

Googleが6月スパムアップデート公開、AI応答の操作もスパム対象に
Googleは2026年6月24日、新しいスパムアップデートの展開を開始した。今回のアップデートでは、生成AIの応答を意図的に操作しようとする行為もスパムポリシー違反とみなされることが明確化された。
同時期に、サーチコンソールのAIレポートにおけるインプレッションの数え方について新たな情報が公開された。また、Advanced Web Rankingの調査ではデスクトップのCTRが上昇する一方、モバイルのトップポジションでクリック率が低下していることが判明。Similarwebのレポートからは、AIの推奨がブランド検索を経由してサイト訪問につながる構図が浮かび上がった。
この記事では、これらの動きを一つひとつ整理し、今後のSEO戦略にどう活かすかの視点を提供する。
AI応答の操作行為もスパムポリシーの対象に
6月24日より展開が始まったスパムアップデートは、従来のリンクスパムやキーワードスタッフィングのような旧来型の不正だけでなく、AI OverviewsやAI Modeといった生成AI検索機能に対する操作行為にも範囲を拡大した。
Googleは2026年5月にスパムポリシーを改定し、生成AIの回答に表示される引用やリンクを不正に購入する行為、情報を書き換える行為がスパムに該当すると明示していた。今回のアップデートはその方針に沿ったアルゴリズムの強化にあたる。
ランキング変動への向き合い方
スパムアップデートは数日かけて完全に適用されるため、ランキングの上下が一過性のものかそうでないかを見極める必要がある。突然順位が下がったとしても、それだけでコンテンツが「質の低いスパム」と判定されたわけではない。
SEOコンサルタントのShushrita M.氏は、変動が起きた際にはまず影響を受けたページタイプやクエリ、ディレクトリを特定し、一貫したパターンを見つけることが回復への第一歩だと指摘している。パニックに陥らず、データに基づいた診断を進める姿勢が求められる。
AIインプレッションはリンクの表示回数、クリックデータはまだない
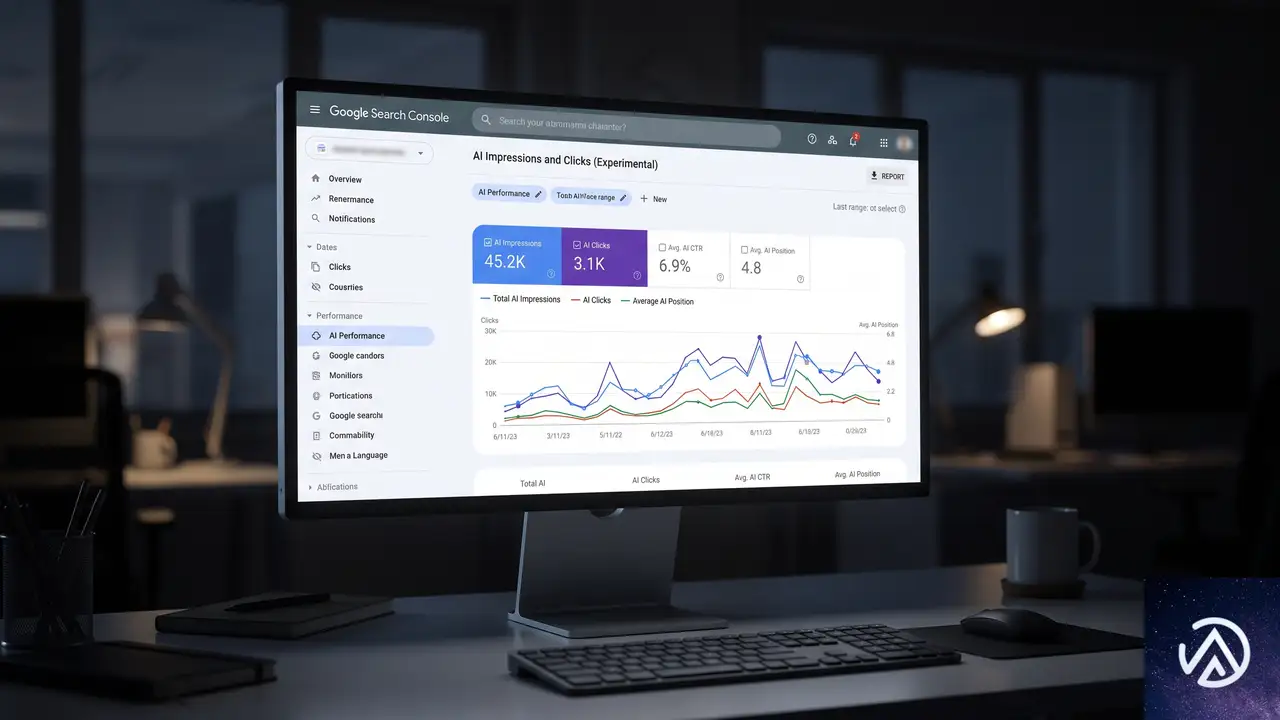
サーチコンソールの生成AIレポートで示されるインプレッションは、AI OverviewsやAI Modeの中で自社ページへのリンクが表示された回数を指す。ただし、回答内で折りたたまれているリンクは、ユーザーが開かない限りカウントされない仕組みである。
Googleのサーチ アドボケートJohn Mueller氏が明らかにしたところによると、現時点ではこのレポートにクリック数は含まれておらず、純粋に表示機会の指標として扱う必要がある。AI回答の中で自社コンテンツが参照されていても、必ずしもユーザーがクリックするとは限らない点を考慮しなければならない。
低い数値が問題とは限らない
折りたたまれたリンクのインプレッションが少ないからといって、コンテンツがAIに無視されているわけではない。ユーザーが積極的に展開しなければカウントされないため、実際の露出機会よりも数字が小さく見える可能性がある。インプレッション数はあくまで最低限の目安として捉え、他の指標と組み合わせて評価することが重要だ。
デスクトップCTRが上昇、モバイルはトップで減速
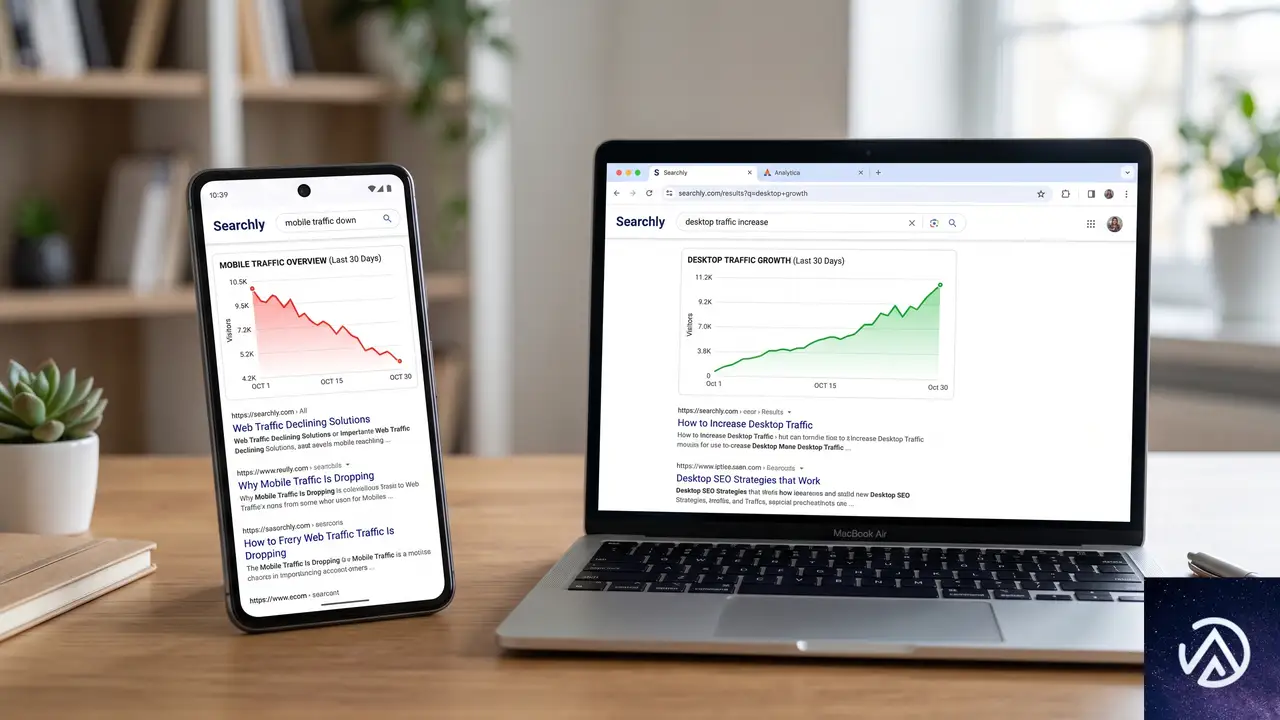
Advanced Web Rankingが公開した2026年第1四半期のベンチマークによると、デスクトップ検索のクリック率は上昇傾向にある一方、モバイル検索では1位のCTRが約2.2ポイント低下した。デスクトップの伸びは3位以下のポジションで顕著に見られた。
これは単純な「復調」ではない。モバイルの軟調が続いているなかでのデスクトップの一時的な上昇であり、両者を合算した数値だけを見ると実態を見誤る恐れがある。自社のデータをデバイス別に切り分けて分析し、それぞれの傾向を別々に把握することが欠かせない。
デバイス別の分析が必須
モバイルでCTRが下がる背景には、AI Overviewsの拡大や検索結果画面の構成変化が影響している可能性がある。デスクトップとモバイルではユーザーの行動や画面占有のされ方が異なるため、両方を一緒くたに評価せず、施策もデバイスごとに最適化していく姿勢が有効だ。
AIの推奨がブランド検索を呼び、サイト訪問数が2.5倍に増加
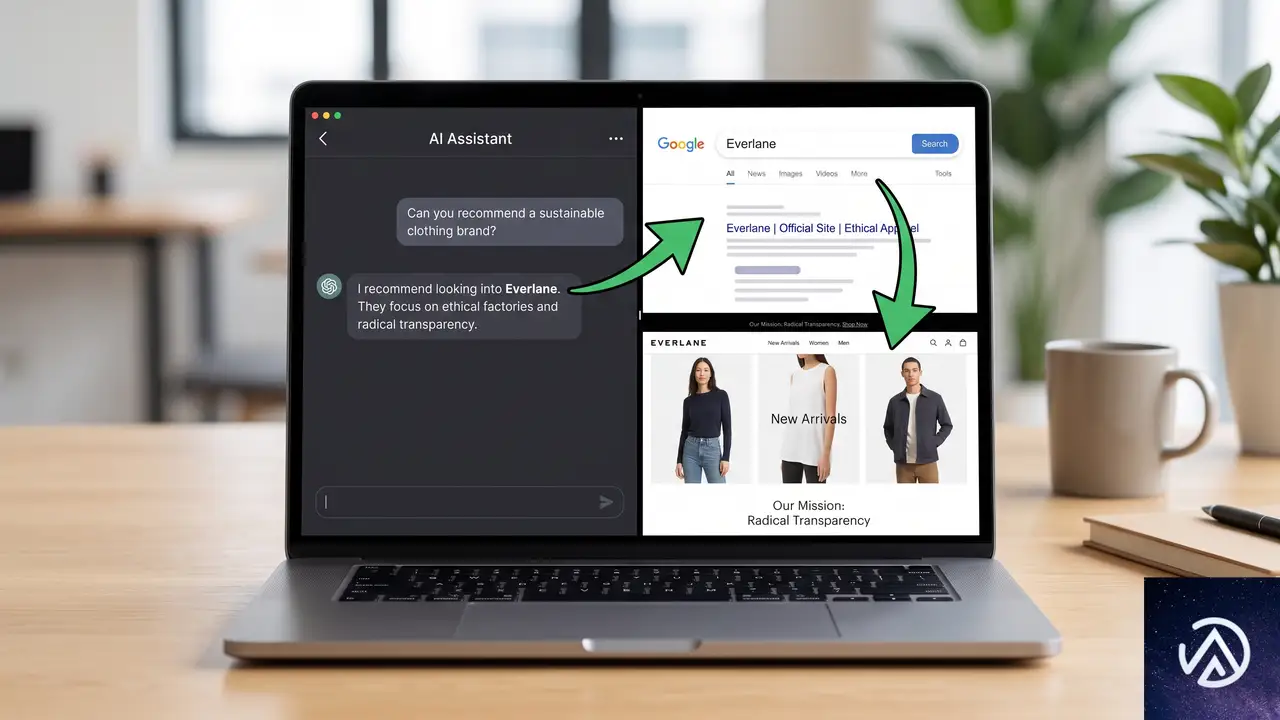
Similarwebのレポートは、ChatGPTなどのAIが特定のブランドを推奨した場合、その後のユーザー行動の55.9%がブランド検索を経由してサイト訪問につながっていると示した。AIが直接リンクをクリックされる以上に、ブランド名を覚えさせて後から検索させる流れが主流になりつつある。
ここで、AI推奨がもたらすユーザー導線の変化をBefore/Afterで視覚化してみる。
上記の図のAfter側では、AIがブランドを推奨した後にユーザーが改めて検索し、最終的にサイトを訪れるという2段階のプロセスが示されている。この流れが全体の55.9%を占めているというデータは、AI検索時代のブランド力の重要性を裏付けるものだ。
ブランド検索ボリュームをKPIに加える
AIが自社名に言及した際、ユーザーはリンクを直接クリックするよりも、ブランド名を検索してからサイトを訪れる傾向が強い。そのため、従来のオーガニック検索の流入数だけでなく、ブランド検索のボリュームそのものを追跡することがAI時代の重要指標になる。
SEOコンサルタントのAleyda Solís氏も、AIの影響はクリックを伴わない形で現れるため、AIリファラルだけを見ていては実態を捉えきれないと警鐘を鳴らしている。ブランド名での検索数や、直接流入・検索流入の増加をAIの露出と結びつけて評価する視点が不可欠だ。
Googleは外部SEOツールを評価せず、内部指標へのアクセスもない
Googleの検索・コマース担当VPであるBrendon Kraham氏は、効果的なSEOの取り組みはそのまま生成AI検索(GEO)にも通用すると述べた。同時に、Googleは第三者のSEOツールやベンダーを評価しておらず、そうしたツールがGoogle内部の指標にアクセスすることも一切ないと明言している。
この発言は、一部のツールが「AI検索に特化した独自のランキング指標」を謳うことに対して釘を刺すものだ。AIが絡む検索環境でも、基本はこれまで通り、ユーザーにとって価値あるコンテンツを提供するというSEOの原則に立ち返る必要がある。
「良いSEOは良いGEO」だが逆は成り立たない
Zyppy SEOの創設者Cyrus Shepard氏は、この「良いSEOは良いGEO」というスローガンにおおむね同意しつつも、AIが存在しなければ絶対にしなかったであろう施策をAIに詳しいSEO担当者がすでに行っていると指摘している。生成AI検索に過度に最適化することは、検索エンジンの変化に振り回されるリスクを高めるため、注意が必要だ。
この記事のポイント
- 6月のスパムアップデートはAI応答の操作行為もスパムと認定。ランキング変動は数日間の経過を見守りながらパターン分析を
- サーチコンソールのAIインプレッションはリンク表示回数のみでクリックデータは未提供。低い数値は過小評価の可能性も
- デスクトップCTRは上昇したがモバイルはトップで低下。デバイス別の分析と施策の切り分けが重要
- AI推奨の55.9%がブランド検索を経由して訪問。ブランド検索ボリュームをAI時代の重要KPIに
- Googleは外部SEOツールの評価や内部指標へのアクセスを否定。AI検索でも基本は質の高いコンテンツ作り

・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

WooCommerce 10.9で「あとで買う」「ほしいものリスト」が実験搭載
WooCommerce 10.9が2026年6月にリリースされ、ログイン顧客向けの実験的なショッピングリスト機能「Shopper Lists」が導入された。カート画面に表示される「あとで買う(Save for Later)」と、商品ページに追加される「ほしいものリスト(Wishlists)」の2機能が含まれている。
いずれもデフォルトでは無効化されており、店舗運営者が明示的にオンにして使うオプトイン方式だ。今回は WooCommerce のブロックベースショッピング体験を前提に設計されており、従来のショートコードベースの店舗では動作が保証されない点に注意が必要だ。
両機能は同じ Shopper Lists バックエンドを共有しており、今回の実験リリースを経て、将来的にはさらに多くのリスト系機能へ拡張される可能性がある。
2つのショッピングリスト機能の詳細
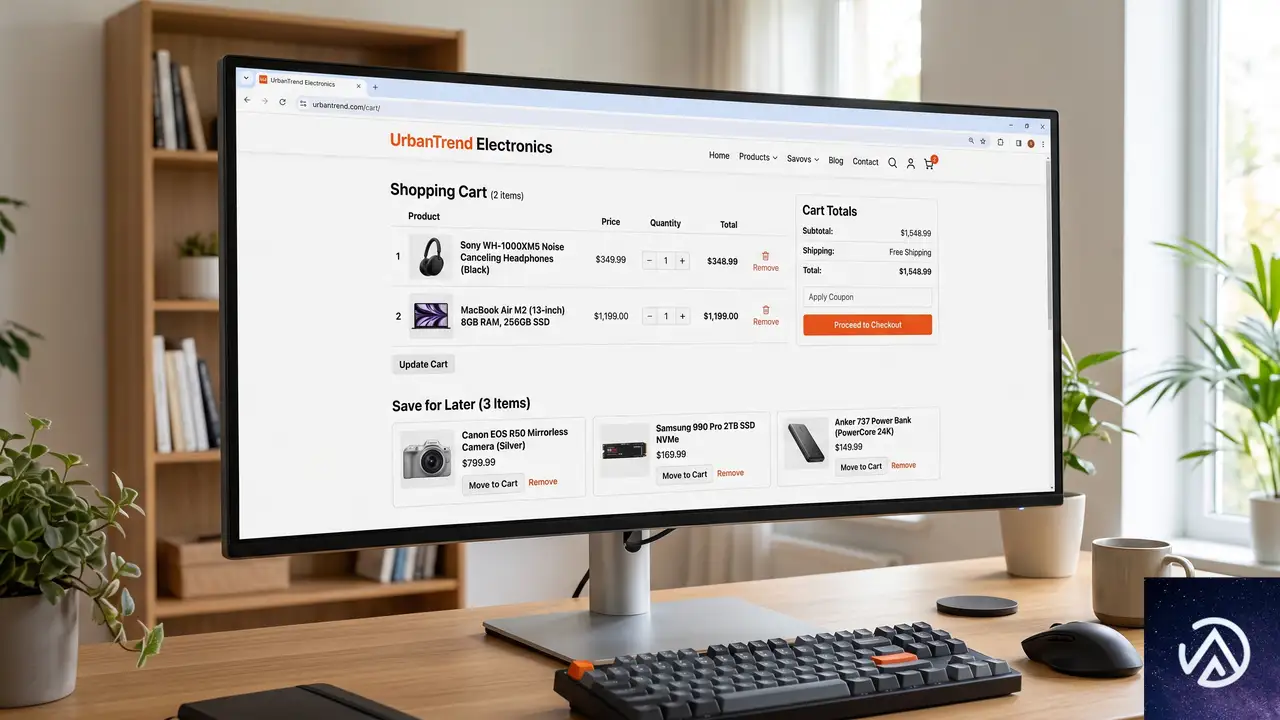
Save for Later(あとで買う)
「Save for Later」はカートブロックの各商品行に「あとで買う」というアクションを追加する。ログイン顧客がこのボタンを使うと、その商品はカートから取り除かれ、カートブロックの下部に新設された「あとで買う」セクションへ移動する。
顧客はあとで買うセクションから商品をカートに戻したり、リストから削除したりできる。バリエーション商品(サイズや色を選択する商品)の場合、選択済みの属性情報が保持されるため、「どのサイズを保存したか」をあとで確認できるのが実務上の利点だ。
現時点ではカートブロックのみ対応で、ミニカートには未対応。WooCommerce 開発チームの発表によれば、ミニカート対応は今回の実験リリースのスコープ外とされている。
Wishlists(ほしいものリスト)
「Wishlists」は Add to Cart with Options ブロックを使っている商品ページに「ほしいものリストに追加」ボタンを表示する。単純商品だけでなく、選択済みのバリエーション商品も保存できる。
保存した商品はマイアカウントの「ほしいものリスト」セクションから一覧表示され、そこからカートへの移動や削除が可能だ。店舗運営者は Wishlist ブロックを任意の固定ページに配置することで、顧客が自分専用のほしいものリストページを持てるようになる。
技術的基盤

Save for Later と Wishlists は、どちらも同一の Shopper Lists バックエンドを土台にしている。Store API、Interactivity API ストア、共有データ構造の3層で構成されており、今後のリスト系機能追加を見据えた拡張性の高い設計だ。
共有 Store API エンドポイント
両機能のデータ操作は、すべて以下の共通エンドポイント群を通じて行われる。
/wc/store/v1/shopper-lists/Store API は WooCommerce のブロックベースショッピング体験を支える REST API 層で、カートやチェックアウト、商品データの取得を担う。今回の Shopper Lists 実装により、この API 層にリスト操作の機能が追加された形だ。
Developer WooCommerce Blog の発表によると、この API 表面はメイン機能マージ(#65263)で導入され、Wishlist ボタンは Add to Cart with Options ブロックへのレンダリング時注入(#65765)によって復帰したとされている。
Interactivity API との統合
Interactivity API は WordPress 6.5 で導入された、ブロックにインタラクティブなフロントエンド動作を追加するための公式 API だ。Shopper Lists では、カートブロック内での「あとで買う」への移動や、商品ページでの「ほしいものリストに追加」といった操作が、ページ遷移なしで即座に反映される。
この API を利用することで、従来の WooCommerce で課題だった「操作のたびにページ全体がリロードされる」問題が解消され、顧客体験が大きく向上する。とくに商品数が多い店舗では、体感速度の差が顕著になるだろう。
機能の有効化手順

これらの機能はカートの挙動、商品ページの表示、マイアカウント、ブロックテンプレート、ログイン顧客データ、Store API との通信と、多岐にわたる領域に影響を与える。そのため WooCommerce チームは「本番環境ではなく、ステージング環境かローカルテストサイトで検証してほしい」と呼びかけている。
有効化に必要な条件
- WooCommerce 10.9.1 以降がインストールされていること
- ステージング環境またはローカルのテストサイトであること
- カートページが Cart ブロックで構築されていること
- 商品詳細ページのテンプレートが Add to Cart with Options ブロックを使用していること
- テスト用の顧客アカウントが用意されていること
設定手順
管理画面の WooCommerce > 設定 > 高度な設定 > 機能 に移動し、以下の2つの実験的機能を有効化するだけだ。
- Save for Later in Cart(カート内のあとで買う)
- Wishlists(ほしいものリスト)
テスト用の商品構成としては、単純商品を1点以上、選択式属性を持つバリエーション商品を1点以上用意しておくと、両機能の動作を網羅的に確認できる。
テストすべきポイント

WooCommerce チームはデベロッパーや制作会社、店舗構築者に対し、実際の店舗構成に近い環境でのフィードバックを求めている。とくにカスタマイズされたブロックテンプレートや多数の拡張機能を導入したサイトでの動作報告が重視されている。
Save for Later のテスト項目
- カート内の商品に対して「あとで買う」ボタンが表示されるか
- ボタン押下後、商品が「あとで買う」セクションに正しく移動するか
- バリエーション商品の選択属性(サイズや色)が保持されているか
- 「カートに戻す」で商品がカートに復帰するか
- 「削除」でリストから消えるか
Wishlists のテスト項目
- 商品ページに「ほしいものリストに追加」ボタンが表示されるか
- 単純商品とバリエーション商品の両方が保存できるか
- マイアカウント > ほしいものリスト に保存商品が正しく表示されるか
- ほしいものリストからカートへの移動が正常に動作するか
- Wishlist ブロックを任意の固定ページに配置して表示できるか
無効化時のクリーンアップ確認
両方の実験的機能を無効化したあと、カート、商品ページ、マイアカウントを再訪問し、Shopper Lists の UI が完全に消えるかを確認する必要がある。無効なブロックが残ったり、テンプレート出力が崩れたりしないことが、安定版への移行条件のひとつになる。
実務への影響と今後の展望

Shopper Lists の登場は、WooCommerce 店舗における顧客維持の選択肢を大きく広げる。従来の「その場で買うか、離脱するか」という二択から、「いったん保存して後日判断する」という選択肢が加わることで、カート放棄率の低減につながる可能性がある。
とくにアパレルや家具など、購入までに検討期間が長い商材を扱う店舗にとっては、ほしいものリスト機能の価値は高い。顧客が複数回にわたって同じ商品を閲覧する行動パターンがある場合、リスト保存によってコンバージョンまでの導線が短縮される。
ただし現時点では実験的機能であり、本番環境での利用は推奨されていない。カスタマイズされたブロックテーマや拡張機能との競合が発生する可能性があるためだ。WooCommerce チームが特に求めているのは、まさにそうした「実店舗に近い複雑な環境」でのテスト報告である。
フィードバックは Developer WooCommerce Blog の該当記事コメント欄、または GitHub ディスカッション(#66038)で受け付けている。制作会社やデベロッパーにとっては、正式リリース前に自社のクライアント店舗との相性を把握できる貴重な機会といえる。
この記事のポイント
- WooCommerce 10.9 が Shopper Lists 機能を実験的に導入した
- 「Save for Later」はカートブロックに商品を一時保存する機能
- 「Wishlists」は Add to Cart with Options ブロックと連携するほしいものリスト
- 両機能はデフォルト無効で、管理画面の「高度な設定 > 機能」から有効化する
- 本番環境ではなくステージング環境でのテストが強く推奨されている
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

OpenAIとBroadcomがLLM専用推論チップJalapeñoを発表
Jalapeño 発表の背景とフルスタック戦略
OpenAIはこれまで、ChatGPTやAPI製品といった「モノを売る」領域と、GPT-5.3に代表される「頭脳を鍛える」領域に注力してきた。今回発表されたJalapeñoは、その下の「足腰を作る」領域、つまり物理的な計算基盤への本格参入を意味する。
従来、大規模言語モデル(LLM)の計算には、NVIDIA製GPUを中心とした汎用アクセラレータが広く使われてきた。汎用性が高い反面、LLMの推論処理に特化させるとデータ移動のオーバーヘッドが生じ、本当に出せるはずの理論性能を引き出しきれない場面があった。Jalapeñoはこの制約を根本から解消する狙いがある。
OpenAIのブログ記事は、Jalapeñoを「フルスタックの優位性」の象徴と呼ぶ。モデルを作り、製品を届け、その下のチップまで自前で設計する一貫体制が、性能とコストの両面で差別化要因になるとの考え方だ。
フルスタック体制が生む「AIのフライホイール」
OpenAIが示す好循環の構図はこうだ。専用チップで推論コストが下がる。コストが下がれば、より多くのユーザーに安価でサービスを届けられる。利用が拡大すれば収益が増え、その収益を次世代チップの研究開発に再投資できる。
この循環は、単に「速いチップを作りました」以上の構想だ。物理的な計算資源の制約そのものを押し広げる試みであり、OpenAIがインフラ企業へと変貌を遂げる宣言でもある。
9か月で仕上げた設計速度とAIの自己適用

Jalapeñoの開発期間は、初期設計から製造テープアウトまでわずか9か月だった。OpenAIのブログによれば、これは高性能先端半導体のASIC開発サイクルとして過去最速と考えられている。一般的に、フルスクラッチの専用チップを起こすには数年を要する。それを1年未満でまとめ上げた点は、技術面以上に開発プロセスそのものの革新を示している。
この速度を支えた要素は大きく3つある。第1に、OpenAIのソフトウェアチームとBroadcomのシリコン実装部隊が深く連携した「ソフト・ハード共創」の手法。第2に、Broadcomのネットワーク技術やCelesticaのシステム統合ノウハウを組み合わせたモジュール化。そして第3に、OpenAI自身のモデルを設計プロセスの一部に活用し、最適化や検証を加速させたことだ。
「AIがAI向けチップの設計を加速する」という構図は、OpenAIにとって象徴的な意味合いが強い。ユーザーに提供しているモデルと同じ技術が、次のモデルを動かすインフラを改善するという自己強化のループが、すでに動き始めている。
性能の初期テスト結果と技術的詳細

OpenAIの発表時点では、Jalapeñoの最終的な性能値は確定していない。今後数か月以内に詳細な技術報告があるとしている。とはいえ、すでにラボ内でエンジニアリングサンプルが稼働しており、GPT-5.3-Codex-Sparkを含むMLワークロードを本番相当の動作周波数と電力で実行している。
現時点で明かされている初期テストの所見は「性能あたりの消費電力が現行の最先端アクセラレータよりも大幅に優れる」というものだ。具体的な数値こそ伏せられているが、ここで注目すべきは単なるワットパフォーマンスの良さだけではない。
「実効利用率」を高める設計思想
Jalapeñoのアーキテクチャの中心には、データ移動の最小化と、計算・メモリ・ネットワーク資源のバランスがある。汎用チップでは、どうしても実際に使える計算能力(実効利用率)が理論ピーク性能を大きく下回る。OpenAIのハードウェア責任者であるRichard Ho氏は、Jalapeñoが「最重要ワークロードをハードウェアの理論限界近くで効率的に実行する」と述べている。
この設計方針は、LLM推論のワークロードが想定する「カーネル」や「サービングパターン」に深く根ざしている。特定の行列演算パターンや注意機構の計算をハードウェアレベルで効率化することで、同じワット数でもより多くの推論リクエストを捌ける見込みだ。
汎用チップとの差別化とLLM専用設計
Jalapeñoは「過去のAIワークロードから流用した汎用アクセラレータ」ではない。ChatGPT、Codex、API、さらに将来のエージェント製品まで見据え、LLM推論という一点に向けて設計を白紙から起こした専用品だ。OpenAIが日常的に運用している推論システムの実測データが、設計の随所に織り込まれている。
狙いは、現行の主力AIアクセラレータが持つ処理能力と、最速の専用推論システムが持つ低遅延性を、1つのパッケージで両立させることだ。対話型の大規模LLM製品に求められるのは、大量のリクエストを高速で処理するスループットと、1つ1つの応答が体感できるほど速いレイテンシの両方である。Jalapeñoはこの2軸を同時に引き上げる設計になっている。
データセンター規模の展開計画とパートナーシップ

Jalapeñoは1枚のチップで完結する話ではない。OpenAIとBroadcomは複数世代にわたる計算プラットフォームの共同開発を掲げており、2026年末からの初期展開を皮切りに、ギガワット級のデータセンターへと拡大していく予定だ。
Broadcomの社長兼CEOであるHock Tan氏は、OpenAIとの提携を「AIの今後10年に必要な物理インフラをスケールさせるための根本的なコミットメント」と表現する。Microsoftをはじめとするデータセンターパートナーと連携し、2026年から巨大規模の展開を始める計画が明言されている。
物理的なチップができても、それを数十万台単位で安定的に動かすには、ボード設計やラック統合、高性能ネットワーク、冷却、電源管理まで含めた総合力がいる。Celesticaはこの領域でOpenAIとBroadcomを支えるパートナーとして参加している。
OpenAIの社長兼共同創業者であるGreg Brockman氏は「世界は計算主導の経済へと移行している」と述べ、Jalapeñoがその長期戦略の一部であることを強調する。同氏の言葉を借りれば、スタックのより多くの部分を自前で設計することで、より多くの知能を、より高い効率で提供できるようになるという。
Jalapeño がAI利用者にもたらす具体的変化

このチップの話は、一見するとデータセンターや半導体産業だけの話題に思える。しかし、Jalapeñoの恩恵は最終的にエンドユーザーと開発者に届く。
- ChatGPTの応答速度が体感できるほど速くなる
- Codexによるコード生成や修正が、待ち時間の少ないままより複雑なタスクを処理できる
- APIの利用料金が下がり、スタートアップや個人開発者でも高度なAI機能を組み込みやすくなる
- 需要が集中する時間帯でも、タイムアウトや遅延に悩まされにくくなる
「推論はAIが人に届く場所だ」とOpenAIのブログは述べる。コスト、速度、信頼性の改善はすべて、最終的に製品体験の改善に直結する。Jalapeñoはそのための物理的基盤を刷新するプロジェクトだ。
この記事のポイント
- JalapeñoはOpenAI初のLLM推論専用アクセラレータで、Broadcomと共同開発
- 白紙設計によりデータ移動を最小化し、理論ピーク性能に近い実効利用率を実現
- 設計からテープアウトまで9か月の最速開発。OpenAIのモデルが設計加速に貢献
- 2026年末からギガワット級データセンターでの展開を計画
- ChatGPT、Codex、APIの低価格化と高速化に直結するフルスタック戦略の核心
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

WordPressを構築する人材は誰なのか、市場縮小の実態
数字が物語る市場の縮図

まずは客観的な立場から現状を整理する。データはシェアの緩やかな縮小を示しているが、これは崩壊ではなく「選択されなくなる」局面への移行を意味する。
全ウェブサイトに占めるWordPressのシェアは、2024年の約43.6%をピークに、2026年6月時点で41.5%まで低下した。CMS市場に限っても、ピークの61.7%から59.3%へとダウンしている。だが、この数値を額面通り受け取るのは早計だ。絶対数ベースで見ればWordPressサイトの総数は依然として増加しており、シェア低下の主因は、ウェブ全体の成長スピードにWordPressの新規サイト獲得が追いついていない点にある。
つまり、既存ユーザーが脱出しているわけではない。リスクは「新しくサイトを作る人がどこから始めるか」という新規獲得市場に潜んでいる。WP Mayorの記事はこれを「維持率は堅いが、新規参入の指標が危険信号を灯している」と総括する。この見立ては、プラットフォームの将来を占う上で極めて重要だ。
シェア低下の構造的要因
シェア低下はWordPressの魅力が失われたというより、ウェブの主戦場とプレイヤーが多様化した結果だ。かつてはサイト構築のデファクトだったWordPressも、今やShopifyやSquarespaceといったホステッドプラットフォーム、SubstackやLinktreeのような単機能サービスと住み分ける局面に入った。WixとShopifyだけで、WordPressが失ったシェアとほぼ同規模の成長を示している。
これはWordPressの「万能性」が、一部の層にとっては「複雑性」として映り始めている証左でもある。ウェブ制作の民主化は確かに進んだが、その民主化を担うツールの主役が交代しつつあるのだ。
変わりゆく作り手の肖像

WordPressを支えるコア人材の年齢層は、確実に上がっている。この構造変化は、エコシステムの将来における最大の不安要素の一つだ。
2003年の誕生から20年以上が経過し、黎明期を支えた開発者やエージェンシー経営者の多くは40代から50代に差し掛かっている。WP Mayorの記事が参照する2023年の公式調査では、回答者の約半数が40歳以上であり、30歳未満は23%に過ぎなかった。この調査は英語圏のコアコミュニティに偏っているという限界はあるが、プロフェッショナル層の高齢化を如実に示している。
より広範な開発者コミュニティに目を向けても傾向は同じだ。Stack Overflowの調査では、35歳以上の開発者の割合が2019年の約4分の1から2025年には47%にまで上昇している。PHP自体の新規学習者も少なく、若年層の関心はJavaScriptやノーコードツール、あるいはWebflowやFramerといった直感的なサイトビルダーに流れている。
新興市場という希望と現実
反論として、インドやブラジル、インドネシアといった新興国での成長を挙げる声は根強い。実際、これらの地域の若年層がWordPressの新たな利用者層を形成している可能性は高い。WP Mayorの記事も「世界全体で見れば、新規ユーザーの中心年齢はむしろ若いかもしれない」と指摘する。
だが、問題はその層が「エコシステムの構築者」、すなわちプラグインを開発し、コミュニティを牽引し、WordPressの未来を形作る人材なのか、という点にある。現状、西側諸国を中心とした従来の強力なコントリビューター層の高齢化と、新たな才能の流入不足は、イノベーションの停滞に直結する構造的な弱点だ。
「WordPressを構築する方法」の終焉

ウェブ制作の前提そのものが根本的に変化し、WordPressが前提としてきた「自分で積み上げる」モデルは、もはや唯一の選択肢ではなくなった。
かつてのように、サーバーを借り、CMSをインストールし、テーマを選び、プラグインを探し、セキュリティを自衛するという一連の体験は、多くの個人やスモールビジネスにとって、もはや過剰な負担でしかない。WP Mayorの記事が指摘する通り、ウェブの消費行動が「所有から利用へ」と移行する中で、この参入障壁の高さは深刻なコストとして認識されるようになった。
公開データが示す調査結果も興味深い。2026年1月の調査では、スモールビジネスの68%がソーシャルメディアと有料広告を成長の最大のドライバーと見なしていた。自社サイトは、かつての「最初の一歩」から「信頼性を担保する二の次の存在」へと役割を変えたのだ。
参入障壁という名のジレンマ
WordPressの柔軟性は、それを楽しめる人にとっては未だ最大の武器だ。しかし、スピードと簡便さを求める一般人にとって、WordPressが要求する「技術的なリテラシー」は、単なる面倒くささでしかない。最近のAIサイトビルダーがこれほど急速に支持を集めているのは、この「面倒くささ」をゼロにしたからに他ならない。
WP Mayorの記事は、この点について「いじくり回すことを楽しむ人が減ったとき、柔軟性はアドバンテージからコストに変わる」と明確に断じている。この変化は、WordPressがターゲットとすべき市場が「手間をかけてでも理想を追求する層」へと限定されつつあることを示唆している。
悪化するブランドパーセプション

構造的な問題に加え、WordPressにはイメージ面での逆風も吹いている。「遅い」「セキュリティが脆弱」というレッテルは、時に誤解を含みつつも、新規ユーザーの選択を阻害する強力な要因だ。
セキュリティに関して言えば、「WordPressコアに重大な脆弱性が多い」という認識は、データに基づくと不正確だ。Patchstackのレポートによれば、2025年に報告されたコアの脆弱性はわずか6件で、いずれも重要度は低かった。問題の91%はサードパーティ製プラグインに集中しており、脆弱性の公開から悪用開始までの時間は中央値で5時間にまで短縮されている。WP Mayorの著者はこの状況を「WordPressコアは安全だが、無数のプラグインで構成される現実のサイトは危険」と評する。
表示速度も同様の構図だ。Core Web Vitalsの合格率は改善傾向にあるものの、モバイルでの合格率は約45%と、Shopify(68〜75%)などに大きく水をあけられている。だが、これは技術的な限界というより、安価なホスティングや無秩序なプラグインの重ねがけによる「運用の問題」が大きい。WP Mayorの記事は「速度問題はWordPressというソフトウェアには不公平だが、典型的な導入実態には妥当な批判」と表現している。
「オープンソース」という逆説
今、オープンソースはAIブームによってかつてない隆盛を極めている。GitHub上では大規模なオープンソースAIプロジェクトが何十万ものスターを集め、コードを公開し合う文化が再び脚光を浴びている。WP Mayorの記事はここにこそ痛烈な皮肉があると指摘する。かつてオープンソースの大衆化を象徴したWordPressは、この新しい潮流から完全に取り残されているのだ。
新しい才能はWordPress.orgではなく、モダンなAIツールやJavaScriptフレームワークのリポジトリに集まっている。知名度はあっても、もはや「カッコよくない」プラットフォーム、それがWordPressの直面するイメージ上の課題だ。
AIが侵食する「すそ野」市場

WP Mayorの記事が最も深刻に捉えているのがこの問題だ。AIによるWebサイト構築の民主化は、WordPressが伝統的に得意としてきた「シンプルなサイト」の市場を根底から解体しつつある。
「サイトが欲しい」というニーズに対する解答は、もはやツールの習得ではない。LovableやCursor、Vercelのv0、WixのAIビルダーといったサービスは、ユーザーがやりたいことを自然言語で伝えれば、数分で動作するサイトを生成する。これらのツールは既に巨大なビジネスに成長しており、単なるバズワードではない。雇用主AIビルダーは、この流れが本物であることを証明している。
WP Mayorの記事は、AIの影響を「底上げ」と「天井上げ」の2つに分類する。すなわち、技術的でない人が簡単なサイトを作れるようにする底上げと、技術者がWordPressではなくCursorやAstroで高度なカスタムサイトを構築する天井上げだ。このうちWordPressにとって脅威なのは、市場規模が大きい前者の「底上げ」部分であり、これはWordPressがこれまで無意識に吸収してきた客層と完全に重なる。
プラグイン市場への波及
シンプルなサイトの需要が減退すれば、それを支えてきたプラグイン市場も連動して縮む。問い合わせフォーム、簡単なSEO対策、ギャラリー表示、ちょっとしたレイアウト変更。これまで無数のプラグインが提供してきたこれらの機能は、今やAIがその場で生成できるものだ。
WP Mayorの記事は、まだAIによるプラグイン収益減少を示す確定的なデータは存在しないと慎重に留保しつつも、「WordPressサイトでなくても済むようになったサイト群」を支えてきたプラグインこそが、エコシステムの中で最大のリスクに晒されている、という明確な見解を示している。これは、WordPressビジネスに携わる者なら誰しも直視すべき未来予測だろう。
プラグインゴールドラッシュの終焉

WP Mayorの記事が最も具体的に警鐘を鳴らすのが、プラグイン開発者の未来だ。AIによるコーディング支援は、プラグイン開発の参入障壁を劇的に下げた。2025年には12,713件のプラグインが新たに審査され、前年比で40%以上も急増した。WP Mayorはこれを「コードという防壁が消え去った状態」と表現する。
この状況下では、コードの機能だけが売りのプラグインに未来はない。誰でもAIを使えば、有料プラグインと同等の機能を一から構築できてしまうからだ。残るのは、コードだけでは再現できない「堀(Moat)」、すなわち、独自に蓄積したデータ、ライセンス認証やアップデート配信といったインフラ、あるいはユーザーからの信頼とブランド力である。
加速する寡占とデータの重要性
この変化を敏感に察知し、行動に移しているのが大手プラグイン企業だ。Awesome Motiveは多数のプラグインを買収し、そのデータと流通網を掌握することで巨大な堀を築いている。2026年5月にはLiquid WebがStellarWPブランドを統合し、傘下のプラグイン群を単一製品ラインに再編した。これらの動きは、企業価値の源泉が「コード」から「データと顧客基盤」へ完全にシフトしたことを示している。
WP Mayorの記事は、「AIは模倣者だけでなく、既存の勝者をも強力にする」と冷静な分析も加えている。すでに巨大なインストールベースを持つ企業は、AI機能を自社製品に迅速に組み込むことができるからだ。重要なのは、自身のビジネスがこの「バーベル」のどこに位置するのかを、今のうちに見極めておくことだろう。
ガバナンス不在が招く開発者離れ

WP Mayorの記事は、技術や市場の変化以上に深刻な問題として「プロジェクトのガバナンス」を挙げる。開発者がリスクを感じて去っていく最大の要因が、ここにあると断じている。
事の発端は、WordPressの共同創設者であるMatt Mullenweg氏が、ホスティング会社WP Engineを公の場で「WordPressのがん」と非難した2024年秋の出来事だ。WP Mayorの著者は、その後の一連の行為、すなわちWP Engineのアップデートサーバーアクセス遮断、ログイン時の「WP Engineと無関係である」という宣誓チェックボックスの設置、そして200万サイト以上で使われていたプラグインの無断フォークと乗っ取りを、「商標権の行使」の枠を超えた、統治機構の欠如を示すデモンストレーションだったと批判する。
連邦裁がAutomattic社に仮差し止め命令を出す事態にまで発展したこの騒動は、コミュニティに深い傷を残した。WP Mayorの記事は、これが単なる企業間紛争ではなく、優秀な開発者に対して「このプラットフォームに貢献する真のコスト」を知らしめる出来事だった、と厳しく指摘している。
構造的欠陥は何も変わっていない
WP Mayorの記事が最も憂慮するのは、問題の根本が2026年半ばの現在まで全く変わっていない点だ。WordPress.orgの配信インフラとプラグインディレクトリは、非営利財団ではなく、Mullenweg氏個人の資産であるという構造的な事実。そこには監視委員会も、コミュニティがリーダーの決定を覆すメカニズムも存在しない。
ガバナンス改革を主導したコミュニティリーダーのアカウントが停止され、代替リポジトリを目指したプロジェクトは出資者を得られず頓挫した。WP Mayorの記事は、この一連の出来事を「才能ある人々は皆、結論を出した。何かが変わるまでは、才能の流出は止まらない」と総括している。これは、WordPressの未来を左右する、極めて政治的な、しかし避けては通れない核心的な課題だ。
この記事のポイント
- WordPressの市場シェア低下は緩やかであり、エコシステムが崩壊しているわけではない。しかし、かつてのように「誰でも最初に選ぶツール」ではなくなりつつある。
- ユーザー層と開発者コミュニティの高齢化は深刻で、若い才能の流入不足が長期的な競争力を削いでいる。
- シンプルなサイト構築需要はAIに奪われつつあり、単機能プラグインの市場は決定的に縮小する公算が大きい。
- 生き残るには、コード以外の独自データや流通網といった「堀」が不可欠だ。ビジネスは二極化し、中間層は消える。
- プラットフォームのガバナンス問題は、今後もエコシステム最大の不安定要因であり続ける。その影響は技術的な課題よりも根深い。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

PayPal Standard終了、WooCommerce事業者が知るべき移行の全容
PayPal Standard終了がもたらすWooCommerce決済の転換点
WooCommerceで長年使われてきたPayPal Standardが、2026年6月に正式に役目を終える。PayPal Payments 4.1.0のリリースに伴い、条件を満たすと自動的に無効化され、管理画面からも非表示になる仕組みだ。すでにPayPal Standardを使っている場合でも、すぐに決済が止まるわけではない。しかし移行計画を立てるべきタイミングが来たことは間違いない。
WooCommerce Developer Blogの記事によれば、この動きは突然の発表ではない。2021年から段階的に縮小されてきた流れの最終段階にあたる。今回のアップデートでは、事業者の操作ミスを防ぎつつ、定期購入(サブスクリプション)の継続性を守る配慮が組み込まれている。
本記事では、PayPal Standard終了の背景、PayPal Payments 4.1.0の具体的な動作、移行を安全に進めるツールの使い方、そしてなぜこの変更が事業者にとってプラスになるのかを整理する。
上の図は、決済フローがどう変わるかの概念を示したものだ。外部サイトへの遷移がなくなるだけで、購入完了率は大きく変わる可能性がある。
これまでの経緯とPayPal Standard廃止の必然性

2021年から始まった段階的縮小
WooCommerceがPayPal Standardを新規店舗向けに非表示にし始めたのは2021年7月のことだ。WooCommerce 5.5では、コアに同梱されていた決済ゲートウェイが新規インストール時にデフォルトで読み込まれなくなり、必要ならばフィルターで再有効化する形に切り替わった。
このフィルターと同梱ゲートウェイ自体が完全に削除されたのはWooCommerce 8.9(2024年5月リリース)である。これ以降、PayPal Standardは「古い設定が残っている店舗」か「回避策のプラグイン」でしか生き延びられなくなっていた。今回のPayPal Payments 4.1.0は、その残存ケースを安全にアップグレードへ誘導する最終段階だ。
なぜこのタイミングなのか
PayPal StandardはAPIの進化に追随できない状態が続いていた。PayPal側が提供する最新のコンバージョン向上施策(Pay Later、Venmo、カード直接入力フィールドなど)を利用するには、PayPal Paymentsへの移行が不可避だった。事業者の売上機会を損なわないためにも、古い統合方式を整理する判断は合理的といえる。
PayPal Payments 4.1.0が実際に行うこと
上記の流れで最も重要なのは、アップデート自体が自動的に何かを変えるわけではない点だ。事業者が自らアカウント接続を行うまでは、従来のPayPal Standardはそのまま動作し続ける。
サブスクリプション保護の設計
WooCommerceの開発チームは、特に継続課金への影響を慎重に設計している。店舗に「アクティブ」または「キャンセル保留中」の定期購入が存在し、それがPayPal Standardで稼働している場合、プラグインはそれを検知し、無効化をスキップする。購読者は引き続き請求を受け、事業者には「影響を受けるサブスクリプションの数と所在」が通知される仕組みだ。
この「まず守る、その後に通知する」という順序は、事業者の売上を止めないための実務的な配慮といえる。移行操作を急ぐあまり、課金が途切れるリスクを負う必要はない。
アップグレード準備ツールで事前確認を徹底する
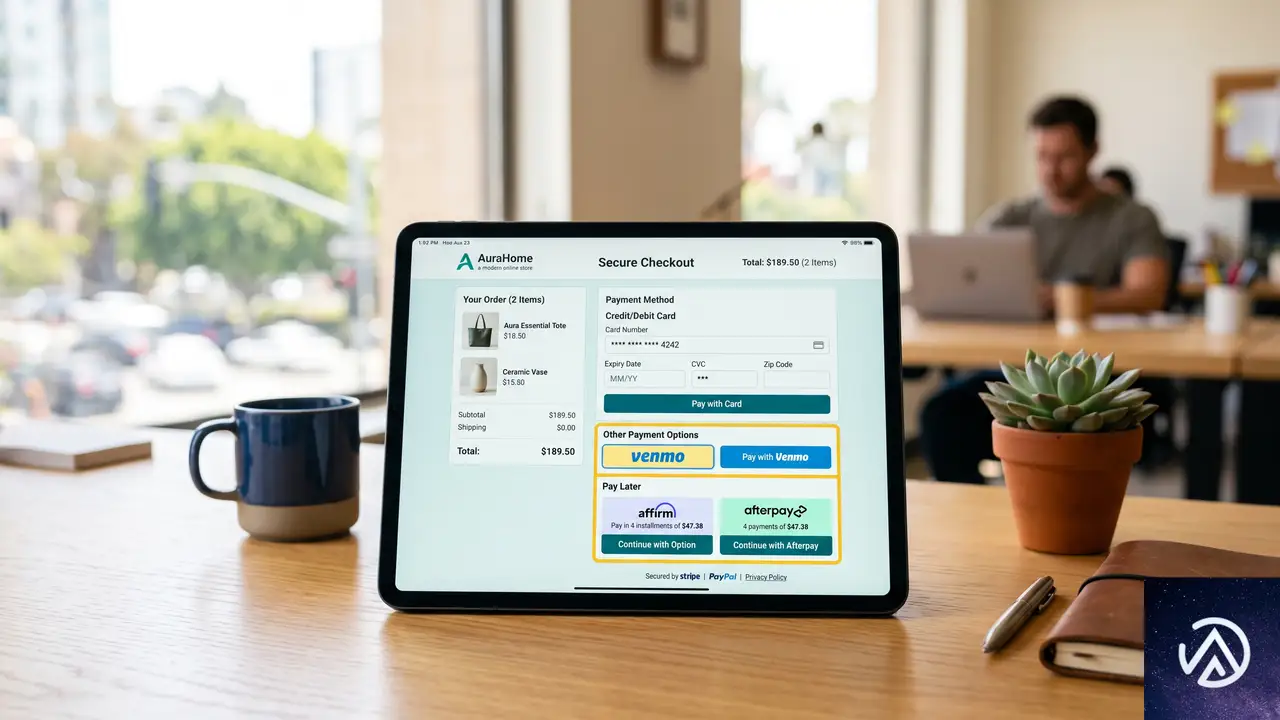
長期運用してきた店舗ほど、設定変更に対する不安は大きい。このツールはWordPress管理画面から操作でき、サイトには一切の変更を加えない読み取り専用設計だ。事前に「移行がどの程度スムーズに進むか」を把握してから行動に移せる点が最大の強みとなる。
なぜPayPal Paymentsへの完全移行が好機なのか

現代のオンライン購入者は、決済ステップでのストレスにきわめて敏感だ。サイトから離れずに支払いを完了できるかどうかが、コンバージョン率を大きく左右する。PayPal Paymentsは、まさにこの「離脱させない体験」を軸に設計されている。
単一プラグインで得られる最新機能群
Pay Later(後払い)、Venmo(米国向け送金・支払いサービス)、カード情報の直接入力フィールドといった機能は、PayPal Standardでは利用できなかった。これらはすべて、単一のプラグインで管理できる。PayPalのAPI変更やWooCommerceのアップデートにも同期してメンテナンスされるため、事業者が個別に対応する手間は大幅に減る。
コアからの分離で保守性が向上
WooCommerce 8.9以降、PayPal Standardはコアに戻る道を完全に断たれた。これは一見すると制約に感じるが、実際には「今後改善されない古いコードに依存し続けるリスク」を取り除く意味がある。PayPal Paymentsに集約することで、決済まわりのコードベースはシンプルになり、トラブルシューティングもしやすくなる。
PayPal Standard利用者が今すぐ着手すべき3つのアクション
- アップグレード準備ツールを実行し、現状のPayPal統合方式と注意点を把握する
- WooCommerce用のPayPal Paymentsプラグインをインストールし、事業者アカウントを接続する
- 定期購入を販売している場合、またはツールの結果に不明点があれば、WooCommerceサポートに相談する
アカウント接続が完了すれば、PayPal Standardからの移行はプラグインが安全に処理してくれる。人の手で設定を削除したり、手動で切り替えたりする必要はない。ツールの結果を踏まえて、確実に行動に移すことが重要だ。
この記事のポイント
- PayPal Standardは2026年6月のPayPal Payments 4.1.0で役目を終え、条件を満たすと自動無効化される
- アップデートだけでは何も変わらず、事業者が自らアカウントを接続するまでは安全に動作し続ける
- 有効な定期購入がある場合は無効化がスキップされ、売上停止のリスクを回避する設計になっている
- アップグレード準備ツールを使えば、サイトに変更を加えずに移行の準備状況を事前確認できる
- PayPal Paymentsへの集約により、最新のコンバージョン機能と継続的なAPI同期の恩恵を受けられる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

ドイツ裁判所、GoogleのAI回答に責任認定。SEO業界に衝撃
ドイツのミュンヘン地方裁判所が2026年5月28日、GoogleのAI Overviewが生成した虚偽の内容についてGoogle自身に責任があるとの仮処分を下した。AIが生成した回答は「プラットフォーム自身の発言」であり、単なる検索結果の羅列ではないという判断だ。この判決はSEOの前提を変える可能性を秘めている。
問題の核心は「AIがビジネスについて語るとき、誰が責任を負うのか」という問いだ。今回の判断は、AI回答が単なる情報の仲介ではなく「独自の編集行為」であると認定した点で画期的だ。つまり検索エンジンは自らが生成した文章に対して法的責任を問われうる時代に入った。この変化は企業のAI対策に根本的な再考を迫る。
裁判所がAI回答を「独自の編集物」と認定した意味

ミュンヘン地方裁判所が下した仮処分(事件番号26 O 869/26)は、GoogleのAI Overviewが2つの地域出版社について虚偽の説明を生成したことを問題視した。AI Overviewはこれらの出版社を詐欺やサブスクリプション詐欺と結びつける文章を生成していたが、引用元として示された情報源のどこにもそのような記述は存在しなかった。
AI Overview(AIによる検索結果の概要表示)とは、検索クエリに対してGoogleが従来のリンク一覧ではなく、AIが生成した要約文を画面上部に表示する機能だ。複数の情報源を読み込んで独自の文章を合成する仕組みで、2024年から本格展開が始まっている。
裁判所はこのAI Overviewについて「独立した新規の実質的な主張を生成している」と評価し、通常の検索結果一覧に適用される免責保護の対象外だと判断した。Google側は「ユーザー自身が回答の正確性を確認すべき」と主張したが、裁判所はこれを退けた。機械が文章を書くなら、その機械の所有者が責任を負うという理屈だ。
このデモが示すように、AI Overviewは従来の検索結果一覧とは法的な位置づけが根本的に異なる。裁判所は情報を「編集し合成する行為」を著作行為とみなし、そこに責任を紐づけたのだ。
この判決が持つ射程の広さ
今回の判断はあくまでドイツの一地裁による仮処分であり、EUの法的枠組みの中で下されたものだ。米国の裁判所が同じ事案を扱えば、プラットフォームを免責された仲介者とみなす従来の考え方から異なる結論に至る可能性は十分にある。ただ方向性は明確だ。AIが自律的に文章を生成する時代において、単なる「情報の受け渡し役」という位置づけは成立しなくなりつつある。
Search Engine Journalの記事では、この判決を1週間前に発表された別の調査結果と並べて論じている。その調査とは「AIに名前を挙げられることと、AIに信頼されることは別である」という分析だ。AI回答におけるビジネスの表現は、信頼の問題であると同時に説明責任の問題でもある。両方の視点が重なったとき、企業に求められる対応の輪郭が浮かび上がる。
責任を負うAIは「慎重になる」という構造的変化

法的責任を問われる可能性があるAIは、リスクを避けるために振る舞いを変える。これが今回の判決がもたらす最大の二次的影響だ。
AI回答が自社の発言として扱われるなら、プラットフォームが取る合理的な行動は「突然正確になること」ではない。「慎重になること」だ。確実に裏付けが取れるビジネスだけを安全圏として提示し、曖昧な存在は言及そのものを避けるようになる。この変化はすでに兆候を見せている。小規模な企業や評価が分かれる事業についてAIに質問すると、回答が急に歯切れが悪くなり、公式情報源に委ねたり、企業の特徴づけを完全に回避したりするケースが増えている。
AI回答「複数の情報源がありますが、公式な確認が取れません。ご自身での確認をお勧めします」
AI回答「△△社は〇〇を提供しています。公式サイトではXXと記載されています」
この変化は「どうやってAIに正しく自社を引用させるか」という問いを「AIが自信を持って名前を出せるビジネスかどうか」という一段上の問いに引き上げる。機械可読なアイデンティティの整備は、もはやSEOの一手ではなく参加資格そのものに近づく。
AIがビジネスを「疑う」4つの原因
Search Engine Journalの記事でCarlo Daniele氏が指摘するように、大半のビジネスはAIに疑念を抱かせる材料を少なくとも一つは抱えている。具体的には以下の4パターンだ。
- 法的実体の不一致:自社サイト、SNSプロフィール、過去のプレス記事で会社名や事業者名が微妙に異なる。AIはどれが正規情報か判断できない
- 役職表記のズレ:会社概要ページと過去のインタビュー記事で創業者の役職表記が食い違っている
- テキスト化されていない重要情報:製品の具体的な機能説明が画像やPDFの中にしか存在せず、AIのパーサーが読み取れない
- カテゴリの曖昧さ:人間が読めば事業内容が明確でも、マークアップ上でカテゴリが明示されておらず機械が判断できない
これらはいずれも従来のコンテンツSEOの発想では見過ごされてきた問題だ。記事が指摘するように、これはコンテンツの問題ではなくアイデンティティの問題である。1万語のコンテンツがあっても自己矛盾した情報を発信していればAIはそのビジネスを「検証困難」と判定する。一方で簡潔でもあらゆる読み取り経路で同一の事実を返すビジネスはAIにとって「引用可能」と判断される。
AIに「確信されるビジネス」になるための実践手順

この変化に対応するために法律家は必要ない。必要なのはAIに「このビジネスは確かだ」と判断させるための基盤整備だ。Search Engine Journalの記事で提示された3ステップを具体的に見ていく。
ステップ1 AIが自社をどう語っているか監査する
まずは自社ブランド名、製品名、事業カテゴリを実際に顧客が使うAI検索エンジンに投入し、生成される回答を第三者の目で読む。AI OverviewだけでなくChatGPTやClaudeなど複数のエンジンで確認することが重要だ。エンジンごとに回答は異なり、そのズレの大きさこそが自社のアイデンティティ監査の出発点になる。
チェックすべき項目は以下の4つだ。AIが自社のカテゴリを正しく述べているか、正しい製品を帰属させているか、正しい人物名を挙げているか、そして実際には無関係なネガティブ情報と結びつけていないか。Search Engine Journalの記事によれば、大半の企業はこのような監査を一度も実施したことがないという。
この監査は企業のAI上の立ち位置を可視化する最初の一歩だ。自社がどのように語られているかを把握せずに対策を立てることはできない。
ステップ2 AIが判断の根拠にする事実情報を整備する
監査で発見されたズレを修正するには、AIが参照する基盤情報の整備が不可欠だ。Search Engine Journalの記事で提唱されているMachine-First Architecture(機械優先アーキテクチャ)の考え方では、以下の3つが中核となる。
第一に、Organization構造化データの実装だ。自社が誰で、何をしており、どこで確認できるかを機械可読な形式で明示する。構造化データ(Schema.orgに準拠したマークアップ)とは、HTMLに埋め込む形で検索エンジンに情報の意味を伝える仕組みであり、AIが情報を正確に抽出するための土台となる。
第二に、全情報発信チャネルでの表記統一だ。自社サイト、Googleビジネスプロフィール、主要SNS、業界ディレクトリで社名・住所・事業内容の表記を完全に一致させる。バリエーションがあるたびにAIは「どれが正しいか」の判断を強いられ、リスク回避のために言及を控える方向に傾く。
第三に、テキスト化の徹底だ。画像やPDFに埋め込まれた重要情報をHTMLテキストとしても提供し、AIのパーサーが確実に読み取れる形にする。特に事業内容の明示的な説明は、人間向けのデザイン性よりも機械向けの明快さを優先すべき局面に入っている。
ステップ3 監査を習慣化する
企業情報は時間とともに変化し、周囲のウェブ環境も変わり、AIモデルも再学習を繰り返す。一度整備して終わりではなく、定期的にAIが自社をどう語っているかを確認する習慣が必要だ。Search Engine Journalの記事はこれを「自社のアナリティクスを確認するのと同じ感覚で」行うべきだと提案している。
訴訟そのものは稀であり管轄も限られる。しかし構造的な影響はゆっくりと確実に広がる。AI回答にリスクが伴うとき、エンジンは慎重になり、慎重なエンジンは裏付けの取れるビジネスだけを積極的に提示する。企業に求められるのは「機械に確信される存在」になるための継続的な努力だ。
この記事のポイント
- ミュンヘン地方裁判所がAI OverviewをGoogle自身のコンテンツと認定し免責を否定した
- AI回答に法的責任が生じるとプラットフォームは「慎重になり言及を避ける」方向に動く
- 企業名・役職・事業内容の表記不一致がAIの信頼を損ねる主要因である
- 構造化データの実装と全チャネルでの情報統一がAI時代の基盤対策となる
- AIによる自社の語られ方を定期的に監査する習慣が不可欠だ
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Astro 7.0リリース、Rustコンパイラでビルド時間を最大61%短縮
Astro 7.0が6月22日に正式リリースされた。今回のメジャーアップデートは「速度」にフォーカスしており、.astroファイルのコンパイラをRustで書き直した点が最大の変更点だ。
ベンチマークによると、ビルド時間は前バージョンと比較して15〜61%短縮される。Astro公式ブログが公開したテスト結果では、13,275ページを持つaspire.devのビルドが半分以下になった事例も報告されている。Rust化された基盤、Vite 8との統合、新しいアドバンストルーティング機能が主要な柱だ。
本記事ではAstro 7.0の全変更点を、実務者の視点から詳しく解説する。
Vite 8によるバンドル基盤の刷新

Astro 7.0のビルド高速化を支える土台が、Vite 8へのアップグレードだ。Vite 8は、JavaScriptツールチェインの世界で最も注目されているリリースのひとつである。最大の変更点は、Rustベースのバンドラ「Rolldown」が標準搭載されたことだ。
Rolldownとは何か
Rolldownは、従来のesbuildとRollupを単一のバンドラで置き換えるツールである。バンドラとは、複数のJavaScriptファイルやコンポーネントを本番用の少数のファイルにまとめる役割を持つ。Rolldownのベンチマークでは、Rollupと比較して10〜30倍高速という結果が出ている。速度だけでなく、既存のRollupプラグインAPIとの互換性も維持している点が実務上の大きな利点だ。
Astroユーザーにとって重要なのは、ほとんどのプロジェクトで設定変更が不要なことだ。Vite 8には既存のesbuild設定やrollupOptions設定を自動的にRolldown用に変換する互換レイヤーが組み込まれている。カスタムViteプラグインを使っている場合も、RolldownがRollupと同じプラグインAPIをサポートするため、そのまま動作する可能性が高い。
Rust化がもたらすビルド性能の飛躍的向上

Astroのビルドプロセスは、大きく2つの段階に分かれる。1つ目はサイトのページやコンテンツ、クライアントコンポーネントをJavaScriptにバンドルする段階。2つ目は、バンドルされたコードを「小さなサーバー」として実行し、プリレンダリング対象の全ページにリクエストを送ってHTMLを生成する段階だ。
Astro 7.0は両方の段階を改善しているが、とくに1つ目のバンドル段階に注力している。ビルド時間のボトルネックになりやすい処理をRustで書かれたネイティブコードに移行することで、大幅な高速化を実現した。
上図の通り、ビルドフローの主要な構成要素がRustベースに置き換えられている。.astroファイルのコンパイル、Markdown/MDXの処理、レンダリングエンジンのすべてが刷新された。以下では各要素を詳しく見ていく。
.astroコンパイラのRust化
Astro 7.0では、.astroコンポーネント形式の新しいコンパイラがRustで構築された。このコンパイラは、以前のGoベースのコンパイラをフルリライトしたものだ。内部的には、oxc(高速なJavaScript/TypeScriptパーサ)を解析に、Lightning CSSをCSSスコープ処理に使っている。
単体ではビルド時間の約6%改善にとどまるが、数千ページ規模の大規模サイトでは、他の改善と相乗効果を発揮する。以下の3点は後方互換性に関わる変更として注意が必要だ。
- HTML自動修正の廃止。旧コンパイラは「正しいHTML」にしようと要素の並べ替えやタグの自動クローズを行っていたが、新コンパイラではマークアップをそのまま扱う。予期せぬ挙動の原因だった自動修正がなくなり、意図した通りに出力されるようになった。
- JSX形式の厳格化。
<div>Helloのような閉じタグ欠落や、<div class="Hello >のような属性の未終端は、自動修正されずエラーになる。旧コンパイラがブラウザの挙動を真似て黙って修正していた部分だ。 - JSXホワイトスペース処理。インライン要素間の改行が可視スペースを生成しなくなる。たとえば、
<span>Hello</span><span>World</span>は「HelloWorld」と表示される。スペースが必要な場合は{' '}を明示的に挿入する。
Markdown/MDX処理のSätteri移行
Astro 7.0では、デフォルトのMarkdownとMDXの処理パイプラインが、Rust製プロセッサ「Sätteri」に置き換えられた。SätteriはAstroコアチームメンバーが開発したツールで、内部的にはpulldown-cmark(CommonMark解析)とoxc(MDX式解析)を使用している。
従来のAstroは、JavaScriptベースのunified(remark/rehypeとそのプラグイン群)でMarkdownを処理していた。数千ページのサイトでは、このパイプラインがビルドの最も遅い段階になることが多かった。Astro公式ブログによれば、AstroドキュメントサイトとCloudflareドキュメントサイトでSätteriに切り替えたところ、ビルド時間が1分以上短縮されたという。
Sätteriには、これまで別途プラグインが必要だったMarkdown機能の多くがビルトインで含まれている。GFM(テーブル、脚注、取り消し線、タスクリスト)、スマートパンクチュエーション(カーリークォート)、見出しID、コンテナディレクティブ、数式、フロントマター(YAML/TOML)、上付き・下付き文字、Wikilinksなどだ。これらはfeaturesオプションで有効化できる。
既存のremark/rehypeプラグインに依存しているプロジェクトは、@astrojs/markdown-remarkを使って従来のunifiedベースのパイプラインを引き続き利用できる。
キュー型レンダリングの安定化
Astro 6.0で実験的機能として導入されたキュー型レンダリングが、Astro 7.0で安定版となりデフォルトのレンダリングエンジンになった。これは、式が密集したページで約2.4倍高速という結果が出ている。
従来のレンダリングは再帰的アプローチを取っていた。親コンポーネントが子コンポーネントを呼び出し、さらにその子が孫を呼び出すという入れ子構造でレンダリングが進む。これに対し、新しいエンジンはキュー(またはスタック)と単一のループを使う。キューに子ノードを正しい順序で追加し、キューが空になるまでループでレンダリングを続ける仕組みだ。
初回の実装では「全コンポーネントの順序付きリストを作成→リストをループしてレンダリング」という2パス方式だったが、最終版ではリスト作成とレンダリングを同時に行う方式に改善された。この方式は再帰的アプローチと比較してメモリ使用量も少ない。
アドバンストルーティングでリクエストパイプラインを完全制御
Astroは静的サイトジェネレーターとしてスタートし、ファイルベースのルーティングを基本としてきた。しかし、ミドルウェア、リダイレクト、リライト、Actions、セッション、i18nといった機能が追加されるにつれ、リクエストのライフサイクル制御が複雑化していた。
認証をActionsより先に実行したい、ログ出力をページレンダリングだけに限定したい、APIリクエストをAstroの外で先に処理したい、といったニーズに応えるため、Astro 7.0ではsrc/fetch.tsファイルを追加することでリクエストパイプラインを完全制御できるようになった。
このパターンは、Cloudflare WorkersやDeno、Bunが採用している標準的なfetchハンドラ形式に準拠している。
import { astro, FetchState } from 'astro/fetch';
export default {
fetch(request: Request) {
const state = new FetchState(request);
// APIリクエストをバックエンドサービスに転送
if (state.url.pathname.startsWith('/api')) {
const url = new URL(
state.url.pathname + state.url.search,
'https://backend-api.example.com'
);
return fetch(new Request(url, request));
}
// それ以外はAstroのページやエンドポイントにフォールバック
return astro(state);
}
}Honoとの統合
アドバンストルーティングAPIはHonoとも互換性がある。Honoは軽量なWebフレームワークで、豊富なミドルウェアエコシステムを持つ。以下のようにBasic認証をAstroアプリケーションに組み込める。
import { astro } from 'astro/hono';
import { Hono } from 'hono';
import { basicAuth } from 'hono/basic-auth';
const app = new Hono();
app.use(basicAuth({ username: 'admin', password: 'secret' }));
app.use(astro());
export default app;より高度な使い方として、個別のAstro機能を別々のミドルウェアとして構成できる。認証、Actions、ミドルウェア、i18n、ページの各レイヤーを任意の順序で積み重ねられるため、認証チェックをActionsより手前に置くといった制御がシンプルに実現できる。このsrc/fetch.tsファイルを追加しなければ、Astroの動作は従来通りだ。
ルートキャッシングとCDNプロバイダ連携
オンデマンドレンダリング応答のキャッシュ制御は、ホスティングサービスごとに異なる仕組みで実装されてきた。Astro 7.0で安定版となったルートキャッシングは、デプロイ先を問わない単一のキャッシングAPIを提供する。
設定の流れはシンプルだ。まずキャッシュプロバイダを一度設定し、あとはページ内でAstro.cache(APIルートではcontext.cache)を使ってレスポンスごとにキャッシュ制御を記述する。標準的なHTTPキャッシングセマンティクスに従うため、特別な知識は不要だ。
import { defineConfig, memoryCache } from 'astro/config';
export default defineConfig({
cache: {
provider: memoryCache(),
},
});---
Astro.cache.set({
maxAge: 120, // 2分間キャッシュ
swr: 60, // 再検証中は1分間 stale を返す
tags: ['products'], // タグベースの無効化用
});
---routeRulesを使えば、ルートグループ単位で宣言的にキャッシュルールを設定できる。
export default defineConfig({
cache: { provider: memoryCache() },
routeRules: {
'/blog/[...path]': { maxAge: 300, swr: 60 },
},
});キャッシュの無効化はcache.invalidate()でタグ単位またはパス単位で行える。CMSのwebhookエンドポイントをAstroで実装し、コンテンツ更新時に該当キャッシュを破棄するといった使い方が可能だ。
CDNキャッシュプロバイダ
Astro 7.0では、Netlify、Vercel、Cloudflare向けのCDNキャッシュプロバイダが実験的機能として追加された(Cloudflareはプライベートベータ)。これらはレスポンスをメモリではなく、各プラットフォームのエッジネットワークにキャッシュする。キャッシュヒット時はサーバー関数を呼び出さず、CDNから直接応答が返るため、さらに高速なレスポンスを実現できる。
アダプタごとに/cacheエントリポイントからプロバイダをインポートする。
import { defineConfig } from 'astro/config';
import netlify from '@astrojs/netlify';
import { cacheNetlify } from '@astrojs/netlify/cache';
export default defineConfig({
adapter: netlify(),
cache: {
provider: cacheNetlify(),
},
});Astro.cache、routeRules、cache.invalidate()のAPIは、どのプロバイダでも同じように動作する。各プロバイダが、Astroのキャッシュディレクティブを各プラットフォームのネイティブなキャッシュ制御ヘッダと無効化APIに変換する仕組みだ。
AIエージェント向け開発サーバー機能

AIコーディングエージェントの普及に伴い、Astro 7.0はエージェント駆動開発を支援する機能を導入した。AIエージェントは、終了しない長時間実行プロセス(開発サーバー)の扱いが苦手だ。シェルコマンドを実行し、終了を待って出力を読むワークフローに、開発サーバーは適合しない。
バックグラウンド開発サーバー
astro dev --backgroundコマンドを使うと、開発サーバーを管理されたバックグラウンドプロセスとして起動できる。コマンドはサーバーがリクエストを受け付け可能になるまでブロックし、URLとプロセスIDを出力してからデタッチする。ポーリングやスリープ、端末出力の解析は一切不要だ。
AstroはAIエージェント内で実行されていることを自動検出し、バックグラウンドモードを自動的に有効にする。エージェントワークフローでは--backgroundフラグの指定すら不要だ。
ロックファイルによって重複インスタンスが防止される。エージェントが誤って2つ目のサーバーを起動しようとすると、既存インスタンスの詳細が返される。astro dev statusで状態確認、astro dev stopで停止、astro dev logsでバックグラウンドサーバーのログを確認できる。また、全実行中の開発サーバーは/_astro/statusヘルスエンドポイントを公開し、エージェントがサーバーの生存を確認できる。
JSONログ出力
Astroのロガーが完全に設定可能になった。AIエージェント向けには、バックグラウンドモードの自動検出時にJSONログが自動的に有効化される。それ以外の用途でも、CLIまたは設定ファイルで有効化できる。
astro dev --jsonimport { defineConfig, logHandlers } from "astro/config";
export default defineConfig({
logger: logHandlers.json()
})構造化ログが必要なユースケースはAIだけではない。SSRで本番運用しているチームは、Kibana、CloudWatch、Grafana/Lokiといったログ集約サービスと統合するために構造化ログを必要としている。従来のAstroのログ出力は、色付き表示や罫線文字、複数行エラーフォーマットなど、人間の可読性に特化しており、機械による解析が困難だった。
compose() APIを使えば、人間向けのコンソール出力と機械向けのJSONログを同時に出力できる。
import { defineConfig, logHandlers } from "astro/config";
export default defineConfig({
logger: logHandlers.compose(
logHandlers.console(),
logHandlers.json()
)
})この記事のポイント
- Astro 7.0は.astroコンパイラとMarkdown/MDX処理をRust化し、ビルド時間を15〜61%短縮した
- Vite 8のRust製バンドラRolldownが標準搭載され、既存の設定をほぼそのまま使える
- アドバンストルーティングでリクエストパイプラインを完全制御でき、Honoとの統合も可能
- ルートキャッシングが安定版となり、Netlify/Vercel/CloudflareのCDNキャッシュプロバイダも追加された
- AIエージェント向けにバックグラウンド開発サーバーとJSONログ出力が自動有効化される
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

CSSスクロール駆動アニメーションで逆方向スクロールを実現
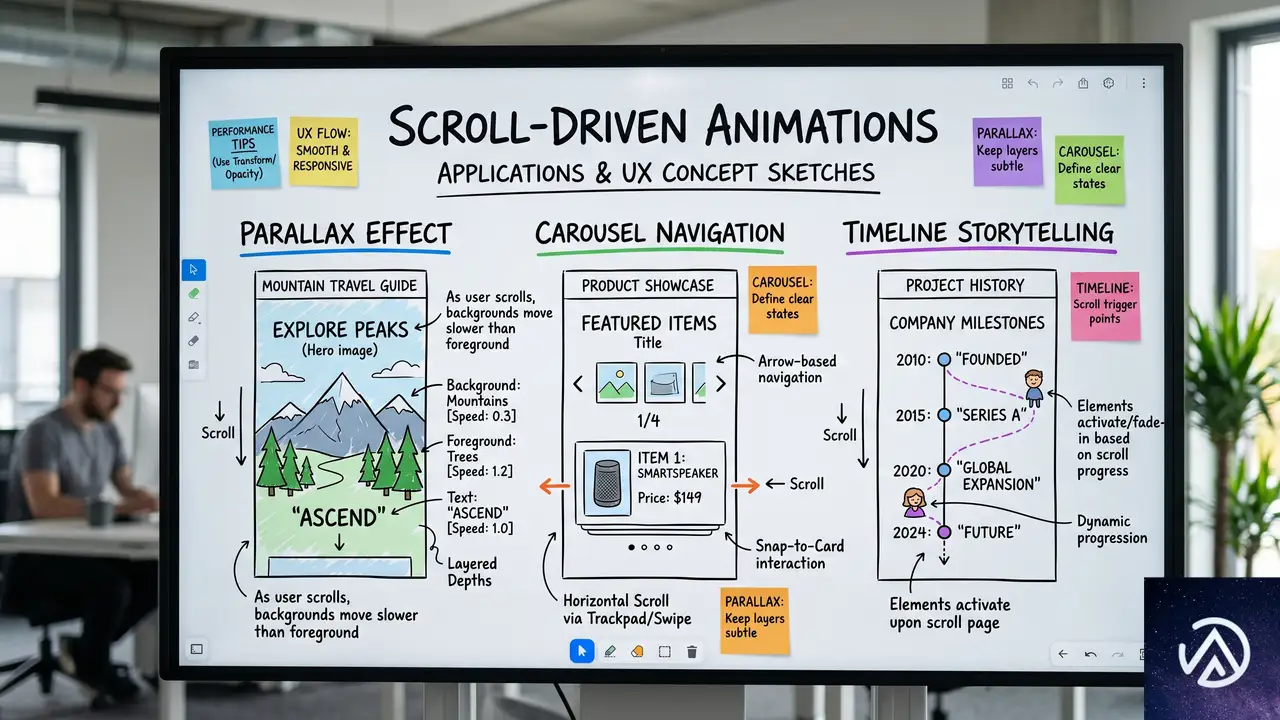
スクロールに応じてアイテムが上下逆方向に動くレイアウトを実現する手法がある。CSS-Tricksの著者が紹介したこのテクニックは、CSSの「スクロール駆動アニメーション」と疑似要素によるマスク効果を組み合わせたものだ。通常のアニメーションと異なり、ユーザーがスクロールした量だけアニメーションが進行するため、インタラクティブな表現が可能になる。本記事ではその仕組みと実装手順を詳しく解説する。
具体的なコードを見ていこう。元記事では3つのカラムがあり、左右のカラムはスクロールに応じて上方向へ、中央のカラムは下方向へ移動する。コンテナの上下端ではアイテムがふわりと消えるフェード効果がかかる。この動きはCSSの animation-timeline プロパティと view() 関数で制御される。
スクロール駆動アニメーションの基本概念
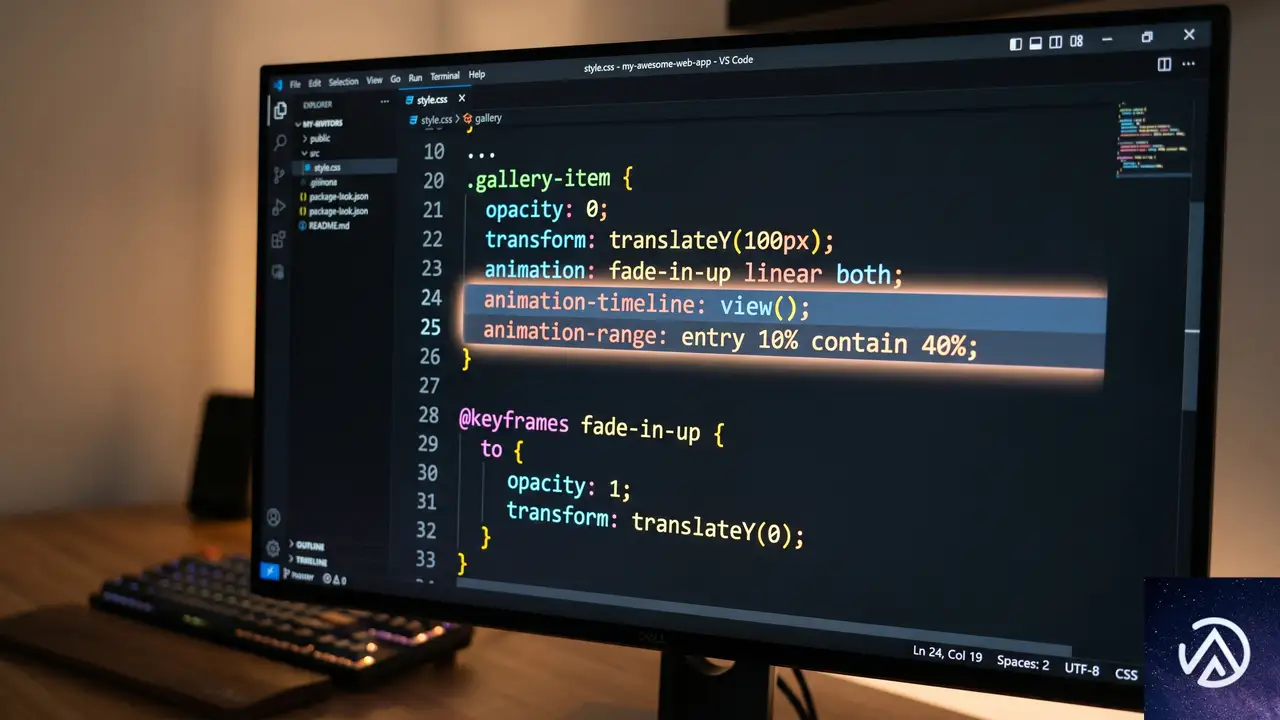
スクロール駆動アニメーション(Scroll-Driven Animations)とは、アニメーションの進行をスクロール位置に連動させるCSSの新機能である。従来のCSSアニメーションは時間ベースで動いていたが、この機能を使えば「要素が画面のどこにあるか」や「スクロール量がどれだけ進んだか」を基準にアニメーションを再生できる。
これを実現するのが animation-timeline プロパティだ。ここには scroll() 関数または view() 関数を指定する。scroll() は親要素やルートのスクロール位置を追跡し、view() は要素自身がスクロールポート(スクロール可能な表示領域)に出入りする過程を追跡する。今回の逆方向スクロールでは、各カラム内のアイテムがコンテナ領域に入ったり出たりする動きが肝になるため、view() が採用された。
view() 関数の仕組み
view() 関数は、アニメーション対象の要素がスクロールポートのどの範囲にあるかを0%から100%の進捗で返す。例えば、要素がスクロールポートの下端にさしかかった瞬間が0%、完全に反対側へ出切った瞬間が100%だ。この進捗をアニメーションのタイムラインにマッピングすることで、スクロールに同期した動きを作れる。
CSS-Tricksの著者は、この関数に「entry 0% cover 100%」というインセットを設定している。これは、要素がスクロールポートに入り始めた瞬間(entry)の0%から、完全に通り抜けて隠れきった瞬間(cover)の100%までをアニメーションの範囲とする指定だ。この設定により、各カラムのアイテムが表示領域に姿を現し、消えるまでの全行程をアニメーションでカバーできる。
このデモは、要素がスクロールポートに出入りする際のマスク効果を静的に表現している。実際のブラウザでは、スクロール量に応じて要素の位置が連続的に変化し、上下のグラデーション部分に重なると自然に溶け込むように見える。
animation-range による範囲の精密制御
animation-range プロパティは、タイムラインのどの区間を使ってアニメーションを再生するかを決める。デフォルトでは「entry 0% exit 100%」だが、CSS-Tricksの例では「entry 0% cover 100%」としている。これは entry が「要素がスクロールポートに入り始める瞬間」、cover が「要素がポートを完全に覆い隠した瞬間(つまり反対側へ出切った瞬間)」の2点を基準にする記法だ。
この指定により、アイテムが画面に現れた瞬間から消える最後までアニメーションが継続する。逆に言えば、画面外に完全に隠れている間はアニメーションが停止しているのと同じ状態になる。結果として、ユーザーがスクロールしている間だけアイテムがスムーズに動き続けるインタラクションが実現する。
HTMLのシンプルな構造
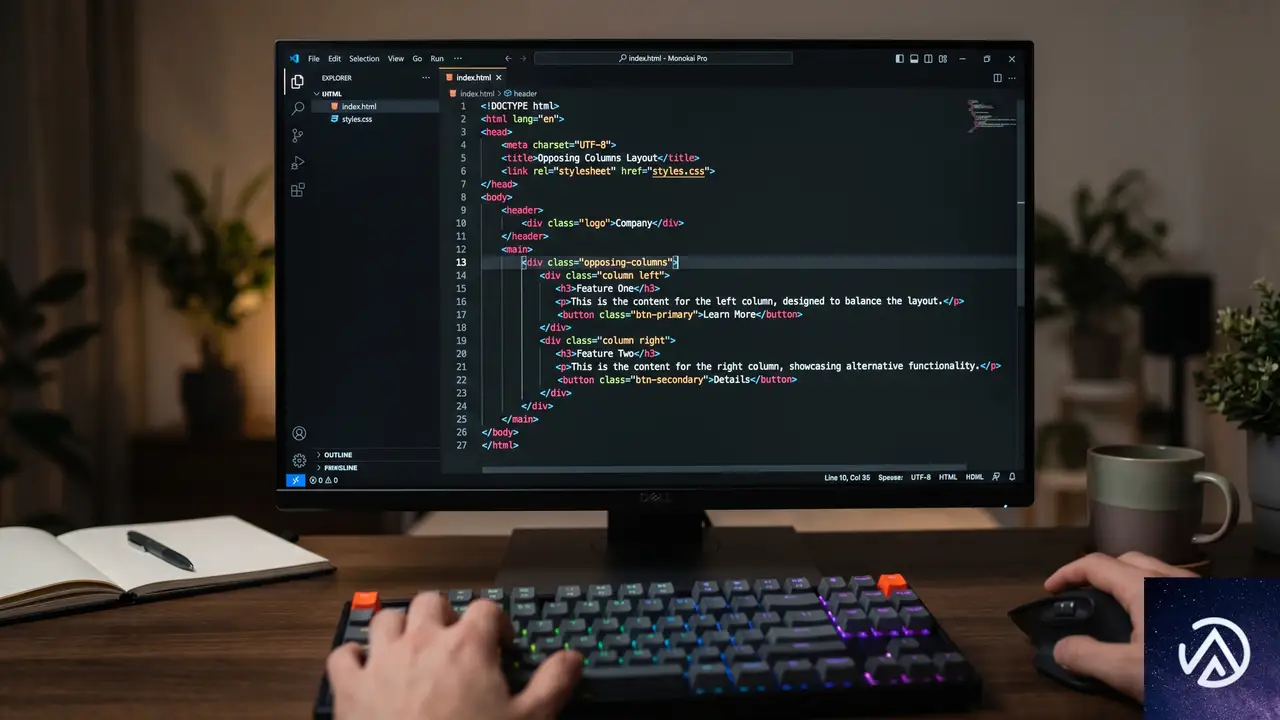
CSS-Tricksの記事で示されているHTMLは非常に簡素だ。複雑なJavaScriptや追加のラッパーは不要で、大きく分けて3階層の要素があればよい。
<div class="opposing-columns">
<div class="opposing-column">
<div class="opposing-item">...</div>
<div class="opposing-item">...</div>
<div class="opposing-item">...</div>
</div>
<div class="opposing-column">
<div class="opposing-item">...</div>
<div class="opposing-item">...</div>
<div class="opposing-item">...</div>
</div>
<div class="opposing-column">
<div class="opposing-item">...</div>
<div class="opposing-item">...</div>
<div class="opposing-item">...</div>
</div>
</div>このシンプルな構造がポイントだ。CSS側でスクロール駆動アニメーションを定義する際、各カラム(.opposing-column)ごとに異なるアニメーションを適用し、その中に含まれるアイテムが一括して動く仕組みになっている。
CSSによるマスク効果の実装
アイテムがコンテナの上下端でふわっと消える演出は、疑似要素とグラデーションによるマスクで作られている。透明度や opacity を直接操作するのではなく、背景色と同じ色のグラデーションを重ねることで、コンテンツが自然に隠れるように見せているのだ。
疑似要素でマスクを生成する
親コンテナ .opposing-columns に position: relative を設定したうえで、::before と ::after 疑似要素を絶対配置している。これらの疑似要素はコンテナの上下にそれぞれ配置され、幅はコンテナ全体、高さはCSS変数 --opposing-mask の3倍に設定されている。
@media screen and (width >= 50rem) {
.opposing-columns {
position: relative;
margin-block: var(--opposing-mask, 3rem);
}
.opposing-columns::before,
.opposing-columns::after {
content: "";
position: absolute;
inset-inline: 0;
block-size: calc(var(--opposing-mask) * 3);
pointer-events: none;
z-index: 1;
}
}疑似要素には pointer-events: none が指定されており、クリックやホバーの邪魔をしない。これはユーザビリティを損なわないための重要な配慮だ。
グラデーションで自然なフェードを生み出す
次に、これらの疑似要素に線形グラデーションを適用する。上側の ::before には to bottom(上から下)方向のグラデーションを設定し、始点をドキュメントの背景色 --opposing-bg、終点を透明にする。下側の ::after はこれを逆にして、to top(下から上)方向のグラデーションを設定する。
.opposing-columns::before {
background-image: linear-gradient(
to bottom,
var(--opposing-bg) var(--opposing-mask),
transparent
);
inset-block-start: calc(var(--opposing-mask) * -1);
}
.opposing-columns::after {
background-image: linear-gradient(
to top,
var(--opposing-bg) var(--opposing-mask),
transparent
);
inset-block-end: calc(var(--opposing-mask) * -1);
}これにより、カラム内のアイテムがコンテナの上下端に近づくと、グラデーション部分に重なって自然に消えていくように見える。背景色とマスクの色が同一であるため、アイテムが溶け込むようなスムーズなフェードが実現する。
キーフレームアニメーションの設計
マスクの準備が整ったら、実際にアイテムを上下に動かすアニメーションを定義する。CSS-Tricksの著者は3つの異なるキーフレームを用意し、各カラムに割り当てている。
3種類の動きをキーフレームで定義
アニメーションは transform: translateY() による垂直移動で構成される。1つ目の scroll1 はアイテムを上方向に移動させ、2つ目の scroll2 はその逆方向(下方向)に動かす。3つ目の scroll3 はややオフセットを持たせた上方向の動きで、カラム間のタイミングにわずかなズレを生み出している。
@keyframes scroll1 {
from { transform: translateY(var(--opposing-mask)); }
to { transform: translateY(calc(var(--opposing-mask) * -1)); }
}
@keyframes scroll2 {
from { transform: translateY(calc(var(--opposing-mask) * -1)); }
to { transform: translateY(var(--opposing-mask)); }
}
@keyframes scroll3 {
from { transform: translateY(calc(var(--opposing-mask) * .66)); }
to { transform: translateY(calc(var(--opposing-mask) * -.33)); }
}このオフセットの考え方は応用が利く。例えば同じ方向に動く2つのカラムでも、開始位置を微妙にずらすだけで視覚的なリズムが生まれ、単調さを回避できる。
カラムごとに異なるアニメーションをバインド
キーフレームを定義したら、各カラムにアニメーション名を割り当てる。nth-of-type 疑似クラスを使い、1番目のカラムには scroll1、2番目には scroll2、3番目には scroll3 を適用する。これにより、カラムの位置に応じて移動方向が自動的に決まる。
.opposing-column:nth-of-type(1) { animation-name: var(--animation-1); }
.opposing-column:nth-of-type(2) { animation-name: var(--animation-2); }
.opposing-column:nth-of-type(3) { animation-name: var(--animation-3); }さらに、これらのアニメーションは animation-timeline: view() と animation-range: entry 0% cover 100%、そして animation-timing-function: linear がセットで指定される。線形のタイミング関数を選ぶことで、スクロール速度に応じてアイテムが等速で動き、自然な同期感が得られる。
アクセシビリティとブラウザ対応
実装にあたっては、モーションに敏感なユーザーへの配慮と、ブラウザ間の互換性を考慮する必要がある。CSS-Tricksの元記事でもこの点に言及しており、適切なフォールバックを組み込んでいる。
prefers-reduced-motion への対応
OSやブラウザの設定で「視差効果を減らす」を有効にしているユーザー向けに、メディアクエリ prefers-reduced-motion: reduce を用いてアニメーションを無効化する。このクエリが一致した場合、アニメーションを unset で打ち消し、さらに疑似要素のマスクも削除する。マスクだけが残ると、動かないアイテムが不自然に隠れてしまうからだ。
@media (prefers-reduced-motion: reduce) {
.opposing-column {
animation: unset;
}
.opposing-column::before,
.opposing-column::after {
content: unset;
}
}これにより、動きを減らしたいユーザーには静的なレイアウトが提供され、意図しないストレスを回避できる。
@supports を使った段階的な実装
スクロール駆動アニメーションは、2026年6月時点でChromeとSafariがサポートしているが、Firefoxは未対応だ。そのため、@supports (animation-timeline: view()) を用いて、機能が使えるブラウザでのみアニメーションを有効化するのが安全だ。サポートされない環境では、通常のスクロールと同様の静的な表示になるよう設計しておけば、すべてのユーザーに破綻のない体験を届けられる。
@supports (animation-timeline: view()) {
/* スクロール駆動アニメーションのスタイル */
}この手法はプログレッシブエンハンスメントの好例で、新しいCSS機能を安全に導入したい現場でも参考になるだろう。
独自の視点:逆方向スクロールの応用可能性
ここまで見てきたテクニックは、単なる逆方向スクロールの演出にとどまらない。CSSのスクロール駆動アニメーションは、タイムラインを自在に操作できるため、さまざまなインタラクティブ表現の土台となる。
タイミングのオフセットを使ったリズム演出
元記事の scroll3 のように、開始位置や終了位置をパーセンテージでずらすことで、カラム間の動きにリズムを生み出せる。たとえば、5カラムのレイアウトでそれぞれの移動量を微調整すれば、波のようなうねりを表現することも可能だ。マスクの高さやアニメーションのインセットをCSS変数で管理しておけば、デザインの微調整も容易になる。
このようなオフセット設計は、プロモーションサイトやポートフォリオのビジュアルリッチなセクションで特に効果を発揮するだろう。
パララックス効果との自然な組み合わせ
従来のパララックス(視差効果)はJavaScriptで実装されることが多かったが、スクロール駆動アニメーションを使えば、CSSだけで多層的な視差を表現できる。背景画像や装飾要素に別の animation-timeline を割り当て、移動速度を変えれば、奥行きのあるスクロール体験をJavaScriptに頼らずに構築できる。
例えば、背景の大きな画像にはゆっくりした上方向のアニメーションを、前景のテキストにはやや速い動きを設定するといった組み合わせだ。マスク効果を応用すれば、画面外への自然な消え方も統一感を持って演出できる。
カルーセルやタイムライン表現への展開
逆方向スクロールの考え方は、横方向のカルーセルやタイムライン表示にも転用できる。view() 関数の軸指定(block や inline)を切り替えれば、水平スクロールにも対応可能だ。また、scroll() 関数と組み合わせれば、ページ全体のスクロール量に応じてインジケーターを進める、といった使い方もできる。
CSS-Tricksの元記事は比較的シンプルな例だが、この基盤さえ理解すれば、より複雑なレイアウトやストーリーテリング演出にも発展させられる。
この記事のポイント
- スクロール駆動アニメーションは
animation-timeline: view()で実装し、スクロールに同期した動きを簡単に作れる - 疑似要素と背景色ベースのグラデーションを組み合わせると、自然なフェード効果を実現できる
- 動きのオフセットや逆方向設定によって、単調でないリズミカルな演出が可能になる
@supportsとprefers-reduced-motionで、アクセシビリティとブラウザ互換性を両立させる- 今回のテクニックはパララックス、水平カルーセル、タイムラインなど多彩な表現に展開できる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

EC向けAIフライホイール構築、4つの価値レバーと実践法
EC事業におけるAI活用は、単純なタスクの自動化から、複数の施策が連鎖的に成果を生み出す仕組み作りへと移行しつつある。マッキンゼー・アンド・カンパニーが2026年6月に公開したレポート「Europe’s new ecommerce agenda How AI is resetting growth and competition」では、AIがもたらす価値は断片的な実験ではなく統合にあると指摘されている。
成功するEC事業者は、商品のパーソナライズ、需要予測、在庫管理、価格設定といった複数の意思決定をAIでつなぎ合わせ、全体として加速度的に回転する「フライホイール」を構築している。このフライホイールは、各施策が互いに強化し合い、一度回り始めると追加のリソースを大きく投じなくても成果が積み上がっていく。
この記事では、マッキンゼーが示した「4つの価値レバー」を軸に、大企業だけでなくデータや人的リソースが限られる中小規模EC事業者でも実践できる小さなAIフライホイールの始め方を、具体例とともに解説する。
AIフライホイールの基本概念
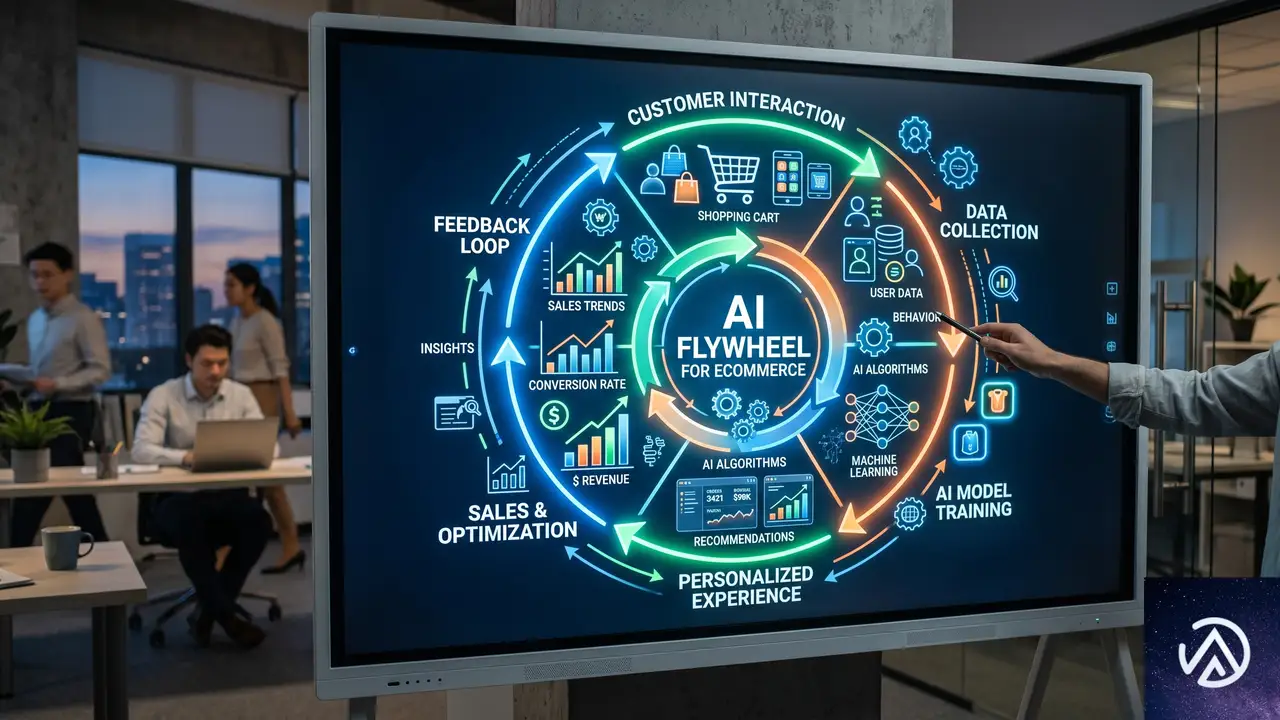
フライホイールが回る仕組み
AIフライホイールとは、あるプロセスが次のプロセスを改善し、その改善が再び最初のプロセスを後押しする、自己強化型の循環システムのことだ。たとえば、AIによるパーソナライズで顧客エンゲージメントが高まると、より正確な需要シグナルが得られる。そのシグナルを使って価格や在庫の判断を最適化すれば、再びエンゲージメントが向上し、さらに多くのデータが蓄積される。
このループを1回転させるごとに、データの質と意思決定の精度が上がり、フライホイールはより少ないエネルギーで回り続ける。一度きりのプロジェクトではなく、持続的な成長エンジンとして機能する点が最大の特徴だ。
単体タスクの自動化との違い
AIフライホイールは、単一の作業をAIに任せる「自動化」とは根本的に異なる。商品説明文をAIで生成すれば時間は短縮できるが、それだけではビジネス全体の流れは変わらない。一方、フライホイール思考では、顧客からの問い合わせ内容をAIで分析し、商品ページの改善に活かし、コンバージョン率の変化を追跡し、その結果を次の仕入れや価格戦略に反映させる。こうした相互連鎖によって、初めて収益構造が強化される。
この概念図では、断片化されたAI活用と、連鎖的に回るフライホイールの違いを視覚化している。単体の導入では部分最適にとどまるが、相互に強化し合うループを作ることで、事業全体の底上げが可能になる。
成長を加速する4つの価値レバー

相互に強化し合う4つの要素
マッキンゼーのレポートでは、ECにおけるAIフライホイールを構成する4つの「価値レバー」として、成長、生産性、バリューチェーン効率、収益性が挙げられている。いずれも独立した施策ではなく、意図的につなぎ合わせることでレバレッジが効く。
成長は、商品発見の最適化やレコメンデーション、メールセグメンテーション、広告クリエイティブの自動生成などを通じて、適切な購入者に適切な商品を届ける活動を指す。AIが顧客行動を深く理解し、一人ひとりに合った購買体験を提供することで、売上の上昇に直結する。
生産性は、カスタマーサポートやコンテンツ制作、販売管理、レポート作成といった反復作業をAIで削減する領域だ。定型業務から人手を解放し、戦略的な思考が求められる高付加価値業務に人材を集中させられる。
バリューチェーン効率は、需要予測と在庫管理、フルフィルメント、返品処理をAIで連携させるものだ。何が売れるか、どこに在庫があるか、いつ届くかをリアルタイムに把握し、コストと在庫リスクを最小化する。
収益性は、価格設定やプロモーション、バンドル販売、値下げ判断をデータ駆動で行う領域である。AIは利益率を損なう過度な値引きや無駄なキャンペーンを可視化し、マージンを最大化する行動を提案する。
商品発見、レコメンド、広告クリエイティブの最適化で適切な顧客にリーチ
反復作業の削減と人員の高付加価値業務へのシフト
需要・在庫・配送・返品を統合しコストを最小化
価格・プロモーション・値下げ判断のデータ駆動化で利益率を向上
これら4つのレバーは、相互にデータを供給し合うことで単体の数倍の効果を発揮する。たとえば、成長施策で得たエンゲージメントデータが在庫効率を改善し、その結果生まれた余剰在庫をデータに基づく値下げ判断で処理しながら収益性を守る、といった連携が可能だ。
中小規模ECが実践できる小さなフライホイール

顧客フィードバック分析から商品ページ改善へ
大企業のように整備されたデータ基盤や高度なシステムがなくても、AIフライホイールは始められる。中小規模EC事業者であっても、問い合わせメールやチャット履歴、レビュー、返品理由といった顧客の声は確実に存在している。これらをAIで分析し、たとえば「サイズ感が合わない」「同梱物がわかりにくい」「配送目安が不明瞭」といった共通の課題を抽出することが、最初の一手になる。
次に、得られたインサイトを商品ページの改善に反映する。サイズガイドの追加や比較表の設置、よくある質問の充実、利用シーンを想起させる商品写真の差し替えなど、具体的な対応を取るのが有効だ。これらの変更は、無料または低コストのAIツールで十分に実施できる。
改善が次のサイクルを生む
商品ページの改修後は、コンバージョン率や返品率、サポートへの問い合わせ件数といった指標を追跡する。ここでもAIを活用すれば、変更の効果を自動で検知し、仮説の精度を高めていくことが可能だ。たとえば「返品理由の上位にあったサイズ感の問題が解消され、返品率が15パーセント低下した」といった成果が得られれば、次の購買データもクリーンになる。
こうした小さなサイクルを繰り返すことで、顧客の声が商品体験を改善し、改善がより良いデータを生み、そのデータがさらに精度の高い意思決定を支えるループが出来上がる。規模は小さくとも、自己強化のメカニズムは大企業のそれと同じだ。
この小さなフライホイールは、初期投資を抑えながら着実に成果を出せる。顧客フィードバックはすでに手元にある資産であり、AIを分析エンジンとして活用するだけで、商品改善と売上向上のエンジンが動き始める。
意思決定の連鎖がもたらすもの

部門を横断したAI活用
AIフライホイールの本質は、カスタマーサービスと商品コンテンツ、サイト内検索とマーチャンダイジング、在庫管理とプロモーションといった、これまで別々に行われてきた意思決定を一本の線でつなぐことにある。AIが仲介役となり、各部門から得られるデータを相互に変換しながら、最適なアクションを導き出す。
たとえば、顧客からの問い合わせに使われる自然言語の傾向をAIが学習すれば、それはサイト内検索のレコメンド精度向上にも活かせる。また、返品理由の分析結果をプロモーション担当に共有すれば、値引きすべき商品や強化すべき訴求ポイントが明確になる。AIがデータの共通言語となることで、組織全体の意思決定が同期し始める。
マネジメント視点の重要性
中小EC事業者が真にAIで競争優位を築けるかどうかは、最新モデルへのアクセスよりも、経営的な視点の差で決まる。AIを単なるツールとして導入するのではなく、業務プロセス全体を俯瞰し、データが流れる経路を設計し、測定と改善を繰り返す管理のしくみを構築することが求められる。
これは技術の話ではなく、経営戦略の話だ。顧客の声を商品に反映し、その成果を在庫や価格に転嫁し、得られた利益を再び顧客体験に投資する。この連鎖を回す主体は、AIではなく事業者自身である。AIはその回転を支えるエンジンに過ぎない。
この記事のポイント
- AIフライホイールは、部分的な自動化ではなく、複数の施策が連鎖して加速する自己強化型のシステムである
- マッキンゼーが示す成長、生産性、バリューチェーン効率、収益性の4つのレバーを組み合わせることで、レバレッジが最大化される
- 中小EC事業者は、すでに保有する顧客フィードバックをAIで分析し、商品ページ改善につなげる小さなサイクルから始められる
- AIの真価は、部門を横断した意思決定の同期と、経営全体をデータ駆動で回すマネジメントの仕組みにある
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

GoogleとMicrosoftがAIエージェント共通仕様ARDを公開、11社が賛同
GoogleとMicrosoftを含む11社が、AIエージェントがウェブ上のツールやスキルを自動検出するための共通仕様「ARD(Agentic Resource Discovery)」を2026年6月17日に公開した。
GitHubやHugging Face、NVIDIA、Salesforceも名を連ねるこの仕様は、各社が公開するAIエージェント向け機能を、事前の手動接続なしに実行時に見つけ出せる仕組みだ。Apache 2.0ライセンスで公開され、同日に複数の参照実装もリリースされた。
この仕様が実用化されれば、AIエージェントは必要なツールを自ら探し出して接続できるようになる。開発者やサービス提供者にとっては、自社のAPIやエージェント機能をAIシステムに自動的に見つけてもらうための新たな方法が生まれることになる。
ARDとは何か

ARD(Agentic Resource Discovery)は、AIエージェントがウェブ上で「使えるツールや機能」を自動的に見つけ出すための共通ルールを定めた仕様だ。Linux Foundationのワーキンググループが管理するAI Catalogデータモデルを基盤に構築されている。
現在のAIエージェントは、あらかじめ各ツールやMCPサーバー、APIとの接続を手動で設定する必要がある。企業が公開する機能が増え続けるなか、この「事前配線」方式では拡張性に限界があった。ARDはこの問題に対処するために設計されている。
ARDの仕組みは、企業が自社ドメインに公開するカタログと、それを収集してインデックス化するレジストリの2層構造で成り立っている。人手による接続設定を実行時の検索に置き換えることで、AIエージェントが自律的に機能を発見できる世界を目指している。
ARDの技術的な仕組み

カタログとレジストリの2層構造
ARDの中核は「カタログ」と「レジストリ」という2つの要素だ。まず、ツールやエージェントを提供する企業は、自社ドメインの定められたパスにai-catalog.jsonというファイルを設置する。このファイルには、公開するツール、MCPサーバー、エージェント、APIの一覧が記述される。
次に「レジストリ」がこれらのカタログを巡回(クロール)してインデックス化する。AIエージェントが「この処理に使えるツールはないか」と自然言語で問い合わせると、レジストリが該当するカタログ情報を返す仕組みだ。
ai-catalog.json を設置カタログが公開者の自社ドメインに置かれることで、ドメイン所有権が公開者の検証手段として機能する。本番運用では、暗号化された信頼メタデータを付与し、接続前に公開者の身元を確認することも可能だ。ツールが選定された後は、ARDの役割は終了し、実際の接続は各ツール固有のプロトコルで直接行われる。
誰に向けた仕様なのか
ARDが主に対象とするのは、APIやMCPサーバー、エージェントといった「呼び出し可能な機能」を提供する企業だ。ツールを公開する企業には、AIエージェントに見つけてもらい、信頼してもらうための明確な方法が提供される。
一方、一般的なコンテンツサイトにとっては、現時点で直接的な活用方法は示されていない。Search Engine Journalの記事でも「典型的なコンテンツサイトに今日すぐ取るべきアクションはない」と指摘されている。
公開当日に登場した参照実装

ARDの草案公開と同日に、複数の参加企業が実際に動作するツールをリリースした。
- GitHub Copilot向けに「Agent Finder」を導入。選択したレジストリからMCPサーバー、スキル、ツール、エージェントを検出し、ユーザーが接続対象を制御できる仕組みだ。
- Hugging Face ARDサービス全体からスキルやMCPサーバーを検索する「Discover Tool」を公開した。
- Cisco Linux Foundation傘下のオープンソースプロジェクト「AGNTCY Agent Directory」にARDを統合した。
GitHubのAgent Finderは特に関心を集めている。Copilotのユーザーがレジストリから必要な機能を見つけ出し、自分の判断で接続を許可できる設計は、エージェントの自律性とユーザー制御のバランスを取る試みといえる。
この流れは、ウェブの「機械可読層」を整備する一連のオープン仕様の延長線上にある。GoogleはARD公開の2日前にも、AIシステム間で組織知識を共有するための「Open Knowledge Format」仕様を発表している。いずれも自社ドメインに構造化ファイルを設置するだけで、AIシステムが人手の配線なしに情報を利用できるようにする考え方だ。
Googleの立ち位置と今後の展開

GoogleはARDにおいて、Gemini Enterprise Agent Platformの一部である「Agent Registry」を中心的な役割として位置づけている。これはエージェント向けリソースのホスティングと検索、企業向けのガバナンス管理を担う基盤だ。
Search Engine Journalの記事によれば、Agent RegistryへのネイティブARD対応は数カ月以内に予定されている。これが実現すれば、組織は内部レジストリを広域ネットワークに接続できるようになる。
ただし現時点でこの対応は稼働しておらず、ARDはあくまで「仕様」であってGoogle検索の機能ではない。検索エンジンとしてのGoogleがARDカタログを直接検索結果に反映するわけではない点は、区別して理解しておく必要がある。
コンテンツ制作者が今考えるべきこと

ARDがもたらす影響は、ビジネスの性質によって大きく異なる。ツールやAPIを提供する企業には、AIエージェントに発見されるための具体的な手段が用意された。一方で、一般的なコンテンツサイト運営者にとっての即効性は限定的だ。
この仕様の価値については業界内でも議論がある。GoogleのJohn Mueller氏は、LLMシステムがllms.txtのようなファイルでサイトを区別することはできないと指摘し、将来のエージェント向け戦略よりも現在のニーズに注力するよう助言している。ARDが対象とするのはツールやエージェントであり、コンテンツではないという点は、こうした議論の背景として押さえておきたい。
仕様はまだv0.9草案であり、GitHubリポジトリで変更提案を受け付けている段階だ。実用性を左右するのは、カタログを大規模にクロールしてインデックス化できるレジストリのエコシステムだが、それもまだ初期段階にある。
エコシステムが成熟した場合に最も恩恵を受けるのは、他者が必要とするツールやエージェントを提供する企業だ。GoogleがUlrtaユーザー向けに展開し始めたエージェント主導の検索機能も、この方向性を示唆している。今すぐ取るべき現実的なアクションは、自社が使っているプラットフォームやツールがARDに対応するかどうか、そして対応時にどのような公開情報が求められるかを注視することだ。
この記事のポイント
- ARDはAIエージェントがツールやAPIを実行時に自動発見するためのオープン仕様である
- カタログ(ai-catalog.json)とレジストリの2層構造で、ドメイン所有権が信頼の基盤となる
- GitHubやHugging Faceが公開初日から参照実装を提供しており、実用化に向けた動きは速い
- 一般的なコンテンツサイトよりも、ツールやAPIを公開する企業に直接的な恩恵がある
- v0.9草案段階であり、レジストリのエコシステム構築が今後の鍵を握る
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験