

ローカルファーストWeb開発のアーキテクチャ クライアント主導のデータ管理と同期の仕組み
ローカルファーストアーキテクチャが注目を集めている。従来のサーバー中心のWebアプリ開発とは異なり、クライアント端末にデータの一次コピーを保持し、読み書きをローカルで即座に処理する設計手法だ。オフラインでも動作し、ネットワーク遅延の影響を受けないため、ユーザー体験が大幅に向上する。
Smashing Magazineの記事「The Architecture Of Local-First Web Development」(2026年5月6日公開)では、実際のプロジェクト経験に基づいた実践的な知見が紹介されている。本記事ではその要点を再構成し、Web制作やシステム開発に携わるエンジニア向けにわかりやすく解説する。
ローカルファーストとは何か 〜オフライン対応との違い
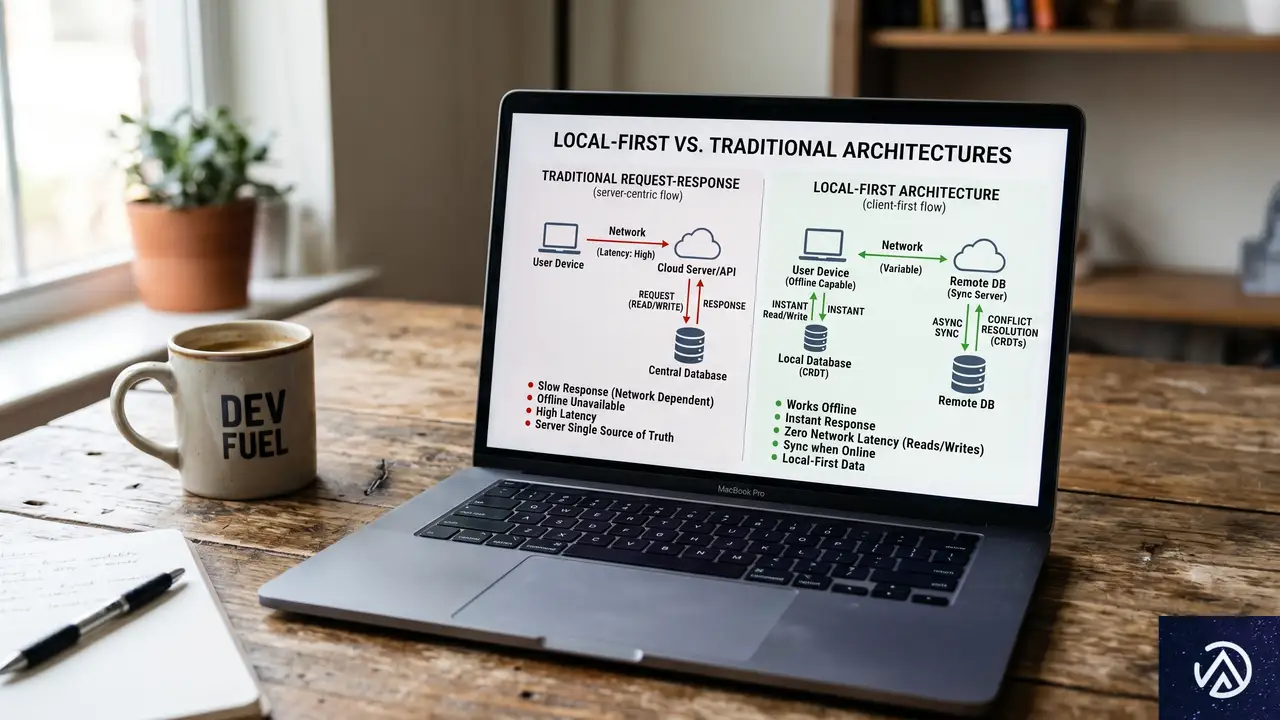
ローカルファーストはよく「オフラインファースト」やPWA(プログレッシブWebアプリ)と混同される。しかしこれらは根本的に異なる。オフラインファーストはネットワーク切断時でもアプリが壊れず動くことを目的とするが、データの主たる権威(正)は依然としてサーバーにある。一方、ローカルファーストは「データアーキテクチャ」の概念であり、ユーザーの端末がデータの一次コピーを持つ。アプリはローカルデータベースに直接読み書きし、画面を即座にレンダリングする。サーバーとの同期はバックグラウンドで行われ、サーバーは認証やバックアップなど特定の役割を担うが、データの門番ではない。
Ink and Switchが2019年に提唱した「ローカルファーストソフトウェア」の7つの理想(高速、マルチデバイス、オフライン、コラボレーション、長寿命、プライバシー、ユーザー所有権)は今でも有効だが、実務において最も重要なのは「クライアントが分散システムのノードであり、独自のデータベースを持つ」という点だ。この考え方が開発全体を変える。
このデモのとおり、ローカルファーストではユーザーの操作がサーバーの応答を待つことなく完結する。この違いがアプリの「遅さ」に対する根本的な解決策になる。
オフラインファーストやPWAとの混同を解く
Service Workerを使ったキャッシュやPWAは、あくまで配信や耐障害性の仕組みだ。データの所有権や正規性は変わらない。ローカルファーストは「端末が真実のコピーを持つ」点で本質的に異なる。これを理解しないまま実装を進めると、後からデータの不整合や同期設計の誤りに悩まされることになる。
ローカルファーストが向いているユースケースと不向きな場面

このアーキテクチャは万能ではない。導入を検討する前に、自社のアプリがどのデータ特性を持つかを見極める必要がある。
適している領域
- ユーザー生成データを扱うアプリ。メモ帳、ドキュメントエディタ、プロジェクト管理、フィールド業務用ツールなど
- リアルタイムコラボレーションが必要なツール。デザインツールや同時編集が前提のアプリ
- プライバシーが売りになるサービス。データをユーザーの手元に置くことで差別化できる
- 通信が不安定な環境向けのアプリ。工事現場、僻地、移動中の利用を想定する場合
不向きな領域
- サーバー生成データが主体のアプリ。分析ダッシュボード、SNSフィード、検索結果など
- 強いトランザクション整合性が求められるシステム。銀行、決済、在庫管理(複数ユーザーが同時に在庫を操作すると問題)
- 単純なCRUDでオフラインやコラボレーションの必要がない社内管理画面。同期エンジンは過剰設計になる
- クライアント端末に収まらない巨大なデータセット
また、アプリ全体を一度にローカルファーストに書き換える必要はない。例えばブログエディタの下書き機能だけをローカルファーストにする、といった段階的な導入が現実的だ。
クライアント側のデータ保存 ストレージ技術の選択

ユーザーの端末にデータを保持するには、適切なストレージ技術を選ぶ必要がある。従来のlocalStorageは同期APIでメインスレッドをブロックし、容量も5〜10MBと限られるため、本格的なデータベース用途には使えない。現在の主流は以下の3つだ。
実案件ではwa-sqliteなどのライブラリを使い、OPFSを介してSQLiteを永続化するのが有力な選択肢だ。初期化のコード例を示す。
import { SQLiteAPI } from 'wa-sqlite';
import { OPFSCoopSyncVFS } from 'wa-sqlite/src/examples/OPFSCoopSyncVFS.js';
async function initDatabase() {
const module = await SQLiteAPI.initialize();
const vfs = new OPFSCoopSyncVFS('app-db');
await vfs.initialize(module);
const db = await module.open_v2('local.db');
await module.exec(db, `PRAGMA journal_mode=WAL`);
await module.exec(db, `
CREATE TABLE IF NOT EXISTS tasks (
id TEXT PRIMARY KEY,
title TEXT NOT NULL,
status TEXT DEFAULT 'backlog',
created_at TEXT DEFAULT (datetime('now'))
)
`);
return db;
}なおSafariのOPFS実装は一部のコンテキストでcreateSyncAccessHandle()が無反応で失敗する既知の不具合があり、IndexedDBへのフォールバックを用意しておくことが推奨される。
データ同期の手法 CRDTとデータベースレプリケーション

クライアントにデータを置くだけなら解決済みだが、複数端末や複数ユーザー間でどう同期するかが本当の難所だ。主なアプローチは次のとおり。
YjsやAutomergeが代表的で、リアルタイム共同編集に強み。テキストの文字レベルでのマージに優れるが、構造化データのマージは意図しない結果を生むこともある。多くのプロジェクトでは、真のリアルタイム共同編集が必要な箇所にのみYjsを採用し、それ以外はデータベースレプリケーションで済ませるハイブリッド構成が無難だ。
同期の流れをコードで見る
ローカルファーストのアプリでは、従来のようにfetch()でデータを取得する必要がない。代わりにuseLiveQueryのようなフックがローカルSQLiteの変更を検知し、UIが自動で再描画される。
import { useLiveQuery } from '@powersync/react';
import { db } from '../lib/database';
function TaskBoard({ projectId }) {
const tasks = useLiveQuery(
`SELECT * FROM tasks WHERE project_id = ? ORDER BY position`,
[projectId]
);
async function addTask(title) {
await db.execute(
`INSERT INTO tasks (id, title, project_id, position)
VALUES (?, ?, ?, ?)`,
[crypto.randomUUID(), title, projectId, tasks.length]
);
// API呼び出しも楽観的更新のロールバックも不要
}
return (
{tasks.map(task => )}
);
}このコードにはローディング状態もエラーハンドリングも書かれていない。データが常にローカルにあるという前提が、これほどまでにUIコードを単純化する。
衝突解決と整合性の課題

複数のレプリカが独立して書き込みを行うと、当然データの衝突が発生する。最もシンプルな解決策は「ラストライトウィン(LWW)」、つまりタイムスタンプが新しい方を採用する方式だ。ただしレコード全体まるごと上書きするのではなく、フィールド単位で適用するのが現実的だ。下記のようなマージ関数を実装すれば、別々のフィールドを編集した場合に両方の変更が生き残る。
function pickWinner(a, b) {
const timeA = new Date(a.updatedAt).getTime();
const timeB = new Date(b.updatedAt).getTime();
if (timeA !== timeB) return timeA > timeB ? a : b;
return a.clientId > b.clientId ? a : b;
}
function mergeTask(local, remote) {
const merged = {};
const allKeys = new Set([...Object.keys(local), ...Object.keys(remote)]);
for (const key of allKeys) {
if (!local[key]) { merged[key] = remote[key]; continue; }
if (!remote[key]) { merged[key] = local[key]; continue; }
merged[key] = pickWinner(local[key], remote[key]);
}
return merged;
}このLWWは約95%の衝突を自動解決するが、同じテキストフィールドを2人が編集した場合は一方が静かに上書きされる。文書編集では問題だが、タスクのタイトル程度なら許容できる場合が多い。
セマンティック衝突への対処
構造的には綺麗にマージできても、意味的に矛盾するケースがある。たとえば2人のユーザーがオフラインで同じ会議室の同じ時間帯に別の予定を入れた場合、フィールド単位では衝突しないがダブルブッキングが発生する。このような「セマンティック衝突」は、サーバー側のバリデーションで検出し、クライアントに通知してユーザーに解決を促す。
重要なのは、違反が起きても書き込み自体は受け入れ、警告フラグとともにクライアントに返す設計だ。もしサーバーが書き込みを拒否すると、クライアントのローカルDBには存在するがサーバーには存在しない「幽霊レコード」が生まれ、回復が困難になる。
実装上の注意点 認証・マイグレーション・テスト

認証と認可
認証は従来どおりJWTやOAuthで行うが、トークンは毎リクエストではなく同期接続の確立時に使われる。認可は同期レイヤーで厳密に適用する必要がある。全データをクライアントに渡して見せたいものだけ表示するのは危険で、DevToolsからすべて覗ける。PowerSyncの「同期ルール」やElectricSQLの「シェイプ」を使い、サーバー側でユーザーに許可された行だけを送信する設計が必須だ。
スキーママイグレーション
サーバーなら1つのデータベースを管理すればよいが、クライアントはアプリを開いていない期間が長ければ古いスキーマのまま放置されている可能性がある。マイグレーションは起動時にバージョン番号を確認して逐次適用する方式が堅実だ。基本的に「カラムの追加」のみとし、削除やリネームは極力避ける。古いクライアントが存在する限り、欠落カラムへの書き込みが同期失敗を引き起こすからだ。
テスト戦略
マージロジックはユニットテストが容易だが、実際のネットワーク断絶や衝突タイミングを再現するのが難しい。2つのクライアントインスタンスをメモリ上で立ち上げ、同時編集後に収束するかを検証する統合テストや、Playwrightのcontext.setOffline(true)を使ったE2Eテストが有効だ。ランダムな操作列を与えて収束性をチェックするプロパティベーステストもCRDTロジックの品質を高める。
この記事のポイント
- ローカルファーストは、クライアント側にデータの一次コピーを置き、読み書きをローカルで即座に行うデータアーキテクチャである
- オフラインファーストやPWAとは異なり、データ所有権と即時性が根本的に変わる
- 向いているのはユーザー生成データを扱う協調ツールやフィールドアプリ。銀行や分析ダッシュボードには不向き
- クライアント側のストレージにはOPFS上のSQLite(WASM)が主力。IndexedDBの直接利用は避ける
- 同期はCRDT(Yjs等)とデータベースレプリケーション(PowerSync等)から選択し、多くの場合は後者で十分
- 衝突解決はフィールド単位のLWWで大半を自動化し、セマンティック衝突はサーバー検出+ユーザー通知で対応する
- 認可・マイグレーション・テストには固有の注意点があり、段階的に導入するのが現実的

・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験