

AI検索の利用率は年収で決まる?EC担当者が知るべき検索行動の二極化と対策
AI検索の普及は、すべてのユーザーに平等に進んでいるわけではない。最新の調査データによると、生成AIツールの利用率は世帯年収によって明確な差が生じている。高所得層ほどAIを使いこなし、情報の探し方が根本から変化している実態が明らかになった。
英国のマーケティングメディアであるMarTechが報じたデータでは、世帯年収が10万ポンド(約2,000万円)を超える層の約半数がAIを常用している。一方で、年収が3万ポンド以下の層ではその割合が2割を下回る。この所得による「検索の二極化」は、EC事業者にとって見過ごせない課題だ。
顧客がどのツールで情報を探し、どのように意思決定を行うのか。その前提条件が所得層によって分断されつつある。本記事では、AI検索の普及がもたらす新たなデジタル格差と、断片化する顧客行動に対応するための戦略を詳しく解説する。
AI検索の普及に潜む年収格差の実態

AI検索はすでに一般的になったという論調が多いが、現実はそれほど単純ではない。MarTechの記事で紹介されているBecky Simms氏の分析によれば、生成AIの採用ペースは世帯年収に強く依存している。これは、単なる技術への関心の差ではなく、社会的な構造が背景にある。
高所得世帯ほど生成AIを日常的に活用している
具体的な数字を見ると、その差は歴然としている。世帯年収が2万5,000〜3万ポンドの層では、ChatGPTなどのAIツールを定期的に利用している割合は約18%にとどまる。しかし、年収が7万ポンドを超えると、その利用率は一気に49%まで跳ね上がる。
年収10万ポンド以上の層に至っては、48%から58%という高い水準でAIを利用している。つまり、高所得層は低所得層の2倍から3倍近い頻度でAIを検索や業務に活用していることになる。この格差を視覚化すると、以下のようになる。
このデモが示す通り、年収の上昇に伴ってAI利用率が加速度的に高まっている。高単価な商品やサービスを扱うブランドにとって、ターゲットとなる層がすでに「AIファースト」な行動をとっている可能性が高いことを示唆している。
デジタルスキルの差が情報のアクセシビリティを左右する
この格差は、単なるツールの所有状況だけではなく、基礎的なデジタルスキルの差とも連動している。非営利団体のFutureDotNowのデータによれば、英国の労働年齢層の約52%が、仕事に必要な基本的なデジタルタスクを完遂できない状態にあるという。
AIの利用は、既存のデジタルスキル格差の上にさらに積み重なる新たな層となっている。情報の検索、評価、そして行動。これらのプロセスをAIで効率化できる層と、従来通りの方法でしか情報を得られない層の間で、情報の非対称性が広がっているのだ。
作家のウィリアム・ギブソンは「未来はすでにここにある。ただ、均等に分配されていないだけだ」という言葉を残している。まさに現在のAI検索の状況は、この言葉を体現しているといえるだろう。
なぜAI利用に格差が生まれるのか(3つの要因)

AIの採用が所得によって分かれるのは、単に「有料プランを契約できるかどうか」という金銭的な理由だけではない。Simms氏の分析によれば、人間の行動に根ざした3つの要素が大きく関わっている。それは「アクセス」「能力」「信頼」だ。
職場環境によるアクセスの差
第一の要因は、日常生活や業務の中でAIに触れる機会、すなわち「アクセス」の差だ。ITやビジネス、知識集約型の職種に従事している人々は、ワークフローの一部としてAIの使用を推奨される、あるいは期待される場面が多い。
こうした環境に身を置く人々は、自然とAIを使いこなすようになる。一方で、物理的な労働が中心の職種や、デジタル化が遅れている現場では、AIに触れる機会はニュースなどの二次的な情報に限られる。この初期段階での露出の差が、後の大きな習熟度の差へとつながる。
プロンプトを操る能力とAIへの信頼
第二の要因は、AIを使いこなす「能力」だ。AIとの対話には、適切な指示を出す「プロンプト(命令文)」のスキルが求められる。日常的にAIを使う層は、回答を洗練させ、間違いを修正し、出力を組み立てる方法を経験から学んでいく。
第三の要因は、AIに対する「信頼」だ。AIが生成する情報の正確性をどう評価し、どの程度頼ってもよいと判断するか。Perplexityのような信頼性を重視するプラットフォームの台頭はあるものの、AIを使い慣れていない層にとっては、未知のツールに対する心理的な障壁や不信感が拭えない場合も多い。
これらの要素が組み合わさることで、デジタルに自信のある層がさらにAIで優位性を高めるという、新たなデジタルデバイド(情報格差)が形成されている。ECサイトの運営者は、自社の顧客がどの程度のAIリテラシーを持っているかを慎重に見極める必要がある。
断片化するユーザーの検索行動パターン

検索行動はもはや一様ではない。かつては「何かを知りたければGoogleで検索する」という単一の道筋があったが、現在はユーザーの属性や目的によって、複数のルートに断片化している。これを理解せずに戦略を立てることは、ターゲットの一部を完全に見落とすリスクを伴う。
AIファースト層からAI回避層までの3つの分類
現代のユーザーは、AIへの関与度によって大きく3つのタイプに分類できる。それぞれの層で、情報の受け取り方や期待するコンテンツの形式が異なっている。
- AIファースト層:タスクの代行、情報の要約、選択肢の絞り込みをAIに委ねる。サイトを訪問する前にAIの回答で完結することを好む。
- AIアシスト層:AIで概要を把握しつつ、従来の検索エンジンやSNSで情報の正しさを検証する。複数のプラットフォームを跨いで行動する。
- AI回避層:従来通りのGoogle検索、小売サイト内の検索、あるいはコミュニティ(Redditや掲示板など)を信頼し、AIツールの利用を避ける。
重要なのは、同じユーザーであっても、タスクの内容によってこれらの行動を使い分ける点だ。例えば、法律文書の草案作成にはAIを使い、商品の口コミを調べる際にはGoogleやSNSを使う、といった具合だ。
同じユーザーでも目的によってツールを使い分ける
検索の断片化は、カスタマージャーニーをより複雑にしている。以前のように「検索キーワード」だけでユーザーの意図を把握することは難しくなっている。AIが情報の「要約」と「簡略化」を担う一方で、SNS(TikTokやInstagram)は「人間味のある文脈」や「視覚的な納得感」を提供する場となっている。
以下のデモは、従来の検索と、現代の断片化された検索プロセスの違いを視覚化したものだ。
この変化により、ECブランドは「サイトに来てから説得する」のではなく、「AIやSNSの段階で選ばれている」状態を作らなければならなくなっている。クリックされる前の段階で、いかにブランドを認知させ、信頼を獲得するかが勝負の分かれ目だ。
EC・マーケティング戦略への影響と具体的な対策

高所得層がAIを使い、意思決定をAIに委ね始めているという事実は、ECのマーケティング戦略を根本から変える。ターゲットがAIファーストであるならば、従来のSEO(検索エンジン最適化)だけでなく、GEO(生成エンジン最適化)への対応が急務となる。
属性ではなく行動でターゲットを分析する
年齢や年収といったデモグラフィック(属性)データは、誰がターゲットかを教えてくれるが、彼らが「どう決めるか」までは教えてくれない。これからは、ユーザーがどのプラットフォームで、どのタイミングでAIを使うのかという「行動」に基づいたセグメンテーションが必要だ。
AIを使いこなす「高自信ユーザー」は、AIに選択肢を絞り込ませることを好む。一方、AIに不慣れな「低自信ユーザー」は、馴染みのある環境や人間の声を求める。ブランドは、この両方のジャーニー(顧客体験)を設計しなければならない。
AIに推奨されるための情報の構造化と信頼性向上
AIに自社ブランドを正しく理解させ、推薦してもらうためには、情報の「明快さ」が不可欠だ。複雑で曖昧な表現は、AIによる解釈ミスを招き、結果として検索結果から除外される原因となる。具体的で構造化されたデータを提供することが、AI時代のSEOの基本となる。
また、AIは効率化には優れているが、最終的な「安心感」を与えるのは依然として人間による証明だ。レビュー、権威ある第三者の評価、ブランドの歴史といった「信頼のシグナル」を強化することで、AIが提示した候補の中から「最後に選ばれるブランド」になることができる。
効率性が重視されるAI検索の世界であっても、最終的な決断を下すのは人間だ。技術の進化に目を向けつつも、その背後にある人間の心理や行動の変化を深く理解することが、これからのEC運営には求められている。
この記事のポイント
- AI検索の利用率は世帯年収に比例し、高所得層は低所得層の2倍以上活用している
- AI採用の差は、職場でのアクセス、プロンプト能力、ツールへの信頼度の違いから生まれる
- 検索行動はAIファースト層、AIアシスト層、AI回避層へと断片化が進んでいる
- 高価値な顧客はサイト訪問前にAIで意思決定を終えている可能性が高いため、AIへの最適化が重要になる
- 技術への対応と同時に、レビューや権威性などの「人間による信頼の証明」が選ばれる鍵となる

・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Googleのタスク型エージェント検索がSEOを今すぐ変える理由と対策
Googleの検索が「タスクを完了する」エージェントへと急速に変化している。従来の「キーワードを入力してウェブサイトのリンクを得る」モデルは、AIが直接レストランの予約を取ったり、情報を収集したりする「タスク実行型」の検索に置き換わりつつある。この変化は未来の話ではなく、すでに現在進行形で起きている。
Search Engine Journalの記事によると、GoogleのCEOサンダー・ピチャイは近い将来、検索の多くが「エージェント型」になると述べている。ユーザーは情報を探すだけでなく、AIエージェントにタスクを管理させ、複数の作業を並行して実行させるようになる。このパラダイムシフトは、SEOとコンテンツ戦略の根本的な見直しを迫るものだ。
検索が「タスク完了」へと変わる瞬間
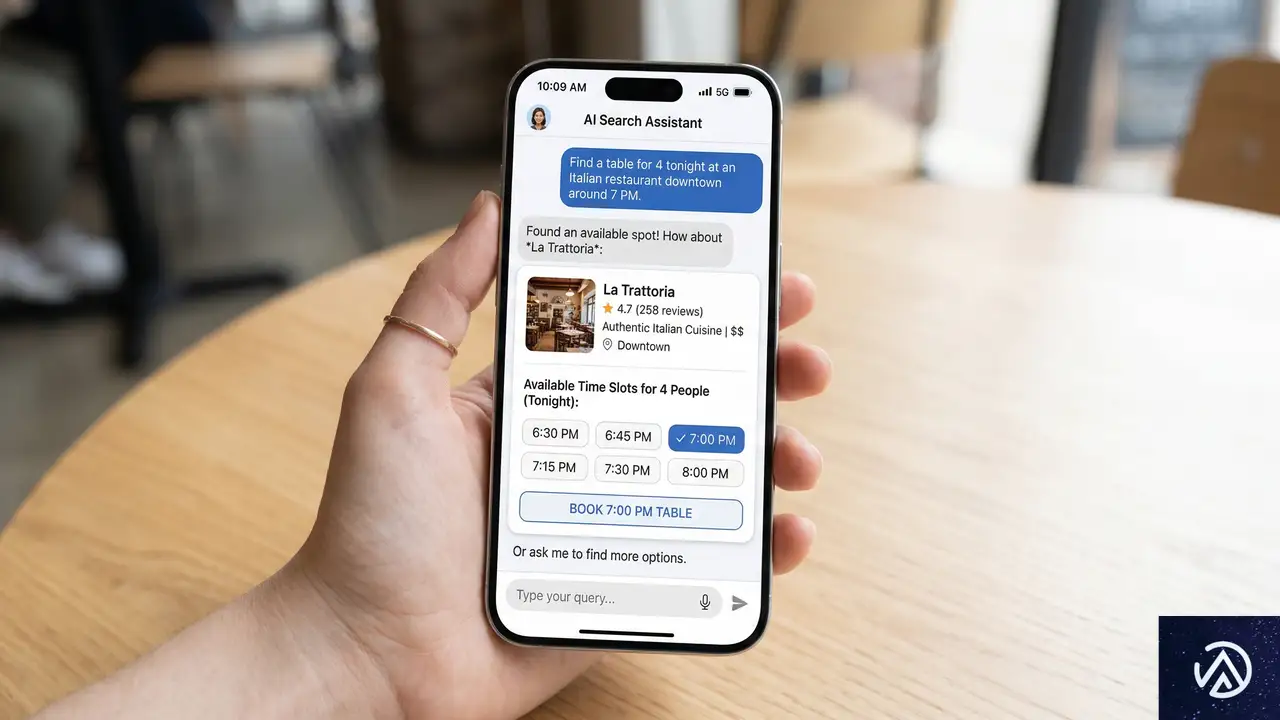
従来のインターネットと検索は、同じキーワードを入力した何百万人ものユーザーに、同じようにインデックスされたウェブページのリストを提供するモデルだった。しかしAIの登場により、ユーザーは単なる情報検索から「トピックの調査」や「タスクの実行」へと行動を移しつつある。リンクをクリックしてサイトを読むだけでは、ユーザーが求める明確な答えが得られないケースが増えている。
レストラン予約にみるエージェント検索の実例
この変化を象徴する具体例が、Googleが全世界で展開を開始した「エージェント型レストラン予約」機能だ。ユーザーは検索ボックスに「6人で土曜の夜、雰囲気の良いイタリアン」といった要望を自然言語で入力する。するとAIエージェントが複数の予約プラットフォームを同時にスキャンし、空き状況やメニューを確認した上で、実際に予約可能な店舗を提示する。
Googleの検索プロダクト責任者であるRose Yao氏は、この機能について「アプリを切り替える必要も、手間もない。ただ美味しい食事を」と説明している。これはもはや従来の「検索」ではなく、「タスクの完了」そのものだ。重要な点は、この機能が「近い将来実現するもの」ではなく、すでに利用可能であることだ。
サイト側に求められる対応
この新しい検索モデルでは、レストランなどの事業者側も対応が迫られる。AIエージェントが情報を取得できるように、空き予約枠やその日のメニュー選択肢などのデータを提供する必要がある。将来的には、AIエージェントと直接予約を完了できる仕組みがウェブサイトに求められるだろう。
これは単なる技術的なアップデートではなく、ビジネスプロセスの変革を意味する。検索マーケティングの専門家は、この変化がもたらす影響を真剣に考える時期に来ている。
「個人専用インターネット」時代の到来

タスク型エージェント検索がもたらすもっと深い変化は、インターネットそのものが「ハイパーパーソナライズ化」する点だ。クラウドフレアは最近の記事で、インターネットの進化を3つの段階に分けて説明している。
インターネット進化の3段階
クラウドフレアの比喩が分かりやすい。従来のアプリケーションは「レストラン」のようなものだ。決まったメニュー(機能)があり、それを大量に提供するために最適化された厨房(インフラ)がある。一方、AIエージェントは「個人専属シェフ」に例えられる。毎回「何が食べたい?」と聞き、その答えに応じて必要な食材や調理法が変わる。レストランの厨房では対応できない。
SEOへの具体的な影響
この変化がSEOに与える影響は計り知れない。ローカルSEO、ショッピング、情報検索のすべてが、ハイパーパーソナライズされたウェブ体験に再構築される。検索が「エージェントマネージャー」に変わるというピチャイの発言は、単なる未来予想ではなく、現在進行形の現実を指している。
デジタルマーケティング担当者が考えるべきは、数十億の人間を代表する数十億のエージェントを支えるインフラではなく、その中で自社のビジネスがどう位置づけられるかだ。エージェントがタスクを完了する過程で、どの情報源を信頼し、どのように意思決定するのか。この「意思決定レイヤー」に自社がどう登場するかが、新しいSEOの核心となる。
コンテンツ管理システムの対応:WordPress 7.0の役割
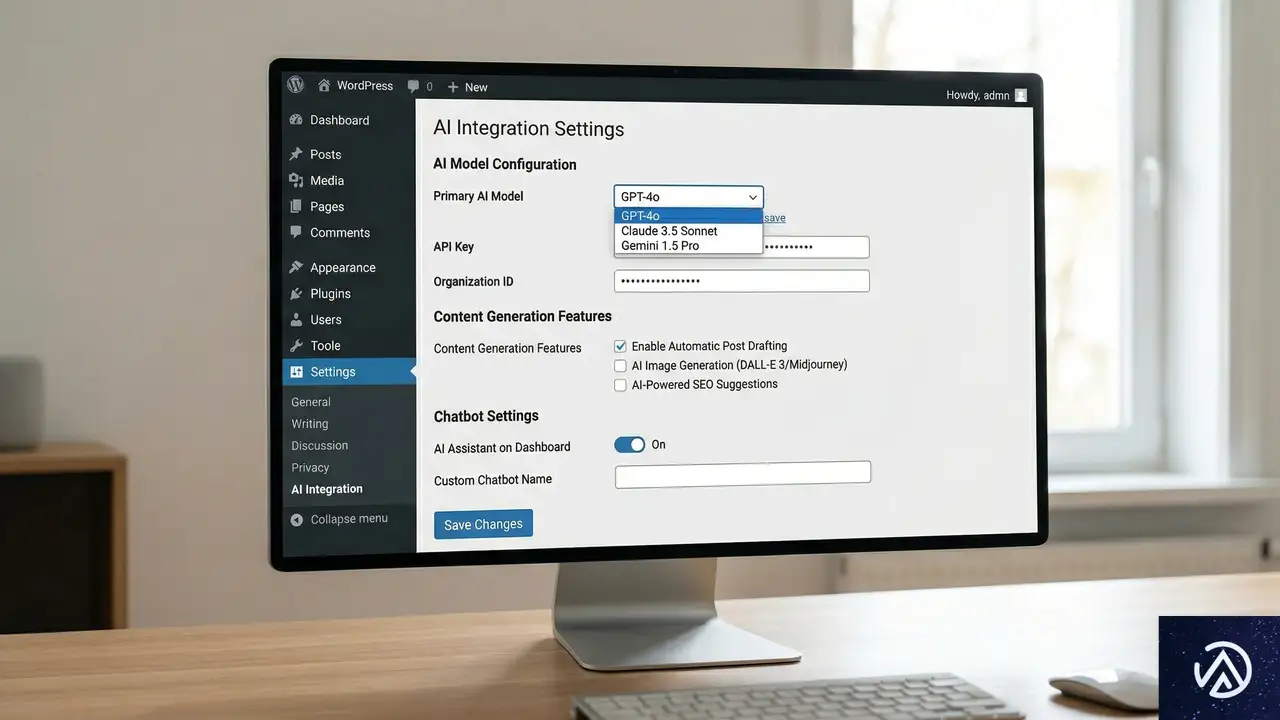
人間中心のウェブからエージェント中心のウェブへの移行に際し、コンテンツ管理システム(CMS)の対応は極めて重要だ。特に間もなくリリース予定のWordPress 7.0は、この変化に対応するための機能が多数盛り込まれている。
AIシステムとの接続機能
現在のインターネットは人間の相互作用のために構築されている。AIエージェントはその構造の中で動作しているが、これは急速に変化する見込みだ。WordPress 7.0が重視しているのは、AIシステムとシームレスに接続する機能だ。これにより、ウェブサイトが人間だけでなく、AIエージェントにも適切に情報を提供できる基盤が整う。
具体的には、構造化データの強化、APIファーストなアーキテクチャ、エージェントが理解しやすいコンテンツ形式などが挙げられる。これらの機能は、従来の人間ユーザー向け最適化に加えて、AIエージェント向けの最適化を可能にする。
エージェントが「信頼する」情報源になるために
検索マーケティングの専門家Mike Stewart氏は、この変化について重要な指摘をしている。彼はFacebookへの投稿で、「これはもはやAIが支援する段階ではなく、AIがあなたに代わって操作する段階だ」と述べた上で、以下の問いを提示している。
Stewart氏はさらに、「エージェント型検索は、それを支えるエコシステム(ウェブサイト、コンテンツ、ビジネス)なしには成立しない。その部分はなくならないが、抽象化される」と付け加えている。つまり、ウェブサイトやコンテンツの重要性は変わらないが、人間が直接アクセスする形ではなく、AIエージェントを通じて間接的に利用される形に変化するということだ。
タスク型エージェント検索への具体的な対策

理論的な理解だけでなく、実際にSEO担当者が今から取り組める対策がある。タスク型エージェント検索の時代に向けて、以下のポイントに注目すべきだ。
構造化データの徹底強化
AIエージェントが情報を正確に理解し、タスクを完了するためには、構造化データがこれまで以上に重要になる。特にSchema.orgの語彙を活用し、以下のような情報を明確にマークアップする必要がある。
APIファーストな情報提供
人間がブラウザで閲覧するHTML形式だけでなく、AIエージェントがプログラム的に情報を取得できるAPIの提供が重要になる。WordPressではREST APIが標準で搭載されているが、エージェント向けに最適化されたエンドポイントを用意する必要があるかもしれない。
情報の更新頻度も鍵となる。エージェントがレストランの空き状況を確認する場合、その情報が数時間前のものでは意味がない。可能な限りリアルタイムに近い情報提供が求められる。
コンテンツの「信頼性」シグナルの強化
Mike Stewart氏が指摘した「エージェントはどの情報源を信頼するのか」という問いは核心を突いている。エージェントが意思決定する際、信頼性の高い情報源を優先するだろう。以下の要素が信頼性シグナルとして機能すると考えられる。
具体的な信頼性シグナルとしては、正確で最新の構造化データ、他の信頼できるサイトからの言及やリンク、ユーザーレビューの質と量、企業の実在証明などが挙げられる。これらは従来のSEOでも重要だったが、エージェント検索ではさらに重要性が増す。
この記事のポイント
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AI検索可視性データを地域戦略に活かす方法——引用ギャップを埋めるSEO実践
AI検索がSEO戦略の中心的な話題となる中、多くのSEO担当者は経営層から「我が社のAI検索対策はどうなっているのか」というプレッシャーを受けている。従来の検索エンジン最適化とは異なるロジックで動くAI検索において、ブランドが引用されるためにはどのようなシグナルが重要になるのか。そしてそのデータをどう地域別の実行戦略(GEO戦略)に落とし込むのか。この問いに答えるための具体的なフレームワークと実行モデルが、最新のデータ分析から明らかになりつつある。
Search Engine Journal主催のウェビナーでは、Writesonicの創業者兼CEOであるSam Garg氏が、5億件以上のAI検索会話データを分析した結果を基に、AI検索で実際に引用されるコンテンツの特徴と、地域別の引用ギャップを埋めるための優先順位付け手法を解説する。本記事では、そのエッセンスを先取りして紹介する。
AI検索における引用のメカニズム
ChatGPT、Perplexity、GeminiといったAI検索ツールは、従来のGoogle検索とは異なる基準で情報源を選択し、回答に引用する。多くのSEOチームは、自社がAI検索で「見えていない」領域をダッシュボードで把握しているが、それを修正する具体的なプロセスを持たない場合が多い。まず理解すべきは、AIがどのようなコンテンツを引用する傾向にあるのか、その根本的なシグナルだ。
従来のSEOとAI検索最適化の根本的な違い
従来の検索エンジン最適化は、キーワードの出現頻度、被リンク、ページの技術的な健全性など、比較的測定可能な数百のシグナルに基づいてランキングが決定される。一方、AI検索ツールは、ユーザーの質問に対する「最も信頼できる回答」を生成するために、情報の新鮮さ、権威性、そして特定の文脈における適切さを総合的に判断する。この判断プロセスにおいて、どの情報源を引用するかは、従来のページランキングとは必ずしも一致しない。
例えば、地域に密着した詳細なデータを持つ中小規模のサイトが、汎用的な大規模メディアよりも特定の質問で優先して引用されるケースがある。AIは、質問の文脈に最も合致し、かつ信頼できると判断したソースを選ぶ。この「信頼性」の判断には、ドメインの権威だけでなく、コンテンツの専門性、構造化データの有無、更新頻度などが複合的に影響する。
引用を獲得するコンテンツの3つの特徴
Writesonicによる大規模データ分析から、AI検索で引用されやすいコンテンツには共通する特徴が浮かび上がっている。
第一に、明確な構造と階層を持つコンテンツだ。見出しタグ(H1〜H3)を適切に使い、箇条書きや表で情報が整理されているページは、AIが内容を理解し、特定の部分を抽出して引用しやすい。逆に、長大な散文調の記事は、関連する部分を見つけるのが難しくなる。
第二に、具体的な数字やデータ、最新の情報を含むこと。AIは「2026年現在」「調査によると約70%」といった定量的で時間的コンテキストが明確な情報を好んで引用する。曖昧な表現や古いデータは信頼性を損なう。
第三に、専門性と権威性を裏付ける外部ソースへのリンクだ。自説を主張するだけでなく、関連する学術論文、公的統計、権威ある業界レポートへのリンクを適切に含めることで、コンテンツ全体の信頼性が高まり、引用される可能性が上がる。
このデモは、AIが引用しやすいコンテンツの特徴を示している。左側の曖昧な表現から、右側のように具体的な数字、調査元、対象地域を明確にした構造に変えることで、情報の信頼性と抽出可能性が高まる。
引用ギャップを特定するデータ分析手法
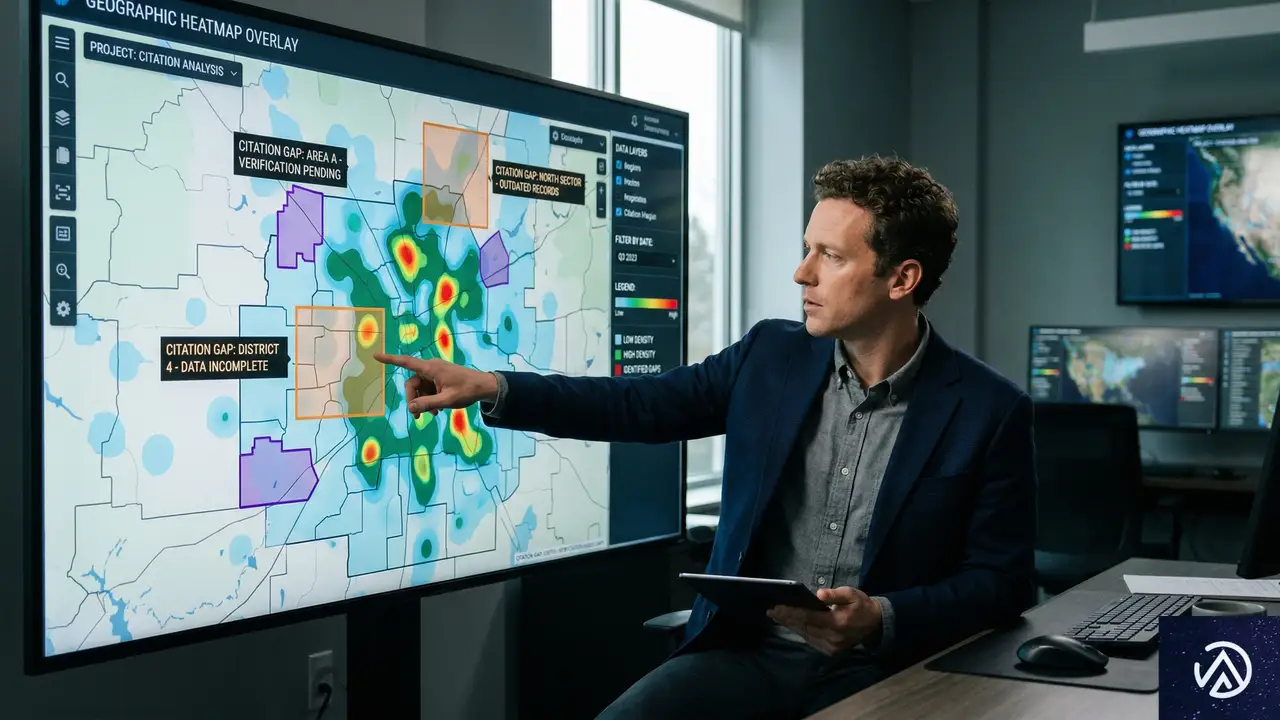
自社ブランドや製品がAI検索でどのように言及されているか、あるいは言及されていないかを把握するには、体系的なデータ分析が必要だ。ここで重要なのは、単に「見えていない」キーワードや地域をリストアップするだけでなく、なぜ見えていないのか、その根本原因を特定することにある。
可視性データの収集と解釈
まず、自社に関連する検索クエリに対して、主要なAI検索ツール(ChatGPT、Perplexity、Gemini等)がどのような回答を生成し、どの情報源を引用しているかをモニタリングする。この際、自社サイトが引用されているか否かだけでなく、競合他社が引用されているクエリ、あるいはどの情報源も引用されていない(AIが独自に生成した回答のみの)クエリも記録する。
得られたデータを「クエリの意図」「地域性」「コンテンツタイプ」の3つの軸で分類する。例えば、「東京 コワーキングスペース おすすめ」というクエリは「商業施設の推薦(意図)」「東京(地域)」「リスト記事(タイプ)」に分類される。この分類ごとに、自社の引用有無と、引用されている他サイトの特徴を分析することで、ギャップのパターンが見えてくる。
ギャップの根本原因を探る優先順位付けフレームワーク
すべての引用ギャップを同時に埋めようとするのは非現実的だ。限られたリソースで最大の効果を上げるためには、優先順位を決める必要がある。Sam Garg氏が提唱するフレームワークでは、以下の2つの指標でギャップを評価する。
第一の指標は「機会の大きさ」だ。そのクエリや地域における検索ボリューム、および自社にとってのビジネス上の重要性(成約率や単価)を数値化する。第二の指標は「埋めやすさ」だ。既存のコンテンツを更新するだけで対応できるのか、ゼロから新しいコンテンツや外部提携が必要なのか。必要な工数と難易度を評価する。
この優先順位付けにより、リソースを「既存資産の最適化」という効果の高い活動に集中させることができる。すべてのギャップを均等に埋めようとする従来のアプローチから脱却する第一歩だ。
AIエージェントを活用した地域戦略の実行自動化
優先すべきギャップが特定できたら、次は実行フェーズだ。特に地域別(GEO)戦略では、対象地域ごとに微妙に異なるコンテンツや情報の更新が必要となり、人的リソースが逼迫しがちである。ここで威力を発揮するのが、AIエージェントを活用したタスクの自動化だ。
無料のオープンソースツールで構築する自動化パイプライン
大規模な予算をかけなくても、現在公開されている無料のオープンソースツールを組み合わせることで、多くのGEO関連タスクを自動化できる。Sam Garg氏のウェビナーでは、具体的なツールの例とその連携方法が紹介される予定だ。
一つの例として、地域別の引用状況を監視するパイプラインを考えてみる。まず、Pythonのスクレイピングライブラリ(BeautifulSoupなど)や、AI検索APIを模倣するツールを使って、定期的に特定の地域クエリに対するAIの回答を収集する。次に、収集したテキストデータから自社ブランドや競合の言及を抽出し、スプレッドシートやデータベースに記録する。このデータ更新をトリガーに、引用ギャップが検出された地域に対して、あらかじめ準備したコンテンツ更新テンプレートや、地域メディアへのコンタクトリストを提示する内部通知システムを構築する。
人的判断とAI自動化の適切な分担
重要なのは、すべてをAIに任せるのではなく、クリエイティブな判断や複雑な交渉が必要な部分は人間が担当し、データ収集、モニタリング、ルーティンワーク、初期ドラフトの作成などをAIエージェントに担当させることだ。この分担を明確にすることで、SEOチームはより戦略的な活動に時間を割くことができる。
例えば、新しい地域での権威構築のために地元メディアへの寄稿を目指す場合、AIエージェントはその地域に関連するメディアリストの作成、編集者の連絡先収集、過去の記事傾向の分析を担当する。人間の担当者は、分析結果を基にパーソナライズされたアプローチ文面を考え、実際のコンタクトと関係構築を行う。
この分担モデルを導入することで、地域別の細やかな対応が人的リソースの限界を超えて可能になる。特に、複数の地域を同時にカバーする必要がある事業者にとって、持続可能な戦略実行の基盤となる。
この記事のポイント
- AI検索での引用は、従来のSEOとは異なるロジックに基づく。具体的なデータ、明確な構造、権威ある外部リンクを含むコンテンツが引用されやすい。
- 引用ギャップを埋めるには、単なる可視性データの収集だけでなく、「機会の大きさ」と「埋めやすさ」で優先順位を付けるフレームワークが有効だ。
- 地域別(GEO)戦略の実行負荷を下げるには、AIエージェントを活用したデータ収集・分析・ルーティンワークの自動化が鍵となる。クリエイティブな判断は人間が担う分担モデルを構築する。
- 無料のオープンソースツールを組み合わせることで、予算をかけずに自動化パイプラインの構築を始めることができる。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AI検索時代のSEO戦略:エンティティ・オーソリティを構築するチーム連携の新基準
AI検索(GEO:Generative Engine Optimization)の台頭により、従来のキーワード単位のSEOは大きな転換点を迎えている。GoogleのAI Overviews(AIによる概要表示)などで引用を勝ち取るためには、特定のトピックに対する「エンティティ・オーソリティ(実体としての権威)」を確立することが不可欠だ。
検索エンジンは現在、単なる単語の羅列ではなく、概念同士のつながりや情報の信頼性を多角的に判断している。この変化に対応するには、コンテンツ制作チームとSEOチームが別々に動く「縦割り」の体制を脱却しなければならない。
本記事では、AI検索時代においてブランドの権威を証明し、検索トラフィックを維持・拡大するための「エンティティ連携フレームワーク」を詳しく解説する。技術的な最適化と高品質なコンテンツをいかに融合させるかが、今後のWebマーケティングの成否を分けることになる。
AI検索で重要性が増す「AEO」と「エンティティ」の基礎知識

まず理解しておくべきは、現在の検索エンジンが「回答エンジン」へと進化しているという事実だ。これに伴い、SEO(検索エンジン最適化)の概念を拡張した「AEO(Answer Engine Optimization / 回答エンジン最適化)」という考え方が重要視されている。
AEO(回答エンジン最適化)とは何か
AEOとは、AIクローラーがウェブサイトの内容を正確に読み取り、ユーザーの質問に対する「回答」として抽出しやすくするための最適化プロセスだ。これには、コンテンツの質だけでなく、データの構造化やブランドの言及(サイテーション)の強化が含まれる。
AIは情報を整理する際、その情報が「どの程度信頼できるソースから発信されているか」を厳格に評価する。そのため、単にキーワードを含めるだけではなく、専門家としての裏付けを示すことが求められる。AEOは、AI検索の結果画面で自社サイトが「引用元」として選ばれる確率を高めるための戦略といえる。
キーワードから「実体(エンティティ)」へのパラダイムシフト
従来のSEOは「特定のキーワードで検索されたときに上位に表示させること」を目的としていた。しかし、現在の検索エンジンは「エンティティ(Entity)」という単位で情報を処理している。エンティティとは、検索システムが他と区別して認識できる「固有の概念」のことだ。
例えば「顧客導入(カスタマーオンボーディング)」というエンティティは、「ユーザー定着」「製品の活性化」「カスタマーサクセス」といった他の概念と密接に結びついている。検索エンジンは、これらの関連性を理解した上で、サイトがそのトピックについてどれだけ深く、網羅的に説明しているかを判断する。つまり、点としてのキーワードではなく、面としての概念ネットワークを構築する必要があるのだ。
● 検索ボリュームの大きい単語を優先的に狙う
● 記事同士の関連性よりも個別の順位を重視する
● AIが理解しやすいよう構造化データで関係性を明示
● 外部サイトからの言及やリンクで信頼性を裏付ける
このデモは、SEOの考え方がキーワード単位からエンティティ単位へと移行している様子を視覚化したものだ。
なぜコンテンツとSEOの「縦割り」が失敗を招くのか

多くの組織では、記事を書く「コンテンツチーム」と、技術的な調整やリンク獲得を行う「SEOチーム」が分断されている。しかし、エンティティ・オーソリティを築く上では、この分断が最大の障害となる。
技術と内容の乖離が招く検索機会の損失
SEOチームがいくら高度なスキーママークアップ(検索エンジンに情報を伝える専用のコード)を実装しても、肝心のコンテンツが薄っぺらであれば、AIはそのサイトを「権威」とは見なさない。逆に、コンテンツチームが素晴らしい調査レポートを書いても、SEOの観点から適切な内部リンクや外部からの裏付けがなければ、検索エンジンはその価値を正しく認識できない。
Search Engine Journalの記事によれば、コンテンツの深さと外部からの検証(リンクなど)が独立して動いている場合、AI検索における「情報の引き出し(リトリーバル)」の機会を逃してしまうリスクが高まる。両チームが同じ「エンティティ」という目標に向かって歩調を合わせることで、初めて強力なシグナルが検索エンジンに届くようになる。
エンティティ・オーソリティを構成する3つの評価軸
検索システムがサイトの権威性を評価する際、主に以下の3つの次元を見ていると指摘されている。
- Recognition(認識):コンテンツがどのエンティティ(概念)について語っているかを識別できるか。
- Relationships(関係性):それらのエンティティが他の概念とどう繋がっているかを理解できるか。
- Corroboration(裏付け):外部の信頼できるソースが、そのサイトの主張を正しいと認めているか(被リンクや言及)。
これらを満たすには、単一のチームの努力では不十分だ。コンテンツが「認識」と「関係性」の土台を作り、SEOが「裏付け」を強化するという共同作業が必要になる。
エンティティを軸とした4フェーズの連携ワークフロー

では、具体的にどのようにチームを連携させるべきか。Victorious社が提唱するフレームワークに基づき、4つのフェーズで構成されるワークフローを解説する。
フェーズ1:SEOチームによるエンティティ調査とベクトル分析
まずSEOチームが主導し、ビジネスの核となるエンティティを特定する。ここでは単なるキーワードリサーチにとどまらず、「ベクトル埋め込み(Vector Embedding)」の視点を取り入れる。これは、言葉の意味を多次元の数値として捉え、概念の近さを分析する手法だ。
GoogleのNatural Language APIなどのツールを使い、自社の主要サービスに関連するトピック(エンティティ・アソシエーション)を洗い出す。例えば「プロジェクト管理」が主軸なら、「リソース計画」「キャパシティ管理」「プロジェクト予測」といった関連概念をリストアップする。この段階で、競合とのギャップや、どの程度の被リンクが必要かという「リンク速度」の要件も算出しておく。
フェーズ2:コンテンツのギャップ分析と優先順位付け
次に、SEOチームとコンテンツチームが共同で既存コンテンツをレビューする。特定したエンティティに対して、カスタマージャーニー(認知・検討・決定)の各段階を網羅できているかを確認するのだ。
「このトピックについて、AIが権威と認めるだけの深さがあるか?」を自問自答する必要がある。調査レポート、ガイド記事、比較記事、ハウツー動画など、多様な形式でエンティティを補強する計画を立てる。ここで重要なのは、両チームが「成功の定義」を共有することだ。単なるPV数だけでなく、特定のエンティティでの順位向上やAI検索での引用率を指標に据えるべきだ。
フェーズ3:スキーマ実装と戦略的なリンクビルディング
実行フェーズでは、コンテンツチームが記事を作成し、SEOチームがそれを技術的に補強する。具体的には、SameAsプロパティなどを用いた構造化データを実装し、エンティティ同士の関係性を検索エンジンに明示する。また、内部リンクを整理し、関連するトピック同士を「クラスター(塊)」としてつなぎ合わせる。
外部対策においても、単にリンクを集めるのではなく、狙っているエンティティについて言及しているメディアからのリンクを優先する。アンカーテキスト(リンクが設定された文字列)にも、エンティティに関連する語句を自然なバリエーションで含めることが求められる。これにより、「このサイトはこのトピックの専門家である」という外部からの裏付けが完成する。
この図は、中心となるエンティティを複数のコンテンツと外部リンクで囲い込み、権威を形成する構造を示している。
実践例:SaaS企業の「リソース管理」エンティティ構築

理論だけでは分かりにくいため、具体的な成功事例を見てみよう。あるプロジェクト管理ツールを提供しているSaaS企業のケースだ。
競合分析から見えたコンテンツとリンクの不足
この企業は「プロジェクト管理」という大きな市場で認知を広げたいと考えていた。ベクトル分析の結果、その下位概念である「リソース計画(Resource Planning)」が、主目的との親和性が非常に高いことが判明した。しかし、自社サイトを確認すると、リソース計画に関する記事は基礎的なブログが1本あるだけだった。
一方で競合他社は、リソース割り当てのトレンド調査、キャパシティ計画の包括的ガイド、手法の比較記事、導入ハウツーなど、あらゆる角度からこのエンティティを攻略していた。また、外部のプロジェクト管理専門メディアからも、これらのページに対して質の高いリンクが集まっていた。この「情報の密度」と「裏付け」の差が、AI検索での露出の差に直結していたのだ。
4ヶ月でAI検索の引用を獲得した具体的プロセス
この企業は4ヶ月間にわたる集中施策を実施した。まずコンテンツチームが、独自の調査データを含むリサーチ記事や、実装に役立つ詳細なガイドを順次公開していった。並行してSEOチームは、これらの新記事を構造化データで紐付け、サイト内の関連ページから最適な内部リンクを設置した。
さらに、外部の業界誌に対し、リソース管理に関する専門的な寄稿やデータ提供を行い、関連性の高いバックリンクを構築した。結果として、リソース計画に関連するクエリでの順位が向上しただけでなく、GoogleのAI Overviewにおいて「リソース計画のベストプラクティス」などの検索時に自社記事が引用されるようになった。これは、単独のチームが独立して動いていては達成できなかったスピード感だといえる。
独自見解:AI時代のSEOは「点」ではなく「面」の勝負になる

今回のフレームワークを分析して感じるのは、SEOがかつての「ハック(裏技)」から、より「本質的な信頼構築」へと回帰しているということだ。AIは単に文字を読んでいるのではなく、その背後にある「情報の網」を見ている。
筆者の見解としては、今後のSEO担当者に求められるのは、テクニカルな知識以上に「トピックの構造化能力」だと考える。どの概念とどの概念を繋げれば、自社がその分野の第一人者だと証明できるか。この「概念の地図」を描く力こそが、AI検索時代の武器になるはずだ。
また、この戦略は小規模なサイトにとってもチャンスとなる。広範なキーワードを狙う体力はなくても、特定のニッチなエンティティにおいて「誰よりも詳しく、かつ外部からの信頼も厚い」という状態を作れば、AI検索はそこをピンポイントで引用してくれる可能性がある。大手が網羅しきれない専門領域で「面」を構築することが、これからの戦い方になるだろう。
この記事のポイント
- AI検索(AEO)時代には、単一キーワードではなく「エンティティ(概念)」単位の最適化が必須となる。
- エンティティ・オーソリティは「認識」「関係性」「裏付け」の3要素で構成される。
- コンテンツチームとSEOチームの分断を解消し、4フェーズの連携ワークフローを回すことが成功の鍵だ。
- ベクトル分析を用いて関連トピックを特定し、カスタマージャーニーを網羅するコンテンツを制作する。
- 技術的な構造化データ実装と、外部ソースからの言及を融合させることで、AI検索での引用率が高まる。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AI検索で勝つのは自社サイトではなくReddit?コミュニティ信号がSEOの鍵を握る理由
AIに「どの製品を買うべきか」や「どのソフトウェアが最適か」を尋ねたとき、その回答の出典がメーカーの公式サイトではないケースが増えている。多くの場合、AIが答えの根拠としているのは、1年以上前にReddit(レディット)に書き込まれた、見知らぬ誰かのコメントだ。Redditは米国最大級の掲示板サイトであり、日本でいえば「5ちゃんねる」に近い側面を持ちつつ、より専門的な議論が行われるプラットフォームだ。
この現象は偶然ではなく、AI検索の構造的な変化によって引き起こされている。2025年にかけてのデータによると、GoogleのAI Overviews(AIによる検索結果の要約)において、Redditの引用数はわずか数ヶ月で450%も増加した。自社でコントロールできる「オウンドメディア」のコンテンツが、コミュニティ内の「生の声」に敗北し始めているのだ。
なぜAIは企業の公式情報よりも、匿名の投稿を信頼するのか。この記事では、AI検索エンジンがコミュニティ信号を重視する仕組みと、企業が今後取るべき具体的な対策について解説する。従来のSEO(検索エンジン最適化)の常識が通用しなくなる中で、新しい「信頼の構築方法」を理解することが重要だ。
AI検索エンジンの主役に躍り出たRedditの影響力

RedditがAI回答の主要なソースになった背景には、巨大なテック企業同士の戦略的な提携がある。Googleは2024年初頭、Redditと年間約6,000万ドルのライセンス契約を結んだ。これにより、GoogleはReddit上の膨大な投稿やコメントにリアルタイムでアクセスし、AIモデルの学習やAI Overviewsの生成に利用できるようになった。同様の契約はOpenAIなどの他のAI企業とも結ばれており、契約総額は2億ドルを超えている。
巨額のライセンス契約と引用データの裏付け
Search Engine Journalの報告によれば、2024年8月から2025年6月にかけて、RedditはGoogle AI OverviewsとPerplexity(パープレキシティ:対話型AI検索エンジン)の両方で、最も引用されるドメインとなった。ChatGPTにおいても、Wikipediaに次いで2番目に多く引用される情報源となっている。特に製品比較やレビューに関するクエリでは、Redditが検索結果に表示される割合は97%以上に達するというデータもある。
これは、AIが「事実」だけでなく「人間の経験」を求めていることを示している。企業の公式サイトには、その製品のメリットが整然と並んでいる。しかし、Redditには「実際に使ってみたらここが不便だった」「競合他社の製品と比べてここが優れている」といった、装飾のない本音が蓄積されている。AIはこの「本音の集積」を、ユーザーにとって最も価値のある情報だと判断しているのだ。
なぜRedditはGoogle検索結果でも強いのか
Redditの強さはAIの回答レイヤーだけにとどまらない。従来のGoogle検索結果(SERP)においても、Redditのスレッドが上位を占める光景は一般的になった。2025年初頭にはRedditのオーガニック順位が一時的に下落した時期もあったが、AI回答層での存在感は依然として揺るぎない。これは、AIシステムが単なるランキングアルゴリズムとは異なる基準で、データの「信頼性」を評価しているためだ。
AIは情報の「新鮮さ」と「多角的な視点」を重視する。1つの企業が発信する情報は一方向的だが、Redditのスレッドは数百人のユーザーによる議論で構成されている。この「多対多」の対話構造が、AIにとっては情報の正確性を担保する強力なシグナルとして機能している。以下に、AIが情報を取得するフローを視覚化したデモを示す。
AIの情報取得フローのデモを見る
企業が発信した情報をそのままユーザーが受け取る構造だ。
AIが複数のコミュニティ信号を分析・統合して、一つの回答を生成する。
このデモのように、AIは単一のソースではなく、複数のコミュニティから得られる「合意」を回答の根拠としている。
AIがコミュニティの「声」を信頼する2つのメカニズム

AIがコミュニティコンテンツを重視する理由は、単なるライセンス契約の結果だけではない。AIのアーキテクチャ自体が、コミュニティの信号を「質の高いデータ」として認識するように設計されているからだ。これには「パラメトリック(Parametric)」と「リトリーバル(Retrieval)」という2つの経路が関係している。
学習データとリアルタイム検索の二段構え
第一の経路であるパラメトリック経路とは、AIモデルの事前学習(トレーニング)の段階でコミュニティの内容が組み込まれることを指す。AIが学習を終えた時点で、すでにそのブランドや製品に関する「世間の評判」がAIの知識の一部として定着している状態だ。もし学習データに含まれるRedditのスレッドで自社製品が酷評されていた場合、AIはその知識に基づいて回答を生成する。
第二の経路は、RAG(Retrieval-Augmented Generation / 検索拡張生成)と呼ばれるリトリーバル経路だ。これは、AIがユーザーの質問に対して、リアルタイムでインターネット上の情報を検索し、その結果を基に回答を補強する仕組みだ。RAGにおいて、AIは最新の議論や特定のトラブル解決策を探すためにコミュニティサイトを優先的にクロールする。つまり、過去の学習データと現在の検索結果の両方でコミュニティ信号が支配的な役割を果たしているのだ。
アップボート(高評価)が質を保証するフィルターになる
AIにとって、情報の「正しさ」を判断するのは難しい。そこでAIが活用しているのが、コミュニティ内の「評価システム」だ。Redditには、良い投稿に投票する「Upvote(アップボート)」という仕組みがある。OpenAIのトレーニングデータ階層に関する報告によると、3つ以上のアップボートを獲得したRedditコンテンツは、Wikipediaやライセンス済みの出版パートナーに次ぐ「ティア2(第2階層)」の高品質データとして扱われている。
数百、数千の人間が「この記事は役に立つ」と判断したという事実は、AIにとって強力な信頼の証となる。企業が自社サイトで「わが社の製品は最高だ」と1万回書くよりも、Redditで100人のユーザーが「この製品は最高だ」と評価する方が、AIの目には価値ある情報として映るのだ。これは、個別のリンクの強さを競っていた従来のSEOから、コミュニティ全体の「文脈上の合意」を重視するSEOへの転換を意味している。
偽装された合意の罠とアストロターフィングの代償

コミュニティの評価がAI回答を左右するのであれば、意図的に高評価を捏造しようと考える者が現れるのは当然だ。これを「アストロターフィング(偽の草の根運動)」、いわゆるステマ(ステルスマーケティング)と呼ぶ。しかし、AI時代のコミュニティ操作は、かつてのリンクスパムよりもはるかに高いリスクを伴う。
ステマ行為に対するコミュニティとAIの監視
2025年後半に起きた「Trap Plan事件」は、このリスクを象徴している。あるマーケティング会社がRedditに約100件の偽の口コミを投稿し、その手法を自慢げにブログで公開した。しかし、Redditのコミュニティと自動監視システムはすぐに不自然な投稿パターン(アカウント作成時期や投稿間隔の偏り)を検知した。結果としてその会社は激しいバッシングを受け、ブランド名は「不正を行う企業」としてRedditのスレッドに永久に刻まれることになった。Googleはこのスレッドもインデックスするため、ブランド名で検索するすべての潜在顧客に不正の事実が知れ渡ることになったのだ。
Redditのモデレーター(管理者)や熱心なユーザーコミュニティは、企業による操作に対して非常に敏感だ。一度「不誠実なブランド」というレッテルを貼られると、そのネガティブな文脈をAIが学習し、将来的に「あのブランドは避けるべきだ」という回答を生成する原因になりかねない。短期的な露出のためにコミュニティの信頼を損なうことは、AI時代のSEOにおいて致命的な戦略ミスとなる。
AI生成コンテンツによる汚染問題
もう一つの懸念は、AI自身がコミュニティを汚染し始めていることだ。Originality.aiの調査によると、2025年のReddit投稿の約15%がAIによって生成された可能性が高いという。これは、人間による純粋な合意形成のプロセスが、AIによる自動投稿によって歪められていることを示唆している。AIが「AIが書いた偽の合意」を学習するという、自己参照的なフィードバックループが発生しているのだ。
このような状況下では、AI検索エンジン側も「人間による真正なシグナル」を判別するためのアルゴリズムを強化せざるを得ない。今後は、単なるアップボートの数だけでなく、投稿者の過去の活動履歴や、議論の深さ、専門性といった「人間らしさ」の証明がより重要視されるようになるだろう。企業ができる最も戦略的な行動は、検出システムが厳格化される前に、本物のコミュニティプレゼンス(存在感)を築いておくことだ。
レビュープラットフォームの選択がAIの視認性を左右する

コミュニティ信号のもう一つの柱は、レビューサイトだ。B2B(企業間取引)のソフトウェア選定において、かつてはGoogle検索が起点だったが、2025年の調査では50%の買い手がAIチャットボットから購買の旅を始めている。AIがどの製品を推奨するかを決定する際、その判断材料の多くはG2やCapterra、Clutchといったレビュープラットフォームから得られている。
クローラーへのアクセス制限がもたらす格差
ここで重要なのが、すべてのレビューサイトがAIに対してオープンではないという点だ。2025年6月の分析によると、レビュープラットフォームはAIクローラー(情報を収集するプログラム)への対応方針によって3つに分類される。ClutchやSourceForgeのように全アクセスを許可しているサイト、G2のように選択的に許可しているサイト、そしてYelpのようにrobots.txt(クローラーへの指示書)でAIを完全に拒絶しているサイトだ。
AIクローラーをブロックしているサイトにどれだけ多くの好意的なレビューがあっても、AIはその情報を回答に反映させることができない。例えば、Perplexityのソフトウェアカテゴリにおける引用の75%はG2から来ている。企業がレビュー獲得施策(レビューマネジメント)を行う際は、そのプラットフォームがAI検索のソースとして機能しているかどうかを確認する必要がある。
B2B比較サイトがAI回答のソースになる理由
AIは「A社とB社の違いは何か?」という比較質問に答える際、構造化されたデータを好む。G2のような比較サイトは、機能ごとのスコアやユーザーの職種、企業規模といったデータが整理されているため、AIにとって非常に解釈しやすい。また、これらのサイトは強力なドメイン権威(サイトの信頼性)を持っており、AIが「信頼できる参照先」として優先的に選択する傾向がある。
以下のデモは、レビューサイトの公開設定(robots.txt)がAIの回答にどう影響するかを簡略化したものだ。
「User-agent: * Allow: /」の設定。AIはすべてのレビューを読み取れる。 「User-agent: GPTBot Disallow: /」の設定。AIはこのサイトの情報を無視する。robots.txtによるAI視認性の違いをデモで見る
このように、レビューを集める場所の選択ミスが、AI検索における「存在の消滅」につながるリスクがある。
ブランドが構築すべき「文脈の堀」と実践的な参加戦略

AI時代における真のSEOとは、自社サイトを最適化することだけではない。インターネット上のあらゆる場所に、自社に関する「好意的な文脈(コンテキスト)」を散りばめることだ。これは、競合他社が簡単には真似できない「文脈の堀(Context Moat)」を築く作業に近い。一朝一夕には完成しないが、一度構築されれば長期的な資産となる。
専門家による実名でのコミュニティ貢献
企業がコミュニティに参加する際、最も効果的なのは「ブランド」としてではなく「個人」として貢献することだ。社内の技術者や専門家が、RedditやStack Overflow、Quoraなどのプラットフォームで、自身の知識を惜しみなく共有する。質問に対して誠実に答え、役立つ情報を提供することで得られるアップボートやカルマ(貢献度スコア)は、AIにとって非常に強力な品質シグナルとなる。
実名での参加は、情報の信頼性を高めるだけでなく、AIに対して「このブランドには信頼できる専門家がいる」という関連付けを強化する。一見、遠回りに見えるこの活動が、実は10本のオウンドメディア記事を書くよりも、AI検索の視認性を高める上で効果的である場合が多い。
8対2の法則で価値を届ける
コミュニティでの活動には黄金律がある。それは「80%の貢献と20%の言及」だ。参加時間の80%は、自社製品とは無関係であっても、コミュニティの課題を解決するために費やすべきだ。残りの20%で、自社製品が本当にその質問の最適な答えである場合にのみ、控えめに紹介する。このバランスを崩して宣伝色を強めた瞬間、コミュニティからの反発を招き、AIにネガティブなシグナルを送ることになる。
また、コミュニティメンバーが「引用したくなるコンテンツ」を作成することも重要だ。独自の調査データ、具体的なベンチマーク数値、失敗談を含む詳細なケーススタディなどは、Redditなどでリンクが共有されやすい。これらの「第三者による言及」こそが、AIが合意を形成するための原材料となる。自社サイトをゴール(終着点)とするのではなく、コミュニティの議論を加速させるための「燃料」としてコンテンツを位置づける発想が必要だ。
この記事のポイント
- AI検索エンジン(Google, ChatGPT等)は、企業の公式サイトよりもRedditなどのコミュニティの声を優先的に引用している。
- AIは学習時とリアルタイム検索の両方でコミュニティ信号を利用しており、特にアップボート(高評価)を信頼の指標としている。
- ステマ行為などの操作は、コミュニティの反発を招くだけでなく、AIに「不誠実なブランド」として学習されるリスクがある。
- レビューサイトを選ぶ際は、AIクローラーへのアクセスを許可しているプラットフォーム(G2, Clutch等)を優先すべきだ。
- 企業は専門家による実名での貢献を通じて、長期的に「文脈の堀」を築くことが、AI時代の新しいSEO戦略となる。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験
検索エンジンシェア2026:Google一強の変容とAI検索が変えるSEOの未来
検索エンジンの世界で、10年以上にわたり不動の地位を築いてきたGoogleのシェアに変化の兆しが見えている。2026年3月時点のデータによれば、Googleの世界シェアは90.01%となり、一時期は90%の大台を割り込む場面もあった。長らく「SEO=Google対策」という図式が続いてきたが、その前提が揺らぎ始めている。
この変化の背景には、ChatGPTやPerplexityといったAI検索ツールの急成長がある。さらに、商品の検索はAmazon、若年層のトレンド検索はTikTokといったように、特定の目的を持った検索行動が専門プラットフォームへ分散している点も見逃せない。従来の検索エンジンという枠組みを超えた、新しい集客戦略が求められている。
本記事では、2026年最新の検索エンジンシェアを紐解き、AI検索の台頭がSEOの実務にどのような影響を与えるのかを解説する。ウェブ担当者や制作エンジニアが、今後どのプラットフォームにリソースを割くべきかの判断材料として役立ててほしい。
Googleの現状:AI Overview(SGE)による検索体験の変容
Googleは依然として検索市場の9割を支配するリーダーだ。StatCounterのデータによると、全世界の検索の10回に9回はGoogleで行われている。しかし、その内部構造はここ1年で劇的に変化した。最も大きな要因は、AI Overviews(AIによる概要回答)の全面的な展開である。
シェアの推移とデバイス別の特徴
Googleのシェアは2015年以降、約89%から93%の間で推移してきた。2024年末には3ヶ月連続で90%を下回り、2026年2月にも再び90%を切るなど、わずかながら低下傾向にある。特にデスクトップ市場ではGoogleのシェアは約82%まで下がり、代わりにMicrosoftのBingが10%を超えるシェアを獲得している。一方で、モバイル市場では94%以上という圧倒的な強さを維持しているのが特徴だ。
「ゼロクリック検索」への対策
AI Overviewsの普及により、ユーザーが検索結果画面(SERP)だけで疑問を解決し、外部サイトをクリックしない「ゼロクリック検索」が増加している。SERP(Search Engine Results Page)とは、検索ボタンを押した後に表示される結果一覧ページのことだ。従来の検索では1位のサイトをクリックするのが一般的だったが、現在はAIの回答や強調スニペット、ローカルパックなどが画面上部を占拠している。これにより、検索順位が上位であっても、必ずしもトラフィック(流入数)に結びつかないケースが増えている。
Bingと第2グループ:AI連携で存在感を増す競合たち

Googleの背後で、MicrosoftのBingが着実に存在感を高めている。グローバルシェアは5.01%と数字上は小さく見えるが、米国市場では10%を超え、デスクトップ環境では無視できない勢力となっている。
Bing:ChatGPTとの連携がもたらすメリット
Bingの成長を支えているのは、AIチャット機能「Copilot」の統合だ。戦略的に重要なのは、ChatGPTの検索機能がウェブ情報の取得にBingのインデックス(索引データ)を利用している点である。つまり、Bingでの評価を高めることは、ChatGPT経由での露出を増やすことにも直結する。競合がGoogle対策に集中している今、Bingへの最適化は比較的少ないコストで成果を出せる「穴場」の戦略と言える。
YahooとDuckDuckGo:特定の層に刺さるプラットフォーム
Yahooのグローバルシェアは1.39%だが、米国では2.86%を保持している。Yahooの検索エンジンはBingの技術を採用しているため、Bing向けの対策を行えば自動的にYahooユーザーにもリーチできる。一方、DuckDuckGoはシェア0.76%ながら、プライバシーを重視する層から根強い支持を得ている。ユーザーの行動を追跡しないという独自性が、GDPR(欧州一般データ保護規則)などのプライバシー規制が厳しい地域で評価されている。
AI検索エンジンの急成長:ChatGPTとPerplexityの影響

従来の検索エンジンシェアの数字には現れないが、ユーザーの検索行動を最も大きく変えているのがAI検索エンジンだ。OpenAIの報告によれば、ChatGPTの週間アクティブユーザー数は2026年2月時点で9億人に達した。これは2025年10月の8億人から数ヶ月で1億人増加した計算になる。
従来の検索と何が違うのか
AI検索の最大の特徴は、複数のリンクを提示するのではなく、情報を統合して「回答」を生成する点にある。ユーザーは対話を通じて情報を深掘りしたり、要約を求めたりできる。Perplexity(パープレキシティ)などのサービスも急成長しており、2025年5月には月間7億8,000万件のクエリ(検索要求)を処理している。これは前年同期の2億3,000万件から3倍以上の成長だ。
新たな手法「GEO(生成エンジン最適化)」の考え方
AI検索の台頭に伴い、SEO業界では「GEO(Generative Engine Optimization:生成エンジン最適化)」という新しい概念が登場している。これは、AIが回答を生成する際の「引用元」として選ばれるための施策だ。Conductorの調査によれば、ウェブ全体のトラフィックのうちAI経由の流入はまだ1.08%程度だが、その伸び率は極めて高い。正確なデータ構造、権威性のあるコンテンツ、そしてAIが理解しやすい論理的な文章構成が、今後の評価を左右することになる。
特定領域でGoogleを凌駕する「垂直検索」の勢力
「何かを探す」という行為は、もはや汎用的な検索エンジンだけで完結しない。特定の目的に特化した「垂直検索」のプラットフォームが、Googleのシェアを実質的に削っている。
Amazon:EC検索の入り口としての地位
Jungle Scoutの調査によると、オンラインでの商品検索の56%は、GoogleではなくAmazonから直接始まっている。Amazonの検索アルゴリズム(A10と呼ばれることもある)は、購入意向の強さを重視する。商品の販売実績やレビュー、在庫状況がランキングに大きく影響するため、物販を行う企業にとってAmazon内でのSEOは、Google対策と同等かそれ以上に重要だ。
TikTok:若年層の「発見」を支えるアルゴリズム
若年層にとって、TikTokは検索ツールとしての役割を強めている。飲食店や旅行先、コスメのレビューなどを探す際、テキストではなく動画での「リアルな体験」を求める傾向がある。TikTokの検索はキーワードの一致よりも、ユーザーのエンゲージメント(反応)を重視する。従来のSEOが「答え」を提示するものだったのに対し、TikTokでの最適化は「発見」されるためのフック(引き)を作ることが中心となる。
2026年以降のSEO戦略:分散投資とAI対応の最適解
Search Engine Journalの記事が指摘するように、単一の検索エンジンだけに依存する時代は終わった。これからのSEO戦略には、以下の3つの視点が必要だ。
第一に、Google内での「AI露出」を狙うことだ。AI Overviewsに引用されるためには、単なるキーワード対策ではなく、トピックに対する網羅的で信頼性の高い回答を提示しなければならない。第二に、BingやChatGPTといったAIプラットフォームへの最適化だ。Bing Webmaster Toolsを活用し、サイトが正しくインデックスされているかを確認するだけでも、競合との差別化になる。
第三に、プラットフォームの使い分けだ。商品ならAmazon、ブランド認知ならTikTok、信頼性の構築なら自社ブログ(Google)というように、目的に応じてリソースを配分する必要がある。検索市場の変化は、ユーザーがより「自分に合った回答」を求めている証拠でもある。技術的なハックに頼るのではなく、ユーザーの検索意図に最も誠実に答えるコンテンツ作りが、結局はどのエンジンでも評価される近道だ。
この記事のポイント
- Googleのシェアは90.01%と依然として高いが、デスクトップでは低下傾向にある
- AI Overviewsの普及により、クリックを伴わない「ゼロクリック検索」への対策が急務となっている
- BingはChatGPTとの連携により、AI検索時代における重要なプラットフォームに浮上した
- ChatGPTやPerplexityなどのAI検索に対応する「GEO」という新しい最適化手法が注目されている
- AmazonやTikTokなど、検索エンジン以外のプラットフォームへの検索分散が進んでいる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AEO(回答エンジン最適化)の新戦略:AI検索でコンテンツを引用させるための構造化手法
検索エンジンの役割が「リンクの羅列」から「直接的な回答」へと劇的に変化している。GoogleのAI OverviewsやMicrosoft Copilot、PerplexityといったAI検索エンジンの普及により、Webサイトの運営者は従来のSEO(検索エンジン最適化)に加えて、AEO(Answer Engine Optimization:回答エンジン最適化)への対応を迫られている状況だ。
最新の調査データによれば、AI検索からのトラフィックは月間約1%のペースで成長を続けており、特定の業界では無視できない規模に達している。AIにコンテンツを引用させ、自社の認知度を高めるためには、これまでの「ページ単位の評価」という考え方を捨てる必要がある。
この記事では、AIがどのようにコンテンツを解析し、どの断片を回答として採用するのかを、最新の研究結果と技術的な視点から詳しく解説する。AI時代に生き残るためのコンテンツ構造の作り方を、具体的なステップと共に見ていこう。
AIは「ページ」ではなく「断片」でコンテンツを評価する

従来の検索エンジンは、キーワードの関連性やリンクの強さを基に「Webページ全体」をランク付けしてきた。しかし、AI検索エンジンは全く異なるアプローチを取る。AIはページを読み込む際、内容を細かな「断片(フラグメント)」に分解して理解しようとする。このプロセスは「パージング(解析)」と呼ばれ、AIが回答を生成するための基礎となる。
パージング(解析)というプロセスの理解
MicrosoftのBingチームでプリンシパル・プロダクトマネージャーを務めるKrishna Madhavan氏によれば、AIアシスタントはコンテンツを構造化された小さな断片に分解し、それぞれの権威性と関連性を評価する。そして、複数のソースから抽出した最適な断片を組み合わせて、一つの首尾一貫した回答を作り出すのだ。
これは、たとえGoogleで検索順位が1位だったとしても、コンテンツの構造がAIにとって抽出困難であれば、AIの回答には引用されない可能性があることを示している。AIは「最も優れたページ」を探しているのではなく、「質問に対する最も適切な回答の断片」を探しているからだ。
AIトラフィックの現状と成長率
2026年1月のConductor AEO/GEOベンチマークレポートによると、AI経由のトラフィックはWebサイト全体のセッションの約1.08%を占めている。数字だけ見れば小さく感じるかもしれないが、前年比で357%もの急増を見せたケースもあり、その成長速度は驚異的だ。
特に医療分野では、Google検索の約2回に1回がAIによる概要表示(AI Overviews)を伴うというデータもある。ユーザーが検索結果のリンクをクリックする前にAIの回答で満足してしまう「ゼロクリック検索」が増える中で、AIの回答内に自社サイトが「出典」として引用されることは、新たな流入経路を確保するための生命線となる。
研究結果から判明した「引用されやすいコンテンツ」の条件

どのようなコンテンツがAIに好まれるのかについては、すでに複数の大学や研究機関が実証実験を行っている。その中でも、プリンストン大学やジョージア工科大学などが発表した「GEO(Generative Engine Optimization:生成エンジン最適化)」に関する論文は、非常に示唆に富んでいる。
GEO(生成エンジン最適化)の有効な手法
この研究では、9つの最適化戦略をテストした結果、特定のテクニックによってAI回答での視認性が最大40%向上することが確認された。最も効果的だったのは「信頼できる情報源の引用」だ。統計データや専門家の発言を適切に引用しているサイトは、そうでないサイトに比べて視認性が115.1%も増加したという。
一方で、意外な事実も判明している。文章を「説得力のあるトーン」や「権威を感じさせる文体」で書くことは、AIの引用率向上にはほとんど寄与しなかった。AIはレトリック(修辞学)に惑わされることはなく、検証可能な事実と論理的な構造を重視している。マーケティング的な装飾よりも、裏付けのある情報提供が優先される環境だ。
第三者メディア(アーンドメディア)の圧倒的な影響力
トロント大学が2025年9月に行った調査では、ChatGPTやPerplexityなどの主要AIエンジンが、自社サイトよりも「第三者による評価」を圧倒的に信頼していることが明らかになった。例えば家電分野では、AIが引用するソースの92.1%が第三者の専門メディアやレビューサイトであり、メーカー公式サイトの引用率は極めて低かった。
これは、自社サイト内でのSEOだけでは不十分であることを意味している。業界紙への寄稿、プレスリリース、信頼性の高い比較サイトへの掲載といった「アーンドメディア(獲得メディア)」での露出が、間接的にAI検索での視認性を高める鍵となる。AIはインターネット全体を俯瞰し、多くの場所で言及されている情報を「真実」として採用する傾向があるからだ。
AIに選ばれるための具体的な構造化テクニック

AIがコンテンツを「断片」として抽出する以上、制作者側も「抽出されやすい形」で情報を提供しなければならない。ここでは、MicrosoftやGoogleのガイドライン、および最新の研究に基づいた具体的な構成案を提示する。
見出しの役割とQ&A形式の採用
見出し(H2やH3タグ)は、AIにとって「ここから新しい概念が始まる」という強力なシグナルになる。「概要」や「詳細はこちら」といった曖昧な見出しは避け、そのセクションの内容を正確に記述した見出しを付けるべきだ。例えば「AIによるコンテンツ解析の仕組み」といった具体的な表現が望ましい。
また、ユーザーの質問をそのまま見出しにし、その直後で端的に回答する「Q&A形式」はAIとの相性が抜群だ。AIアシスタントは、この質問と回答のペアをそのままコピーしてユーザーに提示することが多いため、引用される確率が飛躍的に高まる。結論を先に述べ、その後に詳細な解説を続ける「逆ピラミッド型」の記述を徹底しよう。
「スニッパブル(切り出し可能)」なレイアウト設計
AIは長い段落よりも、箇条書き、番号付きリスト、比較表といった構造化されたデータを好む。これらは「スニッパブル(Snippable)」、つまり簡単に切り出せる形式だからだ。情報を整理して提示することで、AIは人間と同じように「このサイトは情報が整理されていて分かりやすい」と判断する。
以下のデモは、AIが情報を抽出しやすい「構造化された比較」のイメージだ。このように明確な境界線とラベルを持つ構成は、AIによるパージングを助ける効果がある。
<!-- 構造化された情報の例 -->
<div class="comparison-box">
<h4>SEOとAEOの違い</h4>
<ul>
<li>SEO:検索順位を上げ、サイトへの流入を最大化する</li>
<li>AEO:AIの回答に採用され、情報の正確性を担保する</li>
</ul>
</div>対象:ページ全体の評価
指標:クリック率(CTR)
対象:情報の断片(フラグメント)
指標:引用シェア・ブランド認知
このデモのように、情報を対比させて整理することで、AIは「SEOとAEOの違い」という文脈を即座に理解できる。
権威性のシグナルとスキーママークアップの活用
AIに「この情報は正しい」と確信させるためには、技術的な裏付けが必要だ。ここで重要になるのが、Googleも重視しているE-E-A-T(経験・専門性・権威性・信頼性)の概念と、それを機械に伝えるための「構造化データ」である。
E-E-A-Tと情報の鮮度
Microsoftのガイドラインでは、成功するコンテンツの条件として「新鮮で、権威があり、構造化され、意味的に明確であること」を挙げている。特に「意味的な明確さ」についてはシビアだ。「革新的な」「最先端の」といった曖昧な形容詞は、AIにとっては評価の対象にならない。それよりも「従来比で処理速度が30%向上した」といった、測定可能な事実に基づいた記述が求められる。
また、情報の鮮度(フレッシュネス)も重要なシグナルだ。古いデータや更新が止まったコンテンツは、AIに「不正確な可能性がある」と判断され、引用候補から外されやすい。定期的なリライトと、公開日・更新日の明示は必須と言える。
AIの理解を助ける構造化データの種類
スキーママークアップ(構造化データ)は、人間向けのテキストを「機械が理解できるデータ」に変換する翻訳機の役割を果たす。Microsoftは、スキーマを利用することでAIがコンテンツの内容を推測する必要がなくなり、自信を持って回答に採用できるようになると指摘している。
特にAEOにおいて優先順位が高いスキーマは以下の通りだ。
- FAQPage:質問と回答のペアを定義する。AIが最も引用しやすい形式だ。
- HowTo:手順やステップを定義する。ハウツー系の回答に採用されやすくなる。
- Product:価格、在庫、レビューを定義する。ECサイトのAI検索対応には必須だ。
- Article / BlogPosting:著者情報や公開日を定義し、情報の信頼性を高める。
これに加えて、サイトの更新を検索エンジンに即座に通知する「IndexNow」を併用することで、情報の鮮度と正確性を高いレベルで維持することが可能になる。
クローラー制御と計測の進め方

AI検索エンジンに対応するためには、どのクローラーを許可し、どのクローラーを制限するかという戦略も重要になる。また、施策の結果をどのように計測するかも、従来のSEOとは異なる視点が必要だ。
robots.txtによる学習と検索の切り分け
主要なAIプラットフォームは、クローラーを「検索用」と「モデル学習用」で分けていることが多い。例えばOpenAIの場合、OAI-SearchBot はChatGPTの検索機能(回答への引用)に使用されるが、GPTBot は将来のモデル学習に使用される。
自社のコンテンツをAIの回答に引用させたいが、AIモデルの学習に無償で使われるのは避けたいという場合は、robots.txt で個別に制御することが可能だ。検索用ボットを許可し、学習用ボットを拒否することで、著作権を保護しつつ検索流入を確保するバランスが取れる。
AI経由の流入を可視化する方法
AEOの成果を測る最も手軽な方法は、Bing Webmaster Toolsを活用することだ。ここには「AIパフォーマンスレポート」があり、Microsoft Copilotでの引用状況やクリック数を確認できる。Googleについては、Search Consoleの検索パフォーマンスから「検索タイプ:AI Overview(またはそれに類するフィルタ)」で動向を追うことになる。
また、ChatGPTからの流入は、アクセス解析ツールで utm_source=chatgpt.com というパラメータが付与される仕様になっている。これをモニタリングすることで、AI検索がどの程度自社サイトへのトラフィックに貢献しているかを具体的に把握できる。従来の「キーワード順位」だけでなく、「AI回答内でのシェア」を新たな指標として設定すべきだ。
この記事のポイント
- AIはページ全体ではなく、構造化された「断片(フラグメント)」を抽出して回答を生成する。
- 信頼できるソースの引用や統計データは、AI回答での視認性を100%以上向上させる可能性がある。
- 自社サイトの改善だけでなく、第三者メディアでの露出(アーンドメディア)がAIの信頼獲得に直結する。
- Q&A形式、箇条書き、スキーママークアップを活用し、AIが解析しやすい「スニッパブル」な構造を作る。
- Googleは「質の高いコンテンツ」と抽象的に述べるが、Microsoftは具体的な構造化の手法を公開しており、後者のガイドラインがAEOの指針となる。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AIに選ばれるコンテンツの条件とは?ChatGPTの引用元分析から見えたSEOの新常識
ChatGPTなどの生成AIが回答の根拠としてどのウェブサイトを引用するかは、もはや偶然の産物ではない。最新の調査によれば、特定のトピックにおいて引用されるドメインの約67%は、わずか30個程度の主要サイトに集中しているという実態が明らかになった。
このデータは、120万件に及ぶChatGPTの回答を分析した結果に基づくものだ。従来のGoogle検索におけるSEO(検索エンジン最適化)とは異なる、AI時代の情報収集アルゴリズムが透けて見える内容となっている。
検索の主役が従来のリスト形式からAIによる要約へと移り変わる中で、自社のコンテンツがAIに「信頼できるソース」として選ばれるための条件を理解することは、今後のWebマーケティングにおいて死活問題となるだろう。本記事では、AIがソースを選ぶ基準とその背後にある「科学」について詳しく解説していく。
AIに選ばれるドメインの法則:上位30サイトがシェアの67%を独占
従来のGoogle検索は「勝者総取り」のゲームと言われてきた。検索結果の1位がクリックの大部分をさらっていくからだ。ChatGPTのようなAIの回答においても、この傾向はさらに極端な形で現れている。特定のトピックについて、わずか30のドメインが引用全体の3分の2を占めているという事実は、AIが参照する「信頼の枠」が非常に狭いことを示唆している。
業界ごとに異なる「独占率」の実態
記事によれば、この引用の集中度は業界(バーティカル)によって大きく異なる。例えば「教育」分野は非常に独占が進んでおり、上位10%のドメインが引用全体の約60%を占めている。これは、教育コンテンツにおいては特定の公的機関や大規模な専門サイトが圧倒的な信頼を得ているためだと考えられる。
一方で「ヘルスケア(医療)」分野は、引用が数百のドメインに分散している。医療情報は多岐にわたり、特定の症状や法規制、アプリの活用など、ニッチな領域ごとに異なる専門サイトが引用されるためだ。これは、新しく参入するサイトにとってもAIに引用されるチャンスが残されている「開かれた市場」であることを意味している。
「網羅性」がドメイン権威性を上回る瞬間
興味深いのは、単にドメイン全体の評価が高い(ドメイン権威性が強い)サイトが選ばれるわけではないという点だ。著者のケビン・インディグ氏は、特定の1ページが100種類以上の異なる質問(プロンプト)に対して引用されている事例を挙げている。これは、AIが「サイト全体」よりも「そのページがどれだけ多くの関連する問いに答えているか」を重視している証拠だ。
たとえ有名な大企業のサイトであっても、情報が断片的であればAIには選ばれにくい。逆に、1つのページで「とは何か」「選び方」「価格」「比較」といったトピックを網羅しているページは、AIにとって効率的な情報源となり、多くの引用を獲得することになる。
引用獲得の鍵は「文字数」にあり?1万文字の壁と業界別の最適解
SEOの世界では長らく「コンテンツの長さと順位の相関」が議論されてきたが、AIによる引用においても文字数は重要な指標となる。分析結果によると、ページのテキスト量が増えるほど引用される確率は高まり、特に5,000文字から10,000文字(英語圏のデータでは文字数ベース)のレンジで引用率が急増する傾向が見られた。
1万文字を超えると引用率が2倍に跳ね上がる理由
調査データでは、20,000文字(キャラクター数)を超えるページは、500文字未満のページに比べて約4倍の引用を獲得している。これは、AIが複雑な回答を生成する際に、詳細なデータや背景知識が含まれている「厚みのあるコンテンツ」を好んで参照するためだ。LLM(大規模言語モデル)は、文脈を理解するために十分な情報を必要とするため、情報密度の低い薄いコンテンツは無視される傾向にある。
金融やSaaSで見られる「例外」のページ構成
ただし、文字数が多ければ良いというわけではない。業界によっては「短く、正確な情報」が好まれるケースもある。例えば「金融」分野では、10,000文字を超えるような長大な記事よりも、5,000文字程度のコンパクトな記事の方が引用率が高いという逆転現象が起きている。
金融情報の読者は、具体的な利率や規制の要約、比較表などの「即座に使えるデータ」を求めている。AIもそれを理解しており、冗長な解説よりも、データが整理された信頼性の高い要約ページを優先して引用する傾向がある。自分のターゲットとする業界が「網羅的な解説」を求めているのか、それとも「正確なデータの提示」を求めているのかを見極める必要がある。
1枚のページで複数の問いに答える「エバーグリーン戦略」
AI検索における戦略として、著者は「引用の広さ(Breadth)」という概念を提唱している。これは、1つのURLがどれだけ多様な質問に対して引用されたかを示す指標だ。多くのサイトが特定の1つの質問にしか答えられない「使い捨ての回答源」になっている一方で、少数の「エバーグリーン(常緑)なページ」が圧倒的な引用数を稼いでいる。
引用URLの約6割は「一度きり」の使い捨て
分析によると、AIに引用されたURLの約67%は、わずか1種類のプロンプトに対してしか表示されていない。つまり、ほとんどのページは特定のニッチな問いに対する「一発屋」で終わっている。これでは、AI検索からの継続的なトラフィックは期待できない。
複数の意図をカバーする比較・ガイド記事の価値
上位5%に食い込む「エバーグリーンなページ」には共通の構造がある。それは、「2025年最新版:〇〇ツールの比較」といったカテゴリーレベルのガイド形式だ。こうしたページは、「〇〇とは何か」「おすすめはどれか」「価格はいくらか」といった、ユーザーが抱く一連の疑問(クエリクラス)をすべて1ページで解決できるように設計されている。
AIは、複数のソースを行ったり来たりするよりも、1つの信頼できるページから複数の情報を抽出することを好む。そのため、1キーワードに対して1ページを作る従来の「スモールワード狙い」のSEOよりも、トピック全体を構造的に網羅する「トピック・オーソリティ(トピックの権威性)」を意識したページ作りが、AI時代には高い投資対効果(ROI)を生むことになる。
AIが最も注目するのは「ページ冒頭の30%」である

AIがページを「読む」際、すべての箇所を平等に扱っているわけではない。分析の結果、ChatGPTが引用する情報の約44%は、ページの最初の30%の範囲から抽出されていることが分かった。特に、冒頭10〜20%のエリアは「黄金地帯」と呼ばれ、最も高い引用密度を誇っている。
導入文直後の「10-20%」のエリアが黄金地帯
なぜページの最初の方が引用されやすいのか。それは、多くのWebサイトが冒頭に「結論」や「重要な定義」「最新の統計データ」を配置しているからだ。AIは効率を重視するため、ページの深い階層まで読み進める前に、必要な情報を冒頭で見つけようとする。特に金融などのデータ重視の分野では、この「フロントロード(情報を前倒しにする)」傾向が顕著だ。
結論やまとめが引用されにくいという事実
一方で、ページの最後にある「まとめ」や「結論」セクションは、AIにほとんど無視されている。ページの末尾10%から引用される割合は、わずか2.4〜4.4%に過ぎない。人間にとっては親切な「まとめ」も、AIにとっては既出情報の繰り返しに過ぎず、新たな情報のソースとしては価値が低いと判断されている可能性がある。
AIに引用されたいのであれば、重要な主張や独自のデータ、具体的な数値は出し惜しみせず、ページのなるべく早い段階で提示すべきだ。導入文のすぐ後に、その記事の核心となる情報を配置する構成が、AI時代のスタンダードになるだろう。
これからのAI検索最適化(GEO)に向けた独自の考察

今回の調査結果を踏まえると、今後のSEOは「GEO(Generative Engine Optimization / 生成エンジン最適化)」という新しいフェーズに移行していく。これまでのSEOが「検索結果の10個の青いリンクの中にどう入るか」を競っていたのに対し、GEOは「AIの回答の一部としてどう採用されるか」を競うゲームだ。
「1キーワード1ページ」からの脱却
従来の「1つのキーワードに対して1つのページを作る」という手法は、AI検索においては非効率になる可能性がある。AIは散らばった情報を収集するよりも、1つの高密度なソースを好むからだ。これからは、関連する複数のキーワードを包含した、構造的で情報量の多い「ピラーページ(柱となるページ)」の重要性がさらに増すだろう。
構造化データを超えた「情報の密度」の重要性
技術的な側面では、Schema.orgなどの構造化データの実装は引き続き重要だが、それ以上に「テキストそのものの情報密度」が問われるようになる。Jaccard係数(集合の類似度を測る指標)を用いた分析でも、AIはページ内の特定の「情報の塊(チャンク)」を狙い撃ちして引用していることが示されている。つまり、曖昧な表現を避け、AIが抽出しやすい明確な事実とデータの記述が、引用獲得の強力な武器になるのだ。
この記事のポイント
- AIの引用は特定のドメインに集中しており、上位30サイトがシェアの67%を占めている。
- 文字数が多いほど引用されやすい傾向にあるが、金融など業界によっては5,000文字程度の「密度」が重視される。
- 1つのページで複数の問いに答える「網羅的なガイド形式」が、AI検索において高い投資対効果を発揮する。
- AIはページの冒頭30%(特に10-20%付近)を最も重点的に読み、末尾の「まとめ」はほぼ無視する。
- これからのSEOは、断片的なページ作成から、トピック全体を網羅する「トピック・オーソリティ」の構築へとシフトすべきだ。
出典
- Search Engine Journal「The Science Of How AI Picks Its Sources」(2026年3月24日)
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AI検索時代のCMS選び——WebサイトがAI対応できているか実践的な監査手法
AI検索がブランドの可視性とコンバージョンを獲得する方法を再構築している。多くのCMSはこの変化に対応するようには設計されていない。
Search Engine Journalの記事によれば、AI検索対応の監査では構造化データ、柔軟なアーキテクチャ、迅速な適応性が評価基準となる。CMOやマーケティングリーダーは自社のCMSが現代の検索行動をサポートしているか、制限しているかを評価する必要がある。
この記事では、AI検索時代にWebサイトのCMSが備えるべき要件と、実践的な監査手法を解説する。監査を通じて、成長を阻害するリスク領域を事前に特定する方法がわかる。
AI検索が変えるSEOとコンテンツの前提

従来の検索エンジンはユーザーのクエリに合致するWebページをリスト表示していた。AI検索はこのモデルを根本から変える。AIは複数の情報源から情報を統合し、直接的な回答を生成する。
「10個の青いリンク」から「単一の回答」への移行
GoogleのSGE(Search Generative Experience)やMicrosoftのCopilotは、検索結果の上部にAIが生成した回答を表示する。ユーザーは回答を得るために複数のページをクリックする必要がなくなる。
この変化はトラフィックの分散を意味する。かつては1つのクエリで複数のサイトがクリックを獲得できた。AI検索では、回答を生成するために参照された数サイトのみが引用され、他のサイトは結果ページから姿を消す可能性がある。
コンテンツの「解釈可能性」が重要になる
AI検索エンジンはWeb上のコンテンツを読み取り、理解し、要約する。このプロセスで重要なのは、コンテンツが機械的に解釈しやすい構造になっていることだ。
記事によれば、AI対応のCMSはコンテンツを単なるテキストの塊ではなく、意味的に構造化されたデータとして扱う必要がある。著者は、構造化されていないコンテンツはAIによって正確に解釈されず、検索結果で引用される機会を失うと指摘している。
AI対応CMS監査の3つの核心領域

CMOやマーケティング責任者が自社のCMSを評価する際、以下の3つの領域に焦点を当てるべきだ。これらの領域は、AI検索時代における発見可能性とコンバージョン性能を直接左右する。
1. 構造化コンテンツとデータモデリング
構造化コンテンツとは、コンテンツを構成する要素(タイトル、著者、公開日、製品仕様、価格など)を定義し、一貫した形式で保存・管理するアプローチだ。HTMLの見出しタグや段落だけでなく、JSON-LDやMicrodataなどの構造化データマークアップがこれに該当する。
監査の第一歩は、サイトのコンテンツがどの程度構造化されているかを確認することだ。すべてのページに適切なスキーママークアップが実装されているか。ブログ記事、製品ページ、イベント情報など、コンテンツタイプごとに最適な構造化データが使われているか。
記事で言及されているDrupalの例では、エンタープライズ実装において構造化コンテンツのモデリングが不十分なケースが多く、これがAI検索での発見可能性を制限する要因となっている。CMSの管理画面でコンテンツタイプとフィールドを柔軟に定義できるかが、構造化の成否を分ける。
2. コンポーザブルアーキテクチャとAPIファースト設計
コンポーザブルアーキテクチャとは、システムを独立したサービスやコンポーネントに分解し、APIを通じて連携させる設計思想だ。ヘッドレスCMSやAPIファーストCMSはこのアーキテクチャの代表例である。
AI検索エンジンは、コンテンツを取得して処理する必要がある。従来のモノリシックなCMSでは、フロントエンドのHTMLレンダリングとバックエンドのデータ管理が密結合している。これに対してAPIファースト設計のCMSは、純粋なデータ(JSON形式など)を提供できる。
監査では、CMSがRESTful APIやGraphQLを提供しているか、そのAPIがすべてのコンテンツタイプにアクセスできるかを確認する。さらに、APIのレスポンス速度と信頼性も評価項目となる。遅いAPIはAIクローラーのインデックス効率を下げる。
3. オープンソースの柔軟性と開発速度
AI検索の要件は急速に進化する。今日有効な最適化手法が、半年後も通用する保証はない。この変化に対応するには、CMS自体が柔軟で拡張可能である必要がある。
オープンソースCMS(WordPress、Drupal、Joomlaなど)は、コア機能を拡張する無数のプラグインやモジュールを利用できる。プロプライエタリなSaaS型CMSでは、ベンダーが新機能を実装するのを待たなければならない場合がある。
監査では、CMSのエコシステムが活発か、新しい技術(例えば、AI検索向けの新しい構造化データ形式)に対応するモジュールが迅速に開発されるかを調べる。開発チームがカスタム機能を実装するためのドキュメントとAPIは整っているか。
実践的な監査チェックリスト

理論的な要件を理解したら、実際のWebサイトに対して実行できる監査項目を確認する。以下のチェックリストは、Search Engine Journalの記事で紹介された監査手法を基に、実践的な項目をまとめたものだ。
技術的インフラの評価
まず、サイトの技術的基盤がAIクローラーや検索エンジンに友好的かどうかを確認する。
- ページ速度とコアウェブバイタル: GoogleのPageSpeed InsightsやLighthouseでスコアを計測する。特にLCP(Largest Contentful Paint)、FID(First Input Delay)、CLS(Cumulative Layout Shift)の3指標は、ユーザー体験だけでなく、クローラーのページ読み込み効率にも影響する。
- モバイルフレンドリー: Googleのモバイルフレンドリーテストを実行する。AI検索はモバイルユーザーへの回答生成を特に重視する。
- XMLサイトマップの完全性: すべての重要なページがサイトマップに含まれ、正しい更新日付と優先度が設定されているか。サイトマップはAIクローラーに対するナビゲーションの役割を果たす。
- robots.txtの設定: 重要なコンテンツが誤ってクロール禁止になっていないか。動的パラメータなどによる重複コンテンツがインデックスされていないか。
コンテンツ構造とデータの評価
次に、コンテンツそのものの構造と質を評価する。
- 構造化データマークアップの検証: Googleの構造化データテストツールやRich Results Testを使用する。Article、Product、Event、FAQPage、HowToなど、コンテンツに適したスキーマタイプが実装されているか。
- コンテンツの独自性と深さ: AIは表面的なコンテンツを要約しても価値が低い。独自の調査データ、詳細な手順、専門家の洞察など、深みのあるコンテンツがAIに引用される可能性が高い。
- エンティティの明確さ: コンテンツ内で言及されている企業名、人物名、製品名、場所などが明確に定義されているか。これらはAIがコンテキストを理解する上で重要な手がかりとなる。
- コンテンツの新鮮さ: 最終更新日が明示されているか。古い情報はAIの信頼性判断で不利に働く可能性がある。
CMSプラットフォーム固有の評価
最後に、使用しているCMS自体の能力と制限を評価する。
- 構造化コンテンツ管理機能: CMSはカスタムフィールドやコンテンツタイプを直感的に作成・管理できるか。フィールド間の関係性(リレーションシップ)を定義できるか。
- APIの成熟度: CMSが提供するAPIは包括的か、セキュリティとパフォーマンスの面で信頼できるか。ドキュメントは整っているか。
- ワークフローとコラボレーション: AI時代はコンテンツの迅速な更新と最適化が求められる。CMS内で編集、承認、公開のワークフローが効率的か。複数人での同時編集をサポートしているか。
- エコシステムと統合可能性: CDN、分析ツール、マーケティングオートメーションなど、外部サービスと容易に連携できるか。AI関連サービス(自然言語処理APIなど)との統合は想定されているか。
監査結果に基づくアクションプラン

監査は現状分析で終わっては意味がない。結果を基に具体的な改善アクションに落とし込む必要がある。監査で明らかになったギャップは、短期・中期・長期のアクションに分類できる。
短期対応:即効性のある技術的修正
監査で発見された技術的な問題点のうち、比較的少ない工数で修正できるものから着手する。
- 構造化データの追加・修正: 欠落しているスキーママークアップを実装する。既存のマークアップにエラーがあれば修正する。多くのCMSではプラグインやモジュールで比較的簡単に対応可能だ。
- パフォーマンス最適化: 画像の最適化(WebP形式への変換、遅延読み込み)、CSS/JSの最小化と結合、キャッシュ設定の見直しなど、ページ速度を改善する施策を実行する。
- コンテンツの微調整: メタディスクリプションの改善、見出し構造の明確化、内部リンクの追加など、既存コンテンツのAI向け最適化を行う。
中期対応:CMS機能の拡張とプロセス改善
CMSの設定や運用プロセスに関わる、やや規模の大きい改善を行う。
- コンテンツモデルの再設計: 新しいコンテンツタイプを定義したり、既存のフィールド構造を見直したりする。これにより、今後作成するすべてのコンテンツが最初から構造化された状態で生まれる。
- APIエンドポイントの整備: ヘッドレスCMSを検討する、または既存CMSのAPI層を強化する。コンテンツ配信ネットワーク(CDN)やエッジコンピューティングとの連携を容易にする。
- 編集ガイドラインの更新: コンテンツ作成チーム向けに、AI検索を意識した新しい編集ガイドラインを作成する。エンティティの明示的な記述、データの出典明示、構造化されたリストの使用などを含める。
長期対応:アーキテクチャの見直しとプラットフォーム選定
監査の結果、現在のCMSが根本的にAI検索時代の要件に対応できないと判断された場合、プラットフォームそのものの移行を検討する段階だ。
記事では、オープンソースで柔軟性の高いCMSが長期戦略に適しているとの見方が示されている。移行を検討する際は、以下の観点で新しいプラットフォームを評価する。
- ネイティブの構造化データサポート: コア機能として構造化コンテンツ管理をサポートしているか。
- コンポーザブルアーキテクチャ: ヘッドレス、APIファースト、あるいはそれらを選択可能なハイブリッドモデルを採用しているか。
- 開発者エコシステム: 活発なコミュニティと豊富な拡張機能があるか。新しい技術トレンドに迅速に対応するモジュールが開発されるか。
- スケーラビリティとパフォーマンス: コンテンツ量とトラフィックの増加に合わせてスケールできるか。エッジ配信などの現代的なインフラと親和性が高いか。
この記事のポイント
- AI検索は「10個の青いリンク」モデルから「単一のAI回答」モデルへ移行し、コンテンツの発見可能性の条件を変えた。
- AI対応CMS監査の核心は「構造化コンテンツ」「コンポーザブルアーキテクチャ」「オープンソースの柔軟性」の3領域にある。
- 実践的な監査では、技術インフラ、コンテンツ構造、CMSプラットフォームの3レベルを評価する。
- 監査結果は短期・中期・長期の具体的なアクションプランに落とし込み、継続的に改善を進める必要がある。
出典
- Search Engine Journal「Is Your Website Ready for AI Search? A Practical Audit for CMOs」(2026年3月25日)
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

SEOの新戦場「コンセンサス・レイヤー」攻略法——AI検索時代に生き残る信頼の構築術
検索結果の1位を獲得していても、ユーザーからは全く見えない存在になるリスクが高まっている。従来の検索エンジンが「URLのリスト」を提示していたのに対し、生成AIやAI検索エンジンは、複数のソースから情報を合成して「一つの回答」を提示するからだ。
2024年半ば以降、AIによる検索概要(AI Overviews)が表示されるクエリにおいて、オーガニック検索のクリック率(CTR)は61%も低下した。AIが回答を完結させてしまうため、ユーザーはサイトを訪問する必要がなくなっている。この変化は、SEOの主戦場が「掲載順位」から「コンセンサス(合意)」へと移行したことを意味する。
この記事では、AIがどの情報を信頼し、どのブランドを回答に採用するかを決定する「コンセンサス・レイヤー」の仕組みを解説する。最新のSEO戦略において、なぜ分散型の信頼構築が必要なのか、その具体的な手法を紐解いていく。
検索順位の価値が変わる?「コンセンサス・レイヤー」の正体
これまでのSEOは、特定のキーワードで自社サイトを上位に表示させ、クリックを促すことがゴールだった。しかし、ChatGPTやPerplexityのようなAI検索エンジンが登場したことで、その論理は通用しなくなっている。著者のアダム・ハイツマン氏は、これを「リトリーバル(検索)からコンセンサス(合意)への移行」と表現している。
AIが回答を生成する仕組み「RAG」
AI検索の裏側では、RAG(Retrieval-Augmented Generation / 検索拡張生成)という技術が動いている。これは、AIがWeb上の膨大な情報をリアルタイムで検索し、信頼できる複数のソースから共通する主張を抽出して、一つの回答にまとめ上げる仕組みだ。
RAGとは、AIが学習データだけに頼らず、外部の最新情報を参照して回答の精度を高める手法を指す。このプロセスにおいて、AIは一つのサイトの情報だけを信じることはない。複数の独立したメディアやプラットフォームが同じ内容を述べているとき、AIはその情報を「事実」としての確信度が高いと判断し、回答に採用する。
コンセンサス・レイヤーは「パターンの認識」
コンセンサス・レイヤーとは、複数のAIシステムが特定のブランドやサービスについて、どれだけ一貫した情報を出力できるかを示す指標だ。AIはハルシネーション(事実に基づかない嘘)を防ぐために、情報の裏付け(Corroboration)を常に行っている。
例えば、あるブランドが自社サイトだけで「業界No.1」と主張していても、AIはそれをコンセンサスとは見なさない。一方で、複数のニュースサイト、レビュープラットフォーム、SNS、業界フォーラムで同様の評価を受けていれば、AIはそれを強力なパターンとして認識する。孤立した権威ではなく、分散された信頼こそがAI時代のSEOの鍵となる。
AIが信頼性を判断する「コンセンサス」の構成要素

AIがどのブランドを回答に含めるかを決める際、従来のバックリンク(被リンク)以外のシグナルを重視するようになっている。ハイツマン氏は、特に以下の要素がコンセンサス形成に寄与すると指摘している。
リンクのない「サイテーション(言及)」の重み
これまでのSEOでは、リンクがない言及は価値が低いとされることが多かった。しかし、AIシステムはWebページをテキストデータとしてスキャンするため、リンクの有無に関わらずブランド名が語られている文脈を理解する。信頼性の高い業界メディアでブランド名が出るだけで、それは強力なコンセンサス・シグナルとなる。
Semrushの調査によれば、ChatGPTが引用したウェブページの約90%は、同じクエリの検索結果で上位20位以内に入っていないという。これは、AIが「検索順位が高いページ」ではなく「広範囲で信頼されている情報源」を優先して選んでいる証拠だ。
コミュニティとエンティティの明確化
RedditやQuoraなどのコミュニティプラットフォームでの評判も無視できない。AIはリアルなユーザーの声を重視するため、特定のサブレディット(Reddit内の掲示板)で推奨されているブランドは、AIの回答に反映されやすくなる。これは「偽造できない信頼」としてAIに評価されるためだ。
また、エンティティ(実体)の明確化も重要だ。エンティティとは、人、場所、組織など、検索エンジンが識別できる概念を指す。Schema.org(構造化データ)やJSON-LDを適切に設定し、自社が「何者であり、どのカテゴリーで、どのような専門性を持っているか」を機械可読な形式で伝えることで、AIは情報を取得しやすくなる。
実践的な戦略:AI検索で選ばれるブランドになるために

コンセンサスを構築するには、自社サイトの改善だけでは不十分だ。Web全体に自社の信頼の証拠を散りばめる必要がある。具体的なステップは以下の通りだ。
自社LLMオーディット(監査)の実施
まずは、主要なAI(ChatGPT、Perplexity、Geminiなど)に対して、顧客が尋ねそうな質問を投げかけてみることから始める。「〇〇の課題を解決する最適なツールは?」「△△業界の主要なプロバイダーは?」といった質問だ。
この監査により、自社がどのように認識されているか、あるいは無視されているかが浮き彫りになる。もし競合他社ばかりが推奨されているのであれば、どのメディアが引用源になっているかを特定し、そこへの露出を強化する戦略が必要になる。古い情報が回答に使われている場合は、外部メディアの情報を更新する働きかけも重要だ。
独自調査データによる「引用源」の確立
AI時代に最も強力なコンテンツは「独自調査データ」である。業界のベンチマークとなる統計、独自のアンケート結果、実験データなどは、他のメディアやジャーナリストが引用しやすいためだ。多くの外部ソースから引用されることで、そのデータの「発信元」としての地位が確立され、AIは確信を持ってそのブランドを回答に採用するようになる。
また、専門家による監修や寄稿も効果的だ。AIは執筆者の専門性(E-E-A-T)を評価するため、業界で認知されている人物がブランドに関わっている証拠を、構造化データとともにWeb上に残していくことが求められる。
成果をどう測るか?新しいSEOのKPI設定

検索順位が唯一の指標ではなくなった今、計測すべきKPIも変化している。従来の「クリック数」や「順位」だけに固執すると、戦略を見誤る可能性がある。
シェア・オブ・ボイスとエンティティの共起
AIの回答内での「シェア・オブ・ボイス(占有率)」を測定することが重要だ。特定のカテゴリに関するAIの回答のうち、自社ブランドが言及された割合を追跡する。また、どのようなキーワードや競合他社と一緒に語られているかという「共起(Co-occurrence)」のパターンも分析対象となる。
さらに、言及されているドメインの多様性(Mention Density)も指標になる。特定のサイトだけでなく、幅広い独立したメディアで自社が語られている状態を目指すべきだ。これらの指標は、単なるトラフィックよりも、ブランドの長期的な「AI視認性」を正確に表すものとなる。
この記事のポイント
- 順位から合意へ:AI検索は単一のページではなく、Web上の「コンセンサス(合意)」を基に回答を合成する。
- RAGの理解:AIは複数の信頼できるソースから情報を引き出し、裏付けが取れたものだけを回答に採用する。
- サイテーションの重要性:リンクの有無に関わらず、信頼性の高いメディアやコミュニティでの言及がAIの信頼シグナルになる。
- 独自データの活用:独自調査や統計を発信することで、AIが引用せざるを得ない「情報の源泉」としての地位を築く。
- KPIの刷新:クリック率だけでなく、AI回答内でのシェアや言及の多様性を追跡し、分散型のオーソリティを評価する。
出典
- Search Engine Land「SEO’s new battleground: Winning the consensus layer」(2026年3月20日)
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、Java等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験