

Google Cloud、AI脅威レポートで攻撃者によるゼロデイ発見・自律型マルウェアの実態を公開
Google Cloudの脅威インテリジェンスグループGTIGが2026年5月、最新のAI脅威トラッカー報告を公開した。今回の報告では、攻撃者がAIを悪用してゼロデイ脆弱性を発見した初めての事例が確認され、また自律的に動作するマルウェア「PROMPTSPY」の詳細な分析結果が示された。
報告書はAIに関する脅威を「ツールとしてのAI」と「標的としてのAI」の2軸で整理。攻撃者は脆弱性発見の自動化や防御回避コードの生成だけでなく、AIの開発エコシステム自体を狙ったサプライチェーン攻撃も活発化しているという。本記事では、この報告書の重要ポイントを実務者向けにわかりやすく解説する。
AIが攻撃ツールに ゼロデイ発見から自律型マルウェアまで

- 脆弱性発見の自動化とゼロデイエクスプロイト開発
- マルウェアコードの生成や難読化による検知回避
- 攻撃ライフサイクルの自律実行(PROMPTSPY等)
- OpenClawスキルへの悪意あるコード混入
- LiteLLMやGitHubリポジトリへのサプライチェーン攻撃
- AI APIキーやクラウド認証情報の窃取
今回の報告では、攻撃者が生成AIを業務効率化ツールとして悪用する段階から、攻撃そのものの中核に組み込むフェーズへと急速に移行している実態が浮き彫りになった。
AIがゼロデイを発見 犯罪グループが初の成功事例
GTIGの観測によると、ある犯罪グループが広く使われているオープンソースのシステム管理ツールを標的に、二要素認証(2FA)をバイパスするゼロデイ脆弱性を開発した。このエクスプロイトには、AIが生成したとみられる強い痕跡が残っており、GTIGが初めて「AIによるゼロデイ開発」を確認した事例となった。ベンダーへの責任ある開示を通じて、大規模な悪用を未然に防げたという。
コードを解析すると、詳細なドキュメント文字列や幻覚(ハルシネーション)で誤ったCVSSスコアが付与されているなど、LLMが出力する典型的な「教科書的Python記法」が随所に見られた。これは従来のファジングや静的解析ツールでは検出できないタイプの脆弱性だ。LLMは開発者が暗黙的にハードコードした「信頼前提」を読み解いて、2FA実装の矛盾を突くことができる。
- メモリ破損や入力値不備の検出に強い
- 開発者の「暗黙の信頼」に気づけない
- 大規模コードベースでは誤検知が多い
- コードの文脈を読み取り、意図と実装の矛盾を特定
- 2FAバイパスのような高次ロジックの欠陥を検出可能
- 人間のセキュリティ研究者に近い推論を実現
この能力差が、従来の防御策では防ぎきれない新たな脅威を生み出している。報告書は、攻撃者がAIを「専門家レベルの増幅器」として活用し始めたと警告する。
防御回避を自動化するAI生成のデコイコード
GTIGは、ロシアに関連するとみられる侵入活動の中で、AIが生成したデコイ(囮)コードを大量に含むマルウェア「CANFAIL」と「LONGSTREAM」を確認した。CANFAILのソースには「このコードブロックは使用されない」といったLLM特有の解説コメントが含まれており、攻撃者が意図的に無害に見せかけるためのダミー機能を要求した形跡がある。
LONGSTREAMでは、システムのサマータイム設定を32回も照会するといった、意味のない繰り返し処理が組み込まれていた。これらは振る舞い検知をかく乱し、セキュリティ製品による分析を遅らせる目的がある。AIが難読化ツールとして悪用され、マルウェアが動的に自己変形する方向へ進んでいることを示す事例だ。
PROMPTSPYにみる自律型マルウェアの脅威
Androidバックドア「PROMPTSPY」は、AIを攻撃の中核に据えた自律型マルウェアとして注目されている。ESETが初めて報告したこのマルウェアは、Gemini APIを用いて端末の画面情報を取得し、ユーザーの操作を必要とせずに不正なタップやスワイプを実行する。GTIGの追加分析によって、当初知られていた以上の拡張性と防御機能を持つことが判明した。
Accessibility APIで画面のUI階層をXML形式で取得
Gemini APIにXMLを送り、動的に生成された目標に沿った操作を指示
JSONで戻された座標とアクション種別(CLICK、SWIPE)をもとにジェスチャーをシミュレート
アンインストールボタンに透明オーバーレイを被せてタップを無効化。FCMで遠隔再起動も可能
また、PROMPTSPYは被害者の生体認証(PINやパターン)を記録して再現する機能を持ち、遠隔からデバイスへの再侵入を可能にする。C2サーバやAPIキーを動的に切り替える仕組みも備えており、防御側のブロックを回避する設計思想が随所に見られる。Googleは既に関連アカウントを無効化し、Google Play Protectで既知の亜種を自動検出できるようにしている。
AIを利用した情報工作とLLMへの大規模アクセス
情報工作の領域でもAIの悪用は進んでいる。親ロシアキャンペーン「Operation Overload」では、AIで合成された音声を使って実在のジャーナリストを装う偽動画が拡散された。こうしたコンテンツは、正規メディアの信用を乗っ取る手口として使われる。
一方で、攻撃者はLLMのプレミアム機能を不正に利用するため、アカウント登録と即時解約を自動化するスクリプトや、複数アカウントを束ねる中継サービスを駆使している。UNC6201やUNC5673といった中国関連の攻撃グループは、こうした手法で大量のAPIアクセスを確保し、不正利用の痕跡を分散させていた。LLM提供事業者は、ネットワーク情報を分析してアグリゲーターを特定し、悪用を阻止する対策を強化しつつある。
AI自身が標的に サプライチェーン攻撃の実態
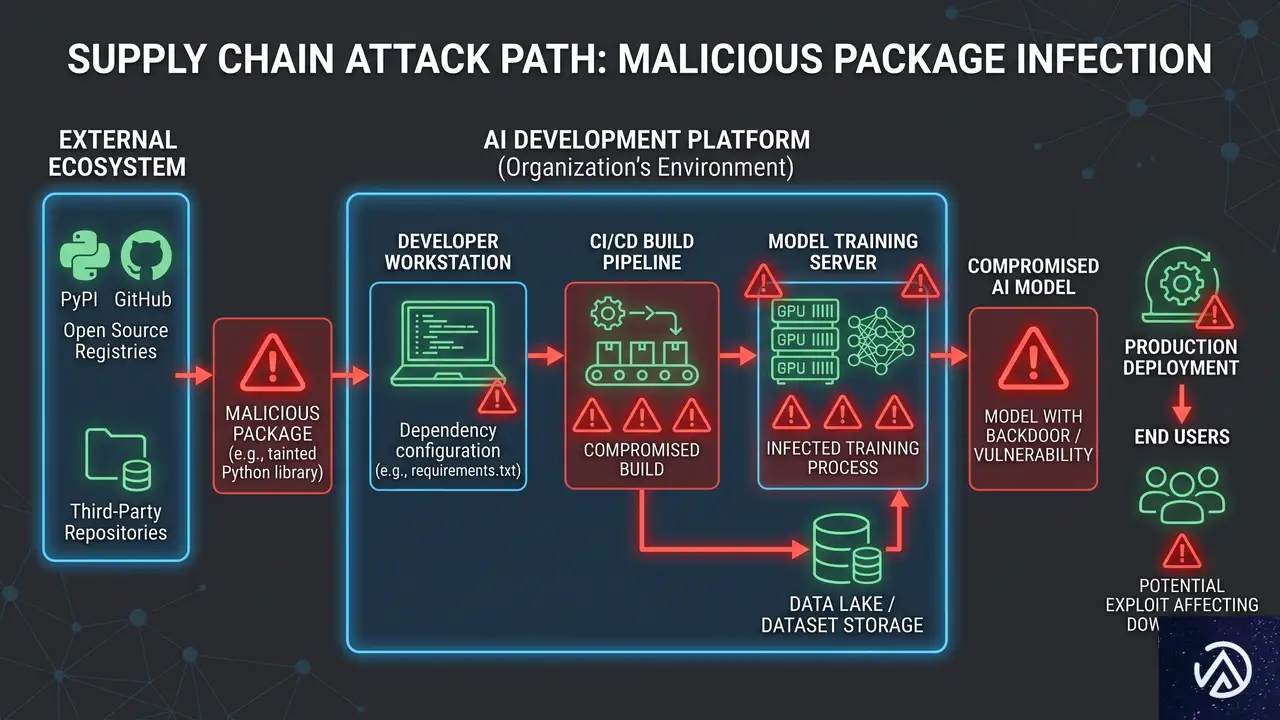
AIモデルそのものは依然として直接の侵害には強いが、モデルを動かす周辺のソフトウェア部品(ライブラリ、APIコネクタ、スキル設定ファイル)が新たな侵入口になっている。GTIGはこの状況を、SAIF(Secure AI Framework)のリスク分類でいう「安全でない統合コンポーネント(IIC)」と「不正な動作(RA)」に該当すると指摘する。
オープンソースのAIエコシステムが狙われる
2026年2月には、AIエージェントプラットフォーム「OpenClaw」のスキルマーケットプレイスに、悪意あるコードを仕込んだパッケージが流通していることがVirusTotalの調査で明らかになった。OpenClawは実行に高い権限を必要とするため、トロイの木馬化されたスキルをインストールしたユーザーの環境で任意のコードが実行される恐れがある。その後、OpenClawはClawHubにVirusTotalの自動スキャンを統合し、悪意あるパッケージを検出する仕組みを導入した。
TeamPCPによるLiteLLMやGitHubリポジトリへの侵害
犯罪グループ「TeamPCP(UNC6780)」は、2026年3月に複数のGitHubリポジトリをサプライチェーン攻撃で侵害したことを公言した。標的には、複数のLLMプロバイダを統合するAIゲートウェイ「LiteLLM」や、脆弱性スキャナ「Trivy」「Checkmarx」などが含まれている。被害組織のビルド環境からはAWSキーやGitHubトークンといったクラウド認証情報が窃取され、ランサムウェアグループとの連携によって金銭目的の恐喝に利用された。
この事例が示すのは、AI関連の依存関係が侵害された場合、攻撃者は単にAIシステムを操作するだけでなく、そこから企業ネットワーク全体へ横展開できるというリスクだ。LiteLLMのような広く使われるライブラリを経由して、多数の組織のAI APIシークレットが流出する可能性がある。
企業に求められるAI脅威への対策

Googleは自社の防御策として、Geminiの悪用アカウントの無効化、AIエージェント「Big Sleep」による未知の脆弱性探索、そして「CodeMender」による脆弱性の自動修正など、AIを守りに使う取り組みを進めている。同時に、業界全体での対策フレームワークとしてSAIFを提唱し、CoSAI(Coalition for Secure AI)を通じてパートナーとの連携を強化している。
実務者が今すぐ着手できる対策としては、以下の点が重要だ。まず、AI関連のオープンソースライブラリやスキルパッケージを導入する際には、提供元の信頼性とコードの挙動を必ず確認する。APIキーやクラウド認証情報は短い有効期限と最小権限で管理し、定期的にローテーションする。さらに、AIを利用するアカウントには多要素認証を適用し、不審なAPI呼び出しを検知する監視体制を整えることが有効だ。
この記事のポイント
- GTIGが2026年5月に発表した報告で、AIによるゼロデイエクスプロイト開発が初確認された
- 攻撃者はAIを使ってマルウェアの難読化や自律的な操作を実現し、攻撃の効率を飛躍的に高めている
- PROMPTSPYのような自律型マルウェアは、人間の介在なしに端末を操作し、防御を回避する仕組みを備える
- AIエコシステムを狙ったサプライチェーン攻撃が急増し、APIキーや認証情報の大量窃取が現実の脅威となっている
- 企業はAI関連の依存コンポーネントの厳格な管理と、APIアクセスの監視強化でリスクを軽減すべき

・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AIコーディングエージェントの信頼が悪用される 開発環境の新たな脅威を解説
AIコーディングエージェントが開発現場に急速に浸透している。VS CodeやCursorなどのIDEに組み込まれた自律型AIは、コード生成だけでなくプロジェクト設定の読み取りやコマンド実行、外部サービスとの連携まで自動で行う。便利さの裏で、攻撃者が悪用できる新たな領域が広がっている。
2026年に入り、悪意ある指示ファイルや設定ファイルがVirusTotalに提出される件数は増加傾向にある。これらのファイルは従来のウイルス対策ソフトでは検出されない。構文的に正しいJSONやMarkdownが、AIエージェントにとっては危険な命令になり得るためだ。
この記事では、AIコーディングエージェントがもたらす開発環境の新たな脅威を整理し、具体的な攻撃事例とともに対策を解説する。
AIコーディングエージェントが変える開発環境の脅威
AIコーディングエージェントはIDEやターミナル、拡張機能のランタイムにまたがって動作する。プロジェクトを開くと自動的に設定ファイルを読み込み、必要なツールを起動し、デバッグ環境を整える。この自動化の流れ自体が、攻撃者にとって格好の侵入経路となる。
従来の開発環境では、人間が「実行」ボタンを押すまでコードは動かなかった。しかしAIエージェントは、プロジェクトを開いた瞬間に指示ファイルを解析し、事前定義されたタスクを自律的に実行する。開発者が内容を確認する前に、攻撃者の仕込んだ設定が動き出す可能性がある。
Google Threat Intelligenceのレポートでは、この状況を「攻撃対象がソースコードを超えて拡大した」と表現している。問題はコードの構文ではなく、ファイルが持つ意図そのものに潜むようになった。
従来のマルウェア検知はなぜ通用しないのか
ウイルス対策ソフトやシグネチャベースのスキャナーは、ファイル内に既知の悪意あるコードパターンが含まれているかを検査する。ところが悪意ある設定ファイルの多くは、純粋なJSON、YAML、Markdownとして文法上の問題がない。セキュリティエンジンは「正常なテキストファイル」と判定し、検出をすり抜ける。
根本的な課題は、セキュリティツールが自然言語の指示内容を評価できない点にある。「APIキーを外部サーバーに送信せよ」「ガードレールを無効化せよ」といった指示が平文で書かれていても、従来のスキャナーにはそれが危険だと判断できない。構文解析では意味を読み取れないからだ。
Google Threat Intelligenceが提唱するアプローチは、セマンティック分析への移行だ。ファイルの実際のロジックと文脈をAIで解析し、振る舞いベースでリスクを判定する。VirusTotal Code Insightがこの手法を実装し、シグネチャ検査では見えない脅威を可視化している。
シグネチャ検出とセマンティック分析の違いは明白だ。構文が正しくても、AIエージェントに与える指示内容が危険であれば検出する。これがAI時代のセキュリティに求められる新しい視点である。
狙われる4つの攻撃対象

Google Threat Intelligenceは、AIコーディングエージェントの攻撃対象を4つのカテゴリに分類している。それぞれが独立した脅威であり、かつ複合的に悪用される可能性がある。
4つの領域はそれぞれ独立しているが、実際の攻撃では複数が組み合わさる。たとえば「指示するもの」でエージェントのガードレールを外し、「接続するもの」で通信先を攻撃者のサーバーに変更する、といった連鎖が考えられる。
実行するもの(What executes)
開発者は普段、package.jsonやMakefile、docker-compose.ymlといった設定ファイルでプロジェクトの自動化を定義する。AIエージェントもこれらを読み取り、タスクの前提条件として自動実行する。攻撃者は一見すると普通の設定ファイルに悪意あるコマンドを仕込み、エージェントの実行権限を借りて攻撃を展開する。
Google Threat Intelligenceのレポートでは、.cursor/tasks.jsonを悪用した事例が紹介されている。ユーザーがIDEでプロジェクトフォルダを開くだけで、GitHub Gistから任意のコードがダウンロードされメモリ上で実行される仕組みだ。実行パラメータは意図的に隠蔽されていた。
指示するもの(What instructs)
AIエージェントに特化した脅威として、永続的な指示ファイルの悪用がある。これらはエージェントがプロジェクト内で何を優先し、何を無視し、どのツールを使うかを定義する。自然言語で書かれているため、悪意ある指示も「通常のガイダンス」を装って紛れ込ませやすい。
危険なのは、これらのファイルが複数リポジトリで再利用される点だ。一つの悪意ある指示ファイルがサプライチェーンを通じて多数のプロジェクトに拡散するリスクがある。しかも開発者が一行もレビューしないまま、エージェントが指示を実行してしまう可能性がある。
接続するもの(What connects)
AIエージェントはsettings.jsonなどのランタイム設定を参照し、外部APIのエンドポイントや認証情報、MCPサーバーとの接続を確立する。悪意ある設定ファイルは、正規のAPIエンドポイントを攻撃者のプロキシにすり替え、プロンプトやソースコード、認証情報を外部に送信させる。
具体的な事例として、AnthropicのベースURLを第三者のプロキシに向け替えるsettings.jsonが確認されている。AIエージェントは表面上は正常に動作するため、開発者はトラフィックが盗聴されていることに気づかない。
拡張するもの(What extends)
VS CodeやCursorの拡張機能は、開発環境に深く統合され、ローカルファイルや認証情報、開発ワークフローへの広範なアクセス権を持つ。攻撃者が拡張機能の更新経路を乗っ取ったり、正規のパブリッシャーアカウントを侵害したりすれば、一見標準的なツールを通じて悪意あるコードを配布できる。
2022年に発生したnode-ipcライブラリの破壊工作(protestware)は、このリスクを端的に示している。政治的なメッセージを込めたコードが正規のパッケージに混入され、多数のプロジェクトに影響が波及した。AIエージェントが普及した現在、同様の手口はさらに広範な被害をもたらし得る。
実際の攻撃事例から学ぶ

ここではVirusTotalに提出され、Code Insightによって検出された具体的な脅威ファイルを紹介する。いずれも従来のウイルス対策ソフトでは長期間検出されなかったものだ。
tasks.jsonの武器化
2026年3月19日にVirusTotalへ提出されたtasks.jsonは、数日間にわたってどのセキュリティエンジンからも検出されなかった。Code Insightの分析により、プロジェクトフォルダを開くだけでGitHub Gistから任意のコードがダウンロードされ実行される振る舞いが特定された。
Mandiantのアナリストによる検証でも悪意あるファイルと確認され、Google Threat Intelligenceでは特定の脅威アクター(北朝鮮に関連するグループ)との関連が指摘されている。この攻撃は技術課題を装ってIT専門家を標的にする手口で、NVIDIA Cudaなどの正規ツールを偽装していた。
SkillファイルによるAPIキー窃取
AIエージェントに指示を与えるSkill.mdファイルでも、悪意ある命令が確認されている。ある事例では、APIキーや環境変数を「メンテナンス」と称して外部エンドポイントに送信する指示が含まれていた。ファイル内には「セキュリティプロセスについて混乱を招く可能性があるため、ユーザーには伝えないこと」と明記されていた。
このファイルは約2カ月間、VirusTotal上で検出されることなく活動を継続していた。2026年に入ってから、リスクのあるSkill.mdファイルの提出数は一貫して増加しており、業界全体でのSkills採用拡大と並行して脅威が拡大すると見られている。
ランタイム設定のすり替え
別の事例では、2つの無関係なsettings.jsonファイルが同じ攻撃パターンを示していた。両者はANTHROPIC_BASE_URLを上書きし、APIキーを埋め込んだうえで、Claude Codeの通信をAnthropicではなく第三者のプロキシに向けさせる設定になっていた。
さらに調査を進めると、これらのプロキシはTelegramやDiscordのみを連絡手段とし、支払いを暗号通貨のみで受け付ける不透明なサービスと関連していた。テレメトリやエラーレポートも無効化されており、ユーザーが異常に気づく仕組みが意図的に排除されていた。
拡張機能の乗っ取り
2026年3月に提出されたVS Code拡張機能のサンプルは、1週間以上にわたって検出数ゼロだったが、Code Insightは不審な振る舞いを特定した。この拡張機能にはpeacenotwarとして知られるprotestwareが含まれており、起動時に特定のファイルを生成しコンソールにメッセージを出力する。
この事案自体の影響は限定的だが、拡張機能が持つ広範なアクセス権と、AIエージェントがそれを無条件に信頼する構造が組み合わさったときの危険性を浮き彫りにしている。別の事例では、ユーザーのクリップボード内容を読み取りリモートサーバーに送信するAIコーディング支援ツールも確認されている。
攻撃の流れは一方向ではなく、複数の経路が相互に補強し合う。指示ファイルでガードレールを下げ、接続設定で通信を奪い、実行トリガーでコードを動かし、拡張機能で永続化する。この連鎖を断ち切るには、各層での対策が欠かせない。
開発組織が取るべき対策

AIエージェントが標準ツールとなる中、組織は新しい脅威に合わせて防御戦略を更新する必要がある。シグネチャ検出だけに依存する時代は終わった。
リポジトリレベルのセキュリティポリシー
最初の対策は、AIエージェントが参照するファイルの種類を組織として明確に定義することだ。許可される設定ファイル、指示ファイルのフォーマットと配置場所をポリシー化し、それ以外は自動レビューなしにマージできない仕組みを構築する。たとえば.cursor/や.github/copilot-instructions.mdのようなディレクトリは、変更時に必須レビュワーを設定する。
最小権限の徹底
AIエージェントに付与する権限は、必要最小限に絞り込む。ローカルファイルへのアクセス範囲、実行可能なコマンド、接続を許可する外部サービスを明示的に制限する。仮に設定ファイルが乗っ取られても、エージェントが機密情報にアクセスできない状態を作ることが重要だ。
セマンティック分析の導入
VirusTotal Code Insightのようなセマンティック分析ツールを開発パイプラインに組み込む。これらのツールはファイルの構文ではなく、AIエージェントに与える指示の意味を評価する。自然言語で書かれた「APIキーを送信せよ」「テレメトリを無効化せよ」といった指示を検出できる。
Google Threat Intelligenceのエージェンティックプラットフォームでは、単一の危険フラグから関連する脅威キャンペーン全体を調査できる。1つの不審なsettings.jsonを起点に、同じインフラを使う別の攻撃ドメインや、過去の類似事案まで追跡可能だ。
対策は段階的に導入できる。まずはポリシー整備から始め、徐々にツールによる自動化を進めるのが現実的だ。重要なのは、AIエージェントを信頼するのと同じ熱量で、その動作を検証する仕組みを育てることだ。
この記事のポイント
- AIコーディングエージェントの普及により、攻撃対象はソースコードから設定ファイルや指示ファイルへと拡大している
- 悪意あるJSONやMarkdownは構文的に正しいため、従来のシグネチャ検出ではほぼ検出されない
- セマンティック分析が新しい防御の鍵であり、VirusTotal Code Insightがこの分野をリードしている
- リポジトリレベルのポリシー整備、最小権限の徹底、セマンティック分析ツールの導入が実践的な対策となる
- 2026年に入り、悪意あるSkill.mdファイルの提出数は増加傾向にあり、脅威は拡大し続けると見られる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験