

AI時代のECはメタデータが鍵。機械に選ばれる商品情報の新常識
AIが検索と推薦を主導する時代、ECサイトの商品情報に求められるルールが根本から変わろうとしている。これまでのSEO対策や広告運用ではカバーしきれない「機械のための情報整理」が、売上を左右する最重要インフラになりつつあるのだ。
MarTechの記事によると、デジタルマーケティングのプロであるBenjamin De Castro氏は、メタデータの戦略的価値がクリエイティブやメディア投資に匹敵する段階に入ったと指摘している。彼がX(旧Twitter)のBlaze社でシニアストラテジストを務めた経験や、Shutterflyのようなフォトプロダクト企業のビジネスモデル変革から得た知見に基づく主張だ。
特にEC制作やWooCommerce運用に携わる者にとって、この変化は「商品マスタの整備」という開発現場の課題が、経営戦略そのものに直結することを意味する。本記事では、AI時代のメタデータ設計について、実務に落とし込む視点で解説する。
メタデータとは何か、AI時代に再定義する

メタデータとは「データについてのデータ」と呼ばれる。商品名や価格、カテゴリ、在庫状況、画像の代替テキスト、更新日時など、情報そのものに付随する説明的な情報を指す。これまでは検索エンジン対策(SEO)の下地として扱われてきた。
しかしAIが介在する今年の検索体験では、メタデータの役割は単なるキーワードの置き場所ではない。機械がコンテンツを「理解」し「文脈を解釈」し「信頼性を評価」するための唯一の手がかりになる。De Castro氏はこれを「通貨」に例えている。通貨が十分でなければ、経済圏に入れないのと同じ理屈だ。
「機械のための設計書」としてのメタデータ
LLM(大規模言語モデル)は、商品情報を確率モデルで処理する。ある商品が「何で」「誰向けで」「どれほど新しく」「信頼できるか」を、メタデータの断片を組み合わせて推論する仕組みだ。統合が不十分だったり、チームごとに異なる用語を使っていたりすると、機械も混乱する。
たとえば「レディース ジャケット」と「女性用 アウター」という商品カテゴリが混在するECサイトでは、AIはこれらを別物と認識するかもしれない。結果として検索の精度が下がり、推薦の精度も落ちる。De Castro氏はこうした非一貫性を「機械に混乱を継承させる」と表現する。
機械にとっての読みやすさは、人間にとってのUIと同じだ。わかりにくいUIのサイトからユーザーが離脱するように、メタデータが不十分だとAIはその商品を見つけられず、推薦対象からも外してしまう。
メタデータがAI体験を駆動する、すでに起きている実例

De Castro氏は具体例として、フォトプロダクト企業のShutterflyやMixbookを挙げる。彼によれば、これらの企業は単なる「写真をグッズにする」サービスではない。ディープラーニングとメタデータを組み合わせて、「デジタルの混沌を物語に変える」事業へと進化した。
デジタル写真には撮影時刻や位置情報、デバイス情報が埋め込まれている。AIが画像認識と組み合わせることで、「誰が写っているか」「どんなシーンか」「天気はどうだったか」まで推論できる。この推論結果をメタデータとして付与することで、ユーザーは「2024年夏、海でのバケーション写真」を瞬時に検索し、自動でアルバムを生成できるようになる。
PinterestとAdobeに学ぶ、メタデータ駆動型の設計
この仕組みはECでも同じだ。Pinterestは商品フィードのメタデータ(タイトル、価格、カテゴリ)を読み取り、プロダクトピンやショッピング広告の表示を最適化している。Adobe Experience ManagerはAIのSmart Tags機能を使い、画像や動画に自動でキーワードを付与する。これにより、社内のクリエイティブチームが必要な素材を高速に見つけられるようになる。
De Castro氏は「メタデータは説明的(descriptive)であるだけでなく、文脈を生成する(generative)ものだ」と述べている。つまり、適切なデータを与えれば、AIはそれをもとに新しい価値(商品説明文の自動生成や、クロスセルの提案など)を生み出せるわけだ。
なぜAI検索でメタデータの比重が増すのか

Google検索はLLMによって、単なる文字列一致から「意図の解釈」へと機能が進化している。検索エンジンは、クエリに対して「このコンテンツは何か」「何に関連するか」「誰のためか」「どれほど新しいか」「信頼できるか」の5つの軸で評価を下す。この5軸すべてを機械に伝えるのがメタデータの仕事だ。
構造化データの実装や商品フィードの最適化が不十分だと、ブランドは機械にとって「曖昧な存在」になる。曖昧な存在は、AIが回答を生成する際に参照されず、結果として検索にも推薦にも現れなくなる。De Castro氏はこれを「フェラーリを買ってきて芝刈り機のエンジンを積むようなものだ」と痛烈に批判する。最先端の生成AIツールを導入しても、その基盤となるデータが貧弱なら意味がない、というわけだ。
「カテゴリ:衣類」
「画像alt:Tシャツの画像」
「カテゴリ:メンズ > トップス > カットソー」
「素材:オーガニックコットン100%」「生産国:日本」
「画像alt:グレーのオーガニックコットンTシャツを着た男性」
GoogleのAI機能に関するガイドラインでも、明確なコンテンツ、クロール可能なページ、構造化されたシグナルというSEOの基本が強調されている。メタデータは、派手なAIツールより地味に見えるかもしれないが、AI時代のマーケティングインフラの中核を担う要素だ。
今すぐ始めるメタデータ戦略の再設計

では、WooCommerceで構築されたECサイトや、企業の商品マスタ管理において、具体的に何を変えるべきなのか。De Castro氏の提言を、国内のEC運用実務に即して再構成する。
メタデータをマーケティング資産として扱う
まず認識を改める必要がある。メタデータは「面倒な登録作業」ではない。検索、再利用、パーソナライゼーション、AI連携のすべてに効く戦略資産だ。商品マスタの仕様策定には、制作チームだけでなくマーケティング責任者も関与すべきだ。
「タクソノミ経典」を作り、組織で統一する
カテゴリ名、属性ラベル、タグの定義を全社で統一したドキュメントを作成する。たとえば「送料無料」という表現を「free_shipping」に統一するのか、「送料込み」と使い分けるのかを決めておく。これがないと、チームごとに異なる用語を使い、AIにノイズを与えてしまう。
WooCommerceの場合、商品属性(Attributes)とカテゴリの設計がこの経典の核になる。グローバル属性を適切に設定し、ぶれのないタクソノミを構築することが、AIへのクリアなシグナルにつながる。
メタデータの取得を制作フローの一部に組み込む
Googleの画像SEOガイドは、説明的なタイトル、altテキスト、ファイル名、周辺コンテキストの重要性を説く。Pinterestも同様に、充実した商品フィード項目を推奨している。つまり、メタデータは後付けではなく、商品登録時に必須項目として組み込まれるべきだ。
WooCommerce運用では、CSV一括登録のテンプレートにメタデータ必須項目を組み込む。商品名の命名規則、カテゴリパスのルール、画像altテキストのガイドラインを、運用マニュアルとして整備する必要がある。
AIをメタデータ作成に使う、ただし最終判断は人間が行う
AdobeのSmart Tagsのように、AIによる自動メタデータ付与は規模の課題を解決する。しかし、タクソノミの品質管理やガバナンスは人間の判断領域だ。機械が機械向けにマーケティングすると、「伝言ゲーム」のように情報が歪み、最終的に人間にとって無意味なコンテンツになるリスクがある。
全システムで一貫したストーリーを保つ
CMS、DAM(デジタルアセット管理)、ECカート、CRM、広告プラットフォームで、同じ商品のメタデータが異なっていてはならない。LLMは自社サイトだけでなく、あらゆるソースを横断的にチェックするからだ。WooCommerceと連携する在庫管理システムや広告管理画面でも、マスタとしての整合性を意識する必要がある。
品質をクリエイティブと同等に追求する
メタデータの品質指標は、完全性、一貫性、鮮度、下流(AIや推薦エンジン)への影響度で測る。優れた広告クリエイティブが売上を生むように、優れたメタデータもまた、AI経由の売上を生むという認識が欠かせない。
メタデータはAI時代のマーケティングインフラである

De Castro氏の主張の核心は、メタデータがもはや「あったらいいもの」ではなく「ないと致命的なもの」になったという点にある。クリエイティブも広告費も依然として重要だが、AIがブランドを理解し、検索し、推薦するための基盤として、メタデータの整備は待ったなしの状況だ。
WooCommerceで構築されたECサイトであれば、商品属性、構造化データ、画像alt、フィードデータを一元的に管理する仕組みを今から作る必要がある。将来のAI検索や会話型コマースの波に乗れるかどうかは、今日の商品マスタ設計にかかっているといっても過言ではない。
この記事のポイント
- AI時代の検索と推薦では、メタデータがクリエイティブや広告費と同等の戦略価値を持つ
- 機械に「理解される」ためには、一貫性があり網羅的な構造化データが必要不可欠である
- WooCommerceでは商品属性、タクソノミ、画像alt、フィードデータの統合管理がカギ
- メタデータは後付けではなく、商品登録フローに組み込むことで最大効果を発揮する

・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AI購買エージェントに選ばれるECコンテンツの作り方
AIが人間に代わって購買候補を絞り込む動きが加速している。特にB2B向けのECサイトでは、購買担当者が「SOC2準拠でPython SDKを提供する上位3社」といった条件をAIに投げかけ、そのレポートを参考に最終判断する流れが現実のものになりつつある。
AIエージェントは人間のようにヒーローイメージやキャッチコピーに惹かれるわけではない。構造化された事実データだけを機械的に読み取り、仕様や準拠基準、統合性といったシグナルからベンダー候補をリストアップする。サイトがPDFやフォームの壁に閉ざされた情報ばかりだと、そもそも検討対象にも上がらない。
ここでは、WooCommerceを中心としたECサイト運営者が、AI購買エージェントに自社の商品や技術情報を正しく伝えるための実践的な手法を解説する。
PDF隠しの製品カタログはもう通用しない
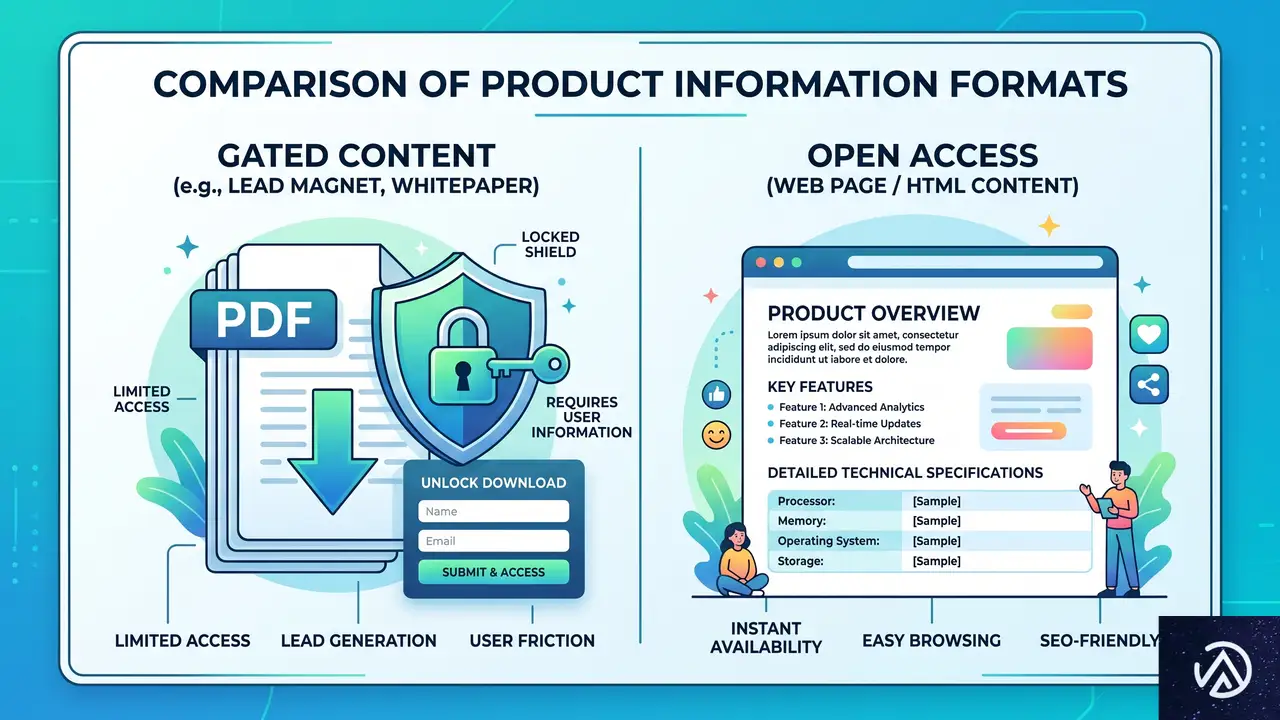
なぜPDFがAIに嫌われるのか
多くのEC事業者はホワイトペーパーや仕様書をPDFで配布し、ダウンロードフォームで囲い込む手法を取ってきた。しかしAIクローラーにとってPDFは重く、内部構造が不統一な場合が多い。テキスト抽出はできても、見出しの階層やリストの関係性を正確に解釈できないケースが少なくない。
結果として、製品スペックや準拠規格といった重要な情報が、AIの「目」にはただの平坦な文字列に映り、意図した評価を得られない。
構造化HTMLへ移行する具体的なステップ
対策はシンプルで、商品の詳細情報を高品質なWebページとして公開することだ。WooCommerceでは標準の商品ページを拡張し、技術仕様を整理したHTMLの表や箇条書きで提供できる。見出しタグの階層を意識し、<h3>に「対応OS」<h4>に「Windows Server 2022」というように、機械が理解しやすい構造を心がける。
次に示すのは、従来のゲート付きPDFとAI向けに最適化したWebページの比較イメージだ。
Model X-210 技術仕様
- 準拠規格: SOC 2 Type II, ISO 27001
- 提供API: Python SDK, RESTful API
- レイテンシ: 99.9%ile 10ms以下
このように、HTML上で仕様が明確に整理されていると、AIクローラーは即座に必要なデータを抽出できる。フォームの壁は不要な離脱を生み、AIには見えない障壁となるだけだ。
スキーママークアップで機械に読ませる
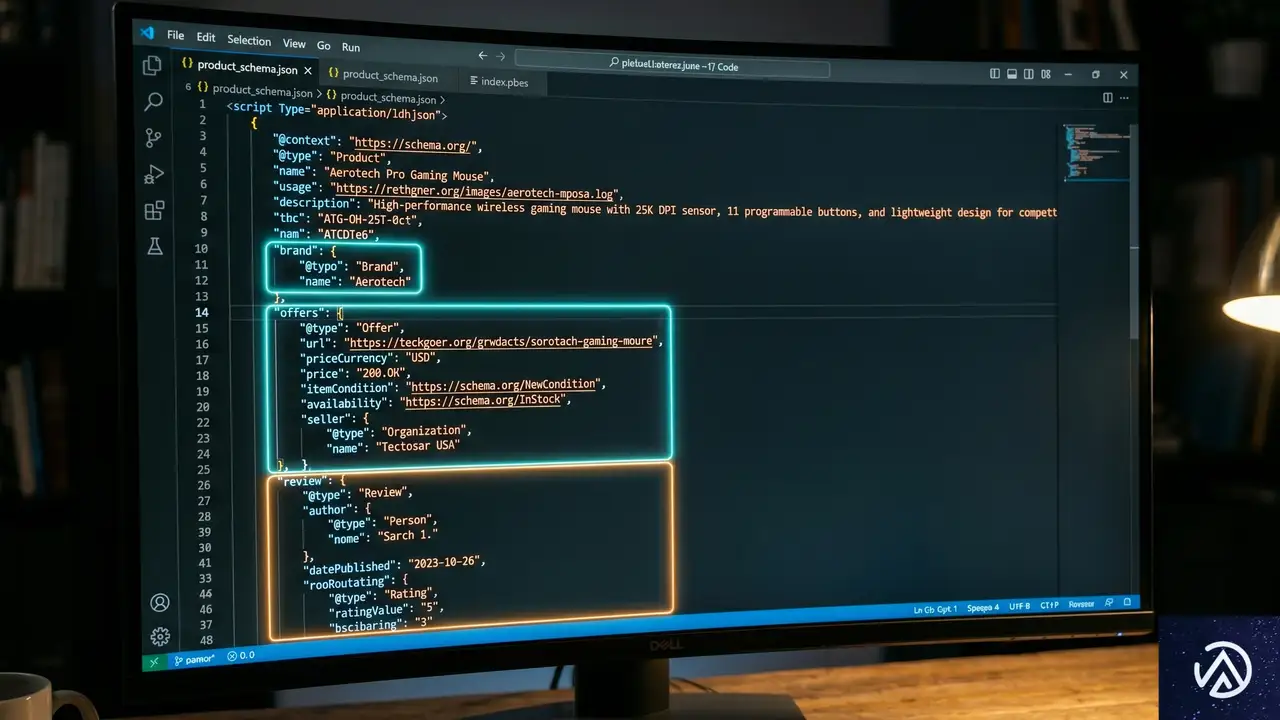
SEO担当者がGoogle向けに構造化データを埋め込むのと同じ理屈で、AIエージェントにページが「製品仕様」や「技術ドキュメント」であることを教え込める。Schema.orgの語彙を使い、製品の互換性や価格体系、認証情報をコード上で明示的に定義するのだ。
高性能プロセッサ搭載、信頼性の高い設計
価格はお問い合わせください
WooCommerceの場合、テーマのfunctions.phpにJSON-LDを追加するか、専用プラグインでProductスキーマを拡張できる。AIはこの情報を読み取り、価格帯や在庫状況、技術的要件を瞬時に理解する。推測の余地が減るほど、自社に有利な評価が返ってくる仕組みだ。
キーワード密度より意味的関連性を重視する
大規模言語モデルを搭載したAIエージェントは、キーワードの出現回数ではなく文脈の深さを評価する。つまり「スケーラブルなクラウドセキュリティパートナー」を探しているエージェントは、単に「スケーラブル」という単語を数えるのではなく、エッジケースへの対応手順や実装上のハードル、セキュリティプロトコルといった周辺知識のまとまりを重視する。
そこで有効なのがトピッククラスターの構築だ。商品ページだけでなく、技術ブログや導入事例、トラブルシューティングガイドなど関連性の高いページ群を内部リンクで結びつける。AIがサイト全体を巡回する際に、自社の専門性と信頼性を一貫したドキュメント群として認識させる狙いがある。
WooCommerceの商品ページでも、関連するドキュメントやFAQをブログカードやカスタムタブで表示する仕組みを導入すると効果的だ。AIはサイト全体の情報密度を評価するため、一貫した情報設計が結果的に購買候補としての優先度を上げる。
長尺資料にはAI向け要約を添える
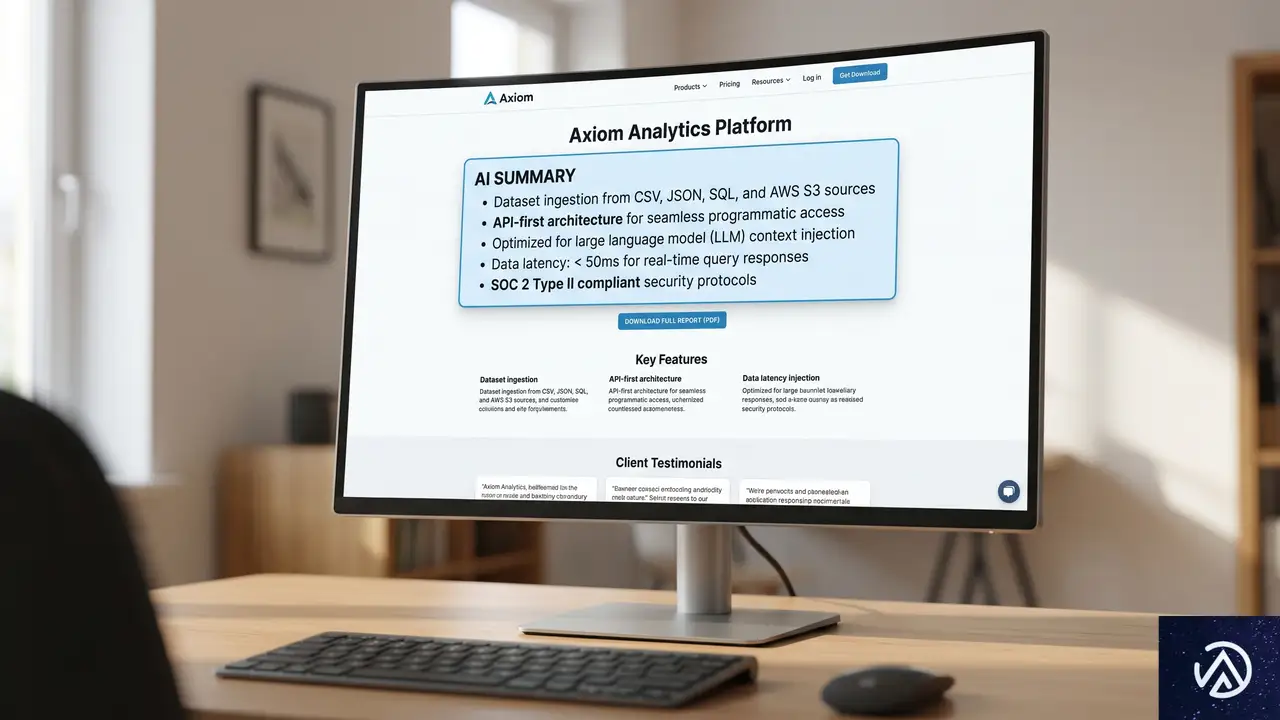
どうしても詳細な技術資料をPDFなどのゲート付きフォーマットで提供しなければならない場合もある。その場合は、ランディングページにAI専用の「機械可読要約(Machine-Readable Abstract)」を配置する戦略が有効だ。
この要約ブロックは、フォームに入力しなくても読めるオープンなHTMLテキストとして設置する。具体的には、製品の主要な主張、データポイント、技術要件を簡潔にまとめる。いわばAIのための「TL;DR(長すぎて読めない人向けの要約)」であり、約100〜200文字で十分だ。
【X-210 エッジコンピューティングノード】
- SOC2 Type II準拠、ISO 27001認証取得済み
- Python SDK と RESTful API を提供
- 99.9%ile レイテンシ 10ms 以下(自社ベンチマーク)
- 年間サブスクリプション:50万円〜(ボリュームディスカウントあり)
WooCommerceの商品説明欄の冒頭にこうした要約を記述するだけで、PDFをダウンロードする前にAIが内容を評価できる。製品の技術的な強みを素早く伝え、検討リスト入りの確率を高める一手になる。
AI購買エージェントに備えたEC設計の考え方

AIが購買活動の初期調査を担う流れは、B2B領域から着実に広がっている。大規模な広告予算より、アクセスしやすく構造化された正確なデータを持つブランドが優位に立つ時代だ。
ECサイト運営者は、自社の商品カタログや技術ドキュメントを「機械が読むことを前提としたアセット」に引き上げる必要がある。具体的な施策は、PDFの非構造化データからの脱却、スキーママークアップによる意味定義、トピッククラスターを用いた文脈強化、そしてAI向け要約の設置だ。
この記事のポイント
- AI購買エージェントは人間向けの装飾を無視し、構造化された仕様・準拠基準だけを評価する
- 商品情報をHTMLで公開し、スキーママークアップで意味を明確化することが不可欠
- キーワード密度より、トピッククラスターで専門性の高さを示す方がAIに信頼される
- ゲート付き資料には、AIが即座に理解できる要約ブロックを必ず付け加える
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

GoogleがFAQリッチリザルト廃止、AhrefsがスキーマのAI引用価値を否定
2026年5月、スキーママークアップの価値に冷や水を浴びせる二つの動きが重なった。GoogleはFAQリッチリザルトを廃止し、Ahrefsは構造化データがAI引用を増やさないとするレポートを公開した。
この連続パンチは、SERPでの視認性向上とAI引用獲得というスキーマの二大セールスポイントを直撃する。本記事では、今回の動きが持つ意味と、データが示すスキーマの未来像を掘り下げていく。
Googleがスキーマ特典を絞り込んだ5年間
FAQリッチリザルト廃止の最終決定
2026年5月12日、GoogleはFAQページ向けの構造化データを正式に廃止した。FAQリッチリザルトは検索結果上に質問と回答を展開表示する機能で、多くのサイトがクリック率向上のために導入してきた。Googleはこの廃止について「検索結果を簡素化し、ユーザーにとって本当に価値のある情報だけを表示するため」と説明している。
この決定は突然ではない。2023年8月にはFAQリッチリザルトの表示対象を政府機関や医療サイトなどの権威的サイトに限定していた。その時点で、一般的な商業サイトやブログでのFAQ表示はすでに停止されていた。今回の完全廃止は、その延長線上にある最終決定といえる。
GoogleのJohn Mueller氏はReddit上で「マークアップの種類は登場と消滅を繰り返すが、ごく一部の重要なものだけは残り続ける」とコメントしている。これはスキーマ全般を否定する発言ではないが、特定のリッチリザルトを戦略の柱に据えることのリスクを暗に示している。
可視的報酬のパターン
過去5年間の動きを振り返ると、明確なパターンが浮かび上がる。新しい構造化データが導入される。SEO業界がその使い方を検証し、広く導入する。数年のうちにGoogleがその表示特典を縮小または廃止する。そして業界は次の新しいスキーマタイプに注目を移す。
重要なのは、マークアップ自体が無効になるわけではない点だ。Googleのシステムは引き続きFAQ構造化データを読み取り、ページ内容の理解に活用する。しかし検索結果上での目に見える特典、つまりリッチリザルト表示という形での直接的なSEO効果は消滅した。
Ahrefsレポートが示したAI引用とスキーマの関係
1,885ページのA/B比較から見えたもの
Ahrefsは2026年5月16日、構造化データとAI引用の関係を検証した大規模レポートを公開した。調査対象はJSON-LD形式のスキーマを追加した1,885のウェブページ。各ページに対し、スキーマを追加しなかった同条件のコントロールページを用意し、Google AI Overviews、Google AI Mode、ChatGPTの3つのAIシステムで引用数の変化を計測した。
結果は次のとおりだ。
- Google AI Modeで引用が2.4%増加
- ChatGPTで引用が2.2%増加
- Google AI Overviewsで引用が4.6%減少
AI ModeとChatGPTの増加率は統計的な誤差の範囲内であり、スキーマの効果とは言い切れない数値だった。AI Overviewsの減少は統計的に有意だったが、Ahrefs自身が「この減少をスキーマが原因と断定することはできない」と慎重な見解を示している。
データが明かさなかった二つの前提
この調査結果を読む上で、二つの前提を見逃してはならない。
第一に、調査対象の全ページはスキーマ追加前からすでにAI Overviewsで100件以上の引用を獲得していた。つまり、これらのページはAIシステムによって十分にクロールされ、認識され、引用されていた。まだAIに認識されていないページでスキーマがクローリングやインデックス登録を助ける可能性は、このデータでは検証されていない。
第二に、この調査では全スキーマタイプを一括りにしている。Article、FAQ、Product、HowTo、Organizationなど種類の異なるスキーマがまとめて「スキーマあり」とラベル付けされた。タイプ別の効果は未検証であり、特定の種類で引用増加が起きる可能性は否定されていない。
Ahrefsのコンテンツマーケティング責任者であるRyan Law氏はLinkedIn上で「スキーママークアップを追加すればAI検索での引用が増えるか?おそらくノーだ」と端的に総括した。Law氏は「スキーマはAI引用を改善する魔法の解決策ではない」とも付け加えている。
業界内で広がった議論の温度感
「FAQスキーマはAI訓練用だった」という仮説
今回のFAQリッチリザルト廃止に対して、業界内ではさまざまな見解が飛び交った。なかでも注目されたのが、Marie Haynes ConsultingのMarie Haynes氏が提示した仮説だ。
Haynes氏は「GoogleはAIを訓練するためにFAQデータが必要だったので、リッチリザルトという形でインセンティブを与えた。そして今、もうそのデータは不要になった」という見方を示した。この説はGoogle自身によって確認されたものではないが、FAQスキーマ導入から廃止までのタイムラインを説明する一つの解釈として、多くの実務者の関心を集めた。
GEO業界への波紋
SEOの専門家であるLily Ray氏(Amsive社、SEO・AIサーチ担当VP)はLinkedIn上で「FAQスキーマはGEOにとって重要」というフレーズが約16万8000ページで使われていることを指摘し、「SEOでスパム可能なものは必ずスパムされる」と述べた。Ray氏は2019年にFAQスキーマが初めて導入された際のMoz記事でこのサイクルを予見していた。
Yoastの創業者であるJoost de Valk氏は、この事態を「GEO業界は初期SEOの歴史を高速で再現している」と表現し、「FAQスキーマの廃止はそのサイクルが再起動した最初の具体的な証拠だ」と自身のブログで述べた。de Valk氏はSchema.orgに対して、FAQSectionという新しいタイプを提案するissueも提出している。これは「このページにFAQセクションがある」という情報と「このページ自体がFAQである」という情報を構造的に分離するための提案だ。
データが答えられなかった問い
■ スキーマタイプ別の効果(Article/Product/FAQを個別検証していない)
■ 30日を超える長期的効果
■ Bing/Copilot/Perplexity/Claude での挙動
■ JavaScript経由で注入したスキーマの効果
検証されていない経路
Ahrefsの計測対象はGoogle AI Overviews、AI Mode、ChatGPTの3システムに限られる。BingやCopilot、Perplexity、Claudeなど他のAI検索システムがスキーマをどのように扱うかは未検証だ。これらのシステムはGoogleとは異なるクローリングやパースの仕組みを持つ可能性がある。
また、searchVIU(2025年)の実験では、5つのAIシステムがページを直接取得する段階で、表示テキスト(HTML)を参照し、JSON-LDやMicrodata、RDFaなどの隠されたマークアップは使用していなかったと報告されている。これは取得段階に限った話であり、インデックス登録やエンティティ理解の段階でスキーマが役立つ可能性を否定するものではない。
計測期間とタイプ混在の問題
Ahrefsの調査期間は30日間である。スキーマ追加の効果がさらに長期間かけて現れる可能性や、スキーマ追加と同時に行われた他のページ変更の影響を分離できていない点も、解釈上の注意が必要だ。
GoogleはFAQスキーマの廃止告知の中で、構造化データを「ページをよりよく理解する」ために使い続けると述べている。この「よりよく理解する」という表現が具体的に何を指し、どのような測定可能な結果につながるのかは、現時点では明らかになっていない。エンティティ理解やソース選定への間接的な影響を測定したデータは、まだ誰も公表していない。
SEO実務者がいま取るべき戦略
■ 「スキーマを追加すればAI引用が増える」というGEOの売り文句はデータで裏付けられていない
■ Organization、Person、Article スキーマ → エンティティ記述としての価値は残る
■ 見出し構造の明確化、本文での直接的な回答提示 → AI引用に効く可能性が高い
特定スキーマへの過度な依存を避ける
まず確認すべきは、今回のFAQリッチリザルト廃止がスキーマ全体の否定ではないという点だ。Product、Review、Event、Videoといった一部の構造化データは、引き続きアクティブなリッチリザルト機能をサポートしている。Organization、Person、Articleマークアップも、エンティティやコンテンツの記述手段として価値を持ち続ける。
問題は、特定のスキーマタイプを戦略の柱にしてしまうことだ。過去5年間のパターンが示すように、Googleは普及したマークアップの表示特典を段階的に縮小する傾向がある。スキーマは検索エンジンにとっての「水道管」であり、一度敷設すれば特定の蛇口(リッチリザルト)が閉まっても、別の形で水(データ)を運び続ける可能性は残る。
AI引用を狙うならHTML構造を見直す
searchVIUの調査が示したのは、AIシステムがページ取得時にJSON-LDではなく表示テキスト(可視HTML)を参照しているという事実だ。この結果は、AI引用を増やすためにはスキーマよりもコンテンツ自体の構造が重要である可能性を示唆する。
具体的には、見出しを階層的に整理すること、質問に対して本文中で直接的な回答を示すこと、情報を明確なセクションに分けること、といった基本的なコンテンツ設計が、マークアップよりもAI引用に効くかもしれない。スキーマの導入を否定するデータではないが、スキーマだけでAI引用が増えるという期待はデータで裏付けられなかった。
この記事のポイント
- Googleは2026年5月にFAQリッチリザルトを完全廃止し、可視的スキーマ特典の縮小傾向が続いている
- Ahrefsの調査(1,885ページ)では、JSON-LD追加によるAI引用の増加は統計的に確認されなかった
- GEO業界で広がった「スキーマでAI引用が増える」という売り文句は、データによる裏付けを欠いている
- ProductやOrganizationなどリッチリザルトが現役のスキーマタイプは引き続き価値を持つ
- AI引用を狙うなら、スキーマ以上にHTML構造の明確化と本文での直接回答が重要になる可能性が高い
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Google Zeroの先にある真実:AIエージェントに最適化する「エージェントSEO」の重要性
Googleからの検索流入がゼロになるという「Google Zero」の言説が、Webマーケティングの世界で波紋を広げている。しかし、真に直面している課題はトラフィックの消失ではなく、Webサイトを訪れる主役が人間から「AIエージェント」へと交代し始めている事実だ。
最新の調査データによれば、Webトラフィックの51%はすでに人間によるものではなく、ボットによる自動化されたアクセスが占めている。この劇的な変化は、従来のSEO戦略を根本から書き換える必要性を物語っている。
本記事では、AIクローラーの急増やAIエージェントによる意思決定の代行がWebサイト運営にどのような影響を与えるのかを分析する。その上で、これからの時代に求められる「エージェントSEO」の具体的な実践方法について解説していく。
「Google Zero」説の裏側とボットトラフィックの急増

SEO業界では、Googleの検索結果にAIによる回答(AI Overview)が表示されることで、Webサイトへのクリックが激減するという懸念が根強い。しかし、SEOコンサルタントのBarry Adams氏が指摘するように、主要なWebサイトへのGoogleトラフィックは世界全体で2.5%程度の減少にとどまっているとのデータもある。
一方で、サーバーログの向こう側では別の巨大な変化が起きている。人間のクリックが完全に消滅したわけではないが、訪問者の構成比率が劇的に変わっているのだ。
AIクローラーが検索エンジンを追い抜く日
Impervaの「2025 Bad Bot Report」によると、自動化されたトラフィックが10年ぶりに人間による活動を上回った。現在、全Webトラフィックの51%がボットによるものだという。これには悪意のある攻撃ボットも含まれるが、最も急速に成長しているのはAIクローラーのセグメントだ。
Cloudflareの分析によれば、AIクローラーは全クローラー・トラフィックの51.69%を占めるまでに成長し、従来の検索エンジンクローラー(34.46%)を追い越した。AIボットによるクロール活動は、前年比で15倍以上に増加している。特にOpenAIの活動は凄まじく、AIボットリクエスト全体の42.4%を占めているとされる。
クローラーとは、Webサイトの情報を収集するために自動でページを巡回するプログラムのことだ。かつてはGooglebotがその主役だったが、現在はChatGPTやClaudeなどのAIをトレーニングするためのボットが、それ以上の頻度でサイトを訪れている状況だ。
「訪問者の半分は人間ではない」という前提
この数字が意味するのは、Webサイト運営者が最適化すべき対象が「人間の読者」だけではなくなっているということだ。AIは情報を収集し、自らの知識ベースに取り込むためにサイトを訪れる。その際、人間のようにバナー広告を見たり、感情に訴えるコピーに反応したりすることはない。AIが必要としているのは、純粋なデータと論理的な構造だ。
崩壊する「コンテンツ提供と引き換えの集客」という互恵関係
これまでの検索エンジンとWebサイト運営者の間には、シンプルな取引が成立していた。サイト側が良質なコンテンツを提供し、Googleがそれをインデックス(登録)する代わりに、情報を探しているユーザーをサイトへ送り返すというモデルだ。しかし、AIの台頭はこの互恵関係を揺るがしている。
AIボットの圧倒的な「持ち去り」比率
Cloudflareが公開した「クロール数に対するリファラル(流入)の比率」は衝撃的だ。Anthropic社のClaudeBotは、1件の流入をサイトに送るために、23,951ページものクロールを行っている。OpenAIのGPTBotも、1,276ページを読み込んでようやく1人をサイトへ送る計算だ。
対照的に、従来のGooglebotはサイトの情報を読み取った後、AIシステムよりも831倍多くの訪問者をサイトに送り返している。AIボットの主な目的は「トレーニング」であり、ユーザーをサイトへ誘導することではない。情報を「取る」だけで「返さない」という、非対称な関係が鮮明になっている。
Google自身のAI化によるゼロクリックの加速
Google自体もこの流れに追随している。AIによる概要表示(AI Overview)が行われる検索クエリでは、オーガニック検索のクリック率が58〜61%低下するという調査結果がある。さらに、Googleの新しい「AIモード」では、ゼロクリック率(検索結果からどこにも遷移しない割合)が93%に達することもあるという。
また、GoogleのAIが回答の引用元として自社サービス(Google.comやYouTubeなど)を優先的に表示する傾向も強まっている。SE Rankingの調査では、AIモードの引用元の約20%がGoogle関連のプロパティで占められていた。外部サイトへのトラフィックを促すという検索エンジンの役割が、自社AIの回答精度を高めるための「データソース利用」へと変質しつつあるのだ。
次の波は「AIエージェント」による意思決定の代行

ボットトラフィックの増加は序章にすぎない。次にやってくるのは、人間に代わって調査、比較、そして購入の意思決定までを行う「AIエージェント」の普及だ。これは単なる検索の自動化ではなく、購買プロセスの構造そのものを変える可能性を秘めている。
購買プロセスの自動化とB2B市場への影響
Gartnerの予測によれば、2028年までにB2B(企業間取引)における購買活動の90%が、AIエージェントを介したものになるという。これは15兆ドルを超える支出が、AI同士のやり取りによって決定されることを意味する。AIエージェントは、調達チームのためにベンダーを調査し、スペックを比較し、最終的な候補リストを作成する。
このプロセスにおいて、AIエージェントはWebサイトの派手なヒーロー画像や、信頼感を演出するバッジには見向きもしない。彼らが読み取るのは、構造化されたデータ、技術仕様、そしてクリーンなHTMLで記述された価格表だ。人間がサイトを訪れて「なんとなく良さそうだ」と感じる前に、マシンが冷徹に候補から外してしまう可能性がある。
人間の目に触れない「訪問」の正体
AIエージェントによる「訪問」は、従来のアクセス解析ツールでは正しく計測できないことが多い。解析画面上では「滞在時間0秒のボットアクセス」として片付けられてしまうか、あるいはフィルタリングされて表示すらされない。しかし、その0秒のアクセスの裏側で、AIが数千万円規模の契約判断を行っているかもしれないのだ。
Salesforceの報告によると、2025年のサイバーウィーク(大規模セール期間)では、AIエージェントが全世界の注文の20%に影響を与え、670億ドルの売上を牽引したという。AIエージェントを活用している小売業者は、活用していない業者に比べて6倍以上の売上成長率を記録している。AIに「見つけてもらい、選んでもらう」ことの経済的価値は、すでに無視できない規模に達している。
マシンに選ばれるための「エージェントSEO」の実践

訪問者が人間からマシン(AIエージェント)へとシフトする中で、私たちは何を最適化すべきなのだろうか。それは従来の「検索順位を上げるためのSEO」とは異なるアプローチ、いわば「エージェントSEO」と呼ぶべき手法だ。
構造化データが「店舗の顔」になる
これまでの構造化データ(Schema markup)は、検索結果に星印や価格を表示させるための「おまけ」のような扱いだった。しかしAIエージェントにとっては、これが情報の主要な入り口となる。構造化データが正しく実装されていれば、AIは推測に頼ることなく、製品のスペックや価格、FAQを正確に読み取ることができる。
以下に、AIエージェントが情報を読み取りやすい構造化データ(JSON-LD)の概念を視覚化してみよう。AIは人間が見るデザインではなく、このような「整理されたデータ」をスキャンしている。
“name”: “CRM Pro”,
“price”: 5000,
“currency”: “JPY”,
“category”: “SaaS”
このデモのように、AIは視覚的なデザインを無視して、背後にあるデータの整合性をチェックする。構造化データは単なるSEOのテクニックではなく、Webサイトという店舗における「AI向けの商品棚」としての役割を担うようになる。
複雑な複合質問(コンパウンド・クエスチョン)への対応
AIエージェントは「中小企業向け CRM」といった単純なキーワードで検索しない。彼らは「月額5,000円以下で、会計ソフトと連携でき、オフライン対応のモバイルアプリがあるCRMはどれか?」といった、複数の条件が重なった複雑な質問(複合質問)を投げかける。
これに対応するには、コンテンツの作り方を変える必要がある。単にキーワードを散りばめるのではなく、具体的な仕様、互換性、価格体系、制限事項などを、明確かつ論理的に記述しなければならない。曖昧な表現を排除し、AIが「この製品は条件を満たしている」と断定できる材料を提供することが重要だ。
計測不能な領域にどう立ち向かうか

「Google Zero」論争が有害なのは、Googleからの流入数という目に見える指標だけに固執させ、その裏で起きている「計測できない価値」を無視させてしまう点にある。GA4などの一般的なアクセス解析ツールでは、AIエージェントがもたらした貢献を追跡することはほぼ不可能だ。
既存のアクセス解析の限界
これまでのWebマーケティングは、クリックからコンバージョンまでを線で結ぶことができた。しかし、AIエージェントの世界では、AIがWebサイトを数回クロールし、その情報を元にユーザーに推薦を出し、ユーザーが直接公式サイトの「購入ページ」を訪れる、あるいはAIが決済まで代行するといった経路を辿る。この場合、最初のきっかけとなったWebサイトへの貢献度は、アクセス解析上では「ノーリファラー(直接流入)」や「ボット」として埋もれてしまう。
この「測定のギャップ」を放置すると、経営層は「SEOの効果が落ちている」と判断し、予算を削ってしまうかもしれない。しかし、実際にはAIエージェントを介して大きな売上が発生している可能性がある。私たちは、クリック数以外の新しい指標――例えば「AIプラットフォームでの言及数」や「ブランド名の指名検索数」などを組み合わせた、多角的な評価軸を持つ必要がある。
今すぐ取り組むべき5つのステップ
AIエージェント時代に備えるために、Webサイト運営者が今すぐ着手すべきアクションをまとめた。これらはGoogle SEOを捨てることではなく、その上に新しいレイヤーを追加する作業だ。
- 構造化データの完全監査:製品、サービス、FAQ、組織情報などのスキーマが正確で最新かを確認する。これはAIにとっての「履歴書」である。
- 複合質問への回答コンテンツ作成:ユーザー(またはAI)が抱く具体的な条件付きの疑問に対し、表やリストを用いて明確に回答するページを用意する。
- サーバーログのモニタリング:GPTBotやClaudeBot、PerplexityBotなどのAIクローラーがどの程度の頻度で訪れているかを把握する。
- robots.txtの戦略的判断:AIへの情報提供を拒否するか、あるいはAIに選ばれるために開放するかを、技術的な設定ではなく「経営判断」として決定する。
- AI引用のトラッキング:SemrushやPerplexityなどのツールを使い、自社ブランドがAIの回答内でどのように引用されているかを定期的にチェックする。
この記事のポイント
- Webトラフィックの51%はすでにボットであり、AIクローラーの活動は前年比15倍に急増している。
- AIボットは情報を収集するだけでサイトへユーザーを返さない傾向があり、従来の互恵関係が崩壊しつつある。
- 2028年までにB2B購買の90%にAIエージェントが介在すると予測され、マシン向けの最適化が不可欠になる。
- 「エージェントSEO」の核は、正確な構造化データの実装と、複雑な条件付き質問への論理的な回答である。
- 従来のアクセス解析ではAIの貢献を測定しきれないため、クリック数以外の新しい評価指標を持つことが求められる。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AEO(回答エンジン最適化)の新戦略:AI検索でコンテンツを引用させるための構造化手法
検索エンジンの役割が「リンクの羅列」から「直接的な回答」へと劇的に変化している。GoogleのAI OverviewsやMicrosoft Copilot、PerplexityといったAI検索エンジンの普及により、Webサイトの運営者は従来のSEO(検索エンジン最適化)に加えて、AEO(Answer Engine Optimization:回答エンジン最適化)への対応を迫られている状況だ。
最新の調査データによれば、AI検索からのトラフィックは月間約1%のペースで成長を続けており、特定の業界では無視できない規模に達している。AIにコンテンツを引用させ、自社の認知度を高めるためには、これまでの「ページ単位の評価」という考え方を捨てる必要がある。
この記事では、AIがどのようにコンテンツを解析し、どの断片を回答として採用するのかを、最新の研究結果と技術的な視点から詳しく解説する。AI時代に生き残るためのコンテンツ構造の作り方を、具体的なステップと共に見ていこう。
AIは「ページ」ではなく「断片」でコンテンツを評価する

従来の検索エンジンは、キーワードの関連性やリンクの強さを基に「Webページ全体」をランク付けしてきた。しかし、AI検索エンジンは全く異なるアプローチを取る。AIはページを読み込む際、内容を細かな「断片(フラグメント)」に分解して理解しようとする。このプロセスは「パージング(解析)」と呼ばれ、AIが回答を生成するための基礎となる。
パージング(解析)というプロセスの理解
MicrosoftのBingチームでプリンシパル・プロダクトマネージャーを務めるKrishna Madhavan氏によれば、AIアシスタントはコンテンツを構造化された小さな断片に分解し、それぞれの権威性と関連性を評価する。そして、複数のソースから抽出した最適な断片を組み合わせて、一つの首尾一貫した回答を作り出すのだ。
これは、たとえGoogleで検索順位が1位だったとしても、コンテンツの構造がAIにとって抽出困難であれば、AIの回答には引用されない可能性があることを示している。AIは「最も優れたページ」を探しているのではなく、「質問に対する最も適切な回答の断片」を探しているからだ。
AIトラフィックの現状と成長率
2026年1月のConductor AEO/GEOベンチマークレポートによると、AI経由のトラフィックはWebサイト全体のセッションの約1.08%を占めている。数字だけ見れば小さく感じるかもしれないが、前年比で357%もの急増を見せたケースもあり、その成長速度は驚異的だ。
特に医療分野では、Google検索の約2回に1回がAIによる概要表示(AI Overviews)を伴うというデータもある。ユーザーが検索結果のリンクをクリックする前にAIの回答で満足してしまう「ゼロクリック検索」が増える中で、AIの回答内に自社サイトが「出典」として引用されることは、新たな流入経路を確保するための生命線となる。
研究結果から判明した「引用されやすいコンテンツ」の条件

どのようなコンテンツがAIに好まれるのかについては、すでに複数の大学や研究機関が実証実験を行っている。その中でも、プリンストン大学やジョージア工科大学などが発表した「GEO(Generative Engine Optimization:生成エンジン最適化)」に関する論文は、非常に示唆に富んでいる。
GEO(生成エンジン最適化)の有効な手法
この研究では、9つの最適化戦略をテストした結果、特定のテクニックによってAI回答での視認性が最大40%向上することが確認された。最も効果的だったのは「信頼できる情報源の引用」だ。統計データや専門家の発言を適切に引用しているサイトは、そうでないサイトに比べて視認性が115.1%も増加したという。
一方で、意外な事実も判明している。文章を「説得力のあるトーン」や「権威を感じさせる文体」で書くことは、AIの引用率向上にはほとんど寄与しなかった。AIはレトリック(修辞学)に惑わされることはなく、検証可能な事実と論理的な構造を重視している。マーケティング的な装飾よりも、裏付けのある情報提供が優先される環境だ。
第三者メディア(アーンドメディア)の圧倒的な影響力
トロント大学が2025年9月に行った調査では、ChatGPTやPerplexityなどの主要AIエンジンが、自社サイトよりも「第三者による評価」を圧倒的に信頼していることが明らかになった。例えば家電分野では、AIが引用するソースの92.1%が第三者の専門メディアやレビューサイトであり、メーカー公式サイトの引用率は極めて低かった。
これは、自社サイト内でのSEOだけでは不十分であることを意味している。業界紙への寄稿、プレスリリース、信頼性の高い比較サイトへの掲載といった「アーンドメディア(獲得メディア)」での露出が、間接的にAI検索での視認性を高める鍵となる。AIはインターネット全体を俯瞰し、多くの場所で言及されている情報を「真実」として採用する傾向があるからだ。
AIに選ばれるための具体的な構造化テクニック

AIがコンテンツを「断片」として抽出する以上、制作者側も「抽出されやすい形」で情報を提供しなければならない。ここでは、MicrosoftやGoogleのガイドライン、および最新の研究に基づいた具体的な構成案を提示する。
見出しの役割とQ&A形式の採用
見出し(H2やH3タグ)は、AIにとって「ここから新しい概念が始まる」という強力なシグナルになる。「概要」や「詳細はこちら」といった曖昧な見出しは避け、そのセクションの内容を正確に記述した見出しを付けるべきだ。例えば「AIによるコンテンツ解析の仕組み」といった具体的な表現が望ましい。
また、ユーザーの質問をそのまま見出しにし、その直後で端的に回答する「Q&A形式」はAIとの相性が抜群だ。AIアシスタントは、この質問と回答のペアをそのままコピーしてユーザーに提示することが多いため、引用される確率が飛躍的に高まる。結論を先に述べ、その後に詳細な解説を続ける「逆ピラミッド型」の記述を徹底しよう。
「スニッパブル(切り出し可能)」なレイアウト設計
AIは長い段落よりも、箇条書き、番号付きリスト、比較表といった構造化されたデータを好む。これらは「スニッパブル(Snippable)」、つまり簡単に切り出せる形式だからだ。情報を整理して提示することで、AIは人間と同じように「このサイトは情報が整理されていて分かりやすい」と判断する。
以下のデモは、AIが情報を抽出しやすい「構造化された比較」のイメージだ。このように明確な境界線とラベルを持つ構成は、AIによるパージングを助ける効果がある。
<!-- 構造化された情報の例 -->
<div class="comparison-box">
<h4>SEOとAEOの違い</h4>
<ul>
<li>SEO:検索順位を上げ、サイトへの流入を最大化する</li>
<li>AEO:AIの回答に採用され、情報の正確性を担保する</li>
</ul>
</div>対象:ページ全体の評価
指標:クリック率(CTR)
対象:情報の断片(フラグメント)
指標:引用シェア・ブランド認知
このデモのように、情報を対比させて整理することで、AIは「SEOとAEOの違い」という文脈を即座に理解できる。
権威性のシグナルとスキーママークアップの活用
AIに「この情報は正しい」と確信させるためには、技術的な裏付けが必要だ。ここで重要になるのが、Googleも重視しているE-E-A-T(経験・専門性・権威性・信頼性)の概念と、それを機械に伝えるための「構造化データ」である。
E-E-A-Tと情報の鮮度
Microsoftのガイドラインでは、成功するコンテンツの条件として「新鮮で、権威があり、構造化され、意味的に明確であること」を挙げている。特に「意味的な明確さ」についてはシビアだ。「革新的な」「最先端の」といった曖昧な形容詞は、AIにとっては評価の対象にならない。それよりも「従来比で処理速度が30%向上した」といった、測定可能な事実に基づいた記述が求められる。
また、情報の鮮度(フレッシュネス)も重要なシグナルだ。古いデータや更新が止まったコンテンツは、AIに「不正確な可能性がある」と判断され、引用候補から外されやすい。定期的なリライトと、公開日・更新日の明示は必須と言える。
AIの理解を助ける構造化データの種類
スキーママークアップ(構造化データ)は、人間向けのテキストを「機械が理解できるデータ」に変換する翻訳機の役割を果たす。Microsoftは、スキーマを利用することでAIがコンテンツの内容を推測する必要がなくなり、自信を持って回答に採用できるようになると指摘している。
特にAEOにおいて優先順位が高いスキーマは以下の通りだ。
- FAQPage:質問と回答のペアを定義する。AIが最も引用しやすい形式だ。
- HowTo:手順やステップを定義する。ハウツー系の回答に採用されやすくなる。
- Product:価格、在庫、レビューを定義する。ECサイトのAI検索対応には必須だ。
- Article / BlogPosting:著者情報や公開日を定義し、情報の信頼性を高める。
これに加えて、サイトの更新を検索エンジンに即座に通知する「IndexNow」を併用することで、情報の鮮度と正確性を高いレベルで維持することが可能になる。
クローラー制御と計測の進め方

AI検索エンジンに対応するためには、どのクローラーを許可し、どのクローラーを制限するかという戦略も重要になる。また、施策の結果をどのように計測するかも、従来のSEOとは異なる視点が必要だ。
robots.txtによる学習と検索の切り分け
主要なAIプラットフォームは、クローラーを「検索用」と「モデル学習用」で分けていることが多い。例えばOpenAIの場合、OAI-SearchBot はChatGPTの検索機能(回答への引用)に使用されるが、GPTBot は将来のモデル学習に使用される。
自社のコンテンツをAIの回答に引用させたいが、AIモデルの学習に無償で使われるのは避けたいという場合は、robots.txt で個別に制御することが可能だ。検索用ボットを許可し、学習用ボットを拒否することで、著作権を保護しつつ検索流入を確保するバランスが取れる。
AI経由の流入を可視化する方法
AEOの成果を測る最も手軽な方法は、Bing Webmaster Toolsを活用することだ。ここには「AIパフォーマンスレポート」があり、Microsoft Copilotでの引用状況やクリック数を確認できる。Googleについては、Search Consoleの検索パフォーマンスから「検索タイプ:AI Overview(またはそれに類するフィルタ)」で動向を追うことになる。
また、ChatGPTからの流入は、アクセス解析ツールで utm_source=chatgpt.com というパラメータが付与される仕様になっている。これをモニタリングすることで、AI検索がどの程度自社サイトへのトラフィックに貢献しているかを具体的に把握できる。従来の「キーワード順位」だけでなく、「AI回答内でのシェア」を新たな指標として設定すべきだ。
この記事のポイント
- AIはページ全体ではなく、構造化された「断片(フラグメント)」を抽出して回答を生成する。
- 信頼できるソースの引用や統計データは、AI回答での視認性を100%以上向上させる可能性がある。
- 自社サイトの改善だけでなく、第三者メディアでの露出(アーンドメディア)がAIの信頼獲得に直結する。
- Q&A形式、箇条書き、スキーママークアップを活用し、AIが解析しやすい「スニッパブル」な構造を作る。
- Googleは「質の高いコンテンツ」と抽象的に述べるが、Microsoftは具体的な構造化の手法を公開しており、後者のガイドラインがAEOの指針となる。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AI検索時代のCMS選び——WebサイトがAI対応できているか実践的な監査手法
AI検索がブランドの可視性とコンバージョンを獲得する方法を再構築している。多くのCMSはこの変化に対応するようには設計されていない。
Search Engine Journalの記事によれば、AI検索対応の監査では構造化データ、柔軟なアーキテクチャ、迅速な適応性が評価基準となる。CMOやマーケティングリーダーは自社のCMSが現代の検索行動をサポートしているか、制限しているかを評価する必要がある。
この記事では、AI検索時代にWebサイトのCMSが備えるべき要件と、実践的な監査手法を解説する。監査を通じて、成長を阻害するリスク領域を事前に特定する方法がわかる。
AI検索が変えるSEOとコンテンツの前提

従来の検索エンジンはユーザーのクエリに合致するWebページをリスト表示していた。AI検索はこのモデルを根本から変える。AIは複数の情報源から情報を統合し、直接的な回答を生成する。
「10個の青いリンク」から「単一の回答」への移行
GoogleのSGE(Search Generative Experience)やMicrosoftのCopilotは、検索結果の上部にAIが生成した回答を表示する。ユーザーは回答を得るために複数のページをクリックする必要がなくなる。
この変化はトラフィックの分散を意味する。かつては1つのクエリで複数のサイトがクリックを獲得できた。AI検索では、回答を生成するために参照された数サイトのみが引用され、他のサイトは結果ページから姿を消す可能性がある。
コンテンツの「解釈可能性」が重要になる
AI検索エンジンはWeb上のコンテンツを読み取り、理解し、要約する。このプロセスで重要なのは、コンテンツが機械的に解釈しやすい構造になっていることだ。
記事によれば、AI対応のCMSはコンテンツを単なるテキストの塊ではなく、意味的に構造化されたデータとして扱う必要がある。著者は、構造化されていないコンテンツはAIによって正確に解釈されず、検索結果で引用される機会を失うと指摘している。
AI対応CMS監査の3つの核心領域

CMOやマーケティング責任者が自社のCMSを評価する際、以下の3つの領域に焦点を当てるべきだ。これらの領域は、AI検索時代における発見可能性とコンバージョン性能を直接左右する。
1. 構造化コンテンツとデータモデリング
構造化コンテンツとは、コンテンツを構成する要素(タイトル、著者、公開日、製品仕様、価格など)を定義し、一貫した形式で保存・管理するアプローチだ。HTMLの見出しタグや段落だけでなく、JSON-LDやMicrodataなどの構造化データマークアップがこれに該当する。
監査の第一歩は、サイトのコンテンツがどの程度構造化されているかを確認することだ。すべてのページに適切なスキーママークアップが実装されているか。ブログ記事、製品ページ、イベント情報など、コンテンツタイプごとに最適な構造化データが使われているか。
記事で言及されているDrupalの例では、エンタープライズ実装において構造化コンテンツのモデリングが不十分なケースが多く、これがAI検索での発見可能性を制限する要因となっている。CMSの管理画面でコンテンツタイプとフィールドを柔軟に定義できるかが、構造化の成否を分ける。
2. コンポーザブルアーキテクチャとAPIファースト設計
コンポーザブルアーキテクチャとは、システムを独立したサービスやコンポーネントに分解し、APIを通じて連携させる設計思想だ。ヘッドレスCMSやAPIファーストCMSはこのアーキテクチャの代表例である。
AI検索エンジンは、コンテンツを取得して処理する必要がある。従来のモノリシックなCMSでは、フロントエンドのHTMLレンダリングとバックエンドのデータ管理が密結合している。これに対してAPIファースト設計のCMSは、純粋なデータ(JSON形式など)を提供できる。
監査では、CMSがRESTful APIやGraphQLを提供しているか、そのAPIがすべてのコンテンツタイプにアクセスできるかを確認する。さらに、APIのレスポンス速度と信頼性も評価項目となる。遅いAPIはAIクローラーのインデックス効率を下げる。
3. オープンソースの柔軟性と開発速度
AI検索の要件は急速に進化する。今日有効な最適化手法が、半年後も通用する保証はない。この変化に対応するには、CMS自体が柔軟で拡張可能である必要がある。
オープンソースCMS(WordPress、Drupal、Joomlaなど)は、コア機能を拡張する無数のプラグインやモジュールを利用できる。プロプライエタリなSaaS型CMSでは、ベンダーが新機能を実装するのを待たなければならない場合がある。
監査では、CMSのエコシステムが活発か、新しい技術(例えば、AI検索向けの新しい構造化データ形式)に対応するモジュールが迅速に開発されるかを調べる。開発チームがカスタム機能を実装するためのドキュメントとAPIは整っているか。
実践的な監査チェックリスト

理論的な要件を理解したら、実際のWebサイトに対して実行できる監査項目を確認する。以下のチェックリストは、Search Engine Journalの記事で紹介された監査手法を基に、実践的な項目をまとめたものだ。
技術的インフラの評価
まず、サイトの技術的基盤がAIクローラーや検索エンジンに友好的かどうかを確認する。
- ページ速度とコアウェブバイタル: GoogleのPageSpeed InsightsやLighthouseでスコアを計測する。特にLCP(Largest Contentful Paint)、FID(First Input Delay)、CLS(Cumulative Layout Shift)の3指標は、ユーザー体験だけでなく、クローラーのページ読み込み効率にも影響する。
- モバイルフレンドリー: Googleのモバイルフレンドリーテストを実行する。AI検索はモバイルユーザーへの回答生成を特に重視する。
- XMLサイトマップの完全性: すべての重要なページがサイトマップに含まれ、正しい更新日付と優先度が設定されているか。サイトマップはAIクローラーに対するナビゲーションの役割を果たす。
- robots.txtの設定: 重要なコンテンツが誤ってクロール禁止になっていないか。動的パラメータなどによる重複コンテンツがインデックスされていないか。
コンテンツ構造とデータの評価
次に、コンテンツそのものの構造と質を評価する。
- 構造化データマークアップの検証: Googleの構造化データテストツールやRich Results Testを使用する。Article、Product、Event、FAQPage、HowToなど、コンテンツに適したスキーマタイプが実装されているか。
- コンテンツの独自性と深さ: AIは表面的なコンテンツを要約しても価値が低い。独自の調査データ、詳細な手順、専門家の洞察など、深みのあるコンテンツがAIに引用される可能性が高い。
- エンティティの明確さ: コンテンツ内で言及されている企業名、人物名、製品名、場所などが明確に定義されているか。これらはAIがコンテキストを理解する上で重要な手がかりとなる。
- コンテンツの新鮮さ: 最終更新日が明示されているか。古い情報はAIの信頼性判断で不利に働く可能性がある。
CMSプラットフォーム固有の評価
最後に、使用しているCMS自体の能力と制限を評価する。
- 構造化コンテンツ管理機能: CMSはカスタムフィールドやコンテンツタイプを直感的に作成・管理できるか。フィールド間の関係性(リレーションシップ)を定義できるか。
- APIの成熟度: CMSが提供するAPIは包括的か、セキュリティとパフォーマンスの面で信頼できるか。ドキュメントは整っているか。
- ワークフローとコラボレーション: AI時代はコンテンツの迅速な更新と最適化が求められる。CMS内で編集、承認、公開のワークフローが効率的か。複数人での同時編集をサポートしているか。
- エコシステムと統合可能性: CDN、分析ツール、マーケティングオートメーションなど、外部サービスと容易に連携できるか。AI関連サービス(自然言語処理APIなど)との統合は想定されているか。
監査結果に基づくアクションプラン

監査は現状分析で終わっては意味がない。結果を基に具体的な改善アクションに落とし込む必要がある。監査で明らかになったギャップは、短期・中期・長期のアクションに分類できる。
短期対応:即効性のある技術的修正
監査で発見された技術的な問題点のうち、比較的少ない工数で修正できるものから着手する。
- 構造化データの追加・修正: 欠落しているスキーママークアップを実装する。既存のマークアップにエラーがあれば修正する。多くのCMSではプラグインやモジュールで比較的簡単に対応可能だ。
- パフォーマンス最適化: 画像の最適化(WebP形式への変換、遅延読み込み)、CSS/JSの最小化と結合、キャッシュ設定の見直しなど、ページ速度を改善する施策を実行する。
- コンテンツの微調整: メタディスクリプションの改善、見出し構造の明確化、内部リンクの追加など、既存コンテンツのAI向け最適化を行う。
中期対応:CMS機能の拡張とプロセス改善
CMSの設定や運用プロセスに関わる、やや規模の大きい改善を行う。
- コンテンツモデルの再設計: 新しいコンテンツタイプを定義したり、既存のフィールド構造を見直したりする。これにより、今後作成するすべてのコンテンツが最初から構造化された状態で生まれる。
- APIエンドポイントの整備: ヘッドレスCMSを検討する、または既存CMSのAPI層を強化する。コンテンツ配信ネットワーク(CDN)やエッジコンピューティングとの連携を容易にする。
- 編集ガイドラインの更新: コンテンツ作成チーム向けに、AI検索を意識した新しい編集ガイドラインを作成する。エンティティの明示的な記述、データの出典明示、構造化されたリストの使用などを含める。
長期対応:アーキテクチャの見直しとプラットフォーム選定
監査の結果、現在のCMSが根本的にAI検索時代の要件に対応できないと判断された場合、プラットフォームそのものの移行を検討する段階だ。
記事では、オープンソースで柔軟性の高いCMSが長期戦略に適しているとの見方が示されている。移行を検討する際は、以下の観点で新しいプラットフォームを評価する。
- ネイティブの構造化データサポート: コア機能として構造化コンテンツ管理をサポートしているか。
- コンポーザブルアーキテクチャ: ヘッドレス、APIファースト、あるいはそれらを選択可能なハイブリッドモデルを採用しているか。
- 開発者エコシステム: 活発なコミュニティと豊富な拡張機能があるか。新しい技術トレンドに迅速に対応するモジュールが開発されるか。
- スケーラビリティとパフォーマンス: コンテンツ量とトラフィックの増加に合わせてスケールできるか。エッジ配信などの現代的なインフラと親和性が高いか。
この記事のポイント
- AI検索は「10個の青いリンク」モデルから「単一のAI回答」モデルへ移行し、コンテンツの発見可能性の条件を変えた。
- AI対応CMS監査の核心は「構造化コンテンツ」「コンポーザブルアーキテクチャ」「オープンソースの柔軟性」の3領域にある。
- 実践的な監査では、技術インフラ、コンテンツ構造、CMSプラットフォームの3レベルを評価する。
- 監査結果は短期・中期・長期の具体的なアクションプランに落とし込み、継続的に改善を進める必要がある。
出典
- Search Engine Journal「Is Your Website Ready for AI Search? A Practical Audit for CMOs」(2026年3月25日)
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験