

AI時代のキャッシュ設計を再考する——AIクローラーがCDNに与える影響と対策
CDN(コンテンツデリバリネットワーク)のキャッシュ設計が、AIクローラーの台頭によって根本的な見直しを迫られている。Cloudflareのデータによると、同社ネットワーク上のトラフィックの32%は自動化されたトラフィックが占める。検索エンジンクローラーや監視ツールに加え、近年はAIアシスタントが回答生成のためにWebから情報を取得するケースが増加している。
AIエージェントは人間とは異なるアクセスパターンを示す。高頻度の並列リクエスト、人気ページではなく長尾コンテンツへの集中的なアクセス、サイト全体の網羅的なスキャンなどが特徴だ。このような振る舞いは、従来の人間向けに最適化されたキャッシュアルゴリズムを無効化し、キャッシュミス率の上昇とオリジンサーバー負荷の増大を引き起こす。
サイト運営者はAIクローラーへの対応に迫られる。ブロックするか、サービスを提供するかの選択を迫られるが、両者のトラフィックパターンは大きく異なるため、既存のキャッシュアーキテクチャでは一方に最適化するしかない。本記事では、AIトラフィックがCDNキャッシュに与える影響を分析し、新しいキャッシュ設計の方向性を探る。
AIクローラーと人間のトラフィックの根本的な違い

AIクローラーのトラフィックは、人間のブラウジング行動と比較して3つの主要な特徴を持つ。高ユニークURL比率、コンテンツの多様性、クロールの非効率性だ。
高ユニークURL比率と長尾コンテンツへのアクセス
Common Crawlの公開データによると、大規模Webクロールでは90%以上のページがコンテンツ的にユニークだ。AIクローラーは特定のコンテンツタイプに特化する傾向があり、技術文書、ソースコード、メディアファイル、ブログ記事など、目的に応じて異なるコンテンツを対象とする。
人間のユーザーがトップページや人気記事に集中するのに対し、AIクローラーはサイトの奥深くまで探索する。Wikipediaの利用データは、かつて「長尾」とされていたほとんどアクセスされないページが、現在では頻繁にリクエストされるようになったことを示している。これはCDNキャッシュ内のコンテンツ人気度分布そのものを変化させている。
クロールの非効率性と反復ループ
AIクローラーは必ずしも最適なクロールパスをたどらない。人気のあるAIクローラーからのフェッチのかなりの割合が404エラーやリダイレクトで終わる。これはURL処理の不備によることが多い。また、ブラウザ側のキャッシュやセッション管理を人間のユーザーと同じように利用しない。
AIエージェントは検索結果を改良するために反復ループを行うことがある。これはRAG(Retrieval-Augmented Generation)における一般的なパターンだ。この反復ループは、エージェントの精度を高める一方で、一貫して高いユニークアクセス比率(70%から100%)を維持する。つまり、各ループで以前に見たページを再訪するのではなく、常に新しいユニークなコンテンツを取得し続ける。
キャッシュへの直接的な影響
長尾アセットへのこのような反復アクセスは、人間のトラフィックが依存するキャッシュをかき回す。既存のプリフェッチや従来のキャッシュ無効化戦略は、クローラートラフィックの量が増加するにつれて効果が低下する。Cloudflareの単一ノードにおけるキャッシュヒット率は、AIクローラーを含む場合と含まない場合で明確な差が見られる。ヒット率の低下は、LRU(Least Recently Used)アルゴリズムがAIクローラーの反復スキャン行動に対処できていないことを示唆している。
実例から見るAIクローラーのインパクト

AIボットトラフィックの急増は、実際のWebサービスに深刻な影響を与えている。大規模サイトにおける影響と対応策は以下の通りだ。
Wikipedia:マルチメディア帯域幅の50%急増
モデル訓練のための画像一括スクレイピングにより、マルチメディア帯域幅使用量が50%急増した。Wikimediaは最終的にクローラートラフィックをブロックする対応を取った。
SourceHutとRead the Docs:サービス不安定化
ソースコードリポジトリをスクレイピングするLLMクローラーにより、サービス不安定化と速度低下が発生。Read the Docsでは、AIクローラーが大きなファイルを1日に数百回ダウンロードし、帯域幅の大幅な増加を引き起こした。両サービスとも一時的にクローラートラフィックをブロックし、IPベースのレート制限を実施した。
FedoraとDiaspora:人間ユーザーへの影響
Fedoraはパッケージミラーを再帰的にクロールするAIスクレイパーにより、人間ユーザーに対する応答速度が低下。Diasporaソーシャルネットワークは、robots.txtを尊重しない積極的なスクレイピングにより、応答速度の低下とダウンタイムを経験した。両者とも既知のボットソースからのトラフィックを地理的にブロックするなどの対応を取った。
これらの事例が示すのは、AIクローラーを単純にブロックするだけでは根本的な解決にならないということだ。よりスマートなキャッシュアーキテクチャがあれば、サイト運営者はAIクローラーにサービスを提供しつつ、人間ユーザーの応答時間を維持できる。
AI時代に向けたキャッシュ設計の新たな方向性

AIトラフィックの特性を考慮した新しいキャッシュ設計が必要とされている。主なアプローチは2つある。AIを意識したキャッシュアルゴリズムによるトラフィックフィルタリングと、AIクローラートラフィック専用の新しいキャッシュ層の追加だ。
ワークロード対応型キャッシュアルゴリズム
現在広く使用されているLRU(Least Recently Used)アルゴリズムは、汎用状況においてシンプルさ、低オーバーヘッド、有効性のバランスが取れている。しかし、人間とAIボットの混合トラフィックに対しては、別のキャッシュ置換アルゴリズムの選択が有効かもしれない。
初期実験では、SEIVEやS3FIFOといったアルゴリズムを使用することで、AIの干渉の有無にかかわらず、人間トラフィックが同じヒット率を達成できる可能性が示されている。さらに、ワークロードを直接意識した機械学習ベースのキャッシュアルゴリズムを開発し、リアルタイムでキャッシュ応答をカスタマイズする実験も進められている。これにより、より高速でコスト効率の高いキャッシュが実現できる。
トラフィック種別に応じた階層化キャッシュアーキテクチャ
長期的には、AIトラフィック専用の別個のキャッシュ層が最善の道となる。人間とAIのトラフィックをネットワークの異なる層に配置された別個の階層にルーティングするキャッシュアーキテクチャが考えられる。
人間トラフィックは、応答性とキャッシュヒット率を優先するCDN PoP(Point of Presence)のエッジキャッシュから引き続きサービスされる。一方、AIトラフィックのキャッシュ処理はタスクタイプによって変えることができる。
RAGやリアルタイム要約のようなライブアプリケーションを支えるAIクローラーでは、レイテンシが重要だ。これらのリクエストは、より大きな容量と適度な応答時間のバランスが取れたキャッシュにルーティングされるべきである。これらのキャッシュは鮮度を保ちつつも、人間向けキャッシュよりもわずかに高いアクセスレイテンシを許容できる。
訓練セットの構築や大規模コンテンツ収集ジョブに使用されるAIクローラーは、かなり高いレイテンシを許容し、時間的制約がない。これらのワークロードは、到達までに時間がかかる深いキャッシュ階層(オリジン側のSSDキャッシュなど)からサービスできる。あるいは、キューベースのアドミッションやレートリミッターを使用して遅延させ、バックエンドの過負荷を防ぐことも可能だ。これにより、インフラに負荷がかかっている場合にバルクスクレイピングを延期する機会も生まれる。
この記事のポイント
- AIクローラーは全ネットワークトラフィックの約3分の1を占め、そのアクセスパターンは人間のブラウジング行動と根本的に異なる。
- 高ユニークURL比率、長尾コンテンツへの集中アクセス、反復ループによるキャッシュチャーンが、従来のLRUキャッシュアルゴリズムの効果を低下させている。
- WikipediaやFedoraなどの大規模サイトでは、AIクローラーによる帯域幅急増やサービス不安定化が実際に発生し、多くのサイトがクローラーブロックに頼らざるを得なくなっている。
- 根本的な解決策として、SEIVEやS3FIFOなどの新しいキャッシュアルゴリズムの採用と、AIトラフィック専用の階層化キャッシュアーキテクチャの構築が検討されている。
- 今後のCDN設計では、人間トラフィックとAIトラフィックを分離し、それぞれの特性に最適化したキャッシュ戦略を適用することが重要になる。

・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Elementor 4.0リリース!Atomic基盤への刷新でサイト制作はどう変わるのか
世界で最も人気のあるWordPressページビルダーの一つであるElementorが、メジャーアップデートとなるバージョン4.0をリリースした。今回のアップデートは単なる機能の追加ではなく、エディタの根本的な基盤を「Atomic(アトミック)」な設計へと刷新する歴史的な転換点となっている。
Elementor 4.0では、新たにインストールされたサイトにおいて「Atomic Elements」「Variables」「Classes」「Components」といった新機能がデフォルトで有効化される。これにより、大規模なサイト制作においても一貫性を保ちながら、より高速で効率的なワークフローが実現可能だ。
既存のウェブサイトを運営しているユーザーにとっても、今回のアップデートは重要だ。アップデート直後に勝手に設定が変わることはないが、管理画面から手動で新しいAtomic機能を有効化することで、従来のウィジェットと新しいアトミック要素を同じページ内で組み合わせて使用できる。
Elementor 4.0がもたらす「Atomic」という新設計

Elementor 4.0の最大のトピックは「Atomic(アトミック)」という概念の導入だ。これは化学の「原子」を意味する言葉で、Webデザインにおいては、ボタンやテキストといった最小単位のパーツを組み合わせてサイトを構築する手法を指す。
なぜ「Atomic」なのか:設計の柔軟性と再利用性
従来のエディタでは、一つの「ウィジェット」の中にタイトルや説明文、ボタンなどがセットになっていた。しかし、Atomic基盤ではこれらが個別の独立した要素として扱われる。例えば、フォームを作成する場合、入力欄や送信ボタンを一つずつキャンバスに配置し、それぞれの配置やスタイルを自由に制御できるようになった。
この設計変更により、エンジニアがコードを書く際にパーツを共通化するような感覚で、ノーコードでのサイト制作が可能になる。一度作った最小単位のスタイルを他の場所で使い回すことが容易になり、サイト全体のデザインに統一感を持たせやすくなるのだ。
既存サイトへの影響と移行のステップ
既存のウェブサイトでElementor 4.0にアップデートしても、レイアウトが崩れる心配はない。新機能はデフォルトではオフになっており、必要に応じて手動で有効化する仕組みだ。WordPressの管理画面から「Elementor」>「Editor」>「Settings」へと進むことで、Atomicエディタの切り替えができる。
既存のページに新しいAtomic要素を追加することも可能だ。これにより、古いパーツを維持したまま、新しいパーツで少しずつリニューアルを進めるといった柔軟な運用ができる。互換性を保ちながら最新の技術を取り入れられる点は、大規模サイトの運営者にとって大きなメリットと言える。
CSS管理を劇的に変える「Classes」と「Variables」

Web制作において、数十個あるボタンのスタイルを一気に変更したい場面は多い。これまでは一つずつ修正するか、複雑な設定を駆使する必要があったが、Elementor 4.0では「Classes(クラス)」と「Variables(変数)」によってこの問題が解決される。
Classes:スタイルの共通化と一括更新
「Classes」は、複数の要素に適用できるスタイルの集合体だ。CSSのクラスと同じ概念で、特定のデザイン(例えば「赤い丸角ボタン」)をクラスとして登録し、それを各ボタンに適用する。もし後から「ボタンを青くしたい」と思えば、そのクラスの設定を一度変えるだけで、サイト内のすべての該当ボタンが瞬時に更新される。
さらに「Class Manager」という司令塔のような機能も追加された。ここでは、作成したすべてのグローバルクラスを一覧で確認し、名前の変更や削除、優先順位の入れ替えをドラッグ&ドロップで行える。複雑になりがちな大規模サイトのスタイル管理が、視覚的に整理できるようになった。
Variables:デザインシステムを支える変数の活用
「Variables」は、色やフォントサイズなどの特定の値を「変数」として定義する機能だ。例えば、ブランドカラーを「primary-color」という名前の変数として定義し、あらゆるクラスや要素の背景色に紐付ける。ブランドのロゴ変更などで色が少し変わった際も、変数の値を書き換えるだけでサイト全体に反映される。
変数の値が「青」の状態
変数を一箇所変えるだけで完了
このデモは、変数の値を変更することで、それを使用しているすべての箇所のデザインが自動的に同期される仕組みを視覚化したものだ。
再利用性を極める「Components」と「Atomic Forms」

Elementor Proユーザー向けには、さらに強力な「Components」と「Atomic Forms」が提供される。これらは制作時間を大幅に短縮し、クライアントへの引き渡し後の運用をスムーズにするための鍵となる機能だ。
Components:一箇所の修正を全ページに反映
「Components」を使うと、任意のレイアウトセクションを再利用可能なパーツとして保存できる。ヘッダーやフッター、共通のCTAバナーなどがその典型だ。一つのコンポーネントを編集すれば、サイト内のすべての設置箇所が自動で更新されるため、メンテナンス性が飛躍的に向上する。
特筆すべきは、コンポーネント内の特定のテキストや画像だけを「インスタンス(個別の設置箇所)」ごとに変更できる点だ。レイアウトやスタイルは共通のまま、中身のコンテンツだけをページに合わせてカスタマイズできる。これは、プロフェッショナルな制作現場で求められていた柔軟なワークフローそのものだ。
Atomic Forms:自由なレイアウトが可能になったフォーム
従来のフォームウィジェットは、一つのパネル内で項目を設定する形式だったため、レイアウトの自由度に限界があった。新しい「Atomic Forms」では、ラベル、入力欄、チェックボックス、送信ボタンがすべて独立した要素として扱われる。これらをエディタ上に自由に配置し、カラムを分けたり、間に画像やテキストを挟んだりすることが可能になった。
各フィールドは他のアトミック要素と同様に、前述のClassesやVariablesを適用できる。つまり、サイト全体のデザインシステムに完全に組み込まれたフォームを、視覚的な操作だけで構築できるようになったのだ。将来のアップデートでは、条件分岐ロジックなどの高度なワークフローも追加される予定だという。
パフォーマンスと操作性の向上:シングルDIVと統一スタイルタブ

Elementor 4.0は、見た目の機能だけでなく、内部構造の最適化にもメスを入れている。特に「シングルDIVラッパー」の採用は、サイトの表示速度に敏感な運営者にとって待望の改善と言えるだろう。
DOM構造のスリム化による表示速度の改善
DOM(Document Object Model)とは、ブラウザがWebページを読み込む際の設計図のようなものだ。これまでのElementorは、一つの要素を表示するために何重ものDIVタグ(箱のようなもの)を重ねていた。これが原因でコードが肥大化し、読み込み速度に影響を与えることがあった。
バージョン4.0のAtomic Elementsでは、この構造を大幅に簡略化し、単一のDIVラッパーで要素を出力する。これによりHTMLが軽量化され、ブラウザの処理負担が軽減される。結果として、ページの表示速度が向上し、Core Web Vitalsのスコア改善やSEOへのポジティブな影響が期待できる。
統一されたスタイルタブによる直感的な編集
操作性の面では「unified Style Tab(統一スタイルタブ)」が導入された。従来はウィジェットごとに異なるスタイル設定項目が存在していたが、新しいAtomic Elementsではすべての要素で共通のスタイルタブが使用される。一度使い方を覚えれば、どの要素に対しても同じ感覚でデザインを調整できる。
「全般タブ」にはコンテンツや機能の設定が集約され、「スタイルタブ」にはすべての視覚的なオプションが並ぶ。この整理されたインターフェースにより、編集作業中の迷いが減り、制作のスピードアップにつながるはずだ。
高度なインタラクションとレスポンシブ制御

現代のWebサイトには、デバイスごとの細かな調整や、ユーザーの操作に応じた動きが欠かせない。Elementor 4.0では、これらの「動き」と「見え方」の制御がさらに進化している。
全プロパティがレスポンシブ対応に
これまでのエディタでは、特定の項目(文字サイズなど)しかレスポンシブ設定ができなかった。しかし、Atomic Elementsでは、ほぼすべてのスタイルプロパティがデバイスごとに調整可能だ。デスクトップ、タブレット、モバイルの各モードを切り替えるだけで、それぞれの画面サイズに最適化したデザインを個別に作り込める。
例えば、デスクトップでは影をつけて浮かせている要素を、モバイルでは影を消してフラットにするといった調整も、コードを一行も書かずに完結する。例外のないレスポンシブ制御が可能になったことで、モバイルユーザーの体験をより高いレベルで磨き上げることができる。
ユーザーの動きに反応する動的な演出
Pro版で提供される「Advanced Interactions」では、スクロールやホバー、クリックといったユーザーの行動をトリガーにした複雑なアニメーションを設計できる。単なる登場アニメーションではなく、ユーザーの動きに連動して要素が変化する「動的な体験」を生み出せるのが特徴だ。
また、これらのインタラクションもブレイクポイント(画面サイズの境界線)ごとに設定できる。PCではリッチなスクロール演出を見せつつ、スペックの限られるモバイルではアニメーションを簡略化してパフォーマンスを優先するといった、賢い使い分けが可能になっている。
独自分析:Elementor 4.0が示す「ノーコード制作」の未来

Elementor 4.0の登場は、ページビルダーが単なる「便利なツール」から「プロフェッショナルな開発プラットフォーム」へと進化したことを象徴している。ClassesやVariablesの導入は、モダンなフロントエンド開発のベストプラクティスをノーコードの世界に持ち込んだものと言える。
デザインツールとの境界がなくなる
今回のアップデートで導入されたComponentsやVariablesといった概念は、Figmaなどのデザインツールですでに一般的となっているものだ。デザイナーが作成したデザインシステムを、そのままの構造でElementor上に再現できるようになった意義は大きい。デザインと実装の間のギャップが埋まり、制作チーム全体の生産性が向上するだろう。
パフォーマンス至上主義への回答
これまでページビルダーは「多機能だが重い」という批判を受けることが多かった。しかし、シングルDIVラッパーによるDOMの軽量化は、その批判に対する強力な回答だ。軽量なコードと高度なデザイン自由度を両立させたことで、Elementorは再び市場での競争力を高めたとの見方が強い。
今後、Web制作の現場では「いかに効率よく、かつ高品質なサイトを維持するか」がさらに重視される。Elementor 4.0のAtomicな基盤は、その要求に応えるための強力な武器になるはずだ。既存ユーザーは、まずはテスト環境で新機能を試し、その圧倒的な自由度と管理のしやすさを体感してみることを勧める。
この記事のポイント
- Elementor 4.0は「Atomic(アトミック)」な新基盤を採用し、要素を最小単位で管理可能になった
- ClassesとVariablesにより、サイト全体のスタイルを一括管理・更新できるデザインシステムを構築できる
- DOM構造のスリム化(シングルDIV)により、ページの読み込み速度とSEOスコアの向上が期待できる
- Atomic FormsやComponentsにより、自由度の高いレイアウトと高い再利用性を実現した
- 全プロパティのレスポンシブ対応と高度なインタラクション機能で、デバイスごとに最適な体験を提供できる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Cloudflare Gen13サーバーの設計思想 192コアAMD EPYCで2倍のスループットを実現
Cloudflareが第13世代サーバー「Gen13」の設計詳細を公開した。192コアのAMD EPYC Turin 9965プロセッサを搭載し、前世代比で最大2倍のスループットを実現している。
Gen13は768GBのDDR5-6400メモリ、24TBのPCIe 5.0 NVMeストレージ、デュアル100GbEネットワークインターフェースを備える。特に注目すべきは、Rustで書き直された新リクエスト処理層「FL2」への移行により、大容量L3キャッシュへの依存を解消した点だ。これによりコア数を2倍に増やしながら、レイテンシの増加を抑えることに成功した。
この記事では、Cloudflare Blogの記事を基に、Gen13サーバーの各コンポーネント選択の背景と設計思想を解説する。
CPU設計の転換:キャッシュからコアへ

Gen13の最大の特徴は、AMD EPYC Turin 9965プロセッサの採用だ。192コア/384スレッドを備え、前世代のGen12(96コア)からコア数を2倍に増やしている。
L3キャッシュ依存からの脱却
興味深いのは、コア数が2倍になった一方で、コアあたりのL3キャッシュ容量が83.3%減少している点だ。Gen12のAMD EPYC Genoa-X 9684Xはコアあたり12MBのL3キャッシュを持っていたが、Gen13のTurin 9965はコアあたり2MBしかない。
この一見逆行するような選択の背景には、Cloudflareのソフトウェアスタックの根本的な変化がある。Cloudflareはリクエスト処理層をFL1からFL2へ移行した。FL2はRustで書き直された新アーキテクチャで、大容量L3キャッシュへの依存度が大幅に低減されている。
Cloudflare Blogの記事によると、FL2ワークロードはコア数に対してほぼ線形にスケールする特性を持つ。このため、コア数を増やすことが直接的なスループット向上につながる。L3キャッシュ容量の減少による潜在的なパフォーマンス低下は、FL2の効率的なメモリ使用によって相殺された。
3つの候補から9965を選んだ理由
Cloudflareのエンジニアチームは、Gen13のCPU候補として3つのAMD Turinプロセッサを評価した。128コアの9755、160コアの9845、そして192コアの9965だ。
評価の結果、9965が選ばれた理由は明確だ。生産環境でのテストにおいて、9965の192コアは最高の総合リクエスト処理性能を示した。さらに、500WのTDP(熱設計電力)における性能/ワット効率も優れており、ラックレベルでの総所有コスト(TCO)が最も低くなると判断された。
運用面でも、192コアという高密度構成はメリットがある。同じ計算能力を提供するために必要なサーバー台数が減るため、プロビジョニング、パッチ適用、監視にかかる運用オーバーヘッドを削減できる。
メモリとストレージの拡張

12チャネルDDR5-6400で帯域幅33%向上
CPUコア数が2倍になったことで、メモリサブシステムにもより高い要求が課せられた。Gen13は12個のDDR5-6400メモリチャネルすべてを活用する構成を採用している。
各チャネルに64GB DIMMを1枚ずつ配置する「1DIMM per channel」構成で、合計768GBのメモリ容量を実現。ピークメモリ帯域幅はソケットあたり614GB/sに達し、Gen12から33.3%向上した。
すべてのチャネルを均等に使用する構成は、メモリインターリーブの観点から重要だ。AMD Turinプロセッサは、同じDIMMタイプ、同じ容量、同じランク構成のメモリチャネル間でインターリーブを行う。インターリーブにより、連続したメモリアクセスが単一のチャネルではなくすべてのチャネルに分散され、実効的なメモリ帯域幅が向上する。
コアあたり4GBの「適正容量」を維持
メモリ容量の決定において、Cloudflareは「コアあたり4GB」という比率を維持することを選択した。Gen12でも同じ比率が採用されており、実績のあるバランスだ。
設計初期には、コアあたり4GBから6GBの範囲が検討された。192コアの場合、768GBから1152GBに相当する。実際のDIMM容量の粒度を考慮すると、選択肢は12x48GB(576GB)、12x64GB(768GB)、12x96GB(1152GB)の3つだった。
12x48GB構成は容量が不足し、メモリを多く消費するワークロードを飢餓状態にするリスクがある。一方、12x96GB構成はコアあたり50%の容量増加となるが、電力消費の増加とコストの大幅な上昇(現在のメモリ価格は1年前の10倍)が問題だ。
12x64GBの768GB構成は、コアあたり4GBという実績のある比率を維持しつつ、サーバーあたりの総容量をGen12の2倍に拡大する。FL2はFL1と比べてメモリ使用効率が大幅に向上しており、ソフトウェアスタックの移行によって生じた余剰容量が、今後数年間のCloudflareの成長を支えるヘッドルームとなる。
ストレージ:PCIe 5.0と容量50%増
ストレージサブシステムも大幅に強化された。Gen13はPCIe Gen 5.0 NVMeドライブを採用し、レイテンシの改善と増大するストレージ帯域幅要求に対応する。
物理的なストレージ容量も、3台のNVMeドライブにより24TBに拡張された。Gen12サーバーは4つのE1.Sストレージスロットを備えていたが、実際に使用されていたのは2スロットのみだった。Gen13では同じ4スロット設計を維持しつつ、3スロットに8TBドライブを実装している。
3台目のドライブ追加により、サーバーあたりのストレージ容量は16TBから24TBへ50%増加した。これはCDNキャッシュ性能の維持・向上に加え、Durable Objects、Containers、Quicksilverサービスなどの成長予測を支えるためだ。
さらにGen13シャーシには、最大10台のU.2 PCIe Gen 5.0 NVMeドライブを収容できるフロントドライブベイが追加された。この設計により、同じシャーシをコンピュートプラットフォームとストレージプラットフォームの両方で使用できる柔軟性が生まれる。必要に応じてコンピュートSKUをストレージSKUに変換することも可能だ。
ネットワークと電源の刷新

8年ぶりのネットワークアップグレード:25GbEから100GbEへ
Gen13で最も大きな変化の一つが、ネットワークインターフェースの刷新だ。8年以上にわたりCloudflareフリートの基盤となってきたデュアル25GbEから、デュアル100GbEへと移行する。
この変更の必要性は明白だ。192コアという高性能CPUがより多くのリクエストを処理できるようになると、ネットワーク帯域幅がボトルネックになる。実際、世界中のコロケーション施設から収集した1週間分の本番データによると、Gen12ではポートあたりのP95帯域幅が利用可能帯域幅の50%を一貫して超えていた。
Gen13ではサーバーあたりのスループットが2倍になるため、NIC帯域幅が飽和するリスクが高まる。100GbEへの移行は、このボトルネックを解消するための必然的な選択だ。
50GbEではなく100GbEを選んだ理由は、産業界の経済性にある。50GbEトランシーバーの市場規模は依然として小さく、サプライチェーン上のリスクが高い。デュアル100GbEポートによりサーバーあたり200Gb/sの集約帯域幅を実現し、今後数年間のトラフィック成長に対応できる将来性も確保した。
電源:800Wから1300Wへ拡張
コンピュート能力とネットワーク能力の向上に伴い、サーバーの電力エンベロープも自然に拡大した。Gen13は必要な電力を供給するため、より大型の電源装置を搭載する。
Gen12ノードは800W 80 PLUS Titanium CRPS(共通冗長電源装置)で十分に動作していたが、Gen13では1300W 80 PLUS Titanium CRPSを選択した。
Gen13の通常動作時の電力消費は850Wに達する。Gen12の600Wから250Wの増加だ。主な要因は、TDPが400Wから500Wに上がったCPU、メモリ容量の2倍化、追加のNVMeドライブである。
1000Wではなく1300Wを選んだ理由は、現在のPSUエコシステムに1000Wの高効率オプションがほとんどないためだ。サプライチェーンの信頼性を確保するために、産業界標準の次の階層である1300Wに移行した。
EU Lot 9規制は、欧州連合に展開するサーバーが、負荷10%、20%、50%、100%において規制で指定された効率率閾値を満たす電源装置を備えることを要求する。この閾値は80 PLUS Power Supply認証プログラムのチタニウムグレードPSU要件と一致する。Gen13ではEU Lot 9に完全準拠するためチタニウムグレードPSUを選択し、欧州のデータセンターをはじめとする全世界での展開を可能にした。
セキュリティと管理の継続性

Project Argus DC-SCM 2.0の継承
Gen13では、Gen12で導入された管理機能とセキュリティ関連コンポーネントをマザーボードから分離するアーキテクチャを維持する。これらは「Project Argus」データセンターセキュアコントロールモジュール2.0(DC-SCM 2.0)に集約されている。
DC-SCMモジュールには、サーバーのセキュリティの中枢となる重要なコンポーネントが収められている。
- 基本入出力システム(BIOS)
- ベースボード管理コントローラ(BMC)
- ハードウェアルートオブトラスト(HRoT)とTPM
- 冗長性のためのデュアルBMC/BIOSフラッシュチップ
このアーキテクチャをGen13でも継続する決定は、前世代で実証されたセキュリティ上の利点に基づく。管理機能を専用モジュールにオフロードすることで、以下のメリットを維持できる。
迅速な回復機能は、デュアルイメージ冗長性により、偶発的な破損や悪意のある更新が検出された場合にBIOS/UEFIおよびBMCファームウェアをほぼ瞬時に復元できる。
物理的耐性については、Gen13シャーシでは侵入検知メカニズムをシャーシの平坦な端からさらに遠ざけ、物理的な傍受を難しくしている。
PCIe暗号化は、Gen10プラットフォームから有効化されていたCPUとメモリ間の暗号化(TSME)に加え、AMD Turin 9965プロセッサがPCIeトラフィックにも暗号化を拡張する。これにより、システム内のすべてのバスを通過するデータが転送中も保護される。
運用的一貫性も重要だ。Gen12管理スタックを維持することで、セキュリティ監査、展開、プロビジョニング、運用標準手順が完全に互換性を保つ。
ドロップインアクセラレータサポートの強化
フリートのモジュール性維持は、Cloudflareのサーバー設計における中核的な要件だ。この要件により、Cloudflareは2024年にGPUを世界中の100以上の都市に迅速に改造・展開できた。
Gen13では、高性能PCIeアドインカードのサポートを継続する。Gen13の2Uシャーシレイアウトは更新され、より要求の厳しい電力と熱要件をサポートするように構成されている。Gen12がシングル幅GPU1枚に制限されていたのに対し、Gen13アーキテクチャはダブル幅PCIeカード2枚をサポートする。
この記事のポイント
- Cloudflare Gen13サーバーは192コアAMD EPYC Turin 9965を採用し、前世代比最大2倍のスループットを実現
- FL2(Rust製新リクエスト処理層)への移行により、大容量L3キャッシュへの依存を解消。コア数増加による性能向上を可能にした
- メモリは12チャネルDDR5-6400構成で768GBを実装。帯域幅33%向上とコアあたり4GBの適正容量を維持
- ネットワークは8年ぶりに刷新。デュアル25GbEからデュアル100GbEへ移行し、帯域幅ボトルネックを解消
- セキュリティはProject Argus DC-SCM 2.0アーキテクチャを継承。PCIe暗号化を追加し、データ転送中の保護を強化
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Kubernetesの1行修正で年600時間を削減——Cloudflareが直面したPVマウントの罠
Kubernetesの設定ファイルをたった1行書き換えるだけで、年間600時間ものエンジニア工数を削減した事例がある。Cloudflare(クラウドフレア)のインフラチームが直面したこの問題は、システムの規模が拡大するにつれて静かに忍び寄る「デフォルト設定の罠」を浮き彫りにした。
原因は、ストレージの権限管理を行うKubernetesの標準的な振る舞いにあった。数百万ものファイルを抱えるボリュームにおいて、再起動のたびに30分ものダウンタイムが発生していた事態を、彼らはどのように特定し、解決したのだろうか。
本記事では、CloudflareのエンジニアであるBraxton Schafer氏が公開したデバッグの過程と、大規模なKubernetes運用において見落としがちなパフォーマンスのボトルネックについて詳しく解説する。
Atlantisの再起動がなぜか「30分」もかかる謎

Cloudflareでは、Terraform(テラフォーム)によるインフラ管理の自動化ツールとして「Atlantis(アトランティス)」を利用している。Terraformはコードでインフラを定義するツールだが、Atlantisを導入することで、GitHubやGitLabのプルリクエスト上で実行計画(Plan)の確認や適用(Apply)が可能になる。
AtlantisはKubernetes上で「StatefulSet(ステートフルセット)」として動作しており、リポジトリの状態を保持するためにPV(Persistent Volume / 永続ボリューム)を使用している。StatefulSetとは、Pod(ポッド)の再起動後もデータの永続性を保証するための仕組みだ。
頻繁な再起動がエンジニアの時間を奪う
問題は、このAtlantisを再起動するたびに発生していた。新しいプロジェクトの設定を読み込ませたり、認証情報を更新したりするために、Cloudflareでは月に約100回ほどの再起動を行っていた。しかし、再起動を開始してからPodが正常に立ち上がるまで、毎回30分もの時間がかかっていたという。
この間、エンジニアはインフラの変更を行うことができず、作業が完全にブロックされてしまう。月100回の再起動で毎回30分待機が発生すれば、月間で50時間、年間では600時間もの時間が「ただの待ち時間」として消えていく計算だ。これは、一人のエンジニアが数ヶ月間フルタイムで働く時間に匹敵する大きな損失である。
「inode不足」がきっかけで表面化した問題
この遅延が決定的な問題として認識されたのは、ストレージの「inode(アイノード)」が枯渇した際だった。inodeとは、ファイルシステム上でファイルやディレクトリの情報を管理するためのデータ構造だ。ファイルが大量に作成されると、ディスク容量が残っていてもinodeが足りなくなり、新しいファイルが作成できなくなる。
Cloudflareの環境では、ファイルシステムを拡張することでしかinodeを増やせない仕様だった。拡張を反映させるにはPodの再起動が必要となり、そのたびに30分のダウンタイムが発生する。チームは当初、アラートの通知設定を調整して「見かけ上の問題」を回避することも検討したが、根本的な原因の調査に乗り出すことを決めた。
Kubernetesのログを深掘りして見えてきたボトルネック
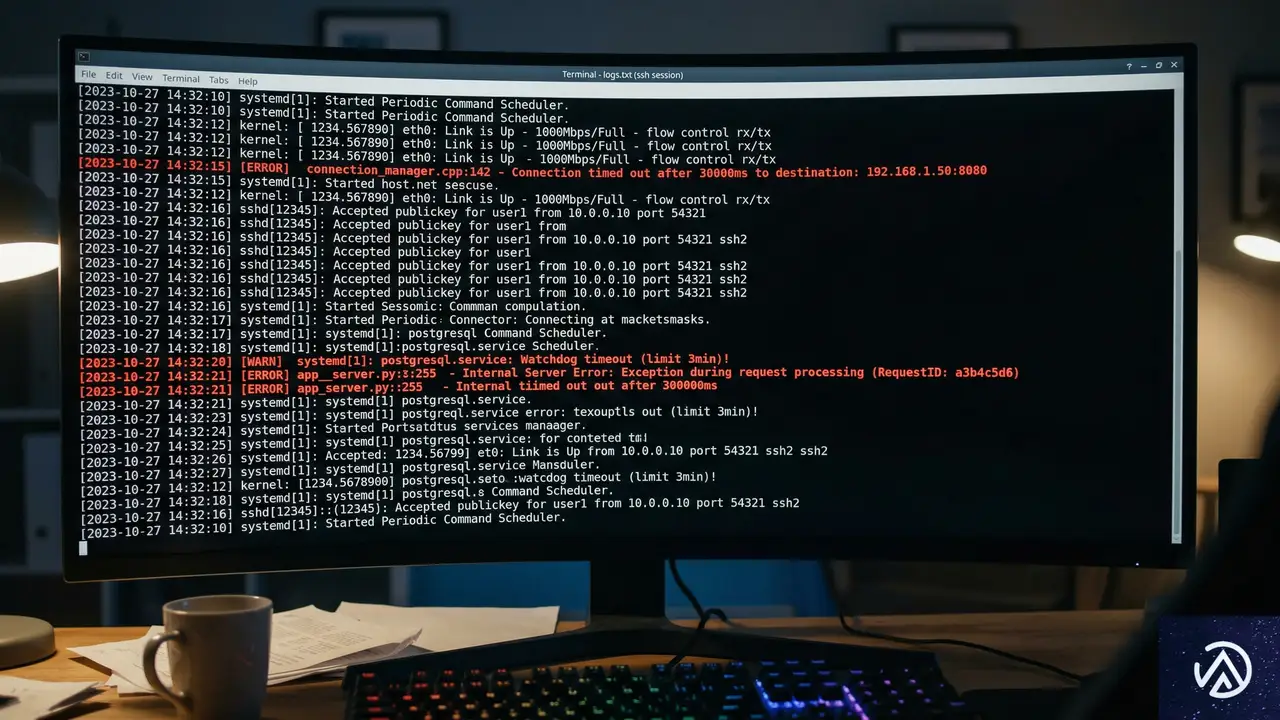
調査を開始したBraxton Schafer氏は、まずkubectl rollout restartコマンドを実行し、新しいPodが立ち上がる様子を観察した。Pod自体はすぐにスケジュールされるものの、ステータスが「Init(初期化中)」のまま30分間も停止していることが判明した。
Podのイベントログを確認しても、イメージのプルが開始されるまでに不可解な空白時間があることしかわからなかった。そこで氏は、より低レイヤーのログを確認するため、各ノードで動作するコンポーネント「kubelet(クブレット)」のログを調査した。
kubeletのログに隠された「空白の時間」
kubeletは、各ノードでPodの実行を管理し、ボリュームのマウントなどを制御する重要なエージェントだ。システム管理ツールであるKibana(キバナ)を使ってログを分析したところ、PVのマウント自体は成功しているものの、その直後にタイムアウトエラーが発生し、リトライを繰り返している様子が記録されていた。
ログには「context deadline exceeded(処理時間の制限を超過した)」というメッセージが並んでいた。何らかの処理が異常に時間を要しており、Kubernetesの監視機構がそれを「失敗」とみなして処理を中断、再試行するというループに陥っていたのだ。
数百万個のファイルが引き起こす権限変更の罠
さらに詳細なログを追うと、決定的なメッセージが見つかった。そこには「Setting volume ownership(ボリュームの所有権を設定中)」という記述があった。実はこれが、30分もの時間を浪費させていた真犯人だった。
Kubernetesには、Pod内のプロセスがボリュームにアクセスできるように、マウント時に所有権を自動で調整する機能がある。具体的には、PodのsecurityContextで指定されたfsGroupのIDに合わせて、ボリューム内の全ファイルに対して再帰的にchgrp(グループ変更)を実行する。Atlantisのようなツールは運用期間が長くなるほど管理するファイル数が増大し、Cloudflareの環境では数百万個ものファイルが蓄積されていた。高速なストレージであっても、数百万個のファイルに対して一つずつ権限を確認・変更していく処理には膨大な時間がかかるのは必然だ。
わずか1行の修正でパフォーマンスが劇的に改善
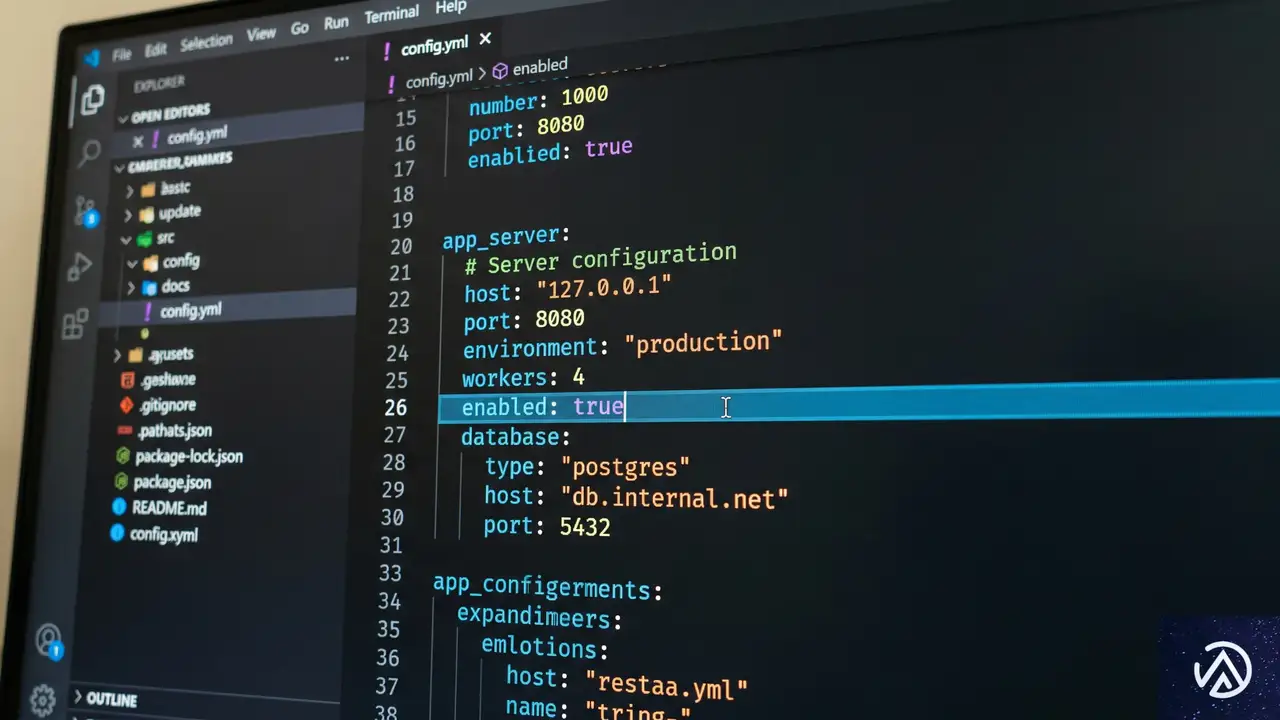
原因が「再帰的な権限変更」であると特定できれば、解決策は非常にシンプルだった。Kubernetes 1.20以降、この振る舞いを制御するための新しい設定項目が追加されている。それがfsGroupChangePolicy(エフエスグループ・チェンジ・ポリシー)だ。
デフォルトでは、このポリシーはAlways(常に実行)に設定されている。つまり、Podが起動するたびに、すでに権限が正しく設定されていようがいまいが、すべてのファイルをスキャンして権限を上書きしようとする。これが大規模なボリュームにおいて致命的な遅延を引き起こす。
fsGroupChangePolicyの設定とは
解決策は、このポリシーをOnRootMismatch(ルートディレクトリが不一致の場合のみ実行)に変更することだ。この設定にすると、Kubernetesはまずボリュームのルートディレクトリの権限を確認する。もしルートの権限がすでに正しく設定されていれば、配下のファイルに対する再帰的なスキャンをスキップする。
spec:
template:
spec:
securityContext:
fsGroupChangePolicy: OnRootMismatchこの1行をマニフェストファイルに追加するだけで、権限変更のプロセスが大幅に簡略化される。Cloudflareのケースでは、これまで30分かかっていた再起動時間が、わずか30秒にまで短縮された。実に60倍の高速化だ。
30分から30秒へ、驚異的な短縮効果
この修正により、エンジニアがデプロイの待ち時間に拘束されることがなくなった。また、再起動が長引くことによって発生していた「Podが正常に起動しない」という偽のアラートに、オンコール担当者が夜中に叩き起こされることもなくなったという。技術的には極めて単純な変更だが、組織全体の生産性に与えたインパクトは計り知れない。
大規模システムにおける「デフォルト設定」の落とし穴

今回の事例から学べる最も重要な教訓は、Kubernetesの「安全なデフォルト設定」が、規模の拡大とともに牙を向く可能性があるということだ。fsGroupによる自動的な権限変更は、初心者が権限エラーに悩まされないようにするための親切な機能として設計されている。
しかし、エンタープライズレベルの運用において、数テラバイトのデータや数百万のファイルを扱うようになると、その「親切心」がシステムの可用性を損なう要因へと変わる。これは、小規模なプロジェクトでは決して表面化しない問題だ。
小規模なら問題ないが、スケールするとボトルネックになる
多くのインフラエンジニアは、マウントが遅い場合にネットワークやストレージ装置の性能を疑う。しかし、今回のケースのように「OSレベルのファイル操作」がバックグラウンドで走っていることに気づくには、深いオブザーバビリティ(観測性)が必要だ。Braxton Schafer氏が、Kubernetesのイベントログだけでなく、kubeletのシステムログまで掘り下げたことが早期解決の鍵となった。
SRE的視点での教訓
SRE(Site Reliability Engineering / サイト信頼性エンジニアリング)の観点では、「なぜシステムはこのように振る舞うのか?」という問いを持ち続けることの重要性が再確認された。30分の待ち時間を「そういうものだ」と受け入れてしまえば、年間600時間の損失は永遠に解消されなかっただろう。
もし読者の環境でも、特定のPodの起動が異常に遅かったり、ボリュームをマウントする際にInitコンテナで止まっていたりする場合は、securityContextの設定を見直してみる価値がある。特に、大量の静的ファイルを保持するCMSや、データベースのバックアップファイルを扱うPodなどは、同様の問題を抱えている可能性が高い。
この記事のポイント
- 原因の特定: Atlantisの再起動に30分かかっていたのは、Kubernetesがマウント時に全ファイルの所有権を再帰的に変更していたため。
- 1行の修正:
fsGroupChangePolicy: OnRootMismatchを設定することで、不要な権限変更をスキップできる。 - 劇的な改善: Cloudflareはこの修正により、再起動時間を30分から30秒に短縮し、年間600時間の工数を削減した。
- 教訓: 安全のためのデフォルト設定が、大規模環境では深刻なパフォーマンス低下を招くことがある。
- 推奨アクション: 大容量PVを使用するPodでは、
securityContextの設定を監査し、不必要な再帰処理を避ける設定を検討すべきだ。
出典
- Cloudflare Blog「A one-line Kubernetes fix that saved 600 hours a year」(2026年3月26日)
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

WordPressレスポンシブ画像の仕組みと最適化術——表示速度を劇的に改善する方法
Webサイトを閲覧するデバイスは、27インチの巨大なモニターから数年前のスマートフォンまで多岐にわたる。すべてのユーザーに対して同じ1200pxの画像を配信することは、モバイルユーザーの帯域を無駄に消費し、表示速度を著しく低下させる要因となる。
WordPressにはバージョン4.4からレスポンシブ画像のサポートが標準で組み込まれているが、デフォルト設定のままでは十分な最適化が行われていないケースが多い。本稿では、WordPressがどのように画像を処理しているのか、そしてさらにパフォーマンスを引き出すための具体的な手法について解説する。
画像の最適化は、Googleの検索評価指標である「Core Web Vitals(コアウェブバイタル)」のスコア改善に直結する。特に、ページ内で最も大きなコンテンツの表示時間を指す「LCP(Largest Contentful Paint)」の改善において、レスポンシブ画像の適切な理解は不可欠だ。
レスポンシブ画像がサイト運営に不可欠な理由

レスポンシブ画像とは、閲覧者のデバイスや画面解像度に合わせて、最適なファイルサイズと解像度の画像を自動的に選択して配信する仕組みを指す。単にCSSで表示サイズを縮小するのではなく、物理的なファイルそのものを切り替える点が重要だ。
データ通信量の節約とユーザー体験の向上
モバイル端末で閲覧しているユーザーに対し、デスクトップ用の1MBを超える画像を送信するメリットはない。80KB程度の縮小版で十分きれいに見える場合、不要なデータ転送は読み込み待ち時間を増大させるだけだ。レスポンシブ画像を採用することで、各訪問者のコンテキストに合わせた最適なデータ量を届けることが可能になる。
Core Web Vitals(LCP)への直接的な影響
Googleの「Core Web Vitals」の中でも、LCPは画像の読み込み速度に大きく左右される。画像が重いページでは、LCPのスコアが悪化し、検索順位やユーザーの離脱率に悪影響を及ぼす。元記事の著者は、オーバーサイズの画像配信がLCPスコアを低下させる最も直接的な要因の一つであると指摘している。
WordPress標準機能による自動処理の仕組み

WordPressは、メディアライブラリに画像をアップロードした際、自動的に複数のサイズバリエーションを作成する。これにより、ユーザーが手動でリサイズ画像を用意する手間を省いている。
自動生成される5つの標準サイズ
デフォルトでは、以下のサイズが生成される仕組みだ。
- サムネイル (Thumbnail): 150x150px(切り抜き)
- 中 (Medium): 最大幅/高さ 300px
- 中大 (Medium Large): 最大幅 768px
- 大 (Large): 最大幅/高さ 1024px
- フルサイズ (Full): アップロードした元の画像
srcset属性とsizes属性によるブラウザへの指示
WordPressはこれらのバリエーションを利用し、HTMLの<img>タグにsrcsetとsizesという2つの属性を自動付与する。srcsetは利用可能な画像リストとその横幅をブラウザに伝え、sizesは画面サイズごとに画像がどのくらいの幅で表示されるべきかのヒントを与える役割を持つ。
<img src="image-1024x683.jpg"
srcset="image-300x200.jpg 300w,
image-768x512.jpg 768w,
image-1024x683.jpg 1024w"
sizes="(max-width: 600px) 100vw,
(max-width: 1024px) 768px,
1024px"
alt="サンプル画像">このコードにより、ブラウザは自身の画面幅や通信環境を確認し、リストの中から最適な画像を1つ選んでダウンロードする。この処理はすべてブラウザ側で完結するため、サーバー側に負荷をかけることなく高速な切り替えが実現される。
標準機能だけでは解決できない注意点

WordPressの自動機能は便利だが、万能ではない。使用しているテーマやブラウザの挙動によっては、期待通りに動作しないケースがある。
テーマによるsizes属性の制御不足
WordPressが生成するデフォルトのsizes属性はあくまで予測値だ。実際の表示幅はテーマのレイアウト(サイドバーの有無や最大コンテンツ幅など)に依存する。適切に設計されていないテーマでは、ブラウザが「実際よりも大きな画像が必要だ」と誤認し、必要以上に大きなファイルを読み込んでしまうことがある。記事によれば、古いテーマや安価なテーマではこの最適化が不十分な場合が多いという。
ブラウザ間での挙動の差異
すべてのブラウザがsrcsetを同じように解釈するわけではない。多くのブラウザはビューポート幅に近い画像を選択するが、一部のブラウザはキャッシュされている大きな画像を優先することもある。もし、モバイルとデスクトップで全く異なる構図の画像(アートディレクション)を見せたい場合は、srcsetではなく<picture>要素を使用すべきだとの見方がある。
画像寸法の明示によるレイアウトシフト防止
レスポンシブ画像であっても、widthとheight属性の指定は必須だ。これがないと、画像が読み込まれる前にブラウザが描画スペースを確保できず、読み込み完了時にコンテンツがガタつく「CLS(Cumulative Layout Shift)」が発生する。WordPressのブロックエディタで挿入した画像には通常これらの属性が付与されるが、カスタムコードで画像を記述する際は注意が必要だ。
Retina・高解像度ディスプレイへの対応戦略

現代のデバイスの多くは、物理的なピクセル数よりも高い解像度を持つ高DPI(Retina)ディスプレイを搭載している。これらに対応するには、通常の2倍の画素密度を持つ画像が必要になる。
「2x」画像の必要性と画質のトレードオフ
Retinaディスプレイで通常の解像度の画像を表示すると、少しぼやけた印象を与える。これを防ぐには、表示サイズの2倍の解像度を持つ画像を用意し、srcsetに含める必要がある。しかし、2倍の解像度はファイルサイズの大幅な増加を招くため、画質とパフォーマンスのバランスを慎重に検討しなければならない。
プラグインによるRetina対応の自動化
WordPress標準ではRetina専用のバリエーションは作成されない。そのため、専用のプラグインを導入して2倍サイズの画像を自動生成し、srcsetに追加する手法が一般的だ。これにより、高解像度デバイスを使用しているユーザーにのみ、鮮明な画像を届けることが可能になる。
さらに一歩進んだ画像最適化のテクニック

標準のレスポンシブ機能に加え、プラグインや外部サービスを組み合わせることで、最適化を極限まで高めることができる。
画像圧縮プラグインの併用
WordPressは複数のサイズを作成するが、それらを「圧縮」する機能は持っていない。元の画像が高画質(低圧縮)であれば、生成されるすべてのバリエーションも重いままとなる。画像圧縮プラグインを導入することで、生成されたすべてのサイズを一括で軽量化し、データ転送量を劇的に削減できる。
アダプティブ画像(動的配信)の導入
WordPressの静的なリサイズには限界がある。例えば、コンテナ幅が550pxの場合でも、WordPressは768pxのバリエーションを配信せざるを得ない。より高度なソリューションでは、リクエスト時にブラウザのコンテナサイズを分析し、その場でぴったりなサイズの画像を生成・配信する「アダプティブ画像」の手法がとられる。これはCDN(コンテンツ・デリバリ・ネットワーク)と組み合わせて運用されることが多く、究極のレスポンシブ配信と言えるだろう。
この記事のポイント
- レスポンシブ画像はCSSの縮小ではなく、デバイスに最適な「ファイル」を切り替える仕組みである
- WordPress 4.4以降は
srcsetとsizesを自動生成するが、テーマの設定次第で効果が半減する - LCPスコアを改善するには、適切な画像サイズ選択と圧縮プラグインの併用が不可欠だ
- Retina対応や動的なサイズ生成には、標準機能以外のプラグインや外部サービスの活用が有効である
- ブラウザの「検証」ツールを使い、実際に意図したサイズの画像が読み込まれているか定期的に確認すべきだ
出典
- WP Mayor「Responsive Images in WordPress: What You Need to Know」(2026年3月26日)
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

WordPress高速化の正攻法。パフォーマンスオーディットで原因を特定する手順
WordPressサイトの表示速度が低下した際、多くの運営者は反射的にキャッシュプラグインを導入しようとする。しかし、根本的な原因を特定せずにツールを重ねる手法は、期待したほどの効果を生まないことが多い。元記事の著者であるMark Zahra氏は、場当たり的な対応ではなく、体系的な「パフォーマンスオーディット(性能調査)」の重要性を説いている。
パフォーマンスオーディットとは、適切なツールを正しい順序で使用し、サイトの遅延を招いている真の要因を突き止める作業だ。本稿では、無料ツールのみを用いて、コードに触れることなくサイトのボトルネックを特定する具体的なステップを解説する。
このプロセスを実践することで、サーバーの応答速度、画像の最適化不足、あるいは特定のプラグインによる負荷など、改善すべき優先順位が明確になるはずだ。
Google Search Consoleで「現場のデータ」を把握する

高速化調査の第一歩は、スピードテストツールを回すことではない。まずはGoogle Search Console(グーグル・サーチコンソール)を開き、左サイドメニューの「エクスペリエンス」内にある「ウェブに関する主な指標」を確認することから始めるべきだ。
多くのガイドがこの手順を飛ばしてシミュレーションテストに移行してしまうが、それは誤りだと指摘されている。Search Consoleが提供するのは「フィールドデータ」と呼ばれるもので、過去28日間に実際の訪問者が体験したパフォーマンスの記録である。Googleが検索順位の決定に使用するのは、シミュレーション値ではなく、この実測データの方だ。
CWV(コアウェブバイタル)のステータスを確認する
レポートでは、ページが「良好」「改善が必要」「不良」の3つのカテゴリに分類される。ここで重要なのは、どの指標が問題を引き起こしているかを特定することだ。例えば、LCP(Largest Contentful Paint / 最大視覚コンテンツの表示時間)に問題があるサイトと、CLS(Cumulative Layout Shift / 視覚的な安定性)に問題があるサイトでは、必要な対策が全く異なる。
LCPとは、ページ内で最も大きなコンテンツ(通常はヒーロー画像や見出し)が表示されるまでの時間を指す。一方、CLSは読み込み中にレイアウトがガタつく度合いを示す指標だ。これらを区別せずに「なんとなく高速化プラグインを入れる」だけでは、特定の問題を解決することはできない。
なお、アクセス数が少ないサイトや公開直後のサイトでは、データが表示されない場合がある。その場合は、次のステップであるPageSpeed Insightsによる診断へ進むことになる。
PageSpeed Insightsでボトルネックを深掘りする

次に、Search Consoleで「不良」と判定されたページや、サイト内で最も重要なページ(通常はトップページや人気記事)のURLをPageSpeed Insights(ページスピード・インサイト / PSI)で測定する。PSIはシミュレーション環境でのテスト結果(ラボデータ)を表示するツールだ。
結果が表示されたら、デスクトップではなく必ず「モバイル」のスコアを重視すべきだ。Googleはモバイル版のパフォーマンスを評価基準とする「モバイルファーストインデックス」を採用しているため、デスクトップで高得点でもモバイルで低得点であれば、改善の優先度は高い。
診断セクションの重要項目を読み解く
PSIのレポートには多くの項目が並ぶが、特に注目すべきは以下の3点だ。まず、TTFB(Time to First Byte / 最初の1バイトが到着するまでの時間)を確認する。これはサーバーがリクエストを受け取ってから、ブラウザに最初のデータを返すまでの時間だ。もしTTFBが600ms(0.6秒)を超えている場合、原因はサーバー側(ホスティング環境)にある可能性が高い。この値が正常であれば、サーバーではなくサイトの構成要素に問題があると判断できる。
次に「レンダリングを妨げるリソース(Render-blocking resources)」をチェックする。これは、ブラウザが画面を表示する前に読み込まなければならないCSSやJavaScriptファイルを指す。ここでの推定短縮時間が1,000msを超える場合は、最優先で対処すべき課題となる。
最後に、どの要素が「LCP要素」として判定されているかを確認する。多くの場合、トップページのヒーロー画像がこれに該当する。画像が適切に圧縮されているか、次世代フォーマット(WebPなど)が使われているか、そして「遅延読み込み(Lazy Load)」が誤って適用されていないかを確認する。ファーストビューの画像に遅延読み込みを適用すると、逆に表示が遅くなり、LCPスコアを悪化させる原因になるからだ。
GTmetrixのウォーターフォール図で読み込み順を可視化する

PSIが「何が起きているか」を教えてくれるのに対し、GTmetrixは「なぜそれが起きているか」を視覚的に理解するのに役立つ。無料アカウントを作成してテストを実行し、「Waterfall(ウォーターフォール)」タブを開くことが推奨されている。
ウォーターフォール図は、ページを構成するすべてのファイルがどの順番で、どれくらいの時間をかけて読み込まれたかを横棒グラフで示したものだ。棒が右に伸びているほど、そのファイルの読み込みに時間がかかっていることを意味する。
グラフから読み取れる遅延のサイン
図の最上部、最初のファイルが読み込まれる前に長い空白時間がある場合は、やはりサーバーの応答速度がボトルネックだ。また、画像ファイルの横棒が極端に長い場合は、ファイルサイズが大きすぎること(未圧縮)を示唆している。
さらに、外部スクリプトの挙動にも注目したい。解析ツール、チャットウィジェット、SNSの埋め込みなどは、読み込みの後半で大きな遅延を引き起こすことが多い。ウォーターフォール図の後半で特定の外部ドメインからの通信が停滞しているのを発見できれば、その機能を停止するか、読み込み方法を最適化する(非同期読み込みなど)といった具体的な対策が打てるようになる。
Query Monitorでサーバー内部の挙動を監視する

これまでのステップはブラウザ側から見た性能調査だったが、最後の手順はサーバー内部の挙動を調査することだ。これには無料プラグインの「Query Monitor(クエリ・モニター)」を使用する。
プラグインをインストールして有効化すると、管理画面の上部ツールバーに数値が表示されるようになる。フロントエンドのページを表示した状態でこの数値をクリックすると、詳細なパネルが開く。開発者でなくても、特定の情報に注目するだけで原因を絞り込むことが可能だ。
データベースクエリとAPIコールの異常を検知する
まずチェックすべきは「Database Queries(データベースクエリ)」のセクションだ。1ページを表示するために発行されたクエリの数と、それぞれの実行時間が表示される。適切に最適化されたサイトであれば、1ページあたりのクエリ数は20〜50個程度に収まる。もし150個を超えていたり、個別のクエリに50ms以上の時間がかかっていたりする場合、特定のプラグインやテーマが非効率な処理を行っている証拠だ。Query Monitorは、どのプラグインがそのクエリを発行したかまで教えてくれる。
もう一つの重要項目は「HTTP API Calls」だ。これは、WordPressがページを生成する過程で外部サービスと通信している記録である。例えば、ライセンス認証や外部データの取得のためにプラグインが外部サーバーへリクエストを送り、その返信を待っている間、サイトの表示はストップしてしまう。もし予期しない外部リクエストが多発しているなら、そのプラグインの設定を見直す必要がある。
優先順位に基づいた改善リストの作成

4つのツールからデータが集まったら、それらを統合して改善の優先順位を決める。著者のMark Zahra氏は、以下の順序で対策を行うことを推奨している。
1. サーバー環境の改善
TTFBが遅い場合は、他のどの対策よりも先にサーバー環境を見直すべきだ。土台となるサーバーが遅ければ、どんなにコードを最適化しても限界がある。パフォーマンスを重視した高品質な国内レンタルサーバーや、マネージドホスティングへの移行を検討するのが最も効果的だ。
2. 画像の最適化
LCPのスコアが低い場合、対象となるヒーロー画像のファイルサイズを削減する。圧縮、WebPへの変換、そしてファーストビュー画像に対する遅延読み込みの解除を行う。これだけでスコアが劇的に改善することも珍しくない。
3. コードの整理とキャッシュ
サーバーと画像がクリアになった段階で、初めてキャッシュプラグインやコードの最適化(CSS/JSの縮小化など)を導入する。Query Monitorで特定された「重いプラグイン」を削除したり、軽量な代替プラグインに差し替えたりすることもこの段階で行う。
4. サードパーティスクリプトの調整
最後に、解析ツールや広告タグなどの外部スクリプトを整理する。これらは利便性とのトレードオフになることが多いため、本当に必要なものだけを残し、遅延読み込みさせるなどの調整を行う。
独自の分析:なぜ「オーディット」が高速化の成否を分けるのか

筆者の見解として、WordPressの高速化において最も大きな障壁は「情報の過多」にあると考える。ネット上には「このプラグインを入れれば速くなる」という断片的な情報が溢れているが、サイトごとに遅延の理由は千差万別だ。あるサイトでは画像が原因であり、別のサイトではデータベースの肥大化が原因かもしれない。
今回紹介した手順の核心は、仮説ではなく「証拠」に基づいて動く点にある。Search Consoleで「何が悪いか」を知り、PSIで「どこが悪いか」を絞り込み、GTmetrixで「読み込みの順序」を確認し、Query Monitorで「内部の犯人」を特定する。この一連の流れは、まさにサイトの健康診断だ。
また、高速化は一度行えば終わりではない。WordPressはプラグインの更新や記事の追加によって、時間の経過とともにパフォーマンスが低下していく傾向がある。数ヶ月に一度、このオーディットをルーチンとして行うことで、サイトの健全性を長期的に維持できるだろう。
この記事のポイント
- 実測データを優先する: Google Search Consoleのフィールドデータが、SEOにおいて最も重要な指標となる。
- サーバーの応答を確認: TTFB(Time to First Byte)をチェックし、問題があればホスティング環境の変更を最優先する。
- LCP要素の特定: ページで最も大きな要素(画像など)を特定し、その読み込みを最速化する。
- 内部負荷の可視化: Query Monitorを使い、プラグインが発行するデータベースクエリや外部通信の異常を突き止める。
- 一歩ずつの改善: 複数の対策を同時に行わず、一つ修正するごとに再テストを行い、効果を検証する。
出典
- WP Mayor「WordPress Performance Audit: How to Find What’s Slowing Down Your Site」(2026年3月25日)
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

WordPress高速化の決定版。表示速度を劇的に改善する8つの施策
WordPressサイトの表示速度は、ユーザー体験だけでなくSEOの順位にも直結する極めて重要な要素だ。多くのサイト運営者が速度改善に頭を悩ませているが、実は問題の根本原因は限られた数箇所に集約されていることが多い。
元記事の著者であるMark Zahra氏は、パフォーマンス監査の結果、モバイルのPageSpeedスコアが34という低スコアだったサイトの事例を挙げている。その原因は、未最適化の画像、キャッシュの欠如、そして2年間にわたって積み重なった不要なプラグインだったという。
この記事では、専門的な知識がなくても取り組める、WordPress高速化のための8つの具体的な手法を解説する。これらを実践することで、サイトのパフォーマンスを次のレベルへと引き上げることが可能だ。
1. 土台となるサーバー環境を慎重に選ぶ

どれほど優れたキャッシュプラグインや画像最適化ツールを導入しても、土台となるサーバーの性能が不足していれば十分な効果は得られない。サーバー選びは、WordPress高速化におけるもっとも基本的な「基盤」である。
共有サーバーからマネージドホスティングへのステップアップ
安価な共有サーバー(シェアードホスティング)は、一つのサーバーリソースを数百のサイトで共有するため、隣接するサイトの負荷にパフォーマンスが左右されやすい。これに対し、WordPressに特化した「マネージドホスティング」は、サーバー側でのキャッシュ処理やPHPの最適化があらかじめ設定されている。
記事によれば、サーバー側でキャッシュやインフラのチューニングが行われることで、TTFB(Time to First Byte / 最初の1バイトが届くまでの時間)が劇的に改善される。国内でも高速なサーバー環境を選択することは、サイト高速化の第一歩となる。
サーバーリソースの重要性
TTFBは、ユーザーがリンクをクリックしてからブラウザがサーバーからデータを受け取り始めるまでの待ち時間だ。この数値が遅いと、その後のすべての読み込みプロセスが遅延する。高性能なサーバー環境は、この待ち時間を最小化するために不可欠な投資といえる。
2. オールインワンのパフォーマンスプラグインを活用する

WordPressの速度低下を招く主な原因は、キャッシュの欠如、画像の未最適化、そしてCDN(コンテンツ・デリバリ・ネットワーク)の不使用の3点に集約される。これらを個別に解決するのではなく、一つのプラグインで一括管理する手法が効率的だ。
クラウド型最適化ツールのメリット
元記事では「FastPixel」のようなクラウドベースのプラグインが紹介されている。この種のツールの最大の特徴は、画像処理などの重い負荷がかかる作業を、自社のサーバーではなくプラグイン側のクラウドサーバーで実行する点にある。
これにより、自サーバーのリソースをサイトの表示そのものに集中させることができる。特に共有サーバーを利用している場合、サーバー負荷を抑えつつ高度な最適化を適用できるメリットは大きい。
一括導入による設定の衝突回避
複数のプラグインを組み合わせて使うと、設定が競合してサイトが崩れたり、逆に速度が低下したりすることがある。オールインワンツールを使えば、キャッシュ、縮小化(Minification)、画像変換などが最適に組み合わされた状態で動作するため、管理コストも大幅に削減できる。
3. 画像の徹底的な軽量化と次世代フォーマットの採用
ウェブページのデータ容量の大部分を占めるのは画像だ。2MBのJPEG画像をそのまま掲載することは、モバイルユーザーにとって大きな負担となり、SEOの評価指標であるCore Web Vitals(コアウェブバイタル)のスコアを著しく低下させる。
WebPやAVIFへの自動変換
「ShortPixel」などの専用プラグインを使用すると、画像をアップロードする際に自動で圧縮し、WebPやAVIFといった次世代フォーマットに変換してくれる。WebP(ウェッピー)は、従来のJPEGやPNGと同等の画質を保ちながら、ファイルサイズを数分の一に削減できるフォーマットだ。
記事によれば、AIを活用して画像のメタデータを最適化し、アクセシビリティを高めるALTテキストを自動生成する機能も有効だという。これは検索エンジンが画像の内容を理解する助けにもなり、SEO効果も期待できる。
既存ライブラリの一括処理
新規にアップロードする画像だけでなく、過去にアップロードしたメディアライブラリ内の画像も一括で最適化することが重要だ。多くの画像最適化プラグインには、既存の画像を一括でリサイズ・圧縮する機能が備わっている。
4. 遅延読み込み(Lazy Loading)の適切な設定

WordPress 5.5以降、画像の遅延読み込み(Lazy Loading)が標準機能として搭載された。これは、ユーザーがスクロールして画像が画面に近づくまで読み込みを保留する仕組みだ。しかし、この機能が「裏目」に出るケースがある。
LCP(最大視覚コンテンツ)を遅延させない
もっとも注意すべきは、ページ上部のヒーロー画像やアイキャッチ画像だ。これらは「LCP(Largest Contentful Paint)」という、ページの主要なコンテンツが表示されるまでの時間を測る指標に影響する。これらの画像に遅延読み込みを適用してしまうと、ブラウザが読み込みを後回しにしてしまい、結果としてLCPスコアが悪化する。
著者の指摘によれば、ページ上部の画像には `loading=”eager”` 属性を付与するか、もしくは `fetchpriority=”high”` を設定して、優先的に読み込ませる必要がある。最新のWordPressでは自動調整が行われるようになっているが、サードパーティのプラグインがこの挙動を上書きしていないか確認が必要だ。
プリロードの活用
重要な画像やフォントファイルを事前に読み込む「プリロード」設定も有効だ。ブラウザに対して「このファイルはすぐに使うので先に準備してほしい」と指示を出すことで、体感速度を向上させることができる。
5. プラグインの精査とデータベースの保守

WordPressの柔軟性はプラグインによって支えられているが、その代償としてパフォーマンスが犠牲になることが多い。プラグインは一つひとつがコードの塊であり、有効化されているだけでサーバーのリソースを消費する。
プラグインの「量」より「質」
記事では、40個以上のプラグインが有効化されているサイトは、それだけでパフォーマンス上の大きな負債を抱えていると指摘されている。定期的にプラグインを監査し、本当に必要なものだけを残す姿勢が重要だ。
特にスライダープラグインやソーシャル共有ボタン、多機能なページビルダーなどは、すべてのページで重いスクリプトを読み込む傾向がある。「Query Monitor」のようなツールを使えば、どのプラグインが読み込みを遅延させているかを特定できる。
データベースの定期的なクリーンアップ
WordPressのデータベースには、記事の「リビジョン(過去の保存履歴)」やスパムコメント、期限切れの一時データ(Transients)が蓄積していく。これらが肥大化すると、データベースへのクエリ(命令)が遅くなり、サイト全体の応答速度が低下する。
「WP-Optimize」などのツールを使い、不要なリビジョンやデータを定期的に削除することで、データベースを軽量な状態に保つことができる。ただし、クリーンアップ作業の前には必ずバックアップを取ることを忘れてはならない。
6. 継続的なパフォーマンス計測の習慣化
サイトの高速化は一度きりの作業ではない。コンテンツが増え、テーマやプラグインが更新されるたびに、パフォーマンスは変化する。そのため、定期的な計測を「習慣」にすることが重要だ。
主要な計測ツールの使い分け
著者は以下の3つのツールを併用することを推奨している。Google PageSpeed Insightsは、ユーザー体験を評価するCore Web Vitalsの把握に最適だ。GTmetrixは、どのファイルがどのタイミングで読み込まれているかを詳細なウォーターフォール図で分析できる。そして、ホスティング会社が提供する独自のパフォーマンス指標も参考になる。
変化をキャッチする体制
新しいプラグインを導入した際や、デザインを大幅に変更した前後で必ずテストを実施する。もし急激にスコアが低下した場合は、直前に行った変更が原因である可能性が高い。問題を早期に発見できれば、修正も容易になる。
独自の分析:高速化は「引き算」の美学である
多くの運営者は、高速化のために「新しいプラグインを追加する」という足し算の思考に陥りがちだ。しかし、真の高速化は「不要なものを削ぎ落とす」という引き算のプロセスこそが本質であると私は考える。
高性能なサーバーを選び、画像を次世代形式に変換し、不要なプラグインを削除する。これらはすべて、ブラウザが処理すべき「無駄な計算」や「無駄な通信」を減らす作業だ。技術的なトリックを駆使する前に、まずはサイトをどれだけシンプルに保てるかを自問自答すべきだろう。
また、モバイルファーストの視点も欠かせない。デスクトップでは高速に動くサイトも、不安定な4G回線のモバイル端末ではストレスを感じるほど遅い場合がある。常に「もっとも厳しい環境のユーザー」に合わせて最適化を行うことが、結果としてすべてのユーザーに対するアクセシビリティ向上につながるのだ。
この記事のポイント
- サーバー選びが最優先: 共有サーバーの限界を感じたら、マネージドホスティングへの移行を検討する。
- 画像の最適化を自動化: WebP/AVIFへの変換と圧縮をプラグインで自動化し、ページ容量を劇的に削減する。
- LCP対策を忘れずに: ページ上部の重要な画像には遅延読み込みを適用せず、優先的に読み込ませる設定を行う。
- 定期的な保守が鍵: データベースのクリーンアップとプラグインの監査を月次ルーチンとして組み込む。
- 計測を習慣化する: 変更のたびにPageSpeed Insightsなどでスコアを確認し、パフォーマンスの退化を防ぐ。
出典
- WP Mayor「How to Speed Up WordPress: 8 Things That Actually Move the Needle」(2026年3月18日)
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

WordPress開発もモダンに。Moment.jsからJavaScript Temporal APIへの移行ガイド
JavaScriptにおける日時操作のデファクトスタンダードであった「Moment.js」が、メンテナンスモードに入って久しい。現在、その後継として期待されているのが、ブラウザ標準の「Temporal API(テンポラルAPI)」だ。
2026年3月現在、Temporal APIは主要なブラウザでの実装が進み、実用段階に入りつつある。本記事では、WordPress開発においてMoment.jsからTemporal APIへ移行するための具体的なレシピと、その重要性を解説する。
この移行は、単なるライブラリの置き換えではない。サイトのパフォーマンス向上と、日時計算における予期せぬバグを根絶するための重要なステップだ。
Moment.jsの終焉とTemporal APIの登場背景

長年、JavaScriptの標準機能であるDateオブジェクトは、その使い勝手の悪さが指摘されてきた。この穴を埋めるために普及したのがMoment.jsだ。しかし、現代のWeb開発において、Moment.jsはいくつかの致命的な課題を抱えている。
Moment.jsが抱えていた3つの課題
第一の課題は、オブジェクトの「可変性(Mutable)」だ。Momentオブジェクトに対して操作を行うと、元のデータ自体が書き換わってしまう。これは、意図しない場所で日付が変わってしまうバグの原因となりやすい。
第二の課題は、バンドルサイズの肥大化だ。Moment.jsは巨大なライブラリであり、一部の機能しか使わない場合でも、ファイル全体を読み込む必要がある。これは、WordPressサイトの表示速度、特にLCP(Largest Contentful Paint)に悪影響を及ぼす。
第三に、タイムゾーン処理の複雑さがある。標準のMoment.jsだけではタイムゾーンを扱えず、追加のライブラリ(moment-timezone)が必要だった。これらの課題を解消すべく、ECMAScriptの標準仕様として策定されたのがTemporal APIだ。
Temporal APIがもたらす技術的メリット
Temporal APIは、不変性(Immutable)を前提に設計されている。すべての計算結果は新しいオブジェクトとして返されるため、元のデータが汚染される心配がない。また、ブラウザにネイティブ実装されるため、追加のライブラリ読み込みが不要になり、JSの実行コストが劇的に低下する。
さらに、月指定が「1から始まる」点も大きな改善だ。従来のDate APIやMoment.jsでは、1月を「0」と数える仕様が直感に反し、多くの開発者を悩ませてきた。Temporalでは、1月は「1」として扱われる。
Temporal APIの基本オブジェクトと使い分け

Temporal APIは、用途に応じて複数のオブジェクトを使い分ける設計になっている。Moment.jsのように1つのオブジェクトですべてを済ませるのではなく、情報の精度に応じて適切な型を選択する。
主要な4つのオブジェクト
- Temporal.Instant: UTC(協定世界時)に基づく特定の瞬間を表す。タイムスタンプの保存に適している。
- Temporal.ZonedDateTime: タイムゾーン情報を含む日時。特定地域の「カレンダー上の日時」を扱う際に使用する。
- Temporal.PlainDate / PlainTime: タイムゾーン情報を持たない、日付のみ、または時刻のみのデータ。
- Temporal.Duration: 「2時間30分」といった、時間の長さを表す。
例えば、WordPressの投稿公開日時を扱う場合は「ZonedDateTime」が適している。一方、ユーザーの誕生日などはタイムゾーンに依存しないため、「PlainDate」を使うのが正しい。このように、データの性質を型で定義できるのがTemporalの強みだ。
実践:Moment.jsからTemporalへの移行レシピ

既存のMoment.jsコードをどのようにTemporalへ書き換えるべきか、代表的なパターンを見ていく。基本的な操作において、Temporalはより厳格な構文を要求するが、その分コードの信頼性は高まる。
日時の生成とパース(解析)
Moment.jsでは、柔軟すぎるがゆえに曖昧な文字列も解釈しようとした。Temporalでは、ISO 8601形式などの標準的な文字列のみを受け付ける。
// Moment.js
const mNow = moment();
const mSpecific = moment("2026-03-15");
// Temporal API
const tNow = Temporal.Now.instant();
const tSpecific = Temporal.PlainDate.from("2026-03-15");「ISO 8601」とは、日付と時刻を表記するための国際規格(例:2026-03-15T13:00:00Z)のことだ。Temporalはこの規格に準拠していない文字列を渡すとエラーを投げるため、開発段階で不具合に気づきやすくなる。
Intl APIを活用したロケール対応のフォーマット
Moment.jsは独自形式のトークン(’YYYY-MM-DD’など)を使用していた。これに対し、Temporalはブラウザ標準の「Intl.DateTimeFormat(国際化API)」と親和性が高く、ユーザーの言語設定に合わせた表示が容易だ。
// Moment.js
moment().format('LL'); // "2026年3月15日"
// Temporal
const now = Temporal.Now.instant();
now.toLocaleString('ja-JP', { dateStyle: 'long' }); // "2026年3月15日"「ロケール」とは、言語や地域による表記規則の集まりを指す。Temporalで`toLocaleString`メソッドを使うことで、エンジニアが手動でフォーマットを指定しなくても、ブラウザが自動的にその国に最適な形式で表示してくれる。
日時計算における「不変性」の重要性

日時の加算や減算において、Temporalの「不変性(イミュータビリティ)」は最大の武器となる。Moment.jsで頻発していた「計算後に元の変数の値が変わってしまう」という副作用が、構造的に排除されている。
副作用のない加減算
以下のコード比較を見れば、その違いは一目瞭然だ。
// Moment.js (元のオブジェクトが書き換わる)
const startDate = moment("2026-03-01");
const endDate = startDate.add(7, 'days');
console.log(startDate.format('YYYY-MM-DD')); // "2026-03-08" (意図せず変更された)
// Temporal (元のオブジェクトはそのまま)
const tStart = Temporal.PlainDate.from("2026-03-01");
const tEnd = tStart.add({ days: 7 });
console.log(tStart.toString()); // "2026-03-01" (安全)この「不変性」により、関数に日付オブジェクトを渡しても、その関数内で勝手に日付が書き換えられる心配がなくなる。これは、大規模なプラグイン開発や複数のエンジニアが関わるプロジェクトにおいて、デバッグ時間を大幅に短縮する要因となる。
タイムゾーン操作とパフォーマンスへの影響

WordPressサイトの多くは、サーバーのタイムゾーンとユーザーのタイムゾーンが異なる環境で運用されている。Temporal APIは、標準で強力なタイムゾーンサポートを備えている。
外部ライブラリ不要のタイムゾーン変換
Moment.jsでタイムゾーンを扱うには、膨大なデータベースを含む`moment-timezone`が必要だった。これがバンドルサイズを1MB近く押し上げることも珍しくない。
// Temporalでのタイムゾーン変換
const instant = Temporal.Now.instant();
const tokyoTime = instant.toZonedDateTimeISO('Asia/Tokyo');
const londonTime = instant.toZonedDateTimeISO('Europe/London');Temporalでは、ブラウザが内部に持っているタイムゾーンデータベースを利用するため、追加のデータ読み込みが一切不要だ。これにより、サイトのJavaScript合計サイズが削減され、モバイルユーザーのUX(ユーザー体験)向上に直結する。
独自の分析:WordPress開発におけるTemporalへの期待

WordPress開発の文脈において、Temporal APIの導入は「管理画面の高速化」と「ブロックエディタの堅牢性向上」に寄与する。特にGutenberg(ブロックエディタ)では、複雑な日時計算を伴うカスタムブロックが増えている。
これまで、イベント予約システムやカレンダー連携機能を実装する際、Moment.jsの重さがネックになることがあった。Temporalへの移行により、スクリプトの実行ブロック時間が短縮され、エディタの入力レスポンスが改善される。また、Polyfill(ポリフィル)を利用することで、Safariなどの未対応ブラウザをサポートしつつ、将来的なネイティブ移行への準備を整えることが可能だ。
「Polyfill」とは、新しい機能をサポートしていない古いブラウザでも、その機能を使えるようにするための補完コードのことだ。現時点では、`@js-temporal/polyfill`を導入することで、最新の構文を安全に使用できる。
この記事のポイント
- Moment.jsはレガシー化: メンテナンスモードであり、新規プロジェクトでの使用は推奨されない。
- 不変性の確保: Temporal APIは計算によって元のデータを書き換えないため、バグが激減する。
- パフォーマンス向上: ブラウザ標準機能のため、ライブラリの読み込みが不要になり軽量化される。
- 1ベースの月指定: 1月を「1」と数える直感的な仕様に変更された。
- 強力なタイムゾーン支援: 外部データなしで正確な地域時刻の変換が可能。
出典
- Smashing Magazine WordPress「Moving From Moment.js To The JS Temporal API」(2026年3月13日)
- MDN Web Docs「Temporal」(2026年3月1日参照)
- Moment.js Documentation「Project Status」(2020年9月)
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Seraphinite Acceleratorの脆弱性、6万サイトに影響 認証済みユーザーが内部データを取得可能
WordPressの高速化プラグイン「Seraphinite Accelerator」に深刻なセキュリティ脆弱性が発見された。この脆弱性により、最低限の権限を持つ認証済みユーザーがサイトの内部データを取得できる状態だった。
影響を受けるのはバージョン2.28.14までの全バージョンで、インストールサイト数は6万以上に及ぶ。開発元はバージョン2.28.15で修正を実施した。
この問題は、パフォーマンス向上を目的としたプラグインが、逆にセキュリティリスクを生み出すという構造的な課題を示している。
脆弱性の概要と影響範囲

2026年3月4日、セキュリティ企業のWordfenceがSeraphinite Acceleratorプラグインに関する2件の脆弱性を公表した。これらの脆弱性は「CVE-2026-XXXXX」および「CVE-2026-XXXXY」として追跡されている。
認証済みユーザーによる情報取得
1つ目の脆弱性は情報漏洩に関わる。プラグインが提供するAPIエンドポイント「seraph_accel_api」に、権限チェックの不備が存在した。
このエンドポイントを通じて「GetData」関数を呼び出すと、内部の「OnAdminApi_GetData()」関数が実行される。本来、この関数は管理者のみがアクセス可能なシステム情報を返すものだ。
しかし、関数内に適切な権限チェック(capability check)が実装されていなかった。その結果、購読者レベル(Subscriber)以上の権限を持つすべての認証済みユーザーが、このAPIを呼び出せた。
取得可能な内部データの具体例
攻撃者がこの脆弱性を悪用した場合、以下のような運用上の機密情報を取得できた。
- キャッシュの状態情報
- スケジュールされたタスクの詳細
- 外部データベースの状態
これらの情報は、サイトの内部構造やプラグインの動作状況を外部から可視化するものだ。直接的な管理者権限の奪取にはつながらないが、サイトのインフラを調査する足がかりとなる。
第二の脆弱性:ログの無許可消去
2つ目の脆弱性も同様の権限チェック不備に起因する。今度は「LogClear」関数に問題があった。
攻撃者はこの関数を呼び出すことで、プラグインのデバッグログや操作ログを消去できた。ログの改ざんや消去は、攻撃の痕跡を隠蔽するために利用される。
Seraphinite Acceleratorの役割とリスクの逆説

Seraphinite AcceleratorはWordPressサイトの表示速度を向上させるパフォーマンスプラグインだ。主な機能はページのキャッシュ生成にある。
サーバーは訪問者が来るたびにページを生成する必要がなくなる。これによりサーバー負荷が軽減され、ページ読み込みが高速化する。プラグインはGZip、Deflate、Brotliといった複数の圧縮形式をサポートする。ブラウザキャッシュの有効化や、デバイス・環境ごとのキャッシュ分離にも対応している。
パフォーマンスとセキュリティのトレードオフ
今回の事例は、パフォーマンス最適化ツールがセキュリティホールになり得ることを示している。キャッシュプラグインはサーバーとクライアントの間に立つ。高度な最適化処理を行うため、システムの深部にアクセスする権限が必要となる。
この特権的なアクセス権を、適切なセキュリティ境界(セキュリティバウンダリ)で保護しなければならない。Seraphinite Acceleratorの場合、管理機能を提供するAPIエンドポイントの実装に不備があった。
「管理者API」の誤った実装
脆弱性の核心は「OnAdminApi_GetData()」という関数名が示す通りだ。この関数は「管理者向けAPI」の一部として設計された。関数名には「Admin」が含まれている。
しかし、実際の実装では管理者権限の有無を確認していなかった。WordPressのプラグイン開発において、管理機能には通常「manage_options」という権限(キャパビリティ)が必要だ。このチェックが欠落していた。
筆者の分析では、これは単純な実装ミスというより、権限モデルの設計段階での見落としの可能性が高い。パフォーマンス系プラグインは、しばしば高度なシステム操作と一般ユーザー向け機能の境界が曖昧になりがちだ。
攻撃シナリオと実際のリスク

この脆弱性を悪用するには、攻撃者はまず対象サイトに「購読者」アカウントを登録する必要がある。多くのWordPressサイトでは、コメント投稿やニュースレター登録のためにユーザー登録を開放している。
低権限アカウントの取得方法
攻撃者は以下のような方法で購読者アカウントを取得する。
- 公開されたユーザー登録フォームを利用する
- ソーシャルエンジニアリングで既存ユーザーの資格情報を窃取する
- 他の脆弱性やパスワード漏洩を利用する
一度購読者権限を取得すれば、攻撃者は特別なツールや高度な技術なしに脆弱性を悪用できる。通常のWebリクエストを送信するだけで済む。
情報収集からさらなる攻撃へ
取得した内部データは、より深刻な攻撃の前段階として利用される。キャッシュの状態やスケジュールタスクの情報から、サイトの運用パターンや使用している技術スタックを推測できる。
例えば、特定のキャッシュシステムの既知の脆弱性を探す材料となる。外部データベースの状態が分かれば、データベースに対する攻撃を計画する際の情報となる。
ログ消去機能の悪用は、防御側の可視性を奪う。攻撃者が他の方法でサイトに侵入した後、痕跡を消すためにこの機能を使う可能性がある。
開発元の対応と修正内容

脆弱性の報告を受け、Seraphinite Acceleratorの開発チームは速やかに対応した。バージョン2.28.15で修正パッチをリリースしている。
修正の技術的詳細
修正内容は明確だ。問題のあった「OnAdminApi_GetData()」関数および「LogClear」関連関数に、適切な権限チェックを追加した。
具体的には、関数の実行前に現在のユーザーが「manage_options」権限を持っているか確認するコードを追加した。この権限はWordPressにおいて、管理画面の設定を変更できる管理者ユーザーに与えられる。
変更履歴(チェンジログ)には、「LogClearおよびGetData API関数が、manage_options権限を持たないユーザーによって呼び出される可能性があった」と記載されている。修正により、これらの関数へのアクセスは管理者のみに制限された。
自動更新の有無と適用状況
WordPressのプラグインは、マイナーアップデートについては自動更新機能が働く場合がある。しかし、セキュリティアップデートが自動的に適用されるかは、サイトの設定に依存する。
多くのレンタルサーバーや管理サービスは、セキュリティ更新を自動適用する設定を推奨している。とはいえ、すべてのサイトが即座に更新されるわけではない。6万サイトという影響範囲を考えると、未適用のサイトが相当数残っている可能性がある。
サイト運営者が取るべき対策

Seraphinite Acceleratorを使用しているサイト運営者は、直ちに行動する必要がある。以下の手順に従って対応すべきだ。
緊急措置:プラグインの更新
まず、プラグインをバージョン2.28.15以降に更新する。WordPress管理画面の「プラグイン」セクションにアクセスし、Seraphinite Acceleratorの横に「更新あり」と表示されていないか確認する。
更新が利用可能な場合は、速やかに実行する。更新後はサイトの表示や機能に問題がないか確認する。パフォーマンスプラグインの更新は、キャッシュの再構築を伴う場合がある。
更新ができない場合の暫定対策
何らかの理由で直ちに更新できない場合、以下の暫定対策を検討する。
- プラグインを一時的に無効化する
- ユーザー登録機能を一時的に停止する
- Webアプリケーションファイアウォール(WAF)で該当APIへのリクエストをブロックする
プラグイン無効化の影響
Seraphinite Acceleratorを無効化すると、キャッシュ機能が停止する。サイトの表示速度が一時的に低下する可能性がある。特にトラフィックの多いサイトではサーバー負荷が増加する。
代替として、他のキャッシュプラグインを一時導入する方法もある。ただし、新たなプラグインの設定や互換性の問題が生じるリスクは承知すべきだ。
長期的なセキュリティ体制の見直し
今回の事例を機に、サイト全体のセキュリティ体制を見直す価値がある。
- 使用プラグインの定期的な監査
- 最小権限の原則に基づくユーザー権限設定
- セキュリティプラグインの導入と適切な設定
- ログの定期的な監視とバックアップ
パフォーマンスプラグインは、その性質上、システムへの深いアクセス権を要求する。導入前に開発元のセキュリティ対応実績を調べる。アクティブインストール数が多いからといって、安全が保証されるわけではない。
パフォーマンスプラグイン選定の新たな視点

Seraphinite Acceleratorの脆弱性は、パフォーマンスツールの選定基準にセキュリティ評価を加える必要性を浮き彫りにした。
コードの質とセキュリティ文化
プラグインを選ぶ際、機能や速度向上効果だけで判断すべきではない。開発チームのセキュリティへの取り組みを評価する材料を探す。
定期的な更新が行われているか。セキュリティアドバイザリに対して迅速に対応しているか。コードが適切に構造化され、権限チェックが一貫して実装されているか。これらの点は、プラグインの長期にわたる信頼性を示す指標となる。
代替手段の検討
サイトの高速化は、単一のプラグインに依存せず、多層的なアプローチで達成できる。サーバーレベルのキャッシュ、CDN(コンテンツデリバリネットワーク)の利用、画像最適化など、リスクを分散させる方法がある。
例えば、信頼性の高い共用サーバーやクラウドサービスでは、サーバー側でキャッシュ機能を提供している場合が多い。これらの機能を最大限活用することで、プラグインへの依存度を下げられる。
この記事のポイント
- Seraphinite Acceleratorの脆弱性は、認証済みユーザーが内部データを取得可能にするものだ。
- 影響を受けるのはバージョン2.28.14までで、6万以上のサイトが該当する。
- 脆弱性の根本原因は、API関数における権限チェックの欠如にある。
- サイト運営者はプラグインをバージョン2.28.15以降に即時更新すべきだ。
- パフォーマンスプラグイン選定には、セキュリティ対応実績の評価が不可欠である。
出典
- Search Engine Journal “Seraphinite Accelerator WordPress Plugin Vulnerabilities Affect 60K Sites” (2026年3月4日)
- Wordfence Threat Intelligence “Seraphinite Accelerator 2.28.14 – Authenticated (Subscriber+) Exposure of Sensitive Information” (2026年3月)
- Wordfence Threat Intelligence “Seraphinite Accelerator 2.28.14 – Missing Authorization to Authenticated (Subscriber+) Log Clearing” (2026年3月)
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験