

KnowledgeDeliver脆弱性、ViewState攻撃の実態と対策まとめ
国内の教育機関や企業研修で広く使われるLMS(学習管理システム)のKnowledgeDeliverに、深刻な脆弱性が見つかった。サーバーに保存された共通の暗号鍵を悪用され、遠隔から不正なコードを実行される恐れがある。
Google Cloudの脅威インテリジェンスチームであるMandiantは、2025年後半に実際の攻撃を確認した。攻撃者はこの脆弱性を足がかりにWebシェルを設置し、サイト訪問者のPCにバックドアを感染させる手口を使っていた。本記事では、この脆弱性の仕組みと攻撃の流れ、具体的な検知方法と対策を整理する。
KnowledgeDeliverが見舞われた脆弱性の正体

共有されたマシンキーが招く全インストール共通の弱点
問題の発端は、ASP.NETアプリケーションの設定ファイル web.config に書き込まれた machineKey の値だ。このキーは、画面の状態情報を保持するViewStateデータの暗号化と署名に使われる。
本来、このキーはサーバーごとに個別のランダムな値を生成すべきものだ。しかし、2026年2月24日より前に配布されたKnowledgeDeliverのパッケージでは、開発元が用意したテンプレートの中に固定のキーが埋め込まれていた。その結果、別々の組織で稼働するすべてのインスタンスが、まったく同じマシンキーを共有する状態になった。
これは、すべての家の玄関に同じ鍵が付いているようなものだ。攻撃者が一つの鍵束を入手すれば、インターネット上に公開された他のすべてのKnowledgeDeliverサーバーに侵入できることを意味する。
ViewState Deserializationが悪用される仕組み
ASP.NETのViewStateは、ページの往復(ポストバック)の間、ユーザーが入力した値や画面の状態を維持するための仕組みだ。ブラウザとサーバーの間で、暗号化された文字列としてやり取りされる。
machineKey を知る攻撃者は、このViewStateの中に悪意あるコードを含んだ特殊なデータ(ペイロード)を埋め込める。サーバーは受け取ったViewStateを復号し、データをオブジェクトに戻す処理(デシリアライゼーション)を実行する。この過程で、埋め込まれたコードがサーバー上で実行されてしまう。
この手法は、以前にMandiantが報告したSitecoreのViewStateゼロデイ脆弱性や、Microsoftが警告したASP.NETマシンキーの悪用事例と同種のものだ。共通鍵を使う設計の危険性を、あらためて浮き彫りにしている。
攻撃者は侵入後に何をしたのか

メモリ内で動作するWebシェル「BLUEBEAM」の投入
Mandiantの調査によれば、攻撃者はまず.NETベースのWebシェル「BLUEBEAM」を展開した。このツールはGodzillaとも呼ばれ、Microsoftも以前に同種の活動を報告している。
BLUEBEAMの特徴は、ファイルとしてディスクに保存されず、IISのワーカープロセス(w3wp.exe)のメモリ空間上だけで動作する点だ。一般的なウイルス対策ソフトによるファイルスキャンをすり抜け、HTTP POSTリクエストのボディに暗号化したコマンドを忍ばせて、遠隔操作を受け付ける。
ファイル改ざんとCobalt Strikeによる端末感染
Webシェルを確保した攻撃者は、サーバー上のファイル権限を変更し、アプリケーションのJavaScriptファイルに細工を加えた。具体的には、次のような改ざんが確認されている。
- 「セキュリティ認証プラグイン」のインストールを促す偽の警告を表示するスクリプトの追加
- 攻撃者が管理する外部ドメインから、不正なスクリプトをひそかに読み込むコードの埋め込み
この偽警告に従って「プラグイン」をダウンロードしたユーザーのPCには、Cobalt StrikeのBEACONバックドアが仕込まれた。ペイロードの暗号化には、標的組織の名称が使われており、攻撃者が特定の組織を狙って準備を進めていたことがわかる。
侵害をいち早く検知するための調査ポイント

イベントログとプロセスの異常を監視する
ViewStateの悪用を試みた痕跡は、Windowsのアプリケーションログに記録される。ソースが ASP.NET 4.0.30319.0 で、イベントID 1316のメッセージに注目する。
- 整合性チェック失敗時は「
Viewstate verification failed. Reason: The viewstate supplied failed integrity check.」と出る。誤った鍵が使われた可能性がある。 - 整合性チェックを通過したものの、ペイロードが無効だった場合は「
Viewstate verification failed. Reason: Viewstate was invalid.」と記録される。この場合、復号は成功しており、コード実行までは至らずとも攻撃の試行があったとみなせる。
Mandiantは、実際にこのログからBLUEBEAMに関連するペイロード文字列を復元できたとしている。
また w3wp.exe を親プロセスとする不自然な子プロセスにも警戒が必要だ。cmd.exe /c ... whoami powershell.exe といったコマンドが実行されていないか、継続的にモニタリングする。
ファイルの改ざんと異常なUser-Agentをつかむ
Webサーバーの公開ディレクトリ内にある .js .aspx .config ファイルについて、想定外の変更が加えられていないか定期的に確認する。特に、外部ドメインへのスクリプト読み込みや、業務と無関係なコードの追加がないかを重点的に調べる。
さらに、Webサーバーのアクセスログに現れるUser-Agent文字列にも特徴がある。Mandiantの調査では、2つの異なるブラウザ識別子が連結された異常な文字列が確認された。以下はその一例だ。
Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.2 (KHTML, like Gecko) Chrome/22.0.1216.0 Safari/537.2 Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36このような連結されたUser-Agentは、通常のブラウザでは生成されない。攻撃ツールによる通信の痕跡として、ログ監視の有効な指標になる。
再発を防ぐための具体的な対策

この脆弱性の根本原因は、全インストールで鍵を共有していたことにある。したがって、最も重要な対策は、マシンキーを一意の値に切り替えることだ。
- マシンキーの再生成:各KnowledgeDeliverインスタンスで、暗号的に安全なランダム値を生成し、設定ファイルに反映する。共通鍵を無効化するには、これ以外の方法はない。
- アクセス制限の見直し:LMSがインターネット全体に公開されている必要がなければ、社内ネットワークや特定のIPアドレス範囲からのみ接続を許可する。
- 徹底的なインシデント調査:ログ監視やファイル整合性チェックを実施し、少しでも疑わしい兆候があれば、外部の専門家も交えて深く調査する。
Vupointブログの分析でも指摘されているとおり、テンプレートに埋め込まれた共通シークレットは、一見すると設定の手間を省く便利な仕組みに見える。しかし、ひとたび鍵が流出すれば、世界中のすべてのサーバーが一瞬で危険にさらされる。利便性と引き換えに、きわめて大きなリスクを抱え込む設計だったわけだ。
今回の事例は、ASP.NETに限らず、あらゆるWebアプリケーションの展開時において「鍵や認証情報は必ず環境ごとにユニークに生成する」という原則を再認識させるものだ。テンプレートや初期設定のまま本番運用に臨むことの危うさを、開発者と運用者の双方が改めて肝に銘じる必要がある。
この記事のポイント
- KnowledgeDeliverの全インストール共通のASP.NETマシンキーが、ViewState Deserialization攻撃の原因になった
- 攻撃者はメモリ内WebシェルBLUEBEAMを使い、サイト改ざんとCobalt Strike感染を連鎖させた
- イベントログやプロセス監視、異常なUser-Agentの検出が有効な調査指標になる
- 最も重要な対策は、各サーバーでユニークなマシンキーを生成し、共通鍵の状態を完全に解消すること

・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AIが変えるのは顧客ロイヤルティではなく商品発見。EC事業者が持つべき3つの視点
AIがECサイトの顧客関係を根本から変えようとしている。しかし、変化の本質は多くのEC事業者が懸念する「顧客ロイヤルティの消滅」ではない。むしろ、商品が顧客に見つかるプロセス、つまり商品発見の構造が変わる点にこそ注目すべきだ。
2026年5月、GoogleはI/OでUniversal Cart構想を発表した。検索やYouTube上で複数店舗の商品を比較し、Googleがカートを「所有」したまま購入まで完結する仕組みだ。この流れは、AIエージェントが購買代理人として機能する「エージェンティックコマース」への移行を加速させる。
EC事業者にとって、これは「誰が顧客との関係を握るのか」という問いの新たな章に過ぎない。実際、ECの歴史は常に商品発見チャネルの変化とともにあった。AIによる変化もまた、その延長線上にある。
商品発見から購買までを握るAIエージェント

AIエージェントとは、ユーザーの購買意図を解釈し、商品を比較・推奨し、カートの構築から購入完了までを自律的に実行するシステムのことだ。単なるレコメンドエンジンとは異なり、購買プロセス全体を代行する点が新しい。
Practical Ecommerceの記事によると、この仕組みが普及すれば、EC事業者は在庫と物流を依然として担う一方で、顧客との関係構築の一部を中間AIに委ねることになる。サイト上で直接購入を促すのではなく、AIシステムに自社商品の優位性を「理解させる」必要が出てくるのだ。
Tools for Working WoodのJoel Moskowitz氏は、Practical Ecommerceの記事の中で次のように指摘している。「エージェンティックな注文の問題は、すべての商品をコモディティ化してしまうことだ。小売業者には販売促進やアップセル、関連商品の閲覧を促す機会がまったくなくなる」
この図が示すように、顧客が直接サイトを訪れて商品を選ぶ従来型のフローから、AIが購買判断を仲介するフローへの移行が進んでいる。EC事業者が直接的に顧客へ訴求できる接点は、AIへの「説明」へと置き換わりつつある。
Google Universal Cartが示す未来
Googleが2026年のI/Oで発表したUniversal Cartは、この変化を象徴する構想だ。検索結果やYouTube上で複数のECサイトの商品を横断的に比較し、Googleがカートを保持したまま決済まで完結する。顧客は個々のECサイトを訪問する必要すらなくなる。
この仕組みでは、EC事業者は販売者であることに変わりはない。しかし、商品発見から比較、購入決定に至るまでの重要なタッチポイントをGoogleが握ることになる。これは単なる広告媒体の変化ではなく、顧客接点の所有権が移行する構造的な変化だ。
ECの流通チャネルは繰り返す。AIもその一幕に過ぎない

一見するとAIによる顧客接点の喪失は新しい脅威に思える。しかし、ECの歴史を振り返れば、同様の構造変化は繰り返し起きてきた。変化したのは常に「商品発見の入り口」であり、顧客ロイヤルティそのものではなかった。
検索エンジンの時代
かつて顧客との関係は検索エンジンから始まった。検索結果で上位表示されることが、集客と売上の生命線だった。EC事業者はSEOに投資し、検索エンジンのアルゴリズムに適応することで成長してきた。しかし、AI Overviewsの登場により、検索結果ページ上で情報が完結するケースが増え、サイトへのクリックは減少傾向にある。
マーケットプレイスの時代
Amazonに代表されるマーケットプレイスでは、顧客関係はプラットフォームが所有する。出店者は手数料を支払い、プラットフォーム内の顧客にアクセスする。価格競争は激化し、利益率は圧迫される。ここでも「誰が顧客を握るか」の主導権はプラットフォーム側にあった。
ソーシャルメディアの時代
SNSでは、アルゴリズムに好まれるコンテンツを作れる事業者がクリックと売上を得た。しかし、プラットフォームは外部リンクを嫌い、エンゲージメントはプラットフォーム内に留めようとする。ここでも顧客との直接的な関係構築は、チャネル運営者のルールに制約されてきた。
AIエージェントの時代
そして今、AIエージェントが商品発見の新たな入り口となる。検索が関連性を、マーケットプレイスが参加を、SNSが拡散を報酬としてきたように、AIショッピングはAIシステムが価値を置くシグナルに報酬を与えるだろう。
この流れの中で一貫しているのは、顧客ロイヤルティを左右するのは常に「チャネル」ではなく「事業者自身の差別化」だという事実だ。チャネルが変わっても、最終的に選ばれる理由は商品力とブランド体験にある。
適応するEC事業者が持つべき3つの視点
Practical Ecommerceの記事でMoskowitz氏は、自社のアプローチについて「私たちはすべての新しいAIプラットフォームを追いかけるつもりはない」と述べている。代わりに注力するのは「自社製品の製造と、ニッチでユニークなアイテムへの集中」だという。
この姿勢には、AI時代のECにおける重要な示唆が含まれている。AIが商品発見のプロセスを支配するほど、逆説的に「AIでは代替できない価値」の重要性が増すのだ。
視点1「チャネル最適化から自社の引力強化へ」
検索エンジン対策、マーケットプレイス出店、SNS運用。これらはすべて、外部チャネルに依存した集客手法だ。AIエージェント時代においては、これらのチャネルがさらにAIの判断に置き換わる可能性が高い。
必要なのは、顧客が能動的に「この店で買いたい」と思う理由を作ることだ。オンリーワンの商品、独自のブランド世界観、有益な情報コンテンツ、特別な購買体験。これらはAIが簡単に複製できるものではない。AIは顧客の代理人であっても、ブランドのファンにはなれない。
視点2「AIに理解されるデータ設計」
一方で、AIエージェントに自社商品を正しく推薦してもらうための施策も必要だ。これは従来のSEOに近いが、最適化の対象が「検索エンジンのクローラー」から「AIエージェントの判断ロジック」に変わる点が異なる。
具体的には、商品データの構造化、商品属性の詳細な記述、独自の差別化要素の明確化が重要になる。AIが商品を比較・評価する際、価格以外の判断材料をどれだけ提供できるかが鍵を握る。
視点3「直接関係を育む仕組みづくり」
AIが購買プロセスを仲介するほど、購入後の顧客との直接的な関係構築が重要になる。メールマガジン、会員限定コンテンツ、パーソナライズされたフォローアップなど、AIの関与しないコミュニケーション回路を太く育てることが、長期的な顧客ロイヤルティの源泉となる。
一度購入した顧客が「次もこの店から直接買いたい」と思える体験設計は、AIに奪われることのないEC事業者固有の武器だ。
これら3つの視点は、いずれも短期的なチャネル対策ではなく、中長期的な事業基盤の構築に関するものだ。AIが商品発見のプロセスを変える速度に振り回されるのではなく、自社の強みを深掘りする方向へリソースを振り向ける判断が求められる。
差別化こそがAI時代の顧客ロイヤルティを守る

Practical Ecommerceの記事は、AIエージェントがECにもたらす変化の本質を「商品発見プロセスの変化」と喝破している。顧客ロイヤルティが消滅するわけではない。むしろ、商品発見の入り口がAIに置き換わることで、どの事業者が選ばれるかの基準がより明確になる。
Moskowitz氏が「有機的な検索流入は衰退しつつある」と述べる一方で、自社製品の製造とニッチな独自商品に活路を見出しているのは示唆的だ。AIがコモディティ商品の価格比較を自動化するほど、人間の関与による「唯一無二の価値」が際立つ。
強力な商品、記憶に残るブランド、有益なコンテンツ、直接的な顧客関係、独自の購買体験。これらはいつの時代も、他者が容易に複製できない差別化要因だった。AI時代においても、その本質は変わらない。変わったのは「見つけてもらう方法」だけだ。
AIが購買の代理人となっても、なぜ顧客が特定の店舗を選ぶのか、その理由まではコモディティ化できない。EC事業者が集中すべきは、AIのアルゴリズムを追いかけることではなく、顧客が自ら選びたくなる事業であり続けることだ。
この記事のポイント
- AIエージェントが変えるのは顧客ロイヤルティではなく、商品発見のプロセスである
- 検索エンジン、マーケットプレイス、SNSと続いたチャネル変化の延長線上にAIがある
- Google Universal Cartは、顧客接点の所有権がプラットフォームへ移行する象徴的事例だ
- 適応策は「自社の引力強化」「AI向けデータ設計」「直接関係の育成」の3軸で考える
- 独自商品とブランド体験という差別化要因は、AI時代でも複製不可能な武器であり続ける
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AI時代のECはメタデータが鍵。機械に選ばれる商品情報の新常識
AIが検索と推薦を主導する時代、ECサイトの商品情報に求められるルールが根本から変わろうとしている。これまでのSEO対策や広告運用ではカバーしきれない「機械のための情報整理」が、売上を左右する最重要インフラになりつつあるのだ。
MarTechの記事によると、デジタルマーケティングのプロであるBenjamin De Castro氏は、メタデータの戦略的価値がクリエイティブやメディア投資に匹敵する段階に入ったと指摘している。彼がX(旧Twitter)のBlaze社でシニアストラテジストを務めた経験や、Shutterflyのようなフォトプロダクト企業のビジネスモデル変革から得た知見に基づく主張だ。
特にEC制作やWooCommerce運用に携わる者にとって、この変化は「商品マスタの整備」という開発現場の課題が、経営戦略そのものに直結することを意味する。本記事では、AI時代のメタデータ設計について、実務に落とし込む視点で解説する。
メタデータとは何か、AI時代に再定義する

メタデータとは「データについてのデータ」と呼ばれる。商品名や価格、カテゴリ、在庫状況、画像の代替テキスト、更新日時など、情報そのものに付随する説明的な情報を指す。これまでは検索エンジン対策(SEO)の下地として扱われてきた。
しかしAIが介在する今年の検索体験では、メタデータの役割は単なるキーワードの置き場所ではない。機械がコンテンツを「理解」し「文脈を解釈」し「信頼性を評価」するための唯一の手がかりになる。De Castro氏はこれを「通貨」に例えている。通貨が十分でなければ、経済圏に入れないのと同じ理屈だ。
「機械のための設計書」としてのメタデータ
LLM(大規模言語モデル)は、商品情報を確率モデルで処理する。ある商品が「何で」「誰向けで」「どれほど新しく」「信頼できるか」を、メタデータの断片を組み合わせて推論する仕組みだ。統合が不十分だったり、チームごとに異なる用語を使っていたりすると、機械も混乱する。
たとえば「レディース ジャケット」と「女性用 アウター」という商品カテゴリが混在するECサイトでは、AIはこれらを別物と認識するかもしれない。結果として検索の精度が下がり、推薦の精度も落ちる。De Castro氏はこうした非一貫性を「機械に混乱を継承させる」と表現する。
機械にとっての読みやすさは、人間にとってのUIと同じだ。わかりにくいUIのサイトからユーザーが離脱するように、メタデータが不十分だとAIはその商品を見つけられず、推薦対象からも外してしまう。
メタデータがAI体験を駆動する、すでに起きている実例

De Castro氏は具体例として、フォトプロダクト企業のShutterflyやMixbookを挙げる。彼によれば、これらの企業は単なる「写真をグッズにする」サービスではない。ディープラーニングとメタデータを組み合わせて、「デジタルの混沌を物語に変える」事業へと進化した。
デジタル写真には撮影時刻や位置情報、デバイス情報が埋め込まれている。AIが画像認識と組み合わせることで、「誰が写っているか」「どんなシーンか」「天気はどうだったか」まで推論できる。この推論結果をメタデータとして付与することで、ユーザーは「2024年夏、海でのバケーション写真」を瞬時に検索し、自動でアルバムを生成できるようになる。
PinterestとAdobeに学ぶ、メタデータ駆動型の設計
この仕組みはECでも同じだ。Pinterestは商品フィードのメタデータ(タイトル、価格、カテゴリ)を読み取り、プロダクトピンやショッピング広告の表示を最適化している。Adobe Experience ManagerはAIのSmart Tags機能を使い、画像や動画に自動でキーワードを付与する。これにより、社内のクリエイティブチームが必要な素材を高速に見つけられるようになる。
De Castro氏は「メタデータは説明的(descriptive)であるだけでなく、文脈を生成する(generative)ものだ」と述べている。つまり、適切なデータを与えれば、AIはそれをもとに新しい価値(商品説明文の自動生成や、クロスセルの提案など)を生み出せるわけだ。
なぜAI検索でメタデータの比重が増すのか

Google検索はLLMによって、単なる文字列一致から「意図の解釈」へと機能が進化している。検索エンジンは、クエリに対して「このコンテンツは何か」「何に関連するか」「誰のためか」「どれほど新しいか」「信頼できるか」の5つの軸で評価を下す。この5軸すべてを機械に伝えるのがメタデータの仕事だ。
構造化データの実装や商品フィードの最適化が不十分だと、ブランドは機械にとって「曖昧な存在」になる。曖昧な存在は、AIが回答を生成する際に参照されず、結果として検索にも推薦にも現れなくなる。De Castro氏はこれを「フェラーリを買ってきて芝刈り機のエンジンを積むようなものだ」と痛烈に批判する。最先端の生成AIツールを導入しても、その基盤となるデータが貧弱なら意味がない、というわけだ。
「カテゴリ:衣類」
「画像alt:Tシャツの画像」
「カテゴリ:メンズ > トップス > カットソー」
「素材:オーガニックコットン100%」「生産国:日本」
「画像alt:グレーのオーガニックコットンTシャツを着た男性」
GoogleのAI機能に関するガイドラインでも、明確なコンテンツ、クロール可能なページ、構造化されたシグナルというSEOの基本が強調されている。メタデータは、派手なAIツールより地味に見えるかもしれないが、AI時代のマーケティングインフラの中核を担う要素だ。
今すぐ始めるメタデータ戦略の再設計

では、WooCommerceで構築されたECサイトや、企業の商品マスタ管理において、具体的に何を変えるべきなのか。De Castro氏の提言を、国内のEC運用実務に即して再構成する。
メタデータをマーケティング資産として扱う
まず認識を改める必要がある。メタデータは「面倒な登録作業」ではない。検索、再利用、パーソナライゼーション、AI連携のすべてに効く戦略資産だ。商品マスタの仕様策定には、制作チームだけでなくマーケティング責任者も関与すべきだ。
「タクソノミ経典」を作り、組織で統一する
カテゴリ名、属性ラベル、タグの定義を全社で統一したドキュメントを作成する。たとえば「送料無料」という表現を「free_shipping」に統一するのか、「送料込み」と使い分けるのかを決めておく。これがないと、チームごとに異なる用語を使い、AIにノイズを与えてしまう。
WooCommerceの場合、商品属性(Attributes)とカテゴリの設計がこの経典の核になる。グローバル属性を適切に設定し、ぶれのないタクソノミを構築することが、AIへのクリアなシグナルにつながる。
メタデータの取得を制作フローの一部に組み込む
Googleの画像SEOガイドは、説明的なタイトル、altテキスト、ファイル名、周辺コンテキストの重要性を説く。Pinterestも同様に、充実した商品フィード項目を推奨している。つまり、メタデータは後付けではなく、商品登録時に必須項目として組み込まれるべきだ。
WooCommerce運用では、CSV一括登録のテンプレートにメタデータ必須項目を組み込む。商品名の命名規則、カテゴリパスのルール、画像altテキストのガイドラインを、運用マニュアルとして整備する必要がある。
AIをメタデータ作成に使う、ただし最終判断は人間が行う
AdobeのSmart Tagsのように、AIによる自動メタデータ付与は規模の課題を解決する。しかし、タクソノミの品質管理やガバナンスは人間の判断領域だ。機械が機械向けにマーケティングすると、「伝言ゲーム」のように情報が歪み、最終的に人間にとって無意味なコンテンツになるリスクがある。
全システムで一貫したストーリーを保つ
CMS、DAM(デジタルアセット管理)、ECカート、CRM、広告プラットフォームで、同じ商品のメタデータが異なっていてはならない。LLMは自社サイトだけでなく、あらゆるソースを横断的にチェックするからだ。WooCommerceと連携する在庫管理システムや広告管理画面でも、マスタとしての整合性を意識する必要がある。
品質をクリエイティブと同等に追求する
メタデータの品質指標は、完全性、一貫性、鮮度、下流(AIや推薦エンジン)への影響度で測る。優れた広告クリエイティブが売上を生むように、優れたメタデータもまた、AI経由の売上を生むという認識が欠かせない。
メタデータはAI時代のマーケティングインフラである

De Castro氏の主張の核心は、メタデータがもはや「あったらいいもの」ではなく「ないと致命的なもの」になったという点にある。クリエイティブも広告費も依然として重要だが、AIがブランドを理解し、検索し、推薦するための基盤として、メタデータの整備は待ったなしの状況だ。
WooCommerceで構築されたECサイトであれば、商品属性、構造化データ、画像alt、フィードデータを一元的に管理する仕組みを今から作る必要がある。将来のAI検索や会話型コマースの波に乗れるかどうかは、今日の商品マスタ設計にかかっているといっても過言ではない。
この記事のポイント
- AI時代の検索と推薦では、メタデータがクリエイティブや広告費と同等の戦略価値を持つ
- 機械に「理解される」ためには、一貫性があり網羅的な構造化データが必要不可欠である
- WooCommerceでは商品属性、タクソノミ、画像alt、フィードデータの統合管理がカギ
- メタデータは後付けではなく、商品登録フローに組み込むことで最大効果を発揮する
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

GoogleのAIユニバーサルカート発表、ECの購買体験はこう変わる
2026年5月19日、Googleは年次開発者会議「I/O」において、小売業界の地図を大きく塗り替える可能性のある発表を行った。ユニバーサルカート(Universal Cart)と呼ばれる新しい仕組みが、まもなく一般に提供される。
これは単なるショッピングカート機能の拡張ではない。AIが消費者の購買意図を横断的に把握し、複数のECサイトをまたいで商品を保存・比較・購入まで支援する、いわゆるエージェント型コマースの基盤だ。ECサイトを運営する事業者にとっては、自社サイト内で完結してきた「カート」という概念そのものが揺らぐことを意味する。
ここではGoogleが発表した3つの柱を整理し、従来のECフローがどう変わるのか、そしてWooCommerceなど自社ECを構える事業者がどのような準備をすべきかを具体的に紐解く。
Google I/Oで発表された3つのエージェント型コマース機能

今回の発表で核となるのは、ユニバーサルカート、ユニバーサルコマースプロトコル(UCP)、そしてエージェント決済プロトコル(AP2)の3つだ。いずれも単独で完結するものではなく、相互に連携して初めて「サイトを離れても機能するカート」が成立する。
AIが常駐する買い物かご ユニバーサルカート
ユニバーサルカートはGoogle検索やGeminiとの対話、YouTube、GmailといったGoogleのサービス全域で機能する。消費者が商品を追加すると、カートはそのまま保持され、AIが価格や在庫、キャンペーン情報を継続的に監視する。
たとえば、ある消費者がキッチンリフォームに伴い、検索中に見つけたミキサーを追加し、後日YouTubeで見た調理器具やアフィリエイトメールで見つけた包丁を同じカートに保存する。夜の映画鑑賞中にもAIが稼働し、よりレビューの良い代替商品や配送が早いオプションを提案する、というシナリオだ。
加盟店とGoogleを繋ぐ UCP
ユニバーサルコマースプロトコル(UCP)は、マーチャントセンターの商品フィードと実際の購入プロセスを橋渡しする技術仕様である。EC事業者が保有する商品情報をGoogleが正確に把握するための従来の仕組みに加え、決済や配送、在庫連携の方法を標準化する。
Practical Ecommerceの記事によれば、UCPは単なる小売カテゴリを超え、異なる市場やチャネルへも拡張される見込みだ。つまり、物販だけでなく、サービスやデジタルコンテンツの決済も将来的に巻き込む可能性がある。
AI自身が支払いを実行する AP2
エージェント決済プロトコル(AP2)は、ユーザーが事前に設定したルールに基づき、AIが購入を完了させる仕組みである。たとえば「合計が5万円を超えない」「特定の加盟店からのみ購入する」といった条件を満たせば、消費者の明示的な承認なしに決済が実行される。
このAP2は、新たに発表された永続型AIエージェント「Gemini Spark」にまず実装される。Sparkがユニバーサルカート内の商品を比較し、条件に合致すれば自動購入にまで進むという流れだ。
上図のように、従来はサイトごとに閉じていたカートが、Googleのエコシステム上で一つに統合され、AIが越境しながら購買を支援する構造へと移行する。
ユニバーサルカートが変える消費者の購買行動

ユニバーサルカートの登場は、消費者の購買行動に根本的な変化をもたらす。これまでEC事業者が長年かけて設計してきた「サイト内での回遊→商品発見→カート投入→購入完了」という直線的な流れが、Googleのサービス全域に拡散するからだ。
ほしい物リスト化するカート
一部の消費者はすでにカートをウィッシュリストのように扱っている。商品を追加したまま放置し、給料日まで保留したり、配偶者と共有してから購入を決めるといった行動だ。こうした場合、最終的には同じECサイトに戻り、取引を完了させるのが一般的だった。
ところが、ユニバーサルカートはその「戻る」という行為を不要にする。AIが価格や在庫を比較し、同じ商品をより安く、あるいはより早く届ける別の加盟店を提案するからだ。消費者が気づいたときには、最初に商品を見つけたサイトではなく、別のサイトで購入が完了している可能性がある。
購買意図がサイトから離れるリスク
Googleのモデルでは、加盟店は依然として「販売者(merchant of record)」として注文を処理し、代金を回収する。しかし、購買意図を形成する場はGoogle側に移る。商品発見から比較検討、最終的な意思決定までが、自社サイトの外で進行するためだ。
これは、SEOや広告運用でトラフィックを集め、自社サイトでコンバージョンを獲得してきた従来型のEC事業者にとって大きな転換点である。カートがGoogle側に置かれることで、リターゲティング広告の効果や、サイト内レコメンデーションの精度にも影響が及ぶ。
EC事業者が直面する具体的なメリットとリスク

ユニバーサルカートには明確な利点もある。カートに残った商品をGoogleがリマインドし、AIが能動的にフォローすることで、カゴ落ち(カート放棄)の回収率が高まる可能性があるのだ。
一方で、競合他社の商品と並べて表示されることによる価格競争の激化や、ブランド体験の希薄化といったリスクも無視できない。
カゴ落ち回収と新たな集客機会
通常、カートに商品が入ったまま放置される確率は業界平均で70%を超えると言われる。ユニバーサルカートは、消費者がYouTubeを視聴しているときやGmailを開いているときにも「カートに○○が入っています」と表示できるため、従来のリマインダーメールよりはるかに高い頻度と文脈で再接触できる。
また、商品フィードを最適化し、UCPに対応することで、新たな集客チャネルとして機能させることも可能だ。とくにWooCommerceを利用している事業者は、すでにGoogleマーチャントセンター向けのフィード連携プラグインが多数存在するため、技術的な導入ハードルは低い。
価格競争とブランド体験の希薄化
AIが価格や配送速度を比較し、自動的に代替商品を提案する仕組みは、消費者にとって便利である一方、加盟店にとっては厳しい価格競争を強いられる要因となる。とくに、汎用的な商品を扱う事業者は「価格以外の差別化」が急務だ。
さらに、購入プロセスがGoogle側で完結するほど、自社のブランドストーリーや世界観を伝える機会は減少する。ランディングページのデザインやUXに投資してきたEC運営者にとっては、資産の一部が間接化されるという見方もできる。
メリットとリスクは表裏一体だ。どちらに比重が傾くかは、扱う商材の独自性やブランド力、そして顧客との関係構築の深度によって変わる。
EC制作会社とWooCommerce事業者がいま着手すべき備え

ユニバーサルカートの米国での一般提供は2026年夏が予定されている。日本市場への展開時期は未発表だが、過去のGoogleの動きを踏まえれば、遅くとも1年以内に何らかの形で影響が及ぶ可能性は高い。
商品フィードの最適化を急ぐ
UCPが求める情報は、従来のGoogleマーチャントセンター向けフィードと大きく変わらない見込みだが、在庫連携や配送情報のリアルタイム性はより厳しく求められる。WooCommerceでは「Google Listings & Ads」などの公式プラグインでフィードを自動生成できるため、まずはこの正確性を検証しておくことが第一歩だ。
とくに商品タイトルや画像、価格、在庫ステータスは、AIが比較・推論を行う際の主要な判断材料になる。欠損や誤表記があると、検討対象から除外されるリスクが高まる。
自社サイトの「買いたくなる理由」を強化する
価格競争に巻き込まれないためには、価格以外の付加価値を明確に打ち出す必要がある。商品ページの情報量、購入後のサポート体制、独自の保証制度、会員限定の特典、ストーリー性のあるブランディングなどが差別化要素になる。
とりわけ、リピーター向けの囲い込み施策は重要度を増す。ユニバーサルカートが一般化すればするほど、一度きりの新規顧客はAIに奪われやすくなるからだ。WooCommerceの会員機能やサブスクリプション拡張を活用し、自社サイトに直接戻ってくる動線を太くしておくことが有効である。
決済フローのモダン化
AP2はGoogle側での決済代行に近い動きをするが、加盟店側の決済基盤が古いままだとスムーズに連携できない可能性がある。WooCommerceのチェックアウトブロックや、Stripe、Amazon Payなどの高速決済手段をすでに導入している場合は、そのまま流用できる見込みだが、独自実装の古い決済システムを使っている場合は移行を検討したい。
上記の4ステップは、ユニバーサルカートの普及に先駆けて今すぐ着手できる具体的な対策だ。いずれも大がかりなシステム刷新ではなく、既存のWooCommerce環境の延長線上で実行できる。
エージェント型コマースはECの構造を変える

Googleが今回示した構想は、ECが「サイト」から「システム」へと進化する大きな転換点を示している。消費者はもはや個別のECサイトを渡り歩くのではなく、AIエージェントに商品の発見・比較・購入を委ねるようになる。
これまでもマーケットプレイス型のカートは存在したが、Googleのアプローチは根本的に異なる。Amazonが一つのサイト内で複数出品者の商品をカートに入れられるのに対し、ユニバーサルカートはGoogleのサービス全域に分散し、AIが自律的に判断を下す点が最大の特徴だ。
EC事業者は短期的にはカゴ落ち回収率の改善という恩恵を受けつつ、中長期的には「自社サイトに来てもらう」から「AIに選ばれる」へとマーケティングの重心を移す必要に迫られる。SEOや広告運用だけでは不十分で、商品データの品質、ブランドの魅力、そして購入後の体験がこれまで以上に試される時代が来る。
WooCommerceのようなオープンソースのECプラットフォームは、拡張性の高さゆえにこの変化に適応しやすい。逆に、カスタマイズの余地が少ないASP型カートサービスを利用している事業者は、ベンダーの対応を待つしかない場面も出てくるだろう。
この記事のポイント
- Googleがユニバーサルカートを発表し、2026年夏に米国で提供開始予定
- AIが複数ECサイトの商品を一元管理し、価格比較や自動購入まで実行する
- EC事業者はカゴ落ち回収の改善が見込める一方、価格競争とブランド希薄化のリスクもある
- WooCommerce事業者は商品フィード最適化とリピーター施策の強化が急務
- エージェント型コマースへの移行は、SEOや広告運用の前提をも変える
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

WooCommerce.comがナイトリーコードで稼働、本番環境で不具合を早期発見
# WooCommerce.comが毎晩の最新コードで稼働開始。本番環境で不具合を早期発見する仕組みとは
2行目
**WooCommerce.comが2026年5月からナイトリー(毎晩)ビルドのWooCommerce Coreで本番稼働を開始した。** 同サイトは商用のWooCommerceストアであり、拡張機能(エクステンション)の販売と実際の決済を処理している。公開から最初の数時間でパフォーマンスの低下を検出し、本流コードに反映される前に修正を提案する成果をすでに上げている。
なぜ本番環境でナイトリービルドを使うのか

通常、ソフトウェア開発では「安定版」以外を本番環境に導入することは避けられる。しかしWooCommerce.comのチームは、WordPress.orgがWordPress trunk(開発のメインブランチ)上で稼働しているのと同じ考え方を採用した。つまり、開発中のコードに近い環境で運用し、問題を早期に発見する手法だ。
このアプローチにより、公開リリース前に実環境での問題を捉えられる。WooCommerce.comは大規模なストアであり、実際のトラフィックと決済が発生するため、机上のテストでは見つけにくいパフォーマンス低下やクエリの問題が浮き彫りになる。
WordPress.orgとの共通点
WordPress.orgは長年にわたり、開発ブランチ(trunk)を本番サイトで稼働させてきた実績がある。WordPress本体の開発チームは、trunkに変更がマージされると即座に本番環境に影響が出る仕組みを意図的に維持している。これにより、問題が発生すれば数時間以内に検出され、修正が迅速に行われる。
WooCommerceのチームも同様に、開発の最前線にコミットし、バグを早期に発見して上流に還元するサイクルを回し始めた。これがWooCommerceエコシステム全体の安定性向上につながる。
構築したパイプラインの全体像

チームが構築したパイプラインは、平日毎日自動実行される一連の処理から成る。開発者ブログの記事に掲載されたフロー図を元に、各ステップを以下に整理する。
AIが担当するのは、紫色で示されたステップ4の一部だ。最終的なマージ判断は依然として人間が行う。チームは今後、デプロイ後のテレメトリ(スロークエリ異常検出、エラー率比較、レイテンシのパーセンタイル計測)が自動判断に耐えうるほど信頼できるものになった段階で、人間の関与を徐々に減らす計画だ。
現時点では平日のみ稼働し、週末は稼働しない。これは十分に監視体制が整っていない段階で、無人運転によるリスクを避けるためだ。
AIが担う3つの重要な工程

このパイプラインで特に注目すべきなのは、従来は人間の開発者が手動で行っていた3つの作業をAIが置き換えた点だ。Developer WooCommerce Blogの記事では、それぞれの詳細が次のように説明されている。
パッチの再適用判断
WooCommerce.comでは、WooCommerce Coreに対して若干のパッチ(修正コード)を適用して運用している。これらのパッチは本来、上流のWooCommerce Core本体やAction Schedulerに取り込まれるべき修正だが、リリースに反映されるまでの暫定対応として独自に適用している。
ナイトリービルドを取り込むたびに、これらのパッチが「まだ必要なのか」「すでに上流に取り込まれたのか」「調整が必要なのか」を判断する必要が生じる。AIはパッチマニフェスト(パッチの一覧と説明)を読み取り、パッチごとに状態を判定し、結果をコミットする。この作業は、最初の稼働時点ですでに高い精度で動作している。
コア差分のコードレビュー
WooCommerce Coreのナイトリービルドは、前日との差分が数千行に及ぶこともある。これを人間がすべてレビューするのは現実的ではない。AIは変更全体をレビューするのではなく、WooCommerce.comの独自コードベースと接する「統合ポイント」に焦点を絞ってレビューを行う。
具体的には、WooCommerce.com側のコードが依存しているフックや関数、データベースクエリパターンに影響しそうな変更をピックアップし、生成された各プルリクエストに対して判定コメントを投稿する。初回の判定は汎用的すぎて実用に耐えなかったが、プロンプトの書き直しと差分の事前絞り込みによって改善されたという。
ステージング環境での探索的テスト
ステージング環境にデプロイした後、AIエージェントが実際のユーザーフローを模して主要な導線を巡回する。たとえば商品購入、アカウント管理、拡張機能の検索といった経路を自動でたどり、異常があればプルリクエストのコメントとして報告する。
この探索的テストは現時点ではv1段階であり、テストチャーター(テストの範囲と観点)のチューニングが必要だ。チームはAIからの報告を「シグナル(兆候)」として扱い、ゲート(通過判定)としては使っていない。
- コードレビューAIは初期には役に立たなかったが、プロンプト改善で実用化
- 探索的テストAIは範囲のチューニングが進行中
- パッチ再適用AIはパッチマニフェストの注釈品質に依存
最初の2週間で何が検出されたか

実際の本番運用開始からわずか2週間で、2件の具体的な問題が検出された。いずれも公開リリース前の時点であり、エコシステム全体への影響を未然に防ぐ成果となった。
1週目:統合テストの破損を検出
最初の実行で、統合テストが壊れていることがAIによってフラグ付けされた。原因は上流の特定の変更にまで追跡可能だった。興味深いのは、この問題に気づいた時点で、すでに上流チームが修正をリバート(巻き戻し)していたことだ。
もし毎日のチェック体制が整っていれば、さらに早い段階で検出できていた可能性が高い。これは、ナイトリービルドを監視することの有効性を示す初期事例となった。
2週目:注文メタデータへのスロークエリを実環境で発見
初の自動生成アップグレードが本番環境に適用されてから数時間後、パフォーマンスへの具体的な影響が観測された。注文メタデータ(order metadata)に対するデータベースクエリが低速化し、チェックアウトの遅延、定期購入(リニューアル)の参照遅延、Webhookの滞留といった二次的な影響が現れた。
原因は、orders metaテーブルに設定されていたデータベースインデックスを簡素化する上流のプルリクエストだった。この変更自体は合理的で、削除されたインデックスは肥大化しており、WooCommerce.comでは約15GBに達していた。しかし、このインデックスに依存していたクエリパターンが複数の拡張機能に存在したことが見落とされていた。WooCommerce Core本体の問題ではなく、その上に構築された拡張機能側の依存だった。
WooCommerce.comのチームは同日中に類似のインデックスを自前で復元して暫定対応し、詳細なスロークエリデータを添えて上流にバグ報告を行った。上流チームはすでに更新版のインデックスをマージしており、WooCommerce 10.8でのリリースが予定されている。
この取り組みがWooCommerceエコシステムに与える影響

WooCommerce.comがナイトリービルドを先行運用することは、拡張機能開発者とコア貢献者の両方にとって意味がある。
拡張機能開発者にとって
WooCommerce.comが本番環境で最新コードを動かし続けることで、WooCommerce Coreのリリースが拡張機能に届く前に、より安定した状態になる。最も有効な対策は、自社の拡張機能をWooCommerce Coreのベータ版やリリース候補版で早期にテストすることだ。
また、Coreの変更によって拡張機能が影響を受ける場合に備えた防御的パターンを構築している開発者からの知見は、コミュニティ全体にとって貴重な資産となる。
WooCommerce Core貢献者にとって
trunkへのマージから1日以内に、実運用している大規模ストアでその変更がテストされる。もしWooCommerce.com側で何かが壊れれば、数時間から数日以内に報告が上がる。公開リリース後に初めて問題が発覚するという従来のパターンと比べて、格段に速いフィードバックループが実現する。
このサイクルは、WordPress.orgが長年実践してきた「自分たちのサイトで自らのソフトウェアを動かす」というドッグフーディング文化の延長にある。WooCommerceエコシステムとしても、同様の姿勢を取ることで開発の健全性を高める狙いだ。
今後の展望。テレメトリと自動化の拡大

チームのロードマップは、より多くの自動化と手動ステップの削減にある。当面の優先課題は、デプロイ後のテレメトリをアップグレードプロセスのコア要素として組み込むことだ。
具体的には以下の3つの指標を自動監視し、異常を検出したら自動的に関係者に通知する仕組みを構築する。
- スロークエリの異常検出(通常と異なる遅いクエリの発生)
- エラー率の比較(デプロイ前後でのエラー発生頻度の変化)
- レイテンシのパーセンタイル計測(P50、P95、P99などの応答時間分布)
これらのデータが十分に信頼できるものになれば、人間によるレビュー工程をさらに省略し、AIがマージ判断まで行う自動化の範囲を広げられる。現時点では平日のみの稼働だが、監視体制が成熟すれば週末も含めた連続運用への移行も視野に入る。
この記事のポイント
- WooCommerce.com本番サイトがナイトリービルドで稼働し、問題の早期発見を実現
- AIがパッチ再適用、コードレビュー、探索的テストを自動化し、従来人手だった工程を連続実行可能に
- 初回稼働から2週間でデータベースインデックス問題を検出し、公開リリース前に対策
- 拡張機能開発者はWooCommerce Coreベータ版での早期テストがこれまで以上に重要に
- テレメトリ自動監視の成熟により、将来的には完全自動化されたデプロイパイプラインを目指す
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AIカスタマーエージェントの失敗がブランドリスクに、74%がロールバック
ECサイトのカスタマーサポートにAIチャットボットを導入したものの、数カ月で機能を停止せざるを得なくなるケースが急増している。顧客対応の自動化は売上向上に直結する一方、ガバナンスの不備がブランド毀損を招くリスクは想像以上に高い。
カスタマーコミュニケーション基盤を提供するSinchが2026年5月に公表した調査によると、AIカスタマーエージェントを本番環境に導入した企業の74%がガバナンス上の失敗を理由にロールバックを経験している。EC事業者にとって、この数字は看過できない。
この記事では、ECの現場で実際に起きたAIエージェントの失敗事例を踏まえ、なぜ安全策を講じた企業ほど失敗率が高いのか、そしてWooCommerceをはじめとするEC基盤でAI導入を進める際に事業者が取るべき実践的な対策を詳しく解説する。
AIカスタマーエージェント導入の実情とリスク

ECサイトにおけるAIカスタマーエージェントとは、商品の在庫確認や注文状況の照会、返品手続きの案内といった顧客対応を自動化するシステムを指す。テキストチャットに加え、音声対応やメール自動返信を組み合わせたオムニチャネル型の導入も広がっている。
74%の企業が経験したロールバックの実態
Sinchが10カ国6業種のエンタープライズ意思決定者2,527名を対象に実施した調査では、AIカスタマーエージェントを導入した企業の62%がすでに本番運用中であり、12カ月以内の導入を計画する企業は88%に達する。現場への導入圧力は極めて強い。
その一方で、導入済みエージェントの74%がガバナンス上の問題でロールバックを強いられた。4社に3社が「一度リリースしたAI機能を引き戻す」という苦い経験をしている計算だ。
AIエージェントの失敗が引き起こす影響のうち、35%はサポートキューへの負荷増大として顕在化し、34%はブランドイメージの毀損に直結する。後者は数値化が難しく、修復にも長期間を要するため、EC事業者にとってはより深刻なダメージとなる。
このデモが示すように、AIが誤った回答を出力した際の被害は顧客対応の混乱にとどまらず、ブランドそのものの信用失墜へと連鎖する。ECでは返金ポリシーや在庫情報といった金銭的影響の大きい領域での誤回答が、直接的に売上損失を生む。
EC事業者にとってのブランド毀損リスク
ECサイトは24時間365日稼働する店舗であり、顧客からの問い合わせも時間を問わない。深夜のチャットボット対応が誤った情報を伝えた場合、SNS上での拡散速度は昼間と変わらない。むしろ、人間の担当者が不在の時間帯だからこそ、AIのみに依存するリスクは高まる。
自動車ディーラーのチャットボットが「1ドルでシボレー・タホを販売する」と応答した事例や、コーディングスタートアップCursorのサポートボットが架空のログインポリシーをでっちあげて解約を誘発した事例は、いずれもECの文脈に置き換えれば「商品を誤った価格で販売する」「返品不可商品の返品を許諾する」といった致命的なトラブルに直結する。
ガバナンスのパラドックス――安全策が失敗を招く理由

Sinchの調査で最も衝撃的な発見は、コンプライアンスや安全プロトコルに最も多く投資した「ガバナンス成熟度の高い」企業ほど、ロールバック率が81%と平均を上回ったことだ。安全策に注力したチームほど失敗するという逆説が浮かび上がっている。
ガードレール税の実態
Sinchの最高製品責任者ダニエル・モリス氏は、この状況を「ガードレール税」と呼ぶ。エンジニアリングチームが本来の顧客体験向上のための開発に割くべき時間を、安全システムの構築と維持に費やしているという構造的な問題だ。
調査対象となったチームの84%が、エンジニアリング工数の少なくとも半分を安全インフラの再構築に充てている。この工数は本来、パーソナライゼーションの高度化やチャネル拡張、キャンペーン最適化といった売上直結型の施策に振り向けられるべき時間である。
さらに、AIエージェント導入の成否を最も強く予測する変数は、モデルの選択でもチーム規模でも予算でもなく「インフラ品質」だった。にもかかわらず、多くの企業が現在のプロバイダーは少なくとも1つの重要領域で要件を満たしていないと回答している。
ECにおける具体的な失敗事例
ECの現場では、顧客がチャットボットに問い合わせた商品在庫情報が実態と異なり、注文後にキャンセル通知が届くというクレームが後を絶たない。AIがデータベースと正しく連携していなかったり、キャッシュされた古い在庫情報を参照したりすることが原因だ。
デジタルエクスペリエンス企業HGSでCXデータとAIを統括するジャヤシュリー・アイアンガー氏は、パイロット段階を過ぎた今、真の課題は運用にあると指摘する。同氏によれば、プロモーション用のチャットボットがキャンペーン内容を誤って伝えるリスクと、請求業務を扱うサービスエージェントが誤った情報を提供するリスクでは重みが異なり、後者こそがロールバックの主要因となっている。
WooCommerceサイトの場合、決済や配送に関する問い合わせは直接的に売上と顧客満足度に影響する。AIが配送予定日を誤って案内すれば、購入後の顧客からの問い合わせが殺到し、サポートコストが急騰するという二次被害も生じる。
EC事業者が取るべき3つの実践策

Sinchの調査と現場の専門家の見解から、EC事業者がAIカスタマーエージェントを安全に導入し、ブランドリスクを最小化するための3つの具体的な行動を整理した。
この3つのステップは、単独で実行するよりも一連の施策として連携させることで効果を発揮する。以下に各ステップの具体的な内容を解説する。
ベンダー選定の基準をインフラ品質に置く
AIチャットボットを提供するベンダーを評価する際、モデルの性能や料金プランよりも先に、ガードレール設計やクロスチャネルオーケストレーションの品質を確認すべきだ。Sinchの調査では、インフラ品質が導入成功の最も強い予測因子であると示されている。
具体的には、「自社のエンジニアリングチームが安全対策にどの程度の工数を割く必要があるか」をベンダーに質問し、回答の明確さを比較する。適切な基盤は安全対策の大部分を吸収し、EC事業者側のチームが顧客体験の向上に集中できる環境を提供する。
ロードマップに安全対策コストを組み込む
安全システムの構築は一度限りの初期投資ではなく、継続的なエンジニアリングリソースを消費する。WooCommerceサイトにAIチャットボットを導入する場合、プラグインの購入費用だけでなく、ガバナンス維持にかかる月次の工数を見積もり、全体のロードマップに織り込む必要がある。
ロールバックが発生してから慌ててリソースを割くのではなく、あらかじめ「安全対策にエンジニアリング工数の20〜30%が常時消費される」という前提で計画を立てることが、プロジェクト遅延を防ぐ鍵となる。
ガバナンス機能の分離を進める
HGSのアイアンガー氏が指摘するように、AIのユースケース開発とガバナンスエンジニアリングを分離し、信頼性やコンプライアンス、セキュリティを専門に扱う集中管理チームを設置する動きが加速している。
EC事業者の場合、マーケティング部門がAIチャットボットの運用を主導しつつ、安全インフラは別のガバナンスチームが担当する体制が理想だ。マーケティングチームはキャンペーン情報の正確な反映やパーソナライゼーションの最適化に集中し、ガバナンスチームが回答の正確性やポリシー遵守を担保する。
WooCommerceサイト運営者が知っておくべきAI導入の現実

WooCommerceは世界で最もシェアの高いECプラットフォームであり、AIチャットボットを追加するプラグインも豊富に提供されている。しかし、中小規模のEC事業者がAIエージェントを導入する際には、大企業とは異なるリスクが存在する。
WooCommerceエコシステムでのAIエージェント活用
WooCommerce向けのAIチャットボットプラグインは、商品レコメンデーションや注文追跡、FAQ応答などの機能を手軽に追加できる。一方で、これらのプラグインが参照するデータの更新頻度や、外部APIとの連携品質にはばらつきがあり、ガバナンスの観点では注意が必要だ。
特に、WooCommerceのコア機能である決済ゲートウェイや配送クラスとAIエージェントが連携する場合、誤った情報が直接的に売上損失やチャージバックの増加につながる。導入前に「AIが誤回答した場合の影響範囲」を洗い出し、高リスク領域では人間による確認フローを必須とする設計が求められる。
カスタマーサービス品質とブランド価値のバランス
AIエージェントの導入は、サポートコストの削減や応答速度の向上といった明確なメリットをもたらす。しかし、Sinchの調査が示すように、AIエージェントの失敗がブランドイメージに与えるダメージは数値化しにくく、修復にも長い時間を要する。
EC事業者、とりわけリピート購入や口コミにビジネスの成長を依存する中小規模のWooCommerceサイト運営者は、AI導入のスピードよりも安全性を優先する判断が長期的な競争力につながる。最初はFAQの自動応答など低リスク領域から始め、運用実績を積みながら徐々に適用範囲を広げる段階的なアプローチが現実的だ。
この記事のポイント
- AIカスタマーエージェントを導入した企業の74%がガバナンス失敗でロールバックを経験している
- 安全対策に最も投資した企業ほどロールバック率が高いというガードレール税の問題が存在する
- ECでは在庫情報や返金ポリシーなど、金銭的影響の大きい領域での誤回答リスクが特に危険
- ベンダー選定はインフラ品質を最優先基準とし、安全対策コストをロードマップに組み込む
- WooCommerceサイトでは低リスク領域から段階的にAIを導入し、高リスク領域では人間の確認を必須にする
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

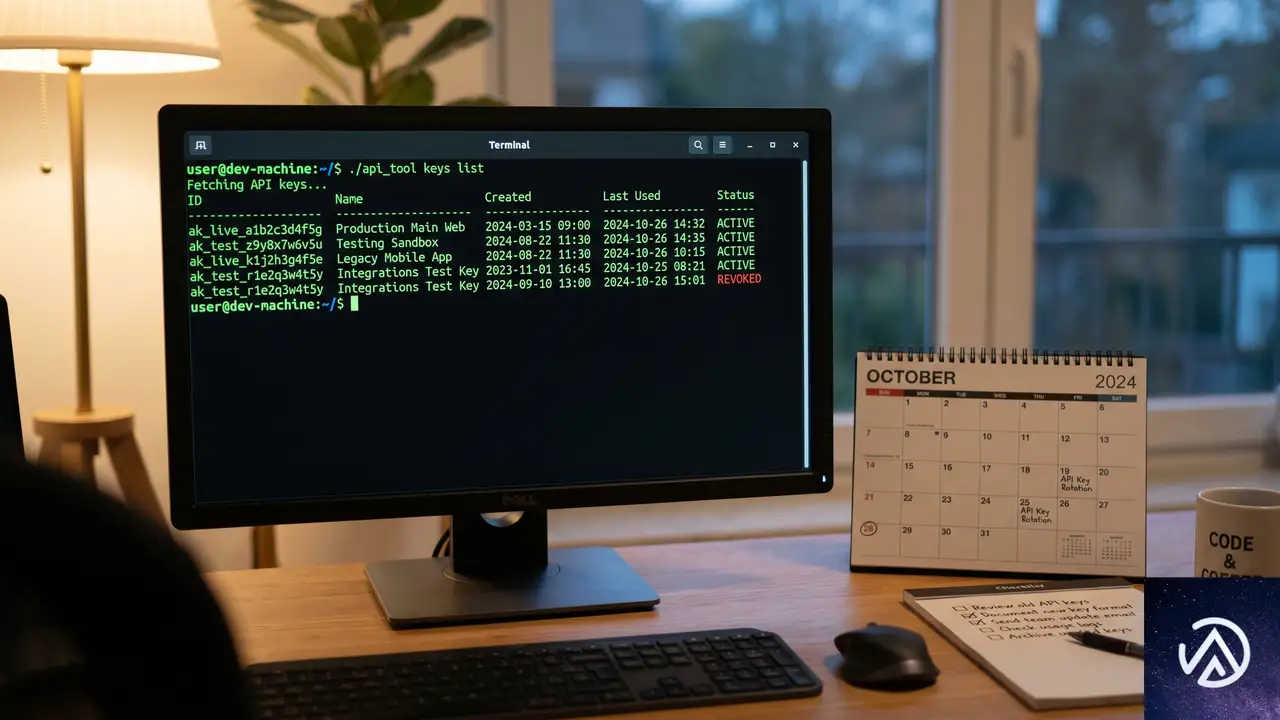
Google APIキーを守る3つの基本手順、悪用と高額請求のリスクを下げる
Google Geminiを含むAIサービスやGoogle Cloud APIを利用する上で、APIキーの安全な管理は避けて通れない課題だ。適切な対策を怠ると、キーの漏洩や悪用により、高額な請求やプロジェクト環境の侵害を引き起こす可能性がある。
APIキーは「使うのは簡単だが、安全でない方法で使うのも同じくらい簡単」とGoogle Cloud Blogの著者Leonid Yankulin氏は指摘する。この記事では、Googleが提供するAPIキーのリスクを大幅に下げるための、すぐに実践できる具体的な手順を解説する。
これらの対策の多くは、Googleに限らず他のサービスで発行されるAPIキーやプロダクトトークンにも応用可能だ。個人開発者から組織の管理者まで、キーの取り扱いを見直すきっかけにしてほしい。
Step 1. 新しいAPIキーは「隔離」と「制限」が大前提

APIキーを作成する際、最初からセキュリティを考慮しておくことで、後々のトラブルを未然に防げる。「とりあえず作成」して放置されている無制限のキーが、組織における最大のリスク要因の一つだ。
キーは専用プロジェクトで作成する
新しいAPIキーを生成する最初のルールは、他の目的に使っていない独立したGoogle Cloudプロジェクト内で作成すること。これにより、仮にキーが漏洩しても、被害がそのプロジェクトのリソースに限定される。
プロジェクトを分けることは、問題発生時の原因特定と影響範囲の調査を大幅に容易にする。本番環境と同じプロジェクトで実験用のAPIキーを発行するといった行為は避けるべきだ。
API制限で「できること」を絞る
APIキーを作成する際、デフォルトではAPI制限がかかっていない。これは、そのキーが有効化されているすべてのサービスにアクセスできる状態を意味する。Google Cloud Blogの著者は「制限のないキーを絶対に作るな」と強調する。
API制限を設定することで、キーがアクセスできるサービスを特定のAPIだけに絞り込める。たとえば、AI Studioで利用するなら「Gemini API」のみ、地図機能だけが必要なら「Maps API」だけに制限する。漏洩時の攻撃範囲を最小化する考え方だ。
注意すべき副次的なポイントとして、AI StudioやFirebaseなど間接的なUIからキーを作成した場合、意図しないAPI群が自動で許可されているケースがある。Firebase経由で作ったキーは24ものAPI(DatastoreやFirestore、Cloud SQLなど)へのアクセスが許可されるため、不要なものは手動で外す必要がある。
制限したいAPIが一覧に表示されない場合は、そのAPIが対象プロジェクトで有効化されていない可能性が高い。APIライブラリから事前に有効化しておく必要がある。
アプリケーション制限で「使う場所」を縛る
API制限が「どのサービスを使えるか」を制御するのに対し、アプリケーション制限は「どのアプリからキーを使えるか」を制御する。こちらも併用することで、セキュリティは飛躍的に高まる。
たとえばAI Studio専用のキーなら、許可するウェブサイトを aistudio.google.com に限定すれば、他のスクリプトや自動化ツールから大量のトークンを消費されるリスクを防げる。指定できる制限タイプは以下の4種類だ。
- ウェブサイト、許可するURLのリストを指定
- サービス(IPアドレス)、IPv4やIPv6アドレス、サブネットマスクで指定
- iOSアプリ、バンドルIDで指定
- Androidアプリ、パッケージ名と証明書フィンガープリントのペアで指定
注意点として、1つのキーに設定できるアプリケーション制限タイプは1種類だけ。複数のアプリ種別で利用する場合は、それぞれ専用のAPIキーを発行する。キーをアプリごとに分けておけば、利用状況の監視や侵害発生時の調査も容易になる。
ウェブサイト
https://aistudio.google.com自動化スクリプトからの呼び出し、不明なIPアドレスからのリクエスト、許可リストにないWebサイト
Step 2. APIキーは「誰でも使える」前提で保管する

APIキーの最大の特性は、特定の個人アカウントと紐づかない点にある。Google Cloud Blogの記事で「誰でも使える」と強調されているように、キー文字列を知っていれば誰でもその権限でAPIを呼び出せる。保管の安全性の重要性はAPI制限と同等だ。
「APIキーを絶対に、見えやすい場所に保存してはいけない」という基本ルールはシンプルだが、実際の開発現場ではしばしば破られている。ソースコードへのハードコードや、Gitリポジトリへの平文でのコミットは典型的なミスだ。
自社アプリケーションではSecret Managerを使う
Google Cloudを利用しているなら、Secret Manager(シークレットマネージャー)のような専用の機密情報管理サービスにキーを格納するのが鉄則だ。Secret Managerを使えば、APIキーをCloud RunやGKEの実行環境に安全に注入できる。
さらに保護レベルを上げたい場合は、キーを環境変数に渡すのではなく、アプリケーションコード内でSecret Managerから直接読み取る方式も選択肢になる。これによりランタイムメモリへの露出時間をさらに短縮できる。
外部アプリケーションではキーの取り扱いを事前調査する
サードパーティ製のツールやサービスにAPIキーを入力する場合、そのアプリケーションがキーをどのように保管し、通信しているかを確認する必要がある。
Webアプリケーションであれば、ブラウザの開発者ツールを使ってトラフィックを調査し、キーが暗号化されていない通信経路で送信されていないかを確認する。「Google AI Studioは暗号化されたローカルストレージを使用し、TLS暗号化チャネル経由でのみキーを送信する」とYankulin氏は具体例を挙げている。こうした設計を満たしていないツールへのキー提供は避けるべきだ。
異常を検知したら「即削除」、調査の手順も把握する

どんなに対策を施しても、キーが侵害される可能性はゼロにはできない。迅速な初動対応が被害を最小化する鍵を握る。Yankulin氏は「クレジットカードを無くしたときと同じように、まずキーを削除すること」と述べている。
Cloudコンソール、または gcloud services api-keys delete コマンドで即座にキーを無効化する。誤報だったと判明した場合でも、削除から30日以内であれば undelete コマンドで復元が可能だ。
侵害されたキーを特定する2段階調査
どのAPIキーが侵害されたか不明な場合は、以下の2段階で調査を進める。
第一段階、組織またはプロジェクト内のすべてのAPIキーを洗い出す。Cloudコンソールの「Asset Inventory」でリソースタイプを apikeys.Key に絞り込む方法と、gcloud services api-keys list コマンドを使う方法がある。組織全体を横断検索する場合は gcloud asset search-all-resources コマンドでJSON出力をフィルタリングする。
第二段階、API消費量のグラフを確認する。Cloud Monitoringの指標 serviceruntime.googleapis.com/api/request_count を使い、credential_id ラベルで特定のAPIキーIDに絞り込む。リクエスト数が異常に急増している場合、そのキーが悪用されている可能性が高い。
APIキーIDは、Cloudコンソールの「Credentials」ページでキーを選択した際のURL(/key/[KEY_ID] 部分)から、または gcloud services api-keys list --format='value(displayName,uid)' コマンドで確認できる。
1時間あたり数千リクエスト。日次グラフはなだらかで安定した波形
1時間あたり数十万リクエストに急増。短時間で不自然なスパイクが出現
Step 3. 日常的な「APIキー衛生管理」を習慣化する
エンジニアだけの話ではない。クラウドをかじり始めたばかりの個人ユーザーも、今すぐAPIキーの「衛生管理」を始めるべきだ。放置されたキーは、知らぬ間に悪用の温床となる。
Yankulin氏が推奨する即時実行すべきアクションは以下の5つだ。
- 自分が保有するすべてのAPIキーを洗い出す
- 使っていないキー、見覚えのないキーはすべて削除する(30日以内なら復元可能)
- 残すキーは、利用するAPIだけに制限し、可能ならクライアントも絞り込む
- 組織の管理者は
apikeys.googleapis.com/Keyの組織ポリシーを設定し、キーの乱立と制限設定の抜けを防ぐ - 定期的なキーのローテーション(再発行と差し替え)を検討する。ただし、既存キーを削除する前に、すべての利用箇所を特定して新しいキーに更新する周到さが必要だ
キーローテーションの際に「既存キーがどこで使われているのか把握しきれていない」という問題に直面するケースは多い。日頃からキーの利用箇所をドキュメント化しておくこと、そして新しいキーの発行時点から適切な制限をかけておくことが、結果的にローテーションのハードルを下げる。
この記事のポイント
- APIキーは「誰でも使える」クレデンシャル。見える場所に保管しないことが大前提
- 新規キー作成時は、API制限とアプリケーション制限を両方設定して攻撃の範囲を狭める
- 保管にはSecret Managerなど専用の機密情報管理サービスを使い、コードへのハードコードを避ける
- 使っていないキーや制限のないキーは即座に削除し、組織ポリシーで乱立を防ぐ
- 侵害が疑われる場合はクレジットカードと同じ感覚で「まず削除」。監視データで異常を検知する
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Google Antigravity 2.0リリース、IDE不要のエージェント体験を実現
Google DeepMindは2026年5月17日、AIエージェントを中核に据えたデスクトップアプリケーション「Google Antigravity 2.0」を発表した。従来のIDE(統合開発環境)を廃し、エージェントとの同期・非同期の対話に完全に最適化された独立アプリケーションとして再設計されている点が最大の特徴だ。
この新バージョンは、2025年11月にリリースされた初代Antigravity IDEの「Agent Manager」を発展させたもので、ソフトウェア開発だけでなく、より広範な知識作業をエージェントと協働するための基盤として位置づけられている。macOS、Linux、Windowsに対応し、最新のGeminiモデルを活用する。
開発者だけでなく、コードやIDEに馴染みのないユーザーにとっても直感的なエージェント体験を提供することが、この2.0の大きな狙いだ。
エージェントファーストの新設計

Antigravity 2.0の最大の転換点は、IDEという概念を完全に取り除いたことにある。従来のAntigravity IDEでは、コードエディタとエージェント管理画面が同居していた。この設計は開発者には便利だが、エージェント本来の可能性を制限する側面もあった。
IDEを捨てた理由
Google DeepMindの記事によれば、開発チームは当初から「コーディングの高速化だけでは、ユーザーに提供できる価値に限界がある」と認識していたという。モデル性能が向上するにつれ、エージェントの活躍領域は自然とコード以外の知識作業へと拡大した。
実際、初代Antigravity IDEのAgent Managerは、開発以外のタスクにも広く使われていた。だが、IDEの枠組みの中でそれを行うのは、非開発者にとっては直感的とは言えなかった。Antigravity 2.0は、その制約を解消し、エージェントとの協働を主役に据えた設計へと舵を切った。
プロジェクトベースの管理方式
もう一つの大きな設計変更が、リポジトリとの密結合の解除だ。Antigravity 2.0では、エージェントの会話は「ワークスペース(リポジトリ)」単位ではなく、「プロジェクト」単位でグループ化される。一つのプロジェクトが複数のフォルダを参照でき、プロジェクトごとにエージェントの設定や権限を個別に定義できる。
これにより、エージェントがより多くの情報源にアクセスし、複雑なタスクに取り組めるようになりつつ、適切なガードレールも維持される。
強化されたエージェント機能群

Antigravity 2.0では、エージェントの能力が大幅に強化された。中核となるのは「動的サブエージェント」「非同期タスク管理」「JSONフック」の3つだ。
動的サブエージェント
メインエージェントがタスクを実行する際、必要に応じてサブエージェントを動的に定義し、呼び出せるようになった。サブエージェントは焦点を絞った部分タスクを担当する。これにより、メインエージェントのコンテキストウィンドウが汚染されず、複数のサブタスクを並列に処理できる。
コンテキストウィンドウとは、エージェントが一度に把握できる会話や情報の範囲のことだ。長大なタスクではここがすぐに一杯になり、エージェントの応答品質が落ちる原因になっていた。サブエージェントへの委譲は、この問題への有効な対策となる。
非同期タスク管理
タスクやコマンドを非同期で実行できるようになった点も大きい。メインエージェントが処理をブロックされることなく、バックグラウンドで複数の作業を進められる。たとえば、コードのビルドを走らせながら次の機能の設計について対話を続ける、といった並行作業が可能になる。
JSONフック
JSONフックは、エージェントの動作を外部から制御する仕組みだ。シンプルなJSON形式でフックを定義し、エージェントの特定の挙動をインターセプトして制御できる。柔軟なカスタマイズを可能にしつつ、設定の複雑さを抑えている。
スケジュールタスクとプロジェクト管理

Antigravity 2.0では、エージェントとの新しい関わり方として「スケジュールタスク」が導入された。cron式を使ってエージェントの起動スケジュールを事前に定義できる。日次レポートの生成、定期的なデータ収集、ナイトリービルドの監視など、手動で毎回指示を出す必要がなくなる。
スラッシュコマンド「/schedule」を使うか、専用のスケジュールタスク画面から設定する。一度だけのタイマー実行と、繰り返しの定期実行の両方に対応している。
新しいスラッシュコマンドと音声入力
Antigravity 2.0には、エージェントとの対話をより精密に制御するための新しいスラッシュコマンドが追加された。
4つの新コマンド
/goalは、指定したタスクを完了まで実行させ、途中でユーザーに入力を求めない。長時間の作業を任せきりにしたい場面で有効だ。/grill-meは実装開始前に、エージェントが逆に質問を投げかけて計画の詳細を詰める。見落としを事前に洗い出すのに役立つ。/scheduleは前述のとおり、タスクのスケジュール実行を指示する。/browserは、エージェントにブラウザ操作を明示的に許可するかどうかを制御する。
音声入力のライブ文字起こし
テキスト入力欄の横にあるマイクアイコンを使った音声入力が、ライブ文字起こしに対応した。従来は生の音声ファイルをモデルに渡していたが、2.0では発話と同時にテキスト化が進む。音声の遅延を感じさせず、より自然な対話が可能になった。
Antigravity IDEとの関係と今後の展望

Antigravity 2.0は独立したアプリケーションとして提供されるが、従来のAntigravity IDEがすぐに置き換わるわけではない。IDE側のAgent Managerも当面は維持され、今後のアップデートでIDEからAgent Managerが分離される予定だ。IDEは純粋なエージェント駆動型IDEとして残る。
すでにAntigravity IDEをインストールしているユーザーは、次回のアップデートで自動的にAntigravity 2.0に更新される。その際、IDEを残すかどうかを選択できる。両アプリはドック上でアイコン背景が異なり、2.0は白背景、IDEは黒グリッド背景で区別される。
Google DeepMindの記事によれば、社内のGooglerたちはすでにAntigravity 2.0と各種IDEを併用しているという。今後、主要なIDE向けの互換拡張機能やプラグインも提供される予定だ。
今後のロードマップ
Antigravity 2.0と同時に、CLI、SDK、APIも発表された。他のGoogle製品や技術スタックとの統合も進められており、エージェントハーネスとモデル層の共同最適化が継続される。記事では、リモートコントロール機能、さらなる製品統合、クラウドデプロイエージェントなどが今後の展開として示唆されている。
この記事のポイント
- Antigravity 2.0はIDEを廃した完全エージェントファーストの独立アプリケーション
- 動的サブエージェントと非同期タスク管理で複雑な作業を効率的に処理
- スケジュールタスクにより、エージェントの定期実行が自動化可能
- 音声入力がライブ文字起こしに対応し、対話のテンポが向上
- 従来のIDEも維持され、開発者は両方を併用できる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

CSSのsibling-index()とsibling-count()でDOMを数式レイアウト
CSSに<sibling-index()>と<sibling-count()>という2つの関数が追加された。これらは要素の兄弟関係を「数値」として取得し、calc()の中で計算できる。2025年6月時点でChrome 138とSafari 26.2が対応済みで、Firefoxも実装が進行中だ。
この新機能の最大の価値は「ブラウザがすでに知っている情報を、CSSから直接引き出せる」点にある。従来はJavaScriptでループ処理するか、Sassで大量の:nth-child()ルールを生成するしかなかった。それが1行のCSSで完結する。
本記事では、sibling-index()とsibling-count()の基本から実践パターン、注意点までを解説する。WordPressサイトのカスタムCSSを書く制作者にも役立つ内容だ。
従来のスタガードアニメーションが抱えていた問題

カードグリッドに1枚ずつ遅延させて表示する「スタガードカスケード効果」は、見た目がよく実装も簡単に思える。ところが実際には、かなり面倒なコードが必要だった。
:nth-child()の限界
10枚のカードに異なるアニメーション遅延を設定したいとする。従来の方法では、こう書くしかなかった。
li:nth-child(1) { --idx: 1; }
li:nth-child(2) { --idx: 2; }
li:nth-child(3) { --idx: 3; }
/* ...8個分続く... */
li:nth-child(10) { --idx: 10; }
li {
animation-delay: calc(var(--idx) * 100ms);
}10項目なら10ルールで済むが、50項目なら50ルールだ。Sassのループでビルド時に数百個のセレクタを生成する方法もあるが、CSSファイルが膨れ上がる。Roman Komarov氏が考案したO(√N)戦略でも、1023要素をカバーするのに63ルールが必要になる。
JavaScript依存の落とし穴
もう1つの方法は、JavaScriptでDOMを走査してインラインスタイルを書き込む方式だ。style="--index: 3" を各要素に付与する。動作はするが、レイアウトのための値がスクリプトに分散し、半年後に別の開発者がコンポーネントをリファクタリングした際に静かに壊れる。ブラウザはすでに「どの要素が3番目の子か」を知っているのに、CSSからはその情報にアクセスできなかった。
Smashing Magazineの記事で著者の一人が指摘するように、この状況は「ブラウザがすでに持っているデータを、わざわざ手動で再計算している」矛盾だった。
sibling-index()とsibling-count()の基本
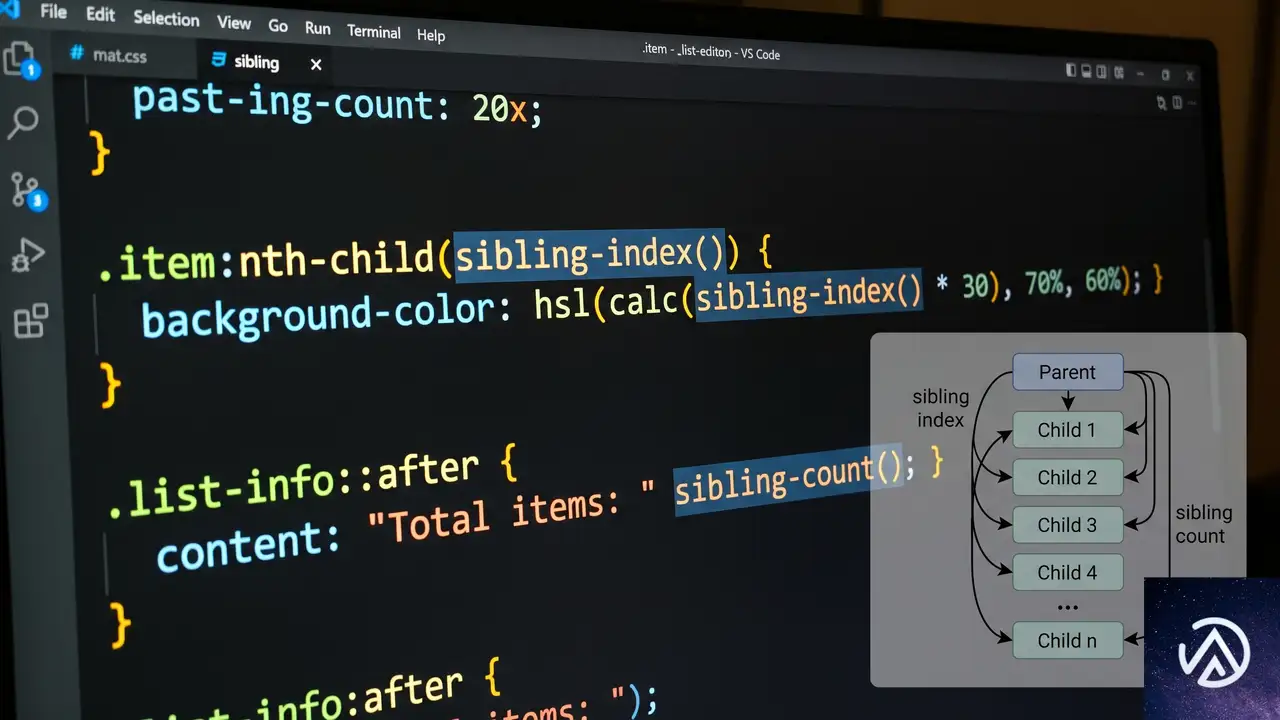
この2つの関数はCSS Values and Units Module Level 5で定義されている。どちらも引数を取らず、CSSの宣言内で直接数値として使える点が革新的だ。
element.parentElement.children.length に相当counter()との違いに注意したい。counter()は文字列を返し、疑似要素のcontentプロパティ内でしか使えない。一方、sibling-index()はCSS内の任意の場所で使える実数だ。時間値や角度、ピクセル値との計算もCSSが自動的に型変換する。
:nth-child()との本質的な違い
:nth-child()は「セレクタ」であり、要素を選択するための仕組みだ。calc(:nth-child() * 10px)のような書き方はできない。sibling-index()は「宣言の中で使える値」を生成する。両者は役割が異なり、補完関係にある。
実践的なユースケース

これらの関数が整数を返すと理解できれば、応用の幅は一気に広がる。以下に、WordPressサイトのカスタマイズにも活用できるパターンを紹介する。
リバーススタガー
最後の項目から先にアニメーションさせたい場合は、引き算で反転する。
.card {
animation: fade-in 0.4s ease both;
animation-delay: calc((sibling-count() - sibling-index()) * 80ms);
}最後の子要素は (N – N) × 80ms = 0ms で即座に表示される。最初の子要素は (N – 1) × 80ms の遅延となる。ページ読み込み直後からアニメーションが始まり、待ち時間が生じない。
自動均等幅
タブやカラムの幅を子要素の数に応じて自動調整する。
.tab {
width: calc(100% / sibling-count());
}5つのタブなら各20%、6つ目が追加されれば約16.66%になる。メディアクエリやリサイズ監視、JavaScriptは不要だ。ただし項目が増えすぎてタブが細くなりすぎる場合は、Flexboxの折り返しなど別の手法を併用する判断も必要になる。
色相分布
カラーホイール上で均等に色を分散させる。
.swatch {
background-color: hsl(
calc((360deg / sibling-count()) * sibling-index()) 70% 50%
);
}3項目なら120度間隔、12項目なら30度刻みで色相が割り当てられる。DOM内の項目数に応じてパレットが自動調整されるため、JavaScriptのカラーライブラリで行っていた処理をCSSだけで完結できる。
円形メニュー
項目を円周上に配置する計算も、CSSの三角関数と組み合わせればシンプルになる。
.radial-item {
--angle: calc((360deg / sibling-count()) * sibling-index());
--radius: 120px;
position: absolute;
left: calc(50% + var(--radius) * cos(var(--angle)));
top: calc(50% + var(--radius) * sin(var(--angle)));
transform: rotate(calc(var(--angle) * -1));
}6項目なら六角形、8項目なら八角形になる。項目を追加・削除すればレイアウトが再計算される。JavaScriptで座標を逐一計算する必要はない。
Z-indexスタッキング
カードを扇状に重ねる表現も1行で済む。
.card {
z-index: calc(sibling-count() - sibling-index());
}最初のカードが最も高いz-indexを持ち、最後のカードは0になる。逆順にしたい場合は計算式を反転すればよい。
注意点と制限事項

仕様を読み込んでも気づきにくい落とし穴がいくつかある。実際に使い始める前に把握しておきたい。
Shadow DOMのスコープ
sibling-index()とsibling-count()は「DOMツリー」に対して動作し、フラット化された視覚ツリーではない。この違いはWeb Componentsを使う場面で問題になる。
カスタム要素内のシャドウDOMで内部のdivにsibling-index()を適用すると、slotで投影された外部コンテンツはカウントされない。slotが300要素を投影していても、シャドウツリー内ではsection直下の子要素はslot要素とdivの2つだけだ。
また、外部のスタイルシートから::part()経由でコンポーネント内部にsibling-index()を使おうとすると、ブラウザは0を返す。これはサードパーティコンポーネントの内部構造を外部CSSから探られるのを防ぐための意図的な設計だ。
疑似要素はカウントされない
::beforeや::afterは兄弟要素ではない。sibling-count()に含まれず、自身のsibling-index()も持たない。ただし、疑似要素の宣言内でこれらの関数を使うことは可能だ。その場合、疑似要素ではなく「元の要素」のインデックスが評価される。
display:noneでもカウントされる
これは特に注意が必要だ。display:noneを指定した要素はレイアウトツリーから消えるが、DOMツリーには残っている。sibling-index()はDOMツリーを見るため、非表示要素もカウントしてしまう。
visibility:hiddenやopacity:0も同様にカウントされるが、これらは要素が空間を占有し続けるため直感的にも理解しやすい。display:noneだけが「視覚的に消えているのにDOMスロットを占有している」という特殊な挙動になる。
カスタムプロパティの即時評価
親要素で –idx: sibling-index() と定義すると、その値は親要素自身のインデックスで即座に解決される。すべての子要素が同じ固定値を継承してしまい、意図した動作にならない。
正しい方法は、関数を必要な要素自身に直接適用することだ。
/* 誤り:親で定義すると全子要素が同じ値を継承 */
.parent {
--idx: sibling-index();
}
/* 正解:各子要素で個別に定義 */
.child {
--idx: sibling-index();
animation-delay: calc(var(--idx) * 100ms);
}CSSWGでは@propertyのinherits:declaration拡張が議論されているが、まだ仕様化には至っていない。当面は各要素に直接適用するのが安全だ。
大規模DOMでのパフォーマンス
DOMの変更(要素の追加、削除、並べ替え)は、影響を受ける兄弟要素すべてのスタイル再計算を引き起こす。この処理はカスケードフェーズで行われるため、JavaScriptでループしてインラインスタイルを書き込む従来の方法よりは高速だ。
ただし、1万子要素を持つコンテナの先頭に要素を挿入すると、後続の全要素のインデックスが再計算される。ナビゲーションやカードグリッドのような通常の用途では問題にならないが、リアルタイム株価表示や無限スクロールフィードなど、数千ノードが常時入れ替わる場面では、仮想化ウィンドウ内でJavaScript管理のインデックスを使い続ける方が無難だ。
アクセシビリティへの配慮
これらの関数は純粋に「視覚的」なものである点を強調しておきたい。見た目を変えるだけで、意味を変えるわけではない。
sibling-index()の計算結果を使ってorderプロパティやグリッド配置でリストを視覚的に並べ替えた場合でも、スクリーンリーダーはDOMのソース順で読み上げる。キーボードのタブ順もDOM順に従う。視覚レイアウトとセマンティック構造が矛盾すれば、アクセシビリティ上の問題になる。
データグリッドやラジアルメニューなど、ツリーカウントに依存するインタラクティブなコンポーネントでは、JavaScriptでARIA属性(aria-posinsetやaria-setsize)を同期させる必要がある。CSSが計算した値とARIAが伝える情報が食い違えば、支援技術のユーザーには壊れた体験が提供される。
ブラウザ対応とフォールバック戦略

2025年6月時点で、Chrome/Edge 138とSafari 26.2が安定版で対応している。FirefoxはMozillaのポジションが肯定的で実装作業が進行中だが、安定版にはまだ含まれていない。最新の対応状況はcaniuseで確認することを推奨する。
ChromeとSafariで世界のトラフィックの約75〜80%をカバーするが、Firefox未対応の間はフォールバックが必須だ。
/* すべてのブラウザで動作するベースライン */
.item {
width: 25%;
animation-delay: 0ms;
}
/* 対応ブラウザでプログレッシブエンハンスメント */
@supports (z-index: sibling-index()) {
.item {
width: calc(100% / sibling-count());
animation-delay: calc(sibling-index() * 80ms);
}
}Firefoxには静的なフォールバック、対応ブラウザには数式レイアウトを提供する。どのブラウザでもページが壊れることはない。
ポリフィルについて補足すると、JavaScriptで兄弟要素をループしてインラインスタイルを設定する方式は、まさにこれらの関数が置き換えようとしているものだ。Juan Diego Rodríguez氏が公開している段階的移行の手法では、Roman Komarov氏のカウンティングハックなど既存のCSSテクニックを橋渡しとして活用し、ネイティブ対応までの移行期間をしのぐアプローチを提案している。
今後の展望

現在の仕様では「すべての要素兄弟」をカウントするのみだが、CSSWGのIssue #9572では、:nth-child()と同様の「of セレクタ」引数の拡張が計画されている。
sibling-index(of .active)のような記法が実現すれば、特定のセレクタに一致する兄弟だけをカウントできる。全体で8番目の子だが.activeクラスを持つ中では3番目、という要素は3を返す。フィルタリングやトグル表示を伴う動的なUIでも、DOM操作なしで連続したインデックスを維持できるようになる。
さらに、children-count()とdescendant-count()の提案もCSSWGで議論されている。children-count()は要素が持つ子要素の数、descendant-count()はすべての子孫を再帰的にカウントする。sibling-index()とsibling-count()が「兄弟の間での自分の位置」という水平方向の情報を提供するのに対し、children-count()とdescendant-count()は「自分の下に何があるか」という垂直方向の情報を提供する。両方が揃えば、CSSからDOMツリーを俯瞰できるようになる。
10個の:nth-child()ルールを書きながら「もっと良い方法があるはずだ」と感じていた制作者にとって、その「もっと良い方法」がようやくブラウザに実装されつつある。CSSがDOMツリーを「理解」し始めたことで、レイアウトの表現力は次の段階に入ったと言える。
この記事のポイント
- sibling-index()とsibling-count()はDOMツリーの構造をCSSから数値として取得できる新関数である
- スタガードアニメーションや均等幅レイアウトが1行のCSSで完結し、JavaScriptや大量の:nth-child()ルールが不要になる
- Chrome 138とSafari 26.2が対応済み、Firefoxは実装進行中で@supportsを使ったフォールバックが必須
- display:noneの要素もカウントされる点、カスタムプロパティの即時評価、Shadow DOMのスコープに注意が必要
- 視覚的な並べ替えはアクセシビリティ上の問題を引き起こすため、ARIA属性との同期が欠かせない
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

エージェント型コマース到来 ECブランドに求められる「証明可能な約束」
AIエージェントが消費者の購買意思決定を代行する「エージェント型コマース」が急速に現実味を帯びている。2030年までに米国のEコマース取引の25%がエージェントAIによって駆動されるとの予測もある。この変化は、ブランドが築いてきた感情的な信頼のあり方そのものを揺るがす。
MarTechのGreg Kihlstrom氏は、エージェント型コマースにおいてブランドの約束は「証明可能」でなければ選ばれなくなると指摘する。従来のように広告やブランドイメージで勝負するだけでなく、価格の透明性、配送の信頼性、返品ポリシー、ロイヤルティの価値など、定量的なシグナルをもとにAIが評価する世界だ。本記事では、EC事業者がこのパラダイムシフトにどう備えるべきか、具体的な戦略と視点を掘り下げる。
AIエージェントがECの購買決定をどう変えるか

すでに加速するエージェント型コマース
マッキンゼーの調査では、すでに消費者の約70%が購買プロセスにAIツールを活用している。B2Bバイヤーに至っては73%がAIを利用して購買を評価しているという。さらにベインの予測では、2030年までに米国Eコマース売上の25%(3000億ドルから5000億ドル相当)がエージェントAIによって駆動される見込みだ。数字だけを見ても、AIエージェントを無視したEC戦略は成り立たなくなっている。
ブランド評価の基準が感情から定量データへ
消費者はテレビCMやSNSの口コミ、ブランドカラーといった「感覚的な信頼」で商品を選んできた。しかしAIエージェントは、価格の透明性、在庫の正確さ、配送実績、返品ポリシーの明快さ、カスタマーサービスの評価など、数値化できる指標だけを抽出して比較する。MarTechの記事が指摘するように、ブランドへの感情的な好意はエージェントのフィルターでは評価外になりやすい。ここでEC事業者が直面するのは、「ブランドらしさ」よりも「ブランドが約束を守れるか」を可視化する必要性だ。
このデモが示すように、AIエージェントはブランドの「なんとなくの評判」を即座に無視し、操作可能なデータだけをもとに推薦を組み立てる。EC事業者は、自社の商品ページやバックエンドの在庫管理、配送ログがエージェントにどう読まれるかを設計段階から意識しなければならない。
ブランド信頼が証拠ベースに変わる

改善すべきブランドオペレーション
これまでのブランド構築は、広告やクリエイティブで「信頼できる」と伝えることに主眼があった。しかしAIエージェントが介在する世界では、ブランドの主張と実態のズレは直ちに排除の原因になる。MarTechの記事がいくつかの具体例を挙げているように、以下のようなギャップは許容されない。
- 「便利さ」を謳いながら、在庫データが不正確で欠品が頻発する
- 「顧客第一」と掲げながら、解約条件をわかりにくくしている
- 「プレミアムサービス」を自称しながら、返品手続きが煩雑で時間がかかる
こうした不一致は、消費者が気づく前にAIエージェントによって検出され、比較リストから外されてしまう。つまり、ブランドの約束はオペレーションの隅々まで証明できなければ、エージェントのレコメンデーションに残る資格を失うのだ。EC事業者にとっては、フルフィルメントの精度やカスタマーサポートの透明性を、ブランド価値の根幹として再定義する必要がある。
ロイヤルティプログラムをエージェントが読み取れる形に

数値化できない特典は存在しないのと同じ
多くのロイヤルティプログラムは、アプリのプッシュ通知やポイント残高、会員ランクといった、人間の感情に訴える仕組みで設計されている。しかしAIエージェントは、ポイントの経済的価値やステータスがもたらす具体的な優遇措置(送料無料、優先サポート、返品猶予など)をリアルタイムで計算できなければ、それらの特典を「存在しない」と見なす。MarTechの記事が強調するように、会員であること自体はエージェントにとって何の意味も持たない。
WooCommerceなどECプラットフォームを運用する事業者は、ロイヤルティ機能(ポイント残高、会員限定価格、送料優遇)を外部システムからAPI経由で読み取れる形に整備する必要がある。たとえばヘッドレス構成を採用し、エージェントが直接クエリできるエンドポイントを用意すれば、ブランドの優位性が定量情報として伝わる。
顧客データが「委任レイヤー」として機能する

許諾と選好をエージェントに伝える
AIエージェントの活躍が広がっても、人間が最終的な購入ボタンを押すケースは当面続く。だからこそ顧客データは、人向けのパーソナライズとエージェント向けの委任情報の両方を扱う必要がある。MarTechの記事は、従来のセグメント分析やキャンペーン適格性だけでなく、顧客がエージェントにどのような権限を委ね、どのような制約(価格帯、サステナビリティ重視、プライバシー限度)を設けているかまで記録すべきだと指摘している。
- ✕ 購買履歴とセグメント情報のみ
- ✕ キャンペーン適格性が中心
- ✕ エージェントへの委任設定なし
- ✓ 価格感度やサステナビリティ志向を記録
- ✓ プライバシー許容度や返品ポリシー選好
- ✓ エージェントに委任する権限の範囲を明示
さらに、本人認証と代理人の識別も複雑化する。人間の顧客、家族、法人アカウント、権限を持つAIエージェントが混在する環境では、誰がどの情報にアクセスし、どれだけの取引を代行できるかを管理する仕組みが不可欠だ。EC事業者は、同意管理と顧客プロファイルの構造を、エージェント時代を見据えて再設計する必要がある。
マーケティング指標をエージェント起点で再設計する

従来のKPIでは見落とすエージェントの動き
サイトのトラフィックや検索順位、最終クリックアトリビューションだけを追いかけていても、エージェント型コマースでは手遅れになる。AIエージェントはブランドのウェブサイトを訪れる前に、商品情報APIやレビューサイト、物流データを横断的に調査し、候補を絞り込む。コンバージョン率が落ちた時点では、すでにエージェントの比較リストから外されている可能性が高い。
MarTechの記事は、まず「エージェントがブランドを正しく見つけ、正確に理解できるか」を測定し、その次に「エージェントが取引まで完結できるか」を追うべきだと示唆している。具体的には、エージェント向けのフィードが正確か、構造化データが最新か、ロイヤルティ情報がAPIで計算可能かといった指標をKPIに加える必要がある。ECの現場では、Google Merchant Centerや構造化データの品質監査、WooCommerce REST APIのレスポンス速度と正確性を定期的に評価する体制が求められる。
この記事のポイント
- エージェント型コマースでは、ブランドの約束を価格や配送実績などの定量データで証明できなければ選ばれない
- AIエージェントは感情的なブランド好意を評価せず、在庫精度や返品ポリシーの明確さを数値化して比較する
- ロイヤルティプログラムの特典はAPIで計算可能でなければ、エージェントの意思決定から除外される
- 顧客データには、人向けのパーソナライズだけでなく、エージェントへの委任設定やプライバシー選好を組み込む必要がある
- マーケティング指標は、エージェントが見つけやすく正確に取引できる状態かどうかを測定する方向へシフトすべきである
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験