

CSS border-shapeプロパティの全容、装飾が形状に追従する新機能
shape() と corner-shape の復習

border-shape を理解するには、まず土台となる shape() 関数と corner-shape プロパティを押さえておくとスムーズだ。いずれも CSS で形状を扱うための新しい道具であり、特に shape() は 2026 年に Baseline(主要ブラウザで広く使える状態)に到達したばかりである。
shape() 関数の基本
shape() は SVG のパス構文を CSS に取り込む関数だ。clip-path や offset-path の値として使う。従来の path() に比べて CSS ネイティブな記述ができ、直感的に複雑な図形を定義できる。たとえばハート形、星形、波線など、従来は polygon() などで苦労していた形状も、少ないコードで表現可能になった。
CSS-Tricks の記事では、shape() に関する全4回のシリーズ解説と、SVG パスを shape() に変換するオンラインコンバーターも公開されている。これにより、既存の SVG 図形を CSS 形状として手軽に流用できるようになった。
corner-shape プロパティの概要
corner-shape は要素の角の形状を変えるプロパティだ。border-radius と組み合わせて使う。値には round(丸)、scoop(えぐり)、bevel(面取り)、notch(切り欠き)、squircle(超楕円)といったキーワードを指定する。squircle は iOS のアイコンなどで見られる、丸みを帯びつつ四角さも残した独特の曲線だ。
corner-shape は単なる角の整形にとどまらず、三角形や菱形、六角形といった CSS のみの図形作成にも使える。何より重要なのは、角を変形させても border や box-shadow がその形状に追従することだ。これこそが border-shape の布石となる考え方である。
border-shape の基礎:clip-path との違い

border-shape の構文と基本動作
border-shape は要素の形状を定義するが、clip-path とは根本的な動作が異なる。clip-path は要素を「切り抜く」(クリッピング)。その結果、border や box-shadow などの装飾も一緒に切り取られ、形状に沿わない。一方、border-shape は要素を「変形させる」(シェイピング)。装飾は新しい形状に沿って描画される。
構文は clip-path とほぼ同じで、shape()、polygon()、circle()、inset() などを受け取る。さらに、2つの値を指定する「フィルモード」も用意されている。最初の値が外側の境界、2番目の値が内側の境界となり、その間を border で塗りつぶす動きだ。
/* 1 値のストロークモード:border が形状をなぞる */
.shape {
border: 8px solid #1976d2;
border-shape: shape("M ...");
}
/* 2 値のフィルモード:境界の間を border で塗る */
.cutout {
border: 12px solid #e74c3c;
border-shape: inset(0) shape("M ...");
}装飾が追従する仕組みを図で見る
このデモは概念を視覚化したイメージだ。実際の border-shape は Chrome で確認できる。clip-path と異なり、星形の頂点やくぼみにぴったり沿った border が手軽に得られる。
border-shape のもう一つの利点は、border-radius を考慮する必要がない点だ。要素が丸められた矩形でなくなれば、角丸の概念自体が不要になる。代わりに形状そのもので角の挙動を制御できる。
ボーダーだけの形状を作る(Border-Only Shapes)

border-shape のわかりやすいユースケースが「輪郭だけの形状」だ。要素の背景を透明にし、border だけを設定するだけで、ハートや星、花、波線といったアウトライン図形を CSS のみで描ける。
.border-only {
background: transparent;
border: 8px solid #e74c3c;
border-shape: shape("..."); /* ハート形などのパス */
}この例も概念のイメージである。実際の border-shape なら、頂点や曲線がより精密に再現される。従来は複数の疑似要素や複雑な box-shadow の重ね合わせが必要だった表現を、数行の CSS で実現できるのが大きな魅力だ。
切り抜き形状とレイアウトの応用

2つの形状値で作る切り抜き
border-shape に inset(0) と任意の形状を組み合わせると、矩形の内側に図形の穴が開いたような「切り抜き」デザインが作れる。これはフィルモードと呼ばれ、外側形状と内側形状の差分を border の領域として塗りつぶす。
.cutout {
border: 12px solid #1976d2;
border-shape: inset(0) circle();
}上図は border-shape のフィルモードを静的に再現したものだ。実際には、border-color や border-width を変えるだけで、動的に切り抜き形状の装飾を調整できる。
ハートや星を使った複合形状
円だけでなく、shape() で定義したハートや星形を内側形状に指定すれば、さらに凝ったデザインが可能だ。たとえば、矩形のカードの中にハート形の窓が空いたような装飾、ポリゴン型のフレームに星形が浮かぶ背景など、CSS だけで容易に作れるようになる。
はみ出し装飾と部分装飾

border-shape は要素の境界を超えて装飾を拡張することもできる。形状を要素の外側に大きく取れば、背景が画面幅いっぱいに広がるブレイクアウト効果を border の太さだけで演出できるのだ。
.breakout {
border: 40px solid #ff9800;
border-shape: inset(0 -100vw) circle(0);
}border-shape では border を画面外まで伸ばせるため、従来の CSS グリッドの「ブレイクアウト」テクニックよりはるかに直感的に、セクションの背景を拡張できる。
テキストに寄り添う部分装飾
shape() 関数の緻密なパス指定と組み合わせれば、テキストの特定の単語にだけ下線を引く、見出しの左端にのみ斜めの背景を付ける、といった部分装飾も可能になる。border-shape は要素全体を変形しつつ、装飾の範囲を自由にコントロールできるため、デザインの表現力が格段に向上する。
アニメーションと次の一手

border-shape はアニメーションもサポートしている。形状を動的に変えたり、border-width を操作したりすることで、多彩なインタラクションを追加できる。
3コマで見る形状アニメーション
以下のデモは、ホバーで円が星形に変化するアニメーションを静的に示したものだ。実際には約 0.5 〜 1.5 秒かけて連続的に変化する。
この変化を border-shape 上で行えば、border や影も一緒に変形するため、よりリッチなエフェクトが可能になる。他にも、border-width を 0 から太くすることで、ホバー時に形状が浮かび上がるリビール効果も実装できる。
実践的なテクニック集
CSS-Tricks の記事では、以下のような応用例も紹介されていた。
- ナビゲーションメニューで、手描き風の下線がホバーアイテムにスライドする
- コンテンツボックスの周囲を電気が走るようなフレームで囲む(タッチデバイスでも安全)
- border のみで構成されたローディングスピナー
- ドラッグ可能な円をつなぐ曲線が、距離に応じて伸び縮みする
いずれもこれまでは JavaScript や SVG を駆使しなければ実現が難しかった表現だ。border-shape と shape() を習得すれば、CSS だけで多くの装飾を完結できるようになる。
この記事のポイント
- border-shape は要素の形状を変えつつ、border や box-shadow を形状に追従させるプロパティ
- clip-path と違い、装飾が失われず、輪郭だけの形状や複雑なフレームが容易に作れる
- 2値指定のフィルモードで切り抜き効果、形状を広げてブレイクアウト背景も実現可能
- アニメーションや部分装飾にも対応し、CSS 表現の幅を大きく広げる
- 2026年7月現在 Chrome のみの先行実装だが、今後の標準化と普及に注目

・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

CSS疑似クラスでJavaScript代用、状態監視の全貌とevent-triggerの将来像
CSSは状態を追跡するための仕組みを着実に増やしている。かつてはJavaScriptでしか扱えなかったUIの変化を、疑似クラスだけで表現できる場面が広がっているのだ。
:hoverや:focusといった基本的なものから、:autofillや:volume-lockedのような新しい疑似クラスまで、その数は増え続けている。これらをJavaScriptイベントリスナーと比較しながら整理すると、CSSの設計思想がより明確に見えてくる。
ポインター系疑似クラス、UI反応の基本
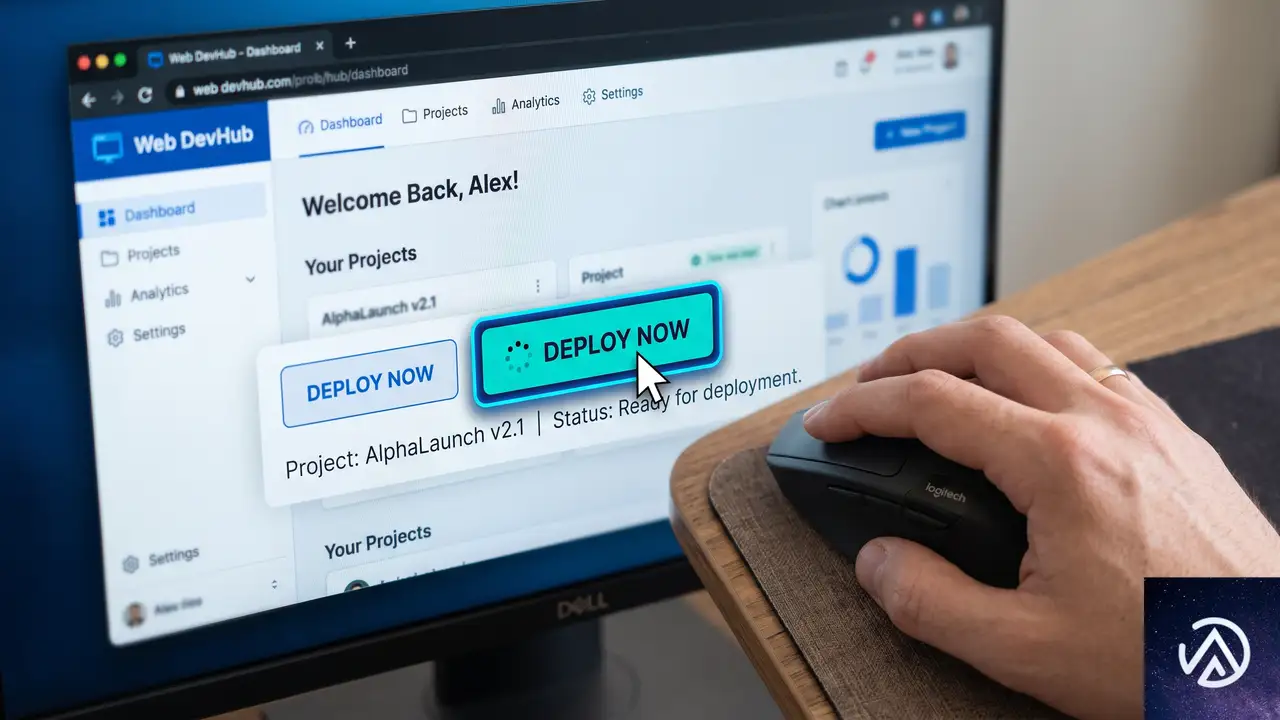
マウスやタッチ操作に反応する疑似クラスは、ウェブデザインの基本だ。:hoverはpointerenterからpointerleaveまでの継続的な状態を表し、:activeは押下中の瞬間を捉える。これらは単なる一時的な出来事ではなく、ブラウザが認識する「状態」として設計されている。
:hoverと:activeの本質
CSS-Tricksの著者Carlo Daniele氏は、疑似クラスが「イベントではなく状態を追跡する」点を強調している。:hoverはpointerenterとpointerleaveという2つのJavaScriptイベントの間を継続的に監視する状態であり、:activeはpointerdownとpointerupの間の押下状態だ。この違いを理解すると、CSSとJavaScriptの適切な役割分担が明確になる。
上記のデモは静的な比較だが、実際の:hoverはカーソルが要素に乗っている間だけ継続する。JavaScriptではpointerenterとpointerleaveを個別に監視する必要があるが、CSSなら1行のセレクタで完結する。この簡潔さがCSSの強みだ。
pointer-eventsプロパティで反応を制御する
pointer-events: noneを指定すると、その要素はポインター関連のイベントを一切発火しなくなる。CSSで直接イベントの発生を抑制できる点は、JavaScriptでpreventDefaultを行うのとは異なる設計思想だ。装飾的なオーバーレイや無効化されたボタンなど、視覚的に存在するが操作対象ではない要素に有効な手法である。
フォーカス系疑似クラス、アクセシビリティの根幹

フォーカス管理はユーザビリティとアクセシビリティの両面で重要だ。CSSの疑似クラスは、JavaScriptのfocus/blurイベントよりも直感的にフォーカス状態をスタイリングできる。
:focusと:focus-visibleの使い分け
:focusは要素がフォーカスを受け取った瞬間に発動するが、マウス操作でもキーボード操作でも一律に適用される。一方、:focus-visibleはブラウザのヒューリスティック(経験則)に基づき、フォーカスインジケーターを表示すべきかどうかを判断する。キーボード操作時にはアウトラインを表示し、マウスクリック時には非表示にする、といった制御がCSSだけで可能だ。
JavaScriptで同等の処理を書く場合、:focus-visible疑似クラスをmatchMediaで問い合わせる必要があるが、CSSならセレクタに:focus-visibleを追加するだけで済む。コード量の差は一目瞭然である。
:focus-withinと:has()の比較
:focus-withinは子孫要素がフォーカスを持っている場合に、親要素をスタイリングできる。フォーム全体をハイライトしたいときに便利だ。:has(:focus)も機能的には同等だが、:has()はより汎用的な「条件付き親セレクタ」として設計されており、フォーカス以外の条件にも対応できる。どちらを使うかは文脈次第だが、フォーカス特化の:focus-withinのほうが意図は明確になる。
このように、子要素のフォーカス状態を親要素のスタイルに反映させる仕組みは、JavaScriptでDOMトラバーサルを書くよりも圧倒的にシンプルだ。
フォーム系疑似クラス、バリデーションをCSSで扱う
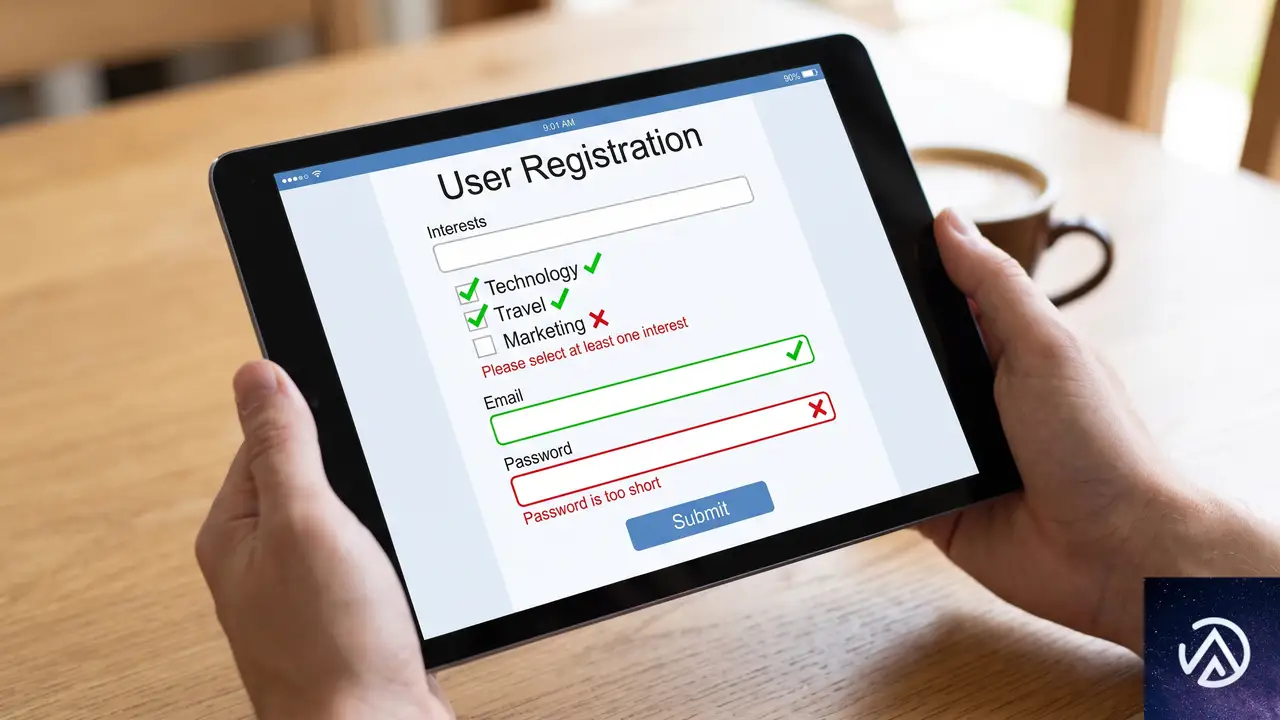
フォームの入力チェックはウェブ開発の定番だが、CSSの疑似クラスを使えば、視覚的なフィードバックの大部分をJavaScriptなしで実装できる。:validや:invalidはもちろん、:user-validや:autofillといった新しい疑似クラスも登場している。
:checkedで切り替えUIを実装する
:checkedはチェックボックスやラジオボタンの選択状態を追跡する。JavaScriptのchangeイベントと異なり、CSSセレクタとしてスタイルに直接結びつく。CSS-Tricksの著者Carlo Daniele氏も指摘しているように、CSS疑似クラスは多くの場合、2つのJavaScriptイベントの間の状態を表現するが、時には条件分岐ロジックそのものを代替する。
この切り替えはJavaScriptのchangeイベントでcheckedプロパティを判定するのと同等だが、CSSではスタイルシート内のセレクタで完結する。コードの見通しが良くなる点が大きな利点だ。
:user-validと:autofill、ユーザー体験を高める新しい疑似クラス
:validや:invalidはページ読み込み直後から評価されるため、未入力の必須フィールドが即座に赤く表示される問題があった。:user-validと:user-invalidは、ユーザーが実際に値を入力しフォーカスを外すまで評価を遅延させる。JavaScriptのchangeイベントに近い挙動だ。
:autofillはブラウザの自動入力機能を検出するJavaScriptイベントが存在しない中で、CSSだけで自動入力されたフィールドをスタイリングできる貴重な手段である。パスワードマネージャーによる自動入力を視覚的に識別したい場合に実用的だ。
JavaScriptで同等の処理を実装する場合、checkValidity()メソッドやValidityStateオブジェクトを使うことになる。フォーム送信時に全体を検証するケースではJavaScriptが適しているが、入力中のリアルタイムフィードバックはCSSの疑似クラスに任せるほうが合理的だ。
メディア要素疑似クラス、動画と音声の状態をスタイリングする
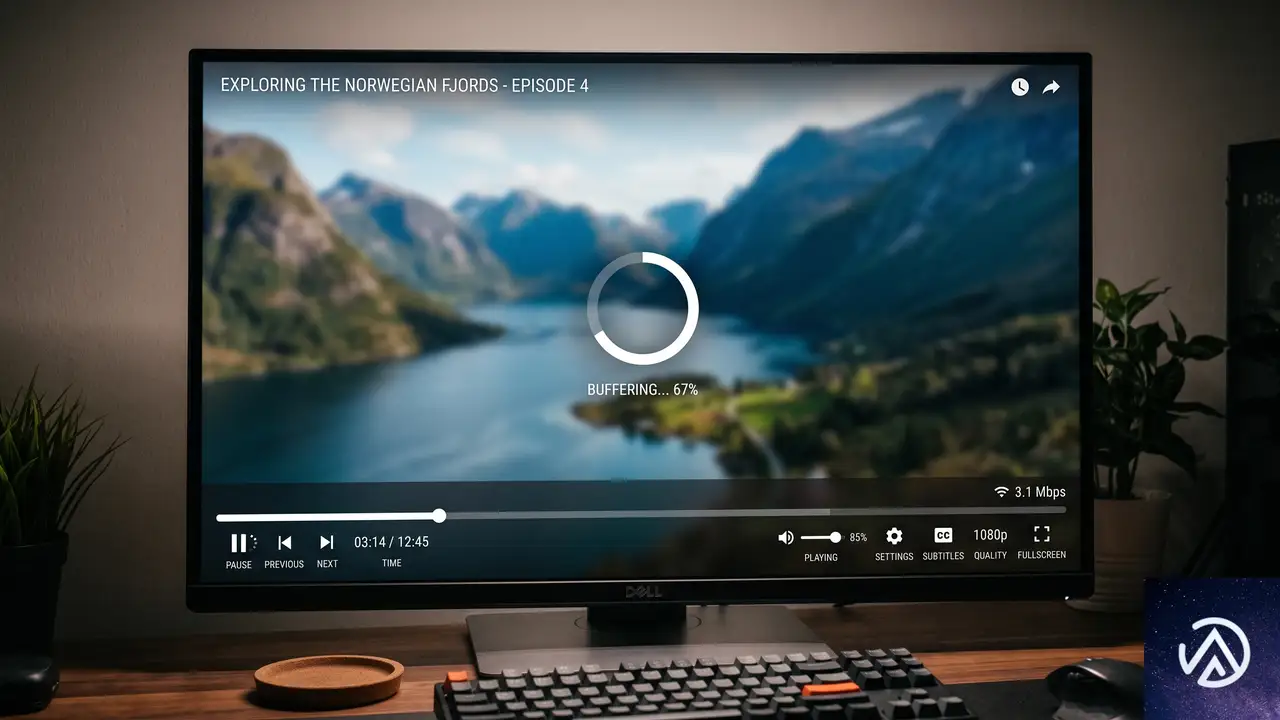
HTML5の<audio>要素や<video>要素は、これまでJavaScriptで状態を監視しなければカスタムコントロールを作成できなかった。しかし、CSSのメディア要素疑似クラスが整備されつつあり、状況は変わりつつある。これらの疑似クラスはInterop 2026の対象にもなっており、ブラウザ間の相互運用性の向上が期待されている。
:volume-lockedは特に興味深い。JavaScriptで音量ロックを検出するには、ダミーのvideo要素を生成してvolumeを設定し、その値が反映されたかどうかを確認するという回りくどい方法が必要になる。CSSなら:volume-locked疑似クラスひとつで完結する。ブラウザ側の制約をCSSが抽象化してくれる好例だ。
インタラクティブ要素疑似クラス、ポップオーバーとダイアログの制御
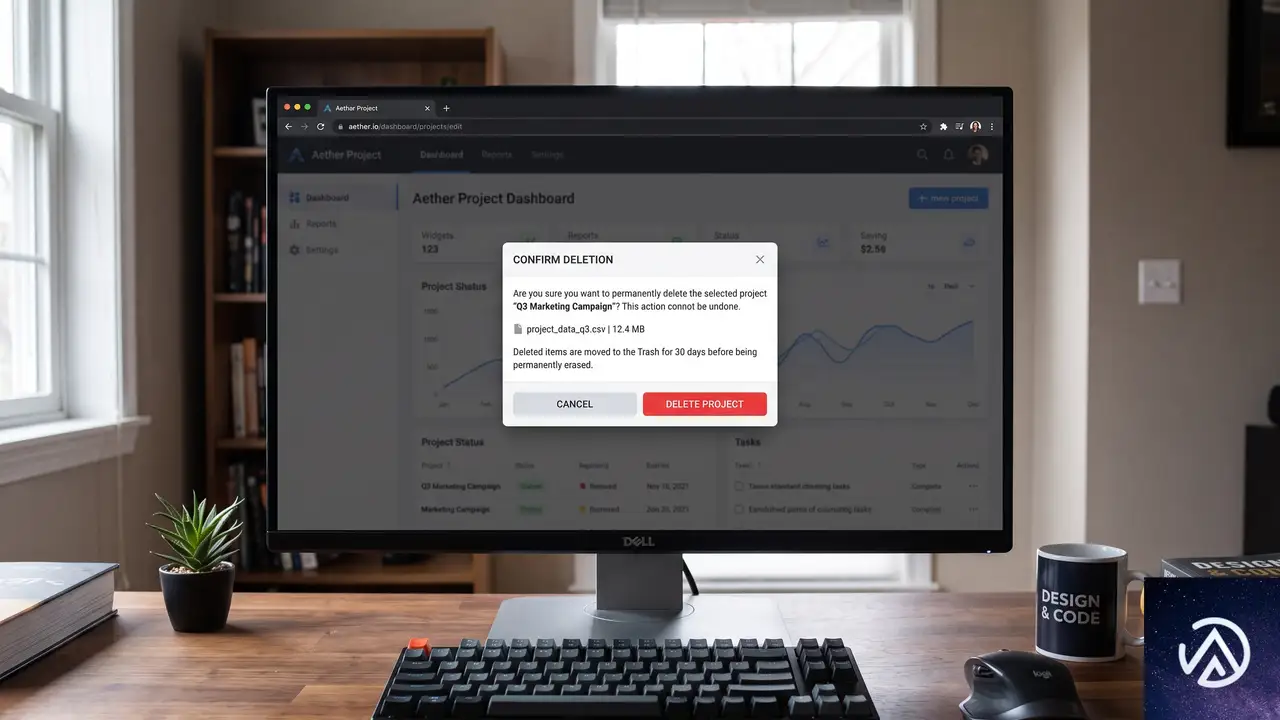
近年HTMLに追加された<dialog>要素やポップオーバー機能は、CSSの疑似クラスと組み合わせることで真価を発揮する。:popover-open、:open、:modal、:fullscreenといった疑似クラスは、JavaScriptのtoggleイベントに頼らずにUIの状態をスタイリングできる。
JavaScriptで同様の処理を書く場合、toggleイベントを監視してから要素のopenプロパティをチェックする2段階の処理が必要になる。CSSの疑似クラスなら、スタイルシート内で直感的に記述できる。モーダルダイアログが開いているときに背景を暗くする処理も、:modal疑似クラスと::backdrop疑似要素の組み合わせで表現可能だ。
event-trigger、CSSに真のイベントリスナーが到来する未来

CSS-Tricksの著者Carlo Daniele氏が紹介しているAnimation Triggers仕様のevent-triggerは、現時点ではどのブラウザも未実装だが、CSSの状態監視を次の段階に引き上げる提案だ。これは従来の疑似クラスとは異なり、JavaScriptのイベントリスナーに近い働きをする。
event-triggerの基本構文
event-triggerは、CSSアニメーションを特定のイベントに結びつける仕組みである。event-trigger-nameでアニメーションの識別子を定義し、event-trigger-sourceで発火条件となるイベント(click、touch、dblclick、keypressなど)を指定する。アニメーションは通常その場で再生されるのではなく、イベントが発生するまで待機する。
@keyframes fade-in {
from { opacity: 0; }
to { opacity: 1; }
}
button {
/* クリック時に --event アニメーションを発火 */
event-trigger: --event click;
}
div {
/* --event が発火したらアニメーションを前方再生 */
animation-trigger: --event play-forwards;
animation: fade-in 300ms both;
}この流れは、従来のCSS疑似クラスが「状態」を追跡していたのに対し、明らかに「イベント」の発生をトリガーとしている点が新しい。clickイベントは元に戻せない不可逆的な出来事だが、interestイベントのように出入りがあるイベントの場合は、ステートフルな双方向トリガーも定義できる。
ステートレスとステートフルの2種類のトリガー
event-triggerには2つのモードが想定されている。ステートレストリガーはclickのような一度きりのイベント向けで、アニメーションは一方向にのみ再生される。ステートフルトリガーはinterestのような持続的な関心を表すイベント向けで、イベントの開始と終了に応じてアニメーションを前後に再生できる。
/* ステートフルトリガーの例 */
button {
event-trigger: --event interest / interest;
}
div {
animation-trigger: --event play-forwards play-backwards;
animation: fade-in 300ms both;
}この構文では、interestの開始時にアニメーションを前方再生し、interestの終了時に逆再生する。ホバーでメニューがスライドインし、カーソルが離れるとスライドアウトするようなUIを、JavaScriptのイベントリスナーなしで実装できる可能性がある。
この仕様が実用化されれば、CSSのみで完結するUIコンポーネントの幅は大幅に広がるだろう。ただし、Carlo Daniele氏自身も記事内で触れているように、仕様は現在編集中であり、今後のドラフトで構成が大きく変わる可能性がある。現時点では構想段階の提案として捉えておくのが適切だ。
この記事のポイント
- CSS疑似クラスはJavaScriptイベントの代替ではなく、状態を監視する独自のレイヤーとして進化している
- :hoverや:focusのような基本疑似クラスから、:autofillや:volume-lockedのような新しい疑似クラスまで、対応範囲は拡大中
- メディア要素疑似クラスはInterop 2026の対象であり、ブラウザ間の相互運用性が今後向上する
- event-trigger仕様はCSSに真のイベントリスナーをもたらす提案だが、現時点では未実装であり将来の動向に注目すべき
- CSSとJavaScriptは競合するものではなく、適材適所で組み合わせることで効率的なUI開発が可能になる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

CSS Gap装飾とrandom()関数、select要素のサイズ制御の最新情報
2026年6月末、CSS-Tricksの定期コラム「What’s !important」第14回が更新された。ギャップ装飾、random()関数、select要素のサイズ制御、モダンテーマ構築など、今後のWeb制作に直結するトピックが盛り込まれている。
ブラウザの安定版に大きな機能追加がなかった時期にも関わらず、開発者コミュニティの実験や標準化の進展は目を見張るものがある。本記事では、これらの最新情報を実務の視点で整理し、各機能の具体的な活用法を示す。
ギャップ装飾とランダム関数 ー 隙間を彩るCSSの新表現

CSS Gap装飾でグリッドの隙間をデザインする
FlexboxやGridレイアウトでおなじみのgapプロパティは、要素間に一定の間隔を生み出す。これまではその隙間自体を装飾する手段がなかったが、CSS Gap Decorationの概念によって新たな表現が可能になった。Temani Afif氏がMaster.devで公開した記事では、gap部分に背景色やボーダー、画像を配置する方法が詳しく解説されている。
上記の例では、flexコンテナに背景色を設定することで、gapが作り出すスペースに色が適用されている。Temani Afif氏の記事では、疑似要素やボーダーを用いて、より複雑な装飾を実現する手法が紹介されており、実務での利用価値が高い。
CSS random()がもたらすランダムな表現
CSSのrandom()関数は、スタイルシートに乱数を導入する試験的な機能だ。現時点ではSafariのみが対応しており、他のブラウザでは動作しない。Polypaneのブログでは、この関数を活用した多彩な実験が公開されている。
Polypaneのデモでは、桜の花びらが舞い散るアニメーションやポラロイド写真の不揃いなスタックなどが実装されており、random()の実用性を感じさせる。ブラウザの対応が進めば、よりナチュラルなUI演出に活用されるだろう。
フォーム要素の可変サイズと動的テーマ構築

field-sizing: contentでselectの幅を動的に調整
Manuel Matuzović氏の記事で取り上げられたfield-sizing: contentは、フォームの見た目を柔軟にする新しいCSSプロパティだ。特に<select>要素に適用すると、選択された<option>のテキスト幅に合わせて自動的にサイズが変わる。Firefox 152のリリースにより、この機能はBaselineに加わり、主要ブラウザで使用可能になった。
なお、size属性を併用してスクロール可能なリストボックスにした場合、field-sizing: contentがsizeを上書きし、すべてのオプションを表示するようになる点には注意が必要だ。
モダンCSSテーマ構築の新たなスタンダード
GoogleのUna Kravets氏は、light-dark()関数やcontrast-color()関数、@property、@container style()を組み合わせた新しいテーマ構築手法を解説した。これらの機能はいずれもBaselineに到達しており、モダンブラウザで広く利用できる。
見出しテキスト
本文のテキストがここに入ります。背景は白、テキストは濃い色。
見出しテキスト
本文のテキストがここに入ります。背景は暗色、テキストは明るい色。
contrast-color()を用いれば、背景色に応じて最適な文字色を自動選択でき、アクセシビリティを確保しつつテーマ構築が容易になる。Una氏の記事は、これらの機能を組み合わせた実装パターンとして参考になる。
プラットフォームの多様性を受け入れたウェブデザイン

Bramus氏がブログで提唱した「ウェブサイトはすべてのプラットフォームで同一に動作する必要はない」という考え方は、レスポンシブデザインを超えた新たな視点だ。入力デバイスの違いや、OSごとのAPIの特性を無理に統一せず、それぞれに適した体験を提供することが重要だと説く。
入力モダリティの多様性に対応する
デスクトップではマウスとキーボード、モバイルではタッチが主要な入力手段だが、ユーザーはスタイラスやゲームパッド、音声入力を併用することもある。すべての操作を全デバイスで同一に再現しようとすると、かえって使い勝手が損なわれるケースがある。Bramus氏は、プラットフォーム固有のインタラクションを許容することで、より自然な操作感を実現できると指摘している。
プラットフォーム依存のAPIと設計
同氏は具体例として、interest invokers(興味を示すUI)やoverscroll actions(スクロールオーバー時の挙動)、Document Picture-in-Picture APIなどを挙げた。これらはOSやブラウザによってふるまいが異なるのが自然であり、無理にクロスプラットフォームで統一するよりも、各環境での最適化を優先すべきだという。
この考え方は、Webアプリの設計においても、無理に同一のUIを強制するのではなく、各環境が持つ強みを活かしたコンテキスト適応の重要性を示している。
クリエイティブな実験とコミュニティの熱

CSSの進化は技術仕様だけでなく、開発者コミュニティの創造的な取り組みによっても加速している。今回の!important #14では、いくつかの目を引くプロジェクトとイベントが紹介された。
CSS QuakeとHyperblam ー コードで遊ぶ
Layoutitが公開したCSS Quakeは、1996年の名作FPSゲーム「Quake」をCSSで再現したプロジェクトだ。PolyCSSを活用し、HTMLとCSSだけで3Dグラフィックス風の表現を実現している。この流れは、先日話題になったCSS DOOMに続くもので、CSSの表現力の高さを改めて示している。
また、Heydon Pickering氏が制作したHyperblamは、HTMLのWeb Componentsを用いて音楽を作るというユニークな試みだ。JavaScriptを一切使わず、HTMLタグだけでWeb Audio APIを操作する。CSSとの直接的な関係は薄いが、ウェブ技術の可能性を広げる実験として注目される。
Web Engines Hackfest 2026の熱気
6月にスペインのガリシア地方で開催されたWeb Engines Hackfestでは、ブラウザエンジンやウェブ標準の未来について活発な議論が交わされた。CSS-Tricksの!important #14では、参加者であるMarina Aísa氏のレポートが紹介されており、初日のハイキングから始まり、二日間にわたるトークやクライミング、アクセシビリティ改善に向けたディスカッションの様子が伝えられている。
こうした草の根の開発者会議は、標準仕様の策定やブラウザ実装に直接影響を与える場でもある。Marina Aísa氏のノートは、今後のWeb制作に携わる者にとって貴重な情報源となるだろう。
この記事のポイント
- CSS Gap装飾は、gapプロパティで生じた隙間に背景色やボーダーを適用し、レイアウトに新たなアクセントを加えられる
- random()関数はSafariのみの対応だが、ランダムな表現を実現する強力なツールであり、今後の普及が期待される
- field-sizing: contentにより、select要素の幅を選択肢に応じて動的に変更可能。すでにBaseline入りしており実務利用が進む
- light-dark()やcontrast-color()、@container style()を組み合わせたテーマ構築は、アクセシビリティと効率を両立する
- プラットフォームごとに異なる操作体系やAPIを尊重し、同一性ではなく最適性を追求する設計が重要視されている
- CSS QuakeやHyperblamといった遊び心のあるプロジェクトは、技術の可能性を広げ、コミュニティの活力を象徴している
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

CSS translateY()の基本と使い方、垂直移動をマスター
translateY() の基本構文と引数
translateY() は CSS の transform プロパティで使用する関数の一つだ。指定した値の分だけ要素を垂直方向に移動させる。正の値なら下へ、負の値なら上へ動く。
構文の基本
構文は極めてシンプルだ。
transform: translateY(値);値には長さ(px, em, rem など)またはパーセンテージを指定できる。パーセンテージは要素自身の高さを基準とする。例えば高さ 100px の要素に translateY(50%) を指定すると、50px 下に移動する。
なお、親要素の高さや余白には一切影響しない。あくまで視覚的な位置だけが変わる点が重要な特徴だ。
length と percentage の使い分け
length(px, rem など)は固定量の移動が必要な場合に使う。一方、percentage は要素のサイズに応じて相対的に位置を変えたいときに便利だ。たとえば、高さが可変するコンテナ内で要素を半分だけ上にずらすには translateY(-50%) と書く。この手法はモーダルやツールチップの中央揃えでもよく使われる。
アニメーションへの応用、カードのスライドイン
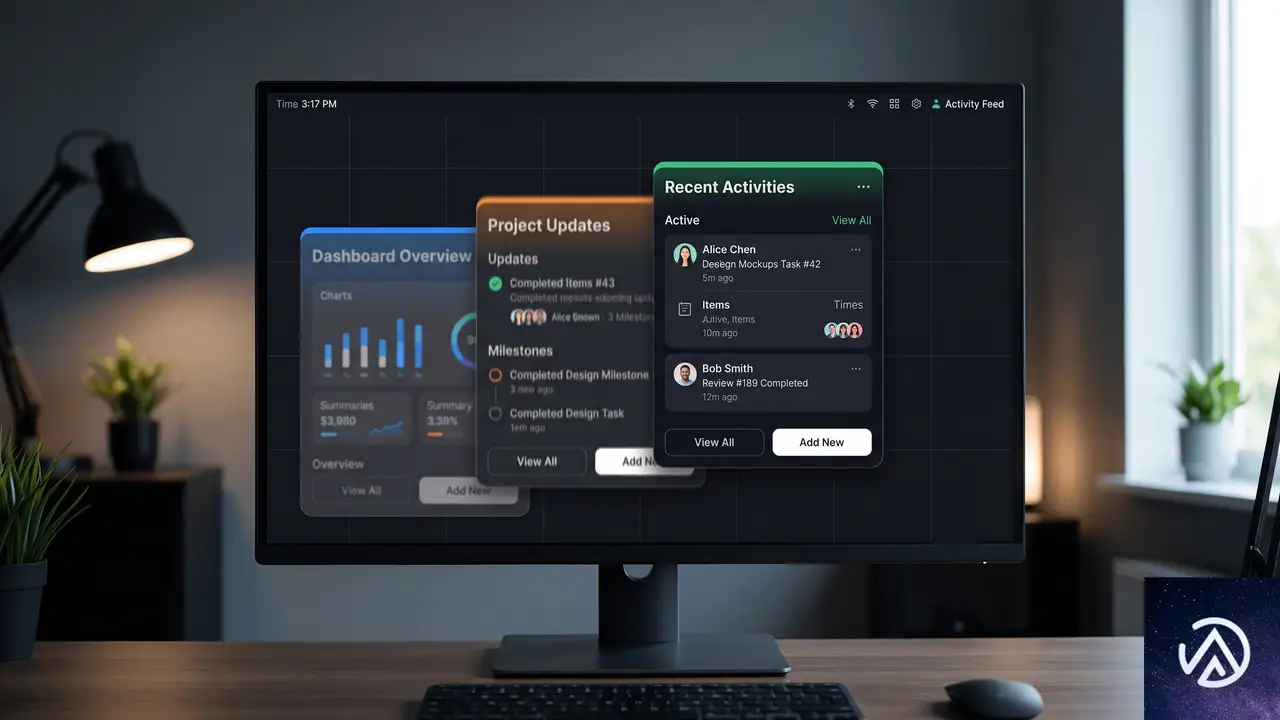
translateY() は CSS アニメーションやトランジションと組み合わせることで、自然な動きを生み出せる。特に「下からスライドイン」「フェードインしながら上昇」といった演出に適している。
カードの表示アニメーション
たとえば、ダッシュボードに統計カードを並べる場合を考えてみよう。初期状態では各カードを少し下にずらし、透明度を 0 にしておく。ページが読み込まれたタイミングやスクロールに合わせて translateY(0) かつ opacity: 1 へトランジションさせる。
.stat-card {
opacity: 0;
transform: translateY(50px);
transition: opacity 0.8s ease-in, transform 0.8s ease-in;
}
.dashboard.active .stat-card {
opacity: 1;
transform: translateY(0);
}この変化が実際は 0.8 秒かけて連続的に行われる。ユーザーは要素が「下から浮き上がってくる」ように感じる。
ホバー時のマイクロインタラクション
表示されたカードにマウスを重ねたとき、ほんの少し上へ移動させる演出もよく使われる。translateY() に負の値を指定すれば良い。
.dashboard.active .stat-card:hover {
transform: translateY(-8px);
}このわずかな動きが、クリック可能な要素であることを直感的に伝える。影(box-shadow)の変化と組み合わせると、よりリッチな表現になる。
フォームラベルの移動アニメーション
translateY() は UI コンポーネントの動きを設計する上でも重宝する。代表例が、入力フィールドのラベルがフォーカス時に上へ移動する「フローティングラベル」パターンだ。
ラベルの初期配置
まず、label 要素を input フィールドの内側に絶対配置で重ねる。ポインターイベントを無効化しておけば、ラベルをクリックしても input にフォーカスが当たる。
label {
position: absolute;
left: 15px;
top: 15px;
pointer-events: none;
transition: transform 0.25s cubic-bezier(0.4, 0, 0.2, 1);
}フォーカス時の移動
input にフォーカスが当たったとき、もしくはプレースホルダーが表示されていない(入力済み)ときに、ラベルを translateY(-32px) で上へ移動させる。同時に少し縮小すると、より洗練された動きになる。
input:focus ~ label,
input:not(:placeholder-shown) ~ label {
transform: translateY(-32px) scale(0.8);
color: #6200ee;
font-weight: bold;
}このアニメーションは実際には約 0.25 秒でスムーズに行われる。ラベルが単に上に動くだけでなく、縮小と色の変化が加わることで、UI に統一感が生まれる。
translateY() の特性、他の要素に影響しない

transform 系の関数全般に言えることだが、translateY() はドキュメントフローを一切変更しない。つまり、要素を移動させても周囲の要素は元の位置を保ったままになる。
ドキュメントフローへの影響
例えば、3つのブロックが縦に並んでいるとする。中央のブロックに translateY(40px) を適用しても、上下のブロックはピクリとも動かない。あくまで中央のブロックの「描画位置」だけが変わる。
margin との違い
似たような位置調整として margin-top がある。しかし margin は要素自体の「占有領域」を変化させるため、後続の要素が押し出される。レイアウト全体に影響を与えたくない場合、translateY() のほうが安全だ。
/* 非推奨: レイアウトシフトを起こす */
.element {
margin-top: 30px;
}
/* 推奨: 描画位置だけを変える */
.element {
transform: translateY(30px);
}また、translateY() は GPU による合成処理が行われるため、アニメーションのパフォーマンス面でも優れる。リフローやリペイントが発生しないからだ。頻繁に動かす要素には積極的に使いたい。
ポインター擬似クラスでの問題と解決策

translateY() を :hover に直接指定すると、意図しないちらつきを起こすことがある。CSS-Tricks の記事でも指摘されている点だ。
ちらつきが起きる仕組み
ホバー時に要素を大きく移動させると、マウスカーソルが要素から外れてしまう。すると :hover 状態が解除されて要素が元の位置に戻り、再びカーソルが要素に重なってまた移動する……という無限ループが発生する。
親要素で包む解決策
最も簡単な対策は、移動させたい要素を親コンテナでラップし、:hover 擬似クラスを親に適用することだ。これでホバー領域が親のサイズで固定され、子要素がどこに移動してもカーソルが外れにくくなる。
.card-container:hover .card {
transform: translateY(-12px);
}この書き方は、ホバーでカードが浮き上がる演出など、あらゆる translateY() アニメーションに応用できる。親要素のサイズに余裕を持たせておけば、より大きな変位にも対応可能だ。
この記事のポイント
- translateY() は要素を垂直方向に移動させる。正の値で下、負の値で上。
- パーセンテージ指定は要素自身の高さが基準。中央配置などに便利。
- アニメーションでは opacity と組み合わせ、スライドインに使える。
- フォームラベルの浮上アニメーションは translateY(-32px) と scale(0.8) で実装。
- ドキュメントフローを壊さないため、margin よりパフォーマンスが良い。
- :hover のちらつきは親要素に擬似クラスを付ければ解消する。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

CSS translateZ()の基本と実践、perspectiveで3D表現をマスター
CSSのtransformプロパティに指定できるtranslateZ()関数は、要素をZ軸方向へ移動させるものである。従来のブラウザ表示は縦と横の2次元だが、translateZ()とperspective(遠近感)を組み合わせることで、奥行きのある3次元的な表現が可能になる。ただし、perspectiveが設定されていないとtranslateZ()は何の変化も起こさない点が、多くの開発者がつまずく最初のポイントだ。
translateZ()を正確に使いこなせば、カードの裏表切り替えや立体カルーセルといったUIの表現力が高まる。さらに、translateZ(0)という小さな指定が、アニメーションのちらつきを抑え、GPUによる高速レンダリングを引き出すパフォーマンスハックとして知られている。本記事では、この関数の基本動作から実践的な活用テクニックまでを図解とともに解説する。
translateZ() の基本動作と perspective の必須条件
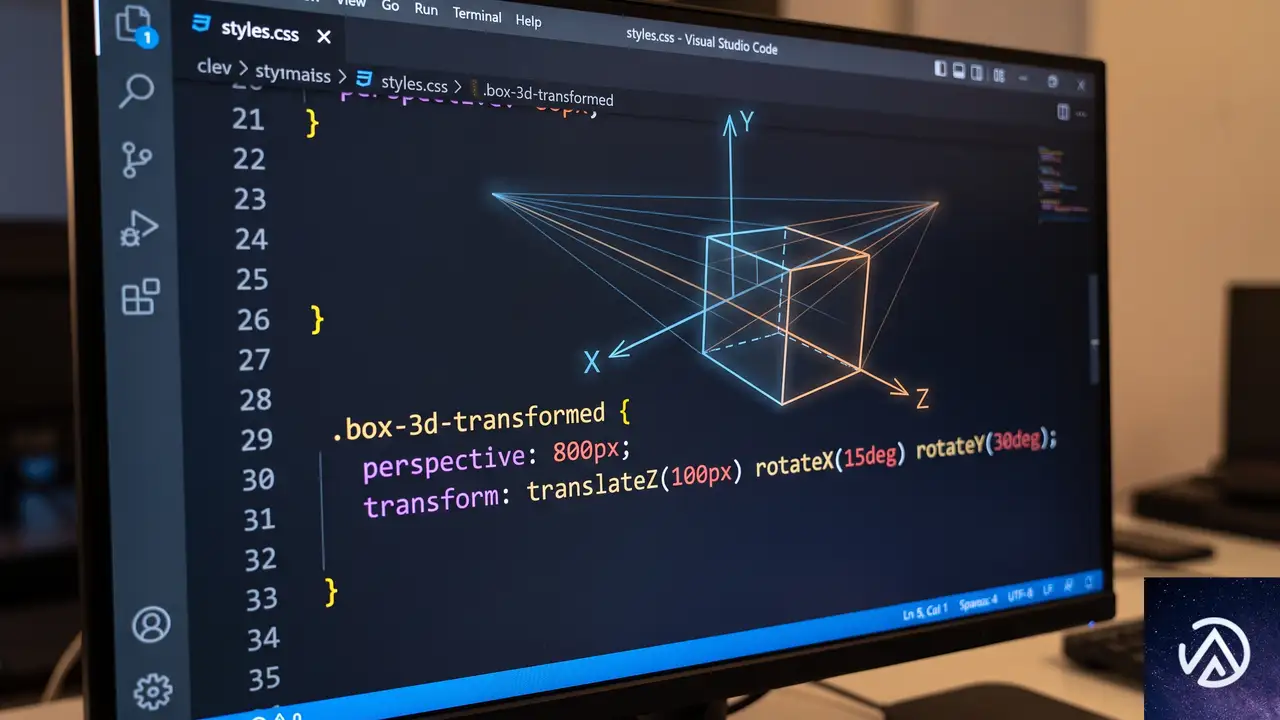
translateZ()は、要素をZ軸(画面の手前または奥)方向に指定した距離だけ移動させる。値が正であれば手前に近づき、負であれば奥に遠ざかる。しかし、単独でtransform: translateZ(100px);と書いても、見た目は何も変わらない。これは、ブラウザがデフォルトで3次元空間の遠近感を持たず、あらゆる要素を画面上に平坦に描画しているためである。
perspective がなければ効果はゼロ
translateZ()の効果を発揮させるには、対象の要素に対して「どれだけ離れて見ているか」を決めるperspective(遠近法の視点距離)の設定が必須になる。perspectiveは、要素の親にプロパティとして指定する方法と、transformの関数perspective()として一時的に指定する方法の2通りがある。まずは、親要素にperspectiveプロパティを設定した場合のコードを見てみよう。
.scene {
perspective: 800px;
}
.box {
transform: translateZ(100px);
}このようにすると、.scene内の全子要素に800pxの視点距離が適用され、その中で.boxが100px手前に移動する。つまり.boxは画面上で拡大されたかのように表示される。しかし、実際の大きさが変わるわけではなく、視点からの距離が短縮された結果、見かけ上のスケールが変わるという理屈である。
上のデモが示す通り、perspectiveを設定していない環境ではtranslateZ(100px)は全く反映されず、元のサイズのままである。一方、perspective:500pxの親で囲むと、ボックスが手前に飛び出して大きくなったように見える。これがZ軸移動の基本的な仕組みである。
perspective プロパティと perspective() 関数の使い分け
perspectiveはプロパティとして親に指定することで、その配下にある複数の3D変形要素に共通の視点距離を与える。一方、perspective()関数は特定のtransform指定の中でのみ有効で、ほかの要素には影響しない。また、関数を使う際は記述順序に注意が必要である。必ずperspective()をtranslateZ()より先に書かなければ、視点距離が適用されない。
/* NG: 後方にあると無効 */
transform: translateZ(100px) perspective(800px);
/* OK: 前方に記述 */
transform: perspective(800px) translateZ(100px);全体の3Dシーンを統一した視点で扱いたい場合はperspectiveプロパティ、特定の要素だけに局所的な遠近感を与えたい場合はperspective()関数を用いると覚えておくとよい。
translateZ() の実践的な使い方

ここからは、実際の開発で役立つtranslateZ()の応用を見ていく。まず、3D空間での奥行きをより直感的に理解できるように、親要素ごと回転させたデモを用意した。
奥行きを可視化する3Dデモ
親コンテナにrotateY()で角度を付け、さらにtransform-style: preserve-3dを指定することで、子要素が3D空間内でどの位置にあるかが一目でわかる。次のデモでは、translateZ(0)(奥行きなし)とtranslateZ(100px)(手前への移動)を比較している。
回転された親の内部で、translateZ(100px)のボックスは手前に飛び出していることが確認できる。要素の横幅や高さのピクセル値そのものは変わっていない。視点距離とZ軸方向の移動量によって、画面上への投影サイズが変化するというのが、translateZ()の本質である。
パフォーマンスハックとしての translateZ(0)
translateZ(0)はZ軸方向へ0ピクセル移動する指定であり、本来は何も変わらない。ところが、この小さな宣言がブラウザのレンダリングエンジンに「3D変形が使われている」と認識させ、対象要素の描画をCPUからGPUへ切り替えさせるトリガーとなる。GPUはグラフィック処理に特化したハードウェアであり、アニメーションやトランジションの再描画を高速に行える。
.animated-box {
transform: translateZ(0);
/* これでレンダリングがGPUに委譲され、ちらつきが抑制される */
}特に、CSSアニメーションで要素がガタつく(ジャンク)現象が発生している場合、translateZ(0)を追加するだけで症状が改善することが多い。ただし、GPUへの過度な依存はメモリ消費を増やすため、必要な要素に絞って適用するのが望ましい。
translateZ() と scale() の混同に注意

translateZ()を適用すると要素が拡大したように見えるため、「scale()と同じではないか」という誤解を招きがちだ。しかし、両者は根本的に異なる概念である。scale()は要素そのものの寸法を乗算で拡大・縮小するのに対し、translateZ()は遠近法による投影上の見かけの大きさを変えるだけだ。
この違いは、レイアウト計算や重なり順の制御において重要だ。scale()による拡大は要素のボックスサイズを変化させ、周囲の要素を押しのける可能性があるが、translateZ()による見かけの拡大はレイアウトフローに影響を与えない。3D変形を使う以上、どの操作が実際の寸法に関わるかを理解しておく必要がある。
ブラウザサポートと仕様

translateZ()関数はCSS Transforms Module Level 2で定義されており、主要なモダンブラウザ(Chrome、Firefox、Safari、Edge)すべてでサポートされている。Internet Explorer 11は3D変形に対応していないが、現在のユーザーシェアから考えると実務上の大きな制約にはならない。また、perspectiveプロパティやtransform-style: preserve-3dとの併用も各ブラウザで一貫した動作を示す。
ただし、古いモバイルOSのブラウザや非常に限定的な環境では、GPUアクセラレーション周りの挙動に差異が生じる場合がある。実装時には実機テストを行い、パフォーマンス面のキャッチアップを心がけたい。
この記事のポイント
translateZ()はZ軸方向への移動を行い、perspectiveがなければ効果は現れない- 遠近感の設定は
perspectiveプロパティ(親要素)とperspective()関数(要素自身)の2方式がある - 要素の実寸を変える
scale()とは異なり、投影上の大きさを変化させる translateZ(0)はGPUレンダリングを誘発し、アニメーションの性能改善に役立つ
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

CSSスクロール駆動アニメーションで逆方向スクロールを実現
スクロールに応じてアイテムが上下逆方向に動くレイアウトを実現する手法がある。CSS-Tricksの著者が紹介したこのテクニックは、CSSの「スクロール駆動アニメーション」と疑似要素によるマスク効果を組み合わせたものだ。通常のアニメーションと異なり、ユーザーがスクロールした量だけアニメーションが進行するため、インタラクティブな表現が可能になる。本記事ではその仕組みと実装手順を詳しく解説する。
具体的なコードを見ていこう。元記事では3つのカラムがあり、左右のカラムはスクロールに応じて上方向へ、中央のカラムは下方向へ移動する。コンテナの上下端ではアイテムがふわりと消えるフェード効果がかかる。この動きはCSSの animation-timeline プロパティと view() 関数で制御される。
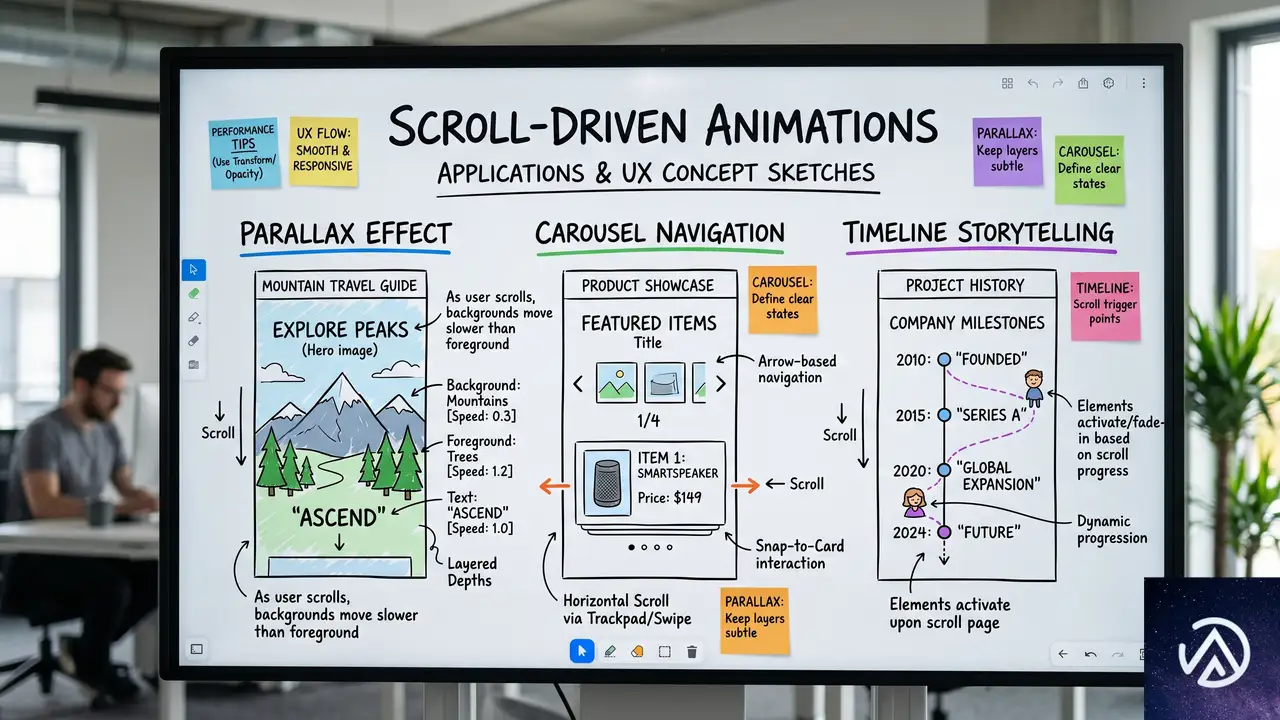
スクロール駆動アニメーションの基本概念
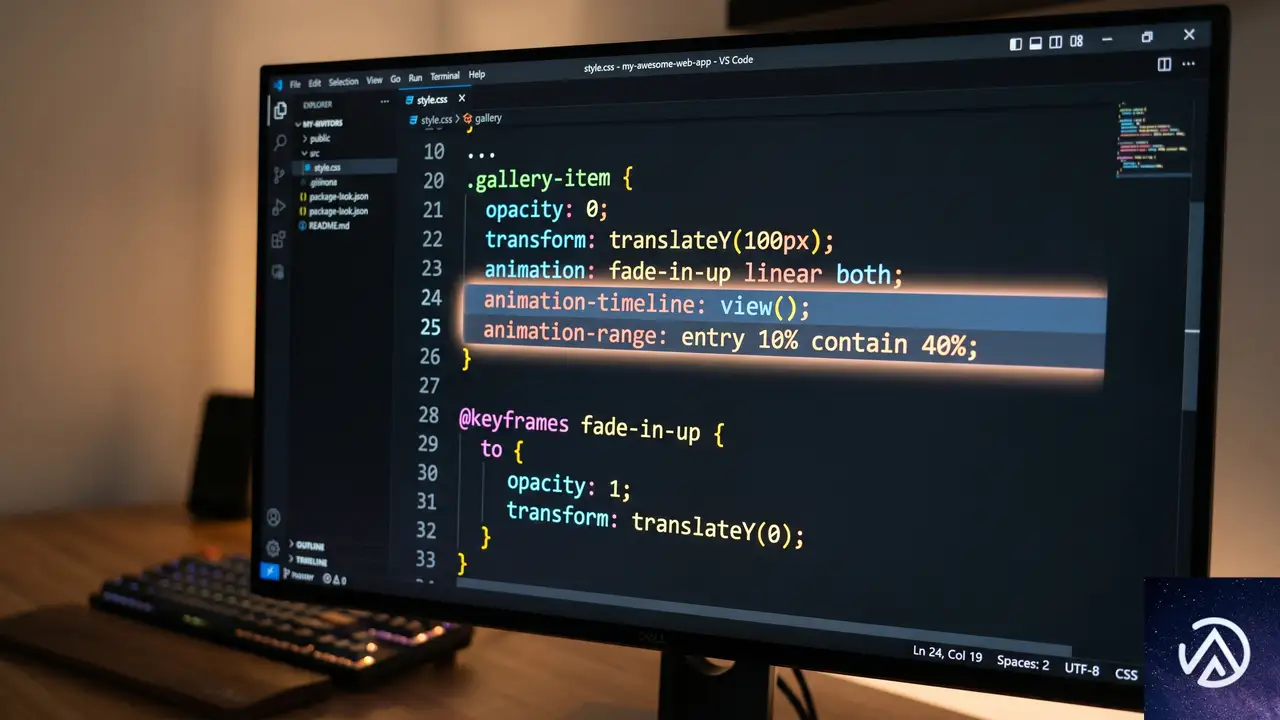
スクロール駆動アニメーション(Scroll-Driven Animations)とは、アニメーションの進行をスクロール位置に連動させるCSSの新機能である。従来のCSSアニメーションは時間ベースで動いていたが、この機能を使えば「要素が画面のどこにあるか」や「スクロール量がどれだけ進んだか」を基準にアニメーションを再生できる。
これを実現するのが animation-timeline プロパティだ。ここには scroll() 関数または view() 関数を指定する。scroll() は親要素やルートのスクロール位置を追跡し、view() は要素自身がスクロールポート(スクロール可能な表示領域)に出入りする過程を追跡する。今回の逆方向スクロールでは、各カラム内のアイテムがコンテナ領域に入ったり出たりする動きが肝になるため、view() が採用された。
view() 関数の仕組み
view() 関数は、アニメーション対象の要素がスクロールポートのどの範囲にあるかを0%から100%の進捗で返す。例えば、要素がスクロールポートの下端にさしかかった瞬間が0%、完全に反対側へ出切った瞬間が100%だ。この進捗をアニメーションのタイムラインにマッピングすることで、スクロールに同期した動きを作れる。
CSS-Tricksの著者は、この関数に「entry 0% cover 100%」というインセットを設定している。これは、要素がスクロールポートに入り始めた瞬間(entry)の0%から、完全に通り抜けて隠れきった瞬間(cover)の100%までをアニメーションの範囲とする指定だ。この設定により、各カラムのアイテムが表示領域に姿を現し、消えるまでの全行程をアニメーションでカバーできる。
このデモは、要素がスクロールポートに出入りする際のマスク効果を静的に表現している。実際のブラウザでは、スクロール量に応じて要素の位置が連続的に変化し、上下のグラデーション部分に重なると自然に溶け込むように見える。
animation-range による範囲の精密制御
animation-range プロパティは、タイムラインのどの区間を使ってアニメーションを再生するかを決める。デフォルトでは「entry 0% exit 100%」だが、CSS-Tricksの例では「entry 0% cover 100%」としている。これは entry が「要素がスクロールポートに入り始める瞬間」、cover が「要素がポートを完全に覆い隠した瞬間(つまり反対側へ出切った瞬間)」の2点を基準にする記法だ。
この指定により、アイテムが画面に現れた瞬間から消える最後までアニメーションが継続する。逆に言えば、画面外に完全に隠れている間はアニメーションが停止しているのと同じ状態になる。結果として、ユーザーがスクロールしている間だけアイテムがスムーズに動き続けるインタラクションが実現する。
HTMLのシンプルな構造
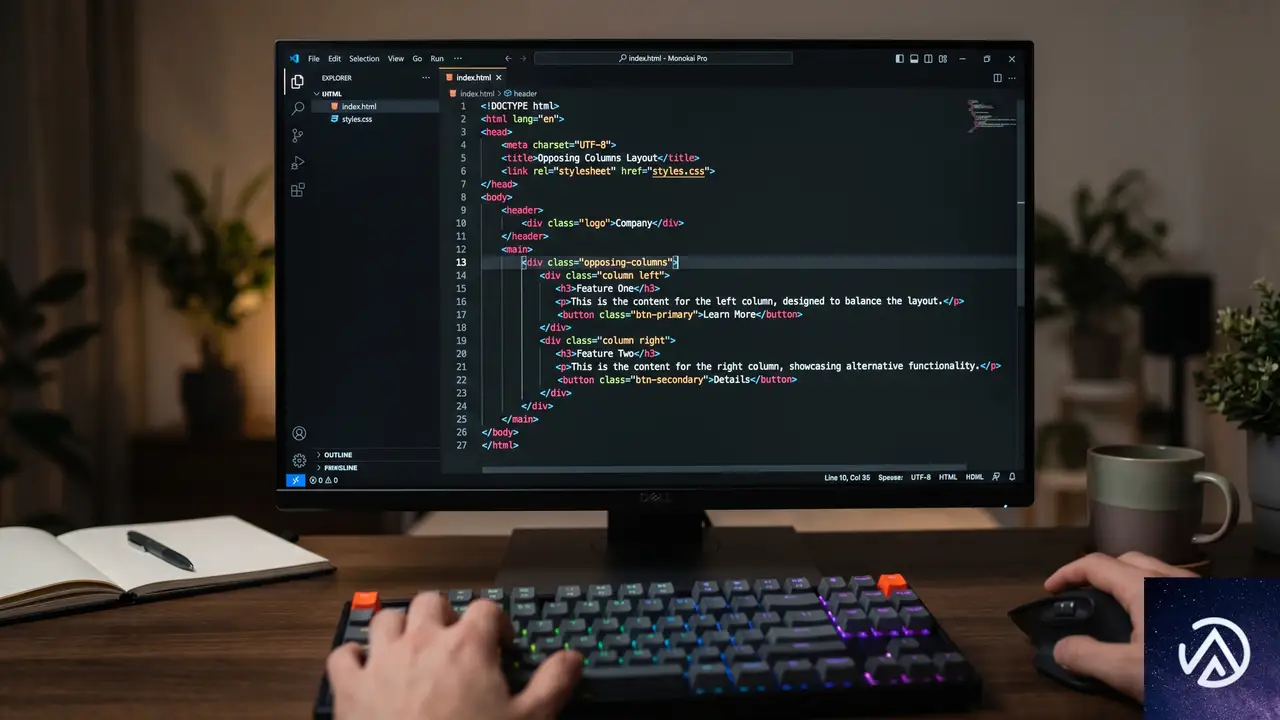
CSS-Tricksの記事で示されているHTMLは非常に簡素だ。複雑なJavaScriptや追加のラッパーは不要で、大きく分けて3階層の要素があればよい。
<div class="opposing-columns">
<div class="opposing-column">
<div class="opposing-item">...</div>
<div class="opposing-item">...</div>
<div class="opposing-item">...</div>
</div>
<div class="opposing-column">
<div class="opposing-item">...</div>
<div class="opposing-item">...</div>
<div class="opposing-item">...</div>
</div>
<div class="opposing-column">
<div class="opposing-item">...</div>
<div class="opposing-item">...</div>
<div class="opposing-item">...</div>
</div>
</div>このシンプルな構造がポイントだ。CSS側でスクロール駆動アニメーションを定義する際、各カラム(.opposing-column)ごとに異なるアニメーションを適用し、その中に含まれるアイテムが一括して動く仕組みになっている。
CSSによるマスク効果の実装
アイテムがコンテナの上下端でふわっと消える演出は、疑似要素とグラデーションによるマスクで作られている。透明度や opacity を直接操作するのではなく、背景色と同じ色のグラデーションを重ねることで、コンテンツが自然に隠れるように見せているのだ。
疑似要素でマスクを生成する
親コンテナ .opposing-columns に position: relative を設定したうえで、::before と ::after 疑似要素を絶対配置している。これらの疑似要素はコンテナの上下にそれぞれ配置され、幅はコンテナ全体、高さはCSS変数 --opposing-mask の3倍に設定されている。
@media screen and (width >= 50rem) {
.opposing-columns {
position: relative;
margin-block: var(--opposing-mask, 3rem);
}
.opposing-columns::before,
.opposing-columns::after {
content: "";
position: absolute;
inset-inline: 0;
block-size: calc(var(--opposing-mask) * 3);
pointer-events: none;
z-index: 1;
}
}疑似要素には pointer-events: none が指定されており、クリックやホバーの邪魔をしない。これはユーザビリティを損なわないための重要な配慮だ。
グラデーションで自然なフェードを生み出す
次に、これらの疑似要素に線形グラデーションを適用する。上側の ::before には to bottom(上から下)方向のグラデーションを設定し、始点をドキュメントの背景色 --opposing-bg、終点を透明にする。下側の ::after はこれを逆にして、to top(下から上)方向のグラデーションを設定する。
.opposing-columns::before {
background-image: linear-gradient(
to bottom,
var(--opposing-bg) var(--opposing-mask),
transparent
);
inset-block-start: calc(var(--opposing-mask) * -1);
}
.opposing-columns::after {
background-image: linear-gradient(
to top,
var(--opposing-bg) var(--opposing-mask),
transparent
);
inset-block-end: calc(var(--opposing-mask) * -1);
}これにより、カラム内のアイテムがコンテナの上下端に近づくと、グラデーション部分に重なって自然に消えていくように見える。背景色とマスクの色が同一であるため、アイテムが溶け込むようなスムーズなフェードが実現する。
キーフレームアニメーションの設計
マスクの準備が整ったら、実際にアイテムを上下に動かすアニメーションを定義する。CSS-Tricksの著者は3つの異なるキーフレームを用意し、各カラムに割り当てている。
3種類の動きをキーフレームで定義
アニメーションは transform: translateY() による垂直移動で構成される。1つ目の scroll1 はアイテムを上方向に移動させ、2つ目の scroll2 はその逆方向(下方向)に動かす。3つ目の scroll3 はややオフセットを持たせた上方向の動きで、カラム間のタイミングにわずかなズレを生み出している。
@keyframes scroll1 {
from { transform: translateY(var(--opposing-mask)); }
to { transform: translateY(calc(var(--opposing-mask) * -1)); }
}
@keyframes scroll2 {
from { transform: translateY(calc(var(--opposing-mask) * -1)); }
to { transform: translateY(var(--opposing-mask)); }
}
@keyframes scroll3 {
from { transform: translateY(calc(var(--opposing-mask) * .66)); }
to { transform: translateY(calc(var(--opposing-mask) * -.33)); }
}このオフセットの考え方は応用が利く。例えば同じ方向に動く2つのカラムでも、開始位置を微妙にずらすだけで視覚的なリズムが生まれ、単調さを回避できる。
カラムごとに異なるアニメーションをバインド
キーフレームを定義したら、各カラムにアニメーション名を割り当てる。nth-of-type 疑似クラスを使い、1番目のカラムには scroll1、2番目には scroll2、3番目には scroll3 を適用する。これにより、カラムの位置に応じて移動方向が自動的に決まる。
.opposing-column:nth-of-type(1) { animation-name: var(--animation-1); }
.opposing-column:nth-of-type(2) { animation-name: var(--animation-2); }
.opposing-column:nth-of-type(3) { animation-name: var(--animation-3); }さらに、これらのアニメーションは animation-timeline: view() と animation-range: entry 0% cover 100%、そして animation-timing-function: linear がセットで指定される。線形のタイミング関数を選ぶことで、スクロール速度に応じてアイテムが等速で動き、自然な同期感が得られる。
アクセシビリティとブラウザ対応
実装にあたっては、モーションに敏感なユーザーへの配慮と、ブラウザ間の互換性を考慮する必要がある。CSS-Tricksの元記事でもこの点に言及しており、適切なフォールバックを組み込んでいる。
prefers-reduced-motion への対応
OSやブラウザの設定で「視差効果を減らす」を有効にしているユーザー向けに、メディアクエリ prefers-reduced-motion: reduce を用いてアニメーションを無効化する。このクエリが一致した場合、アニメーションを unset で打ち消し、さらに疑似要素のマスクも削除する。マスクだけが残ると、動かないアイテムが不自然に隠れてしまうからだ。
@media (prefers-reduced-motion: reduce) {
.opposing-column {
animation: unset;
}
.opposing-column::before,
.opposing-column::after {
content: unset;
}
}これにより、動きを減らしたいユーザーには静的なレイアウトが提供され、意図しないストレスを回避できる。
@supports を使った段階的な実装
スクロール駆動アニメーションは、2026年6月時点でChromeとSafariがサポートしているが、Firefoxは未対応だ。そのため、@supports (animation-timeline: view()) を用いて、機能が使えるブラウザでのみアニメーションを有効化するのが安全だ。サポートされない環境では、通常のスクロールと同様の静的な表示になるよう設計しておけば、すべてのユーザーに破綻のない体験を届けられる。
@supports (animation-timeline: view()) {
/* スクロール駆動アニメーションのスタイル */
}この手法はプログレッシブエンハンスメントの好例で、新しいCSS機能を安全に導入したい現場でも参考になるだろう。
独自の視点:逆方向スクロールの応用可能性
ここまで見てきたテクニックは、単なる逆方向スクロールの演出にとどまらない。CSSのスクロール駆動アニメーションは、タイムラインを自在に操作できるため、さまざまなインタラクティブ表現の土台となる。
タイミングのオフセットを使ったリズム演出
元記事の scroll3 のように、開始位置や終了位置をパーセンテージでずらすことで、カラム間の動きにリズムを生み出せる。たとえば、5カラムのレイアウトでそれぞれの移動量を微調整すれば、波のようなうねりを表現することも可能だ。マスクの高さやアニメーションのインセットをCSS変数で管理しておけば、デザインの微調整も容易になる。
このようなオフセット設計は、プロモーションサイトやポートフォリオのビジュアルリッチなセクションで特に効果を発揮するだろう。
パララックス効果との自然な組み合わせ
従来のパララックス(視差効果)はJavaScriptで実装されることが多かったが、スクロール駆動アニメーションを使えば、CSSだけで多層的な視差を表現できる。背景画像や装飾要素に別の animation-timeline を割り当て、移動速度を変えれば、奥行きのあるスクロール体験をJavaScriptに頼らずに構築できる。
例えば、背景の大きな画像にはゆっくりした上方向のアニメーションを、前景のテキストにはやや速い動きを設定するといった組み合わせだ。マスク効果を応用すれば、画面外への自然な消え方も統一感を持って演出できる。
カルーセルやタイムライン表現への展開
逆方向スクロールの考え方は、横方向のカルーセルやタイムライン表示にも転用できる。view() 関数の軸指定(block や inline)を切り替えれば、水平スクロールにも対応可能だ。また、scroll() 関数と組み合わせれば、ページ全体のスクロール量に応じてインジケーターを進める、といった使い方もできる。
CSS-Tricksの元記事は比較的シンプルな例だが、この基盤さえ理解すれば、より複雑なレイアウトやストーリーテリング演出にも発展させられる。
この記事のポイント
- スクロール駆動アニメーションは
animation-timeline: view()で実装し、スクロールに同期した動きを簡単に作れる - 疑似要素と背景色ベースのグラデーションを組み合わせると、自然なフェード効果を実現できる
- 動きのオフセットや逆方向設定によって、単調でないリズミカルな演出が可能になる
@supportsとprefers-reduced-motionで、アクセシビリティとブラウザ互換性を両立させる- 今回のテクニックはパララックス、水平カルーセル、タイムラインなど多彩な表現に展開できる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Prop For That、CSSで動的プロパティを扱う新ライブラリの全容
CSS-Tricksで紹介された「Prop For That」は、これまでのCSS設計の常識を塗り替える可能性を持つライブラリだ。ブラウザが本来CSS単体では取得できない情報、例えばマウスカーソルの座標やページのスクロール速度、現在時刻などを、あたかもネイティブのカスタムプロパティであるかのように扱えるようにする。開発者はライブラリを読み込み、対象のHTML要素に専用のデータ属性を付与するだけで、これらの動的な値を直接スタイルシートから参照できる。
CSS-Tricksの記事によれば、このライブラリの最大の魅力は、JavaScriptのロジックを意識せずに済む点にある。従来はイベントリスナーで値の変化を監視し、DOMのスタイルを逐次更新するスクリプトが必要だった。Prop For Thatを使えば、宣言的にCSSを記述する感覚のまま、高度なインタラクションを実装できる。本記事では、この新しいアプローチの仕組みや具体的な活用方法、そして現場への影響を掘り下げていく。
Prop For Thatが解決する根本的な課題
CSSは本来、ページが読み込まれた時点の静的なスタイルを定義する仕組みであり、ユーザーの操作に応じて刻一刻と変化するブラウザの内部状態を直接知覚できない。マウスポインターの位置、ページのどこまでスクロールしたか、特定のフォーム要素が今フォーカスを持っているかといった情報は、すべてJavaScriptの領分だった。この断絶が、アニメーションやインタラクションを実装する際のボトルネックになっていた。
このデモが示すように、Prop For ThatはHTMLとCSSだけの世界観を維持したまま、動的な値を扱える設計思想を持つ。これは単なるユーティリティの追加ではなく、スタイリングの責務をCSSに取り戻すパラダイムシフトだ。
主要なライブプロパティとその仕組み
ポインタートラッキングで実現する追従型インタラクション
マウスカーソルの動きをCSSだけで捉えられると、ボタンのホバーエフェクトや視差効果の表現力が格段に上がる。Prop For Thatでは、data-props-for="pointer"という属性を設定した要素に対して、--live-pointer-xと--live-pointer-yという2つのカスタムプロパティが動的に注入される。
<div class="mover" data-props-for="pointer">...</div>left: calc(var(--live-pointer-x, 0) * 1px);top: calc(var(--live-pointer-y, 0) * 1px);これらの値はリアルタイムに更新されるため、要素をposition: absoluteで配置しておけば、CSSの計算式だけで物体がカーソルを追いかける動きを表現できる。マウスの速度に応じてスタイルを変化させるなど、従来は複雑なスクリプトが必要だった演出が、数行のスタイル宣言で完結する。
スクロールベロシティと現在時刻の活用
スクロールの勢いを表すベロシティ(速度)や、刻々と変化する現在時刻も、ライブプロパティとして取得できる。これらを活用すれば、ユーザーがページを勢いよくスクロールしているときだけ特定のアニメーションを発動させたり、時刻に応じて配色を動的に切り替えるといった演出が、CSSの範囲内で実装可能になる。
/* スクロール速度に応じて要素の透明度を変化させる例 */
.scroll-aware {
opacity: calc(var(--live-scroll-velocity, 0) * 0.01);
transition: opacity 0.3s ease;
}CSS-Tricksの記事で特に評価されていたのは、スクロールにモメンタム(慣性)の概念を持ち込める点だ。ユーザーの操作に物理的な手応えを感じさせる、いわゆる「気持ちいいインタラクション」の実装ハードルが大きく下がる。
実装のポイントとコード例
基本的なセットアップ手順
導入は極めてシンプルだ。ライブラリをプロジェクトに読み込んだあと、動的な値を取得したい要素にdata-props-for属性を追加する。あとは通常のCSSカスタムプロパティと同じ感覚で、var()関数を使って値を参照すればよい。
<!-- HTML側 -->
<div class="tracker" data-props-for="pointer">
この要素がカーソルを追跡する
</div>
/* CSS側 */
.tracker {
position: absolute;
width: 60px;
height: 60px;
background: #3498db;
border-radius: 50%;
/* ライブプロパティを参照して位置を動的に計算 */
left: calc(var(--live-pointer-x, 0) * 1px - 30px);
top: calc(var(--live-pointer-y, 0) * 1px - 30px);
/* スムーズな追従のためのトランジション */
transition: left 0.1s ease-out, top 0.1s ease-out;
}このコード例では、カーソルを追いかける円形の要素を定義している。注意すべきは、var()の第2引数でフォールバック値(ここでは0)を指定している点だ。ライブラリが読み込まれる前や、何らかの理由でプロパティが未定義の場合でも、要素が想定外の位置に飛ぶのを防げる。
パフォーマンス上の配慮
ライブプロパティは高頻度で更新されるため、leftやtopのようなレイアウトを再計算させるプロパティの変更は、パフォーマンスの観点から注意が必要だ。可能であればtransformプロパティで位置を制御するほうが、ブラウザの合成処理に乗り、再描画コストを抑えられる。
/* パフォーマンスを考慮した書き方 */
.optimized-tracker {
position: absolute;
width: 60px;
height: 60px;
background: #e74c3c;
border-radius: 50%;
/* transformを使えばGPU合成で高速に描画される */
transform: translate(
calc(var(--live-pointer-x, 0) * 1px - 50%),
calc(var(--live-pointer-y, 0) * 1px - 50%)
);
}このtransformによる制御は、特に多数の要素を同時に動かす場合や、モバイル端末での動作を考慮する際に有効だ。CSS-Tricksの紹介するデモ群でも、このベストプラクティスが採用されている。
Web制作の現場に与える影響
JavaScriptとCSSの新たな役割分担
Prop For Thatの登場は、フロントエンド開発におけるJavaScriptとCSSの役割分担を見直す契機になる。従来は「動的なものはJavaScript、静的なものはCSS」という暗黙の線引きがあった。しかし、このライブラリが示す方向性は、表示やスタイルの変化はCSSに寄せるという考え方だ。
これは単なる書き方の変化ではない。コードの凝集度が高まり、スタイルに関するロジックがCSSファイルに集約されることで、メンテナンス性が向上する。特に、複数人で開発する大規模プロジェクトや、インタラクションの多いランディングページの制作では、このメリットが顕著に現れる。
プロトタイピングスピードの加速
CSS-Tricksの記事が高く評価していたもう一つの側面は、プロトタイピングの速さだ。アイデアを思いついてから、実際にブラウザ上で動くモックアップを作るまでの時間が大幅に短縮される。複雑なJavaScriptの設定なしに、HTMLとCSSだけでリッチなインタラクションを試せることは、クリエイティブな探求の敷居を大きく下げる。
この手軽さは、デザイナーがコーディングに踏み出すきっかけとしても機能するだろう。また、クライアントワークの現場では、「この動きを実装するのにどれだけの工数がかかるか」という見積もりの精度も変わってくる。これまでスクリプトの作成で1日かかっていた表現が、数時間のコーディングで実現できる可能性があるからだ。
この記事のポイント
- Prop For Thatは、マウス位置やスクロール速度などブラウザの動的情報をCSSカスタムプロパティとして参照できるライブラリである
- 導入はライブラリの読み込みとHTML属性の追加のみで、JavaScriptの記述を必要としない
- ポインタートラッキング、スクロールベロシティ、現在時刻など、多彩なライブプロパティが用意されている
- パフォーマンスを考慮する場合は、
leftやtopではなくtransformで位置制御するのが推奨される - JavaScriptとCSSの役割分担を見直し、スタイルの責務をCSSに集約する設計思想が背景にある
- プロトタイピングの高速化や、インタラクション実装の工数削減といった実務的なメリットが大きい
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

CSS @functionとalpha()、Grid Lanesの最新動向
CSSは日々進化している。2026年6月半ば、CSSの関数定義を刷新する@functionや、透明度操作をシンプルにするalpha()、レイアウトの可能性を広げるGrid Lanes、対話要素の使い勝手を高める<dialog>の改良など、実務に直結する話題が相次いでいる。
これらの機能は、現時点ではブラウザ対応が完了していないものも含まれるが、開発体験を大きく変えるポテンシャルを持つ。とくに@functionは今年中にBaseline入りする可能性が高い機能として注目されている。この記事では、それらの仕組みと現場での活用イメージをまとめた。
CSS @functionの基礎と開発体験

CSSのカスタムファンクションを定義できる@functionルールが、2026年の大きなトピックの一つだ。従来のプリプロセッサ(Sassなど)に頼らず、ブラウザ上で直接再利用可能な関数を記述できる点が画期的である。Jane Ori氏が執筆した解説記事は、初心者にも理解しやすいステップバイステップ形式で、CSS-TricksのAlmanacにもドキュメントが用意されている。
@functionの書き方と基本構造
@functionは、入力値を受け取り、計算や変換を経て新たなCSS値を返す仕組みだ。基本的な構文は以下のようになる。
@function --my-function(--param1, --param2) {
result: calc(var(--param1) + var(--param2));
}この例では、2つのパラメータを受け取り、calc()で合計を返すだけのシンプルな関数だが、より複雑な条件分岐やループ処理に相当するロジックも記述できるようになる見込みだ。開発者は、これまでJavaScriptやビルドツールに頼っていたスタイルロジックを、CSSのレイヤーで完結させられる。
実践で役立つユースケース
@functionが威力を発揮するのは、テーマのカラーパレット管理やレスポンシブな余白計算などの局面だ。たとえば、ブランドカラーをベースに明度や彩度を動的に調整する関数を定義すれば、ダークモードへの切り替えも数行で済む。
@function --tint(--color, --amount) {
result: oklch(from var(--color) l, calc(c * var(--amount)), h);
}@functionの概念を視覚化したイメージです。実際の動作はブラウザの対応状況を確認してください。@functionと@ifや@forといった制御ルールを組み合わせれば、Sassの関数に匹敵する表現力が手に入る。ビルドステップを減らせるため、サイトパフォーマンスの向上にも寄与するだろう。
alpha()関数がもたらす色指定の簡素化

CSSの色操作で長年煩わしかったのが、透明度(アルファチャンネル)の指定方法だ。alpha()関数は、このストレスを大幅に軽減する。これまで相対色構文で必須だった長い記述が、直感的な構文に置き換わる。
従来の相対色構文との比較
カスタムプロパティで色を管理している場合、透明度を変更するにはoklch(from var(--color) l c h / 0.5)のように、色空間とチャンネルを明示しなければならなかった。--colorに値だけを格納する回避策もあるが、結局はoklch()を毎回書く手間が残る。
/* 値だけを格納する方式 */
--color-values: 0.65 0.23 230;
color: oklch(var(--color-values));
color: oklch(var(--color-values) / 0.5);/* 関数ごと格納する方式 */
--color: oklch(0.65 0.23 230);
color: var(--color);
color: oklch(from var(--color) l c h / 0.5); /* 冗長 */alpha()を使えば、色空間やチャンネルを意識せずに済む。Jason Leo氏のコメントにもあるように、コードの意図が明確になり、宣言も短くなる。
color: alpha(from var(--color) / 0.5);oklch(from var(--color) l c h / 0.5)alpha(from var(--color) / 0.5)alpha()はAdam Argyle氏が言及した機能で、色フォーマットに依存しない透過度の指定を実現する。カラーデザインシステムを扱うプロジェクトでは、可読性と保守性の両面でメリットが大きい。
Grid Lanesで広がるレイアウトの選択肢

WebKitが公開した「Field Guide to Grid Lanes」は、以前「CSS Masonry Layout」と呼ばれていたレイアウト手法の解説サイトだ。一見するとCSSグリッドの応用に見えるが、要素を自然な流れで敷き詰めるPinterest風のレイアウトを実現する。
Grid Lanesの仕組みと実装例
グリッドレーンは、カラムは固定しつつ、アイテムの高さを内容に応じて自動調整し、空きスペースを詰めて表示する。従来のCSSグリッドでは、各アイテムの行トラックを手動で調整するか、JavaScriptで高さを計算する必要があった。
.masonry {
display: grid;
grid-template-columns: repeat(3, 1fr);
grid-template-rows: masonry;
}grid-template-rows: masonryを疑似的に再現したイメージです。ブラウザのサポート状況を確認してください。WebKitのガイドには、写真ギャラリー、レシピ一覧、新聞スタイル、メガメニュー、タイムライン、ピンボードといった6つの実例デモが含まれている。各デモは最小限のコードで構築されており、実務への応用がしやすい。
レスポンシブ対応とフォールバック
グリッドレーンはまだ実験的な機能だが、プログレッシブエンハンスメントの考え方で導入できる。@supportsを使えば、非対応ブラウザでは従来のグリッドレイアウトにフォールバックさせることも可能だ。
.gallery {
display: grid;
grid-template-columns: repeat(3, 1fr);
gap: 1rem;
}
@supports (grid-template-rows: masonry) {
.gallery {
grid-template-rows: masonry;
}
}WordPressのブロックエディタで動的に生成されるコンテンツ一覧にも、このレイアウトを適用すれば、よりリッチなデザインを提供できる。とくにポートフォリオサイトやECサイトの商品一覧で効果を発揮するだろう。
<dialog>要素の品質向上テクニック

モーダルダイアログやポップアップを実装する<dialog>要素が、さらに使いやすくなる。Una Kravets氏が紹介したclosedby属性とoverscroll-behavior: contain、Chris Coyier氏が解説したアニメーションテクニックを合わせて見ていこう。
closedby属性とスクロール制御
closedby属性は、ダイアログ外のクリック(ライトディスミス)やESCキー押下でダイアログを閉じる動作を制御する。従来はJavaScriptで一つひとつ実装していたが、closedby="any"を指定するだけで標準動作として利用できる(Safariは未対応)。
<dialog closedby="any">
閉じる操作を簡略化したモーダル
</dialog>さらに、overscroll-behavior: containを併用すると、ダイアログ表示中に背面コンテンツがスクロールするのを防げる。コメントではscrollbar-gutter: stableでスクロールバーの有無によるレイアウトシフトを防ぐテクニックも紹介されている。
ダイアログのアニメーション実装
Chris Coyier氏がFrontend Mastersで公開したシリーズでは、@starting-styleを用いたスムーズな開閉アニメーションの手法を解説している。多くの開発者がつまずくポイントであるだけに、実例付きの解説は貴重だ。
dialog {
transition: opacity 0.3s, transform 0.3s;
}
dialog[open] {
opacity: 1;
transform: scale(1);
}
@starting-style {
dialog[open] {
opacity: 0;
transform: scale(0.9);
}
}このアニメーションは実際に約0.3秒かけて連続的に実行される。@starting-styleで初期状態を定義することで、ブラウザが自動的に終了状態との間を補間する。ログインフォームやクッキー同意バナーなど、モーダルの表示が必要なコンポーネントで即座に活用できるテクニックだ。
CSS Day 2026とコミュニティの最新動向

毎年恒例のCSSコミュニティカンファレンス「CSS Day」が、2026年6月11日と12日にアムステルダムで開催された。今年はライブストリーミングがなかったものの、Bluesky上で多くの参加者がリアルタイムに情報を共有している。
講演スライドと舞台裏の共有
発表者のスライドや会場の様子は、#CSSDayのハッシュタグで検索できる。CSS-Tricksの記事には、登壇者のポートレート写真も掲載されており、イベントの雰囲気が伝わってくる。
現地参加できなかった日本の開発者にとっては、6月下旬に公開予定の録画が待ち遠しいところだ。新しい@functionや相対色構文に関するセッションがあったかどうかも気になるところで、動画公開後に改めて重要なポイントを整理したい。
CSS Wordleで遊びながらスキルアップ

学習ツールとして面白いのが、Sunkanmi Fafowora氏が作成した「CSS Wordle」だ。CSSのプロパティ名をWordle形式で当てるゲームで、CSS-Tricksの著者が「ここ一週間ずっとハマっている」と絶賛するほどの中毒性がある。
ゲームの仕組みと学習効果
CSS Wordleは、CSSプロパティのスペルを数回の試行で推測する。正解すると、そのプロパティの簡単な説明やブラウザ対応状況も表示されるため、遊びながら知識が広がる仕組みだ。
実務でCSSを扱うエンジニアはもちろん、これからCSSを学ぶ初心者にも最適なツールだ。隙間時間に数ラウンド遊ぶだけで、プロパティのスペルミスが減り、あまり使ったことのないプロパティにも触れるきっかけになる。
新たにBaseline入りしたCSS機能

2026年6月時点で、いくつかのCSS機能が新たにBaseline(主要ブラウザで安定利用可能)に到達した。Chrome 149に含まれるこれらの機能は、実務への導入のハードルが大きく下がっている。
gap装飾と画像レンダリング
グリッドやフレックスアイテム間の溝に装飾を追加できる「Gap decorations」がBaseline入りし、image-rendering: crisp-edgesによるピクセルアートの鮮明表示も安定して使えるようになった。また、rect()関数とxywh()関数もBaselineに追加され、シェイプの定義が簡素化されている。
一方で、path()を用いたshape-outsideやshape()はまだSafari・Firefoxでの対応が進んでいない。導入する際は@supportsでフォールバックを用意するのが無難だ。
この記事のポイント
@functionで独自のCSS関数を定義でき、ビルドツールへの依存を減らせる。alpha()は色の透明度指定を短く直感的に書ける関数である。- Grid LanesはPinterest風のレイアウトをCSSだけで実現する新しい手法だ。
closedbyやoverscroll-behaviorで<dialog>のUXが大幅に改善される。- CSS Day 2026の録画は6月下旬公開予定、Blueskyでスライドや写真を確認できる。
- CSS Wordleは楽しみながらCSSプロパティのスペルや知識を習得できるゲームだ。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験
CSSスクロールトリガーアニメーション入門、Chrome 146で実装
Chrome 146で、CSSによるスクロールトリガーアニメーションが実装された。これは要素がビューポート内に入ったことをきっかけに、指定した時間だけアニメーションを再生する仕組みだ。従来のスクロール駆動アニメーションとは動作原理が異なる。
スクロール駆動アニメーションが「スクロール位置に合わせてアニメーションの進行度が変化する」のに対し、スクロールトリガーアニメーションは「特定のスクロール地点でアニメーションを発火させる」点が特徴だ。JavaScriptのIntersection Observer APIをCSSで再現したような動きになる。
この記事では、両者の違いを比較したうえで、スクロールトリガーアニメーションの基本的な使い方から応用的なテクニックまでを解説する。複数要素の連動やタイムライン範囲の調整など、実践で役立つ手法をまとめた。
スクロールトリガーアニメーションとスクロール駆動アニメーションの違い

まず、両者の動作の違いを明確にしておく。混同しやすい概念だが、設計思想が根本的に異なる。
スクロール駆動アニメーションの基本動作
スクロール駆動アニメーションは、animation-timeline: view() や animation-timeline: scroll() を使って、スクロール量や要素の交差度合いにアニメーションの進行を同期させる。スクロールが進むほどアニメーションも進み、戻せばアニメーションも戻る。再生時間という概念はなく、ユーザーのスクロール操作がそのままタイムラインになる。
たとえば、画面下から現れた要素が完全に見えるまでフェードインする、といった表現が得意だ。スクロールに吸い付くような動きで、ユーザーに自然なフィードバックを返せる。
スクロールトリガーアニメーションの基本動作
一方、スクロールトリガーアニメーションは、要素が特定のスクロール位置に達した瞬間にアニメーションを開始する。キーになるのは timeline-trigger: view() プロパティだ。これは「要素がビューポート内にどの程度入っているか」を監視し、指定したしきい値を超えた時点でアニメーションを発火させる。
重要なのは、アニメーションが固定の再生時間を持つことだ。たとえば300msかけて背景色を変える、といった指定ができる。スクロール量に進行が左右されないため、発火後の動きは常に一定になる。これにより、スクロール駆動アニメーションでは実現が難しかった「要素が現れた瞬間に一瞬だけフラッシュさせる」といった演出も容易になる。
この概念図では、両者のトリガー条件と進行方法の違いを示している。スクロール駆動は連続的、スクロールトリガーは離散的という理解で問題ない。
基本構文とアニメーションアクション

スクロールトリガーアニメーションの最小構成は、@keyframes でアニメーションを定義し、timeline-trigger と animation-trigger で発火条件を指定する、という流れになる。
基本例とプロパティの役割
たとえば、正方形の要素が完全にビューポートに入った瞬間に、背景色が300msかけてフェードインするアニメーションを考える。コードの基本形は以下のようになる。
/* アニメーションの定義 */
@keyframes fade-bg-in {
to {
background: currentColor;
}
}
.square {
/* アニメーションの宣言 */
animation: fade-bg-in 300ms;
/* 発火条件の定義 */
timeline-trigger: --trigger view() entry 100% exit 0%;
/* 発火時の動作設定 */
animation-trigger: --trigger play-forwards;
}timeline-trigger の値で指定している entry 100% exit 0% はタイムライン範囲と呼ばれる。これは「要素の下端がビューポートに入った瞬間(entry 100%)から、上端がビューポートから出るまで(exit 0%)を発火可能な範囲とする」という意味だ。この範囲内に要素が入っているあいだ、アニメーションの再生が許可される。
animation-trigger に指定した play-forwards は、要素が完全に見えるたびにアニメーションを順方向(0%→100%)で再生するキーワードだ。ただし、このままではアニメーション終了後に背景色が元に戻ってしまう。スタイルを保持するには animation-fill-mode を併用する必要がある。
fill-mode と action の組み合わせ
CSS-Tricksの著者Carlo Daniele氏によると、fill-modeとアニメーションアクションの組み合わせが、スクロールトリガーアニメーションの挙動を大きく左右する。主な選択肢は以下の3パターンだ。
animation: fade-bg-in 300ms;animation: fade-bg-in 300ms forwards;animation-trigger: --trigger play-once;animation: fade-bg-in 300ms forwards;animation-trigger: --trigger play-forwards play-backwards;往復型の play-forwards play-backwards は特に実用的だ。要素がビューポート外に出る際にアニメーションが逆再生されるため、ちらつきが発生しない。fill-modeを forwards にしていても、最終キーフレームが0%でも100%でも「完了時のスタイルを保持する」というルールが適用されるため、自然に動作する。
アクションキーワード一覧
animation-trigger に指定できるアクションキーワードは以下の表にまとめた。設計の幅を広げるために把握しておきたい。
これらのアクションを組み合わせることで、「スクロールに応じてアニメーションを途中で反転させる」「一度だけ発火させて二度と動かさない」といった細かな制御が可能になる。
複数要素への適用とスタッガー効果

スクロールトリガーアニメーションの真価は、複数要素を連動させた演出で発揮される。アクションやfill-modeが独立しているため、共通のトリガー設定を使い回しながら個別のアニメーションを割り当てられる。
CSSカスタムプロパティで設定を再利用する
たとえば、3つの正方形が順番に回転しながら拡大・背景変化する例を考える。各要素に個別のスタイルを書くのではなく、カスタムプロパティで共通設定をまとめると保守性が高まる。
.square {
scale: 70%;
--base-animation: intensify;
animation: var(--base-animation) 300ms forwards;
--animation-trigger: --trigger play-forwards play-backwards;
animation-trigger: var(--animation-trigger), var(--animation-trigger);
timeline-trigger: --trigger view();
timeline-trigger-active-range-end: normal;
}
.square.rotate-left {
animation-name: var(--base-animation), rotate-left;
}
.square.rotate-right {
animation-name: var(--base-animation), rotate-right;
}このコードでは、--animation-trigger に play-forwards play-backwards を格納し、animation-trigger でカンマ区切りによって2つのアニメーションに同じトリガー設定を適用している。これにより、メインのアニメーション(intensify)と回転アニメーションの両方が同じタイミングで発火する。
sibling-index() と sibling-count() による自動スタッガー
スクロールトリガーアニメーションでは、sibling-index() と sibling-count() という2つのCSS関数を使って、兄弟要素のインデックスと数を動的に取得できる。これを利用すると、各要素の発火タイミングを自動的にずらす「スタッガー」が実装可能だ。
.square {
--stagger-interval: calc(100% / sibling-count());
--entry: calc(sibling-index() * var(--stagger-interval));
timeline-trigger: --trigger view() entry var(--entry) exit 0%;
}sibling-count() で親要素内の.squareの数を取得し、それを100%で割ることで1要素あたりの間隔を算出する。次に sibling-index() で現在の要素が何番目かを取得し、間隔を掛け算して各要素の entry 値を動的に決定する。この仕組みがあれば、HTMLの要素数が変わっても手作業で値を調整する必要はない。
ただし、sibling-index() と sibling-count() はFirefoxで未サポートの点に注意が必要だ。プロダクションで使う場合は、フォールバックの指定を検討したい。
特定の要素をトリガーとして他を連動させる
さらに高度な使い方として、最初の要素だけをトリガーにして、残りの要素はアニメーション遅延で続けて発火させる方法がある。トリガー条件を1箇所に集約できるため、管理がしやすくなる。
.square:first-child {
timeline-trigger: --trigger view() entry 50%;
timeline-trigger-active-range-end: normal;
}
.square {
--stagger-interval: calc(300ms / sibling-count());
--animation-delay: calc(sibling-index() * var(--stagger-interval));
animation: var(--base-animation) 300ms var(--animation-delay) forwards;
}最初の要素がビューポートに50%入った時点でトリガーが発火し、残りの要素は animation-delay で順番にアニメーションを開始する。この方法なら、トリガー設定は最初の要素にだけ書けばよい。
ただし、CSS-Tricksの記事では play-backwards 状態のときに遅延が意図通り動作しない可能性が指摘されている。逆再生時にはdelayが含まれてしまい、スタッガーが崩れるようだ。今後のブラウザ実装の改善が待たれる。
タイムライン範囲の理解とカスタマイズ

スクロールトリガーアニメーションには、アクティベーション範囲(発火可能な範囲)とアクティブ範囲(発火後に有効であり続ける範囲)という2つのタイムライン範囲が存在する。この概念を理解しておくと、より精密なトリガー制御が可能になる。
アクティベーション範囲とアクティブ範囲の違い
アクティベーション範囲は「アニメーションが発火できるスクロール区間」を定義する。例えば entry 100% exit 0% は、要素が完全に見えてから完全に隠れるまでを発火可能区間とする。アクティブ範囲は「一度発火したアニメーションが、たとえアクティベーション範囲を外れても有効であり続ける区間」を指す。
例:
entry 100% exit 0% は、要素の下端が入ってから上端が出るまで。timeline-trigger-active-range-end: normal; で制御可能。実際のところ、大半のユースケースでは view() entry 100% exit 0%(要素が完全に見える間)か view() contain(要素がビューポートより大きい場合も含めて交差している間)で十分だ。タイムライン範囲の詳細な制御が必要になるのは、特殊な演出や複雑なレイアウトに限られる。
view() 関数とオフセットの調整
view() 関数はビューポートを基準にしたタイムライン範囲を定義する関数だ。固定ヘッダーなどでビューポートの実質的な領域が狭まっている場合、view(y 0 5rem) のようにオフセットを指定できる。これにより、ヘッダーに隠れる部分を除いた「実際に見えている領域」を基準にできる。
たとえば、上部に高さ5remの固定ヘッダーがあるページでは、view(y 0 5rem) と書くことで、ヘッダーの裏に入った要素はまだトリガー範囲内と見なされない。この調整は、UIコンポーネントとスクロール演出を正確に同期させる際に役立つ。
この記事のポイント
- スクロールトリガーアニメーションは、スクロール駆動アニメーションと異なり、固定時間のアニメーションを特定のスクロール地点で発火させる仕組みである
- fill-modeとanimation-actionの組み合わせで、往復・ロックイン・フラッシュなど多彩な演出が可能
- sibling-index()とsibling-count()を使えば、要素数に依存しない自動スタッガーを実装できる
- 実用上はview() entry 100% exit 0%の指定で十分だが、固定ヘッダーがある場合はview()のオフセット調整を検討する
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

MDN MCPサーバーでAIに正確なCSSブラウザ互換性情報を提供、開発効率が向上
MDN Web DocsがMCP(Model Context Protocol)サーバーを公開した。このサーバーを使うと、AIコーディングアシスタントにMDNの最新ドキュメントとブラウザ互換性データを直接読み込ませられる。CSSの新機能やブラウザサポートを正確に把握できるため、誤ったコード提案を防ぐことが可能だ。
特に、CSSの最新機能(light-dark()画像対応、:buffering疑似クラスなど)はLLMの学習データに含まれていないことが多い。MDN MCPを導入すれば、AIが正しい情報を参照して回答を生成するため、開発者はわざわざブラウザで互換性を調べる手間が省ける。
MDN MCPサーバーとは

MCPはAIツールが外部データソースに接続するためのオープンスタンダードだ。MDN MCPサーバーはこのプロトコルを使って、MDNの豊富なWebプラットフォーム情報(HTML・CSS・JavaScript・Web APIのリファレンス、ブラウザ互換性データ)をAIエージェントやIDEに提供する。これにより、AIが常に最新のWeb標準に基づいてコードを提案できるようになる。
MCPの基本とMDNの役割
MCP(Model Context Protocol)はAnthropicが中心となって策定したオープンプロトコルで、LLMが外部ツールやデータベースと通信するための共通インタフェースを提供する。MDN MCPサーバーはHTTPトランスポートで動作し、クライアント(VS CodeやClaude Codeなど)がリクエストを送ると、MDNのコンテンツAPIから必要な情報を抽出して返す仕組みだ。
たとえば、AIが「CSSのlight-dark()は画像でも使えるか」と問われた場合、通常のLLMは学習時の知識だけを頼りにする。しかしMDN MCPサーバーが接続されていれば、AIはリアルタイムで正式な仕様とブラウザ実装状況を取得し、誤った回答を防げる。
対応しているツール一覧
MDN MCPサーバーは主要な開発ツールと連携する。エディタではVS Code、Zed、Cursorがサポートされており、AIコーディング支援機能から直接MDNを参照できる。ターミナルベースのエージェントとしてはClaude Code、OpenAI Codex CLI、Google Antigravity CLI(旧Gemini CLI)が対応。チャットアプリではClaude Desktopで利用可能だ。
これらのツールにMCPサーバーを登録する手順は各公式ドキュメントに記載されている。基本はHTTPエンドポイントを指定するだけで、追加のAPIキーなどは不要だ。
なぜ今、MCPが必要なのか

Webプラットフォームの進化は速い。CSSだけを見ても、light-dark()の画像対応、@view-transition、:buffering疑似クラスなど、直近1年以内に実装が始まった機能は多い。AIの学習データは数カ月から1年以上前の情報で固定されているため、こうした新機能に関する質問には正確に答えられない可能性がある。
MDN Blogの記事では、Claude Code Opus 4.7を用いてテストを行った結果、MCPなしではWeb Serial APIについて「Firefoxでは未実装で、Mozillaの標準ポジションでは有害とされている」と誤った回答をしたと報告されている。実際にはFirefox 151でサポートが開始されており、MCPを有効にすることでこの誤りは解消された。
AIの回答が誤っていると、開発者はブラウザの実装状況を手動で調べ直す必要が生じる。MDN MCPはその手間を省き、AIが確かなソースに基づいて回答する仕組みを提供する。
実際のCSS機能で検証、MCP有無の比較
light-dark()画像対応のブラウザサポート
light-dark()はカラースキームに応じて値を切り替えるCSS関数だが、画像も受け付ける。たとえば次のように書ける。
.profile-avatar {
background-image: light-dark(url(avatar-light.png), url(avatar-dark.png));
}light-dark()はOSのカラースキームに応じて自動で画像を切り替える。画像以外にもグラデーションやURLが使用可能だ。
このlight-dark()の画像対応について、Claude CodeにMCPなしで質問した場合、色の値に関する説明しか得られず、画像がサポートされていることは明確に示されなかった。一方、MCPを有効にすると、Firefox 150以降、Chrome(フラグ付き)でサポートされていることが即座に回答された。
:buffering疑似クラスとWeb Serial APIの誤情報
:buffering疑似クラスは、メディア要素がバッファリング中であることを検出するため、MCPなしでも正しいブラウザサポート情報が返された数少ない事例だ。しかしshadowrootslotassignment属性やWeb Serial APIについては、MCPなしでは誤った情報が目立った。
MCPを導入すると、最新のブラウザ互換性データが参照されるため、誤情報を防げる。
特にWeb Serial APIのケースでは、MCPなしのAIは「有害」という強い表現を使ってまで非対応と主張しており、誤った知識で開発を妨げるリスクがあった。MDN MCPはこのような誤解を回避し、確かな情報に基づいたコーディング支援を実現する。
導入方法と活用のポイント

Claude Codeでの設定手順
MDN MCPサーバーはHTTPエンドポイントが公開されており、対応クライアントでMCPサーバーとして追加するだけで利用できる。たとえばClaude Codeの場合、次のコマンドをターミナルで実行する。
claude mcp add --transport http mdn https://mcp.mdn.mozilla.net/この設定後、AIアシスタントがMDNの情報を必要とする質問を受け取ると、自動的にMCPサーバーへリクエストが送られ、最新のドキュメントが参照される。他のエディタやCLIツールでも同様に、MCPサーバーのURLを登録するだけで連携が完了する。
プライバシーと注意点
現在のMDN MCPサーバーは実験的な提供段階であり、使用時にはMDNのプライバシー通知を確認することが推奨されている。サーバーは利用者が送信したクエリを一時的に処理するが、データの取り扱いについては今後アップデートされる可能性がある。
また、MCPが参照するデータはMDNの公式コンテンツとブラウザ互換性テーブルであるため、正確だが、あくまでAIの出力はLLMの生成結果である点に注意が必要だ。複数の情報源と組み合わせながら活用するのが賢い使い方といえる。
この記事のポイント
- MDN MCPサーバーは、AIツールにMDNの最新ドキュメントとブラウザ互換性データを提供する。
- CSSの新機能(light-dark()画像対応、:bufferingなど)の正確な情報を得られる。
- MCPなしではWeb Serial APIのように「未実装」と誤った回答をするケースがあった。
- VS CodeやClaude Codeなど主要な開発ツールで利用可能。導入はURL登録のみ。
- AIの回答が古い知識に依存するリスクを減らし、開発効率を高める。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験