

AI時代のテクニカルライティング、人間が書く意味とは
テクニカルライティングの需要が大幅に減少している。CSS-Tricksの編集長Geoff Graham氏が公開した同サイトのトラフィック統計によれば、2020年から2025年にかけてアクセス数は明確な下降線を描いている。Stack Overflowの質問数減少と同様の傾向であり、業界全体に共通する構造変化だ。
スタンフォード大学の「2025 AI Index」によると、企業のAI導入率は2024年に急速に上昇した。開発者がドキュメントを読まずにIDE内のチャットで回答を得る時代において、従来型のリファレンス執筆の価値は再定義を迫られている。
しかしである。だからといって人間による技術記事が不要になったわけではない。むしろ、AIが生成する「正解」では届かない領域にこそ、書き手の存在意義がある。本記事ではCSS-Tricksの見解を踏まえつつ、AI時代のテクニカルライティングが目指すべき方向性を考察する。
テクニカルライティングはなぜ必要とされ続けるのか

AIは人間の欲望や努力なしには新しいことを学べない。ボットが動くのは与えられたプロンプトに対してだけであり、技術を前進させるのは依然として人間の動機だ。Graham氏は「AIをテクニカルライティングの新たな主要読者と見なすつもりはない」と明言している。学習意欲のある実在の人間こそが、この営みを支え続ける存在である。
仕様書と人間のあいだを埋める役割
CSS-Tricksに掲載されているCSSアルマナック(リファレンス集)は2009年から継続的に更新されてきた。一見するとAIチャットで代替可能に思える領域だが、Graham氏はこの役割を「技術的な話題をきわめて人間的な説明で伝えること」と定義する。向かいの席に座る開発者とコーヒーを飲みながら話すような距離感だ。
仕様書はブラウザ実装の正確性を担保するために意図的に緻密に書かれている。CSS-Tricksはその厳密さを崩さずに、アクセスの敷居を下げる翻訳者の役割を担ってきた。この「技術と人間のあいだを埋める」機能は、AIが要約を生成できるようになった現在でも、体験に根ざした説明という点で差別化される。
AI時代の書き手が立つべき場所

Graham氏はテクニカルドキュメントを書く価値が以前より下がったと率直に認める。仕様書やMDNは充実しており、開発者の素朴な疑問はIDE内チャットで即時に解決される。しかしCSS-Tricksは2007年の開設当初から「アイデアの共有プラットフォーム」として機能してきた。ゲスト執筆者748名が蓄積してきた知見は、単なるドキュメントの代替ではない。
新たな執筆指針〜AIにできないことを書く

実体験を軸にすえる
AIはCSSプロパティの定義と簡単なコード例を提示するのが得意だ。既存の技術ドキュメントから引っ張ってくるだけなので、その領域で競うのは得策ではない。Graham氏が推すのは「クライアントから求められた未経験の要件に挑んだ話」のような、実体験に根ざした記事である。
人間は課題に直面したときにもっとも深く学ぶ。初心者から理解者に至るまでの過程そのものが、読者に使えるメンタルモデルを提供する。たとえそのモデルが最終的にAIプロンプトの作成に使われるとしても、思考の枠組みを共有する価値は揺るがない。
権威であろうとしない
CSS-Tricksは「正しいやり方」を保証するサイトではない。CSSには複数のアプローチがあり、書き手自身のメンタルモデルにもっとも馴染む方法が最善であるという立場だ。単なるアイデアの種を共有することにも価値があるとGraham氏は強調する。
「経験はあっても冷笑的になるな」というのが同サイトの指針だ。専門家であることと経験者であることは同じではない。まだ未解決の疑問があっても、試したことの報告には意味がある。
引用を惜しまない
優れた記事は先人の知恵の上に成り立つ。すべてを独自の知見として見せようとする誘惑は強いが、Graham氏は「私たちは互いの仕事の上に構築している」と明言する。ハイパーリンクによる健全な引用文化こそ、ブログの原点である。
検索エンジン最適化よりも読者最適化を

CSS-Tricksは数年前にSEOに軽く手を出したものの、本格的に注力することはなかった。キーワードの詰め込みもクリックベイト的な見出しも避け、人間のための文章、適切な構造、一貫したトーンに集中してきた。皮肉なことに、これらはかつてGoogleが重視すると表明していた要素そのものだ。
Graham氏は検索トラフィックがAI生成回答に奪われている現実を直視しつつも、CSS-TricksがAI回答の参照元として表示されるかどうかにさえ「関心があるか確信が持てない」と率直に述べる。状況は流動的であり、考え方も進化させなければならない段階だ。
AIを執筆に使うなら補助領域に限定する

Graham氏は執筆そのものへのAI利用に否定的だ。理由は二つある。第一に、AIの出力は常に正確とは限らない。第二に、AIは書き手個人の声を希釈してしまう。どちらも執筆という営みにとって致命的な欠陥である。読者がすでにIDEで得られるAI説明と変わらない内容を記事で提供する意味はない。
ただしGraham氏はAIを全面否定しているわけではない。スペルチェックやMarkdownからHTMLへの変換、公開スケジュールの管理といった「執筆とは直接関係のない低負荷な作業」には積極的に活用している。これは今日「AI」と呼ばれる機能の多くが、ブーム以前は単に「自動化」と呼ばれていたものだという冷静な視点に立っている。
この記事のポイント
- テクニカルライティングの需要はAIの普及により構造的に減少しているが、人間による記事の価値が消えたわけではない
- 実体験に基づく試行錯誤のプロセス共有が、AIとの差別化における最大の武器になる
- SEOやAIOに過度に依存せず、特定の読者に向けて明確に書くという基本に立ち返るべき
- AIはスペルチェックやフォーマット変換など執筆周辺の自動化に限定して使うのが現実的

・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

CiscoとOpenAI、Codexでエンタープライズ開発を再定義
CiscoがOpenAI Codexを実際のエンタープライズ開発ワークフローに組み込み、大幅な成果を上げている。AI Defenseをはじめとする新製品の開発スピードは数四半期から数週間に短縮され、1,500時間超の工数が毎月削減された。
新規AI機能の95%以上をCodexが生成し、C/C++の大規模コードベースにおける欠陥修正の処理速度は従来の10〜15倍に達した。大規模リポジトリ間のビルド最適化やフレームワーク移行も短期間で完了している。
単なるコード補完ツールではなく、自律的にコンパイルやテストを繰り返しながら修正を加えるエージェントとして機能する。CiscoはCodexを「もう一人のAIエンジニア」と位置づけ、プロダクション環境全体に組み込んだ。
Codexのエージェント性がもたらす変化

Codexが従来の開発支援ツールと一線を画すのは「エージェント性」だ。Ciscoのエンジニアリングチームは、Codexが単なるコード提案を超えて複雑な判断と実行を繰り返せる点に着目した。相互に依存する大規模リポジトリを横断して推論し、C/C++のような複雑な言語を扱い、CLIベースのコンパイル、テスト、修正ループを自律的に回す。
これらの作業が既存のレビューやセキュリティ、ガバナンスの枠組みの中で動作することも重要だ。CiscoはCodexを「ツール」から「チームの一員」へと位置づけを変えたことで、従来の工数見積もりの概念そのものが変わりつつある。
コード補完とエージェントの違い
一般的なコード補完ツールは、エンジニアが書き始めたコードに対して次の候補を提示する。エンジニアはその候補を読んで判断し、手動で適用する。一方、エージェント型のCodexは「このリポジトリ全体のビルド時間を短縮せよ」といった高レベルな指示を与えると、自らログを解析し依存関係を調査し、修正を加えたうえでテストまで実行する。
この違いが特に威力を発揮するのは、コードベースが巨大で複数のチームやリポジトリにまたがるエンタープライズ環境だ。人間が一つひとつ手作業で確認するには時間がかかりすぎる問題に対して、Codexは自律的に解決策を提示し、適用する。
AI Defenseの開発期間を数四半期から数週間に短縮

CiscoのAIセキュリティ製品「AI Defense」は、このエージェント型開発の成果を如実に示す事例だ。AI DefenseはAIが引き起こす安全性やセキュリティのリスクから組織を守るエンドツーエンドのソリューションである。CiscoのチームはCodexを活用してAI Defenseのコードの大部分を生成し、ほぼすべての新機能をCodexが作成した。
OpenAI Blogの記事によれば、従来の開発手法では数四半期を要していた機能が、Codexの導入により数週間で顧客に提供可能になったという。AIの安全性という領域で、AIを活用した開発が威力を発揮した好例だ。
Daybreak構想とAIセキュリティ
CiscoはOpenAIの「Daybreak」構想にも中核的なセキュリティ組織として参画している。DaybreakはOpenAIのモデル、Codex、セキュリティパートナーを結集し、サイバー防御とソフトウェアの継続的セキュリティを加速させる取り組みだ。このプログラムの一環として、Ciscoはサイバー防御者向けモデル「GPT-5.5-Cyber」へのアクセスを管理している。
また、CiscoはCodexの支援を受けてオープンソースツール「Defense Squad」を構築した。このツールはアイデア出しから開発者コミュニティへの提供まで1週間未満で完了している。Codexの迅速なプロトタイピング能力が、セキュリティ領域におけるOSS開発のスピードを大幅に引き上げた形だ。
ビルド最適化で月1,500時間超の工数を削減

CiscoのエンジニアリングチームがCodexに与えた最初の大きな課題の一つが、クロスリポジトリのビルド最適化だ。15以上の相互接続されたリポジトリにまたがるビルドログと依存関係グラフをCodexが分析し、非効率な箇所を特定した。
その結果、ビルド時間が約20%短縮され、グローバル環境全体で毎月1,500時間以上のエンジニアリング工数が削減された。ビルド時間の短縮は開発サイクル全体を加速させる。待ち時間が減れば、エンジニアはより多くの時間を設計や検証に充てられる。
C/C++コードベースの欠陥修正を10〜15倍に高速化
Codex CLIを使った「CodeWatch」と呼ばれる取り組みでは、大規模なC/C++コードベースを対象に、反復的かつエージェント型の欠陥修正を自動化した。C/C++はメモリ管理やポインタ操作が絡む複雑な言語であり、欠陥の修正には深い理解と慎重なテストが欠かせない。
従来は数週間の手作業を要していた修正が、Codex CLIによって数時間で完了するようになった。欠陥解決のスループットは10〜15倍に向上し、エンジニアは設計や検証といったより高度な判断業務に集中できるようになった。
フレームワーク移行やCI/CDへの統合
Splunkチームの事例では、複数のUIをReact 18からReact 19へ移行する作業にCodexが投入された。Codexが反復的な変更の大部分を自律的に処理したことで、数週間かかる作業が数日に圧縮された。エンジニアは判断を要する部分に集中し、機械的な書き換えはCodexに任せるという分業が成立している。
OpenAI Blogの記事でCiscoの関係者は「Codexに計画ドキュメントを生成させて従わせることで、レビューチームがプロセスと生成されたコードの両方を容易に理解できるようになった」と述べている。コードを書くだけでなく、意図や計画を文書化する能力も実務では大きな価値を持つ。
エンタープライズ開発パイプラインへの組込み
CiscoはCodexをスタンドアロンのツールとしてではなく、既存の開発パイプラインに直接組み込んだ。セキュリティやコンプライアンス、ガバナンスの要件を満たしながら動作させることが、エンタープライズ環境では不可欠だからだ。
この実運用から得られた継続的なフィードバックは、OpenAIがCodexを大企業向けに強化するうえで重要な役割を果たした。特にコンプライアンス対応、長時間実行タスクの管理、既存パイプラインとの統合といった領域が改善された。CiscoとOpenAIの協業は、次世代AIを採用するための再現可能なモデル「深い技術パートナーシップ、実際のワークロード、初日からのリーダーシップの一致」を確立したと言える。
この記事のポイント
- CiscoはCodexを導入し、新規AI機能の95%以上を自動生成している
- AI Defenseの開発期間が数四半期から数週間に短縮された
- クロスリポジトリのビルド最適化で月1,500時間超の工数を削減
- C/C++コードベースの大規模欠陥修正を10〜15倍に高速化
- Codexはコード補完を超えたエージェントとして、自律的にコンパイルとテストを繰り返しながら開発を進める
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

2026年4月のBaseline新機能、contrast-color関数やsearch要素が利用可能に
2026年4月のBaseline月次ダイジェストが公開された。新たに利用可能になった機能として、CSSのcontrast-color()関数やJavaScriptのMath.sumPrecise()メソッドがある。合わせて、search要素やARIA属性リフレクションなど、すでに広く使える段階に達した機能も紹介されている。
今回のアップデートは、アクセシビリティ対応と開発効率の両面で重要な節目だ。ブラウザが自動的に最適な色を算出したり、セマンティックな構造をネイティブに解釈したりする機能が揃い、従来はカスタム実装に頼っていた領域が標準化されつつある。
この記事では、2026年4月のBaselineダイジェストの内容をもとに、新機能の具体的な使い方と、それが開発現場にもたらす変化を解説する。
Baselineとアクセシビリティをめぐる2026年の動向

web.devの記事では、A11y Upが公開した「Baseline and accessibility in 2026」という分析が紹介されている。この分析の核心は、アクセシビリティ対応をウェブ標準に委ねることで、開発の堅牢性と効率が大きく向上するという主張だ。
これまで多くの開発チームは、スクリーンリーダー対応やキーボードナビゲーションといったアクセシビリティ機能を、カスタムのJavaScript実装で再現してきた。しかし、そうした手作りのソリューションは往々にして壊れやすく、支援技術との相性問題を抱え、メンテナンスコストも高かった。
Baselineは、ある機能が主要ブラウザで相互運用可能になった時点を知らせる指標として機能する。この指標を活用すれば、開発者は標準機能への移行タイミングを判断しやすくなる。結果として、ブラウザが自動的に正しいセマンティクスをスクリーンリーダーに伝えてくれるため、開発者が手作業で調整する負担が減るというわけだ。
このデモが示すように、カスタム実装に頼る旧来の手法から、標準化された要素やAPIに移行することで、アクセシビリティの品質が安定し、開発者の負荷も低減する。
Baselineで新たに利用可能になった機能
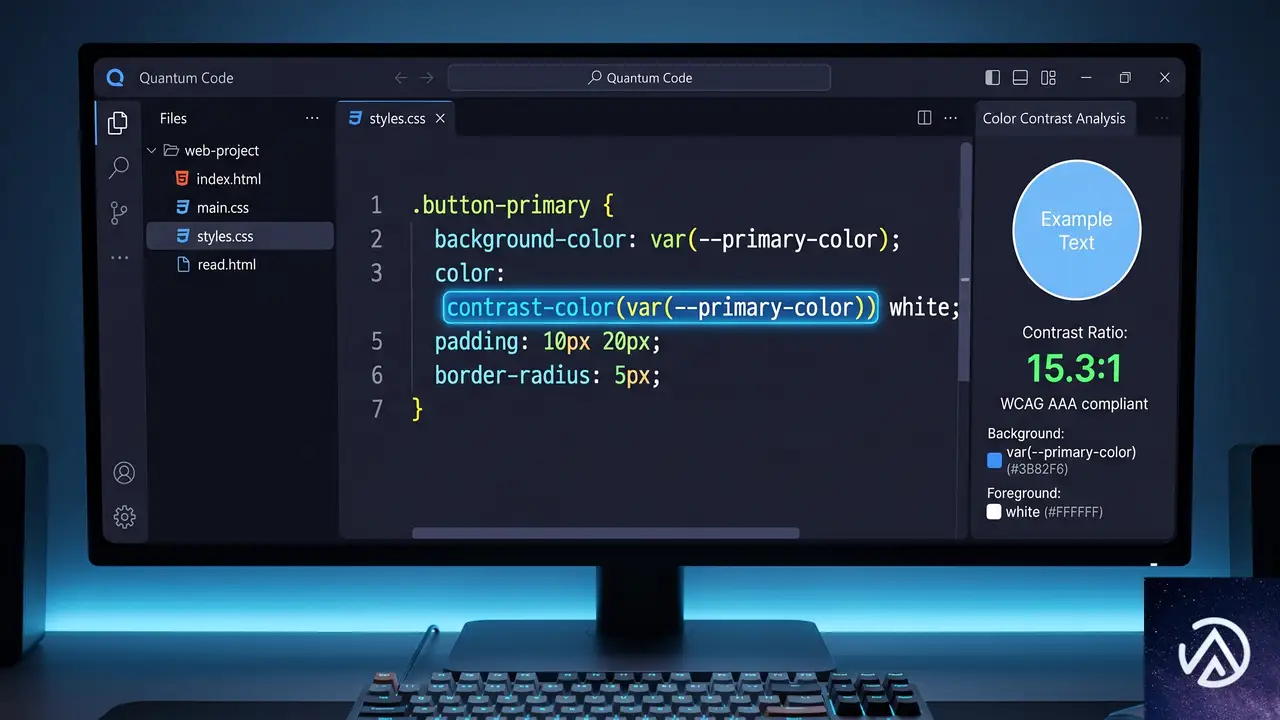
2026年4月の時点で、主要ブラウザ(Chrome、Firefox、Safari)すべてがサポートを開始し、Baseline newly available(新規利用可能)と位置づけられた機能が2つある。CSSのcontrast-color()関数と、JavaScriptのMath.sumPrecise()メソッドだ。
CSSのcontrast-color()関数
contrast-color()は、指定した背景色に対して最も読みやすい対照色(通常は黒か白)をブラウザが自動的に算出するCSS関数だ。動的なテーマエンジンやカスタマイズ可能なコンポーネントを扱う際、開発者がこれまで手作業で管理してきた「背景色に応じた文字色の切り替え」という負担を大幅に軽減する。
具体的な動作として、関数にベースとなる色を渡すと、ブラウザのエンジンがその色の輝度を評価し、最もコントラスト比が高い色を返す。これにより、ユーザーが好みの背景色を選べるUIでも、文字が読みにくくなる問題を自動的に回避できる。
.card-header {
background-color: var(--dynamic-bg-color);
/* 背景色に応じて自動的に最適な文字色が決まる */
color: contrast-color(var(--dynamic-bg-color));
}上記のデモはcontrast-color()の概念を示したイメージだ。実際のブラウザでは、この関数が自動的に背景色を分析し、最も読みやすい文字色を適用する。中間的な明るさの背景色に対しては、ブラウザがどちらを選ぶか注意深く確認する必要があるが、大半のケースでは手動の分岐ロジックが不要になる。
Math.sumPrecise()メソッド
JavaScriptで浮動小数点数の合計を計算する際、従来のArray.prototype.reduce()や単純なループでは、丸め誤差が蓄積する問題があった。金融計算やテレメトリデータの集計といった、正確さが求められる場面ではこの誤差が致命的になることもある。
Math.sumPrecise()は、この問題に対処するために設計された静的メソッドだ。数値のイテラブル(配列など)を受け取り、精度を保ったまま安全に合計を返す。
// 従来の方法では浮動小数点誤差が発生する可能性がある
const values = [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0];
const preciseTotal = Math.sumPrecise(values);
// 誤差なく正確な合計値を返す内部的には、標準化された高精度な加算アルゴリズム(Kahan summation algorithmや類似の手法)を用いて、丸め誤差を最小化する。ECサイトの売上集計や、センサーデータの分析など、正確性が重視されるシナリオで特に有効だ。
この関数を使うことで、フロントエンドでの計算結果に対する信頼性が一段上がる。特に数値の正確さがビジネス上の要件に直結するアプリケーションでは、導入を検討する価値が高い。
Baselineで広く利用可能になった機能

以下の機能は、すでに主要ブラウザで長期間サポートされ、Baseline widely available(広く利用可能)のステータスに達した。実質的にどのプロジェクトでも安心して採用できる段階だ。
search要素
HTMLのsearch要素は、検索フォームやフィルタリング機能といった、サイト内の検索体験を構成する要素群を明示的にラップするためのコンテナだ。従来はdivやformタグで代用されていたが、search要素を使うことでアクセシビリティ上の利点が生まれる。
具体的には、ブラウザがsearch要素に対して暗黙的にARIAランドマークロール「search」を割り当てる。これにより、form要素にrole=”search”を手動で付与する必要がなくなる。スクリーンリーダーのユーザーは、このランドマークを頼りに検索インターフェースへ素早く移動できる。
<search>
<form action="/site-search">
<label for="query">ドキュメントを検索</label>
<input type="search" id="query" name="q">
<button>実行</button>
</form>
</search>このシンプルな変更だけで、検索機能のアクセシビリティがワンランク向上する。既存のプロジェクトでも、該当するセクションをsearch要素に置き換えるリファクタリングを検討するとよい。
Web Authenticationの公開鍵アクセス
パスワードレス認証を実現するWeb Authentication(WebAuthn)APIにおいて、公開鍵情報の取り扱いが大幅に簡素化された。AuthenticatorAttestationResponseインターフェースに追加されたgetPublicKey()やgetPublicKeyAlgorithm()といったメソッドを使うことで、開発者が生のバイナリデータを手動で解析する必要がなくなった。
これまで公開鍵を抽出するには、CBOR(Concise Binary Object Representation)やDERエンコーディングといったバイナリ形式を手作業でパースする処理が必要だった。公開鍵の取り出しに失敗したり、アルゴリズムを誤認したりするリスクが常につきまとっていた。新しいメソッドはブラウザが直接プロパティとして公開鍵情報を提供するため、そのような低レイヤの処理が一切不要になる。
パスキー(Passkeys)の普及が加速する中、このAPIの安定化は認証フロー全体の信頼性を一段引き上げる要素だ。
String.prototype.isWellFormed()とtoWellFormed()
JavaScriptの文字列は内部的にUTF-16でエンコードされている。複雑な文字や絵文字の中には、サロゲートペアと呼ばれる2つの16ビットコード単位で表現されるものがある。文字列を途中で切断してしまうと、ペアの片方だけが残った「孤立サロゲート」という不正な文字が生まれる。
isWellFormed()は、文字列に孤立サロゲートが含まれていないかを真偽値で返すメソッドだ。toWellFormed()は、もし不正なサロゲートが見つかった場合、それをUnicodeの置換文字(U+FFFD)に置き換えた新しい文字列を返す。encodeURI()など、不正な文字列が渡されるとURIErrorをスローする関数にデータを渡す前に、これらのメソッドで検証と修正を行うのが主な用途だ。
const rawString = getUserInput();
// 不正な文字が混入していないか確認
if (!rawString.isWellFormed()) {
// 問題があれば安全な形に修正してから処理を続行
const cleanString = rawString.toWellFormed();
const encoded = encodeURI(cleanString);
// 安全にAPIリクエストなどを実行
}ユーザー入力や外部APIからのレスポンスを扱う場面では、予期せぬデータ不整合による例外発生を未然に防ぐ手段として、これらのメソッドが役立つ。
ARIA属性リフレクション
これまで、ARIA属性の値を更新するにはelement.setAttribute(‘aria-expanded’, ‘true’)のように、DOM属性を文字列で操作する必要があった。ARIA属性リフレクションは、この手順をオブジェクトプロパティへの代入に簡略化する。
ElementインターフェースがariaExpanded、ariaChecked、ariaHiddenといったプロパティを直接公開することで、ドット記法による読み書きが可能になった。これは単なるシンタックスシュガーではなく、UIフレームワークや状態管理ライブラリがアクセシビリティ状態をより正確に追跡し、スクリーンリーダーとの同期を保つうえで重要な基盤となる。
// トグルボタンのアクセシビリティ状態を簡潔に更新
toggleButton.ariaExpanded = toggleButton.ariaExpanded === "true" ? "false" : "true";element.getAttribute(‘aria-expanded’)
element.ariaExpanded
ReactやVueのようなフレームワークで状態とARIA属性を紐付ける際、従来の文字列ベースの操作に比べてコードの見通しが格段に良くなる。特に複雑なUIコンポーネントを構築するチームにとって、採用するメリットは大きい。
この記事のポイント
- contrast-color()関数で、背景色に応じた文字色の自動選択が可能になった
- Math.sumPrecise()で浮動小数点数の正確な合計計算を実現
- search要素が広く利用可能になり、アクセシビリティ対応が容易に
- WebAuthnの公開鍵抽出がメソッド一発で完了するように簡略化
- ARIA属性リフレクションで、状態管理と支援技術の同期が強化
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Google AI Threat Defense発表、AIで脆弱性を自動修正する次世代セキュリティ
Google Cloudは2026年5月27日、AIを活用したセキュリティプラットフォーム「Google AI Threat Defense」を発表した。このシステムは脆弱性のスキャンから修正までを自律的に実行し、攻撃者が悪用する前に防御を固めることを目的としている。
AIの進化に伴い、攻撃者は従来の手作業による対策では追いつけないスピードで脆弱性を悪用するようになった。AI Threat DefenseはWiz、CodeMender、Gemini、Mandiantの各テクノロジーを統合し、組織が機械的な速度で脅威に対抗できる環境を提供する。
AI Threat Defenseが目指す次世代セキュリティ

近年、サイバー攻撃の高速化が顕著だ。従来は数週間かけて実施されていた攻撃が、AIエージェントの支援により数時間〜1日程度で完了するケースが増えている。防御側もこのスピードに追随する必要があり、人手による脆弱性管理やパッチ適用だけでは限界がある。
Google Cloud Blogの記事では、単一のAIモデルですべての脆弱性を捕捉することは難しく、コストと性能のバランスを取るために軽量なモデルと最先端のモデルを組み合わせて使うマルチモデル戦略が有効だと説明している。AI Threat Defenseは、ジェネレーティブAIの推論能力とコード生成能力を核に据えた自動防御システムとして、この考え方を具現化したものだ。
上の比較は、従来型の反応的なセキュリティ運用と、AI Threat Defenseがもたらす自律的な運用の差を端的に表している。プロセス全体が機械速度で回ることで、攻撃者が脆弱性を悪用する「タイムウィンドウ」を最小化できる点が最大の強みだ。
4つのコンポーネントが支える統合防御

AI Threat Defenseは、単一の製品ではなく、複数のクラウドセキュリティ技術を組み合わせた統合プラットフォームだ。基盤にはGoogleのジェネレーティブAIモデル「Gemini」の推論エンジンがあり、周辺にクラウドセキュリティの可視化を担うWiz、コード修正を自動化するCodeMender、そして現場のサイバー攻撃対策ノウハウを持つMandiantが配置される。
Wizによる可視化とリスク優先付け
WizはアプリケーションやAPI、ID、設定、ビジネスロジックなど、クラウド環境のあらゆる要素を継続的に可視化し、実際に悪用可能な攻撃パスをマッピングする。従来の攻撃面管理(ASM)を超え、AIペネトレーションテストエージェントが複雑な連鎖リスクを自動検証する。この結果、ただの脆弱性リストではなく、事業リスクを反映した優先順位付きの修復計画が出力される。
CodeMenderによる自律的なコード修正
CodeMenderはGeminiのコード生成力を活用し、開発者のIDEやCLIに直接パッチ候補を提示する。脆弱なコードの置換、レガシーコードのメモリ安全な言語への書き換え、ライブラリ依存関係の調整までをカバーし、修正後の自動テスト生成も行う。これにより、パッチの生成から検証までの時間が大幅に短縮される。
Geminiの推論とマルチモデル戦略
AI Threat DefenseはGemini Enterprise Agent Platform上で複数の最先端モデルを動かし、モデルごとに得意なタスク(アプリケーションロジック分析、クラウド設定監査、バイナリ解析など)に割り当てる。軽量モデルで広くスキャンし、フロンティアモデルを最高リスク領域に集中させることで、コスト効率と検出範囲の両立を実現している。
Mandiantの現場知見と運用ガイダンス
Mandiantはこれまでに蓄積したサイバー攻撃の最前線知識を、AI駆動の修復プロセスに注入する。重大な脆弱性が一気に表面化した場合の対応戦略や、旧式システムの安全な停止方法、AI生成パッチをエンジニアリングチームに負荷をかけずに展開するノウハウなど、実践的なガイダンスが提供される。
脅威対策の4段階フレームワーク

AI Threat Defenseの運用は「準備(Prepare)」「スキャンと優先順位付け(Scan and prioritize)」「修正(Remediate)」「監視(Monitor)」の4段階で構成される。各ステップがシームレスに連携し、攻撃者が悪用するスピードに追いつくための機械的なワークフローを形成する。
このフレームワークでは、各段階が独立しているのではなく、リアルタイムのリスク情報に基づいてループする。たとえば監視中に新たな暴露経路が見つかれば、即座にスキャンへ戻り、自動的にパッチが生成される。
STEP 1 準備(Prepare)
まず重要なのは、攻撃対象領域を最小化することだ。インターネットから直接到達可能なセンシティブな資産や、信頼できない経路で露出しているサービスを特定し、パッチの有無にかかわらず接続経路そのものを削減する。同時に、各チームの責任範囲とエスカレーションフローを明確化し、次の脆弱性が発見されたときに即応できる体制を整える。
STEP 2 スキャンと優先順位付け(Scan and prioritize)
この段階では、AIによる多層的な分析が行われる。軽量モデルで全資産を継続的にウォッチしつつ、インターネット向けアプリケーションや認証機能などビジネスクリティカルな部分にはフロンティアモデルを用いた深掘りスキャンを実施する。Wizのリアルタイムコンテキストと連携し、単なるコード上の欠陥ではなく「実際に攻撃可能か」という観点で優先度が決定される。
STEP 3 修正(Remediate)
特定された脆弱性は、CodeMenderによって自動的に修正案が生成される。開発者はIDE上でパッチ候補を確認し、承認するだけでよい。また、ライブラリの変更が他のコンポーネントに与える影響も分析され、複数リポジトリにまたがる安全なロールアウトが支援される。修正後には自動テストが走り、パッチの有効性を検証する仕組みも組み込まれている。
STEP 4 監視(Monitor)
最後の監視フェーズでは、Google Security Operationsが提供するエージェント型SOC機能を活用し、ネットワーク、ID、アプリケーションのテレメトリを横断的に分析する。AIが不審な挙動を自律的に検出し、場合によっては自動で封じ込めアクションを発動する。また、日次でビルド・署名されたハードニング済みコンテナイメージを用いることで、基盤自体のセキュリティも維持される。
実践導入とパートナーエコシステム

AI Threat Defenseは、単にツールを導入するだけでは機能しない。クラウドアーキテクチャに適したセキュリティ設計と、既存の開発パイプラインへの組み込みが必要になる。そのため、Google CloudはAccenture、Deloitte、PwC、Netenrich、TENEX.AIなどのパートナー企業と協業し、導入から継続的な管理、カスタムワークフローの構築までを支援する体制を整えている。
パートナー企業の役割
各パートナーは、顧客固有のクラウド構成を評価し、AI駆動のセキュリティ運用を定着させるためのハーネス(カスタム連携基盤)を開発する。これにより、組織ごとのコンプライアンス要件や運用ポリシーに合わせたきめ細かな防御が可能になる。
Google自身のセキュリティ実績
Google Cloudは、このプラットフォームを自らのセキュリティ運用実績の上に構築している。同社は10年以上にわたり、Titanチップによるハードウェア保護やZero Trustアーキテクチャの先駆的導入を進めてきた。現在も毎分数千万件のスパムを自動ブロックし、数十億のユーザーを保護している。こうしたノウハウが、AI Threat Defenseの設計思想に深く反映されている。
この記事のポイント
- AI攻撃の高速化に対抗するため、Google Cloudが自律型防御プラットフォーム「AI Threat Defense」を発表
- Wiz、CodeMender、Gemini、Mandiantの4要素を統合し、脆弱性の可視化からパッチ適用までを機械速度で自動化
- 従来の人間主導のプロセスでは数週間かかっていた対応が、数分〜数時間に短縮される見込み
- 「準備→スキャン→修正→監視」の4段階フレームワークで、攻撃者が悪用する前に防御を完了させる
- パートナー企業による実装支援と既存の開発パイプラインへの統合が、導入の鍵を握る
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

WooCommerce 10.8リリース!レビューメール自動化と各種高速化の全容
WooCommerce 10.8が2026年5月26日にリリースされた。今回のアップデートでは購入後のカスタマーレビュー依頼メールの自動化、カスタム配送業者の設定機能、クーポンコードの動的生成、そして管理画面のパフォーマンス改善が盛り込まれている。
動作条件としてWordPress 6.9以上が必要だ。WooCommerceを更新する前にWordPress本体を最新にしておく必要がある。管理画面の一貫性を保つWordPress 7.0への事前適合も含まれており、今後のスムーズな移行に向けた布石となるリリースだ。
WooCommerce 10.8の主な変更点

WordPress 7.0向けの管理画面スタイル調整
WooCommerce 10.8には約15件のプルリクエストが含まれ、WordPress 7.0の新しい管理画面デザインとの整合性を確保した。対象となったのはフォームコントロールのサイズ、Select2ドロップダウン、ボタンの角丸、通知の色、メタボックス周りのスタイルだ。
従来、WooCommerceの一部画面では青系の管理画面用色が直接ハードコーディングされていた。これがテーマカラー変数に置き換えられ、ユーザーが設定した配色スキームに沿って境界線やホバー状態が変化するようになった。WordPressとWooCommerceを同時に更新すれば、管理画面全体の見た目に統一感が出る。
管理画面の色が選んだテーマに合わせて変化するため、複数サイトを運営している場合でもサイトごとに配色を変えられ、管理ミスの防止にもつながる。
オフライン対応の管理画面
WooCommerceの管理画面がオフラインを検知するようになった。ブラウザのネットワーク接続が切れるとバナーが表示され、保存リクエストがネットワーク喪失で失敗した場合には明確な通知が表示される。
これまで接続の不安定な環境では保存失敗に気づかず、注文データや設定の消失につながるケースもあった。モバイル回線やカフェのWi-Fiなど、接続状態が変わりやすい場所で作業するストア運営者にとっては実用的な改善だ。
パフォーマンス改善の詳細

SQLクエリの削減と高速化
WooCommerce 10.7から続くクエリ削減の取り組みがさらに進んだ。取引IDルックアップ用の索引が wc_orders テーブルに追加され、販売ピーク時の在庫予約に使われる wc_reserved_stock テーブルの索引も改善された。
加えてキャッシュプライミングが商品アーカイブ、商品編集画面、クラシックカート、グループ化商品、Store APIの商品スキーマに拡張された。これにより各パスでデータを1行ずつ取得する代わりにバッチロードできるようになり、データベースへの負荷が大きく下がる。
クーポンの _used_by メタデータは遅延読み込み化された。何千回も使われたクーポンをロードする際に全使用履歴をメモリに展開しなくなり、クーポン読み込み時のパフォーマンスが飛躍的に改善する。レイヤードナビゲーションのフィルターキャッシュにはデフォルトで上限が設定され、wp_options テーブルが無制限に肥大化するのを防ぐ。
ベータ版からの修正点
10.8のベータテスト期間中に見つかった問題も解消された。 WC_Order::payment_complete() に追加予定だったチェックアウト証跡のバリデーション機能は最終版から差し戻され、このリリースには含まれない。
また wc_orders_meta テーブルの meta_key_value 索引から meta_value 列が誤って削除されたパフォーマンス回帰も修正された。注文メタデータの検索速度が低下する問題だったが、10.8で索引構成が復元されている。
新機能の詳細

カスタマーレビュー依頼メールの自動化
10.8の目玉機能の一つが、購入者に商品レビューを依頼する自動メール機能だ。WooCommerceの設定の「メール」タブから有効化でき、Action Schedulerを使って注文完了から設定した日数後に送信される仕組みだ。
注文がキャンセル、返金、削除された場合にはメールは自動キャンセルされる。全額返金された商品はレビュー対象から外されるため、購入者と商品の関係が切れた状態でのレビュー投稿を防げる。顧客はトークン付きの専用読み取り専用ページに誘導され、アクセシブルな5つ星評価のコントロールからレビューを投稿する。投稿されたレビューは「確認済み購入者」の商品レビューとして扱われる。
この仕組みで集まったレビューは確認済み購入者の証跡が残るため、レビュー全体の信頼性を高められる。商品ページの社会的証明を強化したいストアには有効な手段だ。
クーポンコードの自動生成機能
メールブロック内で使えるクーポンコード機能が自動生成に対応した。ストア運営者は割引額やクーポンタイプ、有効期限といったルールを設定し、メール送信時に受信者ごとのユニークなコードを動的に発行できる。
パーソナライズされたクーポンキャンペーンの運用が大幅に簡略化される。全員に同じコードを配布して拡散リスクを抱える必要がなくなり、1人1コードの安全な配布が可能だ。
メールテンプレートの同期とリセット
ブロックメールの投稿にバージョン、ソースハッシュ、同期日時といったメタデータが付与されるようになった。テンプレートが元の配布状態からどれだけ変更されたかを自動検知できる。さらに管理画面からワンクリックでメール本文をプラグイン配布時のオリジナル状態に戻せるリセット機能も追加された。
カスタマイズを重ねたメールテンプレートの管理は煩雑になりがちだが、変更箇所の可視化と即時リセットで運用負荷が下がる。
カスタム配送業者の設定
独自の配送業者を定義できるUIが追加された。業者名と追跡URLテンプレートを登録すれば、注文画面で業者ごとのフィルタリングや、カスタマイズされた追跡リンクを使って出荷状況を確認できる。
国内の小規模な配送業者や地域限定の物流サービスを使っているストアでも、統一された画面から追跡情報を管理しやすくなる。
APIの更新

REST APIとGraphQL
注文APIでは shop_order でないレコードの変換が拒否されるようになり、チェックアウトドラフト注文はデフォルトクエリから除外されるようになった。より明示的なデータ操作が求められる変更だが、意図しないデータ混入を防ぐ点でAPIの堅牢性が増した。
注目すべきはGraphQL APIの導入だ。デュアルコードとGraphQL APIがWooCommerceに組み込まれ、管理画面の「詳細設定」タブにGraphQL設定セクションが追加された。GETエンドポイントのトグル操作で有効にできる。ヘッドレス構成やモダンなフロントエンドスタックからWooCommerceのデータを柔軟に取得したい開発者にとって重要な布石となる。
そのほか商品公開時に発火する product.published ウェブフックトピックの追加や、商品管理権限のないユーザーに対する機密フィールド(ダウンロード、売上原価、仕入メモ)の除外など、セキュリティ面の強化も図られている。
データベースの更新と注意点

このリリースにはデータベース更新が含まれている。自動実行されるスケジュール更新の中では、ブロックメール投稿への同期メタデータ付与、WooCommerce 10.5で名称変更された分析データのインポート設定復元、meta_key_value 索引の調整、レビュー依頼用の専用ランディングページ作成などが行われる。
10.8の更新前には必ずサイト全体のバックアップを取得し、ステージング環境での事前テストを推奨する。またWordPress 6.9以上が必須条件となるため、WordPress本体のバージョンも事前に確認しておく必要がある。
この記事のポイント
- WooCommerce 10.8は購入後のレビュー依頼メールを自動化し、確認済み購入者のレビュー収集を効率化する
- 管理画面のオフライン検知機能が追加され、ネットワーク不安定環境でのデータ消失リスクが低減した
- クーポンコードの自動生成やメールテンプレートのリセット機能で運用負荷を下げられる
- SQLクエリの削減とキャッシュプライミングの拡大により、ストアフロントの応答速度が向上する
- GraphQL APIの導入はヘッドレス構成やモダンフロントエンド開発への対応を見据えた布石となる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

DockerのCopy Fail脆弱性対応とseccomp破壊の教訓
2026年4月末に公開されたLinuxカーネルの脆弱性CVE-2026-31431、通称「Copy Fail」は、2017年以降のほぼ全てのカーネルに影響する深刻な問題だ。Docker社はこの脆弱性に対し、コンテナランタイムレベルでの緩和策を急ピッチで提供した。
その過程で、Docker Engine v29.4.2の修正が32ビットバイナリのネットワーク機能を完全に破壊するという予期せぬ副次的被害を引き起こした。本記事では、この一連の対応と教訓を技術的に深掘りする。
コンテナ運用者は、カーネルパッチの適用が最優先だが、それが叶わない場合でもDocker Engineのアップデートによりリスクを大幅に低減できる。ここで得られた知見は、今後のコンテナセキュリティ対策における多層防御の重要性を浮き彫りにしている。
Copy Fail脆弱性の仕組みとリスク

AF_ALGサブシステムの欠陥
Copy Failは、Linuxカーネルの暗号処理をユーザー空間から利用するためのAF_ALG(Algorithm Sockets)サブシステムに存在する。具体的にはalgif_aeadモジュールの不具合により、特権のないプロセスがページキャッシュに対して不正な書き込みを行える状態になっていた。
ページキャッシュとは、ファイルの読み取りデータをメモリ上に一時保存する仕組みだ。全プロセスが参照するため、ここを汚染されると、システム全体でファイルの内容が改ざんされて見える可能性がある。最も直接的な攻撃経路は、setuidバイナリ(実行時に高い権限で動作するプログラム)の改ざんによる権限昇格である。
この脆弱性の深刻さは、その単純さにある。PoC(概念実証コード)はきわめて簡潔で、カーネルがパッチされていない限り、2017年以降のあらゆるバージョンで動作する。攻撃が成功すると、コンテナ内からホスト全体、そして同じノード上の他コンテナにまで影響が及ぶのだ。
このデモが示す通り、脆弱なカーネルでは攻撃者に一直線のルートを提供してしまう。Dockerの役割は、コンテナランタイムのレイヤーでこの経路を物理的に塞ぐことだった。
コンテナ環境への影響範囲
Dockerのデフォルトセキュリティプロファイルでは、コンテナからのAF_ALGソケット作成が許可されていた。つまり、攻撃者が何らかの方法でコンテナ内でコードを実行できた場合、この脆弱性を利用してホストのroot権限を奪取できる状態にあった。
さらに悪いことに、ページキャッシュはホスト全体で共有される。攻撃が成功した場合、被害はそのコンテナ内に留まらず、同じDockerイメージのレイヤーを共有する他のすべてのコンテナにも波及する。これは、マルチテナント環境やマイクロサービスを密に配置しているノードでは壊滅的な被害につながりかねない。
Docker Engineの対応と失敗の分析

v29.4.2 seccomp修正の試み
Dockerチームは当初、seccomp(Secure Computing Mode / セキュアコンピューティングモード)プロファイルの更新で対応しようとした。seccompは、コンテナが発行できるシステムコールをフィルタリングする仕組みだ。具体的には、socket()システムコールの第一引数を検査し、AF_ALGアドレスファミリが指定された場合に拒否するルールを追加した。
しかし、x86_64 Linuxにはsocketcall()という古い多重化システムコールが存在する。これはsocket()やbind()などの複数のソケット操作を一つのシステムコール番号の背後にまとめたものだ。問題は、socketcall()では実際の引数(アドレスファミリを含む)がユーザー空間の配列にパックされ、そのポインタが渡されることだ。seccompのフィルタエンジンであるBPFは、このポインタ先を参照して検査できない。
つまり、seccompだけではsocketcall()経由のAF_ALGを選択的にブロックできない。やむを得ずDockerチームは、socketcall()全体を拒否するという決断を下し、v29.4.2をリリースした。
この比較が示すのは、セキュリティ対策における粒度の重要性だ。全体をブロックすれば安全だが、システムの機能を破壊する。真に効果的な対策は、悪意のある操作だけをピンポイントで無効化することにある。
32bitバイナリ破壊の実態
socketcall()の一律拒否は、思わぬ大規模な副次的被害を引き起こした。32bit版のglibcは、すべてのソケット操作をsocketcall()経由で行う古いバージョンが残っている。Go言語のランタイムも、GOARCH=386でビルドされたバイナリでは無条件にsocketcall()を利用する。さらに、SteamCMDやWineといったレガシー・ゲーミング系のワークロードも、この仕組みに依存している。
これは単なるi386(32bit)の問題ではない。amd64環境であっても、プロセスはint $0x80命令を使うことでia32互換モードに切り替わり、直接socketcall()を呼び出せる。つまり、64bitのコンテナやバイナリを使っていても、この経路を利用される可能性があるのだ。
結果として、v29.4.2へのアップグレード後に多数の32bitアプリケーションがネットワークに接続できなくなるというインシデントが発生した(GitHub Issue: moby/moby#52506)。セキュリティパッチが新たな機能不全を引き起こすという、運用者にとって最も避けたいシナリオが現実となった。
根本原因:seccompの限界
この問題の本質は、seccompがシステムコール境界でのみ動作する点にある。socketcall()は一つのシステムコール番号の背後に多種の操作を隠蔽する。seccompのフィルタは、その中身である配列のポインタ先を解析できない。これが、seccomp単独では対応できない構造的な限界だ。
Dockerのブログ記事の著者は、「seccompはsocket(AF_ALG)をすべてのシステムでブロックするが、socketcall()に対しては盲目だ」と端的に表現している。この「見えない経路」の存在が、多層防御の必要性を強く示す教訓となった。
v29.4.3 LSMベースの恒久対策

AppArmorとSELinuxによる多層防御
v29.4.3では、より根本的な解決策としてLinuxセキュリティモジュール(LSM)を活用する方針に切り替えた。AppArmorとSELinuxは、カーネル内部のsecurity_socket_create()コールバックに直接フックする。このコールバックは、socket()経由であれsocketcall()経由であれ、カーネルが実際にソケットオブジェクトを生成する瞬間に必ず呼ばれる。システムコールの入り口ではなく、より深いレベルで制御を行うのだ。
具体的な実装として、AppArmorプロファイルには deny network alg, というルールが追加された。これはAF_ALGアドレスファミリだけを対象に拒否する。SELinux環境向けには、すべてのcontainer_domainタイプに対してalg_socketの作成を拒否するCIL(Common Intermediate Language)ポリシーモジュールが提供され、semoduleコマンドでロード可能だ。
対策の全体像と適用優先度
v29.4.3の防御スタックは、以下の3層で構成されている。seccompによる直接のsocket(AF_ALG)ブロックは防御の一層目として維持しつつ、AppArmorまたはSELinuxによってsocketcall()経由の抜け道を塞ぐ。これにより、どちらか一方の防御層が無効化されても、もう一方がカバーする体制を実現した。
ただし、AppArmorやSELinuxはホストの設定に依存するため、LSMが有効化されていない環境ではsocketcall()経路が無防備なままとなる。この点については、依然としてカーネルパッチが唯一の完全な解決策であることに変わりはない。
このステップを踏むことで、カーネルパッチの提供を待つ間のリスクを段階的に低減できる。最優先はカーネル修正だが、それが叶わない状況でもDocker Engineの更新だけで強固な緩和策となる。
コンテナセキュリティのための実践的教訓

ランタイム更新のスピードが生む防御力
Copy Failのケースで特筆すべきは、脆弱性の詳細が公表された時点で、主要ディストリビューションの多くはカーネルパッチを提供できていなかった点だ。Ubuntuは記事執筆時点で未対応であり、DebianやRHEL 9が対応を発表した段階だった。この数日間のギャップにおいて、コンテナランタイムの更新は唯一の実用的な緩和策だった。
コンテナ運用においてDocker Engineを最新に保つことは、単なる機能向上のためではない。カーネル脆弱性の公開からパッチ適用までの「空白期間」を埋める、最も迅速な防御手段の一つなのだ。
多層防御の絶対的必要性
このインシデントは「単一の防御層に頼ることの危険性」を端的に示した。seccompは強力だが、システムコールの粒度でしか制御できない。AppArmorやSELinuxはカーネル内部のオブジェクト生成にフックするため、より精密な制御が可能だが、ホストOSの設定に依存する。両者を組み合わせることで初めて、互いの死角を補完できる。
また、v29.4.2のsocketcall()拒否が引き起こした互換性問題は、セキュリティと互換性のトレードオフの難しさを教えている。広範なブロックは新たな問題を生む。可能な限りピンポイントな制御を追求し、やむを得ず広範な制限をかける場合は、その影響範囲を事前に十分評価する必要がある。
この比較から得られる教訓は明確だ。セキュリティ対策は、異なるレイヤーで相互に補完し合う設計が必須である。一つの仕組みで完璧を目指すのではなく、それぞれの得意領域を理解し、弱点を他の層でカバーする。これこそがコンテナセキュリティの基本原則である。
この記事のポイント
- CVE-2026-31431はAF_ALGソケットを悪用し、2017年以降のLinuxカーネルに影響する
- Docker v29.4.2のseccomp修正は32bitバイナリのネットワークを破壊する副次的被害を起こした
- v29.4.3ではAppArmorとSELinuxを組み合わせた多層防御で選択的なAF_ALG遮断を実現
- カーネルパッチが最も確実な修正だが、エンジン更新が迅速な緩和策として有効
- 単一防御層の限界を認識し、複数の技術で死角を補完する設計が今後の鉄則となる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Vercel Sandboxの永続化機能が正式版に、環境構築の手間を大幅削減
Vercelが提供するクラウド開発環境「Vercel Sandbox」において、filesystemの状態をセッション間で自動保存する永続化機能が正式版(GA)となった。2026年5月26日の発表だ。開発者はこれまで、Sandboxを再起動するたびに依存パッケージのインストールやファイル配置をやり直す必要があったが、今回のアップデートでその手間が大幅に削減される。
永続化はデフォルトで有効化されており、スナップショットの取得や状態管理を手動で行う必要はない。Sandboxに一意の名前を付与すれば、その名前をキーとして環境を再開できる仕組みだ。セッションの起動と停止はVercel側で自動的に処理されるため、開発者はワークフローを中断されることなく作業を継続できる。
Sandbox永続化が解決する課題

クラウドベースの開発環境において、セッション終了後の状態消失は長年の課題だった。従来のVercel Sandboxでは、セッションが終了するたびにfilesystem上の全データが破棄されていた。このため、毎回の起動時に再度依存関係のインストールや環境設定を行う必要があり、開発開始までの待ち時間が大きな非効率を生んでいた。
永続化機能は、この問題に対する直接的な解決策だ。Sandboxのfilesystem状態が自動的にスナップショットとして保存され、次回セッション開始時に自動復元される。スナップショットはユーザーが明示的に操作する必要はなく、セッション終了時に自動取得される仕組みである。これにより、npmパッケージのインストールやプロジェクトファイルの配置といった繰り返し作業から開発者が解放される。
※毎回セッション開始時に環境構築が必要。待ち時間が発生し、開発効率が低下する
※前回の状態が自動的に復元される。セットアップ不要で作業を継続できる
この変化は、継続的な開発やCI/CDパイプラインでの自動テストなど、頻繁な環境再作成が発生するシナリオで特に効果を発揮する。
永続的Sandboxの作成と利用

デフォルトで有効化される永続性
Sandbox.create()を呼び出す際、永続化は自動的に有効になる。特別な設定やオプションの指定は不要だ。作成時にnameパラメータで一意の名前を付与すれば、その名前がプロジェクト内での参照キーとなる。この名前は後から変更することも可能であり、プロジェクトの命名規則に合わせた管理ができる。
名前付きSandboxは単なる識別子以上の役割を持つ。チーム内で「staging-test」「feature-auth」といった意味のある名前を付けることで、目的に応じた環境の使い分けが容易になる。また、存在しない名前を指定した場合は新規作成、既存の名前を指定した場合は既存環境の復元と、名前ベースの直感的な操作が可能だ。
import { Sandbox } from "@vercel/sandbox";
// filesystemは自動的にスナップショット保存される
const sandbox = await Sandbox.create({ name: "my-sandbox" });
await sandbox.runCommand("npm", ["install"]);
await sandbox.stop();上記のコードでは、npm installでインストールされた依存パッケージが自動的にスナップショットとして保存される。次回Sandbox.get({ name: "my-sandbox" })で取得した際には、インストール済みの状態から即座に作業を再開できる。
ステートレスSandboxとの使い分け
永続化は便利だが、すべてのユースケースで必要とは限らない。一時的な検証や使い捨てのテスト環境では、永続化を無効にすることでスナップショット保存にかかるストレージコストを節約できる。スナップショットストレージはコンピューティングリソースとは別の課金体系であり、不要な保存はコスト増につながるためだ。
import { Sandbox } from "@vercel/sandbox";
const sandbox = await Sandbox.create({ persistent: false });
// 既存のSandboxを後から変更することも可能
await sandbox.update({ persistent: false });CLIを利用する場合は、sandbox createコマンドに--non-persistentフラグを付与する。非永続的Sandboxはセッション終了時にfilesystemが完全に破棄されるため、機密データを含む一時的なテストや、毎回クリーンな状態から始めたいCIジョブに適している。
● チーム共有の検証環境
● 長期メンテナンスのテスト環境
● クリーン状態が必要なCIジョブ
● 機密データを含む一時テスト
この使い分けにより、必要な場面では永続化の利便性を享受しつつ、不要な場面ではコストを最適化できる。開発の初期段階で「この環境は使い続けるか、それとも一度限りか」を判断基準にするのが実践的なアプローチだ。
セッション再開の仕組み

永続化されたSandboxの再開は完全に自動化されている。停止中のSandboxに対してrunCommand()やwriteFiles()などの操作を呼び出すと、最新のスナップショットから自動的に新しいセッションが開始される。開発者が明示的に「再開」を指示する必要はなく、操作の実行がトリガーとなって透過的に処理される。
import { Sandbox } from "@vercel/sandbox";
const resumedSandbox = await Sandbox.get({ name: "my-sandbox" });
// 自動的にSandboxが再開される
await resumedSandbox.runCommand("npm", ["test"]);Sandbox.get()で取得した段階ではまだセッションは開始されておらず、実際にコマンドを実行するタイミングでバックグラウンドで復元処理が走る。この遅延実行モデルにより、不要なセッション起動を避け、リソースの効率的な利用が可能になる。復元にかかる時間はスナップショットのサイズに依存するが、一般的なプロジェクト規模であれば数秒から十数秒程度で完了する。
この設計の利点は、開発者が環境のライフサイクル管理から解放される点にある。「今このSandboxは起動しているか」「停止状態からどう再開するか」といった状態管理の認知負荷がなくなり、コードの記述やテストの実行といった本質的な作業に集中できる。
コスト管理とスナップショットストレージの最適化

永続化機能の利用にあたって注意すべき点は、スナップショットストレージの課金だ。Vercel Sandboxの料金体系では、コンピューティングリソースとスナップショットストレージが別々に課金される。永続化を有効にしたSandboxが増えるほど、保存されるスナップショットの総容量も増加し、それに比例してコストが発生する。
では、どのようにコストを最適化すればよいのか。以下の方針が実践的だ。
● npm install に30秒以上かかる大規模プロジェクト
● チームメンバー間で共有する標準環境
● PRごとに自動生成されるCI環境
● 依存関係がほぼない小規模スクリプトの実行
実際の運用では、Sandbox.update({ persistent: false })を使って後から設定を切り替えられるため、最初は永続化ありで作成し、不要と判断した時点で無効化する柔軟な運用が可能だ。また、Sandbox.delete()を使えば不要になったSandboxとそのスナップショットを完全に削除でき、ストレージの無駄遣いを防げる。
スナップショットの保存間隔や保持数については、現時点ではセッション終了時に自動取得される仕組みのみが提供されている。将来的にはスナップショット取得のタイミングを制御するオプションが追加される可能性もあるが、現行バージョンではシンプルに「停止時保存」のモデルで統一されている。このシンプルさが、開発者の意思決定コストを下げている面もある。
その他の重要な改善点

今回のGAリリースでは、永続化機能に加えていくつかの重要なAPI拡張も同時に提供されている。これらは永続化機能と組み合わせることで、より柔軟なSandbox管理を実現する。
Sandbox.fork() による環境の複製
既存のSandboxから新しいSandboxを作成するSandbox.fork()が追加された。特定の時点の環境を複製し、そこから別の検証を分岐させたいケースで役立つ。たとえば、メインの開発環境から「機能Aの実験用」「機能Bの実験用」をそれぞれフォークし、独立してテストを進められる。
Sandbox.getOrCreate() の冪等性
Sandbox.getOrCreate()は、指定した名前のSandboxが存在すれば取得し、存在しなければ新規作成する冪等な操作を提供する。CI/CDパイプラインでの環境セットアップスクリプトなど、「あれば使う、なければ作る」というパターンが1行で完結する。エラーハンドリングの分岐を書く必要がなくなり、コードの可読性が向上する。
ライフサイクルフックとタグ機能
onCreateおよびonResumeフックが追加され、Sandboxの作成時や再開時に任意の処理を挿入できるようになった。環境変数の動的設定や、起動時チェックの自動実行など、プロジェクト固有の初期化処理を組み込める。また、Tags機能によりSandboxにカスタムプロパティを付与でき、マルチテナント環境での追跡や分類が容易になる。たとえば「environment: staging」「team: frontend」といったタグを付けてフィルタリングすることが可能だ。
実践的な活用シナリオ

永続化機能の登場により、Vercel Sandboxの適用範囲は大きく広がる。ここでは具体的な活用シナリオをいくつか挙げる。
すべての依存パッケージがインストール済みのSandboxをSandbox.fork()でメンバーに配布。環境構築の時間をゼロにし、全員が同一条件で開発を始められる。新メンバーのオンボーディング時間も大幅に短縮される。
テストスイートの実行環境を永続化し、依存パッケージのインストール時間を削減。PRごとにSandbox.getOrCreate()で専用環境を用意し、テスト実行後のクリーンアップもSandbox.delete()で自動化できる。
報告されたバグの発生環境をSandboxで再現し、そのまま永続化。修正パッチの検証が完了するまで環境を保持し、必要に応じてSandbox.fork()で別の修正アプローチも並行テストできる。
これらのシナリオに共通する利点は、「環境の再現性」と「セットアップ時間のゼロ化」だ。特にマイクロサービスアーキテクチャのように複数の依存関係が絡むプロジェクトでは、個々の開発者がローカルで依存関係を解決するよりも、クラウド上の永続化環境を共有する方が圧倒的に効率的なケースが多い。
この記事のポイント
- Vercel Sandboxの永続化機能が正式版となり、セッション間のfilesystem自動保存がデフォルトで有効化された
- 名前ベースのSandbox管理で環境の作成・取得・再開が直感的に行え、スナップショット操作は完全自動化されている
- 永続的Sandboxと非永続的Sandboxの使い分けにより、利便性とコスト最適化のバランスが取れる
- forkやgetOrCreateなどのAPI拡張で、チーム開発やCI/CDパイプラインへの統合がより容易になった
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Supabaseプロジェクトをnpmサプライチェーン攻撃から守る7つの防御策
npmエコシステムを狙ったサプライチェーン攻撃が2026年に相次いでいる。5月には、TanStackがGitHub Actionsのワークフローキャッシュを汚染され、正規リリースに悪意あるコードが混入する事件が発生した。Supabaseも同様に、supabase-javascriptというタイポスクワット(入力ミスを狙った偽装パッケージ)がnpm上に現れるなどの標的に遭っている。
同社はこの事態を受け、プロジェクトの保護に向けた社内横断の対応を開始し、誰もが参照できる公式ガイドを公開した。本記事では、そのガイドの中核を抜粋し、攻撃の構造と開発者が今すぐ実施すべき防御策を具体的に解説する。
npmサプライチェーン攻撃の3つの典型的な手口

サプライチェーン攻撃は、直接システムに侵入するのではなく、開発者が信頼しているパッケージに悪意あるコードを忍び込ませる。以下が最も一般的な三つの手口だ。
メンテナの認証情報を奪う「アカウント乗っ取り型」
攻撃者がnpmの公開トークンを盗むか、メンテナをフィッシングして乗っ取り、人気パッケージの新版に悪意あるコードを仕込んで公開する。次にnpm installを実行すると、その悪質なバージョンが導入されてしまう。
入力ミスを誘う「タイポスクワッティング型」
本物のパッケージ名から数文字だけ変えた類似名でパッケージを登録し、開発者やAIコーディングエージェントが誤ってインストールするのを待つ。Supabaseの例では、@supabase/supabase-js ではなく supabase-javascript というスコープなしの名前で公開された。AIエージェントがパッケージ名を幻覚(ハルシネーション)して提案することも多く、この手法は脆弱だ。
ビルドパイプラインを悪用する「CI/CD侵害型」
この手口は、GitHub ActionsなどのCI/CDパイプラインの脆弱なワークフローを突く。攻撃者はフォークしたプルリクエストからワークフローのキャッシュを汚染し、次回の正規リリース実行時にそのキャッシュを拾わせて、正規メンテナの署名で悪意あるコードを公開させる。TanStackを襲った攻撃がまさにこれで、セッションメッセンジャーネットワーク経由で機密情報が流出した。
いずれの手口も、npm install の完了までに環境変数やAWSメタデータ、SSH秘密鍵といった機密情報を根こそぎ奪われる危険がある。
Supabaseが実施するプロジェクト防御策

Supabaseはこの問題に対し、全社的な対応を開始した。以下が現在進行中の主な取り組みである。
公式セキュリティガイドの公開
同社は、npmセキュリティに関する推奨事項をまとめた単一の正規ガイドページを公開した。エージェントが読み取り可能な形式で、具体的なアクションを指示している。
GitHub Actionsの安全性強化
組織全体で pull_request_target の使用を精査し、アクションのバージョン参照をコミットSHAに固定する強制ルールの適用が最終段階に入っている。
クレデンシャル関連APIへの警告注釈
createClient などの関数にTSDoc(TypeScript向けドキュメントコメント)を追加し、エディタ上でホバー時に機密情報を扱う旨の警告が表示されるようにした。
全チャネルでの啓蒙活動
顧客かどうかを問わず、できるだけ多くの開発者に防御策を届けるため、ブログやコミュニティを通じた情報発信を強化している。
依存関係管理の厳格化

以下に挙げる設定変更は、いずれも数分で完了する。どれか一つでは完全な防御にはならないが、複数積み重ねることで攻撃者が諦めるほどの障壁を築ける。
パッケージマネージャを最新にして公開遅延を設定する
pnpm 11(またはnpm v11相当)にアップグレードし、minimumReleaseAge をデフォルトの24時間より長く設定する。多くの悪意あるパッケージはリリース後24〜48時間以内に検出され削除されるため、3〜7日の遅延を設けると、被害を受ける確率を大幅に下げられる。
# pnpm-workspace.yaml または .npmrc
minimumReleaseAge: 4320 # 分単位、3日依存バージョンを固定する
^ や ~ による範囲指定は、npmに対して「次のマイナーやパッチを自動的に取り入れて問題ない」と伝えているに等しい。認証情報やネットワーク通信を扱うパッケージでは、必ず正確なバージョン番号を指定しよう。
"dependencies": {
"@supabase/supabase-js": "^2.39.0",
"axios": "~1.6.0"
}"dependencies": {
"@supabase/supabase-js": "2.39.0",
"axios": "1.6.2"
}ロックファイルをコミットし差分を精査する
pnpm-lock.yaml や package-lock.json は、インストールされた正確なバージョンとハッシュを記録する。攻撃者が同じバージョン番号で悪意あるtarballを差し替えても、ハッシュが一致せずインストールが失敗する。ロックファイルをリポジトリにコミットし、プルリクエストの差分では目的不明な依存関係の変更がないか必ず確認する。
不用なインストールスクリプトを無効化する
サプライチェーン攻撃のペイロードの多くは、preinstall install postinstall といったライフサイクルスクリプトを通じて実行される。ネイティブコードを含むパッケージを必要としないプロジェクトでは、これらをグローバルに無効化する。npmでは npm config set ignore-scripts true または .npmrc に ignore-scripts=true を記述する。pnpmではAllow Buildsモデルを使って、実際に必要なパッケージだけを許可リストに登録する。
安全なパッケージ導入のための実践

パッケージ名を毎回検証する
タイポスクワッティング対策として、以下の点をインストール前に必ず確認する。
- スコープが正しいか。Supabase公式パッケージはすべて
@supabase/配下にある。 - メンテナの一覧が期待通りか。長年維持されてきたパッケージに新しいメンテナが突然加わっていれば警戒信号だ。
- ダウンロード数とリンク先のGitHubリポジトリが、本物のパッケージとして妥当であること。
CI/CDワークフローを狙った攻撃への対策

ActionsをコミットSHAで固定する
ワークフローで参照するサードパーティアクションは、タグではなくコミットの完全なSHAハッシュ(40文字)で固定する。タグは攻撃者が新しいコードで置き換えられるため安全でない。
- uses: actions/checkout@1f9a0c22da41e6ebfa534300ef656b67ce0c5b94 # v6.0.2pull_request_target の危険な使い方を回避する
pull_request_target イベントは、プルリクエストのコードをチェックアウトして実行するコンテキストで使うと、攻撃者がリポジトリのシークレットやキャッシュにアクセスできてしまう。TanStackを襲った攻撃はまさにこのパターンだった。PRのコードに触れる処理は必ず pull_request を使用し、pull_request_target はラベリングやコメント投稿など、コードを実行しない信頼済み操作に限定する。
on:
pull_request_target:
types: [opened, synchronize]
jobs:
build:
- uses: actions/checkout@v4
with:
ref: ${{ github.event.pull_request.head.sha }}on:
pull_request:
types: [opened, synchronize]
jobs:
build:
- uses: actions/checkout@v4インシデント発生時の即応策

クレデンシャルのローテーションと監査
もし疑わしいパッケージを含む環境で npm install を実行してしまったら、そのマシンを危殆化したと見なし、到達可能なすべての認証情報(AWS、GCP、Kubernetes、Vault、GitHub、npm、SSH、Supabaseのサービスロールキー)を直ちにローテーションする。Supabaseのダッシュボードでサービスロールキーの使用状況を監査し、不審なアクセスパターンがないかも確認する。半日はかかる作業だが、顧客への被害を防ぐ価値は十分にある。
スキャナの導入で第二の防御線を
Socket.devやnpq、Snykといったツールは、npmレジストリのパッケージをリアルタイムで監視し、怪しい挙動をフラグ付けしてくれる。これらは万能ではないが、基本的な対策をすでに実施しているチームにとって有効な第二の防御線となる。
AIコーディングエージェントに渡すセキュリティチェックリスト

以下は、Supabaseが推奨するリポジトリ監査プロンプトだ。Claude CodeやCursorなどに貼り付け、変更内容を必ず確認しながら適用する。プッシュやPR作成、依存関係の自動追加、クレデンシャルのローテーションは自動化せず、必ず人間が承認する。
このリポジトリのnpmサプライチェーン衛生状態を監査してください。以下の変更を適用し、何を行ったかを報告してください。明示的な承認なしにプッシュ、PR作成、新しい依存関係のインストール、クレデンシャルのローテーションは行わないでください。
パッケージマネージャ:
- 古いバージョンならpnpm 11+(または最新のyarn/npm/bun)にアップグレード
- 新バージョンに7日間の公開遅延を設定
- pnpm: `minimumReleaseAge: 10080` を pnpm-workspace.yamlに
- npm: `min-release-age=7` を .npmrcに
- yarn (berry): `npmMinimalAgeGate: '7d'` を .yarnrc.ymlに
- bun: `minimumReleaseAge = 604800` を bunfig.tomlの[install]セクションに
- ライフサイクルスクリプトをデフォルトで無効化。pnpmではallowBuildsで明示的に許可するパッケージをリスト。
- 非レジストリの透過的依存参照をブロック。pnpmでは`blockExoticSubdeps: true`等を設定。
- パッケージマネージャ自体を正確なバージョンとsha512ハッシュで固定
ロックファイルと依存関係:
- ロックファイルがコミットされていることを確認(gitignoreされていない)
- 認証、シークレット、通信、暗号、ユーザデータを扱う依存関係では^/~を正確なバージョンに置き換え
- Supabase関連のインポートがすべて`@supabase/`スコープか検証。スコープなしの類似名はタイポスクワットとしてフラグ
GitHub Actions(存在する場合):
- すべてのサードパーティアクションのusesを40文字のコミットSHAに固定し、元タグをコメントで残す
- pull_request_targetを使いPRコードをチェックアウトしているワークフローを抽出し、pull_requestへの書き換えを提案
- インストールワークフローに`npm audit signatures`の非ブロッキングステップを追加
人の確認が必要な項目:
- Dependabotアラートとシークレットスキャンが無効なら有効化を提案
レポート:
- ファイル変更ごとに1行の理由付きリスト
- 自動変更せずに人の判断が必要な項目の一覧
この記事のポイント
- npmサプライチェーン攻撃は、アカウント乗っ取り、タイポスクワッティング、CI/CD侵害の3パターンに大別される
- Supabaseは公式ガイド公開、GitHub Actions強化、API警告追加などで対策を推進中
- 即効性のある防御策として、パッケージマネージャの更新と公開遅延設定、バージョン固定、ロックファイル精査、インストールスクリプト無効化、パッケージ名検証、ActionsのSHA固定、pull_request_targetの回避がある
- 万が一侵害が疑われる場合はクレデンシャル全ローテーションとスキャナ導入で二次被害を防ぐ
- AIエージェントには安全な監査プロンプトを組み込み、自動変更を人の目でレビューする体制を整える
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

View Transitions、大量要素スケーリングにview-transition-classが効く
クロスドキュメントビュートランジション(View Transitions)は、ページ間の遷移をアプリのように滑らかにする強力なAPIだ。しかし本番環境で数十、数百の要素を扱おうとすると、途端にスケーリングの問題に直面する。1つのヒーロー画像を動かすデモは簡単だが、48枚の商品カードを個別に遷移させるとなると話が違う。
本記事では、view-transition-classと動的な名前付けの手法を用いて、大量要素を効率よく扱う方法を解説する。CSS-Tricksで公開された連載Part 2の内容を基に、実践的なパターンとアクセシビリティへの配慮までカバーする。
view-transition-classがスケーリングの鍵

多くのチュートリアルでは、1つの要素にview-transition-name: heroを付与し、ページ間でマッチさせる。しかし実際のプロダクトグリッドでは、48枚のカードには48の一意な名前が必要になる。CSSでこれに対応しようとすると、次のような悪夢が待っている。
::view-transition-group(card-1),
::view-transition-group(card-2),
::view-transition-group(card-3),
::view-transition-group(card-4),
::view-transition-group(card-5),
::view-transition-group(card-6),
::view-transition-group(card-7),
::view-transition-group(card-8)
/* ... さらに92個続く */ {
animation-duration: 0.35s;
animation-timing-function: ease-out;
}この方法は、要素数が増えるほど管理不能になる。100個の商品があれば100個のセレクタを書かなければならず、保守は事実上不可能だ。
名前とクラスの決定的な違い
ここで重要になるのが、view-transition-nameとview-transition-classの使い分けだ。両者は似ているようで役割がまったく異なる。
- nameは「同一性」を表す。ページAのサムネールとページBのヒーロー画像が「同じもの」だとブラウザに伝える。nameはページ内で一意でなければならない。重複するとトランジションは破棄される。
- classは「スタイルのフック」だ。50の要素が
view-transition-class: cardを持てば、1つのCSSルールでそれらすべてのアニメーションを制御できる。通常のCSSクラスと同じ考え方で、特定の要素を指すものではなく「こう見せたい」をグループ化する。
データベースにたとえるなら、nameが主キー、classがカテゴリ列に相当する。主キーは一意に1行を特定し、カテゴリ列はまとめてクエリをかけるために使う。
クラスを使った共通スタイルの記述
実際のCSSはこうなる。6枚のカードに6つのユニークなnameを与えつつ、アニメーションのルールはたった3つで済む。
::view-transition-group(*.card) {
animation-duration: 0.35s;
animation-timing-function: cubic-bezier(0.25, 0.46, 0.45, 0.94);
}
::view-transition-old(*.card),
::view-transition-new(*.card) {
object-fit: cover;
}セレクタの*.cardは「view-transition-classがcardであるすべてのビュートランジショングループ」を意味する。アスタリスクはnameのワイルドカードで、classにマッチする。これでカードが60枚でも600枚でもCSSは変わらない。
このように、view-transition-classは大量要素のビュートランジションにおける、スケーリングの本質的な解決策だ。CSSのみで記述する理想形であるident("card-" sibling-index())のような自動生成はまだブラウザに実装されていないが、クラスを使えば十分なスケールを得られる。
動的名前付けでパフォーマンスを最適化

view-transition-classでスタイルのスケーリングは解決した。しかし、nameをページロード時にすべて付与してしまうと、別の問題が発生する。ユーザーが1枚のカードをクリックするだけでも、ページ上の全カード(48枚)のスナップショットが撮られ、疑似要素ツリーが構築されてしまうのだ。これは余計なコストであり、特にミドルレンジのモバイル端末ではトランジションのカクつきやスキップを引き起こす。
pageswapとpagerevealのライフサイクル
正しいアプローチは、nameを「ジャストインタイム」で付与することだ。ユーザーが操作したその瞬間にだけnameを設定し、遷移が終われば削除する。これにより、実際に遷移する要素だけがキャプチャされ、無駄な処理が発生しない。
流れはこうだ。
- ユーザーが一覧ページでカードをクリックする。
- ブラウザがナビゲーションを開始し、旧ページで
pageswapイベントが発火する。 pageswapハンドラがクリックされたカードを特定し、view-transition-name: product-42を動的にセットする。- ブラウザがその要素のスナップショットを撮る。
- 新ページが読み込まれ、
pagerevealイベントが発火する。 pagerevealハンドラがURLからIDを読み取り、ヒーロー要素に一致するnameを割り当てる。- ブラウザが新旧のスナップショットをマッチさせ、モーフィングアニメーションを再生。
- トランジションが完了したら、
viewTransition.finishedのPromise解決後にnameをクリアする。
この一連の流れで、名付けられるのはたった1つの要素だけだ。48枚のカードのうち47枚は何も関与せず、無駄なスナップショットはゼロになる。
このパターンは、Astroのtransition:nameディレクティブやNuxtのビュートランジションサポートが内部的に行っていることと本質的に同じだ。フレームワークが抽象化している処理を、pageswapとpagerevealで直接制御していると考えればよい。
名前のクリーンアップが重要な理由
トランジション完了後にnameを削除するステップは、単なるお片付けではない。もしユーザーが一覧ページに戻り、別のカードをクリックした場合、古いnameが残っていると重複によるエラー(トランジションが即時破棄される)か、誤った要素とのマッチングが起きる。必ずviewTransition.finishedの解決後にnameをクリアすること。
実践的なパターン集

商品グリッド以外にも、いくつかの典型的なパターンが存在する。実際のサイトで遭遇する状況に合わせて応用できる。
アスペクト比混合のフォトギャラリー
サムネールと拡大画像でアスペクト比が異なるギャラリーは、object-fit: coverで歪みを防ぎつつ、クラスで統一的に制御する。ポイントは、view-transition-nameを<img>自身に付与し、カードの枠やキャプションを含めないことだ。画像だけをモーフィングさせ、背景や枠は別のトランジションとして扱う。
::view-transition-group(*.gallery-item) {
animation-duration: 0.5s;
animation-timing-function: cubic-bezier(0.2, 0, 0, 1);
}
::view-transition-old(*.gallery-item),
::view-transition-new(*.gallery-item) {
object-fit: cover;
overflow: hidden;
}
/* ライトボックス背景は別クラスでフェード */
::view-transition-group(*.lightbox-bg) {
animation-duration: 0.3s;
}ライトボックスの暗いオーバーレイには、別のnameとclassを与え、独立したフェードインアニメーションを適用する。画像のモーフィングと背景のフェードが並行して走り、洗練された印象になる。
タブやセクションの切り替え
ダッシュボードタブやマルチステップフォームなど、同一ページ内でのセクション遷移にも同じ手法が使える。固定ヘッダーにはanimation-duration: 0sを指定して「動かない」ようにし、コンテンツだけがスライドする感覚を出す。
::view-transition-group(*.persistent) {
animation-duration: 0s; /* 動かさない */
}
::view-transition-group(*.tab-content) {
animation-duration: 0.25s;
}
::view-transition-old(*.tab-content) {
animation: slide-out-left 0.25s ease-in;
}
::view-transition-new(*.tab-content) {
animation: slide-in-right 0.25s ease-out;
}永続的な要素にアニメーションをかけないことで、UI全体に安定感が生まれる。
無限スクロールと動的コンテンツ
無限スクロールで後からDOMに追加された要素にも、特別な対応は不要だ。pageswapハンドラはナビゲーション発生時にDOMをクエリする。要素がその時点で存在していれば、問題なくnameを割り当てられる。唯一注意すべきは、data-idなどマッチングに使う識別子が動的に追加されたバッチ間でも一意であることだ。APIが返すIDを利用していれば問題ない。
アクセシビリティとprefers-reduced-motion

アニメーションは、前庭障害を持つユーザーに吐き気やめまい、片頭痛を引き起こす可能性がある。prefers-reduced-motionメディアクエリは、OSレベルで「動きを減らしてほしい」と設定しているユーザーを検出する。ビュートランジションを導入するなら、この対応は必須だ。
@view-transition {
navigation: auto;
}
/* アニメーションのカスタマイズはすべてこのメディアクエリ内に */
@media (prefers-reduced-motion: no-preference) {
::view-transition-group(*.card) {
animation-duration: 0.35s;
animation-timing-function: cubic-bezier(0.4, 0, 0.2, 1);
}
::view-transition-old(*.card),
::view-transition-new(*.card) {
object-fit: cover;
}
::view-transition-old(root) {
animation: fade-out 0.2s ease-in;
}
::view-transition-new(root) {
animation: fade-in 0.3s ease-out;
}
}
/* 動きを減らす設定の場合は0秒で即座に切り替え */
@media (prefers-reduced-motion: reduce) {
::view-transition-group(*),
::view-transition-old(*),
::view-transition-new(*) {
animation-duration: 0s !important;
}
}根本的に安全を取るなら、@view-transitionの宣言自体をprefers-reduced-motion: no-preferenceで囲み、トランジションを完全に無効化する方法もある。どちらを選ぶにせよ、アニメーションを無配慮に提供することだけは避けなければならない。
なお、prefers-reduced-motion: reduceのユーザー向けに、完全に0秒にする代わりに短いクロスフェード(0.15秒)を提供する手法もある。動きそのものをゼロにするのが最も安全だが、穏やかなフェードなら許容できるユーザーもいる。ただし、実際にその設定に依存するユーザーでテストするまでは、0秒を選択しておく方が無難だ。
プログレッシブエンハンスメントとブラウザ対応

ビュートランジションは、プログレッシブエンハンスメントの理想的な例だ。ブラウザが@view-transitionルールを理解しなければ、単に無視され、通常のページ遷移が行われる。何も壊れない。エラーもレイアウトシフトも発生しない。Firefoxがまだサポートしていなくても問題はなく、Safari 18.2以降やChrome、Edgeではフル機能が使える。
唯一、@supports (view-transition-name: none)でガードする価値があるのは、トランジション専用のスタイル(スナップショット品質向上のためのcontain: paintなど)を適用する場合だけだ。それ以外は、古いブラウザでも何もせずにそのまま動く。
この記事のポイント
- view-transition-nameは一意の識別子、view-transition-classはスタイルをグループ化するフック。クラスを使えば、数百要素でも数行のCSSでアニメーションを統制できる。
- nameはページロード時に全要素に付与せず、pageswapとpagerevealを使ってクリック時に動的に設定する。これでパフォーマンスが大幅に向上する。
- トランジション完了後は必ずnameをクリアし、古い名前の衝突を防ぐ。
- prefers-reduced-motionの対応は必須。すべてのアニメーションカスタマイズをメディアクエリ内に閉じ込め、設定ユーザーには0秒または短いフェードを提供する。
- ビュートランジションはプログレッシブエンハンスメント。未対応ブラウザでは何も起こらず、通常のページ遷移となる。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Stack Overflow質問数が激減、AI時代に問いをやめた開発者の未来
2026年5月現在、Stack Overflowの月間質問数は3,000件を下回る水準にまで落ち込んでいる。2014年のピーク時には月間20万件を超えていたことを考えると、この10年余りで実に98%以上が消失した計算だ。
CSS-Tricksに掲載された分析記事は、この急落が単にAIの台頭だけでは説明できないと指摘する。コミュニティのモデレーション方針や初心者への閉鎖性が、ChatGPT登場以前からすでに質問数の減少を招いていたという。本記事では同記事の考察を軸に、AI時代における開発者の「問う力」の行方を掘り下げる。
重要な問いはこうだ。開発者が質問をやめた世界で、AIの学習データはどう更新されるのか。次世代のコード職人は育つのか。これらの懸念はCSS-Tricksの記事全体を貫く核心でもある。
Stack Overflow質問数の急落が示すもの

Stack Overflowは2008年の設立以来、開発者にとって最大級のQ&Aプラットフォームとして機能してきた。しかしData Stack Exchangeで公開されている統計は、驚くべき下落曲線を描いている。
2014年には月間20万件以上の新規質問が投稿されていた。ところが2026年には月間3,000件にも満たない状況だ。このグラフは、単なるプラットフォームの衰退を超えて、ソフトウェア開発における知識共有の在り方そのものが変質したことを物語る。
このグラフが示す事実は重い。Stack Overflowはソフトウェア開発の集合知として15年以上にわたり機能してきたが、その流入がほぼ止まったに等しい。CSS-Tricksの記事では、この減少を「大量のレンガが降ってくるような衝撃」と表現している。
減少の原因はAIだけではない

ChatGPTが公開されたのは2022年11月だ。しかしStack Overflowの質問数減少は、それよりずっと前の2014年から始まっていた。CSS-Tricksの記事は、AIを「最後のとどめ」と位置づけつつ、真の要因は別にあると分析する。
厳格化するモデレーションと閉じたコミュニティ
2014年以降、Stack Overflowは質問の品質を保つためにクローズ・削除の基準を厳格化した。重複質問は容赦なく閉じられ、「すぐに回答できない質問」も排除される方針が取られた。同サイト自身が「社交的ではないが、驚くほどうまくスケールする」と述べていたほどだ。
この運用はGoogle検索経由で既存の回答に誘導するモデルとしては合理的だった。しかし初めて質問しようとする初心者にとっては、門前払いの壁にしか見えなかった。CSS-Tricksの記事は「学びたいという意欲に対して罰を与えられるようなものだ」と表現している。モデレーションの厳しさがコミュニティの新規参加を阻み、質問数の漸減を招いたのだ。
変化の流れははっきりしている。質問を歓迎しないコミュニティの空気がまず参加者を減らし、そこに24時間即答してくれるAIが登場したことで、残っていた質問需要も完全に吸収された形だ。
AIは問題解決の代替になるか

AIはコードを書ける。だが「問題を解決できる」かは別の問いだ。CSS-Tricksの記事は複数の研究を引用しながら、この点を丁寧に解きほぐしている。
AI生成コードの品質
DeepMindのAlphaCodeは競技プログラミングで人間レベルの成績を収めた。しかし実務のソフトウェア開発は競技とは異なる。コーネル大学の研究によれば、AI生成コードは「一般に単純で反復的であり、未使用の構造やハードコードされたデバッグ処理を含みやすい」という。一方で人間のコードは「構造的複雑性が高く、保守性の問題が集中する傾向がある」と報告されている。
セキュリティ面ではさらに深刻だ。VeraCodeが100のAIモデルを対象に脆弱性テストを実施したところ、AI生成コードの45%にセキュリティ上の欠陥が見つかった。CSS-Tricksの記事は「十分な検証なしにAIコードをコピー&ペーストするだけであれば、深刻なバグや脆弱性に必ず直面する」と警告する。
✕ 未使用の変数・関数が残る
✕ ハードコードされたデバッグ処理
✕ 45%にセキュリティ脆弱性
✓ コンテキストを考慮した設計
✓ テスト・エッジケースの考慮
✓ 保守性の問題は多いが、意図は明確
MITの研究も、AIは「良いコードを書けるが、ソフトウェアエンジニアのように思考し判断することはできない」と結論づけている。GitHubが2024年8月に公開した調査では、開発者の97%以上が仕事またはプライベートでAIツールを利用しているという。AIは遍在しているが、それを使いこなす職人技は依然として人間の側にある。
生産性とモチベーションのトレードオフ
Harvard Business Reviewの研究によれば、生成AIは問題解決の生産性を高める一方で、作業者のモチベーションを低下させる副作用がある。CSS-Tricksの記事はこの点を「AIは問題解決を支援する道具としては有効だが、創造性と問題解決アプローチを代替することはできない」とまとめている。
職人はすべての道具を使いこなす。AIもその一つにすぎない。道具の有効性は、それを作った職人の技量と、それを使う工夫によって決まる。CSS-Tricksの記事が引用するCraig D. Lounsbroughの言葉が端的に示す通りだ。
AIを賢く使うための自問

CSS-Tricksの記事では、著者自身が開発作業でAIを使う際に実践している4つのチェック項目が紹介されている。このリストは、AIへの過剰依存を避けつつ生産性を高める実践知として参考になる。
この4つの自問は、AIにすべてを任せるのではなく、開発者自身が主体的にコードの品質と安全性に責任を持つためのガイドラインだ。CSS-Tricksの記事は「AIにすべてを委ねるのは大きな間違いだ」と明言している。
問いをやめた先にあるもの

記事の後半で提起される最も本質的な問いはこれだ。開発者が質問することをやめた世界で、AIの学習データはどう更新されるのか。
CSSを例に取れば、ここ数年でネスト、ビュートランジション、コンテナクエリといった仕様が急速に進化した。数年前のコードと現在のコードでは書き方が根本的に異なる。もし新たな質問と回答の蓄積が止まれば、LLMは古いプラクティスに基づいたコードを出力し続けることになる。CSS-Tricksの記事は「私たちが質問をやめ、回答をやめれば、LLMは時代遅れになるのではないか」という懸念を示している。
Stack Overflowの共同創業者Jeff Atwoodはかつて「Stack Overflowはあなた自身だ」と述べた。同僚プログラマーを信頼することがプラットフォームの核心だった。CSS-Tricksの記事は読者に問いかける。「LLMも同じことをしてくれるだろうか」と。
人間はこれまでも新しい道具とのバランスを見つけてきた。AIも例外ではないだろう。しかし、問うことをやめたコミュニティからは、新しい知見も、次世代の職人も生まれにくい。その危惧がこの記事の底流にある。
この記事のポイント
- Stack Overflowの月間質問数は2014年の20万件超から2026年には3,000件未満へと98%以上減少した
- 減少の原因はAIだけではなく、2014年以降の厳格なモデレーションと初心者排除のコミュニティ構造が先行要因として存在する
- AI生成コードの45%にセキュリティ脆弱性があり、コピー&ペーストだけでは深刻なリスクを招く
- 開発者は小さな質問への分割、出力評価、参照元確認、テストの4ステップでAIと向き合うべきである
- 質問と回答の蓄積が止まれば、LLMは新技術に対応できず陳腐化するという構造的リスクがある
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験