

Google広告にAI Max機能3つ追加。ショッピング広告とテキスト制御が進化
Googleは2026年5月20日のMarketing Liveを前に、広告運用に関する3つのAI Max機能を発表した。ショッピングキャンペーン向けのAI Max拡張、広告主の意向を反映するAI Brief、そして検索広告向けのテキスト免責事項である。
いずれも広告主がAIの制御範囲をより細かく設定できるようにすることを目指したものだ。EC事業者にとっては、商品フィードを活用した広告配信の精度向上と、ブランドイメージを守りながらの自動化が現実的な選択肢になる。
今回はPractical Ecommerceの記事を基に、これら3機能の詳細とEC運用への活かし方を整理する。
AI Max for Shoppingの仕組みと従来との違い
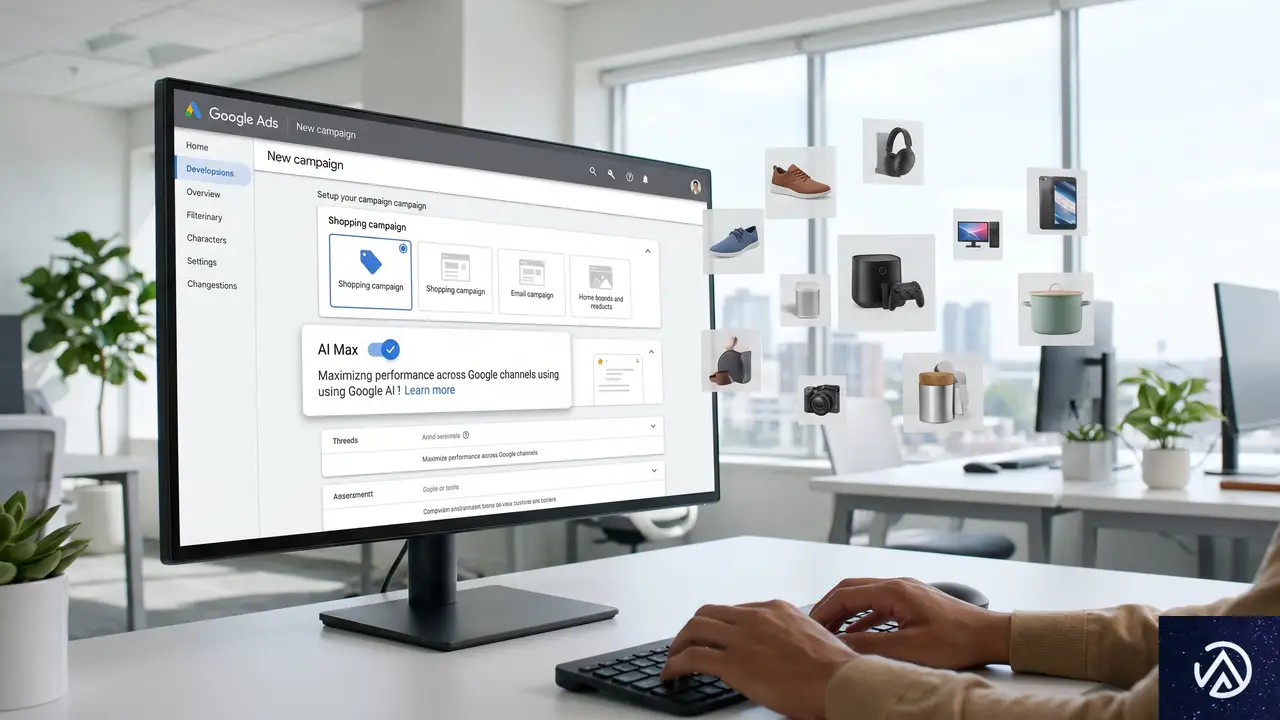
AI Maxは2025年に検索キャンペーン向けに導入され、今回ショッピングキャンペーンにも拡張された。本質的には、Googleが広告表示のクエリ選定や広告文の生成をより自律的に行う仕組みである。
検索AI Maxとの共通点と相違点
従来の検索AI Maxでは、広告主が「透明な収納ケース」というキーワードに入札した場合でも、AIが「透明とプラスチック製の収納ケースの違いは何か」といったクエリに対しても広告を表示できるようになった。さらに広告文や遷移先URLも、コンバージョン向上を目的に自動調整される。
ショッピングAI Maxでもこの仕組みは維持されるが、重要な違いがある。ショッピングキャンペーンでありながら、通常の商品画像付きリスト広告だけでなく、Merchant Centerのデータを基にAIが生成したテキスト広告が表示される可能性がある点だ。またAI OverviewsやAI Mode内への広告表示も対象になる。
Performance Maxとの使い分け
AI MaxとPerformance Maxの違いは混同しやすい。Practical Ecommerceの記事によれば、Googleはマルチチャネル(検索、ショッピング、ディスプレイ、動画)でのプロモーションにPerformance Maxを推奨しており、単一チャネルの検索やショッピングにはAI Maxを推奨している。EC事業者としては、ショッピングに特化して広告を最適化したい場合はAI Maxを選ぶのが筋だろう。
テキストカスタマイズや最終URLの自動拡張をオプトアウトできるかは、まだ明らかにされていない。検索AI Maxではオプトアウトが可能なため、ショッピングAI Maxでも同様の制御が用意される可能性は高い。
AI Briefで広告の方向性を詳細に制御
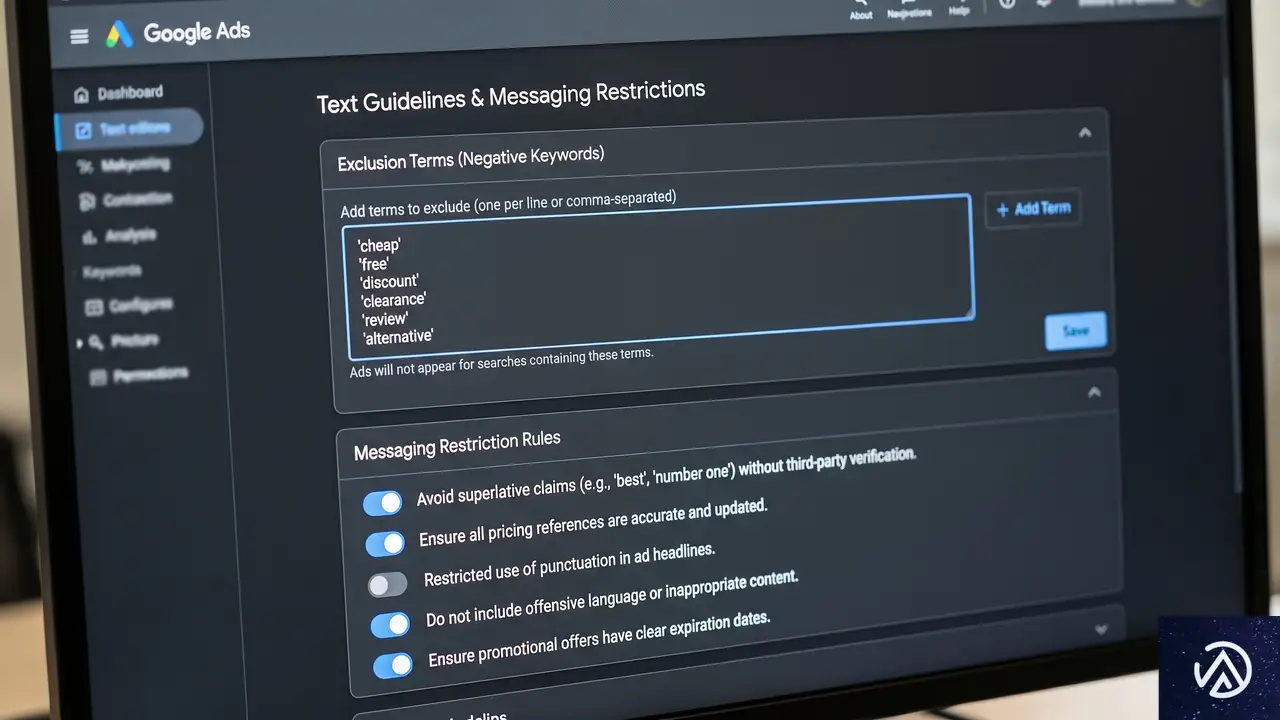
AI Briefは、広告主が自社の意向をAIに伝えるための設定機能である。まず検索AI Max向けに提供され、その後Performance MaxとショッピングAI Maxにも展開される予定だ。
具体的な指示内容
たとえば高級オフィスチェアを販売するEC事業者であれば、「価格を広告に含めてクリック前にユーザーをふるい分ける」「『安価』や『低価格』を含むクエリには広告を表示しない」「『高級』を含むクエリを優先する」といったガイドラインを設定できる。
テキストガイドライン機能
AI Briefには「テキストガイドライン」が含まれる。除外ワード(最大25個)とメッセージ制限(最大40個)を設定可能で、競合名や特定の価格表記の禁止などを指定できる。これにより、ブランドに合った表現をAIが生成するようになる。
ただしPractical Ecommerceの記事では、こうしたガイドラインがパフォーマンスを向上させるケースもある一方で、アルゴリズムの本来の学習を制限してしまう可能性にも触れられている。過度な制限は配信機会を狭めるため、設定後は定期的なパフォーマンス検証が必要だ。
テキスト免責事項で広告の信頼性を底上げ

テキスト免責事項は、検索広告の説明文に広告主の利用規約や注意書きを表示する機能だ。たとえば「本製品はBPAフリーです。詳細はこちら」といった文言を、レスポンシブ検索広告の説明行に固定せずに組み込める。
広告強度スコアを下げない利点
通常、広告文の一部を特定の位置に固定(ピン留め)すると広告強度スコアが下がる。しかしテキスト免責事項はピン留めとは異なり、スコアに影響を与えない。広告強度は指標としての実用性には議論があるものの、スコアが高いほど表示回数が増える傾向があるため、実務上のメリットは無視できない。
設定場所と制限
テキスト免責事項はキャンペーン単位で設定し、「キャンペーン」タブ内の「アセット」セクションで管理する。最初に利用可能な説明スペースに表示され、90文字以内という制限がある。最終URLの自動拡張やテキストカスタマイズとの併用も可能だ。
EC事業者が取るべき対応と今後の見通し

AI Max for Shopping、AI Brief、テキスト免責事項の3機能は、いずれも広告運用におけるAIの役割を拡大しつつ、広告主が制御できる範囲を明確にしたものだ。EC事業者としては、以下の流れで準備を始めるのが現実的だろう。
- Merchant Centerの商品データが最新かつ正確か確認する。AI Maxはデータ品質に依存するため、不備があると意図しないテキストや表示につながる
- AI Briefを使う前提で、ブランドとして許容できない表現や除外したいクエリをリストアップしておく
- テキスト免責事項に記載すべき内容(素材表示、安全規格、返品条件など)を整理し、90文字以内の文案を用意する
- AI Max導入後は、手動キャンペーンとの並行テストでパフォーマンスを比較し、過度なガイドライン設定が配信機会を損なっていないか検証する
GoogleのAI広告機能は、EC事業者の運用負荷を下げるだけでなく、商品フィードとAIの組み合わせにより、従来の手動運用ではリーチできなかったクエリにも対応する可能性を持っている。一方で、ブランド管理の観点からは、AI Briefやテキスト免責事項を適切に設定しなければ、意図しないメッセージが発信されるリスクもある。
Marketing Liveでの詳細発表を待つ必要はあるが、現時点で把握できる仕様を基に準備を始めておけば、機能リリース後すぐに活用できるだろう。
この記事のポイント
- GoogleがAI Max for Shopping、AI Brief、テキスト免責事項の3機能を発表
- ショッピングAI Maxは検索AI Maxと同様の自律配信に加え、AI Overviews表示やテキスト広告生成が可能
- AI Briefでブランドに合わないクエリの除外や優先付けが可能に、過度な制限には注意
- テキスト免責事項は広告強度スコアに影響せず、90文字以内で注意書きを挿入できる
- EC事業者は商品フィードの整備とガイドラインの事前準備を進めておくべき

・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Gmail AI Inboxで変わるECメール到達性、WooCommerceで今すぐできる対策
Gmailが2026年3月に発表したAI Inbox機能は、単なるメール整理ツールにとどまらない。メールマーケティングの根幹である「到達性(deliverability)」の概念そのものを、「発見性(discoverability)」へとシフトさせる可能性をはらんでいる。
世界のメールボックスの25%超を占めるGmailが、AIによるメールの優先順位付けを始めれば、プロモーションメールは要約に埋もれ、トランザクションメールが前面に出る構図が加速する。EC事業者にとって、これは注文確認メールや発送通知の設計を根本から見直す契機だ。
本記事では、Gmail AI InboxがECメール戦略にもたらす具体的な変化と、WooCommerceユーザーが今日から実践できる設定・運用のポイントを解説する。
Gmail AI InboxがECメールにもたらす構造変化
AI Inboxでは、メールが受信トレイに届くだけでは不十分になる。届いた後にAIが「このメールをユーザーに見せるべきか」を判断するからだ。図のように、注文確認や発送通知などの機能的なメールは優先され、セール告知やクーポン配布といったプロモーションメールは要約に埋もれやすくなる。
到達性から発見性へのパラダイムシフト
Stacked Marketerの創業者Manu Cinca氏は、MarTechの記事のなかで「AI Inboxでは、あなたのメールはGeminiが要約に引き込む多数のメールの1つに過ぎなくなる。Geminiがゲートキーパーになれば、購読者との直接的なつながりを失う可能性がある」と指摘している。
従来のメールマーケティングは「いかに受信トレイに届けるか」が勝負だった。スパムフィルターをすり抜け、Primaryタブに表示されることが目標だった。しかしAI Inboxの登場で、「届いた後、AIに選ばれるか」が新たな関門になる。これは、SEOが検索エンジンのランキング要因を追いかけるのと似た構図だ。
ECメールの優先度が逆転する理由
SingulateのCEO Dave Schools氏は「到達性に濃淡が生まれる。もはや通過・不合格の二択ではない」と述べている。GmailのAIはメールの機能性とユーザーにとっての関連性を評価する設計だ。ECメールの文脈では、以下のような優先度の逆転が予想される。
- 優先度が上がるメール:注文確認、発送通知、返金処理、パスワードリセット、予約リマインダー
- 優先度が下がるメール:セール告知、新商品のお知らせ、汎用的なクーポン配布、再入荷通知(緊急性が低い場合)
つまり、トランザクションメールがそのままマーケティングチャネル化する時代が来る。WooCommerceのデフォルトメールをカスタマイズしていないECサイトは、この波に乗り遅れることになる。
WooCommerceメール設定で即効性のある3つの対策
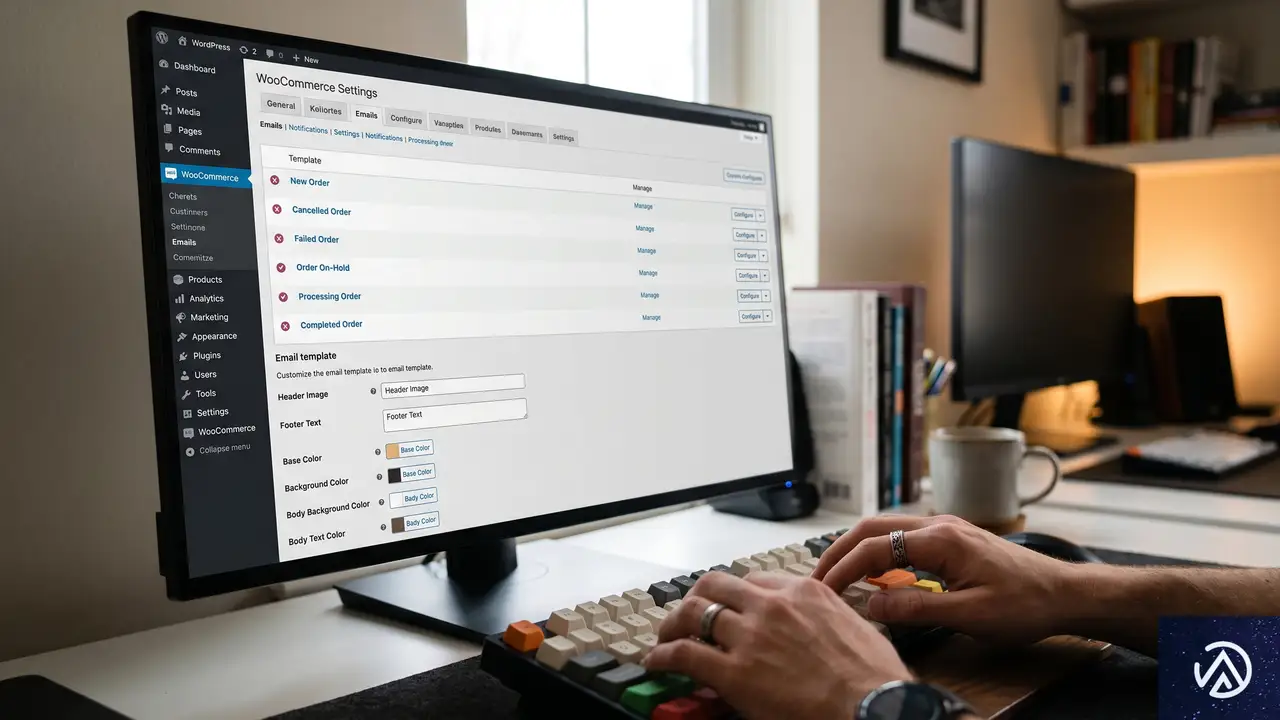
AI Inboxへの対応は、小手先のテクニックではなくメールの「機能価値」を高める方向で進めるべきだ。以下、難易度の低い順に3つの対策を提示する。
対策1 トランザクションメールのマーケティング化
注文確認メールや発送完了メールは、AI Inboxで確実に優先表示されるメールタイプだ。この「開封が約束されたチャネル」をマーケティングに活用しない手はない。WooCommerceでは、以下のようなカスタマイズが有効になる。
// 注文完了メールに関連商品セクションを追加する例
add_action( 'woocommerce_email_after_order_table', function( $order ) {
$related_products = wc_get_related_products(
$order->get_items()[0]->get_product_id(),
3
);
if ( ! empty( $related_products ) ) {
echo '<h3>この商品と一緒に購入されているアイテム</h3>';
echo '<div style="display:flex; gap:12px; margin:16px 0;">';
foreach ( $related_products as $product_id ) {
$product = wc_get_product( $product_id );
echo '<div style="text-align:center;">';
echo '<img src="' . wp_get_attachment_url( $product->get_image_id() ) . '" style="width:120px;" />';
echo '<p>' . $product->get_name() . '</p>';
echo '</div>';
}
echo '</div>';
}
}, 10, 1 );ただし、注意点がある。AIはメールの内容を解析して「機能メールかプロモーションメールか」を判定する。マーケティング要素を入れすぎると、かえって優先度が下がるリスクもある。関連商品の提案はメール後半に控えめに配置し、メインの情報(注文番号、配送状況)を最上部に明確に記述すること。
対策2 プロモーションメールの構造化とパーソナライズ
プロモーションメールがAI要約に埋もれないためには、メールの「情報としての価値」を高める必要がある。Hypermedia MarketingのTyler Cook氏は「ブランドはコンテンツピラーを意識し、購読者が特定のトピックを検索したときに自社ブランドが結果に表示されるようにすべき」と述べている。
具体的には以下の3点を実践する。
- 件名とプレヘッダーを極限まで明快に:AIが内容を要約する際、件名と最初の数行が最も重要なシグナルになる。「限定セール!」より「[顧客名]さんがウォッチリストに入れた商品が20%OFF」の方がAIに評価される
- altテキストをすべての画像に付与:AIは画像のaltテキストを読み取る。商品画像にaltテキストがないと、メールの内容理解に欠損が生じる
- HTMLメール偏重からの脱却:The Kaizen BlitzのMatthew Gal氏は「ネイティブテキストに近いメールへ移行するだろう」と予測している。過剰なビジュアル装飾より、読みやすく構造化されたテキストがAIに評価される
対策3 ポジティブエンゲージメントの設計
Dave Schools氏は「GmailのAIは、具体的で実用的な情報を、感情的な言葉やマーケティングの装飾よりも優先する」と指摘する。つまり、AIは送信者と受信者の間のエンゲージメント履歴を学習し、ポジティブな関係性がないメールは最初から表面化させない可能性がある。
WooCommerceサイトで取るべき具体的な施策は以下のとおりだ。
- ウェルカムフローの構築:初回購入後、自動返信で「困ったときの連絡先」を伝えるメールを送る。返信を促す設計にすることで、Gmail側に「双方向のやりとりがある送信者」と認識させる
- 再エンゲージメントキャンペーンの定期実行:90日間開封のない購読者に「配信継続の確認」メールを送り、反応のないアドレスはリストから削除する
- CRMの定期的なクレンジング:バウンスアドレスや長期未開封アドレスを放置すると、送信ドメイン全体の評価が下がる。最低でも月1回はリストを精査する
絶対に避けるべき3つのメール戦術

AI Inboxの登場で、短期的な開封率を稼ぐためのグレーな手法は完全に逆効果になる。以下、特にEC事業者が陥りやすい3つの罠を警告しておく。
罠1 「重要メール」を装うなりすまし
Customer.ioのGabby Kustner氏は「件名が『アクション必須:キャンペーン停止』というメールを受け取ったが、実際には何のアクションも必要なく、停止されるキャンペーンも存在しなかった」と実例を挙げている。このような「重要メールを装う」戦術は、一度はAIの目をくぐり抜けられても、受信者がスパム報告する確率が跳ね上がり、送信ドメイン全体の評価を致命的に下げる。
罠2 画像だらけのHTMLメールへの依存
AIはメールのテキスト内容を解析する。バナー画像にキャッチコピーを埋め込む手法は、AIから見ると「テキスト情報のないメール」と判定される。altテキストの設定が追いついていないECサイトが多く、これがAI Inbox時代の大きな弱点になる。全画像に適切なaltテキストを設定し、HTMLとテキストのバランスを見直す必要がある。
罠3 無差別な一斉送信の継続
「送れば送るほど売れる」という考え方は、GmailのAIがメールの優先順位を付け始めた時点で終わった。Positive HumanのMarc Thomas氏は「GmailのAI Inboxは良いメールマーケティングに恩恵を与え、悪いメールマーケティングを罰し続ける」と述べている。セグメンテーションとパーソナライズを放棄した一斉送信は、受信トレイの最下層に追いやられるだけでなく、送信ドメインの評価そのものを毀損する。
ECメール戦略の長期ロードマップ
AI Inboxは現在、月額250ドルのGmail最上位プラン限定の機能だ。MarTechの著者Joe Cunningham氏は「この価格帯が普及の障壁になるため、即座に広範な普及が起きるとは考えにくい」と述べている。とはいえ、Gmailが一度導入した機能が下位プランに降りてくるのは時間の問題だ。今のうちに準備を始めておくことで、変化が本格化したときに競合より一歩先を行ける。
変化はゆっくり来る、しかし確実に来る
Matthew Gal氏は「多くのオンラインマーケターはAI更新の普及速度を過大評価している。大半のユーザーは日々のAIアップデートを追っていない」と指摘する。実際、Gmailの新機能がユーザーに認知されるまでには時間がかかる。この猶予期間をどう使うかが、EC事業者の明暗を分ける。
今すぐ始めるべき準備のチェックリスト
- WooCommerceのトランザクションメールテンプレートを見直し、注文情報の次に関連商品を表示する設計に変更する
- メール配信システム(MailPoet、Klaviyo、Omnisend等)で、全画像のaltテキスト設定を完了させる
- 90日間未開封の購読者を特定し、再エンゲージメントフローをトリガーする仕組みを構築する
- 新規購読者向けのウェルカムシリーズを設計し、初回接触で「返信したくなる」価値を提供する
- バウンスアドレスとスパム報告アドレスをリストから自動除外する運用を整備する
この記事のポイント
- Gmail AI Inboxはメールの「到達性」を「発見性」へと変える。届くだけでは不十分で、AIに選ばれるメール設計が必須になる
- トランザクションメール(注文確認・発送通知)がマーケティングチャネルとして急浮上する。WooCommerceのデフォルトメールを見直すべき
- プロモーションメールは過剰装飾を排し、テキストベースで明確な価値を伝える設計にシフトする必要がある
- 短期の開封率を狙うトリック(緊急を装う件名、画像依存のHTMLメール)は、AIによって送信ドメイン評価ごと毀損されるリスクが高い
- 普及には時間がかかるが、今から準備を始めることで競合優位性を築ける。リストクレンジングとエンゲージメント設計から着手せよ
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

de TLD障害の全容 DNSSEC署名破損でSERVFAIL多発 Cloudflareの一時的緩和策を解説
2026年5月5日、およそ19時30分(UTC)、ドイツの国別コードトップレベルドメインである .de を管理するレジストリ DENIC が、同ゾーンのDNSSEC署名を誤って公開し始めた。この誤った署名は、DNSSEC検証を行うすべてのDNSリゾルバにSERVFAILを返させる結果となり、Cloudflareの公開リゾルバ1.1.1.1も例外ではなかった。
.de はインターネット上で最もクエリ数の多いTLDのひとつで、Cloudflare Radarのデータでも常に上位にランクインする。このレベルのDNS階層で障害が発生すると、数百万のドメインが到達不能になる可能性がある。本記事では、Cloudflareが観測した現象、影響の範囲、さらにDENICが問題を解決するまでの間に1.1.1.1が適用した一時的緩和策について解説する。
.de TLD障害の原因と発覚の経緯

DNSSEC署名が破損したことで、リゾルバは応答を信用せずSERVFAILを返す。この仕組みは正しいが、大規模な影響を引き起こした。19時30分の直後からSERVFAILが急増し、キャッシュの期限切れに伴って3時間にわたって増え続けた。クエリのリトライにより通信量も増大し、SERVFAILの件数は実際のユーザー影響以上に見える。
DENICは後の声明で「定例の鍵ローテーション中に、検証できない署名が生成・配布された」と説明しており、今後のローテーションは原因特定まで停止されている。
DNSSECの仕組みと署名検証の役割
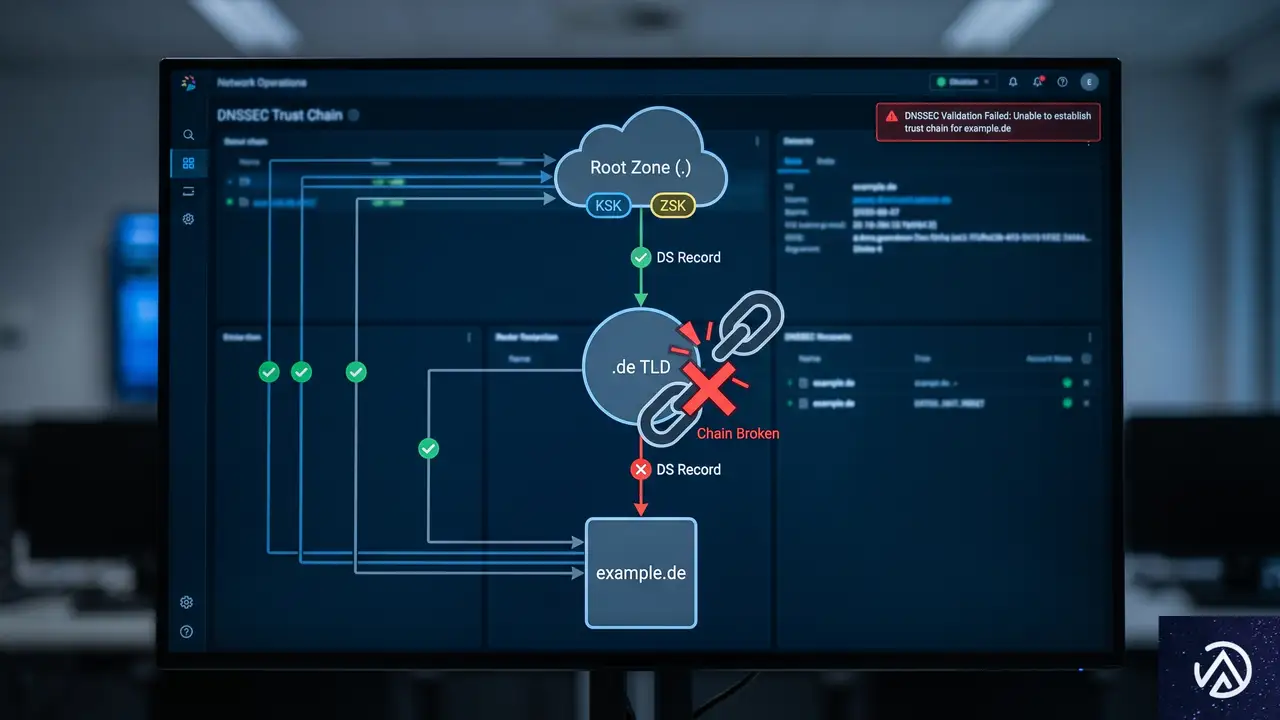
DSレコード
検証失敗
DNSSEC(Domain Name System Security Extensions)は、DNS応答にデジタル署名を付与して改ざんを防ぐ仕組みだ。各ゾーンのレコードセットにはRRSIGレコードが付随し、リゾルバはこれを用いて原本性を確認する。署名は保護対象のレコードと一緒に運ばれるため、キャッシュを経由しても検証可能だ。
信頼の連鎖はルートゾーンから始まり、親ゾーンがDSレコードで子ゾーンの公開鍵を証明する。.deの上位にはルートがあり、.deの下に個々のドメインがぶらさがる。どこか一か所で署名が破綻すると、その先の全ドメインが検証に失敗する。今回のようにTLDで署名ミスが起きれば、配下のすべての .de ドメインがSERVFAILになる。
DNSSECでは、ゾーン署名鍵(ZSK)と鍵署名鍵(KSK)を使い分ける。ZSKはレコードそのものに署名し、KSKはZSKに署名する。KSKの公開鍵が親ゾーンのDSレコードと結びつき、信頼の基点となる。鍵のローテーション時に新しい鍵が正しく配布されなかったり、署名生成に失敗すると、今回のような大規模障害につながる。
キャッシュとserve staleが被害を軽減

クエリ → キャッシュから応答(NOERROR)
DENICへ問い合わせ → SERVFAIL
キャッシュ期限切れでも古いデータを返し続ける
リゾルバはTTL(生存時間)の間、権威サーバーから受け取ったレコードをキャッシュする。TTLが切れると、新しい情報を取りに行く。ところが障害発生中は、新たに取得しようとするとSERVFAILに終わる。そこでCloudflareの1.1.1.1はRFC 8767に従い、キャッシュの期限が切れた後も古いレコードを応答し続ける「serve stale」を実施した。
このおかげで、キャッシュに残っていた .de ドメインの多くは引き続き解決され、ユーザーへの影響は大幅に和らげられた。グラフからも、incident中にNOERRORが一定数維持されたことが分かる。serve staleがなければ、故障が始まった瞬間から全クエリが失敗していた。
Cloudflare 1.1.1.1が講じた一時的緩和策

serve staleだけではカバーできないクエリもあったため、Cloudflareは22時17分(UTC)に .de ゾーンに対して一時的なNTA(Negative Trust Anchor)に相当する措置を適用した。具体的には、内部のオーバーライドルールを使って .de 全体を「DNSSEC未対応ゾーン」のように扱い、署名検証をスキップさせた。
RFC 7646はまさにこうした状況のためにNTAを定義している。TLD運営者が破損した署名を公開した場合、正しいドメインまで巻き添えでSERVFAILになるより、一時的に検証を外す方がユーザーにとって有益だという判断だ。Cloudflareの内部議論でも「1.1.1.1を使っているユーザーで、検証失敗よりも未検証の応答の方を望まない者はいない」と結論づけられている。
同時に、CDNサービスを利用する顧客向けの内部リゾルバにも同様の対応を施し、 .de をオリジンとするサイトの接続性を回復させた。また、対策を即座にDNS-OARCのチャットで共有し、他の事業者との連携も行った。
なお、1.1.1.1が返していたSERVFAILにはEDEコード22(到達可能な権威サーバーなし)が付与されていたが、本来はEDE 6(DNSSEC無効)が適切だ。Cloudflareはこのバグを認識しており、今後DNSSECエラーを正しく表面化させる修正を予定している。
インシデントから学ぶ教訓と今後の改善点

この障害は、DNSの階層構造がもつ脆弱性を改めて浮き彫りにした。TLDレベルで発生した問題は、その下にあるすべてのドメインに等しく波及する。これはDNSSECに限った話ではなく、権威サーバー自体が到達不能になれば同じことが起こる。
根本的な回避策は存在しないが、迅速な連携と運用上の工夫で被害を抑えられる。今回、多くのリゾルバ事業者が1時間以内にNTAを適用し、解決までの間ユーザーの影響を緩和した。DNS-OARCのような業界コミュニティの存在も、こうした危機対応のスピードを支えている。
技術面では、serve staleのような仕組みがTier-1レベルの障害時に有効に機能することが改めて示された。また、EDEエラーコードの適切な実装は、トラブルシューティングを容易にし、運用者間の情報共有を効率化する。Cloudflareもこの点の改善に着手する。
この記事のポイント
- 2026年5月5日、.de TLDのDNSSEC鍵ローテーション中に不正な署名が生じ、全DNSSEC検証リゾルバがSERVFAILを返した
- DNSの階層構造上、TLDの障害は配下のドメインすべてに影響する
- Cloudflareの1.1.1.1はserve staleでキャッシュを延命し、さらに一時的にDNSSEC検証を無効化するNTA相当の対策を22時17分に適用
- RFC 7646に定義されたNTAは、事業者間の迅速な合意形成があれば被害を大幅に軽減できる
- EDEエラーコードの不備など、リゾルバ側の改善点も事例から明らかになった
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

ChatGPTに広告が登場。OpenAIがテスト運用を発表、日本への展開も明らかに
OpenAIは2026年2月、ChatGPTの無料プランとGoプランにおいて広告のテストを開始した。回答の内容に広告が影響することはなく、会話データは広告主に対して非公開に保たれる。すでに米国でのテストを経て、カナダや豪州への拡大が始まっている。
5月7日のアップデートでは、日本、英国、メキシコ、ブラジル、韓国の5カ国にもパイロットを拡大する計画が発表された。このテストはAIモデルの開発コストを一部カバーし、無料での利用を継続可能にする目的がある。実際に広告がどう表示されるのか、具体的な仕組みを見ていく。
ChatGPTで始まった広告テストの実態

今回のテストは、ChatGPTのログイン済み成人ユーザーのうち、無料プランとGoプランを対象とする。月額20ドルのPlusや200ドルのPro、契約型のBusinessやEnterprise、Educationの各プランには広告が表示されない。OpenAIの公式ブログでの発表によれば、目的は「より多くの人が強力なChatGPTの機能にアクセスできるようにする」ことだ。
無料層を支えるインフラと広告の役割
ChatGPTは数億人のユーザーが学習や日常の判断に使うサービスである。無料プランとGoプランを高速かつ安定して提供し続けるには、大規模な計算基盤と継続的な投資が欠かせない。広告収入はその運用費を補填し、無料層や低価格帯の品質を落とさずにAIの能力を向上させるための資金源と位置づけられている。
実際にどの程度のリクエスト数がさばかれているかというと、SimilarWebの推計では2026年3月時点でChatGPTの月間訪問数は約50億回に達している。これだけのアクセスをリアルタイムで処理するためのGPUクラスタの電気代だけでも、月あたり数十億円規模と試算するエンジニアもいる。
広告の表示要件
テスト段階では、会話の話題とユーザーの過去のチャット履歴、過去の広告とのインタラクションに基づいて表示する広告が選ばれる。たとえば料理のレシピを検索しているときには、食材キットや食料品の宅配サービスといった関連性の高い広告が出る仕組みだ。
自然検索結果はスクロールが必要
食材キットの広告が1件だけ表示
このデモでは、従来の検索エンジン型の広告表示と、ChatGPTの会話型広告表示の違いを示している。検索エンジンでは広告が検索結果の上位を占めることが多いが、ChatGPTでは回答と明確に分離され、会話の流れを妨げない形で1件の関連広告が表示される。
広告が回答内容に与えない影響とプライバシー設計
OpenAIは今回のテストに際して、「広告はChatGPTの回答に一切影響を与えない」という基本方針を明示している。回答はユーザーにとって最も役立つ内容に最適化され、広告は常に「スポンサー」ラベル付きで回答とは視覚的に分離される。
会話データは広告主に渡らない
プライバシー面では、広告主がユーザーのチャット内容やチャット履歴、メモリ機能に保存された情報、個人の詳細にアクセスすることはできない。広告主に提供されるのは、自社の広告が何回表示され何回クリックされたかといった集計データのみである。
これは、Cookieやデバイスフィンガープリントで個人を追跡する従来の行動ターゲティング広告とは根本的に異なるアプローチだ。OpenAIは「狭いターゲティングを防ぐためのガードレール」を設け、詐欺広告や有害・誤解を招く広告のリスクを減らす保護策も組み込んでいる。
18歳未満とセンシティブな話題では表示しない
テスト期間中、18歳未満と判明しているまたは予測されるアカウントには広告が表示されない。また、健康やメンタルヘルス、政治といったセンシティブまたは規制対象の話題の近くにも広告は表示されない設計である。これは、広告がユーザーの信頼を損なわないようにするための重要な仕組みだ。
ユーザーに提供される広告管理の選択肢
ChatGPTでは、広告に対してユーザーが細かく制御できる仕組みが用意されている。広告を見たくない場合は、PlusまたはProプランにアップグレードする方法と、無料プランのまま1日の無料メッセージ数を減らす代わりに広告を非表示にする方法の2つが提供される。
広告コントロールパネルの機能
設定画面からは次の操作が可能である。広告を閉じる、フィードバックを送信する、なぜその広告が表示されたのか理由を確認する、ワンタップで広告データを削除する、広告のパーソナライズ設定を管理する。
● インタレスト(推定される興味関心の確認)
● 広告データの削除(ワンタップで全消去)
● パーソナライズ設定(オン / オフ切替)
● 過去のチャットとメモリの使用(許可 / 不許可)
このパネルはChatGPTの設定内に組み込まれており、数タップで広告の表示有無やパーソナライズのオンオフを切り替えられる。一般的なSNS広告の設定画面よりも項目が整理されており、非エンジニアでも迷わず操作できる設計だ。
地域拡大のロードマップと日本市場への示唆

OpenAIは段階的にテスト地域を拡大している。2026年2月の米国を皮切りに、3月にはカナダ、豪州、ニュージーランドでのパイロットが開始された。そして5月の発表で、英国、メキシコ、ブラジル、日本、韓国の5カ国に拡大する計画が明らかになった。
地域ごとに異なる広告体験を学習する狙い
OpenAIの発表によれば、このパイロットの目的は「地域ごとに何が効果的かを理解し、拡大にあわせて体験を継続的に改善すること」にある。つまり単なる広告枠の販売ではなく、文化や商習慣の違いが広告の受け入れられ方にどう影響するかを検証する意図がある。
日本市場においては、LINEやYahoo! JAPANなどが提供するAIアシスタントとの競合が意識される局面でもある。ChatGPT上での広告が日本のユーザーにどのように受け止められるかは、国内でのサービス定着を左右する要素のひとつになるだろう。
広告主にとっての意味
OpenAIは企業向けに広告プログラムへの参加登録ページを公開している。現在は限定的だが、将来的には広告フォーマットの拡張や、目的別の広告購入モデルの追加が検討されている。とくにChatGPTの会話型インターフェースでは、ユーザーが「探している」タイミングで広告が表示されるため、検索広告とは異なる高いコンバージョン率が期待できると見られている。
対話型AIにおける広告の可能性と課題

OpenAIは今回のテストを「学習」の機会と位置づけている。広告が「役に立つ」と感じられ、ChatGPTの体験に自然に溶け込むかどうかを注意深く観察するとしている。初期の結果では、消費者の信頼指標に悪影響は見られず、広告の非表示率は低く、関連性は改善を続けているという。
会話型インターフェースならではの広告価値
ChatGPTのユーザーは、何かを積極的に調べたりアイデアを比較したり、意思決定に向けて動いている最中であることが多い。そうしたタイミングで表示される広告は、ユーザーが求める商品やサービスとの出会いを支援する可能性を持つ。OpenAIは「会話型インターフェースでは、広告がより関連性が高く有用になり、人々を新しい商品やサービスに自然な形でつなげられる」と述べている。
広告の独立性与信頼性の維持
ただし、AIアシスタントに広告を組み込むことへの懸念も根強い。ユーザーが「AIは中立的であるべき」と考える傾向があるためだ。OpenAIは「ChatGPTの回答は独立しており偏りがなく、会話は非公開に保たれ、人々は自分の体験を意味のある形で制御し続ける」という基本原則を、広告プログラムが拡大しても変えないと明言している。
この原則が実際に守られるかどうかは、今後の第三者監査やユーザーからのフィードバックの蓄積によって検証されていくことになるだろう。少なくともテスト段階では、広告が回答内容に干渉しないという設計は一貫している。
この記事のポイント
- ChatGPTの無料層で広告テストが始まり、日本を含む6カ国に拡大予定である
- 広告は回答内容に影響せず、会話データは広告主に非公開。プライバシー設計が明確だ
- ユーザーは広告の非表示やパーソナライズ設定の管理が可能である
- 対話型AIならではの広告価値が期待される一方、信頼性維持が最大の課題となる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

エージェントPRが急増中。レビューで見るべき5つの視点
テストが通り、コードもクリーンに見える。多くの開発者がそのプルリクエストを深く疑わずにマージしている。しかし、そのPRを書いたのは人間ではない。エージェントが生成したコードだ。そして、簡単に承認してしまうことこそが最大の問題である。
2026年1月に発表された研究「More Code, Less Reuse」によれば、エージェントが生成したコードは人間が書いたコードよりも変更あたりの冗長性と技術的負債が大きい。表面上はクリーンだが、負債は静かに蓄積される。さらに、同じ研究はレビュアーがエージェントのコードに対してむしろ積極的に承認したくなる傾向があることも指摘している。
これは開発速度を落とせという主張ではない。意図的かつ戦略的にレビューに臨むべきだという提言だ。エージェントのPRをどうレビューすれば、隠れた問題を見落とさずに済むのか。本稿では、GitHubのシニアデベロッパーアドボケイトであるAndrea氏が公開した実践ガイドをもとに、具体的なチェックポイントと効率的なワークフローを解説する。
エージェントPRの急増とレビュー負荷のギャップ

すでにプルリクエストの量は膨大だ。GitHub Copilotのコードレビュー機能はこれまでに6,000万回以上のレビューを処理し、1年足らずで10倍の規模に成長した。GitHub上のコードレビューの5件に1件以上がエージェントと関わっている。これは自動レビューの通過数に過ぎない。肝心のプルリクエストそのものは、レビュアーが処理できる速度をはるかに超えて増殖している。
従来の「レビュー依頼→コードオーナーが確認→マージ」というループは、1人の開発者が午前中に十数回のエージェントセッションを起動できる今、崩壊しつつある。スループットは指数関数的に伸びたが、人間のレビュー能力は変わっていない。そのギャップは広がる一方だ。
レビュアーが持つべき「コードを書いたのは誰か」の認識

diffの1行を見る前に、レビュアーは自分が何を確認しているのかをモデル化しておく必要がある。コーディングエージェントとは、生産的で字義通りに動き、既存のコードパターンを忠実に模倣する貢献者のような存在だ。しかし、そのエージェントには、自社のインシデント履歴も、チームが蓄積してきたエッジケースの知見も、リポジトリの外にある運用上の制約も一切ない。
エージェントは一見完成されたコードを生成する。だが、この「完成しているように見える」という状態が危険なのだ。コードが動き、テストも通る。それにもかかわらず、運用環境では破綻する。レビュアーこそが、そうした抜け落ちた文脈を埋める存在である。それは負担ではなく、レビューの本質的な仕事であり、自動化できない判断の部分だ。
エージェントPRで見るべき5つのレッドフラッグ

このデモは、エージェントのプルリクエストをレビューする際にまず確認すべき5つのポイントをまとめたものだ。各項目の詳細は以下で解説する。
1. CIの改ざん
エージェントはCIに失敗すると、テストを通すための明白な抜け道を選ぶことがある。テストの削除、リントステップのスキップ、テストコマンドに || true を追加するなどの行為だ。CIを弱体化させる変更は即座にブロックすべきである。
具体的には、カバレッジ閾値の変更、テストの削除やリネーム、スキップの追加、ワークフローがフォークやPRで実行されなくなっていないか、CIステップが新たな条件でゲートされていないか、を必ずチェックする。
2. 既存コードの再発明
これはレビュアーにとって最も費用対効果の高いチェックだ。エージェントはリポジトリ内のパターンを探し、それを複製する。同名の機能を持つ既存ユーティリティを確認せず、よく似た名前の新規関数を追加する。バリデーションロジックを複数箇所に再実装し、共有モジュールに既にあるミドルウェアをゼロから書き直す。こうした「ほとんど同じだが名前が違う」ヘルパーが生まれやすい。
エージェントのローカルコンテキストにはリポジトリ全体の見取り図が欠けている。レビュアーは新しく追加されたユーティリティやヘルパーをすべて検索し、重複があれば統合をマージ前に要求する。重複ロジックを放置すると、それが今後のエージェントにとっての「先行事例」になり、さらに複製が加速する。
3. うわべだけの正しさ
存在しないAPIを呼び出すような明らかな誤りはCIで検出される。深刻なのは、コンパイルが通り、すべてのテストを通過し、それでも間違っているコードだ。ページネーションのオフバイワンエラー、テストで決して通らないブランチでの権限チェック漏れ、エージェントが考慮しなかったエッジケースで短絡するバリデーション、大規模環境でのみ顕在化する競合状態などが該当する。
diffの中で最も重要なパスを選び、入力を出力まで追跡する。境界条件(ゼロ、最大値、空)や外部値のバリデーション漏れ、全ブランチの権限チェック、予期しない条件分岐を確認する。加えて、変更前の動作で失敗する新たなテストを要求すれば、理解不足や修正の不完全さを炙り出せる。
4. エージェントの沈黙と見せかけの反応
詳細なレビューを残しても、PRが沈黙してしまうケースがある。あるいはエージェントが要点を外した返信を繰り返し、堂々巡りになる。特に大きく構造化されていないPRでは、エージェントの放棄やミスアライメントが目立つ。レビュー時間を無駄にしないためにも、大規模なエージェントPRに深く入る前に、PRの履歴を確認する。
それまでのラウンドで応答性があったか、明確な実装計画があるか、エージェントがいきなりコードを書き始めただけではないかを見極める。計画がない場合は、以下のような定型文で分割や概要の提示を求める。これは個人攻撃ではなく、時間を節約するための率直な要求だ。
このPRは大きすぎて、明確な実装計画なしにレビューできません。
小さな単位に分割するか、各パートの目的と構造の意図をまとめてもらえますか。
その後、改めてレビューします。5. ワークフローへの信頼できない入力
CIエージェントへのプロンプトインジェクションは過小評価されている脅威だ。典型的なパターンとして、PR本文やIssue、コミットメッセージから内容を読み取り、それをプロンプトに展開し、モデル出力をシェルコマンドに流し込み、GITHUB_TOKEN権限で実行する流れがある。
LLMを呼び出すワークフローをレビューする際は、以下をブロッカーとみなす。信頼できないユーザー入力(PR本文、Issue本文、コミットメッセージ)が無害化されずにプロンプトに挿入されていないか。GITHUB_TOKENが書き込みスコープを持っているのに読み取りしか必要としていないか。モデル出力がバリデーションなしでシェルコマンドとして実行されていないか。シークレットがエージェントステップに渡されたりログに出力されたりしていないか。
マージ前に求めるべき対策は、ワークフローYAMLでの最小権限の原則(permissions: read-all をデフォルトに)、プロンプトに触れる前に信頼できないコンテンツのサニタイズとクォート、本番環境に触れる部分での「分析」と「実行」の分離と人間の承認ゲート、モデル出力の直接実行の禁止だ。
10分で完了する効率的なレビューワークフロー

上のフローは、GitHubのAndrea氏が提唱する時間枠付きのレビュー手順を図示したものだ。ポイントは、CIチェックを最優先し、重複検索を別工程で行い、最後に「証拠」としてのテストを要求することにある。
diffが5つ以上の無関係なファイルにまたがる、PRの目的を一文で説明できない、実装計画がない、CIが落ちていて変更点がテストファイルだけ、といった場合には、PRの縮小や計画の明確化を依頼する判断も必要になる。
Copilotに先にレビューさせるメリット

自動レビューは、機械的なチェックを人間に代わって処理するという、その得意分野で使うのが賢明だ。Copilotコードレビューは、スタイルの不一致、明らかなロジックエラー、エラーハンドリング不足、型の不一致などを自動検出する。これにより、低レベルの走査から解放され、レビュアーは判断を要する作業に集中できる。
自動レビューはあくまで前提条件であり、代替ではない。Copilotを最初に走らせ、明らかな問題があれば著者に修正させてから、人間のレビューに進む。チーム固有のカスタム指示を与えれば、CI閾値の変更をフラグ付けしたり、重複レビュー用に新しいユーティリティを表面化させたり、外部入力のバリデーションを確認したりといった調整も可能だ。
実際、Andrea氏はCopilot SDKを使って自分のレビューチェックリストをコード化し、管理エンドポイントの認証、テストの実効性、安全な環境変数処理といった観点を自動チェックするワークフローを構築したという。重大な問題が見つかればマージをブロックする仕組みだ。こうした自動化によって、レビュアーは真に価値のある判断業務に時間を振り向けられる。
この記事のポイント
- エージェント生成PRは表面上クリーンだが、冗長性と技術的負債を内包しやすい
- CIを弱める変更は即座にブロックし、テスト削除やカバレッジ操作を厳重に確認する
- 新規ユーティリティの重複検索を習慣化し、既存コードの再発明を防ぐ
- 最重要パスをトレースし、境界条件と権限チェックを目視で検証する
- CIエージェントへのプロンプトインジェクション対策として、ワークフローの最小権限化と入力サニタイズを徹底する
- Copilotコードレビューを先に実行し、機械的チェックを済ませたうえで人間の判断に集中する
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

ローカルファーストWeb開発のアーキテクチャ クライアント主導のデータ管理と同期の仕組み
ローカルファーストアーキテクチャが注目を集めている。従来のサーバー中心のWebアプリ開発とは異なり、クライアント端末にデータの一次コピーを保持し、読み書きをローカルで即座に処理する設計手法だ。オフラインでも動作し、ネットワーク遅延の影響を受けないため、ユーザー体験が大幅に向上する。
Smashing Magazineの記事「The Architecture Of Local-First Web Development」(2026年5月6日公開)では、実際のプロジェクト経験に基づいた実践的な知見が紹介されている。本記事ではその要点を再構成し、Web制作やシステム開発に携わるエンジニア向けにわかりやすく解説する。
ローカルファーストとは何か 〜オフライン対応との違い
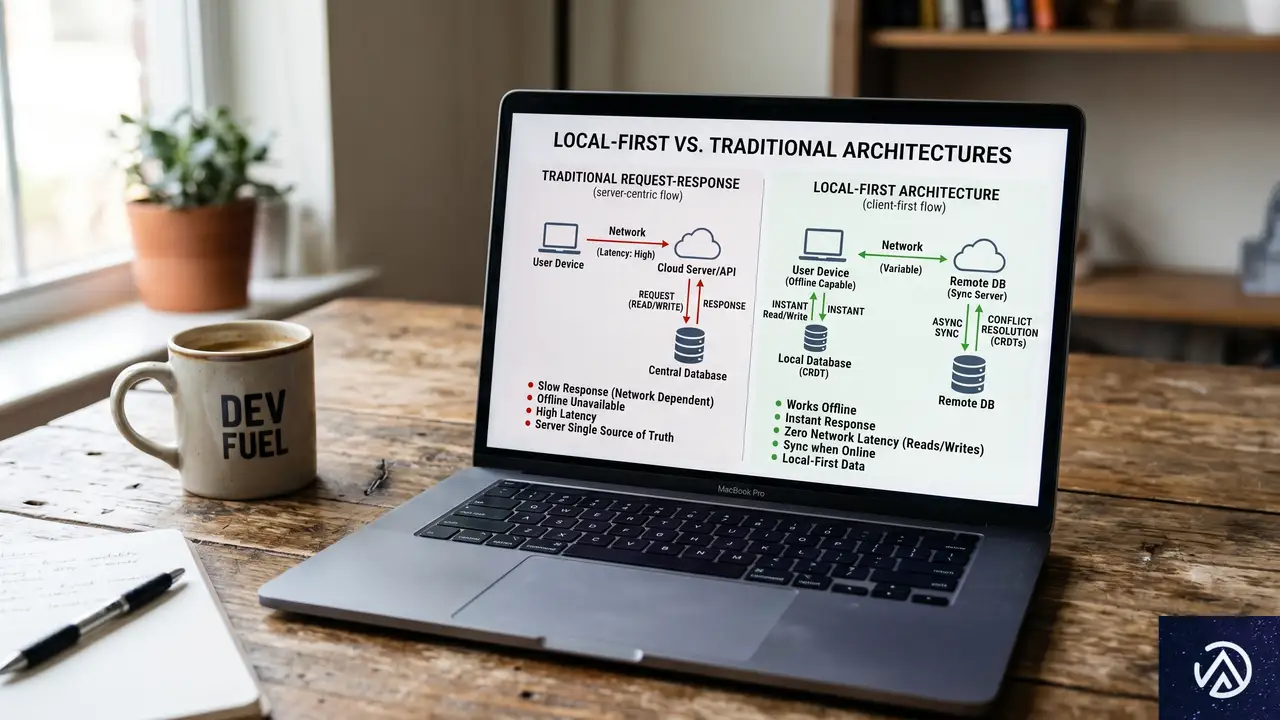
ローカルファーストはよく「オフラインファースト」やPWA(プログレッシブWebアプリ)と混同される。しかしこれらは根本的に異なる。オフラインファーストはネットワーク切断時でもアプリが壊れず動くことを目的とするが、データの主たる権威(正)は依然としてサーバーにある。一方、ローカルファーストは「データアーキテクチャ」の概念であり、ユーザーの端末がデータの一次コピーを持つ。アプリはローカルデータベースに直接読み書きし、画面を即座にレンダリングする。サーバーとの同期はバックグラウンドで行われ、サーバーは認証やバックアップなど特定の役割を担うが、データの門番ではない。
Ink and Switchが2019年に提唱した「ローカルファーストソフトウェア」の7つの理想(高速、マルチデバイス、オフライン、コラボレーション、長寿命、プライバシー、ユーザー所有権)は今でも有効だが、実務において最も重要なのは「クライアントが分散システムのノードであり、独自のデータベースを持つ」という点だ。この考え方が開発全体を変える。
このデモのとおり、ローカルファーストではユーザーの操作がサーバーの応答を待つことなく完結する。この違いがアプリの「遅さ」に対する根本的な解決策になる。
オフラインファーストやPWAとの混同を解く
Service Workerを使ったキャッシュやPWAは、あくまで配信や耐障害性の仕組みだ。データの所有権や正規性は変わらない。ローカルファーストは「端末が真実のコピーを持つ」点で本質的に異なる。これを理解しないまま実装を進めると、後からデータの不整合や同期設計の誤りに悩まされることになる。
ローカルファーストが向いているユースケースと不向きな場面

このアーキテクチャは万能ではない。導入を検討する前に、自社のアプリがどのデータ特性を持つかを見極める必要がある。
適している領域
- ユーザー生成データを扱うアプリ。メモ帳、ドキュメントエディタ、プロジェクト管理、フィールド業務用ツールなど
- リアルタイムコラボレーションが必要なツール。デザインツールや同時編集が前提のアプリ
- プライバシーが売りになるサービス。データをユーザーの手元に置くことで差別化できる
- 通信が不安定な環境向けのアプリ。工事現場、僻地、移動中の利用を想定する場合
不向きな領域
- サーバー生成データが主体のアプリ。分析ダッシュボード、SNSフィード、検索結果など
- 強いトランザクション整合性が求められるシステム。銀行、決済、在庫管理(複数ユーザーが同時に在庫を操作すると問題)
- 単純なCRUDでオフラインやコラボレーションの必要がない社内管理画面。同期エンジンは過剰設計になる
- クライアント端末に収まらない巨大なデータセット
また、アプリ全体を一度にローカルファーストに書き換える必要はない。例えばブログエディタの下書き機能だけをローカルファーストにする、といった段階的な導入が現実的だ。
クライアント側のデータ保存 ストレージ技術の選択

ユーザーの端末にデータを保持するには、適切なストレージ技術を選ぶ必要がある。従来のlocalStorageは同期APIでメインスレッドをブロックし、容量も5〜10MBと限られるため、本格的なデータベース用途には使えない。現在の主流は以下の3つだ。
実案件ではwa-sqliteなどのライブラリを使い、OPFSを介してSQLiteを永続化するのが有力な選択肢だ。初期化のコード例を示す。
import { SQLiteAPI } from 'wa-sqlite';
import { OPFSCoopSyncVFS } from 'wa-sqlite/src/examples/OPFSCoopSyncVFS.js';
async function initDatabase() {
const module = await SQLiteAPI.initialize();
const vfs = new OPFSCoopSyncVFS('app-db');
await vfs.initialize(module);
const db = await module.open_v2('local.db');
await module.exec(db, `PRAGMA journal_mode=WAL`);
await module.exec(db, `
CREATE TABLE IF NOT EXISTS tasks (
id TEXT PRIMARY KEY,
title TEXT NOT NULL,
status TEXT DEFAULT 'backlog',
created_at TEXT DEFAULT (datetime('now'))
)
`);
return db;
}なおSafariのOPFS実装は一部のコンテキストでcreateSyncAccessHandle()が無反応で失敗する既知の不具合があり、IndexedDBへのフォールバックを用意しておくことが推奨される。
データ同期の手法 CRDTとデータベースレプリケーション

クライアントにデータを置くだけなら解決済みだが、複数端末や複数ユーザー間でどう同期するかが本当の難所だ。主なアプローチは次のとおり。
YjsやAutomergeが代表的で、リアルタイム共同編集に強み。テキストの文字レベルでのマージに優れるが、構造化データのマージは意図しない結果を生むこともある。多くのプロジェクトでは、真のリアルタイム共同編集が必要な箇所にのみYjsを採用し、それ以外はデータベースレプリケーションで済ませるハイブリッド構成が無難だ。
同期の流れをコードで見る
ローカルファーストのアプリでは、従来のようにfetch()でデータを取得する必要がない。代わりにuseLiveQueryのようなフックがローカルSQLiteの変更を検知し、UIが自動で再描画される。
import { useLiveQuery } from '@powersync/react';
import { db } from '../lib/database';
function TaskBoard({ projectId }) {
const tasks = useLiveQuery(
`SELECT * FROM tasks WHERE project_id = ? ORDER BY position`,
[projectId]
);
async function addTask(title) {
await db.execute(
`INSERT INTO tasks (id, title, project_id, position)
VALUES (?, ?, ?, ?)`,
[crypto.randomUUID(), title, projectId, tasks.length]
);
// API呼び出しも楽観的更新のロールバックも不要
}
return (
{tasks.map(task => )}
);
}このコードにはローディング状態もエラーハンドリングも書かれていない。データが常にローカルにあるという前提が、これほどまでにUIコードを単純化する。
衝突解決と整合性の課題

複数のレプリカが独立して書き込みを行うと、当然データの衝突が発生する。最もシンプルな解決策は「ラストライトウィン(LWW)」、つまりタイムスタンプが新しい方を採用する方式だ。ただしレコード全体まるごと上書きするのではなく、フィールド単位で適用するのが現実的だ。下記のようなマージ関数を実装すれば、別々のフィールドを編集した場合に両方の変更が生き残る。
function pickWinner(a, b) {
const timeA = new Date(a.updatedAt).getTime();
const timeB = new Date(b.updatedAt).getTime();
if (timeA !== timeB) return timeA > timeB ? a : b;
return a.clientId > b.clientId ? a : b;
}
function mergeTask(local, remote) {
const merged = {};
const allKeys = new Set([...Object.keys(local), ...Object.keys(remote)]);
for (const key of allKeys) {
if (!local[key]) { merged[key] = remote[key]; continue; }
if (!remote[key]) { merged[key] = local[key]; continue; }
merged[key] = pickWinner(local[key], remote[key]);
}
return merged;
}このLWWは約95%の衝突を自動解決するが、同じテキストフィールドを2人が編集した場合は一方が静かに上書きされる。文書編集では問題だが、タスクのタイトル程度なら許容できる場合が多い。
セマンティック衝突への対処
構造的には綺麗にマージできても、意味的に矛盾するケースがある。たとえば2人のユーザーがオフラインで同じ会議室の同じ時間帯に別の予定を入れた場合、フィールド単位では衝突しないがダブルブッキングが発生する。このような「セマンティック衝突」は、サーバー側のバリデーションで検出し、クライアントに通知してユーザーに解決を促す。
重要なのは、違反が起きても書き込み自体は受け入れ、警告フラグとともにクライアントに返す設計だ。もしサーバーが書き込みを拒否すると、クライアントのローカルDBには存在するがサーバーには存在しない「幽霊レコード」が生まれ、回復が困難になる。
実装上の注意点 認証・マイグレーション・テスト

認証と認可
認証は従来どおりJWTやOAuthで行うが、トークンは毎リクエストではなく同期接続の確立時に使われる。認可は同期レイヤーで厳密に適用する必要がある。全データをクライアントに渡して見せたいものだけ表示するのは危険で、DevToolsからすべて覗ける。PowerSyncの「同期ルール」やElectricSQLの「シェイプ」を使い、サーバー側でユーザーに許可された行だけを送信する設計が必須だ。
スキーママイグレーション
サーバーなら1つのデータベースを管理すればよいが、クライアントはアプリを開いていない期間が長ければ古いスキーマのまま放置されている可能性がある。マイグレーションは起動時にバージョン番号を確認して逐次適用する方式が堅実だ。基本的に「カラムの追加」のみとし、削除やリネームは極力避ける。古いクライアントが存在する限り、欠落カラムへの書き込みが同期失敗を引き起こすからだ。
テスト戦略
マージロジックはユニットテストが容易だが、実際のネットワーク断絶や衝突タイミングを再現するのが難しい。2つのクライアントインスタンスをメモリ上で立ち上げ、同時編集後に収束するかを検証する統合テストや、Playwrightのcontext.setOffline(true)を使ったE2Eテストが有効だ。ランダムな操作列を与えて収束性をチェックするプロパティベーステストもCRDTロジックの品質を高める。
この記事のポイント
- ローカルファーストは、クライアント側にデータの一次コピーを置き、読み書きをローカルで即座に行うデータアーキテクチャである
- オフラインファーストやPWAとは異なり、データ所有権と即時性が根本的に変わる
- 向いているのはユーザー生成データを扱う協調ツールやフィールドアプリ。銀行や分析ダッシュボードには不向き
- クライアント側のストレージにはOPFS上のSQLite(WASM)が主力。IndexedDBの直接利用は避ける
- 同期はCRDT(Yjs等)とデータベースレプリケーション(PowerSync等)から選択し、多くの場合は後者で十分
- 衝突解決はフィールド単位のLWWで大半を自動化し、セマンティック衝突はサーバー検出+ユーザー通知で対応する
- 認可・マイグレーション・テストには固有の注意点があり、段階的に導入するのが現実的
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

WordPress 7.0 RC3リリース。RTCは延期、最終版5月20日を前に最後のテストを
WordPress 7.0の3回目のリリース候補版(RC3)が、2026年5月8日に公開された。すでにテストを開始しているサイト管理者や開発者にとっては、最終版の品質を左右する重要なマイルストーンだ。今回のRC3では、前回のRC2以降に報告された143件以上の問題が修正されている。
正式版のリリース日は5月20日を予定しており、このRC3は「最後の仕上げ」をする段階に入ったことを意味する。本番運用中の重要なサイトへのインストールは避け、必ずテスト環境で検証することが強く推奨されている。
とりわけ今回大きな動きとして、かねてから注目を集めていた「リアルタイムコラボレーション(RTC)」機能が、7.0への搭載を見送られることが正式に発表された。この決定により、RC3は当初の開発計画から一部構成が見直されたバージョンとなっている。
RC3で何が変わったのか

RC3は、3月26日に公開されたRC2以降に報告されたバグや課題を集中的に潰し込んだバージョンだ。WordPress.orgの公式発表によれば、今回のRC3では以下のリンク先で確認できるすべての修正が含まれている。
RC2からの主な修正範囲
開発者向けの詳細な技術情報は、WordPress 7.0 Developer Notesにまとめられている。また、コア部分の修正については、3月26日以降にクローズされたTracチケット、およびGutenbergのコミット履歴から追跡できる。これらの情報を確認することで、自分の運用するテーマやプラグインへの影響を事前に評価できるだろう。
リアルタイムコラボレーションは7.1へ延期
最大のトピックは、RTC(Real Time Collaboration)機能の延期決定だ。この機能は、複数ユーザーが同時にブロックエディタ上でコンテンツを編集できるようにするもの。Googleドキュメントのような共同編集体験をWordPress管理画面で実現する構想として、多くの注目を集めていた。
しかし、7.0のリリースサイクル中に十分な安定性を確保できないと判断され、今回のRC3では搭載が見送られた。WordPressコアチームは、この機能を7.1の開発サイクルで再評価するとしている。RC3は、この変更に伴い「新たなBeta 1」とは見なされないポジションとなったことにも注意が必要だ。
RC3のテスト方法

テストは、本番環境を避け、テストサーバーやローカル環境で行うことが大前提だ。WordPress 7.0 RC3を試す方法は大きく4つ用意されている。
wp core update --version=7.0-RC3 コマンドを実行する。なかでもWordPress Playgroundは、ブラウザだけで完結するため手軽だ。環境を汚さずに新機能や互換性をざっくりと確認したい場合に適している。より本格的なテストには、テストサーバーへの直接インストールを推奨する。
開発者とホスティング事業者に求められる対応

RC3の登場は、テーマやプラグインの開発者、そしてホスティング事業者にとっても重要な意味を持つ。最終リリースまで2週間を切った今、互換性の最終確認を急ぐ必要がある。
テーマ・プラグイン開発者のやるべきこと
プラグインやテーマの製作者は、RC3を使って自社製品の動作検証を完了させ、「Tested up to」のバージョンを7.0に更新することが求められている。これは、プラグインのreadmeファイルに記載する情報で、ユーザーが「このプラグインは最新のWordPressで動作確認済みか」を判断する重要な指標となる。
互換性に問題が見つかった場合は、詳細な情報をサポートフォーラムのAlpha/Betaエリアに報告することで、コア開発チームや他の開発者との情報共有につながる。
ホスティング事業者のテスト協力
Webホスト各社も、WordPressのメジャーアップデートに向けて重要な役割を担っている。特に今回の7.0開発サイクルでは、RTCアーキテクチャのテストに複数のホスティング事業者が協力した。Kinsta、Bluehost、GoDaddy、WordPress.com、XServer、Ionosなどの企業が、さまざまなサーバー構成での動作検証に参加している。
ホスティング環境でのテストに関心がある事業者は、Make WordPress Hostingチームのドキュメントに従って分散テストの設定を始めることができる。
翻訳も最終段階。100言語以上への対応が進行中

RC3のリリースは、翻訳作業における「ハードストリングフリーズ」のタイミングでもある。これは、これ以上翻訳対象の文字列が変更されないことを意味し、翻訳ボランティアが安心して作業を進められる段階に入ったということだ。
日本語を含む100以上の言語への翻訳作業が進行中で、5月20日の正式リリースに向けて最終的な仕上げが行われている。翻訳プロジェクトへの参加は、技術的なスキルがなくてもWordPressコミュニティに貢献できる方法のひとつだ。
不具合を見つけたら報告を

テスト中に不具合や予期しない動作を発見した場合、以下のいずれかの方法で報告できる。
- サポートフォーラムのAlpha/Betaエリアに投稿する
- 再現手順を明記したバグレポートをWordPress Tracに直接登録する
- 既知のバグ一覧と照合し、報告済みかどうかを確認する
テストの経験が浅い場合でも、公式のテストガイドが用意されている。手順に沿って進めることで、開発に貢献しながらWordPressの内部構造への理解も深められるだろう。
この記事のポイント
- WordPress 7.0 RC3が5月8日に公開。RC2から143件以上の問題を修正
- RTC(リアルタイムコラボレーション)機能は7.0への搭載を見送り、7.1で再検討
- 正式リリースは5月20日を予定。テスト環境での検証が急がれる
- テーマ・プラグイン開発者は「Tested up to 7.0」への更新を
- テスト方法はプラグイン、直接DL、WP-CLI、Playgroundの4種類
- 翻訳作業はハードストリングフリーズに入り、100言語以上が最終段階
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

OpenAIがGPT-5.5-Cyberを発表、サイバー防御の最前線に信頼済みアクセス基盤を導入
OpenAIは2026年5月7日、サイバーセキュリティの防御側を支援するための新たな取り組み「Trusted Access for Cyber(TAC / サイバー向け信頼済みアクセス)」を発表した。この枠組みに基づき、研究者やセキュリティチーム向けに最適化されたモデル「GPT-5.5-Cyber」の限定プレビューを公開している。
発表の中核にあるのは、AIの強力なサイバー攻撃支援能力を防御者にだけ安全に開放するという思想だ。すべてのユーザーに同じ性能を提供するのではなく、本人確認と用途の認証を経た防御者のみが、より深い支援を受けられる仕組みを設けている。
この記事では、GPT-5.5-CyberとTACの技術的な仕組み、セキュリティ業界全体への波及効果、そして防御者が実際にどのようなワークフローを加速できるのかを解説する。
信頼済みアクセスでAIの性能を防御側だけに開放する

TACは、AIモデルの振る舞いそのものを利用者の属性に応じて段階的に緩和していく枠組みだ。すべてのユーザーに対して一律に機能制限をかけるのではない。防御タスクを担う検証済みの主体に対してのみ、より踏み込んだ支援をモデルが行うように設計されている。
重要なのは、この仕組みが単なるアカウント管理ではないという点だ。モデル内部の分類器による拒否判断をチューニングし、認可された防御ワークフローでは拒否が起こりにくくなる。OpenAIの記事によれば、この変更によって脆弱性のトリアージ、マルウェア解析、バイナリリバースエンジニアリング、検出エンジニアリング、パッチ検証といった領域で、防御者の作業が大きく加速される見込みだ。
一方で、資格情報の窃取やマルウェア配備といった実害を伴う悪用行為に対する防御壁は、そのまま維持される。このバランス設計こそがTACの根幹をなす。
3段階のアクセスレベル
OpenAIは現在、モデルのアクセス権を3つの層に分けて提供している。一般利用向けの標準的なGPT-5.5、防御ワークフロー向けに拒否判断を最適化した「GPT-5.5 with TAC」、そして最も許容度が高く専門用途向けの「GPT-5.5-Cyber」だ。この3層構造により、用途のリスクに応じた比例的な安全策が実現されている。
GPT-5.5 with TACは、全防御ワークフローの大部分をカバーする設計だ。OpenAIの見解では、ほとんどのセキュリティチームはこの層から始めるのが適切であり、許可済みの作業でなおも拒否に遭遇する場合にのみ、より専門的なアクセスレベルを検討すべきだとされている。
認証とアカウントセキュリティの要件
TACの枠組みでは、防御側に対する本人確認と認証の厳格化が同時に進められている。OpenAIの発表によれば、最もサイバー性能が高く許容度の大きいモデルにアクセスする個人ユーザーは、2026年6月1日以降、フィッシング耐性のある高度なアカウントセキュリティの有効化が必須となる。
組織単位での信頼済みアクセスを利用する場合は、シングルサインオンワークフローの一環としてフィッシング耐性認証を導入していることを表明する代替手段も用意されている。この設計により、利便性を損なわずに信頼性を担保するバランスを取っている。
GPT-5.5-Cyberがもたらす防御ワークフローの加速

GPT-5.5-Cyberの公開にあたり、OpenAIは具体的なユースケースを挙げている。公開済みの脆弱性から概念実証コードを生成し、認可された環境下で修正の有効性を検証するといった作業が、モデルによって大幅に効率化されるという。
OpenAIの公式ブログに掲載された比較例では、標準的なGPT-5.5がセキュリティ関連のコード生成を拒否するのに対し、GPT-5.5 with TACは同じプロンプトに対して詳細な概念実証と分析を提供している。この違いは、分類器のチューニングによってもたらされるものだ。
標準モデルとの違いは「ケイパビリティ」より「許容度」
GPT-5.5-Cyberは、一般的な知識作業やセキュリティタスクにおいて最も賢く直感的なモデルであるGPT-5.5を基盤としている。OpenAIは、この初期プレビューがGPT-5.5を超えるサイバー能力を発揮することを主眼とはしていないと明言している。
性能評価の結果でも、すべてのサイバーセキュリティ評価項目でGPT-5.5を上回るわけではない。このモデルの主な価値は、多段階推論やツール利用を含む現実的な防御ワークフローにおいて、より「許可的」に振る舞う点にある。防御者が分析から検証までを止まらずに進められる環境を提供することが目的だ。
このアプローチは、単純にモデルの性能を引き上げるよりも現実的な安全策といえる。より強力な検証と監視の枠組みと組み合わせることで、専門的な作業が必要な場面にだけ踏み込んだ支援を提供できるからだ。
セキュリティエコシステム全体を回す「フライホイール」

OpenAIの戦略で特に注目すべきなのは、モデルの提供先を多層的なエコシステムとして捉えている点だ。セキュリティベンダー各社との連携を通じて、発見から開発、検出、対応、ネットワーク制御に至る防御の全レイヤーを同時に強化しようとしている。
このサイクルは「セキュリティフライホイール」と呼ばれ、各レイヤーの改善が他のレイヤーの改善を加速させる相乗効果を生み出す。研究者が概念実証とパッチガイダンス付きで脆弱性を開示し、サプライチェーンツールが本番環境への侵入を防ぎ、EDRやSIEMが攻撃の兆候を検出し、ネットワークプロバイダーがWAFレベルの緩和策を展開する。この連鎖をAIが加速する構図だ。
このエコシステム戦略が意味するのは、GPT-5.5シリーズが単独のツールとしてではなく、業界全体の防御基盤として設計されているという点だ。OpenAIは既にCisco、Intel、SentinelOne、Snykといった主要ベンダーと協業を進めており、各社の声明も公式ブログに掲載されている。
各レイヤーでの具体的な活用シナリオ
ネットワークプロバイダーは、修正パッチが完全に展開される前の段階で被害を抑え込む役割を担う。GPT-5.5はWAFルールのレビューや構成分析、インシデント調査、安全な変更管理を支援し、インターネット規模での防御展開を可能にする。
脆弱性研究の領域では、未知のコードベースの理解、影響を受ける範囲の特定、根本原因の追跡、パッチの検証、そして深刻度の優先順位付けまでを一貫して支援する。より踏み込んだ概念実証が必要な場合に、GPT-5.5-Cyberが限定的に提供される設計だ。
検出と監視の分野では、EDRやSIEMのテレメトリデータから重要なシグナルを抽出し、分析官が開示情報から調査までを迅速に進められるようにする。とくにクラウド環境では、露出の把握から修正、検出までが密接に結びついており、AIによる接続が効果を発揮する。
ソフトウェアサプライチェーンセキュリティでは、GPT-5.5 with TACが依存関係の変更点の調査や、所有コード内での悪用可能性の推論、不審なパッケージ動作の早期発見を支援する。OpenAIは、axiosの侵害事例のように、脆弱な依存関係がビルドに入り込む前に阻止することが最速の対処法だと位置づけている。
オープンソースとCodex Securityによる上流支援

OpenAIはエコシステムの上流にあたるオープンソースメンテナーへの投資も進めている。Codex Securityを活用し、コードベース固有の脅威モデルを構築した上で、現実的な攻撃経路の探索やパッチの提案を行う仕組みを研究プレビューとして提供中だ。
さらに「Codex for Open Source」プログラムを通じて、重要なプロジェクトのメンテナーにCodex Securityへの条件付きアクセスとAPIクレジットを提供している。これにより、メンテナンスやレビューの負荷を軽減しながら、上流での脆弱性対処を加速させる狙いがある。
Codex Securityのプラグインも公開されており、既存のワークフローの中で脅威モデリングから発見、検証、攻撃経路分析、修正までをシームレスに進められるよう設計されている。
TACへのアクセス方法と今後の展望

Trusted Access for Cyberへの参加は、個人ユーザーであれば専用ページから本人確認を行うだけで申請できる。企業の場合はOpenAIの担当者を通じて、チーム単位での信頼済みアクセスをリクエストする仕組みだ。承認されたユーザーは、二重用途のサイバー活動に対する分類器の拒否が緩和されたモデルを利用できるようになる。
OpenAIの発表によれば、GPT-5.5-Cyberはアルファテストの段階で既に重要システムの自動レッドチーミングや深刻度の高い脆弱性の検証に活用されている。これらの成果については、責任ある開示の一環として、今後技術的な詳細が公開される予定だ。
モデルのサイバー能力が向上するにつれて、その能力を防御側の手に届けるための信頼基盤の重要度も増していく。より強固な本人確認や組織検証、認可された用途のスコープ定義、悪用監視の仕組みが成熟するにつれて、アクセス権は徐々に拡大されていくと見られる。
この記事のポイント
- TACは利用者の属性に応じてAIの防御支援能力を段階的に開放する枠組みである
- GPT-5.5 with TACは大半の防御ワークフローを安全にカバーし、多くのチームにとって最適な出発点となる
- GPT-5.5-Cyberはレッドチーミングなど専門的な二重用途ワークフロー向けの限定プレビューである
- セキュリティベンダーとの連携により、発見から緩和までの全レイヤーを加速するフライホイール効果を狙う
- オープンソースメンテナーへのCodex Security提供など、エコシステム上流への投資も同時に進められている
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Next.js 2026年5月セキュリティリリースの全容、13件の脆弱性を修正
Next.jsの開発元であるVercelは2026年5月7日、調整済みセキュリティリリースを公開した。React Server Componentsの上流脆弱性(CVE-2026-23870)への対応を含む、合計13件の脆弱性が修正されている。フレームワークを利用するすべての開発者にとって、即時のアップデートが強く推奨される内容だ。
今回のリリースで対処された問題は、サービス拒否(DoS)攻撃、ミドルウェアやプロキシのバイパス、サーバーサイドリクエストフォージェリ(SSRF)、キャッシュポイズニング、クロスサイトスクリプティング(XSS)と多岐にわたる。ただちにパッチを適用しなければ、本番環境が深刻な攻撃に晒されるリスクがある。
アップデートの概要と影響範囲
今回のセキュリティリリースはNext.js本体に加え、その根幹をなすReactの特定パッケージにも修正が及ぶ。Vercelの発表によれば、13件の脆弱性アドバイザリが一挙に解決された形だ。アドバイザリの内訳を見ると、攻撃の種類によって影響を受ける機能や設定が明確に分かれている。自社のプロジェクトがどのカテゴリに該当するかを把握することが、迅速な対応への第一歩となる。
● React Server Components の DoS
● キャッシュポイズニング
● SSRF の潜在的リスク
● DoS 攻撃から保護
● キャッシュへの不正注入を防止
● SSRF の脆弱性を遮断
13件の脆弱性が存在する「Before」の状態と、アップデートによってそれらがすべて解決された「After」の状態を比較したイメージだ。リリースによってセキュリティ上のリスクが一掃されることがわかる。
修正対象となったReactとNext.jsのバージョン
影響を受けるバージョンを把握し、修正済みの安全なバージョンへ移行する必要がある。今回のリリースで修正が提供されたバージョンは以下の通りだ。
まず、React本体については、19.0.6、19.1.7、19.2.6の3つのパッチがリリースされた。これらのバージョンでは、サーバーコンポーネントの通信用パッケージである react-server-dom-parcel、react-server-dom-webpack、react-server-dom-turbopack の各パッケージに修正が含まれている。
Next.jsをフレームワークとして利用している場合、これらのReactパッケージはNext.jsのバージョンにバンドルされている。そのため、開発者はNext.js本体を最新のパッチバージョンに更新することで、React側の修正も同時に適用できる。個別にReactパッケージを管理しているプロジェクトは、それらも忘れずにアップデートする必要がある。
各脆弱性の詳細とリスク評価

ここからは、発表されたアドバイザリを深刻度別に整理し、その技術的な背景をひも解いていく。影響を受けるコンポーネントと、攻撃が成立するシナリオを正しく理解することが、開発者としての適切なリスク評価に繋がる。
ミドルウェアとプロキシのバイパス
認証や認可のロジックを middleware.js や proxy.js に依存しているアプリケーションが、致命的な影響を受ける可能性がある。2件の「高」深刻度アドバイザリがこれに該当する。
1件目はApp Routerにおける segment-prefetch のバイパスで、過去の修正が不完全だったための再発フォローアップだ。2件目はPages Routerのi18n機能において、デフォルトロケールのパスがプロキシ認証を迂回してしまう問題である。多言語サイトをPages Routerで運用しており、middlewareでアクセス制御を行っている環境は特に注意が必要だ。
サービス拒否(DoS)攻撃
サーバーのリソースを枯渇させ、正規のユーザーがサイトにアクセスできなくなるDoS攻撃に関する脆弱性が3件報告されている。これらはすべて、Server Functions、Partial Prerendering(PPR)のCache Components、もしくは画像最適化APIの利用が条件となる。
最もクリティカルなものは、React Server Componentsの上流脆弱性(CVE-2026-23870)を突いた攻撃だ。Vercelの発表によると、この脆弱性によりリモートからのDoS攻撃が成立する。また、Cache Componentsを使用するアプリケーションにおける「接続数の枯渇」を引き起こす脆弱性も「高」深刻度と評価されている。画像最適化APIを経由したDoSは「中」深刻度だが、無視できるものではない。
この図は、悪意あるリクエストによってサーバーのリソースが消費され、本来のサービス提供が妨害されるDoS攻撃の基本的な流れを示している。Cache Componentsの脆弱性は、この「リソース枯渇」の段階を特に加速させる危険性がある。
サーバーサイドリクエストフォージェリ(SSRF)
SSRFは、攻撃者がサーバーを踏み台にして内部ネットワークへのリクエストを強制させる攻撃手法だ。今回の脆弱性は、WebSocketへのアップグレードリクエストを処理するアプリケーションが影響を受ける。
この種の攻撃が成功すると、攻撃者は本来アクセスできない内部のメタデータサービスやデータベースと通信できるようになる。クラウド環境(AWSやGCPなど)で稼働しているNext.jsアプリケーションは、特に深刻な被害に繋がる可能性があるため、迅速な対応が求められる。
キャッシュポイズニングとクロスサイトスクリプティング(XSS)
React Server Componentのレスポンスの前にキャッシュ層を配置しているアプリケーションは、キャッシュポイズニングのリスクに晒される。これは、攻撃者が悪意あるレスポンスをキャッシュサーバーに記憶させ、他のユーザーにその不正なコンテンツを配信させる攻撃だ。
XSSに関しては、App RouterでCSP(コンテンツセキュリティポリシー)のnonceを利用しているケース、そして外部からの信頼できない入力を消費する beforeInteractive スクリプトが影響を受ける。これらの設定は比較的高度なカスタマイズで使われるが、該当する場合はすぐに対処しなければ攻撃者によるスクリプト実行を許してしまう。
即時アップデートの必要性と対応手順

Vercelは今回のリリースに際し、新たなWAF(Web Application Firewall)ルールを展開していないと明言している。つまり、これらの脆弱性はWAFレベルで確実にブロックすることができず、パッチ適用が唯一の完全な緩和策となる。
アップデート手順の基本
まず、プロジェクトのNext.jsとReactのバージョンを確認する。package.jsonに記載されているバージョンが、今回の修正対象より古い場合は即座にアップデートを実行する。一般的な手順は以下の通りだ。
# Next.jsのアップデート
npm install next@latest
# 関連するReactパッケージも最新に
npm install react@latest react-dom@latestyarnやpnpmなど、他のパッケージマネージャーを利用している場合も、同等のコマンドで問題ない。パッケージを更新した後は、必ずビルドとテストを実行し、アプリケーションが正常に動作することを確認してほしい。
本番環境でのリスク管理
今回のセキュリティリリースには、破壊的な変更は含まれていない。そのため、動作検証は必要だが、適用を躊躇する技術的理由はほぼない。重要なのは「スピード」だ。
とりわけ、middlewareで認証を実装しているサイト、WebSocketを処理するリアルタイムアプリケーション、そしてPPRやCache Componentsを採用しているパフォーマンス重視のサイトは、緊急度が極めて高い。Vercelの発表でも「all affected users should upgrade immediately(影響を受けるすべてのユーザーは直ちにアップグレードすべき)」と強い表現で呼びかけている。
今回のリリースが示すNext.jsセキュリティの潮流

一見すると大規模な脆弱性の一括修正はネガティブな出来事に思える。しかし、セキュリティの観点からは、むしろフレームワークの成熟度を示すポジティブなシグナルと捉えるべきだ。
まず、対策が「調整済みセキュリティリリース」として計画的に実施されている点が重要だ。これは、VercelとMeta(React)のチームが発見された問題を共有し、エコシステム全体で同時に対処する体制が整っていることを意味する。大規模なOSSプロジェクトでは、このような「調整済み開示」のプロセスがセキュリティ品質の生命線となる。
次に、脆弱性の範囲が「Server Components」「ミドルウェア」「エッジキャッシュ」「画像最適化API」といった、Next.jsの比較的新しい機能や高度な機能に集中している事実に注目したい。これは、攻撃者の標的が、従来のシンプルなWebアプリケーションから、エッジとサーバーを高度に組み合わせたモダンなアーキテクチャへとシフトしている証左だ。
SSRやエッジファンクションの利用が一般化するにつれ、開発者は「新しい機能がもたらす利便性」と「新たな攻撃表面が生まれるリスク」のバランスを常に意識する必要がある。便利なAPIほど、その裏側で何が起きているのかを深く理解することが、これからのフロントエンド開発者には不可欠だ。
この記事のポイント
- Next.js 2026年5月セキュリティリリースは、ReactのCVE-2026-23870を含む13件の脆弱性を修正する
- 影響範囲はDoS、ミドルウェアバイパス、SSRF、キャッシュポイズニング、XSSと多岐にわたる
- WAFでは防げない脆弱性群のため、Next.jsとReact関連パッケージの即時アップデートが唯一の対策
- とくに認証機能やServer Components系の新機能を使うプロジェクトは緊急度が高い
- 調整済みリリースの実施は、Next.jsエコシステムのセキュリティ成熟度を示すポジティブな側面でもある
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験
Chromeが同意なく4GBのAIモデルをダウンロードする問題
Google Chromeがユーザーの明示的な許可なく、約4GBに及ぶGemini Nanoのモデルデータをダウンロードしている事実が明らかになった。このデータは「Prompt API」と呼ばれる新機能のためのものだが、その配信方法と利用規約をめぐって、Web標準の専門家から強い懸念が示されている。
CSS-Tricksの記事によれば、このダウンロードはChromeの標準アップデートの一部として扱われ、ユーザーが削除してもブラウザが自動的に再ダウンロードする仕様だという。2025年5月現在、すでに多くのユーザーのデバイスに配信済みの状態だ。
Chromeが密かにダウンロードするGemini Nanoとは
Gemini NanoはGoogleが開発した軽量AIモデルで、デバイス上で直接テキスト生成や要約などのタスクを実行する。クラウドにデータを送信せず、端末のCPUやGPUのみで推論を行うため、プライバシー保護の観点では優れた設計といえる。
問題はその配信方法だ。CSS-Tricksの著者であるMat Marquis氏が指摘したところによれば、この約4GBのデータはChromeの通常アップデートの一部として、ユーザーに何の通知もなく転送される。U2のアルバムがiTunesライブラリに強制的に追加された過去の事例になぞらえ、同意なき配信の奇妙さを強調している。
Gemini Nano(同意なし・通知なし)
削除してもChromeが再ダウンロードを実行するため、ユーザーに実質的な拒否権はない。Chromeの内部機能として扱われているが、実際にはブラウザに統合されたわけではなく、独立した製品が同梱されている状態に近い。Mat Marquis氏は、かつてスパイウェアとして批判されたBonzi Buddyがブラウザに同梱されていた事例を引き合いに出し、その類似性を指摘している。
Prompt APIの仕組みとGoogleの利用制限
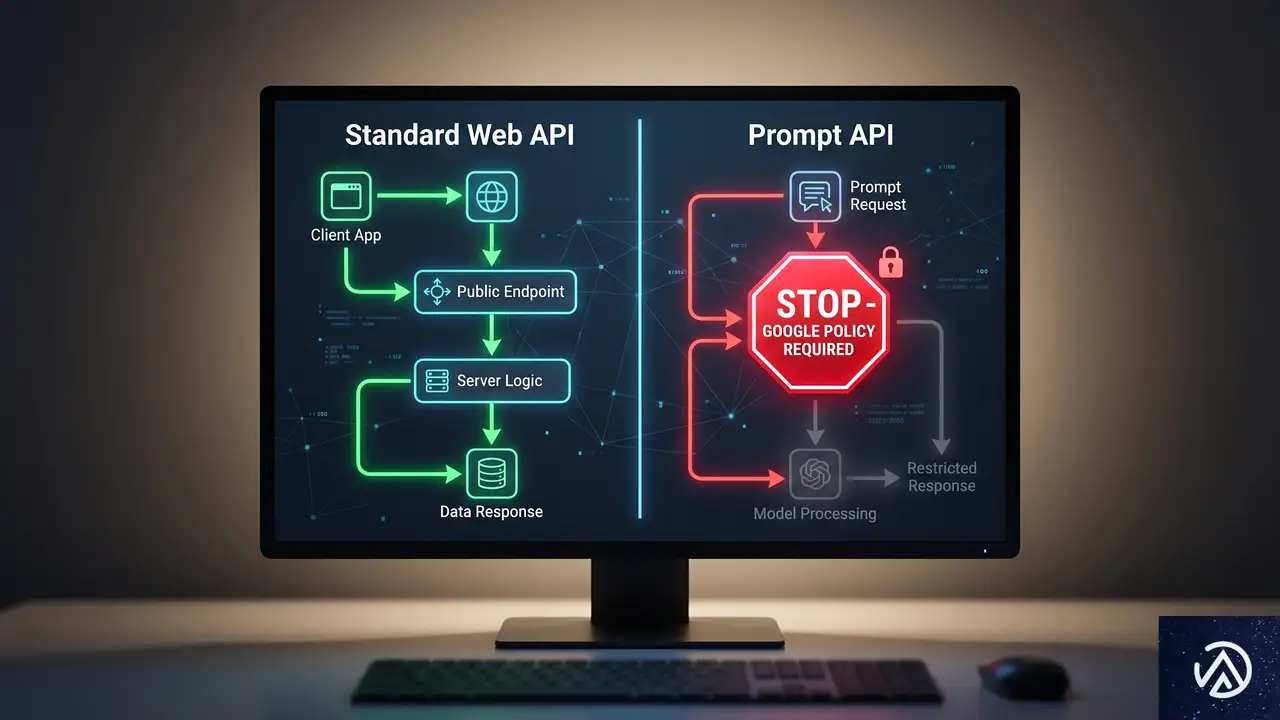
Prompt APIは、Web開発者がChromeの組み込みAIモデルに直接アクセスできるJavaScript APIだ。ユーザーのデバイス上でテキストの要約、文章の言い換え、質問応答といった処理を実行できる。Chromeの開発者向けドキュメントでは、すでに1年以上前から公開されている。
このAPIを利用するには、Googleが定める「Generative AI Prohibited Uses Policy」への同意が必須となる。Mozillaが公式に懸念を表明したのは、この利用ポリシーの内容がWeb標準の原則と相容れないからだ。
Web APIに付随する利用ポリシーの問題点
MozillaのGitHub上のコメントによれば、Googleの禁止事項ポリシーは法律の範囲を超えた制限を含んでいる。具体的には、性的に露骨なコンテンツの生成や配布の禁止、誤情報や政府・民主的プロセスに関する誤解を招く主張の促進禁止などが盛り込まれている。
これらの制限はWebプラットフォームのAPIとしては異例だ。通常、ブラウザAPIは技術的な仕様のみを定義し、その使途を特定企業のポリシーで制限することはない。Mozillaは「これはWebプラットフォームにとって悪しき方向性であり、UA(ユーザーエージェント)固有の使用ルールを持つAPIが増える前例となる」と警告している。
この構造は、Webのオープン性を損なう可能性がある。特定のブラウザベンダーがAPIの利用条件を自由に設定できるなら、Webの相互運用性は徐々に崩れていく。Mozillaの反対表明は、単なる競合他社の立場表明ではなく、Web標準の基本原則を守るための警鐘と受け止めるべきだ。
Web標準プロセスにおけるGoogleの影響力

Mat Marquis氏は、GoogleのWeb標準への関与姿勢を痛烈に批判している。同氏の比喩によれば「GoogleのWeb標準プロセスへの参加は、クマがキャンプに参加するようなものだ」という。つまり、表面上は協調しているように見えても、実質的には自社の都合でプロセスを支配しているという指摘だ。
Googleは「開発者のポジティブな感情」を根拠にPrompt APIの推進を正当化しようとしたが、実際に引用された場所にはポジティブな感情など存在しなかった。この矛盾した説明は、同社がWeb標準を「不可避なもの」として語る際の常套句と重なる。
ブラウザAPIとWeb APIの混同が生むリスク
ここで重要なのは、すべてのブラウザAPIがWeb APIではないという事実だ。Chromeだけが実装するAPIは、事実上の標準として扱われるリスクをはらむ。MicrosoftのIEが独自拡張で市場を支配した過去の過ちを、形を変えて繰り返す可能性がある。
Alex Russell氏が繰り返し指摘しているように、ブラウザの選択肢が限られている現状はすでに問題含みだ。その状況下でGoogleがChrome限定のAI APIを推進することは、Webの多様性をさらに損なう。ブラウザの多様性が生態系に与える影響について、CSS-Tricksでも過去に取り上げられているテーマだ。
ユーザーが取るべき対応と無効化手順

この問題に対して、現時点でユーザーが取れる対応は限られている。Chromeの設定画面で「オンデバイスAI」の項目をオフにすることは可能だが、すでにダウンロードされた4GBのモデルデータを完全に削除し、再ダウンロードを防ぐ方法は提供されていない。
この問題に関する報道は複数のメディアで取り上げられている。Engadgetは「Chromeがユーザーの同意なく4GBのAIファイルをダウンロード」と報じ、Cybernewsは「Chromeが我々のデバイスに静かに4GBのAIモデルをインストールしている」と警告した。Android Authorityでは、このダウンロードがスパイウェアに該当するかどうかの議論まで展開されている。
この記事のポイント
- Google Chromeがユーザーの同意なく約4GBのGemini Nanoモデルをダウンロードしている
- 削除しても自動的に再ダウンロードされ、実質的な拒否手段が提供されていない
- Prompt APIの利用にはGoogle独自のコンテンツポリシーへの同意が必須で、MozillaがWeb標準の観点から反対を表明
- ブラウザベンダー固有のAPI利用制限は、オープンなWebの原則を損なう前例となる危険性がある
- Chrome設定の「オンデバイスAI」から機能自体はオフにできるが、データ削除の確実な方法は提供されていない
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験