

AIエージェントがブランドを推薦する基準とは?「信頼性」が新たなSEO指標になる時代
AIエージェントが人間の代わりに5万ドルの予算を執行し、最適なベンダーを選定して契約まで完了させる。このような「エージェント・コマース」の時代が現実味を帯びている。これまでのSEO(検索エンジン最適化)は、いかにユーザーの目に留まるかという「可視性」を競ってきたが、これからはAIに選ばれるための「適格性」と「信頼性」が問われることになる。
検索エンジンの検索結果に表示されることと、AIが自律的な判断で特定のブランドを推薦することの間には、決定的な違いが存在する。それは「判断に伴うリスクの所在」だ。AIエージェントがユーザーの代理人として振る舞う以上、不適切な推薦はエージェント自身の存在価値を揺るがしかねない。
本記事では、AIエージェントがどのような基準でブランドを評価し、推薦に至るのかを解説する。ウォートン・スクールの研究結果を交えながら、これからのマーケターが取り組むべき「信頼のアーキテクチャ」について深掘りしていく。
AIエージェント時代の到来と「信頼」の重要性

現在のマーケティング業界では、AEO(Answer Engine Optimization / 回答エンジン最適化)やGEO(Generative Engine Optimization / 生成エンジン最適化)といった新しい略語が飛び交っている。これらは主に、ChatGPTやGoogleのGeminiといったLLM(大規模言語モデル)に自社コンテンツを学習・引用させるための手法だ。しかし、著者のPurna Virji氏は、議論の焦点を「WebサイトをLLMに最適化する方法」から「ブランドを自律型エージェントに最適化する方法」へ移すべきだと指摘している。
LLM最適化からエージェント最適化への転換
LLM最適化は、あくまで「情報を提供し、ユーザーに選んでもらうこと」を前提としている。これに対し、AIエージェントへの最適化は「AIに意思決定を委ねてもらうこと」を目指す。AIエージェントとは、ユーザーの指示を受けて自律的にタスクを実行するソフトウェアのことだ。例えば、「最適なCRM(顧客管理システム)を探して、予算内で契約を済ませておいて」という指示に対し、エージェントが市場調査から比較検討、最終的な発注までを行う世界である。
このプロセスにおいて、AIが最も重視するのは機能の多さや価格の安さだけではない。エージェントがそのブランドを「ユーザーに自信を持って推薦できるか」という信頼のレベルが重要になる。信頼とは、ここでは「不確実性を管理し、リスクを最小化できる能力」を指す。
リスクの所在がプラットフォームからエージェントへ移る
従来の検索エンジンでは、不適切なサイトを上位に表示しても、Googleなどのプラットフォーム側が直接的な責任を問われることは少なかった。ユーザーは検索結果から自己責任でサイトを選び、購入を判断するからだ。しかし、AIエージェントが意思決定を代行する場合、その責任はエージェントを開発・提供する側に転嫁される。
もしAIエージェントが、セキュリティに問題のあるベンダーや、倒産リスクの高いサービスを推薦し、ユーザーに損失を与えた場合、ユーザーは二度とそのエージェントを使わなくなるだろう。そのため、AIエージェントは必然的に「保守的」になり、エビデンス(証拠)が豊富で、説明責任を果たせるブランドを優先的に選ぶようになる。これが「信頼が新しいランキング要因になる」と言われる本質的な理由だ。
AIエージェントが信頼を構築する3つのアーキテクチャ
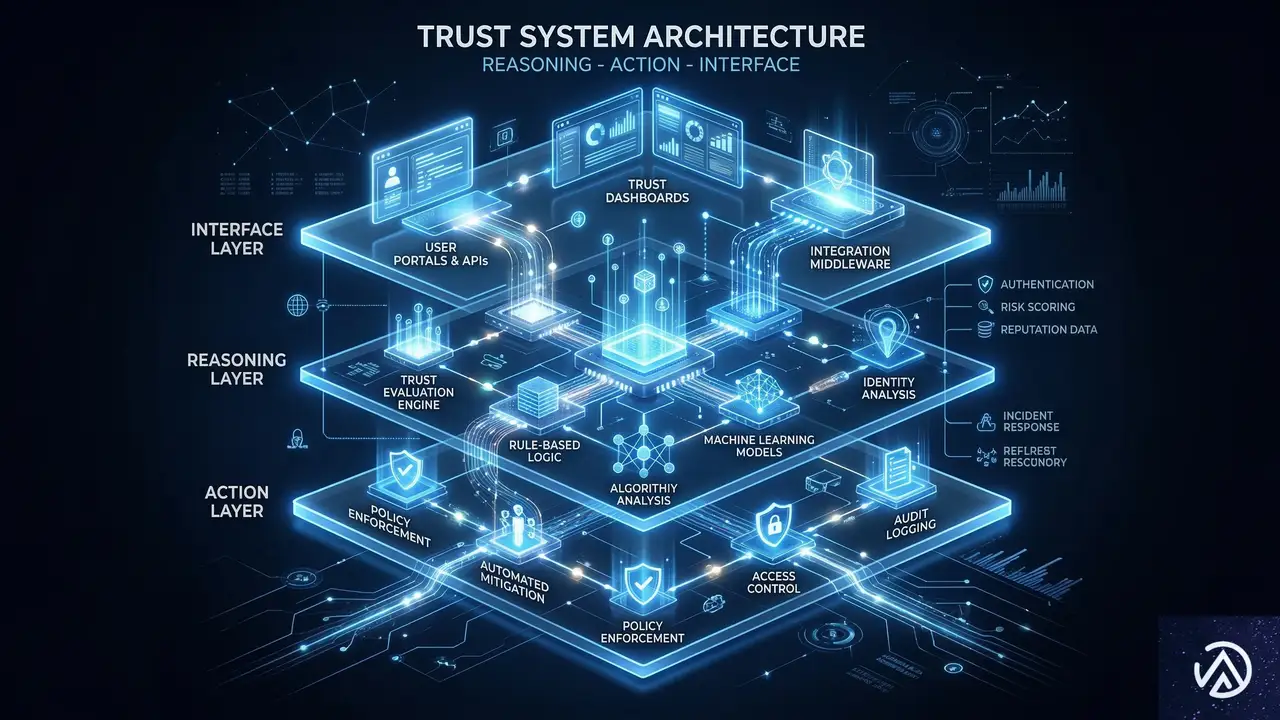
ウォートン・スクールのStefano Puntoni教授らの研究によれば、人間がAIエージェントを信頼し、依存するためには3つの構成要素が必要だとされている。これらは、マーケティングの観点からは「ブランドがAIに推薦されるための設計図」として読み替えることができる。
1. 推論の透明性と目標の整合性
AIエージェントは、なぜそのブランドを選んだのかをユーザーに説明できなければならない。そのためには、ブランド側が提供する情報が、単なる「宣伝文句」ではなく「検証可能な事実」である必要がある。例えば、明確な料金体系、現実的な導入スケジュール、競合他社と比較した際の具体的な優位性などが挙げられる。
AIは、ユーザーの目標(コスト削減、効率化など)とブランドの特性がどれだけ一致しているかを論理的に推論する。この際、曖昧な表現や誇大広告は、AIにとっての「ノイズ」となり、信頼を損なう要因となる。事実に即したデータを提供することが、AIの推論を助け、推薦の確率を高めることにつながる。
2. 予測可能な実行プロセスとフィードバック
エージェントは、選択した後のアクションがスムーズに進むことを好む。例えば、製品の購入手続きが複雑だったり、導入に何度も営業担当者との面談が必要だったりするブランドは、AIエージェントにとって「扱いにくい対象」となる。反対に、ドキュメントが公開されており、API連携が容易で、オンラインで完結するオンボーディング(導入支援)プロセスを持つブランドは、AIに好まれる。
「予測可能性」は、AIエージェントがユーザーに代わってアクションを起こす際の安心感を生む。実行プロセスが透明化されていることは、AIがユーザーに対して「次に何が起こるか」を正確にフィードバックできることを意味し、これがエージェントとユーザー間の信頼を強化するからだ。
3. 忖度しない「非追従性」のインターフェース
優れたAIエージェントは、単にユーザーの言うことを聞く(忖度する)だけではなく、時には「その選択は間違っている」と指摘する能力が求められる。これを「反媚態(Anti-Sycophancy)」と呼ぶ。エージェントはコンサルタントのように、予算や制約、コンプライアンスの観点からブランドを厳しく審査する。
ブランド側は、この「厳しい審査」に耐えうる深みのあるコンテンツを用意しなければならない。例えば、詳細なFAQ、特定の業界特有の制約への対応状況、他社製品からの乗り換え時の注意点などだ。AIエージェントがユーザーの問いかけに対して「このブランドは〇〇の点では優れていますが、△△の制約があるため注意が必要です」と、ニュアンスを含んだ回答ができるような材料を提供することが重要となる。
可視性(Visibility)から適格性(Eligibility)へのパラダイムシフト
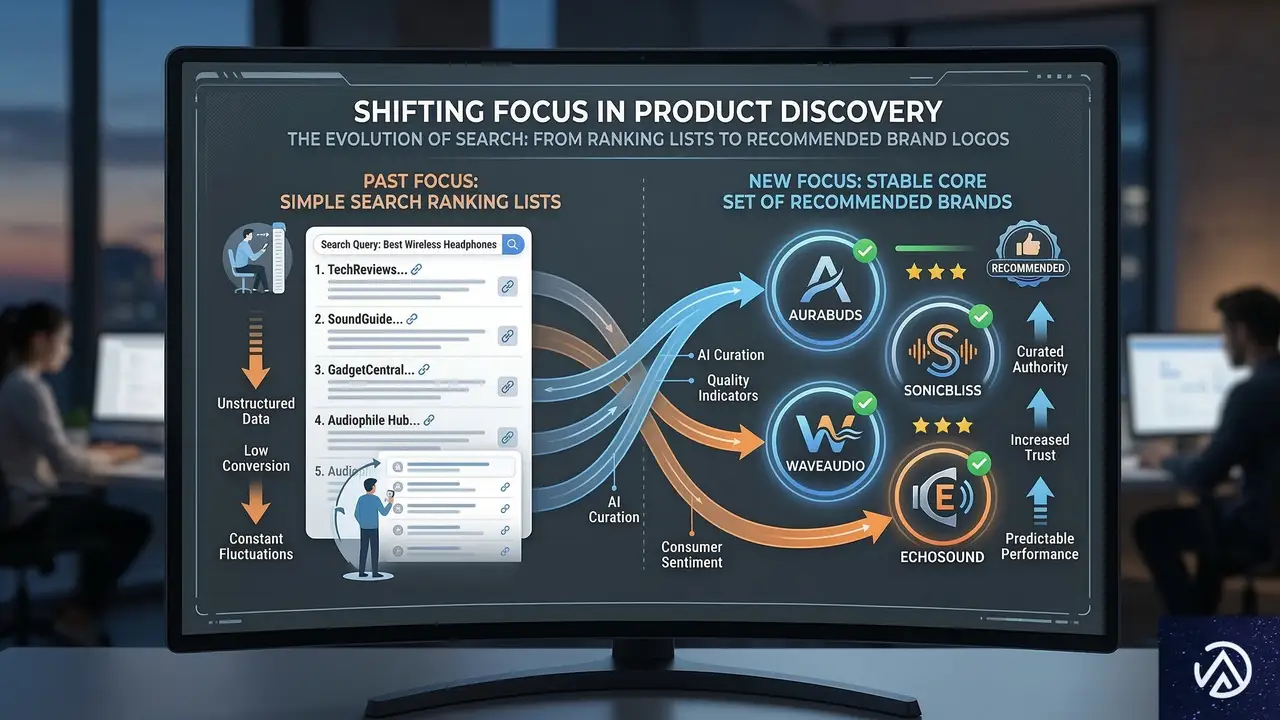
これまでのSEOの成功指標は、特定のキーワードで何位に表示されるかという「可視性」だった。しかし、AIエージェントの世界では、回答のたびに順位や内容が変動することが珍しくない。これについて、Rand Fishkin氏らの調査によれば、AIの回答には大きなばらつきがある一方で、ある「安定した傾向」も見られるという。
AIの回答にはばらつきがあるが「検討セット」は安定する
同じ質問をAIに何度も投げかけると、推薦されるブランドの順序やリストの長さは毎回変わることが多い。このため、「AI検索で1位を取る」といった従来の順位追跡は、あまり意味をなさない可能性がある。しかし、何度も試行を繰り返す中で、常に名前が挙がる「コアなブランド群」が存在する。これが、AIが「安全で推薦に値する」と判断した「検討セット(Consideration Set)」だ。
現代のマーケターが目指すべきは、単なる1位獲得ではなく、この「検討セット」の中に常に入り続けること、すなわち「適格性(Eligibility)」の確保だ。AIがユーザーの代理人として検討を行う際、最初から除外されないための「資格」を得ることが、新しい時代の成功の定義となる。
「選ばれる資格」を持つブランドの特徴
適格性を持つブランドには、共通の特徴がある。それは「デジタル上の信号(シグナル)」が一貫しており、かつ強力であることだ。自社サイトの情報だけでなく、SNSでの評判、専門家によるレビュー、ニュース記事、公的なデータベースなど、インターネット上のあらゆる場所で「信頼できる」という証拠が積み重なっている必要がある。
AIは単一の情報源を鵜呑みにせず、複数のソースをクロスチェックして情報の確からしさを判断する。そのため、自社サイトだけを綺麗に整えても、外部の評価が伴っていなければ適格性は得られない。これを「キャリブレーテッド・トラスト(校正された信頼)」と呼び、証拠の強さと一貫性に比例して高まっていくものだと指摘されている。
AIエージェントに選ばれるための4つの具体的戦略
では、具体的にどのような対策を講じればよいのか。AIエージェントに「信頼できるブランド」として認識され、推薦候補に残るための4つの戦略を提案する。
1. マシンリーダブルなデータ構造の整備
AIエージェントにとって読み取りやすい形式で情報を提供することは、最低限の条件である。構造化データ(Schema.orgなど)を適切に実装し、製品の仕様、価格、在庫状況、レビュー評価などを機械が正確に理解できるようにする必要がある。また、APIの公開や、クリーンなサイトアーキテクチャの構築も不可欠だ。AIが情報を解析する際に「解釈の余地」を減らし、正確なデータを直接渡せるように設計することが求められる。
2. 曖昧さを排除した透明性の高い情報公開
「詳細はお問い合わせください」という形式で情報を隠すことは、AIエージェント時代のマーケティングでは不利に働く。AIエージェントは、推奨の根拠となる具体的な数字や条件を必要としているからだ。価格帯、SLA(サービス品質保証)、システムの要件、解約条件など、ユーザーが判断材料とする項目を可能な限りオープンにするべきだ。情報を隠しているブランドは、情報の透明性が高い競合他社に「推薦のしやすさ」で負けてしまう。
3. 第三者による外部検証と社会的証明の強化
AIは、ブランドの自称よりも、第三者の評価を重く見る。顧客によるレビュー、アクティブなコミュニティでの議論、専門家によるチュートリアル、アナリストのレポートなどが、強力な「信頼のシグナル」となる。特にB2B領域では、導入事例(ケーススタディ)において具体的な数値(ROIなど)を示すことが、AIが推薦の根拠として引用しやすくなるため非常に有効だ。
4. 「推薦の根拠」となる素材の提供
AIエージェントがユーザーに説明する際の「カンニングペーパー」を用意するようなイメージでコンテンツを作成する。他社製品との比較表、投資対効果のシミュレーションモデル、「〇〇な課題を持つ企業に最適」といった具体的なガイドラインなどがこれに当たる。これらの素材は、AIエージェントがユーザーに対して「なぜこのブランドが最適なのか」を説得する際の強力な武器となる。
Web制作・マーケティング担当者が今取り組むべきこと

AIエージェントの普及は、Webサイトの役割を大きく変える。これまでは「人間を惹きつけるためのパンフレット」だったWebサイトは、これからは「AIエージェントが判断を下すためのデータベース」としての側面を強めていくだろう。私たちは、人間向けの魅力的なデザインと、AI向けの高精度なデータ構造を両立させなければならない。
まず取り組むべきは、自社のブランドに関連するキーワードでAI(ChatGPT, Perplexity, Google Geminiなど)がどのような回答を生成しているかを分析することだ。もし自社が推薦されていないのであれば、どの情報の欠落が原因なのか、あるいはどの外部評価が不足しているのかを特定する必要がある。
また、コンテンツ制作のあり方も見直すべきだ。単なる「バズ」を狙うのではなく、長期間にわたって参照され続ける「信頼の蓄積」を意識する必要がある。事実に基づき、検証可能で、かつ他者が引用しやすい高品質なコンテンツこそが、AI時代における最強のSEO資産となるだろう。
この記事のポイント
- 信頼性が最大のランキング要因に: AIエージェントが意思決定を代行する際、リスクを避けるために「信頼できる証拠」を最優先する。
- 可視性から適格性へのシフト: 検索順位に固執するのではなく、AIの「検討セット」に選ばれる資格を持つことが重要になる。
- 信頼の3要素: 推論の透明性、実行の予測可能性、そして忖度しない客観的な評価に耐えうる情報公開が必要だ。
- 具体的アクション: 構造化データの整備、情報の透明化、外部レビューの獲得、AIが引用しやすい比較資料の作成を推進すべきである。
出典
- Search Engine Journal「How AI Agents Decide Which Brands To Recommend: Trust Is The New Ranking Factor」(2026年3月16日)

・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Google Search Consoleに「ブランドフィルタ」が登場。ECサイトのブランド分析を効率化する活用法
Google Search Console(グーグルサーチコンソール)のパフォーマンスレポートに、ブランドに関連する検索クエリを簡単に抽出・除外できる新しいフィルタ機能が追加された。このアップデートにより、自社名や製品名を含む「指名検索」の動向を、これまで以上に迅速かつ直感的に把握することが可能になる。
2026年3月のリリース以降、この機能はAI(人工知能)を活用してクエリを自動分類し、企業のマーケティング担当者やSEOエンジニアの分析工数を削減する役割を担っている。特にブランド認知が売上に直結するECサイト運営者にとって、指名検索の分析は競合対策やキャンペーン評価の要となる要素だ。
本記事では、新しく導入されたブランドフィルタの仕組みと、実務での具体的な活用シナリオ、そしてAIによる分類の限界について、専門的な視点から詳しく解説する。
ブランドフィルタの仕組みとAIによる自動分類

今回追加されたブランドフィルタは、検索パフォーマンスレポート内で「ブランドを含むクエリのみを表示」または「ブランドを除外して表示」を切り替える機能だ。従来、ブランド検索を特定するには正規表現(Regex)を用いた複雑なフィルタリングが必要だったが、新機能によって数クリックで同様の操作が完結するようになった。
AIが判別する「ブランドクエリ」の定義
GoogleはAIを用いてクエリを分類しており、以下の要素がブランドクエリとして認識される。指名検索とは、ユーザーが特定のブランドやサイトを目的地として検索する「ナビゲーショナルクエリ」とも呼ばれるものだ。
- 会社名やサイト名
- ドメイン名(例:example.com)
- ブランド固有の製品名やサービス名
- 一般的なスペルミスや表記揺れ
例えば、Appleというブランドであれば、「iPhone」や「MacBook」といった製品名、さらには「Aple」といったスペルミスもブランドクエリとして統合的に処理される。これにより、ユーザーの検索意図をより正確に反映したデータ抽出が可能となっている。
従来手法(正規表現)との違い
これまで、ブランド名と非ブランド名を分けるには、正規表現(Regex)を使いこなす必要があった。正規表現とは、特定の文字列のパターンを表現する記法のことだ。例えば「自社名|じしゃめい|jisya」といった複数のキーワードを組み合わせた抽出条件を自ら作成し、フィルタに入力する手間が生じていた。
新機能は、こうした手動の設定をAIが代替する。Googleが保有する膨大なナレッジグラフ(実在するモノや概念のデータベース)を参照し、何がそのサイトにとってのブランドであるかを自動的に判断するため、設定の漏れやミスを防ぎやすくなっている。ただし、記事によれば、この機能は利便性を高めるためのものであり、新しいデータそのものを提供するわけではない点に注意が必要だ。
AI分類の精度と現時点での限界

AIによる自動分類は非常に強力だが、完璧ではない。元記事の著者であるアン・スマーティ氏は、自身のテストにおいてAIがいくつかの誤認や見落としを発生させたことを報告している。実務で利用する際には、これらの特性を理解しておく必要がある。
認識されるバリエーションと見落とし
スマーティ氏の検証によると、フィルタは以下のバリエーションを正確に捉えることができたという。
- 1単語または2単語の表記(スペースの有無)
- ハイフン付きの名称
- 略称や一般的な誤字
一方で、特定の製品名や代表者の名前については、認識が不安定な側面も見られた。例えば、創業者の名前はブランドクエリとして認識されたが、その創業者が執筆した書籍のタイトルはブランドとして認識されなかったという。これは、GoogleのAIが「何がブランドの構成要素であるか」を判断する際、その知名度や関連性の強さに依存していることを示唆している。
意図しないクエリの混入
また、自社とは直接関係のない競合他社の名前や、無関係な企業の役員名がフィルタに含まれてしまうケースも確認されている。これは、Googleの「ブランド」に対する定義が広範であるため、あるいはAIの学習データに基づいた関連付けが強すぎるために発生する現象と考えられている。
このように、AIフィルタは「概ね正しいが、細部には手動のチェックが必要なツール」として扱うのが賢明だ。重要な分析を行う際は、引き続き正規表現を用いた厳密なフィルタリングと併用することが推奨される。
ECサイトにおける3つの実戦的活用シーン

このブランドフィルタは、特に競争の激しいEC(電子商取引)領域において強力な武器となる。記事では、具体的な3つのユースケースが紹介されている。
1. 競合による「ブランド乗っ取り」の検知
自社のブランド名で検索した際、検索結果の1位を維持できているか、あるいはクリック率(CTR)が極端に低下していないかを確認することは極めて重要だ。競合他社がGoogle広告で自社のブランド名をターゲットに設定したり、「[自社名] の代替品」といった比較ページを作成したりすることで、顧客を奪おうとする動きは珍しくない。
ブランドフィルタを適用し、平均掲載順位が1位でない場合や、CTRが50%を下回っている場合は、ブランド防衛策を講じる必要がある。これには、自社広告の出稿(リスティング広告でのブランド名入札)や、ブランドキーワードをターゲットにしたコンテンツの強化が含まれる。
2. マーケティングキャンペーンの影響測定
広告、メールマガジン、SNSでのプロモーションなどは、直接的なコンバージョンだけでなく、指名検索の増加という形でも成果が現れる。ブランドフィルタを使用すれば、キャンペーン期間中にブランドトラフィックがどれだけ底上げされたかを容易に可視化できる。
パフォーマンスレポートのグラフ上で右クリックし、「アノテーション(注釈)」を追加することで、施策と数値の変化を紐づけて管理できる。なお、このブランドフィルタのデータは2026年2月21日以降の結果から反映されているため、それ以前の施策との比較には注意が必要だ。
3. 地域別のブランド認知度の比較
グローバルに展開するEC事業者の場合、国ごとのブランド認知度の差を把握することは戦略立案に欠かせない。ブランドフィルタを適用した状態で「国」フィルタを追加すれば、カナダとイギリスでどちらのブランド認知が高いか、といった比較が容易に行える。
特定の地域でブランド検索が少ない場合、その地域に向けたローカライズ広告や認知拡大のための施策を優先的に検討する判断材料となるだろう。
独自分析:ブランド検索はECサイトの「防御壁」である

今回のアップデートは、単なる操作性の向上以上に、SEO戦略のパラダイムシフトを象徴している。現在の検索エンジン最適化において、一般的なキーワード(例:「メンズ スニーカー」)で上位表示を狙う難易度は年々高まっている。一方で、ブランド名そのものを検索して訪れるユーザーは、購入意欲が高く、競合への流出も少ない「良質なトラフィック」だ。
ブランドフィルタを活用することで、Web担当者は「SEO=順位を上げること」という狭い視点から、「SEO=ブランドの信頼を維持・拡大すること」という広い視点へと移行できる。ブランド検索が増えているということは、サイト外でのマーケティングや、顧客満足度の向上が実を結んでいる証拠でもある。
また、Googleのアルゴリズムにおいて「ブランドとしての権威性」はますます重視される傾向にある。ブランド検索が多いサイトは、特定のトピックにおいて信頼できる情報源であると判断されやすく、結果として非ブランド検索(一般キーワード)の順位向上にも寄与する。この「ブランドによるポジティブな循環」をデータで証明し、社内のマーケティング施策にフィードバックできるようになったことが、今回の機能追加の真の価値と言えるだろう。
この記事のポイント
- ブランドフィルタの登場:AIが自社名や製品名を自動判別し、抽出・除外を簡素化する。
- AIによる自動分類:表記揺れやスペルミスにも対応するが、マイナーな製品名などは見落とされる可能性がある。
- 競合対策への活用:ブランドクエリのCTRや掲載順位を監視し、顧客の流出を防ぐ。
- 効果測定の効率化:キャンペーンに伴う指名検索の増減を、アノテーション機能と併用して正確に把握できる。
- 戦略的価値:ブランド検索の動向を追うことは、ECサイトの長期的な信頼性と競争力を測る指標になる。
出典
- Practical Ecommerce「Search Console Adds Brand Filters」(2026年3月16日)
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

CSSの進化と新機能——random()関数からアンカー配置、CSS製DOOMまで
Web制作の最前線では、CSSの進化が凄まじいスピードで進んでいる。かつてはJavaScriptや複雑な画像処理が必要だった表現が、今や数行のスタイルシートで完結する時代だ。
2026年3月に公開されたCSS-Tricksのレポートによれば、ネイティブなランダム値の生成や、要素同士を動的に紐付けるアンカー配置など、制作ワークフローを根本から変える機能が次々と登場している。これらの新機能は、コードの簡略化だけでなく、パフォーマンスの向上にも直結する。
本記事では、最新のCSSプロパティがもたらす可能性と、実務での活用方法について詳しく解説していく。従来の常識を覆すようなテクニックが、現代のWebデザインにどのような変革をもたらすのかを見ていこう。
CSSでランダム値を生成する「random()」と「random-item()」

これまでCSSでランダムな値を扱うには、Sassなどのプリプロセッサで事前に計算するか、JavaScriptでインラインスタイルを書き換える手法が一般的だった。しかし、現在策定が進んでいる「random()」および「random-item()」関数は、CSS単体で動的なランダム性を実現する。
random()関数の仕組みと構文
Alvaro Montoro氏の解説によれば、random()関数は単に数字をランダムに出すだけでなく、特定の識別子(キャッシュキー)を用いて値を制御できる。例えば、同じ要素内では同じランダム値を保持し、異なる要素間では別の値を出すといった高度な指定が可能だ。
/* 1remから2remの間でランダムな幅を指定 */
width: random(--w element-shared, 1rem, 2rem);上記のコードでは、`–w`という識別子を指定することで、要素間で値を共有するか、個別に生成するかを制御している。これにより、レイアウトが崩れない範囲での適度なバラツキをCSSだけで表現できる。これは、背景の装飾ドットや、アニメーションのディレイ(遅延時間)を個別に設定する際に極めて有効だ。
リストから選択するrandom-item()
一方、random-item()は、指定した値のリストからランダムに1つを選択する関数だ。数値だけでなく、色やキーワードも対象にできるため、デザインのバリエーションを増やすのに役立つ。
/* 指定した色の中からランダムに適用 */
color: random-item(--c, red, orange, yellow, darkkhaki);この機能により、リロードするたびにボタンの色が変わるようなUIや、リストアイテムごとに異なるアクセントカラーを割り振る作業が、JavaScriptなしで完結するようになる。Webサイトに「遊び心」や「オーガニックな変化」を加えたい開発者にとって、待望の機能と言える。
clip-pathを活用した「折り畳み角(Folded Corners)」の表現

紙の端を折ったような「折り畳み角」のデザインは、古くからWebデザインで好まれてきた。かつては背景画像や擬似要素を駆使した複雑な実装が必要だったが、Kitty Giraudel氏は「clip-path」を用いたモダンな解決策を提示している。
clip-pathによる形状の切り出し
clip-pathとは、要素を特定の形状で切り抜くためのプロパティだ。Giraudel氏の手法では、多角形(polygon)を指定して要素の角を削り、そこに擬似要素(::before, ::after)で「折れ曲がった破片」と「影」を配置することで、リアルな立体感を演出している。
この手法の利点は、レスポンシブ対応が容易な点にある。画像を使用しないため、要素のサイズが変わっても角の形状が歪むことがない。また、CSS変数(カスタムプロパティ)を組み合わせることで、ホバー時に角がさらに深く折れ曲がるようなアニメーションもスムーズに実装できる。
実務でのアクセシビリティとパフォーマンス
画像による実装と比較して、clip-pathによる表現はデータ転送量を削減できる。また、テキストコンテンツをそのまま保持できるため、検索エンジン(SEO)やスクリーンリーダーへの影響も最小限に抑えられる。デザイン性を維持しつつ、Webサイトの軽量化を図る上での標準的なアプローチとなりつつある。
再評価される「backdrop-filter」と「tabular-nums」

新機能だけでなく、既存のプロパティを再発見する動きも活発だ。特に「backdrop-filter」と「font-variant-numeric」は、UIの質を一段階引き上げるために欠かせない要素として注目されている。
backdrop-filterによるガラス質感(グラスモーフィズム)
Stuart Robson氏は、backdrop-filterの有用性を改めて強調している。このプロパティは、要素自体の背景ではなく、その「背後」にあるコンテンツに対してフィルターを適用するものだ。代表的な例が、背景をぼかす「blur()」である。
/* 背後をぼかして明るくする */
backdrop-filter: blur(10px) brightness(120%);
background-color: rgba(255, 255, 255, 0.1);このデモでは、背後のグラデーションがパネル越しにぼやけて見える「グラスモーフィズム」を表現している。
Robson氏によれば、この機能は単なる装飾ではなく、情報の優先順位を明確にするためにも有効だ。背後の情報を完全に消さずにノイズを抑えることで、前面のテキストの可読性を確保できる。
tabular-numsで数字のガタつきを防ぐ
時計やカウンター、財務データなど、数字が頻繁に更新される箇所で問題になるのが「文字幅の違いによるレイアウトの揺れ」だ。Amit Merchant氏は、これを解決する`font-variant-numeric: tabular-nums`の重要性を説いている。
通常、フォントの数字は「1」は細く「8」は太いといった具合に、文字ごとに幅が異なる(プロポーショナル・フォント)。しかし、`tabular-nums`を指定すると、すべての数字が同じ幅で表示される(等幅化)。
/* 数字を等幅で表示し、レイアウトシフトを防ぐ */
.timer {
font-variant-numeric: tabular-nums;
}11:11:11
88:88:88
11:11:11
88:88:88
上下で数字の幅が揃っているかを確認できる。等幅にすることで、秒数が進むたびに文字が左右に揺れる現象を回避できる。
Popover APIとアンカー配置(Anchor Positioning)の連携

モダンWebにおけるUI構築の大きな転換点となっているのが、Popover APIとアンカー配置(Anchor Positioning)の登場だ。これらは、ツールチップやドロップダウンメニューといった「重ね合わせ」が必要なUIを、JavaScriptに頼らずに構築することを可能にする。
Popover APIによる最前面表示の制御
Godstime Aburu氏が詳説するように、Popover APIはブラウザの「トップレイヤー」を利用して要素を表示する仕組みだ。これにより、親要素の`overflow: hidden`や`z-index`の制限に悩まされることなく、常に最前面にコンテンツを表示できる。
実装は非常にシンプルで、HTML属性に`popover`を付与し、ボタン側の`popovertarget`でそのIDを指定するだけで動作する。キーボードによる「Esc」キーでの閉鎖操作などもブラウザが標準でサポートするため、アクセシビリティの向上にも寄与する。
アンカー配置が解決する「位置決め」の課題
Popover単体では表示位置の制御が難しいが、ここにアンカー配置を組み合わせることで、特定のボタンの「すぐ隣」にポップオーバーを固定できるようになる。Chris Coyier氏は、この機能が従来の「計算に頼った配置」を過去のものにすると指摘している。
/* ボタンに名前を付ける */
.anchor-button {
anchor-name: --my-anchor;
}
/* ポップオーバーをボタンの右側に配置 */
[popover] {
position-anchor: --my-anchor;
position-area: right;
}アンカー配置には、画面端での自動反転(flip)機能も備わっている。例えば、画面の右端にボタンがある場合、ポップオーバーを自動的に左側に表示させるといった制御が、CSSの`position-try`プロパティだけで実現可能だ。これは、これまで「Popper.js」や「Floating UI」といった外部ライブラリが担っていた役割を、ブラウザがネイティブに引き受けることを意味している。
CSSの限界に挑む「DOOM」とブラウザの最新動向

技術の進歩は、時に「実用性」を超えた驚きを提供してくれる。Niels Leenheer氏が公開した「CSS DOOM」は、その象徴的なプロジェクトだ。伝説的なシューティングゲーム『DOOM』のレンダリングを、JavaScriptではなくCSSの3D変換とクリップパスのみで再現している。
CSSのみで3D空間を構築する手法
Leenheer氏の解説によれば、ゲーム内のすべての壁や床は`div`要素で構成されており、それぞれに背景画像と3Dトランスフォーム(回転・移動)が適用されている。CSSには「移動するカメラ」という概念がないため、ユーザーの操作に合わせて「世界全体を逆方向に回転・移動させる」ことで、擬似的な一人称視点を実現しているという。
これは極端な例ではあるが、CSSの描画能力がいかに高度なレベルに達しているかを証明している。複雑な3D演出が必要なキャンペーンサイトなどにおいて、WebGL(Three.jsなど)を使わずにCSSだけで軽量な表現を行うヒントになるだろう。
ブラウザの更新サイクルと将来展望
ブラウザ側の進化も加速している。Chromeは2026年9月から、リリースサイクルを2週間おきに短縮することを発表した。これにより、新しいCSSプロパティがドラフト段階から安定版へと移行するまでの期間がさらに短くなる。Safari Technology Previewでも、カスタマイズ可能な`<select>`要素や、スクロール連動アニメーションの改善が進んでおり、Web制作の可能性は日々広がっている。
この記事のポイント
- random()関数:CSS単体でランダムな数値を生成可能になり、デザインに自然なバラツキを与えられる。
- clip-pathの進化:画像不要で「角折れ」などの複雑な形状をレスポンシブかつ軽量に実装できる。
- 既存プロパティの活用:backdrop-filterやtabular-numsにより、UIの質感と可読性が大幅に向上する。
- Popover & アンカー配置:外部JSライブラリなしで、高度なフローティングUIを構築できる時代になった。
- ブラウザの高速進化:リリースの短サイクル化により、最新機能を実務に投入できるまでの時間が短縮されている。
出典
- CSS-Tricks「What’s !important #7: random(), Folded Corners, Anchored Container Queries, and More」(2026年3月16日)
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

B2B ECテックスタックの進化——CRM・CMSを超えPIMやCPQが必須となる理由
B2B(企業間取引)におけるECサイトの役割が劇的に変化している。従来のB2B取引は営業担当者を介した対面交渉が中心だったが、現代のバイヤーはB2C(消費者向け)と同様のリアルタイムかつセルフサービスな体験を求めている。
最新の調査と分析によれば、これまで基盤とされてきたCRM(顧客関係管理)やCMS(コンテンツ管理システム)だけでは、複雑化するバイヤーの期待に応えることが難しくなっているという。デジタル完結型の購買プロセスが主流となる中、テックスタック(利用する技術の組み合わせ)の再構築が急務だ。
本記事では、これからのB2B ECにおいて「持っていて当たり前(テーブルステークス)」となりつつある5つの主要テクノロジーと、それらがなぜ不可欠なのかを詳しく解説する。
1. 商品情報管理(PIM)によるデータ精度の向上

B2B ECにおいて、最初に取り組むべき課題は商品データの複雑さだ。B2Cと異なり、B2B製品は数百から数千のSKU(最小在庫管理単位)を持ち、それぞれに詳細な技術仕様、適合情報、規制要件などが付随する。
複雑なカタログを中央集権的に管理する
PIM(Product Information Management / 商品情報管理)は、散在する商品情報を一つのプラットフォームに集約し、管理する仕組みだ。記事によれば、B2Bバイヤーはデジタル上での「自己学習」に大きく依存しており、不正確なデータや矛盾した情報は検討段階での離脱を招く直接的な原因となる。
PIMを導入することで、ウェブサイト、モバイルアプリ、紙のカタログ、販売代理店向けデータなど、あらゆるチャネルで一貫した最新情報を配信できる。これは、情報の修正コストを削減するだけでなく、バイヤーの信頼を獲得するための基盤となる。
コンバージョン率向上とサポートコストの削減
正確な商品情報は、カスタマーサポートへの問い合わせを減らす効果もある。バイヤーが自分で仕様を確認し、確信を持って注文できれば、返品率の低下にもつながる。PIMは単なるデータベースではなく、売上を作るための「攻め」のツールとして機能するのだ。
2. デジタルエクスペリエンスプラットフォーム(DXP)への移行

単に情報を掲載するだけのCMSから、個々のバイヤーに最適化された体験を提供するDXP(Digital Experience Platform)への移行が進んでいる。DXPとは、ウェブサイトだけでなく、メール、アプリ、カスタマーポータルなど、あらゆる接点で一貫した体験を設計・管理するための基盤だ。
パーソナライゼーションの自動化
B2Bの購買プロセスは直線的ではなく、検討期間も長い。DXPは、バイヤーの行動ログや属性、購買フェーズに基づき、動的にコンテンツを出し分けることが可能だ。たとえば、初めてサイトを訪れた閲覧者には導入事例を、既に特定の製品を比較している再訪者には詳細なスペック表や見積もりガイドを優先的に表示するといった制御が行える。
営業チームを補完するアダプティブな体験
著者の指摘によれば、DXPは営業担当者が個別に提供していた「コンサルティング」に近い体験を、デジタル上でスケールさせる役割を担う。対面での商談が難しい時間帯や、小規模な案件に対しても、DXPが適切な情報を適切なタイミングで提示することで、機会損失を防ぐことができる。
3. CPQツールによる見積もりプロセスの迅速化

カスタマイズが必要な製品や、顧客ごとに価格が変動するB2B取引において、CPQ(Configure, Price, Quote / 構成・価格・見積り)ツールの重要性が高まっている。これは、製品の組み合わせ(構成)を選び、適切な価格を算出し、即座に見積書を発行するシステムだ。
セルフサービスで見積もりを完結させる
従来のB2Bでは、見積もりを依頼してから回答が届くまで数日かかることも珍しくなかった。しかし、現代のバイヤーはオンライン上での即時回答を求めている。CPQをECサイトに統合することで、バイヤーは自分でオプションを選択し、その場で確定した価格を確認できるようになる。
価格の一貫性と営業の効率化
CPQは、複雑な価格ルールをシステム化するため、人為的な計算ミスや不適切な値引きを防ぐ。また、定型的な見積もり業務を自動化することで、営業チームはより戦略的な提案や大口顧客のフォローアップに集中できるというメリットがある。取引のスピード(ディール・ベロシティ)を加速させるための強力なエンジンとなる。
4. B2B特化型ECプラットフォームの採用

B2C向けのECプラットフォームを無理にカスタマイズしてB2Bに転用するのは、もはや限界に近い。B2Bには、特有の複雑なワークフローが存在するからだ。
B2B固有の機能を標準装備する
現代のB2B ECプラットフォームには、以下のような機能が標準で求められる。
- 顧客ごとの個別契約価格の反映
- 組織内の購入承認ワークフロー
- 大量注文のためのクイックオーダー機能
- 請求書払い(掛け払い)や与信管理との連携
- 過去の注文履歴に基づく再注文(リピートオーダー)の簡略化
収益性の高いスケーラビリティの確保
Adobe CommerceやBigCommerce B2B Editionといった、B2Bに特化したプラットフォームは、これらの機能を「箱から出してすぐに(Out of the box)」使える状態で提供している。これらを活用することで、独自開発のコストを抑えつつ、複雑なB2B要件に対応し、デジタルチャネルの収益性を高めることが可能になる。
5. カスタマーデータプラットフォーム(CDP)によるデータの統合

CRM(顧客関係管理)は連絡先情報の管理には適しているが、リアルタイムの行動データを活用するには不十分な場合が多い。そこで注目されているのがCDP(Customer Data Platform / カスタマーデータプラットフォーム)だ。
アカウント単位での包括的なデータ可視化
B2Bの購買決定は個人ではなく「購買グループ(組織)」で行われる。CDPは、ウェブサイトでの閲覧行動、過去の取引履歴、属性データなどを統合し、特定のアカウント(企業)全体で何が起きているかをリアルタイムで把握できるようにする。これにより、組織全体のニーズに基づいたセグメンテーションやパーソナライズが可能になる。
AIと予測モデルの活用基盤
統合されたクリーンなデータは、AIによるレコメンデーションや離脱予測、アップセルの機会発見などに不可欠だ。記事によれば、B2BバイヤーもAIを活用した高度な提案を期待し始めており、その期待に応えるための「燃料」となるのがCDPに蓄積されたデータであると指摘されている。
独自の分析:B2B ECにおける「コンポーザブル」な戦略の重要性

紹介された5つのテクノロジーをすべて一度に導入するのは、多くの中小企業にとって現実的ではない。ここで重要なのは、必要な機能を組み合わせて構築する「コンポーザブル・コマース」の考え方だ。
ボトルネックから順次解消する
自社のビジネスにおいて、どこが最大の障壁になっているかを見極める必要がある。商品情報の不備で問い合わせが殺到しているならPIMを、見積もりの遅れで失注しているならCPQを優先すべきだ。すべてを統合された一つの巨大なシステム(モノリス)で解決しようとせず、APIを通じて各専門ツールを連携させる柔軟な構成が、変化の速い現代には適している。
「人間」と「デジタル」の役割分担を再定義する
これらのテクノロジーは、営業担当者を排除するものではない。むしろ、定型業務をデジタルに肩代わりさせることで、人間は「バイヤーとの深い関係構築」や「複雑な課題解決」といった、より付加価値の高い業務にシフトできる。テックスタックの刷新は、組織全体の働き方改革でもあるのだ。
この記事のポイント
- B2BバイヤーはB2C並みのセルフサービスとリアルタイム性を求めている
- CRMやCMSだけでは不十分で、PIMやCPQといった専門ツールの導入が必須となっている
- 商品情報の正確性(PIM)と見積もりの迅速化(CPQ)が取引の成否を分ける
- DXPやCDPを活用し、顧客体験をパーソナライズすることが競争優位性につながる
- すべての機能を一度に揃えるのではなく、自社の課題に合わせて段階的に統合する戦略が有効である
出典
- MarTech「The new must-haves in B2B ecommerce tech stacks go beyond CRM and CMS」(2026年3月16日)
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Googlebotの正体は「数百のクローラー」の集合体。未公開システムの仕組みとSEOへの影響
Googlebotは単一のプログラムではなく、実際には数百もの異なるクローラーやフェッチャーが組み合わさった巨大なシステムの総称だ。GoogleのGary Illyes(ゲイリー・イリェーシュ)氏とMartin Splitt(マーティン・スプリット)氏が公開したポッドキャストにより、その複雑な内部構造が明らかになった。
2026年3月に公開されたこの情報によると、Googleが運用するクローラーの大部分は公開ドキュメントに記載されていない。これは、特定のチームが小規模な目的で使用するクローラーが膨大に存在するためだという。
Webサイト運営者やSEO担当者にとって、この事実はログ解析やクローラー制御の考え方を根本から見直すきっかけとなる。Googlebotという名称の裏側に隠された、巨大なクロール・インフラの実態を詳しく紐解いていく。
Googlebotは単一の存在ではない?クローラーの正体
一般的に「Googlebot」といえば、Webサイトを巡回してインデックスを作成する一つのロボットをイメージしがちだ。しかし、著者のGary Illyes氏によれば、現在のGooglebotは独立した一つのシステムではない。
「Googlebot」という名称の歴史的背景
Googlebotという名前が使われ始めた2000年代初頭、Googleには実際に一つのクローラーしか存在しなかった。当時は提供しているサービスも検索エンジンのみであり、単一のシステムで事足りていたからだ。しかし、AdWords(現在のGoogle 広告)などの新サービスが登場するたびに、専用のクローラーが追加されていった経緯がある。
現在では、ニュース、画像、動画、広告など、用途別に最適化された無数のクローラーが動いている。それでも「Googlebot」という名称が使われ続けているのは、歴史的な慣習によるものだ。実態としては、一つの巨大な「クロール・インフラ」を多くのクライアントが利用している状態に近い。
内部インフラとクライアントの関係性
Googlebotの本質は、クロール・インフラそのものではなく、そのインフラを利用する「クライアント」の一つである。これは、図書館(インフラ)に対して、本を借りに行く利用者(Googlebot)が複数いる状態に例えられる。利用者はGooglebotだけでなく、他にも何百人と存在するのだ。
この仕組みにより、Google内部の各開発チームは、共通の強力なクロール基盤を利用しながら、自分たちの目的に合わせた独自のクローラーを走らせることができる。私たちが普段目にしているGooglebotは、氷山の一角に過ぎないのである。
クロール・インフラの仕組みと「SaaS」的側面
Google内部で運用されているクロール・インフラには特定の名称があるが、Gary Illyes氏はその公開を控えた。彼はこのインフラを、ソフトウェアをサービスとして提供する「SaaS(Software as a Service)」のようなものだと説明している。
内部APIを通じたデータの取得プロセス
Googleのエンジニアがインターネット上のデータを取得したい場合、このインフラが提供するAPIエンドポイントを呼び出す。API(Application Programming Interface)とは、ソフトウェア同士が機能を共有するための窓口のことだ。エンジニアはこの窓口を通じて、「このURLのデータを取ってきてほしい」というリクエストを送る。
リクエストを受けたインフラ側は、クラウドやデータセンターのリソースを使い、対象のWebサイトに負荷をかけすぎないよう配慮しながらフェッチ(取得)を実行する。つまり、クローラーをゼロから開発する必要はなく、共通のAPIを叩くだけで高度なクロール機能を利用できる仕組みが整っているのだ。
パラメータ設定による柔軟な制御
APIを呼び出す際には、さまざまなパラメータを指定できる。例えば、データの返信を待つ時間(タイムアウト設定)、名乗る名前(ユーザーエージェント)、遵守すべきrobots.txtのルールなどだ。多くの場合はデフォルト設定が適用されるため、開発者は複雑な設定なしに利用できる。
ユーザーエージェントとは、クローラーがWebサーバーにアクセスする際に提示する「自己紹介文」のようなものだ。この設定を変更することで、特定のチーム専用のクローラーとして振る舞うことが可能になる。この柔軟性が、数百種類ものクローラーを生み出す要因となっている。
なぜ「未公開」のクローラーが数百も存在するのか

Googleの公式サイトには主要なクローラーの一覧が掲載されているが、そこに含まれないクローラーが圧倒的に多い。これには、ドキュメント管理の現実的な限界と、情報の重要度による線引きが関係している。
公開ドキュメントに記載される基準
Gary Illyes氏によれば、すべてのクローラーをドキュメント化することは事実上不可能だという。Googleは巨大な組織であり、数多くのチームがそれぞれの目的でクローラーを運用しているからだ。もし数百のクローラーをすべて詳細に記載すれば、開発者向けのドキュメントページは膨大な量になり、かえって利便性を損なうことになる。
そのため、Googleは「トラフィック量」という基準で線を引いている。インターネット全体に対して目に見えるほどの影響力を持つ、あるいは頻繁にサイトを訪れる主要なクローラーのみを公開対象としている。小規模なテスト用や特定の機能限定のクローラーは、あえて非公開のままにされているのだ。
内部チームによる多様な用途
未公開のクローラーは、検索以外の多種多様な目的で使用されている。例えば、新機能のプロトタイプ作成、内部的なデータ分析、あるいは特定のセキュリティチェックなどが考えられる。これらのクローラーは取得するURLの数が非常に少ないため、一般的なWebサイト運営者がその存在に気づくことはほとんどない。
ただし、特定のクローラーが一定の閾値を超えて大量のアクセスを行うようになった場合、Gary Illyes氏らはそのチームに連絡を取り、動作の正当性を確認した上でドキュメント化を検討するという。これにより、Webエコシステムへの悪影響を防ぐ監視体制が敷かれている。
「クローラー」と「フェッチャー」の決定的な違い
Google内部では、データを取得する仕組みを「クローラー(Crawler)」と「フェッチャー(Fetcher)」の2種類に明確に使い分けている。これらは動作の仕組みも、実行されるタイミングも大きく異なる。
バッチ処理と個別リクエストの使い分け
クローラーは「バッチ処理」で動作する。バッチ処理とは、大量のデータをまとめて一括で処理する方式のことだ。クローラーには常に巡回すべきURLのリストが供給され、24時間365日、システムが空いている時間に継続的にデータを取得し続ける。これが一般的な検索インデックス作成の仕組みだ。
一方、フェッチャーは「個別URL」単位で動作する。特定のURLを指定して、その1件だけを即座に取得するのが役割だ。クローラーが「広範囲を網羅する網」だとすれば、フェッチャーは「ピンポイントで狙う釣り竿」のようなものだと言える。
ユーザー操作がトリガーとなるフェッチ
フェッチャーが動く際の特徴は、多くの場合「ユーザーの操作」が起点となっている点だ。例えば、Search Consoleで「URL検査」を実行し、現在の状態をライブテストする場合などがこれに当たる。画面の向こう側に、結果を待っている人間がいる状態だ。
Googleの内部ポリシーでは、フェッチャーはユーザーの制御下にあるべきだと定められている。これに対してクローラーは、システムの都合に合わせて自律的に動く。この違いを理解しておくことは、サーバーログを見て「なぜ今このアクセスが来たのか」を推測する際の大きなヒントになる。
Webサイト運営者が知っておくべき実務上の注意点

Googlebotが数百のクローラーの集合体であるという事実は、実務においてどのような意味を持つのか。特にセキュリティやパフォーマンスの観点から、サイト運営者が意識すべきポイントを整理する。
未知のユーザーエージェントへの対応
サーバーログを分析していると、GoogleのIPアドレス帯域からのアクセスであるにもかかわらず、ドキュメントに載っていないユーザーエージェントを見かけることがあるかもしれない。これまでは「偽装されたボット」と判断して遮断していたケースもあるだろうが、その一部はGoogle内部の正当な未公開クローラーである可能性がある。
重要なのは、ユーザーエージェント名だけで判断せず、IPアドレスの逆引き(DNSルックアップ)を行って、本当にGoogleからのアクセスかどうかを確認することだ。正当なGoogleのインフラからのアクセスであれば、むやみにブロックせず、サイトのクロールバジェット(クローラーが巡回できる許容量)の範囲内で許容するのが賢明だ。
サーバー負荷とログ解析の視点
数百のクローラーが存在するということは、それだけ多様な目的でサイトがスキャンされる可能性があることを意味する。しかし、Gary Illyes氏が述べている通り、未公開のクローラーは通常、極めて低頻度でしか動作しない。もし特定のボットが大量のアクセスを行い、サーバー負荷を高めているのであれば、それは主要なクローラーであるか、あるいは設定ミスによる異常動作である可能性が高い。
また、robots.txtでの制御も、基本的には「Googlebot」というメインのトークン(識別子)で大部分をカバーできる。個別の未公開クローラーをすべて制御しようとするのは現実的ではなく、主要な指示系統を整理しておくことこそが、SEOにおけるクローラビリティ最適化の王道であることに変わりはない。
この記事のポイント
- Googlebotは単一のプログラムではなく、数百種類のクローラーやフェッチャーが共通のインフラを利用する集合体である。
- Google内部ではクロール機能を「SaaS」のように提供しており、APIを通じて誰でもフェッチリクエストを送れる仕組みがある。
- 公開ドキュメントに載っているのは主要なクローラーのみで、トラフィックの少ない小規模なものは非公開とされている。
- 「クローラー」はバッチ処理で継続的に動き、「フェッチャー」はユーザー操作などを起点に個別URLを取得する。
- サイト運営者は、ドキュメント外のクローラーも存在することを前提に、IPアドレスベースでの正当性確認を行うことが推奨される。
出典
- Search Engine Journal「Google Says Hundreds Of Their Crawlers Are Not Documented」(2026年3月13日)
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Google AI Overviewsで検索クリック42%減。パブリッシャーが生き残るための「速報」と「Discover」戦略
Googleが導入したAI Overviews(AIによる概要回答機能)の影響により、Webサイトへのオーガニック検索トラフィックが劇的な変化を見せている。最新の調査レポートによれば、AI Overviewsの拡大に伴い、従来の検索結果からのクリック数は42%も減少した。一方で、速報ニュースやGoogle Discoverといった特定のチャネルでは、トラフィックが急増するという対照的な動きが確認されている。
このデータは、Define Media Groupが64のWebサイトを対象にGoogle Search Consoleの統計を分析したものだ。AIがユーザーの疑問に直接回答するようになったことで、情報の「まとめ」や「解説」を主軸としていたコンテンツの優位性が揺らいでいる。Webサイト運営者は、従来のSEO戦略を根本から見直す必要に迫られている。
本記事では、AI Overviewsが検索トラフィックに与えた具体的な影響と、その中で成長を続ける「速報ニュース」および「Google Discover」の重要性について深掘りする。AI時代の検索環境で、どのようにコンテンツの露出を確保すべきか、その指針を提示する。
Google AI Overviewsの衝撃——検索トラフィック42%減の現実
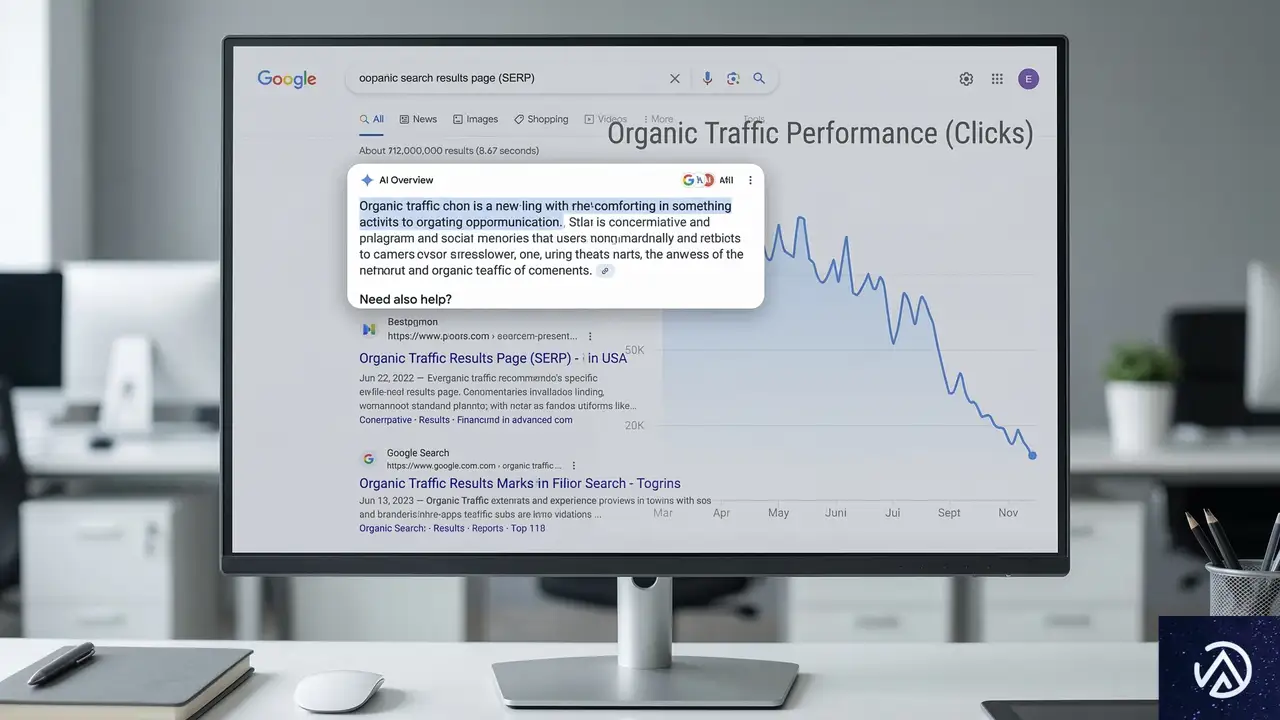
Google AI Overviews(AIO)とは、検索クエリ(検索窓に入力する言葉)に対して、AIがWeb上の情報を要約して回答を表示する機能だ。ユーザーはWebサイトをクリックすることなく、検索結果画面だけで情報を完結できる。この「ゼロクリック検索」の増加が、パブリッシャーにとって大きな打撃となっている。
加速するオーガニック検索の減少
Define Media Groupのレポートによれば、AI Overviewsが本格的に展開された後、オーガニック検索のトラフィックは段階的に減少した。2023年第1四半期から2024年第1四半期にかけて、対象サイトの四半期平均クリック数は約17億回であった。しかし、AI Overviewsの導入直後にトラフィックは16%減少。その後、2025年5月の機能拡張を経て減少は加速し、2025年第4四半期には基準値から42%減という数字を記録した。
この減少は、特に「エバーグリーンコンテンツ」と呼ばれる分野で顕著だ。エバーグリーンコンテンツとは、時間が経過しても価値が損なわれにくい、普遍的な解説記事やハウツー記事を指す。これらはAIが学習しやすく、要約も容易であるため、AI Overviewsによって内容が代替されやすい性質を持っている。
情報の「中抜き」が起きる仕組み
なぜこれほどまでにクリックが減るのか。それは、Googleの検索結果画面(SERP / Search Engine Results Page)の占有率が変化したためだ。AI Overviewsが画面上部の大部分を占めることで、従来の検索1位のサイトであっても、スマートフォンの画面では「ファーストビュー(最初に表示される範囲)」から追い出されるケースが増えている。
ユーザーが「〜のやり方は?」と検索した際、AIが手順を1から10まで箇条書きで示してしまえば、元の解説記事を読む必要性は低くなる。著者のダニー・グッドウィン氏は、AI生成の回答が検索トラフィックの形を根本から作り変えていると指摘している。事実、情報収集を目的としたインフォメーショナルなクエリにおいて、損失が集中しているのが現状だ。
なぜ「速報ニュース」は103%も成長したのか?

検索全体が落ち込む中で、驚異的な成長を見せているのが「速報ニュース(Breaking News)」だ。同レポートによると、2024年11月から2026年初頭にかけて、速報ニュースのトラフィックは103%増加した。AIが席巻する検索環境において、なぜニュースだけがこれほどの伸びを見せているのだろうか。
AIが苦手とする「リアルタイム性」と「正確性」
大きな理由の一つは、Googleがニュースクエリに対してAI Overviewsの表示を意図的に抑制していることにある。Ahrefsのデータを引用したレポートによれば、ニュース関連の検索でAI Overviewsが表示される割合は約15%にとどまる。これは健康や科学といった分野に比べ、3分の1程度の頻度だ。
ニュースは情報の更新速度が極めて速く、AIが誤情報を生成する「ハルシネーション(Hallucination / 幻覚)」のリスクが高い。ハルシネーションとは、AIが事実に基づかない情報を、あたかも真実であるかのように出力する現象だ。正確性が求められる重大なニュースにおいて、GoogleはAIによる要約よりも、信頼できるメディアの最新記事を直接提示する「Top Stories(トップニュース)」カルーセルを優先している。
Top Storiesカルーセルへの集中
国際紛争や大規模なイベントなど、現在進行形で状況が変わるトピックでは、AI Overviewsよりもニュース記事へのリンクが強調される。ユーザーは最新の状況を知るために、AIの要約ではなく、一次情報源であるパブリッシャーのサイトを訪れる傾向がある。この仕組みが、ニュースサイトへの流入を支える防波堤となっている。
Define Media Groupの見解によれば、Googleは急速に変化する事象に対して生成AIを適用することを避けている。これは、AIシステムの学習データがリアルタイムの出来事に追いつかないことや、社会的影響の大きいニュースでの誤報を最小限に抑えるための戦略的判断と言えるだろう。
Google Discoverが新たなトラフィックの柱に
検索クリックが減少する一方で、パブリッシャーの救世主となっているのが「Google Discover」だ。Google Discoverとは、ユーザーの検索履歴や興味関心に基づいて、Googleアプリのホーム画面などに自動で記事をレコメンド(推奨)する機能だ。検索キーワードを入力しなくても情報が届くため、「プッシュ型」のトラフィック源と呼ばれる。
DiscoverとWeb検索のトラフィックが並ぶ
調査対象のサイト群では、Google Discoverからのトラフィックが30%増加した。興味深いことに、レポートのデータセットにおいて、Discoverからの流入数が従来のWeb検索からの流入数とほぼ同等になったことが初めて確認された。これは、ユーザーの情報取得スタイルが「探す(Search)」から「流れてくるものを見る(Discover)」へとシフトしていることを示唆している。
特に2025年12月のコアアップデート以降、Discoverのトラフィックは急増した。2026年2月のアップデートで一部の勢いは落ち着いたものの、依然として強力な集客チャネルであることに変わりはない。Chartbeatのデータでも、ニュースサイトへのGoogleからの参照トラフィックの主役は、もはや伝統的な検索ではなくDiscoverであると報告されている。
パーソナライズがAIの壁を越える
Google Discoverは、AI Overviewsとは対極の存在だ。AI Overviewsが「答えを提示して完結させる」のに対し、Discoverは「興味がありそうな記事を紹介してクリックを促す」仕組みだ。AIによって検索結果が要約されるほど、ユーザーは自分の好みに合った深い情報を求めてDiscoverに流れるという循環が生まれている。
Web制作やコンテンツ運営の現場では、これまで以上に「Discoverに掲載されるための最適化」が重要になる。具体的には、高解像度で魅力的なアイキャッチ画像の使用、ユーザーの興味を引くタイトル設定、そして何よりも特定のトピックに対する専門性と信頼性が鍵を握る。DiscoverはSEOとは異なるアルゴリズムで動いているが、AI時代のトラフィック確保には欠かせない要素だ。
AI時代におけるSEO戦略の再定義
今回のレポートが示す事実は、従来の「検索キーワードに対して答えを用意する」だけのSEOが限界を迎えているということだ。AIが答えを出せる範囲のコンテンツは、今後さらにクリックを奪われ続けるだろう。では、Webサイト運営者はどのような方向に舵を切るべきなのか。
一次情報と専門性の強化
AIが生成できないのは、独自の体験に基づく意見や、現地での取材、実験データなどの「一次情報」だ。単なる知識のまとめではなく、そのサイトにしかない独自の視点や分析が含まれているコンテンツは、AI Overviewsのソース(情報源)として引用される可能性が高まり、結果としてクリックを誘発する。また、Googleは「E-E-A-T(経験、専門性、権威性、信頼性)」を重視しており、これらを証明できるコンテンツはDiscoverでも優先される傾向にある。
マルチチャネルでの集客設計
検索エンジンだけに依存するリスクが顕在化した今、流入経路の多様化は急務だ。今回のデータが示す通り、速報性を活かしたGoogle Newsへの対応や、Discoverを意識したコンテンツ作成、さらにはSNSやメールマガジンを通じた直接的なファンとの繋がりが重要になる。
特に中小企業や個人事業主のサイトにおいては、広範なキーワードで1位を狙うよりも、特定のニッチな分野で「この記事でなければ得られない体験」を提供することが、AIの要約に負けない唯一の方法だ。情報の網羅性ではなく、情報の「深さ」と「鮮度」にリソースを集中させることが、これからのSEOの正攻法となるだろう。
この記事のポイント
- Google AI Overviewsの普及により、従来の検索クリック数は最大42%減少した。
- 解説中心のエバーグリーンコンテンツはAIに代替されやすく、トラフィックが減少しやすい。
- 速報ニュースはAIのハルシネーションリスクを避けるGoogleの仕様により、トラフィックが103%増加した。
- Google Discoverが急成長しており、一部のサイトでは検索流入に匹敵する主要な集客源となっている。
- AI時代には、一次情報の提供、専門性の強化、そしてDiscoverを意識したコンテンツ運用が不可欠である。
出典
- Search Engine Land「Google AI Overviews cut search clicks 42%: Report」(2026年3月12日)
- Define Media Group「BREAKING! News Thrives in the Age of AI」(2026年3月12日)
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

ChatGPTの検索挙動に異変?GPT-5.4と5.3で異なる引用元とSEOへの影響
ChatGPTのデフォルトモデルとプレミアムモデルに同じ質問を投げても、得られる情報源は全く別物になる可能性がある。最新の調査によれば、上位モデルであるGPT-5.4 Thinkingと標準的なGPT-5.3 Instantでは、Web検索の実行プロセスと引用するドメインの傾向に決定的な差があることが判明した。
Writesonicによる分析の結果、プレミアムモデルであるGPT-5.4は引用元の56%を企業のブランドサイトから取得しているのに対し、無料ユーザー向けのGPT-5.3ではその割合がわずか8%に留まっている。両モデルが共有する引用ソースは、全体のわずか7%に過ぎないという事実が、AI検索の不透明さを浮き彫りにしている。
この挙動の違いは、企業がAI検索エンジン最適化(GEO/LLMO)を考える上で無視できない。ユーザーがどのプランを利用しているかによって、自社サイトが「AIに発見されるか」の確率が劇的に変わるからだ。本記事では、この調査結果を基にAI時代の新しいSEOのあり方を分析する。
ChatGPTのモデル間で生じる「検索結果」の決定的な差

ChatGPTは単一の検索アルゴリズムで動いているわけではない。モデルごとに情報の「探し方」そのものが最適化されている。Writesonicの調査によれば、GPT-5.3(Instant)とGPT-5.4(Thinking)に同じプロンプトを入力した際、両者が提示したソースの重複率は極めて低かった。
引用元の重複はわずか7%という衝撃
同じAIチャットボットを使いながら、回答の根拠となるWebサイトが9割以上異なるという事実は、Web担当者にとって驚くべきデータだ。これは、AIが単にGoogleの検索結果を要約しているのではなく、モデルの特性に応じて独自の「フィルタリング」を行っていることを示唆している。
例えば、CRM(顧客管理システム)ソフトウェアについて質問した場合、GPT-5.3は広範な1つのクエリを発行し、一般的な技術解説サイトを引用する。一方、GPT-5.4は特定のブランドサイトを狙い撃ちした検索を行い、より公式サイトに近い情報を収集する傾向がある。この「情報の深さ」の差が、引用元の乖離を生んでいる。
ブランドサイトを重視するプレミアムモデル
特筆すべきは、プレミアムモデルであるGPT-5.4が「一次情報」に強いこだわりを見せている点だ。調査によれば、GPT-5.4が引用したソースの56%がブランドの公式サイトであった。これは、AIがユーザーに対してより正確で責任ある回答をしようと試みた結果、第三者のブログよりも公式サイトの情報を優先したためと考えられる。
対照的に、無料版の標準モデルであるGPT-5.3は、メディアサイトやレビュー記事などの「第三者視点のコンテンツ」を好む傾向がある。これは、計算リソースを抑えつつ、手っ取り早く評価の定まった情報をまとめるのに適した戦略だと言える。ユーザーのプランによって、企業が直接リーチできるか、それともメディアを介して認知されるかが分かれる構造になっているのだ。
検索戦略の深掘り:なぜ引用元が変わるのか

引用元の違いは、各モデルがバックグラウンドで実行している「検索クエリ(検索窓に入力する言葉)」の質と量に起因している。GPT-5.4は、人間が手動でリサーチを行うような高度な検索テクニックを自動で実行していることが判明した。
site:演算子を駆使するGPT-5.4の緻密なリサーチ
GPT-5.4の最大の特徴は、`site:`演算子を多用することだ。`site:`演算子とは、特定のドメイン内だけで検索を行うための検索コマンドである(例:`site:example.com 料金`)。調査期間中、GPT-5.4は423回のクエリのうち156回でこの演算子を使用した。一方で、他のモデルでこの演算子が使われることは全くなかったという。
この挙動により、GPT-5.4は「HubSpotの価格を知りたい」という要求に対し、まずHubSpotの公式サイト内に絞って検索をかける。これにより、情報の正確性が飛躍的に高まる。AIが特定のサイトを指定して情報を抜き取りに来る以上、企業側は「自社サイト内での情報の見つけやすさ」をより意識する必要がある。
サブクエリによる情報の多角的な検証
GPT-5.4は1つの質問に対して、平均8.5回のサブクエリ(追加の検索)を実行する。例えば、「A社とB社の比較」という質問に対し、まず「A社の特徴」「B社の特徴」を個別に検索し、次に「A社の価格」「B社の価格」、さらに「A社の口コミ」「B社の口コミ」といった具合に、情報を分解して収集する。
サブクエリとは、メインの質問を補完するために発行される小さな検索のことだ。これにより、AIは断片的な情報を組み合わせて、より網羅的な回答を作成する。このプロセスにおいて、GPT-5.4はG2やCapterraといった信頼性の高いレビュープラットフォームも併用しており、公式サイトの一次情報と第三者の評価をバランスよく組み合わせていることがわかる。
引用されるコンテンツの性質:メディアか、一次情報か

どのようなページが引用されやすいかという点でも、モデル間で明確な「好み」の差が現れている。これは、コンテンツ制作側がどの層をターゲットにするかによって、注力すべきページが異なることを意味する。
デフォルトモデルが好む「第三者によるレビュー」
GPT-5.3(デフォルトモデル)は、ブログ記事やニュースサイトを引用する割合が32%と高い。引用されたトップドメインには、ForbesやTechRadar、Tom’s Guideといった大手メディアが名を連ねている。これらのサイトは既にSEOに強く、多くのトピックを網羅しているため、AIにとっても「使い勝手の良い」情報源となっている。
この結果から、無料版ユーザーをターゲットにする場合、自社サイトの強化だけでなく、有力な外部メディアに掲載されること(デジタルPR)が依然として重要であることがわかる。AIは権威あるメディアが書いた「まとめ記事」を、信頼できるショートカットとして利用しているからだ。
プレミアムモデルが狙い打つ「価格・製品ページ」
一方、GPT-5.4はブランドのトップページ(22%)、価格ページ(19%)、製品詳細ページ(10%)をダイレクトに引用する。特に価格情報に関しては顕著で、GPT-5.3が全調査中わずか4回しか価格ページを引用しなかったのに対し、GPT-5.4は138回も引用している。
ここで重要な示唆がある。価格情報を「問い合わせ」の裏側に隠している(ゲートコンテンツにしている)ブランドは、GPT-5.4による比較検討の対象から外されるリスクがあるということだ。AIが直接価格ページを見つけられない場合、そのブランドは「情報欠落」として、比較表の中で不利な扱いを受ける可能性がある。
従来のSEO(Google/Bing)との相関関係

AI検索の結果は、従来の検索エンジンの順位とどの程度連動しているのだろうか。調査では、SerpAPIを使用してGoogleおよびBingの検索結果との重複度合いを測定している。
Google検索順位が通用するモデルと通用しないモデル
GPT-5.3の場合、引用したドメインの47%がGoogleの検索結果にも含まれていた。これは、デフォルトモデルがGoogleのランキングアルゴリズムにある程度依存している、あるいは類似の評価指標を用いていることを示している。つまり、従来のSEO対策は、無料版ChatGPTの引用獲得にも一定の効果があると言える。
しかし、GPT-5.4では状況が一変する。引用されたドメインの75%が、GoogleやBingの検索結果には現れなかったのだ。これは、GPT-5.4が従来の検索エンジンの「1ページ目」に縛られず、独自のクエリ(前述のsite:演算子など)によってWebの深部まで探索していることを意味する。検索順位が低くても、情報の網羅性や構造が優れていれば、プレミアムAIに発見されるチャンスがあるということだ。
AI検索最適化(LLMO)の新たな指針
LLMO(Large Language Model Optimization / 大規模言語モデル最適化)とは、AIに自社の情報を正しく理解・引用してもらうための施策だ。今回の調査結果から、LLMOには2つの方向性があることが見えてきた。1つは、メディア露出を増やしてGPT-5.3のようなモデルに「評判」を伝えること。もう1つは、自社サイトの構造を整理し、GPT-5.4のようなモデルが`site:`検索で見つけやすい「事実(価格、仕様、FAQ)」を明示することだ。
特に、構造化データ(Schema.orgなど)の活用や、プレーンテキストでの明確な情報記述が重要になる。AIは派手なデザインよりも、クローラが解析しやすい「整理されたデータ」を好むからだ。プレミアムユーザーという、購買意欲の高い層にリーチするためには、この「AIフレンドリーなサイト構造」が欠かせない。
企業が今取り組むべきAI時代の情報発信

ChatGPTの挙動がモデルによって異なる以上、企業は多角的なアプローチを取らざるを得ない。具体的にどのようなアクションが必要になるのか、Web制作・運用の現場視点で考察する。
自社サイトの一次情報を「AIに見つけやすく」整える
まず優先すべきは、プレミアムモデル(GPT-5.4)への対応だ。彼らは公式サイトの深い階層まで情報を探しに来る。そのため、これまで「PDFの中」や「JavaScriptによる動的表示」に隠れていた重要な仕様や価格情報を、HTMLとしてクローラブルな状態で公開することが推奨される。
また、`utm_source=chatgpt.com` というパラメータが自動で付与される傾向があるため、GoogleアナリティクスなどでAI経由の流入を正確にトラッキングすることが可能だ。どのページがAIに引用され、コンバージョンに繋がっているかを分析し、そのページの情報の鮮度を常に高く保つ運用が求められる。
外部メディア露出による信頼性の担保
次に、デフォルトモデル(GPT-5.3)への対応として、第三者メディアでのポジティブな言及を増やす必要がある。AIは「世間一般ではどう評価されているか」をメディアの記事から学習する。自社サイトで「最高だ」と主張するだけでなく、TechRadarやForbesのような権威あるドメインで紹介されることが、AI検索における「信頼の裏付け」となる。
これは従来のデジタルマーケティングや広報活動の延長線上にあるが、AI時代においては「検索順位を上げるため」だけでなく、「AIの回答の根拠(エビデンス)になるため」という新しい目的が加わることになる。メディア記事は、AIにとっての「知識の要約」として機能し続けるだろう。
この記事のポイント
- ChatGPTのプレミアムモデル(GPT-5.4)は、引用元の56%がブランド公式サイトであり、一次情報を重視する傾向が強い。
- デフォルトモデル(GPT-5.3)は、引用元の多くを第三者メディア(ブログやニュースサイト)に依存しており、ブランドサイトの引用はわずか8%である。
- GPT-5.4は`site:`演算子や平均8.5回のサブクエリを駆使し、従来の検索順位に依存しない独自の探索を行っている。
- 企業は、AIに見つけられやすいように価格や仕様などの情報をHTMLで明示し、かつ外部メディアでの露出を増やす「ハイブリッドな対策」が求められる。
- ChatGPTからの流入はUTMパラメータで計測可能なため、データに基づいたAI検索最適化(LLMO)の改善サイクルを回すことが重要である。
出典
- Search Engine Journal「ChatGPT’s Default & Premium Models Search The Web Differently」(2026年3月12日)
- Writesonic「ChatGPT Citation Study: GPT-5.4 vs GPT-5.3」(2026年3月発表)
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Formidable Formsの支払い検証バイパス脆弱性——30万サイト影響と対策
WordPressのフォーム作成プラグイン「Formidable Forms」に重大なセキュリティ脆弱性が発見された。この脆弱性を悪用すると、攻撃者は認証なしで支払い検証プロセスをバイパスできる。低額取引の決済情報を流用し、高額商品の購入を完了させることが可能だ。
影響を受けるのはバージョン6.28までの全バージョン。インストールサイト数は30万を超える。脆弱性にはCVE-2026-2890が割り当てられ、CVSS深刻度スコアは7.5(高リスク)と評価されている。プラグイン開発元はバージョン6.29で修正をリリース済みだ。
Formidable Formsプラグインと支払い機能
Formidable Formsはドラッグ&ドロップでフォームを作成できるWordPressプラグインだ。コンタクトフォームやアンケート、イベント登録フォームなど多様な用途に使われる。特に重要なのが、StripeやPayPalといった決済サービスと連携した「支払いフォーム」機能である。
ECサイトでの一般的な利用シーン
このプラグインは、会員制サイトの登録料金徴収やデジタル商品の販売、有料イベントのチケット販売などに利用される。ユーザーがフォームで商品を選択し、決済情報を入力すると、プラグインが決済プロバイダーと通信して取引を処理する流れだ。
正常な支払いフローでは、ユーザーが支払うべき金額と、実際に決済プロバイダーを通じて処理された金額が一致しているか検証される。この検証プロセスが脆弱性によって不完全だったことが問題の核心だ。
Stripe連携における標準的な処理
Formidable FormsがStripeと連携する場合、PaymentIntentというStripeのオブジェクトを利用する。PaymentIntentは特定の取引の支払い意図と状態を管理する。プラグインは、ユーザーが支払いを完了した後、Stripeから返されるPaymentIntentの状態を確認して取引を完了させる。
本来ならば、プラグインは「このPaymentIntentがどのフォーム送信に対応するものか」「請求金額と実際の支払金額が一致しているか」を厳密に検証すべきだ。しかし、影響を受けるバージョンではこの検証が不十分だった。
脆弱性の技術的詳細——CVE-2026-2890
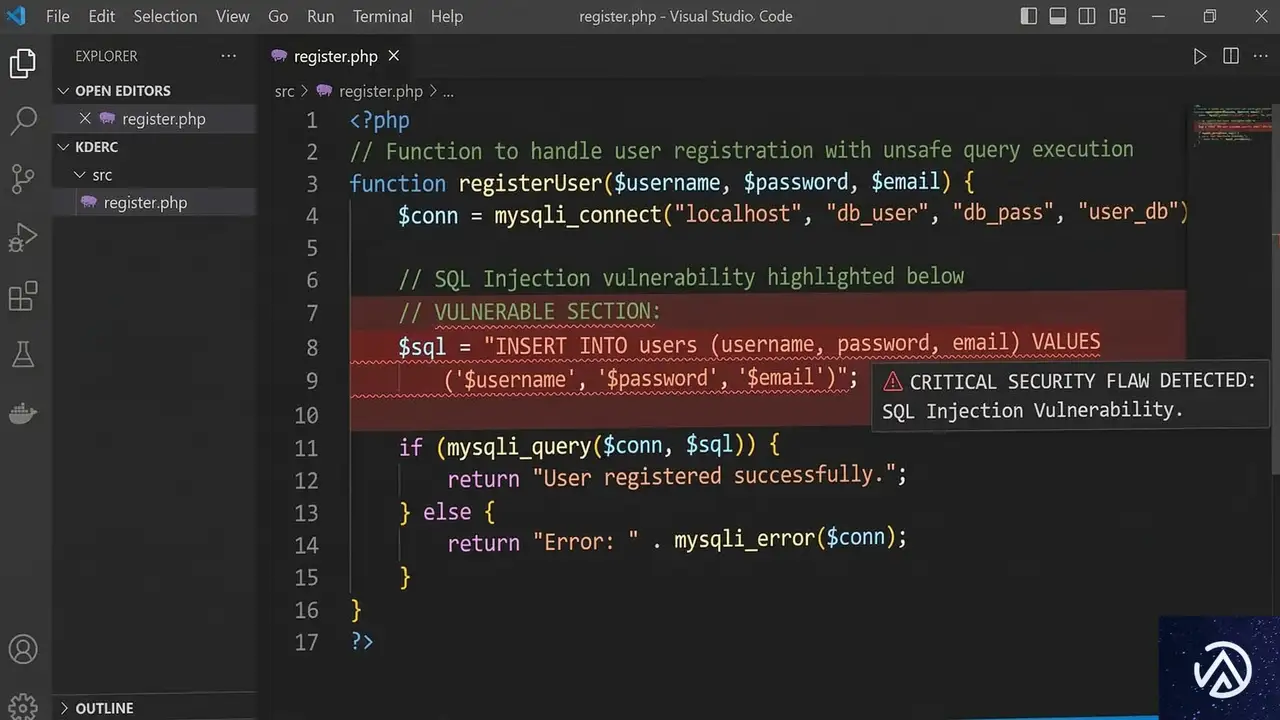
この脆弱性は「支払い完全性バイパス」に分類される。システムが意図した通りの支払いが行われたことを保証するメカニズムを攻撃者が回避できる状態を指す。具体的には、`handle_one_time_stripe_link_return_url`関数と`verify_intent()`関数に実装上の問題があった。
検証不足の2つのポイント
第一の問題は、`handle_one_time_stripe_link_return_url`関数が支払い記録を「完了」とマークする判断基準だ。この関数はStripeのPaymentIntentの状態だけを確認し、そのPaymentIntentが請求された金額と、ユーザーが本来支払うべき金額を比較しなかった。
第二の問題は`verify_intent()`関数の検証範囲にある。この関数はクライアントシークレット(支払いセッションを特定する秘密の文字列)が正当なユーザーに属するかだけを確認した。PaymentIntentが特定のフォーム送信やアクションに紐づいているかの検証を行わなかった。
認証不要という重大な要素
この脆弱性が特に危険とされる理由は、攻撃に認証が不要な点だ。WordPressサイトにログインする権限がなくても、一般訪問者として悪用可能である。サブスクライバーレベルの最小権限すら必要としない。
セキュリティ企業Wordfenceの分析によれば、この組み合わせにより、認証されていない攻撃者が完了済みの低額取引のPaymentIntentを流用し、高額取引を完了済みとしてマークできるという。
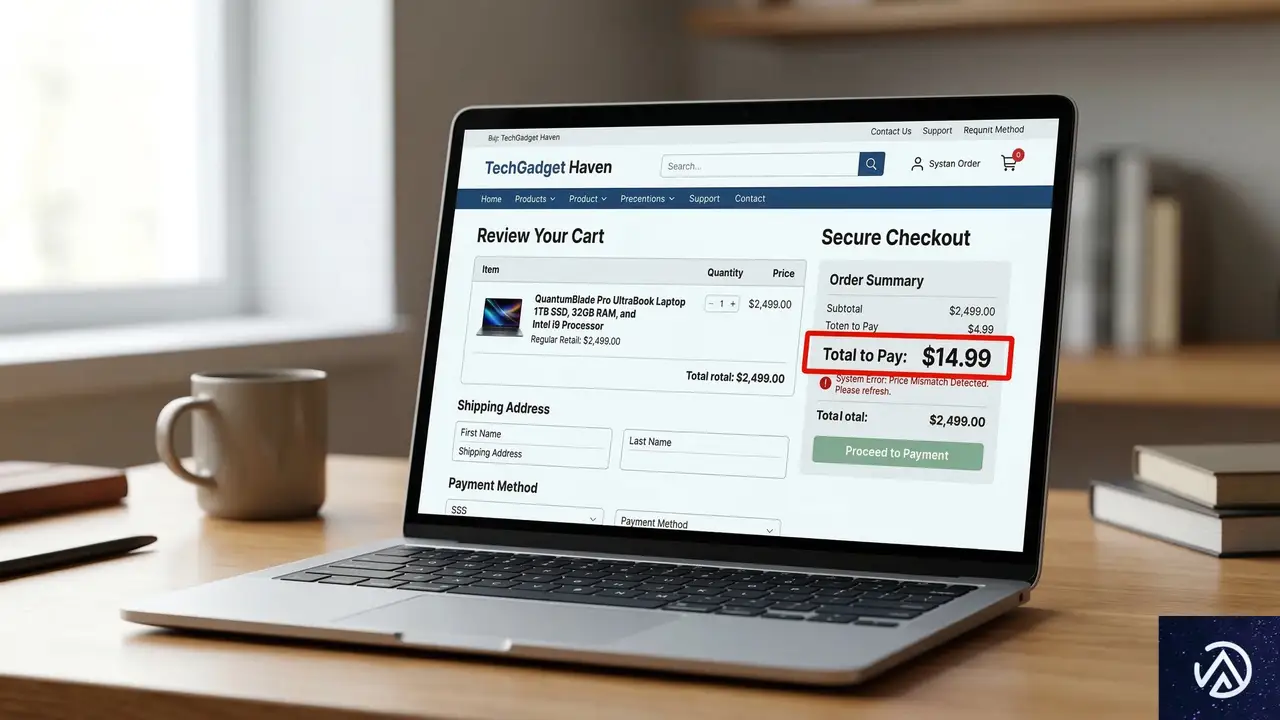
実際の攻撃シナリオと影響範囲
攻撃は現実的な手順で実行可能だ。まず攻撃者は、標的サイトで低額の商品(例えば100円のデジタルコンテンツ)を通常通り購入する。Stripeを通じた正当な支払いが完了し、PaymentIntentが生成される。
支払い情報の流用プロセス
次に攻撃者は、同じサイトで高額商品(例えば5万円のオンラインコース)を購入しようとする。チェックアウトプロセスで、先ほど生成された低額取引のPaymentIntent情報を挿入する。プラグインはPaymentIntentの状態が「成功」であることだけを確認し、金額の不一致を検知しない。
結果として、攻撃者は100円の支払いで5万円の商品を入手できる。サイト運営者は商品を提供したにもかかわらず、4万9900円の収益を失うことになる。
リモートコード実行との違い
この脆弱性は、サーバー自体を乗っ取ったり、任意のコードを実行したりするものではない。しかしECサイトにとっては直接的な金銭的損害につながる。デジタル商品や即時提供されるサービスの場合、取引の取り消しも困難だ。
影響を受ける30万サイトの中には、オンライン予約システムを持つサービス業者、デジタルダウンロード販売者、オンラインコース提供者などが含まれる可能性が高い。これらの事業モデルでは、本脆弱性によるリスクは無視できない。
対応策と今後の予防策
即時実施すべきアップデート
第一の対応はプラグインのバージョンアップだ。Formidable Forms 6.29以降ではこの脆弱性が修正されている。WordPress管理画面の「プラグイン」セクションから更新を実行できる。
更新後は、過去の高額取引について不審な点がないか確認することを推奨する。特に、低額商品の購入記録と高額商品の購入記録が同じユーザーから短時間に行われているケースは要注意だ。
代替手段の検討
Formidable Formsに依存した複雑な支払いフローを運用している場合、一時的に他のフォームプラグインや専用のECプラグインへの移行を検討する価値がある。WooCommerceのような本格的なECソリューションは、支払い検証に関してより堅牢な実装を持つ。
あるいは、フォームの受付だけをFormidable Formsで行い、決済処理は別のシステム(決済プロバイダーの直接埋め込みフォームなど)に委ねる設計も考えられる。これにより、支払い検証ロジックをプラグインの実装に依存しないようにできる。
長期的なセキュリティ対策
この事例は、サードパーティ製プラグインがビジネスの中核プロセス(決済)を担う際のリスクを浮き彫りにした。重要な機能を実装するプラグイン選定時には、開発元のセキュリティ対応実績や、過去の脆弱性開示履歴を確認すべきだ。
また、定期的なセキュリティ監査の実施も有効だ。自社サイトで利用しているプラグインについて、CVE(共通脆弱性識別子)データベースを定期的にチェックする習慣をつける。あるいは、Wordfenceのようなセキュリティプラグインを導入し、脆弱性を自動検知する環境を整える。
この記事のポイント
- Formidable Formsプラグイン(〜v6.28)に支払い検証バイパス脆弱性(CVE-2026-2890)が存在する。
- 攻撃者は認証なしで、低額取引の決済情報を流用して高額商品を入手可能だ。
- 影響を受けるサイトは30万以上。CVSSスコアは7.5(高リスク)と評価されている。
- 即時対応としてバージョン6.29以降へのアップデートが必須である。
- EC機能をプラグインに依存する場合、開発元のセキュリティ対応実績を慎重に評価すべきだ。
出典
- Search Engine Journal “Formidable Forms Flaw Lets Attackers Pay Less For Expensive Purchases” (2026年3月12日)
- Wordfence Threat Intelligence “Formidable Forms Vulnerability: Unauthenticated Payment Integrity Bypass” (2026年3月)
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Google検索の変容:AI Modeの自己引用増加とAsk Maps、ブランドクエリ機能の全容
Google検索の環境が、AIの導入によって急速に変化している。AI Modeにおける自己引用の増加や、Googleマップへの対話型AI「Ask Maps」の搭載など、ユーザーとウェブサイトの接点に変容を迫るアップデートが相次いでいる。これらの変更は、企業のウェブマーケティング戦略に直接的な影響を与えるものだ。
SE Rankingの最新調査によれば、GoogleはAI Modeにおいて自社プロパティへのリンクを9ヶ月前の3倍に増やしたという。また、Search Consoleではブランドクエリの自動フィルタリング機能が全ユーザーに開放された。検索エンジンが「情報の仲介者」から「回答の提供者」へと進化する中で、SEOのあり方も再定義が求められている。
本記事では、Googleが進める最新のAI施策と、検索結果におけるリンクの動向、そして新たに導入された分析ツールの活用法について詳しく解説する。検索ユーザーが自社サイトに到達するまでの「距離」がどのように変化しているのか、その実態を明らかにする。
Google AI Modeの自己引用が3倍に増加

Googleの「AI Mode」において、Google自身のサービスやコンテンツを引用する割合が急増している。SE Rankingが公開した第3回調査レポートによると、自己引用の割合は全引用の7%から21%へと上昇した。これは、AIが生成する回答の5つに1つがGoogle内部へのリンクであることを意味する。
外部サイトへのトラフィック流出を抑制する構造
かつての自己引用は、主に「Googleビジネスプロフィール」へのリンクが中心であった。しかし、今回の報告によれば、現在はGoogle自身のオーガニック検索結果ページへのリンクが増加している。ユーザーを外部のウェブサイトへ送り出すのではなく、Googleのエコシステム内に留める動きが強まっていると著者は指摘している。
エコシステムとは、複数のサービスが連携し、ユーザーがその枠組みの中で完結できる仕組みを指す。Googleの場合、検索、マップ、YouTube、ビジネスプロフィールなどがこれに該当する。AI Modeが外部サイトではなく自社の検索結果を引用することで、ユーザーの検索体験はGoogle内で完結しやすくなる。
ローカルSEO以外への影響拡大
SE Rankingのブランド責任者であるモーディ・オバースタイン氏は、この傾向がローカル検索(地域に根ざした検索)に限定されない点に警鐘を鳴らしている。自己引用の17%がGoogle自身に向けられており、これは他のどの情報源よりも多い数字だ。この現象は、情報の「循環参照」のような状態を作り出しているとの見方もある。
企業にとっては、AI Modeが普及するほど、自社サイトへのクリック機会が減少するリスクがある。特に、事実確認や単純な情報の検索においては、AIがGoogle内部の情報を優先して表示するため、外部メディアやブログ記事への流入が制限される可能性がある。
Googleマップに搭載された「Ask Maps」の衝撃

Googleは、GoogleマップにGemini(ジェミニ)を活用した対話型AI機能「Ask Maps」を導入した。これにより、ユーザーは自然な言葉で場所に関する質問を投げかけ、地図上で直接推奨事項を受け取ることが可能になった。現在は米国とインドで先行リリースされている。
自然言語による場所の発見
Ask Mapsは、Googleが保有する膨大な場所のデータベースとユーザーレビューを基に回答を生成する。「週末に子供連れで行ける、静かなカフェを教えて」といった複雑な要望に対しても、文脈を理解した提案を行う。回答はユーザーの検索履歴や保存済みの場所に基づいてパーソナライズされる仕組みだ。
パーソナライズとは、個々のユーザーの好みや行動に合わせて情報を最適化することを指す。これにより、同じ質問をしてもユーザーごとに異なる最適な結果が表示されるようになる。従来の「キーワード検索」から「対話による探索」へと、ローカル情報の探し方が大きく変わろうとしている。
ビジネスオーナーに求められる対応
この変化は、質の高いレビューや詳細なビジネスプロフィールを維持してきた企業にとって、新たな露出のチャンスとなる。従来のリスト形式の表示では埋もれていた店舗も、AIがユーザーの要望に合致すると判断すれば、対話の中で優先的に紹介される可能性があるからだ。
一方で、Googleがどのような基準で推奨するビジネスを選択しているのか、その詳細は明らかにされていない。また、将来的にこの推奨枠が広告として販売される可能性についても、現時点では言及されていない。企業は、AIに正しく情報を認識させるために、構造化データの整備や最新情報の更新をより徹底する必要がある。
マルチモーダルAIによる音声・動画の直接インデックス

Googleの検索部門責任者であるリズ・リード氏は、AIが文字情報だけでなく、音声や動画の内容を直接理解できるようになったと述べている。これまでの検索エンジンは、主にタイトルや書き起こし(トランスクリプト)に頼って動画や音声をインデックスしていたが、その技術的制約が解消されつつある。
「内容」そのものを理解するインデックス
マルチモーダルAIとは、テキスト、画像、音声、動画といった異なる種類の情報を同時に処理・理解できるAIを指す。リード氏によれば、Googleはこの技術を用いることで、動画の視覚的な内容や音声のニュアンス、話の深みを直接解析できるようになった。これにより、メタデータが不十分だったポッドキャストや動画コンテンツの視認性が向上する見込みだ。
Web Performance Toolsの共同創設者であるスロボダン・マニッチ氏は、この変化を「Googleが動画を視聴し、ポッドキャストを聴くことを学習している」と表現した。単なる文字起こしではなく、コンテンツの本質的な意味やスタイルをAIが把握することで、検索結果の精度は飛躍的に高まると指摘されている。
購読状況を考慮したランキングの可能性
リード氏はまた、有料壁(ペイウォール)があるコンテンツの扱いについても言及した。将来的にGoogleは、特定のパブリッシャーをすでに購読しているユーザーに対して、その有料コンテンツを検索結果の上位に表示させる可能性があるという。これは、アクセス権のないユーザーには価値が低いとされていた有料記事が、既存顧客にとっては価値ある情報として再評価されることを意味する。
この仕組みが実現すれば、サブスクリプションモデルを採用しているメディア企業にとって大きなメリットとなる。検索エンジンが「誰がどのサービスを契約しているか」を認識し、それに基づいて結果を出し分けることで、既存ユーザーのエンゲージメント向上に寄与するからだ。
Search Consoleのブランドクエリフィルタが全公開

Googleは、Search Consoleにおいて「ブランドクエリ」と「非ブランドクエリ」を自動で分類するフィルタ機能を、すべての対象サイトに開放した。この機能はAIを活用しており、サイト運営者が手動で設定することなく、自社名を含む検索とそれ以外を分けることができる。
AIによる自動分類の精度と限界
このフィルタの最大の特徴は、ブランド名のスペルミスや製品名のみの検索も自動的に「ブランドクエリ」として認識する点にある。Googleの検索アドボケイトであるジョン・ミューラー氏は、コミュニティからの質問に対し、現時点ではサイト所有者がどのクエリをブランドとして扱うかをカスタマイズする計画はないと回答している。
「正規表現(Regex)」などの複雑なフィルタ設定を使わずに、ワンクリックでトラフィックの質を分析できるようになった意義は大きい。正規表現とは、特定の文字列のパターンを指定して検索や置換を行う手法だが、非エンジニアにはハードルが高いものだった。今回の自動化により、分析の民主化が進むと言える。
SEO成果の透明化
『Product-Led SEO』の著者であるイーライ・シュワルツ氏は、この機能によってSEOチームが「非ブランドクエリ」での成果をより明確に示せるようになると述べている。一方で、ブランド力に頼った流入をSEOの成果として報告していたケースでは、その実態が浮き彫りになるという側面もある。
成長が新しい発見(非ブランド)によるものなのか、それとも既存の知名度(ブランド)によるものなのかを峻別することは、戦略の立案において極めて重要だ。このフィルタを活用することで、真の新規顧客獲得に向けた改善ポイントがより明確になるだろう。
分析:検索からサイトへの距離が広がる時代

今週の一連のアップデートを俯瞰すると、共通のテーマが浮かび上がる。それは、ユーザーが検索を開始してから特定のウェブサイトに到達するまでの「ステップ」が増加し、距離が遠のいているという事実だ。1年前であれば、検索結果のリンクを直接クリックしていた行動が、現在はAIによる中間プロセスに置き換わりつつある。
AIが「情報の門番」になるリスク
AI Modeでの自己引用の増加やAsk Mapsの導入は、Googleが情報の「仲介者」から、自ら回答を提示する「コンシェルジュ」へと変貌していることを示している。ユーザーにとっては利便性が高まる一方で、コンテンツ制作者にとっては、自社のドメインにユーザーを呼び込む難易度が上がっているのが現状だ。
また、リズ・リード氏が語った「コンテンツの深い評価」も、Googleがユーザーに情報を提示するかどうかを決定する前の「検閲」に近い役割を果たしているとの見方もある。AIがコンテンツの質を直接判断し、その上でGoogle自身のサービスを優先的に引用する構造は、オープンなウェブのあり方に一石を投じている。
企業が取るべき新たな生存戦略
このような状況下で企業が注力すべきは、AIに「引用されるに値するブランド」としての地位を確立することだ。Search Consoleのブランドクエリフィルタが示すように、GoogleはすでにブランドをAIで識別している。単なるキーワード対策ではなく、ブランド名そのものが検索されるような認知度の向上や、AIが理解しやすい形式での情報発信が不可欠となる。
具体的には、音声や動画コンテンツの拡充、構造化データの正確な実装、そしてサードパーティのレビューサイトにおける高評価の獲得などが挙げられる。検索エンジンとの付き合い方が「クリックを待つ」ことから「AIの知識源として選ばれる」ことへとシフトしていることを、マーケターは認識すべきである。
この記事のポイント
- Google AI Modeの自己引用率が21%に達し、Google内部へのトラフィック循環が強まっている。
- Googleマップの「Ask Maps」導入により、ローカル検索が対話型AIによる探索へと進化している。
- マルチモーダルAIの進化で、音声や動画の内容が直接インデックスされ、検索の対象が広がっている。
- Search Consoleのブランドクエリフィルタが全ユーザーに開放され、トラフィックの質の分析が容易になった。
- 検索ユーザーとウェブサイトの距離が広がる中、AIに選ばれるためのブランド構築と多角的なコンテンツ発信が重要だ。
出典
- Search Engine Journal「AI Mode Data, Ask Maps & Branded Queries Go Live – SEO Pulse」(2026年3月13日)
- SE Ranking「Google Links in AI Mode Answers: 3rd Report」(2026年3月)
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

WordPress 7.0開発最新状況——リアルタイム共同編集とAI連携の標準化が加速
WordPress 7.0のリリースサイクルが佳境を迎えている。2026年3月現在、Gutenberg 22.6のリリースによって主要な機能セットが確定し、3月19日にはリリース候補版(RC1)の公開が予定されている。
今回のメジャーアップデートでは、長年待望されていたリアルタイム共同編集(RTC)の基盤実装や、AIサービスとの連携を標準化する「AIコネクター」など、プラットフォームとしての在り方を大きく変える機能が導入される。現在はBeta 3が公開されており、広範囲なテストが呼びかけられている状況だ。
本記事では、WordPress 7.0で導入される主要機能の技術的背景と、開発者が準備すべきポイントについて、最新の動向を基に解説する。
WordPress 7.0の新機軸:リアルタイム共同編集(RTC)の実装

WordPress 7.0における最大の技術的トピックは、リアルタイム共同編集(RTC: Real-time Collaboration)の導入だ。複数のユーザーが同時に同じ投稿を編集できるこの機能は、これまで外部プラグインや特定のホスティング環境に依存していたが、ついにコア機能として組み込まれる。
HTTPポーリングによる高い互換性の確保
RTCの実装において、技術チームは当初検討されていたWebRTCではなく、HTTPポーリングによる同期プロバイダーを選択した。WebRTCはリアルタイム性に優れる一方で、サーバー構成やファイアウォールの設定によっては通信が不安定になる欠点がある。あらゆるホスティング環境での動作を保証するため、あえて汎用性の高いHTTPポーリングが採用された形だ。
データの整合性を保つ仕組みには、CRDT(Conflict-free Replicated Data Type / 衝突のない複製データ型)が採用されている。これは、複数の場所で同時に行われた変更を、矛盾なく統合するための数学的なアルゴリズムだ。更新データは「wp_sync_storage」という内部ポストタイプに保存され、定期的に圧縮・バッチ処理されることで、データベースへの負荷を最小限に抑える工夫がなされている。
拡張性を考慮した同期アーキテクチャ
この同期システムは、トランスポート層(通信手段)とストレージ層(保存先)を差し替え可能な設計になっている。デフォルトでは2名までの同時編集に制限されているが、ホスティング事業者は独自の同期プロバイダーを導入したり、wp-config.phpの設定値を変更したりすることで、より多人数での編集や高度なパフォーマンス最適化を図ることができる。
RTCをデフォルトで有効化するかどうかの最終判断は、RC2(リリース候補版2)前後で行われる予定だ。プラグイン開発者は、既存のメタボックスやカスタムフィールドがこの共同編集モードと競合しないか、事前の検証が求められる。
AI連携の標準化:AIコネクターとプロバイダーパッケージ

WordPress 7.0では、AIサービスとの通信を標準化するための「コネクター」機能が導入される。これは、特定のAIベンダーに依存せず、共通のインターフェースを通じてAI機能を利用できるようにするインフラストラクチャだ。
php-ai-clientによる共通インターフェースの提供
この機能の核となるのは「php-ai-client」パッケージだ。これは、主要なAIサービスとの通信を抽象化するPHPライブラリである。開発者はこの共通インターフェースに対してコードを書くことで、背後のAIプロバイダー(OpenAI、Google、Anthropicなど)が何であっても、同じように機能を実装できるようになる。
すでにプラグインディレクトリには、OpenAI、Google、Anthropicの各プロバイダーパッケージが公開されている。これにより、ユーザーは管理画面の「コネクター」設定から好みのAIサービスを選択し、APIキーを入力するだけで、サイト全体でAI機能を活用できる環境が整う。
プラットフォームとしてのAI対応
これまでAI機能は各プラグインが個別にAPI連携を実装していたが、コアが認証情報の管理やプロバイダーの選択を担うことで、開発効率とセキュリティが向上する。例えば、コンテンツ生成プラグインとSEO最適化プラグインが、同じAIコネクターの設定を共有するといった運用が可能になる。これは、WordPressが単なるCMSから「AI対応のオペレーティングシステム」へと進化する重要な一歩と言えるだろう。
編集体験の進化:視覚的な変更履歴とコンテンツ専用編集モード

ユーザーインターフェース(UI)の面でも、WordPress 7.0は大きな進化を遂げている。特にリビジョン管理とパターン編集の操作性が大幅に改善された。
カラーコードによる直感的なリビジョン管理
新しいリビジョンパネルでは、ドキュメント内の変更箇所が視覚的に強調表示されるようになった。追加されたブロックは緑、削除されたブロックは赤、設定が変更されたブロックは黄色で縁取りされる。テキスト内容についても、下線(追加)や打ち消し線(削除)を用いて、どこがどう変わったのかが一目で判別できる。
この機能はパフォーマンスにも配慮されており、まず変更されたブロックを素早く特定し、その後に詳細なテキスト比較を行う2段階のプロセスを採用している。テーマの色設定に合わせてカラーが自動調整されるため、どのようなデザインの編集画面でも視認性が損なわれない点も特徴だ。
構造を保護するコンテンツ専用編集(Content-Only Mode)
WordPress 7.0から、パターン編集のデフォルトが「コンテンツ専用編集モード」となる。このモードでは、レイアウトやスタイルの設定が隠され、ユーザーはテキストや画像などのコンテンツ入力に集中できる。これにより、誤ってデザインを崩してしまうリスクを低減できる。
構造的な編集が必要な場合は、パターンを「切り離す(Detach)」ことでフルアクセスが可能になる。管理者は、PHPフィルターやJavaScriptを使用して、非同期パターンのコンテンツ専用モードを無効化することも可能だ。制作会社がクライアントにサイトを引き渡す際、運用の安全性を高めるための強力なツールとなるだろう。
開発者向けツールとテーマ機能のアップデート

開発ワークフローを支えるツール群や、テーマ開発に役立つ新機能も多数追加されている。特にWP-CLIの強化と、ブロックの表現力向上に注目したい。
WP-CLIの新コマンドとPlaygroundの拡充
WP-CLIチームは、ブロックエンティティへの読み取り専用アクセスを提供する「wp block」コマンドや、権限管理を行う「ability」コマンドの開発を進めている。これらはWP-CLI v3.0の一部として、3月末の安定版リリースに向けて調整中だ。
また、ブラウザ上でWordPressを動作させる「WordPress Playground」のランタイムにおいて、phpMyAdminのサポートが追加された。wp-env.jsonの設定に1行加えるだけで、Docker環境と同等のデータベース管理ツールが利用可能になる。ローカル開発環境の構築がこれまで以上に迅速化される見込みだ。
アイコンブロックとナビゲーションオーバーレイ
テーマ制作において要望の多かった「アイコンブロック」がついに導入される。SVGアイコンをライブラリから選択して配置できる機能で、サーバーサイドの「SVG Icon Registration API」によって制御される。現在は標準のアイコンセットのみだが、将来的にはサードパーティ製のアイコンコレクションを登録できる拡張性も計画されている。
さらに、ナビゲーションブロックのモバイルメニュー(オーバーレイ)が完全にカスタマイズ可能になった。「ナビゲーションオーバーレイ」というテンプレートパーツとして独立したため、モバイル専用のメニューデザインを自由なレイアウトで作成できる。これは、モバイルファーストのデザインが求められる現代のWeb制作において、非常に価値の高いアップデートだ。
セキュリティアップデートと今後のロードマップ

新機能の開発が進む一方で、既存バージョンのメンテナンスも継続されている。2026年3月10日には、WordPress 6.9.2(および6.9.4までのマイナーアップデート)がリリースされた。これには10件の脆弱性修正が含まれており、中にはSSRF(サーバーサイドリクエストフォージェリ)やXSS(クロスサイトスクリプティング)といった重要度の高いものも含まれる。
開発チームは、すべてのユーザーに対して直ちにこれらのマイナーアップデートを適用するよう強く推奨している。セキュリティはサイト運営の根幹であり、新機能のテストを行う際も、まずは基盤となる環境の安全性を確保することが先決だ。
WordPress 7.0の正式リリースは4月に予定されている。RTCやAIコネクターといった野心的な機能が安定して動作するか、RC版での検証結果が待たれるところだ。開発者は、自身のプラグインやテーマがこれらの新機能とどのように相互作用するかを確認し、必要に応じてコードの修正を進めるべきだろう。
この記事のポイント
- リアルタイム共同編集(RTC): HTTPポーリングとCRDTを採用し、あらゆるホスティング環境で安全な同時編集を可能にする。
- AIコネクターの標準化: 共通インターフェースを通じて主要AIサービスと連携。ベンダーに依存しないAI機能の実装が可能になる。
- 視覚的なリビジョン管理: 変更箇所をカラーコードで強調表示。直感的な変更履歴の追跡が可能になり、編集ミスを防ぐ。
- テーマ・開発ツールの強化: アイコンブロックの導入やナビゲーションオーバーレイの刷新、WP-CLIの新コマンドにより開発効率が向上する。
- セキュリティの重要性: 6.9.x系の脆弱性修正が公開されており、7.0への移行準備と並行して既存サイトの即時アップデートが必要だ。
出典
- Developer WordPress News「What’s new for developers? (March 2026)」(2026年3月10日)
- WordPress.org「WordPress 7.0 Beta 3」(2026年3月5日)
- Make WordPress Core「Real-Time Collaboration in the Block Editor」(2026年3月10日)
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験