

Google Universal Cart発表。AIが越境する新買い物体験と検索広告への波及
Googleは2026年5月のI/Oにおいて、新たなAI買い物かご「Universal Cart(ユニバーサルカート)」を発表した。検索、Gemini、YouTube、Gmail、そして提携小売店を横断し、ユーザーの購買行動をAIが継続的に支援する仕組みだ。単なる商品推薦を超え、価格監視や在庫確認、適合性チェック、決済補助までを自律的にこなす「代理型商取引(エージェンティックコマース)」への本格的な布石といえる。
この発表は、検索広告やEC事業に携わる企業にとって看過できない転換点を含んでいる。Googleが単なる情報の入り口から、商取引自体を内包するプラットフォームへと進化する過程で、広告の役割や商品データの重要性が根本的に変わるからだ。ここでは、Universal Cartの仕組み、基盤となるUniversal Commerce Protocol(UCP)、そして広告主やリテーラーへの影響を掘り下げる。
Universal Cartがもたらす「永続する買い物体験」とは

Universal Cartの核心は、買い物かごを「その場限りの仮置き場」から「AIが能動的に管理する永続的な購買アシスタント」へと変える点にある。Search Engine Journalの記事によれば、Googleはこの機能を「ユーザーを追いかけるインテリジェントなショッピングカート」と表現しているという。
具体的には、ユーザーがGoogle検索で商品を調べ、Geminiとの対話で比較検討し、YouTubeのレビュー動画を見て、Gmailのクーポンを確認するといった一連の行動が、すべて単一のカートに集約される。裏側ではGeminiモデルが稼働し、価格変動や在庫状況、製品同士の互換性までを自動判定する仕組みだ。
AIが「待つ買い物」から「代行する買い物」へ変える
従来のオンラインショッピングでは、ユーザーが自ら価格を監視し、クーポンを探し、セールを待つ必要があった。Universal Cartはこれを反転させる。AIがユーザーに代わってバックグラウンドで価格下落を追跡し、ロイヤルティ特典の適用機会を探し、より適合性の高い代替商品を提案する。
Google Walletとの統合も発表されており、支払い方法やポイントプログラムの情報をAIが参照しながら、購入手続きの手間を減らす方向だ。Search Engine Journalの記事では、Nike、Sephora、Target、Walmart、Wayfair、そしてShopify加盟店などの大手小売業者が、この夏から決済機能の展開に参加すると報じられている。
カスタムPCのような複雑な買い物でも互換性を自動検証
Googleは、複数の小売店にまたがる部品で構成されるカスタムPCの購入においても、Universal Cartが部品間の互換性問題を決済前に検証できると説明している。これは単なるレコメンド機能の延長ではなく、購買判断そのものにAIが深く関与する設計であることを示している。
この能動性こそが、今回の発表の最大の特徴だ。Search Engine Journalの記事も「Googleがいかに積極的にUniversal Cartをリアクティブではなくプロアクティブなものとして位置づけているかが注目に値する」と指摘している。ユーザーが質問するのを待つのではなく、AIが先回りして提案する姿勢への転換である。
Universal Commerce Protocol(UCP)が切り拓く商取引インフラ

Universal Cartの裏側で動くのが、Googleが2026年初頭に発表したUniversal Commerce Protocol(UCP)だ。これは、異なる商取引システムやAIエージェントが共通言語でやり取りするためのインフラ層と位置づけられている。GoogleはI/Oで、すでに複数の小売業者やテクノロジーパートナーがUCPの採用を進めていることを明らかにした。
UCPの役割を簡単にたとえるなら、商取引の世界における「共通通貨」のようなものだ。これまでECサイトごとにバラバラだった商品情報や在庫データ、決済手段の記述方式を統一し、AIがサイトを越えてシームレスに買い物を支援できるようにする。
UCPの地理的・業種的拡大
I/OではUCPに関する以下の拡大計画も発表された。
- UCP経由の決済機能がカナダとオーストラリアに拡大。英国も後日対応予定
- 米国内でYouTubeにUCPが導入される
- ホテル予約や地域のフードデリバリーなど、新たな商取引カテゴリへの展開を計画
特にYouTubeへのUCP導入は、動画コンテンツと商取引の結びつきを一段と強める動きとして重要だ。Search Engine Journalの記事も「YouTubeの拡大は際立っている」と評しており、ブランドにとってYouTubeを単なる認知チャネルではなく、ECチャネルとして捉え直す必要性が高まることを示唆している。
広告主にとってUCPが意味するもの
Search Engine Journalの記事は、UCPの拡大が広告主やリテーラーにとって「カートそのものよりも最終的に重要かもしれない」と指摘している。これは本質を突いた見方だ。Googleは商品の発見から購買行動、決済、AIエージェントまでを包含する商取引インフラを構築しつつある。
このインフラ上では、Merchant Centerの商品データ品質が従来以上に重要になる。AIが商品を理解し、推薦し、互換性を判断するための基盤データとなるからだ。構造化された商品情報の正確さが、AIによる露出機会を左右する時代に入りつつある。
広告主とEC事業者に迫る3つの変化

Universal CartとUCPの登場は、広告主やEC事業者にとって以下の3つの変化をもたらす。
変化1、購買ジャーニーのGoogle内包化
これまでのGoogle検索は、商品情報を提供した後、ユーザーを小売店のサイトへ送り出す役割だった。Universal Cartはこの流れを逆転させ、比較検討や価格監視、再訪問、決済までをGoogleのエコシステム内に引き戻す。
Search Engine Journalの記事でも「歴史的にGoogle検索は主にユーザーを小売店サイトへ送り出していたが、Universal Cartはその活動の多くをGoogle内部に引き戻し始めている」と指摘されている。これは機会であると同時に課題でもある。Google内での露出を最大化できる事業者と、そうでない事業者の差が拡大する可能性が高い。
変化2、商品データがAI時代の新たな広告資産に
AIが能動的に商品を推薦し、価格下落を通知し、互換性を検証する世界では、商品データの質がそのまま販売機会に直結する。正確な在庫情報、詳細な製品スペック、競争力のある価格設定、ロイヤルティプログラムとの統合が、AIによる露出の前提条件となる。
これは従来のShoppingキャンペーンの最適化を超えた、より根源的なデータ戦略を求めている。Merchant Centerのフィード最適化は、もはや運用施策ではなく、AI時代の事業基盤そのものだ。
変化3、YouTubeがECチャネルとして本格化
YouTubeへのUCP導入は、動画プラットフォームが商取引の場へと進化する決定的な一歩だ。商品レビュー動画を見ながらワンクリックでカートに追加し、そのまま購入まで至る体験が現実になる。
この変化は、ブランドのYouTube戦略にも影響を与える。認知獲得のための動画広告から、直接的な売上に結びつく商取引動画へのシフトが加速するだろう。Search Engine Journalの記事も「ブランドはYouTubeを単なる動画認知プラットフォームとしてではなく、ECチャネルとして考える必要性が高まる」と述べている。
計測とアトリビューションの再考が迫られる

Universal Cartが普及すれば、購買行動のより多くの部分がGoogleインターフェース内で完結する。これは広告の効果測定にも大きな影響を与える。従来のクリックベースのアトリビューションモデルでは、Google内で進む比較検討やAIによる価格監視の影響を捉えきれない。
Search Engine Journalの記事は「より多くのショッピング活動がGoogleインターフェース内で発生するようになれば、広告主はアトリビューションやアシストコンバージョン、クロスチャネルのカスタマージャーニーレポートの評価方法を再考する必要があるかもしれない」と指摘している。これは単なる技術的な課題ではなく、広告予算の配分やROI評価の根幹に関わる問題だ。
具体的には、以下のような再考が求められる。
- ラストクリック至上主義からの脱却。AIが長期にわたって関与する購買ジャーニーでは、初期の商品発見や中期の価格監視が持つ価値を適切に評価する必要がある
- Googleエコシステム内の複数タッチポイント(検索、YouTube、Gmail、Gemini)を横断した統合的な計測手法の確立
- AIによるプロアクティブな提案(価格下落通知や互換性アラート)がコンバージョンに与える影響の定量化
代理型商取引の成熟と今後の展望

Universal Cartはまだ初期段階にある。Search Engine Journalの記事も「より高度な代理型商取引機能の多くは成熟に時間がかかるだろう」と現実的な見方を示している。それでも、今回の発表はGoogleがショッピング領域でどこへ向かおうとしているのか、かなり明確な絵を示したといえる。
GoogleはAIによる商品発見の強化を超え、購買ジャーニーのより深い部分へと進出している。商品推薦やカート管理から、価格洞察、決済インフラに至るまで、購買プロセスの占有率を着実に高めているのだ。
広告主やリテーラーにとって、これは単に「広告の表示場所が変わる」という話ではない。ブランドが影響力を測定する方法、コンバージョンを帰属させる枠組み、購買ジャーニーの中で可視性を競う土俵そのものが変わる可能性を秘めている。
こうした変化に備えるには、以下の3点が当面の具体的なアクションとなるだろう。
- Merchant Centerの商品データ品質を最優先で引き上げること。AIが商品を理解し推薦するための「原材料」はデータであり、その質が露出機会を決める
- YouTubeをECチャネルとして位置づけ直し、商取引に直結する動画コンテンツ戦略を構築すること
- アトリビューションモデルを再評価し、AIが介在する長期の購買ジャーニーを捉えられる計測基盤を整えること
この記事のポイント
- Universal Cartは検索・YouTube・Gmailを横断するAI駆動の永続的買い物かごであり、価格監視や互換性チェックまで自律的に実行する
- 基盤となるUCPは商取引の共通言語として機能し、Googleエコシステム内外の決済や商品情報連携を支えるインフラである
- 広告主には購買ジャーニーのGoogle内包化、商品データの戦略的重要性の高まり、YouTubeのECチャネル化という3つの変化が訪れる
- AIが購買判断に深く関与する時代には、アトリビューションや効果測定の抜本的な再考が避けられない

・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Gemini 3.5 Flash がVercel AI Gatewayで利用可能に。並列処理能力と推論機能が大幅向上
Googleの最新モデル「Gemini 3.5 Flash」が2026年5月19日からVercel AI Gatewayで利用可能になった。このモデルはコーディング能力と並列エージェント実行ループの性能が大きく向上し、複雑なタスクでも高い推論精度を発揮する。
AI Gatewayの統合APIを通じて呼び出せ、使用量の追跡やコスト管理、リトライやフェイルオーバーの設定も標準で備わっている。開発者は面倒な基盤管理なしに、最新のAIモデルを本番環境へ素早く組み込める。
この記事では、Gemini 3.5 Flash の進化点、AI Gateway での具体的な使い方、実装時の注意点までを整理する。
Gemini 3.5 Flash の概要と新モデルの位置づけ

Flash シリーズの進化
Gemini Flash シリーズは、Google が提供する軽量で応答速度に優れたAIモデル群だ。前世代のFlash 2.0と比べて、3.5 Flash では単なる速度向上にとどまらず、複数ステップのタスクを自律的に並列実行できるようになった点が大きな違いだ。
これにより、コーディングの効率化や、複数のAPIを同時に呼び出すようなエージェント型アプリケーションで強力なパフォーマンスを発揮する。
今回のアップデートで強化された点
- コーディング補完の精度向上
- 並列エージェント実行ループの大幅な最適化
- コア推論能力と命令追従性の改善
- マルチターン会話の一貫性向上
- 思考モード(thinking mode)での高品質な推論トレースの生成
並列エージェント実行ループの進化

並列化によるパフォーマンス向上
従来のFlashモデルは、一連のタスクを逐次的に処理する傾向があった。たとえばコードリファクタリングの際に「API呼び出しAの完了を待ってからAPI呼び出しBを実行する」といった流れになる。これに対し、3.5 Flash は複数の独立した処理を同時に並列実行する能力が格段に上がっている。
並列実行のメリットは、応答待ち時間の大幅な短縮と、システム全体のスループット向上だ。特にマイクロサービス間の連携や、複数の外部データソースを一括で処理する場面で効果を発揮する。
この比較はあくまで概念図だが、実際のアプリケーションでは複数の独立した処理を同時に走らせることで、体感速度やスループットが大きく改善される。
thinking モードと推論トレースの強化

thinking level の選択
Gemini 3.5 Flash はデフォルトで「medium」のthinking levelが設定されている。これは、応答の品質と生成速度、そしてコスト効率のバランスを取るための設計だ。より複雑な推論が必要な場合は high レベルに変更することも可能で、その場合は推論プロセスがより深く行われる。
たとえば、コードのリファクタリングや多段階の意思決定が必要なタスクでは、thinking level を high に設定することで、AIが問題をより細かく分解し、質の高い答えを導き出す。
マルチターンコヒーレンスと複雑タスク
3.5 Flash では、マルチターンの会話における一貫性も改善されている。以前のFlashモデルに比べて、前のやり取りを適切に保持しながら、矛盾のない回答を返す精度が向上している。これにより、長時間のコード生成や、会話型のエージェントアプリケーションでも安定した挙動が期待できる。
複雑なタスクでは「thinking traces(思考の痕跡)」がより詳細に出力されるため、モデルがどのような過程で結論に至ったかを検証しやすい。デバッグや品質管理の面で大きなメリットだ。
Vercel AI Gateway の機能とメリット

統合APIとプロバイダールーティング
Vercel AI Gatewayは、複数のAIプロバイダーを統一的なインターフェースで利用できるプラットフォームだ。開発者はプロバイダーごとに異なるAPIキー管理やエンドポイントを意識することなく、model の指定だけでモデルを切り替えられる。
さらに、AI Gatewayはインテリジェントなルーティング機能を備えており、特定のプロバイダーに障害が発生した場合に自動で別のモデルへフェイルオーバーしたり、リクエストをリトライしたりできる。これにより、単一プロバイダーを直接使うよりも可用性が向上する。
観測性とカスタムレポート
AI Gatewayには、使用量の追跡やコスト分析のためのカスタムレポート機能が組み込まれている。プロジェクトごと、環境ごとにAPI呼び出し回数やトークン消費量を可視化できるため、予算管理やボトルネックの発見に役立つ。
また、AI SDK Observability との連携により、モデルの応答時間やエラーレートを詳細に監視できる。Bring Your Own Key にも対応しており、自社で契約したAPIキーをAI Gateway経由で安全に利用できる点も企業ユースに適している。
AI SDK での実装方法と注意点

コード例
AI SDK を用いて Gemini 3.5 Flash を呼び出すには、以下のように streamText 関数を使う。モデル名に google/gemini-3.5-flash を指定し、必要に応じて thinking level を設定する。
import { streamText } from 'ai';
const result = streamText({
model: 'google/gemini-3.5-flash',
prompt: 'Refactor this service to run API calls in parallel.',
providerOptions: {
google: {
thinkingConfig: {
thinkingLevel: 'high',
includeThoughts: true,
},
},
},
});thinking level は 'medium'(デフォルト)と 'high' から選択でき、複雑なタスクでは 'high' を指定すると良い。なお、includeThoughts: true にすると推論過程のトレースもレスポンスに含められる。
サポート外のパラメータと制約
Gemini 3.5 Flash では temperature、topP、topK、thinking_budget といったパラメータはサポートされていない。以前のモデルでこれらの値を調整していた場合は、デフォルトの挙動に任せるか、他のモデルを検討する必要がある。
特に thinking_budget が使えない点は、推論にかかるコストを細かく制御したい場合に注意が必要だ。そのぶん thinking level の切り替えで大まかな品質とコストのバランスを取る設計になっている。
この記事のポイント
- Gemini 3.5 Flash は並列エージェント実行ループの性能が大幅に向上し、コーディングや複数API呼び出しに強い
- デフォルトで medium の thinking level を採用し、品質・速度・コストのバランスを最適化
- Vercel AI Gateway によって統合API、リトライ、フェイルオーバー、観測機能をフル活用できる
- temperature や topP などの一部パラメータは非対応のため、移行時には注意が必要
- AI SDK 経由で数行のコードで導入可能、並列化のメリットをすぐに享受できる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

WooCommerceがClaude連携の実験プラグインを公開、AI店舗分析の新形
WooCommerceの開発チームが、AIアシスタント「Claude」とECサイトを直接連携させる実験的プラグインを公開した。このプラグインは、単にAIがサイトのデータを読み取るだけでなく、店舗運営者が実際に求める「売上の傾向分析」や「クーポンの効果測定」といった問いに、具体的で意味のある答えを返すことを目指している。
発表元のWooCommerce Developer Blogの記事によれば、これは「Radical Speed Month」と名付けられた社内実験プロジェクトの一環だ。新機能の発表でも、将来のロードマップへのコミットメントでもない。あくまでアイデアを形にし、コミュニティからのフィードバックを得るための試金石である点が強調されている。
実験「WooCommerce for Claude」が解決しようとする課題

AIとWebサービスの連携は、APIを通じて生のデータを取得させるだけでは不十分だ。データの文脈や、事業者にとっての意味まで理解しなければ、役に立つ回答は得られない。
この実験の核心は、「どうすればAIを単なるデータ呼び出しツールではなく、店舗運営の実用的な相談相手にできるか」という問いにある。WooCommerceの開発チームは、この課題に対して3つの仕組みを基盤となるMCP(Model Context Protocol)の上に構築した。
MCPとは、AIモデルが外部のツールやデータソースと安全にやり取りするための共通規格だ。すでにWooCommerceのコアには開発者向けプレビューとしてMCPサポートが組み込まれている。この実験プラグインは、その仕組みを拡張し、AIに対してより深い店舗理解を与えることを狙っている。
このデモで示したように、AIに「考えるための材料」を構造化して与えることが、この実験の設計思想だ。単に問い合わせの窓口を作るのではなく、AIが店舗の状態を理解した上で回答できるようにする。
分析スキル
店舗運営者が本当に知りたい質問に対して、事前に集計された回答を返す仕組みだ。「今週の売上はどうだったか」「どの商品が売上を牽引しているか」「クーポンは効果を発揮しているか」といった質問が想定されている。
重要な点は、これらの分析が商品投稿(wp_posts)の生データを直接参照するのではなく、WooCommerceの分析用参照テーブルに対して実行されることだ。これにより、データベースへの負荷を抑えつつ、高速に意味のある集計結果を返せる。
知識レイヤー
AIがツールを呼び出す前に、店舗のプロフィール、カタログのスキーマ、ポリシー、拡張された商品データをMCPリソースとして露出させる層だ。これにより、AIは「どのような店舗なのか」という文脈を最初から理解した状態で対話を始められる。
たとえば、投資家に店舗を説明するような抽象度の高い質問や、返金が多い注文を洗い出すような具体的な調査にも、前提知識を持って対応できるようになる。
AI準備スコアリングエンジン
商品の完全性、スキーマの網羅率、コンテンツの品質、ポリシーの完全性という4つの要素を重み付けし、0から100のスコアを算出する。その上で、改善すべき項目を優先順位付きのリストとして提示する機能だ。
このスコアは、AIが店舗データをどれだけ正確に解釈できるかの指標となる。データが整備されていない店舗では、AIの回答精度も下がるという前提に立った、実用的な診断ツールといえる。
実際の使用感とセットアップ

プラグインを導入すると、1つのエンドポイント(/wp-json/woocommerce-claude/mcp)がWordPressの「Abilities」として登録される。別プロセスやcronによる同期処理は一切不要で、MCPリクエストが来たときにだけ動作する省リソース設計だ。
Claude Desktopとの接続は、ワンクリックの.mcpbバンドルファイルで完結する。手動セットアップの場合も、読み取り専用のWooCommerce REST APIキーがあらかじめ埋め込まれたJSONスニペットが店舗ごとに生成されるため、煩雑な設定は不要だ。
接続後は、自然言語で以下のような質問を投げかけられる。
- 過去7日間の売上が振るわないが、何が変わったのか?商品別、カテゴリ別、時間帯別に分解してほしい
- 前回のプロモーションは収益を押し上げたのか、それとも定価販売からの付け替えにすぎないのか
- 新しい投資家になったつもりで、この店舗の全体像を説明してほしい。強み、リスク、成長機会は何か
- 現在の収益漏れはどこにある?最大の値引き、最大の返金、支払い保留や失敗で滞留している最古の注文を洗い出して
- 売上のうちリピート購入者の割合は?どの商品が顧客を呼び戻しているのか
- カタログのAI準備スコアを監査し、最も減点の大きい項目と、最初に改善すべき点を教えてほしい
これらの質問は、単なるデータの抽出ではなく、分析と洞察を求めるものだ。AIが「構造化された店舗知識」を持っているからこそ、意味のある回答が可能になる。
拡張開発者向けの設計思想

このプラグインが実験として公開された目的の一つは、エクステンション開発者からのフィードバック獲得だ。プラグインはプロバイダーパターンを採用しており、あらゆる拡張機能がAIの見る知識レイヤーに自らのデータを流し込める。
add_action( 'woocommerce_claude_register_providers', function( $registry ) {
$registry->register( new My_Extension_Provider() );
});このコードが示すように、開発者は独自のプロバイダーを登録するだけで、AIが参照できる情報を拡張できる。さらに、AI準備スコアに独自の評価基準を追加したり、出力される商品データをフィルタリングしたりすることも可能だ。
開発チームは、この「プロバイダー + アビリティ + 単一MCPエンドポイント」という設計図が、実際にエクステンション作者が採用したいと思える形かどうかを検証したいと考えている。
デモで示したとおり、プロバイダーパターンの追加により、AIが店舗について持つ知識の幅が大きく変わる。このアーキテクチャがコミュニティに受け入れられれば、サードパーティ製プラグインとの連携も大きく加速するだろう。
この実験が探る実用性とリスク

開発チームは、この実験が公式機能でも完成品でもないことを明確にしている。Radical Speed Monthの成果物の一部は将来の正式プロダクトになるが、多くはならない。このプラグインがどちらの道をたどるかも、まだ決まっていない。
だからこそ、実店舗や制作会社の環境でのテストが求められている。特に知りたいのは、以下の3つの失敗モードだ。
- AIが店舗運営者には実行不可能な提案をしてしまわないか
- 集計データから個人情報や秘匿すべきビジネス情報が漏洩しないか
- 大規模カタログ(シードされたデモ店舗よりはるかに大きい規模)でのパフォーマンスは許容範囲か
机上の設計では見えない問題を、実際の多様な店舗環境で洗い出すことが、この公開テストの最大の目的だ。
テスト環境と始め方

リポジトリはGitHubで公開されており、クローン後にcomposer installを実行して有効化するだけで試せる。ローカル開発環境は、npx @wordpress/env start コマンドでWordPress、WooCommerce、そして本プラグインが立ち上がる。
テスト用に、24ヶ月分・5000件の注文データを生成する決定論的シードスクリプトが付属している。これにより、分析機能が十分なデータを基に動作する様子を確認できる。
開発チームは、AIが自信満々に間違った回答をしたケースや、拡張機能の開発者体験に違和感があった場合など、あらゆるフィードバックをGitHubのIssueで求めている。この実験が将来の製品に繋がるかどうかを判断する材料として、コミュニティのテスト結果が重視されているのだ。
この記事のポイント
- WooCommerce for Claudeは、AIと店舗の新しい連携形を模索するRadical Speed Monthの実験プロダクトである
- 分析スキル、知識レイヤー、AI準備スコアの3層構造で、AIが「文脈を理解した回答」を返せるように設計されている
- プロバイダーパターンにより、サードパーティ拡張がAIの知識ベースに自ら統合できる拡張性を持つ
- 公式機能やリリース予定のものではなく、実店舗環境でのテストフィードバックを目的としている
- データプライバシーと大規模カタログでのパフォーマンスが、現時点で確認すべき主要な論点である
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

EU一般製品安全規則(GPSR)の全貌とEC事業者の対応策
EU(欧州連合)向けに商品を販売する越境EC事業者にとって、2024年12月から本格適用された「一般製品安全規則(GPSR)」への対応は、もはや避けて通れない関門となっている。
従来のVAT(付加価値税)登録や通関手続きに加え、域内に拠点を持たない事業者に新たな義務が課せられることになった。この規則への違反は、AmazonやeBayといった販売プラットフォームから強制的に除外されるリスクに直結する。
本記事ではGPSRの全体像を紐解きながら、WooCommerceなど自社ECサイトを運営する事業者が今日から着手すべき実務対応を具体的に解説する。
GPSRの全体像と影響範囲

GPSR(General Product Safety Regulation)は、EU市場における消費者製品の安全性を確保するための包括的な法的枠組みだ。2001年に初版が発行されたのち、2024年12月に全面改訂版が施行された。
玩具や電子機器だけでなく生活用品全般が対象
ポイントとなるのは、この規則が玩具や電子機器といった特定分野向けではなく、既存の安全規制でカバーしきれていない広範な消費者製品に横断的に適用される点だ。具体的には、家庭用品、スポーツ用具、キッチン用品、ファッションアクセサリー、ライフスタイル雑貨など、EU域内で販売されるほぼすべての非食品系消費者製品が対象となる。
つまり、これまで製品安全規制の対象外だった商材を扱っていた事業者こそ、新たにGPSRの網にかかる可能性が高い。自社の商品が対象かどうかを判断するには、まず「消費者向けの非食品製品かどうか」を基準にするのが確実だ。
例:玩具安全指令、電子機器安全指令など
家庭用品、スポーツ用品、日用品なども対象
この比較で明らかなように、対象品目の拡大は越境EC事業者のリスク範囲を劇的に広げた。従来は安全規制を気にせず出品できていた商品が、今や適切な情報表示と責任者の指名なしには販売できなくなっている。
域外事業者を直撃する「責任者」指名義務

GPSR対応で最も大きなハードルとなるのが、EU域内に拠点を持つ「責任者(Responsible Person)」の選任義務だ。責任者は「責任経済事業者(Responsible Economic Operator)」と呼ばれることもある。
責任者に求められる役割と具体的な候補
EU域外の製造業者や販売事業者は、域内の誰かに製品安全の遵守について正式な責任を負わせなければならない。具体的な候補としては、輸入業者、正規代理店、フルフィルメント事業者、物流倉庫事業者、あるいはコンプライアンス専門の代行会社などが挙げられる。
この責任者の氏名または企業名、そして連絡先は、製品本体、パッケージ、または付属書類に必ず記載する必要がある。AmazonやeBayの商品ページ上でも、購入前にこの情報が表示されていなければならない。
従来、自国からの直送モデルに慣れ親しんできた越境事業者にとって、海外の法人や個人と責任委任契約を結ぶことは運営上の大きな負担となる。だが、GPSRにおいてこの手続きを回避する方法は存在しない。
ECサイト運営者が押さえるべき表示要件

GPSRでは、商品の安全性に関する情報を「購入前」にユーザーが確認できる状態にすることを求めている。物理的なパッケージへの表示だけでなく、ECサイトの商品ページ(リスティング)への明示が必須となる。
Amazon・eBay・自社ECすべてに適用される共通ルール
このルールは販売チャネルを問わない。Amazon、eBay、Etsyといったマーケットプレイスはもちろん、WooCommerceやShopifyで構築した自社ECサイトであっても、EUの消費者に販売する以上は同じ条件を満たす必要がある。
商品ページに記載すべき情報は、品目によって異なるが、一般的には以下の要素を含めることになる。製造者名とEU責任者の連絡先は最低限必須の項目だ。さらに、商品を一意に特定できるバッチ番号やシリアル番号、意図された使用目的、緊急時の安全警告、お手入れ方法なども、製品の性質に応じて求められる。
マーケットプレイスによる「門番」としての取り締まり
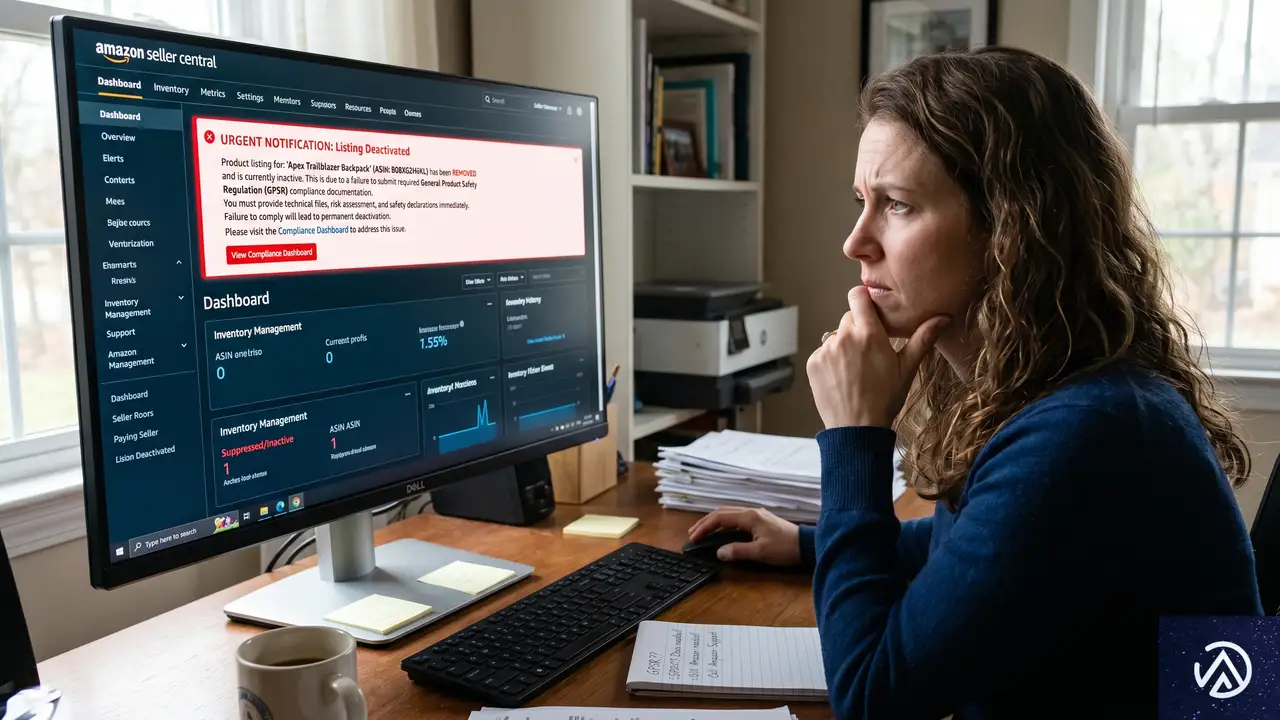
GPSR対応の最前線に立つのがAmazonやeBayといったマーケットプレイスだ。これらのプラットフォームには、法令順守を確認する「ゲートキーパー」としての責任が課せられている。違反を放置すれば、プラットフォーム自体が罰金や営業許可への制裁を受ける可能性がある。
行政指導より先にくる「強制出品停止」の現実
実務上は、規制当局から直接連絡が来るよりも前に、マーケットプレイス側の自動チェックや定期監査によって出品が停止されるケースが急増している。特に、EU責任者の情報が未登録だったり、商品安全情報のセクションが空白だったりすると、システムが即座にリスティングを非表示にする仕組みだ。
これは小規模事業者にとって大きな痛手となる。行政からの警告や改善命令には数週間の猶予が与えられることも多いが、マーケットプレイスのアルゴリズムによる除外は即時かつ無慈悲だ。日々の売上の大部分を特定のモールに依存している事業者ほど、GPSR対応の遅れは事業継続の危機に直結する。
トレーサビリティと10年間の記録保管義務

GPSRのもう一つの柱が、サプライチェーン全体にわたるトレーサビリティ(追跡可能性)の強化だ。製品に問題が発覚した際、当局がその流通経路を遡り、迅速に市場から回収できる体制を構築することを目的としている。
技術文書とリスク評価の保管が必須
具体的には、各製品にロット番号やシリアル番号などの識別情報を付与し、サプライチェーン上で追跡できるようにする義務が生じる。加えて、製造者は最大10年間にわたり、技術文書やリスク評価を含む安全関連の文書を保管しなければならない。
数十から数百のSKU(在庫保管単位)を扱う事業者にとって、これは軽視できない運用作業だ。特にWooCommerceのような自社ECサイトでは、商品登録時のカスタムフィールドを活用し、追跡情報や文書ファイルへのリンクを体系的に管理する仕組みを構築することが望ましい。
商品ごとに識別番号(SKU、バッチ番号等)を付与
製造元からEU責任者までの流通経路を文書化
リスク評価書と安全試験レポートを保管(最大10年間)
この図が示すように、GPSR対策は単に「責任者を決めて終わり」ではなく、データの整備と長期的な文書保管を前提とした継続的なコンプライアンス業務であることを理解しておく必要がある。
事業者が今日から着手すべき3つの対応ステップ

ここまでGPSRの要求事項を整理してきたが、実際にEU向け販売を継続する事業者は、大きく分けて3つのアクションを取る必要がある。
対応ステップと優先順位の整理
- 適用範囲の確定:自社の取り扱い商品がGPSRの対象かを確定させる。ほとんどの非食品系消費者製品は対象となるため、例外を探すより「全商品が対象」という前提で動くのが安全だ。
- EU責任者の選任と表示反映:EU域内に拠点を持つ責任者を指名し、契約を締結する。そのうえで、商品ラベル、パッケージ、そしてECサイトの商品リスティングのすべてに責任者の連絡先を反映させる。WooCommerce利用者であれば、商品編集画面のカスタム属性や専用プラグインで管理する方法が現実的だ。
- 技術文書の整備と保管:各商品のリスク評価書、安全テストの結果、技術仕様書などを収集し、体系的に保管する仕組みを作る。クラウドストレージ上にSKU別のフォルダを設け、いつでも取り出せる状態にしておく必要がある。
これらの対応は、VAT(付加価値税)の登録や通関手続きと同様に、EU市場でビジネスを行うための「必要経費」として捉えるべき段階に入っている。市場参入前にGPSR対策を計画しておくことが、結果的に最もコストのかからない道だ。
この記事のポイント
- GPSRはEU向けの非食品消費者製品ほぼ全てに適用される包括的な安全規制である
- 域外事業者はEU域内に「責任者」を指名し、商品ページに連絡先を表示しなければならない
- マーケットプレイスによる取り締まりは厳格で、違反時は即時に出品停止となるリスクがある
- トレーサビリティ情報と安全文書を最大10年間保管する義務が生じる
- VAT登録と同様に、事業運営の前提コストとして事前準備を進める必要がある
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

WooCommerce 10.9、バリエーションギャラリーがコアに統合。追加プラグイン不要へ
WooCommerce 10.9で「バリエーションギャラリー」機能がコアに統合される。これまで有料の追加プラグイン「Additional Variation Images」で提供されていた機能が、標準で無料利用できるようになる。
WooCommerceチームの「More in Core」構想の一環だ。既存のブランド機能統合に続き、マーチャントが本当に必要とする機能をデフォルトで提供し、開発者はより価値の高い差別化に集中できる環境を整えている。
Daniele氏の公式ブログ記事によると、この変更は段階的にロールアウトされ、10.9ではオプトインによるテストが可能になる。最終的には全ストアで有効化される予定だ。
バリエーションギャラリーがストアにもたらす変化

バリエーションギャラリーとは、ひとつの可変商品の中にある各バリエーション(色違いやサイズ違い)ごとに、複数の商品画像を紐づけられる仕組みだ。従来のWooCommerceでは、バリエーションに設定できる画像は「おもな画像」として1枚だけだった。これがギャラリーとして複数枚扱えるようになる。
購入者がストアフロントでバリエーション(たとえば「色:青」)を選択すると、ギャラリー全体がそのバリエーションの画像セットに切り替わる。管理画面では、バリエーションの「おもな画像」と「ギャラリー」をひとつの統合フィールドで管理し、1枚目が自動的におもな画像として扱われる設計だ。
有効化の手順と段階的ロールアウト

この機能はWooCommerce 10.9で導入されるが、初期状態では全ユーザーに対して無効化されている。利用を開始するには、明示的な有効化操作が必要だ。
管理画面からの有効化
最も簡単なのは、WooCommerceの設定画面からチェックボックスをオンにする方法だ。
コードスニペットでの有効化
よりプログラム的な制御を好む場合は、テーマのfunctions.phpまたはCode Snippetsプラグインなどを通じて以下のコードを追加する。
add_action( 'init', function() {
update_option( 'wc_feature_woocommerce_additional_variation_images_enabled', 'yes' );
} );WP-CLIでの有効化
WP-CLIが利用できる環境なら、以下のコマンドを実行するだけだ。
wp option update wc_feature_woocommerce_additional_variation_images_enabled 'yes'段階的ロールアウトの計画
この機能は3段階で展開される。まず10.9で手動テスト用に提供され、次に後続リリースで5%のストアに対して自動的に有効化される「カナリアリリース」が実施される。カナリアフェーズで問題がなければ、最終的に100%のストアで有効化される計画だ。
カナリアとは、新しい変更を一部のユーザーに先行適用して問題の有無を確認するソフトウェアリリース手法を指す。本番環境全体に影響が及ぶ前に、不具合を検知できる利点がある。
技術的な実装と移行のポイント

今回のコア統合は、既存ユーザーがスムーズに移行できるように慎重に設計されている。技術的な要点を整理しよう。
データの保存場所と後方互換性
バリエーションギャラリーのデータは_product_image_galleryというメタキーに保存される。これはWooCommerceが従来から親商品のギャラリーに使っているキーと同じだ。既存の仕組みを再利用することで、テーマの互換性を保っている。
REST APIでも初日からサポートされ、バリエーションエンドポイントのgallery_image_idsプロパティを通じてギャラリーにアクセスできる。このペイロードは、従来のストアフロント経路でもブロックベースの商品ギャラリーでも内部的に利用されている。
旧プラグインからのデータ移行
現在「Additional Variation Images」拡張機能を使っているストアでは、コア機能の有効化時に自動移行が走る。WooCommerceはAction Schedulerを用いたバックグラウンドジョブをスケジュールし、1回あたり250バリエーションずつレガシーデータを正規の場所にコピーする。全件が完了するまでジョブは自動的に再キューイングされる。
移行はべき等性を持っている。つまり、既に移行済みのバリエーションに対して再実行されても何も変更されず、安全だ。レガシーメタデータ(_wc_additional_variation_images)は意図的にディスク上に保持されるため、サードパーティコードが従来のキーを直接読み取っていても動作し続ける。
ストアフロントの互換性
バリエーションギャラリーは、従来のシングル商品テンプレートとブロックベースの商品ギャラリーの両方で動作する。新旧のブロックが混在する環境でも問題ない。テーマがsingle-product/add-to-cart/variable.phpを上書きしている場合もサポート対象だ。
テストとフィードバックの方法

この機能は6月8日予定のWooCommerce 10.9ベータ版に含まれる。上記のスニペットまたはWP-CLIコマンドで有効化してテストできる。今すぐ試したい場合は、GitHub上のナイトリービルドでも利用可能だ。
本番環境への適用前に、必ずステージング環境でのテストを推奨する。WooCommerceチームはGitHub Discussionを開設しており、フィードバックや使用感の報告を求めている。
スタンドアロン拡張機能の提供終了について

コア統合が100%ロールアウトされた後、スタンドアロンの「Additional Variation Images」拡張機能はWooCommerceマーケットプレイスから提供終了となる。これは先のBrands拡張機能の終了時と同じ手順だ。
現在のサブスクリプションユーザーは、コア機能がストアで有効化されるまで既存プラグインをそのまま使える。有効化時には競合を防ぐため、スタンドアロンプラグインは自動的に無効化される。マーケットプレイスからの提供終了時にはアクティブなサブスクリプションがキャンセルされ、影響を受けるユーザーはサポートチームに返金またはクレジットを申請できる。該当ユーザーにはロールアウトの重要な節目でメール通知が届く予定だ。
この記事のポイント
- WooCommerce 10.9でバリエーションギャラリーがコア機能として無料利用可能になる
- 初期は無効化されており、管理画面・コード・WP-CLIのいずれかで手動有効化が必要
- 既存の「Additional Variation Images」ユーザーは自動移行でデータが引き継がれる
- 段階的ロールアウトで慎重に展開され、最終的には全ストアで有効化される予定
- REST APIも初日から対応、開発者にとって扱いやすい設計になっている
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

OpenAI、Windows版Codexに独自サンドボックス実装 昇格不要プロトタイプから完全制御へ
2026年5月13日、OpenAIはWindows版Codexにおけるサンドボックス実装の技術的詳細を公式ブログで公開した。これまでWindowsユーザーは、コーディングエージェントの操作を逐一承認するか、全アクセスを許可するリスクの高い選択肢しかなかった。今回の独自サンドボックスによって、安全性と生産性を両立する仕組みが実現した。
Codexは開発者のローカルマシン上で動作し、CLIやIDE拡張機能、デスクトップアプリを通じて利用できる。デフォルトではワークスペース内でのファイル書き込みやネットワークアクセスに制限がかかるが、これをOSレベルで強制するサンドボックスが不可欠だった。macOSやLinuxにはSeatbeltやseccompといった確立された分離機能がある一方、Windowsには同様の機能が標準で提供されていなかった。
Codex for Windowsが抱えていた課題

Windows版Codexの初期リリースでは、サンドボックス機能が実装されていなかった。ユーザーは次の2つの不十分な選択肢を強いられていた。
- ほぼすべてのコマンドを手動で承認するモード: ファイル読み取りのような安全な操作も含めて逐一の許可が必要で、煩雑さから本来の自律的作業の利点が損なわれる。
- フルアクセスモード: 承認なしにすべてのコマンドを無制限に実行させる。操作はスムーズだが、意図しないファイル変更やデータ流出のリスクがある。
Codexは本来、ユーザーの代理としてテスト実行やファイル編集、ブランチ作成などを自律的に処理することで生産性を高めるツールだ。したがって、安全性を確保しつつ、許可の承認を最小限に抑える仕組みが求められた。その鍵となるのが、OSが持つ隔離機能を活用したサンドボックスである。
サンドボックスが果たす役割
サンドボックスとは、プロセスに制約を課す隔離実行環境である。Codexがコマンドを実行する際、OSがそのプロセスツリー全体に制限を伝播させることで、許可なくワークスペース外のファイルへ書き込んだり、インターネットへアクセスしたりできないようにする。macOSやLinuxでは標準機能でこれが実現できるが、Windowsでは一から設計する必要があった。
Windowsが提供する3つの分離機能を検証

OpenAIのエンジニアリングチームは、Windowsに用意されている隔離プリミティブとしてAppContainer、Windows Sandbox、Mandatory Integrity Control(MIC)を検討したが、いずれもCodexの用途には合致しなかった。
AppContainer: 強力だがワークフローに柔軟性欠く
AppContainerはWindowsネイティブのサンドボックスで、必要なアクセス権限を事前に定義するケイパビリティベースのモデルである。OS境界による本格的な制限を提供するが、Codexはシェル、Git、Python、パッケージマネージャなど多様なツールを動的に制御する必要がある。事前に厳密に権限を絞るAppContainerでは、エージェントのワークフローに対応できなかった。
Windows Sandbox: 強い隔離だが実環境と分断
Windows Sandboxは、使い捨ての軽量仮想マシンである。セッション終了時に内部の変更はすべて破棄される。セキュリティ面では強力だが、Codexはユーザーの実際のチェックアウト環境やツール群を直接操作する必要があり、外部の仮想デスクトップでは実用的ではなかった。さらにWindows SandboxはHomeエディションでは利用できず、製品上の問題も抱えていた。
MIC: 静的制御だがホストファイルシステムへの影響が大きい
Mandatory Integrity Control(MIC)は、低/中/高の整合性レベルを使ってプロセスやオブジェクトの信頼度を制御する。原則として、低整合性プロセスは高整合性オブジェクトに書き込めない。Codexを低整合性で実行し、書き込み可能ディレクトリを低整合性に再ラベルすることで、書き込み範囲を制限できる可能性があった。
しかし、ワークスペース全体を低整合性にすると、「Codexが書き込める」以上の意味が生じる。低整合性プロセス全般がその領域にアクセスできるようになり、開発マシンの信頼モデルを大きく損なうリスクがあった。またACLと同様に実ファイルシステムに変更を加えるため、サンドボックスの制約を動的に変更することも難しかった。
OpenAIの独自アプローチ: SIDと制限トークンによる非昇格サンドボックス

既存機能では要件を満たせないと判断したOpenAIチームは、WindowsのSID(セキュリティ識別子)と書き込み制限トークンを組み合わせた独自のサンドボックスを設計した。最初のプロトタイプは管理者権限なし(非昇格)で動作することを目標とし、ファイル書き込みとネットワークアクセスを制限する仕組みを目指した。
SIDと書き込み制限トークンの仕組み
SIDはWindowsがユーザーやグループ、ログインセッションを識別するために用いるIDである。たとえば、S-1-5-5-X-Yが現在のセッションに割り当てられる。SIDはACL(アクセス制御リスト)と組み合わせて、ファイルやディレクトリへの読み書き実行権限を制御する。OpenAIのチームは、Codex専用の合成SID sandbox-writeを作成し、このSIDを使って書き込み可能範囲を厳密に定めた。
書き込み制限トークン(write-restricted token)は、プロセストークンに追加の書き込みチェックを課す。通常のユーザー権限に加え、トークン内の制限SIDリストに含まれるSIDのいずれかが書き込み先ACLで許可されていなければ書き込みができない。これにより、Codexプロセスの書き込み権限を、ワークスペースと明示的に許可したディレクトリだけに絞り込んだ。
非昇格プロトタイプの流れ
セットアップ時に、sandbox-write SIDを作成し、カレントディレクトリや設定ファイル config.toml に指定した書き込み可能ルートに書き込み・実行・削除のACLを付与する。一方で .git、.codex、.agents といったディレクトリには明示的に書き込みを拒否した。そのうえでCodexは、制限SIDリストに Everyone、ログインセッションSID、sandbox-write を含む書き込み制限トークンで子プロセスを起動した。
これにより、明示的に許可した場所以外への書き込みはOSレベルでブロックされ、読み取りはユーザー権限で広く許可されるバランスのとれた環境が実現した。しかしネットワーク制御には別の課題が残った。
環境変数によるネットワーク抑制と限界
非昇格環境ではWindows Firewallを管理者権限なしで利用できなかったため、環境変数を用いた間接的なネットワーク抑制が採られた。具体的には HTTPS_PROXY=http://127.0.0.1:9 などのプロキシ変数に無効なアドレスを指定し、GitやSSHなどのツールが外部に接続できないようにした。またPATHにダミーの denybin ディレクトリを追加するなど、一般的なツールの通信を妨げた。
しかしこの方法はあくまで「助言的」な制約であり、プロキシ設定を無視するプログラムや独自のソケット通信を行うバイナリに対しては効果がなかった。悪意あるコードに対しても脆弱だった。
ネットワーク制御を突破した昇格版サンドボックスの実装
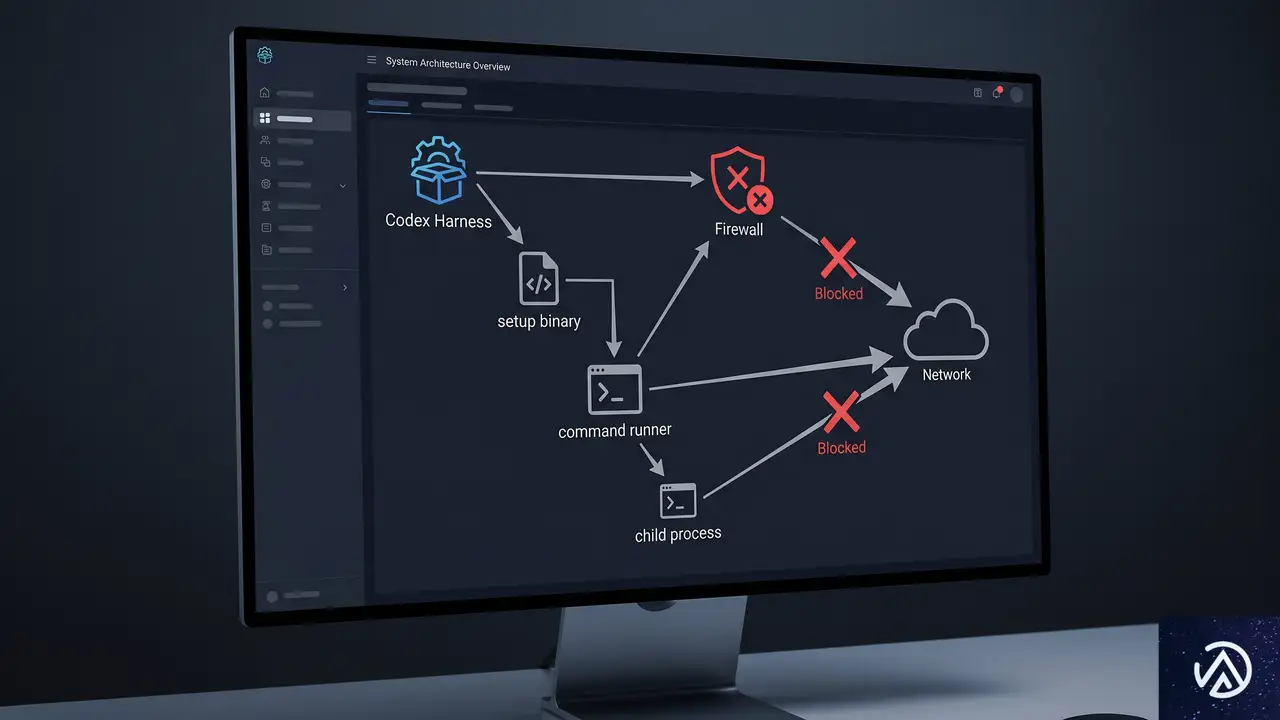
実用的なネットワーク制御を実現するため、OpenAIチームはWindows Firewallの導入を決断した。ファイアウォールルールをプロセスツリー単位で適用するには、サンドボックス専用のユーザー権限が必要となり、結果として管理者権限でのセットアップを許容する「昇格版サンドボックス」へと設計が進化した。
専用ユーザーとファイアウォール
昇格版では、CodexSandboxOffline と CodexSandboxOnline という2つのローカルユーザーを作成する。Offline のユーザーにはすべての外部ネットワーク通信を遮断するファイアウォールルールが適用される。Codexがネットワークを必要としないコマンドを実行する際にはOfflineユーザーで起動し、ネットワーク許可が必要な場合はOnlineユーザーを選択する。これにより、ファイル書き込み制限と同様にOSレベルでの確実なネットワーク遮断が可能になった。
コマンドランナーと4層アーキテクチャ
ユーザー権限を切り替えて子プロセスを起動するには、Windowsのセキュリティ境界を越える必要があった。OpenAIは専用のバイナリ codex-command-runner.exe を導入し、次のような多層構造を採用した。
- codex.exe: 通常のユーザー権限で動作し、コードエージェントのハーネスとして機能する。
- codex-windows-sandbox-setup.exe: 管理者権限でセットアップ処理を担当。サンドボックスユーザーの作成、ファイアウォールルールの追加、必要なACLの付与を実行する。
- codex-command-runner.exe: サンドボックスユーザーとして起動され、自身のトークンから書き込み制限トークンを作成し、最終的な子プロセスを起動する。
- 子プロセス: 制限付きトークンで実行されるGitやPythonなどの実コマンド。
具体的な起動フローは次の通りである。codex.exe が CreateProcessWithLogonW を用いて codex-command-runner.exe をサンドボックスユーザーとして起動。ランナーは自身のプロセストークンからログオンSIDを抽出し、書き込み制限トークンを構築したうえで CreateProcessAsUserW により制限付きの子プロセスを立ち上げる。
このデモで示したように、昇格版ではOSのファイアウォール機能を組み込むことで、非昇格版のネットワーク上の弱点を克服した。また、システム全体へのACL変更は最小限にとどめ、非同期処理を用いてセットアップのブロック時間を短縮している。
この記事のポイント
- Windows版Codexは当初、サンドボックスが存在せず、手動承認かフルアクセスの選択肢しかなかった。
- OpenAIはAppContainer、Windows Sandbox、MICを検討したが、いずれも動的な開発ワークフローに適さず、独自サンドボックスを開発した。
- 最初の非昇格プロトタイプは、SIDと書き込み制限トークンでファイル書き込み範囲を制限したが、ネットワーク抑制は弱かった。
- 最終的な昇格版サンドボックスでは、専用のWindowsユーザーとファイアウォールルールを導入し、ネットワーク遮断をOSレベルで実現。
- codex-command-runner.exeによる多層アーキテクチャで、安全性を保ったままコードエージェントの自律実行を可能にした。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

OpenAI CodexがDellと提携、オンプレミス環境でエージェントAIを実行可能に
OpenAIとDell Technologiesが、エンタープライズ向けAIコーディングツール「Codex」の導入範囲を大幅に拡大する提携を発表した。週間アクティブ開発者数が400万人を突破したCodexは、クラウド利用が難しい重要データを抱える企業のために、Dellのオンプレミスインフラ上で直接稼働する道を手に入れた。
この提携で、CodexはDell AI Data PlatformおよびDell AI Factoryと接続される。ソースコードや社内ドキュメントといった機密性の高い企業データを外部に出さずに、AIエージェントを構築・運用できるようになる点が最大の意義だ。
AIの業務活用を進めたいがデータ主権やセキュリティの壁に阻まれていた企業にとって、この提携は「自社データセンター内で完結する高度なAIエージェント」という現実的な選択肢を提供する。
Codexの現在地 コーディングツールからビジネスエージェント基盤へ

CodexはOpenAIが提供する開発者向けAIツールだ。IDE(統合開発環境)やCLI(コマンドラインインターフェース)上で動作し、コード補完、バグの自動修正、テスト生成などを行う。2026年5月時点で週間アクティブ開発者数は400万人を超え、OpenAIのエンタープライズ製品群の中で最も急成長しているサービスの一つになっている。
Codexの活用範囲は開発現場を超えて広がっている。ツール間のコンテキスト収集、レポート作成、プロダクトフィードバックの整理とルーティング、リードのスコアリングとフォローアップ文面の作成、さらには複数のビジネスシステムを横断した業務調整まで、エージェントとしての機能を実務に組み込む企業が増えている。
Codexが「開発者のためのツール」から「ビジネスプロセスを動かすエージェント基盤」へと進化している点が、今回のDell提携の文脈で重要になる。エージェントが実用的な価値を発揮するには、その企業固有のデータやシステムと深く接続している必要があるからだ。
Dell AI Data Platformとの統合で実現すること

今回の提携の中核は、CodexがDell AI Data Platformと直接接続される点だ。Dell AI Data Platformは、多くの企業がオンプレミス環境でデータの保存・整理・ガバナンス(管理統制)に利用している基盤である。
エージェントが「使える」内部コンテキストへのアクセス
AIエージェントがビジネスで役立つかどうかは、どれだけ深い「コンテキスト(文脈情報)」を取得できるかにかかっている。単に公開情報を検索するだけのエージェントでは、企業内部のコードベースや非公開の運用ドキュメント、過去のインシデント対応履歴といった重要情報にアクセスできない。
CodexがDell AI Data Platform経由でアクセスできるようになる情報には、以下のようなものが含まれるとOpenAIの記事では説明されている。
- 企業の非公開コードベース
- 内部ドキュメントやナレッジベース
- ビジネスシステムの実データ
- 運用知識やチームのワークフロー情報
この仕組みにより、データを社外に送信することなく、AIエージェントが企業内部の文脈を理解して動作する。金融機関や医療機関、製造業など、データ主権が厳格に問われる業界にとっては特に重要な意味を持つ。
ガバナンスを維持したままのAI導入
ガバナンスとは、データの管理体制や利用ルールを整備し、遵守することだ。企業は法規制や社内ポリシーにより、特定のデータを社外のクラウドサービスに保存できないケースが多い。Dellのオンプレミス基盤上でCodexを動作させることで、既存のデータガバナンスの枠組みを壊さずにAIを導入できる。
Dell AI Factoryとの連携がもたらす応用可能性

OpenAIの発表によると、両社はDell AI Factoryとの接続も検討している。Dell AI Factoryは企業がAIワークロードを実行するための基盤で、データ準備やシステム管理、テスト実行、AIアプリケーションのデプロイ(展開)までをカバーする。
この接続が実現すると、Codexに加えてChatGPT Enterpriseやその他のAPIベースのソリューションも、Dellのハイブリッドまたはオンプレミスインフラ上で統合的に動作する可能性がある。
この構想が示すのは、OpenAIがエンタープライズ市場において単なる「API提供者」から「インフラと一体化したAIプラットフォーム」への転換を図っていることだ。Dellの発表文では「Dell AI Factory with OpenAI Codex」という表現が使われており、両社のブランドを冠した統合ソリューションとして展開される可能性が高い。
エンタープライズAI市場における提携の戦略的意味

今回の提携は、企業向けAI市場での競争軸を読み解く上でも示唆に富む。
「データの所在地」がAI導入の決定打になる
2026年現在、多くの企業がAI導入を進めているが、最大の障壁は技術力ではなく「データをどこに置くか」というポリシー問題だ。GDPR(EU一般データ保護規則)や各国のデータローカライゼーション規制により、クラウド上のAIサービスをそのまま使えない企業は少なくない。
Dellとの提携によりCodexは、企業のデータセンター内で動作する選択肢を手に入れた。これは競合のAIコーディングツールにはない差別化要素であり、特に規制産業からの需要を取り込む上で強力な武器になる。
「エージェントの実用化」に必要なのはコンテキスト
AIエージェントが「良いコードを提案する」だけの段階から「ビジネスプロセスを自律的に実行する」段階へ進むためには、企業固有のコンテキストにアクセスできることが不可欠だ。OpenAIの記事でも、エージェントが役立つために必要な内部情報として、コードベースやドキュメント、業務システム、チームのワークフローが挙げられている。
CodexがDell AI Data Platform経由でこれらの情報に安全にアクセスできるようになることで、エージェントが「汎用的なアドバイザー」から「その企業の業務を深く理解した実行者」へと進化する基盤が整う。
OpenAIのエンタープライズ戦略における位置づけ
OpenAIは2025年以降、ChatGPT EnterpriseやCodex CLIといった企業向け製品を相次いで投入してきた。今回のDell提携は、それらの製品群を「インフラレベルで企業の既存環境に溶け込ませる」動きとして位置づけられる。
Microsoft Azureを通じたクラウド提供に加え、オンプレミスという選択肢を加えたことで、OpenAIのエンタープライズ展開は「パブリッククラウド」「ハイブリッド」「オンプレミス」の三層をカバーする体制に近づいている。
企業が今から準備すべきこと

Dellのインフラを既に利用している企業にとって、Codexのオンプレミス展開は比較的スムーズに導入できる見込みだ。OpenAIの発表では、具体的な提供開始時期や料金体系の詳細は明かされていないが、両社の協業が進むにつれて順次情報が公開されるだろう。
企業の開発部門やIT統括部門は、以下の点を事前に整理しておくと、展開開始時のスピードが上がる。
- Codexエージェントにアクセスさせたい内部データの棚卸し(コードベース、ドキュメント、APIなど)
- 既存のDellインフラ(AI Data Platform / AI Factory)の利用状況確認
- データガバナンスポリシーの見直しとAI利用ルールの整備
- セキュリティチームとの事前協議(エージェントがアクセスするデータ範囲の定義)
AIエージェントの導入で先行する企業は、すでにコードレビューやテスト自動化といった開発領域から始め、段階的にビジネスプロセスへ適用範囲を広げている。Codexのオンプレミス対応は、その拡大をより安全に進めるためのインフラ選択肢として機能するだろう。
この記事のポイント
- OpenAI CodexがDell AI Data Platformとの統合により、オンプレミス環境での稼働が可能に
- 企業のコードベースや内部ドキュメントに安全にアクセスし、AIエージェントの実用性が大幅に向上
- Dell AI Factoryとの連携により、ChatGPT Enterpriseなど他のOpenAIサービスもオンプレミス展開を検討
- 金融や医療など厳格なデータガバナンスが求められる業界でのAI導入障壁が下がる
- 企業は今のうちに内部データの棚卸しとガバナンスポリシーの整備を進めておくことが有効
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Googleアナリティクス、AIアシスタントをデフォルトチャネルグループに追加
Googleアナリティクス(GA4)がAIアシスタントをデフォルトチャネルグループとして正式に追加した。ChatGPTやGemini、Claudeといった生成AIプラットフォームからWebサイトへの流入を、自動的に専用チャネルへ分類する仕組みだ。
この変更により、これまで「リファラル」トラフィックの中に埋もれていたAI経由の訪問を、特別な設定なしで分離して分析できるようになる。プロパティ管理者は、生成AIが自社のビジネスに与える影響を、よりクリアに把握できるようになった。
従来は正規表現を用いたカスタムチャネルグループの構築が必要だったが、今回のアップデートでその手間が不要になる。まさに、AIがもたらすトラフィックを「見える化」するための、Googleによる重要な一歩だ。
新たに追加されたAIアシスタントチャネルの詳細
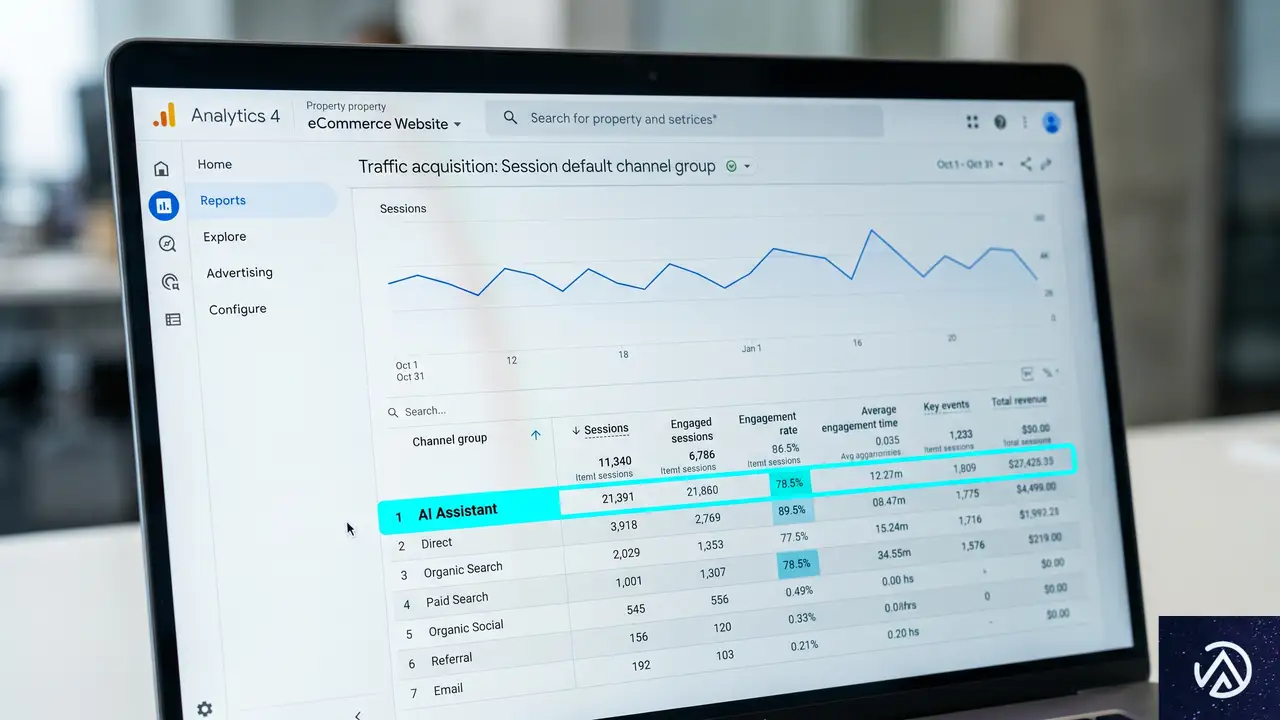
今回のアップデートの中核は、トラフィックの分類方法に関するものだ。これまでAIプラットフォームからの訪問は、単なる「参照(リファラル)」トラフィックとして一括りにされていた。この新機能により、AIアシスタントからの流入は自動的に専用のチャネルグループ「AI Assistant」に振り分けられる。
具体的には、Googleアナリティクスが特定のAIアシスタントのリファラーを検出すると、そのセッションのメディア値に「ai-assistant」が自動的に割り当てられる。その結果、デフォルトチャネルグループレポート上で「AI Assistant」チャネルとして集計される仕組みだ。
chatgpt.com、claude.ai etc.
ChatGPT、Gemini、Claude
その他の参照元
■ 通常の参照トラフィック
このデモが示すように、AIプラットフォームからの流入は「参照」トラフィックの一部として見えづらかった。今回の変更で、専用チャネルとして独立し、そのボリュームが一日で把握できるようになる。
3つのトラフィックソースディメンションが同時に変更
このアップデートは、単にチャネルグループが増えただけではない。トラフィックソースに関連する3つのディメンションが一度に更新されている。
- メディア:AIアシスタントと判定された場合、「ai-assistant」という値が自動付与される
- デフォルトチャネルグループ:該当セッションは新設の「AI Assistant」チャネルにグループ化される
- キャンペーン:ディメンションには予約語「(ai-assistant)」がラベル付けされる
これらの変更はすべてプロパティに自動的に適用される。ユーザー側での手動設定は一切不要だ。
なぜ今、この機能が追加されたのか

GoogleがAIアシスタントを独立したトラフィックチャネルとして扱う動きは、およそ1年前から段階的に進められてきた。Search Engine JournalのMatt G. Southern氏によると、2025年8月に公開されたカスタムチャネルグループ構築ガイドでは、ChatGPTやGemini、Microsoft Copilot、Claude、Perplexityを追跡対象として挙げていた。これは、AIアシスタント経由のトラフィックを「個別に測定すべきカテゴリ」としてGoogleが明示的に認めた瞬間だった。
カスタムチャネルグループが抱えていた課題
これまで、AIアシスタントのトラフィックを分離するには、正規表現によるカスタムチャネルグループの構築が唯一の方法だった。しかし、この手法には運用上のいくつかの壁があった。
- 手動メンテナンスの負荷:AIプラットフォームのドメイン変更に合わせ、正規表現パターンを手動で更新し続ける必要がある
- 権限レベルの制約:GA4プロパティの「編集者」権限が必要で、アクセスできるユーザーが限られる
- リソースの制約:GA4ではカスタムチャネルグループは2つまでという上限がある。AI追跡のために貴重なスロットを1つ消費する必要があった
こうした制約は、特に人員やリソースが限られる中小企業のWeb担当者にとって、大きなハードルとなっていた。
過去の類似アップデートとの共通点
Googleが特定のトラフィックをデフォルトチャネルとして独立させるパターンは、今回が初めてではない。2022年には、Performance MaxキャンペーンやSmart Shoppingキャンペーンのトラフィックを捕捉するため、「クロスネットワーク」チャネルグループが追加された。この時も、手動設定なしにトラフィックを汎用バケットから専用チャネルへ移動させるという、今回と同様のアプローチが取られた。
また、AIトラフィックの計測を巡っては、これまでも課題があった。2025年にはAIモード検索のトラフィックが「参照」ではなく「ダイレクト」として誤って報告されるバグが修正された。さらに、Search ConsoleのパフォーマンスレポートにもAIモードのデータが追加されている。今回のデフォルトチャネル追加は、こうした一連の測定精度向上の流れに位置づけられる。
サイト運営者にとっての実務的メリット

最大の利点は、データ収集と分析の効率化だ。これまでカスタムチャネルグループで対応してきたプロパティは、ネイティブチャネルの適用により、その設定を簡略化できる可能性がある。複雑な正規表現のメンテナンスから解放されることで、分析業務の本質に集中できるようになる。
AI追跡用のチャネルグループを設定していなかったプロパティでは、これまで「参照」として一括りにされていたAIアシスタントからのセッションが、自動的に独立したチャネルとして表示され始める。たとえば、chatgpt.comやclaude.aiからの訪問が「参照」という見出しの下に隠れていた状況が解消され、専用のグラフや数値で確認できるようになる。
注意すべきリファラー制限
ただし、この新機能には依然として限界がある。AIアシスタントからのトラフィックのうち、リファラーヘッダーなしで到達したものは、引き続き「ダイレクト」トラフィックとして分類されてしまう。これは、アプリ内ブラウザやモバイルアプリからのアクセス、ユーザーがAIの回答からURLをコピー&ペーストして訪れた場合などに発生する。新チャネルが捕捉できるのは、あくまでGA4がリファラー情報によって識別できる範囲に限られるのだ。
この図が示すとおり、AIアシスタントからの流入すべてが新チャネルに振り分けられるわけではない。特にモバイルアプリ経由の流入には注意が必要だ。
現時点で判明している制限と今後の展望

Googleは、どのAIアシスタントが「認識済みリファラー」リストに含まれているのか、完全な一覧を公開していない。ヘルプセンターにはChatGPT、Gemini、Claudeの3つが例示されているが、2025年8月のカスタムチャネルガイドでは5つのプラットフォームを挙げていたことを考えると、現行の自動カバー範囲はまだ流動的な部分があると言える。
また、新しいプラットフォームが登場した際に、このリストがどのように更新されるのかについても、具体的なプロセスは示されていない。Search Engine Journalの記事でも指摘されているように、デフォルトチャネルグループの定義ページには、まだ「AI Assistant」がチャネル一覧表に追加されていない。そのため、完全な技術的定義を確認することは現時点ではできない状況だ。
こうしたギャップを埋めるため、昨年公開されたカスタムチャネルグループ向けの正規表現パターンは、依然として有効な補完ツールとなる。認識済みリストに含まれていないAIプラットフォームを個別に追跡したい場合は、従来どおりのカスタム設定が選択肢となる。
この記事のポイント
- GA4がAIアシスタントをデフォルトチャネルグループに追加し、ChatGPT等からのトラフィックを自動分類
- メディア、チャネルグループ、キャンペーンの3ディメンションが同時に更新され、手動設定は不要
- 従来必須だった正規表現によるカスタムチャネル構築が不要に、分析業務の効率が大幅に改善
- リファラーヘッダーがないアプリ経由等の流入は引き続き「ダイレクト」扱いとなる点に注意
- 認識済みAIアシスタントの完全リストは未公開、新興プラットフォームにはカスタム設定が有効
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AI購買エージェントに選ばれるECコンテンツの作り方
AIが人間に代わって購買候補を絞り込む動きが加速している。特にB2B向けのECサイトでは、購買担当者が「SOC2準拠でPython SDKを提供する上位3社」といった条件をAIに投げかけ、そのレポートを参考に最終判断する流れが現実のものになりつつある。
AIエージェントは人間のようにヒーローイメージやキャッチコピーに惹かれるわけではない。構造化された事実データだけを機械的に読み取り、仕様や準拠基準、統合性といったシグナルからベンダー候補をリストアップする。サイトがPDFやフォームの壁に閉ざされた情報ばかりだと、そもそも検討対象にも上がらない。
ここでは、WooCommerceを中心としたECサイト運営者が、AI購買エージェントに自社の商品や技術情報を正しく伝えるための実践的な手法を解説する。
PDF隠しの製品カタログはもう通用しない
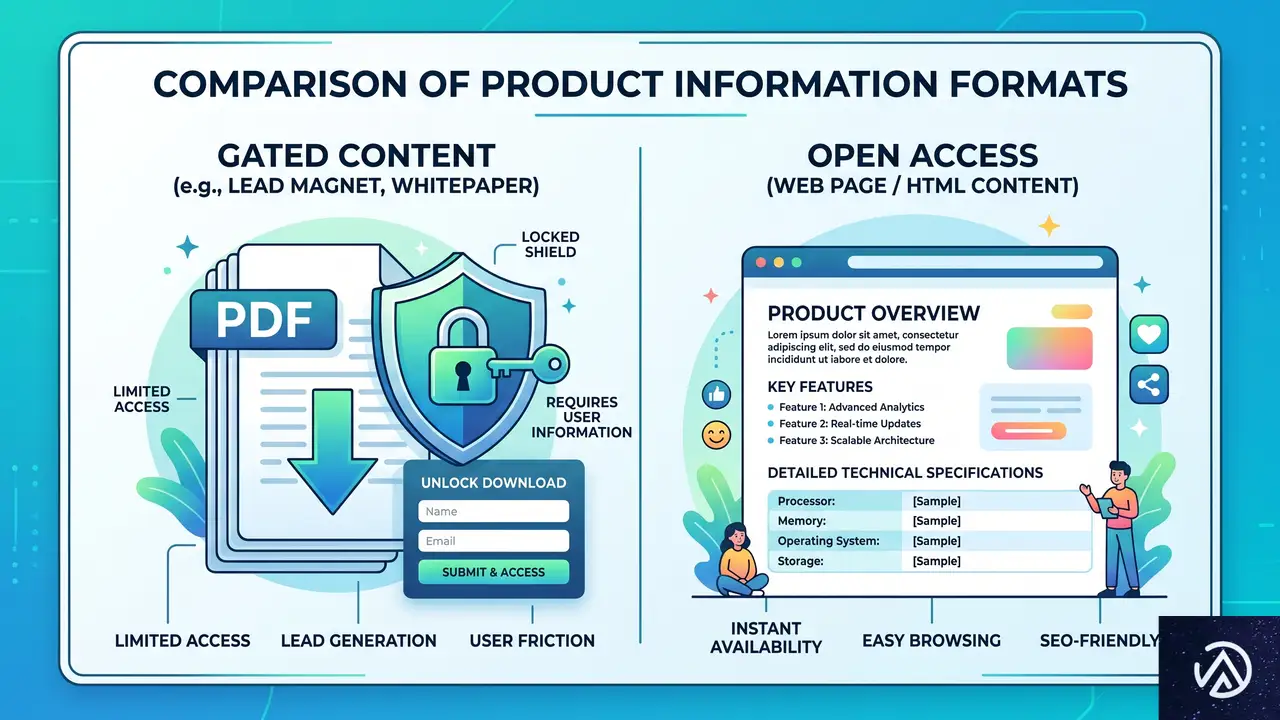
なぜPDFがAIに嫌われるのか
多くのEC事業者はホワイトペーパーや仕様書をPDFで配布し、ダウンロードフォームで囲い込む手法を取ってきた。しかしAIクローラーにとってPDFは重く、内部構造が不統一な場合が多い。テキスト抽出はできても、見出しの階層やリストの関係性を正確に解釈できないケースが少なくない。
結果として、製品スペックや準拠規格といった重要な情報が、AIの「目」にはただの平坦な文字列に映り、意図した評価を得られない。
構造化HTMLへ移行する具体的なステップ
対策はシンプルで、商品の詳細情報を高品質なWebページとして公開することだ。WooCommerceでは標準の商品ページを拡張し、技術仕様を整理したHTMLの表や箇条書きで提供できる。見出しタグの階層を意識し、<h3>に「対応OS」<h4>に「Windows Server 2022」というように、機械が理解しやすい構造を心がける。
次に示すのは、従来のゲート付きPDFとAI向けに最適化したWebページの比較イメージだ。
Model X-210 技術仕様
- 準拠規格: SOC 2 Type II, ISO 27001
- 提供API: Python SDK, RESTful API
- レイテンシ: 99.9%ile 10ms以下
このように、HTML上で仕様が明確に整理されていると、AIクローラーは即座に必要なデータを抽出できる。フォームの壁は不要な離脱を生み、AIには見えない障壁となるだけだ。
スキーママークアップで機械に読ませる
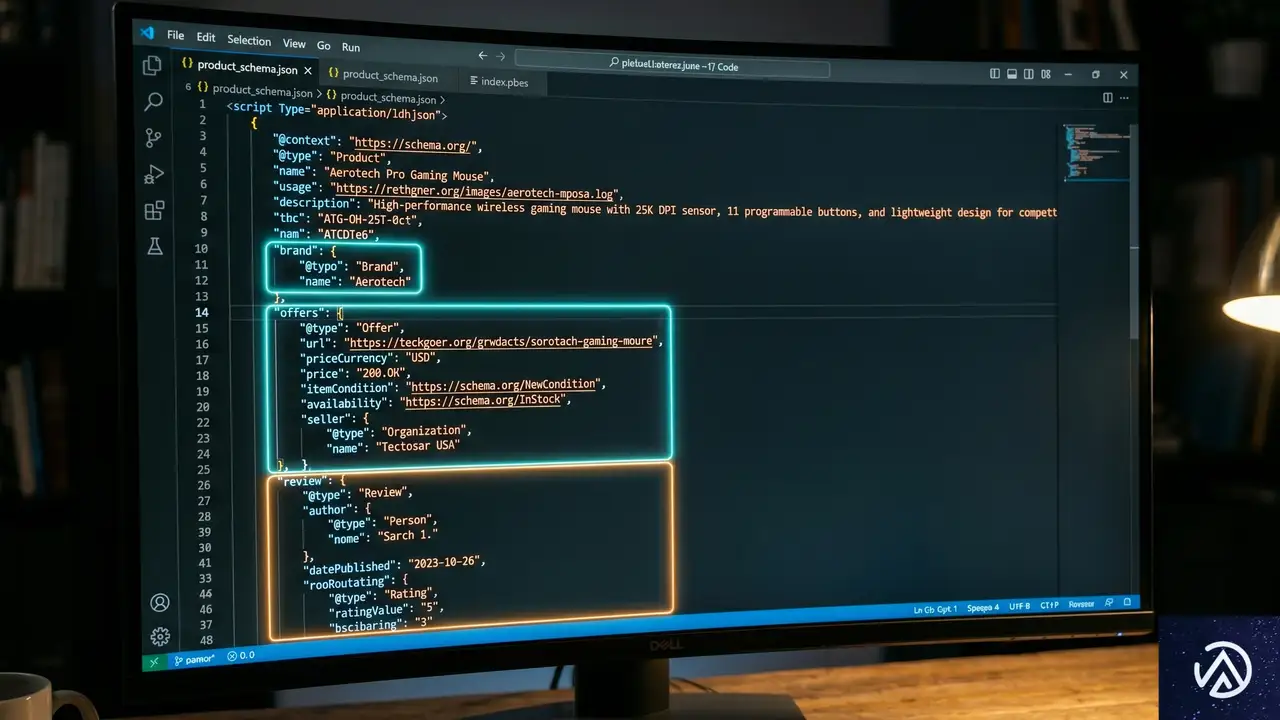
SEO担当者がGoogle向けに構造化データを埋め込むのと同じ理屈で、AIエージェントにページが「製品仕様」や「技術ドキュメント」であることを教え込める。Schema.orgの語彙を使い、製品の互換性や価格体系、認証情報をコード上で明示的に定義するのだ。
高性能プロセッサ搭載、信頼性の高い設計
価格はお問い合わせください
WooCommerceの場合、テーマのfunctions.phpにJSON-LDを追加するか、専用プラグインでProductスキーマを拡張できる。AIはこの情報を読み取り、価格帯や在庫状況、技術的要件を瞬時に理解する。推測の余地が減るほど、自社に有利な評価が返ってくる仕組みだ。
キーワード密度より意味的関連性を重視する
大規模言語モデルを搭載したAIエージェントは、キーワードの出現回数ではなく文脈の深さを評価する。つまり「スケーラブルなクラウドセキュリティパートナー」を探しているエージェントは、単に「スケーラブル」という単語を数えるのではなく、エッジケースへの対応手順や実装上のハードル、セキュリティプロトコルといった周辺知識のまとまりを重視する。
そこで有効なのがトピッククラスターの構築だ。商品ページだけでなく、技術ブログや導入事例、トラブルシューティングガイドなど関連性の高いページ群を内部リンクで結びつける。AIがサイト全体を巡回する際に、自社の専門性と信頼性を一貫したドキュメント群として認識させる狙いがある。
WooCommerceの商品ページでも、関連するドキュメントやFAQをブログカードやカスタムタブで表示する仕組みを導入すると効果的だ。AIはサイト全体の情報密度を評価するため、一貫した情報設計が結果的に購買候補としての優先度を上げる。
長尺資料にはAI向け要約を添える
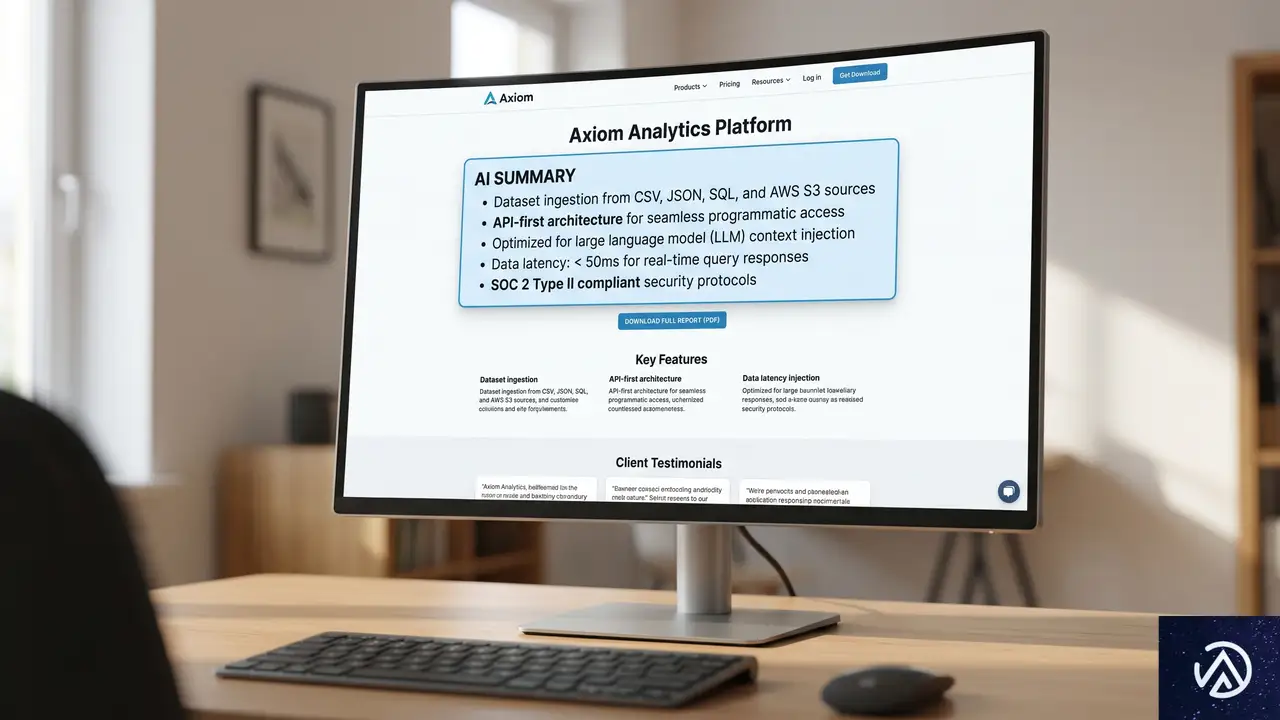
どうしても詳細な技術資料をPDFなどのゲート付きフォーマットで提供しなければならない場合もある。その場合は、ランディングページにAI専用の「機械可読要約(Machine-Readable Abstract)」を配置する戦略が有効だ。
この要約ブロックは、フォームに入力しなくても読めるオープンなHTMLテキストとして設置する。具体的には、製品の主要な主張、データポイント、技術要件を簡潔にまとめる。いわばAIのための「TL;DR(長すぎて読めない人向けの要約)」であり、約100〜200文字で十分だ。
【X-210 エッジコンピューティングノード】
- SOC2 Type II準拠、ISO 27001認証取得済み
- Python SDK と RESTful API を提供
- 99.9%ile レイテンシ 10ms 以下(自社ベンチマーク)
- 年間サブスクリプション:50万円〜(ボリュームディスカウントあり)
WooCommerceの商品説明欄の冒頭にこうした要約を記述するだけで、PDFをダウンロードする前にAIが内容を評価できる。製品の技術的な強みを素早く伝え、検討リスト入りの確率を高める一手になる。
AI購買エージェントに備えたEC設計の考え方

AIが購買活動の初期調査を担う流れは、B2B領域から着実に広がっている。大規模な広告予算より、アクセスしやすく構造化された正確なデータを持つブランドが優位に立つ時代だ。
ECサイト運営者は、自社の商品カタログや技術ドキュメントを「機械が読むことを前提としたアセット」に引き上げる必要がある。具体的な施策は、PDFの非構造化データからの脱却、スキーママークアップによる意味定義、トピッククラスターを用いた文脈強化、そしてAI向け要約の設置だ。
この記事のポイント
- AI購買エージェントは人間向けの装飾を無視し、構造化された仕様・準拠基準だけを評価する
- 商品情報をHTMLで公開し、スキーママークアップで意味を明確化することが不可欠
- キーワード密度より、トピッククラスターで専門性の高さを示す方がAIに信頼される
- ゲート付き資料には、AIが即座に理解できる要約ブロックを必ず付け加える
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

GPT-5.5が企業向けエージェントにもたらす変革、Databricks導入事例
大規模言語モデルの進化が、企業の実務ワークフローに直接的な成果をもたらし始めている。データ分析基盤を提供するDatabricksが、OpenAIの最新モデルGPT-5.5を社内向けAIエージェントに組み込んだ結果、複雑な文書処理タスクを評価するベンチマーク「OfficeQA Pro」でエラーが46%も減少した。GPT-5.5はこのベンチマークで初めて正解率50%を超えたモデルとなった。
この結果は「モデルの性能向上が、実際のビジネス指標にどう結びつくか」を示す重要な事例だ。単なる会話能力の評価ではなく、スキャンされたPDFや古い社内フォーマットの文書を解析し、複数ステップのタスクを自律的に遂行する能力が問われている。本記事ではGPT-5.5がどのような技術的進歩を遂げ、企業のAI活用にどんな可能性を開くのかを解説する。
企業向けAIエージェントの現在地、なぜ文書処理が壁になるのか

企業がAIエージェントを導入する際、最初にぶつかる壁が「社内文書の解析」だ。契約書や見積書、古いシステムから出力されたレポートなど、形式がバラバラな文書をAIに理解させるのは想像以上に難しい。特にスキャンされたPDF(画像として取り込まれた文書)や、数十年前のレガシーフォーマットで保存されたファイルは、最新のAIでも正確なテキスト抽出に失敗することが多い。
この問題の深刻さは、小さな認識ミスが後続の処理全体を狂わせる点にある。たとえば請求書の金額を一桁間違えて抽出すれば、その後の経理処理やレポート作成がすべて誤った情報で進んでしまう。人間なら「明らかにおかしい」と気づくようなエラーでも、AIエージェントは抽出した数値をそのまま信じて処理を続ける。これが企業現場でのAI導入を妨げる最大の障壁となっていた。
OfficeQA Proベンチマークの評価観点とは
Databricksが開発したOfficeQA Proは、こうした実務課題を忠実に再現する評価指標だ。このベンチマークでは、モデルに対して以下の3つの能力が求められる。
- 文書解析(Parsing):スキャンPDFやレガシーファイルから正確に情報を抽出する能力
- 情報検索(Retrieval):長大な文書群の中から必要な情報を見つけ出す能力
- 根拠に基づく推論(Grounded Reasoning):抽出した情報をもとに、論理的な判断や回答を生成する能力
単なる知識クイズではない。バラバラなフォーマットの文書を理解し、複数のステップを経て最終的なアウトプットを出す「エージェントとしての実務能力」が試される設計になっている。
上図のように、GPT-5.5への切り替えによって文書解析のエラーが大幅に減り、後続のワークフロー全体の信頼性が向上した。この改善の背景には、モデルの視覚認識能力と言語理解の統合が進んだことがあると見られている。
GPT-5.5が達成した二つの飛躍的改善

Databricksが報告したGPT-5.5の改善点は、大きく二つの領域に分かれる。一つは文書解析精度の劇的な向上、もう一つは複数ステップのタスクを効率的に管理するオーケストレーション能力の進化だ。
スキャン文書解析の「ステップ関数的」な進歩
Databricksの記事で同社のSinghvi氏が指摘するように、GPT-5.4まではスキャンされた古い文書から数字を正確に読み取れないケースが頻発していた。これに対しGPT-5.5は、古い文書やスキャンPDFの解析において「ステップ関数的な性能向上」を見せたという。「ステップ関数的」とは、なだらかな改善ではなく、階段を一段上がるように非連続的な飛躍があったことを意味する。
この進歩が特に重要なのは、企業が保有する文書の多くが過去の資産だからだ。10年前の契約書、5年前の監査レポート、紙をスキャンしてPDF化した資料。こうした「過去の遺産」を正確に解析できるかどうかが、AIエージェントの実用性を左右する。GPT-5.5はこの壁を一つ越えたと言える。
ムダな遠回りをしないタスク実行能力
もう一つの重要な改善が、複数ステップのタスクを実行する際の軌道(Trajectory)の最適化だ。GPT-5.4では、目的に対して不必要な検索を繰り返す「遠回り」が発生し、非効率な処理経路をたどることがあった。これはエージェントが過剰に「慎重」になりすぎる、あるいは文脈を適切に把握できずに余計な確認作業を挟んでしまう問題だ。
GPT-5.5では、必要な情報を必要なタイミングで的確に取得し、最短のステップでタスクを完了する能力が高まった。追加の監視や人間による修正なしに、複雑なワークフローを完遂できる信頼性が向上している。
この改善は、企業がAIエージェントに求める「人間の監視なしで動く自律性」に直結する。タスクが長引けばそれだけコストも増え、途中で人間が介入する必要性も高まる。GPT-5.5はこの課題に対して明確な前進を示した。
企業ワークフローへの実装、AgentBricksとAI Unity Gateway

DatabricksはGPT-5.5を単独のチャットボットとして使っているわけではない。同社の「AI Unity Gateway」を通じて、AgentBricksやAgent Supervisor APIといったエージェント構築基盤と統合し、実際のビジネスワークフローに組み込んでいる。
AgentBricksとは、Databricksが提供するエージェント構築フレームワークだ。専門特化した複数のエージェントを組み合わせ、複雑な業務プロセスを自動化できる。ここでGPT-5.5は「監督者(Supervisor)」として機能する。各専門エージェントが文書解析やデータ検索、レポート生成といった個別タスクを担当し、GPT-5.5が全体の流れを管理して適切なタイミングで適切なエージェントに指示を出す。このアーキテクチャによって、単一モデルでは扱いきれない複雑な業務フローが実現できる。
この「監督者モデル」のアプローチは、今後の企業向けAI活用の主流になると考えられる。一つの巨大モデルがすべてを処理するのではなく、専門エージェントを束ねる統括役としてLLMを配置する設計だ。GPT-5.5のオーケストレーション能力の向上は、この設計思想と見事にマッチしている。
ナレッジワークにおけるGPT-5.5のインパクト

DatabricksのSinghvi氏は「GPT-5.5は知識作業においてステップ関数的な変化をもたらした」と評している。単に質問に答えるだけでなく、複数の文書を横断して情報を統合し、文脈を理解した上で判断を下す「知識労働の代替」としての性能が大きく向上したという評価だ。
この評価が特に重要なのは、AIが「単なる道具」から「業務のパートナー」へと役割を変えつつあることを示唆しているからだ。従来のAIアシスタントは、人間が明確に指示したタスクを実行するのが限界だった。GPT-5.5を中核に据えたエージェントは、曖昧な指示や複雑な文脈でも自律的に判断し、複数ステップの業務を完遂できる水準に近づきつつある。
日本企業への示唆、データ資産の再活用という視点
この事例から日本企業が学ぶべきポイントは明確だ。多くの企業が「過去の文書資産」を抱えている。紙で保管された契約書、古い基幹システムから出力された帳票、スキャンされたPDFの山。これらをAIで解析し、活用可能なデータに変換する技術が現実のものになりつつある。
ただし注意点もある。GPT-5.5の性能向上が顕著だったのは「スキャン文書の解析」と「複数ステップのオーケストレーション」であり、これはモデル自体の進化に加えて、Databricksのエージェント基盤との統合設計が効いている。単に高性能なLLMを導入するだけでは同様の成果は得られない。データ基盤とエージェント設計の両面からアプローチする必要がある。
この記事のポイント
- GPT-5.5は企業の実務ベンチマークOfficeQA Proでエラーを46%削減し、初めて正解率50%を突破した
- 特にスキャンPDFやレガシー文書の解析精度が飛躍的に向上し、古い文書資産の活用が現実的に
- 複数ステップのタスクを効率的に管理するオーケストレーション能力も改善し、自律的な業務遂行が可能に
- DatabricksではGPT-5.5を監督エージェントとして配置し、専門エージェント群を統括する設計を採用
- 日本企業にとっては、過去の文書資産をAIで再活用できる可能性が開けた事例として注目すべき
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験