

AWS Graviton5搭載EC2 M9g/M9gdがGA。汎用インスタンス性能限界突破の全容
AWSが2026年6月10日、Graviton5プロセッサを搭載したEC2 M9gおよびM9gdインスタンスの一般提供を開始した。Armアーキテクチャベースの第5世代カスタムシリコンであり、前世代比で最大25%の計算性能向上を実現したとされている。
2025年末のプレビュー公開から半年、ClickHouseやHoneycombといった企業が実運用環境で検証を重ね、コード変更ゼロで36%の性能向上を確認している。HubSpotではMySQLデータベースのクエリ処理時間が最大60%短縮されたとの報告もある。
Arm系インスタンスはこれまでも存在したが、192コア、5倍のL3キャッシュ、DDR5-8800対応メモリを搭載したGraviton5は次元が異なる。本記事ではM9g/M9gdの技術的進化と、それがビジネスにどう影響するかを具体的に解説する。
Graviton5とは何か。5世代の進化がもたらしたもの
AWSのGravitonプロセッサは、Armアーキテクチャを採用したAWS独自設計のカスタムシリコンだ。第1世代が登場したのは2018年。以来8年にわたり継続的に投資が続けられ、現在では350以上のインスタンスタイプがGravitonで稼働している。
Arm系クラウドインスタンスの現在地
Armアーキテクチャとは、スマートフォンやタブレットで広く使われている省電力設計のCPU命令セットだ。これに対し、従来のサーバCPUの多くはx86アーキテクチャ(IntelやAMDが採用)で動作していた。Armは消費電力あたりの処理効率に優れており、クラウドの大規模データセンターで電気代を抑えつつ高性能を発揮できる点が評価されている。
AWS広報情報によれば、現在12万以上の顧客がGravitonを採用。スタートアップから大企業まで幅広く、Webアプリケーション、マイクロサービス、データベース、機械学習推論、ゲームサーバ、動画エンコーディングなど多様な用途で使われている。x86依存の強い従来のクラウド常識を、Armが着実に塗り替えつつある。
クラウドインスタンスの選択肢は、この5年で一変した。Armはもはや「実験的な選択肢」ではなく、x86と並ぶ本流の一つとして位置づけられる。特にGraviton5では、その傾向がさらに加速するだろう。
Graviton5が前世代から飛躍した3つの要素
Graviton5の改良点を、AWS公式発表から整理する。最も注目すべきは次の3つだ。
- 計算性能の大幅向上:Graviton4比で最大25%の計算性能向上。Webアプリケーションで最大35%、機械学習推論で最大35%、データベースで最大30%の高速化が実測されている
- 5倍のL3キャッシュ:CPUが頻繁にアクセスするデータを一時保存する高速メモリ領域が前世代比5倍に拡大。コア間のデータ待ち時間が最大33%削減された
- DDR5-8800メモリとPCIe Gen6対応:クラウド上のプロセッサインスタンスとして最速水準のメモリ帯域幅を実現。PCIe Gen6はGen5比でデータ転送速度が2倍となり、NVMeストレージや高速ネットワークとの連携性能が飛躍的に伸びる
L3キャッシュの増量は、単なる数値スペックの向上ではない。CPUは計算のたびにメインメモリまでデータを取りに行くと時間がかかる。L3キャッシュが大きければ近くにデータを置けるため、処理待ちが減り、結果として体感性能が大きく向上する仕組みだ。
実際にAWSの広報記事で紹介された顧客事例では、ClickHouseがコード変更なしでM8g比36%の性能向上を達成。Honeycombは6カ月にわたるA/Bテストで、コアあたりのスループットが36%向上したと報告している。これらの数字は、CPUそのものの改良がアプリケーションレベルで直接的な効果を生むことを示している。
M9g/M9gdのラインアップと性能スペック
インスタンスサイズと性能の詳細
M9gは汎用用途向けで、1vCPUあたり4GiBのメモリ比率を採用している。M9gdはこれに加え、高速ローカルNVMe SSDストレージを搭載したバリエーションだ。ラインアップは1vCPUの小規模構成から、192vCPU・768GiBメモリの大規模構成まで幅広く用意されている。
最大サイズの48xlarge(192vCPU)では、ネットワーク帯域が100Gbpsに達する。前世代比で最大2倍の帯域幅になっており、大量のデータを扱うデータベースやログ処理基盤での効果が特に大きい。
IBC(Instance Bandwidth Configuration)の実用性
M9g/M9gdでは、IBC(インスタンス帯域幅設定)と呼ばれる新機能が利用可能になった。これはEBS(永続ストレージ)とVPCネットワーク間で、帯域幅の配分を最大25%調整できる仕組みだ。
たとえばデータベースサーバではEBSへの書き込み性能がボトルネックになりやすい。IBCを使えばEBS側に帯域を多めに割り当て、クエリ処理やログ書き込みを高速化できる。ネットワーク通信が少ないバッチ処理やキャッシュサーバでも有効だ。
Nitro Isolation Engineが実現する「数学的に証明されたセキュリティ」
Graviton5と同時に発表された技術の中で、最も静かでありながら最も革新的なものがNitro Isolation Engineだ。聞き慣れない用語だが、クラウドセキュリティの考え方を根本から変える可能性がある。
形式検証(Formal Verification)とは何か
通常、ソフトウェアのセキュリティは「テスト」で検証する。攻撃パターンを想定し、実際に動かして問題がないかを確認する手法だ。しかしこの方法では、想定外の攻撃や未知の脆弱性を見逃すリスクが常に残る。
形式検証(Formal Verification)はこれとは根本的に異なる。数学の定理証明と同じアプローチで、「このシステムは絶対に想定外の動作をしない」ことを数理的に証明する技術だ。特定のテストケースだけでなく、あらゆる入力パターンで期待通りに動作することを保証する。
AWSによれば、Nitro Isolation Engineはこの形式検証を適用したクラウドハイパーバイザーとして業界初の事例となる。ハイパーバイザーとは、1台の物理サーバ上で複数の仮想マシンを安全に隔離する基盤ソフトウェアだ。この隔離機能が破られると、他の顧客のデータにアクセスされる重大なセキュリティ事故につながる。Nitro Isolation Engineは、その隔離が破られる可能性を数学的にゼロにする設計となっている。
この技術は金融機関や医療機関など、厳格なデータ保護が求められる業界にとって特に重要な意味を持つ。セキュリティ監査のレベルが一段引き上げられることになるからだ。なおNitro Isolation EngineはM9g/M9gd専用の機能であり、既存のインスタンスタイプには搭載されない。
エージェントAI時代のCPU需要とGraviton5の位置づけ
AIが「考える」から「行動する」へのシフト
ここ数年、AIの進化は大規模言語モデル(LLM)のテキスト生成能力に注目が集まってきた。しかし現在、AIの主戦場は「質問に答える」から「行動を実行する」へと急速に移行している。いわゆるエージェントAIと呼ばれる分野だ。
エージェントAIとは、ユーザーの指示に対して、コードを実行し、ツールを使い、結果を評価し、複数ステップのタスクを自律的に組み立てるAIシステムを指す。たとえば「今月の売上データを分析してグラフ化し、経営陣向けのサマリをSlackに投稿して」という指示に対し、AIがデータベースに接続し、集計処理を実行し、グラフを生成し、メッセージを送信する一連の流れを自律的に処理する。
このような処理は、GPUなどのアクセラレータだけで完結しない。指示の解釈、コードのコンパイル、データベースクエリの実行、APIの呼び出しなど、CPUに依存する処理が大量に発生する。AWSの広報記事で、MetaがエージェントAI基盤として数千万コア規模のGravitonを導入していると報告されているのは、このトレンドを象徴している。
エージェントAIが実用段階に入るにつれ、クラウド上のCPU需要はむしろ増大する。Graviton5が192コアという高密度設計を採用したのは、こうした並列処理ニーズを先取りしたものといえる。
Web開発者にとっての実務的意味
中小企業のWeb担当者や個人事業主にとって、「エージェントAI」や「192コア」という言葉は遠い世界に感じられるかもしれない。しかし実際には、以下のような形でM9gの恩恵は身近な領域に及ぶ。
- MySQL/PostgreSQLの応答速度向上:HubSpotの事例ではクエリ時間が最大60%短縮。WordPressサイトやECサイトのデータベース応答が高速化する可能性がある
- コスト効率の改善:Graviton5はGraviton4比でエネルギー効率も向上。同じ処理をより少ない電力で実行できるため、ランニングコストの削減につながる
- セキュリティの底上げ:Nitro Isolation Engineによる隔離保証は、顧客データを扱うあらゆるサービスに恩恵がある
重要なのは、これらの恩恵がコード変更ゼロで得られるケースが多い点だ。ClickHouseやHoneycombの報告にあるように、Armネイティブ対応が済んでいるアプリケーションであれば、インスタンスタイプをM8gからM9gに変更するだけで性能向上が見込める。
M9g/M9gdへの移行を検討する際の実践ステップ
Graviton5インスタンスの利用を始めるには、いくつかの準備と確認が必要だ。AWS公式が提供する移行ガイドやツールを活用すれば、想定よりスムーズに移行できる。
Arm対応状況の確認と移行パス
最初に行うべきは、現在稼働中のアプリケーションがArmアーキテクチャに対応しているかの確認だ。Java、Python、Node.js、Go、PHPなど主要な言語ランタイムはすでにArm対応が完了している。ただし、x86固有のアセンブリコードを含むC/C++プログラムや、特定のx86向けバイナリに依存しているアプリケーションでは注意が必要になる。
Javaアプリケーションの場合、AWSが提供する「AWS Transform」というAI支援サービスが利用できる。x86用にコンパイルされたJavaアプリケーションをArm向けに自動変換し、互換性分析や依存関係の更新まで処理するツールだ。コードの書き換えが必要なケースでも、変換作業の多くを自動化できる。
コスト面の評価ポイント
M9g/M9gdは、Savings Plans、オンデマンド、スポットインスタンス、Dedicated Hostsのいずれでも購入可能だ。一般にGraviton系インスタンスはx86系より低価格に設定されており、さらにSavings Plansを組み合わせることで長期利用時のコストを大幅に抑えられる。
AWS公式が提供する「Graviton Savings Dashboard」を使えば、Graviton移行によるコスト削減効果を可視化できる。費用対効果を数字で把握しながら、段階的に移行を進めるのが実務的なアプローチだ。
この記事のポイント
- AWS Graviton5搭載M9g/M9gdが一般提供開始。前世代Graviton4比で最大25%の計算性能向上
- ClickHouseで36%、HubSpotのMySQLクエリで最大60%の高速化を実測。コード変更不要のケースが多い
- Nitro Isolation Engineにより、形式検証を用いた数学的に証明されたVM隔離をクラウドで初めて実現
- エージェントAIの普及でCPU需要が急増する中、192コアの高密度設計が新たな計算基盤として台頭
- 移行にはArm対応状況の確認から段階的に進めるのが安全。AWS TransformやSavings Dashboardが支援ツールとして利用可能

・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

法務事務所を狙うデータ恐喝の新手口、遠隔操作から「直接訪問」へ進化
機密文書を扱う法務事務所や士業が、新種のデータ恐喝集団「UNC3753」の標的になっている。Google傘下の脅威分析チーム「Mandiant」が2026年6月5日に公開した報告によると、2026年1月から5月にかけて、全米の法律・金融サービス企業数十社が被害に遭った。攻撃者は電話で偽のITサポートを装い、社内の誰もが持つ画面共有ソフトを悪用してネットワークに侵入する。この手口はテクニカルなハッキングというより、巧みな会話術と信用の悪用で成立する。1営業日以内に情報窃取から恐喝までを完了するスピード感も特徴だ。
さらに深刻なのが、遠隔操作が失敗した場合には「直接オフィスを訪問する」物理的な侵入へのエスカレーションが確認されている点だ。FBIも注意喚起を出したこの事案は、大企業だけの問題ではない。顧客情報や契約書類を抱える士業や制作会社も、十分な対策が求められる。
法務事務所を狙う「偽のITサポート」電話が増加している

この攻撃キャンペーンの主体は、Mandiantが「UNC3753」と呼ぶ経済動機の脅威クラスターだ。2022年3月から活動が確認されており、別名として「Luna Moth(ルナ・モス)」「Silent Ransom Group(サイレントランサムグループ)」とも呼ばれる。元々は請求書を装ったPDFファイルをメールに添付し、偽のコールセンターに電話させる手口を使っていた。しかし2025年3月頃から戦術を変更し、企業内部のITヘルプデスクを名乗る「Vishing(音声フィッシング)」へと完全にシフトした。
この変化には明確な理由がある。メールフィルタやアンチウイルスが高性能化し、マルウェア付き添付ファイルは検知されやすくなった。しかし電話での指示を疑うセキュリティソフトは存在しない。音声フィッシングは防御側の「技術で壁を作る」前提を完全にすり抜ける。
メールは「呼び水」、本番は電話で始まる
攻撃は次の2段階で進む。まず一般消費者向けメールアドレスから「hello, here is the invcoie we talked about yesterday(昨日話した送り状です)」といった短いメールを送りつける。リンクも添付ファイルもなく、セキュリティ検査を素通りする。だがタイプミスを含む不自然な文面は受信者に「怪しい」と思わせる効果があり、まさにそれが狙いだ。標的が警戒したタイミングで、社内IT担当を名乗る電話がかかってくる。「不審なメールが届いていませんか」と切り出すことで信頼を獲得し、画面共有に誘導する。
偽のITサポートが社内ネットワークに侵入する流れ

UNC3753の侵入フローは、技術的には「正規ツールの悪用」で構成される。マルウェアの注入も、脆弱性攻撃も行われない。このため、侵入検知システムやアンチウイルスに記録が残らず、事後の調査を困難にしている。
Mandiantの調査では、この一連の流れがわずか1時間足らずで完了したケースも確認されている。攻撃者はiManageのような文書管理システムを熟知しており、W-2(給与税務申告書)や監査ファイルといった「人質として価値の高い文書」を狙い撃ちする。
個人所有のPCを経由してVDI環境に侵入する抜け穴
もう一つの特徴的な手口が、VDI(仮想デスクトップ環境 / Virtual Desktop Infrastructure)の悪用だ。在宅勤務の社員が私物のPC(BYOD / Bring Your Own Device)で業務システムにアクセスする構成を、攻撃者が逆手に取る。画面共有を仕掛けた社員の個人PCを経由し、VDIクライアント(Windows 365やCitrix)を介して企業の内部ネットワークに自由にアクセスする。会社支給の端末にセキュリティソフトが導入されていても、私物PCの画面共有からは検知できない。
データの送信方法も巧妙化している
窃取したファイルの送信には以下の3つのルートが使い分けられる。1つ目はWinSCPやRcloneといったコマンドラインベースの同期ツールを使った大量転送だ。Mandiantの報告によると、ある被害者ではローカルのOneDriveフォルダから1.7ギガバイト、VDIセッションから追加で14.4ギガバイトが一気に流出した。2つ目はPrivnoteのような「開封後に消えるメモサービス」を使った遠隔指示の中継だ。攻撃者はインストール先URLやコマンドをPrivnote経由で渡し、社内のブラウザ履歴やチャットログに痕跡を残さない。3つ目はごく単純に、被害者のブラウザで直接Googleドライブにログインさせる手口だ。標的企業の名前を付けたフォルダにデータをドラッグ&ドロップさせ、事後に消去を指示する。
「直接訪問」に進化する物理的な脅威

Mandiantの報告で特に目を引くのが、遠隔操作が通用しなかった場合の物理侵入だ。これは単なる仮説ではなく、FBIが2026年5月に発出した「Cyber FLASH Alert」で具体的に警告されている。IT技術者を装った第三者が実際のオフィスを訪れ、「デバイスのイメージ取得が必要」「セキュリティ上の緊急対応」と言ってPCにUSBメモリを差し込ませ、直接データを吸い出す手口が確認された。
技術的な防御が高度化するほど、それを迂回する「人間」を狙う攻撃は増える。物理セキュリティはサイバーセキュリティの一部であり、切り離して考えてはならない。
不正送金より深刻な「データ人質」の手口
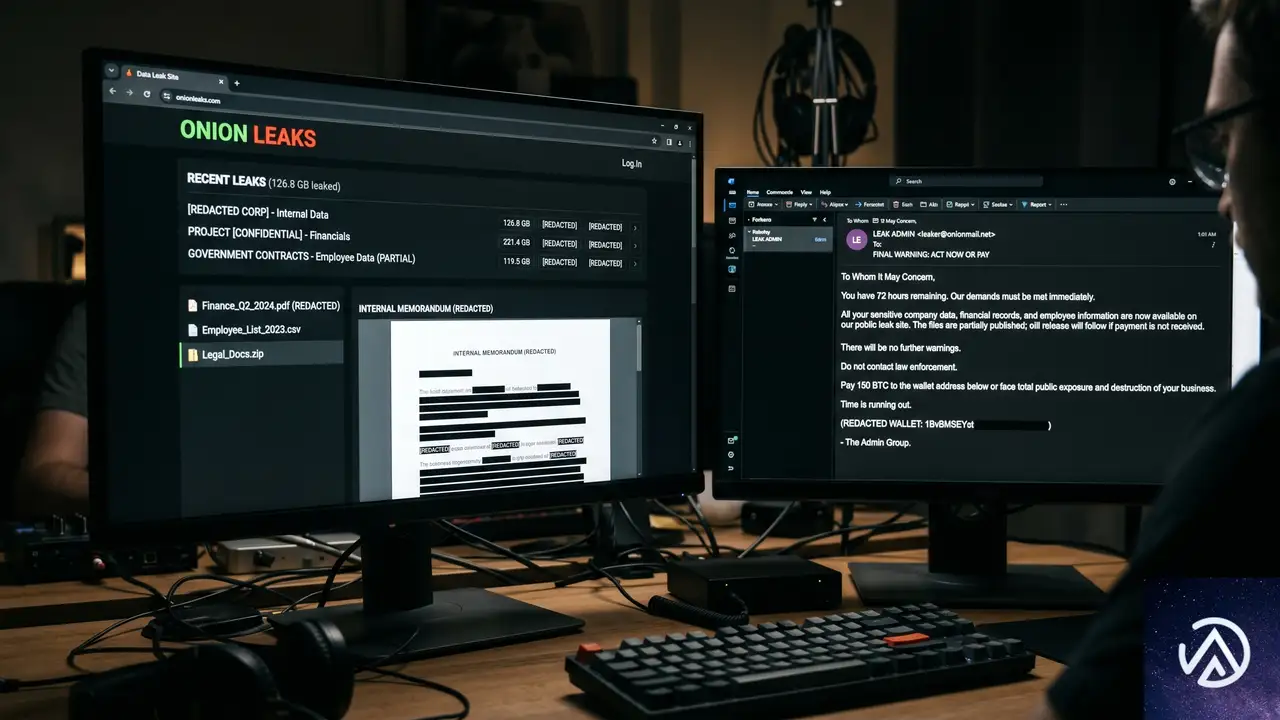
UNC3753の最終目的はファイルを暗号化して身代金を要求する「ランサムウェア」ではない。窃取した機密情報を人質に取り、「3日以内に交渉を始めなければ顧客や取引先に直接リークを通報する」と脅して金銭を要求する「データ恐喝」だ。法務事務所や会計事務所にとって、顧客データの流出はビジネスそのものを揺るがす致命的な事態になる。恐喝メールでは「顧客の信頼は失墜し、多額の規制当局による罰金が発生し、データ管理責任を問われて顧客から訴訟を起こされる」と明記される。心理的圧力を最大限に高める文面だ。
要求に応じなければ、実際に「LEAKEDDATA」というデータリークサイトで情報を公開する。支払ったとしてもデータが確実に削除される保証はなく、沈黙の代償が更なる恐喝を呼ぶリスクもある。この種の「身代金を支払わない」方針を事前に決め、防御にリソースを振ることが重要だ。
今日から始める中小企業の防御策

UNC3753の手口は大手向けに見えるが、個人情報を扱う税理士事務所やWeb制作会社でも全く同じ被害構造が成立する。Google Threat Intelligence Groupの推奨事項を元に、中小企業向けの実践的な対策を示す。
社内教育を最優先に設計する
不審な電話がかかってきた場合の対応手順を社内で標準化しておくべきだ。「社内ヘルプデスクを名乗っても、まず上司や情報システム担当に転送する」というシンプルなルールを周知するだけで、初期侵入の大半を防げる。特に「データ移行プロジェクト」や「セキュリティ上の緊急対応」と言われたら、一度電話を切り、会社に登録されている正規の内線番号にかけ直す習慣を徹底させたい。
VDIとBYODの認証を強化する
個人のPCやタブレットから社内の仮想デスクトップ(VDI)に接続する構成は、多要素認証(MFA)の強化が不可欠だ。さらに「会社支給端末以外からのVDI接続を禁止する」という条件付きアクセスポリシーを設定できれば、私物端末を経由した遠隔操作のリスクを大幅に下げられる。
正規のリモート管理ツールも制限する
AnyDeskやZoho Assistが攻撃に使われる現実を踏まえ、会社で業務利用するリモート管理ツールを限定し、それ以外のインストールをAppLockerやWindows Defender Application Controlで制限する構成が有効だ。ZoomやTeamsの画面共有機能についても、社内ポリシーで利用ガイドラインを定めておくべきだ。
USBメモリの物理的な対策
会社の全PCでUSBストレージの書き込みを無効化する設定は、グループポリシー(GPO)を使えば比較的簡単に実装できる。外部メディアを業務で使う場合も、必ず情報システム担当者が解錠する運用にすることで、なりすましの技術者がUSBメモリでデータを抜く物理攻撃を封じられる。
ネットワーク監視とログ設定
ファイアウォールで外部ファイル共有サービスへの接続を監視し、一定時間内に大量のSSHトラフィック(WinSCPやRcloneの転送に使われる)が発生した際にアラートを出すようにしておくと、データの一括送信を早い段階で検知できる。社内の文書管理システムでも、キーワード検索の急増や大量ダウンロードを監視対象に加えておくべきだ。
この記事のポイント
- 法務事務所を狙うUNC3753は、音声フィッシングで画面共有に誘導し正規ツールを悪用する
- メールは呼び水に過ぎず、マルウェアを使わないため従来の防御策では検知が難しい
- 遠隔操作が失敗すると、IT業者を装った直接訪問でUSBメモリを使った窃取に切り替える
- VDI環境と個人端末の認証強化、USB書き込み禁止設定が即効性の高い対策となる
- 攻撃の最終目的はデータ恐喝であり、要求に応じる前に防御と教育の強化を優先すべき
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AIだけでは企業変革できない、カギは実行基盤(Azureブログ発表)
AIが企業のあらゆるワークフローに浸透し始めている。だが、本当の変革をもたらすのは最先端のAIモデルそのものではなく、それを動かすシステムの設計だという指摘が、マイクロソフトの公式ブログで発表された。同社はエージェントを中心とした統合プラットフォームを打ち出し、開発から運用、ガバナンスまでを一貫して支える環境を構築している。
発表の背景には、個別のAIチャットボットや単発のツール導入に終始する企業では、大規模な業務変革が進まないという現実がある。Azure Blogの記事では、複数のAIエージェントが部門を横断して長期間にわたり作業を実行し、しかも統制の取れた形で運用できる仕組みこそが次世代の競争力を決めると述べられている。
なぜAI単体では不十分なのか

エージェントがもたらす真の変革
Azure Blogによれば、現在の企業AI活用で話題になるのはチャットボットのような対話型インターフェースだ。だが、そうしたエクスペリエンスは便利ではあるものの、組織全体のオペレーションを根本から変えるものではない。真に価値があるのは、ソフトウェア開発、サポート、財務、人事、運用といった複数の業務領域で、複数のAIエージェントが連携し、長期にわたって作業を自律的に遂行することである。
エージェントが本格稼働するには、単に強力なAIモデルやスケーラブルな計算資源が手に入れば良いわけではない。エージェントを「誰が」「どのデータを使って」「どう安全に」動かすかという企業コンテキスト、ポリシー、人的監視の枠組みが不可欠だ。Azure Blogの記事では、これらを欠いた状態では、AIの導入は断片的で脆弱、大規模に信頼するのが難しいと指摘している。
個別ツールの寄せ集めではリスクが高まる
多くの企業は、コード生成ツール、データ連携基盤、実行環境、監視システムをそれぞれ別々に導入し、後付けで連携させる方法を取りがちだ。だがAzure Blogの記事は、こうしたばらばらのツールを寄せ集めただけの環境では、開発速度が落ち、不必要なリスクを招くと警告している。たとえば、エージェントに意図しないアクセス権が渡ったり、部門間でガバナンスが効かなくなったりする問題が起こり得る。
このデモで示したように、断片化したツール群ではエージェントの挙動を一貫して管理できない。マイクロソフトの新たなアプローチは、これらの要素を統合した単一のプラットフォームでエージェントを動かす点にある。
Microsoftの統合エージェントプラットフォームとは
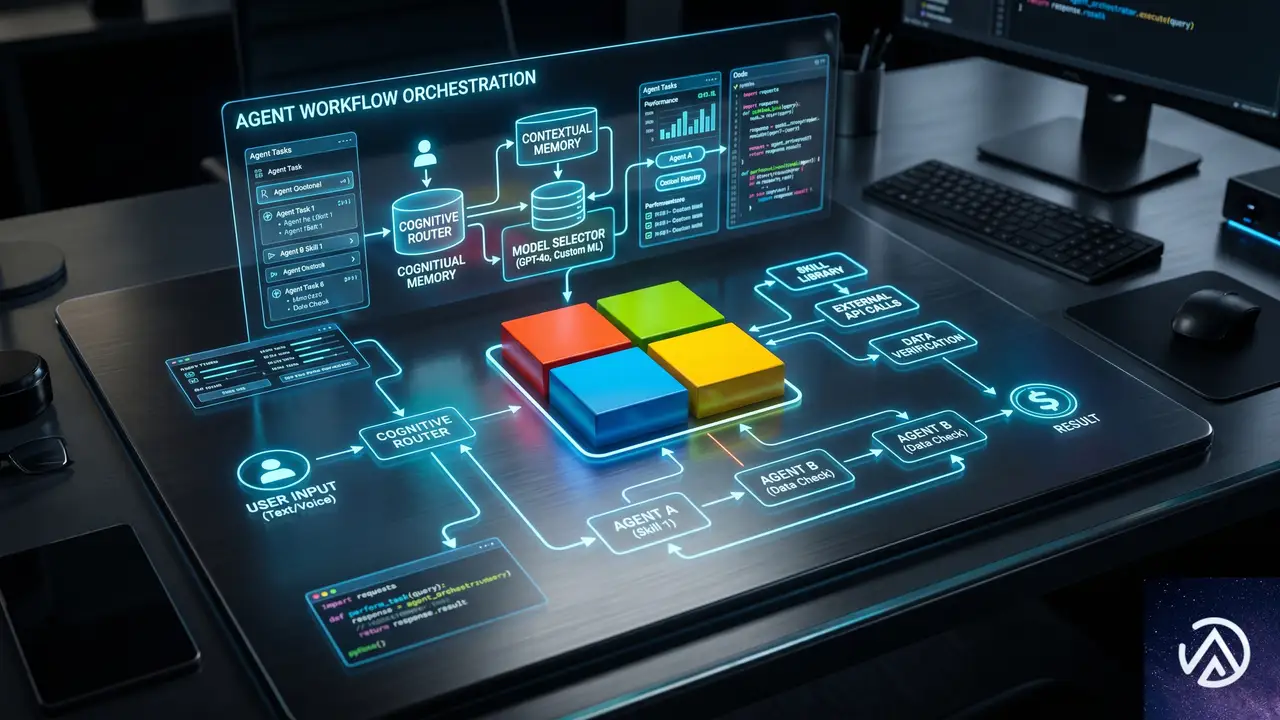
Azure Blogの発表では、同社が「包括的エージェントプラットフォーム」を構築していると説明されている。このプラットフォームは、多様なAIモデルをサポートしながら、開発者を中心に据えた柔軟な設計になっている。そして何より、実際の本番ワークロードを動かし、組織の複雑さとビジネス責任を扱える水準を目指している。
3つの設計原則
このプラットフォームは、以下の3つの基本原則に基づいて設計されている。
- 単一の統合システムで多様なモデルをサポートする:Azure、GitHub、Microsoft IQ、Fabric、Foundry、Windows、Microsoft 365、Microsoft Securityを一つのシステムとして連携させる。これにより、構築から改善までをバラバラのツールなしで行える。さらに、マイクロソフト自社モデルだけでなくパートナーモデルやオープンモデルも自由に選べる。
- セキュリティとガバナンスが設計に組み込まれている:Entra、Purview、Defender、Agent 365といったセキュリティスタックを開発段階から本番まで一貫して適用する。後付けではなく、システムにネイティブに統合されたガバナンスを実現する。
- 継続的に改善する:エージェントの動作結果や人間からのフィードバックをシステムに還元し、時間とともに安全に改善させる。モデルやワークフローが企業固有の業務プロセスに適合し、使い続けるほど価値が複利的に高まる仕組みを目指す。
これらの原則は今や「あると良い」ものではなく、競争力を左右する必須条件になるとAzure Blogの記事は強調している。四半期単位で差がつくという見立てだ。
エージェントライフサイクルの全体像
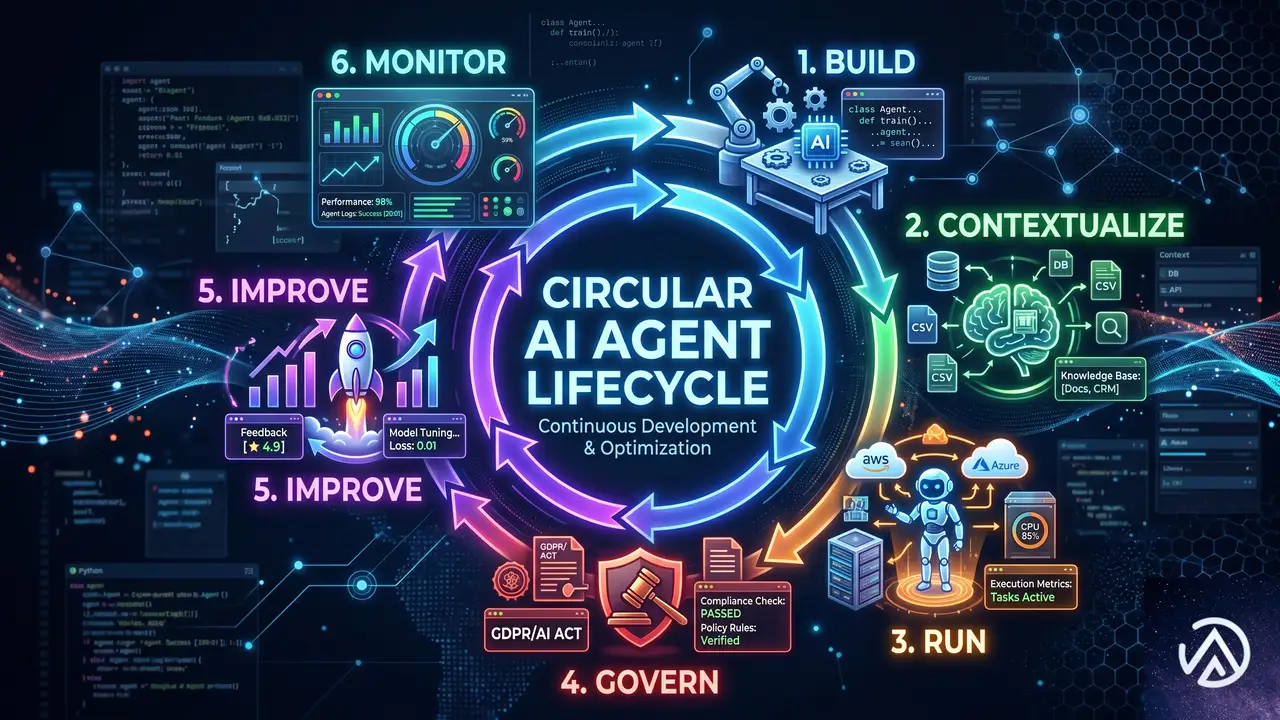
では、このプラットフォーム上でエージェントはどのように構築され、動いていくのか。Azure Blogの発表に沿って、主要な段階を順を追って見ていく。
構築〜GitHubで開発する
エージェントの開発は、すでに多くの開発者が日常的に使うGitHubを起点とする。コードベース、ワークアイテム、スキル、ツールなど重要なアセットを同じ場所に集約し、本番ソフトウェアと同じライフサイクル(ソース管理、テスト、デプロイ、監視、改善)をエージェントにも適用する。
GitHub Copilotを活用してコード作成を加速し、評価(eval)や可観測性(observability)のアセットもバージョン管理下に置く。これにより、最初から適切なガードレールを備えたエージェント開発が可能になる。発表では、このために新しいGitHubアプリが提供されることも述べられている。
企業データの文脈化〜Microsoft IQ
コードだけでは、エージェントは汎用的なAIにとどまる。真に役立つには、顧客情報、製品データ、契約書、業務プロセスといった企業特有の文脈を理解しなければならない。Azure Blogの記事では、いくら高性能なモデルを使っても、企業文脈なしでは推測に過ぎないと指摘している。
Microsoft IQは、Microsoft 365や基幹業務システム、ナレッジベース、自社ウェブサイトなど、社内外のデータソースにエージェントを接続する。さらに、Web IQによってウェブ上の情報も適切に取り込める。単にデータにアクセスさせるのではなく、情報を整理し、エージェントが扱いやすい形で安全に提供する点が重要だ。
さらに、Frontier Tuningと呼ばれる仕組みによって、実際の業務データとワークフローからモデルを改善できる。今回発表された音声、画像、コーディング、推論向けの7つの新しいMAIモデルを含め、モデルが企業のプロセスを学習し、その企業に特化した知能として機能するようになる。学習結果は企業の環境内に保持されるため、知的財産は外部に出ない。
実行環境〜Foundry
構築し文脈化したエージェントは、本番環境で実行されなければならない。Foundryは、エージェント特有の要求(推論、ツール呼び出し、他のエージェントとの連携、時間経過による適応)に応えるランタイムだ。
Foundryでは、タスクやコストに応じて最適なモデルを選択できるルーター機能を備え、Fireworks AIによる高速な推論も統合している。Microsoft Agent Frameworkはもちろん、LangGraph、GitHub Copilot SDK、Claude Agent SDKなど多様なエージェントフレームワークもサポートする。ツールやアクションはMCP、コネクター、API、ワークフロー経由で安全に実行され、評価とトレースによってエージェントの振る舞いを計測可能にしている。
ガバナンス〜Agent 365
ひとたび企業全体で何百、何千ものエージェントが稼働し始めると、全体を把握し制御するガバナンスが不可欠になる。Agent 365は、組織内の全エージェントを単一のカタログに表示し、誰がデプロイしたか、どのデータやツールにアクセスできるか、どのように動作しているか、コストはいくらかをIT管理者が一元的に確認できる仕組みだ。
Entra、Purview、Defenderと連携し、必要に応じてポリシーを強制したりアクションを取ったりできる。これにより、設計の良いエージェントもそうでないエージェントも、組織として統制下に置かれる。Azure Blogでは、ガバナンスの基盤が最初から組み込まれている点が後付けとの大きな違いだと強調されている。
継続的改善ループ
エージェントシステムは静的なままではない。すべての動作結果やフィードバックがシグナルとして蓄積され、評価、改善、安全なロールアウトが繰り返される。この学習ループは本番環境で連続的に動作し、プロンプトの調整からモデルルーティング、ファインチューニング、強化学習まで、段階的に高度化していく。
Azure Blogの記事は、このプロセスを「hill-climbingモデル」と表現し、システムを稼働させながら価値を複利で高める考え方を示している。重要なのは、改善ループが完全な自動化ではなく、人間の監査と修正のもとで制御されることだ。
業務現場への提供〜TeamsとAzure
エージェントの価値は、実際に業務を行う人々の手元に届いて初めて発揮される。このプラットフォームでは、TeamsやMicrosoft 365、自社アプリケーションの中にエージェントが自然に表面化する。アイデンティティ、セキュリティ、コンプライアンスは最初から組み込まれており、日常業務で使うツールと同じ信頼モデルを継承する。
また、Windows環境での最適化されたエージェント実行、クラウドとローカルの両方でのモデル稼働、サンドボックス技術による常駐型エージェントの安全な動作もサポートされる。大規模なAIワークロードやグローバルな展開が必要な場合は、Azureが基盤として全体をスケールさせる。
システムが価値を複利で増幅させる仕組み

Azure Blogの発表は、結局のところ、AI活用で先行する企業は「中央のAIプラットフォーム」を中心に業務を再編し、データ、モデル、エージェント、人間の判断を一つの継続的に改善する安全なシステムへと収斂させていくと述べている。システムが稼働し続けるほどその価値は複利的に増大し、ボトルネックは作業量から人間の創造性と調整へと移行する。
このビジョンでは、個々の担当者が共有された文脈のもとで自律的に仕事を進められるようになり、引き継ぎや摩擦は減り、ビジネス全体のスピードが上がる。マイクロソフトのエージェントプラットフォームは、まさにその「統合されたオペレーティングシステム」として機能することを目指している。
この記事のポイント
- Azure Blogの最新発表では、企業AIの成否はモデル単体ではなく、エージェントを動かすシステム設計にかかっていると指摘されている。
- 個別ツールの寄せ集めはリスクを高めるため、GitHub、Microsoft IQ、Foundry、Agent 365などによる統合アプローチが提唱されている。
- エージェントライフサイクル全体(構築、文脈化、実行、ガバナンス、継続改善)を単一システムで回すことで、信頼性とビジネス価値が複利的に高まる。
- セキュリティとガバナンスは設計段階から組み込まれ、人的監視のもとでAIが安全に改善し続ける仕組みが特徴。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AWS Bedrock刷新、OpenAIとAnthropic API互換コンソールが登場
AWSが2026年6月5日、Amazon Bedrockの管理コンソールを刷新した。この新体験は「bedrock-mantle」エンジン向けに設計されており、Anthropic Messages APIとOpenAI Responses APIに最適化されている。
従来のBedrockコンソールはマネージド機能(AgentsやKnowledge Basesなど)を中心に据えていたが、今回の刷新はAPI直接呼び出しを前提とする開発者向けに設計し直されている。モデル選定からプロダクション実装までの時間を大幅に短縮する狙いだ。
この記事では、新コンソールの主要機能と開発ワークフローへの影響を詳しく見ていく。API互換性を活かしたコードの簡略化や、複数モデルの並列評価がどのように実現されるのかを解説する。
Bedrockの新コンソールが生まれた背景
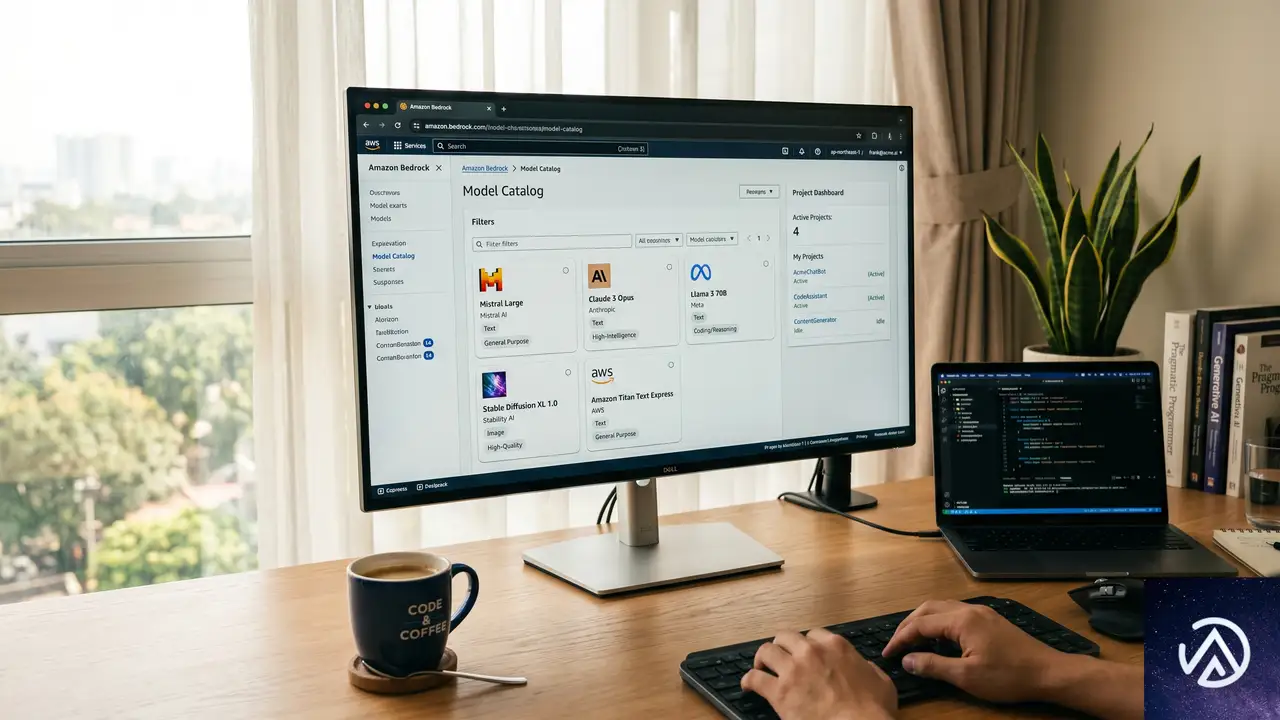
この図が示すように、新コンソールは「プロジェクト」を軸にした作りになっている。モデルの評価から実装、モニタリングまでをひとつの画面で完結させる狙いだ。
bedrock-mantleエンジンとは何か
bedrock-mantleは、Bedrockの第2世代推論エンジンとして位置づけられる。高速な処理性能と高い信頼性、そしてエンタープライズレベルのセキュリティを兼ね備えている。
最大の特徴はAnthropicとOpenAIのAPIプロトコルに互換性を提供することだ。ClaudeモデルにはAnthropic Messages API(メッセージAPI)を、GPTモデルにはOpenAI Responses API(レスポンスAPI)とOpenAI Chat Completions API(チャット補完API)を使える。これにより、既存のSDKコードをほぼ変更せずにBedrockへ移行できる。
従来のbedrock-runtimeエンドポイントを使う既存機能(InvokeModelやConverse API、Agentsなど)は、引き続き従来のBedrockコンソールから利用できる。両者は併存する設計で、急な移行は求められない。
新モデルカタログが提供する高速な比較体験

新コンソールの目玉のひとつが、刷新されたモデルカタログだ。従来は各モデルの仕様を調べるためにドキュメントや料金計算ツールを行き来する必要があったが、それが1画面で完結するようになった。
最大3モデルを並べて比較
カタログ上で最大3つのモデルを選択し、機能、モダリティの対応状況、コンテキストウィンドウの大きさ、利用可能なリージョン、料金体系を横並びで比較できる。
この比較機能は、チーム内でのモデル選定会議や、PoC(概念検証)フェーズでの迅速な意思決定に力を発揮する。料金と性能のトレードオフを視覚的に把握できるのが強みだ。
プロジェクト単位で完結する開発ワークフロー
新コンソールの中核は「プロジェクト」という概念だ。生成AIアプリケーションの開発ライフサイクルをプロジェクトとして管理し、モデルの割り当てからAPIキーの発行、推論リクエストの送信までを一気通貫で行える。
ダッシュボードでトークン消費を可視化
プロジェクトダッシュボードでは、直近の推論リクエスト数やエラー発生率を日付範囲でフィルタリングできる。さらに、総トークン消費量、1分あたりのトークン使用量、推論リクエストの回数、1リクエストあたりの平均トークン数がグラフ表示される。
このデータは、モデルの選択ミスや過剰なトークン消費を早期に発見する手がかりになる。チームの予算管理にも直結するため、プロダクション環境では特に価値が高い。
サイドバイサイド評価でプロンプトを最適化
プロジェクト内で最大3つのモデルを選択し、同じプロンプトに対する応答を横に並べて比較できる評価モードが用意されている。これにより、どのモデルが自社のユースケースに最適かを実データで判断できる。
評価結果はそのままプロダクション環境へ移行する際の根拠資料としても使える。カスタマーサポート用チャットボットであれば、回答の質と応答速度のバランスを定量的に比較できる。
コード生成とAIアシスタント連携の新機能
最も実務インパクトが大きいのが、プロジェクトに紐づいた「ライブドキュメント」機能だ。コードサンプルやSDKスニペット、APIリファレンスにプロジェクトの変数(モデルID、リージョン、エンドポイントURL、APIキー)が自動で埋め込まれる。
コピーするだけで動くコードスニペット
開発者はコンソール上で表示されたコードをそのままコピーし、ローカル環境のアプリケーションに貼り付けるだけで動作確認できる。環境変数の手動設定やエンドポイントURLの確認といった手間が省ける。
AWS_REGION=us-east-1
ENDPOINT=bedrock-mantle
API_KEY=sk-xxxxxx
client = boto3.client()
response = client.invoke(modelId=MODEL_ID)
この仕組みにより、環境構築のミスが大幅に減る。特に複数プロジェクトを抱えるチームでは、設定の食い違いによるトラブルシューティング時間を削減できる。
AIコーディングエージェントとの統合
新コンソールはAIコーディングエージェントとの連携もサポートする。Claude Code、Cline、Codex、Cursor、OpenCodeといった主要なAIアシスタントをBedrockのmantleエンジンにルーティングする手順がガイドされる。
具体的には、AWS IAM認証情報かBedrock APIキーを使い、環境変数を設定したうえで各エージェントからのリクエストをBedrock経由にする設定が案内される。これにより、AIアシスタントのバックエンドをOpenAIやAnthropicのクラウドからAWS環境に切り替えられる。企業ポリシーでデータの外部送信を制限しているケースで有効だ。
利用可能リージョンと今後の展開

新コンソール体験は、bedrock-mantleエンドポイントが提供されている全リージョンで利用可能だ。2026年6月時点での対象は以下の通り。
AWSのドキュメントにはリージョン互換性の一覧ページが用意されており、将来的な拡大があれば随時更新される見込みだ。フィードバックはAWS re:Post for Amazon Bedrock、または通常のAWSサポート窓口を通じて送ることができる。
新コンソールは既存のBedrockコンソールと並行して運用される。急な切り替えを迫られることはなく、チームの準備が整った段階で徐々に移行できる設計だ。
この記事のポイント
- Amazon BedrockにAPI互換性を重視した新コンソールが登場し、モデル評価から実装までの時間が大幅に短縮される
- bedrock-mantleエンジンはAnthropic Messages APIとOpenAI Responses APIに対応し、既存SDKコードの流用が容易
- 最大3モデルのサイドバイサイド比較と、プロジェクト単位のトークン消費可視化が組み込まれている
- コンソール上のコードスニペットはプロジェクト変数が自動プレフィルされ、コピー後即実行できる
- 東京リージョンを含む複数リージョンで利用可能、既存コンソールとの併存もサポートされる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Azure Cobalt 200 VMが50%性能向上、エージェンティックAIに最適化
Cobalt 200 VMの概要とプレビュー提供開始
Microsoft Build 2026にあわせ、Azure Cobalt 200 Armベース仮想マシンの早期アクセスプレビューが発表された。Azure Blogの記事によれば、第2世代の自社設計Armプロセッサを搭載するこのVMは、前世代Cobalt 100と比べて最大50%のCPU性能向上を達成し、とくにエージェンティックAIやクラウドネイティブなスケールアウト型ワークロードでの利用を見据えている。
Cobalt 200はシリコンからサーバー、サービスまでを一貫してMicrosoftが設計し、セキュリティ、ネットワーク、ストレージ、オフロード処理の最新技術を統合した。これにより、AI推論、データパイプライン、Web API層といった多様な負荷で、パフォーマンスとコスト効率の両立を狙う。Azure Blogの記事では「エージェントは従来のワークロードとは異なり、推論や逐次的意思決定を連続的に大規模実行するため、根本的に異なる計算プロファイルが求められる」と指摘している。Cobalt 200はまさにその要件に応える設計だ。
Cobalt 100からの性能向上と新アーキテクチャ

Cobalt 100はすでに世界32のAzureリージョンで稼働し、DatabricksやSnowflakeといったクラウド分析の大手が導入している。Microsoft自身のサービスでも、以前の基盤と比べて最大45%の性能向上を達成しつつ、使用コア数を35%削減できた実績がある。Azure Blogの記事によると、Microsoft Defender for Endpointのサイバーデータキュレーターでは40%の性能改善が確認され、大規模な脅威対応の高速化に貢献した。
Cobalt 200 VMは、この知見を土台にさらに一段上の性能を提供する。SoC(System-on-Chip)には、Arm Neoverse V3 Compute Subsystems(Armの高性能Vシリーズコア)を採用し、TSMCの3nm(N3P)プロセスで製造される。チップレットアーキテクチャ、カスタムアクセラレータ、そして専用設計のメモリコントローラを備え、L2キャッシュはコアあたり3MB、システムレベルのL3キャッシュは192MBに拡張された。これにより、データベースやインメモリキャッシュ、分析エンジンなど、データ集約型サービスのレイテンシ低減と応答性向上が期待できる。
この図は主要なクラウドワークロードにおけるCobalt 100からCobalt 200への相対性能の向上を示している。CPU性能は50%、Webサービングは40%、そしてデータベース処理では最大135%の改善を達成している(Azure Blogの記事に基づく)。
ネットワーク帯域幅は15%向上し、NVMeリモートストレージのIOPSは20%、スループットは10%改善する。さらに最大128vCPUまでのスケールアップが可能になった。メモリ暗号化がデフォルトで有効化されている点も、セキュリティ要件の厳しいエンタープライズ環境にとっては大きな前進だ。
エージェンティックAIに最適化された設計
Azure Blogの説明では、Cobalt 200の各コアは完全な物理コアであり、3MBの専用L2キャッシュとコアあたりの高いメモリ帯域を備える。この設計により、負荷時のアイソレーション性能が高く、エージェントのサンドボックスをVMあたりにより多く詰め込める。エージェンティックAIでは、複数のAIエージェントが並行して推論やツール呼び出しを行うため、スループットとレイテンシの両面で安定した性能が求められる。Cobalt 200はその期待に応える基盤となる。
データ集約型のキャッシュワークロードでは最大80%の性能向上が報告されており、通信暗号化処理では45%、クラウドデータベースでは135%という数字がAzure Blogの記事に示されている。こうした値は、大規模な本番サービスで確認された実測値であり、単なる理論上のピーク性能にとどまらない。
パートナー企業とMicrosoft内部サービスでの導入

プレビュー期間中から複数のテクノロジーパートナーがCobalt 200 VMを評価し、すでに有望な結果を得ている。Azure Blogに掲載されたTeradataのEngineering FellowであるBrandon Mincey氏のコメントでは、早期テストが有望だったとし、両社の共同顧客のニーズに合わせた設計へのフィードバックを続けているという。Elasticのプロダクト管理ディレクターYuvraj Gupta氏も、検索AIプラットフォームの性能とコスト効率のさらなる改善に期待を示した。
ArmのCloud AIビジネスユニット担当VP Eddie Ramirez氏は、エージェンティックAIがクラウドを再構築していると述べ、Arm Neoverse CSS V3をベースにしたCobalt 200が、次世代のAI駆動型サービスを可能にするとコメントしている。CanonicalのPublic Cloud AllianceディレクターJehudi Castro-Sierra氏は、メモリ暗号化のデフォルト有効化や圧縮・暗号化のアクセラレーションといった進歩が本番Linuxワークロードにとって重要だとし、Ubuntu ProのLivepatchによるArm環境での再起動不要なカーネル更新にも言及した。
Microsoft自身のサービスでも導入が進む。Power Platformの中核を担うDataverseでは、Cobalt 100での良好な実績を踏まえ、Cobalt 200の検証でベースワークロードが最大60%高速化したとAzure Blogの記事は紹介している。Azure SQL Databaseにおいても、圧縮・暗号化アクセラレータを活用することで、重要なクエリ処理リソースを解放できると期待されている。
VMファミリーと仕様
Cobalt 200 VMでは、従来の汎用(Dp, Dpl)やメモリ最適化(Ep)に加え、新たに高メモリ最適化Mpsv4シリーズと高密度ローカルストレージのLpsv5シリーズが追加された。これにより、大規模インメモリデータベースやビッグデータ分析、検索エンジンといった多様なニーズに対応できる。以下が主なシリーズの概要だ。
リモートディスクはStandard SSD、Standard HDD、Premium SSD、Ultra Diskに対応し、Azureポータル、SDK、API、CLIなど既存の手法でデプロイできる。プレビューは米国西部3、東部2、中央、スウェーデン中部などから開始され、今後リージョンが拡大される予定だ。
開発者エコシステムとArm互換性

Cobalt 200 VMは、現行のCobalt 100ワークロードとの完全な互換性を維持する。C++、.NET、Java、Python、Rustといった主要言語のArmネイティブ版がすでに最適化されており、GitHub ActionsもセルフホストランナーやGitHub-hostedランナーを通じてArmをサポートする。Azure Kubernetes Service(AKS)ではArmエージェントノードとx86/Arm混在クラスタの両方に対応し、コンテナ化されたワークロードの移行も容易だ。
クラウドインフラにおけるArm採用の流れはとどまるところを知らない。Cobalt 200の登場は、単なる性能向上にとどまらず、エンタープライズ向けのセキュリティと管理性をArmエコシステム全体に持ち込む転換点になるだろう。Azure Blogの記事は「Cobalt 200はAzureのカスタムシリコン戦略の新章」と位置づけており、今後のさらなる展開が注目される。
この記事のポイント
- Cobalt 200 VMがMicrosoft Build 2026で早期アクセスプレビュー公開。Cobalt 100比で最大50%のCPU性能向上
- 128vCPUまでのスケールアップ、NVMeストレージのIOPS/スループット改善、デフォルトのメモリ暗号化を実装
- エージェンティックAIに求められる高い並列性と低レイテンシに最適化された専用設計
- Teradata、Elastic、Arm、Canonicalなど主要パートナーが早期評価で有望な結果を示し、Microsoftの内部サービスでも性能改善を確認
- 新たなVMファミリーでより多様なワークロードに対応し、Armエコシステムの成熟がさらに加速する見通し
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Neon、有料プランのデータ転送量を5倍に増量。500GBで実質エグレスフリー
サーバーレスPostgreSQLサービスのNeonは2026年6月1日、全有料プランに含まれる月間データ転送量を従来の100GBから500GBへと5倍に引き上げた。この変更は自動的に適用され、利用者側での設定変更は不要だ。
500GBという上限は、ほとんどの一般的なワークロードにおける全データ転送(エグレス)コストを実質的にゼロにする水準だ。Neonのブログによれば、チャットボットのバックフィル処理や設定ミスによる超過リスクも、この増量によって大幅に緩和される。
本記事では、増量の具体的な内容と背景、利用者が知っておくべきポイントを整理する。
月間500GBへの増量。その具体的な内容

今回の変更の核心はシンプルだ。Neonの全有料プラン(Launch、Scale、Enterprise)において、月間のパブリックデータ転送(エグレス)の無料枠が100GBから500GBに拡大された。
500GBを超過した場合の追加課金体系に変更はない。超過分はこれまでと同一の従量課金レートで計算される。Neonの記事では「データ転送の計測方法や料金体系に変更は一切ない」と明言されている。
変更は自動適用。請求書にも即時反映
この増量は2026年6月1日からユーザー側の操作なしで自動適用される。Neonのコンソール(管理画面)で利用状況を確認可能で、6月分の請求書には新たな500GBの枠が反映される。
なぜNeonは5倍への増量を決断したのか

Neonのブログ記事は、意思決定の背景を率直に説明している。最大の動機は「予期せぬエグレス課金の排除」だ。
エグレス課金のストレスを根本から減らす
クラウドデータベースにおけるデータ転送料金は、しばしば利用者にとっての「見えないコスト」となる。チャットボットが想定以上にデータを取得したケース、分析ジョブが大量の履歴データを読み込んだケース、設定ミスでループ接続が発生したケースなど、原因は多岐にわたる。
これらの超過は後になってから請求書で気づくことが多く、事後対応が難しい。Neonの著者Carlo Daniele氏は「請求書に届いてからでは遅すぎる」と指摘している。500GBへの増量は、この「事後ショック」をほとんどのユーザーから無くす狙いがある。
競合との差別化とサーバーレスの信頼性向上
サーバーレスデータベース市場では、Vercel PostgresやSupabaseなどもデータ転送枠を設けている。500GBという閾値は、これらのサービスと比較しても実質的な「エグレスフリー」を実現する水準だ。
Neonにとって、この変更はプラットフォームの信頼性向上と、サーバーレスアーキテクチャへの移行障壁を下げる施策といえる。特にスタートアップや個人開発者にとって、突発的なコスト増はサービス継続のリスクになりうる。その不安を軽減する効果は大きい。
利用者に求められる対応と確認方法

必要な対応は一切なし
繰り返しになるが、利用者が実施すべき設定変更や申し込みは存在しない。Neonの全有料プラン契約者に対し、2026年6月1日以降の月間データ転送量が自動的に500GBへと引き上げられている。
利用状況の確認方法
自身のデータ転送量を把握したい場合は、Neon Consoleにログインし、請求および利用状況のダッシュボードでエグレス使用量を追跡できる。不明点はNeon公式Discordコミュニティで質問することも可能だ。
今後のデータ転送戦略とユーザーへの影響

今回の増量は、Neonが「データ転送をコスト障壁にしない」という姿勢を明確に打ち出したものと捉えられる。サーバーレスデータベースの利点である「従量課金の柔軟性」は、往々にして「予測不能なコスト」と紙一重だ。
500GBの無料枠は、その両面を切り離す試みだ。実際の利用データにもとづきNeonが「ほとんどのワークロードでエグレス課金が発生しなくなる」と明言している点は、単なるマーケティングではなくユーザー利用統計に裏付けられた判断といえる。
将来的にNeonがさらなるデータ転送枠の拡大や、完全なエグレスフリー化に踏み切る可能性もあるが、現時点ではこの変更が最大のハードルを解消したと評価できる。
この記事のポイント
- Neonは2026年6月1日より、全有料プランの月間データ転送量を100GBから500GBに増量
- 変更は完全自動適用。利用者による操作や設定変更は不要
- 500GB超過分の従量課金体系に変更はなく、データ転送の計測方法も据え置き
- 大半の一般的なワークロードがエグレス課金の対象外に。実質的なコスト障壁が大幅に低下
- 予期せぬエグレス課金への不安を解消し、サーバーレスデータベースの信頼性を強化
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Gemini 3.5 Flash がVercel AI Gatewayで利用可能に。並列処理能力と推論機能が大幅向上
Googleの最新モデル「Gemini 3.5 Flash」が2026年5月19日からVercel AI Gatewayで利用可能になった。このモデルはコーディング能力と並列エージェント実行ループの性能が大きく向上し、複雑なタスクでも高い推論精度を発揮する。
AI Gatewayの統合APIを通じて呼び出せ、使用量の追跡やコスト管理、リトライやフェイルオーバーの設定も標準で備わっている。開発者は面倒な基盤管理なしに、最新のAIモデルを本番環境へ素早く組み込める。
この記事では、Gemini 3.5 Flash の進化点、AI Gateway での具体的な使い方、実装時の注意点までを整理する。
Gemini 3.5 Flash の概要と新モデルの位置づけ

Flash シリーズの進化
Gemini Flash シリーズは、Google が提供する軽量で応答速度に優れたAIモデル群だ。前世代のFlash 2.0と比べて、3.5 Flash では単なる速度向上にとどまらず、複数ステップのタスクを自律的に並列実行できるようになった点が大きな違いだ。
これにより、コーディングの効率化や、複数のAPIを同時に呼び出すようなエージェント型アプリケーションで強力なパフォーマンスを発揮する。
今回のアップデートで強化された点
- コーディング補完の精度向上
- 並列エージェント実行ループの大幅な最適化
- コア推論能力と命令追従性の改善
- マルチターン会話の一貫性向上
- 思考モード(thinking mode)での高品質な推論トレースの生成
並列エージェント実行ループの進化

並列化によるパフォーマンス向上
従来のFlashモデルは、一連のタスクを逐次的に処理する傾向があった。たとえばコードリファクタリングの際に「API呼び出しAの完了を待ってからAPI呼び出しBを実行する」といった流れになる。これに対し、3.5 Flash は複数の独立した処理を同時に並列実行する能力が格段に上がっている。
並列実行のメリットは、応答待ち時間の大幅な短縮と、システム全体のスループット向上だ。特にマイクロサービス間の連携や、複数の外部データソースを一括で処理する場面で効果を発揮する。
この比較はあくまで概念図だが、実際のアプリケーションでは複数の独立した処理を同時に走らせることで、体感速度やスループットが大きく改善される。
thinking モードと推論トレースの強化

thinking level の選択
Gemini 3.5 Flash はデフォルトで「medium」のthinking levelが設定されている。これは、応答の品質と生成速度、そしてコスト効率のバランスを取るための設計だ。より複雑な推論が必要な場合は high レベルに変更することも可能で、その場合は推論プロセスがより深く行われる。
たとえば、コードのリファクタリングや多段階の意思決定が必要なタスクでは、thinking level を high に設定することで、AIが問題をより細かく分解し、質の高い答えを導き出す。
マルチターンコヒーレンスと複雑タスク
3.5 Flash では、マルチターンの会話における一貫性も改善されている。以前のFlashモデルに比べて、前のやり取りを適切に保持しながら、矛盾のない回答を返す精度が向上している。これにより、長時間のコード生成や、会話型のエージェントアプリケーションでも安定した挙動が期待できる。
複雑なタスクでは「thinking traces(思考の痕跡)」がより詳細に出力されるため、モデルがどのような過程で結論に至ったかを検証しやすい。デバッグや品質管理の面で大きなメリットだ。
Vercel AI Gateway の機能とメリット

統合APIとプロバイダールーティング
Vercel AI Gatewayは、複数のAIプロバイダーを統一的なインターフェースで利用できるプラットフォームだ。開発者はプロバイダーごとに異なるAPIキー管理やエンドポイントを意識することなく、model の指定だけでモデルを切り替えられる。
さらに、AI Gatewayはインテリジェントなルーティング機能を備えており、特定のプロバイダーに障害が発生した場合に自動で別のモデルへフェイルオーバーしたり、リクエストをリトライしたりできる。これにより、単一プロバイダーを直接使うよりも可用性が向上する。
観測性とカスタムレポート
AI Gatewayには、使用量の追跡やコスト分析のためのカスタムレポート機能が組み込まれている。プロジェクトごと、環境ごとにAPI呼び出し回数やトークン消費量を可視化できるため、予算管理やボトルネックの発見に役立つ。
また、AI SDK Observability との連携により、モデルの応答時間やエラーレートを詳細に監視できる。Bring Your Own Key にも対応しており、自社で契約したAPIキーをAI Gateway経由で安全に利用できる点も企業ユースに適している。
AI SDK での実装方法と注意点

コード例
AI SDK を用いて Gemini 3.5 Flash を呼び出すには、以下のように streamText 関数を使う。モデル名に google/gemini-3.5-flash を指定し、必要に応じて thinking level を設定する。
import { streamText } from 'ai';
const result = streamText({
model: 'google/gemini-3.5-flash',
prompt: 'Refactor this service to run API calls in parallel.',
providerOptions: {
google: {
thinkingConfig: {
thinkingLevel: 'high',
includeThoughts: true,
},
},
},
});thinking level は 'medium'(デフォルト)と 'high' から選択でき、複雑なタスクでは 'high' を指定すると良い。なお、includeThoughts: true にすると推論過程のトレースもレスポンスに含められる。
サポート外のパラメータと制約
Gemini 3.5 Flash では temperature、topP、topK、thinking_budget といったパラメータはサポートされていない。以前のモデルでこれらの値を調整していた場合は、デフォルトの挙動に任せるか、他のモデルを検討する必要がある。
特に thinking_budget が使えない点は、推論にかかるコストを細かく制御したい場合に注意が必要だ。そのぶん thinking level の切り替えで大まかな品質とコストのバランスを取る設計になっている。
この記事のポイント
- Gemini 3.5 Flash は並列エージェント実行ループの性能が大幅に向上し、コーディングや複数API呼び出しに強い
- デフォルトで medium の thinking level を採用し、品質・速度・コストのバランスを最適化
- Vercel AI Gateway によって統合API、リトライ、フェイルオーバー、観測機能をフル活用できる
- temperature や topP などの一部パラメータは非対応のため、移行時には注意が必要
- AI SDK 経由で数行のコードで導入可能、並列化のメリットをすぐに享受できる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Vercelがソースマップ保護機能を発表、本番環境のコード露出を防止
Vercelは2026年5月、本番環境のソースマップを安全に配信する新機能「Protected Source Maps」をリリースした。ブラウザが読み取る .map ファイルを Vercel Authentication の背後に置き、開発チームだけがアクセスできる仕組みだ。これにより、デバッグ情報を必要な人間にだけ提供し、それ以外の第三者には 404 を返す。
フロントエンドのバンドルは本番ビルドで圧縮・ミニファイされるため、可読性を保つにはソースマップが欠かせない。しかし従来は、そのソースマップが認証なしで公開されてしまい、コードの内部ロジックやコメントが誰でも閲覧できる状態だった。Protected Source Maps は、このセキュリティリスクを根本的に解決する。
ソースマップがなぜ重要か

ミニファイとデバッグのジレンマ
本番サイトの JavaScript や CSS は、ファイルサイズ削減のためにミニファイされる。変数名を短縮し、空白やコメントを取り除く処理だ。ところが、エラーが発生したとき、ブラウザのコンソールには圧縮後のコードしか表示されず、スタックトレースが「at a.a (bundle.js:1:2345)」のように読めなくなる。デバッグがほぼ不可能になるのだ。
この問題を解決するのがソースマップである。ミニファイ元のファイル名や行番号、元の変数名を記録した .map ファイルとして生成し、ブラウザがそれを使って元のソースコードを復元する。つまり、ビルド後の難読コードを、開発時の読みやすいコードに戻す「翻訳辞書」のような役割だ。
ソースマップの仕組み
ソースマップは通常、ミニファイされたファイルの末尾に //# sourceMappingURL=app.js.map というコメントを挿入することでブラウザに通知される。ブラウザがこのコメントを見つけると、対応する .map ファイルを別途リクエストし、デベロッパーツール上でオリジナルのソースコードを表示する。ここまでは開発者にとって日常的な光景だ。
しかし、本番環境でこの .map ファイルが認証なしに取得できると、第三者が容易にソースコードを読めてしまう。公開を想定していないコメントや、内部のビジネスロジックがダダ漏れになるリスクがある。
本番ソースマップが晒されてきたリスク

従来の典型的な対策は、ビルド時にソースマップを生成しないか、本番サーバーにアップロードしないというものだった。しかし、それでは本番環境で発生したエラーの調査が困難になる。また、サーバー側で特定の IP アドレスや VPN 経由のみアクセスを許可する方法もあるが、設定が複雑で、動的に変わるチームメンバーの管理には向かない。
実際に、JavaScript フレームワークの設定ミスによってソースマップが公開され、内部の API キーやテスト用のパスワードが漏えいした事例も報告されている。ソースマップは開発者にとって便利な一方、扱いを誤ると大きなセキュリティホールになりうる。
上の図は、認証がない場合と今回の保護機能を適用したあとの応答の違いを示している。従来は誰でも .map を取得できたが、Protected Source Maps を有効にすると、チーム外のリクエストには 404 Not Found が返る。
Protected Source Maps の動作と設定

Vercel Authentication によるアクセス制限
この機能の核は、プロジェクトの .map ファイルが Vercel Authentication で保護される点にある。通常、Vercel Authentication はデプロイプレビューや特定のパスをチームメンバーだけに公開するために使われる認証フレームワークだ。今回これがソースマップにも適用された。
つまり、ブラウザがソースマップをリクエストしても、Vercel のエッジネットワークが認証情報を確認する。チームの開発者であれば、普段から使っているブラウザのセッションでそのまま .map ファイルを取得できる。しかし、チーム外の人物や認証されていないブラウザからのリクエストには 404 が返るため、存在そのものを隠蔽する効果もある。
新規プロジェクトではデフォルトで有効、既存も後から移行可能
Vercel は、新規に作成するプロジェクトでは Protected Source Maps をデフォルトで有効にした。これにより、これからデプロイするプロジェクトは意識せずとも本番ソースマップが保護される。既存のプロジェクトについては、管理画面の「Settings」〜「Deployment Protection」からスイッチをオンにするだけで有効化できる。再デプロイも不要だ。
この設定変更は即座にエッジネットワーク全体に反映される。認証なしの .map リクエストはその瞬間から 404 になるため、段階的な移行作業を必要としない。
開発フローへの影響と注意点

セキュリティとデバッグ効率の両立
Protected Source Maps を導入しても、認証済みの開発者には従来通りソースマップが提供される。つまり、ブラウザのデベロッパーツールでエラーを追う際に元のコードが見えなくなることはない。本番環境で発生した問題を調査するチームにとって、利便性は一切損なわれない。
一方で、認証されていないサードパーティには 404 が返るため、ソースコードの漏えいリスクを大幅に低減できる。特に、エラーログに .map ファイルの URL が含まれていた場合でも、外部からはアクセスできない。
導入時に確認すべき点
この機能を使ううえで、いくつか注意点がある。まず、Vercel Authentication はブラウザのセッションを利用するため、開発者がログイン状態である必要がある。シークレットウィンドウやチームアカウント外のブラウザからはデバッグできない点に注意が必要だ。
また、CI/CD ツールなど自動化された環境でソースマップを処理する場合は、Vercel の API トークンを使って認証を通すか、あるいは別途プライベートなストレージにマップをアップロードする運用を検討してもよい。ただし、多くのケースでは開発者のブラウザからのリクエスト以外にソースマップが必要になるシチュエーションは少ないため、まずは Protected Source Maps をオンにして、必要に応じて調整するのが現実的だ。
この記事のポイント
- Vercel が Protected Source Maps をリリース、本番ソースマップをチーム限定に
- ブラウザからの
.mapリクエストは Vercel Authentication で保護される - 認証なしのアクセスには
404 NotFoundを返却、コードの露出を防止 - 新規プロジェクトはデフォルトで有効、既存プロジェクトも管理画面から即時有効化可能
- 導入後も開発者のデバッグ体験は変わらず、セキュリティと利便性を両立
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Amazon RedshiftにGraviton搭載のRGインスタンス登場、データレイククエリエンジンも統合
Amazon Redshiftに新しいインスタンスファミリー「RG」が追加された。AWSのArmベースプロセッサ「Graviton」を採用し、データウェアハウスのワークロード処理を従来のRA3インスタンスと比較して最大2.2倍高速化する。vCPUあたりの価格は30%引き下げられ、分析コストの大幅な圧縮が見込める。
さらに、このRGインスタンスではデータレイクへのSQLクエリ実行機能がクラスタノードに統合された。Apache Icebergテーブルへのクエリは最大2.4倍、Apache Parquetへのクエリは最大1.5倍高速化している。これまで別途必要だったRedshift Spectrumと、1TBあたり5ドルのスキャン料金が不要になる点も見逃せない。
BI(ビジネスインテリジェンス)ダッシュボードやAIエージェントによる大規模なクエリ実行が日常化する中、今回の刷新はパフォーマンスとコストの両立をこれまで以上に高い水準で実現するものだ。
RGインスタンスの概要と主要な性能向上

このデモは従来のRA3構成と新RG構成の違いを視覚化したものだ。RGインスタンスではデータレイククエリ機能が完全に統合され、外部のSpectrum層に依存しないアーキテクチャに変わっている。
Gravitonプロセッサがもたらす価格性能比の改善
RGインスタンスの中核にあるのは、AWSが設計したArmアーキテクチャのカスタムプロセッサ「Graviton」だ。x86系のチップと比べて電力効率が高く、同じ電力あたりの処理量を引き上げられる特徴がある。AWSのサービスにおけるGraviton採用はEC2やRDSなどで既に広がっており、Redshiftでもその恩恵を受けられるようになった。
具体的なインスタンスタイプとしては、エントリー向けの rg.xlarge(4vCPU、32GBメモリ)と、本番ワークロード向けの rg.4xlarge(16vCPU、128GBメモリ)が用意された。従来の ra3.xlplus から rg.xlarge への移行では、vCPU数とメモリ容量は同等だが処理性能自体が大きく向上する。一方、ra3.4xlarge から rg.4xlarge への移行ではvCPU数が12から16へ約1.33倍、メモリも96GBから128GBへと拡張され、単純なスペック面でも上積みがある。
AWS News Blogの記事によれば、これらの新インスタンスはデータウェアハウス処理でRA3比最大2.2倍の性能を達成しているという。企業が日常的に利用するBIダッシュボードの応答速度や、ETL処理のバッチジョブ実行時間が大幅に短縮される計算だ。
データレイククエリエンジン統合の実質的な意味

RGインスタンスで最も構造的な変化が起きたのは、データレイククエリの実行方式だ。これまではS3に置かれたデータレイクに対してSQLで分析する際、Redshift Spectrumという別のサービス層を経由する必要があった。このSpectrum層はクラスタの外部で動作するため、VPCの境界を越えたデータのやり取りが発生し、1TBあたり約5ドルの追加スキャン料金が積み上がる仕組みだった。
Spectrumが不要になったことで変わる運用とコスト
RGインスタンスでは、データレイクへのクエリをクラスタ上のノードで直接実行する。Spectrum層を経由しないため、クエリがVPCの内側に留まり、IAMロールも既存のものをそのまま使える。セキュリティ境界がシンプルになるだけでなく、データレイク利用時の通信レイテンシも低減する。
コスト面では、Spectrumのスキャン料金がゼロになる影響が大きい。例えば月間10TBのデータレイクをスキャンするワークロードの場合、Spectrumだけで月50ドルの追加コストが発生していた。RGインスタンスへの移行後は、このコストが完全に消える。データレイク分析の規模が大きい企業ほど、削減額は積み上がる計算だ。
既存の外部テーブルやスキーマ定義、クエリ構文はそのまま動作するため、アプリケーションコードの修正は不要だ。移行に伴う手間を最小限に抑えつつ、性能向上とコスト削減の両方を手に入れられる設計になっている。
AIエージェント時代を見据えた設計思想

今回のRGインスタンス投入の背景には、AIエージェントによるデータウェアハウス利用の急増がある。自律的に目標を追求するAIエージェントは、人間のアナリストとは比較にならない頻度でクエリを発行する。AWS News BlogのChanny Yun氏は、AIエージェントのクエリ量が「典型的な人間の利用規模を矮小化する」と表現している。
大量の低レイテンシSQLクエリを安定的に処理するには、1クエリあたりのコストを大幅に下げつつ、応答速度も維持しなければならない。vCPU単価で30%のコストダウンを実現しつつ、処理そのものを高速化したRGインスタンスは、まさにこの要求に応える製品だと言える。2026年3月に発表された新規クエリの最大7倍高速化と組み合わせることで、AIエージェントがリアルタイムにデータを参照しながら判断するワークロードにも耐えうる基盤が整った。
移行手順と現在の利用可能リージョン

RGインスタンスへの移行は、AWSマネジメントコンソール、CLI、APIのいずれからでも実行できる。データレイククエリエンジンはデフォルトで有効化されており、クラスタ作成後すぐに統合環境を利用できる。
移行パスは大きく2つある。1つ目は弾力的なリサイズで、互換性のある構成であれば10〜15分のダウンタイムでインプレース移行が完了する。2つ目はスナップショットと復元で、既存のRA3クラスタからスナップショットを取得し、RGインスタンスの新規クラスタとして復元する方法だ。移行時に構成を変更したい場合に適している。
2026年5月時点で、RGインスタンスは以下のAWSリージョンで利用可能だ。米国東部(バージニア北部、オハイオ)、米国西部(北カリフォルニア、オレゴン)、アジアパシフィック(香港、ハイデラバード、ジャカルタ、マレーシア、メルボルン、ムンバイ、大阪、ソウル、シンガポール、シドニー、台湾、東京)、カナダ(中部)、欧州(フランクフルト、アイルランド、ミラノ、ロンドン、パリ、スペイン、ストックホルム)、南米(サンパウロ)と、主要リージョンをほぼ網羅している。東京リージョンも含まれているため、国内のワークロードにも即座に適用可能だ。
実務者が押さえるべき導入判断のポイント

RGインスタンスは確かに魅力的だが、導入にあたってはいくつか確認すべき点がある。まず、オンデマンドインスタンスとリザーブドインスタンスの両方が提供されているため、長期的な利用が見込めるならリザーブドインスタンスによるコスト最適化を検討したい。AWS料金計算ツールで自社のワークロードパターンに基づいたシミュレーションを行うのが確実だ。
次に、Spectrumに依存していた既存のETLパイプラインや外部ツールとの統合に問題がないか、事前に検証環境でテストすることを推奨する。クエリ構文や外部テーブル定義は互換性が保たれているが、パフォーマンス特性が変わるため、実行計画の変化によって一部のクエリで想定外の挙動が生じる可能性はゼロではない。
最後に、データレイクとデータウェアハウスの両方を1つのインスタンスファミリーで処理できるようになったことで、アーキテクチャの簡素化と運用負荷の低減が見込める。特にデータレイクの分析規模が拡大傾向にある企業や、AIエージェントの本格導入を検討しているチームにとって、RGインスタンスへの早期移行は競争力の源泉になりうる。
この記事のポイント
- RGインスタンスはGraviton搭載によりRA3比最大2.2倍の性能とvCPU単価30%削減を両立
- データレイククエリエンジンが統合され、Spectrumと1TBあたり5ドルのスキャン料金が不要に
- Apache Icebergで最大2.4倍、Parquetで最大1.5倍のクエリ高速化を達成
- BIダッシュボードやAIエージェントによる大量クエリを低コストで処理できる基盤が整った
- 移行は弾力的リサイズまたはスナップショット復元で対応、既存クエリの修正は不要
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Amazon WorkSpacesがAIエージェント専用デスクトップを提供開始
企業がAIエージェントを本格導入しようとすると、大きな壁に突き当たる。基幹業務を支える既存のデスクトップアプリケーションやレガシーシステムは、最新のAPIを備えていないことがほとんどだ。2024年のGartnerレポートによれば、75%の組織がモダンなAPIを持たないレガシーアプリを運用しており、Fortune 500社の71%は十分なプログラムアクセス手段のないメインフレーム上で重要プロセスを動かしている。
AWSはこの課題に対して、新しいアプローチを発表した。2026年5月5日、Amazon WorkSpacesがAIエージェントに対して安全なデスクトップ環境を提供する機能をプレビュー公開した。これにより、アプリケーションの改修やAPIの新規開発なしで、AIエージェントが既存のデスクトップアプリケーションを人間と同じように操作できるようになる。
レガシーアプリケーションの課題とAI導入の壁

従来は、AIエージェントが業務システムと連携するには、アプリケーション側にAPIを実装するか、RPAによる擬似的な操作を行うしかなかった。いずれも大がかりな作業とメンテナンスを伴い、特に規制産業では監査やセキュリティ面でハードルが高かった。WorkSpacesの新機能は、仮想デスクトップという“もう一つの画面”をAIエージェントに渡すことで、この問題を一気に解消する。
WorkSpacesがAIエージェントに提供するもの

この新機能の核は、人間用に管理されてきたWorkSpaces環境を、AIエージェントにも安全に割り当てられるようにした点にある。エージェントはAWS Identity and Access Management(IAM)で認証され、WorkSpacesへ接続する。操作はすべてAWS CloudTrailとAmazon CloudWatchで監査ログが残り、既存のセキュリティ制御やコンプライアンスポリシーがそのまま適用される。
また、業界標準のModel Context Protocol(MCP)に対応しているため、LangChainやCrewAI、Strands Agentsなど、さまざまなAIエージェントフレームワークから利用できる。特定のSDKに縛られない設計は、企業の既存AI基盤に組み込みやすい。
AWSのブログ記事では、Nuvens ConsultingのディレクターChris Noon氏が次のようにコメントしている。「WorkSpacesは、クライアントが従業員に提供しているのと同じ安全でガバナンスの効いたデスクトップ環境を、AIエージェントにも提供できる。カスタムAPI統合は不要で、完全な監査証跡とエンタープライズグレードの隔離が最初から組み込まれている。規制の厳しい業界では、これは単なる追加機能ではなく、前提条件だ」
AIエージェント用WorkSpacesの設定手順

AWS Management Consoleから設定を開始する。WorkSpacesコンソールで「スタックの作成」を選択し、スタック名やフリートの関連付け、VPCエンドポイントなどの基本情報を入力する。作成ウィザードのステップ3では、AIエージェント用の新しいセクションが追加されている点がポイントだ。
ここでは「AIエージェントの追加」オプションを選択する。これにより、人間用のスタックとは別に、エージェント専用のIDと権限でデスクトップにアクセスできるようになる。続いてエージェント機能を有効化する設定へ進む。「コンピューター入力」はマウスクリックやキーボード入力、スクロール操作を許可し、「コンピュータービジョン」はエージェントがデスクトップのスクリーンショットを取得できるようにする。これはエージェントが画面を「見る」仕組みだ。さらにスクリーンショットの保存先を指定し、監査やデバッグに備える。
画面レイアウトの設定では、解像度や画像フォーマットを選ぶ。UI要素が密集した複雑なアプリケーションでは高解像度が有効だが、ターミナル風のシステムであれば720pで十分だ。これらの設定を済ませると、WorkSpacesがマネージドMCPエンドポイントを生成する。あとはAIエージェントのフレームワーク側で、このエンドポイントとIAM認証情報を指定するだけで接続が完了する。
実際の動作とユースケース

実際のデモでは、AWSがStrands Agent SDKとAmazon Bedrockを組み合わせて構築したエージェントが、架空の薬局システム上で処方箋の再発行処理を一通り実行している。患者レコードの検索から薬剤の選択、注文、再発行確認まで、すべてAPIなしで完結する。アプリケーション側はエージェントが操作していることを一切意識しておらず、ソフトウェアの改修も再構築も行われていない。
このようなアプローチは、金融機関の勘定系システムや医療機関の電子カルテ、物流システムの倉庫管理アプリなど、何十年も使い続けられている業務アプリケーションにすぐに適用できる。モダナイズに踏み切れずAI導入を断念していた企業にとって、有力な選択肢になるだろう。
今後の展望と利用可能リージョン
今回の機能はパブリックプレビューとして、米国東部(バージニア北部、オハイオ)、米国西部(オレゴン)、カナダ(中部)、欧州(フランクフルト、アイルランド、パリ、ロンドン)、アジアパシフィック(東京、ムンバイ、シドニー、ソウル、シンガポール)の各リージョンで追加料金なしで利用できる。
エージェントが人間と同じデスクトップを共有するという発想は、レガシーシステムとAIの架け橋として大きな可能性を秘めている。AWSのブログでは、GitHubリポジトリにサンプルコードが公開されており、すぐに試せる環境が整っている。今後は、より細かな権限制御やマルチエージェント対応など、エンタープライズ利用を加速させる機能拡張が期待される。
この記事のポイント
- Amazon WorkSpacesがAIエージェントに仮想デスクトップを提供する機能をパブリックプレビュー開始
- レガシーアプリのAPI改修不要で、AIエージェントがクリックや入力、スクリーンショット取得で操作可能
- IAMによる認証とCloudTrailの監査証跡で、既存のセキュリティ・コンプライアンスを維持
- MCP対応でLangChainやCrewAIなど主要フレームワークと接続可能
- 東京リージョンを含む多数のリージョンで追加費用なしで試用可能
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験