

OpenAI GPT-Live登場、ChatGPT Voiceに検索機能を統合
OpenAIが音声会話と検索を融合させた新モデル「GPT-Live」の展開を開始した。2026年7月8日に発表されたこのアップデートにより、ChatGPT Voiceは会話の途中で最新の推論モデルやウェブ検索に質問を引き継げるようになる。
有料ユーザー(Go・Plus・Pro)には「GPT-Live-1」、無料ユーザーには「GPT-Live-1 mini」がデフォルトで提供される。Search Engine JournalのMatt G. Southern氏が報じたところによれば、週に1億5千万人以上がChatGPTと音声や音声入力で会話しており、今回の変更はその巨大なユーザー基盤に直接影響を及ぼす。
SEOの観点から特に注目すべきは、音声経由の検索結果が「どのように引用元を扱うか」の詳細がまだ明らかにされていない点だ。テキストベースのChatGPTでは回答の横にソースリンクが表示されるが、音声会話の中でどの程度サイトへの導線が確保されるかは、今後のトラフィック戦略を左右する。
GPT-Liveの仕組みと変更点

GPT-Liveの最大の特徴は、会話の自然さを追求した「全二重(Full-Duplex)」通信への移行だ。これは音声入力と応答生成を同時に行う技術で、ユーザーが話し終える前に割り込まれにくくなり、より人間らしい対話のテンポが実現される。
具体的に以下の要素で構成されている。
- 音声入力の処理と応答の生成を同時に実行し、待ち時間を短縮
- ユーザーが発話をためらった際に適切な間を取り、自然なターンテイキングを実現
- 有料ユーザー向けのGPT-Live-1と、無料ユーザー向けのGPT-Live-1 miniの2種類を用意
- 深い推論が必要な質問は自動的に最先端モデル(現在はGPT-5.5)に引き継ぐ
OpenAIの社内評価では、5分から10分の会話においてGPT-Live-1とGPT-Live-1 miniは従来のAdvanced Voice Modeよりも高く評価された。評価基準は全体的な好ましさ、ターンテイキング、割り込みの少なさ、会話の流れ、自然さだ。
音声検索の裏で動く推論と視覚カード

GPT-Liveの登場により、ChatGPT Voiceは単なる音声応答の枠を超え、天気や株価、スポーツといったトピックに対して視覚的なカードを画面に表示するようになった。これにより、ユーザーは音声で答えを聞きながら同時に画面で詳細を確認できる。
ユーザーは推論レベルを3段階から選択できる仕組みだ。即時応答を求める「Instant」モードはGPT-5.5 Instantで動作し、より深い回答が必要な「Medium」や「High」モードはGPT-5.5 Thinkingを使用する。音声会話の自然さを保ちながら、必要に応じて高度な推論エンジンに処理を委ねる設計になっている。
この仕組みは、音声経由の検索体験を大きく変える可能性がある。画面に情報カードが表示されることで、ユーザーは検索結果ページを経由せずに目的の情報を得られるからだ。
この変化はSEO担当者にとって無視できないシグナルだ。音声検索の結果が可視化されない形で提供されることで、従来の検索エンジン経由のトラフィックが一部置き換わる可能性がある。
GPT-Liveがまだ実装していない機能
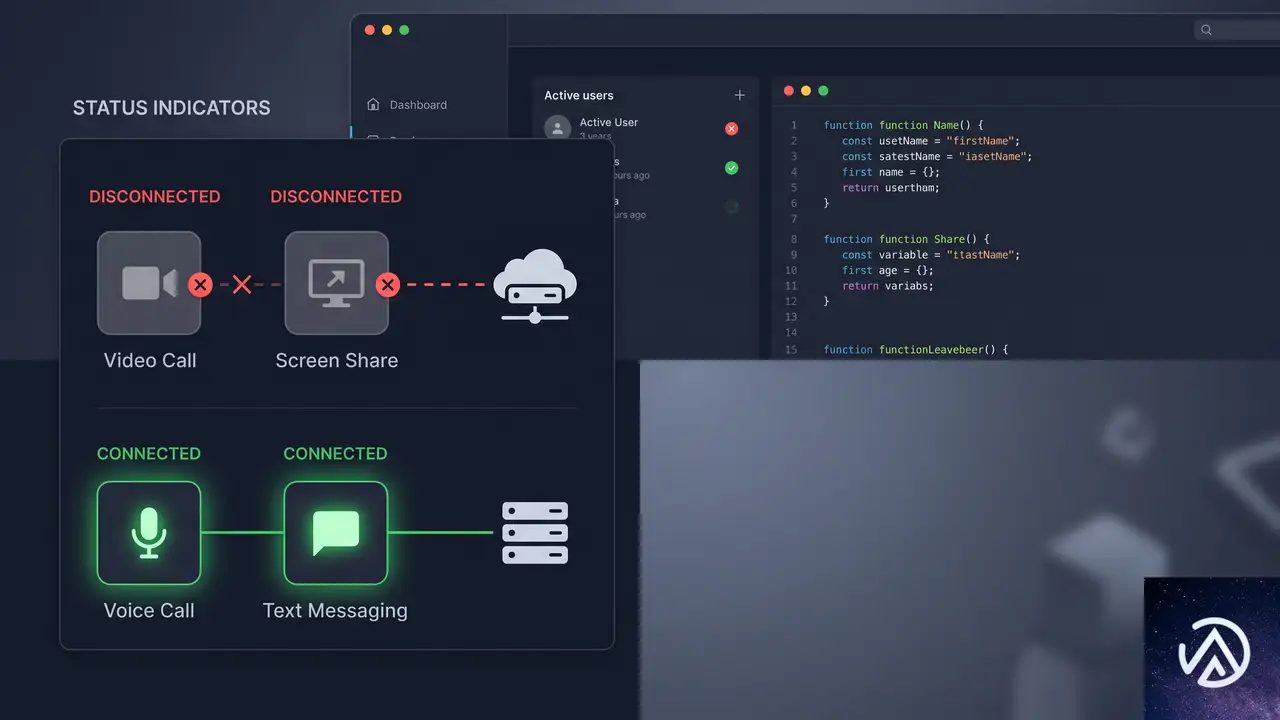
GPT-Liveは現時点で、ChatGPTにおけるビデオや画面共有を伴う音声には対応していない。OpenAIはこれらの機能の追加に取り組んでいることを明言しており、ビデオや画面共有が必要な場面では従来のStandard Voice ModeおよびAdvanced Voice Modeが引き続き利用できる。
実務的に重要なのは、この制約が一時的なものである可能性が高いという点だ。ビデオ・画面共有対応が追加されれば、ユーザーは画面を見せながら質問し、GPT-5.5の推論と検索を組み合わせた回答をその場で得られるようになる。視覚的な情報提供の幅がさらに広がることで、従来型の検索エンジンへの依存はより一層低くなるだろう。
引用とソース表示の不透明さがもたらすSEOリスク
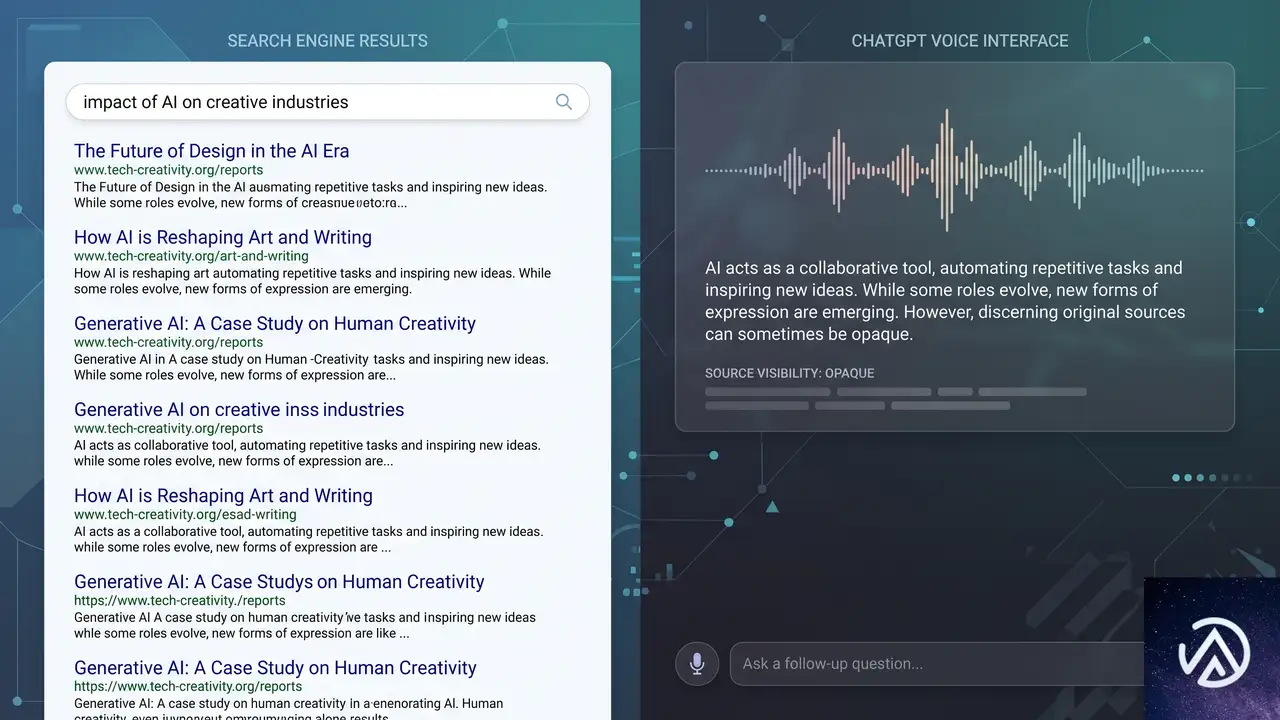
OpenAIの発表で最も詳細が不足しているのが、音声検索結果の引用(Citation)の扱いだ。テキスト版のChatGPTでは、回答の横にソースリンクが明示される。しかしGPT-LiveがGPT-5.5のウェブ検索を通じて得た情報を音声で回答する際、どのように引用元を示すのかはまだ明らかにされていない。
可能性としては以下の3つのシナリオが考えられる。
- 音声でソース名を読み上げて紹介する
- 画面上にテキストと同様のソースリンクを表示する
- ソースを一切提示せずに回答のみを提供する
3番目のシナリオが現実になれば、情報を提供しているウェブサイトにとっては深刻な問題となる。ユーザーが音声で質問し、画面を見ずに回答だけを得て終了すれば、検索トラフィックは完全に消失するからだ。
Search Engine JournalのMatt G. Southern氏は、音声検索結果がソースを「口頭で読み上げるのか、画面に表示するのか、あるいは完全に省略するのか」が、検索からサイトへの送客が維持されるかどうかを決める鍵だと指摘している。ChatGPTの音声会話がウェブサイトのトラフィックに与える影響を測る上で、最も注視すべきポイントだ。
音声検索時代に備えるための実務アプローチ

GPT-Liveのような音声と検索の融合が進む中で、SEO対策は従来のランキング上位表示だけでなく、「AIに情報源として選ばれること」を視野に入れる必要がある。以下の3つの観点が重要になる。
構造化データの強化と情報の整理
AIモデルがウェブ上の情報を正確に取得し、適切に引用するためには、ページの情報構造を機械が読み取りやすい形で提供することが欠かせない。Schema.orgに準拠した構造化データのマークアップは、検索エンジンだけでなくAIによる情報抽出の精度にも影響する。
特にFAQページやHowToコンテンツは、音声での質問応答に直接活用される可能性が高い。質問と回答のペアを明確にマークアップし、簡潔で正確な情報を提供することが有効だ。
ブランド認知と信頼性の蓄積
音声検索の結果としてソースが表示される場合、ユーザーがクリックするのは「知っている名前」や「信頼できると感じるサイト」である可能性が高い。AI時代のSEOでは、単なる検索順位だけでなく、ブランドとしての認知度や専門性の確立がクリック率に直結する。
具体的には、業界内での継続的な情報発信、オリジナルデータや独自調査の公開、著名なメディアからの被リンク獲得など、E-E-A-T(経験・専門性・権威性・信頼性)を高める施策がこれまで以上に重要になる。
音声向けコンテンツの設計
音声で読み上げられることを想定したコンテンツ設計も視野に入れるべき段階に入った。長文の説明よりも、要点を簡潔にまとめた「音声向けサマリー」をページの冒頭に配置することで、AIが情報を抽出しやすくなる。
また、天気や株価、スポーツのスコアといったリアルタイム性の高い情報は、構造化データと組み合わせることでAIに直接取得されやすい。これらの情報を提供しているサイトは、API連携やデータフィードの整備を通じて、機械可読な形式での情報提供を強化することが望ましい。
この記事のポイント
- GPT-Liveは音声会話中にGPT-5.5への推論依頼とウェブ検索を自動的に組み合わせる
- 天気・株価・スポーツなどの視覚カードにより、検索結果ページを経由しない情報取得が拡大
- 音声検索結果の引用表示方法が未公表であり、サイトへのトラフィック維持に直結する課題
- 構造化データの強化とブランド認知の蓄積が、AI時代のSEOにおける重要な差別化要素になる

・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AI検索時代のSEO、5つの教訓と閉ループSEOの実践
はじめに AI検索とSEOの常識が変わった

昨年時点でAI検索経由のリードは全体の2.5%に過ぎなかった。それが2026年3月には35%まで跳ね上がっている。Search Engine JournalのウェビナーでWritesonicのCEOサマニョウ・ガーグ氏が示した数字だ。AI検索はもはや実験段階ではなく、マーケティング成果を左右する主力チャネルに成長している。
だが、この変化は単なる流入経路の増加ではない。「AI検索がSEOを殺したわけではないが、エンジニアリングの問題に変えた」とガーグ氏は指摘する。検索キーワードを詰め込む従来の対策は通用しなくなり、自社サイトの外側でいかに引用を獲得するかという設計思想の転換が求められている。
本記事では、Writesonicの調査から浮き彫りになったAI検索時代の5つの教訓を整理し、具体的なアクションに落とし込む。AI引用の96%が自社外ページから生まれている現実、引用が生き残る時間、そして「閉ループSEO」と呼ばれる継続的改善の仕組みまでを扱う。
従来のSEOは自社サイト内の最適化が中心だったが、AI検索では発想を180度転換する必要がある。
AI引用の96%は自社サイト外から発生している

Writesonicが実施した最新調査で、AI検索が引用するページの96%がサードパーティソースだった。Reddit、YouTube、フォーラム、業界メディアなどだ。数カ月前は約80%だったことから、この傾向は加速しているとみられる。
さらに、AIモデルのアップデートごとに引用先の構成比は大きく変動する。GPT 5.3からGPT 5.5への移行ではRedditとYouTubeの引用が急増し、特定ドメインに依存するリスクの高さが浮き彫りになった。
自社サイトだけに頼るリスク
ガーグ氏は「すべての卵を1つのバスケット(自社サイトや特定のサイト)に入れてはいけない」と警鐘を鳴らす。自社ドメインのページだけを最適化しても、AI検索の引用先としては取りこぼす確率が極めて高いからだ。競合がフォーラムや動画プラットフォームで引用を獲得していれば、検索のたびに自社の露出機会が失われる。
ガーグ氏はウェビナー内で、競合が引用されているのに自社が引用されていないトピックを特定し、アウトリーチ先と連絡先を自動でリスト化するエージェントのデモも披露している。
AI引用の寿命は想定よりはるかに短い

Writesonicが15万件以上の引用を分析した結果、AI検索での引用の平均寿命は多くのコンテンツ担当者が想定するより短かった。モデルは確率的に動作するため、新鮮なソースに入れ替わるたびに自社の引用枠が競合に奪われる可能性がある。
「モデルは本質的に確率的なので、非常に不安定なものだ」とガーグ氏は述べている。一度引用を獲得しても、次のモデル更新でその座を失うことは珍しくない。
引用ローテーションにどう備えるか
Writesonicのチームは引用がローテーションで外れた場合に備え、リフレッシュと多様化をセットで実行している。具体的には、引用が失効したページを即座に更新し、同時に別のプラットフォームで新たな引用候補を育成するという動き方だ。特定の1ページに依存しない体制を作ることが、AI検索での安定した可視性につながる。
1つの引用先に集中するのではなく、常に複数のエントリーポイントを育てておく発想が欠かせない。
SEOエージェントを構成する4つの層
Writesonicが構築しているSEOエージェントは「アイデンティティ」「知識」「スキル」「ツール」の4層で構成される。重要なのは、人間の専門家を置き換えるのではなく、専門家の思考パターンを再現して補佐させる設計思想だ。
ガーグ氏は「世界で最も優秀なインターンがチームに加わったようなものだ」と表現する。ポジショニングエージェントはエイプリル・ダンフォード氏のフレームワークを学習し、個別の専門家の判断ロジックを「セカンドブレイン」文書として構造化する。すべての最終判断は人間の実務者が承認する体制をとっている。
専門家ファイルの作り方
エキスパートファイルとは、特定の専門家が公開している思考フレームワークや講演内容を、AIモデルが消費しやすい構造化マークダウンに落とし込んだものだ。ガーグ氏は「1万ワードのテキストをただ並べるのではなく、モデルが新しいタスクに適用できるよう適切に構造化する必要がある」と述べている。1人の専門家から始め、成果が出てからチーム全体に広げるアプローチが推奨される。
専門家の知見を構造化してエージェントに渡せば、24時間稼働する戦略スタッフとして機能する。ただし最終判断の権限は常に人間が握っておくことが大前提だ。
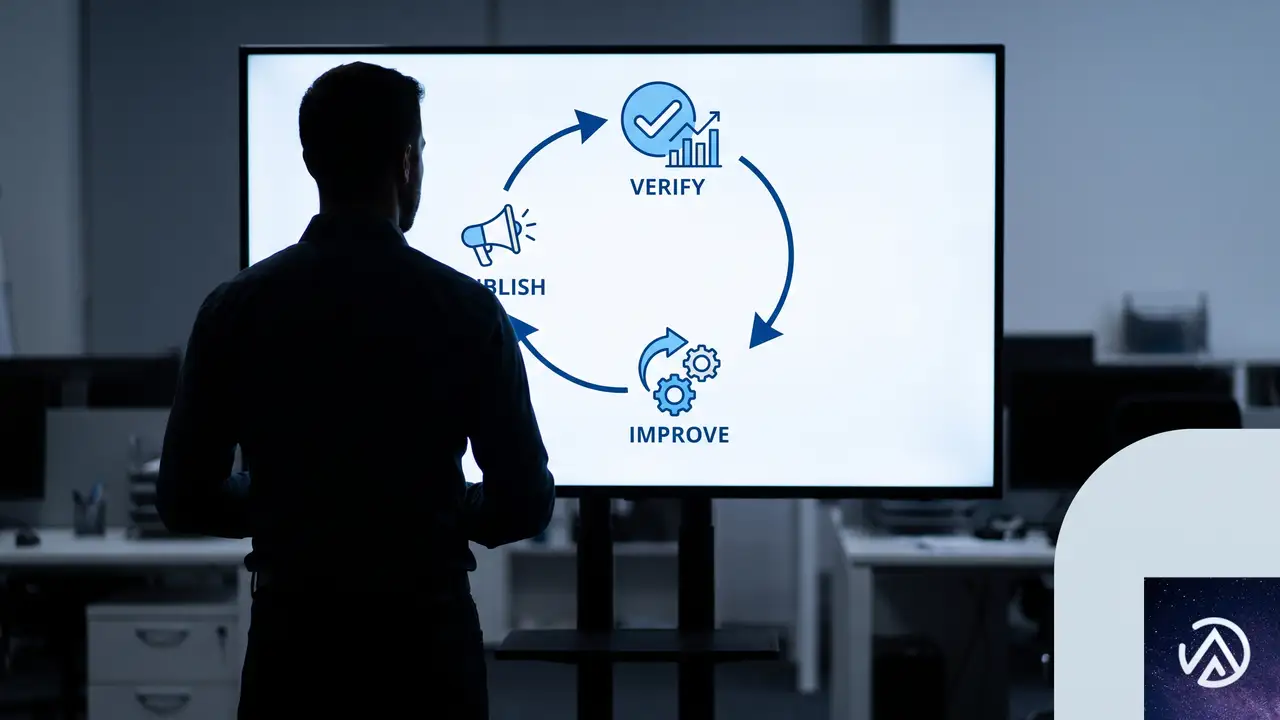
閉ループSEOの考え方 公開・検証・改善を回す

閉ループSEOとは、公開したすべてのページを実験とみなし、Googleがインデックスしたかどうか、ランキングや引用を獲得できたかどうかを検証し、その結果を次の修正にフィードバックする手法だ。ガーグ氏のチームは4つの重み付け指標で全ページをスコアリングし、100ページのバックログを優先度順の作業キューに変換している。
ウェビナーのライブ投票では、参加者の大半が「成果を測定していない」または「測定しているが行動に移していない」と回答した。ガーグ氏は「診断は今や安価になった。重要なのは実行だ」と指摘している。
自動化すべき領域と人間が握るべき領域
まず自動化すべきは、既存データソースの接続とプロアクティブな異常検知のループだ。逆に「公開ボタン」の自動化は避けるべきとガーグ氏は明確に述べている。最終送信の前に人間が検証しテストする「半自律」の状態を維持することが、AI検索対策の品質を保つ要となる。
オンページとオフページ、どちらに注力すべきか
ガーグ氏はオフページに60%、オンページに40%の比重を推奨している。ただし、自社ページが引用を獲得し始めた段階でオンページ比率を引き上げるのが現実的なバランスだ。AI検索の可視性を動かす主なドライバーがオフページ側にあるという認識は、従来のSEOとは大きく異なる点である。
従来のSEOではオンページが主戦場だったが、AI検索では外部プラットフォームでの存在感がものを言う。フォーラムへの参加や動画コンテンツの拡充といったオフページ施策が、直接的な引用獲得につながる。
AI検索経由のリードをどう計測するか
Writesonicでは「どこで当社を知ったか」を問う自己申告フォームと、セールスコールでの二重確認を組み合わせている。ガーグ氏は10〜20%程度のバイアスが入る可能性を認めつつも、「十分な指標になる」と述べている。
AI検索経由の流入を完全に追跡する技術はまだ確立されていないが、少なくとも自己申告ベースで推移をモニタリングすることは、今後の戦略立案に欠かせない。Writesonicのケースでは、この仕組みによってAI検索経由リードが2.5%から35%に伸びた事実を定量的に把握できた。
この記事のポイント
- AI検索の引用の96%は自社サイト外(Reddit、YouTube、フォーラムなど)から発生する
- AI引用の寿命は短く、モデル更新のたびにローテーションが発生するため常時監視が必要
- SEOエージェントは「専門家ファイル」で思考パターンを学習させ、人間が最終判断を下す半自律運用が効果的
- 閉ループSEOで公開→検証→改善を回し続けることが、AI検索時代の競争力を左右する
- リソース配分はオフページ60%、オンページ40%を目安に、引用獲得後にオンページ比率を引き上げる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Google Search Consoleにソーシャル・動画プラットフォームのプロパティが追加
Search Consoleに追加された「プラットフォームプロパティ」の概要

2026年7月7日、GoogleはSearch Consoleに「プラットフォームプロパティ」という新たなプロパティタイプを追加した。Instagram、TikTok、X(旧Twitter)、YouTubeといったソーシャルメディアや動画プラットフォーム上の投稿が、Google検索やDiscoverでどのように表示され、クリックされているかを分析できる仕組みだ。
これまでSearch Consoleはウェブサイトを所有する運営者向けのツールだった。今回の変更により、自社サイトを持たないクリエイターやインフルエンサーも、自身の投稿パフォーマンスをGoogleの公式データで確認できるようになる。
Search Consoleのプロダクトマネージャーを務めるMoshe Samet氏がSearch Centralブログで発表した。同氏によれば、アカウントを連携すると、どの検索キーワードから投稿にアクセスがあったか、ユーザーが投稿に対してどう行動したかを把握できるという。
上の図はSearch Consoleの管理範囲がどのように広がったかを整理したものだ。サイト単位の分析に加え、ソーシャルプラットフォーム上の個別投稿のパフォーマンスも同じダッシュボードで確認できるようになる。
利用可能な3つのレポート機能

プラットフォームプロパティでは、通常のSearch Consoleプロパティと同様のレポート構成が提供される。ただし、ソーシャルメディアや動画コンテンツに最適化された形で表示される点が特徴だ。
パフォーマンスレポート
総クリック数、表示回数(インプレッション)、平均CTR(クリック率)、平均掲載順位といった主要指標を確認できる。フィルタや並べ替え機能を使えば、どの投稿や検索クエリが最も流入に貢献しているかを特定しやすい。データはエクスポートにも対応しており、他の分析ツールでさらに深掘りすることも可能だ。
CTRとは「Click Through Rate」の略で、表示回数のうち実際にクリックされた割合を指す。たとえば100回表示されて3回クリックされればCTRは3%だ。検索結果に表示される頻度と、実際に選ばれる確率のバランスを見るための基本的な指標として使われる。
インサイトレポート
直近のトラフィック傾向や、最も成果を上げた投稿の概要、ユーザーがGoogle上でどのようにアカウントを見つけているかといった俯瞰的な情報を提供する。パフォーマンスレポートが数値ベースの詳細分析であるのに対し、インサイトレポートは「いま何が起きているか」を直感的に把握するためのダッシュボードだ。
アチーブメント
28日間の間に、検索からの総クリック数が一定のしきい値を超えるなどのマイルストーン達成を検出し、通知する仕組みだ。数値目標を持ちにくいソーシャルメディア運用において、客観的な達成基準として活用できる。
3つのレポートは独立しているのではなく、上図のように段階的に活用することで効果を発揮する。数値確認→傾向把握→成果認知→改善実行というサイクルをSearch Console内で完結できるのが強みだ。
プラットフォームプロパティの追加手順
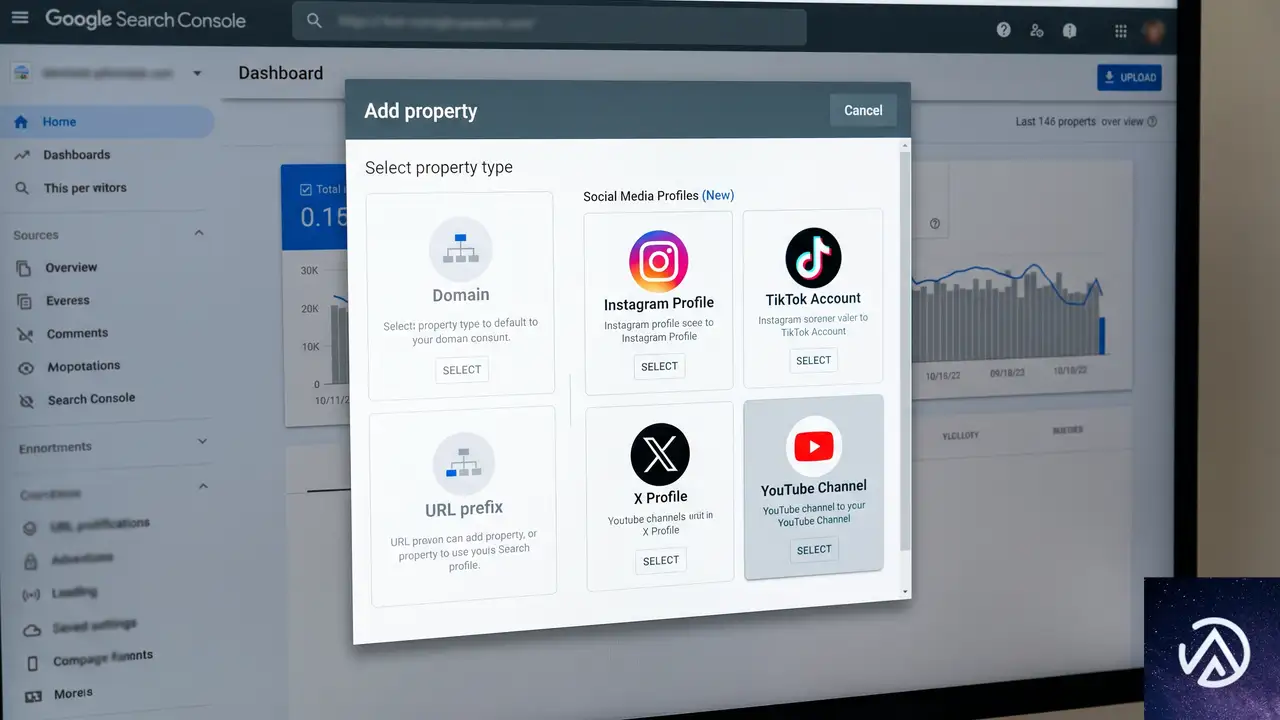
設定はSearch Consoleの所有権確認フローに沿って進める。具体的な流れは以下のとおりだ。
- Search Consoleを開き、所有権の確認ページまたはプロパティセレクタに移動する
- 「プロパティを追加」を選択する
- Instagram、TikTok、X、YouTubeのいずれかを選ぶ
- 画面の指示に従って連携を承認する
これだけで設定は完了する。従来のSearch Consoleプロパティのように、DNSへのTXTレコード追加やHTMLファイルのアップロードといった技術的な作業は不要だ。各プラットフォームのOAuth認証を使ったシンプルな連携方式が採用されている。
サーチプロファイルとの違い

2026年6月、Googleは「サーチプロファイル」という機能を公開した。フォロワー10万人以上のクリエイターやパブリッシャーを対象に、公開プロフィールページを提供する仕組みだ。プラットフォームプロパティと混同しやすいため、両者の違いを明確にしておく。
サーチプロファイルが「見せる」ための公開ページであるのに対し、プラットフォームプロパティは「測る」ための分析ツールだ。両者は補完関係にあり、検索上での存在感を高めたいクリエイターにとってはどちらも有用な機能といえる。
なお、今回のプラットフォームプロパティは、2025年12月に実施されたソーシャルチャネルデータをSearch Consoleに統合する実験を発展させたものだ。
実務への影響と活用ポイント

この機能が実務に与える影響は大きい。従来、ソーシャルメディアの投稿が検索経由でどの程度見られているかを知るには、各プラットフォームのアナリティクスに頼るしかなかった。しかし、プラットフォーム側のデータは検索エンジン経由の流入を正確に分離できないケースが多い。
Google公式のSearch Consoleでデータを取得できる意味は2つある。1つはデータの信頼性が担保されること、もう1つは検索クエリとの紐付けが可能になることだ。たとえば「おすすめ カフェ 東京」という検索キーワードでInstagramの投稿が表示され、クリックされたという因果関係を追跡できる。
ウェブサイトを持たないクリエイターへの恩恵
最大の変化は、自社サイトや個人ブログを持たないクリエイターにもSearch Consoleの門戸が開かれたことだ。これまでSearch Consoleはサイト所有者のツールであり、ドメイン認証が必須だった。今回のプラットフォームプロパティでは、ソーシャルメディアのアカウントさえあれば利用できる。
SEO担当者にとっての新たな分析軸
企業のSEO担当者にとっては、検索結果ページに表示される自社のソーシャル投稿を管理する手段が増えたことを意味する。YouTubeの動画やInstagramの投稿が検索結果に表示されるケースは増えており、それらのパフォーマンスをSearch Console上で一元管理できるメリットは無視できない。
分析ツールの断片化が解消されることは、レポート作成の手間を減らすと同時に、データの解釈を統一する効果も期待できる。これまで「Instagramのインサイトでは伸びているのに、検索からの流入が測れない」というジレンマを抱えていた運用担当者にとっては朗報だ。
今後の展開と注意点

プラットフォームプロパティは数週間かけて段階的に展開されるため、アカウントによってはまだ表示されない場合がある。Googleは初期段階として4つのプラットフォームに対応するが、今後の対応範囲拡大についても示唆している。
設定にあたっては、Googleのヘルプドキュメントが用意されているほか、Search Console内とSearch Central Communityにフィードバックリンクが設置されている。初期リリースということもあり、運用しながら改善が加えられていくフェーズと考えるのが妥当だ。
今すぐ取り組むべき3つの準備
- 利用可能になった時点で迅速に設定できるよう、Search Consoleのアカウントを最新の状態にしておく
- 現在運用中のソーシャルアカウントのうち、どのプラットフォームを優先的に連携するか社内で方針を決めておく
- 連携後にどの指標をKPI(重要業績評価指標)として追うか、事前に整理する
プラットフォームプロパティは、検索マーケティングの対象領域をウェブサイトの外側に拡張する第一歩ともいえる。検索結果が多様化する中で、テキストコンテンツだけでなく動画やソーシャル投稿も含めた総合的な検索対策が求められる時代に向けた布石だ。
この記事のポイント
- Search Consoleにプラットフォームプロパティが追加され、Instagram、TikTok、X、YouTubeの投稿パフォーマンスを分析できるようになった
- パフォーマンスレポート、インサイトレポート、アチーブメントの3種類のデータを提供する
- 自社サイトを持たないクリエイターでもSearch Consoleを利用可能になった点が最大の変化
- サーチプロファイルとは異なり、あくまで分析ツールとして機能する
- 数週間の段階的展開が予定されており、対応プラットフォームは今後拡大する可能性がある
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Safari MCP ServerでAIデバッグ、SEOとCWV改善の新時代
Safari MCP Serverとは何か、その本質
WebKitチームが2026年7月、Safariブラウザ向けのMCPサーバーを発表した。これはAIエージェントがSafariブラウザの内部データに直接アクセスし、デバッグやパフォーマンス分析を自律的に行うための仕組みである。開発者やSEO担当者が手作業で行っていたSafari固有の問題検出が、AIとの対話によって自動化される可能性を示している。
Safariは世界で2番目に利用者の多いブラウザであり、特に米国市場では25%から30%超のシェアを維持する。日本国内でもiPhoneユーザーを中心に無視できない存在だ。つまり、Safariでサイトが正常に動作しないことは、ビジネス機会の直接的な損失を意味する。今回のMCP対応は、この課題を根底から変える契機となる。
デモが示すように、手動で行っていた一連の作業をAIが肩代わりする。この変化は単なる効率化ではなく、Safari対応の質そのものを底上げする力を持つ。
発表の背景とSafariの市場地位
Statcounterの2026年データによれば、Safariの米国市場シェアは四半期によって25%から33%の間で推移している。モバイルに限定すればさらに高く、iOSデバイスが支配的な日本市場でも同様の傾向だ。Web制作者にとってSafari対応は「できれば対応したい」ではなく「対応しなければ事業機会を逃す」段階に入っている。
しかしSafariは、Chromium系ブラウザとは異なるレンダリングエンジン(WebKit)を採用しており、CSSの解釈やJavaScriptの挙動に差異が生じる。これまではMac実機やSafariの開発者ツールを使い、人間が一つひとつ問題を探る必要があった。この非効率をAIで解決するのが、今回のMCPサーバー投入の狙いだ。
MCPが変えるブラウザとAIの関係
MCP(Model Context Protocol)は、AIモデルが外部のツールやデータソースと安全に通信するためのオープンプロトコルである。Anthropicが2024年に提唱し、いまではWordPressやShopify、Google Search Console、Screaming Frogなど主要なCMSやSEOツールが対応している。ブラウザがMCPに対応するのは自然な流れであり、Safariはその先陣を切った形だ。
従来、AIにデバッグを依頼する際は、開発者が問題状況を文章で詳細に説明する必要があった。状況説明が曖昧だとAIの回答精度も落ちる。Safari MCPサーバーはこの壁を取り払う。AIエージェントが自らブラウザのDOM構造やネットワークリクエストを取得し、問題を直接把握できるようになるからだ。
なぜ今Safariのデバッグが重要なのか

Webサイトの表示崩れや機能不全は、直帰率の上昇とコンバージョン率の低下に直結する。とくにSafariはiOSユーザーという購買意欲の高い層を抱えており、ここでの不具合はECサイトや予約サイトにとって致命的だ。にもかかわらず、Safari固有のバグ検出にはこれまで大きな労力がかかっていた。
さらに、Core Web Vitals(CWV)の評価は検索順位にも影響を与える。Googleのランキングシグナルとして機能するCWVにおいて、Safari上での読み込み遅延やレイアウトシフトが起きていれば、それは検索パフォーマンス全体を引き下げる要因になる。AIデバッグによってこの問題を素早く特定し修正できる意義は大きい。
Safari固有の問題がSEOに与える損害
Safariでは、特定のCSSプロパティ(例えばbackdrop-filterの挙動やscroll-behaviorの解釈)が他ブラウザと異なる。JavaScriptにおいてもResizeObserverのループ制限やIntersection Observerのしきい値処理に差異が見られる。これらの不一致がCWVのスコア悪化を引き起こし、結果として検索順位の低下を招く。
従来は、Mac環境がないチームはSafari検証を後回しにする傾向があった。しかしAIが代わりに検証してくれるなら、開発プロセスの初期段階からSafari互換性を組み込める。SEOの観点では、これはリリース後の急な順位下落リスクを減らす直接的な効果を持つ。
デバッグの民主化がもたらす競争環境の変化
AIエージェントによる自動デバッグは、個人事業主や小規模チームにこそ恩恵が大きい。専任のSafari検証担当者を置けない組織でも、AIがその役割を果たすからだ。大企業と中小企業のあいだにあった「ブラウザ互換性の検証格差」が縮まり、Safari上でのユーザー体験を基準にした真の実力勝負に近づく。
これはSEOの世界においても、小手先のテクニックよりも基本品質がモノを言う時代の到来を意味する。Safari MCPサーバーはその流れを加速させるツールであり、いち早く導入したサイト運営者が優位に立つ構図が予想される。
上記のリストは、Safari MCPサーバーがSEO施策に与えるインパクトを整理したものだ。これらの効果はすべて、従来の手動デバッグでは「時間がかかりすぎるから後回し」とされてきた領域である。AIがこの障壁を取り除く。
MCP(Model Context Protocol)の基礎知識

MCPはAIモデルが外部リソースと対話するための標準プロトコルだ。簡単に言えば「AIのためのUSB規格」のような存在である。USBがあらゆる周辺機器を共通の接続方式で扱えるように、MCPはあらゆるデータソースやツールをAIが共通の手順で扱えるようにする。
従来、AIに特定のタスクを実行させるには、そのツール専用のAPI連携を個別に開発する必要があった。MCPはこの非効率を解消する。SafariがMCPサーバーを提供することで、あらゆるMCP対応AIクライアントがSafariのブラウザ情報にアクセスできるようになった。
MCPのエコシステムと業界全体の動き
MCPはAstroやWordPress、WooCommerce、Shopifyといった主要CMSがすでにサポートを表明している。SEOツールのScreaming FrogもMCPを採用し、Google Search Consoleも対応を進めている。Safariの参入は、このプロトコルがブラウザというWeb技術の最前線にまで到達したことを示すマイルストーンだ。
Search Engine Journalの記事では、この流れを「ブラウザとAIの統合が新たな段階に入った」と評している。AIが単にコードを提案するだけの存在から、実行環境の状態をリアルタイムで把握しながら問題解決する存在へと進化しているのだ。
MCP対応の広がりは、AIエージェントが一つのプロトコルで多様なツールを横断的に操作できる未来を示している。SEO担当者はScreaming FrogとSafariとGoogle Search Consoleのデータを、一つのAI対話の中で統合的に扱えるようになるだろう。
Safari MCP Serverが切り拓くAIデバッグの実態

WebKitの公式発表によれば、Safari MCPサーバーは以下の5つの主要ユースケースを想定している。(1)アクセシビリティテスト、(2)Safari互換性テスト、(3)任意のユーザー状態の検証、(4)Safari上でのWeb開発、(5)Webパフォーマンス分析、である。これらはいずれもSEOに密接に関係する領域だ。
特筆すべきは、AIエージェントが「ブラウザの中で何が起きているかを自分で調べる」能力を得た点だ。公式アナウンスにある「完璧なプロンプトを書く必要がなくなる」という言葉が、この変化の本質を突いている。開発者はAIに「このページのCWVを改善して」と大まかに指示するだけで、AIが必要なデータを収集し分析し提案まで行う。
アクセシビリティとSEOの融合
アクセシビリティテストの自動化は、SEOの観点からも見逃せない。画像のalt属性不足やセマンティックHTMLの欠如は、スクリーンリーダー利用者の体験を損なうだけでなく、検索エンジンのコンテンツ理解も阻害する。AIがSafari上でこれらの問題を自動検出することで、SEOとアクセシビリティの両面改善が同時に進む。
Webパフォーマンス分析の深化
Webパフォーマンス分析では、ネットワークリクエストのタイムラインやDOMの構築過程をAIが精査する。従来のLighthouse監査では検出できなかったSafari固有のボトルネック、例えば特定のフォント読み込みがWebKitでだけ遅延する問題なども、AIが実ブラウザ上で直接観測できる。
この「実機ブラウザベースのパフォーマンス分析」は、合成監視では得られないリアルなデータをもたらす。CWVのフィールドデータとラボデータの乖離に悩まされてきたSEO担当者にとって、Safari MCPサーバーは問題の根本原因を特定する強力な武器になる。
5つのユースケースはそれぞれ独立しているが、実際の開発フローではこれらが複合的に作用する。たとえばアクセシビリティの問題を修正した結果、DOM構造が変わりCWVにも影響が出る、といった連鎖的な改善をAIが一括管理できる点が新しい。
SEOとCore Web Vitalsへの実戦的インパクト

Safari MCPサーバーがSEOにもたらす最大の恩恵は、CWV(Core Web Vitals)のスコア改善スピードが飛躍的に上がることだ。これまでLCP(Largest Contentful Paint)の改善には、どのリソースがクリティカルレンダリングパスを塞いでいるかを人間が特定する必要があった。AIがSafariのネットワークタイムラインを直接解析すれば、この作業は数秒で完了する。
CLS(Cumulative Layout Shift)についても同様だ。Safariはフォントのレンダリング方式や画像の遅延読み込みの挙動がChromium系と微妙に異なり、意図しないレイアウトシフトが発生することがある。AIが実際のSafariブラウザ上で測定することで、ラボツールでは再現できない問題まで捕捉できる。
フィールドデータとラボデータの統合分析
Google Search ConsoleのCWVレポートはフィールドデータに基づくが、問題の原因特定にはラボデータが必要になる。Safari MCPサーバーは、実ブラウザのラボデータをAIが直接取得するため、この二つのデータの橋渡し役を担う。フィールドデータでCWV低下を検知したら、すぐにSafari上でAIデバッグを実行し、具体的な修正案を得られる流れが現実的になる。
AI時代のSEOワークフロー
従来のSEOワークフローは「監視→検出→人間が仮説立案→人間が検証→修正→再測定」というサイクルだった。Safari MCPサーバーの登場により、「監視→AIが検出→AIが原因特定→AIが修正案提示→人間が承認→修正→AIが再検証」という形に変わる。人間の役割は「仮説立案」から「AI提案の判断と承認」へとシフトする。
この変化は、SEO担当者のスキルセットにも影響を与えるだろう。Safari DevToolsを細かく操作する技術よりも、AIに適切な指示を出し、出力結果の品質を見極める能力が重視されるようになる。Search Engine Journalの記事が伝える内容からも、このパラダイムシフトは2026年後半から本格化すると見られる。
このワークフロー比較が示すように、Safari MCPサーバーはSEOオペレーションの速度と精度を根本から変える。人間は戦略判断に集中し、反復的な検証作業はAIに任せるという分業が可能になる。
導入から活用までの具体的ステップ

Safari MCPサーバーは発表されたばかりであり、本格的な実装と提供方法についてはAppleからの続報が待たれる段階だ。しかし、すでにMCPを導入している他ツールの事例から、準備すべき環境と心構えは明確になっている。以下に、現時点で想定される導入ステップを示す。
環境準備とAIクライアントの選定
まず必要なのはMac環境と、MCP対応のAIクライアントだ。Claude Desktopや、Cursor、WindsurfなどMCPをサポートするエディタが候補になる。Safari Technology Previewの最新版にMCPサーバー機能が組み込まれる可能性が高く、WebKit公式ブログのアップデートを追うことが最初の一歩になる。
既存のデバッグフローへの組み込み方
AIデバッグは強力だが、いきなり全工程を任せるのではなく、まずは既存のCWV監視フローの補助として導入するのが現実的だ。たとえば、Search ConsoleでCLS悪化を検知したら、AIにSafari上でのCLS発生箇所の特定を依頼する。AIの提案を人間が評価し、問題なければ本番環境に適用するという段階的なアプローチが失敗を防ぐ。
また、AIの出力にはハルシネーション(もっともらしい誤情報)が含まれる可能性がある。特にCSSの修正提案は、Safariで意図通りに動作するかを必ず実機で確認するプロセスを残すべきだ。AIは検出と提案を高速化するが、最終的な品質保証は人間の役割である。
上記の3ステップは、あくまで現時点での想定に基づく。Safari MCPサーバーの正式リリース時に詳細なドキュメントが公開されるはずだ。WebKit公式ブログやApple Developerサイトの情報を定期的に確認し、最新の導入手順に従うことを推奨する。
この記事のポイント
- Safari MCPサーバーはAIエージェントがブラウザ内部データに直接アクセスしデバッグを自動化する仕組みである
- 米国で25%超のシェアを持つSafariの互換性問題をAIが解決することでSEOとCWVが大幅に改善する
- MCPは業界標準プロトコルとしてWordPressやGoogle Search Consoleも対応しておりエコシステムが拡大している
- 導入はMac環境とMCP対応AIクライアントから始め段階的に既存フローへ組み込むのが現実的な戦略だ
- AIの提案を鵜呑みにせず最終的な品質確認は人間が行うプロセスを維持することが失敗を防ぐ鍵になる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

CloudflareのAIクローラールールがGooglebotをブロックする危険性
CloudflareがAIクローラー対策の仕組みを抜本的に見直し、2026年9月15日から新たなデフォルト設定を適用する。この変更は単なるAIボット対策の強化にとどまらず、Googlebotのような検索クローラーまで巻き込む可能性がある。AIにコンテンツを学習されたくないという意図で設定したブロックが、結果的に検索エンジンからの流入を断つリスクをはらんでいるのだ。
特に影響が大きいのは、Cloudflareの無料プランを利用するWordPressサイトや中小企業のオウンドメディアだ。AI学習ブロックの意図がなくても、9月15日以降にデフォルト設定が自動適用され、知らぬ間にGooglebotのクロールが制限される可能性がある。本記事では3つの振る舞い分類、デフォルト変更の詳細、そして今すぐ取るべき対応策を解説する。
CloudflareがAIクローラー対策の方針を転換した背景

Cloudflareは2026年7月2日、第2回「Content Independence Day」の一環として、AIクローラー管理の新方式を発表した。従来の単一の「AIボットをブロック」スイッチを廃止し、クローラーの振る舞いに基づいた3つのカテゴリで制御する仕組みへ移行する。この変更は全顧客(無料プランを含む)に即時適用され、9月15日にはデフォルト設定も自動変更される。
背景にあるのは、AIクローラーによるコンテンツ収集の爆発的な増加だ。Cloudflareのネットワーク上では、AI訓練目的のクローラーリクエストが全体の過半数を占めるまでに成長した。2025年春時点では約20%だったが、1年で状況は一変した。AIエージェントのリクエスト数も前年比1700%増と、指数関数的な伸びを示している。
この急増に対し、多くのパブリッシャーやサイト運営者はAIクローラーを一律ブロックする方向に動いてきた。しかし、その「一律ブロック」が検索クローラーまで巻き込む副作用を生みつつあった。Cloudflareの今回の方針転換は、この問題に正面から取り組むものだが、同時に新たなリスクも生じさせている。
3つの振る舞い分類がクローラー制御を変える

Cloudflareの新方式は、クローラーを「AIかどうか」ではなく「サイト上で何をするか」で分類する。この考え方は、サイト運営者にとってクローラー制御の解像度を格段に上げるものだ。3つのカテゴリは以下のとおり。
Cloudflareは、ボット運営者に対して「振る舞いごとに別々のクローラーを用意すべき」と要求している。サイト側が「なぜそのボットが来ているのか」を判断し、許可・ブロックを適切に選択できるようにするためだ。この考え方自体は合理的だが、現実にはGooglebotのように検索とAI訓練の両方を行う「マルチパーパスクローラー」が存在する。この点が後述する問題の核心となる。
検索クロールとAI訓練クロールの同居がリスクを生む
Googlebot、Applebot、Bingbotは、いずれも検索インデックス作成とAIモデル訓練の両方に使用される。Cloudflareの新ルールでは、こうした「混合用途のクローラー」に対して最も厳しい制限が適用される。つまり、AI訓練目的のクロールをブロックしているサイトでは、同じクローラーによる検索目的のアクセスも自動的にブロックされるのだ。
これはrobots.txtとは根本的に異なる。robots.txtはクローラーへの「お願い」に過ぎず、無視されることもある。しかしCloudflareのブロックはネットワークレベルで動作するため、robots.txtよりはるかに強力だ。グーグルでさえバイパスできない。AI訓練を止めたい一心で設定したブロックが、検索流入というサイトの生命線を断ち切ってしまう皮肉な構造が生まれている。
9月15日のデフォルト変更が生む3つのリスク
2026年9月15日に自動適用されるデフォルト設定の変更は、Cloudflareを利用するあらゆるサイトに影響を及ぼす。特に注意すべきは以下の3点だ。
とりわけ危険なのはリスク3だ。従来の「AIボットをブロック」設定を有効にしたまま放置しているサイトは、9月15日以降にGooglebotのアクセスがネットワークレベルで遮断される可能性がある。検索クロールが停止すれば、新規コンテンツのインデックス登録が滞り、既存ページの再クロール頻度も低下する。検索順位への影響は数週間から数カ月かけて徐々に表面化するため、原因特定が遅れやすい。
robots.txtとの違いを理解しておくべき理由
多くのサイト運営者は「robots.txtでブロックしているから大丈夫」と考えがちだ。しかし、robots.txtはクローラーに対する紳士協定に過ぎず、グーグルも状況によって無視することがある。一方、Cloudflareのブロックはリクエストがオリジンサーバーに到達する前にネットワークエッジで遮断する。この違いは決定的だ。
robots.txtでのブロックは「できれば来ないでほしい」というお願いであり、Cloudflareのネットワークブロックは物理的な門番が門を閉ざすようなものだ。後者のほうが確実だが、その分だけ設定ミスの代償も大きい。AI訓練ブロックのつもりが検索クローラーまで締め出してしまうと、サイトの検索パフォーマンスは確実に悪化する。
実務者が今すぐ取るべき対応チェックリスト

9月15日までに対応を完了する必要がある。以下に具体的なアクションを時系列で整理した。
STEP 5のクロール統計監視は特に重要だ。9月15日以降にGooglebotのクロール頻度が急落した場合、Cloudflare設定に原因がある可能性が高い。Search Consoleの「クロール統計レポート」で1日あたりのクロールリクエスト数を確認し、急激な減少があれば即座にCloudflareダッシュボードを再確認する習慣をつけておきたい。
無料プランユーザーが特に注意すべきポイント
Cloudflareの無料プランを利用しているサイトは、9月15日までに一度もAIクローラー設定を変更していない場合、自動的に新デフォルトへ移行される。つまり「設定を触っていないから大丈夫」という認識が最も危険だ。何もしないことが、意図せずGooglebotブロックを招く可能性がある。
無料プランであっても、ダッシュボードから3カテゴリの設定を手動で確認・変更することは可能だ。Searchカテゴリだけは明示的に「許可」に設定し、TrainingやAgentはサイトのポリシーに応じて判断する。この一手間をかけるかどうかで、9月15日以降の検索パフォーマンスが大きく変わる。
今後の展望とサイト運営者が持つべき視点

Cloudflareは、マルチパーパスクローラーの運営者に対して「振る舞いごとにクローラーを分離する」ことを求めている。グーグルやアップル、マイクロソフトがこの要求に応じてGooglebotを用途別に分割するかどうかが、今後の分岐点となる。仮に分割が実現すれば、サイト運営者はAI訓練だけをブロックし、検索インデックスは許可するという選択が可能になる。
しかし、現時点ではその保証はない。9月15日以降もGooglebotは単一のクローラーとして動作し続ける可能性が高い。つまり、AI訓練をブロックするという選択は、当面の間「検索流入とのトレードオフ」であり続ける。この現実を直視した上で、サイト運営者は自社のコンテンツ戦略とAIポリシーを再定義する必要がある。
Cloudflareは新しいコンテンツ利用シグナルもテスト中だ。robots.txtに記述するContent Signalsの拡張で、immediate(保存しない)、reference(インデックスしてリンクバック、新デフォルト)、full(要約・複製を許可)の3段階を指定できるようにする。ただしこれは設定上の「希望表明」であり、単体ではブロック機能を持たない点に注意が必要だ。
サイト運営者が今から準備すべき3つのこと
AIにコンテンツを学習されることを完全に拒否するのか、それとも検索流入を優先するのか。この問いに明確な答えを持たないまま9月15日を迎えると、Cloudflareの新デフォルトによって想定外のブロックが発生し、検索パフォーマンスが毀損するリスクがある。サイトの規模や収益構造に応じて、今のうちに方針を固めておくことが重要だ。
この記事のポイント
- CloudflareのAIクローラー管理が3つの振る舞い分類(Search、Agent、Training)に再編された
- 9月15日から広告表示ページでTrainingとAgentがデフォルトブロックされ、無料プランユーザーも自動移行の対象
- Googlebotのような混合用途クローラーは、AI訓練をブロックすると検索クロールも停止する
- robots.txtと異なり、Cloudflareのブロックはネットワークレベルで動作しバイパスが困難
- Searchカテゴリの許可確認とSearch Consoleでのクロール統計監視が当面の最優先対応
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Googleが6月スパムアップデート公開、AI応答の操作もスパム対象に
Googleは2026年6月24日、新しいスパムアップデートの展開を開始した。今回のアップデートでは、生成AIの応答を意図的に操作しようとする行為もスパムポリシー違反とみなされることが明確化された。
同時期に、サーチコンソールのAIレポートにおけるインプレッションの数え方について新たな情報が公開された。また、Advanced Web Rankingの調査ではデスクトップのCTRが上昇する一方、モバイルのトップポジションでクリック率が低下していることが判明。Similarwebのレポートからは、AIの推奨がブランド検索を経由してサイト訪問につながる構図が浮かび上がった。
この記事では、これらの動きを一つひとつ整理し、今後のSEO戦略にどう活かすかの視点を提供する。
AI応答の操作行為もスパムポリシーの対象に
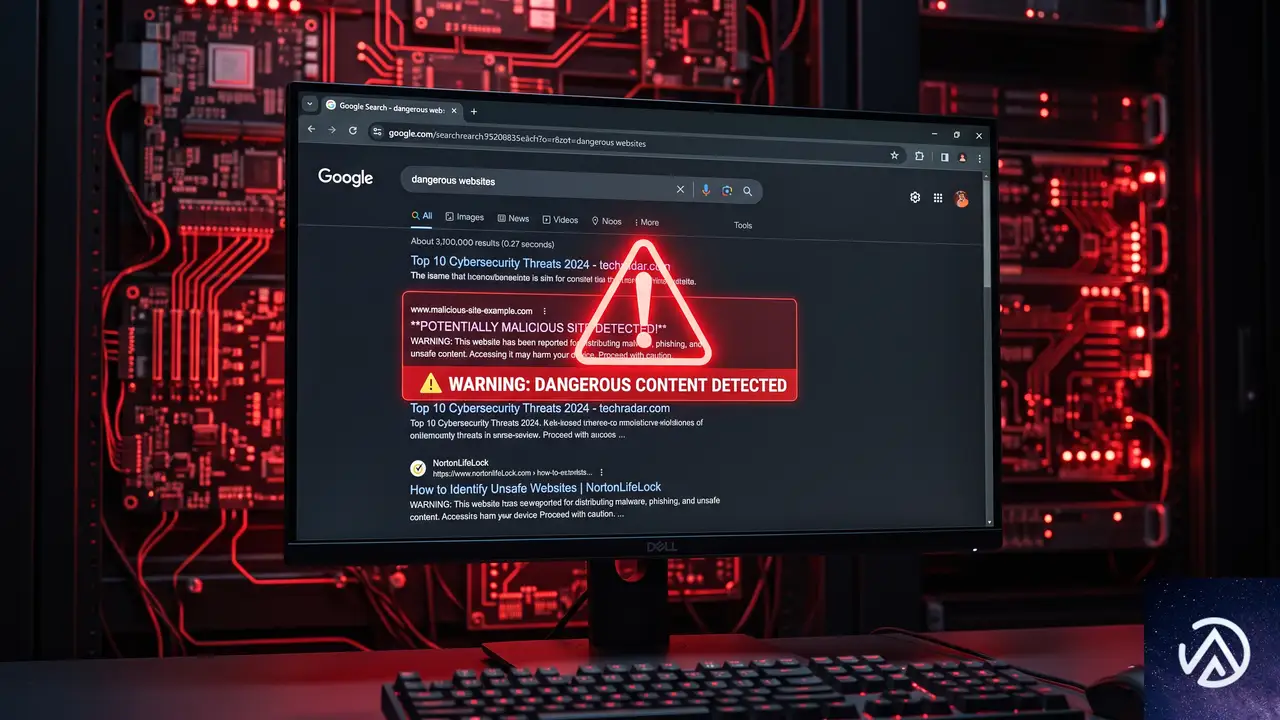
6月24日より展開が始まったスパムアップデートは、従来のリンクスパムやキーワードスタッフィングのような旧来型の不正だけでなく、AI OverviewsやAI Modeといった生成AI検索機能に対する操作行為にも範囲を拡大した。
Googleは2026年5月にスパムポリシーを改定し、生成AIの回答に表示される引用やリンクを不正に購入する行為、情報を書き換える行為がスパムに該当すると明示していた。今回のアップデートはその方針に沿ったアルゴリズムの強化にあたる。
ランキング変動への向き合い方
スパムアップデートは数日かけて完全に適用されるため、ランキングの上下が一過性のものかそうでないかを見極める必要がある。突然順位が下がったとしても、それだけでコンテンツが「質の低いスパム」と判定されたわけではない。
SEOコンサルタントのShushrita M.氏は、変動が起きた際にはまず影響を受けたページタイプやクエリ、ディレクトリを特定し、一貫したパターンを見つけることが回復への第一歩だと指摘している。パニックに陥らず、データに基づいた診断を進める姿勢が求められる。
AIインプレッションはリンクの表示回数、クリックデータはまだない
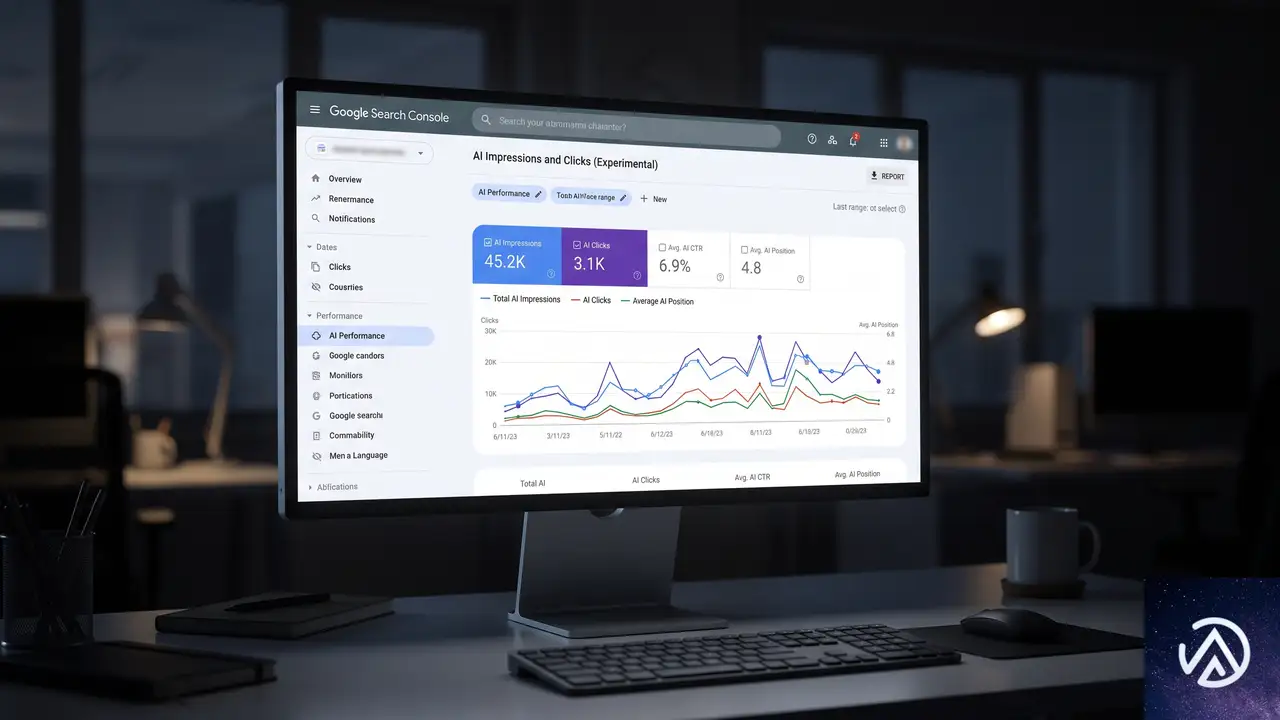
サーチコンソールの生成AIレポートで示されるインプレッションは、AI OverviewsやAI Modeの中で自社ページへのリンクが表示された回数を指す。ただし、回答内で折りたたまれているリンクは、ユーザーが開かない限りカウントされない仕組みである。
Googleのサーチ アドボケートJohn Mueller氏が明らかにしたところによると、現時点ではこのレポートにクリック数は含まれておらず、純粋に表示機会の指標として扱う必要がある。AI回答の中で自社コンテンツが参照されていても、必ずしもユーザーがクリックするとは限らない点を考慮しなければならない。
低い数値が問題とは限らない
折りたたまれたリンクのインプレッションが少ないからといって、コンテンツがAIに無視されているわけではない。ユーザーが積極的に展開しなければカウントされないため、実際の露出機会よりも数字が小さく見える可能性がある。インプレッション数はあくまで最低限の目安として捉え、他の指標と組み合わせて評価することが重要だ。
デスクトップCTRが上昇、モバイルはトップで減速
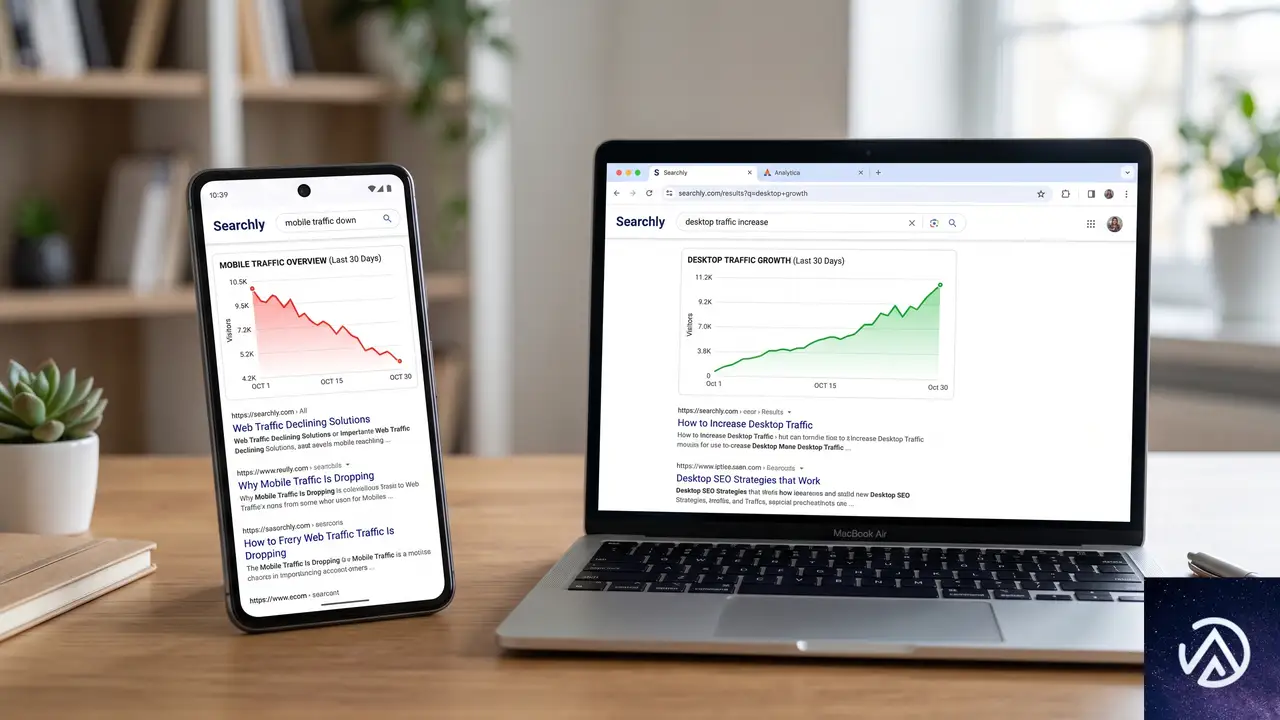
Advanced Web Rankingが公開した2026年第1四半期のベンチマークによると、デスクトップ検索のクリック率は上昇傾向にある一方、モバイル検索では1位のCTRが約2.2ポイント低下した。デスクトップの伸びは3位以下のポジションで顕著に見られた。
これは単純な「復調」ではない。モバイルの軟調が続いているなかでのデスクトップの一時的な上昇であり、両者を合算した数値だけを見ると実態を見誤る恐れがある。自社のデータをデバイス別に切り分けて分析し、それぞれの傾向を別々に把握することが欠かせない。
デバイス別の分析が必須
モバイルでCTRが下がる背景には、AI Overviewsの拡大や検索結果画面の構成変化が影響している可能性がある。デスクトップとモバイルではユーザーの行動や画面占有のされ方が異なるため、両方を一緒くたに評価せず、施策もデバイスごとに最適化していく姿勢が有効だ。
AIの推奨がブランド検索を呼び、サイト訪問数が2.5倍に増加
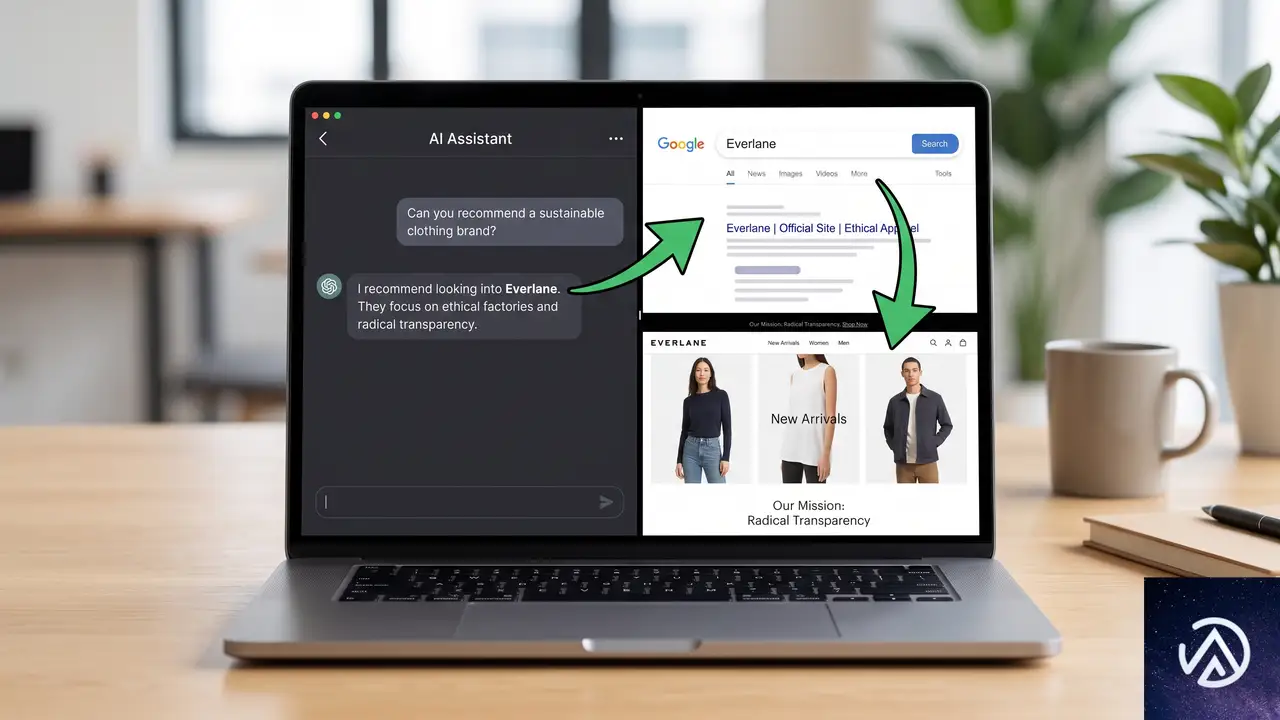
Similarwebのレポートは、ChatGPTなどのAIが特定のブランドを推奨した場合、その後のユーザー行動の55.9%がブランド検索を経由してサイト訪問につながっていると示した。AIが直接リンクをクリックされる以上に、ブランド名を覚えさせて後から検索させる流れが主流になりつつある。
ここで、AI推奨がもたらすユーザー導線の変化をBefore/Afterで視覚化してみる。
上記の図のAfter側では、AIがブランドを推奨した後にユーザーが改めて検索し、最終的にサイトを訪れるという2段階のプロセスが示されている。この流れが全体の55.9%を占めているというデータは、AI検索時代のブランド力の重要性を裏付けるものだ。
ブランド検索ボリュームをKPIに加える
AIが自社名に言及した際、ユーザーはリンクを直接クリックするよりも、ブランド名を検索してからサイトを訪れる傾向が強い。そのため、従来のオーガニック検索の流入数だけでなく、ブランド検索のボリュームそのものを追跡することがAI時代の重要指標になる。
SEOコンサルタントのAleyda Solís氏も、AIの影響はクリックを伴わない形で現れるため、AIリファラルだけを見ていては実態を捉えきれないと警鐘を鳴らしている。ブランド名での検索数や、直接流入・検索流入の増加をAIの露出と結びつけて評価する視点が不可欠だ。
Googleは外部SEOツールを評価せず、内部指標へのアクセスもない
Googleの検索・コマース担当VPであるBrendon Kraham氏は、効果的なSEOの取り組みはそのまま生成AI検索(GEO)にも通用すると述べた。同時に、Googleは第三者のSEOツールやベンダーを評価しておらず、そうしたツールがGoogle内部の指標にアクセスすることも一切ないと明言している。
この発言は、一部のツールが「AI検索に特化した独自のランキング指標」を謳うことに対して釘を刺すものだ。AIが絡む検索環境でも、基本はこれまで通り、ユーザーにとって価値あるコンテンツを提供するというSEOの原則に立ち返る必要がある。
「良いSEOは良いGEO」だが逆は成り立たない
Zyppy SEOの創設者Cyrus Shepard氏は、この「良いSEOは良いGEO」というスローガンにおおむね同意しつつも、AIが存在しなければ絶対にしなかったであろう施策をAIに詳しいSEO担当者がすでに行っていると指摘している。生成AI検索に過度に最適化することは、検索エンジンの変化に振り回されるリスクを高めるため、注意が必要だ。
この記事のポイント
- 6月のスパムアップデートはAI応答の操作行為もスパムと認定。ランキング変動は数日間の経過を見守りながらパターン分析を
- サーチコンソールのAIインプレッションはリンク表示回数のみでクリックデータは未提供。低い数値は過小評価の可能性も
- デスクトップCTRは上昇したがモバイルはトップで低下。デバイス別の分析と施策の切り分けが重要
- AI推奨の55.9%がブランド検索を経由して訪問。ブランド検索ボリュームをAI時代の重要KPIに
- Googleは外部SEOツールの評価や内部指標へのアクセスを否定。AI検索でも基本は質の高いコンテンツ作り
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

ドイツ裁判所、GoogleのAI回答に責任認定。SEO業界に衝撃
ドイツのミュンヘン地方裁判所が2026年5月28日、GoogleのAI Overviewが生成した虚偽の内容についてGoogle自身に責任があるとの仮処分を下した。AIが生成した回答は「プラットフォーム自身の発言」であり、単なる検索結果の羅列ではないという判断だ。この判決はSEOの前提を変える可能性を秘めている。
問題の核心は「AIがビジネスについて語るとき、誰が責任を負うのか」という問いだ。今回の判断は、AI回答が単なる情報の仲介ではなく「独自の編集行為」であると認定した点で画期的だ。つまり検索エンジンは自らが生成した文章に対して法的責任を問われうる時代に入った。この変化は企業のAI対策に根本的な再考を迫る。
裁判所がAI回答を「独自の編集物」と認定した意味

ミュンヘン地方裁判所が下した仮処分(事件番号26 O 869/26)は、GoogleのAI Overviewが2つの地域出版社について虚偽の説明を生成したことを問題視した。AI Overviewはこれらの出版社を詐欺やサブスクリプション詐欺と結びつける文章を生成していたが、引用元として示された情報源のどこにもそのような記述は存在しなかった。
AI Overview(AIによる検索結果の概要表示)とは、検索クエリに対してGoogleが従来のリンク一覧ではなく、AIが生成した要約文を画面上部に表示する機能だ。複数の情報源を読み込んで独自の文章を合成する仕組みで、2024年から本格展開が始まっている。
裁判所はこのAI Overviewについて「独立した新規の実質的な主張を生成している」と評価し、通常の検索結果一覧に適用される免責保護の対象外だと判断した。Google側は「ユーザー自身が回答の正確性を確認すべき」と主張したが、裁判所はこれを退けた。機械が文章を書くなら、その機械の所有者が責任を負うという理屈だ。
このデモが示すように、AI Overviewは従来の検索結果一覧とは法的な位置づけが根本的に異なる。裁判所は情報を「編集し合成する行為」を著作行為とみなし、そこに責任を紐づけたのだ。
この判決が持つ射程の広さ
今回の判断はあくまでドイツの一地裁による仮処分であり、EUの法的枠組みの中で下されたものだ。米国の裁判所が同じ事案を扱えば、プラットフォームを免責された仲介者とみなす従来の考え方から異なる結論に至る可能性は十分にある。ただ方向性は明確だ。AIが自律的に文章を生成する時代において、単なる「情報の受け渡し役」という位置づけは成立しなくなりつつある。
Search Engine Journalの記事では、この判決を1週間前に発表された別の調査結果と並べて論じている。その調査とは「AIに名前を挙げられることと、AIに信頼されることは別である」という分析だ。AI回答におけるビジネスの表現は、信頼の問題であると同時に説明責任の問題でもある。両方の視点が重なったとき、企業に求められる対応の輪郭が浮かび上がる。
責任を負うAIは「慎重になる」という構造的変化

法的責任を問われる可能性があるAIは、リスクを避けるために振る舞いを変える。これが今回の判決がもたらす最大の二次的影響だ。
AI回答が自社の発言として扱われるなら、プラットフォームが取る合理的な行動は「突然正確になること」ではない。「慎重になること」だ。確実に裏付けが取れるビジネスだけを安全圏として提示し、曖昧な存在は言及そのものを避けるようになる。この変化はすでに兆候を見せている。小規模な企業や評価が分かれる事業についてAIに質問すると、回答が急に歯切れが悪くなり、公式情報源に委ねたり、企業の特徴づけを完全に回避したりするケースが増えている。
AI回答「複数の情報源がありますが、公式な確認が取れません。ご自身での確認をお勧めします」
AI回答「△△社は〇〇を提供しています。公式サイトではXXと記載されています」
この変化は「どうやってAIに正しく自社を引用させるか」という問いを「AIが自信を持って名前を出せるビジネスかどうか」という一段上の問いに引き上げる。機械可読なアイデンティティの整備は、もはやSEOの一手ではなく参加資格そのものに近づく。
AIがビジネスを「疑う」4つの原因
Search Engine Journalの記事でCarlo Daniele氏が指摘するように、大半のビジネスはAIに疑念を抱かせる材料を少なくとも一つは抱えている。具体的には以下の4パターンだ。
- 法的実体の不一致:自社サイト、SNSプロフィール、過去のプレス記事で会社名や事業者名が微妙に異なる。AIはどれが正規情報か判断できない
- 役職表記のズレ:会社概要ページと過去のインタビュー記事で創業者の役職表記が食い違っている
- テキスト化されていない重要情報:製品の具体的な機能説明が画像やPDFの中にしか存在せず、AIのパーサーが読み取れない
- カテゴリの曖昧さ:人間が読めば事業内容が明確でも、マークアップ上でカテゴリが明示されておらず機械が判断できない
これらはいずれも従来のコンテンツSEOの発想では見過ごされてきた問題だ。記事が指摘するように、これはコンテンツの問題ではなくアイデンティティの問題である。1万語のコンテンツがあっても自己矛盾した情報を発信していればAIはそのビジネスを「検証困難」と判定する。一方で簡潔でもあらゆる読み取り経路で同一の事実を返すビジネスはAIにとって「引用可能」と判断される。
AIに「確信されるビジネス」になるための実践手順

この変化に対応するために法律家は必要ない。必要なのはAIに「このビジネスは確かだ」と判断させるための基盤整備だ。Search Engine Journalの記事で提示された3ステップを具体的に見ていく。
ステップ1 AIが自社をどう語っているか監査する
まずは自社ブランド名、製品名、事業カテゴリを実際に顧客が使うAI検索エンジンに投入し、生成される回答を第三者の目で読む。AI OverviewだけでなくChatGPTやClaudeなど複数のエンジンで確認することが重要だ。エンジンごとに回答は異なり、そのズレの大きさこそが自社のアイデンティティ監査の出発点になる。
チェックすべき項目は以下の4つだ。AIが自社のカテゴリを正しく述べているか、正しい製品を帰属させているか、正しい人物名を挙げているか、そして実際には無関係なネガティブ情報と結びつけていないか。Search Engine Journalの記事によれば、大半の企業はこのような監査を一度も実施したことがないという。
この監査は企業のAI上の立ち位置を可視化する最初の一歩だ。自社がどのように語られているかを把握せずに対策を立てることはできない。
ステップ2 AIが判断の根拠にする事実情報を整備する
監査で発見されたズレを修正するには、AIが参照する基盤情報の整備が不可欠だ。Search Engine Journalの記事で提唱されているMachine-First Architecture(機械優先アーキテクチャ)の考え方では、以下の3つが中核となる。
第一に、Organization構造化データの実装だ。自社が誰で、何をしており、どこで確認できるかを機械可読な形式で明示する。構造化データ(Schema.orgに準拠したマークアップ)とは、HTMLに埋め込む形で検索エンジンに情報の意味を伝える仕組みであり、AIが情報を正確に抽出するための土台となる。
第二に、全情報発信チャネルでの表記統一だ。自社サイト、Googleビジネスプロフィール、主要SNS、業界ディレクトリで社名・住所・事業内容の表記を完全に一致させる。バリエーションがあるたびにAIは「どれが正しいか」の判断を強いられ、リスク回避のために言及を控える方向に傾く。
第三に、テキスト化の徹底だ。画像やPDFに埋め込まれた重要情報をHTMLテキストとしても提供し、AIのパーサーが確実に読み取れる形にする。特に事業内容の明示的な説明は、人間向けのデザイン性よりも機械向けの明快さを優先すべき局面に入っている。
ステップ3 監査を習慣化する
企業情報は時間とともに変化し、周囲のウェブ環境も変わり、AIモデルも再学習を繰り返す。一度整備して終わりではなく、定期的にAIが自社をどう語っているかを確認する習慣が必要だ。Search Engine Journalの記事はこれを「自社のアナリティクスを確認するのと同じ感覚で」行うべきだと提案している。
訴訟そのものは稀であり管轄も限られる。しかし構造的な影響はゆっくりと確実に広がる。AI回答にリスクが伴うとき、エンジンは慎重になり、慎重なエンジンは裏付けの取れるビジネスだけを積極的に提示する。企業に求められるのは「機械に確信される存在」になるための継続的な努力だ。
この記事のポイント
- ミュンヘン地方裁判所がAI OverviewをGoogle自身のコンテンツと認定し免責を否定した
- AI回答に法的責任が生じるとプラットフォームは「慎重になり言及を避ける」方向に動く
- 企業名・役職・事業内容の表記不一致がAIの信頼を損ねる主要因である
- 構造化データの実装と全チャネルでの情報統一がAI時代の基盤対策となる
- AIによる自社の語られ方を定期的に監査する習慣が不可欠だ
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

GoogleとMicrosoftがAIエージェント共通仕様ARDを公開、11社が賛同
GoogleとMicrosoftを含む11社が、AIエージェントがウェブ上のツールやスキルを自動検出するための共通仕様「ARD(Agentic Resource Discovery)」を2026年6月17日に公開した。
GitHubやHugging Face、NVIDIA、Salesforceも名を連ねるこの仕様は、各社が公開するAIエージェント向け機能を、事前の手動接続なしに実行時に見つけ出せる仕組みだ。Apache 2.0ライセンスで公開され、同日に複数の参照実装もリリースされた。
この仕様が実用化されれば、AIエージェントは必要なツールを自ら探し出して接続できるようになる。開発者やサービス提供者にとっては、自社のAPIやエージェント機能をAIシステムに自動的に見つけてもらうための新たな方法が生まれることになる。
ARDとは何か

ARD(Agentic Resource Discovery)は、AIエージェントがウェブ上で「使えるツールや機能」を自動的に見つけ出すための共通ルールを定めた仕様だ。Linux Foundationのワーキンググループが管理するAI Catalogデータモデルを基盤に構築されている。
現在のAIエージェントは、あらかじめ各ツールやMCPサーバー、APIとの接続を手動で設定する必要がある。企業が公開する機能が増え続けるなか、この「事前配線」方式では拡張性に限界があった。ARDはこの問題に対処するために設計されている。
ARDの仕組みは、企業が自社ドメインに公開するカタログと、それを収集してインデックス化するレジストリの2層構造で成り立っている。人手による接続設定を実行時の検索に置き換えることで、AIエージェントが自律的に機能を発見できる世界を目指している。
ARDの技術的な仕組み

カタログとレジストリの2層構造
ARDの中核は「カタログ」と「レジストリ」という2つの要素だ。まず、ツールやエージェントを提供する企業は、自社ドメインの定められたパスにai-catalog.jsonというファイルを設置する。このファイルには、公開するツール、MCPサーバー、エージェント、APIの一覧が記述される。
次に「レジストリ」がこれらのカタログを巡回(クロール)してインデックス化する。AIエージェントが「この処理に使えるツールはないか」と自然言語で問い合わせると、レジストリが該当するカタログ情報を返す仕組みだ。
ai-catalog.json を設置カタログが公開者の自社ドメインに置かれることで、ドメイン所有権が公開者の検証手段として機能する。本番運用では、暗号化された信頼メタデータを付与し、接続前に公開者の身元を確認することも可能だ。ツールが選定された後は、ARDの役割は終了し、実際の接続は各ツール固有のプロトコルで直接行われる。
誰に向けた仕様なのか
ARDが主に対象とするのは、APIやMCPサーバー、エージェントといった「呼び出し可能な機能」を提供する企業だ。ツールを公開する企業には、AIエージェントに見つけてもらい、信頼してもらうための明確な方法が提供される。
一方、一般的なコンテンツサイトにとっては、現時点で直接的な活用方法は示されていない。Search Engine Journalの記事でも「典型的なコンテンツサイトに今日すぐ取るべきアクションはない」と指摘されている。
公開当日に登場した参照実装

ARDの草案公開と同日に、複数の参加企業が実際に動作するツールをリリースした。
- GitHub Copilot向けに「Agent Finder」を導入。選択したレジストリからMCPサーバー、スキル、ツール、エージェントを検出し、ユーザーが接続対象を制御できる仕組みだ。
- Hugging Face ARDサービス全体からスキルやMCPサーバーを検索する「Discover Tool」を公開した。
- Cisco Linux Foundation傘下のオープンソースプロジェクト「AGNTCY Agent Directory」にARDを統合した。
GitHubのAgent Finderは特に関心を集めている。Copilotのユーザーがレジストリから必要な機能を見つけ出し、自分の判断で接続を許可できる設計は、エージェントの自律性とユーザー制御のバランスを取る試みといえる。
この流れは、ウェブの「機械可読層」を整備する一連のオープン仕様の延長線上にある。GoogleはARD公開の2日前にも、AIシステム間で組織知識を共有するための「Open Knowledge Format」仕様を発表している。いずれも自社ドメインに構造化ファイルを設置するだけで、AIシステムが人手の配線なしに情報を利用できるようにする考え方だ。
Googleの立ち位置と今後の展開

GoogleはARDにおいて、Gemini Enterprise Agent Platformの一部である「Agent Registry」を中心的な役割として位置づけている。これはエージェント向けリソースのホスティングと検索、企業向けのガバナンス管理を担う基盤だ。
Search Engine Journalの記事によれば、Agent RegistryへのネイティブARD対応は数カ月以内に予定されている。これが実現すれば、組織は内部レジストリを広域ネットワークに接続できるようになる。
ただし現時点でこの対応は稼働しておらず、ARDはあくまで「仕様」であってGoogle検索の機能ではない。検索エンジンとしてのGoogleがARDカタログを直接検索結果に反映するわけではない点は、区別して理解しておく必要がある。
コンテンツ制作者が今考えるべきこと

ARDがもたらす影響は、ビジネスの性質によって大きく異なる。ツールやAPIを提供する企業には、AIエージェントに発見されるための具体的な手段が用意された。一方で、一般的なコンテンツサイト運営者にとっての即効性は限定的だ。
この仕様の価値については業界内でも議論がある。GoogleのJohn Mueller氏は、LLMシステムがllms.txtのようなファイルでサイトを区別することはできないと指摘し、将来のエージェント向け戦略よりも現在のニーズに注力するよう助言している。ARDが対象とするのはツールやエージェントであり、コンテンツではないという点は、こうした議論の背景として押さえておきたい。
仕様はまだv0.9草案であり、GitHubリポジトリで変更提案を受け付けている段階だ。実用性を左右するのは、カタログを大規模にクロールしてインデックス化できるレジストリのエコシステムだが、それもまだ初期段階にある。
エコシステムが成熟した場合に最も恩恵を受けるのは、他者が必要とするツールやエージェントを提供する企業だ。GoogleがUlrtaユーザー向けに展開し始めたエージェント主導の検索機能も、この方向性を示唆している。今すぐ取るべき現実的なアクションは、自社が使っているプラットフォームやツールがARDに対応するかどうか、そして対応時にどのような公開情報が求められるかを注視することだ。
この記事のポイント
- ARDはAIエージェントがツールやAPIを実行時に自動発見するためのオープン仕様である
- カタログ(ai-catalog.json)とレジストリの2層構造で、ドメイン所有権が信頼の基盤となる
- GitHubやHugging Faceが公開初日から参照実装を提供しており、実用化に向けた動きは速い
- 一般的なコンテンツサイトよりも、ツールやAPIを公開する企業に直接的な恩恵がある
- v0.9草案段階であり、レジストリのエコシステム構築が今後の鍵を握る
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AI引用シェア率をBingが公開、llms.txtの効果に疑問符
AI検索の可視性をどう測るか、そして構造化データファイルにどこまで期待すべきか。この一週間でその答えに直結する動きが複数出てきた。
MicrosoftがAI引用のシェア率を計測する新機能を公開し、GoogleとAhrefsのデータはllms.txtの効果に冷や水を浴びせた。さらにAIエージェント向けの新仕様が2つ登場するなど、情報が一気に動いている。英国CMAによる公正ランキング命令も含め、今週のトップ4ニュースを実務視点で整理する。
BingがAI引用シェア率を公開。競合との差が初めて数値化された

MicrosoftはBing Webmaster ToolsのAIパフォーマンスダッシュボードに、新たな4機能をプレビュー公開した。追加されたのは「Citation Share(引用シェア率)」「Intents(検索意図別グループ)」「Topics(トピック別グループ)」「Compare(期間比較)」だ。いずれも現在はプレビュー段階でグローバルに順次ロールアウトされている。
このCitation Shareによって、AI検索結果における自サイトの存在感が、競合との比較で初めて把握できるようになる。ただしこのデータはBing独自であり、CopilotやBingの回答を対象とする。Google検索側では検索コンソールにこれに相当する引用カウント機能は提供されていない。
SEO担当者の受け止めと実務への示唆
ILoveSEO.netの創業者Gianluca Fiorelli氏はLinkedInで「Bing Webmaster Toolsこそ、我々がGoogleサーチコンソールに望んでいた姿だ」と評価した。AI可視性を測る新しい物差しが登場したことは、今後の施策優先度をデータドリブンに決める上で大きい。
現時点ではBingに限られた指標だが、AI検索のトラフィックが今後さらに一般化すれば、Googleも類似の指標を導入せざるを得なくなる可能性がある。先行してBing側でのデータ取得と分析のノウハウを積んでおくことは、将来のAI検索対策で優位に立つ一手になる。
llms.txtへの期待に新データが疑問符。97%がアクセスゼロ
llms.txtは、大規模言語モデル(LLM)向けにサイト情報を構造化して提供するテキストファイルだ。AIがサイト内容を理解しやすくする目的で提唱され、導入が進んでいる。しかし今週、その効果に疑念を投げかける材料が二つ重なった。
Mueller氏は「Search Off the Record」ポッドキャストで、llms.txtが自己申告型のファイルである以上、LLMがサイトを発見したり他サイトと比較して評価したりする用途には使えないと明言した。本質的に重要なのは従来のHTMLと内部リンク構造だという立場だ。
Ahrefsのデータも同じ方向を指している。13万7000ドメインのうち、97%のllms.txtファイルには一度もボットからのアクセスがなかった。さらにアクセスが確認されたケースでも、ChatGPTやPerplexityといった引用生成ボットからのリクエストは全体の1%に過ぎない。この結果は、数ヶ月前にSE Rankingが30万ドメインを調査して導いた「llms.txtはAI引用に明確な効果を示さない」という結論とも整合する。
SEO専門家の見解と実務上の落とし所
Clio Websitesの創業者Nat Miletic氏はLinkedInで「llms.txtは公開コストが低いので置いておくのは構わない。ただしそれでAI可視性が上がるとは今は期待しないほうがいい」と総括した。コーディングエージェントや学習用クローラー向けに一部で参照されているため維持コストに見合う面はあるが、AI検索結果への表示を目的とした投資としては優先度を下げる判断が妥当だ。
AIエージェント向け新仕様が2つ登場。OKFとARDの注目点

Google Cloudは「OKF(Open Knowledge Format)」を公開した。組織内の知識(データセット、メトリクス、運用手順書など)をAIエージェントが読めるマークダウン形式でパッケージングする仕様だ。ほぼ同時期に、GoogleやMicrosoft、GitHub、Hugging Faceを含む連合が「ARD(Agentic Resource Discovery)」の草案を発表した。こちらはAIエージェントがツールやスキル、他のエージェントを発見・検証するためのプロトコルを定義する。
両仕様とも現時点で即時の対応を求めるものではない。OKFはバージョン0.1、ARDは0.9と初期段階だ。Harton Worksの創業者Martin Jeffrey氏はARDを「ページではなく機能のためのサイトマップが再来したようなものだ」と表現した。Snippet Digitalの共同創業者Suganthan Mohanadasan氏は「魔法のキノコではない。これで一夜にしてAI可視性が上がるわけではない」と期待値を引き締めている。
実務的には、どのフォーマットが実際に普及するかを見極める観察期間に入る。llms.txtの事例が示すように、仕様の存在と実際の効果は別問題だ。導入判断は普及の兆候を確認してからでも遅くない。
英国CMAがGoogleに公正ランキングを命令。事前通知義務が実務に波及

英国の競争市場庁(CMA)がGoogle検索に対し、新たなルールを設定した。オーガニック検索結果のランキングに客観的かつ非差別的な基準を使うこと、そして大規模な変更の際には事前通知を行うことを義務づける内容だ。
このルールの適用範囲は英国のオーガニック検索結果で、AI Overviewsも対象に含まれる(広告は除く)。Googleは「現行のランキングはすでに公正かつ透明だ」と反論しているが、CMAは6月初旬にもAI検索機能からのオプトアウトを認めるよう命令しており、規制圧力は強まっている。
SEO専門家の反応から読む今後の展開
Searchpediaの創業者Laura Iancu氏はLinkedInで「もうこれで『コアアップデートを突然リリースしました』なんてことはできなくなる」と単刀直入に表現した。Blue Arrayの戦略SEO責任者Chloe Smith氏は「Googleは何らかの回避策を探るだろう」と予測しつつも、事前通知と異議申し立ての枠組みができたこと自体に意味があると見ている。
現状では英国限定の措置だが、EUや他の地域にも波及する可能性は否定できない。特に、大規模アップデートの事前通知が実務化すれば、SEO施策の計画立案や緊急対応のあり方そのものが変わる。今後のGoogleの実装方法を注視する必要がある。
構造化ファイルを置くだけでは済まない。AI可視性の本質に立ち返る
今週のニュースを横断して浮かび上がるテーマは、「構造化ファイルを自ドメインに置いておけばAIに見つけてもらえる」という発想への再考だ。llms.txtはその教訓をすでに示している。ファイルを公開しても、Googleはサイト差別化に寄与しないと断言し、データは大半のファイルが読まれていない事実を突きつけた。
OKFやARDが登場したことで、構造化ファイルへの要求はこれからも繰り返されるだろう。しかし破綻しているのは「ファイルを置けば報われる」という期待のほうだ。BingのCitation Shareは、そうした取り組みが実際に引用に結びついているかを数値で示してくれる、貴重なフィードバックループになり得る。
AI検索時代の可視性は、小手先のファイル配置ではなく、コンテンツそのものの強さと、信頼される情報源としてサイト全体を設計し続ける積み重ねで決まる。今週のデータと専門家の声は、その原則を改めて強調する結果になった。
この記事のポイント
- Bing Webmaster Toolsの新機能「AI Citation Share」で、AI検索での競合とのシェア比較が初めて可能になった。Googleにはまだ同等機能はない
- llms.txtは97%がアクセスゼロ。AI検索可視性への効果はデータで否定され、自己申告ファイルの限界が明確になった
- OKFとARDという新たなAIエージェント向け仕様が登場したが、普及は未知数。llms.txtの教訓を踏まえ導入判断は慎重に行うべきだ
- 英国CMAがGoogleに対し、検索順位の公正化と大規模変更前の事前通知を義務づけた。SEO施策の計画立案に影響する可能性がある
- 結局、AI可視性の本質は構造化ファイルではなく、通常のHTMLコンテンツの品質と情報設計にある
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AnthropicのFable 5が米政府命令で強制停止、SEO業界に衝撃
Fable 5とMythos 5、米国政府の輸出管理命令で突然の利用停止

米国政府は2026年6月13日、国家セキュリティを理由にAnthropicへ輸出管理命令を出し、同社の最新AIモデル「Fable 5」および「Mythos 5」の全利用停止を強制した。命令は外国籍の個人によるアクセスを禁じており、実質的に全顧客の接続を遮断せざるを得ない内容だ。
Anthropicは同日に声明を発表し、政府の見解に反論した。両モデルには強固なセーフガードが重層的に組み込まれており、既存のAIモデルと同等のリスク水準に留まっていると主張している。しかし、命令受領からわずか数時間でFable 5とMythos 5のアクセスは世界中で停止された。
この措置は、SEOやデジタルマーケティングで最先端AIを活用してきた企業・個人に直接的な影響を及ぼす。高性能モデルの急な遮断は、コンテンツ制作フローや競合分析の自動化パイプラインを根底から揺るがすためだ。
このデモでは、Fable 5が突然使えなくなり、SEOワークフローに穴が空く状況を図示している。高性能なモデルに依存していた自動化プロセスは、一気に精度と速度が落ちる。
輸出管理命令の具体的な中身
命令は輸出管理指令と呼ばれる法的措置で、技術やデータの国外移転を制限する。Anthropicはこの命令を「外国籍の者へのアクセスを一切禁じる」と解釈せざるを得ず、結果的に全世界のユーザーが利用不能になった。同社が受けたのは東部夏時間17時21分。ほぼその日のうちに、サービス停止が現実となった。
政府はFable 5のセーフガードを突破する手法があると指摘しているが、Anthropicは提示された事例を「軽微な脆弱性」と一蹴。同社は既に多層防御と厳重なモニタリングでリスクを抑え込んでいる立場だ。
SEO業界が受ける打撃、AI駆動型ワークフローの寸断

Fable 5の急停止は、SEO担当者やアフィリエイトマーケターに具体的な痛みをもたらした。特に月額200ドルの「Claude Max」プランに切り替えたばかりのユーザーからは、返金を求める声がXで相次いだ。新しいモデルを前提にした記事生成や分析タスクが突然止まったためだ。
この流れは、AIモデルをコンテンツ制作パイプラインに組み込んできたSEOチームにとって、サプライチェーン途絶に近い。短納期の記事更新や、多言語でのローカライズ、高度なエンティティ抽出にFable 5を使っていたケースでは、代替モデルへの切り替えに伴う品質低下と工数増加が避けられない。
上のフローは、AIモデルを活用したSEOコンテンツ制作の典型的な手順だ。Fable 5が消失すれば、STEP 1の時点で生産性が大幅に落ちる。
返金要求とMaxプランの混乱
Xの投稿では、多くのユーザーが「Fable 5を使うためにMaxプランに切り替えたのに、当日に遮断された」と訴えている。あるユーザーは「生物学の基本的な質問さえできなかった」と、セーフガードの過剰さを指摘。多額の課金が一瞬で無駄になった苛立ちが広がった。
これはBtoBのSEO支援会社にとっても同様で、クライアント向けのコンテンツをFable 5に依存していた場合、納期の遅延と追加コストが発生する。急速なAI導入が裏目に出る典型例と言える。
国家セキュリティとAI規制、SEOに迫る論点

今回の措置は、AIによるサイバーセキュリティリスクを巡る政府とAnthropicの長年の対立の延長線上にある。Anthropicは大量監視や自律型兵器への技術提供を拒否してきた経緯があり、それが政府の不信感を強めたと見られる。
SEO業界への教訓は単純だ。極めて高性能なAIモデルは、常に地政学的リスクの影響を受ける。特定のベンダーに過度に依存したコンテンツ戦略は、突如として停止する可能性がある。複数のAIプロバイダーを使い分けるマルチベンダー戦略が、今後の安定運用の鍵を握る。
上の図は、リスク分散のためのマルチベンダー構成の一例だ。1つのモデルが遮断されても、他のプロバイダーや自社ホストのモデルでカバーできる。
「強力すぎるAI」を喧伝したツケ
批判の矛先はAnthropic自身にも向いた。同社が長年「極めて強力で危険なAI」と自社モデルを位置付けてきたことが、政府の深刻な受け止めを招いたという指摘だ。Xでは「恐怖をブランドにして政府に輸出管理をかけられ、今更『誤解』と言うのか」と皮肉る投稿が散見された。
SEO担当者にとっては、AIの性能を過大にアピールするマーケティングが規制を早める可能性を認識する契機になる。クライアントや社内で「最強のAIを使っている」と謳う前に、その文言が持つ政治的な重みを考慮すべき局面だ。
SEO戦略に組み込むAIレジリエンス、今後の備え
Fable 5停止のような事態に備え、SEO担当者は次の3つの柱を早急に固める必要がある。第一に、複数AIモデルへのアクセス経路の確保。第二に、AI非依存の編集プロセスとの併用。第三に、オープンソースLLMの社内導入検討だ。
Anthropicは「サービスの早期復旧を目指す」と表明しているが、法的な結末は不透明だ。最悪の場合、最先端モデルへのパブリックアクセスが恒久的に制限される可能性もゼロではない。そのとき、手元に自前の代替手段を持たないチームは、検索順位を維持するための初速で致命的な遅れを取る。
この比較が示す通り、AIに依存するほど、その供給停止がもたらすダメージは大きくなる。今のうちにバックアップのAIパイプラインをテストし、実際に切り替え可能な状態にしておくことが重要だ。
この記事のポイント
- 米国政府の輸出管理命令によりAnthropicのFable 5とMythos 5が全ユーザーに対して突然停止された
- SEO業界では高精度AIを前提としたコンテンツ制作フローが寸断され、返金要求や納期遅延が発生
- 高性能AIのブランディングが規制を呼び込むリスクが現実化した
- マルチベンダー戦略やオープンソースLLMの導入で、AIサービス遮断に強いSEO体制を構築すべき
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験