

Amazon Bedrock AgentCoreにWeb Search機能が一般提供開始、AIエージェントの回答を最新Web情報で根拠づけ
AWSは2026年6月17日、Amazon Bedrock AgentCoreにWeb Search機能の一般提供を開始した。AIエージェントがユーザーからの質問に対し、最新のWeb情報を参照しながら根拠のある回答を提示できるようにする。トレーニングデータだけではカバーしきれない直近の出来事や新事実を、AWS環境内で安全に取得できる点が最大の特徴だ。
この機能は、Amazonが長年培ってきた検索インフラ上に構築されている。Alexa+やAmazon Quick、Kiroといった製品で実績のある基盤を活用し、WebインデックスとAmazon Knowledge Graphを組み合わせたマルチソースな根拠付けを実現する。検索クエリは外部APIプロバイダに送信されず、AWS環境内で完結するため、企業のガバナンス要件にも適合する。
本記事では、Bedrock AgentCore Web Searchの仕組み、料金体系、導入事例を詳しく解説する。
Web Search機能の概要と背景

Bedrock AgentCoreの位置づけ
Amazon Bedrock AgentCoreは、AIエージェントの構築と運用を管理するフレームワークである。エージェントに必要なツールやデータソースとの接続をGatewayという仕組みで一元管理し、モデルの推論と外部機能の呼び出しを連携させる。今回発表されたWeb Searchは、AgentCore Gateway上で利用できる組み込みコネクタターゲットのひとつだ。
Web Searchが解決する課題
LLM(大規模言語モデル)は、学習時点のデータに基づいて回答を生成するため、つねに最新の情報を反映できるとは限らない。たとえば、企業の決算発表や法改正、製品アップデートなど、学習後に発生した出来事には対応できない。Web Searchを用いれば、エージェントがリアルタイムにWeb検索を実行し、得られたスニペットやURLを参照して回答を生成できる。回答には引用元が明示されるため、情報の信頼性をユーザーが確認しやすくなる。
仕組み:MCP接続とAmazon知識グラフによる根拠付け
MCP(Model Context Protocol)の役割
Web Searchは、MCP(Model Context Protocol)と呼ばれる標準プロトコルを介してAgentCore Gatewayに接続される。MCPを使うことで、エージェントは自然言語のクエリを送信し、関連性の高い検索結果(スニペット、URL、タイトル、公開日)を取得できる。GatewayがMCPターゲットとしてWeb Searchツールを仲介するため、開発者が個別に検索APIを実装する必要はない。
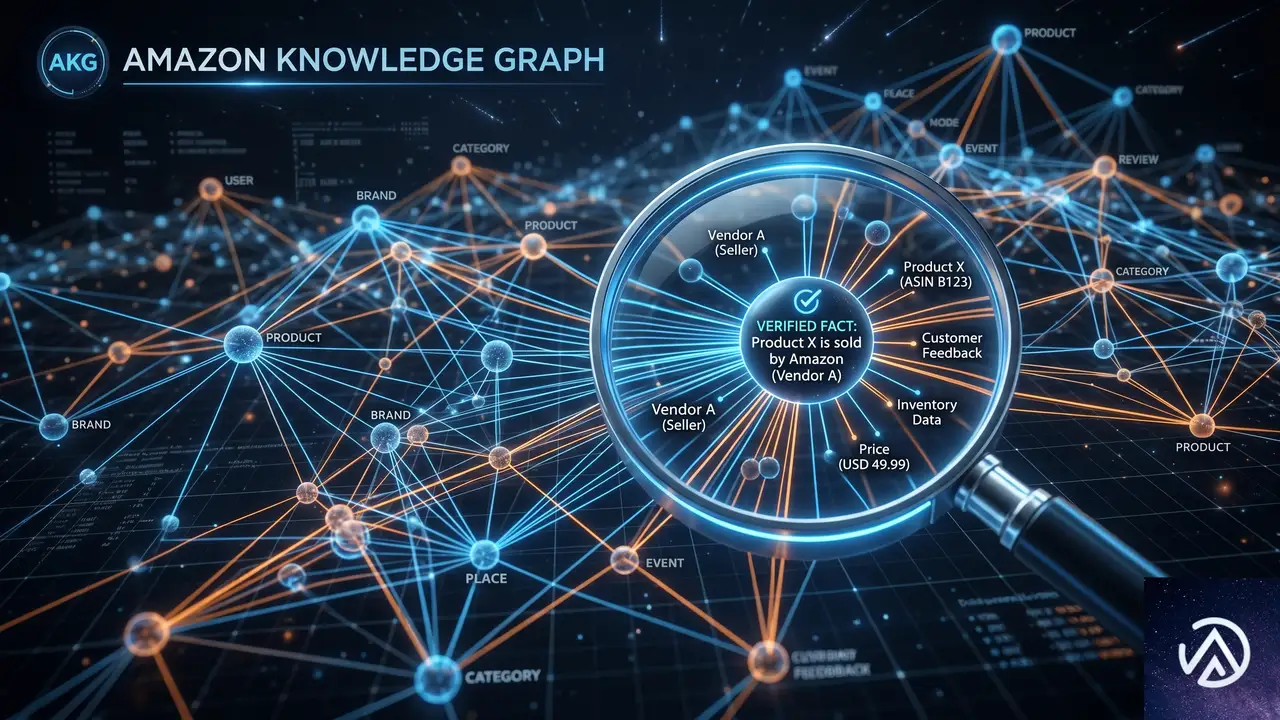
Amazon知識グラフとの統合
一般的なWeb検索に加え、Amazon Knowledge Graphの構造化データが検索結果に組み込まれる。これにより、単なるWebスニペットではカバーしきれない検証済みの事実情報をエージェントが参照できるようになる。AWSのブログ記事によれば、このマルチソースアプローチが従来のWeb検索だけに頼る場合と比較して、より的確な回答につながるとされている。
エージェントが回答を生成するまでの流れ
以下のデモは、ユーザーが質問してからエージェントが根拠付き回答を返すまでの一連のステップを図示したものだ。
STEP 3の段階でAmazon Knowledge Graphが活用される点が、単なるWeb検索を超えた信頼性につながる。エージェントは受け取った情報をそのまま返すのではなく、モデルが内容を推論した上で回答を構成するため、質問の文脈に合った自然な応答になる。
AWS環境内で閉じるセキュアなWeb検索の価値
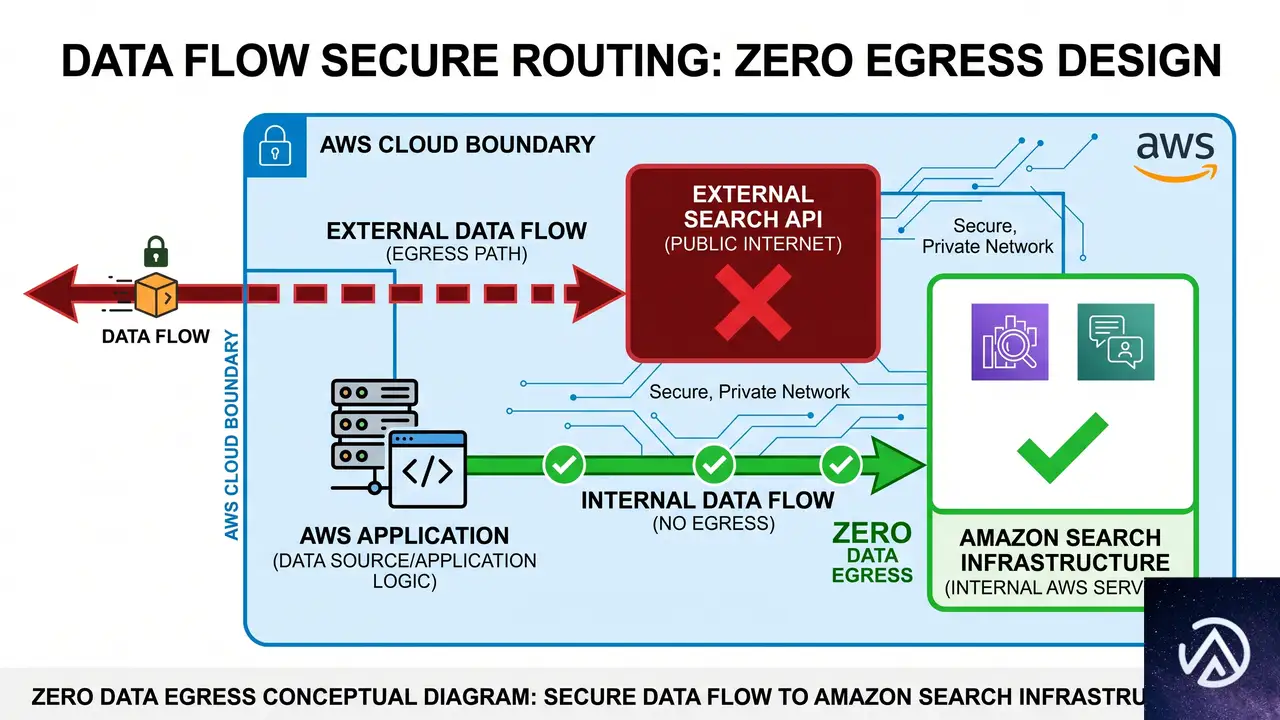
多くのAIエージェント向けWeb検索ソリューションでは、ユーザーのクエリやプロンプトが外部の検索APIプロバイダに送信される。これに対しBedrock AgentCoreのWeb Searchは、Amazon自身の検索インフラを使用するため、データがAWS環境の外に流出しない。これにより、機密性の高い業務データを扱う企業でも、ガバナンスやコンプライアンスの要件を満たしながらエージェントにWeb検索機能を組み込める。
AWSの説明によれば、この仕組みはAlexa+やKiroなどのプロダクトで培われた検索技術を基盤にしており、信頼性とスケーラビリティの両面で実績がある。ユーザーは外部の検索サービス契約やAPIキー管理を気にすることなく、AgentCoreの設定画面上でWeb Searchを有効化するだけで利用を開始できる。
料金体系と利用開始手順
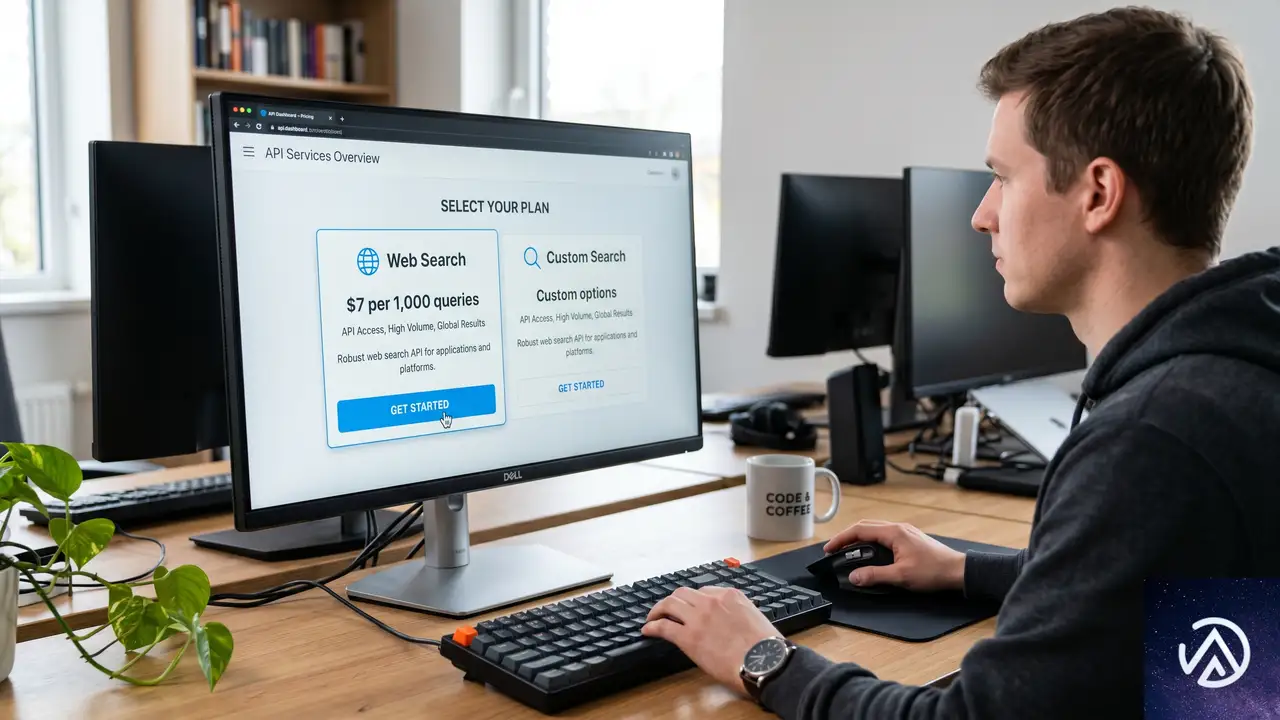
料金詳細
Web Searchの料金は従量課金制で、エージェントが実行した検索クエリの数に応じて計算される。具体的には、1,000クエリあたり7ドルである。新規のAWS顧客には最大200ドル相当の無料利用枠も提供される。利用料はすべてAWSの請求に統合されるため、別途外部サービスへの支払い管理は不要だ。
セットアップ手順
Bedrock AgentCoreコンソール(us-east-1リージョン)にアクセスし、Gatewayを作成する。ターゲットの追加時に「MCP target」プロトコルと「Connectors」タイプを選択し、プリコンフィギュアされた「Web Search tool」を指定する。Gatewayの詳細ページに遷移すると、PythonやMCP Inspectorを用いた呼び出しコードのサンプルが表示されるため、これをコピーして自環境に組み込むだけで統合が完了する。
テスト用途であれば、MCP InspectorをGatewayのリソースURLに接続し、Web Searchツールにクエリを直接入力して動作を確認できる。実運用では、エージェントのプロンプト設計にWeb検索の呼び出しトリガーを組み込み、回答生成時に適宜検索が走るように構成することになる。
企業での活用事例

Benchling:科学研究の加速
ライフサイエンス分野のR&Dプラットフォームを提供するBenchlingは、早期アクセスを通じてWeb Searchを試験導入した。同社AIエージェント責任者Nicholas Larus-Stone氏によると、科学者が研究対象について質問すると、Benchling内の組織データと公開文献の両方に基づく回答が得られるようになったという。これにより、仮説生成の質が向上し、顧客のデータ管理ポリシーにも適合する安全な環境を維持できている。
Gen Digital:オンライン評判管理の強化
消費者向けセキュリティ製品を展開するGen Digital(Nortonブランド)は、Norton RevampというサービスにWeb Searchを組み込んだ。プロフェッショナルが自身のオンライン評判を構築する際、最新のトレンドや事実に基づいたコンテンツアイデアをエージェントが提案できるようになる。同社AI・イノベーション部門シニアディレクターIskander Sanchez-Rola氏は、すべてのクエリが信頼できるAWS環境内で処理される点を高く評価しているとコメントした。
いずれの事例でも、外部サービスを利用せずにAWS内で完結するセキュリティと、Amazon独自の検索インデックスによる高精度な情報取得が決め手となっている。
この記事のポイント
- Amazon Bedrock AgentCoreでWeb Search機能が一般提供開始。MCP経由でWeb検索と知識グラフを統合し、エージェントの回答を最新情報で根拠づける
- 検索クエリはAWS環境外に出ず、Amazonの検索インフラで処理されるため、データガバナンスとコンプライアンスに対応
- 料金は1,000クエリあたり7ドルの従量課金。新規顧客向けに200ドル分の無料枠あり
- BenchlingやGen Digitalなどの企業がすでに導入し、研究支援や評判管理の精度向上に活用している
- us-east-1リージョンで利用可能。AgentCoreコンソールから数ステップで設定できる

・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

ShinyHuntersが教育機関を標的に、Oracle PeopleSoft脆弱性を悪用
CVE-2026-35273を悪用した大規模攻撃、教育機関が標的に

2026年5月下旬から6月上旬にかけて、Oracle PeopleSoftの重大な脆弱性を悪用するサイバー攻撃が発生した。MandiantとGoogle Threat Intelligence Group(GTIG)の調査により、攻撃者はShinyHunters(UNC6240)として知られるグループであり、標的となったのは主に高等教育機関を含む世界中の組織だった。
攻撃の起点となったのはCVE-2026-35273だ。PeopleSoftのEnvironment Managementコンポーネントに存在するリモートコード実行の脆弱性で、CVSSスコアは最高レベルの9.8。この脆弱性は6月10日にOracleからセキュリティアラートが発表されるまでゼロデイとして悪用されていた。
この記事では、本攻撃キャンペーンの技術的な分析、攻撃者の手口、そして組織が今すぐ取るべき具体的な防御策について、技術に詳しい同僚のようにわかりやすく解説する。
グローバル通知の試みと被害の実態
GTIGはスキャン活動と悪用を検知した後、潜在的に脆弱なエンドポイントを持つ100以上の組織に通知を行った。通知対象の大半は米国に拠点を置き、その68%が高等教育機関だった。一部の組織は脆弱性の修正に成功したが、多くの組織で侵害が確認され、窃取されたデータがShinyHuntersのデータリークサイトに公開される事態に至った。
攻撃の起点となったゼロデイ脆弱性
問題のCVE-2026-35273は、PeopleSoftのEnvironment Management Hub(EMHub)における重大な欠陥だ。この機能は管理者やシステム間コンポーネント向けであり、エンドユーザーが直接利用するものではない。しかし、認証なしでリモートからのコード実行が可能であることが攻撃成立の決定的な要因となった。
攻撃基盤の構築から内部偵察までの技術分析
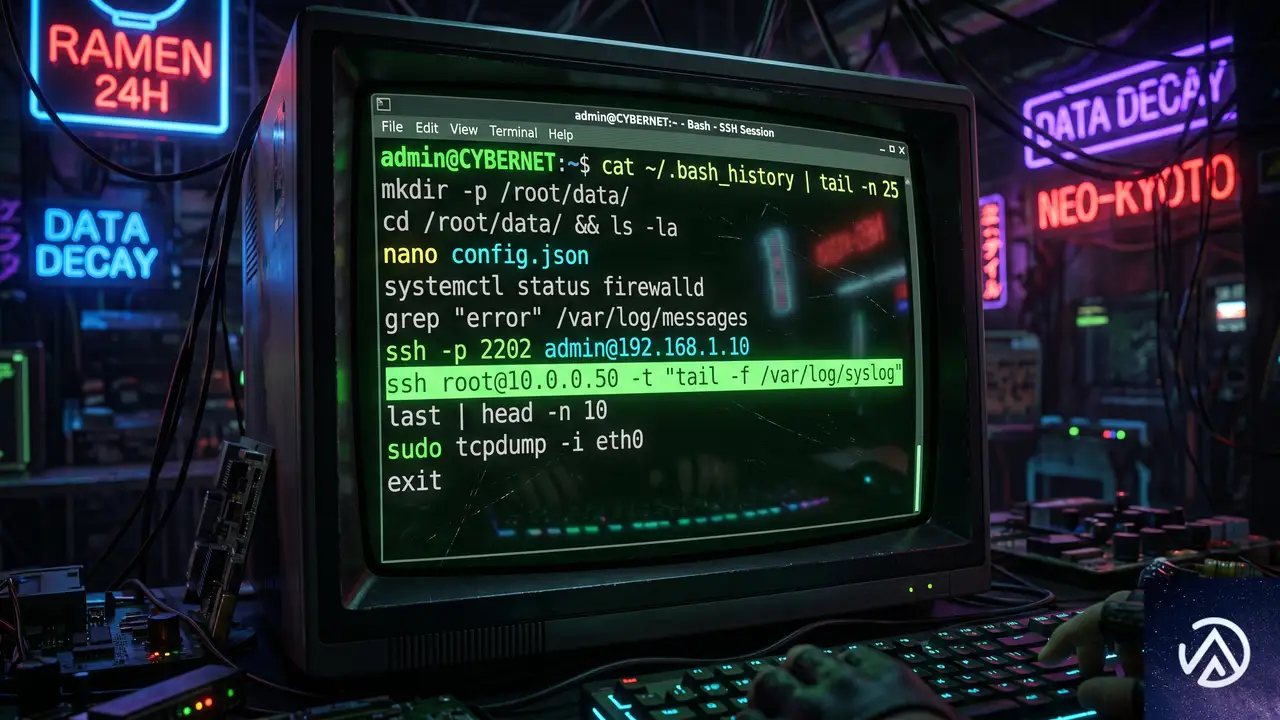
攻撃者の手口は、ステージングサーバーの構築から始まった。2026年5月27日、攻撃者はオープンソースのリモート管理ツールであるMeshCentralをインストールし、C2(コマンド&コントロール)環境を整えた。その際、正規のMicrosoft Azureサービスを装うドメイン「azurenetfiles.net」を取得し、SSL証明書まで自動化する念の入れようだ。
ステージングサーバーには、MeshCentralエージェントが配置された。エージェントのファイル名は「meshagent32-azure-ops.exe」など、正規のAzure運用エージェントに見せかけられていた。これらのエージェントは、攻撃者が自由に遠隔操作を行うためのバックドアとして機能する。
内部ネットワークの探索と情報収集
ステージングサーバーのコマンド履歴(.bash_history)からは、侵入後の詳細な偵察活動が明らかになった。攻撃者はmeshctrl.jsというMeshCentralのCLIツールを使い、侵害したマシン上で以下のようなコマンドを実行し、内部ネットワークの地図を作り出していた。
- システムのホスト名やユーザーIDの確認
- PeopleSoftのプロセススケジューラ設定ファイル(psappsrv.cfg)の解析による、マシン名とIPアドレスの抽出
- ネットワークマウントの確認とPeopleSoft関連領域の特定
- ローカルホストテーブル(/etc/hosts)を精査し、内部の全ノードをマッピング
- WebLogicサーバーのXML設定ファイルからのアプリケーションサーバー情報の収集
これらの偵察は、後の水平展開を効率的に行うための下準備だ。まずは地図を描き、その後に攻撃を拡大するという、組織的な手口が浮かび上がる。
水平展開の自動化スクリプトとデータ窃取の仕組み
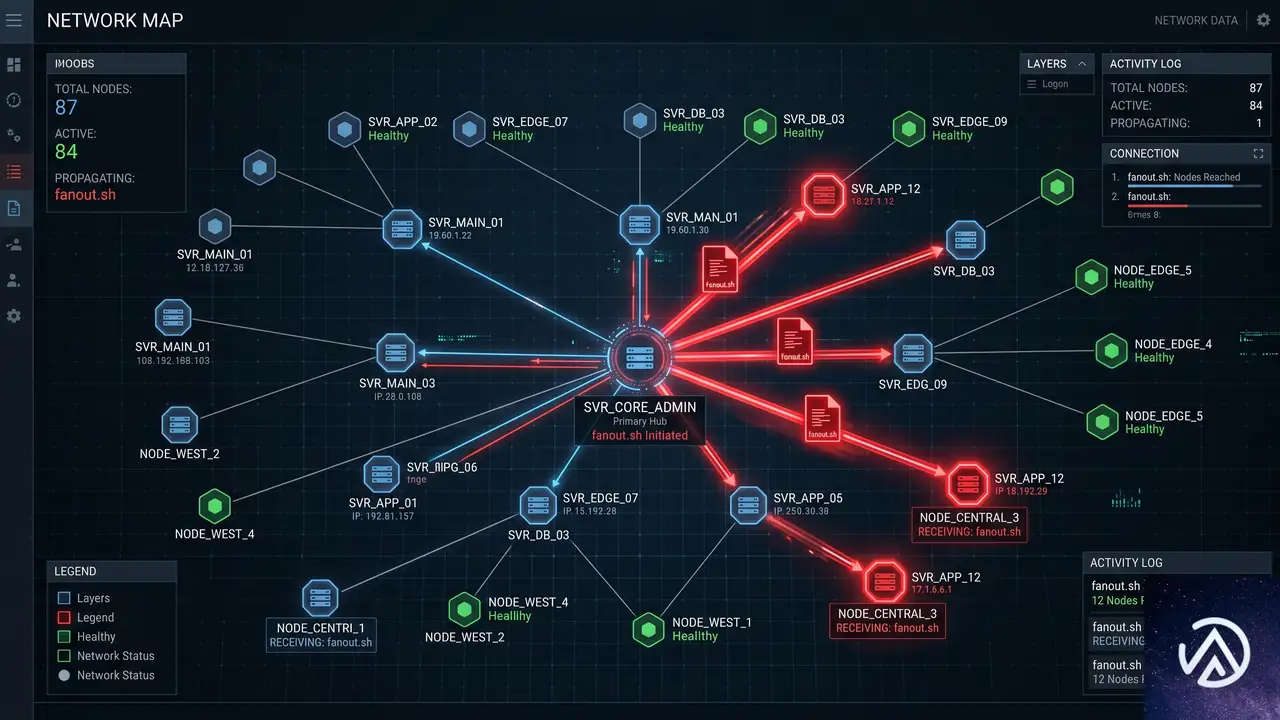
攻撃の核心は、自走式の水平展開スクリプト「[victim_abbreviation]_fanout.sh」にある。このスクリプトは、偵察フェーズで収集した内部ホスト情報を基に、SSHの認証情報を総当たりで試行し、侵害範囲を一気に拡大するよう設計されている。
スクリプトは、特定の命名規則を持つホスト名を/etc/hostsから抽出し、事前にハードコードされた複数のユーザー名とパスワードのリストを使ってSSH接続を試みる。この手法はSSHクレデンシャル・スプレー攻撃と呼ばれるものだ。
攻撃が成功すると、スクリプトはPayloadとして「README-IF-YOU-SEE-THIS-YOUVE-BEEN-HACKED.TXT」というファイルを、WebLogicやプロセススケジューラのディレクトリに書き込む。これは単なる嫌がらせの証跡ではなく、被害組織に対する恐喝のマーカーとして機能した。
データの流出とリークサイトへの接続
水平展開が完了した後、攻撃者は窃取したデータをzstdという高圧縮率のツールでアーカイブし、ステージングサーバー経由で外部へ持ち出した。一連のコマンド履歴の最後には、攻撃者のステージングサーバーから、ShinyHuntersのデータリークサイト公開ミラーをホストするIPアドレス「176.120.22.24」へのSSH接続が記録されていた。
この接続が、侵害された組織のデータが最終的にリークサイトで公開されるまでの一連の流れを決定づけた。実際に2026年6月9日には、複数の被害組織のデータが同サイト上に公開されている。
今すぐ取るべき具体的な防御策

この脅威に対抗するため、GoogleとOracleの両方は、PeopleSoftを運用する組織に対し、以下の即時対応を強く推奨している。対策は、ネットワークの遮断、ログ監視、そしてホストレベルの監査という3つのレイヤーに分類できる。
ネットワークレベルでの緊急対応
最も即効性が高いのは、エンドポイントそのものへの外部からのアクセスを遮断することだ。具体的には、ファイアウォールや境界ネットワークで「/PSEMHUB/hub」と「/PSIGW/HttpListeningConnector」へのHTTP POSTリクエストを遮断する。これらのエンドポイントは一般ユーザー向けの機能ではないため、遮断による業務への影響はない。
WAF(Webアプリケーションファイアウォール)だけに頼るのは危険だ。ルールをすり抜けられる可能性があるため、あくまで補助的な対策と考えるべきだろう。
ログとエンドポイントの徹底監視
次に重要なのが、侵入口と内部活動の痕跡をログから探し出すことだ。WebLogicのアクセスログで「/PSEMHUB/hub」や「/PSIGW/HttpListeningConnector」へのPOSTリクエストを調査する。送信元が外部IPや信頼できないアドレスであれば要注意だ。
特に「/PSIGW/HttpListeningConnector」へのリクエストでは、SSRF(サーバーサイドリクエストフォージェリ)攻撃の兆候を探す。リクエストパラメータに「127.0.0.1」や「localhost」などのループバックアドレス、内部IPレンジが含まれていないか確認する必要がある。
さらに、ネットワークレベルでは、PeopleSoftサーバーから外部の不審な宛先へのSMB通信(TCPポート445)を監視する。これは攻撃チェーンの一環として、WindowsマシンのNetNTLMハッシュを窃取するために悪用される可能性があるためだ。
ホストレベルでのフォレンジック監査
最後に、侵害の有無を確定させるためのファイルシステム調査を行う。以下のディレクトリに、通常存在しないファイルやフォルダがないかを重点的にチェックする。
- WebLogicのアプリケーションディレクトリ内の「PSEMHUB.war」配下に、未知のJSPファイル(WebShell)が生成されていないか
- 「envmetadata/transactions/」ディレクトリに、不審なフォルダや攻撃者のツールがドロップされていないか
- 「envmetadata/data/environment/」配下に、最近更新された怪しいXMLファイルがないか(XMLDecoderを介した永続化の可能性)
これらの調査により、攻撃者が仕掛けたバックドアや永続化の仕組みを特定し、再起動後も安全な状態を確保できる。
この記事のポイント
- ShinyHuntersはCVE-2026-35273をゼロデイとして悪用し、100以上の組織を攻撃した。標的の68%は高等教育機関だった
- 攻撃者は正規クラウドサービスを装う高度なC2インフラを構築し、MeshCentralを悪用して遠隔操作と水平展開を自動化した
- スクリプトによるSSHスプレー攻撃で内部ネットワークに拡散し、最終的にデータを窃取。盗まれた情報はリークサイトで公開された
- 防御の最優先事項は、使用していない管理用エンドポイントをネットワーク境界で遮断すること。これによりWAFバイパスのリスクを根本的に排除できる
- 遮断と並行して、アクセスログの調査、SMB通信の監視、ファイルシステムのフォレンジック監査を速やかに実施する必要がある
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AWS WAFがAIボット収益化機能を追加、コンテンツ所有者が課金可能に
AWSは2026年6月15日、AWS WAFにAIトラフィック収益化機能を追加した。コンテンツ所有者やパブリッシャーが、自社のWebコンテンツにアクセスするAIボットやAIエージェントに対して、ネットワークエッジで直接課金できるようになる。
AIボットによるWebトラフィックは、多くのコンテンツプロバイダーで全体の50%を超え、AI専用クローラーは前年比300%以上増加している。従来の検索エンジンクローラーはリンクを返すことで参照トラフィックをもたらすが、AIボットはコンテンツを要約してAIインターフェイス上で表示するため、元のサイトにはほとんどトラフィックが還元されない。その結果、コンテンツ提供者はインフラコストだけを負担し、広告収入や購読コンバージョンといった従来の収益源が得られない状況が続いていた。
今回の新機能は、このギャップを埋めるものだ。AWS WAF Bot Controlの仕組みを拡張し、コンテンツパスごと、ボットカテゴリごと、検証ティアごとにリクエスト単価を設定できる。また、ステーブルコインによる支払いをウォレットで受け取り、単一のダッシュボードで収益とボットアクティビティを追跡可能にする。
AIボット収益化の新機能がAWS WAFに追加された背景

AIトラフィックの爆発的な増加
GPTBotやClaude-Web、Perplexity-BotといったAIクローラーは、学習用データやリアルタイム情報の収集のためにWebサイトを大量にクロールする。こうしたトラフィックは増加の一途をたどり、一部のコンテンツプロバイダーではAIボットが全リクエストの50%を超えるまでになっている。検索エンジンのクローラーとは異なり、AIボットはインデックスを生成する代わりにテキストを直接消費し、要約をAIチャット画面に表示する。そのため、元記事を読むための流入はほとんど発生しない。
従来のBot Controlでは限界があった理由
AWS WAF Bot Controlはこれまで、650種類以上のAIボットを検出し、ブロックまたはレート制限をかけることができた。しかし、ボットのトラフィックを完全に遮断するのではなく、課金して収益化したいというニーズは強く存在していた。コンテンツを無料で提供し続ければインフラコストがかさむ一方、単純にブロックすればAIサービスへの露出が途絶えてしまう。そこで、ボットにコンテンツ利用の対価を支払わせる仕組みが求められていた。
AIトラフィック収益化の仕組み

x402プロトコルとHTTP 402 Payment Required
今回の収益化機能の核は、x402というマシンツーマシン決済のオープンプロトコルだ。ルールに合致したAIボットからのリクエストに対し、AWS WAFはHTTP 402 Payment Requiredレスポンスを返す。このレスポンスボディには、コンテンツの価格(USDC建て)、受け入れ可能なブロックチェーンネットワーク(BaseやSolanaなど)、送金先ウォレットアドレス、支払いタイムアウトを含むJSON形式のプライスマニフェストが含まれる。これを受け取ったx402対応のエージェントランタイムは、自律的に署名付き支払い承認を提出し、AWS WAFがそれを検証したうえでコンテンツを提供するという流れだ。
ステーブルコイン決済の流れ
決済はステーブルコイン(USDC)で行われ、サードパーティのファシリテーターサービス(現在はCoinbaseのx402 Facilitator)がオンチェーン上の決済処理を支援する。Stripeによる直接アカウント決済やMachine Payments Protocol(MPP)への対応も近日中に予定されている。コンテンツ所有者は、AWS WAFの設定パネルでウォレットアドレスを指定するだけでよく、独自の決済インフラを構築する必要はない。また、AWS自体は決済手数料を徴収しない。
上記のように、収益化を有効にするとAIボットのアクセスが自動的に402レスポンスに切り替わり、支払いが完了したリクエストだけがコンテンツに到達する。コンテンツ所有者はアクセスを遮断する代わりに料金を設定し、ボットトラフィックを収益源に変えることができる。
収益化の設定手順
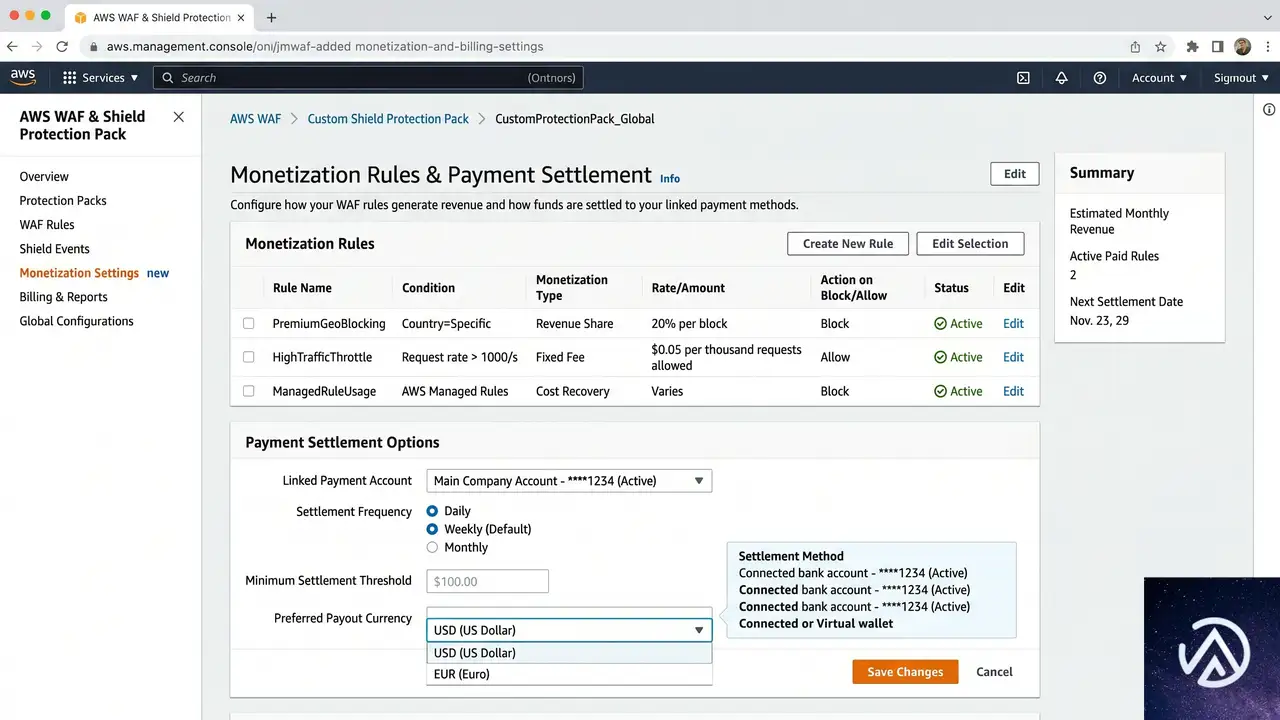
プロテクションパックの作成
AIトラフィック収益化を使うには、まずAWS WAF Bot ControlをCommonまたはTargetedレベルで有効にしたうえで、プロテクションパック(Protection Pack)を作成する。プロテクションパックとは、どのコンテンツパスを収益化するか、各検証ティアにいくら課金するか、どの支払い方法を受け入れるかといったポリシーをまとめた設定単位だ。AWSマネジメントコンソールで「WAF & Shield」を開き、「Protection packs (web ACLs)」から作成を開始する。
作成時にアプリカテゴリ(コンテンツ・パブリッシングシステム、Eコマースなど)を選択し、保護対象のリソース(CloudFrontディストリビューション)をひも付ける。推奨ルールパッケージが提示されるが、個別のルールを選ぶことも可能だ。プロテクションパックを作成したら、必要に応じて価格帯や支払い方法、コンテンツ範囲、ライセンス条項をカスタマイズする。
収益化ルールの設定
プロテクションパックを選び、「Configure AI monetization」から検証ティアごとにアクションを割り当てる。アクションは6種類ある。Monetize(402を返し課金)、Allow(無料アクセス許可)、Block(完全遮断)、Count(課金せずログだけ記録)、CAPTCHA(人間の確認)、Challenge(ブラウザかどうかのサイレントチェック)だ。Monetizeを選択すると、支払い決済用のブロックチェーンネットワーク(BaseやSolanaなど)を指定し、ウォレットアドレスとUSDC建てのページ単価を設定する。
Monetizeアクションは、Amazon CloudFrontディストリビューションに関連付けられたWeb ACLでのみサポートされる。リージョナルWeb ACLでは使えない点に注意が必要だ。また、本番投入前にテストモード(Currency modeをTestに切り替え)で、テストネット(Base SepoliaやSolana Devnet)を使った検証が可能となっている。テストモードでも実際の402レスポンスと支払いフローが再現され、すべてのイベントにCurrencyMode: TESTのログが付与される。
この一連の流れは、サイトのオリジンサーバーに一切手を加えることなく、AWS WAFのエッジで完結する。コンテンツ提供者はアプリケーションコードを修正する必要がないため、既存のWebサイトに迅速に収益化機能を追加できる。
AIトラフィック分析ダッシュボードと収益トラッキング
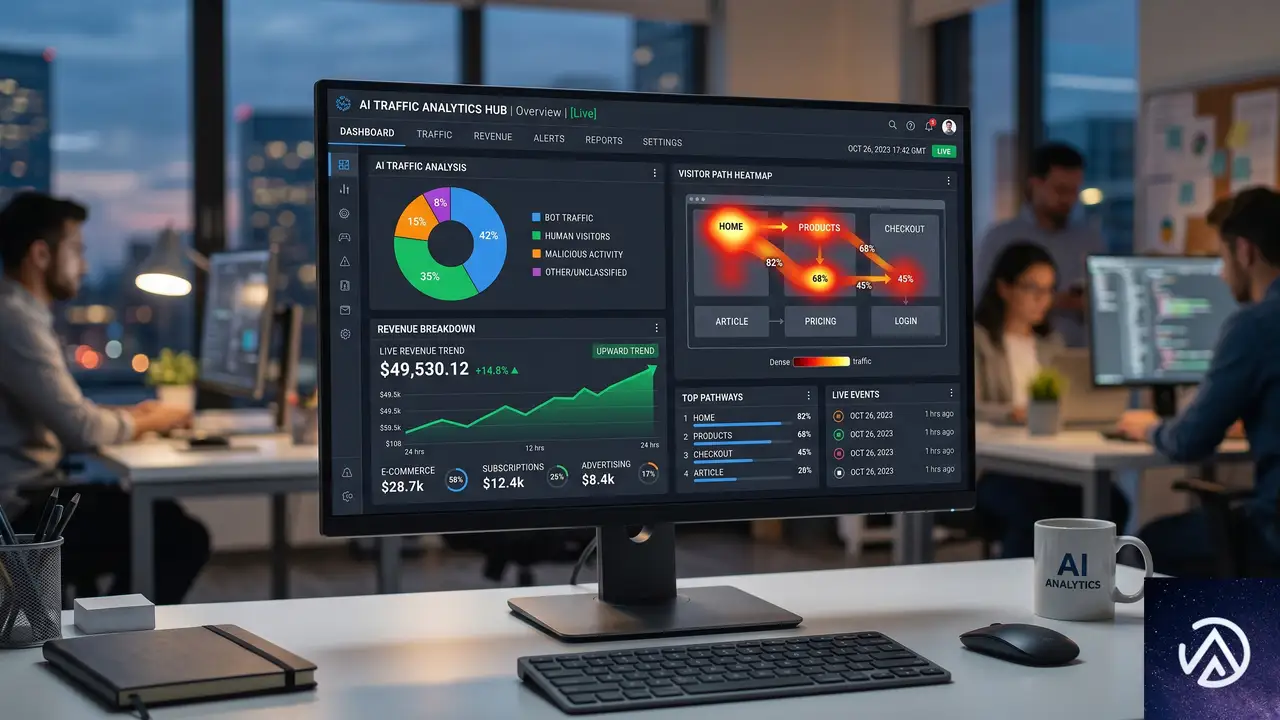
価格設定を最適化するためのAIトラフィック分析ダッシュボードも提供される。プロテクションパックを選択すると、ボットリクエスト全体、AIボットリクエスト、検証済みAIトラフィック、未検証AIトラフィックの4カテゴリに分けてトラフィックを可視化する。帯域幅の消費量、推定月間コスト、ピークリクエストレートといったインフラ影響指標も表示され、パスごとのヒートマップで時間帯別のAIボット集中度がわかる。
Currency modeをRealに切り替えると、「AI access monetization」ダッシュボードで実際の収益をリアルタイムに追跡可能だ。総収益、検証済みボットと未検証ボットの内訳、リクエストあたりの平均単価が表示され、上位の収益ソースやコンテンツパス別の収益ランキングも確認できる。Settlementsタブでは決済プロバイダーごとの精算状況や支払い失敗の分析も行える。
導入のポイントと今後の展望
この機能は、CloudFrontを利用するすべてのAWS WAFユーザーに対して追加料金なしで提供される。ただし、Monetizeを適用できるのはCloudFrontディストリビューションに関連付けたWeb ACLのみである点は押さえておきたい。また、テストモードを活用して本番適用前に価格設定やウォレット設定、x402フローを十分に検証することが推奨される。
今後、Stripeの直接アカウント決済やMPPに対応することで、より多様な支払い手段が利用可能になる見通しだ。AIボットのトラフィックが増え続ける中、コンテンツの価値を適切に回収する仕組みとして、この収益化機能は重要な選択肢となる。自社サイトへのAIクローラーの影響を分析している企業は、まずBot Controlのダッシュボードでトラフィックの可視化から始め、段階的に収益化を検討するのが良いだろう。
この記事のポイント
- AWS WAFにAIボット向け課金機能が追加され、HTTP 402とx402プロトコルでマシンツーマシン決済を実現
- コンテンツパスや検証ティアごとにリクエスト単価を設定でき、ステーブルコインで収益を受け取れる
- 設定はプロテクションパック単位で行い、CloudFront環境のエッジで自律的に課金とコンテンツ配信が完結
- AIトラフィック分析ダッシュボードでコストと収益を可視化し、価格設定を最適化できる
- テストネットを使った検証モードがあり、本番適用前にリスクを評価可能
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AWS Graviton5搭載EC2 M9g/M9gdがGA。汎用インスタンス性能限界突破の全容
AWSが2026年6月10日、Graviton5プロセッサを搭載したEC2 M9gおよびM9gdインスタンスの一般提供を開始した。Armアーキテクチャベースの第5世代カスタムシリコンであり、前世代比で最大25%の計算性能向上を実現したとされている。
2025年末のプレビュー公開から半年、ClickHouseやHoneycombといった企業が実運用環境で検証を重ね、コード変更ゼロで36%の性能向上を確認している。HubSpotではMySQLデータベースのクエリ処理時間が最大60%短縮されたとの報告もある。
Arm系インスタンスはこれまでも存在したが、192コア、5倍のL3キャッシュ、DDR5-8800対応メモリを搭載したGraviton5は次元が異なる。本記事ではM9g/M9gdの技術的進化と、それがビジネスにどう影響するかを具体的に解説する。
Graviton5とは何か。5世代の進化がもたらしたもの
AWSのGravitonプロセッサは、Armアーキテクチャを採用したAWS独自設計のカスタムシリコンだ。第1世代が登場したのは2018年。以来8年にわたり継続的に投資が続けられ、現在では350以上のインスタンスタイプがGravitonで稼働している。
Arm系クラウドインスタンスの現在地
Armアーキテクチャとは、スマートフォンやタブレットで広く使われている省電力設計のCPU命令セットだ。これに対し、従来のサーバCPUの多くはx86アーキテクチャ(IntelやAMDが採用)で動作していた。Armは消費電力あたりの処理効率に優れており、クラウドの大規模データセンターで電気代を抑えつつ高性能を発揮できる点が評価されている。
AWS広報情報によれば、現在12万以上の顧客がGravitonを採用。スタートアップから大企業まで幅広く、Webアプリケーション、マイクロサービス、データベース、機械学習推論、ゲームサーバ、動画エンコーディングなど多様な用途で使われている。x86依存の強い従来のクラウド常識を、Armが着実に塗り替えつつある。
クラウドインスタンスの選択肢は、この5年で一変した。Armはもはや「実験的な選択肢」ではなく、x86と並ぶ本流の一つとして位置づけられる。特にGraviton5では、その傾向がさらに加速するだろう。
Graviton5が前世代から飛躍した3つの要素
Graviton5の改良点を、AWS公式発表から整理する。最も注目すべきは次の3つだ。
- 計算性能の大幅向上:Graviton4比で最大25%の計算性能向上。Webアプリケーションで最大35%、機械学習推論で最大35%、データベースで最大30%の高速化が実測されている
- 5倍のL3キャッシュ:CPUが頻繁にアクセスするデータを一時保存する高速メモリ領域が前世代比5倍に拡大。コア間のデータ待ち時間が最大33%削減された
- DDR5-8800メモリとPCIe Gen6対応:クラウド上のプロセッサインスタンスとして最速水準のメモリ帯域幅を実現。PCIe Gen6はGen5比でデータ転送速度が2倍となり、NVMeストレージや高速ネットワークとの連携性能が飛躍的に伸びる
L3キャッシュの増量は、単なる数値スペックの向上ではない。CPUは計算のたびにメインメモリまでデータを取りに行くと時間がかかる。L3キャッシュが大きければ近くにデータを置けるため、処理待ちが減り、結果として体感性能が大きく向上する仕組みだ。
実際にAWSの広報記事で紹介された顧客事例では、ClickHouseがコード変更なしでM8g比36%の性能向上を達成。Honeycombは6カ月にわたるA/Bテストで、コアあたりのスループットが36%向上したと報告している。これらの数字は、CPUそのものの改良がアプリケーションレベルで直接的な効果を生むことを示している。
M9g/M9gdのラインアップと性能スペック
インスタンスサイズと性能の詳細
M9gは汎用用途向けで、1vCPUあたり4GiBのメモリ比率を採用している。M9gdはこれに加え、高速ローカルNVMe SSDストレージを搭載したバリエーションだ。ラインアップは1vCPUの小規模構成から、192vCPU・768GiBメモリの大規模構成まで幅広く用意されている。
最大サイズの48xlarge(192vCPU)では、ネットワーク帯域が100Gbpsに達する。前世代比で最大2倍の帯域幅になっており、大量のデータを扱うデータベースやログ処理基盤での効果が特に大きい。
IBC(Instance Bandwidth Configuration)の実用性
M9g/M9gdでは、IBC(インスタンス帯域幅設定)と呼ばれる新機能が利用可能になった。これはEBS(永続ストレージ)とVPCネットワーク間で、帯域幅の配分を最大25%調整できる仕組みだ。
たとえばデータベースサーバではEBSへの書き込み性能がボトルネックになりやすい。IBCを使えばEBS側に帯域を多めに割り当て、クエリ処理やログ書き込みを高速化できる。ネットワーク通信が少ないバッチ処理やキャッシュサーバでも有効だ。
Nitro Isolation Engineが実現する「数学的に証明されたセキュリティ」
Graviton5と同時に発表された技術の中で、最も静かでありながら最も革新的なものがNitro Isolation Engineだ。聞き慣れない用語だが、クラウドセキュリティの考え方を根本から変える可能性がある。
形式検証(Formal Verification)とは何か
通常、ソフトウェアのセキュリティは「テスト」で検証する。攻撃パターンを想定し、実際に動かして問題がないかを確認する手法だ。しかしこの方法では、想定外の攻撃や未知の脆弱性を見逃すリスクが常に残る。
形式検証(Formal Verification)はこれとは根本的に異なる。数学の定理証明と同じアプローチで、「このシステムは絶対に想定外の動作をしない」ことを数理的に証明する技術だ。特定のテストケースだけでなく、あらゆる入力パターンで期待通りに動作することを保証する。
AWSによれば、Nitro Isolation Engineはこの形式検証を適用したクラウドハイパーバイザーとして業界初の事例となる。ハイパーバイザーとは、1台の物理サーバ上で複数の仮想マシンを安全に隔離する基盤ソフトウェアだ。この隔離機能が破られると、他の顧客のデータにアクセスされる重大なセキュリティ事故につながる。Nitro Isolation Engineは、その隔離が破られる可能性を数学的にゼロにする設計となっている。
この技術は金融機関や医療機関など、厳格なデータ保護が求められる業界にとって特に重要な意味を持つ。セキュリティ監査のレベルが一段引き上げられることになるからだ。なおNitro Isolation EngineはM9g/M9gd専用の機能であり、既存のインスタンスタイプには搭載されない。
エージェントAI時代のCPU需要とGraviton5の位置づけ
AIが「考える」から「行動する」へのシフト
ここ数年、AIの進化は大規模言語モデル(LLM)のテキスト生成能力に注目が集まってきた。しかし現在、AIの主戦場は「質問に答える」から「行動を実行する」へと急速に移行している。いわゆるエージェントAIと呼ばれる分野だ。
エージェントAIとは、ユーザーの指示に対して、コードを実行し、ツールを使い、結果を評価し、複数ステップのタスクを自律的に組み立てるAIシステムを指す。たとえば「今月の売上データを分析してグラフ化し、経営陣向けのサマリをSlackに投稿して」という指示に対し、AIがデータベースに接続し、集計処理を実行し、グラフを生成し、メッセージを送信する一連の流れを自律的に処理する。
このような処理は、GPUなどのアクセラレータだけで完結しない。指示の解釈、コードのコンパイル、データベースクエリの実行、APIの呼び出しなど、CPUに依存する処理が大量に発生する。AWSの広報記事で、MetaがエージェントAI基盤として数千万コア規模のGravitonを導入していると報告されているのは、このトレンドを象徴している。
エージェントAIが実用段階に入るにつれ、クラウド上のCPU需要はむしろ増大する。Graviton5が192コアという高密度設計を採用したのは、こうした並列処理ニーズを先取りしたものといえる。
Web開発者にとっての実務的意味
中小企業のWeb担当者や個人事業主にとって、「エージェントAI」や「192コア」という言葉は遠い世界に感じられるかもしれない。しかし実際には、以下のような形でM9gの恩恵は身近な領域に及ぶ。
- MySQL/PostgreSQLの応答速度向上:HubSpotの事例ではクエリ時間が最大60%短縮。WordPressサイトやECサイトのデータベース応答が高速化する可能性がある
- コスト効率の改善:Graviton5はGraviton4比でエネルギー効率も向上。同じ処理をより少ない電力で実行できるため、ランニングコストの削減につながる
- セキュリティの底上げ:Nitro Isolation Engineによる隔離保証は、顧客データを扱うあらゆるサービスに恩恵がある
重要なのは、これらの恩恵がコード変更ゼロで得られるケースが多い点だ。ClickHouseやHoneycombの報告にあるように、Armネイティブ対応が済んでいるアプリケーションであれば、インスタンスタイプをM8gからM9gに変更するだけで性能向上が見込める。
M9g/M9gdへの移行を検討する際の実践ステップ
Graviton5インスタンスの利用を始めるには、いくつかの準備と確認が必要だ。AWS公式が提供する移行ガイドやツールを活用すれば、想定よりスムーズに移行できる。
Arm対応状況の確認と移行パス
最初に行うべきは、現在稼働中のアプリケーションがArmアーキテクチャに対応しているかの確認だ。Java、Python、Node.js、Go、PHPなど主要な言語ランタイムはすでにArm対応が完了している。ただし、x86固有のアセンブリコードを含むC/C++プログラムや、特定のx86向けバイナリに依存しているアプリケーションでは注意が必要になる。
Javaアプリケーションの場合、AWSが提供する「AWS Transform」というAI支援サービスが利用できる。x86用にコンパイルされたJavaアプリケーションをArm向けに自動変換し、互換性分析や依存関係の更新まで処理するツールだ。コードの書き換えが必要なケースでも、変換作業の多くを自動化できる。
コスト面の評価ポイント
M9g/M9gdは、Savings Plans、オンデマンド、スポットインスタンス、Dedicated Hostsのいずれでも購入可能だ。一般にGraviton系インスタンスはx86系より低価格に設定されており、さらにSavings Plansを組み合わせることで長期利用時のコストを大幅に抑えられる。
AWS公式が提供する「Graviton Savings Dashboard」を使えば、Graviton移行によるコスト削減効果を可視化できる。費用対効果を数字で把握しながら、段階的に移行を進めるのが実務的なアプローチだ。
この記事のポイント
- AWS Graviton5搭載M9g/M9gdが一般提供開始。前世代Graviton4比で最大25%の計算性能向上
- ClickHouseで36%、HubSpotのMySQLクエリで最大60%の高速化を実測。コード変更不要のケースが多い
- Nitro Isolation Engineにより、形式検証を用いた数学的に証明されたVM隔離をクラウドで初めて実現
- エージェントAIの普及でCPU需要が急増する中、192コアの高密度設計が新たな計算基盤として台頭
- 移行にはArm対応状況の確認から段階的に進めるのが安全。AWS TransformやSavings Dashboardが支援ツールとして利用可能
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Claude Fable 5がGoogle Cloudで一般提供開始。エージェント構築の新たな基盤を考察
Anthropicの最新モデル「Claude Fable 5」が、Google Cloud上で一般提供を開始した。このモデルは複雑な多段階推論や高度なコード生成を得意とし、長期間にわたって自律的に動作するエージェントの構築に適している。クラウドAIの基盤に何が起きているのかを読み解く。
Claude Fable 5の登場とその戦略的な位置付け
Anthropicのモデル群には、Haiku(軽量高速)、Sonnet(バランス)、Opus(超高性能)がある。今回登場したFableシリーズは、これらのニックネームとは明らかに異なる文脈を持つ。筆者の見解では、Fableは「物語(ストーリー)の生成」、つまり長文脈の一貫性維持や、複雑なオーケストレーションを必要とするエージェントタスクに特化した系統と位置付けられる。
このモデルは単に速度や知識量を競うだけでなく、「どれだけ複雑な仕事を最後までやり遂げられるか」を重視している。特に、長期稼働エージェントとしての使用が強く想定されている点が、他のモデルとの差別化要因だ。
Fable 5は、単発のレスポンスを返すだけではない。途中で文脈を見失ったり、指示を忘れたりする問題を大幅に低減し、ソフトウェア開発や分析業務といった長時間の集中を要するタスクで真価を発揮する。
Fable 5の主要な能力と想定されるユースケース

Google Cloudの公式発表とAnthropicのリリースノートから、Fable 5の中核的な機能強化点を読み解くと、以下の3つに集約される。
複雑な多段階推論と高度なコード生成
Fable 5は、数学的推論やコード生成ベンチマークで大幅な性能向上を達成している。これは単にコードを出力するだけでなく、既存のリポジトリ全体を理解し、アーキテクチャレベルの提案ができることを示す。典型的な「次のトークン予測」を超え、人間のソフトウェアアーキテクトのように数手先を読む能力が強化された。
長期稼働エージェントの実現
多くのLLMは文脈が長くなると応答精度が落ちる。Fable 5は「長時間にわたって自律的にツールを使い、タスクを完了させる」というエージェント動作に最適化されている。カスタマーサポートの自動化、継続的なデータ収集、IT運用の自動化など、数時間から数日単位で動くAIエージェント基盤として機能する。
深いマルチモーダル文書分析
テキストだけでなく、PDF内のグラフ、パワーポイントの図表、画像内のテキストまでを横断的に理解する能力が向上した。これにより、企業内に散在する非構造化データの分析ハードルが大幅に下がる。数百ページの契約書や仕様書を読み込ませ、瞬時に要約や矛盾点の洗い出しを行うといった使い方が視野に入る。
これらの能力は、もはや「優秀なアシスタント」ではなく「自立したチームメンバー」という表現が近い。開発現場ではコードレビューを完全自動化し、法務部門では契約書の精査を任せられる。人間が最終判断する仕事の質とスピードが、根本から変わる可能性をはらんでいる。
Google CloudのAgent Platformがもたらす実用性

モデル単体の性能もさることながら、今回の発表で注目すべきはGoogle Cloudの「Agent Platform」上で提供される点だ。これは単なるAPIゲートウェイではない。エージェントの構築、テスト、デプロイ、監視までを垂直統合した基盤である。
具体的には、Googleが持つエンタープライズグレードのセキュリティ(IAM、VPC Service Controls)、Vertex AIのMLOps機能(モデル評価、メタデータ管理)、そしてCloud RunやBigQueryといった周辺サービスとの統合がシームレスに行える。Fable 5のような高度なモデルを「安全に」「堅牢に」本番環境で動かすために必要なピースがあらかじめ揃っている。
ここで重要なのは、強力なモデルを手に入れることと、それをビジネスで使いこなすことの間にあるギャップが、Agent Platformによって埋められる点だ。認証基盤や監査ログが整っていない状態でAIエージェントに重要な業務を任せることは難しい。Google Cloudのプレゼンスは、企業のAI導入における「最後の1マイル」を解決する。
開発者が今日から試すべき3つのアプローチ
Fable 5とAgent Platformが利用可能になったことで、Web制作やシステム開発の現場で即座に試せる実験領域が広がった。筆者の視点から、特に費用対効果が高いと想定される3つのシナリオを提示する。
コードレビューの完全自動化プロトタイプ
GitHub連携をトリガーに、Fable 5がPull Request全体を解析する。コーディング規約のチェックだけでなく、コードの脆弱性、パフォーマンス劣化リスク、過去の類似実装との矛盾点までを自然言語でレビューコメントする。人間のレビューアは、Fable 5が出した指摘が正しいかどうかの最終判断だけに集中できる。
非構造化ドキュメントのデータベース化
クライアントから提供された古い仕様書のPDF、競合分析のスライド、展示会で撮影したホワイトボードの写真などをまとめてFable 5に投入する。モデルはこれらを横断的に解析し、共通する要求定義や矛盾する記述を抽出して構造化データとして出力する。データベースに格納することで、後続の検索やレポート作成が自動化される。
社内向け「なんでも調査エージェント」の起案
定型的なリサーチ業務をエージェント化する。例えば「3ヶ月以内に更新された特定分野の法改正情報を、週次で一覧化してSlackに投げる」といったタスクをFable 5に任せる。モデルが自律的にGoogle検索や社内Wikiを巡回し、複数ステップの推論を経て最終的なサマリーを生成するPoCは、数日あれば構築可能だ。
このアプローチによって、人間の工数は「クリエイティブな問題解決」と「AIの提案に対する最終的な意思決定」に集中できるようになる。
この記事のポイント
- Anthropicの最新モデルClaude Fable 5は、複雑な推論と長期稼働エージェントに特化してGoogle Cloud上で一般提供が開始された
- 高いコード生成能力と深いマルチモーダル分析を持ち、単なるテキスト生成を超えたタスクの自動化が可能になった
- Google CloudのAgent Platformとの統合により、エンタープライズレベルのセキュリティと運用基盤が整備されている
- 人間はAIの最終判断に集中する働き方へシフトするため、コードレビューや文書分析のプロトタイプを早期に試す価値がある
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Claude Fable 5がAWSで利用可能に。長時間実行と安全策を両立する新モデル
AWSがClaude Fable 5のAmazon Bedrock対応を発表した。Anthropicの新モデルはMythosクラスの最高性能を備えつつ、有害利用リスクへの安全策を組み込んだ点が最大の特徴だ。ソフトウェア開発や文書解析など長時間の自律作業を任せられる設計になっている。
Fable 5はほぼすべてのベンチマークで最先端のスコアを記録する。注目すべきは、人間の介入なしで複雑なコーディングやナレッジワークを長時間継続できる実行能力だ。単発の応答を超えた「作業の持続」が可能になったことで、開発現場やビジネスプロセスへの組み込みが現実味を帯びてきた。
Claude Fable 5の3つの技術的特徴
従来のLLM(大規模言語モデル)が得意としてきた「質問への即答」とは異なり、Fable 5は「長時間タスクの遂行」にフォーカスしている。AWS公式ブログとAnthropicの技術発表から、その差別化要素を整理した。
長時間の非同期実行
従来のモデルは数分を超えるタスクで精度が低下したり、文脈を見失ったりする課題があった。Fable 5は複雑なコーディングや調査作業を長時間・自律的に続行できる。具体的には、複数ファイルにまたがる大規模なリファクタリングや、長大なドキュメントの横断的分析といった作業を途中で止めずに完了させる。
これは単にトークン数が増えただけではない。モデル内部のアーキテクチャが「途中経過の自己管理」を強化しており、タスクのゴールを見失わずに作業を継続する仕組みだ。AWSの発表では「長時間のコーディングや知識労働を継続的に実行する」と表現されている。
この変化により、ソフトウェア開発における「任せっぱなし運用」の幅が広がる。たとえばコードベース全体のリファクタリングを夜間に任せ、朝には完了しているというワークフローが視野に入る。
高度なビジョン機能
Fable 5はテキストだけでなく、図表、グラフ、PDF内に埋め込まれた表などを高精度で理解する。金融や法務、建築、ゲーム開発など、文書や設計図を扱う業種での活用が期待される領域だ。
コーディングの文脈でも大きな意味を持つ。デザインファイルを読み取ってUIを実装したり、出力結果のスクリーンショットを自己チェックして「要件と合っているか」を検証したりできる。従来のモデルはテキスト情報だけを頼りにしていたが、Fable 5は「見て判断する」能力を作業フローに組み込める。
プロアクティブな自己検証
Fable 5はタスク実行中に得た学習をもとにスキルを自己更新し、自ら評価用のハーネス(テストフレームワーク)を作成する。AWSの発表では「自身の出力を目標と照らし合わせて批判的に評価する」と説明されている。
これはソフトウェアテストの自動化と深く関わる。たとえば「単体テストのコードを生成する」という指示ではなく「この機能を実装し、テストを作成し、通るまで修正を繰り返せ」という指示が現実的になる。モデルが自律的にPDCAを回すため、人間は成果物の最終確認に集中できる。
安全策の仕組みとMythos 5との棲み分け

Fable 5の最大の独自性は「性能と安全策の両立」にある。同じモデルから安全性を引き上げたFable 5と、制限を外したMythos 5という2つのバリエーションが用意されている。
有害プロンプトは自動でOpus 4.8にルーティング
Fable 5はサイバーセキュリティ、生物学、化学、健康に関連する有害プロンプトを受け取ると、内部で自動的にOpus 4.8へルーティングする。AWSの公式発表では「安全策によって、ほぼすべての最先端機能へのアクセスを提供しつつ、誤用リスクの高い領域では応答を制限する」と説明されている。
重要なのは、ユーザー側で切り替えを意識する必要がない点だ。通常のAPIコールでFable 5を指定しておけば、安全と判断されたプロンプトにはFable 5が、リスクありと判断されたプロンプトにはOpus 4.8が自動で応答する。
Mythos 5は限定的なプレビュー提供
Fable 5の制限を取り払ったMythos 5も、Amazon Bedrockで限定的に利用可能だ。ただしMythos 5はサイバーセキュリティやライフサイエンス(創薬、バイオディフェンススクリーニング等)といった専門領域向けであり、審査を受けた一部の顧客のみアクセスできる。一般提供は行われない。
この「制限付きスーパーモデル」と「制限なし最強モデル」の二層構造は、AIの社会実装における新たなパラダイムとなり得る。AWSの発表でも、Mythos 5はデュアルユース(軍民両用)の性質を持つため厳格な管理下に置かれていると明記されている。
Amazon Bedrockでの利用環境とセットアップ

Fable 5はAmazon BedrockとClaude Platform on AWSの両方で利用できる。ここではBedrock経由のセットアップ手順を中心に解説する。
データ共有へのオプトインが必須
Fable 5を利用するには、データ保持ポリシーでプロバイダーデータ共有(provider_data_share)にオプトインする必要がある。AnthropicはMythosクラスの全モデルで、入力と出力の30日間保持および人間によるレビューを必須としている。これは単一のやり取りでは検出できない誤用パターンを長期的に監視するためだ。
オプトインするとデータはAWSのセキュリティ境界を離れる。機密性の高いデータを扱う場合は、この点を事前に評価しておく必要がある。設定はAWS CLIで以下のように実行する(bedrock-mantleエンジン向け)。
curl -X PUT https://bedrock-mantle.us-east-1.api.aws/v1/data_retention \
-H "x-api-key: <your-bedrock-api-key>" \
-H "Content-Type: application/json" \
-d '{ "mode": "provider_data_share" }'bedrock-runtimeエンジンを使う場合は、エンドポイントと認証方式が異なる点に注意が必要だ。詳細はAWSの公式ドキュメントを参照してほしい。
Python SDKからの呼び出し例
Anthropic SDKをインストールした後、Messages API経由でFable 5を呼び出すコードは以下の通りになる。リージョンは現時点で米国東部(バージニア北部)と欧州(ストックホルム)に対応している。
import anthropic
client = anthropic.Anthropic(
base_url="https://bedrock-mantle.us-east-1.api.aws/anthropic",
api_key=<your-bedrock-api-key>
)
message = client.messages.create(
model="anthropic.claude-fable-5",
max_tokens=4096,
messages=[
{
"role": "user",
"content": "秒間10万リクエストを複数リージョンで処理するAWS分散アーキテクチャを設計してほしい"
}
]
)
print(message.content[0].text)BedrockのConverse APIを使う場合はBoto3経由となる。マルチモデル対応の統一インターフェースが使えるため、既存のBedrockワークロードとの統合が容易だ。
課金体系の注意点
有害プロンプトがOpus 4.8にルーティングされた場合、そのリクエストの課金はOpusの価格で計算される。また途中でブロックされた会話では、Fable 5が処理した初期トークンはFable 5の料金、それ以降はOpusの料金が適用される。大規模なワークロードを計画する際は、見積もりにこの変動要素を含めておく必要がある。
ソフトウェア開発の現場に与える影響

Fable 5の登場は、とりわけソフトウェアエンジニアリングのワークフローを変える可能性が高い。AWSの発表でも「長時間のコーディングタスク」と「自己検証」が前面に押し出されている。
「コードを書く」から「コードを任せる」へ
従来のLLMは「関数を1つ書いて」という短い指示には強かったが、プロジェクト全体を見渡すようなタスクには限界があった。Fable 5は「このリポジトリの全テストを補充し、カバレッジが90%を超えるまで繰り返せ」といった高レベルな指示を理解し、自律的に遂行できる。
これは開発者の役割を「実装者」から「設計者・監督者」へとシフトさせる。コードを書く時間が減り、アーキテクチャの意思決定やビジネスロジックの検討に集中できるようになる。ただし出力の品質チェックは依然として人間の責任だ。
CI/CDパイプラインとの統合可能性
Fable 5の自己検証機能は、CI/CD(継続的インテグレーション/継続的デリバリー)の自動化範囲を拡大する。プルリクエストの自動レビュー、テスト自動生成、失敗時の自律的な修正までを一気通貫で行える可能性がある。
ただし現時点でFable 5は非同期実行向けに設計されており、リアルタイムのチャット応答を前提とした従来のCI/CDトリガーとはワークフローが異なる。ジョブキューと組み合わせたバッチ処理型の統合が現実的なアプローチになるだろう。
日本市場での受け入れと課題
国内のソフトウェア開発現場では、セキュリティ要件の厳しさから「データを外部に出せない」という制約が根強い。Fable 5の必須条件である30日間のデータ保持と人間によるレビューは、金融や医療分野での採用ハードルになる。AWSの東京リージョンでの利用可能時期も現時点では未発表だ。
一方で、スタートアップやゲーム開発のようにスピードを重視する領域では、Fable 5の長時間自律実行能力は強力な武器になる。日本でも段階的に導入が進むと見られる。
この記事のポイント
- Claude Fable 5はMythosクラスの性能を持ちつつ、有害利用を自動遮断する安全策を内蔵している
- 長時間の非同期実行により、コードの大規模リファクタリングや文書横断分析を自律的に完了できる
- 図表やPDFを読み取るビジョン機能が加わり、金融・法務・建築など文書集約型の業種で活用が広がる
- 有害プロンプトは自動でOpus 4.8にルーティングされ、ユーザーはモデルを意識せず使える
- Amazon Bedrockでの利用には30日間のデータ保持オプトインが必須。機密データの扱いには注意が必要だ
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Microsoft Discovery GAとDiscoveryアプリプレビュー
マイクロソフトはMicrosoft Buildにおいて、研究開発向けエージェントAIプラットフォーム「Microsoft Discovery」を一般提供開始した。同時に、研究者がローカル環境で利用できる「Microsoft Discoveryアプリ」のプレビュー版も公開された。
このリリースは、科学研究におけるAIの役割を単なるアシスタントから、反復的な実験計画や仮説検証を統括する「研究の中核」へと引き上げるものだ。製薬業界の新薬探索や材料工学の最適化問題など、複雑な条件が絡み合う領域での利用が見込まれている。
従来のチャット型AIとは異なり、このプラットフォームは専門的なモデリングツールや実験データと連携し、人間の専門家による判断プロセスを補強する設計がなされている。大規模な組織の研究開発(R&D)ワークフローに、再現性と透明性をもたらす点が最大の特徴だ。
エージェントAIによる研究開発ワークフローの再現性確保
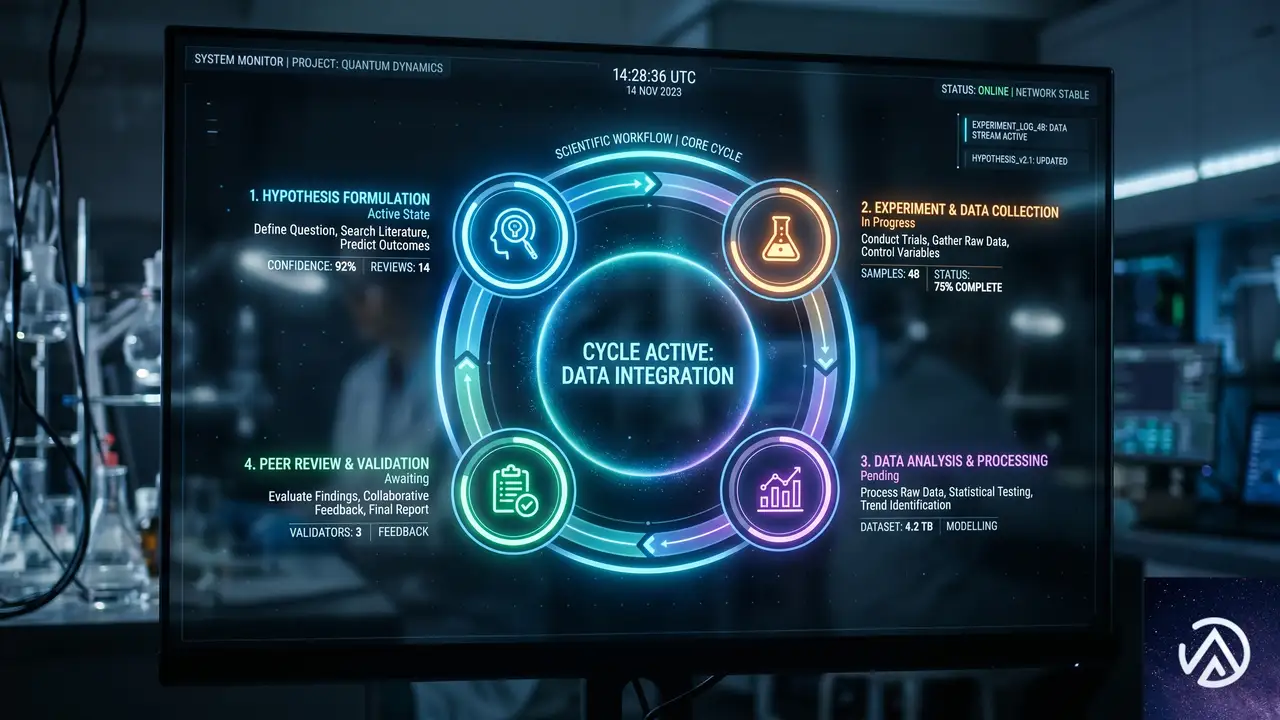
科学研究の突破口は、一度のひらめきで生まれるものではない。仮説、実験、改良、レビューという繰り返しのサイクルの中からしか姿を現さない。Microsoft Discoveryは、この本質的なループ構造を組織的に管理し、加速させるために作られた。
✓ 再現可能なワークフロー
✓ 組織固有の知識との統合
このプラットフォームの中心にあるのが「Microsoft Discovery Engine」だ。これはエビデンス(証拠)から仮説を導き出し、AIエージェントが各種のシミュレーションや分析ツールを呼び出して検証し、次のイテレーションへ進むという一連の流れを支える。Azure Blogの記事によれば、このエンジンは「単発の分析を超えて、比較検討や前提の疑問視を繰り返し可能な形で行える」よう設計されている。
プロダクション環境で求められる信頼性
研究開発の現場にAIを持ち込む際、最も難しいのは「信頼」の確立だ。Microsoft Discoveryの一般提供版では、以下の要件が重視されている。
- ワークフローの再現性
- 出力結果のレビュー可能性
- 企業固有の知的財産の適切な統治
- 既存のR&D組織の運営モデルへの適合
つまり、AIが出した「答え」だけを信じるのではなく、その推論の道筋を後からなぞり、専門家が納得できる形で提示することが求められている。これは、ブラックボックス化しがちな大規模言語モデルの弱点を補うアプローチであり、規制の厳しい製薬業界や材料産業での採用を後押しする要素だ。
ローカル環境を拓く「Discoveryアプリ」のプレビュー公開
組織全体での大規模な導入と並行して、マイクロソフトは個人や小規模チームがすぐに利用を開始できる「Microsoft Discoveryアプリ」のプレビュー版もリリースした。これは、企業のIT部門による本格的なデプロイを待たずに、研究者が自身のマシン上でエージェントAIの能力を試せるようにするための入り口だ。
このアプリは、学術研究室や学生が「まず触ってみる」ことを最重要視している。研究のアイデアが小規模なプロジェクトや個人の探求から始まることは珍しくない。そこから成果が成熟し、より高度な制御や大規模な計算リソースが必要になった段階で、クラウド上のMicrosoft Discoveryへシームレスに移行できる点が特徴だ。
最先端の現場における応用事例

プライベートプレビュー期間中、各分野のリーディングカンパニーとの協業を通じて、このプラットフォームの実践的な価値が検証された。単なる概念実証ではなく、実際の製品開発や学術研究のスピードを変えつつある。
バッテリー科学での分子設計ループ
イェール大学工学部とマイクロソフトリサーチの共同研究では、大規模蓄電向け「有機レドックスフロー電池」の電解質分子設計にDiscovery Engineが利用された。この問題は、酸化還元電位や水溶性、合成のしやすさなど、相反する複数の物性を同時に最適化する必要がある極めて複雑なものだ。
エージェントAIは、実験から得られたデータを解釈して次の候補分子を提案し、さらに診断的な実験計画を立案する役割を担った。実際の実験検証と結果の評価は、人間の専門家が主導している。イェール大学のDavid Kwabi准教授は、この枠組みが「人間主導の実験の強みと、AIの広大な化学空間探索能力を組み合わせたもの」と評価している。
半導体から生命起源まで
Syensqo社は、次世代半導体製造用の熱伝達流体の開発にこの技術を適用し、研究から営業、マーケティングまで含めたビジネス全体の意思決定速度を向上させている。ジョージア工科大学では、生命の起源に関わるアミノ酸「ヒスチジン」の生成経路を、複数のAIエージェントが質量分析データや文献情報を統合して再評価するユニークな試みが進められている。
これらの事例に共通するのは、AIが「単独で答えを出す」のではなく、人間の研究者とツールの間に立って「探索と検証のサイクル」を加速させている点だ。BHPのJessica Farrell氏は、銅の浸出技術開発において「無限に近い可能性の領域を、実用可能な少数の選択肢に絞り込めた」と述べ、数か月単位での成果創出に貢献したことを示唆している。
いずれも「探索 → 検証 → 絞り込み」のループをAIが加速する構造が共通している。
自律ラボとの融合が示す次のフェーズ

パシフィック・ノースウェスト国立研究所(PNNL)との協業は、AIエージェントが物理世界と直接つながる未来を明確に示している。ここでは、Discoveryが仮説を生成するだけでなく、ロボット実験設備を直接駆動し、得られた実験結果をリアルタイムで学習して次の指示を出す「自己駆動型の科学ワークフロー」が実証されている。
PNNLのRobert Runkle氏は、これを「ロボティクスと自律ラボがAIとクラウドインフラと融合した、一つのインテリジェントなクローズドループ発見エンジン」と表現する。アイデアから実際のブレイクスルーまでのタイムラインを劇的に短縮し、材料合成や生物学における新時代の扉を開くものだという。
この動きは、ケンブリッジ・コンサルタンツが「数か月の実験作業を数日から数時間に変える」と表現したインパクトと完全に一致する。AIが提案し、ロボットが試し、その結果をAIが解釈する、このサイクルが自動で回り始めたとき、研究開発の定義そのものが変わるだろう。
この記事のポイント
- Microsoft DiscoveryはR&Dワークフローの再現性と透明性を確保するエージェントAI基盤
- クラウド上の本格運用と、個人が即日試せるローカルアプリの二軸で提供開始
- 研究における「仮説→実験→検証」の反復ループを、専門家の判断を中心に据えつつ加速する設計
- バッテリー開発、創薬、鉱業など、実際の産業応用で開発スピードを劇的に向上させた事例が複数報告されている
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

法務事務所を狙うデータ恐喝の新手口、遠隔操作から「直接訪問」へ進化
機密文書を扱う法務事務所や士業が、新種のデータ恐喝集団「UNC3753」の標的になっている。Google傘下の脅威分析チーム「Mandiant」が2026年6月5日に公開した報告によると、2026年1月から5月にかけて、全米の法律・金融サービス企業数十社が被害に遭った。攻撃者は電話で偽のITサポートを装い、社内の誰もが持つ画面共有ソフトを悪用してネットワークに侵入する。この手口はテクニカルなハッキングというより、巧みな会話術と信用の悪用で成立する。1営業日以内に情報窃取から恐喝までを完了するスピード感も特徴だ。
さらに深刻なのが、遠隔操作が失敗した場合には「直接オフィスを訪問する」物理的な侵入へのエスカレーションが確認されている点だ。FBIも注意喚起を出したこの事案は、大企業だけの問題ではない。顧客情報や契約書類を抱える士業や制作会社も、十分な対策が求められる。
法務事務所を狙う「偽のITサポート」電話が増加している

この攻撃キャンペーンの主体は、Mandiantが「UNC3753」と呼ぶ経済動機の脅威クラスターだ。2022年3月から活動が確認されており、別名として「Luna Moth(ルナ・モス)」「Silent Ransom Group(サイレントランサムグループ)」とも呼ばれる。元々は請求書を装ったPDFファイルをメールに添付し、偽のコールセンターに電話させる手口を使っていた。しかし2025年3月頃から戦術を変更し、企業内部のITヘルプデスクを名乗る「Vishing(音声フィッシング)」へと完全にシフトした。
この変化には明確な理由がある。メールフィルタやアンチウイルスが高性能化し、マルウェア付き添付ファイルは検知されやすくなった。しかし電話での指示を疑うセキュリティソフトは存在しない。音声フィッシングは防御側の「技術で壁を作る」前提を完全にすり抜ける。
メールは「呼び水」、本番は電話で始まる
攻撃は次の2段階で進む。まず一般消費者向けメールアドレスから「hello, here is the invcoie we talked about yesterday(昨日話した送り状です)」といった短いメールを送りつける。リンクも添付ファイルもなく、セキュリティ検査を素通りする。だがタイプミスを含む不自然な文面は受信者に「怪しい」と思わせる効果があり、まさにそれが狙いだ。標的が警戒したタイミングで、社内IT担当を名乗る電話がかかってくる。「不審なメールが届いていませんか」と切り出すことで信頼を獲得し、画面共有に誘導する。
偽のITサポートが社内ネットワークに侵入する流れ

UNC3753の侵入フローは、技術的には「正規ツールの悪用」で構成される。マルウェアの注入も、脆弱性攻撃も行われない。このため、侵入検知システムやアンチウイルスに記録が残らず、事後の調査を困難にしている。
Mandiantの調査では、この一連の流れがわずか1時間足らずで完了したケースも確認されている。攻撃者はiManageのような文書管理システムを熟知しており、W-2(給与税務申告書)や監査ファイルといった「人質として価値の高い文書」を狙い撃ちする。
個人所有のPCを経由してVDI環境に侵入する抜け穴
もう一つの特徴的な手口が、VDI(仮想デスクトップ環境 / Virtual Desktop Infrastructure)の悪用だ。在宅勤務の社員が私物のPC(BYOD / Bring Your Own Device)で業務システムにアクセスする構成を、攻撃者が逆手に取る。画面共有を仕掛けた社員の個人PCを経由し、VDIクライアント(Windows 365やCitrix)を介して企業の内部ネットワークに自由にアクセスする。会社支給の端末にセキュリティソフトが導入されていても、私物PCの画面共有からは検知できない。
データの送信方法も巧妙化している
窃取したファイルの送信には以下の3つのルートが使い分けられる。1つ目はWinSCPやRcloneといったコマンドラインベースの同期ツールを使った大量転送だ。Mandiantの報告によると、ある被害者ではローカルのOneDriveフォルダから1.7ギガバイト、VDIセッションから追加で14.4ギガバイトが一気に流出した。2つ目はPrivnoteのような「開封後に消えるメモサービス」を使った遠隔指示の中継だ。攻撃者はインストール先URLやコマンドをPrivnote経由で渡し、社内のブラウザ履歴やチャットログに痕跡を残さない。3つ目はごく単純に、被害者のブラウザで直接Googleドライブにログインさせる手口だ。標的企業の名前を付けたフォルダにデータをドラッグ&ドロップさせ、事後に消去を指示する。
「直接訪問」に進化する物理的な脅威

Mandiantの報告で特に目を引くのが、遠隔操作が通用しなかった場合の物理侵入だ。これは単なる仮説ではなく、FBIが2026年5月に発出した「Cyber FLASH Alert」で具体的に警告されている。IT技術者を装った第三者が実際のオフィスを訪れ、「デバイスのイメージ取得が必要」「セキュリティ上の緊急対応」と言ってPCにUSBメモリを差し込ませ、直接データを吸い出す手口が確認された。
技術的な防御が高度化するほど、それを迂回する「人間」を狙う攻撃は増える。物理セキュリティはサイバーセキュリティの一部であり、切り離して考えてはならない。
不正送金より深刻な「データ人質」の手口
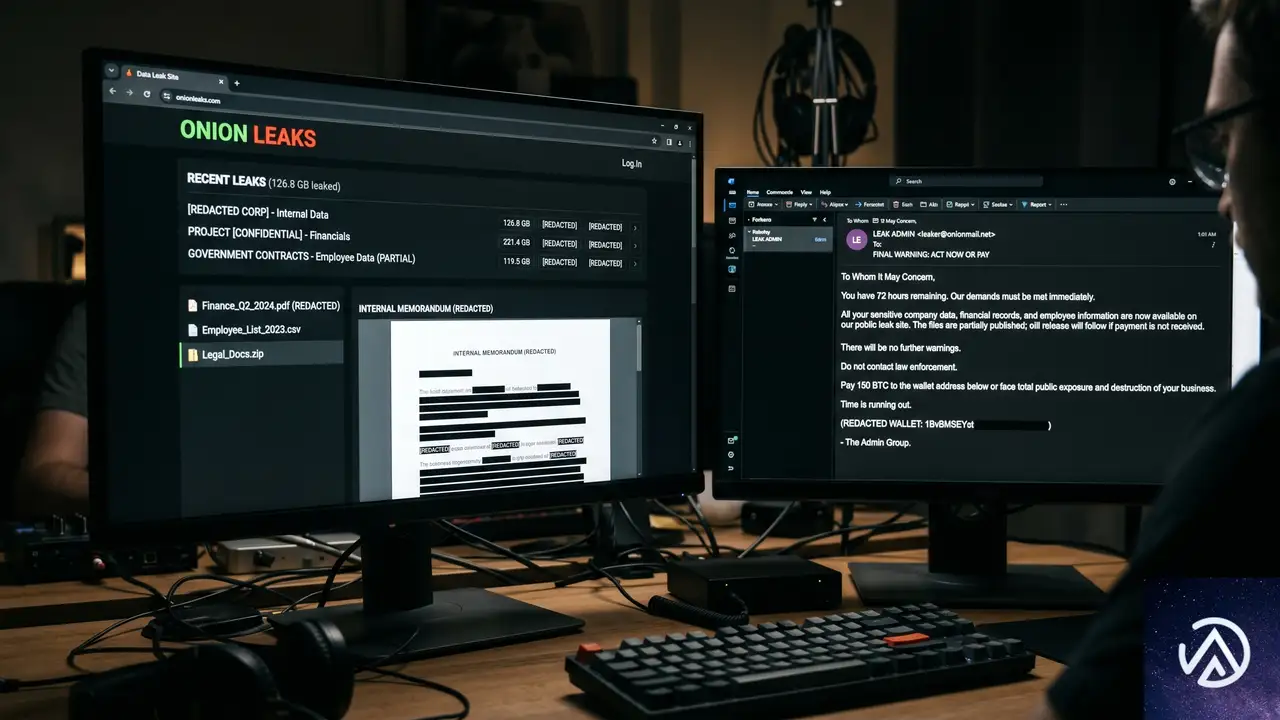
UNC3753の最終目的はファイルを暗号化して身代金を要求する「ランサムウェア」ではない。窃取した機密情報を人質に取り、「3日以内に交渉を始めなければ顧客や取引先に直接リークを通報する」と脅して金銭を要求する「データ恐喝」だ。法務事務所や会計事務所にとって、顧客データの流出はビジネスそのものを揺るがす致命的な事態になる。恐喝メールでは「顧客の信頼は失墜し、多額の規制当局による罰金が発生し、データ管理責任を問われて顧客から訴訟を起こされる」と明記される。心理的圧力を最大限に高める文面だ。
要求に応じなければ、実際に「LEAKEDDATA」というデータリークサイトで情報を公開する。支払ったとしてもデータが確実に削除される保証はなく、沈黙の代償が更なる恐喝を呼ぶリスクもある。この種の「身代金を支払わない」方針を事前に決め、防御にリソースを振ることが重要だ。
今日から始める中小企業の防御策

UNC3753の手口は大手向けに見えるが、個人情報を扱う税理士事務所やWeb制作会社でも全く同じ被害構造が成立する。Google Threat Intelligence Groupの推奨事項を元に、中小企業向けの実践的な対策を示す。
社内教育を最優先に設計する
不審な電話がかかってきた場合の対応手順を社内で標準化しておくべきだ。「社内ヘルプデスクを名乗っても、まず上司や情報システム担当に転送する」というシンプルなルールを周知するだけで、初期侵入の大半を防げる。特に「データ移行プロジェクト」や「セキュリティ上の緊急対応」と言われたら、一度電話を切り、会社に登録されている正規の内線番号にかけ直す習慣を徹底させたい。
VDIとBYODの認証を強化する
個人のPCやタブレットから社内の仮想デスクトップ(VDI)に接続する構成は、多要素認証(MFA)の強化が不可欠だ。さらに「会社支給端末以外からのVDI接続を禁止する」という条件付きアクセスポリシーを設定できれば、私物端末を経由した遠隔操作のリスクを大幅に下げられる。
正規のリモート管理ツールも制限する
AnyDeskやZoho Assistが攻撃に使われる現実を踏まえ、会社で業務利用するリモート管理ツールを限定し、それ以外のインストールをAppLockerやWindows Defender Application Controlで制限する構成が有効だ。ZoomやTeamsの画面共有機能についても、社内ポリシーで利用ガイドラインを定めておくべきだ。
USBメモリの物理的な対策
会社の全PCでUSBストレージの書き込みを無効化する設定は、グループポリシー(GPO)を使えば比較的簡単に実装できる。外部メディアを業務で使う場合も、必ず情報システム担当者が解錠する運用にすることで、なりすましの技術者がUSBメモリでデータを抜く物理攻撃を封じられる。
ネットワーク監視とログ設定
ファイアウォールで外部ファイル共有サービスへの接続を監視し、一定時間内に大量のSSHトラフィック(WinSCPやRcloneの転送に使われる)が発生した際にアラートを出すようにしておくと、データの一括送信を早い段階で検知できる。社内の文書管理システムでも、キーワード検索の急増や大量ダウンロードを監視対象に加えておくべきだ。
この記事のポイント
- 法務事務所を狙うUNC3753は、音声フィッシングで画面共有に誘導し正規ツールを悪用する
- メールは呼び水に過ぎず、マルウェアを使わないため従来の防御策では検知が難しい
- 遠隔操作が失敗すると、IT業者を装った直接訪問でUSBメモリを使った窃取に切り替える
- VDI環境と個人端末の認証強化、USB書き込み禁止設定が即効性の高い対策となる
- 攻撃の最終目的はデータ恐喝であり、要求に応じる前に防御と教育の強化を優先すべき
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AIだけでは企業変革できない、カギは実行基盤(Azureブログ発表)
AIが企業のあらゆるワークフローに浸透し始めている。だが、本当の変革をもたらすのは最先端のAIモデルそのものではなく、それを動かすシステムの設計だという指摘が、マイクロソフトの公式ブログで発表された。同社はエージェントを中心とした統合プラットフォームを打ち出し、開発から運用、ガバナンスまでを一貫して支える環境を構築している。
発表の背景には、個別のAIチャットボットや単発のツール導入に終始する企業では、大規模な業務変革が進まないという現実がある。Azure Blogの記事では、複数のAIエージェントが部門を横断して長期間にわたり作業を実行し、しかも統制の取れた形で運用できる仕組みこそが次世代の競争力を決めると述べられている。
なぜAI単体では不十分なのか

エージェントがもたらす真の変革
Azure Blogによれば、現在の企業AI活用で話題になるのはチャットボットのような対話型インターフェースだ。だが、そうしたエクスペリエンスは便利ではあるものの、組織全体のオペレーションを根本から変えるものではない。真に価値があるのは、ソフトウェア開発、サポート、財務、人事、運用といった複数の業務領域で、複数のAIエージェントが連携し、長期にわたって作業を自律的に遂行することである。
エージェントが本格稼働するには、単に強力なAIモデルやスケーラブルな計算資源が手に入れば良いわけではない。エージェントを「誰が」「どのデータを使って」「どう安全に」動かすかという企業コンテキスト、ポリシー、人的監視の枠組みが不可欠だ。Azure Blogの記事では、これらを欠いた状態では、AIの導入は断片的で脆弱、大規模に信頼するのが難しいと指摘している。
個別ツールの寄せ集めではリスクが高まる
多くの企業は、コード生成ツール、データ連携基盤、実行環境、監視システムをそれぞれ別々に導入し、後付けで連携させる方法を取りがちだ。だがAzure Blogの記事は、こうしたばらばらのツールを寄せ集めただけの環境では、開発速度が落ち、不必要なリスクを招くと警告している。たとえば、エージェントに意図しないアクセス権が渡ったり、部門間でガバナンスが効かなくなったりする問題が起こり得る。
このデモで示したように、断片化したツール群ではエージェントの挙動を一貫して管理できない。マイクロソフトの新たなアプローチは、これらの要素を統合した単一のプラットフォームでエージェントを動かす点にある。
Microsoftの統合エージェントプラットフォームとは
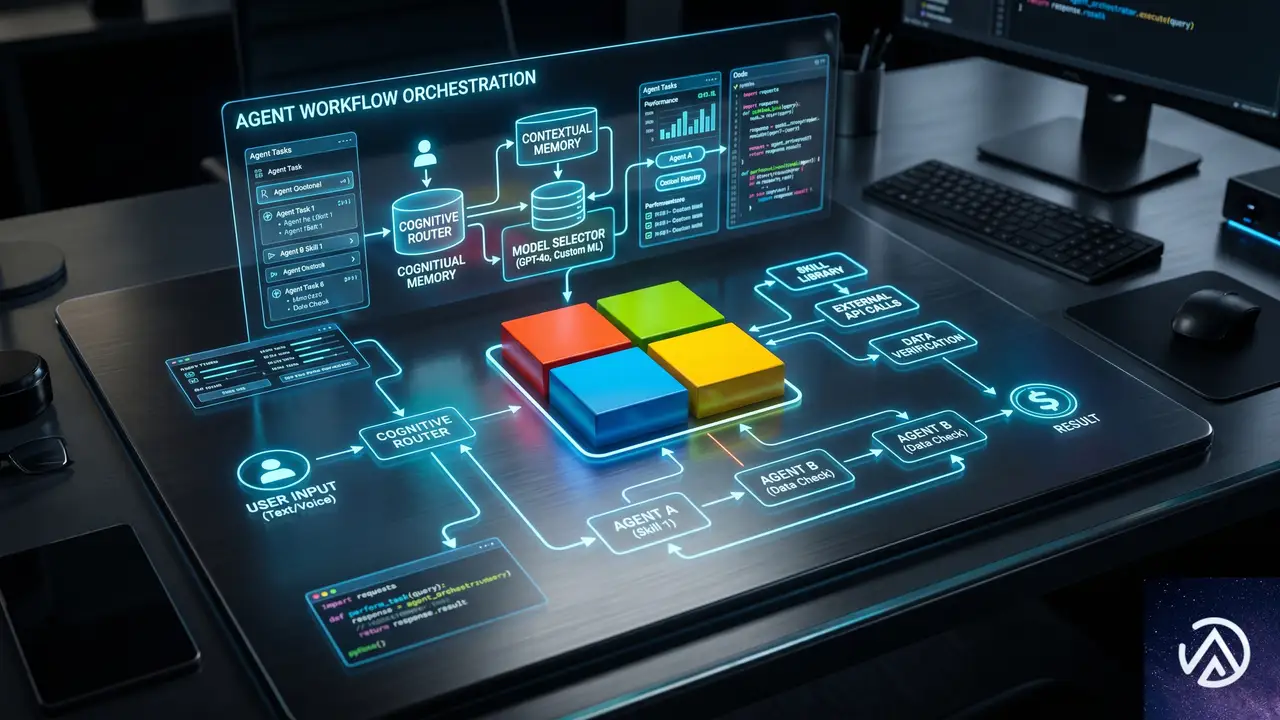
Azure Blogの発表では、同社が「包括的エージェントプラットフォーム」を構築していると説明されている。このプラットフォームは、多様なAIモデルをサポートしながら、開発者を中心に据えた柔軟な設計になっている。そして何より、実際の本番ワークロードを動かし、組織の複雑さとビジネス責任を扱える水準を目指している。
3つの設計原則
このプラットフォームは、以下の3つの基本原則に基づいて設計されている。
- 単一の統合システムで多様なモデルをサポートする:Azure、GitHub、Microsoft IQ、Fabric、Foundry、Windows、Microsoft 365、Microsoft Securityを一つのシステムとして連携させる。これにより、構築から改善までをバラバラのツールなしで行える。さらに、マイクロソフト自社モデルだけでなくパートナーモデルやオープンモデルも自由に選べる。
- セキュリティとガバナンスが設計に組み込まれている:Entra、Purview、Defender、Agent 365といったセキュリティスタックを開発段階から本番まで一貫して適用する。後付けではなく、システムにネイティブに統合されたガバナンスを実現する。
- 継続的に改善する:エージェントの動作結果や人間からのフィードバックをシステムに還元し、時間とともに安全に改善させる。モデルやワークフローが企業固有の業務プロセスに適合し、使い続けるほど価値が複利的に高まる仕組みを目指す。
これらの原則は今や「あると良い」ものではなく、競争力を左右する必須条件になるとAzure Blogの記事は強調している。四半期単位で差がつくという見立てだ。
エージェントライフサイクルの全体像
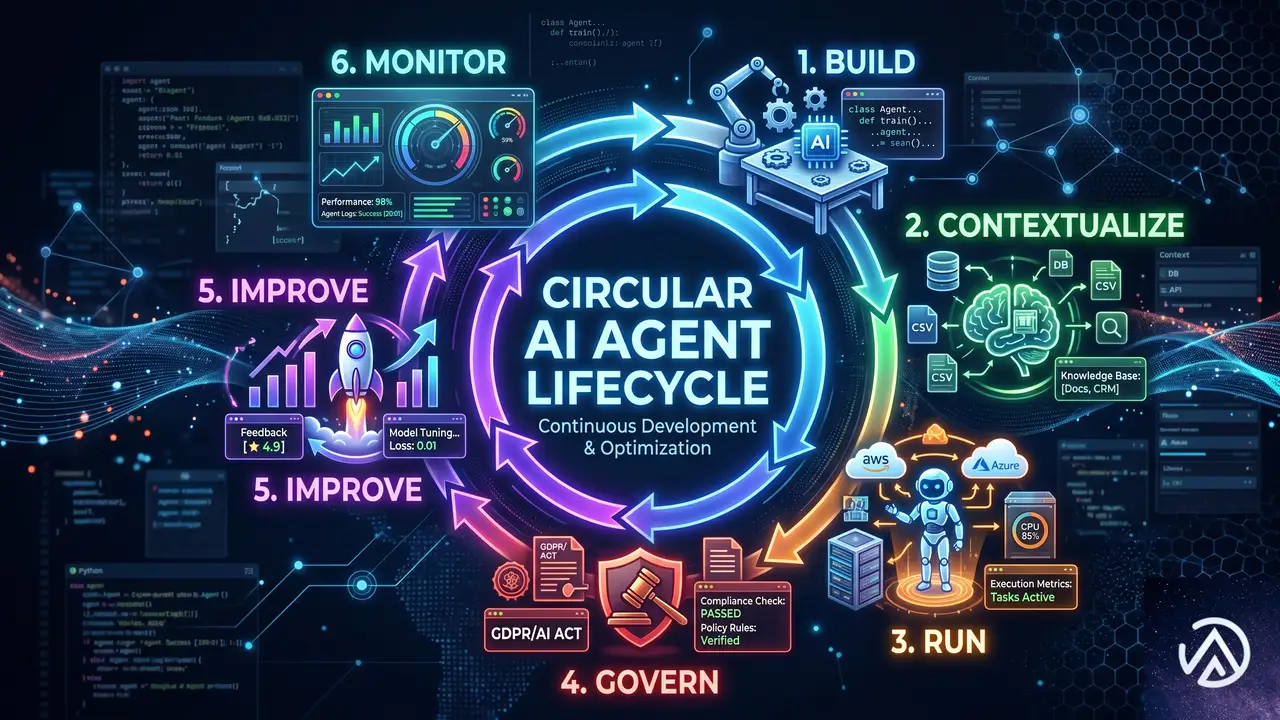
では、このプラットフォーム上でエージェントはどのように構築され、動いていくのか。Azure Blogの発表に沿って、主要な段階を順を追って見ていく。
構築〜GitHubで開発する
エージェントの開発は、すでに多くの開発者が日常的に使うGitHubを起点とする。コードベース、ワークアイテム、スキル、ツールなど重要なアセットを同じ場所に集約し、本番ソフトウェアと同じライフサイクル(ソース管理、テスト、デプロイ、監視、改善)をエージェントにも適用する。
GitHub Copilotを活用してコード作成を加速し、評価(eval)や可観測性(observability)のアセットもバージョン管理下に置く。これにより、最初から適切なガードレールを備えたエージェント開発が可能になる。発表では、このために新しいGitHubアプリが提供されることも述べられている。
企業データの文脈化〜Microsoft IQ
コードだけでは、エージェントは汎用的なAIにとどまる。真に役立つには、顧客情報、製品データ、契約書、業務プロセスといった企業特有の文脈を理解しなければならない。Azure Blogの記事では、いくら高性能なモデルを使っても、企業文脈なしでは推測に過ぎないと指摘している。
Microsoft IQは、Microsoft 365や基幹業務システム、ナレッジベース、自社ウェブサイトなど、社内外のデータソースにエージェントを接続する。さらに、Web IQによってウェブ上の情報も適切に取り込める。単にデータにアクセスさせるのではなく、情報を整理し、エージェントが扱いやすい形で安全に提供する点が重要だ。
さらに、Frontier Tuningと呼ばれる仕組みによって、実際の業務データとワークフローからモデルを改善できる。今回発表された音声、画像、コーディング、推論向けの7つの新しいMAIモデルを含め、モデルが企業のプロセスを学習し、その企業に特化した知能として機能するようになる。学習結果は企業の環境内に保持されるため、知的財産は外部に出ない。
実行環境〜Foundry
構築し文脈化したエージェントは、本番環境で実行されなければならない。Foundryは、エージェント特有の要求(推論、ツール呼び出し、他のエージェントとの連携、時間経過による適応)に応えるランタイムだ。
Foundryでは、タスクやコストに応じて最適なモデルを選択できるルーター機能を備え、Fireworks AIによる高速な推論も統合している。Microsoft Agent Frameworkはもちろん、LangGraph、GitHub Copilot SDK、Claude Agent SDKなど多様なエージェントフレームワークもサポートする。ツールやアクションはMCP、コネクター、API、ワークフロー経由で安全に実行され、評価とトレースによってエージェントの振る舞いを計測可能にしている。
ガバナンス〜Agent 365
ひとたび企業全体で何百、何千ものエージェントが稼働し始めると、全体を把握し制御するガバナンスが不可欠になる。Agent 365は、組織内の全エージェントを単一のカタログに表示し、誰がデプロイしたか、どのデータやツールにアクセスできるか、どのように動作しているか、コストはいくらかをIT管理者が一元的に確認できる仕組みだ。
Entra、Purview、Defenderと連携し、必要に応じてポリシーを強制したりアクションを取ったりできる。これにより、設計の良いエージェントもそうでないエージェントも、組織として統制下に置かれる。Azure Blogでは、ガバナンスの基盤が最初から組み込まれている点が後付けとの大きな違いだと強調されている。
継続的改善ループ
エージェントシステムは静的なままではない。すべての動作結果やフィードバックがシグナルとして蓄積され、評価、改善、安全なロールアウトが繰り返される。この学習ループは本番環境で連続的に動作し、プロンプトの調整からモデルルーティング、ファインチューニング、強化学習まで、段階的に高度化していく。
Azure Blogの記事は、このプロセスを「hill-climbingモデル」と表現し、システムを稼働させながら価値を複利で高める考え方を示している。重要なのは、改善ループが完全な自動化ではなく、人間の監査と修正のもとで制御されることだ。
業務現場への提供〜TeamsとAzure
エージェントの価値は、実際に業務を行う人々の手元に届いて初めて発揮される。このプラットフォームでは、TeamsやMicrosoft 365、自社アプリケーションの中にエージェントが自然に表面化する。アイデンティティ、セキュリティ、コンプライアンスは最初から組み込まれており、日常業務で使うツールと同じ信頼モデルを継承する。
また、Windows環境での最適化されたエージェント実行、クラウドとローカルの両方でのモデル稼働、サンドボックス技術による常駐型エージェントの安全な動作もサポートされる。大規模なAIワークロードやグローバルな展開が必要な場合は、Azureが基盤として全体をスケールさせる。
システムが価値を複利で増幅させる仕組み

Azure Blogの発表は、結局のところ、AI活用で先行する企業は「中央のAIプラットフォーム」を中心に業務を再編し、データ、モデル、エージェント、人間の判断を一つの継続的に改善する安全なシステムへと収斂させていくと述べている。システムが稼働し続けるほどその価値は複利的に増大し、ボトルネックは作業量から人間の創造性と調整へと移行する。
このビジョンでは、個々の担当者が共有された文脈のもとで自律的に仕事を進められるようになり、引き継ぎや摩擦は減り、ビジネス全体のスピードが上がる。マイクロソフトのエージェントプラットフォームは、まさにその「統合されたオペレーティングシステム」として機能することを目指している。
この記事のポイント
- Azure Blogの最新発表では、企業AIの成否はモデル単体ではなく、エージェントを動かすシステム設計にかかっていると指摘されている。
- 個別ツールの寄せ集めはリスクを高めるため、GitHub、Microsoft IQ、Foundry、Agent 365などによる統合アプローチが提唱されている。
- エージェントライフサイクル全体(構築、文脈化、実行、ガバナンス、継続改善)を単一システムで回すことで、信頼性とビジネス価値が複利的に高まる。
- セキュリティとガバナンスは設計段階から組み込まれ、人的監視のもとでAIが安全に改善し続ける仕組みが特徴。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AWS Bedrock刷新、OpenAIとAnthropic API互換コンソールが登場
AWSが2026年6月5日、Amazon Bedrockの管理コンソールを刷新した。この新体験は「bedrock-mantle」エンジン向けに設計されており、Anthropic Messages APIとOpenAI Responses APIに最適化されている。
従来のBedrockコンソールはマネージド機能(AgentsやKnowledge Basesなど)を中心に据えていたが、今回の刷新はAPI直接呼び出しを前提とする開発者向けに設計し直されている。モデル選定からプロダクション実装までの時間を大幅に短縮する狙いだ。
この記事では、新コンソールの主要機能と開発ワークフローへの影響を詳しく見ていく。API互換性を活かしたコードの簡略化や、複数モデルの並列評価がどのように実現されるのかを解説する。
Bedrockの新コンソールが生まれた背景
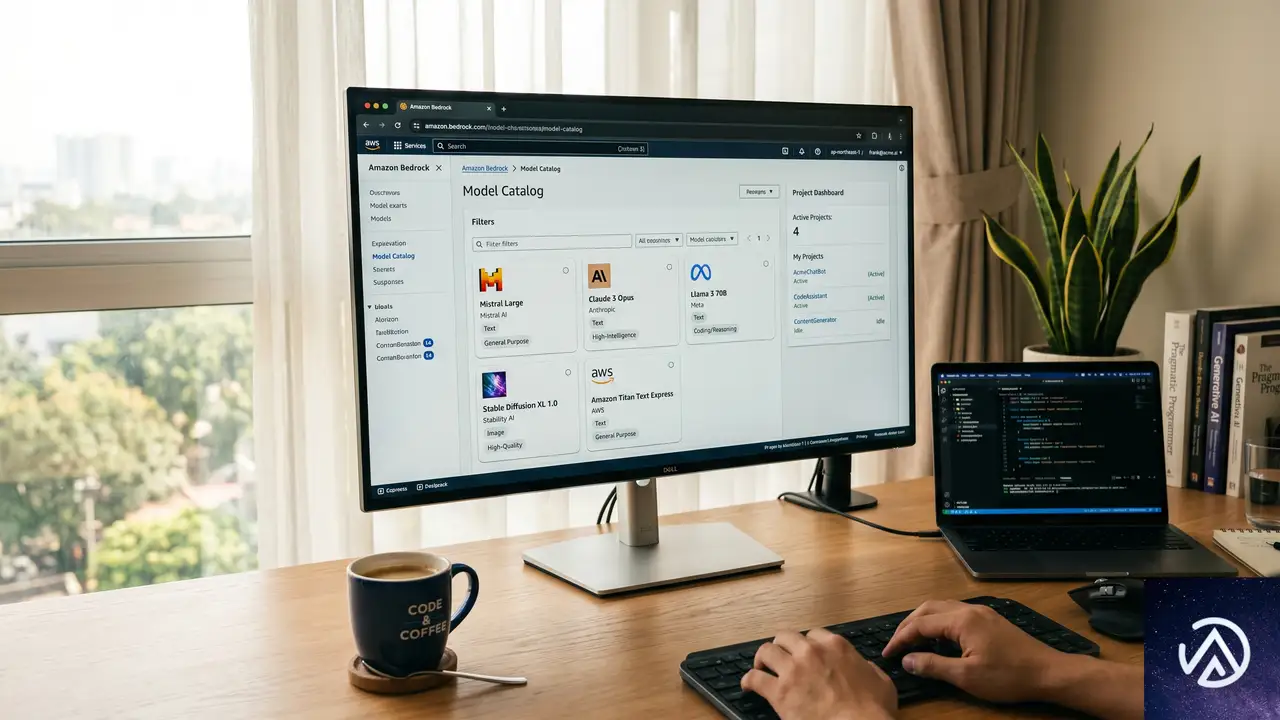
この図が示すように、新コンソールは「プロジェクト」を軸にした作りになっている。モデルの評価から実装、モニタリングまでをひとつの画面で完結させる狙いだ。
bedrock-mantleエンジンとは何か
bedrock-mantleは、Bedrockの第2世代推論エンジンとして位置づけられる。高速な処理性能と高い信頼性、そしてエンタープライズレベルのセキュリティを兼ね備えている。
最大の特徴はAnthropicとOpenAIのAPIプロトコルに互換性を提供することだ。ClaudeモデルにはAnthropic Messages API(メッセージAPI)を、GPTモデルにはOpenAI Responses API(レスポンスAPI)とOpenAI Chat Completions API(チャット補完API)を使える。これにより、既存のSDKコードをほぼ変更せずにBedrockへ移行できる。
従来のbedrock-runtimeエンドポイントを使う既存機能(InvokeModelやConverse API、Agentsなど)は、引き続き従来のBedrockコンソールから利用できる。両者は併存する設計で、急な移行は求められない。
新モデルカタログが提供する高速な比較体験

新コンソールの目玉のひとつが、刷新されたモデルカタログだ。従来は各モデルの仕様を調べるためにドキュメントや料金計算ツールを行き来する必要があったが、それが1画面で完結するようになった。
最大3モデルを並べて比較
カタログ上で最大3つのモデルを選択し、機能、モダリティの対応状況、コンテキストウィンドウの大きさ、利用可能なリージョン、料金体系を横並びで比較できる。
この比較機能は、チーム内でのモデル選定会議や、PoC(概念検証)フェーズでの迅速な意思決定に力を発揮する。料金と性能のトレードオフを視覚的に把握できるのが強みだ。
プロジェクト単位で完結する開発ワークフロー
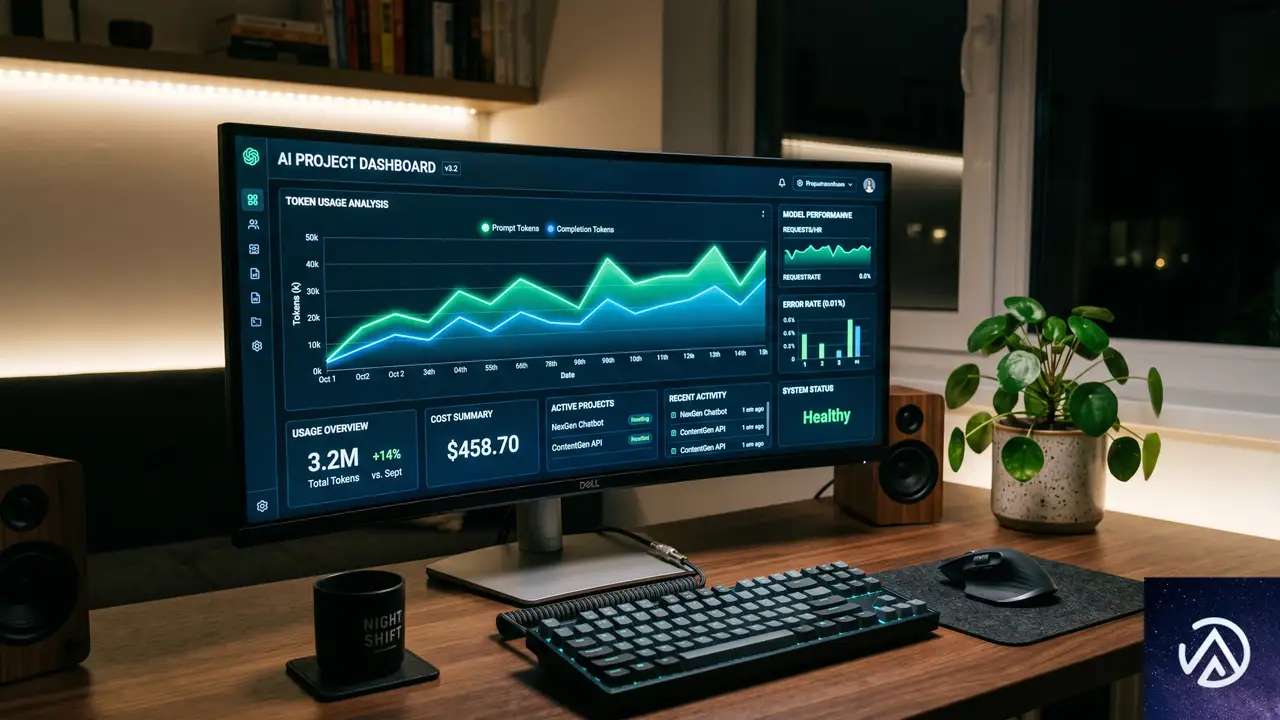
新コンソールの中核は「プロジェクト」という概念だ。生成AIアプリケーションの開発ライフサイクルをプロジェクトとして管理し、モデルの割り当てからAPIキーの発行、推論リクエストの送信までを一気通貫で行える。
ダッシュボードでトークン消費を可視化
プロジェクトダッシュボードでは、直近の推論リクエスト数やエラー発生率を日付範囲でフィルタリングできる。さらに、総トークン消費量、1分あたりのトークン使用量、推論リクエストの回数、1リクエストあたりの平均トークン数がグラフ表示される。
このデータは、モデルの選択ミスや過剰なトークン消費を早期に発見する手がかりになる。チームの予算管理にも直結するため、プロダクション環境では特に価値が高い。
サイドバイサイド評価でプロンプトを最適化
プロジェクト内で最大3つのモデルを選択し、同じプロンプトに対する応答を横に並べて比較できる評価モードが用意されている。これにより、どのモデルが自社のユースケースに最適かを実データで判断できる。
評価結果はそのままプロダクション環境へ移行する際の根拠資料としても使える。カスタマーサポート用チャットボットであれば、回答の質と応答速度のバランスを定量的に比較できる。
コード生成とAIアシスタント連携の新機能
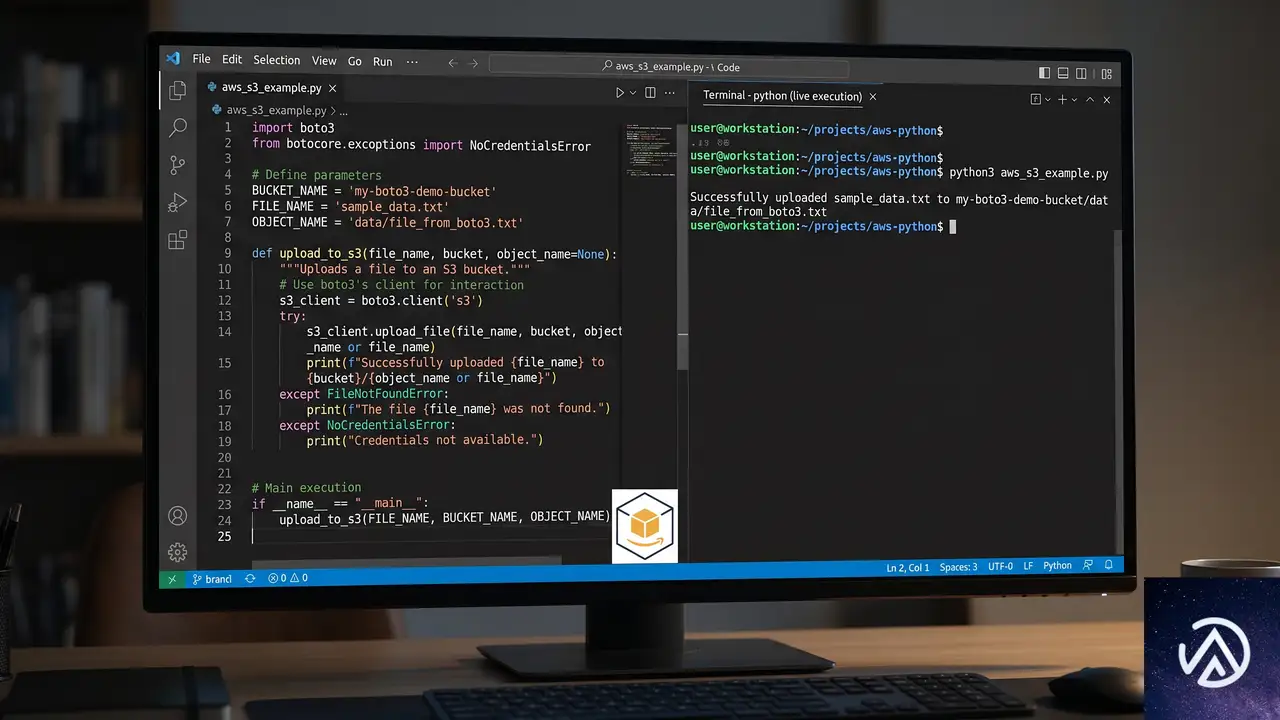
最も実務インパクトが大きいのが、プロジェクトに紐づいた「ライブドキュメント」機能だ。コードサンプルやSDKスニペット、APIリファレンスにプロジェクトの変数(モデルID、リージョン、エンドポイントURL、APIキー)が自動で埋め込まれる。
コピーするだけで動くコードスニペット
開発者はコンソール上で表示されたコードをそのままコピーし、ローカル環境のアプリケーションに貼り付けるだけで動作確認できる。環境変数の手動設定やエンドポイントURLの確認といった手間が省ける。
AWS_REGION=us-east-1
ENDPOINT=bedrock-mantle
API_KEY=sk-xxxxxx
client = boto3.client()
response = client.invoke(modelId=MODEL_ID)
この仕組みにより、環境構築のミスが大幅に減る。特に複数プロジェクトを抱えるチームでは、設定の食い違いによるトラブルシューティング時間を削減できる。
AIコーディングエージェントとの統合
新コンソールはAIコーディングエージェントとの連携もサポートする。Claude Code、Cline、Codex、Cursor、OpenCodeといった主要なAIアシスタントをBedrockのmantleエンジンにルーティングする手順がガイドされる。
具体的には、AWS IAM認証情報かBedrock APIキーを使い、環境変数を設定したうえで各エージェントからのリクエストをBedrock経由にする設定が案内される。これにより、AIアシスタントのバックエンドをOpenAIやAnthropicのクラウドからAWS環境に切り替えられる。企業ポリシーでデータの外部送信を制限しているケースで有効だ。
利用可能リージョンと今後の展開

新コンソール体験は、bedrock-mantleエンドポイントが提供されている全リージョンで利用可能だ。2026年6月時点での対象は以下の通り。
AWSのドキュメントにはリージョン互換性の一覧ページが用意されており、将来的な拡大があれば随時更新される見込みだ。フィードバックはAWS re:Post for Amazon Bedrock、または通常のAWSサポート窓口を通じて送ることができる。
新コンソールは既存のBedrockコンソールと並行して運用される。急な切り替えを迫られることはなく、チームの準備が整った段階で徐々に移行できる設計だ。
この記事のポイント
- Amazon BedrockにAPI互換性を重視した新コンソールが登場し、モデル評価から実装までの時間が大幅に短縮される
- bedrock-mantleエンジンはAnthropic Messages APIとOpenAI Responses APIに対応し、既存SDKコードの流用が容易
- 最大3モデルのサイドバイサイド比較と、プロジェクト単位のトークン消費可視化が組み込まれている
- コンソール上のコードスニペットはプロジェクト変数が自動プレフィルされ、コピー後即実行できる
- 東京リージョンを含む複数リージョンで利用可能、既存コンソールとの併存もサポートされる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験