

AstroでMarkdownを強化するMDX活用術!コンポーネントを自由自在に配置する
静的サイトジェネレーターとして人気を集めるAstroは、標準でMarkdownをサポートしている。しかし、より高度なカスタマイズやインタラクティブな要素を記事内に取り入れたい場合、標準のMarkdownだけでは限界を感じることがあるだろう。
そこで活用したいのがMDXだ。MDXはMarkdownの簡潔さと、JSXによるコンポーネントの柔軟性を兼ね備えた強力なツールとして知られている。AstroにMDXを導入することで、ドキュメントの記述効率は劇的に向上する。
この記事では、CSS-Tricksの記事を基に、AstroでMDXを使用するメリットや具体的な実装方法、そして運用上の注意点を詳しく解説していく。技術的な背景を知る同僚から教わるような感覚で、その可能性を探っていこう。
MDXがAstroの開発体験を劇的に変える理由

MDXとは、Markdownの中でReactやSvelte、Astroといったフレームワークのコンポーネントを直接使えるようにする拡張仕様だ。通常のMarkdownはテキストの装飾には優れているが、複雑なUIパーツを配置するにはHTMLを直接記述しなければならず、管理が煩雑になりやすい。
例えば、記事の中に「補足説明用のカード」や「インタラクティブなグラフ」を置きたい場合を考えてほしい。標準のMarkdownでは、複雑な div タグの階層を書く必要がある。しかしMDXなら、あらかじめ定義したコンポーネントを1行書くだけで済む。
CSS-Tricksの記事でも指摘されている通り、MDXの最大の利点は「Markdownの書きやすさを維持したまま、HTMLの表現力を手に入れられること」にある。これは、コンテンツ制作のスピードと品質を両立させる上で極めて重要な要素だ。
HTML記述の苦痛から解放される
MDXを使用すると、複雑なレイアウトをMarkdownの記法だけで構築できるようになる。例えば、クラス名を持った div で囲まれた見出しやリストを作成する場合、MDXならHTMLタグを最小限に抑えることが可能だ。
<div class="card">
### カードのタイトル
ここにはコンテンツが入る。
- リスト項目1
- リスト項目2
</div>上記のコードは、Astroによって適切なHTMLへと自動変換される。見出しは h3 タグになり、リストは ul と li になる。これをすべてHTMLで書く手間を考えれば、MDXがいかに効率的かがわかるだろう。
<h3>タイトル</h3>
<p>説明文</p>
</div>
### タイトル
説明文
</div>
このデモは、MDXを使うことでHTMLタグの記述量をどれだけ削減できるかを視覚化したものだ。構造が複雑になるほど、この恩恵は大きくなる。
AstroでMDXを使いこなす3つのアプローチ
AstroでMDXを利用するには、まず公式のインテグレーションをインストールする必要がある。準備が整えば、主に3つの方法でコンテンツを管理できるようになる。それぞれの特徴を理解し、プロジェクトに最適な手法を選ぼう。
1. コンポーネントとして直接インポートする
最もシンプルな方法は、MDXファイルを他のAstroコンポーネントと同じようにインポートして使うことだ。特定のページの一部として、固定のコンテンツを表示したい場合に適している。
---
import MyContent from '../components/MyContent.mdx';
---
<MyContent />この方法を使えば、MDXファイルを「再利用可能なパーツ」として扱える。複数のページで同じ説明文を使い回したいときなどに便利だ。ただし、大量のブログ記事を管理するような用途には向いていない。
2. Content Collectionsで一括管理する
Astroの強力な機能である「Content Collections(コンテンツコレクション)」を利用する方法だ。これは、特定のディレクトリ内にあるMarkdownやMDXファイルを一元管理し、型安全なデータとして取り出す仕組みを指す。
src/content/config.js でコレクションを定義する際、読み込むファイルのパターンに .mdx を含めるだけで準備は完了する。記事のメタデータ(フロントマター)を活用して、一覧ページや詳細ページを動的に生成できるのが強みだ。
また、この方法では <Content components={{ Image }} /> のように、すべての記事で共通して使いたいコンポーネントを一括で渡すことができる。各MDXファイルで毎回インポートを書く手間が省けるため、大規模なサイト運用では必須の手法と言える。
3. Layoutフロントマターで共通のデザインを適用する
MDXファイルのフロントマターに layout プロパティを指定することで、その記事を特定のデザイン枠組み(レイアウト)の中に埋め込むことができる。これは、記事ごとに異なるレイアウトを適用したい場合に有効だ。
---
title: 私のブログ記事
layout: ../layouts/BlogPostLayout.astro
---指定されたレイアウトファイル側では、Astro.props を通じて記事のタイトルや公開日などの情報を受け取り、<slot /> タグを使ってMDXの本文をレンダリングする。デザインとコンテンツの分離が明確になり、メンテナンス性が向上するだろう。
実装前に知っておきたいMDXの注意点と対策

MDXは非常に便利だが、導入にあたってはいくつかの課題も存在する。開発をスムーズに進めるために、あらかじめこれらの注意点を把握しておこう。特にツール周りの挙動については、事前の設定が重要になる。
リンターとフォーマッターの限界
現時点では、ESLintやPrettierといったコード整形ツールがMDXファイルを完璧にサポートしているとは言い難い。特に、Markdown記法とJSXが入り混じった複雑な構造では、自動整形が意図しない結果を招くことがある。
CSS-Tricksの著者であるZell Liew氏も、複雑なマークアップをMDXで行う際は手動でのインデント調整が必要になる場合があると述べている。もしマークアップが非常に重くなるのであれば、MDXではなく別のコンポーネント化手法を検討するのも一つの手だ。
RSSフィード生成の工夫
Astroの標準的なRSSインテグレーションは、デフォルトではMDXファイルをそのまま処理できない。RSSは純粋なXML形式を求めるが、MDXにはJavaScriptのロジックやコンポーネントが含まれている可能性があるからだ。
この問題を解決するには、Astroの「Container API」などを使用して、MDXを静的なHTMLにレンダリングしてからRSSに渡す処理が必要になる。ブログサイトでRSS配信を重視している場合は、実装の初期段階でこのワークフローを確認しておくべきだ。
独自の分析:AstroとMDXがもたらす「コンテンツ管理の未来」

AstroとMDXの組み合わせは、単なる「便利な記法」以上の価値を提供している。それは、エンジニアがコードを書く感覚で、ライターが質の高いコンテンツを制作できる環境の構築だ。これを実現しているのが、Astroの「アイランドアーキテクチャ」との親和性である。
アイランドアーキテクチャとは、ページ全体を静的なHTMLとして出力しつつ、必要な部分だけを動的なコンポーネント(アイランド)として動作させる仕組みだ。MDXを使えば、記事の本文という「静的な海」の中に、複雑な機能を持つ「動的な島」を簡単かつ安全に配置できる。
また、Content Collectionsによる型定義は、コンテンツの品質管理にも寄与する。例えば「すべての記事にサムネイル画像と著者情報が必須」というルールをコードレベルで強制できる。これにより、多人数での運用でもサイトの整合性が保たれやすくなるのだ。
筆者の見解としては、今後のWeb制作において「コンテンツのデータ化」はさらに加速するだろう。その際、MDXのような「構造化しやすいドキュメント形式」を採用していることは、将来的なプラットフォームの移行や再利用において大きなアドバンテージとなるはずだ。
この記事のポイント
- MDXはMarkdown内でコンポーネントを使用可能にし、HTML記述の手間を大幅に削減する
- Astroでは、直接インポート、Content Collections、Layoutフロントマターの3つの方法でMDXを活用できる
- Content Collectionsを使えば、共通コンポーネントを全記事に一括で提供でき、管理が効率化される
- フォーマッターの挙動やRSS対応など、一部のツールチェーンには工夫が必要な点に注意する
- AstroのアイランドアーキテクチャとMDXの相性は抜群であり、静的サイトの表現力を最大化させる

・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

MicrosoftがAI Maxを発表!AIエージェントが主役の「Agentic Web」時代に備える新広告ツールとは
Microsoftが「エージェンティック・ウェブ(Agentic Web)」という新しい時代の到来を見据えた、次世代の広告ツール群を発表した。これは人間だけでなく、AIエージェントがネット上の情報を探索し、意思決定や購買を代行する世界を想定したものだ。
2026年4月、Microsoft Advertisingは「AI Max」を含む一連のアップデートを公開した。これには広告配信の最適化だけでなく、AIによるブランドの露出状況を可視化する分析ツールや、AIが直接決済まで完結させるための新しいプロトコルが含まれている。
従来の「検索してクリックする」というユーザー行動が、AIによる「最適な選択と実行」へと置き換わりつつある。企業にとって、この変化は単なる広告手法の変更ではなく、Web上での存在意義を再定義する重要な転換点となるはずだ。
エージェンティック・ウェブの到来とAIエージェントの役割

エージェンティック・ウェブとは、AIエージェントがユーザーの代わりにタスクを遂行するWeb環境を指す。これまでのWebは、人間がブラウザを開き、検索エンジンにキーワードを入力して、表示されたリンク先を一つずつ確認する場所だった。
しかしAIエージェントの普及により、このプロセスが劇的に変化している。ユーザーは「週末の旅行プランを立てて、予算に合うホテルを予約しておいて」とAIに頼むだけで済むようになる。AIは複数のサイトを巡回し、価格や評価を比較し、最終的な選択までを行う。
クリックから「選択」へのパラダイムシフト
これまでの広告ビジネスは「クリック」を指標にしてきた。ユーザーを自社サイトへ誘導し、そこでコンバージョンを狙うのが一般的だ。しかし、AIエージェントが情報を集約して回答する場合、ユーザーは必ずしも元のサイトを訪問する必要がなくなる。
ここで重要になるのが、AIに「選ばれる」ことだ。AIがユーザーに提示する回答の中に、自社の製品やサービスが適切に含まれているか。そして、AIがその情報を信頼できると判断しているか。この「選択の最適化」が、次世代のマーケティングの中心となる。
このデモは、Web利用の構造がどのように変化しているかを視覚化したものだ。ユーザーの行動が簡略化される一方で、AIが裏側で行う処理の重要性が増していることがわかる。
AI MaxとOffer Highlightsの仕組み

Microsoftが導入した「AI Max for Search」は、AI環境に特化した新しいキャンペーン形式だ。これは従来の検索広告を拡張し、CopilotやBingのAIチャット回答内など、AIが生成するあらゆるインターフェースに広告を最適化して配信する。
AI Maxの特徴は、クエリのマッチング精度が大幅に向上している点だ。ユーザーがAIと対話する中で、文脈を深く理解し、最も関連性の高いタイミングで広告を表示する。これにより、単なるキーワード一致を超えた、意図に基づいたリーチが可能になる。
会話の中に溶け込むOffer Highlights
もう一つの注目機能が「Offer Highlights」だ。これはAIとの会話の中で、製品の主要なセールスポイントを直接提示する広告フォーマットである。例えば「送料無料」や「期間限定の割引」といった情報が、AIの回答の一部として自然に組み込まれる。
AIチャットを利用しているユーザーは、情報を素早く得たいと考えている。別サイトに移動して詳細を確認させるのではなく、会話の流れの中でメリットを伝えることで、離脱を防ぎながら購買意欲を高めることができる。これは「AI時代のリスティング広告」とも呼べる進化だ。
AI Visibilityによる露出状況の可視化

新しい時代において、自社がAIにどのように認識されているかを知ることは極めて重要だ。そこでMicrosoftは、ウェブ分析ツール「Microsoft Clarity」に「AI Visibility」という新機能を搭載した。これはAIの回答内で自社ブランドがどのように表示されているかを分析するツールだ。
AI Visibilityでは、どのコンテンツがAIに引用されたか、どのキーワードで自社が推奨されたかを詳しく追跡できる。また、競合他社がAIの回答内でどのような位置を占めているかを比較することも可能だ。これは従来のSEOにおける検索順位チェックの、AI回答版と言えるだろう。
引用元としての信頼性を高める
AIは回答を生成する際、信頼できるソースを引用する。Clarityの新しいレポートを使えば、自社のどのページがAIにとって「引用しやすい」と判断されているかが明確になる。データ構造が整理されているか、主張が明確かといった要素が、AIによる露出度に直結するのだ。
このイメージ図は、AI Visibilityが提供するインサイトを簡略化したものだ。自社サイトのどの部分がAIに評価され、引用されているかを把握することで、次にとるべき施策が明確になる。
Universal Commerce Protocolと直接購入

AIエージェントが「買い物」を代行するためには、商品データがAIにとって読み取りやすい形式である必要がある。Microsoftは「Microsoft Merchant Center」において「Universal Commerce Protocol」のサポートを開始した。これはAIエージェントが製品を発見し、取引を円滑に行うための標準規格だ。
このプロトコルに準拠することで、AIは商品の価格、在庫、仕様だけでなく、配送条件や返品ポリシーまでを正確に把握できるようになる。AIエージェントがユーザーの代理人として「最も条件の良い商品」を選ぶ際、このデータ構造化が勝敗を分けることになる。
Copilot Checkoutで摩擦のない購買体験を
さらにMicrosoftは、Copilot内で直接決済を完結させる「Copilot Checkout」の強化も進めている。ユーザーがAIとの対話で商品を決めた後、外部サイトへ移動することなく、その場で注文を確定できる仕組みだ。
発見から購入までの摩擦(フリクション)を最小限に抑えることで、コンバージョン率は飛躍的に向上すると期待されている。企業側は自社サイトへの流入を失うことになるが、その代わりに「AIエージェント経由の売上」という新しいチャネルを確保することになる。
独自分析:SEOからAIO(AI最適化)への戦略的転換

Microsoftの今回の発表は、Webマーケティングの軸足が「人間向けのSEO」から「AI向けのAIO(AI Optimization)」へ移りつつあることを示唆している。AIエージェントに選ばれるためには、単にキーワードを散りばめるだけでは不十分だ。
AIOにおいて最も重要になるのは、情報の「正確性」と「構造化」である。AIは不確かな情報を嫌う。出典が明確で、構造化データ(Schema.orgなど)によって意味が厳密に定義された情報は、AIに採用される確率が高まる。また、自然言語によるターゲット設定ツールの登場により、広告主は「誰に」届けたいかをより直感的に指定できるようになる。
中小企業が今から準備すべきこと
この変化は、リソースの限られた中小企業にとってもチャンスだ。巨大な広告予算がなくても、特定のニッチな分野で「最もAIに信頼される情報源」になれば、AIエージェントを通じて多くのユーザーにリーチできる可能性がある。
まずは、自社サイトの情報を整理し、AIが理解しやすい形に整えることから始めよう。具体的には、製品のスペックをテーブル形式で明記する、独自の調査データを公開する、といった「AIが引用したくなるコンテンツ」の作成が有効だ。AIエージェントという新しい「顧客」とどう付き合うかが、今後の成長を左右するだろう。
この記事のポイント
- MicrosoftがAIエージェント時代を見据えた広告ツール「AI Max」を発表した
- エージェンティック・ウェブでは、AIがユーザーの代わりに情報を探し、意思決定を行う
- 「AI Visibility」により、自社ブランドがAIの回答にどう露出しているか分析可能になった
- 「Universal Commerce Protocol」により、AIエージェントが直接購入を代行する仕組みが整いつつある
- これからのマーケティングは、検索順位だけでなく「AIに選ばれるための最適化(AIO)」が重要になる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AI時代のSEOで検索エンジンが信頼する3要素——権威性・鮮度・独自性の新基準
検索エンジンの評価基準が根本から変わった。従来のSEO対策だけでは通用しない時代が来ている。
Search Engine Journalの記事によると、AI駆動の検索システムは権威性・鮮度・独自性の3要素を重視する。これらの要素が連動して、コンテンツが検索結果に表示されるか、AI生成回答に引用されるかを決める。
この変化を理解しないと、どんなにキーワードを最適化しても、どんなにバックリンクを増やしても、成果は上がらない。AIが信頼するコンテンツを作るための新たな基準を解説する。
検索エンジンの評価システムが変わった

かつての検索エンジンは定期的なアルゴリズム更新で評価基準を調整していた。コアアップデートが発表され、順位が変動し、業界がパターンを分析して対策を練る。このサイクルは予測可能だった。
しかし今は違う。AI駆動の検索システムは常に学習し、評価基準を微調整している。Search Engine Journalの記事では、この状態を「連続的な調整」と表現する。アルゴリズムの更新のように見える現象の多くは、実際にはAIモデルの継続的な最適化の結果だ。
従来の「ランキング」から「評価」への移行
従来のSEOはページ単位のランキングを競うものだった。バックリンクや関連性、技術的な最適化が評価基準となり、ページ全体が1つの単位として扱われた。
AI駆動の検索では、ページ全体のランキングに加えて「情報の抽出と合成」という第2の層が加わった。検索エンジンは複数のソースから情報を抜き出し、再構成して回答を生成する。この変化により、競争の単位がページ全体から「情報の断片」へと移行している。
具体的には、コンテンツ内の各セクション、各段落、各リストがAI生成回答に引用される候補となる。ページが検索結果に表示されるかどうかだけでなく、ページ内のどの部分がAIによって利用されるかが重要になった。
信頼の評価が「継続的」になった
信頼性の評価も変化した。かつての信頼性は、権威性のシグナル、コンテンツ品質、技術的な健全性を組み合わせた「スコア」のようなものだった。一度高い評価を得れば、しばらくは維持できた。
現在の信頼性評価は「確率」のように振る舞う。継続的に評価され、再計算され、新しいデータに基づいて強化される。一度得た信頼を保持するのではなく、繰り返し獲得し続ける必要がある。
AIが信頼する3つの要素
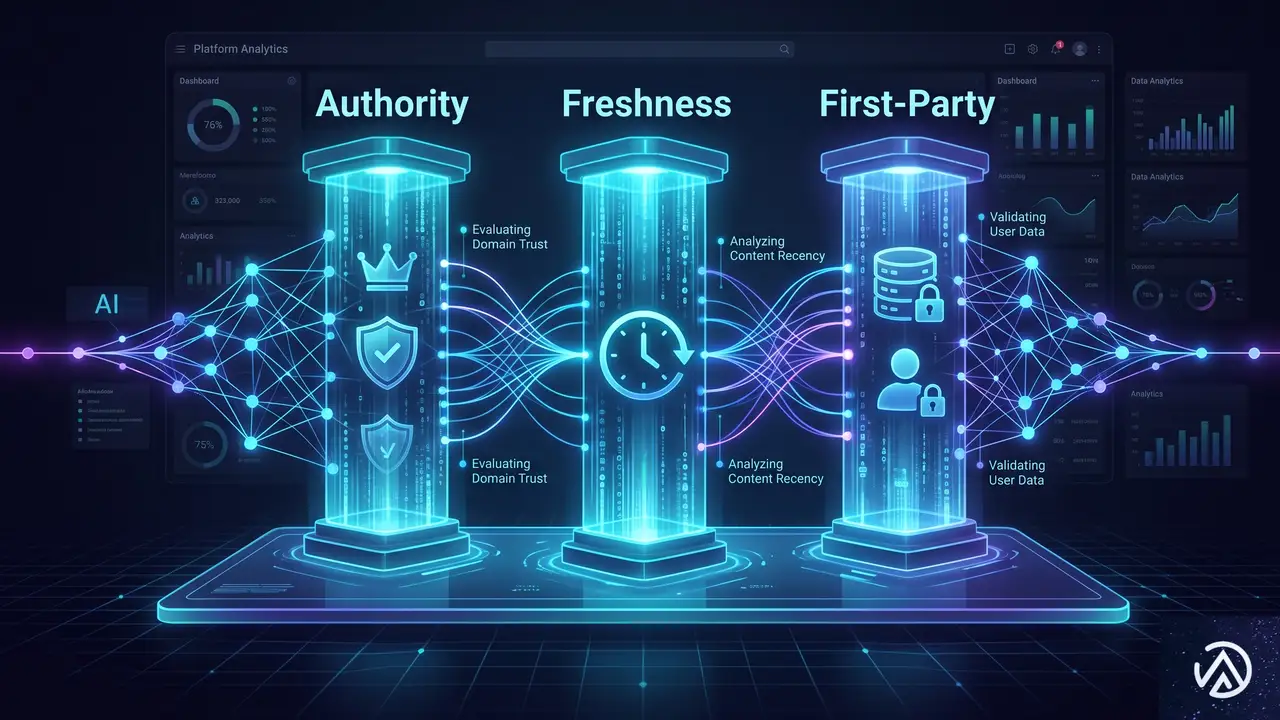
AI駆動の検索システムが信頼性を判断する際、特に重視する要素が3つある。権威性、鮮度、独自性のシグナルだ。それぞれが異なる役割を果たし、コンテンツが検索結果に表示されるか、AI回答に引用されるかを決める。
権威性——評価の入り口
権威性は常に重要だったが、その役割が変化した。AI駆動のシステムでは、権威性は「フィルター」として機能する。コンテンツが評価の対象になるかどうかを最初に決める要素だ。
すべての情報源が平等に扱われるわけではない。検索エンジンは認識しているエンティティ(ブランド、著者、ドメイン)を優先する。これらのエンティティは、ウェブ全体で一貫した専門性と可視性を示している必要がある。
バックリンクの数だけが権威性の指標ではなくなった。エンティティレベルの権威性を証明するには、以下の要素が重要になる。
- 他の権威あるサイトでの言及
- 一貫した著者性とトピックへの集中
- 特定の分野でのブランド認知
- 構造化された知識システムへの組み込み
Search Engine Journalの記事では、これらのシグナルが「エンティティ重力」を作り出すと説明する。存在感が強ければ強いほど、コンテンツが情報抽出の候補セットに含まれやすくなる。
重要なのは、権威性が可視性を保証するわけではないことだ。権威性は「資格」を保証する。権威性がなければ、コンテンツがよく書かれ、よく構成され、技術的に健全であっても、無視される可能性がある。
鮮度——継続的な関連性の証明
鮮度の概念も進化した。あるいは「分化した」と言う方が正確かもしれない。
かつては、すべての種類のコンテンツが鮮度の恩恵を受けた。新しいコンテンツは、特に時間に敏感なクエリに対して一時的なブーストを得られた。
現在、この従来型の鮮度はニュースメディアのような時間に敏感な発信者にしか利益をもたらさない。それ以外の発信者にとって、鮮度は「いつ公開されたか」ではなく「維持されているか」が重要になる。
AI駆動のシステムは、継続的な関連性を示す情報源を優先する。具体的には以下の要素だ。
- 定期的に更新されるコンテンツ
- 明確なタイムスタンプと改訂履歴
- 時間の経過とともに重要なトピックが強化されていること
- 現在の情報と文脈との整合性
古くなったコンテンツはリスクを生む。情報がまだ正確かどうかをシステムが判断できない場合、合成された回答に含まれる可能性が低くなる。
鮮度は、この意味で信頼強化のループになる。コンテンツを更新することは、継続的な専門性を示すシグナルだ。不確実性を減らし、含まれる可能性を高める。
独自性——確かな情報源の証明
3つ目の大きな変化は、独自性のシグナルの重要性が劇的に高まったことだ。AIシステムは情報を合成するように設計されているが、依然としてソース素材に依存している。その素材の品質は、出力の品質に直接影響する。
その結果、システムはリサイクルされた要約ではなく、オリジナルで検証可能な入力を表すコンテンツを重視する。独自性のシグナルには以下が含まれる。
- 独自の調査とデータ
- 独自の洞察と分析
- 直接的な製品やサービス情報
- 直接的な経験と専門知識
これらのシグナルは曖昧さを減らす。明確な情報源を提供し、帰属が容易で、複製が難しい。
これが「大量コンテンツ」モデルが近年苦戦している理由の1つだ。派生コンテンツの大量生産は、新しい情報をほとんど提供しない。価値を増やすことなくノイズを増やすだけだ。
AIシステムはより多くのコンテンツを探しているのではなく、より良い入力を探している。コンテンツが何か独自のものを追加しない限り、選択される可能性は低い。
見落とされがちな第4の要素——使いやすさ

権威性が評価の対象にし、鮮度が関連性を保ち、独自性が信頼性を確立する。しかし、コンテンツが利用できなければ、これらの要素はすべて無意味になる。ここで多くのサイトが失敗している。
ページがよくランキングしていても、AI生成回答に存在しないことがある。その場合、問題はランキングではなく「抽出のしやすさ」にあることがほとんどだ。
AIシステムは人間のようにページを読まない。探索的にナビゲートし、解釈し、合成することはない。抽出しやすいものを取得し、次に進む。
この環境でうまく機能するコンテンツには、いくつかの特徴がある。
- 明確で説明的な見出し
- 論理的な階層構造(H1、H2、H3)
- 段落ごとに1つの主要なアイデア
- 直接的で断定的な表現
- 適切な箇条書きと表
- 重要なポイントは早い段階で紹介(埋もれさせない)
これは文章スタイルの問題ではない。摩擦を減らす問題だ。
システムが回答を分離するためにコンテンツを再解釈する必要がある場合、利用される可能性は低くなる。文やリストを直接引き抜ける場合、含まれる可能性は高くなる。この意味で、構造は見た目の問題ではなく、機能的な問題だ。
- キーワード調査
- メタタグ最適化
- コンテンツ作成
- バックリンク構築
このデモは、同じ内容でも構造化の違いでAIによる抽出のしやすさが変わることを示している。左側は情報が段落内に埋もれており、AIが特定の情報を抽出するには文章全体を解析する必要がある。右側は見出しと箇条書きで明確に構造化されており、AIが「SEOの主要手法」という見出しの下のリストを直接取得できる。
「良いSEO」だけでは不十分な理由

多くのチームが直面しているのは、以下のようなパターンだ。検索順位は良好で、トラフィックも安定しているが、AI生成回答には存在しない。
最初の直感はランキングの問題を探すことだ。それで問題が解決しないと、キーワードの再最適化、より多くのバックリンク構築、より多くのコンテンツ公開に移行する。これらは真の問題に対処しない解決策だ。
ランキングは検索結果に表示されるかどうかを決める。情報抽出は回答に利用されるかどうかを決める。これらは同じシステムではない。ページが従来のSEO指標でうまく機能していても、AIシステムにとってきれいで抽出可能なセグメントを提供できないことがある。
その場合、より明確な構造やより強い権威性を持つ競合他社が、たとえ順位が低くても引用される可能性が高くなる。これは矛盾ではなく、評価の変化だ。
この比較図は、評価基準の変化を視覚化している。左側の従来型SEOでは、バックリンクやキーワードなどの要素が検索結果での表示位置(ランキング)につながる。右側のAI時代の評価では、権威性や鮮度などの要素が、検索結果での表示に加えてAI生成回答への引用有無にも影響する。評価基準が追加され、複雑化した。
実践的な対策——4つのアクションプラン

これらの変化に対する実践的な対策は明確だ。実行は簡単ではないが、方向性ははっきりしている。
1. アップデートを孤立したイベントとして扱うのをやめる
アルゴリズムのアップデートは、連続的なシステムの出力に過ぎない。短期的な変動に対応するよりも、長期的な方向性に向けて最適化する方が効果的だ。
Search Engine Journalの記事では、信号の半減期が短くなったと指摘する。6ヶ月前に有効だった手法が今も重要かもしれないが、定期的ではなく継続的に再評価されている。
2. エンティティレベルでの権威性への投資
自社サイトを超えた認知を構築する。どこで、どのように言及されるかは、何を公開するかと同じくらい重要だ。
PR、パートナーシップ、思想のリーダーシップ、ブランドの存在感などのエンティティ構築努力は、SEOから切り離せなくなった。これらはランキングだけでなく、情報抽出の候補に含まれるかどうかにも影響する。
3. コンテンツの継続的なメンテナンス
鮮度は一度きりのシグナルではない。関連性の継続的な実証だ。重要なコンテンツを維持する。すべてを常に書き直す必要はないが、重要な情報が最新であることを確認する。
4. 独自性のある価値を優先する
独自の洞察、データ、専門知識は、派生コンテンツよりも耐久性がある。AIシステムはより多くのコンテンツを求めているのではなく、より良い入力を求めている。
5. 使いやすさのために構造化する
コンテンツを読みやすくするだけでなく、抽出しやすくする。明確な見出し、論理的な階層、直接的な表現を採用する。AIが情報を簡単に引き抜けるように設計する。
この記事のポイント
- AI駆動の検索システムは権威性・鮮度・独自性の3要素を重視する
- 権威性は評価の「入り口」であり、これがないとコンテンツは考慮されない
- 鮮度は「いつ公開されたか」ではなく「維持されているか」が重要になった
- 独自性のある情報(調査・データ・洞察)がAIに高く評価される
- コンテンツ構造は「見た目」ではなく「抽出のしやすさ」のために重要
- 従来のSEO対策だけではAI生成回答への引用は獲得できない
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験
認証デザインの盲点「セッションタイムアウト」のアクセシビリティ改善ガイド
Webサイトのセッション管理は、ユーザー体験とセキュリティ、そしてリソース管理のバランスを取る高度な技術的判断が求められる領域だ。しかし、多くの開発現場で見落とされがちなのが、このセッションタイムアウトが障害を持つユーザーにとって深刻なアクセシビリティの障壁になっているという事実である。
世界中で約13億人が何らかの重大な障害を抱えており、その多くがデジタル環境での時間制限によって、チケットの購入やローン申請、SNSの閲覧といった日常的な活動を阻害されている。タイムアウトの設定一つが、特定のユーザーにとってはサービスを完全に放棄せざるを得ない原因になりかねない。
バックエンドの設計をわずかに工夫するだけで、こうしたフラストレーションを解消し、誰にとっても使いやすいサイトを構築できる。本記事では、セッションタイムアウトがなぜアクセシビリティの問題となるのか、そしてどのように改善すべきかを専門的な視点から解説する。
なぜセッションタイムアウトがアクセシビリティの障壁になるのか

セッションタイムアウトは、一定時間操作がない場合にセキュリティ保護のためにユーザーをログアウトさせる仕組みだ。しかし、この「操作がない」という判定基準が、特定のユーザーにとっては不当に厳格なものとなっている。
運動機能障害と入力速度のギャップ
脳性麻痺などの運動機能障害を持つユーザーは、筋肉のこわばりや調整の難しさから、情報の入力に非障害者よりも長い時間を要する場合がある。例えば、オンラインでコンサートチケットを購入する際、日付の選択や個人情報の入力に慎重な操作が必要となり、クレジットカード情報の入力にたどり着く前に「タイムアウト」の警告が表示されてしまうといったケースだ。
障害者権利の擁護活動を行っているMatthew Kayne氏によれば、適応デバイスを使用したWeb操作は非常に多大な労力を伴うという。慎重にページを移動している最中に突然ログアウトされることは、単なる不便を超え、数時間に及ぶ作業を無に帰す「デジタル的なグリッチ(不具合)」として機能してしまう。DWPアクセシビリティマニュアルでも、適応技術が入力信号を登録するまでに複数回の試行が必要になることがあり、ユーザーの操作速度が大幅に低下する可能性が指摘されている。
認知特性と情報の処理時間
認知的な違いを持つユーザーにとっても、厳格なタイムアウトは大きな圧力となる。自閉症、ADHD、失読症、あるいは認知症などの特性を持つ人々は、情報を読み取り、理解し、処理するために、より多くの時間を必要とする傾向がある。彼らは決して「非アクティブ」なわけではなく、画面の前で深く考え、処理を行っている最中なのだ。
特に「時間盲(タイムブラインドネス)」と呼ばれる特性を持つADHDのユーザーなどは、時間の経過を正確に把握することが難しい。ADHDの技術リーダーであるKate Carruthers氏は、時間の感覚が一般的なものとは異なり、数時間を失ってしまうこともあると述べている。このようなユーザーにとって、事前の通知なしにセッションが切れる設計は、作業の継続を著しく困難にする。
視覚障害とスクリーンリーダーのオーバーヘッド
全盲やロービジョンのユーザーは、ページ全体を視覚的にスキャンすることができない。スクリーンリーダーを使用してリンク、見出し、フォーム項目を一つずつ音声で確認していく作業は、本質的に視覚的な操作よりも時間がかかる。世界で約4,300万人が全盲、2億9,500万人が中等度から重度の視覚障害を抱えている現状を考えると、これは決して無視できない規模の問題だ。
また、タイムアウトを知らせるライブタイマーが逆に仇となることもある。アクセシビリティに詳しい開発者のBogdan Cerovac氏は、1秒ごとに残り時間を読み上げるカウントダウンタイマーに遭遇した際、その通知メッセージが画面操作を妨げ、実質的にページ操作が不可能になった経験を報告している。アクセシビリティを考慮していないタイマーの実装は、ユーザーを支援するどころか「スパム」のような妨害行為になりかねない。
アクセシビリティ要件を満たさない一般的なタイムアウト設定

セキュリティの観点からは、認証情報を無期限に保持するよりもセッションを適切に管理する方が望ましい。しかし、利便性を損なういくつかのパターンは、現代のアクセシビリティ基準に照らすと不合格と言わざるを得ない。
警告なしのサイレントログアウト
最も深刻なのは、何の前触れもなくユーザーをログアウトさせる設計だ。例えば、米国のビザ申請ページ(DS-260)では、約20分間操作がないと警告なしにセッションが終了する。保存していないデータはすべて消失するため、複雑なフォームを入力しているユーザーにとっては致命的な設計ミスといえる。
スクリーンリーダーを利用している場合、数秒間だけ表示されるポップアップ警告では、音声読み上げが完了する前にセッションが切れてしまうこともある。運動機能障害を持つユーザーにとっても、30秒程度の短いカウントダウンでは、延長ボタンをクリックするまでの時間が足りない場合が多い。
延長不可なセッション設計
セッションが切れた際に「セッションが終了しました」というメッセージと共にログイン画面へ戻されるだけの設計も問題だ。ユーザーが作業を継続したいという意思を示しても、それを反映する手段がなければ、すべての工程を最初からやり直す必要が生じる。これは障害の有無にかかわらずストレスフルな体験だが、操作に多大な労力を要するユーザーにとっては、その日の活動を断念させるほどの打撃を与える。
セッション終了に伴うフォームデータの消失
多くのWebサイトでは、セッションの終了と同時に入力中のフォームデータが破棄される。1時間をかけて入力した申請書や注文書が、わずかな放置時間で消えてしまうのは、設計上の配慮が欠けている証拠だ。データの保存が完了するまで作業が保護されない仕組みは、特に長い思考時間を必要とするユーザーを排除することにつながる。
作業を続けますか? 延長すると現在の入力内容が保持されます。
このデモは、突然の終了(Before)と、十分な猶予を持った警告(After)のUXの違いを示している。
セキュリティとアクセシビリティを両立させる設計パターン
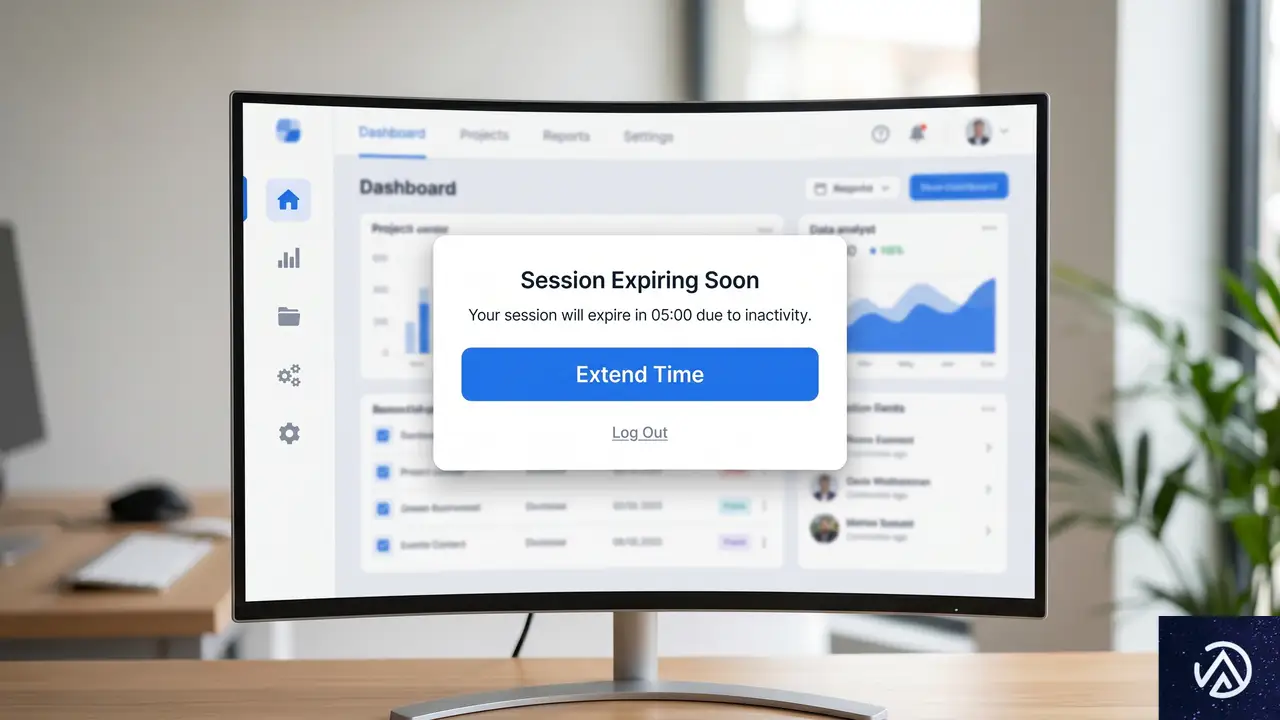
セキュリティを維持しつつ、アクセシビリティを向上させることは十分に可能だ。英国の年金クレジット申請サイトのように、期限の少なくとも2分前に警告を発し、セッションを延長できるように設計されている例もある。これはWCAG 2.2のレベルAAを満たす優れた実装だ。
事前警告システムと延長機能の実装
セッションが開始される前に、タイムリミットの存在とその長さを明示することが重要だ。銀行のフォームなどでは、最初のページで「この手続きには60分の時間制限があります」と伝え、必要に応じて制限時間を調整できるかどうかをユーザーに知らせるべきである。
実際のタイムアウトが近づいた際には、ダイアログを表示してワンクリックで延長できるようにする。この際、スクリーンリーダーのユーザーが即座に反応できるよう、ARIAライブリージョンなどを用いて適切に通知を行う必要がある。ただし、前述のCerovac氏の例のように、過度な頻度でのカウントダウン読み上げは避けるべきだ。
活動ベースと絶対時間の使い分け
セッション管理には「活動ベース(一定時間の無操作で終了)」と「絶対時間(操作の有無にかかわらず一定時間で終了)」の2種類がある。共有PCなどでの利用が想定される場合は絶対時間タイマーが有効だが、ユーザーがいつ終了するかを正確に予見できるため、活動ベースよりもアクセシビリティが高いとされる場合もある。重要なのは、ユーザーが「いつ、なぜ切れるのか」を完全にコントロールできていると感じられることだ。
オートセーブによる入力内容の保護
技術的な解決策として最も強力なのが、localStorageやsessionStorage、あるいはCookieを活用したオートセーブだ。ユーザーの入力を一定間隔でクライアントサイドに保存し、たとえ不意にセッションが切れても、再ログイン後に続きから再開できるようにする。
この仕組みがあれば、タイムアウトによる「やり直し」のペナルティがなくなる。特に複雑なフォームや長文の入力が必要なサイトでは、このデータ保護機能がアクセシビリティにおけるセーフティネットとして機能する。セキュリティ上の懸念がある場合は、再認証後にのみデータを復元する、あるいは機密性の高いフィールド(クレジットカード番号など)のみ除外するといった調整が可能だ。
このデモは、ユーザーが入力中に「保存されている」という安心感を得られるUIの概念を示している。
WCAG準拠とテストの重要性

W3Cが公開しているWeb Content Accessibility Guidelines(WCAG)は、セッションタイムアウトのアクセシビリティを判断する国際的な基準だ。開発者は特に、WCAG 3.0(草案)のガイドライン2.9.2や、現行の2.2.1「調節可能な時間制限」に注目すべきである。
ガイドライン2.2.1「調節可能な時間制限」の理解
このガイドラインでは、時間制限がある場合、ユーザーがその制限を解除、調整、または延長できる手段を提供することを求めている。具体的には、制限時間が切れる前にユーザーに警告し、少なくとも10回以上、簡単な操作(スペースキーを押すなど)で制限を延長できる猶予を与える必要がある。
この基準を満たすことで、運動機能障害や認知特性を持つユーザーが、自分たちのペースで操作を完了できる権利が保証される。Pew Research Centerのデータによれば、障害を持つ成人の62%がコンピュータを所有し、72%が高速インターネットを利用している。これは非障害者と統計的に差がない数字であり、Webサイト側が彼らを排除しない設計を行う責任は大きい。
タイムアウト制限が免除されるケース
ただし、WCAGでも例外は認められている。例えば、ライブのチケット販売のように、在庫を保持できる時間に制限を設けなければ他のユーザーが購入できなくなる場合や、セキュリティリスクが極めて高い特定の金融取引などが該当する。また、制限時間が20時間を超える場合も、実質的にユーザーの操作を妨げないため免除される。
ニュース記事の閲覧、SNSのスクロール、一般的なECサイトの商品検索など、本来時間制限が必要ない場所で恣意的なセッション終了を設けることは避けるべきだ。時間制限が必要な試験などの場面でも、管理者側が障害を持つ学生に対して個別に時間を延長できる仕組みを整えることが推奨されている。
この記事のポイント
- セッションタイムアウトは、運動・認知・視覚障害を持つユーザーにとって重大なアクセスの障壁となる
- 警告なしの強制ログアウトは、それまでの多大な入力作業を無に帰すため、アクセシビリティ上極めて不適切だ
- WCAG準拠のためには、期限の少なくとも2分前に警告を出し、簡単な操作で時間を延長できる機能が必須である
- オートセーブ機能を実装することで、不意の切断時でもデータを保護し、ユーザーのフラストレーションを最小限に抑えられる
- セキュリティとアクセシビリティは対立するものではなく、適切な設計によって両立させることが可能だ
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

CSS最新動向まとめ:clip-pathのジグソーパズル、ビュートランジション、名前付きコンテナ
CSSの進化は止まらない。毎週のように新たな機能や実装が追加され、開発者の表現の幅を広げている。CSS-Tricksの最新レポート「What’s !important #9」では、実用的なclip-pathの応用から、管理が楽になるビュートランジションツールキット、そして長らく待たれたsubgridの本質まで、押さえておくべきトピックがまとめられている。
この記事では、同レポートで紹介された主要なCSS機能とその背景にある動向を解説する。各機能がどのような問題を解決し、実際のプロジェクトでどう活かせるのか、具体例を交えて見ていく。
clip-pathで作るジグソーパズルと角丸ポリゴン

要素の表示領域を自由な形に切り抜くCSSプロパティclip-pathの応用例が注目を集めている。Amit Sheen氏は、このプロパティだけで完全なジグソーパズルを作成する方法を紹介した。パズルそのものが必要になる場面は稀だが、このチュートリアルはclip-pathの可能性とその構文を学ぶ絶好の機会だ。
進化を続けるclip-pathの仕様
clip-pathは当初、基本的な図形の切り抜きしかできなかった。しかし現在はpolygon()関数で複雑な多角形を定義できる。さらに仕様は進化を続けており、Chrome Canaryでは先週、polygon()関数にroundキーワードを追加して角を丸める機能が実装された。
開発者のyisibl氏は、この機能の実装に携わっていると述べている。また、bevel(面取り)のような他の角形状キーワードの実装についても議論が進んでいる。これらが実用化されれば、より滑らかでデザイン性の高いクリッピングが可能になる。
clip-pathアニメーションの実例
Karl Koch氏は、clip-pathを使った印象的なアニメーションのデモを公開している。形状を連続的に変化させることで、モーフィングのような視覚効果をCSSのみで実現できる。JavaScriptを使わないためパフォーマンスに優れ、ユーザーインタラクションへの応答も滑らかだ。
このデモは、clip-pathの値が四角形から星形へ変化する様子を概念的に示している。実際のアニメーションでは、この変化が連続的に行われる。
ビュートランジションを効率化するツールキット

ページや要素が切り替わる際のトランジション効果を簡単に実装できる「ビュートランジションAPI」。Chrome DevRelチームは、このAPIの利用を支援する「ビュートランジションツールキット」を公開した。
要素スコープのビュートランジション
このツールキットが公開された背景には、技術の急速な普及がある。Chromeは先月、ページ全体ではなく特定の要素だけにトランジション効果を適用する「要素スコープのビュートランジション」を正式に実装した。これにより、ページの一部だけを滑らかに更新するといった、より細かい制御が可能になった。
ツールキットには、この新機能を活用したデモも含まれている。開発者は複雑なJavaScriptコードを書かずに、CSSとわずかなマークアップで高度な画面遷移を実現できる。
ツールキットが解決する課題
ビュートランジションAPIは強力だが、適切なタイミングでstartViewTransition()を呼び出し、DOMの更新と連携させる必要がある。ツールキットはこうしたボイラープレートコードを抽象化し、一般的なユースケースを簡単に実装できるユーティリティを提供する。特にReactやVueなどのフレームワークと組み合わせる際の手間を大幅に削減できる見込みだ。
名前付きコンテナと@scopeによるスタイルのスコープ管理
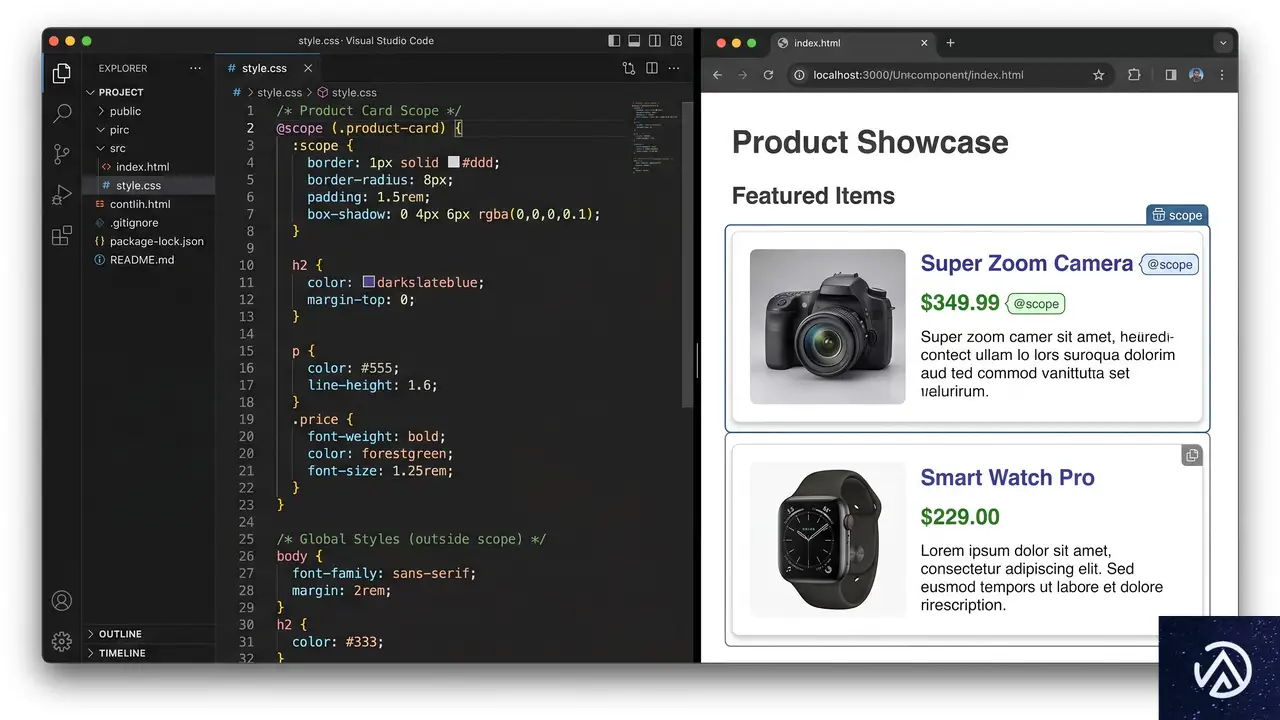
大規模なプロジェクトでは、CSSのスタイルが意図しない要素に影響を与える「スタイルの漏れ」が問題になる。この問題を解決するためのアプローチとして、「名前付きコンテナ」と@scopeルールが注目されている。Chris Coyier氏は両者を比較し、その使い分けについて論じている。
名前付きコンテナの仕組み
名前付きコンテナは、container-nameプロパティでコンテナに名前を付け、@containerルール内でその名前を参照してスタイルを適用する手法だ。これにより、特定のコンテナ内の要素にのみスタイルを限定できる。
.component {
container-name: my-component;
}
@container my-component (min-width: 400px) {
.component .button {
background-color: blue;
}
}このコードでは、.componentというコンテナ内にあり、かつコンテナの幅が400px以上の場合にのみ、ボタンの背景色が青になる。コンテナクエリに近い考え方でスコープを制限する方法だ。
@scopeルールとの比較
一方、@scopeルールは、スタイルの適用範囲を親要素によって直接定義する。
@scope (.component) {
.button {
background-color: blue;
}
}Coyier氏は当初、名前付きコンテナのアプローチを評価していたが、現在はHTMLを汚さず、より直感的にスコープを定義できる@scopeを好む傾向にあると述べている。@scopeを使えば、クラス名を増やすことなく、スタイルの影響範囲を明確にできる利点がある。
<button class=”component__button”>送信</button>
</div>
<button>送信</button>
</div>
どちらの手法を選ぶかはプロジェクトの構造やチームの好みによる。コンテナクエリと連携させたい場合は名前付きコンテナが、純粋にスタイルのカプセル化を目的とする場合は@scopeが適している場合がある。
subgridの本質とその実践的価値
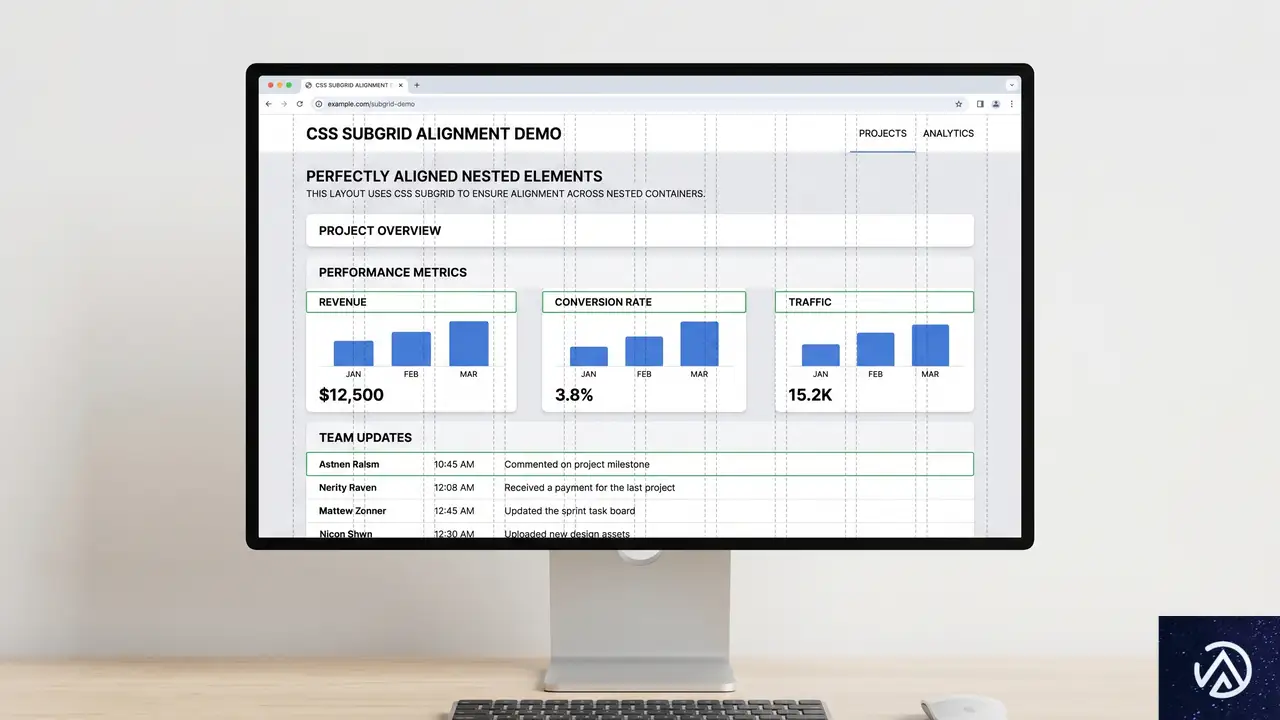
CSS Gridの強力な機能である「subgrid」は、約2年半前に主要ブラウザで利用可能になった。当時はレイアウトの革命とまで言われたが、実際の採用は緩やかだ。David Bushell氏は、subgridの核心をシンプルに解説し、その真価を再評価している。
subgridが解決するレイアウト課題
従来、親グリッドと子要素のグリッドを連動させたい場合、ネストされた<div>要素(いわゆる「ラッパー地獄」)や負のマージンといったハックが必要だった。subgridを使えば、子グリッドが親グリッドのトラック(行や列)を直接継承できる。これにより、マークアップを複雑にすることなく、深い階層の要素も親グリッドにきれいに整列させられる。
このデモは概念を示したものだ。実際のsubgridでは、grid-template-columns: subgridを指定した子アイテムが、親の列トラックをそのまま借用する。
採用が進まない理由と今後
subgridの採用が思ったほど進んでいない理由の一つは、学習コストにある。Grid自体が豊富な概念を持つため、その上位機能であるsubgridの必要性や利点を理解するハードルが高い。Bushell氏の解説は、このハードルを下げ、具体的なメリットを視覚的に示す良いきっかけになる。
カードレイアウトや複雑なフォーム、編集可能なダッシュボードなど、内部構造が異なるコンポーネントを共通のグリッドに揃えたい場面で、subgridの真価が発揮される。Flexboxや従来のGridでは実現が難しかった、高度な整列が可能になる。
CSSの拡張と「JavaScript不要」の潮流

Pavel Laptev氏は「The Great CSS Expansion」と題した記事で、かつてJavaScriptライブラリに頼っていた機能の多くが、現代のCSSで代替可能になっている点を指摘している。これは「You Might Not Need jQuery」の現代版とも言える潮流だ。
例えば、ツールチップやドロップダウンメニューの位置決めには、JavaScriptライブラリが使われてきた。しかし現在では、CSSのanchor()関数やanchor-positionプロパティを用いて、相対的な位置を純粋なCSSで計算できる。同様に、スムーズスクロールやタブインターフェース、アコーディオンなども、scroll-behavior、:target疑似クラス、<details>要素など、CSSとHTMLの組み合わせで実現できるケースが増えている。
この変化の背景には、ブラウザベンダーによるCSS仕様の積極的な拡張がある。開発者は、軽量でパフォーマンスに優れ、ブラウザにネイティブに統合されたCSSソリューションを選択肢として持つようになった。プロジェクトによっては、依存ライブラリを削減し、バンドルサイズを縮小できる可能性がある。
この記事のポイント
clip-pathは角丸ポリゴンなどでさらに進化しており、複雑な形状の作成とアニメーションが可能になった。- Chromeのビュートランジションツールキットは、要素スコープのトランジションなど、最新APIの実装を効率化する。
- スタイルのスコープ管理には
@scopeルールが有力な選択肢で、HTMLをシンプルに保ちながらカプセル化を実現できる。 subgridは親グリッドの構造を子要素が継承する機能で、ネストしたラッパーやハックなしで深い整列を実現する。- かつてJavaScriptが必要だった多くのUI機能が、現代のCSSとHTMLで代替可能になりつつある。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AIエージェントに最適化されたWebサイトとは?Cloudflareが提唱するAgent Readinessスコアの全容
Webサイトのあり方が、人間がブラウザで閲覧するものから、AIエージェントが自律的に情報を収集し処理するものへと劇的に変化している。かつてWebサイトが検索エンジンに最適化(SEO)されたように、これからはAIエージェントが理解しやすい形に最適化される必要がある。
Cloudflare(クラウドフレア)は、自社サイトがどの程度AIエージェントに対応できているかを測定するツール「isitagentready.com」を公開した。これは、AIがサイトをクロールし、内容を理解し、さらには決済まで行える状態にあるかを数値化する指標である。
現在、インターネット上の主要な20万ドメインを調査した結果、AIエージェントへの最適化が進んでいるサイトは極めて少ないことが判明した。しかし、これは早期に対応することで、競合他社よりもAIによる情報提供やサービス利用の面で優位に立てる可能性があることを示唆している。
AIエージェント向けのWeb最適化指標であるAgent Readinessとは

Agent Readiness(エージェント・レディネス)は、WebサイトがAIエージェントという新しい「訪問者」をどれだけ歓迎し、効率的に情報を渡せるかを示す新しい概念である。Cloudflareが提供を開始した「isitagentready.com」では、URLを入力するだけで、そのサイトの対応状況をスコア化できる。
このスコアは、単に「AIを拒否していないか」を確認するだけのものではない。AIがサイト内を迷わずに移動できるか、情報を処理する際のコスト(トークン数)を削減できているか、そしてAIが自律的にアクションを起こせるかといった多角的な視点で評価される。
評価を構成する4つの主要な軸
Agent Readinessスコアは、主に以下の4つのカテゴリに基づいて算出される。それぞれの要素は、AIエージェントがサイトを訪れた際の「体験」を向上させるために不可欠なものだ。
- ディスカバリー(発見しやすさ):AIがサイトの構造を即座に把握し、必要なページへたどり着けるか
- コンテンツの最適化:AIが理解しやすい形式(Markdownなど)でデータを提供しているか
- 制御とセキュリティ:AIの行動範囲を適切に制限し、信頼できるAIかどうかを認証できるか
- インタラクション(相互作用):AIがAPIを介してツールを操作したり、決済を行ったりできるか
Cloudflare Radarの調査によれば、現在インターネット上の主要なサイトの約78%が「robots.txt」を設置しているが、そのほとんどは従来の検索エンジン向けに書かれたものである。AIエージェントに特化した設定を行っているサイトは、まだ全体の数パーセントに過ぎない。
AIエージェントに情報を届けるための新規格と実装方法

AIエージェントがWebサイトを巡回する際、最大の障壁となるのが「HTMLの複雑さ」である。人間向けの装飾や広告が含まれるHTMLは、AIにとってノイズが多く、処理に多くのトークンを消費させる。これを解決するための新しい標準規格が登場している。
llms.txtによる「AI専用のお品書き」の提供
「llms.txt」は、Webサイトのルートディレクトリに配置するプレーンテキストファイルである。これは、AI(大規模言語モデル)に対して、サイトの概要や重要なコンテンツへのリンクをリスト化した「読書リスト」のような役割を果たす。サイトマップをAIが読みやすい言葉で書き直したものと考えると分かりやすい。
# サイト名
> サイトの短い説明文
## 主要ドキュメント
- [導入ガイド](https://example.com/docs/intro.md)
- [APIリファレンス](https://example.com/docs/api.md)このファイルを設置することで、AIは数千ページあるサイトの中から、どのページを優先的に読むべきかを瞬時に判断できる。これにより、AIエージェントの回答精度が向上し、ユーザーが求める情報にたどり着くまでの時間が短縮される。
Markdownコンテンツ・ネゴシエーションによる軽量化
コンテンツ・ネゴシエーションとは、クライアント(訪問者)の要望に合わせて、サーバーが最適な形式のデータを返す仕組みである。AIエージェントがHTTPヘッダーに Accept: text/markdown を含めてリクエストを送った際、サーバーがHTMLではなくMarkdown形式を返すように設定することが推奨されている。
HTMLからMarkdownへの切り替えは、AIが消費するトークン数を最大で80%削減できるというデータがある。トークンの削減は、AIの処理速度を上げ、運用コストを下げることに直結する。以下のデモは、HTMLとMarkdownでどれほど情報の密度が異なるかを視覚化したものである。
投稿日:2026年4月17日
# 最新ニュース
WebサイトのAI最適化が始まりました。
[詳細](https://example.com/news/1)
このデモのように、AIにとっては構造化されたテキストのみの方が扱いやすく、誤認のリスクも低い。Cloudflareでは、URLの末尾に /index.md を付与することで、動的にMarkdownを返す仕組みを推奨している。
AIエージェントの制御とセキュリティの新基準

すべてのAIエージェントにサイトを解放するのが正解とは限らない。コンテンツの無断学習を拒否したい、あるいは特定の信頼できるエージェントにのみアクセスを許可したいというニーズがある。これに対応するための規格が「Content-Signal」と「Web Bot Auth」である。
Content-Signalによる詳細な意思表示
従来の robots.txt では、アクセスを許可するか拒否するかという二択しかできなかった。新しい「Content-Signal」ディレクティブを使うと、AIによる学習(ai-train)、推論への利用(ai-input)、検索結果への表示(search)を個別に制御できる。
User-agent: *
Content-Signal: ai-train=no, search=yes, ai-input=yes例えば、上記の記述では「AIの学習には使わせないが、AIがユーザーの質問に答える際の参考資料(RAG)としての利用や、検索結果への掲載は許可する」という柔軟な設定が可能になる。これにより、著作権を守りつつ、AIを介したトラフィックを確保できる。
Web Bot Authによるエージェントの身元確認
悪意のあるボットがAIエージェントを装ってアクセスしてくるリスクに対し、「Web Bot Auth」という認証規格が提案されている。これは、エージェントがリクエストにデジタル署名を付与し、サイト側がその署名を公開鍵で検証する仕組みである。
これにより、サイト運営者は「このアクセスは確かにOpenAIの公式エージェントからのものだ」と確信を持ってアクセスを許可できるようになる。匿名のスクレイパーと、正当なAIサービスを明確に区別するための重要なインフラとなるだろう。
自律的なアクションを可能にするAPIと決済の統合

AIエージェントの真の価値は、情報の閲覧だけでなく、ユーザーの代わりに「行動」することにある。買い物、予約、データの処理といったタスクをAIが自律的にこなすためには、WebサイトがAI向けの「窓口」を備えていなければならない。
MCP(Model Context Protocol)の活用
MCPは、AIモデルが外部のデータソースやツールと接続するためのオープン標準である。サイト側が「MCPサーバー」を用意し、その機能(ツール)を記述した「サーバーカード」を /.well-known/mcp/server-card.json に配置することで、AIはどのような操作が可能かを理解できる。
例えば、ドキュメント検索ツールや在庫確認ツールをMCP経由で公開すれば、AIエージェントは自らそのツールを呼び出し、ユーザーの複雑な要求に応えることができるようになる。これは、AIが「サイトを読む」段階から「サイトを使う」段階への進化を意味する。
HTTP 402によるマシン間決済の復活
AIエージェントが有料の情報を取得したり、商品を購入したりする場合、人間向けのクレジットカード入力画面は機能しない。そこで注目されているのが、長らく使われてこなかったHTTPステータスコード「402 Payment Required」の活用である。
「x402」と呼ばれるこの新しい決済フローでは、AIがリクエストを送ると、サーバーが402エラーとともに「支払い条件」を機械読み取り可能な形式で返す。エージェントはその条件に従って決済を行い、再度リクエストを送ることでコンテンツを取得できる。人間を介さない、マシン間の経済圏を支える技術である。
Cloudflare ドキュメントに見るAI最適化の実践事例
Cloudflareは自社の開発者向けドキュメントにおいて、これらの規格をいち早く導入している。その結果、AIエージェントによる回答速度が66%向上し、消費トークン数が31%削減されたという。具体的にどのような工夫がなされているのかを見てみよう。
URL書き換えによる動的なMarkdown提供
Cloudflareは、既存のHTMLページをわざわざMarkdownで書き直すのではなく、エッジコンピューティング(Cloudflare Rules)を活用して動的に変換している。URLの末尾に /index.md を付けると、オリジナルのHTMLからタグを取り除き、Markdownとして配信する仕組みだ。
これにより、メンテナンスコストを増やすことなく、人間向けとAI向けのコンテンツを両立させている。また、大規模なサイトでは llms.txt が巨大になりすぎるため、ディレクトリごとに分割した llms.txt を用意し、ルートからそれらをリンクする階層構造を採用している。
古い情報をAIに学習させないためのリダイレクト
Webサイトには、歴史的な理由で残されている古いドキュメント(非推奨のツールなど)が存在する。人間は「非推奨」という警告バナーを見て判断できるが、AIクローラーはテキストをそのまま飲み込んでしまい、古い情報をユーザーに教えてしまうことがある。
Cloudflareでは、AI学習用クローラーを識別し、古いページから最新のページへと強制的にリダイレクトさせる処理を行っている。これにより、AIが常に最新かつ正確な情報のみを学習するように制御している。これは、AI時代の新しいコンテンツ管理の形と言えるだろう。
独自の分析:Webサイトは「読むもの」から「使われるもの」へ

Agent Readinessの普及は、Webサイトの設計思想を根本から変える可能性がある。これまでのWebデザインは、いかに人間の視線を誘導し、クリックさせるかという「UI/UX」が中心だった。しかし、AIエージェントが主役となる世界では、いかに機械が迷わず、低コストで目的を達成できるかという「DX(Developer Experience)ならぬAX(Agent Experience)」が重要になる。
特に注目すべきは、AIエージェントが「ブラウザ」を介さずに直接サーバーと対話するようになる点だ。これは、Webサイトが「情報の展示場」から「プログラム可能なインターフェース」へと進化することを意味している。APIが公開されていない小規模なサイトでも、llms.txt やMarkdown配信を導入することで、AIという強力な力を味方につけることができる。
今後、Googleなどの検索エンジンも、Agent Readinessスコアが高いサイトを「AIフレンドリーな良質なソース」として優遇する可能性がある。SEOの次のステージとして、この「AI最適化」への取り組みは、企業のデジタル戦略において避けて通れない課題となるだろう。
この記事のポイント
- Agent Readinessスコアの登場:WebサイトがAIエージェントにどれだけ最適化されているかを測定する新しい指標が公開された
- llms.txtとMarkdownの重要性:AI専用の案内図(llms.txt)と軽量なデータ形式(Markdown)が、AIの回答精度向上とコスト削減に直結する
- 詳細なアクセス制御:Content-Signalにより、学習は拒否しつつ検索や推論への利用を許可するなど、柔軟な意思表示が可能になる
- マシン間経済の加速:MCPによるツールの公開や、x402による自動決済など、AIが自律的にアクションを起こすためのインフラが整いつつある
- 早期対応のメリット:現状では対応サイトが少ないため、今すぐ対策を始めることでAI経由のトラフィックや利便性において大きなアドバンテージを得られる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

SEOの成果を最大化するホスティングの役割とbrightonSEO 2026の展望
SEO(検索エンジン最適化)において、多くの担当者はコンテンツの質やバックリンクの獲得、キーワード選定に膨大な時間を費やす。しかし、それらの努力を支える「土台」であるホスティング環境が軽視されるケースは少なくない。
2026年4月30日から5月1日にかけて、英国ブライトンで開催される世界最大級の検索会議「brightonSEO 2026」に、ホスティングプロバイダーのKinstaがスポンサーとして参加する。今回のイベントでは、SEOの成果を左右するインフラの重要性が改めて議論される見通しだ。
サーバーの応答速度や安定性が、どのように検索順位やユーザー体験に影響を与えるのか。本記事では、brightonSEO 2026の概要とともに、最新のSEO戦略におけるホスティングの役割を技術的な視点から詳しく解説する。
SEOにおけるホスティングの決定的な役割

SEOチームがコントロールできる要素は多いが、ランキングに直接影響を与えるアルゴリズムのすべてを制御できるわけではない。その中で、ホスティング環境はサイトのパフォーマンス、可用性、そしてクローラーに対する親和性を決定づける重要な基盤となる。
サイトスピードと検索順位の相関
Googleをはじめとする検索エンジンは、ページの読み込み速度をランキング要因の一つとして明示している。特にモバイル検索においては、数秒の遅延が直帰率の劇的な上昇を招き、検索順位の低下に直結する。高速なサーバー環境は、TTFB(Time to First Byte / サーバーがリクエストを受けてから最初の1バイトを返すまでの時間)を短縮し、ページ全体の表示速度を底上げする。
TTFBは、DNSの解決速度、サーバーの処理能力、データベースの最適化状態によって左右される。共有サーバーのようなリソースが制限された環境では、他サイトの負荷に影響を受けてTTFBが悪化することが多いが、マネージドホスティングや専用リソースを持つ環境では、安定した高速レスポンスが期待できる。
サーバーの安定性とインデックスへの影響
サイトが頻繁にダウンしたり、サーバーエラー(5xx系)を返したりする場合、検索エンジンのクローラーはサイトの信頼性が低いと判断する。これが継続すると、インデックスから削除されたり、クローラーの巡回頻度が下げられたりするリスクがある。SEOの成果を維持するためには、99.9%以上の高い稼働率(アップタイム)を保証するインフラが不可欠だ。
以下のデモは、サーバーの応答速度(TTFB)の差が、ユーザーがコンテンツを目にするまでの時間にどのような影響を与えるかを視覚化したものだ。
このデモが示すように、インフラの性能差はページの表示開始タイミングに決定的な差を生む。SEOチームがどれだけ画像を軽量化しても、サーバーの初動が遅ければその効果は半減してしまう。
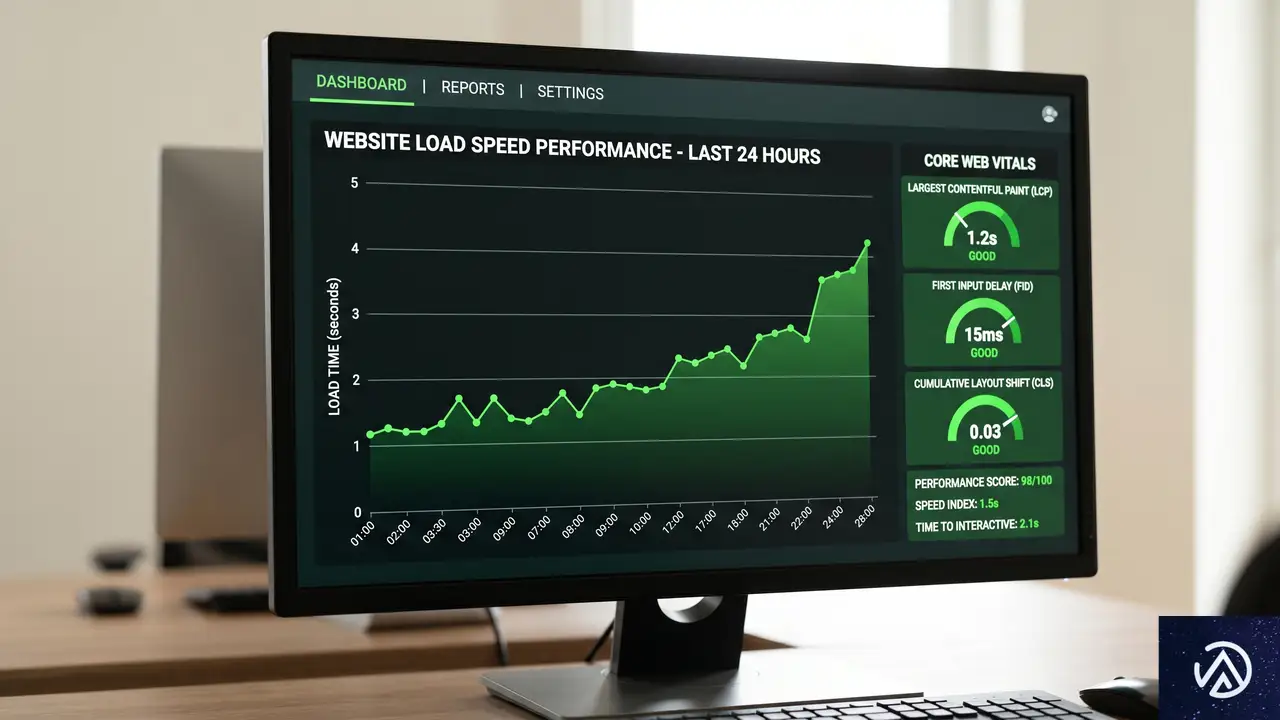
コアウェブバイタルとインフラの最適化
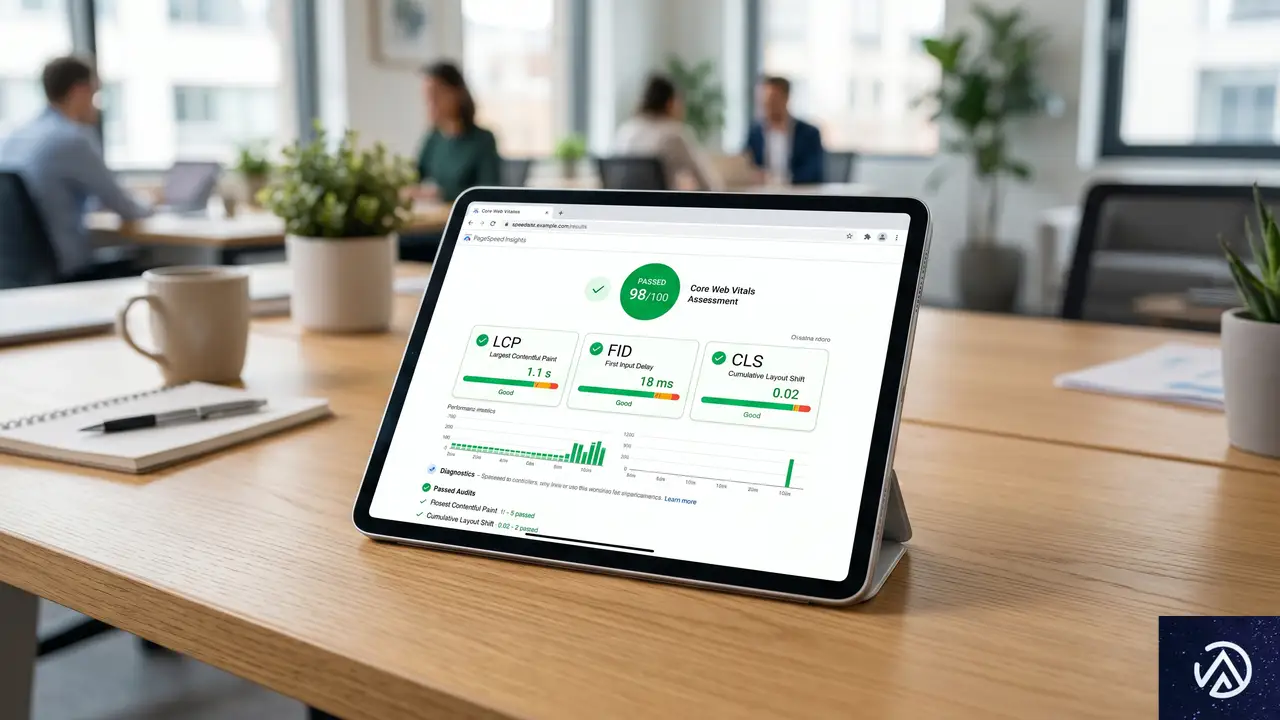
Googleが重要視するCWV(Core Web Vitals / コアウェブバイタル)は、ユーザー体験を数値化した指標だ。これらは単なるフロントエンドの最適化だけでなく、背後のサーバー性能とも密接に関わっている。
LCPを改善するエッジコンピューティング
LCP(Largest Contentful Paint / 最大視覚コンテンツの表示時間)は、ページ内の最も大きな要素(メイン画像や見出し)が表示されるまでの時間を測定する。これを改善するためには、静的資産だけでなく動的なHTMLドキュメントそのものをユーザーに近い場所から配信する必要がある。
CDN(Content Delivery Network)を活用し、エッジサーバーでキャッシュを保持することで、物理的な距離による遅延を解消できる。最近の高性能なホスティングでは、エッジキャッシュを標準搭載し、世界中どこからアクセスしても瞬時にページを表示できる仕組みを整えている。
CLSとインフラの安定性
CLS(Cumulative Layout Shift / 累積レイアウトシフト)は、読み込み中の意図しないレイアウトのズレを測定する。一見するとCSSの問題に見えるが、広告スクリプトや外部リソースの読み込みがサーバーの遅延によって不安定になると、ブラウザがレンダリングのタイミングを測れず、結果としてCLSが悪化することがある。
安定した高帯域幅を持つネットワークインフラは、リソースの並行読み込みをスムーズにし、ブラウザが予測通りにページを組み立てるのを助ける。HTTP/3のような最新プロトコルのサポートも、多重化されたリソース転送を効率化し、ユーザー体験の向上に寄与する。
クローラーの効率を高めるサーバー戦略

SEOにおいて「見落とされがちだが重要」なのが、クローラーに対する最適化だ。検索エンジンのボットがサイトを巡回する際、サーバーの応答が遅かったりエラーが多かったりすると、クローラーはそのサイトの巡回を切り上げてしまう。
クロールバジェットの最適化
クロールバジェットとは、検索エンジンが特定のサイトに対して割り当てる「巡回リソースの総量」のことだ。大規模なサイトや更新頻度の高いサイトでは、このバジェットをいかに効率よく消費させるかが重要になる。
サーバーが高速に応答すれば、同じ時間内にクローラーはより多くのページを巡回できる。結果として、新しい記事のインデックスが早まったり、既存記事の修正が検索結果に素早く反映されたりするメリットが生まれる。インフラの性能向上は、サイト全体の「鮮度」を保つための必須条件といえる。
最新技術によるクロール効率の向上
最近のホスティング環境では、クローラーからのリクエストを識別し、リソース消費を最適化する機能が提供されている。例えば、不要なボットのアクセスを遮断しつつ、Googlebotなどの重要なクローラーには優先的にリソースを割り当てる設定が可能だ。これにより、サイトの負荷を抑えつつSEO効果を最大化できる。
以下の図は、SEO施策のレイヤー構造を示したものである。インフラがすべての施策の土台になっていることがわかるだろう。
(速度・可用性・セキュリティ・クロール効率)
brightonSEO 2026とKinstaの取り組み

2026年4月30日から5月1日に開催される「brightonSEO 2026」は、SEO業界の最前線に立つ専門家が集結するイベントだ。Kinstaはこのイベントのスポンサーとして、SEOにおけるホスティングの役割を再定義しようとしている。
イベントでの主要テーマ
brightonSEOでは、コンテンツ制作やリンクビルディングだけでなく、テクニカルSEOの重要性が毎年強調される。2026年の開催では、AIによる検索体験の変化(SGEなど)や、より高度なユーザー体験の数値化が焦点になると予想される。Kinstaのブース(#29)では、これらの変化に対応するためのインフラ構成について、専門チームによる相談が行われる予定だ。
Kinstaチームとの交流
当日は、KinstaのパートナーシップマネージャーであるMarcel Bootsman氏や、SEOチームリードのAntonio Tinoco氏をはじめとする専門家が参加する。彼らは、ホスティングがいかにコアウェブバイタルを支え、大規模サイトのクロール効率を改善するかについて、具体的な事例を交えて解説するだろう。オレンジ色のTシャツを着たスタッフが、サイトの成長を支える強固な基盤作りのヒントを提供してくれるはずだ。
2026年以降のSEOとインフラ戦略の展望

AI検索エンジンが台頭する2026年において、SEOの定義は「検索結果の1位を取ること」から「AIによって信頼できるソースとして選ばれること」へと広がりつつある。
AIクローラーへの対応
AI検索エンジンは、従来のGooglebotよりも頻繁かつ詳細にサイトをスキャンすることがある。また、情報の正確性だけでなく、情報の「取得のしやすさ」も評価の対象になる可能性が高い。高速で安定したサーバーは、AIクローラーに対しても「信頼できる高品質なサイト」というシグナルを送ることになる。
ユーザー体験の絶対化
SEOのテクニックが高度化する一方で、最終的な評価を下すのは「人間」である。ページが瞬時に開き、ストレスなく操作できることは、どんなコンテンツよりも先にユーザーが感じる価値だ。インフラへの投資は、単なるSEO対策を超えた「ブランド体験」の向上に直結する。
Kinstaのチームは、ホスティングがSEOに与える影響は今後さらに拡大すると見ている。サイトの成長に合わせて柔軟にスケールでき、かつ高度なセキュリティとパフォーマンスを維持できる環境こそが、2026年以降のデジタル戦略の勝敗を分けるだろう。
この記事のポイント
- ホスティングはSEOの「土台」であり、速度・安定性・クロール効率に直結する。
- TTFB(サーバー応答時間)の短縮は、すべてのフロントエンド最適化の前提条件となる。
- コアウェブバイタルの改善には、エッジキャッシュなどのインフラ技術の活用が不可欠だ。
- brightonSEO 2026では、インフラがSEOの成果をいかに最大化するかが議論される。
- AI検索時代において、高速で安定したサイト基盤は「信頼性」の重要な指標となる。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

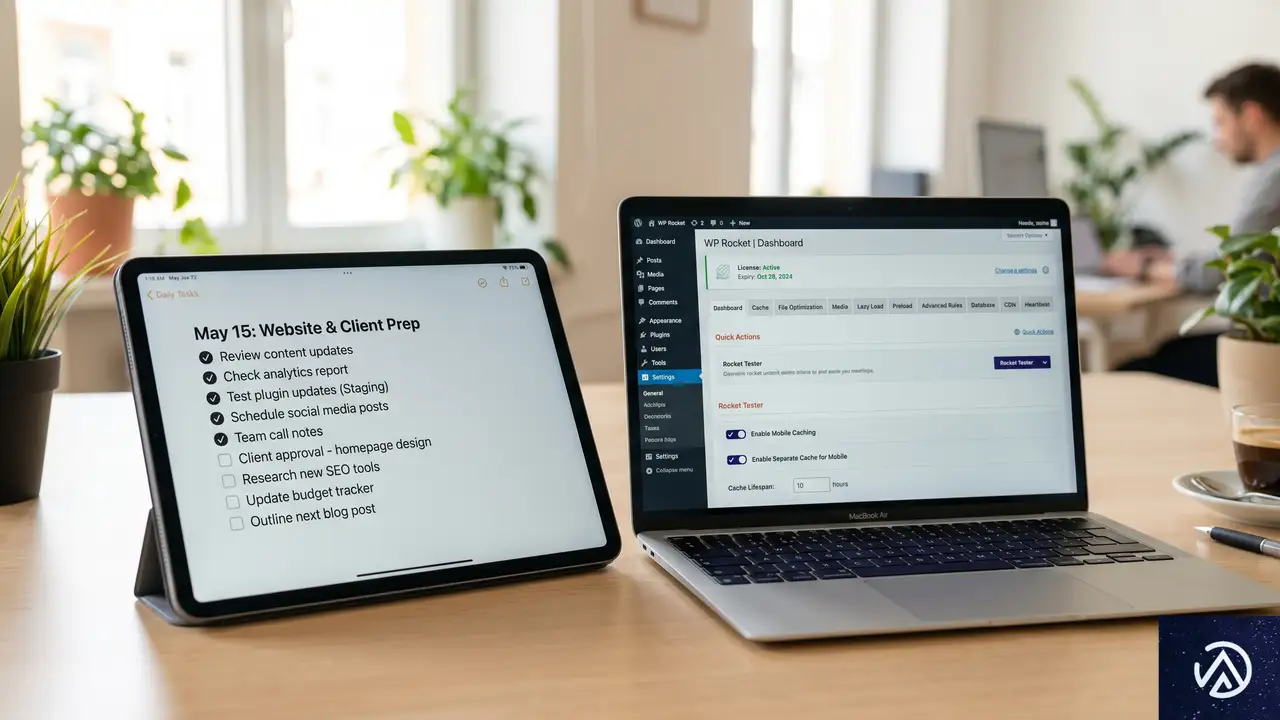
2026年版WordPressクッキープラグイン比較!法規制対応と高速化を両立する選び方
WordPressサイトを運営する上で、クッキー(Cookie)への同意バナーはもはや無視できない存在だ。しかし、法規制を遵守しようとするあまり、サイトの読み込み速度が犠牲になっているケースが後を絶たない。
2026年現在、世界の71%以上の国々で厳格なデータプライバシー法が施行されている。さらにGoogleは、欧州経済領域(EEA)のユーザーを対象とする広告主に対し、同意モード v2(Consent Mode v2)への対応を完全に義務化した。これに対応しなければ、広告の計測やリマーケティング機能が停止するという厳しい状況にある。
本記事では、法的なコンプライアンスを維持しながら、サイトのパフォーマンスを落とさないためのプラグイン選びと設定のポイントを詳しく解説する。技術的な視点から、各ツールの仕組みと最適な運用方法を紐解いていこう。
2026年のプライバシー保護と法規制の現状

かつての「クッキーを使用しています」という単純な通知バナーは、現代の基準では通用しない。2026年のプライバシー基準では、ユーザーが明示的に同意を与えるまで、いかなる追跡スクリプトも実行してはならないという「アクティブ・ブロッキング」が基本だ。これには、Google アナリティクスやFacebookピクセル、YouTubeの埋め込み動画などが含まれる。
Google 同意モード v2(Consent Mode v2)の必須化
Googleが導入した同意モード v2は、ユーザーの同意状態をGoogleのタグ(GA4やGoogle広告など)に伝えるための仕組みだ。ユーザーが同意を拒否した場合、システムは個人を特定しない「クッキーレス・ピング」を送信する。これにより、プライバシーを守りつつ、コンバージョン計測の精度を維持することが可能になる。
Elementor Blogの記事によると、このプロトコルをサポートしていないプラグインを使用している場合、規制地域での広告キャンペーンが正常に機能しなくなるリスクがある。マーケティング予算を無駄にしないためにも、同意モード v2へのネイティブ対応はプラグイン選定の絶対条件といえる。
「拒否」ボタンの重要性と法的リスク
欧州のデータ保護当局は、ユーザーに対して「すべて同意」と同じくらい簡単に「すべて拒否」を選べる環境を求めている。拒否ボタンをメニューの奥深くに隠すような設計は「ダークパターン」とみなされ、多額の制裁金の対象となる。2023年だけでも、データ保護違反による制裁金は総額21億ユーロを超えており、自動化された監視システムによる取り締まりも強化されている。
以下のデモは、正しい同意バナー(Before/After)の構造を示したものだ。ユーザーに不当な操作を強いない、透明性の高い設計が求められている。
当サイトはクッキーを使用します。詳細は設定をご覧ください。
クッキーの使用に同意しますか?詳細な管理も可能です。
※このデモは、法的に推奨されるバナーのレイアウト構造を視覚化したイメージである。
クッキー同意ツールに必須の機能チェックリスト
プラグインを選ぶ際、単に「バナーが出るかどうか」だけで判断するのは危険だ。制作現場で必要とされる技術的な要件は、多岐にわたる。Elementor Blogの分析によれば、特に以下の機能が備わっているかを確認すべきだという。
自動スクリプト遮断と継続的なスキャン
最も重要なのは、ページが完全にレンダリングされる前に、外部スクリプトやiframe、ピクセルを捕捉して一時停止する機能だ。手動で一つ一つのタグにコードを追加するのは現実的ではないため、自動的にこれらを検知し、同意があるまで実行を止める仕組みが求められる。
また、サイトは常に変化する。誰かが新しいYouTube動画を埋め込んだり、マーケティングチームが新しい広告タグを追加したりした際、それを自動で検知してカテゴリー分けする「定期スキャン機能」も必須だ。スキャン漏れはそのまま法的な脆弱性につながる。
ジオターゲティングと非同期読み込み
すべての訪問者に厳しいGDPR(欧州一般データ保護規則)準拠のバナーを見せる必要はない。規制のない地域のユーザーに対しては、バナーを表示しない、あるいは簡略化した通知に留めることで、コンバージョン率の低下を防ぐことができる。これを実現するのがIPアドレスに基づくジオターゲティング機能だ。
さらに、パフォーマンスの観点からは「非同期読み込み(Asynchronous loading)」が欠かせない。同意バナー自体がサイトの主要なコンテンツ(ヒーロー画像など)の表示を邪魔してはならないからだ。バナーの読み込みが「クリティカル・レンダリング・パス(ブラウザが画面を表示するために最低限必要な処理)」を塞いでしまうと、SEOに直結するCore Web Vitalsのスコアを大きく損なうことになる。
主要5大プラグインの徹底比較
2026年現在、WordPress市場で主流となっている5つのプラグインを比較してみよう。それぞれアプローチが異なり、得意とするサイト規模や用途も分かれている。
クラウド型のCookiebotとCookieYes
Cookiebotは、業界でも最大手のクラウド型ソリューションだ。サイトを外部サーバーからスキャンし、膨大なデータベースに基づいてクッキーを自動分類する。最大のメリットはメンテナンスの手間がほぼゼロであることだが、外部スクリプトに依存するため、DNS解決の遅延がサイト速度にわずかな影響を与える可能性がある。
一方のCookieYesは、150万以上のサイトで利用されている人気ツールだ。管理画面が非常に使いやすく、技術に詳しくないクライアントでも運用しやすい。無料枠が月間25,000ページビューまでと広く設定されているため、小規模なビジネスサイトには最適な選択肢となるだろう。
サーバー完結型のComplianzとReal Cookie Banner
Complianzは、WordPressのダッシュボード内で完結するツールだ。外部サーバーとの通信を行わず、プラグインの構成に基づいて法的なポリシーページ(プライバシーポリシーなど)を自動生成する。コストパフォーマンスに優れており、1サイト年間49ドルから利用可能だ。
Real Cookie Bannerは、より技術的な制御を好むエンジニア向けのプラグインだ。160以上のサービス用テンプレートを備え、特定の外部フォントやSpotifyの埋め込みなど、細かいアセット単位での遮断設定ができる。すべてを自社サーバー内で管理したい、あるいは非常に複雑な構成のサイトを運営している場合に力を発揮する。
パフォーマンスへの影響を最小限に抑える技術
クッキー同意バナーを導入した途端、サイトのパフォーマンス指標が悪化することは珍しくない。特に、LCP(Largest Contentful Paint / 最大視覚コンテンツの表示時間)への影響は深刻だ。Elementor BlogのSEOチームリードであるItamar Haim氏によると、重いクラウド型バナーはLCPを300msから600msも遅延させることがあるという。
LCP悪化を防ぐ対策
多くのプラグインは、他のスクリプトを確実に遮断するために、バナーのコードを <head> タグ内の早い段階に配置しようとする。しかし、これがブラウザのメインスレッドを占有し、ヒーローセクションの描画を止めてしまう原因になる。これを防ぐには、スクリプトに defer 属性を付与し、HTMLの解析が終わった後に実行されるように設定することが推奨される。
以下のデモは、バナー読み込みがどのようにレンダリングを阻害するかを可視化したものだ。適切な読み込み順序の設計が、ユーザー体験(UX)を左右する。
バナーの解析中に画像(緑)の読み込みが止まっている。
メインコンテンツ(緑)を先に表示し、バナーは後回しにする。
※このデモは、ブラウザの読み込み順序とレンダリング時間の関係を模式的に示したものである。
アセット読み込みの最適化
外部サーバーからフォントやアイコンを読み込むタイプのバナーは避け、できるだけ自社サーバーから配信(セルフホスト)するように設定しよう。また、バナーのデザインに凝りすぎて巨大なCSSファイルや画像を読み込ませるのもNGだ。インラインCSSを活用し、余計なHTTPリクエストを減らす工夫が求められる。
クッキーレス時代に向けたファーストパーティデータ戦略

2026年には、Chromeによるサードパーティクッキーの完全廃止が定着している。これまでのようにFacebookピクセルなどの外部データに頼ったターゲティングは、ますます困難になるだろう。これからのWebサイト運営は、自社で直接ユーザーから収集する「ファーストパーティデータ」の活用にシフトする必要がある。
ユーザーの信頼をブランド価値に変える透明性
消費者の81%が、データの取り扱い方法が購入の意思決定に影響を与えると回答している。同意バナーを「法的な邪魔者」と捉えるのではなく、ブランドとの最初の信頼構築の場と捉え直すべきだ。
明確で分かりやすいプライバシーポリシーを提供し、なぜそのデータが必要なのかを正直に説明することで、ユーザーは安心して情報を共有してくれるようになる。例えば、単にメールアドレスを求めるのではなく、ユーザーにとって価値のある計算ツールやPDF資料を提供し、その対価として同意を得る「バリュー・エクスチェンジ(価値の交換)」の考え方が重要だ。こうした地道な信頼の積み重ねこそが、クッキーに依存しない強固なマーケティング基盤を作る鍵となる。
この記事のポイント
- 2026年はGoogle 同意モード v2への対応が広告運用における必須条件となっている
- 「すべて拒否」ボタンを「同意」と同じ目立ちやすさで配置しないと法的リスクが高まる
- パフォーマンス維持には非同期読み込み(defer属性)とアセットのセルフホストが有効だ
- 外部サーバー依存のクラウド型か、自社完結のサーバー型かは運用リソースに合わせて選ぶべきだ
- サードパーティクッキー廃止を見据え、透明性の高い情報収集による信頼構築が最優先課題となる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AIが買い物をする時代へ!エージェント・コマース(Agentic Commerce)の仕組みと対応策
ネット通販における「決済ページ」という概念が消えようとしている。これまで30年間、オンラインで物を買うには名前や住所、クレジットカード番号をフォームに入力するのが当たり前だった。しかし、AIエージェントがユーザーの代わりに商品を探し、そのまま購入まで完了させる「エージェント・コマース」が急速に現実のものとなっている。
2025年から2026年にかけて、Stripe、OpenAI、Shopify、Googleといったテック巨人が相次いで新しい決済プロトコルを発表した。これにより、チェックアウトは「Webページ」で行う作業から、システム間で完結する「プロトコル」へと進化を遂げている。もはや人間がフォームを埋める必要はない。
この変化は、Web制作やECサイト運営に携わる者にとって無視できないパラダイムシフトだ。AIエージェントに自社の商品を見つけてもらい、スムーズに決済してもらうためには、サイトの構造そのものを「マシン・リーダブル(機械が理解可能)」に変えていく必要がある。本記事では、最新の業界動向と技術仕様を基に、エージェント・コマースの全貌を解説する。
決済は「ページ」から「プロトコル」へ進化する
1994年に世界で初めてオンライン決済が行われて以来、ECの歴史は「摩擦の解消」の歴史だった。物理的な店舗に行く手間を省き、価格比較の手間を省き、レコメンド機能によって探す手間を省いてきた。エージェント・コマースは、その進化の最終段階といえる。ユーザーが「これを買っておいて」とAIに頼むだけで、決済まで完了するからだ。
30年続いた「フォーム入力」の終焉
従来のECサイトでは、売り手がチェックアウト体験を設計していた。ボタンの色やフォームの配置を工夫し、いかにカゴ落ちを防ぐかがコンバージョン率向上の鍵だった。しかし、エージェント・コマースでは、チェックアウトのインターフェースを作るのはAIエージェント側だ。ChatGPTなどのAIが、チャット画面の中で商品情報と購入ボタンを提示する。ユーザーがそこで承認すれば、裏側でAPIが呼び出され、決済が完了する。
売り手側の仕事は、魅力的なページを作ることではなく、構造化された商品データを提供し、注文を処理するAPIエンドポイントを用意することにシフトする。Stripeの情報によれば、コマースの課題はユーザー体験(UX)の問題からプロトコルの問題へと変化しているという。つまり、見た目の美しさよりも、機械がいかに正確にデータを読み取れるかが重要になるのだ。
AIエージェントが購入を代行する仕組み
AIエージェントによる購入は、人間がブラウザを操作するのとは全く異なるプロセスを辿る。エージェントはサイトの視覚的なデザインを無視し、テキストデータやメタデータ、APIを通じて情報を取得する。決済時には、ユーザーがあらかじめAIプラットフォームに登録しておいた支払い情報が使われる。売り手側のサイトにユーザーが直接クレジットカード情報を入力することはない。
このデモは、購入プロセスの構造的な変化を視覚化したものだ。人間が介在するステップが大幅に短縮されていることがわかる。
二大勢力が競う「エージェント・コマース」の標準規格

現在、この新しい市場を支配しようと、二つの大きなプロトコルが標準化を競っている。一つはOpenAIとStripeが主導する「ACP」、もう一つはGoogleとShopifyが主導する「UCP」だ。これらは対立するものではなく、補完し合う関係にあるが、それぞれの設計思想には違いがある。
StripeとOpenAIによる「ACP」
ACP(Agentic Commerce Protocol / エージェント・コマース・プロトコル)は、2025年9月に発表されたオープン標準だ。主にChatGPT内での「インスタント・チェックアウト」を実現するために設計されている。ACPは、AIエージェント、売り手、支払いサービスプロバイダーの三者が通信するための4つのAPIエンドポイントを定義している。
具体的には、カートの作成、情報の更新、決済の完了、そしてキャンセルの4段階だ。売り手は自社のシステムをこれらのエンドポイントに対応させるだけで、ChatGPTを通じて商品を販売できるようになる。Stripeはこの導入を容易にするために「Agentic Commerce Suite」を提供しており、既存のStripeユーザーであれば最小限のコードで対応が可能だ。すでにWalmartやInstacartといった大手がこの仕組みを導入し、ChatGPT経由での販売を開始している。
ShopifyとGoogleによる「UCP」
UCP(Universal Commerce Protocol / ユニバーサル・コマース・プロトコル)は、2026年1月にGoogleとShopifyが発表した。ACPが決済フローに特化しているのに対し、UCPは商品の発見から購入後のサポートまで、コマース体験の全工程をカバーすることを目指している。その構造はインターネットの基本プロトコルであるTCP/IPをモデルにしており、非常に拡張性が高い。
UCPの特徴は、サイトの特定の場所に設置された「/.well-known/ucp」というエンドポイントを通じて、AIエージェントがそのサイトの販売能力を自動的に認識できる点にある。Google検索やShopifyのプラットフォームと深く統合されており、多くのEC事業者が意識せずともAIエージェントに対応できる環境を整えようとしている。MastercardやVisaといったカードネットワークもUCPへの支持を表明しており、より広範なエコシステムを形成している。
「人がいない決済」を支えるセキュリティ技術

エージェント・コマースにおける最大の課題はセキュリティだ。クレジットカードの持ち主がその場にいない「Person-not-present(本人が不在の決済)」において、どうやって不正を防ぎ、信頼を担保するのか。これまでの「カード番号とCVVを知っていれば本人とみなす」という前提は、AIの時代には通用しない。
Shared Payment Tokens(共有支払いトークン)の役割
この問題に対するStripeの回答が「Shared Payment Tokens(SPT)」だ。これは、AIプラットフォームが発行する、特定の取引専用の使い捨てトークンである。ユーザーがChatGPTで「購入」を承認すると、ChatGPTは特定の売り手、特定の金額、特定の有効期限に限定されたトークンを発行する。売り手はこのトークンを使ってStripeに決済を依頼する。
この仕組みの優れた点は、売り手にもAIエージェントにも、ユーザーの本物のクレジットカード情報が渡らないことだ。万が一データが漏洩しても、そのトークンは他の場所では使えない。また、Googleが推進するAP2プロトコルでは、デジタル署名を用いてユーザーの同意を厳密に検証する仕組みが導入されている。これにより、AIが勝手に高額な買い物をするといったリスクを技術的に排除している。
クレジットカード各社の「Trusted Agent」対応
VisaやMastercardといったカードネットワークも、AI時代に合わせた新しい枠組みを構築している。Visaが発表した「Trusted Agent Protocol」は、正規のAIエージェントと悪意のあるボットを識別するためのフレームワークだ。従来の不正検知システムは、マウスの動きやタイピングの癖といった「人間らしい振る舞い」を指標にしていたが、AIエージェントにはそれが存在しない。
そのため、新しいシステムでは、AIエージェントの身元を暗号学的に証明し、そのエージェントがユーザーから正当な権限を与えられているかを確認することに主眼が置かれている。Stripeの調査によれば、消費者の88%がAIによるなりすまし詐欺を懸念しているが、こうした堅牢なインフラが整備されることで、徐々に信頼が醸成されていくとの見方がある。
自社の商品を「AIに売る」ための具体策

エージェント・コマースの波に乗るために、ECサイトの運営者は今何をするべきか。最新のプロトコルに対応することも重要だが、その基礎となるのは「データ」の質だ。AIエージェントがサイトを訪れた際、迷うことなく商品を理解し、推奨できるように準備しておく必要がある。
マシン・リーダブルな商品データの整備
AIエージェントはプログラムによってカタログを解析する。そのため、曖昧な表現や、画像の中にだけ書かれた情報は理解できない。例えば、商品タイトルを「青いシャツ」とするのではなく、「メンズ オーガニックコットン クルーネック Tシャツ、ネイビー」のように具体的かつ詳細に記述することが求められる。素材、寸法、お手入れ方法、用途といった情報を、すべてテキストデータとして網羅しておくことが重要だ。
また、価格や在庫状況がリアルタイムで正確であることも欠かせない。AIエージェントが「在庫あり」と判断してユーザーに提案したのに、いざ決済しようとしたら「在庫切れ」だったという体験は、エージェントからの信頼を失う原因になる。AIは信頼性の高いソースを優先的に選ぶ傾向があるため、正確な情報提供はSEOならぬ「AI-SEO」の根幹となる。
構造化データ(Schema.org)の重要性
プロトコルへの直接的な統合が難しい場合でも、構造化データのマークアップは今すぐ実行できる強力な対策だ。Schema.orgの Product スキーマを使い、名前、説明、画像、SKU、ブランドなどの情報を正しくタグ付けする。さらに、その中に Offer スキーマをネストさせ、価格、通貨、在庫状況、販売者を明記する。
BingでSchema.orgの立ち上げに携わったDuane Forrester氏によれば、一貫した構造化データを提供し続けることで、AIシステムの中に「マシン・コンフォート・バイアス(機械的な安心感による偏り)」が生まれるという。つまり、AIが「このサイトの情報は常に正確で読み取りやすい」と学習すれば、競合他社よりも優先的に引用・推奨されるようになる可能性があるのだ。
- 商品タイトルを具体的かつ詳細にする
- 素材、サイズ、用途をテキストで網羅する
- Schema.org(Product/Offer)を全商品に適用する
- 在庫と価格をリアルタイムで同期する
- 画像に適切なaltテキスト(代替テキスト)を付与する
このリストにある項目は、従来のSEO対策とも共通する部分が多いが、AIエージェントを意識する場合は「より厳密な正確性」が求められる点に注意が必要だ。
独自の分析:AI SEOがECの勝敗を分ける

エージェント・コマースの普及に伴い、EC業界には「選択の均質化」という新たなリスクが浮上している。コロンビア大学とイェール大学の共同研究によれば、現在のAIショッピングエージェントは、少数の特定商品に需要を集中させる傾向があるという。人間のように検索結果の2ページ目や3ページ目まで丹念に探すことはせず、アルゴリズムが「最適」と判断したトップ数件だけが選ばれる「勝者総取り」の構図が強まるのだ。
これは、中小規模のブランドにとっては大きな脅威であると同時に、チャンスでもある。巨大な広告予算がなくても、AIが理解しやすい高品質なデータを提供し、特定のニッチなニーズに対して「最も正確な回答」を提示できれば、AIエージェントに選ばれる可能性が高まるからだ。これからのEC戦略は、人間の感性に訴えるデザインと、機械の論理に応えるデータの両立が不可欠になる。
また、今後は「AIエージェント向けの広告」という概念も登場するだろう。しかし、Anthropic(Claudeの開発元)のように、広告やスポンサーリンクを一切排除したクリーンなコマース体験を標榜するプラットフォームも存在する。売り手としては、特定のプラットフォームに依存するのではなく、ACPやUCPといったオープンな標準規格に対応し、どこからでも「見つけられ、買える」状態を作っておくことが、長期的な生存戦略となるはずだ。
この記事のポイント
- 決済は「ページ」から「プロトコル」へ移行し、人間によるフォーム入力が不要になる
- StripeとOpenAIの「ACP」、ShopifyとGoogleの「UCP」という二大規格が標準化を競っている
- 「共有支払いトークン(SPT)」などの技術により、本人が不在でも安全な決済が可能になる
- ECサイトは、詳細なテキストデータとSchema.orgの導入により、AIに選ばれる準備をすべきだ
- AIエージェントによる「選択の均質化」が進むため、正確な情報の提供が生き残りの鍵となる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

HubSpotとKinsta APIでWordPressサイト構築を自動化する方法
クライアントとの契約が成立してからWordPressサイトが用意されるまでの時間は、ビジネスの勢いを維持するために極めて重要だ。多くの制作会社にとって、新しいプロジェクトが始まるたびに手動でホスティング環境を整え、WordPressをインストールする作業は、付加価値を生まない繰り返し作業になりがちである。
Kinsta APIを活用すれば、こうした定型業務をプログラムで自動化できる。HubSpotのフォーム送信をトリガーにして、Node.jsのミドルウェア経由でKinsta APIを呼び出せば、顧客がサインアップした瞬間にサイト構築を開始することが可能だ。
本記事では、HubSpotとKinsta APIを連携させ、サイト構築のプロビジョニング(準備)を完全に自動化する仕組みを具体的に解説する。この自動化により、制作チームは手動のセットアップ作業から解放され、よりクリエイティブな業務に集中できるようになるだろう。
なぜサイト構築の自動化が制作会社にとって不可欠なのか

手動によるサイト構築は、クライアントとの関係において最も重要な「熱量」が高い時期に遅延を招く要因となる。新しい申し込みがあるたびに、担当者がホスティング管理画面にログインし、環境を作成してWordPressの設定を行い、ログイン情報を生成してクライアントに通知するという工程が必要だからだ。
手動作業がもたらすボトルネック
管理画面での操作自体はシンプルだが、担当者が他の業務に追われていたり、営業時間外であったりすると、数時間の遅れが発生する。この小さな遅延が積み重なることで、制作会社全体の生産性が低下し、クライアントへのレスポンスも遅れてしまう。自動化は、こうした人的リソースへの依存を排除する唯一の解決策だ。
Kinsta APIを活用したワークフローの効率化
デジタルエージェンシーのStraight out Digital(Sod)は、Kinsta APIを利用して独自の内部ツールを構築し、数百におよぶクライアントサイトの構築とメンテナンスを自動化している。Kinstaの著者Carlo Daniele氏によると、同社はAPIを介してプログラマティックに処理を実行することで、時間のかかる操作を極めてシンプルなものへと変貌させたという。
HubSpotとKinsta APIを接続することで、同様の成果が得られる。クライアントがサインアップフォームを送信すると、HubSpotがWebhook(ウェブフック)を送信する。これを受け取ったミドルウェアがKinsta APIを叩き、サイト作成を開始する。リード獲得から環境構築までのハンドオフが自動で行われるため、オンボーディングの工数を大幅に削減できるのだ。
HubSpotとKinsta APIを連携させるための準備

この仕組みを実現するためには、いくつかの前提条件が必要だ。まず、Kinstaのアカウント内に既存のサイトが少なくとも1つ存在している必要がある。これにより、APIへのアクセスが有効になる。また、Webhookワークフローが利用可能なHubSpotのプレミアムプランと、Node.js 18以降がインストールされた環境も必要だ。
APIキーと会社IDの取得
まずはKinstaの管理画面(MyKinsta)でAPIキーを生成する。「企業の設定」から「APIキー」を選択し、「APIキーを作成」をクリックする。キーの名前と有効期限を設定して生成されたキーは、一度しか表示されないため、安全な場所に保管しておく必要がある。
次に、APIリクエストに不可欠な「会社ID」を確認する。これはMyKinstaにログインしている際のURLから取得できる。これらの情報は、プロジェクトのルートにある .env ファイルに保存して管理するのが一般的だ。
環境変数の設定
APIキーや会社IDをコードに直接記述するのは、セキュリティ上のリスクが高い。そのため、環境変数として管理する。以下のような形式で設定を行う。
KINSTA_API_KEY=your_api_key_here
KINSTA_COMPANY_ID=your_company_id_here
WP_ADMIN_PASSWORD=your_secure_passwordこの設定により、Node.jsアプリケーションから安全に認証情報を読み取ることができるようになる。APIキーは「Bearerトークン」として、すべてのリクエストの Authorization ヘッダーに含まれることになる。
ステップ1:HubSpotのフォームとワークフローを構築する
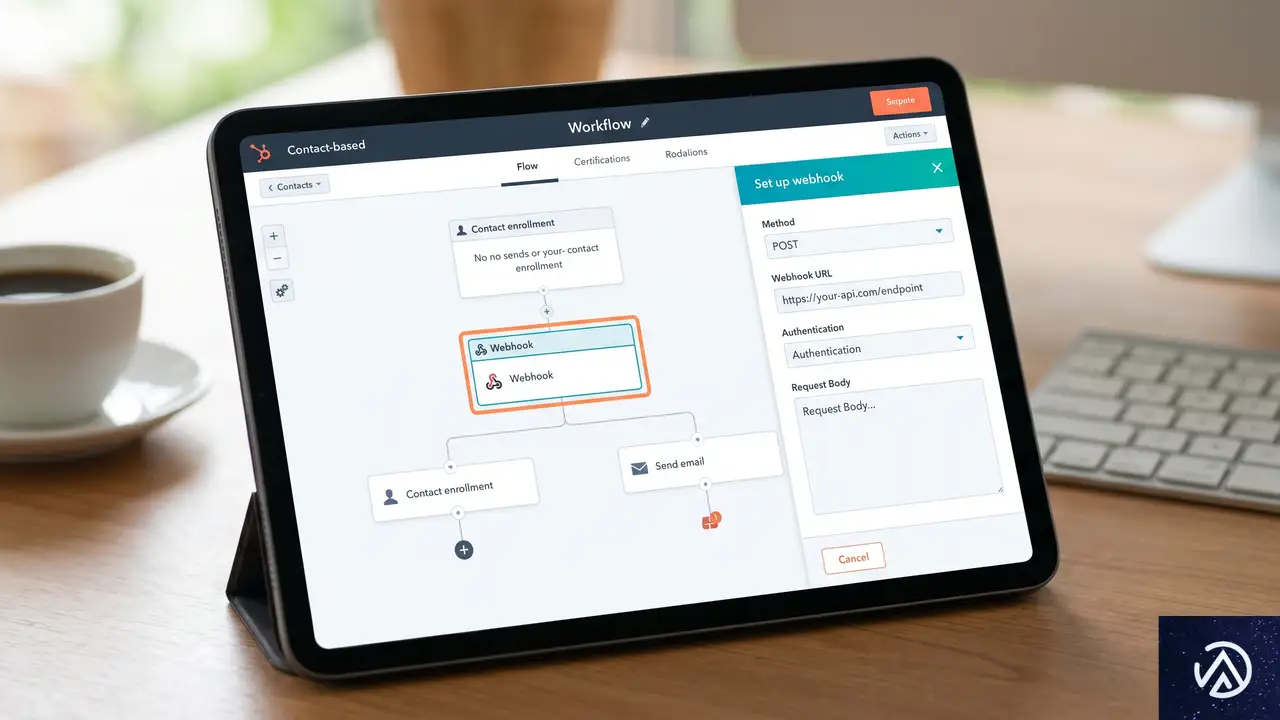
自動化のトリガーとなるのは、HubSpotのフォーム送信だ。まずは、新規クライアントの情報を収集するためのフォームを作成する。少なくとも「名前」「メールアドレス」「会社名」の3つのフィールドを含める必要がある。これらの値が、後にKinsta APIに渡されるパラメータとなる。
Webhookアクションの追加
フォームが完成したら、HubSpotの「自動化」メニューからワークフローを作成する。登録トリガーとして「フォーム送信」を選択し、作成したフォームを指定する。これにより、誰かがフォームを送信するたびにワークフローが起動するようになる。
次に、実行するアクションとして「Webhookを送信」を選択する。メソッドは POST に設定し、送信先のURLには後述するNode.jsアプリの公開エンドポイントを入力する。HubSpotはこのURLに対して、コンタクト情報を含むJSONペイロードを送信する仕組みだ。
ステップ2:Node.jsによるミドルウェアの実装
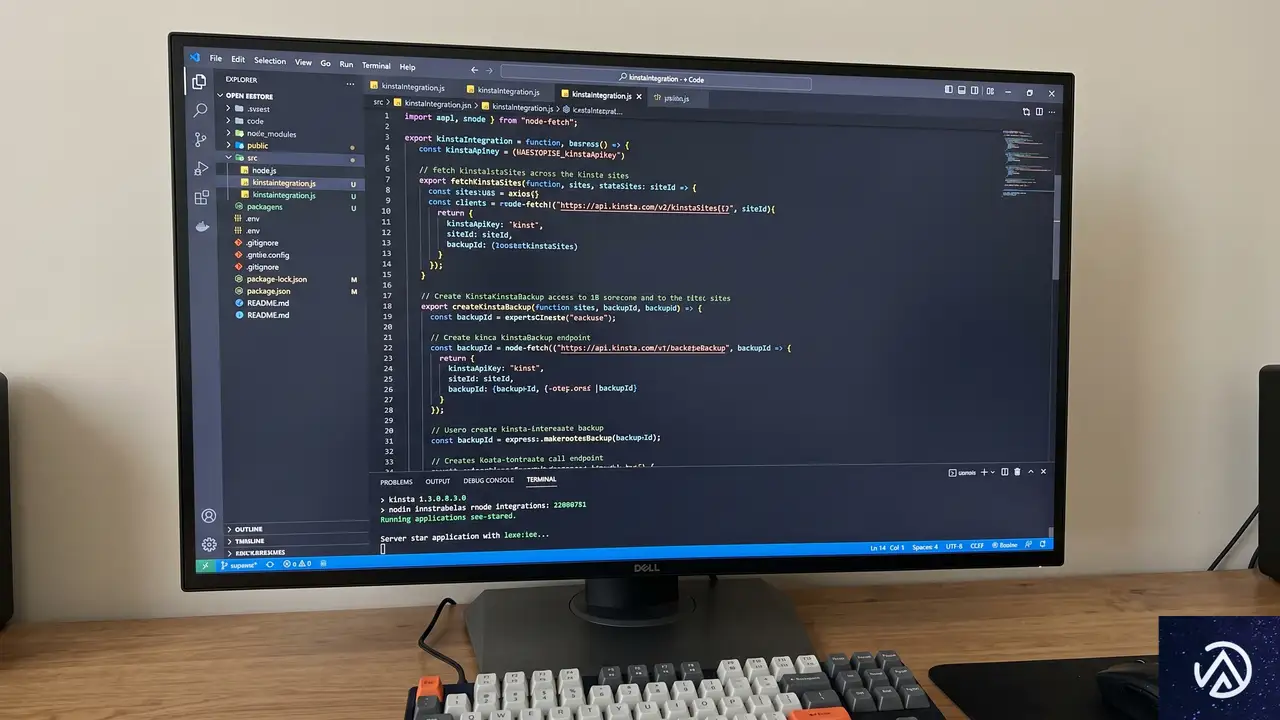
HubSpotはKinsta APIと直接通信することはできない。そのため、両者の橋渡し役となる「ミドルウェア」が必要になる。ここでは軽量なWebフレームワークであるExpress.jsを使用して、HTTPサーバーを構築する。
Express.jsでのサーバー構築
Node.jsプロジェクトを初期化し、必要なパッケージをインストールする。dotenv は環境変数の読み込みに、express はサーバー構築に使用する。Node.js 18以降であれば、標準の fetch 関数が使えるため、HTTPクライアントを別途導入する必要はない。
// app.js の基本構造
const express = require('express');
require('dotenv').config();
const app = express();
app.use(express.json());
const KinstaAPIUrl = 'https://api.kinsta.com/v2';
const headers = {
'Content-Type': 'application/json',
Authorization: `Bearer ${process.env.KINSTA_API_KEY}`
};
app.post('/new-site', async (req, res) => {
// HubSpotからのデータを受け取る処理
const event = Array.isArray(req.body) ? req.body[0] : req.body;
const displayName = event?.properties?.company;
const adminEmail = event?.properties?.email;
if (!displayName || !adminEmail) {
return res.status(400).json({ message: '必須項目が不足しています' });
}
// Kinsta APIの呼び出しへ続く
});
app.listen(3000, () => console.log('Server running on port 3000'));Kinsta APIへのリクエスト送信
ミドルウェアがHubSpotからデータを受け取ったら、次にKinsta APIの /sites エンドポイントに対して POST リクエストを送信する。このリクエストには、サイト名、リージョン、管理者メールアドレスなどの情報を含める。
const response = await fetch(`${KinstaAPIUrl}/sites`, {
method: 'POST',
headers,
body: JSON.stringify({
company: process.env.KINSTA_COMPANY_ID,
display_name: displayName,
region: 'us-central1',
install_mode: 'new',
admin_email: adminEmail,
admin_password: process.env.WP_ADMIN_PASSWORD,
admin_user: 'admin',
site_title: displayName
})
});
const data = await response.json();ここで重要なのは、Kinsta APIはサイト作成を「非同期」で行うという点だ。リクエストが成功すると 200 ではなく 202 Accepted ステータスが返される。レスポンスには operation_id が含まれており、これを使って処理の進捗を追跡することになる。
ステップ3:非同期処理のステータス監視

サイト作成のリクエストを送っただけでは、いつサイトが完成したのかがわからない。そのため、定期的にAPIに問い合わせを行う「ポーリング」という手法を用いる。Kinsta APIの /operations/{operation_id} エンドポイントを呼び出すことで、現在のステータスを確認できる。
ポーリングによる進捗確認
以下のような関数を作成し、30秒間隔でステータスを確認する。ステータスが completed になれば、サイトの構築は完了だ。Kinsta APIには「リソース作成エンドポイントは1分間に5回まで」という制限があるため、30秒間隔のポーリングは制限内で安全に動作する設定といえる。
const pollOperation = (operationId) => {
const interval = setInterval(async () => {
const resp = await fetch(
`${KinstaAPIUrl}/operations/${operationId}`,
{ method: 'GET', headers }
);
const result = await resp.json();
if (result.status === 'completed') {
clearInterval(interval);
console.log('サイトの準備が完了しました:', result);
}
}, 30000);
};この仕組みを導入することで、ミドルウェアはサイト作成の成功を見届けることができる。完了後にSlackへ通知を送ったり、クライアントに自動で「準備完了」のメールを送信したりといった、さらなる自動化の拡張も容易になる。
独自の分析:自動化がビジネスに与える付加価値

今回の自動化連携は、単なる「時短」以上の価値を制作会社にもたらす。筆者の分析によれば、最も大きなメリットは「Time to Value(価値提供までの時間)」の短縮だ。クライアントがサービスに申し込んだ直後に、すでに自分のサイトが立ち上がっているという体験は、プロフェッショナルな印象を強く植え付ける。
また、この仕組みは「人為的ミスの削減」にも寄与する。手動設定では、管理者パスワードの控え忘れや、リージョンの選択ミス、プラグインの入れ忘れなどが起こり得る。API経由であれば、WooCommerceやYoast SEOなどの必須プラグインを事前に指定してインストールすることも可能だ。これにより、すべてのプロジェクトで一定の品質が担保された環境を、瞬時に提供できる。
さらに、このミドルウェアを拡張すれば、ステージング環境の自動作成や、ドメインの自動割り当てまで一気通貫で行えるようになる。Kinsta APIを「自社のサービスの一部」として組み込むことで、競合他社にはない圧倒的なスピード感を武器にできるはずだ。
この記事のポイント
- Kinsta APIを活用すれば、WordPressサイトの作成、管理、監視をプログラムで制御できる。
- HubSpotのワークフローとWebhookを組み合わせることで、顧客の申し込みを直接サイト構築に繋げられる。
- Node.jsのミドルウェアは、HubSpotとKinsta APIの間でデータを変換し、認証を管理する重要な役割を果たす。
- サイト作成は非同期処理のため、operation_idを用いたポーリングによって完了を確認する実装が必要だ。
- 自動化により、制作会社は手動のセットアップ工数を削減し、クライアントに迅速な価値提供が可能になる。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験