

マーケティング予算を動かすのは「成果」ではなく「確信」——2026年の広告投資動向を読み解く
マーケティング予算の配分基準が、純粋な「成果」から「説明のしやすさ」へとシフトしている。
2026年の最新調査では、Google検索やYouTubeなどの定番チャネルへの予算集中が一段と鮮明になった。
EC事業者にとって、この傾向は「新しい集客チャネルへの挑戦」が以前よりも難しくなっていることを意味する。なぜなら、財務部門やステークホルダーに対して、投資の妥当性を証明する「測定の確信」がこれまで以上に求められているからだ。
「成果が出る」ことと「説明できる」ことの決定的な違い

マーケターが予算を投じる際、最も重視するのは何だろうか。かつては「ROI(投資利益率)」や「ROAS(広告費用対効果)」といった数字がすべてだった。しかし、現在では「測定の確信(Measurement Confidence)」という概念が、それらの指標を上回る影響力を持っている。
測定の確信とは、特定のチャネルが収益に与えた影響を、どれだけ明確に説明し、守り抜けるかという能力を指す。つまり、単に売上が上がっただけでなく、「なぜこの広告で売上が上がったのか」を、専門外の人間に対しても論理的に証明できるかどうかが鍵となる。
予算会議で「守れる」チャネルが選ばれる理由
記事によれば、マーケターが自信を持って説明できるチャネルは驚くほど限定されている。Google検索とYouTubeは、回答者の57%が「自信を持って投資を正当化できる」と答えており、この2つを組み合わせるとその数値は75%にまで跳ね上がる。
一方で、TikTokやMeta(Facebook/Instagram)への信頼度は40%台に留まる。インフルエンサーマーケティングやコネクテッドTV(CTV)に至っては、さらに低い水準だ。この差は、各プラットフォームが提供するレポートの透明性や、過去の蓄積データによる再現性の違いから生まれている。
企業が不確実な経済状況に置かれるほど、マーケターは「証明できない成功」よりも「説明可能な安定」を選ぶようになる。これは、失敗した際のリスクヘッジという側面も大きい。誰もが知る定番チャネルでの失敗は「市場環境のせい」にできるが、新興チャネルでの失敗は「選定ミス」と見なされやすいからだ。
EC運営におけるアカウンタビリティの重要性
アカウンタビリティ(説明責任)とは、自分の行動や決定に対して、その理由と結果をステークホルダーに説明する義務のことだ。WooCommerceなどで自社ECを運営している場合、広告費は直接的なキャッシュアウトとして厳しくチェックされる。
例えば、新しいSNS広告を試したいと提案したとき、経営層から「その広告がきっかけで買ったとどうやって証明するのか?」と問われるシーンは多い。ここで「確信」を持って答えられないチャネルは、たとえ潜在的なポテンシャルが高くても、予算獲得の優先順位が下げられてしまう。
GoogleとYouTubeに予算が集中する「安全地帯」の正体

「確信」が予算を動かすという法則は、実際の投資計画にも直結している。2026年の調査では、マーケターが最も自信を持っているチャネルこそが、最も大きな予算増額を見込まれていることがわかった。
Google検索では約80%の回答者が投資を増やすと答え、YouTubeが72%、Metaが71%と続く。このパターンは非常に明確だ。「確信」があるからこそ「正当化」が可能になり、それが「投資」へとつながる構造だ。
なぜGoogle検索は「最強の盾」なのか
Google検索が長年トップに君臨し続ける理由は、ユーザーの「検索意図」が明確だからだ。特定のキーワードで検索して流入し、購入に至るというプロセスは、誰の目にも因果関係が分かりやすい。この「ラストクリック」に近い指標の強さが、予算を守る上での最強の武器となる。
また、Googleは長年の運用データが蓄積されており、どれだけの予算を投じればどれだけの流入が見込めるかという予測精度が非常に高い。この予測可能性こそが、財務部門が最も好む要素である。
YouTubeが「確信」を得た背景
YouTubeがMetaを上回る信頼を得ている点も注目に値する。かつて動画広告は「ブランディング目的」であり、直接的な売上への貢献度が見えにくいとされていた。しかし、Googleエコシステム内での計測技術の向上により、視聴後の検索行動やコンバージョン測定が精緻化したことが功を奏している。
特にECにおいては、商品レビュー動画やチュートリアル動画からの直接的な流入が、測定可能な「確信」として積み上がっている。記事の著者は、こうした「計測のしやすさ」が戦略そのものを形作っていると指摘する。
「測定コンフォートゾーン」が招くイノベーションの停滞

予算が「説明しやすいチャネル」に集中することは、裏を返せば「測定が困難な新しいチャネル」への挑戦を阻害している。これを「測定コンフォートゾーン(測定の快適圏内)」と呼ぶ。
マーケターは、新しいプラットフォームや手法に興味を持っていないわけではない。TikTokやインフルエンサー、ポッドキャスト広告など、将来的な可能性を感じている分野は多い。しかし、それらの「探索」は「最適化」に比べて説明の難易度が高い。
「探索」と「最適化」のジレンマ
既存のGoogle広告を10%改善する(最適化)ための説明は容易だ。しかし、全く新しい媒体に予算を振り向ける(探索)には、なぜそれが必要なのか、どうやって成果を測るのかという高いハードルを越えなければならない。その結果、多くのマーケターは好奇心を持ちつつも、結局は「いつもの場所」に予算を留めてしまう。
これはECサイトの成長戦略において、中長期的なリスクになり得る。競合他社も同じ「安全地帯」に集まるため、広告単価(CPC)は高騰し続け、利益を圧迫するからだ。しかし、このコンフォートゾーンを抜け出すには、単なる「勇気」ではなく、新しい「測定の武器」が必要になる。
プライバシー規制が「確信」を揺るがす
さらに事態を複雑にしているのが、Cookie規制やプライバシー保護の強化だ。以前は当たり前だった「誰がどこから来て何を買ったか」という追跡が難しくなっている。これにより、かつて「確信」を持てていたチャネルですら、その根拠が揺らぎ始めている。
この変化により、マーケターは「プラットフォームが提供する数字」を鵜呑みにするのではなく、自社で独自の測定基準(ファーストパーティデータ)を持つ必要性に迫られている。WooCommerceなどのプラットフォームであれば、顧客データを自社で直接管理できるため、この「確信の再構築」において有利な立場にあると言えるだろう。
EC事業者が「確信」を持って新しい投資を行うための3つのステップ

では、説明責任を果たしながら、新しいチャネルを開拓するにはどうすればよいか。ここでは、独自の分析に基づいた3つのステップを提案する。
1. 測定の「共通言語」を社内で構築する
まず、マーケティングチームと財務チームの間で、成果の定義を統一することが不可欠だ。単なるラストクリックのコンバージョンだけでなく、「増分(インクリメンタリティ)」という考え方を導入することを推奨する。
増分とは、「その広告がなかったら発生しなかった売上」のことだ。これを測定するために、特定の地域だけで広告を停止する「地域テスト(Geo-testing)」などの手法を用いる。こうした客観的なテスト結果があれば、新しいチャネルであっても「確信」を持って予算を要求できる。
2. 混合モデル(MMM)の活用
MMM(マーケティング・ミックス・モデリング)とは、過去の売上データと広告費、さらに季節性や競合の動きなどの外部要因を統計的に分析し、各チャネルの貢献度を算出する手法だ。Cookieに依存しないため、昨今のプライバシー規制下でも有効な「確信」の根拠となる。
以前は大手企業しか導入できなかったが、現在はオープンソースのツールも増えており、中小規模のEC事業者でも活用が可能だ。これにより、TikTokやインフルエンサーといった「ラストクリックがつきにくい」チャネルの真の価値を可視化できる。
3. 小規模な「実験予算」の枠をあらかじめ確保する
すべての予算を「確信」で縛るのではなく、全体の5〜10%を「実験用」として切り出しておく運用も効果的だ。この枠内であれば、失敗しても全体への影響は少なく、成功すれば新しい「確信」の源泉となる。重要なのは、実験の目的を「売上」だけでなく「測定手法の確立」に置くことだ。
この記事のポイント
- 現在のマーケティング予算は、純粋なパフォーマンスよりも「説明のしやすさ(確信)」で決まっている。
- Google検索とYouTubeが圧倒的な支持を得ているのは、成果をステークホルダーに正当化しやすいからだ。
- 「測定コンフォートゾーン」に留まることは、広告費の高騰や成長の鈍化を招くリスクがある。
- 新しいチャネルに挑むには、Cookieに依存しないMMMや増分テストなどの新しい測定武器が必要。
- EC事業者は、自社のファーストパーティデータを活用して独自の「確信」を構築すべきだ。
出典
- MarTech「Why confidence, not performance, is shaping media spend」(2026年3月20日)
- Haus「2026 Haus Decision Confidence Index」

・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

VPNからCloudflare Oneへ——レガシー環境を安全にSASEへ移行するための戦略的ロードマップ
ネットワークエンジニアにとって、既存のVPN環境を新しいアーキテクチャへ切り替える週末は、キャリアの中でも最もストレスのかかる48時間になりかねない。数万人規模の組織が、千を超えるレガシーアプリケーションを断片化されたVPNから新環境へ一斉に移行しようとすれば、そのリスクは計り知れないものになる。
設定ミス一つで基幹サービスが停止し、業務が停滞する恐怖は、多くの組織がZero Trust(ゼロトラスト)への移行を躊躇する最大の要因だ。ゼロトラストとは「何も信頼しない」ことを前提に、すべてのアクセスを検証するセキュリティモデルを指す。本記事では、Cloudflareが提唱する「ビッグバン」を避けた、安全でアジャイルなSASE移行の戦略について解説する。
SASE(Secure Access Service Edge / サシー)は、ネットワーク機能とセキュリティ機能をクラウド上で統合して提供する枠組みだ。この記事を読むことで、レガシーなインフラを抱える企業が、いかにしてダウンタイムなしに最新のセキュリティポスチャ(セキュリティの状況や姿勢)へと進化できるかが理解できるだろう。
なぜレガシーVPNからの脱却は「ビッグバン」ではいけないのか

従来のネットワーク移行でよく見られる失敗は、ネットワークを単なる「配管」として扱ってしまうことだ。元記事の著者であるWarnessa Weaver氏は、多くの組織がアプリケーション間の複雑な依存関係を理解せずに、数百のアプリを一斉に移動させる「リフト・アンド・シフト」の罠に陥っていると指摘している。
ネットワークを単なる「配管」と捉えるリスク
多くの企業において、ネットワークは単にデータを運ぶ土台ではなく、アプリケーションやデータベースが密接に絡み合ったエコシステムとなっている。ある公共部門のプロジェクトでは、4,000以上のアプリケーションのうち500個を一度に移行しようとした結果、システム全体に深刻なサービス中断が発生したという。これは、バックエンドの依存関係を精査せずに移行を強行した典型的な失敗例だ。
依存関係の把握不足が招くサービス停止の連鎖
VPN(Virtual Private Network)は、一度認証されるとネットワーク全体へのアクセスを許可する「境界型セキュリティ」に基づいている。これに対し、SASEへの移行は、アプリケーションごとにアクセス権限を細かく設定する「最小権限の原則」への移行を意味する。事前の調査なしにこの制限を適用すると、本来必要だった内部APIの呼び出しやデータベース接続が遮断され、アプリが正常に動作しなくなる。エンジニアは、移行を「配管の交換」ではなく「アプリケーションの近代化プロジェクト」として捉える必要がある。
Cloudflare Accessによるレガシーアプリケーションの「ラッピング」

移行のリスクを抑えるための鍵は、既存のアプリケーションを書き換えることなく、最新のセキュリティ層で「包み込む(ラッピングする)」ことだ。これには、Cloudflare Accessというツールが活用される。
コードを書き換えずにMFAを導入する仕組み
多くの古い(レガシーな)社内アプリには、多要素認証(MFA / Multi-Factor Authentication)の機能が備わっていない。MFAとは、パスワードだけでなく、スマホの承認や物理キーなど複数の手段で本人確認を行う仕組みだ。通常、これらを導入するにはアプリのコード修正が必要だが、Cloudflare Accessを使えば、アプリの前段に認証ゲートウェイを設置できる。これにより、アプリ自体は古いまま、最新のSSO(Single Sign-On)やMFAを強制することが可能になる。
Cloudflare Tunnelで外部からの攻撃面を最小化する
さらに、Cloudflare Tunnelという技術を組み合わせることで、セキュリティはより強固になる。これは、社内サーバーからCloudflareのネットワークに向かって「外向き」の接続を確立する仕組みだ。サーバーにパブリックIPアドレスを割り当てる必要がなくなるため、インターネット上からサーバーの存在自体を隠すことができる。攻撃者がスキャンしても入り口が見つからない状態、つまり「攻撃面(アタックサーフェス)」がほぼゼロになるのだ。
成功率を高めるための「4つの事前監査」とティア分け

移行を開始する前に、ITリーダーは環境の「建築的準備」を整える必要がある。CDWのセキュリティエグゼクティブであるEric Marchewitz氏によれば、十分な準備なしに最小権限アクセスを適用すると、多くのレガシーアプリが動作しなくなる可能性があるからだ。
IDプロバイダーと依存関係の徹底的な洗い出し
まず最初に行うべきは、アイデンティティ(ID)とアーキテクチャのアセスメントだ。Oktaのようなクラウド型IDプロバイダーを利用しているアプリと、古いローカルディレクトリを使っているアプリを仕分ける。同時に、バックエンドのデータベースやAPIの依存関係をマップ化する。このデータがあれば、切り替え時にどのAPIコールが切断されるかを事前に予見し、対策を講じることができる。
アプリケーションの複雑度に応じた4段階のティア管理
元記事では、アプリケーションをその技術的複雑さに応じて4つの「ティア(階層)」に分類することを推奨している。これにより、現実的な移行スケジュールを立てることが可能になる。
| ティア | 説明 | 推定移行工数 |
|---|---|---|
| ティア 0 (モダンSaaS) | SAML/OIDC対応。CloudflareがIDプロバイダーとして機能する | 1アプリあたり1〜3時間 |
| ティア 1 (内部Webアプリ) | 標準的なWebプロトコル。Cloudflare Tunnelでリバースプロキシ化 | 1アプリあたり3〜6時間 |
| ティア 2 (非Webアプリ) | 特定のポートや厚いクライアントが必要。専用クライアントを使用 | 1アプリあたり4〜8時間 |
| ティア 3 (レガシー基幹) | P2Pや双方向通信が必要。WANデプロイメントなどの補完が必要 | 1アプリあたり1〜3日 |
段階的な移行を実現する「3フェーズ」のロードマップ

レガシーハードウェアからの「脱出速度」を得るために、CDWとCloudflareは、一斉置換ではなく「共存」を優先する段階的なロールアウトを提案している。
戦略策定からパイロット導入までのステップ
第1フェーズでは、戦略チームと実装チームを分離して組織する。第2フェーズでは、少数の従業員グループ(パイロットグループ)に対してCloudflare Oneクライアントを導入する。ここで重要なのは、セキュリティ強化による「遅延(レイテンシ)」がユーザー体験を損なわないかを確認することだ。Cloudflareは世界中にエッジ拠点を持っているため、多くの場合はVPNよりも高速な接続が期待できるが、実環境での検証は欠かせない。
VPNとCloudflare Oneを併用する「デュアルクライアント」期間
第3フェーズの生産スケールでは、既存のVPNとCloudflare Accessを一時的に併用する「デュアルクライアント」期間を設ける。これにより、万が一新環境で問題が発生しても、すぐに旧環境へロールバックできる安全策を確保する。ユーザーは徐々に新しいアクセス手法に慣れていくことができ、IT部門のサポート負担も分散される。このアプローチは、日本の企業における慎重なシステム移行プロセスとも非常に相性が良いと言えるだろう。
パフォーマンスと将来性——セキュリティを高速化の武器にする

セキュリティを強化すると動作が重くなる、という考えはもはや過去のものだ。Cloudflareのシングルパス・アーキテクチャは、すべてのセキュリティチェックを同時に実行するため、効率的なデータ処理が可能だ。
シングルパス・アーキテクチャによる遅延の解消
従来のセキュリティ対策では、ファイアウォール、ウイルススキャン、DLP(データ漏洩防止)などの各装置をデータが順番に通過するため、その都度遅延が発生していた。Cloudflareのアーキテクチャでは、これらをクラウド上の1回のパスで処理する。Cloudflare One GTM責任者のAnnika Garbers氏は、この「接続クラウド」への移行が、セキュリティチームがボトルネックになるのを防ぎ、運用速度を劇的に向上させると述べている。
ポスト量子暗号への対応と将来の脅威への備え
さらに、このプラットフォームは将来の脅威にも備えている。量子コンピュータが実用化されると、現在の暗号技術の多くが突破されるリスクがある。Cloudflareは既に「ポスト量子暗号(PQC / Post-Quantum Cryptography)」に対応した基盤を構築しており、今移行することは、将来的な脅威に対する防御を先行して手に入れることを意味する。一度クラウドベースのSASEに移行してしまえば、こうした最新技術の恩恵を、ハードウェアの買い替えなしに受け続けられるのが大きなメリットだ。
この記事のポイント
- ビッグバン移行を避ける:一斉切り替えはリスクが高すぎるため、段階的な「共存」モデルを採用すべきだ。
- ラッピングで近代化:レガシーアプリのコードを直さず、Cloudflare AccessでMFAやSSOを追加できる。
- 徹底した事前監査:IDプロバイダーの確認とアプリのティア分けが、移行の成功率を左右する。
- パフォーマンスの向上:シングルパス・アーキテクチャにより、セキュリティ強化と高速化を両立できる。
- 将来への備え:クラウド型SASEなら、ポスト量子暗号などの最新機能を即座に利用可能だ。
出典
- Cloudflare Blog「From legacy architecture to Cloudflare One」(2026年3月13日)
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

WordPress制作会社が直面する「成長の壁」と突破口——4人の創業者が語る経営のリアル
Web制作会社が成長の過程で直面する課題は、技術的な問題よりも経営上の意思決定に起因することが多い。特にWordPressを中心とした受託ビジネスでは、案件の獲得、組織の拡大、そして収益性の維持という3つの要素が複雑に絡み合う。15年以上にわたり業界の最前線でエージェンシーを率いてきた4人の創業者は、いかにしてこれらの「成長の壁」を突破してきたのか。
元記事によれば、Kinstaが実施したインタビューシリーズ「They figured it out (mostly)」において、規模も拠点も異なる4つの制作会社が、自らの失敗と成功の軌跡を明かしている。彼らの経験からは、単なるコーディングスキルを超えた、持続可能なビジネスを構築するための共通項が見えてくる。
本記事では、WooCommerceへの特化、エンタープライズ(大規模企業)向けエンジニアリングへの転換、そして1,000社以上のクライアントを抱える組織の管理術など、実務に直結する知見を整理した。Web制作の現場で指揮を執るディレクターや経営者にとって、自社のロードマップを描くための指針となるはずだ。
専門特化(ニッチ)がもたらす競争優位性
「何でもできる」ことは、制作会社にとって初期段階では武器になるが、成長段階では足かせになる場合がある。特定の領域に特化することで、競合との差別化を図り、高単価な案件を獲得する戦略が有効だ。ここでは、WooCommerceとサイバーセキュリティという異なる分野に特化した2社の事例を見ていく。
WooCommerceへの完全特化:Built Mightyの事例
シアトルを拠点とするBuilt Mightyの創業者、ジョニー・マーティン氏は、2009年にオンラインショップの運営者としてキャリアをスタートさせた。しかし、彼は次第にショップを運営することよりも、システムを構築すること自体に強い関心を持つようになった。これが、同社をWooCommerce専門の制作会社へと変貌させるきっかけとなった。
現在、同社はWooCommerceのカスタムプラグイン開発や複雑な外部システム連携を専門としている。他の制作会社が「技術的に難易度が高すぎる」として断るようなプロジェクトが、同社に集まってくる仕組みだ。マーティン氏は、特定のプラットフォームに精通した人材を揃えることが、最大の資産であると指摘している。
WooCommerceとは、WordPressをECサイト(ネットショップ)化するためのプラグインである。世界で最も利用されているECプラットフォームの一つだが、カスタマイズには高度なPHPの知識とデータベースの理解が求められる。Built Mightyはこの「難易度の高さ」を参入障壁として利用し、独自のポジションを確立した。
サイバーセキュリティとエンタープライズ:Fixelと40Q
ヴィン・トーマス氏が率いるFixelは、サイバーセキュリティ分野のスタートアップとの仕事をきっかけに、そのニッチな市場での地位を固めた。初期のクライアントが業界内で買収・統合されるたびに、そのマーケティング担当者が新たな会社でFixelを指名するという「紹介の連鎖」が発生した。これにより、広告費をかけずに専門性の高いポートフォリオを構築することに成功した。
一方、ブエノスアイレスの40Qは、自らを「WordPressデベロッパー」ではなく「WordPressエンジニア」と定義している。同社のエディー・ワイズ氏は、単にテーマをカスタマイズするのではなく、DAM(Digital Asset Management:デジタル資産管理)やLMS(Learning Management System:学習管理システム)といった、複雑なアプリケーション開発の概念をWordPressに持ち込んでいる。
DAMとは画像や動画などの素材を一元管理する仕組み、LMSはオンライン講座などを運営するための基盤である。これらをWordPressで構築するには、一般的なWebサイト制作とは一線を画す設計思想が必要となる。40QはAdobe Experience Managerなどの高価なエンタープライズ向けツールと比較されるレベルのソリューションを提供することで、大規模案件を勝ち取っている。
組織拡大の罠と「正しいサイズ」の再定義

案件が増えれば人を増やす。この一見正論に思えるサイクルが、組織のアイデンティティを損なうリスクを孕んでいる。制作会社が成長する過程で直面する「採用」と「組織規模」の課題について、創業者の実体験に基づいた教訓が語られている。
「Hire Fast, Fire Fast」——採用プロセスの変革
Built Mightyのマーティン氏は、従来の「慎重に採用し、速やかに解雇する(Hire slow, fire fast)」という格言は、現代のスピード感には合わないと考えている。同社では、履歴書を受け取ってから数日以内に、候補者に対して「有償のテストプロジェクト」を依頼する。面接だけで人柄やスキルを見極めるのは不可能に近いからだ。
テストプロジェクトを通過した候補者は、実際のクライアントワークに携わる前に、架空のクライアントを想定したオンボーディング(導入研修)を受ける。このプロセスにより、実務開始から1週間以内にその人材がチームにフィットするかどうかが判明する。マーティン氏によれば、この「高速な試行」こそが、ミスマッチによる損失を最小限に抑える鍵であるという。
140人から80人へ:Pronto Marketingの教訓
タイとフィリピンを拠点に1,000社以上のクライアントを抱えるPronto Marketingは、一時期、従業員数が140名まで膨れ上がった。創業者のティム・ケルシー氏は、エレベーターで一緒になった人物が自社の社員であることに気づかなかった経験を振り返っている。組織が大きくなりすぎたことで、誰が何をしているのかが見えなくなったのだ。
その後、同社はあえて規模を縮小し、現在は約80名の体制で運営している。ケルシー氏は、「自分の組織の限界を知るには、一度その限界を超えてみるしかない」と述べている。規模を追うことだけが正解ではなく、サービスの質を維持しながら管理が行き届く「適正規模」を見極めることの重要性が示唆されている。
収益構造の安定化とリスク管理
制作会社の経営において、特定のクライアントへの過度な依存や、不適切な価格設定は致命的なリスクとなる。4人の創業者は、大きな損失を経験したことで、より強固な収益モデルへと舵を切った。
特定クライアントへの依存という「時限爆弾」
Fixelのトーマス氏は、売上の3分の1を占めていた主要クライアントを失った経験を語っている。そのクライアントが数十億ドル規模で買収された際、継続していたリテーナー(月額固定の保守・運用契約)が突如終了した。大きな売上が一晩で消滅したことは、同社にとって深刻な打撃となった。
この経験から、トーマス氏は「卵を一つのカゴに盛らない」戦略の重要性を再認識した。現在は、特定のクライアントに依存しすぎないよう、顧客ポートフォリオの分散を意識し、不測の事態に備えたクッション(内部留保や複数の小規模案件)を確保することに注力している。
10年越しの価格改定がもたらした意外な結果
Pronto Marketingのケルシー氏は、10年以上据え置いていた月額サポート料金の改定に踏み切った際の出来事を明かしている。値上げの通知メールを送信した際、大量の解約が発生することを覚悟していた。しかし、実際に不満を漏らしたのは1,000社以上のうち、わずか2社だけだったという。
「なぜもっと早くやらなかったのか」とケルシー氏は振り返る。制作会社はクライアントとの関係悪化を恐れて価格改定を躊躇しがちだが、提供している価値に見合った適正な価格設定は、サービスを継続させるための責務でもある。特にインフレや人件費の高騰が続く状況では、定期的な価格見直しが経営の健全性を左右する。
技術トレンドへの向き合い方:AIとパートナーシップ

AIの台頭や広告単価の上昇など、外部環境は常に変化している。創業者の4人は、これらの変化を脅威として捉えるのではなく、自社のワークフローや成長戦略にどう組み込んでいるのだろうか。
AIは「思考」の代替ではなく「ツール」
4人の創業者に共通していたのは、AIを「魔法の杖」とは見なしていない点だ。Fixelではコンテンツ戦略のためにカスタムのClaude(AIモデルの一種)を活用し、40QではAIを活用したページビルダーの開発を進めている。しかし、AIが人間の「思考」そのものを代替することはないというのが彼らの一致した見解だ。
AIはプロセスを効率化し、より多くのタスクをこなす助けにはなるが、アウトプットの質を担保し、戦略的な判断を下すのは依然として人間の役割である。ケルシー氏のチームでは、AIが生成したものを必ず人間が反復(イテレーション)して磨き上げる工程を設けている。AIは戦略ではなく、あくまで道具であるという認識が重要だ。
広告よりも強力な「戦略的パートナーシップ」
40Qのワイズ氏は、デジタルマーケティングによるリード獲得(見込み客探し)よりも、戦略的パートナーシップの方が多くの案件をもたらすと断言している。また、Built Mightyのマーティン氏も、同規模あるいは異なる規模の制作会社とのネットワークを構築している。ある制作会社が閉業した際、長年の信頼関係があったために、50社ものクライアントをそのまま引き継いだ事例もあるという。
Google広告などのWeb広告に頼るのではなく、信頼に基づく紹介ネットワークを構築することが、結果として最も効率的な営業活動になる。これは、制作会社が「単なる下請け」ではなく、業界内での信頼を勝ち取った「パートナー」として認知されているからこそ成し遂げられることだ。
独自の分析:日本の制作会社が学ぶべき3つの教訓

今回の4人の創業者の対話から、日本のWeb制作業界にも共通する重要な示唆が得られる。筆者の分析によれば、特に以下の3点は、これからの厳しい市場環境を生き抜くために不可欠な要素である。
第一に、「WordPressのコモディティ化」への対策だ。単にサイトを立ち上げるだけのスキルは、ノーコードツールの普及やAIの進化により、急速に価値が低下している。40Qのように「エンジニアリング」の領域まで踏み込むか、Built Mightyのように特定のプラグインを極めるか、何らかの「技術的参入障壁」を自ら築く必要がある。
第二に、「採用と教育のリスクマネジメント」である。日本の制作現場でも慢性的な人材不足が続いているが、焦って採用した人材がミスマッチだった場合のコストは、金銭面だけでなく既存メンバーのモチベーションにも悪影響を及ぼす。Built Mightyが実践している「有償テストプロジェクト」は、実務能力とカルチャーフィットを同時に確認する合理的な手法として、日本でも導入を検討する価値があるだろう。
第三に、「リテーナーモデル(継続収益)の質的転換」だ。保守・運用という名目の「何もしない月額費用」は、クライアントにとって真っ先に削減対象となる。FixelやPronto Marketingのように、クライアントのビジネス成長に直接寄与する「パートナー」としての立ち位置を確立し、定期的な価値提供と適正な価格改定を行うことが、長期的な安定経営につながる。
この記事のポイント
- 専門分野の確立: WooCommerceやエンタープライズ向け開発など、特定のニッチに特化することで競合を排除し、高単価案件を獲得できる。
- 採用プロセスの高速化: 面接だけでなく有償のテストプロジェクトを実施し、1週間以内にフィット感を見極める「Hire Fast, Fire Fast」が有効。
- リスク分散と適正価格: 特定クライアントへの依存を避け、提供価値に見合った価格改定を躊躇せずに行うことが組織の持続可能性を高める。
- パートナーシップの活用: 広告による集客よりも、同業者や関連企業との信頼ネットワークを通じた紹介の方が、質の高いリード獲得につながる。
出典
- Kinsta Blog「4 agency founders share the decisions that shaped their businesses」(2026年3月18日)
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AI時代のSEO戦略:コモディティ化したコンテンツを捨て「文脈の堀」を築く方法
半年間の歳月を費やして構築したリソースライブラリが、AIの回答一つで無価値になる時代が訪れている。ガイド、解説記事、比較ページなど、人間が意思決定するために丁寧に書かれたコンテンツであっても、AIはそれを数秒で要約し、ユーザーを自社サイトへ誘導することなく解決策を提示してしまうからだ。
AIプラットフォームが回答を生成する際、引用元として選ばれるのは「正確で丁寧な解説」ではなく「他では手に入らない独自の一次データ」である。情報が正しいだけでは不十分であり、代替不可能であることが、AI時代の視認性を左右する決定的な要因となっている。
本記事では、従来のコンテンツ戦略がなぜ通用しなくなったのかを整理し、AIに選ばれるための「コンテキスト・モート(文脈の堀)」の構築方法について解説する。情報の要約というAIの得意分野に対抗し、ビジネスの優位性を守るための新たな指針を提示したい。
AIによる「要約」がコンテンツの価値を奪う現状

現在の主要なAIプラットフォームは、3,000文字のガイド記事をわずか2秒で3文に要約する能力を備えている。この能力は、コンテンツが価値を生み出す仕組みを根本から変えてしまった。コンテンツが要約によって完全に代替可能であるならば、そのコンテンツに「堀(競合に対する防壁)」は存在しない。
要約されるページは「材料」に過ぎない
記事によれば、要約が製品となり、元のウェブページは他者のシステムが処理して破棄する「原材料」に成り下がっている。ユーザーが元のコンテンツに触れる前に、AIがその価値を抽出して提示してしまうからだ。この現象はすでに多方面で発生している。
例えば、GmailのGemini搭載サマリーカードは、受信者がメール本文を読む前にマーケティングメールの内容を要約する。GoogleのAI Overviews(旧SGE)は、複数のページから回答を合成し、検索結果の最上部に表示する。MicrosoftのCopilotにいたっては、小売サイトを訪れることなく購入手続きまで完了させる機能を備えつつある。
AIによるインターフェースの変化
Samsungは2026年にGalaxy AI搭載デバイスを8億台に倍増させる計画を立てている。これにより、AIを介した情報の発見と要約は、日常的な消費者行動として定着する。コンテンツとオーディエンスの間に位置するAIレイヤーは、四半期ごとにその機能を強化し、厚みを増している。
AIレイヤーがページの価値を再現し、サイトへの送客を不要にしたとき、ページそのものは資産としての価値を失う。これからの資産は、AIレイヤーが再現できない「何か」でなければならないとの見方が強まっている。
「コモディティ・コンテンツ」の定義と限界

多くのマーケティングチームにとって耳の痛い話だが、現在のウェブ上のコンテンツの多くは「コモディティ(汎用品)」に分類される。コモディティ・コンテンツとは、複数の公開情報から入手可能な情報を、独自のデータや方法論、一次的な洞察なしに再パッケージ化したものを指す。
高品質な文章だけでは不十分な理由
読みやすい文章、正確な情報、役立つ構成。これらはかつて「高品質なコンテンツ」と呼ばれたが、現在では最低限の条件(テーブルステークス)に過ぎない。10年前にモバイル対応が必須となったのと同様、AIが公開知識を完璧に合成できる現代において、単に「正しくて読みやすい」だけでは防御壁にはならないのだ。
Content Marketing Instituteの2026年B2B調査によれば、マーケターの悩みは「質の高いコンテンツの不足」や「競合との差別化の困難さ」で停滞している。しかし、AIの登場により、差別化できていないコンテンツの代償は劇的に重くなっている。AIは似たようなガイドが複数ある場合、一つだけを選ぶか、あるいは引用元を明示せずに両方の内容を合成してしまうからだ。
競合と同じ情報を発信するリスク
公開されている統計や一般的なノウハウをまとめた記事は、AIにとって「代替可能なソース」でしかない。著者のDuane Forrester氏は、誰でもアクセスできる公開ソースから組み立てられた情報は、AIによって簡単に処理・統合されると指摘している。独自の視点や検証が欠如したコンテンツは、検索トラフィックを失うだけでなく、AIによる回答生成の過程でその存在を消されてしまうリスクを抱えている。
生き残るための「コンテキスト・モート(文脈の堀)」とは

コンテキスト・モートとは、独自のアクセス権、独自のリサーチ、独自のデータセット、または特定のドメインにおける深い経験がなければ作成できないコンテンツを指す。AIはそれを要約し、参照することはできるが、ソースそのものを複製することはできない。なぜなら、そのソースは世界のどこにも存在しないからだ。
独自の一次データとベンチマーク
最も強力な堀となるのは、自社が保有するデータだ。匿名化・集計された顧客データ、社内のパフォーマンス指標、独自の調査結果などがこれに該当する。例えば、HubSpotがマーケティング白書を、Salesforceが営業白書を公開する場合、AIはその特定の数字を裏付けとして引用せざるを得ない。モデルには他に代替となるソースが存在しないため、この「引用せざるを得ない状況」こそが強力な堀となる。
専門家による「判断」と「具体的」なケーススタディ
単なる情報の羅列ではなく、特定のドメインで20年の経験を持つ人間による「プロフェッショナルな判断」は、AIが模倣しにくい領域だ。また、「あるSaaS企業が解約率を改善した」という抽象的な話ではなく、「オンボーディングをこのように再構築した結果、6ヶ月で解約率を8.2%から4.1%に半減させた」という具体的な手順と数値を含むケーススタディも、当事者にしか書けない独自の価値を持つ。
さらに、独自のテストや実験データも重要だ。変数を制御し、結果を測定したプロセスそのものが資産となる。これらのデータが公開されない限り、AIモデルは回答を生成するための根拠を持つことができないため、必然的に一次情報源への依存度が高まる。
AI時代のSEO:引用されるための戦略
AIによる情報の取得(Retrieval)は、従来の検索エンジンのランキングアルゴリズムとは異なる動きを見せる。AIは「リスクを最小化する」ように設計されており、主張を裏付けるために自信を持って帰属させることができるソースを探している。
統計データがAIの視認性を41%向上させる
プリンストン大学とジョージア工科大学によるGEO(Generative Engine Optimization)の研究によれば、コンテンツに統計データを追加することで、AIによる視認性が41%向上したという結果が出ている。これはテストされた最適化手法の中で最も効果的なものだった。また、Yextの分析では、データが豊富なウェブサイトは、ディレクトリ型のリストに比べてURLあたりの引用回数が4.3倍多いことが判明している。
ブランド認知度と引用のフライホイール効果
Evertune.aiが75,000ブランドを分析した結果、ブランド認知度はAIによる引用の最強の予測因子(相関係数0.334)であることがわかった。ブランド認知度は、独自のデータやリサーチの発信源となることで蓄積される。独自の調査を公開し、それがメディアや業界で言及されることでブランド信号が強化され、AIにとって「引用しても安全な権威あるソース」として認識されるようになる。これが「引用オーソリティ・フライホイール」と呼ばれる好循環だ。
コンテンツ予算の再配分:何を優先すべきか
CMOサーベイによれば、企業はデジタルマーケティング予算の約11.2%をファーストパーティデータの取り組みに割り当てており、2026年には15.8%に達すると予想されている。しかし、重要なのは予算の総額ではなく、その中身だ。自社のコンテンツ予算のうち、どれだけが「コモディティ」に費やされ、どれだけが「コンテキスト・モート」の構築に充てられているかを厳密に評価する必要がある。
眠っている社内データの公開
多くの組織は、公開しているよりもはるかに多くの独自データを保有している。顧客の行動ベンチマーク、運用指標、業界特有のパフォーマンスデータなどは、製品チームやリサーチチームのなかに眠っていることが多い。マーケティングチームは、これらのデータをAIが発見・引用できる形式で公開する「編集上の決断」を下すべきだ。
合成(Synthesis)から分析(Analysis)へのシフト
ライターの役割も変化を求められている。業界のトレンドを要約(合成)するライターは、コモディティ・コンテンツを生産しているに過ぎない。一方で、自社の独自データを分析し、その意味を説明するライターは、コンテキスト・モートを構築している。同じライターであっても、課題の与え方によってビジネスへの貢献度は根本から異なる。
また、社内の専門家(SME)を単なるインタビューの対象として扱うのではなく、コンテンツの資産として位置づけることも重要だ。専門家が自身の名前と資格で詳細な方法論や判断を公開することで、AIに対する強力な権威信号となる。
独自の分析:日本国内の中小企業が取り組むべきデータ活用

この記事の主張を日本国内の市場、特に中小企業のウェブ戦略に当てはめると、非常に大きなチャンスが見えてくる。日本の多くの業界では、まだ詳細なベンチマークデータや運用実績がデジタル化・公開されていない。これは、AI検索(AEO/GEO)において「先行者利益」を得る絶好の機会だと言える。
例えば、製造業であれば特定の加工技術の歩留まりに関する統計、リフォーム業であれば地域別の修繕箇所の傾向、士業であれば特定の法改正後の相談件数の推移など、日常の業務で蓄積されている数字を「〇〇業界白書」として構造化して公開するだけで、AIはその分野の権威として認識し始める。大規模な調査会社に依頼する必要はない。自社の管理画面にある数字を、四半期ごとに1つの指標として branded name(独自の名称)を付けて公開するだけで、それは競合が複製できない「堀」になるのだ。
この記事のポイント
- AIは公開情報を瞬時に要約するため、一般的な解説記事の価値は「材料」へと低下している。
- 生き残る鍵は、他社が複製できない独自のデータや経験に基づく「コンテキスト・モート(文脈の堀)」だ。
- AI(GEO)は統計データを含むコンテンツを優先して引用し、視認性を大幅に向上させる傾向がある。
- コンテンツ予算を「情報の要約」から「独自データの生成と分析」へと再配分することが急務である。
- 社内に眠っている未公開の運用データや専門家の判断を公開することが、AI時代の最強のSEOとなる。
出典
- Search Engine Journal「The Content Moat Is Dead. The Context Moat Is What Survives」(2026年3月19日)
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

WordPress開発の転換点:PHPのみでGutenbergブロックを構築する方法
WordPressのブロックエディタ(Gutenberg)が登場して以来、カスタムブロックの開発にはReactやNode.jsといったJavaScriptベースの技術習得が不可欠だった。しかし、最新のアップデートにより、PHPコードのみでブロックを構築・管理できる手法が確立された。この変更は、従来のPHP中心のWordPress開発者にとって、学習コストを劇的に下げる重要な転換点となる。
Gutenberg 21.8以降で導入されたこの機能により、サーバーサイドのJavaScript環境を構築することなく、PHPの関数だけでエディタとフロントエンドの両方にブロックを表示できる。ビルドプロセスの複雑さを排除し、保守性の高いサイト制作を可能にするのが「PHP-onlyブロック」だ。
本記事では、PHPのみでブロックを登録する具体的な手順から、管理画面UIの自動生成、さらには既存のショートコードをブロック化する実践的なテクニックまでを詳しく解説する。この記事を読むことで、最新のWordPress標準に準拠した効率的な開発手法を習得できるはずだ。
PHP-onlyブロックの概要と導入のメリット

これまで、カスタムブロックを作成するには、Reactの知識に加え、WebpackやNPM(Node Package Manager)を用いたビルド環境の構築が必須であった。これは、主にサーバーサイドのPHPでサイトを構築してきた開発者にとって、非常に高い参入障壁となっていた。PHP-onlyブロックは、この障壁を取り払うために設計された仕組みだ。
なぜPHPだけでブロックが作れるようになったのか
WordPress開発チームは、ブロックエディタの普及をさらに加速させるため、従来のPHP開発者が慣れ親しんだ手法でブロックを作成できる環境を整えた。具体的には、サーバー側で登録されたメタデータをエディタ(JavaScript側)へ自動的に受け渡す「auto_register」機能が実装されたことが大きい。これにより、エディタ用のJSファイルを手動で記述する必要がなくなったのだ。
開発者にとっての3つの主要な利点
第一の利点は、学習コストの圧倒的な低減だ。ReactやNode.jsの複雑なエコシステムを学ぶ時間を、サイトの機能向上やデザインのブラッシュアップに充てることができる。第二に、フロントエンドのパフォーマンス向上が挙げられる。不要なJavaScriptの読み込みを削減できるため、ページの読み込み速度を最適化しやすい。第三に、保守性の向上だ。PHPコード一箇所でブロックの定義と出力(レンダリング)を管理できるため、コードの可読性が高まり、バグの混入を防ぎやすくなる。
基本的なPHP-onlyブロックの作り方

PHP-onlyブロックの作成は、従来の「動的ブロック(Dynamic Blocks)」の登録方法と似ているが、最大の違いはエディタ用のスクリプトを指定せずに、特定のフラグを有効にする点にある。元記事の著者は、最小限のコードでブロックを動作させる手法を示している。
register_block_type と auto_register の役割
ブロックの登録には、WordPress標準の `register_block_type` 関数を使用する。この関数の `supports` 配列内に `’auto_register’ => true` を含めることが、PHP-onlyブロックとして動作させるための鍵となる。このフラグが有効な場合、WordPressは `ServerSideRender` というコンポーネントを自動的に使用し、管理画面上でもPHPで生成されたHTMLをプレビュー表示する。
最小構成のコード例
以下は、プラグインやテーマの `functions.php` に記述することで動作する、最もシンプルなPHP-onlyブロックのコードだ。
/**
* レンダリング用コールバック関数
*/
function my_simple_php_block_render( $attributes ) {
return '<div style="padding: 20px; background: #f0f0f0; border: 2px solid #0073aa;">
<h3>🚀 PHP-only ブロック</h3>
<p>このブロックはPHPのみで生成されています。</p>
</div>';
}
/**
* ブロックの登録
*/
add_action( 'init', function() {
register_block_type( 'my-custom/php-block', array(
'title' => 'シンプルなPHPブロック',
'icon' => 'admin-plugins',
'category' => 'text',
'render_callback' => 'my_simple_php_block_render',
'supports' => array(
'auto_register' => true,
),
) );
});🚀 PHP-only ブロック
このブロックはPHPのみで生成されています。
このコードを有効にすると、ブロックエディタの追加メニューに「シンプルなPHPブロック」が表示され、設置すると即座にグレーの枠線で囲まれたプレビューが表示される。これがPHP-only開発の第一歩だ。
属性(Attributes)を活用した管理画面UIの自動生成

単にHTMLを出力するだけでなく、ユーザーがエディタ上でテキストを変更したり、オプションを選択したりできるようにするには「属性(Attributes)」を定義する必要がある。最新のGutenbergでは、PHPで定義した属性に基づいて、サイドパネル(インスペクター)の入力フィールドを自動生成する機能が追加されている。
属性の定義と入力フィールドの対応関係
属性のデータ型(type)を指定することで、WordPressは適切なUIコンポーネントを割り当てる。著者によれば、現在のところ以下のマッピングがサポートされている。
- string: テキスト入力フィールド
- number / integer: 数値入力フィールド
- boolean: チェックボックス(またはトグル)
- enum(string内): セレクトボックス(ドロップダウン)
実践的な属性付きブロックのコード
以下の例では、タイトル、表示数、有効/無効の切り替え、サイズ選択の4つの属性を持つブロックを定義している。これらはすべて、JavaScriptを一行も書かずに管理画面のサイドバーに表示される。
register_block_type( 'my-plugin/advanced-php-block', array(
'title' => '設定付きPHPブロック',
'attributes' => array(
'blockTitle' => array( 'type' => 'string', 'default' => 'デフォルトタイトル' ),
'itemCount' => array( 'type' => 'integer', 'default' => 5 ),
'isEnabled' => array( 'type' => 'boolean', 'default' => true ),
'displaySize' => array(
'type' => 'string',
'enum' => array( 'small', 'medium', 'large' ),
'default' => 'medium',
),
),
'render_callback' => 'my_advanced_render_func',
'supports' => array( 'auto_register' => true ),
) );この仕組みの導入により、複雑なReactコンポーネント(TextControlやSelectControlなど)を組み合わせて `edit.js` を作成する手間が省ける。ただし、現時点ではリッチテキストエディタ(RichText)や高度なカラーピッカーなど、一部の複雑なコントロールはJS側での定義が必要な場合がある点には注意が必要だ。
実践例:カスタマイズ可能な価格表ブロックの構築

より実用的な例として、Web制作の現場で頻繁に求められる「価格表(料金テーブル)」ブロックをPHPのみで作成する手法を解説する。ここでは、WordPress標準のスタイル機能(色、間隔、タイポグラフィ)を統合する方法が重要となる。
get_block_wrapper_attributes によるネイティブ機能の統合
PHP-onlyブロックで最も強力な武器となるのが `get_block_wrapper_attributes()` 関数だ。この関数は、ユーザーがエディタのサイドバーで設定した背景色、文字色、パディング、マージンなどのスタイル情報をクラス名やインラインスタイルとして一括生成してくれる。これをメインの `div` タグに出力するだけで、自作ブロックがWordPressの標準デザインツールに完全対応する。
価格表ブロックのレンダリング設計
著者が提案する「Smart Pricing Widget」の例では、プラン名、価格、ボタンテキストなどの属性に加え、`supports` 配列で `color`, `spacing`, `typography`, `shadow`, `border` を有効にしている。これにより、エンジニアがCSSを細かく調整しなくても、運用者がエディタ上で自由に見た目をカスタマイズできるようになる。
function render_smart_pricing_block( $attributes ) {
// 属性の取得
$plan_name = esc_html( $attributes['planName'] );
$price = intval( $attributes['price'] );
// スタイル属性の生成
$wrapper_attributes = get_block_wrapper_attributes( array(
'class' => 'my-pricing-card',
) );
return sprintf(
'<div %s>
<h3>%s</h3>
<div class="price">¥%d</div>
<a href="#" class="btn">申し込む</a>
</div>',
$wrapper_attributes,
$plan_name,
$price
);
}プロフェッショナル
PHPのみで作成され、エディタの色設定が反映される価格表ブロックのイメージ
既存のショートコードをブロックへ変換する方法
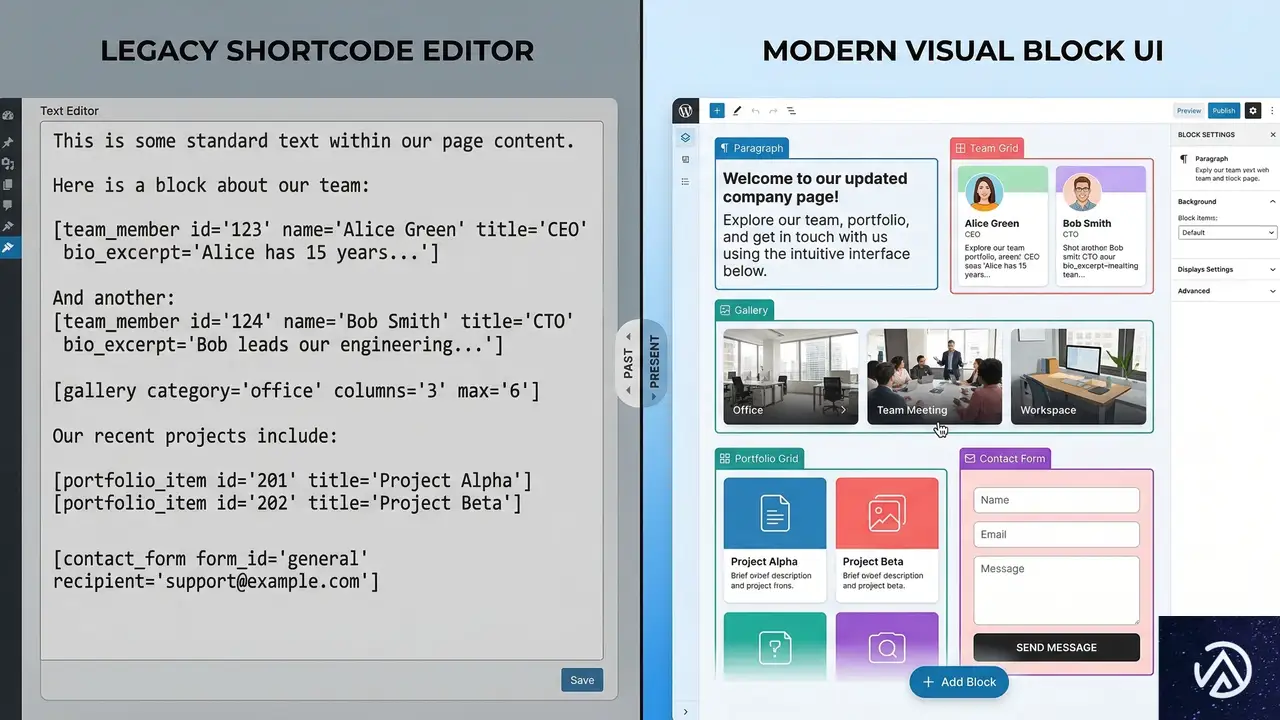
PHP-onlyブロックの最も現実的かつ即効性のある活用シーンは、古いサイトで多用されている「ショートコード」のブロック化だ。ショートコードは入力が煩雑でプレビューも困難だが、PHP-onlyブロックでラップすることで、直感的な操作感へとアップグレードできる。
ショートコードをラップするメリット
ショートコードをそのまま使い続けるのではなく、ブロックとして再定義することで、ユーザーは「`[my_shortcode type=”info”]`」のような文字列を打ち込む必要がなくなる。代わりに、サイドバーのドロップダウンから「情報」「警告」「エラー」を選択するだけで済むようになる。内部的には既存のショートコード関数を呼び出すため、ロジックを書き直す必要もない。
do_shortcode を使ったレンダリング手法
実装方法は非常にシンプルだ。ブロックの `render_callback` 内で、受け取った属性を基にショートコード文字列を組み立て、WordPress標準の `do_shortcode()` 関数に渡すだけである。記事によれば、これにより管理画面上でもショートコードの実行結果がリアルタイムにプレビューされ、編集体験が劇的に向上するという。
function render_shortcode_wrapper_block( $attributes ) {
$type = esc_attr( $attributes['alertType'] );
$msg = esc_attr( $attributes['message'] );
// 既存のショートコードを動的に生成
$shortcode = sprintf( '[my_alert type="%s"]%s[/my_alert]', $type, $msg );
return sprintf(
'<div %s>%s</div>',
get_block_wrapper_attributes(),
do_shortcode( $shortcode )
);
}WordPress開発の未来とPHP-onlyブロックの立ち位置

PHP-onlyブロックは現在、非常に強力なツールとして進化を続けているが、すべてのJavaScript開発を置き換えるものではない。高度なインタラクションや、複雑な状態管理が必要なUI(例:ドラッグ&ドロップを伴う高度なレイアウトエディタなど)には、依然としてReactによる開発が適している。
しかし、中小規模のWebサイト制作や、社内向けのカスタム機能の実装においては、PHP-onlyブロックで十分なケースが大半だ。著者も指摘するように、この機能は「ブロックエコシステムを、高度なJavaScriptを操る層以外にも広げる」ための重要な架け橋となるだろう。今後は、より多くの管理画面コントロールがPHPから定義可能になり、JSを書く必要性はさらに低下していくと予想される。
我々Web制作に携わる者にとって、技術の選択肢が増えることは歓迎すべきことだ。プロジェクトの予算、納期、そして保守を担当するチームのスキルセットに合わせて、ReactベースのブロックとPHP-onlyブロックを適切に使い分ける「ハイブリッドな開発スタイル」が、これからのスタンダードになると考えられる。
この記事のポイント
- React/Node.js不要: 複雑なビルド環境なしでカスタムブロックが作成可能。
- auto_registerフラグ: PHPで定義した属性から管理画面のUIを自動生成できる。
- 保守性の向上: PHPコード一箇所で定義と出力を管理でき、コードの可読性が高い。
- ショートコードの進化: 既存のショートコードを簡単に、プレビュー可能なブロックへ変換できる。
- ネイティブ機能の統合: `get_block_wrapper_attributes` でWordPress標準のスタイル設定に即座に対応可能。
出典
- Kinsta Blog「How to build PHP-only Gutenberg blocks」(2026年3月19日)
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

WooCommerce 10.6.1 リリース解説:属性同期の不具合修正と決済・配送設定の改善
WooCommerce 10.6.1が2026年3月12日にリリースされた。今回のアップデートは、特定の条件下で発生していた不具合を解消するためのメンテナンスリリース(マイナーアップデート)だ。
主な修正内容には、商品属性のバリデーション不備、決済手段の並び順、配送ラベルの表示ロジックが含まれる。これらの変更は、ショップ運営者と顧客の双方にとって、操作性の向上や混乱の回避に直結するものだ。
メンテナンスリリースは新機能の追加こそないが、サイトの安定性と信頼性を維持するために欠かせない。本記事では、修正された3つの主要なポイントと、実務への影響について詳しく解説する。
属性選択ブロックにおける同期不具合の解消

「オプション付きカート投入(Add to Cart with Options)」ブロックにおいて、特定の属性が誤って無効化される問題が修正された。この不具合は、ハイフンを含む「属性スラッグ」を持つバリエーション商品で発生していたものだ。
ハイフンとスペースの不一致が原因
不具合の根本的な原因は、PHP側で処理される属性スラッグ(例:`some-name`)と、Store APIが返すラベル(例:`some name`)の形式が一致していなかったことにある。Store APIとは、WooCommerceのデータを外部やブロックエディタから操作するための仕組みだ。
これまでは厳格な比較が行われていたため、ハイフンとスペースの違いによって「属性が存在しない」と判定され、選択肢がグレーアウトするなどの挙動が生じていた。記事によれば、今回の修正で `normalizeAttributeName()` 関数が更新され、ハイフンをスペースに置換して正規化することで、一貫性のある比較が可能になったという。
ユーザー体験への影響
バリエーション商品(サイズや色などを選べる商品)をブロックエディタで構築しているサイトにとって、この修正は重要だ。顧客が特定のオプションを選択できなくなる事態を防ぎ、カゴ落ち(カート放棄)のリスクを軽減できる。
特に「S-Size」や「Blue-Navy」といった、ハイフンを用いた属性設定を多用しているショップでは、表示が正しく行われているか再確認が必要だろう。今回の修正により、API経由での属性取得がより堅牢になったと言える。
決済ゲートウェイの表示順位の最適化

管理画面における決済手段(決済ゲートウェイ)の並び順に関するロジックが変更された。新しくインストールされた決済プラグインが、オフライン決済(銀行振込や代金引換など)よりも上位に表示されるよう調整されている。
新規導入時の視認性向上
これまでの仕様では、新しく追加した決済手段がリストの最下部に配置される傾向があった。その結果、設定画面で埋もれてしまい、チェックアウト画面でデフォルトで展開されないなどの不便が生じていた。
修正後のロジックでは、ショップ管理者が手動で並び替えを行っていない限り、新しいゲートウェイはオフライン決済グループの上に挿入される。これにより、導入したばかりの決済手段の設定漏れを防ぎ、スムーズな運用開始をサポートする。
チェックアウト画面のデフォルト表示
決済手段の並び順は、顧客が支払い方法を選ぶ際の心理的ハードルにも影響する。上位にあるものほど利用されやすいため、クレジットカード決済などの主要な手段がオフライン決済の下に隠れてしまうのは、コンバージョン率の観点から望ましくない。
今回の変更は、主に管理画面内の初期配置を改善するものだが、結果として適切な決済手段を顧客に提示しやすくなるメリットがある。管理者は、アップデート後に「設定 > 決済」タブで現在の並び順が最適かどうかを確認すべきだ。
配送パッケージ名称のロジック変更

ショートコードを利用したチェックアウト環境において、配送パッケージの名称表示が洗練された。配送先や商品の種類によって荷物が分割されない場合、ラベルの表記が最適化される仕組みだ。
「Shipment 1」から「Shipment」へ
従来、配送パッケージが1つしかない場合でも、システム上は「Shipment 1(配送 1)」と番号付きで表示されていた。これは、複数の荷物に分かれる(分割配送)可能性があるための仕様だが、単一の荷物しかない場合には顧客に違和感を与えることがあった。
WooCommerce 10.6.1では、`get_shipping_package_name()` メソッドがパッケージの総数を受け取るよう変更された。これにより、パッケージが1つだけの場合は単に「Shipment」と表示し、2つ以上ある場合にのみ「Shipment 1」「Shipment 2」と番号を振る挙動へと改善された。
フィルターフックによるカスタマイズ
この変更に関連して、一部のユーザーからは「特定の名称(例:配送手数料など)に翻訳・変更したい」という要望が出ている。これに対し、著者のBrian Coords氏は、`woocommerce_shipping_package_name` というフィルターフックを利用することで、名称を自由に上書きできると回答している。
例えば、配送パッケージの名称を「お届け便」などの独自の言葉に変えたい場合は、テーマの `functions.php` などでこのフィルターを調整すればよい。単なる表示の修正にとどまらず、開発者がカスタマイズしやすい設計が維持されている。
メンテナンスリリースの重要性と適用手順

WooCommerce 10.6.1のような「ドットリリース」は、セキュリティや致命的なバグの修正を目的としている。大規模な機能追加を伴うメジャーアップデートに比べ、既存のカスタマイズへの影響は少ない傾向にあるが、慎重な対応が求められる。
更新前のバックアップと検証
ECサイトは24時間稼働するビジネスの基盤であるため、本番環境への即時適用は避けるべきだ。まず、ステージング環境(本番と同じ設定のテスト用環境)でアップデートを実施し、以下の項目を確認することを推奨する。
- バリエーション商品のカート投入が正常に行えるか
- チェックアウト画面での決済手段の並び順に問題はないか
- 配送ラベルの表記がサイトのデザインや言語設定と乖離していないか
今後のロードマップへの備え
WooCommerceは現在、従来のショートコードベースからブロックベースのストア構築へと大きく舵を切っている。今回の属性バリデーションの修正も、ブロックエディタとの連携を強化する過程で発見されたものだ。
こうした細かな修正を積み重ねることで、次期メジャーバージョンへの移行がスムーズになる。最新のメンテナンス版を適用し続けることは、将来的なシステム刷新時のコストを抑えることにもつながるため、計画的なアップデートを検討してほしい。
この記事のポイント
- 属性同期の修正:ハイフンを含む属性スラッグが正しく正規化され、カートブロックでの選択不具合が解消された。
- 決済順序の改善:新規導入した決済プラグインが管理画面の上位に表示され、設定の視認性が向上した。
- 配送ラベルの最適化:単一パッケージ時の表示が「Shipment 1」から「Shipment」に変更され、顧客の違和感を軽減した。
- カスタマイズ性:配送名称はフィルターフックで変更可能であり、翻訳プラグインとの併用も考慮されている。
出典
- WooCommerce Developer Blog「WooCommerce 10.6.1: Dot Release」(2026年3月12日)
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

ボットトラフィックの見極め方:人間・善玉・悪玉ボットを識別しサイト運営を最適化する
Webサイトのアクセス数が増加しているにもかかわらず、コンバージョンや収益が伸び悩む現象は珍しくない。多くの場合、その原因は「人間ではないトラフィック」の混入にある。自動化されたプログラム、いわゆるボットによる通信は、現代のインターネットにおいて無視できない規模に達している。
2025年の調査レポートによれば、2024年の全Webトラフィックの51%を自動化されたシステムが占めていた。これは過去10年間で初めて、ボットによるリクエストが人間の訪問者を上回ったことを示している。未対策のままでは、アクセス解析のデータは実態とかけ離れたものになり、経営判断を誤らせるリスクがある。
本記事では、Webサイトに訪れるトラフィックを「人間」「善玉ボット」「悪玉ボット」の3つに分類し、それらを識別する方法を解説する。正確なデータに基づいたサイト運営と、インフラ資源の適正な配分を実現するための指針を提示する。
ボットトラフィックの正体と3つの分類

ボットトラフィックとは、ブラウザを操作する人間ではなく、自動化されたソフトウェアによって生成されるリクエストのことだ。これらのプログラムは、人間と同じようにWebページや画像、スクリプト、APIに対してリクエストを送信する。サーバー側から見れば、一見すると通常の訪問者と区別がつかないことも多い。
自動化がインターネットを支える側面
自動化そのものは、必ずしも有害なものではない。現在のインターネットは、Webサイトの稼働状況を監視し、データを収集し、検索エンジンにインデックスさせるための自動システムに依存している。重要なのは、その通信が「なぜ」行われているかという意図を把握することだ。ボットを一括りに排除するのではなく、その役割に応じて分類して管理する必要がある。
トラフィックの3つのカテゴリー
サイトに到達するリクエストは、実務上、以下の3つに分けられる。第一に、実際の顧客となる「人間の訪問者」。第二に、検索エンジンや監視ツールなどの「善玉ボット」。そして第三に、脆弱性を探ったりコンテンツを盗用したりする「悪玉ボット」だ。これらを正しく識別できれば、セキュリティを強化しつつ、SEOや利便性を損なわない運用が可能になる。
人間のトラフィックと「善玉ボット」の特徴

人間の訪問者と有益な自動化プログラムには、それぞれ特有の行動パターンがある。これらを理解することは、トラフィックの健全性を評価する第一歩となる。
不規則で予測困難な人間の動き
人間のアクセスは、極めて不規則だ。ページをスクロールする深さ、リンクをクリックするまでの時間、滞在の長さなどは、人によって千差万別である。同じ広告キャンペーンから流入したユーザーであっても、全く同じ順序でページを遷移することはまずない。また、使用するデバイスやブラウザ、画面サイズ、接続環境も多様であり、データにばらつきが生じるのが自然な状態だ。
サイトの成長を助ける善玉ボット
善玉ボットは、サイトの認知度向上や運営の維持に欠かせない。代表的な例は、GoogleやBingなどの検索エンジンクローラーだ。これらは新しいコンテンツを見つけ、検索結果に反映させるために巡回してくる。クローラーは通常、`robots.txt`で指定されたルールを遵守し、サーバーに過度な負荷をかけないよう制御されている。
また、サイトの死活監視(Uptime Monitor)やパフォーマンス計測ツールも、定期的にリクエストを送信する。これらは数分おきに正確な間隔でアクセスしてくるが、User Agent(ユーザーエージェント:アクセス元の識別情報)を明示していることが多いため、識別は比較的容易だ。これらのアクセスを遮断してしまうと、検索順位の低下や異常検知の遅れを招くことになる。
リスクを引き起こす「悪玉ボット」の脅威

一方で、悪玉ボットはサイトの資源を浪費させ、セキュリティリスクを増大させる。これらは正体を隠し、防御策を回避しようとする傾向がある。
不正ログインと脆弱性スキャン
最も一般的な脅威の一つが、リスト型攻撃(クレデンシャルスタッフィング)や総当たり攻撃(ブルートフォース)だ。盗まれたユーザー名とパスワードのリストを使い、ログイン画面に対して高速で試行を繰り返す。たとえログインに失敗しても、大量のリクエストによってサーバーのCPUやメモリが消費され、一般ユーザーの表示速度が低下する原因となる。
また、脆弱性スキャナーは、古いプラグインや設定ミスがないか、サイト内のディレクトリを片っ端から調査する。放置しておくと、攻撃の足がかりを与えてしまうことになる。
スクレイピングとDDoS攻撃
スクレイピングボットは、サイト上の価格情報や独自コンテンツを無断で収集し、他サイトで再利用するために動く。これにより、独自の価値が損なわれるだけでなく、帯域幅(通信容量)が無駄に消費される。さらに、特定のページにリクエストを集中させてサービスを停止させるDDoS攻撃(分散型サービス拒否攻撃)も、ボットネットを通じて行われる。これらはビジネスの継続性に直接的な打撃を与える。
トラフィックを正確に識別するための5つの指標

人間とボットを完璧に見分ける単一の指標は存在しない。複数の信号を組み合わせて評価することが、精度の高い識別につながる。元記事の著者は、以下の5つのポイントに注目すべきだと指摘している。
1. リクエストの頻度とタイミング
人間は記事を読み、考え、次の行動に移るため、リクエストの間隔が数秒から数分空くのが普通だ。対して、ボットはミリ秒単位の正確な間隔でアクセスしたり、一瞬のうちに数十ページを読み込んだりする。このような超人的なスピードや、機械的な規則性はボットの典型的な兆候だ。
2. User Agent(ユーザーエージェント)の検証
善玉ボットは自身の名前を名乗るが、悪玉ボットは一般的なChromeやSafariなどのブラウザを装う(偽装)ことが多い。しかし、ブラウザの情報を偽っていても、その背後にある挙動が不自然であれば、偽装を見破ることができる。複数のリクエストでUser Agentを頻繁に変更している場合も注意が必要だ。
3. IPレピュテーションとネットワーク属性
アクセス元のIPアドレスが、データセンターやクラウドホスティング、プロキシサーバーのものである場合、それは人間ではなく自動化されたシステムである可能性が高い。通常のユーザーは、ISP(インターネットサービスプロバイダー)経由でアクセスしてくるからだ。過去に攻撃に関与したIPアドレスのデータベース(レピュテーション)と照合することも有効だ。
4. 地理的分布の異常
本来のターゲット層ではない国や地域から、突然大量のアクセスが発生した場合、それはボットネットによる攻撃やスキャンの可能性が高い。特に、その地域の言語設定とブラウザの情報が一致しない場合は、ボットである疑いが強まる。
5. robots.txtへの対応
サイトのルートディレクトリにある`robots.txt`は、ボットに対する「立ち入り禁止区域」の指示書だ。善玉ボットはこのルールを守るが、悪玉ボットはこれを無視して禁止されたパスにアクセスする。この挙動は、ボットの「行儀の良さ」を判断する明確な基準となる。
ボットがアクセス解析と意思決定に与える影響

ボットトラフィックを排除せずに放置すると、マーケティング戦略そのものが歪められる恐れがある。数字上の「成長」に騙されないための視点が必要だ。
歪められるエンゲージメント指標
ボットはページを開いてすぐに離脱したり、逆に特定のページを何度も読み込んだりする。これにより、直帰率や平均滞在時間が異常な値を示す。特定の記事が非常に人気があるように見えても、実はスクレイピングボットが巡回していただけというケースは少なくない。これに基づいたコンテンツ制作は、実際の読者のニーズを反映しないものになってしまう。
インフラコストとリソースの浪費
Webサイトのホスティング費用は、転送量やリクエスト数、サーバー負荷に基づいて決まることが多い。トラフィックの半分以上が価値を生まないボットであれば、その分のコストは純粋な損失となる。また、ボットへの対応でサーバーが重くなれば、本来大切にすべき人間のユーザーがサイトを離れてしまい、コンバージョン機会を逃すという二重の損失を招く。
効果的なトラフィック管理のベストプラクティス

現代のWebサイト運営において、ボットを完全にゼロにすることは不可能に近い。現実的な目標は、ボットを適切に管理・制御し、人間への影響を最小限に抑えることだ。
階層的な防御策の導入
まず、CDN(コンテンツ配信ネットワーク)やWAF(Webアプリケーションファイアウォール)を導入し、サーバーに到達する前の「エッジ」段階で悪質なリクエストを遮断するのが効率的だ。これにより、サーバーの負荷を劇的に軽減できる。また、ログイン画面など特定の場所には、ボットにのみ課題を出す「セキュリティチャレンジ」を設けることも有効だ。
行動ベースの制限(レートリミット)
特定のIPアドレスから短時間に大量のリクエストがあった場合に、一時的にアクセスを制限する「レートリミット」は強力な武器になる。これは静的な拒否リストとは異なり、現在の挙動に基づいて動的に判断するため、新しい攻撃手法にも柔軟に対応できる。ただし、善玉ボットまで遮断しないよう、除外設定を丁寧に行うことが重要だ。
定期的なログ分析と方針の見直し
ボットの技術は日々進化しており、AIを使ったより人間らしい挙動を見せるものも現れている。一度設定して終わりにするのではなく、定期的にサーバーログやアクセス解析を確認し、新しいパターンのボットが紛れ込んでいないかチェックする必要がある。ホスティングサービスの管理画面で提供される分析ツールを活用し、トラフィックの内訳を常に把握しておくことが、健全なサイト運営の鍵となる。
この記事のポイント
- 現代のWebトラフィックの約半分はボットであり、人間とボットの識別は正確なデータ分析に不可欠である。
- ボットは、SEOを助ける「善玉(クローラー等)」と、攻撃や盗用を行う「悪玉」に分け、それぞれ異なる対応が必要だ。
- リクエストの間隔、IPアドレスの属性、robots.txtへの準拠状況などが、ボットを見分ける重要な指標となる。
- 未対策のボットトラフィックは、サーバーコストを増大させ、マーケティング上の意思決定を誤らせるリスクがある。
- CDNやWAFを活用した階層的な防御と、挙動ベースのレートリミット導入が、最も効果的な管理手法である。
出典
- Kinsta Blog「How to distinguish traffic from bots to identify real visits, helpful bots, and harmful attacks」(2026年3月17日)
- Imperva「2025 Bad Bot Report」(2025年発表)
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

ブランド検索が広告効果を偽る?「ブランド税」の実態とAI時代のSEO戦略
Google広告のROAS(Return On Ad Spend / 広告費用対効果)が、自社のブランド力によって不自然に底上げされている事実に気づいているだろうか。ROASとは、支払った広告費に対してどれだけの売上が得られたかを示す指標だが、この数字には「広告がなくても発生したはずの売上」が含まれているケースが少なくない。
近年のデータによれば、広告コストが3年で累積30%上昇する一方でコンバージョン率は低下しており、パフォーマンスマーケティングの効率は悪化の一途を辿っている。特に「ブランド検索」への広告出稿は、本来支払う必要のない「通行料」をプラットフォームに支払っている側面がある。
本記事では、ブランド検索が招く「ブランド税」の仕組みと、AI検索の普及がもたらす新たな戦略的転換点について解説する。広告費の増大に悩む中小企業の担当者や、今後のSEO戦略を再構築したいディレクターにとって、真の獲得コストを見極めるための視点を提供する。
広告コスト30%増の衝撃——悪化するパフォーマンスマーケティングの経済性

デジタルマーケティングの現場では、広告を運用すればするほど利益率が圧迫されるという、皮肉な状況が生まれている。Contentsquare社が990億件のセッションを分析した調査によれば、有料広告を通じたユーザー獲得の効率は、あらゆる指標で悪化しているという。
コンバージョン率の低下と直帰率の課題
調査データによると、1訪問あたりのコストは2025年だけで9.4%上昇し、過去3年間の累計では30%もの増加を記録した。一方で、コンバージョン率(CVR / 訪問者が購入や問い合わせに至る割合)は5.1%低下している。つまり、より高い料金を払って、より成約しにくいユーザーを集めている状態だ。
特に深刻なのが直帰率である。有料検索(リスティング広告)経由のユーザーの59%、SNS広告経由では65%が、最初の1ページを見ただけでサイトを離脱している。これに対し、オーガニック検索(自然検索)の直帰率は約42%に留まる。広告費の半分以上が、サイトの中身をほとんど見ないユーザーのために消費されている計算だ。
AI Overviews(AIO)がクリック単価を押し上げる仕組み
Googleが導入を進めている「AI Overviews(AIO / AIによる検索結果の要約表示)」が、この状況に拍車をかけている。AIOは検索結果の最上部にAIが生成した回答を表示する機能だが、これにより従来の検索結果(青色のリンク)が下方に押しやられ、クリックされる機会(クリック在庫)が減少している。
元記事で紹介されている成長アドバイザーのガラン・チェン氏によれば、多くのクライアントで有料検索のクリック数が20%減少した一方で、クリック単価(CPC)が20%上昇したという。GoogleはAI回答の導入によってクリック数を減らしつつも、残された広告枠の競合を高めることで、自社の収益を維持しているとの見方がある。広告主は、狭まった門戸をくぐるために、より高いコストを支払わざるを得なくなっている。
「ブランド税」の正体——なぜGoogleはあなたのブランドから利益を得るのか

多くの企業が「最も効率が良い」と信じているブランドキーワード(社名やサービス名)への広告出稿には、大きな落とし穴がある。これを元記事の著者であるケビン・インディグ氏は「ブランド税(Brand Tax)」と呼んでいる。
需要の「獲得」と「回収」を混同するリスク
ブランド検索は、厳密には「新規顧客の獲得(Acquisition)」ではなく、すでに発生している「需要の回収(Demand Capture)」である。ユーザーがあなたの会社名で検索している時点で、そのユーザーはSNSや口コミ、あるいは過去の接点によって、すでにあなたのブランドを知っている。
Dreamdata社の分析によれば、B2B企業のGoogle広告予算の約18%(推定470億ドル)がブランドキーワードに費やされている。ブランドキャンペーンのROASは1,299%という驚異的な数字を叩き出すことがあるが、非ブランド(一般ワード)のROASはわずか68%に過ぎない。この1,299%という数字が、広告全体のパフォーマンスを実態以上に良く見せているのだ。
ROASの歪みが生む投資判断の誤り
投資家や経営層は、レポートに並ぶ高いROASを見て「Google広告は素晴らしい」と判断し、さらに予算を投入する。しかし、その売上の多くは、広告を出さなくても自然検索の結果から発生していた可能性が高い。Googleは、企業が自らの努力で築き上げたブランド認知に対し、検索結果の最上部を占拠することで「通行料」を徴収しているに等しい。
サミット・チェイス社のレックス・ゲルブ氏は、ブランドキャンペーンと非ブランドキャンペーンを切り離して報告すべきだと指摘している。両者を混ぜた「ブレンデッドROAS」で判断すると、真の新規顧客獲得にかかっているコストが見えなくなり、ビジネスの成長に必要な投資判断を誤らせるからだ。
検索行動の分散——Google一極集中から41以上のプラットフォームへ

ブランド税を正当化する理由の一つに「競合他社に社名検索の枠を奪われないための防衛」がある。しかし、ユーザーの検索行動がGoogle以外に分散しつつある今、Googleだけに多額の防衛費を投じる戦略はリスクを伴う。
Amazon、YouTube、そしてAIツールへのシフト
SparkToro社とDatos社の最新調査によれば、デスクトップにおける検索の約74%は依然としてGoogleで行われているが、残りの26%は他のプラットフォームに分散している。AmazonやeBayなどのECサイトが10%、YouTubeやTikTokなどのSNSが5.5%、そしてChatGPTやClaudeなどのAIツールが3%を占めている。
特に注目すべきは、上位7サイト以外の「その他34サイト」のシェアが成長している点だ。ユーザーは、特定の目的(商品購入、動画視聴、専門的な回答の入手)に合わせて、Google以外の場所で直接検索を始めている。Googleの検索結果でブランドを守るために予算の90%を投じている企業は、ユーザーが実際に回遊している他の広大な領域を見落としている可能性がある。
ブランド防衛の限界と新たな露出機会
AIツールやSNSの検索インターフェースでは、従来の「キーワード入札による広告枠」という概念が通用しない場面も多い。Googleでのブランド防衛に固執するよりも、ユーザーが情報を探している多様なプラットフォームにおいて、いかに「指名されるブランド」として存在感を示すか、という上流の戦略が重要になっている。
AI時代のSEO戦略——高騰する広告への対抗策としてのAI SEO

広告コストの上昇と直帰率の悪化、そしてAI検索の台頭。これらの課題に対する有力な解決策として、著者のインディグ氏は「AI SEO」への投資を提唱している。
直帰率50%超の広告より「信頼」を醸成するAIプレゼンス
有料広告経由の訪問者の半分以上が直帰する一方で、AIの回答内での言及や、AIからの紹介を通じて流入するユーザーは、より明確な意図を持っており、直帰率が低くコンバージョン率が高い傾向にある。これは、ユーザーが検索行動の「上流」であるAIとの対話の中で、すでにブランドに対する信頼や理解を深めているからだ。
AI SEOとは、大規模言語モデル(LLM / ChatGPTなどのAIの基盤となる仕組み)が、特定のトピックに対して自社を「推奨すべき回答」として認識するように最適化する活動を指す。これは従来のキーワード検索順位を競うSEOとは異なり、ブランドの信頼性や情報の正確性をAIに学習させるプロセスに近い。
ROAS(費用対効果)からブランド認知への評価軸の転換
AI SEOの投資対効果(ROI)を直接的に測定するのは、従来の広告ほど容易ではない。しかし、比較すべき対象は「完璧なROI」ではなく、「悪化し続ける広告の直帰率」であるべきだ。広告費の半分をドブに捨て続けるくらいなら、AIの回答内でブランドの露出を増やし、ユーザーの信頼を勝ち取るためのコンテンツ投資に回す方が、長期的には経済的合理性がある。
最終的なテストはシンプルだ。「ブランド検索への広告支出を減らしても、全体の売上が維持されるか」を確認することである。もし維持されるのであれば、これまで支払っていたのは「ブランド税」という名の不要なコストだったということになる。
この記事のポイント
- 広告の費用対効果は悪化している:コストが30%上昇する一方でコンバージョン率は低下し、広告経由のユーザーの半分以上が直帰している。
- 「ブランド税」に注意する:自社名での検索に対する広告出稿は、本来不要なコストをGoogleに支払っている可能性があり、ROASを偽る要因になる。
- 検索はGoogle以外へ分散している:AmazonやSNS、AIツールなど、ユーザーの検索行動は多様化しており、Google一極集中の防衛策はリスクが高い。
- AI SEOへの投資価値:AIの回答内でブランドが言及されることは、高騰する広告費に頼らず、質の高いユーザーを獲得するための重要な戦略となる。
- 評価軸を見直す:ブランド検索と一般検索の数値を切り離し、真の新規顧客獲得コストを把握することが、健全な成長には不可欠だ。
出典
- Search Engine Journal「The Brand Tax: How Google Profits From Demand You Already Own」(2026年3月17日)
- Contentsquare「2026 Digital Experience Benchmark Report」(2026年2月)
- SparkToro「New Research: Search Happens Everywhere」(2026年3月)
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Cloudflareが「Custom Regions」発表。データ処理の地理的境界を自在に定義、ISMAP対応も拡充
Cloudflare(クラウドフレア)は2026年3月18日、同社の「Regional Services(リージョナル・サービス)」の大幅なアップデートを発表した。今回の更新では、特定の国や地域を自由に組み合わせてデータ処理の境界を定義できる「Custom Regions(カスタム・リージョン)」が導入された。
また、日本政府のセキュリティ評価制度である「ISMAP」への対応を含む、新しい管理リージョンの追加も行われている。これにより、企業はグローバルなDDoS防御の恩恵を受けつつ、各国の法規制やコンプライアンスに基づいた厳格なデータ局所化が可能になる。
データ主権(データ・ソブリンティ)への要求が世界的に高まる中、今回の機能拡張はインフラ構成の柔軟性を大きく向上させるものだ。記事によれば、従来の固定された地域選択から、個別のビジネスニーズに合わせた「独自の境界線」を引くフェーズへと移行したことが示唆されている。
Regional Servicesの仕組み:防御とコンプライアンスの両立

Cloudflareが提供するRegional Servicesは、グローバルネットワークの規模を活かしたセキュリティと、特定の地域内でのデータ処理という、一見相反する要素を両立させる仕組みだ。一般的なソブリンクラウド(主権クラウド)が特定の地域にインフラを隔離するのに対し、Cloudflareはネットワーク全体で攻撃を防ぎつつ、データの「中身」を扱う場所だけを限定する手法をとる。
グローバルなDDoS防御とローカル処理の共存
トラフィックの処理フローは、大きく4つの段階に分かれている。まず、ユーザーに最も近い世界各地のデータセンターでトラフィックを受け入れ、L3/L4(ネットワークおよびトランスポート層)レベルでのDDoS防御を即座に実行する。DDoS防御とは、大量の不要なデータを送りつけてサイトをダウンさせる攻撃を防ぐ仕組みであり、これを世界規模のネットワークで受けることで、攻撃を効率的に分散・無効化できる。
次に、パケットのメタデータを検査し、指定されたリージョン外のデータセンターに届いた場合は、Cloudflareのプライベートバックボーンを経由して指定リージョン内のデータセンターへと転送される。ここで重要なのは、この段階ではまだデータの復号(暗号化の解除)が行われていない点だ。
データの復号、つまりTLS(Transport Layer Security)の終端と、WAF(Web Application Firewall)によるL7(アプリケーション層)の検査、およびCloudflare Workersによるロジックの実行は、必ず指定されたリージョン内のデータセンターで行われる。これにより、機密性の高いデータの解析や処理を特定の地理的境界内に閉じ込めることが可能になる。最終的に、処理されたリクエストは再度暗号化され、オリジンサーバーへと送られる。
Custom Regionsによる柔軟なデータ制御

2020年の提供開始以来、Regional Servicesは欧州、英国、米国などの固定されたリージョンを提供してきた。しかし、各国の規制は複雑化しており、単一の国や特定の組み合わせでのデータ処理を求める声が強まっていた。これに応える形で登場したのがCustom Regionsだ。
独自の地理的境界を定義する「式」の活用
Custom Regionsでは、リストから地域を選ぶのではなく、開発者が「式(Expression)」を用いて処理場所を定義する。例えば、ISOコード(国コード)を使用して、特定の国を含める、あるいは除外するといった柔軟な設定が可能だ。記事では、以下のような定義例が示されている。
- 単一の国のみ(例:トルコのみ)
- 複数の国の組み合わせ(例:ドイツ、フランス、オランダ)
- 特定の国を除外(例:北米以外すべて)
この定義はCloudflareのインフラ全体に配布され、各データセンターが「自分はこのカスタムリージョンに含まれるか」を即座に判断する。インフラが拡張され、新しいデータセンターが稼働した場合も、条件に合致すれば自動的にリージョンに組み込まれるため、運用負荷が低いのも特徴だ。
実務における具体的な活用シナリオ
Custom Regionsの柔軟性は、法規制対応以外の場面でも威力を発揮する。著者のAndrew Berglund氏らは、早期アクセスユーザーによる活用例として、AI推論のリージョン化を挙げている。大規模言語モデル(LLM)へのプロンプトや応答を特定の国々に留めることで、パフォーマンスの最適化とデータ局所化の義務を同時に果たしているという。
また、政府機関との契約に基づいた特定の境界設定や、企業の組織構造(EMEA、APACなど)に合わせたガバナンスの適用にも利用されている。温度単位に華氏を使う国々(米国、バハマなど)といった、極めて特殊なグループ化さえも理論上は可能であり、ビジネス要件に合わせた「境界の設計」が可能になったと言える。
技術的アーキテクチャの深掘り

Custom Regionsがどのようにして最適なパフォーマンスと信頼性を維持しているのか、その裏側にはCloudflare独自のルーティング技術がある。単にデータを転送するだけでなく、リアルタイムのネットワーク品質を考慮した動的な決定が行われている。
最適なインレジョン・ルーティングの算出
リクエストがリージョン外のデータセンターに届いた際、どのリージョン内データセンターに転送すべきかの判断は、2段階のプロセスで行われる。まず、定義されたリージョンのメンバーセット(どのデータセンターが対象か)を特定する。次に、流入地点から見て最もパフォーマンスが高い転送先のリストを作成する。
このランキングは物理的な距離だけでなく、遅延(レイテンシ)、パケットロス、タイムアウトなどのネットワーク品質指標、さらには各拠点のキャパシティや負荷状況、稼働ステータスを基に算出される。この情報は「Quicksilver」と呼ばれるCloudflare独自の分散キーバリューストアを介して、エッジネットワーク全体に瞬時に共有される仕組みだ。
境界の強制とエラーハンドリング
Regional Servicesの設計思想において、レジリエンス(回復力)と境界の強制は最優先事項だ。ルーティング時には複数の候補地が考慮され、特定の拠点がダウンしている場合は、リアルタイムで次善の候補へとフェイルオーバー(切り替え)が行われる。ネットワークの監視データが不十分な場合は、新しいルーティング情報の更新を停止するなどの安全策も講じられている。
特筆すべきは「フェイル・クローズ(Fail-close)」設計だ。もし有効なリージョン内の転送先が一つも見つからない場合、リージョン外で処理を継続するのではなく、接続をエラーとして遮断する。これにより、意図しない場所でデータが復号されるリスクを物理的に排除している。
日本のISMAP対応と管理リージョンの拡大

今回のアップデートでは、Custom Regionsだけでなく、Cloudflareが定義・管理する「Managed Regions」も拡充された。新たにトルコ、アラブ首長国連邦(UAE)、オーストラリアのIRAP、そして日本のISMAPに対応したリージョンが追加され、合計で35のリージョンが利用可能となっている。
ISMAP(Information System Security Management and Assessment Program)とは、日本政府がクラウドサービスのセキュリティを評価するための制度だ。政府機関がクラウドを採用する際の基準となるものであり、民間企業にとっても信頼性の高いサービスの指標となっている。CloudflareがISMAP対応リージョンを明示したことは、日本の公共セクターや厳格なコンプライアンスを求める金融、インフラ企業にとって、導入の大きな後押しとなるだろう。
これらの管理リージョンは、Cloudflareの管理画面(ダッシュボード)やAPIから標準的な手順で有効化できる。一方で、独自の定義が必要なCustom Regionsについては、現時点ではセルフサービス形式ではなく、アカウントチームとの連携による個別設定が必要となる。将来的なセルフサービス化に向けた技術開発も継続されているとのことだ。
独自の分析:データ主権時代のインフラ戦略

Cloudflareの今回の発表は、エッジコンピューティングの役割が「高速化」から「統治(ガバナンス)」へと進化していることを象徴している。かつてのCDN(Content Delivery Network)は、いかにコンテンツを速く届けるかが主眼であったが、現代のWebインフラには「どこでデータを扱うか」という法的な正確性が求められている。
Custom Regionsが提供する「式による境界定義」は、コードによるインフラ管理(IaC)の流れを汲むものだ。地理的な境界をソフトウェア的に定義できるようになったことで、国境という物理的な制約を、アプリケーションのロジックと同じ柔軟さで扱えるようになった。これは、GDPR(欧州一般データ保護規則)などの地域特有の規制と、インターネットのボーダレスな利便性を橋渡しする重要な技術的解決策と言える。
特に日本市場においては、ISMAP対応の明文化が大きな意味を持つ。国内のレンタルサーバーやクラウドから、グローバルなエッジサービスへの移行を検討する際、最大の懸念事項であった「セキュリティ基準の適合」と「データの所在」がクリアされたからだ。今後は、グローバルなDDoS耐性を維持しつつ、日本の法域内で全ての重要処理を完結させる構成が、エンタープライズWebサイトの標準となっていくのではないだろうか。
この記事のポイント
- Cloudflareが「Custom Regions」を導入し、国単位でデータ処理の境界を自由に定義可能になった。
- 世界規模のDDoS防御を維持しつつ、TLS終端やWAF検査などのL7処理を指定地域内に限定できる。
- 日本政府のセキュリティ評価制度「ISMAP」に対応した管理リージョンが追加された。
- 独自のルーティング技術により、リージョン内での最適なパフォーマンスと、フェイル・クローズによる安全性を両立している。
- データ主権の確保とグローバルなセキュリティ対策を、一つのプラットフォームでシームレスに実現できる。
出典
- Cloudflare Blog「Introducing Custom Regions for precision data control」(2026年3月18日)
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AIショッピングエージェントの現状と未来——EC体験はどう変わるのか
AI(人工知能)が消費者に代わって最適な商品を選び、決済まで完了させる「エージェント・コマース」への期待が高まっている。しかし、現時点においてAIショッピングエージェントが完全に普及しているとは言い難い。多くの消費者は依然として自らの手で検索し、比較検討を行っているのが実情だ。
Klaviyo(クラビヨ)の製品ディレクターであるグラント・デーケン氏によれば、AIはすでに商品発見のプロセスを劇的に変え始めているという。同氏は、AIエージェントが真に「買い物を代行する」存在になるまでには、技術的・心理的な複数の壁を乗り越える必要があると指摘している。
本記事では、AIがオンライン小売にどのような変革をもたらしているのか、そしてブランド運営者はこの変化にどう備えるべきなのかを解説する。AIが単なる「検索ツール」から「自律的な代理人」へと進化する過程で、ECのあり方は根本から再定義されることになるだろう。
AIショッピングエージェントの現在地:なぜ「まだ」なのか

AIショッピングエージェントとは、ユーザーの好みや過去の購入履歴を学習し、ユーザーに代わって最適な商品を提案、あるいは購入まで行うソフトウェアのことだ。執事のように振る舞うこの技術は、理論上はすでに実現可能だが、日常的な普及には至っていない。
グラント・デーケン氏は、現在のAI利用は「商品発見(Discovery)」の段階に留まっていると分析している。消費者はChatGPTのようなAIツールを、特定のニーズに合う商品を探すための「高度な検索エンジン」として利用している。しかし、そこから一歩進んで「AIに決済を任せる」という段階には、まだ多くのハードルが存在する。
商品発見から購入代行への高い壁
現在のAI活用が「発見」に止まっている最大の理由は、実行力(Actionability)の欠如だ。AIが「これがあなたに最適な靴です」と提案することは容易だが、そのAIがユーザーのクレジットカード情報を使用し、配送先を指定し、返品ポリシーを確認した上で購入ボタンを押すには、各プラットフォーム間の深い連携が必要になる。
また、心理的な障壁も無視できない。消費者は、AIによる提案を参考にはするが、最終的な決定権を自分自身で保持したいと考える傾向がある。特に高額な商品や嗜好性の強い商品において、AIに全権を委ねるには、AIの判断精度に対する絶対的な信頼が必要だ。デーケン氏は、この信頼構築こそがエージェント・コマース実現への鍵であるとの見方を示している。
従来の検索とAIによるリサーチの違い

消費者がAIを使って商品を探すプロセスは、従来のGoogle検索などとは本質的に異なる。従来の検索は「キーワード」に基づいた断片的な情報の収集だったが、AIによるリサーチは「文脈(コンテキスト)」に基づいた対話となる。
例えば、「キャンプ 初心者 テント」と検索する場合、ユーザーは表示された複数のWebサイトを自分で巡回し、情報を統合しなければならない。一方、AIを利用する場合、「来月、北海道で初めてキャンプをするのだが、夜の寒さに耐えられる4人用の軽量テントを予算5万円以内で教えてほしい」といった具体的な相談が可能になる。
検索キーワードから「対話」へのシフト
この変化は、SEO(検索エンジン最適化)の概念を根底から覆す可能性がある。これまでは「特定の単語」をページ内に含めることが重要だったが、これからは「AIの質問にどう答えるか」というデータ構造が重要視される。AIはWeb上の膨大な情報を要約し、ユーザーに提示するため、ブランド側は自社製品の特徴をAIが理解しやすい形式で提供する必要がある。
デーケン氏によれば、AIを利用する消費者は、より具体的でパーソナライズされた回答を求めている。これは、ブランドにとって「自社の強みを正確にAIに伝える」という新たな課題を突きつけている。単なるスペックの羅列ではなく、どのような利用シーンに最適なのかという「意味的(セマンティック)な情報」が価値を持つようになる。
エージェント・コマース実現への課題

AIが自律的に買い物を完結させる「エージェント・コマース」の実現には、解決すべき3つの大きな課題がある。技術的な相互運用性、決済の安全性、そしてユーザーのプライバシー管理だ。
まず、技術的な相互運用性とは、異なるシステム同士がスムーズに情報をやり取りできる状態を指す。AIエージェントが在庫を確認し、注文を確定させるためには、ECサイト側のAPI(Application Programming Interface / ソフトウェア同士を繋ぐ窓口)がAIに対して開かれていなければならない。現在、多くのECプラットフォームはこの「AI向けインターフェース」の構築を急いでいる。
信頼の構築と決済の自動化
決済の自動化には、さらに高いセキュリティ基準が求められる。AIが不正な注文を行わないか、あるいは誤った判断で過剰な商品を購入しないかという懸念を払拭する必要がある。これには、特定の条件下でのみAIに決済権限を与える「スマートコントラクト」のような仕組みの導入が検討されている。
デーケン氏は、ブランド側が提供するデータの透明性も重要だと指摘している。AIが正しい情報に基づいて推奨を行えるよう、在庫状況や価格、配送期間などのリアルタイムデータを正確に提供することが、結果としてAIエージェントを通じた売上向上に繋がる。AIは「嘘」や「情報の遅れ」を敏感に察知し、信頼できないブランドを推奨リストから外すようになるからだ。
ブランドが今取り組むべきAI戦略

AIショッピングエージェントが主流になる未来に向けて、ブランドやEC事業者は今、何をすべきなのだろうか。デーケン氏は、技術の進化を待つのではなく、現在の消費者の行動変化に即座に対応すべきだと強調している。
具体的には、自社のデータを「AIフレンドリー」に整えることが最優先事項となる。これには、構造化データ(検索エンジンやAIが内容を理解しやすくするためのタグ付け)の最適化や、高品質な商品情報の整備が含まれる。AIはテキストだけでなく、画像や動画からも情報を抽出するため、マルチメディアデータのメタデータ管理も重要だ。
消費者のAI活用スピードに追従する
消費者は、ブランド側が用意した公式ツールよりも先に、汎用的なAI(ChatGPTやPerplexityなど)を使い始めている。ブランドは、これらの外部AIツールが自社製品をどのように紹介しているかを把握し、誤った情報が伝わっている場合は修正を試みる必要がある。これは「AEO(Answer Engine Optimization / 回答エンジン最適化)」と呼ばれる新しいマーケティング領域だ。
また、自社サイト内にもAIチャットボットや推奨エンジンを導入し、顧客がAIを通じた購買体験に慣れるための環境を提供することも有効だ。ただし、それは単なるFAQの自動化であってはならない。顧客の意図を汲み取り、人間味のある(しかし効率的な)サポートを提供することが、将来的なエージェント・コマースへの橋渡しとなる。
独自の分析:EC事業者が備えるべき「AIフレンドリー」な構造

筆者の分析によれば、AIショッピングエージェントの普及は、ECサイトのフロントエンド(見た目)よりもバックエンド(データ構造)の重要性を高めることになる。これまでのECサイトは「人間がいかに見やすく、操作しやすいか」を基準に設計されてきた。しかし、エージェント・コマース時代には「AIがいかに効率よくデータを取得できるか」が成否を分ける。
WooCommerceなどのプラットフォームを利用している事業者は、APIの最適化とデータフィードの精度向上に注力すべきだ。AIエージェントは、ブラウザを介さずに直接サーバーへ情報を照会するようになる。この際、レスポンスが遅かったり、データ形式が不統一だったりするサイトは、AIの選択肢から除外されるリスクがある。
ブランドアイデンティティの維持という課題
もう一つの懸念点は、AIが介在することでブランドの「世界観」や「物語」が消費者に届きにくくなることだ。AIは効率性を重視するため、エモーショナルな訴求を削ぎ落としてスペック比較に終始する可能性がある。これに対抗するためには、ブランド独自の価値観を「AIが理解できる言語」で定義し、データとして埋め込む技術が求められるだろう。
例えば、商品のサステナビリティ(持続可能性)や創業者の想いといった定性的な情報を、数値化・タグ化して提供することで、AIに対して「このユーザーは倫理的な消費を重視しているから、このブランドを薦めるべきだ」という判断材料を与えることができる。AI時代におけるブランディングは、視覚的なデザインから、データの意味論(セマンティクス)へと移行していくと予測される。
この記事のポイント
- AIショッピングエージェントは現在「商品発見」の段階にあり、決済まで行う「代行」への移行期にある。
- 従来のキーワード検索から、文脈を重視した「対話型リサーチ」へのシフトが加速している。
- エージェント・コマースの実現には、システム間の相互運用性と決済の安全性の確保が不可欠。
- ブランドは、AIが情報を抽出しやすい「AIフレンドリー」なデータ構造(構造化データ等)を整備すべき。
- 効率性を重視するAIに対し、ブランドの独自価値をデータとして正しく伝える「AEO」の視点が重要になる。
出典
- MarTech「The age of the AI shopping agent isn’t here… yet」(2026年3月18日)
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験