

GPT-5.5が企業向けエージェントにもたらす変革、Databricks導入事例
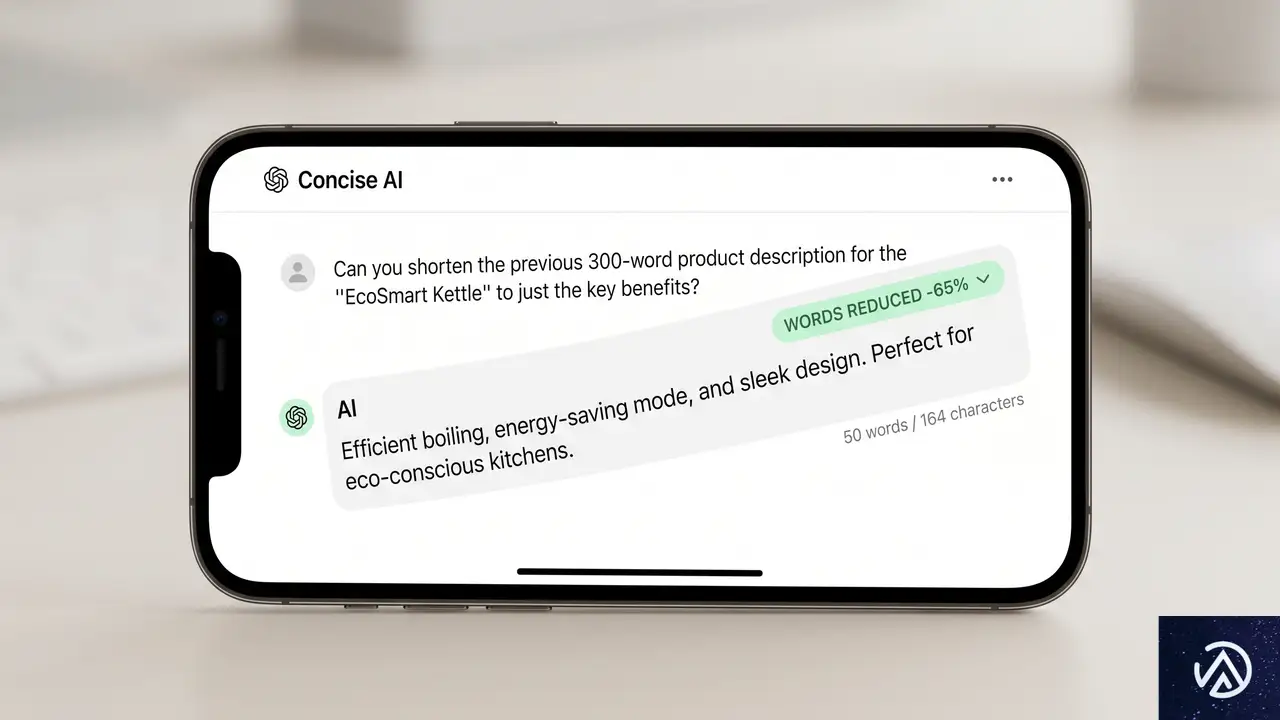
大規模言語モデルの進化が、企業の実務ワークフローに直接的な成果をもたらし始めている。データ分析基盤を提供するDatabricksが、OpenAIの最新モデルGPT-5.5を社内向けAIエージェントに組み込んだ結果、複雑な文書処理タスクを評価するベンチマーク「OfficeQA Pro」でエラーが46%も減少した。GPT-5.5はこのベンチマークで初めて正解率50%を超えたモデルとなった。
この結果は「モデルの性能向上が、実際のビジネス指標にどう結びつくか」を示す重要な事例だ。単なる会話能力の評価ではなく、スキャンされたPDFや古い社内フォーマットの文書を解析し、複数ステップのタスクを自律的に遂行する能力が問われている。本記事ではGPT-5.5がどのような技術的進歩を遂げ、企業のAI活用にどんな可能性を開くのかを解説する。
企業向けAIエージェントの現在地、なぜ文書処理が壁になるのか

企業がAIエージェントを導入する際、最初にぶつかる壁が「社内文書の解析」だ。契約書や見積書、古いシステムから出力されたレポートなど、形式がバラバラな文書をAIに理解させるのは想像以上に難しい。特にスキャンされたPDF(画像として取り込まれた文書)や、数十年前のレガシーフォーマットで保存されたファイルは、最新のAIでも正確なテキスト抽出に失敗することが多い。
この問題の深刻さは、小さな認識ミスが後続の処理全体を狂わせる点にある。たとえば請求書の金額を一桁間違えて抽出すれば、その後の経理処理やレポート作成がすべて誤った情報で進んでしまう。人間なら「明らかにおかしい」と気づくようなエラーでも、AIエージェントは抽出した数値をそのまま信じて処理を続ける。これが企業現場でのAI導入を妨げる最大の障壁となっていた。
OfficeQA Proベンチマークの評価観点とは
Databricksが開発したOfficeQA Proは、こうした実務課題を忠実に再現する評価指標だ。このベンチマークでは、モデルに対して以下の3つの能力が求められる。
- 文書解析(Parsing):スキャンPDFやレガシーファイルから正確に情報を抽出する能力
- 情報検索(Retrieval):長大な文書群の中から必要な情報を見つけ出す能力
- 根拠に基づく推論(Grounded Reasoning):抽出した情報をもとに、論理的な判断や回答を生成する能力
単なる知識クイズではない。バラバラなフォーマットの文書を理解し、複数のステップを経て最終的なアウトプットを出す「エージェントとしての実務能力」が試される設計になっている。
上図のように、GPT-5.5への切り替えによって文書解析のエラーが大幅に減り、後続のワークフロー全体の信頼性が向上した。この改善の背景には、モデルの視覚認識能力と言語理解の統合が進んだことがあると見られている。
GPT-5.5が達成した二つの飛躍的改善

Databricksが報告したGPT-5.5の改善点は、大きく二つの領域に分かれる。一つは文書解析精度の劇的な向上、もう一つは複数ステップのタスクを効率的に管理するオーケストレーション能力の進化だ。
スキャン文書解析の「ステップ関数的」な進歩
Databricksの記事で同社のSinghvi氏が指摘するように、GPT-5.4まではスキャンされた古い文書から数字を正確に読み取れないケースが頻発していた。これに対しGPT-5.5は、古い文書やスキャンPDFの解析において「ステップ関数的な性能向上」を見せたという。「ステップ関数的」とは、なだらかな改善ではなく、階段を一段上がるように非連続的な飛躍があったことを意味する。
この進歩が特に重要なのは、企業が保有する文書の多くが過去の資産だからだ。10年前の契約書、5年前の監査レポート、紙をスキャンしてPDF化した資料。こうした「過去の遺産」を正確に解析できるかどうかが、AIエージェントの実用性を左右する。GPT-5.5はこの壁を一つ越えたと言える。
ムダな遠回りをしないタスク実行能力
もう一つの重要な改善が、複数ステップのタスクを実行する際の軌道(Trajectory)の最適化だ。GPT-5.4では、目的に対して不必要な検索を繰り返す「遠回り」が発生し、非効率な処理経路をたどることがあった。これはエージェントが過剰に「慎重」になりすぎる、あるいは文脈を適切に把握できずに余計な確認作業を挟んでしまう問題だ。
GPT-5.5では、必要な情報を必要なタイミングで的確に取得し、最短のステップでタスクを完了する能力が高まった。追加の監視や人間による修正なしに、複雑なワークフローを完遂できる信頼性が向上している。
この改善は、企業がAIエージェントに求める「人間の監視なしで動く自律性」に直結する。タスクが長引けばそれだけコストも増え、途中で人間が介入する必要性も高まる。GPT-5.5はこの課題に対して明確な前進を示した。
企業ワークフローへの実装、AgentBricksとAI Unity Gateway

DatabricksはGPT-5.5を単独のチャットボットとして使っているわけではない。同社の「AI Unity Gateway」を通じて、AgentBricksやAgent Supervisor APIといったエージェント構築基盤と統合し、実際のビジネスワークフローに組み込んでいる。
AgentBricksとは、Databricksが提供するエージェント構築フレームワークだ。専門特化した複数のエージェントを組み合わせ、複雑な業務プロセスを自動化できる。ここでGPT-5.5は「監督者(Supervisor)」として機能する。各専門エージェントが文書解析やデータ検索、レポート生成といった個別タスクを担当し、GPT-5.5が全体の流れを管理して適切なタイミングで適切なエージェントに指示を出す。このアーキテクチャによって、単一モデルでは扱いきれない複雑な業務フローが実現できる。
この「監督者モデル」のアプローチは、今後の企業向けAI活用の主流になると考えられる。一つの巨大モデルがすべてを処理するのではなく、専門エージェントを束ねる統括役としてLLMを配置する設計だ。GPT-5.5のオーケストレーション能力の向上は、この設計思想と見事にマッチしている。
ナレッジワークにおけるGPT-5.5のインパクト

DatabricksのSinghvi氏は「GPT-5.5は知識作業においてステップ関数的な変化をもたらした」と評している。単に質問に答えるだけでなく、複数の文書を横断して情報を統合し、文脈を理解した上で判断を下す「知識労働の代替」としての性能が大きく向上したという評価だ。
この評価が特に重要なのは、AIが「単なる道具」から「業務のパートナー」へと役割を変えつつあることを示唆しているからだ。従来のAIアシスタントは、人間が明確に指示したタスクを実行するのが限界だった。GPT-5.5を中核に据えたエージェントは、曖昧な指示や複雑な文脈でも自律的に判断し、複数ステップの業務を完遂できる水準に近づきつつある。
日本企業への示唆、データ資産の再活用という視点
この事例から日本企業が学ぶべきポイントは明確だ。多くの企業が「過去の文書資産」を抱えている。紙で保管された契約書、古い基幹システムから出力された帳票、スキャンされたPDFの山。これらをAIで解析し、活用可能なデータに変換する技術が現実のものになりつつある。
ただし注意点もある。GPT-5.5の性能向上が顕著だったのは「スキャン文書の解析」と「複数ステップのオーケストレーション」であり、これはモデル自体の進化に加えて、Databricksのエージェント基盤との統合設計が効いている。単に高性能なLLMを導入するだけでは同様の成果は得られない。データ基盤とエージェント設計の両面からアプローチする必要がある。
この記事のポイント
- GPT-5.5は企業の実務ベンチマークOfficeQA Proでエラーを46%削減し、初めて正解率50%を突破した
- 特にスキャンPDFやレガシー文書の解析精度が飛躍的に向上し、古い文書資産の活用が現実的に
- 複数ステップのタスクを効率的に管理するオーケストレーション能力も改善し、自律的な業務遂行が可能に
- DatabricksではGPT-5.5を監督エージェントとして配置し、専門エージェント群を統括する設計を採用
- 日本企業にとっては、過去の文書資産をAIで再活用できる可能性が開けた事例として注目すべき

・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

GPT-5.5 Instant 登場。回答精度とパーソナライズ性能が大幅に向上
OpenAIがChatGPTのデフォルトモデルを「GPT-5.5 Instant」に更新した。これまで標準搭載されていたGPT-5.3 Instantを置き換える形で、全ユーザーに順次提供が開始されている。
今回のアップデートの核心は3つだ。事実誤認の大幅な減少、回答の簡潔さの向上、そして過去のチャット履歴や接続アプリを活用した高度なパーソナライズ機能の追加である。内部評価では、医療や法律、金融といった高精度が求められる分野でのハルシネーション(もっともらしい嘘)が52.5%も削減された。
何億人ものユーザーが日常的に利用するデフォルトモデルだからこそ、小さな改善の積み重ねが実用面では大きな差を生む。本記事ではGPT-5.5 Instantの具体的な進化点と、それが実際の利用体験にどう影響するのかを掘り下げていく。
事実誤認を半減させた精度向上の仕組み

GPT-5.5 Instantにおける最大の改善点は、事実誤認(ハルシネーション)の劇的な減少だ。特に医療、法律、金融といった「間違いが許されない領域」で顕著な成果が出ている。
なぜここまでの改善が実現できたのか
OpenAIの公式ブログによると、GPT-5.5 Instantは高精度が求められるプロンプトにおいて、GPT-5.3 Instantと比較してハルシネーション(幻覚)を52.5%削減した。さらに、ユーザーが事実誤認を指摘したチャレンジングな会話においても、不正確な回答を37.3%減らしている。
この改善は単なる「よくわからないときは正直にわからないと言う」といった表面的な振る舞いの調整ではない。モデル自身が回答の妥当性を検証する能力が底上げされており、途中で誤りに気づいた際には自律的に修正できるようになった点が本質的な進化だ。
具体的な改善例から見えるもの
OpenAIが公開した比較例では、GPT-5.5 Instantは数学の問題に対して最初に不正確な解法を提示してしまった場合でも、代入チェックによって誤りを検出し、二次方程式の正しい解へと自力で修正している。一方でGPT-5.3 Instantは誤りに気づいてはいるものの、「解がない」と早々に結論づけてしまい、問題の本質に迫れなかった。
日常生活で使うAIアシスタントにとって、この「自己修正能力」は極めて重要だ。最初の回答が100%正しい必要はないが、誤りに気づいて軌道修正できるかどうかが実用性を大きく左右する。GPT-5.5 Instantのこの特性は、ビジネス文書の作成やデータ分析など、正確性が求められるシーンで特に頼りになるだろう。
冗長な表現を30.2%削減、それでも情報量は落とさない
行数:基準値
過剰な絵文字:あり
行数:29.2%削減
不要な装飾:ほぼなし
GPT-5.5 Instantの回答は、前世代モデルと比較して単語数が30.2%、行数が29.2%も削減されている。この数字だけ見ると「情報量が減ったのでは」と心配になるが、実際は逆だ。余計な説明や過剰なフォーマットを省くことで、本当に必要な情報が見つけやすくなっている。
減ったのは「無駄」であって「中身」ではない
OpenAIの説明によると、新モデルは同じ情報をより少ない言葉で届けつつ、むしろ実用性は向上しているという。たとえば職場の人間関係に関するアドバイスを求めるプロンプトでは、GPT-5.3 Instantが「してはいけないこと」を含めた完全なフォーマットで回答するのに対し、GPT-5.5 Instantは状況に応じた実践的な言い回し例を提示し、問題を相手の人格ではなく「境界線」の問題として捉え直す視点を提供している。
ビジネスシーンで重要なのは、この「トーンの適切さ」だ。カジュアルな質問に過剰にフォーマルな回答が返ってくると、むしろ使う側のストレスになる。GPT-5.5 Instantは、状況に応じてフォーマル度を調整できるようになった点で、より人間らしい対話が可能になっている。
チャット履歴や接続アプリを活用した高度なパーソナライズ
会話の開始 → 過去履歴を検索 → 関連コンテキストを取得 → カスタマイズされた回答を生成
GPT-5.5 Instantのもう一つの大きな進化が、パーソナライズ機能だ。過去のチャット履歴やアップロードしたファイル、さらに接続を許可したGmailの情報などを横断的に参照し、より個人に最適化された回答を提供できるようになった。
「メモリーソース」で見える化されたパーソナライズ
今回のアップデートで特筆すべきは「メモリーソース(Memory Sources)」という新機能の導入だ。これは、AIがどの情報を根拠にパーソナライズされた回答を生成したのかを明示する仕組みである。保存されたメモリーや過去のチャットのうち、回答に使用されたものをユーザーが直接確認でき、不要になった情報は削除や修正ができる。
OpenAIのブログ記事では、サンフランシスコ在住のユーザーに対するレストラン提案の比較例が紹介されている。GPT-5.3 Instantが居住地を考慮した一般的な提案にとどまるのに対し、GPT-5.5 Instantは過去の好みや予定をふまえた、より洗練された個別提案を行っている。この差は日常的な使い勝手に直結するだろう。
プライバシーはユーザーが制御できる設計
パーソナライズが強化されると、当然「どこまで自分の情報が使われるのか」という懸念が出てくる。この点についてOpenAIは、メモリーソースはチャットを共有しても他の人には表示されないこと、不要なチャットは削除できること、一時的なチャット(Temporary Chat)を使えばメモリーが使用も更新もされないことを明記している。
また個人情報の扱いについては、企業や教育機関向けプラン(Business、Enterprise、Edu)では、ユーザーデータがモデル学習に使用されない設定がデフォルトで適用される。個人利用でも、設定からデータ提供の可否を切り替えられる。
APIとロールアウトのスケジュール
GPT-5.5 InstantはChatGPTの全ユーザー向けに5月5日から順次提供が開始されている。APIではchat-latestとして利用可能だ。有料ユーザー向けには、旧モデルのGPT-5.3 Instantも3ヶ月間はモデル設定から選択できる形で残される。
パーソナライズ機能の強化は、まずPlusおよびProユーザー向けにWeb版で展開され、モバイル版にもまもなく対応する予定だ。その後、数週間以内にFree、Go、Business、Enterpriseプランにも拡大される。メモリーソース機能はすべてのコンシューマープランでWeb版から提供開始され、モバイル版も順次対応する。
この記事のポイント
- GPT-5.5 Instantは医療や法律など高精度が求められる分野でハルシネーションを52.5%削減した
- 回答の単語数が30.2%削減され、より簡潔で実践的なアドバイスが得られるようになった
- 過去のチャット履歴やGmailなどの接続アプリを活用したパーソナライズ機能が大幅に強化された
- メモリーソースにより、AIが参照した情報をユーザー自身が確認・管理できるようになった
- 全ユーザー向けに順次提供開始、旧モデルは有料プランで3ヶ月間利用可能
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験