

Amazon RedshiftにGraviton搭載のRGインスタンス登場、データレイククエリエンジンも統合
Amazon Redshiftに新しいインスタンスファミリー「RG」が追加された。AWSのArmベースプロセッサ「Graviton」を採用し、データウェアハウスのワークロード処理を従来のRA3インスタンスと比較して最大2.2倍高速化する。vCPUあたりの価格は30%引き下げられ、分析コストの大幅な圧縮が見込める。
さらに、このRGインスタンスではデータレイクへのSQLクエリ実行機能がクラスタノードに統合された。Apache Icebergテーブルへのクエリは最大2.4倍、Apache Parquetへのクエリは最大1.5倍高速化している。これまで別途必要だったRedshift Spectrumと、1TBあたり5ドルのスキャン料金が不要になる点も見逃せない。
BI(ビジネスインテリジェンス)ダッシュボードやAIエージェントによる大規模なクエリ実行が日常化する中、今回の刷新はパフォーマンスとコストの両立をこれまで以上に高い水準で実現するものだ。
RGインスタンスの概要と主要な性能向上

このデモは従来のRA3構成と新RG構成の違いを視覚化したものだ。RGインスタンスではデータレイククエリ機能が完全に統合され、外部のSpectrum層に依存しないアーキテクチャに変わっている。
Gravitonプロセッサがもたらす価格性能比の改善
RGインスタンスの中核にあるのは、AWSが設計したArmアーキテクチャのカスタムプロセッサ「Graviton」だ。x86系のチップと比べて電力効率が高く、同じ電力あたりの処理量を引き上げられる特徴がある。AWSのサービスにおけるGraviton採用はEC2やRDSなどで既に広がっており、Redshiftでもその恩恵を受けられるようになった。
具体的なインスタンスタイプとしては、エントリー向けの rg.xlarge(4vCPU、32GBメモリ)と、本番ワークロード向けの rg.4xlarge(16vCPU、128GBメモリ)が用意された。従来の ra3.xlplus から rg.xlarge への移行では、vCPU数とメモリ容量は同等だが処理性能自体が大きく向上する。一方、ra3.4xlarge から rg.4xlarge への移行ではvCPU数が12から16へ約1.33倍、メモリも96GBから128GBへと拡張され、単純なスペック面でも上積みがある。
AWS News Blogの記事によれば、これらの新インスタンスはデータウェアハウス処理でRA3比最大2.2倍の性能を達成しているという。企業が日常的に利用するBIダッシュボードの応答速度や、ETL処理のバッチジョブ実行時間が大幅に短縮される計算だ。
データレイククエリエンジン統合の実質的な意味

RGインスタンスで最も構造的な変化が起きたのは、データレイククエリの実行方式だ。これまではS3に置かれたデータレイクに対してSQLで分析する際、Redshift Spectrumという別のサービス層を経由する必要があった。このSpectrum層はクラスタの外部で動作するため、VPCの境界を越えたデータのやり取りが発生し、1TBあたり約5ドルの追加スキャン料金が積み上がる仕組みだった。
Spectrumが不要になったことで変わる運用とコスト
RGインスタンスでは、データレイクへのクエリをクラスタ上のノードで直接実行する。Spectrum層を経由しないため、クエリがVPCの内側に留まり、IAMロールも既存のものをそのまま使える。セキュリティ境界がシンプルになるだけでなく、データレイク利用時の通信レイテンシも低減する。
コスト面では、Spectrumのスキャン料金がゼロになる影響が大きい。例えば月間10TBのデータレイクをスキャンするワークロードの場合、Spectrumだけで月50ドルの追加コストが発生していた。RGインスタンスへの移行後は、このコストが完全に消える。データレイク分析の規模が大きい企業ほど、削減額は積み上がる計算だ。
既存の外部テーブルやスキーマ定義、クエリ構文はそのまま動作するため、アプリケーションコードの修正は不要だ。移行に伴う手間を最小限に抑えつつ、性能向上とコスト削減の両方を手に入れられる設計になっている。
AIエージェント時代を見据えた設計思想

今回のRGインスタンス投入の背景には、AIエージェントによるデータウェアハウス利用の急増がある。自律的に目標を追求するAIエージェントは、人間のアナリストとは比較にならない頻度でクエリを発行する。AWS News BlogのChanny Yun氏は、AIエージェントのクエリ量が「典型的な人間の利用規模を矮小化する」と表現している。
大量の低レイテンシSQLクエリを安定的に処理するには、1クエリあたりのコストを大幅に下げつつ、応答速度も維持しなければならない。vCPU単価で30%のコストダウンを実現しつつ、処理そのものを高速化したRGインスタンスは、まさにこの要求に応える製品だと言える。2026年3月に発表された新規クエリの最大7倍高速化と組み合わせることで、AIエージェントがリアルタイムにデータを参照しながら判断するワークロードにも耐えうる基盤が整った。
移行手順と現在の利用可能リージョン

RGインスタンスへの移行は、AWSマネジメントコンソール、CLI、APIのいずれからでも実行できる。データレイククエリエンジンはデフォルトで有効化されており、クラスタ作成後すぐに統合環境を利用できる。
移行パスは大きく2つある。1つ目は弾力的なリサイズで、互換性のある構成であれば10〜15分のダウンタイムでインプレース移行が完了する。2つ目はスナップショットと復元で、既存のRA3クラスタからスナップショットを取得し、RGインスタンスの新規クラスタとして復元する方法だ。移行時に構成を変更したい場合に適している。
2026年5月時点で、RGインスタンスは以下のAWSリージョンで利用可能だ。米国東部(バージニア北部、オハイオ)、米国西部(北カリフォルニア、オレゴン)、アジアパシフィック(香港、ハイデラバード、ジャカルタ、マレーシア、メルボルン、ムンバイ、大阪、ソウル、シンガポール、シドニー、台湾、東京)、カナダ(中部)、欧州(フランクフルト、アイルランド、ミラノ、ロンドン、パリ、スペイン、ストックホルム)、南米(サンパウロ)と、主要リージョンをほぼ網羅している。東京リージョンも含まれているため、国内のワークロードにも即座に適用可能だ。
実務者が押さえるべき導入判断のポイント

RGインスタンスは確かに魅力的だが、導入にあたってはいくつか確認すべき点がある。まず、オンデマンドインスタンスとリザーブドインスタンスの両方が提供されているため、長期的な利用が見込めるならリザーブドインスタンスによるコスト最適化を検討したい。AWS料金計算ツールで自社のワークロードパターンに基づいたシミュレーションを行うのが確実だ。
次に、Spectrumに依存していた既存のETLパイプラインや外部ツールとの統合に問題がないか、事前に検証環境でテストすることを推奨する。クエリ構文や外部テーブル定義は互換性が保たれているが、パフォーマンス特性が変わるため、実行計画の変化によって一部のクエリで想定外の挙動が生じる可能性はゼロではない。
最後に、データレイクとデータウェアハウスの両方を1つのインスタンスファミリーで処理できるようになったことで、アーキテクチャの簡素化と運用負荷の低減が見込める。特にデータレイクの分析規模が拡大傾向にある企業や、AIエージェントの本格導入を検討しているチームにとって、RGインスタンスへの早期移行は競争力の源泉になりうる。
この記事のポイント
- RGインスタンスはGraviton搭載によりRA3比最大2.2倍の性能とvCPU単価30%削減を両立
- データレイククエリエンジンが統合され、Spectrumと1TBあたり5ドルのスキャン料金が不要に
- Apache Icebergで最大2.4倍、Parquetで最大1.5倍のクエリ高速化を達成
- BIダッシュボードやAIエージェントによる大量クエリを低コストで処理できる基盤が整った
- 移行は弾力的リサイズまたはスナップショット復元で対応、既存クエリの修正は不要

・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

GoogleがFAQリッチリザルト廃止、AhrefsがスキーマのAI引用価値を否定
2026年5月、スキーママークアップの価値に冷や水を浴びせる二つの動きが重なった。GoogleはFAQリッチリザルトを廃止し、Ahrefsは構造化データがAI引用を増やさないとするレポートを公開した。
この連続パンチは、SERPでの視認性向上とAI引用獲得というスキーマの二大セールスポイントを直撃する。本記事では、今回の動きが持つ意味と、データが示すスキーマの未来像を掘り下げていく。
Googleがスキーマ特典を絞り込んだ5年間
FAQリッチリザルト廃止の最終決定
2026年5月12日、GoogleはFAQページ向けの構造化データを正式に廃止した。FAQリッチリザルトは検索結果上に質問と回答を展開表示する機能で、多くのサイトがクリック率向上のために導入してきた。Googleはこの廃止について「検索結果を簡素化し、ユーザーにとって本当に価値のある情報だけを表示するため」と説明している。
この決定は突然ではない。2023年8月にはFAQリッチリザルトの表示対象を政府機関や医療サイトなどの権威的サイトに限定していた。その時点で、一般的な商業サイトやブログでのFAQ表示はすでに停止されていた。今回の完全廃止は、その延長線上にある最終決定といえる。
GoogleのJohn Mueller氏はReddit上で「マークアップの種類は登場と消滅を繰り返すが、ごく一部の重要なものだけは残り続ける」とコメントしている。これはスキーマ全般を否定する発言ではないが、特定のリッチリザルトを戦略の柱に据えることのリスクを暗に示している。
可視的報酬のパターン
過去5年間の動きを振り返ると、明確なパターンが浮かび上がる。新しい構造化データが導入される。SEO業界がその使い方を検証し、広く導入する。数年のうちにGoogleがその表示特典を縮小または廃止する。そして業界は次の新しいスキーマタイプに注目を移す。
重要なのは、マークアップ自体が無効になるわけではない点だ。Googleのシステムは引き続きFAQ構造化データを読み取り、ページ内容の理解に活用する。しかし検索結果上での目に見える特典、つまりリッチリザルト表示という形での直接的なSEO効果は消滅した。
Ahrefsレポートが示したAI引用とスキーマの関係
1,885ページのA/B比較から見えたもの
Ahrefsは2026年5月16日、構造化データとAI引用の関係を検証した大規模レポートを公開した。調査対象はJSON-LD形式のスキーマを追加した1,885のウェブページ。各ページに対し、スキーマを追加しなかった同条件のコントロールページを用意し、Google AI Overviews、Google AI Mode、ChatGPTの3つのAIシステムで引用数の変化を計測した。
結果は次のとおりだ。
- Google AI Modeで引用が2.4%増加
- ChatGPTで引用が2.2%増加
- Google AI Overviewsで引用が4.6%減少
AI ModeとChatGPTの増加率は統計的な誤差の範囲内であり、スキーマの効果とは言い切れない数値だった。AI Overviewsの減少は統計的に有意だったが、Ahrefs自身が「この減少をスキーマが原因と断定することはできない」と慎重な見解を示している。
データが明かさなかった二つの前提
この調査結果を読む上で、二つの前提を見逃してはならない。
第一に、調査対象の全ページはスキーマ追加前からすでにAI Overviewsで100件以上の引用を獲得していた。つまり、これらのページはAIシステムによって十分にクロールされ、認識され、引用されていた。まだAIに認識されていないページでスキーマがクローリングやインデックス登録を助ける可能性は、このデータでは検証されていない。
第二に、この調査では全スキーマタイプを一括りにしている。Article、FAQ、Product、HowTo、Organizationなど種類の異なるスキーマがまとめて「スキーマあり」とラベル付けされた。タイプ別の効果は未検証であり、特定の種類で引用増加が起きる可能性は否定されていない。
Ahrefsのコンテンツマーケティング責任者であるRyan Law氏はLinkedIn上で「スキーママークアップを追加すればAI検索での引用が増えるか?おそらくノーだ」と端的に総括した。Law氏は「スキーマはAI引用を改善する魔法の解決策ではない」とも付け加えている。
業界内で広がった議論の温度感
「FAQスキーマはAI訓練用だった」という仮説
今回のFAQリッチリザルト廃止に対して、業界内ではさまざまな見解が飛び交った。なかでも注目されたのが、Marie Haynes ConsultingのMarie Haynes氏が提示した仮説だ。
Haynes氏は「GoogleはAIを訓練するためにFAQデータが必要だったので、リッチリザルトという形でインセンティブを与えた。そして今、もうそのデータは不要になった」という見方を示した。この説はGoogle自身によって確認されたものではないが、FAQスキーマ導入から廃止までのタイムラインを説明する一つの解釈として、多くの実務者の関心を集めた。
GEO業界への波紋
SEOの専門家であるLily Ray氏(Amsive社、SEO・AIサーチ担当VP)はLinkedIn上で「FAQスキーマはGEOにとって重要」というフレーズが約16万8000ページで使われていることを指摘し、「SEOでスパム可能なものは必ずスパムされる」と述べた。Ray氏は2019年にFAQスキーマが初めて導入された際のMoz記事でこのサイクルを予見していた。
Yoastの創業者であるJoost de Valk氏は、この事態を「GEO業界は初期SEOの歴史を高速で再現している」と表現し、「FAQスキーマの廃止はそのサイクルが再起動した最初の具体的な証拠だ」と自身のブログで述べた。de Valk氏はSchema.orgに対して、FAQSectionという新しいタイプを提案するissueも提出している。これは「このページにFAQセクションがある」という情報と「このページ自体がFAQである」という情報を構造的に分離するための提案だ。
データが答えられなかった問い
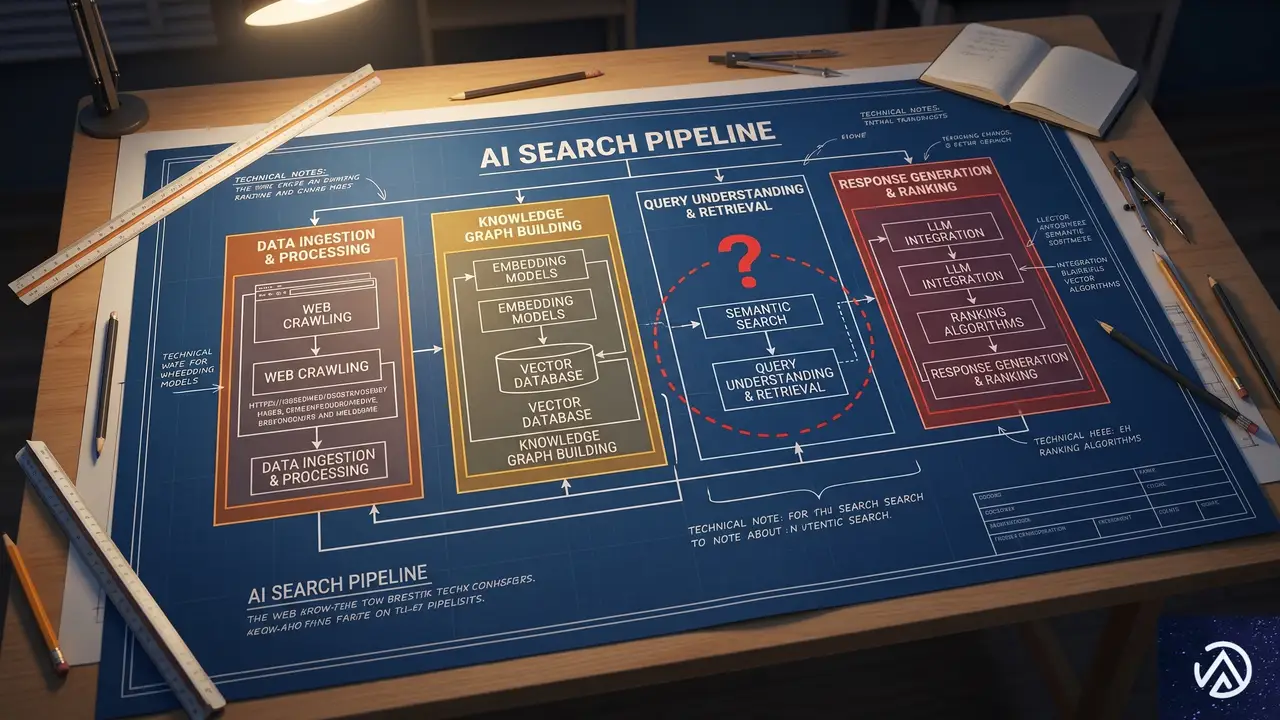
■ スキーマタイプ別の効果(Article/Product/FAQを個別検証していない)
■ 30日を超える長期的効果
■ Bing/Copilot/Perplexity/Claude での挙動
■ JavaScript経由で注入したスキーマの効果
検証されていない経路
Ahrefsの計測対象はGoogle AI Overviews、AI Mode、ChatGPTの3システムに限られる。BingやCopilot、Perplexity、Claudeなど他のAI検索システムがスキーマをどのように扱うかは未検証だ。これらのシステムはGoogleとは異なるクローリングやパースの仕組みを持つ可能性がある。
また、searchVIU(2025年)の実験では、5つのAIシステムがページを直接取得する段階で、表示テキスト(HTML)を参照し、JSON-LDやMicrodata、RDFaなどの隠されたマークアップは使用していなかったと報告されている。これは取得段階に限った話であり、インデックス登録やエンティティ理解の段階でスキーマが役立つ可能性を否定するものではない。
計測期間とタイプ混在の問題
Ahrefsの調査期間は30日間である。スキーマ追加の効果がさらに長期間かけて現れる可能性や、スキーマ追加と同時に行われた他のページ変更の影響を分離できていない点も、解釈上の注意が必要だ。
GoogleはFAQスキーマの廃止告知の中で、構造化データを「ページをよりよく理解する」ために使い続けると述べている。この「よりよく理解する」という表現が具体的に何を指し、どのような測定可能な結果につながるのかは、現時点では明らかになっていない。エンティティ理解やソース選定への間接的な影響を測定したデータは、まだ誰も公表していない。
SEO実務者がいま取るべき戦略
■ 「スキーマを追加すればAI引用が増える」というGEOの売り文句はデータで裏付けられていない
■ Organization、Person、Article スキーマ → エンティティ記述としての価値は残る
■ 見出し構造の明確化、本文での直接的な回答提示 → AI引用に効く可能性が高い
特定スキーマへの過度な依存を避ける
まず確認すべきは、今回のFAQリッチリザルト廃止がスキーマ全体の否定ではないという点だ。Product、Review、Event、Videoといった一部の構造化データは、引き続きアクティブなリッチリザルト機能をサポートしている。Organization、Person、Articleマークアップも、エンティティやコンテンツの記述手段として価値を持ち続ける。
問題は、特定のスキーマタイプを戦略の柱にしてしまうことだ。過去5年間のパターンが示すように、Googleは普及したマークアップの表示特典を段階的に縮小する傾向がある。スキーマは検索エンジンにとっての「水道管」であり、一度敷設すれば特定の蛇口(リッチリザルト)が閉まっても、別の形で水(データ)を運び続ける可能性は残る。
AI引用を狙うならHTML構造を見直す
searchVIUの調査が示したのは、AIシステムがページ取得時にJSON-LDではなく表示テキスト(可視HTML)を参照しているという事実だ。この結果は、AI引用を増やすためにはスキーマよりもコンテンツ自体の構造が重要である可能性を示唆する。
具体的には、見出しを階層的に整理すること、質問に対して本文中で直接的な回答を示すこと、情報を明確なセクションに分けること、といった基本的なコンテンツ設計が、マークアップよりもAI引用に効くかもしれない。スキーマの導入を否定するデータではないが、スキーマだけでAI引用が増えるという期待はデータで裏付けられなかった。
この記事のポイント
- Googleは2026年5月にFAQリッチリザルトを完全廃止し、可視的スキーマ特典の縮小傾向が続いている
- Ahrefsの調査(1,885ページ)では、JSON-LD追加によるAI引用の増加は統計的に確認されなかった
- GEO業界で広がった「スキーマでAI引用が増える」という売り文句は、データによる裏付けを欠いている
- ProductやOrganizationなどリッチリザルトが現役のスキーマタイプは引き続き価値を持つ
- AI引用を狙うなら、スキーマ以上にHTML構造の明確化と本文での直接回答が重要になる可能性が高い
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

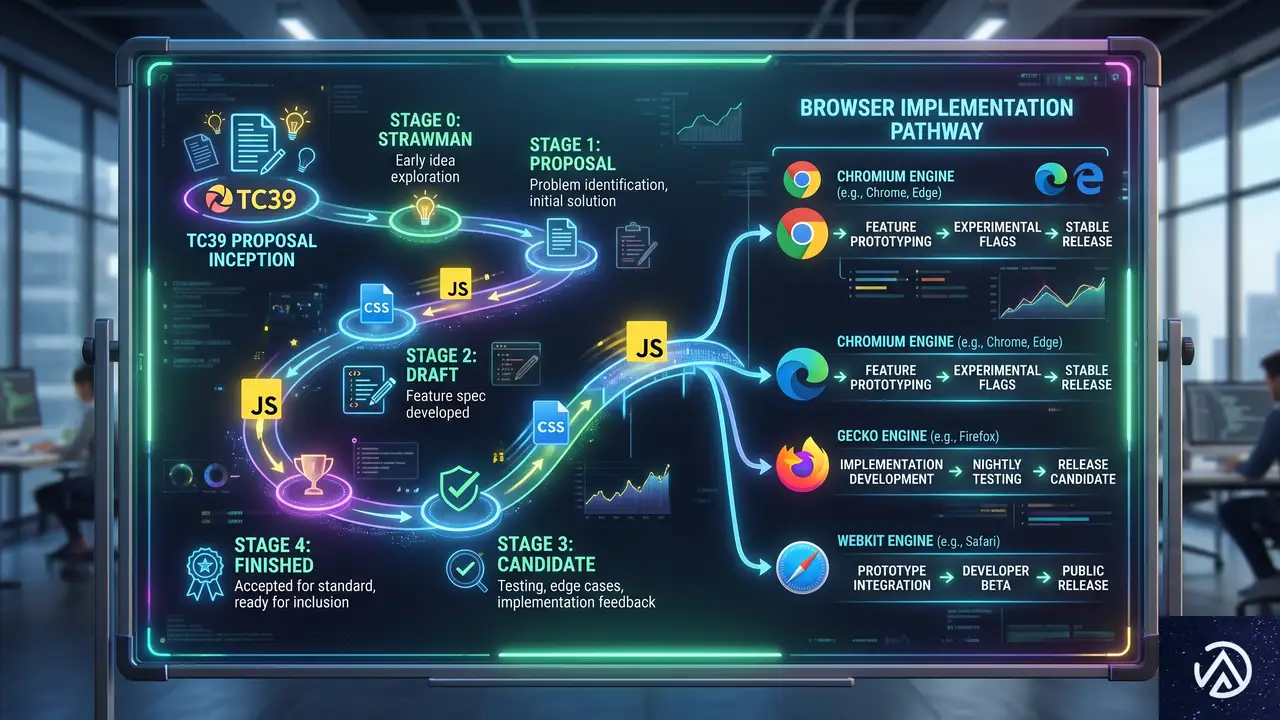
JavaScriptの隔離実行を実現するShadowRealm APIとCSS設計への影響
TC39で策定が進む「ShadowRealm」APIはJavaScriptに新たな隔離実行の仕組みを持ち込む。グローバルスコープを汚染しないサンドボックス環境でコードを動かせるためサードパーティライブラリやテストコードの管理が大きく変わる可能性がある。
CSS設計の観点からもこのAPIは注目に値する。CSS-in-JSの実行や外部スクリプトによるスタイル競合といった問題に対してレルム(領域)レベルの分離が使えるようになればフロントエンド全体の堅牢性が一段上がるからだ。
本記事ではShadowRealmの基本的な考え方から具体的なAPIの使い方、そしてCSS設計との接点までを整理する。
JavaScriptのスレッドとレルム(領域)の基本
「JavaScriptはシングルスレッド言語である」
「ひとつのレルム(領域)はシングルスレッドだがJavaScriptアプリケーションは複数のレルムをまたいでマルチスレッド実行できる」
上の図はよくある「JSはシングルスレッド」という言説が誤解を生む部分を示している。実際にはブラウザのタブひとつがひとつのレルムでありその中でJavaScriptはメインスレッドで動く。一方Web Workersは別のレルムでワーカースレッドを使いiframeもまた独自のレルムを持つ。
シングルスレッド言語の誤解
「JavaScriptはシングルスレッド」というのは「言語仕様としてマルチスレッドを提供していない」という意味では正しい。関数単位で別のスレッドにオフロードするといった仕組みはない。だがWeb Workersを使うとJavaScriptを別スレッドで実行できる。
ここで混乱が生まれる。言語がシングルスレッドでもアプリケーション全体ではマルチスレッド実行が可能だからだ。CSS-Tricksの記事ではこの点を「JavaScriptのレルムはシングルスレッド」と整理している。つまり実行環境の単位であるレルムに着目すれば言語の特性とアプリケーションの振る舞いを矛盾なく説明できる。
レルムとは何か
レルムとはコードが実行される環境そのものを指す。ブラウザタブが持つグローバルオブジェクト(window)や組み込みオブジェクト(ArrayやObjectなど)はすべてそのレルムに紐づく。同じページ内のiframeであっても別のレルムでありwindowもArrayも別物だ。
たとえば親ページで定義したグローバル関数はiframe内のレルムからは見えない。逆も同様だ。こうした隔離は意図しない干渉を防ぐ一方でレルム間の連携にはpostMessageなど特定の手段が必要になる。
グローバルスコープ汚染の現実とCSSへの影響
window.themeColor = '#ff0000';document.body.style.color = window.themeColor;globalThis.themeColor = '#ff0000';document.body.style.color = 'initial';JavaScriptのグローバルスコープは簡単に汚染される。変数のvar宣言の巻き上げや不用意なグローバル変数の追加に加えてサードパーティの広告タグやアナリティクスツール、A/Bテスト用スクリプトが暗黙のうちにグローバル空間へ値を書き込む。これがCSSにまで波及することがある。
サードパーティスクリプトがもたらすCSSの衝突
広告配信スクリプトがwindow.themeColorを書き換えればそれを参照している自前のCSS-in-JSロジックが意図しないスタイルを適用してしまう。また外部ウィジェットがページ全体のfont-sizeを動的に変更すればレイアウトが崩れる原因になる。
こうした問題はグローバルスコープを共有するからこそ起こる。完全に隔離されたレルムで外部コードを動かせれば変数の上書きやオブジェクトの改変は発生せず結果としてCSSの意図しない変化も防げる。
CSS-in-JSにおける隔離の必要性
CSS-in-JSライブラリではスタイルの計算結果をJavaScriptのオブジェクトや変数として管理するケースが多い。テーマ切り替えや動的スタイル生成にグローバル変数を使っていると外部スクリプトがそれらを上書きするリスクがある。ShadowRealmを使ってスタイル計算を隔離すれば外部からの干渉を受けない安全なスタイル生成が可能になる。
ShadowRealm APIの仕組み

TC39で策定中のShadowRealmはコードを独立したグローバル環境で実行するためのAPIだ。このAPIには大きく分けてふたつの機能がある。evaluate()で任意のJavaScript文字列を評価する方法とimportValue()でモジュールを動的インポートしてエクスポートされた値だけを安全に受け取る方法だ。
基本的な使い方
// ShadowRealmインスタンスを作成
const shadow = new ShadowRealm();
// 外側のレルムでグローバル関数を定義
function globalFunction() {}
console.log( globalThis.globalFunction );
// 結果: function globalFunction()
// ShadowRealm内で同じ関数を評価しても未定義
console.log( shadow.evaluate( 'globalThis.globalFunction' ) );
// 結果: undefinedglobalThis.globalFunction → function globalFunction()globalThis.globalFunction → undefinedコードが示すようにShadowRealmインスタンス内部のグローバル環境は外側から完全に切り離されている。しかもこのコードはメインスレッド上でそのまま実行されるためスレッド間通信のコストや複雑さを伴わない。
CSS-Tricksの記事ではこの性質を「無限に使える使い捨てのクリーンルーム」と表現している。テストのモックデータが本番のグローバル変数と衝突する心配もなくサードパーティコードを安全に評価できる環境だ。
importValueによるモジュールの隔離実行
// spookycode.js
export function greeting() {
return "Hello from the ShadowRealm!";
}
// メイン側
async function shadowGreeter() {
const shadow = new ShadowRealm();
const shadowGreet = await shadow.importValue(
"./spookycode.js",
"greeting"
);
shadowGreet(); // "Hello from the ShadowRealm!"
}
shadowGreeter();export function greeting() { ... }const fn = await shadow.importValue("./spookycode.js", "greeting");fn(); // "Hello from the ShadowRealm!"importValue()はPromiseを返し第二引数で指定したエクスポート名の値だけを取り出す。モジュールの内部実装はShadowRealmの隔離環境で動くため外側のグローバル空間を一切汚さない。CSS-in-JSで使うテーマ計算モジュールなどをこの形で読み込めばグローバル変数を介したスタイルの競合を根本から断てる。
ShadowRealmが変えるCSS設計の安全性

window.currentTheme = 'dark';window.currentTheme = 'light'; に上書きShadowRealmはまだブラウザに実装されていないがCSS設計の安全性を高めるうえでいくつかの具体的な使い道が考えられる。
スタイルの衝突防止とテーマ分離
複数の独立したコンポーネントやマイクロフロントエンドがひとつのページに同居するケースではそれぞれが使うCSS変数やテーマオブジェクトが衝突しやすい。ShadowRealmで各コンポーネントのスタイル計算ロジックを包めばそれぞれのグローバル空間は完全に分離され変数の取り合いが起きない。
またユーザーごとにカスタマイズされたテーマを動的に生成するような仕組みでも計算ロジックをShadowRealmに閉じ込めれば他スクリプトによる意図しないテーマ書き換えを防げる。
テスト環境の清浄化
CSS-in-JSの単体テストではグローバルなスタイルシートの状態がテスト結果に影響を与えることがある。ShadowRealm上でテストを実行すればテストごとに完全にクリーンなグローバル環境が得られモックデータの準備も簡素化される。ブラウザテストとNode.jsテストの両方で同じ隔離機構を使える点もメリットだ。
実装状況と将来の展望
ShadowRealmの提案はTC39のステージ2.7にある。これは「原則的に承認され検証段階にある」という位置づけでブラウザへの試験実装が始まれば仕様の微調整が入る可能性は残る。現時点では実際のブラウザやNode.jsで使うことはできない。
CSS-Tricksの記事でも指摘されているようにShadowRealmはセキュリティ境界ではなく完全性境界を提供するものだ。つまり悪意あるコードの実行を完全に防ぐサンドボックスではないがグローバル変数や組み込みオブジェクトを意図せず壊してしまうリスクを封じ込めるには十分な隔離性能を持つ。
ステージ3へ進み主要ブラウザが実装を始めればCSS-in-JSライブラリやテストランナー、サードパーティスクリプト管理の分野でいち早く活用が広がるだろう。
この記事のポイント
- ShadowRealmはコードを独立したグローバル環境で実行するTC39提案のAPI
- メインスレッド上で動くためスレッド間通信の複雑さがない
- サードパーティスクリプトやCSS-in-JSのテーマ計算を隔離しスタイル競合を防げる
- テストコードの実行環境としてもクリーンなグローバル空間を提供する
- 現時点ではステージ2.7で未実装。ブラウザ対応はこれから
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

GoogleがAEOとGEOを「依然としてSEO」と公式見解、新ガイド公開
Googleは2026年5月15日、生成AI検索機能(AI OverviewsやAI Mode)に向けたウェブサイト最適化の公式ガイドを公開した。名称は「Optimizing your website for generative AI features on Google Search」である。
このドキュメントでGoogleは、AEO(Answer Engine Optimization)やGEO(Generative Engine Optimization)と呼ばれる一連の手法について、はっきりとした立場を示した。すなわち「それらは依然としてSEOの一部である」という公式見解だ。同時に、llms.txtファイルの作成やチャンキング(コンテンツの細分化)、不自然な言及の獲得といった、一部で推奨されてきた施策に対しても「必要ない」と明言している。
記事では、この新ガイドのポイントを具体的に紹介しつつ、実務者がAI検索時代に本当に注力すべき施策を整理する。
新ガイド公開の背景と位置づけ
今回のガイドは、2025年に公開されたAI機能の仕組みに関するドキュメントを大幅に拡充したものだ。従来版ではAI機能の動作原理や検索パフォーマンスの測定方法が中心だったが、新ガイドは「何をすべきか」という最適化アドバイスに踏み込んでいる。特に「神話打破(Mythbusting)」というセクションを新設し、業界で流布している誤解に対してGoogleの立場を直接的に表明した点が目を引く。
Googleの生成AI検索機能は、RAG(Retrieval-Augmented Generation / 検索拡張生成)とクエリファンアウトを基盤としており、基本的には既存の検索インデックスからコンテンツを引き出す仕組みだ。このため、コアとなるランキングシステムや品質評価の仕組みは従来と大きく変わらない。ガイドはその点を強調しつつ、AIならではの特性を踏まえた最適化の方向性を示している。
新旧ガイドの差分を見ると、Googleがサイト運営者に対して「何を気にしなくてよいか」を明確に伝えようとしていることがわかる。生成AI検索の登場以降、さまざまなサービスが独自の最適化手法を提唱してきたが、Googleはその多くを不要と断じた形だ。
AEO・GEOは「依然としてSEO」という公式見解
用語の定義とGoogleの立場
ガイドでは、AEOを「Answer Engine Optimization」、GEOを「Generative Engine Optimization」と定義した上で、「Google検索の観点から言えば、生成AI検索のための最適化は検索体験のための最適化であり、したがって依然としてSEOである」と明記した。
この見解は、Googleの検索担当者であるGary Illyes氏やCherry Prommawin氏が過去のカンファレンスで発言してきた内容を公式文書化したものだ。両氏はSearch Central Liveにおいて、GEOやAEOに個別のフレームワークは不要であると述べていた。今回のガイド公開により、その立場が正式な参照可能なドキュメントとして記録されたことになる。
RAGとクエリファンアウトの仕組み
GoogleのAI機能は、RAG(検索拡張生成)という仕組みを使っている。これは、ユーザーの質問に対してまず検索インデックスから関連コンテンツを取得し、その情報をもとに生成AIが回答を構成する方式だ。クエリファンアウトは、ひとつの質問を複数の関連クエリに展開して広範囲の情報を収集する技術を指す。いずれも既存の検索インデックスに依存しているため、ベースとなるSEO対策が効いてくる構造は変わらない。
この点を踏まえると、「AI向けに別の最適化が必要」という発想そのものが、Googleの検索システムの実態と乖離していることになる。
上図のように、AI検索においても検索インデックスが情報取得の起点であることに変わりはない。つまり、クローラビリティやコンテンツ品質といった従来型SEOの基盤が、そのままAI検索のパフォーマンスに直結する。
Googleが必要ないと明言した5つの施策

新ガイドの「神話打破」セクションでは、以下の施策について明示的に「Google検索においては不要」と記載されている。
llms.txtファイルや特殊マークアップ
機械可読なファイルやAI向けテキストファイル、特別なマークアップ、Markdownなどを用意する必要はない。GoogleはHTML以外のさまざまなファイル形式を検出しインデックス登録できるが、それはファイル形式が特別扱いされることを意味しない。
チャンキング(コンテンツの細分化)
AIシステム向けにコンテンツを細かく分割する必要はない。Googleのシステムは「ページ内の複数トピックのニュアンスを理解し、ユーザーに関連する部分を表示できる」能力を持つ。Search Engine Journalの記事によれば、GoogleのDanny Sullivan氏も2026年1月に同様の見解を示しており、社内エンジニアからもチャンキングを推奨しない意見が出ているという。
AI向けの文章リライト
AIシステムは類義語や一般的な意味を理解できるため、すべてのロングテールキーワードバリエーションを網羅したり、生成AI検索向けに特別な文体で書いたりする必要はない。過剰な最適化はむしろ不自然なコンテンツを生むリスクもある。
不自然な言及(メンション)の獲得
AI機能はブログや動画、フォーラムなどで語られている製品やサービスに関する言及を表示することがある。しかし、不自然な形で言及を集めようとする行為は「思われているほど有益ではない」とガイドは指摘する。中核のランキングシステムは品質に焦点を当てており、スパム的な言及は別の仕組みでブロックされる。
生成AI検索向けの専用構造化データ
生成AI検索のために特別なschema.orgマークアップを追加する必要はない。構造化データはリッチリザルトの表示資格を得るために従来通り活用するのがよいとしている。
上記の施策はいずれも、一部のGEO関連リソースやAI検索最適化ガイドで推奨されてきたものだ。しかしGoogleの公式見解は真逆であり、こうした「AI専用対策」にリソースを割くことの費用対効果は極めて低いと言わざるを得ない。
代わりに注力すべき最適化の要点

では実際に何をすべきか。ガイドの推奨事項は、多くのSEO担当者にとって馴染み深い領域に集約されるが、AI検索ならではの文脈も含まれている。
非コモディティコンテンツの重視
ガイドが特に強調するのが「非コモディティコンテンツ」の概念だ。コモディティコンテンツとは、「初めて住宅を購入する人への7つのヒント」のような、どこにでもある一般知識の寄せ集めを指す。対する非コモディティコンテンツの例としてGoogleが挙げるのは「なぜ我々は検査を放棄して節約したのか——下水管内部の実例」のような、独自の経験や視点に基づく記事である。
この区別は、AIが既存の知識を要約して回答を生成できる時代において、人間の独自体験や専門的判断が差別化要因になることを示唆している。単なる情報の列挙ではなく、実際に経験したこと、検証したこと、独自に分析したことを盛り込む姿勢が求められる。
クローラビリティとインデックス
生成AI機能にコンテンツが表示されるには、ページがインデックス登録され、スニペット表示の対象となっている必要がある。具体的には、クロールのベストプラクティスに従うこと、可能な限りセマンティックHTMLを使用すること、JavaScript SEOの基本を守ること、良好なページエクスペリエンスを提供すること、重複コンテンツを減らすことなどが推奨されている。
ローカルビジネスとECの最適化
ローカルビジネスやECサイト向けには、Merchant CenterフィードとGoogleビジネスプロフィールの活用が推奨されている。また、Business Agentという、ユーザーがGoogle検索上でブランドとチャットできる会話型体験についても言及があった。これは、実店舗や商品を持つ事業者にとってAIエージェント経由の接点が増える可能性を示している。
非コモディティコンテンツの作成 独自の経験・分析に基づく記事
クローラビリティとインデックス管理 従来のテクニカルSEO対策
構造化データの適切な活用 リッチリザルト用途として継続
エージェント対策(UCP対応など) ビジネス関連性と余力がある場合
整理すると、AI検索対策の本質は「強いコンテンツを作り、検索エンジンに正しく読み取らせる」という原点に立ち返ることだ。特別なテクニックや抜け道を探す段階は、少なくともGoogleにおいては終わったと言える。
エージェント体験とUCPの初期ガイダンス
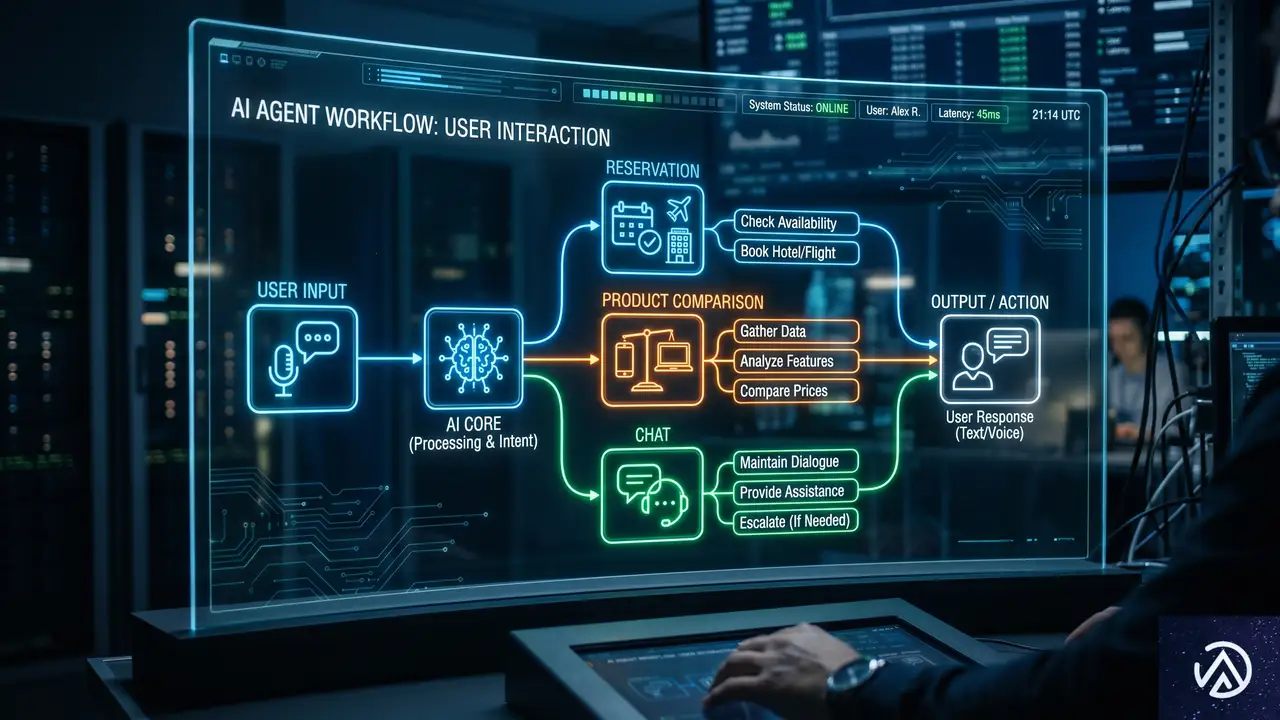
新ガイドでは、エージェント体験についても独立したセクションが設けられた。AIエージェントを「予約の手配や製品仕様の比較など、人に代わってタスクを実行できる自律システム」と定義し、ブラウザエージェントがスクリーンショットの分析、DOMの検査、アクセシビリティツリーの解釈を通じてウェブサイトにアクセスする可能性に言及している。
この文脈で紹介されているのが、web.devの「エージェントフレンドリーなウェブサイトのベストプラクティス」ガイドと、UCP(Universal Commerce Protocol)だ。UCPはGoogleが2026年初頭に発表した新興プロトコルで、Shopifyと共同開発され、すでに20社以上が支持を表明している。Vidhya Srinivasan氏の年次レターでも紹介された。
ただしGoogleは、このセクションについて「ビジネスに関連性があり、余力がある場合に検討するもの」と位置づけている。エージェント最適化は将来的な投資であり、今すぐ取り組まなければ検索順位が下がる性質のものではない。
実務への影響と今後の展望
このガイドの最大の価値は、Googleの立場を一つの文書に集約したことにある。これまでカンファレンスやポッドキャスト、ブログ投稿に分散していた見解が、公式ドキュメントとして参照可能になった。「神話打破」セクションは特に重要で、AEOやGEOのサービスを展開する業界が推奨してきた施策の多くを、Google自身が否定した形だ。
ただし注意すべき点もある。このガイドはあくまでGoogleのAI検索機能に特化したものであり、ChatGPTやPerplexityなど他プラットフォームのAI検索には適用されない可能性がある。これらのサービスは異なるシグナルを重視しているかもしれず、マルチプラットフォーム戦略をとる場合は別途検証が必要だ。
Googleは文書の締めくくりで、「このガイドのすべてを達成しなくても成功できる」と述べている。「多くのコンテンツは、明白なSEO対策を一切施さなくてもGoogle検索(生成AI体験を含む)で成果を上げている」というコメントからは、技術的な最適化よりもコンテンツの本質的な価値が優先されるというメッセージが読み取れる。
SEO担当者やサイト運営者にとって、このガイドは戦略的なリソース配分を見直す良い契機になるだろう。「AI専用の対策」に時間と予算を割くよりも、独自の情報価値を持つコンテンツの制作と、堅実なテクニカルSEOの維持に集中する。それが、Googleの生成AI検索において最も確実なアプローチだと公式に示されたのである。
この記事のポイント
- Googleが生成AI検索最適化の公式ガイドを2026年5月に公開し、AEOやGEOは「依然としてSEOの一部」と明言した
- llms.txt、チャンキング、AI向けリライト、不自然な言及獲得、専用構造化データの5施策を「不要」と断定
- 代わりに非コモディティコンテンツ、クローラビリティ確保、構造化データの適切な活用を推奨
- エージェント体験とUCPに関する初期ガイダンスも含まれるが、優先度は相対的に低い
- ガイドの適用範囲はGoogleに限られるため、他プラットフォームでは別途戦略の検証が必要である
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AWS最新動向(5月11日週) Bedrock AgentCoreの支払い機能とAgent Toolkitを解説
2026年5月11日の週、AWSはAIエージェントの自律的な動作を根本から変える発表を相次いで行った。最も注目すべきは、Amazon Bedrock AgentCoreがエージェント自身による支払い機能のプレビューを開始したことだ。これによりAIエージェントはAPIや外部サービスの利用料を自ら決済し、実行タスクに必要なリソースを動的に調達できるようになる。
AWS News Blogの著者であるChanny Yun氏が執筆した週次ラウンドアップによれば、この支払い機能はCoinbaseおよびStripeとの提携で構築された。さらに、AIコーディングエージェント向けの「Agent Toolkit for AWS」や、エージェントにデスクトップ環境を提供する「WorkSpaces for AI agents」も発表されている。本記事ではこれらの新機能を技術面とビジネスインパクトの両面から分析する。
Amazon Bedrock AgentCoreの支払い機能が示す「エージェント経済圏」の到来

AIエージェントが「考える」だけでなく「支払う」時代が来た。Amazon Bedrock AgentCoreにプレビューとして追加された支払い管理機能は、エージェントがAPI、MCPサーバー、Webコンテンツ、さらには他のエージェントの利用料を自律的に支払うことを可能にする。これは単なる便利機能ではない。エージェントが経済活動の主体になるための第一歩といえる。
この図が示すように、従来は有料サービスへのアクセスがエージェントのボトルネックだった。AgentCore Paymentsによってその制約が取り払われる。
CoinbaseとStripeとの提携が意味するもの
AWSはこの支払い基盤を単独で構築しなかった。暗号資産ウォレットのCoinbase(CDP Wallet)と決済プラットフォームのStripe(Privy Wallet)という、まったく異なる決済レイヤーの企業と提携している。Coinbase連携によりオンチェーン決済が可能になり、Stripe連携は従来型の法定通貨決済をカバーする。この二段構えが示唆するのは、AWSが特定の決済手段に依存せず、マルチペイメントレイヤーのエコシステムを目指しているということだ。
セッション単位の支出制限とガバナンス設計
エージェントに支払い権限を与えると聞いて、真っ先に浮かぶ懸念は「使いすぎ」や「不正利用」だろう。AWSはこの点をセッションレベルの支出制限で対策している。開発者はエージェントの実行セッションごとに予算上限を設定でき、その範囲内でのみ決済が実行される。企業の与信管理と同じ考え方をエージェント単位に落とし込んだ設計だ。
さらに、認証情報管理とコンプライアンス対応も組み込まれている。各エージェントは決済手段に直接アクセスするのではなく、事前に登録されたウォレット接続を通じて取引を実行する。AWSのIAM(Identity and Access Management)に似た権限管理の考え方が、支払い領域にも適用された形だ。
エージェント経済圏が実務にもたらす変化
Channy Yun氏がブログ記事で最も興奮していると述べたポイントは、この機能が解き放つユースケースの広がりだ。たとえば、リサーチエージェントがリアルタイムの市場データを動的に購入して分析に組み込む、あるいはコーディングエージェントがタスク実行中に有料APIを呼び出して機能を補完する、といった動作が実現する。
これはクラウドの従量課金モデルをエージェント自身が直接操作できるようになることを意味する。開発者はあらかじめすべてのAPI契約を整備する必要がなくなり、エージェントが実行時に必要なリソースを判断して調達する。インフラ構築の手間が一段階抽象化されるわけだ。
Agent Toolkit for AWSが実現する「AI時代のインフラ構築」
AgentCore Paymentsと並んで注目を集めたのが、AIコーディングエージェント向けの「Agent Toolkit for AWS」の発表だ。これはエージェントがAWS上で構築作業を行う際のエラー削減、トークンコスト低減、エンタープライズグレードのセキュリティ制御を実現する本番環境向けツールスイートである。追加料金なしで利用できる。
AWS MCPサーバーの一般提供とAgent Toolkitの関係
Agent Toolkitの中核コンポーネントとして、AWS MCP Serverが一般提供(GA)に移行した。MCP(Model Context Protocol)サーバーは、AIエージェントやコーディングアシスタントがAWSの全サービスに対して安全かつ認証付きでアクセスするためのマネージドなリモートサーバーだ。少数の固定ツールセットを通じて、複雑なAWS APIを抽象化する。
端的にいえば、エージェントに「AWS全体への安全なアクセス権」を渡す仕組みである。従来は開発者がIAMポリシーやAPIキーを個別に設定し、エージェントに渡す必要があった。MCPサーバーを使えば、これが統合認証のレイヤーで一元管理される。
ツールキットがエンジニアのワークフローをどう変えるか
Agent Toolkitは、これまでAWS Labsで提供されていたMCPサーバーやプラグイン、スキルの後継に位置づけられる。実験段階から本番利用への移行を意図した製品だ。具体的には以下の3つの価値を提供する。
- エラー削減: エージェントがAWSリソースを操作する際の設定ミスや権限違反を減らす
- トークンコスト低減: 最小限のツール呼び出しで済むよう最適化され、LLMのAPI利用料を抑える
- セキュリティ制御: 企業のセキュリティポリシーに準拠したアクセス制御を適用できる
開発者にとっては、AIエージェントに「AWSの操作方法」を一から教え込む必要がなくなる点が大きい。ツールキットが提供するスキルとプラグインを組み込むだけで、エージェントはAWSリソースのプロビジョニングや監視、トラブルシューティングを標準化された方法で実行できる。
AIエージェントにデスクトップを提供するWorkSpacesの狙い

プレビューとして発表された「Amazon WorkSpaces for AI agents」は、一見すると奇妙な機能に思える。AIエージェントが仮想デスクトップを使うとはどういうことか。狙いは、エージェントにGUIアプリケーションを操作させることにある。
多くの企業には、Web APIを持たない古い業務アプリケーションが残っている。WorkSpaces for AI agentsは、エージェントがこうしたGUIアプリケーションの画面を認識し、クリックやキー入力をエミュレートすることで、人間のオペレーターと同じ操作を実行できるようにする。
セキュリティ面では、エージェント専用のマネージドWorkSpaces環境が割り当てられ、エンタープライズグレードのガバナンスとコンプライアンスを維持したまま動作する。企業が長年抱えてきた「API化できない業務の自動化」という課題に対する、AWSなりの回答といえる。
第6世代Intel搭載の新型EC2インスタンスがもたらす性能向上

AI関連の発表に隠れがちだが、基盤となるコンピュートリソースにも重要なアップデートがあった。Amazon EC2のM8idn/M8idbおよびR8idn/R8idbインスタンスが発表されたのだ。これらはAWS専用にカスタマイズされた第6世代Intel Xeon Scalableプロセッサと、最新の第6世代AWS Nitroカードを搭載する。
vCPUあたり最大43%の性能向上
発表データによれば、前世代インスタンスと比較してvCPUあたりのコンピュート性能が最大43%向上している。この数字は単なるベンチマーク上の改善ではない。同じコストでより多くのワークロードを処理できることを意味する。
ネットワーク帯域とEBS帯域の強化
インスタンスタイプによって提供されるネットワーク性能も明確に差別化されている。M8idn/R8idnは最大600Gbpsのネットワーク帯域を提供し、M8idb/R8idbは最大300GbpsのEBS(Elastic Block Store)帯域に対応する。前者はネットワーク集約型ワークロードに、後者はストレージI/Oが重要なデータベースや分析ワークロードに最適化されている。
実務的には、機械学習のトレーニングデータを高速に読み込む必要があるケースや、大規模な分散データベースを運用するケースで効果を発揮する。M8idnとR8idnの選択肢が増えたことで、ワークロード特性に応じた細かいインスタンス選定が可能になった。
ValkeyとS3 Vectorsに見るデータ基盤の「ベクトル化」と「オープン化」

5月11日の週には、データ基盤に関する注目すべき動きもあった。OSS(オープンソースソフトウェア)のキーバリューストアであるValkeyが2周年を迎え、Amazon S3 VectorsとAurora PostgreSQLの統合に関する詳細なガイドが公開された。
Valkeyの急成長が証明するコミュニティ駆動開発の強さ
AWSのデータベースブログが報じたところによれば、ValkeyはDocker Pull数が1億を突破し、前年比17倍という急成長を遂げた。225人以上のコントリビューターが1,500以上のプルリクエストを提出しており、これは同期間におけるRedisの開発ペースの約2倍に相当する。
この数字が示すのは、単一ベンダー主導の開発モデルよりも、オープンでコミュニティ駆動の開発の方が速く、広範囲にイノベーションを起こせるという事実だ。Valkey 9.0はすでにAmazon ElastiCacheでも利用可能になっており、マネージドサービスとしての利便性とOSSの革新性を両立させている。
10億スケールのベクトル検索をSQLで
Aurora PostgreSQLからS3 Vectorsを標準SQLでクエリできるようになったことも見逃せない。具体的には、ベクトル類似度検索の結果とリレーショナルフィルタを1つのSQL文で組み合わせられる。たとえば、「意味的に最も類似した商品を検索し、その中から価格や在庫状況で絞り込む」といったクエリが単一ステートメントで完結する。
これはベクトルデータベース専用のクエリ言語を習得する必要がなくなることを意味する。すでにSQLを使いこなしているエンジニアであれば、追加学習なしでベクトル検索を業務に組み込める。データ基盤の民主化という観点から、非常に実用的なアップデートだ。
この記事のポイント
- Amazon Bedrock AgentCoreに支払い管理機能が追加され、AIエージェントが自律的にAPIやサービスの利用料を決済できるようになった
- Agent Toolkit for AWSが発表され、AIコーディングエージェントのエラー削減やトークンコスト低減を実現する
- WorkSpaces for AI agentsのプレビュー開始により、レガシーGUIアプリケーションの自動化が現実的になった
- 新型EC2インスタンスはvCPUあたり最大43%の性能向上を達成し、ネットワーク帯域とEBS帯域も強化された
- Valkeyの成長とS3 VectorsのSQL統合は、データ基盤のオープン化とベクトル検索の民主化が加速していることを示している
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

DockerがカスタムMCPカタログとプロファイルを正式提供、企業のAIツール管理が新段階へ
Dockerは2026年5月15日、MCP(Model Context Protocol)サーバーを管理する「カスタムカタログ」と「プロファイル」の一般提供を開始した。組織はこれらを使ってMCPサーバー群を一元的に管理し、開発者は作業内容に応じたツール構成を簡単に切り替えられるようになる。
この発表の背景には、企業へのMCP導入が進むにつれて「誰がどのMCPサーバーを信頼して使うべきか」という調整コストが急増していた現実がある。Dockerの新機能は、プラットフォームチームが推奨するツール群を「カタログ」として配布し、現場の開発者が「プロファイル」で自由に組み替えるという二層構造でこの課題を解決する。
MCP活用の壁とDockerの解決策

MCPはAIエージェントが外部ツールやデータソースと対話するための標準プロトコルだ。ChatGPTのプラグイン機能に相当するが、ベンダーに依存せずオープンな仕様で設計されている。Dockerは2025年後半からMCPサーバーの統合管理機能「MCPカタログ」を提供してきたが、公開サーバーだけでは社内ツールや独自要件に対応しきれないという声が増えていた。
特に大きかったのは「全社で使える信頼済みリストがほしい」というニーズと「開発者個人のワークフローに合わせた構成を使いたい」というニーズのせめぎ合いだ。前者を強めると開発者の自由度が下がり、後者を優先するとセキュリティ基準が守れなくなる。Dockerが今回一般提供を始めたカスタムカタログとプロファイルは、この二つを両立させるインフラにあたる。
カスタムカタログとプロファイルの役割分担
カスタムカタログは「組織が推奨するMCPサーバーの集合」を定義し、OCIアーティファクトとして配布できる仕組みだ。プロファイルは個人がカタログから選んだサーバー群を「コーディング用」「企画用」といった用途別にまとめ、クライアント(Claude Codeなどのエージェント)に切り替えて接続できる。
この二層構造によって「組織が定める信頼の枠組み」と「個人が工夫する効率化」が衝突しなくなる点が最大の価値だ。プラットフォームチームはガードレールを引き、開発者はその中で自由にツールを組み替える。
カスタムMCPカタログの作成と配布手順

Dockerの公式ブログで解説されている手順に沿って、実際にカスタムカタログを作成する流れを見ていこう。ここではDocker Hubをレジストリとして使う例だが、プライベートレジストリにも対応する。
ステップ1 自前のMCPサーバーをイメージ化する
まず、組織内で使いたい独自のMCPサーバーをDockerイメージとしてビルドし、レジストリにプッシュしておく。Dockerの解説では、さいころを振るroll-diceというサンプルサーバーが使われている。stdioで通信する標準的なMCPサーバーであり、Dockerfileからイメージを作成する手順は通常のコンテナ開発と変わらない。
イメージが用意できたら、そのサーバーのメタデータをYAMLファイルに記述する。ファイル名や格納場所は任意だ。
name: roll-dice
title: Roll Dice
type: server
image: roberthouse224/mcp-dice@latest
description: An mcp server that can roll diceこのYAMLにはサーバーの識別名、表示タイトル、Dockerイメージの参照先、説明文が含まれる。実際の運用では、ここにアクセス権限や設定パラメータのメタ情報を追加することも考えられる。
ステップ2 Docker MCPカタログと自前サーバーを束ねる
次に、docker mcp catalog createコマンドを使ってカスタムカタログを作成する。引数にはDocker公式カタログから取り込みたいサーバーと、先ほど用意したYAMLファイルのパスを指定する。
docker mcp catalog create roberthouse224/our-catalog \
--title "Our Catalog" \
--server catalog://mcp/docker-mcp-catalog/playwright \
--server catalog://mcp/docker-mcp-catalog/github-official \
--server catalog://mcp/docker-mcp-catalog/context7 \
--server catalog://mcp/docker-mcp-catalog/atlassian \
--server catalog://mcp/docker-mcp-catalog/notion \
--server catalog://mcp/docker-mcp-catalog/markitdown \
--server file://./mcp-dice.yamlcatalog://スキームでDockerの公式カタログから既存のサーバーを取り込み、file://スキームで自作サーバーのメタデータを追加している。このカタログはローカルマシン上にOCIアーティファクトとして作成され、docker mcp catalog showで内容を確認できる。
ステップ3 カタログをレジストリで共有する
作成したカタログは、docker mcp catalog pushでDocker Hubやプライベートレジストリにプッシュすれば即座に共有可能になる。OCIアーティファクトとしての配布は、組織内のリポジトリアクセス権限をそのまま使えるため、追加のインフラ管理が不要だ。
docker mcp catalog push roberthouse224/our-catalogこれで、組織内の他メンバーはDocker Desktopの「カタログインポート」機能か、docker mcp catalog pullコマンドでこのカタログを取得できる。公式カタログにはない社内ツールが含まれている点、すべてのサーバーが組織としての信頼審査を通過している点が、単なる公開カタログとの決定的な違いだ。
カスタムカタログがエンタープライズにもたらす意味

ここで一歩引いて、この機能が企業のAI活用に何をもたらすかを考えてみたい。単なる「MCPサーバーリストの共有」に見えるが、実際にはもっと大きな変化の起点になる。
第一に、MCPサーバーの発見と評価にかかるコストが大幅に下がる。開発者がインターネット上からMCPサーバーを探して安全性を個別に判断する必要がなくなり、組織が「使ってよいもの」をあらかじめ提示できる。これはソフトウェアサプライチェーン管理の考え方をAIツールに応用したものとも言える。
第二に、プライベートレジストリと組み合わせれば、社内限定のAIツールを企業秘密として保護しながら配布できる。たとえば自社データベースに特化したMCPサーバーを、アクセス権のあるメンバーだけに提供する使い方が想定される。Dockerのブログでも「プライベートカタログ」という方向性が示唆されている。
第三に、OCIアーティファクトという既存の業界標準に乗っていることが地味ながら重要だ。組織はすでにコンテナレジストリの運用ノウハウとアクセス管理の仕組みを持っている。それをそのままMCPに転用できるため、新たに専用の配信インフラを構築する必要がない。
このようにカスタムカタログは「野良ツールの乱立を防ぎつつ、社内イノベーションを促進する」バランサーとして機能する。とはいえ、カタログで提供されるのはあくまで「選択肢の集合」だ。実際の作業でどのツールをどう組み合わせるかは、次のプロファイル機能が受け持つ。
MCPプロファイルで個人ワークフローを最適化する

プロファイルは、カタログから選んだMCPサーバー群を「コーディング」「企画」「調査」などの用途別に束ね、任意のAIクライアントに接続できる仕組みだ。特定のプロファイルには必要なツールだけが含まれるため、エージェントのコンテキストウィンドウを無駄に消費しない利点がある。
作業モードの切り替えを数クリックで実現
Docker Desktop 4.63から利用できるプロファイル機能の基本動作はシンプルだ。カスタムカタログを開き、使いたいサーバーを選択して「新しいプロファイル」を作成する。プロファイルには接続先クライアント(Claude Codeなど)を指定できるが、後から付け替えることも可能だ。
たとえば、Playwright、GitHub、Context7を含む「コーディング」プロファイルと、Atlassian、Markitdown、Notionを含む「企画」プロファイルを別々に作っておけば、作業内容に応じてクライアントの接続先を切り替えるだけでツール環境が丸ごと入れ替わる。これまではツールセットを切り替えるたびに再設定が必要だったが、プロファイルによりワンアクションで済む。
設定の保存と再利用で反復作業を削減
プロファイルのもう一つの利点は、MCPサーバーの設定を永続化できることだ。Markitdownサーバーにアクセス可能なディレクトリパスを指定する場合や、GitHubサーバーのうち使うツールをget_meだけに絞る場合など、一度設定した内容はプロファイルに保存される。これにより、毎回手動で同じ設定を繰り返す手間が省ける。
コンテキストウィンドウの最適化という観点では、大量のツールをエクスポートするMCPサーバーに対して「このタスクではツールAとBだけ有効化する」と制限できる点が実用的だ。エージェントの推論性能を落とさず、必要な機能だけに集中させられる。この仕組みは、社内開発するMCPサーバーにリッチな設定オプションを持たせることで、さらに強力な再利用性を発揮するだろう。
上図のように、同じカタログから異なるプロファイルを複数作成し、用途に応じて切り替える運用が基本スタイルになる。この考え方は、VS Codeのワークスペース設定や、ターミナルのプロファイル管理に近い。AIエージェント時代の「作業環境テンプレート」と捉えるとわかりやすいだろう。
プロファイルの共有と今後の展望

プロファイルもカスタムカタログと同様、OCIアーティファクトとしてレジストリで共有できる。docker mcp profile pushでプッシュすれば、チームメンバーはdocker mcp profile pullで即座に同じツール構成を手に入れられる。うまくいった設定を「テンプレート」として展開できるこの仕組みは、プロジェクト立ち上げ時の環境構築コストを大幅に下げる。
docker mcp profile push coding your-namespace/codingDockerは今後、以下の方向性でカスタムカタログとプロファイルを拡張していくとしている。
- ガバナンスとポリシー制御により、承認されたカスタムカタログ以外からのMCP利用を制限
- カタログとプロファイルのディスカバビリティを向上し、実績のある構成を見つけやすくする
- プロファイルスコープでのシークレット・設定値管理を強化し、セキュアな代替手段として整備
- エージェントスキルとの連携により、プロファイルを依存関係として参照するワークフロー
特に最後の「エージェントスキルがプロファイルを依存関係として参照する」という構想は興味深い。たとえば「データ分析スキル」が起動するときに、必要なMCPサーバー構成をプロファイルから自動で引き込むといった使い方が想定されている。これが実現すれば、AIエージェントが自律的に必要なツールを調達して動く世界がさらに近づく。
この記事のポイント
- DockerがカスタムMCPカタログとプロファイルの一般提供を開始し、企業のAIツール管理に新たな基盤が加わった
- カスタムカタログは組織が信頼するMCPサーバー群をOCIアーティファクトで配布し、発見コストとセキュリティリスクを同時に下げる
- プロファイルは個人が用途別にツール構成を保存・切り替えできる仕組みで、コンテキスト最適化にも有効
- 両方ともOCIアーティファクトで共有可能なため、既存のコンテナレジストリ運用の延長でチーム展開できる
- 今後のポリシー制御やエージェントスキル連携により、エンタープライズMCPのガバナンス基盤として発展が見込まれる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

OpenAIがTanStack npm攻撃に対応、Macユーザーは6月12日までにアプリ更新を
広く利用されるオープンソースライブラリ「TanStack」のnpmパッケージが悪意ある第三者によって改ざんされた「Mini Shai-Hulud」と呼ばれるサプライチェーン攻撃。この影響はOpenAIにも及び、同社は2026年5月13日に公式な対応報告を公開した。
OpenAIの調査によると、ユーザーデータや本番システム、知的財産への不正アクセスは確認されていない。しかし、同社のコード署名証明書が一時的に影響下にあったことから、予防的な措置としてMacユーザーを対象に全アプリケーションの更新を2026年6月12日までに完了するよう呼びかけている。
今回の記事では、攻撃の具体的な影響範囲、OpenAIが講じたセキュリティ対策、なぜMacだけが更新対象なのか、そして実務者が理解すべきサプライチェーンリスクの本質を解説する。
TanStackを狙ったサプライチェーン攻撃とは
2026年5月11日(UTC)、フロントエンド開発で広く使われるJavaScriptライブラリ群「TanStack」のnpmパッケージが、攻撃グループによって改ざんされた。この攻撃は「Mini Shai-Hulud」と名付けられ、ソフトウェアサプライチェーンの弱点を突く大規模なキャンペーンの一環だ。
サプライチェーン攻撃とは、正規のソフトウェアやライブラリを踏み台にし、その利用者にマルウェアを拡散する手法を指す。開発者が信頼して導入するパッケージマネージャー(npm、PyPI、RubyGemsなど)を通じて感染が広がるため、一企業だけでなく、エコシステム全体に被害が連鎖する点が最大の脅威だ。
今回の攻撃では、改ざんされたパッケージをインストールした開発者の端末から認証情報が引き出される挙動が確認されている。OpenAIの事例でも、このメカニズムにより2台の社内端末が侵害を受けた。
攻撃の構造とマルウェアの挙動
Socket.devの分析によれば、Mini Shai-Huludは主に認証情報(トークン、APIキー、セッション情報など)の窃取を目的としている。感染後の典型的な挙動は、開発者端末に保存されたGit認証情報や環境変数への不正アクセス、そして一部の内部コードリポジトリへの侵入だ。
OpenAIが委託した第三者デジタルフォレンジック企業の調査では、影響を受けた2名の社員がアクセス可能だった一部の内部ソースコードリポジトリで、認証情報の引き出しが成功した形跡が確認された。ただし、コードそのものや他の情報が流出した証拠はない。
OpenAIの初動対応と封じ込め
OpenAIは悪意ある活動を検知した直後、以下の封じ込め措置を即座に実行した。
- 影響を受けた端末とIDの隔離
- 全ユーザーセッションの強制無効化
- 影響リポジトリに関連する全認証情報のローテーション(再発行)
- コードデプロイワークフローの一時的制限
- ユーザーおよび認証情報の挙動調査の徹底
これらの対応により、攻撃者による追跡アクセスや窃取された認証情報の悪用は確認されていない。また、顧客データやOpenAIの知的財産への影響は一切なかったと報告されている。
Macユーザーに更新が必要な理由
一見すると「社内端末2台の侵害だけなら、なぜエンドユーザーが対応するのか」と疑問に思うかもしれない。この背景には、コードサイニング証明書(コード署名証明書)の重要性がある。
コードサイニング証明書とは、ソフトウェアの開発元を電子的に証明する仕組みだ。macOSやWindows、iOSといったプラットフォームは、この証明書を確認することで「正規の開発者がリリースしたアプリかどうか」を判定している。
OpenAIの内部リポジトリには、iOS、macOS、Windows、Android向けのコードサイニング証明書が保管されていた。この証明書自体が直接流出したわけではないが、アクセス可能な状態にあったことから、OpenAIは予防的措置としてすべての証明書を新しいものに置き換える判断を下した。
証明書失効のタイムラインと影響
2026年6月12日をもって、旧証明書は完全に失効する。これ以降、旧証明書で署名されたmacOSアプリは、Appleのセキュリティ保護機能(Gatekeeper)によって新規ダウンロードや初回起動がブロックされる。
WindowsやiOS、Androidのアプリについても新しい証明書で再署名されるため、将来的なアップデートは必要になる。ただ、これらのプラットフォームでは即時のユーザー操作は不要とされている。
Macだけが個別アクションを求められる理由は、Appleのセキュリティモデルが証明書の有効性を厳格に検証する設計になっているためだ。更新を怠ると、以下のアプリが正常に動作しなくなる可能性がある。
- ChatGPT Desktop(バージョン 1.2026.125 以前)
- Codex App(バージョン 26.506.31421 以前)
- Codex CLI(バージョン 0.130.0 以前)
- Atlas(バージョン 1.2026.119.1 以前)
なぜ即時の証明書失効ではないのか
OpenAIはすでにプラットフォーム事業者と連携し、旧証明書を用いた新規の公証(ノータリゼーション)を全面的にブロックしている。公証とは、Appleがアプリをスキャンして悪意あるコードが含まれていないことを確認するプロセスだ。
仮に攻撃者が旧証明書を使って偽のOpenAIアプリを作成したとしても、公証を受けられないため、デフォルトのmacOSセキュリティ設定では実行が阻止される。この防御策が機能している間に、ユーザーがスムーズに公式アプリへ移行できるよう約1か月の猶予期間が設けられた。
この猶予期間中に、アプリ内アップデートまたは公式サイトからの再インストールを通じて、最新バージョンへの切り替えを済ませておくことが推奨される。
攻撃が浮き彫りにした開発エコシステムの脆弱性
今回の事案は、特定企業を標的とした攻撃というよりも、オープンソースエコシステム全体の構造的な弱点を突いたものと言える。攻撃者は個別の企業ではなく、広く使われる共有ライブラリを侵害することで、一度に多数の組織へ侵入できる。
現代のソフトウェア開発は、npm、PyPI、Maven Centralといったパッケージレジストリに大きく依存している。1つのパッケージが侵害されれば、依存関係の連鎖によって数百、数千のプロジェクトが影響を受ける。実際、TanStackのパッケージを依存関係に持つプロジェクトは膨大だ。
OpenAIが進めるサプライチェーン防御
OpenAIは2025年末に発生したAxios開発者ツールの侵害を受け、すでにサプライチェーン攻撃への防御を段階的に強化していた。具体的には以下の対策が進められていた。
- CI/CDパイプラインで扱う機密度の高い認証情報の追加保護
minimumReleaseAgeなどの設定を用いたパッケージマネージャーの制御導入- 新規パッケージの信頼性を検証する追加セキュリティソフトウェアの展開
minimumReleaseAge とは、パッケージがレジストリに公開されてから一定時間(例:3日間)経過しないとインストールを許可しない設定だ。これにより、公開直後の悪意あるパッケージを誤って取り込むリスクを低減できる。
しかし、これらの対策が全社的に展開される途中の段階で、今回のインシデントは発生した。侵害を受けた2台の端末には、新たな制御設定がまだ適用されていなかったのである。
実務者が今すぐ取るべき対策
OpenAIの事例から学べる教訓は、単一の企業だけに留まらない。自社の開発環境においても、以下の対策を早急に検討すべきだ。
- パッケージマネージャーのロックファイル(package-lock.jsonなど)を定期的に監査する。 意図しないバージョン変更や新規依存関係が混入していないか、CI環境で自動チェックする仕組みを作る。
- サプライチェーンセキュリティツールの導入。 Socket.dev、Snyk、GitHub Dependabotなどを使い、脆弱性や悪意あるパッケージを早期に検出する。
- コードサイニング証明書の厳格な管理。 CI/CD環境とは完全に切り離し、必要最小限の担当者のみがアクセスできる保管場所を確保する。
- 依存パッケージの更新を自動化しすぎない。 パッチバージョンであっても、公開直後の即時適用は避け、一定の猶予を設ける。
このような防御策は、自社の開発文化や速度とバランスを取りながら段階的に導入していくのが現実的だ。しかし、攻撃の連鎖速度は日に日に速まっている。放置するリスクの方がはるかに大きいことは、今回の事例が明確に示している。
ユーザーが取るべき具体的なアクション

OpenAIのアプリをMacで利用している個人および企業は、以下の手順を確実に実施してほしい。
- 公式の更新経路のみを使用する。 アプリ内のアップデート通知、またはOpenAI公式ウェブサイト(openai.com)からダウンロードする。メール、メッセージ、広告、ファイル共有リンク経由の「ChatGPT」「Codex」インストーラーには絶対に手を出さない。
- 6月12日までに更新を完了する。 期限を過ぎると、旧証明書で署名されたアプリはmacOSによってブロックされる。業務で利用している企業は、社内のIT管理者が一括アップデートを計画すべきだ。
- パスワード変更は不要。 OpenAIは公式に、顧客のパスワードやAPIキーが影響を受けていないと明言している。無用なパスワード変更はフィッシングのリスクを高めるだけだ。
企業のIT管理者向け追加ガイダンス
組織内でOpenAIアプリを管理している場合、6月12日の証明書失効までにMDM(モバイルデバイス管理)やソフトウェア配布ツールを通じて、全Mac端末のアプリを最新バージョンに更新する計画を立てる必要がある。
更新対象となるアプリと、失効する旧バージョンの一覧は以下の通りだ。
- ChatGPT Desktop(旧バージョン 1.2026.125)
- Codex App(旧バージョン 26.506.31421)
- Codex CLI(旧バージョン 0.130.0)
- Atlas(旧バージョン 1.2026.119.1)
これらのバージョンが社内で稼働している場合、速やかに更新手続きを進めることが求められる。
この記事のポイント
- OpenAIはTanStack npmパッケージへのサプライチェーン攻撃により社内端末2台が侵害されたが、ユーザーデータや本番システムへの影響はなかった。
- 予防措置としてコードサイニング証明書を全面的にローテーション。Macユーザーは6月12日までにアプリを更新する必要がある。
- 旧証明書を用いた新規の公証はすでにブロック済みのため、偽アプリがmacOSで実行されるリスクは低い。
- 攻撃の本質はオープンソースエコシステムの脆弱性を突いたものであり、全開発組織がパッケージ管理の防御策強化を求められている。
- パッケージの即時自動更新を避け、minimumReleaseAgeの設定や監査プロセスの導入が有効な対策となる。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

EC成長だけでは救えない郵政の構造危機〜配送依存の限界と日本への教訓
米国郵政公社(USPS)が2026年会計年度第2四半期の決算で、約20億ドルの赤字を報告した。ECの成長に伴い小包収入は前年同期比4.5%増加しているにもかかわらず、だ。赤字幅は前年同期の33億ドルから改善したが、それは決して楽観できる数字ではない。
USPSのデビッド・スタイナー郵政長官は2026年5月8日の理事会で「郵政公社は深刻な財政危機にある。現状は持続不可能であり、そうでないふりをするのは無責任だ」と述べている。ECが郵便事業を支えるという前提が揺らぎ始めているのだ。
この記事では、USPSの決算データを手がかりに、EC事業者が直面する配送インフラの構造問題と、日本市場への示唆を読み解く。
郵政を縛る「ユニバーサルサービス」の重荷

USPSの抱える問題の根幹は、1970年の郵政再編法にまで遡る。この法律は旧郵政省を独立採算制の公社に転換したが、同時に全米1億7千万以上の住所へ週6日配送する責務を課した。人口希薄な地方の不採算ルートも維持しなければならない。
民間の配送業者であれば、採算の合わない地域からは撤退するか、サービス水準を落とす選択ができる。UPSやFedEx、Amazonなどは実際にそうしている。しかしUSPSにはそれが許されない。法律で定められた「ユニバーサルサービス」義務があるからだ。
この構造的緊張はUSPS設立当初から存在していた。スタイナー長官は「議会はユニバーサルサービスのコストが郵政公社の自力でまかなうには大きすぎると予見していた。だからこそ公共サービスに対する償還金を認可したのだ」と指摘する。
減少し続ける第一種郵便のボリューム
かつてUSPSの収益を支えたのは第一種郵便(First-Class Mail)だった。請求書、銀行取引明細、ビジネス文書、個人の手紙が膨大な量で流通していた。2001年のピーク時、全米2億900万人の成人に対して約1040億通が取り扱われ、一人当たり約500通に相当した。
ところが2024年までに第一種郵便の取扱量は443億通まで半減以下に落ち込んだ。成人人口は約2億6000万人に増えているため、一人当たり密度は約170通へ激減している。
問題は、郵政の固定費が比例して縮小しなかったことだ。スタイナー長官によれば、1970年代以降「配達拠点数は数千万件増加し、郵便物量は50%以上減少した」という。少なくなった郵便物を、増えた拠点に届ける構造が続いている。
この構造が、USPSの収益基盤を根本から揺るがしている。日本でも郵便物の取扱量は年々減少しており、構造的に類似した課題を抱えていることは見逃せない。
ECの成長が郵政を支えた10年

第一種郵便が減少する一方で、USPSの収益構造を支えてきたのがECの成長だ。AmazonやWalmartをはじめとするEC事業者の拡大に伴い、軽量な個人向け小包がUSPSのトラックや処理施設、配送ルートを埋めるようになった。
特にパンデミック期には、多くの米国人消費者にとってECが日常的な購買手段となり、ほぼすべての配送事業者に追い風が吹いた。USPSも例外ではなかった。
2021年度には、USPSの総収入に占める小包・配送の割合が41.6%に達し、第一種郵便の30.2%を大きく上回った。6年前の2015年度には小包が21.6%、第一種郵便が40.9%だったことを考えると、わずか数年で主従が完全に入れ替わったことになる。
USPSは事実上、郵便会社から小包物流事業者へと進化しつつある。スタイナー長官は2026年の全米郵便フォーラムで、USPSを米国商取引の中心にある「経済プラットフォーム」と表現し、近代化の取り組みを強調した。
小包収入が増えても赤字が止まらない理由
しかし、ここにパラドックスがある。小包収入が増えているのに、なぜ赤字が続くのか。
2026年第2四半期(2026年3月31日締め)のデータが示す現実は冷徹だ。小包収入は前年同期比4.5%増加した一方、小包の取扱数量は1.4%減少した。収入増は数量増ではなく、単価上昇によるものだったのだ。
これはEC配送市場が成熟段階に入り、数量の成長よりも価格設定と業務効率が利益を左右するフェーズへ移行したことを示唆する。そして、その環境下でUSPSはAmazon、UPS、FedEx、多数のギグワーカー型配送ネットワークとの競争にさらされている。
スタイナー長官は、USPSの財政問題はコスト削減だけでは解決できないと主張する。議会がUSPSにより大きな業務上の柔軟性を与えるか、ユニバーサル配送を公的義務と位置づけて連邦予算で補助するかの二択を迫っているのだ。
日本市場が読み解くべき3つの教訓

USPSの事例は決して対岸の火事ではない。日本のEC事業者や物流事業者にとっても、以下の3つの教訓が浮かび上がる。
配送網への過度な依存リスクを分散する
USPSの収益がECに大きく依存しながらも赤字を脱せない構造は、特定の配送インフラに過度に依存することのリスクを示している。EC事業者としては、単一の配送手段に頼らず、複数のキャリアや配送方法を組み合わせた戦略が求められる。
WooCommerceを利用しているなら、複数配送業者との連携プラグインを活用し、注文内容や配送先に応じて最適な配送方法を自動選択する仕組みを整えておきたい。配送料の値上げやサービス縮小が発生した際の影響を最小限に抑えられる。
配送コストの上昇を価格戦略に織り込む
USPSの小包単価が上昇しているように、世界的にラストワンマイル配送のコストは上昇傾向にある。特に人口減少地域での配送単価は今後さらに上がる可能性が高い。
EC事業者は「送料無料」を安易に標準設定するのではなく、商品価格への適切な配送コストの織り込みや、一定金額以上での送料無料化など、収益性を確保できる送料設計を再点検すべき時期に来ている。
配送インフラの構造変化を先読みする
USPSが直面している「ユニバーサルサービスと収益性の両立」という課題は、日本郵便にも共通する構造問題だ。過疎地域での郵便・物流サービス維持が政治課題化すれば、配送料金の規制や補助金制度の変更がEC事業者に直接影響を与える可能性がある。
店舗受け取りや宅配ボックスの活用、地域ごとの配送ハブ設置など、既存の配送網に依存しないラストワンマイル戦略の検討を始めておくことが、中長期的な競争力につながる。
ECと郵政の共進化は可能か

USPSの決算データは、ECの成長が郵政インフラを支えるという前提が限界に近づいていることを示している。スタイナー長官が言うように、現状維持は持続不可能だ。
では、解決の方向性はどこにあるのか。スタイナー長官が提示したのは大きく二つだ。不採算郵便局の閉鎖や大幅な値上げを含む業務の柔軟性獲得か、ユニバーサルサービスを公共財とみなす連邦補助金の導入か。
いずれの道を選ぶにせよ、EC事業者は配送コストとサービス水準の変化に適応する必要がある。特に小規模EC事業者にとっては、大手ECモールの配送網に頼るだけでは不十分で、自社の配送戦略を主体的に設計することが競争力の分かれ目になるだろう。
日本においても、人口減少とECシフトが同時進行する中で、配送インフラの持続可能性はEC事業者自身の経営課題として捉えるべき段階に入っている。10年先の配送環境を見据えた戦略的な備えを始めるタイミングだ。
この記事のポイント
- USPSは2026年第2四半期に約20億ドルの赤字を計上し、小包収入増にもかかわらず財政危機が継続している
- 第一種郵便の取扱量は2001年の約1040億通から2024年には443億通へ半減以下に落ち込み、固定費を吸収できなくなった
- ECの成長により小包・配送の収益比率は2015年の21.6%から2025年には40.5%へ拡大したが、それでも赤字は埋まらない
- 日本でも同様の構造問題が進行中であり、配送網の過度な依存分散や配送コスト上昇への備えがEC事業者の重要課題となる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Google Cloud、AI脅威レポートで攻撃者によるゼロデイ発見・自律型マルウェアの実態を公開
Google Cloudの脅威インテリジェンスグループGTIGが2026年5月、最新のAI脅威トラッカー報告を公開した。今回の報告では、攻撃者がAIを悪用してゼロデイ脆弱性を発見した初めての事例が確認され、また自律的に動作するマルウェア「PROMPTSPY」の詳細な分析結果が示された。
報告書はAIに関する脅威を「ツールとしてのAI」と「標的としてのAI」の2軸で整理。攻撃者は脆弱性発見の自動化や防御回避コードの生成だけでなく、AIの開発エコシステム自体を狙ったサプライチェーン攻撃も活発化しているという。本記事では、この報告書の重要ポイントを実務者向けにわかりやすく解説する。
AIが攻撃ツールに ゼロデイ発見から自律型マルウェアまで

- 脆弱性発見の自動化とゼロデイエクスプロイト開発
- マルウェアコードの生成や難読化による検知回避
- 攻撃ライフサイクルの自律実行(PROMPTSPY等)
- OpenClawスキルへの悪意あるコード混入
- LiteLLMやGitHubリポジトリへのサプライチェーン攻撃
- AI APIキーやクラウド認証情報の窃取
今回の報告では、攻撃者が生成AIを業務効率化ツールとして悪用する段階から、攻撃そのものの中核に組み込むフェーズへと急速に移行している実態が浮き彫りになった。
AIがゼロデイを発見 犯罪グループが初の成功事例
GTIGの観測によると、ある犯罪グループが広く使われているオープンソースのシステム管理ツールを標的に、二要素認証(2FA)をバイパスするゼロデイ脆弱性を開発した。このエクスプロイトには、AIが生成したとみられる強い痕跡が残っており、GTIGが初めて「AIによるゼロデイ開発」を確認した事例となった。ベンダーへの責任ある開示を通じて、大規模な悪用を未然に防げたという。
コードを解析すると、詳細なドキュメント文字列や幻覚(ハルシネーション)で誤ったCVSSスコアが付与されているなど、LLMが出力する典型的な「教科書的Python記法」が随所に見られた。これは従来のファジングや静的解析ツールでは検出できないタイプの脆弱性だ。LLMは開発者が暗黙的にハードコードした「信頼前提」を読み解いて、2FA実装の矛盾を突くことができる。
- メモリ破損や入力値不備の検出に強い
- 開発者の「暗黙の信頼」に気づけない
- 大規模コードベースでは誤検知が多い
- コードの文脈を読み取り、意図と実装の矛盾を特定
- 2FAバイパスのような高次ロジックの欠陥を検出可能
- 人間のセキュリティ研究者に近い推論を実現
この能力差が、従来の防御策では防ぎきれない新たな脅威を生み出している。報告書は、攻撃者がAIを「専門家レベルの増幅器」として活用し始めたと警告する。
防御回避を自動化するAI生成のデコイコード
GTIGは、ロシアに関連するとみられる侵入活動の中で、AIが生成したデコイ(囮)コードを大量に含むマルウェア「CANFAIL」と「LONGSTREAM」を確認した。CANFAILのソースには「このコードブロックは使用されない」といったLLM特有の解説コメントが含まれており、攻撃者が意図的に無害に見せかけるためのダミー機能を要求した形跡がある。
LONGSTREAMでは、システムのサマータイム設定を32回も照会するといった、意味のない繰り返し処理が組み込まれていた。これらは振る舞い検知をかく乱し、セキュリティ製品による分析を遅らせる目的がある。AIが難読化ツールとして悪用され、マルウェアが動的に自己変形する方向へ進んでいることを示す事例だ。
PROMPTSPYにみる自律型マルウェアの脅威
Androidバックドア「PROMPTSPY」は、AIを攻撃の中核に据えた自律型マルウェアとして注目されている。ESETが初めて報告したこのマルウェアは、Gemini APIを用いて端末の画面情報を取得し、ユーザーの操作を必要とせずに不正なタップやスワイプを実行する。GTIGの追加分析によって、当初知られていた以上の拡張性と防御機能を持つことが判明した。
Accessibility APIで画面のUI階層をXML形式で取得
Gemini APIにXMLを送り、動的に生成された目標に沿った操作を指示
JSONで戻された座標とアクション種別(CLICK、SWIPE)をもとにジェスチャーをシミュレート
アンインストールボタンに透明オーバーレイを被せてタップを無効化。FCMで遠隔再起動も可能
また、PROMPTSPYは被害者の生体認証(PINやパターン)を記録して再現する機能を持ち、遠隔からデバイスへの再侵入を可能にする。C2サーバやAPIキーを動的に切り替える仕組みも備えており、防御側のブロックを回避する設計思想が随所に見られる。Googleは既に関連アカウントを無効化し、Google Play Protectで既知の亜種を自動検出できるようにしている。
AIを利用した情報工作とLLMへの大規模アクセス
情報工作の領域でもAIの悪用は進んでいる。親ロシアキャンペーン「Operation Overload」では、AIで合成された音声を使って実在のジャーナリストを装う偽動画が拡散された。こうしたコンテンツは、正規メディアの信用を乗っ取る手口として使われる。
一方で、攻撃者はLLMのプレミアム機能を不正に利用するため、アカウント登録と即時解約を自動化するスクリプトや、複数アカウントを束ねる中継サービスを駆使している。UNC6201やUNC5673といった中国関連の攻撃グループは、こうした手法で大量のAPIアクセスを確保し、不正利用の痕跡を分散させていた。LLM提供事業者は、ネットワーク情報を分析してアグリゲーターを特定し、悪用を阻止する対策を強化しつつある。
AI自身が標的に サプライチェーン攻撃の実態
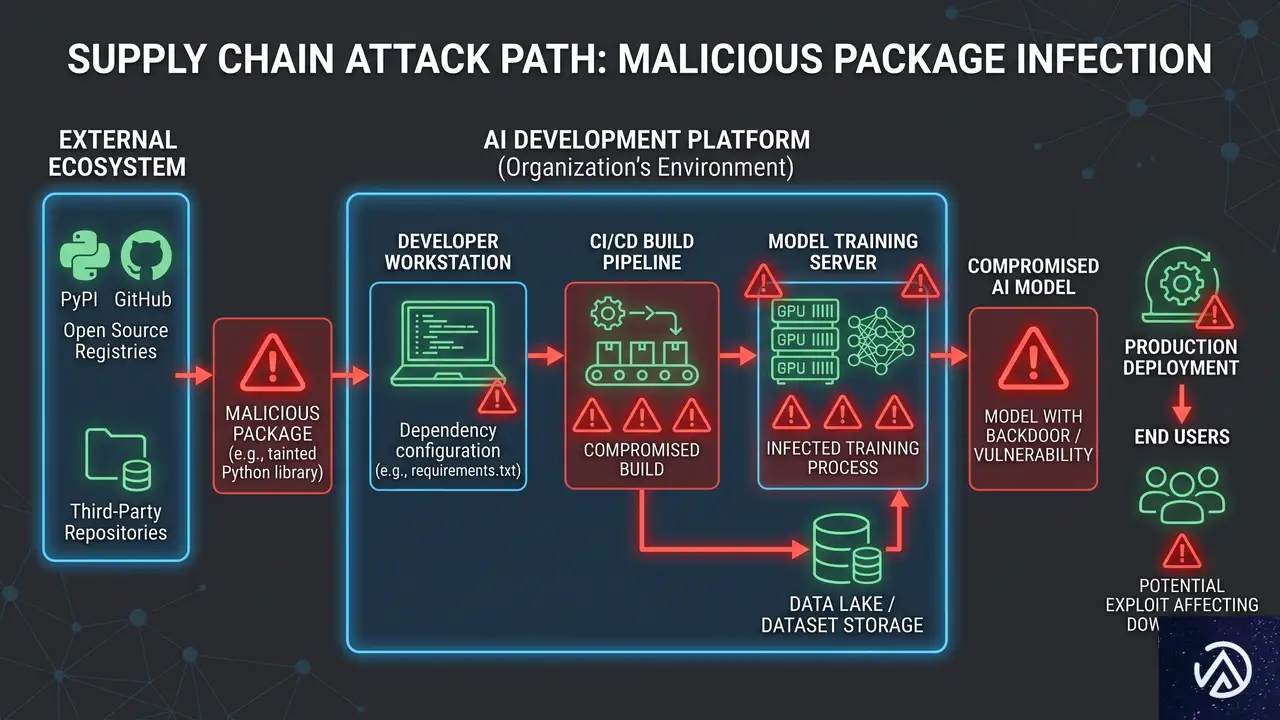
AIモデルそのものは依然として直接の侵害には強いが、モデルを動かす周辺のソフトウェア部品(ライブラリ、APIコネクタ、スキル設定ファイル)が新たな侵入口になっている。GTIGはこの状況を、SAIF(Secure AI Framework)のリスク分類でいう「安全でない統合コンポーネント(IIC)」と「不正な動作(RA)」に該当すると指摘する。
オープンソースのAIエコシステムが狙われる
2026年2月には、AIエージェントプラットフォーム「OpenClaw」のスキルマーケットプレイスに、悪意あるコードを仕込んだパッケージが流通していることがVirusTotalの調査で明らかになった。OpenClawは実行に高い権限を必要とするため、トロイの木馬化されたスキルをインストールしたユーザーの環境で任意のコードが実行される恐れがある。その後、OpenClawはClawHubにVirusTotalの自動スキャンを統合し、悪意あるパッケージを検出する仕組みを導入した。
TeamPCPによるLiteLLMやGitHubリポジトリへの侵害
犯罪グループ「TeamPCP(UNC6780)」は、2026年3月に複数のGitHubリポジトリをサプライチェーン攻撃で侵害したことを公言した。標的には、複数のLLMプロバイダを統合するAIゲートウェイ「LiteLLM」や、脆弱性スキャナ「Trivy」「Checkmarx」などが含まれている。被害組織のビルド環境からはAWSキーやGitHubトークンといったクラウド認証情報が窃取され、ランサムウェアグループとの連携によって金銭目的の恐喝に利用された。
この事例が示すのは、AI関連の依存関係が侵害された場合、攻撃者は単にAIシステムを操作するだけでなく、そこから企業ネットワーク全体へ横展開できるというリスクだ。LiteLLMのような広く使われるライブラリを経由して、多数の組織のAI APIシークレットが流出する可能性がある。
企業に求められるAI脅威への対策

Googleは自社の防御策として、Geminiの悪用アカウントの無効化、AIエージェント「Big Sleep」による未知の脆弱性探索、そして「CodeMender」による脆弱性の自動修正など、AIを守りに使う取り組みを進めている。同時に、業界全体での対策フレームワークとしてSAIFを提唱し、CoSAI(Coalition for Secure AI)を通じてパートナーとの連携を強化している。
実務者が今すぐ着手できる対策としては、以下の点が重要だ。まず、AI関連のオープンソースライブラリやスキルパッケージを導入する際には、提供元の信頼性とコードの挙動を必ず確認する。APIキーやクラウド認証情報は短い有効期限と最小権限で管理し、定期的にローテーションする。さらに、AIを利用するアカウントには多要素認証を適用し、不審なAPI呼び出しを検知する監視体制を整えることが有効だ。
この記事のポイント
- GTIGが2026年5月に発表した報告で、AIによるゼロデイエクスプロイト開発が初確認された
- 攻撃者はAIを使ってマルウェアの難読化や自律的な操作を実現し、攻撃の効率を飛躍的に高めている
- PROMPTSPYのような自律型マルウェアは、人間の介在なしに端末を操作し、防御を回避する仕組みを備える
- AIエコシステムを狙ったサプライチェーン攻撃が急増し、APIキーや認証情報の大量窃取が現実の脅威となっている
- 企業はAI関連の依存コンポーネントの厳格な管理と、APIアクセスの監視強化でリスクを軽減すべき
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

GitHub Copilotに新プランMax登場、Pro/Pro+にFlex割り当てで利用可能額が大幅増
2026年6月1日から、GitHub Copilotの個人向けプランが大きく変わる。利用量に応じた課金への移行に伴い、ProとPro+プランに「Flexアロットメント」と呼ばれる変動型の追加利用枠が導入され、月額100ドルの新プラン「Max」も登場する。
GitHubの公式ブログで発表された今回の変更は、長時間のエージェント駆動作業や複数ステップの複雑なタスクに対応するためのものだ。価格は据え置きで利用可能な総額が大幅に増える仕組みであり、とくにPro+ユーザーには大きな恩恵となる。
この記事では、Flexアロットメントの仕組み、各プランの具体的な料金とクレジット、移行時に注意すべき点を詳しく解説する。
GitHub Copilotの個人向けプラン刷新概要

なぜ今、プランが変わるのか
GitHubは2026年1月に、Copilotの課金方式を「月額固定の定額制」から「利用量ベースの課金(Usage-based billing)」へ切り替える方針を発表した。この移行に伴い、多くのユーザーから「含まれる利用量が十分か」という懸念が寄せられていた。とくに、マルチステップのエージェント作業や、より高性能なモデルの利用が増えるにつれて、当初発表された利用枠では不足するケースが想定されたのである。
公式ブログの記事によれば、GitHubはこのフィードバックを受け、Pro/Pro+プランの利用総量を増やすとともに、新しいMaxプランを追加した。これにより、個人開発者から高負荷のAI活用まで幅広いニーズをカバーする形となる。
新ラインナップの全体像
2026年6月1日以降、個人向けCopilotは「Free」「Pro」「Pro+」「Max」の4プラン体制に再編される。Freeプランは引き続き月に限定的なコード補完とチャット、エージェント機能を提供する。Pro、Pro+、Maxは有料となり、利用量ベースの課金が適用されるが、月額料金に応じた「基本クレジット」と、変動する「Flexアロットメント」の合計が利用可能な総クレジットとなる。
Flexアロットメントの仕組み

基本クレジットとFlex割り当ての関係
有料プランでは、毎月の利用可能額は2つの部分で構成される。一つは「基本クレジット(Base credits)」で、これは月額料金と1対1で対応し、常に固定だ。たとえばProプラン(月額10ドル)なら基本クレジットは10ドル分になる。もう一つが「Flexアロットメント(Flex allotment)」で、これは基本クレジットの上乗せ分として付与される可変の追加枠である。
実際の利用時には、まず基本クレジットが消費される。基本クレジットを使い切ると、自動的にFlexアロットメントが適用される。ユーザーは特別な設定やバケット管理をする必要はなく、ダッシュボードで残りの利用可能額を確認するだけで済む。IDE、github.com、CLIのすべてで共通のレートで消費される仕組みだ。
Flexが無制限ではない理由
FlexアロットメントはAIの経済性の変化に応じて変動するよう設計されている。具体的には、モデルの価格変動や新モデルの登場、推論効率の向上といった要因によって、GitHub側が柔軟に割り当て量を調整する。つまり、利用可能な追加枠は時期によって変わりうる。しかし基本クレジットは常に月額料金と等価のため、最低限保証されるラインはブレない。
このように、Proプランは従来の固定クレジットに上乗せがあるため、実質的なお得感が増す。とりわけPro+プランでは基本の39ドルに加えて31ドル分のFlexが付与され、合計70ドル分の利用が可能になる。頻繁に長大なエージェントタスクを回すパワーユーザー向けにはMaxが用意された形だ。
各プランの料金と利用可能クレジット

Proプラン:月額10ドルで15ドル分
Proプランは月額10ドル。基本クレジットは10ドル分、Flexアロットメントが5ドル分付与され、合計15ドル分の利用枠となる。小規模な個人開発や、日々のコード補完を主に使う層には十分な容量と言える。
Pro+プラン:月額39ドルで70ドル分
Pro+プランは月額39ドル。基本39ドルに加え、Flexで31ドルが追加され、総額70ドル分を利用できる。マルチステップのリファクタリングやドキュメント生成、中規模のエージェントタスクを日常的にこなす開発者にとって、コストパフォーマンスが非常に高い設計だ。
Maxプラン:月額100ドルで200ドル分
新設のMaxプランは月額100ドル。基本クレジット100ドル分に、同じく100ドル分のFlexが加わり、総利用可能額は200ドルになる。大量のコード生成や継続的なエージェント実行を必要とするフルタイムのAI活用シナリオを想定したプランだ。大規模オープンソースプロジェクトのメンテナや、AIを骨太に組み込んだ開発フローを回すチームリーダーに適している。
クレジットの消費ルールと実際の使い方

コード補完と次編集候補は引き続き無制限
有料プランでは、コード補完(Code completions)と次編集候補(Next edit suggestions)は無制限で、クレジットを消費しない。つまり、エディタ上でリアルタイムに表示される補完候補はこれまでどおり使い放題である。クレジットが消費されるのは、チャット形式の問い合わせやエージェントによる複数ステップの実行、より高度なモデルを利用した処理だ。
超過時の追加購入とダッシュボード
もし基本クレジットとFlexアロットメントの両方を使い切ってしまった場合でも、追加のクレジットを購入して作業を続けられる。ダッシュボードには、現在の残りクレジットと消費状況が表示されるため、いつでも確認できる。これにより、月末に突然利用できなくなる心配はなく、プロジェクトの進捗に合わせて柔軟にリソースを追加できる。
Flexアロットメントが変動する背景

AIの経済性の進化に合わせた設計
Flexアロットメントが月によって変わるかもしれない最大の理由は、AIモデルの推論コストが急速に変化しているためだ。新モデルの登場やハードウェア効率の改善、サードパーティのAPI価格改定などが起きれば、GitHubは利用者に提供できる付加価値の量を動的に調整する。固定の枠では、こうした外的要因に対応しきれないリスクがある。
GitHubの発表では、基本クレジットだけは常に月額料金と等価であることを約束している。Flex部分が変動しても、最低限のコストパフォーマンスは損なわれない仕組みだ。このハイブリッドな設計は、ユーザーに安定した基盤を提供しつつ、AI技術の進歩をプランに取り込むGitHub側の狙いが感じられる。
ユーザーが今すぐすべきこと

月額契約者は自動移行、追加操作不要
現在ProまたはPro+の月額プランを利用しているユーザーは、2026年6月1日になると自動的に新しい利用量ベース課金のプランへ移行し、Flexアロットメントが適用される。手動でプランを変更する必要はない。もし年間契約を結んでいる場合は、更新タイミングなどの詳細を公式ドキュメントで確認するとよい。
移行後すぐにダッシュボードでクレジットの残高をチェックし、自分の普段の開発スタイルでどれだけ消費するかを把握しておくことを推奨する。特にエージェント機能を積極的に使っているユーザーは、Pro+やMaxへのアップグレードを検討するタイミングかもしれない。
この記事のポイント
- 2026年6月1日より、GitHub Copilot個人向けプランにFlexアロットメントと新Maxプランが導入される
- Pro(10ドル)とPro+(39ドル)の月額料金は据え置きのまま、利用可能クレジットが増加(Proは15ドル分、Pro+は70ドル分)
- Maxプランは月額100ドルで200ドル分のクレジットを提供し、高負荷なAI活用を想定
- コード補完と次編集候補は有料プランでも無制限で、クレジット消費はチャットやエージェント利用時のみ
- FlexアロットメントはAIの経済性変化に応じて変動するが、基本クレジットは常に固定
- 既存の月額契約者は自動移行のため、追加の操作は不要
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験