

GitHub CopilotでDNS設定ゼロ、Pagesカスタムドメインを14分で公開
GitHub Copilot CLIでDNS設定ゼロ。GitHub Pagesカスタムドメインを14分で公開

カスタムドメインの取得とDNS設定は、多くの開発者にとって「最後の関門」だ。Aレコード、CNAMEエントリ、TTL(Time To Live / DNSキャッシュの有効期間)、そして「設定が反映されたのかどうかもわからない」という長い待ち時間。これらの煩わしさが、せっかくのプロジェクト公開を先延ばしにする原因になっている。
GitHub Blogで2026年7月8日に公開された記事によれば、GitHub Copilot CLIとコミュニティ製のNamecheapスキルを組み合わせることで、DNSレコードを手動で1行も編集せずに、約14分でカスタムドメインの設定からHTTPS化されたサイト公開までを完了できることが実証された。空のリポジトリから公開まで、わずか14分だ。
本記事では、このワークフローをステップごとに分解し、技術的な仕組みと実務への応用方法を解説する。DNSの知識がなくても理解できるよう、専門用語には都度説明を加えながら進める。
Copilot CLIがDNSの常識を変える、手動設定から自動化への転換

従来のDNS設定が抱える3つの課題
カスタムドメインをGitHub Pagesに紐付けるには、従来以下の作業が必要だった。ドメインを購入し、レジストラ(ドメイン管理会社)の管理画面でAレコードとCNAMEレコードを手動で追加し、GitHubリポジトリ側にもCNAMEファイルをコミットする。さらにDNSの伝播(設定がインターネット全体に行き渡るプロセス)を待ち、最大で48時間かかることもある。
この一連の作業には大きく3つの課題がある。第一に手順の複雑さだ。AレコードやCNAMEといったDNSレコードの種類を理解し、正しい値を入力する必要がある。第二にフィードバックの遅さ。設定が正しいかどうかの確認に長時間を要する。第三にミスのリスク。1文字でも間違えるとサイトが表示されず、原因特定にも手間取る。
Copilot CLIが解決するDNS設定の自動化
GitHub Copilot CLIは、自然言語での指示をシェルコマンドやAPI操作に変換するAIアシスタントだ。これにレジストラのAPIと連携するスキルを組み合わせることで、DNSレコードの読み取り・設定・検証までを自動化できる。
今回のワークフローでは、Namecheap(ドメインレジストラ)のAPIを操作するコミュニティ製スキル「namecheap-skill」を使用する。Copilot CLIに対して「このドメインをGitHub Pagesに向けて」と指示するだけで、スキルが必要なAレコードとCNAMEレコードを自動生成し、レジストラのAPI経由で設定する。さらにGitHubリポジトリ側のCNAMEファイルも自動でコミットする。
手動で6ステップかかっていたDNS設定が、自然言語の指示1行で完結する。ミスのリスクが排除され、待ち時間も大幅に短縮される点が最大の利点だ。
準備編、GitHub Pagesへの公開と格安ドメインの取得
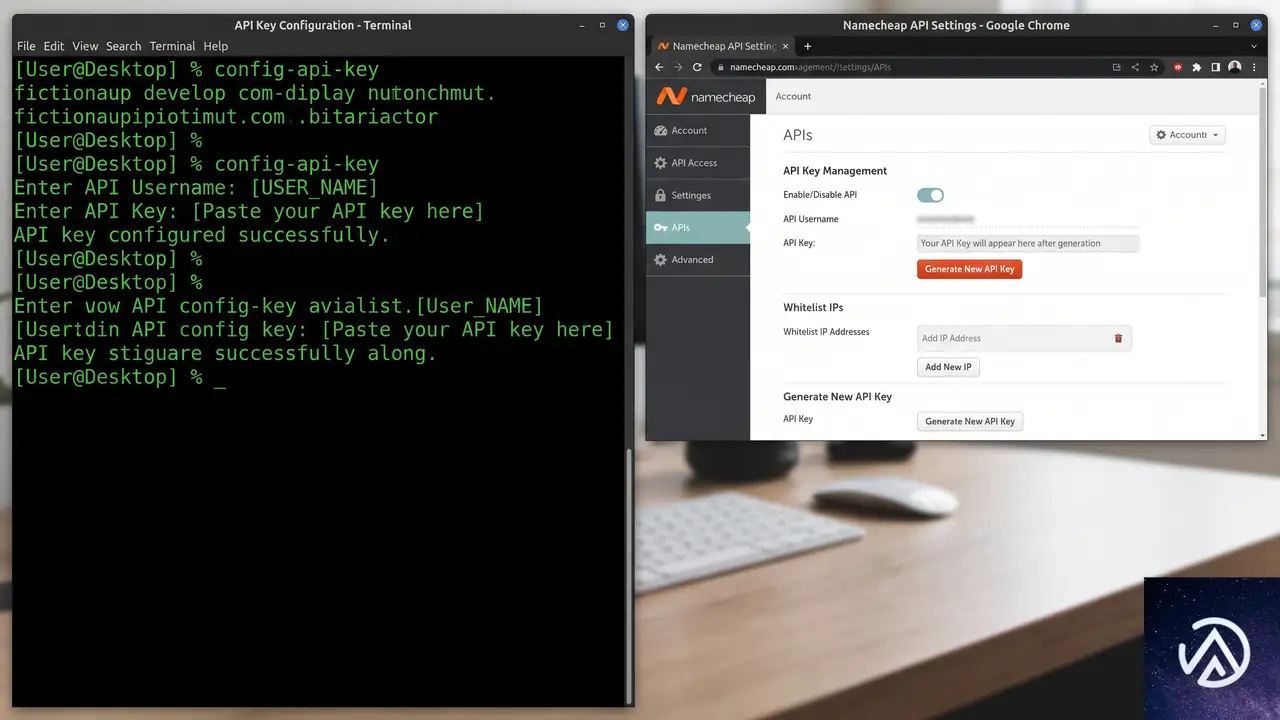
ステップ1、GitHub Pagesでランディングページを公開する
まずは公開用のリポジトリを作成する。空のパブリックリポジトリを用意したら、index.htmlを手書きする必要はない。Copilot CLIに「このリポジトリでGitHub Pagesを有効にして、カスタムドメインに関するランディングページを作成して」と指示するだけで、HTMLの生成からPagesの有効化までを自動実行してくれる。
この時点でサイトは ユーザー名.github.io というURLで公開される。まずはデフォルトドメインでサイトが表示されることを確認し、次に独自ドメインの設定に進む。
ステップ2、低コストでドメインを取得する
サイドプロジェクトにプレミアムな .com ドメインは必須ではない。今回の検証では、最も安価なTLD(トップレベルドメイン / .comや.orgなどのドメイン末尾部分)のひとつである .click が選択された。購入費用はわずか2米ドル(約300円)だ。サイドプロジェクトでカスタムドメインを試すにはリスクの低い金額といえる。
Namecheapでドメインを検索し、利用可能な名前を選んで購入する。決済が完了すれば、次のステップでAPI経由のDNS設定に進む準備が整う。
Namecheap APIとCopilot CLIの連携でDNSレコードを自動設定

Namecheap APIアクセスを有効化する
Copilot CLIがDNSを操作するには、事前にNamecheapのAPIを有効化する必要がある。Namecheapの管理画面で「Profile → Tools → Business & Dev Tools」と進み、Namecheap API Accessの管理画面を開く。ここで3つの設定を行う。
- APIをONに切り替える
- APIを呼び出すマシンのパブリックIPを許可リスト(ホワイトリスト)に追加する
- APIキーをコピーして安全な場所に保管する
APIキーは後続のステップでCopilot CLIに入力するため、手元に控えておく必要がある。NamecheapのAPIを使うと、ドメイン一覧の取得やDNSレコードの読み書きをプログラムから実行できるようになる。
Namecheapスキルをインストールする
続いて、Copilot CLIにNamecheapと通信する能力を与えるスキルをインストールする。以下の1コマンドで完了する。
gh skill install github/awesome-copilot namecheap --scope userスキルのインストール後、Copilot CLIに対して「自分のNamecheapドメインを一覧表示して」と指示すると、初回実行時にAPIキーの入力を求められる。先ほど控えたキーを入力すれば、アカウント内のドメイン一覧が表示され、連携が正常に機能していることを確認できる。
この4ステップで、Copilot CLIがドメインレジストラのAPIを直接操作できる状態になる。従来のように管理画面を手動で操作する必要はない。
ドメインの紐付けと自動検証、すべてが14分で完了

Copilot CLIにドメイン接続を指示する
準備が整ったら、Copilot CLIに対して「このGitHub Pagesサイトでカスタムドメインを有効にして」と指示する。スキルは現在のDNSレコードを確認し、変更を適用する前に確認を求めてくる。これは重要な安全設計だ。誤ったDNS変更がサイトの表示停止につながるリスクを、人間の承認によって防いでいる。
承認後、スキルは以下の作業を自動実行する。
- Namecheapのパーキングレコード(未使用ドメインの仮レコード)を削除
- GitHub PagesのAレコード(IPアドレス指定)を登録
- WWWサブドメイン用のCNAMEレコードを追加
- リポジトリにCNAMEファイルを自動コミット
これらの手順はGitHubが公式に定めるカスタムドメイン設定手順に完全に準拠している。手動で行う場合とまったく同じ結果が、人的ミスのリスクなく得られる。
自動検証でDNS設定の完了を確認する
設定が完了したら、Copilot CLIは自らの作業を検証する。まずドメインが正しく解決されるか(DNSルックアップ)を確認し、次にサイトがHTTP 200(正常応答)を返すかをチェックする。手動での動作確認すら自動化されているのだ。
実際のタイムラインを見てみよう。ドメイン購入は東部時間の午前11時21分27秒に行われた。約14分後の午前11時35分には、カスタムドメインでHTTPS化されたサイトが公開されていた。この14分にはAPIセットアップ、スキルインストール、DNS設定、伝播、検証のすべてが含まれている。
Copilot CLIがDNSルックアップとHTTPステータス確認を自動実行し、人間が待機する必要はない。設定ミスがあればすぐに検出され、修正も対話的に行える。
DNS自動化が変える開発体験、Namecheap以外でも使える汎用ワークフロー
このワークフローの本質は、Namecheapに限ったものではない。APIを提供しているレジストラであれば、同じアプローチが適用できる。専用のスキルがなくても、Copilot CLIにレジストラのAPIドキュメントを読み込ませ、「このAPIを使ってGitHub PagesのDNSレコードを設定して」と指示すればよい。レジストラが変わってもワークフローは変わらない。
DNS設定は「難しくはないが、面倒で失敗しやすく、フィードバックが遅い」という特性を持つ作業だった。Copilot CLIはこの3つの課題を同時に解決する。面倒な手順は自動化され、失敗のリスクは承認プロセスで抑制され、フィードバックは自動検証で即時に得られる。
カスタムドメインの設定を「面倒だから」と後回しにしてきた開発者にとって、このワークフローは心理的な障壁を取り除く。14分という時間は、コーヒーを淹れるのと変わらない。DNS設定がコマンド1行で済む時代が、すでに来ている。
この記事のポイント
- GitHub Copilot CLIとNamecheapスキルでDNSレコードの手動編集が不要になる
- 空のリポジトリからHTTPS化されたカスタムドメインサイトまで約14分で完了
- API経由の自動設定によりAレコードやCNAMEの入力ミスがゼロになる
- 設定後はCopilot CLIがDNS解決とHTTPステータスを自動検証する
- Namecheap以外のレジストラでも、APIがあれば同じワークフローが適用可能

・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AWS Certificate ManagerがACME対応、TLS証明書の自動更新を実現
AWS Certificate Manager が ACME プロトコルに対応

2026年6月30日、AWS Certificate Manager(ACM)が ACME(Automatic Certificate Management Environment)プロトコルに対応した。この機能追加により、AWS 上で稼働するアプリケーションの公開 TLS 証明書の取得・更新を、Certbot や cert-manager といった既存の ACME クライアントから自動化できるようになる。
証明書の有効期限は短縮の一途をたどっている。CA/Browser Forum の規定により、公開 TLS 証明書の最大有効期間は 2027 年 3 月に 100 日へ、さらに 2029 年までに 47 日へと段階的に引き下げられる見通しだ。手動での更新運用はもはや現実的ではなく、自動化が不可避の状況にある。
ACM の ACME 対応は、単なる証明書自動化の一手を超えて、組織全体の証明書ガバナンスを一元化する大きな転換点となる。PKI 管理者は DNS 管理権限をエンドポイントに集約しつつ、アプリケーション担当者には EAB(External Account Binding)認証情報だけを配布すればよく、DNS キーを組織内にばらまくリスクを排除できる。
短命化する証明書と自動化の必然性
従来の TLS 証明書は最大 1 年を超える有効期間が一般的だった。しかし、CA/Browser Forum は証明書のライフサイクル短縮を段階的に進めており、2027 年 3 月には最大 100 日、2029 年までには 47 日への短縮が義務付けられる。これは証明書の更新頻度が年 1 回から年 3〜4 回、最終的には年 7〜8 回に跳ね上がることを意味する。
手動による更新フローでは、この頻度に耐えられない。更新漏れによる証明書切れは顧客にエラー画面を表示させ、サービス自体の停止を招く。ACME プロトコルはこうした課題に対処するために策定されたオープン標準であり、Let’s Encrypt をはじめとする多数の認証局が採用している。
このデモで示すように、ACME プロトコルを利用すると証明書ライフサイクルから人手を排除できる。AWS が ACME エンドポイントをマネージドサービスとして提供することで、利用者は証明書発行インフラの運用負荷からも解放される。
Amazon Trust Services による証明書発行
ACM が ACME 経由で発行するのは、Amazon Trust Services(ATS)を認証局とする公開証明書だ。ATS のルート証明書は主要なブラウザおよび OS にデフォルトで信頼されているため、発行された証明書は即座に本番環境で利用できる。
証明書の鍵タイプは ECDSA P-256 がデフォルトだが、RSA 2048 や ECDSA P-384 も選択可能だ。クライアント側の要件に合わせて設定できる柔軟性を持ちつつ、デフォルトではより高速でセキュアな ECDSA が推奨されている。
ACME エンドポイントの設定とドメイン検証の仕組み

ACM の ACME 対応で最も特徴的なのは、ドメイン検証を PKI 管理者がエンドポイントレベルで一括実施する点だ。一般的な ACME 環境では、証明書を必要とするクライアントごとに DNS レコードの設定権限が必要になる。これに対して ACM の方式では、管理者がエンドポイント作成時にドメインを検証し、以後の証明書リクエストはそのエンドポイントが管理する。
エンドポイントの作成手順
ACM コンソールの「ACME 証明書」ページからエンドポイントを作成する。設定項目は以下の通りだ。
- エンドポイント名(任意の識別名)
- エンドポイントタイプ(Public を選択)
- 証明書タイプ(Public を選択)
- 鍵タイプ(ECDSA P-256 がデフォルト)
- ドメイン名(証明書を発行する対象ドメイン)
- ドメインスコープ(厳密なドメイン、サブドメイン、ワイルドカードの許可設定)
ドメインスコープの設定はガバナンス上とくに重要だ。Exact domain(完全一致ドメイン)だけを許可すれば、サブドメインやワイルドカード証明書の発行を防げる。たとえば本番系のエンドポイントでは Exact domain と Subdomains のみを有効化し、Wildcards は無効にすることで、証明書の発行範囲を厳格に制限できる。
エンドポイント作成後、DNS 検証が実行される。Route 53 を利用していれば CNAME レコードが自動で作成されるため、手動での DNS 設定は不要だ。外部の DNS プロバイダーを使っている場合は、表示される CNAME レコードを手動で登録する必要がある。
EAB 認証情報によるクライアント登録
エンドポイントの準備が整ったら、EAB(External Account Binding)認証情報を発行する。EAB は Key ID と HMAC Key のペアで構成され、ACME クライアントがエンドポイントにアカウントを登録する際の初回認証に使われる。
一度クライアントが登録されれば、以降の証明書リクエストはクライアント自身が生成した非対称鍵ペアで認証される。EAB 認証情報はあくまで登録時のみの使い切りであり、有効期限を設定して不要な長期保管を防ぐのが望ましい。
この仕組みにより、PKI 管理者はドメイン検証という強力な権限をエンドポイントに閉じ込めつつ、アプリケーション担当者には EAB 認証情報だけを安全に配布できる。DNS キーを組織全体に配る必要がなくなる点が、従来の ACME 運用と決定的に異なる。
Certbot を使った証明書リクエストの実例
ACM コンソールには、Certbot と acme.sh 向けの CLI リファレンスが用意されている。以下は AWS News Blog の記事で紹介されている Certbot のコマンド例を再構成したものだ。
certbot certonly --standalone --non-interactive --agree-tos \
--email <EMAIL> \
--server https://acm-acme-enroll.us-east-1.api.aws/<ENDPOINT_ID>/directory \
--eab-kid <EAB_KID> \
--eab-hmac-key <EAB_HMAC_KEY> \
--issuance-timeout <ISSUANCE_TIMEOUT> \
-d <DOMAIN>--eab-kid と --eab-hmac-key に、先ほど発行した EAB 認証情報を指定する。各 ACME クライアントで引数名や設定ファイルの記法は異なるため、利用するクライアントのドキュメントを参照する必要がある。
コマンドが成功すると、Amazon Trust Services によって署名された有効な証明書が発行される。openssl コマンドで証明書の内容を確認したうえで、アプリケーションにインストールすればよい。発行された証明書は ACM コンソールの「ACME 証明書」タブにも表示され、コンソールや API 経由で発行した証明書と統合管理される。
一元管理がもたらす運用面の利点

ACM による ACME 対応は、単に証明書の自動発行を可能にするだけではない。最大の価値は、組織全体の証明書ライフサイクルを可視化し、ガバナンスを一元化できる点にある。
IAM ロールによるきめ細かなアクセス制御
ACM の ACME エンドポイントは IAM ロールと統合されている。ACME アカウントに対して IAM ロールをバインドすることで、どのクライアントがどのドメインの証明書をリクエストできるかを細かく制御できる。これにより、開発チームごとに発行可能なドメイン範囲を限定するといった運用が実現する。
監査ログとメトリクスの統合
すべての証明書リクエストは AWS CloudTrail に記録される。誰がいつどのドメインの証明書を要求したかを完全に追跡できるため、監査要件を満たすうえで強力な武器となる。また Amazon CloudWatch と連携することで、証明書の発行数やエラー率といった運用メトリクスもリアルタイムに把握できる。
ACM が標準で備える有効期限通知機能も ACME 経由で発行された証明書に適用される。更新が迫った証明書のアラートを一元管理でき、従来のように証明書管理ダッシュボードと ACME クライアントの管理画面を行き来する必要はなくなる。
上記のスタックは、ACM 単体で証明書管理から監査、予防までをカバーできることを示している。従来は外部の認証局と ACM の間で証明書管理が分断されていたが、ACME 対応によってこの断絶が解消された。
利用可能リージョンと料金体系
ACM の ACME 対応は、発表時点で全商用 AWS リージョンで利用可能だ。AWS GovCloud(US)および中国リージョン、AWS European Sovereign Cloud パーティションについては、後日の対応が予定されている。
料金は証明書発行時に含まれるドメインごとに課金される方式で、完全修飾ドメイン名(FQDN)とワイルドカードで単価が異なる。ボリュームティアは AWS アカウント単位で月間の全証明書における総ドメイン出現数に基づいて計算される。具体的な価格は ACM の公式料金ページで確認できる。
この課金体系は、ACME 経由で発行される証明書も従来の ACM 証明書と同じ仕組みでカウントされるため、新たなコスト管理の複雑さは生じない。
この記事のポイント
- ACM が ACME プロトコルに対応し、Certbot や cert-manager など既存クライアントからの証明書自動発行が可能になった
- PKI 管理者はエンドポイントレベルでドメイン検証とスコープ制御を一括管理でき、DNS キーを組織内に配布する必要がなくなる
- CloudTrail・CloudWatch・有効期限通知により、証明書ライフサイクル全体を単一ダッシュボードで可視化・監査できる
- 証明書の有効期間短縮が進む中、手動運用からの脱却と自動化基盤の構築が急務となっている
- 全商用リージョンで即日利用可能。費用はドメイン数ベースで、従来の ACM 料金体系に準じる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

英国配送ルール変更、EC事業者が今すぐ監査すべき4つのポイント
英国のEC事業者を取り巻く配送環境が、ここ数年で最も大きな転換期を迎えている。規制変更や旧態依然としたキャリア契約が原因で、気づかぬうちに過剰なコストを支払っていたり、税関で突然荷物が差し止められたりするケースが増えている。根本的な原因は、数年前に構築した配送フローをそのまま使い続けていることにある。
この記事では、WooCommerce Blogが2026年6月29日に公開した最新レポートを基に、英国発送のEC事業者が今すぐ監査すべき4つの大きな運用変更点と、その解決を自動化する手段を具体的に解説する。
税関書類は「完璧」が最低ラインに

ポストBrexitのルールが定着した現在、「だいたい合っていれば通る」という時代は完全に終わった。税関の審査は急速に自動化が進み、以前なら警告で済んでいた標準的な記入ミスが、今では即座に国境での拒否や大幅な配送遅延に直結する。
人の手によるチェックを介さずに貨物を通関させるには、バックエンドで管理する3つのデータを完全にクリーンな状態に保つ必要がある。
税関システムが求めるデータと、実際に記入した内容の不一致が、配送トラブルの最大の要因だ。上記の比較のように、曖昧さを排除した正確な情報が求められる。
HSコードは「素材・構造・用途」で特定する
HSコード(Harmonized Systemコード)は、国際貿易における商品の統一分類番号だ。ここで求められるのは、商品の素材、構造、用途を正確に反映した、もっとも細かいレベルのコードである。「衣類」や「電子機器」といった大雑把な分類は通用しない。
HMRC(英国歳入関税庁)が提供するTrade Tariffツールを使って、自社のSKUカタログ全体の参照スプレッドシートを作成し、手動入力の工程を省くことを推奨する。
コマーシャルインボイスと税関申告書の完全一致
税関申告書に記載する合計金額は、コマーシャルインボイス(商業送り状)と1セントたりともずれてはならない。商品説明についても「gear(道具)」のような一般的な単語は一切使えず、箱の中身を正確に記述する必要がある。単価、通貨、そして明確な原産国も必須の項目だ。
UK EORI番号の必須化
商業目的で英国から輸出する場合、EORI番号(Economic Operator Registration and Identification)は事業者の基本的なライセンスにあたる。すべての英国発輸出品に必要で、HMRCを通じて無料で申請でき、数日以内に発行される。この番号を配送プロファイルに組み込み、常にシステムから自動付与される状態にしておくことが欠かせない。
2026年7月、EU向け少額輸入の免税が撤廃される

2026年7月1日、EUは長年維持してきた150ユーロ以下の少額輸入品に対する関税免除(de minimis)を撤廃する。これにより、EU域内に入るすべての商用貨物が課税対象となり、商品カテゴリごとに一律3ユーロの関税が発生する。
この変更は、消費者直送(D2C)モデルを採用するEC事業者にとって、事業構造を揺るがす大きな運用変更だ。
一律€3の関税が商品カテゴリごとに発生
注意したいのは、課金単位が「箱」ではなく「商品カテゴリ」である点だ。ヨーロッパの顧客が同じ箱にTシャツとサングラスを注文した場合、2つの別カテゴリとして扱われ、6ユーロの一律関税が直接注文に適用され、さらに標準の輸入VATが上乗せされる。商品点数ではなく、HSコードの分類数がコストを決める。
価格戦略の見直しが急務に
安価な小物商品を中心に欧州市場へ越境販売している場合、現在の価格設定はもはや通用しない。利益率を守るためには、直ちに送料設定を更新するか、EU域内にフルフィルメント拠点を設けて国境通過そのものを回避するルートを模索する必要がある。
DDUからDDPへの切り替えが顧客維持を左右する

国際配送をDDU(関税抜き配送)のまま続けているなら、顧客維持に深刻なダメージを与えている可能性が高い。DDUとは、配送業者から届く突然のSMSやメールで、荷物を受け取るための現金支払いを要求される方式だ。購入時に予期していなかった追加の国境手数料に直面した買い物客の多くは、単純に受け取りを拒否する。商品は返送され、事業者は返金処理に加え、往復の国際送料を負担する二重の損失を被る。
DDP(関税込み配送)はこうした摩擦を根本から取り除く。関税額を正確に計算してチェックアウト画面で徴収し、事業者側で配送業者を通じて事前に関税を支払うことで、荷物は税関の留置施設を経由せず、直接顧客の玄関先に届く。
DDUは「サプライズ費用請求」で機会損失を生む
「追加で○ポンド支払ってください」という連絡は、衝動買いに近い感覚で購入した顧客にとって、クーリングオフの引き金になる。商品到着の喜びよりも、予期せぬ出費への苛立ちが勝り、荷物は放置され、やがて返送される。この流れが構造的な機会損失を生んでいる。
DDPでチェックアウト画面から摩擦を除去する
目安として、国際関税が平均バスケット単価の10%を超える場合、DDPのワークフローを構築するだけで、受け取り拒否率の激減によって投資は即座に回収できる。顧客体験の透明性を高め、返品に関わる隠れコストを削減できる点が、DDP最大の利点だ。
北アイルランド向け配送、UKIMS登録で手続き簡略化
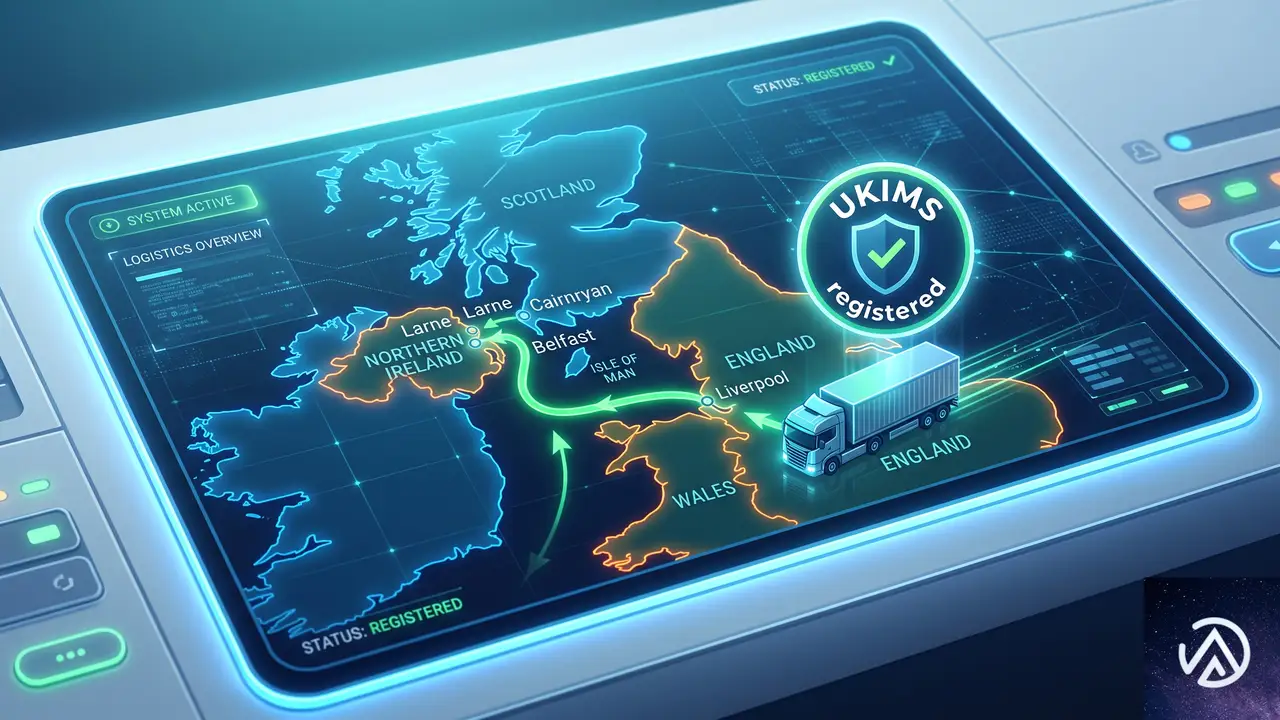
北アイルランドは英国の関税領域に属するが、物品に関してはEUルールに従う特殊な立場にある。このため、グレートブリテン島(イングランド、スコットランド、ウェールズ)から北アイルランドへ商品を送る際の扱いは、その商品が「EU域内に流出するリスクがない」かどうかで変わる。
2025年5月1日から、UKIMS(英国国内市場スキーム)に登録された事業者が、UK Internal Marketレーンを通じて適格商品を移動させる場合、税関申告書の作成が不要になった。UKIMSへの登録は無料で、HMRCは手続きや申告を支援するTrader Support Serviceも無償提供している。北アイルランド向け配送の頻度が高いなら、登録しない手はない。
配送キャリアの料金は半年に1度の見直しが必須

ほとんどの事業者は、開業初期に選んだ配送キャリアと契約したまま、料金交渉をしない。しかし、取引量が少なかった時期の料率シートは、現在の出荷量に見合っていない可能性が極めて高い。
WooCommerce Blogの記事によれば、6〜12カ月に一度はアカウントマネージャーに連絡し、出荷量の増加を伝えて新たな料率シートを要求すべきだとしている。Royal Mail、DPD、Evriなど主要キャリアは段階的な料金体系を採用しており、2年前には関係なかった割引閾値が、今の自分たちには適用されるかもしれない。単一キャリアに依存せず、荷物の重量と目的地ごとに最適なサービスを自動選択するマルチキャリア比較が、継続的なコスト削減の鍵となる。
WooCommerceで配送を自動化する具体的な手段

これらの問題を解決するには、初期設定にある程度の手間はかかるが、一度構築してしまえば配送業務は完全にバックグラウンドで動くようになる。バックエンドのコードを一から書き換えずにこの仕組みを素早く展開するには、ShipStationのようなアグリゲーターを利用するのが最も早い。
ShipStationで注文処理から通関書類作成まで一元化
WooCommerce Blogで紹介されているShipStationは、WooCommerceと直接接続することで、フルフィルメントの全工程を一元管理する。注文の取り込みから、クリーンな通関書類の自動生成、国際発送時の商品HSコードのシステム的な適用までを自動化できる。
英国のWooCommerceストアにとっての最大の利点は、Royal Mail、DPD、Parcelforce、Evriといった英国の主要キャリアと事前交渉済みの割引料金を、契約後すぐに利用できる点にある。個別に初回契約を結ぶ手間が省け、既存のキャリアアカウントを持っている場合は、それを追加することも可能だ。
導入ハードルは30日間の無料トライアルで検証可能
ShipStationは柔軟な月額契約で、クレジットカード不要の30日間無料トライアルを提供している。税関ルールの手動監査に疲弊していたり、実際の配送料率をリスクゼロで比較検証したいなら、自社ストアを接続してテスト出荷のバッチを走らせてみるのも一つの手段だ。
この記事のポイント
- 税関申告では、HSコードを「素材・構造・用途」の3軸で完全に特定し、インボイスと申告書の記載内容を一致させることが必須になっている
- 2026年7月からEU向けの150ユーロ関税免除が撤廃され、商品カテゴリごとに3ユーロの一律関税が発生するため、価格戦略の見直しが急務だ
- DDP(関税込み配送)への切り替えにより、顧客へのサプライズ請求を排除し、受け取り拒否による損失を防止できる
- 北アイルランド向け配送は無料のUKIMSに登録することで、税関申告の手間を大幅に省ける
- 配送キャリアの料率は半年ごとに再交渉し、マルチキャリア比較による自動選定で継続的なコスト削減を図るべきだ
- ShipStationのようなWooCommerce連携ツールで、通関書類の作成からキャリア選択までを自動化し、運用負荷を軽減できる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Gemini 3.5 Flashにコンピュータ操作機能統合、長期業務の自動化を加速
—
Google DeepMindは2026年6月24日、マルチモーダルモデルGemini 3.5 Flashにコンピュータ操作機能を標準搭載したと発表した。これまで専用のGemini 2.5モデルとして提供されていた機能が、メインのFlashモデルに統合された形だ。
この統合により、ブラウザやモバイル、デスクトップ環境をAIエージェントが見て、推論し、実際に操作するという一連の流れが一段と高速かつ安定する。長期間にわたるソフトウェアテストや、複数アプリケーションを横断する知識業務の自動化が、より実用的な選択肢になる。
Gemini 3.5 Flashにコンピュータ操作機能が統合

これまでと何が変わったのか
従来、コンピュータ操作機能はスタンドアロンのGemini 2.5モデルとして提供されていた。このモデルは画面操作に特化していたものの、メインのGemini APIとは別の呼び出しが必要となり、複雑なエージェントを構築する際にレイテンシや統合の手間が課題になりやすかった。
Gemini 3.5 Flashでは、もともと高い性能を誇るFlashモデルに、コンピュータ操作がビルトインツールとして組み込まれている。関数呼び出しや検索、マップグラウンディングと同じレイヤーで扱えるため、開発者は単一のAPIで、テキスト処理から実環境の操作までシームレスに実行できるようになる。
コンピュータ操作機能の仕組み
エージェントは画面のスクリーンショットを画像として受け取り、そのなかのUI要素やテキストを解析する。解析結果に基づいて、次にとるべき操作(クリック、キーボード入力、スクロールなど)を推論し、実際のブラウザやデスクトップ環境でその操作を実行する。このサイクルを繰り返すことで、複数ステップにわたる業務も自動で完遂できる。
このループによって、ユーザーが細かく指示しなくても、自然言語による高レベルの指示だけで長期間の自動化が実現できる。
エンタープライズ向けの安全性対策

標的型敵対的学習と保護機能
実環境で稼働するエージェントのリスクとして、プロンプトインジェクションや不適切な操作が常に課題となる。Gemini 3.5 Flashでは、こうしたリスクを低減するために、コンピュータ操作に特化した標的型敵対的学習(targeted adversarial training)が施されている。
さらに、企業向けのオプションとして2つの保護機能が提供される。ひとつは、機密性の高い操作や元に戻せない操作を実行する前に明示的なユーザー確認を要求する仕組みだ。もうひとつは、間接的プロンプトインジェクションが検知された場合に、タスクを自動停止する仕組みである。
多層防御のベストプラクティス
Google DeepMindは、これらの安全機能だけに頼らず、安全なサンドボックス環境の利用や人間による監視・検証、厳格なアクセス制御を組み合わせる「多層防御」を推奨している。これにより、エージェントが予期せぬ行動をとった場合でも、システム全体への影響を最小限に抑えられる。
導入事例と開発者向けリソース

顧客の声
すでに複数の企業が、このコンピュータ操作統合から価値を引き出している。BrowserbaseのMiguel Gonzalez Fernandez氏は、エンドツーエンドのテスト自動化が大きく前進し、環境構築の手間が格段に減ったと評価する。Browser UseのMagnus Muller氏は、自然言語による指示だけでブラウザ上の複雑なワークフローが完遂できる点を高く評価している。UiPathのAlvin Stanescu氏は、エンタープライズRPAと生成AIの融合が加速し、ノンコードでの高度な自動化が可能になるとコメントしている。
デモ環境とAPIの利用方法
開発者はBrowserbaseがホストするデモ環境ですぐにコンピュータ操作の挙動を試せる。実際の開発には、Gemini APIのドキュメントに従ってリファレンス実装を参照し、Gemini Enterprise Agent Platformを通じてエンタープライズグレードのエージェントを構築できる。GitHub上で公開されているコードサンプルを活用すれば、自社環境への導入もスピーディに進められる。
Gemini 3.5 Flashのコンピュータ操作統合がもたらす価値

今回のアップデートは、Googleがエージェント型AIを本格的にエンタープライズ市場へ押し出す明確な一手といえる。競合各社もブラウザ操作機能を提供し始めているが、既存のFlashモデルにビルトインで組み込む手法は、推論コストと応答速度の面で優位に立つ可能性が高い。多数の業務アプリケーションをまたぐシナリオでも、別モデルの呼び出しオーバーヘッドが不要になるからだ。
安全性への取り組みも、この領域での普及を左右するカギを握る。標的型敵対的学習やオプションの確認機能は、金融や医療など厳格なコンプラ要件が求められる業界でもAIエージェントを受け入れやすくする。ただし、まだ攻撃手法の進化は続くため、多層防御を徹底することが現実的な運用には不可欠だ。
開発者視点では、Gemini APIを通じて簡単に試行錯誤できる環境が整ったことが大きい。自社の業務アプリケーションにエージェント操作を組み込むハードルは確実に下がっており、今後数ヶ月で実運用事例が急増するとみられる。
この記事のポイント
- Gemini 3.5 Flashにコンピュータ操作機能がビルトインされ、専用モデルの呼び出しが不要になった
- 画面を見て操作するエージェントが、長期のソフトウェアテストや業務自動化で威力を発揮する
- 敵対的学習と2つのオプション保護機能により、エンタープライズ環境でも安全性を担保しやすくなった
- Browserbase、Browser Use、UiPathなどがすでに導入しており、導入用のデモ環境やAPIドキュメントが整備されている
- 多層防御の考え方を取り入れることで、より堅牢なエージェント運用が実現できる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

WordPressに登場したエージェンティックAI Angie。ウェブ制作を変える自律型アシスタント
WordPressの開発現場では、コード補完やコンテンツ生成に生成AIを使うのが当たり前になりつつある。しかし2026年、状況はさらに大きく変わる。エージェンティックAIと呼ばれる新たな技術がWordPress内部に直接統合され、サイトのテーマやプラグイン、データベースを理解した上で、コードの作成から実行、テストまでを自律的にこなすようになるのだ。
本記事では、Elementorが提供する「Angie」を中心に、エージェンティックAIがウェブ制作にもたらすインパクトと、その実践的な使い方を掘り下げる。従来の生成AIとの決定的な違い、安全を担保するワークフロー、そしてカスタムウィジェット構築やサイト管理までを一手に引き受ける仕組みを詳しく見ていこう。
エージェンティックAIがWordPressにもたらす本質的な変化
これまでの生成AIは、あくまで「会話する頭脳」だった。コードの断片を提案したり、記事の草案を書いたりはできても、実際にそのコードをサイトに反映させるには、人間がコピー&ペーストし、テストし、不具合があれば修正する必要があった。エージェンティックAIは違う。サイトの内部状態を能動的に読み取り、目的達成のために自ら計画を立て、ファイルやデータベースに直接アクセスして実行する。まるで腕利きのジュニア開発者のように振る舞うのだ。
従来の生成AIは外部ツールとしてブラウザの別タブで使うのが一般的だった。一方、エージェンティックAIはWordPressの管理画面に組み込まれ、許可された範囲でファイルやデータベースにアクセスする。この「コンテキストの有無」が両者の最大の差だ。WordPressサイトは一つひとつ異なるプラグイン構成やカスタムテーマ、PHPバージョンを持つ。エージェンティックAIはこれらをすべて把握した上で、衝突を避けたコードを生成する。
ElementorのAngie──WordPressネイティブの自律型エージェント
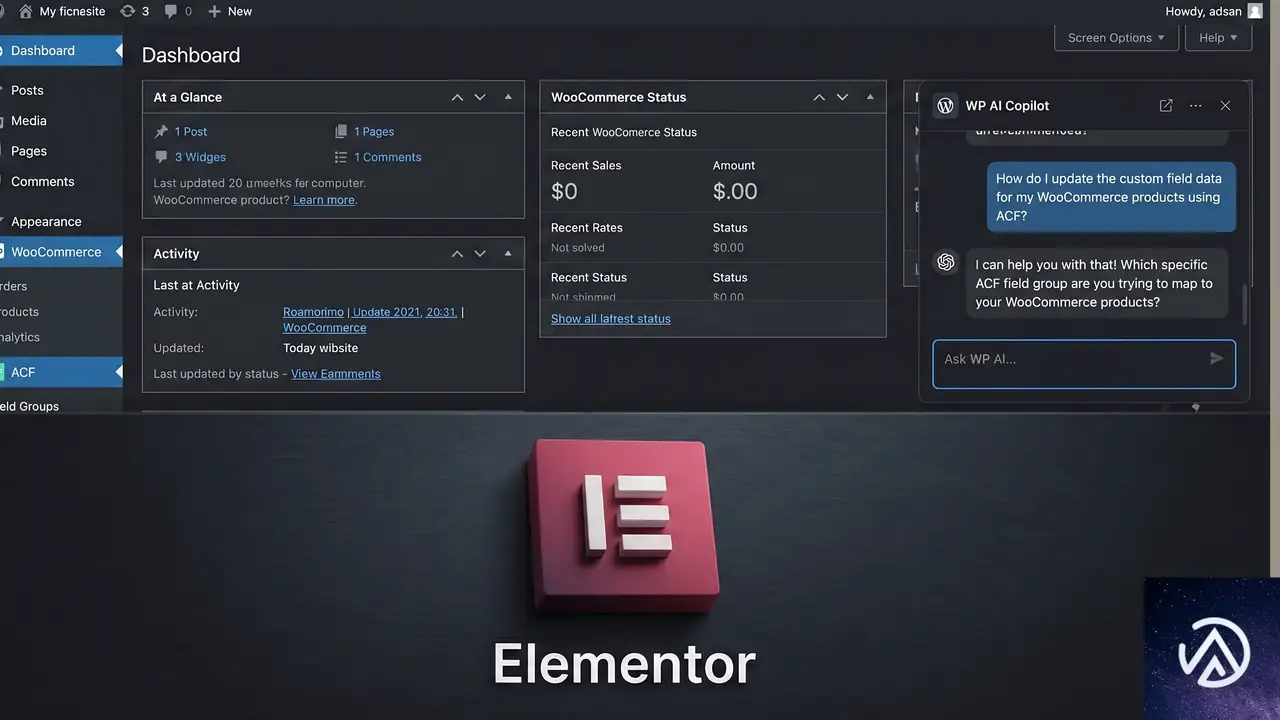
エージェンティックAIの具体的な実装として注目されているのが、Elementorが提供する「Angie」だ。以前のElementor AIがコンテンツ生成や画像編集に主眼を置いていたのに対し、Angieは開発者のためのアクション志向のアシスタントとして設計されている。
Angieは外部APIキーの設定やNodeパッケージのインストールを必要としない。WordPressの管理画面にネイティブ統合され、現在有効なテーマやプラグイン、カスタム投稿タイプ、WooCommerceの商品データ、ACFのフィールド構造などを自動的に認識する。Elementor BlogのItamar Haim氏は「エージェンティックAIはウェブサイト管理の根本的な転換点だ。コードを外部のチャット画面からコピーする代わりに、AIがデータベースやコードファイルの内部でタスクを調整し、開発者は実行の全権を握ったままでいられる」と述べている。
プラグインやテーマを理解したコード生成
Angieに「会員登録フォームを作ってほしい」と指示すれば、単なるHTMLフォームを出力するだけでは終わらない。アクティブなフォームプラグイン(WS Formなど)に接続し、テーマのグローバルカラーやフォントを適用したスタイルで、完全に機能するフォームを構築する。既存のレイアウトを壊すこともない。
また、WooCommerceが有効なら商品ループのカスタマイズ、LearnDashが有効なら学習ポータルの構築、ACFが有効なら構造化された動的コンテンツの表示といった具合に、サイトの「現実」に即したカスタマイズが可能だ。これにより、サードパーティ製プラグインを追加でインストールする必要が減り、サイトの軽量化にもつながる。
安全に機能を実装する5ステップのワークフロー

エージェンティックAIは「ブラックボックス」ではない。人間の承認を組み込んだ明確なワークフローで動作する。Angieは以下の5ステップでタスクを処理する。
特に重要なのがSTEP 2の計画フェーズだ。大規模な変更の場合、Angieは「Brief(Plan Mode)」と呼ばれる詳細な技術計画を提示し、開発者の承認を仰ぐ。データベースのテーブルを変更する際は、対象となる行やフィールドが明示され、問題があればその場で計画を修正できる。この「Human-in-the-loop」設計により、自動化の速度と手動の安全性を両立している。
サンドボックスが本番サイトを守る仕組み
AIが生成したコードをいきなり本番環境にデプロイするのは危険だ。半角セミコロン一つで致命的エラーが発生しうる。Angieはすべてのコードを隔離されたサンドボックスで実行する。無限ループを引き起こしても、クラッシュするのはサンドボックスだけであり、クライアントの公開サイトには影響が及ばない。
開発者はサンドボックス上で生成されたアセットのビジュアルプレビューと機能テストを行い、PHPシンタックスエラーやサーバーリソースの消費も監視される。問題がなければ「承認」をクリックするだけで、本番のWordPress構造に安全にマージされる。このプロセスによって、複雑な機能追加でも安心して試すことができる。
カスタムコード生成とサイト管理の自動化

Angieの真価は、コードの記述とサイト運用の自動化にある。開発者が手作業で行ってきたルーティン作業を、チャットでの会話によって置き換える。
会話するだけでElementorウィジェットを新規作成
Angie Codeは、自然言語の指示からカスタムウィジェットを構築する。たとえば「投資シミュレーターを表示するウィジェットがほしい」と伝えれば、独自のフィールドやスタイルコントロール、動的なフロントエンドの挙動を備えたウィジェットが自動生成される。生成されたPHPクラスファイルはクリーンで、WordPressコーディング規約に準拠しており、Elementorパネルにカスタムコントロールが露出するため、後からクライアントがビジュアル編集することも可能だ。
さらに、Angieは軽量なJavaScriptルーチンを作成し、スクロール演出や独自のナビゲーション、商品マッチングクイズといったインタラクティブなUIを追加できる。これらのスクリプトはCore Web Vitalsを意識して最適化されるため、表示速度を損なわない。
一括データ処理とPHPエラーのデバッグ
サイト管理の面では、Super Admin Modeが強力だ。これはオプトインで有効化する機能で、Angieにファイルシステムとデータベースへの読み書き権限を与える。これにより、商品価格の一括更新やユーザー権限の変更、孤児化したポストメタのクリーンアップといった作業を、チャットでの指示だけで実行できる。処理はタイムアウトを避けるため、小さなバッチに分割して行われる。
PHPエラーが発生した場合も、Angieはスタックトレースを解析し、問題のファイルと行番号を特定する。誤った設定やプラグイン競合を修正するコードを提案し、もし実行中に新たな衝突が生じれば即座にロールバックする。トラブルシューティングにかかっていた数時間が、数分の対話に短縮される。
ウェブ制作の未来──エージェンティックAIが変える開発者の役割

エージェンティックAIの登場は、開発者の仕事を奪うものではない。むしろ、単純作業から開発者を解放し、より高度な設計や戦略に集中できる環境を提供する。Elementor Blogの記事でも、Angieは「開発者の代わりではなく、反復作業やバルク処理を肩代わりする高度なアシスタント」と位置づけられている。
実際の開発フローでは、開発者が建築家として全体像を描き、Angieが大工として実装を進めるイメージだ。コードの品質は開発者が最終確認し、必要に応じてチャットで修正を重ねる。このコラボレーションモデルにより、個人事業主や小規模エージェンシーでも、従来は大規模チームでしか実現できなかったカスタマイズやサイト運用が手の届くものになる。
注意すべきは、Super Admin Modeのような強力な機能を使う際のバックアップ習慣だ。Angieは安全策を講じているが、大規模なデータベース操作の前には必ずサイト全体のバックアップを取ることが推奨される。また、AIが生成するコードは常に最新のWordPressコーディング規約やPHPバージョンに従うが、開発者自身がコードを読み、理解する姿勢も引き続き重要である。
エージェンティックAIは、ウェブ制作における「手動作業の時代」から「対話による構築の時代」への転換を象徴している。今後、Angieのようなツールが普及すれば、WordPressサイトの開発速度は飛躍的に向上し、より少ないリソースで高度な機能を実装できるようになるだろう。
この記事のポイント
- エージェンティックAIはサイトの内部状態を理解し、コード生成から実行までを自律的に行う。
- ElementorのAngieはWordPressにネイティブ統合され、テーマやプラグインを認識した上でカスタム開発が可能。
- プロンプト→計画→接続→実行→反復の5ステップで、人間の承認を挟みながら安全に動作する。
- サンドボックス環境でテストされるため、本番サイトに影響を与えずに複雑な機能追加が試せる。
- Super Admin Modeを使えば、一括データ処理やPHPエラーのデバッグをチャットで完結できる。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

CiscoとOpenAI、Codexでエンタープライズ開発を再定義
CiscoがOpenAI Codexを実際のエンタープライズ開発ワークフローに組み込み、大幅な成果を上げている。AI Defenseをはじめとする新製品の開発スピードは数四半期から数週間に短縮され、1,500時間超の工数が毎月削減された。
新規AI機能の95%以上をCodexが生成し、C/C++の大規模コードベースにおける欠陥修正の処理速度は従来の10〜15倍に達した。大規模リポジトリ間のビルド最適化やフレームワーク移行も短期間で完了している。
単なるコード補完ツールではなく、自律的にコンパイルやテストを繰り返しながら修正を加えるエージェントとして機能する。CiscoはCodexを「もう一人のAIエンジニア」と位置づけ、プロダクション環境全体に組み込んだ。
Codexのエージェント性がもたらす変化

Codexが従来の開発支援ツールと一線を画すのは「エージェント性」だ。Ciscoのエンジニアリングチームは、Codexが単なるコード提案を超えて複雑な判断と実行を繰り返せる点に着目した。相互に依存する大規模リポジトリを横断して推論し、C/C++のような複雑な言語を扱い、CLIベースのコンパイル、テスト、修正ループを自律的に回す。
これらの作業が既存のレビューやセキュリティ、ガバナンスの枠組みの中で動作することも重要だ。CiscoはCodexを「ツール」から「チームの一員」へと位置づけを変えたことで、従来の工数見積もりの概念そのものが変わりつつある。
コード補完とエージェントの違い
一般的なコード補完ツールは、エンジニアが書き始めたコードに対して次の候補を提示する。エンジニアはその候補を読んで判断し、手動で適用する。一方、エージェント型のCodexは「このリポジトリ全体のビルド時間を短縮せよ」といった高レベルな指示を与えると、自らログを解析し依存関係を調査し、修正を加えたうえでテストまで実行する。
この違いが特に威力を発揮するのは、コードベースが巨大で複数のチームやリポジトリにまたがるエンタープライズ環境だ。人間が一つひとつ手作業で確認するには時間がかかりすぎる問題に対して、Codexは自律的に解決策を提示し、適用する。
AI Defenseの開発期間を数四半期から数週間に短縮

CiscoのAIセキュリティ製品「AI Defense」は、このエージェント型開発の成果を如実に示す事例だ。AI DefenseはAIが引き起こす安全性やセキュリティのリスクから組織を守るエンドツーエンドのソリューションである。CiscoのチームはCodexを活用してAI Defenseのコードの大部分を生成し、ほぼすべての新機能をCodexが作成した。
OpenAI Blogの記事によれば、従来の開発手法では数四半期を要していた機能が、Codexの導入により数週間で顧客に提供可能になったという。AIの安全性という領域で、AIを活用した開発が威力を発揮した好例だ。
Daybreak構想とAIセキュリティ
CiscoはOpenAIの「Daybreak」構想にも中核的なセキュリティ組織として参画している。DaybreakはOpenAIのモデル、Codex、セキュリティパートナーを結集し、サイバー防御とソフトウェアの継続的セキュリティを加速させる取り組みだ。このプログラムの一環として、Ciscoはサイバー防御者向けモデル「GPT-5.5-Cyber」へのアクセスを管理している。
また、CiscoはCodexの支援を受けてオープンソースツール「Defense Squad」を構築した。このツールはアイデア出しから開発者コミュニティへの提供まで1週間未満で完了している。Codexの迅速なプロトタイピング能力が、セキュリティ領域におけるOSS開発のスピードを大幅に引き上げた形だ。
ビルド最適化で月1,500時間超の工数を削減

CiscoのエンジニアリングチームがCodexに与えた最初の大きな課題の一つが、クロスリポジトリのビルド最適化だ。15以上の相互接続されたリポジトリにまたがるビルドログと依存関係グラフをCodexが分析し、非効率な箇所を特定した。
その結果、ビルド時間が約20%短縮され、グローバル環境全体で毎月1,500時間以上のエンジニアリング工数が削減された。ビルド時間の短縮は開発サイクル全体を加速させる。待ち時間が減れば、エンジニアはより多くの時間を設計や検証に充てられる。
C/C++コードベースの欠陥修正を10〜15倍に高速化
Codex CLIを使った「CodeWatch」と呼ばれる取り組みでは、大規模なC/C++コードベースを対象に、反復的かつエージェント型の欠陥修正を自動化した。C/C++はメモリ管理やポインタ操作が絡む複雑な言語であり、欠陥の修正には深い理解と慎重なテストが欠かせない。
従来は数週間の手作業を要していた修正が、Codex CLIによって数時間で完了するようになった。欠陥解決のスループットは10〜15倍に向上し、エンジニアは設計や検証といったより高度な判断業務に集中できるようになった。
フレームワーク移行やCI/CDへの統合
Splunkチームの事例では、複数のUIをReact 18からReact 19へ移行する作業にCodexが投入された。Codexが反復的な変更の大部分を自律的に処理したことで、数週間かかる作業が数日に圧縮された。エンジニアは判断を要する部分に集中し、機械的な書き換えはCodexに任せるという分業が成立している。
OpenAI Blogの記事でCiscoの関係者は「Codexに計画ドキュメントを生成させて従わせることで、レビューチームがプロセスと生成されたコードの両方を容易に理解できるようになった」と述べている。コードを書くだけでなく、意図や計画を文書化する能力も実務では大きな価値を持つ。
エンタープライズ開発パイプラインへの組込み
CiscoはCodexをスタンドアロンのツールとしてではなく、既存の開発パイプラインに直接組み込んだ。セキュリティやコンプライアンス、ガバナンスの要件を満たしながら動作させることが、エンタープライズ環境では不可欠だからだ。
この実運用から得られた継続的なフィードバックは、OpenAIがCodexを大企業向けに強化するうえで重要な役割を果たした。特にコンプライアンス対応、長時間実行タスクの管理、既存パイプラインとの統合といった領域が改善された。CiscoとOpenAIの協業は、次世代AIを採用するための再現可能なモデル「深い技術パートナーシップ、実際のワークロード、初日からのリーダーシップの一致」を確立したと言える。
この記事のポイント
- CiscoはCodexを導入し、新規AI機能の95%以上を自動生成している
- AI Defenseの開発期間が数四半期から数週間に短縮された
- クロスリポジトリのビルド最適化で月1,500時間超の工数を削減
- C/C++コードベースの大規模欠陥修正を10〜15倍に高速化
- Codexはコード補完を超えたエージェントとして、自律的にコンパイルとテストを繰り返しながら開発を進める
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Vercel Sandboxの永続化機能が正式版に、環境構築の手間を大幅削減
Vercelが提供するクラウド開発環境「Vercel Sandbox」において、filesystemの状態をセッション間で自動保存する永続化機能が正式版(GA)となった。2026年5月26日の発表だ。開発者はこれまで、Sandboxを再起動するたびに依存パッケージのインストールやファイル配置をやり直す必要があったが、今回のアップデートでその手間が大幅に削減される。
永続化はデフォルトで有効化されており、スナップショットの取得や状態管理を手動で行う必要はない。Sandboxに一意の名前を付与すれば、その名前をキーとして環境を再開できる仕組みだ。セッションの起動と停止はVercel側で自動的に処理されるため、開発者はワークフローを中断されることなく作業を継続できる。
Sandbox永続化が解決する課題

クラウドベースの開発環境において、セッション終了後の状態消失は長年の課題だった。従来のVercel Sandboxでは、セッションが終了するたびにfilesystem上の全データが破棄されていた。このため、毎回の起動時に再度依存関係のインストールや環境設定を行う必要があり、開発開始までの待ち時間が大きな非効率を生んでいた。
永続化機能は、この問題に対する直接的な解決策だ。Sandboxのfilesystem状態が自動的にスナップショットとして保存され、次回セッション開始時に自動復元される。スナップショットはユーザーが明示的に操作する必要はなく、セッション終了時に自動取得される仕組みである。これにより、npmパッケージのインストールやプロジェクトファイルの配置といった繰り返し作業から開発者が解放される。
※毎回セッション開始時に環境構築が必要。待ち時間が発生し、開発効率が低下する
※前回の状態が自動的に復元される。セットアップ不要で作業を継続できる
この変化は、継続的な開発やCI/CDパイプラインでの自動テストなど、頻繁な環境再作成が発生するシナリオで特に効果を発揮する。
永続的Sandboxの作成と利用

デフォルトで有効化される永続性
Sandbox.create()を呼び出す際、永続化は自動的に有効になる。特別な設定やオプションの指定は不要だ。作成時にnameパラメータで一意の名前を付与すれば、その名前がプロジェクト内での参照キーとなる。この名前は後から変更することも可能であり、プロジェクトの命名規則に合わせた管理ができる。
名前付きSandboxは単なる識別子以上の役割を持つ。チーム内で「staging-test」「feature-auth」といった意味のある名前を付けることで、目的に応じた環境の使い分けが容易になる。また、存在しない名前を指定した場合は新規作成、既存の名前を指定した場合は既存環境の復元と、名前ベースの直感的な操作が可能だ。
import { Sandbox } from "@vercel/sandbox";
// filesystemは自動的にスナップショット保存される
const sandbox = await Sandbox.create({ name: "my-sandbox" });
await sandbox.runCommand("npm", ["install"]);
await sandbox.stop();上記のコードでは、npm installでインストールされた依存パッケージが自動的にスナップショットとして保存される。次回Sandbox.get({ name: "my-sandbox" })で取得した際には、インストール済みの状態から即座に作業を再開できる。
ステートレスSandboxとの使い分け
永続化は便利だが、すべてのユースケースで必要とは限らない。一時的な検証や使い捨てのテスト環境では、永続化を無効にすることでスナップショット保存にかかるストレージコストを節約できる。スナップショットストレージはコンピューティングリソースとは別の課金体系であり、不要な保存はコスト増につながるためだ。
import { Sandbox } from "@vercel/sandbox";
const sandbox = await Sandbox.create({ persistent: false });
// 既存のSandboxを後から変更することも可能
await sandbox.update({ persistent: false });CLIを利用する場合は、sandbox createコマンドに--non-persistentフラグを付与する。非永続的Sandboxはセッション終了時にfilesystemが完全に破棄されるため、機密データを含む一時的なテストや、毎回クリーンな状態から始めたいCIジョブに適している。
● チーム共有の検証環境
● 長期メンテナンスのテスト環境
● クリーン状態が必要なCIジョブ
● 機密データを含む一時テスト
この使い分けにより、必要な場面では永続化の利便性を享受しつつ、不要な場面ではコストを最適化できる。開発の初期段階で「この環境は使い続けるか、それとも一度限りか」を判断基準にするのが実践的なアプローチだ。
セッション再開の仕組み

永続化されたSandboxの再開は完全に自動化されている。停止中のSandboxに対してrunCommand()やwriteFiles()などの操作を呼び出すと、最新のスナップショットから自動的に新しいセッションが開始される。開発者が明示的に「再開」を指示する必要はなく、操作の実行がトリガーとなって透過的に処理される。
import { Sandbox } from "@vercel/sandbox";
const resumedSandbox = await Sandbox.get({ name: "my-sandbox" });
// 自動的にSandboxが再開される
await resumedSandbox.runCommand("npm", ["test"]);Sandbox.get()で取得した段階ではまだセッションは開始されておらず、実際にコマンドを実行するタイミングでバックグラウンドで復元処理が走る。この遅延実行モデルにより、不要なセッション起動を避け、リソースの効率的な利用が可能になる。復元にかかる時間はスナップショットのサイズに依存するが、一般的なプロジェクト規模であれば数秒から十数秒程度で完了する。
この設計の利点は、開発者が環境のライフサイクル管理から解放される点にある。「今このSandboxは起動しているか」「停止状態からどう再開するか」といった状態管理の認知負荷がなくなり、コードの記述やテストの実行といった本質的な作業に集中できる。
コスト管理とスナップショットストレージの最適化

永続化機能の利用にあたって注意すべき点は、スナップショットストレージの課金だ。Vercel Sandboxの料金体系では、コンピューティングリソースとスナップショットストレージが別々に課金される。永続化を有効にしたSandboxが増えるほど、保存されるスナップショットの総容量も増加し、それに比例してコストが発生する。
では、どのようにコストを最適化すればよいのか。以下の方針が実践的だ。
● npm install に30秒以上かかる大規模プロジェクト
● チームメンバー間で共有する標準環境
● PRごとに自動生成されるCI環境
● 依存関係がほぼない小規模スクリプトの実行
実際の運用では、Sandbox.update({ persistent: false })を使って後から設定を切り替えられるため、最初は永続化ありで作成し、不要と判断した時点で無効化する柔軟な運用が可能だ。また、Sandbox.delete()を使えば不要になったSandboxとそのスナップショットを完全に削除でき、ストレージの無駄遣いを防げる。
スナップショットの保存間隔や保持数については、現時点ではセッション終了時に自動取得される仕組みのみが提供されている。将来的にはスナップショット取得のタイミングを制御するオプションが追加される可能性もあるが、現行バージョンではシンプルに「停止時保存」のモデルで統一されている。このシンプルさが、開発者の意思決定コストを下げている面もある。
その他の重要な改善点

今回のGAリリースでは、永続化機能に加えていくつかの重要なAPI拡張も同時に提供されている。これらは永続化機能と組み合わせることで、より柔軟なSandbox管理を実現する。
Sandbox.fork() による環境の複製
既存のSandboxから新しいSandboxを作成するSandbox.fork()が追加された。特定の時点の環境を複製し、そこから別の検証を分岐させたいケースで役立つ。たとえば、メインの開発環境から「機能Aの実験用」「機能Bの実験用」をそれぞれフォークし、独立してテストを進められる。
Sandbox.getOrCreate() の冪等性
Sandbox.getOrCreate()は、指定した名前のSandboxが存在すれば取得し、存在しなければ新規作成する冪等な操作を提供する。CI/CDパイプラインでの環境セットアップスクリプトなど、「あれば使う、なければ作る」というパターンが1行で完結する。エラーハンドリングの分岐を書く必要がなくなり、コードの可読性が向上する。
ライフサイクルフックとタグ機能
onCreateおよびonResumeフックが追加され、Sandboxの作成時や再開時に任意の処理を挿入できるようになった。環境変数の動的設定や、起動時チェックの自動実行など、プロジェクト固有の初期化処理を組み込める。また、Tags機能によりSandboxにカスタムプロパティを付与でき、マルチテナント環境での追跡や分類が容易になる。たとえば「environment: staging」「team: frontend」といったタグを付けてフィルタリングすることが可能だ。
実践的な活用シナリオ

永続化機能の登場により、Vercel Sandboxの適用範囲は大きく広がる。ここでは具体的な活用シナリオをいくつか挙げる。
すべての依存パッケージがインストール済みのSandboxをSandbox.fork()でメンバーに配布。環境構築の時間をゼロにし、全員が同一条件で開発を始められる。新メンバーのオンボーディング時間も大幅に短縮される。
テストスイートの実行環境を永続化し、依存パッケージのインストール時間を削減。PRごとにSandbox.getOrCreate()で専用環境を用意し、テスト実行後のクリーンアップもSandbox.delete()で自動化できる。
報告されたバグの発生環境をSandboxで再現し、そのまま永続化。修正パッチの検証が完了するまで環境を保持し、必要に応じてSandbox.fork()で別の修正アプローチも並行テストできる。
これらのシナリオに共通する利点は、「環境の再現性」と「セットアップ時間のゼロ化」だ。特にマイクロサービスアーキテクチャのように複数の依存関係が絡むプロジェクトでは、個々の開発者がローカルで依存関係を解決するよりも、クラウド上の永続化環境を共有する方が圧倒的に効率的なケースが多い。
この記事のポイント
- Vercel Sandboxの永続化機能が正式版となり、セッション間のfilesystem自動保存がデフォルトで有効化された
- 名前ベースのSandbox管理で環境の作成・取得・再開が直感的に行え、スナップショット操作は完全自動化されている
- 永続的Sandboxと非永続的Sandboxの使い分けにより、利便性とコスト最適化のバランスが取れる
- forkやgetOrCreateなどのAPI拡張で、チーム開発やCI/CDパイプラインへの統合がより容易になった
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

2026年Web運用を変えるAIエージェント10選
Webの制作と運用は、静的なページ編集から「アクションウェブ」の時代へと完全に移行した。AIはもはやテキストを下書きするだけではない。状況を理解し、コードを生成し、テストを経て本番環境へ自らデプロイする。エージェンティックAIは、Web制作の現場における実装プロセスそのものを大きく変えつつある。
自律型AIエージェントの市場規模は、年平均44.8%の成長率で拡大し、2030年までに471億ドルに達すると予測されている。Gartnerのレポートによれば、2026年末までに企業アプリケーションの40%が何らかの会話型AIエージェントを内蔵する見込みだ。Web制作者は、手動のコード編集やZapierのルール設定に終止符を打ち、自律的に動くシステムを活用するスキルが求められている。
本記事では、2026年時点で注目すべきエージェンティックAIツールを10本厳選した。WordPressの管理画面に統合されネイティブに動作するプラグインから、大企業向けの高精度な対話型エンジン、ブラウザ操作やデータ収集を自動化するツールまでを機能別に解説する。自社のWebサイトに最もフィットするエージェントを選ぶための指針にしてほしい。
上図のように、AIエージェントは人の手を介さず「計画 → 実行 → 検証 → リリース」のサイクルを自律的に回す。これにより、Webサイトの更新速度は劇的に向上する。
WordPress制作を高速化するAngie by Elementor

Elementorが提供する無料プラグイン「Angie」は、WordPressのダッシュボード内で動作する自律型の開発エージェントだ。従来のAIコーディングアシスタントとは異なり、サイトで有効化されているテーマやプラグインの情報をMCP(モデルコンテキストプロトコル)経由で自動的に取得する。Angieは、ただのコードスニペットを返すのではなく、実際のWordPressアセットを生成して本番に近い環境でテストする。
この仕組みが大きな安心感を生む。ユーザーは自然言語で要望を入力するだけで、Angieがカスタムウィジェットや管理画面用スニペット、カスタム投稿タイプを作成し、隔離されたサンドボックス内で動作を確認する。問題がなければ、ワンクリックで本番サイトに反映される。Elementor Editor Proとの連携時には、世界で2,100万サイト(インターネット全体の約13%)を支えるエコシステムの力をダイレクトに引き出せる。
主な機能と利点
- コンテキスト認識型の実行により、テーマやプラグインとの競合を回避
- サンドボックス環境でカスタムコードを事前検証し、本番サイトへの影響をシャットアウト
- 自然言語から直接、カスタム投稿タイプや管理画面スニペットなどのWordPressアセットを生成
- ビジュアルなフロントエンドインターフェースもテキスト指示で構築可能
- すべての変更はユーザーが承認してから適用されるため、完全なコントロールを維持
料金と評価
Angieは完全無料のWordPressプラグインだ。Elementor Oneとの組み合わせでプロ仕様の体験になるが、単体でも十分に機能する。WordPressの複雑なアーキテクチャをネイティブに理解する専用ツールとして、手動コーディングから解放された開発者や制作会社から高い評価を得ている。
カスタマーサポートを自動化する対話エージェント群

Webサイトの問い合わせ対応は、エージェンティックAIの実力を最も早く体感できる領域だ。高性能な対話エージェントは、FAQのトリアージを超えて、実際の業務処理まで自律的に動く。
Intercom Fin
Intercom Finは、知識ベースを読み取って自律的に回答するサポートエージェントだ。2021年型のチャットボットのように分岐ツリーを使うのではなく、ユーザーの意図を推論し、必要な情報とアクションを組み合わせる。Finはカスタマーサポートチケットの50%を人間の介入なしに解決し、1件あたり0.99ドルという成果報酬型の課金モデルを採用する。
- 既存のヘルプセンターやNotionドキュメントを読み込ませるだけで稼働開始
- 払い戻しなどの業務プロセスもAPI連携で自動実行可能
- 複雑な案件は会話履歴を添えて人間スタッフに引き継ぐ
- 対応チャネルはWebチャット、WhatsApp、メールに対応
大量の問い合わせを抱えるECサイトやSaaS事業者にとって、Finは人手による対応コストを大幅に削減する即戦力になる。
Sierra
Fortune 500企業のようなブランドイメージが優先される現場では、Sierraが選ばれる。元SalesforceのBret Taylor氏が設立したこのプラットフォームは、誤回答(ハルシネーション)を許容できない環境向けに設計されており、高度な安全性と論理推論を兼ね備える。Sierraはバックエンドの在庫データベースや配送システムに深く統合し、商品の交換やサブスクリプションのダウングレードといったトランザクション処理を自律的に行う。ただし、導入には数週間のエンジニアリング作業とエンタープライズ価格が必要で、中小企業には過剰な装備といえる。
マルチエージェントでワークフローを自動化

単一のAIに任せるのではなく、調査・執筆・編集といった複数の専門エージェントをチームとして動かすアプローチが広がっている。これにより、Webサイトのコンテンツ運用やデータ処理のスピードは非連続的に向上する。
Relevance AI
Relevance AIは、マルチエージェントのオーケストレーションに特化したプラットフォームだ。ビジュアルなビルダーでエージェントをドラッグ&ドロップし、競合サイトの価格変動を抽出する担当、比較ページを執筆する担当、HTML整形を担当するチームを構築できる。エージェント同士の連携により、反復作業にかかる時間を平均60%削減した事例も報告されており、デジタルエージェンシーや高頻度でコンテンツを更新するパブリッシャーに適している。料金はチームプランで月額199ドルから。
Zapier Central
Zapier Centralは、6,000を超える外部アプリとの連携にAIの判断力を加えたハブだ。従来のif-thenルールではなく、会話形式で「今日のWeb経由リードを企業規模でスコアリングし、上位3件をSlackで営業チームに通知して」といった複合指示を解釈し、複数アプリをまたいだ自律的なワークフローを実行する。タスクの実行速度は1ステップあたり2秒未満と高速で、すでにZapierのエコシステムを活用しているチームに大きなアドバンテージをもたらす。
ブラウザ操作を自律化するツール

APIが提供されていない外部サイトとの連携は、これまで手作業によるデータ収集やフォーム入力に頼らざるを得なかった。エージェンティックなブラウザ操作ツールは、この壁を取り払う。
MultiOn
MultiOnは、ヘッドレスブラウザをインテリジェントに制御するAPIだ。APIが用意されていない旅行予約サイトでも、MultiOnは画面を視覚的に解析し、「2名でレストランを予約して」といった指示に対して、ボタンのクリックやフォーム入力を自律的に実行する。複雑なマルチステップのフォームでも成功率は90%以上を維持しており、対象サイトのUIが一部変更されても自己修復する。ブラウザベースの処理速度はAPI呼び出しに比べると遅いが、クローズドなWebサービスと連携したいシステムにとって強力な選択肢だ。
Bardeen
BardeenはChrome拡張機能として動作し、ユーザーが現在閲覧しているページのコンテキストを読み取って自動化を提案する。競合サイトのブログ記事一覧をスクレイピングし、要約をコンテンツ計画スプレッドシートに書き込むといった作業をワンクリックで実行できる。月額10ドルからのプロフェッショナルプランで利用でき、ブラウザがアクティブな間だけ動作するため、常時稼働のサーバーエージェントとは異なるが、マーケティングチームのリサーチ負荷を大きく下げる。
コード生成に特化した開発者向けエージェントCursor

カスタムWebアプリケーションの開発において、Cursorは純粋なコード生成の最高峰だ。VS Codeをフォークしたこのエディタは、エージェントAIを深く統合し、単一行の補完ではなくプロジェクト全体を横断するリファクタリングを実行する。Composer機能を使えば、「認証フローを新しいAPI構造に合わせて全面的に書き直して」という指示で、複数のファイルにまたがる変更を計画し、コードを生成する。React、Vue、Node.js、Pythonなど幅広いスタックに対応し、月額20ドルのProプランで強力なモデルを利用できる。ただし、CMSの内部構造に依存するWordPress環境では、Angieのようなネイティブツールを併用する方が効率的だ。
デザイン自動生成のFramer AI

ビジュアル面でのエージェンティックAIとして、Framer AIはプロンプトからレスポンシブなWebサイトのレイアウト、カラーパレット、コピーを一括生成する。CSSグリッドやブレークポイントを自動で処理し、マイクロアニメーションもあらかじめ組み込まれるため、短時間で高品質なランディングページを作成したい場面に適している。ただし、Framerはクローズドなホスティング環境であり、生成したコードの外部エクスポートは容易ではない。静的なマーケティングサイトの高速プロトタイピングには最適だが、複雑な動的機能を後から追加する場合には別のオープンなプラットフォームへの移行が必要になる。
この記事のポイント
- エージェンティックAIは、コード提案にとどまらず、実装・テスト・デプロイまでを自律実行する
- WordPressサイトにはAngieが最も整合性が高く、無料でサンドボックス検証まで行える
- カスタマーサポートにはIntercom Finが有効で、チケットの50%を自動解決する
- マルチエージェントを組めば、コンテンツ更新やデータ処理の反復作業を最大60%削減できる
- API非公開の外部サイトとの連携には、MultiOnやBardeenのようなブラウザ操作エージェントが有効
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AIエージェントがCloudflareで自律デプロイ。Stripe連携でアカウント作成からドメイン購入まで完結
AIエージェントがソフトウェアを開発するだけでなく、本番環境のインフラまで自ら調達し、デプロイを完了させる時代が到来した。Cloudflareは2026年4月30日、AIエージェントがユーザーに代わってCloudflareアカウントを作成し、ドメインを購入し、アプリケーションをデプロイできる新機能を発表した。
この仕組みは決済プラットフォームのStripeが提供する「Stripe Projects」と共同設計された新しいプロトコルによって実現されている。従来は人間が管理画面で行っていたAPIトークンの発行やクレジットカード情報の入力といった作業を、AIが安全かつシームレスに代行する。
開発者は複雑な初期設定に煩わされることなく、AIに指示を出すだけで「ゼロから本番公開まで」を最短距離で駆け抜けられるようになる。これはインフラ構築の在り方を根本から変える可能性を秘めたアップデートだ。
AIエージェントがインフラ構築を担う新時代の幕開け

コーディングエージェントはプログラムを書く能力には長けているが、これまでは本番環境へのデプロイという壁に直面していた。アプリケーションを公開するには、ホスティング先のアカウント、支払い手段、そして操作のためのAPIトークンの3つが不可欠だからだ。
これまでは人間がダッシュボードにログインし、設定を済ませてからエージェントに情報を渡す必要があった。Cloudflareが導入した新機能は、この「人間による介在」を最小限に抑えることを目的としている。
開発者の手作業をゼロにするStripe Projectsとの連携
今回の機能の中核にあるのが、Stripeとの提携による「Stripe Projects」だ。これはAIエージェントが複数のサービスを組み合わせてプロジェクトを立ち上げるためのプラットフォームである。開発者がStripeのアカウントを持っていれば、それを認証の基盤として利用できる。
エージェントはユーザーの許可を得た上で、Cloudflareのアカウントを自動的にプロビジョニング(準備)する。もしユーザーがすでにCloudflareのアカウントを持っている場合は、標準的なOAuthフローを通じてアクセス権が譲渡される。これにより、APIキーのコピペという原始的な作業から解放される。
● カード情報登録(手動)
● APIキー発行とコピペ(手動)
● ドメイン検索と購入(手動)
✔ 支払いトークンの自動受け渡し
✔ ドメインの自律取得とデプロイ
上記の図が示すように、人間が介入すべきポイントは「AIへの指示」と「最終的な承認」だけに集約される。これにより、開発のリードタイムは劇的に短縮されるだろう。
プロトコルを支える3つの柱

AIエージェントが自律的に動くためには、単にAPIを叩くだけでは不十分だ。CloudflareとStripeは、エージェントが環境を理解し、権限を得て、支払いを実行するための3つの要素をプロトコルとして定義した。
サービスカタログからの自律的な発見
まず重要になるのが「Discovery(発見)」だ。エージェントは、利用可能なサービスが何であるかを知る必要がある。新しいプロトコルでは、CloudflareなどのプロバイダーがREST APIを通じてサービスカタログをJSON形式で提供する。
エージェントはユーザーの要望に基づき、このカタログから最適なサービス(ドメイン登録、ストレージ、コンピューティングなど)を選択する。人間が「どのメニューから選ぶか」を悩む必要はなく、エージェントがタスク達成に最適な道具を自ら選び出す仕組みだ。
認証とアカウントの即時発行
次に「Authorization(認証)」だ。Stripeがアイデンティティプロバイダーとして機能し、ユーザーの身元を保証する。Cloudflareはこの情報を基に、未登録のユーザーに対しては即座にアカウントを発行する。
発行された認証情報はStripe Projects CLIによって安全に保管され、エージェントはそれを使ってCloudflareのAPIを操作する。この一連の流れにおいて、ユーザーがサインアップフォームに入力する手間は一切発生しない。
クレジットカード情報を渡さない安全な決済
最も懸念されるのは「Payment(支払い)」の安全性だろう。AIにクレジットカード番号を教えるのはリスクが高い。そこでこのプロトコルでは、カード情報の代わりに「支払いトークン」を使用する。
Stripeから発行されたトークンをCloudflareに渡すことで、エージェントは実際のカード番号に触れることなく、有料プランの購読やドメインの購入を実行できる。決済の利便性とセキュリティを両立させた設計となっている。
実際のワークフローとCLIでの操作感
この新機能を利用するには、Stripe CLIと専用のプラグインが必要になる。セットアップが完了すれば、ターミナルから簡単なコマンドを実行するだけでプロジェクトを開始できる。Cloudflareのブログでは、具体的な手順が紹介されている。
Stripe CLIを用いたプロジェクトの初期化
まず、以下のコマンドでプロジェクトを初期化し、Stripeにログインする。これがすべての作業の起点となる。
stripe projects initその後、AIエージェントに対して「新しいドメインを取得してアプリをデプロイしてほしい」と指示を出す。エージェントは自ら stripe projects catalog コマンドを叩いてCloudflareのドメイン登録サービスを見つけ出し、購入プロセスを開始する。
もしStripeアカウントに支払い方法が登録されていない場合は、エージェントがユーザーに対してカード情報の追加を促すプロンプトを表示する。人間はエージェントが提示した確認事項に対して「Yes」と答えるだけで、裏側で複雑なインフラの紐付けが完了する。
セキュリティとガバナンスへの配慮

AIに支払権限を与えることには、慎重な意見も多い。「エージェントが勝手に高額なドメインを大量購入したらどうするのか」という懸念は当然の反応だ。この問題に対処するため、プロトコルには厳格な制限が設けられている。
予算制限と予算アラートによる暴走防止
Stripe Projectsでは、デフォルトで1つのプロバイダーに対して月額100ドルという支出上限が設定されている。エージェントがこの上限を超えて勝手に課金することはできない仕組みだ。
さらに上限を引き上げたい場合は、ユーザーが明示的に設定を変更し、Cloudflare側で予算アラート(Budget Alerts)を設定する必要がある。これにより、AIの自律性を保ちつつ、予期せぬコスト増大を防ぐガバナンスが効いている。
独自分析。インフラのコモディティ化とエージェントOSの加速

今回のCloudflareの動きは、単なる利便性の向上に留まらない。筆者は、これがインフラの「完全な抽象化」に向けた決定的な一歩であると考えている。かつて開発者はサーバーを自前で立てていたが、クラウドが登場し、さらにサーバーレスへと進化した。そして今、インフラは「AIが勝手に調達するもの」へと変貌しようとしている。
ここで重要なのは、Stripeが単なる決済手段ではなく、Web上の「アイデンティティ(身元)」のハブとして機能し始めている点だ。Stripeでログインしていれば、CloudflareもPlanetScaleもNeonも、あらゆるクラウドサービスが即座に利用可能になる。これは、Web全体が1つの巨大なオペレーティングシステム(OS)のように振る舞い、AIエージェントがその上で自由にリソースを操作できる環境が整いつつあることを意味する。
開発者の役割は、コードを書くことよりも「AIにどのようなビジネスロジックを実現させたいか」を定義することへとシフトしていくだろう。インフラの設定ミスやAPIトークンの管理漏れといった「非本質的なトラブル」から解放される未来は、すぐそこまで来ている。
この記事のポイント
- AIエージェントがCloudflareのアカウント作成、ドメイン購入、デプロイを自律的に行えるようになった。
- Stripe Projectsとの連携により、OAuth認証と支払いトークンを用いた安全なプロトコルが構築されている。
- 人間はダッシュボードを操作することなく、CLIとAIへの指示だけで本番環境を構築できる。
- 月額100ドルのデフォルト支出制限により、AIの暴走による高額請求を防ぐ仕組みが備わっている。
- インフラの調達が自動化されることで、開発者はより高度なアプリケーション設計に集中できるようになる。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

WordPress運用の自動化がもたらす経済的メリットとスケーリング戦略
WordPress制作を主軸とするエージェンシーにとって、クライアントが増えることは喜ばしい。しかし、サイト数が増えるにつれて「保守運用」という目に見えない重荷がチームの時間を奪い始める。手動での管理を続けていると、売上の増加以上に運用コストが膨らみ、利益率が低下する「スケーリングの罠」に陥るリスクがある。
この課題を解決する鍵は、運用の基盤に自動化を組み込むことだ。Kinstaの報告によれば、自動化を取り入れた企業の中には、週のメンテナンス時間を15時間から10時間以下へ削減し、年間で250時間以上の創出に成功した例もあるという。これは単なる時短ではなく、ビジネスの成長モデルそのものを変えるインパクトを持っている。
本記事では、手動管理がもたらす真のコストを明らかにし、インフラ、ツール、APIという3つのレイヤーでどのように自動化を進めるべきかを解説する。技術に詳しい同僚が教えるような視点で、最新のWeb制作現場で求められる効率化の全容を紐解いていこう。
手動管理がもたらす「スケーリングの罠」と真のコスト

多くの制作会社では、サイト管理の内容を「プラグインの更新」や「バックアップの確認」といった目に見えるタスクのリストとして捉えている。しかし、管理サイトが30件、50件と増えたとき、それぞれのタスクが毎週どれだけの時間を消費しているかを正確に把握しているケースは少ない。
目に見えない運用負荷の正体
一般的なメンテナンス業務には、プラグインやコアのアップデート、セキュリティ監視、バックアップの検証、キャッシュ管理などが含まれる。これらを1サイトずつ手動で行う場合、1件あたりの時間は短くても、サイト数が増えるとその合計時間は膨大なものになる。
例えば、30サイトのプラグイン更新に毎週2時間を費やしているとする。この時間は直接的な収益を生まない「維持」のためのコストだ。この時間が積み重なることで、新しいクライアントの獲得や戦略的な提案に割くべき「機会費用」が失われていく。手動管理は、ビジネスの成長を物理的に制限するブレーキとなってしまうのだ。
「人を増やす」解決策が限界を迎える理由
チームが忙しくなると、新しいスタッフを雇用して対応しようとするのが一般的だ。しかし、手動管理を前提とした組織では、人を増やしても1人あたりの管理可能件数は変わらない。給与や採用コスト、管理工数が増えるだけで、サイト1件あたりの利益率は改善しないという問題がある。
一方で、自動化されたワークフローは異なる性質を持つ。20サイトを管理する自動化システムは、200サイトを管理する場合でもほとんどコストが変わらない。つまり、管理数が増えるほど、サイト1件あたりの「限界費用(新しく1サイトを追加する際にかかる費用)」がゼロに近づいていく。これが、自動化がビジネスの経済性を根本から変える理由だ。
インフラ層で実現する「何もしない」運用自動化

自動化の第一歩は、WordPressが動作するサーバーやインフラのレベルで、人間が介入しなくても済む仕組みを整えることだ。これを「インフラレベルの自動化」と呼ぶ。信頼できるホスティングサービスを選択することで、多くの保守作業をシステムに委ねることが可能になる。
自己修復するPHPとデータベース最適化
サイトのダウンタイムを防ぐためには、サーバーの状態を常に監視する必要がある。例えば、Kinstaのようなプラットフォームでは「自己修復PHP」という機能が提供されている。これは、PHPプロセスが停止したことを検知すると、システムが自動的に再起動を試みる仕組みだ。これにより、管理者が気づく前にサイトが復旧し、クライアントへの報告や緊急対応の手間がなくなる。
また、データベースの最適化も自動化できる領域だ。毎週自動的にMySQL(データベース管理システム)の設定を微調整し、パフォーマンスを維持する機能があれば、エンジニアが手動でクエリを最適化する必要はなくなる。こうした「見えない自動化」が、サイトの安定性を底上げしてくれる。
クラウドフレア連携による高度なセキュリティ
セキュリティ対策も、手動で行うには限界がある分野だ。最新のプラットフォームでは、Cloudflare(クラウドフレア)などのエンタープライズ級ファイアウォールが標準で組み込まれている。これにより、DDoS攻撃(大量のアクセスでサイトを落とす攻撃)や不正アクセスを、サーバーに到達する前に自動で遮断できる。
マルウェアのスキャンや脆弱性へのパッチ適用がバックグラウンドで常時実行されていれば、管理者はアラートが出たときだけ対応すれば済むようになる。セキュリティを「個別の作業」から「インフラの標準機能」へ移行させることが、運用の経済性を高める鍵となる。
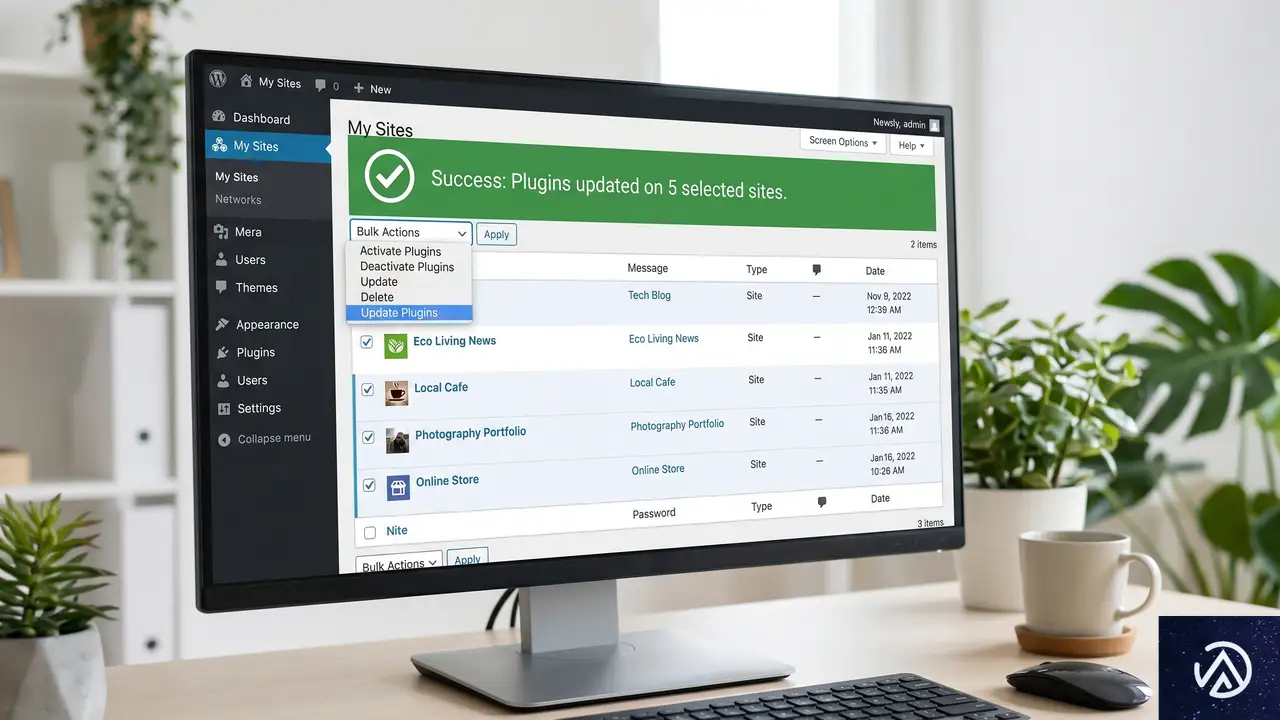
管理画面から一括操作!プラットフォームによる効率化
インフラの次に重要なのが、日常的な運用タスクを効率化するツールだ。複数のWordPressサイトを抱えている場合、それぞれのダッシュボードに個別にログインするのは非常に非効率だ。これを解決するのが「一括操作」の機能である。
複数サイトのキャッシュ・プラグイン一括更新
管理サイトが数十件に及ぶ場合、特定のプラグインに脆弱性が見つかった際の対応は戦場のような忙しさになる。しかし、管理プラットフォームのバルクアクション(一括操作)機能を使えば、チェックボックスでサイトを選択し、一クリックで全サイトのプラグインを更新できる。
キャッシュのクリアも同様だ。CDN(コンテンツ・デリバリー・ネットワーク)やサーバーキャッシュを、管理画面から一括でフラッシュできれば、デプロイ後の表示確認作業が劇的にスムーズになる。以下のデモは、手動でのキャッシュ管理と一括管理のフローを視覚化したものだ。
● サイトBにログイン → キャッシュ削除
● サイトCにログイン → キャッシュ削除
● 「キャッシュをクリア」ボタンを1回押す
このデモのように、作業ステップを「n回(サイト数)」から「1回」に集約することが自動化の本質だ。
視覚的テストを伴う安全な自動アップデート
自動アップデートは便利だが、更新によってサイトのデザインが崩れることを懸念する人は多い。そこで注目されているのが、ビジュアル・リグレッション・テスト(視覚的比較テスト)を組み合わせた自動アップデートだ。
これは、アップデートの前後でサイトのスクリーンショットを自動撮影し、ピクセル単位で差異を比較する技術だ。もし大きな崩れを検知した場合は、自動的にアップデートをロールバック(元の状態に戻す)し、管理者に通知する。この仕組みがあれば、人間が目視で全ページを確認する必要がなくなり、安全に完全自動化へ踏み出せる。
APIとカスタムスクリプトで独自のワークフローを構築する

さらに高度な自動化を目指すなら、API(アプリケーション・プログラミング・インターフェース)の活用が不可欠だ。APIとは、外部のプログラムからシステムを操作するための窓口のようなものだ。これを利用することで、自社の既存ワークフローとホスティング管理を密接に連携させることができる。
サイト構築からログ取得までの自動連携
例えば、新規クライアントの契約が決まった瞬間、CRM(顧客管理システム)の情報をトリガーにして、自動的にWordPressの新規環境を構築し、初期プラグインをインストールするスクリプトを組むことができる。営業担当者が入力を終えたときには、エンジニアが手を動かす前に開発環境が用意されているという状態だ。
また、トラブルシューティングに必要なサーバーログの取得もAPIで自動化できる。以下のコード例は、特定の環境からエラーログを取得するためのJavaScript関数のイメージだ。これを自社の管理ツールに組み込めば、わざわざホスティングの管理画面を開く必要すらなくなる。
async function getSiteLogs(environmentId, fileName, lines) {
const query = new URLSearchParams({
file_name: fileName || 'error',
lines: lines || 1000,
}).toString();
const resp = await fetch(
`https://api.kinsta.com/v2/sites/environments/${environmentId}/logs?${query}`,
{
method: 'GET',
headers: { 'Authorization': 'Bearer YOUR_API_KEY' },
}
);
const data = await resp.json();
return data;
}CI/CDパイプラインへの統合
モダンな開発現場では、CI/CD(継続的インテグレーション/継続的デリバリー)という手法が一般的だ。これは、コードをGitHubなどにアップロードすると、自動的にテストが走り、本番環境へ反映される仕組みを指す。
APIを活用すれば、このデプロイの流れの中に「キャッシュのクリア」や「バックアップの作成」を自動的に組み込める。開発者がコードを書くことに集中し、運用の付随作業を意識しなくて済む環境こそが、高い生産性を生み出す。KinstaのようなAPIを公開しているプラットフォームを選ぶことは、将来的な拡張性を確保する上で極めて重要だ。
自動化が変えるWordPressビジネスの収益構造
自動化を導入した結果、ビジネスにはどのような変化が起きるのだろうか。最も顕著なのは、チームの時間が「守り」から「攻め」へとシフトすることだ。手動のメンテナンスから解放されたスタッフは、より価値の高い業務に集中できるようになる。
浮いた時間を「攻め」の施策に転換する
例えば、あるeコマース特化のエージェンシーでは、ホスティングの切り替えと自動化の導入により、サポート担当者1人あたり1日2時間の削減に成功した。この時間は、クライアントへの戦略的なマーケティング提案や、新しい売上を生む機能の開発に充てられたという。
開発者がアップデート作業に追われなくなれば、クライアントのビジネス成長に直結するコンサルティングが可能になる。これは、単なる「保守費用」以上の付加価値をクライアントに提供できることを意味し、結果として契約単価の向上や顧客満足度の改善につながるのだ。
サイト数が増えるほど利益率が上がる仕組み
自動化の最大のメリットは、ビジネスのスケーラビリティが向上することだ。従来は「サイトが増える = 忙しくなる = 人を雇う = 利益が残らない」という負のループがあった。しかし、自動化スタック(技術の積み重ね)を構築すれば、サイトの追加に伴う運用コストの上昇を最小限に抑えられる。
100サイトを管理する労力が10サイトの時とそれほど変わらなければ、増えた売上の大部分が利益として残るようになる。この「規模の経済」を享受できるかどうかが、制作会社として生き残れるかどうかの分水嶺になるだろう。質の高いホスティングサービスへの投資は、単なる経費ではなく、将来の利益率を確保するための「資本投資」と考えるべきだ。
この記事のポイント
- 手動管理を続けると、サイト数が増えるほど運用コストが利益を圧迫する「スケーリングの罠」に陥る
- 自己修復PHPや自動セキュリティ監視などのインフラ自動化により、日常的なトラブル対応をゼロに近づけられる
- 管理プラットフォームの一括操作機能を活用すれば、数十サイトの更新作業を数分に短縮できる
- APIを利用して独自のワークフローを構築することで、開発から運用までの一貫した自動化が可能になる
- 自動化で浮いた時間を戦略的業務に充てることで、ビジネスの付加価値と利益率を同時に高められる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験