

デザインシステムをAI対応にする実践手法
AIによるプロトタイプ生成は、技術的には可能でも、品質面で期待を下回ることが多い。根本原因はデザインシステムの小さな不整合にある。ハードコードされた値や未定義のルールが、AIの出力を不安定にしているのだ。
Smashing Magazineの記事によれば、AtlassianのHardik Pandya氏がこの問題に対する実践的な解決策を提示している。デザイン判断をインフラとして扱い、AIが読める形式で設計ルールを明文化する手法だ。本稿では、AI対応型デザインシステムを構築するための具体的なステップを解説する。
デザイン判断をソフトウェアインフラとして扱う発想
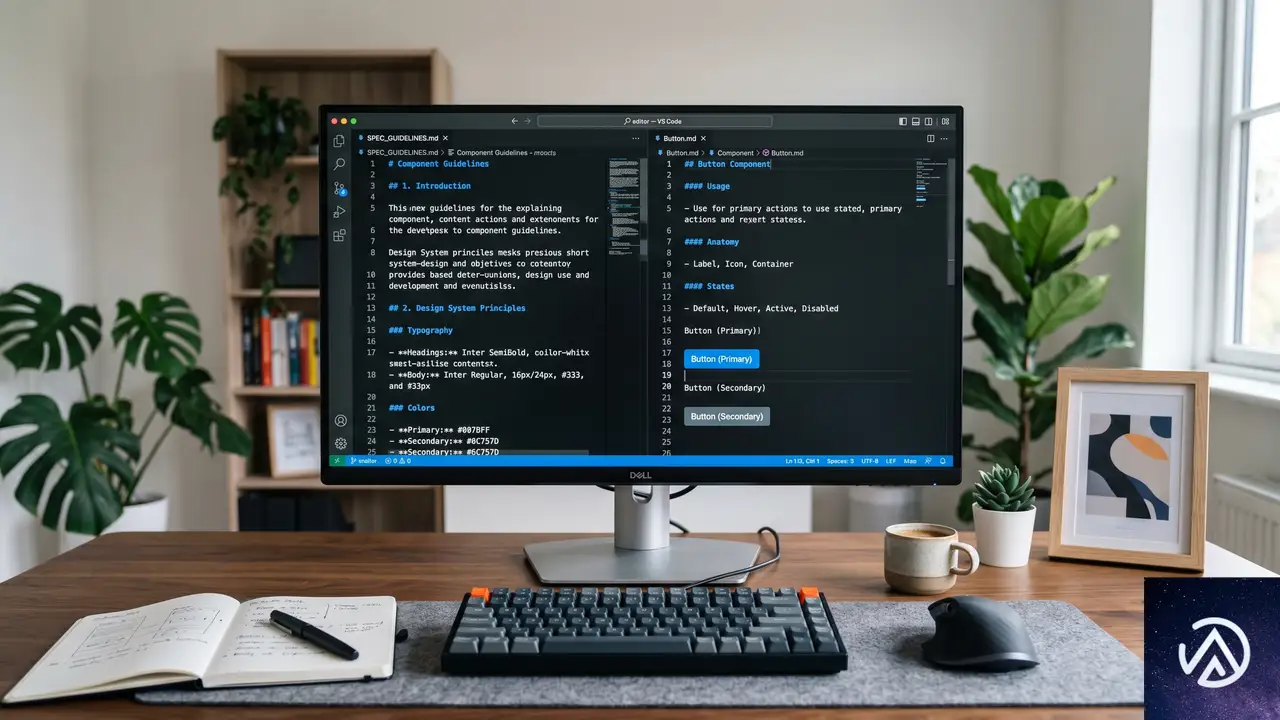
AIに優れた出力を期待するなら、人間側から明確な道筋を示す必要がある。どのコンポーネントを選ぶべきか、アクセシビリティをどう担保するか。そして、判断の優先順位と設計原則を提示する責任はデザイナーにある。
具体的には、デザイン上のあらゆる判断を「Specファイル」という形で構造化し、AIが常に最新の指示を参照できる状態を維持する。これはコードの依存関係管理と本質的に同じ考え方だ。口頭での合意やSlackの過去ログに埋もれた意思決定は、AIにとって存在しないに等しい。
FigmaLintが提供する監査の自動化
FigmaLintは、デザインシステムの監査を支援する無料のFigmaプラグインだ。トークンの一貫性、状態定義の有無、レイヤー命名規則、そしてハードコードされた値の検出を自動化する。デザインデータのクリーンアップを効率的に進められる点が最大の利点である。
このツールの実用的な価値は、監査スクリプトとしての役割にとどまらない。サードパーティから提供されたコンポーネントライブラリを精査する局面でも有効だ。外部ベンダーのデザインシステムが、自社のAI生成プロトタイプと整合するかどうかを定量的に確認できる。
ただし注意すべきは、FigmaLintで検出した問題を手動で修正し続けるだけでは、根本的な解決にならないという点だ。改善したルールをSpecファイルに落とし込み、AI自身が次回から同じミスをしないよう仕組み化することが重要になる。
AI品質を支える三層構造の設計
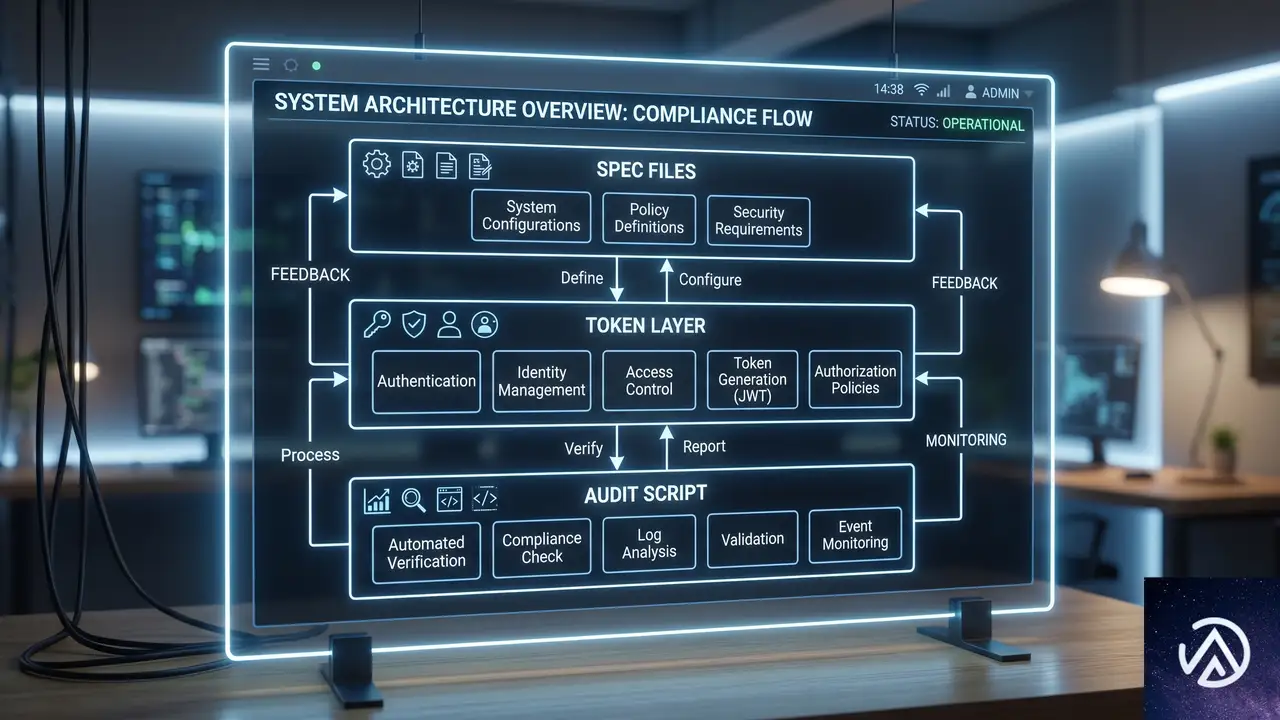
高品質なAIプロトタイプを継続的に得るには、「Specファイル」「トークン層」「監査スクリプト」の三層を整備する必要がある。この構造はソフトウェア開発における「ドキュメント、ライブラリ、CIテスト」の関係と相似形だ。
Specファイルは単なるガイドラインではない。スペーシング、配色、コンポーネントの適切な使い分けといった具体的な制約を、Markdown形式でAIに提供するテキストベースの仕様書である。AIがモックアップ画像を常に正しく解釈できるとは限らないため、テキストによる明示的な指示がコスト効率と精度の両面で優位に立つ。
トークン層はデザイントークンを変数として定義する層だ。AIが自由に「それらしい値」を捏造する余地を排除し、必ず定義済みの閉じたセットから値を選択させる。これにより、ブランドカラーやフォントサイズの意図しない逸脱を防ぐ。
監査スクリプトは、AIが生成した成果物を自動チェックする仕組みである。ハードコードされた値を検出し、Specファイルから逸脱した部分にフラグを立てる。AIが自分のミスを認識し、次回の生成時に改善するためのフィードバックループを形成するわけだ。
デザインシステムのアップデート時には、同期ルーチンがどのSpecファイルを更新すべきかを特定する。AIが古い仕様を参照したままコードを生成する事態を防ぐためだ。バージョン管理され、常に最新のSpecだけがAIに読まれる環境を維持しなければならない。
AI対応デザインシステムがもたらす現場の変化

この手法を導入した組織では、プロトタイプ生成の手戻りが減少し、人間のレビュー工数が大幅に最適化される。IBMのCarbonデザインシステムや、Atlassianの事例では、AIが初回から許容可能な品質のコードを出力する確率が明確に向上したと報告されている。
ただし、これはAIの性能が向上したというより、人間が指示の質を根本的に変えた結果だ。従来の「何百ページもあるPDFの仕様書」をAIに読ませる方法では、文脈の欠落と解釈のブレが避けられなかった。Specファイルはこの問題を、小さく分割され相互参照が明示されたテキストファイルとして解決する。
技術的負債やデザイン負債をAIが魔法のように解消することはない。明確な判断基準と構造化された指示がなければ、AIは単に混乱をコード化するだけである。デザイナーがどれだけ意図的かつ正確にAIを導けるかが、プロトタイプの最終品質を決定づける時代に入った。
この記事のポイント
- AI生成プロトタイプの品質低下は、デザインシステムの小さな不整合に起因する
- 口頭での意思決定をSpecファイルに落とし込み、AIが参照できるインフラとして扱う
- FigmaLintでトークンやハードコード値の監査を自動化し、デザインデータをクリーンに保つ
- Specファイル、トークン層、監査スクリプトの三層構造でAIの出力を継続的に改善する
- テキストベースの明示的指示が、AIのコンテキスト理解精度を劇的に向上させる

・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験
Figma変数でフォント拡大テストを実践する——アクセシビリティ対応の効率的なワークフロー
デジタルアクセシビリティの取り組みは、日常のデザインワークフローに自然に溶け込む時に最も効果を発揮する。大規模な変革ではなく、チームの日常業務にフィットするシンプルな作業プロセスが鍵だ。Figmaの変数機能を使えば、フォントサイズの拡大テストはデザイン作業そのものの一部となり、アクセシビリティ対応が「オプション」ではなく「当然」のプロセスとして感じられるようになる。
Smashing Magazineの記事によれば、アクセシビリティ文化の構築は「どうやって実現するか」という具体的な方法論が重要だと指摘されている。多くのチームが「これをやるか、あれをやるか」の選択を迫られる中で、アクセシビリティは後回しにされがちだ。しかし、Figma変数を活用した体系的なテストプロセスを確立すれば、この状況を変えられる。
特にフォントサイズの拡大対応は、WCAG 2.2のAAレベル必須項目であり、実ユーザーの26%がスマートフォンでフォントサイズを拡大している現実を考えると、無視できない設計課題だ。この記事では、Figma変数を使った実践的なテスト手法を、具体的な手順とともに解説する。
フォントサイズ拡大がアクセシビリティにおいて重要な理由

テキストはデジタル体験において中心的な役割を果たす。操作説明、ボタンのラベル、ナビゲーション要素など、多くの情報がテキストを通じて伝えられる。読みやすさに問題があれば、ユーザー体験は大きく損なわれる。
支援技術としてのフォントサイズ調整
アクセシビリティの文脈では、フォントサイズの拡大は「支援技術・戦略」の一つに分類される。これは、ユーザーがより快適な利用モデルを見つけるために頼る技術的なツールや工夫だ。スクリーンリーダーや色の変更と同様に、フォントサイズの調整も多くのユーザーにとって不可欠な機能となっている。
APPT(Accessible Platform Preferences and Technologies)の2026年2月のデータによると、AndroidとiOSのモバイルデバイスユーザーの26%がデフォルトのフォントサイズを拡大している。これは4人に1人の割合に相当し、無視できない規模のユーザー層だ。
WCAG 1.4.4「テキストのサイズ変更」要件
Webコンテンツアクセシビリティガイドライン(WCAG)2.2の成功基準1.4.4は、AAレベル(必須)の要件として明確に定めている。
キャプションや文字画像を除き、支援技術なしでテキストを200%までサイズ変更しても、コンテンツや機能が失われないこと。
WCAG 2.2 成功基準1.4.4「テキストのサイズ変更」
この「200%」は、初期サイズの2倍まで拡大可能であることを意味する。実際のユーザー設定では120%、140%、160%などの段階的な拡大も一般的だ。重要なのは、インターフェース内に独自の拡大ツールを提供する必要はない点だ。デバイスやブラウザの標準機能で対応すればよく、これはUIの複雑化を避ける合理的なアプローチと言える。
標準化されたアクセス方法
ほとんどのデバイスやブラウザには、フォントサイズ調整機能が標準で搭載されている。ユーザーは特別なソフトウェアを購入する必要なく、システム設定で簡単に調整できる。
iPhoneでは「設定」→「アクセシビリティ」→「視覚」→「テキストサイズと表示」から調整可能だ。Google Chromeでは「設定」→「外観」→「フォントサイズ」で「特大」などのオプションを選択できる。これらの標準機能を正しくサポートすることが、開発側に求められる対応となる。
Figma変数を使ったテストの基本コンセプト
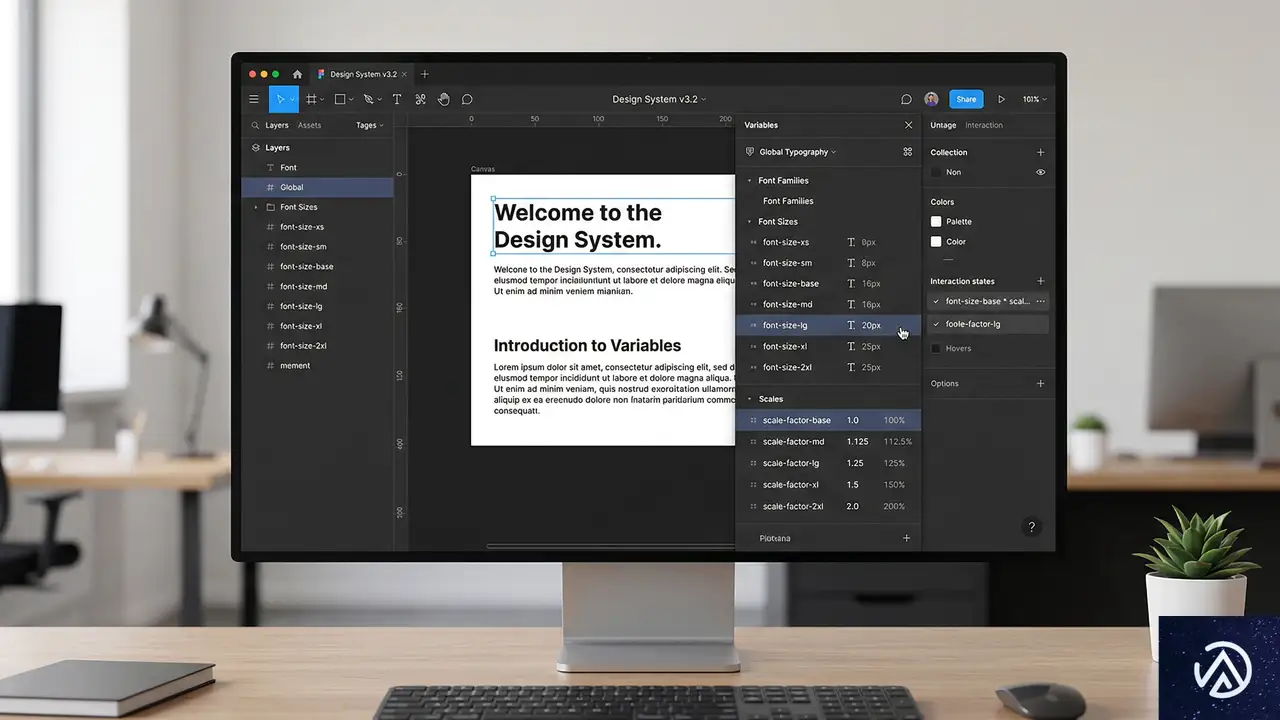
Figmaでフォントサイズ拡大テストを実施する核心は、変数機能の活用にある。このアプローチの目標は、インターフェースのテキストを100%、120%、140%、160%、180%、200%の各スケールで即座に切り替えて確認できる環境を構築することだ。
必要な前提知識
このテストを効果的に実施するには、Figmaの3つの基本機能に対する理解が不可欠だ。テキストスタイル、オートレイアウト、変数の使い方をマスターしている必要がある。元記事の著者であるRuben Ferreira Duarte氏は、これらの機能を体系的に学ぶことを強く推奨している。段階を飛ばすと、後で大きな手戻りが発生する可能性がある。
テストの全体像
基本的なワークフローは、ライトモードとダークモードの切り替えに変数を使う場合と同様の原理に基づく。各テキストスタイルのフォントサイズと行間を変数として定義し、その変数に異なるスケールの値を割り当てる。これにより、変数セットを切り替えるだけで、インターフェース全体のテキストサイズが一括で変更される。
このアプローチの最大の利点は、テストがデザインプロセスに自然に組み込まれる点だ。特別なテスト環境を用意する必要がなく、日常のデザイン作業の中で継続的にアクセシビリティを検証できる。
Figmaでの実践手順:10のステップ
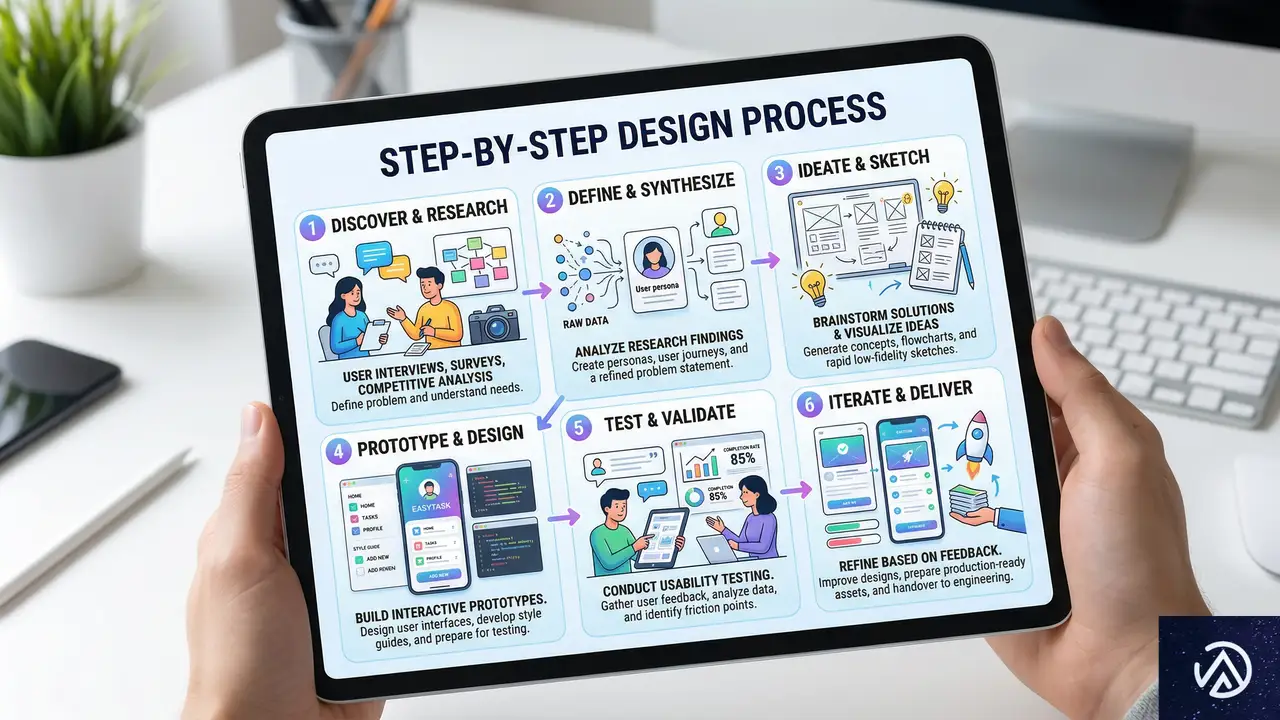
ここからは、具体的な実装手順を10のステップに分けて解説する。各ステップは積み重ね式になっており、前のステップが適切に完了していないと次のステップで問題が発生する。順を追って確実に進めることが重要だ。
ステップ1:インターフェースのデザイン
まずはテスト対象となるインターフェースをデザインする。この段階では、フォントサイズ拡大テストを意識しすぎる必要はない。ただし、基本的なアクセシビリティ原則(色のコントラスト、インタラクションサイズなど)には最初から配慮しておく。後から大きな修正が入らないよう、土台をしっかり作ることが肝心だ。
ステップ2:すべての要素にオートレイアウトを適用
画面デザインのすべての要素に、適切なオートレイアウトを適用する。これは最も重要なステップの一つだ。オートレイアウトの一貫した適用が、後でフォントサイズを拡大した際のインターフェースのスケーラビリティを保証する。このステップをおろそかにすると、テキスト拡大時に「陶器店に象が入り込んだような」崩壊が発生する。
オートレイアウトは、要素間のスペーシングや整列を数学的に管理する。これにより、テキストサイズが変化しても、レイアウトが予測可能な形で調整される。
ステップ3:テキストスタイルの構造化と適用
次に、テキストスタイルを構造化し、インターフェースのすべてのテキスト要素に適用する。多くのデザイナーはデザイン作業中に自然にテキストスタイルを作成していくが、もしまだならこの時点で整理する。テストを正常に動作させるためには、デザイン内のすべてのテキスト要素にテキストスタイルが適用されている必要がある。
テキストスタイルは、見出し、本文、キャプションなど、役割ごとに一貫した設定を保証する。これが変数と連動する基盤となる。
ステップ4:100%スケールの変数セットを定義
ここから変数の本格的な設定が始まる。まず、100%表示モデル(初期参照バージョン)用の変数セットを定義する。Figmaの「数値」タイプの変数を作成し、各テキストスタイルのフォントサイズと行間に対して個別の変数を割り当てる。
例えば、「見出し1」のフォントサイズが32pxなら、`Heading1/font-size`という変数を作成して32を設定する。行間にも同様に変数を設定する。この構造化が、後の拡大スケール計算の基礎となる。
ステップ5:変数をテキストスタイルに適用
定義した変数を、ステップ3で作成したテキストスタイルに適用する。テキストスタイルの編集画面で、フォントサイズと行間の値入力欄の横にあるアイコンをクリックし、対応する変数を選択する。最低でもフォントサイズと行間には変数を適用する必要がある。他のタイポグラフィ変数(字間、フォントファミリーなど)があれば、それらにも変数を適用できるが、必須ではない。
ステップ6:テキスト拡大用の変数を定義
100%スケールの変数が設定できたら、次は拡大スケール用の変数を定義する。120%、140%、160%、180%、200%などの各スケールに対して、各テキストスタイルの新しい変数値を計算する。
計算方法は単純だ。初期値にスケール率を乗算する。例えば、フォントサイズ16pxのテキストスタイルの場合、120%スケールでは16×1.2=19.2pxとなる。行間も同様に計算する。最終値の丸め処理は任意だ。これは近似テストであるため、丸めによるわずかな差異はテスト結果の知覚に影響しない。
ステップ7:異なるスケールバージョンに変数を適用
テストの核心部分だ。元のインターフェースをコピーし、各フォントサイズ拡大率に対応する変数セットを適用する。120%、140%、160%、180%、200%の各スケールに対してこの作業を繰り返す。
作業を簡素化したい場合は、スケールの数を減らしても構わない。ただし、最低でも100%と200%の2スケールは必須だ。WCAG要件を満たすためには、200%スケールでの動作確認が不可欠である。
ステップ8:改善点の特定
同じ画面に異なる拡大スケールを適用すると、どこに改善が必要かが明確になる。これがデザインにおけるフォントサイズ拡大テストの本質であり、最も重要なアクセシビリティ作業の始まりだ。
分析時には以下の点に注意する。
- テキストが巨大に見えること自体は問題ではない。これは、ユーザーが製品やサービスを利用できるかどうかの分かれ目になり得る。
- フォントサイズを拡大した結果、特定のテキストが読めなくなったり、コントロールが操作不能になったりする場合に、初めてアクセシビリティ問題が発生する。
- すでに十分大きなテキスト要素をさらに拡大することは、可読性を向上させず、不必要なスペースを占有するだけの場合がある。
- 要素が画面からはみ出しているように見える場合は、まずオートレイアウトの適用方法を確認する。多くのデザイン上の問題は、適切なオートレイアウト設定で解決できる。
- 拡大スケールに関わらず、タイポグラフィの視覚的階層を維持することが重要だ。情報のレベル差を認識するためには、この読みやすさが不可欠である。
- このテストは、特定の拡大率で正常に機能するためにコード側での調整が必要な要素を特定するのにも役立つ。すべてがデザインだけで解決できるわけではないが、それは問題ない。アクセシビリティは本質的にチーム全体での取り組みだからだ。
ステップ9:デザインの修正と調整
様々な拡大スケールを適用した画面を基に、必要なデザイン変更を実施する。これらの調整の一部はコード側でのみ対応可能な場合もある。その場合は、すべての提案を文書化して開発チームに引き継ぐ。繰り返しになるが、デザインで遭遇する問題の多くは、オートレイアウトプロパティの適切な適用だけで迅速に解決できる。
ステップ10:最初に戻ってプロセスを繰り返す
これは循環的なアプローチだ。プロジェクトを通じて必要に応じてこれらのステップ(またはその変形)を何度も繰り返す。時間の経過とプロセスの最適化に伴い、一部のステップが不要になるのは自然なことだ。しかし、重要なのは、アクセシビリティとこのフォントサイズ拡大テストが一度きりの作業ではないという認識だ。各プロジェクトとチームの日常業務の中で、何度も何度も実施されるテストなのである。
デザインシステムの役割と効率化
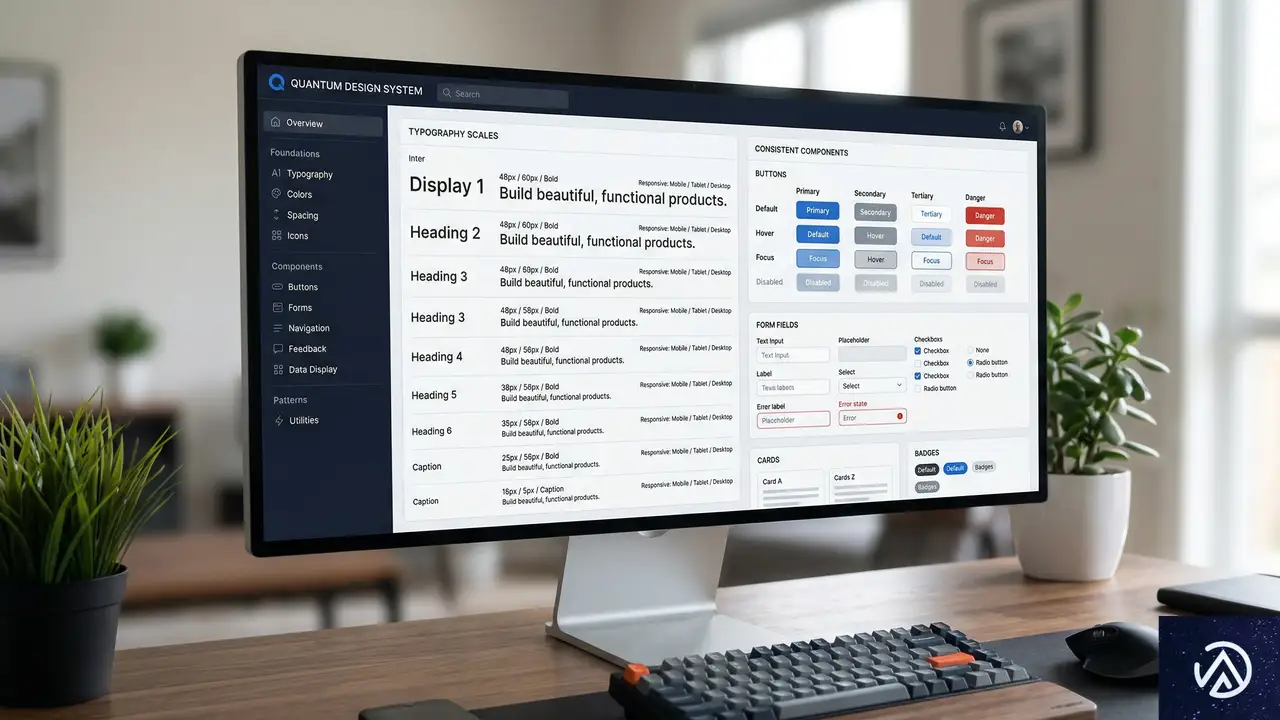
一見すると、この一連のステップは複雑な作業に思えるかもしれない。しかし、デザインシステムが存在する環境では、そのほとんどが容易に実行できる。実際、デザインシステムはプロダクトデザイン業界において「避けられない標準」となっている。各チームが何をデザインシステムと呼ぶかは議論の余地があるが、今日、コンポーネントとスタイルの最小限構造化されたライブラリさえ持たないプロダクトデザインチームを見つけるのは非常に難しい。
この基盤があれば、Figma変数を使ったフォントサイズ拡大テストの適用は非常に容易になる。さらに、デザインシステムがライトモードとダークモード用の構造化変数を既に持っているなら、このテストに適用する原理は全く同じものだ。つまり、新しい概念を導入する必要はない。
デザインシステムでの作業には、この種のテスト作成にも有用な「構造化と組織化」のレベルが伴う。デザインシステムが創造性を制限するという神話があるが、これは誤りだ。デザインシステムはデザインの「事務的」部分を解決し、本当に重要なこと——この場合はアクセシビリティのテストと、より多くの人々に本当にアクセシブルな製品・サービスの構築——に時間を割くことを可能にする。
元記事の著者は、コミュニティに公開されたFigmaファイルを例として提示している。このファイルには、ここで説明したテストプロセスの実践例が含まれている。ただし、これはあくまで一例であり、Figmaファイル内でこの種のテストを実行する方法は無数にある。各チームの具体的な現実、プロセス、成熟度レベルに合わせてアプローチを適応させることが重要だ。
この記事のポイント
- フォントサイズ拡大はWCAG 2.2 AAレベル必須項目であり、実ユーザーの26%が利用している現実的なニーズである。
- Figmaの変数機能を使えば、フォントサイズ拡大テストをデザインワークフローに自然に組み込める。
- テスト実施には、テキストスタイル、オートレイアウト、変数の3つの基本機能の理解が不可欠である。
- 10のステップからなる体系的なアプローチで、誰でも再現可能なテスト環境を構築できる。
- デザインシステムが存在すれば、テストの導入と運用は大幅に効率化される。
出典
- Smashing Magazine「Testing Font Scaling For Accessibility With Figma Variables」(2026年3月24日)
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

z-indexのカオスを卒業する——マジックナンバーを廃止し、トークンで管理する設計手法
CSSの `z-index` は、要素の重なり順を制御するための強力なプロパティだ。モーダルやトースト、ドロップダウンなど、現代のUI(ユーザーインターフェース)実装において欠かすことはできない。
しかし、プロジェクトが大規模になるにつれ、`z-index` の値は制御不能な「マジックナンバー」の温床となる。場当たり的に指定された巨大な数値がコードベースを侵食し、修正が困難なバグを引き起こす。
本記事では、`z-index` の軍拡競争を終わらせるための「トークン化」による管理手法を解説する。この仕組みを導入することで、重なりの優先順位を論理的に整理し、保守性の高いコードを実現できる。
z-indexが引き起こす「軍拡競争」の実態
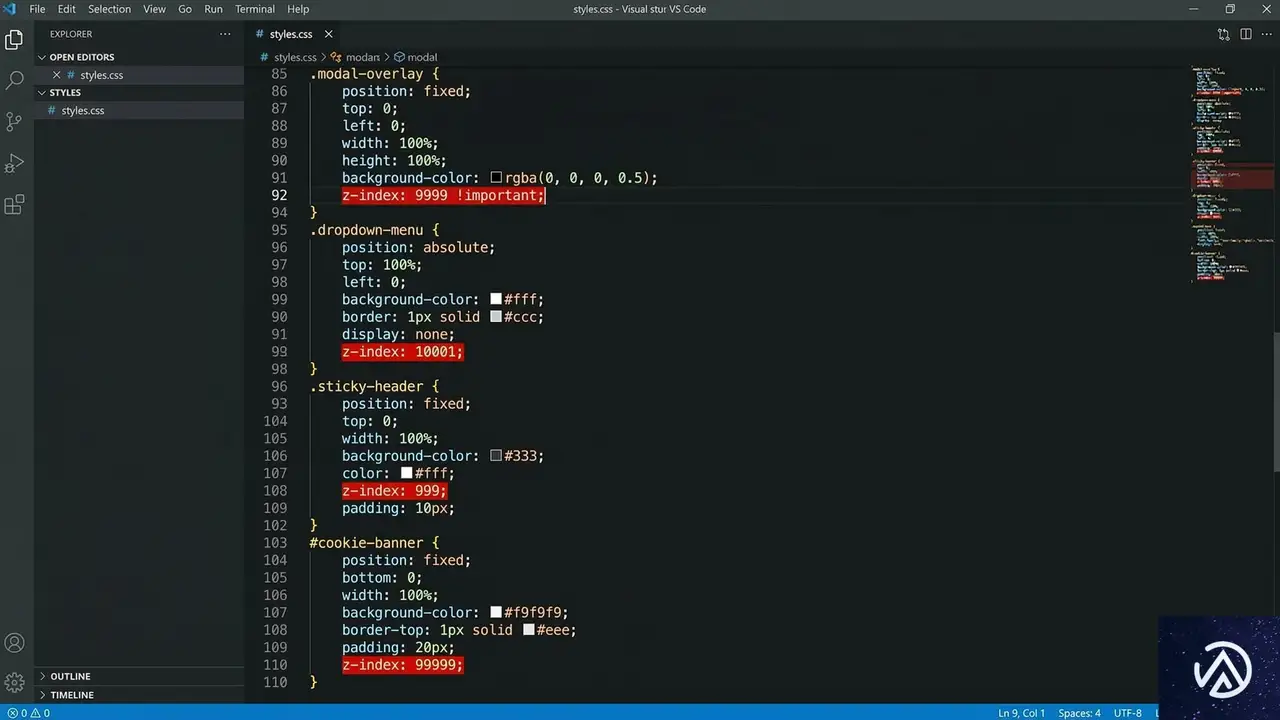
多くの開発現場で、`z-index: 10001` のような不自然に大きな数値を目にすることがある。なぜこのような「マジックナンバー」が生まれるのか。その背景には、開発者が抱く「要素が隠れてしまうことへの恐怖」がある。
なぜ「10001」のような数字が生まれるのか
複数のチームが並行して開発を行う大規模プロジェクトでは、画面上に何が浮いているかを完全に把握するのは難しい。Aチームが作った通知、Bチームのクッキーバナー、マーケティング用のSDKが生成するモーダルなどが混在する。
開発者は「とにかく一番上に表示させたい」という一心で、既存のどの要素よりも大きいと思われる数値を勘で入力する。これが「マジックナンバー」の正体だ。マジックナンバーとは、文脈や根拠がなく、その場しのぎで設定された特定の数値を指す。
一度この軍拡競争が始まると、次の開発者はさらに大きな数値を設定せざるを得なくなる。最終的に `9999999` のような極端な値が並び、コードの意図は完全に消失する。
ブラウザが許容する最大値の罠
`z-index` には設定可能な最大値が存在する。多くのブラウザでは **2147483647** が上限だ。これは32ビット符号付き整数の最大値に由来する。
この数値を超えて指定しても、ブラウザによってこの上限値に丸められる。つまり、無限に数値を大きくして「勝ち続ける」ことは不可能だ。数値の大きさで解決しようとするアプローチは、いずれ技術的な限界に突き当たる。
重ね合わせ文脈(Stacking Context)の基本

`z-index` の問題を難しくしているのは、数値の大小だけで重なりが決まらない点にある。ここで重要になるのが「重ね合わせ文脈(Stacking Context)」という概念だ。
値の大きさよりも「親」が優先される仕組み
重ね合わせ文脈とは、要素の重なりを計算するための独立したグループのようなものだ。例えるなら、書類の束(スタック)が入った「フォルダ」をイメージすると分かりやすい。
どれほど大きな `z-index` を持っていたとしても、その要素が属する「フォルダ(親の重ね合わせ文脈)」自体が低い位置にあれば、他のフォルダより前に出ることはできない。
以下のコードで、その挙動を確認できる。
/* 親要素が重ね合わせ文脈を作る */
.parent-low {
position: relative;
z-index: 1;
}
.parent-high {
position: relative;
z-index: 2;
}
/* 子要素に大きな値を指定しても、親の z-index: 1 に縛られる */
.child-massive {
position: absolute;
z-index: 9999;
}(z: 9999)
子要素はz-index:9999だが、親1(z:1)に縛られ、親2(z:2)の下に隠れている
このデモでは、青い子要素に `z-index: 9999` を指定しているが、親要素の `z-index: 1` という制約により、隣にある `z-index: 2` の親要素(緑)の下に潜り込んでしまう。
このように、`z-index` のトラブルの多くは数値の不足ではなく、重ね合わせ文脈の構造に起因している。
CSS変数(トークン)による設計の体系化
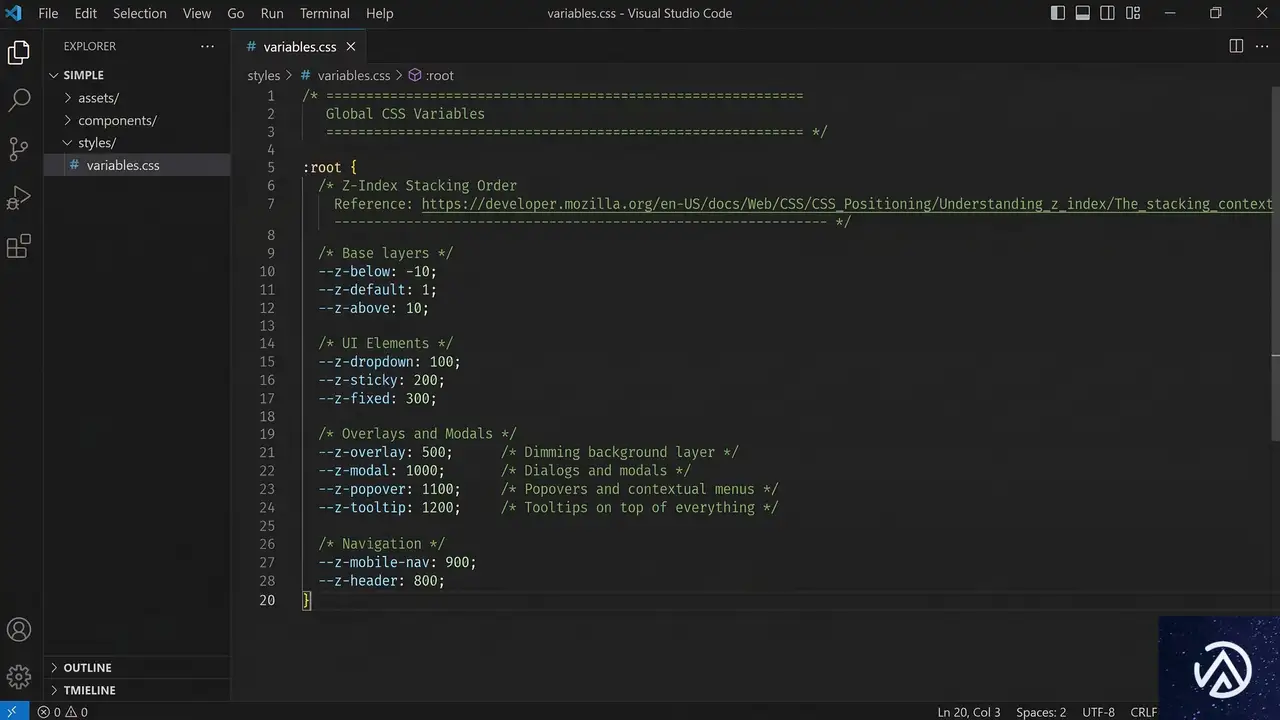
マジックナンバーを排除し、プロジェクト全体で一貫した重なり順を維持するための最も有効な手段は、CSS変数(カスタムプロパティ)を用いた「トークン化」だ。
グローバルトークンで「階層」を定義する
まず、アプリケーション全体で共有する「レイヤー」を定義する。具体的な数値ではなく、その要素が果たす役割(役割ベース)で命名するのがポイントだ。
:root {
--z-base: 0;
--z-sticky: 100;
--z-dropdown: 200;
--z-overlay: 300;
--z-modal: 400;
--z-popover: 500;
--z-toast: 600;
}このように定義しておけば、開発者は「モーダルだから `–z-modal` を使おう」と判断するだけで済む。数値の管理は `:root` の一箇所に集約されるため、後から「トーストをモーダルの背面に移動したい」といった変更が必要になっても、変数の値を入れ替えるだけで全要素に反映される。
calc() を使った相対的なレイヤリング
特定の要素に対して、基準となるレイヤーから少しだけ浮かせたい、あるいは沈ませたい場合がある。例えば、モーダルの背面に敷く背景(バックドロップ)などだ。
この場合、新しいトークンを作るのではなく `calc()` を利用して相対的に指定する。
.modal-backdrop {
/* モーダルのトークンより常に 1 だけ背面に配置 */
z-index: calc(var(--z-modal) - 1);
}これにより、要素間の主従関係がコード上で明示される。`–z-modal` の値が変更されても、バックドロップは常にその背後を追従するため、関係性が崩れる心配がない。
コンポーネント内部での「ローカル管理」
グローバルなトークンは便利だが、あらゆる要素をグローバル変数で管理しようとすると、変数の数が膨大になり管理が破綻する。そこで、コンポーネント内部で完結する「ローカル管理」を併用する。
–z-top と –z-bottom の導入
コンポーネントが独自の重ね合わせ文脈(Stacking Context)を持っている場合、その内部での重なり順はグローバルな値とは無関係になる。
例えば、モーダル内の閉じるボタンと背景装飾の重なりを制御する場合、グローバルトークンを使う必要はない。以下のように、コンポーネント固有の「基準値」を定義するのが賢明だ。
.my-component {
/* 重ね合わせ文脈を強制的に作成 */
isolation: isolate;
z-index: var(--z-overlay);
}
.my-component__decoration {
/* コンポーネント内の底辺 */
z-index: -1;
}
.my-component__close-button {
/* コンポーネント内の最前面 */
z-index: 10;
}`isolation: isolate` は、その要素に新しい重ね合わせ文脈を強制的に作成するプロパティだ。これを使うことで、内部の `z-index` が外部に影響を与えたり、外部の影響を受けたりすることを防ぐ「安全地帯」を作ることができる。
ツールチップやモーダル内での活用
ツールチップのように「どこにでも現れる」コンポーネントは、管理が最も難しい。しかし、これもローカルな視点で考えればシンプルになる。
ツールチップは、常に「自分を呼んだ要素」のすぐ上にいればよい。そのため、コンポーネント内で `z-index: 1` 程度の小さな値を設定するだけで十分だ。そのツールチップがモーダル内で使われれば、モーダルの重ね合わせ文脈の中で最前面に立ち、メインコンテンツで使われればそこで最前面に立つ。
システムを維持するための自動化とルール
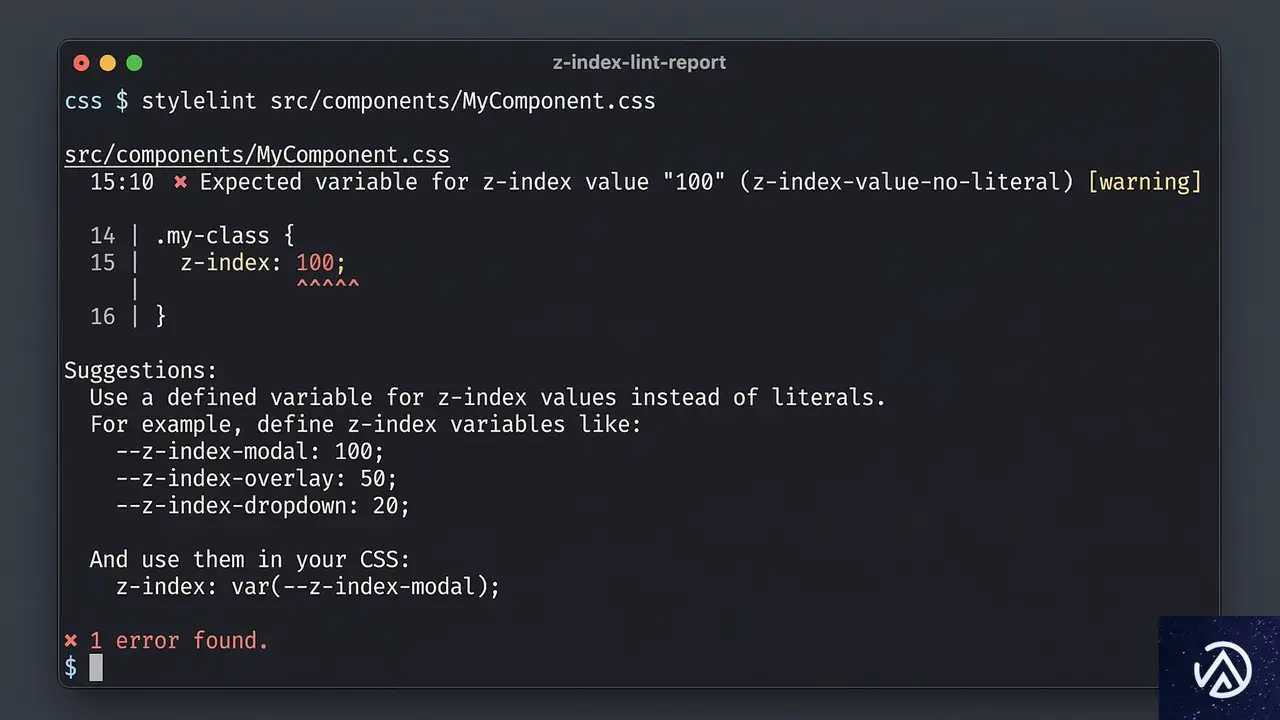
優れた設計も、運用が徹底されなければ形骸化する。特に納期が迫った状況では、つい `z-index: 999` と書き込みたくなるのが開発者の性だ。これを防ぐには、仕組みによる強制が必要だ。
Linterによるマジックナンバーの禁止
Stylelintなどの静的解析ツールを導入し、`z-index` プロパティに直接数値を記述することを禁止する。
例えば、`stylelint-declaration-strict-value` というプラグインを使えば、`z-index` には変数(`var()`)しか使えないように制限できる。
/* .stylelintrc.json */
{
"plugins": ["stylelint-declaration-strict-value"],
"rules": {
"scale-unlimited/declaration-strict-value": ["z-index"]
}
}ビルドプロセスでエラーが出るようになれば、開発者は必然的に定義されたトークンを確認し、適切なレイヤーを選択するようになる。
z-index 設計の黄金律
最後に、保守性の高い `z-index` 管理を維持するためのルールをまとめる。
- マジックナンバーを使わない: 根拠のない数値はバグの元だ。
- トークンを必須とする: すべての値は設計された変数から取得する。
- 重なりがおかしい時は構造を疑う: 数値を増やす前に、重ね合わせ文脈(親要素の z-index や opacity)を確認する。
- 意味のある単位で刻む: 1, 2, 3 ではなく 100, 200, 300 と刻むことで、後からの割り込み(150など)に対応しやすくなる。
- calc() で関係を縛る: 背景と本体のようにセットで動くものは、計算式で結合する。
`z-index` の価値は、数値の大きさではなく、それが属する「システム」の整合性にある。カオスな現状を打破し、予測可能なUI実装を目指すべきだ。
この記事のポイント
- z-indexの軍拡競争は、数値ではなく「役割ベースのトークン」で解決する。
- 重ね合わせ文脈(Stacking Context)を理解し、親要素の影響を考慮する。
- グローバルトークンと、コンポーネント内のローカル管理を使い分ける。
- Stylelintなどのツールを用いて、マジックナンバーの混入を自動的に防ぐ。
- calc() を活用して、要素間の相対的な重なり関係をコードに明文化する。
出典
- CSS-Tricks「The Value of z-index」(2026年3月9日)
- MDN Web Docs「The stacking context」(2025年12月15日)
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験