

AI時代のECはメタデータが鍵。機械に選ばれる商品情報の新常識
AIが検索と推薦を主導する時代、ECサイトの商品情報に求められるルールが根本から変わろうとしている。これまでのSEO対策や広告運用ではカバーしきれない「機械のための情報整理」が、売上を左右する最重要インフラになりつつあるのだ。
MarTechの記事によると、デジタルマーケティングのプロであるBenjamin De Castro氏は、メタデータの戦略的価値がクリエイティブやメディア投資に匹敵する段階に入ったと指摘している。彼がX(旧Twitter)のBlaze社でシニアストラテジストを務めた経験や、Shutterflyのようなフォトプロダクト企業のビジネスモデル変革から得た知見に基づく主張だ。
特にEC制作やWooCommerce運用に携わる者にとって、この変化は「商品マスタの整備」という開発現場の課題が、経営戦略そのものに直結することを意味する。本記事では、AI時代のメタデータ設計について、実務に落とし込む視点で解説する。
メタデータとは何か、AI時代に再定義する

メタデータとは「データについてのデータ」と呼ばれる。商品名や価格、カテゴリ、在庫状況、画像の代替テキスト、更新日時など、情報そのものに付随する説明的な情報を指す。これまでは検索エンジン対策(SEO)の下地として扱われてきた。
しかしAIが介在する今年の検索体験では、メタデータの役割は単なるキーワードの置き場所ではない。機械がコンテンツを「理解」し「文脈を解釈」し「信頼性を評価」するための唯一の手がかりになる。De Castro氏はこれを「通貨」に例えている。通貨が十分でなければ、経済圏に入れないのと同じ理屈だ。
「機械のための設計書」としてのメタデータ
LLM(大規模言語モデル)は、商品情報を確率モデルで処理する。ある商品が「何で」「誰向けで」「どれほど新しく」「信頼できるか」を、メタデータの断片を組み合わせて推論する仕組みだ。統合が不十分だったり、チームごとに異なる用語を使っていたりすると、機械も混乱する。
たとえば「レディース ジャケット」と「女性用 アウター」という商品カテゴリが混在するECサイトでは、AIはこれらを別物と認識するかもしれない。結果として検索の精度が下がり、推薦の精度も落ちる。De Castro氏はこうした非一貫性を「機械に混乱を継承させる」と表現する。
機械にとっての読みやすさは、人間にとってのUIと同じだ。わかりにくいUIのサイトからユーザーが離脱するように、メタデータが不十分だとAIはその商品を見つけられず、推薦対象からも外してしまう。
メタデータがAI体験を駆動する、すでに起きている実例

De Castro氏は具体例として、フォトプロダクト企業のShutterflyやMixbookを挙げる。彼によれば、これらの企業は単なる「写真をグッズにする」サービスではない。ディープラーニングとメタデータを組み合わせて、「デジタルの混沌を物語に変える」事業へと進化した。
デジタル写真には撮影時刻や位置情報、デバイス情報が埋め込まれている。AIが画像認識と組み合わせることで、「誰が写っているか」「どんなシーンか」「天気はどうだったか」まで推論できる。この推論結果をメタデータとして付与することで、ユーザーは「2024年夏、海でのバケーション写真」を瞬時に検索し、自動でアルバムを生成できるようになる。
PinterestとAdobeに学ぶ、メタデータ駆動型の設計
この仕組みはECでも同じだ。Pinterestは商品フィードのメタデータ(タイトル、価格、カテゴリ)を読み取り、プロダクトピンやショッピング広告の表示を最適化している。Adobe Experience ManagerはAIのSmart Tags機能を使い、画像や動画に自動でキーワードを付与する。これにより、社内のクリエイティブチームが必要な素材を高速に見つけられるようになる。
De Castro氏は「メタデータは説明的(descriptive)であるだけでなく、文脈を生成する(generative)ものだ」と述べている。つまり、適切なデータを与えれば、AIはそれをもとに新しい価値(商品説明文の自動生成や、クロスセルの提案など)を生み出せるわけだ。
なぜAI検索でメタデータの比重が増すのか

Google検索はLLMによって、単なる文字列一致から「意図の解釈」へと機能が進化している。検索エンジンは、クエリに対して「このコンテンツは何か」「何に関連するか」「誰のためか」「どれほど新しいか」「信頼できるか」の5つの軸で評価を下す。この5軸すべてを機械に伝えるのがメタデータの仕事だ。
構造化データの実装や商品フィードの最適化が不十分だと、ブランドは機械にとって「曖昧な存在」になる。曖昧な存在は、AIが回答を生成する際に参照されず、結果として検索にも推薦にも現れなくなる。De Castro氏はこれを「フェラーリを買ってきて芝刈り機のエンジンを積むようなものだ」と痛烈に批判する。最先端の生成AIツールを導入しても、その基盤となるデータが貧弱なら意味がない、というわけだ。
「カテゴリ:衣類」
「画像alt:Tシャツの画像」
「カテゴリ:メンズ > トップス > カットソー」
「素材:オーガニックコットン100%」「生産国:日本」
「画像alt:グレーのオーガニックコットンTシャツを着た男性」
GoogleのAI機能に関するガイドラインでも、明確なコンテンツ、クロール可能なページ、構造化されたシグナルというSEOの基本が強調されている。メタデータは、派手なAIツールより地味に見えるかもしれないが、AI時代のマーケティングインフラの中核を担う要素だ。
今すぐ始めるメタデータ戦略の再設計

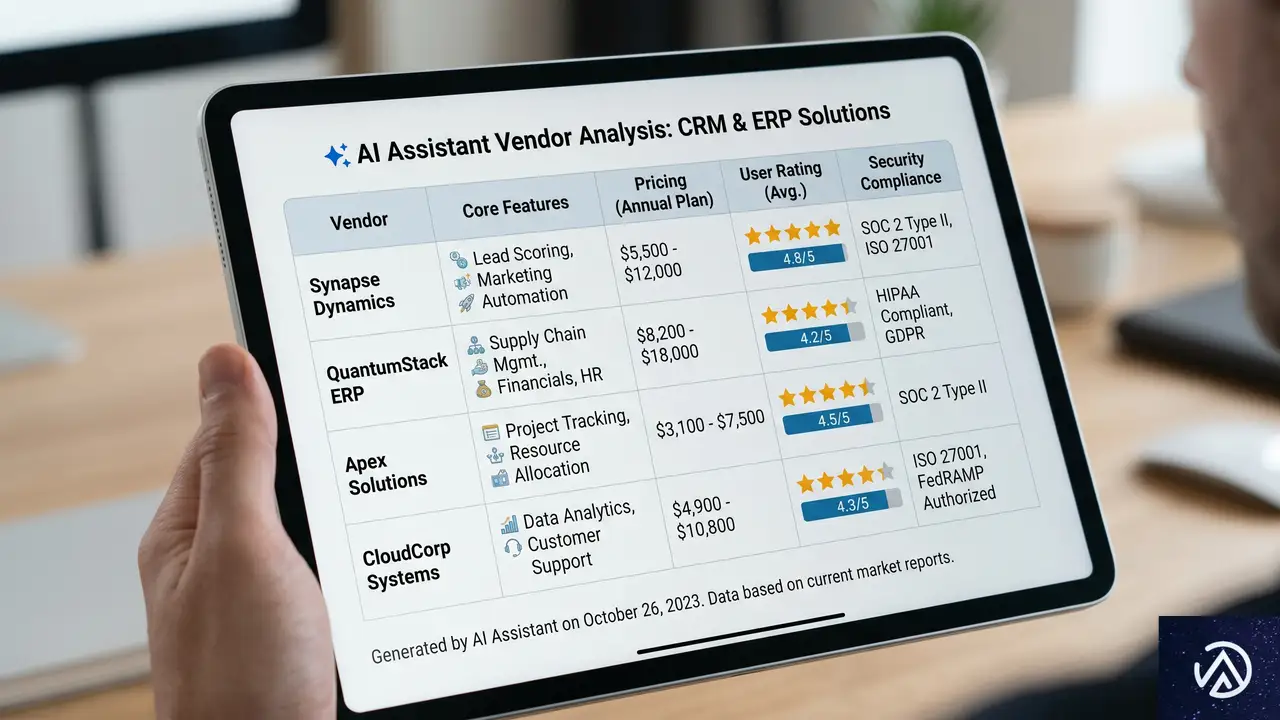
では、WooCommerceで構築されたECサイトや、企業の商品マスタ管理において、具体的に何を変えるべきなのか。De Castro氏の提言を、国内のEC運用実務に即して再構成する。
メタデータをマーケティング資産として扱う
まず認識を改める必要がある。メタデータは「面倒な登録作業」ではない。検索、再利用、パーソナライゼーション、AI連携のすべてに効く戦略資産だ。商品マスタの仕様策定には、制作チームだけでなくマーケティング責任者も関与すべきだ。
「タクソノミ経典」を作り、組織で統一する
カテゴリ名、属性ラベル、タグの定義を全社で統一したドキュメントを作成する。たとえば「送料無料」という表現を「free_shipping」に統一するのか、「送料込み」と使い分けるのかを決めておく。これがないと、チームごとに異なる用語を使い、AIにノイズを与えてしまう。
WooCommerceの場合、商品属性(Attributes)とカテゴリの設計がこの経典の核になる。グローバル属性を適切に設定し、ぶれのないタクソノミを構築することが、AIへのクリアなシグナルにつながる。
メタデータの取得を制作フローの一部に組み込む
Googleの画像SEOガイドは、説明的なタイトル、altテキスト、ファイル名、周辺コンテキストの重要性を説く。Pinterestも同様に、充実した商品フィード項目を推奨している。つまり、メタデータは後付けではなく、商品登録時に必須項目として組み込まれるべきだ。
WooCommerce運用では、CSV一括登録のテンプレートにメタデータ必須項目を組み込む。商品名の命名規則、カテゴリパスのルール、画像altテキストのガイドラインを、運用マニュアルとして整備する必要がある。
AIをメタデータ作成に使う、ただし最終判断は人間が行う
AdobeのSmart Tagsのように、AIによる自動メタデータ付与は規模の課題を解決する。しかし、タクソノミの品質管理やガバナンスは人間の判断領域だ。機械が機械向けにマーケティングすると、「伝言ゲーム」のように情報が歪み、最終的に人間にとって無意味なコンテンツになるリスクがある。
全システムで一貫したストーリーを保つ
CMS、DAM(デジタルアセット管理)、ECカート、CRM、広告プラットフォームで、同じ商品のメタデータが異なっていてはならない。LLMは自社サイトだけでなく、あらゆるソースを横断的にチェックするからだ。WooCommerceと連携する在庫管理システムや広告管理画面でも、マスタとしての整合性を意識する必要がある。
品質をクリエイティブと同等に追求する
メタデータの品質指標は、完全性、一貫性、鮮度、下流(AIや推薦エンジン)への影響度で測る。優れた広告クリエイティブが売上を生むように、優れたメタデータもまた、AI経由の売上を生むという認識が欠かせない。
メタデータはAI時代のマーケティングインフラである

De Castro氏の主張の核心は、メタデータがもはや「あったらいいもの」ではなく「ないと致命的なもの」になったという点にある。クリエイティブも広告費も依然として重要だが、AIがブランドを理解し、検索し、推薦するための基盤として、メタデータの整備は待ったなしの状況だ。
WooCommerceで構築されたECサイトであれば、商品属性、構造化データ、画像alt、フィードデータを一元的に管理する仕組みを今から作る必要がある。将来のAI検索や会話型コマースの波に乗れるかどうかは、今日の商品マスタ設計にかかっているといっても過言ではない。
この記事のポイント
- AI時代の検索と推薦では、メタデータがクリエイティブや広告費と同等の戦略価値を持つ
- 機械に「理解される」ためには、一貫性があり網羅的な構造化データが必要不可欠である
- WooCommerceでは商品属性、タクソノミ、画像alt、フィードデータの統合管理がカギ
- メタデータは後付けではなく、商品登録フローに組み込むことで最大効果を発揮する

・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

GoogleがFAQリッチリザルト廃止、AhrefsがスキーマのAI引用価値を否定
2026年5月、スキーママークアップの価値に冷や水を浴びせる二つの動きが重なった。GoogleはFAQリッチリザルトを廃止し、Ahrefsは構造化データがAI引用を増やさないとするレポートを公開した。
この連続パンチは、SERPでの視認性向上とAI引用獲得というスキーマの二大セールスポイントを直撃する。本記事では、今回の動きが持つ意味と、データが示すスキーマの未来像を掘り下げていく。
Googleがスキーマ特典を絞り込んだ5年間
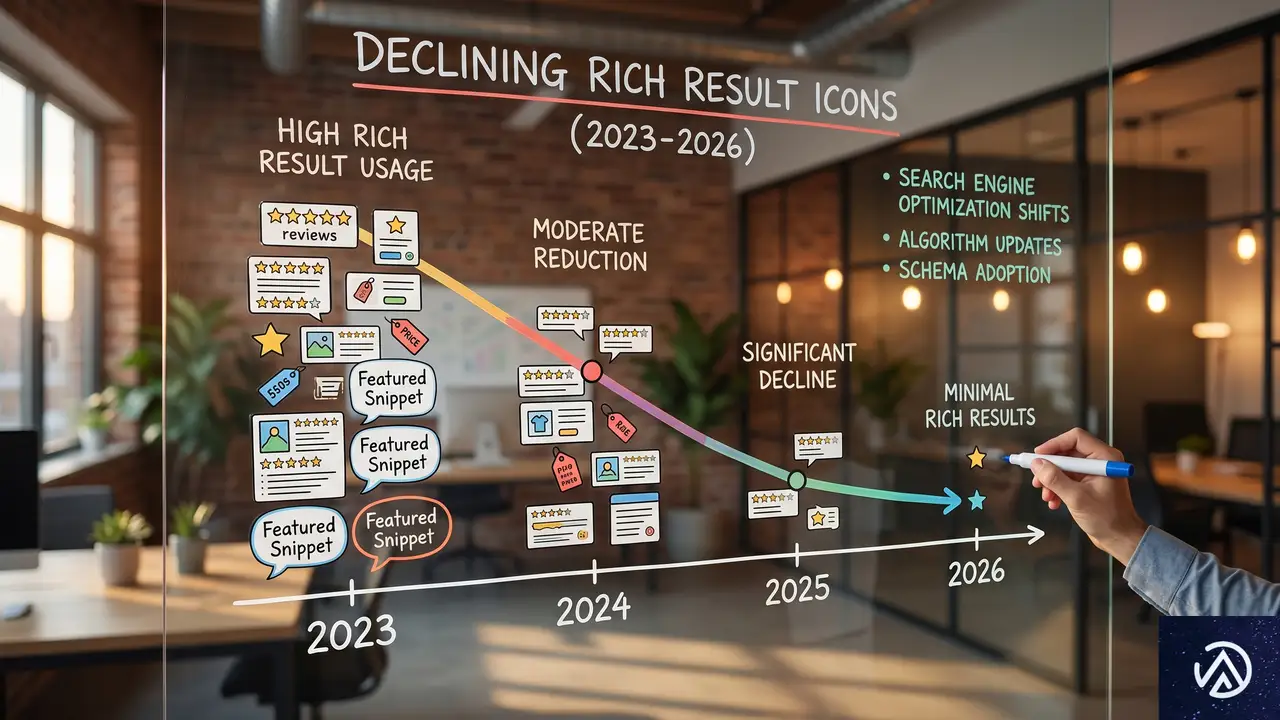
FAQリッチリザルト廃止の最終決定
2026年5月12日、GoogleはFAQページ向けの構造化データを正式に廃止した。FAQリッチリザルトは検索結果上に質問と回答を展開表示する機能で、多くのサイトがクリック率向上のために導入してきた。Googleはこの廃止について「検索結果を簡素化し、ユーザーにとって本当に価値のある情報だけを表示するため」と説明している。
この決定は突然ではない。2023年8月にはFAQリッチリザルトの表示対象を政府機関や医療サイトなどの権威的サイトに限定していた。その時点で、一般的な商業サイトやブログでのFAQ表示はすでに停止されていた。今回の完全廃止は、その延長線上にある最終決定といえる。
GoogleのJohn Mueller氏はReddit上で「マークアップの種類は登場と消滅を繰り返すが、ごく一部の重要なものだけは残り続ける」とコメントしている。これはスキーマ全般を否定する発言ではないが、特定のリッチリザルトを戦略の柱に据えることのリスクを暗に示している。
可視的報酬のパターン
過去5年間の動きを振り返ると、明確なパターンが浮かび上がる。新しい構造化データが導入される。SEO業界がその使い方を検証し、広く導入する。数年のうちにGoogleがその表示特典を縮小または廃止する。そして業界は次の新しいスキーマタイプに注目を移す。
重要なのは、マークアップ自体が無効になるわけではない点だ。Googleのシステムは引き続きFAQ構造化データを読み取り、ページ内容の理解に活用する。しかし検索結果上での目に見える特典、つまりリッチリザルト表示という形での直接的なSEO効果は消滅した。
Ahrefsレポートが示したAI引用とスキーマの関係
1,885ページのA/B比較から見えたもの
Ahrefsは2026年5月16日、構造化データとAI引用の関係を検証した大規模レポートを公開した。調査対象はJSON-LD形式のスキーマを追加した1,885のウェブページ。各ページに対し、スキーマを追加しなかった同条件のコントロールページを用意し、Google AI Overviews、Google AI Mode、ChatGPTの3つのAIシステムで引用数の変化を計測した。
結果は次のとおりだ。
- Google AI Modeで引用が2.4%増加
- ChatGPTで引用が2.2%増加
- Google AI Overviewsで引用が4.6%減少
AI ModeとChatGPTの増加率は統計的な誤差の範囲内であり、スキーマの効果とは言い切れない数値だった。AI Overviewsの減少は統計的に有意だったが、Ahrefs自身が「この減少をスキーマが原因と断定することはできない」と慎重な見解を示している。
データが明かさなかった二つの前提
この調査結果を読む上で、二つの前提を見逃してはならない。
第一に、調査対象の全ページはスキーマ追加前からすでにAI Overviewsで100件以上の引用を獲得していた。つまり、これらのページはAIシステムによって十分にクロールされ、認識され、引用されていた。まだAIに認識されていないページでスキーマがクローリングやインデックス登録を助ける可能性は、このデータでは検証されていない。
第二に、この調査では全スキーマタイプを一括りにしている。Article、FAQ、Product、HowTo、Organizationなど種類の異なるスキーマがまとめて「スキーマあり」とラベル付けされた。タイプ別の効果は未検証であり、特定の種類で引用増加が起きる可能性は否定されていない。
Ahrefsのコンテンツマーケティング責任者であるRyan Law氏はLinkedIn上で「スキーママークアップを追加すればAI検索での引用が増えるか?おそらくノーだ」と端的に総括した。Law氏は「スキーマはAI引用を改善する魔法の解決策ではない」とも付け加えている。
業界内で広がった議論の温度感
「FAQスキーマはAI訓練用だった」という仮説
今回のFAQリッチリザルト廃止に対して、業界内ではさまざまな見解が飛び交った。なかでも注目されたのが、Marie Haynes ConsultingのMarie Haynes氏が提示した仮説だ。
Haynes氏は「GoogleはAIを訓練するためにFAQデータが必要だったので、リッチリザルトという形でインセンティブを与えた。そして今、もうそのデータは不要になった」という見方を示した。この説はGoogle自身によって確認されたものではないが、FAQスキーマ導入から廃止までのタイムラインを説明する一つの解釈として、多くの実務者の関心を集めた。
GEO業界への波紋
SEOの専門家であるLily Ray氏(Amsive社、SEO・AIサーチ担当VP)はLinkedIn上で「FAQスキーマはGEOにとって重要」というフレーズが約16万8000ページで使われていることを指摘し、「SEOでスパム可能なものは必ずスパムされる」と述べた。Ray氏は2019年にFAQスキーマが初めて導入された際のMoz記事でこのサイクルを予見していた。
Yoastの創業者であるJoost de Valk氏は、この事態を「GEO業界は初期SEOの歴史を高速で再現している」と表現し、「FAQスキーマの廃止はそのサイクルが再起動した最初の具体的な証拠だ」と自身のブログで述べた。de Valk氏はSchema.orgに対して、FAQSectionという新しいタイプを提案するissueも提出している。これは「このページにFAQセクションがある」という情報と「このページ自体がFAQである」という情報を構造的に分離するための提案だ。
データが答えられなかった問い
■ スキーマタイプ別の効果(Article/Product/FAQを個別検証していない)
■ 30日を超える長期的効果
■ Bing/Copilot/Perplexity/Claude での挙動
■ JavaScript経由で注入したスキーマの効果
検証されていない経路
Ahrefsの計測対象はGoogle AI Overviews、AI Mode、ChatGPTの3システムに限られる。BingやCopilot、Perplexity、Claudeなど他のAI検索システムがスキーマをどのように扱うかは未検証だ。これらのシステムはGoogleとは異なるクローリングやパースの仕組みを持つ可能性がある。
また、searchVIU(2025年)の実験では、5つのAIシステムがページを直接取得する段階で、表示テキスト(HTML)を参照し、JSON-LDやMicrodata、RDFaなどの隠されたマークアップは使用していなかったと報告されている。これは取得段階に限った話であり、インデックス登録やエンティティ理解の段階でスキーマが役立つ可能性を否定するものではない。
計測期間とタイプ混在の問題
Ahrefsの調査期間は30日間である。スキーマ追加の効果がさらに長期間かけて現れる可能性や、スキーマ追加と同時に行われた他のページ変更の影響を分離できていない点も、解釈上の注意が必要だ。
GoogleはFAQスキーマの廃止告知の中で、構造化データを「ページをよりよく理解する」ために使い続けると述べている。この「よりよく理解する」という表現が具体的に何を指し、どのような測定可能な結果につながるのかは、現時点では明らかになっていない。エンティティ理解やソース選定への間接的な影響を測定したデータは、まだ誰も公表していない。
SEO実務者がいま取るべき戦略
■ 「スキーマを追加すればAI引用が増える」というGEOの売り文句はデータで裏付けられていない
■ Organization、Person、Article スキーマ → エンティティ記述としての価値は残る
■ 見出し構造の明確化、本文での直接的な回答提示 → AI引用に効く可能性が高い
特定スキーマへの過度な依存を避ける
まず確認すべきは、今回のFAQリッチリザルト廃止がスキーマ全体の否定ではないという点だ。Product、Review、Event、Videoといった一部の構造化データは、引き続きアクティブなリッチリザルト機能をサポートしている。Organization、Person、Articleマークアップも、エンティティやコンテンツの記述手段として価値を持ち続ける。
問題は、特定のスキーマタイプを戦略の柱にしてしまうことだ。過去5年間のパターンが示すように、Googleは普及したマークアップの表示特典を段階的に縮小する傾向がある。スキーマは検索エンジンにとっての「水道管」であり、一度敷設すれば特定の蛇口(リッチリザルト)が閉まっても、別の形で水(データ)を運び続ける可能性は残る。
AI引用を狙うならHTML構造を見直す
searchVIUの調査が示したのは、AIシステムがページ取得時にJSON-LDではなく表示テキスト(可視HTML)を参照しているという事実だ。この結果は、AI引用を増やすためにはスキーマよりもコンテンツ自体の構造が重要である可能性を示唆する。
具体的には、見出しを階層的に整理すること、質問に対して本文中で直接的な回答を示すこと、情報を明確なセクションに分けること、といった基本的なコンテンツ設計が、マークアップよりもAI引用に効くかもしれない。スキーマの導入を否定するデータではないが、スキーマだけでAI引用が増えるという期待はデータで裏付けられなかった。
この記事のポイント
- Googleは2026年5月にFAQリッチリザルトを完全廃止し、可視的スキーマ特典の縮小傾向が続いている
- Ahrefsの調査(1,885ページ)では、JSON-LD追加によるAI引用の増加は統計的に確認されなかった
- GEO業界で広がった「スキーマでAI引用が増える」という売り文句は、データによる裏付けを欠いている
- ProductやOrganizationなどリッチリザルトが現役のスキーマタイプは引き続き価値を持つ
- AI引用を狙うなら、スキーマ以上にHTML構造の明確化と本文での直接回答が重要になる可能性が高い
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AdobeのAIトラフィックレポート コンバージョン率が逆転 中小サイトに必要な対策
AIアシスタント経由で小売サイトを訪れるユーザーのコンバージョン率が、2025年春から2026年春の1年間で劇的に変わった。前年は他のチャネルの約半分だったが、2026年3月には逆に42%高くなった。同じチャネル、同じ店舗群だ。
Adobe Analyticsが2026年4月16日に公開した「2026年第2四半期AIトラフィックレポート」によると、米国小売サイトへのAI経由トラフィックは前年同期比393%増、ピークの2025年12月には前年比1,151%に達した。エンゲージメントは12%増、ページ滞在時間は48%増、訪問あたりのページ数は13%増、収益は37%増という数字も並ぶ。
しかし本命は率の逆転だ。1年前は「AIレファラル」が他の流入元よりもはるかに低かった。そのチャネルが今、小売において最も収益性の高い流入経路になっている。
AIトラフィックが小売の最優良チャネルに 2025年春からの大逆転
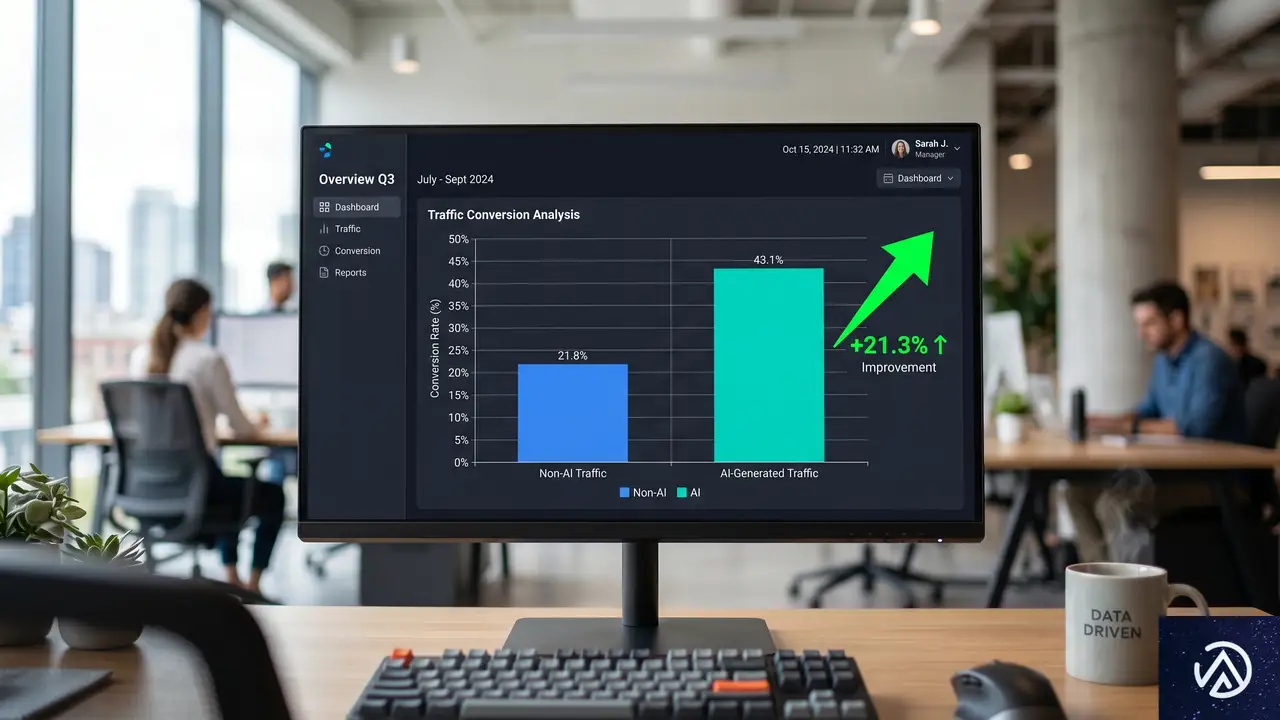
2025年は非AIの半分、2026年3月は42%上回る
Adobeのデータを具体的に見る。2025年3月の時点で、AIアシスタントから米国小売サイトに到達した訪問者のコンバージョン率は、他のチャネル全体の約半分だった。これが2026年3月になると、非AI流入を42%上回るまでに改善している。同じ店舗、同じシステムで、たった12か月の間にチャネルとしての評価が反転したことになる。
成長率393%の内訳 エンゲージメントと収益も向上
量だけではない。AI経由の訪問者は、サイト内での行動もよい。エンゲージメント率は12%増、ページ滞在時間は48%長くなり、訪問あたりのページビューも13%増。さらに重要なのは、訪問あたりの収益が37%増えている点だ。単に流入数が増えただけでなく、質の高い見込み客がAIから直接サイトに送られていることを示している。
「AIトラフィックは未成熟」という見立てが過去のものに

ペイドサーチやSNSが辿った緩やかな成熟カーブとの違い
新しいチャネルが成熟するとき、普通はゆっくりと改善していく。ペイドサーチも、モバイルも、ソーシャルもそうだった。初年度は非AIの半分のコンバージョン率だったものが、25%劣り、10%劣り、やがて均衡し、わずかに上回る。3〜4年をかけてようやく逆転するのが一般的なパターンだ。しかしAdobeのレポートが示すAIレファラルは、この曲線をまったく描いていない。たった2回の測定ポイント、12か月の間に優劣が完全に逆転した。
古い前提で動くエージェンシーへの警告
SEJのSlobodan Manic氏は、「AIトラフィックはまだ初期段階だから、段階的に最適化しよう」という発想そのものが、すでに賞味期限切れだと指摘する。「今年の数字を読んでいなければ、いまだに『未成熟』とか『準備不足』という言葉を使うエージェンシーやコンサルタントがいるが、それは1年前の情報で動いているに等しい」という。同氏は、もし提案が「これから1年かけて何が効くか学びましょう」というものなら、その提案は完全に機会を逃していると分析する。
AIがサイトを読めない根本原因 Citation Readabilityが明かす格差
トップとボトムで可読性スコアが60%以上違う
Adobeのレポートには「Citation Readability(引用可読性)」という指標が紹介されている。これは、ページがAIシステムによってどれだけ正確に解析され、引用されやすいかを示すものだ。トップの小売サイト(AI訪問シェアが高いサイト)のホームページは、下位のサイトと比べて62%も高いスコアを記録した。検索結果ページでは32%高、ブログや記事コンテンツでも30%高い。この差が、AI経由の流入が一部のサイトに偏る理由を明確にしている。
自社サイトの「機械可読性」を把握している経営者はほぼいない
多くのサイト運営者は、毎朝アクセス解析を見て、週次でコンバージョン率を確認し、四半期ごとにCRO(コンバージョン率最適化)戦略を議論している。しかし、GPTBotやClaudeBot、PerplexityBotが自社の商品ページをクロールしたときに、何が見えているのかを把握している企業はほとんどない。ダッシュボードには表示されず、セッション記録にも残らず、正確に「AI経由」とアトリビューションを取れているケースも稀だ。
実際のところ、機械可読性が高いサイトが達成しているコンバージョン率の向上幅は、全体平均の数字よりもさらに大きいと推測される。平均値は、読めないサイトによって押し下げられているからだ。
Dellの「成果なし」とAdobeの「チャネル逆転」 両立する理由
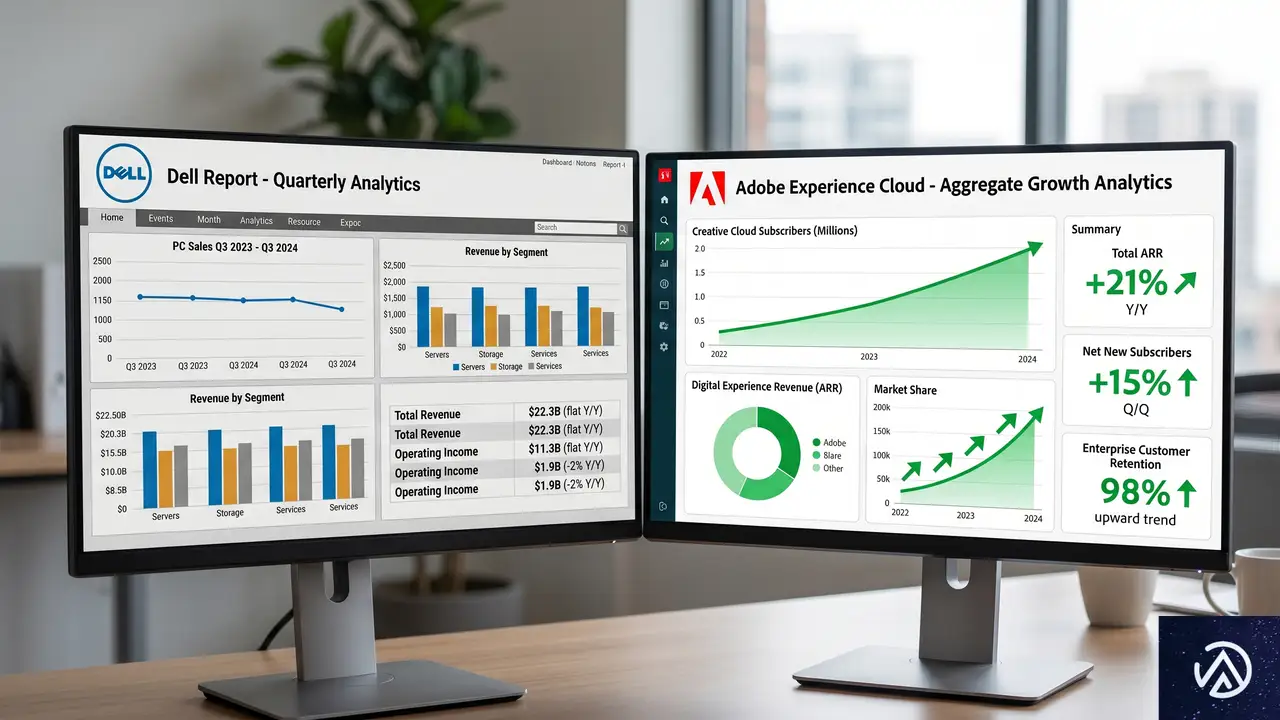
Dell社内データが示した平坦な結果
Adobeのレポートが公開される8日前、Dellのグローバルコンシューマー収益責任者がDigital Commerce 360の取材に対し、「エージェンティックショッピングは、まだ特に大きな成果をもたらしていない」と語った。同社の内部データでは、コンバージョンに目立った変化は見られなかったという。
サイト単位の監査こそが正しいアクション
SEJのManic氏は、この2つのデータは矛盾しないと解説する。Dellは1つのWebサイトを測定し、その結果が横ばいだった。一方、AdobeはAIモデルがきちんと読み取れる多数の小売サイトの集計を見て、チャネル全体が逆転したと結論づけた。自社のコンバージョン率がDellのように停滞しているなら、チャネルの成熟を待つのではなく、まず自社サイトの監査から始めるべきだ。Dellの数字はdell.comの問題を示しており、Adobeのデータはチャネル全体の方向性を示している、と同氏は分析している。
AIアシスタントが購買ファネルを短縮 求められるのは「可読性」

セッション数やインプレッションはもはや重要指標ではない
ここ30年、SEOとCROの世界では「インプレッション」「セッション」「ユニークユーザー」「ページビュー」を増やすことが正義だった。ファネルの入口を広げれば、検討するユーザーが増え、コンバージョンにつながるという計算である。しかしAIレファラルはこの前提を覆す。ChatGPTやPerplexity、Geminiからサイトに訪れるユーザーは、すでにアシスタント内で調査を終え、比較検討し、候補を絞った状態でクリックしている。サイトへの訪問は、意思決定プロセスの最終段階なのである。
上図のように、AI経由ではファネルが大幅に短縮されている。コンバージョンの瞬間だけが可視化されるため、従来型の「流入数を追う」指標は意味を失う。Adobeのデータにあるエンゲージメント48%増や収益37%増は、この短縮された購買行動の結果だ。
AIに引用されリンクされる可読性が勝敗を分ける
393%の成長全体を引き上げているのは、AIアシスタントが実際に引用し、リンクし、購入意欲の高い見込み客を送り込めているサイトだ。これは従来の「検索エンジン向け最適化」ではなく、マシンリーダビリティ(可読性)の問題である。AIに読まれる状態になっているかどうかが、アクセスの有無を決めてしまう。SEJのManic氏は、これを「可読性こそが新しいSEO」と表現し、可読性の低いサイトはチャネル全体の成長から完全に取り残されると警告する。
今週末にできるAIクローラー向けサイト監査の2ステップ
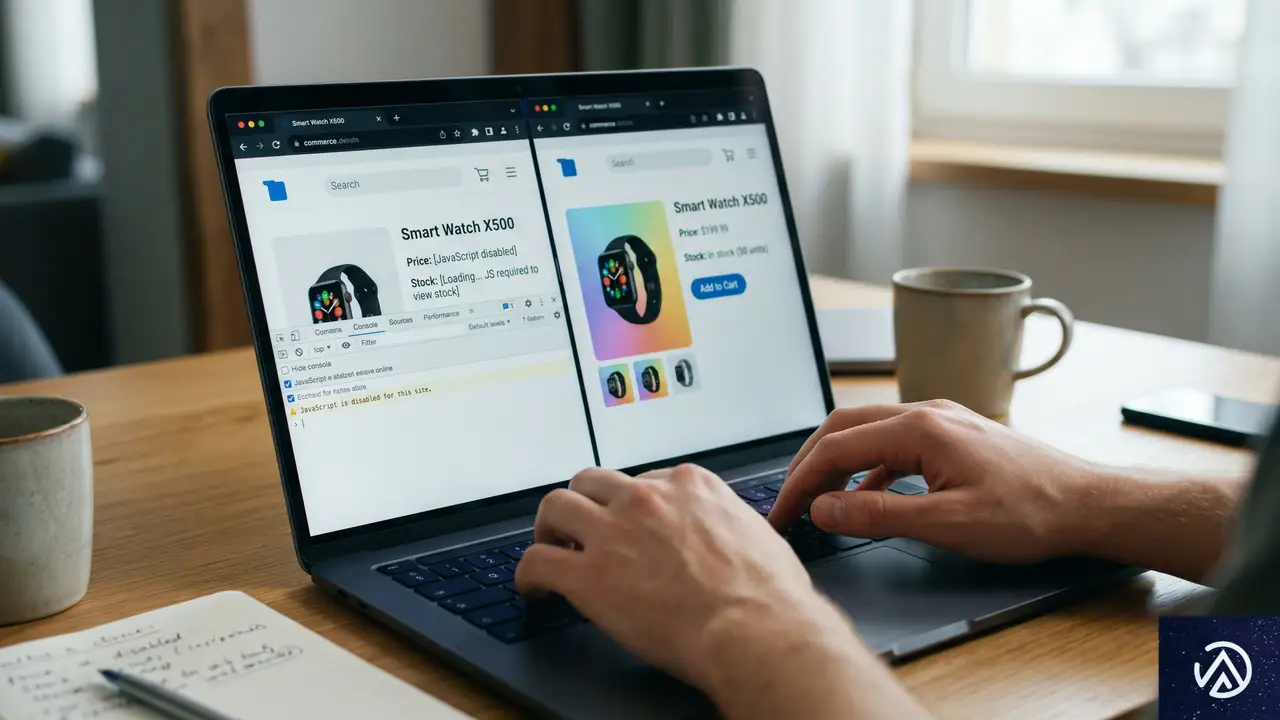
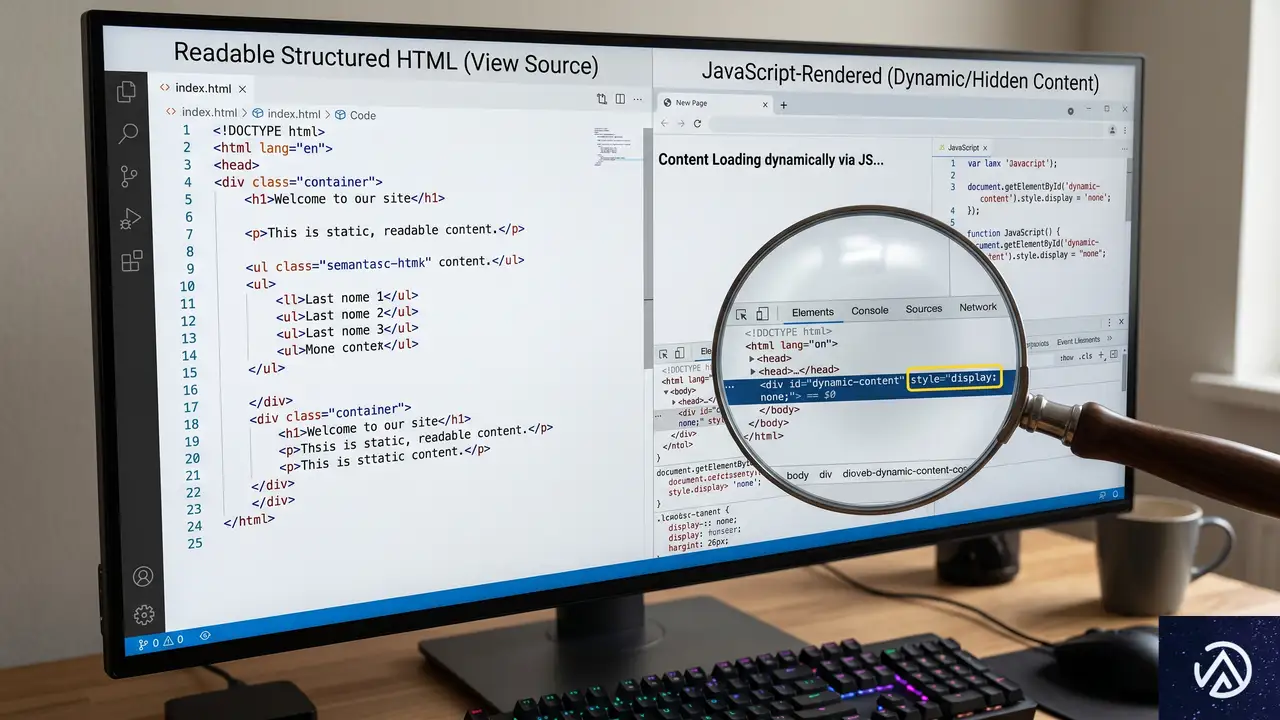
JavaScriptをオフにして価格と在庫を確認する
専門ツールやチームがなくても、すぐに着手できる監査がある。1つ目はJavaScriptを無効化したブラウザで商品ページを再読み込みする方法だ。商品名、価格、在庫状況、購入ボタンがHTMLソース内に静的に存在しているかを確認する。多くのAIクローラーはJavaScriptを実行しない、あるいは実行が不安定なため、重要な情報がすべてJSでレンダリングされていると、AIはその情報を引用できない。引用されなければ、アシスタントの回答にサイトが登場することはない。
上の比較のように、JSオフ時に商品情報が欠落している場合、AIクローラーからは中身のないページに見えている可能性が高い。修正の優先度は非常に高い。
回答先頭テスト ブランド演出よりも事実を最初に置く
2つ目は「回答先頭テスト」と呼ぶチェックだ。商品ページを開いて、最初に目に入るのがブランドナビゲーションやヒーローイメージ、キャッチコピーではなく、「その商品が何か、いくらか、在庫があるか」という事実情報かどうかを確かめる。AIモデルがページを要約するとき、先頭にある構造化された事実を優先的に拾う。人間はブランドの演出を許容するが、AIインデクサーはそれをスクロールで飛ばして価格を探したりはしない。
どちらかが達成できていなければ、それはトラフィックの問題ではなく、サイトアーキテクチャの問題だ。393%という成長の波は、可読性を満たしたサイトにしか届いていない。
この記事のポイント
AI経由の小売トラフィックは、わずか1年でコンバージョン率が非AIを42%上回る優良チャネルに変わった。流入数だけでなく、滞在時間や収益も大幅に伸びている。
「AIは未成熟」という前提はもはや通用しない。緩やかな成熟ではなく、急激な質的逆転が起きているため、段階的最適化という考え方では機会損失になる。
勝敗を分けるのは、AIに正しく読まれ、引用される「可読性」である。自社サイトが機械可読かどうかの監査が、セッション数やインプレッションよりも優先すべき指標になった。
今すぐJavaScriptをオフにした表示確認と、回答先頭テストを実施すれば、AIトラフィックの恩恵を受けられない根本原因を見つけられる。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AIが書き換えるローカル検索のルール、企業が今とるべき4つの対策
AIによる検索体験の変化は、すでにローカルビジネスの集客構造を根本から変え始めている。GoogleのAI OverviewsやGemini、Ask MapsといったAI駆動型の検索機能が一般ユーザーの手に届いたことで、「検索結果の上位に表示されること」だけでは十分ではなくなったのだ。
2026年5月にMarTechが公開したSOCiとGoogleの共同ウェビナー予告記事では、この変化の本質が「AIがどのビジネス情報を信頼し、ユーザーに推奨するか」という新たな競争軸の出現にあると指摘されている。本記事では、この発表内容をベースに、具体的にどのような変化が起きているのか、そして企業は何をすべきかを4つの観点から掘り下げる。
AI Overviewsが変える情報の見せ方

従来の検索結果は、10件のリンクが並ぶリスト形式だった。ユーザーはその中からクリックしてサイトを訪れ、必要な情報を自分で探し出す必要があった。しかし、AI Overviewsの登場でこの体験は大きく変わった。検索結果画面の最上部にAIが生成した要約が表示され、ユーザーはクリックせずとも回答を得られるケースが増えている。
この変化がローカルビジネスに与える影響は極めて大きい。たとえば「東京 駅前 イタリアン ランチ 子連れ」という検索をした場合、従来であれば飲食店のリストが表示されていた。だが、現在ではAIが「子連れに優しいイタリアンレストランとして、A店、B店、C店が評価されています。A店はキッズメニューが充実しており、ベビーカー入店も可能です」といった要約を直接表示する。この要約に含まれなければ、そもそもユーザーの目に触れない時代になったのである。
従来の検索とAI Overviewsの比較
つまり、表示順位を争う従来のSEO(検索エンジン最適化)から、AIに「紹介される」ための情報設計へと、勝負の場が移行しているのだ。
AI Overviewsに表示されるために必要なもの
AI Overviewsが参照する情報源は、Googleビジネスプロフィール(旧Googleマイビジネス)に登録された情報だけではない。ウェブ上の口コミ、公式サイトのコンテンツ、投稿された写真、第三者のレビューサイトの評価など、あらゆる情報がAIによって収集・統合され、要約生成の材料となる。
これは、ビジネス情報の「完全性」と「一貫性」が、かつてないほど重要になったことを意味する。営業時間、所在地、提供サービス、写真、口コミへの返信状況など、あらゆる接点で正確かつ最新の情報を提供し続けることが、AIからの信頼獲得につながる。
Ask Mapsと会話型検索のインパクト

Googleマップに実装されたAsk Maps機能は、地図アプリの枠を超えたAIアシスタントだ。ユーザーは「このエリアでペット同伴OKのカフェは?」「明日の朝8時に開いているドラッグストアは?」といった自然な質問を投げかけることができる。AIは地図上のビジネスデータ、口コミ、営業時間などを解析し、条件に合致する店舗を即座に提示する。
この変化の本質は、検索の「キーワード入力」から「会話」への移行にある。従来の検索では「ペット カフェ 場所」といった断片的なキーワードをつなげていたが、今後は自然言語での質問が主流になる。AIが質問の意図を解釈し、最適なビジネスを選ぶため、商圏内の競合と比べて自社の情報がどれだけ豊かで、的確かを問われることになる。
Ask Mapsの情報処理フロー
「犬同伴OKでテラス席のあるカフェ」
Googleビジネスプロフィール / 口コミ / 写真 / メニュー情報 / 公式サイト
「Aカフェが条件に合います。テラス席があり、犬用の水皿も提供されています」
会話型検索がもたらす口コミの重要性
会話型検索では、ユーザーが求める具体的な条件にAIが答えるため、口コミの内容がこれまで以上に重要になる。たとえば「静かな環境で仕事ができるカフェ」という質問に対して、AIは口コミ内の「静か」「Wi-Fi完備」「コンセントあり」といったキーワードを拾い、推薦を行う。単なる星評価の高さだけでなく、テキスト情報として蓄積された具体的な評価が、AIの選択に直結する時代に入った。
口コミを増やすだけでなく、キーワードを含んだ具体的な口コミを促す施策が、今後のローカルSEOの中心になると見てよい。来店客に「どのような点が良かったか」を丁寧に尋ね、回答を促す仕組みづくりが鍵になる。
ビジネス情報の完全性がもたらす効果

MarTechの記事によれば、SOCiとGoogleは「完全で正確なビジネス情報が、顧客とAIシステムの双方からブランドを理解してもらう助けになる」と述べている。ここでいう完全な情報とは、Googleビジネスプロフィールの全項目が埋まっていることにとどまらず、公式サイトの内容、投稿の頻度、写真の充実度、口コミへの反応速度までも含む概念だ。
ビジネス情報の全体像
営業時間、住所、電話番号、カテゴリ選択
写真、投稿、メニューやサービス一覧、Q&A
口コミの数と内容、返信率、公式サイトの情報との一貫性
情報の一貫性が信頼を生む
住所や電話番号の表記がGoogleビジネスプロフィールと公式サイトで異なっていたり、営業時間が最新でなかったりすると、AIはそのビジネス情報を「信頼性が低い」と判断する可能性がある。これは、人間のユーザーが情報の不一致に不安を感じるのと同じ理屈だ。AIは大量のデータを横断的に照合するため、人の目よりもはるかに厳密に矛盾を検出する。
具体的な対策としては、まずGoogleビジネスプロフィールの全項目を埋め、次に公式サイトの該当ページとの情報の一致を確認する。さらに、Yahoo!や食べログ、Rettyなど、国内の主要プラットフォームでも同一の情報を掲載することが望ましい。情報の「散らばり」をなくし、AIがどこを参照しても同じ情報にたどり着ける状態を目指したい。
実践的な最適化ロードマップ

では、実際に何から着手すべきか。AI時代のローカル検索対策は、従来のMEO(マップエンジン最適化)の延長ではない。情報設計の考え方を抜本的に見直す必要がある。以下に、優先度の高い4つの施策を整理した。
ステップ1:Googleビジネスプロフィールの完全最適化
カテゴリ選択、サービスメニュー、営業時間、写真、属性情報(バリアフリー対応や決済方法など)を完全に埋める。特に、カテゴリ選択はAIがビジネスの業態を理解するための最重要項目だ。メインカテゴリだけでなく、追加カテゴリも可能な限り設定する。写真は外観、内観、商品、スタッフの4種類を最低各5枚以上用意し、定期的な更新を行う。
ステップ2:口コミ戦略のシフト
星の数だけでなく、テキストの質を重視した口コミ施策に切り替える。来店時に「特に良かった点」を尋ね、回答内容をそのまま口コミに書いてもらえるよう自然に促す。AI検索では「店内が静か」「スタッフの対応が丁寧」「駐車場が広い」といった具体的な記述が、条件検索でのヒット率を左右する。
ステップ3:ローカルコンテンツの拡充
公式サイトやGoogleビジネスプロフィールの投稿機能を活用し、地域に根ざしたコンテンツを定期的に発信する。地元のイベント情報、季節限定メニュー、スタッフ紹介などが効果的だ。AIは鮮度の高い情報を評価する傾向があるため、少なくとも週1回の更新を維持したい。
ステップ4:データの一貫性監査
四半期に一度は、Googleビジネスプロフィール、公式サイト、主要ポータルサイト間で、住所、電話番号、営業時間、サービス内容に差異がないかを確認する監査を実施する。情報の不一致はAIの信頼を損なう最大の要因だ。手作業での確認が難しい場合は、ローカルSEOツールを活用した自動監査も検討したい。
この記事のポイント
- AI OverviewsやAsk Mapsの普及で、検索の主役が「リンクリスト」から「AIによる要約と推薦」に移行している
- 情報の完全性と一貫性がAIからの信頼獲得の鍵であり、営業時間や住所の不一致は致命的な評価ダウンにつながる
- 口コミは星の数からテキストの質へと評価軸がシフトし、具体的な体験談がAIの選択に直結する
- Googleビジネスプロフィールの完全最適化、口コミ戦略の見直し、ローカルコンテンツの定期更新、データ一貫性監査の4つが今すぐ取り組むべき施策だ
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

ChatGPTに広告が登場。OpenAIがテスト運用を発表、日本への展開も明らかに
OpenAIは2026年2月、ChatGPTの無料プランとGoプランにおいて広告のテストを開始した。回答の内容に広告が影響することはなく、会話データは広告主に対して非公開に保たれる。すでに米国でのテストを経て、カナダや豪州への拡大が始まっている。
5月7日のアップデートでは、日本、英国、メキシコ、ブラジル、韓国の5カ国にもパイロットを拡大する計画が発表された。このテストはAIモデルの開発コストを一部カバーし、無料での利用を継続可能にする目的がある。実際に広告がどう表示されるのか、具体的な仕組みを見ていく。
ChatGPTで始まった広告テストの実態

今回のテストは、ChatGPTのログイン済み成人ユーザーのうち、無料プランとGoプランを対象とする。月額20ドルのPlusや200ドルのPro、契約型のBusinessやEnterprise、Educationの各プランには広告が表示されない。OpenAIの公式ブログでの発表によれば、目的は「より多くの人が強力なChatGPTの機能にアクセスできるようにする」ことだ。
無料層を支えるインフラと広告の役割
ChatGPTは数億人のユーザーが学習や日常の判断に使うサービスである。無料プランとGoプランを高速かつ安定して提供し続けるには、大規模な計算基盤と継続的な投資が欠かせない。広告収入はその運用費を補填し、無料層や低価格帯の品質を落とさずにAIの能力を向上させるための資金源と位置づけられている。
実際にどの程度のリクエスト数がさばかれているかというと、SimilarWebの推計では2026年3月時点でChatGPTの月間訪問数は約50億回に達している。これだけのアクセスをリアルタイムで処理するためのGPUクラスタの電気代だけでも、月あたり数十億円規模と試算するエンジニアもいる。
広告の表示要件
テスト段階では、会話の話題とユーザーの過去のチャット履歴、過去の広告とのインタラクションに基づいて表示する広告が選ばれる。たとえば料理のレシピを検索しているときには、食材キットや食料品の宅配サービスといった関連性の高い広告が出る仕組みだ。
自然検索結果はスクロールが必要
食材キットの広告が1件だけ表示
このデモでは、従来の検索エンジン型の広告表示と、ChatGPTの会話型広告表示の違いを示している。検索エンジンでは広告が検索結果の上位を占めることが多いが、ChatGPTでは回答と明確に分離され、会話の流れを妨げない形で1件の関連広告が表示される。
広告が回答内容に与えない影響とプライバシー設計
OpenAIは今回のテストに際して、「広告はChatGPTの回答に一切影響を与えない」という基本方針を明示している。回答はユーザーにとって最も役立つ内容に最適化され、広告は常に「スポンサー」ラベル付きで回答とは視覚的に分離される。
会話データは広告主に渡らない
プライバシー面では、広告主がユーザーのチャット内容やチャット履歴、メモリ機能に保存された情報、個人の詳細にアクセスすることはできない。広告主に提供されるのは、自社の広告が何回表示され何回クリックされたかといった集計データのみである。
これは、Cookieやデバイスフィンガープリントで個人を追跡する従来の行動ターゲティング広告とは根本的に異なるアプローチだ。OpenAIは「狭いターゲティングを防ぐためのガードレール」を設け、詐欺広告や有害・誤解を招く広告のリスクを減らす保護策も組み込んでいる。
18歳未満とセンシティブな話題では表示しない
テスト期間中、18歳未満と判明しているまたは予測されるアカウントには広告が表示されない。また、健康やメンタルヘルス、政治といったセンシティブまたは規制対象の話題の近くにも広告は表示されない設計である。これは、広告がユーザーの信頼を損なわないようにするための重要な仕組みだ。
ユーザーに提供される広告管理の選択肢
ChatGPTでは、広告に対してユーザーが細かく制御できる仕組みが用意されている。広告を見たくない場合は、PlusまたはProプランにアップグレードする方法と、無料プランのまま1日の無料メッセージ数を減らす代わりに広告を非表示にする方法の2つが提供される。
広告コントロールパネルの機能
設定画面からは次の操作が可能である。広告を閉じる、フィードバックを送信する、なぜその広告が表示されたのか理由を確認する、ワンタップで広告データを削除する、広告のパーソナライズ設定を管理する。
● インタレスト(推定される興味関心の確認)
● 広告データの削除(ワンタップで全消去)
● パーソナライズ設定(オン / オフ切替)
● 過去のチャットとメモリの使用(許可 / 不許可)
このパネルはChatGPTの設定内に組み込まれており、数タップで広告の表示有無やパーソナライズのオンオフを切り替えられる。一般的なSNS広告の設定画面よりも項目が整理されており、非エンジニアでも迷わず操作できる設計だ。
地域拡大のロードマップと日本市場への示唆

OpenAIは段階的にテスト地域を拡大している。2026年2月の米国を皮切りに、3月にはカナダ、豪州、ニュージーランドでのパイロットが開始された。そして5月の発表で、英国、メキシコ、ブラジル、日本、韓国の5カ国に拡大する計画が明らかになった。
地域ごとに異なる広告体験を学習する狙い
OpenAIの発表によれば、このパイロットの目的は「地域ごとに何が効果的かを理解し、拡大にあわせて体験を継続的に改善すること」にある。つまり単なる広告枠の販売ではなく、文化や商習慣の違いが広告の受け入れられ方にどう影響するかを検証する意図がある。
日本市場においては、LINEやYahoo! JAPANなどが提供するAIアシスタントとの競合が意識される局面でもある。ChatGPT上での広告が日本のユーザーにどのように受け止められるかは、国内でのサービス定着を左右する要素のひとつになるだろう。
広告主にとっての意味
OpenAIは企業向けに広告プログラムへの参加登録ページを公開している。現在は限定的だが、将来的には広告フォーマットの拡張や、目的別の広告購入モデルの追加が検討されている。とくにChatGPTの会話型インターフェースでは、ユーザーが「探している」タイミングで広告が表示されるため、検索広告とは異なる高いコンバージョン率が期待できると見られている。
対話型AIにおける広告の可能性と課題

OpenAIは今回のテストを「学習」の機会と位置づけている。広告が「役に立つ」と感じられ、ChatGPTの体験に自然に溶け込むかどうかを注意深く観察するとしている。初期の結果では、消費者の信頼指標に悪影響は見られず、広告の非表示率は低く、関連性は改善を続けているという。
会話型インターフェースならではの広告価値
ChatGPTのユーザーは、何かを積極的に調べたりアイデアを比較したり、意思決定に向けて動いている最中であることが多い。そうしたタイミングで表示される広告は、ユーザーが求める商品やサービスとの出会いを支援する可能性を持つ。OpenAIは「会話型インターフェースでは、広告がより関連性が高く有用になり、人々を新しい商品やサービスに自然な形でつなげられる」と述べている。
広告の独立性与信頼性の維持
ただし、AIアシスタントに広告を組み込むことへの懸念も根強い。ユーザーが「AIは中立的であるべき」と考える傾向があるためだ。OpenAIは「ChatGPTの回答は独立しており偏りがなく、会話は非公開に保たれ、人々は自分の体験を意味のある形で制御し続ける」という基本原則を、広告プログラムが拡大しても変えないと明言している。
この原則が実際に守られるかどうかは、今後の第三者監査やユーザーからのフィードバックの蓄積によって検証されていくことになるだろう。少なくともテスト段階では、広告が回答内容に干渉しないという設計は一貫している。
この記事のポイント
- ChatGPTの無料層で広告テストが始まり、日本を含む6カ国に拡大予定である
- 広告は回答内容に影響せず、会話データは広告主に非公開。プライバシー設計が明確だ
- ユーザーは広告の非表示やパーソナライズ設定の管理が可能である
- 対話型AIならではの広告価値が期待される一方、信頼性維持が最大の課題となる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AI検索で無名の新ブランドは勝てるのか?1カ月実験で見えた可視化ルール
実在しない架空のブランドでも、AI検索結果に表示され、あたかも業界の有力企業であるかのように引用される。そんな実験結果が、SEOツールを提供するSE Ranking社の研究チームによって2026年4月に公開された。実験開始からわずか1カ月で、作りたてのブランドがAIに「学習」され、検索結果で確固たるポジションを築いたのだ。
この実験が示すのは、AI検索(ChatGPTやGoogleのAI Overviewsなど)の可視性には、明確で再現可能なパターンが存在するということだ。AIはデタラメに結果を表示しているわけではない。特定のシグナルに反応し、そのシグナルは戦略的に操作できる可能性がある。
データに基づいた、AI時代の新しい情報発信のルールを見ていこう。
実験の設計と5つのAIエンジン

この実験を主導したのは、Search Engine Landに寄稿したSE Ranking社の研究チームだ。彼らは実在する市場の中に、完全に架空の新ブランドを作り出した。そのブランドに関する情報を、専用に取得した新しいWebサイトと、過去の運用履歴がある11の追加ドメインに分散して公開。複数のサイト間で情報をどう拾い上げるかも検証した。
作成したコンテンツは以下の7形式に及ぶ。
- 詳細ガイド(5000~6000語の網羅的ページ)
- 「代替品」リスト
- 「ベスト」リスト
- レビュー記事
- 比較(vs)ページ
- ハウツー・チュートリアル記事
- クリックベイト風の記事
2026年3月にコンテンツの公開を開始し、以下の5つのAIシステムがどのように反応するかを1カ月間追跡した。
- ChatGPT
- GoogleのAI Overviews(検索結果の上部に表示される生成AI要約)
- GoogleのAI Mode(AI Overviewsより対話型の検索体験)
- Perplexity(リアルタイムWeb検索に特化したAI)
- Gemini
追跡したプロンプト数は全カテゴリで825件。これに対してAIが生成した回答は合計15,835件にのぼった。各回答において、架空ブランドが「登場したか」「情報源として引用されたか」「1番目の主要な情報源として扱われたか」をチェックしている。
新興ブランドがAI検索を制する3つの発見

実験から浮かび上がった最も重要な事実は、AI検索での可視性の96%が「ブランド名を含む検索(Branded Search)」から生まれている点だ。「最高のプロジェクト管理ツール」のような一般キーワードでは、まったく新しいドメインが既存の権威あるサイトに勝つのは極めて難しい。
しかし、見方を変えれば、これは新規ブランドにとって大きなチャンスでもある。具体的な3つのパターンを見ていこう。
自社の物語は自社で定義できる
架空ブランドのメインサイトでは、ブランド名を含むクエリで10,253件のAI回答が生成されたのに対し、非ブランドクエリではわずか6件だった。その差は約1,700倍だ。AIは、答えが一意に定まる「ブランド固有の質問」に対して、驚くほどの信頼を寄せる。
「御社の製品は元々社内ツールとして開発されたのですか?」といった質問には、そのブランド自身しか答えられない。AIは複数の情報源を比較する必要がなく、結果としてドメインの権威がなくとも、そのサイトの記述をそのまま正解として採用する。実験では、この種のクエリで、権威スコアが40を超える既存の競合を最大32倍も上回る結果を残した。
実際に最も引用されたページは、ブランドの核となる情報をまとめた「完全ガイド」で、1,799件のAI回答に登場した。「会社概要(About Us)」ページも1,500件で続く。LLM(大規模言語モデル)は、これらの基本ページを他のどの追加ドメインよりも3~5倍の頻度で情報源として利用した。
AIはあなたのブランドをすぐに学び始める。しかし、何を学ぶかは、あなたがサイトに何を書くかで決まる。権威がなくとも、「自分たちは何者か」「何を提供しているか」「何が違うのか」を明確に説明することで、AI内でのブランドの語られ方を形成できるのである。
AIエンジンごとの振る舞いはまったく異なる
5つのAIは、それぞれが異なる「性格」を持っていた。この違いを理解することは、AI検索対策において極めて実践的な意味を持つ。
Google AI Mode: 最も安定した支持者
ブランド関連のクエリにおいて、約90%のケースで架空ブランドのドメインを情報源の1位に据えた。変動が少なく、特定の補助ドメインに依存する様子も見られなかった。ブランドの直接的な可視性を最も予測しやすいエンジンと言える。
Google AI Overviews: 高揚感と不安定さの同居
ブランドを認識し、検索結果の上位に表示する能力は高い。しかし、その可視性は安定しない。実験中、2週間連続で1位を維持した後、月中に急に姿を消し、回復しなかったプロンプトもある。AI Overviewsがブランドを「知らない」と回答したり、公開情報がないと主張するケースも散見された。リンクが表示される時は正確な説明を伴うが、その状態を維持するのが難しい。
Perplexity: 俊足の曲者
新しく公開されたページを、インデックスされてからわずか1~3日で拾い上げる圧倒的なスピードを持つ。実験初期の可視性はほぼPerplexityが牽引した。だが、そのスピードにはトレードオフがある。Perplexityは、ブランドのメインサイトよりも、実験用の補助ドメインを情報源として好む傾向を示した。月の後半には、メインのブランドサイトではなく、6つの異なる外部ドメインが引用されるようになった。可視性の総量は増えるが、それが必ずしもブランド本体への直接的な評価向上につながるとは限らない。
ChatGPT: 遅効性で深く浸透
実験開始当初はブランドをまったく認識しなかった。それが月の後半にかけて徐々に可視性を増していく。特に、ブランド固有の主張や製品レビュー、競合との比較ページで強さを発揮した。比較ページでは、月末までに31日中29日間という高い一貫性で引用を続けた。一度認識すると、繰り返し情報源として取り上げる傾向が見て取れる。
Gemini: 最も不安定な存在
実験で最もパフォーマンスが低かった。最初はブランドの事業領域すら誤認するほどだった。プロンプトを「X vs Y」のような比較形式に変えると精度が上がったが、それでもブランド固有のクエリに対して、約60%の回答でブランドへの言及や引用を一切行わなかった。
コンテンツの量と質の意外な関係
AIに引用されやすいコンテンツ形式は明らかだった。1ページあたりのAI回答数で見ると、詳細ガイドが約900件と圧倒的で、レビュー記事(約257件)、比較記事(約145件)がそれに続く。一方、ハウツー記事(22件)やクリックベイト記事(19件)、リスト記事(4~11件)はほとんど引用されなかった。
しかし、ここには明確な逆説がある。実験チームは、1つのテストドメインに、1ページ500~750語程度の薄い内容のページを30ページだけ公開するという、いわば「質より量」のテストも実施した。この30ページは、1ページあたりの平均AI回答数が63件と、詳細ガイドには遠く及ばない。
ところが、ドメイン全体の合計で見ると、総AI回答数は1,897件となり、これが全テストドメインの中で最も高い数値となった。個々のページの質では勝てなくとも、量で総露出を稼ぐ戦略が通用することを示している。これは、Perplexityのように新鮮さを重視するエンジンが存在するAI検索ならではの現象と言える。
トピッククラスターの神話が崩れた瞬間

この実験で最も注目すべき「失敗」のデータがある。それは、従来のSEOで効果的とされてきた「トピッククラスター」が、AI検索ではまったく機能しなかった点だ。
実験チームは、1つのテストドメイン内に、ハブとなる1ページと、それを支える10の関連記事を作成した。これらはすべて適切にインデックスされ、内部リンクで構造化され、検索エンジンにとって意味的なまとまりを形成していた。古典的なSEO理論で言えば、これは「専門性の塊」であり、検索エンジンからの高い評価を得られるはずの構成だ。
結果は、AI回答からの引用ゼロ。1件も引用されなかった。これは、従来の「内部リンクとセマンティックな広がりが権威性を高め、検索されやすくなる」という前提に対する痛烈な反証である。AIが必要としているのは、「構造化された知識のネットワーク」だけではない。AIがその情報を「なぜ、その回答のために引用しなければならないのか」という明確な理由なのだ。そこが欠けていれば、完璧に見えるコンテンツ群もAIの目には留まらない。
AIは「一貫性」に弱い。これはチャンスでありリスクだ

1カ月の実験が突きつけた結論は明快だ。AI検索は、情報の真偽を厳密に検証するよりも、「その情報がどれだけ一貫して、繰り返し、事実のように語られているか」に強く反応する。決して「AIは何でも信じ込む」と言うつもりはない。しかし、ある主張が明確に構造化され、関連する複数のページで何度も繰り返され、それが検索可能な形で存在すれば、AIはそれを驚くほど簡単に「事実」として表面化させる可能性がある。
これは正規のブランドにとっては、自社の強みを定義し、AIに正しく理解させるための能動的な戦略が必要だという警鐘である。AIは黙っていても正確な企業情報を語ってくれるわけではない。こちらから情報環境を整え、学習させにいかなければならない。
同時に、これは大きなリスクでもある。実験では「そのブランドに価値はあるか?」という問いに対し、AIが、まったく無名の架空ブランドを肯定的に推薦するケースも確認された。AIには、まだ情報の空白を批判的に捉えるのではなく、利用可能な限られたシグナルから「中立的」あるいは「好意的」な回答を生成することで埋めようとする傾向があるからだ。
これはAI検索の世界において、ブランド認知がこれまで以上に「柔軟」で、戦略的な影響を受けやすいものであることを意味する。あなたが事業を定義しなければ、他者(あるいは何者でもない情報)が、あなたのブランドの物語を上書きしてしまうかもしれないのだ。
この記事のポイント
- AI検索での可視性の96%は「ブランド名を含む検索」から生まれる。最初に集中すべきは、自社の核となる情報(「私たちは誰か」「何が違うのか」)を明確に定義し公開することである。
- 5つの主要AI(ChatGPT、Google AI Overviews / AI Mode、Perplexity、Gemini)は、情報の拾い上げ速度や引用の安定性がまったく異なる。戦略はこれを前提に設計する必要がある。
- AIに最も引用されるのは網羅的な詳細ガイドや比較記事だ。ただし、質の高い少数の記事が勝つとは限らず、大量のコンテンツが総露出で勝利するケースもある。
- 従来の内部リンクを中心としたトピッククラスター戦略だけでは、AIからの引用を獲得できない。AIに「なぜこれを引用すべきか」という理由を与えることの方が重要である。
- AIの判断は「一貫性」と「反復」に影響を受けやすい。自社のブランド情報を放置すれば、AIは情報の空白を推測で埋め、実態とかけ離れたブランドイメージが形成されるリスクがある。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AI検索エンジンの引用傾向比較、ブランド戦略に示唆
主要なAI検索エンジン5つを比較した調査で、引用されるウェブサイトの種類に大きな差があることがわかった。一方で、特定の製品やサービスと結びついたブランド名は、どのAIでも共通して引用されやすい傾向にある。
この記事では、BrightEdge社の調査データを基に、ChatGPTやGoogle AI Overviews、Gemini、PerplexityといったAIが「何を情報源として選ぶのか」を分析する。AI時代のSEO対策として、自社サイトの情報設計やブランディングにどう活かすべきか、具体的な論点を提示する。
5つのAIサーチエンジンが示す、引用ソースの「分散」と「集中」
今回の調査は、2026年4月にBrightEdge社が実施したものだ。ChatGPT、Google AI Overviews、Google AI Mode、Google Gemini、Perplexityの5つについて、生成された回答の中でどのようなサイトが引用されているかを分析している。
まず注目されたのは、各AIエンジンが引用する上位サイトの重なり具合、つまり「ソース重複率」だ。最も重複が少なかった組み合わせでは、わずか16%の一致率にとどまった。対照的に、最も高い組み合わせでは59%のサイトが重複していた。
この数字が意味するのは、AIによって情報源の選び方が全く異なり得るという事実だ。あるAIで引用されるからといって、別のAIでも同様に扱われる保証はない。複数のAI検索エンジンでの露出を狙うなら、それぞれの特性を踏まえた対策が必要になる。
ブランド名の一致率は相対的に高い
ソース重複率とは対照的に、回答内で言及される「ブランド名」に関しては、AI間でより高い一致が見られた。最も低い組み合わせでも36%、高い組み合わせでは最大55%のブランド名重複率が記録されている。
つまり、各AIは異なるウェブサイトを参照しているにもかかわらず、結果として同じブランド名にたどり着く傾向がある。これは、製品やサービスと強く結びついたブランドが、業界全体で広く認知されていることの反映だ。信頼できるウェブサイトから繰り返し言及されるブランドは、AIの学習や検索プロセスでも再現性が高まる。
Search Engine Journalの著者Roger Montti氏は、この点について「消費者の頭の中でブランドと製品・サービスを結びつけることが、ブランド検索の増加につながる」と指摘している。Googleが2004年頃からNavboostと呼ばれる仕組みでユーザー行動シグナルをランキングに活用してきたことや、ブランドナビゲーションに関する特許を取得している事実も、この考えを裏付けている。
信頼されるサイトの種類はAIごとに大きく異なる

BrightEdgeは引用されたサイトを3つのカテゴリに分類した。政府や教育機関、大企業のサイトを含む「機関系サイト」、メディアやレビューサイト、リスティングを含む「商業・編集系サイト」、そしてフォーラムや動画プラットフォームなどの「UGC(User Generated Content / ユーザー生成コンテンツ)」だ。
分析の結果、すべてのAIエンジンがこれら3つを情報源として使っているが、そのバランスには大きな差があることが判明した。機関系サイトの引用率は低いエンジンで10%、高いエンジンで26%。UGCの引用率に至っては、わずか0.2%から18%まで開いている。
最も引用率が高いのは商業・編集系サイトで、AI Overviewsが51%、Geminiでも37%と、どのエンジンでも大きな割合を占める。BrightEdgeはこの結果を受け、「レビューサイト、比較コンテンツ、業界メディア、小売のリスティング、財務データがAIに最もよく参照される」とまとめている。企業はパブリックリレーションズ(PR)活動、業界メディアへの露出、カテゴリ比較コンテンツへの投資が、単独のエンジンだけでなく全てのAI検索エンジンでの可視性向上につながると考えるべきだ。
GeminiとAI Overviewsで異なる「信頼のベクトル」
同じGoogleが提供するAIサービスでも、GeminiとAI Overviewsの間には明確な傾向の違いがある。Geminiは機関系サイトの引用率が26%と突出して高く、UGCは0.2%と極端に低い。つまり、権威ある公式情報を優先する「保守的なAI」といえる。.govドメインの引用率は13%、.orgは23%にのぼる。
一方、AI OverviewsはUGCの引用率が18%と5つのAIの中で最も高い。機関系サイトは10%と相対的に低く、コミュニティの声を積極的に拾う姿勢が見える。この違いは、AI Overviewsの基盤に「FastSearch」と呼ばれる速度優先の仕組みが使われている可能性を示唆するが、Googleから公式な説明はない。
実際の使用感を調べるため、Roger Montti氏が非公式な実験として、特定の電子部品(オペアンプ)の使用感を両方のAIに質問したところ、Geminiはメーカー公式サイトのみを引用したのに対し、AI Overviewsは公式情報に加えて複数のUGCを引用した。UGCには実際のユーザーによる測定データや比較情報が含まれており、質問の文脈によっては非常に有益だ。このことから、質問の種類やユーザーの目的によって、最適な情報源の組み合わせが変わるといえる。
ChatGPTとPerplexity、それぞれの選び方
ChatGPTは他のAIと比較して、引用ソースの多様性が最も高いというデータが出ている。上位10サイトが総引用に占める割合はわずか18.5%で、特定のサイトへの依存度が低い。対照的にPerplexityは26.7%、Geminiは26.3%と、ChatGPTの約1.5倍の集中度だ。
Perplexityは機関系サイトの引用率が22%と高く、.eduドメインも3.2%と他のAIより多く引用している。BrightEdgeのレポートによれば、Perplexityの引用の約30%は医療機関、政府、百科事典、医学出版社のサイトで占められている。つまり、Perplexityは「権威性」を重視するエンジンと位置づけられる。
興味深いのは、.eduドメイン(教育機関のサイト)の扱いだ。SEOコミュニティでは長らく「.eduサイトは権威性が高い」という信念があったが、今回の調査では、いずれのAIも.eduサイトをさほど引用していない。最も高いPerplexityですら3.2%に過ぎず、ユーザーがAIに尋ねる多くの質問において、.eduサイトは権威ある情報源として選ばれにくい現実が明らかになった。
同じGoogleでも異なるAI、3系統の使い分け
GoogleにはGemini、AI Overviews、AI Modeという3つのAI検索サービスが存在するが、これらは同じ会社のプロダクトでありながら、引用傾向は一様ではない。最もサイト重複率が高いAI OverviewsとAI Modeですら一致率は59%で、GeminiとなるとAI Overviewsとの重複率は34%、AI Modeとは27%まで下がる。
このデータから、「Google AIは単一のシステムではない」という現実が浮かび上がる。各サービスは異なるアルゴリズムやデータセットに基づいて情報を選択しており、同じ質問でも表示される情報源が大きく変わる可能性がある。ウェブサイト運営者にとっては、「Google対策」という単一の施策ではなく、どのAI検索面をターゲットにするかを明確にした戦略立案が求められる。
AIエンジンに選ばれるサイトになるための実践論点

今回の調査データを踏まえると、AI検索エンジンでの可視性を高めるための方針が見えてくる。すべてのエンジンに共通して効くのは、製品やサービスとブランドの結びつきを強化することだ。具体的には、業界メディアやレビューサイトでの記事露出、比較コンテンツへの掲載、プレスリリースの配信などが有効な手段になる。
一方で、AIごとの特性に合わせた対策も検討すべきだ。GeminiやPerplexityでの露出を狙うなら、公的機関や業界団体との協業、公式データの公開、学術的な裏付けの提示といった「権威性」の構築が重要になる。AI Overviewsを意識するなら、フォーラムやコミュニティでの自然な言及、ユーザーレビューの充実といったUGCの活性化も効果が見込める。
また、AI検索は信頼できるウェブサイトに掲載されたスポンサード記事(広告であることが明示された記事)も情報源として引用する。FTC(米国連邦取引委員会)のネイティブ広告ガイドラインや、Googleのスポンサード投稿ポリシーに準拠した形でブランドを訴求する手法も、引き続き検討に値する。
重要なのは、どのAIに最適化するかではなく、自社のブランドがどのカテゴリの情報として認識されるかを設計することだ。AIに「選ばれる」サイトになるには、単なるSEOテクニックではなく、実体のあるブランド価値の醸成と、それを多様なメディアに拡散させる情報戦略が欠かせない。
この記事のポイント
- AI検索エンジン5つのソース重複率は最低16%から最高59%で、引用傾向に大きな差がある
- ブランド名の重複率は最低36%と、製品・サービスに結びついたブランドは横断的に強い
- 商業・編集系サイトが最も多く引用され、PRや比較コンテンツの重要性が高まっている
- Geminiは権威性重視、AI OverviewsはUGC重視と、同じGoogle内でも戦略が異なる
- AI時代のSEOでは、個別のエンジン対策よりブランド価値の醸成と多面的な情報発信が鍵を握る
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AI検索でブランドが消える?「没個性税」を回避する最新SEO戦略
AIは検索の仕組みを変えるだけでなく、どのブランドを「無視するか」を決定する審判になりつつある。従来の検索エンジン最適化(SEO)が通用しなくなる中で、企業は自社の存在がAIによって消し去られるリスクに直面している。
Adobe Summitにおいて、SemrushのCMO(最高マーケティング責任者)であるAndrew Warden氏は、ブランドの可視性が根本から変化したと指摘した。AIシステムが情報をフィルタリングする過程で、特徴のないブランドは組織的に排除される可能性があるという。
本記事では、Warden氏が提唱する「Bland Tax(没個性税)」という概念を中心に、AI検索時代に生き残るためのブランド戦略を深掘りする。AIに選ばれ、ユーザーに届くための新しいルールを理解することが、これからのマーケティングの成否を分けるだろう。
AIが情報のゲートキーパーになるエージェント時代の到来

現在、検索行動のデータには明らかな変化が現れている。Google検索の約60%が、Webサイトへのクリックを伴わずに終了しているという。これは、ユーザーが検索結果画面でAIが生成した回答を読み、そのまま満足して離脱していることを意味する。
GoogleのAI Overviews(AIオーバービュー)やChatGPT、Perplexityといったツールは、もはや単なる検索ツールではない。これらは「新しいゲートキーパー」として機能し、ユーザーと情報の間に立って、どの情報を提示し、どのブランドを紹介するかを選別している。
検索行動の変化とクリックゼロの現実
ユーザーは以前のように複数のサイトを巡回して情報を比較検討する手間をかけなくなっている。対話型のインターフェース内で質問を重ね、解決策を絞り込んでいく「エージェント型」の利用が一般的になりつつある。この環境下では、AIの回答に含まれないブランドは、ユーザーの視界から完全に消滅してしまう。
LLMユーザーのコンバージョン率は4倍高い
一方で、クリック数が減ることは必ずしも悪いことばかりではない。Warden氏は、大規模言語モデル(LLM)を利用している消費者は、従来の検索のみを利用するユーザーに比べて、コンバージョン率が少なくとも4倍高いというデータを提示している。AIを通じて情報を探しているユーザーは、より具体的で強い購入意図を持っているため、AIに選ばれることの価値は極めて高い。
● サイトA ● サイトB ● サイトC
■ 選ばれたブランドのみが表示される
この図は、検索体験が「分散」から「集約」へと変化している様子を示している。AIが情報を統合するため、選ばれなかった情報は存在しないも同然となる。
没個性なブランドを襲うBland Tax(没個性税)の正体

Warden氏が提唱する最も重要な概念が「Bland Tax(没個性税)」だ。これは、特徴のない平凡なコンテンツを発信し続けるブランドが支払うことになる、目に見えないペナルティを指す。AIは現在、平凡な内容(Blandness)を無視するように学習を進めているという。
「平均的であること」や「ジェネリックであること」は、AI検索の世界では「透明であること」と同義だ。どこにでもあるような情報を発信しているブランドは、AIによって他の情報とひとまとめに要約され、ブランド名が引用されることすらなくなる。
平均的なコンテンツはAIに吸収される
AIは複数のソースから似たような情報を集め、1つの簡潔な回答を作成する。この際、独自の見解や新しい事実が含まれていないコンテンツは、AIの知識の一部として吸収されるだけで、出典として明記される価値がないと判断される。これが、ブランドアイデンティティが消去されるプロセスだ。
ブランド名が消え、AIの学習データにされるリスク
独自の価値を提供できないブランドのコンテンツは、AIを賢くするための「無料のトレーニング場」に成り下がってしまう。情報の提供元としての認知を得られないまま、コンテンツだけがAIの回答精度を高めるために消費される。これはマーケティング投資として極めて効率が悪い状態だといえる。
AIに選ばれるための発見可能性と権威性
AI検索時代において、ブランドの可視性は「発見可能性(Discoverability)」と「権威性(Authority)」の掛け合わせで決まる。Warden氏は、この両方が不可欠であると強調している。どちらか一方が欠けても、AIの回答に食い込むことはできない。
「発見可能性」とは、AIがそのブランドの情報を技術的に見つけられるかどうかを指す。そして「権威性」とは、AIがそのブランドを信頼し、回答に含める価値があると判断するかどうかを指す。この2つを高い次元で両立させることが、新時代のSEO戦略の核心だ。
基礎としてのSEOはAIの教本になる
SEOは死んだという極端な意見もあるが、Warden氏はこれを明確に否定している。むしろ、SEOはこれまで以上に基礎的な役割を担うようになっている。現在のSEOは人間に見せるためだけのものではなく、AIに対する「トレーニングマニュアル」としての側面が強まっているからだ。
以下の要素が欠けているブランドは、AIの会話から完全に排除されるリスクがある。
- クローラビリティ(AIが情報を収集できるか)
- インデクサビリティ(情報がデータベースに登録されるか)
- 構造化データ(情報の意味をAIが正しく理解できるか)
- 権威シグナル(信頼に足る情報源か)
エンティティ権威を確立するブランド需要
AIは「エンティティ(実体)」とその関係性を地図のようにマッピングして理解している。AIに特定のトピックの権威として認識されるためには、ブランドそのものに対する需要、つまり「指名検索」が重要になる。人々がそのブランドを探していなければ、AIもまたそのブランドを探そうとはしないからだ。
独自の価値を証明する3つの重要シグナル

Warden氏は、ブランドがAIにフィルタリングされず、優先的に表示されるために必要な3つの具体的なシグナルを挙げている。これらは、AIが「この情報は特別だ」と判断するための基準となるものだ。
単に記事を量産するのではなく、これらのシグナルを意識したコンテンツ制作が求められる。独自性(オリジナリティ)を担保することで、AIの回答における可視性は30%から40%向上する可能性があるという。
1. 情報の密度とオリジナリティ
AIは「新しい事実」を引用することを好む。既存の情報の焼き直しではなく、以下のような要素を含むコンテンツが評価される。
- 独自の調査データや統計
- 自社だけが持つ一次情報
- 専門家による独自の視点や分析
- 具体的な成功事例や失敗談
2. シグナルの整合性と合意
AIは自社サイトの情報だけでなく、ネット上のあらゆる場所にある「他者の声」を参照している。Redditでの議論、YouTubeのレビュー、SNSでの言及、メディアでの報道などが、ブランドの信頼性を裏付ける「合意シグナル」となる。これらの情報が矛盾している場合、AIはそのブランドを「信頼できない」とフラグ立てする恐れがある。
3. エンティティの関連付け
特定のキーワードだけでなく、トピック全体においてブランドがどのように位置づけられているかが問われる。関連するコミュニティでの会話に参加し、専門的なメディアで取り上げられることで、AIの知識グラフ内でのブランドの結びつきを強化できる。
これらの要素が組み合わさることで、AIは「このブランドは引用する価値がある」と確信する。単一の施策ではなく、多角的なシグナルの構築が必要だ。
組織全体で取り組む可視性の再定義

AI検索への対応を難しくしている要因の1つは、組織の断絶にあるとWarden氏は指摘している。多くの企業では、SEOチーム、広報(PR)チーム、ブランドチーム、広告チームが個別に動いており、情報の整合性が取れていないケースが多い。
しかし、AIはこれらすべてのチャネルからデータを吸い上げている。SEOチームがどれほど最適化しても、PRチームが発信するメッセージが異なっていたり、SNSでの評判が悪かったりすれば、AIはそのブランドを高く評価しない。可視性はもはや特定のチームの問題ではなく、組織全体で取り組むべき課題だ。
トラフィックから関連性への評価軸シフト
従来の評価指標も通用しなくなっている。検索順位は安定しているのにトラフィックが減る、という現象が多くのサイトで起きている。これはAIが回答を肩代わりしているためだ。一方で、リード(見込み客)の質や数は向上している場合もある。
マーケターは「何回のクリックを得たか」という指標から、「AIの回答においてどれほど関連性の高い存在として扱われているか」という指標へと視点を移す必要がある。トラフィックはもはや、ブランドの成功を測る唯一の代理指標ではなくなっている。
アルゴリズムはもはや味方ではない
かつてのSEOは、Googleのアルゴリズムを理解し、それに合わせることで「順位」を競うゲームだった。しかし、今のAIは「何が有意義か」を判断する究極の裁定者となっている。アルゴリズムを攻略するハック(手法)よりも、リアルな世界での信頼と独自の価値を積み上げることこそが、最大の防御であり攻撃となる。
この記事のポイント
- AIは平凡なコンテンツを無視する「没個性税(Bland Tax)」を課し始めている
- AI検索時代はトラフィックが減る一方で、コンバージョン率が4倍高まる可能性がある
- SEOはAIにブランドの情報を教えるための「トレーニングマニュアル」として機能する
- 独自の調査データ、外部評価の整合性、専門的な権威性がAIに選ばれる鍵となる
- 可視性の向上には、SEO・PR・ブランドの各チームが連携した一貫した戦略が不可欠だ
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AI時代のSEOで検索エンジンが信頼する3要素——権威性・鮮度・独自性の新基準
検索エンジンの評価基準が根本から変わった。従来のSEO対策だけでは通用しない時代が来ている。
Search Engine Journalの記事によると、AI駆動の検索システムは権威性・鮮度・独自性の3要素を重視する。これらの要素が連動して、コンテンツが検索結果に表示されるか、AI生成回答に引用されるかを決める。
この変化を理解しないと、どんなにキーワードを最適化しても、どんなにバックリンクを増やしても、成果は上がらない。AIが信頼するコンテンツを作るための新たな基準を解説する。
検索エンジンの評価システムが変わった

かつての検索エンジンは定期的なアルゴリズム更新で評価基準を調整していた。コアアップデートが発表され、順位が変動し、業界がパターンを分析して対策を練る。このサイクルは予測可能だった。
しかし今は違う。AI駆動の検索システムは常に学習し、評価基準を微調整している。Search Engine Journalの記事では、この状態を「連続的な調整」と表現する。アルゴリズムの更新のように見える現象の多くは、実際にはAIモデルの継続的な最適化の結果だ。
従来の「ランキング」から「評価」への移行
従来のSEOはページ単位のランキングを競うものだった。バックリンクや関連性、技術的な最適化が評価基準となり、ページ全体が1つの単位として扱われた。
AI駆動の検索では、ページ全体のランキングに加えて「情報の抽出と合成」という第2の層が加わった。検索エンジンは複数のソースから情報を抜き出し、再構成して回答を生成する。この変化により、競争の単位がページ全体から「情報の断片」へと移行している。
具体的には、コンテンツ内の各セクション、各段落、各リストがAI生成回答に引用される候補となる。ページが検索結果に表示されるかどうかだけでなく、ページ内のどの部分がAIによって利用されるかが重要になった。
信頼の評価が「継続的」になった
信頼性の評価も変化した。かつての信頼性は、権威性のシグナル、コンテンツ品質、技術的な健全性を組み合わせた「スコア」のようなものだった。一度高い評価を得れば、しばらくは維持できた。
現在の信頼性評価は「確率」のように振る舞う。継続的に評価され、再計算され、新しいデータに基づいて強化される。一度得た信頼を保持するのではなく、繰り返し獲得し続ける必要がある。
AIが信頼する3つの要素
AI駆動の検索システムが信頼性を判断する際、特に重視する要素が3つある。権威性、鮮度、独自性のシグナルだ。それぞれが異なる役割を果たし、コンテンツが検索結果に表示されるか、AI回答に引用されるかを決める。
権威性——評価の入り口
権威性は常に重要だったが、その役割が変化した。AI駆動のシステムでは、権威性は「フィルター」として機能する。コンテンツが評価の対象になるかどうかを最初に決める要素だ。
すべての情報源が平等に扱われるわけではない。検索エンジンは認識しているエンティティ(ブランド、著者、ドメイン)を優先する。これらのエンティティは、ウェブ全体で一貫した専門性と可視性を示している必要がある。
バックリンクの数だけが権威性の指標ではなくなった。エンティティレベルの権威性を証明するには、以下の要素が重要になる。
- 他の権威あるサイトでの言及
- 一貫した著者性とトピックへの集中
- 特定の分野でのブランド認知
- 構造化された知識システムへの組み込み
Search Engine Journalの記事では、これらのシグナルが「エンティティ重力」を作り出すと説明する。存在感が強ければ強いほど、コンテンツが情報抽出の候補セットに含まれやすくなる。
重要なのは、権威性が可視性を保証するわけではないことだ。権威性は「資格」を保証する。権威性がなければ、コンテンツがよく書かれ、よく構成され、技術的に健全であっても、無視される可能性がある。
鮮度——継続的な関連性の証明
鮮度の概念も進化した。あるいは「分化した」と言う方が正確かもしれない。
かつては、すべての種類のコンテンツが鮮度の恩恵を受けた。新しいコンテンツは、特に時間に敏感なクエリに対して一時的なブーストを得られた。
現在、この従来型の鮮度はニュースメディアのような時間に敏感な発信者にしか利益をもたらさない。それ以外の発信者にとって、鮮度は「いつ公開されたか」ではなく「維持されているか」が重要になる。
AI駆動のシステムは、継続的な関連性を示す情報源を優先する。具体的には以下の要素だ。
- 定期的に更新されるコンテンツ
- 明確なタイムスタンプと改訂履歴
- 時間の経過とともに重要なトピックが強化されていること
- 現在の情報と文脈との整合性
古くなったコンテンツはリスクを生む。情報がまだ正確かどうかをシステムが判断できない場合、合成された回答に含まれる可能性が低くなる。
鮮度は、この意味で信頼強化のループになる。コンテンツを更新することは、継続的な専門性を示すシグナルだ。不確実性を減らし、含まれる可能性を高める。
独自性——確かな情報源の証明
3つ目の大きな変化は、独自性のシグナルの重要性が劇的に高まったことだ。AIシステムは情報を合成するように設計されているが、依然としてソース素材に依存している。その素材の品質は、出力の品質に直接影響する。
その結果、システムはリサイクルされた要約ではなく、オリジナルで検証可能な入力を表すコンテンツを重視する。独自性のシグナルには以下が含まれる。
- 独自の調査とデータ
- 独自の洞察と分析
- 直接的な製品やサービス情報
- 直接的な経験と専門知識
これらのシグナルは曖昧さを減らす。明確な情報源を提供し、帰属が容易で、複製が難しい。
これが「大量コンテンツ」モデルが近年苦戦している理由の1つだ。派生コンテンツの大量生産は、新しい情報をほとんど提供しない。価値を増やすことなくノイズを増やすだけだ。
AIシステムはより多くのコンテンツを探しているのではなく、より良い入力を探している。コンテンツが何か独自のものを追加しない限り、選択される可能性は低い。
見落とされがちな第4の要素——使いやすさ

権威性が評価の対象にし、鮮度が関連性を保ち、独自性が信頼性を確立する。しかし、コンテンツが利用できなければ、これらの要素はすべて無意味になる。ここで多くのサイトが失敗している。
ページがよくランキングしていても、AI生成回答に存在しないことがある。その場合、問題はランキングではなく「抽出のしやすさ」にあることがほとんどだ。
AIシステムは人間のようにページを読まない。探索的にナビゲートし、解釈し、合成することはない。抽出しやすいものを取得し、次に進む。
この環境でうまく機能するコンテンツには、いくつかの特徴がある。
- 明確で説明的な見出し
- 論理的な階層構造(H1、H2、H3)
- 段落ごとに1つの主要なアイデア
- 直接的で断定的な表現
- 適切な箇条書きと表
- 重要なポイントは早い段階で紹介(埋もれさせない)
これは文章スタイルの問題ではない。摩擦を減らす問題だ。
システムが回答を分離するためにコンテンツを再解釈する必要がある場合、利用される可能性は低くなる。文やリストを直接引き抜ける場合、含まれる可能性は高くなる。この意味で、構造は見た目の問題ではなく、機能的な問題だ。
- キーワード調査
- メタタグ最適化
- コンテンツ作成
- バックリンク構築
このデモは、同じ内容でも構造化の違いでAIによる抽出のしやすさが変わることを示している。左側は情報が段落内に埋もれており、AIが特定の情報を抽出するには文章全体を解析する必要がある。右側は見出しと箇条書きで明確に構造化されており、AIが「SEOの主要手法」という見出しの下のリストを直接取得できる。
「良いSEO」だけでは不十分な理由

多くのチームが直面しているのは、以下のようなパターンだ。検索順位は良好で、トラフィックも安定しているが、AI生成回答には存在しない。
最初の直感はランキングの問題を探すことだ。それで問題が解決しないと、キーワードの再最適化、より多くのバックリンク構築、より多くのコンテンツ公開に移行する。これらは真の問題に対処しない解決策だ。
ランキングは検索結果に表示されるかどうかを決める。情報抽出は回答に利用されるかどうかを決める。これらは同じシステムではない。ページが従来のSEO指標でうまく機能していても、AIシステムにとってきれいで抽出可能なセグメントを提供できないことがある。
その場合、より明確な構造やより強い権威性を持つ競合他社が、たとえ順位が低くても引用される可能性が高くなる。これは矛盾ではなく、評価の変化だ。
この比較図は、評価基準の変化を視覚化している。左側の従来型SEOでは、バックリンクやキーワードなどの要素が検索結果での表示位置(ランキング)につながる。右側のAI時代の評価では、権威性や鮮度などの要素が、検索結果での表示に加えてAI生成回答への引用有無にも影響する。評価基準が追加され、複雑化した。
実践的な対策——4つのアクションプラン

これらの変化に対する実践的な対策は明確だ。実行は簡単ではないが、方向性ははっきりしている。
1. アップデートを孤立したイベントとして扱うのをやめる
アルゴリズムのアップデートは、連続的なシステムの出力に過ぎない。短期的な変動に対応するよりも、長期的な方向性に向けて最適化する方が効果的だ。
Search Engine Journalの記事では、信号の半減期が短くなったと指摘する。6ヶ月前に有効だった手法が今も重要かもしれないが、定期的ではなく継続的に再評価されている。
2. エンティティレベルでの権威性への投資
自社サイトを超えた認知を構築する。どこで、どのように言及されるかは、何を公開するかと同じくらい重要だ。
PR、パートナーシップ、思想のリーダーシップ、ブランドの存在感などのエンティティ構築努力は、SEOから切り離せなくなった。これらはランキングだけでなく、情報抽出の候補に含まれるかどうかにも影響する。
3. コンテンツの継続的なメンテナンス
鮮度は一度きりのシグナルではない。関連性の継続的な実証だ。重要なコンテンツを維持する。すべてを常に書き直す必要はないが、重要な情報が最新であることを確認する。
4. 独自性のある価値を優先する
独自の洞察、データ、専門知識は、派生コンテンツよりも耐久性がある。AIシステムはより多くのコンテンツを求めているのではなく、より良い入力を求めている。
5. 使いやすさのために構造化する
コンテンツを読みやすくするだけでなく、抽出しやすくする。明確な見出し、論理的な階層、直接的な表現を採用する。AIが情報を簡単に引き抜けるように設計する。
この記事のポイント
- AI駆動の検索システムは権威性・鮮度・独自性の3要素を重視する
- 権威性は評価の「入り口」であり、これがないとコンテンツは考慮されない
- 鮮度は「いつ公開されたか」ではなく「維持されているか」が重要になった
- 独自性のある情報(調査・データ・洞察)がAIに高く評価される
- コンテンツ構造は「見た目」ではなく「抽出のしやすさ」のために重要
- 従来のSEO対策だけではAI生成回答への引用は獲得できない
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

B2B購買の主戦場はAIチャットボットへ。ショートリスト入りを勝ち取るための新戦略
B2Bビジネスにおける顧客の購買行動が、今まさに劇的な転換点を迎えている。これまではGoogleなどの検索エンジンで情報を探し、複数のウェブサイトを比較検討するのが一般的だった。しかし、最新の調査によれば、多くの購買者がそのプロセスをAIチャットボットに委ね始めていることが明らかになった。
米G2が発表した最新レポートによると、B2Bソフトウェアの購買層のうち71%が、調査の過程でAIチャットボットを利用している。さらに驚くべきことに、51%の購買者が「Googleよりも先にAIチャットボットで調査を開始する」と回答している。これは、従来のSEO(検索エンジン最適化)戦略だけでは、もはや顧客の視界に入ることすら難しくなっていることを示唆している。
本記事では、AIが購買決定の「門番」となる新たな市場環境において、企業がどのように視認性を確保すべきかを解説する。クリックを奪い合う時代から、AIに選ばれる「回答」を勝ち取る時代へのシフト。その具体的な対策と、B2Bマーケティングの未来像を深掘りしていく。
AIチャットボットがB2B購買の「門番」になる日

かつてB2Bの購買担当者は、検索結果の1ページ目に表示される企業を一つずつクリックし、資料をダウンロードして比較表を作成していた。しかし、この「手作業」によるリサーチは、AIの登場によって過去のものになりつつある。AIチャットボットは膨大な情報を瞬時に要約し、ユーザーに最適な推奨リストを提示してくれるからだ。
検索の起点がGoogleからAIへシフト
G2のレポート「The Answer Economy(回答経済)」によれば、AIチャットボットは今や、購買候補のリスト(ショートリスト)に影響を与える最大の情報源となっている。その影響度は54%に達し、ソフトウェアレビューサイト(43%)やベンダーの自社サイト(36%)を大きく上回っている。
これは、購買者が自社サイトを訪れる「前」に、すでにAIによって選別が行われていることを意味する。AIに推奨されなければ、どれほど優れた製品を持ち、美しいウェブサイトを運営していても、検討の土台にすら乗ることができない。視認性の定義が「検索順位」から「AIの回答に含まれること」へと根本的に変わったのだ。
「回答経済」がもたらす情報の要約と効率化
なぜこれほど急速にAIへの移行が進んでいるのか。その理由は圧倒的な「生産性」にある。調査によれば、53%の購買者が「従来の検索よりもAI検索の方がリサーチの生産性が高い」と感じている。7ヶ月前の調査ではこの数値は36%だったため、短期間でAIの有用性が広く認知されたことがわかる。
AIは単にリンクを表示するのではなく、複数のベンダーの強みと弱みを比較し、特定のニーズに合致するかどうかを数秒で判断してくれる。この「情報の統合(シンセシス)」こそが、多忙なB2B購買担当者がAIを支持する最大の理由だ。もはやユーザーは「どこを見ればいいか」を求めているのではなく、「どれが正解か」を求めているのである。
購買プロセスを激変させる「AIショートリスト」の正体
B2Bマーケティングにおいて「ショートリスト」とは、最終的な選定候補として残った数社のリストを指す。従来、このリストに残るためには、数週間にわたるリサーチと営業担当者との接触が必要だった。しかし今、このプロセスが「ワンショット」で完了しようとしている。
ウェブサイト訪問前に勝負が決まる現実
AIチャットボットを利用するユーザーの多くは、一つのプロンプト(指示文)で推奨ベンダーのリストを出力させる。この時点で、AIが把握していない企業や、AIにとって特徴が不明確な企業は排除される。マーケターがアクセス解析で「直帰率」や「滞在時間」を気にする前に、すでに勝負はついているのだ。
G2の調査では、85%の購買者が「AIに引用されたベンダーに対して、より高い評価を抱く」と回答している。AIによる推奨は、単なる情報の提示ではなく、強力な「お墨付き」として機能している。逆に言えば、AIの回答から漏れることは、信頼性の欠如とみなされるリスクすら孕んでいる。
比較検討の自動化と「ワンショット」の意思決定
購買行動の変化を視覚的に理解するために、従来の検索とAI検索のフローを比較してみよう。従来のフローが「拡散(多くのサイトを見る)」から「収束(絞り込む)」という長いプロセスを辿るのに対し、AI検索は最初から「収束した回答」を提示する。
↓ 10件以上のサイトを訪問
2. 情報収集・手動比較
↓ 数日かけてスプレッドシート作成
3. ショートリスト作成
「〇〇の課題を解決する最適なツールを3つ挙げて」
↓ 数秒で回答生成
2. AIによる推奨リスト(即時ショートリスト化)
↓ 特定のサイトのみ確認
3. 問い合わせ・選定
このフローの変化により、ベンダー側は「自社サイトへ誘導した後の説得」に注力するだけでなく、「AIが回答を生成するための材料」をいかにネット上に配置するかに戦略をシフトさせる必要がある。
マーケターが直面する「クリック」から「回答」への転換
これまでのSEOは、特定のキーワードで上位に表示させ、ユーザーにクリックしてもらうことがゴールだった。しかし、AI時代の新たな最適化指標は「回答の占有率」や「推奨の正確性」へと移り変わる。これをAEO(Answer Engine Optimization / 回答エンジン最適化)と呼ぶ動きもある。
順位よりも「正しく理解されること」の重要性
AIはウェブ上のあらゆる情報を学習し、それらを組み合わせて回答を作る。ここで重要なのは、AIがあなたの製品を「正しくカテゴリー分け」し、「独自の強みを把握」しているかどうかだ。もしAIがあなたの製品を誤解していれば、的外れな比較結果を提示されたり、そもそも推奨から外されたりする。
G2の調査では、69%の購買者が「AIの回答によって、当初予想していたのとは別のベンダーを選んだ」と回答している。これは、AIによる情報提示が購買者の先入観を覆すほどの影響力を持っていることを示している。マーケターは、AIが自社製品をどのように記述しているかを定期的にチェックし、誤った認識があればそれを正すための情報発信を行わなければならない。
第三者評価とレビューがAIの推奨を左右する
AIは自社サイトの主張よりも、第三者による客観的な情報を重視する傾向がある。特に、G2のようなレビューサイト、SNSでの評判、専門メディアの記事などは、AIにとって信頼性の高い「学習データ」となる。
AIに選ばれるためには、自社サイトのコンテンツ制作と同じくらい、外部プラットフォームでの存在感を高めることが不可欠だ。良質なレビューを蓄積し、業界の標準的なカテゴリーにおいて明確な評価を確立することが、AIのショートリストに残るための最短ルートとなる。
EC・B2Bサイト運営者が今すぐ取り組むべきAI最適化戦略

では、具体的にどのような対策を講じるべきか。特にWooCommerceなどを利用してB2B向けのECサイトを運営している場合、製品データの構造化と情報の透明性が鍵を握る。
構造化データと明確なカテゴリー定義の徹底
AI(クローラー)がサイトの内容を理解する手助けをするのが、Schema.orgなどの構造化データだ。単にテキストで「高性能なサーバーです」と書くのではなく、価格、スペック、在庫状況、ユーザー評価などを機械可読な形式で提供することが重要だ。
AIは曖昧な表現を嫌う。例えば「多機能なERP」という表現よりも、「中小規模の製造業に特化した、在庫管理と原価計算に強みを持つERP」というように、ターゲットと提供価値を具体的に記述することで、AIは適切なクエリに対してあなたの製品をマッチングしやすくなる。
独自性と信頼性を担保するコンテンツ設計
AIは「一般的で平均的な情報」をまとめるのは得意だが、独自の洞察や最新の事例については、元の情報源に頼らざるを得ない。自社サイトでしか得られない一次情報(独自の調査レポート、詳細な導入事例、技術的な解説など)を公開し続けることは、AI時代においても強力な武器となる。
以下のデモは、AIがウェブサイトから情報を抽出する際、どのような「構造」を読み取っているかを視覚化したものだ。人間が見るデザインの裏側で、いかにデータが整理されているかがAIの理解度を左右する。
“category”: “在庫管理システム”,
“target_industry”: “製造業”,
“price_model”: “サブスクリプション”,
“unique_selling_point”: “リアルタイム原価計算”
※このデモは、AIがウェブページの情報をどのようにデータとして整理し、推奨の判断材料にしているかの概念を視覚化したイメージである。
独自の分析:AI時代のB2Bブランディングとは

AIが購買のショートリストを作る時代において、皮肉にも最も重要になるのは「人間味のあるブランド」だ。AIは論理的で客観的な比較は得意だが、企業のビジョンや信頼感、文化といった「数値化しにくい価値」を完全に代替することはできない。
AIによって提示された3社のうち、最終的にどこを選ぶか。その段階では、やはり直接ウェブサイトを訪れ、事例を読み、担当者の熱量を感じ取ることになる。つまり、AI対策(AEO)は「検討の土台に乗るため」の手段であり、最終的な「成約」を勝ち取るのは、依然としてブランドの物語や顧客体験(CX)であるという点に留意すべきだ。
また、AIは「世の中の平均的な評価」を反映しやすいため、ニッチな分野で圧倒的なNo.1を目指す戦略がこれまで以上に有効になる。広く浅い情報発信ではなく、特定の課題に対して「この問題ならこの会社」とAIに断言させるほどの専門性を磨くことが、これからのB2B生き残り戦略となるだろう。
この記事のポイント
- B2B購買層の51%がGoogleより先にAIチャットボットでリサーチを開始している
- AIはショートリスト(購入候補)作成において、ベンダー公式サイト以上の影響力を持つ
- 視認性の定義が「検索順位」から「AIの回答に引用されること」へと変化した
- AIに選ばれるためには、構造化データ、第三者レビュー、明確な独自性が不可欠である
- AIは効率的な絞り込みを行うが、最終的な選定にはブランドへの信頼感が決定打となる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験