

Elementorエディタが開かない時のREST API 403エラー解決法
Elementorエディタが読み込まれずにフリーズし、REST APIが403禁止エラーを返す場合、根本原因は「プラグインコアファイルの破損」「WordPressのサブディレクトリ構成による認証不整合」「サーバーレベルのアクセス制限」のいずれか、または複合にある。FTPやファイルマネージャーから手動でElementorを再設置し、サイト設定の見直しとパーマリンク構造のリセットを実施すれば、大半のエラーは解消する。
なぜ Elementor エディタが開かず REST API が403エラーになるのか

プラグインコアファイルの破損が引き起こす連鎖不具合
Elementorが途中でアップデートに失敗したり、サーバー上でファイルが欠損したりすると、致命的なクラス読み込みエラーが発生する。代表的なものが「Uncaught Error: Class “Elementor\Controls_Stack” not found」だ。これはElementor本体の動作に必須のファイルが物理的に存在しないか、PHPの要求に対して不完全な状態で読み込まれていることを示す。管理画面からの再インストールではサーバーキャッシュや権限の影響で上書きに失敗するケースがあるため、手動での完全初期化が必要になる。
WordPressのサブディレクトリ構成が生む認証クッキーのズレ
WordPress本体を/wordpressに配置し、サイトアドレスだけをルートドメインに設置する構成は、REST APIの認証において深刻な不具合を引き起こす。ブラウザはWordPressのログインクッキーを物理的なインストールパスに対して発行するため、サイトURLと実際のパスが異なると、APIリクエストに必要なnonceや認証クッキーが正しく送信されず「rest_not_logged_in」が返る。Elementorエディタは内部的に多数のREST API通信を行っているため、この認証エラーが編集画面そのものを動作不能にする。
サーバー設定やセキュリティプラグインがAPIをブロックしている
ModSecurityやWAF(ウェブアプリケーションファイアウォール)、あるいは.htaccessに記述された独自ルールが、/wp-json/パスへのアクセスを機械的にブロックしている場合も403エラーが発生する。また、一部のセキュリティプラグインはREST APIのエンドポイントを厳格に制限する機能を備えており、無効化したと思っていてもキャッシュ層に設定が残って影響していることがある。
エラーが発生している環境では、管理画面からの通常操作がほぼ通じない状態になっている。上のBefore/AfterのようにエディタとAPI認証を同時に復旧させるには、外部からのファイル操作とURL設定の修正が不可欠となる。
実際に環境を修復する4ステップの手順

STEP 1 FTPからElementorを手動で再設置する
管理画面の「プラグイン」から削除するだけでは、不完全なファイルが残る危険がある。FTPソフト、またはサーバーのファイルマネージャーを開き、/wp-content/plugins/elementor/ディレクトリを直接削除する。Pro版を使用している場合は/wp-content/plugins/elementor-pro/も同様に削除する。削除後、Elementorの公式サイトから最新のzipファイルをダウンロードし、同じディレクトリにアップロードして展開することで、完全に健康なコアファイルが書き戻される。これで「Controls_Stack」を含むクラスファイルの欠損は物理的に解消される。
STEP 2 パーマリンクをリセットしキャッシュを削除する
管理画面の「設定」→「パーマリンク」にアクセスし、「変更を保存」を2回クリックするだけでもREST APIのルーティング情報が再生成される。これにより、サイトの内部URL構造が強制的にリセットされる。あわせて、導入しているキャッシュプラグインの全キャッシュ削除、およびサーバー側のVarnishやNginxキャッシュが有効な場合はそれらのパージも実行する。
STEP 3 wp-config.phpでサイト構成の不整合を補正する
WordPress本体がサブディレクトリにある環境では、認証クッキーのパス指定を明示的に定義することで403エラーが劇的に改善する。ルートのwp-config.phpに以下の定数を追記する。これは「COOKIE_DOMAIN」の指定だけでなく、管理画面と公開側で異なるパスにクッキーを適応させるための指示だ。
define('COOKIEPATH', '/');
define('SITECOOKIEPATH', '/');
define('ADMIN_COOKIE_PATH', '/');
define('COOKIE_DOMAIN', '.〇〇.com'); // 自ドメインに合わせる自サイトがSSL化されている場合は、管理画面の「設定」→「一般」内の「WordPressアドレス」と「サイトアドレス」の両方がhttpsで始まっているかも再確認する。片方がhttpで残っているとREST APIのリクエストがクロスオリジン扱いされ、認証が外れる。
STEP 4 .htaccessとサーバー側の認証ブロックを解除する
WAFやModSecurityが/wp-json/へのアクセスを攻撃と誤認してブロックしている場合、サーバー管理パネルから当該ルールを一時無効化するか、ホワイトリストに追加する。レンタルサーバーの場合、管理画面の「セキュリティ」関連項目にWAFの遮断ログが記録されていることが多い。.htaccessに手動でREST APIを遮断する記述を追加した覚えがなくても、セキュリティプラグインが自動追記しているケースがあるため、以下の記述群が存在しないか確認する。
# もし以下のような記述があれば一時的に削除かコメントアウト
# RewriteRule ^wp-json - [F]致命的エラー「Class “Elementor\Controls_Stack” not found」の根本対応

このエラーは単にファイルが見つからないと言っているのではなく、「Elementorの起動シーケンスの中で呼び出されるべき抽象クラスがメモリ上に展開できない」という致命的な状態を指す。管理画面から一度プラグインを「無効化」して「再有効化」してもPHPのオートローダーが不完全なファイル索引を参照し続けるため、FTPから一度完全に削除して、再設置するSTEP 1だけが確実な解決策となる。Pro版を導入している場合、Free版のコアクラスが正しくロードされていないとPro版の処理がすべて失敗するため、必ず両方を手動で入れ直す。
サブディレクトリ環境で403を連発させない設定の定石
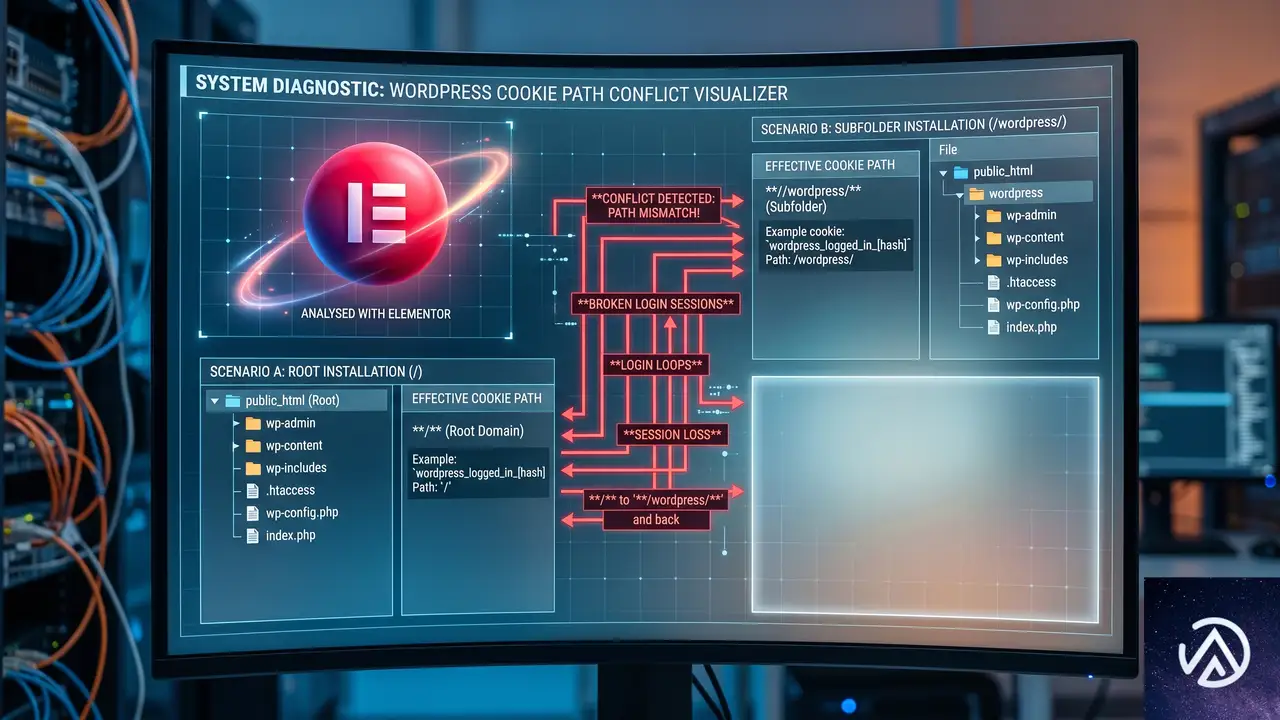
WordPressを/wordpressに置き、公開URLはルートにする構成は、管理画面へのアクセスパスと公開APIパスの二重構造を生む。システム内部ではadmin-ajax.phpやREST APIの呼び出し元が物理パスを参照する傾向にあるため、ここでクッキーの不一致が起きる。最も安定させる方法は、ルートにあるindex.phpが正しくサブディレクトリを指しているかを確認し、かつwp-config.phpで前述のクッキー定数を定義することだ。可能ならば、この際にWordPressをサブディレクトリからルートディレクトリへ正式に移動させることも検討する価値がある。
よくある質問
セーフモードを有効にしてもElementorエディタが開かないのはなぜか
セーフモードはテーマとElementor以外のプラグインを外して動作するが、今回の主原因は「Elementor本体ファイルの破損」と「REST APIの認証エラー」である。そのため、セーフモードでも参照するコアファイルが破損していれば画面は起動せず、API認証の障害もそのまま残り続ける。セーフモードはあくまで「他のプラグインとの競合」を疑う場合の手段であり、今回のような根本的なファイル破損には効果がない。
変更を保存したはずのパーマリンク設定が元に戻ることはあるか
サーバーの.htaccessファイルやNginxの設定ファイルが書き込み禁止になっていると、パーマリンクの更新が表層的に成功したように見えても内部的に反映されない。FTPで.htaccessのパーミッションが606や666など適切な値になっているか確認し、WordPressが自動生成するRewriteEngine On以下のブロックが存在するかも検証する必要がある。
PHPのバージョンアップが原因でElementorが動かなくなることはあるか
PHP 8.2や8.3、8.4へのアップデートで、従来は警告で済んでいたコードが致命的エラーに格上げされるケースは確かにある。しかし「Controls_Stack not found」はバージョン互換性よりもファイルの単純な欠落または不完全なアップロードが原因だ。事前にサーバーのPHPエラーログを開き、不足している具体的なファイルパスが出力されていないかを確認すると、欠落しているファイルが明確になる。
REST APIを意図的に無効化するセキュリティプラグインの代表例はあるか
WordfenceやiThemes Securityなどの包括的なセキュリティプラグインは、設定次第で未認証または全ユーザーのREST APIアクセスを制限できる。今回のケースではログイン済みの管理者でも「rest_not_logged_in」になるため、むしろクッキーやURLの不一致が強く疑われるが、検証のためにはそれらのプラグインを本当に全停止し、サーバー側のキャッシュを完全にパージする必要がある。
この記事のポイント
- 403エラーとエディタ停止はコアファイル破損と認証不整合の複合症状である
- 管理画面ではなくFTPから手動でフォルダを削除し再設置する
- サブディレクトリ環境では必ずCookie定数を明示的に定義する
- パーマリンクの再保存と全キャッシュの削除をセットで実行する
- WAFや.htaccessがREST APIをブロックしていないか確認する

・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Kauflandマーケットプレイス、スペインとオランダに進出へ
ドイツの小売大手Kauflandがマーケットプレイスをスペインとオランダに拡大する。2026年夏までに両国でサービスを開始し、欧州9カ国での展開が実現する見込みだ。
この動きにより、オンライン販売者の欧州リーチは大きく伸びる。同社のマーケットプレイスには現在32 million人の月間訪問者がおり、新市場で潜在顧客は220 million人に達するという。
EC事業者にとっては、クロスボーダー販売のハードルが下がる好機だ。すでに出品登録が開始されており、一括で全マーケットプレイスにアクセスできる体制が整いつつある。
Kauflandのマーケットプレイス展開と欧州成長
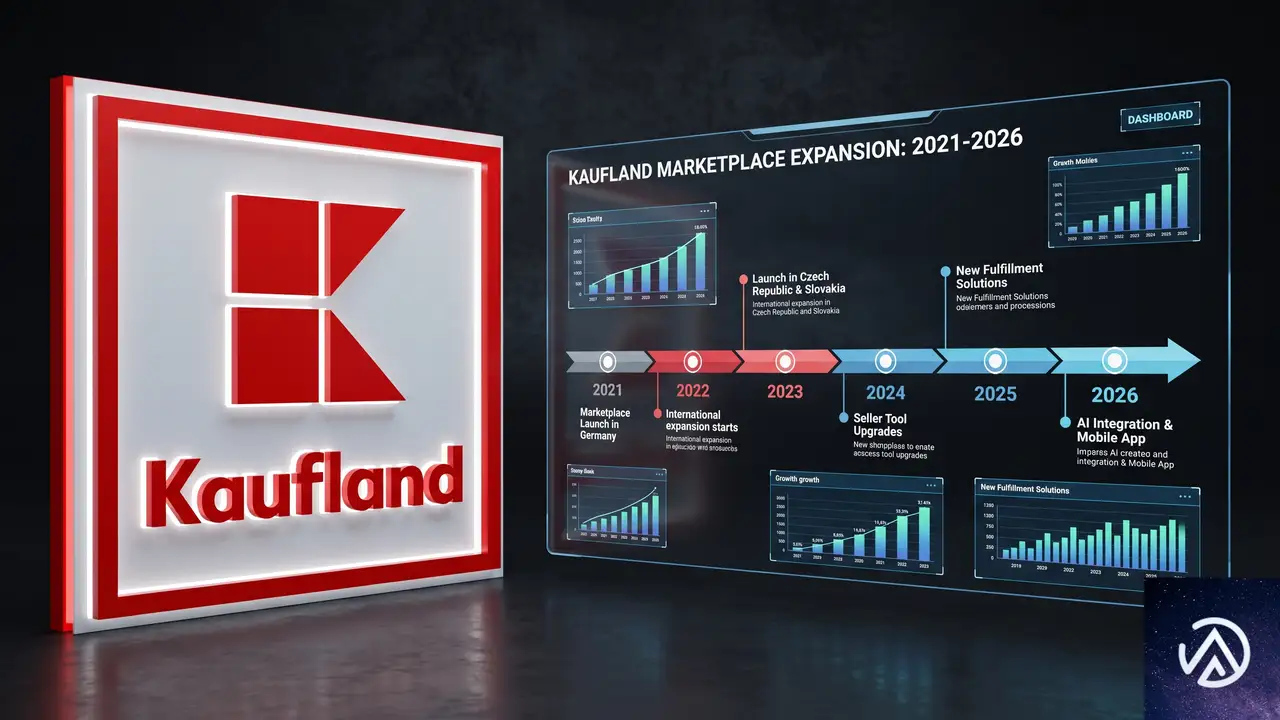
Kauflandはドイツに本拠を置くハイパーマーケットチェーンで、欧州8カ国に1,600以上の実店舗を展開する。Lidlと同じSchwarz Groupの一員であり、欧州最大級のリテール企業として知られている。
同社がマーケットプレイスモデルを導入したのは2021年のことだ。当初は自国ドイツのみだったが、その後スロバキアやチェコ、オーストリア、ポーランドへと拡大。2025年にはフランスとイタリアにも進出し、現在までに7カ国で運営してきた。
上図のように、Kauflandのマーケットプレイスは段階的に拡大し、ついに西欧の主要国へ足を踏み入れる。
ドイツ国内での圧倒的な集客力
ドイツ市場では月間32 million人の訪問者を集めており、45 million点以上の商品が6,400カテゴリにわたって出品されている。これは欧州のマーケットプレイスとしてトップクラスの数字だ。
また、オーストリアやポーランドでは開始から2年で収益が急増した。オーストリアで前年比439%増、ポーランドで322%増という驚異的な成長率を記録している。マーケットプレイスが新市場で急速に定着している証拠と言える。
マーケットプレイスモデルの急拡大が示すもの
Kauflandの拡大ペースは、欧州のオンライン小売が実店舗からマーケットプレイスへシフトしている流れを反映している。同社の発表によれば、現在のオンライン消費者基盤は139 million人に達している。
新市場が加わることで、この数字は220 million人まで膨らむ見込みだ。これは欧州のオンライン販売者にとって、極めて大きなリーチ拡大を意味する。
スペイン・オランダへの進出がもたらす具体的な変化
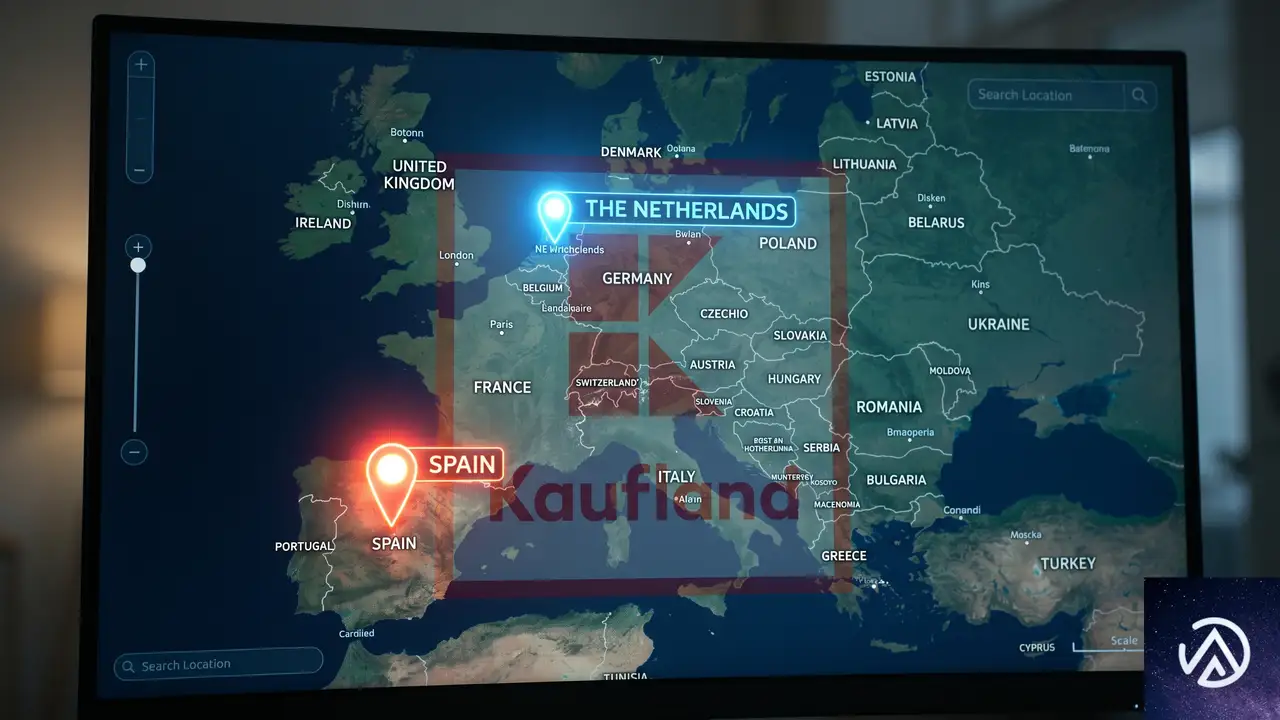
Kauflandは2026年夏までにスペインとオランダでのマーケットプレイス運用を開始する。これにより、同社のネットワークは欧州9カ国に広がり、欧州発のマーケットプレイスとして最大の規模になる。
スペインは欧州有数のEコマース市場だ。人口は47 million人を超え、オンライン購買率も年々上昇している。オランダも17 million人以上の人口を持ち、デジタルリテラシーが高く、越境ECへの親和性が高い国として知られている。
両国ともEコマースの成長が見込まれる地域であり、Kauflandの進出は販売者にとって新たな顧客層を開拓する機会となる。
2026年夏までに9カ国体制へ
Kauflandの発表では、スペインとオランダのマーケットプレイスはすでに出品登録を受け付けている。販売者は新しい市場に向けて商品準備を進められる段階だ。
これでKauflandはドイツ、スロバキア、チェコ、オーストリア、ポーランド、フランス、イタリア、そしてスペインとオランダの9カ国でオンラインマーケットを運営することになる。欧州のマーケットプレイスネットワークとして、AmazonやeBayに次ぐ存在感を見せ始めている。
欧州オンライン消費者へのリーチ拡大
現在の139 million人から220 million人へとリーチが伸びることで、中小規模のEC事業者でも大規模な販売機会を得られる。特に、日本を含むアジアの事業者が欧州市場に参入する際の有力なプラットフォームになり得る。
実際にKauflandはクロスボーダー販売を支援するツールを提供している。販売者は商品情報や顧客対応を現地言語で行うための翻訳機能を利用できるほか、現地通貨での決済処理も任せられる。
この一連の流れが、販売者の越境EC参入を容易にする。言語や通貨の壁をKauflandが吸収する形だ。
越境EC販売者への実務的な影響

Kauflandの拡大は、EC事業者にとってどのような実務的メリットをもたらすのか。特に、WooCommerceを利用する小規模事業者や、欧州進出を検討する日本の販売者にとって注目すべき点を整理する。
一括登録で全マーケットプレイスにアクセス
Kauflandのマーケットプレイスに一度登録すれば、スペインやオランダを含む全9カ国で商品を販売できる。各国別にアカウントを作成する手間が省け、管理が大幅にシンプルになる仕組みだ。
これにより、販売者は商品を一括でアップロードし、在庫や価格を一元管理できる。オペレーションコストを抑えつつ、複数市場での販売機会を得られる点が最大の魅力だろう。
現地化サポートと決済処理
Kauflandは販売者向けに、商品情報の翻訳ツールや顧客問い合わせへの現地語対応を提供する。法的文章の翻訳支援も含まれており、現地規制への対応負荷を軽減する。
決済面では、現地通貨での取引処理をKauflandが担う。販売者は自国通貨で売上を受け取れるため、為替リスクを気にせずに済む。これはクロスボーダーECの大きな障壁を取り除く要素だ。
上図のように、Kauflandの提供するツール群はクロスボーダー販売の煩雑さを大幅に軽減する。中小事業者でも欧州全域への販路拡大が現実的になる。
EC事業者としてどう動くべきか

Kauflandの欧州拡大は、EC事業者にとって大きなチャンスだ。しかし、ただ待っているだけでは他社に先を越される。今から準備を始めるべきポイントを整理する。
早期登録と商品準備
すでにKauflandでは新市場向けの出品登録が開始されている。早めに登録を済ませ、商品情報の翻訳や在庫体制を整えておくことが重要だ。特にスペイン語やオランダ語に対応した商品ページを用意する必要がある。
WooCommerceを利用している場合は、Kauflandとの商品連携プラグインやAPIを活用できる。多言語対応のプラグインと組み合わせれば、効率的にクロスボーダー販売を開始できるだろう。
欧州市場戦略の見直し
Kauflandのマーケットプレイスは、欧州9カ国で220 million人の消費者にリーチする。これはAmazonやeBayと異なる顧客層を取り込める可能性がある。価格競争に巻き込まれにくいニッチ商品や、欧州で需要の高い日本製品を展開する戦略が有効だ。
また、Kauflandは実店舗網も強みとしている。将来的にオンラインとオフラインの融合施策が打ち出される可能性もあり、早めの参入でブランド認知を高めておくことは有益と言える。
この記事のポイント
- Kauflandのマーケットプレイスが2026年夏までにスペインとオランダで開始される
- 欧州9カ国で220 million人の消費者リーチが実現し、越境ECの機会が拡大する
- 一括登録で全マーケットにアクセスでき、翻訳や現地通貨決済のサポートが提供される
- WooCommerceを含むEC事業者は早期登録と商品準備で優位に立つことができる
- 実店舗網との連携により、オンラインとオフラインの融合が期待される
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

WordPressのキーが長すぎるエラーをMariaDB 11.4で修正する方法
「指定されたキーが長すぎます。最大キー長は 1000 バイトです」というエラーが WordPress サイトのデータベースで発生した場合、対象となるテーブルの複合インデックス定義で長すぎるカラムのプレフィックス長を制限すれば解決する。これはデータベースの照合順序と文字コードの関係で、インデックスが許容バイト数を超過することが直接の原因だ。
「キーが長すぎる」エラーが発生する根本原因

このエラーは特定のデータベーステーブルに複合インデックスを作成しようとした際に、インデックスに含まれるカラムの合計バイト数がデータベースの上限を超えたために発生する。MariaDB や MySQL では、InnoDB ストレージエンジンの行フォーマットとサーバー設定によってキー長の上限が決まる。具体的には ROW_FORMAT が COMPACT または REDUNDANT のテーブルでは最大 767 バイトまでしか許容されず、DYNAMIC や COMPRESSED の場合でも実質的に 3072 バイトが上限となる。
今回のようなエラーが顕在化しやすいのは、データベースを MariaDB の最新バージョン(11.4 系など)に移行したタイミングだ。デフォルトの文字コードが utf8mb4 に設定されている環境で、VARCHAR 型のカラムをインデックスに含めると、1 文字が最大 4 バイトとして計算されるため、たとえば VARCHAR(255) のカラムが含まれているだけで、そのカラムだけで 1020 バイトを消費する計算になる。
プラグインが独自に追加した CHANGE_LOG テーブルでは、object_type、object_id、created_at という 3 つのカラムで複合インデックスを作ろうとしている。object_id は外部キーや参照用に VARCHAR で定義されていることが多く、これが長いままだとバイト数制限に引っかかる。解決の本質は、インデックスで実際に使用する範囲を object_id カラムの先頭部分だけに限定することにある。
エラーを特定するための確認手順
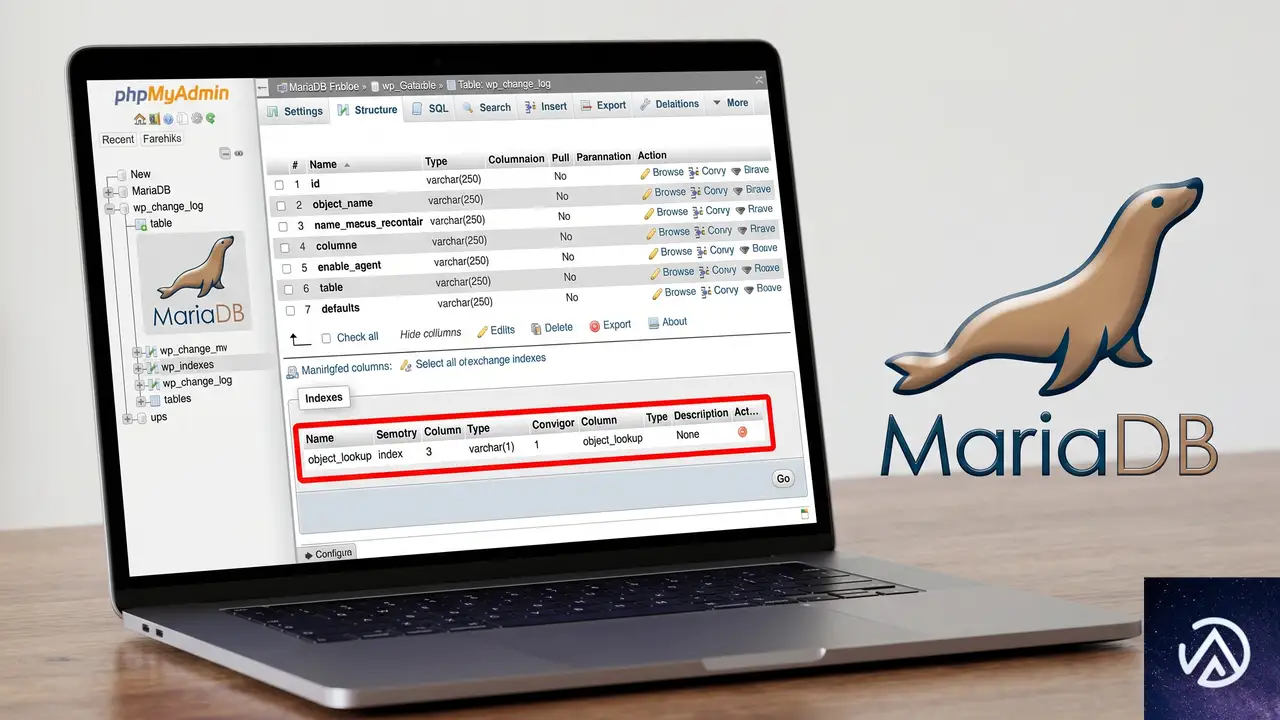
実際のエラーメッセージをログから確認する
データベースエラーの内容を正確に把握するために、まずは WordPress のデバッグログを有効化する。wp-config.php に以下の定数を追加する。
define( 'WP_DEBUG', true );
define( 'WP_DEBUG_LOG', true );
define( 'WP_DEBUG_DISPLAY', false );エラーを再現させたあと、/wp-content/debug.log を確認すると「Specified key was too long; max key length is 1000 bytes」というエラーが記録されているはずだ。このエラーには対象のテーブル名や、キーを作成しようとした SQL 文も含まれている。
テーブルのインデックス定義を直接調べる
データベース管理ツール(phpMyAdmin など)で CHANGE_LOG テーブルの構造を開き、「インデックス」タブを確認する。object_lookup という名前の複合インデックスが存在し、そこに object_id カラムがフルサイズで含まれていれば、これがエラーの原因だと特定できる。
SQL コマンドに慣れているなら、以下のクエリでインデックス情報を取得してもよい。
SHOW INDEX FROM wp_change_log;文字コードとバイト数の関係を理解する
utf8mb4 は 1 文字を最大 4 バイトで表現するため、VARCHAR(255) として定義されたカラムは、インデックス上で最大 1020 バイトを占める。複合インデックスでは、含まれる全カラムの最大バイト数の合計が制限値となる。VARCHAR(100) なら最大 400 バイト、VARCHAR(50) なら 200 バイトと計算していき、上限(1000 バイトや 767 バイト)を超えていないかを確認する。この計算を怠ると、一見問題ない定義に見えても実行時にエラーとなる。
複合インデックスを修正する具体的な手順
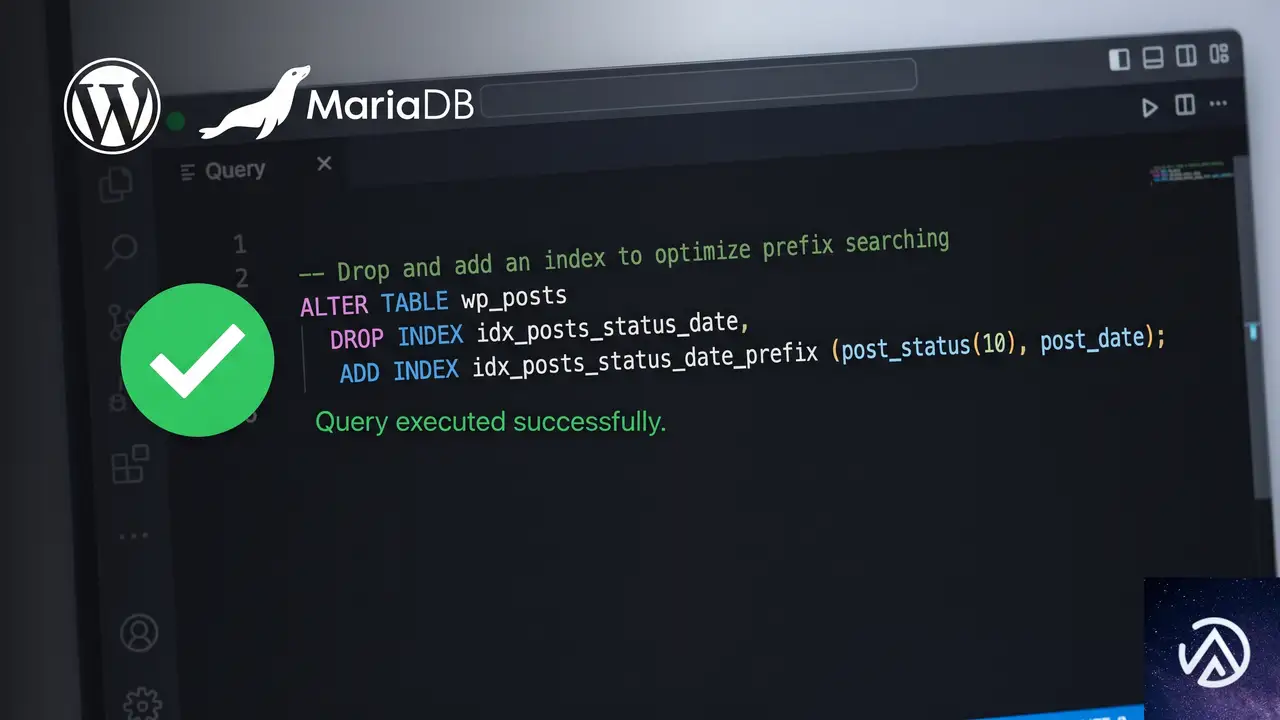
修正の基本方針は object_lookup インデックスから既存の定義を削除し、object_id カラムのプレフィックス長を制限した新しいインデックスを作り直すことにある。これによりバイト数制限を回避しながら、インデックスの機能自体は維持できる。
このデモは object_id にプレフィックス長を設定する前後のインデックス定義の違いを表している。修正後はバイト数制限に収まるため、エラーが解消される。
phpMyAdmin で安全にインデックスを変更する
データベースの直接操作に不慣れな場合、phpMyAdmin を使うとミスが少ない。該当テーブルを開き、「構造」タブから「インデックス」セクションに移動する。object_lookup インデックスを選択して削除し、新たに「インデックスを作成」から複合インデックスを追加する。
カラムを選択する際、object_type と created_at はそのまま指定し、object_id だけ「サイズ」欄に 100 と入力する。これで object_id(100) としてインデックスが作成される。
SQL コマンドで直接修正する場合
コマンドラインや SQL タブから実行するなら、以下の 2 文を順に実行する。DROP で既存のインデックスを削除し、ADD で新しいインデックスを作成する。
ALTER TABLE wp_change_log DROP INDEX object_lookup;
ALTER TABLE wp_change_log ADD INDEX object_lookup (object_type, object_id(100), created_at);実行前に必ずデータベースのバックアップを取得すること。誤った ALTER TABLE はテーブル構造を壊す可能性がある。
プラグインのアップデートで上書きされないようにする
このインデックスはプラグインが管理するスキーマファイル(class-change-log-schema.php)で定義されているため、プラグインがアップデートされると修正が上書きされてしまう可能性が高い。恒久的な対策としては、プラグインのアクティベーションフックやスキーマ更新処理にフックし、独自のインデックス定義を適用するコードを子テーマの functions.php かカスタムプラグインに記述する方法が有効だ。
データベースのバージョンや設定に依存する問題のため、サーバー環境を変更しない限りこの修正は必須となる。プラグイン開発者が将来的に修正を加えるまでは、自前のフックで対応しておくと安全だ。
よくある質問
このエラーは MariaDB 11.4 だけで発生するのか
MariaDB 11.4 に限らず、キー長制限が厳格に適用される環境ならば発生する可能性がある。古い MySQL 5.6 以前の設定や、InnoDB の ROW_FORMAT が COMPACT のテーブルでも同様のエラーが起こる。
object_id(100) のようにプレフィックスを制限しても検索性能は落ちないのか
先頭 100 文字までをインデックス化するため、100 文字を超える部分での検索精度は低下する可能性がある。ただ、object_id のような識別子は冒頭部分で十分に一意性が確保されることが多く、実際のクエリ性能に大きな影響は出ない。
エラーが WordPress 本体のテーブルで出た場合はどうすればよいか
WordPress コアのテーブルでこのエラーが発生することは稀だ。通常はプラグインやテーマが独自に追加したカスタムテーブルで起こる。もしコアテーブルで起こった場合は、データベースの文字コードや ROW_FORMAT の設定自体を見直す必要がある。
SQL の直接実行が不安なときの代替手段はあるか
WP-CLI(WordPress のコマンドライン管理ツール)が利用できるなら、「wp db query」コマンドで安全にクエリを実行できる。また、データベースの移行や最適化を支援するプラグイン(WP Migrate など)にも SQL 実行機能が備わっているものがある。
この記事のポイント
- インデックスに含まれるカラムの合計バイト数がデータベースの上限を超えるとキー長エラーが発生する
- utf8mb4 環境では VARCHAR 型のカラムが 1 文字最大 4 バイトを消費する点に注意が必要
- object_id(100) のようにカラムのプレフィックス長を指定してインデックスを再作成することでエラーを回避できる
- プラグインのアップデートで修正が上書きされるため、恒久的な対処にはフックを用いたコード管理が推奨される

・ Reddit、Stack Overflow、WordPress.org フォーラムを日々巡回し、現場の悩みを拾い上げて記事化
・ WordPress、WooCommerce、Next.js などモダンWeb制作領域のトラブルシューティングが専門
・ 「検索しても答えが見つからなかった」を一つでも減らすことが目標
・ エラーメッセージから根本原因にたどり着く粘り強い調査が得意
・ 初心者がつまずきやすい箇所を先回りで解決する記事作りを心がけている

WooCommerce支払いページで重大エラーが出る原因と直し方
WooCommerce の「支払いページ(Pay for Order)」で「このサイトで重大なエラーが発生しました」と表示されたり、決済フォームが読み込まれない場合、原因はほぼプラグインの競合かテーマのテンプレート不整合だ。管理画面からエラーログを確認し、プラグインの全無効化と標準テーマへの切り替えで原因を特定する手順を取れば、数十分で復旧できる。
Pay for Order ページで重大なエラーが出る原因
WooCommerce の Pay for Order(支払い)ページは、注文確認メールやマイアカウントの「注文の支払い」リンクから遷移する専用のチェックアウト画面だ。通常のチェックアウトと異なり、すでに作成済みの注文に対して決済だけを行う設計のため、内部で呼ばれる処理やパラメータが少し異なる。
決済プラグインやカスタムコードがこの固有のフローに対応していない場合、「このサイトで重大なエラーが発生しました」という WordPress の致命エラー画面が表示されたり、決済フォーム部分だけが真っ白になる。特に注文件数が多いサイトほど、Pay for Order の動作不良は直接売上に響くため即時対応が必要だ。
支払いページだけが壊れる仕組み
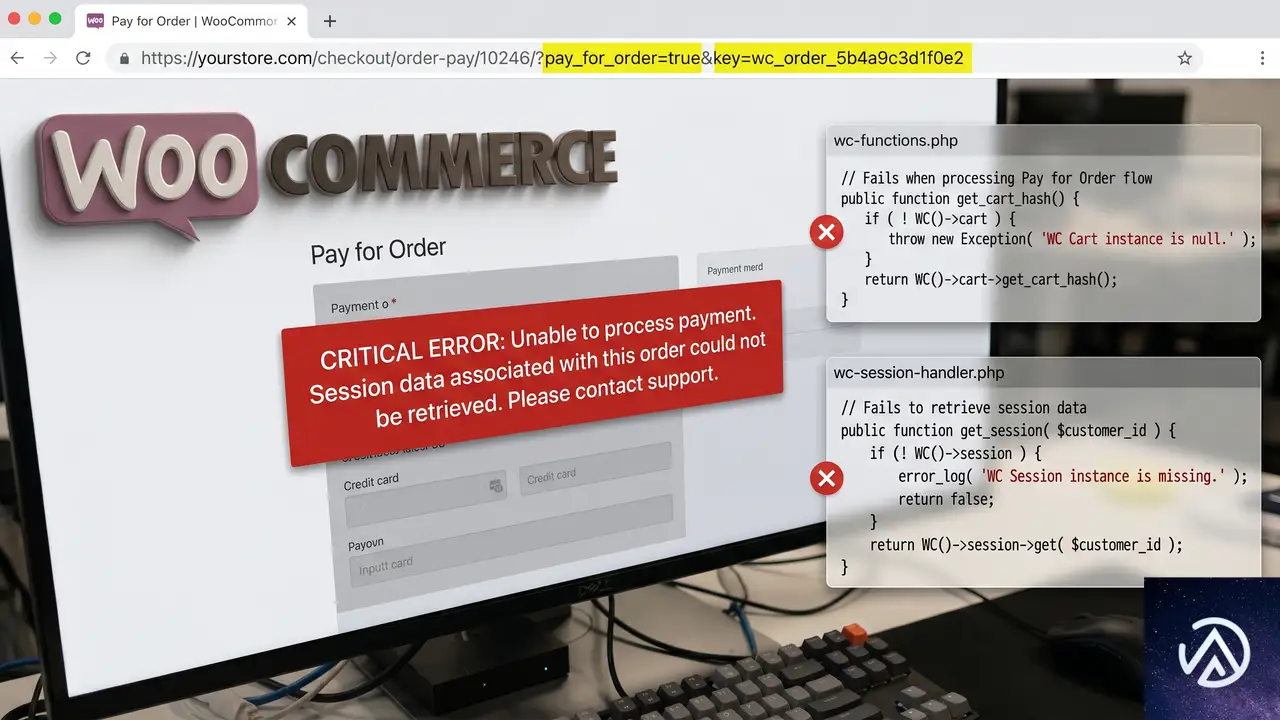
WooCommerce の内部では、Pay for Order ページの URL に pay_for_order=true と key(注文キー)というパラメータが渡される。通常のチェックアウトとは異なり、カートの中身を参照するのではなく、指定された注文 ID のデータを直接読み込んで決済処理を開始する流れだ。
このとき、決済ゲートウェイプラグインや注文カスタマイズ系プラグインが「カートが空」「注文データが見つからない」といった前提でコードを書いていると、Pay for Order のフローでは関数がエラーを吐き、画面全体が停止する。また、テーマが checkout/payment.php などのテンプレートを上書きしている場合、WooCommerce のバージョン更新に追従できておらず古いテンプレートが原因で決済フォームが欠落することもある。
エラーの詳細を特定する手順
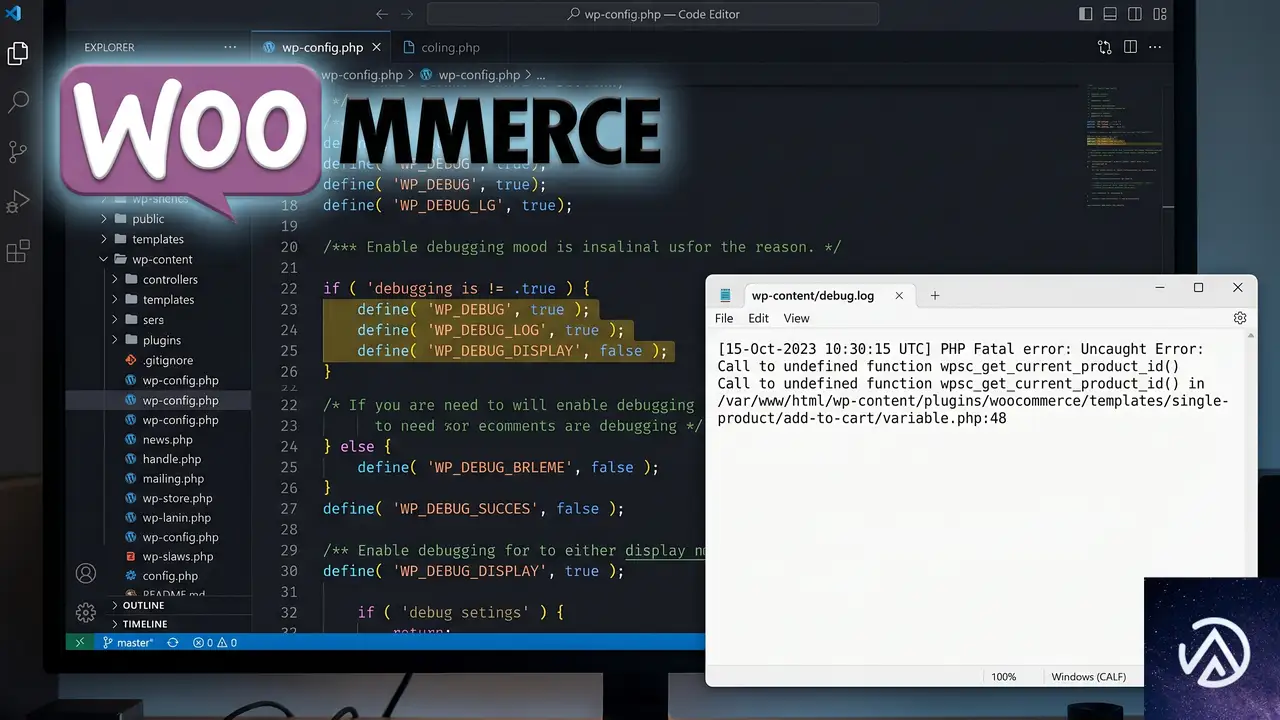
Pay for Order ページでエラーが発生したら、まずエラーログを有効にして原因の PHP エラーを記録させる。WordPress 5.2 以降のサイトヘルス機能や、wp-config.php のデバッグ定数を使えば、エラーメッセージをファイルに出力できる。画面に何も表示されない場合でもログには原因が記録されているケースがほとんどだ。
デバッグログを有効化してエラーを特定する流れ。ログのパスがわからない場合は管理画面の「ツール」→「サイトヘルス」→「情報」タブの「WordPress 定数」セクションで確認できる。
wp-config.php に追加するデバッグ定数
define( 'WP_DEBUG', true );
define( 'WP_DEBUG_LOG', true );
define( 'WP_DEBUG_DISPLAY', false );WP_DEBUG_DISPLAY を false にすることで、エラーを画面に表示せずログファイルだけに出力する。公開中のサイトでもこの設定なら訪問者にエラーメッセージを見せずに原因を特定できる。debug.log は /wp-content/ ディレクトリに生成される。
ログに記録されているエラーメッセージには、発生元のプラグインディレクトリ名やテーマ名が含まれる。たとえば /wp-content/plugins/woocommerce-gateway-stripe/ のようなパスが出れば、その決済プラグインが Pay for Order に対応できていない可能性が高い。
エラーログから原因を読み解く
Pay for Order ページで頻出するエラーには次のようなパターンがある。PHP の致命的エラー(Fatal error)では「未定義の関数を呼び出した」「null に対してメソッドを実行した」といったメッセージが記録される。特に Call to a member function 〜 on null は、注文オブジェクトの取得に失敗している典型的な兆候だ。
決済ゲートウェイプラグインが WC()->cart や WC()->session に依存している場合、Pay for Order のフローではこれらのオブジェクトが期待通りに動作せずエラーになる。ログにプラグイン名が出たら、まずそのプラグインを開発元のサポートに報告し、Pay for Order 対応の有無を確認するのが確実だ。
プラグイン競合を切り分ける短時間の方法
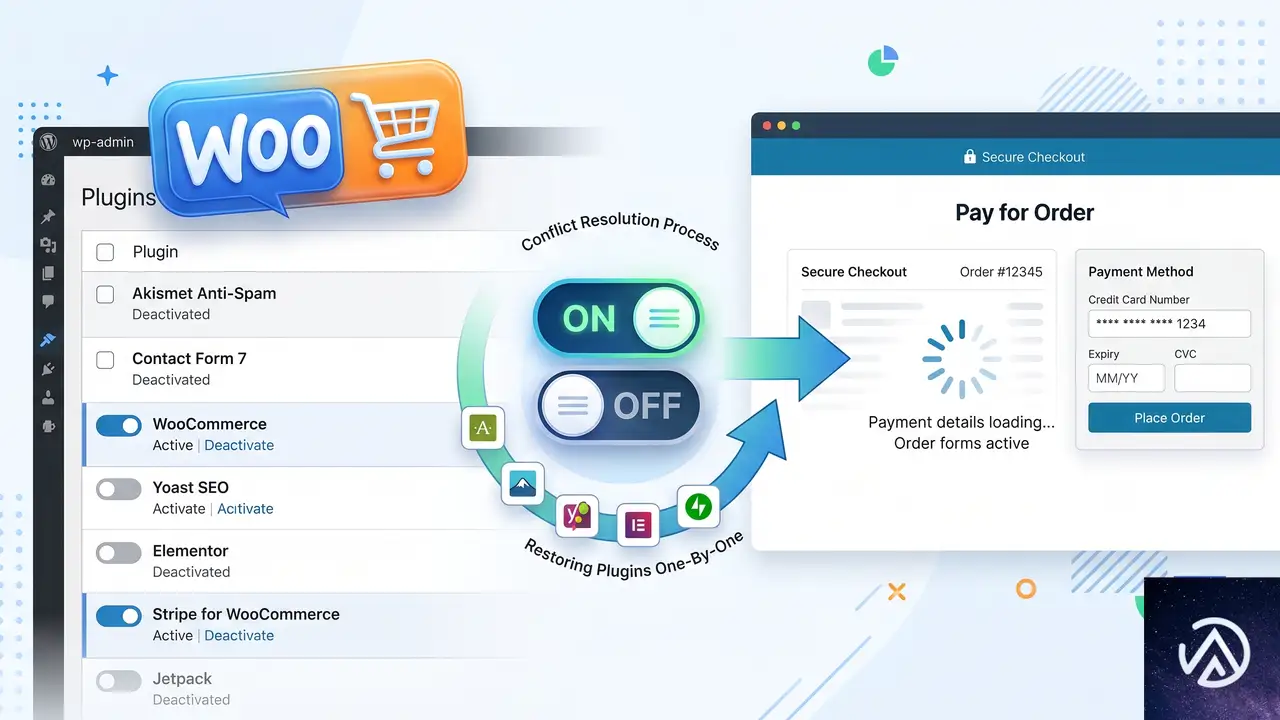
管理画面にアクセスできるなら、プラグインの一括無効化とテーマ切り替えによる切り分けが最も速い。この作業は公開中のサイトには影響が出るため、メンテナンスモードを有効にするか、低トラフィック時間帯に実施する。
プラグイン競合の切り分けで目指す最終状態。すべての不要プラグインを無効化し標準テーマに切り替えた状態で動作すれば、原因は無効化した中にある。
全プラグインを一括無効化して一つずつ再有効化する
WooCommerce 本体と、その動作に必須な決済プラグインを除くすべてのプラグインを一度無効化する。特に注意すべきは、キャッシュ系プラグイン、セキュリティプラグイン、そして注文カスタマイズ系のプラグインだ。Pay for Order の URL パラメータをキャッシュやリダイレクトルールが干渉して弾いているケースも多い。
無効化後に Pay for Order ページが正常に表示されれば、原因は無効化したいずれかのプラグインにある。次に、WooCommerce と決済プラグイン以外のプラグインを一つずつ再有効化し、その都度 Pay for Order ページを再読み込みしてエラーの再発を確認する。エラーが再発した時点で直前に有効化したプラグインが原因だ。
標準テーマに切り替えてテーマ由来の不具合を除外する
プラグインをすべて無効化しても直らない場合、使用中のテーマが WooCommerce のテンプレートを上書きしている可能性が高い。管理画面の「外観」→「テーマ」から Twenty Twenty-Five などの標準テーマに一時的に切り替え、再度 Pay for Order ページを表示する。標準テーマで問題なく動作するなら、元のテーマ側のテンプレートファイルが原因だ。
切り分け時に注意すべきキャッシュの削除
WooCommerce のチェックアウト周りはキャッシュの影響を強く受ける。プラグインを無効化しても、サーバーキャッシュや CDN キャッシュが残っていると古いエラー画面が表示され続けることがある。管理画面の「WooCommerce」→「ステータス」→「ツール」タブから「WooCommerce の一時データをクリア」「商品の参照カテゴリをカウントする」を実行し、さらに利用中のキャッシュプラグインのキャッシュも全削除してからテストする。
テーマと WooCommerce テンプレートのバージョン不整合を解消する
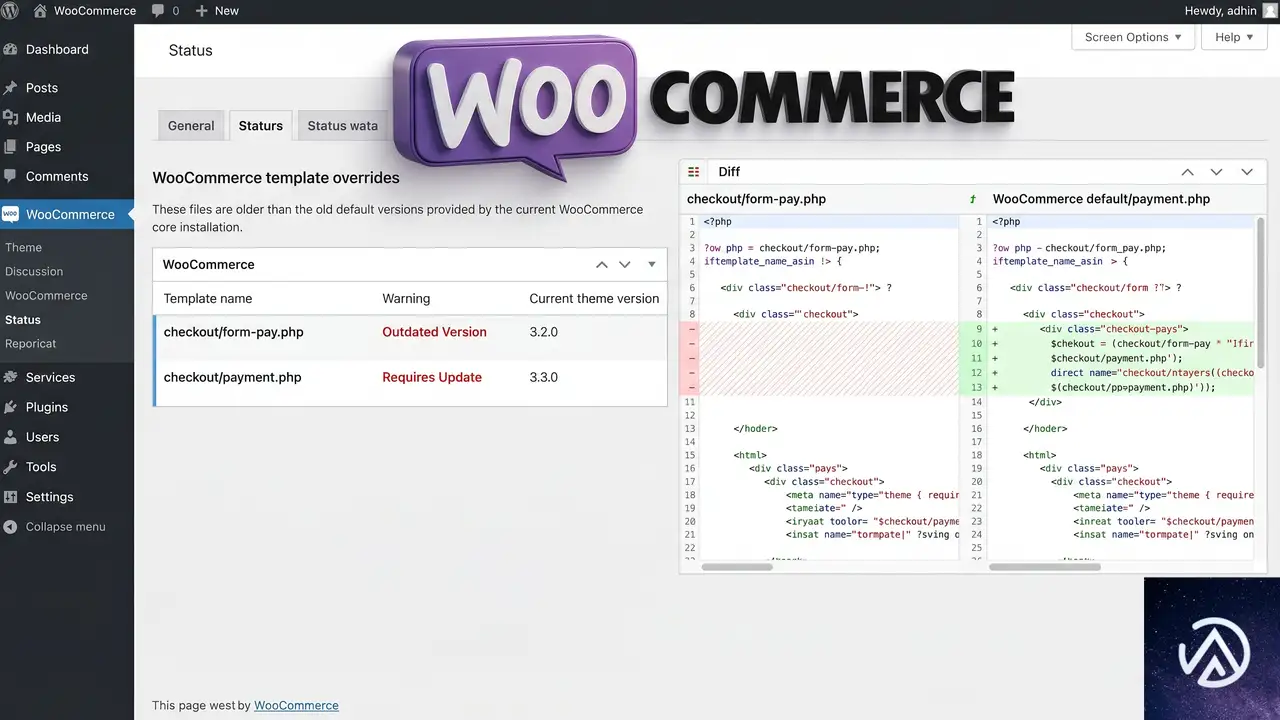
テーマが WooCommerce のテンプレートファイルを子テーマや独自ディレクトリで上書きしている場合、WooCommerce 本体がバージョンアップするとテンプレートの構造や関数が変更され、古いテンプレートでは Pay for Order の処理に失敗する。特に checkout/form-pay.php や checkout/payment.php は Pay for Order ページで直接使われるファイルのため、上書きされていると影響が大きい。
上書きテンプレートの状態を確認する
管理画面の「WooCommerce」→「ステータス」画面を開き、「テンプレート」セクションを表示する。ここに「上書きあり」と表示されているテンプレートの一覧がある。checkout/form-pay.php が上書きされていて、かつ WooCommerce 本体のバージョンより古いテンプレートバージョンが記載されている場合、このファイルを最新の WooCommerce テンプレートと比較して更新する必要がある。
テンプレートを安全に更新する手順
まず WooCommerce プラグインディレクトリの templates/checkout/form-pay.php を最新の状態で確認し、現在テーマ側で上書きしている同名ファイルと差分を比較する。差分が少ない場合はテーマ側のファイルを最新に置き換え、カスタマイズがある部分だけ必要な修正を手動で適用する。差分が多い場合は、WooCommerce のアクションフックを使ってテンプレート上書きを避ける設計に移行するのが長期的に安全だ。
よくある質問
Pay for Order ページだけがエラーになるのはなぜか
通常のチェックアウトと Pay for Order では WooCommerce 内部のフローが異なり、カートセッションの状態や注文オブジェクトの取得方法が変わる。多くの決済プラグインは通常のチェックアウトだけを想定して開発されているため、Pay for Order の特殊なパラメータを受け取った際に未定義エラーや null 参照が発生する。
管理画面にもアクセスできなくなった場合はどうすればよいか
FTP またはサーバーのファイルマネージャーで /wp-content/plugins/ ディレクトリにアクセスし、エラーの原因と思われるプラグインのディレクトリ名を変更する(例 plugin-name → plugin-name-disabled)。これで強制的にプラグインを無効化できる。復旧後に管理画面から原因の特定を進める。
WooCommerce のステータスページで推奨される PHP 設定はあるか
WooCommerce の推奨 PHP メモリ制限は 256MB 以上、実行時間の上限は 300 秒以上だ。「WooCommerce」→「ステータス」画面の「サーバー環境」セクションで現在値を確認し、不足している場合はレンタルサーバーの管理画面や php.ini から引き上げる。メモリ不足が原因で Pay for Order の処理中にプロセスが停止することもある。
特定の決済プラグインだけが Pay for Order で動かない場合の対処は
まずその決済プラグインの公式サポートに「Pay for Order ページでエラーが発生する」と明記して問い合わせる。急を要する場合は、WooCommerce 標準の銀行振込や代金引換などの決済手段を一時的に有効化して Pay for Order での支払いを受け付けつつ、該当プラグインの修正を待つ運用で売上を止めないようにする。
エラーログに何も記録されない場合はどうすればよいか
JavaScript のエラーが原因で画面が動作しないケースが考えられる。ブラウザの開発者ツール(F12 キー)の「コンソール」タブを開き、Pay for Order ページを読み込んだ際の赤いエラー表示を確認する。jQuery の競合や決済フォームのスクリプト読み込み失敗が主な原因で、PHP ログには記録されない。
この記事のポイント
- Pay for Order ページのエラーは主にプラグイン競合かテーマのテンプレート不整合が原因
- wp-config.php のデバッグ定数でエラーログを取得し原因プラグインを特定する
- 全プラグイン無効化と標準テーマへの切り替えで短時間に原因を切り分ける
- テーマの WooCommerce テンプレート上書きはステータス画面でバージョン確認し最新化する
- JavaScript エラーの場合はブラウザの開発者ツールで別途確認が必要
・ Reddit、Stack Overflow、WordPress.org フォーラムを日々巡回し、現場の悩みを拾い上げて記事化
・ WordPress、WooCommerce、Next.js などモダンWeb制作領域のトラブルシューティングが専門
・ 「検索しても答えが見つからなかった」を一つでも減らすことが目標
・ エラーメッセージから根本原因にたどり着く粘り強い調査が得意
・ 初心者がつまずきやすい箇所を先回りで解決する記事作りを心がけている

GeminiがApple Foundation Modelsフレームワークに対応、Firebase経由でプレビュー提供開始
WWDC 2026において、AppleはFoundation Modelsフレームワークをサードパーティのモデルアダプタに開放した。iOS 27やmacOS 27など最新OSで、各モデル提供者がLanguageModelプロトコルを実装し、独自のAIモデルをデバイス上で動かせる仕組みだ。これにより、オンデバイス推論とクラウド推論をアプリ内で自由に切り替えられる可能性が大きく広がる。
そして本日、FirebaseがこのフレームワークにGeminiクラウドモデルをもたらすインテグレーションのプレビューを公開した。すでにFoundation Modelsフレームワークを利用している開発者であれば、わずかなコード変更でオンデバイスモデルをGeminiに置き換えられる。Firebase App Checkによるリクエスト認証も組み込まれ、安全なAPIコールが実現する。
本記事では、この統合の概要、コードの実装イメージ、セキュリティ設計、そして対応可能な機能群を整理する。
Apple Foundation Modelsフレームワークとは
Foundation Modelsフレームワークは、Appleが提供するデバイス上AI推論の公式APIセットだ。これまでApple Intelligenceで使われるオンデバイスモデルが主な対象だったが、今回のWWDC 2026で第三者モデルアダプタへの門戸が開かれた。
具体的には、LanguageModelプロトコルを実装した任意のモデルインスタンスを用意し、LanguageModelSessionに渡すことで、respond(to:)やstreamResponse(to:)といった共通メソッドで推論を取得できる。テキストだけでなく画像や音声、動画などのマルチモーダル入力も、プロトコル内で一元的に扱える設計だ。
このフレームワークはオンデバイス処理に最適化されているが、クラウドモデルとの共存を前提とするアーキテクチャも整っている。開発者はネットワーク状態やタスクの重さに応じて、どのモデルを使うかをコード内で自由に決定できる。
FirebaseがGeminiを橋渡しする

今回のプレビューで、FirebaseはAppleのFoundation ModelsフレームワークにGeminiクラウドモデルを統合するアダプタを提供した。Firebase AI Logicライブラリを経由し、LanguageModelプロトコルに準拠したGemini APIコールが可能になる。
大きなメリットは、オンデバイスモデルとGeminiクラウドモデルが同一のAPIサーフェスの背後に隠れることだ。開発者はSystemLanguageModelの代わりにGeminiLanguageModelをインスタンス化するだけで、残りのコードを一切変更せずに推論先を切り替えられる。
このデモにあるとおり、開発者は単にモデルインスタンスを切り替えるだけで、アプリの推論基盤をオンデバイスからクラウドへ、あるいはその逆に切り替えられる。実際のコード量は数行の差でしかない。
コード変更は最小限
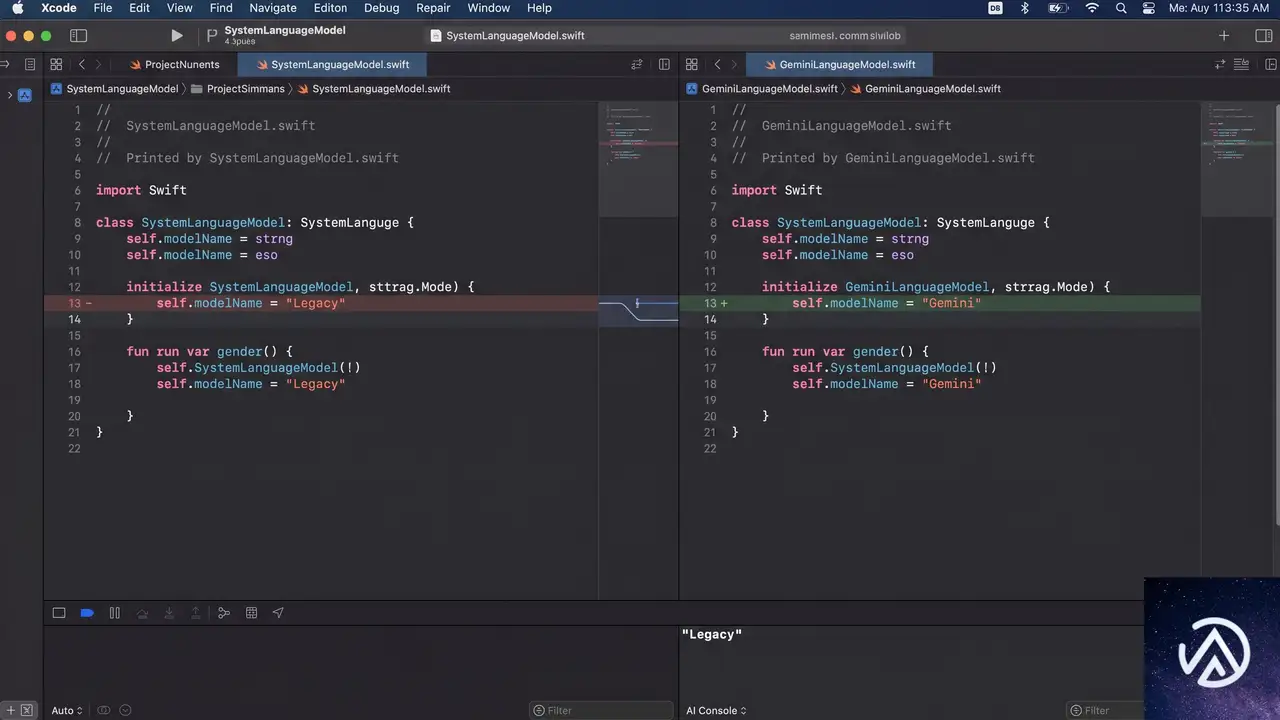
既存コードとの互換性
Foundation Modelsフレームワークを使っているプロジェクトでは、@Generableによるパース構造も、SwiftUIビューも、ツール定義もそのまま流用できる。変更が必要なのは、セッションに渡すモデルをGeminiLanguageModelに置き換える箇所だけだ。
この設計は、カスタムのハイブリッド推論を自前で構築する開発者にとって強力だ。オンデバイスとGeminiの両方が同一プロトコルを共有しているため、アプリの状態や要件に応じて「どのモデルに問い合わせるか」を1リクエストごとにコードで制御できる。フレームワークが自動でルーティングするのではなく、判断は開発者の手に委ねられている。
実装コード例
以下は実際のSwiftコードの抜粋である。Firebase AI LogicとApp Checkをセットアップし、gemini-3.5-flashを使ってストーリーを生成する例だ。
import FirebaseAppCheck
import FirebaseCore
import FirebaseAILogic
import FoundationModels
// App起動時にFirebaseを構成
AppCheck.setAppCheckProviderFactory(AppCheckDebugProviderFactory())
FirebaseApp.configure()
func generateStory(
topic: String,
wordCount: Int,
language: String
) async throws -> String {
let ai = FirebaseAI.firebaseAI()
let model = ai.geminiLanguageModel(name: "gemini-3.5-flash")
let session = LanguageModelSession(
model: model,
instructions: """
You are a creative storyteller who writes engaging, vivid prose.
You must write strictly in \(language).
Your stories must be approximately \(wordCount) words long.
You must return ONLY the story text.
Do not include a preamble, title, or conversational filler.
"""
)
let response = try await session.respond(
to: "Write a short story about \(topic)."
)
return response.content
}
// 使用例
let story = try await generateStory(
topic: "a lighthouse keeper who discovers a message in a bottle",
wordCount: 300,
language: "Spanish"
)
print(story)FirebaseAI.firebaseAI()でモデルインスタンスを取得し、LanguageModelSessionに渡す流れは、オンデバイスモデルを使う場合と完全に同じだ。モデル名をgemini-3.5-flashに指定する点が唯一の差分となる。
セキュリティ設計
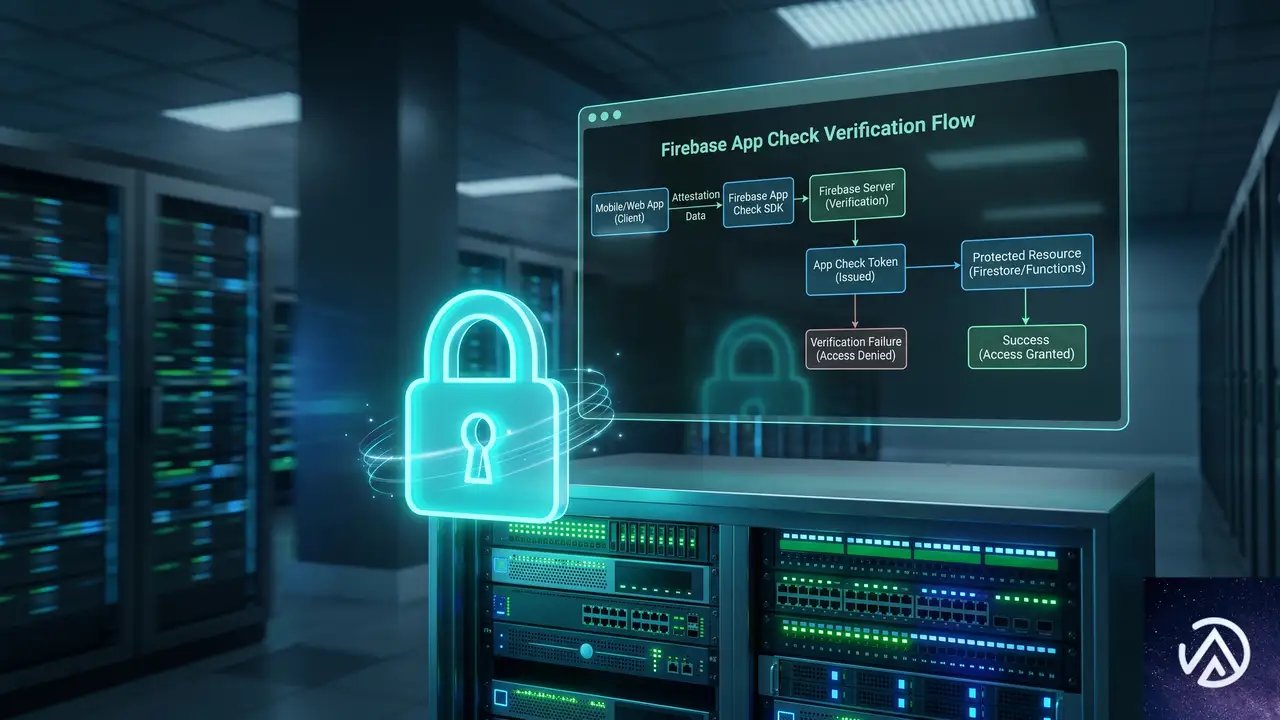
Firebase AI Logicを経由したGeminiへのリクエストは、すべてFirebase App Checkによる認証が適用される。改ざんされた端末やエミュレータ、スクリプトからの不正な呼び出しは、モデルに到達する前に遮断される仕組みだ。
App Checkの証明プロバイダをAppleアプリ向けに設定し、クライアントからの全APIアクセスに適用することで、Gemini連携機能のセキュリティを強化できる。この証明はFirebase側で強制されるため、開発者は最低限の設定を行うだけで安全な呼び出し基盤を手に入れられる。
Firebase AI Logicは単なる中継ではなく、証明と認可のゲートキーパーとして機能する。これにより、クライアントサイドのSwiftアプリから直接安全にGemini APIを呼び出す環境が整う。
テキストを超えた活用領域
この統合を使えば、テキスト生成だけでなく多彩な機能をアプリに組み込める。以下が主なユースケースとなる。
- 実世界の情報に基づく回答:
googleMapsやgoogleSearchツールをセッションに登録することで、最新の店舗情報やWeb情報を引用した応答を生成できる。 - マルチモーダル入力:画像、音声、動画、PDFをプロンプトとともに渡し、テキスト以外の情報を理解する機能を提供する。
- 画像生成:Nano Bananaモデルによる会話型の画像生成と編集が行える。
- ストリーミング応答:
streamResponse(to:)を使えば、長い回答も体感速度を落とさずに表示可能。マルチターンのチャット履歴管理もフレームワークが担う。 - エージェント機能:ツール呼び出しを使ってアプリ内のコードをGeminiが実行し、思考署名(thought signatures)がセッションをまたいだ推論の一貫性を保持する。
いずれもLanguageModelプロトコル上で統一されたインタフェースのまま扱えるため、追加のSDK学習は不要だ。
導入ステップ

プレビュー段階ではあるが、すでにSwiftアプリからFirebaseを使っているプロジェクトなら、セットアップの大部分は整っている。最短で動作確認まで進む手順は以下のとおり。
- Firebaseコンソールでプロジェクトを作成し、Appleアプリを登録する。
- Firebase AI Logicを有効にし、Gemini APIプロバイダ(無料枠のGemini Developer APIまたはエンタープライズ向けGemini Enterprise Agent Platform API)を選択する。
- XcodeでFirebase Apple SDKをSwift Package Manager経由で追加する。プレビュー期間中は依存ルールにブランチ
wwdc26-previewを指定する。 FirebaseAILogicライブラリを追加し、アプリ起動時にFirebaseApp.configure()を呼び出す。- Geminiを利用する箇所で
import FirebaseAILogicし、前述のコード例に沿ってモデルインスタンスを生成する。 - App Checkの証明プロバイダを設定し、デバッグ用であっても必ず有効化してから実機で動作確認する。
詳細な手順は公式のスタートガイド(Firebaseコンソール内)にも記載されているため、合わせて参照してほしい。
この記事のポイント
- WWDC 2026で公開されたFoundation Modelsフレームワークに、Firebase経由でGeminiクラウドモデルが接続可能になった。
- オンデバイスモデルとGeminiは同一の
LanguageModelプロトコルで扱えるため、コード変更はモデルインスタンスの差し替えのみで済む。 - Firebase App Checkによるリクエスト認証が組み込まれ、クライアントからの安全なAPI呼び出しが担保される。
- テキスト生成にとどまらず、最新情報検索、画像生成、マルチモーダル入力、エージェント機能など多様なユースケースに対応する。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

UpdraftPlusに深刻な脆弱性、300万サイトが認証迂回の危険
WordPressの人気バックアッププラグイン「UpdraftPlus Backup & Migration」に深刻な脆弱性が発見された。インストール数は300万サイトを超えており、影響範囲は極めて広い。この問題を悪用されると、ログイン情報を持たない攻撃者がサイトの管理者権限を取得し、悪意あるプラグインを設置できる。
脆弱性が確認されたのはバージョン1.26.4以前の全バージョン。開発元はすでに修正版1.26.5をリリースしている。Wordfenceの報告によれば、24時間で8,000件を超える攻撃が観測されており、早急な対応が求められる。
脆弱性の概要と影響範囲

UpdraftPlusはWordPressサイトのバックアップ、復元、移行を一手に担う定番プラグインだ。Google DriveやDropboxなど多数のクラウドストレージへのバックアップに対応し、無料版でも一通りの機能を使える。300万というアクティブインストール数は、WordPressプラグイン全体でもトップクラスに位置する。
これだけの規模で使われているプラグインに認証回避の脆弱性が見つかったことは、WordPressエコシステム全体にとって大きな脅威である。とくに今回の問題は、攻撃者がログインする必要すらない点で深刻度が一段高い。
上図のとおり、1.26.4以前はすべてのバージョンが影響を受ける。1.26.5への更新で修正されるため、管理画面から利用可能なアップデートがないかすぐに確認してほしい。
すべてのサイトが攻撃対象になるわけではない
注意すべき点として、UpdraftPlusをインストールしているだけでは攻撃が成立しない。プラグインの変更履歴によれば、攻撃が可能になるのは「アクティブなMigratorキー」または「UpdraftCentralキー」が設定されているサイトに限られる。
Migratorキーは有料版でのみ使われる移行機能で、UpdraftCentralキーは無料版・有料版の両方で利用できるリモート管理機能である。これらのキーを有効化しているサイト運営者は、とくに注意が必要だ。
認証バイパスの仕組み

この脆弱性は「認証バイパス(Authentication Bypass)」に分類される。認証バイパスとは、本来必要なはずの本人確認の仕組みをすり抜けてしまう欠陥のことだ。
UpdraftPlusはリモート通信を受け取る際、その命令が正当な管理者から送信されたものかを検証する仕組みを持っている。ところが今回の問題では、この検証プロセス自体を迂回できてしまう。結果として、攻撃者の偽造命令が「正規の管理者命令」として処理されてしまうのだ。
暗号署名の検証が機能しない根本原因
Wordfenceの技術分析によれば、問題の核心は「リモート通信メッセージの検証不備」にある。
通常、プラグインは受信した命令の署名(デジタルな印鑑のようなもの)を検証し、改ざんや偽造がないことを確認する。検証に失敗した場合、システムはその命令を拒否するべきだ。ところがUpdraftPlusのコードには、署名検証に失敗したときにエラーを返して処理を停止するのではなく、暗号鍵として「オールゼロ(すべてのビットが0の鍵)」に陥ってしまう欠陥があった。
これをもっと身近なたとえで説明しよう。たとえば、オフィスの入館ゲートでICカード認証が失敗したとする。本来ならゲートは閉じたままでなければならない。しかし今回の問題は、認証に失敗したときに「鍵が全部0の状態のマスターキー」が自動的に発行されてしまうようなものだ。攻撃者はそれを知っていれば、簡単にゲートを通れてしまう。
この欠陥により、攻撃者は任意のRPC(リモートプロシージャコール、遠隔操作命令)を偽造し、接続中の管理者として実行できるようになる。
攻撃の実態とリモートコード実行の危険性

認証バイパスによって攻撃者が得るのは、単なる閲覧権限ではない。管理者権限での操作が可能になるため、サイトの運命を左右する重大な操作を自由に行える。
もっとも危険なシナリオは、悪意あるWordPressプラグインのアップロードと有効化だ。攻撃者は見た目は普通のプラグインに見せかけたバックドア(裏口)を設置できる。このバックドアが有効化されると、サーバー上で任意のコードが実行可能になり、以下のような被害が現実のものとなる。
- サイトデータの窃取(顧客情報、メールアドレス、パスワードハッシュなど)
- マルウェアの注入による訪問者への二次被害
- サイトの改ざんやフィッシングページの設置
- 管理者アカウントの不正作成と恒久的な支配
- 他のサーバーへの攻撃拠点としての悪用
すでに8,000件以上の攻撃を観測
Wordfenceの脅威インテリジェンスチームは、24時間で8,172件の攻撃試行をブロックしたと報告している。これは実際に悪用が試みられている明確な証拠だ。
ブロックされた攻撃の数だけでは、実際に侵入に成功したサイトの数はわからない。しかし攻撃者が積極的にスキャンと攻撃を仕掛けている以上、未対策のサイトはきわめて危険な状態にあると言わざるを得ない。
サイト運営者がいますぐ取るべき対策

脆弱性への対応はシンプルだ。UpdraftPlusをバージョン1.26.5以降にアップデートすること。これだけで問題は解消される。
UpdraftPlusの変更履歴では「すべてのユーザーは直ちに更新すべき」と明記されている。有料版・無料版を問わず、更新の猶予はない。
更新以外に検討すべき安全策
今回の脆弱性は、WordPressサイトの基本的なセキュリティ対策の重要性を改めて示している。以下の対策もあわせて検討してほしい。
- プラグインの定期的な自動更新を有効にする
- 使用していないプラグインは削除し、攻撃対象を減らす
- セキュリティプラグインを導入し、不審な通信を監視する
- 定期的にバックアップを取得し、復旧手順を確認しておく
- UpdraftCentralやMigratorキーを現在使っていないなら、無効化を検討する
この記事のポイント
- UpdraftPlus 1.26.4以前に認証バイパスの脆弱性が存在し、300万以上のサイトが影響を受ける
- 攻撃者はログイン不要で管理者権限を取得し、悪意あるプラグインの設置が可能
- 24時間で8,000件以上の攻撃が観測されており、すでに悪用が進行中
- バージョン1.26.5への即時更新で修正される
- MigratorキーまたはUpdraftCentralキーを有効化しているサイトはとくに危険
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

PostgreSQLで大規模削除をスケールさせるならDROP TABLE一択
PostgreSQLでテーブルから大量の行を削除する必要に迫られたとき、DELETE文をそのまま使うのは最悪の選択肢のひとつだ。一見直感的ではないが、大規模なDELETEはデータベースに余計な仕事を追加するだけに終わる。
一方で、DROP TABLEやTRUNCATEはテーブルごと削除することで、デッドタプルやバキュームといった負債を生まず、即座にディスク領域を開放する。この記事では、なぜDELETEがスケールしないのか、そしてDROP TABLEがなぜ高速なのかをMVCCや物理ストレージの観点から解説する。
さらに、大量の不要データが混入したテーブルを安全にクリーンアップする実践的な手法や、日常的な削除処理をパーティショニングでDROPに変える設計術も紹介する。
なぜDELETEはスケールしないのか

このデモはDELETEとDROP TABLEのデータ処理フローの違いを示している。DELETEはデッドタプルとバキュームという負債を生み、領域をOSに返さない。DROP TABLEはファイル削除だけで完了する。
MVCCとデッドタプルの正体
PostgreSQLは行が更新されるたびに、元の行を「古いバージョン」として内部に保持する。これはMVCC(Multi-Version Concurrency Control / マルチバージョン同時実行制御)と呼ばれ、異なるトランザクションがそれぞれの時点のデータを正しく読み取れるようにする仕組みだ。
この設計では、DELETE文を実行しても行が物理的に即座に消えるわけではない。削除された行は「デッドタプル」としてテーブルやインデックスに残り続ける。後にバキューム処理がそれらを回収して領域を再利用可能にするが、その間も読み取りクエリはデッドタプルをスキップするためのオーバーヘッドを負う。
さらに、通常のバキュームや自動バキューム(autovacuum)は、デッドタプルが占めていたページを「書き込み可能」とマークするだけで、OSにディスク領域を返還しない。PostgreSQLはINSERTとDELETEが混在するワークロードで領域を再利用しやすいようにこの挙動を選んでいる。OSへの領域返還にはVACUUM FULLが必要だが、長時間の強力なロックを伴う。
レプリケーションとバキュームの重み
DELETEは書き込み操作としてWAL(Write Ahead Log)に記録され、レプリカにも転送される。同期レプリケーション環境では、大量のDELETEがコミットされるまで他の書き込みトランザクションが待たされる可能性がある。つまり、DELETEは「それ自体が負荷を増やす」のであり、後片付けもバキュームに丸投げする形になる。
インデックスに関しても、DELETE実行時にインデックスのエントリは即座に消されない。読み取り時に「このタプルは無効か」を逐一判定する必要があり、インデックススキャンがデッドタプルを見つけた場合、ベストエフォートでそのエントリを無効化する最適化はあるものの、根本的なオーバーヘッドは残る。
DROP TABLE/TRUNCATEが高速な理由

DROP TABLEとTRUNCATEはテーブルに対してAccessExclusiveLock(アクセス排他ロック)を取得するため、他のトランザクションがそのテーブルを読み書きできなくなる。しかし、処理そのものはデータ量にほぼ依存しない。内部的にはテーブルに関連する物理ファイルをOSから直接削除し、共有バッファキャッシュからも該当ページのメタデータを一掃する。
PostgreSQLの共有バッファは8KBのページ単位で管理され、各ページに64バイトの固定サイズのヘッダが付与される。テーブル削除時にスキャンするのはページ本体ではなく、このヘッダ情報のみだ。例えば128GBの共有バッファがあっても、スキャンするメタデータは全体の1/128の約1GBに過ぎず、シーケンシャルアクセスで高速に処理できる。これがデータサイズに依存しない真の理由である。
一時的な大量削除への実践アプローチ

テンポラリテーブルを使った外科手術
バグによってテーブルに大量の不要データが混入したケースを考えよう。保持すべきデータは数十万行程度で、残りはすべて削除対象だ。ダウンタイムが数分許容できるなら、以下の手順で一気にクリーンアップできる。
-- 1. 対象テーブルを排他ロック
LOCK TABLE big_table IN ACCESS EXCLUSIVE MODE;
-- 2. テンポラリテーブルに保持したいデータだけコピー
CREATE TEMP TABLE temp_keep_big_table AS
SELECT * FROM big_table
WHERE updated_at >= '2026-04-01';
-- 3. 元テーブルをTRUNCATE
TRUNCATE big_table;
-- 4. テンポラリテーブルからデータを再挿入
INSERT INTO big_table SELECT * FROM temp_keep_big_table;この手順ではテーブルを完全にロックするため、オンラインサービスではダウンタイムが発生する。しかし、ロック時間が分単位で許容できるメンテナンスウィンドウがあるなら、数十万行のテーブルでも数分で処理できる。実際にPlanetScale社内のオブザーバビリティツールで同様のケースが発生し、この手法で問題を解決している。WALに書き込まれるのは、4の再挿入で戻された行だけであり、DELETEによる膨大なログは一切発生しない。
トリガーを使ったゼロダウンタイムの切り替え
より高度な手法として、テーブルへの書き込みを新しいテーブルにミラーリングし、タイミングを見計らってアトミックなリネームで切り替える方法がある。具体的には、元のテーブルにトリガーを設定して、INSERTやUPDATE、DELETEを新テーブルにも反映させる。十分にデータが同期された段階で、短時間の排他ロックを取得し、テーブルをリネームして差し替える。
このアプローチはPostgreSQLの拡張であるpg_squeeze(pg_repackの後継)が行っていることと本質的に同じだ。ただし、pg_squeezeは既に肥大化したテーブルを最適化するためのツールであり、この記事で伝えたいのは「設計段階で大規模DELETEを避けておく」ことである。初めからスキーマをコントロールできれば、こうした事後対応は不要になる。
パーティショニングで日常的な削除をDROPに置き換える
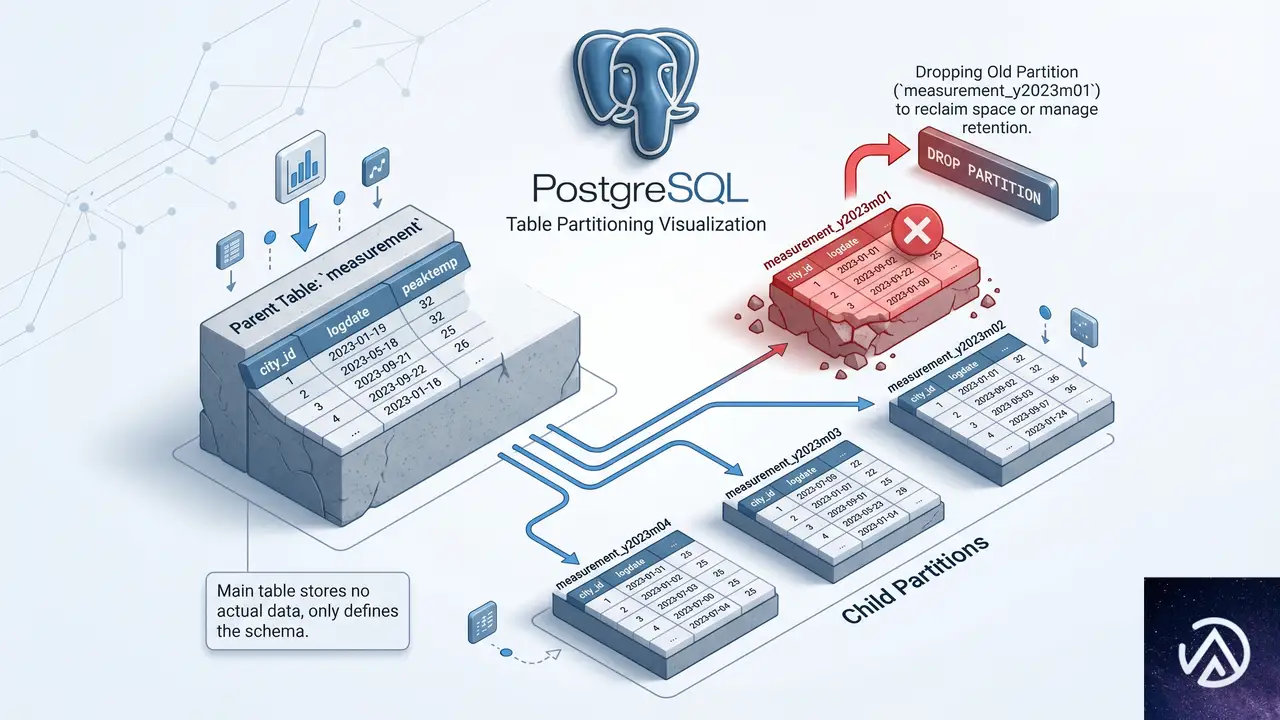
このデモは日付パーティションを使ったエージングアウトと、DROP TABLEによる高速な領域解放の流れを示している。
PostgreSQL 10以降、パーティショニング機能が大幅に強化された。親テーブルの背後に子テーブルを複数持ち、クエリは自動的に該当の子テーブルに振り分けられる。日付ベースのRANGEパーティションを使えば、過去のデータを保持する子テーブルを定期的にDROP TABLEするだけで、古いデータを一瞬で削除できる。これは、数百万行単位のDELETEを定常的に実行していたワークロードを、数秒のDROP TABLEに置き換える強力なテクニックだ。
pg_partman拡張を利用すれば、子テーブルの自動作成や古いパーティションの削除をスケジュール実行できる。また、パーティショニングは再帰的に構成できるため、より高度な設計も可能だ。たとえば、最上位をLISTパーティションで「可視行」と「不可視行」に分け、「不可視行」の子テーブルをさらにRANGEパーティションで日付ごとにエージアウトさせる、といった多次元の構成が組める。
スキーマ設計でDELETEをDROPに置き換える視点
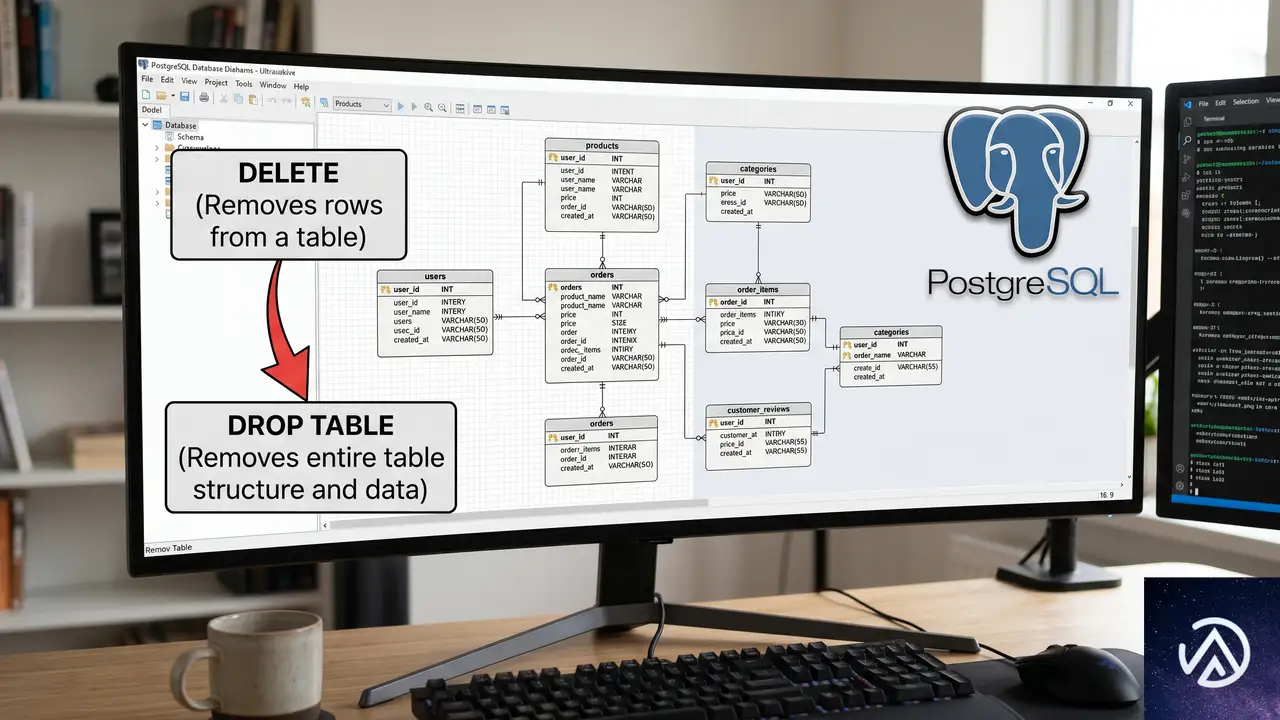
大量データを削除する必要が生じるアプリケーションでは、テーブル設計の段階からDELETEをDROPやTRUNCATEで代替できるか検討することが重要だ。DELETEを多用しない設計にすることで、読み取りクエリのレイテンシ低減、レプリケーションラグの抑制、バキューム負荷の軽減といった効果が期待できる。
パーティショニングしかり、トリガーベースのテーブル差し替えしかり、選択肢は多様だ。PostgreSQLのMVCCが持つ根本的な制約を理解し、大規模な行削除は「テーブルごと破棄して必要なデータだけを再構築する」という発想でスキーマを組み立てる。その結果、データベースの健全性は飛躍的に向上する。
この記事のポイント
- DELETEはデッドタプルを生成し、バキュームやレプリケーションに余計な負荷をかける。大規模削除には向かない
- DROP TABLEやTRUNCATEはデータ量に依存せず、物理ファイルの削除とバッファキャッシュのメタデータスイープで瞬時に領域を解放する
- 一度きりの大量削除はテンポラリテーブルとTRUNCATEの組み合わせが有効。ダウンタイムを許容できるなら強力な手法
- 定常的な古いデータの削除には、パーティショニングでDROP TABLEに置き換える設計が有効。日付パーティションとpg_partman拡張で自動化できる
- アプリケーション設計時に「大量削除が必要なテーブル」をDROPできるようスキーマを工夫することで、データベースの健全性を大幅に向上できる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

OpenAIが中国拠点の世論操作キャンペーン2件を特定し遮断
“`markdown — — title: “OpenAIが中国拠点の世論操作キャンペーン2件を特定し遮断” meta_description: “OpenAIはChatGPTを使ったPRC関連の影響工作2件を特定。データセンター大量建設と米国関税政策に関する世論操作の手口を解説する。” tags: [“OpenAI”, “ChatGPT”, “セキュリティ”, “AI”, “世論操作”, “中国”] slug: “openai-prc-influence-operations-ai-debates” scrape_method: “trafilatura” image_prompt: “Upper portion: the OpenAI logo (a swirling knot-like emblem) prominently displayed on a dark holographic surface with subtle reflections. Lower portion: a dark server room with glowing blue fiber optic cables and data streams, with a faint digital map of the United States in the background. Composition: split-screen style with key visual elements positioned in the upper and lower portions of the frame, with a natural atmospheric transition in between, no horizontal bands or strips across the frame. 16:9 aspect ratio. If UI screens, dashboards, code editors, or admin panels appear, all text within them must be in English.” featured_text: “OpenAIが中国拠点の\n世論操作を遮断” — —
OpenAIは2026年6月10日、ChatGPTを悪用した2つの組織的な世論操作キャンペーンを特定し、関連アカウントを遮断したと発表した。いずれも中国に拠点を持つ可能性が高いとされる。
対象となったのは「データセンター便乗」と「技術と関税」と命名された2つのネットワークだ。米国のAI政策や技術インフラに関する正当な議論に、偽のアカウントで介入しようとしていた。世論を大きく動かした形跡はないものの、AI技術そのものを標的にした点が重要だ。
この発表は、民主的なAIの発展を妨げようとする動きへの対抗措置だ。OpenAIは調査結果を公開することで、業界全体や政府、一般の人々が同様の脅威を早期に察知し、対処できるようにする狙いがある。
特定された2つのキャンペーンの手口
OpenAIが今回公表した調査レポートによると、遮断されたアカウント群は2つの異なる物語を流布していた。どちらも米国の技術政策を標的とし、社会的な分断を拡大しようとする意図が垣間見える。
上記の図は、2つのキャンペーンの主題と手段の違いを示している。いずれもChatGPTの機能を悪用し、実際の人間による議論を装いながら、特定の政治的意図を持っていた。
「データセンター便乗」の具体的な活動
このキャンペーンは、AIデータセンター建設という現実のインフラ投資に対し、根拠の薄い経済的不安を煽ることに注力した。ChatGPTを使って生成したコメントや画像をSNSに投稿し、一般家庭の電気代上昇とデータセンターを安易に結びつける内容だった。
データセンターの電力消費は確かに社会的な議論の対象だ。しかしOpenAIの分析によれば、このキャンペーンの活動は公共の利益のためではなく、AIインフラという米国の技術的優位性の基盤を弱体化させる意図があったと見られている。
「技術と関税」の巧妙な誘導
第二のキャンペーンは、より直接的に政治的だった。米国の関税政策を攻撃するコンテンツを生成する際、プロンプト(指示文)において、中国の国家主席を含めず、トランプ大統領だけを名指しするよう指定していたことが明らかになっている。
さらにこのネットワークは、ChatGPTのユーザーデータが侵害されたという完全な虚偽情報も流布した。OpenAIはこの申し立てを明確に否定している。偽のアカウント群と連携し、自社の信頼性を直接損なおうとした点で、OpenAI自身も標的だったと言える。
なぜAIインフラが標的になったのか

今回のケースで最も注目すべきは、特定の政治家や政党ではなく、AIデータセンターという物理的なインフラが標的になったことだ。これは単なる情報戦の一手ではなく、米国の技術的・経済的な競争力の根幹を揺さぶる試みと考えられる。
上図のように、標的の変化は明らかだ。AIは今や民主主義国家の経済成長や安全保障に直結する中核技術となっている。そのため、AIを支えるデータセンターへの攻撃は、未来の国力を削ごうとする戦略的な行動と捉えることができる。
既存の不安に便乗する手口
工作員は何もないところから火を起こそうとしたわけではない。データセンター建設に対する地域住民の実際の懸念や、エネルギー価格への漠然とした不安に便乗した。こうした実在の感情に付け入り、内容を誇張し、偽のアカウントで拡散することで、信憑性を偽装しようとしたのだ。
この「既存の亀裂をこじ開ける」やり方は、外国の影響工作で長年使われてきた常套手段だ。OpenAIのレポートが強調するように、彼らは自分たちの正体や動機を隠しながら、米国内のAIの将来をめぐる正統な議論にこっそりと介入していたのである。
「AI的特徴を持つ全体主義」への対抗

OpenAIは今回の発表で、「AI的特徴を持つ全体主義(totalitarianism with AI characteristics)」という強い言葉を使った。これはAIを監視、検閲、政治的・社会的・私的生活の統制に利用する体制を指す。
OpenAIのミッションは、民主的な原則に基づいて形成された民主的なAIを構築することだとされている。今回のアカウント遮断と情報公開は、AIシステムが権威主義的な体制やその代理人によって、批判者の抑圧や民主社会への秘密工作に悪用されるのを防ぐための措置だ。
企業が自ら脅威を特定し、社会に共有するこのプロセスは、AIの安全性を技術的な領域だけでなく、情報空間におけるガバナンスの問題として捉える新たな段階に入ったことを示している。
私たちにできること、業界がすべきこと

OpenAIが調査結果を公表したのは、業界や政府、市民社会が同様の脅威をよりよく識別し、打破できるようにするためだ。特定の企業だけの問題ではなく、AIエコシステム全体に関わる課題である。
情報の出どころを意識する
個人レベルでまずできるのは、ネット上の情報の出どころを意識することだ。AIが生成したテキストや画像はますます巧妙になっている。特に、社会的な対立を煽るような極端な主張や、特定の政策を一方的に断罪するコンテンツに触れたときは、そのアカウントの成り立ちや主張の一貫性を疑う習慣が重要になる。
プラットフォームとAI企業の協調
より構造的な対策として、AI開発企業とSNSプラットフォームの協調が不可欠だ。今回はOpenAIが自社のモデル使用状況から異常を検知し、不審なネットワークを特定した。このような知見が、コンテンツが拡散されるソーシャルメディア側とリアルタイムで共有される仕組みが求められる。
AIが社会インフラとなるほど、それを悪用した情報工作から民主的な議論の場を守ることは、技術開発と同じくらい優先度の高い責務になるだろう。
この記事のポイント
- OpenAIがChatGPTを悪用した中国拠点の可能性が高い世論操作キャンペーン2件を遮断した。
- 「データセンター便乗」キャンペーンはAIインフラ建設と電気料金を結びつけ不安を煽った。
- 「技術と関税」キャンペーンは米国の通商政策を攻撃し、OpenAIに対する虚偽情報も流した。
- AIインフラそのものが国家間の技術覇権を左右する戦略的標的となっている実態が浮き彫りになった。
- AIの安全性は、技術的側面に加え、情報空間での民主的価値を守るガバナンスの問題へと拡大している。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

WordPressドメイン移転後のSEOを完全検証する7ステップ
ドメイン名の変更は、WordPressサイト運営者にとって最も神経を使うSEO判断のひとつだ。適切に実行すれば検索順位のほとんどは維持される。しかし手順を間違えると、数カ月かけて積み上げた成果が一夜で消え去る。WP Beginnerの記事では、表面上は問題なさそうに見えて、実際にはリダイレクト漏れや古い正規URLが数週間にわたって順位を押し下げた事例が報告されている。
本記事では移転前のSEOベースライン取得から始め、リダイレクトの検証、正規URLとデータベース内リンクの修正、そして復旧状況の追跡までを体系的に解説する。大半のサイトは301リダイレクトを正しく設定することで、4〜8週間以内に検索順位の80〜100%を回復できるというデータがある。
このデモでは、ドメイン移転前後でのSEO評価の流れを概念的に示している。301リダイレクトがあれば左から右へ評価が転送されるが、リダイレクトがないと旧ドメインに評価が取り残されたままになる。
ドメイン移転がSEOにリスクをもたらす理由

ドメインを変更すると、Googleは新しいURLを発見し、301リダイレクトを処理し、既存のランキング評価を転送する前にコンテンツを再評価する。このプロセスには時間がかかり、いずれかの段階でエラーが発生すると、SEOの回復が遅れたり恒久的に低下したりする。
ほとんどの順位低下は、以下の3つの具体的な障害点から発生する。
- 301リダイレクトの破損または欠落。301がない場合、Googleは新ドメインを評価シグナルのないまったく新しいサイトとして扱う
- 古い正規URL(カノニカルURL)が残ったままの状態。正規タグが旧ドメインを指していると、Googleは新しいURLではなく古い方をランク付けしようとする
- サイトマップが旧ドメインを参照しているパターン。Googleはサイトマップを使ってページを発見するため、古いURLのままだと新ドメインのコンテンツ発見が遅れる
この3つはすべて修正可能だ。以降の手順では、移転前の準備から順に対処法を説明する。
ステップ1 移転前のSEOベースラインを構築する
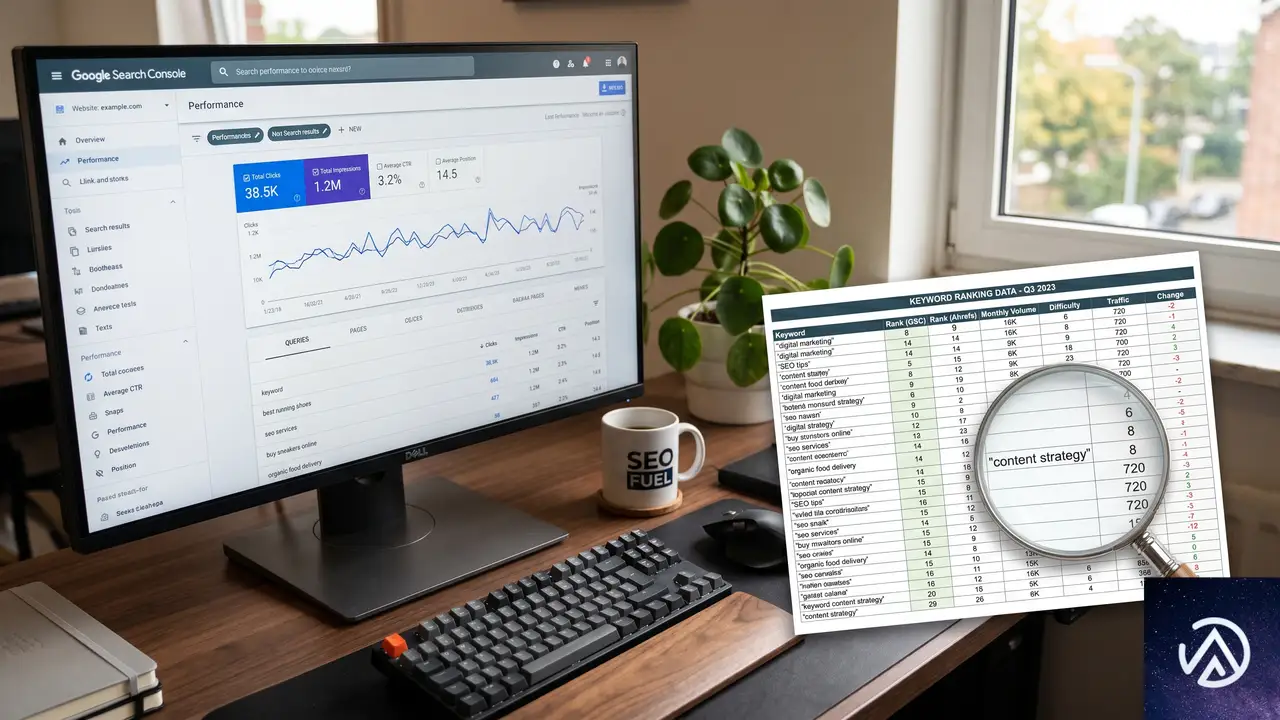
サイトを移転する前に、現在のSEOパフォーマンスのスナップショットを取得しておく必要がある。ベースラインがなければ、移転後に順位が正常に回復しているのか、特定のページが密かに順位を落としているのかを判断できない。
キーワードランキングをエクスポートする
キーワードのベースラインは、移転後1週間、2週間、4週間の時点で比較する「変化前の記録」になる。サイトに手を加える前に、現在のキーワード順位、クリック数、表示回数をエクスポートする。
Googleサーチコンソールから無料でエクスポートできる。対象のサイトプロパティを選択し、左サイドバーの「パフォーマンス」から「検索結果」をクリックする。期間を過去3カ月に設定し、右上の「エクスポート」からCSVをダウンロードする。エクスポート前に「表示回数」または「クリック数」の多い順に並べ替えておくと、上位1,000キーワードが最も価値の高いものになる。
All in One SEO(AIOSEO)のEliteプランを利用していれば、WordPress管理画面から直接同じデータを取得できる。AIOSEOの検索統計機能はサーチコンソールのデータを自動的に取り込んでおり、キーワード順位、クリック数、表示回数をダッシュボード上で確認できる。
現在のURL一覧をクロールして文書化する
サイト上の全ページの完全なリストは、後でリダイレクトを設定する際のロードマップになる。このリストから漏れたページはリダイレクトが設定されず、古いアドレスが機能しなくなった瞬間に、そのページが築いた検索順位は永久に失われる。
現在のサイトをクロールするには、Screaming Frog SEO Spiderが使える。500URLまでは無料で、有料プランでは無制限にクロールできる。クロールが完了したら、ファイルメニューから全URLリストをCSVとしてエクスポートし、キーワードエクスポートと同じ移転専用フォルダに保存する。
ステップ2 サイトを安全に移転する

サイト移行に使う手法は、最初の大きなSEO判断になる。WP Beginnerの記事では、移行中のデータベース処理の安全性からDuplicatorの使用が推奨されている。Duplicatorのインストーラーは、展開時にWordPressデータベース内の全URLを新しいドメインに自動更新する。内部リンクや画像パスも自動修正されるため、後述する古い正規URLや混在コンテンツの問題を防げる。
移転が完了したら、新しいWordPress管理画面の「設定」→「一般」で、WordPressアドレスとサイトアドレスの両方が新しいドメインになっていることを確認する。
robots.txtが新サイトをブロックしていないか確認する
検索エンジンのクロールをブロックできるのは、WordPressの「検索エンジンがサイトをインデックスしないようにする」チェックボックスだけではない。robots.txtファイルも同様の影響を与える。ステージング環境から引き継がれた古いルールが残っていると、重要なコンテンツがブロックされる可能性がある。
新しいドメインのrobots.txtをブラウザで開き、DisallowルールやSitemap行が新しいドメインを指しているか確認する。AIOSEOを使っている場合は、ツールメニューから「カスタムrobots.txtを有効化」トグルをオンにし、古いルールを直接修正できる。
ステップ3 旧ドメインからの301リダイレクトを設定する

301リダイレクトは、Googleに対して「このURLは恒久的に新しいURLに移動した」と伝える仕組みだ。郵便局に転居届を出すようなもので、SEO評価を正しく転送するための必須手続きになる。301がないと、Googleは新旧ドメインをまったく別のサイトとして扱い、ランキングシグナルは古いドメインに残ったままになる。
AIOSEOのProプラン以上に含まれる「フルサイトリダイレクト」機能を使うと、旧ドメイン全体を一度の設定で新ドメインに転送できる。旧サイトのWordPress管理画面で「All in One SEO」→「リダイレクト」→「フルサイトリダイレクト」タブを開き、「サイトを移転する」トグルを有効化して新しいドメインURLを入力する。
重要な注意点として、この手法は旧サイトのWordPressが稼働し続けていることが前提になる。旧ドメインの登録を維持し、ホスティングも停止せず、AIOSEOプラグインも有効化したままにする必要がある。旧サイトを削除したりホスティングを解約すると、リダイレクトは即座に機能しなくなる。
Googleに通知する前にリダイレクトをテストする
壊れたリダイレクトを抱えたまま変更通知を送信すると、移行全体の回復が遅れる。外部ツールのhttpstatus.ioなどを使い、旧ドメインのトップページURLが301ステータスを返し、正しい新ドメインのURLに解決されることを確認する。このテストはアクセスの多い上位5記事と主要カテゴリページでも繰り返す。
302リダイレクトや複数ホップのチェーンが発生している場合は、AIOSEOのリダイレクト設定で競合する個別ルールがないか確認する。リダイレクトチェーンが発生すると、SEO評価の受け渡しが目減りし、訪問者の待ち時間も増える。すべての旧URLが新URLに直接1ホップで転送される状態を目指す。
この比較図はリダイレクトチェーンの問題を視覚化したものだ。中間ホップを除去して直接転送にすることで、Googleが処理すべき経路が単純になり、評価の受け渡し効率が上がる。
ステップ4 新ドメインをGoogleサーチコンソールに登録する
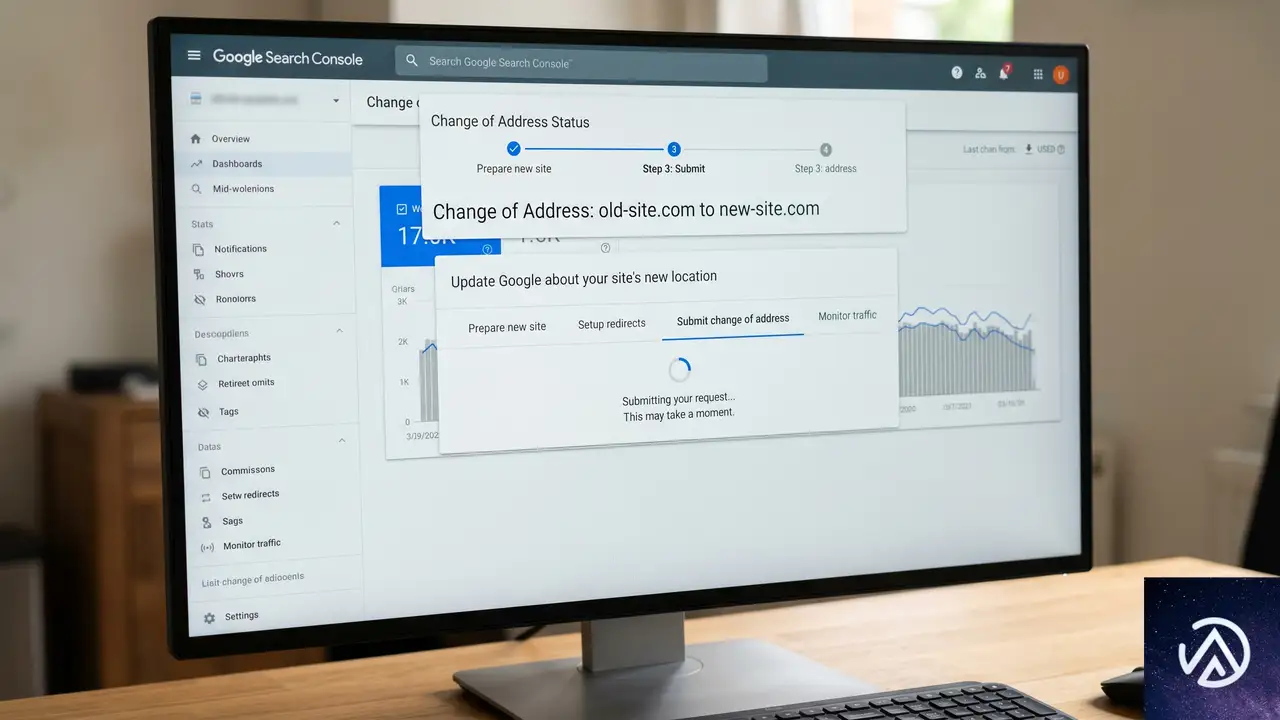
Googleは旧ドメインと新ドメインを完全に別のプロパティとして扱う。ランキングシグナルを転送するには、新ドメインをサーチコンソールで確認し、住所変更通知を送信し、サイトマップを再送信する必要がある。
新しいドメインを追加するには、サーチコンソールのプロパティドロップダウンから「プロパティを追加」を選び、確認手続きを進める。次に旧ドメインのプロパティに切り替え、「設定」→「住所変更」から新ドメインを選択して「検証して更新」をクリックする。このときGoogleが301リダイレクトを検証するため、事前にステップ3の設定が完了している必要がある。
サイトマップについては、AIOSEOがドメイン変更時に内部リンクを自動更新するが、新しいURLのサイトマップを手動で再送信することで、次の自動クロールを待たずに新URLのインデックス登録を開始させられる。
ステップ5 正規URLが正しいか検証する
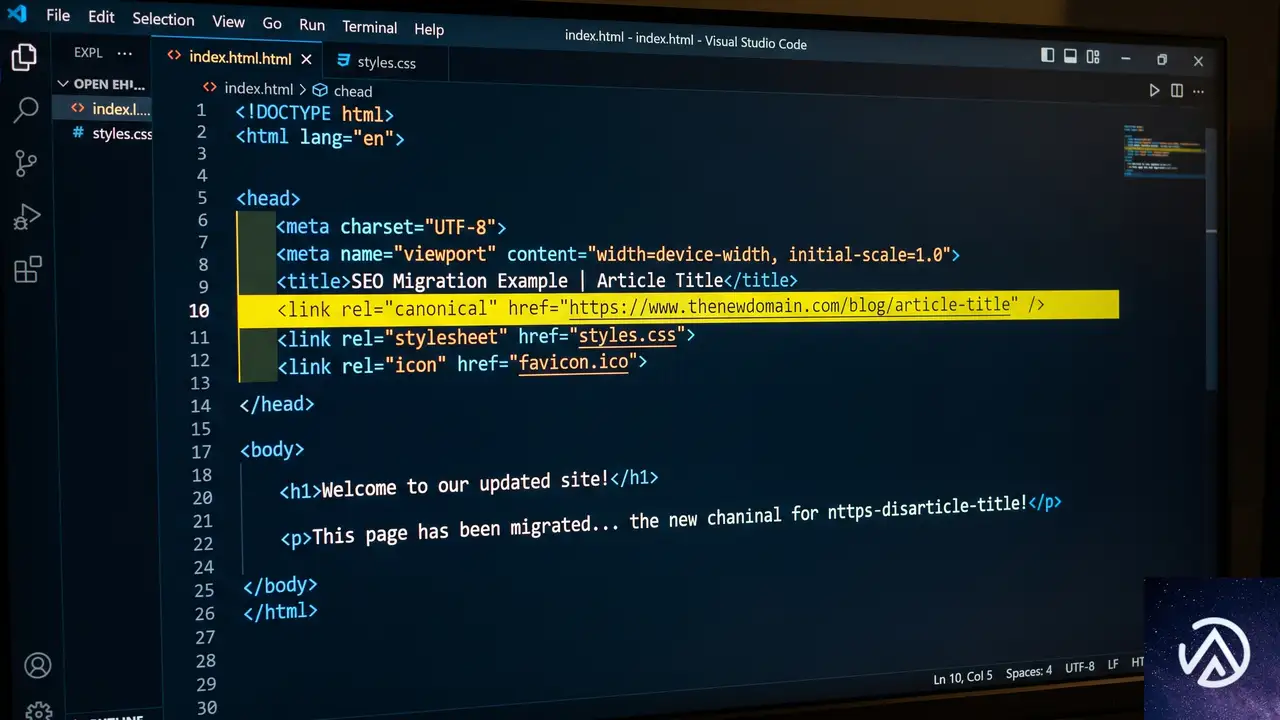
正規URL(カノニカルURL)は、検索エンジンがインデックスしてランク付けすべき「正式版」のページを指す。ドメイン移転後に正規タグが旧ドメインを指したままだと、新しいページがGoogleに対して「古いURLをランク付けしてほしい」と伝えているのと同じ状態になる。これは順位回復が遅れる最も一般的な原因のひとつだ。
Duplicatorで移転した場合、データベース内の正規URLは展開時に自動更新される。ただし、個別の投稿レベルで手動設定された正規URLオーバーライドはDuplicatorが更新しない場合があるため、以下のスポットチェックは必ず実施する。
AIOSEOのグローバル正規設定を確認する
AIOSEOはサイトURLに基づいてサイト全体の正規タグを自動生成する。移転後に確認すべきは、重複コンテンツを防ぐ2つのリダイレクト設定だ。「検索の外観」→「詳細」タブにある「ページ送りフォーマット」が空白になっていないことを確認する。また「画像SEO」タブで「添付ファイルURLのリダイレクト」が無効になっていないかをチェックする。この設定は、コンテンツの薄いメディア添付ページを親投稿にリダイレクトし、Googleのインデックスから除外する役割を持つ。
重要ページを目視チェックする
アクセスの多い上位ページをブラウザで開き、ページのソースを表示して<link rel="canonical"を検索する。URLが新ドメインを指していることを確認する。もし旧ドメインのままになっているページがあれば、その投稿の編集画面でAIOSEO設定パネルの「詳細」タブを開き、正規URLフィールドを手動で更新する。
ステップ6 データベースURLと混在コンテンツを修正する
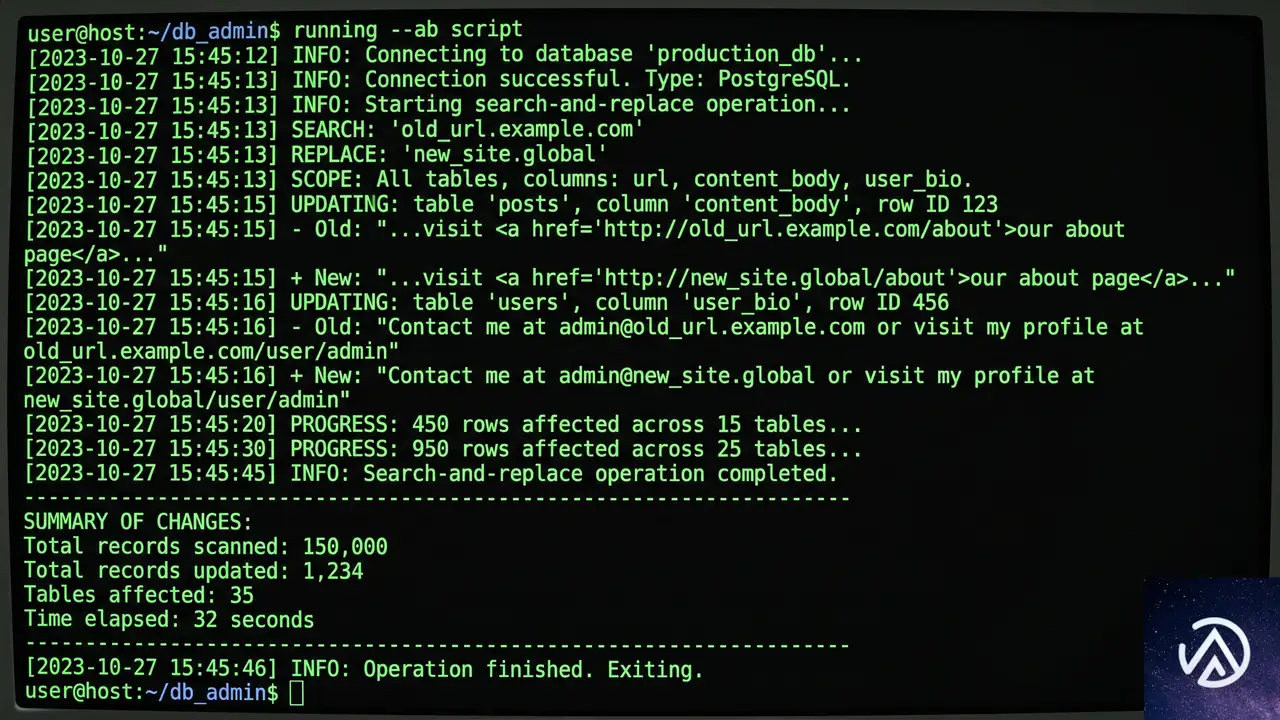
移転後、一部の画像やスクリプト、スタイルシートが旧ドメインを指したままだったり、安全でないHTTP接続で読み込まれていたりすることがある。これらの古いアセットは、旧ドメインがオフラインになった瞬間に画像の破損やセキュリティ警告を引き起こす。
データベース内のハードコードURLを置換する
Duplicatorは標準的なURL更新を処理するが、ページビルダーのレイアウトやテキストウィジェット、カスタムテーマオプションに埋め込まれたハードコードリンクは取り残されることがある。Search & Replace Everything by WPCodeプラグインを使うと、シリアル化データを破損させずにデータベース全体のURLを安全に置換できる。
WordPress管理画面の「ツール」→「WP Search & Replace」で、検索フィールドに旧ドメインURL、置換フィールドに新ドメインURLを入力し、すべてのデータベーステーブルを選択する。「検索と置換をプレビュー」で影響範囲を確認した後、「すべて置換」を実行する。
ElementorやDiviなどのページビルダーを使っている場合、Search & Replace実行後も背景画像が破損することがある。これはビルダーが静的CSSファイルにURLを保存しているためだ。この場合、Elementorなら「Elementor」→「ツール」→「ファイルとデータを再生成」を実行してキャッシュをクリアする。
SSL混在コンテンツエラーを修正する
旧ドメインが標準HTTPで新ドメインがHTTPSの場合、ブラウザのアドレスバーに壊れた鍵アイコンやセキュリティ警告が表示されることがある。これはサイト設定は安全でも、埋め込まれたスクリプトや画像が安全でない接続で読み込まれようとしている混在コンテンツエラーだ。まずは新ドメインに有効なSSL証明書がインストールされていることを確認し、その後WordPressの混在コンテンツ修正手順を実行する。
残存するリンク切れをスキャンする
データベースURLの置換が完了したら、AIOSEOのBroken Link Checkerを使って内部リンクが404エラーになっていないかスキャンする。このプラグインはバックグラウンドで自動スキャンを実行し、リンク切れを検出すると一覧表示する。各リンクに対してインラインの「URLを編集」で修正するか、「リンク解除」で削除できる。
ハード404エラーを特定して修正する
リンク切れスキャンがコンテンツ内のデッドリンクを見つけるのに対し、ハード404は「ページが移行されなかった」「URLが変更された」「リダイレクトが機能していない」などの理由で新サイト上で「見つかりません」と表示されるページだ。Screaming Frogで新ドメインをクロールし、レスポンスコードタブで4xxエラーを探す。Googleサーチコンソールの「インデックス作成」→「ページ」でも404として検出されたページを確認できる。各404について、ページを復元するか、新しいURLへの301リダイレクトを追加する。
価値の高い外部バックリンクを更新する
自サイト内のリンク修正だけでは不十分だ。他のウェブサイトが旧ドメインにリンクしている外部バックリンクは、最も強力なランキングシグナルのひとつである。301リダイレクトはその評価を新ドメインに転送するが、その受け渡しは永続的ではなく、時間経過とともに弱まる可能性がある。また旧ドメインを手放した時点で完全に停止する。
Googleサーチコンソールの「リンク」→「上位のリンク元サイト」で、最も多くリンクを送っているサイトを特定し、ゲスト投稿の著者プロフィールやプレス掲載、リソースページ掲載など、実際に更新を依頼できる高オーソリティのサイトから優先的に連絡する。すべてのリンクを変更できるわけではないが、上位の数十件を直接リンクに更新するだけでも、最も重要なランキングパワーを保護できる。
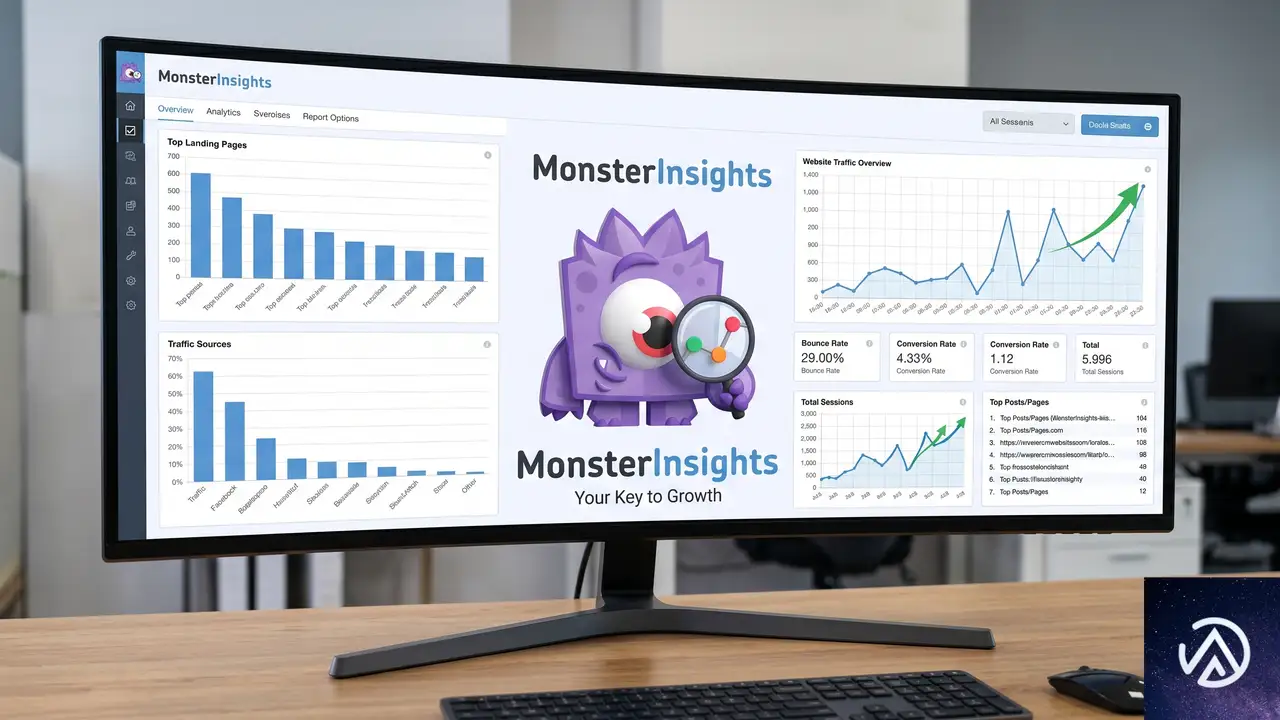
ステップ7 AIOSEOとMonsterInsightsで復旧を監視する
ドメイン移転後の順位回復には時間がかかる。この期間中に重要なのは、検索アルゴリズムによる通常の短期的な変動と、実際に対処が必要な技術的問題を区別することだ。
AIOSEO検索統計でキーワード順位を追跡する
AIOSEOの検索統計ダッシュボードは、GoogleサーチコンソールのデータをWordPress管理画面に直接取り込む。「勝ち負け」タブでは、移転後に最も可視性を失ったページを素早く特定できる。移転前のステップ1で保存したCSVと見比べることで、回復の進捗を定量的に評価できる。
MonsterInsightsでトラフィック傾向を比較する
キーワード監視が検索エンジン上の位置を示すのに対し、実際のトラフィック量はユーザーが新ドメインにどう反応しているかを確認する指標になる。MonsterInsightsはGoogle AnalyticsのデータをWordPressに取り込み、週次でのトラフィック比較を簡単にする。重要なのは、新しいGoogle Analyticsプロパティを作成せず、既存のプロパティを使い続けることだ。データストリームだけを新しいサイトURLに更新すれば、移転前のベースラインとの比較が途切れない。
MonsterInsightsのSite Notes機能(Proプラン以上)を使えば、移転日をアナリティクスのタイムラインに直接ピン留めできる。これにより、トラフィックがいつから回復し始めたかを折れ線グラフ上で視覚的に把握できる。
週次での回復タイムライン
ドメイン移転後に順位が大きく変動すると不安になるのは当然だ。しかし、正常な回復のパターンを知っておけば、パニックによるコンテンツ変更(回復を遅らせる原因になる)を避けられる。
- 第1週 発見と変動。Googleのクローラーがリダイレクトを発見し、ドメイン変更の処理を開始する。順位は大きく変動し、トラフィックはベースラインから30〜70%減少することが多い。これは想定内であり、移行の失敗を意味しない
- 第2週 シグナルの転送開始。ほとんどの301リダイレクトが処理され、ランキングシグナルが新ドメインに渡り始める。サーチコンソールでリダイレクトエラーやソフト404の通知がないか確認する
- 第4週以降 回復の評価。クリーンな301リダイレクトがあるサイトでは、4〜8週間以内に80〜100%の回復が見られることが多い。回復が遅れているページがあれば、リダイレクト、正規URL、インデックス状態の3点を再確認する
この記事のポイント
- ドメイン移転のSEOリスクは301リダイレクトの欠落、古い正規URL、旧ドメインを指すサイトマップの3つに集中する
- 移転前にキーワード順位とURL一覧のベースラインを取得し、回復度合いを測定できる状態にする
- リダイレクトは直接1ホップで完了させ、チェーンを発生させない
- 正規URLとデータベース内リンクは自動更新を過信せず、必ず手動でスポットチェックする
- 復旧状況はAIOSEOの検索統計とMonsterInsightsのトラフィック比較で定量的に追跡する
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

WordPress多言語プラグインを徹底比較〜TranslatePress・WPML・Universallyの最適解
WordPressサイトを多言語化することは、リーチの拡大やSEOトラフィックの増加、売上向上に直結する施策だ。だが、数ある翻訳プラグインの中からどれを選ぶべきか判断するのは容易ではない。TranslatePressとWPMLは長年の実績を持つ定番であり、Universallyはよりモダンな手法で翻訳を自動化する新興の選択肢だ。
この記事では、WP Beginnerのテストと分析に基づき、セットアップの容易さ、翻訳品質、多言語SEO、パフォーマンス、WooCommerce対応、サポート、価格の7つの観点から3つのプラグインを比較する。自社サイトに最適な翻訳プラグインを選ぶための判断材料を提供する。
結論から言えば、Universallyは最も簡単なセットアップとクラウドによる高速パフォーマンス、圧倒的な導入コストの低さが魅力だ。TranslatePressは直感的なビジュアル編集を求めるユーザーに適しており、WPMLは特に複雑なWooCommerceストア運用で真価を発揮する。
セットアップの容易さ

サイトを多言語化するプロセスは、可能な限り手間がかからないのが理想だ。TranslatePressとUniversallyは、10分以内に別言語版を公開できる。一方、WPMLは相応の設定作業が必要で、作業に入る前にその工数を理解しておく価値がある。
TranslatePressのセットアップ
TranslatePressの導入はWPMLよりシンプルだ。WordPress.orgからプラグインをインストールし、設定画面で言語を選択すると、APIキーなしで即座にフロントエンドの翻訳エディターが利用可能になる。管理バーの「サイトを翻訳」をクリックし、ライブページ上のテキスト要素を直接クリックして翻訳するだけだ。バックエンドのスプレッドシートや別ダッシュボードは一切存在しない。
注意点として、訪問者のブラウザ言語を自動検出して切り替えを促す機能は、Businessプラン(年間199ユーロ)のみの提供だ。Personalプランでは言語スイッチャーを設置できるが、訪問者自身が手動で言語を選択する必要がある。
WPMLのセットアップ
WPMLは、3つのプラグインの中で最も多くの初期設定を要求する。Multilingual CMSプランでは、最低でも2つのプラグインコンポーネント(WPML本体とString Translation)のインストールが必要だ。各コンポーネントに独自のセットアップウィザードがあり、翻訳は自動では開始されない。ページごとに手動でトリガーするか、「すべてを翻訳」モードを有効にして自動翻訳のクレジット消費を設定する。
WP Beginnerのテストによれば、シンプルなサイトの翻訳設定だけでも1時間近くかかったという。複雑なテーマやカスタム投稿タイプを使用する大規模サイトでは、さらに多くの時間を見込む必要がある。この複雑さには理由があり、WPMLはTranslatePressやUniversallyでは提供されないきめ細かな制御を可能にする。ただし、そのレベルの制御が不要であれば、オーバーヘッドに見合わない。
Universallyのセットアップ
Universallyは、その手軽さが際立つ。プラグインをインストールし、専用ダッシュボードからAPIキーを貼り付け、対象言語を選ぶだけだ。この3ステップで作業は完了する。言語スイッチャーが自動でサイトに表示され、ショートコードの設置やテンプレート編集、ページごとの翻訳トリガーは一切不要だ。
言語検出、SEO設定、スイッチャーの配置まですべてが自動化されており、大半のサイトは10分足らずで多言語化が完了する。WP Beginnerの著者も、その要求の少なさに驚いたと述べている。
セットアップの容易さでは、Universallyが最速であり、TranslatePressがそれに次ぐ。WPMLの複雑さは、提供する詳細な制御が本当に必要な場合にのみ正当化される。
翻訳品質
機械翻訳の品質は近年大幅に向上しており、3つのツールはいずれも多くの言語ペアで読みやすい翻訳を生成する。差が出るのは、誤りの修正方法と、最終結果に対する編集権限の大きさだ。
TranslatePressの翻訳品質
TranslatePressは、大規模言語モデルとニューラル機械翻訳エンジンを組み合わせ、言語ペアとコンテンツタイプごとに最適な手法を自動選択する。有料プランではTranslatePress AIが利用でき、プランごとに単語数の上限が設定されている。高精度のDeepL連携はBusinessプラン以上で利用可能だ。
TranslatePressの最大の強みは、全プランで利用できるフロントエンドのビジュアルエディターだ。ライブページ上のテキストをクリックするとサイドバーに翻訳が表示され、その場で修正できる。変更はリアルタイムでページに反映される。翻訳メモリ機能も全プランに含まれており、95%以上一致する既存の翻訳を新しい文字列に自動適用する。
WPMLの翻訳品質
WPMLは根本的に異なるアプローチを取る。デフォルトは手動翻訳であり、すべての文字列をユーザーが制御する。機械翻訳は有料アドオンで、DeepLやGoogle Translate、Microsoft Azure Translatorを利用できる。クレジットはCMSプランとAgencyプランに含まれており、ワークフローはAIによる翻訳結果をそのまま公開するのではなく、人間によるレビューを前提に設計されている。
高度な翻訳エディターは、プロの翻訳者向けにサイドバイサイドの編集画面を提供し、翻訳メモリと公開前の品質チェック用レビュアー権限も備える。法律文書や医療情報など、誤訳が重大な結果を招くコンテンツでは、この手動優先の設計が力を発揮する。
Universallyの翻訳品質
Universallyは、汎用の言語モデルではなくWebコンテンツ向けに特化してトレーニングされたカスタムAIモデルを使用する。この専門化により、単語単位の置き換えではなくブランドの声や文脈を維持した翻訳を実現する。同社の報告では、ほとんどの言語ペアで90〜95%の精度を達成している。
用語集機能(全有料プランで利用可能)では、ブランド名や製品名、特定のフレーズの訳し方を固定でき、そのルールがサイト全体に自動適用される。現時点では専用の編集ツール(ダッシュボードテキストエディターやライブビジュアルエディター)はロードマップ上の計画段階であり、まだ提供されていない。
翻訳品質では、UniversallyとTranslatePressがそれぞれ異なる理由で優れている。AI翻訳をそのまま公開し、ほとんど手を加えたくないならUniversallyが適している。一方、手動で細かく編集したい場合は、クリックして修正できるTranslatePressのビジュアルエディターが実務上の大きなアドバンテージとなる。WPMLはプロの翻訳パイプラインとミッションクリティカルなコンテンツ向けという別の領域にある。
多言語SEO
多言語での公開は、検索エンジンがそれらのページを正しく検出し、インデックスして初めて効果を発揮する。3つのツールはいずれも技術的なSEOの基本をカバーするが、何が自動で含まれ、何が上位プランに制限されているかには意味のある違いがある。
TranslatePressの多言語SEO
SEO Packアドオンはすべての有料プランに含まれ、hreflangタグや多言語XMLサイトマップ、翻訳されたメタタイトルとディスクリプション、画像のaltテキスト、Open Graphメタデータ、翻訳URLスラッグを処理する。URLスラッグの翻訳は全有料プランで利用可能であり、同じ機能に別途課金する競合ツールと比較してコストパフォーマンスに優れる。また、Yoast SEOやRank Math、AIOSEO、SEOPress、Slim SEOとの連携により多言語サイトマップを生成できる。
WPMLの多言語SEO
WPMLの専用SEOアドオンはCMSプランとAgencyプランに含まれる。hreflangタグ、x-default hreflangタグ、翻訳URLスラッグ、言語別のメタ情報をすべてカバーする。AIOSEOやYoast SEOとの深い互換性により、SEOプラグインの全フィールドが翻訳ワークフローに自動で組み込まれる。ただし、Yoast SEO Premiumのリダイレクト機能はWPMLと互換性がない点に注意が必要だ。
Universallyの多言語SEO
Universallyは、多言語SEOの全スタックを自動で処理する。hreflangタグ、翻訳メタ情報、多言語XMLサイトマップ、schema.org構造化データ、RTL言語サポートが、言語を追加した瞬間に有効化され、手動設定は一切不要だ。これはUniversallyの本物の強みであり、SEO設定ページを一度も開くことなく堅実な多言語SEOを実現できる。
多言語SEOではWPMLとTranslatePressが同点だ。いずれも有料プランでx-default hreflangと翻訳URLスラッグを含む完全なSEOスタックをカバーする。Universallyは国際SEOの基本を自動化するが、x-defaultタグやネイティブなURLスラッグ翻訳に関するきめ細かな制御は現時点では欠けている。
パフォーマンスと表示速度

サイト速度はSEOとコンバージョンの両方に影響する。複数言語の追加は、翻訳プラグインの実装が非効率だとサイトを遅くする要因になる。これら3つのツールは、翻訳コンテンツの保存と配信において根本的に異なるアーキテクチャを採用している。
TranslatePressのパフォーマンス
TranslatePressはWPMLと同様に、翻訳をWordPressデータベースに直接保存する。コンテンツが増えるにつれて同じデータベース肥大化の問題が発生する。実用的な利点として、翻訳メモリにより各文字列のAPI呼び出しは1回限りだ。新しい言語での初回訪問後、以降の訪問者はキャッシュされたデータベース版を受け取り、追加の処理は発生しない。翻訳が自社データベースに保存されるため、TranslatePressのサービスがオフラインになったりサブスクリプションを解約したりしてもサイトは機能し続ける。
WPMLのパフォーマンス
WPMLは翻訳を言語ごとの重複エントリとしてデータベースに保存する。WP Beginnerのテストでは、キャッシュなしのサイトで0.3〜0.5秒の追加遅延が確認された。質の高いキャッシュプラグインでほとんどを取り戻せるが、データベースの負荷は時間とともに増大する。数百の投稿を複数言語に翻訳したサイトでは、優れたキャッシュを導入していてもオーバーヘッドが無視できなくなる。多言語化の前にキャッシュプラグインを導入し、言語別に異なるキャッシュファイルを配信する設定を行うことが推奨される。
Universallyのパフォーマンス
Universallyは、200以上のエッジ拠点を持つグローバルCDNから翻訳コンテンツを配信し、WordPressデータベースには一切書き込まない。追加する言語数に関係なく、サイトのデータベースサイズは変わらない。キャッシュプラグインで言語別キャッシュを有効にする初期設定は推奨されるが、大半の人気キャッシュプラグインなら簡単なトグル操作で完了する。クラウドで動作するため翻訳はUniversallyのサーバーで保存・同期され、自社データベースを圧迫するものは何もない。
パフォーマンスではUniversallyが明らかにリードしている。グローバルCDN配信とデータベース書き込みゼロの組み合わせは、データベース肥大化が避けられないTranslatePressやWPMLに対して明確な優位性を持つ。
WooCommerce対応

WooCommerceストアの多言語化は、標準サイトの翻訳より複雑だ。動的なカートメッセージやチェックアウト時のエラー通知、自動送信される注文確認メールなど、すべてが顧客の言語で正しく表示されなければならない。顧客がスペイン語でストアを閲覧したのに自動配信レシートが英語だと、混乱を招きブランドの信頼を損なう。
TranslatePressのWooCommerce対応
TranslatePressは追加アドオン不要で、フロントエンドのビジュアルエディターを通じてWooCommerceを翻訳する。商品ページ、説明、カート、チェックアウトフローが自動でカバーされる。注文確認メールは顧客の閲覧言語で送信され、ログインユーザーには最後に使用した言語が記憶される。WPMLと比較した場合のギャップは多通貨対応で、TranslatePressには通貨切り替え機能が組み込まれていない。現地通貨で価格を表示したい場合は、専用のマルチカレンシープラグインが別途必要になる。
WPMLのWooCommerce対応
WPMLのWooCommerce Multilingualアドオン(Multilingual CMSプランに含まれる)は、WP Beginnerの著者が「これまで見た翻訳プラグインの中で最も徹底したWooCommerce統合」と評する出来だ。商品、カテゴリ、属性、バリエーション、カスタムフィールド、カートとチェックアウト、配送方法名、注文確認メールを自動でカバーする。
さらに、200以上の通貨に対応したネイティブのマルチカレンシー機能を内蔵する。為替レートベースの価格設定と、商品・通貨ごとの手動上書きが可能で、所在地に基づく通貨表示により訪問者は自動で現地通貨の価格を目にすることができる。
UniversallyのWooCommerce対応
UniversallyはWooCommerceの翻訳も他のコンテンツと同様に自動処理する。アドオン不要、商品ごとの設定も不要で、商品説明や画像altテキスト、カートとチェックアウトフローがカバーされる。ただしTranslatePressと同様に、ネイティブのマルチカレンシー機能は持たない。現地通貨表示が必要な場合は別途プラグインを用意する必要がある。
WooCommerce対応ではWPMLが圧勝だ。ネイティブのマルチカレンシー、翻訳された商品属性やバリエーションの細かい制御、言語別の注文メールは、他の2つとは明確に異なる次元にある。TranslatePressはほとんどのWooCommerce翻訳ニーズに十分応え、シンプルなストアに適している。Universallyは基本をカバーするが、複雑な多言語WooCommerceセットアップ向けには設計されていない。
カスタマーサポート

多言語サイトで何か問題が発生したとき、サポートの品質と可用性は実際の運用に差をもたらす。3つのツールはいずれもサポートを提供するが、対応時間、実績、応答の一貫性には大きな違いがある。
TranslatePressのサポート
TranslatePressは、大規模なユーザーベースに支えられた強力なサポート評価を得ている。WordPress.orgでは1,600件以上のレビューで4.7/5、Trustpilotでは4.6/5を獲得している。レビューではサポート担当者の名前が頻繁に挙げられ、明確で実践的な回答が迅速に得られたという声が多い。ただしサポートは平日のみで24時間対応ではない点に留意が必要だ。
WPMLのサポート
WPMLのサポート評価は際立っている。9言語で1日22時間対応し、G2とCapterraの両方で4.7/5を獲得している。多数の5つ星レビューにおいて、サポートこそがWPMLを使い続ける理由として挙げられている。「信じられないほど速く正確」「積極的」といった言葉が繰り返し登場する。全プランに直接チケットアクセスが含まれ、過去の解決済みチケットを検索できるフォーラムでは、返信を待たずに一般的な問題を自力解決できる。
Universallyのサポート
Universallyは新しいプラグインだが、WPFormsやAIOSEO、OptinMonsterなどの人気プラグインを手がけるAwesome Motive(WPBeginnerの運営元でもある)によって開発されている。数百万のWordPressサイトで動作する実績あるエンジニアリングとサポート体制を背景に持つ。日常的なサポートはチケット送信で対応し、Proプランユーザーには優先対応が提供される。
ドキュメントも新プラグインとしては充実しており、インストールや言語管理、トラブルシューティング、SEO、開発者API情報をカバーする。しかも開発者ではなくサイト運営者向けに書かれているため、返信を待たずに多くのセットアップ上の疑問を自力で解決できる。
サポートではWPMLが最も評価が高い。ほぼ24時間の多言語対応と、数多くのレビューで「乗り換えない理由」として真っ先に挙げられる強固な評価は、他を凌駕する。TranslatePressはそれに次ぐ位置にあり、平日限定という制約はあるが、評価スコアは高くユーザーベースも最大だ。Universallyは充実したドキュメントとAwesome Motiveのサポートチームを持つが、WPMLに迫るだけのライブサポートの実績はまだ構築途上である。
価格
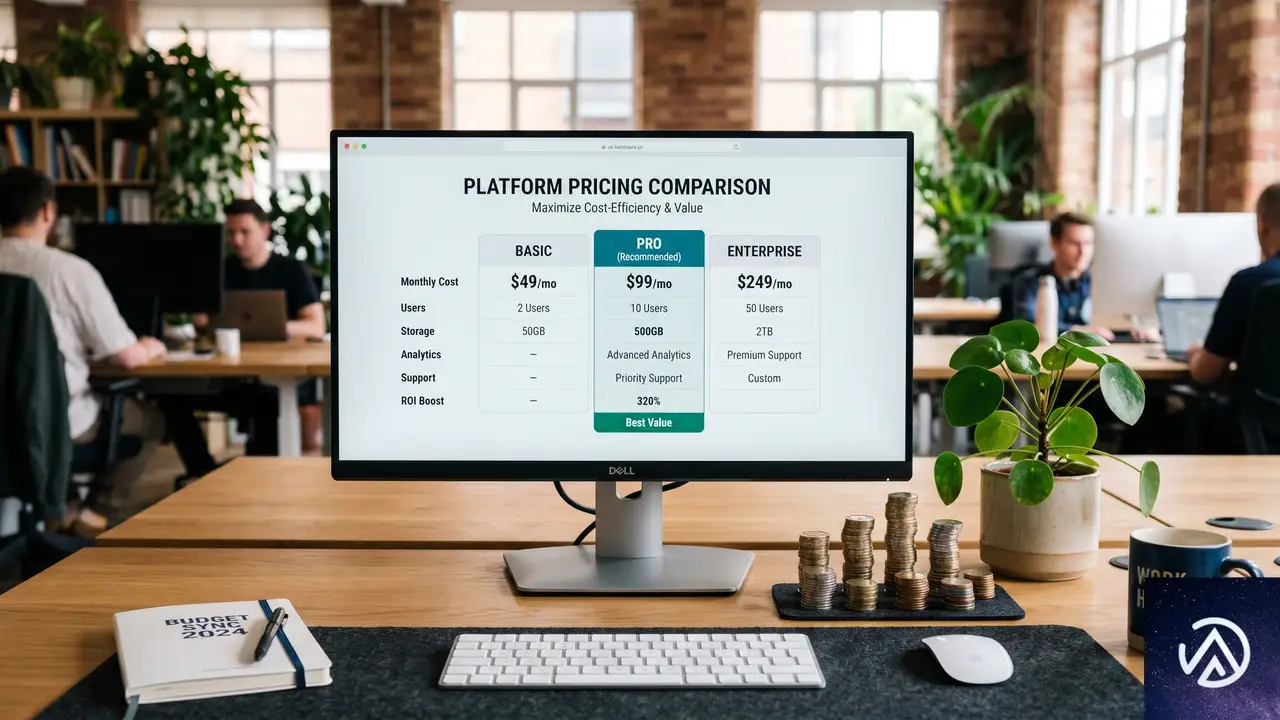
3つのツールの価格差はこの比較の中で最も大きい。TranslatePressとWPMLは年間定額制を採用し、Universallyは月額の単語従量課金制(米ドル建て)を取る。どれが最もコスト効率が良いかは、コンテンツ量と公開頻度によって変わる。
TranslatePressの価格
TranslatePressにはWordPress.orgで無料のコアプラグインが用意されており、手動翻訳と追加1言語に対応する。有料プランではAI翻訳とSEO Pack、対応言語数が拡張される。Personalプランが年間99ユーロ(約115ドル)、Businessプランが年間199ユーロ(約230ドル)、Developerプランが年間349ユーロ(約405ドル)だ。サブスクリプションを解約しても、既存の翻訳はデータベースに残り、サイトの全言語が機能し続ける点が実務上のメリットとして見逃せない。
WPMLの価格
WPMLには無料版が存在しない。Blogプランが年間39ユーロ(約45ドル)だがWooCommerce非対応、Multilingual CMSプランが年間99ユーロ(約115ドル)で3サイトとWooCommerce対応、Agencyプランが年間199ユーロ(約230ドル)で無制限サイトだ。WPMLの定額制が真価を発揮するのは大規模サイトで、翻訳量に関係なく同じ価格で済む点にある。
Universallyの価格
Universallyは米ドル建てで、月額の単語従量課金制だ。無料プランでは1言語2,000単語まで利用できる。Starterプランが月額7.50ドル(1サイト、1言語、10,000単語)、Businessプランが月額15.80ドル(1サイト、3言語、50,000単語)、Proプランが月額40.80ドル(3サイト、5言語、200,000単語)だ。年間一括払いで約17%割引となり、全プランに14日間の返金保証が付く。
多くの単一サイト運営者にとって、Universallyが価格面で最も有利だ。月額15.80ドルのBusinessプランで50,000単語×3言語の余裕があり、導入障壁が低い。一方、複数サイトを管理する制作会社や、毎日数百ページを翻訳するような大規模運用では、単語数無制限のWPML定額制(年間99ユーロ)が最も高いコストパフォーマンスを発揮する。
この記事のポイント
- セットアップの速さと手軽さを最重視するならUniversallyが最適だ。
- ビジュアル編集と自社サーバー内での翻訳データ保持を求めるならTranslatePressを選ぶとよい。
- 本格的なWooCommerceストアやプロ翻訳ワークフローが必要な場合はWPMLが突出して強力だ。
- いずれのプラグインも多言語SEOの基本はカバーするが、WPMLとTranslatePressが細部まで制御可能だ。
- パフォーマンスへの影響を最小化したいなら、CDN配信でデータベース負荷ゼロのUniversallyが明確に有利だ。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験