

CSS段組みレイアウトの革命!column-wrapで横スクロール問題を解消する
CSSのMulti-column Layout(マルチカラムレイアウト)は、長い文章を新聞のように複数の列に分割して表示する仕組みだ。これまでWeb制作の現場では、コンテンツが溢れた際に強制的に横スクロールが発生してしまうという致命的な課題があり、利用シーンが限られていた。しかし、Chrome 145から導入された新しいプロパティによって、この状況が劇的に変わろうとしている。
最新のアップデートでは、column-wrap(カラム・ラップ)とcolumn-height(カラム・ハイト)という2つのプロパティが追加された。これにより、指定した高さを超えたコンテンツを次の「行」へと折り返して表示する、いわゆる「2Dフロー」が可能になった。これはWebにおけるテキスト表現の幅を大きく広げる重要な進化といえる。
本記事では、CSS-Tricksが報じた最新情報を基に、新しい段組みレイアウトの仕組みや具体的な活用方法、そして既存のCSS GridやFlexboxとの使い分けについて詳しく解説する。新しいプロパティがどのようにWebのユーザー体験を改善するのか、その全容を紐解いていこう。
従来のCSS段組みレイアウトが抱えていた大きな課題

CSSの段組みレイアウトは、古くから存在する仕様でありながら、現代のWebデザインでは主役になりきれなかった。その最大の理由は、コンテンツの量が増えたときの挙動がWebの閲覧スタイルに合っていなかったからだ。ここでは、なぜ従来の段組みが使いにくかったのかを振り返る。
横スクロールというUX上の壁
従来の段組みレイアウトでは、column-count(列の数)やcolumn-width(列の幅)を指定して文章を流し込む。しかし、親要素に高さを設定している場合、テキストがその高さを超えると、ブラウザは右側に新しい列を勝手に追加していく。その結果、ユーザーはページを横にスクロールしなければ最後まで読めないという状態に陥る。
Webサイトの基本は垂直(縦)スクロールだ。スマートフォンの普及により、縦に指を動かす操作が標準となった現代において、突如として現れる横スクロールはユーザーに混乱を与える。これが「UX(ユーザーエクスペリエンス)上の禁じ手」とみなされ、多くのデザイナーが段組みの使用を避ける原因となっていた。
レスポンシブ対応の難しさ
また、従来の段組みは「1次元的」な流れしか持っていなかった。コンテンツは常に左から右へと流れるだけで、画面の下に回り込むことはない。画面幅が狭いモバイル端末では、列を1つにするなどの調整が必要だが、高さの制限がある中でコンテンツを適切に収めるには、複雑な計算やJavaScriptによる制御が不可欠だった。CSSだけで完結できない点が、開発のハードルを上げていたのだ。
Chrome 145で登場した「column-wrap」と「column-height」

2026年4月にリリースされたChrome 145では、これらの問題を一挙に解決する新機能が実装された。それがcolumn-wrapプロパティだ。このプロパティの登場により、段組みレイアウトは「横に伸び続ける」仕組みから「縦に折り返す」仕組みへと進化した。
2Dフローを実現する新しい仕組み
新しく導入されたcolumn-wrap: wrapを指定すると、コンテンツが指定された高さを超えた際、右に新しい列を作るのではなく、下に新しい「段組みの行」を作成する。これにより、コンテンツ全体を縦スクロールの中で完結させることができるようになる。これは、Flexboxがflex-wrap: wrapで要素を次の行に送る挙動に近いが、段組みレイアウト独自の「テキストの分割」機能を保持している点が異なる。
具体的なコードの書き方と挙動の変化
新しいプロパティを使用する場合、基本的には対象の要素にcolumn-countとcolumn-wrap、そして基準となる高さを指定する。以下のコード例を見てほしい。column-wrap: wrapを加えるだけで、横への溢れが解消される。
.article {
column-count: 3;
column-gap: 20px;
column-wrap: wrap; /* 新プロパティ */
height: 400px;
}上記のデモが示すように、column-wrap: wrapを適用することで、コンテンツは親要素の幅の中で適切に折り返される。これは単なる見た目の変化ではなく、Webサイト全体のアクセシビリティとユーザビリティを向上させる大きな一歩だ。
新しい段組みプロパティが活躍する3つの具体的な場面

この新機能は、どのようなWebサイトで威力を発揮するのだろうか。CSS-Tricksの記事では、いくつかの実用的なユースケースが紹介されている。特に「固定の高さ」を扱うデザインにおいて、そのメリットは顕著だ。
高さが決まっているカード型レイアウト
もっとも身近な例は、ブログの記一覧や製品紹介などのカード型レイアウトだ。各カードの最大高さが決まっている場合、段組みレイアウトを使うことで、要素を美しく並べることができる。column-wrap: wrapを使えば、カードの数が増えてもレイアウトが崩れず、シームレスに次の行へと流れていく。Flexboxでも同様のことは可能だが、段組みレイアウトは「要素の途中で改行させない」といった制御(break-inside: avoidなど)が容易であるため、より洗練されたカード配置が可能になる。
雑誌や新聞のような本格的なマガジン形式
オンラインマガジンやニュースサイトにおいて、新聞のような多段組みデザインを採用したいケースは多い。これまでは、画面サイズに合わせて手動でコンテンツを分割するか、横スクロールを許容するしかなかった。新しいプロパティを使えば、デバイスの高さに合わせて自動的に段を折り返すことができるため、どの端末で見ても「読みやすい新聞スタイル」を維持できる。これは、コンテンツの連続性を保ちつつ、視覚的なリズムを生み出すのに最適だ。
垂直スクロールを活用したフルスクリーン・カルーセル
個人的に興味深い活用法として挙げられているのが、垂直方向のページめくり体験だ。column-heightをビューポート(画面の表示領域)いっぱいの高さ(100dvhなど)に設定し、CSSのscroll-snap-typeと組み合わせる。すると、コンテンツが画面の高さに合わせて自動的に「ページ」として分割され、ユーザーは縦にフリックするだけで雑誌をめくるように記事を読み進めることができる。JavaScriptを使わずに、CSSだけでこのような高度なインタラクションが実現できるのは驚きだ。
既存のCSSレイアウト手法と新機能の使い分け

新しい段組みレイアウトが登場したからといって、CSS GridやFlexboxが不要になるわけではない。むしろ、それぞれの特性を理解し、適切に使い分けることが重要だ。ここでは、それぞれの設計思想の違いを整理する。
CSS GridやFlexboxとの決定的な違い
CSS GridやFlexboxは、基本的に「個別の要素(子要素)」をどのように配置するかを管理するシステムだ。対して、段組みレイアウト(Multi-column)は「単一の連続したコンテンツ」をどのように分割するかを管理する。この違いは大きい。
例えば、1つの長い長文を途中で切り離すことなく複数の列に流し込みたい場合、GridやFlexboxでは文章を物理的に分割して複数のHTML要素に分ける必要がある。しかし、段組みレイアウトなら1つの<p>タグの中身をそのまま分割できる。構造を壊さずにレイアウトを変更できるのは、段組みレイアウトだけの特権だ。
注目が集まるCSS Masonryとの比較
現在、CSSの仕様策定が進んでいる「Masonry(メーソンリー)レイアウト」とも比較されることが多い。Masonryは高さの異なる要素を隙間なく敷き詰める手法だが、段組みレイアウトもcolumn-countを使えば似たような見た目を作ることができる。ただし、Masonryが「要素の順序」を重視するのに対し、段組みレイアウトはあくまで「コンテンツの流れ」を重視する。情報の優先順位が重要なニュース記事などでは段組みが適しており、ビジュアル重視のギャラリーサイトなどではMasonryが適しているといえるだろう。
導入時に注意すべき制限事項とブラウザ対応状況

非常に便利な新機能だが、実務で採用する際にはいくつか注意点がある。まず、2026年4月時点でのブラウザ対応状況だ。このプロパティは現在、Chrome 145以降でのみサポートされている。FirefoxやSafari、Edgeではまだ利用できないため、現時点では「プログレッシブ・エンハンスメント」の考え方で導入するのが現実的だ。
プログレッシブ・エンハンスメントとは、基本の機能はすべてのブラウザで提供しつつ、最新ブラウザではより良い体験を提供する設計手法を指す。未対応ブラウザでは従来の1カラム表示やシンプルな段組みにし、Chromeユーザーには進化した2Dフローを提供するという構成が望ましい。
また、動的なコンテンツへの対応も課題だ。ユーザーが投稿するコメントやCMSから配信される記事など、高さが予測できないコンテンツの場合、column-heightを固定してしまうと、不自然な余白ができたり、意図しない場所で折り返されたりする可能性がある。完全にレスポンシブな設計にするには、依然としてメディアクエリを駆使して、画面サイズごとに最適な列数や高さを微調整する作業が必要になるだろう。
この記事のポイント
- Chrome 145で導入された
column-wrap: wrapにより、段組みの横スクロール問題が解消された。 - コンテンツが高さを超えた際に「下の行」へ折り返す2Dフローが実現可能になった。
- 固定高のカードレイアウトや、新聞スタイルのデザイン、垂直カルーセルなどで特に威力を発揮する。
- GridやFlexboxが「要素の配置」を得意とするのに対し、段組みは「単一コンテンツの分割」に特化している。
- 現時点ではブラウザ対応が限定的なため、未対応環境へのフォールバックを考慮した設計が不可欠だ。

・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Cloudflare Organizationsベータ版登場!複数アカウントの一元管理とセキュリティ強化の全容
Cloudflare(クラウドフレア)は、大規模なエンタープライズ企業が自社のインフラをより効率的に管理するための新機能「Cloudflare Organizations(クラウドフレア・オーガニゼーションズ)」をベータ版として公開した。この機能は、これまで独立していた複数のCloudflareアカウントを一つの「組織」としてまとめ、一元的な管理を可能にするものだ。
大規模な組織では、数千人規模のユーザーが開発やセキュリティ、ネットワークなどの多岐にわたる業務でCloudflareを利用している。今回のアップデートにより、管理者は個別のログインや設定の繰り返しから解放され、組織全体のアナリティクスやポリシーを一括で制御できるようになる。
なぜこの機能が重要なのか。それは、セキュリティの鉄則である「最小権限の原則」を維持しながら、管理の複雑さを劇的に解消できるからだ。本記事では、Cloudflare Organizationsがもたらす変化とその技術的な背景を詳しく解説していく。
Cloudflare Organizationsが解決する大規模運用の課題

多くのエンタープライズ企業は、セキュリティを担保するために複数のCloudflareアカウントを使い分けている。これは、特定のチームに必要以上の権限を与えないための「最小権限の原則(Principle of Least Privilege)」に基づいた運用だ。
複数アカウントによる管理の断片化
最小権限の原則とは、ユーザーに業務遂行に必要な最小限のアクセス権だけを与える考え方だ。例えば、マーケティングチームが管理する特設サイトの設定と、基幹システムのネットワーク設定は、異なるアカウントで管理するのが望ましい。これにより、万が一ひとつのアカウントが侵害されても、被害を限定的に抑えられるからだ。
しかし、この運用には大きなデメリットがあった。管理者はすべてのアカウントに個別にアクセスし、権限を設定しなければならない。アカウントが増えるほど管理は「断片化」し、誰がどのアカウントに対してどのような権限を持っているのかを把握することが困難になっていたのだ。
運用の煩雑さとヒューマンエラーのリスク
従来、全社的なセキュリティレポートを作成する場合、管理者は各アカウントにログインして個別にデータを収集する必要があった。また、共通のセキュリティポリシーを適用する際も、アカウントごとに同じ設定を手動で繰り返す必要があり、これが設定ミスや漏れといったヒューマンエラーの原因となっていた。
Cloudflare Organizationsは、こうした「セキュリティのためのアカウント分割」が生み出した管理コストを削減するために設計されている。アカウントの独立性を保ったまま、管理レイヤーだけを統合する仕組みだ。
■ アカウントB(本番用)→ 個別にログイン
■ アカウントC(外部用)→ 個別にログイン
※管理者がバラバラに管理する必要がある
├ ■ アカウントB
└ ■ アカウントC
このデモは、Organizationsがアカウントの階層構造をどのように整理するかを視覚化したものだ。
Organizationsの主要機能と新しい管理ロール

Cloudflare Organizationsの導入により、新しい管理権限の仕組みが導入された。その中心となるのが「Org Super Administrator(組織スーパー管理者)」というロールだ。
「Org Super Administrator」の役割
これまで、管理者は各アカウントの「Super Administrator」として登録される必要があった。しかし、Organizationsでは組織レベルで管理者を任命できる。この組織スーパー管理者は、組織に紐づけられたすべてのアカウントに対して、自動的に最高権限を持つことになる。
特筆すべきは、この管理者が個別のアカウントのユーザーリストに表示されない点だ。これにより、アカウント内の一般ユーザーが誤って管理者を削除してしまうといった事故を防ぐことができる。また、新しくアカウントが組織に追加された際も、管理者は即座にそのアカウントを制御できるため、オンボーディングのスピードが向上する。
複数アカウントを横断するダッシュボード
Organizationsのもう一つの大きな特徴は、アカウントを跨いだ情報の集約だ。ベータ版ではまず、HTTPトラフィックのアナリティクスが提供される。これにより、組織全体のトラフィック傾向や、特定のドメインでの異常なアクセス増加を一つの画面で監視できるようになった。
今後は、監査ログ(Audit Logs)や請求レポート(Billing Reports)も組織レベルで統合される予定だ。これにより、誰がいつ、どのアカウントで設定を変更したのかを組織全体で追跡できるようになり、コンプライアンスの強化にもつながる。
セキュリティと効率を両立する共有ポリシー

エンタープライズ企業にとって、セキュリティ基準を社内全体で統一することは至上命題だ。Cloudflare Organizationsは、この課題に対して「共有ポリシー」という強力な解決策を提示している。
WAFやGatewayポリシーの一括適用
これまでは、WAF(Web Application Firewall / ウェブアプリケーションファイアウォール)のルールを更新する場合、各アカウントにログインして同じ作業を繰り返す必要があった。しかし、Organizationsでは、特定のアカウントで作成したポリシーセットを、組織内の他のアカウントへ共有できる。
例えば、セキュリティ専門チームが管理する「マスターアカウント」で最新の脆弱性対策ルールを作成し、それを全社のアカウントに一括で適用するといった運用が可能になる。これにより、セキュリティレベルのばらつきをなくし、全社的な防御力を底上げできる。
この仕組みにより、各チームの担当者は自前で複雑なセキュリティ設定を行う必要がなくなり、本来の開発業務に集中できるようになる。
開発の舞台裏とパフォーマンスの改善

このOrganizations機能の実現は、Cloudflareの内部システムにおける大規模な刷新の結果でもある。Cloudflareのチームは、これを単なる新機能の追加ではなく、システム基盤の再構築として取り組んだ。
13万行のコード刷新とインナーソース開発
開発にあたっては「インナーソース(Innersource)」という手法が採用された。これは、オープンソースの開発手法を社内のプロジェクトに適用するものだ。このプロジェクトでは、約133,000行の新しいコードが追加され、32,000行の古いコードが削除された。Cloudflareの権限システム史上、最大級の変更となったという。
この刷新の目的は、古いコードパスを排除し、すべての認可チェックを「ドメインスコープのロールシステム」に集約することだ。これにより、将来的に新しいロールや機能をより迅速にリリースできる強固な土台が完成した。
権限チェック速度が27%向上
この基盤刷新は、ユーザー体験にも直接的なメリットをもたらしている。特に、数千ものアカウントやゾーン(ドメイン)にアクセス権を持つパワーユーザーにおいて、アカウント一覧やゾーン一覧の表示速度が課題となっていた。今回の最適化により、権限チェックのパフォーマンスが27%向上し、大規模環境での管理画面のレスポンスが大幅に改善された。
Organizationsの導入方法と今後の展望

Cloudflare Organizationsは、まずエンタープライズプランの顧客を対象にパブリックベータとして公開されている。今後数ヶ月以内に、Pay-as-you-go(従量課金)プランを含むすべての顧客に拡大される予定だ。
安全な移行プロセス
導入はセルフサービス形式で行われる。エンタープライズアカウントのスーパー管理者であれば、ダッシュボードに招待が表示される仕組みだ。Cloudflare側が勝手に組織を作成することはない。これは、意図しない権限昇格を防ぐための配慮だ。
もし社内の別のユーザーがすでに組織を作成している場合は、そのユーザーから招待を受けるか、自分を組織の管理者として追加してもらう必要がある。このプロセスにより、どのアカウントを組織に含めるかを、各アカウントの管理者が明示的に承認する形が維持されている。
ロードマップに並ぶ強力な機能
Organizationsは、今後一年をかけてさらに進化する予定だ。現在公開されているロードマップには以下の項目が含まれている。
- 組織レベルの監査ログ(Audit Logs)
- 組織レベルの請求レポート
- より詳細なアナリティクスレポートの拡充
- 組織レイヤーでの追加ユーザーロール
- セルフサービスによる新規アカウント作成
独自の分析:なぜ今、Cloudflareは「組織」単位の管理に注力するのか

今回のアップデートは、Cloudflareが単なる「CDNベンダー」から、企業の「統合ネットワークインフラ」へと完全に脱皮したことを象徴している。かつてCloudflareは、個々のドメインを高速化・保護するためのツールだった。しかし現在、企業はアイデンティティ管理(Zero Trust)やサーバーレス開発(Workers)など、ビジネスの根幹をCloudflare上で動かしている。
利用範囲が広がれば、当然ながら管理する単位はドメインから「組織」へとシフトする。Organizationsの導入は、AWS(Amazon Web Services)が「AWS Organizations」を導入した際と同様の進化のプロセスと言えるだろう。
特に、WAFポリシーの共有機能は、セキュリティの民主化を加速させる可能性がある。高度なスキルを持つ中央のセキュリティチームが作成した「盾」を、全社の開発チームが意識することなく利用できる。この「ガードレール」としての役割こそが、現代のプラットフォームエンジニアリングが目指す姿だ。Cloudflareは今回の基盤刷新により、その理想を実現するための強力な武器を手に入れたと言える。
この記事のポイント
- Cloudflare Organizationsにより、複数のアカウントを一元管理できるようになった
- 「組織スーパー管理者」ロールにより、個別のアカウント管理が不要になる
- WAFやGatewayのポリシーを組織全体で共有・一括適用が可能に
- 内部システムの刷新により、権限チェックの速度が27%向上した
- 現在はエンタープライズ向けベータ版で、順次全ユーザーに開放予定
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

2026年EUクッキー法完全対応ガイド——WordPressサイトの必須対策と実装手順
EU域内のユーザーを対象とするWebサイト運営者にとって、クッキー法への対応はもはや選択肢ではない。2026年現在、規制当局の監視は厳しさを増し、業界全体で21億ユーロに上る制裁金が科せられている。単純なテキストバナーではビジネスを守れない時代だ。
法的に準拠し、高速で、コンバージョンにも寄与する同意管理システムをWordPress上に構築するには、明確なルールに従う必要がある。この記事では、2026年の最新規制を理解し、サイトとユーザーを保護するための具体的な実装ステップを解説する。
2026年のEU法規制を理解する:GDPRとePrivacyの違い

多くの開発者が混同しがちなのが、GDPR(一般データ保護規則)とePrivacy Directive(電子プライバシー指令)の違いだ。GDPRは個人データの収集全般を規定する法律である。一方、ePrivacy Directiveは特にクッキーやローカルストレージといったトラッキング技術そのものを規制する。
基本的な通知を表示するだけでは不十分であり、規制当局は無知を言い訳として認めない。2026年に適用される具体的な法的要件は以下の通りだ。
- 事前同意:ユーザーが「同意する」を能動的にクリックするまで、非必須のトラッカーを一切読み込んではならない。事前にチェックが入ったボックスは法的に無効だ。
- 同等の視認性:「すべて拒否」ボタンは「すべて同意」ボタンと視覚的に同一でなければならない。拒否オプションを二次メニューに隠すことはできない。
- 詳細な制御:ユーザーは、統計トラッカーを拒否しながらマーケティングトラッカーに同意するといった、カテゴリーごとの選択が可能でなければならない。
- 同意の撤回の容易さ:同意を与えるのと同程度に簡単に同意を撤回できる必要がある。ユーザーが考えを変えられるよう、永続的なフローティングアイコンを設置する。
- 証拠の記録:ユーザーがいつ、どのように同意したかをサーバーサイドで記録し、証明を残さなければならない。
世界の同意管理プラットフォーム(CMP)市場は21.3%成長し、24億ドル規模に達すると予測されている。これは、手動での対応がほぼ不可能になったことを示している。専用ツールを活用するにせよ、その背後にある法的ロジックを理解することが第一歩だ。
WordPressサイトのクッキー監査:コンプライアンスギャップの特定
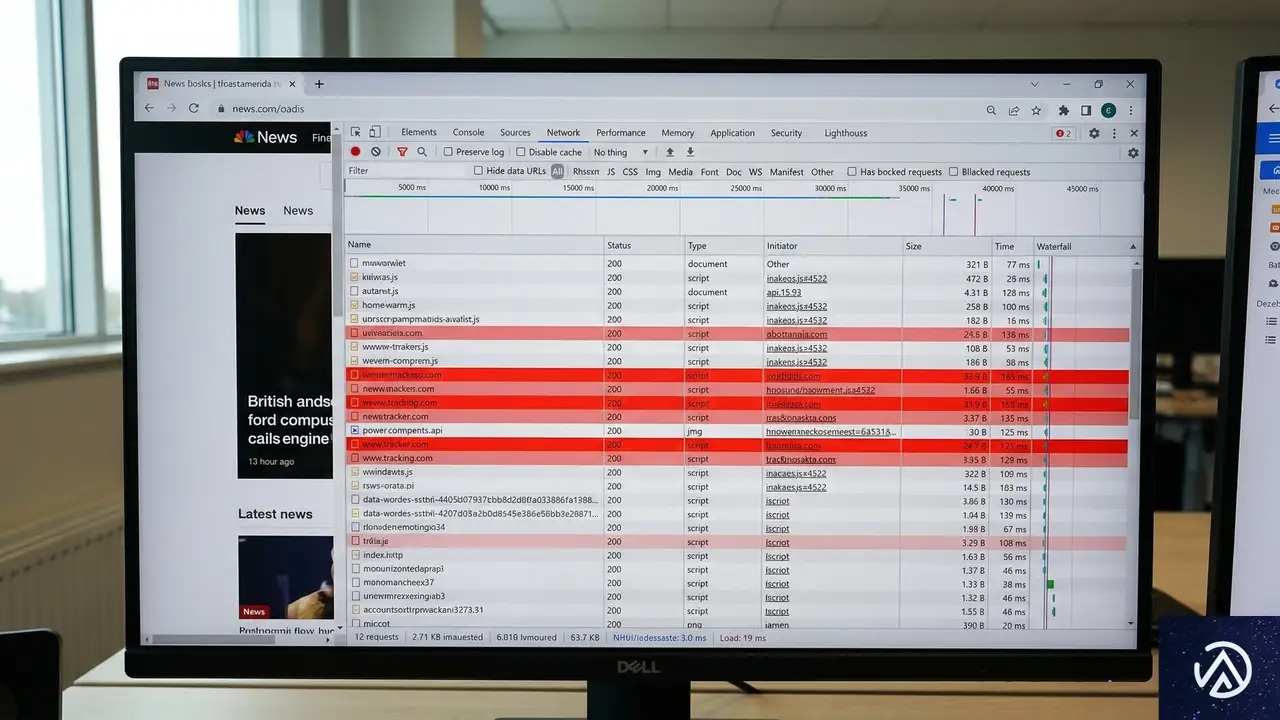
新しいプラグインを導入する前に、自らのWordPressサイトが裏で何をしているかを正確に把握する必要がある。問題を診断できなければ修正もできない。2026年現在、WordPressはインターネットの43.3%を支えており、自動化されたプライバシースキャナーの主要な標的となっている。
平均的なWebサイトは、ユーザーの初回訪問時に22個のサードパーティークッキーを読み込む。これはEU規制当局の目から見れば即座の違反だ。以下の手順で、実際のサイトを監査する。
- シークレットウィンドウを開く:自身の管理者セッションが結果を歪めないよう、ホームページを新規に読み込む。
- 開発者ツールを開く:ページを右クリックして「検証」し、ChromeまたはEdgeの「Application」タブに移動する。
- ローカルストレージとクッキーを確認:左サイドバーの「Cookies」セクションを展開し、バナーに触れる前にここにリストされているすべての項目を記録する。
- Networkタブを確認:ページをリロードしながらNetworkタブを監視し、Google AnalyticsやMeta Pixel、外部広告ネットワークへのリクエストを探す。
- トラッカーを分類:発見したトラッカーを「必須」「分析」「マーケティング」「機能」のカテゴリーにグループ分けする。
多くのプレミアムテーマやページビルダーは、レイアウトの記憶やA/Bテストのために機能的なトラッカーを注入している。サイトの機能に厳密に必要でないものは、デフォルトでブロックされる必要がある。
WordPressへの同意管理プラットフォーム(CMP)導入
同意ロジックシステムをスクラッチでコーディングすべきではない。ルールは頻繁に変更される。代わりに、専用の同意管理プラットフォーム(CMP)が必要だ。これらのシステムはスクリプトをインターセプトし、適切なボタンがクリックされるまで保留する。
適切なCMPの選択は、コンプライアンスプロセスの滑らかさを決定する。Complianz Privacy Suiteのようなソリューションは30万以上のアクティブインストールを誇り、Cookiebotは小規模サイト向けに月額12ユーロから提供している。WordPress環境にCMPを適切に展開する手順は以下の通りだ。
- コアプラグインをインストール:WordPressリポジトリで選択したCMPを検索し、有効化する。
- 初期スキャンを実行:プラグインにサイトのスキャンを許可する。グローバルデータベースと照合し、アクティブなトラッカーを自動的に分類する。
- スクリプトブロッキングを設定:Google Tag ManagerやMeta Pixelのような重いスクリプトをプラグインが正しく識別し、インターセプトしていることを確認する。これが重要だ。
- 法的文書を生成:多くの高品質CMPは、スキャン結果に基づいてCookieポリシーページを自動生成する。このページを即座に公開する。
- バナー制約をテスト:新規のシークレットウィンドウからサイトにアクセスする。「同意する」を明示的にクリックするまで、Networkタブに一切のトラッキングスクリプトが実行されないことを確認する。
5番目のステップを省略すれば、コンプライアンスは達成されない。バナーが見た目上問題なくても、背後でトラッキングスクリプトが即座に実行されているサイトは多い。視覚的な準拠は技術的な準拠と同義ではない。
Elementor Editor Proによるカスタム準拠バナーの構築
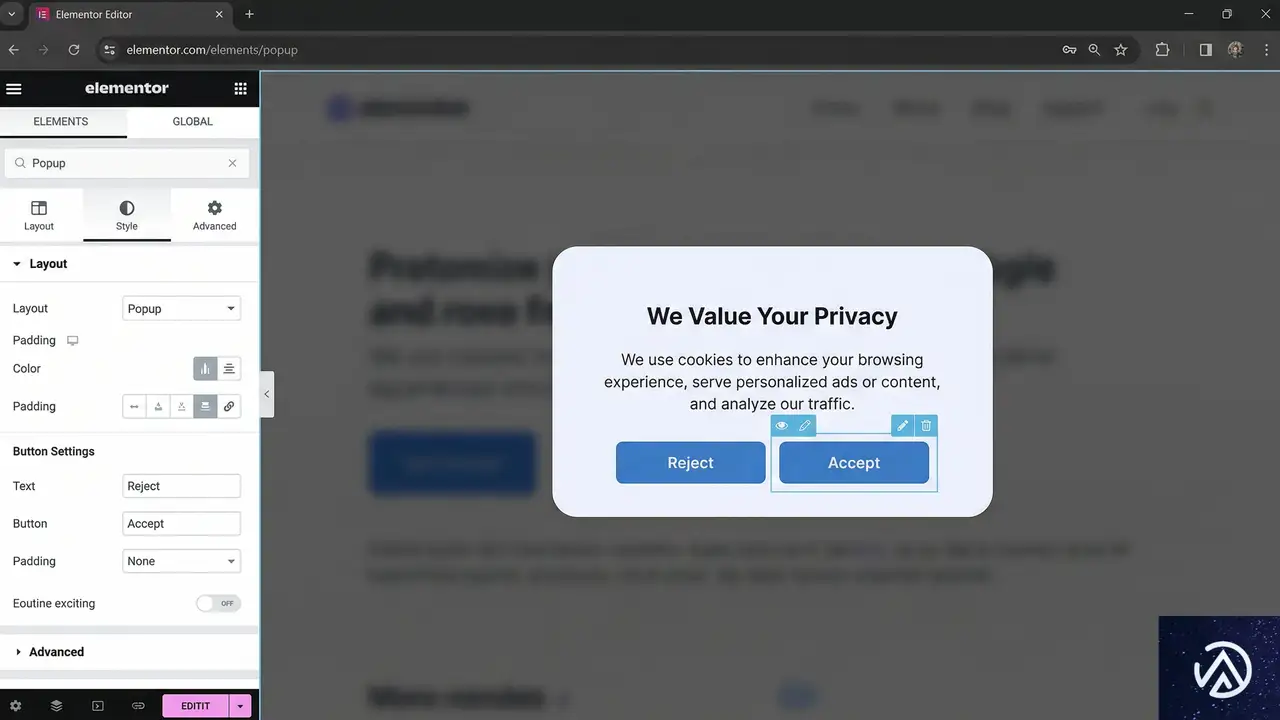
デフォルトのCMPバナーは概して見た目が悪く、ブランドのスタイルに合わないことが多い。しかし、醜い汎用ポップアップに妥協する必要はない。Elementor Editor Proを使えば、サイトの美学にシームレスに統合されながら、厳格な法的基準を満たすカスタム同意バナーをデザインできる。
ユーザーはモバイルデバイスで「すべて同意」をクリックする可能性が25%高い。小さな画面では侵襲的なバナーが煩わしいためだ。より良いユーザー体験を設計することは、マーケティングデータの保持率に直接影響する。
同意ポップアップをデザインする際、法的トラブルを避けるために以下の必須要素を含めなければならない。
- 明確な見出し:ポップアップの目的を正確に述べる。「あなたのプライバシーを尊重します」のような曖昧な表現は避ける。
- 対称的なボタン:「同意」と「拒否」ボタンは、まったく同じサイズ、色のコントラスト、タイポグラフィでなければならない。
- 詳細設定リンク:ユーザーがカテゴリーごとに設定をカスタマイズできる明確なテキストリンクを含める。
- ポリシーリンク:バナーテキスト内に、完全なプライバシーポリシーとクッキーポリシーへの直接リンクを提供する。
- ダークパターンの禁止:ボタンのラベルに紛らわしい言語や二重否定を使用してはならない。
Elementorの高度な表示条件を使って、欧州経済領域(EEA)内に位置する訪問者にのみカスタムクッキーポップアップを表示させる方法もある。これらの要件がない地域からの訪問者に厳格なePrivacyバナーを強制する法的理由はない。
また、バナーにはポップアップの詳細設定で非常に高いZ-index値を設定し、選択が行われるまでスティッキーヘッダーやモバイルメニューの上に確実に表示されるようにする。ウェブアクセシビリティも忘れてはならない。ElementorのHTMLタグコントロールを使って、ポップアップのラッパーに正しいARIAロールを持たせ、スクリーンリーダーが同意オプションを明確に解析できるようにする。
パフォーマンス最適化:速度を損なわないコンプライアンス実装
コンプライアンス層の追加は、ほぼ常にWebサイトの速度を低下させる。最適化されていないサードパーティの同意スクリプトは、平均してTotal Blocking Time(TBT)を200msから500ms増加させる可能性がある。法的に準拠しようとするあまり、Core Web Vitalsを失敗させるわけにはいかない。
WP Rocketのようなトップティアのキャッシュソリューションは、必須のクッキースクリプト用の特定の統合機能を含んでいる。これにより、キャッシュルールが「同意済み」状態をキャッシュして、新しい訪問者に提供してしまうことを防ぐ。CMPによって設定される特定のクッキーをキャッシュのバイパスルールから除外する設定が必須だ。
実装方法がサイト速度に与える影響を比較してみよう。
Cumulative Layout Shift(CLS)にも注意が必要だ。巨大なバナーがページ上部に注入されると、すべてのコンテンツが押し下げられ、パフォーマンススコアを損なう。ビューポート下部にバナーのための固定スペースをCSSで確保するか、ドキュメントフローを乱さないオーバーレイを提供する機能を活用する。
コンプライアンスの維持:月次監査と文書化

コンプライアンスは一度きりのプロジェクトではない。継続的な運用上の要件だ。1月にバナーを設定したきりチェックしなければ、3月までに準拠から外れている可能性が高い。テーマの更新、新しいマーケティングキャンペーン、新規プラグインが常に新しいトラッカーを導入する。
中小企業は、カスタム設定がこれらの厳格な基準を満たしていることを確認するために、平均2500ドルから7000ドルの法律相談費を負担している。簡単に予防できるミスに無駄な出費をしないため、月次のメンテナンスルーチンを構築する。
継続的なコンプライアンスチェックリストには、以下の具体的なアクションを含めるべきだ。
- クッキースキャンの自動化:CMPを設定し、ライブサイトの詳細スキャンを30日ごとに実行する。レポートをリード開発者に直接メール送信させる。
- 同意ログの確認:サーバーがユーザーID、タイムスタンプ、同意した具体的なカテゴリーを正確に記録していることを確認する。監査が入った場合、このログが唯一の防御手段となる。
- 撤回プロセスのテスト:自サイトの永続的な「クッキー設定」ウィジェットをクリックし、以前に付与された権限が即座に取り消され、ローカルクッキーが削除されることを確認する。
- ポリシー日付の更新:新しいツール(新しいCRMや分析プラットフォームなど)を追加するたびに、公開されているクッキーポリシーを更新し、「最終更新日」のタイムスタンプを変更する。
- 業界制裁金の監視:欧州データ保護委員会(EDPB)による最新の裁定に目を配り、執行戦術がどのように変化しているかを把握する。
法的枠組みの突然の変化に不意を突かれたくはない。同意アーキテクチャに行ったすべての変更を完璧な記録として保管することが、ビジネスを救う。
この記事のポイント
- 2026年のコンプライアンスには、単なるバナー表示を超えた技術的なスクリプトブロッキングが必須である。
- 同意管理プラットフォーム(CMP)の選定と正しい設定が、法的リスクと運用負荷を大きく左右する。
- 「すべて拒否」ボタンの視認性と、同意の詳細設定・撤回の容易さは、法的要件の核心部分である。
- コンプライアンス対策はサイト速度に影響を与えるため、キャッシュ設定や実装方法の最適化が不可欠だ。
- コンプライアンスは継続的プロセスであり、プラグイン更新や新機能追加のたびに監査と文書化が必要である。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AIボットのトラフィックが300パーセント急増 パブリッシング業界を牽引するOpenAIとMetaの動向
AIボットによるウェブサイトへのトラフィックが、過去1年間で爆発的に増加している。セキュリティ大手のAkamai(アカマイ)が発表した最新のレポートによると、グローバルでのAIボット活動は300パーセントもの急増を記録した。特にパブリッシング(出版・メディア)業界は、AI開発企業にとって貴重なデータ源として激しいターゲティングを受けている実態が浮き彫りになった。
この調査は、Akamaiのボット管理ツールを通じて収集されたアプリケーション層のトラフィックデータを分析したものだ。AIボットのトラフィックが最も集中しているのはEコマース分野で、全体の48パーセントを占める。それに次ぐのがメディア業界で、全体の13パーセントを記録した。メディア業界の内訳を見ると、パブリッシング企業へのアクセスが40パーセントと最も多く、放送やOTT(動画配信サービス)の29パーセントを大きく上回っている。
パブリッシャーにとって、これらのボットは単なるアクセス増を意味するのではない。自社のコンテンツが無断でAIの学習に利用されたり、検索結果に直接回答を表示されることでサイト訪問者が減少したりするリスクを孕んでいる。本記事では、パブリッシング業界を席巻する主要なAIボットの動向と、それらに対する現実的な防衛策について詳しく解説していく。
パブリッシング業界を狙う主要なAIプレイヤー

メディア企業に送られるAIボットのリクエストにおいて、圧倒的なシェアを誇っているのがOpenAIだ。同社はメディア業界へのリクエストで首位に立っており、そのリクエストの40パーセントがパブリッシング企業に向けられている。OpenAIがこれほど高いトラフィックを生成している背景には、複数の役割を持つボットを使い分けている点がある。
OpenAIが運用する3種類のボット
OpenAIは、用途に応じて主に3つのボットを稼働させている。まず「GPTBot」は、大規模言語モデル(LLM)のトレーニングのためにウェブ上のデータを収集する。次に「OAI-SearchBot」は、AIによる検索機能を支えるための情報を収集する役割を担う。そして「ChatGPT-User」は、ユーザーがChatGPTで質問をした際に、リアルタイムで最新の情報を取得するために動くボットだ。このように、学習、検索、リアルタイム応答という異なる目的でサイトを巡回しているため、トラフィックが累積しやすい構造になっている。
追随するMetaとByteDanceの動向
OpenAIに次いで多くのトラフィックを生成しているのが、MetaとByteDanceだ。MetaはLlamaなどの独自モデルの強化を進めており、SNS以外の外部コンテンツ収集にも力を入れている。TikTokを運営するByteDanceも、AI技術の高度化に向けて広範囲なクローリングを行っている。これら上位3社に続き、Anthropic(アンソロピック)やPerplexity(パープレキシティ)も名を連ねているが、上位陣に比べるとそのボリュームは現時点では小さい。
学習用クローラーとフェッチャーボットの決定的な違い

Akamaiのレポートでは、AIボットをその挙動に基づいて4つのタイプに分類している。その中でも、パブリッシャーが特に注目すべきなのが「学習用クローラー(Training Crawlers)」と「フェッチャーボット(Fetcher Bots)」の2種類だ。これらはサイトに与える影響が根本的に異なる。
長期的な影響を与える学習用クローラー
学習用クローラーは、将来のAIモデルを構築するために膨大なコンテンツを収集することを目的としている。2025年後半のメディア業界におけるAIボット活動の63パーセントをこのタイプが占めていた。これらのボットをブロックすれば、将来のAIが自社のコンテンツを学習することを防げる。しかし、これは「今現在のアクセス」には直接的な影響を及ぼさない長期的な対策という意味合いが強い。
収益に直結するフェッチャーボットの脅威
一方で、より差し迫った脅威とされているのがフェッチャーボットだ。これは、ユーザーがAIチャットボットに質問を投げた際、その回答を作成するためにリアルタイムで特定のページを取得しに行くボットを指す。メディア業界におけるAIボット活動の24パーセントを占め、そのうち43パーセントがパブリッシング企業をターゲットにしている。
フェッチャーボットは、パブリッシャーの収益に直接的なダメージを与える可能性がある。AIが記事の内容を読み取り、要約してユーザーに提示してしまうため、ユーザーは元の記事を読みに行く必要がなくなるからだ。これを「ゼロクリック問題」と呼ぶ。サイトへの流入が失われれば、広告収入や購読者獲得の機会も同時に失われることになる。
■ 影響:数ヶ月〜数年後のAIの回答精度に関わる
■ 影響:現在のサイト流入と広告収益が減少する
上記の図が示すように、学習用クローラーとフェッチャーボットでは対策の優先順位が変わってくる。将来のAIのあり方をコントロールしたいのか、それとも現在の収益を守りたいのかによって、ブロックすべき対象を精査する必要がある。
パブリッシャーが取るべき3つの対抗策

AIボットの急増に対し、サイト運営者はどのような手を打てるのだろうか。Akamaiのレポートによれば、現在多くの企業が採用している対策は主に3つの手法に集約される。単純にすべてを拒否するのではなく、戦略的にボットをコントロールする動きが出ている。
1. 拒否(Deny)による完全遮断
最も一般的な方法は、特定のボットからのリクエストを完全に拒否することだ。robots.txtで指定したり、WAF(Web Application Firewall)の設定でボットのIPアドレスやユーザーエージェントをブロックしたりする。これにより、サーバー負荷を軽減し、コンテンツの無断取得を防ぐことができる。ただし、AI検索からの流入も完全に断たれるリスクがある。
2. ターピット(Tarpit)によるリソース消費
「ターピット(底なし沼)」とは、ボットからの接続をあえて切断せず、非常に遅い速度で応答を返し続ける手法だ。ボット側の接続枠を長時間占有させることで、ボットを運用する側のコンピューティングリソースを無駄に消費させる効果がある。あるパブリッシャーはこの手法を用いて、AIボットのリクエストの97パーセントを制御することに成功したという。完全に拒否するよりも巧妙な対抗策と言える。
3. 遅延(Delay)による制限
応答を返す前に意図的な一時停止を入れる手法だ。これにより、ボットによる高速なクローリングを物理的に不可能にする。サーバーへの瞬間的な負荷を抑えつつ、コンテンツの取得効率を大幅に下げることができる。人間がブラウザで閲覧する分には影響が出ない程度の遅延を設定することで、UX(ユーザーエクスペリエンス)を維持しながら対策が可能だ。
一律ブロックが最適解ではない理由

AIボットをすべて遮断すれば安心かというと、話はそう単純ではない。Akamaiのレポートでは、すべてのAIボットを無差別にブロックすることに対して警鐘を鳴らしている。そこには、将来的なビジネスチャンスを損失するリスクが含まれているからだ。
コンテンツライセンス契約の可能性
現在、OpenAIなどのAI開発企業は、高品質なデータを確保するためにパブリッシャーと直接ライセンス契約を結ぶ動きを加速させている。一律にすべてのアクセスを遮断してしまうと、こうした交渉のテーブルに載る機会を自ら放棄することになりかねない。実際に、一部のパブリッシャーはあえてボットのアクセスを完全に遮断せず、交渉の余地を残しながら「ターピット」などで制御する戦略をとっている。
AI検索経由のトラフィック確保
Googleの「AI Overviews」やPerplexityのようなAI検索エンジンは、回答の根拠として出典元へのリンクを表示することがある。フェッチャーボットをすべてブロックすると、こうしたAI検索の結果に自社のコンテンツが表示されなくなり、新しい形の検索流入を完全に失うことになる。これからのSEO(検索エンジン最適化)は、従来の検索結果だけでなく、AIの回答の中にいかに適切に引用されるかを考える必要が出てくるだろう。
今後の展望とサイト運営者の課題

AIボットの活動は今後さらに洗練され、増加の一途をたどると予想される。パブリッシャーにとって重要なのは、学習用クローラーとフェッチャーボットを区別して管理することだ。学習用をブロックして自社の知財を守りつつ、フェッチャーを部分的に許可してAI検索からの露出を確保するといった、きめ細やかな制御が求められる。
また、Akamaiのようなボット管理ソリューションを導入することも一つの選択肢だが、まずは自社のログを確認し、どのボットがどれだけの頻度でアクセスしているかを把握することから始めるべきだ。AIボットとの共存か、それとも徹底抗戦か。その判断が、今後のパブリッシングビジネスの成否を分けることになるだろう。
この記事のポイント
- AIボットのトラフィックは前年比300パーセント増と爆発的に伸びている。
- OpenAI、Meta、ByteDanceの3社がトラフィックの大部分を占めている。
- 学習用クローラーは将来のモデルのため、フェッチャーは現在の回答のために動く。
- フェッチャーボットはユーザーのサイト訪問を奪う「ゼロクリック問題」を引き起こす。
- 一律ブロックではなく、ターピットや遅延などの手法を組み合わせた戦略的制御が重要だ。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

500 Tbpsに達したCloudflareのネットワーク網!DDoS防御とAI時代のインフラを徹底解説
Cloudflareのグローバルネットワークが、外部接続容量500 Tbps(テラビット毎秒)という大きな節目を超えた。2010年にパロアルトの小さなオフィスから始まった同社のインフラは、16年の歳月を経て世界330以上の都市に広がる巨大なデジタル基盤へと成長している。
この「500 Tbps」という数字は、単なるピーク時のトラフィック量ではない。トランジットプロバイダーやピアリングパートナー、インターネットエクスチェンジ(IX)などと接続された外部ポートの総容量を指している。この膨大な余剰キャパシティこそが、日々発生する大規模なDDoS攻撃を吸収するための「防御予算」として機能しているのだ。
現代のインターネットにおいて、これほどの規模を持つネットワークがどのように構築され、どのように自律的な防御を実現しているのか。最新の技術スタックと、急増するAIトラフィックへの対応策を含めて詳しく紐解いていく。
500 Tbpsの衝撃〜Cloudflareが到達した巨大ネットワークの現在地

Cloudflareのネットワーク容量が500 Tbpsに達したことは、インターネットの歴史における一つの到達点といえる。2010年の設立当初、同社はたった一つのトランジットプロバイダーと契約し、ネームサーバーを2つ書き換えるだけで利用できるリバースプロキシとしてスタートした。それが今や、全ウェブサイトの20%以上を保護する巨大インフラへと変貌を遂げている。
世界330都市以上に広がる物理インフラの重み
「インターネットはクラウドである」と表現されることが多いが、その実体はケーブルとサーバーが詰まった物理的な部屋の集合体だ。Cloudflareはシカゴ、アッシュバーン、サンノゼ、アムステルダム、東京といった主要都市から始まり、カトマンズ、バグダッド、レイキャビクといった地域まで網羅してきた。
データセンターを一つ開設するごとに、コロケーション契約の交渉、光ファイバーの敷設、サーバーのラッキングといった地道な作業が繰り返される。2018年には、わずか24日間で31都市に拠点を展開するという驚異的なスピードで拡張を続けた。この物理的な拠点の多さが、ユーザーに近い場所でコンテンツを配信し、攻撃を水際で食い止めるための鍵となっている。
外部キャパシティ500 Tbpsが意味するもの
500 Tbpsという数字は、すべての外部接続ポートの合計値だ。日常的なトラフィックのピークは、この数字のほんの一部に過ぎない。残りの広大な帯域は、DDoS攻撃が発生した際にその衝撃を和らげるためのバッファとして確保されている。
かつては国家レベルのリソースがなければ対抗できなかったような大規模な攻撃も、この巨大なパイプラインの中では「日常的なイベント」として処理される。ネットワークの規模そのものが、セキュリティにおける最強の武器となっているのだ。
攻撃を呼吸するように受け流す〜31.4 TbpsのDDoSを防ぐ仕組み

2025年、Cloudflareのネットワークは秒間31.4 Tbpsという猛烈なDDoS攻撃を検知し、わずか35秒で完全に無害化した。この攻撃には、感染したAndroid TVなどで構成された「Aisuru-Kimwolf」と呼ばれるボットネットが関与していた。驚くべきは、この規模の攻撃に対してもエンジニアが呼び出されることなく、システムが自律的に対処した点だ。
eBPFとXDPによる超高速パケット処理
この自律的な防御を支えているのが、Linuxカーネル内で動作する「eBPF(extended Berkeley Packet Filter)」と「XDP(eXpress Data Path)」という技術だ。パケットがネットワークカード(NIC)に到着した瞬間、OSの通常のネットワークスタックを通過する前に、XDPプログラムがそのパケットを評価する。
これにより、不正なパケットはCPUサイクルをほとんど消費することなく、入口で即座に破棄される。アプリケーション層に到達する前に処理が終わるため、サーバーの負荷を極限まで抑えることが可能だ。この仕組みを視覚化すると、以下のようになる。
このデモは、パケットがどのように段階を経て処理されるかを示したものだ。XDPレイヤーでのフィルタリングが、後続のシステムをいかに保護しているかがわかる。
自律分散型の防御システム「dosd」
Cloudflareのすべてのサーバーには「dosd」と呼ばれるDDoS対策用のデーモンが常駐している。各サーバーは流入するトラフィックをサンプリングし、異常な通信パターンを検出すると、その情報を同じデータセンター内の全サーバーにブロードキャストする。
データセンター内のすべてのサーバーが同じデータに基づいて判断を下すため、特定のサーバーに負荷が集中することなく、拠点全体で一貫した防御が可能になる。さらに、決定されたルールは同社の分散型キーバリューストア「Quicksilver」を通じて数秒以内に全世界の拠点へ伝播される。これにより、ある拠点で検知された攻撃手法が、瞬時に地球の裏側の拠点でも通用しなくなる仕組みだ。
ネットワーク自体が開発プラットフォームへ〜Edge Computingの進化

ネットワークを保護するためにすべてのサーバーでコードを実行できる環境を整えた結果、そのリソースを顧客に開放するという自然な流れが生まれた。これが「Cloudflare Workers」の始まりだ。現在では、単なるスクリプトの実行にとどまらず、より複雑なワークロードをエッジで動かすことが可能になっている。
WorkersからContainersへ
2025年、CloudflareはWorkersに「Containers」機能を追加した。これにより、V8アイソレートでは難しかった、より重量級のアプリケーションもエッジで動作させることができるようになった。独自のファイルシステムレイヤーにより、コールドスタート(起動時の遅延)を最小限に抑えつつ、ユーザーのすぐそばで計算リソースを提供する。
開発者が書いたコードは、前述のDDoS防御と同じサーバー上で動作する。つまり、攻撃トラフィックがl4dropによって破棄された直後の、クリーンな環境でアプリケーションが実行されるわけだ。インフラのセキュリティとパフォーマンスを同時に享受できるこの構造は、従来の中央集約型クラウドとは一線を画している。
インターネットの信頼性を担保する〜RPKIとASPAの重要性

ネットワークの規模が大きくなるほど、ルーティングの安全性に対する責任も増大する。BGP(Border Gateway Protocol)の脆弱性を突いたルートハイジャックは、インターネットの通信を誤った方向へ誘導し、大規模な障害やセキュリティ侵害を引き起こす原因となる。Cloudflareはこれらのリスクを低減するため、最新のプロトコル採用を強力に推進している。
ルートハイジャックを防ぐRPKI
RPKI(Resource Public Key Infrastructure)は、IPアドレスの所有者が誰であるかを証明するための仕組みだ。Cloudflareは早期からRPKIを導入し、無効なルートからのトラフィックを拒否する設定を徹底している。現在、グローバルなルーティングテーブルのうち、86万7,000件以上のプレフィックスが有効なRPKI証明書を持っており、10年前のほぼゼロに近い状態から劇的に改善された。
パスの正当性を検証するASPA
次に同社が注力しているのが「ASPA(Autonomous System Provider Authorization)」だ。RPKIが「誰が所有しているか」を検証するパスポートチェックだとすれば、ASPAは「どのような経路を通ってきたか」を検証するフライトマニフェスト(搭乗名簿)チェックに相当する。
ASPAが普及すれば、設定ミスによるルート漏洩や、悪意のある経路誘導をより確実に防げるようになる。Cloudflareのような巨大ネットワークが先行して導入することで、インターネット全体のエコシステムを健全な方向へ導く狙いがある。
AIエージェントが変えるトラフィック構造〜4%の衝撃

近年、インターネット上のトラフィックに大きな変化が起きている。人間がブラウザでリンクをクリックして発生する通信に加え、AIクローラーや自律型エージェントによるアクセスが急増しているのだ。現在、Cloudflareのネットワークを流れるHTMLリクエストの4%以上が、AI関連の通信で占められている。
ブラウザとクローラーの挙動の違い
AIクローラーは、人間が操作するブラウザとは根本的に異なる動きを見せる。ブラウザはページを読み込んだ後に一時停止するが、クローラーはリンクされたリソースを最大スループットで、休むことなく次々と取得していく。この挙動は、インフラ側から見るとDDoS攻撃と区別がつきにくい場合がある。
Cloudflareは、正規のAIクローラーと悪意のある攻撃を識別するために、TLSフィンガープリントや行動分析を組み合わせた高度な検知システムを運用している。例えば、ブラウザを装いつつもTLSのライブラリが不自然な構成であれば、それをシグナルとして検出し、サイト所有者が適切な判断を下せるようにデータを提供している。
独自の分析〜500 Tbps時代に企業が備えるべきインフラ戦略

Cloudflareが500 Tbpsという驚異的な容量を確保したことは、一企業のリリースの枠を超えた意味を持っている。これは、インターネットが「物理的な限界」を技術と規模で克服しつつあることを象徴している。しかし、インフラが強力になる一方で、攻撃の質も変化している点には注意が必要だ。
「防御の自動化」が企業の必須条件になる
31.4 Tbpsという攻撃を人間が介在せずに防いだという事実は、もはや「人間がログを見て遮断ルールを書く」という旧来の運用が通用しないフェーズに入ったことを示している。今後の企業インフラには、eBPF/XDPのようなカーネルレベルでの高速処理と、AIを活用した自律的なパターン認識が欠かせなくなるだろう。
エッジシフトとセキュリティの統合
Cloudflareの事例が示すように、これからは「セキュリティ対策」と「アプリケーション実行環境」を切り離して考えるべきではない。攻撃を捨てる場所でコードを動かすという「エッジコンピューティング」の思想は、パフォーマンス向上だけでなく、攻撃の爆風をアプリケーションに届かせない最強の盾となる。企業は、中央集約的なサーバー構成から、分散型のエッジインフラへの移行を真剣に検討すべき時期に来ているといえる。
この記事のポイント
- Cloudflareの外部ネットワーク容量が500 Tbpsの大台を突破した
- eBPFとXDPを活用し、31.4 Tbpsもの巨大DDoS攻撃を自動的に無害化している
- 世界330以上の都市に分散された拠点が、ユーザーに近い場所でセキュリティと計算リソースを提供している
- RPKIやASPAといった次世代プロトコルの導入により、ルーティングの安全性を世界規模で向上させている
- トラフィックの4%を占めるようになったAIクローラーに対し、高度な識別技術で対応している
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験
レガシーシステムのUX改善ガイド〜負債を抱えたWordPressサイトを再生する戦略
10年近く稼働し続けているシステムは、動作が遅く、中身が不透明な「ブラックボックス」になりがちだ。しかし、そのような古いシステムこそが企業の日常業務を支える不可欠な基盤となっているケースは少なくない。
多くの組織では、全業務時間の40%から60%をこうしたレガシーシステムの維持管理や微調整に費やしているという。重要でありながら、維持コストが極めて高いという矛盾を抱えているのが現状だ。
本記事では、Smashing Magazineの記事を基に、複雑に絡み合ったレガシーシステムのUX(ユーザーエクスペリエンス)をどのように改善していくべきか、その具体的なロードマップと戦略を紐解いていく。
レガシーシステムが抱えるUXの現実と課題
レガシーシステムは、いつ廃止されてもおかしくないように見えるかもしれない。しかし現実には、組織のニーズに合わせて高度にカスタマイズされており、日常業務の核心を担っていることが多い。
業務の核心を担うブラックボックスの正体
古いシステムは、もはや誰も全容を把握していない状態で動き続けている。最初に構築した担当者はとうの昔に退職し、ドキュメントも不十分なまま、場当たり的な修正が繰り返されてきた結果だ。
こうした環境では、デザインの選択肢も断片的で一貫性がない。すでに開発が終了した古いデザインツールのバージョンに縛られていることもあり、現代的なUI(ユーザーインターフェース)との乖離が激しくなっている。
フランケンシュタイン化するUIの一貫性欠如
現代のデジタル製品の中にレガシーシステムを組み込もうとすると、まるで「フランケンシュタイン」のような継ぎはぎの状態になる。最新の洗練された画面の中に、突然、動作が重くて使いにくい古い断片が顔を出すからだ。
たとえアプリケーションの大部分に多大な労力を注いで改善したとしても、一箇所の入力フォームやエラーメッセージが致命的に使いにくければ、ユーザーは製品全体が壊れていると感じてしまう。一つの不備が全体のUXを台無しにするリスクを常に孕んでいる。
※入力フィールドがバラバラでエラーが分かりにくい
エラーコード:0x800421(不明なエラーです)
※視認性が高く、次に何をすべきか明確
UIの一貫性が欠如した状態から、視覚的・機能的に整理された状態への変化を示している。
改善に向けた第一歩〜既存の知識とワークフローの可視化

レガシーシステムは関係者全員にフラストレーションを与える存在だが、安易にすべてを捨て去るべきではない。そこには長年のビジネス慣行や、膨大なカスタマイズの知識が蓄積されているからだ。
安易なスクラップ&ビルドが危険な理由
最初からすべてを新しく作り直す「ビッグバン・リデザイン」は、非常に高コストで時間がかかる。さらに、新しいシステムは過去数年分の細かな仕様変更や例外処理を完璧に再現しなければならず、そのリスクは計り知れない。
特にB2Bの現場では、ユーザーは急激な変化を嫌う傾向がある。システムはビジネスの心臓部であるため、大きなリスクを冒すよりも、既存の知識を尊重しながら慎重に準備を進めることが求められる。
依存関係とユーザー行動をマッピングする
改善を始める前に、レガシーシステムがどこで、どのように使われているかを正確に把握する必要がある。調査を進めると、自社製品だけでなく、外部機関のダッシュボードや他社のサービスと複雑に連携している事実に気づくはずだ。
Smashing Magazineの著者Vitaly Friedman氏は、現在のワークフローと依存関係をドキュメント化するためのボードを設置することを推奨している。ステークホルダーやヘビーユーザーを対話に巻き込み、自分たちが把握できていない「ブラックボックス」の中に光を当てていく作業が不可欠だ。
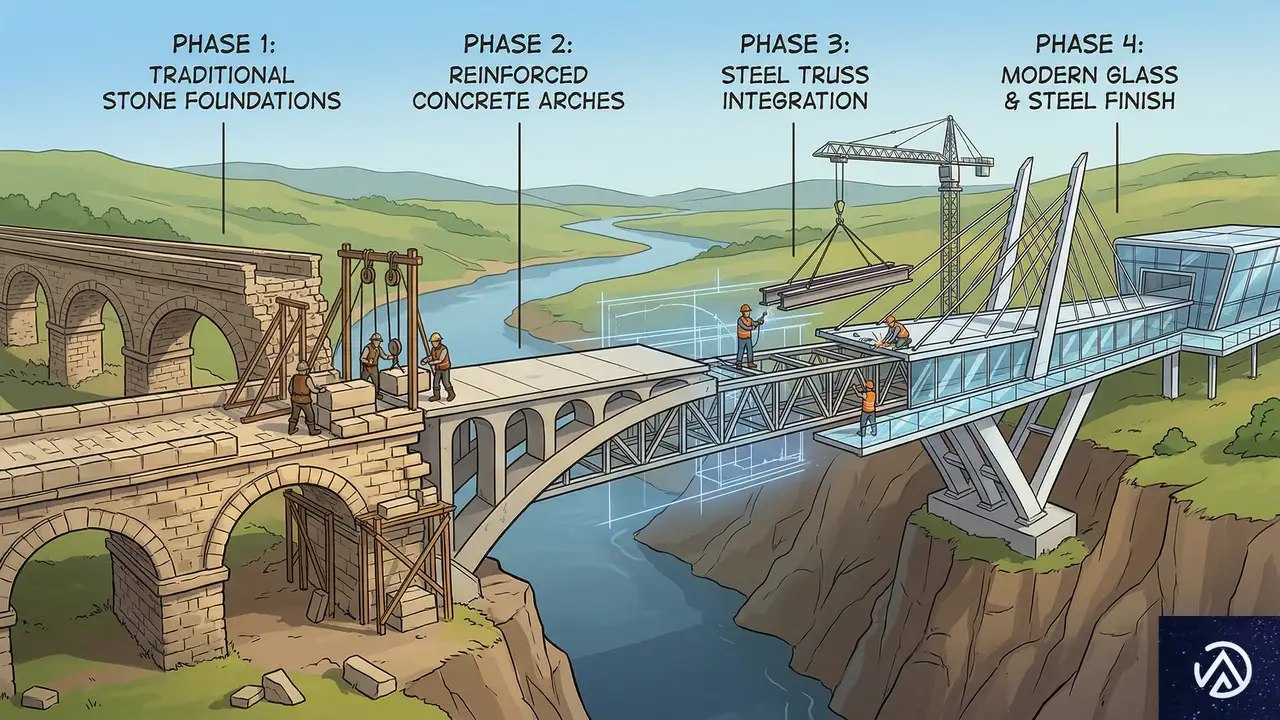
状況に合わせた5つの移行戦略
全体像が見えてきたら、次にどのような手法で移行を進めるかを決定する。一気に作り直すのか、少しずつ改良するのか。プロジェクトの予算や期間、許容できるリスクに応じて、適切な戦略を選ぶ必要がある。
リスクとスピードのバランスをどう取るか
以下に、レガシーシステムから脱却するための主要な5つのアプローチを整理する。
- ビッグバン・リローンチ
一度にすべてを刷新する。最もリスクが高く、完成まで既存システムの改善が止まるが、最終的に完全に新しい基盤へ移行できる。 - インクリメンタル・マイグレーション(段階的移行)
古い部分を小さな単位で新しいデザインに置き換えていく。早い段階で成果が出るが、一時的に新旧が混在する不安定な状態が続く。 - パラレル・マイグレーション(並行運用)
旧システムを動かしながら、新システムの公開ベータ版を並行して走らせる。ユーザーのフィードバックを得やすいが、二つのシステムを維持するコストがかかる。 - インクリメンタル・パラレル・マイグレーション
旧システムの要件をすべて満たす新製品を構築し、パワーユーザーとテストを繰り返しながら、段階的に旧システムを引退させる。 - レガシーUIアップグレード + 公開ベータ
既存システムに低リスクな微調整を施してUXを整えつつ、水面下で新システムを構築する。短期的・長期的の両面でメリットがある。
10年かけて洗練され、カスタマイズされてきたシステムを数週間で再構築することは不可能だ。バッファ時間を十分に確保し、継続的なフィードバックループを回しながら、少しずつ前進していくのが賢明といえる。
【独自分析】WordPress運用におけるレガシー脱却のポイント
WordPressサイトにおいても、長年運用していると「レガシー化」の問題は避けて通れない。特に、数年前に開発が止まったプラグインへの依存や、旧来のPHPバージョンでしか動かない独自カスタマイズは、UXだけでなくセキュリティやパフォーマンスの足かせとなる。
プラグイン依存と独自カスタマイズの整理
WordPressのレガシーUXを改善する際、まず着手すべきは「不要なプラグインの整理」と「ブロックエディタ(Gutenberg)への適応」だ。かつてのカスタムフィールドを多用したガチガチの管理画面は、現代の運用担当者にとっては使いにくいブラックボックスになっていることが多い。
これを改善するには、一気にテーマを替えるのではなく、特定のページテンプレートから段階的にブロックエディタへ移行する「インクリメンタル・マイグレーション」が有効だ。管理画面の操作性が向上すれば、コンテンツ更新のスピードが上がり、結果としてサイト全体の鮮度が保たれるようになる。
PHPバージョンアップと不要プラグインの削除
ブロックパターン導入による更新作業の効率化
LCP(最大視覚コンテンツ表示)などの表示速度改善
WordPressサイトの再生において、どのレイヤーから手をつけるべきかの指針を示している。
ステークホルダーとの信頼構築が成功の鍵

レガシープロジェクトにおいて、失敗は許されない。単にコードやデザインを移行するのではなく、ユーザーの「仕事の進め方」そのものを移行させているからだ。ビジネスの核心部に手を入れる以上、周囲からは懐疑的な目で見られることも覚悟しなければならない。
疑念を信頼に変えるコミュニケーション
ステークホルダーは、新しいシステムが初日から完璧に動くことを期待する一方で、例外的なケースや些細なタスクについて細かく指摘してくるだろう。彼らの不安を解消するには、設計プロセスの初期段階から彼らを巻き込むことが重要だ。
まずは小規模なパイロットプロジェクトを成功させ、目に見える成果を示すことで信頼を築く。進捗状況を繰り返し報告し、レガシーユーザーとの厳格なテストフェーズを設けることで、彼らに「自分たちのための改善である」という当事者意識を持ってもらうことが、プロジェクトを完遂させるための近道となる。
この記事のポイント
- レガシーシステムは業務の核心を担う「不可欠なブラックボックス」であることを認識する
- 安易な全刷新は避け、既存の知識と複雑な依存関係をマッピングすることから始める
- インクリメンタル(段階的)やパラレル(並行)など、リスク許容度に応じた移行戦略を選択する
- WordPress運用では、管理画面のUX改善がコンテンツ運用の効率化に直結する
- ステークホルダーを設計初期から巻き込み、小さな成功を積み重ねて信頼を構築する
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

WooCommerceの未来を変えるAIとMCP。開発効率と店舗運営を劇的に進化させる新技術の全容
WooCommerceのエコシステムにおいて、AI(人工知能)とMCP(Model Context Protocol)の活用が急速に注目を集めている。2026年4月、WooCommerceの開発チームはこれらの技術をテーマにした「Office Hours」の開催を決定した。このイベントは、開発者やショップ運営者がどのようにAIを実務に取り入れているかを共有し、今後の開発優先順位を議論する場となる。
特に注目すべきは、Anthropic社が提唱したオープン標準であるMCPの存在だ。MCPはAIモデルが外部のデータソースやツールと安全に連携するための仕組みであり、WooCommerceの複雑なデータベース構造をAIが理解する助けとなる。これにより、従来のチャット形式を超えた高度な自動化が実現しつつある。
今回の取り組みは、単なる技術的な流行の追随ではない。WooCommerceという巨大なプラットフォームが、AIネイティブな開発環境へと舵を切る重要な転換点といえる。本記事では、Office Hoursの内容を軸に、AIとMCPがWooCommerceの未来をどう変えるのかを深く掘り下げていく。
AIとMCPがWooCommerce開発にもたらす変革
WooCommerceの開発現場では、AIの活用が「あれば便利なツール」から「不可欠なインフラ」へと進化している。その中心にあるのがMCP(Model Context Protocol / モデル・コンテキスト・プロトコル)という新しい規格だ。これはAIが特定のデータや機能にアクセスするための共通言語のような役割を果たす。
MCP(Model Context Protocol)とは何か
MCPは、AIモデル(LLM)に対してローカル環境やクラウド上のデータ、あるいは特定のツールへのアクセス権を安全に提供するためのプロトコルである。例えば、開発者が自分のPC内で動いているWooCommerceのデータベース情報を、AIに直接「見せる」ことができるようになる。これにより、AIはサイトの現在の構成を正確に把握した上で、最適なコードを提案できる。
従来のAI活用では、開発者が手動でコードやエラーログをコピーしてAIに貼り付ける必要があった。しかしMCPを導入すると、AI側から「注文テーブルの構造を確認する」「特定のエラーログを読み取る」といったアクションが可能になる。これは、AIが開発者の隣で一緒に作業する「自律的なアシスタント」になることを意味している。
● AIにテキストを貼り付け
● AIが推測で回答
■ AIがサイト構成を自動把握
■ AIが環境に即した修正を実行
このデモは、MCPの導入によって開発フローがどのように簡略化されるかを示している。手動の介在が減ることで、ミスが軽減され、開発スピードが飛躍的に向上する。
なぜWooCommerceでMCPが重要視されているのか
WooCommerceは、商品、注文、顧客、クーポンなど、膨大かつ複雑なデータ構造を持っている。さらに、無数のプラグインが独自のカスタムテーブルを作成することもある。このような複雑な環境下では、AIに断片的な情報を与えるだけでは不十分だ。MCPによってAIがサイト全体のコンテキスト(文脈)を理解できるようになることは、WooCommerce特有の課題解決に直結する。
Developer WooCommerce Blogの記事によれば、WooCommerceチームはAIツールとMCPが開発者の構築、デバッグ、管理の手法を根本から変えつつあると認識している。今回のOffice Hoursを通じて、MCPサーバーを介したストアデータの活用事例を集めることで、エコシステム全体の底上げを狙っていると考えられる。
開発ワークフローにおけるAI活用術

具体的に、AIとMCPは日々の開発ワークフローをどのように変えるのだろうか。現在、多くの開発者が試行錯誤している領域は、コードの生成、バグの特定、そしてデータの可視化だ。これらがAIによって自動化されることで、開発者はより創造的な業務に集中できるようになる。
コード生成とデバッグの自動化
AIアシスタントを用いたコード生成はすでに一般的だが、WooCommerceにおいては「フック(Hook)」の扱いにAIが威力を発揮する。WooCommerceにはアクションフックやフィルターフックが数千存在し、正確な名称や引数を記憶するのは困難だ。AIはこれらのドキュメントを学習しているため、「カートに商品を追加した際に特定の処理を行うコード」を瞬時に生成できる。
さらに、デバッグにおいてもAIは強力な味方となる。エラーログをAIに読み込ませるだけで、原因となっているプラグインやコードの箇所を特定し、修正案まで提示してくれる。MCPを利用していれば、AIがサーバー上のファイルを直接スキャンし、依存関係を考慮した安全なパッチを作成することも可能だ。
MCPサーバーを活用したストアデータの連携
MCPの真価は、専用の「MCPサーバー」を構築することで発揮される。WooCommerce専用のMCPサーバーを用意すれば、AIに対して「先月の売上が高い順に商品リストを作成して」「特定の顧客の購入履歴に基づいた割引クーポンを生成して」といった指示を、自然言語で出せるようになる。
これは単なるレポート作成ではない。AIがデータベースのクエリを自動生成し、結果を解析し、さらにWooCommerceのAPIを叩いて実際にクーポンを発行するところまでを一貫して行えるようになる。開発者は、この一連のプロセスの「監視役」としての役割を担うことになる。
店舗運営(ストアマネジメント)の効率化
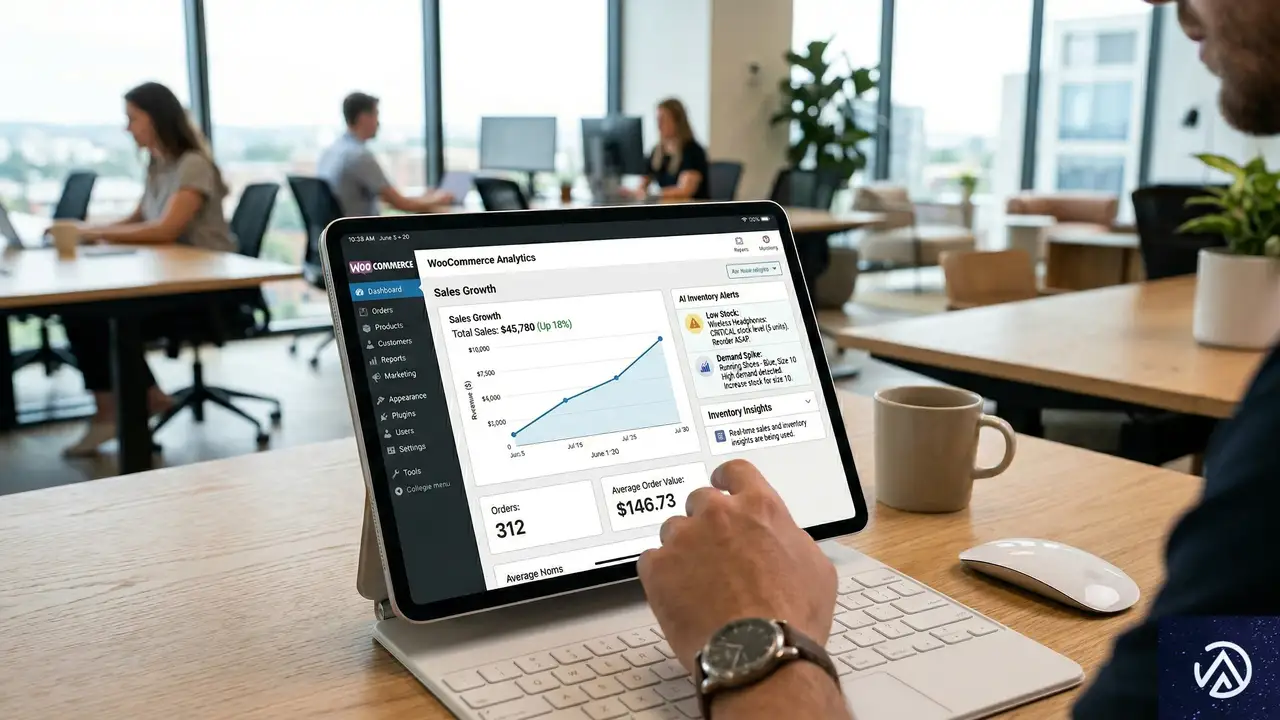
AIの恩恵を受けるのは開発者だけではない。ショップオーナーや運営担当者にとっても、AIとMCPの組み合わせは運営コストの劇的な削減をもたらす。特に、顧客対応と在庫管理という、時間のかかる2つの業務において変化が著しい。
AIによるカスタマーサポートの自動化
従来のチャットボットは、あらかじめ設定されたルールに従って回答するだけだった。しかし、MCPを通じてストアの注文データや配送状況にアクセスできるAIであれば、よりパーソナライズされた対応が可能になる。顧客が「私の注文は今どこにありますか?」と尋ねれば、AIがリアルタイムで配送ステータスを確認し、具体的な日付を添えて回答できる。
また、返品や交換のリクエストに対しても、ストアのポリシーを学習したAIが一次対応を行う。複雑なケースだけを人間にエスカレーション(引き継ぎ)することで、サポートチームの負担を大幅に軽減できる。これは、小規模な店舗が24時間体制のサポートを提供するための現実的な解決策となる。
回答: 「担当者が確認するまでお待ちください」
結果: 解決まで数時間かかる
AI回答: 「現在配送中で、明日14時頃に到着予定です」
結果: 数秒で解決
この比較からわかるように、AIが店舗データに直接アクセスできることで、顧客満足度の向上と運営コストの削減を同時に達成できる。これこそがMCPが店舗運営にもたらす最大のメリットだ。
データ分析と在庫管理の高度化
在庫管理もAIが得意とする分野だ。過去の販売データ、季節性、プロモーションの予定などをAIに学習させることで、精度の高い需要予測が可能になる。「この商品はあと10日で在庫切れになる可能性が高いので、今のうちに50個発注すべきだ」といった具体的なアドバイスをAIから受け取れるようになる。
さらに、ストア内の検索クエリを分析して、顧客が探しているが在庫がない商品を特定することも容易だ。これにより、機会損失を防ぎ、売上の最大化を図ることができる。AIは単なる自動化ツールではなく、ストアの成長戦略を共に考える「データサイエンティスト」としての役割を果たすようになる。
コミュニティとの対話「Office Hours」の重要性

WooCommerceが今回開催するOffice Hoursは、単なる情報の周知ではない。開発チームがコミュニティの声を聞き、AIとMCPをどのようにエコシステムに組み込んでいくべきか、その方向性を定めるための重要な対話の場である。技術の進化が速いAI分野において、現場の開発者が直面している課題や不満を吸い上げることは、プラットフォームの健全な発展に欠かせない。
Developer WooCommerce Blogの記事によると、イベントでは「何がうまくいっているか」「何に不満を感じているか」「次にどこに焦点を当てるべきか」といった問いが投げかけられる予定だ。これは、WooCommerceがAI機能を独断で実装するのではなく、コミュニティと共に「AIパワードな開発環境」を作り上げようとしている姿勢の表れといえる。
参加者は、Slackを通じて直接質問を投げかけたり、自身の実験的な取り組みを共有したりできる。たとえ当日参加できなくても、イベントの内容は記録され、後日公開される予定だ。このようなオープンな議論を通じて、WooCommerceにおけるAI活用のベストプラクティスが形成されていくことが期待される。
この記事のポイント
- MCP(Model Context Protocol)はAIとWooCommerceデータを安全に繋ぐ新しい標準である
- AIを活用することで、複雑なフックの記述やデバッグ作業が大幅に効率化される
- 店舗運営においては、AIが直接注文データにアクセスすることで高度な顧客対応が可能になる
- WooCommerceはコミュニティとの対話を通じてAI機能の優先順位を決定しようとしている
- 2026年4月15日のOffice Hoursは、今後のWooCommerceのAI戦略を知る重要な機会となる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Agentic AIのUX設計:不透明なブラックボックスを解消し信頼を築く手法
自律的にタスクを遂行する「Agentic AI(エージェンティックAI)」の普及により、ウェブサイト運営や業務効率化のあり方が劇的に変わりつつある。しかし、AIに複雑な指示を出した後、結果が出るまでの数十秒から数分間、システムが何をしているのか全く見えないという状況は、ユーザーに強い不安を与える。この「ブラックボックス化」は、AIツールの活用を阻む大きな壁となっている。
多くの開発現場では、この不安を解消するために「情報を一切隠してシンプルにする(ブラックボックス)」か、あるいは「全てのログを垂れ流す(データダンプ)」という極端な二択に陥りがちだ。しかし、Smashing Magazineの記事によれば、どちらのアプローチもユーザー体験を損なう原因になるという。ブラックボックスはユーザーを無力感に陥らせ、データダンプは情報の洪水によって通知疲れを引き起こすからだ。
本稿では、AIの内部プロセスを適切に可視化し、ユーザーとの信頼関係を築くための「意思決定ノード・オーディット(監査)」という手法を詳しく解説する。AIが「なぜその結論に至ったのか」を適切なタイミングで提示することで、WordPressサイトの自動管理や高度なデータ解析ツールにおいて、納得感のあるユーザー体験を実現できるはずだ。
AIの「透明性の瞬間」を特定する重要性

AIが自律的に動く際、ユーザーが最も不安を感じるのは「正しく動いているのか」「自分の意図を誤解していないか」という点だ。この不安を解消するには、AIの動作中に適切な情報を提示する「透明性の瞬間(Transparency Moments)」を設ける必要がある。
ブラックボックスとデータダンプの罠
例えば、車の事故状況を解析して保険金額を算出するAIを考えてみよう。ユーザーが写真をアップロードした後、「計算中」という表示のまま1分間待たされるのは典型的なブラックボックスの状態だ。ユーザーは「警察の報告書は読み込まれたのか?」「写真の傷は正しく認識されたのか?」と疑心暗鬼になる。
一方で、AIが裏側で実行しているAPIコールやサーバーの応答ログを全て画面に表示するのは、単なる情報の押し付けに過ぎない。専門的すぎる情報はユーザーを混乱させ、本当に重要な判断ポイントを見失わせてしまう。必要なのは、情報の量ではなく「質」と「タイミング」の最適化だ。
信頼を構築するインターフェースの役割
適切な透明性が確保されると、待機時間は「不安な時間」から「価値が生成されている時間」へと変化する。AIが「損傷写真を500件の事例と比較中」「法的判例に基づき報告書を分析中」といった具体的なステップを明示することで、ユーザーはAIが高度な専門業務を自分のために遂行していることを実感できる。これは、単なる進捗バー以上の心理的効果をもたらす。
意思決定ノード・オーディットの進め方

AIのプロセスを可視化するためには、まずシステムが内部でどのような「選択」を行っているかを把握しなければならない。そのためのワークフローが「意思決定ノード・オーディット」だ。
AIが「推論」するポイントを可視化する
従来のプログラムは「AならばB」という確定的なルールで動くが、AIは「おそらくAだろう」という確率(プロバビリティ)に基づいて判断を下す。この「確実ではない判断」が行われる瞬間こそが、ユーザーに説明が必要な「意思決定ノード」となる。
オーディットの手順は以下の通りだ。まず、エンジニアやデザイナー、ドメインエキスパートが一同に集まり、AIの全工程をホワイトボードに書き出す。次に、AIが複数の選択肢から一つを選んだり、自信度(コンフィデンススコア)に基づいて推論を行ったりしている箇所を特定する。これらのポイントが、透明性を高めるべき候補となる。
保険金請求AIの改善事例
前述した保険金請求AIの事例では、オーディットの結果、AIが「画像解析」「テキストレビュー」「ポリシー照合」という3つの大きな確率的ステップを踏んでいることが判明した。改善前のインターフェースはこれらを一括りにしていたが、改善後は「損傷写真を解析中:車両衝撃プロフィールと比較しています」といった具合に、ステップごとに具体的なメッセージを表示するように変更された。これにより、ユーザーの信頼度は大幅に向上したという。
抽象的な進捗表示を具体的な業務内容に置き換えることで、ユーザーはAIの専門的な働きを理解できるようになる。
インパクト/リスク・マトリックスによる情報の選別
オーディットで抽出された全てのノードを表示する必要はない。情報の出しすぎはユーザーを疲れさせる。提示すべき情報を絞り込むために「インパクト/リスク・マトリックス」を活用する。
提示すべき情報の境界線
情報の選別基準は「その判断がユーザーに与える影響の大きさ」と「取り返しのつかなさ(非可逆性)」だ。例えば、一時ファイルの名称変更といった低リスクな処理は、わざわざ通知する必要はない。一方で、銀行ローンの拒否や高額な株式トレードの実行など、高リスクかつ取り返しがつかない処理は、最大限の透明性が求められる。
Smashing Magazineの著者によれば、高リスクな判断を行う前には「意図のプレビュー(Intent Preview)」を表示し、ユーザーの明示的な許可を求めるべきだという。これにより、AIが勝手に重大なミスを犯すリスクを軽減できる。
可逆性に基づいたデザインパターンの選択
判断ミスを後から修正できる(可逆的である)場合は、AIに自律的な実行を任せつつ、実行後に「アクション監査(Action Audit)」と「取り消し(Undo)」の機能を提供すればよい。例えば、メールの自動アーカイブやファイルの整理などがこれに該当する。重要なのは、何でもかんでもユーザーに確認を求めるのではなく、リスクに応じて「事前確認」か「事後通知」かを使い分けることだ。
リスクと可逆性を軸に整理することで、ユーザーの作業効率を落とさずに安全性を確保できる。
「Wait, Why?(えっ、なぜ?)」テストによる検証

設計した透明性が適切かどうかを検証するには、ユーザーの実際の反応を観察する必要がある。そのための手法が「Wait, Why?(待って、なぜ?)」テストだ。
ユーザーの不安が生まれるタイミングを特定する
このテストでは、ユーザーにAIツールを使ってもらい、思考を全て口に出してもらう(思考発話法)。ユーザーが「あれ、今何してるの?」「止まってる?」「なぜこうなったの?」と疑問を口にした瞬間を記録する。そのタイミングこそが、透明性が不足している箇所だ。
例えば、医療予約アシスタントのテストでは、画面が4秒間静止した際にユーザーが不安を感じることがわかった。この4秒間を「あなたのカレンダーを確認中」と「医師のスケジュールと同期中」という2つのステップに分割して表示するようにしたところ、ユーザーの不安レベルは劇的に低下したという。技術的な処理時間は同じでも、情報の伝え方一つでユーザーの受け取り方は大きく変わるのだ。
WordPressサイト運営におけるAgentic AI活用の展望
WordPressの世界でも、Agentic AIの活用は急速に進んでいる。例えば、記事の自動リライト、SEO最適化、セキュリティ脆弱性の自動パッチ適用、表示速度の最適化などが挙げられる。これらの処理はサイトの根幹に関わるため、本稿で解説した透明性の設計が極めて重要になる。
自動最適化プラグインへの応用
もしAIプラグインが「サイトの読み込み速度を改善しました」とだけ表示し、裏側で勝手にCSSやJavaScriptを大幅に削除していたらどうだろうか。表示が崩れた際、管理者は何が原因か分からずパニックになるだろう。これを防ぐには、「どのファイルをどのように最適化したか」というアクション監査のログを残し、ワンクリックで元の状態に戻せる設計が必要だ。
独自の分析:透明性が「AIアレルギー」を払拭する
多くのサイト運営者がAI導入をためらう理由は、AIが「何をするか分からない」という恐怖心にある。しかし、意思決定プロセスが可視化され、コントロール権がユーザーにあることが保証されれば、AIは「得体の知れない魔法」から「信頼できる有能な助手」へと変わる。透明性は単なるUIのデザイン要素ではなく、AIという新しい技術を社会に定着させるための「信頼のインフラ」と言えるだろう。
この記事のポイント
- Agentic AIの設計では、情報を隠しすぎる「ブラックボックス」と出しすぎる「データダンプ」の両方を避けるべきだ。
- 「意思決定ノード・オーディット」を実施し、AIが確率に基づいて推論を行うポイントを特定することが透明性への第一歩となる。
- インパクト/リスク・マトリックスを活用し、高リスクな処理には「事前承認」、低リスクな処理には「事後通知」を使い分ける。
- 「Wait, Why?」テストを通じて、ユーザーが不安を感じる空白の時間を特定し、具体的なプロセス説明で埋めることが重要だ。
- 透明性の確保は、AIに対するユーザーの信頼を築き、高度な自動化ツールを実務に定着させるための鍵となる。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AI検索時代のSEO戦略:エンティティ・オーソリティを構築するチーム連携の新基準
AI検索(GEO:Generative Engine Optimization)の台頭により、従来のキーワード単位のSEOは大きな転換点を迎えている。GoogleのAI Overviews(AIによる概要表示)などで引用を勝ち取るためには、特定のトピックに対する「エンティティ・オーソリティ(実体としての権威)」を確立することが不可欠だ。
検索エンジンは現在、単なる単語の羅列ではなく、概念同士のつながりや情報の信頼性を多角的に判断している。この変化に対応するには、コンテンツ制作チームとSEOチームが別々に動く「縦割り」の体制を脱却しなければならない。
本記事では、AI検索時代においてブランドの権威を証明し、検索トラフィックを維持・拡大するための「エンティティ連携フレームワーク」を詳しく解説する。技術的な最適化と高品質なコンテンツをいかに融合させるかが、今後のWebマーケティングの成否を分けることになる。
AI検索で重要性が増す「AEO」と「エンティティ」の基礎知識

まず理解しておくべきは、現在の検索エンジンが「回答エンジン」へと進化しているという事実だ。これに伴い、SEO(検索エンジン最適化)の概念を拡張した「AEO(Answer Engine Optimization / 回答エンジン最適化)」という考え方が重要視されている。
AEO(回答エンジン最適化)とは何か
AEOとは、AIクローラーがウェブサイトの内容を正確に読み取り、ユーザーの質問に対する「回答」として抽出しやすくするための最適化プロセスだ。これには、コンテンツの質だけでなく、データの構造化やブランドの言及(サイテーション)の強化が含まれる。
AIは情報を整理する際、その情報が「どの程度信頼できるソースから発信されているか」を厳格に評価する。そのため、単にキーワードを含めるだけではなく、専門家としての裏付けを示すことが求められる。AEOは、AI検索の結果画面で自社サイトが「引用元」として選ばれる確率を高めるための戦略といえる。
キーワードから「実体(エンティティ)」へのパラダイムシフト
従来のSEOは「特定のキーワードで検索されたときに上位に表示させること」を目的としていた。しかし、現在の検索エンジンは「エンティティ(Entity)」という単位で情報を処理している。エンティティとは、検索システムが他と区別して認識できる「固有の概念」のことだ。
例えば「顧客導入(カスタマーオンボーディング)」というエンティティは、「ユーザー定着」「製品の活性化」「カスタマーサクセス」といった他の概念と密接に結びついている。検索エンジンは、これらの関連性を理解した上で、サイトがそのトピックについてどれだけ深く、網羅的に説明しているかを判断する。つまり、点としてのキーワードではなく、面としての概念ネットワークを構築する必要があるのだ。
● 検索ボリュームの大きい単語を優先的に狙う
● 記事同士の関連性よりも個別の順位を重視する
● AIが理解しやすいよう構造化データで関係性を明示
● 外部サイトからの言及やリンクで信頼性を裏付ける
このデモは、SEOの考え方がキーワード単位からエンティティ単位へと移行している様子を視覚化したものだ。
なぜコンテンツとSEOの「縦割り」が失敗を招くのか

多くの組織では、記事を書く「コンテンツチーム」と、技術的な調整やリンク獲得を行う「SEOチーム」が分断されている。しかし、エンティティ・オーソリティを築く上では、この分断が最大の障害となる。
技術と内容の乖離が招く検索機会の損失
SEOチームがいくら高度なスキーママークアップ(検索エンジンに情報を伝える専用のコード)を実装しても、肝心のコンテンツが薄っぺらであれば、AIはそのサイトを「権威」とは見なさない。逆に、コンテンツチームが素晴らしい調査レポートを書いても、SEOの観点から適切な内部リンクや外部からの裏付けがなければ、検索エンジンはその価値を正しく認識できない。
Search Engine Journalの記事によれば、コンテンツの深さと外部からの検証(リンクなど)が独立して動いている場合、AI検索における「情報の引き出し(リトリーバル)」の機会を逃してしまうリスクが高まる。両チームが同じ「エンティティ」という目標に向かって歩調を合わせることで、初めて強力なシグナルが検索エンジンに届くようになる。
エンティティ・オーソリティを構成する3つの評価軸
検索システムがサイトの権威性を評価する際、主に以下の3つの次元を見ていると指摘されている。
- Recognition(認識):コンテンツがどのエンティティ(概念)について語っているかを識別できるか。
- Relationships(関係性):それらのエンティティが他の概念とどう繋がっているかを理解できるか。
- Corroboration(裏付け):外部の信頼できるソースが、そのサイトの主張を正しいと認めているか(被リンクや言及)。
これらを満たすには、単一のチームの努力では不十分だ。コンテンツが「認識」と「関係性」の土台を作り、SEOが「裏付け」を強化するという共同作業が必要になる。
エンティティを軸とした4フェーズの連携ワークフロー

では、具体的にどのようにチームを連携させるべきか。Victorious社が提唱するフレームワークに基づき、4つのフェーズで構成されるワークフローを解説する。
フェーズ1:SEOチームによるエンティティ調査とベクトル分析
まずSEOチームが主導し、ビジネスの核となるエンティティを特定する。ここでは単なるキーワードリサーチにとどまらず、「ベクトル埋め込み(Vector Embedding)」の視点を取り入れる。これは、言葉の意味を多次元の数値として捉え、概念の近さを分析する手法だ。
GoogleのNatural Language APIなどのツールを使い、自社の主要サービスに関連するトピック(エンティティ・アソシエーション)を洗い出す。例えば「プロジェクト管理」が主軸なら、「リソース計画」「キャパシティ管理」「プロジェクト予測」といった関連概念をリストアップする。この段階で、競合とのギャップや、どの程度の被リンクが必要かという「リンク速度」の要件も算出しておく。
フェーズ2:コンテンツのギャップ分析と優先順位付け
次に、SEOチームとコンテンツチームが共同で既存コンテンツをレビューする。特定したエンティティに対して、カスタマージャーニー(認知・検討・決定)の各段階を網羅できているかを確認するのだ。
「このトピックについて、AIが権威と認めるだけの深さがあるか?」を自問自答する必要がある。調査レポート、ガイド記事、比較記事、ハウツー動画など、多様な形式でエンティティを補強する計画を立てる。ここで重要なのは、両チームが「成功の定義」を共有することだ。単なるPV数だけでなく、特定のエンティティでの順位向上やAI検索での引用率を指標に据えるべきだ。
フェーズ3:スキーマ実装と戦略的なリンクビルディング
実行フェーズでは、コンテンツチームが記事を作成し、SEOチームがそれを技術的に補強する。具体的には、SameAsプロパティなどを用いた構造化データを実装し、エンティティ同士の関係性を検索エンジンに明示する。また、内部リンクを整理し、関連するトピック同士を「クラスター(塊)」としてつなぎ合わせる。
外部対策においても、単にリンクを集めるのではなく、狙っているエンティティについて言及しているメディアからのリンクを優先する。アンカーテキスト(リンクが設定された文字列)にも、エンティティに関連する語句を自然なバリエーションで含めることが求められる。これにより、「このサイトはこのトピックの専門家である」という外部からの裏付けが完成する。
この図は、中心となるエンティティを複数のコンテンツと外部リンクで囲い込み、権威を形成する構造を示している。
実践例:SaaS企業の「リソース管理」エンティティ構築

理論だけでは分かりにくいため、具体的な成功事例を見てみよう。あるプロジェクト管理ツールを提供しているSaaS企業のケースだ。
競合分析から見えたコンテンツとリンクの不足
この企業は「プロジェクト管理」という大きな市場で認知を広げたいと考えていた。ベクトル分析の結果、その下位概念である「リソース計画(Resource Planning)」が、主目的との親和性が非常に高いことが判明した。しかし、自社サイトを確認すると、リソース計画に関する記事は基礎的なブログが1本あるだけだった。
一方で競合他社は、リソース割り当てのトレンド調査、キャパシティ計画の包括的ガイド、手法の比較記事、導入ハウツーなど、あらゆる角度からこのエンティティを攻略していた。また、外部のプロジェクト管理専門メディアからも、これらのページに対して質の高いリンクが集まっていた。この「情報の密度」と「裏付け」の差が、AI検索での露出の差に直結していたのだ。
4ヶ月でAI検索の引用を獲得した具体的プロセス
この企業は4ヶ月間にわたる集中施策を実施した。まずコンテンツチームが、独自の調査データを含むリサーチ記事や、実装に役立つ詳細なガイドを順次公開していった。並行してSEOチームは、これらの新記事を構造化データで紐付け、サイト内の関連ページから最適な内部リンクを設置した。
さらに、外部の業界誌に対し、リソース管理に関する専門的な寄稿やデータ提供を行い、関連性の高いバックリンクを構築した。結果として、リソース計画に関連するクエリでの順位が向上しただけでなく、GoogleのAI Overviewにおいて「リソース計画のベストプラクティス」などの検索時に自社記事が引用されるようになった。これは、単独のチームが独立して動いていては達成できなかったスピード感だといえる。
独自見解:AI時代のSEOは「点」ではなく「面」の勝負になる

今回のフレームワークを分析して感じるのは、SEOがかつての「ハック(裏技)」から、より「本質的な信頼構築」へと回帰しているということだ。AIは単に文字を読んでいるのではなく、その背後にある「情報の網」を見ている。
筆者の見解としては、今後のSEO担当者に求められるのは、テクニカルな知識以上に「トピックの構造化能力」だと考える。どの概念とどの概念を繋げれば、自社がその分野の第一人者だと証明できるか。この「概念の地図」を描く力こそが、AI検索時代の武器になるはずだ。
また、この戦略は小規模なサイトにとってもチャンスとなる。広範なキーワードを狙う体力はなくても、特定のニッチなエンティティにおいて「誰よりも詳しく、かつ外部からの信頼も厚い」という状態を作れば、AI検索はそこをピンポイントで引用してくれる可能性がある。大手が網羅しきれない専門領域で「面」を構築することが、これからの戦い方になるだろう。
この記事のポイント
- AI検索(AEO)時代には、単一キーワードではなく「エンティティ(概念)」単位の最適化が必須となる。
- エンティティ・オーソリティは「認識」「関係性」「裏付け」の3要素で構成される。
- コンテンツチームとSEOチームの分断を解消し、4フェーズの連携ワークフローを回すことが成功の鍵だ。
- ベクトル分析を用いて関連トピックを特定し、カスタマージャーニーを網羅するコンテンツを制作する。
- 技術的な構造化データ実装と、外部ソースからの言及を融合させることで、AI検索での引用率が高まる。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

WooCommerceの決済・配送APIが遅い?サードパーティ障害からサイトを守る技術
WordPressサイト、特にWooCommerceを利用したECサイトの表示が急に重くなったとき、多くの運用者はまずホスティングサーバーの性能を疑う。しかし、実際にはサイトが依存している「外部サービス」が真の原因であるケースが少なくない。
決済ゲートウェイの応答待ち、配送キャリアの送料計算APIの遅延、あるいはアクセス解析スクリプトの読み込み停滞など、サードパーティの不調はサイト全体のパフォーマンスを道連れにする。これらの要素はホスティング側の制御を超えた場所にあり、適切な対策なしにはサイト全体の「連鎖的な崩壊」を招くリスクがある。
本記事では、WordPressにおけるサードパーティ依存の障害がどのようにサイトを停止させるのか、その仕組みを解明する。また、コンテナ隔離技術による保護や、アプリケーションレベルでのタイムアウト設定、フォールバック(代替処理)の実装など、プロが実践すべき具体的な防御策を詳しく解説していく。
サードパーティ依存が引き起こす「連鎖的障害」の正体

現代のWordPressサイトは、単体で完結していることは稀だ。特にWooCommerceを運用している場合、チェックアウトのプロセスだけでも多くの外部APIと通信している。決済処理のためにストライプ(Stripe)やペイパル(PayPal)とやり取りし、リアルタイムの送料を算出するために配送会社のシステムへ問い合わせ、税金の計算サービスと同期するといった具合だ。
これらの依存関係のうち、たった一つでも応答が遅くなると、その影響は特定の機能だけに留まらない。WordPressが外部APIのレスポンスを待っている間、サーバー内の「PHPスレッド」と呼ばれる処理の枠組みが占有されたままになるからだ。これは、レジで客が財布を忘れて取りに戻っている間、後ろに並んでいる全員が待たされる状態に似ている。
PHPスレッドの枯渇と504エラーの相関
PHPスレッドとは、サーバーが一度に実行できる作業の単位だ。例えば、ある決済APIがタイムアウトするまでに30秒かかるとしよう。その間、一つのスレッドはその通信を待つためだけに拘束され、他のリクエストを処理できなくなる。もし複数のユーザーが同時にチェックアウトを試みれば、利用可能なスレッドはあっという間に使い果たされてしまう。
スレッドがすべて埋まると、新しくサイトを訪れたユーザーのリクエストは順番待ちになる。そして一定時間を過ぎても処理が始まらない場合、ブラウザには「504 Gateway Timeout」などのエラーが表示される。このエラーはサーバーのスペック不足で起きるものと見た目が同じであるため、本当の原因が外部APIにあることを見逃しやすいという問題がある。
可視性のギャップ:インフラか外部要因か
504エラーが発生した際、多くの管理者はCPU使用率やメモリ残量といったインフラのメトリクス(指標)を最初に確認する。しかし、外部APIの遅延が原因の場合、インフラ側の負荷はそれほど高くないにもかかわらず、サイトが停止しているという矛盾が生じる。この「可視性のギャップ」が、問題解決を遅らせる大きな要因となるのだ。
↓ API応答待ち(30秒間スレッド占有)
× 後続のユーザー全員がエラーになる
↓ タイムアウト設定(5秒で切り上げ)
○ 予備の送料を表示して処理を続行
外部APIの遅延がサイト全体を停止させる仕組みと、タイムアウト設定による保護のイメージだ。
ホスティング環境による「被害の局所化」:コンテナ隔離の重要性

外部サービスの障害による影響範囲を最小限に抑えるためには、ホスティング側のアーキテクチャが重要になる。一般的な共有サーバーでは、一つのサイトで外部APIの遅延によるスレッド枯渇が起きると、同じサーバーに同居している他の無関係なサイトまで道連れにして停止させてしまうことがある。これは、すべてのサイトが共通のスレッドプールを奪い合っているからだ。
対照的に、Kinstaのようなモダンなホスティング環境では、各WordPressサイトを「隔離されたコンテナ」の中で実行している。この方式の最大のメリットは、障害の「爆発半径」をそのサイト内だけに閉じ込められる点にある。
専用スレッドプールによる防御線
コンテナ技術を採用している環境では、各サイトに専用のPHPスレッドプールが割り当てられている。たとえ自サイトで決済APIの不調によりスレッドがすべて埋まったとしても、同じサーバー上の他のサイトには一切影響が及ばない。また、スレッドが一時的に不足した場合でも、リクエストはNginxやPHP-FPMのキュー(待ち行列)に保持され、スレッドが空き次第順次処理されるため、即座にエラーを返さず踏みとどまることが可能だ。
実行時間制限とタイムアウトの落とし穴
サーバーには通常、max_execution_time という設定があり、PHPスクリプトの実行時間を制限している。しかし、ここに大きな落とし穴がある。Linux環境では、PHPが外部APIとの通信(ストリーム操作)を待っている時間は、この実行時間としてカウントされない仕様なのだ。
つまり、たとえサーバーの制限が30秒に設定されていても、外部APIからの返答を待っている間は、その制限時間を超えてスレッドを占有し続ける可能性がある。このため、サーバー側の設定だけに頼るのではなく、WordPressのアプリケーション側で明示的なタイムアウトを設定することが不可欠となる。
Kinsta APMを活用したボトルネックの特定手順

「サイトが重い」と感じたとき、それがサーバーの問題なのか外部サービスのせいなのかを切り分けるには、APM(Application Performance Monitoring)ツールが威力を発揮する。Kinstaが提供しているAPMツールは、PHPのプロセス、MySQLクエリ、そして外部へのHTTPコールを時系列で詳細に記録してくれる。
「External」タブで外部通信を監視する
APMの管理画面にある「External」タブは、サードパーティ依存の問題を特定するための鍵となる。ここには、プラグインやテーマが実行したすべての外部HTTPリクエストがリストアップされる。各リクエストの平均所要時間、最大所要時間、そして1分あたりのリクエスト数が表示されるため、どのAPIが足を引っ張っているかが一目瞭然だ。
例えば、特定の決済APIの最大所要時間が数秒以上に達していれば、そのサービスがボトルネックであることは疑いようがない。ホスティング環境自体は正常に動作していても、外部の特定のピースが欠けているために全体が遅くなっていることがデータで証明できるのだ。
トランザクショントレースによる詳細分析
さらに詳しく調査したい場合は、個別のリクエストをクリックして「トランザクショントレース」を確認する。これは、一つのリクエストが完了するまでに行われた全処理をタイムライン形式で表示するものだ。処理全体の90%以上を外部APIとの通信が占めているような場合、サーバー構成の変更やキャッシュの調整よりも、そのAPIの利用方法を見直す方が遥かに効果的だと言える。
サイトの表示を止めないための非同期読み込みとタイムアウト戦略

インフラ側での隔離ができたら、次はアプリケーション側での防御策を講じる。最も基本的なのは、スクリプトの「非同期読み込み」だ。WordPressはデフォルトでスクリプトを同期的に読み込むが、これは外部サーバーからスクリプトがダウンロードされるまで、ブラウザがページの描画をストップ(ブロック)してしまうことを意味する。
asyncとdeferの使い分け
アクセス解析やマーケティング用のスクリプトなど、ページの表示に直接関係ないものは、async または defer 属性を付けて読み込むべきだ。WordPress 6.3からは、wp_enqueue_script() 関数でこれらの属性を簡単に指定できるようになった。実行順序が重要なものは defer、順不同で即座に実行して良いものは async を選ぶのが鉄則だ。
add_action( 'wp_enqueue_scripts', function() {
// 解析スクリプト:表示をブロックしないようdeferを指定
wp_enqueue_script(
'google-analytics',
'https://www.googletagmanager.com/gtag/js?id=G-XXXXXXXX',
[],
null,
[ 'strategy' => 'defer', 'in_footer' => false ]
);
// マーケティングツール:順不同で良いのでasyncを指定
wp_enqueue_script(
'marketing-tool',
'https://example.com/script.js',
[],
null,
[ 'strategy' => 'async', 'in_footer' => false ]
);
} );APIタイムアウトのフィルタ設定
PHP側で行うAPI通信についても、待ち時間の上限を厳格に定める必要がある。WordPressには http_request_timeout というフィルタが用意されており、これを使って外部リクエストのタイムアウト時間を制御できる。デフォルトの5秒でも長すぎる場合があるため、重要度に応じて短縮を検討すべきだ。
add_filter( 'http_request_timeout', function( $timeout, $url ) {
// 特定のAPIに対しては、最大3秒までしか待たない設定にする
if ( str_contains( $url, 'api.shipping-service.com' ) ) {
return 3;
}
return $timeout;
}, 10, 2 );障害を「なかったこと」にするフォールバックの実装パターン

タイムアウトを設定して通信を遮断するだけでは、ユーザーにはエラーが表示されてしまう。そこで重要になるのが「フォールバック(代替処理)」の仕組みだ。外部APIが死んでいても、サイトとしての最低限の機能を維持するための工夫である。
具体的には、WordPressの「トランジェント(一時的なキャッシュデータ)」を活用する。APIとの通信が成功した際のレスポンスを一定期間保存しておき、APIがエラーを返したりタイムアウトしたりした場合には、その保存されている「古いデータ」を代わりに使うという手法だ。
二段構えのキャッシュ戦略
より堅牢なシステムにするなら、通常のキャッシュ(1時間程度)とは別に、より長期のバックアップ用キャッシュ(24時間程度)を保持する「二段構え」の構成が推奨される。APIがダウンしている間、ユーザーは昨日時点の送料データを基に買い物を続けることができる。全く注文が受けられない状態に比べれば、多少のデータの古さは許容範囲内であることが多い。
優雅な劣化(Graceful Degradation)
もしキャッシュすら存在しない場合は、あらかじめ設定しておいた「一律料金」などのデフォルト値を返すように設計する。これを「優雅な劣化(Graceful Degradation)」と呼ぶ。システムの一部が壊れても、全体を停止させずに、機能を縮小しながら稼働し続けるという考え方だ。この設計思想があるかないかで、障害時の売上損失は劇的に変わってくる。
外部APIの状況に応じた、段階的なフォールバック(代替処理)の優先順位だ。
この記事のポイント
- サードパーティAPIの遅延は、PHPスレッドを占有し、サイト全体の504エラーを引き起こす。
- サーバー側の実行時間制限(max_execution_time)は、API通信の待機時間には効かない場合がある。
- コンテナ隔離技術を採用したホスティングなら、他サイトのAPI障害による巻き添えを防げる。
- 非同期読み込み(async/defer)やHTTPタイムアウト設定により、アプリ側で防御線を張るべきだ。
- キャッシュ(トランジェント)を活用したフォールバック実装が、障害時のビジネス継続性を左右する。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験