

git push操作でサーバー制御可能なRCE脆弱性 GitHubが2時間で修正完了
2026年3月4日、GitHubはバグ報奨金プログラムを通じて極めて深刻な脆弱性の報告を受けた。対象はgit push 操作のパイプラインであり、悪用されるとGitHubのサーバー上で任意のコマンドを実行される可能性があった。GitHubは報告から2時間以内に修正を展開し、その後の調査で実際の悪用は一切なかったと結論づけている。
この脆弱性は、git push に付与できる --push-option で送った文字列が、サーバー内部で適切にサニタイズされずにメタデータへ挿入されることに起因する。攻撃者は細工したオプションを与えるだけで、本来信頼される内部フィールドを偽装し、サンドボックスを回避してコードを実行できた。
本記事では報告の経緯、脆弱性の仕組み、GitHubの対応と調査結果、そして多層防御の重要性について詳しく解説する。自社運用のGitHub Enterprise Serverを管理するエンジニアは、早急なアップデートが推奨されるため、最後の対応ポイントまで確認してほしい。
バグ報奨金プログラムからの報告と即時対応

2026年3月4日、クラウドセキュリティ企業Wizの研究者らがGitHubのバグ報奨金プログラムにリモートコード実行(RCE)の脆弱性を報告した。この脆弱性は github.com だけでなく、GitHub Enterprise Cloud(データレジデンシーやEnterprise Managed Usersを含む)および GitHub Enterprise Server にも影響するものだった。
報告によれば、リポジトリへのプッシュ権限を持つユーザー(自身で作成したリポジトリを含む)であれば誰でも、単一の git push コマンドでサーバー上での任意コマンド実行が可能だった。攻撃に必要なのは、プッシュ時に指定する --push-option に細工した値を仕込むだけである。
検証から修正までのスピード
GitHubのセキュリティチームは報告を受け取ると直ちに検証を開始した。約40分で社内環境での再現に成功し、重大度を確認。その時点でUTC 17時45分、根本原因の特定と修正パッチの作成が始まった。そして同日19時(UTC)には github.com への修正展開が完了した。報告からわずか2時間弱での出来事だ。
この迅速な対応を可能にしたのは、詳細な再現手順と影響範囲が報告の段階で明確に示されていたことにある。Wizの研究者はプッシュオプションを経由したメタデータ汚染から環境偽装、サンドボックス回避に至る一連の攻撃チェーンを完全に解明していた。
脆弱性の仕組み git push オプションから任意コード実行まで
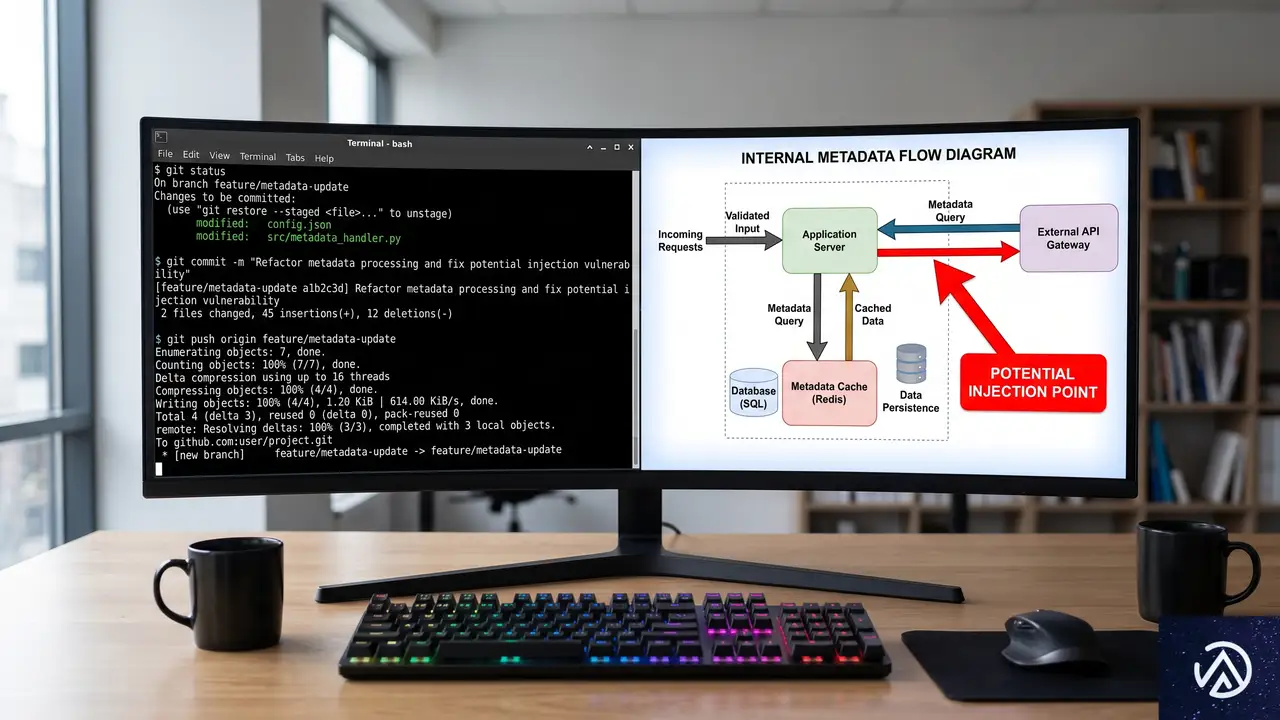
ここでは攻撃手法の技術的な流れを整理する。核となるのは、GitHubの内部サービス間でプッシュメタデータをやり取りする際に使われる区切り文字と、ユーザー入力の不適切な扱いだ。
プッシュオプションが処理される流れ
git push には --push-option(または -o)というオプションがある。これはクライアントがサーバーに対してキーバリューペアの文字列を追加で送るための正当なGit機能だ。CI/CDパイプラインへのパラメータ渡しなどで利用される。
しかしGitHub内部では、このユーザー提供の値がそのままの形で内部プロトコルのメタデータに埋め込まれていた。メタデータには「リポジトリ種別」や「処理環境」などを指定するフィールドが含まれており、各フィールドは特定の区切り文字で分割される。
サニタイズ不足が引き起こす注入攻撃
問題は、この内部区切り文字として使われていた文字が、ユーザー入力にも含まれ得る点だった。攻撃者はプッシュオプションの値に区切り文字を混入させることで、メタデータを意図的に「延長」または「上書き」できた。
より具体的には、プッシュオプションに key=value;injected_field=malicious のような文字列を指定する。内部サービスはこの文字列を単一の値として扱うが、後段のサービスがメタデータをパースする際に、区切り文字 ; で新たなフィールドとして解釈してしまう。こうして下流のサービスは、攻撃者が注入したフィールドを「信頼された内部値」として処理する。
研究者はこの仕組みを連鎖的に利用し、プッシュが処理される環境を上書きし、通常は有効なサンドボックス制限を無効化した。最終的にサーバー上で任意のコマンドを実行するコードパスに到達する。
; が含まれ、内部フィールドを偽装■ 修正後:ユーザー入力がサニタイズされ、注入不可に
上図のように、ユーザーが指定したプッシュオプションが内部の区切り文字を経由してメタデータを汚染していた。修正後はサニタイズ処理が追加され、攻撃者が意図的にフィールドを延長できなくなっている。
脆弱性への修正と悪用調査

github.com への緊急修正
2026年3月4日19時(UTC)、GitHubは github.com に修正を展開した。この修正により、プッシュオプションの値が内部メタデータのフィールド区切り文字を含まないよう適切にエスケープされる。以後、ユーザー入力が信頼された内部フィールドを上書きすることは不可能になった。
GitHub Enterprise Server 向けパッチとCVE
セルフホスト型の GitHub Enterprise Server (GHES) についても、同日中に全サポートバージョン向けのパッチが準備された。具体的には以下のリリース以降で修正が適用されている。
- GHES 3.14.25 以降
- GHES 3.15.20 以降
- GHES 3.16.16 以降
- GHES 3.17.13 以降
- GHES 3.18.7 以降
- GHES 3.19.4 以降
- GHES 3.20.0 以降
この脆弱性には CVE-2026-3854 が割り当てられている。公開されたCVE情報は以下の通りだ。
- CVE番号: CVE-2026-3854
- 深刻度: Critical(緊急)
- 影響範囲: 認証済みかつプッシュ権限を持つユーザーによるリモートコード実行
GitHubのCISOであるAlexis Wales氏は公式ブログで、GHESの全管理者に対し「直ちに最新のパッチリリースへアップグレードすることを強く推奨する」と呼びかけている。
悪用の有無を徹底調査
修正と並行して、GitHubは不正利用の痕跡がないかフォレンジック調査を開始した。この脆弱性には調査を容易にする特異な性質があった。悪用が成功した場合、サーバーは通常運用では決して通過しない特異なコードパスを必ず実行する。攻撃者がこれを回避することは構造上不可能である。
GitHubのエンジニアはこのコードパスにログ出力を仕込み、全テレメトリデータを解析した。その結果、以下の事実が確認された。
- 該当コードパスが実行されたすべてのインスタンスは、Wizの研究者自身の検証作業と完全に一致した。
- 他のユーザーやアカウントによる同コードパスの実行は一度も観測されなかった。
- 顧客データへのアクセス、改ざん、持ち出しは一切発生しなかった。
これにより、github.com 上のリポジトリに対する実際の攻撃は一切なかったと結論づけられた。GHES環境についても、攻撃が成立するにはインスタンス上でプッシュ権限を持つ認証済みユーザーが必要であり、念のため /var/log/github-audit.log を確認し、プッシュオプションに ; を含む不審なログがないか点検することが推奨されている。
多層防御が生んだ追加の発見
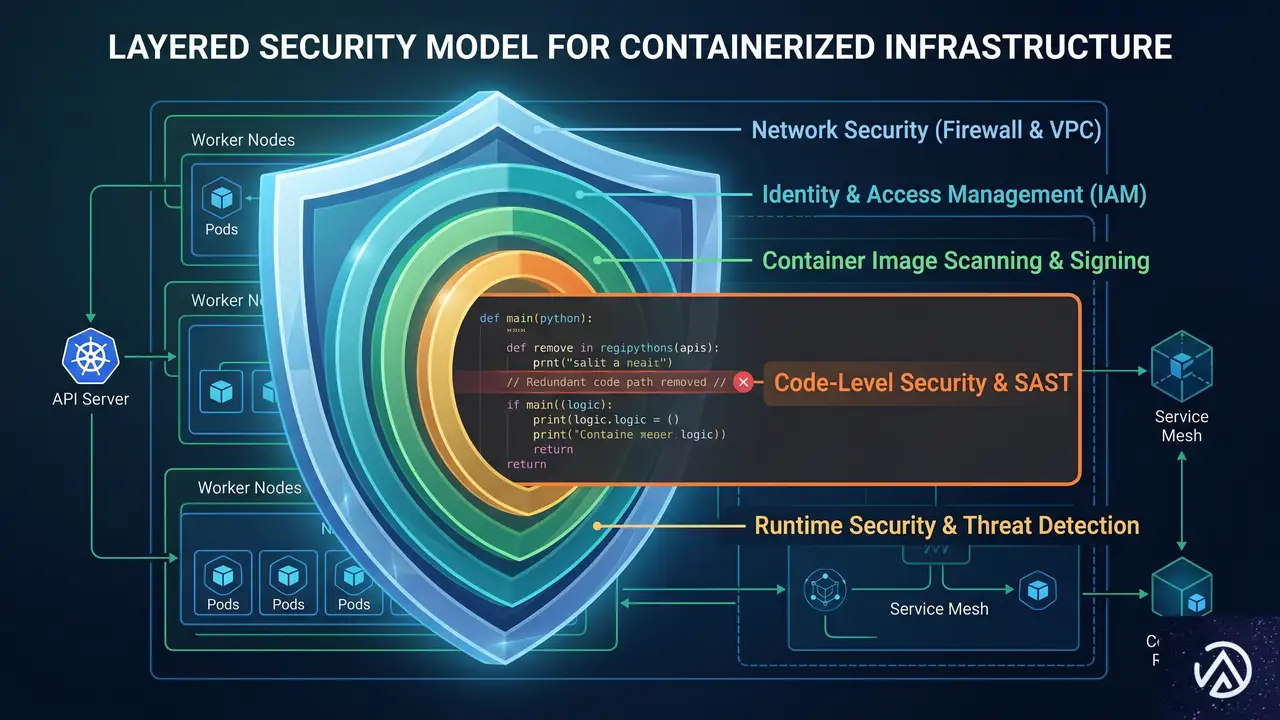
今回のインシデント対応の中で、インプットサニタイズの修正に加えて、防衛の階層化に関わるもう一つの重要な知見が得られた。攻撃が成立した理由の一部は、サーバー上に「その環境では本来不要なはずのコードパス」が存在していたことにある。
具体的には、コンテナイメージのディスク上に、異なる製品構成でのみ使われる想定のコードが含まれていた。過去のデプロイ手法ではこのコードが正しく除外されていたが、デプロイモデルの変更時にその除外ルールが引き継がれなかったのだ。
GitHubはこの不要なコードパスを、当該環境から完全に削除した。たとえ将来同種の注入脆弱性が発見されたとしても、攻撃者の行動範囲を大幅に制限できるようになっている。
このケースは、多層防御(Defense in Depth)が単なる標語ではないことを改めて示している。入力検証という第一の防衛線だけでなく、不必要なコンポーネントの除去という第二の防衛線が被害の拡大を防ぐ鍵になる。
ユーザーが今すぐ取るべき対応

GitHub.com および GitHub Enterprise Cloud ユーザー
github.com、GitHub Enterprise Cloud(Enterprise Managed UsersやData Residencyを含む)の環境は、2026年3月4日の時点で修正済みだ。これらのサービスを利用しているユーザー側での特別な対応は不要である。
GitHub Enterprise Server 管理者
セルフホスト環境では、先述のパッチバージョンへのアップグレードが不可欠だ。さらに、念のため監査ログを確認しておくとよい。具体的には /var/log/github-audit.log を対象に、プッシュオプションにセミコロン(;)を含むプッシュ操作が記録されていないか調査する。
攻撃の成立には認証済みのプッシュ権限が必要なため、内部不正やアカウント乗っ取りのリスクも考慮し、不審なアクティビティがないか定期的に確認することが望ましい。
この記事のポイント
- git push に付与する –push-option のサニタイズ不足が、内部メタデータへのフィールド注入を許しリモートコード実行に繋がった
- GitHubは報告から2時間以内に修正を展開し、サーバーログの解析で悪用の形跡がないことを確認した
- GitHub Enterprise Server 環境では、指定のパッチバージョンへの即時アップグレードが強く推奨される
- 入力サニタイズに加え、不要なコードパスを除去する多層防御の重要性が改めて浮き彫りになった

・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Beaver Builder共同創業者が語る、AI時代のページビルダーとWeb制作のリアル
Beaver Builderは、今年でリリースから12年目を迎えるWordPress用ページビルダーだ。その共同創業者であるRobby McCullough氏が、WP Tavernのポッドキャスト「Jukebox」に出演した。 McCullough氏は、昨今のAIブームに最初から飛びつかなかった理由と、その静観期間を経て見えてきた「真に使えるAI」の形について語っている。
AIがコードを生成してWebサイトを構築する時代に、ドラッグ&ドロップでページを組み立てるツールには意味があるのか。McCullough氏の見解からは、編集や保守といった「作った後」の工程こそが、これからの差別化要因になるという示唆が得られる。Web制作の現場で起きている地殻変動と、そこに適応しようとするプロダクト開発の内側を見ていく。
ページビルダーがもたらした制作ハードルの低下
Beaver Builderは2010年代前半、WordPressで本格的なWebサイトを作るにはHTMLやCSS、PHPの知識が必須だった時代に登場した。 McCullough氏は、番組ホストのNathan Wrigley氏との会話で「ページビルダーは、技術に詳しくないクライアントが自分でコンテンツを更新できる仕組みを作りたくて開発した」と振り返っている。
ノーコードの先駆けと「職人芸」の摩擦
登場当初、ページビルダーには強力な逆風があった。「本来のWordPressの作法ではない」という批判だ。 McCullough氏は最初に参加したWordCampで、「自分はテーマに直接コードを書ける。ページビルダーは不要だ」と言われた経験を明かしている。
この構図は現在の生成AIに対する反発とよく似ている。新しいツールが既存の「正しい」手法を置き換えるとき、必ず「職人芸」の喪失を惜しむ声が上がる。しかし、結果としてページビルダーはWordPressの市場シェアが40%を超える原動力のひとつになったと広く認識されている。
Gutenberg登場で一度は消えたかと思われた市場
その後、WordPress 5.0でブロックエディタ「Gutenberg」がコアに統合された。このときも「ページビルダーは不要になる」という予測が飛び交った。 McCullough氏は「もう数えきれないほど、『1年以内にページビルダーは終わる』と言われてきた」と笑う。 しかし、ビジュアル編集への需要はむしろ多様化し、Beaver Builderのような専用ツールは独自のポジションを保ち続けている。
上の比較図は、制作フローがどのように変化したかを示している。技術的負荷が下がったことで、Webサイト制作の主役は開発者から運用者へと広がった。
AIブームに飛びつかなかった戦略的判断

2023年から2024年にかけて、多くのSaaS企業がChatGPTのAPIをラップしただけの機能を「AI搭載」と謳い始めた。 McCullough氏はこの動きを「AIハイプ・トレイン」と呼び、Beaver Builderはそれに乗らなかったと明言している。 経営陣や株主向けに「AI対応」と謳う必要に迫られる大手とは異なり、自分たちにはそのプレッシャーがなかったからだ。
本質はAIラベルではなく「エージェント化」にある
McCullough氏が今、強い関心を寄せているのは、単なるテキスト生成ではない。 開発環境に深く組み込まれ、コードを理解して自律的にタスクを遂行する「エージェント型AI」だ。 彼はこの半年足らずで、会話だけで10以上のWebサイトを試作した経験を語っている。 「以前なら数週間かかっていた作業が瞬時に終わる」興奮がある一方で、これがWeb制作のプロセスを大きく変えると確信している。
静観期間がもたらした「待ち」のメリット
最初のブームで実装を見送ったことで、Beaver Builderは二つの利点を得た。 ひとつは、技術の成熟を待てたこと。 もうひとつは、ユーザーが本当に必要とするAI体験を設計する余裕が生まれたことだ。 McCullough氏は「最初の波に乗って見せかけのAI機能を追加していたら、今ごろ陳腐化していただろう」と振り返る。
この図は、AIの「見せかけ」と「本質」の違いを時系列で示している。ビジネス視点では、後者の波に合わせてプロダクトを進化させることが競争力を左右する。
AI時代にこそ浮かび上がる「編集」と「保守」の価値
McCullough氏は、AIによるサイト構築が普及しても、ビジュアル編集ツールの役割はむしろ重要性を増すと見ている。その理由は「作った後」にこそ本当の手間がかかるからだ。
プロンプト一発で終わらないWebサイト運用
ポッドキャストの中でWrigley氏は、AIが生成したランディングページを「クリスマス仕様に一部だけ変更する」ような場面を想定した。 こうした部分的な更新は、新しいプロンプトで一から再生成するより、視覚的な編集画面で該当箇所を直接操作するほうが圧倒的に効率が良い。 McCullough氏も「AIがサイトを作り、人間が編集する」という分業モデルに強く共感している。
Beaver Builderが目指す「AIファースト編集」
開発チームは現在、二つのアプローチでAI統合を実験中だ。 一つ目は、ローカルで生成したHTMLページをドラッグ&ドロップでBeaver Builderに取り込む機能。 二つ目は、編集中のセクション(たとえば価格表)に対してチャットで修正を依頼できるエージェント型ツールだ。 McCullough氏は「まだ実験段階」と前置きしつつも、これらの機能がプロダクトの将来像を大きく変える可能性を示唆した。
このフロー図は、AIとページビルダーが対立するのではなく、補完し合う関係になることを示している。 McCullough氏は「コードもマークアップも、将来のバージョンではより表に出していく」と述べており、開発者がAIの出力結果を直接確認・調整できる透明性を重視する姿勢だ。
変化の加速が生むビジネス上の不安と楽観

AIの進化は、プロダクトビジネスにただならぬプレッシャーをもたらす。 McCullough氏も例外ではない。 しかし彼は「根拠のない楽観主義」こそが12年間生き残れた理由だと語る。
過去にもあった「消滅予測」
ページビルダー業界は過去に何度も「終わった」と言われてきた。 Gutenbergの登場時しかり、AIの登場時しかり。 しかし、WordPressサイトの圧倒的な数が一夜にして別のプラットフォームに移行することは現実的ではない。 McCullough氏は「2126年になってもWordPressはどこかで動いているだろう」とジョークを交えつつ、当面はレガシーサイトの保守需要が膨大に残ると指摘する。
新しいツールを学び直す機会として捉える
注目すべきは、McCullough氏自身がエージェント型AIを使う中で、最新のCSSやフレックスボックス、グリッドレイアウトの知識を再習得しているという点だ。 「AIが書いたコードを見て、自分の手でいじる。それが最高の学習体験になっている」と彼は言う。 ツールに使われるのではなく、ツールから学ぶという姿勢が、変化の波を乗りこなす鍵なのかもしれない。
「人間らしさ」とコミュニティへの回帰

技術の話に終始するかと思われた対談は、終盤にかけて「人間同士のつながり」へと焦点を移した。 ここには、AI時代を生きるプロダクト開発者としての本音がにじむ。
AIエージェントとの対話で失われるもの
McCullough氏は、チャットAIがあまりにも有能で、「人と共同作業をしている感覚」を模倣してしまうことに懸念を示した。 在宅勤務で一人きりになる時間が長いと、つい人間よりAIに話しかける頻度が増える。 「このままだと、本当に人とコラボレーションする機会を失ってしまう」という危機感は、技術者としてだけでなく、ひとりの父親としての実感でもある。
WordCampと地域コミュニティの再興を望む声
対談の最後で、McCullough氏はWordPressのオフラインイベントの衰退を惜しんだ。 世界中のWordCampで顔を合わせ、初めて会う相手と食事や飲みに行く体験は、仕事の枠を超えた財産だった。 彼は「AIが進化すればするほど、ああいう場が恋しくなる」と述べ、テクノロジーが人を遠ざけるのではなく、人と人を結びつける方向に使われることを願っている。
この記事のポイント
- Beaver Builderは初期AIブームに乗らず、技術の成熟を待つ戦略を選んだ。その結果、エージェント型AIという本質的な波に集中できている
- AIがサイトを一瞬で作れるようになっても、部分的な編集や保守にはビジュアルツールが不可欠だ。制作より「編集」の時代へ移行しつつある
- McCullough氏はAIを「学習手段」としても評価しており、生成されたコードを自ら触ることで新しいCSS技術を習得している
- AIの進化はビジネスに不安をもたらすが、WordPressの圧倒的な普及率がしばらくの間はレガシーサイトの保守需要を支え続ける
- 便利なAIとの対話が増えるほど、人とのリアルな共同作業やWordCampのようなコミュニティの価値が再認識されている
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

EU消費者向けEC事業者必見、2026年6月から撤回リンクが必須に
EU(欧州連合)域内の消費者を対象に商品やサービスをオンライン販売するすべてのB2C事業者に対し、2026年6月19日までに「契約撤回」機能の設置が義務付けられる。これは、新たなEU指令2023/2673に基づくものだ。WooCommerceで運営している事業者であれば、必要な機能のほとんどは既に備わっていると考えてよい。
今回の指令は、これまで存在していた消費者の「14日間の撤回権」の行使方法を、より具体的かつ利用しやすい形に改めるものだ。事業者は、購入時と同じくらい簡単に契約を解除できる導線を、Webサイト上に確保しなければならない。その内容と実装のポイントをまとめた。
WooCommerce Blogの記事を基に、変更点の概要と具体的な対応ステップを詳しく見ていく。
2026年6月、何が変わるのか

EUでは従来から、指令2011/83に基づき、消費者は契約から14日間以内であれば理由を問わずに契約を撤回できる「クーリングオフ」の権利が認められてきた。今回の指令2023/2673は、この権利を「どのように行使できるようにするか」を具体的に規定し直したものだ。
つまり、オンラインで簡単に契約(購入)できるようにしているなら、同じくらい簡単にオンラインで撤回(解約・返品)できるようにしなければならない、という考え方である。この「対称性」が、今回の改正の中核にある。
事業者に求められる具体的な対応
新しい指令の中核は、サイト上に「契約撤回」のための機能を、目立つ形で常時利用可能な状態にしておくことだ。具体的には、以下のような要素が求められる。
- 常に目に付きやすい場所に「契約を撤回する」ためのボタンまたはリンクを設置する
- そのリンク先では、消費者が誰のどの契約を撤回したいのかを簡単に伝えられる入力フォームを用意する
- 撤回の申し出があったら、事業者側は速やかに確認メールを自動送信する
- 申し出を受けた後の実際の返金・返品処理は、既存の業務フローに沿って行う
ここで注意すべきは、「契約撤回」の権利そのものは以前から存在していたという点だ。今回の変更はあくまで「権利の行使方法」に関するものであり、返品や返金のポリシーそのものを根本から変える必要があるわけではない。
14日間の撤回期間中は機能を維持する
この撤回機能は、消費者が商品を受け取った日、またはサービス契約を結んだ日から14日間、継続的に提供しなければならない。期間が過ぎたら自動的に機能を停止する必要はないが、少なくとも14日間は確実に利用できる状態にしておくことが求められる。
したがって、特定のキャンペーン期間中だけ表示するといった制御は避け、サイト上に恒常的に設置しておくのが無難だ。
WooCommerceを使った実装ステップ
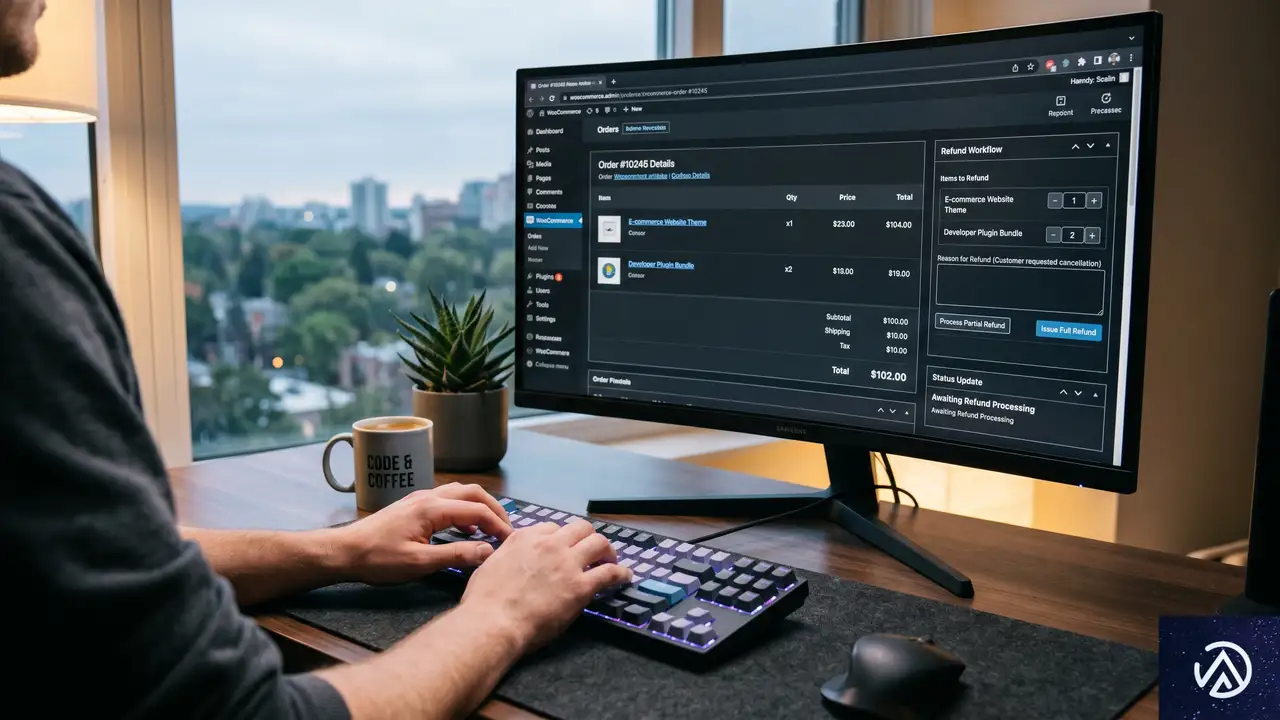
新指令に対応するための技術的なハードルは、それほど高くない。特にWooCommerceを利用している場合、基本的な機能の多くは既にコア機能やプラグインでカバーできる。WooCommerce Blogの記事では、以下の4ステップが推奨されている。
ステップ1:サイトに「契約撤回」リンクを設置する
まず、サイトのフッターやメインナビゲーションなど、訪問者が迷わずに見つけられる位置にリンクを追加する。EU指令では「ここから契約を撤回する」といった趣旨の、機能が明確に分かるラベル表記が求められている。
特殊な装飾ボタンである必要はなく、テキストリンクでも問題ない。しかし、他の利用規約系リンクに埋もれてしまわないよう、視認性には配慮が必要だ。具体的なラベル例としては「契約の撤回はこちら(Withdraw from contract here)」「注文のキャンセルと返品」などが考えられる。
ステップ2:撤回リクエスト用のフォームを作成する
リンク先のページには、消費者が以下の情報を提供または確認できるフォームを設置する。
- 氏名
- 注文番号または契約参照番号
- メールアドレス
フォーム作成には、Contact Form 7やWPForms、Gravity Formsなど、WordPressで広く使われているコンタクトフォームプラグインで十分対応できる。独自のカスタム開発は必須ではない。むしろ、既存のフォームに「お問い合わせ種別:契約撤回」という項目を追加するだけでも、最低限の実装としては成立するだろう。
フォーム設計で気を付けるべきは、顧客が入力に迷わないシンプルさだ。注文番号が分からないケースも想定し、注文時に使用したメールアドレスと氏名だけでもリクエストを受理できるようにしておくと、顧客体験として優れたものになる。
ステップ3:確認メールの自動送信を設定する
消費者から撤回リクエストが送信されたら、それを受け取ったことを証明する確認メールを自動で返信する必要がある。これは、後日の「言った言わない」のトラブルを防ぐための重要なステップだ。
多くのフォームプラグインには、送信完了時の自動返信メール機能が備わっている。そのテンプレートに「契約撤回のリクエストを受け付けました。追って担当者よりご連絡いたします」といった文言を設定しておけばよい。カスタマーサービス用の外部ツール(ZendeskやFreshdeskなど)を使っているなら、そちらの自動応答機能を利用しても構わない。
ステップ4:既存の返金・返品フローで処理する
撤回リクエストを受け取った後の実際の処理(返金、返品受付、在庫戻しなど)は、これまで使ってきたWooCommerceの標準機能で十分対応できる。注文管理画面からの返金処理、注文メモへの記録、在庫の自動復元といった機能は、WooCommerceコアに組み込まれている。
大事なのは、新しい導線で受け取ったリクエストを、既存の処理フローに確実に乗せることだ。フォームからの通知が特定のメールアドレスに飛ぶだけになっていないか、必ず確認しておく必要がある。
WooCommerce事業者が持つ「既存の優位性」
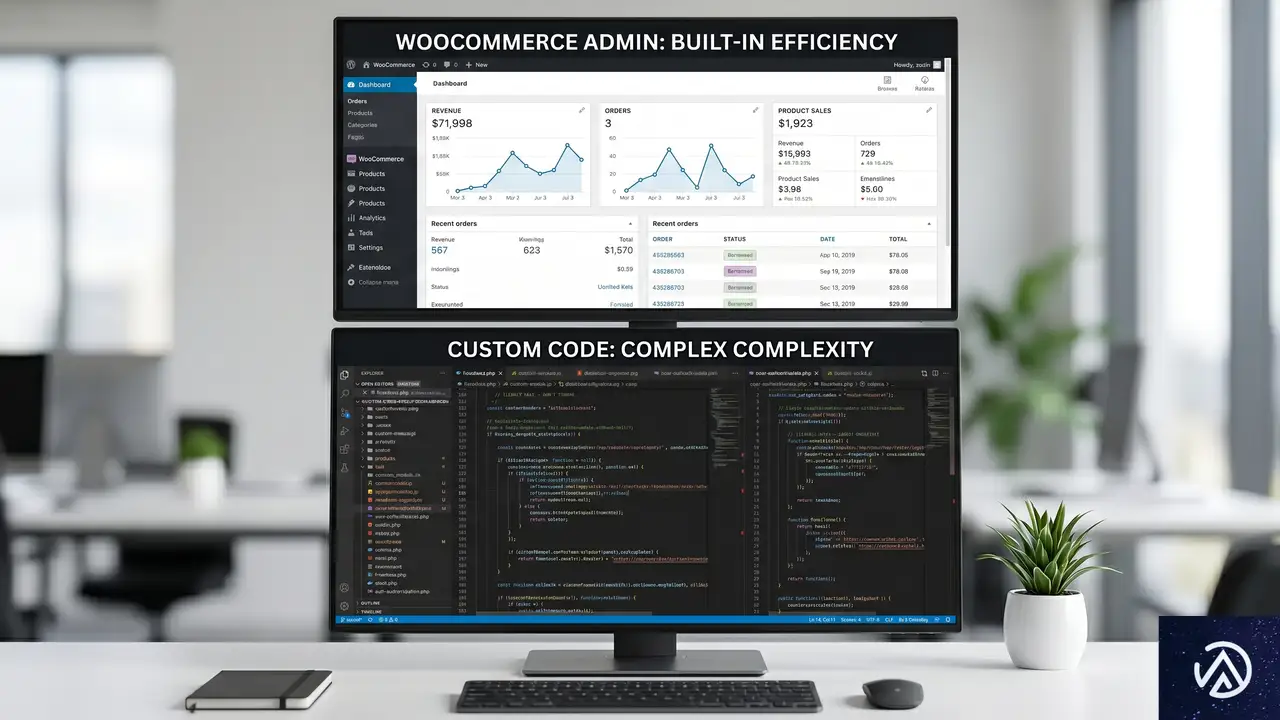
この指令対応に関して、WooCommerce利用者はいくつかの点で有利な立場にある。カスタム構築のECサイトや、SaaS型の海外製ECプラットフォームと比較しても、柔軟性の高さが際立つ。
コア機能だけでもカバーできる範囲の広さ
WooCommerceは、注文管理、返金ワークフロー、注文メモ、ステータス管理といった機能を標準で備えている。これらはすべて、「契約撤回リクエストを受け取った後の処理」にそのまま流用できる。追加プラグインなしでも、管理画面上で返金処理を行い、その履歴を注文メモに残すところまでは実現可能だ。
これは、フルスクラッチでECサイトを構築した場合と比べて、圧倒的に少ない工数で対応できることを意味する。フォームの設置とメール通知の設定さえ済ませれば、運用に乗せられる状態になるだろう。
プラグインによる拡張性
より高度な対応を目指すなら、WooCommerceのプラグインエコシステムが役に立つ。たとえば、フォーム入力を自動的に注文と紐付けて管理画面に表示するプラグインや、返金リクエストを専用のステータスとして管理できる拡張機能などが存在する。
ただ、最初から完璧を目指す必要はない。まずは本稿で紹介した4ステップを実装し、運用しながら徐々に自動化の範囲を広げていくアプローチが、リスクもコストも抑えられて現実的だ。
実装時に気をつけるべきポイントと限界

ここまでの内容は、EU指令の一般的な要件と、技術的な対応の枠組みを説明したものだ。しかし、実際のビジネスに適用する際には、いくつか注意すべき点がある。
国ごとに異なる可能性がある最終要件
EU指令は加盟国に対し、国内法化する際の「最低基準」を示すものだ。つまり、実際にどのような表現や導線が求められるかは、販売先の国によって細部が異なる可能性がある。WooCommerce Blogの記事でも「具体的な要件はEU加盟国によって異なる可能性があるため、ビジネスを展開している国の規制に詳しい法律専門家への相談を推奨する」と言及されている。
特にドイツやフランスなど消費者保護の基準が厳しい国では、ラベルの文言やフォームの項目について、より詳細な要件が課される可能性を考慮しておくべきだ。
「目立つ場所」の解釈
指令は「目立つ、かつ容易にアクセスできる(prominently and easily accessible)」場所への設置を求めている。これはサイト運営者にとって、解釈の余地がある部分だ。フッターにリンクを置くだけで十分なのか、あるいは注文確認画面やマイページにも導線が必要なのかは、今後のガイドラインや各国の運用次第で変わってくる可能性がある。
安全を取るなら、以下の複数の場所に重複してリンクを設置しておくとよい。
- サイト共通フッター
- 注文完了画面(サンキューページ)
- マイアカウントページの注文履歴
- よくある質問(FAQ)ページ
これなら「見つけられなかった」というクレームのリスクを大幅に減らせる。
本記事は法的助言ではない
念のため明記しておくが、本記事は一般的な情報提供を目的としており、特定のビジネスに対する法的助言を構成するものではない。WooCommerce Blogの元記事にも同様の但し書きがある。最終的な判断は、必ず各国の消費者法に詳しい弁護士や法律専門家に相談してほしい。
この記事のポイント
- 2026年6月19日より、EUの消費者向けB2C ECサイトは「契約撤回」機能の設置が必須となる
- 「購入できるなら同じ画面で解約もできる」状態を求めるのが新指令の本質だ
- WooCommerceならコア機能とフォームプラグインで、比較的少ない工数での対応が見込める
- 実装後は、返金フローや自動返信メールが正しく機能するかを必ずテストすること
- 法解釈や最終的な要件は各国で異なるため、弁護士など専門家への相談が不可欠
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

ヘッドレスCMSとWordPressの選び方、2026年版アーキテクチャ比較
CMSの選定は2026年、技術的な好みの問題ではなくなった。その選択がマーケティングキャンペーンの展開速度、コンテンツ更新の自由度、ひいては収益に直結する。WordPressが世界のWebサイトの43.5%を支える支配的な存在である一方、ヘッドレスCMS市場は2027年までに16億ドルに達すると予測されている。
両者の違いは単なる「新しいか古いか」ではない。視覚的な構築の自由と、アーキテクチャの厳格な分離という、根本的に異なる哲学のせめぎ合いだ。本記事ではパフォーマンス、運用コスト、セキュリティ、SEO、そしてチームの働き方という実務の観点から、両アプローチを比較する。
根本的なアーキテクチャの違い
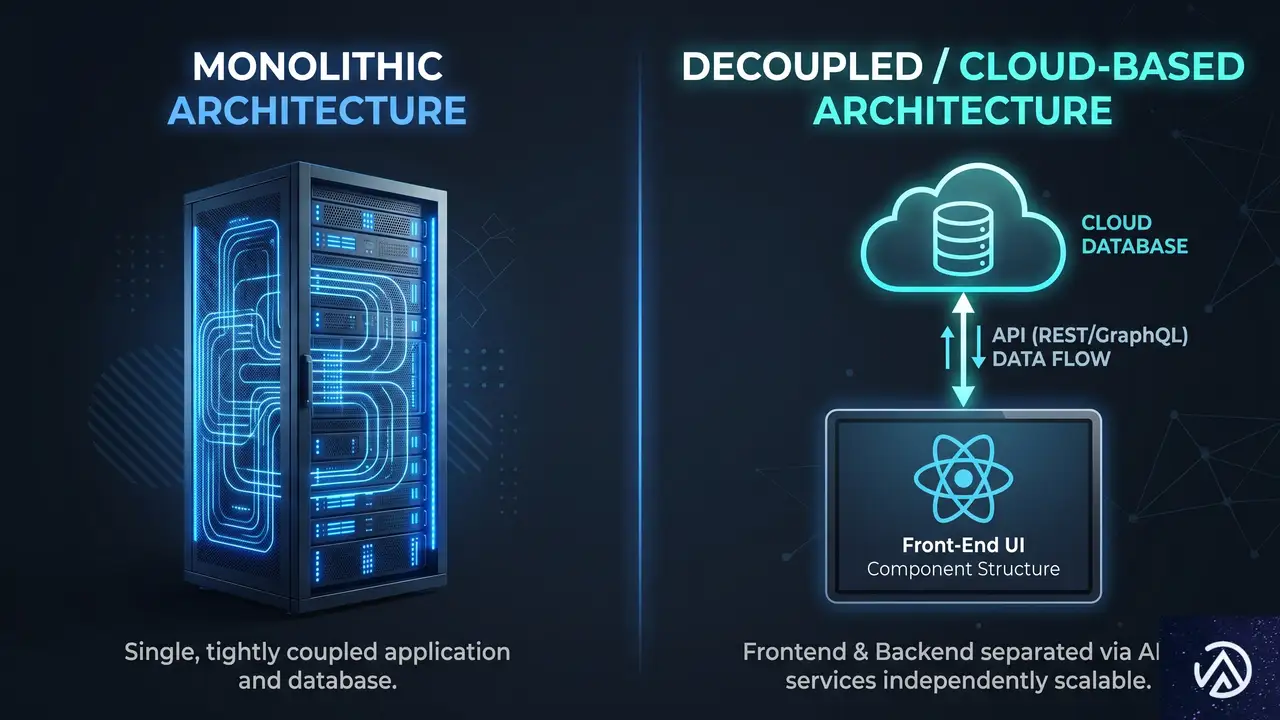
アーキテクチャの議論は開発者だけの専門用語ではない。マーケティングチームが火曜の朝にランディングページを立ち上げられるかどうか、そのスピードを決める。この根本的な違いは採用戦略にも直接影響する。
従来のWordPressはモノリシック(一体型)システムだ。コンテンツデータベース、PHPの処理ロジック、HTML出力がすべて同じアプリケーション環境に同居する。ユーザーがリンクをクリックすると、サーバーはPHPスクリプトを実行しMySQLデータベースに問い合わせ、取得したデータをテーマテンプレートにはめ込み、最終的なHTMLをブラウザに返す。この一連の処理は一つのサーバー内で完結する。
一方、ヘッドレスはデカップルド(分離型)アーキテクチャと呼ばれる。コンテンツはContentfulやStrapiのようなクラウドデータベースに保存され、フロントエンドはReactやVueで構築された完全に別個のアプリケーションになる。フロントエンドアプリはAPIエンドポイントを通じて生のJSONデータを受け取り、コンテンツの見た目には一切関与しない。データの受け渡しと表示が完全に分離されているのだ。
なぜ開発者は分離を好むのか
Elementor Blogの記事によれば、最近のStack Overflow調査でヘッドレス技術への開発者関心が従来のPHPロールと比較して15%増加したという。彼らは「関心の分離」を重視する。バックエンドのコンテンツ管理とフロントエンドのUI実装が完全に切り離されることで、開発効率とコードの保守性が高まるからだ。
ただし、この分離にはトレードオフがある。マーケターがコンテンツの見た目をリアルタイムで確認する「ライブプレビュー」は、ヘッドレス環境では極めて面倒な課題として残っている。草案を確認するだけのために複雑なプレビューサーバーを構築しなければならないケースも多い。
ユーザー体験の決定的な差

ヘッドレスアーキテクチャがマーケティングチームを苦しめる最大の理由がここにある。技術的な純粋さと引き換えに、ワークフローの速度が犠牲になる。
WordPressの視覚的優位性
従来型WordPressは視覚的な構築体験で圧倒的に優位に立つ。Elementor Editor Proを例にとると、118種類以上のウィジェットを使ってCSSを一行も書かずにレイアウトを構築できる。コンテナをドラッグし、ブレークポイントを調整し、すぐに公開する。
ヘッドレスが生む開発者依存
ヘッドレス環境では、ヒーローセクションのレイアウトを変更したいだけでも、マーケターはJiraチケットを発行し、開発者がReactコンポーネントを更新し、GitHubにプッシュし、ビルドパイプラインの完了を待つという手順を踏まなければならない。毎週11本の記事を公開するチームにとって、この依存関係は数百時間の損失になりうる。
Elementor Blogで紹介されているAIアシスタント「Angie」のようなツールは、このギャップを埋めようとしている。チャットで指示するだけで、実用的なレイアウトやフォームを自動生成する。テキスト提案ではなく、実際に動作するアセットを構築する点が従来のAIと異なる。
一方で、スマート冷蔵庫、Apple Watchアプリ、Webサイトに同時にコンテンツを配信する必要があるなら、ヘッドレスのデータエントリーモデルは必須になる。配信先が3つ以上のチャネルに及ぶブランドは、前年比9.5%の収益増加を達成しているとのデータもある。
表示速度、パフォーマンスの現実
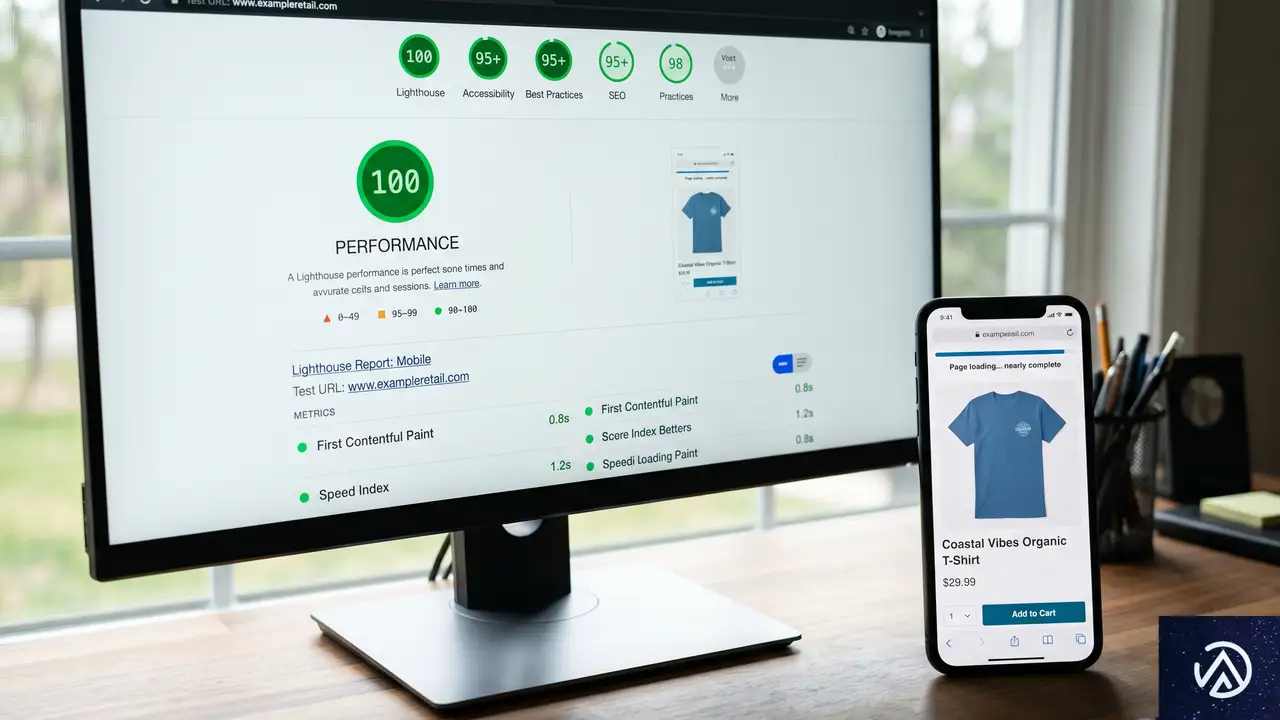
2026年において表示速度は贅沢品ではない。生存のための指標だ。世界のトラフィックの58.67%がモバイルデバイスを経由する中、重いサイトは収益を直接焼き尽くす。
ヘッドレスの圧倒的速度
ヘッドレスシステムは生の速度で容易に優位に立つ。静的サイト生成(SSG)という仕組みを使うからだ。SSGとは、コンテンツのHTMLファイルをあらかじめ生成しておき、CDN(コンテンツ配信ネットワーク。世界中に分散したサーバー拠点から最寄りの場所にデータを届ける仕組み)に保存する手法である。ユーザーがアクセスした瞬間にデータベースへ問い合わせる必要がないため、Next.jsで構築されたサイトは頻繁にLighthouseの満点を叩き出す。
WordPressが抱えるボトルネック
現在、WordPressサイトでGoogleのCore Web Vitals(コアウェブバイタル。ページ体験を測る3つの指標)の全項目を通過しているのは、わずか40.5%だ。PHP処理への依存度の高さと最適化されていないプラグインが深刻なボトルネックを生み出している。参考までに、Next.jsサイトの合格率は約55%に達する。
ただし、WordPressで速度を諦める必要はない。構築方法を変えれば良い。エッジキャッシュの導入、条件付きアセットローディング(必要なときにだけスクリプトを読み込む手法)、画像の自動圧縮、Redisを使ったデータベースクエリのオフロードを徹底する。速度向上は直接売上に跳ね返る。モバイルでわずか0.1秒の改善が小売のコンバージョン率を8.4%押し上げるというデータもある。
セキュリティと保守の実態

セキュリティは従来型CMSエコシステムに突き刺さる最大の棘だ。Elementor Blogの記事が引用する統計は痛烈である。CMS系Webサイトへの攻撃成功事例のうち、実に94%がWordPressを標的にしている。
WordPressの広大な攻撃対象
この数字の理由は明確だ。データベース、ログイン画面(wp-admin)、公開Webサイトがすべて同じサーバーIPアドレスを共有している。攻撃者が古いスライダープラグインの脆弱性を一つ見つければ、データベース全体へのアクセスを奪取できる。攻撃対象領域が極めて広いのだ。
ヘッドレスの構造的安全性
ヘッドレスアーキテクチャはこの攻撃対象領域を劇的に縮小する。フロントエンドはバックエンドから完全に切り離されているため、公開Webサイトにデータベースが接続されていない。ハッカーは静的HTMLファイルにSQLインジェクションを仕掛けることはできない。
もちろん、モノリシックシステムの防御は不可能ではない。共有ホスティングを避け、Cloudflare経由でWAF(Webアプリケーションファイアウォール)を導入し、使っていないプラグインは無効化ではなく即座に削除する。管理ロールには二要素認証を強制し、デフォルトのログインURLを変更する。こうした基本的な対策を徹底するだけでもリスクは大幅に下げられる。
コストの真実、初期費用と総所有コスト

初期構築費用は総所有コスト(TCO)の一部に過ぎない。多くの制作会社がパフォーマンスだけを謳い文句にヘッドレスを販売するが、クライアントに毎月のSaaS料金が重くのしかかる。
ヘッドレスの高い参入障壁
具体的な数字を見てみよう。SANITYのGrowthプランは月額949ドル、ContentfulのTeamティアは月額300ドルからスタートし、エンタープライズプランは通常月額2,000ドルを超える。Strapiのような月額29ドルの選択肢もあるが、Nodeアプリとデータベースを自前でホストする手間が加わる。
WordPressの現実的なコスト
従来型プラットフォームの参入障壁ははるかに低い。中小企業向けの高品質なマネージドWordPressホスティングは、おおむね月額20ドルから115ドルの範囲に収まる。大規模なコンテンツ運用をヘッドレスの数分の一の予算で回せる計算だ。
ただし、WordPressのスケーラビリティは無料ではない。月間100万訪問者を超えると、安価なホスティングは崩壊する。エンタープライズグレードのクラウドインフラ、積極的なキャッシュ階層、高度なセキュリティ設定が必要になる。結局のところ、開発コストもどちらの道でも発生する。ヘッドレスは高給のReact/Vueエンジニアを必要とし、従来型ビルドはPHP/WordPressエキスパートによるテーマロジックの維持や定期的なデータベース最適化を必要とする。
ハイブリッド手法、橋を架ける

極端な二択を迫られる必要はない。2026年、最も賢いチームはハイブリッドアプローチを採用している。ページビルダーの視覚的自由を維持しつつ、特定の機能に最新のAPI技術を利用する。
WordPressを純粋なヘッドレスコンテンツリポジトリとして使うことも可能だ。WordPress REST APIとWPGraphQLを使えば、投稿や固定ページをJSONデータとしてクエリし、Next.jsフロントエンドに供給できる。執筆者には使い慣れたGutenbergインターフェースを提供しながら、開発者はモダンなスタックを手に入れられる。
より効率的なのは、モノリシックを維持しながらスピードを上げるアプローチだ。多数のプラグインをつぎはぎする代わりに、ホスティング、ビジュアルビルド、パフォーマンスツールを一つの環境に統合する。AIにワイヤーフレーム生成を任せ、人間は微調整に集中する。主要なマーケティングサイトはモノリシックのまま実行速度を確保し、求人情報や商品カタログといった特定の投稿タイプだけをREST API経由でモバイルアプリにプッシュする。これでデータを閉鎖的なシステムに閉じ込めず、マーケティングチームも視覚編集から締め出されない。
この記事のポイント
- 従来型WordPressはマーケティングチームの即応性と視覚的編集で圧倒的に優位。
- ヘッドレスは生の表示速度とセキュリティで勝るが、高いSaaSコストと開発者依存が課題。
- WordPressの速度課題はエッジキャッシュと条件付きローディングで大幅に改善可能。
- 3つ以上のチャネルにコンテンツを配信する場合、ヘッドレスのデータエントリーモデルが必須。
- ハイブリッド手法を用いれば、両者の長所を活かした現実的な落とし所が見えてくる。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Cloudflare IPsecが耐量子暗号に対応、2029年完全移行へ前進
Cloudflareは、同社のIPsecサービスに耐量子計算機暗号(PQC)を導入し、一般提供を開始した。ハイブリッドML-KEM(FIPS 203準拠)を採用し、CiscoやFortinetといった主要ベンダーの機器との相互接続を確認済みだ。これにより、量子コンピュータによる将来の解読リスクに備えた広域ネットワーク(WAN)の保護を、既存のハードウェアで開始できる。
同社はかねてから目標としていたシステム全体の完全なPQC対応の期限を2029年に前倒ししている。今回のIPsec対応は、TLSトラフィックの3分の2以上がすでにPQCで保護されている状況にネットワーク層が追いつくための、重要なマイルストーンとなる。
耐量子暗号IPsecが一般提供開始となる背景

インターネット上の通信の多くは、現在のコンピュータでは解読が困難な公開鍵暗号によって保護されている。しかし、大規模な量子コンピュータが実用化されれば、これらの暗号は簡単に破られてしまう。これが「Q-Day」と呼ばれる転換点であり、想定よりも早く訪れる可能性が指摘されている。
ここで警戒すべきなのが「Harvest-now-decrypt-later(今収集し、後で解読する)」攻撃だ。攻撃者は今日の暗号化された通信データを大量に収集・保存し、将来の量子コンピュータで解読する。サイト間のVPNでよく使われるIPsec通信もこの脅威にさらされてきた。
Webブラウジングの通信を暗号化するTLSでは、すでに2022年からハイブリッドPQCの導入が急速に進んだ。実際、Cloudflareのネットワークに到達するユーザー由来のTLSトラフィックの3分の2以上が、耐量子暗号で保護されている。一方で、企業の拠点間を結ぶIPsecの世界では、相互運用性の確保や標準化の遅れが壁となり、導入が4年ほど遅れていた。
ハイブリッドML-KEMが実現する耐量子暗号
ML-KEMとは何か
今回採用されたML-KEM(Module-Lattice-Based Key-Encapsulation Mechanism)は、量子コンピュータによる攻撃が理論的に困難とされる数学的問題(格子暗号)に基づくアルゴリズムだ。これは、通信の両端が持つ特殊なハードウェアや専用の物理回線を必要としない。標準的なプロセッサ上でソフトウェアとして動作するように設計されている点が、実用上の大きな利点である。
「ハイブリッド」方式の重要性
Cloudflareが実装したのは、IETFのドラフト「draft-ietf-ipsecme-ikev2-mlkem」で規定されるハイブリッド方式である。ハイブリッド方式とは、既存の安全性が十分に検証された古典的なDiffie-Hellman鍵交換と、新しいML-KEMを組み合わせる手法だ。
具体的なハンドシェイクの流れは次のとおりだ。まず、従来のDiffie-Hellman鍵交換を実行して共有鍵を生成する。次に、その鍵を使ってML-KEMの鍵交換を暗号化して実行する。最後に、両方の出力を混合して、実際のデータ通信を保護するセッション鍵を作成する。この二重構造により、仮に将来ML-KEMに未知の脆弱性が見つかったとしても、古典暗号の層が安全性を下支えする。
相互運用性の確立と課題

Cisco、Fortinetとの相互接続に成功
PQCの実装において最大の障壁は、異なるベンダー間での相互運用性の確保だ。Cloudflareの発表によると、今回の一般提供開始に先立ち、以下のネットワーク機器との相互接続テストを完了している。
- Cisco: バージョン26.1.1以降のCisco 8000シリーズセキュアルーター
- Fortinet: FortiOS 7.6.6以降を搭載したブランチコネクタ
これらの機器を拠点側に設置することで、Cloudflareのグローバルネットワークとの間に、耐量子暗号で保護されたIPsecトンネルを確立できる。これにより、特別なハードウェアを新たに調達することなく、既存の投資を活かしてセキュリティを強化できる道が開かれた。
標準化の遅れとciphersuite乱立問題
TLSに比べてIPsecでの標準化が遅れた背景には、鍵配送の代替技術としてのQKD(量子鍵配送)への関心が業界の一部にあったことが挙げられる。RFC 8784で規定されたQKDは、量子力学の原理を用いて盗聴を検知するが、専用のハードウェアと物理的な光ファイバー回線が必須だ。これはインターネット規模での展開には根本的に不向きであり、米国NSAや英国NCSCもQKDへの単独依存に警鐘を鳴らしている。
一方で、PQCのソフトウェアベースのアプローチにはこの制約がない。Cloudflareは、インターネットのオープン性と相互運用性を維持するために、PQCの標準化が不可欠であると主張する。
標準化を巡る混乱も導入を遅らせた一因だ。2023年に公開されたRFC 9370は、IPsecで複数の鍵交換を並行実行する枠組みを提供したが、使用すべき暗号スイートを明確に指定しなかった。この隙間を埋めるように、一部のベンダーは「draft-ietf-ipsecme-ikev2-mlkem」が策定される前に独自の暗号スイートを実装して市場に投入した。NIST SP 800-52r2が警告する「暗号スイートの肥大化」が現実のものとなり、結果として相互運用性に支障が生じている。具体的には、Palo Alto NetworksのRFC 9370ベースの実装とは、現時点で相互接続が確立できていないという。Cloudflareは、業界全体が新たなドラフト標準に集約されることで、この問題が解決されることを期待している。
耐量子インターネットに向けたロードマップ

Cloudflareは、2029年までの完全なPQC対応を目標に掲げている。今回のIPsecへのPQC導入は、そのマイルストーンの一つだ。同社は、この機能を顧客に追加コストなしで提供し、特殊なハードウェアを必要とせずに誰もが耐量子セキュリティを利用できる環境を目指している。
しかし、完全な耐量子環境の実現には、まだ解決すべき課題が残る。現在のdraft-ietf-ipsecme-ikev2-mlkemは「通信の暗号化」のための鍵交換を規定しているが、「通信相手の認証」のためのPQC標準はまだ存在しない。認証部分が古典暗号のままであれば、Q-Day以降に攻撃者が他人になりすましてシステムに侵入する「アクティブ攻撃」を防げない。迫る期限を前に、認証のPQC標準化が次の焦点となることは確実だ。
この記事のポイント
- Cloudflare IPsecがハイブリッドML-KEMによる耐量子暗号(PQC)の一般提供を開始し、2029年の完全移行に向けた一歩を踏み出した。
- CiscoやFortinetの既存ルーターとの相互運用性を確保し、追加のハードウェア投資なしでHarvest-now-decrypt-later攻撃への対策が可能になる。
- RFC標準の不在やベンダー間の実装差異によりIPsecのPQC対応はTLSより4年遅れたが、「draft-ietf-ipsecme-ikev2-mlkem」によって相互運用性の基盤が整いつつある。
- 今後の課題は「通信の認証」をPQCに対応させることであり、真の耐量子セキュリティ実現には標準化コミュニティの継続的な協調が不可欠である。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AIエージェントがCloudflareで自律デプロイ。Stripe連携でアカウント作成からドメイン購入まで完結
AIエージェントがソフトウェアを開発するだけでなく、本番環境のインフラまで自ら調達し、デプロイを完了させる時代が到来した。Cloudflareは2026年4月30日、AIエージェントがユーザーに代わってCloudflareアカウントを作成し、ドメインを購入し、アプリケーションをデプロイできる新機能を発表した。
この仕組みは決済プラットフォームのStripeが提供する「Stripe Projects」と共同設計された新しいプロトコルによって実現されている。従来は人間が管理画面で行っていたAPIトークンの発行やクレジットカード情報の入力といった作業を、AIが安全かつシームレスに代行する。
開発者は複雑な初期設定に煩わされることなく、AIに指示を出すだけで「ゼロから本番公開まで」を最短距離で駆け抜けられるようになる。これはインフラ構築の在り方を根本から変える可能性を秘めたアップデートだ。
AIエージェントがインフラ構築を担う新時代の幕開け

コーディングエージェントはプログラムを書く能力には長けているが、これまでは本番環境へのデプロイという壁に直面していた。アプリケーションを公開するには、ホスティング先のアカウント、支払い手段、そして操作のためのAPIトークンの3つが不可欠だからだ。
これまでは人間がダッシュボードにログインし、設定を済ませてからエージェントに情報を渡す必要があった。Cloudflareが導入した新機能は、この「人間による介在」を最小限に抑えることを目的としている。
開発者の手作業をゼロにするStripe Projectsとの連携
今回の機能の中核にあるのが、Stripeとの提携による「Stripe Projects」だ。これはAIエージェントが複数のサービスを組み合わせてプロジェクトを立ち上げるためのプラットフォームである。開発者がStripeのアカウントを持っていれば、それを認証の基盤として利用できる。
エージェントはユーザーの許可を得た上で、Cloudflareのアカウントを自動的にプロビジョニング(準備)する。もしユーザーがすでにCloudflareのアカウントを持っている場合は、標準的なOAuthフローを通じてアクセス権が譲渡される。これにより、APIキーのコピペという原始的な作業から解放される。
● カード情報登録(手動)
● APIキー発行とコピペ(手動)
● ドメイン検索と購入(手動)
✔ 支払いトークンの自動受け渡し
✔ ドメインの自律取得とデプロイ
上記の図が示すように、人間が介入すべきポイントは「AIへの指示」と「最終的な承認」だけに集約される。これにより、開発のリードタイムは劇的に短縮されるだろう。
プロトコルを支える3つの柱

AIエージェントが自律的に動くためには、単にAPIを叩くだけでは不十分だ。CloudflareとStripeは、エージェントが環境を理解し、権限を得て、支払いを実行するための3つの要素をプロトコルとして定義した。
サービスカタログからの自律的な発見
まず重要になるのが「Discovery(発見)」だ。エージェントは、利用可能なサービスが何であるかを知る必要がある。新しいプロトコルでは、CloudflareなどのプロバイダーがREST APIを通じてサービスカタログをJSON形式で提供する。
エージェントはユーザーの要望に基づき、このカタログから最適なサービス(ドメイン登録、ストレージ、コンピューティングなど)を選択する。人間が「どのメニューから選ぶか」を悩む必要はなく、エージェントがタスク達成に最適な道具を自ら選び出す仕組みだ。
認証とアカウントの即時発行
次に「Authorization(認証)」だ。Stripeがアイデンティティプロバイダーとして機能し、ユーザーの身元を保証する。Cloudflareはこの情報を基に、未登録のユーザーに対しては即座にアカウントを発行する。
発行された認証情報はStripe Projects CLIによって安全に保管され、エージェントはそれを使ってCloudflareのAPIを操作する。この一連の流れにおいて、ユーザーがサインアップフォームに入力する手間は一切発生しない。
クレジットカード情報を渡さない安全な決済
最も懸念されるのは「Payment(支払い)」の安全性だろう。AIにクレジットカード番号を教えるのはリスクが高い。そこでこのプロトコルでは、カード情報の代わりに「支払いトークン」を使用する。
Stripeから発行されたトークンをCloudflareに渡すことで、エージェントは実際のカード番号に触れることなく、有料プランの購読やドメインの購入を実行できる。決済の利便性とセキュリティを両立させた設計となっている。
実際のワークフローとCLIでの操作感
この新機能を利用するには、Stripe CLIと専用のプラグインが必要になる。セットアップが完了すれば、ターミナルから簡単なコマンドを実行するだけでプロジェクトを開始できる。Cloudflareのブログでは、具体的な手順が紹介されている。
Stripe CLIを用いたプロジェクトの初期化
まず、以下のコマンドでプロジェクトを初期化し、Stripeにログインする。これがすべての作業の起点となる。
stripe projects initその後、AIエージェントに対して「新しいドメインを取得してアプリをデプロイしてほしい」と指示を出す。エージェントは自ら stripe projects catalog コマンドを叩いてCloudflareのドメイン登録サービスを見つけ出し、購入プロセスを開始する。
もしStripeアカウントに支払い方法が登録されていない場合は、エージェントがユーザーに対してカード情報の追加を促すプロンプトを表示する。人間はエージェントが提示した確認事項に対して「Yes」と答えるだけで、裏側で複雑なインフラの紐付けが完了する。
セキュリティとガバナンスへの配慮

AIに支払権限を与えることには、慎重な意見も多い。「エージェントが勝手に高額なドメインを大量購入したらどうするのか」という懸念は当然の反応だ。この問題に対処するため、プロトコルには厳格な制限が設けられている。
予算制限と予算アラートによる暴走防止
Stripe Projectsでは、デフォルトで1つのプロバイダーに対して月額100ドルという支出上限が設定されている。エージェントがこの上限を超えて勝手に課金することはできない仕組みだ。
さらに上限を引き上げたい場合は、ユーザーが明示的に設定を変更し、Cloudflare側で予算アラート(Budget Alerts)を設定する必要がある。これにより、AIの自律性を保ちつつ、予期せぬコスト増大を防ぐガバナンスが効いている。
独自分析。インフラのコモディティ化とエージェントOSの加速

今回のCloudflareの動きは、単なる利便性の向上に留まらない。筆者は、これがインフラの「完全な抽象化」に向けた決定的な一歩であると考えている。かつて開発者はサーバーを自前で立てていたが、クラウドが登場し、さらにサーバーレスへと進化した。そして今、インフラは「AIが勝手に調達するもの」へと変貌しようとしている。
ここで重要なのは、Stripeが単なる決済手段ではなく、Web上の「アイデンティティ(身元)」のハブとして機能し始めている点だ。Stripeでログインしていれば、CloudflareもPlanetScaleもNeonも、あらゆるクラウドサービスが即座に利用可能になる。これは、Web全体が1つの巨大なオペレーティングシステム(OS)のように振る舞い、AIエージェントがその上で自由にリソースを操作できる環境が整いつつあることを意味する。
開発者の役割は、コードを書くことよりも「AIにどのようなビジネスロジックを実現させたいか」を定義することへとシフトしていくだろう。インフラの設定ミスやAPIトークンの管理漏れといった「非本質的なトラブル」から解放される未来は、すぐそこまで来ている。
この記事のポイント
- AIエージェントがCloudflareのアカウント作成、ドメイン購入、デプロイを自律的に行えるようになった。
- Stripe Projectsとの連携により、OAuth認証と支払いトークンを用いた安全なプロトコルが構築されている。
- 人間はダッシュボードを操作することなく、CLIとAIへの指示だけで本番環境を構築できる。
- 月額100ドルのデフォルト支出制限により、AIの暴走による高額請求を防ぐ仕組みが備わっている。
- インフラの調達が自動化されることで、開発者はより高度なアプリケーション設計に集中できるようになる。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

ストリーミングUIの安定性を高める実装テクニック
WordPressサイトのフロントエンドにチャットボットやリアルタイムのログビューアーを組み込むケースが増えている。こうしたストリーミングUIは、新しいデータが届くたびにDOMを更新するため、適切な制御がないとスクロール位置が勝手に動いたり、ボタンがクリック直前に移動するといった不安定さが目立つ。
特にスクロールの強制移動、レイアウトのシフト、そして過剰な再描画の3つは、ユーザーの操作感を大きく損ねる。本記事では、これらの問題を解決し、WordPressのカスタムエンドポイントや管理画面のダッシュボードにも応用できる安定したUIの実装パターンを紹介する。
ストリーミングUIが不安定になる根本原因
チャット形式のAI応答、ログの逐次表示、ダッシュボードの数値更新。一見異なるこれらのUIは、いずれも同じ3つの根本問題に突き当たる。
スクロールの制御不能
ストリーミング中、多くのUIはビューポートを常に最下部に固定しようとする。これ自体は合理的だが、ユーザーが少し上にスクロールして過去のメッセージを読もうとした瞬間、UIが再び最下部へ引き戻してしまう。ユーザーの意図を無視した自動制御が、インタラクションの邪魔になる。
レイアウトシフト
ストリーミングコンテンツは行数や高さが動的に増えるため、その下にある要素が常に押し下げられる。クリックしようとしたボタンが移動したり、読んでいた行が画面外に消えたりする。DOMを毎回全再構築していると、このシフトはさらに顕著になる。
過剰なレンダリング更新
ブラウザは1秒間に約60回画面を描画するが、ストリームのデータ到着はそれよりも速いことがある。毎回DOMを書き換えていると、実際にはユーザーが目にしないフレームのためにもレイアウト再計算が走り、パフォーマンスがじわじわと低下する。
安定したスクロール動作の実装

まずはスクロールの自動制御をユーザーの意図に合わせる。基本的な考え方は以下の通りだ。
- ユーザーが最下部にいるときは自動スクロールを有効にする
- ユーザーが上方向にスクロールしたら自動スクロールを止める
- 再び最下部に戻ったら自動スクロールを再開する
これを実現するには、ユーザーが意図的にスクロール位置を変えたかどうかを追跡するフラグを設ける。
let userScrolled = false;
chatEl.addEventListener('scroll', () => {
const gap = chatEl.scrollHeight - chatEl.scrollTop - chatEl.clientHeight;
userScrolled = gap > 60; // 60px以上離れたらユーザー操作とみなす
});ここで60pxのしきい値が重要になる。新しい行が追加されて生じる微小な高さ変化でフラグが切り替わらないようにし、本当にユーザーがスクロールした時だけ自動スクロールを停止させる。
自動スクロール関数はフラグを参照するだけでよい。
function autoScroll() {
if (!userScrolled) {
chatEl.scrollTop = chatEl.scrollHeight;
}
}なお、新たなストリームが開始されたら必ず userScrolled をリセットする。これを見落とすと、前回のメッセージでのスクロールが原因で次の自動スクロールが無効になり、読みづらさが続く。
レイアウトシフトを防ぐDOMの差分更新

従来の実装では、新しい文字が届くたびに要素を innerHTML で全再構築することが多い。以下はその典型例だ。
bubble.innerHTML = '';
fullText.split('\n').forEach(line => {
const p = document.createElement('p');
p.textContent = line || '\u00A0';
bubble.appendChild(p);
});
bubble.appendChild(cursorEl);これで動作はするが、更新のたびにDOMツリー全体を破壊して再生成するため、レイアウト再計算が必ず発生する。さらに、カーソルも毎回削除と追加が繰り返され、高速ストリーミング時にはちらつきの原因にもなる。
解決策はシンプルだ。あらかじめ空のテキストノードを持った段落を作り、そこへ直接文字を追記していく。改行が来た時にだけ新しい段落を追加する。
let currentP = null;
function initBubble(bubble, cursor) {
currentP = document.createElement('p');
currentP.appendChild(document.createTextNode(''));
bubble.insertBefore(currentP, cursor);
}
function appendChar(char, bubble, cursor) {
if (char === '\n') {
currentP = document.createElement('p');
currentP.appendChild(document.createTextNode(''));
bubble.insertBefore(currentP, cursor);
} else {
currentP.firstChild.textContent += char;
}
}この方法では、通常の文字追加はテキストノードの拡張だけで済み、レイアウトシフトはほとんど発生しない。改行の時だけ新しい段落が挿入されるが、それ以外の無駄な再構築が一切なくなる。カーソルのちらつきも自然に消える。
レンダリング頻度を抑えるバッファリング戦略
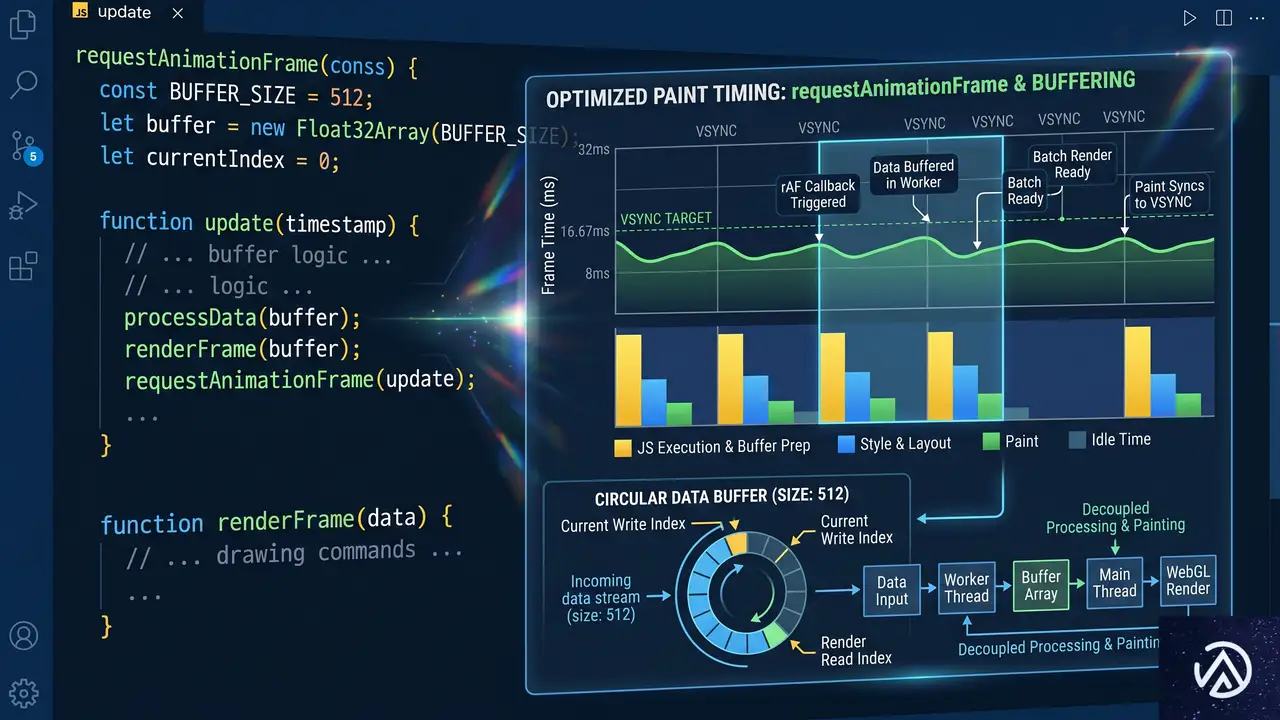
DOMの差分更新だけでもUIは安定するが、まだ文字が届くたびにペイントのトリガーを引いている。特にストリーム速度が速い場合、短時間に大量の小更新が発生し、ブラウザの負荷が積み重なる。
ここで有効なのが受信データのバッファリングと requestAnimationFrame によるフレーム単位のフラッシュだ。到着した文字をいったんバッファに溜め、次の描画直前にまとめてDOMへ書き出す。
let pending = '';
let rafQueued = false;
function onChar(char) {
pending += char;
if (!rafQueued) {
rafQueued = true;
requestAnimationFrame(flush);
}
}
function flush() {
for (const char of pending) {
appendChar(char);
}
pending = '';
rafQueued = false;
autoScroll();
}rafQueued フラグが二重スケジューリングを防ぐ。こうすることで、データ到着頻度とUI更新タイミングが完全に分離され、ブラウザが行う実際の描画回数に最適化されたペースでDOM変更が行われる。変更後の見た目は変わらなくても、特に高速ストリーミング設定時に操作感が格段に滑らかになる。
ストリーム中断への対応とユーザーフィードバック

ユーザーがストリームを途中で停止したり、ネットワークエラーで途切れたりした場合、UIを中途半端な状態のまま放置してはいけない。停止ボタンを押しただけでカーソルが点滅し続けたり、ボタン表示が変わらなかったりすると不信感につながる。
中断時のクリーンアップ
function stopStream() {
clearTimeout(streamTimer);
isStreaming = false;
pending = ''; // 未処理バッファを破棄
rafQueued = false;
if (cursorEl && cursorEl.parentNode) cursorEl.remove();
markStopped(aiBubble); // 「応答が停止しました」ラベルを付与
stopBtn.style.display = 'none';
retryBtn.style.display = '';
retryBtn.focus(); // キーボード操作のため即フォーカス
}バッファをクリアするのは、停止後に残っていた文字が次のフレームで書き込まれるのを防ぐためだ。カーソルの親ノードチェックも、すでに削除済みの場合のエラー回避に必要になる。
再試行機能の提供
中断後は同じ質問を再送信する「リトライ」ボタンを表示する。ユーザーに再度質問を入力させるのではなく、直前の入力を保持しておき、ワンクリックでストリームを最初からやり直せる。
let lastQuestion = '';
function retryStream() {
if (currentMsgEl && currentMsgEl.parentNode) {
currentMsgEl.remove();
}
charIndex = 0;
userScrolled = false;
pending = '';
rafQueued = false;
isStreaming = true;
// ボタン表示切替など
setTimeout(() => {
initAIMsg();
tick(lastAnswer);
}, 200);
}状態の完全リセットが肝だ。前回の文字インデックス、スクロールフラグ、バッファをすべて初期化しなければ、新しいストリームに前の残骸が混ざる。
新規メッセージ送信時の既存ストリーム停止
もう一つ見落としやすいのが、古いストリームが動いている最中に新しいメッセージが送信されたケースだ。そのままにすると2つのストリームが同時にDOMを更新し、文字が混ざり合ってしまう。新しいメッセージの処理を始める前に、必ず進行中のストリームを停止する。
function startStream(question, answer) {
if (isStreaming) {
clearTimeout(streamTimer);
isStreaming = false;
pending = '';
rafQueued = false;
if (cursorEl && cursorEl.parentNode) cursorEl.remove();
}
// ここで新規ストリームのセットアップ
}断りなく上書きするのではなく、明示的に前のストリームをクリーンアップすることで、イレギュラーな重複動作を防ぐ。
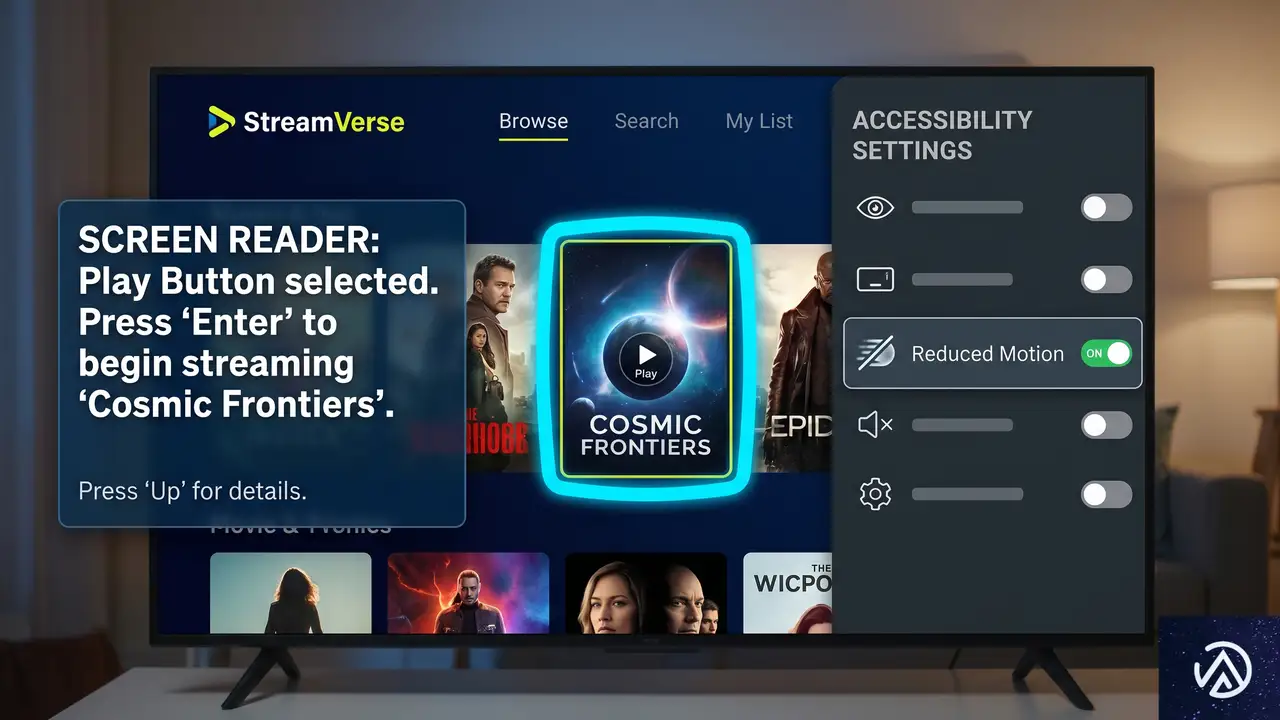
アクセシビリティを考慮したストリーミングUI
ストリーミングUIはマウス操作を前提に開発されがちで、支援技術やキーボード操作、動きへの敏感さへの配慮が後回しにされる。しかし、これらは上乗せの追加対応で十分改善できる。
スクリーンリーダーへの対応
スクリーンリーダーは自動で現れたコンテンツを読み上げない。そこで aria-live 属性を使ってライブリージョンを設定する。
<div id="chat" role="log" aria-live="polite"
aria-atomic="false" aria-label="チャットメッセージ"></div>role="log" はこれが逐次更新されるトランスクリプトであることを支援技術に伝える。aria-atomic="false" によって、新しく追加された部分だけが読み上げられ、全文の再読み上げが発生しない。aria-live="polite" なら現在の読み上げを邪魔せず、適切なタイミングで通知される。
中断時に挿入される「応答が停止しました」ラベルも、このライブリージョン内にあれば自動的にアナウンスされる。リトライボタンには、何をリトライするのか分かるように aria-label を設定する。
retryBtn.setAttribute('aria-label',
`リトライ: ${lastQuestion.slice(0, 60)}`);キーボードナビゲーションの確保
停止ボタンやリトライボタンは、ストリーミング中でもTabキーで到達できなければならない。非表示にする際は display: none を使うことでフォーカス順からも除外される。opacity: 0 や visibility: hidden だと不可視要素にフォーカスが当たり混乱を招く。
カーソル点滅エフェクトには aria-hidden="true" を付け、スクリーンリーダーが読み上げないようにする。フォーカスリングは :focus-visible を用い、マウスクリック時には表示せず、キーボード操作時のみ明示する。
動きの抑制
タイピングアニメーションのような連続的な動きは、前庭障害などを持つユーザーにとって負荷になる。OSレベルで設定された動きの設定を、prefers-reduced-motion メディアクエリで検出し、それに従う。
const reducedMotion = window.matchMedia(
'(prefers-reduced-motion: reduce)'
).matches;
if (reducedMotion) {
initAIMsg();
for (const char of text) appendChar(char);
if (cursorEl && cursorEl.parentNode) cursorEl.remove();
done();
return;
}縮小モードが有効なら、ストリーミングアニメーションを完全にスキップし、完成したテキストを一度に表示する。CSS側でもカーソルの点滅を止める。
@media (prefers-reduced-motion: reduce) {
.cursor { animation: none; opacity: 1; }
}この記事のポイント
- ストリーミングUIの不安定さは、スクロール制御・レイアウトシフト・過剰描画の3点に集約される
- ユーザーのスクロール位置を追跡し、最下部にいる時だけ自動スクロールを有効にする
innerHTMLの全再構築をやめ、テキストノードへの差分追記でレイアウト計算を最小限に抑えるrequestAnimationFrameでデータ到着と描画を分離し、ブラウザの負荷を軽減する- ストリーム中断時はバッファクリア、カーソル除去、リトライ機能などで中途半端な状態を残さない
aria-liveやprefers-reduced-motionを用いて、支援技術や動きに敏感なユーザーにも配慮する
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

ECサイトのAI被リンク戦略、4つの引用タイプを理解する
ECサイトの新たな集客経路として、ChatGPTやGeminiといった生成AIの回答が無視できなくなりつつある。AIが商品を推薦する際、その情報源としてどのECサイトが引用されるのか。実務者にとっては死活問題だ。
Practical Ecommerceの記事によれば、生成AIの引用には大きく分けて4つのタイプがある。これらの構造を理解せずに対策を打つのは、姿の見えない敵と戦うようなものだ。特にEC事業者にとっては、自社の商品ページがどのようにAIに取り込まれ、表示されるのかというメカニズムを知ることが、これからの集客戦略の基礎になる。
表面的なSEO対策だけでは不十分だ。AIが情報を「評価」する仕組みに踏み込み、ECに特化した最適化を考えていく必要がある。
生成AIは何を根拠に商品を推薦するのか

「この季節に合うファッションは?」とAIに尋ねたとき、返ってくる回答には特定のブランドや商品へのリンクが含まれることがある。これが引用(citations)だ。AIは、インターネット上の情報をただ鵜呑みにしているわけではない。独自の判断基準で情報源を選び、回答に組み込んでいる。
まず押さえておくべき大前提がある。生成AIプラットフォームの多くは、検索エンジンのインデックスに依存しているという点だ。分析によれば、ChatGPTやGemini、GoogleのAI Mode、Grokは主にGoogleの検索結果を参照する。一方、ClaudeやPerplexityはBrave検索エンジンの結果を利用する。つまり、従来のSEOで上位表示を獲得することが、AIに引用されるための重要な土台になるわけだ。
ただし例外もある。ChatGPTは、一部の提携パートナー企業の情報を外部評価とは無関係に優先的に引用する動きがある。クローズドなパートナーシップを結べる一部の巨大ブランドを除き、多くのEC事業者はGoogleとBraveの両方で安定したプレゼンスを築くのが現実的な戦略になる。
AIは二段階で情報を処理する
AIが質問に答えるプロセスは、大きく二段階に分けて考えると理解しやすい。第一段階は、AIが事前に学習した「訓練データ」からドラフトの回答を生成するステップだ。この時点では、過去にインターネット上で収集された情報がフル活用される。
第二段階は、生成したドラフトの正確性を高めたり、最新情報を補足したりするために、リアルタイムでWeb検索を行い、外部の情報源を参照するステップだ。この第二段階で参照された情報源が、回答に「引用」として表示されることになる。
この二段階構造が重要なのは、仮に自社ECサイトがAIの回答に直接リンクされていなくても、AIの知識ベース(訓練データ)に自社の情報が含まれていれば、回答内容そのものに影響を与えられる可能性があるからだ。可視化されたリンクの数だけが、AIプレゼンスのすべてではない。
EC事業者が知るべき4つの引用タイプ

生成AIが回答を生成する際の引用は、一括りにできない。専門家による分析や特許情報から、以下の4つのタイプに分類できることがわかってきた。それぞれの特徴をECの文脈で読み解いていこう。
1. 回答に直結する「グラウンデッド(根拠型)引用」
グラウンデッド(grounded)引用とは、AIがリアルタイムでWeb検索を行い、その検索結果から得た情報を回答の骨格として利用するケースを指す。例えば「2026年夏のサンダルトレンド」という質問に対して、AIが最新のファッションECサイトやレビューサイトをクロールし、そこに書かれた内容をもとに「厚底サンダルが再流行している」と回答するパターンだ。
EC事業者にとって、このタイプの引用を獲得するには、まずGoogleやBraveでの上位表示が前提になる。さらに、検索エンジンがページ内容を正確に理解しやすい構造(適切な見出し、明快な商品説明、構造化データの実装)が求められる。どんなに良い商品でも、AIが内容を抽出できなければ引用の対象外になってしまう。
2. 独自判断による「アングラウンデッド(非根拠型)引用」
アングラウンデッド(ungrounded)引用は、AIが自身の訓練データに基づいて回答を生成した後、その回答の信頼性を補強するために後付けで情報源を提示するタイプだ。回答の内容自体は外部の最新情報から生成されたわけではない。AIが「すでに知っていること」を裏付けるために、権威あるサイトのURLを添えるイメージだ。
New York Timesが報じた分析会社Oumiの調査によると、GoogleのAI Overviews(Geminiが生成)に表示される引用の半数以上は、このアングラウンデッド引用に該当するという。AIは回答を変えないまま、権威づけのためにリンクを貼っている可能性がある。
EC事業者にとっては、自社サイトが「権威ある情報源」としてAIに認識されることが、このタイプの引用獲得に繋がる。知名度の高いブランドや、長年にわたって特定カテゴリで情報発信を続けてきた専門ECサイトが有利になる。一朝一夕で得られるものではないが、中長期的なブランディングの重要性を示すデータといえる。
3. 幽霊のように現れる「ゴースト引用」
ゴースト(ghost)引用とは、AIの回答内にリンクは含まれているものの、そのリンク元のサイト名やブランド名が明示されないケースだ。ユーザーから見ると「なぜこのリンクがここにあるのか」が判然としない。
検索最適化の専門家Kevin Indig氏が発表した調査によれば、生成AIの回答の61.7%にこのゴースト引用が含まれているという。原因として考えられるのは、引用元のページが「自社の製品やサービスがなぜその質問の答えになるのか」を明確に説明できていないケースだ。AIが内容を読み取っても、文脈をうまくラベリングできないのだろう。
ECサイトで言い換えれば、商品の特徴だけを羅列したページよりも、「この商品はこんな悩みをこう解決する」というストーリーが明確なページのほうが、ゴースト引用を回避し、ブランド名付きで引用されやすい可能性がある。
4. 見えない「不可視引用」
不可視(invisible)引用は、厳密には引用ですらない。AIが回答を生成する際に自社サイトの情報を利用しているにもかかわらず、一切のリンクも言及もされない状態を指す。Ahrefsの調査では、ChatGPTが回答生成のために取得したURLのうち、実に50.2%が引用されずに終わっているという。
Practical Ecommerceの記事著者も、Redditのスレッドが回答内容に影響を与えることは多いが、引用されることは稀だと指摘している。情報としては使われているが、出典としては表示されない。これが不可視引用の実態だ。
EC事業者からすると釈然としない話かもしれない。しかし、たとえリンクが付かなくとも、自社の商品情報がAIの回答形成に利用されることは、潜在的なブランド露出として価値がある。AIに情報を「使わせる」段階から、最終的に「引用させる」段階へとステップアップしていく戦略が求められる。
EC版GEO戦略は「訓練データ」から始める

ここまで4つの引用タイプを紹介したが、実務者が最初に注力すべきは、見えない土台である「訓練データ」への浸透だ。生成AIは質問を受けた際、まず自らの訓練データを参照して回答のプロトタイプを作る。外部検索はその後に行われるか、あるいは並行して行われる。つまり、訓練データに自社情報が含まれていないECサイトは、スタートラインにすら立てていない可能性がある。
では、どうすれば訓練データに含まれるのか。AI企業が使用するデータセットの詳細は非公開だが、一般的にクロールされやすい公開ウェブページの情報が収集される。以下のような取り組みが効果的だ。
- 商品情報の構造化:AIが内容を正確に抽出できるよう、商品名、価格、レビュー、在庫状況などを機械可読な形式(構造化データ)でマークアップする。
- カテゴリ権威性の確立:特定の商品カテゴリ(例:アウトドア用品、オーガニックコスメ)において、網羅的で深い情報を継続的に発信する。
- 被リンクの多様化:SNSや業界メディア、ブログなど、多様なドメインから自社ECサイトへのリンクを獲得し、AIから見た「重要なサイト」としてのシグナルを強める。
これらの施策は、従来のSEO対策と重なる部分も多い。GEO(Generative Engine Optimization)はSEOの延長線上にある。ただし、キーワードの詰め込みではなく、「AIが理解しやすい形で情報を整理する」という視点が加わる点が新しい。
これからのEC集客は「AIに理解される設計」が鍵
現時点で、主要な生成AIプラットフォームは引用アルゴリズムの詳細を公開していない。また、最適化のための公式ガイドラインも存在しない。そのため、EC事業者は公開されている分析データや特許情報をもとに、手探りで戦略を組み立てる必要がある。
重要なのは、AIに「引用されること」と「回答に影響を与えること」の両方を視野に入れることだ。たとえ自社ECサイトへのリンクが付かなくても、AIが自社の商品を「2026年夏のトレンド」として回答に組み込むことができれば、それは大きな成果だ。
具体的なロードマップとしては、まず技術的なSEO基盤を固め、次にコンテンツの質と構造化でAIの理解を助け、その後、ブランド認知と権威性の向上によって引用の確度を高める、という3段階のアプローチになる。一朝一夕のハックではどうにもならないが、AIが情報収集の主役になりつつある今、GEOに投資しないリスクは無視できない大きさだ。
この記事のポイント
- 生成AIの引用は、グラウンデッド、アングラウンデッド、ゴースト、不可視の4タイプに分類できる。
- GoogleやBrave検索での上位表示が、AIに引用されるための基本的な条件となる。
- まずは訓練データに自社情報を含めることを優先し、その後、引用の質を高める戦略を取るべき。
- 構造化データや明快な商品説明で、AIが内容を抽出しやすいECサイト設計が求められる。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

WooCommerce Subscriptions Health Checkリリース、定期購入の健全性をチェック
WooCommerce Subscriptionsプラグインに、サブスクリプションの支払い状態を可視化する「Subscriptions Health Check」ツールが追加された。WooCommerce Developer Blogの2026年4月30日の記事で発表されている。
このツールは、本来は自動更新されるべき定期購入が手動更新のまま止まっていないか、あるいは次回支払日が欠落していないかを店舗管理者がすぐに把握できるようにするものだ。WooCommerce 3.0以降のサブスクリプションストアであれば、過去のバグの影響有無にかかわらず利用できる。
リリースの直接のきっかけは、定期購入が意図せず手動更新に切り替わる可能性がある4件のバグが公に報告されたことだ。しかし開発チームは、原因がバグに限らず、決済ゲートウェイの変更やインポート時の設定など、同じような「自動更新されない」状態はさまざまな要因で起こり得ると判断。特定のバグ被害者を探すのではなく、潜在的に問題を抱えるサブスクリプションを幅広くリストアップする仕組みを選んだ。
サブスクリプション健全性チェックツールの登場背景
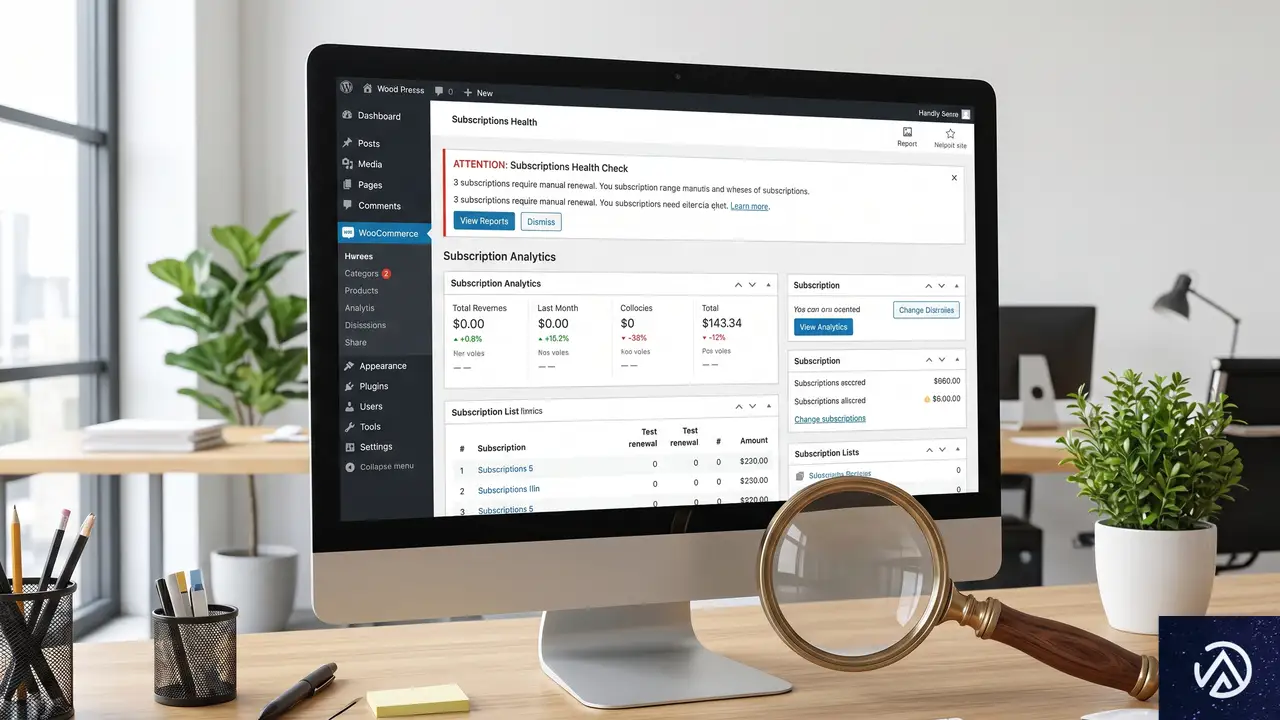
サブスクリプション型ビジネスでは、決済の自動継続が収益の柱になる。そのため、意図せず手動更新に設定されたまま放置されると、気づかないうちに売上を失うリスクがある。開発チームはもともとこうした健全性チェック機能をロードマップに載せていたが、公のバグ報告を受けて開発を前倒しした。
報告されたバグは、WooCommerceの高性能オーダーストレージ(HPOS)環境で、定期購入の作成時に_requires_manual_renewalフラグが誤ってtrueのままになるというものだ。調査の過程で、キャッシュの不整合やデータ同期の欠落といった根本原因がいくつか特定された。しかしチームは、これらが修正済みであっても「自動更新されない定期購入」という状態は他の経路でも発生し得ると考えた。
たとえば、店舗管理者が手動更新設定に切り替えた、決済トークンが削除された、他社のカートシステムからインポートした際に手動扱いになった、カスタムコードやサードパーティ連携がフラグを書き換えた、といったケースだ。これらをすべて機械的に区別するのは難しい。そこで最終的には、自動更新が可能な支払い方法を持ちながら手動更新になっているサブスクリプションをすべて可視化し、その判断をマーチャントに委ねる設計が採用された。
4つのバグが与えた影響の実態
WooCommerce開発者ブログの記事では、公表された4件のバグすべてがすでに修正済みであることが明かされている。しかし、修正当時はこれらのバグが「定期購入をサイレントに手動更新へ切り替える」というマーチャント目線での影響まで認識されていなかった。
バグの組み合わせが実際に問題を引き起こしていたのは、HPOSを有効にしたストアで、かつ特定のバージョンのWooCommerce Subscriptionsを動かしていた期間に限られる。バグ1(期限切れHPOSキャッシュ)は2024年3月に修正済み。バグ2(HPOSバックフィルメソッド欠落)は2023年中に解消。バグ3(再取得による不整合)は2024年5月に修正された。独立して「手動更新化」を引き起こすわけではなく、バグ1とバグ3が同時に存在する環境で、購入手続き時にフラグが誤設定されるという経路だった。
影響を受けた可能性が最も高いのは、2023年10月から2024年3月の間にHPOSを有効化し、かつWooCommerce Subscriptions 6.1.0未満を利用していたストアだ。2024年5月以降にサブスクリプションを開始したストアは、今回のバグの影響を受けていない。ただし、開発チームはこのツールをバグの有無にかかわらず定期購入全体の監視に役立ててほしいとしている。
ツールの使い方と主要機能
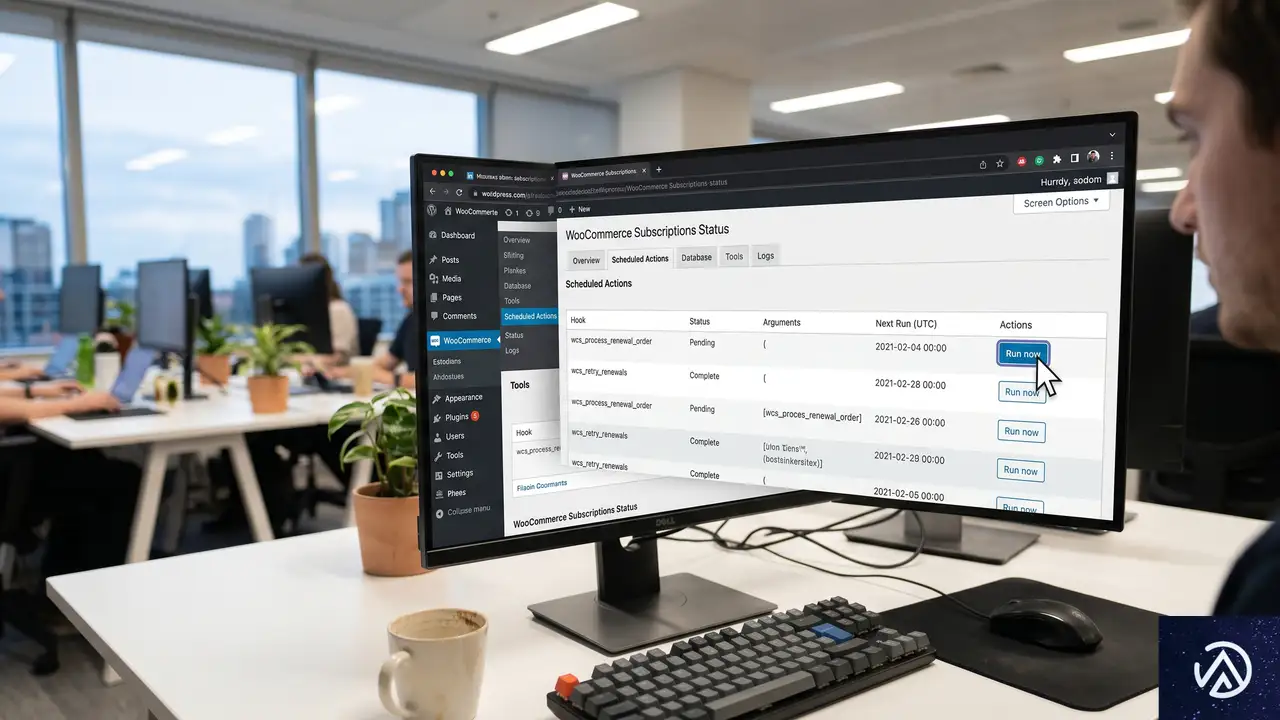
Health Checkツールは、WordPress管理画面の「WooCommerce」→「ステータス」→「サブスクリプション」タブに設置されている。ステータスページには、最終スキャン日時と、手動スキャンの実行ボタンが表示される。
「今すぐ実行」ボタンでオンデマンドのスキャンが可能だ。スキャンはバッチ処理で行われ、サーバーやデータベースに過負荷がかからないようスロットリングが組み込まれている。定期的な自動スキャンも、WooCommerce設定で有効にすれば夜間に実行され、結果が保存される。保存された結果はページを開くたびに即座に表示されるため、毎回重いクエリを待つ必要はない。
3つのタブで状態を整理
ツールを開くと、「すべて」「自動更新をサポート」「更新漏れ」の3つのタブが表示される。
「すべて」タブでは、ストア内の全サブスクリプションが一覧できる。特定の条件で絞り込みたい場合の全体像把握に使う。
「自動更新をサポート」タブは、今回のツールの中核となる部分だ。次の条件をすべて満たすサブスクリプションが表示される。ステータスが「有効」「保留中」「キャンセル保留」のいずれかである、_requires_manual_renewalフラグがtrueである、支払い方法が自動更新をサポートしている、かつ顧客がそのゲートウェイに有効な支払いトークンを保存している。つまり、自動更新できるのに手動扱いになっているサブスクリプションが浮かび上がる。
「更新漏れ」タブには、次回支払日が空欄のまま更新が止まっているものや、過去の支払日から24時間以上経過しても対応する更新注文が生成されていないサブスクリプションが表示される。これらはスケジュールされたアクションの不具合やサーバー移行時の問題など、さまざまな原因で発生し得る。
表示される項目とフィルター
各行には、サブスクリプションID、作成日、顧客名、請求サイクル、ステータス、請求モード(手動/自動)、自動更新の設定(顧客がMy Accountでオプトアウトしたかどうか)、支払い方法、次回支払日、最新の更新注文ステータス、直近の成功支払日が表示される。他社システムから手動更新としてインポートされたものは「インポート(手動)」と明示され、フィルターで除外されるのではなく、タグ付けされる。
フィルターとして、ステータス別、請求モード別、更新注文ステータス別、自動更新オプトアウトの有無別、IDやメールアドレスによる検索が用意されている。列のソートも可能で、デフォルトでは新しいサブスクリプションが先頭に来る。
このツールは、あえて自動修復を行わない設計になっている。たとえば、手動更新に切り替わっているサブスクリプションを自動で「自動更新」に戻したり、店舗全体で「自動支払いを無効化」しているストアのサブスクリプションを非表示にしたりはしない。すべての判断は店舗の文脈を知るマーチャントに委ねられている。
バグの詳細とマーチャントへの影響

公表された4件のバグのうち、定期購入の手動更新化に直接つながったのはバグ1とバグ3の組み合わせだ。バグ2はスケジュールメタデータの不整合を引き起こしたもので、更新日に更新処理そのものが発火しないという別の症状となる。バグ4はゲートウェイ変更時の復旧ギャップで、単体では不具合を生み出さない。
バグ1とバグ3の組み合わせで何が起きたか
HPOS環境で注文が作成されると、バグ1によって定期購入の日付更新後にキャッシュがクリアされず、バグ3の再取得処理がキャッシュ経由で古い状態を読み取ってしまう。その結果、メモリ上でクリアしたはずの_requires_manual_renewalフラグが、保存時に古い値(true)のままデータベースに書き込まれるというものだ。
このフラグが誤ってtrueになると、最初の更新日に定期購入は「保留中」になり、保留中の更新注文が作成され、顧客に「手動で支払いを」というメールが送られる。このメールはデフォルトで有効になっていることが多く、開発チームのオプトインデータによれば約91.8%のストアで送信されていたという。つまり、ほとんどのケースで顧客には支払いを促す通知が届いており、完全にサイレントで見逃される状態ではなかった。
ただし、顧客がそのメールに気づかずに放置すると、更新が止まったままになる。マーチャントにも通知が行かないケースがあったため、結果として気づかないうちに収益機会を失う可能性があった。今回のHealth Checkツールは、まさにこの「更新されていない状態」を検出するためにある。
バグ2の異なる影響
バグ2はスケジュール関連のメタデータがHPOS互換モードで同期されない問題で、更新日時がずれたり、更新イベントが発火しなかったりした。影響範囲は2023年8月から12月にデータ移行が行われた一部のストアに限られる。このケースでは更新注文自体が生成されず、通知の記録すら残らないため、「更新漏れ」タブで初めて表面化する。
今後の展開とマーチャントへの推奨事項

今回のHealth Checkツールは、あくまで「第1弾」と位置づけられている。WooCommerce開発チームは、すでに次のバージョンでツール画面から直接サブスクリプションを修正できる機能の開発に着手している。たとえば、一括で自動更新に戻す、手動更新であることを明示的に確定させるといった操作が、ツール上で完結するようになる見込みだ。
また、今回の一連のバグ対応を受けて、チェンジログの書き方も改善された。今後は、バグ修正がマーチャントの収益や顧客体験に影響を与える可能性がある場合、その内容をチェンジログに明記し、必要に応じて影響を受けるストアに直接連絡する方針だ。これは単なるコミュニケーションギャップの解消ではなく、エコシステム全体での透明性を高める取り組みといえる。
ストア管理者が今すぐやるべきこと
まず、WooCommerce Subscriptionsを最新バージョン(8.6.1以降)にアップデートする。そのうえでHealth Checkツールを実行し、「自動更新をサポート」タブと「更新漏れ」タブの内容を確認してほしい。特に、HPOSを有効にしていて、かつ2024年3月以前からサブスクリプション販売を行っているストアは重点的なチェックが推奨される。
もし手動更新にすべきでないサブスクリプションが見つかった場合は、手動で編集して自動更新に戻すか、WooCommerceサポートに問い合わせてサポートを受けることができる。開発チームは今回のツール公開に合わせてサポート体制を強化しており、結果の解釈に迷った場合でも相談しやすくなっている。
この記事のポイント
- WooCommerce Subscriptionsに定期購入の健全性を可視化するHealth Checkツールが追加された
- 自動更新可能なのに手動更新設定になっているサブスクリプションや、更新日が欠落しているものを一覧できる
- 過去のバグ(HPOS環境でのキャッシュ不整合など)の影響を受けていなくても、すべてのストアで活用できる汎用機能
- ツールは自動修復せず、判断はすべてマーチャントに委ねられる。次のバージョンで一括操作機能が追加予定
- バグの影響が最も疑われるのは2023年10月〜2024年3月にHPOSを有効にしていたストア。2024年5月以降のストアは今回のバグの直接影響なし
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験