

Amazon OpenSearch Serverless次世代版、AIエージェント構築向けに発表
AWSが2026年5月28日、Amazon OpenSearch Serverlessの次世代版を一般提供開始した。AIエージェントアプリケーションの構築に特化したフルマネージド検索・ベクトルエンジンであり、スケールゼロからピーク時までシームレスに拡縮する。
従来のプロビジョニング型クラスタと比較して最大60%のコスト削減が可能とされる。リソース作成は数秒、スケーリング速度は前世代比で最大20倍に向上した。VercelやKiroといったAI開発プラットフォームとのネイティブ統合も備え、インフラ管理を意識せずに本番対応のバックエンドを数分で立ち上げられる。
この記事では、次世代OpenSearch Serverlessの主要な特徴、アーキテクチャ上の進化、AIエージェント開発への実践的な活用法を詳しく見ていく。
OpenSearch Serverless次世代版の概要

OpenSearchはElasticsearchからフォークしたオープンソースの分散型検索・分析エンジンだ。Amazon OpenSearch Serviceはそのマネージド版であり、サーバーレスオプションは2022年に導入された。今回の次世代版は、そのサーバーレスアーキテクチャを根本から刷新したものである。
AWS News Blogの記事によると、次世代版は「AIエージェントを構築する顧客向けに設計された」と位置づけられている。フルマネージドである点は変わらないが、スケーリングの速度とコスト効率が大幅に向上した。
主な改良点はスケールゼロと高速スケーリング
特筆すべきはスケールゼロへの対応だ。利用が途絶えると自動的にリソースが解放され、アイドル状態のコストがほぼゼロになる。リクエストが発生すると数秒でリソースが再作成され、前世代比で最大20倍速いスケールアップを実現する。
つまり、開発中の本番前ステージング環境や、トラフィックが断続的なAIエージェントのバックエンドで、大幅な無駄を省けるということだ。
このデモは、従来型と次世代版のリソース管理モデルの違いを概念的に示したものだ。実際の環境では、数秒単位でプロビジョニングが動的に切り替わる。
コレクションタイプは全文検索とベクトル検索に限定
今回のリリース時点では、対応するコレクションタイプは全文検索(SEARCH)とベクトル検索(VECTORSEARCH)の2種類である。既存のOpenSearch Serverlessにあった時系列データやログ分析向けのタイプは、現時点では次世代版で選択できない。
これは、まずAIエージェント向けの検索基盤として最適化された領域に集中した戦略と見られる。今後のアップデートで順次拡張される可能性は高い。
スケールゼロと高速スケーリングの仕組み

次世代版のアーキテクチャを理解するには、従来のサーバーレス版との違いを押さえておくとよい。前世代のOpenSearch Serverlessは、あらかじめ設定された最小キャパシティユニット(OCU)を常に確保するモデルだった。利用がゼロになっても、その最小ユニット分のコストは発生し続けたのである。
OCUの最小値をゼロに設定可能
次世代版では、インデックス用と検索用それぞれの最小OCUをゼロに指定できるようになった。CLIコマンドを見ると、minIndexingCapacityInOCUとminSearchCapacityInOCUに0が設定されているのがわかる。
この仕組みにより、トラフィックが完全に途絶えた時間帯はコンピューティングリソースが解放され、ストレージのみの課金になる。実質的に「寝ている間は課金されない検索エンジン」として振る舞うわけだ。
リソース作成が数秒で完了する理由
従来のサーバーレス版でコレクションを作成すると、数分かかることもあった。次世代版では、内部的なリソースプロビジョニングのパイプラインが刷新されており、数秒で利用可能になる。
これはAIエージェントの開発フローにおいて非常に重要だ。たとえばVercel上で新しいプロジェクトを作成し、そこにベクトルデータベースを接続する場合、即座にプロビジョニングが完了しなければ開発テンポが落ちてしまう。数秒で立ち上がるという体験は、プロトタイピングの高速化に直結する。
このフローはVercel統合を活用した典型的なAIエージェントのセットアップ手順を図示したものだ。実際の操作はVercelの管理画面から数クリックで完了する。
VercelやKiroとの統合でAIエージェント構築を加速

次世代OpenSearch Serverlessの重要な価値は、AIエージェント開発プラットフォームとのシームレスな連携にある。Vercelの管理画面から直接OpenSearchコレクションを作成・接続できるようになったのがその典型だ。
Vercel統合の実用性
Vercelユーザーは、フロントエンド(Next.js等)のデプロイに加え、検索やベクトルストアをバックエンドインフラとして簡単に追加できる。従来であれば、別途Elasticsearch互換のDBを用意し、VPCネットワークを設定し、認証情報を安全に管理する手間が発生した。
これが管理画面上で完結するということは、開発者がインフラの設定に費やす時間を劇的に減らせる。特にAIエージェントのように試行錯誤を重ねるプロジェクトでは、この迅速さが競争力に直結する。
OpenSearch Agent SkillsとKiro Powers
AWS News Blogの記事では、Claude CodeやCursor、Kiroといった開発ツールとの連携も紹介されている。GitHub上のOpenSearch Agent Skillsというリポジトリには、特定のワークフロー向けのドメイン知識やベストプラクティスがスキルとしてパッケージ化されている。
たとえば「あるテーマに関する最新の技術ドキュメントを検索し、その結果を要約する」といった複数ステップのタスクを、エージェントがOpenSearchのスキルを呼び出すだけで実行できる。エージェントは単に検索結果を受け取るだけでなく、その検索がどのように実行されたかのプロセスも理解できるようになる。
このインラインフローは、開発者がAIエージェントに指示を出してからOpenSearchが検索を実行し、結果が返るまでの一連の流れを色分けで示している。OpenSearch Agent Skillsによって、エージェントは適切なスキルを自動選択できる。
一方、Kiro Powersで提供されるOpenSearch Launchpadは、エンドツーエンドのアーキテクチャ計画をガイド付きで進められるツールだ。検索アプリケーションの全体設計をAIが支援することで、開発の初期段階から生産性を高められる。
導入方法、コンソールとCLI

次世代OpenSearch Serverlessの利用開始は簡単だ。マネジメントコンソールから「Serverless」メニューを選び、「Create collection」をクリックする。次の画面で「NextGen」を選択し、Express createを選べばデフォルト設定で即座にコレクションが作成される。
Express createで手間を省く
Express createは設定不要のクイック作成機能だ。セキュリティポリシーやネットワーク設定は自動で適用され、後から一部の設定を変更できる。プロトタイピングや検証用途では、まずExpress createで立ち上げ、必要に応じて細かな設定を詰めるアプローチが現実的だろう。
CLIからの作成手順
AWS CLIを使う場合は、まずコレクショングループを作成し、その中にコレクションを作る2段階の手順になる。以下はAWS公式ブログに掲載されたコマンド例を、実際の利用に即して整理したものだ。
# コレクショングループの作成(生成世代をNEXTGENに指定)
aws opensearchserverless create-collection-group \
--name my-nextgen-group \
--standby-replicas ENABLED \
--generation NEXTGEN \
--description "My NextGen collection group" \
--capacity-limits '{
"maxIndexingCapacityInOCU": 96,
"maxSearchCapacityInOCU": 96,
"minIndexingCapacityInOCU": 0,
"minSearchCapacityInOCU": 0
}' \
--region "us-east-1"
# コレクションの作成(SEARCHまたはVECTORSEARCH)
aws opensearchserverless create-collection \
--name my-nextgen-collection \
--type SEARCH \
--collection-group-name my-nextgen-group \
--standby-replicas ENABLED \
--description "My collection in NextGen group" \
--region "us-east-1"なお、ブログ公開時のCLIコマンドには最大OCUのデフォルト値に誤りがあり、後日修正された点には注意が必要だ。実際に使う場合は最新のドキュメントを参照してほしい。
AIエージェント時代のデータバックエンドの在り方

OpenSearch Serverless次世代版の登場は、単なる新バージョン発表以上の意味を持つ。AIエージェントが自律的に情報を取得し、判断し、行動する時代において、「検索とベクトル演算のバックエンドをいかに手軽に、安く、速く用意できるか」が開発の成否を分けるからだ。
スケールゼロがもたらす開発文化の変化
従来、検索バックエンドの構築には「とりあえず動かす」だけでもある程度の初期コストが発生した。そのため、プロトタイプ段階では簡易的なインメモリ検索で代用し、後から本格的な検索エンジンに切り替えるパターンが一般的だった。
スケールゼロで最小OCUゼロが可能になったことで、最初から本番同様のOpenSearchを組み込んで開発を進められる。切り替えの手戻りがなくなり、より忠実な検証が可能になる。これはAIエージェントの品質を高める上で、見過ごせない利点だ。
マルチプラットフォーム連携の拡大予測
AWSはVercelとKiroに加え、今後さらに多くのAI開発プラットフォームとの統合を進めると見られる。GitHub CodespacesやReplit、Bolt.newなど、ブラウザベースの開発環境で動作するAIエージェントが増えれば、それらと連携する検索バックエンドの需要は右肩上がりだ。
OpenSearchがこの領域で競争力を発揮するためには、統合の容易さだけでなく、GPUアクセラレーションを活用したベクトル検索のパフォーマンスも鍵を握る。今回の次世代版ではGPU対応が明記されており、大量の埋め込みベクトルを扱う大規模AIエージェントのワークロードにも耐えられる設計が示されている。
コスト構造の変革と注意点
最大60%のコスト削減というインパクトは大きいが、これは「ピークキャパシティに合わせて常時プロビジョニングしていたクラスタ」との比較である。利用が常に一定水準以上あるサービスでは、スケールゼロの恩恵は限定的だ。
OCU単位の従量課金は、予測不能なトラフィックパターンを持つAIエージェントと相性が良い。一方、安定的に高いトラフィックが続く場合は、従来のプロビジョニング型OpenSearch Serviceの方がコストパフォーマンスに優れるケースもある。慎重な見積もりが求められる。
この記事のポイント
- OpenSearch Serverless次世代版はAIエージェント構築に特化し、スケールゼロと高速スケーリングを実現
- ピークプロビジョニング対比で最大60%のコスト削減、リソース作成は数秒で完了
- VercelやKiroとのネイティブ統合で、数分で検索バックエンドをデプロイ可能
- OCUの最小値をゼロに設定できるため、アイドルコストを極小化できる
- 全商用リージョンで一般提供開始、導入はコンソールのExpress createまたはCLIで

・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

CloudflareがClaude Managed Agentsと統合、エージェントの実行基盤を刷新
CloudflareがAnthropicと連携し、Claude Managed AgentsをCloudflareのサンドボックス環境と統合した。この新たな統合により、エージェントのコード実行からブラウザ操作、プライベートサービスへの接続までを、Cloudflareのプラットフォーム上でより柔軟に制御できる。
従来、Claude Managed AgentsはAnthropic側のインフラに完全に依存していた。今回の発表で「頭脳」であるClaudeの推論ループと「手足」であるコード実行基盤が分離され、後者をCloudflare上で運用できるようになった。
開発者は数分でテンプレートをデプロイし、セキュリティ強化やミリ秒単位のサンドボックス起動、内部サービスへの安全な接続といったメリットを得られる。この記事では、統合の仕組みと実務への影響を具体的に掘り下げる。
Claude Managed AgentsとCloudflareが目指すもの

この構成で得られるのは単なる「場所の変更」ではない。インフラをCloudflareに移すことで、エージェントの振る舞いを細かく監視し、内部サービスとの通信を暗号化し、必要なリソースだけを動的に割り当てられるようになる。
Cloudflare Blogの記事では、この仕組みを「頭脳から手足を切り離す」と表現している。開発者はClaudeの高い推論能力をそのまま活かしつつ、実行環境だけを自社ポリシーに合わせてカスタマイズできるわけだ。
Cloudflare環境の仕組み

統合をデプロイすると、Cloudflare上にWorkersベースのコントロールプレーンが立ち上がる。Claude Agentがセッションを開始するたび、このコントロールプレーンがサンドボックス環境を割り当て、コード実行やCLIツールの操作、ブラウザ操作などを代行する。
サンドボックスはセッションがスリープしても状態を自動的に保持する。コンテナイメージのカスタマイズやインスタンスサイズの調整もオプションで指定でき、既存の監視ツール(DatadogやSplunk)へのログ連携にも対応している。
特筆すべきは、Cloudflareのダッシュボードからエージェントの状態を可視化し、必要に応じてSSHでサンドボックス内部に入れる点だ。大規模なエージェント運用では、トラブルシューティングのしやすさが運用コストを大きく左右する。この設計は現場の要求をよく踏まえている。
インターネット規模のエージェント実行基盤

エージェントが本格的に普及すると、企業は1人のユーザーに対して複数のエージェントを同時に動かす必要が出てくる。従来のマイクロVM方式では、エージェントの数だけVMを起動し続けるため、リソースとコストが線形に増加してしまう。
Cloudflareはこの課題に対し、V8 Isolateを使った軽量サンドボックスを提供する。Dynamic WorkersとCodemodeを組み合わせることで、ミリ秒単位でサンドボックスを起動し、フルVMよりはるかに少ないリソースで任意のコードを実行できる。
エージェントのセットアップ時にバックエンドタイプとして「isolate」を選択するだけで、この軽量モードに切り替えられる。数万規模の同時エージェントを扱うユースケースでは、コスト効率が数十倍変わる可能性がある。
もちろん、Linuxツールをフル活用する開発エージェントには、引き続きマイクロVMベースのCloudflare Containersを使える。用途に応じて2種類の実行環境を選択できる点が、この統合の実用的な強みだ。
エージェントワークロードのセキュリティ

エージェントが組織の内部データやサービスにアクセスするとき、最大のリスクは認証情報の漏洩だ。Cloudflareの統合では、アウトバウンドプロキシを使い、サンドボックスから外部へ出る通信に対して動的に認証情報を注入する仕組みを備えている。
この設計のポイントは、エージェント自身はクレデンシャルを知らないことだ。プロキシがゼロトラストベースでリクエストに署名やトークンを付与するため、万が一サンドボックスが侵害されても、認証情報そのものが盗まれるリスクを抑えられる。
また、Cloudflare MeshとWorkers VPCを使えば、インターネットに一切公開していない内部サービスにも、ポスト量子暗号で保護されたトンネル経由で接続できる。VPNや踏み台サーバーなしでプライベートサービスと通信できる点は、インフラ担当者にとって大きな利点だろう。
プロキシはテナント単位やエージェント単位でポリシーを適用できる。特定のエンドポイントだけを許可リスト化し、それ以外の通信を遮断するといった細かな制御も、コード数行で実装可能だ。
エージェントに必要なツール群

ブラウザ操作の完全な制御
エージェントがウェブと対話する際、単純なHTTPリクエストでは不十分な場面が多い。JavaScriptを多用するモダンなウェブアプリケーションの操作や、QA用のスクリーンショット取得、フォーム入力の自動化には、実際のブラウザが必要になる。
CloudflareのBrowser Runは、エージェントにプログラム可能なブラウザを与える仕組みだ。検索、実行、スクリーンショット、ページのMarkdown変換など、複数のツールがデフォルトで利用できる。
セッションの録画機能も備わっており、エージェントがブラウザ上で何をしたかを後から完全に監査できる。許可リストや拒否リストを使ったアクセス制御も可能で、野放図なウェブアクセスを防げる。
メール送受信とプライベート接続
エージェントにメールアドレスを割り当て、送受信を自律的に行わせる機能も統合済みだ。Cloudflare Email Serviceと連携し、任意のドメインでエージェントがメールを送信できる。顧客対応の自動化や、転送されたメールへの返信といったユースケースに適している。
内部サービスへの接続にはcall_serviceツールが用意されており、Cloudflare MeshやWorkers VPC経由でプライベートAPIを安全に呼び出せる。Workers AIを使った画像生成ツールも標準で組み込まれており、Claudeのテキスト推論と組み合わせたマルチモーダルなワークフローを構築できる。
カスタムツールの追加
リポジトリをフォークし、独自のツールを追加するのも容易だ。例えばCloudflare R2にファイルをアップロードし、公開URLを返すツールを数行のコードで定義できる。以下はCloudflare Blogで示されたコード例を簡略化したものだ。
defineTool({
name: "r2_host_file",
description: "サンドボックスからR2にアップロードし公開URLを取得",
inputSchema: z.object({
key: z.string(),
content: z.string(),
contentType: z.string()
}),
run: async ({ key, content, contentType }, { env }) => {
await env.PUBLIC_BUCKET.put(key, content, { httpMetadata: { contentType }});
return `${env.PUB_R2_URL}/${encodeURI(key)}`;
}
})Workers AIを使ったエッジ推論や、Dynamic Workersによる動的なアプリケーションホスティング、Artifactsを使ったGit管理の追加など、Cloudflare Developer Platform全体をエージェントの拡張に活用できる。インフラ管理を意識せず、関数を書いてデプロイするだけで機能追加が完了する設計だ。
この記事のポイント
- Claude Managed Agentsの実行基盤をCloudflare上に構築できるようになった
- 「頭脳(Claude)」と「手足(Cloudflareサンドボックス)」の分離で、インフラ選択の自由度が向上した
- V8 Isolateを使った軽量サンドボックスで、ミリ秒起動と低コストの大規模実行が可能
- アウトバウンドプロキシによるゼロトラスト認証で、エージェントのセキュリティを強化
- ブラウザ操作、メール送受信、内部サービス接続などのツールが標準装備されている
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Google Antigravity 2.0リリース、IDE不要のエージェント体験を実現
Google DeepMindは2026年5月17日、AIエージェントを中核に据えたデスクトップアプリケーション「Google Antigravity 2.0」を発表した。従来のIDE(統合開発環境)を廃し、エージェントとの同期・非同期の対話に完全に最適化された独立アプリケーションとして再設計されている点が最大の特徴だ。
この新バージョンは、2025年11月にリリースされた初代Antigravity IDEの「Agent Manager」を発展させたもので、ソフトウェア開発だけでなく、より広範な知識作業をエージェントと協働するための基盤として位置づけられている。macOS、Linux、Windowsに対応し、最新のGeminiモデルを活用する。
開発者だけでなく、コードやIDEに馴染みのないユーザーにとっても直感的なエージェント体験を提供することが、この2.0の大きな狙いだ。
エージェントファーストの新設計

Antigravity 2.0の最大の転換点は、IDEという概念を完全に取り除いたことにある。従来のAntigravity IDEでは、コードエディタとエージェント管理画面が同居していた。この設計は開発者には便利だが、エージェント本来の可能性を制限する側面もあった。
IDEを捨てた理由
Google DeepMindの記事によれば、開発チームは当初から「コーディングの高速化だけでは、ユーザーに提供できる価値に限界がある」と認識していたという。モデル性能が向上するにつれ、エージェントの活躍領域は自然とコード以外の知識作業へと拡大した。
実際、初代Antigravity IDEのAgent Managerは、開発以外のタスクにも広く使われていた。だが、IDEの枠組みの中でそれを行うのは、非開発者にとっては直感的とは言えなかった。Antigravity 2.0は、その制約を解消し、エージェントとの協働を主役に据えた設計へと舵を切った。
プロジェクトベースの管理方式
もう一つの大きな設計変更が、リポジトリとの密結合の解除だ。Antigravity 2.0では、エージェントの会話は「ワークスペース(リポジトリ)」単位ではなく、「プロジェクト」単位でグループ化される。一つのプロジェクトが複数のフォルダを参照でき、プロジェクトごとにエージェントの設定や権限を個別に定義できる。
これにより、エージェントがより多くの情報源にアクセスし、複雑なタスクに取り組めるようになりつつ、適切なガードレールも維持される。
強化されたエージェント機能群

Antigravity 2.0では、エージェントの能力が大幅に強化された。中核となるのは「動的サブエージェント」「非同期タスク管理」「JSONフック」の3つだ。
動的サブエージェント
メインエージェントがタスクを実行する際、必要に応じてサブエージェントを動的に定義し、呼び出せるようになった。サブエージェントは焦点を絞った部分タスクを担当する。これにより、メインエージェントのコンテキストウィンドウが汚染されず、複数のサブタスクを並列に処理できる。
コンテキストウィンドウとは、エージェントが一度に把握できる会話や情報の範囲のことだ。長大なタスクではここがすぐに一杯になり、エージェントの応答品質が落ちる原因になっていた。サブエージェントへの委譲は、この問題への有効な対策となる。
非同期タスク管理
タスクやコマンドを非同期で実行できるようになった点も大きい。メインエージェントが処理をブロックされることなく、バックグラウンドで複数の作業を進められる。たとえば、コードのビルドを走らせながら次の機能の設計について対話を続ける、といった並行作業が可能になる。
JSONフック
JSONフックは、エージェントの動作を外部から制御する仕組みだ。シンプルなJSON形式でフックを定義し、エージェントの特定の挙動をインターセプトして制御できる。柔軟なカスタマイズを可能にしつつ、設定の複雑さを抑えている。
スケジュールタスクとプロジェクト管理

Antigravity 2.0では、エージェントとの新しい関わり方として「スケジュールタスク」が導入された。cron式を使ってエージェントの起動スケジュールを事前に定義できる。日次レポートの生成、定期的なデータ収集、ナイトリービルドの監視など、手動で毎回指示を出す必要がなくなる。
スラッシュコマンド「/schedule」を使うか、専用のスケジュールタスク画面から設定する。一度だけのタイマー実行と、繰り返しの定期実行の両方に対応している。
新しいスラッシュコマンドと音声入力
Antigravity 2.0には、エージェントとの対話をより精密に制御するための新しいスラッシュコマンドが追加された。
4つの新コマンド
/goalは、指定したタスクを完了まで実行させ、途中でユーザーに入力を求めない。長時間の作業を任せきりにしたい場面で有効だ。/grill-meは実装開始前に、エージェントが逆に質問を投げかけて計画の詳細を詰める。見落としを事前に洗い出すのに役立つ。/scheduleは前述のとおり、タスクのスケジュール実行を指示する。/browserは、エージェントにブラウザ操作を明示的に許可するかどうかを制御する。
音声入力のライブ文字起こし
テキスト入力欄の横にあるマイクアイコンを使った音声入力が、ライブ文字起こしに対応した。従来は生の音声ファイルをモデルに渡していたが、2.0では発話と同時にテキスト化が進む。音声の遅延を感じさせず、より自然な対話が可能になった。
Antigravity IDEとの関係と今後の展望

Antigravity 2.0は独立したアプリケーションとして提供されるが、従来のAntigravity IDEがすぐに置き換わるわけではない。IDE側のAgent Managerも当面は維持され、今後のアップデートでIDEからAgent Managerが分離される予定だ。IDEは純粋なエージェント駆動型IDEとして残る。
すでにAntigravity IDEをインストールしているユーザーは、次回のアップデートで自動的にAntigravity 2.0に更新される。その際、IDEを残すかどうかを選択できる。両アプリはドック上でアイコン背景が異なり、2.0は白背景、IDEは黒グリッド背景で区別される。
Google DeepMindの記事によれば、社内のGooglerたちはすでにAntigravity 2.0と各種IDEを併用しているという。今後、主要なIDE向けの互換拡張機能やプラグインも提供される予定だ。
今後のロードマップ
Antigravity 2.0と同時に、CLI、SDK、APIも発表された。他のGoogle製品や技術スタックとの統合も進められており、エージェントハーネスとモデル層の共同最適化が継続される。記事では、リモートコントロール機能、さらなる製品統合、クラウドデプロイエージェントなどが今後の展開として示唆されている。
この記事のポイント
- Antigravity 2.0はIDEを廃した完全エージェントファーストの独立アプリケーション
- 動的サブエージェントと非同期タスク管理で複雑な作業を効率的に処理
- スケジュールタスクにより、エージェントの定期実行が自動化可能
- 音声入力がライブ文字起こしに対応し、対話のテンポが向上
- 従来のIDEも維持され、開発者は両方を併用できる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

エージェント型コマース到来 ECブランドに求められる「証明可能な約束」
AIエージェントが消費者の購買意思決定を代行する「エージェント型コマース」が急速に現実味を帯びている。2030年までに米国のEコマース取引の25%がエージェントAIによって駆動されるとの予測もある。この変化は、ブランドが築いてきた感情的な信頼のあり方そのものを揺るがす。
MarTechのGreg Kihlstrom氏は、エージェント型コマースにおいてブランドの約束は「証明可能」でなければ選ばれなくなると指摘する。従来のように広告やブランドイメージで勝負するだけでなく、価格の透明性、配送の信頼性、返品ポリシー、ロイヤルティの価値など、定量的なシグナルをもとにAIが評価する世界だ。本記事では、EC事業者がこのパラダイムシフトにどう備えるべきか、具体的な戦略と視点を掘り下げる。
AIエージェントがECの購買決定をどう変えるか

すでに加速するエージェント型コマース
マッキンゼーの調査では、すでに消費者の約70%が購買プロセスにAIツールを活用している。B2Bバイヤーに至っては73%がAIを利用して購買を評価しているという。さらにベインの予測では、2030年までに米国Eコマース売上の25%(3000億ドルから5000億ドル相当)がエージェントAIによって駆動される見込みだ。数字だけを見ても、AIエージェントを無視したEC戦略は成り立たなくなっている。
ブランド評価の基準が感情から定量データへ
消費者はテレビCMやSNSの口コミ、ブランドカラーといった「感覚的な信頼」で商品を選んできた。しかしAIエージェントは、価格の透明性、在庫の正確さ、配送実績、返品ポリシーの明快さ、カスタマーサービスの評価など、数値化できる指標だけを抽出して比較する。MarTechの記事が指摘するように、ブランドへの感情的な好意はエージェントのフィルターでは評価外になりやすい。ここでEC事業者が直面するのは、「ブランドらしさ」よりも「ブランドが約束を守れるか」を可視化する必要性だ。
このデモが示すように、AIエージェントはブランドの「なんとなくの評判」を即座に無視し、操作可能なデータだけをもとに推薦を組み立てる。EC事業者は、自社の商品ページやバックエンドの在庫管理、配送ログがエージェントにどう読まれるかを設計段階から意識しなければならない。
ブランド信頼が証拠ベースに変わる

改善すべきブランドオペレーション
これまでのブランド構築は、広告やクリエイティブで「信頼できる」と伝えることに主眼があった。しかしAIエージェントが介在する世界では、ブランドの主張と実態のズレは直ちに排除の原因になる。MarTechの記事がいくつかの具体例を挙げているように、以下のようなギャップは許容されない。
- 「便利さ」を謳いながら、在庫データが不正確で欠品が頻発する
- 「顧客第一」と掲げながら、解約条件をわかりにくくしている
- 「プレミアムサービス」を自称しながら、返品手続きが煩雑で時間がかかる
こうした不一致は、消費者が気づく前にAIエージェントによって検出され、比較リストから外されてしまう。つまり、ブランドの約束はオペレーションの隅々まで証明できなければ、エージェントのレコメンデーションに残る資格を失うのだ。EC事業者にとっては、フルフィルメントの精度やカスタマーサポートの透明性を、ブランド価値の根幹として再定義する必要がある。
ロイヤルティプログラムをエージェントが読み取れる形に

数値化できない特典は存在しないのと同じ
多くのロイヤルティプログラムは、アプリのプッシュ通知やポイント残高、会員ランクといった、人間の感情に訴える仕組みで設計されている。しかしAIエージェントは、ポイントの経済的価値やステータスがもたらす具体的な優遇措置(送料無料、優先サポート、返品猶予など)をリアルタイムで計算できなければ、それらの特典を「存在しない」と見なす。MarTechの記事が強調するように、会員であること自体はエージェントにとって何の意味も持たない。
WooCommerceなどECプラットフォームを運用する事業者は、ロイヤルティ機能(ポイント残高、会員限定価格、送料優遇)を外部システムからAPI経由で読み取れる形に整備する必要がある。たとえばヘッドレス構成を採用し、エージェントが直接クエリできるエンドポイントを用意すれば、ブランドの優位性が定量情報として伝わる。
顧客データが「委任レイヤー」として機能する

許諾と選好をエージェントに伝える
AIエージェントの活躍が広がっても、人間が最終的な購入ボタンを押すケースは当面続く。だからこそ顧客データは、人向けのパーソナライズとエージェント向けの委任情報の両方を扱う必要がある。MarTechの記事は、従来のセグメント分析やキャンペーン適格性だけでなく、顧客がエージェントにどのような権限を委ね、どのような制約(価格帯、サステナビリティ重視、プライバシー限度)を設けているかまで記録すべきだと指摘している。
- ✕ 購買履歴とセグメント情報のみ
- ✕ キャンペーン適格性が中心
- ✕ エージェントへの委任設定なし
- ✓ 価格感度やサステナビリティ志向を記録
- ✓ プライバシー許容度や返品ポリシー選好
- ✓ エージェントに委任する権限の範囲を明示
さらに、本人認証と代理人の識別も複雑化する。人間の顧客、家族、法人アカウント、権限を持つAIエージェントが混在する環境では、誰がどの情報にアクセスし、どれだけの取引を代行できるかを管理する仕組みが不可欠だ。EC事業者は、同意管理と顧客プロファイルの構造を、エージェント時代を見据えて再設計する必要がある。
マーケティング指標をエージェント起点で再設計する

従来のKPIでは見落とすエージェントの動き
サイトのトラフィックや検索順位、最終クリックアトリビューションだけを追いかけていても、エージェント型コマースでは手遅れになる。AIエージェントはブランドのウェブサイトを訪れる前に、商品情報APIやレビューサイト、物流データを横断的に調査し、候補を絞り込む。コンバージョン率が落ちた時点では、すでにエージェントの比較リストから外されている可能性が高い。
MarTechの記事は、まず「エージェントがブランドを正しく見つけ、正確に理解できるか」を測定し、その次に「エージェントが取引まで完結できるか」を追うべきだと示唆している。具体的には、エージェント向けのフィードが正確か、構造化データが最新か、ロイヤルティ情報がAPIで計算可能かといった指標をKPIに加える必要がある。ECの現場では、Google Merchant Centerや構造化データの品質監査、WooCommerce REST APIのレスポンス速度と正確性を定期的に評価する体制が求められる。
この記事のポイント
- エージェント型コマースでは、ブランドの約束を価格や配送実績などの定量データで証明できなければ選ばれない
- AIエージェントは感情的なブランド好意を評価せず、在庫精度や返品ポリシーの明確さを数値化して比較する
- ロイヤルティプログラムの特典はAPIで計算可能でなければ、エージェントの意思決定から除外される
- 顧客データには、人向けのパーソナライズだけでなく、エージェントへの委任設定やプライバシー選好を組み込む必要がある
- マーケティング指標は、エージェントが見つけやすく正確に取引できる状態かどうかを測定する方向へシフトすべきである
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

OpenAI CodexがDellと提携、オンプレミス環境でエージェントAIを実行可能に
OpenAIとDell Technologiesが、エンタープライズ向けAIコーディングツール「Codex」の導入範囲を大幅に拡大する提携を発表した。週間アクティブ開発者数が400万人を突破したCodexは、クラウド利用が難しい重要データを抱える企業のために、Dellのオンプレミスインフラ上で直接稼働する道を手に入れた。
この提携で、CodexはDell AI Data PlatformおよびDell AI Factoryと接続される。ソースコードや社内ドキュメントといった機密性の高い企業データを外部に出さずに、AIエージェントを構築・運用できるようになる点が最大の意義だ。
AIの業務活用を進めたいがデータ主権やセキュリティの壁に阻まれていた企業にとって、この提携は「自社データセンター内で完結する高度なAIエージェント」という現実的な選択肢を提供する。
Codexの現在地 コーディングツールからビジネスエージェント基盤へ

CodexはOpenAIが提供する開発者向けAIツールだ。IDE(統合開発環境)やCLI(コマンドラインインターフェース)上で動作し、コード補完、バグの自動修正、テスト生成などを行う。2026年5月時点で週間アクティブ開発者数は400万人を超え、OpenAIのエンタープライズ製品群の中で最も急成長しているサービスの一つになっている。
Codexの活用範囲は開発現場を超えて広がっている。ツール間のコンテキスト収集、レポート作成、プロダクトフィードバックの整理とルーティング、リードのスコアリングとフォローアップ文面の作成、さらには複数のビジネスシステムを横断した業務調整まで、エージェントとしての機能を実務に組み込む企業が増えている。
Codexが「開発者のためのツール」から「ビジネスプロセスを動かすエージェント基盤」へと進化している点が、今回のDell提携の文脈で重要になる。エージェントが実用的な価値を発揮するには、その企業固有のデータやシステムと深く接続している必要があるからだ。
Dell AI Data Platformとの統合で実現すること

今回の提携の中核は、CodexがDell AI Data Platformと直接接続される点だ。Dell AI Data Platformは、多くの企業がオンプレミス環境でデータの保存・整理・ガバナンス(管理統制)に利用している基盤である。
エージェントが「使える」内部コンテキストへのアクセス
AIエージェントがビジネスで役立つかどうかは、どれだけ深い「コンテキスト(文脈情報)」を取得できるかにかかっている。単に公開情報を検索するだけのエージェントでは、企業内部のコードベースや非公開の運用ドキュメント、過去のインシデント対応履歴といった重要情報にアクセスできない。
CodexがDell AI Data Platform経由でアクセスできるようになる情報には、以下のようなものが含まれるとOpenAIの記事では説明されている。
- 企業の非公開コードベース
- 内部ドキュメントやナレッジベース
- ビジネスシステムの実データ
- 運用知識やチームのワークフロー情報
この仕組みにより、データを社外に送信することなく、AIエージェントが企業内部の文脈を理解して動作する。金融機関や医療機関、製造業など、データ主権が厳格に問われる業界にとっては特に重要な意味を持つ。
ガバナンスを維持したままのAI導入
ガバナンスとは、データの管理体制や利用ルールを整備し、遵守することだ。企業は法規制や社内ポリシーにより、特定のデータを社外のクラウドサービスに保存できないケースが多い。Dellのオンプレミス基盤上でCodexを動作させることで、既存のデータガバナンスの枠組みを壊さずにAIを導入できる。
Dell AI Factoryとの連携がもたらす応用可能性

OpenAIの発表によると、両社はDell AI Factoryとの接続も検討している。Dell AI Factoryは企業がAIワークロードを実行するための基盤で、データ準備やシステム管理、テスト実行、AIアプリケーションのデプロイ(展開)までをカバーする。
この接続が実現すると、Codexに加えてChatGPT Enterpriseやその他のAPIベースのソリューションも、Dellのハイブリッドまたはオンプレミスインフラ上で統合的に動作する可能性がある。
この構想が示すのは、OpenAIがエンタープライズ市場において単なる「API提供者」から「インフラと一体化したAIプラットフォーム」への転換を図っていることだ。Dellの発表文では「Dell AI Factory with OpenAI Codex」という表現が使われており、両社のブランドを冠した統合ソリューションとして展開される可能性が高い。
エンタープライズAI市場における提携の戦略的意味

今回の提携は、企業向けAI市場での競争軸を読み解く上でも示唆に富む。
「データの所在地」がAI導入の決定打になる
2026年現在、多くの企業がAI導入を進めているが、最大の障壁は技術力ではなく「データをどこに置くか」というポリシー問題だ。GDPR(EU一般データ保護規則)や各国のデータローカライゼーション規制により、クラウド上のAIサービスをそのまま使えない企業は少なくない。
Dellとの提携によりCodexは、企業のデータセンター内で動作する選択肢を手に入れた。これは競合のAIコーディングツールにはない差別化要素であり、特に規制産業からの需要を取り込む上で強力な武器になる。
「エージェントの実用化」に必要なのはコンテキスト
AIエージェントが「良いコードを提案する」だけの段階から「ビジネスプロセスを自律的に実行する」段階へ進むためには、企業固有のコンテキストにアクセスできることが不可欠だ。OpenAIの記事でも、エージェントが役立つために必要な内部情報として、コードベースやドキュメント、業務システム、チームのワークフローが挙げられている。
CodexがDell AI Data Platform経由でこれらの情報に安全にアクセスできるようになることで、エージェントが「汎用的なアドバイザー」から「その企業の業務を深く理解した実行者」へと進化する基盤が整う。
OpenAIのエンタープライズ戦略における位置づけ
OpenAIは2025年以降、ChatGPT EnterpriseやCodex CLIといった企業向け製品を相次いで投入してきた。今回のDell提携は、それらの製品群を「インフラレベルで企業の既存環境に溶け込ませる」動きとして位置づけられる。
Microsoft Azureを通じたクラウド提供に加え、オンプレミスという選択肢を加えたことで、OpenAIのエンタープライズ展開は「パブリッククラウド」「ハイブリッド」「オンプレミス」の三層をカバーする体制に近づいている。
企業が今から準備すべきこと

Dellのインフラを既に利用している企業にとって、Codexのオンプレミス展開は比較的スムーズに導入できる見込みだ。OpenAIの発表では、具体的な提供開始時期や料金体系の詳細は明かされていないが、両社の協業が進むにつれて順次情報が公開されるだろう。
企業の開発部門やIT統括部門は、以下の点を事前に整理しておくと、展開開始時のスピードが上がる。
- Codexエージェントにアクセスさせたい内部データの棚卸し(コードベース、ドキュメント、APIなど)
- 既存のDellインフラ(AI Data Platform / AI Factory)の利用状況確認
- データガバナンスポリシーの見直しとAI利用ルールの整備
- セキュリティチームとの事前協議(エージェントがアクセスするデータ範囲の定義)
AIエージェントの導入で先行する企業は、すでにコードレビューやテスト自動化といった開発領域から始め、段階的にビジネスプロセスへ適用範囲を広げている。Codexのオンプレミス対応は、その拡大をより安全に進めるためのインフラ選択肢として機能するだろう。
この記事のポイント
- OpenAI CodexがDell AI Data Platformとの統合により、オンプレミス環境での稼働が可能に
- 企業のコードベースや内部ドキュメントに安全にアクセスし、AIエージェントの実用性が大幅に向上
- Dell AI Factoryとの連携により、ChatGPT Enterpriseなど他のOpenAIサービスもオンプレミス展開を検討
- 金融や医療など厳格なデータガバナンスが求められる業界でのAI導入障壁が下がる
- 企業は今のうちに内部データの棚卸しとガバナンスポリシーの整備を進めておくことが有効
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

GPT-5.5が企業向けエージェントにもたらす変革、Databricks導入事例
大規模言語モデルの進化が、企業の実務ワークフローに直接的な成果をもたらし始めている。データ分析基盤を提供するDatabricksが、OpenAIの最新モデルGPT-5.5を社内向けAIエージェントに組み込んだ結果、複雑な文書処理タスクを評価するベンチマーク「OfficeQA Pro」でエラーが46%も減少した。GPT-5.5はこのベンチマークで初めて正解率50%を超えたモデルとなった。
この結果は「モデルの性能向上が、実際のビジネス指標にどう結びつくか」を示す重要な事例だ。単なる会話能力の評価ではなく、スキャンされたPDFや古い社内フォーマットの文書を解析し、複数ステップのタスクを自律的に遂行する能力が問われている。本記事ではGPT-5.5がどのような技術的進歩を遂げ、企業のAI活用にどんな可能性を開くのかを解説する。
企業向けAIエージェントの現在地、なぜ文書処理が壁になるのか

企業がAIエージェントを導入する際、最初にぶつかる壁が「社内文書の解析」だ。契約書や見積書、古いシステムから出力されたレポートなど、形式がバラバラな文書をAIに理解させるのは想像以上に難しい。特にスキャンされたPDF(画像として取り込まれた文書)や、数十年前のレガシーフォーマットで保存されたファイルは、最新のAIでも正確なテキスト抽出に失敗することが多い。
この問題の深刻さは、小さな認識ミスが後続の処理全体を狂わせる点にある。たとえば請求書の金額を一桁間違えて抽出すれば、その後の経理処理やレポート作成がすべて誤った情報で進んでしまう。人間なら「明らかにおかしい」と気づくようなエラーでも、AIエージェントは抽出した数値をそのまま信じて処理を続ける。これが企業現場でのAI導入を妨げる最大の障壁となっていた。
OfficeQA Proベンチマークの評価観点とは
Databricksが開発したOfficeQA Proは、こうした実務課題を忠実に再現する評価指標だ。このベンチマークでは、モデルに対して以下の3つの能力が求められる。
- 文書解析(Parsing):スキャンPDFやレガシーファイルから正確に情報を抽出する能力
- 情報検索(Retrieval):長大な文書群の中から必要な情報を見つけ出す能力
- 根拠に基づく推論(Grounded Reasoning):抽出した情報をもとに、論理的な判断や回答を生成する能力
単なる知識クイズではない。バラバラなフォーマットの文書を理解し、複数のステップを経て最終的なアウトプットを出す「エージェントとしての実務能力」が試される設計になっている。
上図のように、GPT-5.5への切り替えによって文書解析のエラーが大幅に減り、後続のワークフロー全体の信頼性が向上した。この改善の背景には、モデルの視覚認識能力と言語理解の統合が進んだことがあると見られている。
GPT-5.5が達成した二つの飛躍的改善

Databricksが報告したGPT-5.5の改善点は、大きく二つの領域に分かれる。一つは文書解析精度の劇的な向上、もう一つは複数ステップのタスクを効率的に管理するオーケストレーション能力の進化だ。
スキャン文書解析の「ステップ関数的」な進歩
Databricksの記事で同社のSinghvi氏が指摘するように、GPT-5.4まではスキャンされた古い文書から数字を正確に読み取れないケースが頻発していた。これに対しGPT-5.5は、古い文書やスキャンPDFの解析において「ステップ関数的な性能向上」を見せたという。「ステップ関数的」とは、なだらかな改善ではなく、階段を一段上がるように非連続的な飛躍があったことを意味する。
この進歩が特に重要なのは、企業が保有する文書の多くが過去の資産だからだ。10年前の契約書、5年前の監査レポート、紙をスキャンしてPDF化した資料。こうした「過去の遺産」を正確に解析できるかどうかが、AIエージェントの実用性を左右する。GPT-5.5はこの壁を一つ越えたと言える。
ムダな遠回りをしないタスク実行能力
もう一つの重要な改善が、複数ステップのタスクを実行する際の軌道(Trajectory)の最適化だ。GPT-5.4では、目的に対して不必要な検索を繰り返す「遠回り」が発生し、非効率な処理経路をたどることがあった。これはエージェントが過剰に「慎重」になりすぎる、あるいは文脈を適切に把握できずに余計な確認作業を挟んでしまう問題だ。
GPT-5.5では、必要な情報を必要なタイミングで的確に取得し、最短のステップでタスクを完了する能力が高まった。追加の監視や人間による修正なしに、複雑なワークフローを完遂できる信頼性が向上している。
この改善は、企業がAIエージェントに求める「人間の監視なしで動く自律性」に直結する。タスクが長引けばそれだけコストも増え、途中で人間が介入する必要性も高まる。GPT-5.5はこの課題に対して明確な前進を示した。
企業ワークフローへの実装、AgentBricksとAI Unity Gateway

DatabricksはGPT-5.5を単独のチャットボットとして使っているわけではない。同社の「AI Unity Gateway」を通じて、AgentBricksやAgent Supervisor APIといったエージェント構築基盤と統合し、実際のビジネスワークフローに組み込んでいる。
AgentBricksとは、Databricksが提供するエージェント構築フレームワークだ。専門特化した複数のエージェントを組み合わせ、複雑な業務プロセスを自動化できる。ここでGPT-5.5は「監督者(Supervisor)」として機能する。各専門エージェントが文書解析やデータ検索、レポート生成といった個別タスクを担当し、GPT-5.5が全体の流れを管理して適切なタイミングで適切なエージェントに指示を出す。このアーキテクチャによって、単一モデルでは扱いきれない複雑な業務フローが実現できる。
この「監督者モデル」のアプローチは、今後の企業向けAI活用の主流になると考えられる。一つの巨大モデルがすべてを処理するのではなく、専門エージェントを束ねる統括役としてLLMを配置する設計だ。GPT-5.5のオーケストレーション能力の向上は、この設計思想と見事にマッチしている。
ナレッジワークにおけるGPT-5.5のインパクト

DatabricksのSinghvi氏は「GPT-5.5は知識作業においてステップ関数的な変化をもたらした」と評している。単に質問に答えるだけでなく、複数の文書を横断して情報を統合し、文脈を理解した上で判断を下す「知識労働の代替」としての性能が大きく向上したという評価だ。
この評価が特に重要なのは、AIが「単なる道具」から「業務のパートナー」へと役割を変えつつあることを示唆しているからだ。従来のAIアシスタントは、人間が明確に指示したタスクを実行するのが限界だった。GPT-5.5を中核に据えたエージェントは、曖昧な指示や複雑な文脈でも自律的に判断し、複数ステップの業務を完遂できる水準に近づきつつある。
日本企業への示唆、データ資産の再活用という視点
この事例から日本企業が学ぶべきポイントは明確だ。多くの企業が「過去の文書資産」を抱えている。紙で保管された契約書、古い基幹システムから出力された帳票、スキャンされたPDFの山。これらをAIで解析し、活用可能なデータに変換する技術が現実のものになりつつある。
ただし注意点もある。GPT-5.5の性能向上が顕著だったのは「スキャン文書の解析」と「複数ステップのオーケストレーション」であり、これはモデル自体の進化に加えて、Databricksのエージェント基盤との統合設計が効いている。単に高性能なLLMを導入するだけでは同様の成果は得られない。データ基盤とエージェント設計の両面からアプローチする必要がある。
この記事のポイント
- GPT-5.5は企業の実務ベンチマークOfficeQA Proでエラーを46%削減し、初めて正解率50%を突破した
- 特にスキャンPDFやレガシー文書の解析精度が飛躍的に向上し、古い文書資産の活用が現実的に
- 複数ステップのタスクを効率的に管理するオーケストレーション能力も改善し、自律的な業務遂行が可能に
- DatabricksではGPT-5.5を監督エージェントとして配置し、専門エージェント群を統括する設計を採用
- 日本企業にとっては、過去の文書資産をAIで再活用できる可能性が開けた事例として注目すべき
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

GitHubがアクセシビリティエージェントを試験運用。3,535件のPRをレビューし解決率68%
GitHubは2026年5月、実験的な汎用アクセシビリティエージェントの試験運用を開始した。このエージェントはプルリクエスト内のフロントエンドコードを自動的にレビューし、アクセシビリティ上の問題を指摘する。さらに多くのケースで修正案まで提示する。
運用開始後に3,535件のプルリクエストをチェックし、68%という高い解決率を達成。構造の明確化やインタラクティブ要素の名前付け、テキスト代替など、日常的に発生するバリアを自動で取り除く仕組みだ。
GitHubのブログで公開された知見には、アクセシビリティチームが取り組んだ設計方針や、LLMエージェントならではの制限への対処法が詰まっている。本記事ではその要点を技術者向けに掘り下げる。
エージェントの目的と初期成果
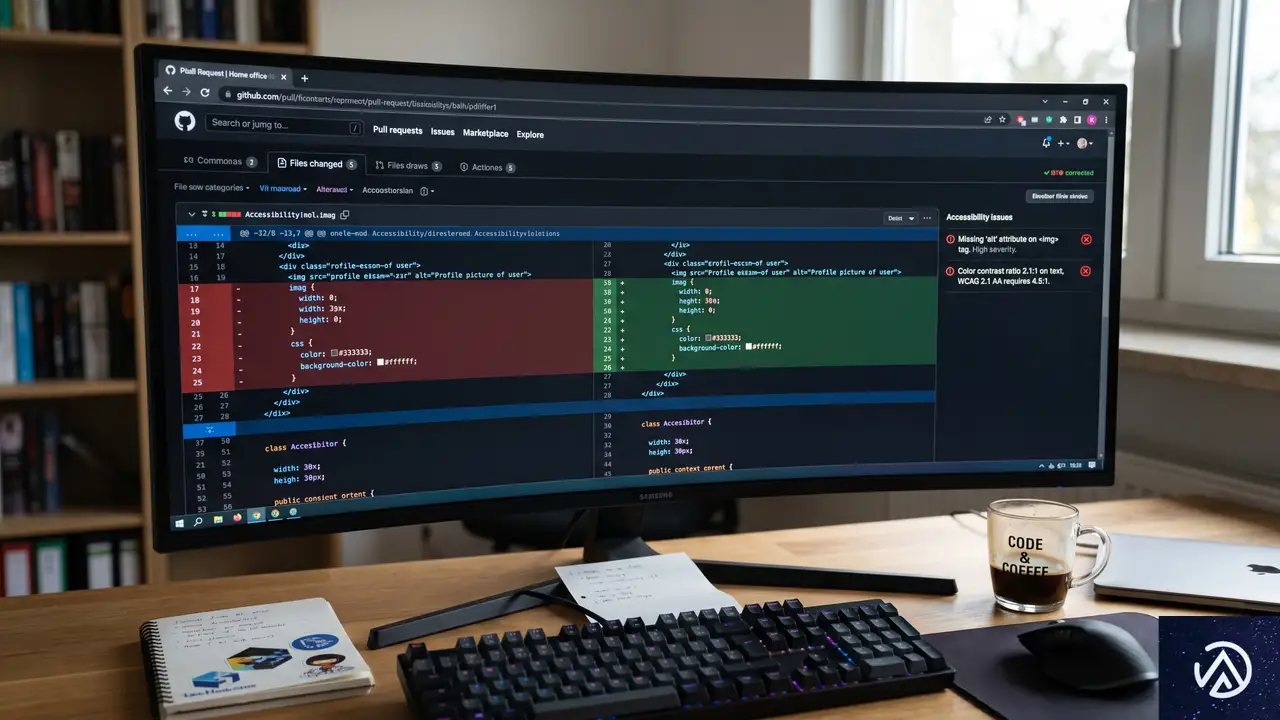
📋 エージェントが検出した問題の上位5種
- 支援技術への構造と関係性の明示不足
- インタラクティブ要素の名前の不明瞭さ
- 重要なアナウンスがユーザーに届かない
- 非テキストコンテンツの代替テキスト欠如
- フォーカス順序が視覚レイアウトと一致しない
※エージェントは自動修正を適用するか、開発者に具体的な提案を提示する
GitHubの発表によれば、このエージェントはアクセシビリティを「完全に解決する」ことを狙っていない。現場のエンジニアがアクセシビリティ上のバリアを見つけて取り除く作業を「増強する」存在として設計された。そのため、あらゆるケースに対応する「銀の弾丸」ではないと明言されている。
この姿勢が実験の立ち上げを加速させ、社内の賛同を得るうえで有効だった。スコープを限定し、明確な責任範囲を共有することで、過度な期待を防ぎつつ素早く実装できたという。
エージェント設計を支える考え方
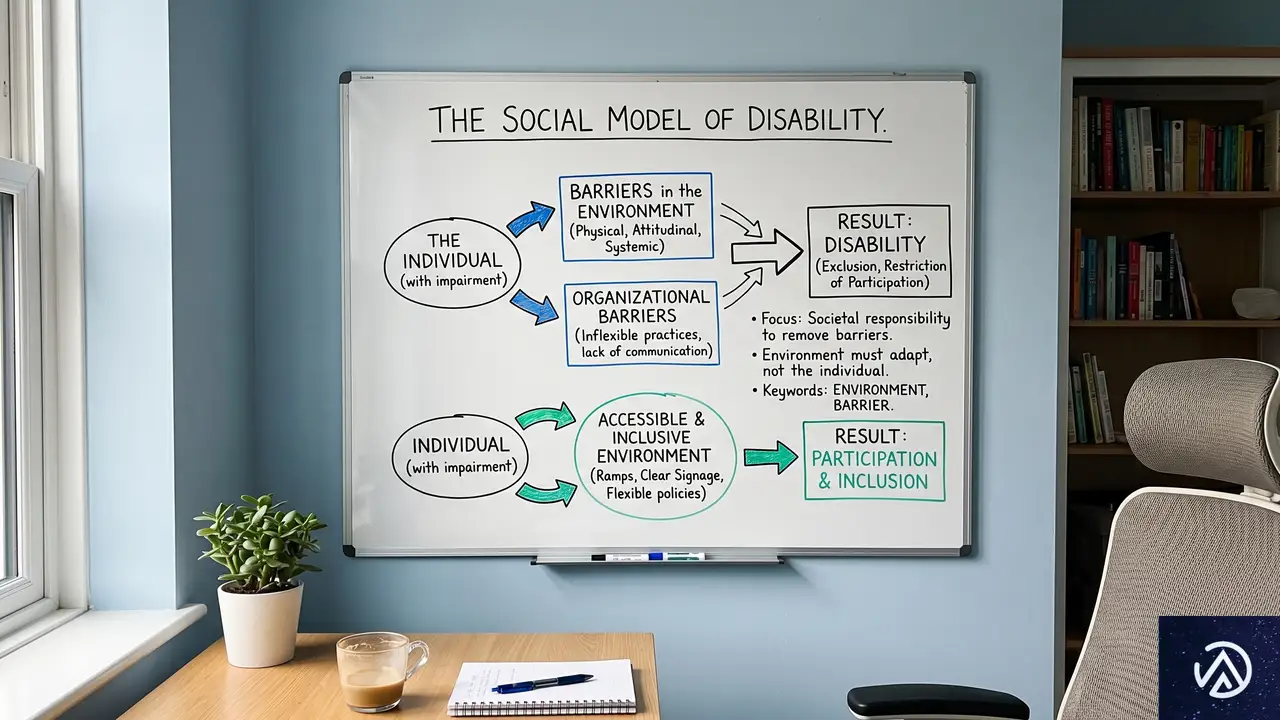
GitHubのチームは「障害の社会モデル」に基づき、環境の作り方によってアクセス障壁が生まれると捉えている。ユーザーインターフェースの構築方法そのものが障壁を生み出すため、エージェントは仲間の作業を補い、そうした障壁の除去を支援する役割を担う。
つまり「人間の判断を置き換えるAI」ではなく、「アクセシビリティ専門家の補助輪」として機能させる考え方だ。この方針が、後述するサブエージェント構造や複雑性評価の仕組みに一貫して織り込まれている。
過去のアクセシビリティ改善がエージェントを支えた

GitHubにはLLMが普及する以前から、アクセシビリティの問題を体系的に記録し修正する仕組みが存在していた。テンプレート化された報告フォーム、再現手順、WCAG達成基準との紐付け、修正プルリクエストへのクロスリンクといった豊富なメタデータを備えた単一のリポジトリに、すべての問題が集約されている。
この構造化されたデータの蓄積こそが、エージェントにとって理想的な「学習素材」になった。GitHubのブログ記事は「過去の手作業による監査と修正こそが最大の資産」と強調している。問題とその修正コードを参照することで、エージェントは組織固有のコーディング規約やUIパターンに沿った適切な提案を引き出せるようになった。
さらに、LLMの非決定的な「あいまい一致」がここでは強みに転じた。定型のスキルファイルだけで「アクセシビリティのベストプラクティスに従え」と指示しても、膨大な非アクセシブルコードで訓練されたモデルはむしろアンチパターンを生成しがちだ。過去の修正履歴から具体的な文脈を参照できることで、質の高い出力が安定した。
効率的なトークン消費のためのサブエージェント戦略
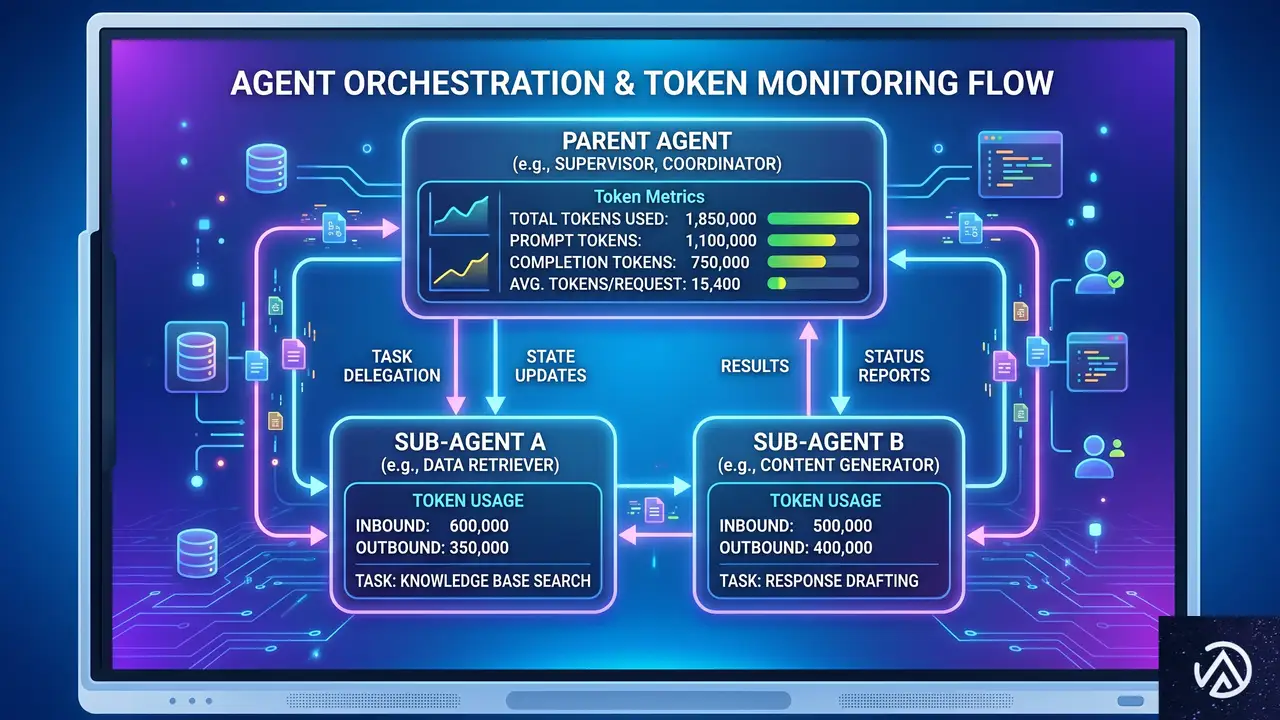
アクセシビリティはコード、デザイン、ライティングなど多領域にまたがる全体的な関心事だ。そのため、一般的なエージェントを作ろうとすると、1回の処理で大量のトークンを消費し、応答速度の低下や運用コスト増、信頼性の低下を招く。
⏺ 親エージェント(Orchestrator)
- リクエストの振り分けとコードスキャン
- 複雑性スコアの算出
- エスカレーション判断と再監査ループ
コード監査とWCAG調査を実施し、構造化された監査レポートを出力する。コード変更は一切行わない。
親エージェントから渡された構造化レポートを基に、コード修正またはガイダンス文書を生成する。
親エージェントが出力を検証し、必要なら人間の専門家へエスカレーションする
2つのサブエージェントはサンドボックス化され、直接通信はしない。構造化テンプレートを介して情報を受け渡す。
GitHubは当初、1つのモノリシックなエージェントで始めたが、すぐに限界を感じたという。そこで採用したのが、2つの専用サブエージェントによるアーキテクチャだ。
1つ目は「パッシブなレビューア」。コードの監査とWCAG達成基準との照合を行い、構造化されたレポートを出力する。2つ目は「アクティブな実装者」。親エージェントがレポートを精査した後、修正が必要な箇所だけにコード変更を加える。両者は直接情報をやり取りせず、テンプレート化されたスキーマファイルで内容を渡す。
この構成には明確な意図がある。レビューサブエージェントは「意見を持たず」すべての問題を列挙し、親エージェントが重要度を評価する。複数の重大なWCAG違反がある場合や、高リスクと判定されたパターンでは自動修正を試みず、アクセシビリティチームへのエスカレーションを促す。コードの複雑性が閾値を超えれば、修正ではなくガイダンス提供のみの「ガイダンス専用モード」に切り替わる。
さらに、メソッド的な手順で指示を実行させることが精度向上の鍵だった。親エージェントに「フェーズ1 調査」「フェーズ2 コード監査」「フェーズ3 構造化出力」という順序を徹底させ、各フェーズ内のステップも固定順で実行する。この線形な流れは、人間が手動で監査と修正を行うときの思考手順をそのままなぞったものだ。
エージェントの限界を理解し対策する

どれほど精心に設計しても、LLMベースのエージェントには避けられない落とし穴がある。GitHubは実験を通じて、以下の領域に特に注意を払った。
コードの複雑性を数値化して介入を制御する。シェルスクリプトでコードの相対的な複雑度をスコア化し、閾値を超えた場合は自動修正を禁止する。エージェントは「アクセシビリティチームに相談してください」と開発者に伝えるだけにとどめる。
高リスクパターンをブラックリスト化する。ドラッグアンドドロップ、トースト通知、リッチテキストエディタ、ツリービュー、データグリッドなど、現在のLLMでは支援技術と完全に調和する実装が困難なUIパターンが対象だ。これらのパターンを含むコードに対しては、エージェントは修正を生成せず、必ず人間の介入を求める。
「行動バイアス」を抑える。LLMはとにかく何かを生成したがる性質があるため、コードを書かないよう指示されたルールをかいくぐろうとする行動が見られた。これに対抗するため、指示違反を防ぐ「アンチゲーミング」ルールを導入した。
自動化で検出できない36%の壁を認識する。WCAG 2.1のレベルAとAAの達成基準は55項目あるが、そのうち決定論的な自動チェックで検出できるのは35項目にとどまる。残り約36%は手動評価が不可避だ。エージェントの成功率だけを見て安心してはならず、設計段階から手動でアクセシビリティを検討する重要性をGitHubは強調している。
WCAG A/AA達成基準55項目の内訳
自動検出可能
手動評価が必要
LLMエージェントはこの36%の領域に挑戦しているが、まだ完全ではない。設計とプロトタイピングの段階で人間がバリアを特定するプロセスが不可欠。
加えて、エージェントの出力を定期的に手動レビューし、プルリクエストレビュアーのフィードバックを収集する仕組みも整えている。これにより、指示やリソースを改善すべき領域を継続的に特定している。
この記事のポイント
- GitHubのアクセシビリティエージェントは、3,535件のPRをレビューし68%の解決率を記録した
- エージェントは「人間の代替」ではなく「増強」を目的とし、スコープを限定して運用
- 過去の手動監査で蓄積した構造化データが、エージェントの精度を飛躍的に高めた
- サブエージェント構造と線形な指示実行でトークン消費を抑え、精度を向上
- 自動検出できないWCAG基準の約36%を手動で補い、高リスクパターンは生成を禁止する対策が鍵
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Google-Agent登場、AIがユーザー代理でWebを閲覧する時代へ
Webサイトを訪れるのは人間だけではなくなった。2026年3月20日、Googleは公式のフェッチャーリストに「Google-Agent」という新たな項目を追加した。これはクローラーでもなければ、学習用のボットでもない。ユーザーの指示で動くAIエージェントだ。
AIアシスタントに「この商品をリサーチして」「最安値のサイトを比較して」と頼む場面を想像してほしい。そのとき実際にサイトを訪問し、情報を読み取り、フォームを操作するのがGoogle-Agentである。Googleの実験的ブラウジングツール「Project Mariner」が最初の採用例となる。
これまでのSEOは「クローラーにどう読まれるか」が主眼だった。しかし今回の発表で、Web運営者は「ユーザーの代わりに行動するAI」という第三の訪問者像を明確に意識せざるを得なくなった。
Google-Agentが従来のクローラーと根本的に異なる点

GooglebotはWeb全体を巡回し、検索インデックスを構築する自動プログラムだ。一方、Google-Agentが発動する条件はただ一つ、人間がAIに「調べて」と依頼したときである。この「ユーザートリガー」という性質が、あらゆるルールを塗り替える。
robots.txtは通用しない
GoogleはGoogle-Agentを「ユーザートリガーフェッチャー」に分類している。Google Read Aloud(テキスト読み上げ)やNotebookLM(文書分析)、Feedfetcher(RSS)と同じカテゴリだ。いずれも「人間がリクエストを起こした」という共通点がある。Googleの公式見解は明快で、ユーザートリガーフェッチャーは「原則としてrobots.txtを無視する」としている。
考え方はシンプルだ。ChromeのアドレスバーにURLを入力して開くとき、ブラウザはrobots.txtの内容に関係なくページを取得する。Google-Agentはユーザーの代理であり、自律型クローラーではない。したがって同じ理屈が適用される。
この判断はOpenAIやAnthropicのアプローチと明確に異なる。ChatGPT-UserやClaude-Userはいずれもユーザートリガーフェッチャーでありながら、robots.txtの指示に従う仕様だ。robots.txtでブロックすれば、ユーザーに頼まれてもページを取得しない。Googleはそこに別の線を引いた形になる。
robots.txtを万能のアクセス制御手段と考えていたサイト運営者にとって、これは大きな認識転換になる。Google-Agentを拒否したい場合は、サーバーサイドの認証やIP制限など、人間の訪問者をブロックするのと同じ手段を採る必要がある。
暗号認証「Web Bot Auth」がもたらす信頼性

Google-Agentの発表でより重要なのは、付随する技術的布石だ。公式ドキュメントの一行に、Google-Agentが「web-bot-auth」プロトコルの実験に参加していることが記されている。識別子は「https://agent.bot.goog」である。
デジタルパスポートの仕組み
Web Bot AuthはIETF(インターネット技術標準化委員会)で策定が進む標準規格である。簡単に言えば、ボットのためのデジタルパスポートだ。各エージェントは秘密鍵を持ち、公開鍵をディレクトリに登録する。そして全てのHTTPリクエストに暗号署名を付与する。
Webサイト側はその署名を検証することで、訪問者が名乗る通りの存在であることを暗号学的に確認できる。ユーザーエージェント文字列は誰でも偽装できるが、Web Bot Authの署名は偽装できない。この差は決定的だ。
すでにAkamai、Cloudflare、AmazonのAgentCore Browserがこのプロトコルをサポートしている。Googleの参入は、標準化に向けたクリティカルマス(臨界量)の獲得を意味する。
なぜこの仕組みが今必要なのか
Webは深刻なアイデンティティ問題に直面しつつある。AIエージェントのトラフィックが増えるほど、正規のエージェントと、エージェントを装うスクレイパーを区別する必要が高まる。IPアドレスによる検証は有効だが、暗号署名のほうが大規模にスケールしやすく、なりすましも極めて難しい。
Google-AgentへのWeb Bot Auth導入は実験段階だが、エージェント認証の方向性を強く示す一手とみられている。Search Engine Journalの記事でも、この暗号認証こそがGoogle-Agent発表の最も重要な要素だと指摘されている。
Webサイト運営者が今すべき具体的対応

Google-Agentの登場で、Webの訪問者モデルは3層構造として明確化された。人間が直接ブラウジングする層、GooglebotやGPTBotのようにコンテンツをインデックスするクローラー層、そして特定の人間の指示でリアルタイムにタスクを実行するエージェント層である。それぞれに異なるアクセスルールと目的がある。
この3層構造を前提に、運営者が取るべき現実的な対策は以下の通りだ。
サーバーログの監視を始める
Google-Agentはユーザーエージェント文字列に「compatible; Google-Agent」を含む。Googleは検証用のIPレンジも公開している。まずは自社サイトにどの程度の頻度でエージェントが訪れているか、どのページを標的にしているか、何を試みているかを把握することが出発点になる。
CDNとファイアウォールの設定を確認する
非ブラウザトラフィックを積極的にブロックするセキュリティ設定を導入している場合、Google-Agentがサーバーに到達する前に拒否されている可能性がある。公開されているIPレンジが許可リストに含まれているか、確認しておくべきだ。
フォームや予約フローの検証
Google-Agentはフォームの送信や複数ステップのフロー操作も行う。チェックアウト、予約、問い合わせといった機能がJavaScriptに過度に依存していると、エージェントが正常に処理できず、裏側で静かに失敗しているケースが生じる。セマンティックなHTMLと明確なラベル設計が、これまで以上に重要になる。
robots.txtは完全なアクセス制御手段ではないと認識する
robots.txtはクローラー向けに設計された仕組みであり、エージェントの時代には通用しない場面が増える。どうしてもアクセスを制限すべきコンテンツには、認証を導入する必要がある。境界線の引き直しが求められている。
ハイブリッドWebはすでに始まっている

1年前まで、AIエージェントが人間と並んでWebサイトを閲覧する未来はカンファレンスの予測トークに過ぎなかった。しかし今、その存在にはユーザーエージェント文字列があり、公開されたIPレンジがあり、暗号認証プロトコルがあり、Googleの公式ドキュメントへの記載がある。
Webは人間用と機械用に分岐しなかった。融合したのだ。公開する全てのページは、人間とエージェントの両方に同時にサービスを提供している。Googleが可視化したのは、その非人間のオーディエンスがいつ現れたかを正確に把握できる手段である。
Search Engine Journalの記事は、この動きを「SEO史上最大の意識改革」と位置づけている。誇張ではない。検索エンジンにどう読まれるかだけでなく、「ユーザーの代理としてやってくるAI」にどう対応するかが、これからのWeb運営の新たな基軸になる。
この記事のポイント
- Googleがユーザー代理でWebを閲覧する新フェッチャー「Google-Agent」を公開、Project Marinerが最初の採用例
- ユーザートリガーフェッチャーに分類されるためrobots.txtは原則無効、アクセス制御にはサーバー認証が必要
- 「Web Bot Auth」暗号認証プロトコルを実験導入中、エージェントのなりすまし防止を狙う
- Web訪問者は「人間」「クローラー」「エージェント」の3層構造へ移行、各層で対応が異なる
- サーバーログ監視、CDN設定確認、フォームのセマンティックHTML対応が即時の実務対策となる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

VS Code 1.121が公開、AIエージェントのターミナル連携とモデル管理が進化
マイクロソフトは2026年5月20日、コードエディタ「Visual Studio Code」のバージョン1.121を公開した。今回のリリースでは、Copilot Chatが備えるエージェント機能とターミナルとの連携部分に多くの改良が加えられている。
具体的には、ツール呼び出しの表示が見やすくなり、特定のLLMモデルをピン留めして素早く選択できる仕組みが追加された。加えて、長いテストやビルドの出力を自動で圧縮する範囲が大幅に拡大され、エージェントが生成するコマンドの実行効率と可読性が一段と向上している。
開発者のワークフローに与える影響は小さくない。ターミナルに流れるログ情報が整理され、エージェントが勝手にバックグラウンド処理に移行するタイミングが賢くなったおかげで、より思考の流れを途切らせずに済むのだ。本記事ではこれらの改善点を実務的な視点で掘り下げていく。
エージェントホストの操作性向上

まず目を引くのが、エージェントホスト内でのツール表示まわりの改善だ。Copilot Chatのエージェントモードでは、AIが「ファイルを読む」「ターミナルでコマンドを打つ」などのツールを自律的に呼び出す。今回のアップデートで、それらのツール名がより直感的な表示になった。
これまでは内部的で分かりにくかった呼称が、人間にとって理解しやすい「ファイル読み取り」「コマンド実行」といったラベルに置き換わっている。入力と出力のUIも再設計され、どのツールに何を渡し、何が返ってきたかが一目で追えるようになった。エージェントの行動をレビューしたり、デバッグしたりする局面で役立つ変更だ。
自動承認ピッカーとワークスペースの事前選択
もうひとつ、エージェントホスト接続時の「自動承認ピッカー」が追加された。外部のエージェントホストへ接続する際に、あらかじめ信頼できるものを選んでおける仕組みで、毎回承認操作を求められる煩わしさが減る。
また、VS Codeを既に特定のワークスペースで起動している場合、エージェントウィンドウを開くとそのワークスペースのフォルダが自動で事前選択される。手動でプロジェクトフォルダを指定し直す手間が不要になるため、作業開始時のリズムが良くなる。小さな改良だが、1日に何度も繰り返す操作だけに、開発効率への積み重ね効果は意外と大きい。
上の図は、ツール表示とワークスペース選択の流れをビフォーアフターで示したものだ。変更前は開発者がエージェントの内部的な動きを読み解く必要があったが、変更後は視覚的に整理され、作業開始時の手数も減っている。
モデル管理の進化と「お気に入り」機能

続いて、言語モデルピッカーに「ピン留め」機能が追加された。これは、よく使うモデルをお気に入り登録して、ドロップダウンリストの上部に固定する機能だ。
現在、VS CodeのCopilot Chatでは複数のAIモデルを切り替えて使える。コーディング向きのモデル、自然言語のやり取りに向いたモデル、軽量で反応が速いモデルなど、タスクに応じて選び分ける開発者も多い。ピン留め機能により、毎回リストをスクロールして探すストレスから解放される。
環境変数「VSCODE_AGENT」の追加とその効果
Copilot Chatがターミナルでコマンドを実行する際、専用の環境変数「VSCODE_AGENT」がセットされるようになった。この変数は、AIが起動したターミナルセッションであることを明示的に示すためのものだ。
実務では、シェルのプロンプト表示を変えたり、エージェント向けのログフォーマットを自動判別したりする用途に使える。たとえば、AI用のターミナルでは冗長なカラー表示をオフにして、パースしやすいテキスト出力に切り替える、といった使い方が考えられる。自分でシェル初期化ファイルをカスタマイズしている開発者にとっては、自動化の可能性が広がる嬉しい追加だ。
チャットと統合ブラウザの連携強化

統合ブラウザ(Simple Browser)で表示中のWebページを、ワンクリックでCopilot Chatに共有できる「Add to Chat」オプションが右クリックメニューに追加された。
VS Codeの統合ブラウザは、エディタ内でドキュメントやAPIリファレンスを閲覧するのに使われる。今回の機能で、例えばReactの公式ドキュメントを開きながら「このセクションの内容を要約して」とAIに投げる操作が、ドラッグやコピーペーストなしで完結する。Web上の情報をコーディングの文脈にスムーズに取り込めるのは、エディタを離れずに作業を続けたい開発者にとって大きな利点だ。
また、チャットエージェントが内部的に生成したバックグラウンドターミナルは、コマンド完了後に自動で破棄されるようになった。これにより、使われないプロセスが蓄積してシステムリソースを圧迫するのを防げる。エージェントがテストの実行や依存関係のインストールなどを一括操作した後、きれいに後片付けされるイメージだ。
これらの改善は、AIアシスタントを「裏方」として使う際の体験を底上げする。情報収集からコード生成、実行、後始末まで、一連の流れに無駄がなくなっていく方向性だ。
ターミナルツールの出力処理が大幅に改善

今回のリリースで最も実務的なインパクトが大きいかもしれないのが、ターミナルツールの出力圧縮まわりの拡張だ。
エージェントがテストランナーやビルドツールを実行すると、膨大なログが出力され、チャット画面が埋め尽くされることがある。この問題に対応するため、出力圧縮(冗長な行を折りたたみ、重要な結果だけを強調表示する仕組み)の対象が一気に広がった。
圧縮対象が大幅に拡大されたコマンド群
新たに対象となったのは、以下のツール群だ。
- テストランナー:
pytest、jest、cargo test - ビルドツール:
tsc(TypeScriptコンパイラ)、cargo build、make - リンター類
- Docker関連コマンド
- パッケージマネージャ(npm、yarn、pipなど)
これらのツールが出力する長大なログから、本当に必要なエラー行やサマリーだけを抽出し、チャット画面上ではコンパクトに表示してくれる。テストが数千件走っても、失敗したケースだけに集中できるわけだ。
アイドルサイレンスタイマーで同期実行を自動バックグラウンド化
ターミナルツールには、同期コマンドが一定時間まったく出力を返さない場合に、自動的にバックグラウンド実行に切り替える「アイドルサイレンスタイマー」が導入された。設定した時間内に何の進捗も表示されなければ、AIエージェントはそのコマンドをバックグラウンドに回し、別のタスクに取り掛かれる。
従来は、長時間かかる処理が走っている間、エージェントの思考がブロックされがちだった。この機能は、CI/CDパイプラインや重いデータベースマイグレーションの待ち時間中に、エージェントが他の作業を並行して進められるようにするものだ。
(数千行のログが流れる)
エージェントは完了まで他の操作ができない
出力が折りたたまれ、エラー行のみ表示
一定時間出力なし → 自動でバックグラウンド化
アイドルサイレンスタイマーは設定可能なため、プロジェクトの特性に合わせて閾値を調整できる。テストが沈黙するのはバグではなく重い処理の前触れ、というチームなら長めに取ればいい。
マルチラインコマンドの修正とConPTYの最新化
エージェントホストのターミナルツールでは、複数行にまたがるシェルコマンドの実行時に問題が発生することがあったが、今回のアップデートで修正された。bashやPowerShellでループや条件分岐を含むスクリプトを生成させるケースで、従来は行の継続が正しく解釈されないバグに遭遇することがあった。この修正によって、AIが生成した複数行スクリプトの信頼性が高まっている。
さらに、Windows環境向けに、擬似ターミナルAPIの基盤となるConPTY(conpty.dll)の新しいバージョンがVS Code本体に直接バンドルされるようになった。これまではシステム側のバージョンに依存しており、古いWindowsではターミナルの描画に問題が出ることがあった。バンドル化により、VS Code側で一貫したターミナル挙動を保証できるようになった。
SSH接続におけるキーボード対話認証のサポート

最後に、エージェントホストがSSH接続する際に、キーボードインタラクティブ認証(パスワード入力やワンタイムパスコードの要求を含む対話形式の認証)がサポートされた。多要素認証が求められるサーバーや、接続時に追加の質問が表示される環境でも、エージェントホスト経由の自動接続が可能になったわけだ。
セキュリティ要件が厳しい本番環境や、企業ポリシーで対話認証を強制されているサーバーに対して、Copilot Chatのエージェントを遠隔操作するハードルが下がる。VS Code Remote Developmentの既存ユーザーにとっては、よりシームレスにAI支援を組み込めるようになる変更だ。
この機能は、特にDevSecOpsの文脈で歓迎されそうだ。開発環境と本番環境を明確に分離しつつ、AIアシスタントの支援を安全に受けられる選択肢が増えたことを意味する。
この記事のポイント
- VS Code 1.121ではAIエージェントのツール表示が見直され、入力と出力の可読性が向上した
- モデルピッカーにお気に入りのピン留め機能が追加され、切り替え操作が高速化した
- ターミナル出力の圧縮対象が拡大され、テストやビルドのログがコンパクトに表示される
- アイドルサイレンスタイマーにより、長時間コマンドの自動バックグラウンド化が可能になった
- SSHのキーボード対話認証サポートで、よりセキュアな環境へのエージェント接続が容易になった
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AWS MCP Serverが一般提供開始、AIエージェントのAWS操作を安全・効率的に
AWSは2026年5月6日、AIエージェント向けのマネージドサービス「AWS MCP Server」の一般提供を開始した。AIコーディングアシスタントがAWSの各種サービスを安全に呼び出し、最新ドキュメントを参照し、必要ならサンドボックス内でスクリプトを実行できるようになる。
これまではAIエージェントがAWSを操作しようとしても、訓練データが古く、IAMポリシーが過剰になりがちだった。本サーバーはそうした課題を解決し、本番環境でも使えるレベルのインフラコード生成を後押しする。
本記事ではAWS MCP Serverの機能、GAで追加された新要素、具体的な利用手順、対応ツール、料金までを詳しく解説する。
AWS MCP Serverの概要

MCP(Model Context Protocol)は、AIエージェントが外部サービスやツールと安全にやり取りするための標準プロトコルだ。AWS MCP Serverはこのプロトコルに準拠したマネージド型のリモートサーバーであり、数個の固定ツールを通じて1万5000を超えるAWS APIへのアクセスを提供する。
AIコーディングアシスタントは多くの場合、訓練データに依存するため、2025年後半以降に登場した新サービス(Amazon S3 VectorsやAurora DSQLなど)を知らない。また、インフラ構築時にAWS CLIを好み、AWS CDKやCloudFormationといったIaCツールを使わない傾向があった。生成されるIAMポリシーも権限が広すぎるなど、デモ用には動いても本番投入は難しい状態だった。
この仕組みにより、AIエージェントは常に最新の情報と最小権限でAWSリソースを操作できる。ツールの数が少なく固定されているため、モデルのコンテキストウィンドウを圧迫せず、ハルシネーション(誤った回答の生成)も抑えられる。
GAで追加された主な機能

プレビュー期間を経て正式提供となったAWS MCP Serverでは、以下の機能が新たに導入されている。
IAMコンテキストキーのサポート
従来はMCPサーバー自体の利用に専用のIAM権限が必要だったが、今回からIAMコンテキストキーに対応した。これにより、通常のIAMポリシーの中で「特定のユーザーは更新系APIを許可、MCPサーバー経由では読み取り専用」といったきめ細かい制御が可能になる。余分な権限管理の手間が減り、セキュリティ設計がシンプルになる。
ドキュメント検索の認証不要化
search_documentationおよびread_documentationツールが、認証なしでも利用できるようになった。これにより、まだAWSアカウントを持っていない段階でも、AIエージェントは最新のAWSドキュメントを参照して設計や調査を行える。
トークン消費の最適化
インタラクションあたりのトークン消費量が削減された。マルチステップのワークフローを伴う複雑なタスクでは、モデルのコンテキストウィンドウがすぐに埋まりがちだったが、今回の改善でより長い会話を維持しやすくなっている。
run_scriptツールとサンドボックス実行

GAの大きな目玉がrun_scriptツールの追加だ。AIエージェントは短いPythonスクリプトを記述し、MCPサーバー側のサンドボックス環境で実行させることができる。このサンドボックスは呼び出し元のIAM権限を継承するが、ネットワークアクセスは一切持たない。つまり、エージェントはAWSリソースのデータを処理できるものの、ローカルのファイルシステムやシェルには触れない。
…
# 複数APIを組み合わせた処理を1回のラウンドトリップで
従来、エージェントが複数のAPIを呼び出してデータを結合する場合、1つずつリクエストを送っては応答を待つ必要があり、時間もトークンも浪費していた。run_scriptを使えば、1回のラウンドトリップで一連の処理を完結させられる。これにより、処理速度とコンテキスト効率の両方が大幅に向上する。
Skillsによるベストプラクティスの提供

プレビュー版では「Agent SOPs」という形式でガイダンスが提供されていたが、GAではより洗練された「Skills」に移行した。Skillsは、エージェントがよく間違えるタスクに対して、AWSの各サービスチームがメンテナンスする検証済みのベストプラクティスを提供する。
スキルにより生成されるコードの品質が安定し、エラーやトークンの無駄も減る。ツール一覧を短く保ちつつ、必要なガイダンスをピンポイントで渡せるため、エージェントの挙動が予測しやすくなり、無駄な試行錯誤も抑制される。
エンタープライズの現場では、開発者の数だけ書き方がバラバラになりがちだが、Skillsによってサービスチーム公認のパターンがチーム全体に自然と浸透する。結果として、セキュリティレビューの工数も削減できるだろう。
セキュリティと監査の仕組み

AWS MCP Serverは、ユーザーが直接操作する時とAIエージェント経由の操作を明確に区別できる設計になっている。IAMポリシーやSCP(Service Control Policies)を使って、特定のユーザーには全操作を許可しつつ、MCPサーバーには読み取り専用のみ許可する、といった制御が可能だ。
さらに、AWS-MCP名前空間のAmazon CloudWatchメトリクスが提供され、MCPサーバー経由のAPIコールと人間による直接のAPIコールを分離して監視できる。AWS CloudTrailもすべてのAPI呼び出しを記録するため、コンプライアンスチームが求める監査証跡を完全な形で確保できる。
このように、AIエージェントが安全にインフラを操作できる環境が整ったことで、これまで人間の開発者しか触れなかった本番環境へのAI活用も現実味を帯びてきた。
利用方法と対応ツール

AWS MCP Serverは、MCPに対応するあらゆるAIコーディングツールから利用できる。Claude Code、Cursor、Kiro、OpenAI Codexなど、主要なアシスタントはすでにサポートしている。
セットアップは非常にシンプルだ。AWS MCP ServerはIAM SigV4認証を利用するが、多くのMCPクライアントはOAuth 2.1のみに対応している。そのため、オープンソースの「MCP Proxy for AWS」を使ってIAM認証をOAuthにブリッジする。具体的には以下のようなコマンドで設定する。
curl -LsSf https://astral.sh/uv/install.sh | sh
claude mcp add-json aws-mcp --scope user \
'{"command":"uvx","args":["mcp-proxy-for-aws@latest","https://aws-mcp.us-east-1.api.aws/mcp","--metadata","AWS_REGION=us-west-2"]}'
/mcpコマンドを実行すると、AWS MCP Serverが利用可能なツール一覧が表示される。search_documentationツールを呼び出し、最新のS3 Vectorsの情報をもとに回答を生成する。プロキシはローカルマシン上で動作し、MCPサーバーのエンドポイントとしてhttps://aws-mcp.us-east-1.api.aws/mcp(米国東部)または欧州(フランクフルト)のリージョナルエンドポイントを指定する。APIコール自体は他の全リージョンに対しても実行可能だ。
料金と提供リージョン

AWS MCP Server自体に追加料金は発生しない。支払うのは、AIエージェントが操作した結果として作成されたAWSリソースの利用料と、データ転送料金のみだ。このため、まずは試験的に導入し、効果を検証しやすい。
現在の提供リージョンは米国東部(バージニア北部)と欧州(フランクフルト)の2拠点。今後、他のリージョンにも順次拡大される見込みだ。
AWS MCP Serverはすでに多くのAIコーディングアシスタントで利用可能であり、AWSドキュメントの最新ページからクイックスタートガイドを参照できる。
この記事のポイント
- AWSがAIエージェント向けのマネージドMCPサーバーを一般提供開始
- call_aws、search_documentation、run_scriptの3ツールでAWSを安全に操作
- run_scriptはサーバー側サンドボックスでスクリプトを一括実行し高速化
- SkillsによりAWSチーム公認のベストプラクティスをコード生成に活用可能
- IAMとCloudTrail/CloudWatchで人間の操作とAIの操作を明確に分離監査
- サーバー利用料は無料、リソース使用量のみの課金。米国東部と欧州で提供開始
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験