旬までは検索結果が不安定な状態が続く可能性がある。コアアップデートとは、Googleの検索アルゴリズムの核となる部分を更新する作業を指す。これにより、以前は高く評価されていたページが下落したり、逆に低迷していたページが上昇したりする現象が起こる。
記事によれば、この変更は特定のコンテンツ形式や特定の違反を対象としたものではない。Googleは「ヘルプフルコンテンツ(読者にとって役立つコンテンツ)」をより正確に識別し、信頼できる情報を上位に表示させるための調整であると説明している。
2026年のアップデート履歴と今回の位置づけ
2026年に入り、Googleはすでにいくつかのアップデートを実施している。2月には「Google Discover」のみを対象としたアップデートが行われたが、これは通常の検索ランキングには影響を与えなかった。また、今回のコアアップデートのわずか2日前には、記録的な速さ(約20時間)で完了した「2026年3月スパムアップデート」が実施されたばかりだ。
これらの背景から、今回のコアアップデートは直前のスパム対策と連動し、より質の高い検索体験を提供するための「仕上げ」のような役割を担っている可能性がある。広範な検索順位に影響を与えるアップデートとしては、2025年12月以来、約3ヶ月ぶりの実施となる。
コアアップデートの本質と評価基準

コアアップデートによる順位変動に直面した際、多くの運営者は「自社のサイトに不備があったのではないか」と不安を感じる。しかし、Googleは順位の下落が必ずしもガイドライン違反を意味するわけではないと明言している。
相対的な評価の見直し
コアアップデートを理解する上で有効なたとえが「映画のトップ10リスト」の更新だ。2024年に作成されたリストが、2026年に新しく公開された優れた映画を含めて更新されるようなものである。以前ランクインしていた映画がリストから漏れたとしても、その映画の質が悪くなったわけではない。単に、より優れた、あるいはより現代のニーズに合った映画が登場したに過ぎないのだ。
ウェブサイトも同様で、他サイトのコンテンツが相対的に向上したり、Googleが「今のユーザーにはこちらの情報がより適切だ」と判断基準を変えたりすることで、順位が変動する。この「相対的な評価」こそが、コアアップデートの本質である。
E-E-A-Tとヘルプフルコンテンツ
Googleが重視している指標は、一貫して「E-E-A-T(経験、専門性、権威性、信頼性)」だ。特に最近では、筆者の実体験に基づいた情報(Experience)がより高く評価される傾向にある。AIによって生成された画一的な情報が増える中で、人間にしか書けない独自の視点や検証データが含まれているかどうかが、評価の分かれ目となる。
ヘルプフルコンテンツとは、検索エンジンのために書かれた文章ではなく、ユーザーの悩みを解決するために書かれた文章を指す。記事によれば、Googleは継続的に小規模なアップデートも行っているが、今回のコアアップデートのような大規模な更新では、これらの評価軸がより強力に適用されることになる。
変動が起きた際の具体的なチェックリスト

アップデートの展開中に順位が大きく動いたとしても、焦ってサイトを修正するのは避けるべきだ。Googleは、アップデートの完了から少なくとも1週間は経過を見てから分析を開始することを推奨している。
Search Consoleを用いたデータ分析
まず行うべきは、Google Search Console(サーチコンソール)での比較分析だ。アップデート開始前の期間と、完了後の期間を比較し、どのキーワードやページでクリック数や掲載順位が減少したのかを特定する。Search Consoleとは、Google検索での自サイトのパフォーマンスを管理する無料ツールである。
分析の際は、サイト全体が下がっているのか、特定のカテゴリーだけが下がっているのかを見極める必要がある。特定のトピックで順位が落ちている場合、その分野において競合サイトがより「ヘルプフル」なコンテンツを提供している可能性がある。
コンテンツの再評価ポイント
順位が下落したページについては、以下の視点でセルフチェックを行うことが推奨される。まず、その記事は独自の調査や分析、体験談を含んでいるか。次に、タイトルは内容を正確に表しており、過度な「釣り」になっていないか。そして、その分野に詳しくない人が読んでも理解しやすい構成になっているか、という点だ。
特に「独自性」は重要だ。他サイトの情報をまとめただけのページは、コアアップデートのたびに評価を落とすリスクが高まっている。自社にしか出せないデータや、実際に製品を使った感想など、付加価値を加えることが長期的な順位維持の鍵となる。
独自分析:AI時代のコンテンツ品質とGoogleの意図

今回のアップデートで注目すべき点は、3月24日から25日にかけて行われた「スパムアップデート」との近接性だ。わずか20時間という異例の速さで完了したスパムアップデートの直後に、このコアアップデートが開始されたことには大きな意味があると考えられる。
低品質なAI生成コンテンツへの包囲網
現在、生成AIの普及により、ウェブ上には大量の「それらしいが中身のない」記事が溢れている。Googleにとっての最大の課題は、これらのノイズを排除し、ユーザーが求める真実味のある情報を届けることだ。直前のスパムアップデートで明らかな悪質サイトを排除し、今回のコアアップデートで「良質だが独自性に欠けるサイト」と「真に価値のあるサイト」の選別を行っているのではないか、との見方がある。
筆者の分析によれば、Googleは単なる「情報の正確さ」だけでなく、「情報の鮮度」と「発信者の実在性」をより厳格に評価するフェーズに入っている。匿名性の高い、いわゆる「こたつ記事(現場に行かずネットの情報だけで書いた記事)」の評価は、今後さらに厳しくなるだろう。
「検索意図の充足」から「ユーザー体験の向上」へ
これまでのSEOは、特定のキーワードに対して適切な答えを返す「検索意図の充足」がゴールだった。しかし、これからのSEOは、ページを開いた後のユーザー体験(UX)までが評価の対象となる。例えば、ページの読み込み速度や、モバイルでの操作性、そして何より「そのページを読んでユーザーの行動がどう変わったか」という定性的な価値が問われている。
今回のアップデートを通じて、Googleは検索結果を単なるリンク集から、信頼できるアドバイザーのような存在へと進化させようとしている。サイト運営者は、テクニカルなSEO手法に固執するのではなく、読者の期待を上回る価値をどう提供するかに注力すべきだ。
この記事のポイント
- 2026年3月27日から、今年初の広範なコアアップデートが開始された。
- 展開の完了には最大で2週間かかる見込みであり、4月上旬までは順位が不安定になる。
- アップデートは特定の違反を罰するものではなく、ウェブ全体の相対的な評価を見直すものだ。
- 順位が変動しても即座に修正せず、展開完了から1週間後にSearch Consoleで詳細な分析を行うべきである。
- AI生成コンテンツが増加する中で、独自の体験や専門性(E-E-A-T)の重要性がさらに高まっている。
出典
- Search Engine Journal「Google Begins Rolling Out March 2026 Core Update」(2026年3月27日)
- Google Search Status Dashboard(2026年3月27日)

・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Kubernetesの1行修正で年600時間を削減——Cloudflareが直面したPVマウントの罠
Kubernetesの設定ファイルをたった1行書き換えるだけで、年間600時間ものエンジニア工数を削減した事例がある。Cloudflare(クラウドフレア)のインフラチームが直面したこの問題は、システムの規模が拡大するにつれて静かに忍び寄る「デフォルト設定の罠」を浮き彫りにした。
原因は、ストレージの権限管理を行うKubernetesの標準的な振る舞いにあった。数百万ものファイルを抱えるボリュームにおいて、再起動のたびに30分ものダウンタイムが発生していた事態を、彼らはどのように特定し、解決したのだろうか。
本記事では、CloudflareのエンジニアであるBraxton Schafer氏が公開したデバッグの過程と、大規模なKubernetes運用において見落としがちなパフォーマンスのボトルネックについて詳しく解説する。
Atlantisの再起動がなぜか「30分」もかかる謎

Cloudflareでは、Terraform(テラフォーム)によるインフラ管理の自動化ツールとして「Atlantis(アトランティス)」を利用している。Terraformはコードでインフラを定義するツールだが、Atlantisを導入することで、GitHubやGitLabのプルリクエスト上で実行計画(Plan)の確認や適用(Apply)が可能になる。
AtlantisはKubernetes上で「StatefulSet(ステートフルセット)」として動作しており、リポジトリの状態を保持するためにPV(Persistent Volume / 永続ボリューム)を使用している。StatefulSetとは、Pod(ポッド)の再起動後もデータの永続性を保証するための仕組みだ。
頻繁な再起動がエンジニアの時間を奪う
問題は、このAtlantisを再起動するたびに発生していた。新しいプロジェクトの設定を読み込ませたり、認証情報を更新したりするために、Cloudflareでは月に約100回ほどの再起動を行っていた。しかし、再起動を開始してからPodが正常に立ち上がるまで、毎回30分もの時間がかかっていたという。
この間、エンジニアはインフラの変更を行うことができず、作業が完全にブロックされてしまう。月100回の再起動で毎回30分待機が発生すれば、月間で50時間、年間では600時間もの時間が「ただの待ち時間」として消えていく計算だ。これは、一人のエンジニアが数ヶ月間フルタイムで働く時間に匹敵する大きな損失である。
「inode不足」がきっかけで表面化した問題
この遅延が決定的な問題として認識されたのは、ストレージの「inode(アイノード)」が枯渇した際だった。inodeとは、ファイルシステム上でファイルやディレクトリの情報を管理するためのデータ構造だ。ファイルが大量に作成されると、ディスク容量が残っていてもinodeが足りなくなり、新しいファイルが作成できなくなる。
Cloudflareの環境では、ファイルシステムを拡張することでしかinodeを増やせない仕様だった。拡張を反映させるにはPodの再起動が必要となり、そのたびに30分のダウンタイムが発生する。チームは当初、アラートの通知設定を調整して「見かけ上の問題」を回避することも検討したが、根本的な原因の調査に乗り出すことを決めた。
Kubernetesのログを深掘りして見えてきたボトルネック
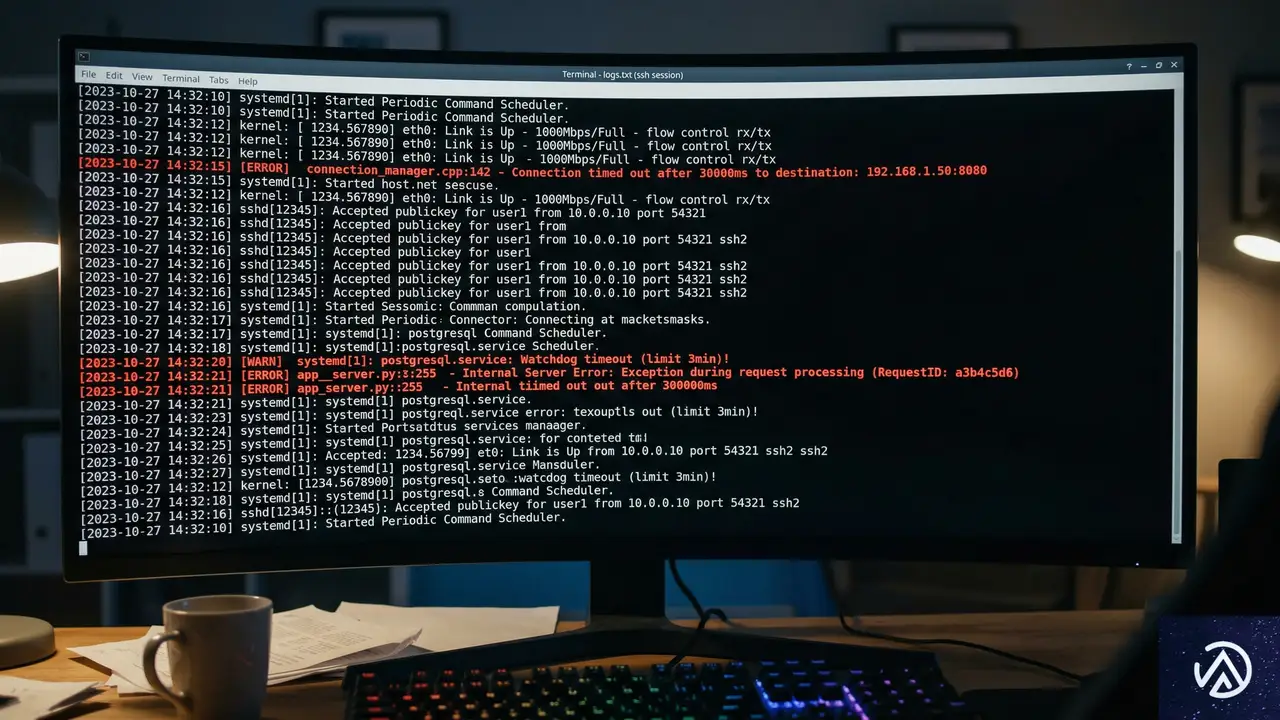
調査を開始したBraxton Schafer氏は、まずkubectl rollout restartコマンドを実行し、新しいPodが立ち上がる様子を観察した。Pod自体はすぐにスケジュールされるものの、ステータスが「Init(初期化中)」のまま30分間も停止していることが判明した。
Podのイベントログを確認しても、イメージのプルが開始されるまでに不可解な空白時間があることしかわからなかった。そこで氏は、より低レイヤーのログを確認するため、各ノードで動作するコンポーネント「kubelet(クブレット)」のログを調査した。
kubeletのログに隠された「空白の時間」
kubeletは、各ノードでPodの実行を管理し、ボリュームのマウントなどを制御する重要なエージェントだ。システム管理ツールであるKibana(キバナ)を使ってログを分析したところ、PVのマウント自体は成功しているものの、その直後にタイムアウトエラーが発生し、リトライを繰り返している様子が記録されていた。
ログには「context deadline exceeded(処理時間の制限を超過した)」というメッセージが並んでいた。何らかの処理が異常に時間を要しており、Kubernetesの監視機構がそれを「失敗」とみなして処理を中断、再試行するというループに陥っていたのだ。
数百万個のファイルが引き起こす権限変更の罠
さらに詳細なログを追うと、決定的なメッセージが見つかった。そこには「Setting volume ownership(ボリュームの所有権を設定中)」という記述があった。実はこれが、30分もの時間を浪費させていた真犯人だった。
Kubernetesには、Pod内のプロセスがボリュームにアクセスできるように、マウント時に所有権を自動で調整する機能がある。具体的には、PodのsecurityContextで指定されたfsGroupのIDに合わせて、ボリューム内の全ファイルに対して再帰的にchgrp(グループ変更)を実行する。Atlantisのようなツールは運用期間が長くなるほど管理するファイル数が増大し、Cloudflareの環境では数百万個ものファイルが蓄積されていた。高速なストレージであっても、数百万個のファイルに対して一つずつ権限を確認・変更していく処理には膨大な時間がかかるのは必然だ。
わずか1行の修正でパフォーマンスが劇的に改善
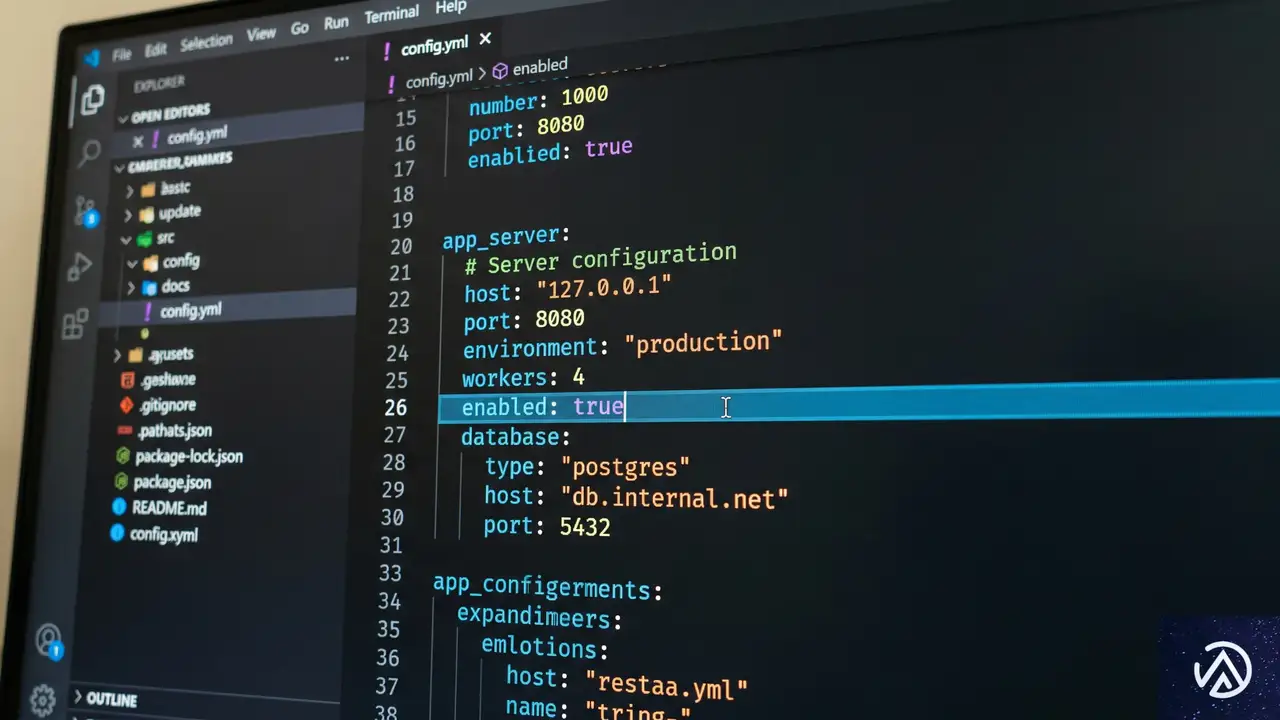
原因が「再帰的な権限変更」であると特定できれば、解決策は非常にシンプルだった。Kubernetes 1.20以降、この振る舞いを制御するための新しい設定項目が追加されている。それがfsGroupChangePolicy(エフエスグループ・チェンジ・ポリシー)だ。
デフォルトでは、このポリシーはAlways(常に実行)に設定されている。つまり、Podが起動するたびに、すでに権限が正しく設定されていようがいまいが、すべてのファイルをスキャンして権限を上書きしようとする。これが大規模なボリュームにおいて致命的な遅延を引き起こす。
fsGroupChangePolicyの設定とは
解決策は、このポリシーをOnRootMismatch(ルートディレクトリが不一致の場合のみ実行)に変更することだ。この設定にすると、Kubernetesはまずボリュームのルートディレクトリの権限を確認する。もしルートの権限がすでに正しく設定されていれば、配下のファイルに対する再帰的なスキャンをスキップする。
spec:
template:
spec:
securityContext:
fsGroupChangePolicy: OnRootMismatchこの1行をマニフェストファイルに追加するだけで、権限変更のプロセスが大幅に簡略化される。Cloudflareのケースでは、これまで30分かかっていた再起動時間が、わずか30秒にまで短縮された。実に60倍の高速化だ。
30分から30秒へ、驚異的な短縮効果
この修正により、エンジニアがデプロイの待ち時間に拘束されることがなくなった。また、再起動が長引くことによって発生していた「Podが正常に起動しない」という偽のアラートに、オンコール担当者が夜中に叩き起こされることもなくなったという。技術的には極めて単純な変更だが、組織全体の生産性に与えたインパクトは計り知れない。
大規模システムにおける「デフォルト設定」の落とし穴

今回の事例から学べる最も重要な教訓は、Kubernetesの「安全なデフォルト設定」が、規模の拡大とともに牙を向く可能性があるということだ。fsGroupによる自動的な権限変更は、初心者が権限エラーに悩まされないようにするための親切な機能として設計されている。
しかし、エンタープライズレベルの運用において、数テラバイトのデータや数百万のファイルを扱うようになると、その「親切心」がシステムの可用性を損なう要因へと変わる。これは、小規模なプロジェクトでは決して表面化しない問題だ。
小規模なら問題ないが、スケールするとボトルネックになる
多くのインフラエンジニアは、マウントが遅い場合にネットワークやストレージ装置の性能を疑う。しかし、今回のケースのように「OSレベルのファイル操作」がバックグラウンドで走っていることに気づくには、深いオブザーバビリティ(観測性)が必要だ。Braxton Schafer氏が、Kubernetesのイベントログだけでなく、kubeletのシステムログまで掘り下げたことが早期解決の鍵となった。
SRE的視点での教訓
SRE(Site Reliability Engineering / サイト信頼性エンジニアリング)の観点では、「なぜシステムはこのように振る舞うのか?」という問いを持ち続けることの重要性が再確認された。30分の待ち時間を「そういうものだ」と受け入れてしまえば、年間600時間の損失は永遠に解消されなかっただろう。
もし読者の環境でも、特定のPodの起動が異常に遅かったり、ボリュームをマウントする際にInitコンテナで止まっていたりする場合は、securityContextの設定を見直してみる価値がある。特に、大量の静的ファイルを保持するCMSや、データベースのバックアップファイルを扱うPodなどは、同様の問題を抱えている可能性が高い。
この記事のポイント
- 原因の特定: Atlantisの再起動に30分かかっていたのは、Kubernetesがマウント時に全ファイルの所有権を再帰的に変更していたため。
- 1行の修正:
fsGroupChangePolicy: OnRootMismatchを設定することで、不要な権限変更をスキップできる。 - 劇的な改善: Cloudflareはこの修正により、再起動時間を30分から30秒に短縮し、年間600時間の工数を削減した。
- 教訓: 安全のためのデフォルト設定が、大規模環境では深刻なパフォーマンス低下を招くことがある。
- 推奨アクション: 大容量PVを使用するPodでは、
securityContextの設定を監査し、不必要な再帰処理を避ける設定を検討すべきだ。
出典
- Cloudflare Blog「A one-line Kubernetes fix that saved 600 hours a year」(2026年3月26日)
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

WordPress移行を劇的に簡略化する「All-in-One WP Migration Pro」徹底レビュー
WordPressサイトを新しいサーバーへ移転させる作業は、多くの運営者にとって最もストレスのかかるタスクの一つだ。単純なファイルのコピーだけでは済まず、データベース内のURL置換や、データの整合性を保つための細かな調整が求められるからだ。
こうした移行作業の複雑さを解消し、数回のクリックで完了させるツールとして定評があるのが「All-in-One WP Migration」である。元記事の著者であるTom Rankin氏は、このプラグインの有料版(Pro)が、エラーの起きやすい手動作業をいかに効率化できるかを詳しく検証している。
本記事では、3,000万件以上のインストール実績を持つこのプラグインのPro版について、その機能や料金体系、そして導入前に知っておくべき制限事項を詳しく解説する。移行作業の「失敗」を避けたい担当者にとって、有力な選択肢になるはずだ。
All-in-One WP Migration Proの基本機能と特徴
All-in-One WP Migration Proは、WordPressのデータベース、メディアライブラリ、テーマ、プラグインを一つのファイルにパッケージ化し、移行先でそのまま復元できるツールだ。最大の強みは、サーバーの設定を直接操作することなく、ブラウザ上の管理画面だけで作業が完結する点にある。
1クリックで完結するサイトのパッケージ化
このプラグインは、サイト全体のデータを独自形式の「.wpress」ファイルとして書き出す。FTP(File Transfer Protocol / ファイルをサーバーに転送する仕組み)を使ってファイルを一つずつダウンロードしたり、phpMyAdminなどのツールでデータベースをエクスポートしたりする手間は一切不要だ。
記事によれば、Pro版はサイトの規模に関わらずエクスポートとインポートが可能となっている。無料版でも基本的な移行は可能だが、サーバー環境によってはアップロードサイズに制限がかかることがある。Pro版では「チャンクアップロード」と呼ばれる、大きなファイルを分割して送信する仕組みを採用しているため、ホスティング側の制限を回避して確実にデータを移行できるのが特徴だ。
15種類以上のクラウドストレージ連携
Pro版の大きなメリットの一つが、外部のクラウドストレージと直接連携できる点だ。Amazon S3、Google Drive、Dropbox、OneDriveといった主要なサービスに加え、Backblaze B2やMegaなどのストレージにも対応している。
これにより、作成したバックアップファイルをPCにダウンロードすることなく、直接クラウドへ保存できる。また、スケジュール設定による自動バックアップも可能だ。単なる「移行ツール」としてだけでなく、万が一の事態に備えた「バックアップソリューション」としても運用できる柔軟性を備えている。
料金体系の注意点——「インストール数」ではなく「使用数」
All-in-One WP Migration Proのライセンス料は、年額99ドルから設定されている。一見すると一般的なプラグインの料金体系と同じように見えるが、そのカウント方式には独特のルールがあるため注意が必要だ。
50サイトまでの制限とカウント方法
標準的なプランでは、最大50サイトまで利用可能だ。ただし、この「50サイト」は「現在プラグインが有効化されているサイト数」ではなく、サブスクリプション期間中に「移行やバックアップを実行したサイトの累計数(usage)」でカウントされる。
例えば、一度きりの移行作業でプラグインを使い、作業完了後に削除したとしても、そのサイトは1枠としてカウントされ続ける。著者のRankin氏は、単発のクライアント案件を数多くこなす制作会社にとっては、この「使用数によるカウント」が制約に感じられる可能性があると指摘している。一方で、自社で管理する特定のサイトを継続的にバックアップ・運用する用途であれば、50サイトという枠は十分な余裕があると言えるだろう。
ローカル環境はカウント対象外
嬉しい点として、Local WPなどのツールを使ったローカル開発環境での利用は、この50サイトの枠に含まれない。開発環境で作ったサイトを本番環境へ移行する、あるいは本番環境のデータをローカルに持ち帰ってテストするといった用途では、枠を気にせず活用できる。これは、日々の開発ワークフローに移行ツールを組み込んでいるエンジニアにとって大きなメリットだ。
実際の移行フローと使い勝手の検証
移行作業がいかにシンプルであるか、元記事で紹介されている手順を基に見ていこう。基本的には「エクスポート」と「インポート」の2ステップで完了する。
エクスポートからインポートまでの手順
まず、移行元のサイトで「エクスポート」メニューを選択する。ここでは、特定のデータをバックアップから除外するオプションも用意されている。例えば、スパムコメントや投稿のリビジョン(編集履歴)を除外することで、ファイルサイズを軽量化し、移行時間を短縮することが可能だ。
次に、移行先のサイト(あらかじめWordPressをインストールし、本プラグインを有効化しておく必要がある)で「インポート」メニューを開き、先ほど作成したファイルをアップロードする。Pro版であれば、PHPの「upload_max_filesize」などのサーバー設定に阻まれることなく、スムーズに処理が進行する。
移行時のURL置換とデータ整合性
サイト移行で最も厄介なのが、データベース内のURLの書き換えだ。単純なテキスト置換では、「シリアライズデータ」と呼ばれる特殊な形式で保存されたデータが破損し、ウィジェットの設定が消えたり画像が表示されなくなったりすることがある。
シリアライズデータとは、データの型や長さを保持したまま文字列化したもので、文字数が1文字でもずれるとデータとして成立しなくなる。All-in-One WP Migration Proは、このシリアライズデータを適切に処理しながらURLを自動で置換する機能を備えている。著者のRankin氏も、この自動置換機能こそが手動移行に比べて圧倒的にミスを減らせるポイントであると評価している。
導入前に確認すべき制限事項と互換性

非常に強力なツールだが、どんな環境でも万能というわけではない。特に、利用しているホスティングサービスや他のプラグインとの相性については、購入前に必ず確認しておく必要がある。
利用できないホスティングサービス
一部のマネージドWordPressホスティング(サーバー側でWordPressに最適化された管理を行っているサービス)では、このプラグインの使用が制限されている場合がある。記事によれば、KinstaやWP Engineといった大手サービスがそのリストに含まれている。
これらのサービスは、サーバー側で高度なバックアップや移行機能を提供しているため、プラグインによるシステムレベルの操作が干渉を招く可能性があるからだ。自社が利用しているサーバーがサポート対象外になっていないか、事前に公式ドキュメント(Unsupported Hosts)をチェックすることが不可欠だ。
競合・不適合プラグインの存在
特定のプラグインが有効化されていると、エクスポートやインポートが正常に動作しないケースもある。例えば、CloudflareのWordPress用プラグインや、SSL化を強制する「Really Simple SSL」などは、移行作業中のみ一時的に無効化することが推奨されている。
また、元記事ではドキュメントの一部が古い(数年前の情報のまま更新されていない箇所がある)ことも指摘されている。基本的な移行フローは変わっていないものの、最新のWordPressバージョンや特定のプラグインとの相性で問題が発生した場合は、ドキュメントに頼りすぎず、直接サポートへ問い合わせる必要があるかもしれない。
独自分析:運用効率を最大化する活用シーン

筆者の見解として、All-in-One WP Migration Proは単なる「引っ越しツール」以上の価値を運用フェーズでもたらすと考える。特に注目すべきは、Pro版に含まれる「WP-CLI」への対応と「Reset Hub」機能だ。
WP-CLI(WordPress Command Line Interface)は、コマンドラインからWordPressを操作するツールだ。これを利用すれば、ブラウザを開くことなくスクリプトによる自動移行や一括バックアップが可能になる。制作会社が複数の保守サイトを一括管理する場合、この自動化の恩恵は非常に大きい。
また、「Reset Hub」はサイトの状態を素早くリセットできる機能だ。テーマの開発やプラグインのテストを行っている際、データベースをクリーンな状態に何度も戻す必要がある開発者にとって、この機能は作業時間を大幅に短縮してくれるだろう。移行時だけでなく、日常的な「開発・検証環境のメンテナンス」にこそ、Pro版の真価があると言える。
この記事のポイント
- 圧倒的な簡便さ:データベース、メディア、プラグインを1ファイルにまとめ、数クリックで移行が完了する。
- URL自動置換の信頼性:壊れやすいシリアライズデータを保護しながら、移行先のURLへ正確に書き換えてくれる。
- 大容量サイトへの対応:Pro版のチャンクアップロード機能により、サーバーのアップロード制限を気にせず移行が可能。
- ライセンスの特殊性:インストール数ではなく、移行を実行した「サイト使用数」でカウントされる点に注意が必要。
- 環境の事前確認が必須:一部のマネージドホスティングや特定のプラグインとは互換性がないため、導入前の調査が欠かせない。
出典
- WP Mayor「All-in-One WP Migration Pro Review: The Simplest Way to Move a WordPress Site」(2026年3月23日)
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

WordPressでAIを活用したインタラクティブなアンケートを作成する方法:WPFormsの実績ガイド
WordPressサイトでアンケートを実施しても、回答が集まらずに悩む担当者は多い。従来の静的なフォームは項目が長くなりがちで、ユーザーが途中で離脱してしまう傾向があるからだ。WP Beginnerの記事によれば、この問題を解決する鍵は、AIと条件分岐を活用した「インタラクティブ(双方向)なアンケート」の構築にあるという。
最新のプラグイン機能を活用すれば、手動での複雑な設定をスキップし、約15分でプロ仕様のアンケートを完成させることが可能だ。ユーザーの回答に応じて質問を変化させるパーソナライズ機能により、データの質と完了率を劇的に向上させられる。本記事では、WPFormsを用いたAIアンケートの具体的な構築手順と、そのメリットを深掘りしていく。
なぜ従来のアンケートは回答率が低いのか

多くのWebサイトで見かけるアンケートは、すべてのユーザーに同じ質問を順番にぶつける「静的」な構造をしている。この形式では、ユーザーに関係のない質問まで表示されるため、心理的な負担が増え、離脱を招く原因となる。記事では、インタラクティブなアンケートを導入することで、ユーザー体験(UX)を損なわずに質の高い回答を得られると指摘されている。
ユーザーの興味を維持するパーソナライズの力
インタラクティブなアンケートとは、ユーザーの入力内容に基づいてリアルタイムに質問が変化する仕組みを指す。例えば、サービスの満足度を5段階評価で「1」と答えた人だけに改善点の詳細を尋ね、「5」と答えた人にはレビューの投稿を促すといった制御が可能だ。このように一人ひとりに最適化された質問を提示することで、ユーザーは「自分の声が聞かれている」という感覚を持ちやすくなる。
データの精度を高める専門的な評価指標
単なる「はい・いいえ」の回答ではなく、NPS(Net Promoter Score / ネットプロモータースコア)やリッカート尺度といった専門的な指標を簡単に導入できる点も重要だ。NPSとは、顧客のロイヤルティを0〜10の数値で測定する指標であり、大手ブランドも採用している標準的な手法である。リッカート尺度は「非常に同意する」から「全く同意しない」までの多段階で意見を測る手法で、ユーザーの微妙な心理をデータ化するのに適している。
AIを活用したアンケート作成の準備

WordPressで高度なアンケートを構築するには、ドラッグ&ドロップ形式のフォーム作成ツールである「WPForms」が適している。無料版でも基本的なフォームは作成できるが、AIによる自動生成や視覚的なレポート機能、会話型レイアウトを使用するには、有料の「WPForms Pro」が必要となる。
必要なアドオンのインストール
WPForms Proを導入した後、アンケート機能を有効化するために「Surveys and Polls(アンケートと投票)」アドオンをインストールする。これにより、回答データのグラフ化や特殊な評価フィールドが利用可能になる。さらに、記事の著者は「Conversational Forms(会話型フォーム)」アドオンの併用も強く推奨している。これは、Typeformのように一画面に一つの質問を表示するスタイルを実現するツールであり、スマートフォンユーザーの回答率向上に大きく寄与する。
プライバシーポリシーの更新
アンケートでユーザーの情報を収集する場合、プライバシーポリシー(個人情報保護方針)の更新を忘れてはならない。どのような目的でデータを収集し、どう管理するかを明記することは、GDPR(EU一般データ保護規則)などの法律を遵守するだけでなく、ユーザーからの信頼を得るためにも不可欠なステップだ。
AIプロンプトでアンケートの骨組みを作る

WPFormsの最新機能である「Generate With AI」を使えば、ゼロから質問項目を考える手間を省くことができる。AIアシスタントに対して、どのようなアンケートを作りたいかを自然な文章(プロンプト)で伝えるだけで、適切なフィールドが配置されたフォームのドラフトが作成される。
効果的なプロンプトの書き方
AIに指示を出す際は、具体的なフィールド名を指定するのがコツだ。例えば「カフェの顧客満足度調査を作成し、コーヒーの品質に関するリッカート尺度と、友人への推奨度を測るNPSフィールドを含めてください」といった指示を出す。AIはこれらの要望を解釈し、標準的な0〜10の評価スケールなどを自動的にセットアップしてくれる。
生成されたフォームの微調整
AIが生成したフォームは、プレビュー画面で対話しながら修正できる。「ニュースレター購読のチェックボックスを追加して」や「全体をスペイン語に翻訳して」といった追加の指示も可能だ。ただし、AIによる修正はプレビューセッション中のみ有効であるため、一度エディタに移行した後は手動で調整を行う必要がある。エディタ上では、ブランドのトーンに合わせて質問の文言を微調整し、評価尺度が意図通りかを確認する作業が推奨される。
条件分岐(スマートロジック)によるパーソナライズ

AIで骨組みを作った後は、「条件分岐(スマートロジック)」を設定してアンケートを真にインタラクティブなものにする。条件分岐とは、特定の回答が選ばれたときだけ、関連する別の質問を表示させる機能だ。これにより、ユーザーに不要な質問を見せず、フォームを短く保つことができる。
ロジックの設定手順
設定は非常にシンプルだ。表示を制御したいフィールド(例えば「詳細な理由を教えてください」というテキストボックス)を選択し、設定パネルの「Smart Logic」タブを開く。「Enable Conditional Logic」をオンにし、「評価が3つ星以下の場合のみ表示する」といったルールを作成する。この設定により、満足度が高いユーザーには詳細入力を求めず、不満を感じているユーザーからのみ具体的なフィードバックを収集できるようになる。
AIによるロジックの自動設定
実は、最初のAIプロンプトの段階で「2つ星以下のときだけフィードバックボックスを表示して」と指示に含めることも可能だ。AIが自動的にロジックを組んでくれるため、設定時間をさらに短縮できる。ただし、意図しない挙動を防ぐためにも、設定完了後に「Preview」ボタンを押し、実際に回答を選んでフィールドの表示・非表示が切り替わるかを手動でテストすることが重要だ。
回答率を最大化する「会話型フォーム」の導入

アンケートの形式が整ったら、仕上げに「会話型フォームモード」を有効にする。これは、一般的なWebフォームの見た目を捨て、フルスクリーンの没入型インターフェースに変換する機能だ。視覚的なノイズが排除されるため、ユーザーは目の前の質問だけに集中できる。
専用ランディングページの作成
会話型フォームを有効にすると、専用のパーマリンク(URL)が生成される。例えば `example.com/feedback` のような分かりやすいURLを設定し、メールマガジンやSNSで直接共有することが可能だ。サイトのヘッダーやフッターにある通常のメニューが表示されないため、回答を完了するまでユーザーが他のページへ移動するのを防ぐ効果がある。
モバイル最適化と進行状況の可視化
会話型レイアウトでは、大きなボタンや読みやすいフォントが採用されており、スマートフォンでも快適に操作できる。また、画面下部に「完了まであと30%」といったプログレスバーを表示させることで、ユーザーの完遂意欲を高めることができる。記事の著者は、公開前に自分のスマートフォンで「親指テスト(片手で操作しやすいか)」を行うことを勧めている。
収集したデータの視覚化と分析

アンケートが公開され、回答が集まり始めたら、WPFormsのダッシュボードで結果を分析する。WPForms Proには、生のデータを自動的に美しいグラフやチャートに変換する機能が備わっている。数値をExcelに書き出して手動で集計する必要はない。
インタラクティブなレポート機能
「Survey Results」画面では、各質問に対する回答分布が円グラフや棒グラフで表示される。チャートの形式はワンクリックで切り替え可能で、最も傾向を把握しやすいスタイルを選択できる。このレポート機能の優れた点は、アンケート機能を有効化する前に入力された過去のデータに対しても適用できることだ。これにより、既存のフォームをアンケート形式にアップグレードした際も、すぐに分析を開始できる。
チームへの共有とエクスポート
生成されたグラフは、画像やPDFとして個別にエクスポートできる。プレゼンテーション資料やクライアントへの報告書にそのまま貼り付けられるため、実務上の効率が非常に高い。また、リアルタイムの結果をユーザーに公開したい場合は、「Poll Results(投票結果)」機能を有効にすることで、送信直後に他のユーザーの回答傾向をグラフで見せることも可能だ。
この記事のポイント
- 静的なアンケートを避け、条件分岐を活用したインタラクティブな構成にすることで離脱を防ぐ
- WPFormsのAI生成機能を使えば、プロンプト一つで専門的な評価指標を含むフォームが構築できる
- 「会話型フォーム」モードにより、スマホユーザーに優しいフルスクリーンの回答体験を提供する
- 収集したデータは自動的にグラフ化され、分析やレポート作成の時間を大幅に短縮できる
- ユーザーの回答データはAIに送信されず、自社のWordPressデータベースに安全に保存される
出典
- WP Beginner「Forget Boring Forms: How to Build Interactive WordPress Surveys with AI」(2026年3月23日)
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Cloudflare Workflowsの可視化技術——ASTを活用したコードから図への変換プロセスを解説
Cloudflare Workflowsでデプロイされたすべてのワークフローに対し、ダッシュボード上で完全な視覚的図解(ダイアグラム)を表示する機能が追加された。この機能は、YAMLやJSONのような宣言的な設定ファイルからではなく、実際に記述されたJavaScript/TypeScriptのコードを直接解析して生成される点が最大の特徴だ。
開発者が記述したコードを「oxc-parser」を用いてAST(Abstract Syntax Tree / 抽象構文木)へと変換し、静的解析によってステップ間の依存関係や並列処理を抽出している。これにより、複雑なループや条件分岐を含む動的なワークフローであっても、その構造を一目で把握することが可能になった。
AIエージェントによるコード生成が増加する現代において、人間がコードの全容を即座に理解するための補助ツールとして、この可視化技術は極めて重要な役割を果たす。本記事では、難解な最小化済みコードからどのようにして意味のある図を導き出しているのか、その技術的な裏側を詳しく見ていく。
Cloudflare Workflowsの可視化機能とその背景
なぜ「コードからの可視化」が必要なのか
従来のワークフロー構築ツールの多くは、ドラッグ&ドロップのビジュアルエディタや、YAML/JSONによる宣言的な定義をベースにしていた。これらは図解しやすい反面、複雑なロジックを記述する際の柔軟性に欠けるという弱点がある。
対してCloudflare Workflowsは「コードがすべて」というモデルを採用している。Promise.allによる並列実行、複雑なforループ、条件分岐などが通常のJavaScriptとして記述できる。しかし、自由度が高い反面、コードが複雑になると全体の流れを把握するのが難しくなる。記事によれば、特にAIが生成したコードを人間が確認する際、その「形状(shape)」を視覚的に理解できるメリットは大きいという。
動的実行モデルという技術的ハードル
Workflowsは「動的実行モデル」に従っている。これは、ランタイムがコードを実行中にステップ(step.do)に遭遇するたびに、制御をエンジン(Durable Object)に渡す仕組みだ。エンジンは実行されたステップの結果を保存するが、次にどのステップが来るかを事前には知らない。
図を作成するには、実行前(デプロイ時)に全体の構造を知る必要がある。しかし、エンジンが実行時にしかステップを把握できないのであれば、静的な図を作ることはできない。そこで、Cloudflareのチームはデプロイ時にスクリプトを解析し、コードの構造を「読み解く」アプローチを選択した。
AST(抽象構文木)を用いたコード解析の仕組み
最小化されたJavaScriptという難問
デプロイされるコードは、通常esbuildやrspack、viteなどのツールによって「最小化(Minify)」されている。変数名はaやbに書き換えられ、改行は消え、人間には解読不能な1行の巨大な文字列となる。この状態からワークフローのステップを抽出するのは容易ではない。
AST(Abstract Syntax Tree / 抽象構文木)とは、プログラミング言語の構文構造を樹木構造で表現したデータ形式だ。コードをトークンに分解し、どの関数がどの引数で呼び出されているかを構造的に把握できる。Cloudflareは、このASTを利用して最小化されたコードのジャングルからstep.doやstep.sleepといった特定の呼び出しを特定している。
高速な解析を実現するoxc-parserの採用
解析エンジンには、Rust製の高速なJavaScriptツールチェーンである「OXC(JavaScript Oxidation Compiler)」のoxc-parserが採用された。当初はコンテナ上でRustを動かしていたが、最終的にはWebAssembly(Wasm)を介してCloudflare Workers上で動作するRust Workerへと移行されたという。
このRust Workerが最小化されたJSをASTに変換し、定義されたノードタイプ(LoopNode, ParallelNode, IfNodeなど)にマッピングしていく。以下に、コードがどのようにASTを経て図の要素へ変換されるかの概念図を示す。
step.do('task', ...)このデモは、ソースコードがAST解析を経て、最終的にダッシュボード上の視覚的なステップノードへとマッピングされる流れを視覚化したものだ。
複雑なロジックをグラフ構造にマッピングする手法
並列処理を表現する「開始」と「解決」のインデックス
Workflowsにおいて最も表現が難しいのが、並列処理だ。JavaScriptではawaitを付けずにステップを呼び出すと並列に実行され、Promise.allでそれらをまとめて待機できる。これを図にするため、Cloudflareのチームは各ノードにstartsとresolvesというフィールドを持たせた。
解析中にawaitされていないPromiseに遭遇すると、そのノードに「開始(starts)」のインデックスを付与する。その後、awaitに遭遇した時点でインデックスを増やし、「解決(resolves)」として記録する。この数値の重なりを見ることで、どのステップが垂直方向に並ぶべきか(=並列か)、どのステップが完了を待って次に進むべきかを正確に判定している。
制御構文(ループ・分岐)のパターン網羅
単なる直線的なフローだけでなく、実務では多様な構文が使われる。著者のAndré氏とMia氏は、以下のような多岐にわたるパターンをASTから抽出できるように設計したと述べている。
- ループ:
for...of,while,items.map,forEach - 分岐:
switch/case,if/else, 三項演算子 - エラーハンドリング:
try/catch/finally - 関数呼び出し: ステップをラップした関数の追跡
特に、関数の中に隠れたステップの追跡は工夫が必要だ。ある関数が直接ステップを呼び出していなくても、その中で呼び出している別の関数がステップを含んでいる場合、その依存関係をグラフに含める必要がある。記事によれば、関数ごとのサブグラフを作成し、最終的にステップを含まない「葉」の部分をトリミングすることで、ノイズのない図を実現している。
開発体験(DX)における可視化の価値と今後の展望

デバッグ効率を劇的に高めるリアルタイム追跡
この可視化機能は単なる「清書された図」ではない。Cloudflareは、これをフルサービスのデバッグツールへと進化させる計画だ。具体的には、実行中のワークフローが今どのノードにいるのかをグラフ上でリアルタイムに追跡できるようにするという。
エラーが発生した場所の特定、人間による承認待ちの状態確認、あるいはテスト目的での特定ステップのスキップなど、ビジュアルインターフェースを通じて操作できる未来を目指している。さらに、ローカル開発環境での可視化も視野に入れているとのことで、開発サイクル全体での利便性向上が期待される。
独自の分析:コードを「正解」とするアプローチの意義
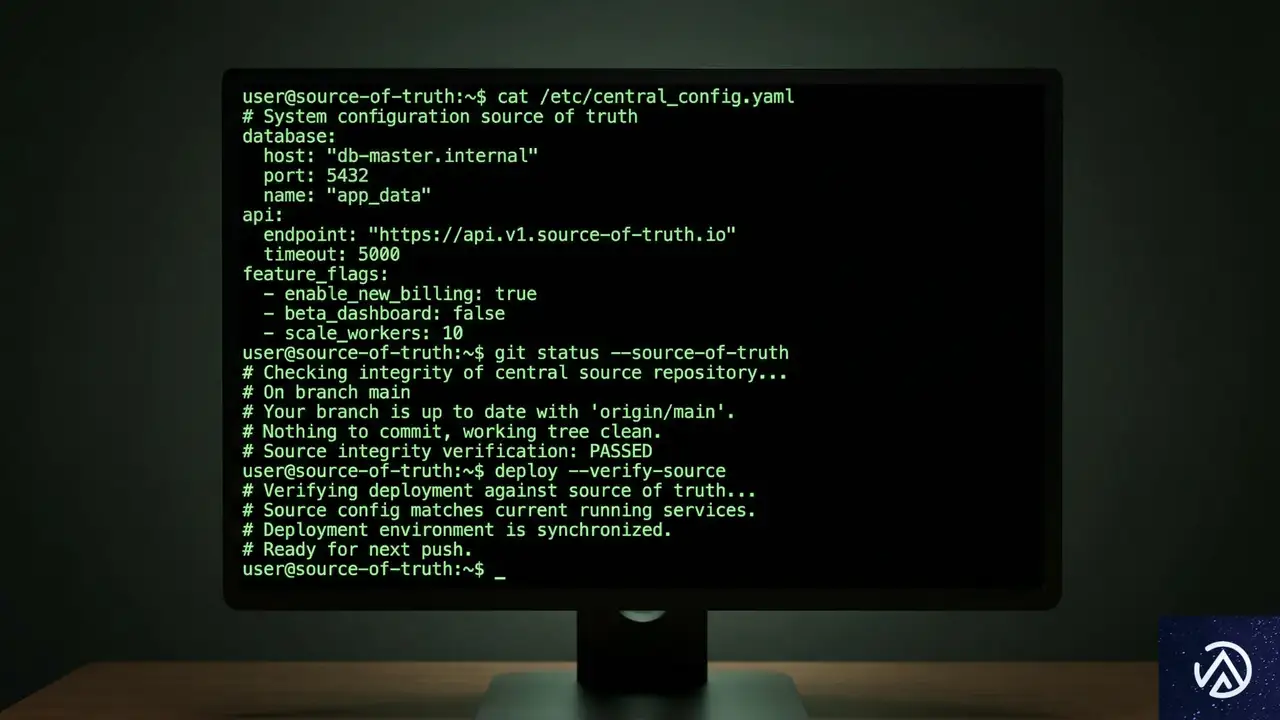
今回のCloudflareの取り組みで特筆すべきは、「ビジュアルエディタで作ったものをコードに書き出す」のではなく、「コードからビジュアルを逆生成する」という方向性を徹底している点だ。これは、エンジニアにとっての真実の源泉(Source of Truth)が常にコードであることを尊重している。
このアプローチの利点は、Gitによるバージョン管理やコードレビューといった既存の開発フローと完全に共存できることにある。図を作成するために特別な設定ファイルを書く必要がなく、普段通りにコードを書くだけで、非エンジニアのステークホルダーにも共有しやすい図が手に入る。これは、開発組織におけるコミュニケーションコストを大幅に下げる可能性を秘めている。
また、AST解析という「枯れた」技術を、最小化されたJSという「汚れた」実データに適用し、それをWasmでエッジ上で高速実行するという構成は、非常にCloudflareらしい合理的でパワフルな解決策だと言えるだろう。
この記事のポイント
- コードから図を自動生成: Cloudflare Workflowsは、JS/TSコードを解析して視覚的な図を自動作成する。
- AST(抽象構文木)の活用: 最小化された難解なコードも、AST解析によって構造的に理解し、ステップを抽出する。
- oxc-parserによる高速処理: Rust製の解析器をWasmで動かすことで、デプロイ時の高速な図解生成を実現した。
- 並列処理の可視化:
startsとresolvesというインデックスを用いて、複雑な並列実行の関係を正確に図示する。 - デバッグツールへの進化: 今後はリアルタイムの実行追跡や、図からの操作機能も追加される予定だ。
出典
- Cloudflare Blog「How we use Abstract Syntax Trees (ASTs) to turn Workflows code into visual diagrams」(2026年3月27日)
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

サイト内検索の「パラドックス」を解消する——Googleに負けないUX設計術とIAの重要性
現代のWebサイトにおいて、成功の鍵はコンテンツの量ではない。ユーザーが目的の情報を「いかに早く見つけられるか」という「ファインダビリティ(見つけやすさ)」にある。しかし、皮肉なことに、データやツールが進化している今、多くのサイト内検索がユーザーの期待を裏切り続けている。
ユーザーがサイト内で目的のページを探せないとき、彼らはサイト独自のナビゲーションを学習しようとはしない。代わりに検索ボックスへ向かうが、そこでも失敗すれば、彼らはサイトを離脱してGoogleへ戻ってしまう。そして「site:サイトURL [検索語句]」と入力するか、最悪の場合は競合他社のサイトへ流れていく。
これを「サイト内検索のパラドックス」と呼ぶ。数兆ドル規模のグローバル検索エンジンが、わずか数百、数千ページのローカルサイト内を探すよりも使い勝手が良いという逆転現象だ。この記事では、なぜ「巨大な検索エンジン」が勝ち、私たちのサイト内検索が負けるのか、その構造的な理由と改善策を解説する。
構文税(Syntax Tax)がユーザーを遠ざける理由

サイト内検索が失敗する最大の原因は、元記事の著者が「構文税(Syntax Tax)」と呼ぶ概念にある。これは、ユーザーがデータベースに登録されている正確な文字列を推測しなければならないという、認知的な負荷のことだ。
文字列(String)ではなく概念(Thing)で捉える
調査によれば、Webサイトにアクセスしたユーザーの約50%が、真っ先に検索バーを利用するという。例えば、家具サイトでユーザーが「ソファ(Sofa)」と検索した際、サイト側が「カウチ(Couch)」というカテゴリー名しか持っていなかったらどうなるか。検索結果が0件であれば、ユーザーは「類義語を試そう」とは考えず、「このサイトには欲しいものがない」と判断して立ち去る。
これは情報設計(IA:Information Architecture)の敗北だ。IAとは、情報を整理・分類し、ユーザーが迷わず目的に辿り着けるようにする設計図のことである。従来のシステムは「文字列(文字の並び)」の一致だけを見ていたが、ユーザーが求めているのは「概念(その言葉が指し示すもの)」との一致だ。ユーザーに特定の語彙(ブランド用語など)を強いることは、ユーザーに「脳の税金」を払わせているのと同じだと言える。
41%のECサイトが基本的な検索に対応できていない
Baymard Instituteのデータによれば、ECサイトの41%が記号や略語を含む基本的な検索クエリに対応できていない。単数形と複数形の違い(例:「靴」と「靴下」ではなく、「Shoe」と「Shoes」)を区別できないシステムは、ユーザーに人間らしい曖昧さを許容せず、機械に合わせた入力を要求している。この「不寛容さ」が、ユーザーの離脱を招く直接的な原因となっている。
なぜGoogleは「文脈」を理解できるのか
Googleの検索が圧倒的に使いやすいのは、単にサーバーが強力だからではない。検索を技術的なユーティリティとしてではなく、高度なIAの課題として捉えているからだ。
ステミングとレマタイゼーション
Googleは「ステミング(語幹抽出)」や「レマタイゼーション(補題化)」といった技術を駆使している。これらは、単語の語尾が変化しても、その根本的な意味(辞書の見出し語)を特定する技術だ。例えば「running」と「ran」が、どちらも「run(走る)」という意図に基づいていることを認識する。
多くのサイト内検索は、これらの文脈に対して「盲目」だ。「Running Shoe」と「Running Shoes」を全く別の実体として扱う。もしあなたのサイトの検索機能が、単純なスペルミスや複数形を処理できないのであれば、ユーザーに対して「人間であることへの罰金」を課しているも同然だと著者は指摘している。
「おそらく」を許容するインターフェースの設計
従来のIAは、ページがあるカテゴリーに「属しているか、いないか」という二進法で考えがちだった。しかし、現代の検索に求められるのは「確信度(Confidence Level)」に基づいた確率論的なアプローチだ。100%の正解がない場合でも、関連性が高いと思われる選択肢を提示する柔軟性が求められる。
「0件ヒット」というデッドエンドをなくすUXデザイン

検索を利用するユーザーは、利用しないユーザーに比べてコンバージョン率が2〜3倍高いというデータがある。しかし、検索結果が貧弱であれば、80%のユーザーがサイトを去る。デザイナーが設計すべきは、「結果あり」と「結果なし」の2つの状態だけではない。その中間にある「もしかして(Did you mean?)」の状態だ。
メタデータを活用した「曖昧検索」の実装
冷淡に「0件の結果が見つかりました」と表示するのではなく、保有しているメタデータ(情報の属性データ)を駆使して、「『電子機器』にはありませんでしたが、『アクセサリー』に3件の候補があります」といった提案を行うべきだ。これにより、ユーザーの探索フローを途切れさせずに済む。
以下に、理想的な検索UIの概念を視覚化したデモを示す。検索結果が完全一致しない場合でも、関連するカテゴリーや人気商品を提案することで、ユーザーを次の行動へ導く設計だ。
もしかしてこちらをお探しですか?
人気のカテゴリーから探す:
このデモは、検索キーワードがデータベースと一致しなかった際に、代替案を提示するUIの概念を視覚化したイメージだ。※実際の動作にはバックエンドの検索エンジンとの連携が必要となる。
サイト内検索を改善する4ステップの監査フレームワーク

Googleにユーザーを奪われないためには、検索機能を「一度設定して終わり」のツールではなく、常に改善し続ける「生きている製品」として扱う必要がある。元記事の著者が提唱する、検索体験を最適化するための4つのフェーズを紹介する。
フェーズ1:ゼロ件ヒットの監査
過去90日間の検索ログを抽出し、結果が0件だったクエリを分析する。これらは以下の3つのバケツに分類できる。
- 真の欠落: ユーザーが求めているが、サイトに存在しないコンテンツ。コンテンツ戦略の見直しが必要だ。
- 類義語の欠落: コンテンツはあるが、ユーザーの言葉と一致していない(例:「ソファ」と「カウチ」)。
- 形式の欠落: ユーザーは「動画」や「PDF」を探しているが、テキストしかインデックスされていない。
フェーズ2:検索意図(インテント)のマッピング
上位50個のクエリを分析し、それらが「ナビゲーショナル(特定のページを探している)」「インフォメーショナル(方法を知りたい)」「トランザクショナル(特定の製品を買いたい)」のどれに該当するかを分類する。ナビゲーショナルな検索(例:「ログイン」)であれば、検索結果一覧を飛ばして直接そのページへリンクさせるなどの工夫が有効だ。
フェーズ3:曖昧一致(ファジーマッチ)のテスト
意図的にスペルミスや単数・複数形、表記揺れ(例:「カラー」と「色」)で検索してみる。これで結果が出ない場合、検索エンジンに「ステミング」のサポートが欠けている。これはエンジニアリングチームに改善を求めるべき技術的要件となる。
フェーズ4:スコープとフィルタリングのUX
結果ページに表示されるフィルターが、検索内容に即しているかを確認する。「靴」と検索したなら「サイズ」や「色」のフィルターが必要であり、サイト全体の汎用的なフィルターを表示し続けるのは不適切だ。
WordPressでの検索体験を向上させる具体策
WordPressのデフォルト検索は、残念ながら非常にシンプルだ。投稿タイトルや本文にキーワードが含まれているかを調べるだけで、これまで述べてきたような「文脈の理解」や「類義語の対応」はほとんど行われない。しかし、いくつかの戦略を組み合わせることで、Googleに頼らない強力な検索機能を構築できる。
構造化されたメタデータの整備
検索エンジンの性能は、与えられた「地図」の精度に依存する。ある企業では、5,000件の技術文書のタイトルがすべて社内の管理番号(例:DOC-9928-X)だったため、検索が機能していなかった。これを人間が理解できる「インストールガイド」などの名称にマッピングし直し、メタデータとして付与したところ、検索ページからの離脱率が40%減少したという。WordPressであれば、カスタムフィールドを活用して、ユーザーが検索しそうな別名やキーワードをあらかじめ登録しておくことが重要だ。
「司書」ではなく「コンシェルジュ」になる
司書は本が棚のどこにあるかを正確に教える。しかし、コンシェルジュはユーザーが何を達成したいかを聞き、推奨事項を提示する。検索バーのオートコンプリート(自動補完)機能を使って、単に単語を補完するだけでなく、「注文を追跡する」といった「意図(アクション)」を提案するように設計すべきだ。
また、大学のサイトなどでよく見かける「Googleカスタム検索」の導入は、安易な解決策に見えるが、ビジネスにおいてはリスクも伴う。ユーザーを外部のアルゴリズムに委ねることになり、競合の広告が表示されたり、サイト独自の製品プロモーションができなくなったりするからだ。自社でコントロール可能な検索体験を構築することこそが、長期的な信頼につながる。
この記事のポイント
- 構文税を廃止する: ユーザーに正確なキーワードを推測させる負荷(構文税)を減らし、類義語や曖昧な表現を許容するシステムを構築する。
- IAは検索の燃料である: 検索エンジンの性能を上げる前に、メタデータの整理や人間中心のタクソノミー(分類学)を整備する。
- デッドエンドを作らない: 検索結果が0件の場合でも、関連カテゴリーや人気コンテンツを提案し、ユーザーの探索を止めない。
- 定期的なログ監査: 検索ログから「ユーザーが求めているが届いていない情報」を特定し、サイトのナビゲーションやコンテンツを改善する。
- 速度は信頼: 検索結果の表示が1秒を超えるとユーザーはGoogleへ逃げる。パフォーマンスの最適化はUXの基本である。
出典
- Smashing Magazine “The Site-Search Paradox: Why The Big Box Always Wins”(2026年3月26日)
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

WordPressエコシステムの未来は「信頼」で決まる——Zach Stepekが語る2026年のパートナーシップ論
WordPressサイトの構築と運用は、単独の企業や個人の力だけで成り立っているわけではない。その背後には、エージェンシー(制作会社)、プロダクト企業(テーマ・プラグイン開発者)、ホスティング(インフラ提供者)という3つの層が複雑に絡み合ったエコシステムが存在する。
2026年3月、WP TavernのポッドキャストでZach Stepekがこのエコシステムの現状と未来について語った。彼は自身のキャリアを振り返りながら、現在のWordPress界隈で進行する「短期的利益」と「長期的信頼」のせめぎ合いを指摘する。経済的不確実性が高まる中、パートナーシップの在り方は転換点を迎えている。
この記事では、Stepekの見解を基に、WordPressエコシステムを支えるパートナーシップの本質と、持続可能な成長のために必要な考え方を解説する。
WordPressエコシステムを構成する3つの層

Zach Stepekは、成功するWordPressサイトの背後には常に3つの主要なプレイヤーが存在すると説明する。これらは独立しているのではなく、ケルトの結び目のように複雑に絡み合い、互いに依存し合っている。
1. エージェンシー/個人事業主
クライアントの要望を聞き、実際にサイトを構築・管理する実行者だ。フリーランスの開発者から大規模な制作会社まで、その規模は多様である。彼らはクライアントと最も近い位置にあり、具体的な課題と要件を把握している。
2. プロダクト企業
WordPressを拡張するテーマやプラグインを開発・提供する企業を指す。Gravity FormsやKadence Themeなどが該当する。彼らの提供するソフトウェアがなければ、多くの高度な機能を実現できない。オープンソースのプラグインを提供し、コミュニティに還元している企業も多い。
3. ホスティング/インフラ
サイトが動作する土台となるサーバーやネットワークを提供する層だ。Stepekはこれを「小売店の立地」に例える。安価で制限の多い共有ホスティングは人通りの少ない路地裏の店舗のようなものだ。一方、高パフォーマンスで信頼性の高いマネージドホスティングは、ニューヨークのマディソン通りやシカゴのミラクルマイルのような一等地に相当する。
特にEコマースサイトでは、この「立地」が収益に直結する。大量のトラフィックを捌けずにサイトがダウンすることは、客足が途絶えるのと同じだ。Stepekは自身の経験として、感謝祭のアメリカンフットボール中継で紹介された非営利団体のWooCommerceサイトが、たった14件の注文処理でサーバーがクラッシュした事例を挙げている。メールスプールがメモリを食い尽くしたことが原因だった。
「取引」から「信頼」へ——パートナーシップの質的変化

Stepekは、WordPress界隈のパートナーシップを「取引型」と「価値観共有型」の2つに分類する。近年、前者が増加していることに懸念を示す。
取引型パートナーシップの限界
取引型パートナーシップは、短期的な収益(ROI)を最優先する。例えば、ホスティング会社がエージェンシーに対して、自社サービスを紹介する見返りに高額のアフィリエイト報酬を支払う関係がこれに当たる。この関係は、金銭的インセンティブが続く限りしか維持されない。
Stepekは、このような関係を「リンゴの木からリンゴを収穫する行為」に例える。すべての実を収穫した後、木そのものの世話をしなければ、次の収穫は期待できない。パートナーを単なる「ロゴ集め」や収益の「項目」として扱うことは、関係の脆さを増すだけだ。
価値観共有型パートナーシップの重要性
これに対し、価値観共有型パートナーシップは「森を育てる」ことに似ているとStepekは言う。互いのビジネスを理解し、成功を願い、長期的な視点で関係を構築する。収益は、このような健全な関係を築いた結果として後からついてくるものだ。
具体例として、Fueled(10up)が開発したElasticPressや、WebDevStudiosがリリースしたTheme Switcher Proを挙げている。これらは、自社の顧客課題を解決するために開発されたツールが、そのままオープンソースとしてコミュニティに還元されたケースだ。コミュニティからのフィードバックやコントリビューションが製品をさらに改善するという好循環が生まれている。
Stepekは、ホスティング企業にも同様の「良き管理者」としての役割が求められると主張する。自社のパートナープログラムを通じて、エージェンシーとプロダクト企業が出会い、互いの成功に投資できる場を提供するのだ。このような「関係性の資本」の蓄積こそが、エコシステム全体の強靭さを決定する。
2026年の現実——経済的圧力と「恐怖」がもたらす短絡思考

では、なぜ価値観共有型のパートナーシップが難しくなっているのか。Stepekは、2026年現在のマクロ経済環境と業界固有の課題に原因を見出す。
投資家のプレッシャーとオープンソース精神の衝突
多くのWordPress関連企業がベンチャーキャピタルなどの外部資金を受け入れている。投資家の関心は往々にして短期的な投資回収率(ROI)に向けられる。この「取引」のみを重視する論理は、相互依存と協調を基盤とするオープンソースコミュニティの在り方と根本的に相容れない、とStepekは指摘する。
ホスティング業界を襲うコスト増の波
さらに、ホスティング業界には具体的なコスト圧力が迫っている。大規模言語モデル(LLM)などの需要急増によるサーバー部品(GPU、メモリなど)の不足だ。Stepekはデータセンターで目撃した光景を語る。AI企業のサーバーラックは非常に高温になるため、その周辺だけが極端に冷やされていたという。
このようなハードウェア需要の高まりは、部品コストの上昇を招き、最終的にはホスティングサービスの原価を押し上げる。月額3ドルのような安価な共有ホスティングのビジネスモデルは、根本から揺らぎ始めている可能性がある。
コミュニティ活動の縮小
こうした不確実性は、企業のコミュニティへの関与にも影響を与えている。WordCampや大規模テックカンファレンスのスポンサーリストを見ると、参加企業数は減少傾向にある。多くのホスティング企業が、従業員の海外出張を今年は控えるとStepekは聞いている。経費削減のあおりだ。
「恐怖が最初に犠牲にするのは、『忍耐』だ」とStepekは言う。長期的なパートナーシップの育成には時間がかかる。しかし、経済的恐怖が蔓延する環境下では、この「待つこと」が最初に切り捨てられる対象となる。
持続可能なエコシステムのために——「信頼」を測定可能な資産に
短期的な収益圧力が強まる中で、オープンソースのWordPressエコシステムを維持・成長させるにはどうすればよいか。Stepekは、無形の「信頼」や「評判」を、より可視化し、評価可能なものにしていく必要性を説く。
収益以外の成功指標
企業の成功を測る指標は月間経常収益(MRR)や年間経常収益(ARR)だけではない。Stepekは、以下のような「シグナル」にも注目すべきだと提案する。
- チーム間の信頼度
- パートナー同士が能動的に協業する頻度
- パートナーシップの結果、顧客がより良い成果を上げているか
これらは直接的な収益には表れにくいが、長期的なビジネスの安定性と成長可能性を左右する重要な要素だ。関係性の資本(Relationship Equity)は、収益に先立って築かれるものだ。
コントリビューションの「見える化」
また、企業がWordPressコアやコミュニティに対して行う貢献(コントリビューション)を、何らかの形で認識・評価する仕組みの重要性が高まっている。かつては、企業が従業員にコア開発の時間を与えることは、暗黙の「善行」として認識されていた。しかし、すべてが数値化され、説明責任が求められる現在、このような無形の貢献は「スプレッドシートに載らない」活動として軽視されがちだ。
貢献時間の追跡、貢献者バッジの付与、公開された謝辞など、企業のコミュニティへの関与を「見える化」する取り組みは、企業が長期的な視点を持っていることの証左となり得る。これは、単なる慈善活動ではなく、エコシステムという「共通の土台」への投資であるという認識が広まる必要がある。
コミュニティの監視役としての役割
Stepekは最後に、WordPressコミュニティ自身の力にも言及する。コミュニティは、利益のみを追求し、還元を怠る企業に対して非常に厳しい目を向ける。このコミュニティの「評判」こそが、企業の長期的なブランド価値を大きく左右する力を持つ。短期的な思考はブランドの資本を毀損するが、長期的な思考はそれを築き上げる。
「信頼こそが最も耐久性のある資産だ」というStepekの言葉は、変化の時代における不変の原則を示している。
この記事のポイント
- WordPressエコシステムは、エージェンシー、プロダクト企業、ホスティングの3層が相互依存することで成り立っている。
- 短期的な「取引」を重視するパートナーシップが増える一方、長期的な「信頼」に基づく協力関係がエコシステムの持続可能性には不可欠だ。
- 2026年の経済的圧力(投資家のROI要求、ホスティングコスト増)が、企業の短絡的思考を助長している。
- 収益以外の指標(信頼度、協業頻度、顧客成果)でパートナーシップの成功を測る視点が必要である。
- 企業のコミュニティ貢献を「見える化」し、エコシステム全体への投資として評価する文化が重要となる。
出典
- WP Tavern 「#210 – Zach Stepek on the Interconnected WordPress Ecosystem, Partnerships and Trust」(2026年3月25日)
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

WordPress開発の新標準?コミュニティ主導の「WP Packages」へ移行すべき理由
WordPressのプラグインやテーマを管理するエンジニアにとって、デファクトスタンダードだった「WPackagist」に大きな転換期が訪れた。2026年3月12日、大手ホスティング企業のWP EngineがWPackagistの買収を発表したことが発端だ。これを受け、開発者コミュニティからは特定の企業によるインフラ独占を懸念する声が上がっている。
こうした状況下で、完全に独立したコミュニティ主導の代替サービス「WP Packages」が3月16日に正式リリースされた。WP Packagesは、単なる代替品にとどまらず、最新のComposer仕様への対応や劇的なパフォーマンス向上を実現している。10個のプラグインを解決する速度がWPackagistの約17倍にあたる0.7秒まで短縮されるなど、実務上のメリットも極めて大きい。
この記事では、なぜ今WPackagistからの移行が推奨されているのか、技術的な背景と具体的な移行手順を詳しく解説する。企業の意向に左右されない、持続可能な開発インフラを選択することは、長期的なプロジェクト運営において不可欠な視点だ。
WPackagistの買収とWP Packages誕生の背景

WPackagistが抱えていた長年の課題
WPackagist(ダブリューピー・パケジスト)は、2013年から提供されているWordPress専用のComposerリポジトリだ。ComposerとはPHPのライブラリ依存関係を管理するツールで、これを使うことでプラグインのインストールや更新をコマンド一つで自動化できる。しかし、WPackagistは近年、メンテナンスの停滞が指摘されていた。
記事によれば、WPackagistは更新サイクルが遅く、コミュニティからのフィードバックも反映されにくい状態が続いていた。また、古いプロトコルに依存していたため、プロジェクトが大規模になるほどライブラリの依存関係を解決する「名前解決」に時間がかかるというパフォーマンス上のボトルネックも抱えていた。
企業によるインフラ独占への懸念
WP Engineによる買収後、開発者のターミナルには「WPackagistはWP Engineによって維持されています」という通知が表示されるようになった。これは小さな変更だが、オープンソースの公共インフラが特定企業の管理下に置かれたことを象徴する出来事だ。著者のBen Word氏は、こうした企業主導の体制に対し、透明性の高いコミュニティ主導のインフラの必要性を説いている。
WP Packagesは、Rootsチーム(BedrockやSageの開発元)によって構築された。実は買収騒動が起きる前の2025年8月から開発が進められており、買収のニュースを受けてリリースが前倒しされた形だ。特定の企業の利益に左右されず、開発者が開発者のために運営する体制が整えられたのである。
WP Packagesが技術的に優れている4つのポイント
Composer v2最適化による圧倒的な高速化
WP Packagesの最大の技術的特徴は、Composer v2の「metadata-url」プロトコルを全面的に採用している点だ。従来のWPackagistでは、依存関係を解決するために巨大なインデックスファイルをすべてダウンロードする必要があった。これを「provider-includes」方式と呼び、通信量が増大する原因となっていた。
一方、WP Packagesはプロジェクトに必要なパッケージのメタデータのみをピンポイントで取得する。記事が示す検証結果によれば、10個のプラグインを含むプロジェクトでの解決時間は、WPackagistの12.3秒に対し、WP Packagesはわずか0.7秒だ。約17倍の高速化は、CI/CD(継続的インテグレーション/デリバリー)環境でのビルド時間を大幅に短縮する。
更新頻度の向上と命名規則の改善
情報の鮮度も大幅に向上している。WPackagistの更新サイクルが約90分であったのに対し、WP Packagesはわずか5分間隔で同期される。WordPress.orgの公式ディレクトリに新しいプラグインが公開されたり、既存のプラグインがアップデートされたりした際、ほぼリアルタイムでComposer経由の取得が可能になる。
また、パッケージの命名規則も直感的になった。従来は wpackagist-plugin/akismet のように長いプレフィックスが必要だったが、WP Packagesでは wp-plugin/akismet や wp-theme/twentytwentyfive といった、より簡潔な名称が採用されている。メタデータには作者情報や説明文、ホームページURLも含まれており、開発時の視認性が向上している。
WPackagistからWP Packagesへの移行手順
既存のプロジェクトをWPackagistからWP Packagesへ移行するのは非常に簡単だ。手動でコマンドを実行する方法と、公式が提供する移行スクリプトを使用する方法の2通りがある。
手動での移行コマンド
手動で行う場合は、既存のパッケージを一度削除し、リポジトリの設定を書き換えてから再インストールする手順を踏む。以下に主要なコマンドの流れを示す。
# 1. 既存のWPackagistパッケージを削除(例:テーマの場合)
composer remove wpackagist-theme/twentytwentyfive
# 2. WPackagistリポジトリを削除し、WP Packagesを追加
composer config --unset repositories.wpackagist
composer config repositories.wp-composer composer https://repo.wp-packages.org
# 3. 新しい命名規則でパッケージを追加
composer require wp-theme/twentytwentyfive移行スクリプトによる一括処理
プロジェクト内の composer.json に記述された多数のパッケージを一つずつ手動で変更するのは手間がかかる。その場合は、Rootsチームが公開している移行スクリプトを利用するとよい。このスクリプトは、ファイル内の記述を自動で新しい命名規則に置換してくれる。
# 移行スクリプトのダウンロードと実行
curl -sO https://raw.githubusercontent.com/roots/wp-packages/main/scripts/migrate-from-wpackagist.sh && bash migrate-from-wpackagist.shなお、Rootsが提供しているWordPressスターターテーマ「Bedrock」を新規で利用する場合、すでにWP Packagesがデフォルトで設定されている。これから新しいプロジェクトを立ち上げるのであれば、設定の手間なく最新のインフラを利用できる。
オープンソースとしての透明性と持続可能性
完全に公開されたインフラ構成
WP Packagesの特筆すべき点は、アプリケーションのコードだけでなく、サーバーの構築設定(Ansible構成など)まで含めてGitHub上で完全に公開されていることだ。これは「オープンソースのリポジトリであること」と「透明なシステムであること」は別物であるという、Ben Word氏の信念に基づいている。
万が一、WP Packagesの運営に問題が生じたとしても、誰でもリポジトリをフォーク(複製)して自分たちの環境で同じレジストリを立ち上げることができる。特定の企業に依存しない、真の意味での「公共財」としての設計がなされている。インフラの構築プロセス自体が公開されているため、セキュリティ面での検証も容易だ。
広告やマーケティングを排除する姿勢
WP Packagesは、開発者のターミナル(黒い画面)を聖域として扱っている。企業運営のツールでは、コマンド実行時に広告や自社サービスへの誘導メッセージが表示されることがあるが、WP Packagesはこれを一切行わないと公約している。これは、コミュニティの寄付によって運営資金を賄っているからこそ可能な判断だ。
現在、WP PackagesはGitHub Sponsorsを通じて資金を募っており、KinstaやWordPress.comといった主要な企業もスポンサーとして名を連ねている。特定の親会社を持たず、複数の企業や個人が支える「非中央集権」的なモデルは、WordPressエコシステム全体の健全性を保つ上で重要な役割を果たしている。
独自の分析:WordPressエコシステムにおける「非中央集権」の重要性

今回のWP Packagesの誕生は、単なる技術的なアップデート以上の意味を持っている。それは、WordPressという巨大なプラットフォームにおける「インフラの民主化」だ。これまで私たちは、WPackagistのような便利なツールを「当たり前にあるもの」として利用してきたが、それが一晩で企業買収の対象になり得ることを再認識させられた。
技術的な視点で見れば、WP PackagesがComposer v2に最適化されたことは、Web制作の現場におけるDX(デジタルトランスフォーメーション)を加速させるだろう。17倍の高速化は、1日のうちに何度もビルドを繰り返すエンジニアにとって、積み重なれば数時間の節約につながる。しかし、それ以上に重要なのは「自分たちの道具を自分たちでコントロールできる」という安心感だ。
今後、WordPressのコア開発や周辺ツールにおいて、同様の「コミュニティへの回帰」が加速する可能性がある。特定のホスティングベンダーに依存しすぎることのリスクを回避し、オープンな標準技術を選択する動きは、サイトの長期的な保守性を高める。WP Packagesへの移行は、その第一歩として極めて理にかなった選択だと言えるだろう。
この記事のポイント
- WPackagistがWP Engineに買収されたことを受け、独立した代替サービス「WP Packages」が登場した。
- WP PackagesはComposer v2に最適化されており、依存関係の解決速度が従来比で約17倍高速化されている。
- データの更新間隔が5分に短縮され、常に最新のプラグインやテーマを取得できる環境が整った。
- 移行は数行のコマンド、または公式のスクリプトで簡単に行うことができ、既存プロジェクトへの導入障壁は低い。
- GitHub Sponsorsによるコミュニティ支援で運営されており、広告や特定企業の干渉を受けない透明性が確保されている。
出典
- WordPress.org News「WP Packages is Working the Way Open Source Should」(2026年3月25日)
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験
AIエージェント実行を100倍高速化。Cloudflare Dynamic Worker Loaderの革新性
AIエージェントが自らコードを書き、それを実行してタスクを完結させる「コード実行型」のワークフローが注目を集めている。しかし、AIが生成したコードを安全に動かすには、メインのシステムから隔離された「サンドボックス」が不可欠だ。
Cloudflareは2026年3月24日、このサンドボックスをオンデマンドで、かつ従来のコンテナ技術より100倍高速に起動できる「Dynamic Worker Loader」のオープンベータ公開を発表した。V8 Isolate技術を基盤とすることで、ミリ秒単位の起動と圧倒的なリソース効率を実現している。
この記事では、Dynamic Worker LoaderがなぜAIエージェントのスケールにおいて重要なのか、そしてエンジニアがどのようにこれを活用できるのかを詳しく解説する。
AIエージェントの安全性を支える「サンドボックス」の課題

AIエージェントがAPIを呼び出す際、単なる「ツール呼び出し(Tool Calling)」ではなく、コードを生成して実行させる手法は、トークン消費量を大幅に削減できることが分かっている。記事によれば、TypeScript APIを使用することで、トークン使用量を最大81%削減できた例もあるという。
なぜAI生成コードの直接実行は危険なのか
AIが生成したコードをアプリケーション内で直接実行(evalなど)することは、セキュリティ上の致命的なリスクとなる。悪意のあるユーザーがプロンプトを通じて脆弱性を注入し、システムの機密情報にアクセスしたり、不正な操作を行ったりする可能性があるからだ。
そのため、コードを実行する場所は、アプリケーションや他の環境から完全に隔離された「サンドボックス(砂場)」でなければならない。サンドボックスとは、特定の権限やリソースのみにアクセスを制限した実行環境のことだ。
既存のコンテナ技術が抱える「重さ」の壁
これまで、サンドボックスの構築にはDockerなどのLinuxコンテナが一般的に使われてきた。しかし、コンテナには大きな弱点がある。起動に数百ミリ秒から数秒かかり、メモリ消費量も数百MB単位と「重い」ことだ。
数百万人のユーザーがそれぞれAIエージェントを動かすようなコンシューマー規模のサービスでは、コンテナを都度立ち上げるコストは無視できない。かといって、セキュリティのためにコンテナを使い回さず、リクエストごとにクリーンな環境を用意しようとすると、パフォーマンスとコストの両面で限界に突き当たる。
Dynamic Worker Loader:V8 Isolateによる100倍速の革新
Cloudflareが提供する「Dynamic Worker Loader」は、この「重さ」の問題を根本から解決する。その鍵となるのが、Google Chromeでも採用されているJavaScript実行エンジン「V8」の「Isolate(アイソレート)」という仕組みだ。
起動時間は数ミリ秒、メモリ消費も最小限
Isolateは、OSレベルの仮想化であるコンテナとは異なり、プロセス内でメモリを論理的に分離する。これにより、起動時間はわずか数ミリ秒、メモリ消費も数MB程度に抑えられる。著者のKenton Varda氏らは、これが一般的なコンテナと比較して「100倍高速で、10〜100倍メモリ効率が良い」と指摘している。
この軽量さにより、1つのリクエストごとに新しいサンドボックスを生成し、実行が終わったら即座に破棄するという運用が現実的になる。同時並行で数百万のリクエストが発生しても、Cloudflareのインフラ上でシームレスにスケール可能だ。
世界数百拠点でのゼロレイテンシ実行
Dynamic Worker Loaderで生成されたワーカーは、通常、それを作成した親ワーカーと同じマシン、あるいは同じスレッド上で動作する。そのため、遠くのサーバーにある「ウォーム状態のコンテナ」を探しに行く必要がない。
Cloudflareが世界中に持つ数百の拠点すべてで動作するため、ユーザーに最も近い場所で、遅延(レイテンシ)をほぼ感じさせることなくAIコードを実行できるのが強みだ。
TypeScript RPCによる効率的なAPI連携
AIエージェントが外部のAPIと通信する際、従来はOpenAPI(REST)などの定義ファイルが使われてきた。しかし、Dynamic Worker Loaderでは、より簡潔な「TypeScript」による定義を推奨している。
OpenAPIより優れたトークン効率
OpenAPIの定義ファイルは冗長になりがちで、LLM(大規模言語モデル)に読み込ませる際のトークン消費が激しい。一方、TypeScriptのインターフェース定義は非常にコンパクトだ。AIにとっても理解しやすく、少ないトークン数でAPIの仕様を正確に伝えられる。
Dynamic Worker Loaderは「Cap’n Web RPC」という技術を使って、サンドボックス内のエージェントと親ワーカーの間で高速な通信を行う。エージェント側からは、あたかもローカルライブラリを使っているかのように、型安全なメソッド呼び出しが可能になる。
認証情報の注入とセキュアな外部接続
セキュリティ面でも、このRPCモデルは有利に働く。例えば、外部サービスへの認証トークンをエージェントに直接教える必要はない。エージェントがHTTPリクエストを送る際、親ワーカー側でリクエストをインターセプト(傍受)し、そこで認証ヘッダーを付与する「Credential Injection(認証情報の注入)」が可能だからだ。
これにより、万が一AIが生成したコードに悪意があったとしても、生の認証情報がエージェント側に漏洩するリスクを最小限に抑えられる。
AI開発を加速させる3つの公式ヘルパーライブラリ

Cloudflareは、Dynamic Worker Loaderをより使いやすくするために、3つの強力なヘルパーライブラリを提供している。これらを組み合わせることで、高度なAIエージェント環境を短期間で構築できる。
コード実行を簡略化する「Code Mode」
@cloudflare/codemodeは、LLMが生成したコードの実行を管理するライブラリだ。コードの正規化(フォーマットエラーの修正)や、fetch()の挙動制御を簡単に行える。完全に隔離された状態(ネットワークアクセス禁止)から、特定のプロキシ経由の通信まで、柔軟に設定可能だ。
ランタイムでのバンドルを可能にする「Worker Bundler」
Dynamic Workerは、依存関係が解決された「バンドル済み」のモジュールを必要とする。@cloudflare/worker-bundlerを使えば、実行時にnpmパッケージを含むソースコードをバンドルできる。例えば、Honoなどの軽量フレームワークをAIエージェントに使わせることも容易だ。
仮想ファイルシステムを提供する「Shell」
@cloudflare/shellは、サンドボックス内に仮想的なファイルシステムを提供する。エージェントはファイルの読み書き、検索、置換、diffの取得などが可能になる。ストレージの実体はSQLiteやR2(Cloudflareのオブジェクトストレージ)に保存されるため、実行を跨いでファイルを永続化させることもできる。
実務への応用とコストパフォーマンスの分析
Dynamic Worker Loaderの導入は、AIアプリケーションのアーキテクチャに大きな変革をもたらす。筆者の分析によれば、特に以下の3つの分野で大きなメリットがある。
第一に、「Tool Calling」のオーバーヘッド削減だ。従来のように、AIが1つずつツールを呼び出して結果を待ち、次のアクションを決めるループを繰り返すと、その都度コンテキストが膨らみ、レイテンシも増大する。Dynamic Workerを使えば、AIが「一連の処理をまとめたスクリプト」を一度に書き、それを実行するだけで済む。これは、大規模なAPIセットを持つシステムほど効果が高い。
第二に、コスト効率の劇的な向上だ。Dynamic Workerの料金は、ロード1回につき0.002ドル(ベータ期間中は無料)に、通常のCPU使用料が加算される仕組みだ。これはLLMの推論コストと比較すれば微々たるものだ。重いコンテナを常時起動させておく「ウォームスタンバイ」のコストから解放される意味は大きい。
第三に、プロトタイピングの高速化だ。Ziteなどの企業がすでに導入しているように、ユーザーの要望に応じてその場でCRUDアプリや自動化ロジックを生成し、即座にデプロイして動かすような「AIネイティブなPaaS」の構築が容易になる。
この記事のポイント
- 100倍の高速化: V8 Isolateにより、コンテナより圧倒的に速く軽量なサンドボックスを実現。
- セキュアな隔離: AI生成コードをメインシステムから分離し、安全にオンデマンド実行できる。
- 高いトークン効率: TypeScript RPCを活用し、冗長なOpenAPI定義を避けてコストを削減。
- 充実のライブラリ: コード実行、バンドル、ファイル操作を支援する公式ツールが提供されている。
- スケーラビリティ: Cloudflareのグローバルネットワーク上で、数百万のリクエストに即座に対応可能。
出典
- Cloudflare Blog「Sandboxing AI agents, 100x faster」(2026年3月24日)
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AIがマーケティングの常識を書き換える——データは「資産」から「AIの燃料」へ
かつて、データは「ビジネスの副産物」に過ぎなかった。しかし、AIの急速な普及により、その価値は「蓄積すべき資産」から「AIを動かすためのリアルタイムな燃料」へと劇的な変化を遂げている。マーケターは今、従来のデータ収集のあり方を根本から見直す必要に迫られている。
2026年3月現在、大規模言語モデル(LLM)は単なる便利なツールを超え、企業の意思決定プロセスを再構築する存在となった。元記事の著者であるクリス・ロブソン氏は、データがマーケティングの中心となった経緯を振り返りつつ、AIがどのようにそのルールを書き換えようとしているかを鋭く分析している。
この記事では、データがたどってきた歴史的な変遷と、AI時代における「新しいデータの役割」について詳しく解説する。特に、自社独自のデータをいかにしてAIに読み込ませ、具体的なアクション(処方箋)へとつなげるかが、今後の競争力を左右する重要なポイントだ。
データは「ゴミ」から「資産」へ:マーケティングにおけるデータの変遷

1970年代のオフィスを想像してみてほしい。そこには書類が詰まったキャビネットが並び、必要な情報だけがカード型インデックスに記録されていた。当時のビジネスにおいて、データは「どうしても必要なもの」だけを保管する対象であり、それ以外は「ビジネス上のゴミ」として扱われていたのだ。
70年代の「不要な副産物」時代
当時はデジタルストレージが極めて高価で、速度も遅かった。そのため、企業の基幹業務に関わる最小限のデータ以外を保存することは、コスト面でもリスク面でも現実的ではなかった。記事によれば、この時代のデータは「一度書き込んだら二度と参照されない」ことも珍しくなく、活用されることはほとんどなかったという。
「新しい石油」となった現代のデータ活用
テクノロジーの進化により、ストレージコストが劇的に低下すると、データの価値は一変した。あらゆるトランザクションデータを保存する「データレイク」や「データオーシャン」といった概念が登場し、データは「新しい石油」と呼ばれるほどの重要な資産へと昇華した。企業は「いつか役に立つかもしれない」という期待のもと、膨大なデータを蓄積し始めたのである。
予測から「処方」へ:AI以前のデータ分析の限界

データの蓄積が進むにつれ、分析の手法も高度化していった。しかし、従来のデータサイエンスには明確なステップが存在し、現在のAIによる革命が起こるまでは、人間がその結果を解釈して行動を決定する必要があった。
分析の3段階(記述・予測・処方)
データ分析は、大きく分けて以下の3つのステップで進化してきた。まず「何が起きたか」を把握する記述的分析(Descriptive)、次に「次に何が起きるか」を推測する予測的分析(Predictive)、そして「何をすべきか」を提示する処方的分析(Prescriptive)だ。
処方的分析とは、例えば「この顧客には20%の割引クーポンを提示すべきだ」といった具体的なアクションをシステムが提案することを指す。ロブソン氏によれば、これまではこの「処方」の範囲は限定的であり、常に過去のデータを参照して「より良いレンズ」で現状を見るための作業に過ぎなかったという。
AI(LLM)が変えるデータの役割:なぜ「保存」だけでは足りないのか

LLM(大規模言語モデル)の登場は、この「処方」のプロセスを根底から変えた。AIは単にデータを分析するだけでなく、膨大な知識ベースを基に自ら思考し、最適なアクションを生成できるようになったからだ。ここで重要になるのが、AIがデータをどのように「記憶」しているかという点である。
LLMは「ウェブ全体のぼやけたJPEG」である
SF作家のテッド・チャン氏は、LLMを「ウェブ全体のぼやけたJPEG」と表現した。これは非常に的を射た比喩だ。LLMは学習データそのものをデータベースとして持っているわけではなく、数十億のパラメータを通じて、知識を高度に圧縮した状態で保持している。画像ファイルを圧縮すると細部がぼやけるように、AIの記憶もまた、完全な複製ではない。
独自データがAIに「高精細な視力」を与える
AIが「フランスの首都は?」という問いに「パリ」と答えられるのは、学習時にそのパターンを圧縮して記憶したからだ。しかし、あなたの会社の昨日の売上や、特定の顧客の好みまでは知らない。そこで必要になるのが、AIという「ぼやけた画像」に、自社独自の「高精細なデータ」を補足として与える作業だ。これにより、汎用的なAIが「自社専用の極めて賢いアドバイザー」へと変貌する。
新しいデータ戦略「MCP」とリアルタイム性の重要性
AIに自社データを効率的に読み込ませるための技術として、現在注目されているのが「MCP(Model Context Protocol)」だ。これは、AIモデルが企業のライブデータベースを直接参照できるようにするための標準的な接続方式を指す。
Model Context Protocol(MCP)とは何か
MCPは、いわばAIとデータの間の「ユニバーサルアダプター」のような役割を果たす。これまでのAI活用では、データを一度AIに学習させる(ファインチューニング)か、プロンプトに大量のデータを詰め込む必要があった。しかしMCPを使えば、AIは必要な時に、必要なデータだけを、安全にデータベースから読み取ることができる。
ロブソン氏は、MCPはまだ初期段階にあるものの、データ資産のあり方を再考する上で不可欠な要素になると述べている。データを「溜め込む」のではなく、AIがいつでも「つまみ食い」できる状態に整えておくことが、これからのデータ戦略の肝となるのだ。
ECサイト運営者が今すぐ見直すべきデータ収集のポイント

WooCommerceなどのECサイトを運営している場合、この変化は売上に直結する。単に「購入履歴」を保存するだけでなく、AIがそのデータを活用して「次にこの顧客が欲しがるもの」をリアルタイムで提案できる環境を整えなければならない。
「何でも貯める」から「AIが使いやすい」形へ
これからのデータ収集で意識すべきは、データの「鮮度」と「構造」だ。AIは古いデータよりも、今この瞬間のユーザーの行動を重視する。例えば、カートを放棄した理由や、特定の商品ページでの滞在時間など、文脈(コンテキスト)を含んだデータを構造化して保持しておくことが、AIによる精度の高い「処方」を引き出す鍵となる。
このデモは、データ活用の目的が「過去の振り返り」から「即時のアクション」へとシフトしている様子を視覚化したものだ。AIが介在することで、データは単なる記録から、ビジネスを動かす動的なエネルギーへと変わる。
独自分析:AI時代の「ゼロパーティデータ」の重要性
ここで筆者(当ブログ)独自の視点を加えたい。AIが「ウェブ全体の知識」をすでに持っている以上、企業が今後最も注力すべきは「ゼロパーティデータ」の収集である。ゼロパーティデータとは、顧客が意図的かつ積極的に企業と共有するデータ(好み、購入動機、将来の計画など)を指す。
GoogleやMetaが持つ膨大な行動データ(サードパーティデータ)は、AIモデルの基礎訓練にすでに使われている。しかし、あなたのサイトを訪れた顧客が「なぜこの商品に興味を持ったのか」という具体的な動機は、AIも持っていない。この「AIが持っていないパズルの一片」をいかにして収集し、AIに与えるかが、パーソナライズの精度を劇的に高める差別化要因になるだろう。
この記事のポイント
- データは「保存すべき資産」から「AIを動かすための燃料」へと役割を変えた。
- LLMは知識を圧縮して保持しているため、自社独自の「高精細なデータ」による補完が不可欠。
- MCP(Model Context Protocol)などの新技術により、AIがライブデータを直接参照する環境が整いつつある。
- ECサイト運営者は、単なる履歴だけでなく、顧客の「文脈」や「動機」を構造化して収集すべきだ。
- AI時代における最大の武器は、汎用AIが持ち得ない「自社独自のクリーンなデータ」である。
出典
- MarTech「Data built modern marketing, but AI is rewriting the rules」(2026年3月26日)
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験