

WooCommerceモノレポのビルドが大幅高速化、コールドビルド60%減。メモリ使用量84%削減
WooCommerceのモノレポ(単一リポジトリ)を使った開発において、ビルドにかかる時間とメモリ消費が大幅に改善された。2026年6月5日、Developer WooCommerce Blogで公開された記事によると、コールドビルド時間が60%削減、ウォッチ(ファイル監視)の準備完了時間が75%短縮、開発時ウォッチプロセスのメモリ使用量が84%削減されたという。
計測環境はM4 Maxプロセッサ(48GB RAM、macOS 26)で、ベースラインから顕著な低下を確認している。一連のプルリクエストによってビルドプロセスを再設計し、開発者体験を飛躍的に向上させた内容を解説しよう。
本記事では、実際に実施されたビルド最適化の技術的詳細と、今後のCIスループット向上計画を紹介する。
WooCommerceモノレポのビルドが抱えていた課題
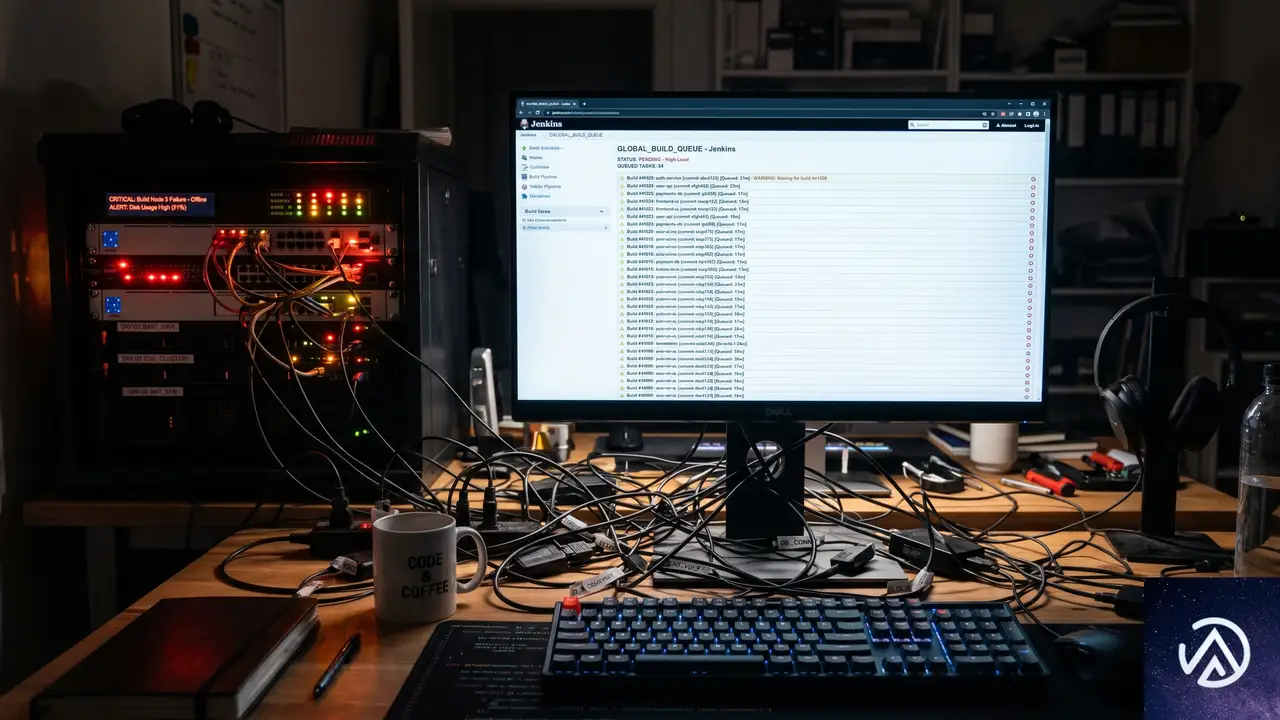
WooCommerceのコードベースは多数のパッケージと連携しており、開発時のwatch:buildコマンドは最大128個のプロセスを起動していた。それぞれがESM(ECMAScript Modules)やCJS(CommonJS)、webpackによる監視を分担し、さらにwireitモニターとPNPMのランチャープロセスが重なり、24.4GBものメモリを消費する状態だった。
このままでは開発マシンのリソースを圧迫し、CI(継続的インテグレーション)実行時にもジョブの待機時間が増大する。ビルド速度の遅延はフィードバックサイクルを長びかせ、生産性に悪影響を及ぼしていた。その根本原因を取り除くため、重複作業の排除とツールチェーンの刷新に着手した。
上記の数値が示す通り、ビルド時間とメモリ消費の両面で大幅な改善が実現された。この結果をもたらした主要な施策は以下の3段階に分けられる。
重複ビルドの排除とTypeScriptコンパイラからの脱却
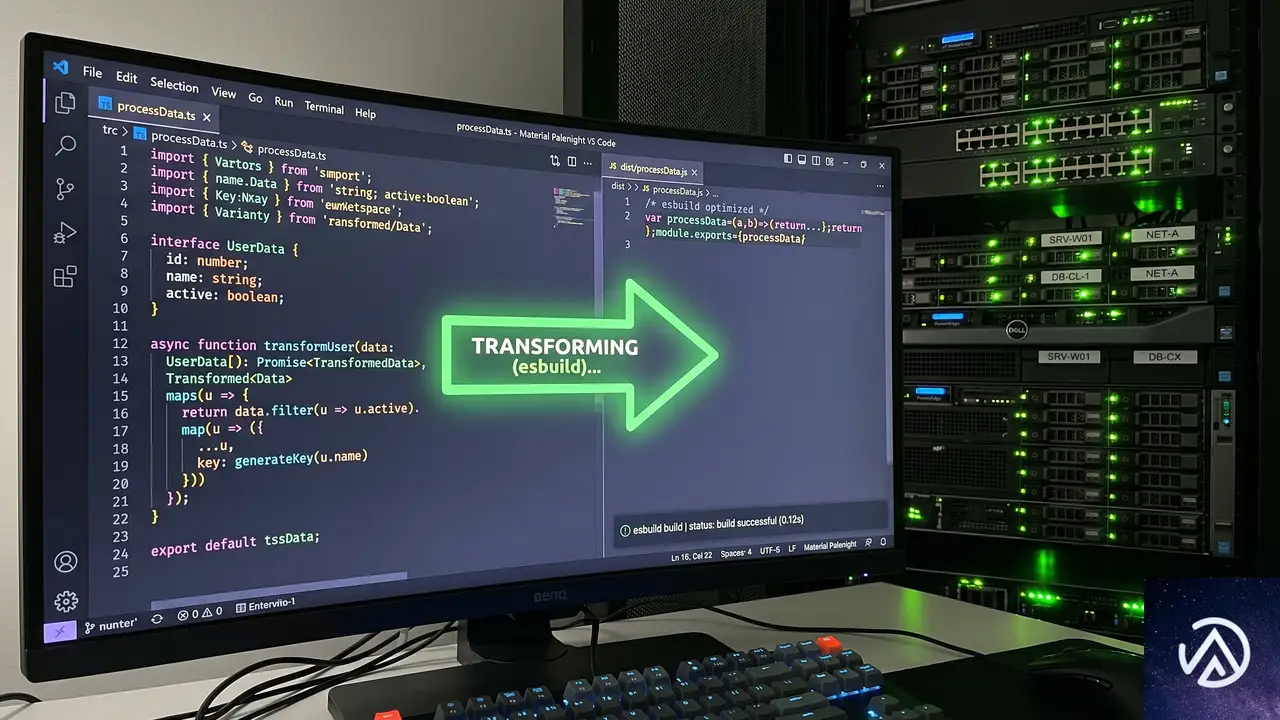
最初に取り組まれたのは、不必要なモジュール形式のビルド重複の解消だ。WooCommerceはESMとCJSの両方を配布しているが、内部のバンドラ(webpack)ではESMのみが消費されていた。にもかかわらず、開発フローでは常に両方を生成していたため、無駄なビルドコストがかかっていた。
PR #64876では、パブリッシング専用のプリパックビルドコマンドを新設し、普段の開発時にはESMのみを生成するよう分離した。これによりビルドプロセスがスリム化され、コールドビルドの短縮に寄与している。
続いて、TypeScriptのコンパイル基盤をtscからesbuildへ移行するための準備が行われた。型チェックは独立したLintステップに分離し、型定義ファイルの生成はパブリッシュ時のみ実行する方式に切り替えた。こうしてビルド本体からTypeScriptコンパイラを外し、高速なバンドラに置き換える土台が整った。
esbuildへの移行とビルド設定の一元化

型チェックとビルドの分離が完了したあと、全パッケージのビルドをesbuildへ切り替えた。esbuildはGo言語で実装されており、TypeScriptのトランスパイルにおいてtscやBabelよりもはるかに高速だ。この移行だけでウォームビルドの速度は顕著に向上した。
しかし、急いで移行した結果、各パッケージに似たようなbuild.mjsファイルが散在するという新たな課題が生まれた。これに対処するため、PR #65422ではビルド用の内部パッケージ@woocommerce/internal-buildを新設し、従来の設定パッケージ(internal-ts-configやinternal-style-build)を統合した。開発マシン上のスクリプトが整理され、今後の保守性も高まった。
Admin/Blocksによるパッケージビルド統合、メモリ大幅削減の鍵
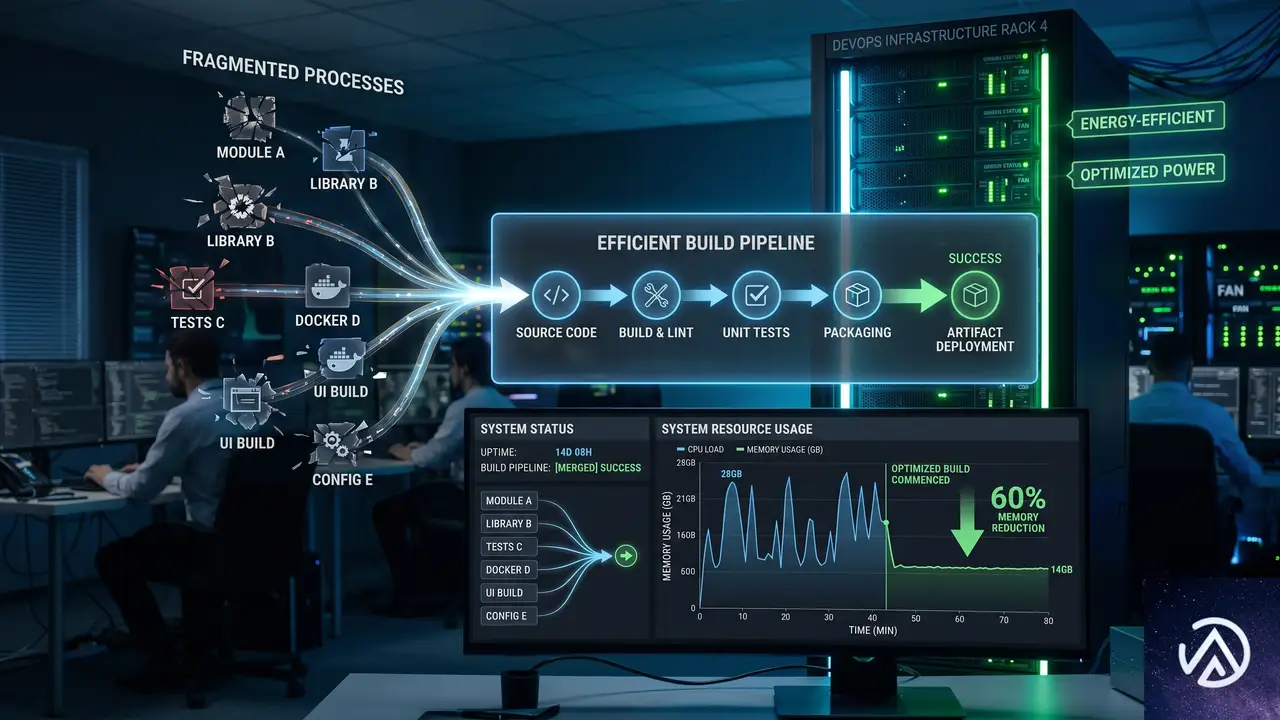
一連の改善の集大成となったのが、PR #65254で実施されたAdminおよびBlocks向けのビルド統合だ。それまでwatch:buildコマンドが128プロセスも必要だった最大の要因は、Admin用webpackとBlocks用webpackがトランスパイル済みESMを外部パッケージとして消費していたことにある。
このPRでは、各パッケージのソースを直接AdminおよびBlocksのwebpackビルドに含める方式へと変更した。その結果、128プロセスが大幅に削減され、メモリ使用量が24.4GBから3.9GBへと激減した。ウォッチ準備時間も132秒から33秒へと4分の1に短縮されている。
トレードオフとして、パッケージのトランスパイルがesbuildではなくBabelで行われるため、コールドビルドの速度が一部でわずかに後退した(38秒)。しかし、webpackのファイルシステムキャッシュによって日常的な開発では体感されず、E2E(End-to-End)テストのCIジョブが約1分長くなる程度にとどまった。全体のメモリ削減と開発体験の向上に比べれば、十分に許容できる交換だったと言える。
次のターゲットはCIスループットの改善

ビルドプロセス自体の最適化が完了した現在、開発チームはCIのスループット向上に注力する方針だ。WooCommerceのCIはジョブをマトリクスシャーディングで分散実行しているが、GitHub Actionsのワーカーが枯渇しやすく、各ジョブの実行時間が短くなってもワーカー獲得に20分以上待たされる局面がある。
この問題を解消するため、同一ワーカー上で複数のタスクを並列実行する方式への移行が計画されている。ワーカー台数に依存しない設計に切り替えることで、CI全体のスループットを大幅に引き上げる狙いだ。さらに、E2Eテストスイートの高速化として、マルチサイト構成などを活用し、単一環境内でテストスイートを並列実行する手法も検討されている。
これらの施策が実装されれば、コードをプッシュしてからCIが完了するまでの時間がさらに短縮され、開発のスピードは一段と加速するだろう。
この記事のポイント
- WooCommerceモノレポの開発ビルドが全面的に見直され、コールドビルド60%減、メモリ使用量84%減を達成
- 重複ビルドの排除と
esbuild移行により、トランスパイル速度が大幅に向上 - Admin/Blocksへのパッケージ統合で128プロセスを一掃し、メモリ消費を劇的に低減
- 今後のCIスループット改善では、ワーカー枯渇問題の解決と並列化が焦点

・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Gemini 3.5 Live Translate公開、自然な音声翻訳の全容
はじめに

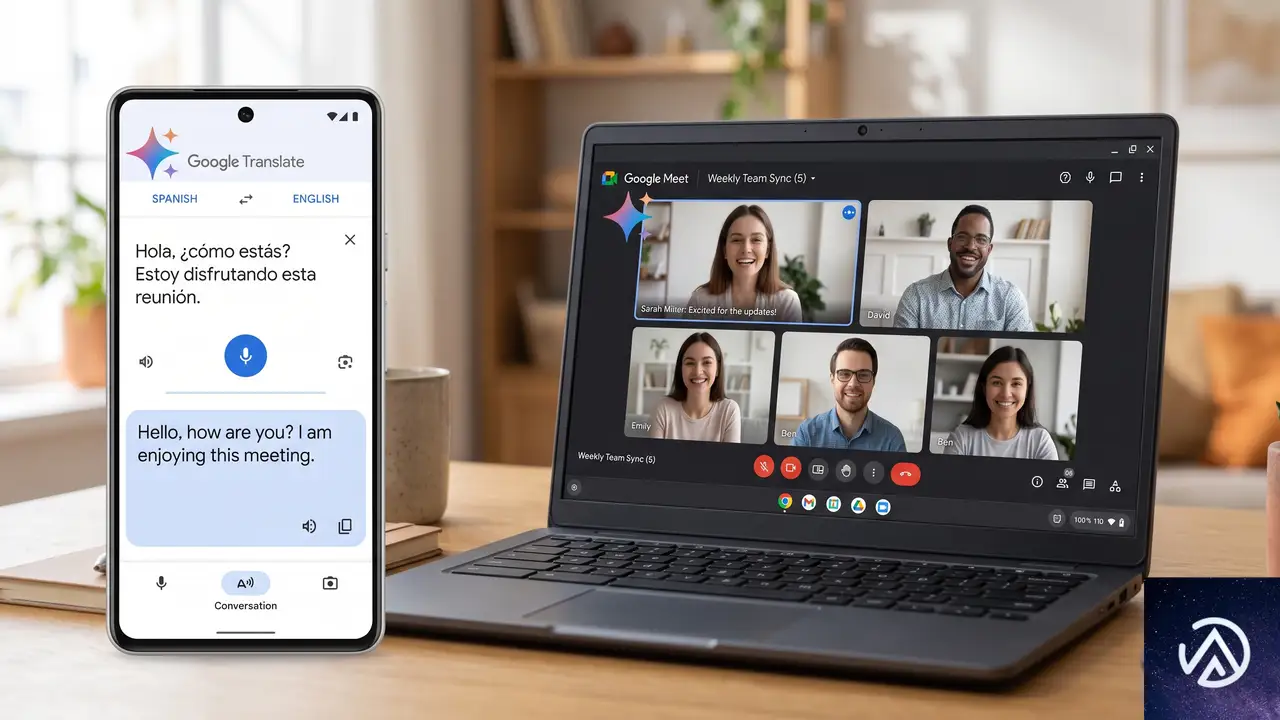
Gemini 3.5 Live Translateが2026年6月9日に公開された。これは音声をリアルタイムで翻訳し、話者の抑揚や間合いを保ったまま自然な音声を生成するAIモデルだ。
従来の逐次翻訳とは異なり、相手が話し終えるのを待たずに翻訳を開始する。遅延は数秒程度に抑えられ、70以上の言語を自動検出して処理する。Google DeepMindが発表した本モデルは、開発者向けAPIやGoogle Meet、Google翻訳アプリを通じて順次利用可能になる。
このリリースは、音声翻訳の「待ち時間」という長年の課題に正面から取り組んだものだ。翻訳品質とリアルタイム性の両立にどこまで迫れたのか、開発者や企業にとっての実用性はどの程度か、本記事で詳細を解説する。
上図のように、逐次翻訳の「全文処理待ち」というボトルネックが解消される。リアルタイム性を重視するビデオ会議や同時通訳の現場では、この差が決定的だ。
Gemini 3.5 Live Translateの技術的な特長
音声ストリーミングによる連続翻訳
最大の特長は、音声をストリーミング処理しながら翻訳結果を連続的に生成する点にある。話者が文を完結させるのを待たず、部分的な発話から逐次翻訳を開始する。
この方式では「コンテクストを待って翻訳精度を高める」ことと「即座に翻訳を開始する」ことのトレードオフが発生する。Gemini 3.5 Live Translateは、両者のバランスを自動調整しながら、自然な間合いを保ったまま数秒の遅延で追随する。
音声通話において「間」はコミュニケーションの質を大きく左右する。2秒の無音がストレスになるシーンは多い。本モデルはその課題に直接応える設計思想だ。
70以上の言語を自動検出して翻訳
手動での言語設定は不要だ。入力音声を分析し、70以上の言語を自動識別する。多言語が混在する会議やイベントでも、参加者ごとの言語選択といった事前設定なしに翻訳が動作する。
多言語対応の自動化は、実際の運用負荷を大幅に下げる要素だ。特にエンタープライズ領域では、IT管理者が会議ごとに翻訳設定を手動で行う手間が削減される。
抑揚・テンポ・ピッチの保持
単なる文字起こし翻訳とは異なり、元の話者の声の高さや抑揚、話す速度までも翻訳音声に反映する。これにより「機械的な翻訳音声」から「人格を感じる翻訳」へと体験が変化する。
感情表現や強調、皮肉といったパラ言語情報が翻訳でも伝わる可能性が生まれる点は、ビジネス通話や国際交渉の現場で特に重要だ。
ノイズ耐性の高さ
屋外やイベント会場など、騒がしい環境でも動作するノイズ耐性を備えている。Google DeepMindの公式ブログでは「loud, unpredictable environments(騒がしく予測不能な環境)」でもアプリケーションが機能すると明記されている。
これは実用面で極めて重要な仕様だ。空港や駅、工事現場、混雑したカンファレンス会場など、現実の翻訳需要は静かな会議室だけではない。ノイズ耐性の高さは、本モデルが実世界での利用を前提に設計されている証左と言える。
開発者向けの提供形態とAPI活用法
Gemini Live APIとGoogle AI Studio
開発者はGemini Live APIを通じて本モデルにアクセスできる。現在はパブリックプレビュー段階で、Google AI Studioからも試用可能だ。
APIを利用すれば、自社のビデオ会議システムや通話アプリ、配信プラットフォームにリアルタイム翻訳機能を組み込める。音声ストリームをAPIに送信するだけで翻訳音声が返ってくるため、インフラ構築のハードルは低い。
対応する開発者プラットフォーム
Agora、Fishjam、LiveKit、Pipecat、Vision Agentsといったプラットフォームが既にGemini Live APIとの統合を完了している。これらのプラットフォームはリアルタイムメディアストリーミングの複雑なインフラ部分を抽象化するため、開発者はユーザー体験の設計に集中できる。
Google DeepMindのGitHubリポジトリ(Gemini Cookbook)では、LiveKitを使った同時多言語翻訳のデモコードが公開されている。実際の実装イメージを掴みたい開発者は参照するとよい。
Grabでの導入事例
東南アジアの配車サービス大手Grabは、ドライバーと乗客間の多言語通話に本モデルを試験導入している。同社では月間1,000万件以上の音声通話が発生しており、ピックアップ時のコミュニケーション障壁を低減する狙いだ。
多言語国家での配車サービスでは、ドライバーと乗客の言語不一致が日常的に発生する。リアルタイム翻訳が実用レベルに達すれば、この摩擦は大幅に軽減される。Grabの事例は、本モデルの実運用における有効性を示す重要な先行例である。
Google MeetとGoogle翻訳アプリでの展開

Google Meetでの通訳機能が大幅強化
Google Meetの音声翻訳機能にGemini 3.5 Live Translateが統合される。従来は5言語のみの対応だったが、70以上の言語に拡大される。さらに、英語を介した翻訳のみだった制限が外れ、2,000以上の言語ペアでの双方向翻訳が可能になる。
本機能は今月から一部のGoogle Workspace企業向けにプライベートプレビューとして提供開始され、年内に広範なロールアウトが予定されている。
Google翻訳アプリでの新体験
AndroidおよびiOS版のGoogle翻訳アプリにも本モデルが展開される。有線・無線を問わずヘッドフォンを接続するだけで、70以上の言語に対応したリアルタイム翻訳が利用可能になる。
特に注目すべきはAndroid向けの新機能「リスニングモード」だ。スマートフォンを受話器のように耳に当てるだけで、翻訳音声が端末のイヤースピーカーから直接再生される。ヘッドフォンを持っていない場面や、周囲に翻訳音声を聞かれたくない場面で有用だ。
例として、スペイン語のガイドツアーを英語の翻訳音声で聞くといったユースケースが公式ブログで紹介されている。観光や出張先での利用シーンが明確に想定されている。
SynthIDによる安全性担保
本モデルが生成するすべての音声には、SynthIDによる電子透かしが埋め込まれる。この透かしは人間の耳では検知できないが、AI生成音声であることを機械的に判別可能にする。
音声のAI生成が一般化するにつれ、なりすましや偽情報への対策は避けて通れない課題だ。リアルタイム翻訳という機能の利便性と、AI生成コンテンツの検出可能性を両立させる設計は、今後のAIサービスにおける標準的な取り組みになるだろう。
詳細な安全性の取り組みについては、Google DeepMindが公開するモデルカードで確認できる。
この記事のポイント
- Gemini 3.5 Live Translateは70以上の言語を自動検出し、話者の抑揚を保ったまま連続的に翻訳する
- 従来の逐次翻訳とは異なり、話し終えを待たずに数秒遅れで追随するストリーミング処理を採用
- 開発者はGemini Live APIやGoogle AI Studioからパブリックプレビューとして利用可能
- Google Meetでは対応言語が5から70以上に拡大し、2,000超の言語ペアでの双方向翻訳が実現
- 生成音声にはSynthIDの電子透かしが埋め込まれ、AI生成コンテンツの検出が可能
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

ChatGPT広告に複数広告主表示、EC事業者の獲得機会が拡大
OpenAIはChatGPT内の広告において、1つの広告枠に複数の広告主を表示するテストを開始した。これまで1枠1広告主だった配信形態が変わる可能性がある。EC事業者にとっては、商品の検討段階にあるユーザーへのリーチ機会が増えることを意味する。
このテストはChatGPTの広告在庫を増やす施策の一環であり、OpenAIは広告管理ツールの機能拡張や配信対象地域の拡大も同時に進めている。AI上での商品発見と購買行動が一般化しつつある中、広告プラットフォームとしての進化はEC事業者の広告戦略にも影響を与える見込みだ。
本記事では、新しい広告フォーマットの仕組み、広告管理機能の変更点、そしてWooCommerceをはじめとするEC事業者が取るべき対応を整理する。
1枠に複数広告主を表示する新テストの仕組み

従来のChatGPT広告では、1つの広告枠に表示されるのは1広告主のみだった。今回のテストでは、同じ枠内に複数の広告主を同時に掲載できるようになる。ユーザーが商品比較や購入に関する質問をした際、関連性の高い複数ブランドの提案が一度に表示されることを意味する。
セカンドプライスオークションの採用
広告枠の販売には「セカンドプライスオークション」方式が使われる。これは、最も高い入札額を提示した広告主が勝者となるが、実際に支払う金額は2番目に高い入札額よりわずかに高い水準になる仕組みだ。Google広告をはじめ、多くのデジタル広告プラットフォームで採用されている方式である。
EC事業者にとってのポイントは、単に高額入札をすれば良いわけではなく、入札戦略の最適化がより複雑になる可能性がある点だ。複数広告主が1つの枠を奪い合う形になるため、広告の関連性や品質スコアに相当する指標の重要性が増すと予想される。
広告管理機能が従来型プラットフォームに接近
OpenAIは広告主向けの管理ツール「Ads Manager」にも複数の改良を加えた。EC事業者が普段使い慣れている広告プラットフォームに近い操作性を目指した動きといえる。主な変更点は以下の通りだ。
- キャンペーン予算を「ライフタイム予算」から「1日あたり予算」に変換可能に
- CPM(インプレッション課金)キャンペーンをCPC(クリック課金)キャンペーンに1クリックで複製
- インプレッション課金キャンペーンでCPM上限単価のカスタム設定が可能に
- 複数キャンペーンを一括編集できるツールを追加
- 1日あたり予算が「平均日予算モデル」に移行し、週単位での柔軟な予算配分が可能に
予算管理の柔軟性が高まったことで、ECサイトの広告運用チームはキャンペーンのパフォーマンスに応じて素早く予算を振り替えられるようになる。既存の検索広告やSNS広告と並行してChatGPT広告を運用する場合の管理負荷も下がるだろう。
配信対象国が10カ国に拡大

配信対象地域も拡大された。従来は米国、カナダ、オーストラリア、ニュージーランドの4カ国のみだったが、今回以下の5カ国が追加され、計9カ国となった。
- 英国
- 日本
- 韓国
- ブラジル
- メキシコ
日本が対象に含まれたことは、国内でWooCommerceを運営するEC事業者にとって大きな意味を持つ。ChatGPTの日本での利用者数は増加傾向にあり、AI経由の商品検索が徐々に浸透しつつある。早い段階でテストに参加できれば、競合より先行してユーザーデータを蓄積できる可能性がある。
EC事業者が注目すべき3つの変化

広告在庫が増え、クリエイティブの重要性が上がる
OpenAIは広告表示回数を大幅に増やさずに在庫を拡大する手段として、複数広告主の同時表示を選んだ。ユーザー体験を損なわずに収益を伸ばす設計といえる。しかし同じ枠に競合他社の広告が並ぶということは、EC事業者の広告クリエイティブがより直接的に比較される状況を生む。
商品画像、テキスト、価格訴求の質がそのままクリック率の差になる。特にChatGPT上ではユーザーが「買いたい」という意図を持って質問しているケースが多いため、コンバージョンに直結するクリエイティブ設計が求められる。
オークション設計が価格競争に影響を与える
セカンドプライスオークションは理論上、広告主が自分の評価額に近い金額を入札しやすくなる特性を持つ。しかし複数広告主が1枠を争う形式では、枠内での表示順位や視認性の差が生じる可能性もある。具体的な表示アルゴリズムの詳細は明らかにされていないが、入札額以外の要素(関連性スコアやCTRなど)が順位決定に影響する可能性は高い。
EC事業者は「とにかく高い金額を入れれば良い」という単純な戦略ではなく、商品の属性やターゲットに合った入札設計を検討する必要がある。
AI上の購買行動データが新しい競争軸になる
ChatGPT上でのユーザー行動は、従来の検索エンジンとは異なるパターンを示す。キーワード検索ではなく自然言語での質問から商品発見が始まるため、ユーザーの潜在的なニーズを捉えやすい半面、従来のSEO施策だけではカバーしきれない領域だ。
WooCommerceを運営する事業者であれば、商品データの構造化や、AIが商品を適切に理解できるようなフィードの最適化が今後さらに重要になる。具体的には、商品名や説明文を自然言語での質問にマッチしやすい形で整備すること、そして在庫情報や価格情報をリアルタイムで正確に提供できる体制を整えることが求められる。
この記事のポイント
- ChatGPT広告で複数広告主の同時表示テストが始まり、EC事業者の露出機会が拡大する
- セカンドプライスオークション採用により、入札戦略とクリエイティブ品質の両立が課題になる
- 日本が配信対象国に追加され、国内EC事業者もChatGPT広告を活用できる段階に入った
- 広告管理機能の強化で、既存プラットフォームと並行した運用がしやすくなっている
- AI経由の商品発見に対応するには、商品データの構造化とフィード最適化が必須となる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Multigres v0.1 α版リリース、Postgres向け水平スケーリングOSの概要
2026年6月4日、SupabaseのチームがオープンソースプロジェクトMultigresの初のパブリックマイルストーンとなるv0.1 Alphaを公開した。このプロジェクトはPostgresにVitess級の水平スケーリング、高可用性、運用のシンプルさをもたらす「オペレーティングシステム」を目指している。
v0.1 Alphaでは高度なコネクションプーリング、自動フェイルオーバー、Kubernetesオペレーターが提供される。シャーディング機能は今後のリリースで追加予定だ。以下の記事ではその設計思想と仕組みを掘り下げる。
Multigresとは
・フェイルオーバーは運用者が判断
・コネクション制限への個別対処
・バックアップは別ツールで管理
・自動フェイルオーバーでダウンタイム最小
・コンテキスト認識型コネクションプーリング
・バックアップとリストアを統合管理
MultigresはPostgresインスタンスを包括的に管理する「スケーラブルなオペレーティングシステム」だ。シャーディング、コネクションプーリング、自動フェイルオーバー、バックアップオーケストレーションを単一のシステムで提供する。
Postgresスケーリングの課題
Postgresを大規模に運用する際、読み取りレプリカの管理、フェイルオーバーの対応、コネクション上限対策、バックアップのスケジューリングなど、運用負荷が高い。これらをバラバラのツールで解決しようとすると、複雑さが増していく。
Multigresが解決すること
Multigresはこれらを一貫したシステムとして自動化する。データベースのスケールが必要になったタイミングでシャーディングも処理し、水平スケーリングを実現する。v0.1 Alphaではまだ単一シャードだが、基盤は整っている。
Kubernetesオペレーター
Kubernetesオペレーターによって、Multigresクラスタのデプロイと管理が抽象化される。必要なのはKubernetesクラスタとバックアップ用のストレージ(共有ファイルシステムやAWS S3バケット)だけだ。ローカルのKindクラスタでも動作検証が可能で、必要なコンテナイメージはすべて公開されている。
高可用性(HA)の仕組み
データの不整合やコミット消失のリスク
耐久性ポリシーをユーザーが自由に定義可能
MultigresはHAを合意形成の問題として扱い、スプリットブレインが起きてもコミット済みデータを失わない。これを一般化合意(generalized consensus)モデルで実現している。これは従来のコンセンサスベースシステムにはない柔軟性をもたらす。
一般化合意モデル
Multigresは無修正のPostgresレプリケーションの上に実装されており、厳密な一貫性要件を満たす。さらに、過半数のクォーラムのような制約に縛られず、ユーザーが任意の耐久性ポリシーを定義できる。例えば「単一のアベイラビリティゾーン(AZ)障害に耐える」を設定すれば、それ以上のゾーンにスタンバイを配置することも可能だ。
レプリカの動的追加と削除
クラスタ稼働中にレプリカを安全に増減できる。パフォーマンスに影響を与えず、設定された耐久性ポリシーと整合性を保ったままスケーリングが可能だ。
コネクションプーリングの革新
Multigresは独自の2サービスアーキテクチャによるコネクションプーリングを採用している。クライアント接続を受け付ける「multigateway」と、バックエンド接続を管理する「multipooler」で構成され、単一プロセスのプーラーにはない利点がある。
トラフィックルーティングとフェイルオーバー
HAシステムとの統合により、multigatewayは常に現在のプライマリに透過的に接続を転送する。フェイルオーバー発生時は新しいプライマリが昇格するまでリクエストを保留し、エラーを最小化する。読み取り負荷は複数レプリカに分散可能で、将来的にはシャード間のルーティングにも対応予定だ。
コンテキストアウェアプーリング
Multigresはトランザクションやセッションといったプーリングモードを明示的に選択する必要がない。組み込みのパーサーが各リクエストの効果を理解し、接続状態を追跡する。ステートフルなトランザクションが必要な場合だけ接続をそのクライアントに固定し、それ以外は再利用する。
ユーザー別プールとプリペアドステートメント
ユーザーごとに独立したコネクションプールを保持し、SET ROLEによるなりすましを使わない。固定の接続予算をフェアシェアアルゴリズムで分配する。さらに、プリペアドステートメントはゲートウェイ間で重複排除され、Postgres側で文の解析、計画、キャッシュが1回だけ行われる。
バックアップ戦略
MultigresはバックアップにpgBackRestを使用し、プライマリに負荷をかけないようレプリカから取得する。バックアップの種類は完全、増分、差分の3つで、通常は定期的な完全バックアップと短い間隔の増分・差分を組み合わせる。
オンデマンドとスケジュール
CLIでバックアップの一覧表示や手動バックアップ、リストアが可能だ。スケジュール機能は今後のクラスタスペックを通じて追加予定となっている。
クラスターブートストラップ
クラスタ起動時にMultigresが自動的にプライマリを特定し、バックアップを取得して他のレプリカを初期化する。これにより人手を介さずに即座に利用可能なクラスタが立ち上がる。
アルファ版の制限と今後の展望
・既知の課題がGitHubイシューにあり
・将来バージョンとの後方互換性は保証されない
・CR APIが安定していない
・パフォーマンスベンチマーク未公開
・スケジュールバックアップのサポート
・APIの安定化とベンチマークの公開
・コミュニティからのフィードバック集約
v0.1 Alphaは実験とフィードバックに十分な安定性を持つが、本番運用にはまだ適さない。シャーディングは今後のリリースで追加予定の主力機能であり、現在はHAとプーリングを備えた単一シャードクラスタの形で提供されている。ベータやv1.0に向けてAPIの安定化とベンチマークの公開が進められる見通しだ。
この記事のポイント
- MultigresはPostgresのスケーリングと運用を自動化するオープンソースOS
- v0.1 AlphaでKubernetesオペレーター、HA、高度なコネクションプーリングを提供
- 一般化合意モデルによりスプリットブレインを安全に解決
- コンテキストアウェアプーリングでモード選択不要、ユーザー別プールも実装
- シャーディングは将来リリース予定、現在はフィードバック収集段階
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AIエージェントがECデータを扱うには MCPでアクセスと安全を両立する方法
AIエージェントにGoogle広告の運用を任せようとした検索広告担当者は、同じ話を口にする。パフォーマンスデータをエクスポートし、チャット画面に貼り付け、的確な回答を得て、翌日も同じ作業を繰り返す。
これは自動化ではない。手作業の窓口が変わっただけだ。AIツール自体に問題があるわけではない。主要なモデルは、適切なデータが目の前にあれば高度な分析をこなせる。課題は、そのデータをリアルタイムに、かつ人間がコピーして渡さなくても届けられるかどうかだ。
2026年現在も、ほとんどのPPCアカウントはAIエージェント登場以前とほぼ同じ運用フローにとどまっている。その根本原因は「データの壁」にある。本記事では、この壁を壊す技術であるMCP(Model Context Protocol)と、ECや広告運用の現場で安全に導入するための考え方を整理する。
「もっと良いプロンプト」では解決できない問題
広告プラットフォームは設計上、それぞれがサイロ化している。Google広告はコンバージョンを記録する。CRMはそのリードが商談化可能かを管理する。在庫システムはクリックされた商品がまだ倉庫にあるかを知っている。どのシステムも、意図的な配管なしには相互に会話しない。
検索広告の担当者は長年、このギャップを手作業で埋めてきた。週次のエクスポート、突合せ用のスプレッドシート、月曜朝には最新ではなくなっているダッシュボード。人が決まったスケジュールで橋渡しする分には成り立っていたが、AIエージェントに実行を委ねる瞬間、構造的な問題として立ちはだかる。
たとえば、Google広告上は表示回数も多く、許容範囲のCPA(顧客獲得単価)とCVR(コンバージョン率)を示すキーワードがあったとする。しかしHubSpotでは、そのコンバージョンは「商談不適格」とタグ付けされている。地域が違う、予算がない、まったく別の企業規模だ。エージェントには知る術がない。入札を続け、予算を消費し、問題は月次の振り返りでようやく表面化する。
これはプロンプトの問題ではない。データアクセスの問題だ。より良い指示文では修正できないが、より良いパイプラインなら解決できる。
MCPがエージェントにデータとスキルを渡す仕組み

Model Context Protocol(MCP)は、AIクライアントが外部のツールやデータソースと接続するためのオープン標準だ。個別のカスタム統合を書く代わりに、プラットフォームが一度MCPサーバーを公開すれば、ClaudeやChatGPTのエージェントモード、自社構築のエージェントなど、互換性のあるあらゆるAIクライアントが接続できるようになる。
これまでエージェントにGoogle広告とCRMと在庫システムを読ませようとすると、3つのコネクターを個別に作り、保守する必要があった。データソースが増えるたびに負荷は増大する。MCPは握手の手順を標準化し、インフラの複雑さを解消する。
この図のように、MCPを導入するとエージェントは必要なデータソースに直接アクセスできる。GoogleはすでにGoogle Ads API MCPサーバーをGitHub上でオープンソース化しており、エージェントがGAQL(Google Ads Query Language)クエリをライブアカウントデータに対して直接実行できる環境が整いつつある。
データが流れ始めると何が起こるか
まずCRMとの断絶が解消される。Google広告とHubSpotの両方に接続したエージェントは、先月のコンバージョンを取得し、CRM上の商談結果と突合して、不適格リードを生んでいるキーワードを特定できる。そして、該当するキーワードの入札を自動的に下げる。これまで半日かかっていたループが、スケジュール実行に変わる。
在庫も同じ盲点だった。Shopifyに接続したエージェントは、週末キャンペーンが開始される前に在庫レベルをチェックできる。SKUがしきい値を下回ったら、関連する商品グループを一時停止し、もはやコンバージョンが見込めないページへのトラフィックを未然に防ぐ。
データパイプラインの構築作業自体も高速化する。PPC専門家のLars Maat氏は、Pythonの経験がない状態から、Google Maps APIとGoogleのThings To Do機能、Ahrefsを接続し、駐車場クライアント向けに最適化されたランディングページを生成するパイプラインをわずか2週間で構築したという。必要なデータをAIの前に正しく置くことさえできれば、あとはエージェントが実行する。
アクセスだけでは足りない ガードレールなきリスク
ここからが本題だ。書き込み権限のあるGoogle広告アカウントへのアクセスを、確率的な言語モデルの手に渡すことは、新たなリスクカテゴリを生む。キャンペーンを一時停止できるエージェントには、どのしきい値で動作をトリガーするか、発動前に誰に通知するか、どのキャンペーンタイプは人間の承認が必要かといったパラメータが不可欠だ。こうした制約はAIツールの内部には存在せず、周囲に構築しなければならない。
Anicca Digital創設者で英国有数のペイドメディア実務者であるAnn Stanley氏は、効果的なAI導入を「サンドイッチ」にたとえている。最前線には目標を理解し正確な指示を与える人間がおり、最後尾には出力をレビューし何を反映するか判断する人間がいる。AIはその中間で実行を担う。出力の品質は、投入されるデータの品質と、中間層に制約が存在するかどうかに左右される。
Googleがオープンソース化したMCPサーバーは優れたインフラだが、安全網ではない。エージェントが構築したクエリや変更を忠実に実行し、エージェントがキャンペーンIDを誤認したり誤ったルックバックウィンドウを選んだりすれば、その結果は広告アカウントが引き受けることになる。LLMは確率的であり、広告プラットフォームのAPIはそうではない。だからこそ、その間に座る仕組みが必要だ。
Optmyzr MCPが提供する安全な実行レイヤー
PPC管理プラットフォームを提供するOptmyzrは、Google広告の実際の振る舞いを10年以上にわたってコード化してきた。APIが公開する情報だけでなく、設定間の相互依存関係、キャンペーンタイプごとのエッジケース、重複キーワードの真偽判定といったナレッジが同社のビジネスインテリジェンス層として蓄積されている。OptmyzrのMCPコネクターは、その知見をAIエージェントが借りられるようにするためのものだ。
ClaudeやChatGPT、あるいはチームのカスタムエージェントがOptmyzr MCPに接続すると、同プラットフォームで提供されているSidekick機能と同等の能力を得る。豊富なフィルタとセグメントによるPPCレポートの取得、設定済みアラートの表示と編集、マーチャントフィードの詳細取得、全アクティブアカウントのポートフォリオ健全性の要約などが可能になる。そして最も見落とされがちなのが、自然言語の指示からルールエンジン戦略を生成し実行する機能だ。
このアプローチが、多くの自作セットアップと異なる理由は3つある。
- 一文から戦略を生成し、Optmyzr内で実行する。 MCPのルールエンジン機能は、「過去14日間でCPAが目標から20%以上乖離したキャンペーンを見つけ、入札調整戦略を立案して」といった自然言語の指示を受け取り、対応する戦略を生成してアカウントに適用し、結果を分析して推奨事項を返す。LLMが意図を書き、Optmyzrの決定論的エンジンが作業を行う。この実行と制御の層は、生の広告プラットフォーム向けMCPにはないものだ。
- クロスアカウントかつポートフォリオ規模の分析が可能。 OptmyzrのUI内のSidekickは単一アカウントの単一ページの文脈では優れている。MCPは「保有する80アカウントのうち、今月除外キーワードの浪費が上昇傾向にあるのはどれか」といった問いに答えるために使う。Optmyzr MCPに接続したAIクライアントは、1回のプロンプトで全アカウントに問い合わせを展開できる。代理店が生のAds APIではなくOptmyzr MCPを選ぶ最大の理由がここにある。
- Sidekickから継承されるガードレール。 Optmyzr MCPを通じて実行されるすべてのアクションは、Sidekickを直接使用する場合と同じ権限とワークフローロジックの下で動作する。エージェントは分析、戦略立案、アラート通知を行い、変更案を作成する。実際の変更は人間または既存の承認フローが送り出す。Stanley氏の言う「安全のサンドイッチ」が製品に組み込まれている。
結果として、APIの到達範囲と、AIエージェントというカテゴリが生まれる前からこの分野にいるプラットフォームの判断力、そして自前で回路遮断器を構築せずに済む安全な姿勢を兼ね備えたエージェントが、ポートフォリオ全体で稼働する。
実践的な導入ステップ
まずは読み取り専用で様子を見たいなら、Windsor.aiやZapierのMCP統合が最も手早い。ガードレールの管理に自信があるなら、GitHub上のGoogle Ads API MCPサーバーで正確なGAQL制御を手に入れられるが、そのぶん安全層の構築は自前になる。
ミスが許されないクライアントアカウントを運用している場合、あるいはAIエージェントにシニアPPCストラテジストの判断力で全ポートフォリオを考えさせたい場合は、Optmyzr MCPが安全に「鍵を渡せる」エージェントへの最短経路だ。Claude Desktop(カスタムコネクターまたは手動設定)、Claude Code、ChatGPT(Developer Modeアプリ)、その他MCP互換クライアントで動作し、セットアップは数分で完了する。Optmyzrの設定画面でAPIキーを生成し、サーバーURLをAIクライアントに貼り付けるだけで、プロフィール上の全アクティブアカウントにエージェントが接続される。
データの壁はどちらにせよ崩れつつある。問題は、エージェントがその壁を計画を持って通り抜けるか、それともプロンプトと祈りだけで通り抜けようとするかだ。
この記事のポイント
- AIエージェントが実務で使えない最大の原因は、データソースとの接続不足にある
- MCPはAIクライアントと各種ツールを標準化された方法で接続し、手作業のエクスポートを不要にする
- 書き込みアクセスにはガードレールが必須で、人間の承認や制約の設計が欠かせない
- Optmyzr MCPは、10年以上のPPC知見と安全な実行レイヤーを兼ね備えた選択肢であり、クロスアカウント分析や自然言語からの戦略実行を実現する
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Microsoft Discovery GAとDiscoveryアプリプレビュー
マイクロソフトはMicrosoft Buildにおいて、研究開発向けエージェントAIプラットフォーム「Microsoft Discovery」を一般提供開始した。同時に、研究者がローカル環境で利用できる「Microsoft Discoveryアプリ」のプレビュー版も公開された。
このリリースは、科学研究におけるAIの役割を単なるアシスタントから、反復的な実験計画や仮説検証を統括する「研究の中核」へと引き上げるものだ。製薬業界の新薬探索や材料工学の最適化問題など、複雑な条件が絡み合う領域での利用が見込まれている。
従来のチャット型AIとは異なり、このプラットフォームは専門的なモデリングツールや実験データと連携し、人間の専門家による判断プロセスを補強する設計がなされている。大規模な組織の研究開発(R&D)ワークフローに、再現性と透明性をもたらす点が最大の特徴だ。
エージェントAIによる研究開発ワークフローの再現性確保
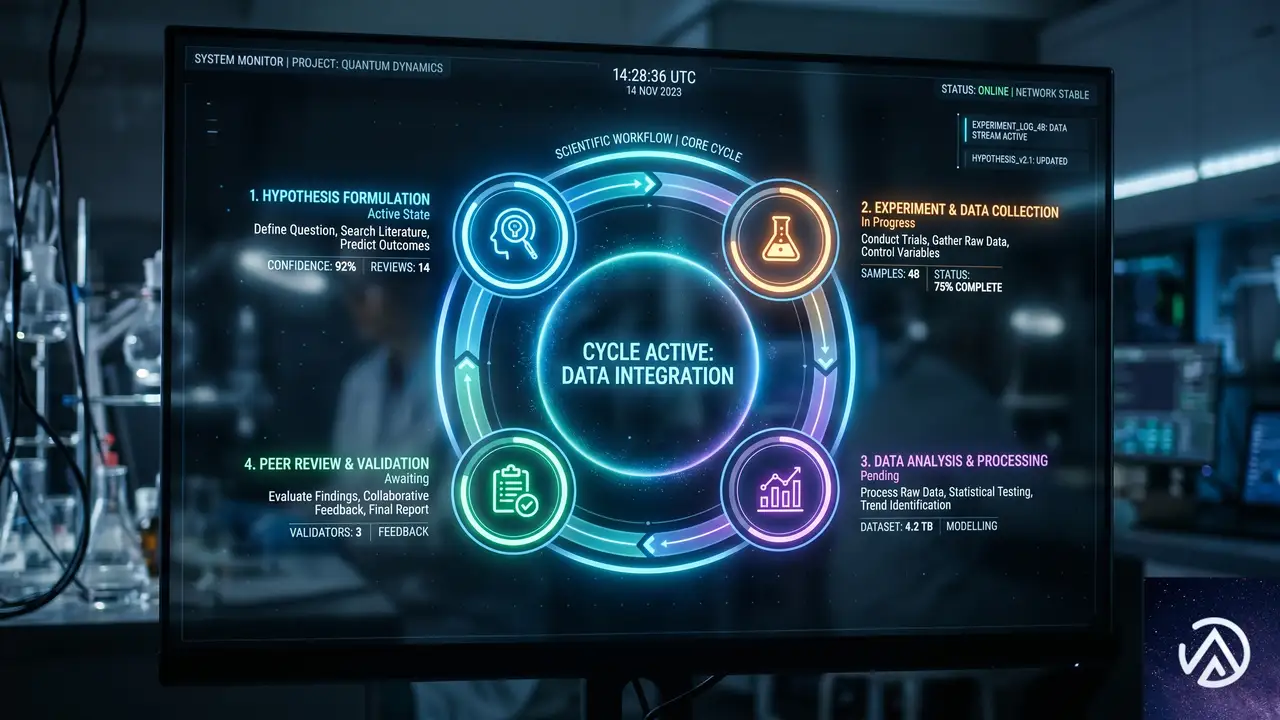
科学研究の突破口は、一度のひらめきで生まれるものではない。仮説、実験、改良、レビューという繰り返しのサイクルの中からしか姿を現さない。Microsoft Discoveryは、この本質的なループ構造を組織的に管理し、加速させるために作られた。
✓ 再現可能なワークフロー
✓ 組織固有の知識との統合
このプラットフォームの中心にあるのが「Microsoft Discovery Engine」だ。これはエビデンス(証拠)から仮説を導き出し、AIエージェントが各種のシミュレーションや分析ツールを呼び出して検証し、次のイテレーションへ進むという一連の流れを支える。Azure Blogの記事によれば、このエンジンは「単発の分析を超えて、比較検討や前提の疑問視を繰り返し可能な形で行える」よう設計されている。
プロダクション環境で求められる信頼性
研究開発の現場にAIを持ち込む際、最も難しいのは「信頼」の確立だ。Microsoft Discoveryの一般提供版では、以下の要件が重視されている。
- ワークフローの再現性
- 出力結果のレビュー可能性
- 企業固有の知的財産の適切な統治
- 既存のR&D組織の運営モデルへの適合
つまり、AIが出した「答え」だけを信じるのではなく、その推論の道筋を後からなぞり、専門家が納得できる形で提示することが求められている。これは、ブラックボックス化しがちな大規模言語モデルの弱点を補うアプローチであり、規制の厳しい製薬業界や材料産業での採用を後押しする要素だ。
ローカル環境を拓く「Discoveryアプリ」のプレビュー公開
組織全体での大規模な導入と並行して、マイクロソフトは個人や小規模チームがすぐに利用を開始できる「Microsoft Discoveryアプリ」のプレビュー版もリリースした。これは、企業のIT部門による本格的なデプロイを待たずに、研究者が自身のマシン上でエージェントAIの能力を試せるようにするための入り口だ。
このアプリは、学術研究室や学生が「まず触ってみる」ことを最重要視している。研究のアイデアが小規模なプロジェクトや個人の探求から始まることは珍しくない。そこから成果が成熟し、より高度な制御や大規模な計算リソースが必要になった段階で、クラウド上のMicrosoft Discoveryへシームレスに移行できる点が特徴だ。
最先端の現場における応用事例

プライベートプレビュー期間中、各分野のリーディングカンパニーとの協業を通じて、このプラットフォームの実践的な価値が検証された。単なる概念実証ではなく、実際の製品開発や学術研究のスピードを変えつつある。
バッテリー科学での分子設計ループ
イェール大学工学部とマイクロソフトリサーチの共同研究では、大規模蓄電向け「有機レドックスフロー電池」の電解質分子設計にDiscovery Engineが利用された。この問題は、酸化還元電位や水溶性、合成のしやすさなど、相反する複数の物性を同時に最適化する必要がある極めて複雑なものだ。
エージェントAIは、実験から得られたデータを解釈して次の候補分子を提案し、さらに診断的な実験計画を立案する役割を担った。実際の実験検証と結果の評価は、人間の専門家が主導している。イェール大学のDavid Kwabi准教授は、この枠組みが「人間主導の実験の強みと、AIの広大な化学空間探索能力を組み合わせたもの」と評価している。
半導体から生命起源まで
Syensqo社は、次世代半導体製造用の熱伝達流体の開発にこの技術を適用し、研究から営業、マーケティングまで含めたビジネス全体の意思決定速度を向上させている。ジョージア工科大学では、生命の起源に関わるアミノ酸「ヒスチジン」の生成経路を、複数のAIエージェントが質量分析データや文献情報を統合して再評価するユニークな試みが進められている。
これらの事例に共通するのは、AIが「単独で答えを出す」のではなく、人間の研究者とツールの間に立って「探索と検証のサイクル」を加速させている点だ。BHPのJessica Farrell氏は、銅の浸出技術開発において「無限に近い可能性の領域を、実用可能な少数の選択肢に絞り込めた」と述べ、数か月単位での成果創出に貢献したことを示唆している。
いずれも「探索 → 検証 → 絞り込み」のループをAIが加速する構造が共通している。
自律ラボとの融合が示す次のフェーズ

パシフィック・ノースウェスト国立研究所(PNNL)との協業は、AIエージェントが物理世界と直接つながる未来を明確に示している。ここでは、Discoveryが仮説を生成するだけでなく、ロボット実験設備を直接駆動し、得られた実験結果をリアルタイムで学習して次の指示を出す「自己駆動型の科学ワークフロー」が実証されている。
PNNLのRobert Runkle氏は、これを「ロボティクスと自律ラボがAIとクラウドインフラと融合した、一つのインテリジェントなクローズドループ発見エンジン」と表現する。アイデアから実際のブレイクスルーまでのタイムラインを劇的に短縮し、材料合成や生物学における新時代の扉を開くものだという。
この動きは、ケンブリッジ・コンサルタンツが「数か月の実験作業を数日から数時間に変える」と表現したインパクトと完全に一致する。AIが提案し、ロボットが試し、その結果をAIが解釈する、このサイクルが自動で回り始めたとき、研究開発の定義そのものが変わるだろう。
この記事のポイント
- Microsoft DiscoveryはR&Dワークフローの再現性と透明性を確保するエージェントAI基盤
- クラウド上の本格運用と、個人が即日試せるローカルアプリの二軸で提供開始
- 研究における「仮説→実験→検証」の反復ループを、専門家の判断を中心に据えつつ加速する設計
- バッテリー開発、創薬、鉱業など、実際の産業応用で開発スピードを劇的に向上させた事例が複数報告されている
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

WooCommerce 10.9 Beta公開、決済フローの改善と管理画面刷新の全容
WooCommerce 10.9 のベータ版が公開された。正式リリースは2026年6月23日の予定だ。今回のアップデートでは、決済フローのデータベース負荷を下げる施策と管理画面の UI 刷新、そしてコアへのメールログ機能の統合という 3 つの柱に加え、多数の実験的機能が同梱されている。
中でも決済の「離脱」を減らす設計変更は、100 を超える細かなデータベース処理の整理とともに、ストア運営者にとって直接的なパフォーマンス向上をもたらす。また、長年要望の多かったバリエーション画像ギャラリーやカラースウォッチが機能フラグとしてコアに組み込まれ、開発者向けの新 API 群も登場する。本記事では、EC サイト運営者が知っておくべき変更点を中心に、WooCommerce 10.9 の内容をわかりやすく解説する。
決済フローの最適化とデータベース負荷低減

WooCommerce では従来、ユーザーが商品をカートに入れて決済画面を開いた時点で「下書きの注文(draft order)」というレコードを作成していた。この下書きは、購入を完了しなかった訪問者でもそのままデータベースに残り、時間が経つと大量の孤立レコードとなってストアのパフォーマンスを圧迫する原因になっていた。
10.9 ではこの処理が見直され、注文確定の直前まで下書きの作成を遅延させる設計に切り替わる。具体的には、Store API が新規セッションの GET リクエストや PATCH リクエストを受けても、すぐに下書き注文を永続化しない。結果として、購入が成立しなかったユーザーによる不要なレコードが大幅に減少し、データベースへの書き込み負荷が軽減される仕組みだ。
これに付随し、決済処理の保存回数やルックアップの最適化、商品フィルタの SQL 挙動の改善、管理画面と店舗側の商品ページにおけるクエリ数の抑制も同時に行われる。全体として、特に商品数が多いストアでは、管理画面やチェックアウト時の体感スピードが段違いに変わるだろう。
上図は旧来のやり方と 10.9 の改善点を概念的に示したものだ。実際の実装では Store API と内部の注文管理の細かい連携が組み合わさり、データベースへの影響はより精密にコントロールされる。
WooCommerce管理画面のUIが刷新
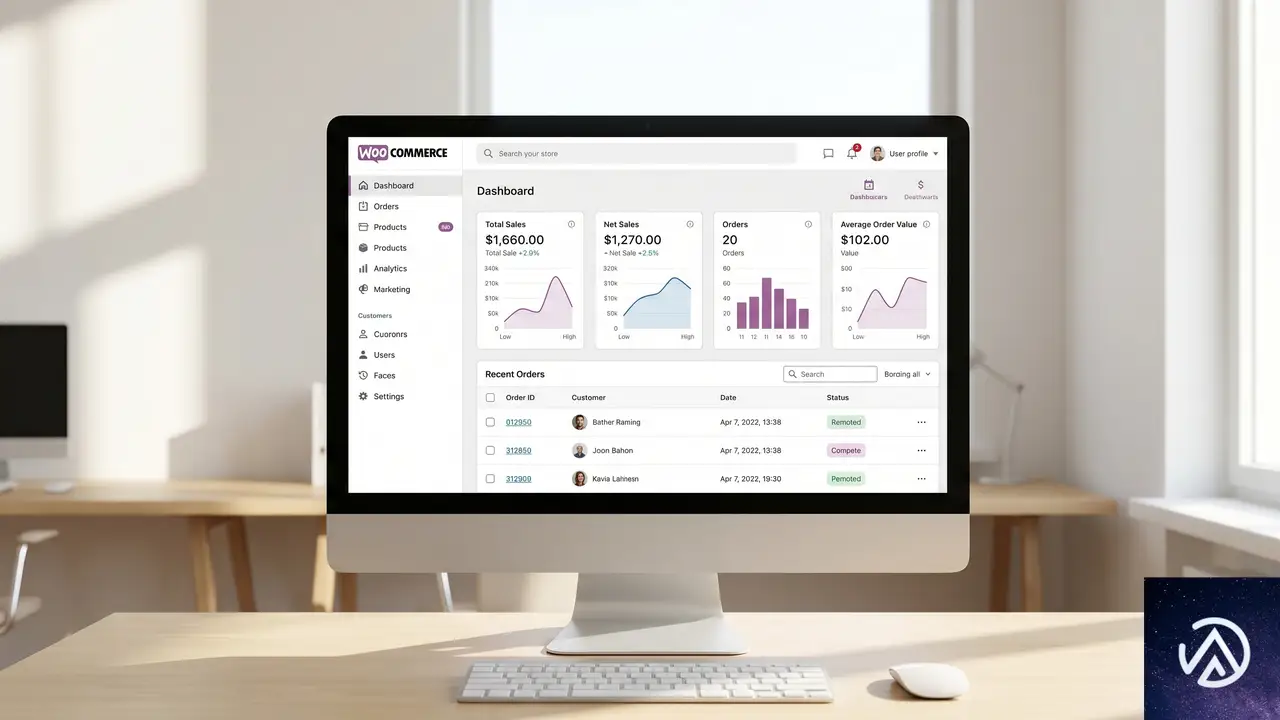
店舗の管理画面にアクセスしたときに「すっきりした」と感じるようであれば、それは錯覚ではない。10.9 では WooCommerce の管理ヘッダーが WordPress のデザインシステムに合わせて洗練され、全体的な見た目が統一される。
加えて、小さな画面サイズで表示が崩れていた管理画面の各ビューには個別の修正が行われ、管理画面全体で利用されるモーダル(ポップアップ)も一貫性のあるスタイルに揃えられた。これまで各ページでちらばっていた「タスクリストのリマインダーバー」は大部分の管理画面から削除されるが、初期設定の案内自体は WooCommerce ダッシュボードやアクティビティパネルから引き続き確認できる。
この UI 調整は、一見すると小さな変更に見えるが、日常的に管理画面を操作する運営者にとっては、不要な情報を減らし、必要な操作に集中しやすくなる利点がある。パフォーマンス面でも、画面描画に使われる余分な JS や CSS が整理されているため、軽量化にもつながっている。
トランザクションメールのログ機能がコアに実装
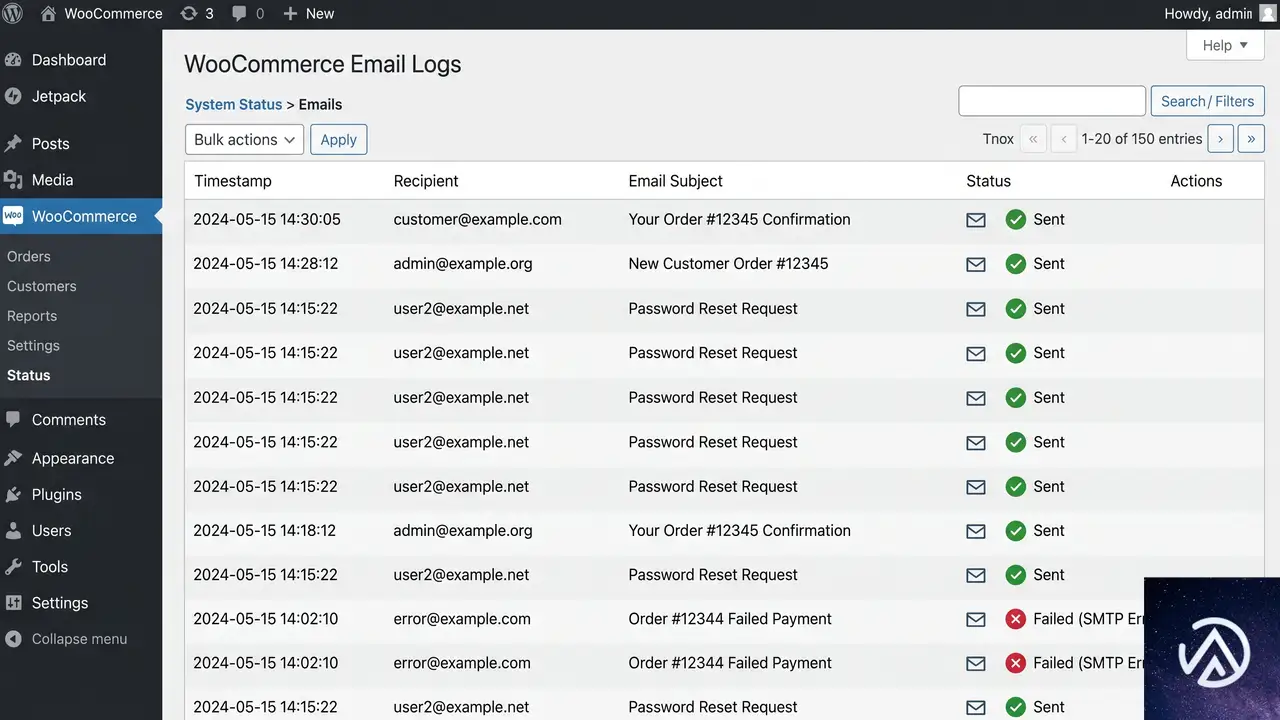
これまで WooCommerce で送信される注文確認メールやステータス更新のメールが「届いていない」というトラブルに遭遇した場合、原因を特定するには別途メールログ用のプラグインをインストールするか、テストメールを手動で送信するしかなかった。
10.9 からは、こうしたトランザクションメールの送信状況が WooCommerce コア内で直接記録されるようになる。ログは WooCommerce → ステータス → ログ の画面から確認でき、送信結果(成功・失敗)や、利用可能な場合は失敗理由も表示される。新たにプラグインを追加する必要はない。
この機能により、店舗運営者はメール不達の調査がはるかにスムーズになる。ログには日時やトリガーとなったアクションも含まれるため、顧客から「メールが届かない」という問い合わせがあった際、迅速に状況を確認できるようになるだろう。
実験的機能の最新情報

WooCommerce 10.9 は Automattic の「Radical Speed Month」の勢いもあり、数多くの実験的・ベータ機能が盛り込まれている。いずれもオプトインまたは機能フラグで有効化するタイプだが、将来の標準機能を見据えた重要な布石だ。
Canonical WooCommerce abilities 〜商品と注文の操作を抽象化〜
WooCommerce 10.9 では、商品や注文を操作するための最初の「カノニカル(標準的)な abilities」が導入される。abilities は、REST API のエンドポイントを 1 対 1 でラップするのではなく、スキーマで定義されたビジネス操作(商品の問い合わせ、作成・更新、注文の検索、ステータス変更、注文メモの追加など)を、権限チェックやメタデータを伴って提供する仕組みだ。
これにより、WooCommerce は WordPress Abilities API や MCP、管理ツール、CLI、自動化処理、そして将来のあらゆる「エージェント」インターフェースに対して、トランスポートに依存しない共通の契約を持つことになる。最初に商品と注文の abilities が提供され、既存の WooCommerce 専用 MCP エンドポイントは猶予期間として残される。さらに、同じパターンがサブスクリプションや決済口座、配送ルール、商品アドオン、ギフトカードといった拡張機能の領域にも展開される予定だ。
商品管理エディタの移行と製品エディタ v2 の廃止予定
実験的な商品カタログエディタは 10.9 でも成熟を続けており、クラッシュリカバリ、ドロワーや URL 状態の処理改善、よりタイプを認識したクイック編集フィールド、バリエーション編集の強化などが含まれる。一方で、ブロックベースの製品エディタ(Product Editor)ベータとその拡張 API は、WooCommerce 11.0 での削除を前に非推奨となる。
拡張機能の開発者はこの API を利用しているかを今すぐ監査し、移行パスを計画する必要がある。ただし、この廃止は WooCommerce 内の商品データやコンテンツには一切の影響を及ぼさないため、商品情報そのものが消える心配はない。
バリエーション画像ギャラリーとカラースウォッチ
同じ商品の色違いやサイズ違いに対して、画像ギャラリーを切り替える「バリエーション画像ギャラリー」がネイティブ機能として WooCommerce に追加される(デフォルトではオフ)。WooCommerce → 設定 → 詳細 → 機能 の「Variation gallery」トグルから有効化できる。
さらに、ビジュアル属性とカラースウォッチも機能フラグ制御で試験的に導入される。属性の各項目(例えば「赤」「青」)に色データや画像データを持たせ、商品フィルターやバリエーションセレクターのブロックでスウォッチを表示できるようになる。ストア API のレスポンスも、ビジュアル属性が必要な場合にだけ関連フィールドを返すよう配慮されているため、既存の連携に影響は少ない。
この他にも、買い物客向けのコレクション機能(ウィッシュリストや後で買う)、ブロックベースのメールエディタのテンプレート更新検知と部分適用、在庫復活通知、顧客レビューリクエストメール、実験的なデュアル API と GraphQL 基盤など、多岐にわたるベータ機能が同時に公開されている。いずれも開発者フィードバックを受け付けながら、今後のバージョンで徐々に本格導入される見込みだ。
この記事のポイント
- WooCommerce 10.9 では、決済前の下書き注文作成が遅延され、データベース負荷が大幅に軽減される
- 管理画面のヘッダーやモーダル、タスクリストの表示が整理され、よりスッキリした UI に
- メール送信の成否を WooCommerce の管理画面内でログ確認できるようになった
- 商品と注文の操作を抽象化する abilities や、バリエーション画像ギャラリーなど実験的機能が多数追加
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

スクロール駆動アニメーションとスクロール状態、ビュー遷移の違いを整理
CSSのスクロール系アニメーションは混同しやすい概念が多い。スクロール駆動アニメーション、スクロールトリガーアニメーション、コンテナクエリのスクロール状態、そしてビュー遷移。いずれも「動き」を伴う機能だが、仕組みは大きく異なる。それぞれの動作を整理し、いつどの技術を使うべきかを明確にする。
CSS-Tricksの著者Geoff Graham氏も自身の記事で「言いたいことと意味することが違っていたり、必要な場面で別のものを選んでしまったりする」と述べており、開発者であれば誰もが直面する混乱だ。この記事では、4つの技術の本質的な違いをデモとともに確認していく。
スクロール駆動アニメーションとは
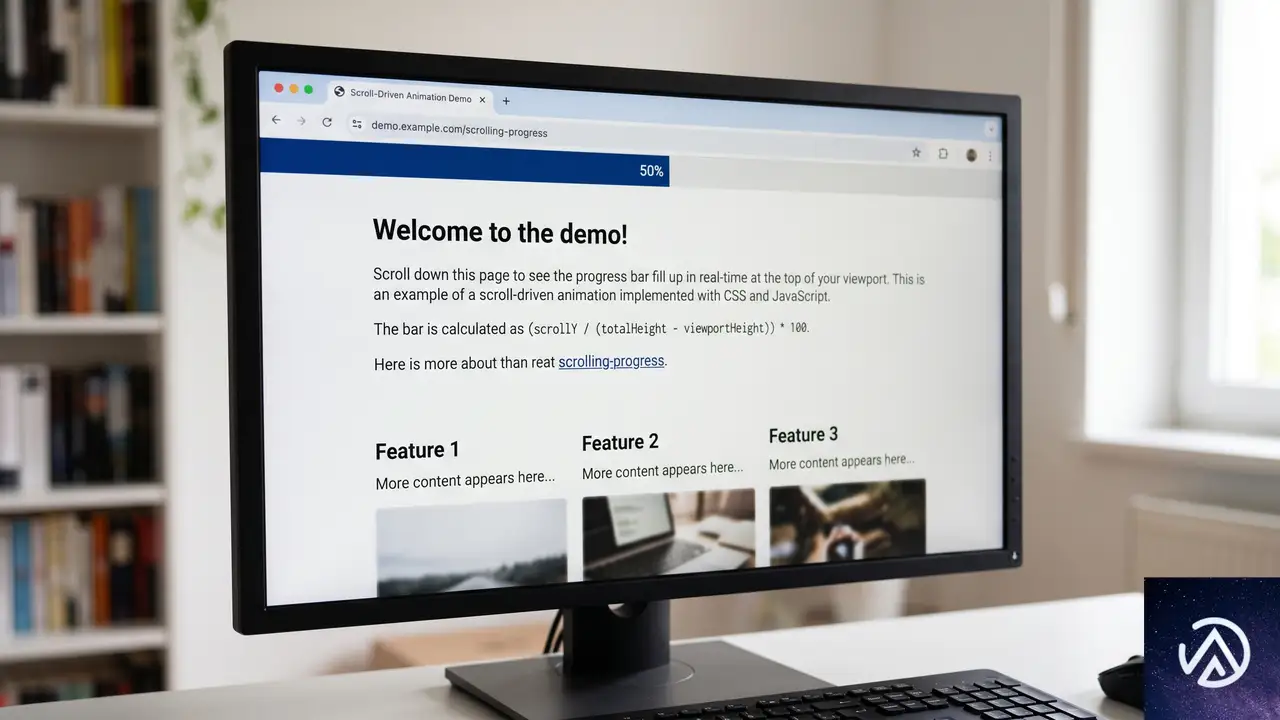
スクロール駆動アニメーション(Scroll-Driven Animations)は、スクロールの進行状況とアニメーションの進行が直接連動する仕組みだ。ユーザーがスクロールバーを動かすとアニメーションが同じ比率で動き、スクロールを止めればアニメーションも止まる。逆方向にスクロールすれば、アニメーションも逆再生される。
これはつまり、スクロール位置がアニメーションのタイムラインを完全にコントロールすることを意味する。アニメーションの各フレームがスクロールの各ピクセルに紐づいているイメージだ。
このデモで示すように、スクロール駆動アニメーションはスクロールという入力装置がそのままアニメーションの進行度を決める。ユーザーが任意の位置で停止できるし、前後にも動かせる。パララックス効果やプログレスバーなど、スクロールに完全に同期した視覚効果を作るのに向いている。
基本的なCSSの書き方
.element {
animation: grow-progress linear forwards;
animation-timeline: scroll();
}animation-timeline: scroll() がキモだ。通常のアニメーションは時間ベースのタイムラインで動くが、これをscroll()にすることで、スクロール位置をタイムラインとして使えるようになる。これにより、スクロール量に応じて要素の透明度・サイズ・位置などを段階的に変化させられる。
スクロールトリガーアニメーションとは
スクロールトリガーアニメーション(Scroll-Triggered Animations)は、スクロール駆動と名前が似ているが、動作原理はまったく異なる。こちらはスクロール位置とアニメーション進行が連動しない。ある要素が特定のしきい値(トリガー活性化範囲)を越えた瞬間にアニメーションが発火し、最後まで一気に実行される。
トリガーは要素がスクロールポートに「入った」「出た」といったイベントだ。アニメーションが走り出してしまえば、その後のスクロール操作は関係ない。スクロール駆動アニメーションが「巻き戻せるビデオテープ」だとすれば、スクロールトリガーアニメーションは「一度押したら最後まで流れる再生ボタン」だ。
どんな場面で使うか
画面に要素が現れた瞬間にフェードインさせたり、スライドインさせたりするUI演出が代表的な用途だ。一度表示された後にスクロールで逆再生する必要がなければ、トリガー方式のほうがシンプルで意図が明確になる。逆にパララックスやプログレスインジケーターのように常時追従が必要な場合は、スクロール駆動を使う。
コンテナクエリのスクロール状態
コンテナクエリのスクロール状態(Container Query Scroll State)は、CSS Conditional Rules Module Level 5のワーキングドラフトに含まれる比較的新しい概念だ。一言でいうと、コンテナが特定のスクロール条件に達したときにスタイルを更新する仕組みである。
スクロール駆動とスクロールトリガーの中間のような動きをする。スクロール位置に応じて何かが変わる点では駆動に近いが、アニメーションではなく「状態の切り替え」を扱う点が異なる。
.sticky-nav {
container-type: scroll-state;
position: sticky;
top: 0;
@container scroll-state(stuck: top) {
background: orangered;
border-radius: 0;
flex-direction: row;
width: 100%;
a {
text-decoration: none;
}
}
}この例では、position: stickyのナビゲーションがビューポート上部に張り付いた瞬間にレイアウトや配色が切り替わる。JavaScriptなしでスクロールに応じた状態管理をCSSだけで行える点が強力だ。ただし、2026年6月時点ではまだワーキングドラフト段階であり、ブラウザの対応状況を確認してから使う必要がある。
ビュー遷移(View Transitions)
ビュー遷移は、ここまでの3つとは根本的に異なる。スクロールとは関係がない。CSSとJavaScriptが連携する完全なAPIで、ページ遷移や同一ページ内の状態変化をアニメーションさせる仕組みである。
同一ドキュメント遷移
同一ドキュメント遷移(Same-document transitions)は、ユーザー操作によって同一ページ上の要素がある状態から別の状態へ変化する際に使う。たとえばラジオボタンの選択状態が別の項目に移動するアニメーションや、グリッドビューからリストビューへの切り替えアニメーションなどが該当する。
クロスドキュメント遷移
クロスドキュメント遷移(Cross-document transitions)は、ページAからページBへ移動する際のアニメーションを実現する。デフォルトではクロスフェード(ページAが徐々に消え、ページBが徐々に現れる)で、実装も比較的簡単だ。複雑なエフェクトも可能で、たとえば円形のclip-pathで最初のページをワイプアウトしながら次のページを表示する、といった演出もできる。
ビュー遷移の大きな利点は、MPA(マルチページアプリケーション)でもSPA(シングルページアプリケーション)のようなスムーズなページ遷移を実現できることだ。ChromeチームのBramus氏が多数の美しいデモを公開しており、実践的な実装例も増えている。
4つの技術をどう使い分けるか

ここまでの整理を踏まえて、実務での使い分けを考える。選択の基準は「スクロールとアニメーションがどう関係するか」に尽きる。
スクロール駆動はスクロール量に完全同期させたい場合、スクロールトリガーは「画面に入ったらポン」と動かしたい場合、スクロール状態は「ある条件下で見た目をパッと切り替えたい」場合、ビュー遷移は「ページ間や状態間をなめらかにつなぎたい」場合に選ぶ。
技術選定でよくある失敗は、スクロール駆動で十分な場面でトリガーを使ってしまったり、逆にトリガーで済む場面で複雑な駆動ロジックを書いてしまうことだ。要件に対してシンプルなほうを選ぶのが鉄則である。また、ビュー遷移をスクロール系の技術と混同しないことも重要だ。ビュー遷移はスクロールとは独立したレイヤーで動作するため、併用も可能だが別物として扱う必要がある。
この記事のポイント
- スクロール駆動アニメーションはスクロール位置とアニメーション進行が双方向に連動する
- スクロールトリガーアニメーションはしきい値で発火し、最後まで一気に実行される
- コンテナクエリのスクロール状態は特定のスクロール条件でスタイルを切り替える(ドラフト段階)
- ビュー遷移はスクロールとは無関係で、ページ遷移や状態変化をアニメーションさせるAPI
- 実装前に「スクロールとどう関係するか」を明確にし、最もシンプルな技術を選ぶ
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Redditが生成AIの表示順位を左右する。実データが示す影響力と企業が取るべき対策
生成AIが回答の情報源として最も参照するプラットフォームがRedditだ。SEO対策から「AI最適化」へと重心が移りつつある今、Redditでの立ち振る舞いを無視することはビジネス上のリスクになりつつある。
AI最適化プラットフォームProfoundが2026年5月に公開した分析によれば、ChatGPTがユーザーの質問に回答する際、訓練データとリアルタイム検索の双方でRedditの情報を最大の情報源として利用しているという。Redditはもはや単なる掲示板ではない。大規模言語モデル(LLM)があなたのブランドについて「知っていること」そのものを形成する場になっている。
この記事では、Redditの投稿がどのように生成AIの回答を左右するのか、その具体的なデータを示すとともに、企業が取るべき具体的な対策を解説する。
ChatGPTがRedditを最重要視する理由
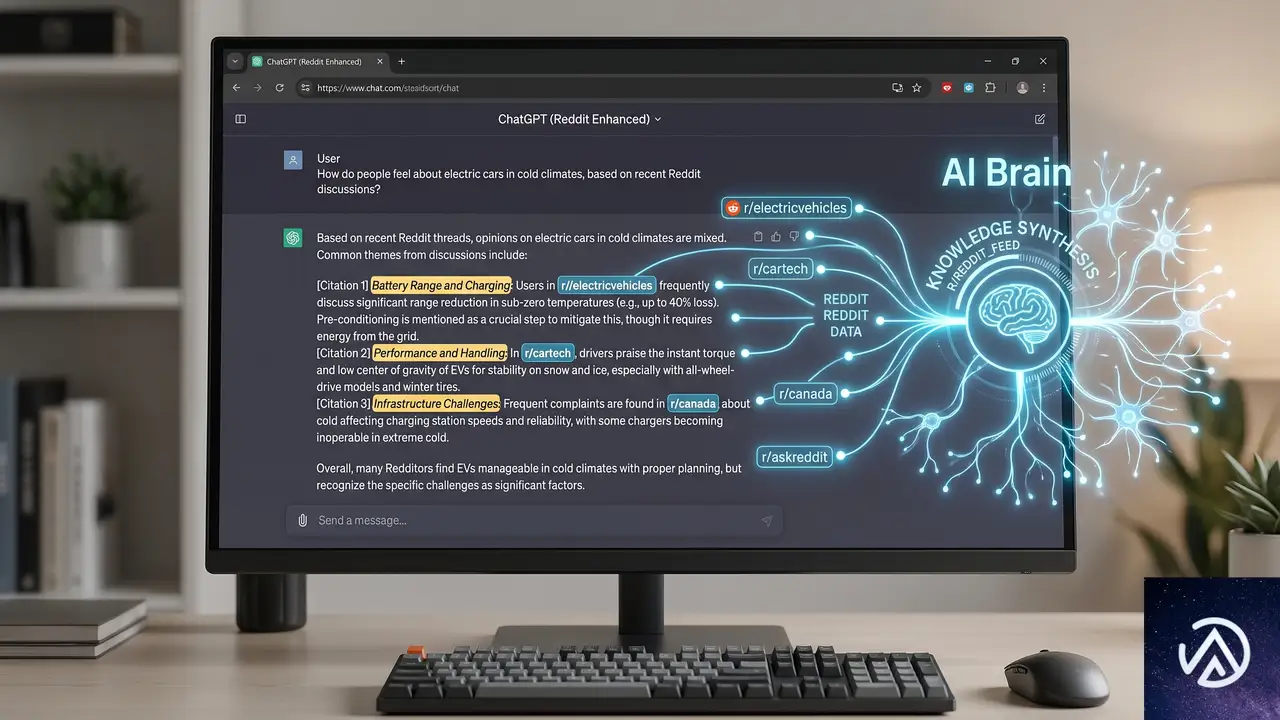
実務者の間では「Redditの影響力が増している」という肌感覚が広がっていた。だが、AIリサーチ企業Profoundの分析は、それを単なるトレンドではなく確固たるデータとして裏付けた。同社が2026年1月から5月にかけてChatGPTの引用と「ファンアウト」データを解析した結果、Redditは引用回数でトップに立った。
ファンアウトとは、AIが1つの質問に対してどれだけ多角的に情報源を展開したかを示す指標だ。Redditはこのファンアウト数においても他を圧倒していた。つまり、ChatGPTは単にRedditを引用するだけでなく、1つのスレッドから複数の関連情報を芋づる式に収集し、回答の骨格を作っている。
検索クエリへの「reddit」自動付与
この解析で興味深いのは、ChatGPTがリアルタイム検索を実行する際、クエリの末尾に「reddit」というキーワードを自発的に追加する挙動が確認された点だ。人間が「商品名 レビュー Reddit」と検索するのと同じ行動を、AIが自律的に行っている。生成AIが「実体験に基づく生の声」を求めている証左といえる。
従来の検索エンジン最適化が「アルゴリズムに評価される公式情報」を重視していたのに対し、AI最適化では「訓練データとライブ検索の両方で参照される草の根の評判」が問われる。Redditがその中心にある。
安易な口コミ操作が通用しない構造的理由
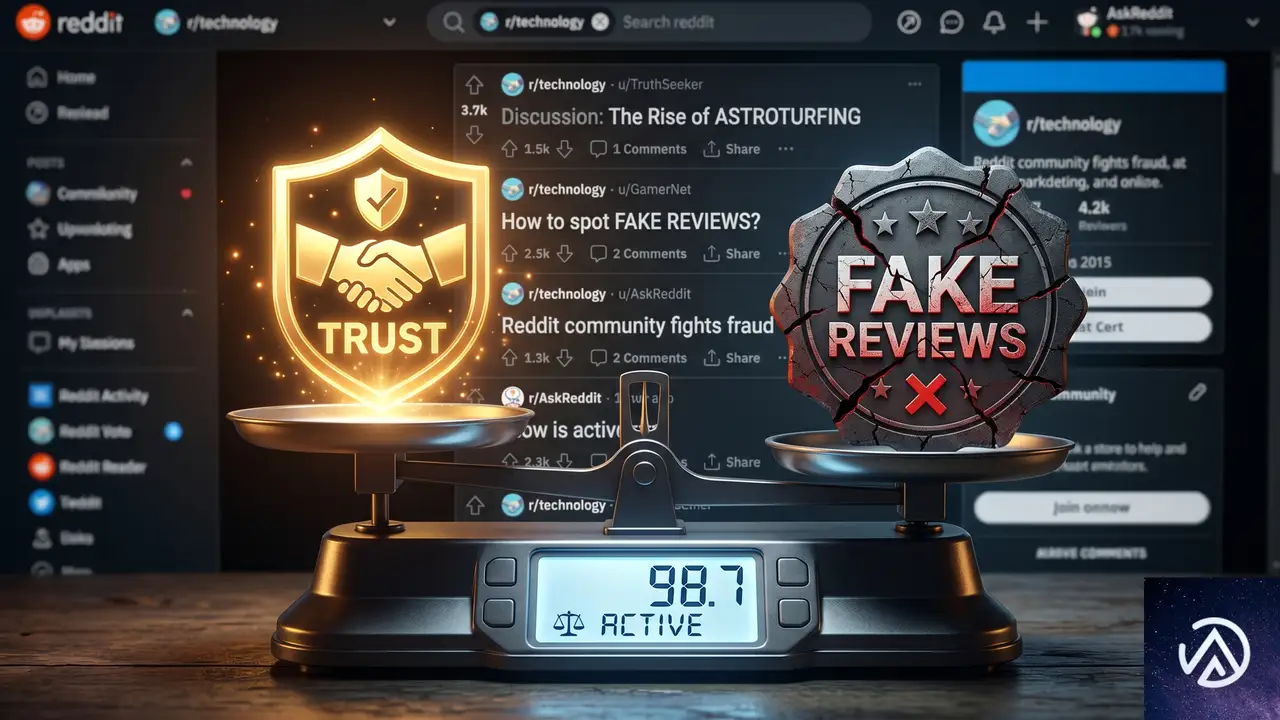
ここで多くの企業が「ならばRedditに肯定的な投稿を大量にすればいい」と短絡的に考える。だが、生成AI時代のReddit戦略は、そうした「やらせレビュー」的な手法とは根本的に相性が悪い。構造的な理由が2つある。
訓練データに刻まれたネガティブ情報は消せない
1つ目は、LLMの訓練データの問題だ。仮にReddit上の自社に不都合なスレッドをModeratorに削除してもらえたとしても、その情報はすでにGPT-4やClaudeといったモデルの訓練データに組み込まれている。モデルの重みの中にネガティブな文脈が残り続けるため、単純な「投稿削除」ではAIの感情分析(センチメント)を覆せない。
Redditのコミュニティは作為を見抜く
2つ目は、サブレディット(コミュニティ単位の掲示板)の自主管理能力の高さだ。各サブレディットには人間のModeratorが存在し、不自然なプロモーション投稿や作為的なポジティブレビューは極めて高い精度で検知される。露骨なステマが削除されるだけでなく、アカウントがスパム判定を受ければドメイン単位でブランドの信用が失墜するリスクもある。
重要なのは、AIは情報の「出所」よりも「文脈」と「一貫性」を評価する傾向がある点だ。作為的なポジティブキャンペーンは、むしろAIによる評価を歪ませ、長期的にはブランド毀損につながりかねない。
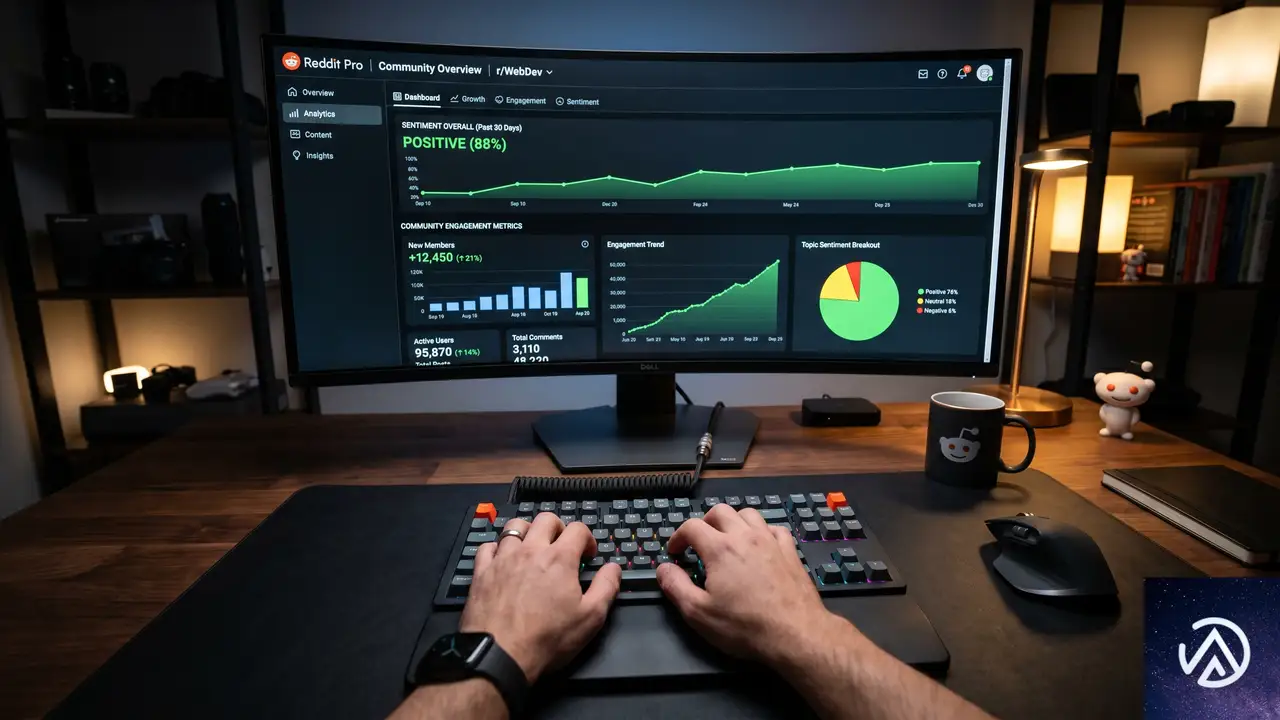
RedditでAI表示を味方につける3段階のプロセス
では、企業は具体的に何をすればいいのか。短期的なハックではなく、AIとアルゴリズムの両方に評価される正攻法のプロセスを3段階に分けて解説する。
STEP 1. 観察に徹してコミュニティの文法を学ぶ
Redditビジネスアカウントを作成したら、すぐに投稿やコメントを始めてはいけない。少なくとも数週間は「ROM(Read Only Member)」として、ターゲットとするサブレディットの文化を観察する期間を設ける。
各サブレディットには明文化されたルールに加え、暗黙の行動規範がある。企業アカウントがそれを無視して宣伝めいた投稿をすれば、即座にアカウント停止(BAN)の対象となる。Redditのアカウント停止は異議申し立てが極めて困難なことで知られており、一度BANされるとブランド名で再登録すること自体が難しくなる。
STEP 2. Reddit Proで自社の立ち位置を可視化する
観察期間と並行して、Reddit Pro(無料のビジネス向け分析ツール)の導入をお勧めする。このツールを使うと、以下の情報がダッシュボードで把握できる。
- ユーザーが自社ブランドについてどのような文脈で言及しているか
- 競合ブランドと比較した際のセンチメント(肯定的・否定的感情)の差異
- 自社の製品カテゴリに関連して今活発に議論されているスレッド
闇雲に投稿する前に、データに基づいて「どのサブレディットで、どんなトピックなら、企業として価値を提供できるか」を特定することが先決だ。
STEP 3. ブランド認知より「権威構築」を優先する
初期の投稿やコメントでは、自社製品の宣伝を一切排除し、純粋に専門知識を提供することに集中する。たとえば、ECプラットフォームを提供する企業なら「物流のボトルネックを解消するパッキングの工夫」、マーケティングツール企業なら「GA4で離脱率を下げるレポートの読み方」といった具合だ。
この段階でブランド名を出すことは、コミュニティから「売り込み」と見なされるリスクが高い。まずは個人としての信頼を積み上げ、その後に「そういえば、この分野のプロダクトを開発している」と自然に言及できる流れを作る。
ブランド専用サブレディットという選択肢

自社ブランドへの言及が一定数を超えてきた段階で、ブランド専用のサブレディットを開設することも有効な一手だ。すでに多くのテック企業がこの手法を取り入れている。
専用サブレディットの利点は、分散していた自社関連の会話を一箇所に集約できる点にある。ユーザー同士のQAやトラブルシューティングが活発になれば、それはそのままLLMが参照する「構造化されたナレッジベース」として機能する。サポートコストの削減とAI表示の最適化を同時に実現できるわけだ。
ただし、ここでも運営姿勢が問われる。企業が一方的に情報を発信する場ではなく、ユーザーが自由に意見を交わせる「公共広場」としての設計が不可欠だ。Moderatorが批判的な投稿を削除するような運営は、Reddit全体からの強い反発を招く。
この記事のポイント
- RedditはChatGPTが回答を生成する際の最重要情報源であり、訓練データとリアルタイム検索の双方で参照される
- ネガティブスレッドの削除や偽のポジティブ投稿は、LLMの訓練データに残る情報を覆せず、コミュニティからも排除されるリスクが高い
- アカウント作成後はまず観察に徹し、Reddit Proでデータを分析した上で、ブランド宣伝ではなく専門知識の提供による権威構築を優先する
- 長期的な視点でコミュニティに貢献し、AIに「信頼できる情報源」として学習させることが、生成AI時代のブランド防衛につながる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

法務事務所を狙うデータ恐喝の新手口、遠隔操作から「直接訪問」へ進化
機密文書を扱う法務事務所や士業が、新種のデータ恐喝集団「UNC3753」の標的になっている。Google傘下の脅威分析チーム「Mandiant」が2026年6月5日に公開した報告によると、2026年1月から5月にかけて、全米の法律・金融サービス企業数十社が被害に遭った。攻撃者は電話で偽のITサポートを装い、社内の誰もが持つ画面共有ソフトを悪用してネットワークに侵入する。この手口はテクニカルなハッキングというより、巧みな会話術と信用の悪用で成立する。1営業日以内に情報窃取から恐喝までを完了するスピード感も特徴だ。
さらに深刻なのが、遠隔操作が失敗した場合には「直接オフィスを訪問する」物理的な侵入へのエスカレーションが確認されている点だ。FBIも注意喚起を出したこの事案は、大企業だけの問題ではない。顧客情報や契約書類を抱える士業や制作会社も、十分な対策が求められる。
法務事務所を狙う「偽のITサポート」電話が増加している

この攻撃キャンペーンの主体は、Mandiantが「UNC3753」と呼ぶ経済動機の脅威クラスターだ。2022年3月から活動が確認されており、別名として「Luna Moth(ルナ・モス)」「Silent Ransom Group(サイレントランサムグループ)」とも呼ばれる。元々は請求書を装ったPDFファイルをメールに添付し、偽のコールセンターに電話させる手口を使っていた。しかし2025年3月頃から戦術を変更し、企業内部のITヘルプデスクを名乗る「Vishing(音声フィッシング)」へと完全にシフトした。
この変化には明確な理由がある。メールフィルタやアンチウイルスが高性能化し、マルウェア付き添付ファイルは検知されやすくなった。しかし電話での指示を疑うセキュリティソフトは存在しない。音声フィッシングは防御側の「技術で壁を作る」前提を完全にすり抜ける。
メールは「呼び水」、本番は電話で始まる
攻撃は次の2段階で進む。まず一般消費者向けメールアドレスから「hello, here is the invcoie we talked about yesterday(昨日話した送り状です)」といった短いメールを送りつける。リンクも添付ファイルもなく、セキュリティ検査を素通りする。だがタイプミスを含む不自然な文面は受信者に「怪しい」と思わせる効果があり、まさにそれが狙いだ。標的が警戒したタイミングで、社内IT担当を名乗る電話がかかってくる。「不審なメールが届いていませんか」と切り出すことで信頼を獲得し、画面共有に誘導する。
偽のITサポートが社内ネットワークに侵入する流れ

UNC3753の侵入フローは、技術的には「正規ツールの悪用」で構成される。マルウェアの注入も、脆弱性攻撃も行われない。このため、侵入検知システムやアンチウイルスに記録が残らず、事後の調査を困難にしている。
Mandiantの調査では、この一連の流れがわずか1時間足らずで完了したケースも確認されている。攻撃者はiManageのような文書管理システムを熟知しており、W-2(給与税務申告書)や監査ファイルといった「人質として価値の高い文書」を狙い撃ちする。
個人所有のPCを経由してVDI環境に侵入する抜け穴
もう一つの特徴的な手口が、VDI(仮想デスクトップ環境 / Virtual Desktop Infrastructure)の悪用だ。在宅勤務の社員が私物のPC(BYOD / Bring Your Own Device)で業務システムにアクセスする構成を、攻撃者が逆手に取る。画面共有を仕掛けた社員の個人PCを経由し、VDIクライアント(Windows 365やCitrix)を介して企業の内部ネットワークに自由にアクセスする。会社支給の端末にセキュリティソフトが導入されていても、私物PCの画面共有からは検知できない。
データの送信方法も巧妙化している
窃取したファイルの送信には以下の3つのルートが使い分けられる。1つ目はWinSCPやRcloneといったコマンドラインベースの同期ツールを使った大量転送だ。Mandiantの報告によると、ある被害者ではローカルのOneDriveフォルダから1.7ギガバイト、VDIセッションから追加で14.4ギガバイトが一気に流出した。2つ目はPrivnoteのような「開封後に消えるメモサービス」を使った遠隔指示の中継だ。攻撃者はインストール先URLやコマンドをPrivnote経由で渡し、社内のブラウザ履歴やチャットログに痕跡を残さない。3つ目はごく単純に、被害者のブラウザで直接Googleドライブにログインさせる手口だ。標的企業の名前を付けたフォルダにデータをドラッグ&ドロップさせ、事後に消去を指示する。
「直接訪問」に進化する物理的な脅威

Mandiantの報告で特に目を引くのが、遠隔操作が通用しなかった場合の物理侵入だ。これは単なる仮説ではなく、FBIが2026年5月に発出した「Cyber FLASH Alert」で具体的に警告されている。IT技術者を装った第三者が実際のオフィスを訪れ、「デバイスのイメージ取得が必要」「セキュリティ上の緊急対応」と言ってPCにUSBメモリを差し込ませ、直接データを吸い出す手口が確認された。
技術的な防御が高度化するほど、それを迂回する「人間」を狙う攻撃は増える。物理セキュリティはサイバーセキュリティの一部であり、切り離して考えてはならない。
不正送金より深刻な「データ人質」の手口
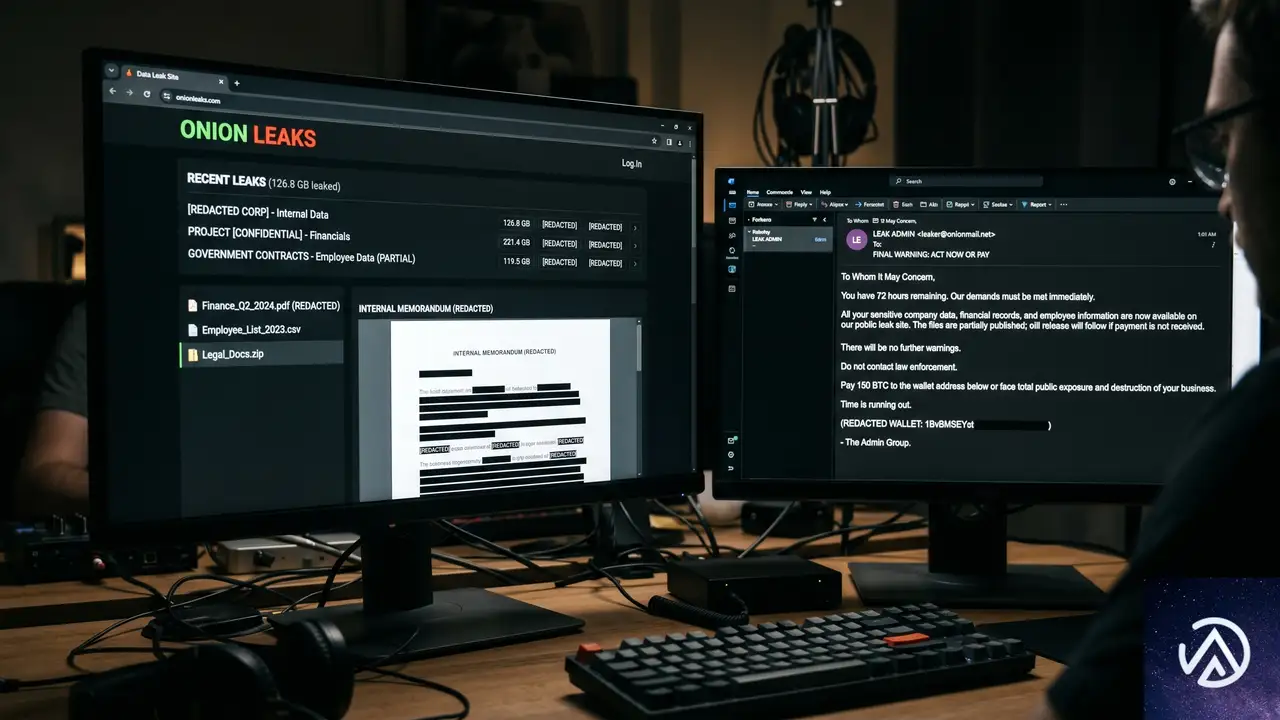
UNC3753の最終目的はファイルを暗号化して身代金を要求する「ランサムウェア」ではない。窃取した機密情報を人質に取り、「3日以内に交渉を始めなければ顧客や取引先に直接リークを通報する」と脅して金銭を要求する「データ恐喝」だ。法務事務所や会計事務所にとって、顧客データの流出はビジネスそのものを揺るがす致命的な事態になる。恐喝メールでは「顧客の信頼は失墜し、多額の規制当局による罰金が発生し、データ管理責任を問われて顧客から訴訟を起こされる」と明記される。心理的圧力を最大限に高める文面だ。
要求に応じなければ、実際に「LEAKEDDATA」というデータリークサイトで情報を公開する。支払ったとしてもデータが確実に削除される保証はなく、沈黙の代償が更なる恐喝を呼ぶリスクもある。この種の「身代金を支払わない」方針を事前に決め、防御にリソースを振ることが重要だ。
今日から始める中小企業の防御策

UNC3753の手口は大手向けに見えるが、個人情報を扱う税理士事務所やWeb制作会社でも全く同じ被害構造が成立する。Google Threat Intelligence Groupの推奨事項を元に、中小企業向けの実践的な対策を示す。
社内教育を最優先に設計する
不審な電話がかかってきた場合の対応手順を社内で標準化しておくべきだ。「社内ヘルプデスクを名乗っても、まず上司や情報システム担当に転送する」というシンプルなルールを周知するだけで、初期侵入の大半を防げる。特に「データ移行プロジェクト」や「セキュリティ上の緊急対応」と言われたら、一度電話を切り、会社に登録されている正規の内線番号にかけ直す習慣を徹底させたい。
VDIとBYODの認証を強化する
個人のPCやタブレットから社内の仮想デスクトップ(VDI)に接続する構成は、多要素認証(MFA)の強化が不可欠だ。さらに「会社支給端末以外からのVDI接続を禁止する」という条件付きアクセスポリシーを設定できれば、私物端末を経由した遠隔操作のリスクを大幅に下げられる。
正規のリモート管理ツールも制限する
AnyDeskやZoho Assistが攻撃に使われる現実を踏まえ、会社で業務利用するリモート管理ツールを限定し、それ以外のインストールをAppLockerやWindows Defender Application Controlで制限する構成が有効だ。ZoomやTeamsの画面共有機能についても、社内ポリシーで利用ガイドラインを定めておくべきだ。
USBメモリの物理的な対策
会社の全PCでUSBストレージの書き込みを無効化する設定は、グループポリシー(GPO)を使えば比較的簡単に実装できる。外部メディアを業務で使う場合も、必ず情報システム担当者が解錠する運用にすることで、なりすましの技術者がUSBメモリでデータを抜く物理攻撃を封じられる。
ネットワーク監視とログ設定
ファイアウォールで外部ファイル共有サービスへの接続を監視し、一定時間内に大量のSSHトラフィック(WinSCPやRcloneの転送に使われる)が発生した際にアラートを出すようにしておくと、データの一括送信を早い段階で検知できる。社内の文書管理システムでも、キーワード検索の急増や大量ダウンロードを監視対象に加えておくべきだ。
この記事のポイント
- 法務事務所を狙うUNC3753は、音声フィッシングで画面共有に誘導し正規ツールを悪用する
- メールは呼び水に過ぎず、マルウェアを使わないため従来の防御策では検知が難しい
- 遠隔操作が失敗すると、IT業者を装った直接訪問でUSBメモリを使った窃取に切り替える
- VDI環境と個人端末の認証強化、USB書き込み禁止設定が即効性の高い対策となる
- 攻撃の最終目的はデータ恐喝であり、要求に応じる前に防御と教育の強化を優先すべき
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験