

Cloudflareが企業のAIコスト爆発を制御、AI Gatewayに利用上限を搭載
企業におけるAI導入の最大の壁はもはや技術力ではない。管理不能なコストの爆発だ。2026年6月5日、Cloudflareは自社のAI Gatewayに新たな「利用上限」機能を搭載し、この課題への直接的な解決策を提示した。
多くの企業では全エンジニアに最先端モデルのAPIキーを共有している。月末に届く高額な請求書を見て、経理とCTOが頭を抱える。誰が何に使ったのか全く分からないのだ。Cloudflareの今回の発表は、まさにこの無法地帯に統制をもたらすものだ。
併せて発表されたアイデンティティベースの予算管理は、Cloudflare Accessと既存のIdP(Identity Provider / アイデンティティプロバイダー)を組み合わせ、個人やチーム単位での正確なコスト帰属を実現する。
なぜAIコストは制御不能に陥るのか
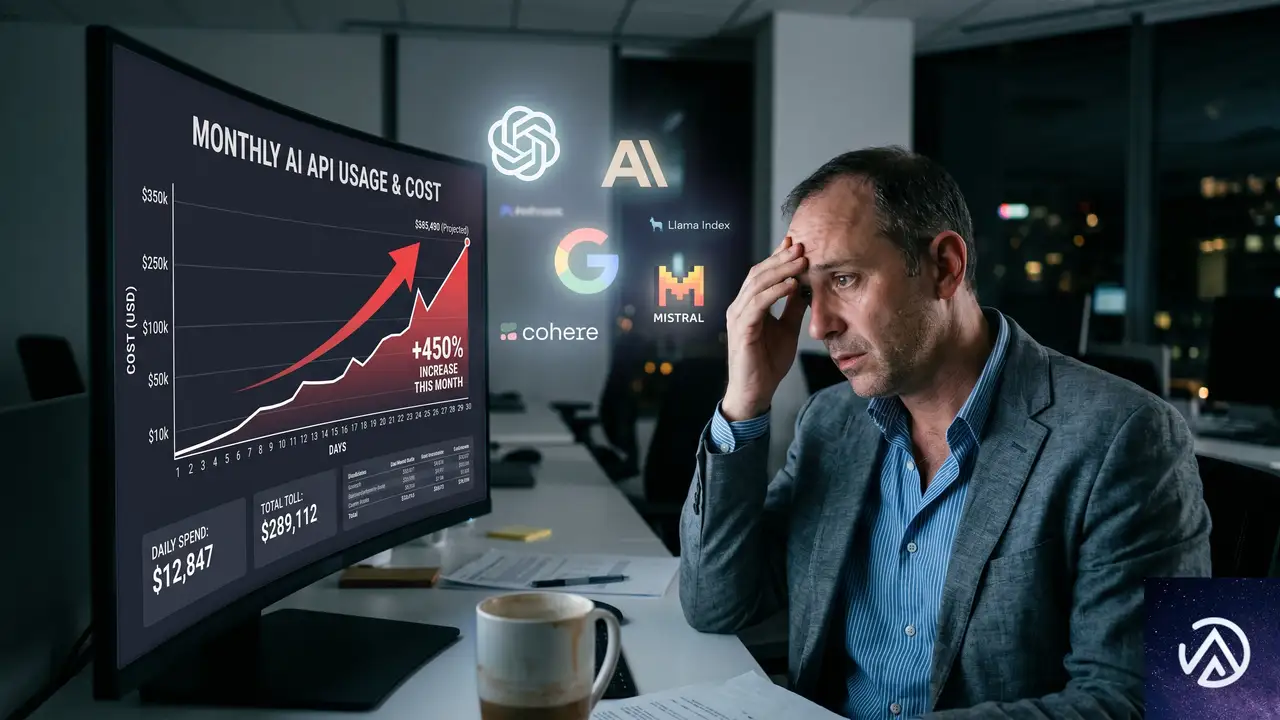
AI導入を進める企業で、まったく同じストーリーが繰り返されている。現場には「まずは最速でAIを使え。勘定は後でなんとかする」という号令が飛ぶ。これは大抵の場合うまくいく。実際、AIを積極的に取り入れたチームの生産性は飛躍的に向上している。しかし、その代償は安くない。月末に経理がAPI利用料の請求書を開くと、にわかには信じがたい桁の数字が目に飛び込んでくるのだ。
Cloudflareのブログ記事でも、この構図は明確に描写されている。社内で共有されているAPIキーでは、コストの発生源を追跡できない。機械学習チームの新規パイプライン構築が原因なのか、インターンがメールの仕分けに高額なClaude Opusを使い倒したのか、あるいはCI/CDジョブが週末のうちに何千万トークンも消費したのか、誰にも分からない。
問題の本質は、指標と制御の欠如により、合理的な判断が歪められてしまうことにある。予算も可視化もなければ、常に最も強力で高価なモデルを選ぶのが個々のエンジニアにとっては合理的な行動となる。コードレビューの要約に、大規模なアーキテクチャ再設計と同じモデルは必要ない。ログパーサーに、顧客向けコンテンツ生成と同じモデルは不要だ。しかし、現場には適切な道具を選ぶ動機も手段も存在しなかったのである。
利用上限機能を深掘りする
中核となる仕組み
AI GatewayはアプリケーションとAIプロバイダーの中継点として機能する。OpenAIやAnthropicへの直接APIコールを、まずこのゲートウェイを経由させる仕組みだ。これにより、リクエストの永続化ログ、キャッシュ、レート制限、リトライ、分析といった恩恵が得られていた。しかし、従来は「誰がいくら使ったか」の正確なトラッキングに限界があった。
ここに新たに導入された利用上限機能は、真のコスト統制を実現する。トークンベースではなく、ドルベースの予算で累積支出を追跡する点が実務的だ。制限のスコープは、モデル、プロバイダー、ユーザーやチームといった管理者定義のカスタム属性の任意の組み合わせで設定できる。期間も固定(月初リセットや月曜リセット)かローリング(直近N日間)かを選べ、日次、週次、月次での運用が可能だ。
予算超過時の現実的な選択肢
最も重要なポイントは、上限到達時の処理だろう。デフォルトではリクエストをブロックする。だが、ワークフローを完全に止めないための工夫として、ダイナミックルートと連携したフォールバックモデルへの切り替えが可能だ。これなら、最大予算額に達してもエンジニアの作業が完全に停止することはない。
この機能群は本日から全プランの全ユーザーにオープンベータとして提供されており、ダッシュボードかAPI経由で即座に設定できる。
アイデンティティ駆動の予算管理がもたらす透明性

利用上限機能と同時に、Cloudflareはアイデンティティベースの予算とポリシーを限定ベータとして発表した。利用上限がモデルやカスタム属性による制御であるのに対し、こちらは実在の個人とチームに紐づく。アプリケーション側でメタデータを渡す必要はなく、信頼性の低いヘッダー情報に頼る必要もない。
Cloudflare Accessとの統合が生む確実な帰属
AI GatewayをCloudflare Accessと連携させると、リクエストの送信者が誰かを確実に特定できる。単なるアカウント単位ではなく、個々の従業員、IdPグループ、サービス単位だ。Cloudflare社内では既にこの仕組みを実践しており、全従業員がAIツールを利用する中で月間数十億トークンが流れるトラフィックを可視化している。
仕組みはシンプルだ。従業員がCloudflare Access経由で認証されると、そのアイデンティティがJWT(JSON Web Token)から抽出され、AI Gatewayのリクエストにメタデータとして添付される。これにより、ユーザー単位のトークン消費、チーム単位の使用量内訳、組織全体のコスト帰属が一元管理できるようになる。
CI/CDパイプラインへの適用とボット予算
この機能は人間だけのものではない。Accessサービスアカウントを利用すれば、自律的なエージェントやCI/CDパイプラインにも名前付きのIDを付与できる。コードレビューボットが今週500万トークンを消費し、ドキュメント生成器が50万トークンだった、といった詳細が手に取るように分かる。あるエージェントが制御不能に陥ったとしても、他のエージェントに影響を与えることなく個別に予算ポリシーを適用できるのだ。
Cloudflare自身、全社でこのスタックを運用した経験に基づいて本機能を公開した。自社で構築したものを他社もゼロから作る必要はない、という明快なスタンスである。
次の段階はコスト最適化の自動化
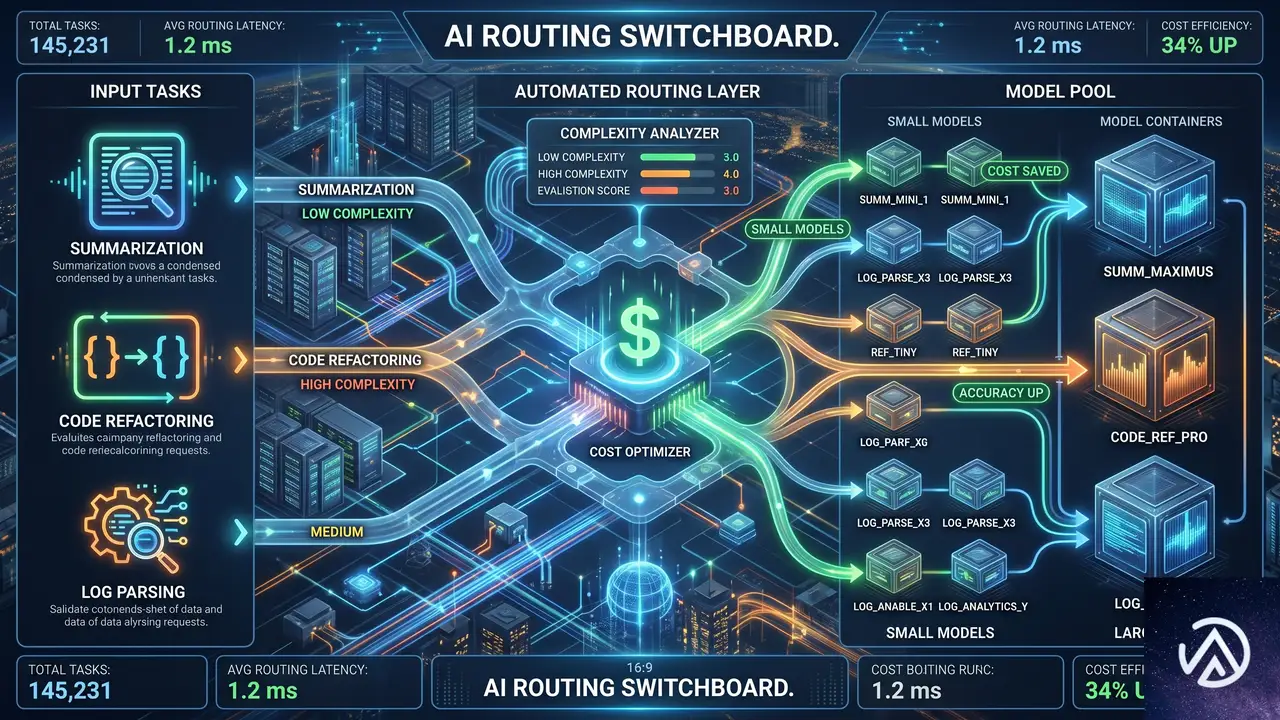
予算を設定し可視化することは、第一段階に過ぎない。次の課題は、限られた予算で最大の成果をどう引き出すかだ。現実には、すべてのリクエストに最先端モデルは不要である。要約タスクはより小さな安価なモデルでも品質を損なわずに実行できる。一方、大規模なコードリファクタリングには最新鋭のモデルが必要だ。しかし、制御がなければ人は常に最も高機能なモデルへ流れてしまう。
この問題に対し、Cloudflareはタスクベースのインテリジェントルーティングを鋭意開発中であると明かした。リクエストを分析し、最もコスト効率の良い結果を導くモデルへ自動的にルーティングする機能だ。詳細はデベロッパードキュメントとチェンジログで追って発表される。
この記事のポイント
- Cloudflare AI Gatewayにドル建ての利用上限機能が全プラン向けに登場した
- 上限到達時はリクエストをブロックするか、より安価なフォールバックモデルに自動で切り替えられる
- 限定ベータのアイデンティティベース予算は、個人やチーム単位で正確なコスト管理を実現する
- これらの機能はCloudflareが自社の大規模AI運用で実証した手法を外部化したものである
- 今後はタスクの複雑さに応じて最適なモデルへ自動ルーティングする機能の開発が予定されている

・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Amazon Cognitoがマルチリージョンレプリケーションに対応、耐障害性向上とCMKサポートの詳細
AWSがAmazon Cognitoにマルチリージョンレプリケーション機能を追加した。ユーザーデータとM2M(Machine-to-Machine)シークレットを別のAWSリージョンに自動同期し、認証基盤の耐障害性を高める。あわせてカスタマーマネージドキー(CMK)による暗号化制御もサポートされた。
これまでマルチリージョンでの整合性維持には、エンジニアリングチームが手動で複製ソリューションを構築・運用する必要があった。今回のアップデートで、Cognitoが自動的にセカンダリリージョンへデータを複製し、リージョン障害時でも認証を継続できるようになる。
レプリケーションは一方向(プライマリ→セカンダリ)で動作し、プライマリリージョンの障害発生時にはセカンダリで認証処理を受け持つ。セッション継続性も担保され、既存ユーザーは資格情報の再設定なしでサインインを続けられる。
従来は手動レプリケーションに依存し、データ不整合やセキュリティリスクがつきまとっていた。新機能により、複製にかかる運用負荷を大幅に削減しつつ、認証の継続性を確保できる。
Cognitoマルチリージョンレプリケーションとは何か
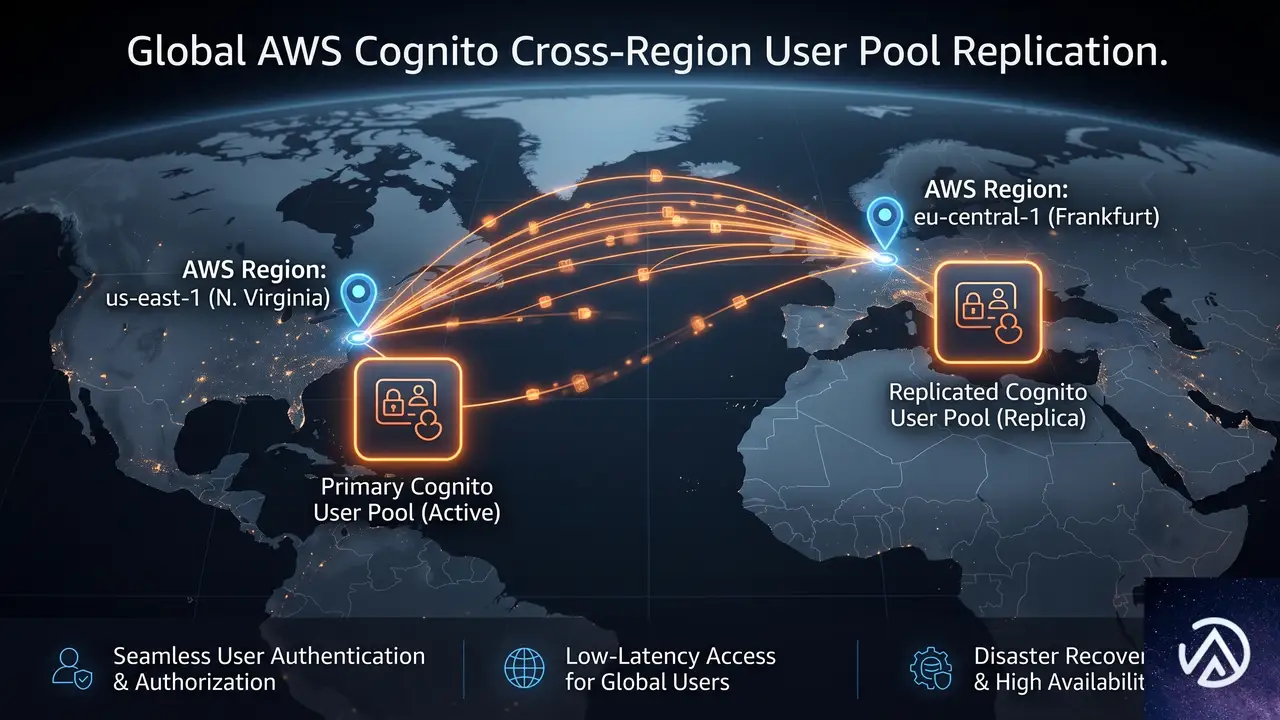
マルチリージョンレプリケーションは、Amazon CognitoがユーザーデータとM2Mシークレットの複製を自動管理する機能だ。プライマリリージョンからユーザーが選択したセカンダリリージョンへ、一方向でデータを同期する。
カバーされるデータの範囲と動作モード
複製の対象はユーザープロファイル、資格情報、ユーザープールの設定全体に及ぶ。セカンダリリージョンは読み取り専用モードで動作し、認証機能の維持に特化する。つまり、新規ユーザー登録やプロファイル更新といった書き込み操作はフェイルオーバー中には行えない。
この設計により、すべての認証方式(ソーシャルプロバイダ経由のフェデレーテッドサインイン、SAML、OIDC連携、API認可フロー)がサポートされる。対人認証だけでなく、バックエンドサービス間のM2M通信もレプリケーションの恩恵を受けられる点がポイントだ。
セッション継続性とトークンの相互認識
レプリケーション済みのユーザープールでは、プライマリ・セカンダリの双方が、どちらのリージョンで発行されたアクセストークンも有効とみなす。そのため、アクティブなセッションはリージョン切り替え前後を通じて中断されない。
この仕組みは、エンドユーザーにとって「裏側でリージョンが切り替わった」ことをまったく意識させずに済むという、実運用上の大きな利点になる。パスワードリセットの強制や再認証といった、ユーザー体験を損なう事態を回避できるわけだ。
CMKサポートで変わる暗号化の主導権

マルチリージョンレプリケーションの利用には、AWS KMS(Key Management Service)上のマルチリージョンカスタマーマネージドキー(CMK)が必須となる。CMKはユーザーデータの保存時暗号化に一貫性をもたらし、利用者側に暗号化戦略の主導権を与える。
CMKの利用は、レプリケーション機能とは独立して提供される。つまり、単一リージョンのユーザープールでもCMKによる暗号化制御は利用可能だ。医療や金融サービスなど、規制の厳しい業界ではとくに重要な選択肢となる。
3ステップで始めるレプリケーション設定
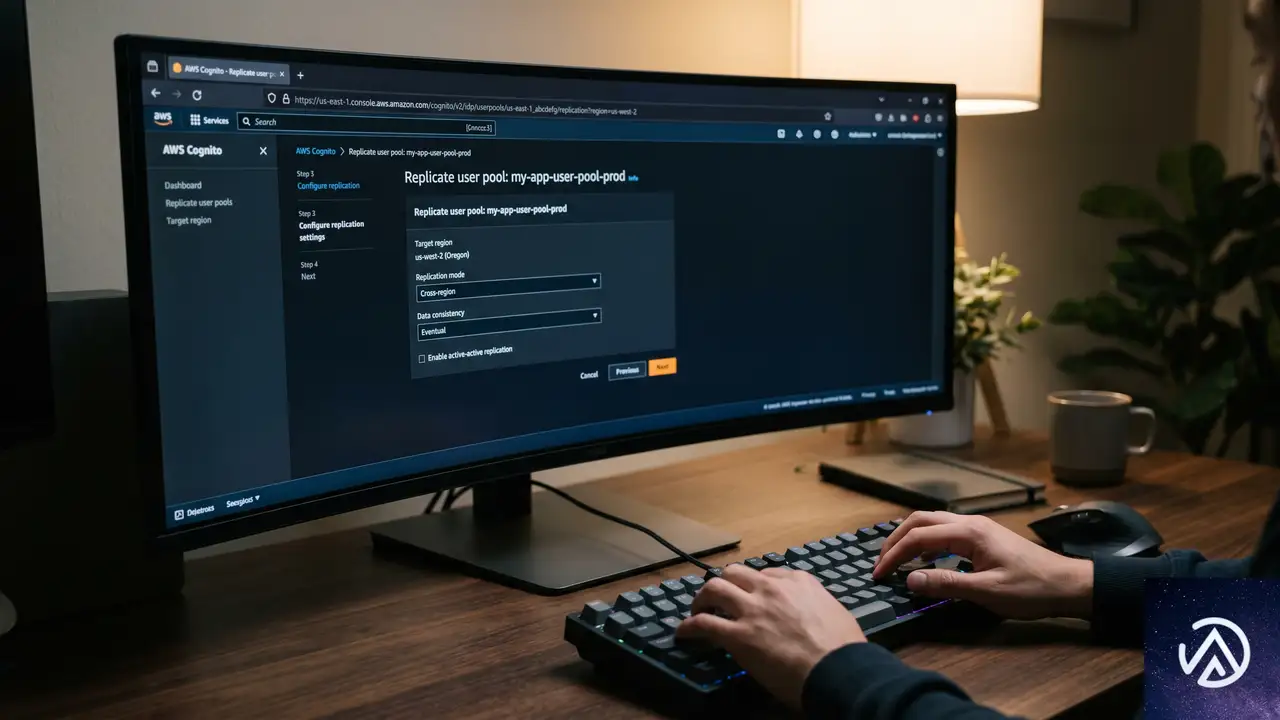
AWS News Blogの記事では、us-west-2(オレゴン)の既存ユーザープールをus-east-1(バージニア北部)に複製するデモが紹介されている。設定は管理コンソールから3つのステップで完了する。
STEP 2のOIDCエンドポイント更新は、クライアントアプリケーション側の必須対応となる。サーバーサイドアプリは再デプロイ、モバイルアプリはストアへの更新申請が必要だ。この変更を怠ると、旧エンドポイントへのリクエストが正しくルーティングされず、認証障害を引き起こす。
追加で必要な設定と注意点
レプリケーション設定の完了後も、いくつかの付随リソースは手動でセカンダリリージョンに展開する必要がある。具体的には、カスタム認証フローに使うLambda関数、SMSやメール通知の設定、ログストリーミング、AWS WAFの構成が該当する。
AWS News Blogの記事では、これらの追加設定を計画的に実施するようコンソール上でトラッキングできる点も紹介されている。フェイルオーバー前に抜け漏れを防ぐ仕掛けとして有効だ。
フェイルオーバー運用とヘルスチェックの設計
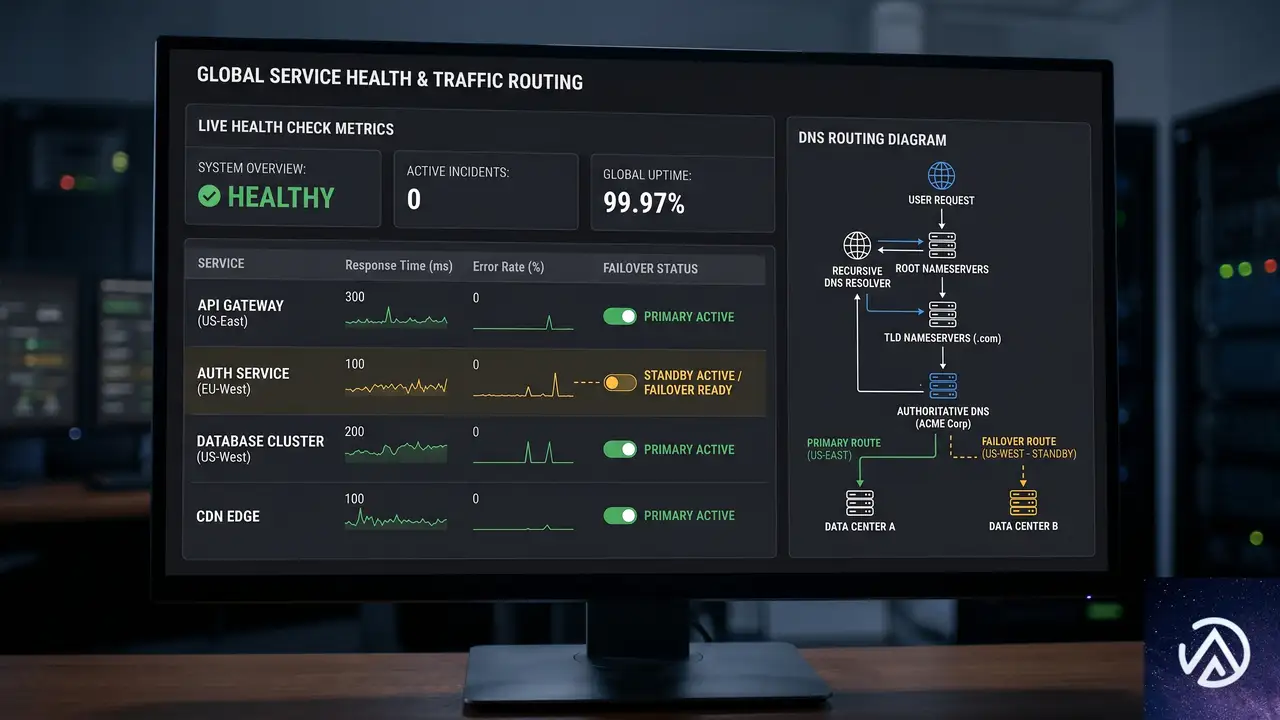
プライマリとセカンダリの両エンドポイントは常時アクティブで、いつでもトラフィックを受け入れ可能な状態にある。フェイルオーバーの判断と実行は、アプリケーションの要件に合わせて利用者側が設計する形だ。
ヘルスチェックでは、エラーレートやレイテンシのパターン、サービスアラートを監視し、事前定義した基準を満たした場合にDNSの切り替えでセカンダリへトラフィックを誘導する。オフピーク時間帯に少量のトラフィックをセカンダリに流し、認証が期待通り動作するか検証しておくことが推奨されている。
カスタムドメインでのマネージドログインやフェデレーションを利用している場合、Amazon Route 53のヘルスチェックIDをCognitoに提供することで、トラフィックルーティング機能を組み込むこともできる。これによりDNSレベルでの自動切り替えが容易になる。
料金体系と利用可能リージョン

マルチリージョンレプリケーションは、EssentialsティアおよびPlusティアのアドオン機能として提供される。料金は認証の種類によって異なる。
利用可能リージョンは、米国東部(オハイオ、バージニア北部)、米国西部(北カリフォルニア、オレゴン)、アジアパシフィック(ムンバイ、ソウル、シンガポール、シドニー、東京)、カナダ(中部)、欧州(フランクフルト、アイルランド、ロンドン、パリ、ストックホルム)、南米(サンパウロ)となっている。これらのリージョンはソース・デスティネーションのどちらとしても使用可能だ。
CMKサポートの提供リージョンはさらに広く、アフリカ(ケープタウン)、アジアパシフィック(香港、ハイデラバード、ジャカルタ、マレーシア、メルボルン、ニュージーランド、大阪など)や、イスラエル(テルアビブ)、メキシコ(中部)、AWS GovCloudもカバーされている。
この記事のポイント
- Amazon Cognitoにマルチリージョンレプリケーション機能が追加され、ユーザーデータとM2Mシークレットの自動同期が可能になった
- レプリケーションにはAWS KMSのマルチリージョンCMKが必須で、暗号化制御の主導権を利用者側に与える
- 設定は3ステップで完了するが、OIDCエンドポイント変更に伴うアプリ側の対応が必須となる
- フェイルオーバー時のセッション継続性が担保され、エンドユーザーはパスワード再設定なしで認証を継続できる
- 料金はアドオン形式で、ユーザー認証はMAUあたりの課金、M2M認証はトークンボリュームに対する30%追加となる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Azure Cobalt 200 VMが50%性能向上、エージェンティックAIに最適化
Cobalt 200 VMの概要とプレビュー提供開始
Microsoft Build 2026にあわせ、Azure Cobalt 200 Armベース仮想マシンの早期アクセスプレビューが発表された。Azure Blogの記事によれば、第2世代の自社設計Armプロセッサを搭載するこのVMは、前世代Cobalt 100と比べて最大50%のCPU性能向上を達成し、とくにエージェンティックAIやクラウドネイティブなスケールアウト型ワークロードでの利用を見据えている。
Cobalt 200はシリコンからサーバー、サービスまでを一貫してMicrosoftが設計し、セキュリティ、ネットワーク、ストレージ、オフロード処理の最新技術を統合した。これにより、AI推論、データパイプライン、Web API層といった多様な負荷で、パフォーマンスとコスト効率の両立を狙う。Azure Blogの記事では「エージェントは従来のワークロードとは異なり、推論や逐次的意思決定を連続的に大規模実行するため、根本的に異なる計算プロファイルが求められる」と指摘している。Cobalt 200はまさにその要件に応える設計だ。
Cobalt 100からの性能向上と新アーキテクチャ

Cobalt 100はすでに世界32のAzureリージョンで稼働し、DatabricksやSnowflakeといったクラウド分析の大手が導入している。Microsoft自身のサービスでも、以前の基盤と比べて最大45%の性能向上を達成しつつ、使用コア数を35%削減できた実績がある。Azure Blogの記事によると、Microsoft Defender for Endpointのサイバーデータキュレーターでは40%の性能改善が確認され、大規模な脅威対応の高速化に貢献した。
Cobalt 200 VMは、この知見を土台にさらに一段上の性能を提供する。SoC(System-on-Chip)には、Arm Neoverse V3 Compute Subsystems(Armの高性能Vシリーズコア)を採用し、TSMCの3nm(N3P)プロセスで製造される。チップレットアーキテクチャ、カスタムアクセラレータ、そして専用設計のメモリコントローラを備え、L2キャッシュはコアあたり3MB、システムレベルのL3キャッシュは192MBに拡張された。これにより、データベースやインメモリキャッシュ、分析エンジンなど、データ集約型サービスのレイテンシ低減と応答性向上が期待できる。
この図は主要なクラウドワークロードにおけるCobalt 100からCobalt 200への相対性能の向上を示している。CPU性能は50%、Webサービングは40%、そしてデータベース処理では最大135%の改善を達成している(Azure Blogの記事に基づく)。
ネットワーク帯域幅は15%向上し、NVMeリモートストレージのIOPSは20%、スループットは10%改善する。さらに最大128vCPUまでのスケールアップが可能になった。メモリ暗号化がデフォルトで有効化されている点も、セキュリティ要件の厳しいエンタープライズ環境にとっては大きな前進だ。
エージェンティックAIに最適化された設計
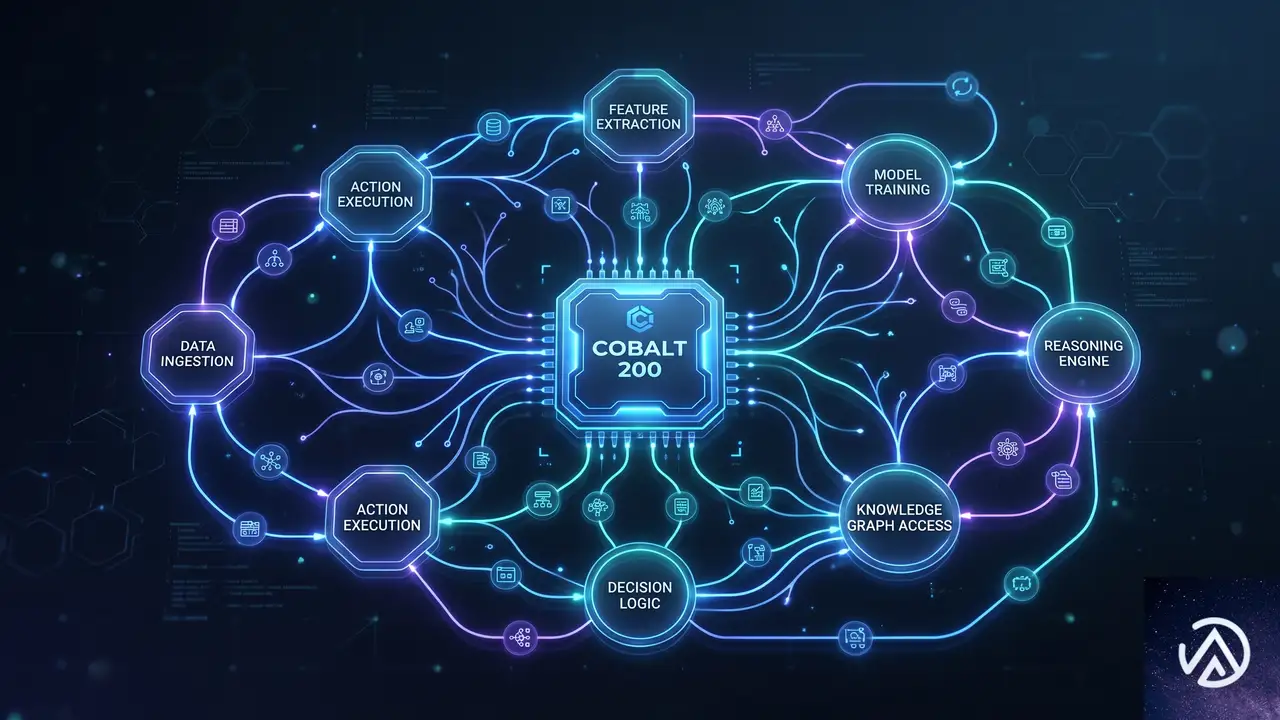
Azure Blogの説明では、Cobalt 200の各コアは完全な物理コアであり、3MBの専用L2キャッシュとコアあたりの高いメモリ帯域を備える。この設計により、負荷時のアイソレーション性能が高く、エージェントのサンドボックスをVMあたりにより多く詰め込める。エージェンティックAIでは、複数のAIエージェントが並行して推論やツール呼び出しを行うため、スループットとレイテンシの両面で安定した性能が求められる。Cobalt 200はその期待に応える基盤となる。
データ集約型のキャッシュワークロードでは最大80%の性能向上が報告されており、通信暗号化処理では45%、クラウドデータベースでは135%という数字がAzure Blogの記事に示されている。こうした値は、大規模な本番サービスで確認された実測値であり、単なる理論上のピーク性能にとどまらない。
パートナー企業とMicrosoft内部サービスでの導入

プレビュー期間中から複数のテクノロジーパートナーがCobalt 200 VMを評価し、すでに有望な結果を得ている。Azure Blogに掲載されたTeradataのEngineering FellowであるBrandon Mincey氏のコメントでは、早期テストが有望だったとし、両社の共同顧客のニーズに合わせた設計へのフィードバックを続けているという。Elasticのプロダクト管理ディレクターYuvraj Gupta氏も、検索AIプラットフォームの性能とコスト効率のさらなる改善に期待を示した。
ArmのCloud AIビジネスユニット担当VP Eddie Ramirez氏は、エージェンティックAIがクラウドを再構築していると述べ、Arm Neoverse CSS V3をベースにしたCobalt 200が、次世代のAI駆動型サービスを可能にするとコメントしている。CanonicalのPublic Cloud AllianceディレクターJehudi Castro-Sierra氏は、メモリ暗号化のデフォルト有効化や圧縮・暗号化のアクセラレーションといった進歩が本番Linuxワークロードにとって重要だとし、Ubuntu ProのLivepatchによるArm環境での再起動不要なカーネル更新にも言及した。
Microsoft自身のサービスでも導入が進む。Power Platformの中核を担うDataverseでは、Cobalt 100での良好な実績を踏まえ、Cobalt 200の検証でベースワークロードが最大60%高速化したとAzure Blogの記事は紹介している。Azure SQL Databaseにおいても、圧縮・暗号化アクセラレータを活用することで、重要なクエリ処理リソースを解放できると期待されている。
VMファミリーと仕様
Cobalt 200 VMでは、従来の汎用(Dp, Dpl)やメモリ最適化(Ep)に加え、新たに高メモリ最適化Mpsv4シリーズと高密度ローカルストレージのLpsv5シリーズが追加された。これにより、大規模インメモリデータベースやビッグデータ分析、検索エンジンといった多様なニーズに対応できる。以下が主なシリーズの概要だ。
リモートディスクはStandard SSD、Standard HDD、Premium SSD、Ultra Diskに対応し、Azureポータル、SDK、API、CLIなど既存の手法でデプロイできる。プレビューは米国西部3、東部2、中央、スウェーデン中部などから開始され、今後リージョンが拡大される予定だ。
開発者エコシステムとArm互換性

Cobalt 200 VMは、現行のCobalt 100ワークロードとの完全な互換性を維持する。C++、.NET、Java、Python、Rustといった主要言語のArmネイティブ版がすでに最適化されており、GitHub ActionsもセルフホストランナーやGitHub-hostedランナーを通じてArmをサポートする。Azure Kubernetes Service(AKS)ではArmエージェントノードとx86/Arm混在クラスタの両方に対応し、コンテナ化されたワークロードの移行も容易だ。
クラウドインフラにおけるArm採用の流れはとどまるところを知らない。Cobalt 200の登場は、単なる性能向上にとどまらず、エンタープライズ向けのセキュリティと管理性をArmエコシステム全体に持ち込む転換点になるだろう。Azure Blogの記事は「Cobalt 200はAzureのカスタムシリコン戦略の新章」と位置づけており、今後のさらなる展開が注目される。
この記事のポイント
- Cobalt 200 VMがMicrosoft Build 2026で早期アクセスプレビュー公開。Cobalt 100比で最大50%のCPU性能向上
- 128vCPUまでのスケールアップ、NVMeストレージのIOPS/スループット改善、デフォルトのメモリ暗号化を実装
- エージェンティックAIに求められる高い並列性と低レイテンシに最適化された専用設計
- Teradata、Elastic、Arm、Canonicalなど主要パートナーが早期評価で有望な結果を示し、Microsoftの内部サービスでも性能改善を確認
- 新たなVMファミリーでより多様なワークロードに対応し、Armエコシステムの成熟がさらに加速する見通し
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

VoidZeroがCloudflareに参画、ビルドツールViteはオープンソースを維持
Vite、Vitest、Rolldown、OxcといったJavaScriptエコシステムの中核ツールを開発するVoidZeroが、Cloudflareに参画した。全チームメンバーがCloudflareに合流する大規模な動きだ。
この発表で最も強調されているのは、これらのプロジェクトがこれからもオープンソースであり続けるという点だ。ViteはMITライセンスを維持し、ベンダーに依存せず、コミュニティ主導で開発が進められる。この原則が揺らぐことはないとCloudflareは明言する。
背景には、AI時代のソフトウェア開発の変化と、フルスタック化するモダンアプリケーションの複雑さがある。Viteがエコシステム全体の共有基盤となった今、この参画はツールチェーンの未来を左右する重要な転換点だ。
VoidZeroのCloudflare参画の内容

オープンソースとベンダー中立の堅持
Cloudflareは、Viteや周辺ツールの独立性を何よりも優先するとしている。具体的な約束は以下の通りだ。
- Vite、Vitest、Rolldown、Oxc、Vite+は今後もMITライセンスのオープンソースであり続ける
- 特定のクラウドベンダーに依存しない設計を維持する。Viteで構築したアプリケーションは、どこでも動作し続ける
- ロードマップはViteチームとコミュニティが引き続き主導し、公開の場で開発される
- Evan You氏をはじめとするVoidZeroチームが、プロジェクトのリーダーシップを継続する
- Cloudflareはこれらのプロジェクトにエンジニアリングリソースを投入するが、方向性を自社向けに曲げることはしない
Cloudflareのブログ記事では、このコミットメントを「言葉ではなく、日々の開発支援とプロジェクト運営で証明していく」と表現している。年初にAstroがCloudflareに参画した際と同様の、独立性を尊重するモデルだ。
100万ドルのViteエコシステム基金
この参画に伴い、CloudflareはViteエコシステム基金として100万ドルを拠出する。この基金はViteのコアチームによって管理され、メンテナーやコントリビューターへの支援に充てられる。
「ViteはVoidZeroやCloudflareよりも大きな存在だ」とCloudflareは述べており、エコシステムを支える無数の開発者を巻き込む意図が明確に示された。オープンソースの持続可能性を金銭面から支える、具体的な施策である。
この比較から分かるように、今回の参画はエコシステムの信頼を損なわないための設計が徹底されている。Viteが多くのフレームワークに採用されている共有基盤だからこそ、中立性の維持は絶対条件となる。
AIが変えたビルドツールの役割
エージェントがツールチェーンを回す時代
Cloudflareのブログ記事は、Viteの驚異的な普及の背景にAIの存在があると分析する。現在Viteの週間ダウンロード数は約1億2900万回、Cloudflare Viteプラグイン(@cloudflare/vite-plugin)は約1400万回に達している。これはVite本体のダウンロード数の10%を超える規模だ。
この急成長を牽引しているのが、AIコーディングエージェントだ。開発者だけが使っていた開発サーバーやリンター、フォーマッターを、今やAIエージェントが常時利用している。彼らはプロジェクトのスキャフォールディングから開発サーバーの起動、エラー解析、テスト実行までを自動で行う。
エージェントにとって重要なのは、高速なフィードバックループだ。ビルドが速く、テストが速く、エラーが明確で、CLIの挙動が一貫していること。VoidZeroのツールチェーン(Vitest、Rolldown、Oxc、Oxlint、Oxfmt)は、まさにこの要件に最適化されている。それぞれのカテゴリで最速クラスの性能を持ち、エージェントが何度も繰り返し実行してもストレスが少ない。
この図は、AIエージェントがコード生成からテスト、リント、修正までのサイクルを高速に回す様子を表している。各ツールの応答速度がエージェントの生産性に直結するため、VoidZeroのツールチェーンが選ばれる理由が明確になる。
フルスタック化するViteとVoidの知見

ビルドツールを超えた役割
モダンなアプリケーションは、単なる静的ファイルのバンドルでは完結しない。サーバーサイドレンダリング、API、バックグラウンドジョブ、キュー、データベース、オブジェクトストレージ、リアルタイム通信、認証、そしてAIエージェントの統合までが必要になる。
Viteはこれに対応するため、ビルドツールからフルスタックアプリケーションの基盤へと進化しつつある。Cloudflareはこの流れを加速させるために、Vite本体にプロバイダ非依存の抽象化レイヤーを追加していく方針だ。バックエンド、API、エージェント、デプロイメントのためのフックをVite側に用意し、各クラウドベンダーがそれを実装する形を目指している。
すでにVoidZeroが実験していた「Void」プラットフォームの知見が、この方向性を後押ししている。VoidはVite向けのデプロイメントプラットフォームとして設計され、モダンアプリのライフサイクル全体を一つのツールチェーンで統一する試みだった。Cloudflareは将来的にこのVoidプラットフォームをオープンソース化し、誰でも独自のプラットフォームをVite上に構築できるようにする計画も示している。
Workerd統合による開発体験の向上
CloudflareとViteの協業は2024年のVite Environment APIから始まっている。このAPIによって、Viteの開発サーバーはNode.js以外のランタイムでもサーバーコードを実行できるようになった。
Cloudflare Viteプラグインを使用すると、vite devの実行時にサーバーコードがWorkerd(Cloudflare Workersのオープンソースランタイム)上で動作する。Durable Objects、D1、KV、R2、Workers AI、エージェントなど、本番環境と同じランタイムモデルがローカルで再現される。開発環境が本番の劣化版だった時代は、このAPIによって終わりを迎えつつある。
この図が示すように、Environment APIの導入前後で開発体験は大きく変わった。ローカル環境と本番環境のランタイムが一致することで、デプロイ後の予期せぬエラーが激減する。
CloudflareがVite基盤に移行する意味

CLI統合とcfコマンドの未来
Cloudflareは自社ツールの方向性を「Viteに合わせる」と明確に宣言している。最近テクニカルプレビューが公開された新しい統合CLI「cf」は、Viteを基盤として設計される。
このCLIの目指す姿は、ViteのエルゴノミクスをそのままCloudflareプラットフォーム全体に拡張することだ。cf devはvite devのスーパーセットとして動作し、同じ速度、同じホットモジュールリプレースメント、同じプラグインモデルを持ちながら、必要に応じてCloudflareのランタイムとバインディングを利用できる。cf buildはViteプロジェクトをネイティブに理解し、cf deployはViteアプリのデプロイをシンプルにする。
すでにCloudflareのダッシュボード自体がVite上に構築されており、OxlintはCloudflareのコードベースで「数日分のエンジニアリング時間を節約している」と報告されている。Astroチームのエージェントハーネスフレームワーク「Flue」もVite基盤に移行中だ。Cloudflare自身がViteをドッグフーディングし、その価値を内部で証明している。
短期的な影響と長期的な展望
短期的には、Viteユーザーにとって何も変わらない。Vite、Vitest、Rolldown、Oxc、Vite+は引き続きリリースされ、VoidZeroチームがこれらを主導する。Cloudflare Viteプラグインも改善が続き、Environment APIもCloudflare以外のランタイムを含めて進化していく。
長期的には、CloudflareのCLIがVite上に完全に統合される。Viteにはフルスタックアプリとエージェントのためのプロバイダ非依存のプリミティブが追加され、あらゆるプラットフォームで利用可能になる。そしてVoidプラットフォームがオープンソース化され、誰でもViteとCloudflareの上に独自のプラットフォームを構築できるようになる。
この計画が実現すれば、ViteはJavaScriptエコシステムの単なるビルドツールから、アプリケーション開発全体を支える普遍的な基盤へと進化する。Cloudflareのインフラは、その基盤の上で最も統合された選択肢の一つとして位置づけられることになる。
この記事のポイント
- VoidZeroの全メンバーがCloudflareに参画。ViteやVitestなどのツールはMITライセンスのままでベンダー中立を維持する
- CloudflareはViteエコシステム基金として100万ドルを拠出し、コミュニティ主導の開発を資金面から支援する
- Viteの週間ダウンロード数1億2900万回の背景には、AIエージェントによる高速フィードバックループ需要がある
- Environment APIにより、ローカル開発環境でも本番と同じWorkerdランタイムが使用可能になった
- Cloudflareの新CLI「cf」はViteを基盤に統合され、全プラットフォームで一貫した開発体験を提供する計画だ
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Google Cloud、AlloyDB向けリモートMCPサーバーがGA。AIエージェントとDBの安全な統合を実現
Google CloudがAlloyDB向けのリモートMCP(Model Context Protocol)サーバーの一般提供を発表した。これまでローカル開発が中心だったMCPだが、本番環境での運用に耐えるフルマネージドな仕組みとして登場した。AIエージェントが企業のオペレーショナルデータベースに直接アクセスし、安全にクエリを実行できるようになる。
この記事では、リモートMCPサーバーが解決する技術的課題と、AlloyDBを基盤にしたエージェントアプリケーションの構築方法を解説する。データの鮮度、セキュリティ、運用負荷のバランスを取るアーキテクチャを具体的に示す。
リモートMCPとは何か(ローカルMCPとの違い)

MCP(Model Context Protocol)とは、大規模言語モデル(LLM)が外部のデータソースやツールと安全に通信するためのオープン標準プロトコルだ。Anthropicが提唱し、現在では多くのAIエージェントフレームワークで採用されている。従来は開発者のローカルマシン上で動作する「ローカルMCPサーバー」が主流だった。
ローカルMCPサーバーは標準入出力(stdio)を使ってプロセス間通信を行う。これは開発段階では手軽だが、本番環境に持ち込むと途端に問題が顕在化する。複数のエージェントインスタンスが同時にデータベースへアクセスする場合、プロセス管理が複雑化し、ネットワーク越しのセキュリティ確保も難しくなる。
リモートMCPサーバーは、これらの課題をHTTPエンドポイント経由で解決する。Google Cloudのマネージドインフラ上で動作し、OAuth 2.0ベアラートークンによる認証とIAM(Identity and Access Management)によるきめ細かな権限制御を提供する。エージェント開発者はインフラ管理から解放され、クエリ実行に集中できる。
なぜAlloyDBと組み合わせるのか
AlloyDBはGoogle CloudのフルマネージドPostgreSQL互換データベースだ。標準PostgreSQLと比較して、ベクトル検索では最大6倍高速、フィルタ付きクエリでは最大10倍高速というパフォーマンスを備える。ScaNNインデックスを使えば100億ベクトル規模まで拡張でき、AIエージェントのRAG(検索拡張生成)ワークロードに最適化されている。
さらにAlloyDBには、データベース内で直接埋め込みベクトルを生成するAI Functionsや、Gemini Enterprise Platformモデルを使った検索結果のリランキング機能が組み込まれている。エージェントがデータベースにクエリを投げるだけで、最新のオペレーショナルデータに基づいた回答を得られる。データの鮮度を保つためのETLパイプラインが不要になるケースも多い。
リモートMCPサーバーが解決する5つの本番課題

Google Cloudブログの発表によると、リモートMCPサーバーは単なる通信方式の変更にとどまらない。本番環境でAIエージェントを運用するチームが直面する、以下の5つの課題を包括的に解決する設計になっている。
特に注目すべきはIAMによる権限制御だ。従来のデータベース接続では、共有パスワードやAPIキーを使うことが多かった。しかしリモートMCPでは、エージェントごとに特定のテーブルやビューへのアクセス権をIAMで付与できる。読み取り専用のSQL実行ツールを選択すれば、エージェントが誤ってデータを削除するリスクを根本から排除できる。
Model Armorによるプロンプトセキュリティ
リモートMCPサーバーは、Google CloudのModel Armorと統合されている。Model Armorはプロンプトとレスポンスの両方をスクリーニングし、プロンプトインジェクション攻撃や機密データの意図しない流出を防ぐ。エージェントのサービスアカウントが広範なデータベース権限を持っていても、Model Armorがデータの出し方をフィルタリングする仕組みだ。
たとえば、エージェントが顧客のクレジットカード番号を含むカラムにアクセスできる権限を持っていたとしても、Model Armorがレスポンスからその情報を除去できる。これは「権限はあるが出力は制限する」という新しいセキュリティモデルであり、ゼロトラストの考え方をAIエージェントに適用した形だ。
エージェントから見たAlloyDBの強み

リモートMCPサーバーは接続の仕組みを提供するが、その先にあるデータベース自体の性能も重要だ。AlloyDBはエージェントアプリケーションに特化したいくつかの特徴を持つ。
まず、ベクトル検索性能だ。ScaNNインデックスを使うと、標準PostgreSQLの最大6倍の速度でベクトルクエリを実行できる。100億ベクトルまでスケールするため、大規模なRAGアプリケーションでもパフォーマンスが劣化しない。フィルタ条件付きのベクトル検索では最大10倍高速化される。これは「直近30日以内のドキュメントから類似検索」のような実用的なクエリで差が出る。
次に、ハイブリッド検索とリランキングだ。RUM(RUMインデックス / Row Usage Matrix)を使った全文検索とベクトル検索の組み合わせや、Reciprocal Rank Fusionによる結果の融合が可能だ。さらにGemini Enterprise Platformモデルを使ったインテリジェントなリランキングにより、エージェントは最も関連性の高い情報を優先的に取得できる。
また、AlloyDBのAI Functionsはデータベース内部で埋め込みを生成する。外部の埋め込みAPIを呼び出す必要がなく、数百万件の埋め込みを効率的に生成できる。Lakehouse Federationを使えば、BigQueryの分析データやIcebergテーブルのアーカイブデータにも、同じPostgreSQLインターフェースから透過的にアクセスできる。
AIエージェントにとって重要なのは「データの鮮度」と「アクセスの容易さ」だ。AlloyDBのリアルタイム埋め込み生成とLakehouse Federationの組み合わせにより、エージェントは最新のオペレーショナルデータと過去の分析データを区別なく扱える。配送車両の位置情報のような刻々と変化するデータでも、クエリを発行した瞬間の状態を取得できる。
実際の導入手順とデモの流れ
Google Cloudは今回のGA発表にあわせて、Codelab(ハンズオン形式のチュートリアル)を公開した。導入手順は以下の4ステップに整理されている。
接続が確立すると、エージェントは自動的にデータベースのスキーマを把握する。テーブル名やカラム名をイントロスペクションクエリで取得し、ユーザーの質問に応じて適切なJOINや集計クエリを組み立てられる。たとえば「過去24時間で最も遅延が発生している配送ルートは?」という質問に対して、エージェントが配送テーブルと車両テーブルをJOINし、リアルタイムの位置情報と組み合わせて回答する。
AIエージェントが実行できる操作の範囲
リモートMCPサーバー経由でエージェントが実行できる操作は、単なるSELECTクエリにとどまらない。AlloyDBのツールセットを使うと、以下のような運用操作も可能になる。
- データのエクスポートとインポート
- バックアップの作成とリストア
- クラスタの設定更新
- AI Functionsを使ったテキストのランキング(AI.RANK())
もちろん、これらの操作はIAM権限の範囲内でのみ実行される。読み取り専用のSQLツールを選択していれば、データ定義や変更を伴う操作はブロックされる。本番環境での安全な運用を第一に設計されている点が重要だ。
導入時に検討すべきポイント
リモートMCPサーバーのGAは、AIエージェントとデータベースの統合を大きく前進させる。しかし導入にあたっては、いくつかの点を事前に検討する必要がある。
まず、コスト構造の把握だ。AlloyDB自体がエンタープライズ向けのプレミアムデータベースであり、さらにMCPサーバーの利用にもGoogle Cloudの料金が発生する。30日間の無料トライアルが提供されているので、まずは小規模なクラスタで検証し、ワークロードに応じたコストを見積もることを推奨する。
次に、IAMポリシーの設計だ。エージェントに必要最小限の権限を付与する「最小権限の原則」を徹底する必要がある。テーブル単位、カラム単位でのアクセス制御が可能だが、データベースの規模が大きくなるとポリシー管理が複雑化する。事前にアクセス制御のルールを整理しておくことが重要だ。
最後に、プロンプト設計の重要性も変わらない。MCPサーバーがデータへのアクセスを提供しても、エージェントが適切なクエリを生成できるかどうかはプロンプトの質に依存する。スキーマの説明やクエリの方針をプロンプトに含めることで、より正確な結果を得られる。
この記事のポイント
- AlloyDB向けリモートMCPサーバーがGAとなり、HTTPエンドポイント経由でAIエージェントが安全にデータベースへアクセス可能になった
- IAMによるテーブル単位の権限制御と、Model Armorによるプロンプトセキュリティで本番運用に耐える設計
- AlloyDBのベクトル検索性能とAI Functionsの組み合わせにより、RAGアプリケーションの構築が効率化される
- 30日間の無料トライアルとCodelabが提供されており、小規模な検証から始められる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Google SREが語る、エージェントAIで変わる運用の新常識
GoogleがSRE(Site Reliability Engineering)にエージェントAIを本格導入し、運用の自動化レベルを引き上げている。異常検知やインシデント管理、信頼性設計といった領域で、AIエージェントが「力の倍増器」として機能し始めたのだ。
この取り組みは、2026年5月に公開されたホワイトペーパー「AI in SRE Practice」で詳細に語られている。本記事ではその核心にある5つの重点領域と、Googleが定めた7つの設計原則を整理しながら、エージェントAIがSREにもたらす変化を読み解く。
なぜ今、SREにエージェントAIなのか

GoogleがSREの概念を提唱してから20年以上が経つ。その間、信頼性を担保すべきシステムは幾重にも複雑化した。マイクロサービス化による分散配置の拡大、クラウド製品群の機能爆発、そしてAIコード生成によるソースコード量の急増。それぞれが単独でも運用負荷を押し上げる要因だが、これらが同時に進行している点が問題を大きくしている。
SREチームは従来、サービスレベル指標(SLI)やサービスレベル目標(SLO)に基づく静的な閾値監視で信頼性を守ってきた。しかし、多様な顧客ワークロードを扱うGoogle Cloudのような製品では、一律の閾値で異常を捉えきれないケースが増えている。そこで注目されるのが、AIによる異常検知とエージェント型の自律対応だ。
エラーレート > 1% でアラート
このデモが示すように、AIエージェントは単に閾値を超えたかどうかではなく、平常時の振る舞いパターンからの逸脱を捉える。これにより、多様なワークロードが混在する環境でも、真に対処すべき異常だけを抽出できる確度が高まる。
SRE AIがカバーする5つの重点領域

Google SREチームは、ソフトウェア開発ライフサイクル(SDLC)全体を見渡し、AIエージェントが価値を発揮できる領域を5つに整理した。いずれも従来のSREプラクティスを補完し、人間の意思決定を加速させることを狙いとしている。
信頼性設計への組み込み
従来、SREは設計段階から信頼性を織り込むため、ポリシー策定やランブック(運用手順書)の整備に多くの時間を割いてきた。AIエージェントはこのプロセスを効率化する。具体的には、過去のインシデントから得た知見を基にランブックを自動生成し、本番環境に近い構成に対して信頼性リスクを事前検出する。人間のレビューは高リスクな変更に絞られ、トイル(労苦)の大幅な削減が見込めるという。
異常検知とアラート処理
この領域はエージェントAIの導入効果が最も顕著に表れる部分だ。Google SREは、TimesFMのような時系列予測モデルを使い、過去の正常パターンから逸脱する動きをAIが検知する仕組みを採用している。異常が検知されると、専用のアラート処理エージェントが起動し、関連情報の集約やコンテキスト付与を自動実行する。その後、自律型のアラートハンドラが可能な範囲で一次対応まで完遂する。
このパイプラインにより、人間のSREが対応すべきアラート件数そのものを減らせる。大事なのは、エージェントがどのデータをどう評価したのか、一貫して透明性を保つ設計になっている点だ。本番状態に意図しない変更を加えないための制御機構も当然組み込まれている。
インシデント管理の高度化
GoogleにはIMAG(Incident Management at Google)という確立されたインシデント管理プロセスがある。SRE AIはその上にエージェント型のオーケストレーション層を追加する形で実装されている。
- チャットや動画、追跡ドキュメントなどインシデント中に発生するコミュニケーションを集約・要約
- 担当者交代時のハンドオフドキュメントを自動生成
- ポストモーテム(障害分析書)のドラフトを自動作成し、品質向上と工数削減に貢献
- 社内外向けのインシデント報告の管理
これらは一見地味だが、大規模インシデントでは情報の混乱が復旧遅延の最大要因になる。エージェントが情報整理を肩代わりすることで、SREは本質的な判断と対応に集中できる。
インシデント調査の自律化
AIエージェントは監視データ(ログ、メトリクス、トレース)に加え、システムトポロジや依存関係情報を使い、ドメイン知識を獲得した上で調査を開始する。ランブックのナビゲーション、アラート参照、異常検知、インサイト抽出といった個別の機能エージェントと連携しながら、仮説形成から緩和策の提案までを行う。状況によっては自律的な緩和実行も視野に入れている。
インサイトとリスク管理
AIエージェントが継続的に学習し続けるための仕組みとして、Google SREは「AI Insights」というシステムを開発した。これは過去の全インシデントを分析し、構造化された知見を抽出する。Geminiの埋め込みモデルとベクターデータベースを活用し、各インシデントにリスクカテゴリを自動付与する。これにより、エージェントは将来の調査時により精度の高い緩和策を提案でき、人間のSREも優先的に対処すべき領域を俯瞰できる。
このように複数のエージェントが役割分担しながら、一つのインシデントに対して協調的に動作する。単一の巨大なAIではなく、目的別に分割されたエージェント群が連携する設計思想がGoogle SREの特徴だ。
エージェント導入に先立つ7つの設計原則

Google SREはエージェントAIを闇雲に導入したわけではない。顧客への約束を守りながら信頼性を向上させるため、以下の7つの高レベル原則を定めている。
- 既存の自動化が機能している領域は、ビジネス要件を満たしている限り無理に置き換えない。
- 新しいAIシステムは、既存および将来のポリシーと手順に準拠すること。
- SRE AIエージェントは、人間と同等のセキュリティ・安全性・プライバシー要件を満たすこと。
- エージェントは強力なアイデンティティを持ち、ロールベースで権限が割り当てられること。
- エージェント自体に高い信頼性SLOを設定し、自動または手動のバックアップ手段を明確に用意すること。
- エージェントは実行したアクションの理由と、検討し却下した選択肢を説明できなければならない。ブラックボックス自動化より透明性を重視する。
- 事業継続計画にAI障害時のコンティンジェンシーを含めること。
とりわけ6番目の「説明可能性」は、SREという領域において極めて重要だ。なぜそのインシデントが発生し、なぜその緩和策を選んだのか。説明できない自動化は、ポストモーテム文化と相性が悪い。GoogleがエージェントAIに対して透明性を強く要求しているのは、SREの根本思想である「非難しない文化」と「学習する組織」をAI時代にも維持するためといえる。
この対比は、単なる技術選定の話ではない。SREの運用文化そのものをどう進化させるかという問いに直結している。
SRE AIを支えるGoogleの基盤技術

これらのエージェント群は、個別の新規プロジェクトとして開発されたものではない。Googleが長年培ってきたインフラストラクチャの上に構築されている。主要な構成要素は次のとおりだ。
- Gemini — 基盤モデル。SREチームは社内データでファインチューニングしたカスタムGeminiモデルも併用。
- Gemini Enterprise Agent Platform(旧Vertex AI) — エージェント開発のためのフルAIスタック。
- Agent Development Kit(ADK) — エージェント構築の開発プラットフォーム。
- MCPサーバー — 標準のGoogle APIインフラ上で動作し、外部顧客向けMCPサポートにも使われるものと同一基盤。
- BigQuery / ベクターデータベース — AI Insightsシステムのデータ基盤。Gemini埋め込みモデルと連携。
- 標準Observabilityインフラ — 監視、ログ、トレーシング。
特筆すべきは、これらの技術がすでにGoogle Cloudの顧客向けにも提供されている点だ。ホワイトペーパーで語られているSRE AIのアーキテクチャは、決してGoogle内部だけの秘伝のたれではなく、クラウド利用者にとっても参照可能な設計パターンとして公開されている。
SRE AIが目指す先

Google SREチームは、SRE AIが達成すべき目標として、次の5つを掲げている。
- 退屈で反復的な運用からエンジニアを解放する
- 意思決定と実行の質と速度を向上させる
- これまで対処できなかった問題の予防・検知・緩和を可能にする
- 信頼性向上に向けた自律的なフィードバックループを形成する
- 全体的な運用コストを削減する
これらは一見するとAI導入の一般的な利点に見える。しかしGoogle SREが強調するのは、単なる効率化ではない。AIが複雑さを増幅させた側面があるからこそ、同じAIを使って複雑さを制御するという考え方だ。SRE AIの本質は「AIがもたらした運用課題を、AI自身の力で解決する」逆説的なアプローチにある。
Googleは以前から自律システムを本番運用してきた実績を持つ。しかし現在のAIベースの自律システムは、非決定的な振る舞いをする点で従来と大きく異なる。この性質を正しく理解し制御するために、自律レベルのトラッキング手法も開発されている。詳細はホワイトペーパー「AI in SRE Practice: Moving Beyond Automation at Google」に譲るが、決定論的自動化からエージェントAIへの移行は、SREという分野にとって20年来の転換点になる可能性を秘めている。
この記事のポイント
- Google SREはAIエージェントを「力の倍増器」と位置づけ、運用の自動化レベルを次の段階へ引き上げている
- 静的な閾値監視からAIによる異常検知への移行は、多様なワークロードに対応するための不可避な進化である
- 7つの設計原則のなかでも「説明可能性」の重視は、SRE文化との整合性を保つ上でとりわけ重要だ
- SRE AIの構成要素はGoogle Cloudの顧客向け技術スタックと地続きであり、外部組織も同様のアーキテクチャを参照できる
- 決定論的自動化からエージェントAIへの移行は、SREの根本的な運用思想を再定義する可能性がある
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AWS BedrockでOpenAI GPT-5.5とCodexが利用可能に。開発効率が飛躍
AWSが2026年6月、Amazon Bedrock上でOpenAI GPT-5.5モデル、GPT-5.4モデル、そしてコーディングエージェントCodexの一般提供を開始した。これにより、Bedrockのセキュアなインフラ上で最先端の大規模言語モデルを利用できる。
GPT-5.5は最も難しいタスク向け、GPT-5.4はコストパフォーマンス重視のシナリオに適する。いずれも、新しい推論エンジン上で高速かつ信頼性の高い応答が得られる。Codexは週あたり400万人以上の開発者が使用するAIコーディングツールで、複数のIDEと連携しつつ、推論エンジン経由でBedrockからモデルを呼び出す。
データ主権要件に対応するため、すべての処理は選択したBedrockリージョン内に留まる。トークン単位の課金で、シートライセンスや開発者あたりの固定費は発生しない。本記事では利用開始手順と技術的な注意点を解説する。
AWS BedrockでOpenAI GPT-5.5とCodexが一般提供
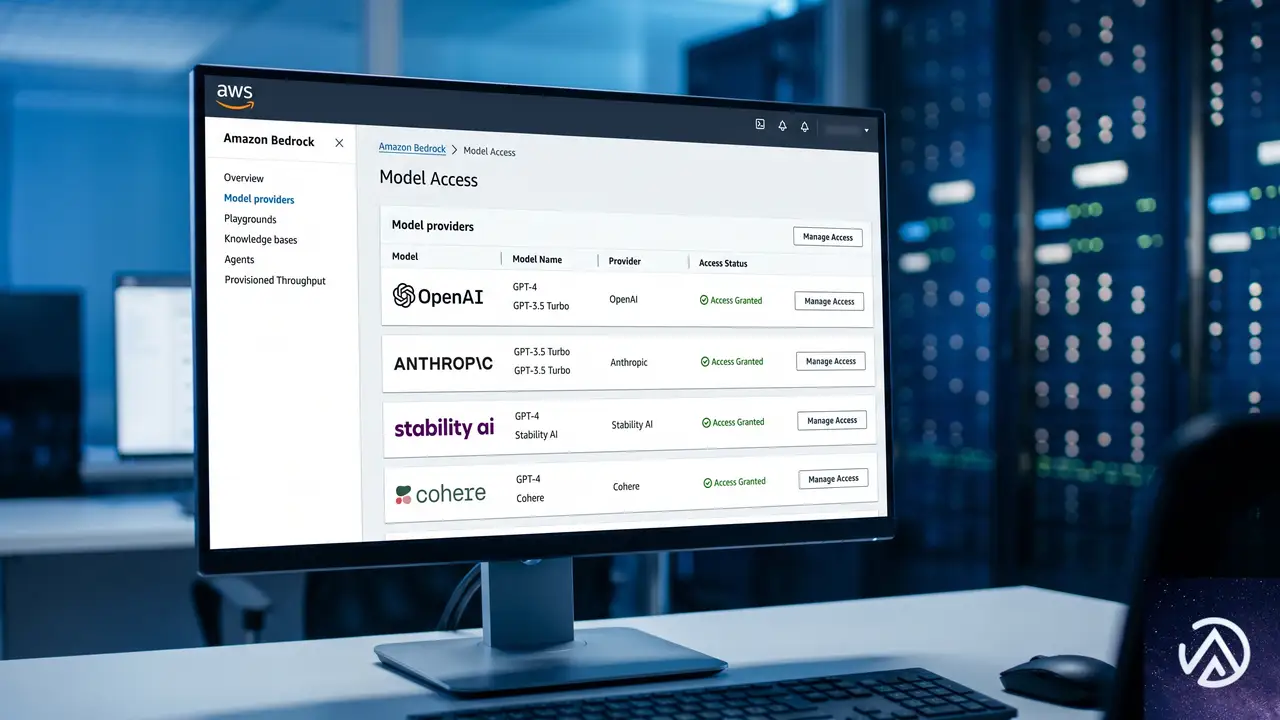
AWSの年次カンファレンスでプレビューされていたOpenAIモデルの対応が、正式に利用可能になった。GPT-5.5とGPT-5.4は、コーディング、推論、エージェントワークフロー、複雑な専門業務に優れる。AWS News BlogのChanny Yun氏は、GPT-5.5を「最も難しい顧客のワークロード」向け、GPT-5.4を「最良の価格性能比」と位置づける。
モデルへのアクセスは、新しいBedrock推論エンジンが提供するResponses APIを介して行う。このAPIは、マルチターン状態管理、ホストツール、ファンクションツール、バックグラウンド実行をサポートする。
この構成により、機密データを外部に送信することなく、AWSの管理下で最先端AIを活用できる。リージョンごとのデータ主権も担保される。
GPT-5.5モデルの利用方法

モデルへは、OpenAIのResponses APIを用いてアクセスする。Bedrock専用のエンドポイントbedrock-mantleを経由し、OpenAI SDKやcurlから呼び出す形だ。以下にセットアップ手順を示す。
Python SDKを使った呼び出し
まずOpenAI SDKを最新版にアップデートする。
pip install -U openai認証用の環境変数を設定する。BedrockのAPIキーはAWSマネジメントコンソールから取得できる。
export OPENAI_BASE_URL="https://bedrock-mantle.us-east-2.api.aws/openai/v1"
export OPENAI_API_KEY="<BEDROCK_API_KEY>"
export BEDROCK_OPENAI_MODEL_ID="openai.gpt-5.5"以下のサンプルコードで、GPT-5.5に分散アーキテクチャの設計を依頼できる。
import os
from openai import OpenAI
client = OpenAI(
base_url=os.environ["OPENAI_BASE_URL"],
api_key=os.environ["OPENAI_API_KEY"],
)
response = client.responses.create(
model=os.environ["BEDROCK_OPENAI_MODEL_ID"],
input=[
{
"role": "developer",
"content": "You are a software engineer with excellent AWS cloud knowledge. Be concise and practical.",
},
{
"role": "user",
"content": "Design a distributed architecture on AWS in Python that should support 100k requests per second across multiple geographic regions.",
},
],
reasoning={"effort": "medium"},
text={"verbosity": "low"},
)
print(response.output_text)curlによる直接アクセス
curlを使う場合も同様に環境変数を設定した上で、エンドポイントへPOSTリクエストを送る。
curl "$OPENAI_BASE_URL/responses" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "openai.gpt-5.5",
"input": [
{
"role": "developer",
"content": "You are a software engineer with excellent AWS cloud knowledge."
},
{
"role": "user",
"content": "Design a distributed architecture on AWS in Python that should support 100k requests per second across multiple geographic regions."
}
],
"reasoning": {"effort": "medium"},
"text": {"verbosity": "low"}
}'コード内のreasoning.effortは推論の深さを制御する。GPT-5.5ではmediumから始め、必要に応じてhighに変更すると良い。GPT-5.4の場合は明示的にeffortを指定すべきだ(デフォルトがnoneのため)。
CodexでAI駆動開発を体験する
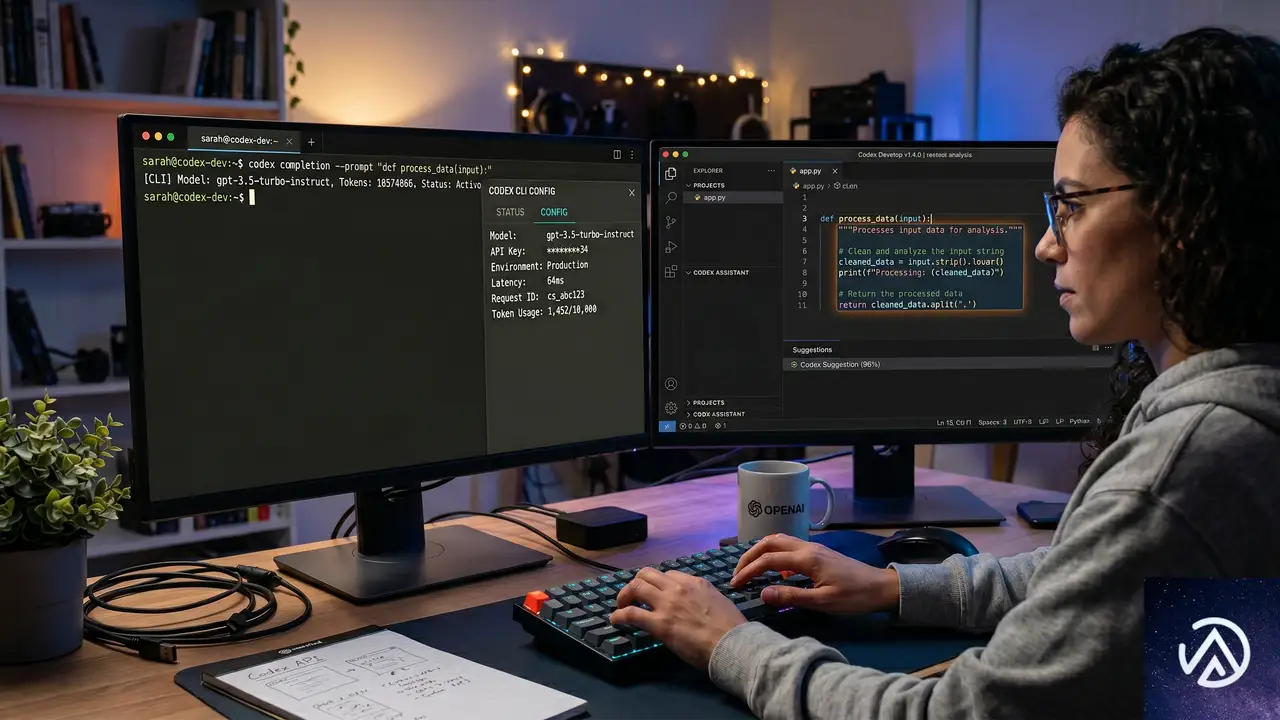
Codexは、GPT-5.5を推論エンジンとしてバックグラウンドで利用するコーディングエージェントだ。CLI、デスクトップアプリ、VS CodeやJetBrains、Xcodeの拡張機能が提供され、大規模コードベースの作成、リファクタリング、デバッグ、テスト、検証をAIが支援する。
Codex CLIの設定手順
Codex CLIをインストール後、Bedrock認証を有効にする。APIキー認証とAWS SDKの認証情報チェーンの2方式があり、APIキーが優先される。
export AWS_BEARER_TOKEN_BEDROCK=<your-bedrock-api-key>次に、~/.codex/config.tomlにモデル情報とリージョンを記述する。
model = "openai.gpt-5.5"
model_provider = "amazon-bedrock"
[model_providers.amazon-bedrock.aws]
region = "us-east-2"デスクトップアプリやVS Code拡張では、必要な環境変数を~/.codex/.envに記述しておく。設定変更後はアプリケーションを再起動すれば反映される。
CLIで/statusタブを表示すると、モデルがBedrock経由で接続されていることを確認できる。Channy Yun氏の記事では、実際のステータス画面が示されており、モデルとしてopenai.gpt-5.5と表示される。
レイテンシやスケーリングの注意点

本番利用を始めるにあたり、いくつかの技術的なポイントを把握しておく必要がある。
モデルレイテンシの特性
GPT-5.5は高速、GPT-5.4は中速と位置づけられるが、実際の遅延は推論の深さ、出力長、ツール呼び出しの有無、バックグラウンドモード、リージョン、クォータ、スロットリング、プロンプトサイズ、キャッシュヒットに依存する。GPT-5.5ではreasoning.effortをmediumで開始し、GPT-5.4では明示的にeffortを設定することを推奨する(デフォルトがnoneで十分な推論が得られない可能性があるため)。
スケーリングとキャパシティ管理
Bedrockの新しい推論エンジンは、多数のモデルにわたって迅速にキャパシティをプロビジョニングし、需要変動に応じてスケールする設計だ。定常的なワークロードの実行を優先し、需要急増時にはリクエストをキューイングする(拒否はしない)。そのため、予期せぬトラフィック増加時にも安定した動作が期待できる。ただし、クォータ上限を事前に確認し、必要に応じて引き上げ申請を行うことが望ましい。
この記事のポイント
- Amazon Bedrock上でOpenAI GPT-5.5・GPT-5.4モデルとCodexが一般提供開始
- Responses APIを通じてモデルを呼び出し、複雑なワークロードに対応
- CodexはGPT-5.5をバックエンドに、CLI・デスクトップアプリ・IDE拡張で利用可能
- データは選択したBedrockリージョン内で処理され、データ主権を確保
- レイテンシは複数要因に依存し、effort設定やキャッシュが影響するため、初期はmediumから
- スケーリングは自動だが、クォータ管理を怠らないこと
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

イランのインターネットが部分的に復旧。Cloudflare Radarが87日ぶりの通信量増加を観測
2026年5月26日、イランで約3か月にわたって継続していた全国的なインターネット遮断が、部分的に解除された。Cloudflare Radarの観測データは、通信量とDNSクエリの急激な増加を記録しており、市民のオンラインアクセスが再開されつつあることを示している。
今回の復旧は、2月28日に始まった2度目の大規模遮断から87日目にあたる。遮断開始以来、ほぼゼロにまで落ち込んでいたイラン発の通信量が、突如として前週比の約15倍に跳ね上がった。もっとも、この回復は完全ではなく、ピーク時のトラフィックは今年の最大値と比較して40%にとどまっている。
Cloudflareのネットワークを流れるデータの詳細を読み解くことで、長期化した遮断の実態と、今回の部分復旧の意味するところが浮かび上がる。本記事では、一連のデータポイントを分析し、イランのインターネット接続状況が現在どのようなフェーズにあるのかを解説する。
2026年にイランで発生した2度の大規模インターネット遮断

イランでは今年に入り、すでに2度の全国的なインターネット遮断が発生している。最初の遮断は1月8日に始まり、数日間でほぼすべての通信量が消失した。短期間の部分回復を挟みつつ、本格的な復旧は1月27日までずれ込んでいる。
2度目となる今回の遮断は、情勢の緊迫化を背景に2月28日から開始された。現地時間の午前10時30分ごろ、イラン国内から国外へ向かうウェブ通信量とDNSトラフィックは、遮断前の1%未満にまで急落した。それ以降、わずかなデータ漏洩を除けば、実質的に国全体がグローバルネットワークから隔絶された状態が続いていた。
この約3か月間、イランの一般市民はオンラインバンキング、地図アプリ、メッセージツール、海外のニュースメディアなど、日常生活やビジネスに不可欠なデジタルサービスから切り離されてきた。
上図の比較からわかるように、遮断期間中の通信は事実上ストップしていた。5月26日以降のデータは、国全体のネットワークが一斉に「息を吹き返した」かのような変化を示している。
トラフィック急増の詳細なデータが示すもの
通信量は前週の約15倍に跳ね上がった
Cloudflareのネットワーク上を転送されたバイト数のデータを見ると、復旧の兆候は明瞭だ。協定世界時(UTC)の5月26日11時45分に最初のスパイクが記録され、12時00分からは持続的な増加へと転じた。この通信量の急増は、遮断期間中の前週の水準と比較して約15倍に達している。
転送バイト数の増加とは、単に「接続が戻った」というだけでなく、画像や動画、ファイルダウンロードといった実データが国境を越えて再び流れ始めたことを意味する。ウェブの閲覧だけでなく、アプリのアップデートやクラウドストレージへの同期など、より帯域を消費する活動が再開された可能性が高い。
トラフィックの推移は、人間の生活リズムと一致する日内変動にも従っている。UTCの21時ごろ(現地時間の深夜0時30分ごろ)に通信量が減少し、翌27日の3時(現地時間6時30分ごろ)から再び増加に転じた。このパターンは、実際に人々が朝を迎えて端末を操作し始めたことを如実に反映している。
この比較は、ネットワークが単に技術的に「オン」になったのではなく、エンドユーザーによる実需要が即座に反映されたことを示している。
全体の91.6%がテヘランに集中する地域別の偏り
回復したトラフィックのほとんどは、首都テヘランに集中している。Cloudflare Radarの地域別データによれば、HTTPリクエスト全体の実に91.6%がテヘラン州から発信されていた。他の地域でもわずかな増加は見られるものの、テヘランとの差は圧倒的だ。
この極端な偏りからは、いくつかのシナリオが推測できる。第一に、政府や通信規制当局が首都から優先的に復旧を進めている可能性が高い。第二に、テヘランには国内で最も多くのデータセンターや国際接続ポイントが集中しており、物理的に復旧作業が行いやすいというインフラ面の要因も考えられる。
ただし、この偏りが地方に住む大多数の市民にとって「ネットが戻った」という実感からはほど遠い状況を生んでいる点は重要だ。現在の復旧状況は、あくまで「部分的」であり、国の隅々まで接続性が戻るにはさらなる時間を要するだろう。
ネットワーク事業者別に見る復旧状況
通信量の増加は、複数の主要なインターネットサービス事業者(ISP)で同時に観測されている。11時45分の最初のバーストに続いて、TCI(イラン通信)、IranCell、RighTel、MCCIといった事業者のネットワークで一斉にトラフィックが立ち上がった。
これらの事業者は、それぞれ異なる自律システム番号(ASN)という一意の識別子で管理されている。ASNとは、インターネット上で個々のネットワークを識別するための番号で、例えるなら「インターネット世界における電話の市外局番と加入者番号を組み合わせたようなもの」だ。複数のASNで同時に復旧が確認されたことは、特定の事業者のみの一時的な不具合ではなく、国家レベルでの規制変更やゲートウェイの開放が行われたことを強く示唆している。
複数事業者での同時回復という事実は、今回の復旧が偶発的なものではなく、中央政府の明確な意図に基づいて実行された可能性が高いことを示している。
DNSクエリの急増と1.1.1.1への影響

転送バイト数だけでなく、DNS(ドメインネームシステム)クエリの数も急増している。DNSとは、人間が覚えやすい「google.com」のようなドメイン名を、コンピュータが理解できるIPアドレスに変換する、インターネットの「電話帳」にあたる仕組みだ。このDNSクエリが増えるということは、利用者が実際にウェブサイトやアプリに接続しようとしている直接的な証拠となる。
Cloudflareが提供するパブリックDNSリゾルバ「1.1.1.1」へのクエリも、5月26日を境にスパイクを記録した。このリゾルバは、インターネットサービス事業者が提供するデフォルトのDNSよりも高速で、プライバシーに配慮していることから、技術に詳しいユーザーを中心に世界中で広く利用されている。イラン国内から1.1.1.1へのクエリが増えたことは、単にネットが使えるようになっただけでなく、ユーザーが意識的に「より速く、より自由な」DNS解決手段を選択し始めた可能性を示唆する。
DNSトラフィックの回復は、ウェブページの閲覧だけに留まらない。メールの送受信、アプリのプッシュ通知、VoIP通話など、多種多様なインターネットサービスは、すべて通信の最初の段階でDNSクエリを発生させる。したがって、DNSクエリの増加傾向は、デジタル社会の活動そのものが再開されつつあることの強い指標と言える。
通信量はピーク時の40%にとどまる依然として本格復旧には遠い現実

今回の回復を楽観視するのはまだ早い。5月26日のピーク時でさえ、トラフィックは今年に入ってから遮断前に記録された最大通信量のわずか40%にとどまっている。ネットワークの「部分的」復旧という言葉が示す通り、まだ多くの障害が残っていると見るべきだ。
加えて、1月の事例が示すように、一時的な復旧はすぐに逆戻りするリスクをはらんでいる。1月にも、一度は戻ったかに見えた通信が24時間足らずで再び遮断された経緯がある。現時点でのトラフィックの増加は心強い兆候ではあるが、これが持続的な復旧の始まりなのか、それとも再び訪れる「通信のブラックアウト」の前触れなのかは、今後の数日から数週間のデータを注視しなければ判断できない。
上記の警告表示が示す通り、ネットワーク状況は依然として流動的だ。本来あるべき水準からはほど遠く、完全な「日常」のネット利用が戻ったとは到底言えない。
IPv6アドレス消失が示す遮断の技術的メカニズム

イランのインターネット遮断を語る上で、見逃せないデータポイントがある。IPv6(インターネットプロトコルバージョン6)アドレス空間の消失だ。
IPv6とは、次世代のインターネットアドレス規格である。従来のIPv4アドレスが世界的に枯渇しつつある中で、ほぼ無限に近いアドレス数を提供できるIPv6への移行が世界中で進められている。このIPv6アドレスの広報(グローバルな経路表に自ネットワークのアドレスを登録すること)が、1月の最初の遮断が始まる数時間前に、イラン国内からほぼ完全に消失した。そして、驚くべきことに、5月の部分復旧後もIPv6アドレス空間の広報量は事実上ゼロのままだ。
一方、旧来のIPv4アドレス空間の広報は、2度の大規模遮断中も一貫して安定的に維持されていた。一見すると矛盾するこの事実は、イランの遮断が物理的なケーブルの切断やルーターの停止といった単純な手法ではなく、より高度なフィルタリング技術によって達成されていたことを強く示唆している。
この対比から導き出される仮説は明快だ。イランの規制当局は、特定のアプリケーションやプロトコルを識別して遮断するDPI(ディープパケットインスペクション)や、許可リストに登録された宛先以外への通信をすべて遮断するホワイトリスト方式を用いて、通信を制御していた可能性が高い。IPv4が「抜け殻」として維持されていたのは、将来的な復旧を想定した準備であったとも考えられる。IPv6が戻らない理由は定かではないが、次世代プロトコルに対する管理・監視体制が整っていないことが一因かもしれない。
この記事のポイント
- 2月28日から87日間続いたイランのインターネット遮断が、5月26日に部分的に解除された。
- Cloudflare Radarのデータでは、前週比約15倍の通信量とDNSクエリの急増が観測された。
- 回復したトラフィックの91.6%は首都テヘランに集中しており、地方との格差が大きい。
- 通信量は遮断前の通常時と比較すると40%の水準に留まり、本格復旧には至っていない。
- IPv6アドレス空間の広報は依然として消失したままであり、遮断の技術的複雑さを示している。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Amazon OpenSearch Serverless次世代版、AIエージェント構築向けに発表
AWSが2026年5月28日、Amazon OpenSearch Serverlessの次世代版を一般提供開始した。AIエージェントアプリケーションの構築に特化したフルマネージド検索・ベクトルエンジンであり、スケールゼロからピーク時までシームレスに拡縮する。
従来のプロビジョニング型クラスタと比較して最大60%のコスト削減が可能とされる。リソース作成は数秒、スケーリング速度は前世代比で最大20倍に向上した。VercelやKiroといったAI開発プラットフォームとのネイティブ統合も備え、インフラ管理を意識せずに本番対応のバックエンドを数分で立ち上げられる。
この記事では、次世代OpenSearch Serverlessの主要な特徴、アーキテクチャ上の進化、AIエージェント開発への実践的な活用法を詳しく見ていく。
OpenSearch Serverless次世代版の概要

OpenSearchはElasticsearchからフォークしたオープンソースの分散型検索・分析エンジンだ。Amazon OpenSearch Serviceはそのマネージド版であり、サーバーレスオプションは2022年に導入された。今回の次世代版は、そのサーバーレスアーキテクチャを根本から刷新したものである。
AWS News Blogの記事によると、次世代版は「AIエージェントを構築する顧客向けに設計された」と位置づけられている。フルマネージドである点は変わらないが、スケーリングの速度とコスト効率が大幅に向上した。
主な改良点はスケールゼロと高速スケーリング
特筆すべきはスケールゼロへの対応だ。利用が途絶えると自動的にリソースが解放され、アイドル状態のコストがほぼゼロになる。リクエストが発生すると数秒でリソースが再作成され、前世代比で最大20倍速いスケールアップを実現する。
つまり、開発中の本番前ステージング環境や、トラフィックが断続的なAIエージェントのバックエンドで、大幅な無駄を省けるということだ。
このデモは、従来型と次世代版のリソース管理モデルの違いを概念的に示したものだ。実際の環境では、数秒単位でプロビジョニングが動的に切り替わる。
コレクションタイプは全文検索とベクトル検索に限定
今回のリリース時点では、対応するコレクションタイプは全文検索(SEARCH)とベクトル検索(VECTORSEARCH)の2種類である。既存のOpenSearch Serverlessにあった時系列データやログ分析向けのタイプは、現時点では次世代版で選択できない。
これは、まずAIエージェント向けの検索基盤として最適化された領域に集中した戦略と見られる。今後のアップデートで順次拡張される可能性は高い。
スケールゼロと高速スケーリングの仕組み

次世代版のアーキテクチャを理解するには、従来のサーバーレス版との違いを押さえておくとよい。前世代のOpenSearch Serverlessは、あらかじめ設定された最小キャパシティユニット(OCU)を常に確保するモデルだった。利用がゼロになっても、その最小ユニット分のコストは発生し続けたのである。
OCUの最小値をゼロに設定可能
次世代版では、インデックス用と検索用それぞれの最小OCUをゼロに指定できるようになった。CLIコマンドを見ると、minIndexingCapacityInOCUとminSearchCapacityInOCUに0が設定されているのがわかる。
この仕組みにより、トラフィックが完全に途絶えた時間帯はコンピューティングリソースが解放され、ストレージのみの課金になる。実質的に「寝ている間は課金されない検索エンジン」として振る舞うわけだ。
リソース作成が数秒で完了する理由
従来のサーバーレス版でコレクションを作成すると、数分かかることもあった。次世代版では、内部的なリソースプロビジョニングのパイプラインが刷新されており、数秒で利用可能になる。
これはAIエージェントの開発フローにおいて非常に重要だ。たとえばVercel上で新しいプロジェクトを作成し、そこにベクトルデータベースを接続する場合、即座にプロビジョニングが完了しなければ開発テンポが落ちてしまう。数秒で立ち上がるという体験は、プロトタイピングの高速化に直結する。
このフローはVercel統合を活用した典型的なAIエージェントのセットアップ手順を図示したものだ。実際の操作はVercelの管理画面から数クリックで完了する。
VercelやKiroとの統合でAIエージェント構築を加速

次世代OpenSearch Serverlessの重要な価値は、AIエージェント開発プラットフォームとのシームレスな連携にある。Vercelの管理画面から直接OpenSearchコレクションを作成・接続できるようになったのがその典型だ。
Vercel統合の実用性
Vercelユーザーは、フロントエンド(Next.js等)のデプロイに加え、検索やベクトルストアをバックエンドインフラとして簡単に追加できる。従来であれば、別途Elasticsearch互換のDBを用意し、VPCネットワークを設定し、認証情報を安全に管理する手間が発生した。
これが管理画面上で完結するということは、開発者がインフラの設定に費やす時間を劇的に減らせる。特にAIエージェントのように試行錯誤を重ねるプロジェクトでは、この迅速さが競争力に直結する。
OpenSearch Agent SkillsとKiro Powers
AWS News Blogの記事では、Claude CodeやCursor、Kiroといった開発ツールとの連携も紹介されている。GitHub上のOpenSearch Agent Skillsというリポジトリには、特定のワークフロー向けのドメイン知識やベストプラクティスがスキルとしてパッケージ化されている。
たとえば「あるテーマに関する最新の技術ドキュメントを検索し、その結果を要約する」といった複数ステップのタスクを、エージェントがOpenSearchのスキルを呼び出すだけで実行できる。エージェントは単に検索結果を受け取るだけでなく、その検索がどのように実行されたかのプロセスも理解できるようになる。
このインラインフローは、開発者がAIエージェントに指示を出してからOpenSearchが検索を実行し、結果が返るまでの一連の流れを色分けで示している。OpenSearch Agent Skillsによって、エージェントは適切なスキルを自動選択できる。
一方、Kiro Powersで提供されるOpenSearch Launchpadは、エンドツーエンドのアーキテクチャ計画をガイド付きで進められるツールだ。検索アプリケーションの全体設計をAIが支援することで、開発の初期段階から生産性を高められる。
導入方法、コンソールとCLI

次世代OpenSearch Serverlessの利用開始は簡単だ。マネジメントコンソールから「Serverless」メニューを選び、「Create collection」をクリックする。次の画面で「NextGen」を選択し、Express createを選べばデフォルト設定で即座にコレクションが作成される。
Express createで手間を省く
Express createは設定不要のクイック作成機能だ。セキュリティポリシーやネットワーク設定は自動で適用され、後から一部の設定を変更できる。プロトタイピングや検証用途では、まずExpress createで立ち上げ、必要に応じて細かな設定を詰めるアプローチが現実的だろう。
CLIからの作成手順
AWS CLIを使う場合は、まずコレクショングループを作成し、その中にコレクションを作る2段階の手順になる。以下はAWS公式ブログに掲載されたコマンド例を、実際の利用に即して整理したものだ。
# コレクショングループの作成(生成世代をNEXTGENに指定)
aws opensearchserverless create-collection-group \
--name my-nextgen-group \
--standby-replicas ENABLED \
--generation NEXTGEN \
--description "My NextGen collection group" \
--capacity-limits '{
"maxIndexingCapacityInOCU": 96,
"maxSearchCapacityInOCU": 96,
"minIndexingCapacityInOCU": 0,
"minSearchCapacityInOCU": 0
}' \
--region "us-east-1"
# コレクションの作成(SEARCHまたはVECTORSEARCH)
aws opensearchserverless create-collection \
--name my-nextgen-collection \
--type SEARCH \
--collection-group-name my-nextgen-group \
--standby-replicas ENABLED \
--description "My collection in NextGen group" \
--region "us-east-1"なお、ブログ公開時のCLIコマンドには最大OCUのデフォルト値に誤りがあり、後日修正された点には注意が必要だ。実際に使う場合は最新のドキュメントを参照してほしい。
AIエージェント時代のデータバックエンドの在り方

OpenSearch Serverless次世代版の登場は、単なる新バージョン発表以上の意味を持つ。AIエージェントが自律的に情報を取得し、判断し、行動する時代において、「検索とベクトル演算のバックエンドをいかに手軽に、安く、速く用意できるか」が開発の成否を分けるからだ。
スケールゼロがもたらす開発文化の変化
従来、検索バックエンドの構築には「とりあえず動かす」だけでもある程度の初期コストが発生した。そのため、プロトタイプ段階では簡易的なインメモリ検索で代用し、後から本格的な検索エンジンに切り替えるパターンが一般的だった。
スケールゼロで最小OCUゼロが可能になったことで、最初から本番同様のOpenSearchを組み込んで開発を進められる。切り替えの手戻りがなくなり、より忠実な検証が可能になる。これはAIエージェントの品質を高める上で、見過ごせない利点だ。
マルチプラットフォーム連携の拡大予測
AWSはVercelとKiroに加え、今後さらに多くのAI開発プラットフォームとの統合を進めると見られる。GitHub CodespacesやReplit、Bolt.newなど、ブラウザベースの開発環境で動作するAIエージェントが増えれば、それらと連携する検索バックエンドの需要は右肩上がりだ。
OpenSearchがこの領域で競争力を発揮するためには、統合の容易さだけでなく、GPUアクセラレーションを活用したベクトル検索のパフォーマンスも鍵を握る。今回の次世代版ではGPU対応が明記されており、大量の埋め込みベクトルを扱う大規模AIエージェントのワークロードにも耐えられる設計が示されている。
コスト構造の変革と注意点
最大60%のコスト削減というインパクトは大きいが、これは「ピークキャパシティに合わせて常時プロビジョニングしていたクラスタ」との比較である。利用が常に一定水準以上あるサービスでは、スケールゼロの恩恵は限定的だ。
OCU単位の従量課金は、予測不能なトラフィックパターンを持つAIエージェントと相性が良い。一方、安定的に高いトラフィックが続く場合は、従来のプロビジョニング型OpenSearch Serviceの方がコストパフォーマンスに優れるケースもある。慎重な見積もりが求められる。
この記事のポイント
- OpenSearch Serverless次世代版はAIエージェント構築に特化し、スケールゼロと高速スケーリングを実現
- ピークプロビジョニング対比で最大60%のコスト削減、リソース作成は数秒で完了
- VercelやKiroとのネイティブ統合で、数分で検索バックエンドをデプロイ可能
- OCUの最小値をゼロに設定できるため、アイドルコストを極小化できる
- 全商用リージョンで一般提供開始、導入はコンソールのExpress createまたはCLIで
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AWS Resilience Hubが大幅刷新、生成AIで障害モードを分析しSREの信頼性管理を効率化
AWSが「Resilience Hub」の次世代版を一般公開した。最大の変更点は生成AIを活用した障害モード評価の搭載だ。組織全体の信頼性を構造化されたポリシーで管理し、数百に及ぶアプリケーションの可用性リスクを一元的に可視化する。
今回の刷新では新たなアプリケーションモデルが導入され、依存関係の自動検出機能やモジュール式の信頼性ポリシーも追加された。SREチームと開発チームが同じ指標で対話し、エンタープライズ全体のレジリエンスを継続的に改善する基盤が整った形だ。
従来のResilience Hubが個々のアプリケーション評価に留まっていたのに対し、今回の刷新は「信頼性の管理」を組織のガバナンス領域に引き上げる。本記事ではその具体的な機能と実務への影響を詳しく解説する。
AWS Resilience Hubの全体像と考え方の変化
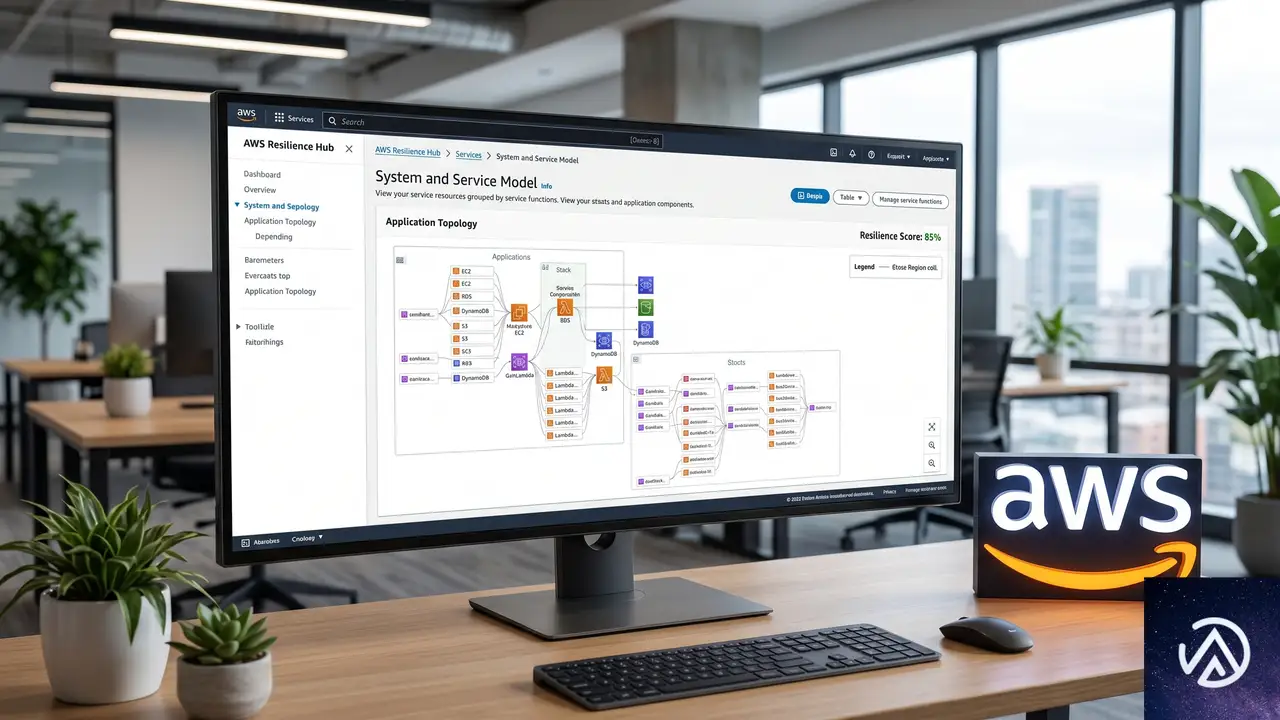
この比較が示すように、次世代版の本質は「個別最適から全体最適への転換」だ。AWS Organizationsとの統合により、委任管理者アカウントから複数アカウントを横断したレジリエンス評価が可能になった。
「ビジネス視点」で捉え直されたアプリケーションモデル
新しいモデルは3層構造になっている。最上位にビジネスアプリケーション全体を表す「システム」、その下にクリティカルな業務経路を示す「ユーザージャーニー」、さらに実際のデプロイ単位である「サービス」が配置される。サービスはAWSリソースやコード、オブザーバビリティの構成要素を束ねる役割だ。
この構造により「ログインできないと売上が止まる」という業務インパクトと、IAMロールの設定ミスという技術的リスクが地続きで評価できるようになる。AWS News Blogの記事でChanny氏は「ビジネス成果に直接結びつくクリティカルなエンドユーザー経路」という表現でこの概念を説明している。
モジュール式ポリシーでチーム間の共通言語を確立
信頼性ポリシーも大きく変わった。旧来は固定されたポリシータイプを選ぶ方式だったが、次世代版では必要な要件を組み合わせて構築できる。たとえば「可用性SLO 99.95%」「マルチリージョン災害復旧」「RTO 15分、RPO 5分」といった要素を選択し、金融系アプリケーション用のポリシーとして再利用する運用が可能だ。
SREと開発チームの間で「どの水準を目指すか」の共通理解が生まれ、属人的な判断を減らせる効果が期待できる。特に複数の開発チームを持つ組織では、この統一ポリシーがガバナンスの要になる。
生成AIが障害モードを評価する仕組み

次世代版の目玉機能が、生成AIを用いた障害モード評価である。サービスにポリシーを紐付けて評価を実行すると、AIが自動的に設定ミスや単一障害点を洗い出し、具体的な改善策を提案する。
この4ステップのフローにより、人手では発見が難しいクロスアカウントの依存関係や、リージョンをまたぐ意図しない呼び出しまで検出できる。AIは単にデータを収集するだけでなく、障害が発生した場合の影響範囲を推定し、優先度付きの修正ガイダンスを出力する。
AWS Well-Architectedと分析フレームワークの統合
AIの評価ロジックはAWS Well-Architectedフレームワークのベストプラクティスと、AWS Resilience Analysis Frameworkを参照している。これにより「なんとなく不安」ではなく、定義された基準に照らした再現性のある評価が実現する。
評価結果では「どのポリシー要件に違反しているか」が明示される。たとえば「RTO 15分を満たすには、このAuto Scalingグループのインスタンスが起動するまでの時間が長すぎる」といった具体的な指摘が得られる。対策の優先順位をビジネスインパクトに基づいて判断できる点が実務的に価値が高い。
また、ユーザーがAssertion(表明)を追加してAIの分析精度を高める仕組みも用意されている。たとえば「このサービスは特定のリージョンでのみ稼働する」といった前提条件をAIに伝えることで、無関係なマルチリージョン構成の提案を除外できる。
依存関係の自動検出がもたらす可視性の向上

多くの障害は「認識されていない依存関係」から発生する。次世代Resilience HubはDNSクエリログを解析し、VPC内のエンドポイントから呼び出されているAWSサービスや内部API、サードパーティの外部エンドポイントを自動で特定する。
この機能の価値は運用の暗黙知を形式知に変換する点にある。「ベテランSREだけが知っている」依存関係を、システムが自動でドキュメント化してくれる。異動や退職によるナレッジロスを防ぎ、障害対応の属人性を低減する効果が期待できる。
依存関係検出はサービス作成時に有効化する。VPCフローログではなくDNSクエリログを解析する仕組みのため、ネットワークトラフィックの暗号化状況に影響されず、比較的軽量に動作する設計だ。不要な場合は管理画面の設定から無効化できる。
実際の利用フローと移行パス

新規導入の基本的な流れ
導入の流れはシンプルだ。まず信頼性ポリシーを作成し、次にビジネスアプリケーションを表す「システム」を登録する。システム配下に、マイクロサービスなどのデプロイ単位である「サービス」を作成し、AWSリソースのタグやCloudFormationスタック、Terraformのステートファイル、EKSクラスタなどを指定してリソースを関連付ける。
準備が整ったら「障害モード評価の実行」をクリックする。Resilience HubがInvokerロールを引き受け、指定されたリソースの親子関係を解析し、トポロジを構築。その上でAIがポリシーに対するギャップを評価する。
評価完了後は「サービス詳細」画面の「Assessment」タブで発見事項を確認できる。各項目には障害モードの説明、アーキテクチャへの影響、修正方法、関連するポリシー要件が明記される。対応が完了した項目は「Mark as resolved」でクローズし、未対応の課題だけをトラッキングできる。
既存ユーザー向けの移行API
すでに従来版のResilience Hubを利用している組織向けには、移行用APIが提供されている。従来の評価ポリシーを新ポリシー形式に変換し、複数の関連アプリケーションを新モデルの「1システム配下の複数サービス」構造に再マッピングする機能だ。
手動での再設定が不要なため、既存の評価データを活かしつつスムーズな移行が可能になっている。大規模組織ほどこの移行APIの価値は大きい。
運用に組み込む際のポイントと今後の展望

Resilience Hubの次世代版を実運用に組み込む場合、いくつか意識すべき点がある。第1にポリシー設計の重要性だ。SLOやRTO、RPOの値はビジネス要件から逆算する必要がある。「とりあえず99.99%」といった一律設定では、過剰なコストを生むか、逆に重要なサービスを見落とすリスクがある。
第2に、依存関係検出のスコープ調整だ。DNSクエリログ解析は強力だが、ノイズとなる外部通信も拾う可能性がある。検出結果を精査し、クリティカルでない依存関係をフィルタリングする運用プロセスを組み込むことが望ましい。
第3に、AIの分析結果を鵜呑みにしないことだ。Assertion機能を活用し、自社のアーキテクチャ特性をAIに正しく伝える努力が求められる。あくまで「AIの提案をSREが判断する」という協調モデルが効果的である。
料金体系は新たなサービスベースモデルに移行した。各サービスにつき月2回の障害モード評価が含まれ、依存関係の自動評価はオプションとなる。大規模環境では評価回数がボトルネックになる可能性があるため、クリティカルなサービスに絞って評価頻度を設定するなどの工夫が必要だ。
今後はAWS Organizationsとの統合がさらに強化され、組織全体のレジリエンススコアをスコアカード化する機能や、CI/CDパイプラインへの組み込みによるシフトレフトな信頼性評価への展開が期待される。
この記事のポイント
- 生成AIによる障害モード評価で、人手では困難な依存関係や設定ミスを自動的に発見できる
- ビジネス視点のアプリケーションモデルにより、技術リスクと業務インパクトを地続きで評価可能になった
- モジュール式ポリシーがチーム間の共通言語として機能し、ガバナンスの実効性が高まる
- DNSクエリログ解析による依存関係の自動可視化で、運用の暗黙知を形式知に変換できる
- 既存ユーザー向けの移行APIが用意されており、大規模組織でもスムーズに移行可能である
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験