

WordPress 7.0開発最新状況——リアルタイム共同編集とAI連携の標準化が加速
WordPress 7.0のリリースサイクルが佳境を迎えている。2026年3月現在、Gutenberg 22.6のリリースによって主要な機能セットが確定し、3月19日にはリリース候補版(RC1)の公開が予定されている。
今回のメジャーアップデートでは、長年待望されていたリアルタイム共同編集(RTC)の基盤実装や、AIサービスとの連携を標準化する「AIコネクター」など、プラットフォームとしての在り方を大きく変える機能が導入される。現在はBeta 3が公開されており、広範囲なテストが呼びかけられている状況だ。
本記事では、WordPress 7.0で導入される主要機能の技術的背景と、開発者が準備すべきポイントについて、最新の動向を基に解説する。
WordPress 7.0の新機軸:リアルタイム共同編集(RTC)の実装

WordPress 7.0における最大の技術的トピックは、リアルタイム共同編集(RTC: Real-time Collaboration)の導入だ。複数のユーザーが同時に同じ投稿を編集できるこの機能は、これまで外部プラグインや特定のホスティング環境に依存していたが、ついにコア機能として組み込まれる。
HTTPポーリングによる高い互換性の確保
RTCの実装において、技術チームは当初検討されていたWebRTCではなく、HTTPポーリングによる同期プロバイダーを選択した。WebRTCはリアルタイム性に優れる一方で、サーバー構成やファイアウォールの設定によっては通信が不安定になる欠点がある。あらゆるホスティング環境での動作を保証するため、あえて汎用性の高いHTTPポーリングが採用された形だ。
データの整合性を保つ仕組みには、CRDT(Conflict-free Replicated Data Type / 衝突のない複製データ型)が採用されている。これは、複数の場所で同時に行われた変更を、矛盾なく統合するための数学的なアルゴリズムだ。更新データは「wp_sync_storage」という内部ポストタイプに保存され、定期的に圧縮・バッチ処理されることで、データベースへの負荷を最小限に抑える工夫がなされている。
拡張性を考慮した同期アーキテクチャ
この同期システムは、トランスポート層(通信手段)とストレージ層(保存先)を差し替え可能な設計になっている。デフォルトでは2名までの同時編集に制限されているが、ホスティング事業者は独自の同期プロバイダーを導入したり、wp-config.phpの設定値を変更したりすることで、より多人数での編集や高度なパフォーマンス最適化を図ることができる。
RTCをデフォルトで有効化するかどうかの最終判断は、RC2(リリース候補版2)前後で行われる予定だ。プラグイン開発者は、既存のメタボックスやカスタムフィールドがこの共同編集モードと競合しないか、事前の検証が求められる。
AI連携の標準化:AIコネクターとプロバイダーパッケージ

WordPress 7.0では、AIサービスとの通信を標準化するための「コネクター」機能が導入される。これは、特定のAIベンダーに依存せず、共通のインターフェースを通じてAI機能を利用できるようにするインフラストラクチャだ。
php-ai-clientによる共通インターフェースの提供
この機能の核となるのは「php-ai-client」パッケージだ。これは、主要なAIサービスとの通信を抽象化するPHPライブラリである。開発者はこの共通インターフェースに対してコードを書くことで、背後のAIプロバイダー(OpenAI、Google、Anthropicなど)が何であっても、同じように機能を実装できるようになる。
すでにプラグインディレクトリには、OpenAI、Google、Anthropicの各プロバイダーパッケージが公開されている。これにより、ユーザーは管理画面の「コネクター」設定から好みのAIサービスを選択し、APIキーを入力するだけで、サイト全体でAI機能を活用できる環境が整う。
プラットフォームとしてのAI対応
これまでAI機能は各プラグインが個別にAPI連携を実装していたが、コアが認証情報の管理やプロバイダーの選択を担うことで、開発効率とセキュリティが向上する。例えば、コンテンツ生成プラグインとSEO最適化プラグインが、同じAIコネクターの設定を共有するといった運用が可能になる。これは、WordPressが単なるCMSから「AI対応のオペレーティングシステム」へと進化する重要な一歩と言えるだろう。
編集体験の進化:視覚的な変更履歴とコンテンツ専用編集モード

ユーザーインターフェース(UI)の面でも、WordPress 7.0は大きな進化を遂げている。特にリビジョン管理とパターン編集の操作性が大幅に改善された。
カラーコードによる直感的なリビジョン管理
新しいリビジョンパネルでは、ドキュメント内の変更箇所が視覚的に強調表示されるようになった。追加されたブロックは緑、削除されたブロックは赤、設定が変更されたブロックは黄色で縁取りされる。テキスト内容についても、下線(追加)や打ち消し線(削除)を用いて、どこがどう変わったのかが一目で判別できる。
この機能はパフォーマンスにも配慮されており、まず変更されたブロックを素早く特定し、その後に詳細なテキスト比較を行う2段階のプロセスを採用している。テーマの色設定に合わせてカラーが自動調整されるため、どのようなデザインの編集画面でも視認性が損なわれない点も特徴だ。
構造を保護するコンテンツ専用編集(Content-Only Mode)
WordPress 7.0から、パターン編集のデフォルトが「コンテンツ専用編集モード」となる。このモードでは、レイアウトやスタイルの設定が隠され、ユーザーはテキストや画像などのコンテンツ入力に集中できる。これにより、誤ってデザインを崩してしまうリスクを低減できる。
構造的な編集が必要な場合は、パターンを「切り離す(Detach)」ことでフルアクセスが可能になる。管理者は、PHPフィルターやJavaScriptを使用して、非同期パターンのコンテンツ専用モードを無効化することも可能だ。制作会社がクライアントにサイトを引き渡す際、運用の安全性を高めるための強力なツールとなるだろう。
開発者向けツールとテーマ機能のアップデート

開発ワークフローを支えるツール群や、テーマ開発に役立つ新機能も多数追加されている。特にWP-CLIの強化と、ブロックの表現力向上に注目したい。
WP-CLIの新コマンドとPlaygroundの拡充
WP-CLIチームは、ブロックエンティティへの読み取り専用アクセスを提供する「wp block」コマンドや、権限管理を行う「ability」コマンドの開発を進めている。これらはWP-CLI v3.0の一部として、3月末の安定版リリースに向けて調整中だ。
また、ブラウザ上でWordPressを動作させる「WordPress Playground」のランタイムにおいて、phpMyAdminのサポートが追加された。wp-env.jsonの設定に1行加えるだけで、Docker環境と同等のデータベース管理ツールが利用可能になる。ローカル開発環境の構築がこれまで以上に迅速化される見込みだ。
アイコンブロックとナビゲーションオーバーレイ
テーマ制作において要望の多かった「アイコンブロック」がついに導入される。SVGアイコンをライブラリから選択して配置できる機能で、サーバーサイドの「SVG Icon Registration API」によって制御される。現在は標準のアイコンセットのみだが、将来的にはサードパーティ製のアイコンコレクションを登録できる拡張性も計画されている。
さらに、ナビゲーションブロックのモバイルメニュー(オーバーレイ)が完全にカスタマイズ可能になった。「ナビゲーションオーバーレイ」というテンプレートパーツとして独立したため、モバイル専用のメニューデザインを自由なレイアウトで作成できる。これは、モバイルファーストのデザインが求められる現代のWeb制作において、非常に価値の高いアップデートだ。
セキュリティアップデートと今後のロードマップ

新機能の開発が進む一方で、既存バージョンのメンテナンスも継続されている。2026年3月10日には、WordPress 6.9.2(および6.9.4までのマイナーアップデート)がリリースされた。これには10件の脆弱性修正が含まれており、中にはSSRF(サーバーサイドリクエストフォージェリ)やXSS(クロスサイトスクリプティング)といった重要度の高いものも含まれる。
開発チームは、すべてのユーザーに対して直ちにこれらのマイナーアップデートを適用するよう強く推奨している。セキュリティはサイト運営の根幹であり、新機能のテストを行う際も、まずは基盤となる環境の安全性を確保することが先決だ。
WordPress 7.0の正式リリースは4月に予定されている。RTCやAIコネクターといった野心的な機能が安定して動作するか、RC版での検証結果が待たれるところだ。開発者は、自身のプラグインやテーマがこれらの新機能とどのように相互作用するかを確認し、必要に応じてコードの修正を進めるべきだろう。
この記事のポイント
- リアルタイム共同編集(RTC): HTTPポーリングとCRDTを採用し、あらゆるホスティング環境で安全な同時編集を可能にする。
- AIコネクターの標準化: 共通インターフェースを通じて主要AIサービスと連携。ベンダーに依存しないAI機能の実装が可能になる。
- 視覚的なリビジョン管理: 変更箇所をカラーコードで強調表示。直感的な変更履歴の追跡が可能になり、編集ミスを防ぐ。
- テーマ・開発ツールの強化: アイコンブロックの導入やナビゲーションオーバーレイの刷新、WP-CLIの新コマンドにより開発効率が向上する。
- セキュリティの重要性: 6.9.x系の脆弱性修正が公開されており、7.0への移行準備と並行して既存サイトの即時アップデートが必要だ。
出典
- Developer WordPress News「What’s new for developers? (March 2026)」(2026年3月10日)
- WordPress.org「WordPress 7.0 Beta 3」(2026年3月5日)
- Make WordPress Core「Real-Time Collaboration in the Block Editor」(2026年3月10日)

・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Google AI Modeの自己引用が3倍に。検索・マップ・GSCの最新アップデートを解説
Googleの検索体験がAIによって急速に変容している。最新の調査報告によれば、AI ModeにおけるGoogle自身のプロパティへの引用率が、過去9ヶ月で大幅に増加したことが明らかになった。
2026年3月、GoogleはAIを活用した対話型検索「Ask Maps」の導入や、検索コンソールにおけるブランドクエリフィルタの全ユーザー開放など、重要なアップデートを立て続けに実施した。これらの変更は、Webサイトへのトラフィック流入経路に大きな影響を与える可能性がある。
本記事では、Google検索の責任者が語ったマルチモーダルAIによる音声・動画のインデックス化や、検索結果のパーソナライズ化の展望を含め、SEO担当者が今把握すべき重要事項を解説する。
Google AI Modeの自己引用率が21%に上昇
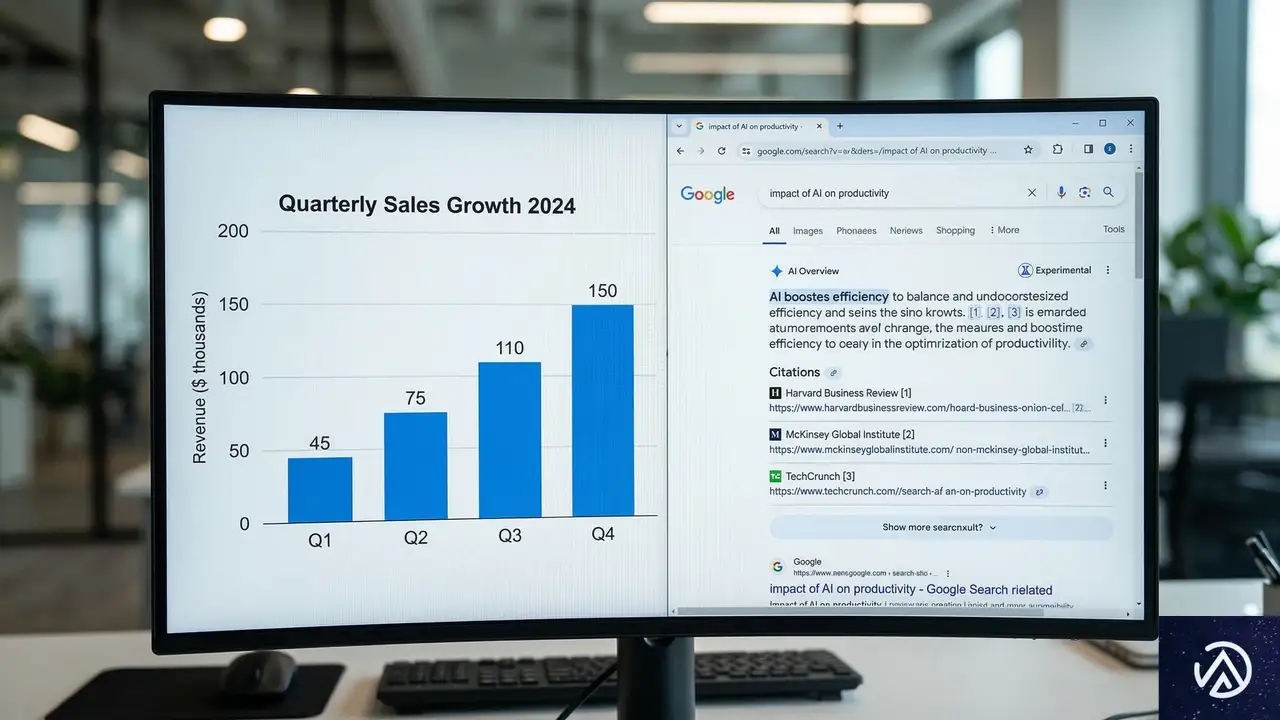
SE Rankingが発表した第3回「Google AI Mode引用レポート」によると、GoogleがAI Modeの回答内で自社プロパティへリンクを貼る割合が急増している。9ヶ月前には全引用の7%に過ぎなかった自己引用率が、現在は21%に達しているという。
外部サイトへの流入減少への懸念
AI Modeの引用のうち、5回に1回は外部のWebサイトではなく、Google自身のページに向けられている計算だ。これは、AI Overviews(AIによる概要表示)で見られた傾向と同様に、Googleがユーザーを自社のエコシステム内に留めようとする戦略を強化していることを示唆している。
SE Rankingのブランド責任者であるモーディ・オーバースタイン氏は、この現状を「巨大な循環」と表現している。同氏によれば、全引用の17%がGoogle自身に向けられており、他のどの情報源よりも高い割合を占めている。
ローカル検索からオーガニック検索への誘導シフト
以前の自己引用は、主にGoogleビジネスプロフィールのリスティング(店舗情報など)に向けられていた。しかし、今回の調査ではGoogle自身のオーガニック検索結果ページへのリンクが増加している。
これは、AIが回答の根拠として特定のWebサイトを個別に紹介するのではなく、「詳細はGoogleで検索してください」という形で自社の検索結果へユーザーを戻していることを意味する。結果として、個別のパブリッシャーが獲得できるトラフィックが減少するリスクがある。
GoogleマップにAI対話機能「Ask Maps」が登場

Googleは、Geminiを活用した対話型AI機能「Ask Maps」をGoogleマップに導入した。ユーザーは自然な言葉で場所について質問し、マップ上でおすすめの提案を受け取ることができる。
レビューとプロフィールの重要性が再定義される
Ask Mapsは、Googleが保有する膨大な場所のデータベースとユーザーレビューを基に回答を生成する。従来の「キーワード一致」によるリスト表示ではなく、文脈を理解した推薦が行われるのが特徴だ。
例えば「静かで作業に適した、Wi-Fiのあるカフェ」といった複雑な要望に対しても、レビュー内容を解析して最適な場所を提示する。店舗運営者にとっては、良質なレビューの獲得とビジネスプロフィールの充実が、AIに推奨されるための必須条件となるだろう。
パーソナライズ化による検索体験の変化
この機能は現在、米国とインドで提供されている。回答はユーザーの検索履歴や保存済みの場所に基づいてパーソナライズされるため、ユーザーごとに異なる結果が表示される。
ただし、Googleはどのような基準で特定のビジネスを優先的に推薦しているのか、その詳細なアルゴリズムは公開していない。また、将来的にこの推薦枠の中に広告(有料の配置)が含まれるかどうかも現時点では不明だ。
音声と動画の「直接理解」によるインデックスの進化

Googleの検索責任者であるエリザベス・リード氏は、AIがコンテンツをどのように理解し、インデックス(検索エンジンに登録すること)を行っているかの変化について言及した。
マルチモーダルAIが文字起こしを超越する
リード氏によれば、マルチモーダルLLM(大規模言語モデル)の導入により、Googleは音声や動画のコンテンツを直接処理できるようになった。マルチモーダルAIとは、テキストだけでなく画像、音声、動画など複数の種類の情報を同時に処理できるAIのことだ。
これまでのGoogleは、主に動画のタイトルや説明文、あるいは自動生成されたトランスクリプト(文字起こし)に頼って内容を把握していた。しかし現在は、動画内の視覚的な変化や音声のトーン、内容の深さをAIが直接「視聴」して理解しているという。これにより、これまで検索結果で過小評価されていたポッドキャストや動画コンテンツの露出が増える可能性がある。
サブスクリプション購読者向けの優先表示
リード氏は、将来的な展望として「サブスクリプションを認識したランキング」についても触れた。これは、特定のニュースサイトなどを有料購読しているユーザーに対し、そのサイトのコンテンツを検索結果の上位に表示する仕組みだ。
通常、ペイウォール(有料の壁)があるコンテンツは、多くのユーザーがアクセスできないため検索順位が上がりにくい傾向にある。しかし、購読者であることをGoogleが認識できれば、そのユーザーにとって価値の高い情報を優先的に届けることが可能になる。
サーチコンソールのブランドクエリフィルタが全ユーザーに開放
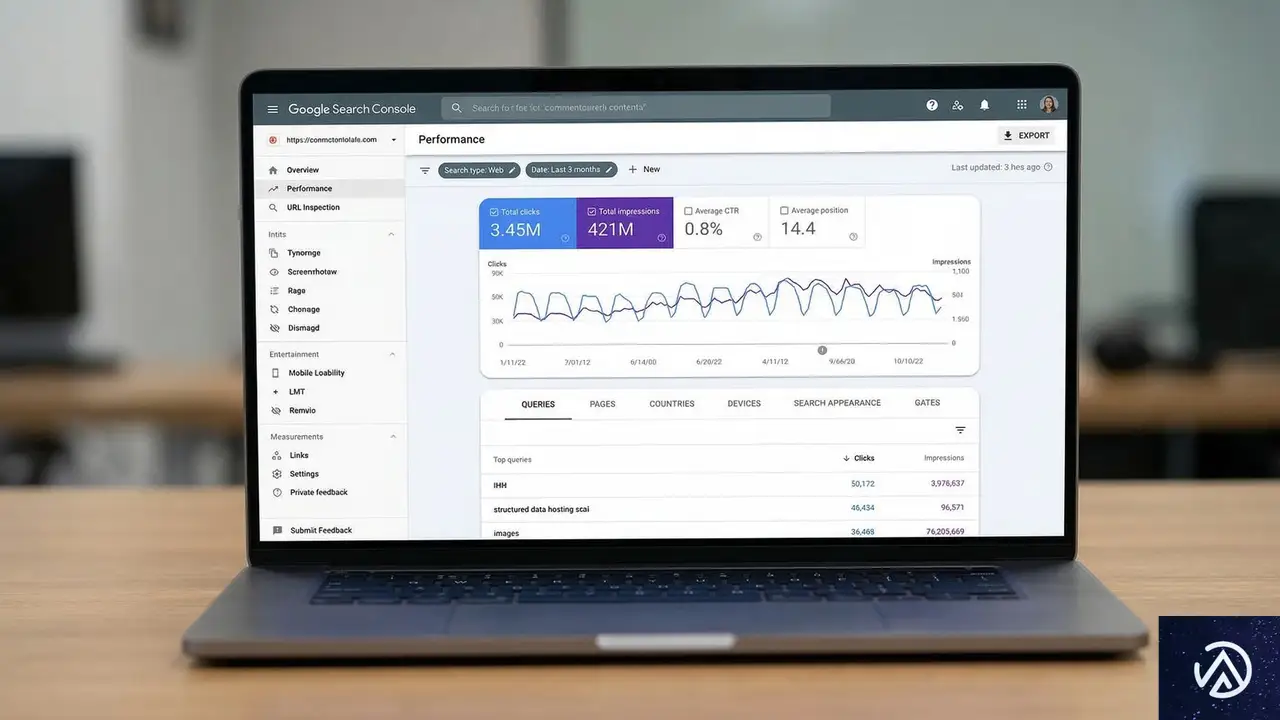
Google検索コンソール(GSC)において、ブランドクエリと非ブランドクエリを自動で分類するフィルタ機能が、すべての対象サイトで利用可能になった。
AIによる自動分類と精度の向上
このフィルタはAIを用いて、ユーザーの検索語句を「ブランド名を含むもの」と「それ以外」に自動で仕分けする。特筆すべきは、ブランド名のタイポ(打ち間違い)や、製品名のみの検索も自動的にブランドクエリとして認識する点だ。
これまでは、ブランドトラフィックを除外するためにREGEX(正規表現)を用いた複雑なフィルタ設定が必要だった。REGEXとは、文字列のパターンを指定して検索や置換を行う手法のことだ。新機能により、専門知識がなくても純粋な新規顧客の流入(非ブランドトラフィック)を正確に把握できるようになる。
戦略的なトラフィック分析の効率化
「Product-Led SEO」の著者であるイーライ・シュワルツ氏は、このアップデートによりSEOチームが「非ブランド領域での貢献」を明確に示せるようになると指摘している。
一方で、ブランドの知名度だけに頼ったトラフィック増加を「SEOの成果」として報告することが難しくなる側面もある。企業にとっては、純粋な検索需要(悩みや目的による検索)に対して自社サイトがどれだけ応えられているかを、より厳密に評価するツールとなるだろう。
独自分析:検索ユーザーとWebサイトの「距離」が広がる時代

今回の一連のアップデートを俯瞰すると、共通する一つのテーマが浮かび上がる。それは、ユーザーが検索を開始してからWebサイトに到達するまでの「距離」が物理的にも心理的にも遠くなっているという事実だ。
ゼロクリック検索の加速とブランド認知の重要性
AI Modeの自己引用率増加やAsk Mapsの導入は、ユーザーがGoogleのインターフェース内で完結する「ゼロクリック検索」を加速させる。ユーザーはWebサイトを訪れることなく、AIとの対話だけで解決策を得てしまうからだ。
このような環境下では、従来の「キーワードで上位表示してクリックを待つ」というモデルだけでは不十分だ。AIが回答の根拠として自社を「認識」し、推奨してくれる状態を作らなければならない。
今後は、直接的なトラフィックだけでなく、AIの回答に含まれる「ブランドの言及」や「推奨」をKPI(重要業績評価指標)に含める視点が必要になるだろう。また、リード氏が語ったように、動画や音声、さらにはサブスクリプションモデルとの連携など、テキスト以外のチャネルを統合したSEO戦略が、Webサイトの生存戦略において鍵となる。
この記事のポイント
- Google AI Modeの自己引用率が21%に上昇し、Google自身へのトラフィック誘導が強まっている。
- 「Ask Maps」の導入により、Googleマップでの検索が対話型かつパーソナライズされたものへ進化している。
- マルチモーダルAIの進化で、動画や音声コンテンツがテキストを介さず直接インデックスされるようになりつつある。
- 検索コンソールのブランドクエリフィルタにより、ブランド認知による流入と純粋なSEO成果の切り分けが容易になった。
- ユーザーがサイトへ到達する前にAIが回答を完結させる傾向が強まっており、ブランドの「言及」を増やす戦略が重要視される。
出典
- Search Engine Journal「AI Mode Data, Ask Maps & Branded Queries Go Live – SEO Pulse」(2026年3月13日)
- SE Ranking「Google Links in AI Mode Answers: Third Report」(2026年3月)
- Access Podcast「Interview with Elizabeth Reid, Head of Google Search」(2026年3月)
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Google Discover 2026年コアアップデート分析:地域メディアの全国リーチ減少と大手サイトの苦戦
Google Discover(グーグル・ディスカバー)の2026年2月コアアップデート完了後、パブリッシャー間の明暗が鮮明になっている。今回のアップデートは、ユーザーの所在地に基づいた「情報の最適化」をより強力に推し進めるものとなった。
最新の調査データによると、地域メディアが地元以外のユーザーに表示される割合が急落している。これは、GoogleがDiscoverにおける「地域性」の定義を再定義した結果と考えられる。
この記事では、複数の分析ツールが示したデータに基づき、今回のアップデートがWebサイトのトラフィックにどのような影響を与えたのかを解説する。
Google Discover 2026年2月コアアップデートの概要

Google Discoverとは、ユーザーの検索履歴やブラウジング習慣に基づいて、関心がありそうな記事を自動的に表示する機能だ。検索キーワードを入力せずに情報が届くため、Webサイト運営者にとっては爆発的なアクセス(通称:Discover砲)の源泉となっている。
2026年2月に実施されたコアアップデートは、このレコメンドエンジンの心臓部を刷新するものだった。Googleは公式に「その国や地域に関連性の高いコンテンツをより多く表示する」と発表していたが、その実態は予想以上にドラスティックなものとなっている。
コアアップデートがもたらす変化
コアアップデートとは、Googleが検索アルゴリズムやシステムに対して行う大規模な変更を指す。Discoverにおけるアップデートは、単なる「質の向上」だけでなく、「誰にどの情報を届けるか」というマッチング精度の調整が主眼に置かれる。
今回のアップデートでは、特に「E-E-A-T(Experience:経験、Expertise:専門性、Authoritativeness:権威性、Trustworthiness:信頼性)」の指標がより厳格に適用されたとの見方が強い。しかし、後述するように一部のデータではその原則に反するような挙動も確認されている。
米国での先行導入と今後の展開
現在、このアップデートの影響を強く受けているのは、米国内の英語ユーザーだ。Googleは今後、他の言語や地域にもこの仕組みを順次拡大していく予定としている。日本のWebサイト運営者にとっても、対岸の火事ではなく、近い将来の標準となるアルゴリズムの変化として注視する必要がある。
地域メディアに起きた「リーチの局所化」という異変

今回のアップデートで最も顕著な影響を受けたのが、特定の地域に根ざした情報を発信するローカルパブリッシャーだ。これまでは良質な記事であれば全米規模でDiscoverに表示されていたが、その「全国リーチ」が遮断されつつある。
地元ユーザーは維持、他県ユーザーは激減
分析データによると、ニューヨーク州の地元メディア「Syracuse.com」は、記事の掲載数が36%減少し、オーディエンススコア(読者の反応率)は全体で80%も下落した。しかし、詳細な内訳を見ると、ニューヨーク州内での露出は安定していたという。
大幅な下落を招いた要因は、フロリダ州やカリフォルニア州など、そのメディアの拠点から離れた地域での露出がほぼゼロになったことにある。これは、Googleが「その地域のニュースはその地域の人に届ける」という、情報の地産地消をアルゴリズムで強制的に強化した結果といえる。
「情報の地産地消」がSEOに与える意味
この変化は、地域メディアにとって必ずしもマイナスではない。遠方のユーザーによる「クリックだけしてすぐに離脱する」という質の低いトラフィックが減り、地元のコアな読者への占有率が高まる可能性があるからだ。
ただし、広域からのアクセスを収益の柱にしていたメディアにとっては、ビジネスモデルの再考を迫られる事態となっている。コンテンツのターゲット設定を「誰に」だけでなく「どこに住んでいる人に」まで踏み込んで設計することが、今後のDiscover対策の肝となる。
大手パブリッシャーとSNSが直面した厳しい現実

影響を受けたのは地域メディアだけではない。YahooやForbes、Fox Newsといった、膨大なトラフィックを誇る大手パブリッシャーも大きな打撃を受けている。
YahooやForbesの20%以上の露出低下
調査レポートによると、YahooはDiscoverでの記事掲載数を約半分に減らし、オーディエンススコアは62%も低下した。ランキング順位も3位から9位へと大きく後退している。Forbesも同様に掲載数が21%減、スコアは67%減と、壊滅的な数字を記録した。
これらの大手サイトは、幅広いジャンルの記事を大量に投稿することで、Discoverの広範な枠を占有してきた。しかし、Googleは「汎用的なポータルサイト」よりも「特定のトピックに特化した専門サイト」を優先する傾向を強めており、その煽りを受けた形だ。
X(旧Twitter)の掲載順位とタイミングの相関
SNSプラットフォームであるX(旧Twitter)の動向も興味深い。アップデートの途中経過では掲載順位を上げていたが、完了後のデータでは記事掲載数が22%減少、オーディエンススコアも32%低下している。
これは、Discoverにおける「情報の鮮度」と「信頼性」のバランスが再調整されたことを示唆している。速報性のあるSNS投稿が一時的に浮上しても、最終的には校閲された記事コンテンツが優先される仕組みが強化されたとの見方がある。
データから読み解く勝者と敗者の分岐点

一方で、今回のアップデートで明確にシェアを伸ばした勢力も存在する。その筆頭がYouTubeだ。
YouTubeのシェア拡大とGoogleの意図
アップデート完了後の窓口において、YouTubeの掲載数は15%増加し、約1万8,000件に達した。Googleは自社のプラットフォームをコアアップデートの悪影響から保護する傾向があるとの指摘もあるが、それ以上に「動画コンテンツ」へのユーザーニーズに応えた結果と見るのが妥当だろう。
Discoverのフィードをスクロールすると、以前よりもショート動画やYouTube動画のカードが目に付くようになっている。テキスト主体のメディアは、動画を記事内に埋め込む、あるいはYouTubeチャンネルとの連携を強めるなどの対策が不可避となっている。
「Psychology says」現象に見るアルゴリズムの隙
特筆すべき例外として、「Geediting.com」というサイトが掲載数を531%、オーディエンススコアを900%も爆発的に伸ばした事例がある。このサイトの記事の75%以上は、タイトルが「Psychology says(心理学によれば)」で始まっている。
本来、Googleが推奨するE-E-A-Tの観点からは、このようなパターン化されたタイトルや、専門家による厳密な裏付けが不明瞭なコンテンツは評価されにくいはずだ。しかし、データはこのサイトが「勝者」であることを示している。これは、アルゴリズムが「ユーザーが思わずクリックしてしまう心理的なフック」を、依然として強く評価している可能性を示唆している。
独自の分析:今後のDiscover対策で意識すべき3つのポイント

今回のデータ分析を踏まえ、Web制作会社やマーケティング担当者が今後取り組むべき戦略を3つのポイントにまとめた。
1. ターゲット地域の明確化とローカルタグの活用
地域メディアや店舗ブログを運営している場合、記事内で対象地域を明示することが重要だ。HTMLのメタデータや構造化データ(Schema.org)を用いて、そのコンテンツがどの地域に関連するものかを検索エンジンに正しく伝える必要がある。
「全国の誰かに届けばいい」という曖昧な姿勢ではなく、「特定の地域の人にとって不可欠な情報」を目指すことが、結果としてDiscoverでの安定した露出につながるだろう。
2. 動画コンテンツとのシナジー
YouTubeの露出増は、Googleの明確な意思表示だ。ブログ記事を書くだけでなく、その要約を動画にしてYouTubeにアップロードし、記事内に埋め込む手法が有効だ。
動画とテキストの両方を用意することで、Discoverの「ウェブ枠」と「動画枠」の両方にエントリーできる可能性が高まる。これは、トラフィックの入り口を多角化する上で極めて強力な武器になる。
3. クリック率と読了率のバランス
「Psychology says」の事例が示す通り、魅力的なタイトル(クリック率の向上)は依然としてDiscoverの強力なトリガーだ。しかし、クリックした後の体験が伴わなければ、長期的にはドメイン全体の評価を落とすリスクがある。
ユーザーの興味を惹くフックを用意しつつ、中身ではしっかりと専門性と信頼性(E-E-A-T)を担保する。この「入り口の親しみやすさ」と「出口の満足度」の両立が、2026年以降のDiscover運用のスタンダードになるだろう。
この記事のポイント
- 2026年2月のコアアップデートにより、地域メディアの「地元以外」での露出が激減した。
- YahooやForbesなどの大手サイトも、汎用的な内容が災いして20%以上の掲載減となった。
- YouTubeなどの動画コンテンツは露出を伸ばしており、動画活用がDiscover攻略の鍵となる。
- 「心理学によれば」といった引きの強いタイトルが依然として効果を発揮している側面もある。
- 今後の対策は、ターゲット地域の明確化と、動画とテキストを組み合わせた多角的な発信が重要だ。
出典
- Search Engine Journal「Google Discover Core Update Data: Local Publishers Lost Reach」(2026年3月13日)
- DiscoverSnoop「Google Discover Core Update Feb 2026: Winners, Losers, and Unexpected Outcomes」(2026年3月10日)
- Google Search Central Blog「What publishers should know about Discover core updates」(2026年2月)
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

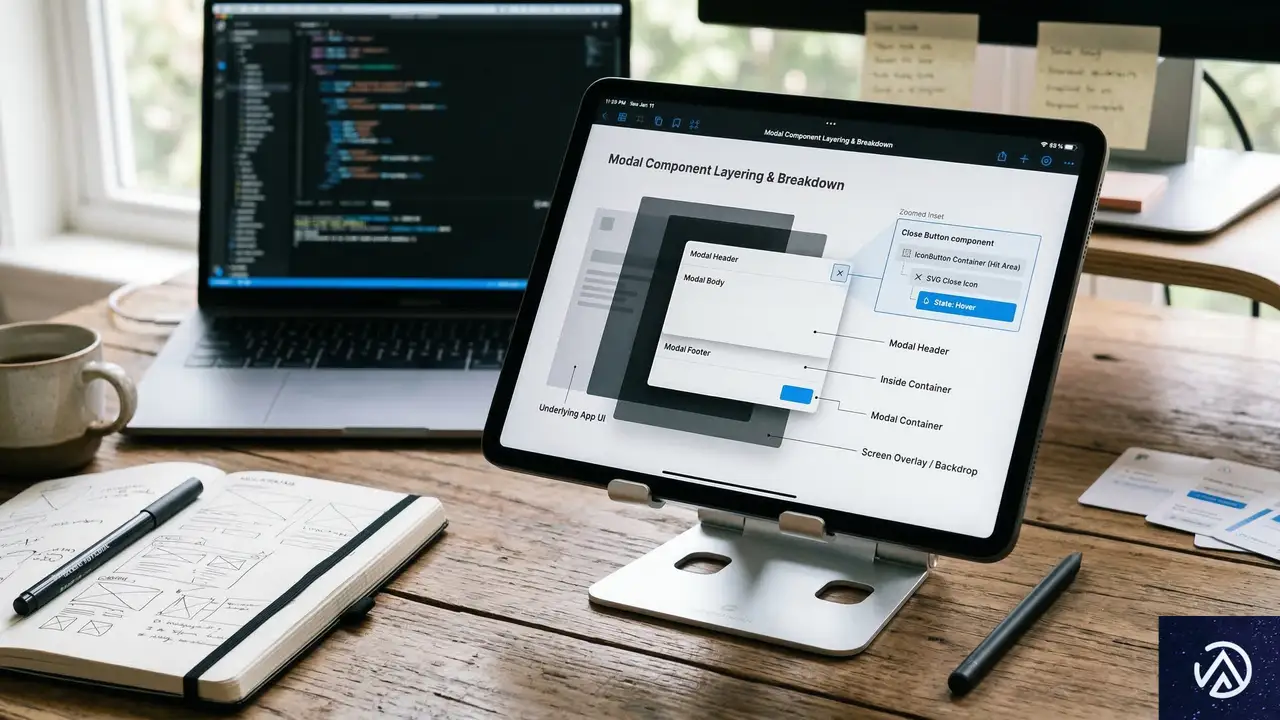
z-indexのカオスを卒業する——マジックナンバーを廃止し、トークンで管理する設計手法
CSSの `z-index` は、要素の重なり順を制御するための強力なプロパティだ。モーダルやトースト、ドロップダウンなど、現代のUI(ユーザーインターフェース)実装において欠かすことはできない。
しかし、プロジェクトが大規模になるにつれ、`z-index` の値は制御不能な「マジックナンバー」の温床となる。場当たり的に指定された巨大な数値がコードベースを侵食し、修正が困難なバグを引き起こす。
本記事では、`z-index` の軍拡競争を終わらせるための「トークン化」による管理手法を解説する。この仕組みを導入することで、重なりの優先順位を論理的に整理し、保守性の高いコードを実現できる。
z-indexが引き起こす「軍拡競争」の実態
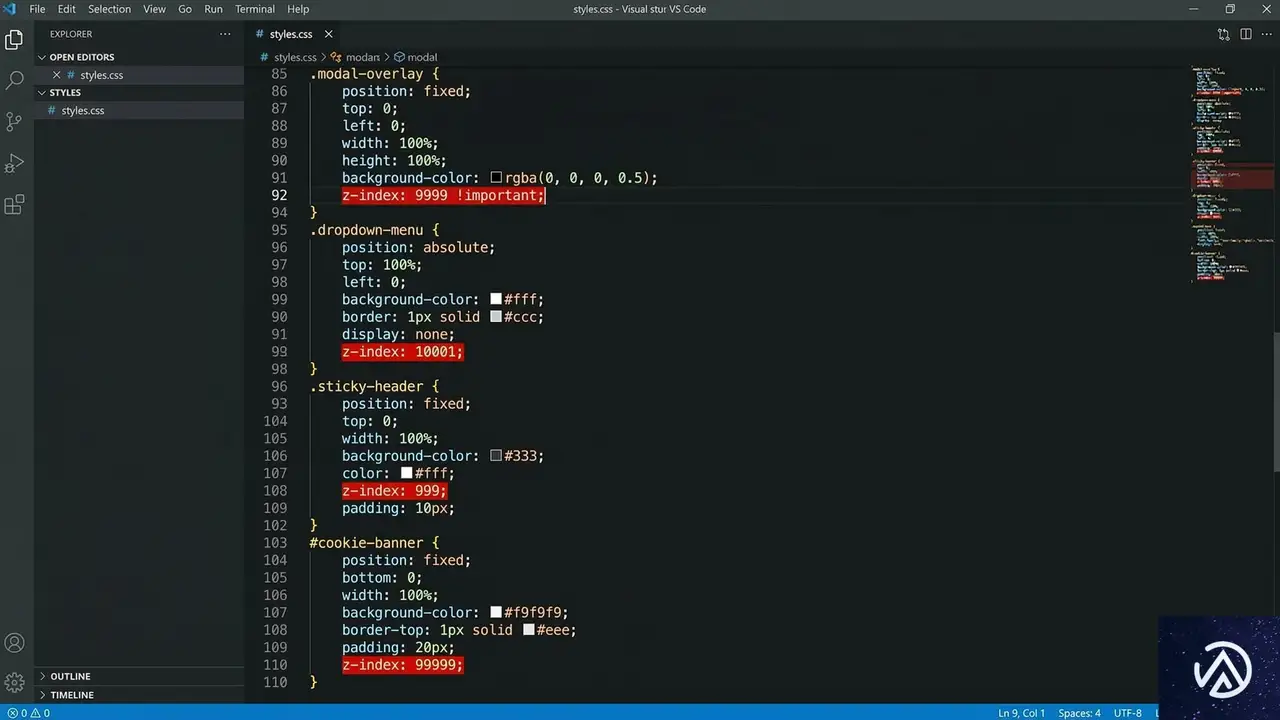
多くの開発現場で、`z-index: 10001` のような不自然に大きな数値を目にすることがある。なぜこのような「マジックナンバー」が生まれるのか。その背景には、開発者が抱く「要素が隠れてしまうことへの恐怖」がある。
なぜ「10001」のような数字が生まれるのか
複数のチームが並行して開発を行う大規模プロジェクトでは、画面上に何が浮いているかを完全に把握するのは難しい。Aチームが作った通知、Bチームのクッキーバナー、マーケティング用のSDKが生成するモーダルなどが混在する。
開発者は「とにかく一番上に表示させたい」という一心で、既存のどの要素よりも大きいと思われる数値を勘で入力する。これが「マジックナンバー」の正体だ。マジックナンバーとは、文脈や根拠がなく、その場しのぎで設定された特定の数値を指す。
一度この軍拡競争が始まると、次の開発者はさらに大きな数値を設定せざるを得なくなる。最終的に `9999999` のような極端な値が並び、コードの意図は完全に消失する。
ブラウザが許容する最大値の罠
`z-index` には設定可能な最大値が存在する。多くのブラウザでは **2147483647** が上限だ。これは32ビット符号付き整数の最大値に由来する。
この数値を超えて指定しても、ブラウザによってこの上限値に丸められる。つまり、無限に数値を大きくして「勝ち続ける」ことは不可能だ。数値の大きさで解決しようとするアプローチは、いずれ技術的な限界に突き当たる。
重ね合わせ文脈(Stacking Context)の基本

`z-index` の問題を難しくしているのは、数値の大小だけで重なりが決まらない点にある。ここで重要になるのが「重ね合わせ文脈(Stacking Context)」という概念だ。
値の大きさよりも「親」が優先される仕組み
重ね合わせ文脈とは、要素の重なりを計算するための独立したグループのようなものだ。例えるなら、書類の束(スタック)が入った「フォルダ」をイメージすると分かりやすい。
どれほど大きな `z-index` を持っていたとしても、その要素が属する「フォルダ(親の重ね合わせ文脈)」自体が低い位置にあれば、他のフォルダより前に出ることはできない。
以下のコードで、その挙動を確認できる。
/* 親要素が重ね合わせ文脈を作る */
.parent-low {
position: relative;
z-index: 1;
}
.parent-high {
position: relative;
z-index: 2;
}
/* 子要素に大きな値を指定しても、親の z-index: 1 に縛られる */
.child-massive {
position: absolute;
z-index: 9999;
}(z: 9999)
子要素はz-index:9999だが、親1(z:1)に縛られ、親2(z:2)の下に隠れている
このデモでは、青い子要素に `z-index: 9999` を指定しているが、親要素の `z-index: 1` という制約により、隣にある `z-index: 2` の親要素(緑)の下に潜り込んでしまう。
このように、`z-index` のトラブルの多くは数値の不足ではなく、重ね合わせ文脈の構造に起因している。
CSS変数(トークン)による設計の体系化
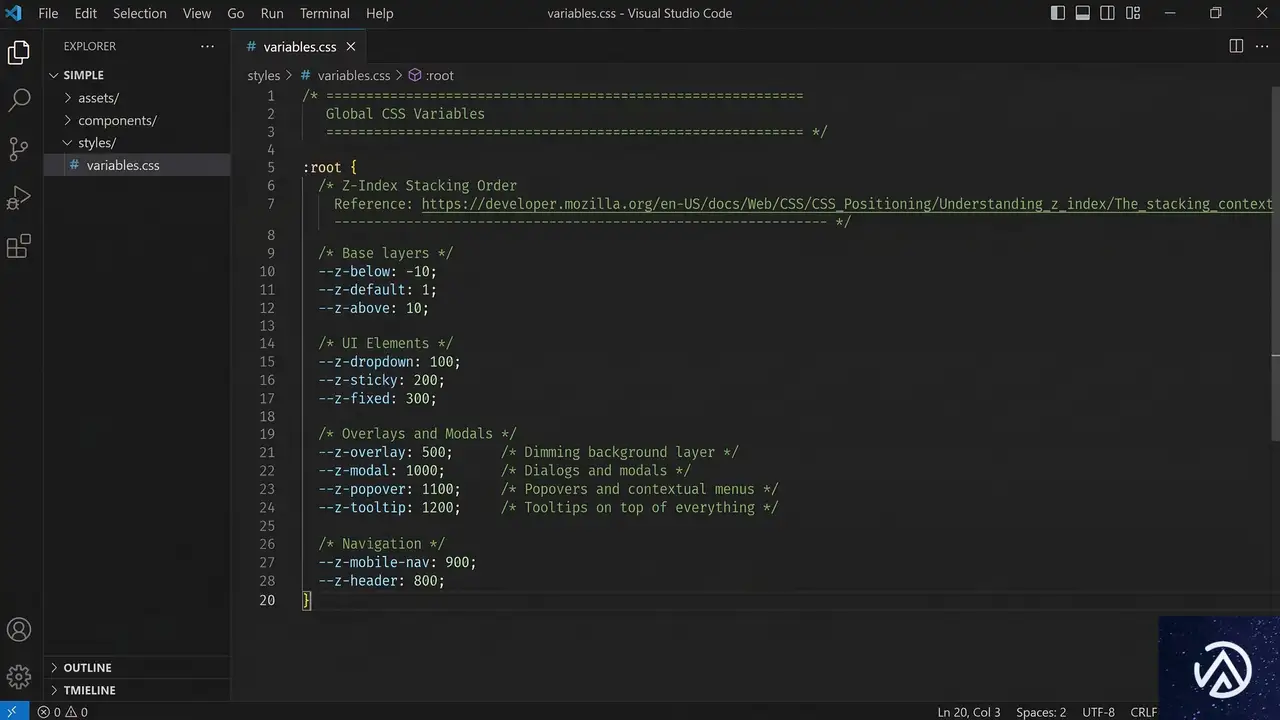
マジックナンバーを排除し、プロジェクト全体で一貫した重なり順を維持するための最も有効な手段は、CSS変数(カスタムプロパティ)を用いた「トークン化」だ。
グローバルトークンで「階層」を定義する
まず、アプリケーション全体で共有する「レイヤー」を定義する。具体的な数値ではなく、その要素が果たす役割(役割ベース)で命名するのがポイントだ。
:root {
--z-base: 0;
--z-sticky: 100;
--z-dropdown: 200;
--z-overlay: 300;
--z-modal: 400;
--z-popover: 500;
--z-toast: 600;
}このように定義しておけば、開発者は「モーダルだから `–z-modal` を使おう」と判断するだけで済む。数値の管理は `:root` の一箇所に集約されるため、後から「トーストをモーダルの背面に移動したい」といった変更が必要になっても、変数の値を入れ替えるだけで全要素に反映される。
calc() を使った相対的なレイヤリング
特定の要素に対して、基準となるレイヤーから少しだけ浮かせたい、あるいは沈ませたい場合がある。例えば、モーダルの背面に敷く背景(バックドロップ)などだ。
この場合、新しいトークンを作るのではなく `calc()` を利用して相対的に指定する。
.modal-backdrop {
/* モーダルのトークンより常に 1 だけ背面に配置 */
z-index: calc(var(--z-modal) - 1);
}これにより、要素間の主従関係がコード上で明示される。`–z-modal` の値が変更されても、バックドロップは常にその背後を追従するため、関係性が崩れる心配がない。
コンポーネント内部での「ローカル管理」
グローバルなトークンは便利だが、あらゆる要素をグローバル変数で管理しようとすると、変数の数が膨大になり管理が破綻する。そこで、コンポーネント内部で完結する「ローカル管理」を併用する。
–z-top と –z-bottom の導入
コンポーネントが独自の重ね合わせ文脈(Stacking Context)を持っている場合、その内部での重なり順はグローバルな値とは無関係になる。
例えば、モーダル内の閉じるボタンと背景装飾の重なりを制御する場合、グローバルトークンを使う必要はない。以下のように、コンポーネント固有の「基準値」を定義するのが賢明だ。
.my-component {
/* 重ね合わせ文脈を強制的に作成 */
isolation: isolate;
z-index: var(--z-overlay);
}
.my-component__decoration {
/* コンポーネント内の底辺 */
z-index: -1;
}
.my-component__close-button {
/* コンポーネント内の最前面 */
z-index: 10;
}`isolation: isolate` は、その要素に新しい重ね合わせ文脈を強制的に作成するプロパティだ。これを使うことで、内部の `z-index` が外部に影響を与えたり、外部の影響を受けたりすることを防ぐ「安全地帯」を作ることができる。
ツールチップやモーダル内での活用
ツールチップのように「どこにでも現れる」コンポーネントは、管理が最も難しい。しかし、これもローカルな視点で考えればシンプルになる。
ツールチップは、常に「自分を呼んだ要素」のすぐ上にいればよい。そのため、コンポーネント内で `z-index: 1` 程度の小さな値を設定するだけで十分だ。そのツールチップがモーダル内で使われれば、モーダルの重ね合わせ文脈の中で最前面に立ち、メインコンテンツで使われればそこで最前面に立つ。
システムを維持するための自動化とルール
優れた設計も、運用が徹底されなければ形骸化する。特に納期が迫った状況では、つい `z-index: 999` と書き込みたくなるのが開発者の性だ。これを防ぐには、仕組みによる強制が必要だ。
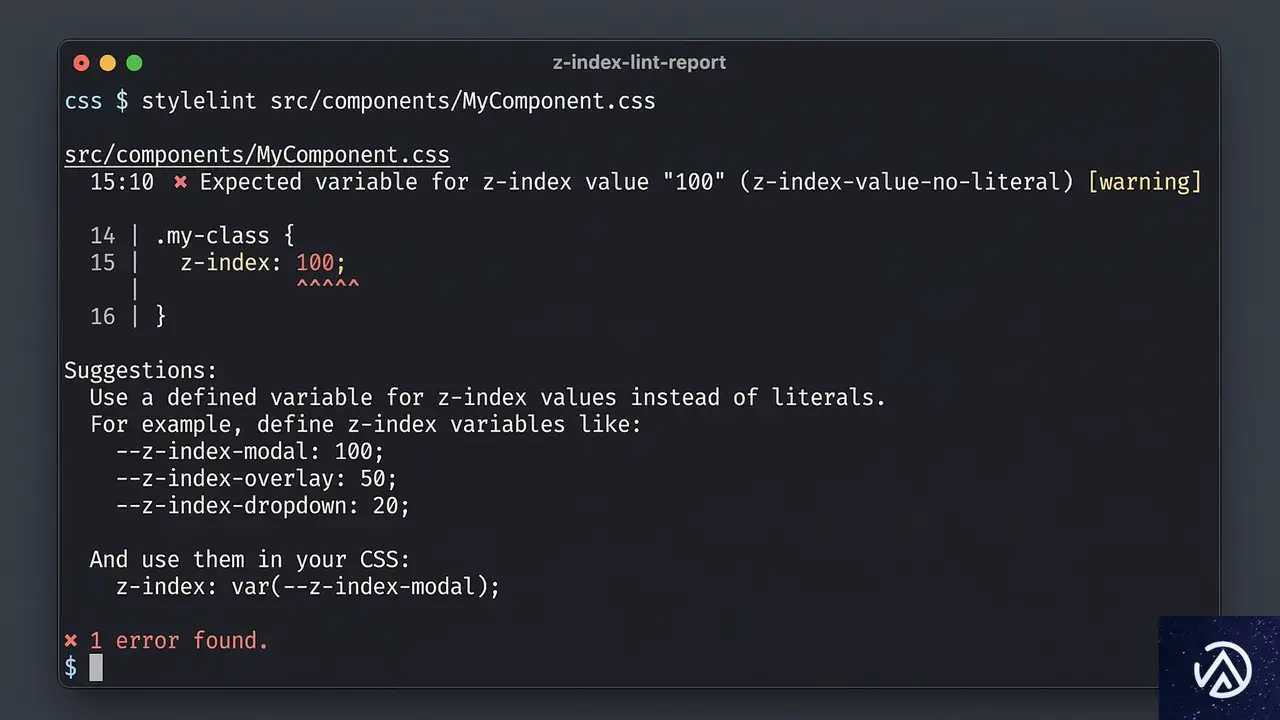
Linterによるマジックナンバーの禁止
Stylelintなどの静的解析ツールを導入し、`z-index` プロパティに直接数値を記述することを禁止する。
例えば、`stylelint-declaration-strict-value` というプラグインを使えば、`z-index` には変数(`var()`)しか使えないように制限できる。
/* .stylelintrc.json */
{
"plugins": ["stylelint-declaration-strict-value"],
"rules": {
"scale-unlimited/declaration-strict-value": ["z-index"]
}
}ビルドプロセスでエラーが出るようになれば、開発者は必然的に定義されたトークンを確認し、適切なレイヤーを選択するようになる。
z-index 設計の黄金律
最後に、保守性の高い `z-index` 管理を維持するためのルールをまとめる。
- マジックナンバーを使わない: 根拠のない数値はバグの元だ。
- トークンを必須とする: すべての値は設計された変数から取得する。
- 重なりがおかしい時は構造を疑う: 数値を増やす前に、重ね合わせ文脈(親要素の z-index や opacity)を確認する。
- 意味のある単位で刻む: 1, 2, 3 ではなく 100, 200, 300 と刻むことで、後からの割り込み(150など)に対応しやすくなる。
- calc() で関係を縛る: 背景と本体のようにセットで動くものは、計算式で結合する。
`z-index` の価値は、数値の大きさではなく、それが属する「システム」の整合性にある。カオスな現状を打破し、予測可能なUI実装を目指すべきだ。
この記事のポイント
- z-indexの軍拡競争は、数値ではなく「役割ベースのトークン」で解決する。
- 重ね合わせ文脈(Stacking Context)を理解し、親要素の影響を考慮する。
- グローバルトークンと、コンポーネント内のローカル管理を使い分ける。
- Stylelintなどのツールを用いて、マジックナンバーの混入を自動的に防ぐ。
- calc() を活用して、要素間の相対的な重なり関係をコードに明文化する。
出典
- CSS-Tricks「The Value of z-index」(2026年3月9日)
- MDN Web Docs「The stacking context」(2025年12月15日)
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AI検索が引き起こすECマーケティングの「アトリビューションの盲点」とその対策
人工知能(AI)の進化は、消費者が商品を見つけるプロセスを根本から変えつつある。この変化は、EC事業者にとって「アトリビューションの盲点」という新たな課題を突きつけている。
現在、少数の、しかし確実に増えつつある消費者が、検索エンジンやマーケットプレイスではなく、AIアシスタントへの対話型クエリから商品のリサーチを始めている。Perplexity(パープレキシティ)のようなジェネレーティブAI(生成AI)プラットフォームは、商品の推奨だけでなく、直接購入への導線も提供し始めている。
従来の検索結果では複数のブランドが1ページに並び、ユーザーの比較検討プロセスを追跡できた。しかし、AIによる回答は「10個のリンクから1つの回答」へと収束しており、これがマーケティング効果の測定を困難にしている。
AIによる「検索から回答へ」のパラダイムシフト
オンラインでの商品発見プロセスは、これまでGoogleなどの検索エンジン、Amazonなどのマーケットプレイス、そしてSNSが中心であった。ここに現在、対話型AIツールが加わっている。
10個のリンクから1つの回答へ
従来の検索エンジン最適化(SEO)の世界では、検索結果に表示される「青色のリンク」をいかにクリックさせるかが重要であった。しかし、AIアシスタントは膨大な情報から最適な選択肢を絞り込み、ユーザーに提示する。
データ分析企業LatentViewのビジネスヘッドであるKaushik Boruah氏は、「発見可能性が10個のリンクから1つの回答へと崩壊した」と指摘している。ユーザーが複数のサイトを巡回して比較する手間が省かれる一方で、ブランド側がユーザーの目に触れる機会は極端に狭まっている。
購買プロセスの「上流」への移動
消費者はAIに対し、「着心地の良い服」や「無香料の石鹸」といった具体的な悩みを相談する。AIはそれに対する解決策を提案し、その理由を説明する。
この段階で、消費者はすでに「何を買うか」を決めていることが多い。販売者のウェブサイトに到達したときには、検討プロセスは完了している。つまり、商品発見のプロセスが、EC事業者が制御できず、かつ測定も困難な「上流」へとシフトしているのだ。
なぜAI経由の貢献は「見えない」のか(アトリビューションの盲点)
アトリビューション(Attribution)とは、コンバージョン(商品購入などの成果)に至るまでの各広告やチャネルの貢献度を正しく評価することを指す。AIの台頭により、この評価に「盲点」が生じている。
複数チャネルを跨ぐ複雑な足跡
例えば、ある消費者がAIアシスタントに商品の推奨を求めたとする。回答を得た後、その消費者はGoogleでブランド名を検索し、Amazonで購入を完了させる。
この場合、AmazonやGoogle Analytics(グーグルアナリティクス)のデータ上では、売上は「検索」や「直接流入」に割り当てられる。最初にAIが与えた影響は、データとして記録されない。
マーケティング担当者は、消費者の行動が変化していることを認識しながらも、投資対効果(ROI)が不明確なため、予算をAIチャネルにシフトさせることに慎重にならざるを得ない。結果として、測定可能なチャネルばかりが優先される事態を招いている。
サードパーティクッキー廃止との共通点
このAIによる計測の難しさは、サードパーティクッキー(ウェブサイトを跨いでユーザーを追跡する技術)の廃止に伴う課題と似ている。どちらもカスタマージャーニー(顧客が購入に至るまでの道のり)の可視性を低下させ、計測をモデリング(統計的な予測)へとシフトさせる要因となっている。
しかし、AIの盲点はクッキーの問題よりも解決が難しいとの見方がある。クッキーは技術的な代替案が模索されているが、AIアシスタント内部の推奨アルゴリズムや、ユーザーとAIのクローズドな対話を外部から把握する手段は極めて限られているからだ。
計測不能な影響を可視化する3つの代替手法

直接的なアトリビューション計測が困難な中、先進的な企業はAIの影響を測定するために代替的なアプローチを試行している。
1. インクリメンタル・テスト(増分テスト)
インクリメンタル・テストとは、特定の地域やオーディエンスに対してのみキャンペーンを実施し、実施しなかったグループとの売上の差(リフト)を測定する手法だ。
個々のユーザーの動きを追跡できなくても、統計的に「その施策がどれだけの純増売上をもたらしたか」を推定できる。AIプラットフォームへの露出を強化した場合の売上増を測る際にも有効な手段となる。
2. MMM(マーケティング・ミックス・モデリング)
MMM(Marketing Mix Modeling)は、広告費、価格、季節性、競合の動きなどの膨大なデータセットを統計的に分析し、各要素が売上に与えた影響を算出する手法だ。
これは「種をまいてから芽が出るまで」を俯瞰するような分析であり、AIアシスタントのような計測しにくいチャネルの貢献度を、他の変数との相関関係から導き出すことができる。近年、プライバシー規制の強化に伴い、再び注目を集めている。
3. ユーザーアンケートとブランドリフト調査
デジタルな足跡を追えないのであれば、直接ユーザーに聞くという原始的な手法も重要になる。購入完了ページでの「このサイトをどこで知りましたか?」というアンケートに、選択肢としてAIアシスタントを加えるだけでも、貴重な一次データが得られる。
また、ブランドリフト調査(広告接触による認知度や購入意向の変化を測る調査)を通じて、AIの推奨がブランドイメージにどう寄与しているかを定性的に把握することも推奨される。
WooCommerce・EC事業者が今取り組むべき戦略的視点

AIが購買決定を左右する時代において、ECサイト(特にWooCommerceなどの柔軟なプラットフォーム)を運営する事業者は、単なるSEOの延長線上ではない対策を求められる。
AIO(AI検索最適化)への意識
SEO(検索エンジン最適化)に代わり、AIO(AI Optimization)やGEO(Generative Engine Optimization)という概念が登場している。AIに正しく自社の商品を認識・推奨させるためには、構造化データ(Schema.orgなど)の徹底的な実装が不可欠だ。
構造化データとは、検索エンジンやAIに対して「これは商品名」「これは価格」「これはレビュー」と、データの意味を機械が理解できる形式で伝えるためのコードだ。これを適切に記述することで、AIアシスタントの回答に自社商品が含まれる確率を高めることができる。
自社データ(ファーストパーティデータ)の強化
外部チャネルの計測が不透明になるほど、自社サイト内で取得できるデータの価値は高まる。顧客の購買履歴、閲覧行動、会員情報などのファーストパーティデータを統合し、顧客理解を深めることが、AI時代の不確実性に対する最大の防御策となる。
WooCommerceであれば、プラグインを活用して詳細な顧客行動ログを収集し、自社独自の分析基盤を構築することが比較的容易だ。計測できない「外部の動き」に一喜一憂するよりも、確実に見える「自社内のデータ」を盤石にすることが先決と言える。
この記事のポイント
- AIアシスタントは商品比較プロセスを省略し、消費者の意思決定を「上流」で完了させる。
- AI経由の流入は「直接流入」や「検索」に紛れ込み、真の貢献度が見えなくなる「アトリビューションの盲点」を生む。
- インクリメンタル・テストやMMM(マーケティング・ミックス・モデリング)など、統計的なアプローチによる効果測定が不可欠。
- 構造化データの最適化(AIO)と、自社データの活用強化が、AI時代のEC運営における重要な戦略となる。
出典
- Practical Ecommerce「The AI Attribution Blind Spot」(2026年3月8日)
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

WordPress開発もモダンに。Moment.jsからJavaScript Temporal APIへの移行ガイド
JavaScriptにおける日時操作のデファクトスタンダードであった「Moment.js」が、メンテナンスモードに入って久しい。現在、その後継として期待されているのが、ブラウザ標準の「Temporal API(テンポラルAPI)」だ。
2026年3月現在、Temporal APIは主要なブラウザでの実装が進み、実用段階に入りつつある。本記事では、WordPress開発においてMoment.jsからTemporal APIへ移行するための具体的なレシピと、その重要性を解説する。
この移行は、単なるライブラリの置き換えではない。サイトのパフォーマンス向上と、日時計算における予期せぬバグを根絶するための重要なステップだ。
Moment.jsの終焉とTemporal APIの登場背景

長年、JavaScriptの標準機能であるDateオブジェクトは、その使い勝手の悪さが指摘されてきた。この穴を埋めるために普及したのがMoment.jsだ。しかし、現代のWeb開発において、Moment.jsはいくつかの致命的な課題を抱えている。
Moment.jsが抱えていた3つの課題
第一の課題は、オブジェクトの「可変性(Mutable)」だ。Momentオブジェクトに対して操作を行うと、元のデータ自体が書き換わってしまう。これは、意図しない場所で日付が変わってしまうバグの原因となりやすい。
第二の課題は、バンドルサイズの肥大化だ。Moment.jsは巨大なライブラリであり、一部の機能しか使わない場合でも、ファイル全体を読み込む必要がある。これは、WordPressサイトの表示速度、特にLCP(Largest Contentful Paint)に悪影響を及ぼす。
第三に、タイムゾーン処理の複雑さがある。標準のMoment.jsだけではタイムゾーンを扱えず、追加のライブラリ(moment-timezone)が必要だった。これらの課題を解消すべく、ECMAScriptの標準仕様として策定されたのがTemporal APIだ。
Temporal APIがもたらす技術的メリット
Temporal APIは、不変性(Immutable)を前提に設計されている。すべての計算結果は新しいオブジェクトとして返されるため、元のデータが汚染される心配がない。また、ブラウザにネイティブ実装されるため、追加のライブラリ読み込みが不要になり、JSの実行コストが劇的に低下する。
さらに、月指定が「1から始まる」点も大きな改善だ。従来のDate APIやMoment.jsでは、1月を「0」と数える仕様が直感に反し、多くの開発者を悩ませてきた。Temporalでは、1月は「1」として扱われる。
Temporal APIの基本オブジェクトと使い分け

Temporal APIは、用途に応じて複数のオブジェクトを使い分ける設計になっている。Moment.jsのように1つのオブジェクトですべてを済ませるのではなく、情報の精度に応じて適切な型を選択する。
主要な4つのオブジェクト
- Temporal.Instant: UTC(協定世界時)に基づく特定の瞬間を表す。タイムスタンプの保存に適している。
- Temporal.ZonedDateTime: タイムゾーン情報を含む日時。特定地域の「カレンダー上の日時」を扱う際に使用する。
- Temporal.PlainDate / PlainTime: タイムゾーン情報を持たない、日付のみ、または時刻のみのデータ。
- Temporal.Duration: 「2時間30分」といった、時間の長さを表す。
例えば、WordPressの投稿公開日時を扱う場合は「ZonedDateTime」が適している。一方、ユーザーの誕生日などはタイムゾーンに依存しないため、「PlainDate」を使うのが正しい。このように、データの性質を型で定義できるのがTemporalの強みだ。
実践:Moment.jsからTemporalへの移行レシピ

既存のMoment.jsコードをどのようにTemporalへ書き換えるべきか、代表的なパターンを見ていく。基本的な操作において、Temporalはより厳格な構文を要求するが、その分コードの信頼性は高まる。
日時の生成とパース(解析)
Moment.jsでは、柔軟すぎるがゆえに曖昧な文字列も解釈しようとした。Temporalでは、ISO 8601形式などの標準的な文字列のみを受け付ける。
// Moment.js
const mNow = moment();
const mSpecific = moment("2026-03-15");
// Temporal API
const tNow = Temporal.Now.instant();
const tSpecific = Temporal.PlainDate.from("2026-03-15");「ISO 8601」とは、日付と時刻を表記するための国際規格(例:2026-03-15T13:00:00Z)のことだ。Temporalはこの規格に準拠していない文字列を渡すとエラーを投げるため、開発段階で不具合に気づきやすくなる。
Intl APIを活用したロケール対応のフォーマット
Moment.jsは独自形式のトークン(’YYYY-MM-DD’など)を使用していた。これに対し、Temporalはブラウザ標準の「Intl.DateTimeFormat(国際化API)」と親和性が高く、ユーザーの言語設定に合わせた表示が容易だ。
// Moment.js
moment().format('LL'); // "2026年3月15日"
// Temporal
const now = Temporal.Now.instant();
now.toLocaleString('ja-JP', { dateStyle: 'long' }); // "2026年3月15日"「ロケール」とは、言語や地域による表記規則の集まりを指す。Temporalで`toLocaleString`メソッドを使うことで、エンジニアが手動でフォーマットを指定しなくても、ブラウザが自動的にその国に最適な形式で表示してくれる。
日時計算における「不変性」の重要性

日時の加算や減算において、Temporalの「不変性(イミュータビリティ)」は最大の武器となる。Moment.jsで頻発していた「計算後に元の変数の値が変わってしまう」という副作用が、構造的に排除されている。
副作用のない加減算
以下のコード比較を見れば、その違いは一目瞭然だ。
// Moment.js (元のオブジェクトが書き換わる)
const startDate = moment("2026-03-01");
const endDate = startDate.add(7, 'days');
console.log(startDate.format('YYYY-MM-DD')); // "2026-03-08" (意図せず変更された)
// Temporal (元のオブジェクトはそのまま)
const tStart = Temporal.PlainDate.from("2026-03-01");
const tEnd = tStart.add({ days: 7 });
console.log(tStart.toString()); // "2026-03-01" (安全)この「不変性」により、関数に日付オブジェクトを渡しても、その関数内で勝手に日付が書き換えられる心配がなくなる。これは、大規模なプラグイン開発や複数のエンジニアが関わるプロジェクトにおいて、デバッグ時間を大幅に短縮する要因となる。
タイムゾーン操作とパフォーマンスへの影響

WordPressサイトの多くは、サーバーのタイムゾーンとユーザーのタイムゾーンが異なる環境で運用されている。Temporal APIは、標準で強力なタイムゾーンサポートを備えている。
外部ライブラリ不要のタイムゾーン変換
Moment.jsでタイムゾーンを扱うには、膨大なデータベースを含む`moment-timezone`が必要だった。これがバンドルサイズを1MB近く押し上げることも珍しくない。
// Temporalでのタイムゾーン変換
const instant = Temporal.Now.instant();
const tokyoTime = instant.toZonedDateTimeISO('Asia/Tokyo');
const londonTime = instant.toZonedDateTimeISO('Europe/London');Temporalでは、ブラウザが内部に持っているタイムゾーンデータベースを利用するため、追加のデータ読み込みが一切不要だ。これにより、サイトのJavaScript合計サイズが削減され、モバイルユーザーのUX(ユーザー体験)向上に直結する。
独自の分析:WordPress開発におけるTemporalへの期待

WordPress開発の文脈において、Temporal APIの導入は「管理画面の高速化」と「ブロックエディタの堅牢性向上」に寄与する。特にGutenberg(ブロックエディタ)では、複雑な日時計算を伴うカスタムブロックが増えている。
これまで、イベント予約システムやカレンダー連携機能を実装する際、Moment.jsの重さがネックになることがあった。Temporalへの移行により、スクリプトの実行ブロック時間が短縮され、エディタの入力レスポンスが改善される。また、Polyfill(ポリフィル)を利用することで、Safariなどの未対応ブラウザをサポートしつつ、将来的なネイティブ移行への準備を整えることが可能だ。
「Polyfill」とは、新しい機能をサポートしていない古いブラウザでも、その機能を使えるようにするための補完コードのことだ。現時点では、`@js-temporal/polyfill`を導入することで、最新の構文を安全に使用できる。
この記事のポイント
- Moment.jsはレガシー化: メンテナンスモードであり、新規プロジェクトでの使用は推奨されない。
- 不変性の確保: Temporal APIは計算によって元のデータを書き換えないため、バグが激減する。
- パフォーマンス向上: ブラウザ標準機能のため、ライブラリの読み込みが不要になり軽量化される。
- 1ベースの月指定: 1月を「1」と数える直感的な仕様に変更された。
- 強力なタイムゾーン支援: 外部データなしで正確な地域時刻の変換が可能。
出典
- Smashing Magazine WordPress「Moving From Moment.js To The JS Temporal API」(2026年3月13日)
- MDN Web Docs「Temporal」(2026年3月1日参照)
- Moment.js Documentation「Project Status」(2020年9月)
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

WordPressが重い4つの根本原因と解決策——高速化のための診断・改善ロードマップ
WordPressサイトの表示速度が低下する原因は、大きく分けて4つのカテゴリーに集約される。これらを知らずに場当たり的なプラグイン導入を繰り返しても、根本的な解決には至らない。
Googleは2021年より、CWV(Core Web Vitals / コアウェブバイタル)を検索ランキングの評価指標として正式に採用した。表示速度の改善は、SEO(検索エンジン最適化)とコンバージョン率の双方に直結する極めて重要な課題だ。
本記事では、低速化を招く4つの核心的な要因を特定し、専門的な知見から優先度の高い診断ステップを解説する。
表示速度がビジネスに与える影響とCWVの重要性

サイトの読み込み速度は、単なるユーザー体験の向上にとどまらず、売上に直結する数値だ。読み込みに1秒の遅延が生じるだけで、コンバージョン率が大幅に低下するというデータも存在する。
CWV(コアウェブバイタル)の主要指標
Googleが測定するCWVには、主に3つの重要な指標がある。1つ目はLCP(Largest Contentful Paint)で、ページ内で最も大きなコンテンツ(メイン画像や見出し)が表示されるまでの時間を指す。これが2.5秒以内であることが推奨される。
2つ目はCLS(Cumulative Layout Shift)だ。これは読み込み中にページレイアウトがどれだけ予期せず動いたかを示す。広告や画像の読み込みでテキストが押し下げられる現象などが該当し、0.1以下が理想的だ。
3つ目はINP(Interaction to Next Paint)で、ユーザーの操作(クリックやタップ)に対して、ブラウザが次のフレームを描画するまでの応答性を測定する。これらはすべて、ユーザーが「ストレスなく閲覧できるか」を数値化したものだ。
PageSpeed Insightsのスコアの捉え方
PageSpeed Insightsで算出される0から100のスコアは、あくまで総合的な目安に過ぎない。重要なのはスコアそのものよりも、その下にある個別のメトリクス(数値)だ。
特にモバイル環境でのスコアは、デスクトップと比較して厳しく算出される傾向がある。Googleはモバイルファーストインデックス(モバイル版サイトを基準に評価する仕組み)を採用しているため、モバイルでの数値を優先して改善すべきだ。ただし、スコア100を目指すこと自体が目的化しないよう注意が必要である。現実的な通信環境(4G回線など)で、ユーザーが快適に操作できるかどうかが本質的なゴールとなる。
WordPressを低速化させる4つの根本原因

多くのサイトを分析した結果、低速化の原因は「ホスティング」「画像」「コードの肥大化」「キャッシュ不足」のいずれか、あるいは複数に集約されることが判明している。
1. ホスティング環境の限界
ホスティング、つまりサーバーの性能はすべての土台となる。どれだけサイト側で軽量化を図っても、サーバーの応答速度が遅ければ限界がある。特にTTFB(Time to First Byte)が600ms(0.6秒)を超えている場合、サーバー環境の見直しが不可欠だ。
TTFBとは、ブラウザがリクエストを送ってから、サーバーから最初の1バイトが届くまでの時間を指す。安価な共用サーバーでは、他のユーザーの利用負荷に影響を受けやすく、この数値が不安定になりがちだ。ビジネス用途であれば、リソースが保証された国内の高速レンタルサーバーや、KinstaのようなWordPress専用マネージドホスティングを選択するのが賢明だ。
2. 画像の最適化不足
画像ファイルは、Webページの中で最もデータ容量を占める要素だ。未加工のJPEGやPNG画像を使用していると、1枚で数MBに達することもあり、これがLCPの数値を悪化させる最大の要因となる。
解決策は、次世代画像フォーマットであるWebP(ウェッピー)への変換と、適切な圧縮だ。WebPは従来のJPEGよりも高い圧縮率を保ちながら画質を維持できる。また、ファーストビュー(画面を開いて最初に見える範囲)以外の画像を遅延読み込みさせる「Lazy Load」の導入も効果的だ。ただし、LCPの対象となるメイン画像にLazy Loadを適用すると、逆に表示が遅れるため注意が必要である。
3. コードとプラグインの肥大化
WordPressの利便性はプラグインにあるが、これが「技術的負債」となるケースも多い。各プラグインは独自のCSSやJavaScriptを読み込むため、プラグインが増えるほどブラウザが処理すべきコード量が増大する。
特に、ページビルダー(Elementor等)や多機能テーマは、使用していない機能のコードまで読み込む傾向がある。不要なプラグインの削除はもちろん、特定のページでしか使わないプラグインのスクリプトを、他のページでは読み込まないように制御する「アセット管理」が有効な対策となる。
4. キャッシュ戦略の不在
WordPressは、アクセスがあるたびにPHPを実行し、データベースから情報を取得してページを生成する「動的」なシステムだ。このプロセスはサーバーに負荷をかけ、表示時間を長くする。
キャッシュとは、一度生成したページのデータを一時保存しておき、次の訪問者にそれを再利用する仕組みだ。これにより、PHPやデータベースの処理をスキップできるため、表示速度は劇的に向上する。ページキャッシュだけでなく、ブラウザキャッシュ(訪問者のデバイスにデータを保存する)を適切に設定することが、リピーターの体験向上につながる。
専門家が実践する高速化診断の優先順位

高速化に取り組む際、最も効率的なのは「ボトルネック(全体の速度を制限している箇所)」から順に解消することだ。やみくもにプラグインを導入する前に、以下の手順で診断を行うべきだ。
ステップ1:TTFBの測定とサーバー評価
まず最初に行うべきは、サーバーの応答速度の確認だ。PageSpeed Insightsの「診断」セクションにある「最初のサーバー応答時間を短縮してください」という項目をチェックする。
ここがフラグ(警告)として表示されている場合、画像やコードをいくら最適化しても大幅な改善は見込めない。土台であるサーバーを、より高性能なプランや、最新のPHPバージョンに対応した環境へ移設することを検討すべきだ。サーバーの引っ越しは手間がかかるが、最も劇的な効果を生む投資となる。
ステップ2:LCP要素の特定と画像調整
次に、ページ内で最も表示が遅れている大きな要素(LCP要素)を特定する。多くの場合、それはトップページのヒーロー画像や記事のアイキャッチ画像だ。
この画像に対して、適切なサイズへのリサイズ、WebP化、そして「先行読み込み(Preload)」の設定を行う。Preloadとは、ブラウザに対して「この重要な画像を優先的にダウンロードせよ」と命令を出す技術だ。これにより、他の不要なファイルの読み込みを待たずにメインコンテンツを表示させることが可能になる。
ステップ3:レンダリングをブロックするリソースの排除
HTMLの解析を中断させてしまうJavaScriptやCSSは「レンダリングブロックリソース」と呼ばれる。これらが原因で、画面が真っ白な時間が長くなる。これには、不要なスクリプトの遅延読み込み(defer)や非同期読み込み(async)の適用が有効だ。また、クリティカルCSS(ファーストビューに必要な最小限のスタイル)をインライン化することで、視覚的な表示を早める手法もプロの現場では一般的だ。
独自分析:便利さと引き換えに蓄積される「コードの贅肉」

近年のWordPressサイトにおいて、最大の課題は「多機能すぎるテーマとプラグイン」によるコードの肥大化だ。ノーコードでサイトが構築できるページビルダーは非常に便利だが、その裏側では膨大なDOM(Document Object Model / HTMLの階層構造)が生成されている。
DOMの階層が深くなればなるほど、ブラウザは要素の配置を計算するのに多くのリソースを消費する。これがINPやCLSの悪化を招く一因となる。Web制作の現場では、あえて多機能なプラグインを避け、必要な機能だけを自前で実装する「軽量化」への回帰が起きている。利便性とパフォーマンスのバランスをどこで取るかが、今後のサイト運営の鍵となるだろう。
また、広告配信やSNSの埋め込みといった「サードパーティスクリプト」の影響も無視できない。これらは自社サーバーの制御外にあるため、読み込みを遅延させる、あるいは必要最小限に絞るといった戦略的な判断が求められる。表示速度を追求することは、サイトの機能を「引き算」で考えるプロセスでもあるのだ。
この記事のポイント
- 表示速度はSEO(CWV)とコンバージョン率に直結するビジネス指標である。
- 低速化の4大原因は「サーバー性能」「画像最適化」「コード肥大化」「キャッシュ不足」に集約される。
- 改善の第一歩はTTFB(サーバー応答時間)の確認であり、土台が悪い場合はサーバー移設が最優先となる。
- LCP改善にはWebPの活用と、メイン画像の先行読み込み(Preload)が効果的だ。
- 利便性の高いプラグインやページビルダーはコードを肥大化させるため、定期的なアセット監査が必要である。
出典
- WP Mayor「Why Your WordPress Site Is Slow (and What’s Actually Causing It)」(2026年3月11日)
- Google Search Central「Core Web Vitals の紹介」(2021年)
- web.dev「Optimize Largest Contentful Paint」(2023年)
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AI利用者は急増も「信頼」には大きな壁——ECサイトが取り組むべき次世代の顧客体験
消費者のAI利用が急速に浸透する一方で、その回答や推薦に対する信頼度は依然として低い水準に留まっている。最新のグローバル調査では、週に1回以上AIツールを利用する層が60%に達したことが明らかになった。しかし、AIを完全に信頼していると回答した割合はわずか13%に過ぎない。
この調査は、マーケティング自動化プラットフォームを提供するKlaviyoが、世界約8,000人の消費者を対象に実施したものだ。AIが商品の発見や購買意思決定に影響を与え始めている事実は無視できない。しかし、利用率と信頼性の乖離は、マーケターにとって新たな課題を突きつけている。
本記事では、AIが変えつつある購買プロセスと、消費者が抱く不信感の正体を分析する。その上で、EC事業者が今後どのような姿勢でAIを導入し、顧客との信頼関係を構築すべきかを考察する。
AI利用と信頼の「ギャップ」が浮き彫りに
AI技術の普及速度は、過去のどのテクノロジーよりも速い。生成AI(Generative AI)の登場以降、日常的にAIと接する機会は劇的に増加した。しかし、技術の普及が必ずしも心理的な受容を意味するわけではない。
週1回以上の利用者が6割に達する現状
調査データによると、消費者の60%が少なくとも週に1回はAIツールを利用している。AIツールとは、ChatGPTのような対話型AIや、検索エンジンに統合されたAI回答生成機能、さらにはECサイトのレコメンドエンジンなどを指す。
利用目的は多岐にわたるが、特に「情報の整理」や「アイデアの創出」においてAIは不可欠な道具になりつつある。多くのユーザーは、複雑な選択肢を絞り込むための補助手段としてAIを活用している。
完全な信頼を寄せているのはわずか13%
利用率の高さとは対照的に、AIに対する信頼は極めて限定的だ。「AIを完全に信頼している」と答えたのは全体の13%にとどまる。多くの消費者は、AIが提供する情報を「参考」にはするが、最終的な判断を下すための「権威」とは見なしていない。
この現象は、AIが誤った情報を生成する「ハルシネーション(Hallucination / もっともらしい嘘)」への警戒心から生じている。ハルシネーションとは、AIが学習データに基づき、事実とは異なる情報を自信満々に回答してしまう現象を指す。消費者は、利便性を享受しながらも、常に情報の真偽を疑う姿勢を維持している。
AIが変える購買プロセスと商品発見の仕組み
信頼の欠如に関わらず、AIはすでに実際の購買行動に影響を及ぼしている。消費者はAIを「信頼できるアドバイザー」ではなく、「効率的な検索フィルター」として活用し始めている。
商品発見の「第一接点」としてのAI
調査では、20%以上の消費者が、新しいことを学びたいときや問題を解決したいとき、あるいは商品の評価を行いたいときに、まずAIツールから入ると回答した。これは、従来の「ググる(Google検索)」という行動が、AIとの対話に置き換わりつつあることを示唆している。
カスタマージャーニー(顧客が商品を知り、購入に至るまでのプロセス)において、AIは最上流の「認知・興味」のフェーズに食い込んでいる。ブランド側から見れば、AIによる回答の中に自社製品が含まれるかどうかが、今後の売上を左右する重要な要因となる。
AI推薦による購買行動の実態
過去6ヶ月間に、AIが推薦した商品を購入したことがある消費者は41%に上る。さらに、27%の消費者は「AIによって初めてその商品を知り、その後自分で詳細を調べてから購入した」と回答している。
ここで重要なのは、AIの推薦をそのまま鵜呑みにして即決するのではなく、多くのユーザーが「再確認」のプロセスを挟んでいる点だ。AIはあくまで「選択肢の提示」を行い、最終的な信頼の裏付けは公式サイトやレビューなどの従来型ソースに依存している。
4つのAIペルソナから見るユーザー心理の多様化

Klaviyoの調査では、AIの利用頻度と信頼度の度合いに基づき、消費者を4つの「ペルソナ」に分類している。ペルソナとは、ターゲットとなる顧客像を具体化したモデルのことだ。
積極利用層と慎重層の境界線
1つ目のグループは「AI Enthusiasts(AI熱狂層)」だ。全体の約26%を占め、高い利用頻度と比較的高い信頼度を併せ持つ。この層の89%は過去半年間にショッピングでAIを活用しており、AIの推薦によって未知の商品を購入することにも抵抗が少ない。
2つ目は「AI Evaluators(AI評価層)」である。彼らはAIを頻繁に利用するが、その回答には慎重だ。AIをリサーチや比較には使うが、行動に移す前に必ず情報の検証を行う。熱狂層と評価層を合わせると、全消費者の約70%に達する。
AIを拒絶する層へのアプローチ
3つ目の「AI Skeptics(AI懐疑層)」は、AIの存在を理解し時折利用するものの、マーケティングへの活用には強い警戒心を抱いている。そして4つ目の「AI Holdouts(AI停滞層)」は、全体の約21%を占め、ショッピングでのAI利用をほとんど行わず、人間による対面や直接のガイドを好む。
EC事業者は、自社の顧客がどのペルソナに属しているかを把握する必要がある。すべてをAI化することは、懐疑層や停滞層の離反を招くリスクがあるためだ。
ヘビーユーザーほど「低品質なAIコンテンツ」を嫌う
今回の調査で得られた興味深い知見の一つは、AIを最も使いこなしている層ほど、ブランドが提供するAIコンテンツの質に厳しいという事実だ。
汎用的な自動生成コンテンツの限界
AI熱狂層の40%は、ブランドが発信する「低品質で汎用的なAI生成コンテンツ」を週に何度も目にしていると回答した。AIの利用経験が豊富なユーザーは、AI特有の言い回しや、具体性に欠ける説明を瞬時に見抜く能力を備えている。
AIを使って大量のメールマガジンや商品説明文を生成することは容易だが、それが「どこかで見たような内容」であれば、かえってブランドイメージを損なう。消費者はAIの便利さを求めているのであって、手抜きを求めているわけではない。
AIリテラシーの向上がブランドに求める質
消費者のAIリテラシー(AIを正しく理解し使いこなす能力)が高まるにつれ、ブランド側には「AIをどう隠すか」ではなく「AIをどう使いこなして価値を高めるか」が問われるようになる。
例えば、単なる自動応答チャットボットではなく、顧客の過去の購買履歴や好みを深く理解した上での「パーソナライズされた提案」ができるかどうかが鍵となる。AIの出力に人間の編集(Human-in-the-loop)を加え、ブランド独自のトーン&マナーを維持することが不可欠だ。
検索行動の進化:キーワードから「対話」へ
AIの普及は、ユーザーが情報を探す際の「言葉遣い」にも変化をもたらしている。従来のキーワード検索から、文脈を含んだ対話形式への移行が進んでいる。
プロンプトの長文化と文脈の重要性
調査によると、消費者の30%がAIへの入力(プロンプト)に8単語以上を使用している。従来の検索エンジンでは「キャンプ テント おすすめ」といった短いキーワードが主流だったが、AIに対しては「家族4人で夏に北海道で使う、設営が簡単なテントを教えて」といった、具体的で長い指示を出すようになっている。
プロンプトとは、AIに対する命令や指示文のことだ。ユーザーがより詳細なコンテキスト(背景情報)をAIに与えるようになったことは、ECサイト側もより詳細な商品データ(構造化データ)を用意しなければならないことを意味する。
感情的なコンテキストを含む検索
さらに、78%の消費者は、AIとのやり取りにおいて感情的または個人的な背景を含めることがあると答えた。「大切な友人の結婚祝いなので、失礼のない上質なものを選びたい」といった、従来の検索エンジンでは汲み取りにくかったニュアンスをAIにぶつけているのだ。
このような「意図の深掘り」に対応できるAI体験を提供できるかどうかが、今後のECサイトの競争力を左右する。キーワードの一致だけでなく、ユーザーの「悩み」や「願い」に寄り添う回答が求められている。
EC事業者が信頼を獲得するための3つの戦略

AI利用と信頼のギャップを埋めるためには、技術の導入そのものよりも、その運用方法に工夫が必要だ。筆者は、以下の3つの戦略が重要になると考えている。
1. 情報源の透明性と裏付けの提示
AIが推薦を行う際、なぜその商品を選んだのかという「根拠」を明示することだ。「あなたの過去の購入傾向に基づき、かつ他の100人のユーザーが高評価を付けているため」といった具体的な理由が、信頼の架け橋となる。
また、AIの回答から直接、人間が書いた詳細なレビューや仕様表へアクセスできる導線を確保することも重要だ。AIを入り口としつつ、信頼の拠り所は「事実」に置く設計が求められる。
2. パーソナライズとプライバシーのバランス
消費者は自分に最適化された体験を望んでいるが、同時にデータの取り扱いには敏感だ。AI活用のためにどのようなデータを使用し、それがどう顧客の利益につながるのかを明確に説明する姿勢が必要だ。
WooCommerceなどのプラットフォームを利用している場合、顧客データを外部のAIモデルに送信する際のセキュリティ対策を徹底し、それをプライバシーポリシーとして明文化しておくことが、長期的な信頼につながる。
3. 「人間らしさ」を補完するAI活用
AIにすべての接客を任せるのではなく、AIを「人間のスタッフを支援するツール」として位置づける。例えば、AIが顧客の意図をあらかじめ要約し、最終的な回答は人間のスタッフが確認して送信するハイブリッド型のカスタマーサポートなどが有効だ。
AIの効率性と人間の共感性を組み合わせることで、懐疑的なユーザー層も安心して利用できる環境が整う。
この記事のポイント
- 消費者の60%がAIを日常利用しているが、完全に信頼しているのはわずか13%である。
- AIは商品発見の「第一接点」として定着しつつあり、41%がAI推薦による購入を経験している。
- 利用頻度が高いユーザーほど、ブランドによる低品質なAI生成コンテンツに対して批判的である。
- 検索行動はキーワード型から、長文で感情的なコンテキストを含む対話型へと進化している。
- EC事業者はAIの根拠を明示し、人間によるチェックを介在させることで「信頼のギャップ」を埋めるべきだ。
出典
- MarTech「Most consumers use AI, but few fully trust it」(2026年3月13日)
- Klaviyo「Klaviyo AI Persona Research」(2026年3月公開)
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

my.WordPress.net登場——サーバー不要でブラウザが自分専用のWordPressになる
WordPress.orgは、ブラウザ上でWordPressを永続的に実行できる新サービス「my.WordPress.net」を公開した。
WordPress Playground技術を基盤とし、サーバーの契約やドメインの取得といった従来の手順を一切省いた環境を提供する。
これはWebサイト公開のためのツールから、個人の主権を守るワークスペースへの転換を意味しているとの見方が強い。
my.WordPress.netの概要と技術的背景

my.WordPress.netは、WebブラウザそのものをWordPressのサーバーとして機能させるプロジェクトだ。
ユーザーがサイトにアクセスした瞬間、ブラウザ内に独立したWordPress環境が構築される。従来のホスティングサービスとは異なり、サインアップや月額費用の支払いは発生しない。この即時性は、これまでの「5分間インストール」という象徴的な概念を塗り替えるものだ。
WordPress Playgroundによる仮想化技術
この仕組みの核となるのが「WordPress Playground(ワードプレス・プレイグラウンド)」という技術である。
通常、WordPressを動かすにはPHPというプログラミング言語を実行するサーバーと、データを保存するMySQLというデータベースが必要になる。Playgroundでは、これらをWebAssembly(Wasm)という技術を用いてブラウザ上で直接実行できるようにした。
WebAssemblyとは、ブラウザ上で高速なプログラムを動かすためのバイナリ形式のデータだ。これにより、パソコンやスマートフォンのブラウザさえあれば、外部サーバーに頼らずにフル機能のWordPressを稼働させることが可能になった。
「デジタル主権」の民主化
WordPressの共同創設者らは、このプロジェクトが「デジタル主権の民主化」を推し進めると指摘している。
デジタル主権とは、自分のデータや使用するソフトウェアを自分自身でコントロールできる権利を指す。my.WordPress.netでは、データはユーザーのブラウザ内にのみ保存される。特定の企業が運営するクラウドサービスに依存せず、自分だけの閉じた環境で情報を管理できる点が、既存のブログサービスとの決定的な違いだ。
「プライベートな空間」としてのWordPress

my.WordPress.netで作成されたサイトは、デフォルトで外部のインターネットからはアクセスできない非公開設定となっている。
これは、WordPressを「他人に情報を発信する場所」ではなく、「自分のための作業場」として定義し直す試みだ。アクセス数やSEO(検索エンジン最適化)を意識する必要がないため、より自由な試行錯誤が可能になる。
思考の整理とプロトタイピング
公開を前提としないため、my.WordPress.netはメモ帳や研究用のスクラップブックとして機能する。アイデアをドラフトとして書き溜めたり、複雑な情報を整理したりする用途に適している。また、新しいプラグインやテーマの挙動を確認するためのテスト環境としても最適だ。
プロトタイピング(試作)の場として活用すれば、本番のWebサイトに影響を与えることなく、新しいデザインや機能を試すことができる。失敗してもブラウザのデータをリセットするだけで済むため、学習コストや心理的ハードルが大幅に下がる効果が期待される。
学習ツールとしての役割
初心者にとって、サーバーのセットアップはWordPress学習における最大の障壁の一つだった。my.WordPress.netを使えば、その工程をスキップして即座にブロックエディタやサイトエディタの操作を学べる。
専門用語や複雑な設定に悩まされることなく、実際に手を動かしながら機能を体験できる。この「習うより慣れろ」を体現した環境は、Web制作の教育現場においても大きな変革をもたらすと予測されている。
App Catalogによる実務的な活用シーン

my.WordPress.netには、特定の用途に合わせて事前設定された「App Catalog(アプリカタログ)」が用意されている。
これらはWordPressのプラグインを組み合わせたパッケージであり、ワンクリックで特定の機能を持ったワークスペースを構築できる。単なるブログシステムを超えた、実務的なツールとしての側面を強調している。
個人用CRM(顧客関係管理)
CRM(Customer Relationship Management)とは、顧客や知人との連絡履歴や属性を管理するためのシステムだ。
my.WordPress.netでは、自分専用の連絡先管理ツールとしてWordPressを利用できる。チャットデータのインポート機能や、再連絡のリマインダー機能を備えた環境が提供される。すべてのデータがローカルに保存されるため、機密性の高い個人情報を外部サーバーに預けるリスクを回避できるのが利点だ。
アルゴリズムに依存しないRSSリーダー
「Friends」プラグインを活用することで、WordPressを自分だけのRSSリーダーとして機能させることができる。
RSSリーダーとは、お気に入りのWebサイトの更新情報を一括で受け取るためのツールだ。SNSのようなアルゴリズムによる情報の取捨選択が行われないため、自分のペースで必要な情報だけを追跡できる。広告や不要な通知に邪魔されない、静かな読書環境が手に入る。
AI連携とナレッジベースの構築
AIアシスタントを統合したワークスペースも提供されている。AIがWordPress内のデータを理解し、プラグインのカスタマイズや新しいブロックの作成をサポートする。
蓄積された情報を基にAIと対話することで、WordPressを自分だけのナレッジベース(知識ベース)へと進化させることが可能だ。AIによるコード生成やコンテンツの要約機能を、安全なローカル環境で活用できるメリットは大きい。
導入前に知っておくべき技術的制約と運用ルール

my.WordPress.netは画期的なツールだが、ブラウザ上で動作するという性質上、いくつかの重要な制約が存在する。
これらは従来のサーバー型WordPressとの大きな違いであり、運用にあたっては正しく理解しておく必要がある。特にデータの永続性とリソースの制限については注意が必要だ。
ストレージ容量と初回起動の負荷
初期状態でのストレージ容量は約100MBに制限されている。大量の高解像度画像や動画をアップロードする用途には向いていない。あくまでテキストベースのメモや、小規模なツールの構築を想定した設計となっている。
また、初回の起動時にはWordPress本体や必要なプログラムをダウンロードするため、表示までに数十秒程度の時間を要する場合がある。一度読み込まれればブラウザにキャッシュされるが、ネットワーク環境によっては待ち時間が発生することを考慮すべきだ。
データの保存場所とバックアップの重要性
データはすべてブラウザの「IndexedDB」という領域に保存される。サーバーに送信されないためプライバシーは守られるが、ブラウザのキャッシュを削除したり、デバイスを紛失したりするとデータは消失する。
そのため、重要な作業を行った後は定期的にバックアップファイルをダウンロードする必要がある。デバイス間での同期機能も現時点では提供されていないため、別のパソコンで同じ環境を使いたい場合は、エクスポートとインポートの作業が必須となる。
ブラウザの互換性とパフォーマンス
WebAssemblyを利用するため、最新のWebブラウザ(Chrome, Firefox, Safari, Edgeなど)を使用することが前提となる。古いブラウザや、極端にスペックの低いデバイスでは動作が不安定になる可能性がある。
ブラウザのメモリを消費して動作するため、多数のタブを開いた状態で重いプラグインを動かすと、動作が重くなることがある。快適な利用には、ある程度のシステムリソースが必要とされる点は留意しておきたい。
ウェブ制作現場における活用の可能性

Web制作会社やエンジニアにとって、my.WordPress.netは業務効率化の強力な武器になり得る。
これまでローカル開発環境の構築には、専用のソフトウェアのインストールや設定が必要だった。my.WordPress.netは、これらの手間を一切排除し、URLを共有するだけで共通の検証環境を立ち上げられる可能性を秘めている。
クライアントへのデモンストレーション
新しい機能やデザインの提案時に、一時的なプレビュー環境として活用できる。サーバーを契約する前の段階で、実際の管理画面を見せながら操作説明を行うことが可能だ。クライアントは自分のブラウザ上で実際にブロックを動かす体験ができ、導入後のイメージを具体化しやすくなる。
プラグイン・テーマの安全な検証
本番環境に影響を与えずに、特定のプラグインが自分のサイト構成で正しく動作するかをテストできる。特に、メジャーアップデート前の挙動確認において、手軽なサンドボックス(隔離された実験場)として機能する。エンジニアは、環境構築の時間を節約し、本来の検証作業に集中できるだろう。
この記事のポイント
- my.WordPress.netは、サーバー不要でブラウザ上で完結する新しいWordPress環境である
- WordPress Playground技術(Wasm)により、高速かつプライベートな動作を実現している
- 個人用CRMやRSSリーダーなど、公開を前提としない「ワークスペース」としての活用が期待される
- データはブラウザ内に保存されるため、定期的な手動バックアップが不可欠である
- Web制作の現場では、手軽なデモ環境やプラグイン検証用のサンドボックスとして有用である
出典
- WordPress.org News「Your Browser Becomes Your WordPress」(2026年3月11日)
- WordPress Playground「Documentation」(2026年3月時点)
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AI時代の検索対策「GEO」とは?引用されるコンテンツの共通点とECサイトの活用法
検索エンジンのあり方が、従来のリスト形式から生成AIによる回答形式へと急速に変化している。Googleの「AIによる概要(旧SGE)」やPerplexity、ChatGPTのサーチ機能など、ユーザーが直接回答を得る機会が増えた。
こうした「生成AIエンジン」に自社の情報を引用させ、トラフィックを獲得する手法はGEO(Generative Engine Optimization)と呼ばれる。最新の研究により、AIがどのような基準でウェブサイトの情報を引用しているのか、その具体的な手がかりが明らかになった。
本記事では、2つの大規模な調査データを基に、AIに選ばれるコンテンツの構造を分析する。特に情報量が多くなりがちなECサイトや技術ブログにおいて、明日から取り入れられる最適化の指針を提示する。
AIによる引用のメカニズムと最新の研究結果

生成AIが回答を生成する際、どのウェブサイトを情報源として参照し、リンク(引用)を掲示するかには一定のパターンが存在する。これまでブラックボックスとされていたこの仕組みについて、2つの重要な研究が発表された。
ChatGPTとGeminiの引用傾向の違い
オーガニック検索コンサルタントのケビン・インディグ氏は、ChatGPTによる120万件の回答と1万8,012件の引用を分析した。一方で、Bright Dataのダニエル・シャシュコ氏は、GrokやGeminiを含む6つのプラットフォームを対象に4万2,971件の引用を調査している。
調査の結果、プラットフォームによって引用の積極性に大きな差があることが分かった。例えば、X(旧Twitter)傘下のGrokは1クエリあたり平均33件もの引用を行うのに対し、ChatGPTはわずか1.5件にとどまる。AIモデルによって、情報の裏付けをどの程度詳細に示すかのアルゴリズムが異なる実態が浮き彫りになった。
引用元として選ばれる「場所」の重要性
両氏の研究で共通して導き出された結論は、情報の「掲載位置」が引用の成否を分けるという点だ。AIはページ全体を均等に評価するのではなく、特定のエリアを重点的にスキャンしている。
ケビン氏の調査では、ChatGPTの引用の44.3%がページ内のテキストの最初の30%から抽出されていた。ダニエル氏の調査でも、GeminiやGoogleのAIモードにおける引用の74.8%がページの半分より上部に集中し、そのうち46.1%が最初の30%に含まれていた。
この結果は、結論を後回しにする伝統的な起承転結の文章構造が、AI時代には不利に働く可能性を示唆している。ユーザーだけでなくAIにとっても、ページを開いてすぐに核心に触れられる構成が望ましい。
「アトミック・ファクト」が握る引用の鍵

AIに引用されやすい文章には、構造的な特徴がある。ダニエル・シャシュコ氏が提唱した「アトミック・ファクト(Atomic Fact)」という概念は、今後のコンテンツ制作において極めて重要な指標となる。
短文で完結する情報の有用性
アトミック・ファクトとは、それ単体で意味が通じ、一つの事実を完結に述べている一文を指す。たとえるなら「一口サイズの栄養補助食品」のようなものだ。前後の文脈に過度に依存せず、独立して情報を伝達できる文章が、AIには好まれる。
調査によると、Geminiなどのプラットフォームで引用された文章の92.4%が、6語から20語(英語基準)の短文であった。日本語に換算すると、概ね40文字から80文字程度の簡潔な一文に相当する。
理想的な文章構造とノイズの排除
AIは文章の途中で引用を開始したり終了したりすることはない。常に「句点から句点まで」の完全な一文を引用単位とする。そのため、一文の中に複数のトピックを詰め込んだ長文や、情緒的で実質的な情報を含まない導入文は、引用の対象から外れやすい。
ECサイトの商品説明であれば、「この商品は〜という特徴があり、さらに〜というメリットも期待でき、多くのユーザーに支持されています」と繋げるのではなく、「この商品は〜という特徴を持つ。〜というメリットがある」と事実を切り分けて記述する方が、AIによる認識精度は高まる。
ECサイトが取り組むべき具体的なGEO対策
WooCommerceなどのプラットフォームを利用しているEC事業者にとって、商品ページやブログ記事をGEOに最適化することは、将来的な集客チャネルの確保に直結する。研究結果を実務に落とし込むための3つのステップを提案する。
商品説明文の構成を「逆ピラミッド型」にする
前述の通り、ページの上部30%が引用の主戦場となる。ECサイトの商品ページであれば、スペック表や主要なメリットの要約を、ページ下部ではなくファーストビューに近い位置に配置すべきだ。
具体的には、商品のキャッチコピーの直後に「この記事のポイント」や「商品の3つの特徴」といった要約セクションを設ける。これにより、AIがページをクロールした際に、最も重要な情報を即座にキャッチできるようになる。
ユーザーの疑問に「一文」で答えるFAQの設置
AIサーチを利用するユーザーは、具体的な疑問(例:「このサイズは10畳の部屋に合うか?」)を持って検索する。これに応えるためには、商品ページ内に「アトミック・ファクト」に基づいたFAQ(よくある質問)を設置するのが効果的だ。
「はい、この製品は10畳の広さに対応した設計となっている」といった簡潔な回答文を用意することで、AIの回答内にそのまま引用される確率を高めることができる。冗長な解説はFAQの折りたたみメニュー内や詳細セクションに逃がし、表面上は簡潔さを維持するのがコツだ。
検索エンジン最適化(SEO)と生成AI最適化(GEO)の共存
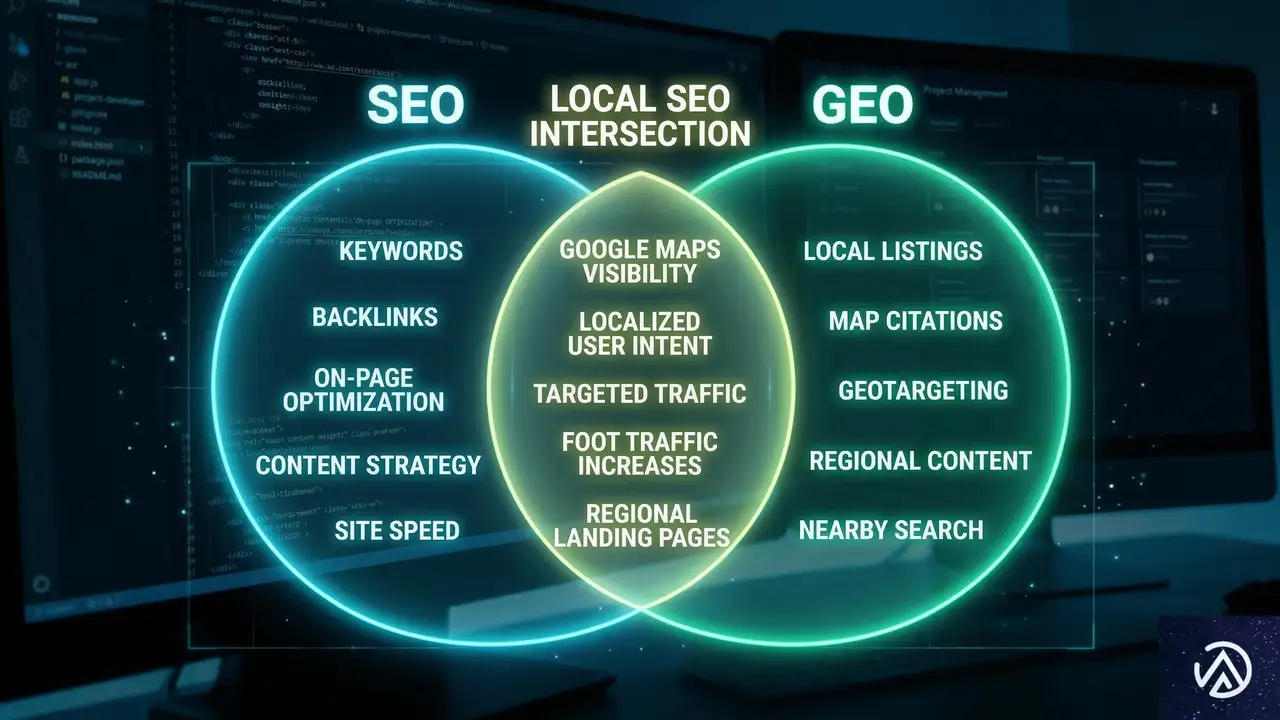
GEOは従来のSEOを否定するものではない。むしろ、SEOの基本である「ユーザーの意図に応える」という姿勢を、より構造的に、より簡潔に突き詰めた形と言える。
従来のSEOとの共通点と相違点
高品質なコンテンツ、専門性、権威性(E-E-A-T)が重視される点はSEOもGEOも共通だ。しかし、SEOが「キーワードの網羅性」や「滞在時間」を重視する傾向があるのに対し、GEOは「情報の抽出のしやすさ」に重きを置く。
例えば、1万文字の網羅的な記事はSEOでは高く評価されるが、AIがその中から特定の事実を見つけ出すのはコストがかかる。GEOの観点では、長い記事であってもセクションごとに明確な要約があり、アトミック・ファクトが散りばめられている構造が理想的だ。
ブランド認知を高めるための学習データ対策
引用(リンク付きの参照)だけでなく、AIが回答の中で自社ブランドに言及してくれる状態(Visibility)を目指す必要もある。これには、特定のページを最適化するだけでなく、ウェブ上のあらゆる場所でブランド名と特定のキーワードが結びついている状態を作らなければならない。
プレスリリース、SNSでの言及、他社メディアでのレビューなど、AIの学習データに含まれるソース全体で一貫したブランドポジションを確立することが、長期的にはGEOの成果を最大化させる。
この記事のポイント
- AIはページの冒頭30%にある情報を優先的に引用する傾向がある
- 一文で事実が完結する「アトミック・ファクト」を意識したライティングが有効
- 6語〜20語程度の簡潔な文章が、GeminiなどのAIに最も好まれる
- ECサイトでは商品説明の要約やFAQを上部に配置し、AIが情報を抽出しやすくする
- GEOはSEOを補完するものであり、情報の「見つけやすさ」を追求する手法である
出典
- Practical Ecommerce「Studies Reveal AI Citation Clues」(2026年3月9日)
- Growth Memo「The science of how AI pays attention」(2026年3月)
- Bright Data「Platform-by-Platform Optimisation Playbook」(2026年3月)
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験