

Google APIキーを守る3つの基本手順、悪用と高額請求のリスクを下げる
Google Geminiを含むAIサービスやGoogle Cloud APIを利用する上で、APIキーの安全な管理は避けて通れない課題だ。適切な対策を怠ると、キーの漏洩や悪用により、高額な請求やプロジェクト環境の侵害を引き起こす可能性がある。
APIキーは「使うのは簡単だが、安全でない方法で使うのも同じくらい簡単」とGoogle Cloud Blogの著者Leonid Yankulin氏は指摘する。この記事では、Googleが提供するAPIキーのリスクを大幅に下げるための、すぐに実践できる具体的な手順を解説する。
これらの対策の多くは、Googleに限らず他のサービスで発行されるAPIキーやプロダクトトークンにも応用可能だ。個人開発者から組織の管理者まで、キーの取り扱いを見直すきっかけにしてほしい。
Step 1. 新しいAPIキーは「隔離」と「制限」が大前提

APIキーを作成する際、最初からセキュリティを考慮しておくことで、後々のトラブルを未然に防げる。「とりあえず作成」して放置されている無制限のキーが、組織における最大のリスク要因の一つだ。
キーは専用プロジェクトで作成する
新しいAPIキーを生成する最初のルールは、他の目的に使っていない独立したGoogle Cloudプロジェクト内で作成すること。これにより、仮にキーが漏洩しても、被害がそのプロジェクトのリソースに限定される。
プロジェクトを分けることは、問題発生時の原因特定と影響範囲の調査を大幅に容易にする。本番環境と同じプロジェクトで実験用のAPIキーを発行するといった行為は避けるべきだ。
API制限で「できること」を絞る
APIキーを作成する際、デフォルトではAPI制限がかかっていない。これは、そのキーが有効化されているすべてのサービスにアクセスできる状態を意味する。Google Cloud Blogの著者は「制限のないキーを絶対に作るな」と強調する。
API制限を設定することで、キーがアクセスできるサービスを特定のAPIだけに絞り込める。たとえば、AI Studioで利用するなら「Gemini API」のみ、地図機能だけが必要なら「Maps API」だけに制限する。漏洩時の攻撃範囲を最小化する考え方だ。
注意すべき副次的なポイントとして、AI StudioやFirebaseなど間接的なUIからキーを作成した場合、意図しないAPI群が自動で許可されているケースがある。Firebase経由で作ったキーは24ものAPI(DatastoreやFirestore、Cloud SQLなど)へのアクセスが許可されるため、不要なものは手動で外す必要がある。
制限したいAPIが一覧に表示されない場合は、そのAPIが対象プロジェクトで有効化されていない可能性が高い。APIライブラリから事前に有効化しておく必要がある。
アプリケーション制限で「使う場所」を縛る
API制限が「どのサービスを使えるか」を制御するのに対し、アプリケーション制限は「どのアプリからキーを使えるか」を制御する。こちらも併用することで、セキュリティは飛躍的に高まる。
たとえばAI Studio専用のキーなら、許可するウェブサイトを aistudio.google.com に限定すれば、他のスクリプトや自動化ツールから大量のトークンを消費されるリスクを防げる。指定できる制限タイプは以下の4種類だ。
- ウェブサイト、許可するURLのリストを指定
- サービス(IPアドレス)、IPv4やIPv6アドレス、サブネットマスクで指定
- iOSアプリ、バンドルIDで指定
- Androidアプリ、パッケージ名と証明書フィンガープリントのペアで指定
注意点として、1つのキーに設定できるアプリケーション制限タイプは1種類だけ。複数のアプリ種別で利用する場合は、それぞれ専用のAPIキーを発行する。キーをアプリごとに分けておけば、利用状況の監視や侵害発生時の調査も容易になる。
ウェブサイト
https://aistudio.google.com自動化スクリプトからの呼び出し、不明なIPアドレスからのリクエスト、許可リストにないWebサイト
Step 2. APIキーは「誰でも使える」前提で保管する

APIキーの最大の特性は、特定の個人アカウントと紐づかない点にある。Google Cloud Blogの記事で「誰でも使える」と強調されているように、キー文字列を知っていれば誰でもその権限でAPIを呼び出せる。保管の安全性の重要性はAPI制限と同等だ。
「APIキーを絶対に、見えやすい場所に保存してはいけない」という基本ルールはシンプルだが、実際の開発現場ではしばしば破られている。ソースコードへのハードコードや、Gitリポジトリへの平文でのコミットは典型的なミスだ。
自社アプリケーションではSecret Managerを使う
Google Cloudを利用しているなら、Secret Manager(シークレットマネージャー)のような専用の機密情報管理サービスにキーを格納するのが鉄則だ。Secret Managerを使えば、APIキーをCloud RunやGKEの実行環境に安全に注入できる。
さらに保護レベルを上げたい場合は、キーを環境変数に渡すのではなく、アプリケーションコード内でSecret Managerから直接読み取る方式も選択肢になる。これによりランタイムメモリへの露出時間をさらに短縮できる。
外部アプリケーションではキーの取り扱いを事前調査する
サードパーティ製のツールやサービスにAPIキーを入力する場合、そのアプリケーションがキーをどのように保管し、通信しているかを確認する必要がある。
Webアプリケーションであれば、ブラウザの開発者ツールを使ってトラフィックを調査し、キーが暗号化されていない通信経路で送信されていないかを確認する。「Google AI Studioは暗号化されたローカルストレージを使用し、TLS暗号化チャネル経由でのみキーを送信する」とYankulin氏は具体例を挙げている。こうした設計を満たしていないツールへのキー提供は避けるべきだ。
異常を検知したら「即削除」、調査の手順も把握する

どんなに対策を施しても、キーが侵害される可能性はゼロにはできない。迅速な初動対応が被害を最小化する鍵を握る。Yankulin氏は「クレジットカードを無くしたときと同じように、まずキーを削除すること」と述べている。
Cloudコンソール、または gcloud services api-keys delete コマンドで即座にキーを無効化する。誤報だったと判明した場合でも、削除から30日以内であれば undelete コマンドで復元が可能だ。
侵害されたキーを特定する2段階調査
どのAPIキーが侵害されたか不明な場合は、以下の2段階で調査を進める。
第一段階、組織またはプロジェクト内のすべてのAPIキーを洗い出す。Cloudコンソールの「Asset Inventory」でリソースタイプを apikeys.Key に絞り込む方法と、gcloud services api-keys list コマンドを使う方法がある。組織全体を横断検索する場合は gcloud asset search-all-resources コマンドでJSON出力をフィルタリングする。
第二段階、API消費量のグラフを確認する。Cloud Monitoringの指標 serviceruntime.googleapis.com/api/request_count を使い、credential_id ラベルで特定のAPIキーIDに絞り込む。リクエスト数が異常に急増している場合、そのキーが悪用されている可能性が高い。
APIキーIDは、Cloudコンソールの「Credentials」ページでキーを選択した際のURL(/key/[KEY_ID] 部分)から、または gcloud services api-keys list --format='value(displayName,uid)' コマンドで確認できる。
1時間あたり数千リクエスト。日次グラフはなだらかで安定した波形
1時間あたり数十万リクエストに急増。短時間で不自然なスパイクが出現
Step 3. 日常的な「APIキー衛生管理」を習慣化する
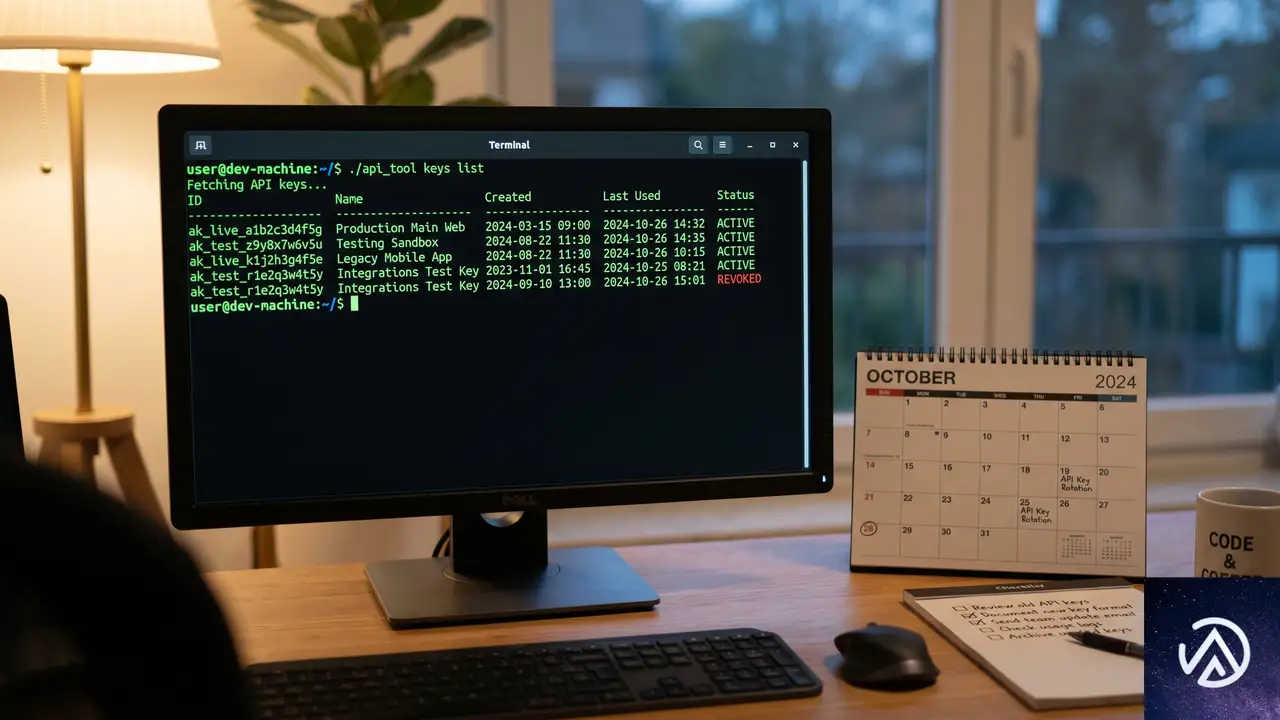
エンジニアだけの話ではない。クラウドをかじり始めたばかりの個人ユーザーも、今すぐAPIキーの「衛生管理」を始めるべきだ。放置されたキーは、知らぬ間に悪用の温床となる。
Yankulin氏が推奨する即時実行すべきアクションは以下の5つだ。
- 自分が保有するすべてのAPIキーを洗い出す
- 使っていないキー、見覚えのないキーはすべて削除する(30日以内なら復元可能)
- 残すキーは、利用するAPIだけに制限し、可能ならクライアントも絞り込む
- 組織の管理者は
apikeys.googleapis.com/Keyの組織ポリシーを設定し、キーの乱立と制限設定の抜けを防ぐ - 定期的なキーのローテーション(再発行と差し替え)を検討する。ただし、既存キーを削除する前に、すべての利用箇所を特定して新しいキーに更新する周到さが必要だ
キーローテーションの際に「既存キーがどこで使われているのか把握しきれていない」という問題に直面するケースは多い。日頃からキーの利用箇所をドキュメント化しておくこと、そして新しいキーの発行時点から適切な制限をかけておくことが、結果的にローテーションのハードルを下げる。
この記事のポイント
- APIキーは「誰でも使える」クレデンシャル。見える場所に保管しないことが大前提
- 新規キー作成時は、API制限とアプリケーション制限を両方設定して攻撃の範囲を狭める
- 保管にはSecret Managerなど専用の機密情報管理サービスを使い、コードへのハードコードを避ける
- 使っていないキーや制限のないキーは即座に削除し、組織ポリシーで乱立を防ぐ
- 侵害が疑われる場合はクレジットカードと同じ感覚で「まず削除」。監視データで異常を検知する

・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Google Antigravity 2.0リリース、IDE不要のエージェント体験を実現
Google DeepMindは2026年5月17日、AIエージェントを中核に据えたデスクトップアプリケーション「Google Antigravity 2.0」を発表した。従来のIDE(統合開発環境)を廃し、エージェントとの同期・非同期の対話に完全に最適化された独立アプリケーションとして再設計されている点が最大の特徴だ。
この新バージョンは、2025年11月にリリースされた初代Antigravity IDEの「Agent Manager」を発展させたもので、ソフトウェア開発だけでなく、より広範な知識作業をエージェントと協働するための基盤として位置づけられている。macOS、Linux、Windowsに対応し、最新のGeminiモデルを活用する。
開発者だけでなく、コードやIDEに馴染みのないユーザーにとっても直感的なエージェント体験を提供することが、この2.0の大きな狙いだ。
エージェントファーストの新設計

Antigravity 2.0の最大の転換点は、IDEという概念を完全に取り除いたことにある。従来のAntigravity IDEでは、コードエディタとエージェント管理画面が同居していた。この設計は開発者には便利だが、エージェント本来の可能性を制限する側面もあった。
IDEを捨てた理由
Google DeepMindの記事によれば、開発チームは当初から「コーディングの高速化だけでは、ユーザーに提供できる価値に限界がある」と認識していたという。モデル性能が向上するにつれ、エージェントの活躍領域は自然とコード以外の知識作業へと拡大した。
実際、初代Antigravity IDEのAgent Managerは、開発以外のタスクにも広く使われていた。だが、IDEの枠組みの中でそれを行うのは、非開発者にとっては直感的とは言えなかった。Antigravity 2.0は、その制約を解消し、エージェントとの協働を主役に据えた設計へと舵を切った。
プロジェクトベースの管理方式
もう一つの大きな設計変更が、リポジトリとの密結合の解除だ。Antigravity 2.0では、エージェントの会話は「ワークスペース(リポジトリ)」単位ではなく、「プロジェクト」単位でグループ化される。一つのプロジェクトが複数のフォルダを参照でき、プロジェクトごとにエージェントの設定や権限を個別に定義できる。
これにより、エージェントがより多くの情報源にアクセスし、複雑なタスクに取り組めるようになりつつ、適切なガードレールも維持される。
強化されたエージェント機能群

Antigravity 2.0では、エージェントの能力が大幅に強化された。中核となるのは「動的サブエージェント」「非同期タスク管理」「JSONフック」の3つだ。
動的サブエージェント
メインエージェントがタスクを実行する際、必要に応じてサブエージェントを動的に定義し、呼び出せるようになった。サブエージェントは焦点を絞った部分タスクを担当する。これにより、メインエージェントのコンテキストウィンドウが汚染されず、複数のサブタスクを並列に処理できる。
コンテキストウィンドウとは、エージェントが一度に把握できる会話や情報の範囲のことだ。長大なタスクではここがすぐに一杯になり、エージェントの応答品質が落ちる原因になっていた。サブエージェントへの委譲は、この問題への有効な対策となる。
非同期タスク管理
タスクやコマンドを非同期で実行できるようになった点も大きい。メインエージェントが処理をブロックされることなく、バックグラウンドで複数の作業を進められる。たとえば、コードのビルドを走らせながら次の機能の設計について対話を続ける、といった並行作業が可能になる。
JSONフック
JSONフックは、エージェントの動作を外部から制御する仕組みだ。シンプルなJSON形式でフックを定義し、エージェントの特定の挙動をインターセプトして制御できる。柔軟なカスタマイズを可能にしつつ、設定の複雑さを抑えている。
スケジュールタスクとプロジェクト管理

Antigravity 2.0では、エージェントとの新しい関わり方として「スケジュールタスク」が導入された。cron式を使ってエージェントの起動スケジュールを事前に定義できる。日次レポートの生成、定期的なデータ収集、ナイトリービルドの監視など、手動で毎回指示を出す必要がなくなる。
スラッシュコマンド「/schedule」を使うか、専用のスケジュールタスク画面から設定する。一度だけのタイマー実行と、繰り返しの定期実行の両方に対応している。
新しいスラッシュコマンドと音声入力
Antigravity 2.0には、エージェントとの対話をより精密に制御するための新しいスラッシュコマンドが追加された。
4つの新コマンド
/goalは、指定したタスクを完了まで実行させ、途中でユーザーに入力を求めない。長時間の作業を任せきりにしたい場面で有効だ。/grill-meは実装開始前に、エージェントが逆に質問を投げかけて計画の詳細を詰める。見落としを事前に洗い出すのに役立つ。/scheduleは前述のとおり、タスクのスケジュール実行を指示する。/browserは、エージェントにブラウザ操作を明示的に許可するかどうかを制御する。
音声入力のライブ文字起こし
テキスト入力欄の横にあるマイクアイコンを使った音声入力が、ライブ文字起こしに対応した。従来は生の音声ファイルをモデルに渡していたが、2.0では発話と同時にテキスト化が進む。音声の遅延を感じさせず、より自然な対話が可能になった。
Antigravity IDEとの関係と今後の展望

Antigravity 2.0は独立したアプリケーションとして提供されるが、従来のAntigravity IDEがすぐに置き換わるわけではない。IDE側のAgent Managerも当面は維持され、今後のアップデートでIDEからAgent Managerが分離される予定だ。IDEは純粋なエージェント駆動型IDEとして残る。
すでにAntigravity IDEをインストールしているユーザーは、次回のアップデートで自動的にAntigravity 2.0に更新される。その際、IDEを残すかどうかを選択できる。両アプリはドック上でアイコン背景が異なり、2.0は白背景、IDEは黒グリッド背景で区別される。
Google DeepMindの記事によれば、社内のGooglerたちはすでにAntigravity 2.0と各種IDEを併用しているという。今後、主要なIDE向けの互換拡張機能やプラグインも提供される予定だ。
今後のロードマップ
Antigravity 2.0と同時に、CLI、SDK、APIも発表された。他のGoogle製品や技術スタックとの統合も進められており、エージェントハーネスとモデル層の共同最適化が継続される。記事では、リモートコントロール機能、さらなる製品統合、クラウドデプロイエージェントなどが今後の展開として示唆されている。
この記事のポイント
- Antigravity 2.0はIDEを廃した完全エージェントファーストの独立アプリケーション
- 動的サブエージェントと非同期タスク管理で複雑な作業を効率的に処理
- スケジュールタスクにより、エージェントの定期実行が自動化可能
- 音声入力がライブ文字起こしに対応し、対話のテンポが向上
- 従来のIDEも維持され、開発者は両方を併用できる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

CSSのsibling-index()とsibling-count()でDOMを数式レイアウト
CSSに<sibling-index()>と<sibling-count()>という2つの関数が追加された。これらは要素の兄弟関係を「数値」として取得し、calc()の中で計算できる。2025年6月時点でChrome 138とSafari 26.2が対応済みで、Firefoxも実装が進行中だ。
この新機能の最大の価値は「ブラウザがすでに知っている情報を、CSSから直接引き出せる」点にある。従来はJavaScriptでループ処理するか、Sassで大量の:nth-child()ルールを生成するしかなかった。それが1行のCSSで完結する。
本記事では、sibling-index()とsibling-count()の基本から実践パターン、注意点までを解説する。WordPressサイトのカスタムCSSを書く制作者にも役立つ内容だ。
従来のスタガードアニメーションが抱えていた問題

カードグリッドに1枚ずつ遅延させて表示する「スタガードカスケード効果」は、見た目がよく実装も簡単に思える。ところが実際には、かなり面倒なコードが必要だった。
:nth-child()の限界
10枚のカードに異なるアニメーション遅延を設定したいとする。従来の方法では、こう書くしかなかった。
li:nth-child(1) { --idx: 1; }
li:nth-child(2) { --idx: 2; }
li:nth-child(3) { --idx: 3; }
/* ...8個分続く... */
li:nth-child(10) { --idx: 10; }
li {
animation-delay: calc(var(--idx) * 100ms);
}10項目なら10ルールで済むが、50項目なら50ルールだ。Sassのループでビルド時に数百個のセレクタを生成する方法もあるが、CSSファイルが膨れ上がる。Roman Komarov氏が考案したO(√N)戦略でも、1023要素をカバーするのに63ルールが必要になる。
JavaScript依存の落とし穴
もう1つの方法は、JavaScriptでDOMを走査してインラインスタイルを書き込む方式だ。style="--index: 3" を各要素に付与する。動作はするが、レイアウトのための値がスクリプトに分散し、半年後に別の開発者がコンポーネントをリファクタリングした際に静かに壊れる。ブラウザはすでに「どの要素が3番目の子か」を知っているのに、CSSからはその情報にアクセスできなかった。
Smashing Magazineの記事で著者の一人が指摘するように、この状況は「ブラウザがすでに持っているデータを、わざわざ手動で再計算している」矛盾だった。
sibling-index()とsibling-count()の基本
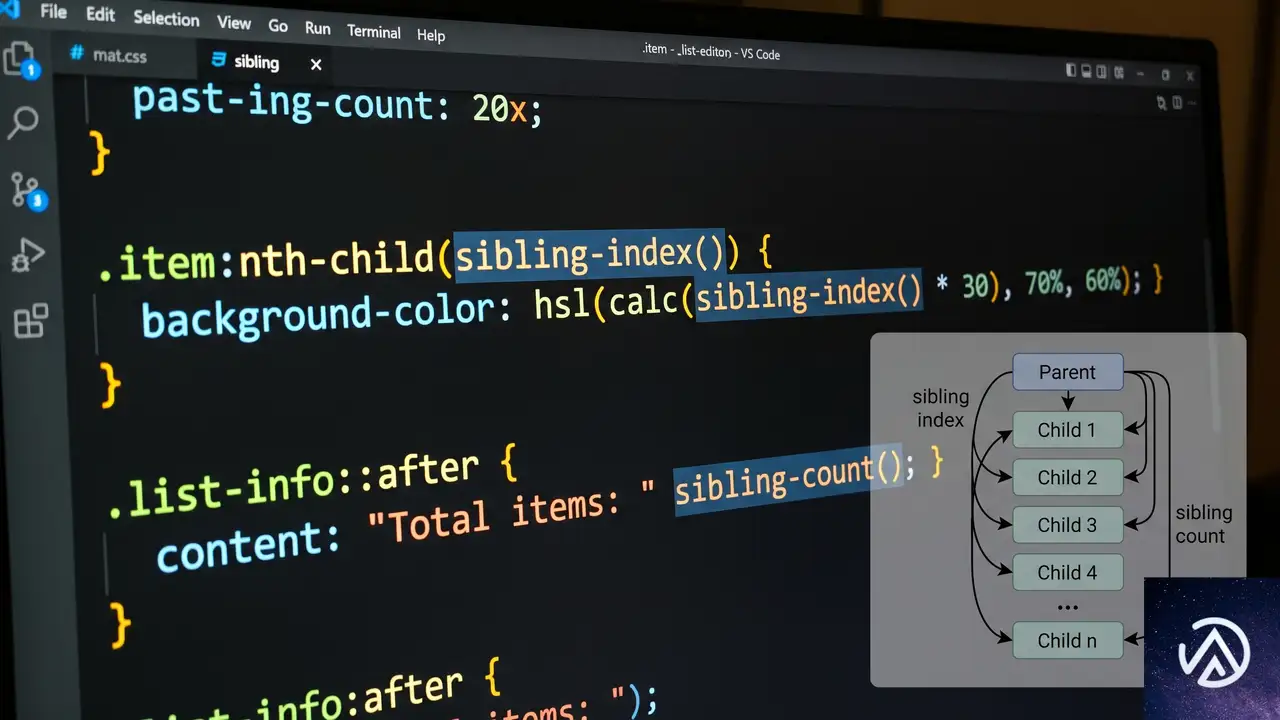
この2つの関数はCSS Values and Units Module Level 5で定義されている。どちらも引数を取らず、CSSの宣言内で直接数値として使える点が革新的だ。
element.parentElement.children.length に相当counter()との違いに注意したい。counter()は文字列を返し、疑似要素のcontentプロパティ内でしか使えない。一方、sibling-index()はCSS内の任意の場所で使える実数だ。時間値や角度、ピクセル値との計算もCSSが自動的に型変換する。
:nth-child()との本質的な違い
:nth-child()は「セレクタ」であり、要素を選択するための仕組みだ。calc(:nth-child() * 10px)のような書き方はできない。sibling-index()は「宣言の中で使える値」を生成する。両者は役割が異なり、補完関係にある。
実践的なユースケース

これらの関数が整数を返すと理解できれば、応用の幅は一気に広がる。以下に、WordPressサイトのカスタマイズにも活用できるパターンを紹介する。
リバーススタガー
最後の項目から先にアニメーションさせたい場合は、引き算で反転する。
.card {
animation: fade-in 0.4s ease both;
animation-delay: calc((sibling-count() - sibling-index()) * 80ms);
}最後の子要素は (N – N) × 80ms = 0ms で即座に表示される。最初の子要素は (N – 1) × 80ms の遅延となる。ページ読み込み直後からアニメーションが始まり、待ち時間が生じない。
自動均等幅
タブやカラムの幅を子要素の数に応じて自動調整する。
.tab {
width: calc(100% / sibling-count());
}5つのタブなら各20%、6つ目が追加されれば約16.66%になる。メディアクエリやリサイズ監視、JavaScriptは不要だ。ただし項目が増えすぎてタブが細くなりすぎる場合は、Flexboxの折り返しなど別の手法を併用する判断も必要になる。
色相分布
カラーホイール上で均等に色を分散させる。
.swatch {
background-color: hsl(
calc((360deg / sibling-count()) * sibling-index()) 70% 50%
);
}3項目なら120度間隔、12項目なら30度刻みで色相が割り当てられる。DOM内の項目数に応じてパレットが自動調整されるため、JavaScriptのカラーライブラリで行っていた処理をCSSだけで完結できる。
円形メニュー
項目を円周上に配置する計算も、CSSの三角関数と組み合わせればシンプルになる。
.radial-item {
--angle: calc((360deg / sibling-count()) * sibling-index());
--radius: 120px;
position: absolute;
left: calc(50% + var(--radius) * cos(var(--angle)));
top: calc(50% + var(--radius) * sin(var(--angle)));
transform: rotate(calc(var(--angle) * -1));
}6項目なら六角形、8項目なら八角形になる。項目を追加・削除すればレイアウトが再計算される。JavaScriptで座標を逐一計算する必要はない。
Z-indexスタッキング
カードを扇状に重ねる表現も1行で済む。
.card {
z-index: calc(sibling-count() - sibling-index());
}最初のカードが最も高いz-indexを持ち、最後のカードは0になる。逆順にしたい場合は計算式を反転すればよい。
注意点と制限事項

仕様を読み込んでも気づきにくい落とし穴がいくつかある。実際に使い始める前に把握しておきたい。
Shadow DOMのスコープ
sibling-index()とsibling-count()は「DOMツリー」に対して動作し、フラット化された視覚ツリーではない。この違いはWeb Componentsを使う場面で問題になる。
カスタム要素内のシャドウDOMで内部のdivにsibling-index()を適用すると、slotで投影された外部コンテンツはカウントされない。slotが300要素を投影していても、シャドウツリー内ではsection直下の子要素はslot要素とdivの2つだけだ。
また、外部のスタイルシートから::part()経由でコンポーネント内部にsibling-index()を使おうとすると、ブラウザは0を返す。これはサードパーティコンポーネントの内部構造を外部CSSから探られるのを防ぐための意図的な設計だ。
疑似要素はカウントされない
::beforeや::afterは兄弟要素ではない。sibling-count()に含まれず、自身のsibling-index()も持たない。ただし、疑似要素の宣言内でこれらの関数を使うことは可能だ。その場合、疑似要素ではなく「元の要素」のインデックスが評価される。
display:noneでもカウントされる
これは特に注意が必要だ。display:noneを指定した要素はレイアウトツリーから消えるが、DOMツリーには残っている。sibling-index()はDOMツリーを見るため、非表示要素もカウントしてしまう。
visibility:hiddenやopacity:0も同様にカウントされるが、これらは要素が空間を占有し続けるため直感的にも理解しやすい。display:noneだけが「視覚的に消えているのにDOMスロットを占有している」という特殊な挙動になる。
カスタムプロパティの即時評価
親要素で –idx: sibling-index() と定義すると、その値は親要素自身のインデックスで即座に解決される。すべての子要素が同じ固定値を継承してしまい、意図した動作にならない。
正しい方法は、関数を必要な要素自身に直接適用することだ。
/* 誤り:親で定義すると全子要素が同じ値を継承 */
.parent {
--idx: sibling-index();
}
/* 正解:各子要素で個別に定義 */
.child {
--idx: sibling-index();
animation-delay: calc(var(--idx) * 100ms);
}CSSWGでは@propertyのinherits:declaration拡張が議論されているが、まだ仕様化には至っていない。当面は各要素に直接適用するのが安全だ。
大規模DOMでのパフォーマンス
DOMの変更(要素の追加、削除、並べ替え)は、影響を受ける兄弟要素すべてのスタイル再計算を引き起こす。この処理はカスケードフェーズで行われるため、JavaScriptでループしてインラインスタイルを書き込む従来の方法よりは高速だ。
ただし、1万子要素を持つコンテナの先頭に要素を挿入すると、後続の全要素のインデックスが再計算される。ナビゲーションやカードグリッドのような通常の用途では問題にならないが、リアルタイム株価表示や無限スクロールフィードなど、数千ノードが常時入れ替わる場面では、仮想化ウィンドウ内でJavaScript管理のインデックスを使い続ける方が無難だ。
アクセシビリティへの配慮
これらの関数は純粋に「視覚的」なものである点を強調しておきたい。見た目を変えるだけで、意味を変えるわけではない。
sibling-index()の計算結果を使ってorderプロパティやグリッド配置でリストを視覚的に並べ替えた場合でも、スクリーンリーダーはDOMのソース順で読み上げる。キーボードのタブ順もDOM順に従う。視覚レイアウトとセマンティック構造が矛盾すれば、アクセシビリティ上の問題になる。
データグリッドやラジアルメニューなど、ツリーカウントに依存するインタラクティブなコンポーネントでは、JavaScriptでARIA属性(aria-posinsetやaria-setsize)を同期させる必要がある。CSSが計算した値とARIAが伝える情報が食い違えば、支援技術のユーザーには壊れた体験が提供される。
ブラウザ対応とフォールバック戦略

2025年6月時点で、Chrome/Edge 138とSafari 26.2が安定版で対応している。FirefoxはMozillaのポジションが肯定的で実装作業が進行中だが、安定版にはまだ含まれていない。最新の対応状況はcaniuseで確認することを推奨する。
ChromeとSafariで世界のトラフィックの約75〜80%をカバーするが、Firefox未対応の間はフォールバックが必須だ。
/* すべてのブラウザで動作するベースライン */
.item {
width: 25%;
animation-delay: 0ms;
}
/* 対応ブラウザでプログレッシブエンハンスメント */
@supports (z-index: sibling-index()) {
.item {
width: calc(100% / sibling-count());
animation-delay: calc(sibling-index() * 80ms);
}
}Firefoxには静的なフォールバック、対応ブラウザには数式レイアウトを提供する。どのブラウザでもページが壊れることはない。
ポリフィルについて補足すると、JavaScriptで兄弟要素をループしてインラインスタイルを設定する方式は、まさにこれらの関数が置き換えようとしているものだ。Juan Diego Rodríguez氏が公開している段階的移行の手法では、Roman Komarov氏のカウンティングハックなど既存のCSSテクニックを橋渡しとして活用し、ネイティブ対応までの移行期間をしのぐアプローチを提案している。
今後の展望

現在の仕様では「すべての要素兄弟」をカウントするのみだが、CSSWGのIssue #9572では、:nth-child()と同様の「of セレクタ」引数の拡張が計画されている。
sibling-index(of .active)のような記法が実現すれば、特定のセレクタに一致する兄弟だけをカウントできる。全体で8番目の子だが.activeクラスを持つ中では3番目、という要素は3を返す。フィルタリングやトグル表示を伴う動的なUIでも、DOM操作なしで連続したインデックスを維持できるようになる。
さらに、children-count()とdescendant-count()の提案もCSSWGで議論されている。children-count()は要素が持つ子要素の数、descendant-count()はすべての子孫を再帰的にカウントする。sibling-index()とsibling-count()が「兄弟の間での自分の位置」という水平方向の情報を提供するのに対し、children-count()とdescendant-count()は「自分の下に何があるか」という垂直方向の情報を提供する。両方が揃えば、CSSからDOMツリーを俯瞰できるようになる。
10個の:nth-child()ルールを書きながら「もっと良い方法があるはずだ」と感じていた制作者にとって、その「もっと良い方法」がようやくブラウザに実装されつつある。CSSがDOMツリーを「理解」し始めたことで、レイアウトの表現力は次の段階に入ったと言える。
この記事のポイント
- sibling-index()とsibling-count()はDOMツリーの構造をCSSから数値として取得できる新関数である
- スタガードアニメーションや均等幅レイアウトが1行のCSSで完結し、JavaScriptや大量の:nth-child()ルールが不要になる
- Chrome 138とSafari 26.2が対応済み、Firefoxは実装進行中で@supportsを使ったフォールバックが必須
- display:noneの要素もカウントされる点、カスタムプロパティの即時評価、Shadow DOMのスコープに注意が必要
- 視覚的な並べ替えはアクセシビリティ上の問題を引き起こすため、ARIA属性との同期が欠かせない
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

エージェント型コマース到来 ECブランドに求められる「証明可能な約束」
AIエージェントが消費者の購買意思決定を代行する「エージェント型コマース」が急速に現実味を帯びている。2030年までに米国のEコマース取引の25%がエージェントAIによって駆動されるとの予測もある。この変化は、ブランドが築いてきた感情的な信頼のあり方そのものを揺るがす。
MarTechのGreg Kihlstrom氏は、エージェント型コマースにおいてブランドの約束は「証明可能」でなければ選ばれなくなると指摘する。従来のように広告やブランドイメージで勝負するだけでなく、価格の透明性、配送の信頼性、返品ポリシー、ロイヤルティの価値など、定量的なシグナルをもとにAIが評価する世界だ。本記事では、EC事業者がこのパラダイムシフトにどう備えるべきか、具体的な戦略と視点を掘り下げる。
AIエージェントがECの購買決定をどう変えるか

すでに加速するエージェント型コマース
マッキンゼーの調査では、すでに消費者の約70%が購買プロセスにAIツールを活用している。B2Bバイヤーに至っては73%がAIを利用して購買を評価しているという。さらにベインの予測では、2030年までに米国Eコマース売上の25%(3000億ドルから5000億ドル相当)がエージェントAIによって駆動される見込みだ。数字だけを見ても、AIエージェントを無視したEC戦略は成り立たなくなっている。
ブランド評価の基準が感情から定量データへ
消費者はテレビCMやSNSの口コミ、ブランドカラーといった「感覚的な信頼」で商品を選んできた。しかしAIエージェントは、価格の透明性、在庫の正確さ、配送実績、返品ポリシーの明快さ、カスタマーサービスの評価など、数値化できる指標だけを抽出して比較する。MarTechの記事が指摘するように、ブランドへの感情的な好意はエージェントのフィルターでは評価外になりやすい。ここでEC事業者が直面するのは、「ブランドらしさ」よりも「ブランドが約束を守れるか」を可視化する必要性だ。
このデモが示すように、AIエージェントはブランドの「なんとなくの評判」を即座に無視し、操作可能なデータだけをもとに推薦を組み立てる。EC事業者は、自社の商品ページやバックエンドの在庫管理、配送ログがエージェントにどう読まれるかを設計段階から意識しなければならない。
ブランド信頼が証拠ベースに変わる

改善すべきブランドオペレーション
これまでのブランド構築は、広告やクリエイティブで「信頼できる」と伝えることに主眼があった。しかしAIエージェントが介在する世界では、ブランドの主張と実態のズレは直ちに排除の原因になる。MarTechの記事がいくつかの具体例を挙げているように、以下のようなギャップは許容されない。
- 「便利さ」を謳いながら、在庫データが不正確で欠品が頻発する
- 「顧客第一」と掲げながら、解約条件をわかりにくくしている
- 「プレミアムサービス」を自称しながら、返品手続きが煩雑で時間がかかる
こうした不一致は、消費者が気づく前にAIエージェントによって検出され、比較リストから外されてしまう。つまり、ブランドの約束はオペレーションの隅々まで証明できなければ、エージェントのレコメンデーションに残る資格を失うのだ。EC事業者にとっては、フルフィルメントの精度やカスタマーサポートの透明性を、ブランド価値の根幹として再定義する必要がある。
ロイヤルティプログラムをエージェントが読み取れる形に

数値化できない特典は存在しないのと同じ
多くのロイヤルティプログラムは、アプリのプッシュ通知やポイント残高、会員ランクといった、人間の感情に訴える仕組みで設計されている。しかしAIエージェントは、ポイントの経済的価値やステータスがもたらす具体的な優遇措置(送料無料、優先サポート、返品猶予など)をリアルタイムで計算できなければ、それらの特典を「存在しない」と見なす。MarTechの記事が強調するように、会員であること自体はエージェントにとって何の意味も持たない。
WooCommerceなどECプラットフォームを運用する事業者は、ロイヤルティ機能(ポイント残高、会員限定価格、送料優遇)を外部システムからAPI経由で読み取れる形に整備する必要がある。たとえばヘッドレス構成を採用し、エージェントが直接クエリできるエンドポイントを用意すれば、ブランドの優位性が定量情報として伝わる。
顧客データが「委任レイヤー」として機能する

許諾と選好をエージェントに伝える
AIエージェントの活躍が広がっても、人間が最終的な購入ボタンを押すケースは当面続く。だからこそ顧客データは、人向けのパーソナライズとエージェント向けの委任情報の両方を扱う必要がある。MarTechの記事は、従来のセグメント分析やキャンペーン適格性だけでなく、顧客がエージェントにどのような権限を委ね、どのような制約(価格帯、サステナビリティ重視、プライバシー限度)を設けているかまで記録すべきだと指摘している。
- ✕ 購買履歴とセグメント情報のみ
- ✕ キャンペーン適格性が中心
- ✕ エージェントへの委任設定なし
- ✓ 価格感度やサステナビリティ志向を記録
- ✓ プライバシー許容度や返品ポリシー選好
- ✓ エージェントに委任する権限の範囲を明示
さらに、本人認証と代理人の識別も複雑化する。人間の顧客、家族、法人アカウント、権限を持つAIエージェントが混在する環境では、誰がどの情報にアクセスし、どれだけの取引を代行できるかを管理する仕組みが不可欠だ。EC事業者は、同意管理と顧客プロファイルの構造を、エージェント時代を見据えて再設計する必要がある。
マーケティング指標をエージェント起点で再設計する

従来のKPIでは見落とすエージェントの動き
サイトのトラフィックや検索順位、最終クリックアトリビューションだけを追いかけていても、エージェント型コマースでは手遅れになる。AIエージェントはブランドのウェブサイトを訪れる前に、商品情報APIやレビューサイト、物流データを横断的に調査し、候補を絞り込む。コンバージョン率が落ちた時点では、すでにエージェントの比較リストから外されている可能性が高い。
MarTechの記事は、まず「エージェントがブランドを正しく見つけ、正確に理解できるか」を測定し、その次に「エージェントが取引まで完結できるか」を追うべきだと示唆している。具体的には、エージェント向けのフィードが正確か、構造化データが最新か、ロイヤルティ情報がAPIで計算可能かといった指標をKPIに加える必要がある。ECの現場では、Google Merchant Centerや構造化データの品質監査、WooCommerce REST APIのレスポンス速度と正確性を定期的に評価する体制が求められる。
この記事のポイント
- エージェント型コマースでは、ブランドの約束を価格や配送実績などの定量データで証明できなければ選ばれない
- AIエージェントは感情的なブランド好意を評価せず、在庫精度や返品ポリシーの明確さを数値化して比較する
- ロイヤルティプログラムの特典はAPIで計算可能でなければ、エージェントの意思決定から除外される
- 顧客データには、人向けのパーソナライズだけでなく、エージェントへの委任設定やプライバシー選好を組み込む必要がある
- マーケティング指標は、エージェントが見つけやすく正確に取引できる状態かどうかを測定する方向へシフトすべきである
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

WooCommerce商品管理が大幅刷新へ、DataViewsで超高速カタログ操作
WooCommerceの商品管理画面が、WordPressのDataViewsとDataFormsという基盤技術を用いて根本から再構築された。2026年5月21日、Automatticの開発者らが4週間の「Radical Speed Month」で生み出した概念実証(PoC)として公開したものだ。
このPoCは実際に動作し、WooCommerceのコアに機能フラグ付きで組み込まれている。商品一覧の高速な検索・絞り込み、バリエーションの階層表示、そして長年要望の多かったクイック編集と一括編集を、サードパーティ製プラグインなしで実現する。現在50以上存在する補完系拡張機能の多くが不要になる可能性を秘めた、意欲的な試みだ。
これはリリースを約束するものではなく、コミュニティからのフィードバックを得るための実験的ビルドである。大規模カタログでのパフォーマンス、拡張機能向けのAPI整備、一括編集の堅牢化など、まだ多くの課題は残る。しかし、WooCommerceの管理画面体験がどこへ向かおうとしているのか、その方向性をはっきり示すものとなっている。
カタログ管理が抱えてきた構造的な問題

商品管理はWooCommerce店舗運営の中核業務だ。それにもかかわらず、管理画面の体験はマーチャントの期待に追いついていなかった。ユーザーから繰り返し寄せられていた要望は、より優れた検索とフィルタリング、多数の商品を横断的に操作できる一括編集、情報量の多いクイック編集、そしてバリエーションを親商品から開かずに一覧できる仕組みだった。
このギャップを最も如実に物語るのが、エコシステムの現状だ。WooCommerceの商品管理ワークフローを補完するために、クイック編集拡張、一括編集ツール、スプレッドシート形式のグリッド、カスタムカラムマネージャーなど、50以上の拡張機能が存在している。これは「拡張性がある」という健全な状態ではない。コアが基本的な操作フローすら提供できておらず、マーチャントが他社製プラグインで組み立てざるを得ない状況を意味する。
今回のプロジェクトが問いかけたのは、WordPressコアがDataViewsとDataFormsをプリミティブとして提供するようになった今、「全商品」画面をそれらのネイティブ機能で再構築できるのか、そして拡張機能エコシステムが補ってきた機能を失わずに済むのか、という点だ。
この比較図が示す通り、刷新後の画面では商品操作の導線が大幅に短縮される。特にバリエーションの扱いは、従来の「個別クリックで詳細画面へ」から「一覧上で即時展開」へと変化し、数十のバリエーションを持つストアでの作業効率が大きく変わる見込みだ。
4週間で構築された3つの主要機能

この概念実証は、フル機能の再設計ではなく、最も差し迫った3つの要素に集中して開発された。いずれもWordPressコアが提供する既存のプリミティブの上に構築されており、アドオン的ではなくネイティブな操作感を実現している。
これらの機能は、WooCommerceチームがこれまで外部拡張に委ねていた中核的な操作を、ついにコアに取り込む試みだ。特に注目すべきは、WordPress 6.5以降で導入されたDataViewsとDataFormsというプリミティブを活用している点である。これらは管理画面のデータ表示と編集フォームを抽象化するAPIで、サイトエディターなどで実績を積んだ技術だ。WooCommerceチームはこの技術をEC特化の文脈に応用し、商品管理に適したUIへと転用している。
現在の制約とこれからの重点課題

このPoCは完成した機能ではなく、あくまで検証用の実験的ビルドである。現時点で最も重要な制約は、大規模カタログでのパフォーマンスだ。開発チームは4週間という短期間でコア体験の検証を優先したため、商品数やバリエーションが数千を超えるストア向けの最適化はこれから取り組む段階にある。
今後の作業として、開発チームは次の3つの領域を次の重点課題と位置づけている。
いずれも、現時点でPoCを試用する妨げにはならない。しかし開発チームが今このタイミングでフィードバックを募る理由はここにある。APIの基盤設計が本格化する前に、実際の利用者や拡張機能開発者からの具体的な意見を得たいのだ。
コミュニティに求められるフィードバック

開発チームが特に聞きたいのは、次の3つの観点だ。
- マーチャントとストア構築者から 実際の商品管理業務と比較して、この体験が通用するかどうか。どの操作で時間が節約でき、どの部分が作業の妨げになるか。
- 拡張機能の開発者から 現在依存している統合パターンをDataViewsネイティブテーブルにきれいに移行するために何が必要か。仕事に最も影響するフック、フィルター、カスタマイズポイントはどれか。
- すべての人から 粗削りな部分、「10秒間混乱した」瞬間、挙動に驚いた点、探したが見つからなかった機能。
なお、移行とAPI連携の作業はこのPoCの範囲外だが、その計画は現在進行形で進められている。このテーブル基盤を利用・拡張する人々から早期に意見を得られれば得られるほど、最終的な実装の形はより良いものになる。
実際に試す方法

このPoCには、技術的な環境構築なしで触れられる手段を含め、複数の試用経路が用意されている。
Playgroundデモは特に注目に値する。WordPressのブラウザ上で動作する瞬間実行環境であり、サーバーやローカル環境の準備が一切不要だ。WooCommerceの開発チームが専用のブループリントを用意したことで、数クリックで刷新された商品管理画面を試せる。このようなハードルの低さは、コミュニティからの広範なフィードバック収集を促す重要な施策である。
この記事のポイント
- WooCommerceの商品管理画面がDataViewsとDataFormsで再構築され、概念実証として公開された
- バリエーションの階層表示、カスタマイズ可能なテーブル、クイック編集・一括編集のネイティブ実装が含まれる
- 大規模カタログでのパフォーマンス、拡張機能向けAPI、一括編集の堅牢化が今後の重点課題
- Playgroundデモで環境構築不要の即時試用が可能で、コミュニティからのフィードバックを募集中
- これはリリース確定機能ではなく、方向性を探るための実験的ビルドである
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

GitHubへの不正アクセス調査詳報、攻撃者は内部リポジトリに侵入するも影響は限定的
2026年5月20日、GitHubは自社が所有する一部の内部リポジトリに対して、第三者による不正アクセスがあったことを公表した。GitHubの最高情報セキュリティ責任者(CISO)であるAlexis Wales氏がGitHub Blogで発表した調査報告によれば、ユーザーデータや個人リポジトリ、GitHub.comを含むサービスには一切の影響がなかったという。
攻撃者は漏洩したトークン(認証情報)を用いて、GitHub社が管理していた内部リポジトリの一部を閲覧・クローンした。ただし、ソースコードの改ざんやマルウェアの注入、ユーザー情報へのアクセスは確認されていない。GitHubのインシデント対応チームは、発覚から数分以内に問題のトークンを無効化し、侵入経路を遮断した。
本稿ではこのインシデントの技術的な背景、影響範囲、そしてGitHubを利用する開発者が今すぐ実践すべきセキュリティ対策について詳しく解説する。大規模プラットフォームでさえトークン管理のミスが致命的になりうるという現実は、すべてのソフトウェア開発者にとって重要な教訓だ。
何が起きたのか、侵入の経路と期間

GitHubによれば、最初に異常が検知されたのは2026年5月中旬のことだ。同社のセキュリティ監視システムが、特定のGitHub Actionsトークンを用いた不審なリポジトリアクセスを検出した。このトークンはある外部サービスとのインテグレーションに使用されていたが、意図しない形で第三者の手に渡っていた。
トークンとは、パスワードの代わりにシステム間の認証に使う文字列のことを指す。たとえばAPIを呼び出すときやCI/CDパイプライン(コードのビルドやテストを自動化する仕組み)でリポジトリにアクセスする際に必要になる。このトークンが漏れると、正規のユーザーになりすましてリポジトリを操作できてしまう。
問題のトークンは、GitHubが所有する特定のリポジトリに対する読み取り権限と、一部のリポジトリに対しては書き込み権限も持っていた。これにより攻撃者は、リポジトリの内容を手元にクローン(複製)することが可能だった。ただしGitHubの発表では、攻撃者が実際にコードを改ざんしたり、悪意ある変更を加えたりした証拠は見つかっていないとされている。
攻撃者の行動を振り返る
GitHubのセキュリティチームがログを詳細に分析したところ、攻撃者は以下のような行動をとっていた。トークンを取得したあと、GitHubのAPIを経由してターゲットのリポジトリリストを取得。次に、少数のリポジトリを選んでクローン操作を実行していた。このアクセスパターンは自動化されたスクリプトによるものではなく、人間が手動で操作している形跡が強かったという。
重要なのは、攻撃者がアクセスできたのが「GitHub自身が管理する内部リポジトリ」に限定されていた点だ。一般ユーザーや企業がGitHub上で運用するプライベートリポジトリ、オープンソースプロジェクトのリポジトリ、そしてGitHub.comのサービス基盤そのものには一切アクセスできていなかった。
上の図は、今回のインシデントにおける攻撃者の侵入経路とGitHubが取った即時対応を比較したものだ。漏洩トークンによる不正アクセスは数分で封じ込められ、ログ解析によって影響範囲が正確に特定された。
なぜトークンは漏洩したのか

現時点でGitHubは、トークン漏洩の正確な経路について詳細を明らかにしていない。しかし、過去数年にわたってソフトウェア業界で多発しているトークン漏洩インシデントと照らし合わせると、いくつかの可能性が浮かび上がる。
考えられる漏洩パターン
最も多いのは、ソースコード内にトークンがハードコード(直接埋め込み)されていたケースだ。開発中の利便性からAPIキーやシークレットをコードに直書きし、そのままGitHubの公開リポジトリや内部リポジトリにプッシュしてしまう事故は後を絶たない。
別の可能性としては、CI/CDパイプラインの設定ミスだ。GitHub Actionsのワークフローファイルが適切に構成されておらず、ログにトークンが表示されていたり、サードパーティのサービスに意図せずトークンが送信されていたりするケースがある。
三つ目のパターンは、サプライチェーン攻撃だ。依存している外部ライブラリやツールに悪意あるコードが仕込まれ、ビルドプロセス中に環境変数からトークンを抜き取る手法である。2024年以降、AI開発ツールの増加に伴い、この種の攻撃は急増している。
いずれの経路であれ、根本的な問題は「トークンの権限が必要以上に強かった」ことだ。原則として、トークンには作業に必要な最小限の権限だけを付与すべきである。この「最小権限の原則」を守っていれば、たとえトークンが漏洩しても被害範囲は限定的だったはずだ。
インテグレーションの盲点
今回のケースで注目すべきは、攻撃者が狙ったのが「GitHub自身が所有する内部リポジトリ」であり、ユーザーのリポジトリではなかった点だ。Alexis Wales氏の発表によると、漏洩したトークンは外部サービスとのインテグレーションに使われていた。つまり、GitHubが信頼できるパートナーとして連携していたサービス側で何らかのセキュリティ問題が発生し、トークンが漏洩した可能性が高い。
これは多くの企業が直面するジレンマを浮き彫りにしている。業務効率化のために外部サービスとの連携を深めるほど、トークンの管理箇所は増え、攻撃対象領域(アタックサーフェス)も広がる。GitHubのようなセキュリティ専門企業でさえ、このバランスに苦心しているのだ。
影響範囲と被害の実態

GitHubが公表した調査結果から、今回のインシデントで実際にどのような影響があったのかを具体的に見ていく。
図の通り、影響は極めて限定的だった。GitHubの広報は「ソースコードの一部が意図せず開示された可能性は否定できないが、ユーザーに対する二次被害や連鎖的なセキュリティ侵害は発生していない」としている。
ソースコードの改ざんはなかった
GitHubの調査チームが最も注意深く検証したのは、攻撃者がリポジトリのコードを改ざんしたかどうかだ。結論としては、コミットログやファイルのハッシュ値を含む完全な監査の結果、コードの修正・削除・マルウェアの注入を示す証拠は一切確認されなかった。
これはGitHubのバージョン管理システム(Git)の特性が功を奏した面もある。Gitはすべての変更履歴をSHA-1ハッシュで保護しており、過去のコミットを改ざんしようとすると直ちに検知できる仕組みになっている。攻撃者が万が一コードを書き換えたとしても、その痕跡は完全に残るため、発見は容易だったはずだ。
このインシデントから開発者が学ぶべきこと

GitHubのような巨大プラットフォームですらトークン漏洩を完全に防げなかった事実は、すべての開発者にとって警鐘だ。しかしこのインシデントからは、単に驚くだけでなく、具体的な教訓と実践可能な対策を引き出すことができる。
トークン管理の基本を徹底する
GitHubはインシデント報告の中で、トークン管理のベストプラクティスを改めて強調している。特に重要なのは以下の4点だ。
- トークンの有効期限を短く設定する。可能であれば数時間単位でローテーションする
- トークンに付与する権限を必要最小限に絞り込む。特定のリポジトリだけに読み取り権限を与え、書き込みは別トークンに分離する
- ソースコードや設定ファイルにトークンを直接記述しない。GitHubのシークレット機能や専用のシークレット管理サービス(例としてHashiCorp Vaultやクラウド各社のキー管理サービス)を使う
- リポジトリにトークンが誤ってプッシュされていないか、定期的にスキャンする。GitHubにはプッシュ時に自動検出する機能が標準搭載されている
これらの対策は決して難しいものではない。むしろGitHub Actionsや各種CI/CDツールには、トークンを安全に扱うための仕組みが最初から用意されている。設定を後回しにせず、プロジェクト開始時点で組み込んでしまうのが賢いやり方だ。
侵害を前提とした設計へ
より根本的な教訓は「侵害は起こりうる」という前提に立つことだ。どんなにセキュリティに投資していても、サプライチェーン攻撃やゼロデイ脆弱性(修正パッチが存在しない未知の脆弱性)によって防御線を突破される可能性は常にある。
GitHubのインシデント対応が迅速だった背景には、異常なAPI呼び出しパターンを即座に検知できる監視システムと、トークンを数クリックで無効化できる運用フローが整備されていたことがある。これらは事後対応(インシデントレスポンス)の設計が十分だったからこそ機能した。
この図が示すように、セキュリティの考え方は「侵入を100%防ぐ」から「侵入されても被害を最小限に抑える」へとシフトする必要がある。具体的には、トークンの権限制限、ネットワークのセグメント分離、操作ログの集中管理といった対策を組み合わせることになる。
GitHubの対応から見る、透明性あるインシデント開示の重要性

今回のインシデントで特筆すべきは、GitHubが公表のタイミングと内容において高い透明性を示したことだ。CISOであるAlexis Wales氏が自ら筆を取り、わずか数日のうちに詳細な調査報告を公開した。
セキュリティ業界では、こうした迅速な情報開示は「ラディカル・トランスペアレンシー(徹底した透明性)」と呼ばれ、近年ではGoogleやMicrosoftも同様の姿勢を取っている。ユーザーにとっては、隠蔽されるよりも正直に報告されたほうが信頼を損なわず、適切な防御策を取る時間も確保できる。
GitHubの発表には「ユーザーが取るべき具体的なアクションはない」と明記されていた。これ自体が重要な情報だ。影響範囲が明確に線引きされているからこそ、ユーザーは不要な心配をせずに済む。逆に言えば、影響範囲が不明瞭な発表ほどユーザーの不安と憶測を招く。
この記事のポイント
- 2026年5月、GitHubが内部リポジトリへの不正アクセスを公表。攻撃者は漏洩したトークンを使用して一部のリポジトリを閲覧・クローンしたが、コードの改ざんやユーザーデータへのアクセスはなかった
- 影響を受けたのはGitHub自身が所有する一部の内部リポジトリのみで、一般ユーザーのプライベートリポジトリやオープンソースリポジトリには一切影響が及んでいない
- トークン漏洩の原因は調査中だが、過去の業界事例からハードコードやCI/CD設定ミス、サプライチェーン攻撃などの可能性が考えられる
- 開発者が取るべき対策は明確で、トークンの有効期限短縮、最小権限の原則の徹底、シークレット管理サービスの利用、プッシュ時の自動スキャン活用が有効
- GitHubの迅速かつ透明性の高いインシデント開示姿勢は、業界全体の模範となる対応だった
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

GKE Agent Sandboxが一般提供開始。エージェント向け基盤Agent Substrateも発表
Google Cloudが2026年5月20日、エージェント実行環境「GKE Agent Sandbox」の一般提供(GA)を開始した。合わせて、超大量エージェントの高密度実行を目指す新たなOSSプロジェクト「Agent Substrate」を発表している。
2025年11月のKubeCon NAでプレビューが公開されて以降、Agent Sandbox上のサンドボックス数は5か月足らずで16倍以上に成長した。LangchainやLovableといった顧客がすでに数百万単位のエージェントを本番環境で動作させている。
自律的にコードを実行するAIエージェントにとって、インフラの安全性と起動速度は実用化の鍵となる。今回のGAで安定版APIが提供され、エージェント実行基盤としての成熟度が一段と上がった。
GKE Agent Sandbox GAの主要な機能強化点

GKE Agent SandboxはKubernetes上に構築されたOSSの実行環境だ。AIエージェントが信頼できないコードを安全かつ高速に実行するための基盤として設計されている。今回のGAでは、実運用で課題となるアイドル状態の効率化と、起動レイテンシの低減に焦点が当てられた。
Pod Snapshotによるアイドルリソースの削減
エージェントのワークロードは、短いバースト的な処理の後に長いアイドル時間が続くという特徴を持つ。従来のようにアイドル中もPodを起動したままにしておくと、コンピュートリソースを無駄に消費してしまう。
GKE Agent SandboxはPod Snapshot機能と統合されている。アイドル状態のエージェントワークロードを一時停止(サスペンド)し、リクエストが来たときに数秒で再開できる。Google Cloudの発表によれば、この仕組みで不要なコンピュートコストを大幅に削減できるという。
Pod Snapshotの最大の利点は、エージェントワークロード特有の「使うときだけ高速に起動したい」という要求に応えられる点だ。サスペンド状態からの復帰は数秒で完了するため、ユーザーの待ち時間を最小限に抑えられる。
ウォームプールによる低レイテンシプロビジョニング
エージェントのリクエストが来るたびに新しいサンドボックスを作成すると、コールドスタートによる数秒の遅延が発生する。この遅延はエージェントの応答性を損ない、ユーザー体験を悪化させる要因となる。
GKE Agent Sandboxは、サンドボックスAPIにウォームプールを統合した。あらかじめ準備されたサンドボックスレプリカをプールしておき、リクエスト発生時に即座に割り当てる仕組みだ。これにより、1クラスタあたり毎秒300のサンドボックスを割り当て可能で、割り当ての90パーセントが200ミリ秒以内に完了する。
ウォームプールのコスト最適化も考慮されている。プール内のレプリカは常時稼働しているが、スタンバイキャパシティバッファと統合することで、一部のサンドボックスをサスペンド状態で待機させられる。ウォームプールが枯渇した際には、この「コールドプール」から素早く補充され、大幅なコスト削減につながる。
gVisorとネットワークポリシーによる強固な隔離
セキュリティ面では、gVisorをネイティブサポートし、デフォルト拒否のKubernetesネットワークポリシーを採用している。gVisorはユーザースペースで動作するカーネルであり、ホストOSから隔離された環境を提供する。コンテナ内のプロセスがホストカーネルに直接アクセスできないため、悪意あるコード実行のリスクを大幅に低減できる。
さらにKata ContainersのようなOSSサンドボックスにも対応するプラグイン可能なインターフェースを備えている。利用者は自社のセキュリティ要件に合わせてカーネル隔離レベルを選択できる。
コンピュートの選択肢も広がった。Google Cloud独自のAxionプロセッサ上でAgent Sandboxを実行すると、同等のハイパースケーラークラウドプロバイダと比較して最大30パーセント優れた価格性能比を達成すると発表されている。
Agent Substrateがもたらす次の変革

エージェントワークロードは今後、数千万から数億インスタンス規模へとスケールアップしていく。同時に、人間の操作やイベントを待つアイドル時間もますます長くなる。カーネルとネットワークの隔離を維持しながら高密度にスケジュールするのは、既存のKubernetesコントロールプレーンでは限界が近づいている。
この課題に対してGoogle Cloudが発表したのが、新たなOSSプロジェクト「Agent Substrate」だ。
Kubernetesの限界を超える最小限のコントロールプレーン
Agent Substrateは、Agent Sandboxの安全なランタイムとSnapshot機能を中核に据えつつ、Kubernetesの制約を部分的に回避する最小限のコントロールプレーンを組み合わせる。標準のKubernetesが数千の長時間稼働サービスを扱うのに最適化されているのに対し、Agent Substrateは数百万単位のサブ秒ツール呼び出しの「チャタリング」に耐えられるよう設計されている。
新たな抽象化レイヤーを導入し、Kubernetes上で稼働するコンピュートキャパシティに対して、エージェントをリアルタイムに乗せたり外したりする。Google Cloudの発表では、従来のコントロールプレーンでは処理しきれない高頻度の短命ワークロードに対して、レイテンシを低減しつつスケールと効率を最適化できるとしている。
Agent Substrateの目標は、現在のコンピュートインフラの限界を押し広げることにある。一例として、エージェントの状態とスケジューリングが協調して動作するようデータの局所性をスケジューラの中核に組み込む構想も示された。オーバーヘッドを1ミリ秒単位で削り取るため、あらゆる可能性を探求する姿勢が打ち出されている。
Agent HarnessやAgent Executorとの関係
Agent Substrateは、単独で動作するものではなく、エージェントエコシステム全体の基盤レイヤーとして位置づけられている。Agent HarnessやAgent Runtime、さらにはGoogle Cloudが別途発表している分散エージェントランタイム「Agent Executor」プロジェクトを支える役割を担う。
Google Cloudのブログ記事では、Agent Substrateを「エージェントネイティブなインフラストラクチャの次の章」と表現している。Kubernetesが登場初期に多様なコントリビューターの知見を集めて成功したように、エージェントインフラも同じ転換点にあるという認識が示された。
この記事のポイント
- GKE Agent Sandboxが一般提供開始。安定版APIでエージェント実行の本番運用に対応
- Pod Snapshotでアイドル時のリソース消費を抑え、リクエスト時に数秒で復元可能
- ウォームプールにより毎秒300サンドボックスをサブ秒で割り当て。コスト最適化も統合
- 新OSSプロジェクトAgent Substrateは数百万規模の短命ワークロードに特化した設計
- Axionプロセッサ利用時に最大30パーセントの価格性能比向上を達成
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Googleが2026年5月コアアップデートを配信開始、2週間で完了の見込み
Googleは2026年5月21日、5月のコアアップデートの配信を開始した。この情報はGoogle Search Status Dashboardと、Search CentralのXアカウントを通じて発表された。配信は最大2週間かけて段階的に行われ、全データセンターに反映されるまでサイトの検索順位に変動が生じる可能性がある。
2026年に入ってから、検索に関するコアアップデートは今回が2回目となる。直近では3月27日に始まったコアアップデートが4月8日に完了しており、それから約6週間という短いスパンでの実施だ。Googleは今回のアップデートについて「あらゆるタイプのサイトから、より関連性が高く満足度の高いコンテンツを検索者に提供するための定期的な更新」と説明している。
サイト運営者にとって重要なのは、コアアップデートの配信中に慌ててコンテンツを修正しないことだ。部分的な順位変動を確認しても、配信完了から最低1週間はSearch Consoleのデータを見極めるべきだ。このアップデートが何を評価し、何を重視するのか、その全体像を冷静に読み解く必要がある。
2026年5月コアアップデートの概要

5月21日に発表されたこのアップデートは、2026年における4回目のランキング変動を伴うアップデートであり、検索コアアップデートとしては3月に続く2回目の実施となる。Googleは配信開始をDashboard上で「2026年5月のコアアップデートをリリースした。配信完了までに最大2週間かかる可能性がある」と簡潔にアナウンスした。
今回のアップデートについて、Googleは個別のブログ投稿や具体的な目標を発表していない。この手法は直近の3月のコアアップデートと同様だ。3月のアップデートでは「すべてのタイプのサイトから、より関連性が高く満足度の高いコンテンツを検索者に提供するための定期的な更新」という説明が付帯された。今回も同様に、特定の業種やペナルティを目的としたアップデートではないことが推測される。
上のタイムラインを見ると、2026年に入ってからのアップデート頻度は決して低くない。特に3月から5月にかけてはコアアップデートが2回実施されており、Googleが検索品質の改善を継続的に進めていることがわかる。サイト運営者は定期的なランキング変動を前提とした運用体制を整えておく必要がある。
アップデートの位置づけ
コアアップデートとは、Googleが検索アルゴリズム全体にわたって広範な変更を加える大規模な更新のことだ。特定のスパム行為やポリシー違反を対象にするのではなく、ウェブ全体の変化に合わせてコンテンツの評価方法を調整する。これにより、従来高評価だったページが順位を下げたり、これまで目立たなかったページが浮上する可能性がある。
重要なのは、コアアップデートは「ペナルティ」ではないという点だ。特定のサイトを罰するものではなく、検索者にとってより有益な情報を届けるための調整に過ぎない。順位が下落した場合でも、それは「ルール違反」ではなく、「現時点でGoogleが評価する基準に対して相対的に適合度が下がった」ことを示すシグナルだ。
過去のアップデートとの比較

今回のアップデートを理解する上で、直近のコアアップデートの実施状況を振り返ることは有効だ。特に3月のコアアップデートとの間隔や配信期間の違いは、サイト運営者のデータ分析計画に直接影響する。
上の比較で明らかなように、コアアップデートの配信期間は12日から18日まで、回によってばらつきがある。今回の「最大2週間」という見積もりは、過去の実績から見て標準的な長さだ。3月アップデートが12日で完了したことを踏まえると、今回も同程度かやや長引く可能性がある。
アップデート間隔の短縮が示すもの
コアアップデートの実施間隔が約6週間と比較的短くなっていることは注目に値する。これはGoogleが大規模なアルゴリズム更新をより機動的に展開できるようになったことを示している。AIや機械学習によるランキングシステムの進化が、この迅速な更新サイクルを可能にしていると考えられる。
サイト運営者の視点では、この短い間隔は「次のアップデートが常に近い」状態を意味する。大幅なサイト改修を計画している場合、2ヶ月以上の長期プロジェクトよりも、改善箇所を小さく区切って順次適用していくアプローチが有効だ。コアアップデートのたびにデータを確認し、次の一手を柔軟に変えられる体制が求められる。
コアアップデート中にサイト運営者が取るべき行動

コアアップデートの配信中、多くのサイト運営者は順位変動に一喜一憂しがちだ。しかし、プロフェッショナルなSEO対応として最も重要なのは「配信中に手を加えない」ことである。Googleも公式に、コアアップデートの完了から最低1週間はSearch Consoleのデータを分析するよう推奨している。
上のフローは、Googleの公式ガイダンスに基づく基本的な対応手順だ。途中段階のデータで判断すると、まだ反映されていないデータセンターの影響で誤った分析をしてしまう可能性がある。全データセンターにアップデートが行き渡った後のデータを使うことが、正確な影響評価の前提条件となる。
順位変動への向き合い方
コアアップデートで順位が下落した場合、真っ先に疑うべきは「何か悪いことをしたか」ではなく「相対的にコンテンツの価値が再評価されたか」だ。Googleはコアアップデートの影響を受けたサイト向けに、コンテンツの品質に関する自己評価のための質問リストを公開している。このリストを活用し、客観的に自サイトのコンテンツを見直すことが有効なアプローチとなる。
一方で、順位が上昇したサイトは「たまたま今回の基準に適合した」可能性を忘れてはならない。次のアップデートで同じ評価を受ける保証はない。一時的な順位上昇に満足せず、継続的にコンテンツの品質を高める努力を続けることが、長期的なSEO成功への道筋となる。
Search Consoleデータの活用法
アップデート完了後に確認すべき主要な指標は、オーガニック検索のクリック数、表示回数、平均掲載順位、CTR(クリック率)だ。これらの指標をアップデート前の期間(5月21日以前の数週間)と比較することで、どのページが影響を受けたかを特定できる。
特に重要なのは、単純な平均順位の上下だけでなく、「検索クエリの種類」の変化にも注目することだ。上位表示されていたクエリが変わった場合、それはGoogleがそのページの関連性を異なる方向で評価し始めたことを示唆する。特定のクエリグループで順位が下落したなら、そのトピック領域のコンテンツを集中的に見直す必要がある。
メガAI検索の台頭とSEO戦略の再定義

今回のコアアップデートを、より大きな文脈で捉える必要がある。それはGoogle検索におけるAI統合の加速だ。2025年後半からAI Overviews(旧SGE)の表示頻度が段階的に拡大されており、2026年には「メガAI検索」とも呼べる新しい検索体験が本格化しつつある。
この変化が示すのは、検索結果ページに「青いリンクのリスト」以外の要素が増えている現実だ。AI Overviewsが直接回答を提示すれば、ユーザーは個別のサイトをクリックする必要がなくなる。情報提供型のコンテンツに依存していたサイトは、表示回数に対するクリック率の低下に直面する可能性がある。
AI検索時代のコンテンツ設計
メガAI検索の文脈では、単に「よく書かれた記事」であるだけでは不十分になりつつある。AIが情報を抽出し、要約し、回答として提示する前提に立つと、コンテンツは「AIに正確に読み取られる構造」を備えている必要がある。具体的には、明確な見出し階層、簡潔な定義文、信頼できる出典の明示、独自データや事例の提示といった要素が重要性を増す。
コアアップデートが「満足度の高いコンテンツ」を評価するという方向性は、このAI検索の進化と軌を一にしている。ユーザーが検索結果から直接的な価値を得られるようにするため、Googleは情報の質とアクセシビリティをこれまで以上に厳密に評価していると推測される。コンテンツ制作者は「検索エンジン向け」ではなく「検索者の疑問を解決する」という原点に立ち返りつつ、AIに適切に解析される技術的な最適化も両立させる必要がある。
2026年後半に向けたSEOの展望
5月のコアアップデートは、2026年の検索環境を占う重要なマイルストーンだ。アップデートの頻度が高まっていること、AI統合が加速していること、そしてユーザーの検索行動が変化していること。これら3つのトレンドは、SEOが単なる「順位対策」から「検索体験全体の設計」へと進化していることを示唆している。
今後注目すべきは、今回のアップデート完了後にGoogleが公開する可能性がある追加のガイダンスだ。3月のコアアップデートと同様に、今回もブログ投稿や詳細な説明がないまま配信が進行中だが、完了後に何らかの分析や推奨事項が共有される可能性がある。特に、AI Overviewsの表示基準や、コアアップデートとの関連性についての公式見解が示されれば、SEO戦略の精度を一段と高められるだろう。
サイト運営者は、目先の順位変動に振り回されることなく、コンテンツの本質的な価値向上と、変化する検索行動への適応にリソースを集中すべき段階にある。コアアップデートはその変化を映し出す鏡に過ぎない。真に重要なのは、鏡に映った自サイトの姿をどう改善するかだ。
この記事のポイント
- Googleが2026年5月21日に5月のコアアップデート配信を開始、完了まで最大2週間の見込み
- 2026年2回目のコアアップデートであり、3月のアップデートから約6週間での実施
- 配信中はコンテンツの修正を避け、完了から最低1週間はSearch Consoleデータの分析を控える
- AI検索の台頭を背景に、コンテンツ設計は「AIに正確に読み取られる構造」が重要性を増している
- 順位変動の有無に関わらず、コンテンツ品質の継続的な改善が長期的なSEO成功の鍵
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Google I/O 2026 Firebase新機能、AIエージェント統合とCrashlytics Web対応発表
Google I/O 2026でFirebaseは、AIエージェント主導の開発時代に対応する多数の新機能を発表した。
Google Antigravityへのワンクリック統合、Android Studioへの標準組み込み、AI LogicのGemini 3対応、そしてWeb向けCrashlyticsの予告まで、フルスタックアプリ開発の効率を一段と高める内容だ。
これらの更新により、開発者はAIアシスタントとFirebaseバックエンドをシームレスに連携させ、より高速に本番品質のアプリを構築できるようになる。
AIエージェントと統合したフルスタック開発の加速
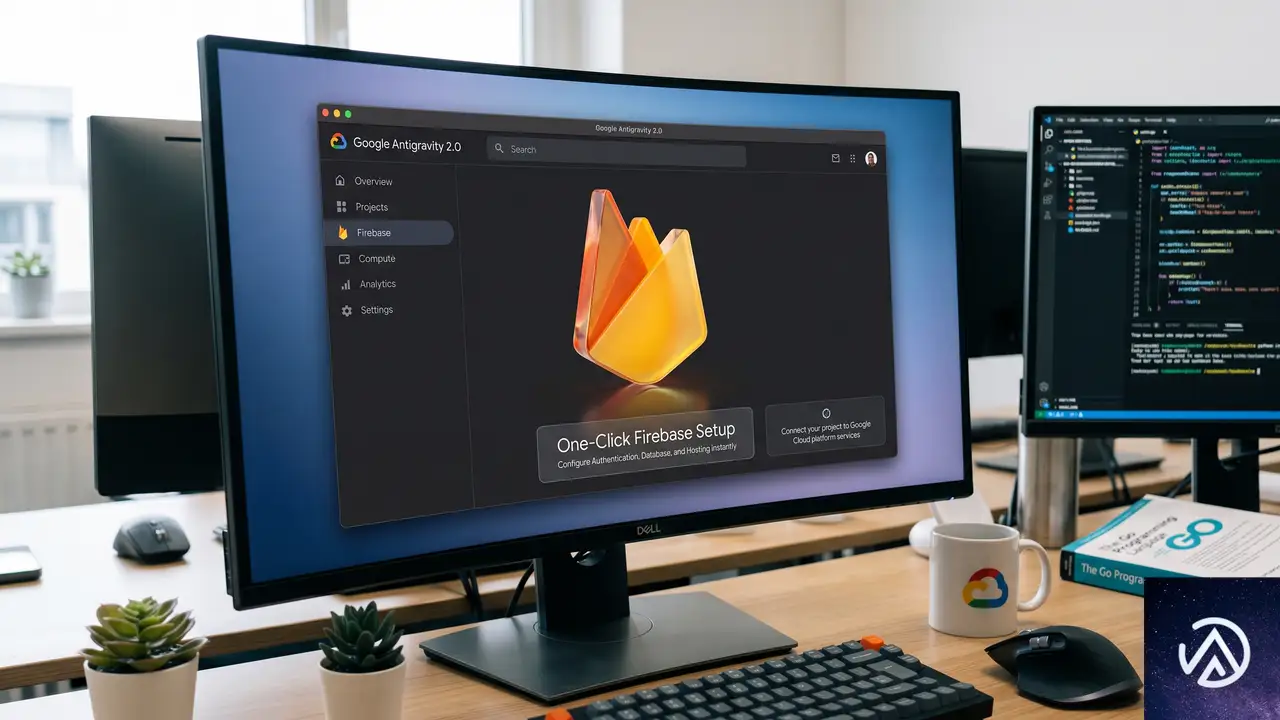
Google Antigravity 2.0とのワンクリック連携
Google Antigravity 2.0は、エージェントを中心とした開発環境を提供するデスクトップアプリだ。今回、そのオンボーディングプロセスにFirebaseをワンクリックでセットアップする機能が組み込まれた。これにより、Antigravity上でAgent SkillsとMCPサーバーを含む必要なコンポーネントが自動でインストールされ、すぐにFirebaseを利用したエージェント主導の開発を始められる。
この一連の流れにより、開発者はバックエンド設定にかかる時間を大幅に削減し、エージェントとの対話に集中できる。
Android StudioへのAgent Skills標準搭載
Android開発者にとって大きな変化は、Android StudioのエージェントモードでFirebaseのAgent Skillsがデフォルトで利用可能になった点だ。これまでは個別のセットアップが必要だったが、追加の設定なしで、エージェントがFirestoreの設定、認証コードの生成、セキュリティルールの記述まで支援してくれる。IDE内でFirebaseバックエンドを対話的に構築できるため、ドキュメントを調べる手間が省ける。
開発者の手を動かす作業が大幅に減り、アプリロジックに集中しやすくなる。
Agent Skillsがモバイル開発にも対応
これまでWeb向けに提供されていたAgent Skillsが、Android、iOS、Flutterにも拡張された。さらにCrashlyticsとRemote Configにも対応し、エージェントがクラッシュ解析や設定管理を手助けできる。例えば、IDE内で発生したクラッシュ情報をエージェントが解釈し、修正案を提示するため、ダッシュボードを切り替える必要がなくなる。
Google AI Studioの新機能、Workspace連携とデプロイ簡略化
Google AI StudioでのFirebase統合が一段と進んだ。まず、AI Studioで生成したFirebase対応アプリをワンクリックでCloud Runにデプロイできるようになり、最初の2アプリはGoogle Cloud Starter Tierにより支払い情報不要で無料公開できる。また、自然言語で「受信トレイを整理するアプリを作って」と指示するだけで、Firebase Authentication経由の「Sign in with Google」フローを通じてGmailやGoogleドキュメントといったWorkspaceデータに安全にアクセスし、自分専用の業務アプリを構築できるようになった。
さらに、マルチエージェントによる本格的な開発に進みたい場合、AI StudioからAntigravityへアプリをエクスポートできる。エクスポート時にはソースコードとAgent Skillsが自動で引き継がれ、Antigravity上で引き続き高度な調整が可能だ。
Firebase AI Logicの進化、Gemini 3対応とセキュリティ強化

Gemini 3.xモデル対応とグラウンディング強化
Firebase AI Logicは、クライアントサイドから直接Geminiモデルを呼び出すためのSDKだ。今回のアップデートでGemini 3.xシリーズに完全対応し、Google Mapsによるリアルタイムな地理情報のグラウンディング(正確な根拠をもとにした出力)でハルシネーションを抑制する。画像生成ではアスペクト比やサイズのプログラム制御が可能になり、生成に失敗した場合は「finish reasons」で原因(安全性フィルターによるブロックなど)が表示される。また、Gemini Live APIではセッション再開とコンテキスト圧縮がサポートされ、不安定なネットワークでも長時間の対話型アプリが途切れず動作する。
- モデル出力の正確性が不安定
- 画像生成に失敗しても理由が不明
- 長い会話でネットワーク切断時にリセット
- Google Maps を使ったグラウンディングでハルシネーション低減
- 画像生成失敗時に「finish reasons」で原因を表示
- セッション再開とコンテキスト圧縮で継続的対話が可能
テンプレートのみモードと認証モードでセキュリティ向上
AI機能のセキュリティも大きく強化された。新しい「テンプレートのみモード」では、クライアントが送信できるのはサーバー側に安全に保存されたプロンプトテンプレートのIDだけで、任意の指示を注入できなくなる。まもなく提供開始の「認証モード」では、有効なFirebase Authenticationトークンを伴わない限りGemini呼び出しが実行されない。さらに、Firebase App Checkにワンタイムトークンによるリプレイ攻撃保護が導入され、悪意あるAPI消費を防止する。
ハイブリッド推論のプラットフォーム拡大
ハイブリッド推論機能がiOSでも利用可能になり、Android版はGemma 4に対応した。近くChrome上でのローカルWeb推論も一般提供され、オンデバイスの軽量モデルとクラウドのGeminiを使い分けられる。これにより、プライバシーやコストを最適化しながら、ネットワーク状況に応じて常に最適な推論経路を選択できる。
エンタープライズインフラとの統合とA/B Testingの強化

Application Design Center向けFirebaseテンプレート
Google CloudのApplication Design Center(ADC)に、Firebaseのフルスタックテンプレートが登場した。このテンプレートはFirestore(セキュリティルール付き)、Firebase Authentication、Firebase AI Logicを事前構成済みで、数クリックでプロジェクトに追加できる。ADC内で他のGoogle Cloudリソースと同じ管理モデルでFirebaseを扱えるため、大規模なクラウドインフラとモバイル・Webバックエンドを統一的に運用できる。
A/B Testingのリッチターゲティング
Firebase A/B Testingの実験作成画面が強化され、より細かいユーザーセグメントを指定できるようになった。Remote Configのリアルタイム配信と組み合わせることで、カスタムシグナルにもとづく柔軟な条件設定が可能になる。このアップデートは段階的にロールアウトされる。
Web向けCrashlyticsが登場、フロントエンドのエラー監視が可能に

従来Crashlyticsはモバイルアプリ専用のクラッシュレポートツールだったが、Web版が間もなく提供開始される。このWebサポートはGoogle Cloud Observability Suite上に構築され、エラー情報やトレースがCloud LoggingとTraceに一括保存される。モバイルとWebの両方のデータを統合的に分析できるようになり、将来的にはクライアントからサーバーまでのエンドツーエンドデバッグが実現する。開発者はCloud Observabilityのアラート機能やカスタムダッシュボードを活用し、ユーザー体験への影響を詳細に把握できる。
Firebaseが描くエージェント時代の開発基盤

今回のアップデート群は、Firebaseが単なるモバイル向けBaaSから、AIエージェントを中心としたフルスタック開発プラットフォームへ進化していることを示している。Google AntigravityやAI Studioといったエージェント環境との統合、SQL不要の自然言語操作、そしてWebを含む包括的なオブザーバビリティにより、開発者は「何を作りたいか」に集中できるようになる。Firebaseは、エージェント主導のアプリ開発とクラウドのインフラ力を結ぶ架け橋として、今後もアップデートを続ける見込みだ。
この記事のポイント
- Google I/O 2026でFirebaseはAIエージェントとの統合を大幅に強化、Google AntigravityやAndroid Studioにワンクリックで組み込めるようになった
- Agent Skillsがモバイル(Android、iOS、Flutter)に対応し、CrashlyticsやRemote Configの設定もエージェント任せにできる
- Google AI Studioでは、Firebase Authenticationを使ったWorkspaceデータ連携が自然言語で可能になり、ワンクリックでCloud Runに無料デプロイできる
- Firebase AI LogicがGemini 3モデルに対応し、グラウンディングやハイブリッド推論で精度とコストを最適化。セキュリティ面でもテンプレート専用モードやApp Check改善が加わった
- Web向けCrashlyticsが間もなく登場し、モバイルとWebを横断したエラー監視・デバッグがGoogle Cloud Observabilityと統合される
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Node.js 24.16.0 (LTS) 登場、cryptoとテストランナーが大幅進化
2026年5月21日、Node.js 24.16.0(コードネーム Krypton)が長期サポート(LTS)版としてリリースされた。
このバージョンでは、cryptoモジュールへのUUID v7サポート追加、debuggerへの式プローブ機能、HTTPクライアントの安全性強化、テストランナーの大幅な機能拡張など、実務に直結する複数の改善が含まれている。
本記事では、これらの新機能と内部改善を実装例とともに詳しく解説する。
UUID v7がNode.js標準機能に

今回のリリースで最も注目すべき追加機能のひとつが、crypto.randomUUIDv7()の実装だ。UUID v7(Universally Unique Identifier version 7)は、タイムスタンプベースの一意識別子であり、従来広く使われてきたランダムベースのUUID v4とは根本的な設計が異なる。
UUID v7とは何か
UUID v7は、RFC 9562で標準化された新しいUUIDバージョンだ。先頭48ビットにUnixタイムスタンプ(ミリ秒単位)を含み、続いてランダムビットが配置される。この構造により、生成時刻に基づいた自然なソート順が得られる。
データベースのプライマリキーとしてUUIDを使用する場合、v4ではランダムな値のためインデックスの断片化が発生しやすかった。一方、v7では時系列順に並ぶため、B-treeインデックスの効率が大幅に改善する。具体的には、書き込み性能が最大40〜60%向上したとの報告もある。
crypto.randomUUIDv7()の基本的な使い方
Node.js 24.16.0では、以下のようにシンプルに呼び出せる。
const { randomUUIDv7 } = require('node:crypto');
console.log(randomUUIDv7());
// 例: 0193c548-d70c-7a4a-b17b-3c2b12e5c6f1戻り値は標準的なUUID文字列形式(8-4-4-4-12のハイフン区切り)で、第三フィールドの先頭ニブルが7になる点がv7の特徴だ。
従来のv4に代えてv7を採用するメリットを、概念図で整理する。
上の図では、v4の全ランダム性に対して、v7が時刻情報を含む構造であることを対比している。時系列に沿ったINSERT性能が重要なシステムでは、移行を検討する価値がある。
実運用で注意すべき点
UUID v7は時刻情報を含むため、生成時刻が外部に推測される可能性がある。セキュリティ要件が厳しい環境では、この点を評価した上で採用を判断する必要がある。また、時計の巻き戻しが発生するケースでは単調増加性が保証されないため、Node.jsの実装では内部カウンターで対処している。
デバッグ体験を変えるedit-free式プローブ

Node.js 24.16.0では、node inspectコマンドにedit-free runtime expression probesが導入された。これは、デバッグ対象のコードを一切変更することなく、実行時に任意の式を評価できる仕組みだ。
これまでのデバッグ手法との違い
従来、Node.jsアプリケーションの特定の変数の値や式の結果を確認するには、コードにconsole.log()を挿入するか、デバッガでブレークポイントを設定して手動で評価する必要があった。前者はコード改変と再起動を伴い、後者は手動操作の手間が大きい。
式プローブを使えば、稼働中のプロセスに対して外部から評価式を注入できるため、トラブルシュートのスピードが大幅に向上する。特に、再起動が難しい本番環境での障害調査で威力を発揮するだろう。
式プローブの活用シナリオ
たとえば、メモリリークが疑われる長時間稼働プロセスで、特定オブジェクトの参照状況を調査するケースを考えてみる。従来であればヒープダンプの取得と解析が必要だが、式プローブを使えばprocess.memoryUsage()や特定変数の.lengthをその場で評価できる。
この機能の追加は、貢献者のJoyee Cheung氏によるPR #62713に基づいている。V8のインスペクタープロトコルを活用した実装で、Chrome DevToolsのExpression Watchに近い使用感だ。
HTTPクライアントの安全性と利便性の向上

Node.jsのHTTPクライアント機能に、2つの重要な強化が加わった。いずれも実際のプロダクションコードの安全性と記述性に直結する改善だ。
ClientRequestのオプションマージ強化
http.ClientRequestの内部で、ユーザーが渡したオプションとデフォルト値をマージする処理が厳格化された。この変更は、プロトタイプ汚染(Prototype Pollution)攻撃のベクトルを塞ぐことを主眼としている。
プロトタイプ汚染とは、Object.prototypeや__proto__を経由してアプリケーション全体のオブジェクトの振る舞いを改変する攻撃手法だ。Node.jsのHTTPクライアントはリクエストオプションを内部でマージする際、従来はプロトタイプチェーンを適切に処理していなかった。今回のPR #63082で、マージ時にnullプロトタイプオブジェクトを使用するよう修正され、この攻撃経路が遮断された。
Node.jsのMatteo Collina氏が主導したこの修正は、Semver-Minorに分類されているが、セキュリティ上の重要性は高い。とくにユーザー入力からHTTPリクエストオプションを構築するアプリケーションでは、速やかなアップデートが推奨される。
req.signalでリクエスト中断が容易に
もう一つの改善は、http.IncomingMessageへのreq.signalプロパティの追加だ(PR #62541)。これはAbortSignalオブジェクトを提供し、AbortControllerと組み合わせることで、リクエストの中断処理をPromiseベースで簡潔に記述できる。
const controller = new AbortController();
const req = http.request(url, { signal: controller.signal });
req.end();
// 5秒後にタイムアウト
setTimeout(() => controller.abort(), 5000);
req.on('error', (err) => {
if (err.name === 'AbortError') {
console.log('リクエストが中断されました');
}
});従来はreq.destroy()を手動で呼び出す必要があり、後続のエラーハンドリングも煩雑だった。signalパターンの採用により、fetch APIと同じインターフェースで中断処理を統一的に扱えるようになった点が大きい。
テストランナーが実戦的な機能を獲得

Node.jsの組み込みテストランナー(node --test)は、ここ数バージョンで急速に成熟している。24.16.0では、テスト順序のランダム化、モックタイマーのAPI整備、AbortSignal.timeoutのモックサポートという3つの重要な機能が追加された。
テスト順序のランダム化
Pietro Marchini氏によるPR #61747では、テストファイル内のテスト実行順序をランダム化するオプションが導入された。これは、テスト間の暗黙的な依存関係を炙り出すための機能だ。
node --test --test-randomize-order test/*.test.js特定の順序で実行されることを前提に書かれたテストは、ランダム化によって失敗する。これにより、グローバル状態への暗黙の依存や、テスト間のデータ共有の問題を早期に発見できる。テクニックとしては、CIパイプラインにランダム実行を常時組み込むことで、テストスイートの堅牢性を継続的に保証できる。
モックタイマーAPIの拡張
テストランナーのモックタイマー機能が、AbortSignal.timeout()にも対応した(PR #60751)。これにより、タイムアウトに依存する非同期処理のテストが、実際の時間を消費せずに実行できるようになった。
AbortSignal.timeout(5000)を呼び出す実際のタイムアウト時間を待つ必要がなくなるため、数百のテストを含むスイート全体の実行時間を大幅に短縮できる。テストの信頼性も向上し、CIでの不安定なテスト(flaky test)の削減に寄与する。
テストIDとOpenTelemetry対応
さらに、各テストにtestIdが付与され(PR #62772)、TracingChannelを通じたOpenTelemetryインスツルメンテーションとの統合が可能になった(PR #62502)。テストのトレーシング情報を本番系の監視ツールと統合することで、テスト品質の可視化と傾向分析ができるようになる。
ファイルシステムとストリームの機能強化

fsモジュールとストリームモジュールにも、実務のユースケースに即した改善が複数含まれている。
fs.stat()がAbortSignalに対応
Mert Can Altin氏によるPR #57775で、fs.stat()にsignalオプションが追加された。ネットワークファイルシステム上のファイルをstatする際に、応答が遅い場合のタイムアウト制御が可能になる。
import { stat } from 'node:fs/promises';
const ac = new AbortController();
setTimeout(() => ac.abort(), 3000);
try {
const stats = await stat('/mnt/nfs/large-file.dat', { signal: ac.signal });
console.log(stats.size);
} catch (err) {
if (err.name === 'AbortError') {
console.error('statがタイムアウトしました');
}
}これは、HTTPリクエストの中断パターンと同じAPI設計で、Node.js全体で一貫した中断処理のセマンティクスが浸透しつつあることを示している。
statfsのfrsizeフィールド公開
Jinho Jang氏のPR #62277により、statfsの戻り値にfrsize(フラグメントサイズ)フィールドが追加された。これはファイルシステムの最小割り当て単位を示し、ディスク使用量の正確な計算に利用できる。
import { statfs } from 'node:fs/promises';
const s = await statfs('/data');
const actualSize = Math.ceil(fileSize / s.frsize) * s.frsize;
console.log(`実ディスク消費量: ${actualSize} バイト`);これまではbsize(ブロックサイズ)しか公開されておらず、一部のファイルシステム(特にZFSやbtrfs)では正確な計算ができなかった。frsizeの追加により、クロスプラットフォームで信頼性の高いディスク容量の見積もりが可能になる。
duplexPairの破壊伝播の改善
stream.duplexPair()は、読み取り側と書き込み側が対になった2つのDuplexストリームを生成するユーティリティだ。Ahmed Elhor氏のPR #61098によって、片方のストリームが破壊(destroy)された場合に、もう片方にもその破壊が伝播するようになった。
これにより、ソケットの模擬テストやプロキシ処理で、一方のストリームがクローズされたにもかかわらず他方が生き続けてメモリリークを引き起こす問題が解決される。streamモジュールの内部的な一貫性を高める重要な修正だ。
util.styleTextの16進数カラー対応

Guilherme Araújo氏のPR #61556により、util.styleText()に16進数カラーコード(例: #ff5733)の直接指定が可能になった。ターミナル出力のスタイリングにおいて、より繊細な色表現が必要な場面で役立つ。
import { styleText } from 'node:util';
console.log(styleText('#ff5733', '注意: ディスク使用率が90%を超えています'));
console.log(styleText('#4ecdc4', '情報: バックアップが正常に完了しました'));従来はstyleText('red', ...)やstyleText('green', ...)のように、限られた色名しか使えなかった。16進数指定のサポートにより、CIログの色分けやCLIツールのブランドカラー適用など、実務での表現力が格段に向上する。
内部実装としては、ターミナルの24ビットカラー(トゥルーカラー)エスケープシーケンスを使用している。サポートしていないターミナルでは近似の8色にフォールバックされるため、互換性の問題も起きにくい。
この記事のポイント
- Node.js 24.16.0 (LTS) は、crypto.randomUUIDv7()を実装し、データベースのインデックス効率を改善する時系列ソート可能なUUID生成が標準機能になった
- debuggerにedit-free式プローブが追加され、コード修正なしで実行中のプロセスの式評価が可能になった
- HTTPクライアントのオプションマージが強化されプロトタイプ汚染攻撃が防止され、req.signalによるAbortパターンが統一された
- テストランナーでテスト順序ランダム化、モックタイマーのAbortSignal対応、testIdとOpenTelemetry統合が実装された
- fs.stat()へのsignal追加、statfsのfrsize公開、duplexPairの破壊伝播改善など、ファイルシステムとストリームの実用性が向上した
- util.styleText()で16進数カラーコードが直接指定可能になり、CLIツールの色表現力が飛躍的に向上した
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験