

Google AI Overviews、リンク表示拡大へ。ゼロクリック検索に変化の兆し
GoogleがAIによる検索結果表示「AI Overviews」内のリンクを拡充するアップデートを2026年5月6日に発表した。この変更は「ゼロクリック検索」の割合がわずかながら低下傾向にあるという業界レポートと同時期に重なり、ECサイト運営者にとっては見過ごせないシグナルだ。
Semrush傘下のDatosが発表した「State of Search Q1 2026」レポートによると、米国におけるゼロクリック検索の割合は2025年12月の24.5%から2026年3月には22.4%へと縮小した。オーガニック検索からのクリック率は同期間に42.0%から44.9%へと上昇している。
今回のGoogleの動きは、AIに代替され続けるウェブサイトへの流入経路に新たな選択肢が生まれる兆しだ。特に、商品ページへの直接的な流入が生命線となるECサイトにとって、この変化への適応は売上を左右する。
ゼロクリック検索の減少が示す潮目の変化

ゼロクリック検索とは、ユーザーが検索結果ページ内で目的の情報を得てしまい、どのウェブサイトにも遷移せずに検索を終えることだ。定義のハイライトやAIによる要約がこれに該当する。ECサイトにとってゼロクリック検索の増加は、検索順位が高くても実際の訪問者や売上に結びつかない状態を意味するため、長らく懸念材料だった。
この変化が意味するのは、AI Overviewsが単なる「流入を阻害する壁」から「新たな流入経路」へと徐々に進化している可能性だ。ゼロクリックが減少に転じたとはいえ、以前と比較すれば高止まりしているのが現状であり、油断は禁物だが、風向きはわずかに変わってきている。
Googleが追加した新たなリンクとその仕組み

Googleの発表によれば、今回のアップデートではAI OverviewsおよびAI Mode内に以下の2種類のリンクが追加される。
- 信頼できる著者やブランドの引用。SNSでの議論も含む。
- 「さらに読む」ための詳細な記事や分析。
加えて、リンク先のソース名とタイトルが検索結果上に明示されるようになった。有料購読が必要なコンテンツの場合、ユーザーが購読者かどうかも表示される。この変更は、ユーザーがどのような情報源をクリックしようとしているのかを事前に判断できるようにする意図がある。
このリンクは、Search Consoleの検索パフォーマンスレポートでは「平均掲載順位 1」としてカウントされる。つまり、AI Overviews内に自社コンテンツが引用されれば、検索結果の最上部に表示されているのと同じ扱いを受けることになる。
EC担当者が監視すべきSearch Consoleの指標
AI Overviews専用のレポートがSearch Consoleに実装される計画は、現時点では確認されていない。しかし、既存の検索パフォーマンスレポートを活用することで、ある程度の状況把握は可能だ。
- 平均掲載順位が1のクエリ群を定期的にチェックする。
- クリック率が急上昇したページがあれば、AI Overviewsに取り上げられた可能性が高い。
- 新規に表示されるようになったクエリをカテゴリ別に整理し、どのテーマのコンテンツがAIに評価されているのかを分析する。
ECサイトの場合、商品名や比較キーワードで突然流入が増えた場合は、AI Overviewsに商品情報が引用されたシグナルと捉えてよい。
ECサイトが取るべきコンテンツ戦略の転換点

Practical Ecommerceの記事では、今回のGoogleの動きから読み取れる方向性として、以下の3点が挙げられている。
- GoogleはAI Overviewsの実験を継続しており、サイトへのクリックを促す方向に舵を切りつつある。
- 新設された「さらに読む」セクションは、データ駆動型のレポートや調査記事を訴求する場になる。
- UGC(ユーザー生成コンテンツ)やSNSでの議論がAI Overviews内での可視性を高めている。
特に注目すべきは3つ目だ。SNS上の口コミやRedditのスレッドがAI Overviewsに直接引用されるケースが増えている。商品の評判が可視化されることで、ECサイト運営者は自社サイト外でのブランド管理にも注力する必要がある。
データドリブンコンテンツがリンク獲得の鍵
AIに要約されるだけの情報ではなく、「リンクをクリックしなければ全体像が理解できない」コンテンツこそが、今後の検索流入を維持するために有効だ。具体的には、独自調査データを含む記事や、比較検証レポート、専門家による詳細な分析がこれに該当する。
たとえば、ショッピングカートの放棄率に関する業界平均データと自社の改善施策を組み合わせたレポートや、特定商品カテゴリの価格推移を可視化した調査記事は、AI Overviewsの「さらに読む」リンクに選ばれやすい傾向がある。
伝統的なSEO施策を捨てるべきではない

今回のレポートとGoogleの動きは「希望のシグナル」ではあるが、従来のSEO戦略を即座に放棄する理由にはならない。ゼロクリック検索がやや減少したとはいえ、全体としてのオーガニック検索流入は依然として厳しい状況が続いている。
むしろ、以下のような複合的なアプローチが求められる。
- 従来のSEO施策(技術的SEO、コンテンツ最適化)は継続する。
- YouTubeやRedditなどのプラットフォームでの情報発信を拡大する。購買意思決定に直結するチャネルとして重要性が増している。
- AI Overviewsに引用されることを目的としたデータドリブンコンテンツを新たに制作する。
- SNS上でのブランド評判を定期的にモニタリングし、ネガティブな口コミには誠実に対応する。
検索の世界は確実に変化しているが、基本に忠実でありつつ、新しい潮流に適応していく柔軟性がECサイトの明暗を分けることになるだろう。
この記事のポイント
- ゼロクリック検索は米国で24.5%から22.4%に減少し、オーガニッククリック率は44.9%に上昇した。
- GoogleはAI Overviews内のリンクを拡充し、信頼できる情報源への誘導を強化している。
- ECサイトはデータドリブンな独自コンテンツを制作し、AIに引用される質の高い情報を提供する必要がある。
- SNSやUGCプラットフォームでのブランドプレゼンスが検索可視性に直結する時代に入った。
- 従来のSEO施策を継続しつつ、YouTubeやRedditなど複数チャネルでの展開を強化するのが得策だ。

・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

SupabaseがChatGPT公式アプリに。データベースとEdge Functionsを自然言語で操作可能に
SupabaseがChatGPTの公式アプリとして提供を開始した。これにより、ChatGPTの対話画面から直接Supabaseプロジェクトのデータベース管理やEdge Functionsのデプロイが可能になる。コードを書かずに自然言語でインフラを操作できる時代が一歩進んだ形だ。
今回の連携では、全部で29種類のツールが提供される。SQLクエリの実行、テーブルスキーマの設計変更、セキュリティアドバイザーの確認と修正、開発用ブランチの作成とマージなど、データベース運用に必要なほぼすべての操作をカバーしている。対象は全Supabaseプランと、ChatGPTの有料プラン(Plus / Pro / Team / Enterprise)だ。
この記事では、Supabase ChatGPTアプリで実現できること、導入方法、技術的な仕組み、そして国産の類似サービスと比較した実務的な評価を解説する。データベース管理の自動化に興味がある開発者や、Supabaseを使ったプロダクト開発の効率化を目指すチームにとって役立つ情報をまとめた。
ChatGPT側からSupabaseを直接操作できるようになった背景
これまでSupabaseの管理は、公式ダッシュボードやCLI(コマンドラインインターフェース)から手動で行うのが一般的だった。開発者であればSQLクライアントを起動し、APIキーを確認し、適切なエンドポイントを叩く。これらの手順に慣れている人にとっては日常的な作業だが、チームに非エンジニアが加わったり、素早いプロトタイピングが求められる場面では操作のハードルが高かった。
一方でChatGPTは、2025年以降、外部アプリとの連携機能を急速に拡充してきた。単なるテキスト生成AIから、実際のサービスを操作する「AIエージェント」としての側面を強めている。この流れの中で、SupabaseがChatGPTの公式アプリとして認定されたのは、両者の方向性が一致した自然な結果といえる。
この連携を支える技術が、MCP(Model Context Protocol / モデルコンテキストプロトコル)だ。MCPは、AIモデルが外部のツールやサービスと安全にやり取りするための標準プロトコルである。ChatGPTはこのMCPを通じてSupabaseのAPIを呼び出し、ユーザーの自然言語による指示を実際のデータベース操作に変換している。
従来のデータベース管理とChatGPT連携の比較
従来のSupabase管理(Before)
※非エンジニアが操作できない。ツールの切り替えが発生
ChatGPTアプリ連携後(After)
※対話の中でデータベース操作が完結。非エンジニアも参加可能
この仕組みは、単に検索して情報を得るだけの従来のAIアシスタントとは一線を画す。ChatGPTはSupabaseのAPIを通じて実際にテーブルを作成し、SQLを実行し、Edge Functionsをデプロイする。つまり「調べるAI」から「実行するAI」への進化を象徴する連携だ。
実務におけるインパクト
開発現場では、ちょっとしたデータ確認のためにSQLクライアントを起動する手間が意外に大きい。ChatGPT上で「先週登録したユーザーの数を教えて」と入力するだけで結果が返ってくれば、コンテキストスイッチ(作業の切り替えにかかる認知的負荷)が大幅に減る。また、セキュリティアドバイザーの指摘に対して「修正して」と指示するだけで実際の設定変更が行われる点は、運用負荷の軽減に直結する。
Supabaseの記事によれば、ChatGPTの「プロジェクト」機能と組み合わせることで、特定のSupabaseプロジェクトに会話のスコープを固定することもできる。プロジェクトの参照IDを一度設定しておけば、その後の会話では自動的に正しいデータベースに接続される仕組みだ。
ChatGPTアプリが提供する29種類の操作ツール

Supabase ChatGPTアプリには、以下の5カテゴリにわたる29種類のツールが実装されている。いずれも自然言語での指示をChatGPTが解釈し、適切なAPI呼び出しに変換して実行する形式だ。
データベース管理(Database Management)
Postgresデータベースに対するSQLクエリの実行、テーブルスキーマの設計と変更、テーブルや拡張機能の一覧表示、セキュリティに関する推奨事項の取得が含まれる。たとえば「usersテーブルに最終ログイン日時のカラムを追加して」と依頼すれば、ChatGPTが適切なALTER TABLE文を生成し、実行する。
セキュリティアドバイザーの確認機能はとくに実用的だ。RLS(Row Level Security / 行レベルセキュリティ)の設定漏れや、公開すべきでないAPIエンドポイントの検出など、見落としがちな設定項目を自動でチェックし、必要に応じて修正まで行える。
プロジェクト運用(Project Operations)
プロジェクトの作成と一覧表示、コスト見積もりの取得、プロジェクトの一時停止と再開、リアルタイムログへのアクセスといった運用系の操作をカバーする。開発用に一時的なプロジェクトを作成して使い終わったら停止する、といったライフサイクル管理をChatGPT上で完結できる。
ブランチとマイグレーション(Branching and Migrations)
データベースの開発用ブランチ作成、変更のマージ、リベースやリセット、マイグレーションの一覧表示と適用が可能だ。Supabaseのブランチ機能は、Gitを使ったコード管理と同様の考え方をデータベースに適用したもので、スキーマ変更を安全にテストしてから本番環境に反映できる。ChatGPT経由で「開発ブランチを作って、そこに新しいインデックスを追加して」と指示するだけで、一連の作業が実行される。
Edge Functions(エッジファンクション)
サーバーレス関数の一覧表示、デプロイ、管理を行う。Edge Functionsとは、ユーザーに近い地理的に分散したサーバー上で実行される軽量なサーバーレス関数のことで、低レイテンシでの処理が求められるAPIエンドポイントやWebhook処理に適している。ChatGPTに「新規ユーザー登録時にウェルカムメールを送信するEdge Functionを作ってデプロイして」と指示すれば、コードの生成からデプロイまでを自動で処理する。
ドキュメント検索(Documentation)
ChatGPTから直接Supabaseの公式ドキュメントを検索できる。コーディング中に詰まったとき、別タブでドキュメントを開かずに会話の流れの中で解決策を見つけられるのは、開発スピードの向上に寄与する。
29ツールのカテゴリ構成
データベース管理
■ SQL実行 ■ スキーマ設計 ■ テーブル一覧 ■ セキュリティ推奨
プロジェクト運用
■ プロジェクト作成・一覧 ■ コスト見積もり ■ 一時停止・再開 ■ リアルタイムログ
ブランチとマイグレーション
■ 開発ブランチ作成 ■ マージ ■ リベース ■ マイグレーション適用
Edge Functions
■ 一覧表示 ■ デプロイ ■ 関数管理
ドキュメント検索
■ Supabase Docsの直接検索
※各カテゴリのツール数はSupabase公式ブログの発表に基づく(2026年5月8日時点)
これらのツールは単独でも有用だが、組み合わせることで真価を発揮する。たとえば「セキュリティアドバイザーを実行して、問題があれば修正用のブランチを作成し、修正後に本番へマージして」という一連の指示を自然言語で伝えられる。従来であれば複数の画面とCLI操作を往復する必要があったフローが、1つの会話で完結する。
利用開始手順と対応プラン
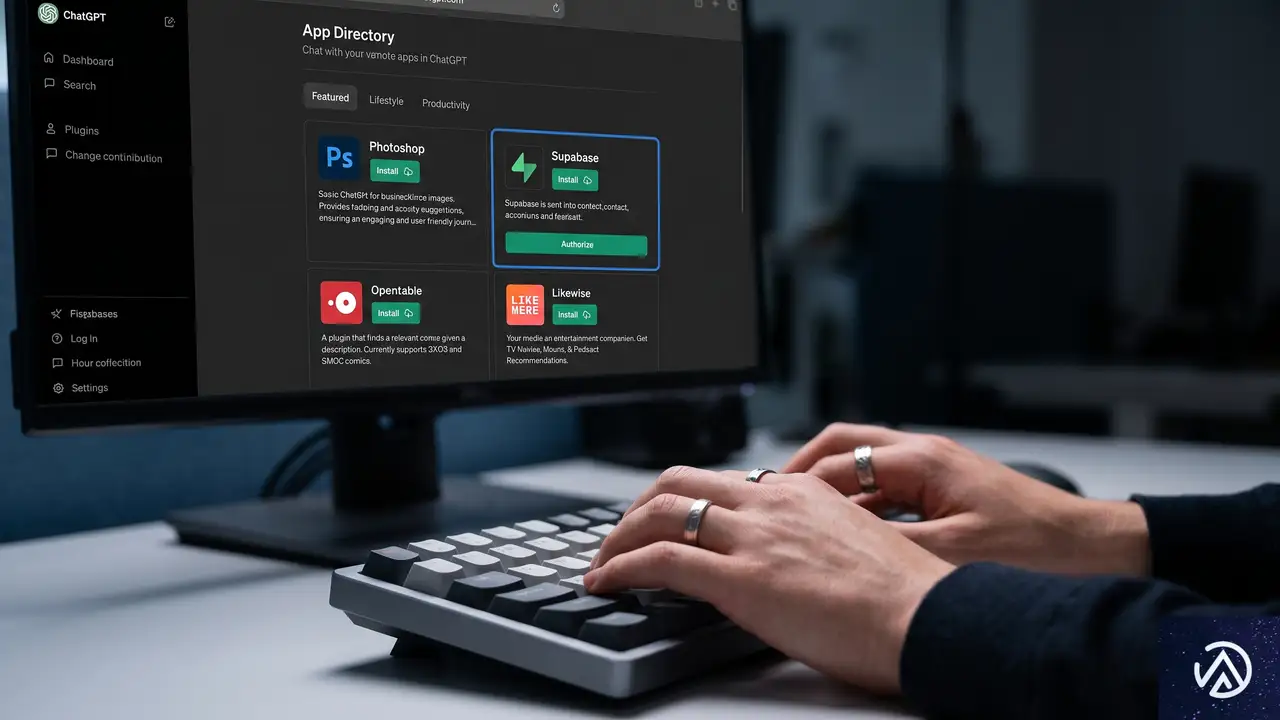
利用開始はシンプルだ。ChatGPTのアプリディレクトリで「Supabase」を検索するか、直接Supabaseのアプリページにアクセスして認証を行う。ChatGPTにSupabase組織へのアクセスを許可すれば、すぐに使い始められる。
対応しているのは全Supabaseプラン(無料プランを含む)と、ChatGPTの有料プランだ。ChatGPT側はPlus、Pro、Team、Enterpriseのいずれかの契約が必要になる。無料のChatGPTアカウントではこのアプリを利用できない点に注意したい。Supabase側に有料プランの制限はなく、無料枠のプロジェクトでも問題なく連携できる。
Supabaseアカウントをまだ持っていない場合は、supabase.comから無料でプロジェクトを開始できる。作成後、ChatGPTに接続して自然言語での管理を始める流れになる。認証にはSupabaseのアクセストークンが使用され、ChatGPTがユーザーに代わってAPIを呼び出す際の権限管理はこのトークンを通じて行われる。
ChatGPTプロジェクトとの連携で効率をさらに上げる
OpenAIが提供する「ChatGPT Projects」機能を使えば、会話のスコープを特定のSupabaseプロジェクトに固定できる。プロジェクトの参照IDをプロジェクト指示に一度設定しておくと、そのプロジェクト内のすべての会話が自動的に正しいデータベースを参照する。複数のSupabaseプロジェクトを抱えるチームでは、この設定で誤操作を防ぎつつ作業効率を高められる。
技術的な仕組みとMCPプロトコル
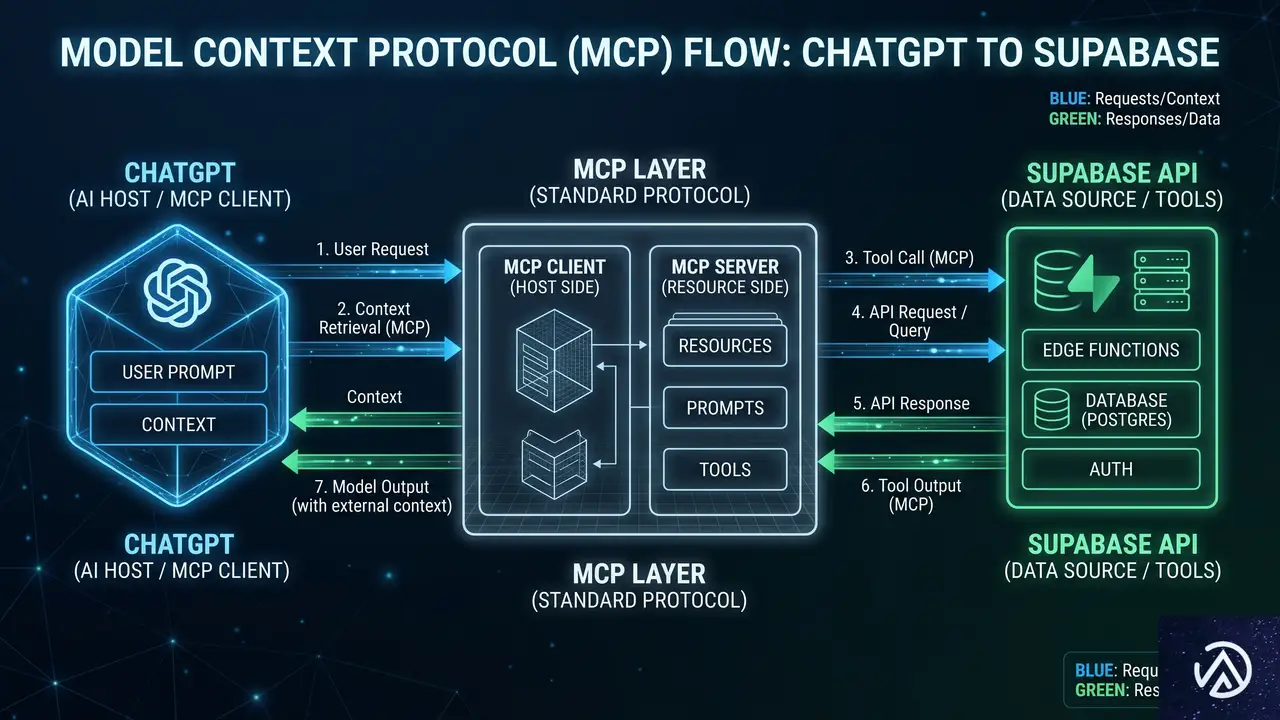
この連携の技術基盤となっているのが、MCP(Model Context Protocol)だ。MCPは2024年にAnthropicが提唱し、現在ではOpenAIを含む複数のAIプラットフォームで採用が進んでいるオープンプロトコルである。AIモデルが外部ツールやデータソースとやり取りするための共通言語のような役割を果たす。
MCPの仕組みを簡単に説明すると、AIモデルに対して「このツールはこういう機能を持っていて、こういう引数を受け取る」という定義(ツールディスクリプション)を提供する。ユーザーが自然言語で指示を出すと、AIはその定義を参照して適切なツールを選択し、必要なパラメータを推論して実行する。Supabaseの29ツールも、このMCPの枠組みに沿ってChatGPTに公開されている。
認証にはOAuth 2.0が使われており、ChatGPTがユーザーのSupabaseアカウントに代わってAPIを呼び出す際の権限は、ユーザーが許可した範囲に制限される。すべての操作はユーザーの認可の下で実行され、ChatGPTが勝手にデータベースを変更することはない。また、実行前にはChatGPTが「これからこういう操作をしますがよろしいですか」と確認を求める設計になっており、安全性にも配慮されている。
MCPによるSupabase操作の流れ
例「先月の売上を商品カテゴリ別に集計して」
「execute_sql_query」ツールを呼び出し、適切なSQLを生成
OAuth認証を通じてユーザーの権限でPostgresにクエリを発行
クエリ結果を要約してチャットで表示。必要に応じてグラフ化も提案
※実際の処理では、破壊的操作の前にChatGPTが確認を求める安全機構が働く
特筆すべきは、この仕組みが単なる「自然言語からSQLへの変換」にとどまらない点だ。ChatGPTはSupabaseから返ってきたデータを解釈し、必要に応じて追加の質問をしたり、結果をわかりやすく要約したりする。エラーが発生した場合も、ログを解析して原因を特定し、修正案を提示できる。
セキュリティと権限管理
AIにデータベースの操作権限を与えることに対する懸念は当然ある。SupabaseのChatGPTアプリでは、以下の3層の安全機構が実装されている。1つ目はOAuth 2.0によるスコープ制限で、ChatGPTがアクセスできる操作はユーザーが明示的に許可した範囲に限定される。2つ目は破壊的操作(DROP、DELETE、スキーマ変更など)の実行前確認だ。3つ目は、すべての操作がSupabaseの監査ログに記録される点で、事後的な追跡と検証が可能になっている。
国産データベースサービスとの比較と実務評価
SupabaseとChatGPTの連携は、BaaS(Backend as a Service / バックエンドをサービスとして提供する形態)市場全体に波及効果をもたらす可能性がある。現時点で国内の類似サービスには、このレベルのAI連携を実装しているものは見当たらない。国産BaaSの多くは管理画面のUI/UX改善に注力しており、自然言語による操作という発想自体がまだ新しい。
ただし、実務に導入する際にはいくつかの注意点がある。第一に、ChatGPTが生成するSQLが常に最適とは限らない点だ。複雑なJOINやサブクエリを含むクエリでは、パフォーマンスの観点から人手によるレビューが推奨される。第二に、ChatGPTの有料プランが必要なため、チーム全体で利用する場合はコストの試算が欠かせない。第三に、プロダクション環境での破壊的操作をAIに委ねることのリスクは依然として存在する。スキーマ変更やデータ削除を伴う操作は、ステージング環境でのテストを挟む運用ルールを設けるのが現実的だ。
一方で、この連携が真価を発揮するのはプロトタイピングとトラブルシューティングの場面だ。アイデアを素早く形にしたいとき、あるいは深夜の障害対応で素早く原因を特定したいときに、ChatGPT上でSupabaseを直接操作できる利便性は大きい。とくにスタートアップや少人数チームでは、開発リソースの制約を補う手段として有効に機能するだろう。
今後の展望
SupabaseがChatGPT公式アプリとなったことで、他のBaaSやクラウドサービスにもAI連携の波が広がるのはほぼ確実だ。すでにVercelやCloudflareもAIエージェントとの統合を進めており、2026年後半には「ChatGPTから操作できるクラウドサービス」が標準的な提供形態になっていく可能性がある。
開発者にとっては、コーディングの効率化だけでなく、インフラ管理や運用監視といった領域までAIがカバーする時代が目前に迫っている。Supabaseの今回の発表は、その転換点を象徴する出来事といえる。
この記事のポイント
- SupabaseがChatGPT公式アプリとして提供開始。チャットからデータベース管理が可能になった
- SQL実行、スキーマ変更、Edge Functionsのデプロイなど29種類のツールを搭載
- 全SupabaseプランとChatGPT有料プランで利用可能。無料枠のプロジェクトでも連携できる
- 技術基盤はMCP(Model Context Protocol)。OAuth 2.0による権限制御で安全性を確保
- 実務導入ではSQLの最適性確認や本番操作の運用ルール整備が推奨される
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

WooCommerce 10.8でOrder更新APIが非Order IDを弾く仕様に。サブスク型データの消失を防止
WooCommerce 10.8が2026年5月19日にリリース予定で、そのなかでREST APIの注文更新エンドポイントに重要な変更が入る。具体的には、/wc/v3/orders/{id} および /wc/v2 相当のルートが、注文ID以外のIDを指定された場合にHTTP 400エラーを返すようになる。
一見すると小さな修正に思えるが、この変更の背景には「サブスクリプションなどの注文以外のデータが、注文更新APIを通じて誤って通常注文に変換され、種別固有のデータが消失する」という深刻な問題がある。WooCommerceのサブスクリプション機能を使っている事業者や、カスタム連携を組んでいる開発者にとっては見逃せない変更だ。
注文更新APIの型検証が強化された背景

従来、WooCommerceのREST API v2およびv3における注文更新エンドポイントは、指定されたIDが本当に注文(shop_order)レコードに属するかをチェックしていなかった。Developer WooCommerce Blogの記事によると、このエンドポイントはサブスクリプション(shop_subscription)など、注文以外のレコードのIDを受け付け、保存時にそれらを通常の注文へとサイレントに変換していたという。
この挙動が引き起こす最大の問題は、サブスクリプション固有のデータ(定期購読の周期、支払いスケジュール、関連する親注文とのひも付けなど)が完全に失われることだ。データが失われているにもかかわらず、APIはHTTP 200で成功を返すため、開発者もサイト運営者も異常に気づきにくい。この問題は GitHub Issue #63936 で報告された。
実はこの「エンドポイントが受け付けるIDの型を事前に検証する」仕組み自体は、v1エンドポイントには当初から存在していた。v2とv3で欠落していた検証が、10.8でようやく追加される形になる。後方互換性を多少犠牲にしても、データの整合性を守ることを優先した判断といえる。
影響を受けるのはどのようなケースか

Developer WooCommerce Blogの記事では、影響を受ける開発者の条件が明示されている。/wc/v2/orders/{id} または /wc/v3/orders/{id} に対して、shop_order レコード以外のIDを指定した更新リクエストを送信しているコードやインテグレーションが該当する。
具体的なシナリオとしては、以下のようなケースが考えられる。
- サブスクリプションの更新処理を誤って注文エンドポイントで行っている
- カスタムプラグインが注文IDとサブスクリプションIDを区別せずに同一の処理関数に渡している
- 外部のCRMや基幹システムとの連携で、IDの種別チェックを怠っている
- バッチ処理やデータ移行スクリプトが注文以外のレコードもまとめて注文APIに送っている
10.8にアップグレードした後、これらのリクエストは以下のようなエラーレスポンスを受け取ることになる。
{
"code": "woocommerce_rest_shop_order_invalid_id",
"message": "ID is invalid.",
"data": {
"status": 400
}
}エラーコード woocommerce_rest_shop_order_invalid_id は、今後ログ監視のキーワードとして覚えておくとよい。このエラーが出ている場合は、注文更新APIに誤ったIDが渡されていることを示す。
過去に影響を受けたデータの取り扱い

ここで重要なのは、過去にすでに変換されてしまったデータは元に戻らないという点だ。10.8より前のバージョンで、非 shop_order のIDに対して注文更新APIが200を返したケースでは、そのレコードはすでに通常注文へと変換されており、種別固有のデータは削除されている。
この変更の根本にあるPull Request(#64050)は、型検証の追加というよりも「これ以上のデータ破壊を防ぐ安全装置の設置」と捉えるのが正確だ。10.8は事後対応ではなく、予防措置としてのアップデートである。
開発者が取るべき具体的な対応

サブスクリプション更新処理の移行
WooCommerce Subscriptionsプラグインを使用している場合、サブスクリプションの更新には注文エンドポイントではなく、サブスクリプション専用のRESTエンドポイントを使う必要がある。具体的には /wc/v3/subscriptions/{id} だ。
Developer WooCommerce Blogの記事でも、この移行が最初に推奨されている。コードレベルの修正は単純で、API呼び出しのパスを /orders/ から /subscriptions/ に変更するだけだが、同時にリクエストボディの構造もサブスクリプション用のフォーマットに合わせる必要がある点に注意が必要だ。注文APIとサブスクリプションAPIでは受け付けるパラメータが異なる。
APIログの監査
アップグレード前に、これまでのAPIリクエストログを精査しておくことを強く推奨する。特に以下のシグネチャに注目してほしい。
/wc/v2/orders/または/wc/v3/orders/へのPATCH/PUTリクエスト- レスポンスが200だが、対象IDが注文以外のレコード(サブスクリプション、返品、クーポンなど)
- サードパーティプラグインや外部サービスからの自動連携リクエスト
影響を受けたレコードが見つかった場合、バックアップからの復元が必要になるケースもある。特にサブスクリプション型のビジネスモデル(定期購入、メンバーシップ、SaaS課金など)を運用している事業者は、この監査を優先タスクとして扱うべきだ。
エラーハンドリングの追加
10.8以降、woocommerce_rest_shop_order_invalid_id エラーが新たに発生し得ることを踏まえ、APIクライアント側のエラーハンドリングにもこのケースを追加しておく必要がある。HTTP 400が返ってきた場合に、単に「リクエスト失敗」としてログに残すだけでなく、IDの種別が誤っていないかをチェックするフローを組み込むとよい。
// ID の種別を確認し、適切なエンドポイントに振り分ける
if ( isSubscription( id ) ) {
patch( `/wc/v3/subscriptions/${id}`, body );
}
}
この変更の本質的な意味

今回の変更は、単なる「バグ修正」ではなく、WooCommerceのREST APIがデータの型安全性を重視する方向へ舵を切ったことを示すシグナルだ。従来は「多少のデータ不整合には目をつぶり、とにかく動かす」というPHP/WordPressエコシステムの寛容な文化が反映されていたが、ECプラットフォームとしての成熟に伴い、データの一貫性を厳格に守る姿勢へとシフトしている。
実際、GitHub上での議論を見ると、この問題が最初に報告されたのはv1エンドポイントがすでに型検証を持っていたにもかかわらず、v2/v3でそれが欠落していたことへの疑問からだった。APIバージョン間での挙動の不一致が長年放置されていたこと自体が、WooCommerceのREST APIの設計上の技術的負債だったといえる。
EC事業者にとっての実務的な教訓は明確だ。サブスクリプション、予約、会員権など、WooCommerceのカスタム注文タイプを利用している場合は、それぞれのデータ種別に対応する専用エンドポイントの使用を徹底すること。複数の注文タイプを横断するような汎用的なAPIクライアントを自作している場合は、今回の変更を機にアーキテクチャの見直しを検討する価値がある。
この記事のポイント
- WooCommerce 10.8で注文更新APIが非注文IDをHTTP 400で拒否するようになる
- これまではサブスクリプションなどのデータが誤って通常注文に変換され、固有情報が消失していた
- サブスクリプション更新は
/wc/v3/subscriptions/{id}専用エンドポイントへ移行が必要 - 過去に変換されたレコードはバックアップからの復元以外に手段がないため、APIログの監査が急務
- 正式リリースは2026年5月19日を予定、事前対応の猶予は短い
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AllegroがOpenAIと提携。欧州ECのAI活用戦略と日本市場への示唆
ポーランドのECプラットフォームAllegroが、ChatGPTで知られるOpenAIとの提携を発表した。この提携により、AllegroはOpenAIの先端AI技術へアクセスし、ECに特化した新たなAIソリューションを共同開発する。同時期に、販売者向けAIアシスタントのパイロット版も導入済みだ。
ECプラットフォームとAI企業の直接提携は、欧州市場で急速に進むAI実装競争の新段階を示している。ZalandoやAmazon、bol.comも同様のAIアシスタントを導入しており、Allegroの動きは「後追い」ではなく「標準化」を主導する狙いがあると見られる。本記事では提携の詳細と、日本のEC事業者が読み取るべきポイントを解説する。
重要なポイントは3つある。第1にプラットフォーム主導でAIを「売り手」と「買い手」双方に実装する流れが加速していること。第2にOpenAIとの提携が単なるAPI利用ではなく、EC特化モデルの共同開発を含むこと。第3にこの動きが欧州EC市場の「AI標準」を形成しつつあることだ。
AllegroとOpenAIの提携内容

・汎用AIのAPI利用(ChatGPT等)
・機能ごとに個別開発
・OpenAIの新モデルへの早期アクセス
・導入支援と最適化のサポート
Ecommerce News EUの記事によると、この提携にはECユースケース向けAIの共同設計・テスト・展開が含まれる。Allegroが掲げる目標は「買い物体験の簡素化」「販売者支援」「マーケティング効果の向上」「新製品開発の加速」の4点だ。
単なるAPI利用を超えた関係
一般的な企業のAI活用は、OpenAIやGoogleの提供するAPIを自社サービスに組み込む形が多い。今回の提携が異なるのは、ECに特化したAIモデルやユースケースを「共同で設計・開発」する点だ。AllegroはOpenAIの最新モデルや新機能に優先的にアクセスできる立場を得ることになる。
これは、汎用AIをEC向けにチューニングするだけでなく、ECプラットフォームが蓄積する購買データ・出品データ・行動ログを基にした独自AIの開発が可能になることを意味する。Allegroが欧州EC市場で先行者優位を築くための戦略的投資と見てよい。
AllegroのAI戦略と販売者向けアシスタント

Allegroは以前からAI投資を積極化してきた。モバイルアプリにはバーチャルショッピングアシスタントを導入し、ZalandoのAIファッションアシスタントやAmazonの類似機能と並ぶ水準を目指している。さらにGoogleともブラウザ内のインテリジェントショッピングアシスタントで協業中だ。
販売者向けAIアシスタントの機能
2026年5月初旬、Allegroはラスベガスで販売パートナー向けAIアシスタントを発表した。このツールはリアルタイムのインサイト提供、質問応答、品質スコアの解説、改善点の特定を行う。現在パイロットフェーズを終了し、まもなく本格提供が始まる。
2. 販売品質スコアの解説
3. 改善ポイントの自動特定
4. 出品最適化(予定)
5. 価格戦略支援(予定)
6. 物流サポート(予定)
今後の追加機能として、出品の最適化、価格設定、物流サポートが挙げられている。ECの売り手が日常的に直面する「価格競争」「在庫管理」「品質維持」という3大課題に対して、AIが直接的な解決策を提示する世界が近づいている。
購入者向けAIアシスタントとの両面展開
AllegroのAI戦略の特徴は「売り手」と「買い手」の両面にAIを実装している点だ。モバイルアプリのバーチャルショッピングアシスタントは購入者の商品検索や比較を支援し、販売者向けアシスタントは出品と運営を効率化する。この両面展開により、プラットフォーム全体の取引効率を高める設計になっている。
日本のECモールでもAIチャットボットの導入は進んでいるが、多くはカスタマーサポートの自動化にとどまる。Allegroのアプローチは「売上向上」と「運営効率化」に直結するAI活用であり、よりビジネスインパクトの大きい設計といえる。
欧州EC市場における競争構図

AllegroはポーランドのEC市場で最大手であり、自らを「ポーランド経済のフライホイール(弾み車)」と位置づけている。スロベニアやクロアチアの子会社を売却して財務をスリム化する一方、国際展開も継続中だ。4.2百万人の海外顧客を持つ。
Amazonとの対抗軸としてのAI
注目すべきは、Amazonがポーランドに50億ユーロ超の投資を発表している点だ。世界的なEC巨人が地元市場に本格攻勢をかける中、Allegroが選んだ対抗策が「OpenAIとの提携」と「AIによる差別化」だった。価格や物流網でAmazonと正面から戦うのではなく、AIによる販売者支援と買い物体験の質で独自の地位を築く戦略だ。
▶ 物流インフラの拡充
▶ 世界的ブランド力
▶ 販売者向けAIアシスタント
▶ 地元市場への深い理解
この構図は日本のEC事業者にとっても示唆に富む。大手モールや海外プラットフォームとの競争において、AIを活用した運営効率化や顧客体験の向上は、資金力や物流網の差を埋める有力な手段になり得る。
日本のEC事業者への実践的示唆

Allegroの事例はポーランドという特定市場の話だが、抽出できる教訓は国境を越える。以下では日本のEC事業者、特にWooCommerceを使った自社ECサイト運営者が今から取り組める施策を整理する。
AIアシスタントは「売り手支援」から始める
Allegroが最初に注力したのは販売者向けAIアシスタントだった。購入者向けのバーチャルアシスタントは導入コストが高く、精度への要求も厳しい。一方、販売者向けの「品質スコア解説」や「出品最適化提案」は、比較的導入ハードルが低く、売上への直接効果を測定しやすい。
WooCommerceサイト運営者であれば、以下のような段階的アプローチが現実的だ。まず商品説明文のAI生成、次に在庫切れ予測や価格最適化の自動提案、最終的にカスタマーサポートのAI化へと広げていく。重要なのは「一度に完璧を目指さない」ことだ。
プラットフォーム選定におけるAI視点
AllegroがOpenAIと直接提携した背景には、プラットフォーム事業者として「AIを外部委託するのではなく、自社の競争力の源泉として内製化する」という判断がある。自社ECサイトを運営する事業者も、カートシステムやホスティングサービスを選ぶ際に「AI機能の拡張性」を評価軸に加えるべき段階だ。
WooCommerceはオープンソースであり、OpenAI APIやGoogle AIとの連携プラグインがすでに多数提供されている。Shopifyなどのクローズドプラットフォームと比較すると、AI連携の自由度という点で優位性がある。この柔軟性を活かせるかどうかが、中規模EC事業者の今後の差別化要素になる。
ECとAIの今後 5年で何が起きるか

AllegroのCEOであるMarcin Kuśmierz氏は、Ecommerce News EUの記事によると「AIはECの運営方法を根本的に変革している」「我々のアプローチが欧州の次世代商業サービスの新標準を打ち立てると確信している」と述べている。この発言は単なるビジョン表明ではなく、実際にOpenAIとの提携と販売者向けAIアシスタントの導入で実行に移されている点が重要だ。
AIネイティブなECプラットフォームの台頭
今後5年で想定される変化はこうだ。商品検索はキーワードから自然言語対話へ移行し、価格設定はAIによる動的最適化が標準になる。在庫管理は需要予測AIが担い、カスタマーサポートの一次対応は完全自動化される。AllegroとOpenAIの提携は、こうした変化を「プラットフォーム標準機能」として実装しようとする試みだ。
価格 → 手動調整
在庫 → ルールベース発注
サポート → 有人チャット
価格 → AI動的最適化
在庫 → 需要予測AI
サポート → 完全自動化
日本のEC事業者がこの波に乗るために必要なのは、大規模投資ではない。まずは既存のWooCommerceサイトにAIプラグインを1つ導入し、商品説明の自動生成やレコメンドのAI化を試すことだ。小さな成功体験を積みながら、AIネイティブな運営体制へ徐々に移行するアプローチが現実的だ。
越境ECにおけるAIの役割
Allegroが海外展開を継続している点も見逃せない。AIアシスタントは言語の壁を低減し、海外市場への出品最適化を支援する。日本のEC事業者が越境ECを検討する際、AIによる翻訳・ローカライズ・価格最適化・カスタマーサポートは、これまで以上に強力な武器になる。
WooCommerceの多言語対応プラグインとAI翻訳を組み合わせれば、中小企業でも多言語ECサイトの運営は技術的に十分可能だ。Allegroの事例は、AIが大企業だけでなく、地域のプラットフォームや中小事業者にも競争力をもたらすことを示している。
この記事のポイント
- AllegroとOpenAIの提携はEC特化型AIの共同開発を含む、単なるAPI利用を超えた関係
- 販売者向けAIアシスタントがパイロット完了、リアルタイムインサイトや品質スコア解説を提供
- Amazonの50億ユーロ投資に対抗する差別化戦略としてAIを位置づけ
- WooCommerce運営者はAIプラグインから段階的に導入可能、オープンソースの柔軟性が強み
- 今後5年でEC運営の主要領域がAIネイティブへ移行、越境ECの障壁もAIが低減
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AIが書き換えるローカル検索のルール、企業が今とるべき4つの対策
AIによる検索体験の変化は、すでにローカルビジネスの集客構造を根本から変え始めている。GoogleのAI OverviewsやGemini、Ask MapsといったAI駆動型の検索機能が一般ユーザーの手に届いたことで、「検索結果の上位に表示されること」だけでは十分ではなくなったのだ。
2026年5月にMarTechが公開したSOCiとGoogleの共同ウェビナー予告記事では、この変化の本質が「AIがどのビジネス情報を信頼し、ユーザーに推奨するか」という新たな競争軸の出現にあると指摘されている。本記事では、この発表内容をベースに、具体的にどのような変化が起きているのか、そして企業は何をすべきかを4つの観点から掘り下げる。
AI Overviewsが変える情報の見せ方

従来の検索結果は、10件のリンクが並ぶリスト形式だった。ユーザーはその中からクリックしてサイトを訪れ、必要な情報を自分で探し出す必要があった。しかし、AI Overviewsの登場でこの体験は大きく変わった。検索結果画面の最上部にAIが生成した要約が表示され、ユーザーはクリックせずとも回答を得られるケースが増えている。
この変化がローカルビジネスに与える影響は極めて大きい。たとえば「東京 駅前 イタリアン ランチ 子連れ」という検索をした場合、従来であれば飲食店のリストが表示されていた。だが、現在ではAIが「子連れに優しいイタリアンレストランとして、A店、B店、C店が評価されています。A店はキッズメニューが充実しており、ベビーカー入店も可能です」といった要約を直接表示する。この要約に含まれなければ、そもそもユーザーの目に触れない時代になったのである。
従来の検索とAI Overviewsの比較
つまり、表示順位を争う従来のSEO(検索エンジン最適化)から、AIに「紹介される」ための情報設計へと、勝負の場が移行しているのだ。
AI Overviewsに表示されるために必要なもの
AI Overviewsが参照する情報源は、Googleビジネスプロフィール(旧Googleマイビジネス)に登録された情報だけではない。ウェブ上の口コミ、公式サイトのコンテンツ、投稿された写真、第三者のレビューサイトの評価など、あらゆる情報がAIによって収集・統合され、要約生成の材料となる。
これは、ビジネス情報の「完全性」と「一貫性」が、かつてないほど重要になったことを意味する。営業時間、所在地、提供サービス、写真、口コミへの返信状況など、あらゆる接点で正確かつ最新の情報を提供し続けることが、AIからの信頼獲得につながる。
Ask Mapsと会話型検索のインパクト

Googleマップに実装されたAsk Maps機能は、地図アプリの枠を超えたAIアシスタントだ。ユーザーは「このエリアでペット同伴OKのカフェは?」「明日の朝8時に開いているドラッグストアは?」といった自然な質問を投げかけることができる。AIは地図上のビジネスデータ、口コミ、営業時間などを解析し、条件に合致する店舗を即座に提示する。
この変化の本質は、検索の「キーワード入力」から「会話」への移行にある。従来の検索では「ペット カフェ 場所」といった断片的なキーワードをつなげていたが、今後は自然言語での質問が主流になる。AIが質問の意図を解釈し、最適なビジネスを選ぶため、商圏内の競合と比べて自社の情報がどれだけ豊かで、的確かを問われることになる。
Ask Mapsの情報処理フロー
「犬同伴OKでテラス席のあるカフェ」
Googleビジネスプロフィール / 口コミ / 写真 / メニュー情報 / 公式サイト
「Aカフェが条件に合います。テラス席があり、犬用の水皿も提供されています」
会話型検索がもたらす口コミの重要性
会話型検索では、ユーザーが求める具体的な条件にAIが答えるため、口コミの内容がこれまで以上に重要になる。たとえば「静かな環境で仕事ができるカフェ」という質問に対して、AIは口コミ内の「静か」「Wi-Fi完備」「コンセントあり」といったキーワードを拾い、推薦を行う。単なる星評価の高さだけでなく、テキスト情報として蓄積された具体的な評価が、AIの選択に直結する時代に入った。
口コミを増やすだけでなく、キーワードを含んだ具体的な口コミを促す施策が、今後のローカルSEOの中心になると見てよい。来店客に「どのような点が良かったか」を丁寧に尋ね、回答を促す仕組みづくりが鍵になる。
ビジネス情報の完全性がもたらす効果

MarTechの記事によれば、SOCiとGoogleは「完全で正確なビジネス情報が、顧客とAIシステムの双方からブランドを理解してもらう助けになる」と述べている。ここでいう完全な情報とは、Googleビジネスプロフィールの全項目が埋まっていることにとどまらず、公式サイトの内容、投稿の頻度、写真の充実度、口コミへの反応速度までも含む概念だ。
ビジネス情報の全体像
営業時間、住所、電話番号、カテゴリ選択
写真、投稿、メニューやサービス一覧、Q&A
口コミの数と内容、返信率、公式サイトの情報との一貫性
情報の一貫性が信頼を生む
住所や電話番号の表記がGoogleビジネスプロフィールと公式サイトで異なっていたり、営業時間が最新でなかったりすると、AIはそのビジネス情報を「信頼性が低い」と判断する可能性がある。これは、人間のユーザーが情報の不一致に不安を感じるのと同じ理屈だ。AIは大量のデータを横断的に照合するため、人の目よりもはるかに厳密に矛盾を検出する。
具体的な対策としては、まずGoogleビジネスプロフィールの全項目を埋め、次に公式サイトの該当ページとの情報の一致を確認する。さらに、Yahoo!や食べログ、Rettyなど、国内の主要プラットフォームでも同一の情報を掲載することが望ましい。情報の「散らばり」をなくし、AIがどこを参照しても同じ情報にたどり着ける状態を目指したい。
実践的な最適化ロードマップ

では、実際に何から着手すべきか。AI時代のローカル検索対策は、従来のMEO(マップエンジン最適化)の延長ではない。情報設計の考え方を抜本的に見直す必要がある。以下に、優先度の高い4つの施策を整理した。
ステップ1:Googleビジネスプロフィールの完全最適化
カテゴリ選択、サービスメニュー、営業時間、写真、属性情報(バリアフリー対応や決済方法など)を完全に埋める。特に、カテゴリ選択はAIがビジネスの業態を理解するための最重要項目だ。メインカテゴリだけでなく、追加カテゴリも可能な限り設定する。写真は外観、内観、商品、スタッフの4種類を最低各5枚以上用意し、定期的な更新を行う。
ステップ2:口コミ戦略のシフト
星の数だけでなく、テキストの質を重視した口コミ施策に切り替える。来店時に「特に良かった点」を尋ね、回答内容をそのまま口コミに書いてもらえるよう自然に促す。AI検索では「店内が静か」「スタッフの対応が丁寧」「駐車場が広い」といった具体的な記述が、条件検索でのヒット率を左右する。
ステップ3:ローカルコンテンツの拡充
公式サイトやGoogleビジネスプロフィールの投稿機能を活用し、地域に根ざしたコンテンツを定期的に発信する。地元のイベント情報、季節限定メニュー、スタッフ紹介などが効果的だ。AIは鮮度の高い情報を評価する傾向があるため、少なくとも週1回の更新を維持したい。
ステップ4:データの一貫性監査
四半期に一度は、Googleビジネスプロフィール、公式サイト、主要ポータルサイト間で、住所、電話番号、営業時間、サービス内容に差異がないかを確認する監査を実施する。情報の不一致はAIの信頼を損なう最大の要因だ。手作業での確認が難しい場合は、ローカルSEOツールを活用した自動監査も検討したい。
この記事のポイント
- AI OverviewsやAsk Mapsの普及で、検索の主役が「リンクリスト」から「AIによる要約と推薦」に移行している
- 情報の完全性と一貫性がAIからの信頼獲得の鍵であり、営業時間や住所の不一致は致命的な評価ダウンにつながる
- 口コミは星の数からテキストの質へと評価軸がシフトし、具体的な体験談がAIの選択に直結する
- Googleビジネスプロフィールの完全最適化、口コミ戦略の見直し、ローカルコンテンツの定期更新、データ一貫性監査の4つが今すぐ取り組むべき施策だ
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Copy Fail脆弱性にCloudflareがどう立ち向かったか
2026年4月29日、Linuxカーネルにローカル権限昇格をもたらす脆弱性「Copy Fail(CVE-2026-31431)」が公開された。この脆弱性を悪用すれば攻撃者はroot権限を取得でき、多くのサーバが影響を受け得る深刻なものだ。
Cloudflareは世界中の330都市に展開する大規模なLinuxサーバ基盤を運用している。同社は開示直後からセキュリティチームとエンジニアリングチームが動き、既存の振る舞い検知が数分で攻撃パターンを特定できることを確認し、また再起動不要の緩和策としてeBPF LSMを展開した。結果として顧客データへの影響やサービス停止は一切発生していない。
Copy Fail脆弱性(CVE-2026-31431)の全容

Linuxカーネルのcrypto APIには、AF_ALGソケットファミリ経由で一般ユーザプロセスが暗号化・復号を要求できる仕組みがある。ここで問題となったのは「aead」テンプレートを用いるモジュール `algif_aead` の欠陥だ。2017年に導入されたin-place最適化によって、復号時に割り当てられた出力領域を超えた4バイトの書き込みが発生するようになっていた。
攻撃者はまず `splice()` システムコールを使い、`/usr/bin/su` のようなsetuidバイナリのファイル記述子からページキャッシュの参照を暗号化操作のscatterlistにチェインさせる。その状態で `recvmsg()` を呼ぶと、本来許される範囲外の4バイトがターゲットのページキャッシュに書き込まれる。汚染されたバイナリを `execve()` で実行すれば、root権限で任意のコードが動くという筋書きだ。
socket(AF_ALG, SOCK_SEQPACKET, 0) でAEADテンプレートにバインド
setuidバイナリ(例:/usr/bin/su)のファイル記述子からページキャッシュを暗号scatterlistにチェイン
復号処理中に4バイトのスクラッチデータがターゲットページキャッシュへ書き込まれる
ページキャッシュが汚染された状態でsetuid-rootプログラムを実行し、シェルコードがrootとして動作
このエクスプロイトの流れは、Cloudflareのブログで詳述された技術情報と、Xint Codeによる元の開示記事を基にしている。Linuxコミュニティはコミット a664bf3d603d で2017年の最適化を差し戻しており、それが正式な修正となる。
CloudflareのLinuxカーネル管理プロセス

CloudflareはカスタムLinuxカーネルを自前でビルドし、コミュニティの長期サポート(LTS)バージョンをベースにしている。新型カーネルの選定からグローバル展開まで、およそ4週間のサイクルでシステム的なアップデートと再起動を実施している。公開前に既知のセキュリティパッチがマージされるのが常だが、Copy Failの修正はメインラインにマージされてから1ヶ月経っても主要LTSラインへのバックポートが完了していなかった。このタイムラグが生じたため、Cloudflareの大部分のサーバは6.12 LTSカーネルを稼働させており、脆弱性が残る状態だった。
Cloudflareの多層防御:検知から再起動不要の緩和まで

振る舞いベースの検出が数分で作動
Cloudflareのエンドポイントには、プロセスの振る舞いを常時監視する検知プラットフォームが導入されている。特定の脆弱性シグネチャに頼るのではなく、通常とは異なる実行パターンを検出する仕組みだ。専用ルールの更新や人の介入なしに、社内で実施した検証でエクスプロイトの試行が数分以内に悪性と判定され、アラートが発報された。これは攻撃チェーン全体(スクリプトインタプリタ → AF_ALG経由の暗号サブシステム呼び出し → 権限昇格バイナリの実行)を一つの振る舞いパターンとして捉えた結果だ。
脅威ハンティングと過去48時間のログ調査
セキュリティチームは「公開前から悪用されていた可能性を前提にする」という原則に立ち、エクスプロイトが残すカーネルログの痕跡を独自の集約ログ基盤で検索した。また、関係するシステムへの全アクセスログを収集し、接続元や実行コマンドを再構成、システムバイナリのハッシュ整合性を検証した。その結果、過去48時間においてCloudflareのインフラ上で悪用された証拠は一切確認されなかった。
eBPF LSMによる緊急緩和の展開
根本対策であるパッチ済みカーネルのロールアウトには時間がかかるため、チームは無効化モジュール `algif_aead` の削除をまず試みた。しかし実際にはレガシーな社内サービスがcrypto APIを利用しており、削除すると障害を招くことがステージング環境のテストで判明した。そこで再起動不要の外科的対策として、BPF Linux Security Module(bpf-lsm)を使ったプログラムを導入した。
# 素朴な緩和(モジュール無効化)は依存関係のため断念
echo "install algif_aead /bin/false" > /etc/modprobe.d/disable-algif.conf
rmmod algif_aead 2>/dev/null || true
bpf-lsmプログラムは `socket_bind` LSMフックにアタッチし、AF_ALGソケットを開こうとするバイナリのパスをホワイトリストと照合する。許可リストにないバイナリからの `bind()` 呼び出しは拒否するため、悪用の入口を完全に封鎖する。このアプローチを採る前に、Prometheus eBPF Exporterを使って艦隊全体のAF_ALG利用実態を可視化し、許可リストに載せるべき正当なサービスが本当に1つだけであることを検証した。
# eBPF LSMプログラムの擬似フロー
- ソケットファミリがAF_ALGでなければ通過
- AF_ALGの場合、呼び出し元バイナリのパスを許可リストと照合
- 許可されていればbindを許可、それ以外は拒否
これにより、大部分のサーバはパッチ済みカーネルが配布されるまでの間、bpf-lsmによって保護された。テスト用ノードで実際にエクスプロイトコードを実行し、PermissionError が返され攻撃が不可能になったことを確認している。
攻撃者のbind()成功 → recvmsg()で範囲外書き込み → root取得
非許可バイナリからのAF_ALG bindを拒否 → PermissionError → 攻撃失敗
一連の対応から得た教訓と今後の改善

Cloudflareは今回の対応を通じていくつかの改善点を特定した。まず、カーネルAPIの依存関係をより深く可視化し、将来の緊急緩和時にサービス停止を避けられるようにすること。次にbpf-lsm自体の展開速度やログの充実を図り、ランタイム防御の即応性を高めること。さらに、カーネルコンフィギュレーションの監査を進め、使われていないモジュールや機能を事前にビルドから除去することで攻撃対象領域を縮小していく方針だ。
今回のインシデントで、Cloudflareは顧客影響ゼロを達成した。パッチ済みカーネルのリリースとbpf-lsmによるレイヤーが艦隊全体に行き渡り、脆弱性が悪用される余地は残らなかった。Linuxコミュニティの責任ある開示、社内の可視化ツール、そしてbpf-lsmというプリミティブが、迅速な防御を可能にしたといえる。
この記事のポイント
- Linuxカーネルの脆弱性「Copy Fail」はローカルからroot権限を奪取できる深刻な問題
- Cloudflareは公開と同時に既存の振る舞い検知で即座に捕捉し、過去ログの脅威ハンティングで未然悪用がないことを確認
- 再起動不要の緩和策としてeBPF LSMを導入し、AF_ALGソケットへの不正アクセスをホワイトリスト方式で遮断
- 根本パッチのロールアウトと並行して運用し、結果的に顧客データやサービスへの影響は皆無
- 可視化ツール(Prometheus eBPF Exporter)の事前整備が緩和策の意思決定を支えた
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Contact Form 7新機能凍結、WPForms移行完全ガイド
WordPressの定番お問い合わせフォームプラグイン「Contact Form 7」が、今後新機能を追加しない方針を正式に発表した。開発者のTakayuki Miyoshi氏がWordCamp Asia 2026のステージ上で明らかにしたもので、バージョン6.2を最後にメンテナンスモードへ移行する。
既存のフォームが即座に壊れるわけではないが、機能凍結されたプラグインは徐々に競合から遅れをとる。サイトの成長に合わせてモダンなフォーム機能を求めるなら、今が移行の最適なタイミングだ。本記事ではWPFormsを使ったスムーズな移行手順を9つのステップで解説する。
Contact Form 7新機能凍結の真実とリスク

「Contact Form 7が廃止される」という見出しはややセンセーショナルだが、実態を正しく理解しておく必要がある。開発チームは完全な開発中止ではなく「フィーチャーフリーズ(新機能凍結)」を発表した。これはセキュリティパッチや致命的なバグ修正は継続する一方、新機能の追加やモダンな統合は一切行われない状態を指す。
上の比較にあるように、ビジネスサイトではすでに条件分岐やAIによるフォーム生成が当たり前になりつつある。放置すれば、古いフォームがサイト全体の印象を下げたり、コンバージョンの機会損失につながる可能性が高い。
WPFormsへの移行が推奨される理由

WP Beginnerの編集チームは、多数のフォームプラグインを試した結果、長年にわたりWPFormsを第一推奨としている。その理由はシンプルで、初心者にとっての圧倒的な使いやすさと、サイトの成長に伴って必要になる高度な機能が両立している点にある。特にContact Form 7からの移行を考えるユーザーには、ビルトインのインポートツールが強力な決め手となる。
- フォーム作成にHTML/PHP知識が必要
- デザインはテーマ任せで調整が難しい
- スパム対策は別途プラグインが必要
- エントリー保存機能は標準ではない
- ドラッグ&ドロップで直感的に作成
- テーマに自然に溶け込むスタイル
- 独自のスパム防止機能を内蔵
- フォーム送信内容を管理画面で確認可能
WPFormsの無料版(Lite)にも、Contact Form 7のフォームを数クリックで読み込み、そのままエディタ上に再現するインポート機能が搭載されている。フィールドラベルや通知設定も自動で引き継がれるため、移行のためにコードを書く必要は一切ない。有料版にアップグレードすれば、2,100以上のテンプレートや条件分岐、決済統合などが追加され、フォームをより強力なマーケティングツールに変えられる。
9ステップで完了、CF7からWPFormsへの移行手順

ここからは実際の移行手順を解説する。所要時間は10分〜15分で、技術的な知識は不要だ。作業を始める前に、念のためサイト全体のバックアップを取っておくとより安全である。
プラグインのインストールとセットアップ
まずWPForms LiteをWordPress管理画面からインストールし、有効化する。無料版は公式リポジトリから入手可能で、予算を問わずすぐに移行を開始できる。有効化後、自動でセットアップウィザードが立ち上がるので、表示される手順に従って基本設定を完了させる。有料版にアップグレードする場合は、ここでライセンスキーを入力する。
インポートツールで既存フォームを読み込む
管理画面の「WPForms」→「ツール」に移動し、「インポート」タブを開く。「他のフォームプラグインからインポート」のドロップダウンで「Contact Form 7」を選択し、インポートボタンを押す。WPFormsがサイト内のすべてのCF7フォームを自動検出し、一覧表示してくれる。
移行したいフォームにチェックを入れるか、「すべて選択」で一括指定する。不要なテストフォームや重複があれば、このタイミングで整理しておくとサイトがすっきりする。選択後、再度インポートを実行すると、各フォームがWPFormsのドラッグ&ドロップエディタ上に再構築される。
インポート結果の確認と微調整
インポートが完了すると、結果画面に各フォームのステータスが表示される。大半のテキスト、メール、ドロップダウンなどの標準フィールドは問題なく移行されるが、CF7独自のカスタムフィールドやショートコードが含まれている場合、「要確認」としてフラグが立つ。対象フォームを開き、必須項目やドロップダウンの選択肢、通知メールの送信先アドレスを中心に目視チェックしよう。
ページ上のフォームを置き換える
フォームの準備が整ったら、表示されているページや投稿を編集する。古いContact Form 7のブロック(またはショートコード)を削除し、新しくWPFormsブロックを追加。ブロックのドロップダウンから該当のフォームを選ぶだけで、エディタ内に実際のフォームが即座に表示される。WPFormsはテーマのスタイルを自動的に引き継ぐため、デザインが大きく崩れる心配はまずない。
動作テストと最終確認
公開前に、実際のブラウザでフォームを開き、テスト送信を必ず1回は行う。送信後、自分宛の通知メールが届くか受信トレイを確認する。もしメールが届かない場合は、サイト側のメール配信設定に問題がある可能性が高い。その際はSMTPプラグインを導入し、信頼性の高いメール送信経路を確保するのが一般的な解決策だ。
Contact Form 7の無効化と削除
すべてのフォームがWPFormsで正常に動いていることを確認したら、プラグイン一覧からContact Form 7を無効化する。サイト全体をもう一度巡回し、古いショートコードが残っていないか最終チェックしてから、完全に削除しよう。この手順を踏めば、サイトからCF7依存を完全に取り除ける。
移行後に試すべきWPFormsの先進機能

無事に移行が完了したら、Contact Form 7にはなかったWPFormsのユニークな機能をいくつか試してみる価値がある。特にビジネスサイトでは、これらが問い合わせ率や顧客体験を大きく変えるきっかけになる。
上記は会話型フォームの一例だが、これ以外にもAIフォーム生成(自然言語で「評価機能付きフィードバックフォーム」と指示するだけで自動構築)、見えないスパム検証、条件分岐、StripeやPayPalを使った決済フォーム、フォーム離脱者の部分入力データ取得など、CF7時代には考えられなかった機能が揃っている。
よくある質問

Contact Form 7は完全に放棄されたのか
技術的には放棄ではなくフィーチャーフリーズだ。Miyoshi氏はWordCamp Asiaで、バージョン6.2をもって新機能の追加を停止し、以降は深刻なバグ修正とセキュリティパッチのみを提供すると明言した。プラグインがリポジトリから消えるわけではないが、新機能やモダンな統合は今後一切追加されない。
移行しないと既存フォームは突然壊れるのか
すぐに壊れることはない。セキュリティパッチが提供される限り、WordPressのコア更新との互換性は当面維持される。しかし機能凍結により、数年後には他のプラグインやテーマとの相性問題が発生するリスクが高まる。加えて、競合が提供するモダンなフォーム体験との差は広がるばかりだ。
後継のContactable.ioを待つべきか
WP Beginnerの見解では、待つメリットはほとんどない。Contactable.ioの正式リリースは早くても2028年とされており、安定版が広く使えるようになるまでにはさらに時間がかかる。WPFormsのような実績あるプラグインに今移行しておけば、すぐに最新機能を享受でき、将来Contactable.ioが登場した際に再検討すればよい。
無料版のWPFormsでもCF7からの移行は可能か
可能である。WPForms LiteにはContact Form 7インポーターとドラッグ&ドロップビルダーが標準搭載されており、大半のユーザーは無料版だけで十分に移行を完了できる。より高度な決済フォームやマーケティング連携が必要になった時点で、有料版へアップグレードすれば問題ない。
過去の送信データは引き継がれるか
引き継がれない。Contact Form 7は送信内容をデータベースに保存せず、メールで送信する仕様のため、インポートできるエントリーデータが存在しない。過去の送信内容を残したい場合は、メールアーカイブやFlamingoプラグインでCSVエクスポートしたデータを別途保管しておく必要がある。
この記事のポイント
- Contact Form 7はバージョン6.2で新機能凍結。セキュリティ修正のみ継続される
- モダンなフォーム機能(条件分岐、AI生成、決済統合)は今後も追加されない
- WPFormsへの移行は無料のLite版でも可能で、専用インポートツールが用意されている
- 9ステップの手順に沿えば、コードの知識なしで10〜15分程度で移行が完了する
- 移行後は会話型フォームやスパム防止など、CF7にない機能をすぐに活用できる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AWS MCP Serverが一般提供開始、AIエージェントのAWS操作を安全・効率的に
AWSは2026年5月6日、AIエージェント向けのマネージドサービス「AWS MCP Server」の一般提供を開始した。AIコーディングアシスタントがAWSの各種サービスを安全に呼び出し、最新ドキュメントを参照し、必要ならサンドボックス内でスクリプトを実行できるようになる。
これまではAIエージェントがAWSを操作しようとしても、訓練データが古く、IAMポリシーが過剰になりがちだった。本サーバーはそうした課題を解決し、本番環境でも使えるレベルのインフラコード生成を後押しする。
本記事ではAWS MCP Serverの機能、GAで追加された新要素、具体的な利用手順、対応ツール、料金までを詳しく解説する。
AWS MCP Serverの概要

MCP(Model Context Protocol)は、AIエージェントが外部サービスやツールと安全にやり取りするための標準プロトコルだ。AWS MCP Serverはこのプロトコルに準拠したマネージド型のリモートサーバーであり、数個の固定ツールを通じて1万5000を超えるAWS APIへのアクセスを提供する。
AIコーディングアシスタントは多くの場合、訓練データに依存するため、2025年後半以降に登場した新サービス(Amazon S3 VectorsやAurora DSQLなど)を知らない。また、インフラ構築時にAWS CLIを好み、AWS CDKやCloudFormationといったIaCツールを使わない傾向があった。生成されるIAMポリシーも権限が広すぎるなど、デモ用には動いても本番投入は難しい状態だった。
この仕組みにより、AIエージェントは常に最新の情報と最小権限でAWSリソースを操作できる。ツールの数が少なく固定されているため、モデルのコンテキストウィンドウを圧迫せず、ハルシネーション(誤った回答の生成)も抑えられる。
GAで追加された主な機能

プレビュー期間を経て正式提供となったAWS MCP Serverでは、以下の機能が新たに導入されている。
IAMコンテキストキーのサポート
従来はMCPサーバー自体の利用に専用のIAM権限が必要だったが、今回からIAMコンテキストキーに対応した。これにより、通常のIAMポリシーの中で「特定のユーザーは更新系APIを許可、MCPサーバー経由では読み取り専用」といったきめ細かい制御が可能になる。余分な権限管理の手間が減り、セキュリティ設計がシンプルになる。
ドキュメント検索の認証不要化
search_documentationおよびread_documentationツールが、認証なしでも利用できるようになった。これにより、まだAWSアカウントを持っていない段階でも、AIエージェントは最新のAWSドキュメントを参照して設計や調査を行える。
トークン消費の最適化
インタラクションあたりのトークン消費量が削減された。マルチステップのワークフローを伴う複雑なタスクでは、モデルのコンテキストウィンドウがすぐに埋まりがちだったが、今回の改善でより長い会話を維持しやすくなっている。
run_scriptツールとサンドボックス実行

GAの大きな目玉がrun_scriptツールの追加だ。AIエージェントは短いPythonスクリプトを記述し、MCPサーバー側のサンドボックス環境で実行させることができる。このサンドボックスは呼び出し元のIAM権限を継承するが、ネットワークアクセスは一切持たない。つまり、エージェントはAWSリソースのデータを処理できるものの、ローカルのファイルシステムやシェルには触れない。
…
# 複数APIを組み合わせた処理を1回のラウンドトリップで
従来、エージェントが複数のAPIを呼び出してデータを結合する場合、1つずつリクエストを送っては応答を待つ必要があり、時間もトークンも浪費していた。run_scriptを使えば、1回のラウンドトリップで一連の処理を完結させられる。これにより、処理速度とコンテキスト効率の両方が大幅に向上する。
Skillsによるベストプラクティスの提供

プレビュー版では「Agent SOPs」という形式でガイダンスが提供されていたが、GAではより洗練された「Skills」に移行した。Skillsは、エージェントがよく間違えるタスクに対して、AWSの各サービスチームがメンテナンスする検証済みのベストプラクティスを提供する。
スキルにより生成されるコードの品質が安定し、エラーやトークンの無駄も減る。ツール一覧を短く保ちつつ、必要なガイダンスをピンポイントで渡せるため、エージェントの挙動が予測しやすくなり、無駄な試行錯誤も抑制される。
エンタープライズの現場では、開発者の数だけ書き方がバラバラになりがちだが、Skillsによってサービスチーム公認のパターンがチーム全体に自然と浸透する。結果として、セキュリティレビューの工数も削減できるだろう。
セキュリティと監査の仕組み

AWS MCP Serverは、ユーザーが直接操作する時とAIエージェント経由の操作を明確に区別できる設計になっている。IAMポリシーやSCP(Service Control Policies)を使って、特定のユーザーには全操作を許可しつつ、MCPサーバーには読み取り専用のみ許可する、といった制御が可能だ。
さらに、AWS-MCP名前空間のAmazon CloudWatchメトリクスが提供され、MCPサーバー経由のAPIコールと人間による直接のAPIコールを分離して監視できる。AWS CloudTrailもすべてのAPI呼び出しを記録するため、コンプライアンスチームが求める監査証跡を完全な形で確保できる。
このように、AIエージェントが安全にインフラを操作できる環境が整ったことで、これまで人間の開発者しか触れなかった本番環境へのAI活用も現実味を帯びてきた。
利用方法と対応ツール

AWS MCP Serverは、MCPに対応するあらゆるAIコーディングツールから利用できる。Claude Code、Cursor、Kiro、OpenAI Codexなど、主要なアシスタントはすでにサポートしている。
セットアップは非常にシンプルだ。AWS MCP ServerはIAM SigV4認証を利用するが、多くのMCPクライアントはOAuth 2.1のみに対応している。そのため、オープンソースの「MCP Proxy for AWS」を使ってIAM認証をOAuthにブリッジする。具体的には以下のようなコマンドで設定する。
curl -LsSf https://astral.sh/uv/install.sh | sh
claude mcp add-json aws-mcp --scope user \
'{"command":"uvx","args":["mcp-proxy-for-aws@latest","https://aws-mcp.us-east-1.api.aws/mcp","--metadata","AWS_REGION=us-west-2"]}'
/mcpコマンドを実行すると、AWS MCP Serverが利用可能なツール一覧が表示される。search_documentationツールを呼び出し、最新のS3 Vectorsの情報をもとに回答を生成する。プロキシはローカルマシン上で動作し、MCPサーバーのエンドポイントとしてhttps://aws-mcp.us-east-1.api.aws/mcp(米国東部)または欧州(フランクフルト)のリージョナルエンドポイントを指定する。APIコール自体は他の全リージョンに対しても実行可能だ。
料金と提供リージョン

AWS MCP Server自体に追加料金は発生しない。支払うのは、AIエージェントが操作した結果として作成されたAWSリソースの利用料と、データ転送料金のみだ。このため、まずは試験的に導入し、効果を検証しやすい。
現在の提供リージョンは米国東部(バージニア北部)と欧州(フランクフルト)の2拠点。今後、他のリージョンにも順次拡大される見込みだ。
AWS MCP Serverはすでに多くのAIコーディングアシスタントで利用可能であり、AWSドキュメントの最新ページからクイックスタートガイドを参照できる。
この記事のポイント
- AWSがAIエージェント向けのマネージドMCPサーバーを一般提供開始
- call_aws、search_documentation、run_scriptの3ツールでAWSを安全に操作
- run_scriptはサーバー側サンドボックスでスクリプトを一括実行し高速化
- SkillsによりAWSチーム公認のベストプラクティスをコード生成に活用可能
- IAMとCloudTrail/CloudWatchで人間の操作とAIの操作を明確に分離監査
- サーバー利用料は無料、リソース使用量のみの課金。米国東部と欧州で提供開始
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Google広告にAI Max機能3つ追加。ショッピング広告とテキスト制御が進化
Googleは2026年5月20日のMarketing Liveを前に、広告運用に関する3つのAI Max機能を発表した。ショッピングキャンペーン向けのAI Max拡張、広告主の意向を反映するAI Brief、そして検索広告向けのテキスト免責事項である。
いずれも広告主がAIの制御範囲をより細かく設定できるようにすることを目指したものだ。EC事業者にとっては、商品フィードを活用した広告配信の精度向上と、ブランドイメージを守りながらの自動化が現実的な選択肢になる。
今回はPractical Ecommerceの記事を基に、これら3機能の詳細とEC運用への活かし方を整理する。
AI Max for Shoppingの仕組みと従来との違い
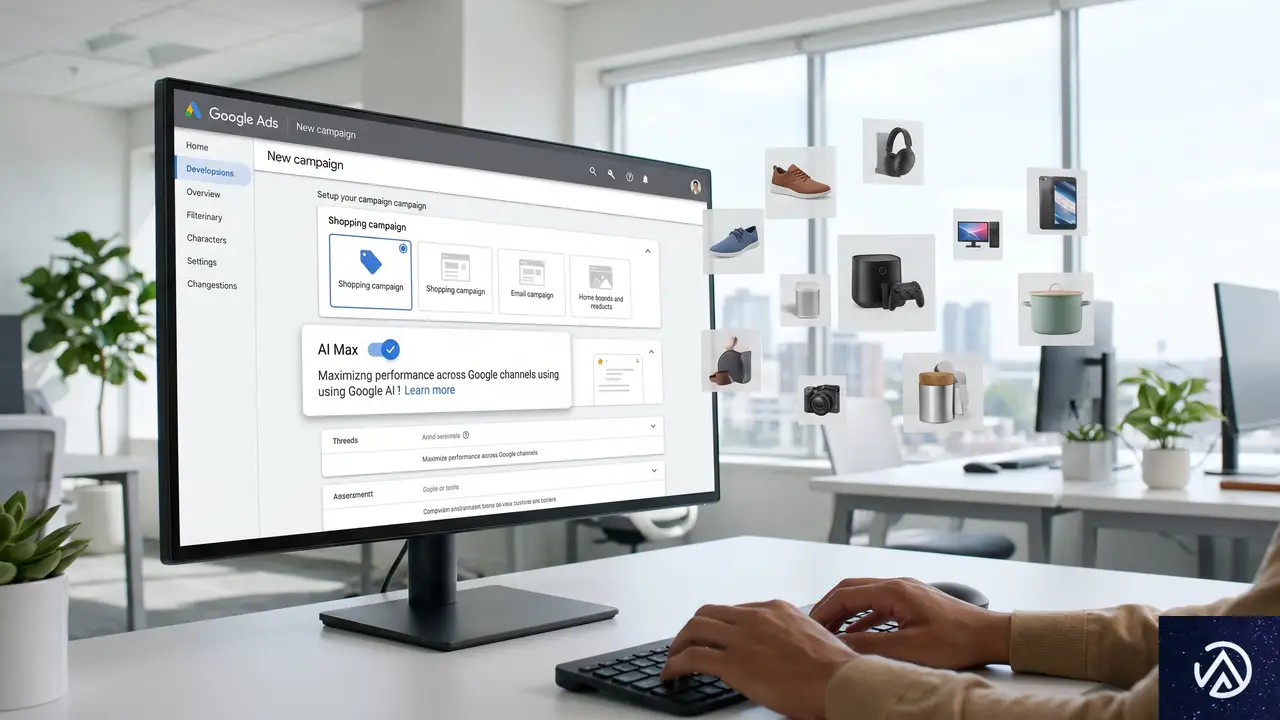
AI Maxは2025年に検索キャンペーン向けに導入され、今回ショッピングキャンペーンにも拡張された。本質的には、Googleが広告表示のクエリ選定や広告文の生成をより自律的に行う仕組みである。
検索AI Maxとの共通点と相違点
従来の検索AI Maxでは、広告主が「透明な収納ケース」というキーワードに入札した場合でも、AIが「透明とプラスチック製の収納ケースの違いは何か」といったクエリに対しても広告を表示できるようになった。さらに広告文や遷移先URLも、コンバージョン向上を目的に自動調整される。
ショッピングAI Maxでもこの仕組みは維持されるが、重要な違いがある。ショッピングキャンペーンでありながら、通常の商品画像付きリスト広告だけでなく、Merchant Centerのデータを基にAIが生成したテキスト広告が表示される可能性がある点だ。またAI OverviewsやAI Mode内への広告表示も対象になる。
Performance Maxとの使い分け
AI MaxとPerformance Maxの違いは混同しやすい。Practical Ecommerceの記事によれば、Googleはマルチチャネル(検索、ショッピング、ディスプレイ、動画)でのプロモーションにPerformance Maxを推奨しており、単一チャネルの検索やショッピングにはAI Maxを推奨している。EC事業者としては、ショッピングに特化して広告を最適化したい場合はAI Maxを選ぶのが筋だろう。
テキストカスタマイズや最終URLの自動拡張をオプトアウトできるかは、まだ明らかにされていない。検索AI Maxではオプトアウトが可能なため、ショッピングAI Maxでも同様の制御が用意される可能性は高い。
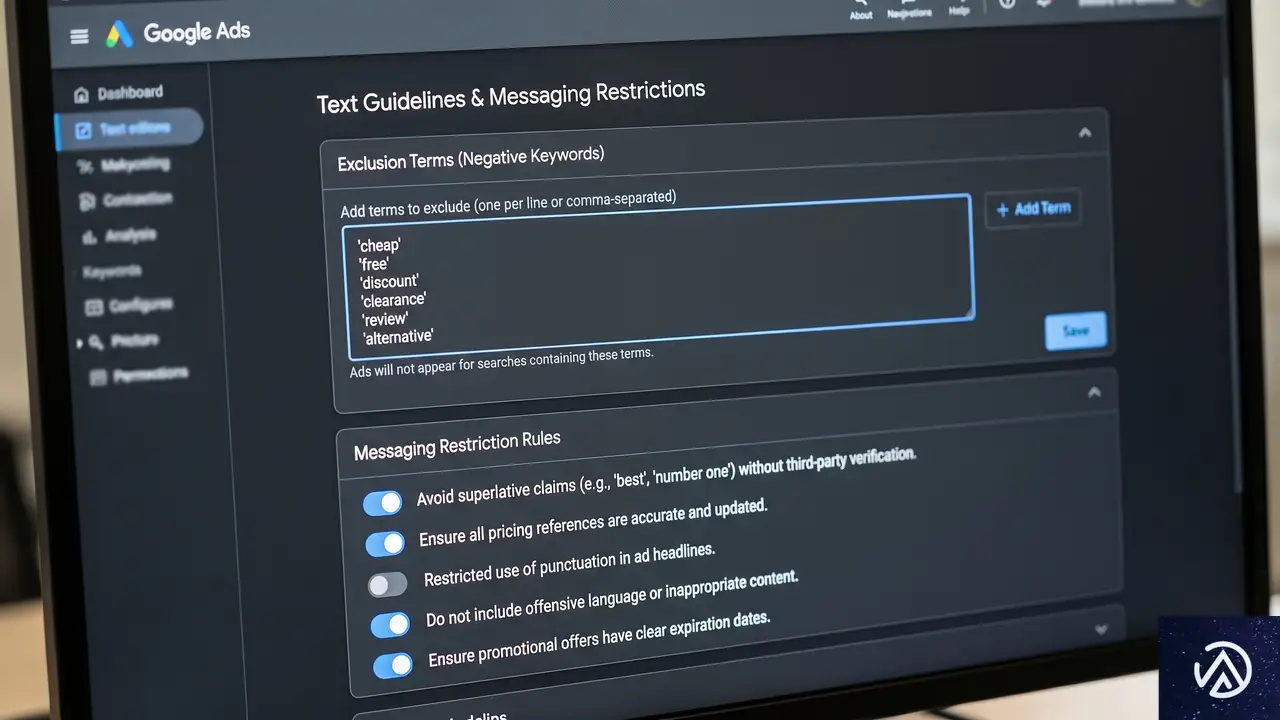
AI Briefで広告の方向性を詳細に制御
AI Briefは、広告主が自社の意向をAIに伝えるための設定機能である。まず検索AI Max向けに提供され、その後Performance MaxとショッピングAI Maxにも展開される予定だ。
具体的な指示内容
たとえば高級オフィスチェアを販売するEC事業者であれば、「価格を広告に含めてクリック前にユーザーをふるい分ける」「『安価』や『低価格』を含むクエリには広告を表示しない」「『高級』を含むクエリを優先する」といったガイドラインを設定できる。
テキストガイドライン機能
AI Briefには「テキストガイドライン」が含まれる。除外ワード(最大25個)とメッセージ制限(最大40個)を設定可能で、競合名や特定の価格表記の禁止などを指定できる。これにより、ブランドに合った表現をAIが生成するようになる。
ただしPractical Ecommerceの記事では、こうしたガイドラインがパフォーマンスを向上させるケースもある一方で、アルゴリズムの本来の学習を制限してしまう可能性にも触れられている。過度な制限は配信機会を狭めるため、設定後は定期的なパフォーマンス検証が必要だ。
テキスト免責事項で広告の信頼性を底上げ

テキスト免責事項は、検索広告の説明文に広告主の利用規約や注意書きを表示する機能だ。たとえば「本製品はBPAフリーです。詳細はこちら」といった文言を、レスポンシブ検索広告の説明行に固定せずに組み込める。
広告強度スコアを下げない利点
通常、広告文の一部を特定の位置に固定(ピン留め)すると広告強度スコアが下がる。しかしテキスト免責事項はピン留めとは異なり、スコアに影響を与えない。広告強度は指標としての実用性には議論があるものの、スコアが高いほど表示回数が増える傾向があるため、実務上のメリットは無視できない。
設定場所と制限
テキスト免責事項はキャンペーン単位で設定し、「キャンペーン」タブ内の「アセット」セクションで管理する。最初に利用可能な説明スペースに表示され、90文字以内という制限がある。最終URLの自動拡張やテキストカスタマイズとの併用も可能だ。
EC事業者が取るべき対応と今後の見通し

AI Max for Shopping、AI Brief、テキスト免責事項の3機能は、いずれも広告運用におけるAIの役割を拡大しつつ、広告主が制御できる範囲を明確にしたものだ。EC事業者としては、以下の流れで準備を始めるのが現実的だろう。
- Merchant Centerの商品データが最新かつ正確か確認する。AI Maxはデータ品質に依存するため、不備があると意図しないテキストや表示につながる
- AI Briefを使う前提で、ブランドとして許容できない表現や除外したいクエリをリストアップしておく
- テキスト免責事項に記載すべき内容(素材表示、安全規格、返品条件など)を整理し、90文字以内の文案を用意する
- AI Max導入後は、手動キャンペーンとの並行テストでパフォーマンスを比較し、過度なガイドライン設定が配信機会を損なっていないか検証する
GoogleのAI広告機能は、EC事業者の運用負荷を下げるだけでなく、商品フィードとAIの組み合わせにより、従来の手動運用ではリーチできなかったクエリにも対応する可能性を持っている。一方で、ブランド管理の観点からは、AI Briefやテキスト免責事項を適切に設定しなければ、意図しないメッセージが発信されるリスクもある。
Marketing Liveでの詳細発表を待つ必要はあるが、現時点で把握できる仕様を基に準備を始めておけば、機能リリース後すぐに活用できるだろう。
この記事のポイント
- GoogleがAI Max for Shopping、AI Brief、テキスト免責事項の3機能を発表
- ショッピングAI Maxは検索AI Maxと同様の自律配信に加え、AI Overviews表示やテキスト広告生成が可能
- AI Briefでブランドに合わないクエリの除外や優先付けが可能に、過度な制限には注意
- テキスト免責事項は広告強度スコアに影響せず、90文字以内で注意書きを挿入できる
- EC事業者は商品フィードの整備とガイドラインの事前準備を進めておくべき
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Gmail AI Inboxで変わるECメール到達性、WooCommerceで今すぐできる対策
Gmailが2026年3月に発表したAI Inbox機能は、単なるメール整理ツールにとどまらない。メールマーケティングの根幹である「到達性(deliverability)」の概念そのものを、「発見性(discoverability)」へとシフトさせる可能性をはらんでいる。
世界のメールボックスの25%超を占めるGmailが、AIによるメールの優先順位付けを始めれば、プロモーションメールは要約に埋もれ、トランザクションメールが前面に出る構図が加速する。EC事業者にとって、これは注文確認メールや発送通知の設計を根本から見直す契機だ。
本記事では、Gmail AI InboxがECメール戦略にもたらす具体的な変化と、WooCommerceユーザーが今日から実践できる設定・運用のポイントを解説する。
Gmail AI InboxがECメールにもたらす構造変化
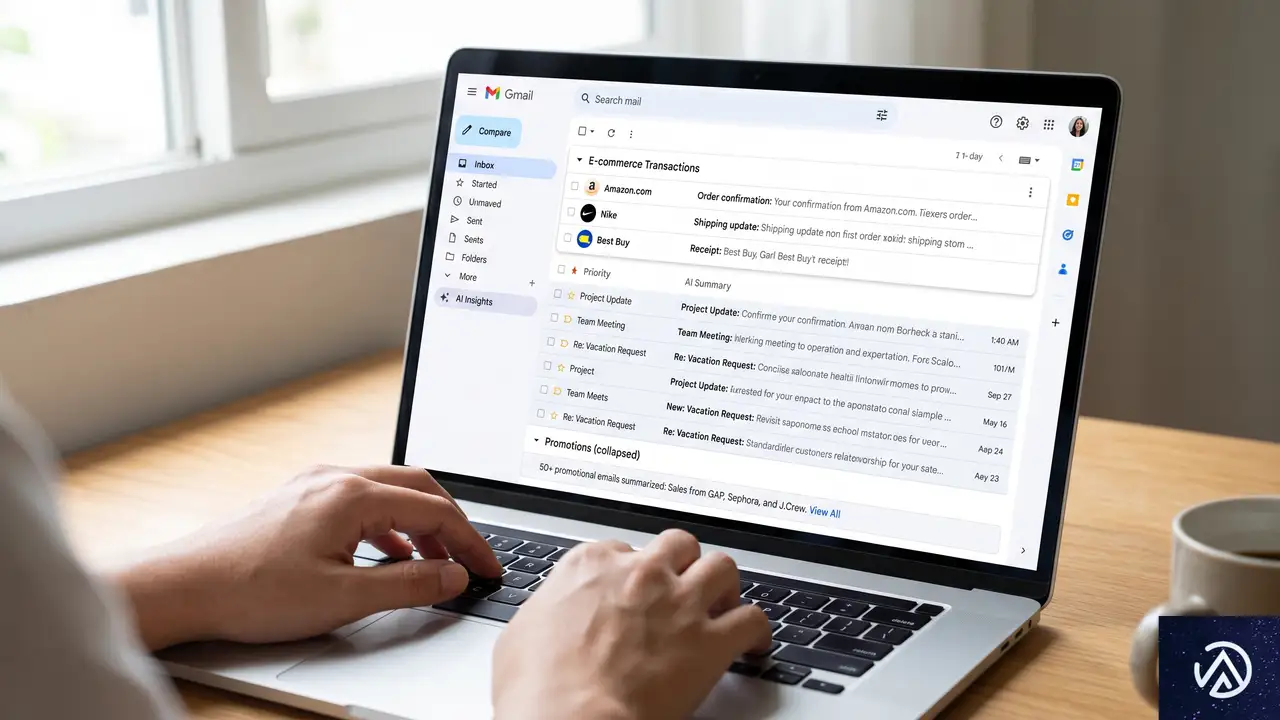
AI Inboxでは、メールが受信トレイに届くだけでは不十分になる。届いた後にAIが「このメールをユーザーに見せるべきか」を判断するからだ。図のように、注文確認や発送通知などの機能的なメールは優先され、セール告知やクーポン配布といったプロモーションメールは要約に埋もれやすくなる。
到達性から発見性へのパラダイムシフト
Stacked Marketerの創業者Manu Cinca氏は、MarTechの記事のなかで「AI Inboxでは、あなたのメールはGeminiが要約に引き込む多数のメールの1つに過ぎなくなる。Geminiがゲートキーパーになれば、購読者との直接的なつながりを失う可能性がある」と指摘している。
従来のメールマーケティングは「いかに受信トレイに届けるか」が勝負だった。スパムフィルターをすり抜け、Primaryタブに表示されることが目標だった。しかしAI Inboxの登場で、「届いた後、AIに選ばれるか」が新たな関門になる。これは、SEOが検索エンジンのランキング要因を追いかけるのと似た構図だ。
ECメールの優先度が逆転する理由
SingulateのCEO Dave Schools氏は「到達性に濃淡が生まれる。もはや通過・不合格の二択ではない」と述べている。GmailのAIはメールの機能性とユーザーにとっての関連性を評価する設計だ。ECメールの文脈では、以下のような優先度の逆転が予想される。
- 優先度が上がるメール:注文確認、発送通知、返金処理、パスワードリセット、予約リマインダー
- 優先度が下がるメール:セール告知、新商品のお知らせ、汎用的なクーポン配布、再入荷通知(緊急性が低い場合)
つまり、トランザクションメールがそのままマーケティングチャネル化する時代が来る。WooCommerceのデフォルトメールをカスタマイズしていないECサイトは、この波に乗り遅れることになる。
WooCommerceメール設定で即効性のある3つの対策
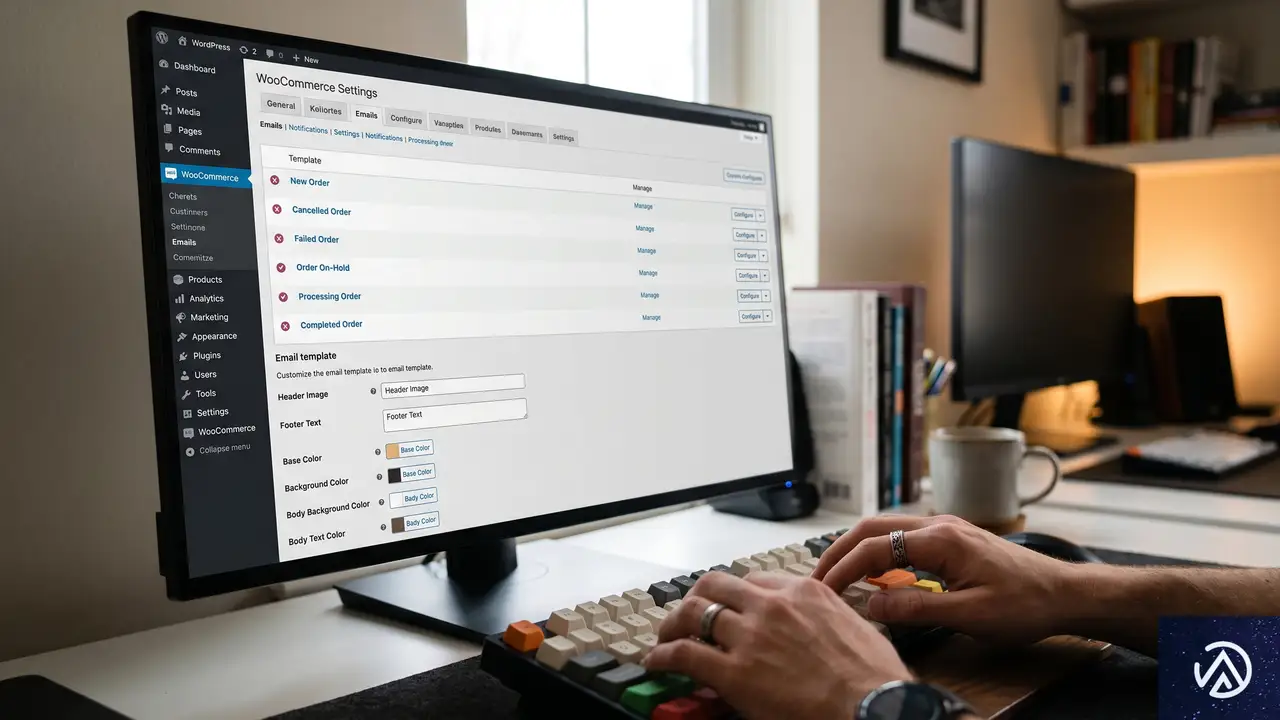
AI Inboxへの対応は、小手先のテクニックではなくメールの「機能価値」を高める方向で進めるべきだ。以下、難易度の低い順に3つの対策を提示する。
対策1 トランザクションメールのマーケティング化
注文確認メールや発送完了メールは、AI Inboxで確実に優先表示されるメールタイプだ。この「開封が約束されたチャネル」をマーケティングに活用しない手はない。WooCommerceでは、以下のようなカスタマイズが有効になる。
// 注文完了メールに関連商品セクションを追加する例
add_action( 'woocommerce_email_after_order_table', function( $order ) {
$related_products = wc_get_related_products(
$order->get_items()[0]->get_product_id(),
3
);
if ( ! empty( $related_products ) ) {
echo '<h3>この商品と一緒に購入されているアイテム</h3>';
echo '<div style="display:flex; gap:12px; margin:16px 0;">';
foreach ( $related_products as $product_id ) {
$product = wc_get_product( $product_id );
echo '<div style="text-align:center;">';
echo '<img src="' . wp_get_attachment_url( $product->get_image_id() ) . '" style="width:120px;" />';
echo '<p>' . $product->get_name() . '</p>';
echo '</div>';
}
echo '</div>';
}
}, 10, 1 );ただし、注意点がある。AIはメールの内容を解析して「機能メールかプロモーションメールか」を判定する。マーケティング要素を入れすぎると、かえって優先度が下がるリスクもある。関連商品の提案はメール後半に控えめに配置し、メインの情報(注文番号、配送状況)を最上部に明確に記述すること。
対策2 プロモーションメールの構造化とパーソナライズ
プロモーションメールがAI要約に埋もれないためには、メールの「情報としての価値」を高める必要がある。Hypermedia MarketingのTyler Cook氏は「ブランドはコンテンツピラーを意識し、購読者が特定のトピックを検索したときに自社ブランドが結果に表示されるようにすべき」と述べている。
具体的には以下の3点を実践する。
- 件名とプレヘッダーを極限まで明快に:AIが内容を要約する際、件名と最初の数行が最も重要なシグナルになる。「限定セール!」より「[顧客名]さんがウォッチリストに入れた商品が20%OFF」の方がAIに評価される
- altテキストをすべての画像に付与:AIは画像のaltテキストを読み取る。商品画像にaltテキストがないと、メールの内容理解に欠損が生じる
- HTMLメール偏重からの脱却:The Kaizen BlitzのMatthew Gal氏は「ネイティブテキストに近いメールへ移行するだろう」と予測している。過剰なビジュアル装飾より、読みやすく構造化されたテキストがAIに評価される
対策3 ポジティブエンゲージメントの設計
Dave Schools氏は「GmailのAIは、具体的で実用的な情報を、感情的な言葉やマーケティングの装飾よりも優先する」と指摘する。つまり、AIは送信者と受信者の間のエンゲージメント履歴を学習し、ポジティブな関係性がないメールは最初から表面化させない可能性がある。
WooCommerceサイトで取るべき具体的な施策は以下のとおりだ。
- ウェルカムフローの構築:初回購入後、自動返信で「困ったときの連絡先」を伝えるメールを送る。返信を促す設計にすることで、Gmail側に「双方向のやりとりがある送信者」と認識させる
- 再エンゲージメントキャンペーンの定期実行:90日間開封のない購読者に「配信継続の確認」メールを送り、反応のないアドレスはリストから削除する
- CRMの定期的なクレンジング:バウンスアドレスや長期未開封アドレスを放置すると、送信ドメイン全体の評価が下がる。最低でも月1回はリストを精査する
絶対に避けるべき3つのメール戦術

AI Inboxの登場で、短期的な開封率を稼ぐためのグレーな手法は完全に逆効果になる。以下、特にEC事業者が陥りやすい3つの罠を警告しておく。
罠1 「重要メール」を装うなりすまし
Customer.ioのGabby Kustner氏は「件名が『アクション必須:キャンペーン停止』というメールを受け取ったが、実際には何のアクションも必要なく、停止されるキャンペーンも存在しなかった」と実例を挙げている。このような「重要メールを装う」戦術は、一度はAIの目をくぐり抜けられても、受信者がスパム報告する確率が跳ね上がり、送信ドメイン全体の評価を致命的に下げる。
罠2 画像だらけのHTMLメールへの依存
AIはメールのテキスト内容を解析する。バナー画像にキャッチコピーを埋め込む手法は、AIから見ると「テキスト情報のないメール」と判定される。altテキストの設定が追いついていないECサイトが多く、これがAI Inbox時代の大きな弱点になる。全画像に適切なaltテキストを設定し、HTMLとテキストのバランスを見直す必要がある。
罠3 無差別な一斉送信の継続
「送れば送るほど売れる」という考え方は、GmailのAIがメールの優先順位を付け始めた時点で終わった。Positive HumanのMarc Thomas氏は「GmailのAI Inboxは良いメールマーケティングに恩恵を与え、悪いメールマーケティングを罰し続ける」と述べている。セグメンテーションとパーソナライズを放棄した一斉送信は、受信トレイの最下層に追いやられるだけでなく、送信ドメインの評価そのものを毀損する。
ECメール戦略の長期ロードマップ
AI Inboxは現在、月額250ドルのGmail最上位プラン限定の機能だ。MarTechの著者Joe Cunningham氏は「この価格帯が普及の障壁になるため、即座に広範な普及が起きるとは考えにくい」と述べている。とはいえ、Gmailが一度導入した機能が下位プランに降りてくるのは時間の問題だ。今のうちに準備を始めておくことで、変化が本格化したときに競合より一歩先を行ける。
変化はゆっくり来る、しかし確実に来る
Matthew Gal氏は「多くのオンラインマーケターはAI更新の普及速度を過大評価している。大半のユーザーは日々のAIアップデートを追っていない」と指摘する。実際、Gmailの新機能がユーザーに認知されるまでには時間がかかる。この猶予期間をどう使うかが、EC事業者の明暗を分ける。
今すぐ始めるべき準備のチェックリスト
- WooCommerceのトランザクションメールテンプレートを見直し、注文情報の次に関連商品を表示する設計に変更する
- メール配信システム(MailPoet、Klaviyo、Omnisend等)で、全画像のaltテキスト設定を完了させる
- 90日間未開封の購読者を特定し、再エンゲージメントフローをトリガーする仕組みを構築する
- 新規購読者向けのウェルカムシリーズを設計し、初回接触で「返信したくなる」価値を提供する
- バウンスアドレスとスパム報告アドレスをリストから自動除外する運用を整備する
この記事のポイント
- Gmail AI Inboxはメールの「到達性」を「発見性」へと変える。届くだけでは不十分で、AIに選ばれるメール設計が必須になる
- トランザクションメール(注文確認・発送通知)がマーケティングチャネルとして急浮上する。WooCommerceのデフォルトメールを見直すべき
- プロモーションメールは過剰装飾を排し、テキストベースで明確な価値を伝える設計にシフトする必要がある
- 短期の開封率を狙うトリック(緊急を装う件名、画像依存のHTMLメール)は、AIによって送信ドメイン評価ごと毀損されるリスクが高い
- 普及には時間がかかるが、今から準備を始めることで競合優位性を築ける。リストクレンジングとエンゲージメント設計から着手せよ
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験