

Gemini 3.5 Live Translate公開、自然な音声翻訳の全容
はじめに

Gemini 3.5 Live Translateが2026年6月9日に公開された。これは音声をリアルタイムで翻訳し、話者の抑揚や間合いを保ったまま自然な音声を生成するAIモデルだ。
従来の逐次翻訳とは異なり、相手が話し終えるのを待たずに翻訳を開始する。遅延は数秒程度に抑えられ、70以上の言語を自動検出して処理する。Google DeepMindが発表した本モデルは、開発者向けAPIやGoogle Meet、Google翻訳アプリを通じて順次利用可能になる。
このリリースは、音声翻訳の「待ち時間」という長年の課題に正面から取り組んだものだ。翻訳品質とリアルタイム性の両立にどこまで迫れたのか、開発者や企業にとっての実用性はどの程度か、本記事で詳細を解説する。
上図のように、逐次翻訳の「全文処理待ち」というボトルネックが解消される。リアルタイム性を重視するビデオ会議や同時通訳の現場では、この差が決定的だ。
Gemini 3.5 Live Translateの技術的な特長
音声ストリーミングによる連続翻訳
最大の特長は、音声をストリーミング処理しながら翻訳結果を連続的に生成する点にある。話者が文を完結させるのを待たず、部分的な発話から逐次翻訳を開始する。
この方式では「コンテクストを待って翻訳精度を高める」ことと「即座に翻訳を開始する」ことのトレードオフが発生する。Gemini 3.5 Live Translateは、両者のバランスを自動調整しながら、自然な間合いを保ったまま数秒の遅延で追随する。
音声通話において「間」はコミュニケーションの質を大きく左右する。2秒の無音がストレスになるシーンは多い。本モデルはその課題に直接応える設計思想だ。
70以上の言語を自動検出して翻訳
手動での言語設定は不要だ。入力音声を分析し、70以上の言語を自動識別する。多言語が混在する会議やイベントでも、参加者ごとの言語選択といった事前設定なしに翻訳が動作する。
多言語対応の自動化は、実際の運用負荷を大幅に下げる要素だ。特にエンタープライズ領域では、IT管理者が会議ごとに翻訳設定を手動で行う手間が削減される。
抑揚・テンポ・ピッチの保持
単なる文字起こし翻訳とは異なり、元の話者の声の高さや抑揚、話す速度までも翻訳音声に反映する。これにより「機械的な翻訳音声」から「人格を感じる翻訳」へと体験が変化する。
感情表現や強調、皮肉といったパラ言語情報が翻訳でも伝わる可能性が生まれる点は、ビジネス通話や国際交渉の現場で特に重要だ。
ノイズ耐性の高さ
屋外やイベント会場など、騒がしい環境でも動作するノイズ耐性を備えている。Google DeepMindの公式ブログでは「loud, unpredictable environments(騒がしく予測不能な環境)」でもアプリケーションが機能すると明記されている。
これは実用面で極めて重要な仕様だ。空港や駅、工事現場、混雑したカンファレンス会場など、現実の翻訳需要は静かな会議室だけではない。ノイズ耐性の高さは、本モデルが実世界での利用を前提に設計されている証左と言える。
開発者向けの提供形態とAPI活用法
Gemini Live APIとGoogle AI Studio
開発者はGemini Live APIを通じて本モデルにアクセスできる。現在はパブリックプレビュー段階で、Google AI Studioからも試用可能だ。
APIを利用すれば、自社のビデオ会議システムや通話アプリ、配信プラットフォームにリアルタイム翻訳機能を組み込める。音声ストリームをAPIに送信するだけで翻訳音声が返ってくるため、インフラ構築のハードルは低い。
対応する開発者プラットフォーム
Agora、Fishjam、LiveKit、Pipecat、Vision Agentsといったプラットフォームが既にGemini Live APIとの統合を完了している。これらのプラットフォームはリアルタイムメディアストリーミングの複雑なインフラ部分を抽象化するため、開発者はユーザー体験の設計に集中できる。
Google DeepMindのGitHubリポジトリ(Gemini Cookbook)では、LiveKitを使った同時多言語翻訳のデモコードが公開されている。実際の実装イメージを掴みたい開発者は参照するとよい。
Grabでの導入事例
東南アジアの配車サービス大手Grabは、ドライバーと乗客間の多言語通話に本モデルを試験導入している。同社では月間1,000万件以上の音声通話が発生しており、ピックアップ時のコミュニケーション障壁を低減する狙いだ。
多言語国家での配車サービスでは、ドライバーと乗客の言語不一致が日常的に発生する。リアルタイム翻訳が実用レベルに達すれば、この摩擦は大幅に軽減される。Grabの事例は、本モデルの実運用における有効性を示す重要な先行例である。
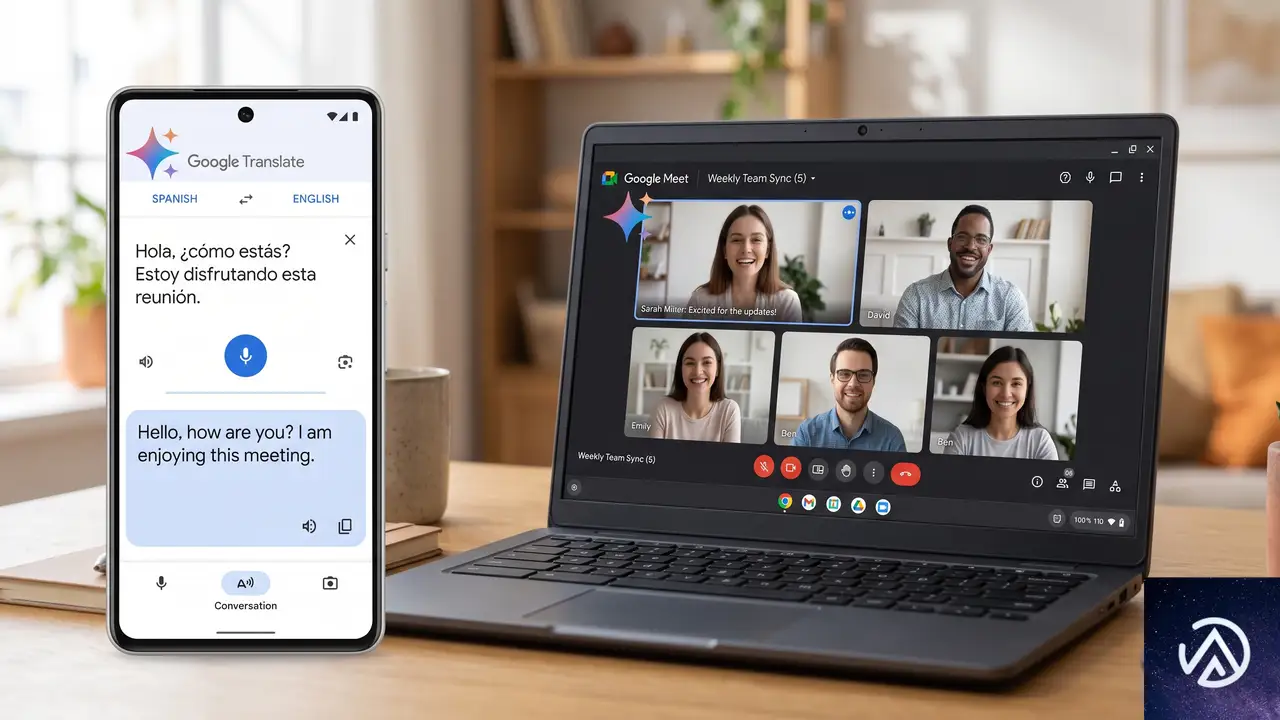
Google MeetとGoogle翻訳アプリでの展開

Google Meetでの通訳機能が大幅強化
Google Meetの音声翻訳機能にGemini 3.5 Live Translateが統合される。従来は5言語のみの対応だったが、70以上の言語に拡大される。さらに、英語を介した翻訳のみだった制限が外れ、2,000以上の言語ペアでの双方向翻訳が可能になる。
本機能は今月から一部のGoogle Workspace企業向けにプライベートプレビューとして提供開始され、年内に広範なロールアウトが予定されている。
Google翻訳アプリでの新体験
AndroidおよびiOS版のGoogle翻訳アプリにも本モデルが展開される。有線・無線を問わずヘッドフォンを接続するだけで、70以上の言語に対応したリアルタイム翻訳が利用可能になる。
特に注目すべきはAndroid向けの新機能「リスニングモード」だ。スマートフォンを受話器のように耳に当てるだけで、翻訳音声が端末のイヤースピーカーから直接再生される。ヘッドフォンを持っていない場面や、周囲に翻訳音声を聞かれたくない場面で有用だ。
例として、スペイン語のガイドツアーを英語の翻訳音声で聞くといったユースケースが公式ブログで紹介されている。観光や出張先での利用シーンが明確に想定されている。
SynthIDによる安全性担保
本モデルが生成するすべての音声には、SynthIDによる電子透かしが埋め込まれる。この透かしは人間の耳では検知できないが、AI生成音声であることを機械的に判別可能にする。
音声のAI生成が一般化するにつれ、なりすましや偽情報への対策は避けて通れない課題だ。リアルタイム翻訳という機能の利便性と、AI生成コンテンツの検出可能性を両立させる設計は、今後のAIサービスにおける標準的な取り組みになるだろう。
詳細な安全性の取り組みについては、Google DeepMindが公開するモデルカードで確認できる。
この記事のポイント
- Gemini 3.5 Live Translateは70以上の言語を自動検出し、話者の抑揚を保ったまま連続的に翻訳する
- 従来の逐次翻訳とは異なり、話し終えを待たずに数秒遅れで追随するストリーミング処理を採用
- 開発者はGemini Live APIやGoogle AI Studioからパブリックプレビューとして利用可能
- Google Meetでは対応言語が5から70以上に拡大し、2,000超の言語ペアでの双方向翻訳が実現
- 生成音声にはSynthIDの電子透かしが埋め込まれ、AI生成コンテンツの検出が可能

・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験