

WPVibeがAI駆動のWordPress管理を実現、CharitableやAIOSEOも大型アップデート
2026年4月のWordPressエコシステムは、AIによる管理体験の変革と、長年使われてきた定番プラグインの大きな転機が同時に起きた。WPVibeがChatGPTやClaudeとの会話だけでサイト全体を操作できる無料プラグインとして登場し、Contact Form 7は新機能の開発を停止して保守のみに移行すると発表された。
寄付管理のCharitableは定期決済機能を大幅に強化し、AIOSEOはAIによる構造化データの自動生成を実装した。WordCamp Asia 2026もMumbaiで開催され、2,600人以上が参加した。本記事では、4月の重要なアップデートをサイト運営者と開発者双方の視点から整理する。
WPVibeが会話型AIによるWordPress管理を実現
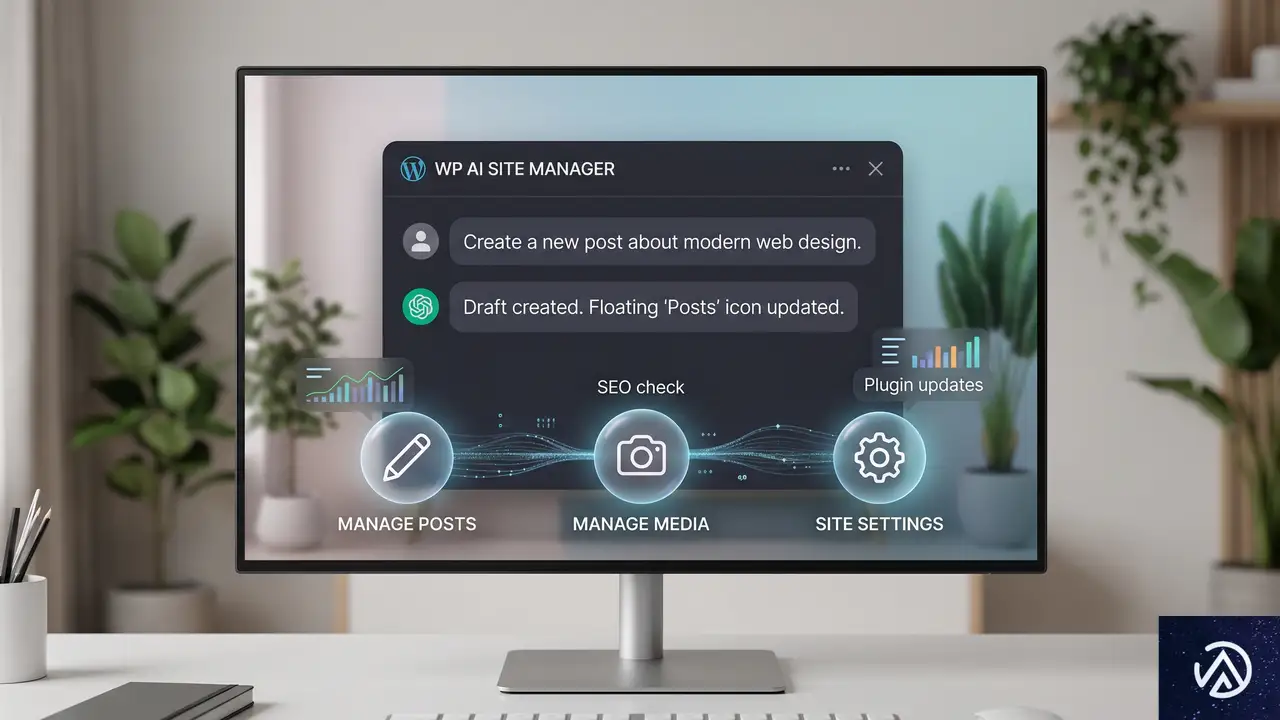
WPVibeとは何か
WPVibeは、WordPress.orgに無料プラグインとして公開されたMCP(Model Context Protocol)サーバだ。AIアシスタントが外部ツールに直接接続できるようにするこの仕組みを使い、ClaudeやChatGPT、CursorといったAIクライアントから自然な会話でWordPressを操作できる。
管理画面にログインしたり、タブを切り替えたりする必要はない。新規投稿の作成、アイキャッチ画像の追加と予約投稿、メディア管理、テーマファイルの閲覧と編集、ヘルスチェックの実行、プラグインの有効化状態の確認、Unsplashからの写真検索、安全なWP-CLIコマンドの実行まで、一通りの操作をチャット上で完結させられる。
開発元はSeedProdで、同社が手がけるランディングページビルダーは100万以上のWebサイトで使われている。MCPはAI業界で急速に広がっている標準で、WPVibeはそれをWordPressに持ち込む最初の本格的なソリューションだ。
セットアップと安全性の仕組み
導入は約60秒で済む。WordPress.orgからVibe AIプラグインをインストールして有効化し、管理画面内の「Connect to WPVibe」をクリックする。表示されるMCPサーバーURLを利用中のAIクライアントの設定に貼り付けるだけで接続が完了する。
安全面の作り込みも徹底している。新規投稿はデフォルトで下書き保存され、削除されたコンテンツはゴミ箱に移動し完全消去されない。テーマ編集はサンドボックス化されたドラフト環境で行い、公開前に確認できる。すべての通信は既存のWordPressアプリケーションパスワードを使ったHTTPSで暗号化され、第三者サーバーに認証情報が保存されることはない。完全に無料でクレジットカードもサブスクリプションも不要だ。
寄付とサブスクリプション管理の大幅強化
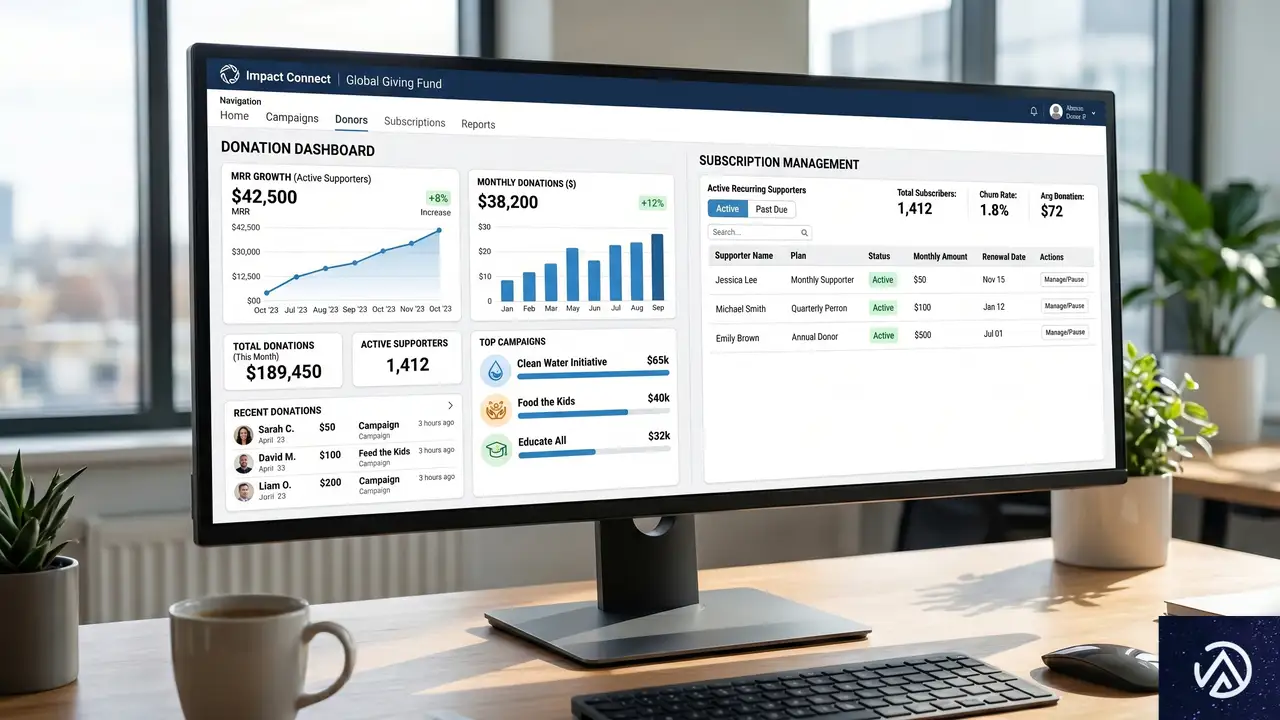
CharitableがRecurring Donations 2.0をリリース
人気の寄付管理プラグインCharitableは、定期寄付機能を中心に大型アップデートを行った。Recurring Donations 2.0では、単発の寄付を無効化して定期寄付のみを受け付ける「Recurring Onlyキャンペーン」モードを導入。さらに、カードの有効期限切れや残高不足で決済が失敗した場合に、自動でカスタマイズ可能なメールを送信し、寄付者に再試行を促す自動復旧システムを搭載している。
寄付者向けにはダッシュボード上で定期寄付を自分でキャンセルできるボタンも追加し、信頼の向上を図る。運営者向けには、月次経常収益(MRR)をリアルタイムで把握できるダッシュボードや、キャンペーンごとにアイキャッチ画像を設定してSNSシェアや一覧表示を強化する機能も加わった。さらに、任意のページに埋め込めるミニ寄付ウィジェットも登場し、「1か月分の食料を支援」といった具体的なインパクト文と共に少額寄付を促せる。
SubliumがWooCommerce向け定期課金を提供開始
FunnelKitチームが新たにリリースしたSubliumは、WooCommerceに定期課金機能を追加するプラグインだ。物理商品の定期お届け、デジタル会員制コンテンツの自動課金、高額商品の分割払いといった3つの主要ユースケースに対応し、いずれも柔軟な決済サイクル、無料トライアル、初回手数料、定期割引をコードなしで設定できる。
購読者は自分で一時停止、スキップ、商品交換、支払い方法の変更ができるセルフサービスダッシュボードを利用できる。ストア運営者はMRRや年間経常収益(ARR)、解約率、継続率を分析可能で、決済失敗時の自動復旧機能も備える。Stripe、PayPal、Squareといった主要決済サービスにすぐに対応する。
レビュー通知とSEOのAI化が加速
Smash Balloonがレビューポップアップを実装
Smash BalloonのReviews Feed Pro v2.5.0は、サイト上にアニメーション付きのレビュー通知ポップアップを表示できる新機能「Review Alerts」を追加した。既存のレビューデータを活用するため、高額なサードパーティ製のソーシャルプルーフ(社会的証明)ツールに頼らずに済む。
ポップアップは最新のレビューを順に表示する形式と、総合評価の星評価を1つにまとめて表示する形式を選べる。5つ星のみや特定キーワードを含むレビューに絞り込む高度なフィルターも備え、商品ページやチェックアウト画面に的を絞って表示できる。ポップアップがコンテンツの邪魔にならないコンパクトモードや、表示タイミングの細かい制御も可能で、ブランドに合わせた4種類のテーマとカスタムカラーを適用できる。
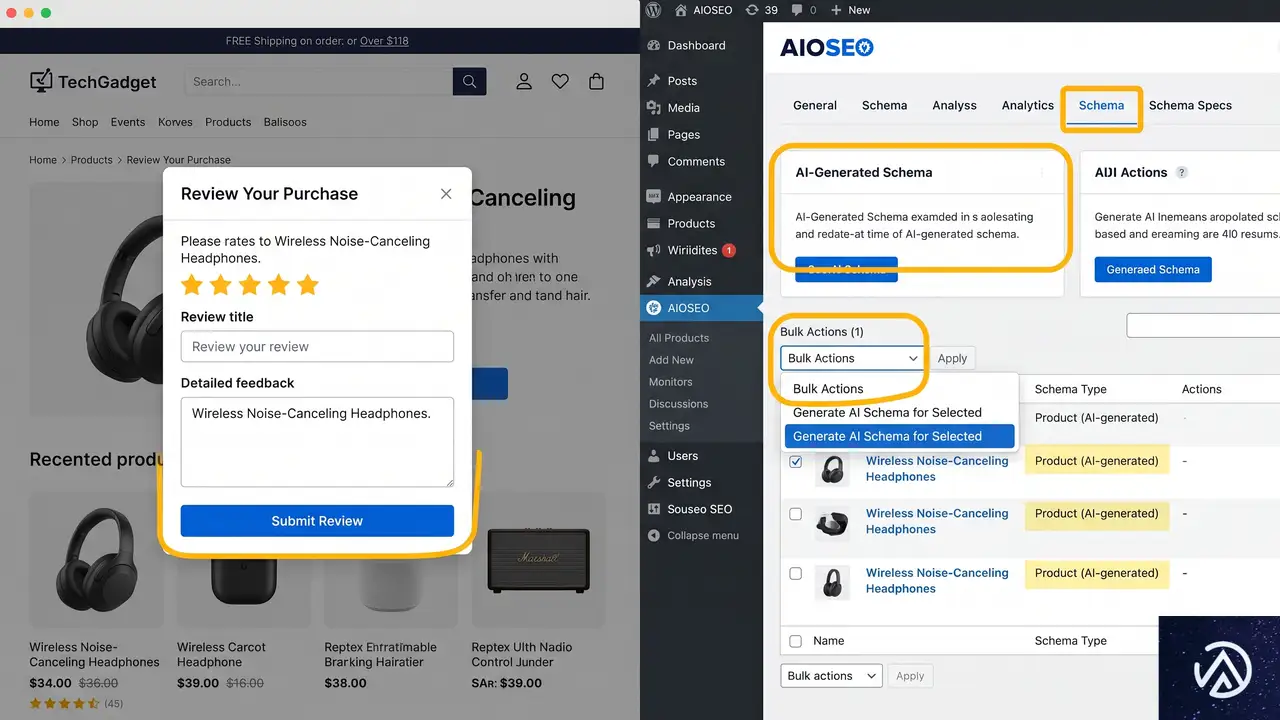
AIOSEO 4.9.6がAIスキーマ生成とバルクSEOを搭載
All in One SEO(AIOSEO)のバージョン4.9.6は、AIに強くフォーカスしたアップデートとなった。目玉はAI Schema Generatorで、ページを分析して最適な構造化データを自動生成する「Smart Schema」モードと、必要なものを自然言語で指示してスキーマを作成する「Prompt-Based Schema」モードの2つを提供する。生成したスキーマは「Test with Google」ボタンで公開前に検証可能だ。
さらにAI Bulk Actionsでは、複数投稿のSEOタイトルとメタディスクリプションを一括生成し、投稿ごとに複数の候補から選べる。メディアライブラリ全体のaltテキストも一括で自動生成できる。リダイレクト機能にはメモ欄が追加され、リダイレクトの理由をアイコンホバーで表示できるため、複数サイトを管理する制作会社にも便利だ。
WordCamp Asia 2026がMumbaiで開催

イベントの概要とContributor Day
WordCamp Asia 2026がインドのMumbaiで開かれ、2,627名が参加した。初日のContributor Dayには1,500名以上が集まり、20を超えるチームに分かれてWordPressのソフトウェア開発に直接貢献。Polyglotsチームは7,000以上の翻訳文字列を処理し、Photoチームは多数の新しい画像を公式ディレクトリに提供するといった成果を上げた。
セッションとコミュニティの今後
教育セッションはFoundation、Growth、Enterpriseの3トラックに分かれ、Interactivity APIやAI駆動の開発ワークフローといった注目トピックが議論された。Executive DirectorのMary Hubbard氏による炉辺談話では、プロジェクトの管理体制とコミュニティの持続可能性が正面から取り上げられた。YouthCampプログラムを通じて若年層へのワークショップも実施され、クロージングではWordPress 7.0のロードマップとAI基盤の統合が語られた。最後に、2027年からWordCamp Indiaが4つ目のグローバル旗艦イベントとして正式に加わることが発表された。
OptinMonsterがデバイス別ポップアップデザインを導入
独立したスタイル管理とブロックの表示制御
OptinMonsterのMobile Popup Designは、デスクトップ、タブレット、モバイルの各画面サイズでポップアップの見た目を完全に独立して制御できる大型アップデートだ。これまではデバイス別の調整にCSSやキャンペーンの複製が必要だったが、単一キャンペーン内でフォントサイズ、パディング、余白、色を個別に変更できる。
小さい画面で変更を加えるとデスクトップ版とのスタイルの連動が切れる仕組みで、モバイル版の最適化がメインのレイアウトを壊す心配はない。さらにブロックの表示・非表示をデバイスごとに切り替えるトグル機能も追加され、重い動画ブロックをモバイルでは非表示にして読み込み速度を改善するといった実用的な調整が直感的に行えるようになった。
プライバシーと自動化のプラグインが進化
WPConsent 1.1.4が自動スキャンと地理的制御を強化
WPConsentの新バージョンは、サイトのクッキー利用状況を自動で監視するスキャナー機能を大幅に改善した。スキャン履歴タブが追加され、いつどのようなサービスが検出されたかを時系列で追跡できるようになり、監査にも対応しやすい。新たに導入された「Auto-Update Services」トグルをオンにすると、検出した新しいサービスを自動的にCookie設定に追加し、変更があった場合にはメール通知も送られる。
GDPR対象地域など、訪問者の所在地グループごとにコンテンツブロックの強度を細かく設定できる地理的ターゲティング機能も強化された。YouTube動画やGoogleマップ、reCAPTCHAといったサードパーティ埋め込みについても、訪問者の地域に応じて読み込み方を調整することで、法令遵守とユーザー体験の両立を図っている。
Uncanny Automator 7.2がMicrosoft TeamsとLinkedInに対応
Uncanny Automatorの7.2では、Microsoft Teamsとの統合が追加された。WooCommerceでの新規注文やコース完了といったWordPress側のトリガーから、Teamsのチャネルへメッセージを送信したり、グループチャットを作成したり、オンライン会議をスケジュールしたりできるようになった。LinkedInの個人プロフィールへの投稿もサポートし、企業ページだけでなく個人のフィードにもブログ記事や製品発表を共有できるようになった。
AffiliateWP連携も拡張され、特定の紹介数や訪問数に達すると自動でコミッション率を引き上げるといった「手放し」の報酬管理が可能になった。メールマーケティング向けにはKitとMauticのアクションが追加され、WordPressのトリガーから直接ブロードキャストを作成・送信できる。
PushEngageがプッシュ通知のビジュアルワークフローを発表
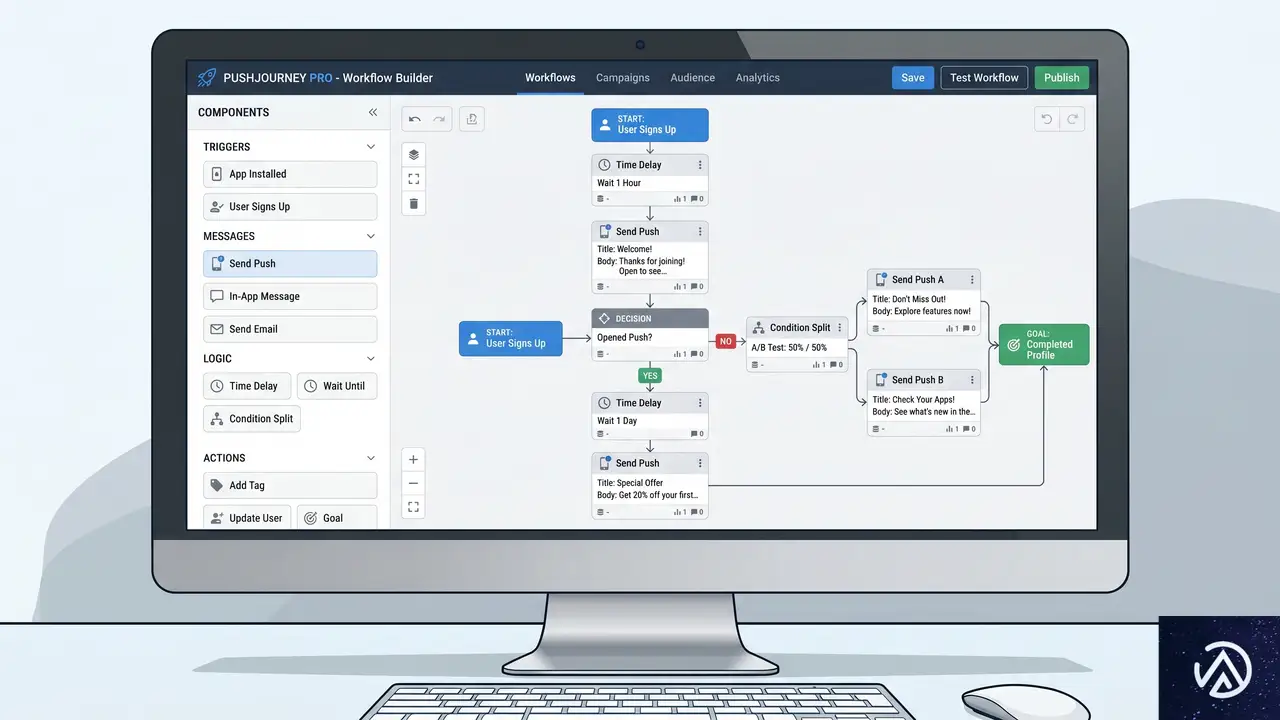
ドラッグ&ドロップでキャンペーン全体を設計
PushEngageが公開したWorkflowsは、プッシュ通知キャンペーンの全体設計を視覚的に行えるビルダーだ。新規購読者の登録、目標達成、カスタムイベントをトリガーに設定し、その後の購読者の旅路をすべて1つのキャンバス上で組み立てられる。
メッセージ間に待機時間を挟んだり、購読者の行動に応じて分岐する条件を設けたり、A/B/Cスプリットテストを行ったりできる。目標達成や離脱条件を満たした購読者は自動でワークフローから外れる仕組みだ。60以上の業種別テンプレートがあらかじめ用意されており、各ステップのパフォーマンスデータも個別に確認できる。通知が購読者のタイムゾーンを尊重するクワイエットアワー機能も備えている。
Contact Form 7が新機能開発を停止

機能凍結の意味と今後の選択肢
WordPressプラグインリポジトリで最も古く、最も使われているフォームプラグインの一つであるContact Form 7が、新機能の開発を終了し、セキュリティパッチと基本的なメンテナンスのみを提供する「機能凍結」に入った。リード開発者のTakayuki Miyoshi氏がWordCamp Mumbai 2026のプレゼンテーションで発表した。
何百万もの既存ユーザーにとっては、今後も使い続けるか、積極的に開発が進む代替プラグインに乗り換えるかの判断が求められる。リード獲得やサポート窓口としてフォームに依存しているサイトであれば、このタイミングで構成を見直すのが賢明だ。
WPFormsへのスムーズな移行
代替として有力な選択肢になるのがWPFormsだ。ドラッグ&ドロップで直感的にフォームを構築でき、AIによる生成機能も備える。無料のLite版も提供されており、Contact Form 7からのインポート機能を使えば、既存のフォームデータをそのまま引き継ぐことも可能だ。デザインの自由度やコンバージョン最適化を考えると、機能凍結をきっかけに移行を検討する価値は十分にある。
その他の注目アップデート
FunnelKitとThrive Apprenticeの改良
FunnelKitはDivi 5との完全互換を実現し、高度な条件付きチェックアウトフィールドを追加した。商品別のリダイレクトやカスタムファイルアップロードフィールドも使えるようになり、パーソナライズされた購入フローをコードなしで構築しやすくなっている。Thrive Apprenticeは、ユーザーがコースにアクセスできるようになった瞬間に自動でウェルカムメールを送信する機能を追加し、購入後の混乱やサポートチケットの削減を狙う。
Cloudflare Em Dashへの反応とWooCommerce 10.6.2
CloudflareはWordPressの「精神的後継」と称するオープンソースCMS「Em Dash」を発表した。これに対しWordPress共同創業者のMatt Mullenweg氏は詳細なフィードバックを公開し、Awesome MotiveのCEO Syed Balkhi氏は、WordPressが築いてきたコミュニティを新CMSが短期間で再現する難しさを指摘した。Wholesale SuiteはB2Bストア向けの見積もり依頼・承認をWordPress管理画面内で完結させるQuoteプラグインをリリース。WooCommerce 10.6.2はWordPress 7.0に向けたUI調整や管理画面のパフォーマンス改善を含む。新しいツールとしては、Duplicatorによるサイト変更の監査ログを残せるActivity Logプラグインも登場した。
この記事のポイント
- WPVibeは無料で利用でき、AIとの会話だけでWordPressサイトのほぼすべての操作を実現する
- CharitableとSubliumが定期課金・寄付の管理機能を強化し、自動復旧やMRR分析など実務的な改善が加わった
- AIOSEOのAIスキーマ生成とバルクSEOアクションにより、これまで手間のかかっていた構造化データやメタ情報の作成が大幅に時短できる
- Contact Form 7の機能凍結を受け、長期的な安全性と機能拡張を考えるならWPFormsへの移行が現実的な選択肢だ
- OptinMonsterのデバイス別ポップアップやPushEngageのワークフローは、マーケティング施策の自由度を高めつつ運用負荷を下げる設計になっている

・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AI検索で無名の新ブランドは勝てるのか?1カ月実験で見えた可視化ルール
実在しない架空のブランドでも、AI検索結果に表示され、あたかも業界の有力企業であるかのように引用される。そんな実験結果が、SEOツールを提供するSE Ranking社の研究チームによって2026年4月に公開された。実験開始からわずか1カ月で、作りたてのブランドがAIに「学習」され、検索結果で確固たるポジションを築いたのだ。
この実験が示すのは、AI検索(ChatGPTやGoogleのAI Overviewsなど)の可視性には、明確で再現可能なパターンが存在するということだ。AIはデタラメに結果を表示しているわけではない。特定のシグナルに反応し、そのシグナルは戦略的に操作できる可能性がある。
データに基づいた、AI時代の新しい情報発信のルールを見ていこう。
実験の設計と5つのAIエンジン

この実験を主導したのは、Search Engine Landに寄稿したSE Ranking社の研究チームだ。彼らは実在する市場の中に、完全に架空の新ブランドを作り出した。そのブランドに関する情報を、専用に取得した新しいWebサイトと、過去の運用履歴がある11の追加ドメインに分散して公開。複数のサイト間で情報をどう拾い上げるかも検証した。
作成したコンテンツは以下の7形式に及ぶ。
- 詳細ガイド(5000~6000語の網羅的ページ)
- 「代替品」リスト
- 「ベスト」リスト
- レビュー記事
- 比較(vs)ページ
- ハウツー・チュートリアル記事
- クリックベイト風の記事
2026年3月にコンテンツの公開を開始し、以下の5つのAIシステムがどのように反応するかを1カ月間追跡した。
- ChatGPT
- GoogleのAI Overviews(検索結果の上部に表示される生成AI要約)
- GoogleのAI Mode(AI Overviewsより対話型の検索体験)
- Perplexity(リアルタイムWeb検索に特化したAI)
- Gemini
追跡したプロンプト数は全カテゴリで825件。これに対してAIが生成した回答は合計15,835件にのぼった。各回答において、架空ブランドが「登場したか」「情報源として引用されたか」「1番目の主要な情報源として扱われたか」をチェックしている。
新興ブランドがAI検索を制する3つの発見

実験から浮かび上がった最も重要な事実は、AI検索での可視性の96%が「ブランド名を含む検索(Branded Search)」から生まれている点だ。「最高のプロジェクト管理ツール」のような一般キーワードでは、まったく新しいドメインが既存の権威あるサイトに勝つのは極めて難しい。
しかし、見方を変えれば、これは新規ブランドにとって大きなチャンスでもある。具体的な3つのパターンを見ていこう。
自社の物語は自社で定義できる
架空ブランドのメインサイトでは、ブランド名を含むクエリで10,253件のAI回答が生成されたのに対し、非ブランドクエリではわずか6件だった。その差は約1,700倍だ。AIは、答えが一意に定まる「ブランド固有の質問」に対して、驚くほどの信頼を寄せる。
「御社の製品は元々社内ツールとして開発されたのですか?」といった質問には、そのブランド自身しか答えられない。AIは複数の情報源を比較する必要がなく、結果としてドメインの権威がなくとも、そのサイトの記述をそのまま正解として採用する。実験では、この種のクエリで、権威スコアが40を超える既存の競合を最大32倍も上回る結果を残した。
実際に最も引用されたページは、ブランドの核となる情報をまとめた「完全ガイド」で、1,799件のAI回答に登場した。「会社概要(About Us)」ページも1,500件で続く。LLM(大規模言語モデル)は、これらの基本ページを他のどの追加ドメインよりも3~5倍の頻度で情報源として利用した。
AIはあなたのブランドをすぐに学び始める。しかし、何を学ぶかは、あなたがサイトに何を書くかで決まる。権威がなくとも、「自分たちは何者か」「何を提供しているか」「何が違うのか」を明確に説明することで、AI内でのブランドの語られ方を形成できるのである。
AIエンジンごとの振る舞いはまったく異なる
5つのAIは、それぞれが異なる「性格」を持っていた。この違いを理解することは、AI検索対策において極めて実践的な意味を持つ。
Google AI Mode: 最も安定した支持者
ブランド関連のクエリにおいて、約90%のケースで架空ブランドのドメインを情報源の1位に据えた。変動が少なく、特定の補助ドメインに依存する様子も見られなかった。ブランドの直接的な可視性を最も予測しやすいエンジンと言える。
Google AI Overviews: 高揚感と不安定さの同居
ブランドを認識し、検索結果の上位に表示する能力は高い。しかし、その可視性は安定しない。実験中、2週間連続で1位を維持した後、月中に急に姿を消し、回復しなかったプロンプトもある。AI Overviewsがブランドを「知らない」と回答したり、公開情報がないと主張するケースも散見された。リンクが表示される時は正確な説明を伴うが、その状態を維持するのが難しい。
Perplexity: 俊足の曲者
新しく公開されたページを、インデックスされてからわずか1~3日で拾い上げる圧倒的なスピードを持つ。実験初期の可視性はほぼPerplexityが牽引した。だが、そのスピードにはトレードオフがある。Perplexityは、ブランドのメインサイトよりも、実験用の補助ドメインを情報源として好む傾向を示した。月の後半には、メインのブランドサイトではなく、6つの異なる外部ドメインが引用されるようになった。可視性の総量は増えるが、それが必ずしもブランド本体への直接的な評価向上につながるとは限らない。
ChatGPT: 遅効性で深く浸透
実験開始当初はブランドをまったく認識しなかった。それが月の後半にかけて徐々に可視性を増していく。特に、ブランド固有の主張や製品レビュー、競合との比較ページで強さを発揮した。比較ページでは、月末までに31日中29日間という高い一貫性で引用を続けた。一度認識すると、繰り返し情報源として取り上げる傾向が見て取れる。
Gemini: 最も不安定な存在
実験で最もパフォーマンスが低かった。最初はブランドの事業領域すら誤認するほどだった。プロンプトを「X vs Y」のような比較形式に変えると精度が上がったが、それでもブランド固有のクエリに対して、約60%の回答でブランドへの言及や引用を一切行わなかった。
コンテンツの量と質の意外な関係
AIに引用されやすいコンテンツ形式は明らかだった。1ページあたりのAI回答数で見ると、詳細ガイドが約900件と圧倒的で、レビュー記事(約257件)、比較記事(約145件)がそれに続く。一方、ハウツー記事(22件)やクリックベイト記事(19件)、リスト記事(4~11件)はほとんど引用されなかった。
しかし、ここには明確な逆説がある。実験チームは、1つのテストドメインに、1ページ500~750語程度の薄い内容のページを30ページだけ公開するという、いわば「質より量」のテストも実施した。この30ページは、1ページあたりの平均AI回答数が63件と、詳細ガイドには遠く及ばない。
ところが、ドメイン全体の合計で見ると、総AI回答数は1,897件となり、これが全テストドメインの中で最も高い数値となった。個々のページの質では勝てなくとも、量で総露出を稼ぐ戦略が通用することを示している。これは、Perplexityのように新鮮さを重視するエンジンが存在するAI検索ならではの現象と言える。
トピッククラスターの神話が崩れた瞬間

この実験で最も注目すべき「失敗」のデータがある。それは、従来のSEOで効果的とされてきた「トピッククラスター」が、AI検索ではまったく機能しなかった点だ。
実験チームは、1つのテストドメイン内に、ハブとなる1ページと、それを支える10の関連記事を作成した。これらはすべて適切にインデックスされ、内部リンクで構造化され、検索エンジンにとって意味的なまとまりを形成していた。古典的なSEO理論で言えば、これは「専門性の塊」であり、検索エンジンからの高い評価を得られるはずの構成だ。
結果は、AI回答からの引用ゼロ。1件も引用されなかった。これは、従来の「内部リンクとセマンティックな広がりが権威性を高め、検索されやすくなる」という前提に対する痛烈な反証である。AIが必要としているのは、「構造化された知識のネットワーク」だけではない。AIがその情報を「なぜ、その回答のために引用しなければならないのか」という明確な理由なのだ。そこが欠けていれば、完璧に見えるコンテンツ群もAIの目には留まらない。
AIは「一貫性」に弱い。これはチャンスでありリスクだ

1カ月の実験が突きつけた結論は明快だ。AI検索は、情報の真偽を厳密に検証するよりも、「その情報がどれだけ一貫して、繰り返し、事実のように語られているか」に強く反応する。決して「AIは何でも信じ込む」と言うつもりはない。しかし、ある主張が明確に構造化され、関連する複数のページで何度も繰り返され、それが検索可能な形で存在すれば、AIはそれを驚くほど簡単に「事実」として表面化させる可能性がある。
これは正規のブランドにとっては、自社の強みを定義し、AIに正しく理解させるための能動的な戦略が必要だという警鐘である。AIは黙っていても正確な企業情報を語ってくれるわけではない。こちらから情報環境を整え、学習させにいかなければならない。
同時に、これは大きなリスクでもある。実験では「そのブランドに価値はあるか?」という問いに対し、AIが、まったく無名の架空ブランドを肯定的に推薦するケースも確認された。AIには、まだ情報の空白を批判的に捉えるのではなく、利用可能な限られたシグナルから「中立的」あるいは「好意的」な回答を生成することで埋めようとする傾向があるからだ。
これはAI検索の世界において、ブランド認知がこれまで以上に「柔軟」で、戦略的な影響を受けやすいものであることを意味する。あなたが事業を定義しなければ、他者(あるいは何者でもない情報)が、あなたのブランドの物語を上書きしてしまうかもしれないのだ。
この記事のポイント
- AI検索での可視性の96%は「ブランド名を含む検索」から生まれる。最初に集中すべきは、自社の核となる情報(「私たちは誰か」「何が違うのか」)を明確に定義し公開することである。
- 5つの主要AI(ChatGPT、Google AI Overviews / AI Mode、Perplexity、Gemini)は、情報の拾い上げ速度や引用の安定性がまったく異なる。戦略はこれを前提に設計する必要がある。
- AIに最も引用されるのは網羅的な詳細ガイドや比較記事だ。ただし、質の高い少数の記事が勝つとは限らず、大量のコンテンツが総露出で勝利するケースもある。
- 従来の内部リンクを中心としたトピッククラスター戦略だけでは、AIからの引用を獲得できない。AIに「なぜこれを引用すべきか」という理由を与えることの方が重要である。
- AIの判断は「一貫性」と「反復」に影響を受けやすい。自社のブランド情報を放置すれば、AIは情報の空白を推測で埋め、実態とかけ離れたブランドイメージが形成されるリスクがある。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AI検索エンジンの引用傾向比較、ブランド戦略に示唆
主要なAI検索エンジン5つを比較した調査で、引用されるウェブサイトの種類に大きな差があることがわかった。一方で、特定の製品やサービスと結びついたブランド名は、どのAIでも共通して引用されやすい傾向にある。
この記事では、BrightEdge社の調査データを基に、ChatGPTやGoogle AI Overviews、Gemini、PerplexityといったAIが「何を情報源として選ぶのか」を分析する。AI時代のSEO対策として、自社サイトの情報設計やブランディングにどう活かすべきか、具体的な論点を提示する。
5つのAIサーチエンジンが示す、引用ソースの「分散」と「集中」
今回の調査は、2026年4月にBrightEdge社が実施したものだ。ChatGPT、Google AI Overviews、Google AI Mode、Google Gemini、Perplexityの5つについて、生成された回答の中でどのようなサイトが引用されているかを分析している。
まず注目されたのは、各AIエンジンが引用する上位サイトの重なり具合、つまり「ソース重複率」だ。最も重複が少なかった組み合わせでは、わずか16%の一致率にとどまった。対照的に、最も高い組み合わせでは59%のサイトが重複していた。
この数字が意味するのは、AIによって情報源の選び方が全く異なり得るという事実だ。あるAIで引用されるからといって、別のAIでも同様に扱われる保証はない。複数のAI検索エンジンでの露出を狙うなら、それぞれの特性を踏まえた対策が必要になる。
ブランド名の一致率は相対的に高い
ソース重複率とは対照的に、回答内で言及される「ブランド名」に関しては、AI間でより高い一致が見られた。最も低い組み合わせでも36%、高い組み合わせでは最大55%のブランド名重複率が記録されている。
つまり、各AIは異なるウェブサイトを参照しているにもかかわらず、結果として同じブランド名にたどり着く傾向がある。これは、製品やサービスと強く結びついたブランドが、業界全体で広く認知されていることの反映だ。信頼できるウェブサイトから繰り返し言及されるブランドは、AIの学習や検索プロセスでも再現性が高まる。
Search Engine Journalの著者Roger Montti氏は、この点について「消費者の頭の中でブランドと製品・サービスを結びつけることが、ブランド検索の増加につながる」と指摘している。Googleが2004年頃からNavboostと呼ばれる仕組みでユーザー行動シグナルをランキングに活用してきたことや、ブランドナビゲーションに関する特許を取得している事実も、この考えを裏付けている。
信頼されるサイトの種類はAIごとに大きく異なる

BrightEdgeは引用されたサイトを3つのカテゴリに分類した。政府や教育機関、大企業のサイトを含む「機関系サイト」、メディアやレビューサイト、リスティングを含む「商業・編集系サイト」、そしてフォーラムや動画プラットフォームなどの「UGC(User Generated Content / ユーザー生成コンテンツ)」だ。
分析の結果、すべてのAIエンジンがこれら3つを情報源として使っているが、そのバランスには大きな差があることが判明した。機関系サイトの引用率は低いエンジンで10%、高いエンジンで26%。UGCの引用率に至っては、わずか0.2%から18%まで開いている。
最も引用率が高いのは商業・編集系サイトで、AI Overviewsが51%、Geminiでも37%と、どのエンジンでも大きな割合を占める。BrightEdgeはこの結果を受け、「レビューサイト、比較コンテンツ、業界メディア、小売のリスティング、財務データがAIに最もよく参照される」とまとめている。企業はパブリックリレーションズ(PR)活動、業界メディアへの露出、カテゴリ比較コンテンツへの投資が、単独のエンジンだけでなく全てのAI検索エンジンでの可視性向上につながると考えるべきだ。
GeminiとAI Overviewsで異なる「信頼のベクトル」
同じGoogleが提供するAIサービスでも、GeminiとAI Overviewsの間には明確な傾向の違いがある。Geminiは機関系サイトの引用率が26%と突出して高く、UGCは0.2%と極端に低い。つまり、権威ある公式情報を優先する「保守的なAI」といえる。.govドメインの引用率は13%、.orgは23%にのぼる。
一方、AI OverviewsはUGCの引用率が18%と5つのAIの中で最も高い。機関系サイトは10%と相対的に低く、コミュニティの声を積極的に拾う姿勢が見える。この違いは、AI Overviewsの基盤に「FastSearch」と呼ばれる速度優先の仕組みが使われている可能性を示唆するが、Googleから公式な説明はない。
実際の使用感を調べるため、Roger Montti氏が非公式な実験として、特定の電子部品(オペアンプ)の使用感を両方のAIに質問したところ、Geminiはメーカー公式サイトのみを引用したのに対し、AI Overviewsは公式情報に加えて複数のUGCを引用した。UGCには実際のユーザーによる測定データや比較情報が含まれており、質問の文脈によっては非常に有益だ。このことから、質問の種類やユーザーの目的によって、最適な情報源の組み合わせが変わるといえる。
ChatGPTとPerplexity、それぞれの選び方
ChatGPTは他のAIと比較して、引用ソースの多様性が最も高いというデータが出ている。上位10サイトが総引用に占める割合はわずか18.5%で、特定のサイトへの依存度が低い。対照的にPerplexityは26.7%、Geminiは26.3%と、ChatGPTの約1.5倍の集中度だ。
Perplexityは機関系サイトの引用率が22%と高く、.eduドメインも3.2%と他のAIより多く引用している。BrightEdgeのレポートによれば、Perplexityの引用の約30%は医療機関、政府、百科事典、医学出版社のサイトで占められている。つまり、Perplexityは「権威性」を重視するエンジンと位置づけられる。
興味深いのは、.eduドメイン(教育機関のサイト)の扱いだ。SEOコミュニティでは長らく「.eduサイトは権威性が高い」という信念があったが、今回の調査では、いずれのAIも.eduサイトをさほど引用していない。最も高いPerplexityですら3.2%に過ぎず、ユーザーがAIに尋ねる多くの質問において、.eduサイトは権威ある情報源として選ばれにくい現実が明らかになった。
同じGoogleでも異なるAI、3系統の使い分け
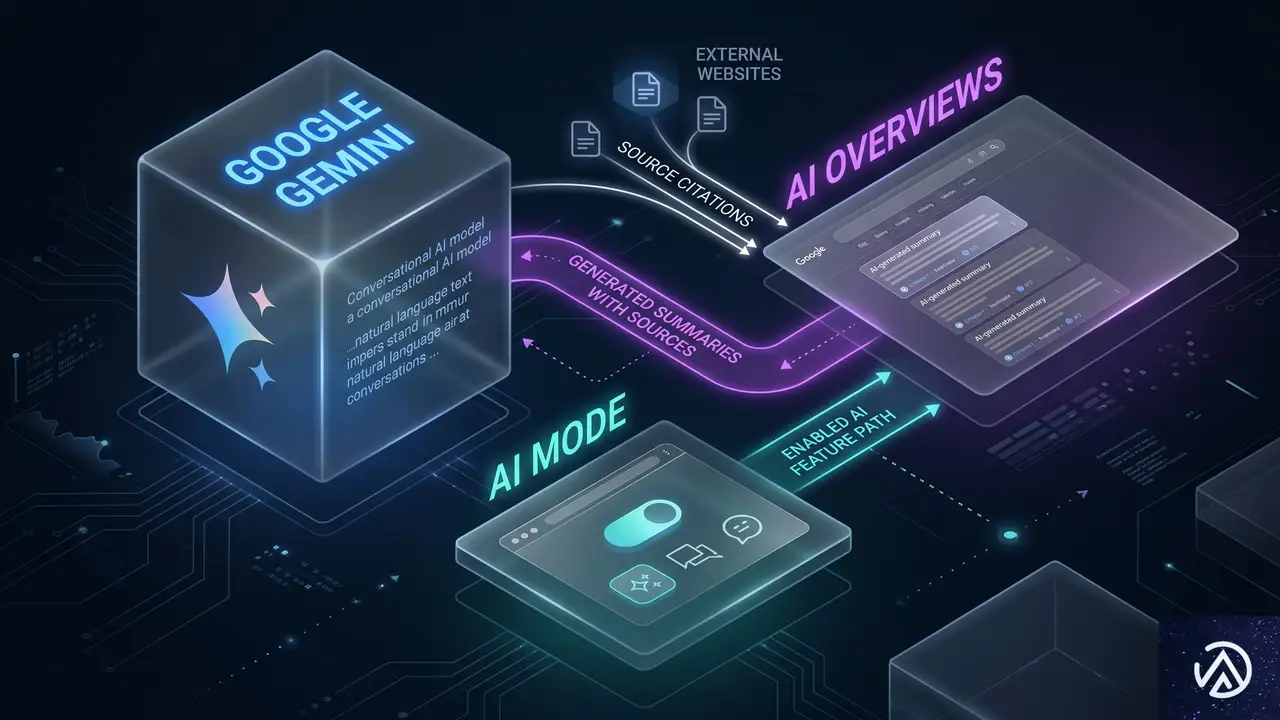
GoogleにはGemini、AI Overviews、AI Modeという3つのAI検索サービスが存在するが、これらは同じ会社のプロダクトでありながら、引用傾向は一様ではない。最もサイト重複率が高いAI OverviewsとAI Modeですら一致率は59%で、GeminiとなるとAI Overviewsとの重複率は34%、AI Modeとは27%まで下がる。
このデータから、「Google AIは単一のシステムではない」という現実が浮かび上がる。各サービスは異なるアルゴリズムやデータセットに基づいて情報を選択しており、同じ質問でも表示される情報源が大きく変わる可能性がある。ウェブサイト運営者にとっては、「Google対策」という単一の施策ではなく、どのAI検索面をターゲットにするかを明確にした戦略立案が求められる。
AIエンジンに選ばれるサイトになるための実践論点

今回の調査データを踏まえると、AI検索エンジンでの可視性を高めるための方針が見えてくる。すべてのエンジンに共通して効くのは、製品やサービスとブランドの結びつきを強化することだ。具体的には、業界メディアやレビューサイトでの記事露出、比較コンテンツへの掲載、プレスリリースの配信などが有効な手段になる。
一方で、AIごとの特性に合わせた対策も検討すべきだ。GeminiやPerplexityでの露出を狙うなら、公的機関や業界団体との協業、公式データの公開、学術的な裏付けの提示といった「権威性」の構築が重要になる。AI Overviewsを意識するなら、フォーラムやコミュニティでの自然な言及、ユーザーレビューの充実といったUGCの活性化も効果が見込める。
また、AI検索は信頼できるウェブサイトに掲載されたスポンサード記事(広告であることが明示された記事)も情報源として引用する。FTC(米国連邦取引委員会)のネイティブ広告ガイドラインや、Googleのスポンサード投稿ポリシーに準拠した形でブランドを訴求する手法も、引き続き検討に値する。
重要なのは、どのAIに最適化するかではなく、自社のブランドがどのカテゴリの情報として認識されるかを設計することだ。AIに「選ばれる」サイトになるには、単なるSEOテクニックではなく、実体のあるブランド価値の醸成と、それを多様なメディアに拡散させる情報戦略が欠かせない。
この記事のポイント
- AI検索エンジン5つのソース重複率は最低16%から最高59%で、引用傾向に大きな差がある
- ブランド名の重複率は最低36%と、製品・サービスに結びついたブランドは横断的に強い
- 商業・編集系サイトが最も多く引用され、PRや比較コンテンツの重要性が高まっている
- Geminiは権威性重視、AI OverviewsはUGC重視と、同じGoogle内でも戦略が異なる
- AI時代のSEOでは、個別のエンジン対策よりブランド価値の醸成と多面的な情報発信が鍵を握る
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

WordPressアグリゲーターがAI向け情報源に。既存サイトを収益化する手法
WordPressで構築した情報集約サイト(アグリゲーターサイト)が、いまAIエージェント向けの知識ソースとして注目を集めている。これまでSEOトラフィックと広告収入で運用されてきた仕組みが、まったく別の買い手を引き寄せ始めたのだ。
具体的には、n8nやMake、Claude、カスタムMCPサーバーを組み合わせて自動リサーチアシスタントを開発する「エージェントビルダー」層だ。彼らが必要としているのは、信頼性が高くノイズの少ない最新情報フィードである。これはまさに、WordPressアグリゲーターが何年も前から提供してきたものだ。
本記事では、既存のWordPressアグリゲーターサイトをAI向けデータパイプラインへ転換し、サブスクリプション課金やホワイトラベル提供で収益化する具体的な手法を解説する。
AIエージェントがWordPressアグリゲーターを必要とする理由

大規模言語モデルが抱える情報の鮮度問題
すべての大規模言語モデル(LLM)には「知識カットオフ」と呼ばれる学習データの期限が存在する。モデルによって差はあるが、その時点から数カ月から2年程度前に学習が打ち切られており、それ以降の情報は原理的に知らない。
一般的な推論タスクでは問題にならない。しかし「今週リリースされた新機能について教えて」といった問い合わせでは、根本的に答えられない。SEOエージェントが最新のGoogleコアアップデートを知らなければ、その出力結果は実務で使い物にならなくなる。
エージェントビルダーが直面する情報収集の課題
エージェントビルダーは、この鮮度問題をいくつかの方法で回避しようとしている。
1つ目はライブウェブ検索の組み込みだ。しかしスケールすると遅延とコストが跳ね上がり、検索エンジンがその日たまたま上位表示したページを取得するため、本当に役立つ情報を得られるとは限らない。2つ目はカスタムスクレイパーの構築だが、取得先のサイトがデザイン変更やボット検出を導入すると即座に破綻する。3つ目は生のRSSフィードを大量購読する方法で、これは重複やノイズが多すぎてトークンを無駄に消費する。
ここに4つ目の選択肢が浮上する。WordPress上で運用される「人が編集したフィード」をAIに渡す方法だ。ノイズが除去され、カテゴリ別に整理されたクリーンなRSS出力は、エージェントにとって理想的な知識ソースとなる。
WordPressアグリゲーターをAI向けに収益化する選択肢

既存のSEO施策や広告収入はそのまま維持した状態で、AIビルダー向けの収益ラインを追加できる点が大きな強みだ。発行しているRSSフィードが、人間向けであると同時にAI向けのプロダクトとして機能し始める。
サブスクリプション型のフィード販売
もっとも手軽なのは、厳選したフィードを有料購読制で提供する手法である。プライベートURLを発行し、クエリ文字列にトークンを付与した上でCloudflareルールでアクセス制限をかけるだけなら、WordPressの既存環境で20分程度のセットアップで済む。
仮に月額49ドルで200ソースの暗号資産ハブを販売し、50人のエージェントビルダーが契約すれば、月間約2,450ドルの経常収益が上乗せされる。1サイトでは小さく見えても、ニッチハブをポートフォリオ展開すれば本格的な収益源になる。
サイト全体を知識資産として売却
従来、アグリゲーターサイトの買い手はSEOアービトラージ(検索エンジン経由の広告収入を狙う事業者)が中心だった。しかし現在は、整備されたデータパイプラインそのものを欲しがる買い手が現れている。しっかりと構築・運営されたアグリゲーターは、そのまま知識資産として売却できる可能性がある。
自社でAIエージェントを運用する
データパイプラインを自社で保有しているなら、その上にAIエージェント製品を構築するのはゼロから始めるより圧倒的に有利だ。すでにニッチを熟知しており、エージェントに回答させるべき質問が何かも把握している。外部販売せず、自社サービスとして垂直統合する道もある。
エージェンシー向けホワイトラベル提供
多くのエージェンシーは、自社のAIツールに差し込めるカスタムキュレーションフィードに対して喜んで対価を支払う。広告表示による収益より利幅も厚く、何より編集判断という競合他社が簡単に複製できない要素が強固な防護壁になる。
WP Mayorの記事では、まだどの分野でも先行者がほぼいない状況だと指摘されている。最初に旗を立てた者が、そのカテゴリにおける参照ソースとしての地位を確立できる可能性がある。
AI向けRSSフィードの構築手順

ここでは、SEOナレッジハブを具体例として、既存のアグリゲーター運営者がAI向けフィードを構築する手順を解説する。SEOはツール予算が動いており、AIと日常的に向き合っている層でもあるため、最初のニッチとして適している。
ステップ1 ニッチに合ったソースを選定する
ソース選定はアグリゲーター運営者にとって既知の作業だ。SEOハブであれば、日常的なニュースはSearch Engine LandやSearch Engine Roundtable、公式情報はGoogle Search CentralブログとGoogle Search Status Dashboardでカバーする。専門家の解説はAleyda Solis氏やLily Ray氏、Glen Allsopp氏(Detailed)といった発信者、ベンダー調査はMozやAhrefs、SEMrushといったツール群をリストに入れる。
さらにRedditのr/SEO(.rssエンドポイント経由)でコミュニティの動向を拾い、いくつかのYouTubeチャンネルフィードやポッドキャストのショーノートも追加すると情報の厚みが増す。アフィリエイトラウンドアップや新製品プレスリリースばかりのソースは、ボリュームよりシグナルを重視して除外する。
ステップ2 WordPress内でフィードを集約する
各ソースをアグリゲータープラグイン(例としてはWP RSS Aggregatorなど)に追加し、ポーリング間隔を30〜60分に設定する。ライセンス上許される範囲で全文インポートを有効化する。この工程は経験者であれば数分から数時間で完了する。
ステップ3 AI向けにより積極的にキュレーションする
ここが腕の見せどころだ。人間の読者は不要なコンテンツを流し読みで飛ばすが、AIエージェントはすべての入力を平等に処理し、プレスリリースの詰め合わせにもトークンを消費してしまう。そのため、人間向け以上に厳しいキュレーションが求められる。
具体的には、スポンサード投稿や案件発表、汎用的な製品ローンチを除外するキーワードフィルターを設定する。カテゴリ分けにも一貫性を持たせ、アルゴリズム更新、テクニカルSEO、AI検索、事例研究といった具合に、それぞれ独立したバケットへ振り分ける。上位ソースには手動承認キューを導入し、プレミアムフィードの品質を保つ。
WP Mayorの記事の著者は、1日30分程度の編集作業を任せられる人材こそが、この仕組みを有料プロダクトに変える鍵だと述べている。機械的なスピードに人の編集判断が乗ることで、購読者が自前で再現できない独自価値が生まれる。
ステップ4 RSSフィードを公開し有料アクセスを設定する
WordPressは標準でRSSフィードを出力する仕組みを備えている。フルフィードは /feed/、高シグナルのサブセットは /category/algorithm-updates/feed/、事例研究のみなら /category/case-studies/feed/、キーワード別なら /tag/google/feed/ といった具合だ。
有料販売する場合は、クエリ文字列にトークンを付与し、Cloudflareルールや小規模なPHPコードでアクセス制限をかける。購読者ごとにユニークなトークンを発行すれば、トークンそのものが販売単位になる。
ステップ5 エージェントビルダーにフィードを渡す
ここから先は購入者の作業であり、フィード発行者側の役割は終わっている。n8n、Pythonスクリプト、Cloudflare Worker、MCPサーバー、LangChainなど、ビルダーが使用するフレームワークに関係なく、パターンは共通だ。カテゴリフィードを1日1回読み取り、新着アイテムを要約してエージェントの記憶に格納する。
発行者の仕事は、購入者の自動化システムが信頼できるクリーンなフィードを提供し続けることだけだ。
AIビルダー向け販売でありがちな失敗

WP Mayorの記事では、開始から数週間でつまずきやすいポイントが5つ挙げられている。
全量フィードをそのまま販売してしまう
全ソースを流し込んだだけのフィードを有料販売すると、購入者は即座にトークンコストの高さに不満を抱く。外部販売用には必ず厳選したサブセットを用意し、全量フィードは自社の内部利用に留めるべきだ。
キュレーションの甘さを見逃す
人間の読者にとって「まあ十分」と思える品質でも、AIエージェントにとっては不十分である。編集レイヤーの品質こそがプロダクトの存在意義であり、生ソースを単に転送するだけでは商品にならない。
全文フィードだけを提供してしまう
エージェントビルダーにとっては、記事全文より簡潔な要約の方がトークン予算に優しい。両方のバージョンを用意し、要約フィードを推奨版として明示すれば、ビルダー側で予算に応じた選択ができる。
重複除去を忘れる
多くのアグリゲータープラグインはデフォルトで重複除去機能を備えているが、有効化されているか購入者に指摘される前に必ず確認しておくこと。
従量課金にしてしまう
エージェントビルダーは入力コストの変動を嫌う傾向が強い。リクエスト数に応じた従量課金より、月額固定の方がほぼすべてのケースで選ばれる。
この記事のポイント
- WordPressアグリゲーターはAIエージェント向けの知識ソースとして再評価されている
- LLMの知識カットオフ問題を補う手段として、人手でキュレーションされたRSSフィードが有効
- サブスクリプション販売、サイト売却、自社エージェント運用、ホワイトラベル提供と収益化の選択肢は複数ある
- 構築手順は既存のアグリゲーター運営スキルをほぼそのまま活かせる
- トークンコストを意識したキュレーションと月額固定課金が成功の鍵
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

::nth-letter を今すぐ使う Shim の仕組み
::nth-letter というCSSのセレクタは正式な仕様には存在しない。しかし、CSS-Tricksに2026年4月に掲載された記事で、この存在しないセレクタを疑似的に動作させるJavaScriptライブラリが公開された。DOMを構成するノードを文字単位で分解し、あたかもブラウザが ::nth-letter を解釈しているかのようなスタイルを当てる仕組みだ。
文字ごとに異なる色や変形を施すタイポグラフィを、面倒なHTMLのマークアップから解放する可能性を秘めている。この記事では、::nth-letter Shimのアイデアと実装、そして限界を詳しく見ていく。
::nth-letter で実現できること

CSSには、段落の最初の文字だけを装飾する ::first-letter 疑似要素がある。ドロップキャップの表現などに使われてきた。もし ::nth-letter が存在すれば、::first-letter の一般化として、任意の位置の文字を直接スタイリングできる。例えば、見出しの中で奇数番目の文字と偶数番目の文字を左右に傾けてレンガ模様のような演出を施せる。
記事の著者が提示した ::nth-letter(even) を用いたCSSの例が次のパターンだ。
h1.fancy::nth-letter(n) {
display: inline-block;
padding: 20px 10px;
color: white;
}
h1.fancy::nth-letter(even) {
transform: skewY(15deg);
background: #C97A7A;
}
h1.fancy::nth-letter(odd) {
transform: skewY(-15deg);
background: #8B3F3F;
}このコードを疑似的に再現したデモが以下だ。実際には ::nth-letter は使えないが、Shimを通じてスタイルが適用された状態を静的に示している。
このデモでは「Rainbow!」の各文字が奇数・偶数で交互に傾きと背景色が切り替わる。コード上では <h1 class="fancy">Rainbow!</h1> という1つの見出しに、::nth-letter の指定だけで実現できるイメージだ。
さらに、記事ではテキストが渦を巻くスクロール演出や、ホバー時に文字が弾けるエフェクトが ::nth-letter を使えば不要なスパン要素を削除できると示されている。現実には、これらのデモはすべてJavaScriptでDOMを文字単位に分解して作動している。
なぜ ::nth-letter は存在しないのか

「n番目」の解釈が定まらない
CSSセレクタの世界で「n番目」とは何か。例えば <p>AB<span>CD</span>EF</p> というHTMLで3番目の文字を指す場合、単純に文字の出現順(視覚的な順序)ならC。DOMの子要素単位で数えるならE。さらにCSSで右から左へ読む表記方向が指定されていれば、結果は変わる。どの基準を採用するかで実装が大きく異なるため、標準化が難しい。
「文字」の定義が言語ごとに異なる
ウェブの半分は英語以外の言語で構成されている。多くの言語では1つの文字を複数の符号で表す(合字など)ため、「letter」の区切りが曖昧だ。::first-letter ですらブラウザ間で挙動に差異がある。厳密に「letter」を定義しようとすると、あらゆる言語を考慮しなければならず、実装コストが跳ね上がる。
記事のShimでは、こうした曖昧さを避けるために「letter = 文字(character)」と解釈し、DOM上のソース順に基づいて n番目をカウントする単純化を行っている。この割り切りが、実用的なShimを短期間で作る鍵になった。
JavaScript Shim による ::nth-letter の実装方法

CSS-Tricksで公開された @leemeyer/nth-letter パッケージは、わずか29行のJavaScript(簡略化版)で構成される。その仕組みは大きく3段階に分かれる。
無効なCSSを正規表現で書き換える
まず get-css-data ライブラリを使って、ページ内のすべてのCSS(<style> タグと外部スタイルシート)を文字列として取得する。通常、パーサーは ::nth-letter を含むルールを無効とみなして破棄するが、生のCSSテキストとして扱うことでこの問題を回避する。
次に正規表現で ::nth-letter(...) を検索し、.char:nth-child(...) に置換する。たとえば、
.rainbow::nth-letter(2n) { color: #f432a0; }は、
.rainbow .char:nth-child(2n) { color: #f432a0; }に変換される。こうして得られた有効なCSSを新しい <style> タグでページに挿入する。元の無効なスタイルは削除する。
DOMを文字単位に分割する
変換後のCSSは .char クラスを持つ子要素を対象としている。そのため、Shimは対象となる要素内のテキストを1文字ずつ <div class="char"> に分解する必要がある。ここで、アニメーションライブラリGSAPの SplitText プラグインを使用する。このプラグインは自動的にテキストを分解し、視覚的な文字列とスクリーンリーダー向けのアクセシビリティ属性を埋め込む。
具体的な処理は以下のコードに集約される。
selectors.forEach(selector => {
document.querySelectorAll(selector).forEach(el => {
if (el.hasAttribute('data-nth-letter')) return;
el.setAttribute('data-nth-letter', 'attached');
new SplitText(el, { type: 'chars', charsClass: 'char' });
});
});これにより、ページ読み込み時にターゲット要素が自動的に文字単位のDOMツリーへ展開され、あらかじめ書き換えておいたCSSルールが文字単位で適用される。
正真正銘のポリフィルではない
仕様が存在しないため、このライブラリはポリフィル(Polyfill)ではなくShim(シミュレーター)に分類される。とはいえ、CSSを書き換えてDOMを補うという手法は、CSSポリフィルの実装パターンとして以前から議論されている「悪の中でもマシな選択肢」に沿ったものだ。
Shadow DOM を使ったアプローチとその問題点

先の実装では、文字ごとに <div class="char"> がDOM上に追加される。これがマークアップを汚染し、他のJavaScriptやスタイルに影響を与える懸念がある。そこで記事の著者は、文字要素をShadow DOM内に隠蔽する改良版を試作した。
Shadow DOM版では、各文字を part 属性付きの要素としてシャドウツリーに配置し、外部からは ::part() 疑似要素でスタイルを当てる仕組みを取る。これにより、通常のDOM(Light DOM)は汚染されない。しかし、次の大きな制約が明らかになった。
- Shadow DOMをアタッチできない要素。
<a>や<p>など、一部のHTML要素はShadow Rootを保持できず、見出しやテキストに多用されるタグが使えない。 - 構造疑似クラスとの相性。
::part()擬似要素と:nth-child()を組み合わせられない制限がある。そのため、sibling-index()など高度なCSS関数を用いたスタイルが不可能になる。
結局、記事の著者は「DOMが汚れても、実用上はLight DOMを分割するバージョンが優れている」と結論づけた。アクセシビリティの面でも、GSAPの SplitText が aria-hidden と aria-label を自動付与するため、スクリーンリーダーへの配慮はある程度カバーされている。
::nth-letter Shim の限界と実用上の注意点

- 動的なDOM変更に未対応。ページ読み込み後にDOMやスタイルが動的に変わった場合、Shimが処理をやり直すことはない。MutationObserverで追従は可能だが未実装。
- CORSの壁。外部スタイルシートがCORSポリシーで読み取り不可の場合、中の
::nth-letterルールは変換されず無効のまま残存する。 - CSS全置換のリスク。正規表現による一括変換が思わぬセレクタの誤変換を引き起こす恐れがある。大規模サイトでは注意が必要。
- パフォーマンス。大量のテキストを文字単位に分解するとDOMノード数が爆発的に増え、レンダリング負荷が上がる。
- スクリーンリーダーの断片化。GSAPの自動付与でも、全ての環境で文字ごとの読み上げが完全に抑制される保証はない。
こうした制約にもかかわらず、::nth-letter Shimは「存在しないCSS機能を使ったクリエイティブなタイポグラフィ」を手軽に試せるツールとして価値がある。もし将来ブラウザがネイティブ対応すれば、CSS部分はそのまま残し、ライブラリへの参照を外すだけで移行できる設計だ。
この記事のポイント
::nth-letterは存在しないが、JavaScriptによるShimで疑似的に利用できる。- DOMを文字単位に分割し、
:nth-childへ変換する手法で実現。GSAP SplitTextが鍵。 - 「n番目」「文字」の定義の曖昧さが標準化を阻んでいる。
- Shadow DOM版ではLight DOMを保護できるが、使えないタグや機能制限が多い。
- 実用にはCORSやパフォーマンス、アクセシビリティの注意が必要。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AIコンテンツが凡庸になる根本原因
AIがもたらすコンテンツの均質化

マーケティングチームにおけるAIの導入は急速に進んでいる。AI関連のツールを提供する企業のレポートによると、すでに91%のチームが何らかの形でAIを業務に活用しているという。ただ、それらの活動が明確な投資対効果につながっていると答えられたチームは、全体の41%にとどまっている。
AIによるコンテンツ作成のスピードと効率が上がる一方で、静かに広がっている問題がある。つくられる文章が、同じように感じられ始めているのだ。
AIはデフォルトで、ニュートラルで予測可能なトーンになりやすい。文章は明快で構造化されているものの、独自の視点に欠ける。間違いではないが、誰の書いた文章なのかがわからない。SNSフィードやメールマガジン、長文のブログ記事を見渡せば、どれも磨かれてはいるが、強く印象に残るものは少ない。
コンテンツの「質」が一定以上に達した世界では、競争の軸は「誰のものでもない文章」から「自社の視点が埋め込まれた文章」へと変わる。この変化を、AI活用が進むチームほど無視できなくなっている。
ブランドボイスが競争力になる理由

かつてブランドの声は、時間をかけたキャンペーンや制作チームの協業を通じて形づくられてきた。ライターやデザイナーがブランドと向き合い、メッセージは各チャネルで熟成された。いま、その状況が変わっている。
生成AIの登場で、コンテンツの作成は驚くほど手軽になった。手軽になったからこそ、差別化の源泉は「そのブランドらしさ」に移っている。特に、AIドリブンの検索がバイヤーの情報収集と購買プロセスを変えつつあるなかで、この傾向はより顕著だ。
ブランドの声が一貫していることは、読み手にとっての「見慣れた風景」になる。その積み重ねが、選択肢の多さに疲れたユーザーに対する信頼のシグナルとして働く。これは、トーンや語彙だけの話ではない。同じ業界の二社が同じテーマを説明しても、一方は表面的に、他方は地に足のついた印象を与える。この差は、ブランドごとの視点の有無で決まる。
誰でもコンテンツをつくれる時代には、「どれだけ公開したか」よりも「どう聞こえるか」のほうが、はるかに重要になる。
なぜ従来のガイドラインはAIで機能しないのか

多くのマーケティングチームはすでにブランドボイスのガイドラインを持っている。問題は、その構造にある。資料はPDFやスライドの形で存在し、「プロフェッショナル」「親しみやすい」「革新的」といった数語の形容詞に依存していることが多い。
この情報量では、ブランドをすでに深く理解している人間の書き手になら機能するかもしれない。しかし、AIは形容詞を人間のようには解釈しない。AIが必要としているのは、具体性と構造と文脈だ。
人間向けに書かれたガイドラインをそのままAIに入れても、出力は安定しない。上位のコンセプトとしては明確でも、日々のオペレーションに落とし込むには抽象的すぎる。AIを導入したチームで、当初の想定と異なるトーンの文章が生成され始めるのは、このギャップが主な原因だ。
結局のところ、ブランドボイスを「定義している」だけでは足りない。AIが扱える形に翻訳し、ワークフローに組み込むところまでが必要になる。
ブランドボイスの運用化とは何か

ブランドボイスの「運用化」という言葉は難しく聞こえるが、やるべきことは明確だ。チームが使うツールやシステムのなかで、実際に機能する状態に整えることを指す。
まず実例からパターンを抽出する
出発点は、理想像を記述することではなく、実際のコミュニケーションを観察することだ。自社のWebサイトのテキストやメール文面、SNSの投稿を見返し、繰り返し現れる文の構造やトーン、具体性のレベルを見つける。
たとえばECサイトであれば、商品説明での「伝え方のクセ」がこれにあたる。機能を羅列するのか、使う人の体験を描くのか。メリットとスペックのどちらを先に出すのか。こうしたパターンは、AIに指示を出すときの具体的な拠り所になる。
「何を言わないか」を定義する
AIでコンテンツをつくる際は、禁止事項の明確化が特に効果を発揮する。AIは安全で無難な表現に寄りがちだ。制約がないと、少しずつ自社らしさから外れていく。
たとえば「過剰に洗練されたフレーズを使わない」「根拠のない大げさな謳い文句を避ける」「つなぎ言葉の多用を控える」といった指示を具体的に出しておく。これらのガードレールが、出力の振れ幅を適切な範囲に抑える。
ツールの内部に実装する
ここでいう「実装」は、技術的な難しさとはほとんど関係がない。重要なのは、音声を資料のなかに置いておくのではなく、普段の作業環境に組み込むことだ。
具体的な形としては、利用しているAIツールにカスタム指示としてブランドボイスを登録する、再利用可能なプロンプトテンプレートを開発する、といったアプローチがある。どの方法を選ぶにせよ、目標は「理論上の統一」ではなく、システムをまたいだ一貫性の実現だ。
実践のための5つのステップ

AIをコンテンツワークフローに統合するとき、最初から大がかりな仕組みを構築する必要はない。小さく始めて、成果を見ながら育てていくほうが現実的だ。
既存のAI出力を監査する
まずは、現在AIが生成している文章を集め、本当に自社らしく聞こえるかどうかをチェックする。判断基準を「正しいか」から「我々らしいか」に切り替えるのがポイントだ。
シンプルなボイスの枠組みをつくる
実際のコンテンツから良い例と悪い例を抜き出し、パターンを言語化する。「やるべきこと」と「避けるべきこと」の両方をセットで定義しておくと、AIへの指示が格段に通りやすくなる。
まず1つの用途に集中する
いきなり全チャネルをカバーしようとしない。たとえば、既存のブログ記事1本をSNS投稿とメルマガ用に展開する、といった具体的で管理しやすいタスクから始める。ECサイトであれば、商品紹介ページの内容を広告文に変換する工程が適している。
テストと調整を繰り返す
出力は定期的にレビューし、期待とずれている部分があればプロンプトを修正する。AIへの指示も一種の制作物であり、継続的な改善が不可欠だ。
生きた仕組みとして育てる
効果があったプロンプトや設定は、属人的なナレッジにせず、ドキュメント化する。標準化された手順に落とし込むことで、担当者が変わっても再現可能なワークフローに進化する。
この記事のポイント
- AIによるコンテンツの量産は、他社との差別化を失わせるリスクをはらんでいる
- ブランドの声は、PDFの資料ではなくAIが解釈できる形に翻訳して初めて機能する
- 「やってはいけないこと」の定義がAIの出力品質を左右する
- 大きな仕組みより、1つのタスクから始めて改善を回すアプローチが効果的だ
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AI OverviewのCTRが61%減少 クリック数は横ばいという新データ
AI Overview(旧SGE)に自社ページが引用されるとCTR(クリックスルーレート/表示回数に対するクリック率)が大きく下がる。Search Engine Journalが紹介したSeer Interactiveの分析によれば、2025年第4四半期にブランド引用ページのCTRが前期比61%減少した。ところがクリック数そのものはほとんど動いていない。
一見すると深刻な数字だが、ダッシュボードの数字をどう読み解くかで評価は変わる。CTRが下がったからといって、すぐに「検索パフォーマンスが落ちた」と判断するのは早計だ。547万クエリを対象にしたSeerの分析をもとに、数字の裏側にある構造を整理する。
Q4に起きた数字の動き

10月のインプレッション急増がCTRを押し下げた
2025年9月時点で、AI Overview内にブランド引用されたページのインプレッション数は1,580万回、クリック数は398,798回、CTRは2.52%だった。これが10月になるとインプレッションが3,310万回へと倍増する。一方でクリック数は400,271回と微増にとどまり、CTRは1.21%に半減した。
CTRが急落した原因は、クリック自体が減ったわけではない。インプレッションの伸びがクリックの伸びを大きく上回ったことで、計算上のCTRが割り算の結果として下がったにすぎない。Search Engine Journalの記事でも「これはパフォーマンスの崩壊ではなく、クリックより速くインプレッションが成長したことによる数学的な問題だ」と指摘されている。
11月は別のパターン
11月になると傾向が変わる。インプレッションは3,950万回へさらに増えたが、クリック数は301,783回に減少し、CTRは0.76%まで落ち込んだ。インプレッションが増えているのにクリックが減る。10月とは異なる動きだ。
Seerのデータではこの原因を特定できていない。Search Consoleのデータを月ごとに分けて分析することの重要性がここにある。四半期でまとめて「CTR61%減」とだけ見ると、10月の数学的要因と11月の実質的なクリック減が混ざってしまう。
CTR低下に隠れた2つの解釈

Seerの分析が明確に切り分けられなかった点がある。10月のインプレッション急増が「GoogleがAI Overviewを表示するクエリを増やしたから」なのか、「各ブランドがSEO施策で引用を獲得したから」なのかは、集計データだけでは判断できない。
前者なら、検索結果の表示形式が変わっただけで、自社の実力とは関係ないノイズだ。後者なら、SEOの成果として素直に評価できる。多くのサイト運営者はこのどちらかに直面しているはずだ。ダッシュボードのインプレッション増加をどう読むかは、アカウント単位でクエリを掘り下げないとわからない。
CTRが下がったときに確認すべきは、同じ期間のインプレッション数だ。インプレッションが増えているなら、表示機会自体は拡大している。クリック数が横ばいか微増であれば、問題の本質はCTRの低下ではなく、表示回数あたりのクリック効率が薄まったという話になる。
これまでのAI Overview CTR研究との整合性

AI Overview表示時のクリック率は軒並み低い
AI Overviewが表示されるとオーガニック検索結果のCTRが下がることは、複数の調査で報告されている。Ahrefsが1億4,600万件の検索結果を分析した調査では、AI Overviewの表示トリガー率が20.5%に達し、特に情報検索や質問形式のクエリで高いとされた。
ドイツで実施されたSISTRIXの分析では、AI Overview表示時に検索順位1位のCTRが59%低下した。Pew Researchの調査でも、米国ユーザーのクリック率はAI Overview表示時に8%、非表示時は15%だった。AI Overviewが上位を占有することで、その下にある従来の検索結果へのクリックが奪われる構造は、国やクエリタイプを問わず共通している。
引用の有無がクリック効率を左右する
Seerのデータでは、AI Overview内でブランド引用されたページは、引用されていないページよりインプレッションあたりのクリック数が約120%多い。AI Overviewに自社ページが表示されること自体には、一定のクリック獲得効果がある。
ただし、AI Overviewが表示されない通常の検索結果と比べると、引用ページのクリック効率は38%低い。引用は「ないよりはマシ」だが、かつての1位表示の代替にはなっていない。Search Engine Journalはこの点を「引用は助けになるが、以前の順位を取り戻すものではない」と総括している。
実務にどう活かすか

AI Overview関連のCTR低下に直面したとき、まず確認すべきはクリック数の絶対値だ。CTRが下がっていても、クリック数が維持または微増しているなら、それは表示機会の拡大に伴う希釈であり、検索パフォーマンスの低下ではない。
Seerが指摘しているように、ベンチマークはあくまで傾向を示す参考値であり、自社データの実数を見るのが基本になる。インプレッションとクリックの増減を月単位で分解し、CTRだけを追わない分析習慣が求められる。
また、2025年12月から2026年2月にかけてAI Overview表示時のオーガニックCTRが1.3%から2.4%へ上昇したというデータもある。ただしSeerはこれを「回復というより横ばいへの落ち着き」と評価しており、2か月分のデータで先行きを予測するのは避けるべきだとしている。
この記事のポイント
- AI Overviewのブランド引用ページCTRはQ4で61%減少したが、クリック数はほぼ横ばい
- 10月はインプレッション急増による数学的CTR低下、11月は実質的なクリック減と原因が異なる
- インプレッション増がGoogleの仕様変更か自社SEOの成果かは、アカウント単位の分析が必要
- CTRだけを見ず、インプレッションとクリックの絶対数を月別に追うことが実務では重要
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

消費者はファネルを放棄——流動化する購買行動にマーケターはどう対応すべきか
消費者の購買行動が、もはやマーケティングの教科書通りには動かなくなっている。MiQ Sigmaが2026年4月に発表したレポート「From Funnel to Flexibility」によれば、消費者の86%が1時間に1回以上デジタル活動を切り替え、42%が自分の購買までの道のりは「ランダムだ」と回答した。
視聴、閲覧、購買というステップを順に踏むのではなく、同じ30分の間にこれらを行き来する消費者が大多数を占める。ECサイトを運営する事業者にとって、この変化は「待っていれば買ってくれる」時代の終わりを意味している。
ファネルはもはや機能しない——データが示す消費者行動の実態

86%が1時間以内に活動を切り替える時代
従来のマーケティングファネルは、認知から興味、比較検討、購入へと消費者が段階的に進むことを前提に設計されている。各段階に応じた広告やコンテンツを用意し、じっくりと購買意欲を醸成する。このモデルは長年、ECを含むあらゆる業界のマーケティング戦略の土台だった。
しかし現実は異なる。MiQ Sigmaの調査では、86%の消費者が1時間に1回以上の頻度でデジタル活動の種類を切り替えており、SNSのチェックから動画視聴、商品検索、そして購入までを短時間で行き来している。42%が「自分の購買プロセスはランダムだ」と考えている点も見逃せない。これは特定のパターンや順序に沿って購買が進むわけではない、という消費者自身の実感を裏付けている。
最短10分で完了する購買——圧縮されるタイムライン
さらに衝撃的なのは、購買までの時間が極端に短縮されていることだ。レポートによれば、ある種の購買はわずか10分で完了するケースもある。つまり消費者が商品を認知し、情報を集め、比較し、決断するまでの全プロセスが、以前は数日から数週間かかっていたのに対し、いまや数十分、ときには数分で終わってしまう。
このスピード感は、段階別にキャンペーンを設計する従来の手法を根本から揺るがす。認知フェーズ用の広告を配信している間に、消費者はすでに購入を終えている可能性があるのだ。
「視聴・閲覧・購買」が30分の間に同時発生する

ステップではなく「状態の切り替え」としての購買行動
レポートが明らかにした最も重要な発見のひとつは、消費者が「視聴」「閲覧」「購買」という状態を、段階的に進むのではなく、短いバーストの中で頻繁に行き来している点だ。30分という短い時間枠のなかで、動画を観て、SNSをチェックし、検索して、そして購入する。この一連の動きは直線的ではなく、行ったり来たりを繰り返す。
これはメディアプランニングに直接的な影響を与える。メッセージを段階ごとに配置する戦略から、活動が活発化する瞬間を捉えてカバレッジ(網羅率)と応答性を最大化する戦略へと、優先順位を切り替える必要がある。
91%がテレビ視聴中に別のデバイスを使用
デバイスの利用実態も、この行動パターンをさらに加速させている。レポートによると、消費者の91%がテレビを観ながら別のデバイス(スマートフォンやタブレット)を同時に使用している。これは、コンテンツへの接触と購買アクションがほぼ同時に発生しうることを意味する。
たとえばテレビCMや番組内で紹介された商品を、その場でスマートフォンから検索し、数分後には購入している。この「接触とアクションの同時性」は、チャネルごとに独立したキャンペーンを組む従来のやり方では対応が難しい。1つのインプレッション(広告表示)が、即座にクロスチャネルな行動を引き起こすため、全プラットフォームで一貫したメッセージと即応性を備えた施策が求められる。
ソーシャルとAIが購買の入り口を無数に増やす

50%以上がSNSを複数目的で利用——若年層では80%超
購買行動の入り口も大きく変わっている。レポートでは、消費者の50%以上が同じ日にSNSを複数の目的で利用していることが示された。若年層ではこの割合が80%を超える。情報収集、エンターテインメント、友人とのコミュニケーション、そして商品の発見と購入まで、1つのプラットフォーム上で完結するケースが増えている。
これはブランド側にとって重要な意味を持つ。発見(ディスカバリー)の場が予測しにくく、かつ分散しているということは、企業が消費者をファネルに誘導するのではなく、消費者の興味が芽生えたその場所で「存在している」ことが競争力の源泉になる。検索広告だけでも、SNS広告だけでも不十分で、あらゆる接点にブランドが顔を出す体制が必要だ。
AIが評価から意思決定までの時間を短縮する
この流れをさらに加速させているのがAIツールの普及だ。調査対象の45%以上が、商品比較、レビューの要約、おすすめ情報の取得にAIツールを利用している。AIは人間が情報を処理する時間を大幅に短縮するため、評価から意思決定までのリードタイムがさらに圧縮される。
EC事業者にとっての示唆は明確だ。商品説明やレビュー、比較情報などのコンテンツは、AIによって解釈・抽出されることを前提に、明瞭で構造化された形で提供する必要がある。AIが読み取りやすいデータ構造(たとえば構造化データマークアップの適切な実装)や、要点が整理されたコンテンツ設計が、これまで以上に重要になる。
マーケターに求められるスピードと柔軟性

段階別アトリビューションは信頼性を失う
購買行動が複数チャネルを同時並行的に行き来するようになると、広告効果の測定手法にも変革が迫られる。「この広告が認知に貢献し、こちらが比較検討を後押しした」という段階別のアトリビューション(貢献度分析)モデルは、現実の複雑な行動を捉えきれなくなる。
MarTechの記事によれば、段階ベースのアトリビューションに代わり、シグナル(行動の兆候)とアウトカム(成果)に焦点を当てたモデルへの移行が必要だと指摘されている。また、データ、メディア、分析システムの統合レベルを引き上げ、クロスチャネルでの同時発生を捉えられる基盤が前提となる。
キャンペーン展開の遅延が機会損失に直結する
意思決定のスピードが上がると、マーケティング施策の実行速度がボトルネックになる。キャンペーンの立ち上げやクリエイティブの更新に時間がかかればかかるほど、購買の瞬間に自社のメッセージを届けられる確率は下がる。
これは単に「素早く動く」という精神論ではなく、運用体制の設計問題だ。広告クリエイティブのパターン出しを自動化する、パフォーマンスデータをリアルタイムで反映して配信を動的に切り替える、在庫や価格の変動に連動した広告を即時生成する——こうした仕組みの有無が、成果を左右する時代に入っている。
この記事のポイント
- 消費者の86%が1時間以内にデジタル活動を切り替え、購買プロセスは「ランダム」とする回答が42%に達する
- 「視聴・閲覧・購買」が30分以内に同時発生し、最短10分で購買が完了するケースもある
- 91%がテレビ視聴中に別デバイスを使用し、接触と購買アクションがほぼ同時に発生する
- AIツールの利用拡大により評価〜意思決定の時間がさらに短縮され、構造化されたコンテンツ設計が不可欠になる
- 段階別アトリビューションは機能しなくなり、シグナルとアウトカムに基づく測定モデルへの移行が必要
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

WordPressで商品診断クイズを作成し売上を伸ばす方法を徹底解説
ECサイト(電子商取引サイト)を運営していて、訪問者が商品を見つけられずに離脱してしまう課題を抱えていないだろうか。膨大な商品ラインナップは魅力だが、選択肢が多すぎるとユーザーは「選べない」というストレスを感じてしまう。
この問題を解決する強力なツールが「商品診断クイズ」だ。ユーザーにいくつかの質問に答えてもらうだけで、最適な商品を提案し、同時にメールアドレスなどのリード(見込み客情報)を獲得できる仕組みである。
商品診断クイズは単なるエンターテインメントではない。顧客の悩みをパーソナライズされた提案で解決し、購入への心理的ハードルを下げるための戦略的なマーケティング手法だ。本記事では、WordPressでこの機能を実装する具体的な手順と、成功のためのポイントを詳しく解説する。
商品診断クイズを導入すべき3つの理由

なぜ今、多くのオンラインショップがクイズ形式のナビゲーションを取り入れているのか。それは、従来のカテゴリー検索やフィルタリング機能にはない、対話型のメリットがあるからだ。
1. ユーザー体験(UX)の向上と離脱防止
クイズは対話形式で進むため、ユーザーは「自分のために選んでくれている」という特別感を得られる。単に商品一覧を眺めるよりもエンゲージメント(関与度)が高まり、サイトへの滞在時間が伸びる傾向にある。また、選択肢を絞り込んで提示することで、決定回避の法則(選択肢が多すぎると選べなくなる心理)を防ぎ、スムーズな購入体験を提供できる。
2. 質の高いリード獲得とリスト構築
診断結果を表示する直前にメールアドレスの入力を求める「オプトインゲート」を設置することで、効率的にメールリストを構築できる。診断を完了したユーザーは結果を知りたいという強い動機があるため、通常のポップアップよりも登録率が高くなりやすい。獲得したアドレスは、診断結果に基づいたセグメント(グループ分け)ごとに管理できるため、その後のステップメールの成約率も飛躍的に向上する。
3. 顧客データの蓄積とマーケティングへの活用
クイズの回答データは、顧客が何を求めているかを知るための宝庫だ。予算感、肌の悩み、好みの味など、通常のアクセス解析では得られない「顧客の生の声」を数値化できる。これらのデータを分析すれば、新商品の開発や在庫管理、広告のターゲット設定をより正確に行うことが可能になる。
このデモは、商品診断クイズがユーザーの意思決定プロセスをいかに簡略化するかを示している。
事前準備としての診断結果ページの設計
クイズの作成を始める前に、必ず「診断結果ページ」を個別に用意しておく必要がある。クイズのゴールは、ユーザーに最適な商品を提示し、その場で購入してもらうことだ。そのため、診断結果ごとに専用のランディングページ(LP)を作成することが推奨される。
結果ページに含めるべき要素
効果的な結果ページには、以下の3つの要素が不可欠だ。まず、診断結果を強調した見出し。次に、なぜその商品がユーザーに合っているのかを説明する2〜3文の解説。そして、商品詳細ページやカートへの直接的なリンクを含む「CTA(Call to Action / 行動喚起)ボタン」だ。
例えば、コーヒー豆の販売サイトであれば「あなたはコクのある深煎りタイプ」という結果に対し、その豆の特徴と淹れ方のアドバイスを添え、すぐに購入できるボタンを配置する。複数の選択肢を出すよりも、最も適した1つを強調するほうがコンバージョン(成約)に繋がりやすい。
方法1 WPFormsでシンプルな診断フォームを作る

すでにWordPressでWPFormsを使用している、あるいはシンプルなフォーム形式でクイズを実装したい場合に最適な方法だ。WPForms Pro以上のライセンスに含まれる「Quiz Addon(クイズアドオン)」を使用する。
クイズモードの有効化とタイプ選択
WPFormsで新規フォームを作成し、設定画面から「Quiz」タブを選択してクイズモードを有効にする。商品診断の場合は、点数を競う「Graded Quiz」ではなく、回答の傾向から分類する「Personality Quiz(性格・タイプ診断)」を選択するのがポイントだ。ここで、あらかじめ想定している診断結果のパターン(例〜「乾燥肌タイプ」「混合肌タイプ」など)を「Personality Types」として登録しておく。
設問の作成と回答のマッピング
質問項目には、視認性の高い「Multiple Choice(多肢選択)」フィールドを多用するとよい。各回答の選択肢に対して、どの診断結果タイプに紐付けるかを設定していく。例えば、「肌の悩みは何ですか?」という質問の選択肢「カサつき」を「乾燥肌タイプ」にマッピングする作業だ。WPFormsの「Conditional Logic(条件付きロジック)」を組み合わせれば、回答に応じて次の質問を変えるといった複雑な挙動も可能になる。
メールサービスとの連携
診断結果ごとに異なるメールリストへ登録されるよう設定する。WP Beginnerの記事ではConstant Contact(コンスタント・コンタクト)を例に挙げているが、Mailchimpや国内の主要なメール配信サービスでも同様の設定が可能だ。診断結果AのユーザーにはリストA、結果BにはリストBというように条件付きロジックで振り分けることで、その後のフォローアップメールのパーソナライズが可能になる。
方法2 Thrive Quiz Builderで高度な診断体験を構築する

よりリッチな視覚効果や、複雑な分岐ロジック(Branching Logic)を必要とする場合は、Thrive Quiz Builderが適している。このプラグインはマーケティングに特化しており、クイズ専用の管理画面から直感的にフローを構築できるのが特徴だ。
カテゴリーベースの評価システム
Thrive Quiz Builderでは、評価タイプとして「Category(カテゴリー)」を選択する。これにより、回答者がどのカテゴリーに最も多く当てはまったかを自動計算し、最終的な診断結果を導き出す。このプラグインの強みは、質問の合間に「スプラッシュページ(導入画面)」を挟んだり、画像付きの回答ボタンを簡単に作成できたりする点にある。
オプトインゲートの戦略的配置
Thrive Quiz Builderには「Opt-in Gate(オプトインゲート)」という専用機能がある。これは、すべての質問に答え終わった後、結果を表示する直前にメールアドレス入力を求める画面だ。ユーザーはすでに数分間の時間をクイズに費やしており、「結果を知りたい」という心理的コミットメントが高まっているため、非常に高い登録率を期待できる。ここで入力されたデータは、WordPressのユーザーリストや外部のCRM(顧客関係管理)ツールへ自動的に同期される。
視覚的な分岐エディタ
質問のフローをキャンバス上でドラッグ&ドロップして繋いでいく「ビジュアルエディタ」により、複雑な分岐も迷わずに作成できる。例えば、最初の質問で「男性」か「女性」かを選ばせ、その後の質問セットを完全に入れ替えるといった設計も、線で繋ぐだけで完結する。これにより、より精度の高い商品提案が可能になる。
→ Q2(保湿重視の質問)へ
→ Q3(皮脂ケアの質問)へ
この図は、分岐ロジックによってユーザーごとに異なる質問経路をたどり、最終的な提案を最適化する流れを表している。
商品診断クイズを成功させるための運用ポイント

ツールを導入するだけでなく、以下のポイントを意識することで、クイズのコンバージョン率はさらに向上する。筆者の見解として、特に重要なのは「心理的摩擦の軽減」と「データの継続的改善」だ。
設問数は「3〜5問」に絞る
質問が多すぎると、ユーザーは途中で飽きて離脱してしまう。逆に少なすぎると、診断結果への信頼性が損なわれる。実務上のベストバランスは3問から5問だ。どうしても多くの情報を得たい場合は、進捗状況を示す「プログレスバー」を表示し、あとどれくらいで終わるかを可視化すると離脱を防ぎやすい。
診断後の「期間限定クーポン」で背中を押す
診断結果を提示する際、その商品に使える「10%OFFクーポン」や「送料無料コード」を同時に発行する手法は非常に有効だ。「自分にぴったりの商品が見つかった」という高揚感がある瞬間に限定特典を提示することで、即時購入を強力に促すことができる。この際、クーポンに有効期限(例〜24時間以内)を設けることで、緊急性を演出するのも定石だ。
ABテストによる継続的な改善
クイズのタイトルや、最初の質問の言い回し一つで完了率は大きく変わる。Thrive Quiz Builderなどの高度なツールにはABテスト機能が備わっているため、複数のパターンを試して最も数値の良いものを採用し続けることが重要だ。また、どの質問でユーザーが離脱しているかを分析し、難解な質問や答えにくい選択肢を排除する努力も欠かせない。
この記事のポイント
- 商品診断クイズは、ユーザーの意思決定を助け、CVRとリード獲得率を同時に高める
- WPFormsはシンプルで使いやすく、既存のフォームに診断機能を追加するのに適している
- Thrive Quiz Builderは分岐ロジックやオプトインゲートが強力で、高度なマーケティングに適している
- 診断結果ページは個別のLPとして設計し、明確な解説とCTAボタンを配置する
- 設問数は3〜5問に抑え、クーポン配布などのインセンティブを組み合わせると効果的だ
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

ChatGPTでWooCommerce商品を販売する方法!最新のショッピング機能を導入する全手順
ChatGPTのチャット画面の中で、ユーザーが直接商品を探して購入できる機能が注目を集めている。ユーザーが「4,000円以下の青いヨガマットが欲しい」と入力すると、ChatGPTが登録された店舗から実際の商品を提案し、価格や在庫状況まで表示する仕組みだ。
これは「Agentic Commerce(エージェンティック・コマース)」と呼ばれる新しい販売チャネルだが、多くのWooCommerce運営者は自分の商品をどうやって掲載すればよいか分からずにいる。OpenAIは2025年後半にマーチャントプログラムを開始しており、先行して対応することで競合に差をつけることが可能だ。
この記事では、WooCommerceの商品をChatGPTの検索結果に表示させるための具体的な手順を解説する。OpenAIへのマーチャント登録から、AIが読み取りやすい商品フィードの作成、そして承認を得るためのポイントまでを詳しく見ていこう。
ChatGPT Agentic Commerceとは何か

ChatGPT Agentic Commerce(またはChatGPT Shopping)は、ユーザーがChatGPTとの会話を通じて商品を発見し、そのまま販売元のショップへ移動して購入できる機能だ。従来の検索エンジンとは異なり、AIがユーザーの意図を深く理解した上で、最適な商品を「推薦」してくれるのが特徴である。
この仕組みを支えているのが、ACP(Agentic Commerce Protocol)というプロトコルだ。これはWooCommerceなどのECサイトとChatGPTのショッピング層を接続するための規格である。ChatGPTはこのプロトコルを通じてショップの商品フィードを読み取り、内容を理解して会話の中に反映させる。
上記のように、AIがコンシェルジュのように振る舞うことで、購入意欲の高いユーザーを直接ショップへ誘導できる。ユーザーはショップの決済画面で最終的な購入手続きを行うため、顧客データやブランドのつながりはショップ側が保持し続けられる点も大きなメリットだ。
なぜChatGPTで販売すべきなのか
最大の理由は、購買意欲が非常に高いタイミングでユーザーに接触できることだ。特定の悩みや要望をAIに相談しているユーザーに対し、解決策として自社商品を提示できるため、成約率が高まりやすい。また、AI向けに整理されたデータ(構造化データ)を提供することは、将来的なAI検索最適化(AEO)にもつながる。
さらに、ChatGPTから直接自社サイトへ送客されるため、メールマガジンの登録を促したり、関連商品をアップセルしたりといった従来のマーケティング施策もそのまま活用できる。プラットフォームに完全に依存するのではなく、集客の入り口としてAIを活用する形になるからだ。
準備すべきものと商品識別コードの重要性

ChatGPTに商品を掲載するためには、正確な商品データが必要不可欠だ。特に多くのWooCommerce運営者がつまずきやすいのが、GTIN(国際取引商品番号)やMPN(製造者パーツ番号)といった識別コードの設定である。OpenAIは、フィード内の各商品にこれらの一意の識別子が含まれていることを求めている。
GTINには、バーコードでおなじみのJANコード(日本)やEANコード、書籍に使われるISBNなどが含まれる。他社ブランドの商品を転売している場合は、パッケージやメーカーサイトでこれらの番号を確認できる。自社製品の場合は、独自に管理番号(MPN)を割り当てる必要がある。
世界共通のバーコード番号。転売品や一般流通品に必須。
製造者が独自に付ける型番。自社製品やハンドメイド品で使用。
書籍専用の国際標準図書番号。
WooCommerceの標準機能では、SKU(在庫管理単位)を入力する欄はあるが、GTIN専用の入力欄が不足している場合がある。その場合は、プラグインを使用して項目を追加するか、SKU欄をMPNとして代用することになる。商品数が多い場合は、CSVファイルで一括エクスポートし、表計算ソフトで番号を入力してから再インポートする方法が効率的だ。
ハンドメイドや一点物の扱いはどうなるか
独自の商品を作っている場合、GTINを持っていないことも多いだろう。その場合は、自分たちで一貫したフォーマットのMPNを作成すればよい。例えば「SHOPNAME-ITEM-001」のような形式で、重複しない番号を各商品に割り当てる。これにより、AIはそれぞれのアイテムを個別の商品として認識できるようになる。
ChatGPT向け商品フィードの作成手順

OpenAIの仕様に適合した商品フィードを作成するには、専用のプラグインを活用するのが最も確実だ。WP Beginnerの著者によれば、この用途で特に実績があるのは「Product Feed Pro by AdTribes」だという。このプラグインはOpenAI専用の出力フォーマットをサポートしており、設定が容易だ。
まず、プラグインをインストールして有効化したら、ライセンスキーを入力する。その後、管理画面の「Create Feed」から新しいフィードの作成を開始する。ここで、チャンネルの選択肢から「OpenAI Product Feed」を選ぶのがポイントだ。
出力形式とフィールドマッピングの設定
ファイル形式については、OpenAIが推奨している「JSONL(JSON Lines)」を選択しよう。これは各行が独立したJSONオブジェクトになっている形式で、大量のデータを効率的に処理できる特徴がある。次に、フィールドマッピングの画面で、WooCommerceの各項目がOpenAIの属性と正しく結びついているか確認する。
通常、商品名や説明文、価格などは自動で紐付けられるが、先ほど準備したGTINやMPNが正しくマッピングされているかは入念にチェックすべきだ。もし独自のカスタムフィールドを使っている場合は、手動でマッピングを追加することも可能である。設定が完了したら「Generate Product Feed」をクリックしてフィードを生成する。
トラッキング設定で効果を測定する
フィードを生成する際、GoogleアナリティクスのUTMパラメータを有効にしておくことをおすすめする。これにより、ChatGPT経由でどれくらいのユーザーが流入し、実際に購入に至ったかを正確に把握できるようになる。AIチャネルがどれだけ利益に貢献しているかを可視化することは、今後の戦略立案において非常に重要だ。
OpenAIへの申請とフィードの送信

フィードの準備ができたら、OpenAIのマーチャントポータルから登録申請を行う。ビジネスの詳細や販売している商品のカテゴリー、対象地域などを入力して送信する。申請後、OpenAIによる審査が行われるが、この期間は数日から数週間かかる場合があると言われている。現在は米国から順次拡大中だが、早めに列に並んでおくことが得策だ。
審査を通過すると、商品フィードのURLを提出するための案内が届く。WooCommerceの管理画面からコピーしたフィードのURLを送信すると、自動検証プロセスが開始される。通常、24時間から48時間以内に検証結果が判明し、問題がなければChatGPTの検索結果に商品が表示され始める仕組みだ。
よくあるエラーと解決策
フィードの検証でエラーが出る場合、その原因の多くはデータの不備にある。WP Beginnerの記事では、よくある問題として「GTINの欠落」「価格フォーマットの誤り(通貨コードが含まれていないなど)」「商品画像が小さすぎる、またはサポートされていない形式である」といった点が挙げられている。
検証ツールが指摘した箇所を修正し、プラグインでフィードを再生成してから再提出しよう。特に画像については、AIが視覚的に商品を理解するためにも、高解像度でクリアなものを用意することが推奨される。一度承認されれば、あとは商品の在庫状況や価格変更が自動的にフィードに反映され、ChatGPT側の情報も更新されるようになる。
独自の分析:AI検索時代のEC戦略

今回のChatGPT連携は、単なる「新しい広告枠」以上の意味を持っている。これまでのSEO(検索エンジン最適化)が「キーワード」を重視していたのに対し、Agentic Commerceでは「データの構造化」と「文脈の理解」が鍵となる。AIが商品を正しく理解できるように情報を提供することは、もはやオプションではなく必須のスキルになりつつある。
また、この変化は中小規模のショップにとって大きなチャンスだ。巨大なモールの中で価格競争に巻き込まれるのではなく、AIが「このユーザーの悩みを解決するには、このショップのこの商品がベストだ」と判断してくれれば、ブランドの知名度が低くても選ばれる可能性があるからだ。そのためには、商品タイトルや説明文を、人間だけでなくAIにとっても分かりやすく、詳細に記述する努力が求められる。
今後はChatGPTだけでなく、Googleの「AI Overviews」や他のAIエージェントも同様の仕組みを取り入れていくだろう。今のうちにWooCommerceで商品データを整理し、外部プラットフォームへ高品質なフィードを提供できる体制を整えておくことは、数年後のショップの生存を左右する重要な投資になるはずだ。
この記事のポイント
- ChatGPT Agentic Commerceにより、チャット内での商品検索と提案が可能になった
- 掲載にはOpenAIのマーチャント登録と、GTIN/MPNを含む正確な商品データが必要である
- 専用プラグインを使用して、OpenAI推奨のJSONL形式で商品フィードを作成する
- フィードURLを提出し、自動検証をパスすることでChatGPTに商品が表示されるようになる
- AI向けにデータを最適化することは、将来的なAI検索(AEO)対策としても非常に有効である
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験