

de TLD障害の全容 DNSSEC署名破損でSERVFAIL多発 Cloudflareの一時的緩和策を解説
2026年5月5日、およそ19時30分(UTC)、ドイツの国別コードトップレベルドメインである .de を管理するレジストリ DENIC が、同ゾーンのDNSSEC署名を誤って公開し始めた。この誤った署名は、DNSSEC検証を行うすべてのDNSリゾルバにSERVFAILを返させる結果となり、Cloudflareの公開リゾルバ1.1.1.1も例外ではなかった。
.de はインターネット上で最もクエリ数の多いTLDのひとつで、Cloudflare Radarのデータでも常に上位にランクインする。このレベルのDNS階層で障害が発生すると、数百万のドメインが到達不能になる可能性がある。本記事では、Cloudflareが観測した現象、影響の範囲、さらにDENICが問題を解決するまでの間に1.1.1.1が適用した一時的緩和策について解説する。
.de TLD障害の原因と発覚の経緯

DNSSEC署名が破損したことで、リゾルバは応答を信用せずSERVFAILを返す。この仕組みは正しいが、大規模な影響を引き起こした。19時30分の直後からSERVFAILが急増し、キャッシュの期限切れに伴って3時間にわたって増え続けた。クエリのリトライにより通信量も増大し、SERVFAILの件数は実際のユーザー影響以上に見える。
DENICは後の声明で「定例の鍵ローテーション中に、検証できない署名が生成・配布された」と説明しており、今後のローテーションは原因特定まで停止されている。
DNSSECの仕組みと署名検証の役割
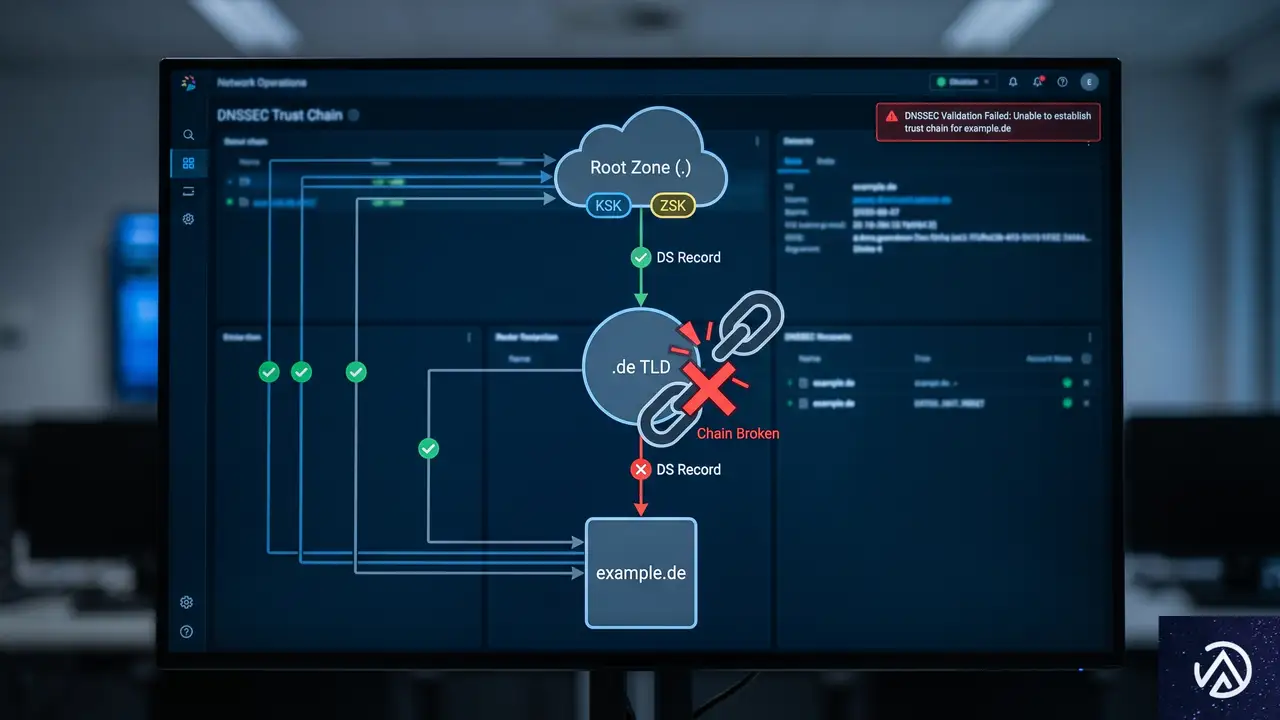
DSレコード
検証失敗
DNSSEC(Domain Name System Security Extensions)は、DNS応答にデジタル署名を付与して改ざんを防ぐ仕組みだ。各ゾーンのレコードセットにはRRSIGレコードが付随し、リゾルバはこれを用いて原本性を確認する。署名は保護対象のレコードと一緒に運ばれるため、キャッシュを経由しても検証可能だ。
信頼の連鎖はルートゾーンから始まり、親ゾーンがDSレコードで子ゾーンの公開鍵を証明する。.deの上位にはルートがあり、.deの下に個々のドメインがぶらさがる。どこか一か所で署名が破綻すると、その先の全ドメインが検証に失敗する。今回のようにTLDで署名ミスが起きれば、配下のすべての .de ドメインがSERVFAILになる。
DNSSECでは、ゾーン署名鍵(ZSK)と鍵署名鍵(KSK)を使い分ける。ZSKはレコードそのものに署名し、KSKはZSKに署名する。KSKの公開鍵が親ゾーンのDSレコードと結びつき、信頼の基点となる。鍵のローテーション時に新しい鍵が正しく配布されなかったり、署名生成に失敗すると、今回のような大規模障害につながる。
キャッシュとserve staleが被害を軽減

クエリ → キャッシュから応答(NOERROR)
DENICへ問い合わせ → SERVFAIL
キャッシュ期限切れでも古いデータを返し続ける
リゾルバはTTL(生存時間)の間、権威サーバーから受け取ったレコードをキャッシュする。TTLが切れると、新しい情報を取りに行く。ところが障害発生中は、新たに取得しようとするとSERVFAILに終わる。そこでCloudflareの1.1.1.1はRFC 8767に従い、キャッシュの期限が切れた後も古いレコードを応答し続ける「serve stale」を実施した。
このおかげで、キャッシュに残っていた .de ドメインの多くは引き続き解決され、ユーザーへの影響は大幅に和らげられた。グラフからも、incident中にNOERRORが一定数維持されたことが分かる。serve staleがなければ、故障が始まった瞬間から全クエリが失敗していた。
Cloudflare 1.1.1.1が講じた一時的緩和策

serve staleだけではカバーできないクエリもあったため、Cloudflareは22時17分(UTC)に .de ゾーンに対して一時的なNTA(Negative Trust Anchor)に相当する措置を適用した。具体的には、内部のオーバーライドルールを使って .de 全体を「DNSSEC未対応ゾーン」のように扱い、署名検証をスキップさせた。
RFC 7646はまさにこうした状況のためにNTAを定義している。TLD運営者が破損した署名を公開した場合、正しいドメインまで巻き添えでSERVFAILになるより、一時的に検証を外す方がユーザーにとって有益だという判断だ。Cloudflareの内部議論でも「1.1.1.1を使っているユーザーで、検証失敗よりも未検証の応答の方を望まない者はいない」と結論づけられている。
同時に、CDNサービスを利用する顧客向けの内部リゾルバにも同様の対応を施し、 .de をオリジンとするサイトの接続性を回復させた。また、対策を即座にDNS-OARCのチャットで共有し、他の事業者との連携も行った。
なお、1.1.1.1が返していたSERVFAILにはEDEコード22(到達可能な権威サーバーなし)が付与されていたが、本来はEDE 6(DNSSEC無効)が適切だ。Cloudflareはこのバグを認識しており、今後DNSSECエラーを正しく表面化させる修正を予定している。
インシデントから学ぶ教訓と今後の改善点

この障害は、DNSの階層構造がもつ脆弱性を改めて浮き彫りにした。TLDレベルで発生した問題は、その下にあるすべてのドメインに等しく波及する。これはDNSSECに限った話ではなく、権威サーバー自体が到達不能になれば同じことが起こる。
根本的な回避策は存在しないが、迅速な連携と運用上の工夫で被害を抑えられる。今回、多くのリゾルバ事業者が1時間以内にNTAを適用し、解決までの間ユーザーの影響を緩和した。DNS-OARCのような業界コミュニティの存在も、こうした危機対応のスピードを支えている。
技術面では、serve staleのような仕組みがTier-1レベルの障害時に有効に機能することが改めて示された。また、EDEエラーコードの適切な実装は、トラブルシューティングを容易にし、運用者間の情報共有を効率化する。Cloudflareもこの点の改善に着手する。
この記事のポイント
- 2026年5月5日、.de TLDのDNSSEC鍵ローテーション中に不正な署名が生じ、全DNSSEC検証リゾルバがSERVFAILを返した
- DNSの階層構造上、TLDの障害は配下のドメインすべてに影響する
- Cloudflareの1.1.1.1はserve staleでキャッシュを延命し、さらに一時的にDNSSEC検証を無効化するNTA相当の対策を22時17分に適用
- RFC 7646に定義されたNTAは、事業者間の迅速な合意形成があれば被害を大幅に軽減できる
- EDEエラーコードの不備など、リゾルバ側の改善点も事例から明らかになった

・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

500 Tbpsに達したCloudflareのネットワーク網!DDoS防御とAI時代のインフラを徹底解説
Cloudflareのグローバルネットワークが、外部接続容量500 Tbps(テラビット毎秒)という大きな節目を超えた。2010年にパロアルトの小さなオフィスから始まった同社のインフラは、16年の歳月を経て世界330以上の都市に広がる巨大なデジタル基盤へと成長している。
この「500 Tbps」という数字は、単なるピーク時のトラフィック量ではない。トランジットプロバイダーやピアリングパートナー、インターネットエクスチェンジ(IX)などと接続された外部ポートの総容量を指している。この膨大な余剰キャパシティこそが、日々発生する大規模なDDoS攻撃を吸収するための「防御予算」として機能しているのだ。
現代のインターネットにおいて、これほどの規模を持つネットワークがどのように構築され、どのように自律的な防御を実現しているのか。最新の技術スタックと、急増するAIトラフィックへの対応策を含めて詳しく紐解いていく。
500 Tbpsの衝撃〜Cloudflareが到達した巨大ネットワークの現在地

Cloudflareのネットワーク容量が500 Tbpsに達したことは、インターネットの歴史における一つの到達点といえる。2010年の設立当初、同社はたった一つのトランジットプロバイダーと契約し、ネームサーバーを2つ書き換えるだけで利用できるリバースプロキシとしてスタートした。それが今や、全ウェブサイトの20%以上を保護する巨大インフラへと変貌を遂げている。
世界330都市以上に広がる物理インフラの重み
「インターネットはクラウドである」と表現されることが多いが、その実体はケーブルとサーバーが詰まった物理的な部屋の集合体だ。Cloudflareはシカゴ、アッシュバーン、サンノゼ、アムステルダム、東京といった主要都市から始まり、カトマンズ、バグダッド、レイキャビクといった地域まで網羅してきた。
データセンターを一つ開設するごとに、コロケーション契約の交渉、光ファイバーの敷設、サーバーのラッキングといった地道な作業が繰り返される。2018年には、わずか24日間で31都市に拠点を展開するという驚異的なスピードで拡張を続けた。この物理的な拠点の多さが、ユーザーに近い場所でコンテンツを配信し、攻撃を水際で食い止めるための鍵となっている。
外部キャパシティ500 Tbpsが意味するもの
500 Tbpsという数字は、すべての外部接続ポートの合計値だ。日常的なトラフィックのピークは、この数字のほんの一部に過ぎない。残りの広大な帯域は、DDoS攻撃が発生した際にその衝撃を和らげるためのバッファとして確保されている。
かつては国家レベルのリソースがなければ対抗できなかったような大規模な攻撃も、この巨大なパイプラインの中では「日常的なイベント」として処理される。ネットワークの規模そのものが、セキュリティにおける最強の武器となっているのだ。
攻撃を呼吸するように受け流す〜31.4 TbpsのDDoSを防ぐ仕組み

2025年、Cloudflareのネットワークは秒間31.4 Tbpsという猛烈なDDoS攻撃を検知し、わずか35秒で完全に無害化した。この攻撃には、感染したAndroid TVなどで構成された「Aisuru-Kimwolf」と呼ばれるボットネットが関与していた。驚くべきは、この規模の攻撃に対してもエンジニアが呼び出されることなく、システムが自律的に対処した点だ。
eBPFとXDPによる超高速パケット処理
この自律的な防御を支えているのが、Linuxカーネル内で動作する「eBPF(extended Berkeley Packet Filter)」と「XDP(eXpress Data Path)」という技術だ。パケットがネットワークカード(NIC)に到着した瞬間、OSの通常のネットワークスタックを通過する前に、XDPプログラムがそのパケットを評価する。
これにより、不正なパケットはCPUサイクルをほとんど消費することなく、入口で即座に破棄される。アプリケーション層に到達する前に処理が終わるため、サーバーの負荷を極限まで抑えることが可能だ。この仕組みを視覚化すると、以下のようになる。
このデモは、パケットがどのように段階を経て処理されるかを示したものだ。XDPレイヤーでのフィルタリングが、後続のシステムをいかに保護しているかがわかる。
自律分散型の防御システム「dosd」
Cloudflareのすべてのサーバーには「dosd」と呼ばれるDDoS対策用のデーモンが常駐している。各サーバーは流入するトラフィックをサンプリングし、異常な通信パターンを検出すると、その情報を同じデータセンター内の全サーバーにブロードキャストする。
データセンター内のすべてのサーバーが同じデータに基づいて判断を下すため、特定のサーバーに負荷が集中することなく、拠点全体で一貫した防御が可能になる。さらに、決定されたルールは同社の分散型キーバリューストア「Quicksilver」を通じて数秒以内に全世界の拠点へ伝播される。これにより、ある拠点で検知された攻撃手法が、瞬時に地球の裏側の拠点でも通用しなくなる仕組みだ。
ネットワーク自体が開発プラットフォームへ〜Edge Computingの進化

ネットワークを保護するためにすべてのサーバーでコードを実行できる環境を整えた結果、そのリソースを顧客に開放するという自然な流れが生まれた。これが「Cloudflare Workers」の始まりだ。現在では、単なるスクリプトの実行にとどまらず、より複雑なワークロードをエッジで動かすことが可能になっている。
WorkersからContainersへ
2025年、CloudflareはWorkersに「Containers」機能を追加した。これにより、V8アイソレートでは難しかった、より重量級のアプリケーションもエッジで動作させることができるようになった。独自のファイルシステムレイヤーにより、コールドスタート(起動時の遅延)を最小限に抑えつつ、ユーザーのすぐそばで計算リソースを提供する。
開発者が書いたコードは、前述のDDoS防御と同じサーバー上で動作する。つまり、攻撃トラフィックがl4dropによって破棄された直後の、クリーンな環境でアプリケーションが実行されるわけだ。インフラのセキュリティとパフォーマンスを同時に享受できるこの構造は、従来の中央集約型クラウドとは一線を画している。
インターネットの信頼性を担保する〜RPKIとASPAの重要性

ネットワークの規模が大きくなるほど、ルーティングの安全性に対する責任も増大する。BGP(Border Gateway Protocol)の脆弱性を突いたルートハイジャックは、インターネットの通信を誤った方向へ誘導し、大規模な障害やセキュリティ侵害を引き起こす原因となる。Cloudflareはこれらのリスクを低減するため、最新のプロトコル採用を強力に推進している。
ルートハイジャックを防ぐRPKI
RPKI(Resource Public Key Infrastructure)は、IPアドレスの所有者が誰であるかを証明するための仕組みだ。Cloudflareは早期からRPKIを導入し、無効なルートからのトラフィックを拒否する設定を徹底している。現在、グローバルなルーティングテーブルのうち、86万7,000件以上のプレフィックスが有効なRPKI証明書を持っており、10年前のほぼゼロに近い状態から劇的に改善された。
パスの正当性を検証するASPA
次に同社が注力しているのが「ASPA(Autonomous System Provider Authorization)」だ。RPKIが「誰が所有しているか」を検証するパスポートチェックだとすれば、ASPAは「どのような経路を通ってきたか」を検証するフライトマニフェスト(搭乗名簿)チェックに相当する。
ASPAが普及すれば、設定ミスによるルート漏洩や、悪意のある経路誘導をより確実に防げるようになる。Cloudflareのような巨大ネットワークが先行して導入することで、インターネット全体のエコシステムを健全な方向へ導く狙いがある。
AIエージェントが変えるトラフィック構造〜4%の衝撃

近年、インターネット上のトラフィックに大きな変化が起きている。人間がブラウザでリンクをクリックして発生する通信に加え、AIクローラーや自律型エージェントによるアクセスが急増しているのだ。現在、Cloudflareのネットワークを流れるHTMLリクエストの4%以上が、AI関連の通信で占められている。
ブラウザとクローラーの挙動の違い
AIクローラーは、人間が操作するブラウザとは根本的に異なる動きを見せる。ブラウザはページを読み込んだ後に一時停止するが、クローラーはリンクされたリソースを最大スループットで、休むことなく次々と取得していく。この挙動は、インフラ側から見るとDDoS攻撃と区別がつきにくい場合がある。
Cloudflareは、正規のAIクローラーと悪意のある攻撃を識別するために、TLSフィンガープリントや行動分析を組み合わせた高度な検知システムを運用している。例えば、ブラウザを装いつつもTLSのライブラリが不自然な構成であれば、それをシグナルとして検出し、サイト所有者が適切な判断を下せるようにデータを提供している。
独自の分析〜500 Tbps時代に企業が備えるべきインフラ戦略

Cloudflareが500 Tbpsという驚異的な容量を確保したことは、一企業のリリースの枠を超えた意味を持っている。これは、インターネットが「物理的な限界」を技術と規模で克服しつつあることを象徴している。しかし、インフラが強力になる一方で、攻撃の質も変化している点には注意が必要だ。
「防御の自動化」が企業の必須条件になる
31.4 Tbpsという攻撃を人間が介在せずに防いだという事実は、もはや「人間がログを見て遮断ルールを書く」という旧来の運用が通用しないフェーズに入ったことを示している。今後の企業インフラには、eBPF/XDPのようなカーネルレベルでの高速処理と、AIを活用した自律的なパターン認識が欠かせなくなるだろう。
エッジシフトとセキュリティの統合
Cloudflareの事例が示すように、これからは「セキュリティ対策」と「アプリケーション実行環境」を切り離して考えるべきではない。攻撃を捨てる場所でコードを動かすという「エッジコンピューティング」の思想は、パフォーマンス向上だけでなく、攻撃の爆風をアプリケーションに届かせない最強の盾となる。企業は、中央集約的なサーバー構成から、分散型のエッジインフラへの移行を真剣に検討すべき時期に来ているといえる。
この記事のポイント
- Cloudflareの外部ネットワーク容量が500 Tbpsの大台を突破した
- eBPFとXDPを活用し、31.4 Tbpsもの巨大DDoS攻撃を自動的に無害化している
- 世界330以上の都市に分散された拠点が、ユーザーに近い場所でセキュリティと計算リソースを提供している
- RPKIやASPAといった次世代プロトコルの導入により、ルーティングの安全性を世界規模で向上させている
- トラフィックの4%を占めるようになったAIクローラーに対し、高度な識別技術で対応している
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

BPFバックドアのマジックパケットをZ3で自動生成する手法
Linuxマルウェア解析の現場で、手作業による逆アセンブリがボトルネックになっている。特に、Berkeley Packet Filter(BPF)ソケットプログラムに隠された「マジックパケット」待ち受け型のバックドアは、フィルタが数百命令に及ぶこともあり、解析に膨大な時間を要する。
Cloudflareのセキュリティ研究者らはこの課題に対し、シンボリック実行とZ3定理証明器を組み合わせた自動化手法を開発した。これにより、従来は数時間から数日かかっていたマジックパケットの特定を、数秒で完了させられるようになった。本記事では、その技術的アプローチと実装の詳細を解説する。
BPFがマルウェアに利用される理由

Berkeley Packet Filter(BPF)は、ネットワークスタックから特定のパケットを効率的に取り出すためのカーネル内技術だ。tcpdumpなどのツールでおなじみの「クラシックBPF」は、2つのレジスタしか持たないシンプルな仮想マシンで、高速なパケットフィルタリングを実現する。
ユーザー空間から見えなくなる特性
このBPFがマルウェア作者に好まれる理由は、その「不可視性」にある。カーネル深くで動作するBPFプログラムは、特定の条件を満たすパケットだけをユーザー空間のプロセスに渡すことができる。逆に言えば、条件を満たさないパケットは、ユーザー空間のネットワーク監視ツールから完全に隠蔽できる。
これにより、攻撃者は「マジックパケット」と呼ばれる特定のバイト列を含むパケットが到着するまで、バックドアを完全に休眠状態に保てる。通常のポートスキャンでは検出されず、ネットワーク上に痕跡を残さない、極めて隠密性の高い持続的脅威(APT)が実現する。
手動解析の限界
マルウェア対策の研究者がこの種のバックドアを分析する場合、BPFのバイトコードを逆アセンブルし、条件分岐を一つずつ追跡する必要があった。20命令程度の単純なフィルタなら問題ないが、実際には100命令を超える複雑なロジックを持つサンプルが観測されている。
Cloudflare Blogの記事によると、複雑なBPFプログラムの手動解析には「少なくとも1日」を要する場合があったという。この時間的コストが、脅威の早期分析と対策の迅速な展開を妨げるボトルネックとなっていた。
BPFDoorの実例から見るBPFフィルタ

この手法の具体例として、高度なLinuxバックドア「BPFDoor」のBPFフィルタを見てみる。Fortinetが分析したサンプル(ハッシュ値: 82ed617816453eba2d755642e3efebfcbd19705ac626f6bc8ed238f4fc111bb0)の逆アセンブル結果は次の通りだ。
(000) ldh [0xc] ; オフセット12から2バイト読み込み(EtherType)
(001) jeq #0x86dd, jt 2, jf 6 ; 0x86DD(IPv6)なら002へ、そうでなければ006へ
(002) ldb [0x14] ; オフセット20から1バイト読み込み(プロトコル)
(003) jeq #0x11, jt 4, jf 15 ; 0x11(UDP)なら004へ、そうでなければ015(DROP)へ
(004) ldh [0x38] ; オフセット56から2バイト読み込み(宛先ポート)
(005) jeq #0x35, jt 14, jf 15 ; 0x35(DNSポート53)なら014(ACCEPT)へ、そうでなければ015へ
(006) jeq #0x800, jt 7, jf 15 ; 0x800(IPv4)なら007へ、そうでなければ015へ
(007) ldb [23] ; オフセット23から1バイト読み込み(プロトコル)
(008) jeq #0x11, jt 9, jf 15 ; 0x11(UDP)なら009へ、そうでなければ015へ
(009) ldh [20] ; オフセット20から2バイト読み込み(フラグメント)
(010) jset #0x1fff, jt 15, jf 11 ; フラグメントされていれば015へ、そうでなければ011へ
(011) ldxb 4*([14]&0xf) ; インデックスレジスタXに(IHL & 0xF)*4をロード
(012) ldh [x + 16] ; オフセットX+16から2バイト読み込み(宛先ポート)
(013) jeq #0x35, jt 14, jf 15 ; 0x35(DNSポート53)なら014へ、そうでなければ015へ
(014) ret #0x40000 (ACCEPT) ; パケット受理
(015) ret #0 (DROP) ; パケット破棄このフィルタは、IPv6パケットとIPv4パケットの両方の経路でDNSポート(53)へのUDPパケットを待ち受ける。IPv4の経路ではさらに、パケットがフラグメントされていないこと、IPヘッダ長が標準の20バイトであることなどの追加チェックが入る。
ACCEPTに至る2つの経路
上記のコードから、パケットがACCEPT(受理)される条件は2つの経路で満たされることがわかる。
- 経路1(IPv6): EtherTypeが0x86DD(IPv6)→ プロトコルが0x11(UDP)→ 宛先ポートが0x35(53)
- 経路2(IPv4): EtherTypeが0x0800(IPv4)→ プロトコルが0x11(UDP)→ フラグメントなし → IPヘッダ長が5(20バイト)→ 宛先ポートが0x35(53)
手動で分析すれば、これらの条件から「DNSポート53へのUDPパケット」がマジックパケットの候補だと推測できる。しかし、より複雑な算術演算やビット演算が絡むフィルタの場合、この推測は困難を極める。
シンボリック実行とZ3による自動化

Cloudflareの研究者らは、この「制約条件を満たす入力値の発見」という問題を、シンボリック実行と定理証明器Z3によって自動化するアプローチを取った。
シンボリック実行の基本概念
シンボリック実行とは、プログラムの入力を具体的な値ではなく「記号(シンボル)」として扱い、実行経路を数学的な制約の集合として表現する手法だ。BPFプログラムの場合、入力となるネットワークパケットの各バイトを未知の変数とみなす。
プログラムが条件分岐(jeqなど)に到達すると、「変数Aが値Bと等しい」という制約が真となる経路と、偽となる経路の両方を探索する。最終的にACCEPT命令に到達する経路において、変数が満たすべきすべての制約を収集する。
Z3定理証明器による制約解決
収集された制約を、Microsoft Researchが開発した定理証明器「Z3」に与える。Z3はこれらの制約を満たす具体的な変数値(つまり、パケットの各バイトの値)を自動的に計算する。
このプロセスは、複数の連立方程式を解くことに似ている。ただし、方程式が単純な等号ではなく、ビット演算、比較、条件分岐を含む複雑な論理式となる点が異なる。
最短経路の探索アルゴリズム
すべてのACCEPT経路を探索する前に、まず最短の経路を見つける。これは、後続のシンボリック実行の計算コストを抑えるためだ。擬似コードで示すと、次のような幅優先探索(BFS)が用いられる。
paths = []
queue = deque([(0, [0])]) # (プログラムカウンタ, 経路履歴)
while queue:
pc, path = queue.popleft()
if pc >= len(instructions):
continue
instruction = instructions[pc]
if instruction.class == return_instruction:
if instruction_constant != 0: # ACCEPTの場合
paths.append(path)
continue # DROPまたはACCEPTでこの経路の探索終了
if instruction.class == jump_instruction:
if instruction.operation == unconditional_jump:
next_pc = pc + 1 + instruction_constant
queue.append((next_pc, path + [next_pc]))
continue
# 条件付きジャンプの場合、真偽両方の経路を探索
pc_true = pc + 1 + instruction.jump_true
pc_false = pc + 1 + instruction.jump_false
queue.append((pc_true, path + [pc_true]))
queue.append((pc_false, path + [pc_false]))
else:
# 逐次実行命令の場合、次の命令へ
queue.append((pc + 1, path + [pc + 1]))このアルゴリズムを先ほどのBPFDoorフィルタに適用すると、より短いIPv6経路(命令000→001→002→003→004→005→014)が最短経路として特定される。
BPFシンボリック実行マシンの実装

最短経路がわかれば、次はその経路上でシンボリック実行を行うマシンを実装する。Cloudflareが開発した「BPFPacketCrafter」クラスの骨格は以下のようになる。
class BPFPacketCrafter:
MIN_PKT_SIZE = 64 # 最小パケットサイズ
LINK_ETHERNET = "ethernet" # イーサネットヘッダから始まる
MEM_SLOTS = 16 # スクラッチメモリM[0]〜M[15]
def __init__(self, instructions, pkt_size=128, ltype="ethernet"):
self.instructions = instructions
self.pkt_size = max(self.MIN_PKT_SIZE, pkt_size)
self.ltype = ltype
# シンボリックなパケットバイト(各バイトが独立した変数)
self.packet = [BitVec(f"pkt_{i}", 8) for i in range(self.pkt_size)]
# シンボリックなレジスタ(32ビット)
self.A = BitVecVal(0, 32) # アキュムレータ
self.X = BitVecVal(0, 32) # インデックスレジスタ
# スクラッチメモリ
self.M = [BitVecVal(0, 32) for _ in range(self.MEM_SLOTS)]ここでBitVecはZ3が提供するビットベクトル(固定長のビット列)型で、パケットの各バイトを8ビットの未知変数として表現する。レジスタAとXも同様に32ビットのビットベクトルとしてモデル化される。
BPF命令のZ3操作へのマッピング
シンボリック実行マシンは、BPFの各命令を対応するZ3の操作に変換しながら実行する。例えば、加算命令(ADD)は次のように処理される。
def _execute_ins(self, insn):
cls = insn.cls
if cls == BPFClass.ALU: # 算術論理演算命令
op = insn.op
src_val = BitVecVal(insn.k, 32) if insn.src == BPFSrc.K else self.X
if op == BPFOp.ADD:
self.A = self.A + src_val # Z3の加算演算でレジスタAを更新比較命令(jeq)の場合は、条件式を制約として記録し、分岐先のプログラムカウンタへ実行を進める。クラシックBPFの命令セットは小さいため、このマッピングは比較的容易に実装できる。
制約の収集とパケット生成
最短経路に沿ってシンボリック実行を進めると、ACCEPT命令に到達した時点で、パケット変数が満たすべき制約の集合が完成する。Z3ソルバーはこの制約集合を解き、各pkt_i変数に具体的なバイト値を割り当てる。
得られた制約の例を、Z3が内部で生成する式の形で示すと以下のようになる。
0x86DD == ZeroExt(16, Concat(pkt_12, pkt_13))
0x11 == ZeroExt(24, pkt_20)
0x35 == ZeroExt(16, Concat(pkt_56, pkt_57))これは、「オフセット12-13の2バイト(ビッグエンディアン)が0x86DD(IPv6)と等しい」「オフセット20の1バイトが0x11(UDP)と等しい」「オフセット56-57の2バイトが0x35(ポート53)と等しい」という3つの制約を表す。
Z3がこれらの制約を満たす解(例えばpkt_12=0x86, pkt_13=0xDD, pkt_20=0x11, ...)を求めると、それを実際のバイト列に変換する。最後に、Pythonのパケット操作ライブラリscapyを使って、このバイト列からネットワークパケットオブジェクトを組み立てる。
###[ Ethernet ]###
dst = 00:00:00:00:00:00
src = 00:00:00:00:00:00
type = IPv6
###[ IPv6 ]###
version = 6
nh = UDP
src = ::
dst = ::
###[ UDP ]###
sport = 0
dport = domain # ポート53生成されたパケットは、分析者がネットワーク上でバックドアの活性化テストを行う際の入力として、または検出用のシグネチャ作成のベースとして利用できる。
ツール「filterforge」と今後の展望

Cloudflareはこの研究成果をオープンソースツール「filterforge」として公開している。このツールを使えば、BPFバイトコードを含むファイルを入力とするだけで、マジックパケットの条件を満たすパケットのスケルトンを自動生成できる。
ツールの公開により、セキュリティコミュニティ全体でBPFベースの脅威に対する分析速度が向上することが期待される。特に、以下のような応用が考えられる。
- マルウェアサンプルの自動分類: 生成されたマジックパケットの特徴から、同一グループによる活動を関連付けられる。
- ネットワーク監視の強化: 生成されたパケットをプローブとして送信し、感染ホストの検出に利用する。
- 教育・研究: 複雑なBPFフィルタの動作を、具体的なパケット例とともに理解する教材となる。
LLMとの組み合わせ可能性
Cloudflare Blogの記事では、LLM(大規模言語モデル)を用いてBPF命令の文脈的説明を生成する取り組みにも言及している。シンボリック実行による自動パケット生成とLLMによる自然言語説明を組み合わせれば、分析者の作業負荷はさらに軽減される。
ただし現状では、LLMだけに複雑なBPFフィルタの解析とパケット生成を任せるには限界がある。Z3を用いた形式的な手法は、その正確性と完全性において依然として重要な役割を果たす。
この記事のポイント
- Linuxマルウェアは、カーネル内で動作するBPFソケットプログラムを利用し、特定の「マジックパケット」が到着するまで休眠する隠密性の高いバックドアを構築する。
- 手動でのBPFバイトコード逆解析は、数百命令に及ぶ複雑なフィルタの場合、数日を要するボトルネックだった。
- シンボリック実行によりBPFプログラムの入力を記号化し、定理証明器Z3で制約を解くことで、マジックパケットを数秒で自動生成できる。
- この手法は、最短経路探索、BPF仮想マシンのシンボリックモデル化、Z3制約ソルバー、scapyによるパケット組み立ての4ステップから構成される。
- Cloudflareが公開したオープンソースツール「filterforge」は、BPFベース脅威の分析速度をコミュニティ全体で向上させる可能性を秘めている。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Cloudflare Gen13サーバーの設計思想 192コアAMD EPYCで2倍のスループットを実現
Cloudflareが第13世代サーバー「Gen13」の設計詳細を公開した。192コアのAMD EPYC Turin 9965プロセッサを搭載し、前世代比で最大2倍のスループットを実現している。
Gen13は768GBのDDR5-6400メモリ、24TBのPCIe 5.0 NVMeストレージ、デュアル100GbEネットワークインターフェースを備える。特に注目すべきは、Rustで書き直された新リクエスト処理層「FL2」への移行により、大容量L3キャッシュへの依存を解消した点だ。これによりコア数を2倍に増やしながら、レイテンシの増加を抑えることに成功した。
この記事では、Cloudflare Blogの記事を基に、Gen13サーバーの各コンポーネント選択の背景と設計思想を解説する。
CPU設計の転換:キャッシュからコアへ

Gen13の最大の特徴は、AMD EPYC Turin 9965プロセッサの採用だ。192コア/384スレッドを備え、前世代のGen12(96コア)からコア数を2倍に増やしている。
L3キャッシュ依存からの脱却
興味深いのは、コア数が2倍になった一方で、コアあたりのL3キャッシュ容量が83.3%減少している点だ。Gen12のAMD EPYC Genoa-X 9684Xはコアあたり12MBのL3キャッシュを持っていたが、Gen13のTurin 9965はコアあたり2MBしかない。
この一見逆行するような選択の背景には、Cloudflareのソフトウェアスタックの根本的な変化がある。Cloudflareはリクエスト処理層をFL1からFL2へ移行した。FL2はRustで書き直された新アーキテクチャで、大容量L3キャッシュへの依存度が大幅に低減されている。
Cloudflare Blogの記事によると、FL2ワークロードはコア数に対してほぼ線形にスケールする特性を持つ。このため、コア数を増やすことが直接的なスループット向上につながる。L3キャッシュ容量の減少による潜在的なパフォーマンス低下は、FL2の効率的なメモリ使用によって相殺された。
3つの候補から9965を選んだ理由
Cloudflareのエンジニアチームは、Gen13のCPU候補として3つのAMD Turinプロセッサを評価した。128コアの9755、160コアの9845、そして192コアの9965だ。
評価の結果、9965が選ばれた理由は明確だ。生産環境でのテストにおいて、9965の192コアは最高の総合リクエスト処理性能を示した。さらに、500WのTDP(熱設計電力)における性能/ワット効率も優れており、ラックレベルでの総所有コスト(TCO)が最も低くなると判断された。
運用面でも、192コアという高密度構成はメリットがある。同じ計算能力を提供するために必要なサーバー台数が減るため、プロビジョニング、パッチ適用、監視にかかる運用オーバーヘッドを削減できる。
メモリとストレージの拡張

12チャネルDDR5-6400で帯域幅33%向上
CPUコア数が2倍になったことで、メモリサブシステムにもより高い要求が課せられた。Gen13は12個のDDR5-6400メモリチャネルすべてを活用する構成を採用している。
各チャネルに64GB DIMMを1枚ずつ配置する「1DIMM per channel」構成で、合計768GBのメモリ容量を実現。ピークメモリ帯域幅はソケットあたり614GB/sに達し、Gen12から33.3%向上した。
すべてのチャネルを均等に使用する構成は、メモリインターリーブの観点から重要だ。AMD Turinプロセッサは、同じDIMMタイプ、同じ容量、同じランク構成のメモリチャネル間でインターリーブを行う。インターリーブにより、連続したメモリアクセスが単一のチャネルではなくすべてのチャネルに分散され、実効的なメモリ帯域幅が向上する。
コアあたり4GBの「適正容量」を維持
メモリ容量の決定において、Cloudflareは「コアあたり4GB」という比率を維持することを選択した。Gen12でも同じ比率が採用されており、実績のあるバランスだ。
設計初期には、コアあたり4GBから6GBの範囲が検討された。192コアの場合、768GBから1152GBに相当する。実際のDIMM容量の粒度を考慮すると、選択肢は12x48GB(576GB)、12x64GB(768GB)、12x96GB(1152GB)の3つだった。
12x48GB構成は容量が不足し、メモリを多く消費するワークロードを飢餓状態にするリスクがある。一方、12x96GB構成はコアあたり50%の容量増加となるが、電力消費の増加とコストの大幅な上昇(現在のメモリ価格は1年前の10倍)が問題だ。
12x64GBの768GB構成は、コアあたり4GBという実績のある比率を維持しつつ、サーバーあたりの総容量をGen12の2倍に拡大する。FL2はFL1と比べてメモリ使用効率が大幅に向上しており、ソフトウェアスタックの移行によって生じた余剰容量が、今後数年間のCloudflareの成長を支えるヘッドルームとなる。
ストレージ:PCIe 5.0と容量50%増
ストレージサブシステムも大幅に強化された。Gen13はPCIe Gen 5.0 NVMeドライブを採用し、レイテンシの改善と増大するストレージ帯域幅要求に対応する。
物理的なストレージ容量も、3台のNVMeドライブにより24TBに拡張された。Gen12サーバーは4つのE1.Sストレージスロットを備えていたが、実際に使用されていたのは2スロットのみだった。Gen13では同じ4スロット設計を維持しつつ、3スロットに8TBドライブを実装している。
3台目のドライブ追加により、サーバーあたりのストレージ容量は16TBから24TBへ50%増加した。これはCDNキャッシュ性能の維持・向上に加え、Durable Objects、Containers、Quicksilverサービスなどの成長予測を支えるためだ。
さらにGen13シャーシには、最大10台のU.2 PCIe Gen 5.0 NVMeドライブを収容できるフロントドライブベイが追加された。この設計により、同じシャーシをコンピュートプラットフォームとストレージプラットフォームの両方で使用できる柔軟性が生まれる。必要に応じてコンピュートSKUをストレージSKUに変換することも可能だ。
ネットワークと電源の刷新

8年ぶりのネットワークアップグレード:25GbEから100GbEへ
Gen13で最も大きな変化の一つが、ネットワークインターフェースの刷新だ。8年以上にわたりCloudflareフリートの基盤となってきたデュアル25GbEから、デュアル100GbEへと移行する。
この変更の必要性は明白だ。192コアという高性能CPUがより多くのリクエストを処理できるようになると、ネットワーク帯域幅がボトルネックになる。実際、世界中のコロケーション施設から収集した1週間分の本番データによると、Gen12ではポートあたりのP95帯域幅が利用可能帯域幅の50%を一貫して超えていた。
Gen13ではサーバーあたりのスループットが2倍になるため、NIC帯域幅が飽和するリスクが高まる。100GbEへの移行は、このボトルネックを解消するための必然的な選択だ。
50GbEではなく100GbEを選んだ理由は、産業界の経済性にある。50GbEトランシーバーの市場規模は依然として小さく、サプライチェーン上のリスクが高い。デュアル100GbEポートによりサーバーあたり200Gb/sの集約帯域幅を実現し、今後数年間のトラフィック成長に対応できる将来性も確保した。
電源:800Wから1300Wへ拡張
コンピュート能力とネットワーク能力の向上に伴い、サーバーの電力エンベロープも自然に拡大した。Gen13は必要な電力を供給するため、より大型の電源装置を搭載する。
Gen12ノードは800W 80 PLUS Titanium CRPS(共通冗長電源装置)で十分に動作していたが、Gen13では1300W 80 PLUS Titanium CRPSを選択した。
Gen13の通常動作時の電力消費は850Wに達する。Gen12の600Wから250Wの増加だ。主な要因は、TDPが400Wから500Wに上がったCPU、メモリ容量の2倍化、追加のNVMeドライブである。
1000Wではなく1300Wを選んだ理由は、現在のPSUエコシステムに1000Wの高効率オプションがほとんどないためだ。サプライチェーンの信頼性を確保するために、産業界標準の次の階層である1300Wに移行した。
EU Lot 9規制は、欧州連合に展開するサーバーが、負荷10%、20%、50%、100%において規制で指定された効率率閾値を満たす電源装置を備えることを要求する。この閾値は80 PLUS Power Supply認証プログラムのチタニウムグレードPSU要件と一致する。Gen13ではEU Lot 9に完全準拠するためチタニウムグレードPSUを選択し、欧州のデータセンターをはじめとする全世界での展開を可能にした。
セキュリティと管理の継続性

Project Argus DC-SCM 2.0の継承
Gen13では、Gen12で導入された管理機能とセキュリティ関連コンポーネントをマザーボードから分離するアーキテクチャを維持する。これらは「Project Argus」データセンターセキュアコントロールモジュール2.0(DC-SCM 2.0)に集約されている。
DC-SCMモジュールには、サーバーのセキュリティの中枢となる重要なコンポーネントが収められている。
- 基本入出力システム(BIOS)
- ベースボード管理コントローラ(BMC)
- ハードウェアルートオブトラスト(HRoT)とTPM
- 冗長性のためのデュアルBMC/BIOSフラッシュチップ
このアーキテクチャをGen13でも継続する決定は、前世代で実証されたセキュリティ上の利点に基づく。管理機能を専用モジュールにオフロードすることで、以下のメリットを維持できる。
迅速な回復機能は、デュアルイメージ冗長性により、偶発的な破損や悪意のある更新が検出された場合にBIOS/UEFIおよびBMCファームウェアをほぼ瞬時に復元できる。
物理的耐性については、Gen13シャーシでは侵入検知メカニズムをシャーシの平坦な端からさらに遠ざけ、物理的な傍受を難しくしている。
PCIe暗号化は、Gen10プラットフォームから有効化されていたCPUとメモリ間の暗号化(TSME)に加え、AMD Turin 9965プロセッサがPCIeトラフィックにも暗号化を拡張する。これにより、システム内のすべてのバスを通過するデータが転送中も保護される。
運用的一貫性も重要だ。Gen12管理スタックを維持することで、セキュリティ監査、展開、プロビジョニング、運用標準手順が完全に互換性を保つ。
ドロップインアクセラレータサポートの強化
フリートのモジュール性維持は、Cloudflareのサーバー設計における中核的な要件だ。この要件により、Cloudflareは2024年にGPUを世界中の100以上の都市に迅速に改造・展開できた。
Gen13では、高性能PCIeアドインカードのサポートを継続する。Gen13の2Uシャーシレイアウトは更新され、より要求の厳しい電力と熱要件をサポートするように構成されている。Gen12がシングル幅GPU1枚に制限されていたのに対し、Gen13アーキテクチャはダブル幅PCIeカード2枚をサポートする。
この記事のポイント
- Cloudflare Gen13サーバーは192コアAMD EPYC Turin 9965を採用し、前世代比最大2倍のスループットを実現
- FL2(Rust製新リクエスト処理層)への移行により、大容量L3キャッシュへの依存を解消。コア数増加による性能向上を可能にした
- メモリは12チャネルDDR5-6400構成で768GBを実装。帯域幅33%向上とコアあたり4GBの適正容量を維持
- ネットワークは8年ぶりに刷新。デュアル25GbEからデュアル100GbEへ移行し、帯域幅ボトルネックを解消
- セキュリティはProject Argus DC-SCM 2.0アーキテクチャを継承。PCIe暗号化を追加し、データ転送中の保護を強化
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験