

Google Merchant CenterにAIショッピング可視性機能、表示シェア分析が可能に
GoogleがMerchant CenterにAIを活用した新しい可視性レポート機能を追加した。EC事業者は自社商品がAI検索結果やGeminiなどの会話型ショッピング体験でどのように表示されているかを詳細に分析できるようになる。
提供されるデータは表示シェア(Share of Voice)、購買ファネル分析、商品検索キーワードインサイト、商品属性ギャップの4種類だ。従来のランキング指標だけでは測れなかった「AIがどのように商品を推薦しているか」が数値化される点が最大の変化である。
この機能は米国、カナダ、オーストラリア、インド、ニュージーランドで今後数ヶ月以内に展開される。商品データの充実度がAI時代のEC競争力を左右する局面に入ったといえる。
AIショッピング可視性インサイトの全容

4つの指標はそれぞれ独立して参照できるが、実際の運用では相互に関連づけて分析するのが効果的だ。例えば「属性ギャップ」がある商品が「表示シェア」で競合に劣っているケースは頻出する。
表示シェアと購買ファネルの可視化
表示シェア(Share of Voice)は、AIショッピング体験において自社商品がどの程度の頻度で表示されるかを示す指標だ。従来の検索順位とは異なり、AIが生成する回答文や推薦リスト内での出現比率を数値化する。
購買ファネル分析と組み合わせることで「表示はされているが購入に至っていない」段階を特定できる。AI検索で発見された後に詳細ページへ遷移しない商品や、比較対象には上がるが最終選択されない商品の傾向が明らかになる。
検索キーワードと商品属性ギャップの分析
商品検索キーワードインサイトでは、買い物客がAIに対して自然言語で入力したクエリが収集される。「軽量で防水性のある黒いリュック」といった具体的な条件がレポートに現れるため、商品データに不足している情報が一目でわかる仕組みだ。
商品属性ギャップレポートは、色、素材、スタイル、サイズといった構造化データの欠損を自動検出する。AI検索はこれらの属性を照合材料として使うため、未入力の項目があると「検索条件に合致しない」と判定されて表示機会を失う。MarTechの記事では、AIショッピングシステムが完全かつ整理された商品データを求める理由がこの点にあると指摘されている。
Merchant CenterがAIコマース最適化プラットフォームへ進化

Merchant Centerは当初、商品フィードの管理ツールとしてスタートした。しかし今回のアップデートで、AIコマース時代の最適化プラットフォームへと明確に舵を切ったことになる。
最大の変化は、商品フィードが単なる在庫リストではなく、SEOコンテンツと同様の扱いを受けるようになる点だ。商品名や説明文の「自然言語としての充実度」がAI検索での可視性を直接左右する。キーワードの羅列ではなく、文脈を持った商品情報が求められる。
商品フィードのSEO的発想が不可欠に
従来の商品フィード最適化といえば、タイトルにキーワードを盛り込む、画像を高解像度にする、価格と在庫を正確に保つといった基本事項が中心だった。AIショッピング時代では、これらに加えて「会話型検索で問い合わせられるであろう具体的な条件」を先回りしてデータ化する必要がある。
具体的には色のバリエーション名(「チャコールグレー」「アイボリーホワイト」など)、素材の特性(「撥水加工」「UVカット」)、使用シーン(「オフィス向け」「アウトドア用」)といった属性を構造化データとして登録することが重要になる。これらの情報がAIの推薦ロジックにおいて、商品の「選ばれる理由」を構成するからだ。
EC事業者が今すぐ着手すべき施策

新機能の展開を前に、EC事業者は商品データの棚卸しを始めるべきタイミングだ。Merchant Centerの属性ギャップレポートは提供開始後に活用できるとしても、今から準備できることは多い。
商品データの完璧な構造化
色、素材、サイズ、スタイル、使用シーンといった基本属性をすべて埋めることは、検索エンジン向けの対策であると同時に、AIが「この商品はどんな買い物客に向いているか」を判断する材料を提供する行為でもある。
WooCommerceを利用している場合、商品編集画面の「商品データ」セクションで属性を追加できる。ブランドやメーカー情報も忘れずに登録する。GoogleのAIはブランド名を重要な推薦シグナルとして扱う傾向がある。
AI時代の商品コンテンツ戦略
商品説明文は「どんな人が、どんな場面で、どんな目的で使うのか」を自然な文章で書くことがこれまで以上に重要になる。キーワードの羅列やコピー&ペーストの説明文は、AIによる文脈理解の妨げになる。
具体的な対策として以下の3つを推奨する。1つ目は商品名に主要な属性を含めること(例「防水ポリエステル製 20L ブラックリュック」)。2つ目は説明文の冒頭2〜3文で商品の特徴と使用シーンを伝えること。3つ目はユーザーレビューを積極的に収集し、AIが実利用者の声を参照できるようにすることだ。AI検索はレビュー内容も回答生成の材料に使うため、これも間接的な可視性向上につながる。
この記事のポイント
- Google Merchant CenterにAI可視性レポート機能が追加。表示シェア、購買ファネル、キーワードインサイト、属性ギャップの4指標が利用可能に
- AI検索では商品の表示が「ランキング」より「推薦」に近い形になるため、商品属性の充実度が選ばれるかどうかを左右する
- 商品フィードはSEOコンテンツと同じ発想で整備する必要がある。キーワードの羅列ではなく、文脈と完全性が求められる
- 今すぐ着手すべき施策は、商品属性の100%入力、自然な説明文への書き直し、ユーザーレビューの収集の3つ
- WooCommerce利用者は商品編集画面の属性セクションを今すぐ確認し、未入力項目をなくすことから始めるのが有効

・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

WooCommerceがAI商品提案プラグインβ版公開、カタログ改善を自動化
WooCommerceが2026年5月25日、商品カタログの品質改善を支援する新プラグイン「AI Product Advisor」のパブリックベータ版を公開した。このツールはサイト内の全商品を分析し、改善の余地が大きい商品を特定した上で、タイトルや説明文の修正案を提示する。EC担当者が抱える「どこから手をつければいいかわからない」という課題に、AIが直接答えを出す形だ。
商品カタログのメンテナンスは後回しにされがちな作業の一つである。タイトル、説明文、カテゴリ、タグ、バリエーション情報と、改善ポイントは無数に存在する。人的リソースが限られる中小規模のECサイトでは、優先順位をつけること自体が難しかった。AI Product Advisorはこの問題に対して、データに基づく判断軸を提供する。
本記事では、AI Product Advisorの主要機能と導入方法を解説する。さらに、このツールがEC運営にもたらす実務的な変化と、AIエージェントの台頭がECサイト運用に与える構造的な影響について考察する。WooCommerceユーザーはもとより、EC業界全体のトレンドを掴みたい担当者にも有用な情報だ。
AI Product Advisorの概要

AI Product Advisorは、WooCommerce管理画面に専用のメニューを追加するプラグインである。アクティベート後の初回起動時にオンボーディングプロセスが走り、既存ストアのコンテンツを分析する。このとき単に商品データを読み込むだけでなく、ストア固有のブランドトーンを学習する点が特徴だ。これにより、AIが生成する提案文が「無機質なAIコピー」ではなく、ストアの世界観に沿った自然な文体になる。
分析完了後、プラグインは商品タイトル、詳細説明、短い説明文、カテゴリ、タグ、バリエーション詳細といったフィールド単位で改善提案を生成する。提案は一覧画面にキューとして蓄積され、EC担当者は優先度の高いものから順に確認できる。各提案はサイドバイサイドの差分表示で提示され、元のテキストとAI提案文を比較しながら、ワンクリックで適用するか編集するかを選べる。
3つの主要ビュー
本プラグインは、EC担当者の業務フローに合わせた3つの画面で構成されている。
保留中の提案数、承認率、週間利用状況をダッシュボード表示。変更適用済み商品には「受注増減インジケーター」が付き、改善後の効果を数値で追跡できる。
優先度順にソートされた改善提案の一覧。商品をクリックするとインライン編集可能な差分画面が開き、その場でテキストを調整できる。
承認したすべての変更を時系列で記録する監査ログ。各変更は元に戻すことができ、誤った適用を即座にリバート可能。
3つのビューは、EC担当者の「状況把握→改善実行→事後検証」という一連の業務サイクルに対応している。特に履歴画面の存在は重要だ。AI提案を機械的に適用するのではなく、人間が判断し、結果を検証し、必要に応じて差し戻すという運用プロセスを前提に設計されている。
ブランドトーン学習の仕組み

AI Product Advisorが他のAIライティングツールと一線を画すのは、ストア固有のブランドトーンを学習する機能である。オンボーディング時にプラグインは既存の商品説明文やストア情報を分析し、「です・ます調」「だ・である調」の文体選択にとどまらず、語彙の傾向、感情表現の強さ、専門性のレベルまでプロファイル化する。
Developer WooCommerce Blogの記事によれば、このトーンプロファイルは提案生成時に参照され、AIが出力するテキストをストアの世界観に自動調整する仕組みだ。たとえばカジュアルなファッションブランドであれば親しみやすい口調で、ビジネス向けのBtoB商材なら専門的でフォーマルな表現で提案が生成される。AIコピーにありがちな「無機質さ」や「浮いた感じ」を抑える狙いがある。
この機能がもたらす実務上の恩恵は大きい。従来のAIライティングツールは「それっぽい文章」を出力できても、ストアの声と一致させるには結局人間が手直しする必要があった。トーンプロファイルによる自動調整は、この手直し工程を大幅に削減する可能性を秘めている。もっとも、ベータ版であるため、現時点では学習精度にばらつきが出ることも想定しておくべきだろう。
導入方法とベータ版の注意点

インストール手順
- GitHubのリリースページからプラグインZIPファイルをダウンロードする
- WordPress管理画面で「プラグイン」→「新規追加」→「プラグインをアップロード」を開く
- ダウンロードしたZIPファイルを選択し、インストール後に有効化する
- 管理メニューに追加された「Product Advisor」を開き、オンボーディングを完了させる
オンボーディングではストアの接続とブランドトーンの設定を行う。所要時間はストアの商品点数によって変動するが、Developer WooCommerce Blogの記事では明示的な所要時間の言及はない。小規模ストアであれば数分、数千SKUを抱える大規模ストアでは相応の処理時間を見込む必要があるだろう。
ベータ版利用時の注意点
AI Product Advisorは「実験的なプラグイン」という位置づけである。WooCommerce開発チームは「実際の利用から学ぶために早期公開した」と明言しており、本番環境への導入はステージング環境での十分なテスト後が推奨される。フィードバックはGitHub IssuesまたはDeveloper WooCommerce Blogのコメント欄で受け付けている。
また、AIが提案するテキストはあくまで「提案」であり、最終的な判断と責任はストア運営者にある。特に法的表記が必要な商品(食品表示、薬機法関連、特定商取引法に基づく表記など)については、AI提案をそのまま適用せず、必ず担当者が内容を確認する必要がある。
AI Product Advisorが示すEC運営の変化

AI Product Advisorの登場は、単なる「便利なプラグインが増えた」という話にとどまらない。EC運営におけるAIの役割が「分析補助」から「実行提案」へと明確にシフトしている点が重要だ。
従来のEC向けAIツールは、アクセス解析や売上レポートといった「現状把握」を支援するものが中心だった。データを見て、そこから改善策を考えるのは人間の役割である。一方、AI Product Advisorは「この商品の説明文にこういう問題がある」「こう書き換えると効果が見込める」という具体的な行動提案まで踏み込んでいる。WooCommerceのエコシステムにおいて、AIが「実行レイヤー」に進出した最初期の事例と言える。
このフロー変化が示すのは、EC担当者の役割が「考えて書く人」から「判断して承認する人」へと変わりつつあることだ。時間を奪われていた反復作業から解放され、本来注力すべき「戦略立案」や「ブランド育成」にリソースを振り向けられるようになる。WooCommerceがAIエージェントへの布石を打ったと見ることもできる。
AIエージェント型EC運用の展望
AI Product Advisorはまだ「提案→人間が判断」という協調型だが、この延長線上には「AIが自動的にA/Bテストを実施し、勝ちパターンを学習して自律的にカタログを最適化し続ける」エージェント型運用が想定される。WooCommerceの開発チームがGitHub上で公開しているソースコードには、将来的な拡張を見越したアーキテクチャが示唆されている。
EC運営者はこの流れを「自分たちの仕事が奪われる」と警戒するのではなく、「ルーティンワークから解放されるチャンス」と捉えるべきだ。AIが商品説明文を最適化している間、人間は新商品の企画や顧客体験の設計といった、より創造的な業務に集中できる。中小規模のEC事業者にとって、この人的リソースの再配分が競争力の源泉になる。
この記事のポイント
- AI Product Advisorは商品カタログ全体を分析し、改善余地の大きい商品を優先度順に提示する
- ブランドトーン学習機能により、ストア固有の文体に合わせた自然な提案文が生成される
- 3つのビュー(概要・提案キュー・履歴)で、改善実行から効果検証まで一貫して管理できる
- ベータ版のため、本番適用はステージング環境でのテスト後に実施することが推奨される
- AIが「実行提案」まで踏み込むことで、EC担当者の役割は「判断と承認」へシフトしつつある
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

VS Codeで始めるGitHub超入門!リポジトリ作成からAI活用まで
VS CodeとGitを連携させれば、エディタから離れることなくGitHub上のバージョン管理が完結する。コードを書きながらコミット、ブランチの切り替え、プッシュまで行えるため、作業の中断が大幅に減る。
本記事では、フォルダの初期化から変更の追跡、ブランチのマージ、リモートへの公開、さらにMCP(Model Context Protocol)を使ったAI支援まで、実務で頻繁に使う一連の流れを手順を追って解説する。Gitの概念を簡単な言葉で補足しながら進めるので、バージョン管理が初めてでも迷わないはずだ。
VS Codeで始めるGitとGitHubの基本

GitとGitHubの役割
Gitはソースコードの変更履歴を管理するプログラムだ。GitHubはその履歴を保管するリモートの場所で、いわば「コードの倉庫」である。Gitでローカルに記録した履歴をGitHubにアップロードすることで、チームでの共有やバックアップが実現する。
VS Codeが開発効率を上げる理由
VS Code(Visual Studio Code)はMicrosoftが提供する無料のソースコードエディタだ。内部にGit機能が統合されており、GUI上でリポジトリの初期化やコミット、ブランチ操作を行える。ターミナルとエディタを行き来する手間を省き、エディタのサイドバーやコマンドパレットからほとんどのGit操作を実行できる。
リポジトリの初期化と最初のコミット

まずはローカルのフォルダをGitリポジトリとして初期化し、ファイルを追跡してコミットする流れを確認しよう。
VS Codeを起動し、左側のアクティビティバーにあるExplorerアイコン(重なったファイルのような形)をクリックする。次に「Open Folder」ボタンから、GitHubに上げたいコードが入ったフォルダを開く。
続いて、アクティビティバーの上から3番目にあるSource Controlアイコンを選択する。すると「Initialize Repository」ボタンが表示されるので、これをクリックする。これでフォルダがGitリポジトリとして機能し始める。
初期化直後は、Source Controlパネル内のファイル名の横に「U」(Untracked)が表示される。ファイルを追跡対象にするには、ファイル名の隣のプラス記号をクリックする。全ファイルを一括でステージングしたい場合は「CHANGES」の右にあるプラスを押せばよい。ステージングされるとファイルの状態は「A」(Added)に変わる。
ステージングした変更を記録するには、Source Controlパネル上部のメッセージ入力欄にコミットメッセージを記入し、「Commit」ボタンを押す。ここでCopilotの提案機能を使えば、差分に合ったメッセージを自動生成することも可能だ。
ブランチの作成と切り替え

コマンドパレットからのブランチ作成
デフォルトでは通常「main」ブランチが使われる。新機能の開発や修正作業は、別のブランチを切って進めるのが一般的だ。
Shift + Command + P(Mac)またはCtrl + Shift + P(Windows)でコマンドパレットを開き、「create branch」と入力する。候補から「Git: Create Branch…」を選び、任意のブランチ名(例「new-features」)を入力してEnterで確定する。すると新しいブランチが作成され、自動的にそのブランチに切り替わる。ウィンドウ左下のブランチ名表示で確認できる。
作業ブランチでの変更と確認
新しいブランチ上でコードを編集すると、後述するようにエディタの左側(ガター)に色付きのインジケータが現れる。この状態でファイルを保存し、Source Controlパネルから変更をステージングしてコミットする流れは先ほどと同じだ。
変更の追跡と差分の確認

ガターに表示される変更インジケーター
VS Codeでファイルを編集すると、行番号の左側にあるガターと呼ばれる領域に色分けされた目印が表示される。新しく追加した行には緑色のバー、既存の行を修正した箇所には青色の模様付きバー、行を削除した場所には赤色の矢印が現れる。これによって、どの変更が未コミットなのかを瞬時に把握できる。
このように、エディタの左側にある「ガター」に色付きのインジケーターが表示され、どの行を追加・変更・削除したかが一目でわかる。
差分の表示(並列表示とインラインビュー)
変更内容を詳しく比較したいときは、Source Controlパネルでファイル名をクリックする。すると左右に分割された差分ビューが開き、変更前後のコードを横に並べて確認できる。分割ビューの右上にある三点リーダーから「Inline View」を選ぶと、ひとつの画面内に差分がインラインで表示される。このビュー上で直接編集を加えることも可能だ。
ブランチのマージとGitHubへの公開

マージ手順
作業ブランチでの変更をmainブランチに取り込むには、まずmainブランチに切り替える。ウィンドウ左下のブランチ名をクリックし、表示される一覧から「main」を選択する。その後、Source Controlパネルの三点リーダーから「Branch」にカーソルを合わせ、「Merge…」をクリックする。マージ元として先ほどまで作業していたブランチを選べば、mainブランチに変更が統合される。
リポジトリのプッシュと公開
ローカルのリポジトリをGitHub上に公開するには、Source Controlパネルにある「Publish Branch」ボタンを押す。VS Codeが公開時の可視性(プライベートかパブリックか)を尋ねてくるので、目的に合わせて選択する。処理が完了すると、通知からそのままGitHub上のリポジトリを開ける。
リポジトリのクローン

既存のリポジトリを手元に複製して作業したい場合は、GitHubのリポジトリページで緑色の「<> Code」ボタンをクリックし、URLをコピーする。VS Codeのコマンドパレットを開き「clone」と入力して「Git: Clone」を選び、URLを貼り付ける。保存先フォルダを指定すると、クローンが開始される。完了後に「Open」を選択すれば、すぐにローカルで開発を始められる。
MCPでAIを活用する

GitHub MCP拡張機能のインストール
MCP(Model Context Protocol)は、AIツールが安全に外部サービスと連携するためのプロトコルだ。VS CodeでGitHubのMCPを利用すると、Copilotチャットがリポジトリの情報を参照しながらコード生成やIssue作成を行えるようになる。
アクティビティバーのExtensionsアイコンを開き、「@mcp github」で検索する。該当するGitHub公式の拡張機能をインストールし、認証を許可すると、下部のパネルにMCPサーバーが追加される。これで準備は完了だ。
Copilotチャットとの連携
チャットウィンドウから自然言語で「フラッシュカードアプリに新機能を追加して」などと指示すると、Copilotが必要なツールを自動的に呼び出し、コードやIssueを生成する。手作業でファイルを開いて確認していた手順をAIに任せられるため、プロトタイピングの速度が格段に上がる。
この記事のポイント
- VS Codeに統合されたGit機能を使えば、エディタだけでコミットやブランチ操作が完結する
- リポジトリの初期化から最初のコミットまでは四つのステップで完了
- ガターの色分けインジケーターで、追加・変更・削除を瞬時に識別できる
- ブランチのマージやGitHubへの公開もボタンひとつで実行可能
- MCP拡張機能を導入すると、Copilotがリポジトリの文脈を理解したAI支援を提供する
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

GitHub Shop新作「ESC」コレクション、開発者のまま外へ出かけよう
GitHubは2026年5月28日、公式ショップの新作コレクション「ESC」を発表した。Tシャツやキャップ、スライドサンダル、さらにはタコキャット型のドリンクホルダーまで、デスクを離れて過ごす夏のためのグッズが揃っている。単なるノベルティではなく、開発者コミュニティの遊び心を形にしたラインアップだ。
このコレクション最大の特徴は、HTMLタグをあしらったアパレルと、CopilotやOctocatのトロピカルデザインだ。「デスクの外にも良いアイデアは転がっている」という考え方が企画の起点になっている。プールサイドやビーチでリラックスしながら、ふとバグの解決策を思いつく瞬間を後押しする仕掛けだ。
HTMLタグが服に 開発者ジョークを身にまとう

「ESC」コレクションの中心は、普段着として着られるアパレル製品だ。特に話題を呼んでいるのが、Tシャツ、キャップ、スライドサンダルにそれぞれHTMLタグの<body>、<header>、<footer>をあしらったデザインである。
これまでのGitHub Shopではキャップや靴下が定番だった。一方で「Tシャツはないのか」という声がコミュニティから多く寄せられていた。今回の<body>Tシャツは、まさにその要望に応えたかたちだ。
<header>ハットは新しいカラーバリエーションが追加されている。頭部を飾るという意味で、HTMLのセマンティクスと物理的な位置が見事に一致している点が面白い。スライドサンダルに<footer>と書かれているのも、同じ発想だ。
このネーミングは単なるジョークに留まらず、開発者文化のアイデンティティを日常生活に溶け込ませる工夫と言える。GitHub Shopの担当者は、デスクの外でこそ優れた問題解決が生まれるというメッセージを、商品名そのものに込めたのだろう。
ビーチでもCopilot トロピカルデザインのCabanaセット

より大胆なデザインを求める開発者には、トロピカル柄のCabanaセットが用意された。上下が揃いになったシャツとショーツには、OctocatことMona、GitHub Copilot、そしてラバーダックのキャラクターがヤシの木や花とともに描かれている。
ラバーダックは「ラバーダックデバッグ」と呼ばれるプログラミング技法に由来する。コードの問題を誰かに説明する過程で自己解決する手法で、開発者にはおなじみの存在だ。GitHub Copilotと並べて配置することで、AI時代の新しいペアプログラミングを連想させるデザインになっている。
派手なCabanaセットの対極として、より控えめなリネンシャツも用意されている。Hibiscus Tocatリネンシャツは、ハイビスカス柄の中に小さくOctocatを忍ばせたデザインで、開発者と気づかれずに開発者アピールできる逸品だ。
さらに、クーラートートバッグも注目に値する。Invertocatデザインの保冷バッグは、ビーチやプールサイドに飲み物を持ち運ぶのに最適なサイズ感だ。開発者がコードから離れて過ごす時間を、きちんとサポートする機能性を持っている。
ドリンクを冷やす小さなパーカー 人気商品をミニチュア化

ESCコレクションのユニークなアイテムとして、ブラックInvertocatパーカーのデザインをそのまま缶クーラー(クージー)に落とし込んだ製品がある。フード付きパーカーを模した小さなドリンクホルダーで、人気アパレル商品のミニチュア版という発想が秀逸だ。
本家のInvertocatパーカーはGitHub Shopのベストセラーである。今回それを「缶用」として展開したことは、スケーリングとユーモアの両面で開発者マインドをくすぐる。実用品でありながら、コードレビューで突っ込みたくなる会話のきっかけにもなるだろう。
さらに、プール用のドリンクフロートとしてMonaフロートも登場した。Octocatの形状をした浮き輪型ドリンクホルダーで、プールに浮かべながら飲み物を楽しめる。開発者のデスク周りにOctocatグッズが並ぶように、水辺にもOctocatを持ち込む発想である。
これらの商品からは、「開発者であることをオフの時間にも楽しもう」というブランドの一貫した姿勢が感じられる。コードを書くことだけが開発者ではない。問題解決の思考は日常のあらゆる場面で活きるという考え方だ。
ショッピング体験にも技術を パーソナライズ機能と今後の展開

GitHub Shopのサイト自体にも技術的な工夫が施されている。商品画像の背景にはLiDARスキャナーが使われており、ユーザーは色味やズームを自由に変更して、自分好みのビジュアルで商品を確認できる。ECサイトの枠を超え、開発者に「どんな技術で実装しているのか」を想像させる仕掛けだ。
これは単なるファッション販売ではなく、GitHubブランドの世界観をデジタル上で体験させる戦略と言える。商品を選ぶ行為そのものをインタラクティブな開発者体験に昇華している点がユニークだ。
ESCコレクションの発表と併せて、GitHubは近くワールドカップ関連の特別企画も準備していると予告している。開発者文化と世界的なスポーツイベントをどう結びつけるのか、続報が待たれるところだ。
この記事のポイント
- GitHub Shopの新作「ESC」コレクションは、デスクを離れた場所でのリラックスをテーマにしている
- HTMLタグにちなんだアパレルや、Copilot・Octocatをあしらったトロピカルデザインが特徴
- ベストセラーパーカーを模した缶クーラーなど、実用品に開発者向けの遊び心を落とし込んでいる
- 商品画像にLiDARスキャナーを使うなど、ショッピング体験そのものにも技術的工夫がある
- コードから離れる時間が、むしろ良いアイデアを生むというブランド思想が商品全体を貫いている
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

イランのインターネットが部分的に復旧。Cloudflare Radarが87日ぶりの通信量増加を観測
2026年5月26日、イランで約3か月にわたって継続していた全国的なインターネット遮断が、部分的に解除された。Cloudflare Radarの観測データは、通信量とDNSクエリの急激な増加を記録しており、市民のオンラインアクセスが再開されつつあることを示している。
今回の復旧は、2月28日に始まった2度目の大規模遮断から87日目にあたる。遮断開始以来、ほぼゼロにまで落ち込んでいたイラン発の通信量が、突如として前週比の約15倍に跳ね上がった。もっとも、この回復は完全ではなく、ピーク時のトラフィックは今年の最大値と比較して40%にとどまっている。
Cloudflareのネットワークを流れるデータの詳細を読み解くことで、長期化した遮断の実態と、今回の部分復旧の意味するところが浮かび上がる。本記事では、一連のデータポイントを分析し、イランのインターネット接続状況が現在どのようなフェーズにあるのかを解説する。
2026年にイランで発生した2度の大規模インターネット遮断

イランでは今年に入り、すでに2度の全国的なインターネット遮断が発生している。最初の遮断は1月8日に始まり、数日間でほぼすべての通信量が消失した。短期間の部分回復を挟みつつ、本格的な復旧は1月27日までずれ込んでいる。
2度目となる今回の遮断は、情勢の緊迫化を背景に2月28日から開始された。現地時間の午前10時30分ごろ、イラン国内から国外へ向かうウェブ通信量とDNSトラフィックは、遮断前の1%未満にまで急落した。それ以降、わずかなデータ漏洩を除けば、実質的に国全体がグローバルネットワークから隔絶された状態が続いていた。
この約3か月間、イランの一般市民はオンラインバンキング、地図アプリ、メッセージツール、海外のニュースメディアなど、日常生活やビジネスに不可欠なデジタルサービスから切り離されてきた。
上図の比較からわかるように、遮断期間中の通信は事実上ストップしていた。5月26日以降のデータは、国全体のネットワークが一斉に「息を吹き返した」かのような変化を示している。
トラフィック急増の詳細なデータが示すもの
通信量は前週の約15倍に跳ね上がった
Cloudflareのネットワーク上を転送されたバイト数のデータを見ると、復旧の兆候は明瞭だ。協定世界時(UTC)の5月26日11時45分に最初のスパイクが記録され、12時00分からは持続的な増加へと転じた。この通信量の急増は、遮断期間中の前週の水準と比較して約15倍に達している。
転送バイト数の増加とは、単に「接続が戻った」というだけでなく、画像や動画、ファイルダウンロードといった実データが国境を越えて再び流れ始めたことを意味する。ウェブの閲覧だけでなく、アプリのアップデートやクラウドストレージへの同期など、より帯域を消費する活動が再開された可能性が高い。
トラフィックの推移は、人間の生活リズムと一致する日内変動にも従っている。UTCの21時ごろ(現地時間の深夜0時30分ごろ)に通信量が減少し、翌27日の3時(現地時間6時30分ごろ)から再び増加に転じた。このパターンは、実際に人々が朝を迎えて端末を操作し始めたことを如実に反映している。
この比較は、ネットワークが単に技術的に「オン」になったのではなく、エンドユーザーによる実需要が即座に反映されたことを示している。
全体の91.6%がテヘランに集中する地域別の偏り
回復したトラフィックのほとんどは、首都テヘランに集中している。Cloudflare Radarの地域別データによれば、HTTPリクエスト全体の実に91.6%がテヘラン州から発信されていた。他の地域でもわずかな増加は見られるものの、テヘランとの差は圧倒的だ。
この極端な偏りからは、いくつかのシナリオが推測できる。第一に、政府や通信規制当局が首都から優先的に復旧を進めている可能性が高い。第二に、テヘランには国内で最も多くのデータセンターや国際接続ポイントが集中しており、物理的に復旧作業が行いやすいというインフラ面の要因も考えられる。
ただし、この偏りが地方に住む大多数の市民にとって「ネットが戻った」という実感からはほど遠い状況を生んでいる点は重要だ。現在の復旧状況は、あくまで「部分的」であり、国の隅々まで接続性が戻るにはさらなる時間を要するだろう。
ネットワーク事業者別に見る復旧状況
通信量の増加は、複数の主要なインターネットサービス事業者(ISP)で同時に観測されている。11時45分の最初のバーストに続いて、TCI(イラン通信)、IranCell、RighTel、MCCIといった事業者のネットワークで一斉にトラフィックが立ち上がった。
これらの事業者は、それぞれ異なる自律システム番号(ASN)という一意の識別子で管理されている。ASNとは、インターネット上で個々のネットワークを識別するための番号で、例えるなら「インターネット世界における電話の市外局番と加入者番号を組み合わせたようなもの」だ。複数のASNで同時に復旧が確認されたことは、特定の事業者のみの一時的な不具合ではなく、国家レベルでの規制変更やゲートウェイの開放が行われたことを強く示唆している。
複数事業者での同時回復という事実は、今回の復旧が偶発的なものではなく、中央政府の明確な意図に基づいて実行された可能性が高いことを示している。
DNSクエリの急増と1.1.1.1への影響

転送バイト数だけでなく、DNS(ドメインネームシステム)クエリの数も急増している。DNSとは、人間が覚えやすい「google.com」のようなドメイン名を、コンピュータが理解できるIPアドレスに変換する、インターネットの「電話帳」にあたる仕組みだ。このDNSクエリが増えるということは、利用者が実際にウェブサイトやアプリに接続しようとしている直接的な証拠となる。
Cloudflareが提供するパブリックDNSリゾルバ「1.1.1.1」へのクエリも、5月26日を境にスパイクを記録した。このリゾルバは、インターネットサービス事業者が提供するデフォルトのDNSよりも高速で、プライバシーに配慮していることから、技術に詳しいユーザーを中心に世界中で広く利用されている。イラン国内から1.1.1.1へのクエリが増えたことは、単にネットが使えるようになっただけでなく、ユーザーが意識的に「より速く、より自由な」DNS解決手段を選択し始めた可能性を示唆する。
DNSトラフィックの回復は、ウェブページの閲覧だけに留まらない。メールの送受信、アプリのプッシュ通知、VoIP通話など、多種多様なインターネットサービスは、すべて通信の最初の段階でDNSクエリを発生させる。したがって、DNSクエリの増加傾向は、デジタル社会の活動そのものが再開されつつあることの強い指標と言える。
通信量はピーク時の40%にとどまる依然として本格復旧には遠い現実

今回の回復を楽観視するのはまだ早い。5月26日のピーク時でさえ、トラフィックは今年に入ってから遮断前に記録された最大通信量のわずか40%にとどまっている。ネットワークの「部分的」復旧という言葉が示す通り、まだ多くの障害が残っていると見るべきだ。
加えて、1月の事例が示すように、一時的な復旧はすぐに逆戻りするリスクをはらんでいる。1月にも、一度は戻ったかに見えた通信が24時間足らずで再び遮断された経緯がある。現時点でのトラフィックの増加は心強い兆候ではあるが、これが持続的な復旧の始まりなのか、それとも再び訪れる「通信のブラックアウト」の前触れなのかは、今後の数日から数週間のデータを注視しなければ判断できない。
上記の警告表示が示す通り、ネットワーク状況は依然として流動的だ。本来あるべき水準からはほど遠く、完全な「日常」のネット利用が戻ったとは到底言えない。
IPv6アドレス消失が示す遮断の技術的メカニズム

イランのインターネット遮断を語る上で、見逃せないデータポイントがある。IPv6(インターネットプロトコルバージョン6)アドレス空間の消失だ。
IPv6とは、次世代のインターネットアドレス規格である。従来のIPv4アドレスが世界的に枯渇しつつある中で、ほぼ無限に近いアドレス数を提供できるIPv6への移行が世界中で進められている。このIPv6アドレスの広報(グローバルな経路表に自ネットワークのアドレスを登録すること)が、1月の最初の遮断が始まる数時間前に、イラン国内からほぼ完全に消失した。そして、驚くべきことに、5月の部分復旧後もIPv6アドレス空間の広報量は事実上ゼロのままだ。
一方、旧来のIPv4アドレス空間の広報は、2度の大規模遮断中も一貫して安定的に維持されていた。一見すると矛盾するこの事実は、イランの遮断が物理的なケーブルの切断やルーターの停止といった単純な手法ではなく、より高度なフィルタリング技術によって達成されていたことを強く示唆している。
この対比から導き出される仮説は明快だ。イランの規制当局は、特定のアプリケーションやプロトコルを識別して遮断するDPI(ディープパケットインスペクション)や、許可リストに登録された宛先以外への通信をすべて遮断するホワイトリスト方式を用いて、通信を制御していた可能性が高い。IPv4が「抜け殻」として維持されていたのは、将来的な復旧を想定した準備であったとも考えられる。IPv6が戻らない理由は定かではないが、次世代プロトコルに対する管理・監視体制が整っていないことが一因かもしれない。
この記事のポイント
- 2月28日から87日間続いたイランのインターネット遮断が、5月26日に部分的に解除された。
- Cloudflare Radarのデータでは、前週比約15倍の通信量とDNSクエリの急増が観測された。
- 回復したトラフィックの91.6%は首都テヘランに集中しており、地方との格差が大きい。
- 通信量は遮断前の通常時と比較すると40%の水準に留まり、本格復旧には至っていない。
- IPv6アドレス空間の広報は依然として消失したままであり、遮断の技術的複雑さを示している。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Amazon OpenSearch Serverless次世代版、AIエージェント構築向けに発表
AWSが2026年5月28日、Amazon OpenSearch Serverlessの次世代版を一般提供開始した。AIエージェントアプリケーションの構築に特化したフルマネージド検索・ベクトルエンジンであり、スケールゼロからピーク時までシームレスに拡縮する。
従来のプロビジョニング型クラスタと比較して最大60%のコスト削減が可能とされる。リソース作成は数秒、スケーリング速度は前世代比で最大20倍に向上した。VercelやKiroといったAI開発プラットフォームとのネイティブ統合も備え、インフラ管理を意識せずに本番対応のバックエンドを数分で立ち上げられる。
この記事では、次世代OpenSearch Serverlessの主要な特徴、アーキテクチャ上の進化、AIエージェント開発への実践的な活用法を詳しく見ていく。
OpenSearch Serverless次世代版の概要

OpenSearchはElasticsearchからフォークしたオープンソースの分散型検索・分析エンジンだ。Amazon OpenSearch Serviceはそのマネージド版であり、サーバーレスオプションは2022年に導入された。今回の次世代版は、そのサーバーレスアーキテクチャを根本から刷新したものである。
AWS News Blogの記事によると、次世代版は「AIエージェントを構築する顧客向けに設計された」と位置づけられている。フルマネージドである点は変わらないが、スケーリングの速度とコスト効率が大幅に向上した。
主な改良点はスケールゼロと高速スケーリング
特筆すべきはスケールゼロへの対応だ。利用が途絶えると自動的にリソースが解放され、アイドル状態のコストがほぼゼロになる。リクエストが発生すると数秒でリソースが再作成され、前世代比で最大20倍速いスケールアップを実現する。
つまり、開発中の本番前ステージング環境や、トラフィックが断続的なAIエージェントのバックエンドで、大幅な無駄を省けるということだ。
このデモは、従来型と次世代版のリソース管理モデルの違いを概念的に示したものだ。実際の環境では、数秒単位でプロビジョニングが動的に切り替わる。
コレクションタイプは全文検索とベクトル検索に限定
今回のリリース時点では、対応するコレクションタイプは全文検索(SEARCH)とベクトル検索(VECTORSEARCH)の2種類である。既存のOpenSearch Serverlessにあった時系列データやログ分析向けのタイプは、現時点では次世代版で選択できない。
これは、まずAIエージェント向けの検索基盤として最適化された領域に集中した戦略と見られる。今後のアップデートで順次拡張される可能性は高い。
スケールゼロと高速スケーリングの仕組み

次世代版のアーキテクチャを理解するには、従来のサーバーレス版との違いを押さえておくとよい。前世代のOpenSearch Serverlessは、あらかじめ設定された最小キャパシティユニット(OCU)を常に確保するモデルだった。利用がゼロになっても、その最小ユニット分のコストは発生し続けたのである。
OCUの最小値をゼロに設定可能
次世代版では、インデックス用と検索用それぞれの最小OCUをゼロに指定できるようになった。CLIコマンドを見ると、minIndexingCapacityInOCUとminSearchCapacityInOCUに0が設定されているのがわかる。
この仕組みにより、トラフィックが完全に途絶えた時間帯はコンピューティングリソースが解放され、ストレージのみの課金になる。実質的に「寝ている間は課金されない検索エンジン」として振る舞うわけだ。
リソース作成が数秒で完了する理由
従来のサーバーレス版でコレクションを作成すると、数分かかることもあった。次世代版では、内部的なリソースプロビジョニングのパイプラインが刷新されており、数秒で利用可能になる。
これはAIエージェントの開発フローにおいて非常に重要だ。たとえばVercel上で新しいプロジェクトを作成し、そこにベクトルデータベースを接続する場合、即座にプロビジョニングが完了しなければ開発テンポが落ちてしまう。数秒で立ち上がるという体験は、プロトタイピングの高速化に直結する。
このフローはVercel統合を活用した典型的なAIエージェントのセットアップ手順を図示したものだ。実際の操作はVercelの管理画面から数クリックで完了する。
VercelやKiroとの統合でAIエージェント構築を加速

次世代OpenSearch Serverlessの重要な価値は、AIエージェント開発プラットフォームとのシームレスな連携にある。Vercelの管理画面から直接OpenSearchコレクションを作成・接続できるようになったのがその典型だ。
Vercel統合の実用性
Vercelユーザーは、フロントエンド(Next.js等)のデプロイに加え、検索やベクトルストアをバックエンドインフラとして簡単に追加できる。従来であれば、別途Elasticsearch互換のDBを用意し、VPCネットワークを設定し、認証情報を安全に管理する手間が発生した。
これが管理画面上で完結するということは、開発者がインフラの設定に費やす時間を劇的に減らせる。特にAIエージェントのように試行錯誤を重ねるプロジェクトでは、この迅速さが競争力に直結する。
OpenSearch Agent SkillsとKiro Powers
AWS News Blogの記事では、Claude CodeやCursor、Kiroといった開発ツールとの連携も紹介されている。GitHub上のOpenSearch Agent Skillsというリポジトリには、特定のワークフロー向けのドメイン知識やベストプラクティスがスキルとしてパッケージ化されている。
たとえば「あるテーマに関する最新の技術ドキュメントを検索し、その結果を要約する」といった複数ステップのタスクを、エージェントがOpenSearchのスキルを呼び出すだけで実行できる。エージェントは単に検索結果を受け取るだけでなく、その検索がどのように実行されたかのプロセスも理解できるようになる。
このインラインフローは、開発者がAIエージェントに指示を出してからOpenSearchが検索を実行し、結果が返るまでの一連の流れを色分けで示している。OpenSearch Agent Skillsによって、エージェントは適切なスキルを自動選択できる。
一方、Kiro Powersで提供されるOpenSearch Launchpadは、エンドツーエンドのアーキテクチャ計画をガイド付きで進められるツールだ。検索アプリケーションの全体設計をAIが支援することで、開発の初期段階から生産性を高められる。
導入方法、コンソールとCLI

次世代OpenSearch Serverlessの利用開始は簡単だ。マネジメントコンソールから「Serverless」メニューを選び、「Create collection」をクリックする。次の画面で「NextGen」を選択し、Express createを選べばデフォルト設定で即座にコレクションが作成される。
Express createで手間を省く
Express createは設定不要のクイック作成機能だ。セキュリティポリシーやネットワーク設定は自動で適用され、後から一部の設定を変更できる。プロトタイピングや検証用途では、まずExpress createで立ち上げ、必要に応じて細かな設定を詰めるアプローチが現実的だろう。
CLIからの作成手順
AWS CLIを使う場合は、まずコレクショングループを作成し、その中にコレクションを作る2段階の手順になる。以下はAWS公式ブログに掲載されたコマンド例を、実際の利用に即して整理したものだ。
# コレクショングループの作成(生成世代をNEXTGENに指定)
aws opensearchserverless create-collection-group \
--name my-nextgen-group \
--standby-replicas ENABLED \
--generation NEXTGEN \
--description "My NextGen collection group" \
--capacity-limits '{
"maxIndexingCapacityInOCU": 96,
"maxSearchCapacityInOCU": 96,
"minIndexingCapacityInOCU": 0,
"minSearchCapacityInOCU": 0
}' \
--region "us-east-1"
# コレクションの作成(SEARCHまたはVECTORSEARCH)
aws opensearchserverless create-collection \
--name my-nextgen-collection \
--type SEARCH \
--collection-group-name my-nextgen-group \
--standby-replicas ENABLED \
--description "My collection in NextGen group" \
--region "us-east-1"なお、ブログ公開時のCLIコマンドには最大OCUのデフォルト値に誤りがあり、後日修正された点には注意が必要だ。実際に使う場合は最新のドキュメントを参照してほしい。
AIエージェント時代のデータバックエンドの在り方

OpenSearch Serverless次世代版の登場は、単なる新バージョン発表以上の意味を持つ。AIエージェントが自律的に情報を取得し、判断し、行動する時代において、「検索とベクトル演算のバックエンドをいかに手軽に、安く、速く用意できるか」が開発の成否を分けるからだ。
スケールゼロがもたらす開発文化の変化
従来、検索バックエンドの構築には「とりあえず動かす」だけでもある程度の初期コストが発生した。そのため、プロトタイプ段階では簡易的なインメモリ検索で代用し、後から本格的な検索エンジンに切り替えるパターンが一般的だった。
スケールゼロで最小OCUゼロが可能になったことで、最初から本番同様のOpenSearchを組み込んで開発を進められる。切り替えの手戻りがなくなり、より忠実な検証が可能になる。これはAIエージェントの品質を高める上で、見過ごせない利点だ。
マルチプラットフォーム連携の拡大予測
AWSはVercelとKiroに加え、今後さらに多くのAI開発プラットフォームとの統合を進めると見られる。GitHub CodespacesやReplit、Bolt.newなど、ブラウザベースの開発環境で動作するAIエージェントが増えれば、それらと連携する検索バックエンドの需要は右肩上がりだ。
OpenSearchがこの領域で競争力を発揮するためには、統合の容易さだけでなく、GPUアクセラレーションを活用したベクトル検索のパフォーマンスも鍵を握る。今回の次世代版ではGPU対応が明記されており、大量の埋め込みベクトルを扱う大規模AIエージェントのワークロードにも耐えられる設計が示されている。
コスト構造の変革と注意点
最大60%のコスト削減というインパクトは大きいが、これは「ピークキャパシティに合わせて常時プロビジョニングしていたクラスタ」との比較である。利用が常に一定水準以上あるサービスでは、スケールゼロの恩恵は限定的だ。
OCU単位の従量課金は、予測不能なトラフィックパターンを持つAIエージェントと相性が良い。一方、安定的に高いトラフィックが続く場合は、従来のプロビジョニング型OpenSearch Serviceの方がコストパフォーマンスに優れるケースもある。慎重な見積もりが求められる。
この記事のポイント
- OpenSearch Serverless次世代版はAIエージェント構築に特化し、スケールゼロと高速スケーリングを実現
- ピークプロビジョニング対比で最大60%のコスト削減、リソース作成は数秒で完了
- VercelやKiroとのネイティブ統合で、数分で検索バックエンドをデプロイ可能
- OCUの最小値をゼロに設定できるため、アイドルコストを極小化できる
- 全商用リージョンで一般提供開始、導入はコンソールのExpress createまたはCLIで
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

contrast-color()で自己修正するカラーシステム構築、動的テーマにブラウザネイティブ対比色
ウェブ上のカラーコントラスト問題は長らく手つかずだった。HTTP Archiveの調査によれば、2025年時点で約70%のサイトがWCAGの最低限の対比率を満たせていない。WebAIMの2026年データでは、ホームページの83.9%が低コントラストと判定されている。多くの開発者は対比に配慮しているが、実装の手間やランタイム計算の煩雑さが壁になっていた。この状況を根本から変えるCSSの新機能が、
contrast-color()関数だ。背景色を渡すだけで、ブラウザが適切な文字色(黒または白)を計算して返す。JavaScriptやビルドステップは不要で、スタイル計算の段階で解決される。
contrast-color() とは何か

基本的な動作
CSS Color Level 5で導入されたこの関数は、引数に与えた色に対して最適な対比を持つblackまたはwhiteを返す。使い方はシンプルだ。
.button {
background-color: var(--brand-color);
color: contrast-color(var(--brand-color));
}--brand-colorを蛍光グリーンに変えれば文字色が黒になり、ネイビーに変えれば白になる。ランタイムのテーマ変更にもリアルタイムで追従する。
返り値と名称の変遷
contrast-color()は色値を返すため、border-colorやbox-shadowなど色を受け付けるあらゆるプロパティで使える。初期の仕様ドラフトではcolor-contrast()という名前だったが、対比率(数値)を返すように見えるという理由で改名された。古い記事やチュートリアルの構文は現在のブラウザでは動作しないので注意が必要だ。
ブラウザ対応状況

Chrome 147、Firefox 146、Safari 26.0のすべての安定版で出荷済みだ。2026年4月にはBaseline Newly Availableステータスを獲得し、主要エンジン間で実装が揃った。Web Platform Testsもパスしており、エッジケースの挙動も統一されている。
グローバルサポート率は一見低く見えるが、更新しないエンタープライズ環境が大半を占める。実際に最新ブラウザを使っている読者なら、ほぼ確実に利用できる。
/* プログレッシブエンハンスメント */
.card {
background: var(--bg);
color: #fff;
text-shadow: 0 0 4px rgb(0 0 0 / 0.8);
}
@supports (color: contrast-color(red)) {
.card {
color: contrast-color(var(--bg));
text-shadow: none;
}
}@supportsで未対応ブラウザには影つきの白文字をフォールバックとして提供できる。ただし自動アクセシビリティチェッカー(Lighthouseなど)はtext-shadowを評価せず、フォールバック側をコントラスト違反と誤判定する点は把握しておきたい。
実践的な使い方

コンポーネントのベースカラーに
ボタンやカードなど、背景色が変わるUI部品であれば、contrast-color()を一行加えるだけで文字色が自動調整される。
.btn {
background-color: var(--accent);
color: contrast-color(var(--accent));
border: 1px solid contrast-color(var(--accent));
}複合的なカラー生成との統合
単に黒か白を返すだけでは味気ない場合、他のCSSカラー関数と組み合わせることで表現の幅が広がる。
/* 背景色の色相を取り入れたテキスト */
.card {
--bg-hue: 260;
--bg: oklch(0.6 0.1 var(--bg-hue));
background: var(--bg);
color: oklch(from contrast-color(var(--bg)) l 0.05 var(--bg-hue));
}contrast-color()の出力の明度を維持しつつ、少しだけ彩度と背景の色相を加えることで、単なる黒や白ではない深みのある文字色になる。ただし対比が落ちる可能性があるため、最終的な色はアクセシビリティチェッカーで確認しよう。
/* color-mix でソフトな対比を実現 */
.alert {
--bg: var(--alert-color);
background: var(--bg);
color: color-mix(in oklch, contrast-color(var(--bg)) 80%, var(--bg));
border: 1px solid color-mix(in oklch, contrast-color(var(--bg)) 40%, var(--bg));
}上記デモのAfterで使われている色#2E0F0Cは、color-mix(in oklch, black 80%, #e74c3c)を簡易的に再現したものだ。実際のコードではブラウザが動的に最適な中間色を生成してくれる。
light-dark() との連携
システムのカラースキーム(ライト/ダーク)に対応する場合、light-dark()と組み合わせるだけで、OSの設定に応じた対比色が自動的に決まる。
:root {
color-scheme: light dark;
--surface: light-dark(#fff, #121212);
}
.component {
background: var(--surface);
color: contrast-color(var(--surface));
}知っておくべき注意点

トランジションでスナップする
背景色をアニメーションさせると、contrast-color()の返す黒か白の値は離散的なため、スムーズに補間されずに切り替わる。しかも切り替えタイミングはWCAG 2.xの相対輝度の特性上、アニメーションの終盤に偏る。
このアニメーションは実際には約1秒かけて連続的に行われるが、文字色だけは終盤でカットインするように変わる。transition-behavior: allow-discreteを使っても、切り替えのタイミングが50%地点にずれるだけで、根本的なジャンプは解消されない。スムーズにしたい場合はcolor-mix()で中間色を手動管理する必要がある。
完全中立のグレーでは白が優先される
両方の対比率がまったく同じになる完全な中間グレー(およそ相対輝度17.9%)では、仕様上白が選ばれる。グレースケールパレットを扱う際に頭の片隅に入れておけば混乱しない。
透明色やグラデーションには使えない
引数は単一の不透明な色に限られる。半透明の色を渡すと、ブラウザが不透明なキャンバス(通常は白)に合成した上で計算するため、意図しない結果になることもある。グラデーションや画像のURLを渡すとパースエラーになる。
従来のアプローチが不要になる

これまで開発者は、Sassのlightness()関数でコンパイル時に判定したり、--r --g --bチャンネルを分割してcalc()内で輝度計算を行ったりと、複雑なハックで対比色を実現してきた。chroma-jsやpolishedといったライブラリも広く使われてきたが、いずれもランタイムにメインスレッドで計算が走り、SSR時のハイドレーションフラッシュの問題も抱えていた。
contrast-color()はこれらすべてをネイティブのスタイル計算フェーズに置き換える。テーマが変わっても、JavaScriptが走る前から正しい文字色が描画される。対比の自動化は、ケアすることのハードルを限りなくゼロに近づける。
この記事のポイント
contrast-color()はCSS Color Level 5で導入され、背景色に応じて黒か白を返す- Chrome 147、Firefox 146、Safari 26で出荷済み。主要ブラウザすべてで使える
- 動的テーマでもJavaScript不要。スタイル計算時に即座に反映される
- トランジション中はスナップする点や、透明色・グラデーション非対応など注意が必要
- 他のCSSカラー関数と組み合わせることで、より高度なカラーシステムを構築できる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AWS Resilience Hubが大幅刷新、生成AIで障害モードを分析しSREの信頼性管理を効率化
AWSが「Resilience Hub」の次世代版を一般公開した。最大の変更点は生成AIを活用した障害モード評価の搭載だ。組織全体の信頼性を構造化されたポリシーで管理し、数百に及ぶアプリケーションの可用性リスクを一元的に可視化する。
今回の刷新では新たなアプリケーションモデルが導入され、依存関係の自動検出機能やモジュール式の信頼性ポリシーも追加された。SREチームと開発チームが同じ指標で対話し、エンタープライズ全体のレジリエンスを継続的に改善する基盤が整った形だ。
従来のResilience Hubが個々のアプリケーション評価に留まっていたのに対し、今回の刷新は「信頼性の管理」を組織のガバナンス領域に引き上げる。本記事ではその具体的な機能と実務への影響を詳しく解説する。
AWS Resilience Hubの全体像と考え方の変化
この比較が示すように、次世代版の本質は「個別最適から全体最適への転換」だ。AWS Organizationsとの統合により、委任管理者アカウントから複数アカウントを横断したレジリエンス評価が可能になった。
「ビジネス視点」で捉え直されたアプリケーションモデル
新しいモデルは3層構造になっている。最上位にビジネスアプリケーション全体を表す「システム」、その下にクリティカルな業務経路を示す「ユーザージャーニー」、さらに実際のデプロイ単位である「サービス」が配置される。サービスはAWSリソースやコード、オブザーバビリティの構成要素を束ねる役割だ。
この構造により「ログインできないと売上が止まる」という業務インパクトと、IAMロールの設定ミスという技術的リスクが地続きで評価できるようになる。AWS News Blogの記事でChanny氏は「ビジネス成果に直接結びつくクリティカルなエンドユーザー経路」という表現でこの概念を説明している。
モジュール式ポリシーでチーム間の共通言語を確立
信頼性ポリシーも大きく変わった。旧来は固定されたポリシータイプを選ぶ方式だったが、次世代版では必要な要件を組み合わせて構築できる。たとえば「可用性SLO 99.95%」「マルチリージョン災害復旧」「RTO 15分、RPO 5分」といった要素を選択し、金融系アプリケーション用のポリシーとして再利用する運用が可能だ。
SREと開発チームの間で「どの水準を目指すか」の共通理解が生まれ、属人的な判断を減らせる効果が期待できる。特に複数の開発チームを持つ組織では、この統一ポリシーがガバナンスの要になる。
生成AIが障害モードを評価する仕組み

次世代版の目玉機能が、生成AIを用いた障害モード評価である。サービスにポリシーを紐付けて評価を実行すると、AIが自動的に設定ミスや単一障害点を洗い出し、具体的な改善策を提案する。
この4ステップのフローにより、人手では発見が難しいクロスアカウントの依存関係や、リージョンをまたぐ意図しない呼び出しまで検出できる。AIは単にデータを収集するだけでなく、障害が発生した場合の影響範囲を推定し、優先度付きの修正ガイダンスを出力する。
AWS Well-Architectedと分析フレームワークの統合
AIの評価ロジックはAWS Well-Architectedフレームワークのベストプラクティスと、AWS Resilience Analysis Frameworkを参照している。これにより「なんとなく不安」ではなく、定義された基準に照らした再現性のある評価が実現する。
評価結果では「どのポリシー要件に違反しているか」が明示される。たとえば「RTO 15分を満たすには、このAuto Scalingグループのインスタンスが起動するまでの時間が長すぎる」といった具体的な指摘が得られる。対策の優先順位をビジネスインパクトに基づいて判断できる点が実務的に価値が高い。
また、ユーザーがAssertion(表明)を追加してAIの分析精度を高める仕組みも用意されている。たとえば「このサービスは特定のリージョンでのみ稼働する」といった前提条件をAIに伝えることで、無関係なマルチリージョン構成の提案を除外できる。
依存関係の自動検出がもたらす可視性の向上

多くの障害は「認識されていない依存関係」から発生する。次世代Resilience HubはDNSクエリログを解析し、VPC内のエンドポイントから呼び出されているAWSサービスや内部API、サードパーティの外部エンドポイントを自動で特定する。
この機能の価値は運用の暗黙知を形式知に変換する点にある。「ベテランSREだけが知っている」依存関係を、システムが自動でドキュメント化してくれる。異動や退職によるナレッジロスを防ぎ、障害対応の属人性を低減する効果が期待できる。
依存関係検出はサービス作成時に有効化する。VPCフローログではなくDNSクエリログを解析する仕組みのため、ネットワークトラフィックの暗号化状況に影響されず、比較的軽量に動作する設計だ。不要な場合は管理画面の設定から無効化できる。
実際の利用フローと移行パス

新規導入の基本的な流れ
導入の流れはシンプルだ。まず信頼性ポリシーを作成し、次にビジネスアプリケーションを表す「システム」を登録する。システム配下に、マイクロサービスなどのデプロイ単位である「サービス」を作成し、AWSリソースのタグやCloudFormationスタック、Terraformのステートファイル、EKSクラスタなどを指定してリソースを関連付ける。
準備が整ったら「障害モード評価の実行」をクリックする。Resilience HubがInvokerロールを引き受け、指定されたリソースの親子関係を解析し、トポロジを構築。その上でAIがポリシーに対するギャップを評価する。
評価完了後は「サービス詳細」画面の「Assessment」タブで発見事項を確認できる。各項目には障害モードの説明、アーキテクチャへの影響、修正方法、関連するポリシー要件が明記される。対応が完了した項目は「Mark as resolved」でクローズし、未対応の課題だけをトラッキングできる。
既存ユーザー向けの移行API
すでに従来版のResilience Hubを利用している組織向けには、移行用APIが提供されている。従来の評価ポリシーを新ポリシー形式に変換し、複数の関連アプリケーションを新モデルの「1システム配下の複数サービス」構造に再マッピングする機能だ。
手動での再設定が不要なため、既存の評価データを活かしつつスムーズな移行が可能になっている。大規模組織ほどこの移行APIの価値は大きい。
運用に組み込む際のポイントと今後の展望

Resilience Hubの次世代版を実運用に組み込む場合、いくつか意識すべき点がある。第1にポリシー設計の重要性だ。SLOやRTO、RPOの値はビジネス要件から逆算する必要がある。「とりあえず99.99%」といった一律設定では、過剰なコストを生むか、逆に重要なサービスを見落とすリスクがある。
第2に、依存関係検出のスコープ調整だ。DNSクエリログ解析は強力だが、ノイズとなる外部通信も拾う可能性がある。検出結果を精査し、クリティカルでない依存関係をフィルタリングする運用プロセスを組み込むことが望ましい。
第3に、AIの分析結果を鵜呑みにしないことだ。Assertion機能を活用し、自社のアーキテクチャ特性をAIに正しく伝える努力が求められる。あくまで「AIの提案をSREが判断する」という協調モデルが効果的である。
料金体系は新たなサービスベースモデルに移行した。各サービスにつき月2回の障害モード評価が含まれ、依存関係の自動評価はオプションとなる。大規模環境では評価回数がボトルネックになる可能性があるため、クリティカルなサービスに絞って評価頻度を設定するなどの工夫が必要だ。
今後はAWS Organizationsとの統合がさらに強化され、組織全体のレジリエンススコアをスコアカード化する機能や、CI/CDパイプラインへの組み込みによるシフトレフトな信頼性評価への展開が期待される。
この記事のポイント
- 生成AIによる障害モード評価で、人手では困難な依存関係や設定ミスを自動的に発見できる
- ビジネス視点のアプリケーションモデルにより、技術リスクと業務インパクトを地続きで評価可能になった
- モジュール式ポリシーがチーム間の共通言語として機能し、ガバナンスの実効性が高まる
- DNSクエリログ解析による依存関係の自動可視化で、運用の暗黙知を形式知に変換できる
- 既存ユーザー向けの移行APIが用意されており、大規模組織でもスムーズに移行可能である
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

VS Code 1.123リリース、エージェント画面刷新とチャット機能の進化
Visual Studio Codeのバージョン1.123が2026年5月末にリリースされた。このアップデートの中核は、AIエージェントとの対話体験を根本から再設計したことにある。エージェント画面のグリッド表示、スタンドアローン環境とのセッション受け渡し、そしてチャット機能の柔軟性向上が主な柱だ。
基盤となるElectronは42へとメジャーバージョンアップし、内部ブラウザのChromiumが148、ランタイムのNode.jsが22.xへと刷新された。これにより、VS Code全体の安定性とパフォーマンスが底上げされている。開発者はこの新バージョンにより、AIとの共同作業をより自然に、より強力に進められるようになる。
本記事では、今回のアップデートで開発現場に最もインパクトを与える4つの変更点を掘り下げ、その実務的な意味を解き明かす。
Electron 42基盤刷新がもたらす安定性とパフォーマンス

VS Code 1.123の最大の土台変更は、フレームワークの中枢であるElectronをバージョン42に引き上げたことだ。この一言で片付けるにはあまりに影響範囲が広い。Electronとは、ウェブ技術(HTML、CSS、JavaScript)でデスクトップアプリケーションを構築するためのプラットフォームである。VS CodeもこのElectronの上に成り立っている。
この変更は、VS Codeの内部ブラウザ機能や拡張機能の動作環境に直接影響する。
Chromium 148への移行で変わる統合ブラウザの実用性
VS Codeには簡易ウェブブラウザ機能が統合されており、フロントエンド開発者は別途ブラウザを立ち上げずにプレビューを確認できる。Chromium 148とは、Google Chromeの基盤部分のことだ。今回のアップデートでこの基盤がバージョン148へと刷新されたことで、最新のウェブ標準に準拠した表示が可能になった。
具体的には、新しいCSSプロパティやWeb APIが利用できるようになり、プレビュー表示の信頼性が向上する。また、ブラウザ関連の設定が設定エディタ内で独立したセクションにまとめられ、管理しやすくなった点も見逃せない。設定画面の見通しが良くなったことで、開発者は必要な項目に素早くアクセスできる。
Node.js 22.xによる拡張機能の実行速度向上
Node.jsとは、サーバーサイドでJavaScriptを動かす実行環境である。VS Codeの拡張機能やターミナル機能はこの上で動作している。ランタイムが20.xから22.xへと一段階飛び級でアップグレードされたことで、JavaScriptエンジン「V8」の最適化が進み、拡張機能の起動時間やターミナルでのコマンド実行が高速化される見込みだ。
さらに、BYOK(Bring Your Own Key)環境でOpenRouterやDeepSeekといった外部推論モデルを利用している場合、ツール呼び出し後にHTTP 400エラーが発生する不具合も今回のNode.js更新に伴い修正された。これにより、外部AIプロバイダーとの連携がより安定する。
エージェント画面の進化、グリッド表示とスレッド返信で管理性が向上
VS CodeのAIエージェント機能は、コード編集やタスク実行を自律的に支援する存在だ。このエージェントとの対話履歴を確認する「エージェント画面」が、バージョン1.123で大幅に再設計された。最も目を引くのは、セッション一覧が従来のリスト形式からグリッド形式に変わった点である。
多数のエージェントセッションを並行して扱う開発者にとって、この変更は作業効率の大幅な改善につながる。
スレッド返信機能でフィードバックが対話的に
エージェント画面に追加されたもうひとつの重要な機能が、スレッド形式の返信だ。これまではエージェントの出力に対するフィードバックを一方向的に追加することしかできなかった。しかし今回のアップデートにより、特定のコメントに対して個別に返信できるようになった。
これは、チームでのコードレビューに近い体験をエージェントとの対話にもたらす。エージェントが生成したコードの特定の部分に対し「このロジックを修正してほしい」と指摘したり、複数の修正案を比較検討したりするコミュニケーションが、より構造化された形で可能になる。
チャットセッションを受け渡すハンドオフ機能
VS Codeの編集画面で進行中のチャットを、スタンドアローンのエージェント画面にそのまま移行できるハンドオフ機能も追加された。編集画面ではコードに集中したいが、エージェントとの対話は続けたい、という状況で役立つ。
また、エージェントホストセッション中に送信されたステアリングメッセージが、従来は実行中のターンに埋め込まれていたが、今回から独立したユーザーターンとしてチャット上に表示されるようになった。これにより、どの指示がどのタイミングで送られたのかが明確になり、対話の透明性が高まっている。
チャット機能が柔軟に、添付ファイルのみの送信やエリアスクリーンショットに対応
日々のコーディングで最も頻繁に使われるチャット機能にも、実用的な改善が施された。中でも画期的なのは、テキストメッセージなしで添付ファイルだけを送信できるようになった点である。
この一見小さな変更が意味するところは大きい。エラー画面のスクリーンショットを撮ってそのまま投げ込むといったフローが、ワンアクションで完結するのだ。
統合ブラウザのエリアスクリーンショット機能
統合ブラウザ上で、ページ全体ではなく特定の領域だけを選択し、そのスクリーンショットをチャットのコンテキストとして追加できる機能も実装された。デザインの微調整をAIに依頼する場合や、特定のUI要素について質問する場合に、余計な情報を省いた的確なコミュニケーションが可能になる。
並列ターミナルコマンドの完了通知がバッチ化
エージェントモードが複数のターミナルコマンドを並列実行する際、これまではコマンドごとに個別のエージェントターンが作成され、チャット画面が完了通知で埋め尽くされる問題があった。今回のアップデートでは、これらの通知が1つのメッセージにまとめてバッチ化される。チャット画面がすっきりと整理され、本質的な対話に集中しやすくなった。
プロンプトファイルと外部環境連携の改善
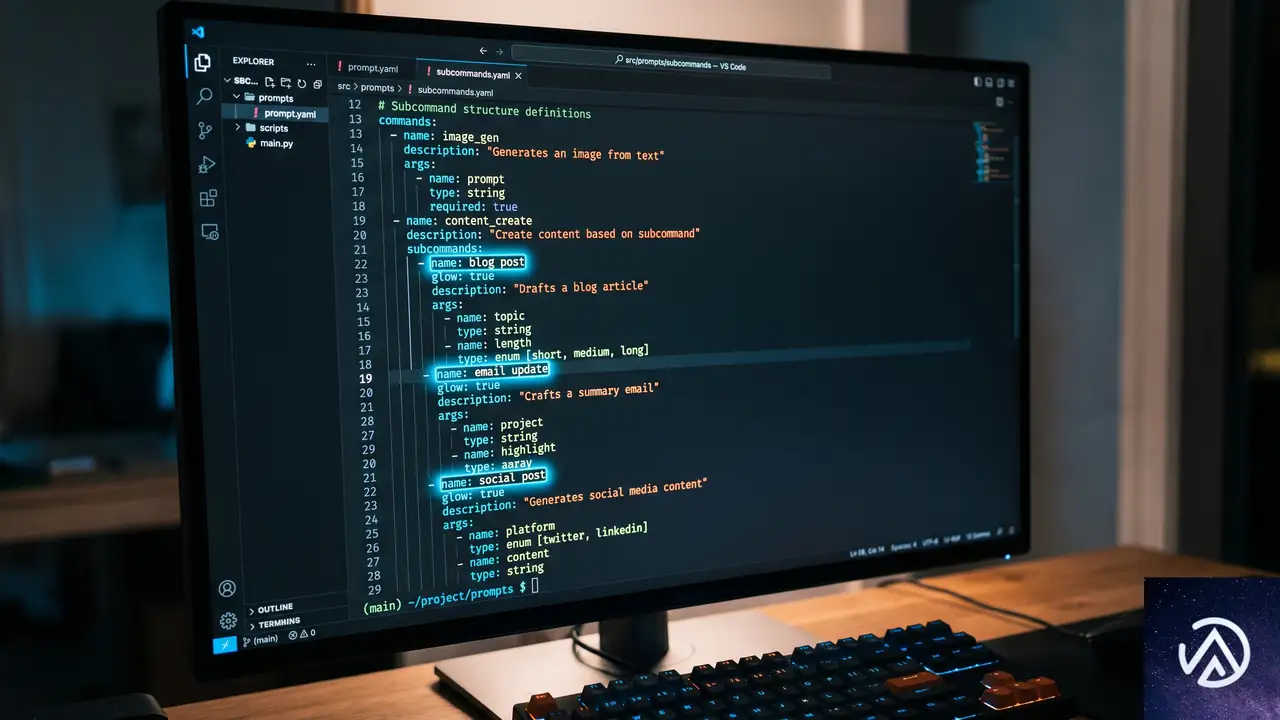
開発者がAIに与える指示をファイル化する「プロンプトファイル」の仕組みにも、いくつかの使い勝手の向上が図られた。
サブコマンド呼び出しの直感的な書式
プロンプトファイル内でサブコマンドを呼び出す際、従来はコロン区切りの形式(例、/chronicle:tips)が必須だった。この構文がスペース区切り(例、/chronicle tips)でも動作するようになった。この変更は表記法の微細な違いに過ぎないように見えるが、シェルコマンドや自然言語の記法に慣れ親しんだ開発者にとって、認知負荷を下げる効果がある。
外部AI推論モデルとの互換性修正
BYOK(Bring Your Own Key)モデルで、OpenRouterやDeepSeekといった推論特化型プロバイダーを利用する場合、ツール呼び出し後にHTTP 400エラーが発生する不具合があった。これはVS Codeが送信するリクエスト形式と、一部のプロバイダー側のパース処理の間に生じていた非互換が原因だ。今回の修正により、これらの外部モデルが安定して動作するようになった。
Cloudタスクの出力がローカルと同等の表現力に
GitHub CopilotのCloudタスク機能では、これまで実行結果の表示がテキスト主体で、ターミナル出力の表現力に限界があった。今回のアップデートで、CloudタスクもローカルのCopilot CLIセッションと同様に、ツールカードや編集差分、ターミナル出力をリッチにレンダリングできるようになった。リモート実行とローカル実行の間で、視覚的な体験が統一される。
細部に及ぶ品質改善と不具合修正

メジャーな機能追加の裏で、開発者の日常業務にじわじわと効いてくる細かな修正も数多く含まれている。
/docコマンドのPython docstring配置修正
/doc コマンドを使ってPythonコードにドキュメント文字列を生成する際、docstringがデコレータの前に挿入されるという不具合があった。本来は関数本体の内部に配置されるべきものであり、修正により正しい位置に生成されるようになった。Python開発者にとっては、コードの可読性を保つ上で見過ごせない変更だ。
Zenモード時のインジケーター非表示
Zenモードは、余計なUI要素を排除してコードに没頭するための表示モードだ。しかしエージェントモードのインジケーターがタイトルバーに表示され続けることで、没入感が損なわれていた。今回の修正で、Zenモード時にはこれらのインジケーターが自動的に非表示になる。
Windows環境でのCLIフラグ問題を解消
Windows環境限定の問題として、--folder-uri や --file-uri といったCLIフラグが特定の条件下で無視される不具合が解消された。引数の順序が最後でない場合や --wait フラグと併用した場合に発生していたこの問題は、VS Codeをスクリプトや外部ツールから起動するワークフローで特に支障をきたしていた。修正により、コマンドラインからの起動オプションが全プラットフォームで一貫して動作する。
この記事のポイント
- VS Code 1.123の中核はエージェント画面のグリッド表示とスレッド返信だ、多数のAIセッションを並行管理する開発者の負荷が下がる
- Electron 42への基盤刷新によりChromium 148とNode.js 22.xが導入され、統合ブラウザの互換性と拡張機能の実行速度が向上する
- チャットに添付ファイルのみを送信できる新機能で、エラー共有や画像解析の依頼が1アクションで完結する
- 外部AI推論モデルとの非互換やPython docstring生成位置の不具合など、現場の開発者が直面していた細かな問題が着実に修正されている
- プロンプトファイルのサブコマンド記法が簡略化され、AIへの指示をより直感的に記述できるようになった
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Astro 6.4リリース。プラグ可能なMarkdownパイプラインとRust製プロセッサーSätteriが登場
Astro 6.4が2026年5月28日にリリースされた。Markdown処理パイプラインを自由に差し替え可能にする新API「markdown.processor」、Rustで書かれた高速MarkdownプロセッサーSätteriの試験的導入、そしてCloudflare環境向けのルーティングヘルパーが追加された。
これまでの設定方法は非推奨となり、将来的なAstro 8.0では完全に廃止される予定だ。今回のアップデートで、静的サイト構築におけるMarkdown処理の柔軟性とパフォーマンスが大幅に向上する。
プラグ可能なMarkdownプロセッサーAPI

AstroのMarkdownパイプラインはこれまで、unified(remark/rehype)エコシステムを中心に構築されてきた。強力で数千ものプラグインが利用できる一方、特定のプロジェクトの要求に合わない場合もあった。今回追加されたmarkdown.processor設定オプションでは、そのパイプライン全体を丸ごと差し替えられる。
設定の変更方法
デフォルトのプロセッサーは従来通りunified()が使われるため、既存プロジェクトは何も変更せずにそのまま動き続ける。remark/rehypeプラグインも同じ挙動を保つが、設定場所がトップレベルのmarkdownからプロセッサー内に移行した。
import { defineConfig } from 'astro/config';
import { unified } from '@astrojs/markdown-remark';
import remarkToc from 'remark-toc';
export default defineConfig({
markdown: {
processor: unified({
remarkPlugins: [remarkToc],
}),
},
});従来のトップレベルオプション(markdown.remarkPlugins, markdown.rehypePlugins, markdown.remarkRehype, markdown.gfm, markdown.smartypants)も引き続き動作するが非推奨となり、Astro 8.0で完全に削除される予定だ。
移行の注意点
既存プロジェクトの移行は比較的簡単だ。unified({...})内にプラグインをまとめて記述するだけでよい。ただし、マークダウン処理をカスタマイズした複雑な設定を行っている場合は、コードの再構成が必要になる。公式ドキュメントのMarkdownガイドが更新されているため、詳細はそちらを参照してほしい。
Rust製MarkdownプロセッサーSätteri

プラグ可能なプロセッサーAPIの追加により、Astroは標準とは異なるMarkdownプロセッサーも同梱できるようになった。今回導入された@astrojs/markdown-satteriパッケージは、Rustで書かれた高速なMarkdown/MDXパイプライン「Sätteri」をベースにしている。
パフォーマンスの劇的な向上
Sätteriはデフォルトのunifiedベースのパイプラインよりも大幅に高速で、多くのMarkdown機能をプラグインなしでネイティブ実装している。Astroの公式ブログによれば、自社のドキュメントサイトをSätteriに切り替えたところ、ビルド時間が1分以上短縮されたという。
npm install @astrojs/markdown-satteriimport { defineConfig } from 'astro/config';
import { satteri } from '@astrojs/markdown-satteri';
export default defineConfig({
markdown: {
processor: satteri({
features: { directive: true },
}),
},
});この数値はあくまで一例だが、コンテンツ量の多いサイトでは特に効果が大きい。Rustで記述されているため、CPUバウンドな処理が高速化される仕組みだ。
プラグイン互換性と今後のデフォルト化
Sätteriはremark/rehypeプラグインを実行しない。unifiedエコシステムのプラグインに依存している場合は、当面unified()を使い続けるか、SätteriのMDAST/HASTプラグインに移植する必要がある。Astroチームは、将来のメジャーバージョンでSätteriをデフォルトのMarkdownプロセッサーにすることを目指している。
Rustプロセッサーや新APIに関するフィードバックは、公式のRFCDiscussionで受け付けている。興味がある開発者はぜひ参加してほしい。
Cloudflare向け高度ルーティングヘルパー

Astro 6.3で導入された実験的な高度ルーティング機能をCloudflare環境で使いやすくするため、@astrojs/cloudflareパッケージにcf()ヘルパーが追加された。SESSION KVバインディングの注入、ASSETSバインディングによる静的アセット配信、クライアントIPアドレスやwaitUntilの処理など、Cloudflare特有の面倒な設定を一手に引き受ける。
Fetchハンドラでの利用
import { astro, FetchState } from 'astro/fetch';
import { cf } from '@astrojs/cloudflare/fetch';
export default {
async fetch(request: Request, env: Env, ctx: ExecutionContext) {
const state = new FetchState(request);
const asset = await cf(state, env, ctx);
if (asset) return asset;
return astro(state);
},
};Honoミドルウェアでの利用
import { Hono } from 'hono';
import { actions, middleware, pages, i18n } from 'astro/hono';
import { cf } from '@astrojs/cloudflare/hono';
const app = new Hono<{ Bindings: Env }>();
app.use(cf());
app.use(actions());
app.use(middleware());
app.use(pages());
app.use(i18n());
export default app;このヘルパーにより、Cloudflare上で高度なルーティングを実装する際のボイラープレートコードが大幅に削減される。実験的機能ではあるが、実用段階に入りつつあると言えるだろう。
その他の改善とアップグレード手順

細かなバグ修正と今後のロードマップ
今回のリリースには、上記の主要機能以外にも多数のバグ修正と小さな改善が含まれている。詳細は公式の変更履歴を確認してほしい。また、Astroコアチームは活発に開発を続けており、コミュニティからのコントリビュートも盛んだ。
アップグレードの手順
既存のAstroプロジェクトをアップグレードするには、自動アップグレードツールを使うのが推奨だ。
# 推奨
npx @astrojs/upgrade
# 手動の場合
npm install astro@latest
pnpm upgrade astro --latest
yarn upgrade astro --latest自動ツールは非推奨設定の移行などもサポートする。手動で行う場合は、設定ファイルの変更点を確認しながらアップデートしよう。
この記事のポイント
- Markdown処理を差し替え可能にする
markdown.processorAPIが追加された - RustベースのSätteriプロセッサーによりビルド時間を大幅に短縮できる
- Cloudflare向け
cf()ヘルパーで高度ルーティングの設定が簡略化された - 従来の設定方法は非推奨となり、Astro 8.0で廃止予定。早めの移行が望ましい
- アップグレードは
npx @astrojs/upgradeで簡単に行える
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験