

Google AI Threat Defense発表、AIで脆弱性を自動修正する次世代セキュリティ
Google Cloudは2026年5月27日、AIを活用したセキュリティプラットフォーム「Google AI Threat Defense」を発表した。このシステムは脆弱性のスキャンから修正までを自律的に実行し、攻撃者が悪用する前に防御を固めることを目的としている。
AIの進化に伴い、攻撃者は従来の手作業による対策では追いつけないスピードで脆弱性を悪用するようになった。AI Threat DefenseはWiz、CodeMender、Gemini、Mandiantの各テクノロジーを統合し、組織が機械的な速度で脅威に対抗できる環境を提供する。
AI Threat Defenseが目指す次世代セキュリティ

近年、サイバー攻撃の高速化が顕著だ。従来は数週間かけて実施されていた攻撃が、AIエージェントの支援により数時間〜1日程度で完了するケースが増えている。防御側もこのスピードに追随する必要があり、人手による脆弱性管理やパッチ適用だけでは限界がある。
Google Cloud Blogの記事では、単一のAIモデルですべての脆弱性を捕捉することは難しく、コストと性能のバランスを取るために軽量なモデルと最先端のモデルを組み合わせて使うマルチモデル戦略が有効だと説明している。AI Threat Defenseは、ジェネレーティブAIの推論能力とコード生成能力を核に据えた自動防御システムとして、この考え方を具現化したものだ。
上の比較は、従来型の反応的なセキュリティ運用と、AI Threat Defenseがもたらす自律的な運用の差を端的に表している。プロセス全体が機械速度で回ることで、攻撃者が脆弱性を悪用する「タイムウィンドウ」を最小化できる点が最大の強みだ。
4つのコンポーネントが支える統合防御

AI Threat Defenseは、単一の製品ではなく、複数のクラウドセキュリティ技術を組み合わせた統合プラットフォームだ。基盤にはGoogleのジェネレーティブAIモデル「Gemini」の推論エンジンがあり、周辺にクラウドセキュリティの可視化を担うWiz、コード修正を自動化するCodeMender、そして現場のサイバー攻撃対策ノウハウを持つMandiantが配置される。
Wizによる可視化とリスク優先付け
WizはアプリケーションやAPI、ID、設定、ビジネスロジックなど、クラウド環境のあらゆる要素を継続的に可視化し、実際に悪用可能な攻撃パスをマッピングする。従来の攻撃面管理(ASM)を超え、AIペネトレーションテストエージェントが複雑な連鎖リスクを自動検証する。この結果、ただの脆弱性リストではなく、事業リスクを反映した優先順位付きの修復計画が出力される。
CodeMenderによる自律的なコード修正
CodeMenderはGeminiのコード生成力を活用し、開発者のIDEやCLIに直接パッチ候補を提示する。脆弱なコードの置換、レガシーコードのメモリ安全な言語への書き換え、ライブラリ依存関係の調整までをカバーし、修正後の自動テスト生成も行う。これにより、パッチの生成から検証までの時間が大幅に短縮される。
Geminiの推論とマルチモデル戦略
AI Threat DefenseはGemini Enterprise Agent Platform上で複数の最先端モデルを動かし、モデルごとに得意なタスク(アプリケーションロジック分析、クラウド設定監査、バイナリ解析など)に割り当てる。軽量モデルで広くスキャンし、フロンティアモデルを最高リスク領域に集中させることで、コスト効率と検出範囲の両立を実現している。
Mandiantの現場知見と運用ガイダンス
Mandiantはこれまでに蓄積したサイバー攻撃の最前線知識を、AI駆動の修復プロセスに注入する。重大な脆弱性が一気に表面化した場合の対応戦略や、旧式システムの安全な停止方法、AI生成パッチをエンジニアリングチームに負荷をかけずに展開するノウハウなど、実践的なガイダンスが提供される。
脅威対策の4段階フレームワーク

AI Threat Defenseの運用は「準備(Prepare)」「スキャンと優先順位付け(Scan and prioritize)」「修正(Remediate)」「監視(Monitor)」の4段階で構成される。各ステップがシームレスに連携し、攻撃者が悪用するスピードに追いつくための機械的なワークフローを形成する。
このフレームワークでは、各段階が独立しているのではなく、リアルタイムのリスク情報に基づいてループする。たとえば監視中に新たな暴露経路が見つかれば、即座にスキャンへ戻り、自動的にパッチが生成される。
STEP 1 準備(Prepare)
まず重要なのは、攻撃対象領域を最小化することだ。インターネットから直接到達可能なセンシティブな資産や、信頼できない経路で露出しているサービスを特定し、パッチの有無にかかわらず接続経路そのものを削減する。同時に、各チームの責任範囲とエスカレーションフローを明確化し、次の脆弱性が発見されたときに即応できる体制を整える。
STEP 2 スキャンと優先順位付け(Scan and prioritize)
この段階では、AIによる多層的な分析が行われる。軽量モデルで全資産を継続的にウォッチしつつ、インターネット向けアプリケーションや認証機能などビジネスクリティカルな部分にはフロンティアモデルを用いた深掘りスキャンを実施する。Wizのリアルタイムコンテキストと連携し、単なるコード上の欠陥ではなく「実際に攻撃可能か」という観点で優先度が決定される。
STEP 3 修正(Remediate)
特定された脆弱性は、CodeMenderによって自動的に修正案が生成される。開発者はIDE上でパッチ候補を確認し、承認するだけでよい。また、ライブラリの変更が他のコンポーネントに与える影響も分析され、複数リポジトリにまたがる安全なロールアウトが支援される。修正後には自動テストが走り、パッチの有効性を検証する仕組みも組み込まれている。
STEP 4 監視(Monitor)
最後の監視フェーズでは、Google Security Operationsが提供するエージェント型SOC機能を活用し、ネットワーク、ID、アプリケーションのテレメトリを横断的に分析する。AIが不審な挙動を自律的に検出し、場合によっては自動で封じ込めアクションを発動する。また、日次でビルド・署名されたハードニング済みコンテナイメージを用いることで、基盤自体のセキュリティも維持される。
実践導入とパートナーエコシステム

AI Threat Defenseは、単にツールを導入するだけでは機能しない。クラウドアーキテクチャに適したセキュリティ設計と、既存の開発パイプラインへの組み込みが必要になる。そのため、Google CloudはAccenture、Deloitte、PwC、Netenrich、TENEX.AIなどのパートナー企業と協業し、導入から継続的な管理、カスタムワークフローの構築までを支援する体制を整えている。
パートナー企業の役割
各パートナーは、顧客固有のクラウド構成を評価し、AI駆動のセキュリティ運用を定着させるためのハーネス(カスタム連携基盤)を開発する。これにより、組織ごとのコンプライアンス要件や運用ポリシーに合わせたきめ細かな防御が可能になる。
Google自身のセキュリティ実績
Google Cloudは、このプラットフォームを自らのセキュリティ運用実績の上に構築している。同社は10年以上にわたり、Titanチップによるハードウェア保護やZero Trustアーキテクチャの先駆的導入を進めてきた。現在も毎分数千万件のスパムを自動ブロックし、数十億のユーザーを保護している。こうしたノウハウが、AI Threat Defenseの設計思想に深く反映されている。
この記事のポイント
- AI攻撃の高速化に対抗するため、Google Cloudが自律型防御プラットフォーム「AI Threat Defense」を発表
- Wiz、CodeMender、Gemini、Mandiantの4要素を統合し、脆弱性の可視化からパッチ適用までを機械速度で自動化
- 従来の人間主導のプロセスでは数週間かかっていた対応が、数分〜数時間に短縮される見込み
- 「準備→スキャン→修正→監視」の4段階フレームワークで、攻撃者が悪用する前に防御を完了させる
- パートナー企業による実装支援と既存の開発パイプラインへの統合が、導入の鍵を握る

・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Vercel Sandboxの永続化機能が正式版に、環境構築の手間を大幅削減
Vercelが提供するクラウド開発環境「Vercel Sandbox」において、filesystemの状態をセッション間で自動保存する永続化機能が正式版(GA)となった。2026年5月26日の発表だ。開発者はこれまで、Sandboxを再起動するたびに依存パッケージのインストールやファイル配置をやり直す必要があったが、今回のアップデートでその手間が大幅に削減される。
永続化はデフォルトで有効化されており、スナップショットの取得や状態管理を手動で行う必要はない。Sandboxに一意の名前を付与すれば、その名前をキーとして環境を再開できる仕組みだ。セッションの起動と停止はVercel側で自動的に処理されるため、開発者はワークフローを中断されることなく作業を継続できる。
Sandbox永続化が解決する課題

クラウドベースの開発環境において、セッション終了後の状態消失は長年の課題だった。従来のVercel Sandboxでは、セッションが終了するたびにfilesystem上の全データが破棄されていた。このため、毎回の起動時に再度依存関係のインストールや環境設定を行う必要があり、開発開始までの待ち時間が大きな非効率を生んでいた。
永続化機能は、この問題に対する直接的な解決策だ。Sandboxのfilesystem状態が自動的にスナップショットとして保存され、次回セッション開始時に自動復元される。スナップショットはユーザーが明示的に操作する必要はなく、セッション終了時に自動取得される仕組みである。これにより、npmパッケージのインストールやプロジェクトファイルの配置といった繰り返し作業から開発者が解放される。
※毎回セッション開始時に環境構築が必要。待ち時間が発生し、開発効率が低下する
※前回の状態が自動的に復元される。セットアップ不要で作業を継続できる
この変化は、継続的な開発やCI/CDパイプラインでの自動テストなど、頻繁な環境再作成が発生するシナリオで特に効果を発揮する。
永続的Sandboxの作成と利用

デフォルトで有効化される永続性
Sandbox.create()を呼び出す際、永続化は自動的に有効になる。特別な設定やオプションの指定は不要だ。作成時にnameパラメータで一意の名前を付与すれば、その名前がプロジェクト内での参照キーとなる。この名前は後から変更することも可能であり、プロジェクトの命名規則に合わせた管理ができる。
名前付きSandboxは単なる識別子以上の役割を持つ。チーム内で「staging-test」「feature-auth」といった意味のある名前を付けることで、目的に応じた環境の使い分けが容易になる。また、存在しない名前を指定した場合は新規作成、既存の名前を指定した場合は既存環境の復元と、名前ベースの直感的な操作が可能だ。
import { Sandbox } from "@vercel/sandbox";
// filesystemは自動的にスナップショット保存される
const sandbox = await Sandbox.create({ name: "my-sandbox" });
await sandbox.runCommand("npm", ["install"]);
await sandbox.stop();上記のコードでは、npm installでインストールされた依存パッケージが自動的にスナップショットとして保存される。次回Sandbox.get({ name: "my-sandbox" })で取得した際には、インストール済みの状態から即座に作業を再開できる。
ステートレスSandboxとの使い分け
永続化は便利だが、すべてのユースケースで必要とは限らない。一時的な検証や使い捨てのテスト環境では、永続化を無効にすることでスナップショット保存にかかるストレージコストを節約できる。スナップショットストレージはコンピューティングリソースとは別の課金体系であり、不要な保存はコスト増につながるためだ。
import { Sandbox } from "@vercel/sandbox";
const sandbox = await Sandbox.create({ persistent: false });
// 既存のSandboxを後から変更することも可能
await sandbox.update({ persistent: false });CLIを利用する場合は、sandbox createコマンドに--non-persistentフラグを付与する。非永続的Sandboxはセッション終了時にfilesystemが完全に破棄されるため、機密データを含む一時的なテストや、毎回クリーンな状態から始めたいCIジョブに適している。
● チーム共有の検証環境
● 長期メンテナンスのテスト環境
● クリーン状態が必要なCIジョブ
● 機密データを含む一時テスト
この使い分けにより、必要な場面では永続化の利便性を享受しつつ、不要な場面ではコストを最適化できる。開発の初期段階で「この環境は使い続けるか、それとも一度限りか」を判断基準にするのが実践的なアプローチだ。
セッション再開の仕組み

永続化されたSandboxの再開は完全に自動化されている。停止中のSandboxに対してrunCommand()やwriteFiles()などの操作を呼び出すと、最新のスナップショットから自動的に新しいセッションが開始される。開発者が明示的に「再開」を指示する必要はなく、操作の実行がトリガーとなって透過的に処理される。
import { Sandbox } from "@vercel/sandbox";
const resumedSandbox = await Sandbox.get({ name: "my-sandbox" });
// 自動的にSandboxが再開される
await resumedSandbox.runCommand("npm", ["test"]);Sandbox.get()で取得した段階ではまだセッションは開始されておらず、実際にコマンドを実行するタイミングでバックグラウンドで復元処理が走る。この遅延実行モデルにより、不要なセッション起動を避け、リソースの効率的な利用が可能になる。復元にかかる時間はスナップショットのサイズに依存するが、一般的なプロジェクト規模であれば数秒から十数秒程度で完了する。
この設計の利点は、開発者が環境のライフサイクル管理から解放される点にある。「今このSandboxは起動しているか」「停止状態からどう再開するか」といった状態管理の認知負荷がなくなり、コードの記述やテストの実行といった本質的な作業に集中できる。
コスト管理とスナップショットストレージの最適化

永続化機能の利用にあたって注意すべき点は、スナップショットストレージの課金だ。Vercel Sandboxの料金体系では、コンピューティングリソースとスナップショットストレージが別々に課金される。永続化を有効にしたSandboxが増えるほど、保存されるスナップショットの総容量も増加し、それに比例してコストが発生する。
では、どのようにコストを最適化すればよいのか。以下の方針が実践的だ。
● npm install に30秒以上かかる大規模プロジェクト
● チームメンバー間で共有する標準環境
● PRごとに自動生成されるCI環境
● 依存関係がほぼない小規模スクリプトの実行
実際の運用では、Sandbox.update({ persistent: false })を使って後から設定を切り替えられるため、最初は永続化ありで作成し、不要と判断した時点で無効化する柔軟な運用が可能だ。また、Sandbox.delete()を使えば不要になったSandboxとそのスナップショットを完全に削除でき、ストレージの無駄遣いを防げる。
スナップショットの保存間隔や保持数については、現時点ではセッション終了時に自動取得される仕組みのみが提供されている。将来的にはスナップショット取得のタイミングを制御するオプションが追加される可能性もあるが、現行バージョンではシンプルに「停止時保存」のモデルで統一されている。このシンプルさが、開発者の意思決定コストを下げている面もある。
その他の重要な改善点

今回のGAリリースでは、永続化機能に加えていくつかの重要なAPI拡張も同時に提供されている。これらは永続化機能と組み合わせることで、より柔軟なSandbox管理を実現する。
Sandbox.fork() による環境の複製
既存のSandboxから新しいSandboxを作成するSandbox.fork()が追加された。特定の時点の環境を複製し、そこから別の検証を分岐させたいケースで役立つ。たとえば、メインの開発環境から「機能Aの実験用」「機能Bの実験用」をそれぞれフォークし、独立してテストを進められる。
Sandbox.getOrCreate() の冪等性
Sandbox.getOrCreate()は、指定した名前のSandboxが存在すれば取得し、存在しなければ新規作成する冪等な操作を提供する。CI/CDパイプラインでの環境セットアップスクリプトなど、「あれば使う、なければ作る」というパターンが1行で完結する。エラーハンドリングの分岐を書く必要がなくなり、コードの可読性が向上する。
ライフサイクルフックとタグ機能
onCreateおよびonResumeフックが追加され、Sandboxの作成時や再開時に任意の処理を挿入できるようになった。環境変数の動的設定や、起動時チェックの自動実行など、プロジェクト固有の初期化処理を組み込める。また、Tags機能によりSandboxにカスタムプロパティを付与でき、マルチテナント環境での追跡や分類が容易になる。たとえば「environment: staging」「team: frontend」といったタグを付けてフィルタリングすることが可能だ。
実践的な活用シナリオ

永続化機能の登場により、Vercel Sandboxの適用範囲は大きく広がる。ここでは具体的な活用シナリオをいくつか挙げる。
すべての依存パッケージがインストール済みのSandboxをSandbox.fork()でメンバーに配布。環境構築の時間をゼロにし、全員が同一条件で開発を始められる。新メンバーのオンボーディング時間も大幅に短縮される。
テストスイートの実行環境を永続化し、依存パッケージのインストール時間を削減。PRごとにSandbox.getOrCreate()で専用環境を用意し、テスト実行後のクリーンアップもSandbox.delete()で自動化できる。
報告されたバグの発生環境をSandboxで再現し、そのまま永続化。修正パッチの検証が完了するまで環境を保持し、必要に応じてSandbox.fork()で別の修正アプローチも並行テストできる。
これらのシナリオに共通する利点は、「環境の再現性」と「セットアップ時間のゼロ化」だ。特にマイクロサービスアーキテクチャのように複数の依存関係が絡むプロジェクトでは、個々の開発者がローカルで依存関係を解決するよりも、クラウド上の永続化環境を共有する方が圧倒的に効率的なケースが多い。
この記事のポイント
- Vercel Sandboxの永続化機能が正式版となり、セッション間のfilesystem自動保存がデフォルトで有効化された
- 名前ベースのSandbox管理で環境の作成・取得・再開が直感的に行え、スナップショット操作は完全自動化されている
- 永続的Sandboxと非永続的Sandboxの使い分けにより、利便性とコスト最適化のバランスが取れる
- forkやgetOrCreateなどのAPI拡張で、チーム開発やCI/CDパイプラインへの統合がより容易になった
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

CloudflareがClaude Managed Agentsと統合、エージェントの実行基盤を刷新
CloudflareがAnthropicと連携し、Claude Managed AgentsをCloudflareのサンドボックス環境と統合した。この新たな統合により、エージェントのコード実行からブラウザ操作、プライベートサービスへの接続までを、Cloudflareのプラットフォーム上でより柔軟に制御できる。
従来、Claude Managed AgentsはAnthropic側のインフラに完全に依存していた。今回の発表で「頭脳」であるClaudeの推論ループと「手足」であるコード実行基盤が分離され、後者をCloudflare上で運用できるようになった。
開発者は数分でテンプレートをデプロイし、セキュリティ強化やミリ秒単位のサンドボックス起動、内部サービスへの安全な接続といったメリットを得られる。この記事では、統合の仕組みと実務への影響を具体的に掘り下げる。
Claude Managed AgentsとCloudflareが目指すもの

この構成で得られるのは単なる「場所の変更」ではない。インフラをCloudflareに移すことで、エージェントの振る舞いを細かく監視し、内部サービスとの通信を暗号化し、必要なリソースだけを動的に割り当てられるようになる。
Cloudflare Blogの記事では、この仕組みを「頭脳から手足を切り離す」と表現している。開発者はClaudeの高い推論能力をそのまま活かしつつ、実行環境だけを自社ポリシーに合わせてカスタマイズできるわけだ。
Cloudflare環境の仕組み

統合をデプロイすると、Cloudflare上にWorkersベースのコントロールプレーンが立ち上がる。Claude Agentがセッションを開始するたび、このコントロールプレーンがサンドボックス環境を割り当て、コード実行やCLIツールの操作、ブラウザ操作などを代行する。
サンドボックスはセッションがスリープしても状態を自動的に保持する。コンテナイメージのカスタマイズやインスタンスサイズの調整もオプションで指定でき、既存の監視ツール(DatadogやSplunk)へのログ連携にも対応している。
特筆すべきは、Cloudflareのダッシュボードからエージェントの状態を可視化し、必要に応じてSSHでサンドボックス内部に入れる点だ。大規模なエージェント運用では、トラブルシューティングのしやすさが運用コストを大きく左右する。この設計は現場の要求をよく踏まえている。
インターネット規模のエージェント実行基盤

エージェントが本格的に普及すると、企業は1人のユーザーに対して複数のエージェントを同時に動かす必要が出てくる。従来のマイクロVM方式では、エージェントの数だけVMを起動し続けるため、リソースとコストが線形に増加してしまう。
Cloudflareはこの課題に対し、V8 Isolateを使った軽量サンドボックスを提供する。Dynamic WorkersとCodemodeを組み合わせることで、ミリ秒単位でサンドボックスを起動し、フルVMよりはるかに少ないリソースで任意のコードを実行できる。
エージェントのセットアップ時にバックエンドタイプとして「isolate」を選択するだけで、この軽量モードに切り替えられる。数万規模の同時エージェントを扱うユースケースでは、コスト効率が数十倍変わる可能性がある。
もちろん、Linuxツールをフル活用する開発エージェントには、引き続きマイクロVMベースのCloudflare Containersを使える。用途に応じて2種類の実行環境を選択できる点が、この統合の実用的な強みだ。
エージェントワークロードのセキュリティ

エージェントが組織の内部データやサービスにアクセスするとき、最大のリスクは認証情報の漏洩だ。Cloudflareの統合では、アウトバウンドプロキシを使い、サンドボックスから外部へ出る通信に対して動的に認証情報を注入する仕組みを備えている。
この設計のポイントは、エージェント自身はクレデンシャルを知らないことだ。プロキシがゼロトラストベースでリクエストに署名やトークンを付与するため、万が一サンドボックスが侵害されても、認証情報そのものが盗まれるリスクを抑えられる。
また、Cloudflare MeshとWorkers VPCを使えば、インターネットに一切公開していない内部サービスにも、ポスト量子暗号で保護されたトンネル経由で接続できる。VPNや踏み台サーバーなしでプライベートサービスと通信できる点は、インフラ担当者にとって大きな利点だろう。
プロキシはテナント単位やエージェント単位でポリシーを適用できる。特定のエンドポイントだけを許可リスト化し、それ以外の通信を遮断するといった細かな制御も、コード数行で実装可能だ。
エージェントに必要なツール群

ブラウザ操作の完全な制御
エージェントがウェブと対話する際、単純なHTTPリクエストでは不十分な場面が多い。JavaScriptを多用するモダンなウェブアプリケーションの操作や、QA用のスクリーンショット取得、フォーム入力の自動化には、実際のブラウザが必要になる。
CloudflareのBrowser Runは、エージェントにプログラム可能なブラウザを与える仕組みだ。検索、実行、スクリーンショット、ページのMarkdown変換など、複数のツールがデフォルトで利用できる。
セッションの録画機能も備わっており、エージェントがブラウザ上で何をしたかを後から完全に監査できる。許可リストや拒否リストを使ったアクセス制御も可能で、野放図なウェブアクセスを防げる。
メール送受信とプライベート接続
エージェントにメールアドレスを割り当て、送受信を自律的に行わせる機能も統合済みだ。Cloudflare Email Serviceと連携し、任意のドメインでエージェントがメールを送信できる。顧客対応の自動化や、転送されたメールへの返信といったユースケースに適している。
内部サービスへの接続にはcall_serviceツールが用意されており、Cloudflare MeshやWorkers VPC経由でプライベートAPIを安全に呼び出せる。Workers AIを使った画像生成ツールも標準で組み込まれており、Claudeのテキスト推論と組み合わせたマルチモーダルなワークフローを構築できる。
カスタムツールの追加
リポジトリをフォークし、独自のツールを追加するのも容易だ。例えばCloudflare R2にファイルをアップロードし、公開URLを返すツールを数行のコードで定義できる。以下はCloudflare Blogで示されたコード例を簡略化したものだ。
defineTool({
name: "r2_host_file",
description: "サンドボックスからR2にアップロードし公開URLを取得",
inputSchema: z.object({
key: z.string(),
content: z.string(),
contentType: z.string()
}),
run: async ({ key, content, contentType }, { env }) => {
await env.PUBLIC_BUCKET.put(key, content, { httpMetadata: { contentType }});
return `${env.PUB_R2_URL}/${encodeURI(key)}`;
}
})Workers AIを使ったエッジ推論や、Dynamic Workersによる動的なアプリケーションホスティング、Artifactsを使ったGit管理の追加など、Cloudflare Developer Platform全体をエージェントの拡張に活用できる。インフラ管理を意識せず、関数を書いてデプロイするだけで機能追加が完了する設計だ。
この記事のポイント
- Claude Managed Agentsの実行基盤をCloudflare上に構築できるようになった
- 「頭脳(Claude)」と「手足(Cloudflareサンドボックス)」の分離で、インフラ選択の自由度が向上した
- V8 Isolateを使った軽量サンドボックスで、ミリ秒起動と低コストの大規模実行が可能
- アウトバウンドプロキシによるゼロトラスト認証で、エージェントのセキュリティを強化
- ブラウザ操作、メール送受信、内部サービス接続などのツールが標準装備されている
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

中国語フィッシング即サービスの進化、リアルタイムOTP傍受とデジタルウォレット悪用の実態
フィッシングはもはや、偽のメールを大量にばらまくだけの手口ではない。中国語圏のアンダーグラウンドでは、フィッシングをサービス化したPhaaS(Phishing-as-a-Service)が急速に成熟している。2026年5月にGoogle脅威インテリジェンスグループが公開した分析によれば、これらのサービスは静的なパスワード収集から脱却し、リアルタイムでのワンタイムパスコード(OTP)傍受やデジタルウォレットの悪用へと移行している。
特に警戒すべきは、RCSやiMessageといった暗号化通信を配信経路に選び、多要素認証(MFA)をリアルタイムで突破する手口だ。AIによるフィッシングページの自動生成や、日本市場を狙った高度なローカライズも確認されている。もはや攻撃者のゴールはログイン情報の窃取にとどまらず、被害者の金融口座を直接掌握することにある。
中国語圏PhaaSエコシステムの独自性

これまでPhaaSといえばロシア語圏の攻撃者が主流だった。だが中国語圏のエコシステムは、単なる地域的な派生版ではなく、独自の文化とビジネスモデルを持つ市場として確立されている。Google脅威インテリジェンスグループが分析した12の現行PhaaSサービスは、いずれも成熟しており、多くが地域の犯罪エコシステムと密接に結びついている。
ロシア語圏との違い
最も大きな違いは標的の選び方だ。ロシア語圏の主要PhaaSは大企業の顧客を狙う傾向があるのに対し、中国語圏のサービスは一般市民を日和見的に攻撃するケースが多い。また、運用の透明さも対照的だ。ロシア語圏の攻撃者が厳格な運用セキュリティを保つのに対し、中国語圏の運営者はTelegramで高級な生活ぶりを公開するなど、オープンに活動する傾向がある。
もうひとつの特徴は、模倣対象となる正規組織のほぼすべてが中国国外の企業である点だ。つまり、これらのフィッシングサービスは自国市場を標的にしていない。広告や勧誘は中国で人気のWeChatやQQよりTelegramで行われることが多く、これは中国語圏のサイバー犯罪エコシステム全体に共通する傾向だ。
エコシステムの構造
PhaaSを中核としつつも、これらのサービス運営者は多岐にわたる付随サービスを提供している。個人識別情報(PII)の販売、ドメイン登録や仮想プライベートサーバー(VPS)の提供、マネーロンダリング支援、盗聴デバイスの販売、スパムメッセージ送信代行などだ。一部の業者は盗難支払いカード情報の取引にも関与している。フィッシング単体ではなく、犯罪の全工程をパッケージ化した総合サービスへと発展しているのである。
進化した攻撃手法

中国語圏PhaaSの技術的進化を理解するには、従来のフィッシングと現在の手口を比較するのが早い。下の図は、その変化を視覚化したものだ。
従来型では攻撃者が認証情報を入手しても、OTPに阻まれてアカウントへ侵入できなかった。しかし現在のPhishingは、被害者がコードを入力する瞬間をリアルタイムで傍受し、数秒のうちに悪用する。MFAはもはや万能の防御策ではない。
RCSとiMessageを悪用した配信
攻撃の起点は、信頼できる通信手段の悪用だ。これらのPhishingサービスは従来のSMSではなく、RCS(リッチコミュニケーションサービス)やAppleのiMessageを多用する。両プロトコルはエンドツーエンド暗号化を採用しており、サーバーサイドで悪意あるリンクを検査・フィルタリングすることが難しい。つまり、キャリア側のセキュリティフィルターを素通りする。
さらに、開封確認やタイピングインジケーター、高解像度画像の送信といった機能が、メッセージの信憑性を高める。被害者にとっては正規の連絡と見分けがつかず、ソーシャルエンジニアリングの成功率を大幅に引き上げる要因となっている。
リアルタイムOTP傍受
被害者がフィッシングリンクをクリックして認証情報を入力すると、そのデータは攻撃者の管理パネルに即時表示される。攻撃者はこれを見ながら、被害者のアカウントでOTPリクエストを自らトリガーする。被害者は届いたコードを偽サイトに入力し、攻撃者はそれをコードの有効期限が切れる前に傍受して利用する。この一連の流れは数十秒で完結する。
デジタルウォレットトークン化
最終的な目的は、盗んだ支払いカード情報をデジタルウォレットに登録し、トークン化することだ。攻撃者は入手した認証情報とOTPを使い、被害者のカードを自分の管理するデバイスのウォレットにプロビジョニングする。トークン化されたカードは、高額決済や非接触支払い、ATM引き出しに利用可能になる。もはやログイン情報の窃取ではなく、金融口座への直接的な不正アクセスを実現する手口である。
AIによる自動化
複数の中国語圏PhaaS事業者がAIを運用に取り入れている。たとえば、UNC5814として追跡されている「Darcula」プラットフォームは、静的なテンプレートを廃止し、AI駆動のページ生成とPuppeteerのようなブラウザ自動化ツールを採用した。標的サイトのURLを入力するだけで、そのHTMLやCSS、JavaScript、ビジュアル要素を複製し、動的に偽ページを生成する。ページごとに構成が異なるため、シグネチャベースの検出はほぼ無力化される。
ローカライズのサービス化とYY来魚の事例

これらのPhishingサービスは、単に多言語対応するだけではない。地域ごとの消費者文化に深く入り込んだ、高度なローカライズを実現している。その代表例が「YY来魚」だ。
YY来魚の標的と戦術
2024年8月に広告が確認されたYY来魚は、119カ国をサポートするが、最大の注力先は日本だ。2025年11月以降、400以上のフィッシングテンプレートを顧客に提供してきた。対象は銀行や証券にとどまらず、AmazonやApple、PayPay、メルカリ、任天堂、東日本旅客鉄道(JR)、佐川急便など、日本の消費者生活に密着したブランドが並ぶ。
特筆すべきは、単なる偽ログインページの提供ではない点だ。日本の消費者が慣れ親しんだ「ポイント」や「報酬交換」の仕組みを悪用し、「有効期限切れのポイントを現金や商品に交換」といった偽の案内で被害者を誘導する。さらに、光熱費補助をかたるなど、足元の経済状況に乗じたルアーも展開している。
インフラと運営
YY来魚のフィッシングサイトには、人間による認証操作を求めるアンチボット画面が実装されていた。手動クリックがないと先に進めない仕組みで、セキュリティベンダーによる自動分析を妨害する。管理パネルでは、フィッシングで収集したデータの検索、カードのBIN番号に基づくブロックリスト管理、国別の配信制限、Alibabaのドメイン登録サービスを使った新規ドメインの登録と管理が可能だ。さらにシステム管理者はオペレーターユーザーを作成し、権限を細かく割り当てることができる。
YY来魚は日本に焦点を当てた一例だが、中国語圏PhaaSの網は米州、欧州、豪州、中東にも広がっている。特定の地域文化に合わせたローカライズを自動化できるインフラが、低スキルの攻撃者にも高精度なキャンペーンを可能にしている。
防御側の対策と展望

ユーザー教育は依然として重要な防御線だが、それだけでは不十分だ。中国語圏PhaaSの拡散は、人を介さない技術的な制御の必要性を強く示している。
FIDO2/WebAuthnへの移行
最も効果的な対策のひとつが、FIDO2/WebAuthnインフラへの移行だ。公開鍵暗号方式に基づくこの認証は、OTPのように通信経路上で傍受されるリスクがない。セキュリティキーは、ユーザーがフィッシングサイトに支払い情報を直接入力する行為そのものを防ぐことはできないが、盗まれた認証情報の悪用難易度を大幅に引き上げる。攻撃者がログインできない時点で、カード情報のトークン化も成立しない。
発行体側の検証強化
金融機関やカード発行体には、デジタルウォレットへのプロビジョニング時にリスクベース検証とデバイスフィンガープリントを組み合わせる対策が求められる。見慣れないデバイスや異常な利用パターンを検知し、トークン化の前に追加検証を挟む仕組みだ。
防御側の目標は「フィッシングの検知」から「盗まれた認証情報を技術的に無力化すること」へと移行しつつある。中国語圏のPhaaS事業者は現在もツールの改良を続けており、グローバルな影響力をさらに拡大しようとしている。対策もそれに合わせて進化させねばならない。
この記事のポイント
- 中国語圏Phishing-as-a-Serviceは、OTPのリアルタイム傍受とデジタルウォレット悪用によりMFAを突破する
- RCSやiMessageのエンドツーエンド暗号化が、キャリア側のフィルタリングを無効化し配信成功率を高めている
- AIによる動的ページ生成で、シグネチャベースの検出回避が容易になった
- 日本市場を狙うYY来魚のように、地域経済や消費者文化に深く適応したローカライズが進んでいる
- 対策にはFIDO2/WebAuthnの採用と、カード発行体によるプロビジョニング時のリスク検証が有効
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

KnowledgeDeliver脆弱性、ViewState攻撃の実態と対策まとめ
国内の教育機関や企業研修で広く使われるLMS(学習管理システム)のKnowledgeDeliverに、深刻な脆弱性が見つかった。サーバーに保存された共通の暗号鍵を悪用され、遠隔から不正なコードを実行される恐れがある。
Google Cloudの脅威インテリジェンスチームであるMandiantは、2025年後半に実際の攻撃を確認した。攻撃者はこの脆弱性を足がかりにWebシェルを設置し、サイト訪問者のPCにバックドアを感染させる手口を使っていた。本記事では、この脆弱性の仕組みと攻撃の流れ、具体的な検知方法と対策を整理する。
KnowledgeDeliverが見舞われた脆弱性の正体

共有されたマシンキーが招く全インストール共通の弱点
問題の発端は、ASP.NETアプリケーションの設定ファイル web.config に書き込まれた machineKey の値だ。このキーは、画面の状態情報を保持するViewStateデータの暗号化と署名に使われる。
本来、このキーはサーバーごとに個別のランダムな値を生成すべきものだ。しかし、2026年2月24日より前に配布されたKnowledgeDeliverのパッケージでは、開発元が用意したテンプレートの中に固定のキーが埋め込まれていた。その結果、別々の組織で稼働するすべてのインスタンスが、まったく同じマシンキーを共有する状態になった。
これは、すべての家の玄関に同じ鍵が付いているようなものだ。攻撃者が一つの鍵束を入手すれば、インターネット上に公開された他のすべてのKnowledgeDeliverサーバーに侵入できることを意味する。
ViewState Deserializationが悪用される仕組み
ASP.NETのViewStateは、ページの往復(ポストバック)の間、ユーザーが入力した値や画面の状態を維持するための仕組みだ。ブラウザとサーバーの間で、暗号化された文字列としてやり取りされる。
machineKey を知る攻撃者は、このViewStateの中に悪意あるコードを含んだ特殊なデータ(ペイロード)を埋め込める。サーバーは受け取ったViewStateを復号し、データをオブジェクトに戻す処理(デシリアライゼーション)を実行する。この過程で、埋め込まれたコードがサーバー上で実行されてしまう。
この手法は、以前にMandiantが報告したSitecoreのViewStateゼロデイ脆弱性や、Microsoftが警告したASP.NETマシンキーの悪用事例と同種のものだ。共通鍵を使う設計の危険性を、あらためて浮き彫りにしている。
攻撃者は侵入後に何をしたのか

メモリ内で動作するWebシェル「BLUEBEAM」の投入
Mandiantの調査によれば、攻撃者はまず.NETベースのWebシェル「BLUEBEAM」を展開した。このツールはGodzillaとも呼ばれ、Microsoftも以前に同種の活動を報告している。
BLUEBEAMの特徴は、ファイルとしてディスクに保存されず、IISのワーカープロセス(w3wp.exe)のメモリ空間上だけで動作する点だ。一般的なウイルス対策ソフトによるファイルスキャンをすり抜け、HTTP POSTリクエストのボディに暗号化したコマンドを忍ばせて、遠隔操作を受け付ける。
ファイル改ざんとCobalt Strikeによる端末感染
Webシェルを確保した攻撃者は、サーバー上のファイル権限を変更し、アプリケーションのJavaScriptファイルに細工を加えた。具体的には、次のような改ざんが確認されている。
- 「セキュリティ認証プラグイン」のインストールを促す偽の警告を表示するスクリプトの追加
- 攻撃者が管理する外部ドメインから、不正なスクリプトをひそかに読み込むコードの埋め込み
この偽警告に従って「プラグイン」をダウンロードしたユーザーのPCには、Cobalt StrikeのBEACONバックドアが仕込まれた。ペイロードの暗号化には、標的組織の名称が使われており、攻撃者が特定の組織を狙って準備を進めていたことがわかる。
侵害をいち早く検知するための調査ポイント

イベントログとプロセスの異常を監視する
ViewStateの悪用を試みた痕跡は、Windowsのアプリケーションログに記録される。ソースが ASP.NET 4.0.30319.0 で、イベントID 1316のメッセージに注目する。
- 整合性チェック失敗時は「
Viewstate verification failed. Reason: The viewstate supplied failed integrity check.」と出る。誤った鍵が使われた可能性がある。 - 整合性チェックを通過したものの、ペイロードが無効だった場合は「
Viewstate verification failed. Reason: Viewstate was invalid.」と記録される。この場合、復号は成功しており、コード実行までは至らずとも攻撃の試行があったとみなせる。
Mandiantは、実際にこのログからBLUEBEAMに関連するペイロード文字列を復元できたとしている。
また w3wp.exe を親プロセスとする不自然な子プロセスにも警戒が必要だ。cmd.exe /c ... whoami powershell.exe といったコマンドが実行されていないか、継続的にモニタリングする。
ファイルの改ざんと異常なUser-Agentをつかむ
Webサーバーの公開ディレクトリ内にある .js .aspx .config ファイルについて、想定外の変更が加えられていないか定期的に確認する。特に、外部ドメインへのスクリプト読み込みや、業務と無関係なコードの追加がないかを重点的に調べる。
さらに、Webサーバーのアクセスログに現れるUser-Agent文字列にも特徴がある。Mandiantの調査では、2つの異なるブラウザ識別子が連結された異常な文字列が確認された。以下はその一例だ。
Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.2 (KHTML, like Gecko) Chrome/22.0.1216.0 Safari/537.2 Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.0.0 Safari/537.36このような連結されたUser-Agentは、通常のブラウザでは生成されない。攻撃ツールによる通信の痕跡として、ログ監視の有効な指標になる。
再発を防ぐための具体的な対策

この脆弱性の根本原因は、全インストールで鍵を共有していたことにある。したがって、最も重要な対策は、マシンキーを一意の値に切り替えることだ。
- マシンキーの再生成:各KnowledgeDeliverインスタンスで、暗号的に安全なランダム値を生成し、設定ファイルに反映する。共通鍵を無効化するには、これ以外の方法はない。
- アクセス制限の見直し:LMSがインターネット全体に公開されている必要がなければ、社内ネットワークや特定のIPアドレス範囲からのみ接続を許可する。
- 徹底的なインシデント調査:ログ監視やファイル整合性チェックを実施し、少しでも疑わしい兆候があれば、外部の専門家も交えて深く調査する。
Vupointブログの分析でも指摘されているとおり、テンプレートに埋め込まれた共通シークレットは、一見すると設定の手間を省く便利な仕組みに見える。しかし、ひとたび鍵が流出すれば、世界中のすべてのサーバーが一瞬で危険にさらされる。利便性と引き換えに、きわめて大きなリスクを抱え込む設計だったわけだ。
今回の事例は、ASP.NETに限らず、あらゆるWebアプリケーションの展開時において「鍵や認証情報は必ず環境ごとにユニークに生成する」という原則を再認識させるものだ。テンプレートや初期設定のまま本番運用に臨むことの危うさを、開発者と運用者の双方が改めて肝に銘じる必要がある。
この記事のポイント
- KnowledgeDeliverの全インストール共通のASP.NETマシンキーが、ViewState Deserialization攻撃の原因になった
- 攻撃者はメモリ内WebシェルBLUEBEAMを使い、サイト改ざんとCobalt Strike感染を連鎖させた
- イベントログやプロセス監視、異常なUser-Agentの検出が有効な調査指標になる
- 最も重要な対策は、各サーバーでユニークなマシンキーを生成し、共通鍵の状態を完全に解消すること
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

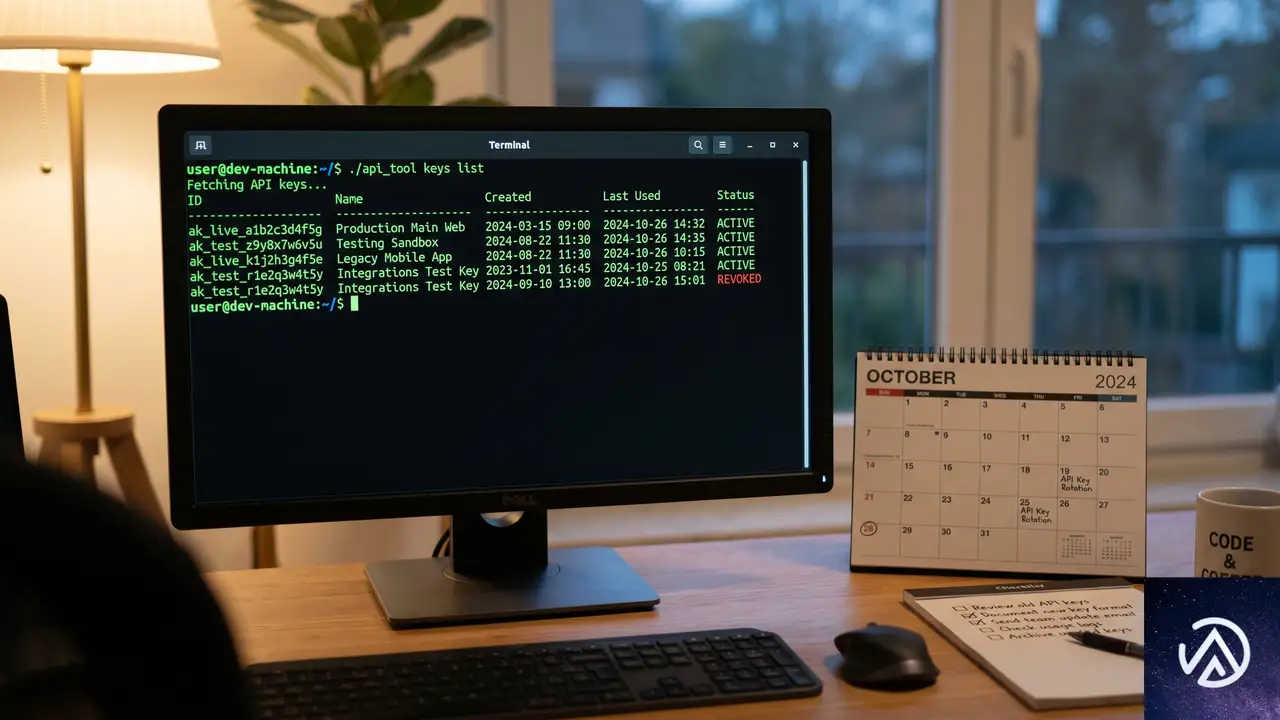
Google APIキーを守る3つの基本手順、悪用と高額請求のリスクを下げる
Google Geminiを含むAIサービスやGoogle Cloud APIを利用する上で、APIキーの安全な管理は避けて通れない課題だ。適切な対策を怠ると、キーの漏洩や悪用により、高額な請求やプロジェクト環境の侵害を引き起こす可能性がある。
APIキーは「使うのは簡単だが、安全でない方法で使うのも同じくらい簡単」とGoogle Cloud Blogの著者Leonid Yankulin氏は指摘する。この記事では、Googleが提供するAPIキーのリスクを大幅に下げるための、すぐに実践できる具体的な手順を解説する。
これらの対策の多くは、Googleに限らず他のサービスで発行されるAPIキーやプロダクトトークンにも応用可能だ。個人開発者から組織の管理者まで、キーの取り扱いを見直すきっかけにしてほしい。
Step 1. 新しいAPIキーは「隔離」と「制限」が大前提

APIキーを作成する際、最初からセキュリティを考慮しておくことで、後々のトラブルを未然に防げる。「とりあえず作成」して放置されている無制限のキーが、組織における最大のリスク要因の一つだ。
キーは専用プロジェクトで作成する
新しいAPIキーを生成する最初のルールは、他の目的に使っていない独立したGoogle Cloudプロジェクト内で作成すること。これにより、仮にキーが漏洩しても、被害がそのプロジェクトのリソースに限定される。
プロジェクトを分けることは、問題発生時の原因特定と影響範囲の調査を大幅に容易にする。本番環境と同じプロジェクトで実験用のAPIキーを発行するといった行為は避けるべきだ。
API制限で「できること」を絞る
APIキーを作成する際、デフォルトではAPI制限がかかっていない。これは、そのキーが有効化されているすべてのサービスにアクセスできる状態を意味する。Google Cloud Blogの著者は「制限のないキーを絶対に作るな」と強調する。
API制限を設定することで、キーがアクセスできるサービスを特定のAPIだけに絞り込める。たとえば、AI Studioで利用するなら「Gemini API」のみ、地図機能だけが必要なら「Maps API」だけに制限する。漏洩時の攻撃範囲を最小化する考え方だ。
注意すべき副次的なポイントとして、AI StudioやFirebaseなど間接的なUIからキーを作成した場合、意図しないAPI群が自動で許可されているケースがある。Firebase経由で作ったキーは24ものAPI(DatastoreやFirestore、Cloud SQLなど)へのアクセスが許可されるため、不要なものは手動で外す必要がある。
制限したいAPIが一覧に表示されない場合は、そのAPIが対象プロジェクトで有効化されていない可能性が高い。APIライブラリから事前に有効化しておく必要がある。
アプリケーション制限で「使う場所」を縛る
API制限が「どのサービスを使えるか」を制御するのに対し、アプリケーション制限は「どのアプリからキーを使えるか」を制御する。こちらも併用することで、セキュリティは飛躍的に高まる。
たとえばAI Studio専用のキーなら、許可するウェブサイトを aistudio.google.com に限定すれば、他のスクリプトや自動化ツールから大量のトークンを消費されるリスクを防げる。指定できる制限タイプは以下の4種類だ。
- ウェブサイト、許可するURLのリストを指定
- サービス(IPアドレス)、IPv4やIPv6アドレス、サブネットマスクで指定
- iOSアプリ、バンドルIDで指定
- Androidアプリ、パッケージ名と証明書フィンガープリントのペアで指定
注意点として、1つのキーに設定できるアプリケーション制限タイプは1種類だけ。複数のアプリ種別で利用する場合は、それぞれ専用のAPIキーを発行する。キーをアプリごとに分けておけば、利用状況の監視や侵害発生時の調査も容易になる。
ウェブサイト
https://aistudio.google.com自動化スクリプトからの呼び出し、不明なIPアドレスからのリクエスト、許可リストにないWebサイト
Step 2. APIキーは「誰でも使える」前提で保管する

APIキーの最大の特性は、特定の個人アカウントと紐づかない点にある。Google Cloud Blogの記事で「誰でも使える」と強調されているように、キー文字列を知っていれば誰でもその権限でAPIを呼び出せる。保管の安全性の重要性はAPI制限と同等だ。
「APIキーを絶対に、見えやすい場所に保存してはいけない」という基本ルールはシンプルだが、実際の開発現場ではしばしば破られている。ソースコードへのハードコードや、Gitリポジトリへの平文でのコミットは典型的なミスだ。
自社アプリケーションではSecret Managerを使う
Google Cloudを利用しているなら、Secret Manager(シークレットマネージャー)のような専用の機密情報管理サービスにキーを格納するのが鉄則だ。Secret Managerを使えば、APIキーをCloud RunやGKEの実行環境に安全に注入できる。
さらに保護レベルを上げたい場合は、キーを環境変数に渡すのではなく、アプリケーションコード内でSecret Managerから直接読み取る方式も選択肢になる。これによりランタイムメモリへの露出時間をさらに短縮できる。
外部アプリケーションではキーの取り扱いを事前調査する
サードパーティ製のツールやサービスにAPIキーを入力する場合、そのアプリケーションがキーをどのように保管し、通信しているかを確認する必要がある。
Webアプリケーションであれば、ブラウザの開発者ツールを使ってトラフィックを調査し、キーが暗号化されていない通信経路で送信されていないかを確認する。「Google AI Studioは暗号化されたローカルストレージを使用し、TLS暗号化チャネル経由でのみキーを送信する」とYankulin氏は具体例を挙げている。こうした設計を満たしていないツールへのキー提供は避けるべきだ。
異常を検知したら「即削除」、調査の手順も把握する

どんなに対策を施しても、キーが侵害される可能性はゼロにはできない。迅速な初動対応が被害を最小化する鍵を握る。Yankulin氏は「クレジットカードを無くしたときと同じように、まずキーを削除すること」と述べている。
Cloudコンソール、または gcloud services api-keys delete コマンドで即座にキーを無効化する。誤報だったと判明した場合でも、削除から30日以内であれば undelete コマンドで復元が可能だ。
侵害されたキーを特定する2段階調査
どのAPIキーが侵害されたか不明な場合は、以下の2段階で調査を進める。
第一段階、組織またはプロジェクト内のすべてのAPIキーを洗い出す。Cloudコンソールの「Asset Inventory」でリソースタイプを apikeys.Key に絞り込む方法と、gcloud services api-keys list コマンドを使う方法がある。組織全体を横断検索する場合は gcloud asset search-all-resources コマンドでJSON出力をフィルタリングする。
第二段階、API消費量のグラフを確認する。Cloud Monitoringの指標 serviceruntime.googleapis.com/api/request_count を使い、credential_id ラベルで特定のAPIキーIDに絞り込む。リクエスト数が異常に急増している場合、そのキーが悪用されている可能性が高い。
APIキーIDは、Cloudコンソールの「Credentials」ページでキーを選択した際のURL(/key/[KEY_ID] 部分)から、または gcloud services api-keys list --format='value(displayName,uid)' コマンドで確認できる。
1時間あたり数千リクエスト。日次グラフはなだらかで安定した波形
1時間あたり数十万リクエストに急増。短時間で不自然なスパイクが出現
Step 3. 日常的な「APIキー衛生管理」を習慣化する
エンジニアだけの話ではない。クラウドをかじり始めたばかりの個人ユーザーも、今すぐAPIキーの「衛生管理」を始めるべきだ。放置されたキーは、知らぬ間に悪用の温床となる。
Yankulin氏が推奨する即時実行すべきアクションは以下の5つだ。
- 自分が保有するすべてのAPIキーを洗い出す
- 使っていないキー、見覚えのないキーはすべて削除する(30日以内なら復元可能)
- 残すキーは、利用するAPIだけに制限し、可能ならクライアントも絞り込む
- 組織の管理者は
apikeys.googleapis.com/Keyの組織ポリシーを設定し、キーの乱立と制限設定の抜けを防ぐ - 定期的なキーのローテーション(再発行と差し替え)を検討する。ただし、既存キーを削除する前に、すべての利用箇所を特定して新しいキーに更新する周到さが必要だ
キーローテーションの際に「既存キーがどこで使われているのか把握しきれていない」という問題に直面するケースは多い。日頃からキーの利用箇所をドキュメント化しておくこと、そして新しいキーの発行時点から適切な制限をかけておくことが、結果的にローテーションのハードルを下げる。
この記事のポイント
- APIキーは「誰でも使える」クレデンシャル。見える場所に保管しないことが大前提
- 新規キー作成時は、API制限とアプリケーション制限を両方設定して攻撃の範囲を狭める
- 保管にはSecret Managerなど専用の機密情報管理サービスを使い、コードへのハードコードを避ける
- 使っていないキーや制限のないキーは即座に削除し、組織ポリシーで乱立を防ぐ
- 侵害が疑われる場合はクレジットカードと同じ感覚で「まず削除」。監視データで異常を検知する
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

GKE Agent Sandboxが一般提供開始。エージェント向け基盤Agent Substrateも発表
Google Cloudが2026年5月20日、エージェント実行環境「GKE Agent Sandbox」の一般提供(GA)を開始した。合わせて、超大量エージェントの高密度実行を目指す新たなOSSプロジェクト「Agent Substrate」を発表している。
2025年11月のKubeCon NAでプレビューが公開されて以降、Agent Sandbox上のサンドボックス数は5か月足らずで16倍以上に成長した。LangchainやLovableといった顧客がすでに数百万単位のエージェントを本番環境で動作させている。
自律的にコードを実行するAIエージェントにとって、インフラの安全性と起動速度は実用化の鍵となる。今回のGAで安定版APIが提供され、エージェント実行基盤としての成熟度が一段と上がった。
GKE Agent Sandbox GAの主要な機能強化点

GKE Agent SandboxはKubernetes上に構築されたOSSの実行環境だ。AIエージェントが信頼できないコードを安全かつ高速に実行するための基盤として設計されている。今回のGAでは、実運用で課題となるアイドル状態の効率化と、起動レイテンシの低減に焦点が当てられた。
Pod Snapshotによるアイドルリソースの削減
エージェントのワークロードは、短いバースト的な処理の後に長いアイドル時間が続くという特徴を持つ。従来のようにアイドル中もPodを起動したままにしておくと、コンピュートリソースを無駄に消費してしまう。
GKE Agent SandboxはPod Snapshot機能と統合されている。アイドル状態のエージェントワークロードを一時停止(サスペンド)し、リクエストが来たときに数秒で再開できる。Google Cloudの発表によれば、この仕組みで不要なコンピュートコストを大幅に削減できるという。
Pod Snapshotの最大の利点は、エージェントワークロード特有の「使うときだけ高速に起動したい」という要求に応えられる点だ。サスペンド状態からの復帰は数秒で完了するため、ユーザーの待ち時間を最小限に抑えられる。
ウォームプールによる低レイテンシプロビジョニング
エージェントのリクエストが来るたびに新しいサンドボックスを作成すると、コールドスタートによる数秒の遅延が発生する。この遅延はエージェントの応答性を損ない、ユーザー体験を悪化させる要因となる。
GKE Agent Sandboxは、サンドボックスAPIにウォームプールを統合した。あらかじめ準備されたサンドボックスレプリカをプールしておき、リクエスト発生時に即座に割り当てる仕組みだ。これにより、1クラスタあたり毎秒300のサンドボックスを割り当て可能で、割り当ての90パーセントが200ミリ秒以内に完了する。
ウォームプールのコスト最適化も考慮されている。プール内のレプリカは常時稼働しているが、スタンバイキャパシティバッファと統合することで、一部のサンドボックスをサスペンド状態で待機させられる。ウォームプールが枯渇した際には、この「コールドプール」から素早く補充され、大幅なコスト削減につながる。
gVisorとネットワークポリシーによる強固な隔離
セキュリティ面では、gVisorをネイティブサポートし、デフォルト拒否のKubernetesネットワークポリシーを採用している。gVisorはユーザースペースで動作するカーネルであり、ホストOSから隔離された環境を提供する。コンテナ内のプロセスがホストカーネルに直接アクセスできないため、悪意あるコード実行のリスクを大幅に低減できる。
さらにKata ContainersのようなOSSサンドボックスにも対応するプラグイン可能なインターフェースを備えている。利用者は自社のセキュリティ要件に合わせてカーネル隔離レベルを選択できる。
コンピュートの選択肢も広がった。Google Cloud独自のAxionプロセッサ上でAgent Sandboxを実行すると、同等のハイパースケーラークラウドプロバイダと比較して最大30パーセント優れた価格性能比を達成すると発表されている。
Agent Substrateがもたらす次の変革

エージェントワークロードは今後、数千万から数億インスタンス規模へとスケールアップしていく。同時に、人間の操作やイベントを待つアイドル時間もますます長くなる。カーネルとネットワークの隔離を維持しながら高密度にスケジュールするのは、既存のKubernetesコントロールプレーンでは限界が近づいている。
この課題に対してGoogle Cloudが発表したのが、新たなOSSプロジェクト「Agent Substrate」だ。
Kubernetesの限界を超える最小限のコントロールプレーン
Agent Substrateは、Agent Sandboxの安全なランタイムとSnapshot機能を中核に据えつつ、Kubernetesの制約を部分的に回避する最小限のコントロールプレーンを組み合わせる。標準のKubernetesが数千の長時間稼働サービスを扱うのに最適化されているのに対し、Agent Substrateは数百万単位のサブ秒ツール呼び出しの「チャタリング」に耐えられるよう設計されている。
新たな抽象化レイヤーを導入し、Kubernetes上で稼働するコンピュートキャパシティに対して、エージェントをリアルタイムに乗せたり外したりする。Google Cloudの発表では、従来のコントロールプレーンでは処理しきれない高頻度の短命ワークロードに対して、レイテンシを低減しつつスケールと効率を最適化できるとしている。
Agent Substrateの目標は、現在のコンピュートインフラの限界を押し広げることにある。一例として、エージェントの状態とスケジューリングが協調して動作するようデータの局所性をスケジューラの中核に組み込む構想も示された。オーバーヘッドを1ミリ秒単位で削り取るため、あらゆる可能性を探求する姿勢が打ち出されている。
Agent HarnessやAgent Executorとの関係
Agent Substrateは、単独で動作するものではなく、エージェントエコシステム全体の基盤レイヤーとして位置づけられている。Agent HarnessやAgent Runtime、さらにはGoogle Cloudが別途発表している分散エージェントランタイム「Agent Executor」プロジェクトを支える役割を担う。
Google Cloudのブログ記事では、Agent Substrateを「エージェントネイティブなインフラストラクチャの次の章」と表現している。Kubernetesが登場初期に多様なコントリビューターの知見を集めて成功したように、エージェントインフラも同じ転換点にあるという認識が示された。
この記事のポイント
- GKE Agent Sandboxが一般提供開始。安定版APIでエージェント実行の本番運用に対応
- Pod Snapshotでアイドル時のリソース消費を抑え、リクエスト時に数秒で復元可能
- ウォームプールにより毎秒300サンドボックスをサブ秒で割り当て。コスト最適化も統合
- 新OSSプロジェクトAgent Substrateは数百万規模の短命ワークロードに特化した設計
- Axionプロセッサ利用時に最大30パーセントの価格性能比向上を達成
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Gemini 3.5 Flash がVercel AI Gatewayで利用可能に。並列処理能力と推論機能が大幅向上
Googleの最新モデル「Gemini 3.5 Flash」が2026年5月19日からVercel AI Gatewayで利用可能になった。このモデルはコーディング能力と並列エージェント実行ループの性能が大きく向上し、複雑なタスクでも高い推論精度を発揮する。
AI Gatewayの統合APIを通じて呼び出せ、使用量の追跡やコスト管理、リトライやフェイルオーバーの設定も標準で備わっている。開発者は面倒な基盤管理なしに、最新のAIモデルを本番環境へ素早く組み込める。
この記事では、Gemini 3.5 Flash の進化点、AI Gateway での具体的な使い方、実装時の注意点までを整理する。
Gemini 3.5 Flash の概要と新モデルの位置づけ

Flash シリーズの進化
Gemini Flash シリーズは、Google が提供する軽量で応答速度に優れたAIモデル群だ。前世代のFlash 2.0と比べて、3.5 Flash では単なる速度向上にとどまらず、複数ステップのタスクを自律的に並列実行できるようになった点が大きな違いだ。
これにより、コーディングの効率化や、複数のAPIを同時に呼び出すようなエージェント型アプリケーションで強力なパフォーマンスを発揮する。
今回のアップデートで強化された点
- コーディング補完の精度向上
- 並列エージェント実行ループの大幅な最適化
- コア推論能力と命令追従性の改善
- マルチターン会話の一貫性向上
- 思考モード(thinking mode)での高品質な推論トレースの生成
並列エージェント実行ループの進化

並列化によるパフォーマンス向上
従来のFlashモデルは、一連のタスクを逐次的に処理する傾向があった。たとえばコードリファクタリングの際に「API呼び出しAの完了を待ってからAPI呼び出しBを実行する」といった流れになる。これに対し、3.5 Flash は複数の独立した処理を同時に並列実行する能力が格段に上がっている。
並列実行のメリットは、応答待ち時間の大幅な短縮と、システム全体のスループット向上だ。特にマイクロサービス間の連携や、複数の外部データソースを一括で処理する場面で効果を発揮する。
この比較はあくまで概念図だが、実際のアプリケーションでは複数の独立した処理を同時に走らせることで、体感速度やスループットが大きく改善される。
thinking モードと推論トレースの強化

thinking level の選択
Gemini 3.5 Flash はデフォルトで「medium」のthinking levelが設定されている。これは、応答の品質と生成速度、そしてコスト効率のバランスを取るための設計だ。より複雑な推論が必要な場合は high レベルに変更することも可能で、その場合は推論プロセスがより深く行われる。
たとえば、コードのリファクタリングや多段階の意思決定が必要なタスクでは、thinking level を high に設定することで、AIが問題をより細かく分解し、質の高い答えを導き出す。
マルチターンコヒーレンスと複雑タスク
3.5 Flash では、マルチターンの会話における一貫性も改善されている。以前のFlashモデルに比べて、前のやり取りを適切に保持しながら、矛盾のない回答を返す精度が向上している。これにより、長時間のコード生成や、会話型のエージェントアプリケーションでも安定した挙動が期待できる。
複雑なタスクでは「thinking traces(思考の痕跡)」がより詳細に出力されるため、モデルがどのような過程で結論に至ったかを検証しやすい。デバッグや品質管理の面で大きなメリットだ。
Vercel AI Gateway の機能とメリット

統合APIとプロバイダールーティング
Vercel AI Gatewayは、複数のAIプロバイダーを統一的なインターフェースで利用できるプラットフォームだ。開発者はプロバイダーごとに異なるAPIキー管理やエンドポイントを意識することなく、model の指定だけでモデルを切り替えられる。
さらに、AI Gatewayはインテリジェントなルーティング機能を備えており、特定のプロバイダーに障害が発生した場合に自動で別のモデルへフェイルオーバーしたり、リクエストをリトライしたりできる。これにより、単一プロバイダーを直接使うよりも可用性が向上する。
観測性とカスタムレポート
AI Gatewayには、使用量の追跡やコスト分析のためのカスタムレポート機能が組み込まれている。プロジェクトごと、環境ごとにAPI呼び出し回数やトークン消費量を可視化できるため、予算管理やボトルネックの発見に役立つ。
また、AI SDK Observability との連携により、モデルの応答時間やエラーレートを詳細に監視できる。Bring Your Own Key にも対応しており、自社で契約したAPIキーをAI Gateway経由で安全に利用できる点も企業ユースに適している。
AI SDK での実装方法と注意点

コード例
AI SDK を用いて Gemini 3.5 Flash を呼び出すには、以下のように streamText 関数を使う。モデル名に google/gemini-3.5-flash を指定し、必要に応じて thinking level を設定する。
import { streamText } from 'ai';
const result = streamText({
model: 'google/gemini-3.5-flash',
prompt: 'Refactor this service to run API calls in parallel.',
providerOptions: {
google: {
thinkingConfig: {
thinkingLevel: 'high',
includeThoughts: true,
},
},
},
});thinking level は 'medium'(デフォルト)と 'high' から選択でき、複雑なタスクでは 'high' を指定すると良い。なお、includeThoughts: true にすると推論過程のトレースもレスポンスに含められる。
サポート外のパラメータと制約
Gemini 3.5 Flash では temperature、topP、topK、thinking_budget といったパラメータはサポートされていない。以前のモデルでこれらの値を調整していた場合は、デフォルトの挙動に任せるか、他のモデルを検討する必要がある。
特に thinking_budget が使えない点は、推論にかかるコストを細かく制御したい場合に注意が必要だ。そのぶん thinking level の切り替えで大まかな品質とコストのバランスを取る設計になっている。
この記事のポイント
- Gemini 3.5 Flash は並列エージェント実行ループの性能が大幅に向上し、コーディングや複数API呼び出しに強い
- デフォルトで medium の thinking level を採用し、品質・速度・コストのバランスを最適化
- Vercel AI Gateway によって統合API、リトライ、フェイルオーバー、観測機能をフル活用できる
- temperature や topP などの一部パラメータは非対応のため、移行時には注意が必要
- AI SDK 経由で数行のコードで導入可能、並列化のメリットをすぐに享受できる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Vercelがソースマップ保護機能を発表、本番環境のコード露出を防止
Vercelは2026年5月、本番環境のソースマップを安全に配信する新機能「Protected Source Maps」をリリースした。ブラウザが読み取る .map ファイルを Vercel Authentication の背後に置き、開発チームだけがアクセスできる仕組みだ。これにより、デバッグ情報を必要な人間にだけ提供し、それ以外の第三者には 404 を返す。
フロントエンドのバンドルは本番ビルドで圧縮・ミニファイされるため、可読性を保つにはソースマップが欠かせない。しかし従来は、そのソースマップが認証なしで公開されてしまい、コードの内部ロジックやコメントが誰でも閲覧できる状態だった。Protected Source Maps は、このセキュリティリスクを根本的に解決する。
ソースマップがなぜ重要か

ミニファイとデバッグのジレンマ
本番サイトの JavaScript や CSS は、ファイルサイズ削減のためにミニファイされる。変数名を短縮し、空白やコメントを取り除く処理だ。ところが、エラーが発生したとき、ブラウザのコンソールには圧縮後のコードしか表示されず、スタックトレースが「at a.a (bundle.js:1:2345)」のように読めなくなる。デバッグがほぼ不可能になるのだ。
この問題を解決するのがソースマップである。ミニファイ元のファイル名や行番号、元の変数名を記録した .map ファイルとして生成し、ブラウザがそれを使って元のソースコードを復元する。つまり、ビルド後の難読コードを、開発時の読みやすいコードに戻す「翻訳辞書」のような役割だ。
ソースマップの仕組み
ソースマップは通常、ミニファイされたファイルの末尾に //# sourceMappingURL=app.js.map というコメントを挿入することでブラウザに通知される。ブラウザがこのコメントを見つけると、対応する .map ファイルを別途リクエストし、デベロッパーツール上でオリジナルのソースコードを表示する。ここまでは開発者にとって日常的な光景だ。
しかし、本番環境でこの .map ファイルが認証なしに取得できると、第三者が容易にソースコードを読めてしまう。公開を想定していないコメントや、内部のビジネスロジックがダダ漏れになるリスクがある。
本番ソースマップが晒されてきたリスク

従来の典型的な対策は、ビルド時にソースマップを生成しないか、本番サーバーにアップロードしないというものだった。しかし、それでは本番環境で発生したエラーの調査が困難になる。また、サーバー側で特定の IP アドレスや VPN 経由のみアクセスを許可する方法もあるが、設定が複雑で、動的に変わるチームメンバーの管理には向かない。
実際に、JavaScript フレームワークの設定ミスによってソースマップが公開され、内部の API キーやテスト用のパスワードが漏えいした事例も報告されている。ソースマップは開発者にとって便利な一方、扱いを誤ると大きなセキュリティホールになりうる。
上の図は、認証がない場合と今回の保護機能を適用したあとの応答の違いを示している。従来は誰でも .map を取得できたが、Protected Source Maps を有効にすると、チーム外のリクエストには 404 Not Found が返る。
Protected Source Maps の動作と設定

Vercel Authentication によるアクセス制限
この機能の核は、プロジェクトの .map ファイルが Vercel Authentication で保護される点にある。通常、Vercel Authentication はデプロイプレビューや特定のパスをチームメンバーだけに公開するために使われる認証フレームワークだ。今回これがソースマップにも適用された。
つまり、ブラウザがソースマップをリクエストしても、Vercel のエッジネットワークが認証情報を確認する。チームの開発者であれば、普段から使っているブラウザのセッションでそのまま .map ファイルを取得できる。しかし、チーム外の人物や認証されていないブラウザからのリクエストには 404 が返るため、存在そのものを隠蔽する効果もある。
新規プロジェクトではデフォルトで有効、既存も後から移行可能
Vercel は、新規に作成するプロジェクトでは Protected Source Maps をデフォルトで有効にした。これにより、これからデプロイするプロジェクトは意識せずとも本番ソースマップが保護される。既存のプロジェクトについては、管理画面の「Settings」〜「Deployment Protection」からスイッチをオンにするだけで有効化できる。再デプロイも不要だ。
この設定変更は即座にエッジネットワーク全体に反映される。認証なしの .map リクエストはその瞬間から 404 になるため、段階的な移行作業を必要としない。
開発フローへの影響と注意点

セキュリティとデバッグ効率の両立
Protected Source Maps を導入しても、認証済みの開発者には従来通りソースマップが提供される。つまり、ブラウザのデベロッパーツールでエラーを追う際に元のコードが見えなくなることはない。本番環境で発生した問題を調査するチームにとって、利便性は一切損なわれない。
一方で、認証されていないサードパーティには 404 が返るため、ソースコードの漏えいリスクを大幅に低減できる。特に、エラーログに .map ファイルの URL が含まれていた場合でも、外部からはアクセスできない。
導入時に確認すべき点
この機能を使ううえで、いくつか注意点がある。まず、Vercel Authentication はブラウザのセッションを利用するため、開発者がログイン状態である必要がある。シークレットウィンドウやチームアカウント外のブラウザからはデバッグできない点に注意が必要だ。
また、CI/CD ツールなど自動化された環境でソースマップを処理する場合は、Vercel の API トークンを使って認証を通すか、あるいは別途プライベートなストレージにマップをアップロードする運用を検討してもよい。ただし、多くのケースでは開発者のブラウザからのリクエスト以外にソースマップが必要になるシチュエーションは少ないため、まずは Protected Source Maps をオンにして、必要に応じて調整するのが現実的だ。
この記事のポイント
- Vercel が Protected Source Maps をリリース、本番ソースマップをチーム限定に
- ブラウザからの
.mapリクエストは Vercel Authentication で保護される - 認証なしのアクセスには
404 NotFoundを返却、コードの露出を防止 - 新規プロジェクトはデフォルトで有効、既存プロジェクトも管理画面から即時有効化可能
- 導入後も開発者のデバッグ体験は変わらず、セキュリティと利便性を両立
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Amazon RedshiftにGraviton搭載のRGインスタンス登場、データレイククエリエンジンも統合
Amazon Redshiftに新しいインスタンスファミリー「RG」が追加された。AWSのArmベースプロセッサ「Graviton」を採用し、データウェアハウスのワークロード処理を従来のRA3インスタンスと比較して最大2.2倍高速化する。vCPUあたりの価格は30%引き下げられ、分析コストの大幅な圧縮が見込める。
さらに、このRGインスタンスではデータレイクへのSQLクエリ実行機能がクラスタノードに統合された。Apache Icebergテーブルへのクエリは最大2.4倍、Apache Parquetへのクエリは最大1.5倍高速化している。これまで別途必要だったRedshift Spectrumと、1TBあたり5ドルのスキャン料金が不要になる点も見逃せない。
BI(ビジネスインテリジェンス)ダッシュボードやAIエージェントによる大規模なクエリ実行が日常化する中、今回の刷新はパフォーマンスとコストの両立をこれまで以上に高い水準で実現するものだ。
RGインスタンスの概要と主要な性能向上

このデモは従来のRA3構成と新RG構成の違いを視覚化したものだ。RGインスタンスではデータレイククエリ機能が完全に統合され、外部のSpectrum層に依存しないアーキテクチャに変わっている。
Gravitonプロセッサがもたらす価格性能比の改善
RGインスタンスの中核にあるのは、AWSが設計したArmアーキテクチャのカスタムプロセッサ「Graviton」だ。x86系のチップと比べて電力効率が高く、同じ電力あたりの処理量を引き上げられる特徴がある。AWSのサービスにおけるGraviton採用はEC2やRDSなどで既に広がっており、Redshiftでもその恩恵を受けられるようになった。
具体的なインスタンスタイプとしては、エントリー向けの rg.xlarge(4vCPU、32GBメモリ)と、本番ワークロード向けの rg.4xlarge(16vCPU、128GBメモリ)が用意された。従来の ra3.xlplus から rg.xlarge への移行では、vCPU数とメモリ容量は同等だが処理性能自体が大きく向上する。一方、ra3.4xlarge から rg.4xlarge への移行ではvCPU数が12から16へ約1.33倍、メモリも96GBから128GBへと拡張され、単純なスペック面でも上積みがある。
AWS News Blogの記事によれば、これらの新インスタンスはデータウェアハウス処理でRA3比最大2.2倍の性能を達成しているという。企業が日常的に利用するBIダッシュボードの応答速度や、ETL処理のバッチジョブ実行時間が大幅に短縮される計算だ。
データレイククエリエンジン統合の実質的な意味

RGインスタンスで最も構造的な変化が起きたのは、データレイククエリの実行方式だ。これまではS3に置かれたデータレイクに対してSQLで分析する際、Redshift Spectrumという別のサービス層を経由する必要があった。このSpectrum層はクラスタの外部で動作するため、VPCの境界を越えたデータのやり取りが発生し、1TBあたり約5ドルの追加スキャン料金が積み上がる仕組みだった。
Spectrumが不要になったことで変わる運用とコスト
RGインスタンスでは、データレイクへのクエリをクラスタ上のノードで直接実行する。Spectrum層を経由しないため、クエリがVPCの内側に留まり、IAMロールも既存のものをそのまま使える。セキュリティ境界がシンプルになるだけでなく、データレイク利用時の通信レイテンシも低減する。
コスト面では、Spectrumのスキャン料金がゼロになる影響が大きい。例えば月間10TBのデータレイクをスキャンするワークロードの場合、Spectrumだけで月50ドルの追加コストが発生していた。RGインスタンスへの移行後は、このコストが完全に消える。データレイク分析の規模が大きい企業ほど、削減額は積み上がる計算だ。
既存の外部テーブルやスキーマ定義、クエリ構文はそのまま動作するため、アプリケーションコードの修正は不要だ。移行に伴う手間を最小限に抑えつつ、性能向上とコスト削減の両方を手に入れられる設計になっている。
AIエージェント時代を見据えた設計思想

今回のRGインスタンス投入の背景には、AIエージェントによるデータウェアハウス利用の急増がある。自律的に目標を追求するAIエージェントは、人間のアナリストとは比較にならない頻度でクエリを発行する。AWS News BlogのChanny Yun氏は、AIエージェントのクエリ量が「典型的な人間の利用規模を矮小化する」と表現している。
大量の低レイテンシSQLクエリを安定的に処理するには、1クエリあたりのコストを大幅に下げつつ、応答速度も維持しなければならない。vCPU単価で30%のコストダウンを実現しつつ、処理そのものを高速化したRGインスタンスは、まさにこの要求に応える製品だと言える。2026年3月に発表された新規クエリの最大7倍高速化と組み合わせることで、AIエージェントがリアルタイムにデータを参照しながら判断するワークロードにも耐えうる基盤が整った。
移行手順と現在の利用可能リージョン

RGインスタンスへの移行は、AWSマネジメントコンソール、CLI、APIのいずれからでも実行できる。データレイククエリエンジンはデフォルトで有効化されており、クラスタ作成後すぐに統合環境を利用できる。
移行パスは大きく2つある。1つ目は弾力的なリサイズで、互換性のある構成であれば10〜15分のダウンタイムでインプレース移行が完了する。2つ目はスナップショットと復元で、既存のRA3クラスタからスナップショットを取得し、RGインスタンスの新規クラスタとして復元する方法だ。移行時に構成を変更したい場合に適している。
2026年5月時点で、RGインスタンスは以下のAWSリージョンで利用可能だ。米国東部(バージニア北部、オハイオ)、米国西部(北カリフォルニア、オレゴン)、アジアパシフィック(香港、ハイデラバード、ジャカルタ、マレーシア、メルボルン、ムンバイ、大阪、ソウル、シンガポール、シドニー、台湾、東京)、カナダ(中部)、欧州(フランクフルト、アイルランド、ミラノ、ロンドン、パリ、スペイン、ストックホルム)、南米(サンパウロ)と、主要リージョンをほぼ網羅している。東京リージョンも含まれているため、国内のワークロードにも即座に適用可能だ。
実務者が押さえるべき導入判断のポイント

RGインスタンスは確かに魅力的だが、導入にあたってはいくつか確認すべき点がある。まず、オンデマンドインスタンスとリザーブドインスタンスの両方が提供されているため、長期的な利用が見込めるならリザーブドインスタンスによるコスト最適化を検討したい。AWS料金計算ツールで自社のワークロードパターンに基づいたシミュレーションを行うのが確実だ。
次に、Spectrumに依存していた既存のETLパイプラインや外部ツールとの統合に問題がないか、事前に検証環境でテストすることを推奨する。クエリ構文や外部テーブル定義は互換性が保たれているが、パフォーマンス特性が変わるため、実行計画の変化によって一部のクエリで想定外の挙動が生じる可能性はゼロではない。
最後に、データレイクとデータウェアハウスの両方を1つのインスタンスファミリーで処理できるようになったことで、アーキテクチャの簡素化と運用負荷の低減が見込める。特にデータレイクの分析規模が拡大傾向にある企業や、AIエージェントの本格導入を検討しているチームにとって、RGインスタンスへの早期移行は競争力の源泉になりうる。
この記事のポイント
- RGインスタンスはGraviton搭載によりRA3比最大2.2倍の性能とvCPU単価30%削減を両立
- データレイククエリエンジンが統合され、Spectrumと1TBあたり5ドルのスキャン料金が不要に
- Apache Icebergで最大2.4倍、Parquetで最大1.5倍のクエリ高速化を達成
- BIダッシュボードやAIエージェントによる大量クエリを低コストで処理できる基盤が整った
- 移行は弾力的リサイズまたはスナップショット復元で対応、既存クエリの修正は不要
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験