

GA4にAI Assistantチャネル追加、ChatGPT流入を可視化
Google Analytics 4(GA4)に2026年5月、生成AIプラットフォームからの流入を可視化する「AI Assistant」チャネルが追加された。ECサイト運営者にとって、ChatGPTやClaudeが商品情報を紹介した結果のトラフィックを正確に把握できる初めての標準機能だ。
この記事ではAI Assistantチャネルの基本的な仕組みと、ECサイトでの具体的な活用法を解説する。設定不要でデータが自動収集される一方、AI Overviewsは含まれないといった注意点もあるため、正しい読み方を押さえておく必要がある。
WooCommerceサイトを運営する中小企業の担当者や、ECのアクセス解析を担当するWeb担にとって、これまで「参照元不明」だったAI経由の流入を可視化できる意味は大きい。
AI Assistantチャネルとは何か
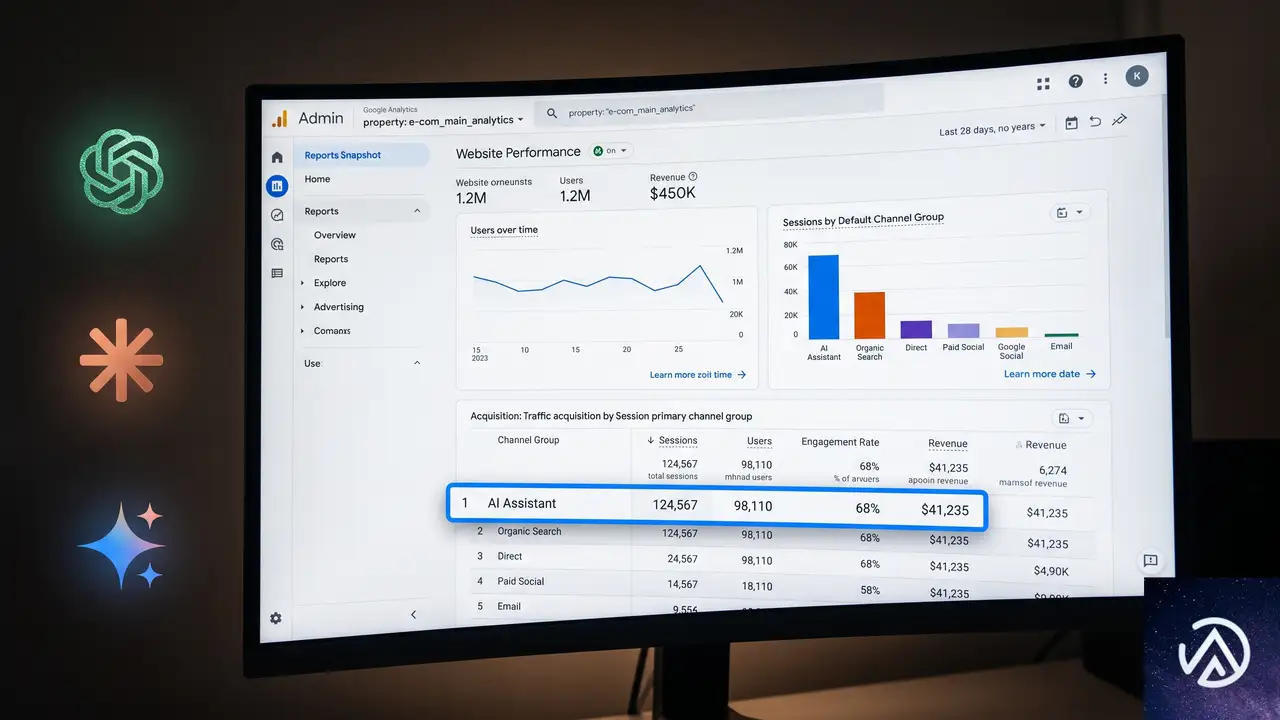
AI Assistantチャネルは、GA4のデフォルトチャネルグループに追加された新しい分類項目だ。ChatGPTやGemini、Claudeといった主要な生成AIプラットフォームからのトラフィックを自動的に判別し、ひとつのチャネルとして集計する。
計測対象となるプラットフォーム
Googleの公式ヘルプドキュメントによると、AI Assistantチャネルに含まれるのは「ChatGPT、Gemini、Claudeといったチャットボット」からのトラフィックだ。具体的な全リストは公開されていないが、主要な生成AIサービスはおおむねカバーされていると見てよい。
ここで重要な注意点がある。Google検索のAI Overviews(旧SGE)やAI Modeは、このチャネルには含まれない。これらは引き続き「Organic Search(オーガニック検索)」チャネルとして報告される。同じAI由来の流入でも、検索エンジン経由かチャットボット経由かで扱いが異なるわけだ。
ECサイトにとっての意味
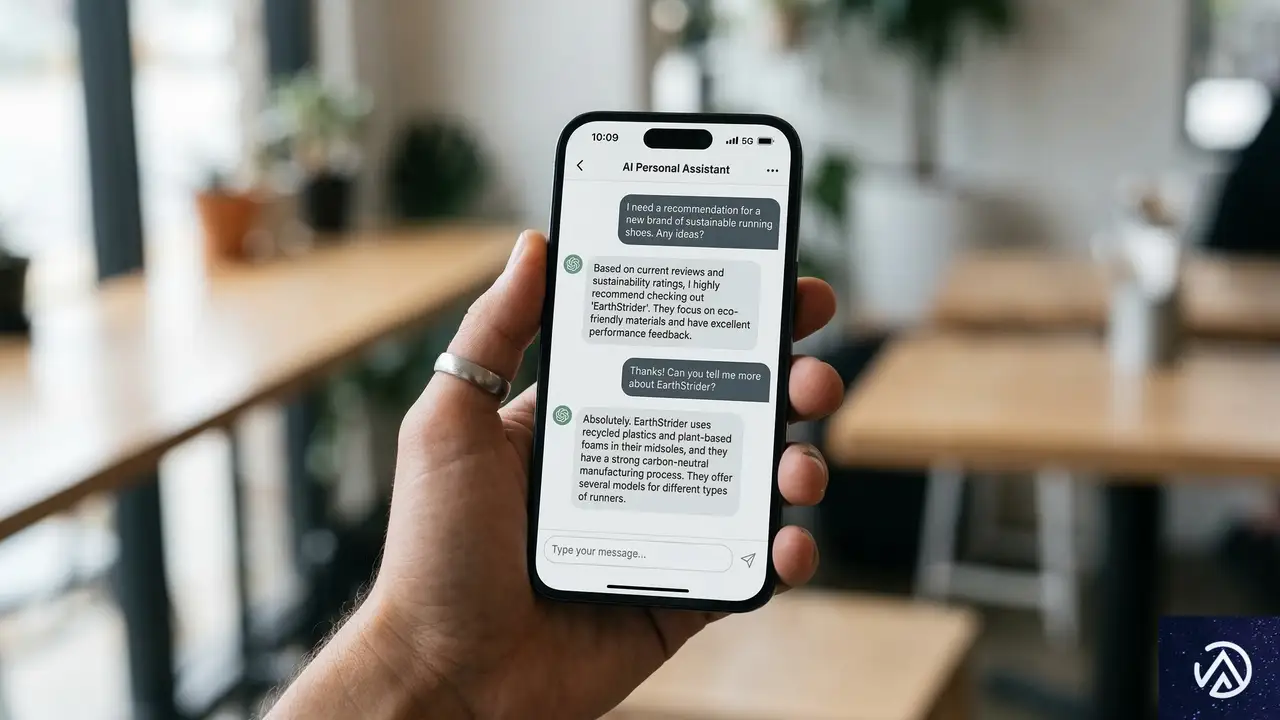
ECサイト運営者にとって、AIチャットボット経由の流入は従来のSEOとは異なる文脈で発生する。たとえば「予算3万円で買えるおすすめのワイヤレスイヤホン」といった自然言語の質問に対し、ChatGPTが具体的な製品名とURLを提示するケースだ。この流入経路を正確に把握できれば、AIに自社商品がどのような文脈で言及されているかを分析できる。
AIトラフィックの確認手順
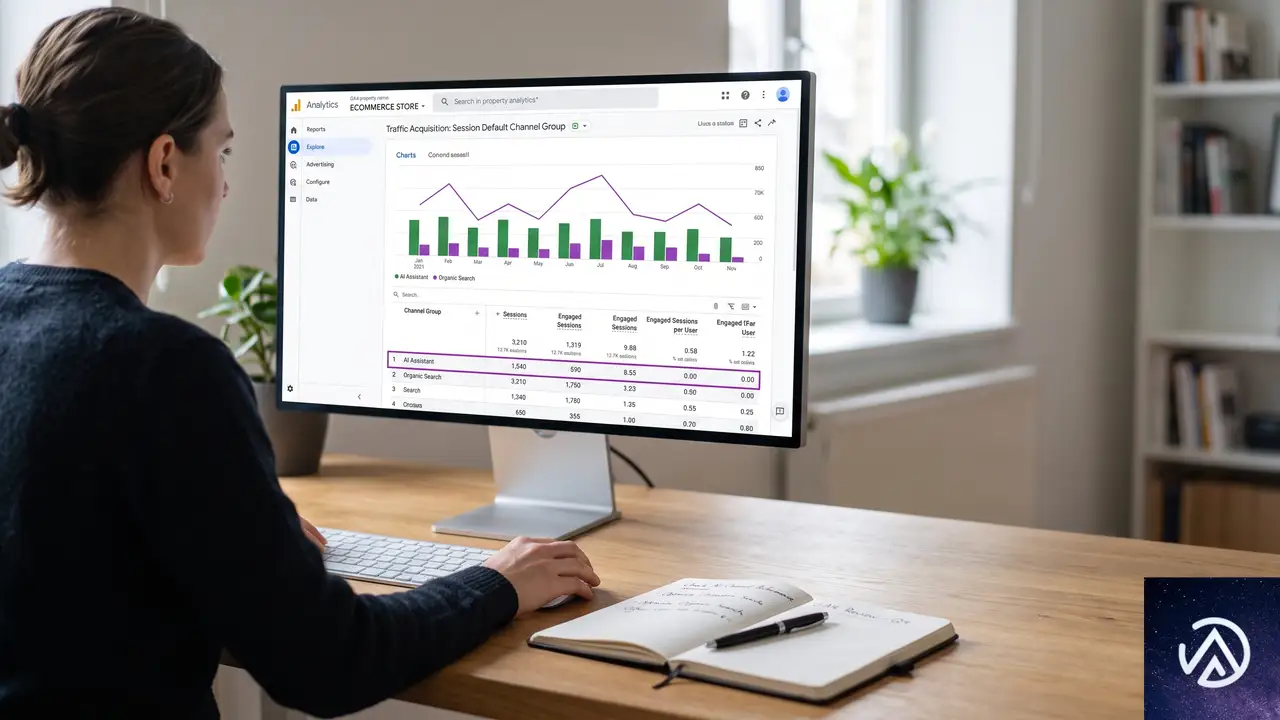
GA4でAI Assistantチャネルのデータを見るための手順を解説する。初期設定は不要で、GA4が自動的に分類を開始しているため、すぐに確認できる。WooCommerceサイトでGA4を導入済みであれば、追加のコード実装も必要ない。
トラフィック全体像の把握
まずはECサイト全体で、AI経由の流入がどの程度あるのかを確認する。GA4管理画面で「レポート」→「集客」→「トラフィック獲得」の順に開き、「セッションのデフォルトチャネルグループ」ディメンションを選択する。ここで「AI Assistant」という行が表示されていれば、すでにAI経由のトラフィックが発生している。
表示される指標はエンゲージメント率、セッションあたりのイベント数、平均セッション時間などだ。これらの数字をOrganic Searchチャネルと比較することで、AI経由ユーザーの行動特性が見えてくる。
ランディングページの特定
AIがどの商品ページを参照しているのかを特定するには、「レポート」→「エンゲージメント」→「ページとスクリーン」を開く。画面上部の「フィルタを追加」から、以下の条件で絞り込む。
- ディメンション:セッションのデフォルトチャネルグループ
- マッチタイプ:完全一致
- 値:AI Assistant
このフィルタを適用すると、AIプラットフォームからのクリックが多いページが上位に表示される。WooCommerceの商品ページやカテゴリページのうち、どのURLがAIに評価されているかを把握できるはずだ。
AIトラフィックと他チャネルの比較
同じ「ページとスクリーン」レポートで「比較を追加」ボタンを使うと、AI経由とオーガニック検索経由のトラフィックを横並びで比較できる。Practical Ecommerceの記事著者Carlo Daniele氏の検証によれば、オーガニック検索で上位のページとAI Assistant経由で上位のページは重複しなかったという。
これはEC担当者にとって示唆が大きい。Google検索で上位表示されている商品と、AIがユーザーに推薦する商品が異なる可能性があるためだ。AI経由の流入を伸ばすには、従来のSEO対策とは別のアプローチが必要になるかもしれない。
正規表現を使った詳細なソース分析

AI Assistantチャネルは便利だが、どのAIプラットフォームからの流入なのかまでは分解できない。ChatGPT経由なのかClaude経由なのかを個別に知りたい場合は、正規表現(regex)を使ったフィルタリングが有効だ。
設定手順
「レポート」→「集客」→「トラフィック獲得」で、グラフ上部の「フィルタを追加」をクリックする。ディメンションに「セッションの参照元/メディア」、マッチタイプに「matches regex」を選択し、以下の正規表現を値欄に貼り付ける。
.*chatgpt.com.*|.*perplexity.*|.*edgepilot.*|.*copilot.microsoft.com.*|.*openai.com.*|.*gemini.google.com.*|.*claude.ai.*|.*grok.x.ai.*このフィルタを適用すると、AIプラットフォームごとのセッション数やエンゲージメント指標を一覧できる。ただしPractical Ecommerceの記事でも指摘されているように、AI Assistantチャネルとの間にわずかなデータの不一致が生じる場合がある。これは「Organic」や「(not set)」と分類される一部のAIトラフィックが正規表現では拾えていないためだ。
WooCommerceサイトでの活用ポイント
正規表現フィルタを使えば、たとえば「ChatGPT経由では商品Aへの流入が多いが、Claude経由では商品Bが多い」といったプラットフォーム別の傾向を把握できる。AIによって得意とする商品カテゴリや、参照する情報ソースが異なる可能性があるためだ。
このデータをもとに、特定のAIプラットフォームで自社商品が言及されやすいコンテンツを強化するといった戦略が考えられる。Semrushなどの外部ツールで、どのようなプロンプトがAIの引用を生んでいるのかを調査するのも有効だ。
EC担当者が今すぐやるべき3つのアクション

AI Assistantチャネルの登場を受けて、ECサイトのアクセス解析にすぐに組み込むべき施策を整理する。いずれも追加コストなしで今すぐ始められるものばかりだ。
特にアクション2は重要だ。AIは商品スペックや口コミ、価格情報を総合的に評価して回答を生成する。商品ページの情報が不十分だとAIに引用されにくくなるため、商品説明の充実や構造化データの実装はAI時代のECに不可欠な施策といえる。
AIトラフィックとECの未来
GA4のAI Assistantチャネルは、ECにとって「AI経由の流入」という新たな指標を提供し始めた。現時点ではまだAIトラフィックの絶対量は小さいかもしれないが、ChatGPTやClaudeがデフォルトでWeb検索を行うようになり、AIを経由した商品発見は確実に増えていく。
AI OverviewsがOrganic Searchに含まれるという設計からもわかるように、GoogleはAIを「検索の拡張」と位置づけている。EC担当者はSEOとAI最適化を別物ではなく、同じ「検索体験」の両輪として捉えるべきフェーズに入ったといえる。
WooCommerceサイトであれば、GA4の標準機能だけでAIトラフィックの可視化は十分に可能だ。まずはデータを取得し、AIが自社商品をどう評価しているのかを把握することから始めてほしい。
この記事のポイント
- GA4に2026年5月追加のAI Assistantチャネルで、ChatGPTやClaudeなど生成AIからの流入が自動分類される
- AI OverviewsやAI Modeは含まれず、これらはOrganic Searchとして報告される点に注意が必要
- ページとスクリーンレポートでAI経由ランディングページを特定し、商品情報の最適化に活かせる
- 正規表現フィルタでAIプラットフォーム別の傾向を把握し、より細かな流入分析が可能
- AIトラフィックはSEOと地続きの指標であり、商品ページの情報充実がAIからの引用を増やす鍵になる

・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

WordPress解析の限界を突破する!「何が起きたか」ではなく「なぜ起きたか」を知る運用分析の重要性
アクセス解析のダッシュボードを開き、トラフィックの減少やコンバージョン率の低下、あるいはページ読み込み速度の悪化に気づくことがある。レポートには「何かが変わった」という事実がはっきりと示されているが、その「なぜ」を説明してくれることは稀だ。
Googleアナリティクスはセッションの減少を示し、パフォーマンス測定ツールは読み込みの遅延を警告する。しかし、これらのツールはあくまで表面的な症状を記録しているに過ぎない。サイトの背後で動いているWordPressアプリケーションやサーバー環境で何が起きたのか、その実態までは見えてこないのが現状だ。
WordPressサイトを安定して運営し、成長させるためには、数字という「結果」だけでなく、システムという「原因」を可視化する視点が欠かせない。本記事では、従来の解析ツールが抱える限界と、トラブルの根本原因を特定するために必要な「運用分析」の重要性について深掘りしていく。
成果分析と運用分析の違いとは?
一般的に広く使われている解析ツールの多くは「成果分析(Outcome Analytics)」に分類される。これは、訪問者がサイト上でどのような体験をしたかを測定するものだ。トラフィック量、エンゲージメント、検索順位、そしてページの表示速度といった指標がこれに該当する。
一方で「運用分析(Operational Analytics)」は、ウェブサイトを支えるシステムそのものに焦点を当てる。リクエストのパターン、サーバーの負荷状況、キャッシュの挙動、データベースの処理能力、そしてアプリケーションエラーの発生状況などが主な指標となる。
成果分析は「マーケティングの成果」を判断するのに役立つが、システムに問題が発生した際の「原因究明」には力不足だ。例えば、サイトが重くなったという「結果(成果分析)」に対して、PHPの処理待ちが発生しているという「原因(運用分析)」を特定することで、初めて具体的な対策が可能になる。
・コンバージョン率、離脱率
・LCP(最大視覚コンテンツの表示時間)
・キャッシュヒット率(Cache Hit Ratio)
・スロークエリ(DBの遅い処理)
このデモは、2つの分析手法の視点の違いを視覚化したものだ。ユーザーに見える表面的な数字から、その背後にあるシステムの動きへと視点を移すことが、トラブル解決の第一歩となる。
なぜ従来のツールでは「原因」がわからないのか

多くの解析プラットフォームは、診断ではなく報告のために設計されている。症状を特定することは得意だが、なぜその症状が出たのかという文脈が欠落していることが多い。その理由は、収集しているデータの種類にある。
ユーザー行動に特化しすぎている
Googleアナリティクスのようなツールは、訪問者の動きを追跡することに特化している。どのページが人気で、どこでユーザーが離脱したかを知るには最適だ。しかし、サーバーがリクエストを処理する際にどれほどの負荷がかかっていたかは教えてくれない。
また、高度なボットやクローラーによるトラフィックは、しばしば「実ユーザーの訪問」としてカウントされてしまう。急激なアクセス増がキャンペーンの成功によるものなのか、それとも悪意のあるスクレイピングによるものなのかを、表面的なレポートだけで判断するのは困難だ。
パフォーマンス指標に文脈がない
CWV(Core Web Vitals / コアウェブバイタル)などの指標は、サイトの「体感速度」を測る優れた基準だ。しかし「LCPが悪化した」という報告だけでは、原因が重い画像なのか、非効率なプラグインなのか、あるいはサーバーのリソース不足なのかを特定できない。
TTFB(Time to First Byte / 最初の1バイトが届くまでの時間)が遅延している場合、その裏にはデータベースのクエリ詰まりや、キャッシュ層のバイパスなど、複数の要因が隠れている可能性がある。結果だけを見るツールでは、これらの要因を切り分けることができないのだ。
WordPress特有のパフォーマンス低下を招く5つの要因

運用分析のデータがない環境でのトラブルシューティングは、消去法による推測の繰り返しになりがちだ。WordPressの現場で頻発するパフォーマンス低下の要因を整理すると、その多くがサーバー内部の挙動に起因していることがわかる。
1. PHPスレッドの飽和
WordPressはページを動的に生成するため、リクエストごとにPHPスレッドを消費する。アクセスが集中し、利用可能なスレッドを使い果たすと、後続のリクエストは「待ち行列(キュー)」に並ぶことになる。この状態になると、サイトはオンラインであっても、ユーザーには極めて重く感じられるようになる。
2. プラグイン更新によるデータベース負荷
特定のプラグインを更新したり、新機能を追加したりした直後に、データベースの負荷が急増することがある。最適化されていないクエリが発行されるようになると、CPU使用率が跳ね上がり、サイト全体の応答速度が低下する。これはアクセス数とは無関係に発生するため、表面的な解析では見落としやすい。
3. キャッシュ層の機能不全
キャッシュが正しく機能していれば、サーバーはWordPressを介さずにページを即座に返せる。しかし、設定ミスや特定のクエリパラメータによってキャッシュがバイパス(回避)されるようになると、すべてのリクエストをゼロから処理しなければならず、サーバー負荷が劇的に増加する。
4. ボットトラフィックの増大
検索エンジンのクローラーや、データを収集するスクレイパー、あるいは攻撃を試みる悪意のあるボットは、サーバーリソースを大量に消費する。これらはGA4などのダッシュボードでは「セッション」として表示されることもあるが、実態はサーバーを疲弊させる要因でしかない。
5. バックグラウンドタスクの重複
予約投稿の確認、バックアップの作成、インデックスの更新などのスケジュールされたタスク(wp-cron)が、背後でCPUやメモリを静かに消費している。これらが重なり合うと、通常のユーザーリクエストに割り当てるリソースが不足し、突発的な速度低下を引き起こす。
このデモは、運用分析で可視化されるサーバー内部の状態を簡略化したものだ。PHPスレッドが限界に近い場合、キャッシュが機能していてもサイト全体の応答は不安定になる。こうした「リソースの競合」を把握することが不可欠だ。
サーバー側で見るべき「4つの重要指標」

運用分析を実務に取り入れる際、具体的にどの数字を追えばよいのだろうか。WordPressの健全性を維持するために特に重要な指標が4つある。これらを監視することで、トラブルの兆候を早期に察知できるようになる。
リクエスト数とトラフィックパターン
サーバーが処理しているリクエストの総数と、その時間的な推移を確認する。トラフィックは常に一定ではない。キャンペーンやクローラーの巡回によって突発的な山ができる。このパターンを把握することで、現在の負荷が「想定内のアクセス増」なのか「異常なボット攻撃」なのかを判別できる。
PHPスレッドの利用率
PHPスレッドはWordPressの「エンジン」にあたる。各リクエストがどれくらいの時間スレッドを占有しているか、そして空きスレッドがどれくらいあるかを追跡する。利用率が100%に近づく時間が頻発しているなら、サーバープランのアップグレードやコードの最適化が必要なサインだ。
キャッシュ効率(ヒット率)
キャッシュヒット率は、全リクエストのうちどれだけをキャッシュから返せたかを示す割合だ。この数字が急落した場合、サイトのどこかでキャッシュを無効化する変更が行われた可能性が高い。ヒット率が高いほどサーバーの負荷は抑えられ、ユーザーへの応答速度は向上する。
エラーコードとレスポンスログ
HTTPステータスコード(500エラーなど)やPHPの警告ログをリアルタイムで監視する。これらは「壊れている箇所」を直接指し示してくれる。特定のプラグインがエラーを吐き続けている場合、それが全体のパフォーマンスを引き下げている根本原因であることは少なくない。
解析を「運用ツール」として再定義するメリット

多くの組織では、解析を「マーケティング担当者のためのツール」と考えている。しかし、システムレベルの可視化を含めることで、解析は「サイト運営の意思決定ツール」へと進化する。運用分析を導入することでもたらされる実務上のメリットは大きい。
第一に、トラブルシューティングの時間が劇的に短縮される。原因がわからないままプラグインを一つずつ停止して確認するような「手探りの作業」から解放され、データに基づいたピンポイントな修正が可能になる。これは開発コストの削減に直結する。
第二に、インフラのスケーリングを最適化できる。なんとなく「重いから」という理由で高価なサーバーへ移行するのではなく、PHPスレッドやメモリの消費実態に合わせて最適なリソースを選択できるようになる。過剰な投資を防ぎつつ、必要なパフォーマンスを確保できるのが強みだ。
最後に、障害の予兆を捉えられるようになる。完全にサイトがダウンする前に、エラー率の上昇やキャッシュヒット率の低下を検知できれば、ユーザーが異変に気づく前に対策を講じることができる。これは信頼性が求められるECサイトや企業サイトにおいて、極めて重要な価値となる。
この記事のポイント
- 従来のアクセス解析は「何が起きたか」という結果はわかるが、原因を特定する力は弱い。
- トラブル解決には、サーバー内部の動きを可視化する「運用分析(Operational Analytics)」が不可欠。
- PHPスレッドの飽和やキャッシュミス、ボットの挙動を把握することで、手探りの調査を卒業できる。
- ホスティングレベルの解析データを活用し、マーケティングと運用の両面からサイトを管理すべきだ。
- 「なぜ」を知ることで、インフラ投資の最適化とサイトの信頼性向上を同時に実現できる。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

ボットトラフィックの見極め方:人間・善玉・悪玉ボットを識別しサイト運営を最適化する
Webサイトのアクセス数が増加しているにもかかわらず、コンバージョンや収益が伸び悩む現象は珍しくない。多くの場合、その原因は「人間ではないトラフィック」の混入にある。自動化されたプログラム、いわゆるボットによる通信は、現代のインターネットにおいて無視できない規模に達している。
2025年の調査レポートによれば、2024年の全Webトラフィックの51%を自動化されたシステムが占めていた。これは過去10年間で初めて、ボットによるリクエストが人間の訪問者を上回ったことを示している。未対策のままでは、アクセス解析のデータは実態とかけ離れたものになり、経営判断を誤らせるリスクがある。
本記事では、Webサイトに訪れるトラフィックを「人間」「善玉ボット」「悪玉ボット」の3つに分類し、それらを識別する方法を解説する。正確なデータに基づいたサイト運営と、インフラ資源の適正な配分を実現するための指針を提示する。
ボットトラフィックの正体と3つの分類

ボットトラフィックとは、ブラウザを操作する人間ではなく、自動化されたソフトウェアによって生成されるリクエストのことだ。これらのプログラムは、人間と同じようにWebページや画像、スクリプト、APIに対してリクエストを送信する。サーバー側から見れば、一見すると通常の訪問者と区別がつかないことも多い。
自動化がインターネットを支える側面
自動化そのものは、必ずしも有害なものではない。現在のインターネットは、Webサイトの稼働状況を監視し、データを収集し、検索エンジンにインデックスさせるための自動システムに依存している。重要なのは、その通信が「なぜ」行われているかという意図を把握することだ。ボットを一括りに排除するのではなく、その役割に応じて分類して管理する必要がある。
トラフィックの3つのカテゴリー
サイトに到達するリクエストは、実務上、以下の3つに分けられる。第一に、実際の顧客となる「人間の訪問者」。第二に、検索エンジンや監視ツールなどの「善玉ボット」。そして第三に、脆弱性を探ったりコンテンツを盗用したりする「悪玉ボット」だ。これらを正しく識別できれば、セキュリティを強化しつつ、SEOや利便性を損なわない運用が可能になる。
人間のトラフィックと「善玉ボット」の特徴

人間の訪問者と有益な自動化プログラムには、それぞれ特有の行動パターンがある。これらを理解することは、トラフィックの健全性を評価する第一歩となる。
不規則で予測困難な人間の動き
人間のアクセスは、極めて不規則だ。ページをスクロールする深さ、リンクをクリックするまでの時間、滞在の長さなどは、人によって千差万別である。同じ広告キャンペーンから流入したユーザーであっても、全く同じ順序でページを遷移することはまずない。また、使用するデバイスやブラウザ、画面サイズ、接続環境も多様であり、データにばらつきが生じるのが自然な状態だ。
サイトの成長を助ける善玉ボット
善玉ボットは、サイトの認知度向上や運営の維持に欠かせない。代表的な例は、GoogleやBingなどの検索エンジンクローラーだ。これらは新しいコンテンツを見つけ、検索結果に反映させるために巡回してくる。クローラーは通常、`robots.txt`で指定されたルールを遵守し、サーバーに過度な負荷をかけないよう制御されている。
また、サイトの死活監視(Uptime Monitor)やパフォーマンス計測ツールも、定期的にリクエストを送信する。これらは数分おきに正確な間隔でアクセスしてくるが、User Agent(ユーザーエージェント:アクセス元の識別情報)を明示していることが多いため、識別は比較的容易だ。これらのアクセスを遮断してしまうと、検索順位の低下や異常検知の遅れを招くことになる。
リスクを引き起こす「悪玉ボット」の脅威

一方で、悪玉ボットはサイトの資源を浪費させ、セキュリティリスクを増大させる。これらは正体を隠し、防御策を回避しようとする傾向がある。
不正ログインと脆弱性スキャン
最も一般的な脅威の一つが、リスト型攻撃(クレデンシャルスタッフィング)や総当たり攻撃(ブルートフォース)だ。盗まれたユーザー名とパスワードのリストを使い、ログイン画面に対して高速で試行を繰り返す。たとえログインに失敗しても、大量のリクエストによってサーバーのCPUやメモリが消費され、一般ユーザーの表示速度が低下する原因となる。
また、脆弱性スキャナーは、古いプラグインや設定ミスがないか、サイト内のディレクトリを片っ端から調査する。放置しておくと、攻撃の足がかりを与えてしまうことになる。
スクレイピングとDDoS攻撃
スクレイピングボットは、サイト上の価格情報や独自コンテンツを無断で収集し、他サイトで再利用するために動く。これにより、独自の価値が損なわれるだけでなく、帯域幅(通信容量)が無駄に消費される。さらに、特定のページにリクエストを集中させてサービスを停止させるDDoS攻撃(分散型サービス拒否攻撃)も、ボットネットを通じて行われる。これらはビジネスの継続性に直接的な打撃を与える。
トラフィックを正確に識別するための5つの指標

人間とボットを完璧に見分ける単一の指標は存在しない。複数の信号を組み合わせて評価することが、精度の高い識別につながる。元記事の著者は、以下の5つのポイントに注目すべきだと指摘している。
1. リクエストの頻度とタイミング
人間は記事を読み、考え、次の行動に移るため、リクエストの間隔が数秒から数分空くのが普通だ。対して、ボットはミリ秒単位の正確な間隔でアクセスしたり、一瞬のうちに数十ページを読み込んだりする。このような超人的なスピードや、機械的な規則性はボットの典型的な兆候だ。
2. User Agent(ユーザーエージェント)の検証
善玉ボットは自身の名前を名乗るが、悪玉ボットは一般的なChromeやSafariなどのブラウザを装う(偽装)ことが多い。しかし、ブラウザの情報を偽っていても、その背後にある挙動が不自然であれば、偽装を見破ることができる。複数のリクエストでUser Agentを頻繁に変更している場合も注意が必要だ。
3. IPレピュテーションとネットワーク属性
アクセス元のIPアドレスが、データセンターやクラウドホスティング、プロキシサーバーのものである場合、それは人間ではなく自動化されたシステムである可能性が高い。通常のユーザーは、ISP(インターネットサービスプロバイダー)経由でアクセスしてくるからだ。過去に攻撃に関与したIPアドレスのデータベース(レピュテーション)と照合することも有効だ。
4. 地理的分布の異常
本来のターゲット層ではない国や地域から、突然大量のアクセスが発生した場合、それはボットネットによる攻撃やスキャンの可能性が高い。特に、その地域の言語設定とブラウザの情報が一致しない場合は、ボットである疑いが強まる。
5. robots.txtへの対応
サイトのルートディレクトリにある`robots.txt`は、ボットに対する「立ち入り禁止区域」の指示書だ。善玉ボットはこのルールを守るが、悪玉ボットはこれを無視して禁止されたパスにアクセスする。この挙動は、ボットの「行儀の良さ」を判断する明確な基準となる。
ボットがアクセス解析と意思決定に与える影響

ボットトラフィックを排除せずに放置すると、マーケティング戦略そのものが歪められる恐れがある。数字上の「成長」に騙されないための視点が必要だ。
歪められるエンゲージメント指標
ボットはページを開いてすぐに離脱したり、逆に特定のページを何度も読み込んだりする。これにより、直帰率や平均滞在時間が異常な値を示す。特定の記事が非常に人気があるように見えても、実はスクレイピングボットが巡回していただけというケースは少なくない。これに基づいたコンテンツ制作は、実際の読者のニーズを反映しないものになってしまう。
インフラコストとリソースの浪費
Webサイトのホスティング費用は、転送量やリクエスト数、サーバー負荷に基づいて決まることが多い。トラフィックの半分以上が価値を生まないボットであれば、その分のコストは純粋な損失となる。また、ボットへの対応でサーバーが重くなれば、本来大切にすべき人間のユーザーがサイトを離れてしまい、コンバージョン機会を逃すという二重の損失を招く。
効果的なトラフィック管理のベストプラクティス

現代のWebサイト運営において、ボットを完全にゼロにすることは不可能に近い。現実的な目標は、ボットを適切に管理・制御し、人間への影響を最小限に抑えることだ。
階層的な防御策の導入
まず、CDN(コンテンツ配信ネットワーク)やWAF(Webアプリケーションファイアウォール)を導入し、サーバーに到達する前の「エッジ」段階で悪質なリクエストを遮断するのが効率的だ。これにより、サーバーの負荷を劇的に軽減できる。また、ログイン画面など特定の場所には、ボットにのみ課題を出す「セキュリティチャレンジ」を設けることも有効だ。
行動ベースの制限(レートリミット)
特定のIPアドレスから短時間に大量のリクエストがあった場合に、一時的にアクセスを制限する「レートリミット」は強力な武器になる。これは静的な拒否リストとは異なり、現在の挙動に基づいて動的に判断するため、新しい攻撃手法にも柔軟に対応できる。ただし、善玉ボットまで遮断しないよう、除外設定を丁寧に行うことが重要だ。
定期的なログ分析と方針の見直し
ボットの技術は日々進化しており、AIを使ったより人間らしい挙動を見せるものも現れている。一度設定して終わりにするのではなく、定期的にサーバーログやアクセス解析を確認し、新しいパターンのボットが紛れ込んでいないかチェックする必要がある。ホスティングサービスの管理画面で提供される分析ツールを活用し、トラフィックの内訳を常に把握しておくことが、健全なサイト運営の鍵となる。
この記事のポイント
- 現代のWebトラフィックの約半分はボットであり、人間とボットの識別は正確なデータ分析に不可欠である。
- ボットは、SEOを助ける「善玉(クローラー等)」と、攻撃や盗用を行う「悪玉」に分け、それぞれ異なる対応が必要だ。
- リクエストの間隔、IPアドレスの属性、robots.txtへの準拠状況などが、ボットを見分ける重要な指標となる。
- 未対策のボットトラフィックは、サーバーコストを増大させ、マーケティング上の意思決定を誤らせるリスクがある。
- CDNやWAFを活用した階層的な防御と、挙動ベースのレートリミット導入が、最も効果的な管理手法である。
出典
- Kinsta Blog「How to distinguish traffic from bots to identify real visits, helpful bots, and harmful attacks」(2026年3月17日)
- Imperva「2025 Bad Bot Report」(2025年発表)
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

小規模サイトの検索流入が60%激減。AI時代のSEO戦略と生き残り策をデータから読み解く
小規模なウェブサイト運営者(パブリッシャー)が、Googleなどの検索エンジンから獲得する流入数が過去2年間で60%減少したことが明らかになった。アクセス解析ツールを提供するChartbeat(チャートビート)の調査データによれば、この減少幅は大規模なサイトと比較して約3倍に達している。検索アルゴリズムの変化とAIチャットボットの普及が、個人や中小規模のメディアに深刻な影響を与えている現状が浮き彫りとなった。
調査対象となったサイト群のうち、1日のページビュー(PV)が1万件未満の「小規模パブリッシャー」は、2024年から2026年にかけて検索経由のトラフィックを最も大きく失った。一方で、1日10万PVを超える大規模サイトの減少率は22%に留まっている。この格差は、検索エンジンが大手ブランドを優先する傾向を強めていることや、リソースの乏しい小規模サイトが急激な環境変化に対応できていないことを示唆している。
本記事では、この衝撃的なデータの詳細を分析し、なぜ小規模サイトだけがこれほど大きな打撃を受けているのかを考察する。また、検索流入に頼らない「脱・検索依存」の集客モデルについても、具体的な数値と共に解説していく。ウェブサイトを運営する中小企業の担当者や個人事業主にとって、今後のコンテンツ戦略を見直す重要な指標となるはずだ。
小規模パブリッシャーを襲う「検索流入60%減」の衝撃

Chartbeatが数千のクライアントウェブサイトを対象に実施した調査によると、検索エンジンからのリファラル(流入)トラフィックは、サイトの規模によってその減少幅に劇的な差が出ている。リファラルとは、他のサイトや検索エンジンにあるリンクを辿って自分のサイトへ訪れる仕組みを指す。この「検索エンジンという入り口」が、小規模なサイトでは半分以下に狭まっているのが現状だ。
サイト規模によって異なる減少幅の格差
データによれば、1日のページビューが1,000〜10,000件の小規模パブリッシャーは、過去2年間で検索流入が60%減少した。対して、10,000〜100,000件の中規模サイトは47%の減少、100,000件を超える大規模サイトは22%の減少となっている。大規模サイトも影響は受けているものの、小規模サイトの被害は突出して大きい。
この格差が生じる背景には、Googleの検索品質評価ガイドラインにおける「E-E-A-T(経験・専門性・権威性・信頼性)」の重視がある。大手メディアは組織としての信頼性や過去の蓄積があり、アルゴリズムの変動に対して耐性が高い。一方で、特定のトピックに特化した小規模サイトは、アルゴリズムの変更によって「信頼性の証明」が不十分と判断されやすく、掲載順位を大きく落とす傾向にある。
Google検索とDiscoverの同時衰退
検索流入の内訳を見ると、Google検索そのものからのトラフィックは2024年12月から2025年12月の1年間で34%減少した。追い打ちをかけるように、Google Discover(グーグル・ディスカバー)からの流入も15%減少している。Discoverとは、ユーザーの興味関心に合わせてスマートフォンのGoogleアプリなどに記事が自動表示される機能だ。
従来、検索順位が低くてもDiscoverで「バズる」ことで大量のアクセスを稼ぐ手法が存在したが、その窓口も狭まりつつある。Chartbeatのデータは、検索キーワードを打ち込んで探す「能動的な流入」と、おすすめに表示される「受動的な流入」の両方が、小規模パブリッシャーから失われていることを示している。これは、従来のSEO(検索エンジン最適化)だけではアクセスを維持できない時代の到来を意味する。
AIチャットボットは検索の代替になり得るか
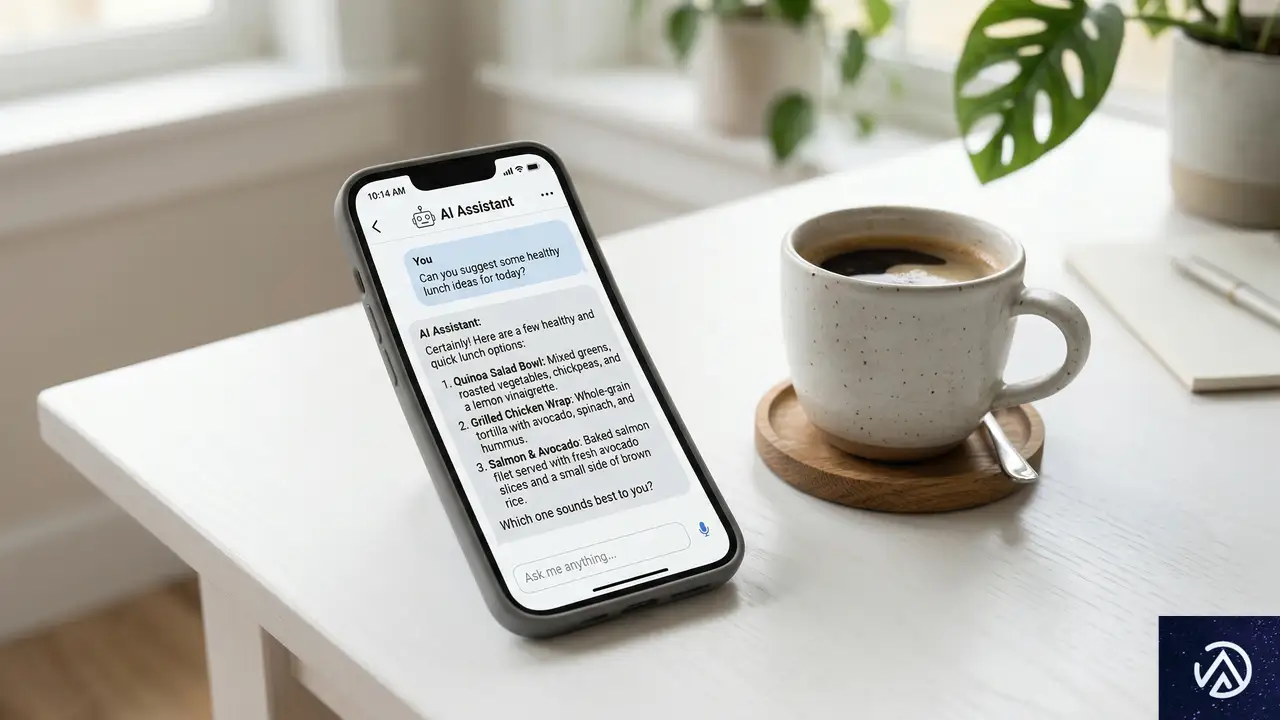
検索流入が減少する一方で、ChatGPTなどのAIチャットボットからの流入は急増している。Chartbeatのデータによると、2024年末からの1年間で、ChatGPT経由のトラフィックは200%以上の成長を記録した。しかし、この数字には注意が必要だ。成長率こそ高いものの、全トラフィックに占めるAIチャットボットのシェアは依然として1%未満に過ぎない。
ChatGPT経由の流入は200%増もシェアは1%未満
AIチャットボットは、ユーザーの質問に対してウェブ上の情報を要約して回答する。回答内に引用元としてリンクが表示されることもあるが、ユーザーの多くはAIの回答だけで満足し、元のサイトをクリックしない。これを「ゼロクリック検索」と呼ぶ。辞書代わりの調べ物であれば、わざわざサイトを訪れる必要がなくなるためだ。
結果として、AI経由の流入が200%増えたところで、検索エンジンから失われた膨大なトラフィックを補填するには全く足りていない。著者のマット・G・サザン氏は、チャットボットの成長が検索の損失を置き換えるにはほど遠い状態であると指摘している。AIは情報の「消費場所」にはなっているが、サイトへの「送客装置」としてはまだ未成熟と言える。
サイトジャンルで分かれる「AI流入」の質
興味深い事実は、サイトのジャンルによってAIチャットボットからの流入の「質」が異なる点だ。ニュースやメディアサイトの場合、AIからの流入総数は多いものの、1記事あたりのエンゲージメント(滞在時間や読了率)は極めて低い。ユーザーはAIの回答が正しいかを確認するために、一瞬だけサイトを訪れる「ファクトチェック」的な使い方をしていると考えられる。
一方で、健康のアドバイスや園芸のヒントなどを提供する「実用的なサイト(Utilitarian sites)」では、AIからの流入数自体は少ないが、1記事あたりのページビューや滞在時間は長い傾向にある。ハウツーものや深い専門知識を求めるユーザーは、AIの簡潔な回答では満足せず、詳細な解説を求めてサイトを読み込むためだ。コンテンツの性質によって、AI時代における価値の残り方が分かれている。
大手メディアが実践する「脱・検索依存」の具体策
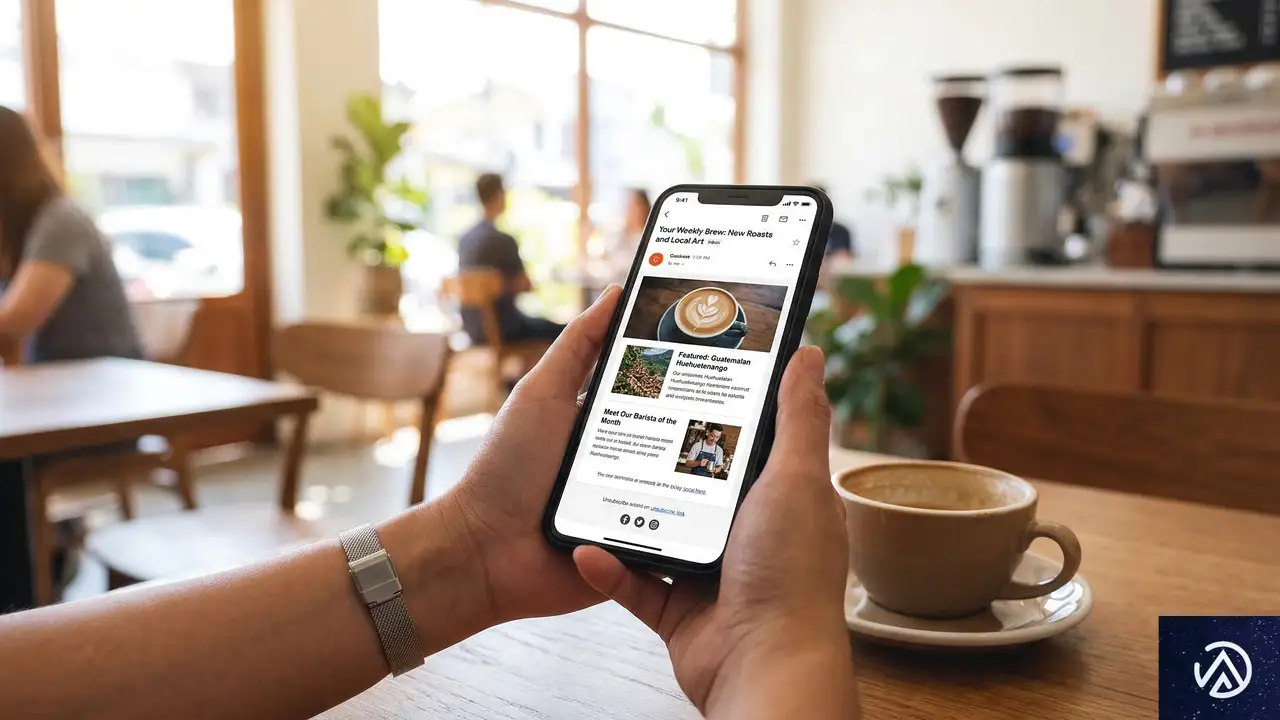
検索流入が22%の減少で済んでいる大規模パブリッシャーは、単にドメインが強いだけでなく、検索に頼らない集客経路の構築に成功している。Chartbeatの分析によれば、大手ニュースサイトなどでは「ダイレクト流入」や「内部トラフィック」の割合が増加している。これは、ユーザーが検索エンジンを経由せず、直接そのサイトを指名して訪れていることを示している。
ダイレクト流入と内部回遊の強化
ダイレクト流入とは、ブラウザのブックマークやURLの直接入力によってサイトを訪れることだ。いわば「常連客」の動きである。大手メディアは、ブランド認知度を高めることで「ニュースならこのサイト」という習慣をユーザーに植え付けている。また、一度訪れたユーザーを逃さないよう、関連記事への誘導(内部回遊)を徹底し、1回の訪問で複数のページを見てもらう工夫を凝らしている。
小規模サイトが1ページだけ読まれて離脱される「一見さん」中心の構造であるのに対し、大規模サイトはサイト内を回遊させる仕組みが強固だ。これにより、検索エンジンからの新規流入が減っても、全体のページビューの落ち込みを最小限に食い止めている。サイトを一つの「島」として完結させ、島内での滞在を最大化する戦略が功を奏している形だ。
所有メディア(メール・アプリ)への投資加速
さらに、大手パブリッシャーは「所有メディア(Owned Media)」への投資を加速させている。具体的には、メールマガジンの配信や独自アプリの提供だ。これらは検索アルゴリズムの影響を一切受けない。ユーザーのメールボックスやスマートフォンの通知に直接情報を届けられるため、非常に安定した流入源となる。
2026年1月のロイター研究所の調査でも、多くのパブリッシャーが「自社チャネルへの投資を増やす」と回答している。検索エンジンという他者のプラットフォームに依存するリスクを回避するため、顧客との直接的な接点を持つことの重要性が再認識されている。小規模サイトであっても、SNSのフォロワーやメルマガ登録者を地道に増やす「リストビルディング」が、かつてないほど重要になっている。
【独自分析】中小規模サイトが今後取るべき3つの生存戦略

今回のChartbeatのデータは、小規模サイトにとって絶望的な数字に見えるかもしれない。しかし、検索流入が減るからといってウェブサイトの価値がなくなるわけではない。むしろ、AIが一般情報を網羅する時代だからこそ、小規模サイトには「人間にしか書けない、特定の誰かのための情報」という独自の価値が求められている。以下に、中小規模サイトが今後取るべき戦略を3つ提案する。
「検索キーワード」から「読者の課題」へのシフト
これまでのSEOは「検索ボリュームの多いキーワード」を狙って記事を書くのが定石だった。しかし、一般的なキーワードに対する回答はAIが独占しつつある。今後は「キーワード」ではなく、特定のターゲットが抱える「具体的で深い悩み」にフォーカスすべきだ。検索回数は少なくても、その情報を切実に求めている読者に届くコンテンツは、AIには代替できない価値を持つ。
たとえば「美味しいカレーの作り方」という記事はAIに勝てないが、「築50年のキッチンで、限られた火力を使って本格スパイスカレーを作るコツ」という記事なら、同じ境遇の読者にとって唯一無二の存在になれる。ターゲットを極限まで絞り込み、その人たちのコミュニティ(SNSや専門掲示板)でシェアされることを目指すのが、現代の集客の基本となる。
滞在時間を重視した「実用・専門特化」コンテンツ
Chartbeatのデータが示した通り、実用的なハウツーサイトはAI経由でも高いエンゲージメントを維持している。これは、読者が「単なる事実」ではなく「実行するためのプロセス」を求めているからだ。小規模サイトは、表層的な情報をなぞるのではなく、著者自身の体験や独自の検証データ、失敗談などを盛り込んだ「厚みのあるコンテンツ」に特化すべきだ。
滞在時間が長いサイトは、Googleからも「ユーザーの課題を解決している」と評価されやすくなる。また、読者がその記事を保存(ブックマーク)したり、何度も読み返したりするようになれば、検索エンジンに依存しないリピーターへと変化する。PV数という「量」を追うのではなく、読了率や再訪問率という「質」をKPI(重要業績評価指標)に据えるべきだ。
ゼロクリック検索を逆手に取ったブランド構築
AIの回答に引用されることは、短期的には流入減につながるが、長期的には「ブランド名の露出」というメリットがある。AIが「〇〇サイトによれば〜」と繰り返し引用すれば、ユーザーの脳内にはその分野の専門家としてサイト名が刻まれる。これを逆手に取り、あえてAIが引用しやすい高品質な要約データや、独自の図解、統計を提供し続ける戦略も有効だ。
「検索結果で1位を取る」ことだけがSEOではない。AIの回答の一部になり、信頼できる情報源としての地位を確立することで、最終的には「詳しいことは直接あのサイトで確認しよう」という直接訪問を促す。流入経路が変化しても、情報の信頼性という価値は変わらない。小規模だからこそ、顔の見える専門家としてのブランディングを強化することが、最大の防御であり攻撃になる。
この記事のポイント
- 小規模パブリッシャーの検索流入は2年間で60%減少し、大規模サイトより打撃が大きい。
- Google検索だけでなくGoogle Discoverからの流入も減少傾向にあり、既存のSEO手法が限界を迎えている。
- ChatGPT経由の流入は200%増と急成長しているが、全体のシェアはまだ1%未満で検索の代わりにはならない。
- 大手メディアはダイレクト流入やメルマガ、アプリなど、検索に依存しない自社チャネルの強化で対策している。
- 小規模サイトは、AIに真似できない「体験談」や「超専門特化」コンテンツへ舵を切ることが生存の鍵となる。
出典
- Search Engine Journal「Search Referral Traffic Down 60% For Small Publishers, Data Shows」(2026年3月17日)
- Axios「Exclusive: Chartbeat data shows search traffic decline by publisher size」(2026年3月17日)
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

GA4の「Direct」トラフィックの正体——AIの影響と計測の限界を読み解く
Googleアナリティクス4(GA4)において、Direct(直接流入)の増加は必ずしもブランド認知の向上を意味しない。 多くのマーケティング担当者は、Directトラフィックを「ユーザーがURLを直接入力した、またはブックマークから訪問したロイヤリティの高い行動」と解釈している。 しかし、実態は「参照元を特定できなかったトラフィックのゴミ箱」に近い側面がある。
GA4のレポートでDirectが急増している場合、そこにはAIによる回答エンジンやプライバシー保護機能の影響が隠れている。 データの裏側にある技術的背景を理解しなければ、誤った投資判断を下すリスクがある。 本記事では、Directトラフィックが実際に何を計測しているのか、そしてAI時代にどう向き合うべきかを解説する。
GA4におけるDirectトラフィックの定義と実態
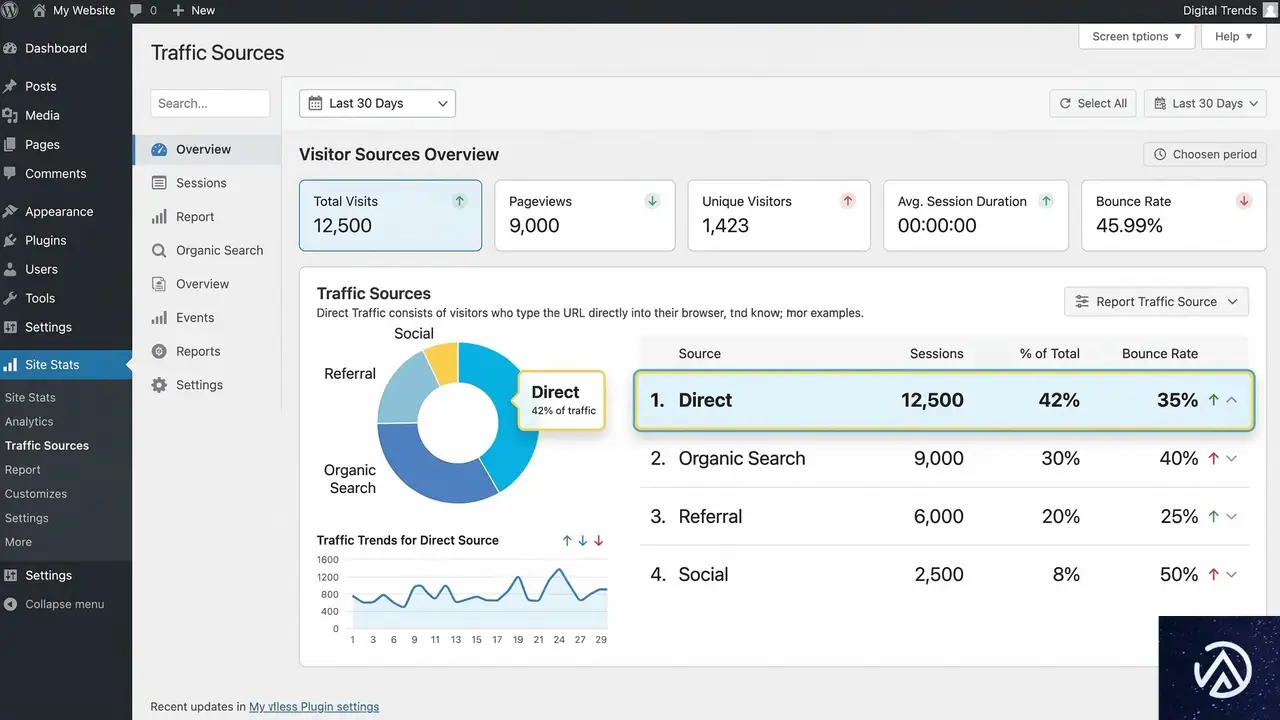
GA4において、セッションのソース(流入元)やメディアが特定できない場合、その訪問は自動的に「Direct」として分類される。 一般的には、ブラウザのURLバーに直接ドメインを入力する、あるいはブラウザの「お気に入り」からアクセスする行動がこれに該当する。 有名ブランドであれば、この種の直接訪問が一定数存在するのは自然なことだ。
リファラ情報の欠落が招く「擬似的なDirect」
しかし、実際には「リファラ(Referrer)」と呼ばれる参照元情報が失われたことで、Directに分類されるケースが非常に多い。 リファラとは、ユーザーがどのページからリンクを辿ってきたかを伝える仕組みだ。 例えば、LINEやSlackなどのメッセージアプリ内のリンク、あるいはモバイルアプリ内からWebサイトへ遷移する場合、このリファラ情報が正しく引き継がれないことがある。
また、セキュリティ上の理由でHTTPSサイトからHTTPサイトへ遷移する際も、リファラは送信されない。 このように、ユーザーの意図的な直接訪問ではなく、技術的な制約によって「正体不明」となったアクセスがDirectとしてカウントされている。 これは計測側の限界であり、ユーザーのブランド愛着度を示しているわけではない。
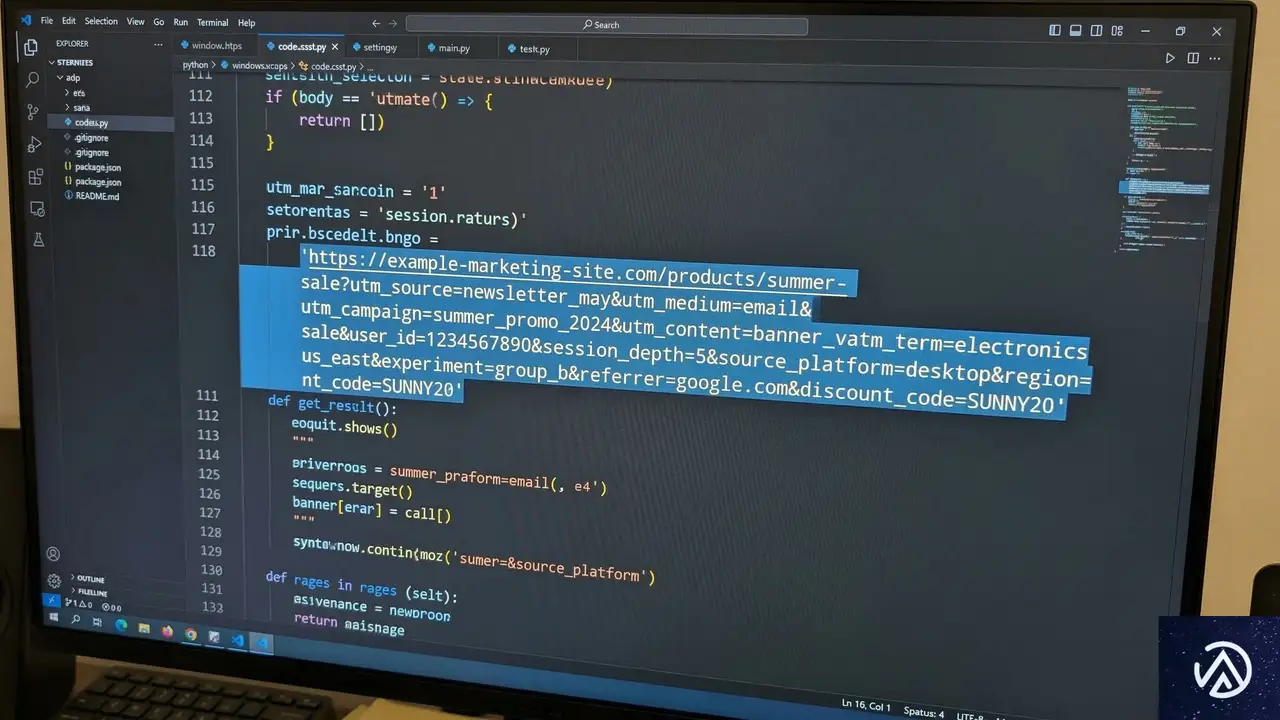
なぜDirectトラフィックの増加を誤読してしまうのか
マーケティングレポートにおいて、Directの増加は「施策が当たって指名検索や直接訪問が増えた」とポジティブに報告されやすい。 経営層やクライアントにとっても、広告費をかけずにユーザーが自発的に訪れる数字は魅力的に映る。 だが、この解釈には大きな落とし穴がある。
キャンペーンタグの不備という技術的要因
Direct急増の裏には、多くの場合、タグ設定のミスが隠れている。 メールマガジンやPDF資料、SNSの投稿に設置したリンクにUTMパラメータが付与されていない場合、それらはすべてDirectとして処理される。 UTMパラメータとは、URLの末尾に追加する「?utm_source=…」といった文字列で、流入元を明示するためのものだ。
特に、複数のチームで運用している場合、タグ付けのルールが統一されていないと計測漏れが発生しやすい。 インフルエンサー施策や有料広告であっても、リンク先のURLが適切に管理されていなければ、その成果はすべてDirectの中に埋もれてしまう。 これは、マーケティング活動の投資対効果(ROI)を正しく評価できない原因となる。
クロスデバイスとカスタマージャーニーの断絶
ユーザーの行動が複雑化していることも、Directトラフィックを複雑にしている。 例えば、スマートフォンで通勤中に検索し、サイトを見つけたユーザーがいたとする。 その後、帰宅してからPCを立ち上げ、ブラウザに社名を入力して購入に至った場合、GA4はこれを「Directによるコンバージョン」と記録することが多い。
実際には最初の検索(オーガニック検索)がきっかけだが、デバイスを跨ぐことで計測の紐付けが途切れてしまう。 この場合、Directは「ロイヤリティの証」ではなく、単なる「最終接触チャネル」に過ぎない。
AIによる「静かなインフレ」とDirectの関係
2026年現在、AI検索やチャット型アシスタントの普及により、Directトラフィックの性質がさらに変化している。 ユーザーがGoogle検索の代わりにAIに質問し、AIが特定のブランドや製品を推奨するシーンが増えた。 この際、AIが提示した情報を元にユーザーが新しいタブを開き、直接ドメインを入力してサイトに訪れる行動が頻発している。
AIアシスタント経由の「ダークサーチ」
AI経由の訪問は、GA4のレポート上では多くの場合、参照元不明のDirectとして現れる。 AIツールがブラウザ内でリンクを生成して誘導する場合でも、従来のような検索エンジンからの流入(Organic Search)としてはカウントされない。 このように、出所が特定できないものの、実際には外部の影響を受けている流入を「ダークサーチ」と呼ぶ。
AIの影響力が強まるほど、オーガニック検索の数字は横ばい、あるいは減少する一方で、Directだけが伸び続ける現象が起きる。 これを「ブランド力が上がった」と単純に喜ぶのは危険だ。 実際にはAIへの露出度(AI Visibility)が高まった結果であり、その因果関係を把握するには別の分析手法が必要になる。
プライバシー保護の強化が計測を不透明にする

近年のプライバシー保護の潮流も、Directトラフィックを増大させる要因となっている。 ブラウザ各社によるトラッキング防止機能(ITPなど)や、ユーザーによるクッキー(Cookie)の拒否設定が、アトリビューション(貢献度)解析を困難にしている。
リファラ情報の削除とURLクリーンアップ
一部のブラウザやメッセージングアプリでは、プライバシー保護のためにURLからトラッキング用のパラメータを自動的に削除する機能を備えている。 これにより、本来なら「広告経由」や「SNS経由」と識別されるべきアクセスが、丸裸のURLとしてサーバーに届くことになる。 結果として、GA4はこれらをDirectとして分類せざるを得ない。
ユーザーの行動自体は変わっていないが、計測システムの「目」が塞がれている状態だ。 今後、プライバシー規制がさらに厳格化される中で、Directトラフィックの比率はさらに高まっていくと予想される。 もはや「Direct=直接訪問」という前提は成り立たない。
Directトラフィックを正しく診断するための実務チェックリスト

Directが急増した際、それが「良い兆候」なのか「計測の不備」なのかを判断するための具体的なステップを紹介する。 単一の指標に惑わされず、複数のデータを掛け合わせることが重要だ。
1. ランディングページの分布を確認する
Direct流入の受け皿となっているページを調査する。 トップページ(/)への流入であれば、直接入力やブックマークの可能性が高い。 しかし、URLが長く複雑な「ブログ記事」や「特定の商品ページ」にDirectが集中している場合、それはメッセージアプリや未計測のキャンペーンからの流入である可能性が極めて高い。
2. 指名検索(ブランド検索)の推移と比較する
Google Search Console(サーチコンソール)を使用し、社名やサービス名での検索クリック数を確認する。 Directトラフィックと指名検索が連動して増えているなら、テレビCMや展示会などのオフライン施策、あるいはAIでの露出によって認知が拡大したと推測できる。 逆に、指名検索が増えていないのにDirectだけが急増しているなら、技術的なタグの欠落を疑うべきだ。
3. ブラウザとデバイスのセグメント分析
特定のブラウザ(例:iOSのSafari)や、特定のアプリ内ブラウザだけでDirectが増えていないかを確認する。 特定の環境だけで増えている場合、それはOSのアップデートによるプライバシー制限や、アプリの仕様変更が原因である可能性が高い。
4. キャンペーンタグ(UTM)の再点検
現在配信しているすべての外部チャネルをリストアップし、UTMパラメータが正しく設定されているかテストする。 特に以下の項目は見落とされやすい。
- メールマガジン内のボタンやテキストリンク
- 公式SNSアカウントのプロフィール欄にあるURL
- カスタマーサポートがチャットで送信するURL
- QRコード経由のアクセス
独自の分析:ECサイトにおけるDirectトラフィックの「意味」
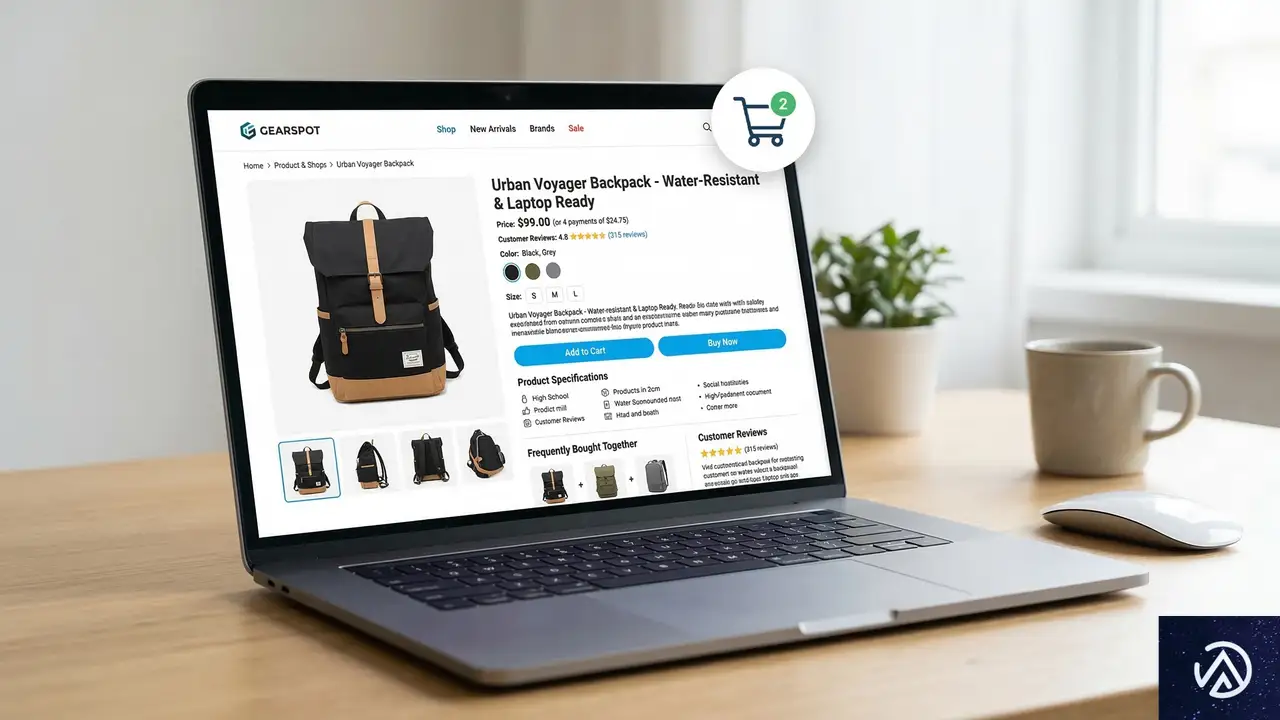
WooCommerceなどのECサイトを運営している場合、Directトラフィックの質を見極めることは売上に直結する。 筆者の分析によれば、ECにおける「健全なDirect」は、リピート購入の直前に発生する傾向がある。 一方で、新規ユーザーによるDirect流入が特定の「セール対象商品」に集中している場合、それはアフィリエイトやSNSでの「タグなし紹介」が原因であることが多い。
これを放置すると、どの媒体が売上に貢献しているのかが分からず、広告予算の最適化ができなくなる。 対策として、サイト内に「どこで知りましたか?」というアンケートを設置したり、特定の流入元専用のクーポンコードを発行したりすることで、GA4の数字を補完する努力が求められる。
技術的な限界を認めた上で、定性的なデータで「Directの正体」を埋めていく姿勢が、これからのWeb担当者には不可欠だ。
この記事のポイント
- GA4のDirectは「参照元が特定できないアクセス」の総称であり、必ずしも直接訪問ではない。
- AI検索やチャットツールの普及により、出所不明の「ダークサーチ」が増加している。
- プライバシー保護機能の強化により、リファラ情報が削除され、Directへ分類されるケースが増えている。
- Directの急増時は、ランディングページや指名検索の推移を確認し、計測不備がないか診断する必要がある。
- データの不透明さを前提に、アンケートやクーポン活用などの補完的な分析手法を組み合わせることが重要だ。
出典
- MarTech「Why direct traffic in GA4 isn’t what it looks like」(2026年3月9日)
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験