

WooCommerce 10.9で取引メールログ機能がコアに統合、送信失敗の可視化でトラブル解決が容易に
WooCommerceのメールトラブルシューティング用ドキュメントは、サポート対応の中で常に上位のアクセス数を記録してきた。全サポートやり取りの1%以上で、最終的にこのドキュメントを案内する流れになっているという。こうした状況を踏まえ、WooCommerce開発チームは問題の切り分けに不可欠なログ機能をコアプラグインに組み込む判断を下した。
WooCommerce 10.9では、取引メール(トランザクショナルメール)の送信ログ機能が標準搭載される。店舗運営者はどのメールが正常に送信され、どのメールが失敗したのかをログで一元的に確認できるようになる。失敗時には具体的なエラー理由も記録されるため、従来のように外部のログ取得プラグインを導入する手間が省ける。
取引メールのログ機能の仕組み

このデモ図で示すように、従来はエラーのたびに外部ツールやプラグインを頼っていたが、10.9以降はWooCommerce本体が自動的にメール送信のログを取得する。店舗運営者の負担が一段階減る形だ。
内部設計の要点
新たに導入されるEmailLoggerクラスは、以下の4つのフックに接続される。これにより、メール送信のあらゆる局面を捕捉できる仕組みになっている。
- woocommerce_email_sent:WooCommerceがメールを送信するたびに発火し、成功または失敗の真偽値と
WC_Emailインスタンスを受け取る。 - woocommerce_email_disabled:メール種別が設定で無効化されていて送信が行われなかった場合に発火する。
- woocommerce_email_skipped:受信者が存在しないなどの前提条件を満たさず、送信がスキップされた場合に発火する。短い理由識別子も渡される。
- wp_mail_failed:WordPress全体のメール送信失敗フック。ここから
WP_Errorメッセージを取得し、SMTP接続エラーなどの具体的な原因をログに含める。
いずれの結果も、wc_get_logger()を通じて新しいソース名transactional-emailsの下に書き込まれる。WooCommerce標準のロガーを経由するため、店舗側がすでに設定しているログハンドラ(ファイルまたはデータベース)とログレベルしきい値をそのまま利用できる。
- ログハンドラ:デフォルトは
wp-content/uploads/wc-logs/ディレクトリへのファイル出力だが、WooCommerce > ステータス > ログ画面でデータベース保存に切り替えている場合はそちらが使われる。新たなストレージ層は不要だ。 - ログレベル:送信成功は
INFO、失敗はWARNING、無効化やスキップによる未送信はNOTICEとして記録される。本番環境でエラーレベルのみ取得する設定にしておけば、失敗だけを素早く把握できる。 - 保持期間:他のWooCommerceログと同様に、WooCommerce > ステータス > ログ > 設定から保持ポリシーを管理できる。
ログに記録される情報
各ログエントリは1行で完結し、大量のメールが飛び交う店舗でもストレージへの影響はほとんどない。文脈情報は次のような構造で出力される。
context = [
'source' => 'transactional-emails',
'email_type' => 'customer_processing_order',
'status' => 'sent' | 'failed' | 'disabled' | 'skipped',
'recipient' => 'jdoe' | 'guest' | 'jdoe, guest',
'reason' => 'no_recipient', // スキップ時のみ
'order' => 12345, // 注文ID、状況に応じて'product'や'user'が入る
]ログレベルが3段階に整理されているため、WARNINGなら即座に問題を疑い、NOTICEなら設定通りの挙動であることを確認し、INFOなら正常に送信されたと判断できる。フィルタリングやアラートの仕組みと組み合わせれば、運用の自動化にもつなげやすい。
注文画面での確認
ログとは別に、個々の注文に関連づいたメールの履歴が注文ノートにも表示されるようになった。WooCommerce > 注文から任意の注文を開くと、その注文に対して送信が試みられた取引メールとその成否が一覧できる。
ここで注意したいのは、注文ノートに表示されるのは「実際に送信が試みられたメール」だけという点だ。設定で無効化されているメール種別や、受信者不在でスキップされたものは表示されない。注文ノートを無駄に長くせず、期待される挙動とその結果に焦点を絞る設計思想がうかがえる。
プライバシーと拡張性への配慮

上図のように、メールアドレスが直接ログに書き込まれることはない。プライバシー保護と拡張性の両面に配慮した設計が盛り込まれている。
プライバシー保護の仕組み
受信者のメールアドレスはログに一切出力されない。resolve_recipient()メソッドが各アドレスをWordPressのユーザー名に変換する。アカウントを持たない購入者(ゲスト)の場合は'guest'というラベルに置き換えられる。BCCなどで複数の受信者がいる場合は、カンマ区切りのラベル一覧が記録される。
PHPMailerが返すエラー文字列には、しばしば受信者アドレスが直接埋め込まれているが、これもredact_emails()という正規表現によるスクラブ処理で除去される。この処理はRemoteLogger::redact_user_data()と同等のロジックを採用しており、WooCommerce全体で一貫したプライバシー保護が維持される。
拡張ポイント
WooCommerce 10.9では、メールログの動作をカスタマイズするためのフィルターフックが2つ追加されている。
- woocommerce_email_log_enabled:ログ出力の有効・無効を切り替える。グローバルに無効化したり、
$email_idをチェックして特定のメール種別だけ対象外にできる。 - woocommerce_email_log_context:ログに書き込まれる文脈情報を書き換える。フィルターには書き込み前の配列が渡されるため、項目の追加・削除・変更が自由に行える。
ログ機能そのものは、WooCommerce > ステータス > ログ > 設定タブから管理画面でオフにできる。特定の機能のみを無効にしたい場合は、以下のコードをテーマのfunctions.phpなどに追加する。
add_filter( 'woocommerce_email_log_enabled', '__return_false' );パフォーマンスへの影響を最小限にしたい場合や、すでに別のシステムでメールログを収集している場合は、このフィルターで柔軟に対応できる。
実装上の注意点と今後の展望

ログ機能にはひとつ、既知の制限が存在する。wp_mail_failedはWordPress全体のグローバルなフックであるため、WooCommerceのメール送信処理の直後に別のプラグインが送信に失敗した場合、そのエラーが誤ってWooCommerceのメールに紐づく可能性がある。
$last_mail_errorはWooCommerceのメール送信ごとにクリアされるため、古いエラーが後続の処理に引き継がれることはない。しかし、送信の直後という非常に狭い時間枠では、別のエラーが紛れ込む余地が理論上残る。この事象は実際にはまれであり、影響を受けるのは人間が読むための失敗理由テキストだけだ。email_typeやstatusといった主要な情報は常に正確である。
この取引メールログ機能は、Automatticが実施した「Radical Speed Month」の一環として開発された。まずは診断機能としての土台を固め、次のステップではWooCommerceが自らメールエラーを警告し、修正を支援する能動的なレイヤーの追加を検討しているという。トラブルシューティングにかかる時間をさらに短縮し、より多くの店舗運営者がメール問題に煩わされずに済む未来を描いている。
この記事のポイント
- WooCommerce 10.9から、取引メールのログ機能がコアプラグインに標準搭載される。外部ツール不要で送信の成否と失敗理由を把握できる。
- ログは
INFO(成功)、WARNING(失敗)、NOTICE(未送信)の3段階で出力され、管理画面の注文ノートにも関連メールの履歴が表示される。 - メールアドレスはログに直接記録されず、ユーザー名やゲストラベルに変換される。エラーメッセージ内のアドレス情報も自動で除去される。
- フィルターフックを使ってログ出力の無効化や文脈情報のカスタマイズが可能。パフォーマンスや既存システムとの兼ね合いで柔軟に調整できる。
- 開発チームは今後の展開として、エラーを自動検知して運営者に通知する仕組みの追加を視野に入れている。

・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

WordPressサイトの信頼性を再定義する。ヒューマンエラーを前提とした回復力の高め方
WordPressサイトがダウンする原因の多くは、サーバーの物理的な故障や急激なアクセス増加ではない。実は、日々の管理業務の中で発生する「人為的なミス」が最も大きな要因となっている。
プラグインの更新、設定ファイルのわずかな書き換え、あるいは新しいコードの追加といった日常的な操作が、予期せぬ不具合を引き起こす。WordPressは柔軟で強力なシステムだが、その運用は人間に依存しており、ミスを完全に排除することは不可能に近い。
本記事では、ヒューマンエラーを前提とした「真の信頼性」について考える。エラーをゼロにすることを目指すのではなく、万が一問題が発生した際に、いかに迅速かつ安全に元の状態へ戻せるかという「回復力」の重要性を深掘りしていく。
なぜWordPressの障害は「人」から生まれるのか

多くのサイト運営者は、ダウンタイム(サイトが閲覧できなくなる時間)の原因をインフラの不備だと考えがちだ。しかし、実際にはサイト自体に加えられた変更が引き金となるケースが圧倒的に多い。
日常的な変更がリスクに変わる瞬間
WordPressは常に進化を続けている。新しい機能を導入するためにプラグインを追加し、デザインを整えるためにテーマを調整し、パフォーマンスを上げるために設定ファイルを最適化する。これらの変更はすべて「サイトを良くしたい」という意図で行われるものだ。
しかし、システムが多層的で複雑になればなるほど、小さな変更が全体に与える影響を予測しにくくなる。一つの設定ミスがドミノ倒しのように他の機能に干渉し、最終的にサイト全体を停止させてしまうことがある。Kinstaの記事でも指摘されている通り、ヒューマンエラーは避けられない自然な結果として捉えるべきだろう。
柔軟性と引き換えに生じる不安定さ
WordPressの最大のメリットは、誰でも簡単にカスタマイズできる柔軟性にある。しかし、その柔軟性は「壊しやすさ」と表裏一体だ。専門的な知識がなくても重要なファイルを編集できてしまうため、初心者はもちろん、経験豊富な開発者であっても、一瞬の油断で致命的なミスを犯す可能性がある。
サイトを壊す「よくある4つのミス」とその正体
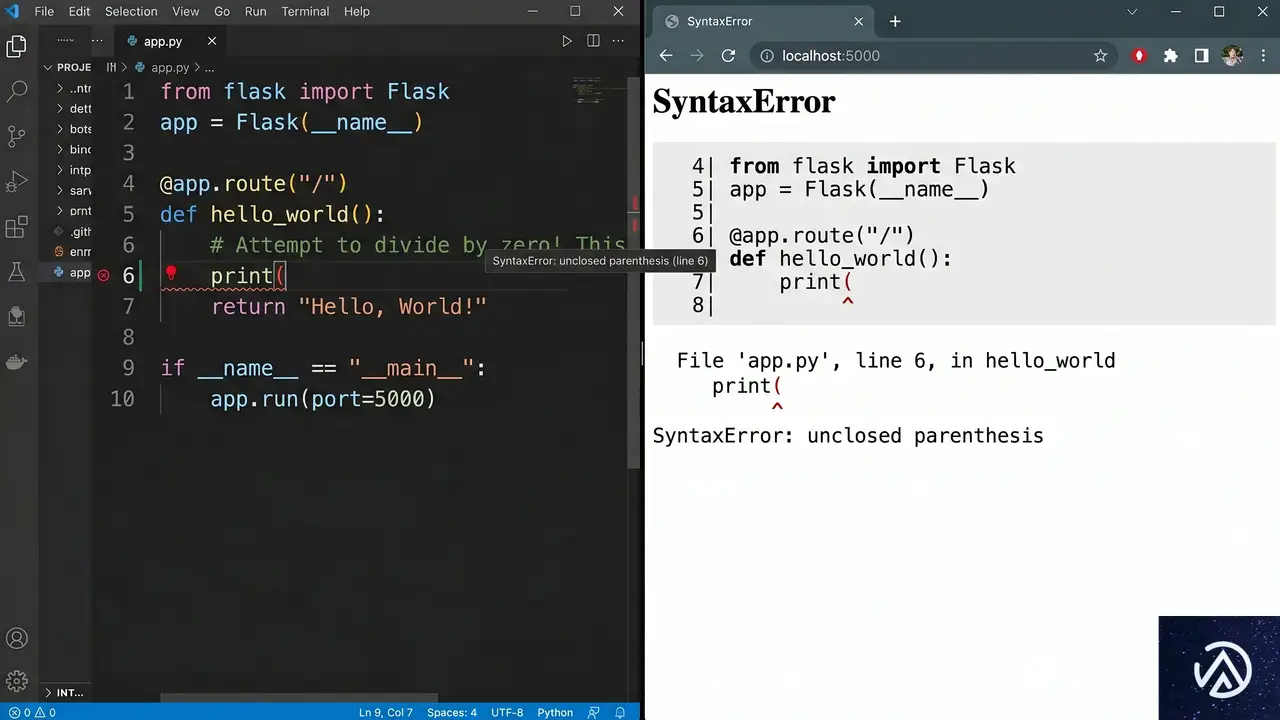
不具合が発生する場所には、一定のパターンが存在する。これらを事前に把握しておくだけでも、トラブル発生時の調査スピードは格段に上がるだろう。
1. 設定ファイル(.htaccessやwp-config.php)の構文ミス
サーバーの動作を制御する .htaccess ファイルの編集は、最も注意が必要な作業の一つだ。例えば、リダイレクトの設定中に括弧を一つ閉じ忘れただけで、サーバーは「500 Internal Server Error」を返し、サイトは即座に閲覧不能になる。
# 誤った記述の例(閉じ括弧がない)
RewriteEngine On
RewriteRule ^index\.php$ - [Lまた、データベースの接続情報を管理する wp-config.php でパスワードを1文字打ち間違えれば、「データベース接続確立エラー」が発生する。これらのファイルはサイトの根幹を支えているため、わずかな記述ミスも許されない。
2. アップデート後のプラグインやテーマの競合
プラグインの更新ボタンを押す行為は、日常的だがリスクを伴う。個々のプラグインは正常に動作していても、特定の組み合わせによって予期せぬエラーが発生することがあるからだ。これを「競合」と呼ぶ。特にECサイト(WooCommerceなど)において、決済に関わるプラグインが競合で動かなくなれば、ビジネスへの損害は計り知れない。
3. JavaScriptエラーによる管理画面のフリーズ
最近のWordPressはブロックエディタ(Gutenberg)を中心に、JavaScriptへの依存度が高まっている。テーマやプラグインに含まれるスクリプトに不備があると、エディタが読み込まれなかったり、保存ボタンが反応しなくなったりする。表側の表示は正常でも、裏側の管理画面が使えなくなるという、発見が遅れやすいトラブルだ。
4. theme.jsonの構造的な不備
最新のブロックテーマでは theme.json というファイルでサイトのデザインを一括管理する。このファイルはJSON形式で記述されるが、カンマの打ち忘れや階層構造のミスがあると、WordPressは設定を正しく読み込めない。エラーメッセージが出ないまま、特定のスタイルが適用されなかったり、編集画面のコントロールが消えたりするため、原因の特定に時間がかかることがある。
予防策を徹底しても「不具合」がゼロにならない理由
慎重に作業を進め、テストを繰り返せばエラーは防げるはずだ、と考えるかもしれない。しかし、現実にはどれほど注意深く運用していても、不具合は発生する。
システム間の予期せぬ相互作用
WordPressサイトは、コア、テーマ、多数のプラグイン、サーバー環境、そしてデータベースが複雑に絡み合って動いている。テスト環境では完璧に動いていた変更が、本番環境のリアルなデータや特定のトラフィック状況下で予期せぬ挙動を示すことは珍しくない。すべての組み合わせを事前に網羅することは、物理的に不可能なのだ。
「バックアップがあるから安心」の落とし穴
バックアップは必須の備えだが、それだけで十分ではない。重要なのは、バックアップを使って「どれだけ早く復旧できるか」だ。復旧作業に数時間を要したり、専門知識が必要でサポートの返信を待たなければならなかったりする場合、その間の機会損失は防げない。バックアップの存在と同じくらい、復旧プロセスの簡便さが重要になる。
真の信頼性とは「失敗した後の回復スピード」にある

ここで、信頼性の考え方を180度変えてみよう。信頼できるサイトとは「決して壊れないサイト」ではなく「壊れてもすぐに直せるサイト」のことだ。この考え方を「レジリエンス(回復力)」と呼ぶ。
リスクを封じ込める設計
レジリエンスの高いシステムでは、変更を加える際のリスクが適切に管理されている。例えば、本番サイトを直接触るのではなく、本番のコピー環境である「ステージング環境」でテストを行う。これにより、万が一エラーが起きても、影響をその環境内だけに封じ込めることができる。ユーザーが閲覧している本番サイトには一切の悪影響を与えない。
ECサイトにおける「回復力」の可視化
例えば、WooCommerceを利用しているECサイトで、プラグイン更新により「カートに入れる」ボタンが動かなくなった状況を想定してみよう。以下のデモは、エラー発生時と、回復力が機能して即座に復旧した状態を比較したものだ。
(コンソールにJavaScriptエラーが表示されている状態)
(原因調査はステージング環境で別途実施)
このデモのように、エラーを検知してから正常な状態に戻すまでの時間をいかに短縮できるかが、ビジネスの継続性を左右する。
リスクを最小化するホスティング環境の選び方
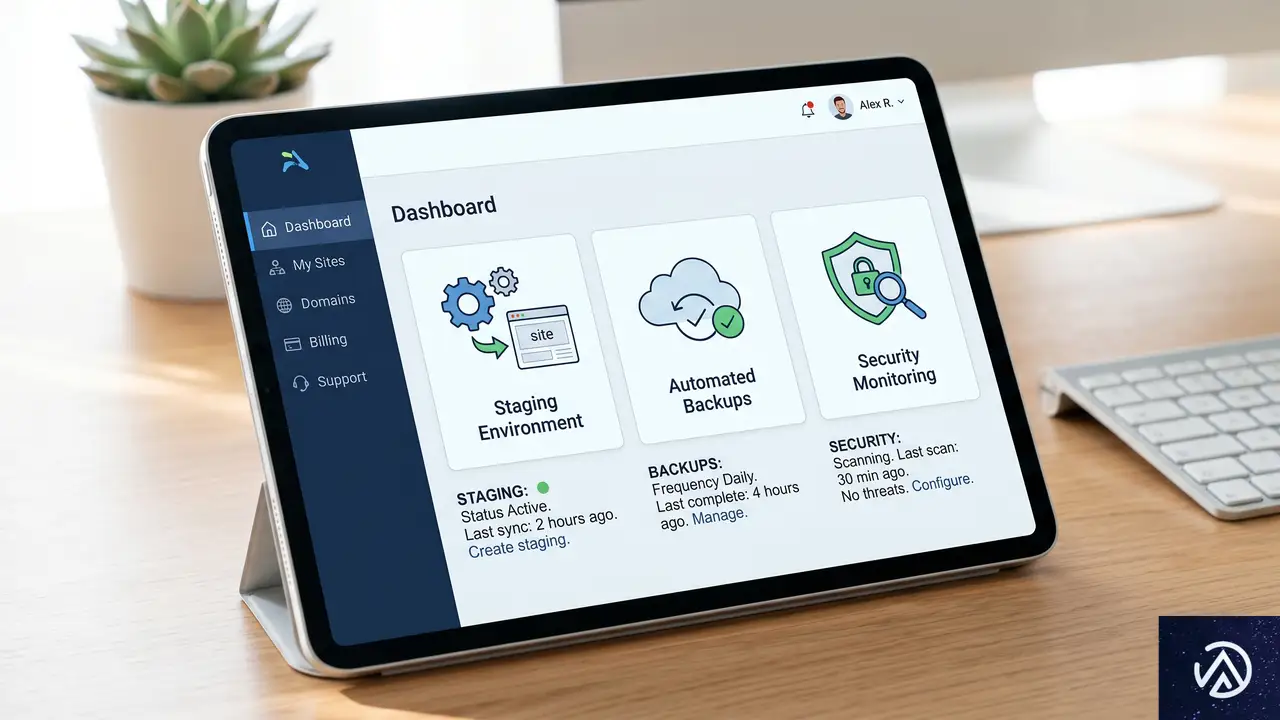
回復力を高めるためには、運用者の努力だけでなく、それを受け止める土台となるホスティング環境が重要だ。優れた環境は、人間がミスをすることを前提とした「安全装置」を標準で備えている。
1. ワンクリックで作成できるステージング環境
ステージング環境の作成に手間がかかるようでは、ついつい本番サイトを直接編集したくなってしまう。ボタン一つで本番と全く同じ環境をコピーでき、テストが終わればボタン一つで本番に反映(デプロイ)できる仕組みがあることが望ましい。これにより「まずはテストする」という習慣が自然に身につく。
2. 自動バックアップと高速なリストア
毎日、あるいは変更を加える直前に自動でバックアップが作成されることは最低条件だ。さらに重要なのは、そのバックアップを数分以内に本番サイトへ反映できる「リストア(復元)」のスピードだ。リストア中にサイトが長時間止まってしまう環境では、回復力が高いとは言えない。
3. 異常を早期に知らせる監視システム
エラーは、ユーザーから指摘される前に自分たちで気づくのが理想だ。サイトの表示が遅くなっていないか、特定のページでエラーが発生していないかを常時監視し、異常があればすぐに通知が届く仕組みがあれば、問題が深刻化する前に手を打つことができる。監視とは、サイトの健康状態をチェックする検診のようなものだ。
独自分析:エラーを許容する文化がサイトを強くする
技術的な備えと同じくらい大切なのが、運用チームの考え方だ。筆者の分析によれば、最も安定しているサイトを運営しているチームは「ミスを責めない」文化を持っている。ミスをした個人を責めるのではなく「なぜこのミスが起きたのか」「どうすれば次からシステムがこのミスを防げるか」という点に注力しているのだ。
これを「ブレイムレス・ポストモーテム(非難なしの事後検証)」と呼ぶ。例えば、あるプラグインの更新でサイトが壊れた際、担当者を叱責するのではなく、更新前に必ずステージング環境でチェックするワークフローを自動化する、といった解決策を導き出す。人間に完璧を求めるのではなく、システムで人間をサポートする姿勢こそが、長期的な信頼性を生む鍵となる。
この記事のポイント
- WordPressのダウンタイムの主因は、トラフィック増加ではなく人為的なミスである。
- 設定ファイルの記述ミスやプラグインの競合は、どれほど熟練した人でも避けられない。
- 真の信頼性とは、エラーをゼロにすることではなく、迅速に復旧できる「回復力」を指す。
- ステージング環境や高速なリストア機能を備えたインフラを選ぶことが、最大の安全策になる。
- ミスを責めるのではなく、システムでミスをカバーする運用文化が安定したサイトを作る。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験