

AWS Resilience Hubが大幅刷新、生成AIで障害モードを分析しSREの信頼性管理を効率化
AWSが「Resilience Hub」の次世代版を一般公開した。最大の変更点は生成AIを活用した障害モード評価の搭載だ。組織全体の信頼性を構造化されたポリシーで管理し、数百に及ぶアプリケーションの可用性リスクを一元的に可視化する。
今回の刷新では新たなアプリケーションモデルが導入され、依存関係の自動検出機能やモジュール式の信頼性ポリシーも追加された。SREチームと開発チームが同じ指標で対話し、エンタープライズ全体のレジリエンスを継続的に改善する基盤が整った形だ。
従来のResilience Hubが個々のアプリケーション評価に留まっていたのに対し、今回の刷新は「信頼性の管理」を組織のガバナンス領域に引き上げる。本記事ではその具体的な機能と実務への影響を詳しく解説する。
AWS Resilience Hubの全体像と考え方の変化
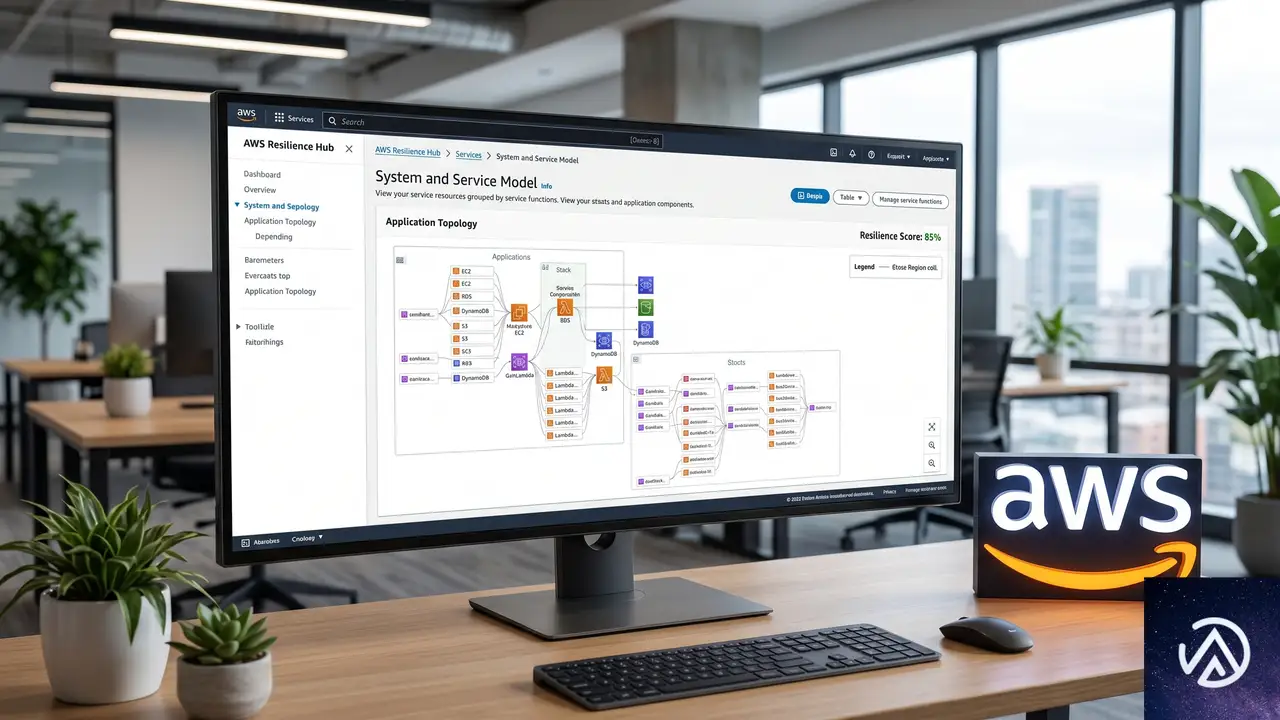
この比較が示すように、次世代版の本質は「個別最適から全体最適への転換」だ。AWS Organizationsとの統合により、委任管理者アカウントから複数アカウントを横断したレジリエンス評価が可能になった。
「ビジネス視点」で捉え直されたアプリケーションモデル
新しいモデルは3層構造になっている。最上位にビジネスアプリケーション全体を表す「システム」、その下にクリティカルな業務経路を示す「ユーザージャーニー」、さらに実際のデプロイ単位である「サービス」が配置される。サービスはAWSリソースやコード、オブザーバビリティの構成要素を束ねる役割だ。
この構造により「ログインできないと売上が止まる」という業務インパクトと、IAMロールの設定ミスという技術的リスクが地続きで評価できるようになる。AWS News Blogの記事でChanny氏は「ビジネス成果に直接結びつくクリティカルなエンドユーザー経路」という表現でこの概念を説明している。
モジュール式ポリシーでチーム間の共通言語を確立
信頼性ポリシーも大きく変わった。旧来は固定されたポリシータイプを選ぶ方式だったが、次世代版では必要な要件を組み合わせて構築できる。たとえば「可用性SLO 99.95%」「マルチリージョン災害復旧」「RTO 15分、RPO 5分」といった要素を選択し、金融系アプリケーション用のポリシーとして再利用する運用が可能だ。
SREと開発チームの間で「どの水準を目指すか」の共通理解が生まれ、属人的な判断を減らせる効果が期待できる。特に複数の開発チームを持つ組織では、この統一ポリシーがガバナンスの要になる。
生成AIが障害モードを評価する仕組み

次世代版の目玉機能が、生成AIを用いた障害モード評価である。サービスにポリシーを紐付けて評価を実行すると、AIが自動的に設定ミスや単一障害点を洗い出し、具体的な改善策を提案する。
この4ステップのフローにより、人手では発見が難しいクロスアカウントの依存関係や、リージョンをまたぐ意図しない呼び出しまで検出できる。AIは単にデータを収集するだけでなく、障害が発生した場合の影響範囲を推定し、優先度付きの修正ガイダンスを出力する。
AWS Well-Architectedと分析フレームワークの統合
AIの評価ロジックはAWS Well-Architectedフレームワークのベストプラクティスと、AWS Resilience Analysis Frameworkを参照している。これにより「なんとなく不安」ではなく、定義された基準に照らした再現性のある評価が実現する。
評価結果では「どのポリシー要件に違反しているか」が明示される。たとえば「RTO 15分を満たすには、このAuto Scalingグループのインスタンスが起動するまでの時間が長すぎる」といった具体的な指摘が得られる。対策の優先順位をビジネスインパクトに基づいて判断できる点が実務的に価値が高い。
また、ユーザーがAssertion(表明)を追加してAIの分析精度を高める仕組みも用意されている。たとえば「このサービスは特定のリージョンでのみ稼働する」といった前提条件をAIに伝えることで、無関係なマルチリージョン構成の提案を除外できる。
依存関係の自動検出がもたらす可視性の向上

多くの障害は「認識されていない依存関係」から発生する。次世代Resilience HubはDNSクエリログを解析し、VPC内のエンドポイントから呼び出されているAWSサービスや内部API、サードパーティの外部エンドポイントを自動で特定する。
この機能の価値は運用の暗黙知を形式知に変換する点にある。「ベテランSREだけが知っている」依存関係を、システムが自動でドキュメント化してくれる。異動や退職によるナレッジロスを防ぎ、障害対応の属人性を低減する効果が期待できる。
依存関係検出はサービス作成時に有効化する。VPCフローログではなくDNSクエリログを解析する仕組みのため、ネットワークトラフィックの暗号化状況に影響されず、比較的軽量に動作する設計だ。不要な場合は管理画面の設定から無効化できる。
実際の利用フローと移行パス

新規導入の基本的な流れ
導入の流れはシンプルだ。まず信頼性ポリシーを作成し、次にビジネスアプリケーションを表す「システム」を登録する。システム配下に、マイクロサービスなどのデプロイ単位である「サービス」を作成し、AWSリソースのタグやCloudFormationスタック、Terraformのステートファイル、EKSクラスタなどを指定してリソースを関連付ける。
準備が整ったら「障害モード評価の実行」をクリックする。Resilience HubがInvokerロールを引き受け、指定されたリソースの親子関係を解析し、トポロジを構築。その上でAIがポリシーに対するギャップを評価する。
評価完了後は「サービス詳細」画面の「Assessment」タブで発見事項を確認できる。各項目には障害モードの説明、アーキテクチャへの影響、修正方法、関連するポリシー要件が明記される。対応が完了した項目は「Mark as resolved」でクローズし、未対応の課題だけをトラッキングできる。
既存ユーザー向けの移行API
すでに従来版のResilience Hubを利用している組織向けには、移行用APIが提供されている。従来の評価ポリシーを新ポリシー形式に変換し、複数の関連アプリケーションを新モデルの「1システム配下の複数サービス」構造に再マッピングする機能だ。
手動での再設定が不要なため、既存の評価データを活かしつつスムーズな移行が可能になっている。大規模組織ほどこの移行APIの価値は大きい。
運用に組み込む際のポイントと今後の展望

Resilience Hubの次世代版を実運用に組み込む場合、いくつか意識すべき点がある。第1にポリシー設計の重要性だ。SLOやRTO、RPOの値はビジネス要件から逆算する必要がある。「とりあえず99.99%」といった一律設定では、過剰なコストを生むか、逆に重要なサービスを見落とすリスクがある。
第2に、依存関係検出のスコープ調整だ。DNSクエリログ解析は強力だが、ノイズとなる外部通信も拾う可能性がある。検出結果を精査し、クリティカルでない依存関係をフィルタリングする運用プロセスを組み込むことが望ましい。
第3に、AIの分析結果を鵜呑みにしないことだ。Assertion機能を活用し、自社のアーキテクチャ特性をAIに正しく伝える努力が求められる。あくまで「AIの提案をSREが判断する」という協調モデルが効果的である。
料金体系は新たなサービスベースモデルに移行した。各サービスにつき月2回の障害モード評価が含まれ、依存関係の自動評価はオプションとなる。大規模環境では評価回数がボトルネックになる可能性があるため、クリティカルなサービスに絞って評価頻度を設定するなどの工夫が必要だ。
今後はAWS Organizationsとの統合がさらに強化され、組織全体のレジリエンススコアをスコアカード化する機能や、CI/CDパイプラインへの組み込みによるシフトレフトな信頼性評価への展開が期待される。
この記事のポイント
- 生成AIによる障害モード評価で、人手では困難な依存関係や設定ミスを自動的に発見できる
- ビジネス視点のアプリケーションモデルにより、技術リスクと業務インパクトを地続きで評価可能になった
- モジュール式ポリシーがチーム間の共通言語として機能し、ガバナンスの実効性が高まる
- DNSクエリログ解析による依存関係の自動可視化で、運用の暗黙知を形式知に変換できる
- 既存ユーザー向けの移行APIが用意されており、大規模組織でもスムーズに移行可能である

・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AWS MCP Serverが一般提供開始、AIエージェントのAWS操作を安全・効率的に
AWSは2026年5月6日、AIエージェント向けのマネージドサービス「AWS MCP Server」の一般提供を開始した。AIコーディングアシスタントがAWSの各種サービスを安全に呼び出し、最新ドキュメントを参照し、必要ならサンドボックス内でスクリプトを実行できるようになる。
これまではAIエージェントがAWSを操作しようとしても、訓練データが古く、IAMポリシーが過剰になりがちだった。本サーバーはそうした課題を解決し、本番環境でも使えるレベルのインフラコード生成を後押しする。
本記事ではAWS MCP Serverの機能、GAで追加された新要素、具体的な利用手順、対応ツール、料金までを詳しく解説する。
AWS MCP Serverの概要

MCP(Model Context Protocol)は、AIエージェントが外部サービスやツールと安全にやり取りするための標準プロトコルだ。AWS MCP Serverはこのプロトコルに準拠したマネージド型のリモートサーバーであり、数個の固定ツールを通じて1万5000を超えるAWS APIへのアクセスを提供する。
AIコーディングアシスタントは多くの場合、訓練データに依存するため、2025年後半以降に登場した新サービス(Amazon S3 VectorsやAurora DSQLなど)を知らない。また、インフラ構築時にAWS CLIを好み、AWS CDKやCloudFormationといったIaCツールを使わない傾向があった。生成されるIAMポリシーも権限が広すぎるなど、デモ用には動いても本番投入は難しい状態だった。
この仕組みにより、AIエージェントは常に最新の情報と最小権限でAWSリソースを操作できる。ツールの数が少なく固定されているため、モデルのコンテキストウィンドウを圧迫せず、ハルシネーション(誤った回答の生成)も抑えられる。
GAで追加された主な機能

プレビュー期間を経て正式提供となったAWS MCP Serverでは、以下の機能が新たに導入されている。
IAMコンテキストキーのサポート
従来はMCPサーバー自体の利用に専用のIAM権限が必要だったが、今回からIAMコンテキストキーに対応した。これにより、通常のIAMポリシーの中で「特定のユーザーは更新系APIを許可、MCPサーバー経由では読み取り専用」といったきめ細かい制御が可能になる。余分な権限管理の手間が減り、セキュリティ設計がシンプルになる。
ドキュメント検索の認証不要化
search_documentationおよびread_documentationツールが、認証なしでも利用できるようになった。これにより、まだAWSアカウントを持っていない段階でも、AIエージェントは最新のAWSドキュメントを参照して設計や調査を行える。
トークン消費の最適化
インタラクションあたりのトークン消費量が削減された。マルチステップのワークフローを伴う複雑なタスクでは、モデルのコンテキストウィンドウがすぐに埋まりがちだったが、今回の改善でより長い会話を維持しやすくなっている。
run_scriptツールとサンドボックス実行

GAの大きな目玉がrun_scriptツールの追加だ。AIエージェントは短いPythonスクリプトを記述し、MCPサーバー側のサンドボックス環境で実行させることができる。このサンドボックスは呼び出し元のIAM権限を継承するが、ネットワークアクセスは一切持たない。つまり、エージェントはAWSリソースのデータを処理できるものの、ローカルのファイルシステムやシェルには触れない。
…
# 複数APIを組み合わせた処理を1回のラウンドトリップで
従来、エージェントが複数のAPIを呼び出してデータを結合する場合、1つずつリクエストを送っては応答を待つ必要があり、時間もトークンも浪費していた。run_scriptを使えば、1回のラウンドトリップで一連の処理を完結させられる。これにより、処理速度とコンテキスト効率の両方が大幅に向上する。
Skillsによるベストプラクティスの提供

プレビュー版では「Agent SOPs」という形式でガイダンスが提供されていたが、GAではより洗練された「Skills」に移行した。Skillsは、エージェントがよく間違えるタスクに対して、AWSの各サービスチームがメンテナンスする検証済みのベストプラクティスを提供する。
スキルにより生成されるコードの品質が安定し、エラーやトークンの無駄も減る。ツール一覧を短く保ちつつ、必要なガイダンスをピンポイントで渡せるため、エージェントの挙動が予測しやすくなり、無駄な試行錯誤も抑制される。
エンタープライズの現場では、開発者の数だけ書き方がバラバラになりがちだが、Skillsによってサービスチーム公認のパターンがチーム全体に自然と浸透する。結果として、セキュリティレビューの工数も削減できるだろう。
セキュリティと監査の仕組み

AWS MCP Serverは、ユーザーが直接操作する時とAIエージェント経由の操作を明確に区別できる設計になっている。IAMポリシーやSCP(Service Control Policies)を使って、特定のユーザーには全操作を許可しつつ、MCPサーバーには読み取り専用のみ許可する、といった制御が可能だ。
さらに、AWS-MCP名前空間のAmazon CloudWatchメトリクスが提供され、MCPサーバー経由のAPIコールと人間による直接のAPIコールを分離して監視できる。AWS CloudTrailもすべてのAPI呼び出しを記録するため、コンプライアンスチームが求める監査証跡を完全な形で確保できる。
このように、AIエージェントが安全にインフラを操作できる環境が整ったことで、これまで人間の開発者しか触れなかった本番環境へのAI活用も現実味を帯びてきた。
利用方法と対応ツール

AWS MCP Serverは、MCPに対応するあらゆるAIコーディングツールから利用できる。Claude Code、Cursor、Kiro、OpenAI Codexなど、主要なアシスタントはすでにサポートしている。
セットアップは非常にシンプルだ。AWS MCP ServerはIAM SigV4認証を利用するが、多くのMCPクライアントはOAuth 2.1のみに対応している。そのため、オープンソースの「MCP Proxy for AWS」を使ってIAM認証をOAuthにブリッジする。具体的には以下のようなコマンドで設定する。
curl -LsSf https://astral.sh/uv/install.sh | sh
claude mcp add-json aws-mcp --scope user \
'{"command":"uvx","args":["mcp-proxy-for-aws@latest","https://aws-mcp.us-east-1.api.aws/mcp","--metadata","AWS_REGION=us-west-2"]}'
/mcpコマンドを実行すると、AWS MCP Serverが利用可能なツール一覧が表示される。search_documentationツールを呼び出し、最新のS3 Vectorsの情報をもとに回答を生成する。プロキシはローカルマシン上で動作し、MCPサーバーのエンドポイントとしてhttps://aws-mcp.us-east-1.api.aws/mcp(米国東部)または欧州(フランクフルト)のリージョナルエンドポイントを指定する。APIコール自体は他の全リージョンに対しても実行可能だ。
料金と提供リージョン

AWS MCP Server自体に追加料金は発生しない。支払うのは、AIエージェントが操作した結果として作成されたAWSリソースの利用料と、データ転送料金のみだ。このため、まずは試験的に導入し、効果を検証しやすい。
現在の提供リージョンは米国東部(バージニア北部)と欧州(フランクフルト)の2拠点。今後、他のリージョンにも順次拡大される見込みだ。
AWS MCP Serverはすでに多くのAIコーディングアシスタントで利用可能であり、AWSドキュメントの最新ページからクイックスタートガイドを参照できる。
この記事のポイント
- AWSがAIエージェント向けのマネージドMCPサーバーを一般提供開始
- call_aws、search_documentation、run_scriptの3ツールでAWSを安全に操作
- run_scriptはサーバー側サンドボックスでスクリプトを一括実行し高速化
- SkillsによりAWSチーム公認のベストプラクティスをコード生成に活用可能
- IAMとCloudTrail/CloudWatchで人間の操作とAIの操作を明確に分離監査
- サーバー利用料は無料、リソース使用量のみの課金。米国東部と欧州で提供開始
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AI時代のキャッシュ設計を再考する——AIクローラーがCDNに与える影響と対策
CDN(コンテンツデリバリネットワーク)のキャッシュ設計が、AIクローラーの台頭によって根本的な見直しを迫られている。Cloudflareのデータによると、同社ネットワーク上のトラフィックの32%は自動化されたトラフィックが占める。検索エンジンクローラーや監視ツールに加え、近年はAIアシスタントが回答生成のためにWebから情報を取得するケースが増加している。
AIエージェントは人間とは異なるアクセスパターンを示す。高頻度の並列リクエスト、人気ページではなく長尾コンテンツへの集中的なアクセス、サイト全体の網羅的なスキャンなどが特徴だ。このような振る舞いは、従来の人間向けに最適化されたキャッシュアルゴリズムを無効化し、キャッシュミス率の上昇とオリジンサーバー負荷の増大を引き起こす。
サイト運営者はAIクローラーへの対応に迫られる。ブロックするか、サービスを提供するかの選択を迫られるが、両者のトラフィックパターンは大きく異なるため、既存のキャッシュアーキテクチャでは一方に最適化するしかない。本記事では、AIトラフィックがCDNキャッシュに与える影響を分析し、新しいキャッシュ設計の方向性を探る。
AIクローラーと人間のトラフィックの根本的な違い

AIクローラーのトラフィックは、人間のブラウジング行動と比較して3つの主要な特徴を持つ。高ユニークURL比率、コンテンツの多様性、クロールの非効率性だ。
高ユニークURL比率と長尾コンテンツへのアクセス
Common Crawlの公開データによると、大規模Webクロールでは90%以上のページがコンテンツ的にユニークだ。AIクローラーは特定のコンテンツタイプに特化する傾向があり、技術文書、ソースコード、メディアファイル、ブログ記事など、目的に応じて異なるコンテンツを対象とする。
人間のユーザーがトップページや人気記事に集中するのに対し、AIクローラーはサイトの奥深くまで探索する。Wikipediaの利用データは、かつて「長尾」とされていたほとんどアクセスされないページが、現在では頻繁にリクエストされるようになったことを示している。これはCDNキャッシュ内のコンテンツ人気度分布そのものを変化させている。
クロールの非効率性と反復ループ
AIクローラーは必ずしも最適なクロールパスをたどらない。人気のあるAIクローラーからのフェッチのかなりの割合が404エラーやリダイレクトで終わる。これはURL処理の不備によることが多い。また、ブラウザ側のキャッシュやセッション管理を人間のユーザーと同じように利用しない。
AIエージェントは検索結果を改良するために反復ループを行うことがある。これはRAG(Retrieval-Augmented Generation)における一般的なパターンだ。この反復ループは、エージェントの精度を高める一方で、一貫して高いユニークアクセス比率(70%から100%)を維持する。つまり、各ループで以前に見たページを再訪するのではなく、常に新しいユニークなコンテンツを取得し続ける。
キャッシュへの直接的な影響
長尾アセットへのこのような反復アクセスは、人間のトラフィックが依存するキャッシュをかき回す。既存のプリフェッチや従来のキャッシュ無効化戦略は、クローラートラフィックの量が増加するにつれて効果が低下する。Cloudflareの単一ノードにおけるキャッシュヒット率は、AIクローラーを含む場合と含まない場合で明確な差が見られる。ヒット率の低下は、LRU(Least Recently Used)アルゴリズムがAIクローラーの反復スキャン行動に対処できていないことを示唆している。
実例から見るAIクローラーのインパクト

AIボットトラフィックの急増は、実際のWebサービスに深刻な影響を与えている。大規模サイトにおける影響と対応策は以下の通りだ。
Wikipedia:マルチメディア帯域幅の50%急増
モデル訓練のための画像一括スクレイピングにより、マルチメディア帯域幅使用量が50%急増した。Wikimediaは最終的にクローラートラフィックをブロックする対応を取った。
SourceHutとRead the Docs:サービス不安定化
ソースコードリポジトリをスクレイピングするLLMクローラーにより、サービス不安定化と速度低下が発生。Read the Docsでは、AIクローラーが大きなファイルを1日に数百回ダウンロードし、帯域幅の大幅な増加を引き起こした。両サービスとも一時的にクローラートラフィックをブロックし、IPベースのレート制限を実施した。
FedoraとDiaspora:人間ユーザーへの影響
Fedoraはパッケージミラーを再帰的にクロールするAIスクレイパーにより、人間ユーザーに対する応答速度が低下。Diasporaソーシャルネットワークは、robots.txtを尊重しない積極的なスクレイピングにより、応答速度の低下とダウンタイムを経験した。両者とも既知のボットソースからのトラフィックを地理的にブロックするなどの対応を取った。
これらの事例が示すのは、AIクローラーを単純にブロックするだけでは根本的な解決にならないということだ。よりスマートなキャッシュアーキテクチャがあれば、サイト運営者はAIクローラーにサービスを提供しつつ、人間ユーザーの応答時間を維持できる。
AI時代に向けたキャッシュ設計の新たな方向性

AIトラフィックの特性を考慮した新しいキャッシュ設計が必要とされている。主なアプローチは2つある。AIを意識したキャッシュアルゴリズムによるトラフィックフィルタリングと、AIクローラートラフィック専用の新しいキャッシュ層の追加だ。
ワークロード対応型キャッシュアルゴリズム
現在広く使用されているLRU(Least Recently Used)アルゴリズムは、汎用状況においてシンプルさ、低オーバーヘッド、有効性のバランスが取れている。しかし、人間とAIボットの混合トラフィックに対しては、別のキャッシュ置換アルゴリズムの選択が有効かもしれない。
初期実験では、SEIVEやS3FIFOといったアルゴリズムを使用することで、AIの干渉の有無にかかわらず、人間トラフィックが同じヒット率を達成できる可能性が示されている。さらに、ワークロードを直接意識した機械学習ベースのキャッシュアルゴリズムを開発し、リアルタイムでキャッシュ応答をカスタマイズする実験も進められている。これにより、より高速でコスト効率の高いキャッシュが実現できる。
トラフィック種別に応じた階層化キャッシュアーキテクチャ
長期的には、AIトラフィック専用の別個のキャッシュ層が最善の道となる。人間とAIのトラフィックをネットワークの異なる層に配置された別個の階層にルーティングするキャッシュアーキテクチャが考えられる。
人間トラフィックは、応答性とキャッシュヒット率を優先するCDN PoP(Point of Presence)のエッジキャッシュから引き続きサービスされる。一方、AIトラフィックのキャッシュ処理はタスクタイプによって変えることができる。
RAGやリアルタイム要約のようなライブアプリケーションを支えるAIクローラーでは、レイテンシが重要だ。これらのリクエストは、より大きな容量と適度な応答時間のバランスが取れたキャッシュにルーティングされるべきである。これらのキャッシュは鮮度を保ちつつも、人間向けキャッシュよりもわずかに高いアクセスレイテンシを許容できる。
訓練セットの構築や大規模コンテンツ収集ジョブに使用されるAIクローラーは、かなり高いレイテンシを許容し、時間的制約がない。これらのワークロードは、到達までに時間がかかる深いキャッシュ階層(オリジン側のSSDキャッシュなど)からサービスできる。あるいは、キューベースのアドミッションやレートリミッターを使用して遅延させ、バックエンドの過負荷を防ぐことも可能だ。これにより、インフラに負荷がかかっている場合にバルクスクレイピングを延期する機会も生まれる。
この記事のポイント
- AIクローラーは全ネットワークトラフィックの約3分の1を占め、そのアクセスパターンは人間のブラウジング行動と根本的に異なる。
- 高ユニークURL比率、長尾コンテンツへの集中アクセス、反復ループによるキャッシュチャーンが、従来のLRUキャッシュアルゴリズムの効果を低下させている。
- WikipediaやFedoraなどの大規模サイトでは、AIクローラーによる帯域幅急増やサービス不安定化が実際に発生し、多くのサイトがクローラーブロックに頼らざるを得なくなっている。
- 根本的な解決策として、SEIVEやS3FIFOなどの新しいキャッシュアルゴリズムの採用と、AIトラフィック専用の階層化キャッシュアーキテクチャの構築が検討されている。
- 今後のCDN設計では、人間トラフィックとAIトラフィックを分離し、それぞれの特性に最適化したキャッシュ戦略を適用することが重要になる。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験