

AWS WAFがAIボット収益化機能を追加、コンテンツ所有者が課金可能に
AWSは2026年6月15日、AWS WAFにAIトラフィック収益化機能を追加した。コンテンツ所有者やパブリッシャーが、自社のWebコンテンツにアクセスするAIボットやAIエージェントに対して、ネットワークエッジで直接課金できるようになる。
AIボットによるWebトラフィックは、多くのコンテンツプロバイダーで全体の50%を超え、AI専用クローラーは前年比300%以上増加している。従来の検索エンジンクローラーはリンクを返すことで参照トラフィックをもたらすが、AIボットはコンテンツを要約してAIインターフェイス上で表示するため、元のサイトにはほとんどトラフィックが還元されない。その結果、コンテンツ提供者はインフラコストだけを負担し、広告収入や購読コンバージョンといった従来の収益源が得られない状況が続いていた。
今回の新機能は、このギャップを埋めるものだ。AWS WAF Bot Controlの仕組みを拡張し、コンテンツパスごと、ボットカテゴリごと、検証ティアごとにリクエスト単価を設定できる。また、ステーブルコインによる支払いをウォレットで受け取り、単一のダッシュボードで収益とボットアクティビティを追跡可能にする。
AIボット収益化の新機能がAWS WAFに追加された背景

AIトラフィックの爆発的な増加
GPTBotやClaude-Web、Perplexity-BotといったAIクローラーは、学習用データやリアルタイム情報の収集のためにWebサイトを大量にクロールする。こうしたトラフィックは増加の一途をたどり、一部のコンテンツプロバイダーではAIボットが全リクエストの50%を超えるまでになっている。検索エンジンのクローラーとは異なり、AIボットはインデックスを生成する代わりにテキストを直接消費し、要約をAIチャット画面に表示する。そのため、元記事を読むための流入はほとんど発生しない。
従来のBot Controlでは限界があった理由
AWS WAF Bot Controlはこれまで、650種類以上のAIボットを検出し、ブロックまたはレート制限をかけることができた。しかし、ボットのトラフィックを完全に遮断するのではなく、課金して収益化したいというニーズは強く存在していた。コンテンツを無料で提供し続ければインフラコストがかさむ一方、単純にブロックすればAIサービスへの露出が途絶えてしまう。そこで、ボットにコンテンツ利用の対価を支払わせる仕組みが求められていた。
AIトラフィック収益化の仕組み

x402プロトコルとHTTP 402 Payment Required
今回の収益化機能の核は、x402というマシンツーマシン決済のオープンプロトコルだ。ルールに合致したAIボットからのリクエストに対し、AWS WAFはHTTP 402 Payment Requiredレスポンスを返す。このレスポンスボディには、コンテンツの価格(USDC建て)、受け入れ可能なブロックチェーンネットワーク(BaseやSolanaなど)、送金先ウォレットアドレス、支払いタイムアウトを含むJSON形式のプライスマニフェストが含まれる。これを受け取ったx402対応のエージェントランタイムは、自律的に署名付き支払い承認を提出し、AWS WAFがそれを検証したうえでコンテンツを提供するという流れだ。
ステーブルコイン決済の流れ
決済はステーブルコイン(USDC)で行われ、サードパーティのファシリテーターサービス(現在はCoinbaseのx402 Facilitator)がオンチェーン上の決済処理を支援する。Stripeによる直接アカウント決済やMachine Payments Protocol(MPP)への対応も近日中に予定されている。コンテンツ所有者は、AWS WAFの設定パネルでウォレットアドレスを指定するだけでよく、独自の決済インフラを構築する必要はない。また、AWS自体は決済手数料を徴収しない。
上記のように、収益化を有効にするとAIボットのアクセスが自動的に402レスポンスに切り替わり、支払いが完了したリクエストだけがコンテンツに到達する。コンテンツ所有者はアクセスを遮断する代わりに料金を設定し、ボットトラフィックを収益源に変えることができる。
収益化の設定手順
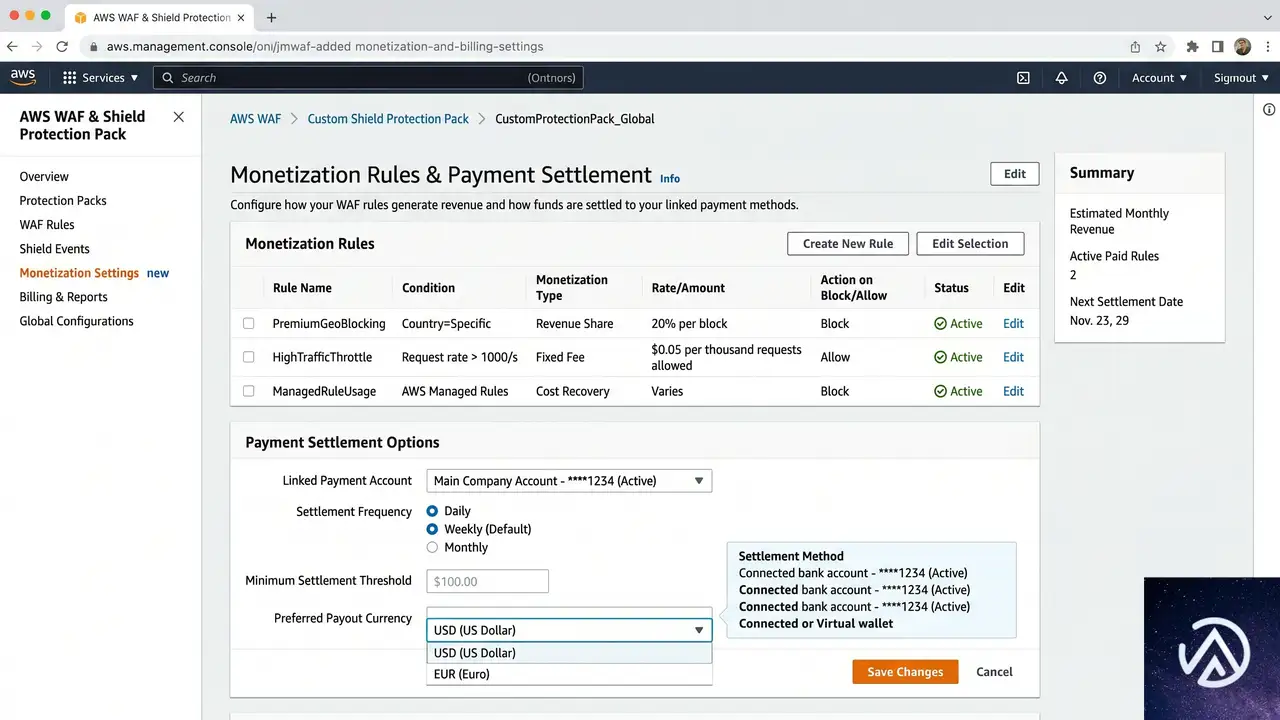
プロテクションパックの作成
AIトラフィック収益化を使うには、まずAWS WAF Bot ControlをCommonまたはTargetedレベルで有効にしたうえで、プロテクションパック(Protection Pack)を作成する。プロテクションパックとは、どのコンテンツパスを収益化するか、各検証ティアにいくら課金するか、どの支払い方法を受け入れるかといったポリシーをまとめた設定単位だ。AWSマネジメントコンソールで「WAF & Shield」を開き、「Protection packs (web ACLs)」から作成を開始する。
作成時にアプリカテゴリ(コンテンツ・パブリッシングシステム、Eコマースなど)を選択し、保護対象のリソース(CloudFrontディストリビューション)をひも付ける。推奨ルールパッケージが提示されるが、個別のルールを選ぶことも可能だ。プロテクションパックを作成したら、必要に応じて価格帯や支払い方法、コンテンツ範囲、ライセンス条項をカスタマイズする。
収益化ルールの設定
プロテクションパックを選び、「Configure AI monetization」から検証ティアごとにアクションを割り当てる。アクションは6種類ある。Monetize(402を返し課金)、Allow(無料アクセス許可)、Block(完全遮断)、Count(課金せずログだけ記録)、CAPTCHA(人間の確認)、Challenge(ブラウザかどうかのサイレントチェック)だ。Monetizeを選択すると、支払い決済用のブロックチェーンネットワーク(BaseやSolanaなど)を指定し、ウォレットアドレスとUSDC建てのページ単価を設定する。
Monetizeアクションは、Amazon CloudFrontディストリビューションに関連付けられたWeb ACLでのみサポートされる。リージョナルWeb ACLでは使えない点に注意が必要だ。また、本番投入前にテストモード(Currency modeをTestに切り替え)で、テストネット(Base SepoliaやSolana Devnet)を使った検証が可能となっている。テストモードでも実際の402レスポンスと支払いフローが再現され、すべてのイベントにCurrencyMode: TESTのログが付与される。
この一連の流れは、サイトのオリジンサーバーに一切手を加えることなく、AWS WAFのエッジで完結する。コンテンツ提供者はアプリケーションコードを修正する必要がないため、既存のWebサイトに迅速に収益化機能を追加できる。
AIトラフィック分析ダッシュボードと収益トラッキング
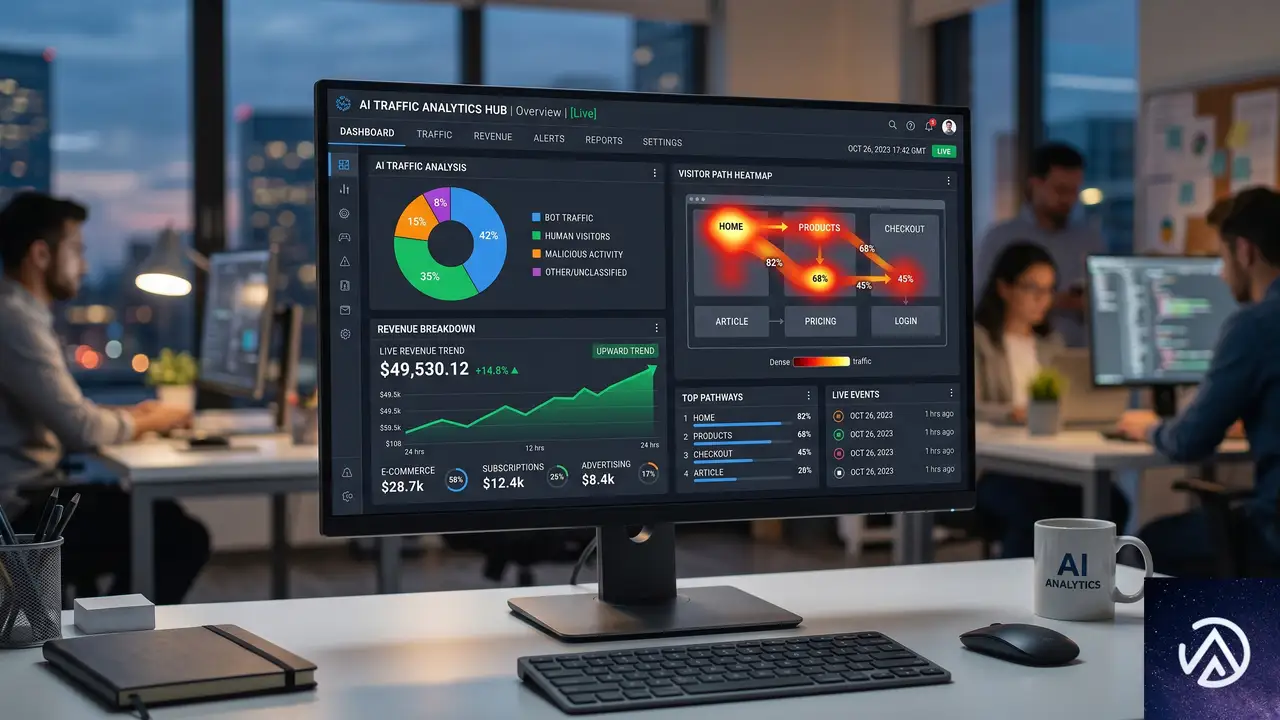
価格設定を最適化するためのAIトラフィック分析ダッシュボードも提供される。プロテクションパックを選択すると、ボットリクエスト全体、AIボットリクエスト、検証済みAIトラフィック、未検証AIトラフィックの4カテゴリに分けてトラフィックを可視化する。帯域幅の消費量、推定月間コスト、ピークリクエストレートといったインフラ影響指標も表示され、パスごとのヒートマップで時間帯別のAIボット集中度がわかる。
Currency modeをRealに切り替えると、「AI access monetization」ダッシュボードで実際の収益をリアルタイムに追跡可能だ。総収益、検証済みボットと未検証ボットの内訳、リクエストあたりの平均単価が表示され、上位の収益ソースやコンテンツパス別の収益ランキングも確認できる。Settlementsタブでは決済プロバイダーごとの精算状況や支払い失敗の分析も行える。
導入のポイントと今後の展望
この機能は、CloudFrontを利用するすべてのAWS WAFユーザーに対して追加料金なしで提供される。ただし、Monetizeを適用できるのはCloudFrontディストリビューションに関連付けたWeb ACLのみである点は押さえておきたい。また、テストモードを活用して本番適用前に価格設定やウォレット設定、x402フローを十分に検証することが推奨される。
今後、Stripeの直接アカウント決済やMPPに対応することで、より多様な支払い手段が利用可能になる見通しだ。AIボットのトラフィックが増え続ける中、コンテンツの価値を適切に回収する仕組みとして、この収益化機能は重要な選択肢となる。自社サイトへのAIクローラーの影響を分析している企業は、まずBot Controlのダッシュボードでトラフィックの可視化から始め、段階的に収益化を検討するのが良いだろう。
この記事のポイント
- AWS WAFにAIボット向け課金機能が追加され、HTTP 402とx402プロトコルでマシンツーマシン決済を実現
- コンテンツパスや検証ティアごとにリクエスト単価を設定でき、ステーブルコインで収益を受け取れる
- 設定はプロテクションパック単位で行い、CloudFront環境のエッジで自律的に課金とコンテンツ配信が完結
- AIトラフィック分析ダッシュボードでコストと収益を可視化し、価格設定を最適化できる
- テストネットを使った検証モードがあり、本番適用前にリスクを評価可能

・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Googleのノンコモディティ方針、ECサイトが取るべきコンテンツ戦略
Googleが2026年5月、AI検索時代を見据えた新しい可視性ガイドラインを公開した。その中核にあるのが「ノンコモディティ・コンテンツ(Non-Commodity Content)」という概念だ。誰にでも書ける凡庸な情報ではなく、書き手自身の経験や独自の視点がにじむコンテンツを評価するという方針である。
Practical Ecommerceの記事によると、この考え方自体は目新しいものではない。Googleは長年にわたりEEAT(経験・専門性・権威性・信頼性)を重視してきた。しかしAIによるゼロクリック検索が急速に台頭する中で、改めて「人間にしか書けないコンテンツ」の重要性が言語化された形だ。
この記事では、Googleの「ノンコモディティ」方針の具体的な内容を整理する。あわせて、ECサイトを運営する事業者やWooCommerceユーザーがこの変化をどう受け止め、どんなコンテンツ戦略を取るべきかを実務目線で解説する。
Googleが定義する「コモディティコンテンツ」とは何か

GoogleのAI可視性ガイドラインは、検索上位を目指すコンテンツを2つに大別している。「コモディティコンテンツ」と「ノンコモディティコンテンツ」だ。まず前者の定義から確認しよう。
誰が書いても同じになる情報
コモディティコンテンツとは、いわゆる「一般的な知識」に基づいて書かれた情報のことだ。具体例としてGoogleが挙げているのが「初めて住宅を購入する人への7つのヒント」といった記事である。この手の内容は、どの書き手が担当しても似たような仕上がりになる。
実務的にいえば、競合他社の記事を参考に構成し、公開データだけを元にまとめた商品比較記事や、製品スペックを並べただけの紹介ページが該当する。生成AIを使えば数分で量産できるタイプのコンテンツだ。
検索におけるコモディティコンテンツの限界
Google検索のインハウスリエゾンであるダニー・サリバン氏は、2026年4月のSearch Central Live Torontoでこのテーマを取り上げている。同氏が示した業界別の対比表を見ると、コモディティコンテンツの問題点がより明確になる。
- ランニングシューズ販売店の場合「ランニングシューズ購入時に考慮すべき10のポイント」
- インテリアデザイナーの場合「2024年に見逃せないキッチントレンド」
これらは情報として誤りではない。しかし、検索エンジンから見れば「どのサイトを上位表示してもユーザー体験に大差がない」と判断されるリスクをはらむ。AIによる回答生成が進むほど、この傾向は強まるだろう。
ノンコモディティコンテンツが評価される理由

一方のノンコモディティコンテンツは、書き手固有の経験や専門知識に裏打ちされた情報を指す。生成AIが簡単に要約したり、出典なしで再利用したりしにくい性質を持つ。
Googleが示した具体例
先のダニー・サリバン氏による業界別の対比表では、ノンコモディティに該当する例として以下が挙げられている。
- ランニングシューズ販売店「なぜこの顧客のシューズは400マイルで壊れたのか、摩耗パターンの分析」
- インテリアデザイナー「大理石 vs ブドウジュース、5人家族に石材を勧めなかった理由」
どちらも実際の顧客対応や施工現場で起きた具体的なエピソードだ。競合が簡単に真似できる内容ではなく、読み手に「この店で買いたい」「このデザイナーに依頼したい」と思わせる力がある。
EEATとの関係性
ノンコモディティという用語は新しいが、背景にある考え方はGoogleが長年重視してきたEEATと重なる。EEATとは「Experience(経験)」「Expertise(専門性)」「Authoritativeness(権威性)」「Trustworthiness(信頼性)」の頭文字を取った評価基準だ。
Practical Ecommerceの記事では、Googleが以前から人間の評価者に対してEEATに基づくサイト評価を指示しており、ランキングアルゴリズムにもヘルプフルコンテンツシステムの一部としてEEATに似た要素が組み込まれている可能性が高いと指摘している。要するに、新しい概念が登場したというより、AI時代に合わせて既存の評価軸を再定義したと見るのが自然だ。
上図の対比からわかるように、ノンコモディティコンテンツは「そのサイトでなければ読めない情報」を提供する。この一点がAI時代の検索評価において決定的な差となる。
ECサイトが取り組むべきコンテンツ戦略

では、WooCommerceをはじめとするECサイト運営者は、この方針転換にどう対応すればよいのか。具体的な打ち手を3つの軸で整理する。
独自データに基づく分析記事
顧客の購買データや問い合わせ履歴を分析し、傾向を記事化する手法はノンコモディティコンテンツの典型例だ。「昨年と比べて20代女性の購入単価が15%上昇した理由」「雨の日に売れる商品トップ5とその背景」といった内容である。
WooCommerceのレポート機能やGoogleアナリティクスのデータを活用すれば、小規模店舗でも十分に独自性のある分析が可能だ。数字と具体的な事例をセットにすることで、読み手の信頼を得やすくなる。
実際の使用例や顧客ストーリー
商品紹介ページに顧客の使用シーンを詳細に盛り込むことも効果的だ。「30代男性がキャンプで3日間使用した感想」「子育て中の女性が選んだ理由と1カ月後の変化」といった具体的なエピソードは、スペック表では伝わらない価値を読者に届ける。
重要なのは、単なるレビュー評価の転載ではなく、店舗スタッフが直接ヒアリングした内容や観察した気づきを文章化することだ。この一手間が、生成AIでは代替できない独自性を生む。
専門家としての見解や実験結果
自社で取り扱う商材について、スタッフが実際に検証した結果を公開する方法もある。「3種類の防水スプレーを実際に試して効果を比較した」「同価格帯の Bluetooth イヤホン5製品を音質測定器でテストした」といった記事だ。
これらは手間とコストがかかるが、検索エンジンからの評価だけでなく、ブランドの信頼構築やリピーター獲得にも直結する。YouTube動画と組み合わせれば、さらに効果は高まるだろう。
コモディティコンテンツが無価値というわけではない

ここまでノンコモディティの重要性を強調してきたが、誤解してはいけない点がある。商品リリース情報や価格改定のお知らせ、採用情報といった「コモディティ的」なコンテンツにも確かな価値は存在する。
読者が求めるなら迷わず発信する
Practical Ecommerceの記事はこの点を明確に指摘している。読者が知りたい情報であれば、それがコモディティコンテンツであっても積極的に発信すべきだ。自社ブランドのファンは新製品の発表を待っているし、既存顧客はメンテナンス情報を必要としている。
直接流入の強化は、結局のところ最も確実なSEO対策である。コモディティかノンコモディティかという区分に過度に縛られるより、まずは目の前の顧客が何を求めているかに集中する姿勢が大切だ。
バランスの取れたコンテンツ設計を
理想的なのは、両方のタイプをバランスよく配置することだ。商品ページはコモディティ的な基本情報をしっかり押さえつつ、ブログ記事ではノンコモディティ的な独自コンテンツで差別化する。この二層構造が、AI検索時代のECサイトに求められるコンテンツ戦略の基本線となる。
WooCommerceサイト運営者が今すぐ始めるべき3つの施策

ここまでの内容を踏まえ、WooCommerceでECサイトを運営する事業者が今日から取り組める具体的なアクションを3つに絞って提案する。
1. 商品説明文に実体験を注入する
メーカー提供のスペック情報をそのまま転載している商品説明ページがあるなら、すぐに手を入れるべきだ。スタッフが実際に商品を使った感想や、想定外の使い方の発見、競合品との微妙な違いなどを追記するだけで、コンテンツの独自性は格段に高まる。
2. 社内ブログに顧客事例カテゴリを新設する
WooCommerceサイトにブログ機能を追加するのは難しくない。そこに「お客様事例」というカテゴリを作り、月1本のペースで実際の顧客ストーリーを掲載していく。許可を得た上で、購入のきっかけや使用後の変化を具体的に聞き取って記事化する。
3. アクセス解析から問いの種を探す
Googleサーチコンソールで自社サイトに流入している検索クエリを確認し、まだ十分に回答できていない質問を特定する。「〇〇 比較」「〇〇 口コミ」「〇〇 使い方」といったクエリに対して、自社の実体験やデータに基づいた回答記事を用意すれば、それがそのままノンコモディティコンテンツになる。
この記事のポイント
- GoogleはAI検索時代に対応するため「ノンコモディティコンテンツ」の重要性を正式に打ち出した
- ノンコモディティとは、書き手固有の経験や専門知識に裏打ちされた、生成AIでは簡単に再現できない情報を指す
- ECサイトでは顧客データ分析、使用事例の詳細な紹介、自社検証記事の公開が有効な差別化策となる
- 読者が求める情報であれば、コモディティ的なコンテンツにも価値はある、バランスが肝心
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

会員制サイトSEOの7つの戦略、ティーザーで制限コンテンツを検索上位に
会員制サイトを運営していると、せっかく質の高いコンテンツを制作しても、Google検索にまったく表示されないという問題に直面しやすい。原因の多くは、価値のある記事やコースがログインページやペイウォールの奥に隠れていることにある。検索エンジンは会員専用エリアをクロールできず、サイト全体のテーマを正しく把握できないのだ。
しかし、コンテンツ保護とSEOはトレードオフではない。適切な設計を施せば、プレビュー部分を検索エンジンに読み取らせつつ、中核の有料コンテンツはしっかり守れる。WPBeginnerがまとめた「会員制サイトSEOの7つの戦略」をもとに、具体的な実装方法を解説する。
会員制サイトのSEO課題と「ティーザーコンテンツ」の考え方

会員制サイトには特有のSEOの壁がある。Googleは公開されている情報だけをインデックスするため、ログイン必須のレッスンやダウンロード資料、会員ダッシュボードの中身は一切読み取れない。一方で、完全に閉ざしてしまうと検索流入を失い、新規会員の獲得機会が減ってしまう。
検索エンジンはゲート付きコンテンツをどう扱うか
Googleは、ログイン前の訪問者にも表示される「公開プレビュー」部分をインデックス可能だ。一方、認証画面の奥にある会員専用ページはクローラーのアクセス対象外となる。この仕組みを逆手に取り、ティーザーコンテンツ(Teaser Content)と呼ばれる一部公開方式を採用するサイトが多い。WPBeginnerの著者も、これが会員制サイトのSEOにおいて最も効果的で安全な手法だと述べている。
ティーザーコンテンツが有効な理由
ティーザーとは、記事の導入部やレッスンの要約、キーポイントなどを会員以外にも公開し、続きはログイン後に読めるようにする仕組みだ。Googleはこの公開部分をもとにページの主題を理解し、検索結果に表示できるようになる。訪問者にとっては内容の魅力を事前に感じられるため、会員登録へのコンバージョン率も向上しやすい。WPBeginnerの実践では、無料の動画コース一覧を誰でも閲覧可能にし、レッスン本体は会員登録後に開放する形で、SEOと会員獲得を両立している。
このデモのように、Googleは公開部分のテキストからページの内容を把握し、ランキング評価に活用する。訪問者にとっては「続きも見たい」というモチベーションが生まれ、会員獲得の導線としても機能する。
ティーザーとコンテンツドリッピングを安全に運用する
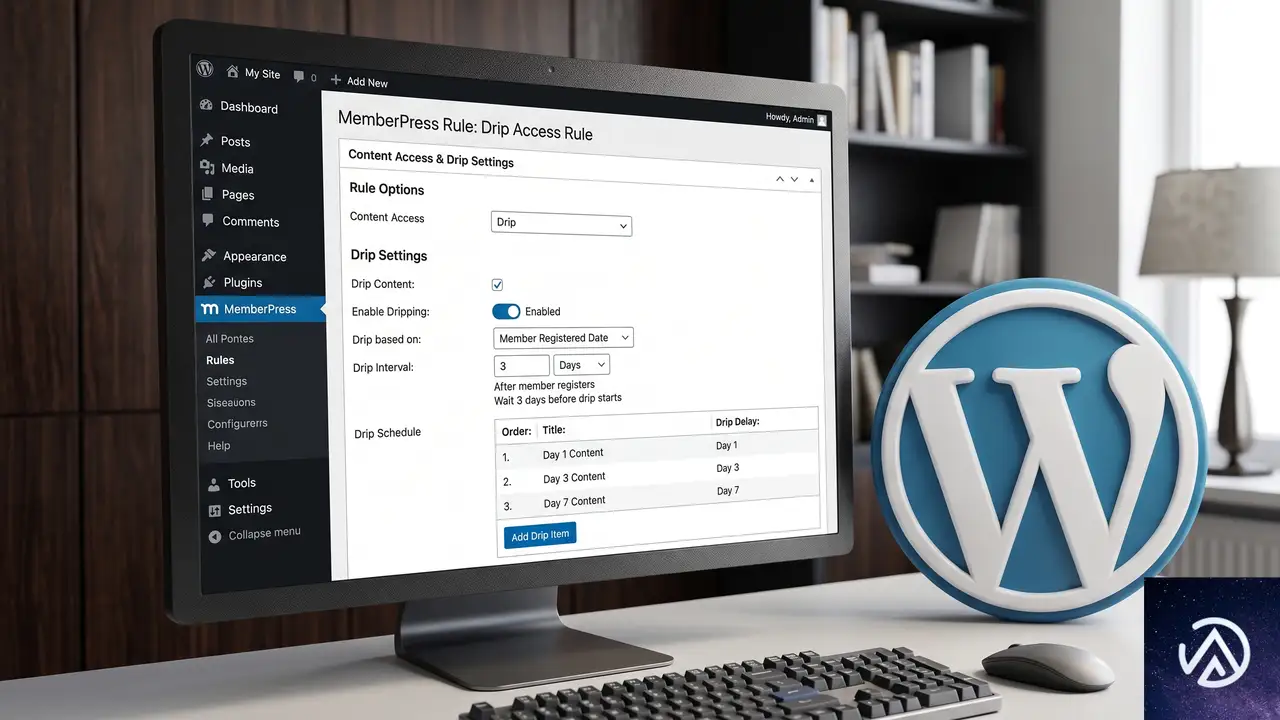
ティーザー表示の設定ができたら、次は会員にコンテンツを段階的に提供する「コンテンツドリッピング」について理解しておきたい。これはオンラインコースなどでよく使われる手法で、SEOに悪影響を及ぼさないためにはいくつかの注意点がある。
MemberPressを使ったティーザー公開の設定手順
WordPressで会員制サイトを構築する場合、高い機能を持つプラグインとしてMemberPressが広く使われている。管理画面の「MemberPress」→「ルール」から新規ルールを追加し、保護したい投稿やカテゴリを選択する。その後「アクセス条件」で特定の会員レベルを指定し、「未認証時のアクション」で抜粋の表示を有効にすれば、公開ティーザーが実装できる。
抜粋の長さは200〜300語程度を目安に設定すると、検索エンジンがページ主題を理解するのに十分な情報量を提供できる。WPBeginnerのガイドでは、未認証時に表示されるメッセージに料金ページや登録ページへのリンクを埋め込むことで、コンバージョン向上を図る方法も推奨されている。
コンテンツドリッピングがSEOに与える影響と事前対策
ドリッピングとは、会員登録後の日数経過や特定の日付に合わせて、レッスンを少しずつ開放していく仕組みだ。未解放のコンテンツは検索エンジンからも見えないため、その期間はインデックスされない。しかし、事前にティーザーページやレッスン概要を用意しておけば、後日開放されたときにスムーズにクロールされる。
動画コースの場合は、各レッスンに短いプレビュー動画や書き起こしテキスト、キーポイントをまとめた公開ランディングページを設ける方法が有効だ。WPBeginnerの著者は、これによって開放前から検索エンジンに内容を認識させられると指摘している。
無料コンテンツを拡充して検索トラフィックを底上げする
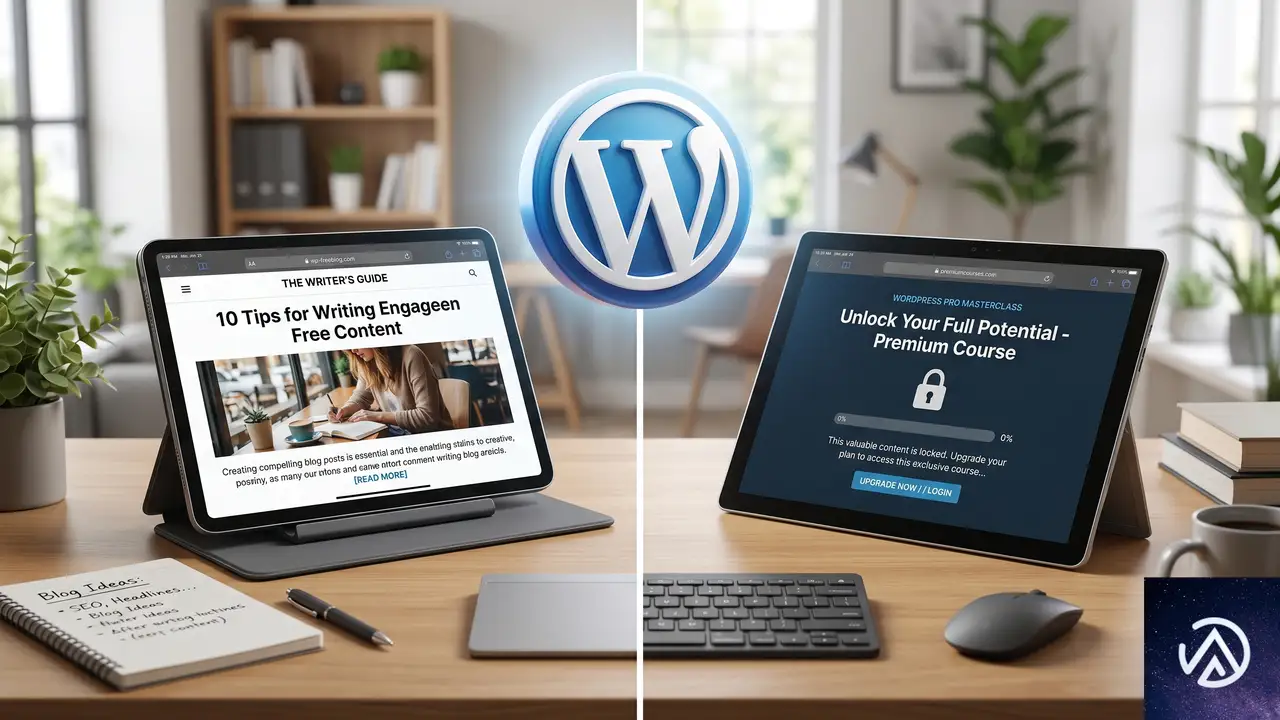
会員制サイトの運営者の中には、コンテンツの大半をペイウォールの内側に置いてしまうケースがある。だが、それではGoogleがサイト全体の専門性を評価する材料が不足し、オーガニック流入が伸び悩む。実際に成果を上げているサイトは、無料コンテンツを充実させ、そこから有料会員プログラムへと誘導する設計をとっている。
無料と有料の境界線の引き方
無料コンテンツは、幅広い検索キーワードでアクセスを集める役割を担う。一方、有料コンテンツにはテンプレートやワークシート、詳細な実装ガイドなど、より深い価値を置く。WPBeginnerが提示する枠組みでは、初心者向けチュートリアルや統計レポート、業界の基礎知識は無料とし、高度なノウハウや会員限定のツールキットは有料会員向けに保護する。
- 無料コンテンツ:検索ボリュームの大きいキーワードを狙うブログ記事、初心者向け解説、バックリンクを獲得しやすいリソース
- 有料コンテンツ:テンプレート、ワークシート、オンラインコース、会員限定の実装ガイド
このように切り分けると、無料記事で集めた訪問者に「より深い学びを得たければ会員登録を」と自然に促せる。
E-E-A-Tシグナルとキーワード戦略で信頼を構築する
会員制サイトは、専門知識やトレーニングを販売する性質上、訪問者からの信頼獲得が欠かせない。Googleが評価するE-E-A-T(経験、専門性、権威性、信頼性)の観点からも、無料コンテンツを使って実績や実例を示すことが有効だ。WPBeginnerの著者は、実際に自分たちでツールを使い、結果やケーススタディを共有することで、サイトの専門性を高めている。
具体的には、著者プロフィールの充実、会員の声や成功事例の掲載、実際の運用画面の紹介などが信頼構築に役立つ。無料記事にこうしたシグナルを埋め込んでおくと、検索エンジンだけでなく、人間の読者にも「このサイトは信用できる」と感じてもらいやすい。
テクニカルSEOとnoindex設定でクローラーの集中力を高める

どれだけ優れたコンテンツ戦略を立てても、サイトの技術的な土台が整っていなければ、検索順位は伸びにくい。会員制サイトでは特に、ログインページやアカウントページといった「低価値ページ」が検索結果に紛れ込むのを防ぐことも重要になる。
サイトスピードやHTTPSなど基盤のチェックリスト
- HTTPSによるセキュリティ保護とランキングシグナルの確保
- キャッシュプラグインの導入と画像最適化によるサイトスピード改善
- モバイルフレンドリーなデザインの採用
- XMLサイトマップを生成し、検索エンジンにサイト構造を伝える
- リンク切れや404エラーを定期的に検出し修正する
これらの対策は会員制サイトに限らず重要だが、ペイウォールがあるぶん、クローラビリティの健全性を保つ意識がより求められる。
ログインページやアカウントページをnoindexに
会員ログインページやアカウント管理画面、決済完了後のサンキューページなどは、検索結果に表示されてもユーザーにとってほとんど価値がない。むしろ、これらのページがインデックスされると、サイトの評価につながる重要なコンテンツの存在が薄れてしまう可能性がある。
そのため、All in One SEO(AIOSEO)などのSEOプラグインを使って、該当ページの編集画面から「Robots Meta」設定で「No Index」を有効にすることを推奨する。WPBeginnerの著者も、会員向け機能ページはnoindexに設定し、ブログ記事やコースランディングページなどの集客に集中させる方針をとっている。
内部リンクとコンバージョン最適化で会員化を加速する

無料コンテンツで訪れたユーザーを会員登録へと導くためには、サイト内の動線設計が欠かせない。内部リンクを活用して無料記事から有料プランへつなぎ、さらにポップアップやスライドインなどの施策で後押しすれば、SEOで獲得したトラフィックを収益に結びつけられる。
無料記事から有料コンテンツへの自然な導線
ブログ記事で「会員制サイトの始め方」を解説しているなら、記事の途中や末尾に「さらに詳しいテンプレートは会員プログラムでダウンロード可能」といったリンクを設置する。リンクのアンカーテキストは「こちらをクリック」ではなく「会員限定テンプレートを入手する」のように具体的に書くと、クリック率とSEO評価の両面で効果が高い。
- ブログ記事 → 関連する有料コースのランディングページ
- 無料のチュートリアル → 会員限定の上級編トレーニング
- リソースガイド → プレミアムテンプレートのダウンロードページ
内部リンクを張り巡らせると、Googleがサイト構造を理解しやすくなるのに加え、訪問者を収益化ページへ自然に誘導できる。
OptinMonsterによるExit-Intentやスライドインの活用
WPBeginnerの著者が特に効果的だと評価しているのが、OptinMonsterを使った出口検知ポップアップやスクロール連動スライドインだ。MemberPressとの連携機能により、未会員の訪問者だけを対象にキャンペーンを表示できるため、無料トライアルや割引オファーを最適なタイミングで提示できる。
たとえば、記事を最後まで読んだユーザーに対して「続きは会員限定です。今なら初月無料」と表示するスライドインは、押しつけがましくなく自然に感じられる。実際に、WPBeginnerの運営する複数のサイトでも、こうした導線によってメールリストの拡大や会員登録数の増加を実現している。
効果測定の指標とMonsterInsightsでの追跡
会員制サイトのSEO施策が成果を上げているかは、アクセス数だけでなく会員登録数やコンバージョン率で判断する必要がある。MonsterInsightsを使えば、GoogleアナリティクスのデータをWordPress管理画面に取り込み、どの記事が最も会員登録につながっているかを直感的に把握できる。
- オーガニックトラフィックの推移
- ティーザーページへの流入と直帰率
- 会員登録完了ページへの到達数
- バックリンク獲得状況
定期的にこれらの指標を確認し、特に会員登録につながっているコンテンツを強化していくと、施策の費用対効果を最大化しやすい。
この記事のポイント
- 会員制サイトのSEOには、公開ティーザーで検索エンジンに内容を伝える手法が欠かせない
- MemberPressで抜粋表示を設定し、一部のコンテンツを誰でも見られるようにする
- コンテンツドリッピングは事前にティーザーページを用意すればSEO上のデメリットは最小限
- 無料コンテンツで集客し、内部リンクとコンバージョン施策で有料会員へ誘導する
- 会員向け機能ページはnoindexにして、クロールのリソースを重要なページに集中させる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AnthropicのFable 5が米政府命令で強制停止、SEO業界に衝撃
Fable 5とMythos 5、米国政府の輸出管理命令で突然の利用停止

米国政府は2026年6月13日、国家セキュリティを理由にAnthropicへ輸出管理命令を出し、同社の最新AIモデル「Fable 5」および「Mythos 5」の全利用停止を強制した。命令は外国籍の個人によるアクセスを禁じており、実質的に全顧客の接続を遮断せざるを得ない内容だ。
Anthropicは同日に声明を発表し、政府の見解に反論した。両モデルには強固なセーフガードが重層的に組み込まれており、既存のAIモデルと同等のリスク水準に留まっていると主張している。しかし、命令受領からわずか数時間でFable 5とMythos 5のアクセスは世界中で停止された。
この措置は、SEOやデジタルマーケティングで最先端AIを活用してきた企業・個人に直接的な影響を及ぼす。高性能モデルの急な遮断は、コンテンツ制作フローや競合分析の自動化パイプラインを根底から揺るがすためだ。
このデモでは、Fable 5が突然使えなくなり、SEOワークフローに穴が空く状況を図示している。高性能なモデルに依存していた自動化プロセスは、一気に精度と速度が落ちる。
輸出管理命令の具体的な中身
命令は輸出管理指令と呼ばれる法的措置で、技術やデータの国外移転を制限する。Anthropicはこの命令を「外国籍の者へのアクセスを一切禁じる」と解釈せざるを得ず、結果的に全世界のユーザーが利用不能になった。同社が受けたのは東部夏時間17時21分。ほぼその日のうちに、サービス停止が現実となった。
政府はFable 5のセーフガードを突破する手法があると指摘しているが、Anthropicは提示された事例を「軽微な脆弱性」と一蹴。同社は既に多層防御と厳重なモニタリングでリスクを抑え込んでいる立場だ。
SEO業界が受ける打撃、AI駆動型ワークフローの寸断

Fable 5の急停止は、SEO担当者やアフィリエイトマーケターに具体的な痛みをもたらした。特に月額200ドルの「Claude Max」プランに切り替えたばかりのユーザーからは、返金を求める声がXで相次いだ。新しいモデルを前提にした記事生成や分析タスクが突然止まったためだ。
この流れは、AIモデルをコンテンツ制作パイプラインに組み込んできたSEOチームにとって、サプライチェーン途絶に近い。短納期の記事更新や、多言語でのローカライズ、高度なエンティティ抽出にFable 5を使っていたケースでは、代替モデルへの切り替えに伴う品質低下と工数増加が避けられない。
上のフローは、AIモデルを活用したSEOコンテンツ制作の典型的な手順だ。Fable 5が消失すれば、STEP 1の時点で生産性が大幅に落ちる。
返金要求とMaxプランの混乱
Xの投稿では、多くのユーザーが「Fable 5を使うためにMaxプランに切り替えたのに、当日に遮断された」と訴えている。あるユーザーは「生物学の基本的な質問さえできなかった」と、セーフガードの過剰さを指摘。多額の課金が一瞬で無駄になった苛立ちが広がった。
これはBtoBのSEO支援会社にとっても同様で、クライアント向けのコンテンツをFable 5に依存していた場合、納期の遅延と追加コストが発生する。急速なAI導入が裏目に出る典型例と言える。
国家セキュリティとAI規制、SEOに迫る論点

今回の措置は、AIによるサイバーセキュリティリスクを巡る政府とAnthropicの長年の対立の延長線上にある。Anthropicは大量監視や自律型兵器への技術提供を拒否してきた経緯があり、それが政府の不信感を強めたと見られる。
SEO業界への教訓は単純だ。極めて高性能なAIモデルは、常に地政学的リスクの影響を受ける。特定のベンダーに過度に依存したコンテンツ戦略は、突如として停止する可能性がある。複数のAIプロバイダーを使い分けるマルチベンダー戦略が、今後の安定運用の鍵を握る。
上の図は、リスク分散のためのマルチベンダー構成の一例だ。1つのモデルが遮断されても、他のプロバイダーや自社ホストのモデルでカバーできる。
「強力すぎるAI」を喧伝したツケ
批判の矛先はAnthropic自身にも向いた。同社が長年「極めて強力で危険なAI」と自社モデルを位置付けてきたことが、政府の深刻な受け止めを招いたという指摘だ。Xでは「恐怖をブランドにして政府に輸出管理をかけられ、今更『誤解』と言うのか」と皮肉る投稿が散見された。
SEO担当者にとっては、AIの性能を過大にアピールするマーケティングが規制を早める可能性を認識する契機になる。クライアントや社内で「最強のAIを使っている」と謳う前に、その文言が持つ政治的な重みを考慮すべき局面だ。
SEO戦略に組み込むAIレジリエンス、今後の備え
Fable 5停止のような事態に備え、SEO担当者は次の3つの柱を早急に固める必要がある。第一に、複数AIモデルへのアクセス経路の確保。第二に、AI非依存の編集プロセスとの併用。第三に、オープンソースLLMの社内導入検討だ。
Anthropicは「サービスの早期復旧を目指す」と表明しているが、法的な結末は不透明だ。最悪の場合、最先端モデルへのパブリックアクセスが恒久的に制限される可能性もゼロではない。そのとき、手元に自前の代替手段を持たないチームは、検索順位を維持するための初速で致命的な遅れを取る。
この比較が示す通り、AIに依存するほど、その供給停止がもたらすダメージは大きくなる。今のうちにバックアップのAIパイプラインをテストし、実際に切り替え可能な状態にしておくことが重要だ。
この記事のポイント
- 米国政府の輸出管理命令によりAnthropicのFable 5とMythos 5が全ユーザーに対して突然停止された
- SEO業界では高精度AIを前提としたコンテンツ制作フローが寸断され、返金要求や納期遅延が発生
- 高性能AIのブランディングが規制を呼び込むリスクが現実化した
- マルチベンダー戦略やオープンソースLLMの導入で、AIサービス遮断に強いSEO体制を構築すべき
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

OpenAIがSECにS-1を機密提出、IPO準備を正式発表
OpenAIが2026年6月8日、米証券取引委員会(SEC)に新規株式公開(IPO)に向けた機密のS-1書類を提出した。情報漏洩を想定し、同社は自らこの事実を公式ブログで公表している。
ただし上場の具体的な日程は決まっていない。OpenAIの発表によれば、非公開企業のまま進めたいプロジェクトが複数あり、時期は未定だという。それでもS-1を提出したことで、市場環境が整い次第すぐに公開企業へ移行できる選択肢を確保した形だ。
この動きはAI開発における資金調達競争の節目となる可能性がある。特にChatGPTやAPIを活用するWeb制作・開発の現場では、OpenAIのガバナンスやサービス継続性に直結する話だ。本記事ではS-1提出の背景、上場がAI業界と開発現場に与える影響、今後の注目点を整理する。
OpenAIがSECにS-1を機密提出、IPO準備を正式発表
OpenAIは2026年6月8日、公式ブログでSECへのS-1草案提出を明らかにした。同社の発表文は極めて短く、「機密S-1を最近提出した。リークが予想されるため、こちらから発表する」と率直に述べている。企業がIPO準備を進める際、まず機密扱いでS-1を提出し、SECの審査を受けるのは一般的な手続きだ。
提出の事実そのものは珍しくないが、OpenAIがそれを自ら公表した点は異例といえる。通常、機密S-1の存在は企業が正式にIPOを発表するまで非公開だ。OpenAIはリークによる憶測や誤情報の拡散を避けるため、先手を打った格好になる。
開示された情報は限られるが、OpenAIは1933年証券法規則135に基づく告知であることを明記し、証券の売却や購入勧誘を構成しないと注意を添えている。これは法的に必要な但し書きであり、正式なIPO日程の発表ではない点を強調する意図がある。
S-1提出の背景、非公開企業としてのメリットと上場のジレンマ
OpenAIが「非公開のまま進めたいこと」とは何か
OpenAIの発表文には「非公開企業のままの方が進めやすいプロジェクトがいくつかある」と書かれている。具体的な内容は明かされていないが、考えられるのはAGI(汎用人工知能)やそれを超える知能の基礎研究だ。四半期ごとの決算発表や投資家への説明責任が生じる公開企業では、短期的な収益に結びつかない長期的R&Dへの巨額投資が説明しづらい面がある。
OpenAIのミッションは「安全で人類全体に利益をもたらすAGIの開発」だ。過去の投資ラウンドでも、同社は営利企業でありながら非営利組織のガバナンス下に置く独自の「キャップド・プロフィット」構造を採用してきた。上場後もこの構造を維持できるかは不明で、株主価値最大化の圧力がミッションと衝突するリスクは以前から指摘されている。
「上場する選択肢を残す」ことの戦略的意味
S-1を提出しておきながら日程を決めないのは、OpenAIが複数のシナリオに備えている証拠だ。AI市場の成長や競合の資金調達動向を見極め、最適なタイミングでIPOを実行できる準備を整えたと読める。
競合のAnthropic(Claude開発元)は2026年時点で非公開のまま巨額のベンチャー資金を調達し続けており、Google DeepMindは親会社Alphabetの資金力を背景に研究を進めている。一方で、xAIやMetaのAI部門は独自の資金調達経路を模索中だ。OpenAIが上場すれば、AIスタートアップとしては初の大型IPOとなり、市場の評価基準が形成される可能性がある。
- ✓ 長期的R&Dに集中しやすい
- ✓ ミッション優先の経営判断が可能
- ✗ 資金調達は投資ラウンド頼み
- ✗ 社員のストックオプション流動性に制限
- ✓ 株式市場から巨額の資金を調達可能
- ✗ 四半期決算のプレッシャーが発生
- ✗ AGIの安全性研究が投資家の短期的利益と衝突する可能性
- ✗ 情報開示義務により競合に戦略が筒抜けになるリスク
この図式から分かるように、非公開状態には研究の自由度という明確な強みがある。その一方で、AI開発には数百億ドル単位の計算資源投資が必要であり、公開市場からの資金調達は無視できない武器になる。OpenAIはこのジレンマを抱えながら、IPOの理想的なタイミングを慎重に見定めている段階だ。
上場がAI開発競争とエコシステムに与える影響

AIインフラ市場への資金流入が加速する可能性
OpenAIが上場すれば、AI開発のためのインフラ投資が一段と加速する可能性が高い。同社は既にMicrosoftとの提携を通じて大規模な計算基盤を確保しているが、IPOで得た資金は独自のデータセンター建設やチップ開発に振り向けられると予想される。これはAWSやGoogle Cloud、NVIDIAのようなインフラ企業の売上をさらに押し上げる連鎖を生む。
同時に、公開市場の投資家がAI企業の評価基準をどう設定するかが、後続のAIスタートアップのIPOや資金調達環境を左右する。OpenAIが高評価で上場すれば、AnthropicやCohereといった競合の評価も連動して上昇するだろう。逆に、収益化の遅れが嫌気されて株価が低迷すれば、AIバブル崩壊の引き金になるリスクも否定できない。
API料金とサービス品質への影響
Web制作やアプリ開発の現場で最も直接的な影響を受けるのは、OpenAIのAPI料金とサービス品質だ。非公開企業の間は、利用促進のために無料枠の拡大や試験的な価格引き下げを柔軟に行える。しかし上場後は、株主に対して持続可能な収益構造を示す必要があるため、価格体系の安定化と同時に無料枠の縮小や値上げが行われる可能性がある。
- 新モデルを積極的に投入し開発者を囲い込む段階
- 価格改定は頻繁だが、引き下げ方向が中心
- 利用規約やレート制限が実験的に変更されることがある
- 価格体系が安定し長期契約が組みやすくなる
- 収益報告により財務の透明性が向上
- ⚠ コスト削減圧力で無料枠廃止や値上げの可能性
Web開発者としては、OpenAIのAPIに依存したサービスを構築している場合、上場後の価格変更やSLA(サービスレベル契約)の変動に備えておく必要がある。マルチベンダー戦略としてClaude APIやGemini APIなど複数のAIプロバイダを併用する設計が、リスクヘッジとして有効になるだろう。
Web制作・開発現場にとっての意味と今後の備え
API依存サービスのリスク管理が急務に
WordPressのプラグインやSaaS型のWebサービスでは、ChatGPT APIを組み込んでコンテンツ生成やチャットボット機能を提供する事例が急増している。上場に伴いOpenAIの事業戦略が変化すれば、これらのサービスは価格改定の影響を直接受ける立場にある。
例えば、現在は無料枠で運用できている小規模なブログ向けAI機能が、上場後に有料化されるケースが想定される。開発段階からOpenAIだけでなくAnthropicやGoogleのAPIを抽象化レイヤーで切り替えられる設計を採用しておくと、将来的なベンダーロックインを回避できる。
AI開発の民主化とコモディティ化の加速
OpenAIのIPOは、AIが「特殊な研究分野」から「公開市場で評価される一般事業」へ移行する象徴的な出来事だ。上場によってOpenAIの財務情報や事業計画が公開されれば、他のAI企業の評価や投資判断も透明性を増す。これは長期的に見れば、API価格の競争を促し、Web制作現場にとってはAI導入コストの低下につながる可能性が高い。
一方で、AIモデルの開発コストは依然として巨額であり、上位プレイヤーへの集中が進む構造は変わらない。公開市場からの資金調達でさらに差が広がる可能性もある。開発者コミュニティとしては、オープンソースモデル(Llama、Mistralなど)の進化も視野に入れながら、特定企業のAPIに過度に依存しないアーキテクチャ選択が重要になる。
今後のスケジュールと注目点
OpenAIのS-1提出により、IPOプロセスは正式に開始された。ただし、日程が未定である以上、実際の上場までには少なくとも数ヶ月から1年以上かかる可能性がある。SECの審査には通常3〜6ヶ月を要し、その後に投資家向けのロードショーや価格決定プロセスが続く。
業界関係者が注視するのは次の3点だ。第一に、S-1の内容がどのタイミングで公開されるか。機密扱いから公開段階に移行すると、OpenAIの売上高、利益率、研究開発費の内訳、大株主の構成などが明らかになる。第二に、AGIの安全性研究と営利事業のバランスをどう開示するか。第三に、上場時の評価額がAIバリュエーションの天井をどこに設定するか。
この一連のプロセスを通じて、OpenAIが非公開企業としての柔軟性をどこまで維持するか、あるいは短期間で上場に踏み切るかが最大の焦点になる。AI開発の進捗と市場環境の変化が、その決断を左右するだろう。
この記事のポイント
- OpenAIが2026年6月8日、SECに機密S-1を提出しIPO準備を正式に開始。上場時期は未定で、非公開のまま進めたいプロジェクトが複数あると発表した
- 非公開企業のメリットとして長期的なR&Dの自由度があり、上場のメリットとして巨額の資金調達がある。OpenAIは両者のジレンマの中で最適なタイミングを模索中だ
- 上場が実現すれば、AIインフラ市場への資金流入加速、API料金の安定化と無料枠縮小の可能性、Web開発現場におけるベンダーロックインリスクの高まりが想定される
- 開発者やWeb制作事業者は、OpenAI APIに依存しないマルチベンダー設計を検討し、価格変動やサービス変更に備えることが重要になる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

MonsterInsights公式サイトが攻撃、フィッシングメールに警戒を
WordPress向けGoogle Analytics連携プラグイン「MonsterInsights」の公式サイトがサイバー攻撃を受け、一時的にオフラインとなった。さらに深刻なのは、同プラグインを装ったフィッシングメールがユーザーに送信されている点だ。無料版だけでも200万サイト以上にインストールされており、影響は広範囲に及ぶ。
この記事では、MonsterInsightsが直面している攻撃の実態と、ユーザー側が直ちに取るべき対策を整理する。サイトに同プラグインを導入している運営者は、偽の更新通知やダウンロードリンクに十分な警戒が必要だ。
MonsterInsightsとは何か、なぜ影響が大きいのか
MonsterInsightsは、WordPressサイトにGoogle Analytics(GA)のデータを直感的に表示するプラグインだ。管理画面内のダッシュボードでアクセス解析を完結できる点が評価され、広く普及している。無料版のインストール数は200万サイトを超え、有料版を含めると約300万サイトに導入されているとされる。
上図のように、MonsterInsightsは本来、GAデータをWordPress管理画面に橋渡しする安全なツールだ。しかし今回、攻撃者がその信頼性を逆手に取り、ユーザーを偽サイトへ誘導する手口が確認されている。
インストールベースが極めて大きいため、被害が連鎖的に広がるリスクがある。攻撃者がMonsterInsightsの顧客リストにアクセスした場合、正規のユーザー情報を使って説得力のあるフィッシングメールを送信できるからだ。
公式サイトのダウンと攻撃の兆候
Search Engine Journalの記事によれば、MonsterInsightsの公式サイトは2026年6月12日時点でオフラインとなり、トップページには以下のような告知が表示されている。
Our website is offline as we’re mitigating an attack. Your analytics and tracking aren’t affected. Please DO NOT download MonsterInsights from any 3rd party website as there is a known phishing attempt happening right now.
この告知から読み取れるのは、攻撃がWebサイトそのものを標的にしている一方で、既存ユーザーのアナリティクス機能やトラッキングには影響が出ていないという点だ。MonsterInsightsはプラグインとして各サイトにローカルインストールされているため、公式サイトが落ちても、すでに導入済みのサイトでGAデータの取得が止まることはない。
ただし、公式サイトにアクセスできない状態が続くと、正規のアップデートを受け取れなくなるリスクがある。攻撃者はその隙を突き、「MonsterInsightsの緊急アップデート」を装ったメールを流している。
攻撃の種類とフィッシングの手口
現時点で攻撃の詳細な手法は明らかにされていない。しかし、公式サイトの差し替えと顧客へのフィッシングメール送信が同時に発生していることから、次のようなシナリオが推測される。
- 攻撃者が何らかの方法でMonsterInsightsの顧客データベースまたはメール配信システムにアクセスした
- 入手したメールアドレスに対して、MonsterInsightsを装ったフィッシングメールを一斉送信している
- メールには偽のダウンロードリンクが含まれ、サードパーティサイトから不正なプラグインをインストールさせる狙いがある
フィッシングメールを受け取ったユーザーがリンクをクリックし、指示に従って「更新」を実行すると、マルウェアを含む偽のプラグインがWordPressサイトにインストールされる可能性がある。これにより、サイトの乗っ取りや情報漏洩といった二次被害が発生するリスクが高まる。
✅ 公式サイト(復旧後)またはWordPress管理画面からのみ更新する
✅ 不審なメールは support@monsterinsights.com に報告する
上記のような緊急性を煽る文言が使われている場合、特に注意が必要だ。MonsterInsightsの公式Xアカウントも、サードパーティサイトからのダウンロードをしないよう強く呼びかけている。
ユーザーからの報告とSNS上の反応
X(旧Twitter)上では、実際にフィッシングメールを受け取ったユーザーが複数報告している。
ユーザーの @alliemims 氏は、フィッシングメールを受け取ったがリンクには触れず、公式サイトの問い合わせフォームから報告しようとしたところ、403エラーでアクセスできなかったと投稿している。別のユーザー @biancavandepoel 氏は、攻撃者がすでに顧客リストを入手している可能性を指摘し、MonsterInsights側から全顧客への迅速な警告メール送信を求めている。
これらの投稿からは、ユーザーが混乱しつつも冷静に対処しようとしている様子がうかがえる。報告しようとしても公式サイトにアクセスできないという状況が、事態をより複雑にしている。
MonsterInsightsの公式対応と今後の展望
MonsterInsightsは公式Xアカウントで、攻撃を緩和するための対応を進めていると発表している。また、サードパーティサイトからのダウンロード禁止を改めて警告し、ユーザーに対しては support@monsterinsights.com への問い合わせを案内している。
現時点では、公式サイトの復旧時期や攻撃の全容については明らかにされていない。しかし、過去のWordPressプラグインに対するサプライチェーン攻撃の事例から見ると、今回のインシデントは以下のような段階を経て収束に向かうと予想される。
- 攻撃経路の特定と遮断
- 流出した可能性のある顧客データの範囲特定
- 公式サイトの復旧とセキュリティ強化
- 影響を受けたユーザーへの個別通知
重要なのは、MonsterInsightsのプラグインそのものに脆弱性が見つかったわけではないという点だ。今回の問題は公式サイトと顧客コミュニケーション経路への攻撃であり、既存のインストール済みプラグインが直接危険にさらされているわけではない。ただし、フィッシングによって偽のプラグインをインストールさせられるリスクは現実に存在する。
サイト運営者が直ちに取るべき5つの対策
MonsterInsightsを導入している、または同プラグインの利用を検討しているサイト運営者は、以下の対策を即座に実行することを推奨する。
特に重要なのは、落ち着いて公式情報を待つことだ。攻撃者は混乱に乗じてユーザーを騙そうとする。MonsterInsightsのプラグイン自体が危険になったわけではないため、慌ててプラグインを削除したり、非公式の「修正版」をインストールしたりする必要はない。
WordPressプラグインのエコシステム全体を見渡すと、今回のようなサプライチェーン攻撃は増加傾向にある。2024年にも複数の人気プラグインが同様の手口で攻撃を受けた事例がある。自社サイトのセキュリティ対策として、以下の日常的な施策も合わせて見直すことを推奨する。
- プラグインの自動更新を有効にし、公式リポジトリからの更新のみを許可する
- 管理画面へのアクセスに二要素認証を導入する
- 定期的にサイトのプラグイン一覧を監査し、不要なものは削除する
- セキュリティプラグインでファイル変更の監視を行う
この記事のポイント
- MonsterInsights公式サイトが攻撃を受け、フィッシングメールが顧客に送信されている
- 既存のプラグイン機能(アナリティクス・トラッキング)には影響なし
- メール内のリンクからサードパーティサイトでプラグインをダウンロードしないこと
- プラグイン更新はWordPress管理画面または公式サイトからのみ行う
- 不審なメールは公式サポートに報告し、自社サイトのプラグイン一覧も確認する
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Amazonプライムデーが変えた夏季EC商戦、中小事業者が取るべき戦略
Amazonプライムデーは11年を経て、夏のeコマース商戦を完全に塗り替えた。2025年の米国EC売上高はプライムデー期間中だけで241億ドルに達し、前年比30.3%増を記録している。今やブラックフライデーに次ぐ第二の商戦期として、大手企業だけでなく中小EC事業者にも波及する新しい季節が誕生した。
かつて夏はECにとって「閑散期」だった。しかし今では消費者が値引きを待ち構え、競合が一斉にセールを重ねる構図が定着している。本記事ではこの変化をデータとともに整理し、中小規模のネットショップが取るべき具体的な戦略を掘り下げる。
Amazonプライムデーの変遷

初年度から4日間開催への拡大
プライムデーは2015年、Amazonが会員向けに24時間限定の特別セールとしてスタートした。当初は夏の販売不振を補う実験的な位置づけだったが、マーケティングと大幅な割引により消費者が「夏の買い時」を学習するきっかけを作った。
その後、期間は段階的に延長され、昨年は4日間の大型イベントへと成長した。開催期間の長期化は売上拡大に直結しており、Adobe Analyticsのデータによると、プライムデー中の米国業界全体のオンライン支出は年々増加し、2025年には過去最高を更新した。
2025年の売上高と市場への影響
2025年のプライムデー期間中、米国全体のEC売上は約241億ドル。Amazon自身の売上高は非公開だが、複数の推計では約130億ドルとされ、全体の半分強を占めた。これは単なるAmazonの成功事例ではなく、EC市場全体の底上げを意味する。
重要なのは、この期間に合わせて消費者が購買を先延ばしする行動が定着した点だ。夏のセールを待つという消費者心理が強まり、プライムデーをピークとした数週間が「第二のブラックフライデー」の様相を呈している。
このように、プライムデーは夏季のECカレンダーを根本から変えた。11年の歴史を経て、ブラックフライデーに次ぐ第二の商戦シーズンが確立されているのである。
競合他社が追従する新たなセールシーズン

ウォルマートやターゲットが重ねる独自セール
プライムデーの影響力を示す最も明確な証拠は、競合各社の反応だ。Amazonが2026年のプライムデー日程を発表すると、わずか1週間後にはウォルマートが「Walmart Deals」を6月22日〜28日に設定し、ターゲットも「Circle Deal Days」を23日〜26日に開催すると公表した。いずれもプライムデーに軒並み日程を重ねている。
ベストバイや倉庫型クラブ、アパレルチェーン、ホームセンター、D2Cブランドに至るまで、似たようなプロモーションが同時多発的に展開される。この現象は単なる模倣ではない。消費者がAIや検索エンジン、マーケットプレイス、SNSで商品を横断比較する時代に、購買意欲がピークに達するタイミングに合わせなければ機会損失が生じるという現実への適応なのだ。
結果として、プライムデー単体のイベントを超えた「夏の新商戦シーズン」が形成されつつある。アクセス集中と高い購買意欲が広範囲に波及し、EC事業者全体がこの波に備えなければならない状況だ。
製造業や広告業界にも波及する影響
影響は小売業者だけにとどまらない。メーカーはこの時期に合わせて新製品の投入を計画し、販売店はベンダーとのプロモーション資金の交渉を前倒しする。マーケティング担当者は6〜7月の広告予算を確保し、値引きをしないブランドでさえコンテンツカレンダーやメール配信のタイミングを調整している。
ブラックフライデーには秋を通じた準備が必要だが、プライムデーも同様に数か月前からの在庫計画、人員配置、マーチャンダイジングの見直しを迫る。もはや無視できない恒常的な「商戦カレンダー」の一部なのである。
中小規模EC事業者が取るべき戦略
価格競争を回避する3つのアプローチ
プライムデーの主役は間違いなくAmazonであり、ウォルマートやターゲットなどの大手も恩恵を受ける。しかし中小ECにもチャンスはある。消費者はこの期間、積極的に買い物をしようというモードに入っているため、代替品や専門性の高い商品を探す動きが活発になるのだ。
重要なのはAmazonや大手と真っ向から値下げ合戦をしないこと。代わりに以下の3つの戦術が有効だ。
- 独自カテゴリの訴求。大手が扱いにくい専門商品やニッチなジャンルで存在感を出す
- 商品バンドル。複数の関連商品をセット販売し、単純な価格比較をかわしながら平均注文単価を上げる
- プライベートブランドや独占アイテムの活用。他店との直接比較を不可能にし、価格主導の競争から脱却する
いずれも「価格」ではなく「価値」で勝負する発想である。プライムデーの波に乗りつつ、自社の強みを際立たせる戦略が求められる。
- 低価格と大量広告で集客
- セール期間の重複で市場を占有
- 会員プログラムを活用
- 在庫・物流の大規模な事前準備
- 独自カテゴリで差別化
- 商品バンドルで単価向上
- プライベートブランドで価格比較を回避
- メール・SMS・コンテンツマーケティングを活用
中小事業者は、大手と同じ土俵で価格勝負をする必要はない。購入意欲の高い消費者に対して自社ブランドや独自商品を提示することで、持続的な顧客獲得を目指すべきだ。
マーケティングとコンテンツで存在感を高める
プライムデー前後は、消費者の情報収集行動が活発化する絶好のタイミングだ。メールマーケティング、SMS、リスティング広告、SNS広告はいずれも高い反応率が見込める。特に、あらかじめセグメントを組んだ既存顧客へのアプローチが費用対効果に優れる。
また、コンテンツマーケティングでは「購入ガイド」「比較記事」「おすすめ特集」といった形式が効果を発揮する。目的はAmazonの顧客を奪うことではなく、買い物モードに入った消費者に自社ブランドを認知してもらい、将来的な購入につなげることだ。1回のセールで終わらせず、長期的な関係構築を見据えた施策が求められる。
この記事のポイント
- Amazonプライムデーは夏季のEC商戦を一変させ、今やブラックフライデーに次ぐ大規模セールシーズンに成長した
- 競合他社が相次いでセールを重ねることで、業界全体に波及効果が生まれ、製造業や広告出稿計画にも影響が及んでいる
- 中小EC事業者は、独自カテゴリ・バンドル・プライベートブランドで価格競争を回避しつつ、マーケティング施策で購買意欲の高い消費者を捉える戦略が有効
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

中央欧州EC市場は8%成長へ。購買頻度向上がEC成長の主軸に
中央欧州のEC市場が安定的な成長局面に入った。ECDBとMastercardが公表した最新レポートによれば、2026年のオンライン支出は前年比8%増の2066億ユーロに達する見込みだ。
2027年には2235億ユーロまで拡大すると予測されており、パンデミック特需の反動や数年にわたる停滞を経て、EC市場は着実な回復から持続的成長へとフェーズを移している。成長の主なけん引役は、新規ユーザーの獲得ではなく、既存の購買客による注文頻度の向上だ。
この記事では、同レポートのデータをもとに、中央欧州11カ国のEC成長率、国別の購入頻度の重要性、越境ECの割合といったトピックを掘り下げる。国内の中小EC事業者にとっても、顧客維持戦略のヒントとなる内容だ。
中央欧州EC市場、8%の安定成長へ
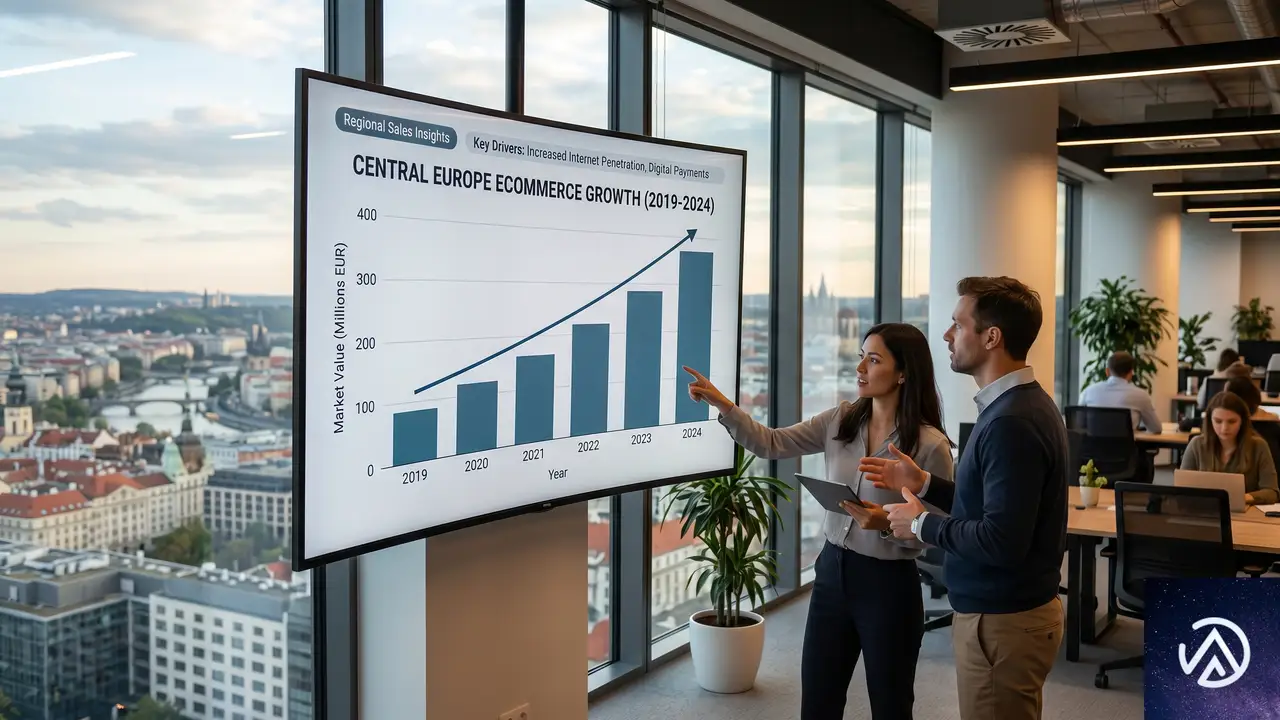
調査パートナーであるECDBとMastercardの報告では、中央欧州のオンライン支出は2025年の1913億ユーロから、2026年には2066億ユーロへと増加する。2027年には2235億ユーロに達し、年平均約8%の成長が続く見通しだ。レポートは「予測される年間成長率が8%前後に収れんすることで、中央欧州のEC市場はより安定した予測可能なフェーズに入り、長期的な事業計画の確度が高まる」と指摘している。
国別にみる成長率のばらつき

中央欧州の平均成長率はヨーロッパ全体の水準とおおむね一致するが、国ごとの差は依然として大きい。最大の市場であるドイツでは、2026年の成長率は約8%と予想されている。スイスも同程度で、オーストリアはわずかに高い成長が見込まれる。
より高い伸びを示すのがポーランドとギリシャだ。ポーランドは約9%の成長率、ギリシャは約11%と二桁成長が予測されている。小国マルタではさらに高い成長が見込まれるが、市場規模は限られる。レポートでは「中央欧州全体を通じて、EC普及率と成長率には明確な関連性がある」と分析されている。
成長を牽引する「購入頻度」の向上

ECDBとMastercardの調査で最も注目すべき点は、EC成長の主因が既存顧客の購入頻度の上昇にあることだ。レポートは購買頻度を「EC成長の主戦場」と表現している。顧客一人あたりの購入回数は、新規のオンライン買い物客数や一回あたりの平均購入額を上回るペースで増加している。
この傾向は、オンライン小売事業者にとって顧客維持(リテンション)の戦略的重要性が高まっていることを示唆する。新規獲得に注力するよりも、すでに自社を利用したことがある顧客に繰り返し購入してもらう仕組みを整えることが、安定的な収益拡大につながる。
以下の概念図は、新規顧客の獲得に偏重した運用と、リテンション施策を強化した運用の対比だ。
この対比が示すように、既存顧客の購入頻度を高めることで、少ない獲得コストで収益を伸ばせる。中央欧州のEC市場では、まさにこの「頻度」を巡る競争が激化している。
越境ECの比率から読み解く市場特性
レポートは国別の越境EC支出のシェアも明らかにしている。越境購入の割合が最も高いのはオーストリアで、オンライン支出の44%が海外のウェブショップに流れている。一方、マルタでは越境比率が最も低い。ドイツも国内ECが非常に充実しており、越境依存度は低い。なお、Amazon.deは米国企業による運営だが、今回の調査ではドイツ国内のプレイヤーとして扱われている。
越境ECの割合は、市場の成熟度や消費者の嗜好、物流インフラの整備状況などさまざまな要因で変わる。自国通貨での価格表示や現地カスタマーサポートが充実しているかどうかも、購入先選択に影響する。
実際の国ごとの差を視覚化すると次のようになる。
このように、越境EC比率は国の規模やECエコシステムの成熟度を映し出す。EC事業者が海外展開を検討する際は、ターゲット国の越境購入の受け入れ度合いを把握することが不可欠だ。
この記事のポイント
- 中央欧州のEC市場は2026年に8%成長し、2066億ユーロ規模へ。安定成長局面に移行
- 成長の主因は既存顧客の購入頻度向上。新規獲得よりリテンションが重要に
- 国別ではポーランド(約9%)、ギリシャ(約11%)が高成長。ドイツは最大市場で約8%
- 越境EC比率はオーストリアが44%と突出。市場特性に応じた戦略が必要
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Joybuyがマーケットプレイス化、欧州と中国のセラーに開放
中国EC大手JD.comが運営する総合オンラインストアJoybuyが、マーケットプレイスへの転換を正式に発表した。これまで自社で仕入れた商品のみを販売してきた同プラットフォームが、欧州と中国のサードパーティーセラーに門戸を開く。
英国の業界誌The Grocerの報道によれば、2026年下半期に厳選されたブランドによるマーケットプレイスのテストを開始する見込みだ。併せて6月15日から30日までの16日間、初のSummer Black Fridayと銘打った大型プロモーションを打ち出す。
Joybuyは2025年3月に英国、ドイツ、フランス、オランダ、ベルギー、ルクセンブルクの欧州6カ国で正式ローンチしたばかりだ。今回のマーケットプレイス化は、AlibabaやAmazonがしのぎを削る欧州市場での競争力を一気に高める布石と見られている。
自社販売からマーケットプレイスへの転換
このデモはJoybuyのビジネスモデル転換を可視化したものだ。自社仕入れのみのクローズドな構造から、外部セラーが参加するオープンなマーケットプレイスへと進化する。
Joybuyの広報担当者はThe Grocerに対し「信頼できるブランドと協力し、2026年下半期に厳選型マーケットプレイスをテストする」と述べている。単にセラー数を増やすのではなく、品質を維持するためのキュレーション型アプローチを取る点が特徴だ。
この方針は、粗悪品や偽造品の混入リスクを抑えつつ、品揃えを拡大するバランスを狙ったものといえる。JoybuyはJD.comのブランド力を背景に、AmazonやAlibaba系プラットフォームとの差別化を図る構えだ。
ハイブリッド物流モデルの採用

マーケットプレイスセラーが販売する商品の物流は、2つの選択肢が用意される。Joybuyの倉庫に在庫を預けてフルフィルメントを委託する方法と、セラー自身が保管から配送までを管理する方法だ。
このデモはセラーが選択できる2つの物流オプションを示している。AmazonのFBAやTikTok Shopと同様の柔軟なモデルをJoybuyも採用した格好だ。
JD.comは欧州で物流ネットワークを拡大しており、自社の宅配サービスJoyExpressも展開している。このインフラをマーケットプレイスセラーの配送にも活用できる点は、競合他社に対する優位性になり得る。
さらにJD.comは欧州の家電量販店MediaMarktとSaturnを運営するCeconomyの買収手続きを進めており、英オンライン小売のThe Very Group買収も検討中と報じられている。これらの流通網とJoybuyの物流ネットワークが統合されれば、欧州全体をカバーする巨大なフルフィルメント基盤が形成される可能性がある。
Summer Black Fridayで欧州消費者を狙う

Joybuyは6月15日から30日までの16日間、Summer Black Fridayと称する大規模セールを欧州6カ国で開催する。同社はこれを「新しい年に一度のショッピングの祭典」と位置づけ、低価格と信頼できるブランド、迅速な配送を前面に打ち出している。
興味深いのは、Joybuyがこのセールを「誰でも参加可能で、サブスクリプション不要」と強調している点だ。6月23日から26日にAmazon Prime Day 2026が全世界で開催されることを踏まえた、Amazonの有料会員限定セールへの対抗姿勢と見られている。
このデモは2つのセールイベントの参加条件の違いを対比したものだ。Joybuyは「誰でも参加できる」点をAmazonに対する明確な差別化要因としてアピールしている。
Joybuyはキャッチコピーに「11月まで賢いショッピングを待つ必要はない(Why wait until November to shop smarter?)」というフレーズを掲げている。年末商戦を待たずに大規模セールを仕掛けることで、欧州消費者の購買意欲を早期に取り込む狙いが透けて見える。
欧州EC市場への影響と展望
JD.comはAlibabaに次ぐ中国第2位のEC企業であり、その資本力と物流基盤は欧州市場でも大きな脅威となる。すでにOchamaを通じて24カ国でオンライン販売の実績があり、欧州での事業運営ノウハウは着実に蓄積されてきた。
マーケットプレイス化によってJoybuyが取扱商品カテゴリーを拡大すれば、総合ECとしての競争力は一気に高まる。特に欧州のローカルブランドを取り込む戦略は、中国発プラットフォームに対する「安かろう悪かろう」のイメージを払拭する効果も期待できる。
ただし欧州ではEUのデジタルサービス法(DSA)や一般製品安全規則(GPSR)など規制対応のハードルが高く、マーケットプレイス運営にはコンプライアンス体制の構築が欠かせない。Joybuyがどこまで欧州規制に適合した運営を実現できるかが、今後の成長を左右する鍵となる。
WooCommerceで越境ECサイトを運営する事業者にとって、Joybuyのマーケットプレイス開放は新たな販路としての可能性を持つ。欧州向けの商品をJoybuy経由で展開する選択肢が生まれれば、自社サイトとマーケットプレイスのハイブリッド戦略を検討する価値は十分にある。
この記事のポイント
- Joybuyが自社販売モデルからマーケットプレイスへ転換し、欧州と中国のサードパーティーセラーを募集開始
- 物流はJoybuy倉庫委託かセラー直接配送かを選択できるハイブリッドモデルを採用
- 6月15日から初のSummer Black Fridayを16日間開催し、Amazon Prime Dayと競合
- JD.comの欧州物流網と買収案件がJoybuyの成長を後押しする見込み
- WooCommerce事業者にとって欧州越境ECの新たな販路として注目すべき動き
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験
PHP 8.5でCannot use bool as array警告が出る原因と直し方
PHP 8.5 環境の WordPress 7.0 で「Cannot use bool as array」の警告が出るのは、oEmbed レスポンスが想定する配列ではなく false(真偽値)を返し、それを配列として処理しようとした型エラーです。コード改修に踏み切らなくても、`oembed_response_data` フィルタで安全性を担保する一時回避が有効です。
PHP 警告の原因は何か「Cannot use bool as array」
この警告は `wp-includes/embed.php` 742 行目付近、oEmbed レスポンスを iframe 埋め込みコードに加工するフィルタ処理で出ています。もともと配列が入る想定の変数に真偽値 `false` が入り、その要素にアクセスして停止するパターンです。
外部 oEmbed プロバイダへの通信失敗、エンドポイントの一時停止、クラウドや CDN 経由のキャッシュが古い応答を返した場合などに起きます。WordPress コアの型チェックがまだ強化しきれていない箇所で、PHP 8.5 の厳格な型チェックとぶつかったものです。投稿本文に貼られた Twitter / YouTube / Vimeo 等の埋め込みが読み込まれるたびに断続的に発生します。
なぜ PHP 8.5 で特に出やすいのか
PHP 8.0 以降、型の不一致に対する警告やエラーが段階的に強化されています。8.5 では false 値を直接配列の添字アクセスに使おうとすると通らなくなり、今回のような「発生条件がまれで、一度に複数回出る」断続的な警告になります。
エラー箇所をサーバーエラーログで特定する手順

まずログを正確に把握します。レンタルサーバーの管理画面やコントロールパネルから PHP エラーログを確認しましょう。ログには `/wp-includes/embed.php` の行番号と `Cannot use bool as array` の文言が残っています。
上のデモはエラーログに現れる典型的な記録と、原因特定後の流れを示しています。ログ内で同じ秒に 3 回出現したという報告もあるように、1 件の埋め込みが複数のインスタンスを生む場合があります。
コード編集せずに一時回避する方法
今すぐ警告を止めたい場合は、テーマの functions.php やサイト専用のプラグインに以下の `add_filter` を追加します。これは oEmbed レスポンス加工の入り口で変数が配列であることを確かめ、配列でなければ空の配列を返す安全策です。
add_filter( 'oembed_response_data', function( $data ) {
if ( ! is_array( $data ) ) {
$data = array();
}
return $data;
}, 0 );上記はコアファイルを触らず、フィルタ段階で致命的な型エラーを封じます。本来 WordPress が返すはずの埋め込みは表示されませんが、警告の発生そのものは止まり、画面の上部にエラー文言が出る状況を解消できます。
functions.php に記述する際の注意
- 子テーマの functions.php に必ず追記する(親テーマ直編集は更新で消える)
- コードスニペット系プラグイン(WPCode 等)を使うと管理が楽になる
- 記述後はサーバーの OPCache やプラグインキャッシュをクリアする
根本対応としての oEmbed プロバイダ見直し
外部 oEmbed の呼び出しに失敗している場合、根本的には該当 URL が貼られた投稿を編集し埋め込み形式を変えるのが一番です。エンドポイントが停止したサービスや、TLS 設定が古いプロバイダを指しているときにも警告が出ます。
特定の URL パターンだけ埋め込みを無効化したい場合は、`oembed_discovery_links` フィルタやキャッシュ期間を変える方法も検討できます。社内のプライベートクラウド上にある独自メディアサーバーを oEmbed で呼んでいる場合などは、ネットワーク設定や HTTP タイムアウトの調整も必要です。
よくある質問
コアファイルを直接修正してもよいのか
コアの embed.php を修正するとアップデートで上書きされるため、現実的ではありません。どうしても早期にパッチしたい場合も、WordPress コアの Trac に報告する形が安全です。上書きリスクを避けるため、必ずフィルタで対処しましょう。
警告は出ているが埋め込みは見えている場合の対処は
画面に埋め込みは表示されるがデバッグログだけ警告が出る状態なら、前述の `is_array()` チェックを入れたフィルタでログ汚染を防げます。ただし埋め込みが正しく機能しているなら、根本原因(特定の URL の一時的応答失敗)が解消されるのを待つだけでも構いません。
PHP 7.x に戻すのは対策になるか
PHP のバージョンを下げると表面的に警告が消える可能性はありますが、セキュリティ面で大きなリスクがあります。PHP 8.5 環境のままで、WordPress とプラグインを最新に保ちながらフィルタで予防する方向が安全です。
WordPress 7.0 のアップデートでこのエラーが起きた可能性は
WP 7.0 固有の不具合というより、PHP 8.5 との組み合わせで型チェックが厳しくなった影響です。特に大きなリファクタリングが行われたコア部分で、今まで隠れていた型不一致が警告として顕在化している状況です。
埋め込みをすべて無効にする設定はあるか
完全に oEmbed 機能を止めるには `remove_action` で関連フックを外す方法もあります。ただし、既存の埋め込み投稿の見栄えが大きく変わるため、テスト環境で事前検証する必要があります。
この記事のポイント
- PHP 8.5 と WP 7.0 の型不一致が原因で oEmbed 処理中に「Cannot use bool as array」警告が発生する
- 即効の回避策は `oembed_response_data` フィルタで `is_array()` チェックを追加すること
- コアファイルの直接修正は避け、子テーマの functions.php または専用プラグインで管理する
- 外部 oEmbed プロバイダの応答エラーが根本原因の場合、該当 URL の見直しやキャッシュ設定の再考も検討する
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験