

VercelがBetter Authを買収、TypeScript認証ライブラリとエージェントIDの未来
VercelがBetter Authを買収。TypeScript認証ライブラリとエージェントアイデンティティの取り込み

2026年7月7日、VercelはオープンソースのTypeScript認証ライブラリ「Better Auth」を買収したと発表した。ライブラリの週間npmダウンロード数は470万を超え、すでに850人以上のコントリビューターが開発に参加している。創設者のBereket Engida氏とコアチームはVercelに加わり、Better Authそのものと、関連プロジェクトであるエージェント認証プロトコル「Agent Auth」の開発を続ける。
今回の買収は、認証の仕組みをフレームワークやプラットフォームに依存しない形で提供する動きであり、なかでも「エージェントに独自のアイデンティティを与える」という構想が注目を集めている。背景と具体的な影響を順に整理していく。
Better Authとは何か。週間470万DLの認証ライブラリ

Better Authは、TypeScriptで書かれたオープンソースの認証ライブラリだ。従来の認証ライブラリに比べて設定がシンプルで、Next.jsやNuxtなど特定のフレームワークに依存しない。データベースやセッション管理の選択肢も広く、開発者が自前で認証周りをコントロールできる点が特徴である。
フレームワーク非依存の設計思想
多くの認証ライブラリは特定のフレームワークと密結合だったり、プラットフォームの管理画面を通さなければ設定が完了しなかったりする。Better Authは「どこでも動き、開発者が認証を所有する」という原則で作られている。これにより、プロジェクトの要件が変わっても認証部分の移行が容易になる。
コミュニティ主導の成長
470万ダウンロードと850人以上のコントリビューターという数字は、単なるGitHubスターの数ではない。実際に本番環境で使われ、機能追加やバグ修正が活発に行われている証拠である。Vercelは買収後もMITライセンスを維持し、コミュニティガバナンスを継続すると明言している。
買収の背景。Vercelが描く「オープンウェブ」と認証の位置づけ

Vercelは2025年に公開した「オープンSDK戦略」のなかで、ソフトウェアはデフォルトでオープンであり、疎結合で、どのプラットフォームにも移植可能であるべきだと述べている。Next.jsやAI SDK、Nuxtにもこの方針が適用されており、今回のBetter Auth買収もその延長線上にある。
認証を「所有する」という考え方
クラウドサービスが認証を代行する形は便利だが、ロックインのリスクがある。Better Authのようにライブラリ単位で認証を導入できれば、インフラを移行しても同じ仕組みを使い続けられる。Vercelはこの「所有可能な認証」をエコシステムに取り込むことで、開発者にとっての自由度を高めようとしている。
エージェントアイデンティティが切り開く、新しい認証の形

買収発表のなかで特に強調されたのが、エージェント(自律的に動作するソフトウェア)に「自分自身のID」を持たせるという構想だ。Better Authチームが開発している「Agent Auth」プロトコルは、まさにこれを実現するためのものである。
この概念図で示すように、Agent AuthではエージェントごとにIDを発行し、スコープを絞った権限と失効可能な認証情報を持たせることができる。ユーザーが単一のコントロールポイントから、個々のエージェントの権限を管理できる点が革新的だ。
なぜエージェントに独自IDが必要なのか
現在、AIエージェントがユーザーに代わって予約や購入を行う場合、エージェントはユーザー自身の認証情報を使ってサービスにアクセスする。この方式では、エージェントに渡す権限を細かく制御できない。また、不正が疑われた場合に特定のエージェントだけを停止することが難しく、結局すべての連携を遮断する必要があった。
Agent Authは、エージェントひとつひとつに「ペルソナ」のようなIDを割り当てる。たとえば「カレンダー参照専用エージェント」「メール送信専用エージェント」といった具合に役割を分け、不要になればそのIDだけを無効化できる。これはエージェントが当然のように動く世界において、セキュリティと管理性を両立する基盤技術といえる。
Vercel Connect と eve への統合
Better AuthチームはVercelに加わり、このエージェントアイデンティティをVercel Connectとeveに組み込むと発表されている。Vercel Connectは開発者がさまざまなサービスやAPIを安全に連携させるための仕組みであり、eveはVercelが提供するAIエージェントプラットフォームである。認証レイヤーが標準装備されることで、エージェントを使った機能をより安全かつ手軽に実装できるようになるだろう。
開発者コミュニティとライブラリの今後

買収によってBetter Authのライセンスや開発体制が変わるのではないかと懸念する声もある。しかしVercelは、ライブラリはMITライセンスのまま無料で提供され、名称も変更されず、同じコミュニティガバナンスモデルで開発が続くと明確に述べている。
オープンソースとしての継続
Better AuthのGitHubリポジトリは引き続き公開され、プルリクエストやIssueを通じたコミュニティ参加も歓迎される。Vercelのリソースが投入されることで、ロードマップの進行速度が上がったり、ドキュメントの整備が進んだりするメリットが期待できる。
フレームワークサポートの拡大
Better AuthはすでにNext.js以外にもNuxt、SvelteKit、Remixなど多様なフレームワークで利用できる。Vercelは特定のフレームワークに偏らないサポートを続ける方針を示しており、エコシステム全体への貢献が加速する可能性がある。
Vercelの戦略から見る、認証とエージェントの未来

今回の買収は、単に認証ライブラリを手に入れる以上の意味を持つ。Vercelはすでにホスティング、サーバーレス関数、エッジネットワーク、AI SDKと積み上げてきた。そこに「認証」と「エージェントアイデンティティ」というピースが加わることで、開発者がアプリケーションを作り、デプロイし、AIエージェントを安全に動かすための一気通貫のプラットフォームが姿を現しつつある。
「エージェントインフラ」の基盤として
Vercelは以前から「エージェントインフラストラクチャ(agentic infrastructure)」という概念を掲げている。これは、AIエージェントが動くための実行環境だけでなく、ストレージ、キュー、認証といったバックエンドの一式を提供する考え方だ。Better Authの買収によって、その認証レイヤーが大きく強化されることになる。
競合との差別化要因
他社のクラウドプラットフォームも認証機能を提供しているが、多くはプロプライエタリなサービスである。Better AuthのようにオープンソースでMITライセンスの認証ライブラリを中核に据えるアプローチは、ベンダーロックインを嫌う開発者層に強く支持されるだろう。とくにエージェントの台頭により認証の複雑さが増すなかで、「所有できる認証」の価値はますます高まっていく。
この記事のポイント
- VercelがオープンソースのTypeScript認証ライブラリ「Better Auth」を買収。創設者とコアチームがVercelに参加する。
- Better Authは週間470万ダウンロード、850人以上のコントリビューターを持つ。MITライセンスとコミュニティガバナンスは維持される。
- エージェントに独自のIDと制限付き権限を与える「Agent Auth」プロトコルの開発が加速し、Vercel Connectやeveに統合される予定。
- 従来のエージェント実行における権限制御の課題を解決し、エージェントごとの失効やスコープ管理が可能になる。
- Vercelは「オープンSDK戦略」に沿って認証レイヤーを強化し、エージェントインフラの基盤を固める動きを加速させている。

・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

WooCommerce 11.0で配送クラスが非公開タクソノミーに変更
WooCommerce 11.0が2026年7月28日にリリースされる。このアップデートでは、商品の送料計算に使われる「product_shipping_class」タクソノミーが非公開に変更される。これまで明示的に設定されていなかった公開フラグが、WordPress のデフォルトで true 扱いとなっていた状態が解消され、内部データとしての扱いが明確になる。
多くの店舗や拡張機能では特別な対応は不要だが、配送クラスを公開タクソノミーとして利用していたコードは見直しが必要だ。この変更の背景と、開発者が確認すべきポイントを整理する。
WooCommerce 11.0で配送クラスのタクソノミーが非公開になる
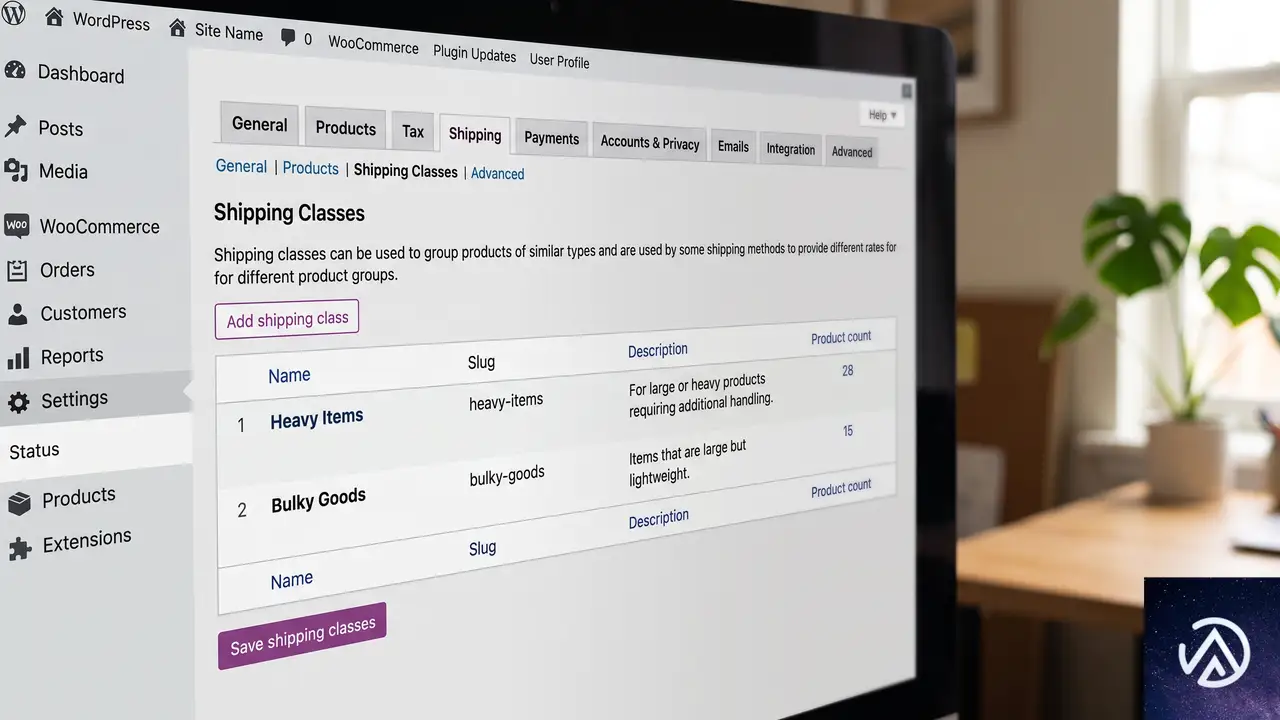
配送クラス(product_shipping_class)は、商品を送料計算のグループに割り当てるための仕組みだ。たとえば「大型商品」「冷蔵商品」といったクラスを作り、各商品に紐づけることで、配送方法ごとに異なる送料を設定できる。
これまでの動き(Before)
WooCommerce 11.0 より前のバージョンでは、配送クラスをタクソノミーとして登録する際に public 引数が指定されていなかった。WordPress のタクソノミー登録関数は public が省略されるとデフォルトで true を適用する。そのため、配送クラスは「公開タクソノミー」として扱われ、is_taxonomy_viewable() が true を返していた。
この状態では、サイトマップ生成、タクソノミーアーカイブの処理、パブリックタクソノミーを列挙するクエリなどに配送クラスが意図せず含まれることがあった。
変更後の動作(After)
WooCommerce 11.0 からは、タクソノミー登録時に 'public' => false が明示的に設定される。これにより is_taxonomy_viewable( 'product_shipping_class' ) は false を返すようになり、WordPress の各種 API で配送クラスが非公開タクソノミーとして扱われる。
この変更はデータそのものを削除するものではない。すでに登録された配送クラスのタームや商品との紐づけ、送料ルールはそのまま維持される。
なぜこの変更が必要だったのか

配送クラスは本来、商品カテゴリーやタグのように顧客に見せるためのカタログ用タクソノミーではない。あくまでも送料計算のための内部データである。ところが公開タクソノミーとして振る舞うことで、サイトマップに配送クラスのアーカイブ URL が含まれたり、SEO ツールが意図しないページを認識したりといった副作用が生じていた。
一部のストアでは、この挙動を避けるために手動で除外設定を行なっていた。WooCommerce コアの修正により、根本的な原因を取り除き、特に設定をしなくても配送クラスが公開面に漏れ出さないようになる。
また、WordPress の public フラグが false になると、publicly_queryable も自動的に false を継承する。つまり、URL で配送クラスの一覧ページに直接アクセスすることもできなくなる。こうした一貫した内部データとしての扱いが、開発者にとっても予測しやすい動作につながる。
影響を受けるコードのチェックポイント
WooCommerce Developer Blog の案内に沿って、以下のようなコードを含むテーマやプラグインは変更後の動作を確認する必要がある。
is_taxonomy_viewable( 'product_shipping_class' )が true を返すことを前提にしている- 配送クラスのアーカイブページへのリンクをフロントエンドに生成している
- サイトマップや SEO、ナビゲーションの生成時に
product_shipping_classを public タクソノミーとして含めている get_taxonomies()などで公開タクソノミー一覧を取得し、その中に配送クラスが含まれることを期待している- タクソノミーの公開ステータスをもとに REST API や GraphQL のスキーマ、検索、フィルタリングをカスタマイズしている
- 送料計算以外の汎用的な商品グルーピングに配送クラスを流用している
ごく単純に、配送クラスを送料計算だけに使っている場合は影響を受けない。商品編集画面で配送クラスを設定したり、フックで送料を分岐させたりするコードはそのまま動作する。
開発者が取るべき具体的な対応

基本は何もしなくてよい
配送クラスを送料計算のみに使っているのであれば、コードの修正は不要だ。WooCommerce のコア変更がそのまま適用され、配送クラスは内部タクソノミーとして適切に管理される。
どうしても公開が必要な場合のフィルターフック
特定のサイトや拡張機能で、あえて配送クラスを公開タクソノミーとして扱い続けたいケースもあるだろう。たとえば、配送クラスのアーカイブページをカスタムデザインで用意している場合などだ。
そのような場合は、WooCommerce が用意している register_product_shipping_class_taxonomy_args フィルターを使って、登録時の引数を上書きできる。
add_filter(
'register_product_shipping_class_taxonomy_args',
function ( $args ) {
$args['public'] = true;
$args['publicly_queryable'] = true;
return $args;
}
);ただし、この方法はあくまで例外的な対応である。WooCommerce Developer Blog も述べているように、公開タクソノミーとして再利用するのではなく、本来の目的に合ったカスタムタクソノミーを新たに用意するほうが長期的に健全だ。
長期的にはカスタムタクソノミーへの移行を
商品を顧客向けにグルーピングしたい場合は、商品カテゴリー、商品タグ、商品属性、あるいは専用のカスタムタクソノミーを利用すべきだ。配送クラスはあくまで内部の送料計算用と割り切り、公開用の分類とは役割を分けることで、サイト構造が整理され、SEO の観点からも無駄なアーカイブページが生まれなくなる。
この変更はデータ移行を伴わない「公開状態の切り替え」であり、既存の設定には一切手が加えられない。しかし、今回のバージョンアップをきっかけに、配送クラスを公開タクソノミーとして使っていたコードがあれば、設計を見直す良い機会になるだろう。
この記事のポイント
- WooCommerce 11.0 で配送クラスのタクソノミーが非公開になり、サイトマップやアーカイブに現れなくなる
- 送料計算だけに使っているストアや拡張機能は特別な対応不要
is_taxonomy_viewable()や公開タクソノミーの一覧に依存しているコードは見直しが必要- どうしても公開が必要な場合はフィルターフックで復活できるが、長期的にはカスタムタクソノミーの利用を推奨
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

CSS border-shapeプロパティの全容、装飾が形状に追従する新機能
shape() と corner-shape の復習

border-shape を理解するには、まず土台となる shape() 関数と corner-shape プロパティを押さえておくとスムーズだ。いずれも CSS で形状を扱うための新しい道具であり、特に shape() は 2026 年に Baseline(主要ブラウザで広く使える状態)に到達したばかりである。
shape() 関数の基本
shape() は SVG のパス構文を CSS に取り込む関数だ。clip-path や offset-path の値として使う。従来の path() に比べて CSS ネイティブな記述ができ、直感的に複雑な図形を定義できる。たとえばハート形、星形、波線など、従来は polygon() などで苦労していた形状も、少ないコードで表現可能になった。
CSS-Tricks の記事では、shape() に関する全4回のシリーズ解説と、SVG パスを shape() に変換するオンラインコンバーターも公開されている。これにより、既存の SVG 図形を CSS 形状として手軽に流用できるようになった。
corner-shape プロパティの概要
corner-shape は要素の角の形状を変えるプロパティだ。border-radius と組み合わせて使う。値には round(丸)、scoop(えぐり)、bevel(面取り)、notch(切り欠き)、squircle(超楕円)といったキーワードを指定する。squircle は iOS のアイコンなどで見られる、丸みを帯びつつ四角さも残した独特の曲線だ。
corner-shape は単なる角の整形にとどまらず、三角形や菱形、六角形といった CSS のみの図形作成にも使える。何より重要なのは、角を変形させても border や box-shadow がその形状に追従することだ。これこそが border-shape の布石となる考え方である。
border-shape の基礎:clip-path との違い

border-shape の構文と基本動作
border-shape は要素の形状を定義するが、clip-path とは根本的な動作が異なる。clip-path は要素を「切り抜く」(クリッピング)。その結果、border や box-shadow などの装飾も一緒に切り取られ、形状に沿わない。一方、border-shape は要素を「変形させる」(シェイピング)。装飾は新しい形状に沿って描画される。
構文は clip-path とほぼ同じで、shape()、polygon()、circle()、inset() などを受け取る。さらに、2つの値を指定する「フィルモード」も用意されている。最初の値が外側の境界、2番目の値が内側の境界となり、その間を border で塗りつぶす動きだ。
/* 1 値のストロークモード:border が形状をなぞる */
.shape {
border: 8px solid #1976d2;
border-shape: shape("M ...");
}
/* 2 値のフィルモード:境界の間を border で塗る */
.cutout {
border: 12px solid #e74c3c;
border-shape: inset(0) shape("M ...");
}装飾が追従する仕組みを図で見る
このデモは概念を視覚化したイメージだ。実際の border-shape は Chrome で確認できる。clip-path と異なり、星形の頂点やくぼみにぴったり沿った border が手軽に得られる。
border-shape のもう一つの利点は、border-radius を考慮する必要がない点だ。要素が丸められた矩形でなくなれば、角丸の概念自体が不要になる。代わりに形状そのもので角の挙動を制御できる。
ボーダーだけの形状を作る(Border-Only Shapes)

border-shape のわかりやすいユースケースが「輪郭だけの形状」だ。要素の背景を透明にし、border だけを設定するだけで、ハートや星、花、波線といったアウトライン図形を CSS のみで描ける。
.border-only {
background: transparent;
border: 8px solid #e74c3c;
border-shape: shape("..."); /* ハート形などのパス */
}この例も概念のイメージである。実際の border-shape なら、頂点や曲線がより精密に再現される。従来は複数の疑似要素や複雑な box-shadow の重ね合わせが必要だった表現を、数行の CSS で実現できるのが大きな魅力だ。
切り抜き形状とレイアウトの応用

2つの形状値で作る切り抜き
border-shape に inset(0) と任意の形状を組み合わせると、矩形の内側に図形の穴が開いたような「切り抜き」デザインが作れる。これはフィルモードと呼ばれ、外側形状と内側形状の差分を border の領域として塗りつぶす。
.cutout {
border: 12px solid #1976d2;
border-shape: inset(0) circle();
}上図は border-shape のフィルモードを静的に再現したものだ。実際には、border-color や border-width を変えるだけで、動的に切り抜き形状の装飾を調整できる。
ハートや星を使った複合形状
円だけでなく、shape() で定義したハートや星形を内側形状に指定すれば、さらに凝ったデザインが可能だ。たとえば、矩形のカードの中にハート形の窓が空いたような装飾、ポリゴン型のフレームに星形が浮かぶ背景など、CSS だけで容易に作れるようになる。
はみ出し装飾と部分装飾

border-shape は要素の境界を超えて装飾を拡張することもできる。形状を要素の外側に大きく取れば、背景が画面幅いっぱいに広がるブレイクアウト効果を border の太さだけで演出できるのだ。
.breakout {
border: 40px solid #ff9800;
border-shape: inset(0 -100vw) circle(0);
}border-shape では border を画面外まで伸ばせるため、従来の CSS グリッドの「ブレイクアウト」テクニックよりはるかに直感的に、セクションの背景を拡張できる。
テキストに寄り添う部分装飾
shape() 関数の緻密なパス指定と組み合わせれば、テキストの特定の単語にだけ下線を引く、見出しの左端にのみ斜めの背景を付ける、といった部分装飾も可能になる。border-shape は要素全体を変形しつつ、装飾の範囲を自由にコントロールできるため、デザインの表現力が格段に向上する。
アニメーションと次の一手

border-shape はアニメーションもサポートしている。形状を動的に変えたり、border-width を操作したりすることで、多彩なインタラクションを追加できる。
3コマで見る形状アニメーション
以下のデモは、ホバーで円が星形に変化するアニメーションを静的に示したものだ。実際には約 0.5 〜 1.5 秒かけて連続的に変化する。
この変化を border-shape 上で行えば、border や影も一緒に変形するため、よりリッチなエフェクトが可能になる。他にも、border-width を 0 から太くすることで、ホバー時に形状が浮かび上がるリビール効果も実装できる。
実践的なテクニック集
CSS-Tricks の記事では、以下のような応用例も紹介されていた。
- ナビゲーションメニューで、手描き風の下線がホバーアイテムにスライドする
- コンテンツボックスの周囲を電気が走るようなフレームで囲む(タッチデバイスでも安全)
- border のみで構成されたローディングスピナー
- ドラッグ可能な円をつなぐ曲線が、距離に応じて伸び縮みする
いずれもこれまでは JavaScript や SVG を駆使しなければ実現が難しかった表現だ。border-shape と shape() を習得すれば、CSS だけで多くの装飾を完結できるようになる。
この記事のポイント
- border-shape は要素の形状を変えつつ、border や box-shadow を形状に追従させるプロパティ
- clip-path と違い、装飾が失われず、輪郭だけの形状や複雑なフレームが容易に作れる
- 2値指定のフィルモードで切り抜き効果、形状を広げてブレイクアウト背景も実現可能
- アニメーションや部分装飾にも対応し、CSS 表現の幅を大きく広げる
- 2026年7月現在 Chrome のみの先行実装だが、今後の標準化と普及に注目
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

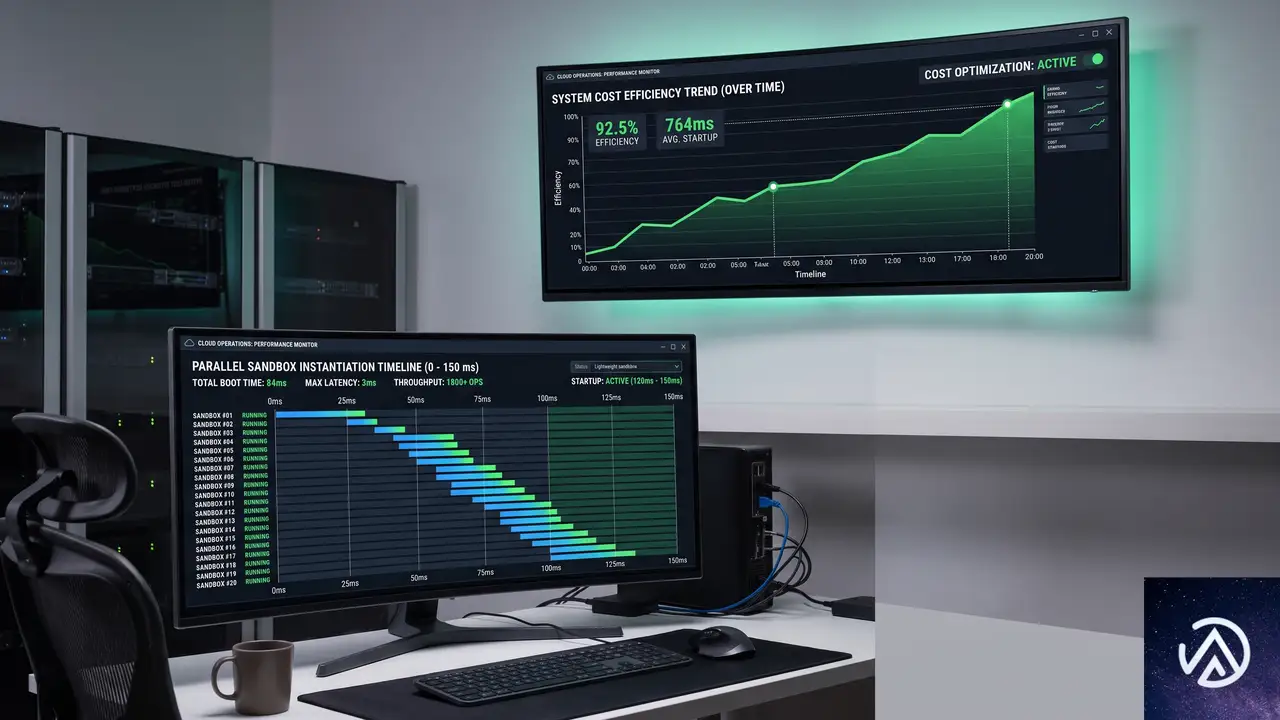
Cloud Run Sandboxesがパブリックプレビュー、AI生成コードを安全に隔離実行
Cloud Run Sandboxesがパブリックプレビューに。AI生成コードを隔離実行

Google Cloudは2026年7月9日、Cloud Run上で信頼できないコードを安全に実行するサンドボックス機能をパブリックプレビューとして公開した。AIが生成したプログラムや、エンドユーザーがアップロードしたスクリプトを、ホスト環境やクラウドの認証情報から完全に分離した状態で動かせる。
起動はミリ秒単位で、既存のCloud RunインスタンスのCPUやメモリを共有する。追加のVMや専用のサンドボックスホスティングプラットフォームを使う必要はなく、追加料金も発生しない。この発表はベルリンで開催中のWeAreDevelopers World Congressで行われた。
これまで開発者は、AIが動的に生成したコードを安全に実行するために、コンテナクラスタを組んだり、サードパーティのmicroVMランタイムを契約したりする必要があった。Cloud Run Sandboxesは、その複雑さを取り除くサーバーレスネイティブの仕組みだ。
サンドボックスとは何か、なぜ必要なのか

サンドボックスとは、プログラムを隔離された領域で実行する仕組みのことだ。子供が砂場(サンドボックス)の中で自由に遊んでも、砂が外に散らばらないのと同じで、中で何が起きても外側のシステムには影響を与えない。
AIエージェントやLLM(大規模言語モデル)がコードを生成する時代では、この隔離が極めて重要になる。モデルが書いたPythonスクリプトに意図しないファイル削除やネットワーク経由のデータ流出が含まれていたとしても、サンドボックス内で止められるからだ。
Cloud Run Sandboxesは、既存のCloud Runサービスインスタンス内でほぼ瞬時に生成できる軽量な隔離実行境界だ。専用のVMを立ち上げる必要がなく、サーバーレス環境を離れずにすべてが完結する。
サンドボックスの仕組みとセキュリティ設計

シンプルな有効化とネイティブな呼び出し
利用開始は驚くほど簡単だ。Cloud Runサービスをデプロイする際に、gcloudコマンドまたはYAML設定でサンドボックスランチャーを有効にするフラグを1つ追加するだけでよい。有効化すると、軽量なサンドボックスCLIバイナリが実行環境に自動でマウントされ、標準的なサブプロセス呼び出しでプログラムからサンドボックスを生成できる。
実際の動作例として、LLMが動的に生成したPythonコードを安全に実行するデモが公開されている。1000個のサンドボックスを起動し、それぞれの処理を実行して停止するまでの平均レイテンシは500ミリ秒だ。
ゼロトラストを前提とした3層のセキュリティ境界
Cloud Run Sandboxesは、悪意あるコードや誤ったコードからホストアプリケーションとクラウドリソースを守るために、3つの重要なセキュリティ境界を強制する。
この3層構造によって、AIが生成したコードがどれほど予測不能な動作をしても、ホスト側への影響は生じない。セキュリティを理由にAIコード実行を諦めていた開発者にとって、大きな転換点になる。
3つの主要ユースケース
Cloud Run Sandboxesは特に以下の3つの用途で力を発揮する。いずれも「信頼できないコードを隔離実行する」という共通の要件を持つシナリオだ。
ADKとComputeSDKとの統合
Cloud Run Sandboxesは、Googleのエージェント開発キットであるADK(Agent Development Kit)の次期バージョンでネイティブサポートされる。新しいCloudRunSandboxCodeExecutorを使うと、ADKエージェントがわずか1行のコードでサンドボックス内のコード実行を指示できる。
また、ベンダーに依存しないサンドボックス実行用SDKであるComputeSDKにも対応が追加された。このSDKを使えば、Cloud Runサービスの外部からリモートでサンドボックスを呼び出すことも、サービス上のローカルツールとして直接使うこともできる。既存のツールチェーンにスムーズに組み込める設計だ。
コスト面の利点と実運用への影響
Cloud Run Sandboxesの大きな特長は、追加コストが一切かからないことだ。オンデマンドのVMに対して高いプレミアムを課金する専用サンドボックスホスティングプラットフォームとは異なり、既存のCloud Runインスタンスに割り当てられたCPUとメモリを直接共有する。
起動時間がミリ秒単位であることも実運用上の利点だ。従来のVMベースの隔離環境では、新しいVMを立ち上げるたびに数秒から数十秒の待ち時間が発生していた。Cloud Run Sandboxesなら、ユーザーからのリクエストに対してほぼ待ち時間なく応答できる。
Google Cloud Blogの記事で紹介されたデモでは、1000個のサンドボックスを起動してコードを実行し、終了するまでの平均レイテンシが500ミリ秒だった。これは「AIが生成したコードをリアルタイムで安全に実行する」という要件に対して十分実用的な数値だ。
この記事のポイント
- Cloud Run SandboxesはAI生成コードや信頼できないバイナリを安全に実行する隔離環境で、パブリックプレビューとして公開された
- 起動はミリ秒単位で、既存のCloud Runインスタンスのリソースを共有するため追加コストは発生しない
- 環境変数の隔離、ネットワーク通信のデフォルト遮断、安全なファイルシステムオーバーレイの3層でセキュリティを確保
- LLMコードインタプリタ、ヘッドレスブラウザ、ユーザー提出コードの実行が主要ユースケース
- ADKとComputeSDKに組み込み対応し、開発者は1行のコードでサンドボックス実行を指示できる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

GPT 5.6 Sol、Terra、LunaがAI Gatewayで利用可能に
GPT 5.6の3モデルがAI Gatewayで利用可能に
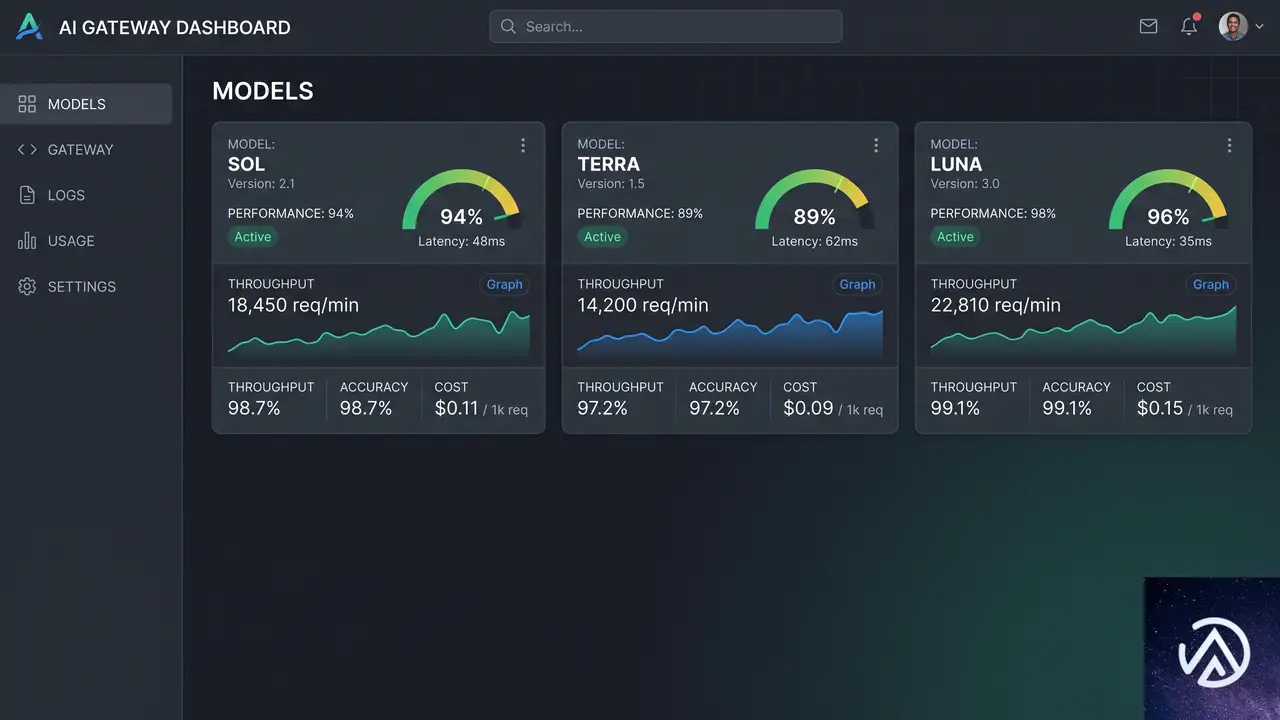
OpenAIの最新モデルシリーズ「GPT 5.6」が、VercelのAI Gatewayで限定的なプレビュー提供を開始した。Sol・Terra・Lunaの3モデルが揃い、いずれもコーディングや生物学、サイバーセキュリティといったエージェント的なタスクで従来世代より強化されている。トークン効率も向上しており、同等の処理をより少ないコストで実行できるのが特徴だ。
AI Gatewayは複数のAIプロバイダに統一APIでアクセスできるサービスで、利用状況の追跡やコスト管理、リトライやフェイルオーバー、パフォーマンス最適化を一手に引き受ける。今回の追加により、開発者はコードを変更せずに最新のGPTモデルへ移行できるルーティング機能も利用可能になった。
GPT 5.6 Sol・Terra・Lunaの違い
モデル指定はAI SDKでopenai/gpt-5.6-solのようにスラッグを渡すだけだ。用途や予算に応じて切り替えやすい設計になっている。
コードを触らずにモデルを切り替えるルーティングルール
AI Gatewayのルーティングルール機能を使うと、既存のコードを一切変更せずにモデルを差し替えられる。たとえばopenai/gpt-5.5で動いているアプリケーションを、コマンド1行でopenai/gpt-5.6-solへ振り向けることが可能だ。
rewriteルールを設定するだけで、アプリコードに手を入れず最新モデルへ移行できる。ルーティングルールはモデルのA/Bテストや段階的なロールアウトにも活用できる。本番環境でいきなり全トラフィックを新モデルに向けるのではなく、一部だけ振り分けて様子を見る運用も現実的だ。
AI Gatewayの料金体系とその他の機能

AI Gatewayはプロバイダの利用料金に上乗せせず、推論に対するプラットフォーム手数料も請求しない。BYOK(Bring Your Own Key)で自身のAPIキーを持ち込んだ場合でも同様に手数料は発生しないため、コストを厳密に管理したいチームにとっては安心できる設計だ。
利用状況の可視化と制御に役立つ機能も充実している。主なものは以下のとおりだ。
- カスタムレポートでチームやプロジェクト単位の利用状況を把握できる
- ゼロデータ保持(ZDR)に対応し、機密性の高いプロンプトの取り扱いも安心
- APIキー単位で予算上限を設定し、予期せぬコスト超過を防ぐ
- ルーティングルールでモデル切り替えやフェイルオーバーを自動化する
実際の開発フローに組み込む際の注意点
GPT 5.6シリーズは限定的なプレビュー提供の段階にある。本番環境で全面的に切り替える前に、モデルプレイグラウンドで動作を検証し、期待する出力品質やレイテンシが得られるか確認することを推奨する。特にエージェント的な使い方をする場合、従来モデルとはプロンプトの最適な書き方が変わる可能性もある。
また、Terraは「前世代と同等性能・半額」というコストメリットが明確だが、SolとLunaはユースケースによって費用対効果が大きく変わる。まずは低コストのLunaでプロトタイプを作り、本格的なタスクではSolに切り替えるといった段階的な活用が現実的な戦略になるだろう。
この記事のポイント
- GPT 5.6のSol・Terra・LunaがAI Gatewayで限定プレビュー提供を開始
- Terraは前世代と同等の性能を半額で提供するコストパフォーマンスが最大の魅力
- ルーティングルールによりコード変更なしでモデルを切り替え可能
- AI Gatewayはプロバイダ料金に上乗せせず、BYOKでも手数料なし
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

GPT-5.5の応答を改善、VS Codeのプロンプトチューニング手法
GPT-5.5の応答が改善された技術的背景

VS Codeが提供するAIエージェント機能は、コード生成の裏側で「コーディングハーネス」と呼ばれる仕組みが動いている。これはモデルとツール、コンテキスト、指示、エージェントのループを繋ぐ層だ。モデルがコードを書くための土台となる部分といえる。
2026年7月、VS CodeチームはOpenAIと協力し、GPT-5.5向けのシステムプロンプトを改善する実験を実施した。焦点は「エージェントの探索を減らし、検証を早める」ことにある。この変更で応答速度とコストの両方を改善できるかどうかが検証された。
プロンプトチューニングの目的と仮説
GPT-5.5のリリース後、VS Codeチームはエージェントがトークンをどのように消費しているかを分析した。分析の結果、モデルが実際の編集に入る前に過剰な探索を行っているパターンが浮かび上がった。具体的には、ファイルの再読込や周辺コードの比較に多くのトークンが費やされていた。
この観察から1つの仮説が導かれた。それは「エージェントはさまよう努力を減らし、証拠、行動、検証という意図的なループに注力すべきである」というものだ。この仮説を検証するため、2種類のプロンプトが用意された。
エージェントが編集前に「考えすぎる」状態を減らし、必要最小限の探索で行動に移すよう誘導する。この考え方は、トークン消費と応答時間の両方に直接影響を与える。
実験の中身と2つのアプローチ
実験は2週間にわたって実施された。GPT-5.5のエージェントトラフィックを、対照群と2つの処置群に25%ずつ分割し、残りの25%はスコアカード外でデフォルトプロンプトが使用された。この設計により、同じ種類のユーザートラフィックで公平な比較が可能になる。
処置A「PRPT_SRCH」簡潔な探索と編集
処置Aは小規模で焦点を絞った変更だ。プロンプトに1つのコンパクトな指示を追加し、不必要な探索を減らすようモデルに促す。この指示は「economical_search_and_edit」セクションと呼ばれる。
具体的には、次の5つの行動指針が与えられた。最も具体的なアンカー(ファイル、シンボル、失敗している動作など)から開始すること。1つの仮説とそれを否定できる安価なチェックを選ぶために十分な周辺コンテキストだけを集めること。広範なリポジトリ探索より1回の対象検索を優先すること。最も安価な判別チェックがわかったら即座に行動すること。そして、新しい結果が関連性を示さない限り、変更されていないコンテキストを再読しないことだ。
economical_search_and_edit:
- 最も具体的なアンカーから開始する
- 1つの仮説とその反証チェックに十分なコンテキストだけを集める
- 広範な探索より1回の対象検索を優先する
- 最も安価な判別チェックがわかったら即行動する
- 変更されていないコンテキストは再読しない処置B「PRPT_LRG」大規模プロンプト再構成
処置Bは同じ仮説をより広範に展開したものだ。エージェントのワークフローを「Before_the_first_edit(最初の編集前)」と「After_the_first_edit(最初の編集後)」の2つの明示的なセクションに再編成する。
このアプローチの狙いは、検索ステップだけでなくループ全体を解決することにある。最初の編集前に局所的な仮説を形成し、広範な探索を避け、根拠のある最初の編集を行い、最初の実質的な編集後に即座に検証する。処置Aと異なり、プロンプト自体のサイズは大きくなるため、構造の追加が効率を改善できるかどうかが重要な論点だった。
両処置の設計思想の違いは明確だ。処置Aは最小限の介入で探索を抑えるのに対し、処置Bはエージェントの行動全体を構造化して制御しようとする。この差が実際のパフォーマンスにどう現れるかが実験の焦点になった。
2週間のスコアカードが示した結果
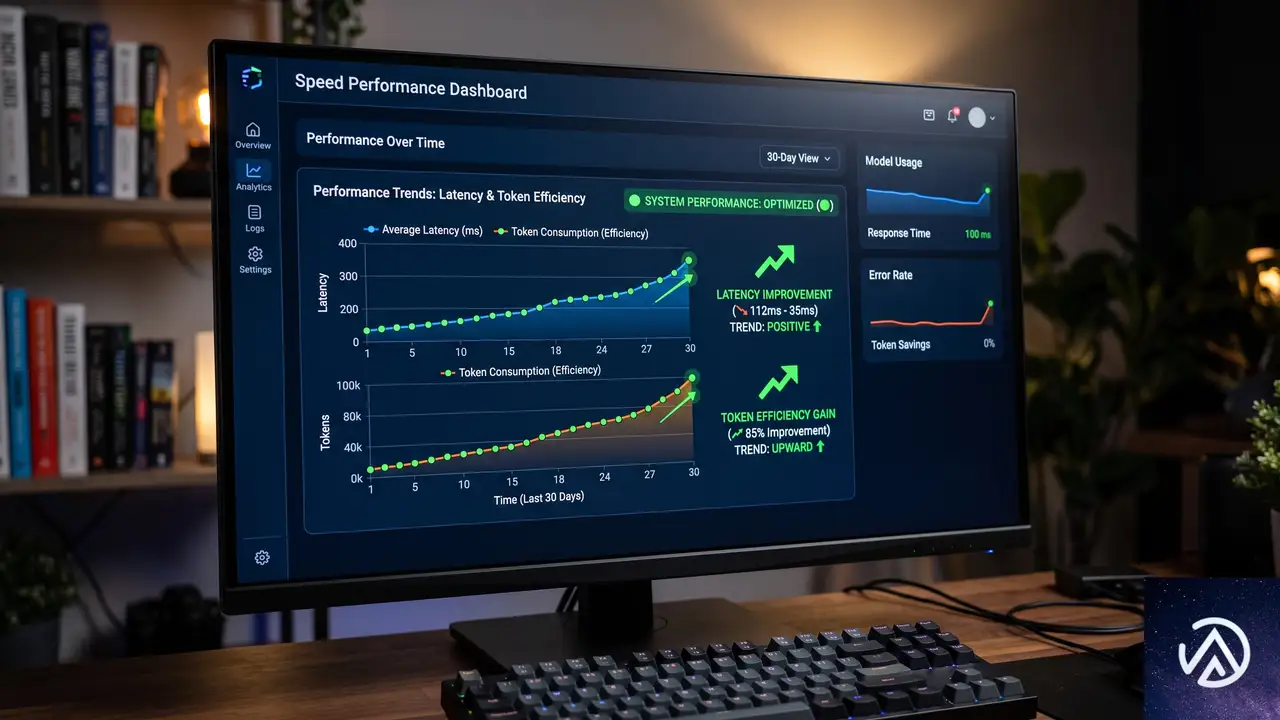
実験では品質、レイテンシ、効率の3つの次元で評価が行われた。品質は「コードが定着するか」、レイテンシは「最初の編集がどれだけ早く行われるか」、効率は「トークンとツール呼び出しの数」で測定される。
品質指標 10分生存率とコミット生存率
10分生存率は、AIが書いたコードのうち10分後もファイルに残っている割合を示す。コミット生存率は、さらに厳格にgitコミットまで生き残ったコードの割合だ。この2つが品質のガードレール指標となる。
結果として、コミット生存率は処置Bで+0.68%とわずかに上昇し、処置Aでは-0.48%とわずかに低下したが、いずれも統計的に有意ではなかった。10分生存率は両処置ともわずかに低下し、処置Bの-0.44%だけが統計的有意の閾値をわずかに超えた(p=0.0493)。VS Codeチームはこれを「実際のトレードオフとして考慮すべきだが、動きは小さく、他の品質ガードレールは後退しなかった」と評価している。
レイテンシ指標 初回編集までの時間
編集レイテンシでは処置Bが最も強い改善を示した。p50(中央値)の初回編集時間は-5.68%(3.9秒高速化、p=2e-5)、p95(下位5%の遅いケース)では-9.30%(38.8秒高速化、p=1e-10)といずれも高い統計的有意性を示した。
処置Aもp50で-2.88%(2.0秒高速化、p=0.0271)と改善したが、p95の改善は統計的に有意ではなかった。遅いケースでの差が特に顕著で、「なぜこれが遅いのか」というストレスを感じる場面での改善が大きかったことになる。
トークン効率とツール呼び出し回数
1ユーザーあたりの日次トークン消費量(p50)は両処置とも減少したが、統計的有意ではなかった。しかし、トークン消費の裾野(p95、特に重いリクエスト)では、処置Bが-7.64%(p=0.0003)、処置Aが-5.19%(p=0.0157)と明確な改善を示した。
平均ツール呼び出し回数も両処置で減少した。処置Bは-8.54%(1ターンあたり2.04回の呼び出し削減、p=1e-12)、処置Aは-3.19%(0.77回削減、p=0.0091)だ。処置Bの優位性は極めて高い統計的有意性で裏付けられた。
処置Bは総合的に最も強いプロファイルを示した。レイテンシの明確な勝利、裾野トークンの有意な削減、ツール呼び出しの減少、そして品質ガードレールのほぼ安定。10分生存率のわずかな低下は軽微な有意性(p=0.0493)にとどまり、レイテンシやトークン、ツール呼び出しの改善ははるかに大きく堅牢だった。
プロンプトチューニングが示す開発体験の進化
この実験の成果は数字の変化だけではない。重要なのは、プロバイダからのフィードバックに基づく検証可能な仮説を、オフライン評価で事前検証し、2週間の本番環境で確認するという一連のループが機能したことだ。
モデルのリリースはチューニングループの終点ではない。VS Code上の実際の動作を観察し、焦点を絞った改善をテストし、より速く、信頼性が高く、効率的な体験を実現する新たな方法を見つける機会となる。このプロンプトチューニングは、その1つの具体的な実例だ。
使用量ベース課金におけるトークン効率の重要性
この改善が特に重要なのは、使用量ベースの課金モデルが前提にあるからだ。トークン効率は単なるインフラ指標ではない。エージェントが探索に費やすすべてのトークンは、ユーザーが支払い、待たされる対象だ。根拠のある編集に早く到達するエージェントは、より良い体験とより小さい請求額の両方をもたらす。
VS Codeチームはこの取り組みを継続する方針を示している。モデル、プロンプト、ツール、コーディングハーネス全体にわたって改善点を探し続け、エージェントの予算が必要な作業に集中できるよう最適化していくという。
このループが示すのは、AI開発支援ツールの進化がモデルの性能向上だけに依存する段階から、プロンプト設計やツール連携の最適化を含む総合的な取り組みへと移行していることだ。モデルが高性能でも、使い方が適切でなければ本来の力を発揮できない。その橋渡しをするのがプロンプトチューニングの役割といえる。
この記事のポイント
- GPT-5.5向けのプロンプトチューニングで、エージェントの探索を抑制し検証を早める改善が実施された
- 処置B(大規模プロンプト再構成)が最も優れた結果を示し、p95の初回編集時間を9.30%短縮した
- ツール呼び出し回数は8.54%削減され、トークン消費の裾野(重いリクエスト)でも7.64%の改善が確認された
- 品質指標(コード定着率)はほぼ維持され、速度と効率の改善が品質を犠牲にしないことが実証された
- 使用量ベース課金の文脈では、トークン効率の改善がユーザーのコスト削減に直結する重要性を持つ
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Vercel Agentが本番環境に進出、プラン即許可で安全なAI運用を実現
Vercelが2026年7月8日、自社のAIエージェント「Vercel Agent」の大幅な機能拡張を発表した。従来はアラートのトリアージやプルリクエストのレビューが中心だったが、今回のアップデートでダッシュボード上に常設され、本番環境の調査やプロジェクトへの質問応答、承認後のアクション実行まで可能になった。
Vercel Agentの最大の特徴は「プラン即許可(Plan-to-Permission)」という新しい権限モデルだ。デフォルトで読み取り専用として動作し、デプロイのロールバックや設定変更といった操作は、具体的な作業計画を提案して承認を得たうえで、そのタスクに限定された一時的な権限のみを使って実行する。
本番稼働中のアプリケーションにAIを介入させるには、安全性の担保が不可欠である。Vercel Agentは独立したIDで動作し、生成したコードは隔離されたサンドボックスで検証する。この設計により「自律的でありながら制御された状態」を実現しており、AIエージェントの運用にまつわる信頼の課題に対して、具体的な解決策を示した製品といえる。
Vercel Agentの全体像と導入背景

Vercel Agentは、Vercelプラットフォーム上で動作するAIエージェントだ。アプリケーションのデプロイと実行を支えるインフラに組み込まれているため、本番環境で問題が発生した際に、最初に対応を開始できるポジションにある。アラートを受けてから自律的にログやメトリクス、デプロイ履歴を調査し、根本原因を特定して修正案を提示する。
Vercel社内では数ヶ月前から本番運用に組み込まれており、すでに具体的な成果が出ている。典型的な事例として、深夜23時に不良デプロイが行われ、チェックアウト用のエンドポイントが500エラーを返し始めたケースでは、オンコールエンジニアがログインする前にAgentがエラーを4分前のデプロイまでトレースし、即時ロールバックを推奨した。エンジニアが計画を承認すると、Agentが前の正常なビルドにロールバックし、エンドポイント修正用のプルリクエスト作成まで自動で進めた。アラート発生から問題緩和までの時間は3分未満だったという。
このデモは、同じインシデントに対する従来の対応とVercel Agent導入後の対応を比較した概念図である。Agentが自律的に調査と提案を行い、人間は最終判断に集中できる点が最大の違いだ。
本番環境にAIを近づけるための新セキュリティモデル

アプリケーションの修正や設定変更が可能なAIエージェントを本番環境に導入する場合、最も重要な問いは「どう安全にデプロイや設定変更を任せられるか」である。多くのAIエージェントはユーザーの全権限を引き継いで動作するため、誤った指示や混乱したサブエージェントの被害がそのまま本番に及ぶという構造的な課題を抱えている。
Vercel Agentはこの問題に対して、3つの要素からなる新しい権限モデルを実装した。エージェント自身の固有ID(Principal)、タスクごとの一時的な権限付与(Plan-to-Permission)、そして生成コードの隔離実行環境(Sandbox)である。これらはプラットフォームレベルで強制されるため、AIモデルの挙動にかかわらず安全策が機能する。
エージェント固有のIDによる帰属と権限の分離
一般的なAIエージェントは、操作する人間のIDと権限をそのまま使って動作する。その場合、エージェントが行った操作と人間が行った操作を区別できず、誰が何を指示し実行したのか追跡不可能になる。
Vercel Agentは「vercel-agent」という固有のプリンシパル(主体)として動作する。すべての変更操作には「誰が依頼したか」「誰が承認したか」「Vercel Agentが実行した」という記録が必ず残る。さらに、Agentに付与される権限は、操作を指示した人間がもつ権限の範囲を超えることはない。この設計により、説明責任(アトリビューション)と権限の透明性を両立している。
⚠️ 誤指示や誤動作の影響範囲がユーザーと同等
✅ 付与される権限は承認された計画の範囲に限定
この図は、従来型エージェントとVercel Agentの権限構造の違いを表している。Vercel Agentでは、常に「依頼者」「承認者」「実行者」の3者が記録され、権限も計画単位で一時的に付与されるため、誤動作の被害範囲が極めて狭い。
プラン即許可(Plan-to-Permission)の仕組み
多くの組織がAIエージェントを開発フローに統合する際、最初に直面するのが「事前に広範な権限を付与してしまう」という課題だ。これはエージェントに必要以上の権限を、必要以上の期間与えることになる。そのエージェントにプロンプトを送れる人なら誰でも、付与された権限の範囲にアクセスできてしまうため、権限の広さがそのままセキュリティリスクの大きさに直結する。
Vercel Agentはデフォルトで読み取り専用である。デプロイのロールバック、設定変更、キャッシュのクリアといった操作が必要な場合、Agentはまず実行計画を提案し、その計画に限定されたアクセス権限を要求する。ユーザーが計画を承認すると、Agentはそのタスクに必要な能力を一時的に取得し、作業完了後は自動的に読み取り専用状態に戻る。
Agentが行うすべてのAPI呼び出しは、3つのチェックを通過する必要がある。承認された計画で付与された能力(Capability)、トークンのスコープ、そしてチームの既存権限だ。これら3つすべてが許可する場合にのみ操作が実行され、このチェックはプラットフォーム側で強制されるため、AIモデルがどのような挙動をとっても安全策が破られることはない。Vercelはこの仕組みを「プラン即許可(Plan-to-Permission)」モデルと呼び、最小権限の原則を設計レベルで組み込んでいる。
この一連の流れでは、Agentが自律的に調査と提案を行う一方で、実際の操作権限は人間の承認を経て初めて発行される。人間の判断を挟むことで安全性を確保しつつ、Agentの自律性を最大限に活かせる設計だ。
サンドボックスによる生成コードの安全な検証
コードを生成するAIエージェントにはもうひとつ重大な課題がある。それは「生成されたコードが実際に動くかどうかは、実行してみるまでわからない」という点だ。動作確認されていない修正を本番環境に適用することは、さらなる障害を引き起こすリスクを伴う。
Vercel Agentが生成したコードは、Vercel Sandbox(FirecrackerマイクロVMによる短寿命の隔離環境)内で実行される。このサンドボックスは実際のプロジェクトのコピーを持っており、Agentは生成したコードを本物のビルドプロセス、テスト、リンターに対して実行し、問題なくパスしたものだけをPRとして提示する。たとえば壊れた設定ファイルを修正する場合、Agentが変更を加えてサンドボックス内でビルドテストを通過させ、その結果をPRにまとめるという流れになる。
この仕組みにより、Agentは自由にコードを生成して実行できるが、検証に失敗したコードや壊れた修正が人間の前に提示されたり、本番環境に直接届いたりすることはない。コードレベルの安全性をインフラ側で担保している点が重要だ。
現場の開発フローがどう変わるか

Vercel Agentはインシデント対応だけでなく、開発者が日常的に直面するさまざまなタスクを支援する。具体的なユースケースを4つ紹介する。
プルリクエストのレビュー
AgentにPRの確認を依頼すると、CIがパスしているだけでは検出できないパフォーマンスの低下やリスクの高い変更を指摘する。たとえば、ある変更によってページが毎回サーバーサイドレンダリングされるようになり、キャッシュが効かなくなっていないかといった観点までチェックできる。
コスト増加の原因追及
「なぜ今月の請求額が跳ね上がったのか」という問いに対して、Agentはコード変更履歴を調査し、コスト急増の原因となった特定のコミットを特定する。たとえば、あるページがキャッシュされずに毎回サーバーサイドレンダリングされるようになったコード変更を検出し、承認を得たうえで修正PRを作成する。
ビルド失敗の修正
失敗したデプロイをAgentに調査させると、ログを読み取り、問題のある設定ファイルを特定し、修正の許可を求めてくる。ユーザーが承認すれば、Agentが設定を修正し、サンドボックス内でビルドをテストしてからPRとして提出する。
本番リリースの安全性確認
フィーチャーフラグに関する質問に対して、Agentはコードと本番のライブメトリクスの両方を分析し、その機能をロールアウトしても安全かどうかを判断する。データに基づいた客観的な判断が得られるため、リリース判断の品質が向上する。
この比較図は、日常的な開発タスクにおける負荷の変化を表している。Agentが調査と提案を担うことで、開発者はコードの質やビジネス判断といったより本質的な業務に集中できる。
反脆弱性インフラがもたらす意味

Vercel Agentの発表で最も重要なポイントは、単にAIエージェントの機能が追加されたという話ではない。AIエージェントを「本番環境に近づけても安全に運用できる」という状態を、プラットフォームの設計で実現したことだ。
AIエージェントの時代において、真の限界は2つの天井で決まる。ひとつはモデルが「何をできるか」、もうひとつはユーザーが「何を許可するか」だ。モデル性能が向上し続けるなかで、実際の運用において重要になるのは後者、すなわち信頼の設計である。どれほど高性能なモデルでも非決定論的であり、非決定論的なシステムは非決定論的に失敗する。安全性は「エージェントが毎回正しい判断をすること」に依存してはならず、システムそのものに組み込まれていなければならない。
Vercelは長年にわたり、イミュータブルデプロイメント(デプロイが書き換え不可で、不良デプロイは1回のロールバックで元に戻せる仕組み)をはじめとする安全策を積み上げてきた。これらはもともとAIエージェントのために設計されたものではないが、自律システムが必要とするガードレールそのものとして機能する。Vercelはこの考え方を「反脆弱性インフラ(Anti-fragile Infrastructure)」と呼んでいる。
反脆弱性インフラの本質は、エージェントに誤りがあっても被害を局所化でき、人間のミスさえもコストを抑えられる点にある。安全性がインフラ層に組み込まれているため、エージェントが正しいことを前提にせずとも、実用的な権限を委譲できる。Vercel Agentのケースでは、自律的に調査と提案を行い、人間が承認した範囲内でのみ操作を実行し、何か問題があれば即座にロールバックできる。
このモデルは、AIエージェントの実運用における「自律性 vs 安全性」というトレードオフに対して、明快な解を示している。エージェントが仕事をし、人間が最終判断を保持し、インフラがフェイルセーフとして機能する。この3層構造が揃って初めて、本番環境にAIを近づける信頼の土台が成立する。
Vercel Agentの将来展望と利用開始方法
現時点でのVercel Agentは、異常の調査、プルリクエストの作成、プロジェクトや本番アプリに関する質問への回答が可能だ。今後のロードマップとして、特定分野の専門家エージェントへの委任機能が予定されている。たとえば、コードベース全体に対する詳細なセキュリティレビューや、フロントエンドのデザイン・UXレビューを、オンデマンドで専門家AIに依頼できるようになる見込みだ。
Vercel Agentは、ProプランおよびEnterpriseプランのチームに対して段階的にロールアウトされている。利用を希望する場合は、Vercelのアーリーアクセスページから申請するか、ダッシュボードのサイドバーにある「Agent」セクションから有効化できる。
この記事のポイント
- Vercel Agentは本番環境の異常を自律的に調査し、人間の承認を得て修正を実行するAIエージェントである
- 「プラン即許可」モデルにより、Agentの権限はタスク単位で一時的に付与され、完了後は読み取り専用に戻る
- 生成されたコードは隔離されたサンドボックスで検証され、本番環境に直接影響を与えない設計になっている
- イミュータブルデプロイメントなどのインフラ安全策と組み合わせることで、エージェントの誤動作コストを最小化する
- AIエージェントの実運用における信頼の課題に対して、プラットフォーム設計で安全性を担保するアプローチを具体化した製品といえる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

OpenAI GPT-Live登場、ChatGPT Voiceに検索機能を統合
OpenAIが音声会話と検索を融合させた新モデル「GPT-Live」の展開を開始した。2026年7月8日に発表されたこのアップデートにより、ChatGPT Voiceは会話の途中で最新の推論モデルやウェブ検索に質問を引き継げるようになる。
有料ユーザー(Go・Plus・Pro)には「GPT-Live-1」、無料ユーザーには「GPT-Live-1 mini」がデフォルトで提供される。Search Engine JournalのMatt G. Southern氏が報じたところによれば、週に1億5千万人以上がChatGPTと音声や音声入力で会話しており、今回の変更はその巨大なユーザー基盤に直接影響を及ぼす。
SEOの観点から特に注目すべきは、音声経由の検索結果が「どのように引用元を扱うか」の詳細がまだ明らかにされていない点だ。テキストベースのChatGPTでは回答の横にソースリンクが表示されるが、音声会話の中でどの程度サイトへの導線が確保されるかは、今後のトラフィック戦略を左右する。
GPT-Liveの仕組みと変更点

GPT-Liveの最大の特徴は、会話の自然さを追求した「全二重(Full-Duplex)」通信への移行だ。これは音声入力と応答生成を同時に行う技術で、ユーザーが話し終える前に割り込まれにくくなり、より人間らしい対話のテンポが実現される。
具体的に以下の要素で構成されている。
- 音声入力の処理と応答の生成を同時に実行し、待ち時間を短縮
- ユーザーが発話をためらった際に適切な間を取り、自然なターンテイキングを実現
- 有料ユーザー向けのGPT-Live-1と、無料ユーザー向けのGPT-Live-1 miniの2種類を用意
- 深い推論が必要な質問は自動的に最先端モデル(現在はGPT-5.5)に引き継ぐ
OpenAIの社内評価では、5分から10分の会話においてGPT-Live-1とGPT-Live-1 miniは従来のAdvanced Voice Modeよりも高く評価された。評価基準は全体的な好ましさ、ターンテイキング、割り込みの少なさ、会話の流れ、自然さだ。
音声検索の裏で動く推論と視覚カード

GPT-Liveの登場により、ChatGPT Voiceは単なる音声応答の枠を超え、天気や株価、スポーツといったトピックに対して視覚的なカードを画面に表示するようになった。これにより、ユーザーは音声で答えを聞きながら同時に画面で詳細を確認できる。
ユーザーは推論レベルを3段階から選択できる仕組みだ。即時応答を求める「Instant」モードはGPT-5.5 Instantで動作し、より深い回答が必要な「Medium」や「High」モードはGPT-5.5 Thinkingを使用する。音声会話の自然さを保ちながら、必要に応じて高度な推論エンジンに処理を委ねる設計になっている。
この仕組みは、音声経由の検索体験を大きく変える可能性がある。画面に情報カードが表示されることで、ユーザーは検索結果ページを経由せずに目的の情報を得られるからだ。
この変化はSEO担当者にとって無視できないシグナルだ。音声検索の結果が可視化されない形で提供されることで、従来の検索エンジン経由のトラフィックが一部置き換わる可能性がある。
GPT-Liveがまだ実装していない機能
GPT-Liveは現時点で、ChatGPTにおけるビデオや画面共有を伴う音声には対応していない。OpenAIはこれらの機能の追加に取り組んでいることを明言しており、ビデオや画面共有が必要な場面では従来のStandard Voice ModeおよびAdvanced Voice Modeが引き続き利用できる。
実務的に重要なのは、この制約が一時的なものである可能性が高いという点だ。ビデオ・画面共有対応が追加されれば、ユーザーは画面を見せながら質問し、GPT-5.5の推論と検索を組み合わせた回答をその場で得られるようになる。視覚的な情報提供の幅がさらに広がることで、従来型の検索エンジンへの依存はより一層低くなるだろう。
引用とソース表示の不透明さがもたらすSEOリスク
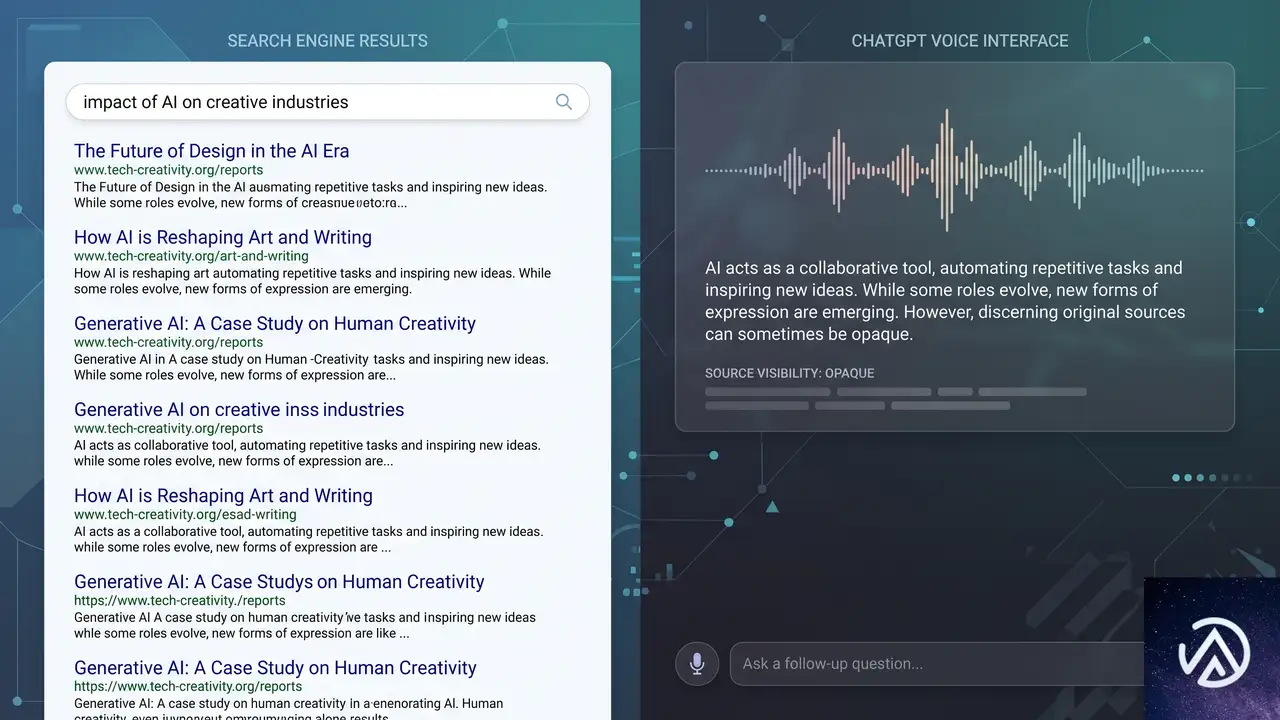
OpenAIの発表で最も詳細が不足しているのが、音声検索結果の引用(Citation)の扱いだ。テキスト版のChatGPTでは、回答の横にソースリンクが明示される。しかしGPT-LiveがGPT-5.5のウェブ検索を通じて得た情報を音声で回答する際、どのように引用元を示すのかはまだ明らかにされていない。
可能性としては以下の3つのシナリオが考えられる。
- 音声でソース名を読み上げて紹介する
- 画面上にテキストと同様のソースリンクを表示する
- ソースを一切提示せずに回答のみを提供する
3番目のシナリオが現実になれば、情報を提供しているウェブサイトにとっては深刻な問題となる。ユーザーが音声で質問し、画面を見ずに回答だけを得て終了すれば、検索トラフィックは完全に消失するからだ。
Search Engine JournalのMatt G. Southern氏は、音声検索結果がソースを「口頭で読み上げるのか、画面に表示するのか、あるいは完全に省略するのか」が、検索からサイトへの送客が維持されるかどうかを決める鍵だと指摘している。ChatGPTの音声会話がウェブサイトのトラフィックに与える影響を測る上で、最も注視すべきポイントだ。
音声検索時代に備えるための実務アプローチ

GPT-Liveのような音声と検索の融合が進む中で、SEO対策は従来のランキング上位表示だけでなく、「AIに情報源として選ばれること」を視野に入れる必要がある。以下の3つの観点が重要になる。
構造化データの強化と情報の整理
AIモデルがウェブ上の情報を正確に取得し、適切に引用するためには、ページの情報構造を機械が読み取りやすい形で提供することが欠かせない。Schema.orgに準拠した構造化データのマークアップは、検索エンジンだけでなくAIによる情報抽出の精度にも影響する。
特にFAQページやHowToコンテンツは、音声での質問応答に直接活用される可能性が高い。質問と回答のペアを明確にマークアップし、簡潔で正確な情報を提供することが有効だ。
ブランド認知と信頼性の蓄積
音声検索の結果としてソースが表示される場合、ユーザーがクリックするのは「知っている名前」や「信頼できると感じるサイト」である可能性が高い。AI時代のSEOでは、単なる検索順位だけでなく、ブランドとしての認知度や専門性の確立がクリック率に直結する。
具体的には、業界内での継続的な情報発信、オリジナルデータや独自調査の公開、著名なメディアからの被リンク獲得など、E-E-A-T(経験・専門性・権威性・信頼性)を高める施策がこれまで以上に重要になる。
音声向けコンテンツの設計
音声で読み上げられることを想定したコンテンツ設計も視野に入れるべき段階に入った。長文の説明よりも、要点を簡潔にまとめた「音声向けサマリー」をページの冒頭に配置することで、AIが情報を抽出しやすくなる。
また、天気や株価、スポーツのスコアといったリアルタイム性の高い情報は、構造化データと組み合わせることでAIに直接取得されやすい。これらの情報を提供しているサイトは、API連携やデータフィードの整備を通じて、機械可読な形式での情報提供を強化することが望ましい。
この記事のポイント
- GPT-Liveは音声会話中にGPT-5.5への推論依頼とウェブ検索を自動的に組み合わせる
- 天気・株価・スポーツなどの視覚カードにより、検索結果ページを経由しない情報取得が拡大
- 音声検索結果の引用表示方法が未公表であり、サイトへのトラフィック維持に直結する課題
- 構造化データの強化とブランド認知の蓄積が、AI時代のSEOにおける重要な差別化要素になる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

GitHub CopilotでDNS設定ゼロ、Pagesカスタムドメインを14分で公開
GitHub Copilot CLIでDNS設定ゼロ。GitHub Pagesカスタムドメインを14分で公開

カスタムドメインの取得とDNS設定は、多くの開発者にとって「最後の関門」だ。Aレコード、CNAMEエントリ、TTL(Time To Live / DNSキャッシュの有効期間)、そして「設定が反映されたのかどうかもわからない」という長い待ち時間。これらの煩わしさが、せっかくのプロジェクト公開を先延ばしにする原因になっている。
GitHub Blogで2026年7月8日に公開された記事によれば、GitHub Copilot CLIとコミュニティ製のNamecheapスキルを組み合わせることで、DNSレコードを手動で1行も編集せずに、約14分でカスタムドメインの設定からHTTPS化されたサイト公開までを完了できることが実証された。空のリポジトリから公開まで、わずか14分だ。
本記事では、このワークフローをステップごとに分解し、技術的な仕組みと実務への応用方法を解説する。DNSの知識がなくても理解できるよう、専門用語には都度説明を加えながら進める。
Copilot CLIがDNSの常識を変える、手動設定から自動化への転換

従来のDNS設定が抱える3つの課題
カスタムドメインをGitHub Pagesに紐付けるには、従来以下の作業が必要だった。ドメインを購入し、レジストラ(ドメイン管理会社)の管理画面でAレコードとCNAMEレコードを手動で追加し、GitHubリポジトリ側にもCNAMEファイルをコミットする。さらにDNSの伝播(設定がインターネット全体に行き渡るプロセス)を待ち、最大で48時間かかることもある。
この一連の作業には大きく3つの課題がある。第一に手順の複雑さだ。AレコードやCNAMEといったDNSレコードの種類を理解し、正しい値を入力する必要がある。第二にフィードバックの遅さ。設定が正しいかどうかの確認に長時間を要する。第三にミスのリスク。1文字でも間違えるとサイトが表示されず、原因特定にも手間取る。
Copilot CLIが解決するDNS設定の自動化
GitHub Copilot CLIは、自然言語での指示をシェルコマンドやAPI操作に変換するAIアシスタントだ。これにレジストラのAPIと連携するスキルを組み合わせることで、DNSレコードの読み取り・設定・検証までを自動化できる。
今回のワークフローでは、Namecheap(ドメインレジストラ)のAPIを操作するコミュニティ製スキル「namecheap-skill」を使用する。Copilot CLIに対して「このドメインをGitHub Pagesに向けて」と指示するだけで、スキルが必要なAレコードとCNAMEレコードを自動生成し、レジストラのAPI経由で設定する。さらにGitHubリポジトリ側のCNAMEファイルも自動でコミットする。
手動で6ステップかかっていたDNS設定が、自然言語の指示1行で完結する。ミスのリスクが排除され、待ち時間も大幅に短縮される点が最大の利点だ。
準備編、GitHub Pagesへの公開と格安ドメインの取得
ステップ1、GitHub Pagesでランディングページを公開する
まずは公開用のリポジトリを作成する。空のパブリックリポジトリを用意したら、index.htmlを手書きする必要はない。Copilot CLIに「このリポジトリでGitHub Pagesを有効にして、カスタムドメインに関するランディングページを作成して」と指示するだけで、HTMLの生成からPagesの有効化までを自動実行してくれる。
この時点でサイトは ユーザー名.github.io というURLで公開される。まずはデフォルトドメインでサイトが表示されることを確認し、次に独自ドメインの設定に進む。
ステップ2、低コストでドメインを取得する
サイドプロジェクトにプレミアムな .com ドメインは必須ではない。今回の検証では、最も安価なTLD(トップレベルドメイン / .comや.orgなどのドメイン末尾部分)のひとつである .click が選択された。購入費用はわずか2米ドル(約300円)だ。サイドプロジェクトでカスタムドメインを試すにはリスクの低い金額といえる。
Namecheapでドメインを検索し、利用可能な名前を選んで購入する。決済が完了すれば、次のステップでAPI経由のDNS設定に進む準備が整う。
Namecheap APIとCopilot CLIの連携でDNSレコードを自動設定

Namecheap APIアクセスを有効化する
Copilot CLIがDNSを操作するには、事前にNamecheapのAPIを有効化する必要がある。Namecheapの管理画面で「Profile → Tools → Business & Dev Tools」と進み、Namecheap API Accessの管理画面を開く。ここで3つの設定を行う。
- APIをONに切り替える
- APIを呼び出すマシンのパブリックIPを許可リスト(ホワイトリスト)に追加する
- APIキーをコピーして安全な場所に保管する
APIキーは後続のステップでCopilot CLIに入力するため、手元に控えておく必要がある。NamecheapのAPIを使うと、ドメイン一覧の取得やDNSレコードの読み書きをプログラムから実行できるようになる。
Namecheapスキルをインストールする
続いて、Copilot CLIにNamecheapと通信する能力を与えるスキルをインストールする。以下の1コマンドで完了する。
gh skill install github/awesome-copilot namecheap --scope userスキルのインストール後、Copilot CLIに対して「自分のNamecheapドメインを一覧表示して」と指示すると、初回実行時にAPIキーの入力を求められる。先ほど控えたキーを入力すれば、アカウント内のドメイン一覧が表示され、連携が正常に機能していることを確認できる。
この4ステップで、Copilot CLIがドメインレジストラのAPIを直接操作できる状態になる。従来のように管理画面を手動で操作する必要はない。
ドメインの紐付けと自動検証、すべてが14分で完了

Copilot CLIにドメイン接続を指示する
準備が整ったら、Copilot CLIに対して「このGitHub Pagesサイトでカスタムドメインを有効にして」と指示する。スキルは現在のDNSレコードを確認し、変更を適用する前に確認を求めてくる。これは重要な安全設計だ。誤ったDNS変更がサイトの表示停止につながるリスクを、人間の承認によって防いでいる。
承認後、スキルは以下の作業を自動実行する。
- Namecheapのパーキングレコード(未使用ドメインの仮レコード)を削除
- GitHub PagesのAレコード(IPアドレス指定)を登録
- WWWサブドメイン用のCNAMEレコードを追加
- リポジトリにCNAMEファイルを自動コミット
これらの手順はGitHubが公式に定めるカスタムドメイン設定手順に完全に準拠している。手動で行う場合とまったく同じ結果が、人的ミスのリスクなく得られる。
自動検証でDNS設定の完了を確認する
設定が完了したら、Copilot CLIは自らの作業を検証する。まずドメインが正しく解決されるか(DNSルックアップ)を確認し、次にサイトがHTTP 200(正常応答)を返すかをチェックする。手動での動作確認すら自動化されているのだ。
実際のタイムラインを見てみよう。ドメイン購入は東部時間の午前11時21分27秒に行われた。約14分後の午前11時35分には、カスタムドメインでHTTPS化されたサイトが公開されていた。この14分にはAPIセットアップ、スキルインストール、DNS設定、伝播、検証のすべてが含まれている。
Copilot CLIがDNSルックアップとHTTPステータス確認を自動実行し、人間が待機する必要はない。設定ミスがあればすぐに検出され、修正も対話的に行える。
DNS自動化が変える開発体験、Namecheap以外でも使える汎用ワークフロー
このワークフローの本質は、Namecheapに限ったものではない。APIを提供しているレジストラであれば、同じアプローチが適用できる。専用のスキルがなくても、Copilot CLIにレジストラのAPIドキュメントを読み込ませ、「このAPIを使ってGitHub PagesのDNSレコードを設定して」と指示すればよい。レジストラが変わってもワークフローは変わらない。
DNS設定は「難しくはないが、面倒で失敗しやすく、フィードバックが遅い」という特性を持つ作業だった。Copilot CLIはこの3つの課題を同時に解決する。面倒な手順は自動化され、失敗のリスクは承認プロセスで抑制され、フィードバックは自動検証で即時に得られる。
カスタムドメインの設定を「面倒だから」と後回しにしてきた開発者にとって、このワークフローは心理的な障壁を取り除く。14分という時間は、コーヒーを淹れるのと変わらない。DNS設定がコマンド1行で済む時代が、すでに来ている。
この記事のポイント
- GitHub Copilot CLIとNamecheapスキルでDNSレコードの手動編集が不要になる
- 空のリポジトリからHTTPS化されたカスタムドメインサイトまで約14分で完了
- API経由の自動設定によりAレコードやCNAMEの入力ミスがゼロになる
- 設定後はCopilot CLIがDNS解決とHTTPステータスを自動検証する
- Namecheap以外のレジストラでも、APIがあれば同じワークフローが適用可能
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AI可視性スコアは無意味、EC事業者が取るべき代替指標と施策
AI検索の可視性スコアは、特定のプロンプトと計測条件に強く依存する。実務的な指標として機能しないケースが多く、一部の代理店ではスコアの水増しまで行われているのが現状だ。
Practical Ecommerceに掲載された論考は、この問題を「AI Visibility Scores Are Useless(AI可視性スコアは役に立たない)」と断じている。本記事では、EC事業者がすぐに着手できる代替指標と、AI検索で自社のプレゼンスを高めるための具体的な施策を解説する。
AI可視性スコアが当てにならない3つの理由
AI可視性スコアとは、ChatGPTやPerplexityといった生成AIの回答に、自社のブランドや商品がどれだけ登場するかを数値化した指標を指す。直感的には便利に思えるが、現場で使うには欠陥が多い。
プロンプトに結果が左右される脆弱さ
AIの回答は、与えられたプロンプト(質問文)によって内容が大きく変わる。たとえば「東京 おすすめ ランニングシューズ」と「[自社ブランド名] ランニングシューズ 評判」では、同じAIでも表示される情報がまったく異なるのだ。
可視性ツールの多くは、事前に用意された少数のプロンプトでスコアを算出する。そのプロンプトに自社名が含まれていればスコアは跳ね上がり、含まれていなければゼロになる。実務を反映しない、操作しやすい設計といえる。
プロンプトに自社名が入った「仕込み」の質問でスコアを稼ぐ行為は、実務的な意味を持たない。実際の消費者は、もっと漠然とした言葉で商品を探しているからだ。
スコアを水増しする手法が横行している
業界の一部では、プロンプトを加工してわざと自社が上位表示されるように誘導する操作が行われている。Practical Ecommerceの記事もこの点を指摘しており、自社名を盛り込んだプロンプトを大量に使えば、全体の平均スコアを簡単に引き上げられてしまう。
外部のコンサルタントや代理店から「AI可視性スコアが○%向上しました」といった報告を受けても、その数字がどんなプロンプトに基づくのかを確かめなければ、まったく意味が変わってくる。
引用されても購買につながらないケース
生成AIの回答には、ブランド名が明示される「見える引用」と、リンクだけが貼られてブランド名が出ない「見えない引用」の2種類がある。後者はクリックされる確率が極めて低く、トラフィックにほとんど寄与しない。
Redditの報告によれば、ChatGPT経由のトラフィックはGoogle検索と比べて極端に少ない。引用数だけをKPIにすると、実態とかけ離れた数値を追いかけることになる。
EC事業者が追うべき実践的なAI指標

AI可視性スコアに代わる指標として、Practical Ecommerceの著者は大きく4つのポイントを挙げている。いずれも特定のツールに依存せず、自社のコンテンツ戦略に直結する項目だ。
複数AIで引用されるドメインを分析する
単一のAIモデルでの引用率ではなく、ChatGPT、Claude、Perplexity、Google AI Overviewsなど、複数の生成AIプラットフォームにまたがって引用されているドメインを追う方が有益だ。このアプローチにより、次の3つを把握できる。
- AIが回答の根拠として信頼するメディアやパブリッシャー
- AIに影響力を持つUGC(ユーザー生成コンテンツ)やSNSプラットフォーム
- 高頻度で引用されている競合サイト
複数プラットフォームで共通して引用されるドメインは、AIが「信頼できる情報源」と評価している証拠だ。ECサイトであれば、商品説明の充実度や口コミの多さ、専門メディアでの露出が共通項になりやすい。
競合の引用状況からコンテンツの穴を探す
従来のSEOではキーワードギャップ分析が行われてきたが、AI検索の文脈では「引用ギャップ」とも呼べる視点が重要になる。特定の質問に対して競合が引用されているのに自社が引用されていない場合、サイト上の情報に不足があると考えられる。
たとえば、競合ECサイトが「サイズ選びの失敗を防ぐ方法」という記事で頻繁に引用されているなら、消費者はその情報をAIに求めているとわかる。自社も同様のコンテンツを用意し、AIに拾われやすい構造で公開すれば、自然と引用対象に入りやすくなる。
見えない引用を「見える引用」に変える
AI回答にリンクは貼られているが、ブランド名やサイト名が一切表示されない状態を「見えない引用」と呼ぶ。この状態では、ユーザーがリンクをクリックする動機が弱く、トラフィック増加にはつながりにくい。
一方、ブランド名が明示される「見える引用」は、ユーザーの購買判断に直接的な影響を与える。Practical Ecommerceの著者のテストでも、見える引用が購買決定を後押しする結果が出ているという。
見えない引用を改善するには、AIが回答の要約を作る際に「ブランド名を自然に含められる」形でオンページのテキストを整備する必要がある。「当店のシューズは」ではなく「[ブランド名]のシューズは」と書くだけでも、AIの引用表記は変わりうる。
ブランドプロンプトで自社の情報鮮度を測る
AIに自社情報がどの程度正確に、どの程度詳しく伝わっているかを確かめるには、ブランド名を明示したプロンプトが有効だ。実務の文脈で使える質問例として、以下が挙げられる。
- 「[自社ブランド名]とはどんなブランドか?」
- 「[自社ブランド名]と[競合ブランド名]の違いは?」
- 「[自社ブランド名]の評判や口コミは?」
- 「[自社ブランド名]は信頼できるか?」
これらの質問に対してAIが具体的かつ最新の情報を返せるなら、オンページの情報整備とブランドシグナルが機能している証拠といえる。回答が古かったり、内容が薄い場合は、AIが参照できる情報源が不足している可能性が高い。
ECサイトが今すぐ始めるAI検索対策
上記の指標を踏まえ、EC事業者がすぐに取り組める具体的な施策を整理する。特別なツールへの投資は不要で、サイト運営の延長線上にある作業ばかりだ。
商品ページの情報を「AIが引用しやすい形」に整える
AIは構造化された情報を好む。商品ページでは、箇条書きのスペック表、FAQ、Q&A形式の説明文などを積極的に挿入しよう。とくに、ユーザーが検索しそうな疑問文をそのまま見出しにしたFAQセクションは、AI回答の直接的な引用元になりやすい。
また、商品説明にブランド名を適度に繰り返し入れることで、「見える引用」を誘発しやすくなる。過剰なキーワード連打は避けるが、自然な文脈でブランド名を含める意識が重要だ。
UGC(口コミ・レビュー)を強化する
AIはユーザー生成コンテンツ(UGC)を重視する傾向がある。商品レビューやQ&A、SNS上の口コミなど、実際の購入者による生の声が豊富なECサイトは、AIの回答で引用される確率が上がる。
レビュー数の少ない商品については、購入後のフォローメールでレビュー依頼を自動化したり、レビュー投稿者にクーポンを提供する仕組みを導入するとよい。WooCommerceであれば、プラグインを使ってこうした導線を簡単に追加できる。
外部メディアや比較記事での露出を増やす
AIが高頻度で引用するのは、編集プロセスを経た信頼性の高いメディア記事だ。自社商品が比較記事やレビュー記事で取り上げられれば、その記事経由でAIの回答に自社ブランドが登場しやすくなる。
AI検索の時代は「自社サイトだけで完結させない」発想が求められる。第三者メディアへの露出や、インフルエンサーによる紹介記事の獲得が、間接的にAI可視性を押し上げるのだ。
この記事のポイント
- AI可視性スコアはプロンプト依存度が高く、水増し操作も容易なため実務指標として機能しない
- 複数の生成AIプラットフォームにまたがる引用ドメイン分析が、より正確な現状把握につながる
- 競合の引用状況を調べれば、自社サイトに足りないコンテンツテーマが明らかになる
- ブランド名が表示される「見える引用」を増やすために、オンページの表現とUGCの充実が有効
- 特別なツールに頼らず、商品ページのFAQ拡充やレビュー施策から着手できる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験