

Google検索で勝つサイトの共通点とは?400サイトの分析から見えた5つの成功法則
Googleの検索アルゴリズムが複雑化する中で、どのようなサイトが実際にトラフィックを伸ばしているのかを把握することは容易ではない。Zyppyの創設者であるCyrus Shepard氏が実施した400以上のウェブサイトに対する分析により、オーガニックトラフィックを増加させたサイトに共通する5つの特徴が明らかになった。
この調査では、過去12ヶ月間のトラフィック推移を第三者ツールで測定し、サイトのビジネスモデルやコンテンツの性質との相関関係を調べている。その結果、単なる情報の羅列ではなく、ユーザーに対して実利的な価値を提供しているサイトが優位に立っている実態が浮き彫りとなった。
SEOの成功は一つの要因で決まるものではないが、特定の要素を積み重ねることで検索順位の「勝率」を劇的に高められる可能性がある。本記事では、データに基づいた5つの成功要因と、それらを実務にどう活かすべきかを詳しく解説していく。
400サイトのデータが示す勝てるサイトの共通点

Cyrus Shepard氏の調査は、SEO専門家のLily Ray氏が以前に行ったコアアップデートの分析対象サイトを再訪する形で実施された。サイトをビジネスモデルやコンテンツタイプごとに分類し、トラフィックの変化との相関(スピアマンの順位相関係数)を算出している。
調査の概要と相関関係の測定方法
分析の対象となったのは、アフィリエイトサイト、ECサイト、サービス提供サイトなど多岐にわたる。ここで重要なのは、Google Search Consoleの生データではなく、外部ツールによる推定トラフィックに基づいている点だ。しかし、400件というサンプルサイズは、現在の検索環境における大きな傾向を掴むには十分な規模といえる。
調査では、サイトが持つ特定の機能や性質がトラフィックの増減とどれほど強く結びついているかを数値化している。相関係数は0.206から0.391という中程度の値を示しており、これは「その要素があれば必ず勝てる」という魔法の杖ではないものの、無視できない明確な傾向が存在することを示唆している。
・アフィリエイトリンクへの誘導が主目的
・サイト独自のツールや機能がない
■ ユーザーがその場で問題を解決できる機能
■ 他者が模倣できない独自のデータ資産
上記の図が示すように、従来の「情報を整理して伝えるだけ」のスタイルから、より実用的で独自性の高い「価値提供型」のスタイルへの転換が求められていることがわかる。では、具体的にどのような指標が重要視されているのかを深掘りしていこう。
トラフィック増に直結する5つの重要指標

分析の結果、トラフィックを伸ばしたサイト(勝者)と減らしたサイト(敗者)の間で、顕著な差が見られた要素は5つに集約される。これらはGoogleが「どのようなサイトをユーザーにとって有益だと判断しているか」を考える上での強力なヒントになる。
自社製品の有無とタスクの完遂
第一の特徴は「自社製品またはサービスの提供」だ。勝者の70%が自社で何らかの製品やサービスを販売していたのに対し、敗者ではその割合は34%にとどまった。これには物理的な商品だけでなく、サブスクリプション型のサービスやデジタルコンテンツも含まれる。自社製品を持つことは、サイトの信頼性やビジネスとしての実体を示す強力なシグナルになっていると考えられる。
第二に「タスクの完遂が可能であること」が挙げられる。勝者の83%が、ユーザーが検索した目的をそのサイト内で完結できる仕組みを持っていた。例えば、計算ツール、予約フォーム、詳細な比較シミュレーターなどがこれに該当する。単に「やり方を教える」だけでなく「その場で実行できる」環境を提供しているサイトが、Googleからの評価を勝ち取っている。
模倣困難な独自資産とトピックの専門性
第三の要素は「独自の資産(Proprietary Assets)」だ。勝者の92%が、他者が容易に真似できない独自のデータセット、ユーザー生成コンテンツ(UGC)、あるいは専門的なソフトウェアを保有していた。インターネット上に溢れる情報の焼き直しではなく、そのサイトでしか得られない「一次情報」や「ツール」の価値がかつてないほど高まっている。
第四に「絞り込まれたトピックへの特化」がある。単に「特定のジャンルを扱っている」というレベルではなく、一つの狭いテーマを極めて深く掘り下げているサイトが勝者となる傾向が見られた。広範なトピックを浅くカバーする総合サイトよりも、特定のニッチ領域で「このテーマならこのサイト」と言わしめるほどの専門性が、現在のアルゴリズムには好まれている。
最後に「強いブランド力」だ。全体トラフィックに対する指名検索(ブランド名での検索)の割合が高いサイトほど、トラフィックを維持・拡大させている。勝者のブランド検索比率は敗者の2倍に達しており、検索エンジン経由だけでなく、ユーザーから直接指名される存在になることがSEOの安定にも寄与していることがわかる。
意外にも相関が見られなかった要素とその背景

今回の調査では、SEOの世界で重要だと信じられてきたいくつかの要素が、意外にもトラフィックの増減と直接相関しなかったという結果も出ている。この事実は、SEO戦略の優先順位を見直す上で非常に興味深い示唆を含んでいる。
体験談やUGCが決定打にならなかった理由
Cyrus Shepard氏の分析によれば、一次体験(First-hand experience)の記述、個人的な視点、ユーザー生成コンテンツ(UGC)、コミュニティ機能の有無などは、今回のデータセットにおいては勝者と敗者を分ける決定的な要因にはならなかった。また、情報の独自性そのものも、単体では強い相関を示さなかったという。
ただし、Shepard氏はこの結果を「これらの要素が不要である」と解釈すべきではないと注意を促している。これらの要素はすでにGoogleのアルゴリズムに深く組み込まれており、ベースライン(最低限必要な条件)となっている可能性があるからだ。つまり、体験談があるのは「当たり前」であり、それだけで他サイトに差をつけることは難しくなっているという見方ができる。
重要なのは、これらの要素を「持っているかどうか」ではなく、前述した5つの重要指標とどのように組み合わせて、ユーザーの課題解決(タスク完遂)に結びつけるかという点にある。単なる日記のような体験談ではなく、それが自社製品の信頼性を裏付けたり、独自のデータ資産の一部として機能したりすることで、初めて強力な武器になるのだ。
複数の特徴を組み合わせる加点方式の重要性

この調査で最も注目すべき発見は、5つの特徴が「累積的」に作用するという点だ。一つひとつの要素の相関は中程度でも、複数を組み合わせることでサイトの勝率は飛躍的に高まることがデータで示されている。
具体的には、5つの特徴のうち一つも持たないサイトの勝率はわずか13.5%だった。特徴を一つだけ持っている場合も15%程度と、大きな変化は見られない。しかし、3つ以上の特徴を備えるあたりから勝率は急上昇し、5つすべての特徴を持つサイトの勝率は69.7%にまで達した。この「3つの壁」を越えられるかどうかが、SEOの成否を分ける境界線といえそうだ。
このデータから得られる教訓は、部分的な改善に終始するのではなく、サイトの構造やビジネスモデルそのものを「勝者のパターン」に近づけていく努力が必要だということだ。例えば、アフィリエイト記事を書くだけでなく、簡易的な診断ツールを導入したり、独自のアンケート調査結果を公開したりすることで、複数の特徴を同時に満たすことができる。
【独自分析】今後のSEO戦略にどう活かすべきか

今回の分析結果を踏まえると、今後のSEOは「コンテンツ制作」の枠を超え、「サービス設計」に近い領域へとシフトしていくと考えられる。Googleは情報の正確性だけでなく、その情報が「実際に役立ったか」というユーザー体験の完結を重視しているからだ。
情報提供から価値提供への転換
サイト運営者がまず取り組むべきは、自分のサイトが単なる「情報の通過点」になっていないかを確認することだ。ユーザーが検索した後に、別のサイトへ移動して作業を続ける必要があるなら、それは「タスクの完遂」を妨げていることになる。自社でツールを開発するのが難しい場合でも、詳細なステップバイステップのガイドや、独自のチェックリストを提供することで、ユーザーの利便性を高めることは可能だ。
また、ブランド力の強化も欠かせない。指名検索を増やすためには、検索エンジン以外の流入経路(SNS、メールマガジン、外部メディアへの露出など)を確保し、「〇〇のことならこのサイト」という認知を広げる必要がある。これは一朝一夕には達成できないが、長期的なSEOの安定には最も効果的な投資となるだろう。
最後に、独自資産の構築だ。これは必ずしも高度な技術を必要としない。自社で蓄積した顧客の声、独自の実験結果、あるいは膨大な公開データを独自の切り口で分析したレポートなどは、AIには生成できない強力な武器になる。これらをトピックの深掘りと組み合わせることで、競合が容易に追随できない「勝てるサイト」へと進化させることができるはずだ。
この記事のポイント
- トラフィックを伸ばしているサイトの70%は自社製品やサービスを提供している
- ユーザーがサイト内で目的を完遂できる「タスク完了」の仕組みが評価を分ける
- 他者が模倣できない独自データやツールを持つサイトは92%という高い勝率を誇る
- 広範なテーマよりも、一つのニッチなトピックを深く掘り下げることが重要だ
- 5つの成功要因を3つ以上組み合わせることで、検索での勝率が飛躍的に高まる

・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AI検索可視性データを地域戦略に活かす方法——引用ギャップを埋めるSEO実践
AI検索がSEO戦略の中心的な話題となる中、多くのSEO担当者は経営層から「我が社のAI検索対策はどうなっているのか」というプレッシャーを受けている。従来の検索エンジン最適化とは異なるロジックで動くAI検索において、ブランドが引用されるためにはどのようなシグナルが重要になるのか。そしてそのデータをどう地域別の実行戦略(GEO戦略)に落とし込むのか。この問いに答えるための具体的なフレームワークと実行モデルが、最新のデータ分析から明らかになりつつある。
Search Engine Journal主催のウェビナーでは、Writesonicの創業者兼CEOであるSam Garg氏が、5億件以上のAI検索会話データを分析した結果を基に、AI検索で実際に引用されるコンテンツの特徴と、地域別の引用ギャップを埋めるための優先順位付け手法を解説する。本記事では、そのエッセンスを先取りして紹介する。
AI検索における引用のメカニズム
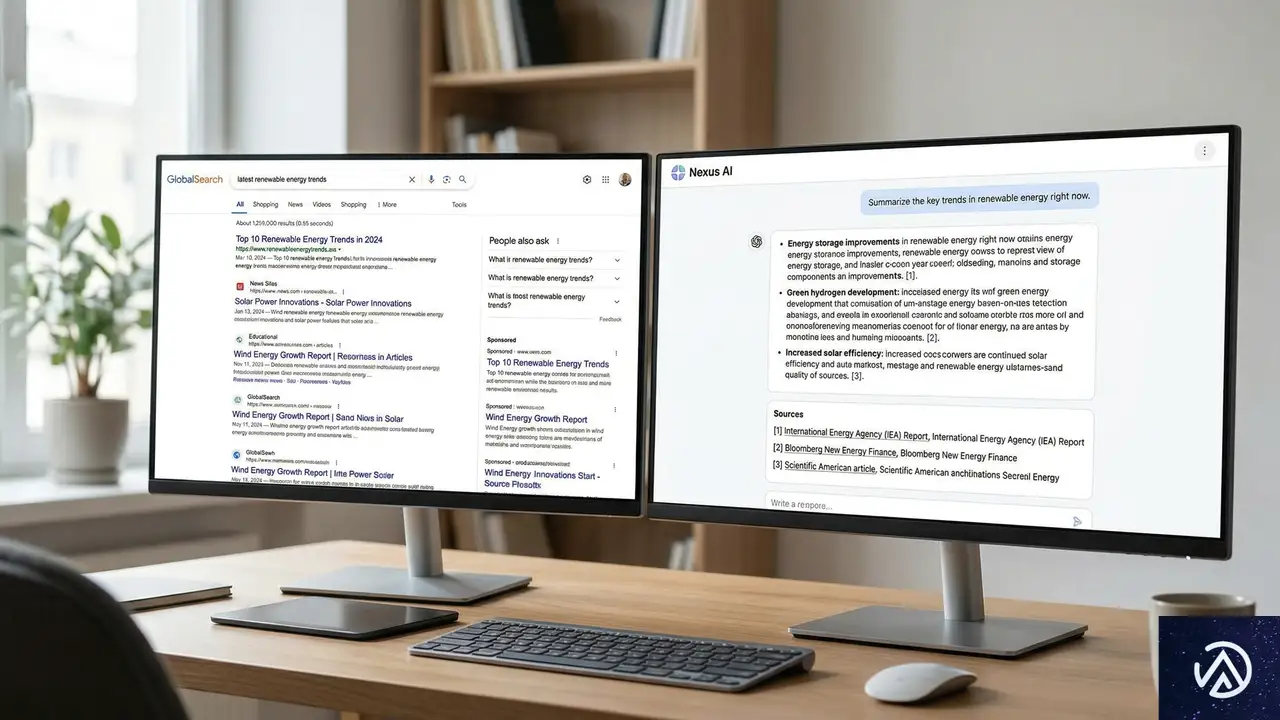
ChatGPT、Perplexity、GeminiといったAI検索ツールは、従来のGoogle検索とは異なる基準で情報源を選択し、回答に引用する。多くのSEOチームは、自社がAI検索で「見えていない」領域をダッシュボードで把握しているが、それを修正する具体的なプロセスを持たない場合が多い。まず理解すべきは、AIがどのようなコンテンツを引用する傾向にあるのか、その根本的なシグナルだ。
従来のSEOとAI検索最適化の根本的な違い
従来の検索エンジン最適化は、キーワードの出現頻度、被リンク、ページの技術的な健全性など、比較的測定可能な数百のシグナルに基づいてランキングが決定される。一方、AI検索ツールは、ユーザーの質問に対する「最も信頼できる回答」を生成するために、情報の新鮮さ、権威性、そして特定の文脈における適切さを総合的に判断する。この判断プロセスにおいて、どの情報源を引用するかは、従来のページランキングとは必ずしも一致しない。
例えば、地域に密着した詳細なデータを持つ中小規模のサイトが、汎用的な大規模メディアよりも特定の質問で優先して引用されるケースがある。AIは、質問の文脈に最も合致し、かつ信頼できると判断したソースを選ぶ。この「信頼性」の判断には、ドメインの権威だけでなく、コンテンツの専門性、構造化データの有無、更新頻度などが複合的に影響する。
引用を獲得するコンテンツの3つの特徴
Writesonicによる大規模データ分析から、AI検索で引用されやすいコンテンツには共通する特徴が浮かび上がっている。
第一に、明確な構造と階層を持つコンテンツだ。見出しタグ(H1〜H3)を適切に使い、箇条書きや表で情報が整理されているページは、AIが内容を理解し、特定の部分を抽出して引用しやすい。逆に、長大な散文調の記事は、関連する部分を見つけるのが難しくなる。
第二に、具体的な数字やデータ、最新の情報を含むこと。AIは「2026年現在」「調査によると約70%」といった定量的で時間的コンテキストが明確な情報を好んで引用する。曖昧な表現や古いデータは信頼性を損なう。
第三に、専門性と権威性を裏付ける外部ソースへのリンクだ。自説を主張するだけでなく、関連する学術論文、公的統計、権威ある業界レポートへのリンクを適切に含めることで、コンテンツ全体の信頼性が高まり、引用される可能性が上がる。
このデモは、AIが引用しやすいコンテンツの特徴を示している。左側の曖昧な表現から、右側のように具体的な数字、調査元、対象地域を明確にした構造に変えることで、情報の信頼性と抽出可能性が高まる。
引用ギャップを特定するデータ分析手法
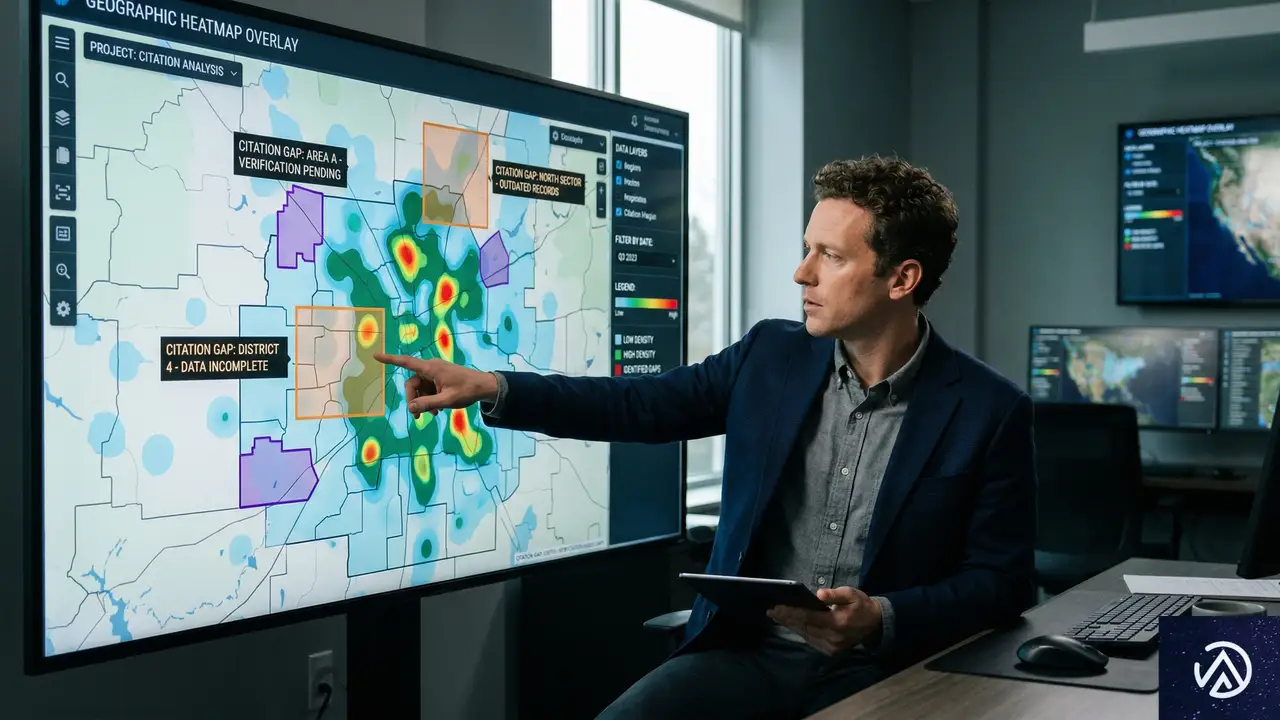
自社ブランドや製品がAI検索でどのように言及されているか、あるいは言及されていないかを把握するには、体系的なデータ分析が必要だ。ここで重要なのは、単に「見えていない」キーワードや地域をリストアップするだけでなく、なぜ見えていないのか、その根本原因を特定することにある。
可視性データの収集と解釈
まず、自社に関連する検索クエリに対して、主要なAI検索ツール(ChatGPT、Perplexity、Gemini等)がどのような回答を生成し、どの情報源を引用しているかをモニタリングする。この際、自社サイトが引用されているか否かだけでなく、競合他社が引用されているクエリ、あるいはどの情報源も引用されていない(AIが独自に生成した回答のみの)クエリも記録する。
得られたデータを「クエリの意図」「地域性」「コンテンツタイプ」の3つの軸で分類する。例えば、「東京 コワーキングスペース おすすめ」というクエリは「商業施設の推薦(意図)」「東京(地域)」「リスト記事(タイプ)」に分類される。この分類ごとに、自社の引用有無と、引用されている他サイトの特徴を分析することで、ギャップのパターンが見えてくる。
ギャップの根本原因を探る優先順位付けフレームワーク
すべての引用ギャップを同時に埋めようとするのは非現実的だ。限られたリソースで最大の効果を上げるためには、優先順位を決める必要がある。Sam Garg氏が提唱するフレームワークでは、以下の2つの指標でギャップを評価する。
第一の指標は「機会の大きさ」だ。そのクエリや地域における検索ボリューム、および自社にとってのビジネス上の重要性(成約率や単価)を数値化する。第二の指標は「埋めやすさ」だ。既存のコンテンツを更新するだけで対応できるのか、ゼロから新しいコンテンツや外部提携が必要なのか。必要な工数と難易度を評価する。
この優先順位付けにより、リソースを「既存資産の最適化」という効果の高い活動に集中させることができる。すべてのギャップを均等に埋めようとする従来のアプローチから脱却する第一歩だ。
AIエージェントを活用した地域戦略の実行自動化
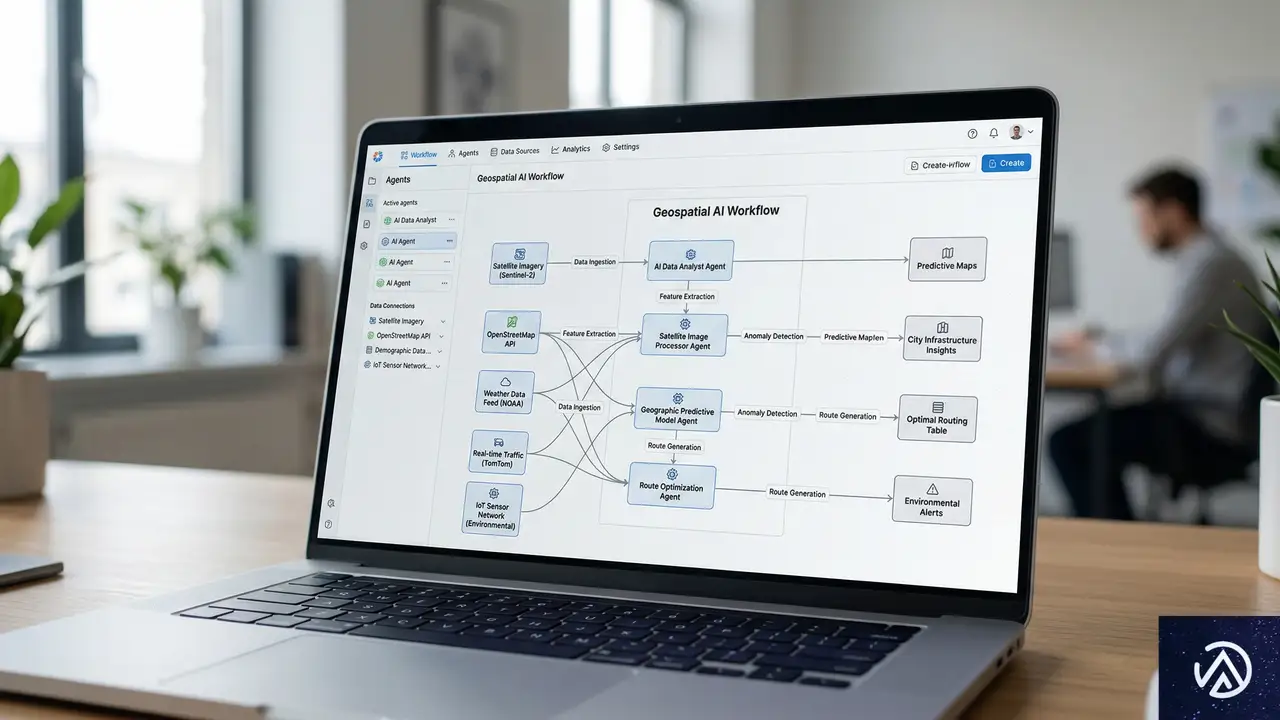
優先すべきギャップが特定できたら、次は実行フェーズだ。特に地域別(GEO)戦略では、対象地域ごとに微妙に異なるコンテンツや情報の更新が必要となり、人的リソースが逼迫しがちである。ここで威力を発揮するのが、AIエージェントを活用したタスクの自動化だ。
無料のオープンソースツールで構築する自動化パイプライン
大規模な予算をかけなくても、現在公開されている無料のオープンソースツールを組み合わせることで、多くのGEO関連タスクを自動化できる。Sam Garg氏のウェビナーでは、具体的なツールの例とその連携方法が紹介される予定だ。
一つの例として、地域別の引用状況を監視するパイプラインを考えてみる。まず、Pythonのスクレイピングライブラリ(BeautifulSoupなど)や、AI検索APIを模倣するツールを使って、定期的に特定の地域クエリに対するAIの回答を収集する。次に、収集したテキストデータから自社ブランドや競合の言及を抽出し、スプレッドシートやデータベースに記録する。このデータ更新をトリガーに、引用ギャップが検出された地域に対して、あらかじめ準備したコンテンツ更新テンプレートや、地域メディアへのコンタクトリストを提示する内部通知システムを構築する。
人的判断とAI自動化の適切な分担
重要なのは、すべてをAIに任せるのではなく、クリエイティブな判断や複雑な交渉が必要な部分は人間が担当し、データ収集、モニタリング、ルーティンワーク、初期ドラフトの作成などをAIエージェントに担当させることだ。この分担を明確にすることで、SEOチームはより戦略的な活動に時間を割くことができる。
例えば、新しい地域での権威構築のために地元メディアへの寄稿を目指す場合、AIエージェントはその地域に関連するメディアリストの作成、編集者の連絡先収集、過去の記事傾向の分析を担当する。人間の担当者は、分析結果を基にパーソナライズされたアプローチ文面を考え、実際のコンタクトと関係構築を行う。
この分担モデルを導入することで、地域別の細やかな対応が人的リソースの限界を超えて可能になる。特に、複数の地域を同時にカバーする必要がある事業者にとって、持続可能な戦略実行の基盤となる。
この記事のポイント
- AI検索での引用は、従来のSEOとは異なるロジックに基づく。具体的なデータ、明確な構造、権威ある外部リンクを含むコンテンツが引用されやすい。
- 引用ギャップを埋めるには、単なる可視性データの収集だけでなく、「機会の大きさ」と「埋めやすさ」で優先順位を付けるフレームワークが有効だ。
- 地域別(GEO)戦略の実行負荷を下げるには、AIエージェントを活用したデータ収集・分析・ルーティンワークの自動化が鍵となる。クリエイティブな判断は人間が担う分担モデルを構築する。
- 無料のオープンソースツールを組み合わせることで、予算をかけずに自動化パイプラインの構築を始めることができる。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

WordPressでAIを活用したインタラクティブなアンケートを作成する方法:WPFormsの実績ガイド
WordPressサイトでアンケートを実施しても、回答が集まらずに悩む担当者は多い。従来の静的なフォームは項目が長くなりがちで、ユーザーが途中で離脱してしまう傾向があるからだ。WP Beginnerの記事によれば、この問題を解決する鍵は、AIと条件分岐を活用した「インタラクティブ(双方向)なアンケート」の構築にあるという。
最新のプラグイン機能を活用すれば、手動での複雑な設定をスキップし、約15分でプロ仕様のアンケートを完成させることが可能だ。ユーザーの回答に応じて質問を変化させるパーソナライズ機能により、データの質と完了率を劇的に向上させられる。本記事では、WPFormsを用いたAIアンケートの具体的な構築手順と、そのメリットを深掘りしていく。
なぜ従来のアンケートは回答率が低いのか

多くのWebサイトで見かけるアンケートは、すべてのユーザーに同じ質問を順番にぶつける「静的」な構造をしている。この形式では、ユーザーに関係のない質問まで表示されるため、心理的な負担が増え、離脱を招く原因となる。記事では、インタラクティブなアンケートを導入することで、ユーザー体験(UX)を損なわずに質の高い回答を得られると指摘されている。
ユーザーの興味を維持するパーソナライズの力
インタラクティブなアンケートとは、ユーザーの入力内容に基づいてリアルタイムに質問が変化する仕組みを指す。例えば、サービスの満足度を5段階評価で「1」と答えた人だけに改善点の詳細を尋ね、「5」と答えた人にはレビューの投稿を促すといった制御が可能だ。このように一人ひとりに最適化された質問を提示することで、ユーザーは「自分の声が聞かれている」という感覚を持ちやすくなる。
データの精度を高める専門的な評価指標
単なる「はい・いいえ」の回答ではなく、NPS(Net Promoter Score / ネットプロモータースコア)やリッカート尺度といった専門的な指標を簡単に導入できる点も重要だ。NPSとは、顧客のロイヤルティを0〜10の数値で測定する指標であり、大手ブランドも採用している標準的な手法である。リッカート尺度は「非常に同意する」から「全く同意しない」までの多段階で意見を測る手法で、ユーザーの微妙な心理をデータ化するのに適している。
AIを活用したアンケート作成の準備

WordPressで高度なアンケートを構築するには、ドラッグ&ドロップ形式のフォーム作成ツールである「WPForms」が適している。無料版でも基本的なフォームは作成できるが、AIによる自動生成や視覚的なレポート機能、会話型レイアウトを使用するには、有料の「WPForms Pro」が必要となる。
必要なアドオンのインストール
WPForms Proを導入した後、アンケート機能を有効化するために「Surveys and Polls(アンケートと投票)」アドオンをインストールする。これにより、回答データのグラフ化や特殊な評価フィールドが利用可能になる。さらに、記事の著者は「Conversational Forms(会話型フォーム)」アドオンの併用も強く推奨している。これは、Typeformのように一画面に一つの質問を表示するスタイルを実現するツールであり、スマートフォンユーザーの回答率向上に大きく寄与する。
プライバシーポリシーの更新
アンケートでユーザーの情報を収集する場合、プライバシーポリシー(個人情報保護方針)の更新を忘れてはならない。どのような目的でデータを収集し、どう管理するかを明記することは、GDPR(EU一般データ保護規則)などの法律を遵守するだけでなく、ユーザーからの信頼を得るためにも不可欠なステップだ。
AIプロンプトでアンケートの骨組みを作る

WPFormsの最新機能である「Generate With AI」を使えば、ゼロから質問項目を考える手間を省くことができる。AIアシスタントに対して、どのようなアンケートを作りたいかを自然な文章(プロンプト)で伝えるだけで、適切なフィールドが配置されたフォームのドラフトが作成される。
効果的なプロンプトの書き方
AIに指示を出す際は、具体的なフィールド名を指定するのがコツだ。例えば「カフェの顧客満足度調査を作成し、コーヒーの品質に関するリッカート尺度と、友人への推奨度を測るNPSフィールドを含めてください」といった指示を出す。AIはこれらの要望を解釈し、標準的な0〜10の評価スケールなどを自動的にセットアップしてくれる。
生成されたフォームの微調整
AIが生成したフォームは、プレビュー画面で対話しながら修正できる。「ニュースレター購読のチェックボックスを追加して」や「全体をスペイン語に翻訳して」といった追加の指示も可能だ。ただし、AIによる修正はプレビューセッション中のみ有効であるため、一度エディタに移行した後は手動で調整を行う必要がある。エディタ上では、ブランドのトーンに合わせて質問の文言を微調整し、評価尺度が意図通りかを確認する作業が推奨される。
条件分岐(スマートロジック)によるパーソナライズ

AIで骨組みを作った後は、「条件分岐(スマートロジック)」を設定してアンケートを真にインタラクティブなものにする。条件分岐とは、特定の回答が選ばれたときだけ、関連する別の質問を表示させる機能だ。これにより、ユーザーに不要な質問を見せず、フォームを短く保つことができる。
ロジックの設定手順
設定は非常にシンプルだ。表示を制御したいフィールド(例えば「詳細な理由を教えてください」というテキストボックス)を選択し、設定パネルの「Smart Logic」タブを開く。「Enable Conditional Logic」をオンにし、「評価が3つ星以下の場合のみ表示する」といったルールを作成する。この設定により、満足度が高いユーザーには詳細入力を求めず、不満を感じているユーザーからのみ具体的なフィードバックを収集できるようになる。
AIによるロジックの自動設定
実は、最初のAIプロンプトの段階で「2つ星以下のときだけフィードバックボックスを表示して」と指示に含めることも可能だ。AIが自動的にロジックを組んでくれるため、設定時間をさらに短縮できる。ただし、意図しない挙動を防ぐためにも、設定完了後に「Preview」ボタンを押し、実際に回答を選んでフィールドの表示・非表示が切り替わるかを手動でテストすることが重要だ。
回答率を最大化する「会話型フォーム」の導入

アンケートの形式が整ったら、仕上げに「会話型フォームモード」を有効にする。これは、一般的なWebフォームの見た目を捨て、フルスクリーンの没入型インターフェースに変換する機能だ。視覚的なノイズが排除されるため、ユーザーは目の前の質問だけに集中できる。
専用ランディングページの作成
会話型フォームを有効にすると、専用のパーマリンク(URL)が生成される。例えば `example.com/feedback` のような分かりやすいURLを設定し、メールマガジンやSNSで直接共有することが可能だ。サイトのヘッダーやフッターにある通常のメニューが表示されないため、回答を完了するまでユーザーが他のページへ移動するのを防ぐ効果がある。
モバイル最適化と進行状況の可視化
会話型レイアウトでは、大きなボタンや読みやすいフォントが採用されており、スマートフォンでも快適に操作できる。また、画面下部に「完了まであと30%」といったプログレスバーを表示させることで、ユーザーの完遂意欲を高めることができる。記事の著者は、公開前に自分のスマートフォンで「親指テスト(片手で操作しやすいか)」を行うことを勧めている。
収集したデータの視覚化と分析

アンケートが公開され、回答が集まり始めたら、WPFormsのダッシュボードで結果を分析する。WPForms Proには、生のデータを自動的に美しいグラフやチャートに変換する機能が備わっている。数値をExcelに書き出して手動で集計する必要はない。
インタラクティブなレポート機能
「Survey Results」画面では、各質問に対する回答分布が円グラフや棒グラフで表示される。チャートの形式はワンクリックで切り替え可能で、最も傾向を把握しやすいスタイルを選択できる。このレポート機能の優れた点は、アンケート機能を有効化する前に入力された過去のデータに対しても適用できることだ。これにより、既存のフォームをアンケート形式にアップグレードした際も、すぐに分析を開始できる。
チームへの共有とエクスポート
生成されたグラフは、画像やPDFとして個別にエクスポートできる。プレゼンテーション資料やクライアントへの報告書にそのまま貼り付けられるため、実務上の効率が非常に高い。また、リアルタイムの結果をユーザーに公開したい場合は、「Poll Results(投票結果)」機能を有効にすることで、送信直後に他のユーザーの回答傾向をグラフで見せることも可能だ。
この記事のポイント
- 静的なアンケートを避け、条件分岐を活用したインタラクティブな構成にすることで離脱を防ぐ
- WPFormsのAI生成機能を使えば、プロンプト一つで専門的な評価指標を含むフォームが構築できる
- 「会話型フォーム」モードにより、スマホユーザーに優しいフルスクリーンの回答体験を提供する
- 収集したデータは自動的にグラフ化され、分析やレポート作成の時間を大幅に短縮できる
- ユーザーの回答データはAIに送信されず、自社のWordPressデータベースに安全に保存される
出典
- WP Beginner「Forget Boring Forms: How to Build Interactive WordPress Surveys with AI」(2026年3月23日)
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Search Console「平均掲載順位」の正体——数字の裏側にある仕組みと活用術
Google Search Console(グーグル・サーチコンソール)は、Webサイトの検索パフォーマンスを把握するために欠かせないツールだ。しかし、管理画面に表示される「平均掲載順位」という指標を見て、その数字の低さに頭を抱える担当者は少なくない。
検索結果で1位を獲得しているキーワードがある一方で、全体の平均順位が「25位」や「40位」と表示されるのはなぜか。この数字は、サイト全体の評価が低いことを意味しているわけではない。むしろ、この指標の計算ロジックを正しく理解していないと、的外れなSEO施策にリソースを割いてしまうリスクがある。
本記事では、Search Consoleにおける平均掲載順位の仕組みを解説し、AI概要(AI Overviews)や画像パックといった最新の検索要素が順位にどう影響するのかを紐解く。数字の裏側にある事実を知ることで、実務に役立つデータ分析が可能になるはずだ。
全体の「平均掲載順位」が低くなる仕組み

Search Consoleの「検索パフォーマンス」レポートを開くと、まず目に飛び込んでくるのがサイト全体の「平均掲載順位」だ。この数字は、サイトがランクインしている「すべてのクエリ」の掲載順位を合算し、平均したものである。
全クエリの合算値という性質
Googleの検索結果は、通常1ページに10件のオーガニック検索結果(広告以外の通常の検索結果)が表示される。平均順位が25位であれば、平均して検索結果の3ページ目付近に表示されている計算になる。しかし、この数字には落とし穴がある。
元記事の著者であるアン・スマーティ氏は、この全体平均の数字にはほとんど洞察が含まれていないため、基本的には無視することを推奨している。その理由は、サイトが意図せずランクインしてしまった関連性の低いクエリや、100位近くに表示されているロングテールキーワード(複数の単語を組み合わせた検索ボリュームの少ないキーワード)まで、すべてが平均計算に含まれてしまうからだ。
なぜ「全体平均」は分析に向かないのか
例えば、主力商品で1位を獲得していても、何千ものマイナーなキーワードで80位に表示されていれば、全体の平均順位は大きく押し下げられる。これはサイトの健全性が損なわれているわけではなく、単にGoogleが膨大なキーワードに対してそのサイトをインデックス(検索エンジンに登録)している結果に過ぎない。
したがって、経営層やクライアントに報告する際は、サイト全体の平均順位を追うのではなく、主要なキーワード群や、特定のディレクトリ(URLの階層)に絞った平均順位を見るべきだ。全体平均の上下に一喜一憂することは、SEO戦略においてあまり意味をなさないと言える。
クエリごとの「平均掲載順位」の計算ロジック

全体平均とは異なり、個別のクエリ(検索語句)ごとの掲載順位は非常に重要な指標になる。ただし、この数字も「ある時点での絶対的な順位」ではなく、あくまで「平均値」であることを忘れてはならない。
ユーザーごとの変動と平均値
検索順位は、検索するユーザーの場所、使用デバイス、過去の検索履歴などによって動的に変化する。Search Consoleに表示されるクエリごとの順位は、実際にそのクエリで検索結果が表示された際の全セッションの平均だ。
仮に2人のユーザーが同じキーワードで検索し、1人には1位、もう1人には2位で表示された場合、Search Consoleでの平均順位は「1.5位」と報告される。このように、整数ではない順位が表示されるのは、複数ユーザーの結果を統計的に処理しているためだ。
特殊な検索要素の数え方
現在のGoogle検索結果(SERP / Search Engine Result Page)には、通常のテキストリンク以外にもさまざまな要素が含まれる。Googleの定義によれば、外部サイトへのリンクを持つ特別な要素はすべて「1つの順位」としてカウントされる。
- 画像パック: 検索結果の上部に表示される複数の画像。これが最上部にあれば1位とカウントされる。
- AI概要(AI Overviews): AIが生成した回答。ここに含まれるリンクも順位カウントの対象だ。
- 他の人はこちらも質問(PAA / People Also Ask): よくある質問のリスト。クリックして展開された中のリンクも、表示されれば順位に含まれる。
以下のデモは、検索結果画面における「掲載順位」がどのように割り振られるかを視覚化したものだ。通常のオーガニック検索結果が1位であっても、その上に画像パックがあれば、オーガニック結果の順位は「2位」になる仕組みがわかる。
このデモでは、画像パックが最上部にある場合の順位カウント方法を示している。このように、Webサイトがオーガニック検索で「実質1位」であっても、Search Console上の数字が「2位」や「3位」になるのは、こうした検索要素の介在が原因だ。
順位が確認できない・変動する要因

Search Consoleのデータと、実際に自分で検索した結果が一致しないことは珍しくない。これには、Googleの検索エンジンが持つ高度なパーソナライズ機能や、デバイスごとの最適化が関係している。
デバイスによる表示順の違い
Googleは、PC(デスクトップ)とモバイルで検索結果の並び順を変えることが多い。モバイル版では画面の制約上、特定の特殊セクション(画像パックなど)が表示されない場合があり、その分だけオーガニック検索結果の順位が繰り上がることがある。
Search Consoleのデフォルト画面では、これらのデバイスデータが混ざった状態で表示されている。正確な分析を行うには、「+新規」フィルタから「デバイス」を選択し、デスクトップとモバイルを分けて比較することが重要だ。特定のキーワードでモバイルの順位だけが低い場合、そのページのモバイルフレンドリー(スマートフォンでの見やすさ)に問題がある可能性も示唆される。
AI概要(AI Overviews)内のリンクの扱い
近年導入が進んでいるAI概要は、掲載順位の計測をさらに複雑にしている。AI概要の中に引用元としてリンクが表示された場合、そのリンクは「1位」としてカウントされることが多い。しかし、AI概要はすべてのユーザーに表示されるわけではなく、また生成される内容も検索のたびに変化する「流動的」なものだ。
記事によれば、AI概要に含まれるリンクが常にSearch Consoleに反映されるわけではないという。ユーザーがAI概要の「詳細を表示」をクリックして初めて露出するリンクなどは、インプレッション(表示回数)としてカウントされないケースもある。このため、平均順位が急激に変動した際は、AI概要の表示有無が影響していないか疑う必要がある。
実務で役立つ「掲載順位」の分析方法

平均掲載順位を単なる「成績表」として眺めるだけでは不十分だ。エンジニアやマーケターがこの数字をどう活用すべきか、独自の分析視点を交えて解説する。
「11位〜20位」のクエリを特定する
SEOにおいて最も効率的な改善ポイントは、平均順位が11位から20位(検索結果の2ページ目)に位置しているクエリだ。これらはGoogleから「ある程度の評価」を得ているものの、ユーザーの目には触れにくい状態にある。
これらのページに対して、コンテンツの加筆や内部リンクの強化を行うことで、比較的容易に1ページ目(10位以内)へ押し上げることができる。平均順位をフィルタリングして、この「あと一歩」のクエリを抽出することは、ECサイトなどの大規模サイト運営において非常に有効な戦略となる。
CTR(クリック率)との相関をチェックする
平均順位が上がっているのにクリック数が増えない、あるいは順位は低いのにクリック率(CTR / Click Through Rate)が高いというケースがある。これは、検索結果に表示されるタイトル(titleタグ)やディスクリプション(meta description)が、ユーザーの検索意図にどれだけ合致しているかを示している。
もし平均順位が3位以内なのにCTRが極端に低い場合、検索結果に表示されているスニペット(説明文)が魅力的でないか、あるいは広告や画像パックにユーザーを奪われている可能性がある。数字を単体で見るのではなく、順位とCTRをセットで分析することで、コンテンツ修正の優先順位を判断できるようになる。
この記事のポイント
- サイト全体の「平均掲載順位」は、全クエリの合算値であるため、分析指標としては重要度が低い。
- クエリごとの順位は、ユーザーのデバイスや場所による変動を平均化した数字である。
- 画像パックやAI概要などの特殊な検索要素も「1つの順位」としてカウントされる。
- 正確な分析のためには、デバイス(モバイル・デスクトップ)ごとのフィルタ活用が必須である。
- 順位だけでなくCTRと組み合わせて分析することで、真の改善ポイントが見えてくる。
出典
- Practical Ecommerce「Search Console’s Average Position, Explained」(2026年3月23日)
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

マーケティング予算を動かすのは「成果」ではなく「確信」——2026年の広告投資動向を読み解く
マーケティング予算の配分基準が、純粋な「成果」から「説明のしやすさ」へとシフトしている。
2026年の最新調査では、Google検索やYouTubeなどの定番チャネルへの予算集中が一段と鮮明になった。
EC事業者にとって、この傾向は「新しい集客チャネルへの挑戦」が以前よりも難しくなっていることを意味する。なぜなら、財務部門やステークホルダーに対して、投資の妥当性を証明する「測定の確信」がこれまで以上に求められているからだ。
「成果が出る」ことと「説明できる」ことの決定的な違い

マーケターが予算を投じる際、最も重視するのは何だろうか。かつては「ROI(投資利益率)」や「ROAS(広告費用対効果)」といった数字がすべてだった。しかし、現在では「測定の確信(Measurement Confidence)」という概念が、それらの指標を上回る影響力を持っている。
測定の確信とは、特定のチャネルが収益に与えた影響を、どれだけ明確に説明し、守り抜けるかという能力を指す。つまり、単に売上が上がっただけでなく、「なぜこの広告で売上が上がったのか」を、専門外の人間に対しても論理的に証明できるかどうかが鍵となる。
予算会議で「守れる」チャネルが選ばれる理由
記事によれば、マーケターが自信を持って説明できるチャネルは驚くほど限定されている。Google検索とYouTubeは、回答者の57%が「自信を持って投資を正当化できる」と答えており、この2つを組み合わせるとその数値は75%にまで跳ね上がる。
一方で、TikTokやMeta(Facebook/Instagram)への信頼度は40%台に留まる。インフルエンサーマーケティングやコネクテッドTV(CTV)に至っては、さらに低い水準だ。この差は、各プラットフォームが提供するレポートの透明性や、過去の蓄積データによる再現性の違いから生まれている。
企業が不確実な経済状況に置かれるほど、マーケターは「証明できない成功」よりも「説明可能な安定」を選ぶようになる。これは、失敗した際のリスクヘッジという側面も大きい。誰もが知る定番チャネルでの失敗は「市場環境のせい」にできるが、新興チャネルでの失敗は「選定ミス」と見なされやすいからだ。
EC運営におけるアカウンタビリティの重要性
アカウンタビリティ(説明責任)とは、自分の行動や決定に対して、その理由と結果をステークホルダーに説明する義務のことだ。WooCommerceなどで自社ECを運営している場合、広告費は直接的なキャッシュアウトとして厳しくチェックされる。
例えば、新しいSNS広告を試したいと提案したとき、経営層から「その広告がきっかけで買ったとどうやって証明するのか?」と問われるシーンは多い。ここで「確信」を持って答えられないチャネルは、たとえ潜在的なポテンシャルが高くても、予算獲得の優先順位が下げられてしまう。
GoogleとYouTubeに予算が集中する「安全地帯」の正体

「確信」が予算を動かすという法則は、実際の投資計画にも直結している。2026年の調査では、マーケターが最も自信を持っているチャネルこそが、最も大きな予算増額を見込まれていることがわかった。
Google検索では約80%の回答者が投資を増やすと答え、YouTubeが72%、Metaが71%と続く。このパターンは非常に明確だ。「確信」があるからこそ「正当化」が可能になり、それが「投資」へとつながる構造だ。
なぜGoogle検索は「最強の盾」なのか
Google検索が長年トップに君臨し続ける理由は、ユーザーの「検索意図」が明確だからだ。特定のキーワードで検索して流入し、購入に至るというプロセスは、誰の目にも因果関係が分かりやすい。この「ラストクリック」に近い指標の強さが、予算を守る上での最強の武器となる。
また、Googleは長年の運用データが蓄積されており、どれだけの予算を投じればどれだけの流入が見込めるかという予測精度が非常に高い。この予測可能性こそが、財務部門が最も好む要素である。
YouTubeが「確信」を得た背景
YouTubeがMetaを上回る信頼を得ている点も注目に値する。かつて動画広告は「ブランディング目的」であり、直接的な売上への貢献度が見えにくいとされていた。しかし、Googleエコシステム内での計測技術の向上により、視聴後の検索行動やコンバージョン測定が精緻化したことが功を奏している。
特にECにおいては、商品レビュー動画やチュートリアル動画からの直接的な流入が、測定可能な「確信」として積み上がっている。記事の著者は、こうした「計測のしやすさ」が戦略そのものを形作っていると指摘する。
「測定コンフォートゾーン」が招くイノベーションの停滞

予算が「説明しやすいチャネル」に集中することは、裏を返せば「測定が困難な新しいチャネル」への挑戦を阻害している。これを「測定コンフォートゾーン(測定の快適圏内)」と呼ぶ。
マーケターは、新しいプラットフォームや手法に興味を持っていないわけではない。TikTokやインフルエンサー、ポッドキャスト広告など、将来的な可能性を感じている分野は多い。しかし、それらの「探索」は「最適化」に比べて説明の難易度が高い。
「探索」と「最適化」のジレンマ
既存のGoogle広告を10%改善する(最適化)ための説明は容易だ。しかし、全く新しい媒体に予算を振り向ける(探索)には、なぜそれが必要なのか、どうやって成果を測るのかという高いハードルを越えなければならない。その結果、多くのマーケターは好奇心を持ちつつも、結局は「いつもの場所」に予算を留めてしまう。
これはECサイトの成長戦略において、中長期的なリスクになり得る。競合他社も同じ「安全地帯」に集まるため、広告単価(CPC)は高騰し続け、利益を圧迫するからだ。しかし、このコンフォートゾーンを抜け出すには、単なる「勇気」ではなく、新しい「測定の武器」が必要になる。
プライバシー規制が「確信」を揺るがす
さらに事態を複雑にしているのが、Cookie規制やプライバシー保護の強化だ。以前は当たり前だった「誰がどこから来て何を買ったか」という追跡が難しくなっている。これにより、かつて「確信」を持てていたチャネルですら、その根拠が揺らぎ始めている。
この変化により、マーケターは「プラットフォームが提供する数字」を鵜呑みにするのではなく、自社で独自の測定基準(ファーストパーティデータ)を持つ必要性に迫られている。WooCommerceなどのプラットフォームであれば、顧客データを自社で直接管理できるため、この「確信の再構築」において有利な立場にあると言えるだろう。
EC事業者が「確信」を持って新しい投資を行うための3つのステップ

では、説明責任を果たしながら、新しいチャネルを開拓するにはどうすればよいか。ここでは、独自の分析に基づいた3つのステップを提案する。
1. 測定の「共通言語」を社内で構築する
まず、マーケティングチームと財務チームの間で、成果の定義を統一することが不可欠だ。単なるラストクリックのコンバージョンだけでなく、「増分(インクリメンタリティ)」という考え方を導入することを推奨する。
増分とは、「その広告がなかったら発生しなかった売上」のことだ。これを測定するために、特定の地域だけで広告を停止する「地域テスト(Geo-testing)」などの手法を用いる。こうした客観的なテスト結果があれば、新しいチャネルであっても「確信」を持って予算を要求できる。
2. 混合モデル(MMM)の活用
MMM(マーケティング・ミックス・モデリング)とは、過去の売上データと広告費、さらに季節性や競合の動きなどの外部要因を統計的に分析し、各チャネルの貢献度を算出する手法だ。Cookieに依存しないため、昨今のプライバシー規制下でも有効な「確信」の根拠となる。
以前は大手企業しか導入できなかったが、現在はオープンソースのツールも増えており、中小規模のEC事業者でも活用が可能だ。これにより、TikTokやインフルエンサーといった「ラストクリックがつきにくい」チャネルの真の価値を可視化できる。
3. 小規模な「実験予算」の枠をあらかじめ確保する
すべての予算を「確信」で縛るのではなく、全体の5〜10%を「実験用」として切り出しておく運用も効果的だ。この枠内であれば、失敗しても全体への影響は少なく、成功すれば新しい「確信」の源泉となる。重要なのは、実験の目的を「売上」だけでなく「測定手法の確立」に置くことだ。
この記事のポイント
- 現在のマーケティング予算は、純粋なパフォーマンスよりも「説明のしやすさ(確信)」で決まっている。
- Google検索とYouTubeが圧倒的な支持を得ているのは、成果をステークホルダーに正当化しやすいからだ。
- 「測定コンフォートゾーン」に留まることは、広告費の高騰や成長の鈍化を招くリスクがある。
- 新しいチャネルに挑むには、Cookieに依存しないMMMや増分テストなどの新しい測定武器が必要。
- EC事業者は、自社のファーストパーティデータを活用して独自の「確信」を構築すべきだ。
出典
- MarTech「Why confidence, not performance, is shaping media spend」(2026年3月20日)
- Haus「2026 Haus Decision Confidence Index」
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Google Search Consoleに「ブランドフィルタ」が登場。ECサイトのブランド分析を効率化する活用法
Google Search Console(グーグルサーチコンソール)のパフォーマンスレポートに、ブランドに関連する検索クエリを簡単に抽出・除外できる新しいフィルタ機能が追加された。このアップデートにより、自社名や製品名を含む「指名検索」の動向を、これまで以上に迅速かつ直感的に把握することが可能になる。
2026年3月のリリース以降、この機能はAI(人工知能)を活用してクエリを自動分類し、企業のマーケティング担当者やSEOエンジニアの分析工数を削減する役割を担っている。特にブランド認知が売上に直結するECサイト運営者にとって、指名検索の分析は競合対策やキャンペーン評価の要となる要素だ。
本記事では、新しく導入されたブランドフィルタの仕組みと、実務での具体的な活用シナリオ、そしてAIによる分類の限界について、専門的な視点から詳しく解説する。
ブランドフィルタの仕組みとAIによる自動分類

今回追加されたブランドフィルタは、検索パフォーマンスレポート内で「ブランドを含むクエリのみを表示」または「ブランドを除外して表示」を切り替える機能だ。従来、ブランド検索を特定するには正規表現(Regex)を用いた複雑なフィルタリングが必要だったが、新機能によって数クリックで同様の操作が完結するようになった。
AIが判別する「ブランドクエリ」の定義
GoogleはAIを用いてクエリを分類しており、以下の要素がブランドクエリとして認識される。指名検索とは、ユーザーが特定のブランドやサイトを目的地として検索する「ナビゲーショナルクエリ」とも呼ばれるものだ。
- 会社名やサイト名
- ドメイン名(例:example.com)
- ブランド固有の製品名やサービス名
- 一般的なスペルミスや表記揺れ
例えば、Appleというブランドであれば、「iPhone」や「MacBook」といった製品名、さらには「Aple」といったスペルミスもブランドクエリとして統合的に処理される。これにより、ユーザーの検索意図をより正確に反映したデータ抽出が可能となっている。
従来手法(正規表現)との違い
これまで、ブランド名と非ブランド名を分けるには、正規表現(Regex)を使いこなす必要があった。正規表現とは、特定の文字列のパターンを表現する記法のことだ。例えば「自社名|じしゃめい|jisya」といった複数のキーワードを組み合わせた抽出条件を自ら作成し、フィルタに入力する手間が生じていた。
新機能は、こうした手動の設定をAIが代替する。Googleが保有する膨大なナレッジグラフ(実在するモノや概念のデータベース)を参照し、何がそのサイトにとってのブランドであるかを自動的に判断するため、設定の漏れやミスを防ぎやすくなっている。ただし、記事によれば、この機能は利便性を高めるためのものであり、新しいデータそのものを提供するわけではない点に注意が必要だ。
AI分類の精度と現時点での限界

AIによる自動分類は非常に強力だが、完璧ではない。元記事の著者であるアン・スマーティ氏は、自身のテストにおいてAIがいくつかの誤認や見落としを発生させたことを報告している。実務で利用する際には、これらの特性を理解しておく必要がある。
認識されるバリエーションと見落とし
スマーティ氏の検証によると、フィルタは以下のバリエーションを正確に捉えることができたという。
- 1単語または2単語の表記(スペースの有無)
- ハイフン付きの名称
- 略称や一般的な誤字
一方で、特定の製品名や代表者の名前については、認識が不安定な側面も見られた。例えば、創業者の名前はブランドクエリとして認識されたが、その創業者が執筆した書籍のタイトルはブランドとして認識されなかったという。これは、GoogleのAIが「何がブランドの構成要素であるか」を判断する際、その知名度や関連性の強さに依存していることを示唆している。
意図しないクエリの混入
また、自社とは直接関係のない競合他社の名前や、無関係な企業の役員名がフィルタに含まれてしまうケースも確認されている。これは、Googleの「ブランド」に対する定義が広範であるため、あるいはAIの学習データに基づいた関連付けが強すぎるために発生する現象と考えられている。
このように、AIフィルタは「概ね正しいが、細部には手動のチェックが必要なツール」として扱うのが賢明だ。重要な分析を行う際は、引き続き正規表現を用いた厳密なフィルタリングと併用することが推奨される。
ECサイトにおける3つの実戦的活用シーン

このブランドフィルタは、特に競争の激しいEC(電子商取引)領域において強力な武器となる。記事では、具体的な3つのユースケースが紹介されている。
1. 競合による「ブランド乗っ取り」の検知
自社のブランド名で検索した際、検索結果の1位を維持できているか、あるいはクリック率(CTR)が極端に低下していないかを確認することは極めて重要だ。競合他社がGoogle広告で自社のブランド名をターゲットに設定したり、「[自社名] の代替品」といった比較ページを作成したりすることで、顧客を奪おうとする動きは珍しくない。
ブランドフィルタを適用し、平均掲載順位が1位でない場合や、CTRが50%を下回っている場合は、ブランド防衛策を講じる必要がある。これには、自社広告の出稿(リスティング広告でのブランド名入札)や、ブランドキーワードをターゲットにしたコンテンツの強化が含まれる。
2. マーケティングキャンペーンの影響測定
広告、メールマガジン、SNSでのプロモーションなどは、直接的なコンバージョンだけでなく、指名検索の増加という形でも成果が現れる。ブランドフィルタを使用すれば、キャンペーン期間中にブランドトラフィックがどれだけ底上げされたかを容易に可視化できる。
パフォーマンスレポートのグラフ上で右クリックし、「アノテーション(注釈)」を追加することで、施策と数値の変化を紐づけて管理できる。なお、このブランドフィルタのデータは2026年2月21日以降の結果から反映されているため、それ以前の施策との比較には注意が必要だ。
3. 地域別のブランド認知度の比較
グローバルに展開するEC事業者の場合、国ごとのブランド認知度の差を把握することは戦略立案に欠かせない。ブランドフィルタを適用した状態で「国」フィルタを追加すれば、カナダとイギリスでどちらのブランド認知が高いか、といった比較が容易に行える。
特定の地域でブランド検索が少ない場合、その地域に向けたローカライズ広告や認知拡大のための施策を優先的に検討する判断材料となるだろう。
独自分析:ブランド検索はECサイトの「防御壁」である

今回のアップデートは、単なる操作性の向上以上に、SEO戦略のパラダイムシフトを象徴している。現在の検索エンジン最適化において、一般的なキーワード(例:「メンズ スニーカー」)で上位表示を狙う難易度は年々高まっている。一方で、ブランド名そのものを検索して訪れるユーザーは、購入意欲が高く、競合への流出も少ない「良質なトラフィック」だ。
ブランドフィルタを活用することで、Web担当者は「SEO=順位を上げること」という狭い視点から、「SEO=ブランドの信頼を維持・拡大すること」という広い視点へと移行できる。ブランド検索が増えているということは、サイト外でのマーケティングや、顧客満足度の向上が実を結んでいる証拠でもある。
また、Googleのアルゴリズムにおいて「ブランドとしての権威性」はますます重視される傾向にある。ブランド検索が多いサイトは、特定のトピックにおいて信頼できる情報源であると判断されやすく、結果として非ブランド検索(一般キーワード)の順位向上にも寄与する。この「ブランドによるポジティブな循環」をデータで証明し、社内のマーケティング施策にフィードバックできるようになったことが、今回の機能追加の真の価値と言えるだろう。
この記事のポイント
- ブランドフィルタの登場:AIが自社名や製品名を自動判別し、抽出・除外を簡素化する。
- AIによる自動分類:表記揺れやスペルミスにも対応するが、マイナーな製品名などは見落とされる可能性がある。
- 競合対策への活用:ブランドクエリのCTRや掲載順位を監視し、顧客の流出を防ぐ。
- 効果測定の効率化:キャンペーンに伴う指名検索の増減を、アノテーション機能と併用して正確に把握できる。
- 戦略的価値:ブランド検索の動向を追うことは、ECサイトの長期的な信頼性と競争力を測る指標になる。
出典
- Practical Ecommerce「Search Console Adds Brand Filters」(2026年3月16日)
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AI検索が引き起こすECマーケティングの「アトリビューションの盲点」とその対策
人工知能(AI)の進化は、消費者が商品を見つけるプロセスを根本から変えつつある。この変化は、EC事業者にとって「アトリビューションの盲点」という新たな課題を突きつけている。
現在、少数の、しかし確実に増えつつある消費者が、検索エンジンやマーケットプレイスではなく、AIアシスタントへの対話型クエリから商品のリサーチを始めている。Perplexity(パープレキシティ)のようなジェネレーティブAI(生成AI)プラットフォームは、商品の推奨だけでなく、直接購入への導線も提供し始めている。
従来の検索結果では複数のブランドが1ページに並び、ユーザーの比較検討プロセスを追跡できた。しかし、AIによる回答は「10個のリンクから1つの回答」へと収束しており、これがマーケティング効果の測定を困難にしている。
AIによる「検索から回答へ」のパラダイムシフト
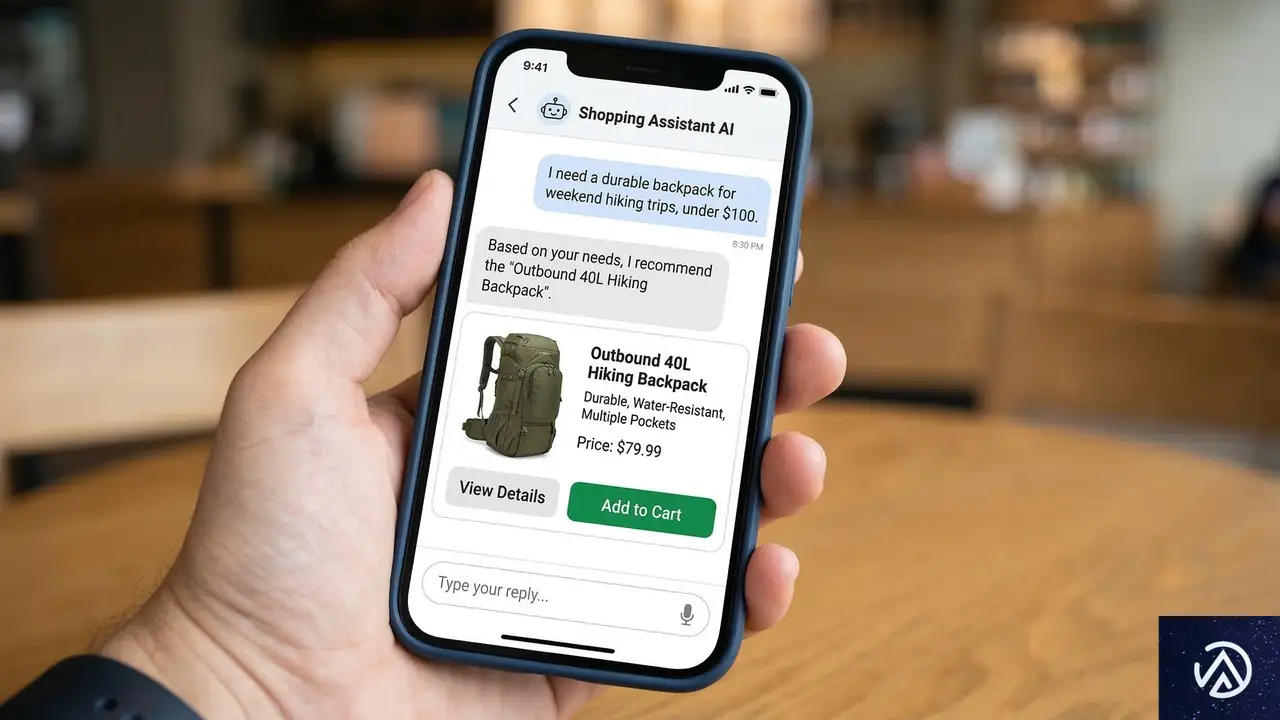
オンラインでの商品発見プロセスは、これまでGoogleなどの検索エンジン、Amazonなどのマーケットプレイス、そしてSNSが中心であった。ここに現在、対話型AIツールが加わっている。
10個のリンクから1つの回答へ
従来の検索エンジン最適化(SEO)の世界では、検索結果に表示される「青色のリンク」をいかにクリックさせるかが重要であった。しかし、AIアシスタントは膨大な情報から最適な選択肢を絞り込み、ユーザーに提示する。
データ分析企業LatentViewのビジネスヘッドであるKaushik Boruah氏は、「発見可能性が10個のリンクから1つの回答へと崩壊した」と指摘している。ユーザーが複数のサイトを巡回して比較する手間が省かれる一方で、ブランド側がユーザーの目に触れる機会は極端に狭まっている。
購買プロセスの「上流」への移動
消費者はAIに対し、「着心地の良い服」や「無香料の石鹸」といった具体的な悩みを相談する。AIはそれに対する解決策を提案し、その理由を説明する。
この段階で、消費者はすでに「何を買うか」を決めていることが多い。販売者のウェブサイトに到達したときには、検討プロセスは完了している。つまり、商品発見のプロセスが、EC事業者が制御できず、かつ測定も困難な「上流」へとシフトしているのだ。
なぜAI経由の貢献は「見えない」のか(アトリビューションの盲点)
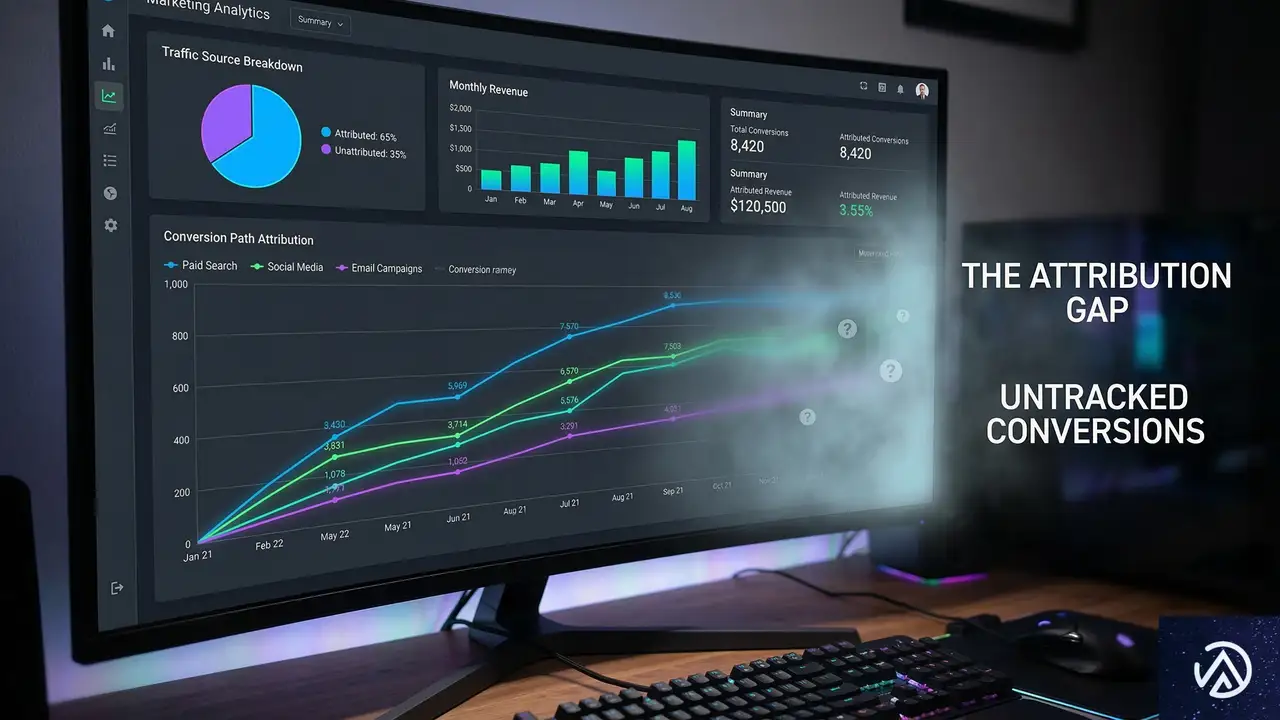
アトリビューション(Attribution)とは、コンバージョン(商品購入などの成果)に至るまでの各広告やチャネルの貢献度を正しく評価することを指す。AIの台頭により、この評価に「盲点」が生じている。
複数チャネルを跨ぐ複雑な足跡
例えば、ある消費者がAIアシスタントに商品の推奨を求めたとする。回答を得た後、その消費者はGoogleでブランド名を検索し、Amazonで購入を完了させる。
この場合、AmazonやGoogle Analytics(グーグルアナリティクス)のデータ上では、売上は「検索」や「直接流入」に割り当てられる。最初にAIが与えた影響は、データとして記録されない。
マーケティング担当者は、消費者の行動が変化していることを認識しながらも、投資対効果(ROI)が不明確なため、予算をAIチャネルにシフトさせることに慎重にならざるを得ない。結果として、測定可能なチャネルばかりが優先される事態を招いている。
サードパーティクッキー廃止との共通点
このAIによる計測の難しさは、サードパーティクッキー(ウェブサイトを跨いでユーザーを追跡する技術)の廃止に伴う課題と似ている。どちらもカスタマージャーニー(顧客が購入に至るまでの道のり)の可視性を低下させ、計測をモデリング(統計的な予測)へとシフトさせる要因となっている。
しかし、AIの盲点はクッキーの問題よりも解決が難しいとの見方がある。クッキーは技術的な代替案が模索されているが、AIアシスタント内部の推奨アルゴリズムや、ユーザーとAIのクローズドな対話を外部から把握する手段は極めて限られているからだ。
計測不能な影響を可視化する3つの代替手法

直接的なアトリビューション計測が困難な中、先進的な企業はAIの影響を測定するために代替的なアプローチを試行している。
1. インクリメンタル・テスト(増分テスト)
インクリメンタル・テストとは、特定の地域やオーディエンスに対してのみキャンペーンを実施し、実施しなかったグループとの売上の差(リフト)を測定する手法だ。
個々のユーザーの動きを追跡できなくても、統計的に「その施策がどれだけの純増売上をもたらしたか」を推定できる。AIプラットフォームへの露出を強化した場合の売上増を測る際にも有効な手段となる。
2. MMM(マーケティング・ミックス・モデリング)
MMM(Marketing Mix Modeling)は、広告費、価格、季節性、競合の動きなどの膨大なデータセットを統計的に分析し、各要素が売上に与えた影響を算出する手法だ。
これは「種をまいてから芽が出るまで」を俯瞰するような分析であり、AIアシスタントのような計測しにくいチャネルの貢献度を、他の変数との相関関係から導き出すことができる。近年、プライバシー規制の強化に伴い、再び注目を集めている。
3. ユーザーアンケートとブランドリフト調査
デジタルな足跡を追えないのであれば、直接ユーザーに聞くという原始的な手法も重要になる。購入完了ページでの「このサイトをどこで知りましたか?」というアンケートに、選択肢としてAIアシスタントを加えるだけでも、貴重な一次データが得られる。
また、ブランドリフト調査(広告接触による認知度や購入意向の変化を測る調査)を通じて、AIの推奨がブランドイメージにどう寄与しているかを定性的に把握することも推奨される。
WooCommerce・EC事業者が今取り組むべき戦略的視点

AIが購買決定を左右する時代において、ECサイト(特にWooCommerceなどの柔軟なプラットフォーム)を運営する事業者は、単なるSEOの延長線上ではない対策を求められる。
AIO(AI検索最適化)への意識
SEO(検索エンジン最適化)に代わり、AIO(AI Optimization)やGEO(Generative Engine Optimization)という概念が登場している。AIに正しく自社の商品を認識・推奨させるためには、構造化データ(Schema.orgなど)の徹底的な実装が不可欠だ。
構造化データとは、検索エンジンやAIに対して「これは商品名」「これは価格」「これはレビュー」と、データの意味を機械が理解できる形式で伝えるためのコードだ。これを適切に記述することで、AIアシスタントの回答に自社商品が含まれる確率を高めることができる。
自社データ(ファーストパーティデータ)の強化
外部チャネルの計測が不透明になるほど、自社サイト内で取得できるデータの価値は高まる。顧客の購買履歴、閲覧行動、会員情報などのファーストパーティデータを統合し、顧客理解を深めることが、AI時代の不確実性に対する最大の防御策となる。
WooCommerceであれば、プラグインを活用して詳細な顧客行動ログを収集し、自社独自の分析基盤を構築することが比較的容易だ。計測できない「外部の動き」に一喜一憂するよりも、確実に見える「自社内のデータ」を盤石にすることが先決と言える。
この記事のポイント
- AIアシスタントは商品比較プロセスを省略し、消費者の意思決定を「上流」で完了させる。
- AI経由の流入は「直接流入」や「検索」に紛れ込み、真の貢献度が見えなくなる「アトリビューションの盲点」を生む。
- インクリメンタル・テストやMMM(マーケティング・ミックス・モデリング)など、統計的なアプローチによる効果測定が不可欠。
- 構造化データの最適化(AIO)と、自社データの活用強化が、AI時代のEC運営における重要な戦略となる。
出典
- Practical Ecommerce「The AI Attribution Blind Spot」(2026年3月8日)
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

GA4の「Direct」トラフィックの正体——AIの影響と計測の限界を読み解く
Googleアナリティクス4(GA4)において、Direct(直接流入)の増加は必ずしもブランド認知の向上を意味しない。 多くのマーケティング担当者は、Directトラフィックを「ユーザーがURLを直接入力した、またはブックマークから訪問したロイヤリティの高い行動」と解釈している。 しかし、実態は「参照元を特定できなかったトラフィックのゴミ箱」に近い側面がある。
GA4のレポートでDirectが急増している場合、そこにはAIによる回答エンジンやプライバシー保護機能の影響が隠れている。 データの裏側にある技術的背景を理解しなければ、誤った投資判断を下すリスクがある。 本記事では、Directトラフィックが実際に何を計測しているのか、そしてAI時代にどう向き合うべきかを解説する。
GA4におけるDirectトラフィックの定義と実態
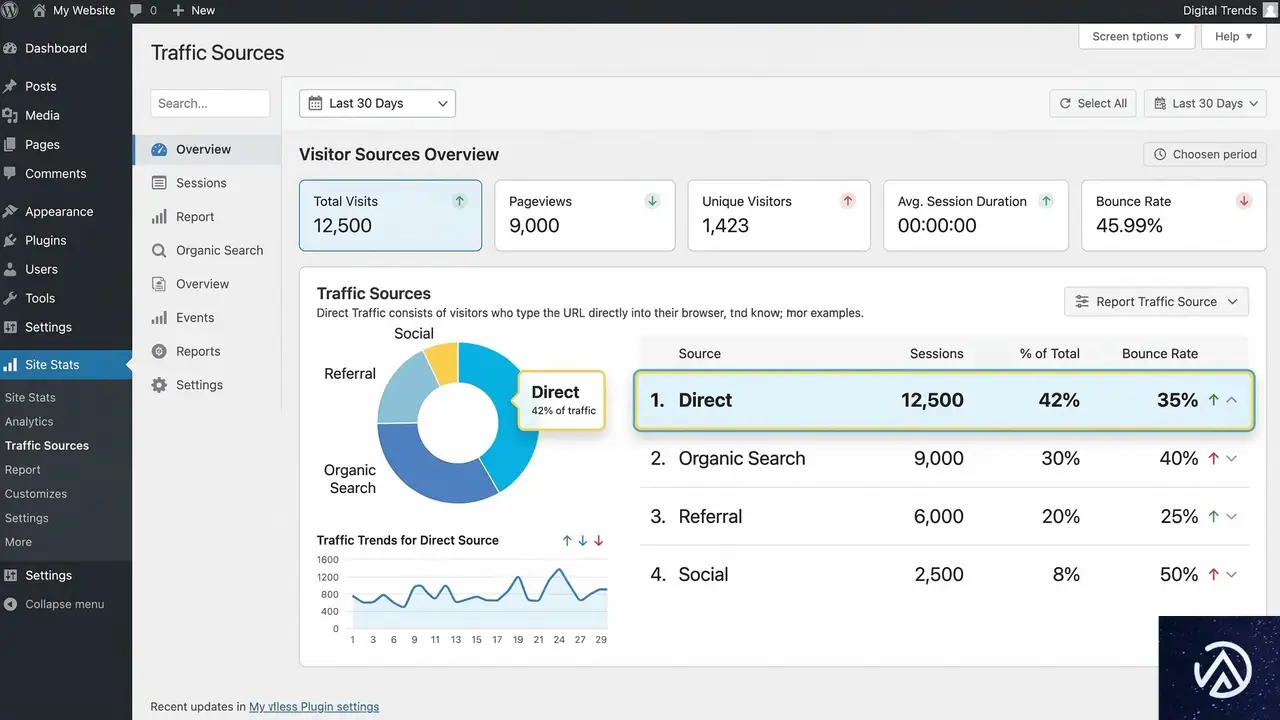
GA4において、セッションのソース(流入元)やメディアが特定できない場合、その訪問は自動的に「Direct」として分類される。 一般的には、ブラウザのURLバーに直接ドメインを入力する、あるいはブラウザの「お気に入り」からアクセスする行動がこれに該当する。 有名ブランドであれば、この種の直接訪問が一定数存在するのは自然なことだ。
リファラ情報の欠落が招く「擬似的なDirect」
しかし、実際には「リファラ(Referrer)」と呼ばれる参照元情報が失われたことで、Directに分類されるケースが非常に多い。 リファラとは、ユーザーがどのページからリンクを辿ってきたかを伝える仕組みだ。 例えば、LINEやSlackなどのメッセージアプリ内のリンク、あるいはモバイルアプリ内からWebサイトへ遷移する場合、このリファラ情報が正しく引き継がれないことがある。
また、セキュリティ上の理由でHTTPSサイトからHTTPサイトへ遷移する際も、リファラは送信されない。 このように、ユーザーの意図的な直接訪問ではなく、技術的な制約によって「正体不明」となったアクセスがDirectとしてカウントされている。 これは計測側の限界であり、ユーザーのブランド愛着度を示しているわけではない。
なぜDirectトラフィックの増加を誤読してしまうのか
マーケティングレポートにおいて、Directの増加は「施策が当たって指名検索や直接訪問が増えた」とポジティブに報告されやすい。 経営層やクライアントにとっても、広告費をかけずにユーザーが自発的に訪れる数字は魅力的に映る。 だが、この解釈には大きな落とし穴がある。
キャンペーンタグの不備という技術的要因
Direct急増の裏には、多くの場合、タグ設定のミスが隠れている。 メールマガジンやPDF資料、SNSの投稿に設置したリンクにUTMパラメータが付与されていない場合、それらはすべてDirectとして処理される。 UTMパラメータとは、URLの末尾に追加する「?utm_source=…」といった文字列で、流入元を明示するためのものだ。
特に、複数のチームで運用している場合、タグ付けのルールが統一されていないと計測漏れが発生しやすい。 インフルエンサー施策や有料広告であっても、リンク先のURLが適切に管理されていなければ、その成果はすべてDirectの中に埋もれてしまう。 これは、マーケティング活動の投資対効果(ROI)を正しく評価できない原因となる。
クロスデバイスとカスタマージャーニーの断絶
ユーザーの行動が複雑化していることも、Directトラフィックを複雑にしている。 例えば、スマートフォンで通勤中に検索し、サイトを見つけたユーザーがいたとする。 その後、帰宅してからPCを立ち上げ、ブラウザに社名を入力して購入に至った場合、GA4はこれを「Directによるコンバージョン」と記録することが多い。
実際には最初の検索(オーガニック検索)がきっかけだが、デバイスを跨ぐことで計測の紐付けが途切れてしまう。 この場合、Directは「ロイヤリティの証」ではなく、単なる「最終接触チャネル」に過ぎない。
AIによる「静かなインフレ」とDirectの関係
2026年現在、AI検索やチャット型アシスタントの普及により、Directトラフィックの性質がさらに変化している。 ユーザーがGoogle検索の代わりにAIに質問し、AIが特定のブランドや製品を推奨するシーンが増えた。 この際、AIが提示した情報を元にユーザーが新しいタブを開き、直接ドメインを入力してサイトに訪れる行動が頻発している。
AIアシスタント経由の「ダークサーチ」
AI経由の訪問は、GA4のレポート上では多くの場合、参照元不明のDirectとして現れる。 AIツールがブラウザ内でリンクを生成して誘導する場合でも、従来のような検索エンジンからの流入(Organic Search)としてはカウントされない。 このように、出所が特定できないものの、実際には外部の影響を受けている流入を「ダークサーチ」と呼ぶ。
AIの影響力が強まるほど、オーガニック検索の数字は横ばい、あるいは減少する一方で、Directだけが伸び続ける現象が起きる。 これを「ブランド力が上がった」と単純に喜ぶのは危険だ。 実際にはAIへの露出度(AI Visibility)が高まった結果であり、その因果関係を把握するには別の分析手法が必要になる。
プライバシー保護の強化が計測を不透明にする

近年のプライバシー保護の潮流も、Directトラフィックを増大させる要因となっている。 ブラウザ各社によるトラッキング防止機能(ITPなど)や、ユーザーによるクッキー(Cookie)の拒否設定が、アトリビューション(貢献度)解析を困難にしている。
リファラ情報の削除とURLクリーンアップ
一部のブラウザやメッセージングアプリでは、プライバシー保護のためにURLからトラッキング用のパラメータを自動的に削除する機能を備えている。 これにより、本来なら「広告経由」や「SNS経由」と識別されるべきアクセスが、丸裸のURLとしてサーバーに届くことになる。 結果として、GA4はこれらをDirectとして分類せざるを得ない。
ユーザーの行動自体は変わっていないが、計測システムの「目」が塞がれている状態だ。 今後、プライバシー規制がさらに厳格化される中で、Directトラフィックの比率はさらに高まっていくと予想される。 もはや「Direct=直接訪問」という前提は成り立たない。
Directトラフィックを正しく診断するための実務チェックリスト

Directが急増した際、それが「良い兆候」なのか「計測の不備」なのかを判断するための具体的なステップを紹介する。 単一の指標に惑わされず、複数のデータを掛け合わせることが重要だ。
1. ランディングページの分布を確認する
Direct流入の受け皿となっているページを調査する。 トップページ(/)への流入であれば、直接入力やブックマークの可能性が高い。 しかし、URLが長く複雑な「ブログ記事」や「特定の商品ページ」にDirectが集中している場合、それはメッセージアプリや未計測のキャンペーンからの流入である可能性が極めて高い。
2. 指名検索(ブランド検索)の推移と比較する
Google Search Console(サーチコンソール)を使用し、社名やサービス名での検索クリック数を確認する。 Directトラフィックと指名検索が連動して増えているなら、テレビCMや展示会などのオフライン施策、あるいはAIでの露出によって認知が拡大したと推測できる。 逆に、指名検索が増えていないのにDirectだけが急増しているなら、技術的なタグの欠落を疑うべきだ。
3. ブラウザとデバイスのセグメント分析
特定のブラウザ(例:iOSのSafari)や、特定のアプリ内ブラウザだけでDirectが増えていないかを確認する。 特定の環境だけで増えている場合、それはOSのアップデートによるプライバシー制限や、アプリの仕様変更が原因である可能性が高い。
4. キャンペーンタグ(UTM)の再点検
現在配信しているすべての外部チャネルをリストアップし、UTMパラメータが正しく設定されているかテストする。 特に以下の項目は見落とされやすい。
- メールマガジン内のボタンやテキストリンク
- 公式SNSアカウントのプロフィール欄にあるURL
- カスタマーサポートがチャットで送信するURL
- QRコード経由のアクセス
独自の分析:ECサイトにおけるDirectトラフィックの「意味」
WooCommerceなどのECサイトを運営している場合、Directトラフィックの質を見極めることは売上に直結する。 筆者の分析によれば、ECにおける「健全なDirect」は、リピート購入の直前に発生する傾向がある。 一方で、新規ユーザーによるDirect流入が特定の「セール対象商品」に集中している場合、それはアフィリエイトやSNSでの「タグなし紹介」が原因であることが多い。
これを放置すると、どの媒体が売上に貢献しているのかが分からず、広告予算の最適化ができなくなる。 対策として、サイト内に「どこで知りましたか?」というアンケートを設置したり、特定の流入元専用のクーポンコードを発行したりすることで、GA4の数字を補完する努力が求められる。
技術的な限界を認めた上で、定性的なデータで「Directの正体」を埋めていく姿勢が、これからのWeb担当者には不可欠だ。
この記事のポイント
- GA4のDirectは「参照元が特定できないアクセス」の総称であり、必ずしも直接訪問ではない。
- AI検索やチャットツールの普及により、出所不明の「ダークサーチ」が増加している。
- プライバシー保護機能の強化により、リファラ情報が削除され、Directへ分類されるケースが増えている。
- Directの急増時は、ランディングページや指名検索の推移を確認し、計測不備がないか診断する必要がある。
- データの不透明さを前提に、アンケートやクーポン活用などの補完的な分析手法を組み合わせることが重要だ。
出典
- MarTech「Why direct traffic in GA4 isn’t what it looks like」(2026年3月9日)
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験