

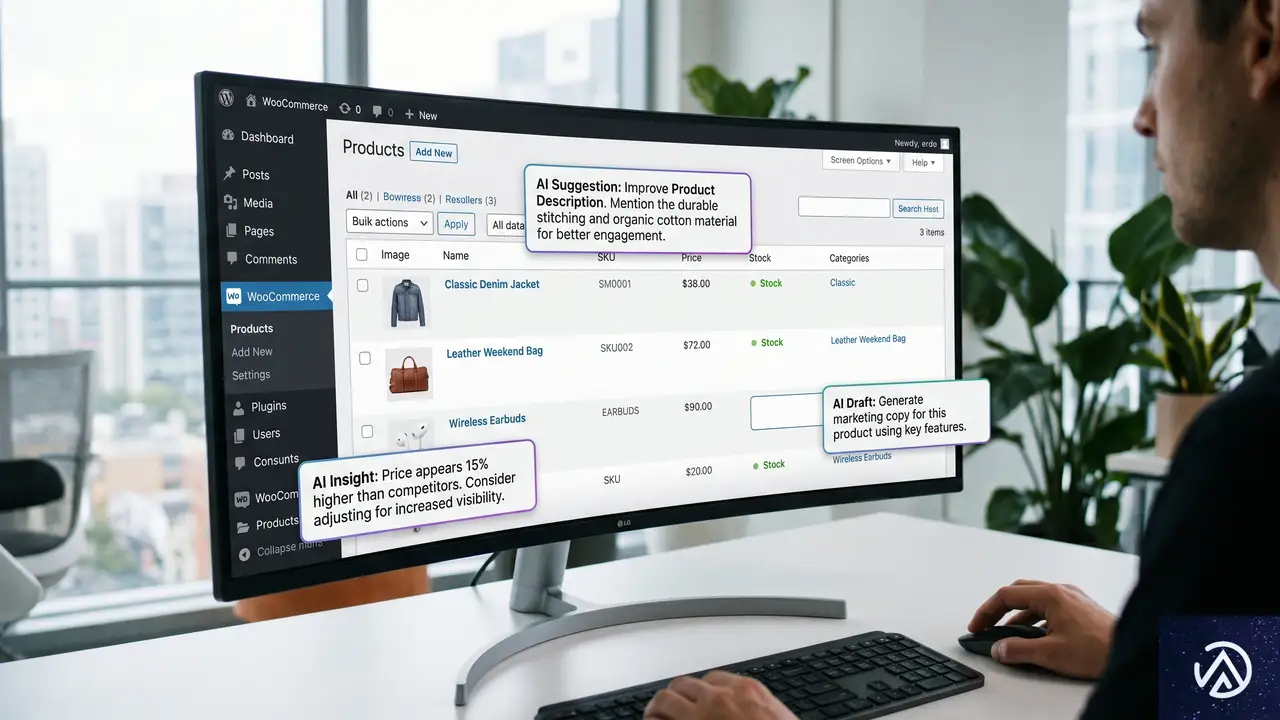
CSSだけでApple Vision Pro風スクロールアニメーションを再現する高度なテクニック
Appleの製品ページで多用される、スクロールに連動したダイナミックなアニメーションは、多くのWeb制作者にインスピレーションを与えてきた。特にVision Proの紹介ページで見られる、デバイスが分解されながら迫ってくるような演出は、技術的にも非常に洗練されている。
これまでこうした演出の多くはJavaScriptを用いて制御されていたが、最新のCSS機能を駆使することで、スクリプトなしでの再現が可能になりつつある。CSS-Tricksの記事では、スクロール駆動アニメーション(Scroll-driven Animations)を活用し、Apple風の演出をCSSだけで構築する手法が提案された。
本記事では、その実装の核心となる「パーツの分解」と「デバイスの反転」という2つのステージを、最新のCSSプロパティを用いてどのように制御するのかを深掘りしていく。パフォーマンスとレスポンシブ対応を両立させるための、具体的な計算式や構造の設計についても詳しく見ていこう。
Appleのスクロール演出を構成する2つのステージ

Vision Proのアニメーションを再現するためには、まずその動きを論理的に分解する必要がある。CSS-Tricksの分析によれば、この演出は大きく分けて2つの段階で構成されているという。
ステージ1 ハードウェアの分解表示
最初の段階では、デバイスの底部から3つの主要な電子部品が順番に浮き上がってくる。それぞれのコンポーネントは、他の部品を挟み込むように配置された2枚の画像で構成されている。これにより、部品が重なり合いながらも奥行きを感じさせる、立体的な「爆発図」のような効果が生まれる。
この視覚効果のポイントは、透明な領域を含む複数のレイヤーが、スクロールに合わせて異なる速度やタイミングで移動することだ。最前面と最後面に配置された画像が、中間にある部品を包み込むように動くことで、単なる平面の移動ではない3D的な深みが表現されている。
ステージ2 接眼レンズへのフリップアップ
部品の分解が終わると、次にデバイス全体が滑らかに回転し、接眼レンズ(アイピース)が見える状態へと変化する。Appleの公式サイトでは、この部分はJavaScriptで動画の再生位置をスクロール量に合わせて制御することで実現されている。
これをCSSだけで再現する場合、動画ファイルの代わりに大量の静止画を高速で切り替える手法が検討される。スクロールというユーザーの入力に対して、パラパラ漫画のように画像を差し替えていくことで、動画と同等の滑らかな回転アニメーションを作り出すアプローチだ。
Gridレイアウトによる要素の重ね合わせと配置

アニメーションを実装する前の準備として、複数の部品画像を正確に重ね合わせる必要がある。従来は position: absolute を多用していたが、これでは要素が通常の文書フローから外れてしまい、レスポンシブ対応やスクロール位置の管理が複雑になるという課題があった。
CSS-Tricksの筆者は、この問題の解決策として display: grid の活用を挙げている。親要素を1カラム・1行のグリッドに設定し、すべての部品画像を同じグリッドエリア(grid-area: 1 / 1 / 2 / 2)に割り当てることで、文書フローを維持したまま完璧な重ね合わせを実現できる。
このデモのように、グリッドを使うことで要素の順序(z-index)を保ちながら、個々のパーツに自由なアニメーションを適用できる土台が整う。また、各画像に background-size: cover を適用することで、アスペクト比を維持したまま画面幅に合わせることも容易になる。
StickyとView Timelineによるスクロール制御

スクロールに応じてアニメーションを動かす際、最も重要なのが「要素が画面内の特定の場所に留まり続けること」と「要素の表示状態を検知すること」の2点だ。これを実現するのが position: sticky と view-timeline プロパティである。
要素を画面に固定するStickyの役割
アニメーションが実行されている間、対象のデバイスが画面外に流れていってしまっては意味がない。そこで、アニメーション全体を包むコンテナ要素に十分な高さを設定し、中のデバイス要素に position: sticky; top: 0; を指定する。これにより、ユーザーがスクロールしている間、デバイスは画面上部に固定され、アニメーションの変化だけが視覚的に伝わるようになる。
View Timelineによる実行タイミングの最適化
従来、スクロールアニメーションの開始位置を特定するには、JavaScriptでスクロール量を監視し、要素のオフセットを計算する必要があった。しかし、最新のCSSでは view-timeline-name を定義するだけで、その要素がビューポート(画面)に入ってきたことをトリガーにアニメーションを開始できる。
CSS-Tricksの記事では、scroll-timeline ではなく view-timeline を選択した理由として、レスポンシブ性の向上を挙げている。ページの総高さに依存する scroll-timeline よりも、要素自体の表示状態に基づく view-timeline の方が、画面サイズが変わっても正確なタイミングでアニメーションを開始できるからだ。
レスポンシブ対応のための動的な高さ計算

アニメーションの移動量を固定値(px)で指定すると、画面サイズが小さいデバイスではパーツが画面外に飛び出したり、逆に移動が足りなかったりする問題が発生する。これを防ぐために、数学的なアプローチが必要となる。
デバイスの画像サイズが 960px × 608px である場合、現在の表示幅に基づいた動的な高さを calc() 関数で算出できる。具体的には、以下の計算式を用いることで、画像の比率を維持した高さを取得し、それを移動量の基準にする手法だ。
:root {
--stage2-height: calc(min(100vw, 960px) * 608 / 960);
}
@media screen and (max-height: 608px) {
:root {
--stage2-height: 100vh;
}
}この計算式により、ブラウザの幅が狭いときは 100vw に基づいた高さが計算され、画面の高さが極端に低い場合は 100vh が優先される。こうして得られた --stage2-height 変数を translate プロパティに適用することで、どのような画面サイズでもパーツが適切な位置まで移動し、重なりを維持できるようになる。
パラパラ漫画方式による「動画風」アニメーション

前述の通り、CSSだけで動画のフレームを制御することはできない。そこで、ステージ2のフリップアップ演出では、背景画像を高速で切り替える手法が採用された。これは、キーフレームアニメーションの中で background-image を順番に指定していく方法だ。
具体的には、0%から100%までの進行度に合わせて、数十枚の静止画(00011.jpg、00013.jpg…)を切り替えていく。この際、パフォーマンスを向上させるために、HTMLの <link rel="preload" as="image"> タグを使用して、すべての画像を事前に読み込んでおくことが推奨されている。これにより、スクロール時の画像のチラつきや遅延を防ぐことができる。
この手法のデメリットは、1つの動画ファイルの代わりに大量の静止画をダウンロードする必要がある点だ。CSS-Tricksの筆者は、フレーム数を半分に間引くことでファイル数を削減しつつ、視覚的な滑らかさを維持する工夫を凝らしている。実運用では、画像の最適化やスプライト画像化などのさらなる対策が有効だろう。
Animation Rangeによる精緻なタイミング調整

view-timeline を使うだけでは、アニメーションが開始・終了するタイミングを細かく制御できない場合がある。そこで役立つのが animation-range プロパティだ。これは、要素がビューポートのどの位置に来たときにアニメーションを開始し、どこで終了するかを定義するものだ。
例えば、部品の分解アニメーション(ステージ1)では animation-range: contain cover; が使用された。これは、要素が完全に画面内に入ってから(contain)アニメーションを開始し、画面から消え去るまで(cover)継続することを意味する。一方、回転アニメーション(ステージ2)では、画面から消える前に動きを完結させる必要があるため、animation-range: cover 10% contain; のような指定で調整が行われている。
このように、スクロール量という「時間軸」に対して、アニメーションの「区間」を定義することで、JavaScriptを使わずとも極めて精度の高い演出制御が可能になる。これは、現代のCSSにおける大きな進化の一つだ。
独自の分析:CSS主導のアニメーションがもたらす変化

今回紹介した手法は、単に「Appleの真似ができる」という以上の意味を持っている。最大の利点は、ブラウザのメインスレッドをJavaScriptの計算から解放できることにある。スクロール駆動アニメーションは、ブラウザのコンポジタースレッドで処理されるため、ページの読み込みや他の処理が重い状況でも、カクつきの少ないスムーズな動きを提供できる。
一方で、実務上の課題も残されている。大量の画像を切り替える手法は、LCP(Largest Contentful Paint)などのパフォーマンス指標に悪影響を与える可能性があるからだ。また、現時点ではFirefoxがこのCSS機能に完全対応していないため、フォールバック(代替表示)の用意が欠かせない。
しかし、これまで「実装コストが高すぎる」と諦めていた高度な演出が、CSS数行で記述できるようになった意義は大きい。今後は、動画ファイルとCSSアニメーションをより高度に組み合わせた、ハイブリッドな実装が主流になっていくのではないかと推測される。
この記事のポイント
- Apple風のスクロール演出は、部品の分解と回転という2つのステージに分けて考える
display: gridを使うことで、要素の重ね合わせとレスポンシブな配置を両立できるview-timelineとposition: stickyの組み合わせが、スクロール連動の鍵となる- 大量の画像をCSSで切り替える際は、
preloadによる事前読み込みが不可欠だ animation-rangeを活用することで、JSなしでも精緻な実行タイミングの制御が可能になる

・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Google検索結果の「続きを読む」リンク表示を増やす3つの法則!robots.txtドキュメント拡充と最新SEO動向
Googleが検索結果の表示をより詳細にする「続きを読む(Read more)」ディープリンクのベストプラクティスを公開した。これは検索結果のスニペット内に、ページ内の特定セクションへ直接ジャンプできるリンクを表示させるための指針だ。これまで経験則で語られてきた部分が、公式ドキュメントによって明確化された形となる。
あわせて、robots.txtのドキュメント拡充や、EUでのAIチャットボットに対するデータ共有規制、さらには検索画面上でタスクを完結させる新機能についても動きがある。2026年4月の最新情報を踏まえ、Webサイト運営者が今取り組むべき構造改革について解説する。
これらのアップデートは単なる表示の変化ではなく、Googleが「AIエージェントにとって読みやすい構造」をWebサイトに求めていることの表れだ。サイトの構造が古いままでは、検索結果での露出機会を大きく損なう可能性がある。技術的な背景とともに、具体的な対策を確認していこう。
Google検索のディープリンク表示を増やす3つの鉄則
Googleは検索結果のスニペット(説明文)の下に表示される「続きを読む」リンクについて、その出現率を高めるための具体的な方法を明らかにした。ディープリンクとは、ページ全体ではなくページ内の特定の章や節に直接ユーザーを誘導するリンクのことだ。これが表示されると、検索結果の占有面積が増え、クリック率の向上が期待できる。
コンテンツはページ読み込み時に即座に表示させる
最も重要なポイントは、ユーザーがページを開いた瞬間にコンテンツが人間にとって可視化されていることだ。クリックしないと中身が見えない「折りたたみ式(アコーディオン)」や「タブ切り替え」の中に重要な情報を隠している場合、ディープリンクとして採用される確率は下がる。Googleは、ユーザーの操作なしにレンダリングされる情報を優先して評価している。
これは「隠れたテキスト」がインデックスされないという意味ではないが、検索結果の拡張機能(リッチスニペットやディープリンク)においては、露出の優先度が低くなることを示唆している。特にモバイルユーザー向けに情報をコンパクトにまとめようとして、重要な見出しや本文をアコーディオン内に閉じ込める設計には注意が必要だ。
H2やH3の見出しタグを適切に活用する
ディープリンクのリンク先となるセクションには、必ず <h2> や <h3> といった見出しタグを使用する必要がある。Googleのシステムは、これらの見出しをページの構造的な区切りとして認識し、リンクのアンカー(目的地)として利用するからだ。
また、検索結果に表示されるスニペットのテキストと、実際のページ内の見出しや本文の内容が一致していることも条件となる。見出しが画像だけで構成されていたり、装飾目的で <div> タグにスタイルを当てただけの「見出し風」のデザインになっていたりすると、Googleはそこをセクションの開始点として正しく認識できない。
UIデザインのBeforeとAfter比較
ディープリンクが表示されにくい構造(タブ・アコーディオン)と、表示されやすい構造(フラットな見出し構成)を比較してみよう。以下のデモは、コンテンツの露出度による構造の違いを視覚化したものだ。
このデモのように、すべての主要コンテンツがページロード時に露出している構成の方が、Googleは各セクションをディープリンクとして採用しやすくなる。ユーザーの利便性を損なわない範囲で、情報の「隠しすぎ」を避けることが重要だ。
robots.txtの公式ドキュメント拡充とスペルミスへの寛容さ
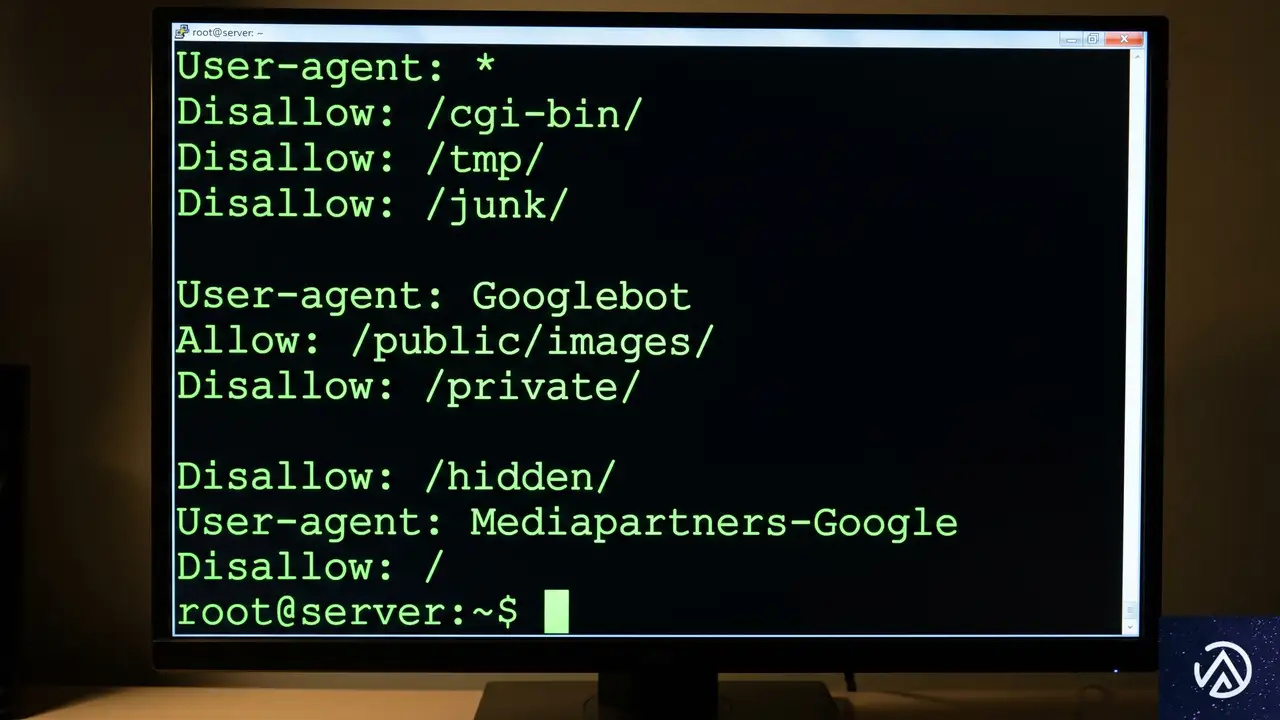
GoogleのGary Illyes(ゲイリー・イリェーシュ)氏とMartin Splitt(マーティン・スプリット)氏は、ポッドキャスト「Search Off the Record」にて、robots.txtに関する新たなプロジェクトについて語った。Googleは現在、HTTP Archiveのデータを分析し、実際に世界中のサイトで使用されているrobots.txtの記述パターンを調査している。
非サポートルールの明文化
robots.txtには、Googleが公式にサポートしていない独自の命令(ディレクティブ)が記述されているケースが多々ある。例えば、クロールの頻度を指定する Crawl-delay や、特定の条件下でのみ適用されるカスタムルールなどだ。Googleは今回の分析に基づき、よく使われているが実際にはGoogleが無視している「非サポートルール」のトップ10から15をドキュメントに追加する予定だ。
これにより、Webサイト運営者は「自分が設定しているルールがGoogleに効いているのか」を正確に判断できるようになる。もしGoogleがサポートしていないルールに頼ってクロール制御を行っている場合、それは期待通りに機能していない可能性が高い。公式ドキュメントが更新された際には、自サイトのrobots.txtを改めて監査する必要があるだろう。
記述ミスの自動補完が進む可能性
さらに興味深い点として、Googleのrobots.txtパーサー(解析機)が、記述のスペルミスをより柔軟に受け入れるようになる可能性が示唆された。例えば disallow を dissallow と書き間違えた場合でも、Googleがそれを意図通りの命令として解釈してくれるようになるかもしれない。
ただし、これはあくまで「Googleが親切に解釈してくれる」という話であり、ミスを放置してよいという意味ではない。他の検索エンジン(Bingなど)が同様の寛容さを持っているとは限らないからだ。robots.txtはサイトの立ち入り禁止区域を指定する「地図」のようなものだ。記述ミスがあれば、検索エンジンにインデックスさせたくないページが公開されてしまうリスクがある。基本的には、標準的なスペルを厳守すべきだ。
EUのデータ共有規制がAIチャットボットに波及

欧州委員会(EC)は、デジタル市場法(DMA)に基づき、Googleに対して検索データを競合他社と共有するよう求める予備的な見解を示した。この規制の対象には、従来の検索エンジンだけでなく、特定の条件を満たす「AIチャットボット」も含まれる見通しだ。
AIチャットボットが「検索エンジン」として定義される日
これまでSEO業界では、Googleのような検索エンジンと、ChatGPTやPerplexityのようなAIチャットボットを別物として扱ってきた。しかし、EUの規制当局は「オンライン検索エンジン」の定義を広げ、AIチャットボットもその範疇に含める動きを見せている。これが確定すれば、Googleが持つ膨大なランキングデータやクリックデータが、競合するAIサービスに提供されることになる。
この変化は、EU圏内での検索市場の流動性を高める可能性がある。Googleのデータを活用して精度を高めたAIチャットボットが普及すれば、ユーザーの検索行動はさらに分散するだろう。Webサイト運営者にとっては、Googleだけでなく「AIチャットボットからどう参照されるか」という視点が、法規制の面からも裏付けられた重要な課題となる。
匿名化された検索シグナルの行方
共有されるデータは匿名化されるものの、ランキング、クエリ、クリック、閲覧データといった核心的な情報が含まれる。これにより、新興のAI検索サービスが「どのコンテンツがユーザーに支持されているか」をより正確に把握できるようになる。日本国内のサイトであっても、EUからのアクセスがある場合は、これらのデータ共有の影響を間接的に受けることになるだろう。
検索結果でタスクを完結させる新機能の追加
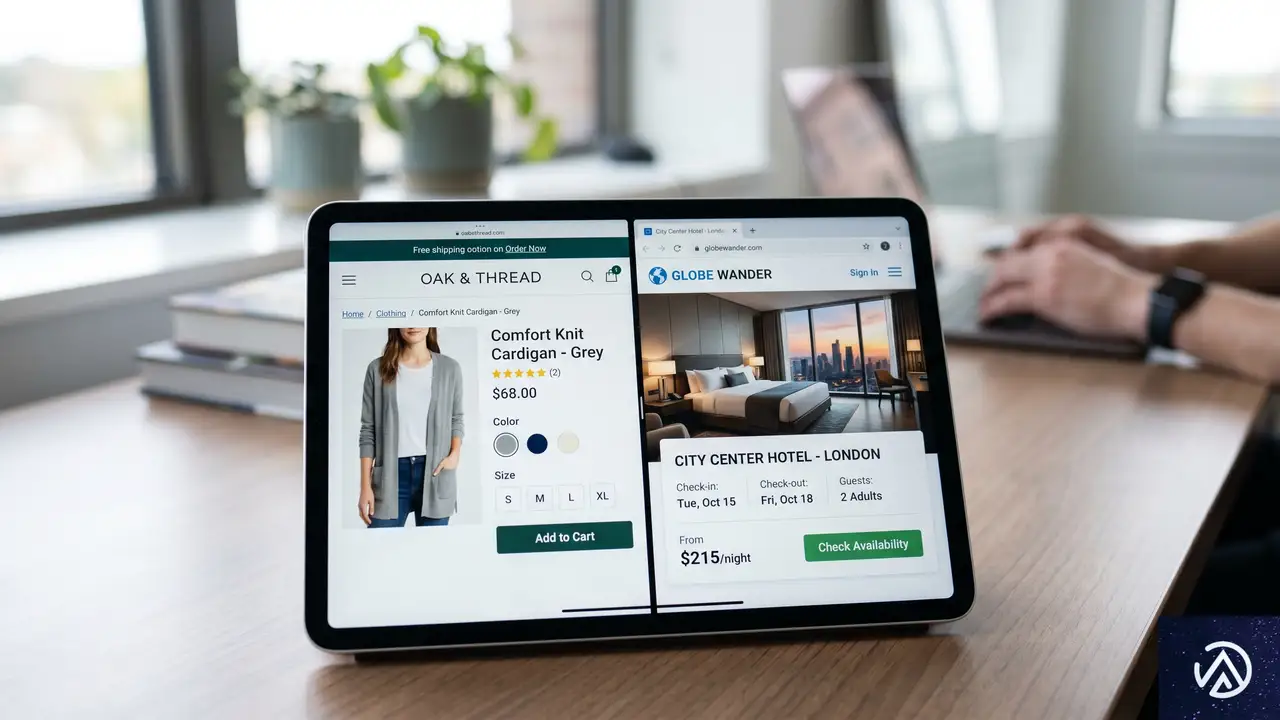
Googleは検索結果画面(SERP)上で直接ユーザーの目的を達成させる「タスクベース」の機能を強化している。その一環として、特定のホテルの価格下落を追跡できるトグルスイッチが導入された。これは、ユーザーがホテル予約サイトへ移動することなく、Google内で価格監視を開始できる機能だ。
Webサイトへの流入機会が「Google内」に吸収される
これまで、価格下落通知は旅行予約サイトや比較サイトが提供する主要なサービスの一つだった。Googleがこの機能を検索結果に直接組み込むことで、ユーザーが各サイトを再訪する動機が減少する可能性がある。GoogleのSundar Pichai(サンダー・ピチャイ)CEOが語っていた「エージェントとしての検索」が、着実に具現化していると言える。
この変化への対策として、ホテルなどのサービス事業者はGoogleビジネスプロフィールの情報を最新に保ち、Googleのフィードに対して正確なデータを提供し続ける必要がある。検索結果が単なる「リンク集」から「実行プラットフォーム」へと進化する中で、プラットフォームとのデータ連携の重要性はかつてないほど高まっている。
AIエージェントの起動ボタン
また、Googleの「AIモード」から直接AIエージェントを起動し、複雑なタスクを委任できる機能もテストされている。例えば「旅行の計画を立てて予約まで進める」といった一連の動作を、AIが代行する仕組みだ。この際、AIがどのWebサイトの情報をソース(情報源)として採用するかは、前述した「ディープリンクのベストプラクティス」のような構造化された情報の有無に左右される。
AIエージェントは、人間と同じようにWebページを「読み」に行く。その際、Javascriptの実行や複雑なクリック操作を必要とするページよりも、シンプルで見出し構造が明確なページを好む。検索がタスク完結型になればなるほど、Webサイトは「人間が見る場所」であると同時に「AIがデータを取得するAPI」のような役割を求められるようになるのだ。
この記事のポイント
- 「続きを読む」リンクを表示させるには、コンテンツをアコーディオンやタブに隠さず、ページロード時に露出させることが重要だ。
- 適切な見出しタグ(H2、H3)を使用し、検索スニペットとページ内容の整合性を保つことで、ディープリンクの採用率が高まる。
- robots.txtの公式ドキュメントが拡充され、Googleがサポートしていないルールの実態が明確になるため、定期的な記述の監査が推奨される。
- EUの規制によりAIチャットボットが「検索エンジン」として扱われ始め、Googleの検索データが競合AIに共有される道が開かれつつある。
- Google検索は「情報を探す場所」から「タスクを完結させる場所」へ進化しており、WebサイトにはAIエージェントが読み取りやすい構造が求められている。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Googleへのスパム報告に新ルール。個人情報を含むと処理されない理由
Googleがスパム報告に関する公式ドキュメントを更新し、報告プロセスにおける重要な変更を明らかにした。今後、報告内容に個人を特定できる情報が含まれている場合、Googleはその報告に基づいた調査や対処を行わない方針だ。
この変更は、スパムサイトに対して「手動対策(マニュアルアクション)」が実施される際、報告内容の一部がサイト所有者に共有される仕組みに起因している。Googleはプライバシー保護と法規制への対応を優先し、不適切な情報を含む報告をあらかじめ排除する決断を下した。
SEO担当者やサイト運営者にとって、この変更は単なる手続きの修正ではない。悪質なサイトを排除するための正当な報告が無効化されるリスクを避けるため、報告の作法を再確認する必要がある。
Googleスパム報告の仕様変更。個人情報の記載が「無効」に
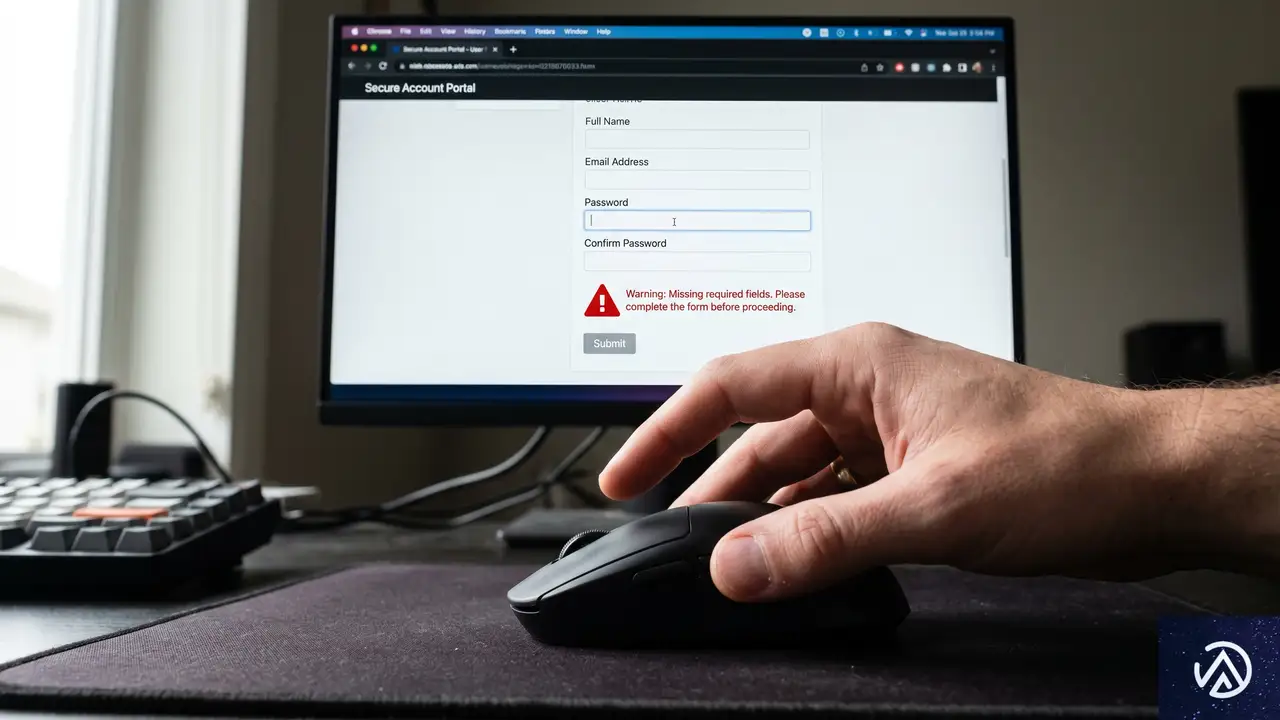
Googleは検索結果の品質を維持するため、ユーザーからのスパム報告を受け付けている。しかし、2026年4月に更新されたドキュメントによれば、報告フォームの自由記述欄に個人情報が含まれている場合、その報告は処理されなくなった。これは、報告者が意図せず自身の身元を相手に明かしてしまうリスクを防ぐための措置だ。
なぜ個人情報が含まれると処理されないのか
最大の理由は、Googleがスパムサイトの所有者に送る通知の仕組みにある。Googleが報告に基づいて手動対策を下した場合、その根拠となった情報をサイト所有者に伝えることがある。この際、報告者が記述したテキストがそのまま引用される可能性があるためだ。
もし報告文の中に、報告者の名前や会社名、あるいは特定のサイト運営者であることを示唆する情報が含まれていれば、スパムサイト側に報告者の正体が筒抜けになってしまう。Googleはこのような事態を避けるため、個人情報が含まれる報告自体を「破棄」するというルールを明文化した。
ドキュメントから削除された「匿名性」の記述
以前のドキュメントでは、自由記述欄に個人情報を書かない限り、報告は匿名に保たれるという主旨の記述があった。しかし、今回の更新でこの文言は削除された。代わりに「法規制を遵守するため、手動対策の文脈を理解させる目的で、提出されたテキストをサイト所有者に送信しなければならない」という強い表現が追加されている。
これは、Googleが報告者の匿名性を保証する努力をするのではなく、報告者自身に「特定される情報を一切書かないこと」を義務付けたことを意味する。ルールを守らない報告は、どれほど証拠が揃っていても無視されることになるため、注意が必要だ。
手動対策通知の仕組みと報告者が負うべきリスク

手動対策(マニュアルアクション)とは、Googleの担当者が目視でサイトを確認し、ガイドライン違反と判断した場合に検索順位を下げたり、インデックスから削除したりする処置を指す。このプロセスにおいて、ユーザーからの報告は重要な判断材料の一つとなる。
報告内容がそのまま相手に届くという事実
Googleが違反サイトの運営者に送る通知には、どのような違反があったのかを説明するテキストが含まれる。このテキストに、報告者がフォームに記入した内容が「原文のまま」転載されるケースがある。これは、違反者が自サイトのどこに問題があるのかを正確に把握させ、修正を促すための透明性を確保する目的で行われる。
しかし、この透明性が報告者にとってはリスクとなる。例えば「私のサイトの画像を盗用している」といった文言で報告すれば、相手は即座に報告者が誰であるかを特定できる。このような情報の流出は、報告者への逆恨みやさらなる攻撃を招く恐れがある。
情報の流れを視覚化する
スパム報告がどのように処理され、どの段階で情報が共有されるのかを整理しておくことは重要だ。以下のデモは、不適切な報告と適切な報告で情報の伝わり方がどう変わるかを示している。
このデモのように、自分を特定する情報を削ぎ落とし、客観的な事実のみを伝えることが、報告を有効にするための鉄則だ。
プライバシー保護と透明性のジレンマ。Googleの狙い

Googleがなぜこのような厳しいルールを設けたのか。その背景には、欧州のGDPR(一般データ保護規則)をはじめとする、世界的なプライバシー保護規制の強化がある。個人データの取り扱いには極めて慎重な対応が求められており、検索エンジンも例外ではない。
法規制への対応とユーザー保護の両立
GDPRなどの法規制下では、データの主体(この場合はサイト所有者)は、自分に関するどのような情報が収集され、誰から提供されたのかを知る権利を持つ場合がある。Googleが「報告文を相手に送る」としているのは、こうした法的要求に応えるための苦肉の策とも言える。
一方で、報告者の身の安全を守る必要もある。そこでGoogleが導き出した答えが、「個人情報が含まれる報告は最初から受け取らない(処理しない)」というフィルタリングだ。これにより、法的義務を果たしつつ、報告者が不用意に特定される事態を未然に防いでいる。
「質の高い報告」を求めるGoogleの姿勢
今回の変更は、スパム報告の「質」を向上させる狙いもあると考えられる。感情的な訴えや個人的な利害関係を排除し、アルゴリズムやガイドラインに照らして何が違反なのかを論理的に説明する報告を、Googleは求めている。
報告が無効化される条件を明確にすることで、Google側の処理コストも削減される。明らかにガイドラインを理解していない報告や、嫌がらせ目的の報告を、情報の形式だけで自動的に弾くことができるからだ。
効果的なスパム報告を行うための実践的なアドバイス

スパムサイトによって検索順位を下げられたり、コンテンツを盗用されたりした場合、冷静に報告を行うのは難しい。しかし、確実にGoogleに対処してもらうためには、以下のポイントを意識してフォームを記入する必要がある。
匿名性を保ちつつ証拠を提示するコツ
まず、一人称(私、弊社など)や固有名詞を避けることだ。例えば「私のサイトのこの記事がコピーされた」と書くのではなく、「該当URLのコンテンツは、別のドメイン(URLを提示)のオリジナルコンテンツを無断で複製している」といった書き方にする。
次に、違反の種類を具体的に指摘することだ。単に「スパムだ」と主張するのではなく、「隠しテキストが使用されている」「リンクプログラムに参加している」「クローキングが行われている」など、Googleのスパムポリシーに基づいた用語を使うと、担当者の理解が早まる。
報告文のチェックリスト
送信ボタンを押す前に、以下の項目が含まれていないか確認しよう。一つでも当てはまる場合は、処理されない可能性が高い。
- 自分の氏名や会社名、部署名
- 自分のメールアドレスや電話番号
- 自分が管理しているサイトのドメイン名(証拠として必要な場合を除く)
- 相手を非難する感情的な言葉
- 過去のやり取りや個人的なトラブルの経緯
独自の分析。SEO担当者が今後意識すべき報告の作法
今回のGoogleの対応は、SEO業界における「スパム報告」の立ち位置を大きく変える可能性がある。これまでは「困った時の神頼み」のような側面もあったが、今後はより専門的で客観的な「証拠提出」の場へと変わっていくだろう。
競合への嫌がらせ対策としての側面
この新ルールは、競合サイトを陥れるための「虚偽の報告」に対する牽制にもなる。報告内容が相手に公開される可能性がある以上、安易な嘘や根拠のない誹謗中傷は、報告者自身の首を絞めることになるからだ。Googleは情報の透明性を高めることで、報告システム自体の健全性を保とうとしている。
AI時代におけるスパム報告の価値
AIによって生成された低品質なコンテンツが急増する中、Googleのアルゴリズムだけですべてを検知するのは難しくなっている。人間の目による「これはスパムだ」というフィードバックの価値はむしろ高まっていると言えるだろう。
だからこそ、私たちは「正しい報告の作法」を身につけるべきだ。適切な形式で、個人情報を排除し、事実に基づいた報告を行うことは、検索エンジンのエコシステムを守るための貢献にもなる。今回の仕様変更を機に、社内での報告フローやテンプレートを見直してみるのも良いだろう。
この記事のポイント
- Googleへのスパム報告に個人情報が含まれている場合、調査は行われず破棄される。
- 手動対策が実施される際、報告文がそのままサイト所有者に共有されるリスクがあるためだ。
- 報告文には自分の名前や会社名を入れず、客観的な事実と違反箇所のみを記述する。
- この変更は、プライバシー保護規制への対応と報告システムの健全化を目的としている。
- 正当な報告を有効にするため、送信前のセルフチェックがこれまで以上に重要となる。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

LinkedInアルゴリズム激変!AIシステム360Brewが評価する専門性と保存の価値
LinkedInのタイムラインで、数千件の「いいね」を集めた名言投稿がすぐに消え去る一方で、反応は少なくても専門的な解説投稿が数週間にわたって表示され続ける現象が起きている。これは偶然ではなく、LinkedInが導入した新しいAIシステムによる意図的な変化だ。プラットフォーム側が「どのようなコンテンツを価値があるか」と判断する基準を根本から書き換えたことを意味している。
最新の調査によれば、現在のLinkedInでは1件の「保存」が1件の「いいね」よりも5倍も多くのリーチをもたらすという。さらに、投稿を保存したユーザーが投稿者をフォローする確率は、通常の130%にまで跳ね上がる。AIがユーザーの反応だけでなく、コンテンツの「中身」そのものを高度に分析し始めた結果、従来のSNS運用における常識が通用しなくなっているのだ。
本記事では、LinkedInが新たに投入した大規模AIモデル「360Brew」の仕組みと、それに対応するために不可欠なコンテンツ戦略について解説する。専門知識を持つ個人や企業が、この変化を味方につけてリーチを最大化するための具体的な手法を探っていく。
LinkedInの配信ロジックを塗り替えたAI「360Brew」

LinkedInは「360Brew」と呼ばれる新しいAIシステムを導入した。これは1,500億個ものパラメータを持つ巨大なモデルであり、投稿されたテキストの内容を人間のように深く理解することを目指している。パラメータとはAIの「脳のシワ」のようなもので、この数が多いほど複雑な文脈や専門性の高さを正確に判別できるようになる。従来のアルゴリズムが「誰が反応したか」という外的なシグナルを重視していたのに対し、360Brewは「何が書かれているか」という内的な質を評価の軸に据えている。
このシステムの導入により、コンテンツの寿命が劇的に変化した。これまでは投稿直後の数時間が勝負とされていたが、AIが「この内容は特定の専門家にとって長期的に有益だ」と判断すれば、数週間、時には数ヶ月にわたってターゲットとなるユーザーのフィードに表示され続ける。逆に、中身のない煽り文句や、どこかで見たような自己啓発的なフレーズは、たとえ初動で多くの反応を得ても、AIによって「低品質」とみなされ、配信が早期に停止される仕組みだ。
AuthoredUpの研究によると、この新システムの導入後、全ユーザーの約98%がリーチの減少を経験したと報告されている。しかし、これはプラットフォーム全体の衰退ではなく、評価基準の「適正化」が行われた結果だと言える。AIが求める「専門性」という新しい通貨を正しく支払っている発信者にとっては、むしろかつてないほど質の高いリーチを獲得できるチャンスが訪れているのだ。
「いいね」よりも「保存」が重視される理由

現在のLinkedInにおいて、最も価値のあるユーザーアクションは「保存(Save)」だ。なぜAIは、これほどまでに保存という行為を重視するのだろうか。その理由は、保存というアクションが「後で見返したいほどの実益がある」という、最強の品質証明になるからだ。「いいね」は反射的に押せるが、保存はユーザーの将来の活動に役立つと判断された場合にのみ行われる。AIはこのシグナルを、コンテンツが専門的で実用的であるという確実な証拠として扱う。
具体的な数字で見ると、その差は歴然としている。1件の保存がもたらすリーチへの貢献度は、1件のコメントの2倍、1件の「いいね」の5倍に相当するという分析がある。保存されるコンテンツは、単なるエンターテインメントではなく「仕事の道具」として認識されている。LinkedInがビジネスプラットフォームとしてのアイデンティティを強化しようとしている中で、この実用性の評価は極めて論理的な帰結だと言えるだろう。
また、保存というアクションは、長期的な信頼関係の構築にも直結する。自分の役に立つ情報を継続的に提供してくれる相手を、ユーザーは「権威」として認識し始める。保存をきっかけとしたフォロー率が130%向上するというデータは、保存されるコンテンツこそが、単なるフォロワー数ではない「質の高いネットワーク」を構築するための最短距離であることを示している。
このデモは、LinkedInの評価軸が「瞬発的な反応」から「継続的な実用性」へとシフトした様子を示している。
AIが瞬時に専門性を判断する「冒頭の数行」

AIシステム「360Brew」は、人間が投稿を読み始めるよりも早く、その内容をスキャンしてカテゴリー分けを行う。ここで最も重要なのが、投稿の冒頭1〜2文だ。AIは文章の書き出しを、その投稿がどの程度の専門性を持っているかを判断するための強力なシグナルとして利用する。例えば、「今日は生産性について考えてみました」という書き出しは、AIによって「一般的で付加価値の低い内容」と瞬時にラベル付けされてしまう恐れがある。
対照的に、具体的な数字や専門用語、成果を盛り込んだ書き出しは、AIの評価を劇的に高める。例えば「ECサイトのチェックアウト工程を3ステップ簡略化した結果、カゴ落ち率が22%改善した」といった書き出しだ。AIはここから「EC制作」「UX最適化」「データ分析」といったドメイン知識(特定の領域における専門知識)を読み取り、その情報を必要としている適切なユーザーのフィードへと優先的に送り込む。
リード文で「喉を鳴らす(本題に入る前の無駄な挨拶)」時間は、今のLinkedInにはない。最初の一文で、自分がどのような専門家であり、読者にどのような具体的利益をもたらすのかを証明しなければならない。これは、履歴書の最初の1行で採用担当者の目を引くのと似ている。AIという「最初の読者」を納得させることが、広大なネットワークへの扉を開く鍵となるのだ。
クロスリファレンス問題と発信の一貫性

LinkedInのAIは、単体の投稿だけでなく、ユーザーの「デジタル履歴全体」をチェックしている。これをクロスリファレンス(相互参照)と呼ぶ。プロフィールに記載された職位、過去の投稿内容、さらには他人の投稿に残したコメントの内容までを一貫性のフィルターにかける。AIは、そのユーザーが本当にその分野の権威であるかどうかを、点ではなく線で判断しているのだ。
例えば、プロフィールの肩書きが「ECコンサルタント」であるにもかかわらず、ある日は自己啓発、次の日は最新のガジェット、その次は暗号資産の予測といった具合に発信内容がバラバラだと、AIは「明確な専門領域を持たないアカウント」と判断する。その結果、個々の投稿がいくら優れていても、配信スコアが抑制されてしまうという現象が起きる。専門領域を絞り、その範囲内で一貫した発信を続けることが、AIによる権威性の承認を受けるための必須条件だ。
これは、大学の教授が自分の専門分野の論文を書き続けることで信頼を築くプロセスに似ている。化学の教授が突然、経済学や料理についてのみ語り始めれば、アカデミックな場での信頼は揺らぐだろう。LinkedInのAIは、まさにこの「学術的な信頼構築」に近いロジックをビジネスSNSに持ち込んでいる。自分の「領土」を明確にし、そこを深く耕し続けることが、長期的には最大のリーチへと繋がる。
投稿2:「ビットコインの今後について」
投稿3:「WooCommerceの最新機能解説」
投稿2:「Stripe導入時にハマる落とし穴」
投稿3:「購入完了率を高めるサンクスページの設計」
このデモでは、発信内容の「散らかり」がAIの評価にどう影響するかを視覚化している。
EC事業者がLinkedInで権威性を築くための実践ステップ

このAIの変化は、特にEC制作やWooCommerceに関わるプロフェッショナルにとって大きな追い風となる。なぜなら、ECの分野には「具体的な数字」と「深い専門知識」が豊富にあるからだ。LinkedInを単なる宣伝の場ではなく、業界の課題を解決する「動くホワイトペーパー」として活用することで、AIに高く評価されるプレゼンスを構築できる。
まず取り組むべきは、過去の知見を「保存可能な形式」にパッケージ化することだ。単に「サイトを作りました」と報告するのではなく、「表示速度を1.2秒短縮するために行った3つの技術的施策」といった、同業者が思わず保存して後で参考にしたいと思う形式で投稿を作成する。この際、技術的な詳細を惜しみなく公開することが、AIに対して「このユーザーは本物の専門家である」と認識させるための最も強力な手段となる。
また、他者の投稿へのコメントも重要な戦略の一部だ。自分の専門分野に関連する投稿に対し、補足情報や独自の洞察をコメントとして残すことで、AIのクロスリファレンス機能を味方につけることができる。Bufferの報告によれば、自らの投稿への返信を丁寧に行っているアカウントは、そうでないアカウントに比べて格段に高いパフォーマンスを発揮している。AIは投稿主だけでなく、その周囲に形成されるコミュニティの質も監視しているのだ。
LinkedInのAIが求めるのは、一時のバズではなく、持続的な価値の提供だ。専門知識を隠さず、一貫性を持って発信し続けることで、AIはそのアカウントを特定の業界における「必須の情報源」として認定するようになる。この「認定」こそが、広告費をかけずに理想的なビジネスパートナーと繋がるための、現代における最強の資産となるだろう。
この記事のポイント
- LinkedInの新AI「360Brew」は、反応数よりもコンテンツの専門性と質を評価する
- 1件の「保存」は「いいね」の5倍のリーチ効果があり、フォロー率を130%向上させる
- 冒頭の1〜2文で具体的な成果や専門用語を出すことで、AIに専門家として認識させる
- 発信内容の一貫性(クロスリファレンス)が、アカウントの権威性スコアを左右する
- SNSを「保存される実用的なツール」として運用することが、最新アルゴリズム攻略の鍵となる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

WordPressサイトの信頼性を再定義する。ヒューマンエラーを前提とした回復力の高め方
WordPressサイトがダウンする原因の多くは、サーバーの物理的な故障や急激なアクセス増加ではない。実は、日々の管理業務の中で発生する「人為的なミス」が最も大きな要因となっている。
プラグインの更新、設定ファイルのわずかな書き換え、あるいは新しいコードの追加といった日常的な操作が、予期せぬ不具合を引き起こす。WordPressは柔軟で強力なシステムだが、その運用は人間に依存しており、ミスを完全に排除することは不可能に近い。
本記事では、ヒューマンエラーを前提とした「真の信頼性」について考える。エラーをゼロにすることを目指すのではなく、万が一問題が発生した際に、いかに迅速かつ安全に元の状態へ戻せるかという「回復力」の重要性を深掘りしていく。
なぜWordPressの障害は「人」から生まれるのか

多くのサイト運営者は、ダウンタイム(サイトが閲覧できなくなる時間)の原因をインフラの不備だと考えがちだ。しかし、実際にはサイト自体に加えられた変更が引き金となるケースが圧倒的に多い。
日常的な変更がリスクに変わる瞬間
WordPressは常に進化を続けている。新しい機能を導入するためにプラグインを追加し、デザインを整えるためにテーマを調整し、パフォーマンスを上げるために設定ファイルを最適化する。これらの変更はすべて「サイトを良くしたい」という意図で行われるものだ。
しかし、システムが多層的で複雑になればなるほど、小さな変更が全体に与える影響を予測しにくくなる。一つの設定ミスがドミノ倒しのように他の機能に干渉し、最終的にサイト全体を停止させてしまうことがある。Kinstaの記事でも指摘されている通り、ヒューマンエラーは避けられない自然な結果として捉えるべきだろう。
柔軟性と引き換えに生じる不安定さ
WordPressの最大のメリットは、誰でも簡単にカスタマイズできる柔軟性にある。しかし、その柔軟性は「壊しやすさ」と表裏一体だ。専門的な知識がなくても重要なファイルを編集できてしまうため、初心者はもちろん、経験豊富な開発者であっても、一瞬の油断で致命的なミスを犯す可能性がある。
サイトを壊す「よくある4つのミス」とその正体
不具合が発生する場所には、一定のパターンが存在する。これらを事前に把握しておくだけでも、トラブル発生時の調査スピードは格段に上がるだろう。
1. 設定ファイル(.htaccessやwp-config.php)の構文ミス
サーバーの動作を制御する .htaccess ファイルの編集は、最も注意が必要な作業の一つだ。例えば、リダイレクトの設定中に括弧を一つ閉じ忘れただけで、サーバーは「500 Internal Server Error」を返し、サイトは即座に閲覧不能になる。
# 誤った記述の例(閉じ括弧がない)
RewriteEngine On
RewriteRule ^index\.php$ - [Lまた、データベースの接続情報を管理する wp-config.php でパスワードを1文字打ち間違えれば、「データベース接続確立エラー」が発生する。これらのファイルはサイトの根幹を支えているため、わずかな記述ミスも許されない。
2. アップデート後のプラグインやテーマの競合
プラグインの更新ボタンを押す行為は、日常的だがリスクを伴う。個々のプラグインは正常に動作していても、特定の組み合わせによって予期せぬエラーが発生することがあるからだ。これを「競合」と呼ぶ。特にECサイト(WooCommerceなど)において、決済に関わるプラグインが競合で動かなくなれば、ビジネスへの損害は計り知れない。
3. JavaScriptエラーによる管理画面のフリーズ
最近のWordPressはブロックエディタ(Gutenberg)を中心に、JavaScriptへの依存度が高まっている。テーマやプラグインに含まれるスクリプトに不備があると、エディタが読み込まれなかったり、保存ボタンが反応しなくなったりする。表側の表示は正常でも、裏側の管理画面が使えなくなるという、発見が遅れやすいトラブルだ。
4. theme.jsonの構造的な不備
最新のブロックテーマでは theme.json というファイルでサイトのデザインを一括管理する。このファイルはJSON形式で記述されるが、カンマの打ち忘れや階層構造のミスがあると、WordPressは設定を正しく読み込めない。エラーメッセージが出ないまま、特定のスタイルが適用されなかったり、編集画面のコントロールが消えたりするため、原因の特定に時間がかかることがある。
予防策を徹底しても「不具合」がゼロにならない理由
慎重に作業を進め、テストを繰り返せばエラーは防げるはずだ、と考えるかもしれない。しかし、現実にはどれほど注意深く運用していても、不具合は発生する。
システム間の予期せぬ相互作用
WordPressサイトは、コア、テーマ、多数のプラグイン、サーバー環境、そしてデータベースが複雑に絡み合って動いている。テスト環境では完璧に動いていた変更が、本番環境のリアルなデータや特定のトラフィック状況下で予期せぬ挙動を示すことは珍しくない。すべての組み合わせを事前に網羅することは、物理的に不可能なのだ。
「バックアップがあるから安心」の落とし穴
バックアップは必須の備えだが、それだけで十分ではない。重要なのは、バックアップを使って「どれだけ早く復旧できるか」だ。復旧作業に数時間を要したり、専門知識が必要でサポートの返信を待たなければならなかったりする場合、その間の機会損失は防げない。バックアップの存在と同じくらい、復旧プロセスの簡便さが重要になる。
真の信頼性とは「失敗した後の回復スピード」にある

ここで、信頼性の考え方を180度変えてみよう。信頼できるサイトとは「決して壊れないサイト」ではなく「壊れてもすぐに直せるサイト」のことだ。この考え方を「レジリエンス(回復力)」と呼ぶ。
リスクを封じ込める設計
レジリエンスの高いシステムでは、変更を加える際のリスクが適切に管理されている。例えば、本番サイトを直接触るのではなく、本番のコピー環境である「ステージング環境」でテストを行う。これにより、万が一エラーが起きても、影響をその環境内だけに封じ込めることができる。ユーザーが閲覧している本番サイトには一切の悪影響を与えない。
ECサイトにおける「回復力」の可視化
例えば、WooCommerceを利用しているECサイトで、プラグイン更新により「カートに入れる」ボタンが動かなくなった状況を想定してみよう。以下のデモは、エラー発生時と、回復力が機能して即座に復旧した状態を比較したものだ。
(コンソールにJavaScriptエラーが表示されている状態)
(原因調査はステージング環境で別途実施)
このデモのように、エラーを検知してから正常な状態に戻すまでの時間をいかに短縮できるかが、ビジネスの継続性を左右する。
リスクを最小化するホスティング環境の選び方
回復力を高めるためには、運用者の努力だけでなく、それを受け止める土台となるホスティング環境が重要だ。優れた環境は、人間がミスをすることを前提とした「安全装置」を標準で備えている。
1. ワンクリックで作成できるステージング環境
ステージング環境の作成に手間がかかるようでは、ついつい本番サイトを直接編集したくなってしまう。ボタン一つで本番と全く同じ環境をコピーでき、テストが終わればボタン一つで本番に反映(デプロイ)できる仕組みがあることが望ましい。これにより「まずはテストする」という習慣が自然に身につく。
2. 自動バックアップと高速なリストア
毎日、あるいは変更を加える直前に自動でバックアップが作成されることは最低条件だ。さらに重要なのは、そのバックアップを数分以内に本番サイトへ反映できる「リストア(復元)」のスピードだ。リストア中にサイトが長時間止まってしまう環境では、回復力が高いとは言えない。
3. 異常を早期に知らせる監視システム
エラーは、ユーザーから指摘される前に自分たちで気づくのが理想だ。サイトの表示が遅くなっていないか、特定のページでエラーが発生していないかを常時監視し、異常があればすぐに通知が届く仕組みがあれば、問題が深刻化する前に手を打つことができる。監視とは、サイトの健康状態をチェックする検診のようなものだ。
独自分析:エラーを許容する文化がサイトを強くする
技術的な備えと同じくらい大切なのが、運用チームの考え方だ。筆者の分析によれば、最も安定しているサイトを運営しているチームは「ミスを責めない」文化を持っている。ミスをした個人を責めるのではなく「なぜこのミスが起きたのか」「どうすれば次からシステムがこのミスを防げるか」という点に注力しているのだ。
これを「ブレイムレス・ポストモーテム(非難なしの事後検証)」と呼ぶ。例えば、あるプラグインの更新でサイトが壊れた際、担当者を叱責するのではなく、更新前に必ずステージング環境でチェックするワークフローを自動化する、といった解決策を導き出す。人間に完璧を求めるのではなく、システムで人間をサポートする姿勢こそが、長期的な信頼性を生む鍵となる。
この記事のポイント
- WordPressのダウンタイムの主因は、トラフィック増加ではなく人為的なミスである。
- 設定ファイルの記述ミスやプラグインの競合は、どれほど熟練した人でも避けられない。
- 真の信頼性とは、エラーをゼロにすることではなく、迅速に復旧できる「回復力」を指す。
- ステージング環境や高速なリストア機能を備えたインフラを選ぶことが、最大の安全策になる。
- ミスを責めるのではなく、システムでミスをカバーする運用文化が安定したサイトを作る。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Cloudflareが提唱するエージェント指向クラウド。Agents Week 2026の全発表まとめ
AIエージェントが自律的にコードを書き、顧客サポートを完結させ、複雑なリサーチを数分でこなす時代が到来した。これまでのクラウドは「1つのアプリケーションが多くのユーザーにサービスを提供する」というモデルで設計されていたが、その前提が根底から覆されようとしている。
Cloudflareは2026年4月、AIエージェントが主役となる新しいインフラ「Agentic Cloud(エージェント指向クラウド)」の構築に向けた大規模なアップデート「Agents Week」を実施した。数千万のエージェントが並列稼働する世界を支えるため、計算資源からセキュリティ、開発ツールまで、全レイヤーにわたる新機能が公開された。
本記事では、Cloudflareが目指す「Cloud 2.0」の全容と、発表された膨大な新機能のポイントを整理して解説する。開発者がプロトタイプから本番環境へとエージェントをスケールさせるための、具体的な武器が揃ったと言える。
エージェントのための新しい計算基盤と実行環境

エージェントは人間とは異なり、24時間365日、膨大な数で並列に動作する。そのため、従来の仮想マシンやコンテナよりも軽量で、かつ持続性のある計算資源が必要だ。Cloudflareは、エージェントが自由にコードを書き、実行できる専用の環境を整備した。
Git互換ストレージ「Artifacts」と隔離環境「Sandboxes」
「Artifacts(アーティファクツ)」は、エージェントが生成したコードやデータを保存するための、Git互換のバージョン管理ストレージだ。エージェントは数千万のリポジトリを動的に作成し、既存のリモート環境からフォーク(複製)して作業を進めることができる。これにより、エージェントが書いたコードを即座にGitクライアントで引き継ぐことが可能になった。
また、エージェントが実際にコマンドを実行し、パッケージをインストールするための環境として「Cloudflare Sandboxes」が正式リリース(GA)された。これは、ファイルシステムやシェルを備えた本物のコンピュータのような環境でありながら、ミリ秒単位で起動し、必要に応じて状態を保存・再開できる。エージェントごとに「専用のパソコン」を割り当てるイメージだ。
Durable Objectsによるエージェント専用データベース
「Durable Objects(デュラブル・オブジェクト)」は、特定の状態を保持できるサーバーレスの仕組みだ。今回のアップデートでは、Durable ObjectsにSQLiteデータベースを内蔵できる「Facets」という機能が追加された。これにより、エージェントが動的に生成したアプリケーションごとに、完全に隔離された専用のデータベースを持たせることが可能になる。
エージェントごとの隔離が難しく、管理が複雑。
エージェント B ➔ 専用SQLite DB
個別に隔離され、ミリ秒で起動・破棄が可能。
この仕組みにより、開発者は数万人のユーザーに対して、それぞれ専用のAIエージェントと専用のDBを瞬時に提供するプラットフォームを構築できる。スケーラビリティの概念が、ユーザー単位からエージェント単位へとシフトしている。
自律動作を支えるセキュリティとネットワーク

エージェントが社内ネットワークにアクセスしたり、ユーザーに代わって決済を行ったりする場合、セキュリティが最大の懸念となる。Cloudflareは、エージェントを「非人間(Non-human)のアイデンティティ」として定義し、その行動を厳密に制御する仕組みを導入した。
プライベート接続を簡素化する「Cloudflare Mesh」
「Cloudflare Mesh(クラウドフレア・メッシュ)」は、ユーザー、デバイス、そしてAIエージェントを安全につなぐプライベートネットワーク機能だ。これまでは、エージェントが社内のデータベースにアクセスするためには複雑なトンネル設定が必要だったが、Meshを使えば、エージェントに最小限の権限(最小特権原則)を与えて直接接続させることができる。
ユーザーに代わって認証する「Managed OAuth」
エージェントがユーザーの代わりにSaaSツールを操作する場合、これまではセキュリティ的に危うい「サービスアカウント」が使われることが多かった。今回発表された「Managed OAuth for Access」は、RFC 9728という新しい規格を採用し、エージェントがユーザーの権限を安全に借用して認証を行う仕組みを提供する。これにより、エージェントが何をしたかの監査ログも正確に残るようになる。
エージェントを「知能」に変えるツールボックス
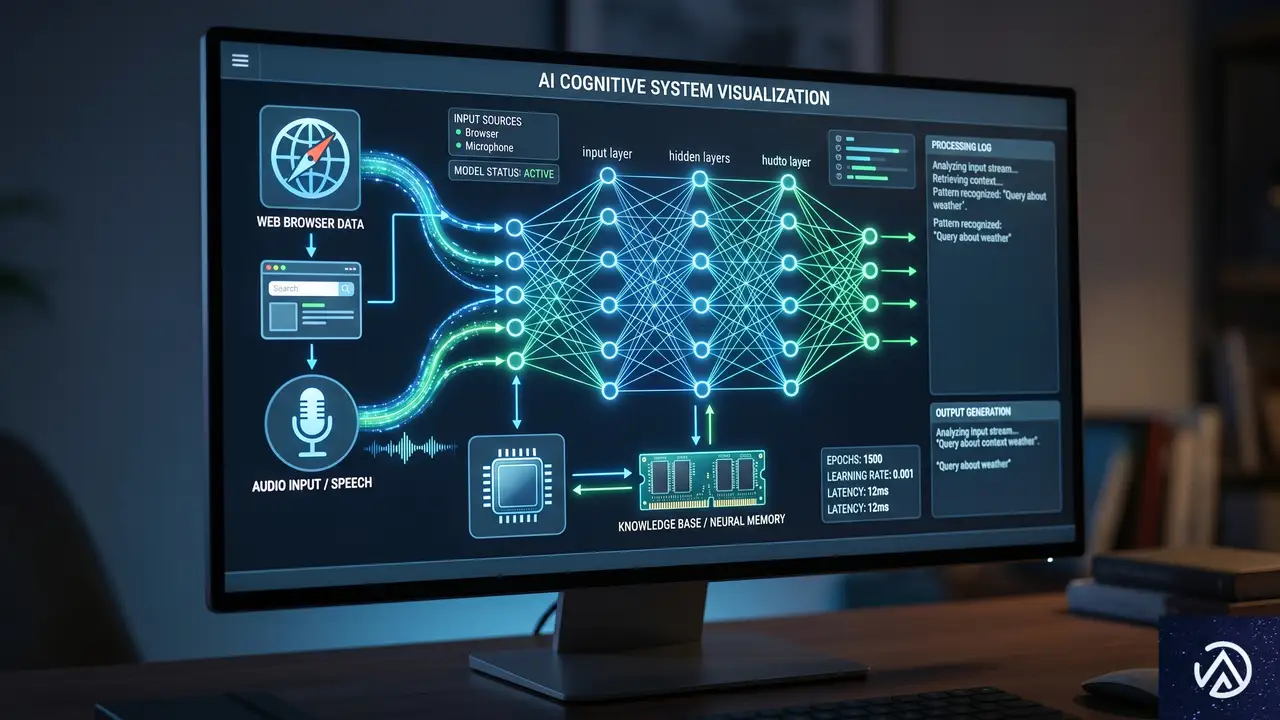
計算資源があるだけではエージェントは動けない。適切なモデル(脳)、記憶(メモリー)、そして外部世界を認識する手段(ブラウザや音声)が必要だ。Cloudflareはこれらを「Agents SDK」として統合し、数行のコードで実装可能にした。
長期記憶と高度な検索機能
エージェントが過去の会話や作業内容を忘れないようにするための「Agent Memory」が導入された。これは、エージェントに必要な情報を記憶させ、不要な情報を忘れさせるマネージドサービスだ。また、「AI Search」という新しい検索プリミティブ(基本要素)を使えば、エージェントが膨大な文書の中から必要な情報をハイブリッド検索(キーワードと意味の両方で検索)して取り出せるようになる。
ブラウザ操作とマルチモーダル対応
「Browser Run(旧Browser Rendering)」は、エージェントにブラウザを与える機能だ。エージェントはウェブサイトを閲覧し、フォームを入力し、スクリーンショットを撮ることができる。新機能の「Human in the Loop」を使えば、エージェントが判断に迷ったときだけ人間に確認を求めるフローも構築可能だ。
さらに、音声認識(STT)と音声合成(TTS)をリアルタイムで行うパイプラインも追加された。WebSocket(ウェブソケット:双方向通信を行うための規格)を使い、わずか30行程度のコードで「声で会話するエージェント」を実装できる。メールの送受信も「Cloudflare Email Service」を通じてネイティブにサポートされた。
開発効率を最大化するインターフェースの進化

Cloudflareそのものの使い勝手も、エージェント時代に合わせて変化している。開発者が管理画面でポチポチと設定を変えるのではなく、エージェントがAPIを通じてインフラを操作するシーンが増えるからだ。
統一CLI「cf」と管理画面AI「Agent Lee」
約3,000ものAPI操作を統合した新しいCLI(コマンドライン・インターフェース)「cf」が登場した。これは人間だけでなく、エージェントがインフラを操作する際の一貫性を保つために設計されている。また、Cloudflareのダッシュボード内には「Agent Lee」というAIアシスタントが常駐するようになった。ユーザーはプロンプトを入力するだけで、複雑なスタックのトラブルシューティングや設定変更を行える。
ドメイン登録もAPIから可能に
「Cloudflare Registrar API」がベータ版として公開された。これにより、エージェントが自らドメインを検索し、空き状況を確認して登録するまでを完全に自動化できる。エージェントが新しいサービスを立ち上げ、ドメインを取得し、デプロイするまでの全工程がプログラム可能になったことを意味する。
ウェブ全体をエージェント対応へアップデートする

現在のインターネットは人間が読むことを前提に作られているが、これからはエージェントが読みやすい「Agentic Web」への適応が求められる。Cloudflareは、サイト運営者がこの変化に対応するためのツールも提供開始した。
Agent Readiness ScoreとAIトレーニング用リダイレクト
自分のサイトがどれだけAIエージェントにとって読みやすいかを測定する「Agent Readiness Score」が導入された。構造化データが適切か、ボットのアクセスを過度に制限していないかなどを評価する。また、古いコンテンツをAIが学習しないように、検証済みのクローラーを最新のページへ自動で誘導する「Redirects for AI Training」機能も追加された。これにより、古い情報に基づいたAIの回答(ハルシネーション)を防ぐことができる。
独自の分析:Cloudflareが描く「Cloud 2.0」の正体

今回のAgents Weekを通じて見えてきたのは、Cloudflareが「エッジコンピューティング」の強みを最大限に活かし、他社とは異なるアプローチでAIインフラを構築しようとしている点だ。AWSやGoogle Cloudが巨大なGPUセンターに注力する一方で、Cloudflareは「エージェントの実行場所(推論と実行の融合)」という独自のポジションを狙っている。
筆者の見解では、Cloudflareが提唱する「Cloud 2.0」の核心は、ステート(状態)とコンピューティングの極限までの近接にある。Durable Objectsによる超低遅延な状態管理と、ミリ秒で起動するSandboxesの組み合わせは、数千万という単位で増殖するエージェントを効率よく捌くための唯一の解かもしれない。中央集権的なクラウドでは、これほど大量の独立したセッションを低コストで維持するのは困難だからだ。
また、セキュリティを「後付け」ではなく「デフォルト」に置いている点も重要だ。エージェントが自律的に動く世界では、一度の権限設定ミスが致命的な被害を招く。MeshやManaged OAuthをインフラ層で提供することで、開発者はセキュリティの専門知識がなくても「安全なエージェント」を構築できるようになる。これはエージェントの普及を加速させる大きな要因になるだろう。
この記事のポイント
- Cloudflareは、AIエージェントが主役となる「Agentic Cloud(Cloud 2.0)」への進化を宣言した。
- Git互換ストレージ「Artifacts」や隔離環境「Sandboxes」により、エージェント専用の計算基盤が整った。
- 「Cloudflare Mesh」や「Managed OAuth」により、非人間(エージェント)の安全な認証とアクセス制御が可能になった。
- 「Agents SDK」に記憶、検索、ブラウザ操作、音声、メール機能が統合され、開発効率が飛躍的に向上した。
- サイトのエージェント親和性を測る「Agent Readiness Score」など、ウェブ自体をエージェント向けに最適化するツールが登場した。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

WordPress運用の自動化がもたらす経済的メリットとスケーリング戦略
WordPress制作を主軸とするエージェンシーにとって、クライアントが増えることは喜ばしい。しかし、サイト数が増えるにつれて「保守運用」という目に見えない重荷がチームの時間を奪い始める。手動での管理を続けていると、売上の増加以上に運用コストが膨らみ、利益率が低下する「スケーリングの罠」に陥るリスクがある。
この課題を解決する鍵は、運用の基盤に自動化を組み込むことだ。Kinstaの報告によれば、自動化を取り入れた企業の中には、週のメンテナンス時間を15時間から10時間以下へ削減し、年間で250時間以上の創出に成功した例もあるという。これは単なる時短ではなく、ビジネスの成長モデルそのものを変えるインパクトを持っている。
本記事では、手動管理がもたらす真のコストを明らかにし、インフラ、ツール、APIという3つのレイヤーでどのように自動化を進めるべきかを解説する。技術に詳しい同僚が教えるような視点で、最新のWeb制作現場で求められる効率化の全容を紐解いていこう。
手動管理がもたらす「スケーリングの罠」と真のコスト

多くの制作会社では、サイト管理の内容を「プラグインの更新」や「バックアップの確認」といった目に見えるタスクのリストとして捉えている。しかし、管理サイトが30件、50件と増えたとき、それぞれのタスクが毎週どれだけの時間を消費しているかを正確に把握しているケースは少ない。
目に見えない運用負荷の正体
一般的なメンテナンス業務には、プラグインやコアのアップデート、セキュリティ監視、バックアップの検証、キャッシュ管理などが含まれる。これらを1サイトずつ手動で行う場合、1件あたりの時間は短くても、サイト数が増えるとその合計時間は膨大なものになる。
例えば、30サイトのプラグイン更新に毎週2時間を費やしているとする。この時間は直接的な収益を生まない「維持」のためのコストだ。この時間が積み重なることで、新しいクライアントの獲得や戦略的な提案に割くべき「機会費用」が失われていく。手動管理は、ビジネスの成長を物理的に制限するブレーキとなってしまうのだ。
「人を増やす」解決策が限界を迎える理由
チームが忙しくなると、新しいスタッフを雇用して対応しようとするのが一般的だ。しかし、手動管理を前提とした組織では、人を増やしても1人あたりの管理可能件数は変わらない。給与や採用コスト、管理工数が増えるだけで、サイト1件あたりの利益率は改善しないという問題がある。
一方で、自動化されたワークフローは異なる性質を持つ。20サイトを管理する自動化システムは、200サイトを管理する場合でもほとんどコストが変わらない。つまり、管理数が増えるほど、サイト1件あたりの「限界費用(新しく1サイトを追加する際にかかる費用)」がゼロに近づいていく。これが、自動化がビジネスの経済性を根本から変える理由だ。
インフラ層で実現する「何もしない」運用自動化

自動化の第一歩は、WordPressが動作するサーバーやインフラのレベルで、人間が介入しなくても済む仕組みを整えることだ。これを「インフラレベルの自動化」と呼ぶ。信頼できるホスティングサービスを選択することで、多くの保守作業をシステムに委ねることが可能になる。
自己修復するPHPとデータベース最適化
サイトのダウンタイムを防ぐためには、サーバーの状態を常に監視する必要がある。例えば、Kinstaのようなプラットフォームでは「自己修復PHP」という機能が提供されている。これは、PHPプロセスが停止したことを検知すると、システムが自動的に再起動を試みる仕組みだ。これにより、管理者が気づく前にサイトが復旧し、クライアントへの報告や緊急対応の手間がなくなる。
また、データベースの最適化も自動化できる領域だ。毎週自動的にMySQL(データベース管理システム)の設定を微調整し、パフォーマンスを維持する機能があれば、エンジニアが手動でクエリを最適化する必要はなくなる。こうした「見えない自動化」が、サイトの安定性を底上げしてくれる。
クラウドフレア連携による高度なセキュリティ
セキュリティ対策も、手動で行うには限界がある分野だ。最新のプラットフォームでは、Cloudflare(クラウドフレア)などのエンタープライズ級ファイアウォールが標準で組み込まれている。これにより、DDoS攻撃(大量のアクセスでサイトを落とす攻撃)や不正アクセスを、サーバーに到達する前に自動で遮断できる。
マルウェアのスキャンや脆弱性へのパッチ適用がバックグラウンドで常時実行されていれば、管理者はアラートが出たときだけ対応すれば済むようになる。セキュリティを「個別の作業」から「インフラの標準機能」へ移行させることが、運用の経済性を高める鍵となる。
管理画面から一括操作!プラットフォームによる効率化
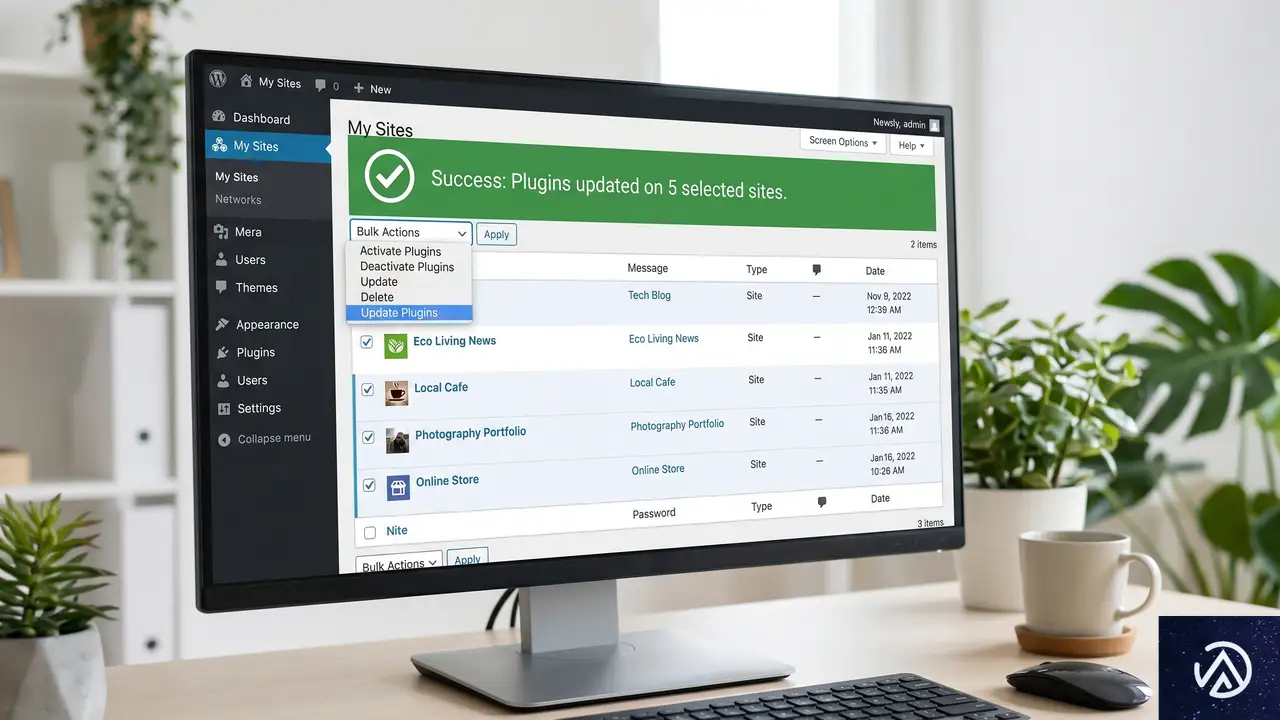
インフラの次に重要なのが、日常的な運用タスクを効率化するツールだ。複数のWordPressサイトを抱えている場合、それぞれのダッシュボードに個別にログインするのは非常に非効率だ。これを解決するのが「一括操作」の機能である。
複数サイトのキャッシュ・プラグイン一括更新
管理サイトが数十件に及ぶ場合、特定のプラグインに脆弱性が見つかった際の対応は戦場のような忙しさになる。しかし、管理プラットフォームのバルクアクション(一括操作)機能を使えば、チェックボックスでサイトを選択し、一クリックで全サイトのプラグインを更新できる。
キャッシュのクリアも同様だ。CDN(コンテンツ・デリバリー・ネットワーク)やサーバーキャッシュを、管理画面から一括でフラッシュできれば、デプロイ後の表示確認作業が劇的にスムーズになる。以下のデモは、手動でのキャッシュ管理と一括管理のフローを視覚化したものだ。
● サイトBにログイン → キャッシュ削除
● サイトCにログイン → キャッシュ削除
● 「キャッシュをクリア」ボタンを1回押す
このデモのように、作業ステップを「n回(サイト数)」から「1回」に集約することが自動化の本質だ。
視覚的テストを伴う安全な自動アップデート
自動アップデートは便利だが、更新によってサイトのデザインが崩れることを懸念する人は多い。そこで注目されているのが、ビジュアル・リグレッション・テスト(視覚的比較テスト)を組み合わせた自動アップデートだ。
これは、アップデートの前後でサイトのスクリーンショットを自動撮影し、ピクセル単位で差異を比較する技術だ。もし大きな崩れを検知した場合は、自動的にアップデートをロールバック(元の状態に戻す)し、管理者に通知する。この仕組みがあれば、人間が目視で全ページを確認する必要がなくなり、安全に完全自動化へ踏み出せる。
APIとカスタムスクリプトで独自のワークフローを構築する

さらに高度な自動化を目指すなら、API(アプリケーション・プログラミング・インターフェース)の活用が不可欠だ。APIとは、外部のプログラムからシステムを操作するための窓口のようなものだ。これを利用することで、自社の既存ワークフローとホスティング管理を密接に連携させることができる。
サイト構築からログ取得までの自動連携
例えば、新規クライアントの契約が決まった瞬間、CRM(顧客管理システム)の情報をトリガーにして、自動的にWordPressの新規環境を構築し、初期プラグインをインストールするスクリプトを組むことができる。営業担当者が入力を終えたときには、エンジニアが手を動かす前に開発環境が用意されているという状態だ。
また、トラブルシューティングに必要なサーバーログの取得もAPIで自動化できる。以下のコード例は、特定の環境からエラーログを取得するためのJavaScript関数のイメージだ。これを自社の管理ツールに組み込めば、わざわざホスティングの管理画面を開く必要すらなくなる。
async function getSiteLogs(environmentId, fileName, lines) {
const query = new URLSearchParams({
file_name: fileName || 'error',
lines: lines || 1000,
}).toString();
const resp = await fetch(
`https://api.kinsta.com/v2/sites/environments/${environmentId}/logs?${query}`,
{
method: 'GET',
headers: { 'Authorization': 'Bearer YOUR_API_KEY' },
}
);
const data = await resp.json();
return data;
}CI/CDパイプラインへの統合
モダンな開発現場では、CI/CD(継続的インテグレーション/継続的デリバリー)という手法が一般的だ。これは、コードをGitHubなどにアップロードすると、自動的にテストが走り、本番環境へ反映される仕組みを指す。
APIを活用すれば、このデプロイの流れの中に「キャッシュのクリア」や「バックアップの作成」を自動的に組み込める。開発者がコードを書くことに集中し、運用の付随作業を意識しなくて済む環境こそが、高い生産性を生み出す。KinstaのようなAPIを公開しているプラットフォームを選ぶことは、将来的な拡張性を確保する上で極めて重要だ。
自動化が変えるWordPressビジネスの収益構造
自動化を導入した結果、ビジネスにはどのような変化が起きるのだろうか。最も顕著なのは、チームの時間が「守り」から「攻め」へとシフトすることだ。手動のメンテナンスから解放されたスタッフは、より価値の高い業務に集中できるようになる。
浮いた時間を「攻め」の施策に転換する
例えば、あるeコマース特化のエージェンシーでは、ホスティングの切り替えと自動化の導入により、サポート担当者1人あたり1日2時間の削減に成功した。この時間は、クライアントへの戦略的なマーケティング提案や、新しい売上を生む機能の開発に充てられたという。
開発者がアップデート作業に追われなくなれば、クライアントのビジネス成長に直結するコンサルティングが可能になる。これは、単なる「保守費用」以上の付加価値をクライアントに提供できることを意味し、結果として契約単価の向上や顧客満足度の改善につながるのだ。
サイト数が増えるほど利益率が上がる仕組み
自動化の最大のメリットは、ビジネスのスケーラビリティが向上することだ。従来は「サイトが増える = 忙しくなる = 人を雇う = 利益が残らない」という負のループがあった。しかし、自動化スタック(技術の積み重ね)を構築すれば、サイトの追加に伴う運用コストの上昇を最小限に抑えられる。
100サイトを管理する労力が10サイトの時とそれほど変わらなければ、増えた売上の大部分が利益として残るようになる。この「規模の経済」を享受できるかどうかが、制作会社として生き残れるかどうかの分水嶺になるだろう。質の高いホスティングサービスへの投資は、単なる経費ではなく、将来の利益率を確保するための「資本投資」と考えるべきだ。
この記事のポイント
- 手動管理を続けると、サイト数が増えるほど運用コストが利益を圧迫する「スケーリングの罠」に陥る
- 自己修復PHPや自動セキュリティ監視などのインフラ自動化により、日常的なトラブル対応をゼロに近づけられる
- 管理プラットフォームの一括操作機能を活用すれば、数十サイトの更新作業を数分に短縮できる
- APIを利用して独自のワークフローを構築することで、開発から運用までの一貫した自動化が可能になる
- 自動化で浮いた時間を戦略的業務に充てることで、ビジネスの付加価値と利益率を同時に高められる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AIと人間の知性が交差するEC制作! チームの創造力を最大化する技術統合の秘訣
AIの導入は、もはや避けて通れない課題となっている。しかし、多くの現場では「既存の優れたワークフローを壊してしまうのではないか」という懸念が根強い。特にブランドイメージが重要なECサイト制作において、AIによる自動化と人間らしい感性の両立は最大のテーマだ。
2026年5月に開催予定のMarTechカンファレンスでは、この「AIと人間の知性の融合」をテーマにしたセッションが予定されている。クリエイティブチームと技術チームがどのように同期し、ブランドの声を保護しながらAIを味方につけるべきか。その具体的な道筋が示される予定だ。
本記事では、このセッションで議論される予定の内容を基に、EC制作やWooCommerce運営に携わるチームが直面する課題と解決策を深掘りする。AIを単なる代替手段ではなく、アイデアを増幅させる「力」として活用するためのヒントを探っていく。
AIと人間の協創がECサイト運営にもたらす変革

AIを導入する際、最も大きな障壁となるのは「技術的な複雑さ」よりも「心理的な抵抗感」である。長年かけて磨き上げてきたチームの制作フローを、AIという新しい要素が乱してしまうことへの不安だ。しかし、本来AIは既存のプロセスを破壊するものではなく、補強するものとして捉えるべきである。
ワークフローを壊さずにAIを組み込む重要性
EC制作の現場では、商品登録からバナー制作、コーディングまで多岐にわたる工程が存在する。これらすべてを一度にAI化しようとすれば、必ず混乱が生じる。MarTechの記事で紹介されている専門家たちは、AIを「副操縦士(コパイロット)」として既存のスタックに埋め込む手法を推奨している。
例えば、WooCommerceのカスタマイズを行う際、開発者がゼロからPHPコードを書くのではなく、AIが生成したコードの断片を人間が検証して組み込む。これにより、開発スピードを上げつつ、サイトの安定性を人間が担保するという理想的な役割分担が可能になる。
クリエイティブと技術の橋渡しとしてのAI
クリエイティブチームが描くビジョンと、技術チームが実装する機能の間には、しばしば「言語の壁」が存在する。AIはこの両者を結びつける共通言語になり得る。画像生成AIを使ってプロトタイプを素早く共有したり、技術的な仕様書を非エンジニアにも分かりやすい言葉に変換したりすることで、チーム内の疎通が劇的に改善される。
Walk WestのCEOであるGreg Boone氏らは、AIを「最高のアイデアを増幅させる力」と位置づけている。技術的な制約で諦めていた表現が、AIの助けを借りることで実現可能になるケースも少なくない。AIは、クリエイティブと技術の境界線を曖昧にし、より統合されたチーム体験を提供するツールとなる。
ブランドの声を保護しながらAIを活用する方法
AIが生成するコンテンツは、時として「無機質」や「ブランドイメージに合わない」という問題を抱える。ECサイトにおいて、ブランド独自のトーン&マナー(語り口や雰囲気)は顧客の信頼に直結する。AIを活用しつつ、いかにしてブランドの独自性を守り抜くかが運用の鍵を握る。
生成コンテンツの品質管理とガードレール
ブランドの声を保護するためには、AIに対する明確な「ガードレール」の設定が必要だ。これは、AIが越えてはいけない一線や、必ず守るべきルールを定義することを指す。InvocaのCMOであるPeter Isaacson氏らは、AIツールを導入する際にこのガイドラインの策定を重視している。
具体的には、過去の成功したキャッチコピーやブランドガイドラインをAIに学習させ、出力されるテキストのトーンを固定する手法が有効だ。また、不適切な表現や競合他社の名称を出さないためのネガティブプロンプトの活用も、ブランド保護の重要な一環となる。
このデモのように、AIにブランドの性格を教え込むことで、単なる事実の羅列から「心に響くコピー」へと進化させることができる。
人間による最終チェックの役割
どれほどAIの精度が上がっても、最終的な判断を下すのは人間であるべきだ。CellaのKate Roberts氏は、AIによるコンテンツ制作において「人間による編集(Human-in-the-loop)」の重要性を説いている。AIは初稿を作成するスピードは圧倒的だが、文脈の微細なニュアンスや、その時々の社会情勢に配慮した調整は苦手だ。
EC制作チームにおいては、AIを「ライター」としてではなく「リサーチ兼下書き担当」として活用するのが現実的だ。AIが生成した複数の案から、ブランド担当者が最適なものを選び、磨き上げる。このプロセスを経ることで、効率化とブランド品質の維持を高い次元で両立できる。
ECチームのためのAI導入実践ガイド
具体的に、WooCommerceなどのECサイトを運営するチームがどのようにAIを導入すべきか。理論だけでなく、実務に直結するステップを整理する。重要なのは、小さな成功を積み重ねながら、徐々に適用範囲を広げていくことだ。
WooCommerce開発におけるAIコパイロットの活用
技術チームにとって、AIは強力なデバッグツールであり、学習支援ツールだ。例えば、WooCommerceの特定のアクションフックを探したり、複雑な条件分岐を持つ配送料計算ロジックを書いたりする際、GitHub Copilotのようなツールは大きな助けになる。
「このフックの使い方を教えて」とAIに問いかければ、公式ドキュメントを探し回る時間を大幅に短縮できる。ただし、AIが提案するコードには古いバージョンのAPIが含まれている可能性もあるため、必ず最新のWooCommerce環境でテストを行う必要がある。AIは「調べる時間」を削り、人間が「設計とテスト」に集中できる環境を作る。
コンテンツ制作の効率化とスピードアップ
クリエイティブチームにとってのAIは、アイデアの壁打ち相手だ。新商品のランディングページを作る際、構成案をAIに複数出させることで、自分たちだけでは思いつかなかった切り口が見つかることもある。また、商品画像の背景をAIで差し替えるといった作業は、すでに多くのECサイトで実用化されている。
大量の商品バリエーションがある場合、それぞれの特徴を捉えた説明文を個別に書くのは膨大な労力がかかる。ここでAIを活用し、基本スペックから魅力的な紹介文を自動生成する仕組みを構築すれば、サイト公開までのリードタイムを数日から数時間に短縮することも可能だ。
組織文化の醸成! 不安を実験に変えるアプローチ

AI導入を成功させるための最後のピースは、ツールでも技術でもなく「文化」である。チームメンバーがAIを自分たちの仕事を奪う脅威ではなく、自分たちの能力を拡張するパートナーとして受け入れられるかどうかが重要だ。そのためには、不確実性を恐れず、実験を称賛する雰囲気作りが欠かせない。
チーム全体のリスキリングとマインドセット
AI時代に求められるスキルは、自ら手を動かす技術から、AIを使いこなし、その出力を評価する技術へとシフトしている。これを「リスキリング(スキルの再習得)」と呼ぶ。MarTechのカンファレンスで議論されるように、組織はメンバーがAIを試行錯誤するための時間と環境を保証する必要がある。
「この作業をAIに任せたらどうなるか?」という問いを日常的に投げかける文化が重要だ。最初から完璧な成果を求めるのではなく、AIとの対話を通じてプロセスを改善していく姿勢が、長期的なチームの競争力を高める。失敗は「AIの限界を知るための貴重なデータ」としてポジティブに捉えるべきである。
失敗を許容するプロトタイピングの文化
EC制作においては、本番環境に影響を与えない「サンドボックス(実験場)」での試行が推奨される。AIが提案した新しいデザインや機能を、まずは一部のユーザーやテスト環境で試し、データを取る。こうした「小さく試して早く失敗する」サイクルを回すことが、AI活用の熟練度を上げる近道だ。
MarTechのセッションを主宰するMarc Sirkin氏らは、AI導入の成功は「確信」ではなく「実験」から生まれると指摘している。正解が分からない中で一歩を踏み出す勇気を、組織全体でサポートする体制が求められている。AIと人間が互いの得意分野を補完し合う関係を築けたとき、ECサイトは単なる販売チャネルを超え、ブランドの新たな価値を生む場所へと進化するだろう。
この記事のポイント
- AIは既存のワークフローを壊すものではなく、チームの能力を増幅させる「副操縦士」である
- ブランドの声を保護するために、AIに対する明確なガイドライン(ガードレール)と人間の最終チェックが不可欠
- WooCommerce開発やコンテンツ制作において、AIはリサーチや下書きの時間を劇的に短縮する
- 成功の鍵は、不安を実験に変える組織文化と、失敗を許容するプロトタイピングの姿勢にある
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

WooCommerce売上を最大化するセールスファンネルの作り方!成約率を高める5つのステップ
WooCommerceサイトの売上を伸ばすために最も重要なのは、アクセス数そのものではなく、訪問者をいかに効率よく購入へ導くかという導線設計だ。
統計によれば、一般的なECサイトではカートに商品を入れたユーザーの約70%が最終的に購入せずに離脱している。この「穴の空いたバケツ」のような状態を放置したまま広告費を投じても、期待する収益は得られない。
本記事では、特別なプログラミング知識を使わずに、WooCommerceで成約率を劇的に高める「セールスファンネル」を構築する具体的な手順を解説する。この仕組みを整えることで、一度限りの購入客をリピーターに変え、収益を自動的に積み上げる体制が整うはずだ。
セールスファンネルの基本概念と重要性

セールスファンネルとは、見込み客が商品を知り、興味を持ち、最終的に購入に至るまでのプロセスを「漏斗(ファンネル)」に見立てたモデルのことだ。WooCommerceにおいてこの概念が重要なのは、単に商品を並べるだけのショップから、顧客の心理に寄り添った「売れる仕組み」へと進化させる必要があるからだ。
ファンネルを構成する4つのステージ
セールスファンネルは大きく分けて4つの段階で構成される。第1段階は「認知(Awareness)」で、検索エンジンやSNSを通じてショップを発見してもらうフェーズだ。第2段階は「興味・検討(Interest / Consideration)」で、商品の詳細を確認し、他社と比較検討する。ここで信頼を勝ち取ることが重要になる。
第3段階は「決定・購入(Decision / Purchase)」で、実際に決済を行う。この段階での摩擦(入力のしにくさや不安感)を最小限に抑えることが、成約率に直結する。そして最後の第4段階が「保持・忠誠(Retention / Loyalty)」だ。購入後のフォローを通じて、再購入やファン化を促す。WP Beginnerの指摘によれば、これらのステージを明確に理解し、各フェーズで適切な施策を打つことで、コンバージョンは即座に改善され始めるという。
なぜWooCommerceにファンネルが必要なのか
多くのストアオーナーはトップページへの集客に注力しがちだが、情報が多すぎるトップページは逆にユーザーを迷わせてしまう。セールスファンネルを構築すると、特定のオファーに対してユーザーの注意を一点に集中させることができる。これにより、不必要な選択肢を排除し、購入という最終目標への最短ルートを提供できるのが最大のメリットだ。
高い成約率を生むランディングページの構築

ファンネルの入り口となるのがランディングページ(LP)だ。WooCommerceの標準的な商品ページは情報が整理されているが、セールスに特化しているわけではない。成約率を高めるには、余計なリンクを排除し、商品のベネフィットを強調した専用のページが必要になる。
ランディングページに必須の5要素
効果的なLPには共通の構成要素がある。まず「ベネフィットを伝える見出し」だ。その商品が顧客のどのような悩みを解決するのかを一目で伝えなければならない。次に「高品質な画像や動画」で、使用シーンを具体的にイメージさせる。3つ目は「社会的証明(口コミや評価)」で、他者の満足度を示すことで購入の不安を払拭する。
4つ目は「特徴ではなく利点を伝える説明文」だ。「1000mAhのバッテリー」というスペックではなく「外出先でも1日中充電を気にせず使える」という利点を強調する。最後は「明確な1つのコール・トゥ・アクション(CTA)」だ。ボタンは大きく、目立つ色で配置し、次に何をすべきかを迷わせないことが重要だ。SeedProdのようなページビルダーを活用すれば、これらの要素をドラッグ&ドロップで簡単に配置できる。
リード獲得用フォームの設置
すべての訪問者がすぐに購入するわけではない。そのため、購入に至らなかったユーザーのメールアドレスを収集する仕組みが不可欠だ。これを「リードマグネット」と呼ぶ。初回購入限定のクーポンや、商品の選び方ガイド(PDF)などを特典として提供することで、将来的な顧客リストを構築できる。OptinMonsterなどのツールを使い、離脱しようとした瞬間にポップアップを表示させる手法は非常に効果的だ。
顧客単価を向上させるアップセルとクロスセルの戦略
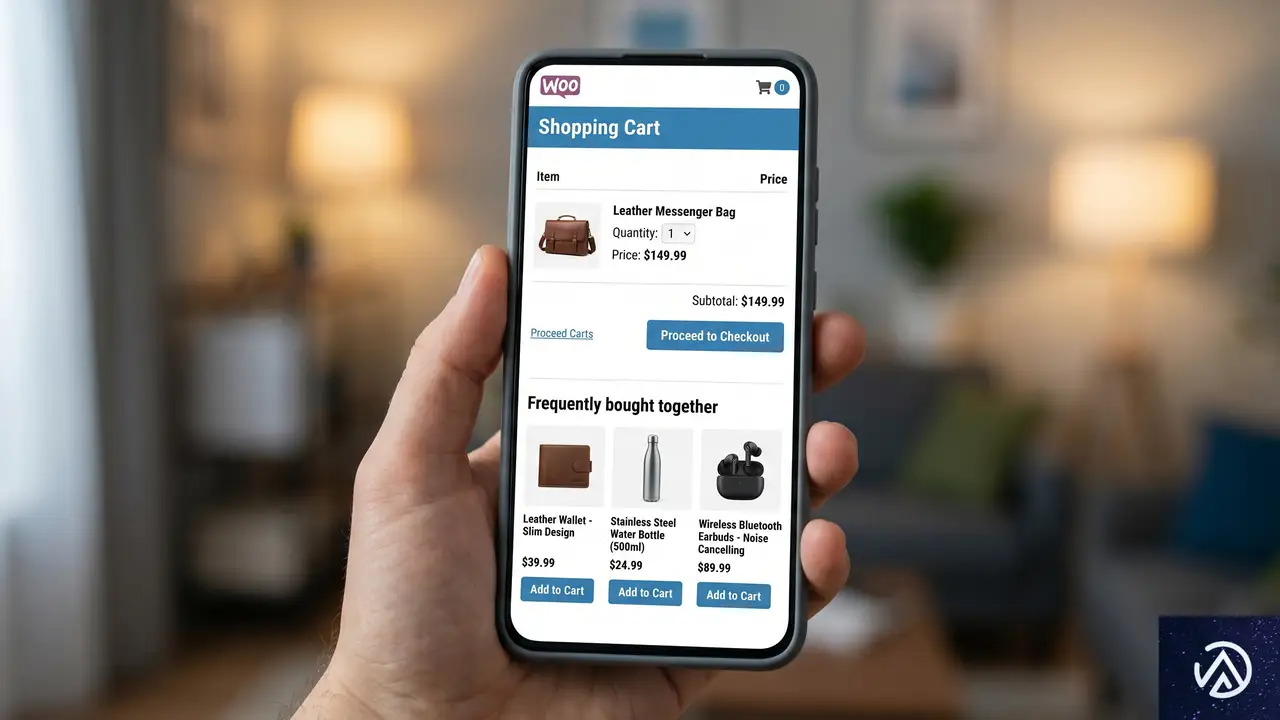
売上を増やすためのもう一つの鍵は、顧客1人あたりの購入単価(AOV)を上げることだ。商品を購入しようとしている、あるいは購入した直後のユーザーは、追加の提案を受け入れやすい心理状態にある。
アップセルとクロスセルの使い分け
アップセルとは、検討中の商品よりも上位のモデルや大容量版を提案することだ。一方、クロスセルは関連する補完商品を提案することを指す。例えば、カメラを買おうとしている人に、より高性能なレンズを勧めるのがアップセル、カメラケースやメモリーカードを勧めるのがクロスセルだ。さらに、提案を断った場合に少し安い選択肢を提示する「ダウンセル」も、機会損失を防ぐために有効だ。
このデモのように、決済プロセスの中で適切な提案を行うことで、同じ集客数でも売上を大幅に伸ばすことが可能になる。WP Beginnerの推奨によれば、アップセルの価格は元の商品の25〜50%程度に設定するのが最も成約率が高いという。
オファーを提示する最適なタイミング
提案のタイミングは「購入前(カート内)」と「購入後(決済完了直後のページ)」の2つがある。特に「ポストパーチェス(購入後)アップセル」は非常に強力だ。一度クレジットカード情報を入力して決済を終えた直後は、心理的なハードルが下がっているため、ワンクリックで追加購入できるオファーは非常に高い成約率を記録する傾向がある。
離脱を防ぐチェックアウト画面の最適化手法
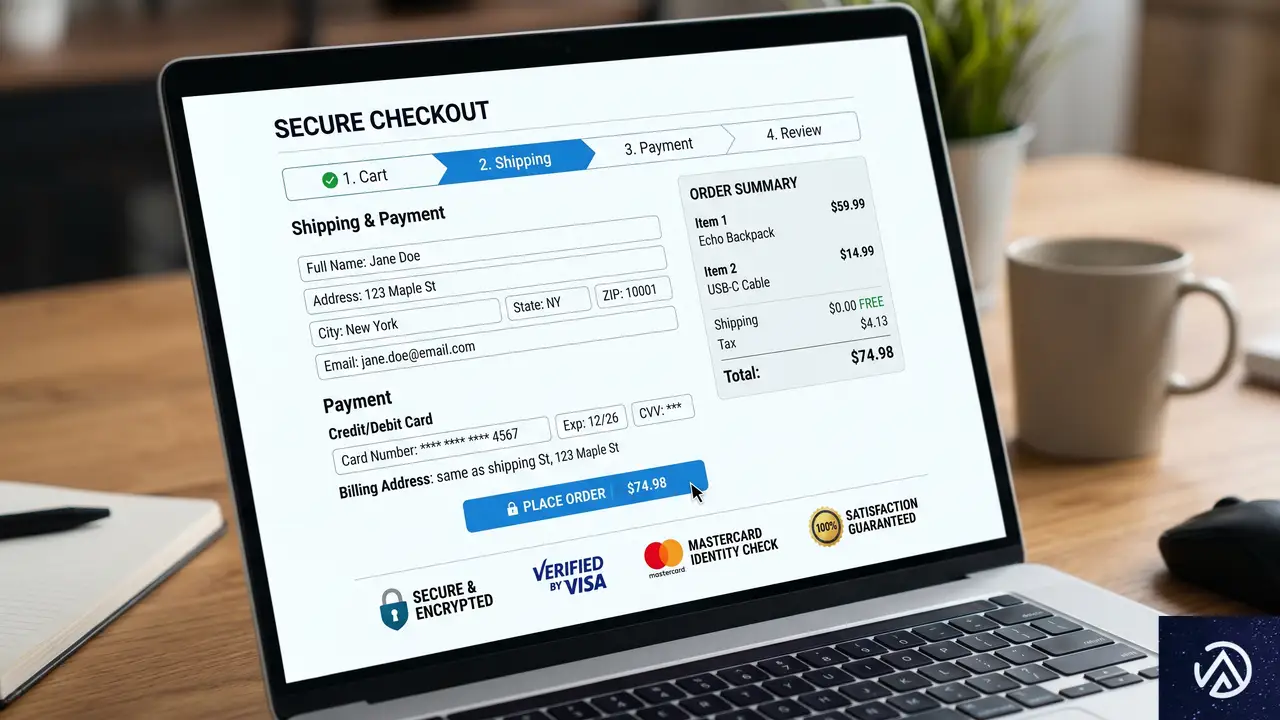
チェックアウト(決済)画面は、ファンネルの中で最も離脱が発生しやすい場所だ。入力項目が多すぎたり、送料が最後に表示されたりすると、ユーザーはストレスを感じてページを閉じてしまう。ここでの目標は「摩擦(フリクション)」を徹底的に排除することだ。
フォームの簡素化とゲスト購入の許可
まず取り組むべきは、入力フィールドを最小限に絞ることだ。配送に不要な電話番号の必須入力を外したり、デジタル商品の場合は住所入力を省略したりすることで、完了までの時間を短縮できる。また、アカウント作成を必須にせず「ゲスト購入」を許可することも重要だ。会員登録の手間を省くことで、初回購入の障壁を大幅に下げることができる。
信頼の構築と進捗の可視化
ユーザーが安心して決済できるように、SSL証明書のロゴや「30日間返金保証」といった信頼バッジをチェックアウトボタンの近くに配置しよう。また、ステップ形式のチェックアウトを採用している場合は、進捗インジケーターを表示して「あとどれくらいで終わるか」を明示する。これにより、ゴールの見えないストレスによる離脱を防ぐことができる。MerchantやFunnelKitといったプラグインを使えば、WooCommerceの標準的なチェックアウト画面を、モバイル最適化された1ページ構成にカスタマイズすることが可能だ。
購入後のフォローアップとリピーター獲得の仕組み

商品が売れたら終わりではない。真の収益はリピート購入から生まれる。購入直後の顧客はブランドに対して最も関心が高いため、このタイミングで適切な自動メールを送ることが、LTV(顧客生涯価値)の向上に繋がる。
カゴ落ちメールの自動化
カートに商品を入れたまま離脱したユーザーに対して、自動的にリマインドを送る「カゴ落ちメール」は必須の施策だ。WP Beginnerが推奨するスケジュールは、離脱から1時間後に「お忘れではありませんか?」という親切な通知、24時間後に「他のお客様のレビュー」で信頼を補強、そして72時間後に「期間限定クーポン」で最後の一押しをすることだ。この3ステップのシーケンスだけで、失われるはずだった売上の10〜20%を回収できる可能性がある。
サンキューページと次回のオファー
決済完了後の「サンキューページ」を単なる確認画面にしておくのはもったいない。ここにSNSのフォローボタンを置いたり、次回使えるクーポンを表示したり、関連商品の動画を載せたりすることで、顧客との接点を維持できる。FunnelKit Automationsのようなツールを使えば、購入した商品に基づいてパーソナライズされたフォローアップメールを自動送信し、数週間後の再来店を促す仕組みも構築できる。
この記事のポイント
- セールスファンネルは、認知からリピートまでを最適化する「売れる仕組み」である
- ランディングページでは、機能ではなく「顧客が得られる利点」を強調する
- アップセルは決済直後の心理的ハードルが低いタイミングで提案するのが最も効果的だ
- チェックアウト画面から不要な入力項目を削り、摩擦をゼロに近づける
- カゴ落ちメールや購入後の自動フォローで、一度きりの顧客をファンに変える
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AI検索でブランドが消える?「没個性税」を回避する最新SEO戦略
AIは検索の仕組みを変えるだけでなく、どのブランドを「無視するか」を決定する審判になりつつある。従来の検索エンジン最適化(SEO)が通用しなくなる中で、企業は自社の存在がAIによって消し去られるリスクに直面している。
Adobe Summitにおいて、SemrushのCMO(最高マーケティング責任者)であるAndrew Warden氏は、ブランドの可視性が根本から変化したと指摘した。AIシステムが情報をフィルタリングする過程で、特徴のないブランドは組織的に排除される可能性があるという。
本記事では、Warden氏が提唱する「Bland Tax(没個性税)」という概念を中心に、AI検索時代に生き残るためのブランド戦略を深掘りする。AIに選ばれ、ユーザーに届くための新しいルールを理解することが、これからのマーケティングの成否を分けるだろう。
AIが情報のゲートキーパーになるエージェント時代の到来

現在、検索行動のデータには明らかな変化が現れている。Google検索の約60%が、Webサイトへのクリックを伴わずに終了しているという。これは、ユーザーが検索結果画面でAIが生成した回答を読み、そのまま満足して離脱していることを意味する。
GoogleのAI Overviews(AIオーバービュー)やChatGPT、Perplexityといったツールは、もはや単なる検索ツールではない。これらは「新しいゲートキーパー」として機能し、ユーザーと情報の間に立って、どの情報を提示し、どのブランドを紹介するかを選別している。
検索行動の変化とクリックゼロの現実
ユーザーは以前のように複数のサイトを巡回して情報を比較検討する手間をかけなくなっている。対話型のインターフェース内で質問を重ね、解決策を絞り込んでいく「エージェント型」の利用が一般的になりつつある。この環境下では、AIの回答に含まれないブランドは、ユーザーの視界から完全に消滅してしまう。
LLMユーザーのコンバージョン率は4倍高い
一方で、クリック数が減ることは必ずしも悪いことばかりではない。Warden氏は、大規模言語モデル(LLM)を利用している消費者は、従来の検索のみを利用するユーザーに比べて、コンバージョン率が少なくとも4倍高いというデータを提示している。AIを通じて情報を探しているユーザーは、より具体的で強い購入意図を持っているため、AIに選ばれることの価値は極めて高い。
● サイトA ● サイトB ● サイトC
■ 選ばれたブランドのみが表示される
この図は、検索体験が「分散」から「集約」へと変化している様子を示している。AIが情報を統合するため、選ばれなかった情報は存在しないも同然となる。
没個性なブランドを襲うBland Tax(没個性税)の正体

Warden氏が提唱する最も重要な概念が「Bland Tax(没個性税)」だ。これは、特徴のない平凡なコンテンツを発信し続けるブランドが支払うことになる、目に見えないペナルティを指す。AIは現在、平凡な内容(Blandness)を無視するように学習を進めているという。
「平均的であること」や「ジェネリックであること」は、AI検索の世界では「透明であること」と同義だ。どこにでもあるような情報を発信しているブランドは、AIによって他の情報とひとまとめに要約され、ブランド名が引用されることすらなくなる。
平均的なコンテンツはAIに吸収される
AIは複数のソースから似たような情報を集め、1つの簡潔な回答を作成する。この際、独自の見解や新しい事実が含まれていないコンテンツは、AIの知識の一部として吸収されるだけで、出典として明記される価値がないと判断される。これが、ブランドアイデンティティが消去されるプロセスだ。
ブランド名が消え、AIの学習データにされるリスク
独自の価値を提供できないブランドのコンテンツは、AIを賢くするための「無料のトレーニング場」に成り下がってしまう。情報の提供元としての認知を得られないまま、コンテンツだけがAIの回答精度を高めるために消費される。これはマーケティング投資として極めて効率が悪い状態だといえる。
AIに選ばれるための発見可能性と権威性
AI検索時代において、ブランドの可視性は「発見可能性(Discoverability)」と「権威性(Authority)」の掛け合わせで決まる。Warden氏は、この両方が不可欠であると強調している。どちらか一方が欠けても、AIの回答に食い込むことはできない。
「発見可能性」とは、AIがそのブランドの情報を技術的に見つけられるかどうかを指す。そして「権威性」とは、AIがそのブランドを信頼し、回答に含める価値があると判断するかどうかを指す。この2つを高い次元で両立させることが、新時代のSEO戦略の核心だ。
基礎としてのSEOはAIの教本になる
SEOは死んだという極端な意見もあるが、Warden氏はこれを明確に否定している。むしろ、SEOはこれまで以上に基礎的な役割を担うようになっている。現在のSEOは人間に見せるためだけのものではなく、AIに対する「トレーニングマニュアル」としての側面が強まっているからだ。
以下の要素が欠けているブランドは、AIの会話から完全に排除されるリスクがある。
- クローラビリティ(AIが情報を収集できるか)
- インデクサビリティ(情報がデータベースに登録されるか)
- 構造化データ(情報の意味をAIが正しく理解できるか)
- 権威シグナル(信頼に足る情報源か)
エンティティ権威を確立するブランド需要
AIは「エンティティ(実体)」とその関係性を地図のようにマッピングして理解している。AIに特定のトピックの権威として認識されるためには、ブランドそのものに対する需要、つまり「指名検索」が重要になる。人々がそのブランドを探していなければ、AIもまたそのブランドを探そうとはしないからだ。
独自の価値を証明する3つの重要シグナル

Warden氏は、ブランドがAIにフィルタリングされず、優先的に表示されるために必要な3つの具体的なシグナルを挙げている。これらは、AIが「この情報は特別だ」と判断するための基準となるものだ。
単に記事を量産するのではなく、これらのシグナルを意識したコンテンツ制作が求められる。独自性(オリジナリティ)を担保することで、AIの回答における可視性は30%から40%向上する可能性があるという。
1. 情報の密度とオリジナリティ
AIは「新しい事実」を引用することを好む。既存の情報の焼き直しではなく、以下のような要素を含むコンテンツが評価される。
- 独自の調査データや統計
- 自社だけが持つ一次情報
- 専門家による独自の視点や分析
- 具体的な成功事例や失敗談
2. シグナルの整合性と合意
AIは自社サイトの情報だけでなく、ネット上のあらゆる場所にある「他者の声」を参照している。Redditでの議論、YouTubeのレビュー、SNSでの言及、メディアでの報道などが、ブランドの信頼性を裏付ける「合意シグナル」となる。これらの情報が矛盾している場合、AIはそのブランドを「信頼できない」とフラグ立てする恐れがある。
3. エンティティの関連付け
特定のキーワードだけでなく、トピック全体においてブランドがどのように位置づけられているかが問われる。関連するコミュニティでの会話に参加し、専門的なメディアで取り上げられることで、AIの知識グラフ内でのブランドの結びつきを強化できる。
これらの要素が組み合わさることで、AIは「このブランドは引用する価値がある」と確信する。単一の施策ではなく、多角的なシグナルの構築が必要だ。
組織全体で取り組む可視性の再定義

AI検索への対応を難しくしている要因の1つは、組織の断絶にあるとWarden氏は指摘している。多くの企業では、SEOチーム、広報(PR)チーム、ブランドチーム、広告チームが個別に動いており、情報の整合性が取れていないケースが多い。
しかし、AIはこれらすべてのチャネルからデータを吸い上げている。SEOチームがどれほど最適化しても、PRチームが発信するメッセージが異なっていたり、SNSでの評判が悪かったりすれば、AIはそのブランドを高く評価しない。可視性はもはや特定のチームの問題ではなく、組織全体で取り組むべき課題だ。
トラフィックから関連性への評価軸シフト
従来の評価指標も通用しなくなっている。検索順位は安定しているのにトラフィックが減る、という現象が多くのサイトで起きている。これはAIが回答を肩代わりしているためだ。一方で、リード(見込み客)の質や数は向上している場合もある。
マーケターは「何回のクリックを得たか」という指標から、「AIの回答においてどれほど関連性の高い存在として扱われているか」という指標へと視点を移す必要がある。トラフィックはもはや、ブランドの成功を測る唯一の代理指標ではなくなっている。
アルゴリズムはもはや味方ではない
かつてのSEOは、Googleのアルゴリズムを理解し、それに合わせることで「順位」を競うゲームだった。しかし、今のAIは「何が有意義か」を判断する究極の裁定者となっている。アルゴリズムを攻略するハック(手法)よりも、リアルな世界での信頼と独自の価値を積み上げることこそが、最大の防御であり攻撃となる。
この記事のポイント
- AIは平凡なコンテンツを無視する「没個性税(Bland Tax)」を課し始めている
- AI検索時代はトラフィックが減る一方で、コンバージョン率が4倍高まる可能性がある
- SEOはAIにブランドの情報を教えるための「トレーニングマニュアル」として機能する
- 独自の調査データ、外部評価の整合性、専門的な権威性がAIに選ばれる鍵となる
- 可視性の向上には、SEO・PR・ブランドの各チームが連携した一貫した戦略が不可欠だ
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験