

AI検索時代のSEO、5つの教訓と閉ループSEOの実践
はじめに AI検索とSEOの常識が変わった

昨年時点でAI検索経由のリードは全体の2.5%に過ぎなかった。それが2026年3月には35%まで跳ね上がっている。Search Engine JournalのウェビナーでWritesonicのCEOサマニョウ・ガーグ氏が示した数字だ。AI検索はもはや実験段階ではなく、マーケティング成果を左右する主力チャネルに成長している。
だが、この変化は単なる流入経路の増加ではない。「AI検索がSEOを殺したわけではないが、エンジニアリングの問題に変えた」とガーグ氏は指摘する。検索キーワードを詰め込む従来の対策は通用しなくなり、自社サイトの外側でいかに引用を獲得するかという設計思想の転換が求められている。
本記事では、Writesonicの調査から浮き彫りになったAI検索時代の5つの教訓を整理し、具体的なアクションに落とし込む。AI引用の96%が自社外ページから生まれている現実、引用が生き残る時間、そして「閉ループSEO」と呼ばれる継続的改善の仕組みまでを扱う。
従来のSEOは自社サイト内の最適化が中心だったが、AI検索では発想を180度転換する必要がある。
AI引用の96%は自社サイト外から発生している

Writesonicが実施した最新調査で、AI検索が引用するページの96%がサードパーティソースだった。Reddit、YouTube、フォーラム、業界メディアなどだ。数カ月前は約80%だったことから、この傾向は加速しているとみられる。
さらに、AIモデルのアップデートごとに引用先の構成比は大きく変動する。GPT 5.3からGPT 5.5への移行ではRedditとYouTubeの引用が急増し、特定ドメインに依存するリスクの高さが浮き彫りになった。
自社サイトだけに頼るリスク
ガーグ氏は「すべての卵を1つのバスケット(自社サイトや特定のサイト)に入れてはいけない」と警鐘を鳴らす。自社ドメインのページだけを最適化しても、AI検索の引用先としては取りこぼす確率が極めて高いからだ。競合がフォーラムや動画プラットフォームで引用を獲得していれば、検索のたびに自社の露出機会が失われる。
ガーグ氏はウェビナー内で、競合が引用されているのに自社が引用されていないトピックを特定し、アウトリーチ先と連絡先を自動でリスト化するエージェントのデモも披露している。
AI引用の寿命は想定よりはるかに短い

Writesonicが15万件以上の引用を分析した結果、AI検索での引用の平均寿命は多くのコンテンツ担当者が想定するより短かった。モデルは確率的に動作するため、新鮮なソースに入れ替わるたびに自社の引用枠が競合に奪われる可能性がある。
「モデルは本質的に確率的なので、非常に不安定なものだ」とガーグ氏は述べている。一度引用を獲得しても、次のモデル更新でその座を失うことは珍しくない。
引用ローテーションにどう備えるか
Writesonicのチームは引用がローテーションで外れた場合に備え、リフレッシュと多様化をセットで実行している。具体的には、引用が失効したページを即座に更新し、同時に別のプラットフォームで新たな引用候補を育成するという動き方だ。特定の1ページに依存しない体制を作ることが、AI検索での安定した可視性につながる。
1つの引用先に集中するのではなく、常に複数のエントリーポイントを育てておく発想が欠かせない。
SEOエージェントを構成する4つの層
Writesonicが構築しているSEOエージェントは「アイデンティティ」「知識」「スキル」「ツール」の4層で構成される。重要なのは、人間の専門家を置き換えるのではなく、専門家の思考パターンを再現して補佐させる設計思想だ。
ガーグ氏は「世界で最も優秀なインターンがチームに加わったようなものだ」と表現する。ポジショニングエージェントはエイプリル・ダンフォード氏のフレームワークを学習し、個別の専門家の判断ロジックを「セカンドブレイン」文書として構造化する。すべての最終判断は人間の実務者が承認する体制をとっている。
専門家ファイルの作り方
エキスパートファイルとは、特定の専門家が公開している思考フレームワークや講演内容を、AIモデルが消費しやすい構造化マークダウンに落とし込んだものだ。ガーグ氏は「1万ワードのテキストをただ並べるのではなく、モデルが新しいタスクに適用できるよう適切に構造化する必要がある」と述べている。1人の専門家から始め、成果が出てからチーム全体に広げるアプローチが推奨される。
専門家の知見を構造化してエージェントに渡せば、24時間稼働する戦略スタッフとして機能する。ただし最終判断の権限は常に人間が握っておくことが大前提だ。
閉ループSEOの考え方 公開・検証・改善を回す

閉ループSEOとは、公開したすべてのページを実験とみなし、Googleがインデックスしたかどうか、ランキングや引用を獲得できたかどうかを検証し、その結果を次の修正にフィードバックする手法だ。ガーグ氏のチームは4つの重み付け指標で全ページをスコアリングし、100ページのバックログを優先度順の作業キューに変換している。
ウェビナーのライブ投票では、参加者の大半が「成果を測定していない」または「測定しているが行動に移していない」と回答した。ガーグ氏は「診断は今や安価になった。重要なのは実行だ」と指摘している。
自動化すべき領域と人間が握るべき領域
まず自動化すべきは、既存データソースの接続とプロアクティブな異常検知のループだ。逆に「公開ボタン」の自動化は避けるべきとガーグ氏は明確に述べている。最終送信の前に人間が検証しテストする「半自律」の状態を維持することが、AI検索対策の品質を保つ要となる。
オンページとオフページ、どちらに注力すべきか
ガーグ氏はオフページに60%、オンページに40%の比重を推奨している。ただし、自社ページが引用を獲得し始めた段階でオンページ比率を引き上げるのが現実的なバランスだ。AI検索の可視性を動かす主なドライバーがオフページ側にあるという認識は、従来のSEOとは大きく異なる点である。
従来のSEOではオンページが主戦場だったが、AI検索では外部プラットフォームでの存在感がものを言う。フォーラムへの参加や動画コンテンツの拡充といったオフページ施策が、直接的な引用獲得につながる。
AI検索経由のリードをどう計測するか
Writesonicでは「どこで当社を知ったか」を問う自己申告フォームと、セールスコールでの二重確認を組み合わせている。ガーグ氏は10〜20%程度のバイアスが入る可能性を認めつつも、「十分な指標になる」と述べている。
AI検索経由の流入を完全に追跡する技術はまだ確立されていないが、少なくとも自己申告ベースで推移をモニタリングすることは、今後の戦略立案に欠かせない。Writesonicのケースでは、この仕組みによってAI検索経由リードが2.5%から35%に伸びた事実を定量的に把握できた。
この記事のポイント
- AI検索の引用の96%は自社サイト外(Reddit、YouTube、フォーラムなど)から発生する
- AI引用の寿命は短く、モデル更新のたびにローテーションが発生するため常時監視が必要
- SEOエージェントは「専門家ファイル」で思考パターンを学習させ、人間が最終判断を下す半自律運用が効果的
- 閉ループSEOで公開→検証→改善を回し続けることが、AI検索時代の競争力を左右する
- リソース配分はオフページ60%、オンページ40%を目安に、引用獲得後にオンページ比率を引き上げる

・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

CloudflareのAIクローラールールがGooglebotをブロックする危険性
CloudflareがAIクローラー対策の仕組みを抜本的に見直し、2026年9月15日から新たなデフォルト設定を適用する。この変更は単なるAIボット対策の強化にとどまらず、Googlebotのような検索クローラーまで巻き込む可能性がある。AIにコンテンツを学習されたくないという意図で設定したブロックが、結果的に検索エンジンからの流入を断つリスクをはらんでいるのだ。
特に影響が大きいのは、Cloudflareの無料プランを利用するWordPressサイトや中小企業のオウンドメディアだ。AI学習ブロックの意図がなくても、9月15日以降にデフォルト設定が自動適用され、知らぬ間にGooglebotのクロールが制限される可能性がある。本記事では3つの振る舞い分類、デフォルト変更の詳細、そして今すぐ取るべき対応策を解説する。
CloudflareがAIクローラー対策の方針を転換した背景

Cloudflareは2026年7月2日、第2回「Content Independence Day」の一環として、AIクローラー管理の新方式を発表した。従来の単一の「AIボットをブロック」スイッチを廃止し、クローラーの振る舞いに基づいた3つのカテゴリで制御する仕組みへ移行する。この変更は全顧客(無料プランを含む)に即時適用され、9月15日にはデフォルト設定も自動変更される。
背景にあるのは、AIクローラーによるコンテンツ収集の爆発的な増加だ。Cloudflareのネットワーク上では、AI訓練目的のクローラーリクエストが全体の過半数を占めるまでに成長した。2025年春時点では約20%だったが、1年で状況は一変した。AIエージェントのリクエスト数も前年比1700%増と、指数関数的な伸びを示している。
この急増に対し、多くのパブリッシャーやサイト運営者はAIクローラーを一律ブロックする方向に動いてきた。しかし、その「一律ブロック」が検索クローラーまで巻き込む副作用を生みつつあった。Cloudflareの今回の方針転換は、この問題に正面から取り組むものだが、同時に新たなリスクも生じさせている。
3つの振る舞い分類がクローラー制御を変える

Cloudflareの新方式は、クローラーを「AIかどうか」ではなく「サイト上で何をするか」で分類する。この考え方は、サイト運営者にとってクローラー制御の解像度を格段に上げるものだ。3つのカテゴリは以下のとおり。
Cloudflareは、ボット運営者に対して「振る舞いごとに別々のクローラーを用意すべき」と要求している。サイト側が「なぜそのボットが来ているのか」を判断し、許可・ブロックを適切に選択できるようにするためだ。この考え方自体は合理的だが、現実にはGooglebotのように検索とAI訓練の両方を行う「マルチパーパスクローラー」が存在する。この点が後述する問題の核心となる。
検索クロールとAI訓練クロールの同居がリスクを生む
Googlebot、Applebot、Bingbotは、いずれも検索インデックス作成とAIモデル訓練の両方に使用される。Cloudflareの新ルールでは、こうした「混合用途のクローラー」に対して最も厳しい制限が適用される。つまり、AI訓練目的のクロールをブロックしているサイトでは、同じクローラーによる検索目的のアクセスも自動的にブロックされるのだ。
これはrobots.txtとは根本的に異なる。robots.txtはクローラーへの「お願い」に過ぎず、無視されることもある。しかしCloudflareのブロックはネットワークレベルで動作するため、robots.txtよりはるかに強力だ。グーグルでさえバイパスできない。AI訓練を止めたい一心で設定したブロックが、検索流入というサイトの生命線を断ち切ってしまう皮肉な構造が生まれている。
9月15日のデフォルト変更が生む3つのリスク
2026年9月15日に自動適用されるデフォルト設定の変更は、Cloudflareを利用するあらゆるサイトに影響を及ぼす。特に注意すべきは以下の3点だ。
とりわけ危険なのはリスク3だ。従来の「AIボットをブロック」設定を有効にしたまま放置しているサイトは、9月15日以降にGooglebotのアクセスがネットワークレベルで遮断される可能性がある。検索クロールが停止すれば、新規コンテンツのインデックス登録が滞り、既存ページの再クロール頻度も低下する。検索順位への影響は数週間から数カ月かけて徐々に表面化するため、原因特定が遅れやすい。
robots.txtとの違いを理解しておくべき理由
多くのサイト運営者は「robots.txtでブロックしているから大丈夫」と考えがちだ。しかし、robots.txtはクローラーに対する紳士協定に過ぎず、グーグルも状況によって無視することがある。一方、Cloudflareのブロックはリクエストがオリジンサーバーに到達する前にネットワークエッジで遮断する。この違いは決定的だ。
robots.txtでのブロックは「できれば来ないでほしい」というお願いであり、Cloudflareのネットワークブロックは物理的な門番が門を閉ざすようなものだ。後者のほうが確実だが、その分だけ設定ミスの代償も大きい。AI訓練ブロックのつもりが検索クローラーまで締め出してしまうと、サイトの検索パフォーマンスは確実に悪化する。
実務者が今すぐ取るべき対応チェックリスト

9月15日までに対応を完了する必要がある。以下に具体的なアクションを時系列で整理した。
STEP 5のクロール統計監視は特に重要だ。9月15日以降にGooglebotのクロール頻度が急落した場合、Cloudflare設定に原因がある可能性が高い。Search Consoleの「クロール統計レポート」で1日あたりのクロールリクエスト数を確認し、急激な減少があれば即座にCloudflareダッシュボードを再確認する習慣をつけておきたい。
無料プランユーザーが特に注意すべきポイント
Cloudflareの無料プランを利用しているサイトは、9月15日までに一度もAIクローラー設定を変更していない場合、自動的に新デフォルトへ移行される。つまり「設定を触っていないから大丈夫」という認識が最も危険だ。何もしないことが、意図せずGooglebotブロックを招く可能性がある。
無料プランであっても、ダッシュボードから3カテゴリの設定を手動で確認・変更することは可能だ。Searchカテゴリだけは明示的に「許可」に設定し、TrainingやAgentはサイトのポリシーに応じて判断する。この一手間をかけるかどうかで、9月15日以降の検索パフォーマンスが大きく変わる。
今後の展望とサイト運営者が持つべき視点

Cloudflareは、マルチパーパスクローラーの運営者に対して「振る舞いごとにクローラーを分離する」ことを求めている。グーグルやアップル、マイクロソフトがこの要求に応じてGooglebotを用途別に分割するかどうかが、今後の分岐点となる。仮に分割が実現すれば、サイト運営者はAI訓練だけをブロックし、検索インデックスは許可するという選択が可能になる。
しかし、現時点ではその保証はない。9月15日以降もGooglebotは単一のクローラーとして動作し続ける可能性が高い。つまり、AI訓練をブロックするという選択は、当面の間「検索流入とのトレードオフ」であり続ける。この現実を直視した上で、サイト運営者は自社のコンテンツ戦略とAIポリシーを再定義する必要がある。
Cloudflareは新しいコンテンツ利用シグナルもテスト中だ。robots.txtに記述するContent Signalsの拡張で、immediate(保存しない)、reference(インデックスしてリンクバック、新デフォルト)、full(要約・複製を許可)の3段階を指定できるようにする。ただしこれは設定上の「希望表明」であり、単体ではブロック機能を持たない点に注意が必要だ。
サイト運営者が今から準備すべき3つのこと
AIにコンテンツを学習されることを完全に拒否するのか、それとも検索流入を優先するのか。この問いに明確な答えを持たないまま9月15日を迎えると、Cloudflareの新デフォルトによって想定外のブロックが発生し、検索パフォーマンスが毀損するリスクがある。サイトの規模や収益構造に応じて、今のうちに方針を固めておくことが重要だ。
この記事のポイント
- CloudflareのAIクローラー管理が3つの振る舞い分類(Search、Agent、Training)に再編された
- 9月15日から広告表示ページでTrainingとAgentがデフォルトブロックされ、無料プランユーザーも自動移行の対象
- Googlebotのような混合用途クローラーは、AI訓練をブロックすると検索クロールも停止する
- robots.txtと異なり、Cloudflareのブロックはネットワークレベルで動作しバイパスが困難
- Searchカテゴリの許可確認とSearch Consoleでのクロール統計監視が当面の最優先対応
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

ドイツ裁判所、GoogleのAI回答に責任認定。SEO業界に衝撃
ドイツのミュンヘン地方裁判所が2026年5月28日、GoogleのAI Overviewが生成した虚偽の内容についてGoogle自身に責任があるとの仮処分を下した。AIが生成した回答は「プラットフォーム自身の発言」であり、単なる検索結果の羅列ではないという判断だ。この判決はSEOの前提を変える可能性を秘めている。
問題の核心は「AIがビジネスについて語るとき、誰が責任を負うのか」という問いだ。今回の判断は、AI回答が単なる情報の仲介ではなく「独自の編集行為」であると認定した点で画期的だ。つまり検索エンジンは自らが生成した文章に対して法的責任を問われうる時代に入った。この変化は企業のAI対策に根本的な再考を迫る。
裁判所がAI回答を「独自の編集物」と認定した意味

ミュンヘン地方裁判所が下した仮処分(事件番号26 O 869/26)は、GoogleのAI Overviewが2つの地域出版社について虚偽の説明を生成したことを問題視した。AI Overviewはこれらの出版社を詐欺やサブスクリプション詐欺と結びつける文章を生成していたが、引用元として示された情報源のどこにもそのような記述は存在しなかった。
AI Overview(AIによる検索結果の概要表示)とは、検索クエリに対してGoogleが従来のリンク一覧ではなく、AIが生成した要約文を画面上部に表示する機能だ。複数の情報源を読み込んで独自の文章を合成する仕組みで、2024年から本格展開が始まっている。
裁判所はこのAI Overviewについて「独立した新規の実質的な主張を生成している」と評価し、通常の検索結果一覧に適用される免責保護の対象外だと判断した。Google側は「ユーザー自身が回答の正確性を確認すべき」と主張したが、裁判所はこれを退けた。機械が文章を書くなら、その機械の所有者が責任を負うという理屈だ。
このデモが示すように、AI Overviewは従来の検索結果一覧とは法的な位置づけが根本的に異なる。裁判所は情報を「編集し合成する行為」を著作行為とみなし、そこに責任を紐づけたのだ。
この判決が持つ射程の広さ
今回の判断はあくまでドイツの一地裁による仮処分であり、EUの法的枠組みの中で下されたものだ。米国の裁判所が同じ事案を扱えば、プラットフォームを免責された仲介者とみなす従来の考え方から異なる結論に至る可能性は十分にある。ただ方向性は明確だ。AIが自律的に文章を生成する時代において、単なる「情報の受け渡し役」という位置づけは成立しなくなりつつある。
Search Engine Journalの記事では、この判決を1週間前に発表された別の調査結果と並べて論じている。その調査とは「AIに名前を挙げられることと、AIに信頼されることは別である」という分析だ。AI回答におけるビジネスの表現は、信頼の問題であると同時に説明責任の問題でもある。両方の視点が重なったとき、企業に求められる対応の輪郭が浮かび上がる。
責任を負うAIは「慎重になる」という構造的変化

法的責任を問われる可能性があるAIは、リスクを避けるために振る舞いを変える。これが今回の判決がもたらす最大の二次的影響だ。
AI回答が自社の発言として扱われるなら、プラットフォームが取る合理的な行動は「突然正確になること」ではない。「慎重になること」だ。確実に裏付けが取れるビジネスだけを安全圏として提示し、曖昧な存在は言及そのものを避けるようになる。この変化はすでに兆候を見せている。小規模な企業や評価が分かれる事業についてAIに質問すると、回答が急に歯切れが悪くなり、公式情報源に委ねたり、企業の特徴づけを完全に回避したりするケースが増えている。
AI回答「複数の情報源がありますが、公式な確認が取れません。ご自身での確認をお勧めします」
AI回答「△△社は〇〇を提供しています。公式サイトではXXと記載されています」
この変化は「どうやってAIに正しく自社を引用させるか」という問いを「AIが自信を持って名前を出せるビジネスかどうか」という一段上の問いに引き上げる。機械可読なアイデンティティの整備は、もはやSEOの一手ではなく参加資格そのものに近づく。
AIがビジネスを「疑う」4つの原因
Search Engine Journalの記事でCarlo Daniele氏が指摘するように、大半のビジネスはAIに疑念を抱かせる材料を少なくとも一つは抱えている。具体的には以下の4パターンだ。
- 法的実体の不一致:自社サイト、SNSプロフィール、過去のプレス記事で会社名や事業者名が微妙に異なる。AIはどれが正規情報か判断できない
- 役職表記のズレ:会社概要ページと過去のインタビュー記事で創業者の役職表記が食い違っている
- テキスト化されていない重要情報:製品の具体的な機能説明が画像やPDFの中にしか存在せず、AIのパーサーが読み取れない
- カテゴリの曖昧さ:人間が読めば事業内容が明確でも、マークアップ上でカテゴリが明示されておらず機械が判断できない
これらはいずれも従来のコンテンツSEOの発想では見過ごされてきた問題だ。記事が指摘するように、これはコンテンツの問題ではなくアイデンティティの問題である。1万語のコンテンツがあっても自己矛盾した情報を発信していればAIはそのビジネスを「検証困難」と判定する。一方で簡潔でもあらゆる読み取り経路で同一の事実を返すビジネスはAIにとって「引用可能」と判断される。
AIに「確信されるビジネス」になるための実践手順

この変化に対応するために法律家は必要ない。必要なのはAIに「このビジネスは確かだ」と判断させるための基盤整備だ。Search Engine Journalの記事で提示された3ステップを具体的に見ていく。
ステップ1 AIが自社をどう語っているか監査する
まずは自社ブランド名、製品名、事業カテゴリを実際に顧客が使うAI検索エンジンに投入し、生成される回答を第三者の目で読む。AI OverviewだけでなくChatGPTやClaudeなど複数のエンジンで確認することが重要だ。エンジンごとに回答は異なり、そのズレの大きさこそが自社のアイデンティティ監査の出発点になる。
チェックすべき項目は以下の4つだ。AIが自社のカテゴリを正しく述べているか、正しい製品を帰属させているか、正しい人物名を挙げているか、そして実際には無関係なネガティブ情報と結びつけていないか。Search Engine Journalの記事によれば、大半の企業はこのような監査を一度も実施したことがないという。
この監査は企業のAI上の立ち位置を可視化する最初の一歩だ。自社がどのように語られているかを把握せずに対策を立てることはできない。
ステップ2 AIが判断の根拠にする事実情報を整備する
監査で発見されたズレを修正するには、AIが参照する基盤情報の整備が不可欠だ。Search Engine Journalの記事で提唱されているMachine-First Architecture(機械優先アーキテクチャ)の考え方では、以下の3つが中核となる。
第一に、Organization構造化データの実装だ。自社が誰で、何をしており、どこで確認できるかを機械可読な形式で明示する。構造化データ(Schema.orgに準拠したマークアップ)とは、HTMLに埋め込む形で検索エンジンに情報の意味を伝える仕組みであり、AIが情報を正確に抽出するための土台となる。
第二に、全情報発信チャネルでの表記統一だ。自社サイト、Googleビジネスプロフィール、主要SNS、業界ディレクトリで社名・住所・事業内容の表記を完全に一致させる。バリエーションがあるたびにAIは「どれが正しいか」の判断を強いられ、リスク回避のために言及を控える方向に傾く。
第三に、テキスト化の徹底だ。画像やPDFに埋め込まれた重要情報をHTMLテキストとしても提供し、AIのパーサーが確実に読み取れる形にする。特に事業内容の明示的な説明は、人間向けのデザイン性よりも機械向けの明快さを優先すべき局面に入っている。
ステップ3 監査を習慣化する
企業情報は時間とともに変化し、周囲のウェブ環境も変わり、AIモデルも再学習を繰り返す。一度整備して終わりではなく、定期的にAIが自社をどう語っているかを確認する習慣が必要だ。Search Engine Journalの記事はこれを「自社のアナリティクスを確認するのと同じ感覚で」行うべきだと提案している。
訴訟そのものは稀であり管轄も限られる。しかし構造的な影響はゆっくりと確実に広がる。AI回答にリスクが伴うとき、エンジンは慎重になり、慎重なエンジンは裏付けの取れるビジネスだけを積極的に提示する。企業に求められるのは「機械に確信される存在」になるための継続的な努力だ。
この記事のポイント
- ミュンヘン地方裁判所がAI OverviewをGoogle自身のコンテンツと認定し免責を否定した
- AI回答に法的責任が生じるとプラットフォームは「慎重になり言及を避ける」方向に動く
- 企業名・役職・事業内容の表記不一致がAIの信頼を損ねる主要因である
- 構造化データの実装と全チャネルでの情報統一がAI時代の基盤対策となる
- AIによる自社の語られ方を定期的に監査する習慣が不可欠だ
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AI引用シェア率をBingが公開、llms.txtの効果に疑問符
AI検索の可視性をどう測るか、そして構造化データファイルにどこまで期待すべきか。この一週間でその答えに直結する動きが複数出てきた。
MicrosoftがAI引用のシェア率を計測する新機能を公開し、GoogleとAhrefsのデータはllms.txtの効果に冷や水を浴びせた。さらにAIエージェント向けの新仕様が2つ登場するなど、情報が一気に動いている。英国CMAによる公正ランキング命令も含め、今週のトップ4ニュースを実務視点で整理する。
BingがAI引用シェア率を公開。競合との差が初めて数値化された

MicrosoftはBing Webmaster ToolsのAIパフォーマンスダッシュボードに、新たな4機能をプレビュー公開した。追加されたのは「Citation Share(引用シェア率)」「Intents(検索意図別グループ)」「Topics(トピック別グループ)」「Compare(期間比較)」だ。いずれも現在はプレビュー段階でグローバルに順次ロールアウトされている。
このCitation Shareによって、AI検索結果における自サイトの存在感が、競合との比較で初めて把握できるようになる。ただしこのデータはBing独自であり、CopilotやBingの回答を対象とする。Google検索側では検索コンソールにこれに相当する引用カウント機能は提供されていない。
SEO担当者の受け止めと実務への示唆
ILoveSEO.netの創業者Gianluca Fiorelli氏はLinkedInで「Bing Webmaster Toolsこそ、我々がGoogleサーチコンソールに望んでいた姿だ」と評価した。AI可視性を測る新しい物差しが登場したことは、今後の施策優先度をデータドリブンに決める上で大きい。
現時点ではBingに限られた指標だが、AI検索のトラフィックが今後さらに一般化すれば、Googleも類似の指標を導入せざるを得なくなる可能性がある。先行してBing側でのデータ取得と分析のノウハウを積んでおくことは、将来のAI検索対策で優位に立つ一手になる。
llms.txtへの期待に新データが疑問符。97%がアクセスゼロ
llms.txtは、大規模言語モデル(LLM)向けにサイト情報を構造化して提供するテキストファイルだ。AIがサイト内容を理解しやすくする目的で提唱され、導入が進んでいる。しかし今週、その効果に疑念を投げかける材料が二つ重なった。
Mueller氏は「Search Off the Record」ポッドキャストで、llms.txtが自己申告型のファイルである以上、LLMがサイトを発見したり他サイトと比較して評価したりする用途には使えないと明言した。本質的に重要なのは従来のHTMLと内部リンク構造だという立場だ。
Ahrefsのデータも同じ方向を指している。13万7000ドメインのうち、97%のllms.txtファイルには一度もボットからのアクセスがなかった。さらにアクセスが確認されたケースでも、ChatGPTやPerplexityといった引用生成ボットからのリクエストは全体の1%に過ぎない。この結果は、数ヶ月前にSE Rankingが30万ドメインを調査して導いた「llms.txtはAI引用に明確な効果を示さない」という結論とも整合する。
SEO専門家の見解と実務上の落とし所
Clio Websitesの創業者Nat Miletic氏はLinkedInで「llms.txtは公開コストが低いので置いておくのは構わない。ただしそれでAI可視性が上がるとは今は期待しないほうがいい」と総括した。コーディングエージェントや学習用クローラー向けに一部で参照されているため維持コストに見合う面はあるが、AI検索結果への表示を目的とした投資としては優先度を下げる判断が妥当だ。
AIエージェント向け新仕様が2つ登場。OKFとARDの注目点

Google Cloudは「OKF(Open Knowledge Format)」を公開した。組織内の知識(データセット、メトリクス、運用手順書など)をAIエージェントが読めるマークダウン形式でパッケージングする仕様だ。ほぼ同時期に、GoogleやMicrosoft、GitHub、Hugging Faceを含む連合が「ARD(Agentic Resource Discovery)」の草案を発表した。こちらはAIエージェントがツールやスキル、他のエージェントを発見・検証するためのプロトコルを定義する。
両仕様とも現時点で即時の対応を求めるものではない。OKFはバージョン0.1、ARDは0.9と初期段階だ。Harton Worksの創業者Martin Jeffrey氏はARDを「ページではなく機能のためのサイトマップが再来したようなものだ」と表現した。Snippet Digitalの共同創業者Suganthan Mohanadasan氏は「魔法のキノコではない。これで一夜にしてAI可視性が上がるわけではない」と期待値を引き締めている。
実務的には、どのフォーマットが実際に普及するかを見極める観察期間に入る。llms.txtの事例が示すように、仕様の存在と実際の効果は別問題だ。導入判断は普及の兆候を確認してからでも遅くない。
英国CMAがGoogleに公正ランキングを命令。事前通知義務が実務に波及

英国の競争市場庁(CMA)がGoogle検索に対し、新たなルールを設定した。オーガニック検索結果のランキングに客観的かつ非差別的な基準を使うこと、そして大規模な変更の際には事前通知を行うことを義務づける内容だ。
このルールの適用範囲は英国のオーガニック検索結果で、AI Overviewsも対象に含まれる(広告は除く)。Googleは「現行のランキングはすでに公正かつ透明だ」と反論しているが、CMAは6月初旬にもAI検索機能からのオプトアウトを認めるよう命令しており、規制圧力は強まっている。
SEO専門家の反応から読む今後の展開
Searchpediaの創業者Laura Iancu氏はLinkedInで「もうこれで『コアアップデートを突然リリースしました』なんてことはできなくなる」と単刀直入に表現した。Blue Arrayの戦略SEO責任者Chloe Smith氏は「Googleは何らかの回避策を探るだろう」と予測しつつも、事前通知と異議申し立ての枠組みができたこと自体に意味があると見ている。
現状では英国限定の措置だが、EUや他の地域にも波及する可能性は否定できない。特に、大規模アップデートの事前通知が実務化すれば、SEO施策の計画立案や緊急対応のあり方そのものが変わる。今後のGoogleの実装方法を注視する必要がある。
構造化ファイルを置くだけでは済まない。AI可視性の本質に立ち返る
今週のニュースを横断して浮かび上がるテーマは、「構造化ファイルを自ドメインに置いておけばAIに見つけてもらえる」という発想への再考だ。llms.txtはその教訓をすでに示している。ファイルを公開しても、Googleはサイト差別化に寄与しないと断言し、データは大半のファイルが読まれていない事実を突きつけた。
OKFやARDが登場したことで、構造化ファイルへの要求はこれからも繰り返されるだろう。しかし破綻しているのは「ファイルを置けば報われる」という期待のほうだ。BingのCitation Shareは、そうした取り組みが実際に引用に結びついているかを数値で示してくれる、貴重なフィードバックループになり得る。
AI検索時代の可視性は、小手先のファイル配置ではなく、コンテンツそのものの強さと、信頼される情報源としてサイト全体を設計し続ける積み重ねで決まる。今週のデータと専門家の声は、その原則を改めて強調する結果になった。
この記事のポイント
- Bing Webmaster Toolsの新機能「AI Citation Share」で、AI検索での競合とのシェア比較が初めて可能になった。Googleにはまだ同等機能はない
- llms.txtは97%がアクセスゼロ。AI検索可視性への効果はデータで否定され、自己申告ファイルの限界が明確になった
- OKFとARDという新たなAIエージェント向け仕様が登場したが、普及は未知数。llms.txtの教訓を踏まえ導入判断は慎重に行うべきだ
- 英国CMAがGoogleに対し、検索順位の公正化と大規模変更前の事前通知を義務づけた。SEO施策の計画立案に影響する可能性がある
- 結局、AI可視性の本質は構造化ファイルではなく、通常のHTMLコンテンツの品質と情報設計にある
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Microsoft Web IQでAIエージェントがBing検索を利用可能に。SEOへの影響を考察
Microsoftが2026年6月2日、AIエージェント向けの検索基盤「Web IQ」を発表した。Bingの検索インデックスに蓄積された情報を、AIシステムが推論やタスク実行に直接利用できるようにするAPI群である。
従来のBingが人間にウェブページを提供するのに対し、Web IQはAIに「パッセージ」と呼ばれる情報の断片を返す。この違いがAI時代のコンテンツ最適化とSEO戦略に大きな影響を与える可能性がある。
この記事では、Web IQの技術的な仕組み、従来の検索エンジンとの違い、パフォーマンス、そしてパブリッシャーにとっての意味を詳しく解説する。
Web IQの基本構造 〜AIエージェントが必要とする情報だけを届ける〜

Web IQの中核にあるのは、Bingのインデックスを土台に再構築された検索スタックだ。コンテンツのインデックス化、ランキング、選択の仕組みがAIエージェントの利用を前提に設計し直されている。AIエージェントはタスクの複数ステップにわたって厳しい時間制約の中で繰り返し検索を行うため、その動作特性に合わせた設計が求められた。
パッセージ単位の情報提供
Web IQが返すのは、ウェブページ全体ではない。「パッセージ」と「構造化されたエビデンスオブジェクト」だ。ページ中からAIにとって有用な部分だけを切り出して渡す。
AIモデルが処理するトークン(テキストの最小単位)にはコストがかかり、レイテンシ(応答遅延)にも直結する。Microsoftによれば、「少ないトークンでより良い回答を、1回の呼び出しあたりのコストを抑える」という三拍子を実現するのがWeb IQの設計思想だ。
このアプローチは、SEOの世界で徐々に広がっている「パッセージベースの検索」という概念とも整合する。Googleが2020年に導入したPassage Ranking(パッセージランキング)は、ページ全体ではなくその一部を検索クエリに最も関連する情報として抽出する技術だ。Web IQはこの考え方をAIエージェント向けに特化させたものと見ることができる。
従来の検索エンジンとは何が違うのか 〜ランキングと評価基準の再設計〜

MicrosoftがWeb IQの品質評価に使う指標は「GDSAT(Grounding Satisfaction / グラウンディング満足度)」と呼ばれる。情報の新鮮さと信頼性を測定するために設計された指標で、3,000件のサンプルクエリを用いたテストでは競合他社より高いスコアを記録したと発表している。
応答速度についても具体的な数字が示された。5つのデータセンターにまたがるテストで、P95(リクエストの95%がこの時間内に完了する値)で165ミリ秒未満を達成。競合と比較して約2.5倍高速だとしている。
ここで重要なのは、Web IQが従来の検索エンジンとまったく異なる評価軸で動いている点だ。人間向けの検索では、ページ全体の権威性や被リンクプロファイル、滞在時間など多面的なシグナルが使われる。一方、Web IQでは「AIエージェントがその情報を使ってどれだけ正確にタスクを遂行できるか」という一点が重視される。
全文からパッセージへの転換が意味すること
Search Engine Journalの記事で、Microsoftの発表を引用する形で指摘されているのは「従来の検索で上位表示されるページの特徴と、AIのグラウンディングに有用なパッセージの特徴は必ずしも重ならない」という点だ。同社が2026年前半に公開したグラウンディングフレームワークの記事でも、検索インデックスとグラウンディングの違いが詳述されている。
たとえば、あるページが検索キーワードに対して高い順位を得ていても、そのページ内のどの部分がAIにとって最も価値があるかは別問題だ。見出し構造、段落のまとまり、事実と意見の明確な区別など、AIが情報を抽出しやすい構造になっているかどうかが新たな評価ポイントになる可能性が高い。
検索体験からAI体験へ 〜パブリッシャーが知っておくべき変化〜

Bing Webmaster Toolsとの連携
Web IQは突然現れたわけではない。Microsoftは2026年に入って、段階的にAI向け検索の基盤整備を進めてきた。
- 2月、Bing Webmaster ToolsにAI引用データ(AI Citation Data)機能を追加
- 3月、グラウンディングクエリと引用ページを関連付けるAIダッシュボードを公開
- SEO Week期間中、Citation Share(AI向け引用シェア)のプレビューを発表
これらはいずれも、パブリッシャーが自分のコンテンツがAIにどのように使われているかを把握するためのツールだ。Web IQは、その裏側でAIがコンテンツを取得する仕組みに当たる。表と裏の関係にある。
つまり、Web IQの登場は「AI検索時代のSEO指標」が具体的な形を取り始めたことを意味する。従来の検索順位チェックに加えて、AIによる引用回数やパッセージ採用率といった新しいKPIが重要になる展開が予想される。
パッセージ最適化という新しい考え方
Web IQがパッセージ単位で情報を返す以上、パブリッシャー側もパッセージ単位でコンテンツを最適化する必要性が出てくる。具体的には以下のような施策が考えられる。
- 見出しと本文の関係を明確にし、各セクションが独立して意味を持つように書く
- 箇条書きや表組みを使って、AIが情報を構造的に読み取りやすくする
- 事実情報と意見・解釈を明確に分け、どちらを参照しているかAIが判断しやすくする
- 更新日を明示し、情報の鮮度をAIが評価できるようにする
これらの手法は、従来のSEOで言われてきた「E-E-A-T(経験・専門性・権威性・信頼性)」の強化とも多くの部分で重なる。違いは、AIが評価する点まで意識するかどうかだ。たとえば、ページの末尾にある免責事項や、サイドバーの関連記事リンクは従来の検索評価には影響しても、AIのパッセージ抽出ではノイズとして無視される可能性が高い。
技術面の詳細 〜オープンソース埋め込みモデルと高速検索〜

Web IQの検索パイプラインは3つの主要コンポーネントで構成される。埋め込みモデル、高速検索エンジン、そしてパッセージ選定モデルだ。
埋め込みモデルとDiskANN
Microsoftは2026年4月に、業界トップクラスの埋め込みモデル(Embedding Model)をオープンソース化した。テキストをベクトル(数値列)に変換し、意味の近さを計算できるようにする技術だ。Web IQはこのモデルを使って関連コンテンツを特定する。
大規模なインデックスを高速に検索するために使われるのが「DiskANN」という技術だ。これは全データをメモリに読み込まずに、ディスク上で効率的に類似検索を行うための仕組みだ。膨大なBingインデックスを対象に、165ミリ秒未満の応答を実現する鍵がここにある。
特筆すべきは、これらのモデルが単体のベンチマークスコアではなく、AI推論の中で実際に使われる状況を想定して訓練されている点だ。実用性を重視した設計と言える。
パブリッシャーコントロールと業界標準化
Web IQは、Bingがすでに準拠しているrobots.txtやメタタグによるクロール制御ルールを継承する。パブリッシャーが「AIにコンテンツを使われたくない」と設定していれば、Web IQもその指示に従う。
MicrosoftはIETF(インターネット技術標準化委員会)や他の業界団体とも協力し、AIシステムがウェブコンテンツにアクセスする際の標準ルール策定にも参加している。この動きは、Googleが進める「AIモード」や、その他のAI検索プロダクトとの間で、コンテンツ利用に関する共通ルールが形成されつつある兆候だ。
今後の展望と未解決の課題

現時点でWeb IQは「関心表明」を受け付けている段階であり、一般提供開始時期や価格、どのAIプラットフォームが採用するかは発表されていない。Microsoftの既存製品であるCopilotやBing Chatのグラウンディング機能がWeb IQを使っているのか、それとも別系統なのかも明らかにされていない。
とはいえ、Web IQの登場はAI検索時代の本格的な到来を示すマイルストーンだ。パブリッシャーは従来の検索エンジン最適化に加えて、「AIエージェントにどう使われるか」という視点でのコンテンツ設計を求められる局面に入ったと言える。
Bing Webmaster Toolsが提供を始めたAI引用データやCitation Shareは、そのための具体的な指標になる。まだ試験段階の数値ではあるが、早期にこれらのデータを確認し、自社コンテンツがAIにどう評価されているかを把握しておくことが競争優位につながるだろう。
この記事のポイント
- Web IQはAIエージェント向けのBing検索基盤APIであり、全文ではなくパッセージ単位で情報を返す
- 従来の検索評価とAI向け評価は異なる基準で動くため、SEO戦略の再考が必要になる
- Bing Webmaster ToolsのAI引用データやCitation Shareを使えば、AIからの評価を可視化できる
- パッセージ単位の情報設計が、今後のコンテンツ最適化の鍵になる
- 一般提供の時期や価格、対応AIプラットフォームは未発表だが、早期の動向把握が競争力を左右する
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Google AI Overviews、リンク表示拡大へ。ゼロクリック検索に変化の兆し
GoogleがAIによる検索結果表示「AI Overviews」内のリンクを拡充するアップデートを2026年5月6日に発表した。この変更は「ゼロクリック検索」の割合がわずかながら低下傾向にあるという業界レポートと同時期に重なり、ECサイト運営者にとっては見過ごせないシグナルだ。
Semrush傘下のDatosが発表した「State of Search Q1 2026」レポートによると、米国におけるゼロクリック検索の割合は2025年12月の24.5%から2026年3月には22.4%へと縮小した。オーガニック検索からのクリック率は同期間に42.0%から44.9%へと上昇している。
今回のGoogleの動きは、AIに代替され続けるウェブサイトへの流入経路に新たな選択肢が生まれる兆しだ。特に、商品ページへの直接的な流入が生命線となるECサイトにとって、この変化への適応は売上を左右する。
ゼロクリック検索の減少が示す潮目の変化

ゼロクリック検索とは、ユーザーが検索結果ページ内で目的の情報を得てしまい、どのウェブサイトにも遷移せずに検索を終えることだ。定義のハイライトやAIによる要約がこれに該当する。ECサイトにとってゼロクリック検索の増加は、検索順位が高くても実際の訪問者や売上に結びつかない状態を意味するため、長らく懸念材料だった。
この変化が意味するのは、AI Overviewsが単なる「流入を阻害する壁」から「新たな流入経路」へと徐々に進化している可能性だ。ゼロクリックが減少に転じたとはいえ、以前と比較すれば高止まりしているのが現状であり、油断は禁物だが、風向きはわずかに変わってきている。
Googleが追加した新たなリンクとその仕組み

Googleの発表によれば、今回のアップデートではAI OverviewsおよびAI Mode内に以下の2種類のリンクが追加される。
- 信頼できる著者やブランドの引用。SNSでの議論も含む。
- 「さらに読む」ための詳細な記事や分析。
加えて、リンク先のソース名とタイトルが検索結果上に明示されるようになった。有料購読が必要なコンテンツの場合、ユーザーが購読者かどうかも表示される。この変更は、ユーザーがどのような情報源をクリックしようとしているのかを事前に判断できるようにする意図がある。
このリンクは、Search Consoleの検索パフォーマンスレポートでは「平均掲載順位 1」としてカウントされる。つまり、AI Overviews内に自社コンテンツが引用されれば、検索結果の最上部に表示されているのと同じ扱いを受けることになる。
EC担当者が監視すべきSearch Consoleの指標
AI Overviews専用のレポートがSearch Consoleに実装される計画は、現時点では確認されていない。しかし、既存の検索パフォーマンスレポートを活用することで、ある程度の状況把握は可能だ。
- 平均掲載順位が1のクエリ群を定期的にチェックする。
- クリック率が急上昇したページがあれば、AI Overviewsに取り上げられた可能性が高い。
- 新規に表示されるようになったクエリをカテゴリ別に整理し、どのテーマのコンテンツがAIに評価されているのかを分析する。
ECサイトの場合、商品名や比較キーワードで突然流入が増えた場合は、AI Overviewsに商品情報が引用されたシグナルと捉えてよい。
ECサイトが取るべきコンテンツ戦略の転換点

Practical Ecommerceの記事では、今回のGoogleの動きから読み取れる方向性として、以下の3点が挙げられている。
- GoogleはAI Overviewsの実験を継続しており、サイトへのクリックを促す方向に舵を切りつつある。
- 新設された「さらに読む」セクションは、データ駆動型のレポートや調査記事を訴求する場になる。
- UGC(ユーザー生成コンテンツ)やSNSでの議論がAI Overviews内での可視性を高めている。
特に注目すべきは3つ目だ。SNS上の口コミやRedditのスレッドがAI Overviewsに直接引用されるケースが増えている。商品の評判が可視化されることで、ECサイト運営者は自社サイト外でのブランド管理にも注力する必要がある。
データドリブンコンテンツがリンク獲得の鍵
AIに要約されるだけの情報ではなく、「リンクをクリックしなければ全体像が理解できない」コンテンツこそが、今後の検索流入を維持するために有効だ。具体的には、独自調査データを含む記事や、比較検証レポート、専門家による詳細な分析がこれに該当する。
たとえば、ショッピングカートの放棄率に関する業界平均データと自社の改善施策を組み合わせたレポートや、特定商品カテゴリの価格推移を可視化した調査記事は、AI Overviewsの「さらに読む」リンクに選ばれやすい傾向がある。
伝統的なSEO施策を捨てるべきではない

今回のレポートとGoogleの動きは「希望のシグナル」ではあるが、従来のSEO戦略を即座に放棄する理由にはならない。ゼロクリック検索がやや減少したとはいえ、全体としてのオーガニック検索流入は依然として厳しい状況が続いている。
むしろ、以下のような複合的なアプローチが求められる。
- 従来のSEO施策(技術的SEO、コンテンツ最適化)は継続する。
- YouTubeやRedditなどのプラットフォームでの情報発信を拡大する。購買意思決定に直結するチャネルとして重要性が増している。
- AI Overviewsに引用されることを目的としたデータドリブンコンテンツを新たに制作する。
- SNS上でのブランド評判を定期的にモニタリングし、ネガティブな口コミには誠実に対応する。
検索の世界は確実に変化しているが、基本に忠実でありつつ、新しい潮流に適応していく柔軟性がECサイトの明暗を分けることになるだろう。
この記事のポイント
- ゼロクリック検索は米国で24.5%から22.4%に減少し、オーガニッククリック率は44.9%に上昇した。
- GoogleはAI Overviews内のリンクを拡充し、信頼できる情報源への誘導を強化している。
- ECサイトはデータドリブンな独自コンテンツを制作し、AIに引用される質の高い情報を提供する必要がある。
- SNSやUGCプラットフォームでのブランドプレゼンスが検索可視性に直結する時代に入った。
- 従来のSEO施策を継続しつつ、YouTubeやRedditなど複数チャネルでの展開を強化するのが得策だ。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Google 3月コアアップデートで何が変わったか、集約サイトに逆風で自社サイトに追い風
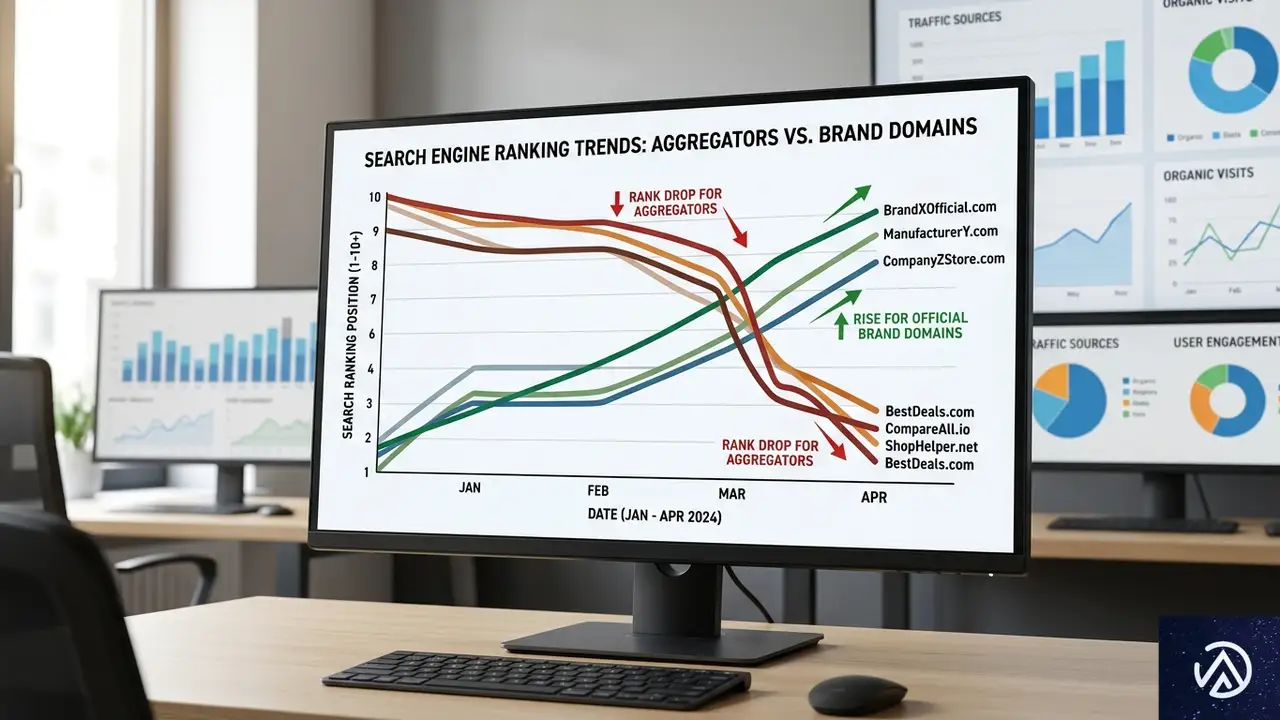
2026年3月に実施されたGoogleのコアアップデートで、検索結果の可視性に大きな地殻変動が起きた。特に影響を受けたのは、YouTubeやRedditに代表される「集約サイト」や「ユーザー投稿型プラットフォーム」だ。これらが軒並み可視性を落とす一方で、ブランドの公式サイトや政府機関ドメインが上昇した。
デジタルマーケティング企業Amsiveの分析によれば、YouTubeは可視性スコアを567ポイントも失い、全ドメイン中最大の下落を記録した。TripAdvisorも45ポイント減、Redditも64ポイント減と、多くの有名サービスが影響を受けている。こうした動きは「情報の一次発信者をより重視する」というGoogleの姿勢を反映したものだと受け止められている。
この記事では、Amsiveの調査データの詳細に加え、業界別の勝ち組・負け組、そして復活パターンまでを解説する。3月のアップデートで自社サイトがどう評価されたかを振り返り、今後のSEO戦略を練るための材料としてほしい。
3月コアアップデートで何が起きたのか
AmsiveはSISTRIX Visibility Indexを用いて、2,000以上のドメインを分析した。分析対象期間は2026年3月27日(ロールアウト開始日)から4月8日(完了日)までである。さらにDataForSEO APIを使い、各ドメインにGoogleの商品分類タグを付与して、業界別の傾向を浮き彫りにした。
ここで言う「可視性スコア」とは、SISTRIXが算出するキーワード単位の表示機会の指標であり、実際のオーガニックトラフィックそのものとは異なる。ただ、大規模なランキング変動を捉えるには十分なデータセットだ。
「情報の一次発信者」を優遇する流れ
Amsiveは今回の変化を「過度にインデックスされていたUGCやアグリゲーターコンテンツに対する是正」と位置づけている。つまり、「ある物事について人々が話し合うプラットフォーム」よりも、「その物事を実際に提供・所有する企業や組織」のサイトを上位に表示しようという補正だ。
この傾向は、旅行、求人、健康など複数の業界で一貫して見られた。たとえば旅行分野では、OTA(オンライン旅行代理店)が集客力を落とし、ホテルチェーンや空港の公式サイトが上昇した。これは、単なるアルゴリズムの一時的な揺らぎではなく、意図的な方向修正である可能性が高い。
このデモで示したように、単なる口コミや他者コンテンツの再掲載ではなく、自社サービスや公式情報そのものを発信するサイトが検索上で優位に立つ構図が鮮明になった。
ドメイン別の勝者と敗者
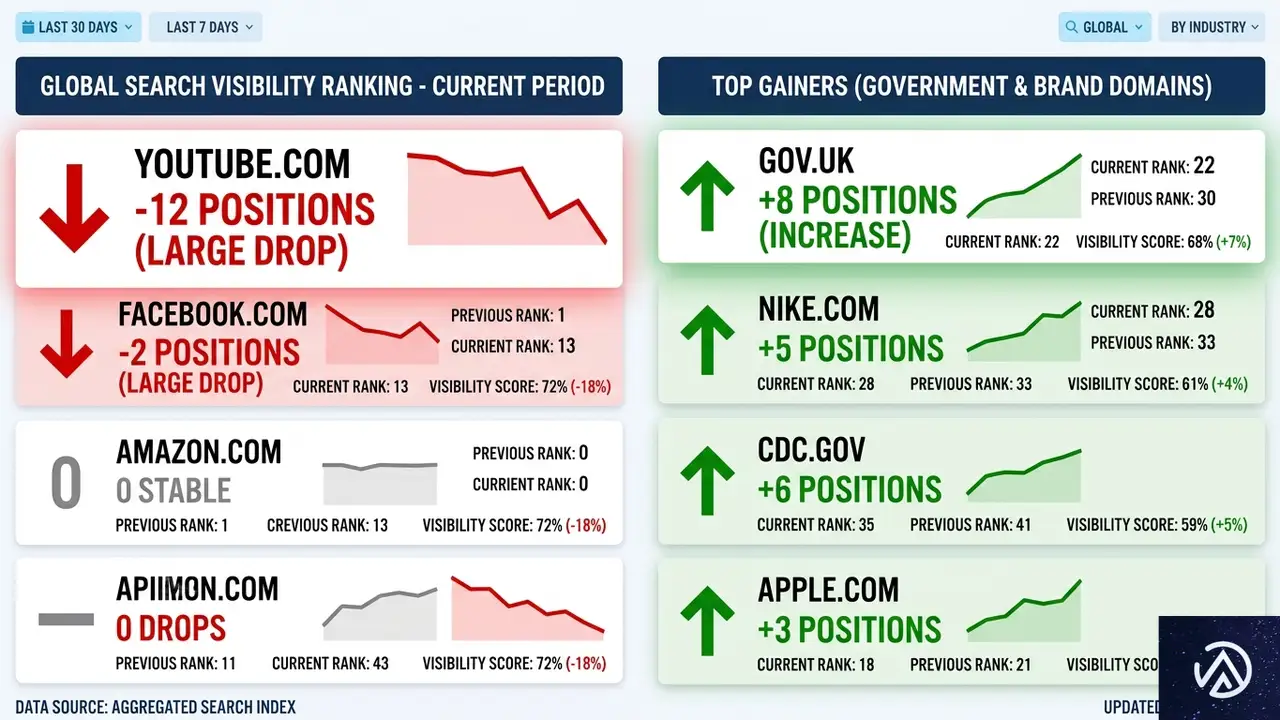
Amsiveのデータセットで最も激しい動きを見せたのはYouTubeだった。可視性スコアを567ポイントも下げており、これは全ドメイン中最大の下落幅である。比較対象として、2025年12月のコアアップデートでWikipediaが経験した435ポイント減よりも約30%大きい。
主要ドメインのスコア変動
以下のリストは、AmsiveがSISTRIXデータから抽出した可視性変動の一部である。
- YouTube 567ポイント減(最大の下げ幅)
- Reddit 64ポイント減
- Instagram 48ポイント減
- X(旧Twitter) 46ポイント減
- TripAdvisor 45ポイント減
- Yelp 33ポイント減
- Expedia 33ポイント減
注目すべきは、YouTubeの下落が「過去の一時的な急騰の反動」である可能性だ。AmsiveのLily Ray氏は、YouTubeの可視性は3月初旬の急上昇前の水準に戻ったに過ぎず、過去最低を更新したわけではないと補足している。つまり、異常値の補正と見ることもできる。
一方で、RedditやXといったテキスト系UGCプラットフォームの低下は構造的だ。これらは2024年から2025年にかけて大幅に検索可視性を伸ばしてきた経緯があり、今回のアップデートはその反動という見方が強い。
この視覚化からもわかるとおり、減少幅ではYouTubeが突出している。それでも、複数のUGC系プラットフォームがまとまってスコアを落とした点が、今回のアップデートの特徴と言える。
業界別の影響 旅行、求人、健康
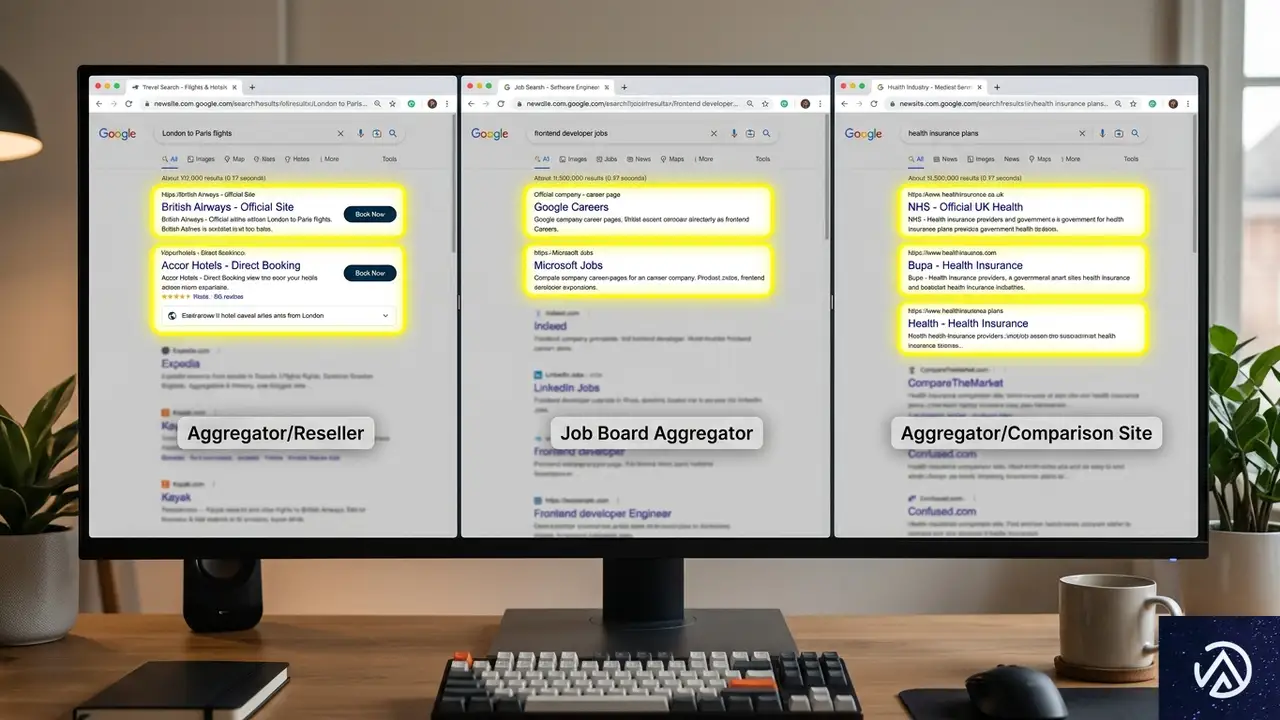
ドメイン単位の分析に加えて、業界カテゴリ別のパターンも明確になった。AmsiveはDataForSEOのAPI経由でGoogle商品分類タグを各ドメインに割り当て、旅行、求人、健康の3分野を重点的に分析している。
旅行分野 OTAが後退しホテル公式が台頭
旅行業界では、TripAdvisor(45ポイント減)、Yelp(33ポイント減)、Expedia(33ポイント減)がそろって下げた。代わりに上昇したのは、ヒルトンの公式サイト(4ポイント増)、Hotels.com(3.6ポイント増)、Trivago(3.2ポイント増)だった。さらに、米国国立公園局のNPS.govが9.9ポイント増、複数の空港公式サイトも大幅に上げている。
これは「旅行先を探す」という行動において、Googleが「個人のレビューを集めたサイト」よりも「宿泊施設や交通機関の公式情報」を優先するようになったことを示唆する。OTAのマーケティング担当者にとっては、SEOの前提を見直す転換点になるかもしれない。
求人分野 雇用主のキャリアページが評価上昇
求人・教育カテゴリでも、Indeed(18ポイント減)、ZipRecruiter(13ポイント減)といった求人アグリゲーターが下げた一方で、米国労働統計局のBLS.gov(5.4ポイント増)、米国政府求人サイトのUSAJobs.gov(16%増)、Disney Careers(59%増)、CVS Health Careers(45%増)といった雇用主直轄のキャリアページや政府系ドメインが目立って上昇した。
求職者が「特定の企業で働きたい」と考えたとき、検索結果の上位に企業の公式採用ページが表示されやすくなった形だ。これにより、求人専門サイト経由での応募導線に依存していた企業は、自社キャリアページのSEO強化が急務となっている。
健康分野 信頼できる公的機関が選ばれる傾向
健康分野では、処方薬割引サービスのGoodRxが55%増(9.5ポイント増)と大幅に伸び、米国国立衛生研究所(NIH.gov)も9.3ポイント増えた。その一方で、クリーブランドクリニックは12ポイント減、WebMDは9ポイント減、メイヨークリニックは6ポイント減と、有名な消費者向け健康情報サイトが軒並み下げた。
ここでの解釈は慎重を要するが、「権威性の高い公的機関の情報」をより重視する動きの一環と見ることができる。医学情報のように正確性が求められるジャンルでは、この傾向が今後も強まる可能性がある。
回復パターンと注意点
今回の分析で興味深いのは、一部の「敗者」ドメインがアップデート直後に可視性を急回復させた点だ。RedditとIndeedは、ロールアウト完了からほどなくしてスコアを取り戻した。このことから、アップデート期間中のスナップショットだけを見て「負けた」と判断するのは早計であることがわかる。
AmsiveのLily Ray氏も、今回の敗者リストはあくまで「アップデート期間中」の変動を捉えたものであり、その後に各ドメインがどこに落ち着いたかまでは示していないと強調している。SEO担当者は、ランキング変動を確認する際に、少なくともロールアウト完了後1〜2週間のデータを見て判断することが重要だ。
Zyppyの先行分析とも整合
今回のAmsiveによる発見は、同月に公開された別の分析結果とも整合している。ZyppyのCyrus Shepard氏が400以上のサイトを調査したレポートでは、「タスクを完了させる製品・サービスを提供するサイト」がオーガニックトラフィックを伸ばす傾向が示されていた。
手法は異なる。Shepard氏はサードパーティのトラフィック推計データとの相関を測定したのに対し、AmsiveはSISTRIXの可視性スコアをアップデート期間で追跡した。それでも、到達した結論はほぼ同じで、「情報の受け売りではなく、本物の価値を提供するサイト」が評価されるという方向性は確からしい。
さらに、ドイツのデータを用いたSISTRIX独自の分析でも同様の結果が得られている。オンラインショップや便利系サイトが可視性を下げ、公式サイトやブランドドメインが相対的に強かった。この世界的な共通傾向は、Googleがグローバルに同様の評価軸を適用している可能性を示す。
自社サイトへの示唆と対策

今回の一連のデータは、あくまでGoogleが内部で何を変更したかを確定するものではない。しかし、旅行、求人、健康、金融、エンターテインメントという異なる業界で同じパターンが繰り返された事実は重い。これは単発の異常値ではなく、検索エンジンの評価基準に構造的なシフトがあったことを示唆している。
つまり、「他人のコンテンツを集めて並べるだけのサイト」や「ユーザーが自発的に投稿したレビューに依存するサイト」よりも、「その分野の専門知識や実サービスを持つサイト」が優遇される方向へとかじが切られたのだ。
上記の診断フローは、今回のアップデートで評価されたサイトの特徴を整理したものだ。たとえば、自社商品の技術仕様を詳述したページを持っているか、実際の導入事例データを公開しているか。そうした「自社ならではの資産」をコンテンツ化できているかどうかが、これまで以上にSEOの成否を分ける。
また、Cyrius Shepard氏の分析が示す「タスク完了型サイトの優位性」も見逃せない。ユーザーが情報を得たあとに、そのまま資料請求、購入、予約へと進める流れをサイト内で完結させることが、オーガニック検索からの流入増加につながっている。
この記事のポイント
- 2026年3月のGoogleコアアップデートでは、YouTubeやRedditなどの集約サイトが可視性を大幅に下げた
- 旅行、求人、健康の各分野でブランド公式サイトや政府ドメインが評価を上げた
- 一部ドメインはアップデート後に急回復しており、短期的なスコアだけで判断するのは危険
- 自社の一次情報を強化し、タスクをその場で完了できる体験を提供することが今後のSEOの軸になる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Googleへのスパム報告に新ルール。個人情報を含むと処理されない理由
Googleがスパム報告に関する公式ドキュメントを更新し、報告プロセスにおける重要な変更を明らかにした。今後、報告内容に個人を特定できる情報が含まれている場合、Googleはその報告に基づいた調査や対処を行わない方針だ。
この変更は、スパムサイトに対して「手動対策(マニュアルアクション)」が実施される際、報告内容の一部がサイト所有者に共有される仕組みに起因している。Googleはプライバシー保護と法規制への対応を優先し、不適切な情報を含む報告をあらかじめ排除する決断を下した。
SEO担当者やサイト運営者にとって、この変更は単なる手続きの修正ではない。悪質なサイトを排除するための正当な報告が無効化されるリスクを避けるため、報告の作法を再確認する必要がある。
Googleスパム報告の仕様変更。個人情報の記載が「無効」に
Googleは検索結果の品質を維持するため、ユーザーからのスパム報告を受け付けている。しかし、2026年4月に更新されたドキュメントによれば、報告フォームの自由記述欄に個人情報が含まれている場合、その報告は処理されなくなった。これは、報告者が意図せず自身の身元を相手に明かしてしまうリスクを防ぐための措置だ。
なぜ個人情報が含まれると処理されないのか
最大の理由は、Googleがスパムサイトの所有者に送る通知の仕組みにある。Googleが報告に基づいて手動対策を下した場合、その根拠となった情報をサイト所有者に伝えることがある。この際、報告者が記述したテキストがそのまま引用される可能性があるためだ。
もし報告文の中に、報告者の名前や会社名、あるいは特定のサイト運営者であることを示唆する情報が含まれていれば、スパムサイト側に報告者の正体が筒抜けになってしまう。Googleはこのような事態を避けるため、個人情報が含まれる報告自体を「破棄」するというルールを明文化した。
ドキュメントから削除された「匿名性」の記述
以前のドキュメントでは、自由記述欄に個人情報を書かない限り、報告は匿名に保たれるという主旨の記述があった。しかし、今回の更新でこの文言は削除された。代わりに「法規制を遵守するため、手動対策の文脈を理解させる目的で、提出されたテキストをサイト所有者に送信しなければならない」という強い表現が追加されている。
これは、Googleが報告者の匿名性を保証する努力をするのではなく、報告者自身に「特定される情報を一切書かないこと」を義務付けたことを意味する。ルールを守らない報告は、どれほど証拠が揃っていても無視されることになるため、注意が必要だ。
手動対策通知の仕組みと報告者が負うべきリスク

手動対策(マニュアルアクション)とは、Googleの担当者が目視でサイトを確認し、ガイドライン違反と判断した場合に検索順位を下げたり、インデックスから削除したりする処置を指す。このプロセスにおいて、ユーザーからの報告は重要な判断材料の一つとなる。
報告内容がそのまま相手に届くという事実
Googleが違反サイトの運営者に送る通知には、どのような違反があったのかを説明するテキストが含まれる。このテキストに、報告者がフォームに記入した内容が「原文のまま」転載されるケースがある。これは、違反者が自サイトのどこに問題があるのかを正確に把握させ、修正を促すための透明性を確保する目的で行われる。
しかし、この透明性が報告者にとってはリスクとなる。例えば「私のサイトの画像を盗用している」といった文言で報告すれば、相手は即座に報告者が誰であるかを特定できる。このような情報の流出は、報告者への逆恨みやさらなる攻撃を招く恐れがある。
情報の流れを視覚化する
スパム報告がどのように処理され、どの段階で情報が共有されるのかを整理しておくことは重要だ。以下のデモは、不適切な報告と適切な報告で情報の伝わり方がどう変わるかを示している。
このデモのように、自分を特定する情報を削ぎ落とし、客観的な事実のみを伝えることが、報告を有効にするための鉄則だ。
プライバシー保護と透明性のジレンマ。Googleの狙い

Googleがなぜこのような厳しいルールを設けたのか。その背景には、欧州のGDPR(一般データ保護規則)をはじめとする、世界的なプライバシー保護規制の強化がある。個人データの取り扱いには極めて慎重な対応が求められており、検索エンジンも例外ではない。
法規制への対応とユーザー保護の両立
GDPRなどの法規制下では、データの主体(この場合はサイト所有者)は、自分に関するどのような情報が収集され、誰から提供されたのかを知る権利を持つ場合がある。Googleが「報告文を相手に送る」としているのは、こうした法的要求に応えるための苦肉の策とも言える。
一方で、報告者の身の安全を守る必要もある。そこでGoogleが導き出した答えが、「個人情報が含まれる報告は最初から受け取らない(処理しない)」というフィルタリングだ。これにより、法的義務を果たしつつ、報告者が不用意に特定される事態を未然に防いでいる。
「質の高い報告」を求めるGoogleの姿勢
今回の変更は、スパム報告の「質」を向上させる狙いもあると考えられる。感情的な訴えや個人的な利害関係を排除し、アルゴリズムやガイドラインに照らして何が違反なのかを論理的に説明する報告を、Googleは求めている。
報告が無効化される条件を明確にすることで、Google側の処理コストも削減される。明らかにガイドラインを理解していない報告や、嫌がらせ目的の報告を、情報の形式だけで自動的に弾くことができるからだ。
効果的なスパム報告を行うための実践的なアドバイス

スパムサイトによって検索順位を下げられたり、コンテンツを盗用されたりした場合、冷静に報告を行うのは難しい。しかし、確実にGoogleに対処してもらうためには、以下のポイントを意識してフォームを記入する必要がある。
匿名性を保ちつつ証拠を提示するコツ
まず、一人称(私、弊社など)や固有名詞を避けることだ。例えば「私のサイトのこの記事がコピーされた」と書くのではなく、「該当URLのコンテンツは、別のドメイン(URLを提示)のオリジナルコンテンツを無断で複製している」といった書き方にする。
次に、違反の種類を具体的に指摘することだ。単に「スパムだ」と主張するのではなく、「隠しテキストが使用されている」「リンクプログラムに参加している」「クローキングが行われている」など、Googleのスパムポリシーに基づいた用語を使うと、担当者の理解が早まる。
報告文のチェックリスト
送信ボタンを押す前に、以下の項目が含まれていないか確認しよう。一つでも当てはまる場合は、処理されない可能性が高い。
- 自分の氏名や会社名、部署名
- 自分のメールアドレスや電話番号
- 自分が管理しているサイトのドメイン名(証拠として必要な場合を除く)
- 相手を非難する感情的な言葉
- 過去のやり取りや個人的なトラブルの経緯
独自の分析。SEO担当者が今後意識すべき報告の作法
今回のGoogleの対応は、SEO業界における「スパム報告」の立ち位置を大きく変える可能性がある。これまでは「困った時の神頼み」のような側面もあったが、今後はより専門的で客観的な「証拠提出」の場へと変わっていくだろう。
競合への嫌がらせ対策としての側面
この新ルールは、競合サイトを陥れるための「虚偽の報告」に対する牽制にもなる。報告内容が相手に公開される可能性がある以上、安易な嘘や根拠のない誹謗中傷は、報告者自身の首を絞めることになるからだ。Googleは情報の透明性を高めることで、報告システム自体の健全性を保とうとしている。
AI時代におけるスパム報告の価値
AIによって生成された低品質なコンテンツが急増する中、Googleのアルゴリズムだけですべてを検知するのは難しくなっている。人間の目による「これはスパムだ」というフィードバックの価値はむしろ高まっていると言えるだろう。
だからこそ、私たちは「正しい報告の作法」を身につけるべきだ。適切な形式で、個人情報を排除し、事実に基づいた報告を行うことは、検索エンジンのエコシステムを守るための貢献にもなる。今回の仕様変更を機に、社内での報告フローやテンプレートを見直してみるのも良いだろう。
この記事のポイント
- Googleへのスパム報告に個人情報が含まれている場合、調査は行われず破棄される。
- 手動対策が実施される際、報告文がそのままサイト所有者に共有されるリスクがあるためだ。
- 報告文には自分の名前や会社名を入れず、客観的な事実と違反箇所のみを記述する。
- この変更は、プライバシー保護規制への対応と報告システムの健全化を目的としている。
- 正当な報告を有効にするため、送信前のセルフチェックがこれまで以上に重要となる。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AI時代のSEOで検索エンジンが信頼する3要素——権威性・鮮度・独自性の新基準
検索エンジンの評価基準が根本から変わった。従来のSEO対策だけでは通用しない時代が来ている。
Search Engine Journalの記事によると、AI駆動の検索システムは権威性・鮮度・独自性の3要素を重視する。これらの要素が連動して、コンテンツが検索結果に表示されるか、AI生成回答に引用されるかを決める。
この変化を理解しないと、どんなにキーワードを最適化しても、どんなにバックリンクを増やしても、成果は上がらない。AIが信頼するコンテンツを作るための新たな基準を解説する。
検索エンジンの評価システムが変わった

かつての検索エンジンは定期的なアルゴリズム更新で評価基準を調整していた。コアアップデートが発表され、順位が変動し、業界がパターンを分析して対策を練る。このサイクルは予測可能だった。
しかし今は違う。AI駆動の検索システムは常に学習し、評価基準を微調整している。Search Engine Journalの記事では、この状態を「連続的な調整」と表現する。アルゴリズムの更新のように見える現象の多くは、実際にはAIモデルの継続的な最適化の結果だ。
従来の「ランキング」から「評価」への移行
従来のSEOはページ単位のランキングを競うものだった。バックリンクや関連性、技術的な最適化が評価基準となり、ページ全体が1つの単位として扱われた。
AI駆動の検索では、ページ全体のランキングに加えて「情報の抽出と合成」という第2の層が加わった。検索エンジンは複数のソースから情報を抜き出し、再構成して回答を生成する。この変化により、競争の単位がページ全体から「情報の断片」へと移行している。
具体的には、コンテンツ内の各セクション、各段落、各リストがAI生成回答に引用される候補となる。ページが検索結果に表示されるかどうかだけでなく、ページ内のどの部分がAIによって利用されるかが重要になった。
信頼の評価が「継続的」になった
信頼性の評価も変化した。かつての信頼性は、権威性のシグナル、コンテンツ品質、技術的な健全性を組み合わせた「スコア」のようなものだった。一度高い評価を得れば、しばらくは維持できた。
現在の信頼性評価は「確率」のように振る舞う。継続的に評価され、再計算され、新しいデータに基づいて強化される。一度得た信頼を保持するのではなく、繰り返し獲得し続ける必要がある。
AIが信頼する3つの要素
AI駆動の検索システムが信頼性を判断する際、特に重視する要素が3つある。権威性、鮮度、独自性のシグナルだ。それぞれが異なる役割を果たし、コンテンツが検索結果に表示されるか、AI回答に引用されるかを決める。
権威性——評価の入り口
権威性は常に重要だったが、その役割が変化した。AI駆動のシステムでは、権威性は「フィルター」として機能する。コンテンツが評価の対象になるかどうかを最初に決める要素だ。
すべての情報源が平等に扱われるわけではない。検索エンジンは認識しているエンティティ(ブランド、著者、ドメイン)を優先する。これらのエンティティは、ウェブ全体で一貫した専門性と可視性を示している必要がある。
バックリンクの数だけが権威性の指標ではなくなった。エンティティレベルの権威性を証明するには、以下の要素が重要になる。
- 他の権威あるサイトでの言及
- 一貫した著者性とトピックへの集中
- 特定の分野でのブランド認知
- 構造化された知識システムへの組み込み
Search Engine Journalの記事では、これらのシグナルが「エンティティ重力」を作り出すと説明する。存在感が強ければ強いほど、コンテンツが情報抽出の候補セットに含まれやすくなる。
重要なのは、権威性が可視性を保証するわけではないことだ。権威性は「資格」を保証する。権威性がなければ、コンテンツがよく書かれ、よく構成され、技術的に健全であっても、無視される可能性がある。
鮮度——継続的な関連性の証明
鮮度の概念も進化した。あるいは「分化した」と言う方が正確かもしれない。
かつては、すべての種類のコンテンツが鮮度の恩恵を受けた。新しいコンテンツは、特に時間に敏感なクエリに対して一時的なブーストを得られた。
現在、この従来型の鮮度はニュースメディアのような時間に敏感な発信者にしか利益をもたらさない。それ以外の発信者にとって、鮮度は「いつ公開されたか」ではなく「維持されているか」が重要になる。
AI駆動のシステムは、継続的な関連性を示す情報源を優先する。具体的には以下の要素だ。
- 定期的に更新されるコンテンツ
- 明確なタイムスタンプと改訂履歴
- 時間の経過とともに重要なトピックが強化されていること
- 現在の情報と文脈との整合性
古くなったコンテンツはリスクを生む。情報がまだ正確かどうかをシステムが判断できない場合、合成された回答に含まれる可能性が低くなる。
鮮度は、この意味で信頼強化のループになる。コンテンツを更新することは、継続的な専門性を示すシグナルだ。不確実性を減らし、含まれる可能性を高める。
独自性——確かな情報源の証明
3つ目の大きな変化は、独自性のシグナルの重要性が劇的に高まったことだ。AIシステムは情報を合成するように設計されているが、依然としてソース素材に依存している。その素材の品質は、出力の品質に直接影響する。
その結果、システムはリサイクルされた要約ではなく、オリジナルで検証可能な入力を表すコンテンツを重視する。独自性のシグナルには以下が含まれる。
- 独自の調査とデータ
- 独自の洞察と分析
- 直接的な製品やサービス情報
- 直接的な経験と専門知識
これらのシグナルは曖昧さを減らす。明確な情報源を提供し、帰属が容易で、複製が難しい。
これが「大量コンテンツ」モデルが近年苦戦している理由の1つだ。派生コンテンツの大量生産は、新しい情報をほとんど提供しない。価値を増やすことなくノイズを増やすだけだ。
AIシステムはより多くのコンテンツを探しているのではなく、より良い入力を探している。コンテンツが何か独自のものを追加しない限り、選択される可能性は低い。
見落とされがちな第4の要素——使いやすさ

権威性が評価の対象にし、鮮度が関連性を保ち、独自性が信頼性を確立する。しかし、コンテンツが利用できなければ、これらの要素はすべて無意味になる。ここで多くのサイトが失敗している。
ページがよくランキングしていても、AI生成回答に存在しないことがある。その場合、問題はランキングではなく「抽出のしやすさ」にあることがほとんどだ。
AIシステムは人間のようにページを読まない。探索的にナビゲートし、解釈し、合成することはない。抽出しやすいものを取得し、次に進む。
この環境でうまく機能するコンテンツには、いくつかの特徴がある。
- 明確で説明的な見出し
- 論理的な階層構造(H1、H2、H3)
- 段落ごとに1つの主要なアイデア
- 直接的で断定的な表現
- 適切な箇条書きと表
- 重要なポイントは早い段階で紹介(埋もれさせない)
これは文章スタイルの問題ではない。摩擦を減らす問題だ。
システムが回答を分離するためにコンテンツを再解釈する必要がある場合、利用される可能性は低くなる。文やリストを直接引き抜ける場合、含まれる可能性は高くなる。この意味で、構造は見た目の問題ではなく、機能的な問題だ。
- キーワード調査
- メタタグ最適化
- コンテンツ作成
- バックリンク構築
このデモは、同じ内容でも構造化の違いでAIによる抽出のしやすさが変わることを示している。左側は情報が段落内に埋もれており、AIが特定の情報を抽出するには文章全体を解析する必要がある。右側は見出しと箇条書きで明確に構造化されており、AIが「SEOの主要手法」という見出しの下のリストを直接取得できる。
「良いSEO」だけでは不十分な理由

多くのチームが直面しているのは、以下のようなパターンだ。検索順位は良好で、トラフィックも安定しているが、AI生成回答には存在しない。
最初の直感はランキングの問題を探すことだ。それで問題が解決しないと、キーワードの再最適化、より多くのバックリンク構築、より多くのコンテンツ公開に移行する。これらは真の問題に対処しない解決策だ。
ランキングは検索結果に表示されるかどうかを決める。情報抽出は回答に利用されるかどうかを決める。これらは同じシステムではない。ページが従来のSEO指標でうまく機能していても、AIシステムにとってきれいで抽出可能なセグメントを提供できないことがある。
その場合、より明確な構造やより強い権威性を持つ競合他社が、たとえ順位が低くても引用される可能性が高くなる。これは矛盾ではなく、評価の変化だ。
この比較図は、評価基準の変化を視覚化している。左側の従来型SEOでは、バックリンクやキーワードなどの要素が検索結果での表示位置(ランキング)につながる。右側のAI時代の評価では、権威性や鮮度などの要素が、検索結果での表示に加えてAI生成回答への引用有無にも影響する。評価基準が追加され、複雑化した。
実践的な対策——4つのアクションプラン

これらの変化に対する実践的な対策は明確だ。実行は簡単ではないが、方向性ははっきりしている。
1. アップデートを孤立したイベントとして扱うのをやめる
アルゴリズムのアップデートは、連続的なシステムの出力に過ぎない。短期的な変動に対応するよりも、長期的な方向性に向けて最適化する方が効果的だ。
Search Engine Journalの記事では、信号の半減期が短くなったと指摘する。6ヶ月前に有効だった手法が今も重要かもしれないが、定期的ではなく継続的に再評価されている。
2. エンティティレベルでの権威性への投資
自社サイトを超えた認知を構築する。どこで、どのように言及されるかは、何を公開するかと同じくらい重要だ。
PR、パートナーシップ、思想のリーダーシップ、ブランドの存在感などのエンティティ構築努力は、SEOから切り離せなくなった。これらはランキングだけでなく、情報抽出の候補に含まれるかどうかにも影響する。
3. コンテンツの継続的なメンテナンス
鮮度は一度きりのシグナルではない。関連性の継続的な実証だ。重要なコンテンツを維持する。すべてを常に書き直す必要はないが、重要な情報が最新であることを確認する。
4. 独自性のある価値を優先する
独自の洞察、データ、専門知識は、派生コンテンツよりも耐久性がある。AIシステムはより多くのコンテンツを求めているのではなく、より良い入力を求めている。
5. 使いやすさのために構造化する
コンテンツを読みやすくするだけでなく、抽出しやすくする。明確な見出し、論理的な階層、直接的な表現を採用する。AIが情報を簡単に引き抜けるように設計する。
この記事のポイント
- AI駆動の検索システムは権威性・鮮度・独自性の3要素を重視する
- 権威性は評価の「入り口」であり、これがないとコンテンツは考慮されない
- 鮮度は「いつ公開されたか」ではなく「維持されているか」が重要になった
- 独自性のある情報(調査・データ・洞察)がAIに高く評価される
- コンテンツ構造は「見た目」ではなく「抽出のしやすさ」のために重要
- 従来のSEO対策だけではAI生成回答への引用は獲得できない
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

生成AIの普及率は3年で53%に到達。PCやネットを超える速度がSEOに与える衝撃
スタンフォード大学の人間中心人工知能研究所(HAI)が、最新の調査報告書「2026 AI Index Report」を公開した。このレポートは400ページを超え、技術的パフォーマンスから投資状況、労働市場への影響まで多岐にわたるデータを網羅している。
報告書の中で最も大きな反響を呼んでいるのが、生成AIの普及スピードだ。ChatGPTのリリースからわずか3年で、世界人口の53%が生成AIを採用するに至った。これは、かつてのパーソナルコンピュータ(PC)やインターネットが辿った普及速度を大きく上回る数字である。
検索エンジン最適化(SEO)に携わる実務者にとって、この急速な変化は無視できない。ユーザーの検索行動が根本から塗り替えられつつある現状において、データの背後にある真実を理解することが、これからの戦略を左右するだろう。
生成AIの普及速度はPC・インターネットを凌駕
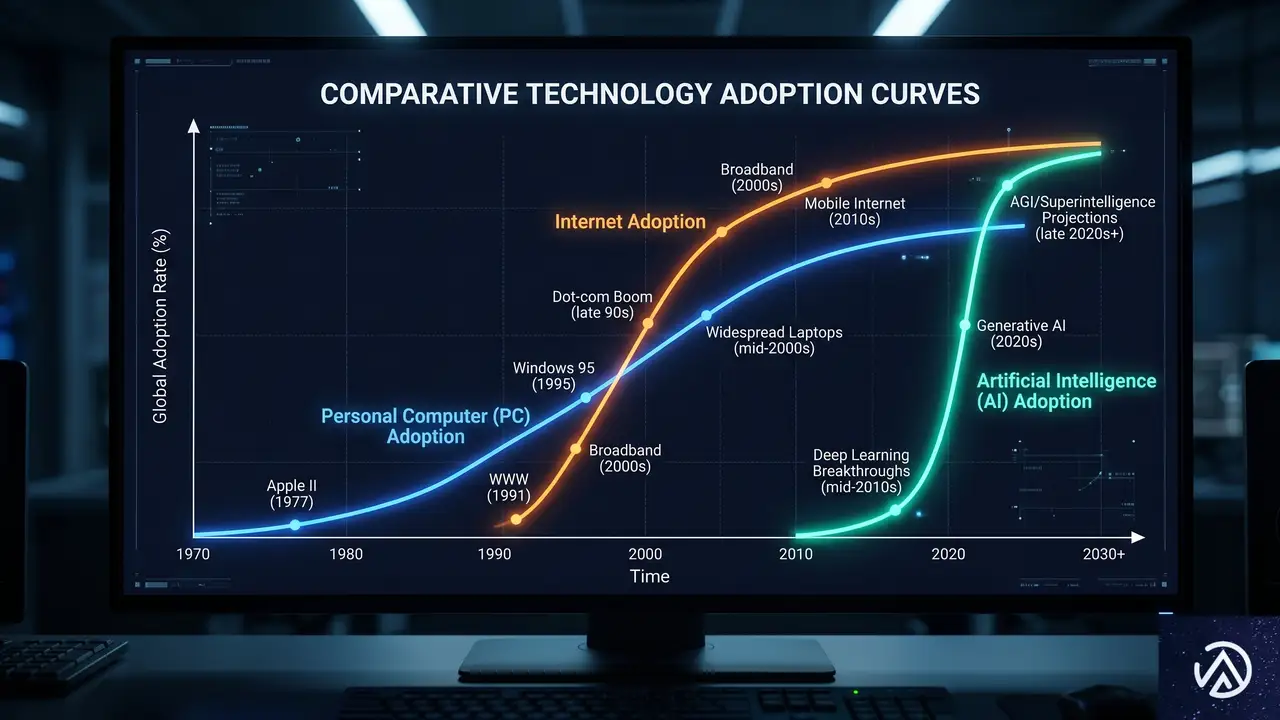
生成AIの普及は、過去のどの技術革新よりも速い。レポートによれば、主要なテクノロジーが一般に浸透するまでの期間を比較した際、生成AIの立ち上がりは際立っている。1981年のIBM PC登場や1995年のインターネット商用化と比較しても、普及曲線は急峻だ。
なぜこれほどまでに速いのか
この爆発的な普及には、先行したインフラの存在が大きく寄与している。ハーバード大学のデビッド・デミング氏は、AIが既存のPCやインターネットの上に構築されたツールであることを理由に挙げている。ユーザーは新しいハードウェアを購入する必要がなく、すでに手元にあるスマートフォンやPCから即座にアクセスできたためだ。
水道や電気が通っている家に、新しい蛇口を取り付けるような手軽さが、53%という驚異的な数字を支えている。インフラ整備の時間を飛び越えて、アプリケーションとしての利便性だけが先行して広がった結果といえる。
「普及」の定義と実態の差
ただし、この53%という数字を鵜呑みにするのは注意が必要だ。レポートでは、一度でもChatGPTなどのツールを試したユーザーも「採用者」としてカウントされている可能性がある。毎日8時間フル活用している専門家と、一度だけ挨拶を入力してみただけのユーザーが同列に扱われている側面がある。
また、国によっても普及率には大きな開きがある。スタンフォードのデータでは米国の普及率を28%としているが、セントルイス連邦準備銀行の調査では54%と、倍近い開きが出ている。これは調査の質問順序や定義の微妙な違いによるものだ。SEO担当者は、数字の大きさに圧倒されるのではなく、ユーザーが「どれほど深く、どのような文脈で」AIを使っているのかを注視すべきである。
能力の「ギザギザのフロンティア」と検索の不安定さ
AIの能力向上は目覚ましいが、その進化は均一ではない。レポートでは「ギザギザのフロンティア(Jagged Frontier)」という概念を用いて、AIの得意不得意が極端に分かれている現状を説明している。
高度な知性と単純なミスが同居する現状
最新のAIモデルは、博士レベルの科学問題や数学の難問で人間を凌駕するスコアを叩き出す。しかしその一方で、アナログ時計の針を正しく読み取るという単純なタスクにおいて、正解率が10%を切るようなケースも報告されている。複雑な推論は得意だが、直感的な視覚理解や多段階の計画立案には依然として課題が残っているのだ。
この「能力のムラ」は、検索体験にも直結している。特定の専門的な質問には驚くほど正確な回答を返す一方で、日常的な事実関係の確認で突拍子もない間違い(ハルシネーション)を犯す。AI Index運営委員会のレイ・ペロー氏は、ベンチマークテストの結果が必ずしも実世界の業務での信頼性を保証するものではないと警鐘を鳴らしている。
AI検索結果の不確実性をどう捉えるか
SEOの現場では、Googleの「AI Overviews(AIによる概要)」や「AI Mode」の挙動がクエリによって大きく変動することが確認されている。Ahrefsの調査によれば、同じクエリであってもAI OverviewsとAI Modeが参照するURLの重複率はわずか13%に過ぎない。システムごとに異なる情報源を選択しており、その基準は依然として不透明だ。
Googleのロビー・スタイン氏は、ユーザーが反応を示さない場合、AIによる回答を意図的に抑制していることを認めている。つまり、AI検索の表示は固定されたものではなく、ユーザーのエンゲージメントに応じて動的に変化する不安定なものだ。私たちは、特定のキーワードで「AIに選ばれる」ことの難しさと、その持続性の低さを認識しなければならない。
※既存の情報を要約しただけで、具体的な戦略や独自性がない。
※実体験と具体的な数字に基づき、AIには真似できない価値を提供している。
このデモは、AIによる一般的な要約と、人間が提供すべき独自情報の違いを視覚化したものだ。
低下する透明性とブラックボックス化するSEO

SEO業界にとって最も懸念すべきデータの一つが、AIモデルの「透明性の低下」だ。レポートによれば、主要なAIモデルの透明性指数は、1年間で58から40へと急落した。モデルが高度になればなるほど、その中身が隠される傾向にある。
公開されないトレーニングデータ
Google、Anthropic、OpenAIといった主要プレイヤーは、最新モデルのトレーニングデータセットのサイズや、トレーニングに要した期間の開示を停止している。2025年にリリースされた著名なAIモデル95個のうち、トレーニングコードを公開したのはわずか15個にとどまる。
これは、検索エンジンのアルゴリズムがかつてないほど「ブラックボックス化」していることを意味する。どのようなコンテンツが評価され、なぜそのURLが引用されたのかという根拠を、プラットフォーム側が説明しなくなっているのだ。最適化のヒントが減り、推測に頼らざるを得ない領域が増えている。
「説明できない」アルゴリズムへの対策
透明性が失われる中で、SEO担当者が取るべき道は「アルゴリズムのハック」から「ユーザー価値の構築」へのシフトだ。レポート内では、AIに対する一般市民の信頼が低下していることも示されている。特に米国の公的機関によるAI規制能力への信頼度は31%と低い。
プラットフォームが詳細を明かさない以上、私たちは「AIが何を好むか」ではなく、「ユーザーが何を信頼するか」に立ち返る必要がある。AIによる回答が不透明で説明責任を果たせないからこそ、発信者の顔が見え、根拠が明示されたコンテンツの価値が相対的に高まっていく。透明性の欠如を、自サイトの透明性向上で補う戦略が求められる。
労働市場の変化と「独自の価値」の再定義

AIの普及は、コンテンツ制作の現場にも直接的な影響を及ぼしている。レポートが指摘する労働市場の変化は、Web制作やSEOに携わるチームの構成にも示唆を与えている。
若手エンジニアの雇用減少が示唆するもの
22歳から25歳のソフトウェアデベロッパーの雇用が、2024年以降で約20%減少したというデータがある。一方で、経験豊富なシニア層の雇用数は維持、あるいは増加傾向にある。これは、AIが「ジュニアレベルの定型業務」を代替し始めている可能性を示唆している。
SEOやライティングの分野でも同様のことがいえる。既存の情報を整理し、無難な構成で記事を書くといったエントリーレベルの仕事は、AIによって急速に置き換えられている。20%の雇用減少という数字は、単なる不況の影響だけでなく、業務プロセスの構造的な変化を反映していると見るべきだ。
AIに代替されない「ゴールデン・ナレッジ」
こうした状況下で提唱されているのが、シェリー・ウォルシュ氏らが言及する「ゴールデン・ナレッジ(黄金の知識)」という概念だ。これは、AIのトレーニングデータには含まれていない、独自の調査データや実体験、深い洞察に基づくコンテンツを指す。
スタンフォードのレポートが示す「AIの普及」と「能力のムラ」は、この戦略の正しさを裏付けている。AIは広く普及したが、その回答は依然として不安定で、深みに欠ける。AIがどれほど速く情報を要約しても、その元となる「新しい事実」を作り出すことはできない。一次情報の発信者としての地位を確立することが、AI時代を生き抜くための構造的なアドバンテージとなる。
2026年以降のSEO戦略(独自の分析)

スタンフォードのレポートから読み解ける未来は、AIと共存しつつ、その「隙間」を埋める戦略の重要性だ。AI Overviewsが月間15億人のユーザーにリーチし、AI Modeが日常化する中で、従来の「検索順位」という指標だけでは不十分になっている。
まず、モニタリングの単位を細分化する必要がある。AIの能力が「ギザギザ」である以上、カテゴリー単位の分析では実態を見誤る。特定のクエリでは正確な回答が出るが、少し表現を変えるだけでハルシネーションが起きる。この不安定さを逆手に取り、AIが正しく答えられない「複雑で多面的な問い」に対して、人間が最高の回答を用意しておくべきだ。
次に、検索コンソールなどのツールに頼りすぎない姿勢も重要だ。現在のツールでは、AI Overviews経由のトラフィックと通常の検索トラフィックを明確に分離して把握することが難しい。不透明なプラットフォームに依存するリスクを分散するためにも、SNSやメールマガジンといった、ユーザーと直接つながる「脱検索エンジン」のチャネル強化を並行して進めるべきだろう。
最後に、AIの普及速度を脅威ではなく「機会」として捉え直したい。53%の人がAIを使うということは、それだけ多くの人が「迅速な回答」を求めている証拠だ。しかし、迅速さと正確さは必ずしも両立しない。人々がAIの回答に物足りなさを感じたとき、真っ先に参照される「信頼の拠点」になれるかどうかが、2026年以降の勝負を分けることになる。
この記事のポイント
- 生成AIはChatGPT登場から3年で53%の普及率に達し、PCやネットを凌駕する速度で浸透している。
- AIの能力は「ギザギザのフロンティア」と呼ばれ、高度な推論と初歩的なミスの同居が検索結果の不安定さを招いている。
- AIモデルの透明性は低下しており、トレーニングデータやアルゴリズムのブラックボックス化が加速している。
- 労働市場では若手の定型業務がAIに代替され始めており、SEOでも「独自の一次情報」の価値が相対的に高まっている。
- 今後のSEOは、AIが苦手とする領域を特定し、ユーザーとの直接的な信頼関係を構築する戦略への転換が不可欠だ。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験