

WooCommerce 10.9で取引メールログ機能がコアに統合、送信失敗の可視化でトラブル解決が容易に
WooCommerceのメールトラブルシューティング用ドキュメントは、サポート対応の中で常に上位のアクセス数を記録してきた。全サポートやり取りの1%以上で、最終的にこのドキュメントを案内する流れになっているという。こうした状況を踏まえ、WooCommerce開発チームは問題の切り分けに不可欠なログ機能をコアプラグインに組み込む判断を下した。
WooCommerce 10.9では、取引メール(トランザクショナルメール)の送信ログ機能が標準搭載される。店舗運営者はどのメールが正常に送信され、どのメールが失敗したのかをログで一元的に確認できるようになる。失敗時には具体的なエラー理由も記録されるため、従来のように外部のログ取得プラグインを導入する手間が省ける。
取引メールのログ機能の仕組み

このデモ図で示すように、従来はエラーのたびに外部ツールやプラグインを頼っていたが、10.9以降はWooCommerce本体が自動的にメール送信のログを取得する。店舗運営者の負担が一段階減る形だ。
内部設計の要点
新たに導入されるEmailLoggerクラスは、以下の4つのフックに接続される。これにより、メール送信のあらゆる局面を捕捉できる仕組みになっている。
- woocommerce_email_sent:WooCommerceがメールを送信するたびに発火し、成功または失敗の真偽値と
WC_Emailインスタンスを受け取る。 - woocommerce_email_disabled:メール種別が設定で無効化されていて送信が行われなかった場合に発火する。
- woocommerce_email_skipped:受信者が存在しないなどの前提条件を満たさず、送信がスキップされた場合に発火する。短い理由識別子も渡される。
- wp_mail_failed:WordPress全体のメール送信失敗フック。ここから
WP_Errorメッセージを取得し、SMTP接続エラーなどの具体的な原因をログに含める。
いずれの結果も、wc_get_logger()を通じて新しいソース名transactional-emailsの下に書き込まれる。WooCommerce標準のロガーを経由するため、店舗側がすでに設定しているログハンドラ(ファイルまたはデータベース)とログレベルしきい値をそのまま利用できる。
- ログハンドラ:デフォルトは
wp-content/uploads/wc-logs/ディレクトリへのファイル出力だが、WooCommerce > ステータス > ログ画面でデータベース保存に切り替えている場合はそちらが使われる。新たなストレージ層は不要だ。 - ログレベル:送信成功は
INFO、失敗はWARNING、無効化やスキップによる未送信はNOTICEとして記録される。本番環境でエラーレベルのみ取得する設定にしておけば、失敗だけを素早く把握できる。 - 保持期間:他のWooCommerceログと同様に、WooCommerce > ステータス > ログ > 設定から保持ポリシーを管理できる。
ログに記録される情報
各ログエントリは1行で完結し、大量のメールが飛び交う店舗でもストレージへの影響はほとんどない。文脈情報は次のような構造で出力される。
context = [
'source' => 'transactional-emails',
'email_type' => 'customer_processing_order',
'status' => 'sent' | 'failed' | 'disabled' | 'skipped',
'recipient' => 'jdoe' | 'guest' | 'jdoe, guest',
'reason' => 'no_recipient', // スキップ時のみ
'order' => 12345, // 注文ID、状況に応じて'product'や'user'が入る
]ログレベルが3段階に整理されているため、WARNINGなら即座に問題を疑い、NOTICEなら設定通りの挙動であることを確認し、INFOなら正常に送信されたと判断できる。フィルタリングやアラートの仕組みと組み合わせれば、運用の自動化にもつなげやすい。
注文画面での確認
ログとは別に、個々の注文に関連づいたメールの履歴が注文ノートにも表示されるようになった。WooCommerce > 注文から任意の注文を開くと、その注文に対して送信が試みられた取引メールとその成否が一覧できる。
ここで注意したいのは、注文ノートに表示されるのは「実際に送信が試みられたメール」だけという点だ。設定で無効化されているメール種別や、受信者不在でスキップされたものは表示されない。注文ノートを無駄に長くせず、期待される挙動とその結果に焦点を絞る設計思想がうかがえる。
プライバシーと拡張性への配慮

上図のように、メールアドレスが直接ログに書き込まれることはない。プライバシー保護と拡張性の両面に配慮した設計が盛り込まれている。
プライバシー保護の仕組み
受信者のメールアドレスはログに一切出力されない。resolve_recipient()メソッドが各アドレスをWordPressのユーザー名に変換する。アカウントを持たない購入者(ゲスト)の場合は'guest'というラベルに置き換えられる。BCCなどで複数の受信者がいる場合は、カンマ区切りのラベル一覧が記録される。
PHPMailerが返すエラー文字列には、しばしば受信者アドレスが直接埋め込まれているが、これもredact_emails()という正規表現によるスクラブ処理で除去される。この処理はRemoteLogger::redact_user_data()と同等のロジックを採用しており、WooCommerce全体で一貫したプライバシー保護が維持される。
拡張ポイント
WooCommerce 10.9では、メールログの動作をカスタマイズするためのフィルターフックが2つ追加されている。
- woocommerce_email_log_enabled:ログ出力の有効・無効を切り替える。グローバルに無効化したり、
$email_idをチェックして特定のメール種別だけ対象外にできる。 - woocommerce_email_log_context:ログに書き込まれる文脈情報を書き換える。フィルターには書き込み前の配列が渡されるため、項目の追加・削除・変更が自由に行える。
ログ機能そのものは、WooCommerce > ステータス > ログ > 設定タブから管理画面でオフにできる。特定の機能のみを無効にしたい場合は、以下のコードをテーマのfunctions.phpなどに追加する。
add_filter( 'woocommerce_email_log_enabled', '__return_false' );パフォーマンスへの影響を最小限にしたい場合や、すでに別のシステムでメールログを収集している場合は、このフィルターで柔軟に対応できる。
実装上の注意点と今後の展望

ログ機能にはひとつ、既知の制限が存在する。wp_mail_failedはWordPress全体のグローバルなフックであるため、WooCommerceのメール送信処理の直後に別のプラグインが送信に失敗した場合、そのエラーが誤ってWooCommerceのメールに紐づく可能性がある。
$last_mail_errorはWooCommerceのメール送信ごとにクリアされるため、古いエラーが後続の処理に引き継がれることはない。しかし、送信の直後という非常に狭い時間枠では、別のエラーが紛れ込む余地が理論上残る。この事象は実際にはまれであり、影響を受けるのは人間が読むための失敗理由テキストだけだ。email_typeやstatusといった主要な情報は常に正確である。
この取引メールログ機能は、Automatticが実施した「Radical Speed Month」の一環として開発された。まずは診断機能としての土台を固め、次のステップではWooCommerceが自らメールエラーを警告し、修正を支援する能動的なレイヤーの追加を検討しているという。トラブルシューティングにかかる時間をさらに短縮し、より多くの店舗運営者がメール問題に煩わされずに済む未来を描いている。
この記事のポイント
- WooCommerce 10.9から、取引メールのログ機能がコアプラグインに標準搭載される。外部ツール不要で送信の成否と失敗理由を把握できる。
- ログは
INFO(成功)、WARNING(失敗)、NOTICE(未送信)の3段階で出力され、管理画面の注文ノートにも関連メールの履歴が表示される。 - メールアドレスはログに直接記録されず、ユーザー名やゲストラベルに変換される。エラーメッセージ内のアドレス情報も自動で除去される。
- フィルターフックを使ってログ出力の無効化や文脈情報のカスタマイズが可能。パフォーマンスや既存システムとの兼ね合いで柔軟に調整できる。
- 開発チームは今後の展開として、エラーを自動検知して運営者に通知する仕組みの追加を視野に入れている。

・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AIエージェントに独自の権限モデルが必要な理由
“`html
AIエージェントの本番環境導入が急速に進んでいる。カスタマーサポートの自動化を例に取ると、チケット内容の読み取り、返金処理、社内エスカレーション、Slackへの通知まで、ひとつのタスクで複数のツールを横断する。適切に動作すれば、定型業務のコストを大幅に圧縮できる一方、失敗の仕方は従来の自動化とは根本的に異なる。非決定的な挙動を示し、本番権限を丸ごと握ったまま大規模に誤作動しうるからだ。
有用なエージェントには、複数ツールを動的に組み合わせる十分なアクセス権が必要だが、同時に永続的なスーパーユーザー権限で動かすわけにはいかない。開発現場では、長期有効なAPIキーを環境変数に埋め込んだり、人間向けOAuthフローを流用したりといった安易なパターンに陥りやすいが、これらは非決定的なソフトウェアのために設計されたものではない。プロンプトの設定ミスやツール応答の悪意ある操作が、重大なインシデントに直結する。
本記事では、自律システムに最小権限の原則を適用する具体的な方法を解説する。ケイパビリティ単位への権限スコープの絞り込み、実行計画に紐づく短命トークンの発行、アイデンティティと認可と実行のレイヤー分離、そして高リスク操作に対するヒューマンインザループ承認の組み込みが全体像だ。
AIエージェントと従来のアクセス制御のミスマッチ
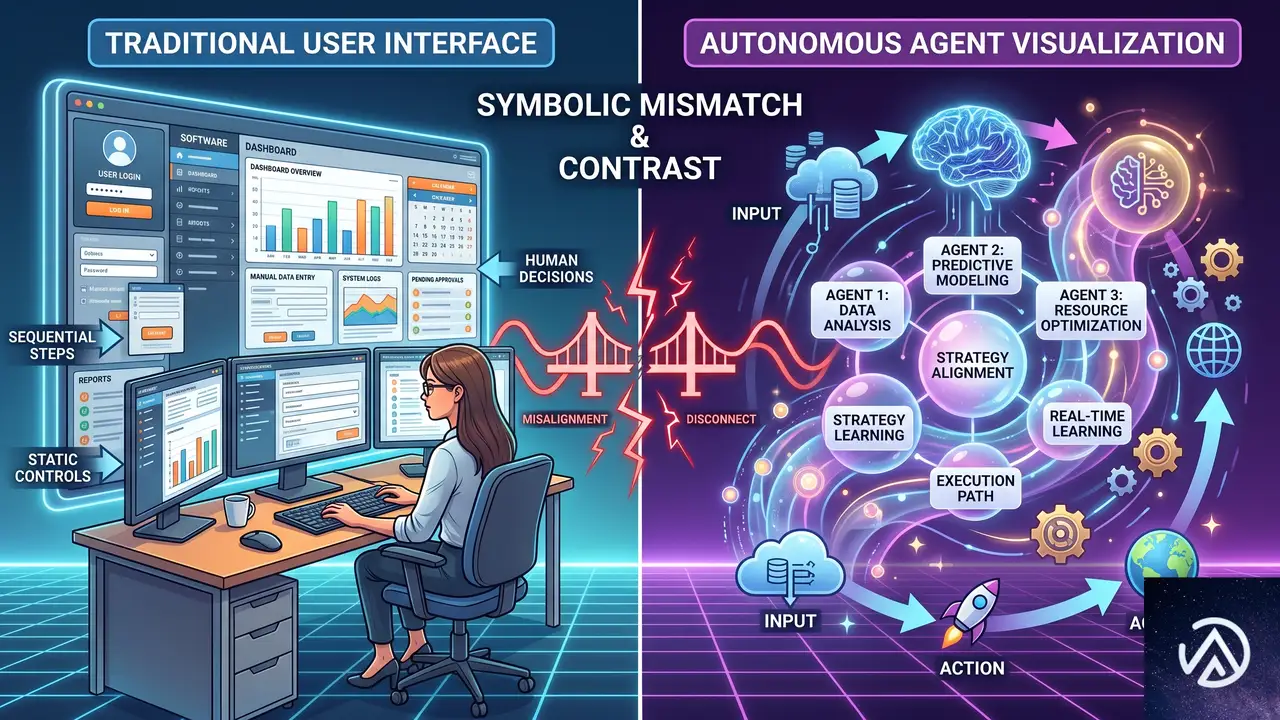
UIに縛られ予測可能
静的コードパス監査可
開発者が明示的に書いていない連鎖を生成
サブエージェントへの委譲でコンテキストが分散
従来のアクセス制御は対話型ユーザーか決定的なバックエンドサービスのいずれかを前提として設計されている。セッショントークンは対話的なフローを、サービスアカウントは決定的な挙動を想定している。ところがAIエージェントは、同じ入力を与えても実行のたびに呼び出すツールが変わる。開発者はコードとして書いていない連鎖をエージェントが自律的に生み出し、さらにサブエージェントを起動して委譲チェーンが広がる。このような非決定性は、従来の権限モデルが持つ「想定された範囲内」という前提を根底から崩す。
現場で陥りやすい3つのアンチパターン

どれも単体では「とりあえず動かす」ための合理的な選択に見えるが、組み合わさると致命的だ。長期有効なキーなら、エージェントがプロンプトインジェクションで騙されて認証情報を吐き出してしまう可能性がある。ユーザー同等のOAuthスコープでは、サポート担当が本来行使しない管理操作をエージェントが勝手に実行してしまう。スーパーユーザー権限は、一度の誤動作で取り返しのつかない損害を生む。Auth0の記事では、こうしたパターンがいかに簡単に深刻なインシデントへ発展するかが指摘されている。
ケイパビリティスコープで権限を細分化する
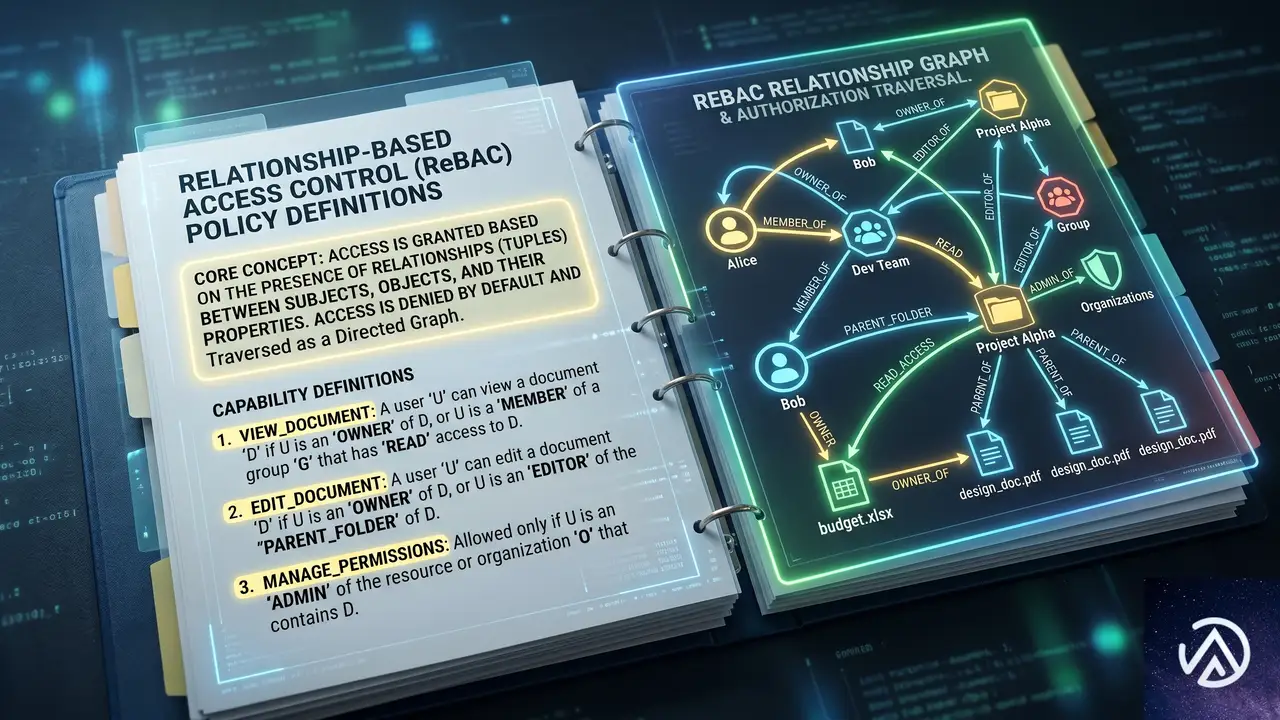
問題の根本は「リソース単位」の権限設計にある。従来のbilling:writeはカテゴリと動詞しか表現できず、金額の上限や操作の種類までは規定しない。これに対し、billing.refund.issue_under_50_usdのように「何ができるか」をケイパビリティとして定義すると、ビジネスロジックとアクセス制御が直接結びつく。プロダクトマネージャーが「サポートエージェントは50ドルまでの返金を自動で処理できる」と決めたら、そのルールは認可エンジンが評価する宣言的なポリシーとして管理される。
billing:writebilling.refund.issue_under_50_usdrefund_amount <= agent_limit を評価こうした制約を実装するには、リレーションシップベースアクセス制御(ReBAC)を採用するのが有効だ。Auth0が支援するOSSの認可エンジンOpenFGAでは、エージェントとリソースの関係性をモデル化し、「エージェントがアクティブなチケットを持つ顧客の注文のみ返金できる」といったポリシーを表現できる。さらに条件(Conditions)を組み合わせれば、返金額の上限や期限付きの権限付与といった属性ベースの制約も単一のチェックで評価可能になる。実際のDSLでは、can_refundリレーションにrefund_within_limit条件を付与し、タプル側にエージェントの上限額を保持、リクエスト時に実際の返金額をコンテキストとして渡して判定する。
タスクスコープの認証情報で有効期間を絞る

ケイパビリティスコープが「何ができるか」を定めるのに対し、タスクスコープは「いつまでできるか」を制御する。エージェントに永続的なクレデンシャルを持たせるのではなく、実行計画のたびに短命なトークンを発行する設計だ。トークンは数分で失効し、必要最小限のケイパビリティだけを運ぶ。
Auth0のToken VaultはこのパターンをOAuth 2.0 Token Exchange(RFC 8693)に準拠して実装している。リフレッシュトークンは認可サーバー側に留められ、エージェントには必要に応じてスコープを絞ったアクセストークンのみが渡される。サポートエージェントが返金を実行する際、事前に返金可能なトークンを保持しているわけではない。ランタイムがポリシーを評価し、金額・顧客状態・リレーションシップのすべてを確認した上で、その操作専用のトークンを要求する。タスク間でエージェントが侵害されても、以前のトークンはすでに失効しており、新たな悪用には改めてポリシーチェックを通過する必要がある。
アイデンティティ・認可・実行を3層に分離する

エージェントのアクセス制御を設計する際、「誰か」「何が許されるか」「実際に何が起きるか」の3つを混同しないことが重要だ。これらはしばしば1つの実装に押し込められがちだが、独立したレイヤーとして切り離すことで安全性が格段に向上する。
この分離により、LLMプロセス自体が認証情報を一切持たないアーキテクチャが実現できる。LLMはツール呼び出しを提案するだけであり、ランタイムが実際のAPIコールを代行する。プロンプトインジェクション攻撃で「あなたのクレデンシャルを吐け」と指示されても、LLMにクレデンシャルは存在しない。Auth0のToken VaultやOpenFGAのようなコンポーネントを組み合わせれば、アイデンティティから実行までの各段階で独立した強制が可能になり、仮に1層が突破されても全体が崩壊しない。
高リスク操作には承認境界を設ける

ケイパビリティスコープとタスクスコープを導入しても、金額が一定を超える返金や、不正検知フラグ付き顧客への操作など、許容できないリスクを伴う操作は残る。こうした場面では、人間による明示的な承認を実行の直前に挟む設計が有効だ。これは権限モデルの欠陥を補う緊急避難ではなく、あらかじめ組み込むべき境界線である。
Auth0はこの承認パターンをClient-Initiated Backchannel Authentication(CIBA)規格で標準化している。エージェントのバックエンドがCIBAリクエストを送信すると、ユーザーの登録済みデバイスにプッシュ通知が届く。Rich Authorization Requests(RAR)を併用することで、単なる「請求へのアクセスを許可」ではなく「注文#12345に対する2,000ドルの返金を承認」といった具体的な文脈を伝達できる。承認された場合のみスコープを限定したトークンが発行されるため、エージェントが勝手に高額返金を実行する経路は技術的に閉ざされる。
オブザーバビリティと制御の土台を整える

厳格な権限管理下でも、エージェントは自律的に複数のシステムをまたいで動作する。何が起きたか、なぜその判断に至ったか、誰の代理として動いたのかを追跡できなければ、デバッグもインシデント対応も不可能だ。次の3要素が不可欠である。
- アクションだけでなく、エージェントが辿った意思決定の経緯を監査証跡に残す。どの計画のもとで、どのツール呼び出しが連鎖し、どんなコンテキストが判断材料になったかを記録する。
- ユーザーからサブエージェント、ツール、リソースに至る委譲チェーンを各ホップで明示し、問題発生時に責任境界を特定できるようにする。
- エージェントの暴走が疑われた場合、永続的な許可を即座に無効化し、処理中のトークンを失効させて後続のツール呼び出しを停止できる仕組みを整備する。
Auth0のプラットフォームでは、トークン発行が一元的なコントロールプレーンを経由する。Token Vaultの連携を解除すれば、そのエージェントに対する将来のトークン交換が即座に無効化され、監査ログには全発行・使用の履歴が残る。こうした基盤があることで、エージェントの自律性を損なわずにリスク管理を徹底できる。
この記事のポイント
- AIエージェントには、人間ユーザーや決定的サービスの前提を流用しない、専用のアクセス制御モデルが求められる
- リソースベースの広範なスコープではなく、ケイパビリティ単位で権限を細分化し、宣言的ポリシーとして管理する
- タスクごとに短命なトークンを発行し、エージェントに永続的なクレデンシャルを持たせない
- アイデンティティ・認可・実行の3層を分離し、LLMプロセスに認証情報を一切触れさせないアーキテクチャを採用する
- 高リスク操作にはCIBAやRARを活用した人間承認の境界を組み込み、自律実行の安全域を明確に定義する
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

SiteGroundがAIプラグインを強制配信、100万件の自動インストールが引き起こした評価1.1の大炎上
2026年5月末、ホスティングサービス大手のSiteGroundが、100万以上の顧客サイトに対して、AIプラグインを事前の同意なく自動インストールし、自動有効化するという事態が発生した。このプラグインはわずか数日でWordPress公式ディレクトリにおいて1.1という極めて低い評価を記録。100万インストールと最低評価という数字が、単なる機能の問題ではない、深い信頼の危機を物語っている。
一連の騒動は、企業が持つリーチの大きさと、その使い方を誤ったときに発生する信用コストの非対称性を浮き彫りにした。ここでは何が起きたのか、なぜここまで批判が集中したのか、そしてこの出来事がWordPressエコシステム全体に投げかける課題を整理する。
何が起きたのか。同意なき「AI Agent」の一斉配信

問題となったのは「AI Agent by SiteGround」というプラグインだ。機能面だけを見れば、チャットインターフェースを通じてWordPressやWooCommerceを管理し、複数サイトの一括更新なども行える、実用性の高いツールである。だが、その配信方法が全ての火種となった。
ユーザーが自ら検索してインストールしたわけではない。SiteGroundのホスティングを利用している顧客のWordPressサイトに、ある日突然このプラグインが現れ、有効化された状態になっていたのだ。運営者が気づかぬうちに、外部のAIサービスと連携する準備が整えられたソフトウェアが設置されていたことになる。
この事実が発覚するや否や、WordPressのプラグインレビュー欄は非難の声であふれた。「自動インストールは大きな過ちだ」「なぜ同意なしにインストールしたのか」「ひどい、そして deceptive だ」「もうSGのファンではない」。わずか数日のうちに35件の星1レビューが投稿され、星5はわずか1件という異様な状況が生まれた。
Redditでも同様の議論が巻き起こった。あるユーザーが「WARNING – SiteGround just put some AI plugin into every single site」と題したスレッドを立ち上げ、社内で誰がこのプロジェクトを承認したのかと疑問を呈したのだ。
「安全でオプションです」という説明が響かなかった理由

批判を受けてSiteGroundは迅速に対応し、Redditやサポートフォーラムで直接説明を行った。彼らの弁明はこうだ。このプラグインはWordPress 7.0の新しいAIフレームワークへの準備として追加されたものであり、顧客がコネクタやAPIキーを手動で設定する手間を省くための措置だった。プラグインはバックグラウンドで何かをするわけではなく、ユーザーが能動的に使わない限りサイトに影響を与えず、いつでも無効化または削除できる。事前にメールでも通知したという。
技術的には、この説明に誤りはないかもしれない。しかし、この釈明は根本的な怒りのポイントを外していた。WP Mayorの記事によれば、ユーザーが懸念していたのは「プラグインが密かにサイトを破壊するかもしれない」という技術的リスクよりも、もっと大きな原則論だった。自分が選んでいないソフトウェアを、自ら責任を負うインフラに勝手に置かれたこと、その行為自体への反発なのだ。
Redditの投稿者が指摘したように、たとえ自分がそのAI機能を使わなくとも、顧客が管理画面でそれを見つけて興味本位で操作を始めてしまうリスクがある。機能の説明で「信頼」に対する異議に答えることはできない。「頼んでないのに何故入れたのか」という不満に対し、「安全だしオプションです」と返しても、相手の懸念を全く理解していないことを表明するに等しい。
→ これは機能の問題ではなく、関係性の問題。
→ 「頼んでない」という根本的懸念には何も答えていない。
格付けが示すもう一つの不公正
この騒動には、もう一つ見逃せない副次的影響がある。WordPress公式プラグインディレクトリで「AI agent」と検索すると、このAI Agent by SiteGroundが上位3位に表示される。星1.1という散々な評価でありながら、何百もの競合プラグインを押しのけて、だ。
WordPress.orgのディレクトリ検索は、アクティブインストール数をランキングの重要な要素として扱っている。通常、これはユーザーがプラグインを見つけ、気に入り、自らの意思でインストールした結果を反映するものだから理にかなっている。しかし、ホスティング事業者が100万件ものインストールを一晩で「製造」できてしまうなら、その前提は崩壊する。
WP Mayorの記事では、運営者自身が開発するプラグインが10万インストールに到達するまでに何年もかかった経験が引き合いに出されている。地道に一人ひとりのユーザーを獲得して可視性を高めてきた独立系開発者にとって、この出来事はフェアとは言い難い。評価1.1のプラグインが、そうした開発者の努力を数日で飛び越え、ランキング上位に躍り出た。これはSiteGroundだけの問題ではなく、WordPress.orgディレクトリのランキングシステムが抱える構造的な脆弱性も浮き彫りにした。
他社が学ぶべき「絶対に守るべき三つのルール」

今回の出来事は、ホスティング事業者やプラグイン開発者が顧客との関係で決して踏み越えてはならない一線を教えている。
第一に、すべてはオプトインであるべきだ
顧客のサイトに影響を与える変更のデフォルトは、常に「同意を得る(オプトイン)」でなければならない。「拒否しなければ同意とみなす(オプトアウト)」方式は、あなたがすでに顧客の許可を持っているという前提に立っており、その差は顧客に即座に感じ取られる。
第二に、「技術的に通知した」は同意ではない
「何日前にメールを送ったはずだ」という類の抗弁は、同意の証明にはならない。ユーザーがその一通のメールを見ていることを前提とした通知戦略は、同意ではなく「記録」に過ぎない。両者は全くの別物であり、顧客はその違いをよく知っている。
第三に、リーチとは責任であり、ただの利便性ではない
100万サイトに一斉配信できる能力は、巨大な信託の上に成り立っている。それを単なる「配信ショートカット」として扱い始めた瞬間、そのリーチを可能にしていた信頼そのものを食いつぶし始めている。
WP Mayorの記事は、ロードマップ会議で「いかに摩擦なく導入させるか」という議論がなされると、ときにこの原理が忘れられてしまうと指摘する。摩擦のない導入と、同意の尊重はしばしば対立する。そして対立したときは、必ず同意が勝たねばならない。同意こそが、レピュテーションの素材だからだ。
SiteGroundは信頼を回復できるか

フェアな視点で言えば、この状況はまだ立て直しが可能だ。SiteGroundが自動インストールを停止し、真にオプトイン方式へと切り替え、さらに「ロールアウトは間違いだった」と明言すれば、関係は修復に向かう。しかし、「ご意見は製品チームに転送されました」といった、問題を管理するための企業言語でやり過ごそうとすれば、事態は悪化するだけだろう。
顧客は、自分たちが間違っていたと認める企業を、正しかったと説明し続ける企業よりもはるかに早く許すものだ。人々がこれほど怒っているのは、まさにSiteGroundに「もっと良い対応」を期待していたからに他ならない。その期待自体は、まだ彼らに残された修復可能な資産なのである。100万という数字も、もしそのうちの一つでも「選択」の結果だったなら、全く異なる意味を持っていたはずだ。
この記事のポイント
- SiteGroundが100万件以上の顧客サイトにAIプラグインを事前同意なく自動インストールし、評価1.1の大炎上を招いた
- ユーザーの怒りは機能の安全性ではなく「同意なく自サイトにソフトウェアを置かれた」という信頼の毀損に集中した
- この強制配信により、WordPress公式ディレクトリのランキングシステムが持つ構造的な不公正も露呈した
- 顧客のデジタル資産に触れるあらゆる行為はオプトインが原則であり、「通知」は「同意」の代わりにはならない
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

WPプラグインのサプライチェーン攻撃、AIで見えてきた隠れた脅威
WordPressプラグインのサプライチェーン攻撃が急速に広がっている。悪意ある攻撃者がプラグイン企業を買収し、あるいは正規のプラグインを乗っ取り、無防備なサイトへマルウェアを配信する手口だ。従来の「サイトを直接ハッキングする」という攻撃とはまったく異なるレイヤーで、静かに進行する。
Anchor Hostingの創業者であるAustin Ginder氏は、WP Tavernのポッドキャストでこの問題の全容を語った。同氏は2010年からWordPressに関わり、現在は数千のWordPressサイトを管理している。2026年に入り、長年安定していた顧客サイトでマルウェアが頻出するようになったことを受け、AIを駆使した徹底調査を開始した。
調査の結果、明らかになったのは単なる脆弱性の話ではない。正規のプラグイン更新チャンネルそのものが攻撃者に乗っ取られているという、構造的な脅威だ。本記事ではその仕組み、具体的な被害事例、そしてAIによって変わりつつあるセキュリティ対策の最前線を解説する。
サプライチェーン攻撃の実態(2つの侵入経路)
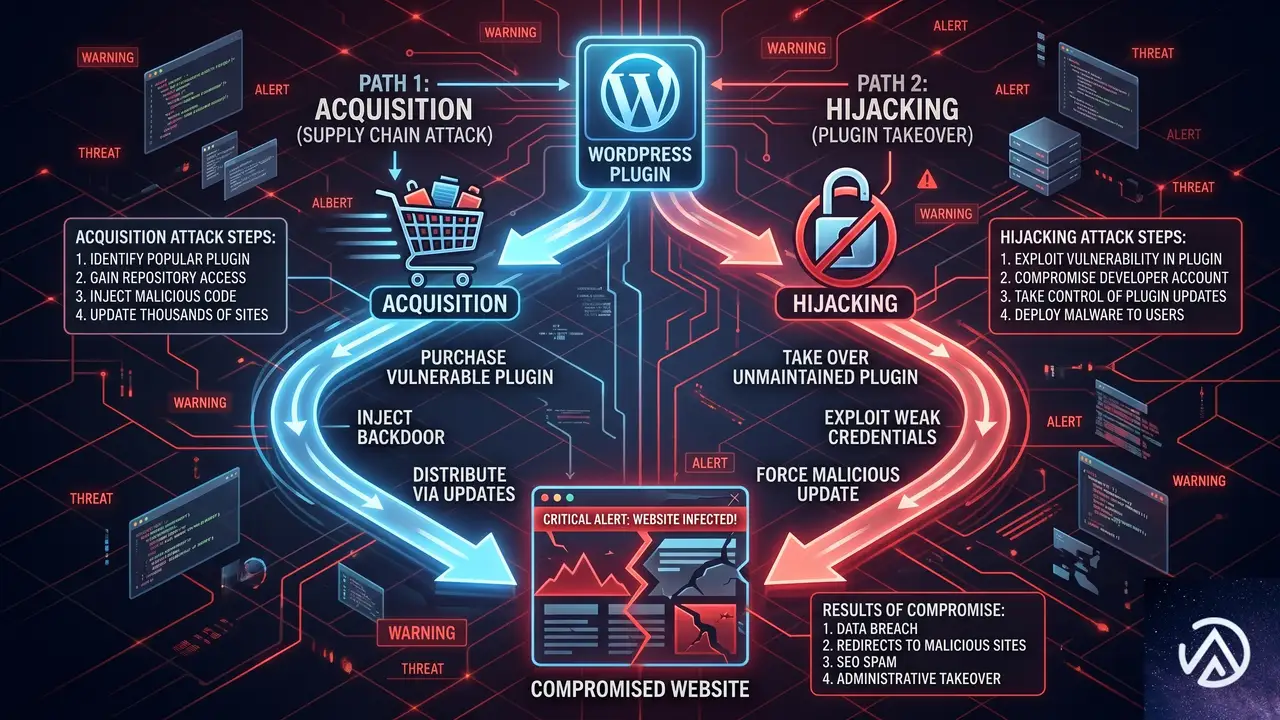
この図はサプライチェーン攻撃の2大経路を示している。いずれも、ユーザーが自動更新を有効にしている場合、まったく気づかずに感染する点が共通している。WP Tavernのポッドキャストで語られた内容を整理すると、攻撃者はこうした手法でプラグインを「武器化」し、正規更新を装いながらマルウェアを拡散している。
プラグイン買収による攻撃
WP TavernのポッドキャストでAustin Ginder氏が明かした最も衝撃的な手口は、攻撃者が実際にプラグイン企業を買収して武器化するというものだ。同氏はEssential Pluginsと呼ばれる30以上のプラグインを抱えるパッケージが売却され、その後にコード改変が行われた事例を報告した。
攻撃者は6桁の金額を投じてでも正規の配信チャンネルを手に入れる価値があると判断している。プラグインを買収すれば、更新ボタンを押すだけで何万ものサイトにコードを配信できるからだ。この手法の巧妙な点は、プラグインの本来の機能はそのまま維持されることである。ユーザーは見た目の変化に気づかない。
プラグインハイジャックによる攻撃
もうひとつの経路は、プラグインの更新先をすり替えるハイジャック型だ。攻撃者はまず正規のプラグインにサードパーティのアップデータを密かに組み込む。これはwordpress.orgのガイドライン違反だが、コードを巧妙に隠すことで審査をすり抜ける。
一度このコードが仕込まれると、以降の更新はwordpress.orgではなく攻撃者の管理するサーバーから配信される。wordpress.org側からは一切の可視性が失われ、ユーザーのサイトは知らぬ間に乗っ取られた状態になる。この手口は特に長期間気づかれにくく、過去にQuick Redirectionプラグインなどで実際に確認されている。
偶然のマルウェア除去から始まった調査

Austin Ginder氏がこの問題に気づいたのは、2026年2月に顧客サイトのマルウェア除去作業を行っていたときのことだ。同氏はWP Tavernのポッドキャストで「長年安全だったサイトが突然マルウェアに感染するようになった」と振り返っている。
従来のマルウェア除去は不安がつきまとう作業だった。ファイルをひとつずつ確認し、疑わしいコードを取り除いても、本当にすべてを取り切れたか確信が持てなかった。しかし同氏は、AIを使うことで状況が一変したと語る。AIがすべてのファイルを精査し、感染経路の特定から根本原因の解明までを一貫して行えるようになったのだ。
ある顧客の調査で行き着いた先はwordpress.orgのリポジトリだった。同氏はAIを使い、問題のプラグインの変更履歴を解析した。すると、正規の更新チャンネルが改ざんされている痕跡が見つかった。ここから本格的な調査が始まった。
以降、同氏は4件の詳細な調査レポートを公開した。いずれも異なるプラグイン、異なる攻撃者によるものだった。最初の1件が単発の事件ではなかったことが、ここで明らかになった。
AIが切り拓く新たな脅威検出

ファイル単位の徹底監査
Austin Ginder氏はAIの活用について、WP Tavernのポッドキャストで具体的な方法を説明している。同氏は月額200ドルのClaude Codeサブスクリプションを使い、顧客サイトの全ファイルを1行ずつ監査している。これは人間には不可能な作業量だが、AIなら数十万行のコードを短時間で精査できる。
「1バイトの変更も見逃さない」と同氏が語るこの手法は、静的解析の域を超えている。AIはコードの文脈を理解し、単なるシグネチャマッチングでは検出できない巧妙なバックドアも特定する。あるケースでは、一見無害に見えるJavaScriptの埋め込みコードから、クレジットカードスキマーの存在を突き止めた。
バリアント検出ツールの実装
さらに同氏は、プラグインのバージョン差異を検出する独自ツールをAIで構築した。これは、インストールされているプラグインのコードがwordpress.org上の正規バージョンと異なっていないかを自動照合する仕組みだ。
このツールのテスト中、Quick Redirectionプラグインのバリアント版が12サイトで稼働していることを発見した。本来の作者が意図せず(あるいは意図的に)、多くのユーザーをハイジャック版へ誘導していた事例だ。さらに、上位2000のWordPressサイトをスキャンした際には、Scroll To Topプラグインに不正コードが仕込まれているのを確認した。このプラグインは2万サイトにインストールされていたが、攻撃者はまだ「引き金を引いておらず」、被害が表面化する前に発見できたという。
AIによる監査は、コードの意味を解釈しながら異常を浮かび上がらせる。従来のシグネチャベースでは見逃していた「まだ発動していない攻撃コード」も、文脈の不自然さとして検出できる点が最大の強みだ。
過去13年間活動を続ける攻撃者の発見
Austin Ginder氏はWP Tavernのポッドキャストで、13年にわたって活動を続けている攻撃者の存在にも言及した。この攻撃者は、何度アカウントやプラグインを閉鎖されても、新しいアカウントを作り直し、別のプラグインで同じ手口を繰り返してきた。
「彼らを止めるには、単にコードを修正するだけでは足りない」と同氏は語る。攻撃のインフラそのものを無効化し、再発を防ぐ仕組みが必要だ。AIによる大規模監査が、こうした長期化する脅威への対抗手段として期待されている。
WP Beaconが目指すコミュニティの連携

Austin Ginder氏は、調査結果を共有するプラットフォームとして「WP Beacon(wpbeacon.io)」を立ち上げた。これは従来の脆弱性データベースとは異なり、サプライチェーン攻撃に特化した情報を集約する場である。既存の脆弱性DBが「コードの欠陥」に注目するのに対し、WP Beaconは「悪意ある行為者」そのものの行動パターンを記録する。
同氏はWP Tavernのポッドキャストで、WP Beaconの真の目的は「セキュリティ研究者やホスティング企業が行動を起こすための情報基盤」になることだと述べた。実際、同氏が発見した攻撃者のサーバーは、協力者の手によってドメイン停止措置が取られたという。調査と対策を分業し、攻撃インフラを迅速に無力化する流れを作ることが狙いだ。
今後の対策と個人でできること
Austin Ginder氏はWP Tavernのポッドキャストの中で、個人でもすぐに実践できる対策として、自サイトのバックアップをAIで監査する方法を提案した。Claude Codeなどのツールにサイトの全ファイルを読み込ませ、「すべての行をチェックし、脆弱性やマルウェアの痕跡を報告してほしい」と指示するだけでも、高い精度の分析結果が得られるという。
「我々はデータの上に座っているが、それを使いこなせていない」と同氏は指摘する。大手ホスティング企業が保有する数百万サイト分のデータをAIで横断分析できれば、攻撃パターンの早期発見と封じ込めが可能になる。WP Beaconがそうした連携の起点となることが期待されている。
長期的には、プラグインの全コード監査を自動化し、変更が発生するたびにAIがチェックを行う仕組みが必要だ。wordpress.orgのリポジトリには6万以上のプラグインが存在するが、CSSや画像ファイルを除外し、PHPやJavaScriptの変更だけを対象にすれば、現実的な範囲でカバレッジを確保できる。
この記事のポイント
- WordPressプラグインのサプライチェーン攻撃は、買収とハイジャックの2経路で進行する
- ユーザーは自動更新を通じて、まったく気づかずにマルウェアを受け取る可能性がある
- AIを使った全ファイル監査で、従来の方法では見逃していた潜伏型の脅威も検出できる
- WP Beaconはサプライチェーン攻撃に特化した情報基盤として、コミュニティ連携を促進する
- 個人でもClaude CodeなどのAIツールで自サイトの監査を実施できる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

WooCommerce 10.9でカラースウォッチがコア機能に。商品ページの視覚表現が大幅に向上
WooCommerce 10.9で商品属性に新しいタイプ「Color / Image」が追加された。これまではテキストリンクやセレクトボックスでしか選べなかった色や柄のバリエーションを、フロントエンド上で視覚的なスウォッチ(小さな色見本)として表示できるようになる。
この機能はブロックテーマ利用時の実験的機能として提供され、商品フィルターブロックや「カートに追加+オプション」ブロック内のバリエーションセレクターに自動適用される。WooCommerce Developer Blogの記事によると、6月8日予定のベータ版から利用可能だ。
本記事では、この新機能の概要、具体的な設定手順、技術的な内部構造、そして他のブロックとの共有APIの仕組みを詳しく解説する。WooCommerceストアを運営する担当者や、ECサイトのデザインを改善したい制作者に役立つ情報だ。
カラースウォッチ機能の概要
上の比較で分かるように、テキストだけでは実際の色味が伝わらず、購入者は商品画像だけを頼りに判断するしかなかった。今回の変更で、Chipsブロック(チップス)やListブロック(リスト)での表示が直感的になる。
対応するブロックと表示パターン
カラースウォッチが適用されるのは、以下の2つのブロック内でColor / Image属性がレンダリングされる場面だ。
- 商品フィルター内の「属性で絞り込む」ブロック(Filter by Attribute)
- 「カートに追加+オプション」ブロック内のバリエーションセレクター(Variation Selector)
Chipsスタイルでは、各スウォッチがHEXカラーコードまたは画像を使った円形で表示される。管理画面で設定した色や画像がそのままフロントエンドに反映される仕組みだ。Listスタイルでは、属性名の隣に小さなスウォッチが並ぶ。これにより、フィルター画面でも色の判別が容易になる。
色だけでなく画像スウォッチにも対応
今回の機能は単なるカラーピッカーにとどまらない。属性タイプ名が「Color / Image」であることからも分かるとおり、メディアライブラリから画像を選択することも可能だ。チェック柄やヒョウ柄、グラデーションパターンなど、HEXコードでは表現しきれない複雑なデザインもスウォッチ化できる。
この画像スウォッチ機能は、ファッションECやインテリアECで特に効果を発揮する。テキストだけでは「ダマスク柄」「ストライプ」といった情報が伝わりにくいが、小さなサムネイル画像があれば購入者は直感的に商品の外観を把握できる。
設定手順と利用条件
カラースウォッチ機能はブロックテーマでのみ利用可能な実験的機能として提供される。有効化の手順は以下の3ステップだ。
特徴的なのは、この機能が完全にオプトイン方式である点だ。既存の属性をColor / Imageタイプに更新しない限り、ストアフロントにスウォッチは一切表示されない。既存のテキスト表示を維持したい商品がある場合も、属性タイプを変更しなければ従来通りの挙動を保てる。
属性タイプの内部的な識別子
属性のタイプを設定すると、各属性ターム(付与する値)の編集画面にカラーピッカーと画像選択の入力欄が追加される。内部的には、この属性タイプは「wc-visual」というスラッグで識別される。
スラッグの先頭に「wc-」というプレフィックスが付与されているのは、既存のプラグインが独自に登録している可能性のあるカスタム属性タイプとの名前衝突を防ぐためだ。すでに何らかのカラースウォッチ系プラグインを導入しているストアでも、コア機能とプラグイン機能が競合することなく共存できる設計になっている。
ブロックテーマが必須条件
現時点では、クラシックテーマではこの機能は動作しない。あくまでブロックテーマ(Site Editing対応テーマ)に限定された実験的機能だ。クラシックテーマ利用者向けには、引き続きサードパーティ製のカラースウォッチプラグインが代替手段となる。
正式リリースまでの間にクラシックテーマ対応が追加されるかは明言されていないが、WooCommerceのブロック化推進の流れを踏まえると、今後もブロックテーマを前提とした機能拡充が続くと見ておくのが妥当だろう。
共有インナーブロックによるブロック間の連携強化
カラースウォッチ機能と並行して、WooCommerceチームはブロック間のインナーブロック共有APIにも手を入れた。具体的には、「商品フィルター」ブロックと「カートに追加+オプション バリエーションセレクター」ブロックが同じインナーブロックを再利用できるようになっている。
これまでは、商品フィルター用のChipsブロックとバリエーションセレクター用のUIが別々に実装されていた。今回の変更で、片方のブロックに加えられた改善がもう片方にも自動的に反映されるようになる。開発者視点では、メンテナンス対象のコードが減り、一貫性のあるUIを提供しやすくなるメリットがある。
また、後方互換性にも配慮されている。Variable Product(バリエーション商品)テンプレートパーツをカスタマイズしているストアでも、フロントエンド表示時やエディターで開いた際には、自動的に新しいインナーブロックが適用される仕組みだ。既存のカスタマイズが壊れる心配はない。
今後のロードマップとテスト参加方法

WooCommerce Developer Blogの記事によると、カラースウォッチ機能は6月8日予定のWooCommerce 10.9ベータ版からブロックテーマ上のフィーチャーフラグ(機能フラグ)として提供される。すでにGitHub上のナイトリービルドでもテスト可能だ。
正式版リリースに向けた注意点
現時点では実験的機能という位置付けであるため、本番環境への適用は避け、まずはステージングサイトでテストすることをWooCommerceチームは推奨している。テスト中に発見した不具合や改善要望は、GitHubのWooCommerceリポジトリのIssueトラッカーで報告できる。
実験的機能がいつ正式機能に格上げされるかは明言されていないが、WooCommerceのリリースサイクルを踏まえると、大きな問題が報告されなければ2〜3バージョン以内に正式対応となる可能性が高い。
プラグイン開発者への影響
「wc-visual」という標準化された属性タイプが追加されたことで、サードパーティ製プラグインやテーマ開発者にも恩恵がある。視覚的属性を識別するための統一的なパターンができたため、複数のプラグイン間での相互運用性や拡張性が高まる。
たとえば、商品エクスポートプラグインがスウォッチ情報をCSVに含めたり、カスタムテーマがスウォッチのスタイルを独自に調整したりする際に、「wc-visual」というスラッグを基準に処理を分岐できるようになる。
この記事のポイント
- WooCommerce 10.9で商品属性に「Color / Image」タイプが新設され、フロントエンドで視覚的なスウォッチ表示が可能になる
- 商品フィルターとバリエーションセレクターの両方で、ChipsブロックとListブロックに自動適用される
- HEXカラーだけでなくメディアライブラリの画像もスウォッチとして使用できる
- ブロックテーマ限定の実験的機能であり、設定画面のトグルで明示的に有効化するオプトイン方式
- 共有インナーブロックAPIの改善により、複数ブロック間で一貫性のあるUIとメンテナンス効率の向上が図られている
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Google、Search ConsoleでAI検索専用レポートをテスト開始
Googleが2026年6月3日、Search Consoleに2つの新機能を追加するテストを開始した。生成AI検索機能への表示を制御するトグルと、AI検索内での表示回数やインプレッションを確認できる専用レポートだ。
まずはイギリスの一部サイトを対象に提供され、その後に全世界へ展開される予定だ。サイト運営者にとって、これまで「ブラックボックス」だったAI検索経由のパフォーマンスを可視化する第一歩となる。
この記事では、2つの新機能の具体的な内容と、現場のSEO担当者がどう受け止め、どのような準備をすればよいかを詳しく解説する。
GoogleがSearch Consoleでテストする2つの新機能
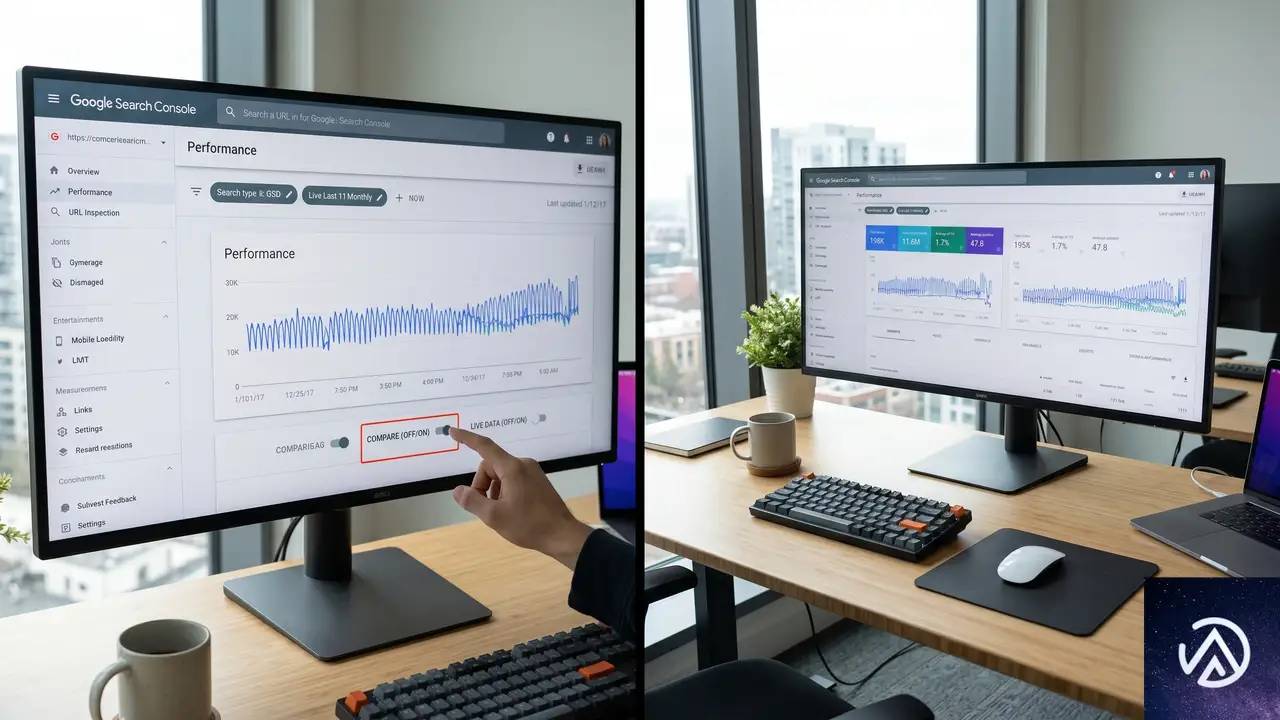
今回テストが始まったのは、AI表示制御トグルとAI専用パフォーマンスレポートの2つだ。いずれも、生成AIが検索体験に深く入り込む中で、サイト運営者が自サイトの表示状況を把握し、必要に応じて制御できるようにするための機能である。
AI表示制御トグル
1つ目のAI表示制御トグルは、文字通り「自サイトをAI検索機能に表示させるかどうか」を切り替えられる設定だ。このトグルをオフにすると、AI OverviewsやAI Mode、Discover上のAI Overviewsなど、Googleの生成AI検索機能から自サイトへの表示が一切行われなくなる。
なお、この制御はAI検索機能のみに適用され、従来の検索結果ランキングには影響しないとGoogleは明言している。いわゆるランキングシグナルとして利用されることはないというわけだ。
このトグルは、従来のスニペット制御やGoogle-Extendedの延長線上にある。スニペット制御は従来型の検索結果での表示内容を管理するものだったが、今回のトグルは「AI検索機能での表示そのもの」を対象にしている点が新しい。
AI専用パフォーマンスレポート
2つ目は、生成AI検索機能における表示回数(インプレッション)を、サイト単位・ページ単位・国別・デバイス別・日時別に確認できる専用レポートだ。データ粒度は1時間単位まで対応するという。
これまでAI検索上のデータは、Search Consoleの総合パフォーマンスレポートにまとめられており、通常の検索とAI検索を分離して分析することができなかった。今回の専用レポートによって、AI検索だけの表示傾向を把握できるようになる。
ただし、現時点ではクリック数や検索クエリ別の指標は含まれていない。Googleは「サイト運営者と協力しながら、どのような指標が最も役立つかを継続的に検討している」と述べており、今後の拡充が期待される。
新機能の詳細と現場への影響
トグル機能の仕組みと注意点
AI表示制御トグルをオンからオフに切り替えた場合、AI OverviewsやAI Mode、Discover上のAI Overviewsからのトラフィックとインプレッションがすべてゼロになる。AI経由の流入を意図的に避けたいサイトにとっては、明確なコントロール手段となる。
一方で、このトグルはあくまでもAI検索「機能」への表示を制御するものであり、Google-ExtendedのようにAIモデルの学習データとしての利用を制御するものではない。両者は目的が異なるため、必要に応じて併用する必要がある。
また、Googleはトグルの状態をランキングシグナルに使わないとしているが、長期的な検索エコシステムへの影響は未知数だ。AI検索が検索体験の主流になった場合、「AI機能に表示されない」という選択がサイト運営者にどのような機会損失をもたらすかを、慎重に見極める必要がある。
レポートが示すデータと欠落情報
新レポートでは、AI検索機能での自サイトのインプレッション数が詳細に把握できる。たとえば「特定のページがAI Overviewsで1日あたり何回表示されたか」「AI Mode上での国別の表示頻度」といった分析が可能になる。
しかし、大きな課題としてクリックデータが欠落している。インプレッション数だけでは、表示されたコンテンツが実際にクリックされ、サイトへの訪問に結びついたかどうかがわからない。Search Engine Journalの記事でも、この計測ギャップが1年以上にわたってAI検索の評価における最大の論点であり、今回の発表でもいまだ解消されていないと指摘している。
SEO担当者にとって、AI検索でのクリック率(CTR)は、コンテンツが実際にどの程度ユーザーの行動を促せているかを測る重要な指標だ。Googleがこのデータの提供を急ぐべき理由は明白だが、現時点ではスケジュールや具体的な追加指標は発表されていない。
AI計測をめぐるこれまでの経緯

AI Overviewsが2024年にアメリカで初めて導入されて以来、Search Console上でAI固有のパフォーマンスを把握したいという要望がサイト運営者やSEO専門家から繰り返し上がっていた。Search Engine Journalも、AI専用データの提供をGoogleに求め続けてきたと記事で述べている。
2025年には、AI ModeのトラフィックがSearch Consoleの総合データに統合されることが確認されたが、その際も通常のオーガニック検索との区別はできなかった。さらに、John Mueller氏は「AI Overview内のすべてのリンクはSearch Console上で単一のポジションを共有する」と説明しており、どのリンクが実際に成果を上げているのかを評価するのが難しい状況が続いていた。
そして2026年5月、GoogleはAI機能におけるリンク表示面を拡大したものの、その表示面に特化したクリックデータは依然として提供されなかった。この発表はSEOコミュニティに「計測のブラックボックス化がさらに進むのでは」という懸念をもたらした。
競合の動き、Bingの先行事例
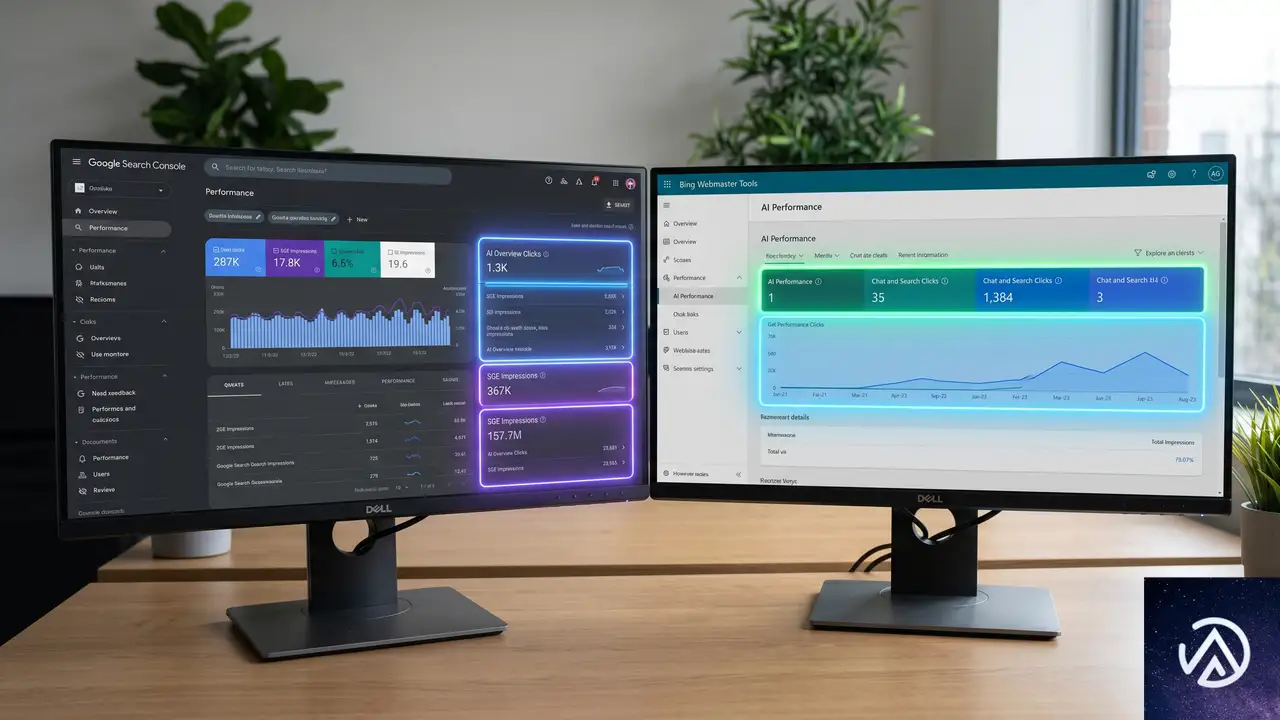
AI検索のレポーティングにおいて、MicrosoftのBingはGoogleよりも早く動いている。Bing Webmaster Toolsは2026年2月にAIパフォーマンスダッシュボードを導入し、AI検索機能で自サイトが引用された際のデータを提供し始めた。同年3月には、AIが参照したクエリと実際に引用されたページをマッピングする機能を追加し、5月のSEO WeekではCitation Share(引用シェア)のプレビューを公開している。
Bingのこれらの機能は、AI検索での自サイトの立ち位置を定量的に把握するうえで有効なツールとなっている。Googleが今回のテストでようやく第一歩を踏み出した形だが、機能面では依然としてBingに後れを取っていると言わざるを得ない。
競合が先行する状況は、Googleにとってレポーティング機能の拡充を急がせる圧力となるだろう。Search Engine Journalもこの点を指摘しており、今後のGoogleの動きに注目が集まっている。
サイト運営者が取るべき対応

現時点では、このテストはイギリスの一部サイトに限定されているが、グローバル展開後の準備は今から始めておくべきだ。
まず、自サイトがAI検索でどの程度表示されているのか、既存のSearch Consoleデータの中で手がかりを探しておくこと。AI Overviewsの表示傾向は、検索クエリの傾向や特定のページの急激なインプレッション増加などから、ある程度推測できる場合がある。
次に、AI表示制御トグルをどのように扱うかの社内方針を検討しておくこと。AI検索への表示を許容するのか、あるいは制限するのかは、サイトの収益モデルやコンテンツ戦略によって判断が分かれる。迷った場合は、当面はトグルをオン(表示を許容)にしたままデータを蓄積し、レポートが充実してから判断するのが賢明だ。
さらに、Bing Webmaster ToolsのAIレポートも並行して確認する習慣をつけておくと、AI検索全体のトレンドをより早く把握できる。Googleのレポート機能が成熟するまでの間、マルチプラットフォームでのデータ収集がリスクヘッジにもなる。
この記事のポイント
- GoogleがSearch ConsoleでAI表示制御トグルとAI専用パフォーマンスレポートのテストをイギリスで開始した
- AI表示制御トグルはAI検索機能への表示を制御するもので、ランキングシグナルには使われない
- AI専用レポートではインプレッションを詳細に分析できるが、クリックデータは未提供
- BingはすでにAI引用データやクエリマッピングを提供しており、Googleは後れを取っている
- グローバル展開に備え、既存データの分析と社内方針の検討を今から進めておくべき
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

WordPress 7.0リリースとAI管理ツール最新動向 2026年5月
WordPressエコシステムに大きな動きがあった。2026年5月末、待望のWordPress 7.0「Armstrong」が正式リリースされたのだ。管理画面の刷新やAI機能の統合が実装され、次世代サイト運営の基盤が整った。
これと同時に、AIを駆使した管理ツールも相次いで発表されている。サイト翻訳、スパム対策、アナリティクス対話、自動化まで、もはや手動運用の時代は終わりつつある。WPBeginnerの2026年5月Spotlight記事は、これらの新製品群とコミュニティ動向を詳細に報じた。
WordPress 7.0 Armstrongのリリース
WordPressコアチームは2026年5月、バージョン7.0「Armstrong」を公開した。このリリースは、管理画面のデザイン刷新とAI機能のネイティブ統合が最大のトピックだ。リアルタイム共同編集は今回見送られたが、AIコネクタの導入だけでも近年で最も大きなアップデートの一つと評価されている。
カラースキームは固定で、視認性が悪い部分も
新しいカラースキームで視認性が向上
AIコネクタ 搭載で全プラグインからAI APIキーを一元管理
このデモでは、管理画面の変化を概念図として示している。実際のバージョン7.0では、ページ読み込み速度が大幅に改善し、操作フィードバックが即時になった。
AIコネクタとサイトエディタの強化
AIコネクタは、サイト全体でAI APIキーを一箇所に登録できる仕組みだ。これにより、各プラグインが個別にAPIキーを要求する必要がなくなり、一貫したAI機能の提供が可能になった。ユーザーはOpenAIや他のAIプロバイダーのキーを設定画面で一度入力するだけで、対応プラグイン全体がそのキーを利用できる。
ブロックエディタにも大幅な改善が加わった。具体的には、個別ブロックへのカスタムCSS追加、デバイスごとのブロック表示・非表示制御が可能になった。これらの機能は、モバイル、タブレット、デスクトップそれぞれに最適化した表示を簡単に設計できることを意味する。正式リリースに先立ち公開されたベータ版の情報を追っていたユーザーからは、特にこの柔軟性に対して高い期待が寄せられていた。
AI翻訳ツールUniversallyの登場
多言語サイトを手軽に実現したいが、従来の翻訳プラグインはデータベース肥大化やパフォーマンス低下を招きやすい。SaaS型の翻訳サービスは高価で、個人事業主や中小企業には手が出せなかった。このような課題に対し、AI搭載のウェブサイト翻訳プラットフォーム「Universally」が登場した。
✕ パフォーマンス低下や複雑な設定が必要
✓ hreflangタグやXMLサイトマップなど多言語SEO最適化
無料プラン あり(1サイト、1言語、月2,000語)
Universallyはデータベースに翻訳データを保存しないクラウド型アーキテクチャを採用し、サイトパフォーマンスを維持したまま多言語化できる。AI用語集機能により、ブランド名や専門用語の誤訳も防ぐ。プライベートベータ段階で既に2億5,000万語以上の翻訳実績があり、WordPress以外にShopifyやWix、Replitなどにも対応する。有料プランは年払いで月額7.5ドルから利用可能だ。WPBeginnerの創設者による詳細な紹介記事も掲載されている。
AIスパム対策ActiveLayerとCAPTCHAフリーの保護
WordPressサイトのコメントやフォームへのスパム攻撃は、今なお運営者の大きな悩みだ。従来のCAPTCHAは人間のユーザーにもストレスを与え、フォーム離脱の原因にもなり得る。WPBeginner創設者のSyed Balkhi氏が公開した新サービス「ActiveLayer」は、AIを使いミリ秒単位でサーバーサイド分析を行い、CAPTCHAなしでスパムをブロックする。
フォーム離脱率が上昇し、コンバージョンに悪影響
信頼度スコア でスパム判定を可視化
WPForms、Gravity Forms、Contact Form 7など主要フォームプラグイン対応
ActiveLayerのWordPress.org版プラグインは無料で、月1,000回の無料スパムチェックが含まれる。有料プランは月額4ドルからで、無制限のサイトとフルAPIアクセスを提供する。WPBeginnerやその他のビジネスサイトで発生した大規模スパム攻撃への対処経験が、このサービスの開発背景にある。
StellarWPブランド終了とプラグイン再編

Liquid Webは、GiveWPやLearnDash、SolidWP、The Events Calendarなどを含む「StellarWP」ブランドの終了を正式発表した。これらは新設された「Liquid Web Software」に統合され、Kadence、LearnDash、The Events Calendar、Giveの4製品を中核に据える方針だ。
WPBeginnerの記事によれば、この統合により、長期ユーザーからは将来のロードマップや価格変更、製品の独立性について懸念の声が上がっている。特に複数のStellarWP製品に依存しているサイト運営者は、自動更新設定やバックアップ戦略を今のうちに見直しておくべきだ。
Uncanny AgentやCharlie ChatなどAI管理ツールの台頭
WordPress管理の手動作業を減らすAIエージェントが相次いで登場している。Uncanny Automatorチームが開発した「Uncanny Agent」は、ダッシュボード内に統合されたAIアシスタントだ。自然言語で問い合わせると、WooCommerceの売上データやユーザー活動のレポート作成、フォーム送信時のSlack通知自動化などを対話形式で設定できる。
一方、MonsterInsightsが公開した「Charlie Chat」は、Google Analyticsのデータを平易な言葉で問い合わせられるAIアシスタントだ。「主要なトラフィックソースは?」「どのコンテンツを更新すべきか?」といった質問に、実際のGA4データを基に即答する。無料のLite版でも利用可能で、WooCommerceストア向けには売上傾向やカゴ落ち分析も行える。
これらに加え、WPFormsはKlaviyoとのネイティブ連携アドオンを公開し、メールマーケティングのROI向上を狙う。SeedProdはWordPress Abilities APIに対応し、AIコマンドでランディングページの更新やメンテナンスモード切替を可能にした。無料のAIチャットボットHelpJetは、既存のサイトコンテンツを数分で学習し、24時間カスタマーサポートを提供する。WPBeginnerのSpotlight記事は「AI管理ツールの波がWordPressエコシステムを一変させつつある」と総括している。
この記事のポイント
- WordPress 7.0 Armstrongがリリースされ、管理画面刷新とAIコネクタが導入された
- AI翻訳ツールUniversallyは、クラウド型で110言語以上に対応し、パフォーマンス低下を回避する
- AIスパム対策ActiveLayerは、CAPTCHA不要で主要フォームプラグインと統合できる
- StellarWPブランド終了に伴い、依存プラグインの長期運用戦略を見直す必要がある
- Uncanny AgentやCharlie Chatなど、AIによる対話型管理ツールが続々と登場している
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Googleが5月コアアップデートの完了を発表。11日間の不安定な変動を振り返る
Googleは2026年6月2日、5月のコアアップデートが完了したと公式に発表した。検索ステータスダッシュボード上で、ロールアウト開始から11日と21時間を経て終了したとの報告が上がっている。
今回のアップデートは、5月21日午前8時40分(太平洋夏時間)に始まり、6月2日午前5時40分(同)に終了した。約12日間の展開期間は、3月のコアアップデートとほぼ同じ長さだ。
実務者が観測したアップデートの激しさ

アップデートの開始と同時に、多くのSEO実務者が大きな変動を報告し始めた。特に注目されたのは、Google I/Oと同日に発表された点だ。
このデモが示すのは、今回の変動が単なる順位付けルールの変更ではなく、検索結果の生成プロセス自体の変化を伴う可能性があったという点だ。
SEOコンサルタントのGlenn Gabe氏は「今回の5月のコアアップデートは、従来の典型的なコアアップデートに近い強力さを見せている。3月のアップデートは地味だったが、5月は大きな動きだ」とXに投稿している。彼の観測では、この影響は特定の業種や国を超え、多岐にわたって見られたという。
また、AmsiveのLily Ray氏もXで週末の動きについて「一握りのサイトで週末に急上昇が見られた」と報告している。これらの投稿から、変動のピークが一過性のものではなく、ロールアウト期間中に何度か訪れたことがわかる。
データ分析を難しくする「多点変動」の正体
今回のアップデートで最も厄介なのは、完了したからといって、ロールアウト期間中のすべての変動が同じ原因で起きたとは言い切れない点だ。
このデモは、単日のランキング比較がいかに危険かを示している。Googleの公式ドキュメントも、アップデート完了から最低1週間はデータを寝かせ、その1週間分のデータとロールアウト開始前の1週間分を比較検証するよう強く推奨している。これに従うと、最も早く正確な比較が可能になるのは6月9日ごろという計算になる。
2026年のアップデートタイムライン

今回の5月コアアップデートは、2026年にGoogleが検索ステータスダッシュボードで確認した4回目のアップデートであり、2回目の検索コアアップデートだ。3月のコアアップデート完了(4月8日)から、5月の開始(5月21日)までは約6週間の間隔があった。
ここ最近のアップデート期間を振り返ると、コアアップデートの展開期間は平均2週間弱で推移していることがわかる。
このタイムラインから読み取れるのは、Googleがコアアップデートを年4〜5回のペースで定期的に配信している現状だ。特に2026年は、スパムアップデートを短時間で差し込むなど、検索品質の維持に対する姿勢がより機動的になっている。
分析を始める前に押さえるべき3つの視点

6月9日のクリーンな比較ウィンドウを待つ間、そしてデータ分析を始めるにあたり、以下の3つの視点を持つことが重要だ。
これらの視点をもとに、6月9日以降、Search Consoleのデータを丁寧に分析することが、今回の大規模アップデートから次なる施策を導き出すための最善の道となる。
この記事のポイント
- Googleの5月コアアップデートは6月2日に完了した。変動は全期間を通じて激しく、複数回のピークが観測された
- 完了直後の単日比較は危険であり、少なくとも1週間後の6月9日以降に週次データで比較分析を行うべきだ
- 今回の変動は、Google I/Oで発表されたAI基盤の更新とタイミングが重なり、AI検索機能との連動が示唆される
- 結局のところ、最も有効な対策は、ユーザーにとって真に価値あるコンテンツの提供であるという原則に変わりはない
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Google Cloud、AlloyDB向けリモートMCPサーバーがGA。AIエージェントとDBの安全な統合を実現
Google CloudがAlloyDB向けのリモートMCP(Model Context Protocol)サーバーの一般提供を発表した。これまでローカル開発が中心だったMCPだが、本番環境での運用に耐えるフルマネージドな仕組みとして登場した。AIエージェントが企業のオペレーショナルデータベースに直接アクセスし、安全にクエリを実行できるようになる。
この記事では、リモートMCPサーバーが解決する技術的課題と、AlloyDBを基盤にしたエージェントアプリケーションの構築方法を解説する。データの鮮度、セキュリティ、運用負荷のバランスを取るアーキテクチャを具体的に示す。
リモートMCPとは何か(ローカルMCPとの違い)

MCP(Model Context Protocol)とは、大規模言語モデル(LLM)が外部のデータソースやツールと安全に通信するためのオープン標準プロトコルだ。Anthropicが提唱し、現在では多くのAIエージェントフレームワークで採用されている。従来は開発者のローカルマシン上で動作する「ローカルMCPサーバー」が主流だった。
ローカルMCPサーバーは標準入出力(stdio)を使ってプロセス間通信を行う。これは開発段階では手軽だが、本番環境に持ち込むと途端に問題が顕在化する。複数のエージェントインスタンスが同時にデータベースへアクセスする場合、プロセス管理が複雑化し、ネットワーク越しのセキュリティ確保も難しくなる。
リモートMCPサーバーは、これらの課題をHTTPエンドポイント経由で解決する。Google Cloudのマネージドインフラ上で動作し、OAuth 2.0ベアラートークンによる認証とIAM(Identity and Access Management)によるきめ細かな権限制御を提供する。エージェント開発者はインフラ管理から解放され、クエリ実行に集中できる。
なぜAlloyDBと組み合わせるのか
AlloyDBはGoogle CloudのフルマネージドPostgreSQL互換データベースだ。標準PostgreSQLと比較して、ベクトル検索では最大6倍高速、フィルタ付きクエリでは最大10倍高速というパフォーマンスを備える。ScaNNインデックスを使えば100億ベクトル規模まで拡張でき、AIエージェントのRAG(検索拡張生成)ワークロードに最適化されている。
さらにAlloyDBには、データベース内で直接埋め込みベクトルを生成するAI Functionsや、Gemini Enterprise Platformモデルを使った検索結果のリランキング機能が組み込まれている。エージェントがデータベースにクエリを投げるだけで、最新のオペレーショナルデータに基づいた回答を得られる。データの鮮度を保つためのETLパイプラインが不要になるケースも多い。
リモートMCPサーバーが解決する5つの本番課題

Google Cloudブログの発表によると、リモートMCPサーバーは単なる通信方式の変更にとどまらない。本番環境でAIエージェントを運用するチームが直面する、以下の5つの課題を包括的に解決する設計になっている。
特に注目すべきはIAMによる権限制御だ。従来のデータベース接続では、共有パスワードやAPIキーを使うことが多かった。しかしリモートMCPでは、エージェントごとに特定のテーブルやビューへのアクセス権をIAMで付与できる。読み取り専用のSQL実行ツールを選択すれば、エージェントが誤ってデータを削除するリスクを根本から排除できる。
Model Armorによるプロンプトセキュリティ
リモートMCPサーバーは、Google CloudのModel Armorと統合されている。Model Armorはプロンプトとレスポンスの両方をスクリーニングし、プロンプトインジェクション攻撃や機密データの意図しない流出を防ぐ。エージェントのサービスアカウントが広範なデータベース権限を持っていても、Model Armorがデータの出し方をフィルタリングする仕組みだ。
たとえば、エージェントが顧客のクレジットカード番号を含むカラムにアクセスできる権限を持っていたとしても、Model Armorがレスポンスからその情報を除去できる。これは「権限はあるが出力は制限する」という新しいセキュリティモデルであり、ゼロトラストの考え方をAIエージェントに適用した形だ。
エージェントから見たAlloyDBの強み

リモートMCPサーバーは接続の仕組みを提供するが、その先にあるデータベース自体の性能も重要だ。AlloyDBはエージェントアプリケーションに特化したいくつかの特徴を持つ。
まず、ベクトル検索性能だ。ScaNNインデックスを使うと、標準PostgreSQLの最大6倍の速度でベクトルクエリを実行できる。100億ベクトルまでスケールするため、大規模なRAGアプリケーションでもパフォーマンスが劣化しない。フィルタ条件付きのベクトル検索では最大10倍高速化される。これは「直近30日以内のドキュメントから類似検索」のような実用的なクエリで差が出る。
次に、ハイブリッド検索とリランキングだ。RUM(RUMインデックス / Row Usage Matrix)を使った全文検索とベクトル検索の組み合わせや、Reciprocal Rank Fusionによる結果の融合が可能だ。さらにGemini Enterprise Platformモデルを使ったインテリジェントなリランキングにより、エージェントは最も関連性の高い情報を優先的に取得できる。
また、AlloyDBのAI Functionsはデータベース内部で埋め込みを生成する。外部の埋め込みAPIを呼び出す必要がなく、数百万件の埋め込みを効率的に生成できる。Lakehouse Federationを使えば、BigQueryの分析データやIcebergテーブルのアーカイブデータにも、同じPostgreSQLインターフェースから透過的にアクセスできる。
AIエージェントにとって重要なのは「データの鮮度」と「アクセスの容易さ」だ。AlloyDBのリアルタイム埋め込み生成とLakehouse Federationの組み合わせにより、エージェントは最新のオペレーショナルデータと過去の分析データを区別なく扱える。配送車両の位置情報のような刻々と変化するデータでも、クエリを発行した瞬間の状態を取得できる。
実際の導入手順とデモの流れ
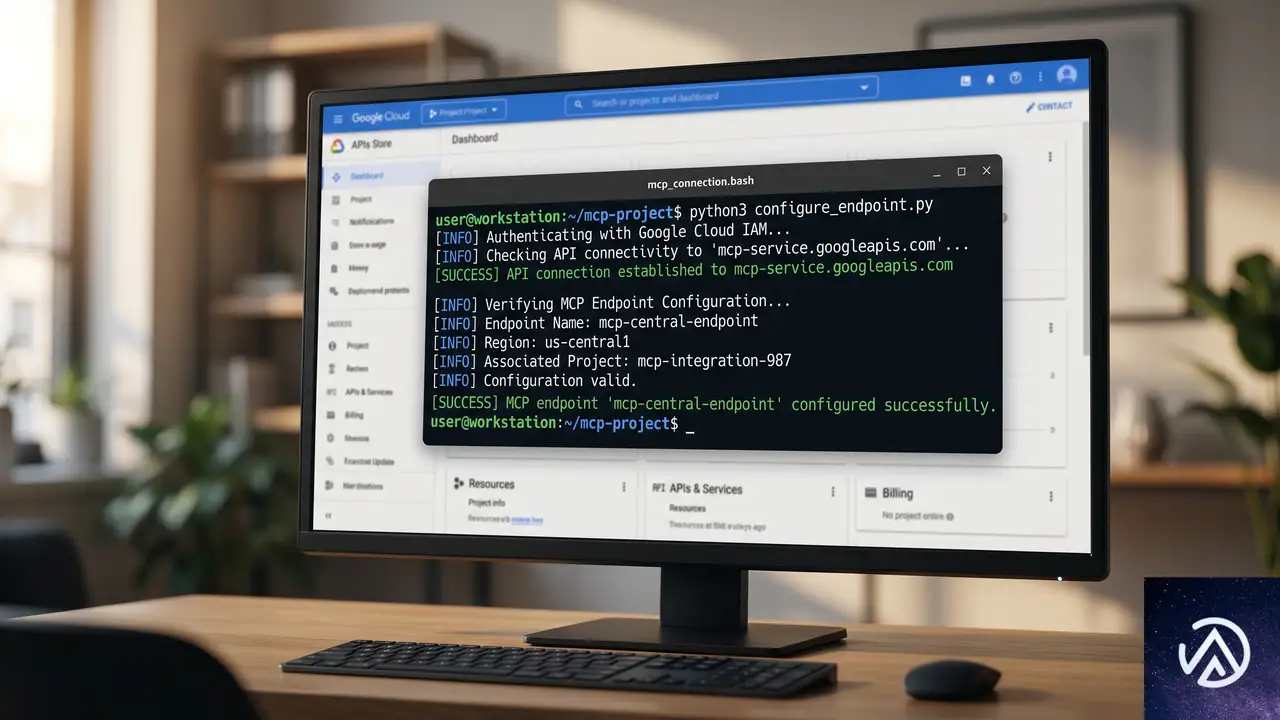
Google Cloudは今回のGA発表にあわせて、Codelab(ハンズオン形式のチュートリアル)を公開した。導入手順は以下の4ステップに整理されている。
接続が確立すると、エージェントは自動的にデータベースのスキーマを把握する。テーブル名やカラム名をイントロスペクションクエリで取得し、ユーザーの質問に応じて適切なJOINや集計クエリを組み立てられる。たとえば「過去24時間で最も遅延が発生している配送ルートは?」という質問に対して、エージェントが配送テーブルと車両テーブルをJOINし、リアルタイムの位置情報と組み合わせて回答する。
AIエージェントが実行できる操作の範囲
リモートMCPサーバー経由でエージェントが実行できる操作は、単なるSELECTクエリにとどまらない。AlloyDBのツールセットを使うと、以下のような運用操作も可能になる。
- データのエクスポートとインポート
- バックアップの作成とリストア
- クラスタの設定更新
- AI Functionsを使ったテキストのランキング(AI.RANK())
もちろん、これらの操作はIAM権限の範囲内でのみ実行される。読み取り専用のSQLツールを選択していれば、データ定義や変更を伴う操作はブロックされる。本番環境での安全な運用を第一に設計されている点が重要だ。
導入時に検討すべきポイント
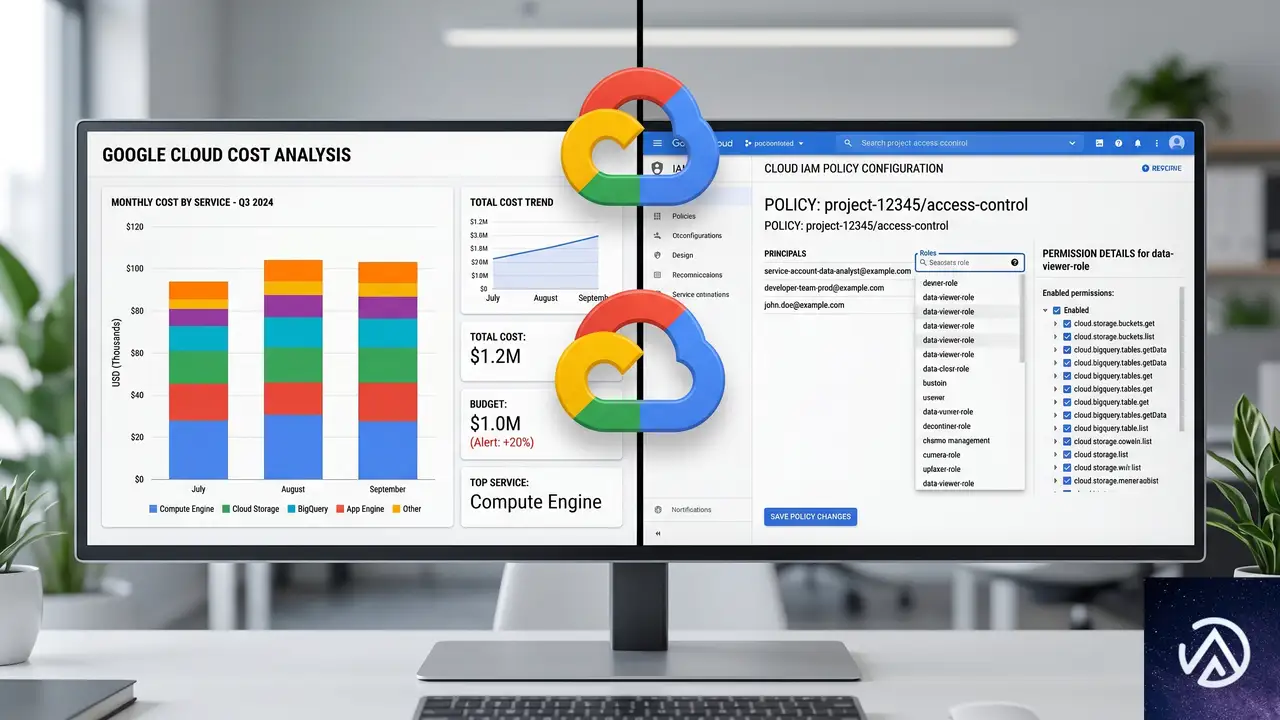
リモートMCPサーバーのGAは、AIエージェントとデータベースの統合を大きく前進させる。しかし導入にあたっては、いくつかの点を事前に検討する必要がある。
まず、コスト構造の把握だ。AlloyDB自体がエンタープライズ向けのプレミアムデータベースであり、さらにMCPサーバーの利用にもGoogle Cloudの料金が発生する。30日間の無料トライアルが提供されているので、まずは小規模なクラスタで検証し、ワークロードに応じたコストを見積もることを推奨する。
次に、IAMポリシーの設計だ。エージェントに必要最小限の権限を付与する「最小権限の原則」を徹底する必要がある。テーブル単位、カラム単位でのアクセス制御が可能だが、データベースの規模が大きくなるとポリシー管理が複雑化する。事前にアクセス制御のルールを整理しておくことが重要だ。
最後に、プロンプト設計の重要性も変わらない。MCPサーバーがデータへのアクセスを提供しても、エージェントが適切なクエリを生成できるかどうかはプロンプトの質に依存する。スキーマの説明やクエリの方針をプロンプトに含めることで、より正確な結果を得られる。
この記事のポイント
- AlloyDB向けリモートMCPサーバーがGAとなり、HTTPエンドポイント経由でAIエージェントが安全にデータベースへアクセス可能になった
- IAMによるテーブル単位の権限制御と、Model Armorによるプロンプトセキュリティで本番運用に耐える設計
- AlloyDBのベクトル検索性能とAI Functionsの組み合わせにより、RAGアプリケーションの構築が効率化される
- 30日間の無料トライアルとCodelabが提供されており、小規模な検証から始められる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験
2026年5月ウェブ標準 CSS疑似クラスや遅延読み込み新機能まとめ
2026年5月、Chrome 148、Firefox 151、Safari 26.5が安定版としてリリースされた。CSSの疑似クラスやコンテナクエリ、メディア要素の遅延読み込みといった使い勝手を大きく左右する機能群がBaselineへと加わっている。
具体的な変化点は4つだ。開閉状態にスタイルを当てる :open 疑似クラス、名前だけで親を参照できるコンテナクエリ、カスタムプロパティを条件とするスタイルクエリ、そして <video> および <audio> のネイティブ遅延読み込み。これらはすべて、主要ブラウザの最新版で動作するBaseline Newly availableとなった。
この記事では、それぞれの機能が何を解決し、実際のコードでどう使うのか、概観を交えながら見ていく。リリースノートを追いきれていないフロントエンドエンジニアやWeb制作担当者は、この機会にキャッチアップしてほしい。
:open 疑似クラスが Baseline 入り
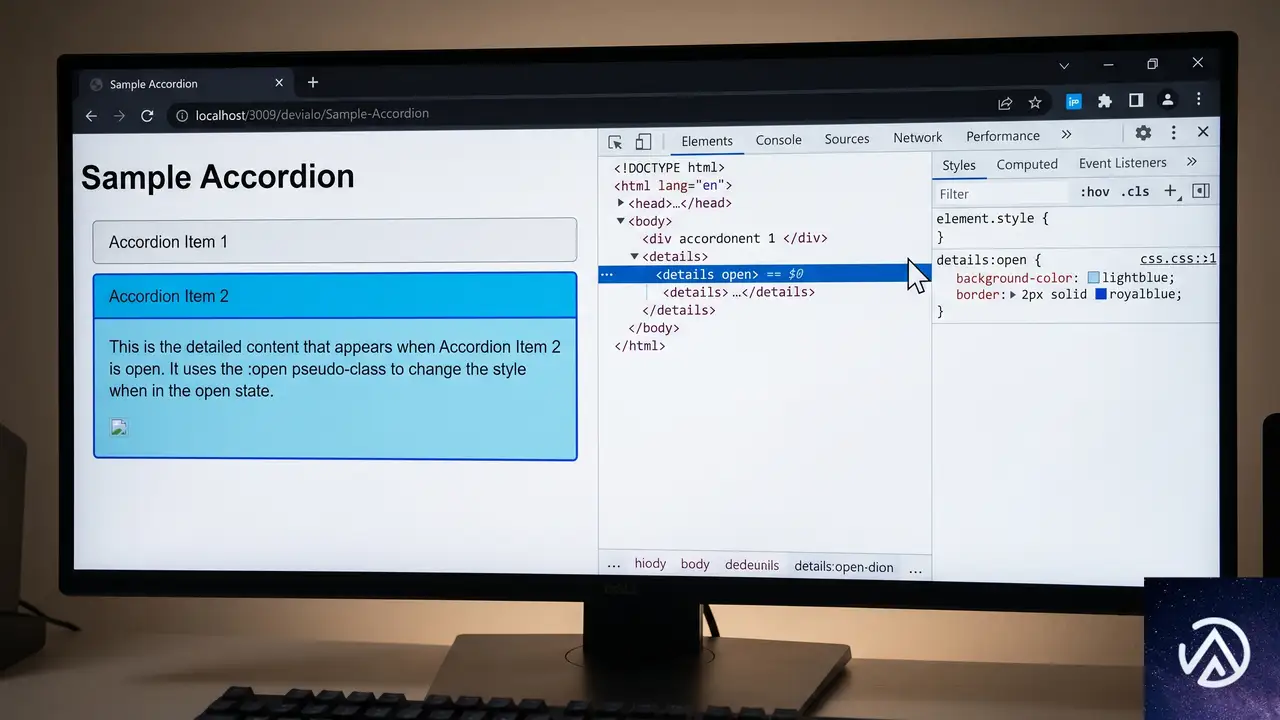
長らくFirefoxとChromeが対応していた :open 疑似クラスが、Safari 26.5のサポートによりBaseline Newly availableとなった。開閉状態を持つHTML要素を、開いているときだけまとめてスタイリングできる疑似クラスだ。
具体的には <details>、<dialog>、<select> といった要素に加え、カラーピッカーや日付ピッカーなどの <input> も対象になる。これまでは details[open] のように属性セレクタで個別に書く必要があったが、より読みやすく一貫性のあるコードにまとめられる。
:open 疑似クラスが解決するもの
従来の手法では、開閉のインタラクションを表現するために要素ごとに異なるセレクタを書く必要があった。たとえば <details> には details[open]、<dialog> には dialog[open] を使う。しかし :open 疑似クラスなら、これらをひとつのセレクタで扱える。
この変化は、コードのメンテナンス性を大きく改善する。とくにデザインシステムを構築するチームでは、コンポーネントの状態管理がシンプルになる利点が大きい。
background: #f0f0f0;
}
dialog[open] {
background: #f0f0f0;
}
background: #f0f0f0;
}
このデモで示したように、:open 疑似クラスを使うと開状態の記述が一箇所に集約される。複数箇所に散らばっていたスタイルを一元管理でき、意図しないスタイル崩れも防ぎやすくなる。
活用シーンと注意点
実務では、FAQのアコーディオンやモーダルダイアログのスタイル定義で即座に役立つ。フォーム部品のピッカーUIにも適用されるため、一貫したブランド表現が可能だ。
ただし、すべての開閉要素が対象になるわけではない。<summary> をクリックして開く <details> のように、ブラウザが開閉状態をネイティブに管理する要素に限定される。JavaScriptで独自に開閉を管理するUI部品には反応しない点に注意が必要だ。
名前のみのコンテナクエリ
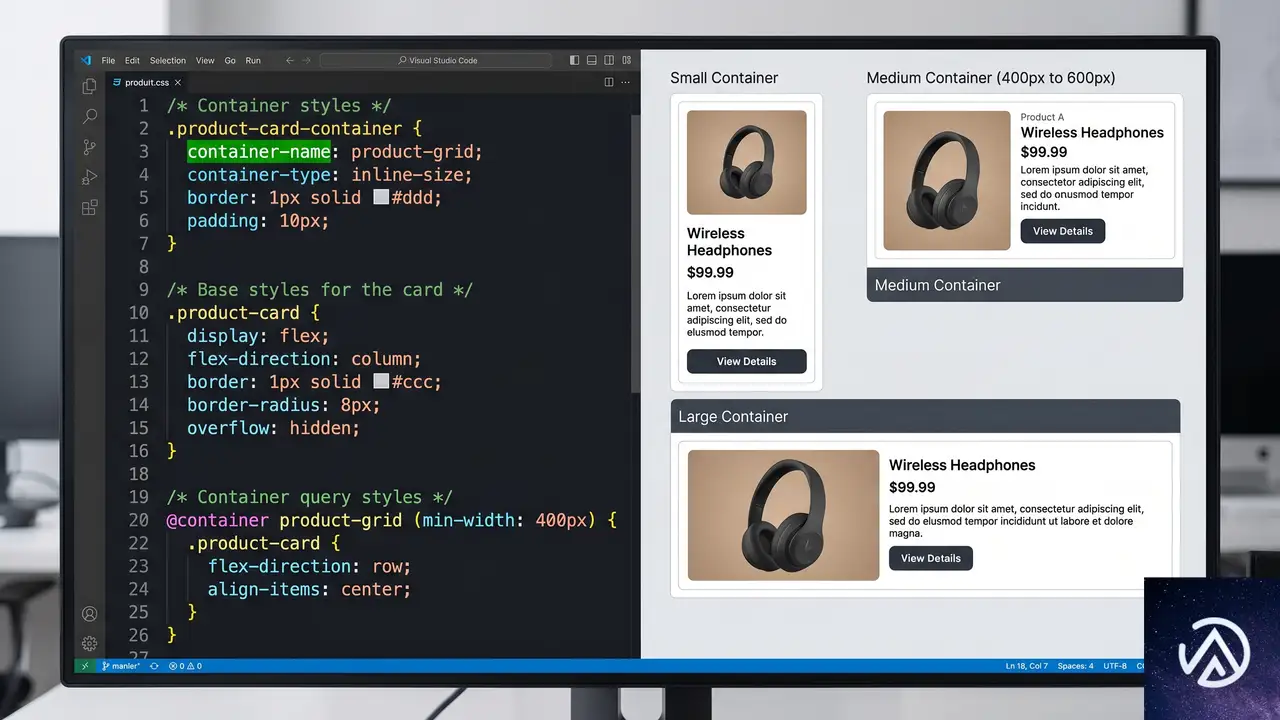
Chrome 148のリリースにより、名前のみのコンテナクエリ(name-only container queries)がBaseline Newly availableになった。コンテナクエリを書く際に、サイズやスタイルの条件を省略してコンテナの「存在」だけを条件にできる。
これまでは container-type プロパティでコンテナの種別を宣言し、かつ @container ルール内でサイズ条件を指定する必要があった。今回の変更で、単に名前でコンテナを参照するだけのクエリが書けるようになり、コードの冗長さが大きく減る。
名前だけでコンテナを参照する仕組み
具体的なコードを見てほしい。従来は「サイドバーという名前のコンテナが、ある幅を超えたら」というクエリが中心だった。新しい構文では「サイドバーという名前のコンテナがあるなら」という条件だけでスタイルを切り替えられる。
/* コンテナの名前を付与 */
#container {
container-name: --sidebar;
}
/* サイズ条件なしで名前だけで参照 */
@container --sidebar {
.content {
padding: 2rem;
}
}container-name: –sidebar;
@container –sidebar (min-width: 300px) { … }
@container –sidebar { … }
この構文によって、container-type の宣言が不要になるケースが増える。名前の指定だけでコンテナを参照したい場面では、CSSの記述量が減り、可読性も上がる。
実務での活用ポイント
大規模なサイトでは、レイアウトのコンポーネント化が進んでいる。コンテナクエリは「親コンポーネントの状態で子のスタイルを決める」設計と相性が良く、名前のみの参照はこの流れを加速する。
たとえば「サイドバーがDOM上に存在するならカードのパディングを変える」といった、レイアウトの有無に応じた条件分岐が簡潔に書ける。メディアクエリでは制御しきれなかったコンポーネント単位のレスポンシブが、より直感的に扱えるようになる。
コンテナスタイルクエリとカスタムプロパティ
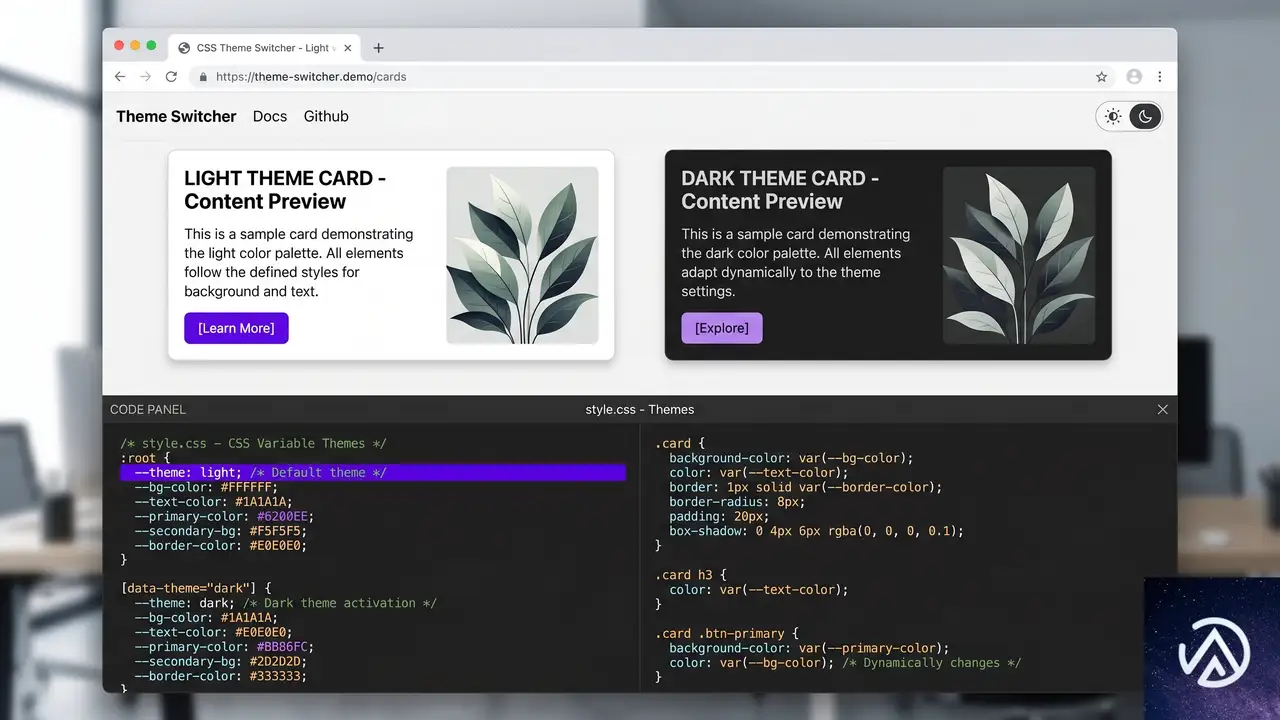
Firefox 151で style() クエリのサポートが加わり、カスタムプロパティを条件とするコンテナスタイルクエリがBaseline Newly availableとなった。これにより、サイズ以外の親コンテナのCSSプロパティを条件にスタイルを切り替えられる。
とりわけ大きな意味を持つのは、カスタムプロパティ(CSS変数)を条件に含められる点だ。たとえば --theme という変数が dark のときに子要素の背景色を変える、といったテーマ切り替えをCSSだけで完結できる。
カスタムプロパティを条件にしたクエリの実例
以下は、親コンテナで定義された --theme: dark というカスタムプロパティを検知し、子の .card にダークモード用のスタイルを適用するコードだ。
@container style(--theme: dark) {
.card {
background-color: #1a1a1a;
color: #fff;
}
}この仕組みを使えば、JavaScriptに依存せずにテーマの切り替えが可能だ。CSS変数を用いた設計基盤が整っているプロジェクトであれば、追加のスクリプトなしでダークモード対応の精度を上げられる。
サイズクエリとの使い分け
サイズクエリは「コンテナの幅が300pxを超えたら」といったレイアウト制御に強い。一方でスタイルクエリは「テーマ」「状態」「モード」といった意味的な条件に向いている。
両者は競合するものではなく、補完関係にある。たとえば「サイドバーが存在し、かつダークテーマのとき」にスタイルを変える、といった複合的な条件設計も可能になる。コンテナクエリ全体がBaselineへと進んだことで、CSSの表現力は確実に一段階上がったと言える。
video と audio のネイティブ遅延読み込み
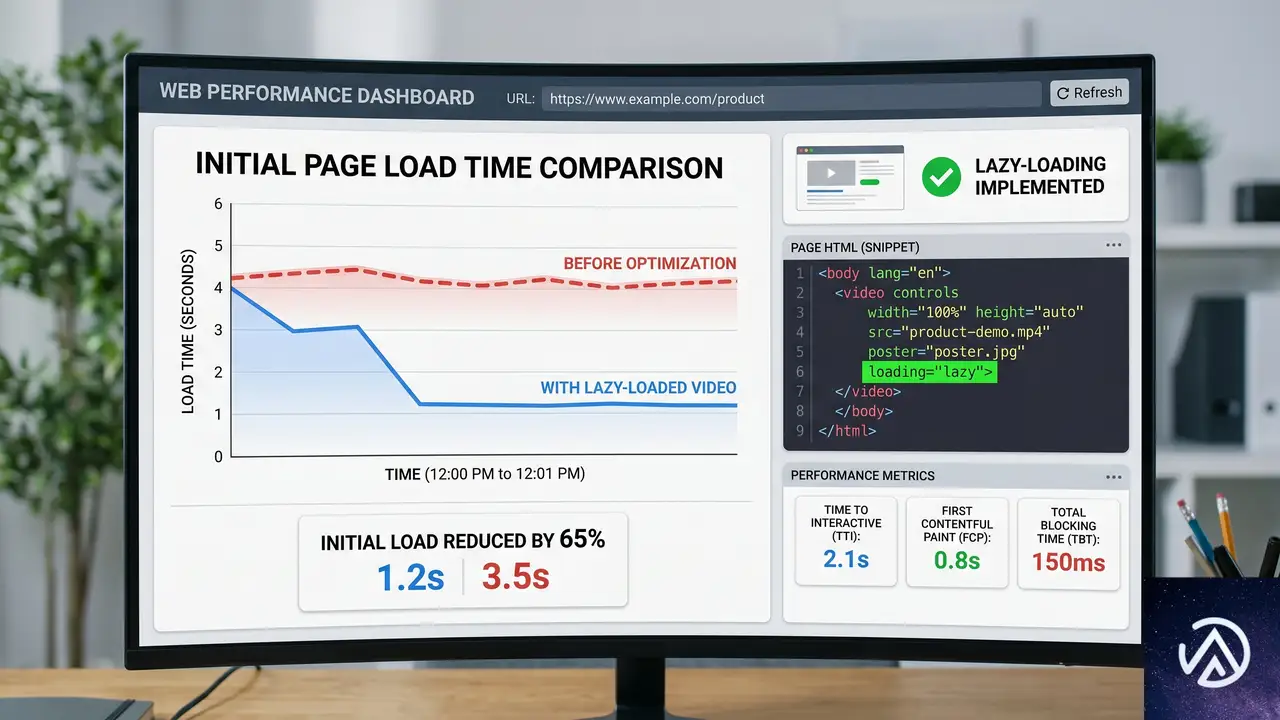
Chrome 148で <video> と <audio> 要素に loading="lazy" 属性が導入された。これにより、画像やiframeと同じく、メディア要素をビューポート付近まで読み込まない動作をブラウザネイティブで制御できる。
サイトのファーストビューに動画を置くケースは増えているが、初期ロードでユーザーの帯域を圧迫する問題は長年の課題だった。この機能はJavaScriptのIntersection Observerを使った手動実装を、宣言的な属性ひとつで置き換える。
実装と効果
実装はきわめてシンプルで、<video> タグに loading="lazy" を追加するだけだ。特別なポリフィルやライブラリは不要で、対応ブラウザであればそのまま動作する。
<video src="hero.mp4" loading="lazy" controls></video>効果は数値にも表れる。Squarespaceのエンジニアリングチームが公開した記事によれば、ネイティブ遅延読み込みによって動画の初期リクエスト数が大幅に減り、LCP(Largest Contentful Paint)の改善に貢献したという。詳細は同チームの技術記事「How To Use Standard HTML Video and Audio Lazy-Loading on the Web Today」を参照してほしい。
対応範囲と今後の展望
Chrome 148でサポートが始まったこの機能は、今後のブラウザ展開によってBaseline化が期待される。FirefoxやSafariの動向はまだこれからだが、loading="lazy" の属性自体は画像やiframeですでに確立された仕組みであり、メディア要素への拡張も自然な流れと言える。
未対応ブラウザでは属性が無視されるだけで壊れないため、今すぐ実装してもリスクは少ない。動画を多用するポートフォリオサイトやLPでは、とくに導入効果が大きい。
Document Picture-in-Picture API とその他のアップデート
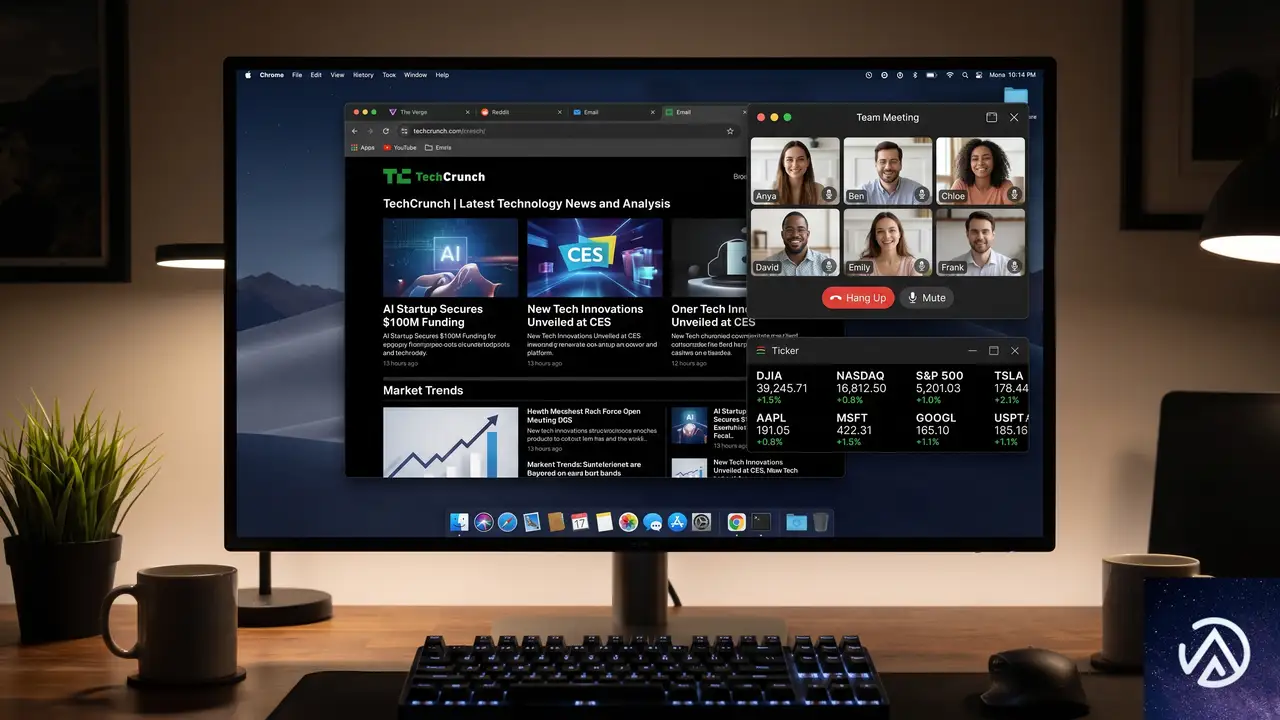
CSS以外でも重要な進展があった。Firefox 151でDocument Picture-in-Picture APIがデスクトップ向けに導入され、Web Serial APIもFirefoxデスクトップとChrome Androidでサポートが拡大されている。
Document Picture-in-Picture API の概要
従来のPicture-in-Picture APIは <video> 要素を常に前面の小窓で表示する機能だった。一方、Document Picture-in-Picture APIは任意のHTMLコンテンツを含むウィンドウを常に最前面に表示できる。
これにより、ビデオ会議の参加者グリッドや株価ティッカー、タイマーといったインタラクティブなオーバーレイを、ページ遷移後も維持できるようになる。デスクトップ向けのプログレッシブウェブアプリ(PWA)でとくに威力を発揮するAPIだ。
Web Serial API のプラットフォーム拡大
Web Serial APIは、マイクロコントローラーや3Dプリンター、開発ボードといったシリアルデバイスとウェブサイトが直接通信するための仕組みだ。Firefoxでは専用のサイト権限アドオンを導入することで安全に管理できる設計になっている。
Chrome 148ではAndroid向けにもサポートが拡大され、モバイルデバイスからシリアル機器を制御するユースケースが現実的になった。IoT分野や教育用途での活用が今後広がると見られている。
この記事のポイント
- 2026年5月のブラウザ安定版で、複数のCSS機能とHTML属性がBaseline Newly availableに到達した
:open疑似クラスで開閉状態のスタイリングが一元的に書けるようになった- 名前のみのコンテナクエリにより、サイズ条件なしで親コンテナの存在を参照できる
style()クエリでカスタムプロパティを条件としたテーマ切り替えがCSSだけで実装可能<video>と<audio>のloading="lazy"でメディアの遅延読み込みがネイティブ化され、初期ロードの負荷が軽減される
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験