

MetaがGoogleの広告収益を逆転へ!2026年に起きる歴史的転換の背景とSEO・広告戦略への影響
デジタル広告の世界で、長らくトップに君臨してきたGoogleの牙城がついに崩れようとしている。2026年、Metaの広告収益がGoogleを追い抜き、世界シェア1位に躍り出る見通しが明らかになった。これは単なる収益の逆転ではなく、広告の仕組みそのものが「検索」から「AIによる自動最適化」へとシフトしている現実を物語っている。
米調査会社のEmarketerが発表した予測によれば、2026年のMetaの広告収益は2,434億6,000万ドル(約37兆円)に達する見込みだ。対するGoogleは2,395億4,000万ドルにとどまり、僅差ながらも首位が入れ替わることになる。Googleがデジタル広告のトップから陥落するのは、同社が市場を支配して以来、初めての出来事だ。
この変化は、Webサイトを運営する企業や個人にとって無視できない兆候といえる。ユーザーの行動がGoogle検索から、InstagramやFacebook、WhatsAppといったSNS上の「発見」へと移り変わっているからだ。本記事では、この歴史的な逆転劇の背景と、今後のWebマーケティングに与える影響を深掘りしていく。
数字で見る広告市場の勢力図塗り替え

広告収益のシェアで見ると、その変化はより鮮明になる。2026年、Metaは世界のデジタル広告支出の26.8%を占めると予測されている。一方で、Googleのシェアは26.4%まで低下する見込みだ。かつてはGoogleが圧倒的な差をつけていたが、この数年でMetaが猛烈な勢いで差を詰めてきた結果である。
Googleの成長鈍化とMetaの加速
Googleの広告ビジネスが停滞しているわけではない。検索広告やYouTube広告は依然として巨大な収益源だが、その成長スピードが以前に比べて緩やかになっている。背景には、検索市場の成熟と、後述するAI検索の台頭による不確実性がある。既存の検索広告モデルが、かつてのような爆発的な伸びを維持できなくなっているのだ。
対照的に、MetaはAIを活用した広告運用の自動化に成功し、収益を飛躍的に伸ばしている。特に「Advantage+」などのAIツールが、広告主にとっての投資対効果(ROI)を劇的に改善させた。人間が細かくターゲットを設定しなくても、AIが最適なユーザーに広告を届ける仕組みが、企業の予算を引き寄せている。
マクロ経済が後押しするパフォーマンス広告
世界的な経済の先行き不透明感も、この逆転を後押ししている。景気が厳しくなると、企業は「認知」を目的としたブランディング広告よりも、直接的な「売上」につながるパフォーマンス広告を優先する傾向がある。Metaの広告プラットフォームは、ユーザーの興味関心に基づいた高精度なターゲティングが可能であり、より短いスパンで成果を証明しやすい。この「測れる成果」こそが、現在の市場で最も求められている価値だといえる。
なぜMetaがGoogleに競り勝つのか

Metaが勝利を収めつつある最大の要因は、広告運用の「手軽さ」と「精度の高さ」の両立にある。Google検索広告は、適切なキーワードを選定し、競合の入札状況を監視するなど、運用に一定のスキルと工数が必要とされる。しかし、Metaの最新の広告システムは、クリエイティブ(画像や動画)を用意するだけで、あとはAIがすべてを最適化してくれるレベルに達している。
AIによる「運用の民主化」
Metaは広告主に対し、AIを使ってターゲット設定やクリエイティブの生成を自動化する機能を次々と提供している。これにより、専門の広告運用担当者がいない中小企業でも、大企業に引けを取らない成果を出せるようになった。この「運用の民主化」が、Metaの広告主の裾野を大きく広げている。
● ターゲット層の細かな手動設定
● 入札単価の頻繁な調整
★ 画像・動画の自動バリエーション生成
★ リアルタイムでの予算最適化
この図は、広告運用の手間がAIによっていかに削減され、成果へと直結するようになったかを示している。
「検索」を必要としない発見のプロセス
Googleの強みは「ユーザーが何かを探している瞬間」を捉えることにある。しかし、Metaは「ユーザーが気づいていなかった欲しいもの」を提示することに長けている。SNSのタイムラインを流れるパーソナライズされた広告は、ユーザーにとって受動的な発見をもたらす。検索という能動的なアクションを必要としないこのプロセスは、スマホ時代の消費行動に極めて適合している。
Googleが直面する三重苦

王座を明け渡す形となるGoogleだが、同社は現在、非常に困難な舵取りを迫られている。主な要因は、AIによる検索体験の変化、法的な規制、そして主力事業の成熟という3つの課題だ。
AI検索(SGEなど)による広告モデルの破壊
PerplexityやChatGPTのようなAI回答エンジン、そしてGoogle自身が導入を進める「AI Overviews(旧SGE)」は、従来の検索広告のあり方を根底から変えようとしている。AIが直接回答を提示することで、ユーザーは検索結果のリンクをクリックする必要がなくなる。これは、クリック課金で収益を上げてきたGoogleにとって、自らのビジネスモデルを破壊しかねないリスクを孕んでいる。
独占禁止法を巡る法廷闘争
Googleは米国や欧州で、広告技術における市場独占を巡る厳しい監視下に置かれている。複数の訴訟が進行中であり、最悪の場合、広告事業の分割を命じられる可能性もゼロではない。こうした法的なリスクは、同社の積極的な事業拡大の足かせとなっており、投資家や広告主の心理に影を落としている。
YouTubeの競争激化
Googleのもう一つの柱であるYouTubeも、TikTokという強力なライバルの出現により、若年層の視聴時間と広告予算を奪われている。ショート動画市場での競争は激しさを増しており、かつてのような独走状態ではない。MetaもInstagramのリール(Reels)を通じてこの分野で強く対抗しており、動画広告の予算もMetaへと流れる要因となっている。
Web担当者が取るべき今後の戦略

広告収益のシェアが逆転するということは、ユーザーの関心がどこに集まっているかを示す指標でもある。これからのWebマーケティングでは、Google検索だけに頼るのではなく、プラットフォームの変化に合わせた柔軟な予算配分と戦略の構築が求められる。
マルチチャネルでの予算配分の再考
もし現在の集客をGoogle検索広告に依存しているなら、Meta広告への予算分散を検討する時期だ。特に、AIによる自動運用ツール(Advantage+など)を積極的に活用し、自社のデータとAIを組み合わせた最適化を試すべきである。Googleが弱体化するわけではないが、Metaの方が「安く、広く、正確に」リーチできるケースが増えている事実は無視できない。
「検索される」から「見つけられる」コンテンツ作り
SEO(検索エンジン最適化)の重要性は変わらないが、その定義は広がりつつある。これからはGoogleの検索窓に入力される言葉を狙うだけでなく、SNSのアルゴリズムに「おすすめ」として選ばれるためのコンテンツ作りが必要だ。視覚的に訴求力のある画像や、数秒で価値が伝わる縦型動画の制作は、もはやSNS担当者だけの仕事ではなく、Webマーケター全体の必須スキルとなっている。
独自の分析:広告は「意図」から「予測」へ

今回の逆転劇を分析すると、広告の本質的な価値が「ユーザーの意図に応えること」から「ユーザーの行動を予測すること」へと移行したことがわかる。Googleは、ユーザーが入力したキーワードという「明確な意図」を収益化してきた。しかしMetaは、膨大な行動データから「次に何に興味を持つか」をAIで予測し、意図が生まれる前に先回りして広告を提示する。
この「予測型広告」の勝利は、現代人が「探す」という手間を極限まで嫌っていることを示唆している。Webサイトの運営においても、ユーザーに検索させて情報を探させる構造よりも、パーソナライズされたおすすめを提示するような体験の提供が、今後のコンバージョン率を左右する鍵になるだろう。
この記事のポイント
- 2026年にMetaの広告収益がGoogleを上回り、世界シェア1位になる見通しだ
- Metaの勝因はAIによる広告運用の自動化であり、高いROIが広告主を惹きつけている
- GoogleはAI検索の台頭や独占禁止法の訴訟など、構造的な課題に直面している
- Web担当者は「検索」だけでなく、SNSでの「発見」を重視した戦略への転換が必要だ
- 今後のマーケティングは、ユーザーの意図を待つのではなく、行動を予測するアプローチが主流になる

・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

WooCommerceで注文制限を設定する方法!最小・最大数量で在庫と利益を守る
WooCommerceでネットショップを運営していると、注文の「量」に関する悩みに直面することがある。安価な商品を1点だけ注文されて送料や決済手数料で赤字になったり、逆に人気商品を1人で買い占められて在庫が底をついたりするケースだ。
これらの問題は、注文の最小数量や最大数量を適切に設定することで解決できる。適切な制限を設けることは、在庫管理を容易にするだけでなく、配送の効率化やビジネスの収益性向上に直結する重要な戦略だ。
本記事では、WooCommerceで注文制限をかけるための3つの手法を詳しく解説する。無料のプラグインで手軽に始める方法から、B2B(企業間取引)向けの高度な設定まで、サイトの状況に合わせた最適な方法が見つかるはずだ。
なぜWooCommerceで注文制限が必要なのか

注文制限を導入する最大の理由は、店舗の予測可能性を高めて運営を安定させることにある。制限がない状態では、予期せぬ少額注文や極端な大量注文によって、梱包作業の負担や配送コストの増大を招くリスクがある。
少額注文による「送料負け」を防ぐ
数百円の小物を1点だけ購入された場合、梱包資材費や発送の手間、決済手数料を差し引くと利益がほとんど残らない場合がある。WP Beginnerの記事でも指摘されているが、例えば2ドルのキーホルダー1点の注文に対し、配送コストがそれを上回ってしまうような事態は避けなければならない。
最小注文金額や数量を設定することで、顧客に対して「ついで買い」を促す効果も期待できる。これは客単価の向上につながり、ショップ全体の収益構造を改善するきっかけとなる。
在庫の枯渇と買い占めを防止する
一方で、最大数量の制限は在庫保護に役立つ。特定の顧客が在庫をすべて買い占めてしまうと、他の多くの顧客に商品が行き渡らなくなり、ショップの評判を下げる要因になりかねない。
特に限定品やセール品において「1人5点まで」といった制限を設けることは、公平な販売機会を提供するために不可欠だ。また、配送業者の重量制限や梱包サイズの上限に合わせることで、配送トラブルを未然に防ぐ役割も果たす。
● 特定ユーザーが100個まとめ買い → 即完売で機会損失
● 「1人最大5個まで」に設定 → 多くの顧客に商品を供給
このデモは注文制限を導入した際のメリットを視覚化したイメージだ。
無料プラグインで手軽に数量制限をかける方法

予算をかけずに基本的な制限を導入したい場合、無料のプラグインを利用するのが最も効率的だ。初心者でも扱いやすく、コードを書く必要がない選択肢として「Minimum and Maximum Quantity for WooCommerce」が挙げられる。
プラグインの導入と基本設定
まずはWordPressの管理画面から「Plugins」の「Add New」へ進み、プラグイン名で検索してインストールと有効化を行う。Dotstoreという開発者によるものが対象だ。有効化すると、管理画面のメニューに専用の設定項目が追加される。
設定画面では「Add New」ボタンから新しいルールを作成する。ルールには任意の名前を付け、どの商品やカテゴリに適用するかを選択する仕組みだ。特定の1商品だけに制限をかけることも、特定のカテゴリ全体にルールを適用することもできる。
具体的な制限値の入力
ルールの詳細設定では「Action」セクションで最小数量(Min Quantity)と最大数量(Max Quantity)を入力する。例えば、最小を2、最大を5に設定した場合、顧客はカートに最低2個入れる必要があり、6個以上は追加できなくなる。
設定を保存して公開すると、商品詳細ページの「カートに入れる」ボタンの横に、設定した最小数量が初期値として表示されるようになる。顧客がこの範囲外の数量を指定しようとすると、自動的に制限がかかる仕組みだ。これにより、管理者の意図しない注文をシステム的にブロックできる。
商品・カテゴリごとに高度な制御を行う方法

無料プラグインよりも柔軟な設定が必要な場合、有料の「YITH WooCommerce Minimum Maximum Quantity」が有力な候補となる。このツールは、カート全体の合計金額に基づいて制限をかけたり、特定のタグが付いた商品群を一括で制御したりする機能に優れている。
カート全体の制限(グローバル設定)
YITHのプラグインでは、個別の商品だけでなくカート全体に対して「合計10点以上、50点以内」といった制限をかけることができる。また、合計金額(サブトータル)による制限も可能だ。例えば「合計5,000円以上の注文のみ受け付ける」といった運用が容易になる。
さらに「グループ購入」の強制機能も興味深い。これは「6の倍数でのみ購入可能」といった設定だ。ワインのダース販売や、特定の梱包箱にぴったり収まる数量で販売したい場合に非常に重宝する機能だ。
バリエーション商品の柔軟な集計
サイズや色が異なるバリエーション商品(Variable Product)の扱いも高度だ。例えば「Tシャツを合計5枚以上」というルールを作った際、赤を3枚、青を2枚選んだ場合に「合計5枚」としてカウントするか、あるいは「各色5枚ずつ」必要とするかを設定で選べる。
WP Beginnerの調査によれば、多くのストアではバリエーションの合計で判定する「sum」オプションが好まれている。顧客にとって柔軟性が高く、買い物のハードルを上げすぎずに制限を適用できるからだ。こうした細かな配慮が、カゴ落ちを防ぐ鍵となる。
B2B・卸売サイト向けの高度な設定方法

企業間取引(B2B)や卸売をメインとするサイトでは、一般顧客と卸先顧客で異なる制限を設ける必要がある。このようなケースでは「Wholesale Prices」プラグインが適している。これは「Wholesale Suite」の一部として提供されており、ユーザー権限(ロール)に基づいた制御が可能だ。
ユーザー権限ごとの注文条件
この手法の最大の特徴は、ログインしているユーザーの役割に応じて条件を動的に変えられる点にある。一般の小売客には制限をかけず、卸売客(Wholesale Customer)に対してのみ「1回100個以上」や「合計3万円以上」といった厳しい条件を課すことができる。
卸売客が条件を満たしていない場合、カート内では通常価格が表示され、条件を満たすまで卸売価格が適用されないという通知が表示される。これにより、小口注文で卸売価格を乱用されるリスクを確実に防ぐことができる。
商品ごとの個別オーバーライド
サイト全体の基本ルールとは別に、特定の商品だけ特別な条件を設定することも可能だ。例えば、通常は「合計10点以上」が条件であっても、非常に高価な商品や大型の商品については「1点から卸売価格を適用する」といった例外設定ができる。
このような柔軟な設定は、手動での注文管理コストを大幅に削減する。システムが自動で条件を判定するため、管理者は不適切な注文のキャンセル作業に追われることなく、本来の業務に集中できるようになる。
顧客満足度を下げずに注文制限を運用するコツ

注文制限は店舗側には都合が良いが、顧客にとっては不便に感じられることもある。制限を導入する際は、顧客が納得して買い物を続けられるような工夫が欠かせない。心理的なハードルを下げるための施策をいくつか紹介する。
制限の理由を明確に伝える
単に「注文できません」と表示するのではなく、なぜその制限があるのかを短く添えるのが効果的だ。例えば「配送品質を維持するため、2点以上からのご注文をお願いしております」や「卸売専用価格のため、最低数量を設定しております」といった説明があるだけで、顧客の受ける印象は大きく変わる。
また、商品詳細ページの「カートに入れる」ボタンの近くに、あらかじめ制限の内容を明記しておくことも重要だ。決済画面に進んでから初めてエラーが出ると、顧客のフラストレーションが最大化し、離脱の原因となるからだ。
インセンティブとの組み合わせ
制限を「強制」ではなく「特典への条件」として見せる手法もある。例えば、最小注文金額を送料無料のラインと一致させる方法だ。「5,000円以上の注文で送料無料(かつ、5,000円未満は注文不可)」とすることで、顧客は「制限されている」という感覚よりも「送料無料の恩恵を受けている」という感覚を強く持つようになる。
こうしたUX(ユーザー体験)の設計は、店舗の信頼性を高める。技術的な制限をかけるだけでなく、それが顧客にとってどのようなメリット、あるいは納得感につながるかを常に考える必要がある。
このチェックリストは、注文制限を導入する際のUX設計の指針となる。
この記事のポイント
- 注文制限は、少額注文による赤字防止や在庫の買い占め対策に非常に有効だ。
- 初心者は無料の「Minimum and Maximum Quantity for WooCommerce」で十分対応できる。
- 高度な制御や金額ベースの制限が必要なら「YITH」のプラグインが適している。
- B2Bや卸売サイトでは「Wholesale Prices」を使い、ユーザー権限ごとに条件を変えるのが正解だ。
- 制限を導入する際は、顧客を突き放さないメッセージングとUXの工夫が成功の鍵を握る。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Googleが「戻るボタンの乗っ取り」をスパムと定義。6月15日からペナルティ対象に
Googleは検索セントラルのスパムポリシーを更新し、ブラウザの「戻る」操作を妨害する行為を「悪意のある行為」として明確に禁止した。この新ルールは2026年6月15日から適用が開始される予定だ。
ポリシーの追加により、ユーザーの意図に反して履歴を操作するサイトは検索順位の低下や手動ペナルティの対象となる。サイト運営者には2ヶ月の猶予期間が与えられており、その間に自社サイトの挙動を確認する必要がある。
今回の変更は、長年ユーザーから報告されていた「ページを戻ろうとしても同じサイト内に留め置かれる」という不快な体験を根絶するための強力な措置といえる。
戻るボタンの乗っ取り(Back Button Hijacking)とは何か
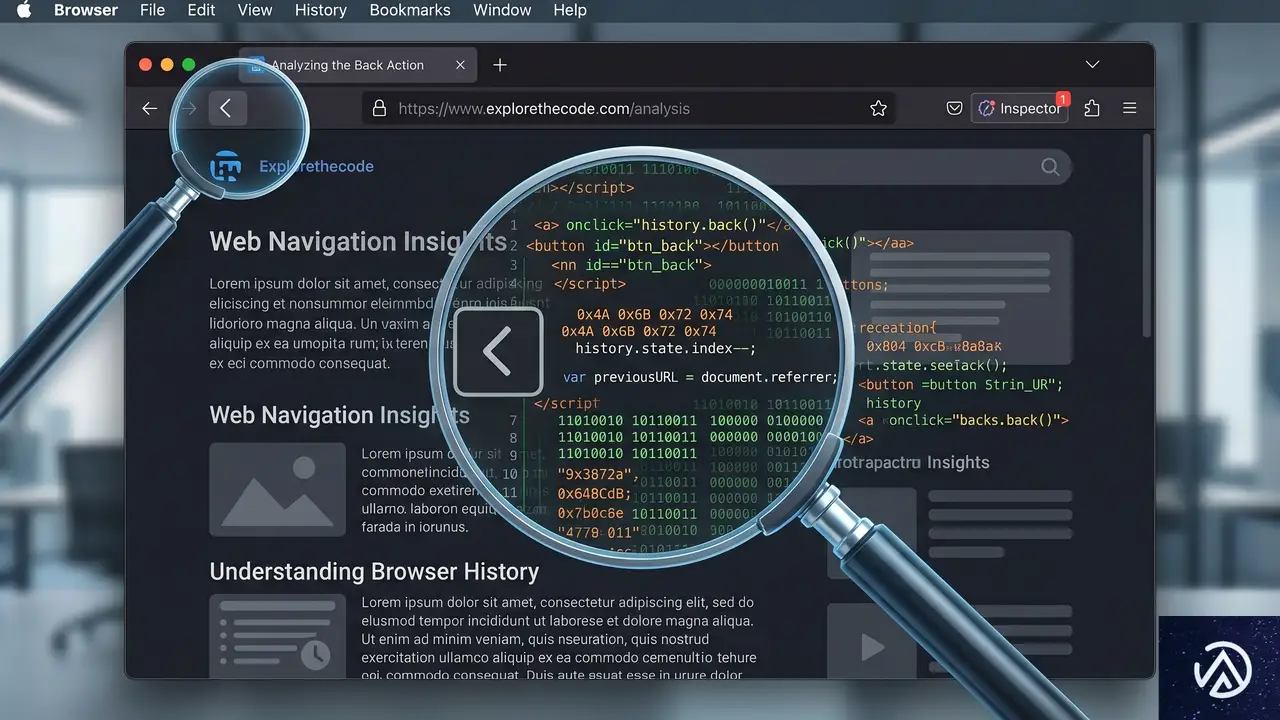
戻るボタンの乗っ取りとは、ウェブサイトのスクリプトを使用してブラウザのナビゲーション機能を操作し、ユーザーが前のページに戻るのを阻止する手法を指す。本来、ブラウザの「戻る」ボタンを押せば直前に閲覧していたページに戻るはずだが、この手法が使われていると正常に機能しない。
Googleの公式ブログによれば、この乗っ取りにはいくつかのパターンが存在する。代表的なものは、ユーザーが一度も訪問していないページをブラウザ履歴に強制的に挿入する手法だ。これにより、戻るボタンを押しても同じサイト内の別の広告ページや推奨記事ページが表示される仕組みになっている。
また、戻るボタンを完全に無効化したり、クリックした瞬間に別のURLへ強制リダイレクトをかけたりする悪質なケースも確認されている。これらはすべて、ユーザーの「前の画面に戻りたい」という基本的な期待を裏切る行為であり、Googleはこれをスパムと定義した。
上記の図のように、ユーザーの意図しない遷移を強制することがポリシー違反の核心だ。
技術的な仕組みと履歴の操作
この乗っ取りの多くは、JavaScriptの history.pushState() という関数を悪用して実現されている。この関数は、ページをリロードせずにブラウザの履歴スタックに新しいエントリを追加できる便利な機能だが、これを悪用すると「戻る」ボタンの行き先を勝手に書き換えることが可能になる。
例えば、ページが読み込まれた瞬間に、現在のページの履歴を2回分挿入するスクリプトが動くとする。ユーザーが「戻る」を1回押しても、履歴スタックにはまだ同じサイトのエントリが残っているため、画面が切り替わらない。このような挙動は、ユーザーに「ブラウザが故障した」あるいは「このサイトから逃げられない」という恐怖感や不快感を与える。
Googleがポリシー改訂に踏み切った背景

Googleが今回の決定を下した背景には、ウェブ全体でこの「戻るボタンの操作」を伴う悪質なサイトが増加しているという事実がある。Googleの報告によれば、多くのユーザーがこうした操作によって「操作されている」と感じ、見知らぬサイトへの訪問をためらうようになっているという。
実は、Googleは2013年の時点ですでに、ブラウザの履歴に欺瞞的なページを挿入することに対して警告を発していた。しかし、当時は「推奨されない行為」という扱いに近く、明確なスパムポリシーとしての定義はされていなかった。今回の更新により、この行為は「マルウェアの配布」や「不要なソフトウェアのインストール」と同等の「悪意のある行為」として格上げされた形だ。
検索エンジンとしての信頼性を維持するためには、検索結果から訪れたサイトがユーザーを「閉じ込める」ような挙動を許してはならない。Googleは、ユーザー体験(UX)を著しく損なう要素を排除することで、検索エコシステム全体の健全性を高めようとしている。
6月15日からの取り締まりプロセス
今回のポリシー適用には、約2ヶ月の猶予期間が設けられている。2026年6月15日以降、Googleは自動化されたシステム(SpamBrainなど)および手動レビューの両面で違反サイトの特定を開始する。違反が確認されたサイトには、検索順位の極端な低下や、検索結果からの完全な削除といった厳しいペナルティが科される可能性がある。
このスケジュール感は、2024年3月に行われた大規模なスパムアップデート(サイト評判の不正利用など)の際と同様だ。十分な準備期間を与えることで、意図せず違反状態にあるサイト運営者が修正を行う機会を提供している。
サードパーティ製スクリプトによる意図しない違反のリスク
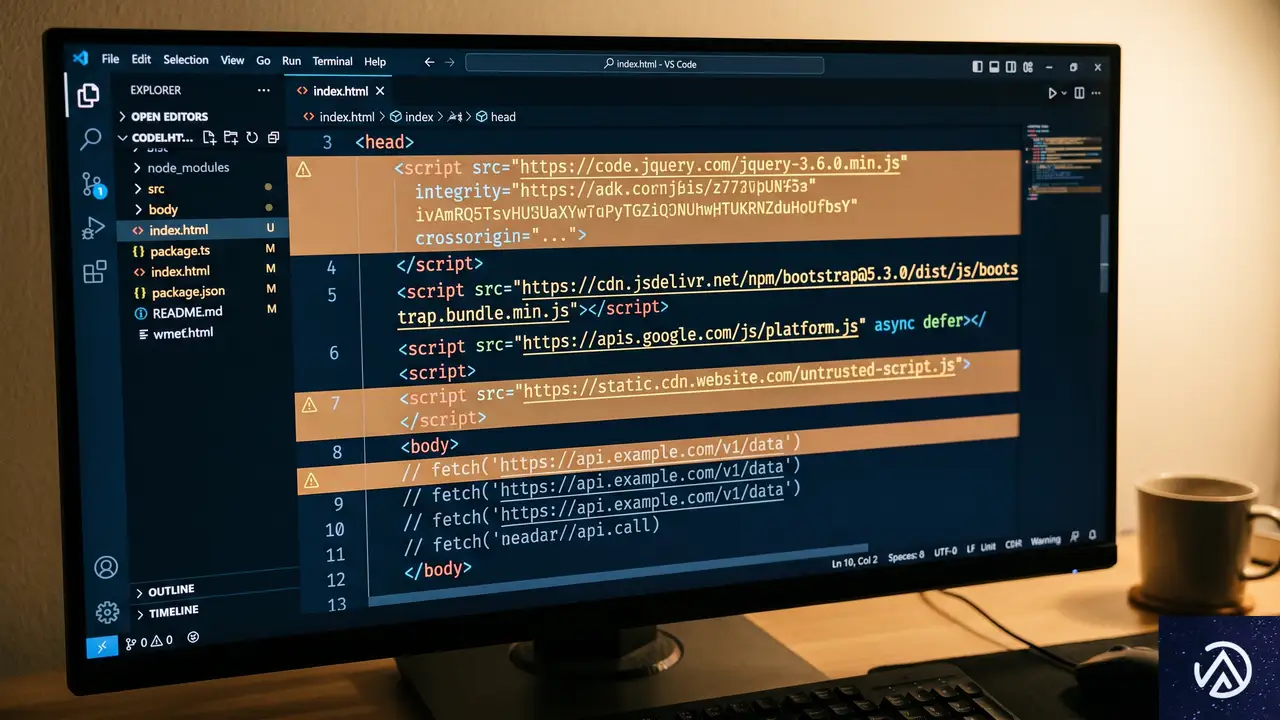
サイト運営者にとって最も注意すべき点は、自らが意図的に乗っ取りを行っていなくても、ポリシー違反と判定される可能性があることだ。Googleのブログでは、一部の「戻るボタンの乗っ取り」は、サイトに組み込まれた外部ライブラリや広告プラットフォームが原因である可能性を指摘している。
例えば、無料で利用できるアクセス解析ツールや、コンテンツ推奨ウィジェット(レコメンドエンジン)、あるいは収益性の高さを謳う特定の広告ネットワークなどが、勝手に履歴を操作しているケースがある。運営者が「便利なツールを導入しただけ」のつもりでも、そのコードがユーザーのナビゲーションを妨害していれば、サイト全体の責任としてペナルティを受けることになる。
このため、自社のエンジニアが書いたコードだけでなく、外部から読み込んでいるすべてのスクリプトがどのような挙動をしているかを把握することが不可欠だ。特に、ページ遷移を伴わないSPA(シングルページアプリケーション)構成のサイトでは、履歴管理のロジックが複雑になりやすいため、意図しないバグが乗っ取りと見なされないよう注意が必要である。
外部ツールを導入する際は、そのツールがブラウザ履歴(History API)に干渉していないか、ドキュメントを確認したり実際にテスト環境で挙動を検証したりすることが求められる。
サイト運営者が今すぐ実施すべき対策と監査方法

猶予期間である6月15日までに、サイト運営者は自社サイトの「戻るボタン」の挙動を徹底的にチェックすべきだ。最も確実な方法は、シークレットモード(プライベートブラウジング)を使用して、一般的なユーザーと同じ条件でサイトを回遊してみることである。
チェックの際は、検索エンジンからサイトへ流入し、数ページ閲覧した後に「戻る」ボタンを連打してみる。もし、前のページに戻るために2回以上のクリックが必要だったり、見たこともない広告ページに飛ばされたりする場合は、即座に原因を特定しなければならない。開発者ツールの「Network」タブや「Console」タブを確認し、履歴を操作している不審なスクリプトが動いていないかを調査する。
もし万が一、6月15日以降に手動ペナルティ(手動による対策)を受けてしまった場合は、Google Search Consoleを通じて通知が届く。その際は問題を修正した上で、再審査リクエストを送信する必要がある。自動アルゴリズムによる順位下落の場合は通知が来ないため、定期的な順位計測とUX指標の監視が重要となる。
チェックリスト:ポリシー違反を避けるために
以下の項目に当てはまる挙動がないか、サイトの全ページを確認することを推奨する。
- 戻るボタンを1回押しただけで、直前のページ(検索結果など)に戻れるか
- 履歴スタックに、ユーザーが訪問していないURLが勝手に追加されていないか
- 戻る操作をした際に、ポップアップ広告や全画面広告が表示されないか
- 特定のサードパーティ製スクリプトを停止した状態で、戻るボタンの挙動が変わらないか
特に、収益化を優先するあまり過度な広告設定を行っているサイトや、古いJavaScriptライブラリを更新せずに使い続けているサイトは、意図せずスパムと判定されるリスクが高い。技術的な負債を解消し、ユーザーが自由にサイトを出入りできる環境を整えることが、長期的なSEOの成功につながる。
独自の分析:UXの健全化がSEOの「最低条件」になる時代

今回のポリシー更新は、Googleが「コンテンツの質」だけでなく「ブラウザ操作の安全性」を極めて重視していることの表れだ。かつては検索順位を上げるためのテクニックが注目されていたが、現在は「ユーザーに不快な思いをさせないこと」がSEOのスタートラインとなっている。
戻るボタンの乗っ取りは、短期的な滞在時間やページビュー(PV)を稼ぐためには有効だったかもしれない。しかし、そうした小細工はブランドの信頼を損なうだけでなく、今や検索エンジンによって明確に排除される対象となった。サイト運営者は、数字上の指標を追う前に、ユーザーがブラウザの標準機能をストレスなく使えるかどうかを最優先すべきだ。
また、この動きは今後、他のブラウザ操作(右クリックの禁止やテキストコピーの妨害など)にも波及する可能性がある。ウェブのオープンな性質を損なう実装は、長期的には検索トラフィックの損失を招くリスクであることを、すべてのマーケターやエンジニアは再認識すべきだろう。
この記事のポイント
- Googleが「戻るボタンの乗っ取り」をスパムポリシーの違反項目に追加した
- ユーザーの意図に反して履歴を操作し、前のページに戻らせない行為が禁止される
- 新ルールは2026年6月15日から適用され、順位下落やペナルティの対象となる
- 自社コードだけでなく、広告や外部ウィジェットなどのサードパーティ製スクリプトも監査が必要だ
- 猶予期間中に「戻る」ボタンの挙動を実機でテストし、不審な挙動を修正すべきだ
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AI検索の利用率は年収で決まる?EC担当者が知るべき検索行動の二極化と対策
AI検索の普及は、すべてのユーザーに平等に進んでいるわけではない。最新の調査データによると、生成AIツールの利用率は世帯年収によって明確な差が生じている。高所得層ほどAIを使いこなし、情報の探し方が根本から変化している実態が明らかになった。
英国のマーケティングメディアであるMarTechが報じたデータでは、世帯年収が10万ポンド(約2,000万円)を超える層の約半数がAIを常用している。一方で、年収が3万ポンド以下の層ではその割合が2割を下回る。この所得による「検索の二極化」は、EC事業者にとって見過ごせない課題だ。
顧客がどのツールで情報を探し、どのように意思決定を行うのか。その前提条件が所得層によって分断されつつある。本記事では、AI検索の普及がもたらす新たなデジタル格差と、断片化する顧客行動に対応するための戦略を詳しく解説する。
AI検索の普及に潜む年収格差の実態

AI検索はすでに一般的になったという論調が多いが、現実はそれほど単純ではない。MarTechの記事で紹介されているBecky Simms氏の分析によれば、生成AIの採用ペースは世帯年収に強く依存している。これは、単なる技術への関心の差ではなく、社会的な構造が背景にある。
高所得世帯ほど生成AIを日常的に活用している
具体的な数字を見ると、その差は歴然としている。世帯年収が2万5,000〜3万ポンドの層では、ChatGPTなどのAIツールを定期的に利用している割合は約18%にとどまる。しかし、年収が7万ポンドを超えると、その利用率は一気に49%まで跳ね上がる。
年収10万ポンド以上の層に至っては、48%から58%という高い水準でAIを利用している。つまり、高所得層は低所得層の2倍から3倍近い頻度でAIを検索や業務に活用していることになる。この格差を視覚化すると、以下のようになる。
このデモが示す通り、年収の上昇に伴ってAI利用率が加速度的に高まっている。高単価な商品やサービスを扱うブランドにとって、ターゲットとなる層がすでに「AIファースト」な行動をとっている可能性が高いことを示唆している。
デジタルスキルの差が情報のアクセシビリティを左右する
この格差は、単なるツールの所有状況だけではなく、基礎的なデジタルスキルの差とも連動している。非営利団体のFutureDotNowのデータによれば、英国の労働年齢層の約52%が、仕事に必要な基本的なデジタルタスクを完遂できない状態にあるという。
AIの利用は、既存のデジタルスキル格差の上にさらに積み重なる新たな層となっている。情報の検索、評価、そして行動。これらのプロセスをAIで効率化できる層と、従来通りの方法でしか情報を得られない層の間で、情報の非対称性が広がっているのだ。
作家のウィリアム・ギブソンは「未来はすでにここにある。ただ、均等に分配されていないだけだ」という言葉を残している。まさに現在のAI検索の状況は、この言葉を体現しているといえるだろう。
なぜAI利用に格差が生まれるのか(3つの要因)

AIの採用が所得によって分かれるのは、単に「有料プランを契約できるかどうか」という金銭的な理由だけではない。Simms氏の分析によれば、人間の行動に根ざした3つの要素が大きく関わっている。それは「アクセス」「能力」「信頼」だ。
職場環境によるアクセスの差
第一の要因は、日常生活や業務の中でAIに触れる機会、すなわち「アクセス」の差だ。ITやビジネス、知識集約型の職種に従事している人々は、ワークフローの一部としてAIの使用を推奨される、あるいは期待される場面が多い。
こうした環境に身を置く人々は、自然とAIを使いこなすようになる。一方で、物理的な労働が中心の職種や、デジタル化が遅れている現場では、AIに触れる機会はニュースなどの二次的な情報に限られる。この初期段階での露出の差が、後の大きな習熟度の差へとつながる。
プロンプトを操る能力とAIへの信頼
第二の要因は、AIを使いこなす「能力」だ。AIとの対話には、適切な指示を出す「プロンプト(命令文)」のスキルが求められる。日常的にAIを使う層は、回答を洗練させ、間違いを修正し、出力を組み立てる方法を経験から学んでいく。
第三の要因は、AIに対する「信頼」だ。AIが生成する情報の正確性をどう評価し、どの程度頼ってもよいと判断するか。Perplexityのような信頼性を重視するプラットフォームの台頭はあるものの、AIを使い慣れていない層にとっては、未知のツールに対する心理的な障壁や不信感が拭えない場合も多い。
これらの要素が組み合わさることで、デジタルに自信のある層がさらにAIで優位性を高めるという、新たなデジタルデバイド(情報格差)が形成されている。ECサイトの運営者は、自社の顧客がどの程度のAIリテラシーを持っているかを慎重に見極める必要がある。
断片化するユーザーの検索行動パターン

検索行動はもはや一様ではない。かつては「何かを知りたければGoogleで検索する」という単一の道筋があったが、現在はユーザーの属性や目的によって、複数のルートに断片化している。これを理解せずに戦略を立てることは、ターゲットの一部を完全に見落とすリスクを伴う。
AIファースト層からAI回避層までの3つの分類
現代のユーザーは、AIへの関与度によって大きく3つのタイプに分類できる。それぞれの層で、情報の受け取り方や期待するコンテンツの形式が異なっている。
- AIファースト層:タスクの代行、情報の要約、選択肢の絞り込みをAIに委ねる。サイトを訪問する前にAIの回答で完結することを好む。
- AIアシスト層:AIで概要を把握しつつ、従来の検索エンジンやSNSで情報の正しさを検証する。複数のプラットフォームを跨いで行動する。
- AI回避層:従来通りのGoogle検索、小売サイト内の検索、あるいはコミュニティ(Redditや掲示板など)を信頼し、AIツールの利用を避ける。
重要なのは、同じユーザーであっても、タスクの内容によってこれらの行動を使い分ける点だ。例えば、法律文書の草案作成にはAIを使い、商品の口コミを調べる際にはGoogleやSNSを使う、といった具合だ。
同じユーザーでも目的によってツールを使い分ける
検索の断片化は、カスタマージャーニーをより複雑にしている。以前のように「検索キーワード」だけでユーザーの意図を把握することは難しくなっている。AIが情報の「要約」と「簡略化」を担う一方で、SNS(TikTokやInstagram)は「人間味のある文脈」や「視覚的な納得感」を提供する場となっている。
以下のデモは、従来の検索と、現代の断片化された検索プロセスの違いを視覚化したものだ。
この変化により、ECブランドは「サイトに来てから説得する」のではなく、「AIやSNSの段階で選ばれている」状態を作らなければならなくなっている。クリックされる前の段階で、いかにブランドを認知させ、信頼を獲得するかが勝負の分かれ目だ。
EC・マーケティング戦略への影響と具体的な対策

高所得層がAIを使い、意思決定をAIに委ね始めているという事実は、ECのマーケティング戦略を根本から変える。ターゲットがAIファーストであるならば、従来のSEO(検索エンジン最適化)だけでなく、GEO(生成エンジン最適化)への対応が急務となる。
属性ではなく行動でターゲットを分析する
年齢や年収といったデモグラフィック(属性)データは、誰がターゲットかを教えてくれるが、彼らが「どう決めるか」までは教えてくれない。これからは、ユーザーがどのプラットフォームで、どのタイミングでAIを使うのかという「行動」に基づいたセグメンテーションが必要だ。
AIを使いこなす「高自信ユーザー」は、AIに選択肢を絞り込ませることを好む。一方、AIに不慣れな「低自信ユーザー」は、馴染みのある環境や人間の声を求める。ブランドは、この両方のジャーニー(顧客体験)を設計しなければならない。
AIに推奨されるための情報の構造化と信頼性向上
AIに自社ブランドを正しく理解させ、推薦してもらうためには、情報の「明快さ」が不可欠だ。複雑で曖昧な表現は、AIによる解釈ミスを招き、結果として検索結果から除外される原因となる。具体的で構造化されたデータを提供することが、AI時代のSEOの基本となる。
また、AIは効率化には優れているが、最終的な「安心感」を与えるのは依然として人間による証明だ。レビュー、権威ある第三者の評価、ブランドの歴史といった「信頼のシグナル」を強化することで、AIが提示した候補の中から「最後に選ばれるブランド」になることができる。
効率性が重視されるAI検索の世界であっても、最終的な決断を下すのは人間だ。技術の進化に目を向けつつも、その背後にある人間の心理や行動の変化を深く理解することが、これからのEC運営には求められている。
この記事のポイント
- AI検索の利用率は世帯年収に比例し、高所得層は低所得層の2倍以上活用している
- AI採用の差は、職場でのアクセス、プロンプト能力、ツールへの信頼度の違いから生まれる
- 検索行動はAIファースト層、AIアシスト層、AI回避層へと断片化が進んでいる
- 高価値な顧客はサイト訪問前にAIで意思決定を終えている可能性が高いため、AIへの最適化が重要になる
- 技術への対応と同時に、レビューや権威性などの「人間による信頼の証明」が選ばれる鍵となる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

WordPressで性格診断クイズを作成しリード獲得を自動化する方法
Webサイトの訪問者を単なる閲覧者で終わらせず、メールマガジンの購読者や顧客へと転換させることは、多くのサイト運営者にとって共通の課題だ。従来の「ホワイトペーパーのダウンロード」や「ニュースレター登録」といった手法は、今や一般的になりすぎてしまい、ユーザーの反応が鈍くなっている傾向がある。
WPBeginnerの記事によると、こうした状況を打破する強力なツールとして「性格診断クイズ」が注目されている。診断クイズは、ユーザーが能動的に参加するインタラクティブなコンテンツであり、楽しみながら自身の特性を知ることができるため、心理的なハードルが低いのが特徴だ。
この記事では、WordPressプラグインのWPFormsを活用して、専門的なコードを一切書かずに高度な性格診断クイズを構築する方法を詳しく解説する。診断結果を表示する直前にメールアドレスの入力を促すことで、高い転換率を実現するリード獲得マシンへとサイトを進化させることが可能だ。
なぜ性格診断クイズがリード獲得に強力なのか

診断クイズが従来のリードマグネット(メールアドレス登録の対価として提供する無料特典)よりも優れている理由は、その「パーソナライズ性」にある。ユーザーは自分自身に関する情報を求めており、その答えを得るためであれば、メールアドレスを提供する心理的コストを許容しやすい。
コンテンツの双方向性が滞在時間を延ばす
静的な記事を読むだけの体験とは異なり、クイズはユーザーに選択を求める。この双方向のやり取りはユーザーのエンゲージメントを高め、結果としてサイトへの滞在時間を延ばす効果がある。滞在時間の向上は、検索エンジンからの評価にも好影響を与える重要な指標だ。
また、クイズの回答を通じてユーザーは自身の悩みや興味を再認識する。例えば「あなたの旅行スタイル診断」というクイズがあれば、ユーザーは設問に答える過程で「自分はリラックスよりも冒険を求めているのだ」と自覚する。この自覚が、その後に提示される提案への納得感を高めることになる。
ユーザーの興味関心に基づいたセグメンテーション
セグメンテーションとは、顧客を特定の属性や興味に基づいてグループ分けすることだ。診断クイズの最大の利点は、リードを獲得した瞬間にそのユーザーの属性が判明している点にある。従来の登録フォームでは「誰が登録したか」はわかっても「その人が何を求めているか」までは把握しにくい。
WPBeginnerの著者によれば、診断結果に基づいて購読者をリスト分けすることで、その後のメールマーケティングの精度が劇的に向上するという。例えば「冒険家タイプ」と診断されたユーザーにはアウトドア用品の情報を、「リラックス派」にはスパやホテルの情報を送るといった、パーソナライズされたアプローチが可能になる。
「最新情報をお届けします」
専用オファー
専用オファー
専用オファー
このデモは、クイズを導入することでユーザーを自動的に分類し、適切なアプローチへつなげる流れを示している。
WPFormsを使った診断クイズの作成手順

WordPressで診断クイズを作成するためのツールはいくつかあるが、操作性と機能のバランスで優れているのがWPFormsだ。特にPro版以上に搭載されている「Quiz Addon(クイズアドオン)」を使用すると、複雑なスコアリング設定を直感的なUIで行うことができる。
診断モードの有効化とタイプ選択
まず、WPFormsの管理画面から「Addons」を選択し、Quiz Addonをインストールして有効化する。その後、新規フォーム作成画面で「Settings」タブの「Quiz」メニューを開き、「Enable Quiz Mode」にチェックを入れる。これでフォームがクイズ機能を備えた状態になる。
診断クイズを作成する場合、クイズタイプとして「Personality Quiz(性格診断クイズ)」を選択することが重要だ。これは正解・不正解を判定するテスト形式ではなく、ユーザーの回答傾向から最も合致する「タイプ」を導き出す形式だ。
診断結果(パーソナリティタイプ)の定義
質問を作り始める前に、まずは「どのような結果を用意するか」を定義する。これをパーソナリティタイプと呼ぶ。例えば旅行サイトであれば「アドベンチャー派」「リラックス派」「文化探求派」といった具合だ。
WPBeginnerの記事では、このタイプ数を3〜5個に絞ることを推奨している。選択肢が多すぎると回答の紐付けが複雑になり、ユーザーにとっても結果の差異が分かりにくくなるからだ。各タイプには、ユーザーが納得し、かつ次の行動(商品の購入や記事の閲覧)に移りたくなるような魅力的な名前を付ける必要がある。
回答と結果を紐づけるロジックの構築

診断クイズの核心部分は、ユーザーの回答をあらかじめ定義したパーソナリティタイプにどう結びつけるかというロジックにある。WPFormsでは、各質問の選択肢ごとに「この回答を選んだらどのタイプにカウントするか」を個別に設定できる。
質問項目の作成とAI活用
質問の作成には「Multiple Choice(多肢選択)」フィールドを主に使用する。ユーザーが直感的に答えられるよう、画像付きの選択肢(Image Choices)を活用するのも有効だ。視覚的な情報はテキストよりも素早く認識されるため、回答の離脱率を下げる効果が期待できる。
質問のアイデアに詰まった場合は、WPFormsに搭載されている「AI Choices」機能を利用するとよい。質問文を入力してプロンプトを送るだけで、AIが関連性の高い選択肢を自動生成してくれる。これにより、クイズ作成にかかる時間を大幅に短縮することが可能だ。
回答ごとのスコアリング設定
各質問のフィールド設定を開くと、各選択肢の横にパーソナリティタイプを選択するドロップダウンが表示される。ここで「海で泳ぐのが好き」という回答には「リラックス派」を、「未開の地を歩きたい」という回答には「アドベンチャー派」を割り当てていく。
最終的な診断結果は、全設問を通じて最も多くカウントされたタイプが表示される仕組みだ。そのため、すべての選択肢に漏れなくタイプを割り当てることが重要となる。一つでも未設定の項目があると、計算が狂い、ユーザーに不適切な結果を表示してしまう恐れがあるため注意が必要だ。
診断結果をメールマガジン登録につなげる設計

クイズを単なる娯楽で終わらせず、リード獲得の手段とするためには、導線の設計が極めて重要だ。最も効果的なのは、診断結果を表示する直前にメールアドレスの入力を求める「ゲート型」の配置だ。
ページ区切りとメールアドレス入力欄の設置
すべての質問が終わった後に「Page Break(ページ区切り)」を挿入し、新しいページにメールアドレス入力フィールドを配置する。ここで「あなたの診断結果をメールで送信します」や「結果を見るためにメールアドレスを入力してください」といったメッセージを添える。
ユーザーはすでに数分を費やしてクイズに回答しており、「答えを知りたい」という欲求が高まっている。このタイミングでの入力要請は、通常の登録フォームよりもはるかに高いコンバージョン率を記録する傾向がある。ただし、プライバシーポリシーへの同意チェックボックスを設置するなど、法的・倫理的な配慮も忘れてはならない。
外部メール配信サービスとの連携
獲得したメールアドレスは、自動的にメール配信サービス(Constant ContactやMailchimpなど)へ転送されるよう設定する。WPFormsの「Marketing」タブから、利用しているサービスとの連携が可能だ。
この際、単にリストに追加するだけでなく、診断されたタイプに応じた「タグ」を付与するように設定する。これにより、登録直後から「アドベンチャー派の人だけに向けたウェルカムメール」を自動配信できるようになり、非常に高い開封率とクリック率を実現できる。
全10問の設問にユーザーが回答
「結果を見るためにメールを入力してください」
診断結果を表示し、配信サービスへデータを送信
このフロー図は、ユーザーが診断結果という報酬を得るためにメールアドレスを提供する心理的なプロセスを視覚化したものだ。
独自の分析:クイズを「売れる仕組み」に変えるためのポイント

WPFormsでクイズを作成するのは技術的に難しくないが、それを実際の収益や成果につなげるには、マーケティング視点での工夫が必要だ。ここでは、診断クイズの効果を最大化するための独自の分析結果を紹介する。
結果画面でのパーソナライズされた提案
診断結果の画面(Outcome)は、ユーザーが最も集中して画面を見ている瞬間だ。ここに単なる「あなたは〜タイプです」という説明だけで終わらせるのは、大きな機会損失と言える。各タイプの結果画面に、その属性に最適化された「次にとるべき行動(CTA)」を配置すべきだ。
例えば「アドベンチャー派」と出たユーザーには、おすすめの登山靴の商品リンクや、秘境ツアーの予約ページへのリンクを表示する。WPFormsのスマートタグ({quiz_personality_type}など)を活用すれば、ユーザーの名前や診断結果を文章の中に自然に組み込むことができ、親近感と信頼感を醸成できる。
診断データを活用したステップメール配信
クイズで獲得したデータは、登録直後のメール配信だけでなく、中長期的なナーチャリング(顧客育成)にも活用できる。診断結果に基づいて、そのユーザーが抱えているであろう課題を推測し、解決策を提示するステップメールを組むのが効果的だ。
この手法は、サードパーティクッキーの規制が進む現代において、ユーザーから直接提供される「ゼロパーティデータ」を活用する極めて健全かつ強力な戦略となる。ユーザーは自分の好みを伝えているため、その後に届くメールを「自分向けの有益な情報」として受け取り、広告としての嫌悪感を抱きにくいからだ。
この記事のポイント
- 性格診断クイズは、従来のリードマグネットよりも高いエンゲージメントと登録率を期待できる。
- WPFormsのQuiz Addonを使えば、ノーコードで高度な診断ロジックとスコアリングを構築可能。
- 診断結果を表示する直前にメール入力を求める「ゲート設計」がリード獲得の鍵となる。
- 獲得した属性データ(タイプ)をメール配信サービスと連携させ、パーソナライズされた追客を行う。
- 結果画面に具体的な商品提案やCTAを配置することで、診断を直接的な収益機会に変えることができる。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Google特許が示す検索の新たな層——AI生成ランディングページの衝撃
Googleが取得した特許が、検索エンジンの未来像に大きな一石を投じた。特許の内容は、ユーザーの検索クエリとコンテキストに応じて、AIがその場でランディングページを生成するシステムだ。
この技術が実用化されれば、検索結果と従来のウェブサイトの間に、新たな「層」が出現することになる。EC事業者やコンテンツ発信者は、自社サイトのデザインやメッセージングをユーザーに直接届ける機会を、さらに奪われる可能性がある。
本記事では、特許の内容を詳細に読み解き、検索の進化の歴史に照らし合わせてその意味を考察する。さらに、この変化に対応するためにEC事業者が今から取り組むべき具体的な対策を提示する。
特許が描く「AI生成ランディングページ」の仕組み

ユーザーごとに最適化されたページを動的生成
2026年1月27日に米国特許商標庁から発行された特許「US12536233B1」は、AI生成コンテンツページに関するものだ。特許が示すシステムの核は、検索クエリとユーザー情報を基に、そのユーザー専用のランディングページを動的に生成する点にある。
システムはまず、検索クエリとユーザーのコンテキスト、そして従来のランキングアルゴリズムが選び出した候補となるランディングページ群を評価する。評価基準は多岐にわたり、商品情報の不足、コンテンツの薄さ、ナビゲーションの弱さ、ユーザーエンゲージメントの低さなどが低評価の要因となる。
評価の結果、既存ページが不十分と判断されると、システムはそれらのページを「素材」として使い、個々のユーザー向けに最適化された新たなバージョンのページを生成する。例えば、全く同じ「ランニングシューズ」というクエリを検索した二人のユーザーが、異なるランディングページに誘導される可能性がある。一人には商品比較表を中心にしたページが、もう一人には直接購入に導くページが表示されるかもしれない。
フィードバックループによる継続的改善
特許が示すもう一つの重要な要素は、フィードバックループだ。生成されたページは静的なものではない。ユーザーのクリック、ページ滞在時間、コンバージョンなどの行動データがシステムにフィードバックされ、将来生成されるページの精度を高めるために利用される。
この仕組みにより、Googleは膨大な数のユニークなページを生成し、それぞれの検索者をカスタマイズされたバージョンに誘導する動的な体験を提供できる。特に商品検索に関連するクエリでは、購入オプションを前面に押し出したページが生成される可能性が高い。
Practical Ecommerceの記事によれば、この動的ページ実現への現実的な経路は、既に導入されている「AIオーバービュー」を通じたものだと考えられる。AIオーバービューは情報を要約して提示するが、次のステップとして、その要約をインタラクティブな体験に拡張し、最終的には独立したウェブページとして展開する流れが想定される。
検索進化の歴史から見る「新たな層」の位置付け

検索とコンテンツの関係性の変遷
ECコンサルタントのGreg Zakowicz氏は、この特許の概念を「検索の経済学における新たな層」と表現した。この「層」という考え方は、検索エンジンとウェブサイト所有者の間の力関係の変化を理解する上で有効だ。
かつては、検索プラットフォームとコンテンツ所有者は相互依存の関係にあった。プラットフォームは質の高いコンテンツを必要とし、コンテンツ所有者はプラットフォームからのトラフィックを必要とした。しかし、検索産業の進化は、顧客と事業者を次第に引き離す方向に進んでいる。
この図が示すように、モノetization(広告)、Answers(ナレッジグラフ)、Evaluation(リッチリザルト)、Extraction(特集スニペット)、Interaction(垂直検索)、Synthesis(AIオーバービュー)と、各層が追加されるごとに、ユーザーが元のウェブサイトに直接アクセスする必要性は薄れてきた。AI生成ランディングページは、この流れの延長線上にある「最終的な層」と言えるかもしれない。
「検索の経済学」の変化が事業者に与える影響
Zakowicz氏が指摘する「検索の経済学」の変化とは、トラフィックと収益の流れの再分配を意味する。新しい層が出現するたびに、ウェブサイト所有者がレイアウト、メッセージング、商品提示をコントロールする影響力は弱まる。ユーザー体験は、ますますアルゴリズムによって組み立てられるものになる。
Practical Ecommerceの記事は、この状況を「サイトはGoogleの検索結果ページにおいてほとんどコントロールを失っている」と表現する。検索結果ページ自体が、外部サイトへの単なる入り口ではなく、完結した体験の場へと変貌しつつある。
EC事業者が取るべき具体的な対策

オウンドメディアと直接的な顧客関係の構築
アルゴリズムが仲介する体験の影響力が強まる中で、事業者が取るべき第一の対策は、自分自身でコントロールできるチャネルを強化することだ。具体的には、メールマーケティングやSMSなどのオウンドメディアが該当する。
ニュースレターやマーケティングメッセージを通じてサイトに訪れるユーザーは、アルゴリズムが組み立てたページではなく、ブランドそのものを選択して訪問している。検索プラットフォーム内で行われる発見が増えるほど、このような直接的な接点は「絶縁材」としての価値を高める。顧客との関係性を自ら所有することは、検索エンジンの変化に対する最も強力な防御策となる。
構造化データと高品質な入力情報の提供
第二の対策は、アルゴリズムが「読みやすい」データを提供することに注力する姿勢への転換だ。仮に特許のようなシステムが実装されれば、その生成体験は構造化された入力情報に大きく依存するだろう。
この場合、事業者の役割は、美しいランディングページをデザインすることから、正確で豊富な商品属性データ、Schema.orgマークアップ、整った商品フィードといった「高品質な入力情報」を提供することへとシフトする。ボットやプログラム、アルゴリズムが容易に理解し、利用できる形式で情報を提供することが、生成された体験の中に商品が表示され、クリックを獲得するための前提条件となる。
説得力のあるコピー、視覚的な階層、直感的なCTAボタンの配置など、人間のユーザーを説得するためのページ作りが中心だった。
正確な商品仕様、構造化されたレビュー、機械が解釈しやすい属性データなど、AIが「素材」として活用できる高品質な情報の提供が重要になる。
この変化は、SEOの本質的な作業が「検索エンジン向け」から「AI生成システム向け」に移行することを意味する。クリックを獲得する機会は残るが、その入り口の形と、そこに至るための最適化方法が根本から変わる可能性がある。
この記事のポイント
- Googleの特許は、検索クエリとユーザーごとにAIがランディングページを動的に生成するシステムを明らかにした。これは検索結果とウェブサイトの間に現れる「新たな層」となり得る。
- 検索は「発見」から「回答抽出」「統合」へと進化し、ユーザーが元サイトに到達する前の段階で体験が完結する方向にある。AI生成ページはこの流れの延長線上にある。
- この変化により、EC事業者はサイトのデザインやメッセージングを直接ユーザーに届けるコントロールをさらに失う可能性がある。
- 対策の二本柱は「オウンドメディアによる直接的な顧客関係の構築」と「構造化データなどアルゴリズム向けの高品質な入力情報の提供」である。人間向けのデザインから、機械が利用しやすいデータ提供への重心移動が求められる。
- 特許は必ずしも実用化を保証するものではないが、検索プラットフォームの長期的な方向性を示す重要なシグナルとして捉えるべきだ。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Googleのタスク型エージェント検索がSEOを今すぐ変える理由と対策
Googleの検索が「タスクを完了する」エージェントへと急速に変化している。従来の「キーワードを入力してウェブサイトのリンクを得る」モデルは、AIが直接レストランの予約を取ったり、情報を収集したりする「タスク実行型」の検索に置き換わりつつある。この変化は未来の話ではなく、すでに現在進行形で起きている。
Search Engine Journalの記事によると、GoogleのCEOサンダー・ピチャイは近い将来、検索の多くが「エージェント型」になると述べている。ユーザーは情報を探すだけでなく、AIエージェントにタスクを管理させ、複数の作業を並行して実行させるようになる。このパラダイムシフトは、SEOとコンテンツ戦略の根本的な見直しを迫るものだ。
検索が「タスク完了」へと変わる瞬間
従来のインターネットと検索は、同じキーワードを入力した何百万人ものユーザーに、同じようにインデックスされたウェブページのリストを提供するモデルだった。しかしAIの登場により、ユーザーは単なる情報検索から「トピックの調査」や「タスクの実行」へと行動を移しつつある。リンクをクリックしてサイトを読むだけでは、ユーザーが求める明確な答えが得られないケースが増えている。
レストラン予約にみるエージェント検索の実例
この変化を象徴する具体例が、Googleが全世界で展開を開始した「エージェント型レストラン予約」機能だ。ユーザーは検索ボックスに「6人で土曜の夜、雰囲気の良いイタリアン」といった要望を自然言語で入力する。するとAIエージェントが複数の予約プラットフォームを同時にスキャンし、空き状況やメニューを確認した上で、実際に予約可能な店舗を提示する。
Googleの検索プロダクト責任者であるRose Yao氏は、この機能について「アプリを切り替える必要も、手間もない。ただ美味しい食事を」と説明している。これはもはや従来の「検索」ではなく、「タスクの完了」そのものだ。重要な点は、この機能が「近い将来実現するもの」ではなく、すでに利用可能であることだ。
サイト側に求められる対応
この新しい検索モデルでは、レストランなどの事業者側も対応が迫られる。AIエージェントが情報を取得できるように、空き予約枠やその日のメニュー選択肢などのデータを提供する必要がある。将来的には、AIエージェントと直接予約を完了できる仕組みがウェブサイトに求められるだろう。
これは単なる技術的なアップデートではなく、ビジネスプロセスの変革を意味する。検索マーケティングの専門家は、この変化がもたらす影響を真剣に考える時期に来ている。
「個人専用インターネット」時代の到来

タスク型エージェント検索がもたらすもっと深い変化は、インターネットそのものが「ハイパーパーソナライズ化」する点だ。クラウドフレアは最近の記事で、インターネットの進化を3つの段階に分けて説明している。
インターネット進化の3段階
クラウドフレアの比喩が分かりやすい。従来のアプリケーションは「レストラン」のようなものだ。決まったメニュー(機能)があり、それを大量に提供するために最適化された厨房(インフラ)がある。一方、AIエージェントは「個人専属シェフ」に例えられる。毎回「何が食べたい?」と聞き、その答えに応じて必要な食材や調理法が変わる。レストランの厨房では対応できない。
SEOへの具体的な影響
この変化がSEOに与える影響は計り知れない。ローカルSEO、ショッピング、情報検索のすべてが、ハイパーパーソナライズされたウェブ体験に再構築される。検索が「エージェントマネージャー」に変わるというピチャイの発言は、単なる未来予想ではなく、現在進行形の現実を指している。
デジタルマーケティング担当者が考えるべきは、数十億の人間を代表する数十億のエージェントを支えるインフラではなく、その中で自社のビジネスがどう位置づけられるかだ。エージェントがタスクを完了する過程で、どの情報源を信頼し、どのように意思決定するのか。この「意思決定レイヤー」に自社がどう登場するかが、新しいSEOの核心となる。
コンテンツ管理システムの対応:WordPress 7.0の役割
人間中心のウェブからエージェント中心のウェブへの移行に際し、コンテンツ管理システム(CMS)の対応は極めて重要だ。特に間もなくリリース予定のWordPress 7.0は、この変化に対応するための機能が多数盛り込まれている。
AIシステムとの接続機能
現在のインターネットは人間の相互作用のために構築されている。AIエージェントはその構造の中で動作しているが、これは急速に変化する見込みだ。WordPress 7.0が重視しているのは、AIシステムとシームレスに接続する機能だ。これにより、ウェブサイトが人間だけでなく、AIエージェントにも適切に情報を提供できる基盤が整う。
具体的には、構造化データの強化、APIファーストなアーキテクチャ、エージェントが理解しやすいコンテンツ形式などが挙げられる。これらの機能は、従来の人間ユーザー向け最適化に加えて、AIエージェント向けの最適化を可能にする。
エージェントが「信頼する」情報源になるために
検索マーケティングの専門家Mike Stewart氏は、この変化について重要な指摘をしている。彼はFacebookへの投稿で、「これはもはやAIが支援する段階ではなく、AIがあなたに代わって操作する段階だ」と述べた上で、以下の問いを提示している。
Stewart氏はさらに、「エージェント型検索は、それを支えるエコシステム(ウェブサイト、コンテンツ、ビジネス)なしには成立しない。その部分はなくならないが、抽象化される」と付け加えている。つまり、ウェブサイトやコンテンツの重要性は変わらないが、人間が直接アクセスする形ではなく、AIエージェントを通じて間接的に利用される形に変化するということだ。
タスク型エージェント検索への具体的な対策

理論的な理解だけでなく、実際にSEO担当者が今から取り組める対策がある。タスク型エージェント検索の時代に向けて、以下のポイントに注目すべきだ。
構造化データの徹底強化
AIエージェントが情報を正確に理解し、タスクを完了するためには、構造化データがこれまで以上に重要になる。特にSchema.orgの語彙を活用し、以下のような情報を明確にマークアップする必要がある。
APIファーストな情報提供
人間がブラウザで閲覧するHTML形式だけでなく、AIエージェントがプログラム的に情報を取得できるAPIの提供が重要になる。WordPressではREST APIが標準で搭載されているが、エージェント向けに最適化されたエンドポイントを用意する必要があるかもしれない。
情報の更新頻度も鍵となる。エージェントがレストランの空き状況を確認する場合、その情報が数時間前のものでは意味がない。可能な限りリアルタイムに近い情報提供が求められる。
コンテンツの「信頼性」シグナルの強化
Mike Stewart氏が指摘した「エージェントはどの情報源を信頼するのか」という問いは核心を突いている。エージェントが意思決定する際、信頼性の高い情報源を優先するだろう。以下の要素が信頼性シグナルとして機能すると考えられる。
具体的な信頼性シグナルとしては、正確で最新の構造化データ、他の信頼できるサイトからの言及やリンク、ユーザーレビューの質と量、企業の実在証明などが挙げられる。これらは従来のSEOでも重要だったが、エージェント検索ではさらに重要性が増す。
この記事のポイント
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Google検索で勝つサイトの共通点とは?400サイトの分析から見えた5つの成功法則
Googleの検索アルゴリズムが複雑化する中で、どのようなサイトが実際にトラフィックを伸ばしているのかを把握することは容易ではない。Zyppyの創設者であるCyrus Shepard氏が実施した400以上のウェブサイトに対する分析により、オーガニックトラフィックを増加させたサイトに共通する5つの特徴が明らかになった。
この調査では、過去12ヶ月間のトラフィック推移を第三者ツールで測定し、サイトのビジネスモデルやコンテンツの性質との相関関係を調べている。その結果、単なる情報の羅列ではなく、ユーザーに対して実利的な価値を提供しているサイトが優位に立っている実態が浮き彫りとなった。
SEOの成功は一つの要因で決まるものではないが、特定の要素を積み重ねることで検索順位の「勝率」を劇的に高められる可能性がある。本記事では、データに基づいた5つの成功要因と、それらを実務にどう活かすべきかを詳しく解説していく。
400サイトのデータが示す勝てるサイトの共通点

Cyrus Shepard氏の調査は、SEO専門家のLily Ray氏が以前に行ったコアアップデートの分析対象サイトを再訪する形で実施された。サイトをビジネスモデルやコンテンツタイプごとに分類し、トラフィックの変化との相関(スピアマンの順位相関係数)を算出している。
調査の概要と相関関係の測定方法
分析の対象となったのは、アフィリエイトサイト、ECサイト、サービス提供サイトなど多岐にわたる。ここで重要なのは、Google Search Consoleの生データではなく、外部ツールによる推定トラフィックに基づいている点だ。しかし、400件というサンプルサイズは、現在の検索環境における大きな傾向を掴むには十分な規模といえる。
調査では、サイトが持つ特定の機能や性質がトラフィックの増減とどれほど強く結びついているかを数値化している。相関係数は0.206から0.391という中程度の値を示しており、これは「その要素があれば必ず勝てる」という魔法の杖ではないものの、無視できない明確な傾向が存在することを示唆している。
・アフィリエイトリンクへの誘導が主目的
・サイト独自のツールや機能がない
■ ユーザーがその場で問題を解決できる機能
■ 他者が模倣できない独自のデータ資産
上記の図が示すように、従来の「情報を整理して伝えるだけ」のスタイルから、より実用的で独自性の高い「価値提供型」のスタイルへの転換が求められていることがわかる。では、具体的にどのような指標が重要視されているのかを深掘りしていこう。
トラフィック増に直結する5つの重要指標

分析の結果、トラフィックを伸ばしたサイト(勝者)と減らしたサイト(敗者)の間で、顕著な差が見られた要素は5つに集約される。これらはGoogleが「どのようなサイトをユーザーにとって有益だと判断しているか」を考える上での強力なヒントになる。
自社製品の有無とタスクの完遂
第一の特徴は「自社製品またはサービスの提供」だ。勝者の70%が自社で何らかの製品やサービスを販売していたのに対し、敗者ではその割合は34%にとどまった。これには物理的な商品だけでなく、サブスクリプション型のサービスやデジタルコンテンツも含まれる。自社製品を持つことは、サイトの信頼性やビジネスとしての実体を示す強力なシグナルになっていると考えられる。
第二に「タスクの完遂が可能であること」が挙げられる。勝者の83%が、ユーザーが検索した目的をそのサイト内で完結できる仕組みを持っていた。例えば、計算ツール、予約フォーム、詳細な比較シミュレーターなどがこれに該当する。単に「やり方を教える」だけでなく「その場で実行できる」環境を提供しているサイトが、Googleからの評価を勝ち取っている。
模倣困難な独自資産とトピックの専門性
第三の要素は「独自の資産(Proprietary Assets)」だ。勝者の92%が、他者が容易に真似できない独自のデータセット、ユーザー生成コンテンツ(UGC)、あるいは専門的なソフトウェアを保有していた。インターネット上に溢れる情報の焼き直しではなく、そのサイトでしか得られない「一次情報」や「ツール」の価値がかつてないほど高まっている。
第四に「絞り込まれたトピックへの特化」がある。単に「特定のジャンルを扱っている」というレベルではなく、一つの狭いテーマを極めて深く掘り下げているサイトが勝者となる傾向が見られた。広範なトピックを浅くカバーする総合サイトよりも、特定のニッチ領域で「このテーマならこのサイト」と言わしめるほどの専門性が、現在のアルゴリズムには好まれている。
最後に「強いブランド力」だ。全体トラフィックに対する指名検索(ブランド名での検索)の割合が高いサイトほど、トラフィックを維持・拡大させている。勝者のブランド検索比率は敗者の2倍に達しており、検索エンジン経由だけでなく、ユーザーから直接指名される存在になることがSEOの安定にも寄与していることがわかる。
意外にも相関が見られなかった要素とその背景

今回の調査では、SEOの世界で重要だと信じられてきたいくつかの要素が、意外にもトラフィックの増減と直接相関しなかったという結果も出ている。この事実は、SEO戦略の優先順位を見直す上で非常に興味深い示唆を含んでいる。
体験談やUGCが決定打にならなかった理由
Cyrus Shepard氏の分析によれば、一次体験(First-hand experience)の記述、個人的な視点、ユーザー生成コンテンツ(UGC)、コミュニティ機能の有無などは、今回のデータセットにおいては勝者と敗者を分ける決定的な要因にはならなかった。また、情報の独自性そのものも、単体では強い相関を示さなかったという。
ただし、Shepard氏はこの結果を「これらの要素が不要である」と解釈すべきではないと注意を促している。これらの要素はすでにGoogleのアルゴリズムに深く組み込まれており、ベースライン(最低限必要な条件)となっている可能性があるからだ。つまり、体験談があるのは「当たり前」であり、それだけで他サイトに差をつけることは難しくなっているという見方ができる。
重要なのは、これらの要素を「持っているかどうか」ではなく、前述した5つの重要指標とどのように組み合わせて、ユーザーの課題解決(タスク完遂)に結びつけるかという点にある。単なる日記のような体験談ではなく、それが自社製品の信頼性を裏付けたり、独自のデータ資産の一部として機能したりすることで、初めて強力な武器になるのだ。
複数の特徴を組み合わせる加点方式の重要性

この調査で最も注目すべき発見は、5つの特徴が「累積的」に作用するという点だ。一つひとつの要素の相関は中程度でも、複数を組み合わせることでサイトの勝率は飛躍的に高まることがデータで示されている。
具体的には、5つの特徴のうち一つも持たないサイトの勝率はわずか13.5%だった。特徴を一つだけ持っている場合も15%程度と、大きな変化は見られない。しかし、3つ以上の特徴を備えるあたりから勝率は急上昇し、5つすべての特徴を持つサイトの勝率は69.7%にまで達した。この「3つの壁」を越えられるかどうかが、SEOの成否を分ける境界線といえそうだ。
このデータから得られる教訓は、部分的な改善に終始するのではなく、サイトの構造やビジネスモデルそのものを「勝者のパターン」に近づけていく努力が必要だということだ。例えば、アフィリエイト記事を書くだけでなく、簡易的な診断ツールを導入したり、独自のアンケート調査結果を公開したりすることで、複数の特徴を同時に満たすことができる。
【独自分析】今後のSEO戦略にどう活かすべきか

今回の分析結果を踏まえると、今後のSEOは「コンテンツ制作」の枠を超え、「サービス設計」に近い領域へとシフトしていくと考えられる。Googleは情報の正確性だけでなく、その情報が「実際に役立ったか」というユーザー体験の完結を重視しているからだ。
情報提供から価値提供への転換
サイト運営者がまず取り組むべきは、自分のサイトが単なる「情報の通過点」になっていないかを確認することだ。ユーザーが検索した後に、別のサイトへ移動して作業を続ける必要があるなら、それは「タスクの完遂」を妨げていることになる。自社でツールを開発するのが難しい場合でも、詳細なステップバイステップのガイドや、独自のチェックリストを提供することで、ユーザーの利便性を高めることは可能だ。
また、ブランド力の強化も欠かせない。指名検索を増やすためには、検索エンジン以外の流入経路(SNS、メールマガジン、外部メディアへの露出など)を確保し、「〇〇のことならこのサイト」という認知を広げる必要がある。これは一朝一夕には達成できないが、長期的なSEOの安定には最も効果的な投資となるだろう。
最後に、独自資産の構築だ。これは必ずしも高度な技術を必要としない。自社で蓄積した顧客の声、独自の実験結果、あるいは膨大な公開データを独自の切り口で分析したレポートなどは、AIには生成できない強力な武器になる。これらをトピックの深掘りと組み合わせることで、競合が容易に追随できない「勝てるサイト」へと進化させることができるはずだ。
この記事のポイント
- トラフィックを伸ばしているサイトの70%は自社製品やサービスを提供している
- ユーザーがサイト内で目的を完遂できる「タスク完了」の仕組みが評価を分ける
- 他者が模倣できない独自データやツールを持つサイトは92%という高い勝率を誇る
- 広範なテーマよりも、一つのニッチなトピックを深く掘り下げることが重要だ
- 5つの成功要因を3つ以上組み合わせることで、検索での勝率が飛躍的に高まる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AI検索可視性データを地域戦略に活かす方法——引用ギャップを埋めるSEO実践
AI検索がSEO戦略の中心的な話題となる中、多くのSEO担当者は経営層から「我が社のAI検索対策はどうなっているのか」というプレッシャーを受けている。従来の検索エンジン最適化とは異なるロジックで動くAI検索において、ブランドが引用されるためにはどのようなシグナルが重要になるのか。そしてそのデータをどう地域別の実行戦略(GEO戦略)に落とし込むのか。この問いに答えるための具体的なフレームワークと実行モデルが、最新のデータ分析から明らかになりつつある。
Search Engine Journal主催のウェビナーでは、Writesonicの創業者兼CEOであるSam Garg氏が、5億件以上のAI検索会話データを分析した結果を基に、AI検索で実際に引用されるコンテンツの特徴と、地域別の引用ギャップを埋めるための優先順位付け手法を解説する。本記事では、そのエッセンスを先取りして紹介する。
AI検索における引用のメカニズム
ChatGPT、Perplexity、GeminiといったAI検索ツールは、従来のGoogle検索とは異なる基準で情報源を選択し、回答に引用する。多くのSEOチームは、自社がAI検索で「見えていない」領域をダッシュボードで把握しているが、それを修正する具体的なプロセスを持たない場合が多い。まず理解すべきは、AIがどのようなコンテンツを引用する傾向にあるのか、その根本的なシグナルだ。
従来のSEOとAI検索最適化の根本的な違い
従来の検索エンジン最適化は、キーワードの出現頻度、被リンク、ページの技術的な健全性など、比較的測定可能な数百のシグナルに基づいてランキングが決定される。一方、AI検索ツールは、ユーザーの質問に対する「最も信頼できる回答」を生成するために、情報の新鮮さ、権威性、そして特定の文脈における適切さを総合的に判断する。この判断プロセスにおいて、どの情報源を引用するかは、従来のページランキングとは必ずしも一致しない。
例えば、地域に密着した詳細なデータを持つ中小規模のサイトが、汎用的な大規模メディアよりも特定の質問で優先して引用されるケースがある。AIは、質問の文脈に最も合致し、かつ信頼できると判断したソースを選ぶ。この「信頼性」の判断には、ドメインの権威だけでなく、コンテンツの専門性、構造化データの有無、更新頻度などが複合的に影響する。
引用を獲得するコンテンツの3つの特徴
Writesonicによる大規模データ分析から、AI検索で引用されやすいコンテンツには共通する特徴が浮かび上がっている。
第一に、明確な構造と階層を持つコンテンツだ。見出しタグ(H1〜H3)を適切に使い、箇条書きや表で情報が整理されているページは、AIが内容を理解し、特定の部分を抽出して引用しやすい。逆に、長大な散文調の記事は、関連する部分を見つけるのが難しくなる。
第二に、具体的な数字やデータ、最新の情報を含むこと。AIは「2026年現在」「調査によると約70%」といった定量的で時間的コンテキストが明確な情報を好んで引用する。曖昧な表現や古いデータは信頼性を損なう。
第三に、専門性と権威性を裏付ける外部ソースへのリンクだ。自説を主張するだけでなく、関連する学術論文、公的統計、権威ある業界レポートへのリンクを適切に含めることで、コンテンツ全体の信頼性が高まり、引用される可能性が上がる。
このデモは、AIが引用しやすいコンテンツの特徴を示している。左側の曖昧な表現から、右側のように具体的な数字、調査元、対象地域を明確にした構造に変えることで、情報の信頼性と抽出可能性が高まる。
引用ギャップを特定するデータ分析手法
自社ブランドや製品がAI検索でどのように言及されているか、あるいは言及されていないかを把握するには、体系的なデータ分析が必要だ。ここで重要なのは、単に「見えていない」キーワードや地域をリストアップするだけでなく、なぜ見えていないのか、その根本原因を特定することにある。
可視性データの収集と解釈
まず、自社に関連する検索クエリに対して、主要なAI検索ツール(ChatGPT、Perplexity、Gemini等)がどのような回答を生成し、どの情報源を引用しているかをモニタリングする。この際、自社サイトが引用されているか否かだけでなく、競合他社が引用されているクエリ、あるいはどの情報源も引用されていない(AIが独自に生成した回答のみの)クエリも記録する。
得られたデータを「クエリの意図」「地域性」「コンテンツタイプ」の3つの軸で分類する。例えば、「東京 コワーキングスペース おすすめ」というクエリは「商業施設の推薦(意図)」「東京(地域)」「リスト記事(タイプ)」に分類される。この分類ごとに、自社の引用有無と、引用されている他サイトの特徴を分析することで、ギャップのパターンが見えてくる。
ギャップの根本原因を探る優先順位付けフレームワーク
すべての引用ギャップを同時に埋めようとするのは非現実的だ。限られたリソースで最大の効果を上げるためには、優先順位を決める必要がある。Sam Garg氏が提唱するフレームワークでは、以下の2つの指標でギャップを評価する。
第一の指標は「機会の大きさ」だ。そのクエリや地域における検索ボリューム、および自社にとってのビジネス上の重要性(成約率や単価)を数値化する。第二の指標は「埋めやすさ」だ。既存のコンテンツを更新するだけで対応できるのか、ゼロから新しいコンテンツや外部提携が必要なのか。必要な工数と難易度を評価する。
この優先順位付けにより、リソースを「既存資産の最適化」という効果の高い活動に集中させることができる。すべてのギャップを均等に埋めようとする従来のアプローチから脱却する第一歩だ。
AIエージェントを活用した地域戦略の実行自動化
優先すべきギャップが特定できたら、次は実行フェーズだ。特に地域別(GEO)戦略では、対象地域ごとに微妙に異なるコンテンツや情報の更新が必要となり、人的リソースが逼迫しがちである。ここで威力を発揮するのが、AIエージェントを活用したタスクの自動化だ。
無料のオープンソースツールで構築する自動化パイプライン
大規模な予算をかけなくても、現在公開されている無料のオープンソースツールを組み合わせることで、多くのGEO関連タスクを自動化できる。Sam Garg氏のウェビナーでは、具体的なツールの例とその連携方法が紹介される予定だ。
一つの例として、地域別の引用状況を監視するパイプラインを考えてみる。まず、Pythonのスクレイピングライブラリ(BeautifulSoupなど)や、AI検索APIを模倣するツールを使って、定期的に特定の地域クエリに対するAIの回答を収集する。次に、収集したテキストデータから自社ブランドや競合の言及を抽出し、スプレッドシートやデータベースに記録する。このデータ更新をトリガーに、引用ギャップが検出された地域に対して、あらかじめ準備したコンテンツ更新テンプレートや、地域メディアへのコンタクトリストを提示する内部通知システムを構築する。
人的判断とAI自動化の適切な分担
重要なのは、すべてをAIに任せるのではなく、クリエイティブな判断や複雑な交渉が必要な部分は人間が担当し、データ収集、モニタリング、ルーティンワーク、初期ドラフトの作成などをAIエージェントに担当させることだ。この分担を明確にすることで、SEOチームはより戦略的な活動に時間を割くことができる。
例えば、新しい地域での権威構築のために地元メディアへの寄稿を目指す場合、AIエージェントはその地域に関連するメディアリストの作成、編集者の連絡先収集、過去の記事傾向の分析を担当する。人間の担当者は、分析結果を基にパーソナライズされたアプローチ文面を考え、実際のコンタクトと関係構築を行う。
この分担モデルを導入することで、地域別の細やかな対応が人的リソースの限界を超えて可能になる。特に、複数の地域を同時にカバーする必要がある事業者にとって、持続可能な戦略実行の基盤となる。
この記事のポイント
- AI検索での引用は、従来のSEOとは異なるロジックに基づく。具体的なデータ、明確な構造、権威ある外部リンクを含むコンテンツが引用されやすい。
- 引用ギャップを埋めるには、単なる可視性データの収集だけでなく、「機会の大きさ」と「埋めやすさ」で優先順位を付けるフレームワークが有効だ。
- 地域別(GEO)戦略の実行負荷を下げるには、AIエージェントを活用したデータ収集・分析・ルーティンワークの自動化が鍵となる。クリエイティブな判断は人間が担う分担モデルを構築する。
- 無料のオープンソースツールを組み合わせることで、予算をかけずに自動化パイプラインの構築を始めることができる。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AIエージェントに最適化するWeb制作の新常識!アクセシビリティツリーが鍵を握る理由
主要なAIプラットフォームのすべてが、今やウェブサイトを自律的に閲覧できる能力を備えている。Google Chromeの自動ブラウジング機能はページをスクロールしてクリックを行い、ChatGPTのAtlas(アトラス)はフォームへの入力や購入手続きまで代行する。しかし、これらのAIエージェントは、私たち人間と同じようにウェブサイトを見ているわけではない。
サイバーセキュリティ企業であるImperva(インパーバ)の調査によれば、2024年には自動化されたトラフィックが人間によるトラフィックを初めて追い越し、全ウェブインタラクションの51%に達した。この数字のすべてがAIエージェントではないが、ウェブの主役が非人間に移りつつある事実は明らかだ。私たちは今、人間だけでなくマシンに対しても最適化されたサイトを構築する必要がある。
AIエージェントとの互換性を高めるために最も効果的な方法は、実はウェブアクセシビリティの向上である。かつてはスクリーンリーダーのために用意されていた「アクセシビリティツリー」が、今やAIエージェントがサイトを理解するための主要なインターフェースへと進化している。この記事では、AIがサイトをどのように認識し、制作者がどう対応すべきかを詳しく紐解いていく。
AIエージェントはウェブサイトをどう認識しているのか
人間がサイトを訪れるとき、色やレイアウト、画像、タイポグラフィといった視覚的な情報を処理する。これに対し、AIエージェントがサイトを訪問した際に受け取る情報は、そのプラットフォームの設計思想によって大きく3つのアプローチに分かれる。それぞれの違いを理解することが、対応の第一歩となる。
スクリーンショットによる視覚的解析(Vision)
Anthropic(アンソロピック)の「Computer Use(コンピューター・ユース)」は、最も直感的なアプローチを採用している。AIモデルのClaude(クロード)がブラウザのスクリーンショットを撮影し、その画像を解析して「どこをクリックすべきか」「何をタイプすべきか」を判断する。これは、人間が画面を見て操作するプロセスをデジタルで再現したものだ。
Googleの「Project Mariner(プロジェクト・マリナー)」も同様のループを採用しており、視覚的な要素と背後のコード構造を組み合わせて動作する。この「視覚ベース」のアプローチは汎用性が高い一方で、計算コストが非常に高く、レイアウトのわずかな変更に影響を受けやすいという弱点がある。また、画面に描画されていない情報を読み取ることはできない。
アクセシビリティツリーによる構造把握(Structure)
OpenAIのChatGPT Atlasは、異なる道を選んだ。彼らの公式ドキュメントによれば、AtlasはARIA(エリア)タグを活用してページの構造や対話型要素を解釈している。ARIAとは、視覚障害者が使うスクリーンリーダーなどにウェブサイトの構造を伝えるための技術規格だ。
Atlasはレンダリングされたピクセルを解析するのではなく、ブラウザが生成する「アクセシビリティツリー」に問い合わせを行う。ここから「ボタン」「リンク」といった役割(ロール)や、その要素の名前を取得する。MicrosoftのPlaywright(プレイライト)MCPも同様で、視覚的なレンダリングよりも構造化されたアクセシビリティデータを優先してブラウザの自動操作を行っている。
視覚と構造を組み合わせたハイブリッド方式
実務で最も強力なエージェントは、これら両方の手法を組み合わせている。OpenAIの「Computer-Using Agent(CUA)」は、スクリーンショットの解析に加えて、DOM(ドキュメント・オブジェクト・モデル)の処理とアクセシビリティツリーのパースをレイヤー化して実行する。DOMとは、HTML文書をプログラムから扱うためのデータ構造のことだ。
Perplexity(パープレキシティ)の調査でも、アクセシビリティツリーのスナップショットと選択的な視覚解析を組み合わせた「ハイブリッド・コンテキスト管理」が有効であるとされている。視覚だけで判断するよりも、構造化されたデータを利用する方が、情報の信頼性と処理効率が格段に向上するためだ。
アクセシビリティツリーがAIとの接点になる理由
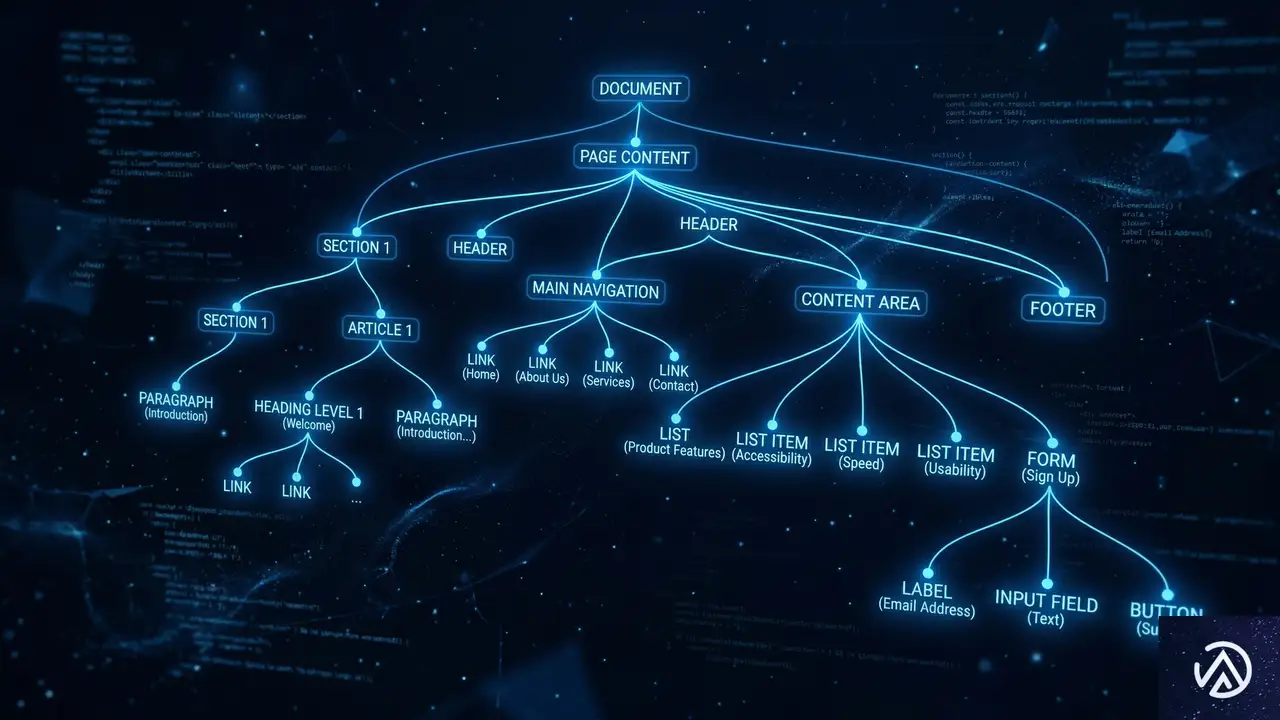
アクセシビリティツリーとは、ブラウザが支援技術のために生成する、DOMの簡略化された表現だ。通常のDOMには、デザインのための <div> や <span> 、スタイル指定、スクリプトなど、膨大な「ノイズ」が含まれている。これに対し、アクセシビリティツリーはそれらを削ぎ落とし、操作に関わる重要な要素だけを抽出する。
AIモデルにとって、処理できる情報の量(コンテキストウィンドウ)には限りがある。数千ものノードがあるDOMをすべて読み込ませるよりも、ボタンやリンク、見出し、フォームといった「意味のある要素」だけに絞り込まれたアクセシビリティツリーを渡す方が、AIははるかに正確にサイトを理解できる。OpenAIが「アクセシブルなサイトにすることは、Atlasがサイトを理解する助けになる」と明言しているのは、このためだ。
研究データが示すアクセシビリティの効果
カリフォルニア大学バークレー校とミシガン大学が2026年に発表した共同研究では、アクセシビリティの状態がAIエージェントの成功率にどう影響するかが検証された。Claude Sonnet 4.5を用いたテストの結果、標準的なアクセシビリティを備えた状態でのタスク成功率は78.33%であった。しかし、アクセシビリティを制限した条件では、その成功率は劇的に低下した。
例えば、キーボード操作のみ(スクリーンリーダー利用時を想定)に制限すると、成功率は41.67%にまで落ち込み、完了時間は2倍に増えた。さらに表示領域を制限した条件では、成功率は28.33%にまで低下している。この結果は、視覚的なヒントや複雑なJavaScript操作に頼り、アクセシブルな代替手段を提供していないサイトでは、AIエージェントが失敗する確率が高まることを示している。
構造化されたデータの優先順位
Perplexityの検索APIに関する論文(2025年9月)によると、彼らのインデックスシステムは、元の構造やレイアウトが保持された高品質なコンテンツを優先している。特にリストやテーブル形式で整理された「構造化データ」が豊富なサイトは、パース(解析)や情報の抽出が容易であるため、AIの回答に引用されやすくなるメリットがある。
セマンティックHTMLで構築するAIフレンドリーな基盤
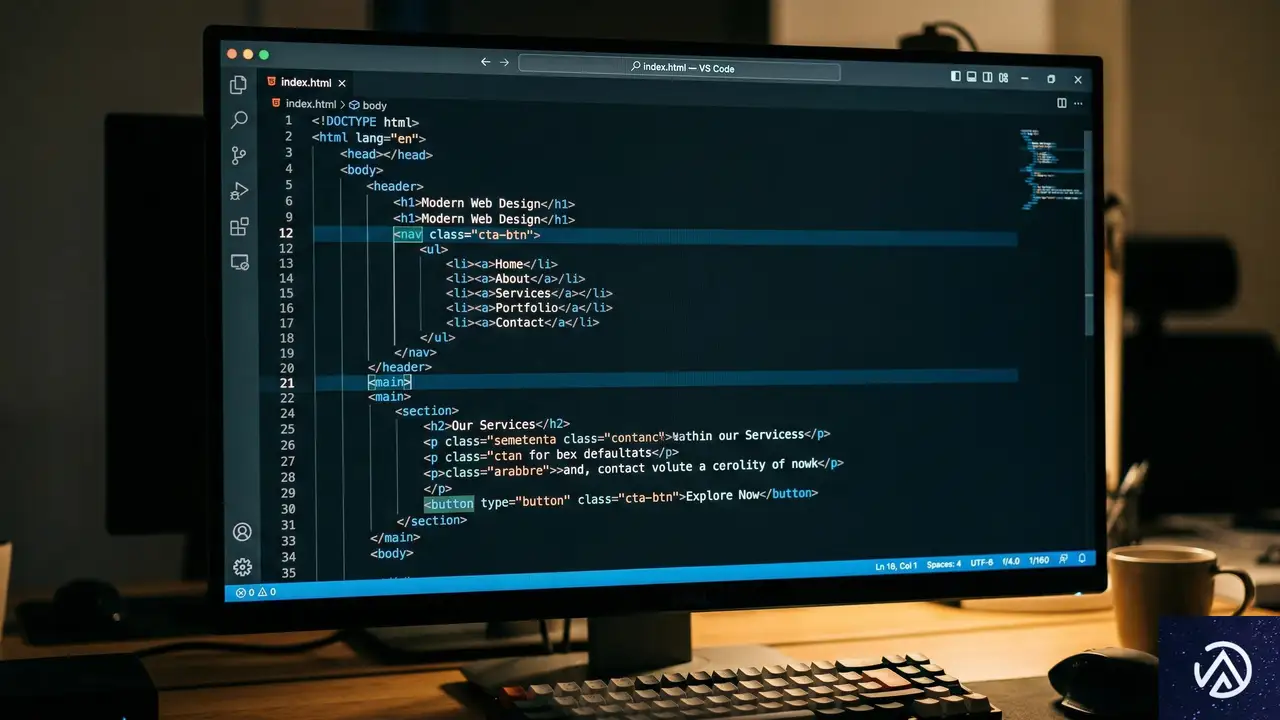
アクセシビリティツリーはHTMLから構築される。つまり、正しい「セマンティックHTML」を使うことが、AI対応の最も基本的かつ強力な手段となる。セマンティックHTMLとは、タグそのものが意味を持つHTMLの書き方のことだ。例えば、単なる <div> ではなく <button> を使うことで、ブラウザは自動的にその要素を「ボタン」としてアクセシビリティツリーに登録する。
ネイティブ要素の活用とフォームのラベル付け
開発者が <div onclick="..."> のようなコードを書くと、AIはその要素がクリック可能であることを認識できない場合がある。一方で、ネイティブの <button> 要素を使えば、その役割とテキスト内容が正確に伝わる。同様に、フォームの入力フィールドには必ず <label> を紐付けるべきだ。ラベルがない入力欄を、AIは「何を入れればよいか不明な箱」として扱ってしまう。
また、 autocomplete 属性の活用も重要だ。これを使うことで、「名前」「メールアドレス」「住所」といったデータの種類をAIに明示できる。AIエージェントがユーザーに代わってフォームを入力する際、この属性があれば推測に頼らず自信を持ってフィールドを埋めることが可能になる。
見出しの階層とランドマークの明示
見出しタグ( h1 から h6 )を論理的な順序で使用することも欠かせない。AIエージェントは、見出しを頼りにページの構造を把握し、特定のセクションを探し出す。階層を飛ばして( h1 の次に h4 を使うなど)しまうと、コンテンツの親子関係に混乱が生じる。さらに、 <nav> 、 <main> 、 <footer> といったランドマーク要素を使うことで、ページ内のどこに何があるのかをAIに一義的に伝えることができる。
このデモは、HTMLタグの選び方によってAIエージェントへの情報の伝わり方がどう変わるかを視覚化したものだ。
ARIAとレンダリング戦略の注意点
OpenAIは、動的なウェブコンテンツをアクセシブルにするための標準規格であるARIAの使用を推奨している。しかし、ARIAはあくまで「補足」であり、不完全なHTML構造を隠すための魔法ではない。W3C(ワールド・ワイド・ウェブ・コンソーシアム)が定めた「ARIAの第一ルール」は、ネイティブなHTML要素で実現できるならARIAを使うな、というものだ。
ARIAの誤用が招くリスク
アクセシビリティの専門家であるAdrian Roselli(エイドリアン・ロセリ)氏は、OpenAIの推奨が不適切なARIAの多用を招く可能性を懸念している。実際、WebAIMの調査によれば、ARIAを使用しているサイトは、そうでないサイトよりもアクセシビリティエラーが多い傾向にある。これは、ARIAが「とりあえずの修正」として誤って使われることが多いためだ。
正しいアプローチは、まずセマンティックなHTMLで土台を作り、タブパネルやツリービューのようにHTML標準にないカスタムコンポーネントを作る場合に限って、ARIAで役割や状態( aria-expanded など)を補完することだ。キーワードを aria-label に詰め込むような行為は、初期のSEOにおけるメタキーワードの乱用と同じく、逆効果になる可能性がある。
サーバーサイドレンダリング(SSR)の必須性
ブラウザベースのAIエージェントはJavaScriptを実行できるが、すべてのAIクローラーがそうであるとは限らない。PerplexityBotやOAI-SearchBotなどは、コンテンツを収集する際にクライアント側のJavaScriptを実行しないことが多い。もしサイトがReactなどで構築され、ブラウザで実行されるまで中身が空の <div id="root"></div> であれば、AIは何も見つけることができない。
AIエコシステムにおいて「存在しない」と見なされないためには、サーバーサイドレンダリング(SSR)やプリレンダリングが不可欠だ。また、重要な情報をタブや展開メニューの中に隠さないことも推奨される。Microsoftのガイドラインによれば、AIシステムは隠されたコンテンツをレンダリングしない場合があるため、重要な詳細は初期表示のHTMLに含めるべきだとしている。
AI対応状況を確認するためのテスト手法

サイトを公開する前にブラウザで表示を確認するように、AIエージェントがどう認識しているかをテストすることも重要だ。最も手軽で効果的な方法は、スクリーンリーダー(macOSのVoiceOverやWindowsのNVDA)を使ってサイトを操作してみることだ。視覚を使わずに主要なタスクを完了できるなら、AIエージェントも同様に操作できる可能性が高い。
ツールによるアクセシビリティスナップショット
より直接的にAIの「目」を確認したい場合は、MicrosoftのPlaywright MCPが提供するアクセシビリティスナップショット機能が役立つ。これは視覚的なプレゼンスを取り除き、AIが処理する「役割」「名前」「状態」だけを構造化されたテキストとして出力してくれる。もし重要なボタンがこのスナップショットに現れない、あるいは適切な名前が付いていない場合は、改善が必要だ。
テキストブラウザでの見え方を確認する
Lynx(リンクス)のようなテキスト専用ブラウザでサイトを表示してみるのも有効な手段だ。画像やレイアウトをすべて剥ぎ取った状態で、コンテンツの順序や階層が論理的に整理されているかを確認できる。AIエージェントは、私たちがデザインした美しいレイアウトを見ているのではなく、その背後にある情報の流れを読み取っているからだ。
この記事のポイント
- AIエージェントはアクセシビリティツリーを主要なインターフェースとして利用している
- セマンティックHTML(正しいタグ選び)がAI最適化の最も重要な基盤となる
- ARIAは魔法ではなく、ネイティブHTMLで足りない部分を補うために使うべきだ
- JavaScriptに依存しすぎず、SSRを活用して初期HTMLにコンテンツを含めることが重要だ
- スクリーンリーダーでのテストは、AIエージェントとの互換性を測る最良の指標になる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験