

AWS WAFがAIボット収益化機能を追加、コンテンツ所有者が課金可能に
AWSは2026年6月15日、AWS WAFにAIトラフィック収益化機能を追加した。コンテンツ所有者やパブリッシャーが、自社のWebコンテンツにアクセスするAIボットやAIエージェントに対して、ネットワークエッジで直接課金できるようになる。
AIボットによるWebトラフィックは、多くのコンテンツプロバイダーで全体の50%を超え、AI専用クローラーは前年比300%以上増加している。従来の検索エンジンクローラーはリンクを返すことで参照トラフィックをもたらすが、AIボットはコンテンツを要約してAIインターフェイス上で表示するため、元のサイトにはほとんどトラフィックが還元されない。その結果、コンテンツ提供者はインフラコストだけを負担し、広告収入や購読コンバージョンといった従来の収益源が得られない状況が続いていた。
今回の新機能は、このギャップを埋めるものだ。AWS WAF Bot Controlの仕組みを拡張し、コンテンツパスごと、ボットカテゴリごと、検証ティアごとにリクエスト単価を設定できる。また、ステーブルコインによる支払いをウォレットで受け取り、単一のダッシュボードで収益とボットアクティビティを追跡可能にする。
AIボット収益化の新機能がAWS WAFに追加された背景

AIトラフィックの爆発的な増加
GPTBotやClaude-Web、Perplexity-BotといったAIクローラーは、学習用データやリアルタイム情報の収集のためにWebサイトを大量にクロールする。こうしたトラフィックは増加の一途をたどり、一部のコンテンツプロバイダーではAIボットが全リクエストの50%を超えるまでになっている。検索エンジンのクローラーとは異なり、AIボットはインデックスを生成する代わりにテキストを直接消費し、要約をAIチャット画面に表示する。そのため、元記事を読むための流入はほとんど発生しない。
従来のBot Controlでは限界があった理由
AWS WAF Bot Controlはこれまで、650種類以上のAIボットを検出し、ブロックまたはレート制限をかけることができた。しかし、ボットのトラフィックを完全に遮断するのではなく、課金して収益化したいというニーズは強く存在していた。コンテンツを無料で提供し続ければインフラコストがかさむ一方、単純にブロックすればAIサービスへの露出が途絶えてしまう。そこで、ボットにコンテンツ利用の対価を支払わせる仕組みが求められていた。
AIトラフィック収益化の仕組み

x402プロトコルとHTTP 402 Payment Required
今回の収益化機能の核は、x402というマシンツーマシン決済のオープンプロトコルだ。ルールに合致したAIボットからのリクエストに対し、AWS WAFはHTTP 402 Payment Requiredレスポンスを返す。このレスポンスボディには、コンテンツの価格(USDC建て)、受け入れ可能なブロックチェーンネットワーク(BaseやSolanaなど)、送金先ウォレットアドレス、支払いタイムアウトを含むJSON形式のプライスマニフェストが含まれる。これを受け取ったx402対応のエージェントランタイムは、自律的に署名付き支払い承認を提出し、AWS WAFがそれを検証したうえでコンテンツを提供するという流れだ。
ステーブルコイン決済の流れ
決済はステーブルコイン(USDC)で行われ、サードパーティのファシリテーターサービス(現在はCoinbaseのx402 Facilitator)がオンチェーン上の決済処理を支援する。Stripeによる直接アカウント決済やMachine Payments Protocol(MPP)への対応も近日中に予定されている。コンテンツ所有者は、AWS WAFの設定パネルでウォレットアドレスを指定するだけでよく、独自の決済インフラを構築する必要はない。また、AWS自体は決済手数料を徴収しない。
上記のように、収益化を有効にするとAIボットのアクセスが自動的に402レスポンスに切り替わり、支払いが完了したリクエストだけがコンテンツに到達する。コンテンツ所有者はアクセスを遮断する代わりに料金を設定し、ボットトラフィックを収益源に変えることができる。
収益化の設定手順
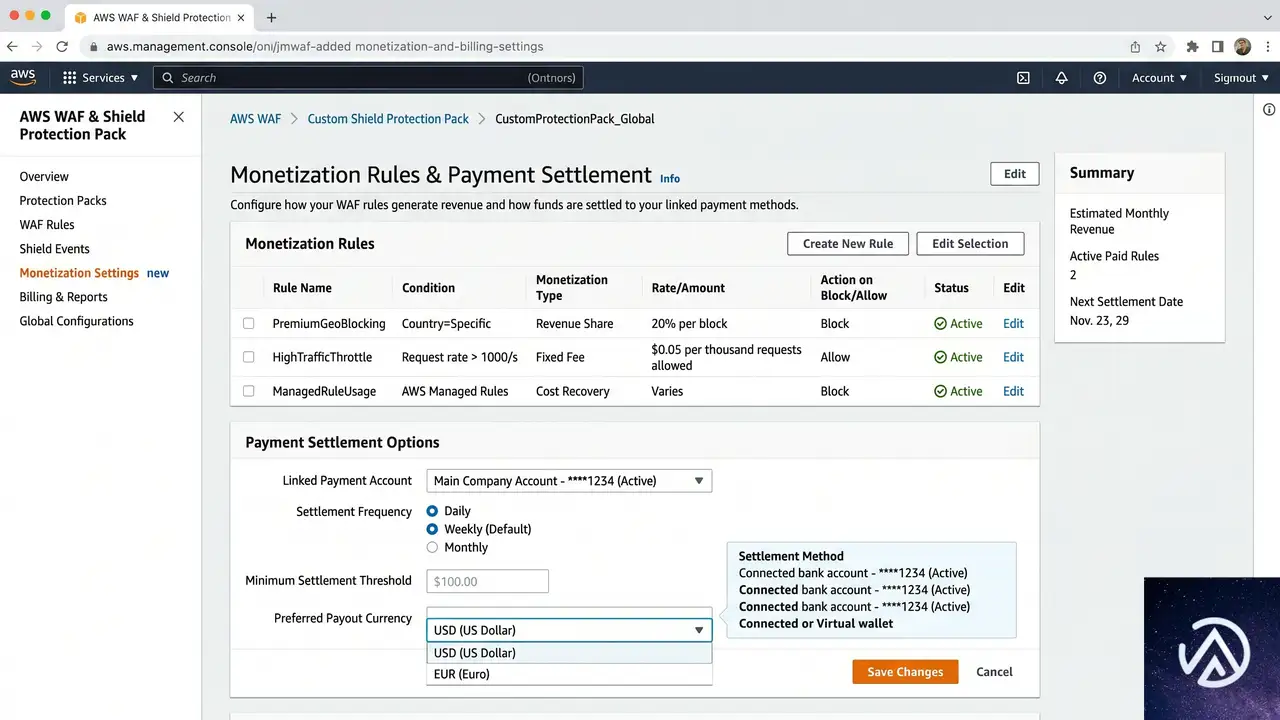
プロテクションパックの作成
AIトラフィック収益化を使うには、まずAWS WAF Bot ControlをCommonまたはTargetedレベルで有効にしたうえで、プロテクションパック(Protection Pack)を作成する。プロテクションパックとは、どのコンテンツパスを収益化するか、各検証ティアにいくら課金するか、どの支払い方法を受け入れるかといったポリシーをまとめた設定単位だ。AWSマネジメントコンソールで「WAF & Shield」を開き、「Protection packs (web ACLs)」から作成を開始する。
作成時にアプリカテゴリ(コンテンツ・パブリッシングシステム、Eコマースなど)を選択し、保護対象のリソース(CloudFrontディストリビューション)をひも付ける。推奨ルールパッケージが提示されるが、個別のルールを選ぶことも可能だ。プロテクションパックを作成したら、必要に応じて価格帯や支払い方法、コンテンツ範囲、ライセンス条項をカスタマイズする。
収益化ルールの設定
プロテクションパックを選び、「Configure AI monetization」から検証ティアごとにアクションを割り当てる。アクションは6種類ある。Monetize(402を返し課金)、Allow(無料アクセス許可)、Block(完全遮断)、Count(課金せずログだけ記録)、CAPTCHA(人間の確認)、Challenge(ブラウザかどうかのサイレントチェック)だ。Monetizeを選択すると、支払い決済用のブロックチェーンネットワーク(BaseやSolanaなど)を指定し、ウォレットアドレスとUSDC建てのページ単価を設定する。
Monetizeアクションは、Amazon CloudFrontディストリビューションに関連付けられたWeb ACLでのみサポートされる。リージョナルWeb ACLでは使えない点に注意が必要だ。また、本番投入前にテストモード(Currency modeをTestに切り替え)で、テストネット(Base SepoliaやSolana Devnet)を使った検証が可能となっている。テストモードでも実際の402レスポンスと支払いフローが再現され、すべてのイベントにCurrencyMode: TESTのログが付与される。
この一連の流れは、サイトのオリジンサーバーに一切手を加えることなく、AWS WAFのエッジで完結する。コンテンツ提供者はアプリケーションコードを修正する必要がないため、既存のWebサイトに迅速に収益化機能を追加できる。
AIトラフィック分析ダッシュボードと収益トラッキング
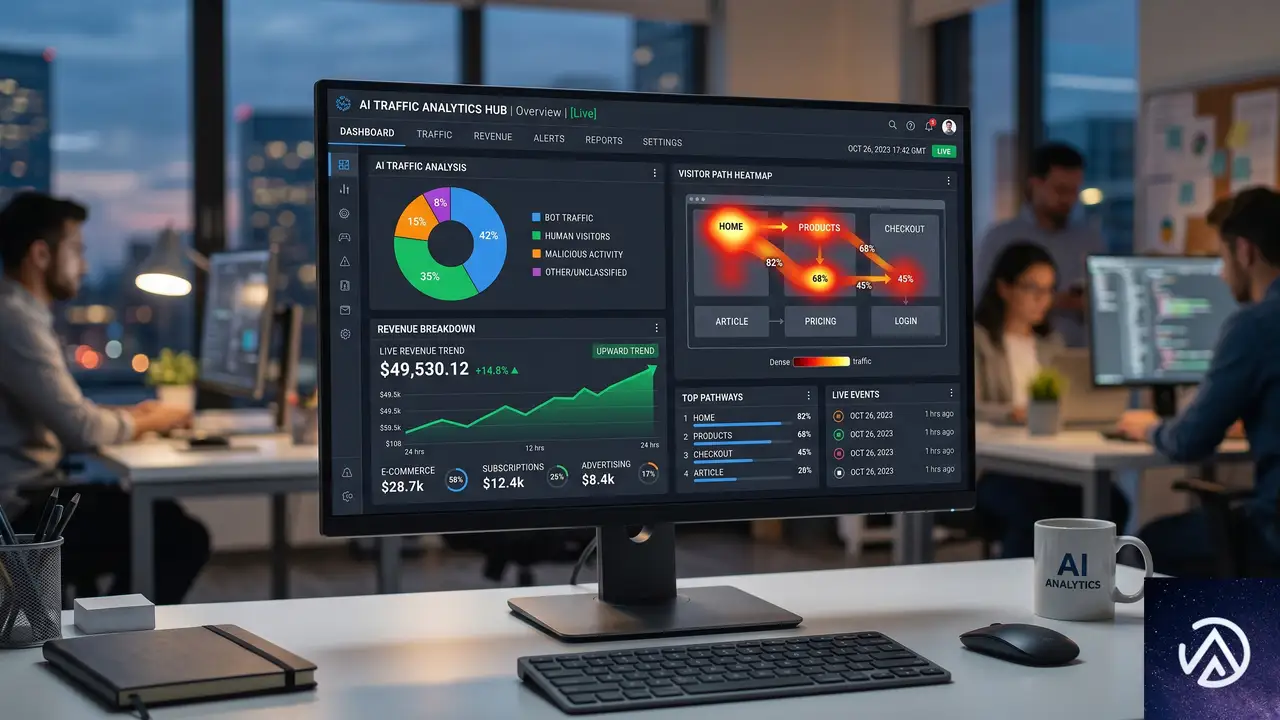
価格設定を最適化するためのAIトラフィック分析ダッシュボードも提供される。プロテクションパックを選択すると、ボットリクエスト全体、AIボットリクエスト、検証済みAIトラフィック、未検証AIトラフィックの4カテゴリに分けてトラフィックを可視化する。帯域幅の消費量、推定月間コスト、ピークリクエストレートといったインフラ影響指標も表示され、パスごとのヒートマップで時間帯別のAIボット集中度がわかる。
Currency modeをRealに切り替えると、「AI access monetization」ダッシュボードで実際の収益をリアルタイムに追跡可能だ。総収益、検証済みボットと未検証ボットの内訳、リクエストあたりの平均単価が表示され、上位の収益ソースやコンテンツパス別の収益ランキングも確認できる。Settlementsタブでは決済プロバイダーごとの精算状況や支払い失敗の分析も行える。
導入のポイントと今後の展望
この機能は、CloudFrontを利用するすべてのAWS WAFユーザーに対して追加料金なしで提供される。ただし、Monetizeを適用できるのはCloudFrontディストリビューションに関連付けたWeb ACLのみである点は押さえておきたい。また、テストモードを活用して本番適用前に価格設定やウォレット設定、x402フローを十分に検証することが推奨される。
今後、Stripeの直接アカウント決済やMPPに対応することで、より多様な支払い手段が利用可能になる見通しだ。AIボットのトラフィックが増え続ける中、コンテンツの価値を適切に回収する仕組みとして、この収益化機能は重要な選択肢となる。自社サイトへのAIクローラーの影響を分析している企業は、まずBot Controlのダッシュボードでトラフィックの可視化から始め、段階的に収益化を検討するのが良いだろう。
この記事のポイント
- AWS WAFにAIボット向け課金機能が追加され、HTTP 402とx402プロトコルでマシンツーマシン決済を実現
- コンテンツパスや検証ティアごとにリクエスト単価を設定でき、ステーブルコインで収益を受け取れる
- 設定はプロテクションパック単位で行い、CloudFront環境のエッジで自律的に課金とコンテンツ配信が完結
- AIトラフィック分析ダッシュボードでコストと収益を可視化し、価格設定を最適化できる
- テストネットを使った検証モードがあり、本番適用前にリスクを評価可能

・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AnthropicのFable 5が米政府命令で強制停止、SEO業界に衝撃
Fable 5とMythos 5、米国政府の輸出管理命令で突然の利用停止

米国政府は2026年6月13日、国家セキュリティを理由にAnthropicへ輸出管理命令を出し、同社の最新AIモデル「Fable 5」および「Mythos 5」の全利用停止を強制した。命令は外国籍の個人によるアクセスを禁じており、実質的に全顧客の接続を遮断せざるを得ない内容だ。
Anthropicは同日に声明を発表し、政府の見解に反論した。両モデルには強固なセーフガードが重層的に組み込まれており、既存のAIモデルと同等のリスク水準に留まっていると主張している。しかし、命令受領からわずか数時間でFable 5とMythos 5のアクセスは世界中で停止された。
この措置は、SEOやデジタルマーケティングで最先端AIを活用してきた企業・個人に直接的な影響を及ぼす。高性能モデルの急な遮断は、コンテンツ制作フローや競合分析の自動化パイプラインを根底から揺るがすためだ。
このデモでは、Fable 5が突然使えなくなり、SEOワークフローに穴が空く状況を図示している。高性能なモデルに依存していた自動化プロセスは、一気に精度と速度が落ちる。
輸出管理命令の具体的な中身
命令は輸出管理指令と呼ばれる法的措置で、技術やデータの国外移転を制限する。Anthropicはこの命令を「外国籍の者へのアクセスを一切禁じる」と解釈せざるを得ず、結果的に全世界のユーザーが利用不能になった。同社が受けたのは東部夏時間17時21分。ほぼその日のうちに、サービス停止が現実となった。
政府はFable 5のセーフガードを突破する手法があると指摘しているが、Anthropicは提示された事例を「軽微な脆弱性」と一蹴。同社は既に多層防御と厳重なモニタリングでリスクを抑え込んでいる立場だ。
SEO業界が受ける打撃、AI駆動型ワークフローの寸断

Fable 5の急停止は、SEO担当者やアフィリエイトマーケターに具体的な痛みをもたらした。特に月額200ドルの「Claude Max」プランに切り替えたばかりのユーザーからは、返金を求める声がXで相次いだ。新しいモデルを前提にした記事生成や分析タスクが突然止まったためだ。
この流れは、AIモデルをコンテンツ制作パイプラインに組み込んできたSEOチームにとって、サプライチェーン途絶に近い。短納期の記事更新や、多言語でのローカライズ、高度なエンティティ抽出にFable 5を使っていたケースでは、代替モデルへの切り替えに伴う品質低下と工数増加が避けられない。
上のフローは、AIモデルを活用したSEOコンテンツ制作の典型的な手順だ。Fable 5が消失すれば、STEP 1の時点で生産性が大幅に落ちる。
返金要求とMaxプランの混乱
Xの投稿では、多くのユーザーが「Fable 5を使うためにMaxプランに切り替えたのに、当日に遮断された」と訴えている。あるユーザーは「生物学の基本的な質問さえできなかった」と、セーフガードの過剰さを指摘。多額の課金が一瞬で無駄になった苛立ちが広がった。
これはBtoBのSEO支援会社にとっても同様で、クライアント向けのコンテンツをFable 5に依存していた場合、納期の遅延と追加コストが発生する。急速なAI導入が裏目に出る典型例と言える。
国家セキュリティとAI規制、SEOに迫る論点

今回の措置は、AIによるサイバーセキュリティリスクを巡る政府とAnthropicの長年の対立の延長線上にある。Anthropicは大量監視や自律型兵器への技術提供を拒否してきた経緯があり、それが政府の不信感を強めたと見られる。
SEO業界への教訓は単純だ。極めて高性能なAIモデルは、常に地政学的リスクの影響を受ける。特定のベンダーに過度に依存したコンテンツ戦略は、突如として停止する可能性がある。複数のAIプロバイダーを使い分けるマルチベンダー戦略が、今後の安定運用の鍵を握る。
上の図は、リスク分散のためのマルチベンダー構成の一例だ。1つのモデルが遮断されても、他のプロバイダーや自社ホストのモデルでカバーできる。
「強力すぎるAI」を喧伝したツケ
批判の矛先はAnthropic自身にも向いた。同社が長年「極めて強力で危険なAI」と自社モデルを位置付けてきたことが、政府の深刻な受け止めを招いたという指摘だ。Xでは「恐怖をブランドにして政府に輸出管理をかけられ、今更『誤解』と言うのか」と皮肉る投稿が散見された。
SEO担当者にとっては、AIの性能を過大にアピールするマーケティングが規制を早める可能性を認識する契機になる。クライアントや社内で「最強のAIを使っている」と謳う前に、その文言が持つ政治的な重みを考慮すべき局面だ。
SEO戦略に組み込むAIレジリエンス、今後の備え
Fable 5停止のような事態に備え、SEO担当者は次の3つの柱を早急に固める必要がある。第一に、複数AIモデルへのアクセス経路の確保。第二に、AI非依存の編集プロセスとの併用。第三に、オープンソースLLMの社内導入検討だ。
Anthropicは「サービスの早期復旧を目指す」と表明しているが、法的な結末は不透明だ。最悪の場合、最先端モデルへのパブリックアクセスが恒久的に制限される可能性もゼロではない。そのとき、手元に自前の代替手段を持たないチームは、検索順位を維持するための初速で致命的な遅れを取る。
この比較が示す通り、AIに依存するほど、その供給停止がもたらすダメージは大きくなる。今のうちにバックアップのAIパイプラインをテストし、実際に切り替え可能な状態にしておくことが重要だ。
この記事のポイント
- 米国政府の輸出管理命令によりAnthropicのFable 5とMythos 5が全ユーザーに対して突然停止された
- SEO業界では高精度AIを前提としたコンテンツ制作フローが寸断され、返金要求や納期遅延が発生
- 高性能AIのブランディングが規制を呼び込むリスクが現実化した
- マルチベンダー戦略やオープンソースLLMの導入で、AIサービス遮断に強いSEO体制を構築すべき
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

OpenAIがSECにS-1を機密提出、IPO準備を正式発表
OpenAIが2026年6月8日、米証券取引委員会(SEC)に新規株式公開(IPO)に向けた機密のS-1書類を提出した。情報漏洩を想定し、同社は自らこの事実を公式ブログで公表している。
ただし上場の具体的な日程は決まっていない。OpenAIの発表によれば、非公開企業のまま進めたいプロジェクトが複数あり、時期は未定だという。それでもS-1を提出したことで、市場環境が整い次第すぐに公開企業へ移行できる選択肢を確保した形だ。
この動きはAI開発における資金調達競争の節目となる可能性がある。特にChatGPTやAPIを活用するWeb制作・開発の現場では、OpenAIのガバナンスやサービス継続性に直結する話だ。本記事ではS-1提出の背景、上場がAI業界と開発現場に与える影響、今後の注目点を整理する。
OpenAIがSECにS-1を機密提出、IPO準備を正式発表
OpenAIは2026年6月8日、公式ブログでSECへのS-1草案提出を明らかにした。同社の発表文は極めて短く、「機密S-1を最近提出した。リークが予想されるため、こちらから発表する」と率直に述べている。企業がIPO準備を進める際、まず機密扱いでS-1を提出し、SECの審査を受けるのは一般的な手続きだ。
提出の事実そのものは珍しくないが、OpenAIがそれを自ら公表した点は異例といえる。通常、機密S-1の存在は企業が正式にIPOを発表するまで非公開だ。OpenAIはリークによる憶測や誤情報の拡散を避けるため、先手を打った格好になる。
開示された情報は限られるが、OpenAIは1933年証券法規則135に基づく告知であることを明記し、証券の売却や購入勧誘を構成しないと注意を添えている。これは法的に必要な但し書きであり、正式なIPO日程の発表ではない点を強調する意図がある。
S-1提出の背景、非公開企業としてのメリットと上場のジレンマ
OpenAIが「非公開のまま進めたいこと」とは何か
OpenAIの発表文には「非公開企業のままの方が進めやすいプロジェクトがいくつかある」と書かれている。具体的な内容は明かされていないが、考えられるのはAGI(汎用人工知能)やそれを超える知能の基礎研究だ。四半期ごとの決算発表や投資家への説明責任が生じる公開企業では、短期的な収益に結びつかない長期的R&Dへの巨額投資が説明しづらい面がある。
OpenAIのミッションは「安全で人類全体に利益をもたらすAGIの開発」だ。過去の投資ラウンドでも、同社は営利企業でありながら非営利組織のガバナンス下に置く独自の「キャップド・プロフィット」構造を採用してきた。上場後もこの構造を維持できるかは不明で、株主価値最大化の圧力がミッションと衝突するリスクは以前から指摘されている。
「上場する選択肢を残す」ことの戦略的意味
S-1を提出しておきながら日程を決めないのは、OpenAIが複数のシナリオに備えている証拠だ。AI市場の成長や競合の資金調達動向を見極め、最適なタイミングでIPOを実行できる準備を整えたと読める。
競合のAnthropic(Claude開発元)は2026年時点で非公開のまま巨額のベンチャー資金を調達し続けており、Google DeepMindは親会社Alphabetの資金力を背景に研究を進めている。一方で、xAIやMetaのAI部門は独自の資金調達経路を模索中だ。OpenAIが上場すれば、AIスタートアップとしては初の大型IPOとなり、市場の評価基準が形成される可能性がある。
- ✓ 長期的R&Dに集中しやすい
- ✓ ミッション優先の経営判断が可能
- ✗ 資金調達は投資ラウンド頼み
- ✗ 社員のストックオプション流動性に制限
- ✓ 株式市場から巨額の資金を調達可能
- ✗ 四半期決算のプレッシャーが発生
- ✗ AGIの安全性研究が投資家の短期的利益と衝突する可能性
- ✗ 情報開示義務により競合に戦略が筒抜けになるリスク
この図式から分かるように、非公開状態には研究の自由度という明確な強みがある。その一方で、AI開発には数百億ドル単位の計算資源投資が必要であり、公開市場からの資金調達は無視できない武器になる。OpenAIはこのジレンマを抱えながら、IPOの理想的なタイミングを慎重に見定めている段階だ。
上場がAI開発競争とエコシステムに与える影響

AIインフラ市場への資金流入が加速する可能性
OpenAIが上場すれば、AI開発のためのインフラ投資が一段と加速する可能性が高い。同社は既にMicrosoftとの提携を通じて大規模な計算基盤を確保しているが、IPOで得た資金は独自のデータセンター建設やチップ開発に振り向けられると予想される。これはAWSやGoogle Cloud、NVIDIAのようなインフラ企業の売上をさらに押し上げる連鎖を生む。
同時に、公開市場の投資家がAI企業の評価基準をどう設定するかが、後続のAIスタートアップのIPOや資金調達環境を左右する。OpenAIが高評価で上場すれば、AnthropicやCohereといった競合の評価も連動して上昇するだろう。逆に、収益化の遅れが嫌気されて株価が低迷すれば、AIバブル崩壊の引き金になるリスクも否定できない。
API料金とサービス品質への影響
Web制作やアプリ開発の現場で最も直接的な影響を受けるのは、OpenAIのAPI料金とサービス品質だ。非公開企業の間は、利用促進のために無料枠の拡大や試験的な価格引き下げを柔軟に行える。しかし上場後は、株主に対して持続可能な収益構造を示す必要があるため、価格体系の安定化と同時に無料枠の縮小や値上げが行われる可能性がある。
- 新モデルを積極的に投入し開発者を囲い込む段階
- 価格改定は頻繁だが、引き下げ方向が中心
- 利用規約やレート制限が実験的に変更されることがある
- 価格体系が安定し長期契約が組みやすくなる
- 収益報告により財務の透明性が向上
- ⚠ コスト削減圧力で無料枠廃止や値上げの可能性
Web開発者としては、OpenAIのAPIに依存したサービスを構築している場合、上場後の価格変更やSLA(サービスレベル契約)の変動に備えておく必要がある。マルチベンダー戦略としてClaude APIやGemini APIなど複数のAIプロバイダを併用する設計が、リスクヘッジとして有効になるだろう。
Web制作・開発現場にとっての意味と今後の備え
API依存サービスのリスク管理が急務に
WordPressのプラグインやSaaS型のWebサービスでは、ChatGPT APIを組み込んでコンテンツ生成やチャットボット機能を提供する事例が急増している。上場に伴いOpenAIの事業戦略が変化すれば、これらのサービスは価格改定の影響を直接受ける立場にある。
例えば、現在は無料枠で運用できている小規模なブログ向けAI機能が、上場後に有料化されるケースが想定される。開発段階からOpenAIだけでなくAnthropicやGoogleのAPIを抽象化レイヤーで切り替えられる設計を採用しておくと、将来的なベンダーロックインを回避できる。
AI開発の民主化とコモディティ化の加速
OpenAIのIPOは、AIが「特殊な研究分野」から「公開市場で評価される一般事業」へ移行する象徴的な出来事だ。上場によってOpenAIの財務情報や事業計画が公開されれば、他のAI企業の評価や投資判断も透明性を増す。これは長期的に見れば、API価格の競争を促し、Web制作現場にとってはAI導入コストの低下につながる可能性が高い。
一方で、AIモデルの開発コストは依然として巨額であり、上位プレイヤーへの集中が進む構造は変わらない。公開市場からの資金調達でさらに差が広がる可能性もある。開発者コミュニティとしては、オープンソースモデル(Llama、Mistralなど)の進化も視野に入れながら、特定企業のAPIに過度に依存しないアーキテクチャ選択が重要になる。
今後のスケジュールと注目点
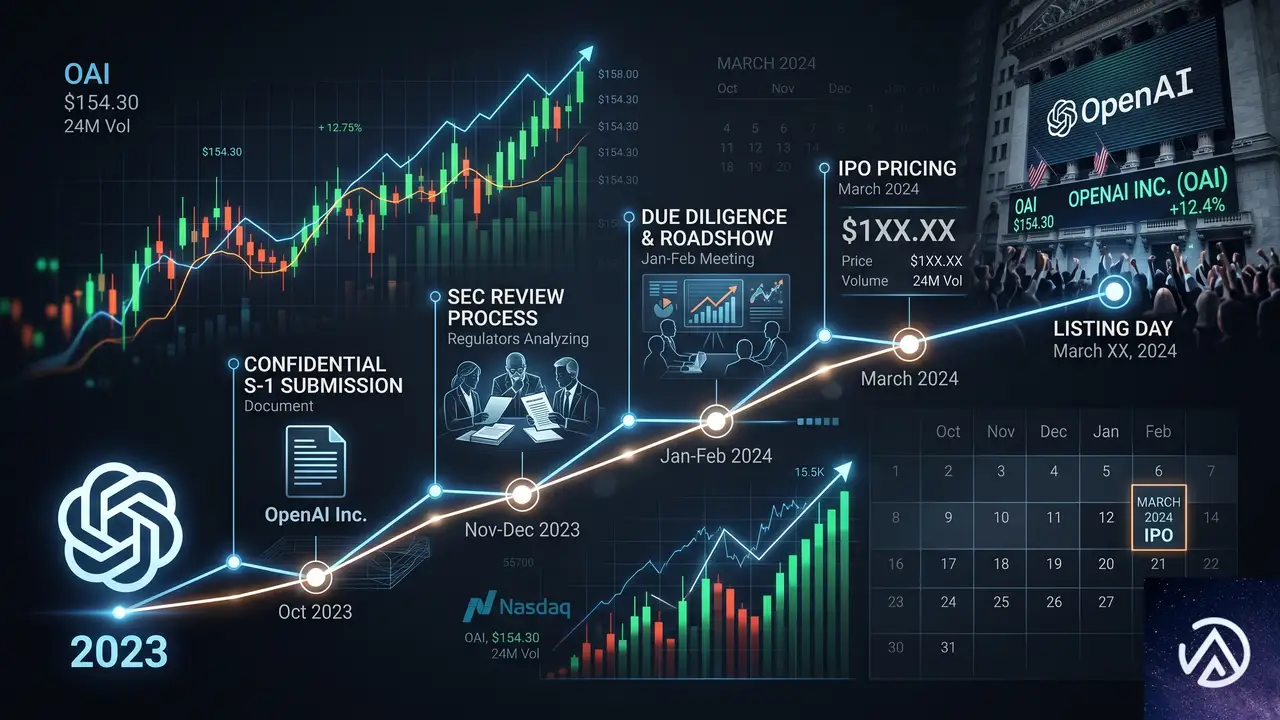
OpenAIのS-1提出により、IPOプロセスは正式に開始された。ただし、日程が未定である以上、実際の上場までには少なくとも数ヶ月から1年以上かかる可能性がある。SECの審査には通常3〜6ヶ月を要し、その後に投資家向けのロードショーや価格決定プロセスが続く。
業界関係者が注視するのは次の3点だ。第一に、S-1の内容がどのタイミングで公開されるか。機密扱いから公開段階に移行すると、OpenAIの売上高、利益率、研究開発費の内訳、大株主の構成などが明らかになる。第二に、AGIの安全性研究と営利事業のバランスをどう開示するか。第三に、上場時の評価額がAIバリュエーションの天井をどこに設定するか。
この一連のプロセスを通じて、OpenAIが非公開企業としての柔軟性をどこまで維持するか、あるいは短期間で上場に踏み切るかが最大の焦点になる。AI開発の進捗と市場環境の変化が、その決断を左右するだろう。
この記事のポイント
- OpenAIが2026年6月8日、SECに機密S-1を提出しIPO準備を正式に開始。上場時期は未定で、非公開のまま進めたいプロジェクトが複数あると発表した
- 非公開企業のメリットとして長期的なR&Dの自由度があり、上場のメリットとして巨額の資金調達がある。OpenAIは両者のジレンマの中で最適なタイミングを模索中だ
- 上場が実現すれば、AIインフラ市場への資金流入加速、API料金の安定化と無料枠縮小の可能性、Web開発現場におけるベンダーロックインリスクの高まりが想定される
- 開発者やWeb制作事業者は、OpenAI APIに依存しないマルチベンダー設計を検討し、価格変動やサービス変更に備えることが重要になる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

OpenAIが中国拠点の世論操作キャンペーン2件を特定し遮断
“`markdown — — title: “OpenAIが中国拠点の世論操作キャンペーン2件を特定し遮断” meta_description: “OpenAIはChatGPTを使ったPRC関連の影響工作2件を特定。データセンター大量建設と米国関税政策に関する世論操作の手口を解説する。” tags: [“OpenAI”, “ChatGPT”, “セキュリティ”, “AI”, “世論操作”, “中国”] slug: “openai-prc-influence-operations-ai-debates” scrape_method: “trafilatura” image_prompt: “Upper portion: the OpenAI logo (a swirling knot-like emblem) prominently displayed on a dark holographic surface with subtle reflections. Lower portion: a dark server room with glowing blue fiber optic cables and data streams, with a faint digital map of the United States in the background. Composition: split-screen style with key visual elements positioned in the upper and lower portions of the frame, with a natural atmospheric transition in between, no horizontal bands or strips across the frame. 16:9 aspect ratio. If UI screens, dashboards, code editors, or admin panels appear, all text within them must be in English.” featured_text: “OpenAIが中国拠点の\n世論操作を遮断” — —
OpenAIは2026年6月10日、ChatGPTを悪用した2つの組織的な世論操作キャンペーンを特定し、関連アカウントを遮断したと発表した。いずれも中国に拠点を持つ可能性が高いとされる。
対象となったのは「データセンター便乗」と「技術と関税」と命名された2つのネットワークだ。米国のAI政策や技術インフラに関する正当な議論に、偽のアカウントで介入しようとしていた。世論を大きく動かした形跡はないものの、AI技術そのものを標的にした点が重要だ。
この発表は、民主的なAIの発展を妨げようとする動きへの対抗措置だ。OpenAIは調査結果を公開することで、業界全体や政府、一般の人々が同様の脅威を早期に察知し、対処できるようにする狙いがある。
特定された2つのキャンペーンの手口
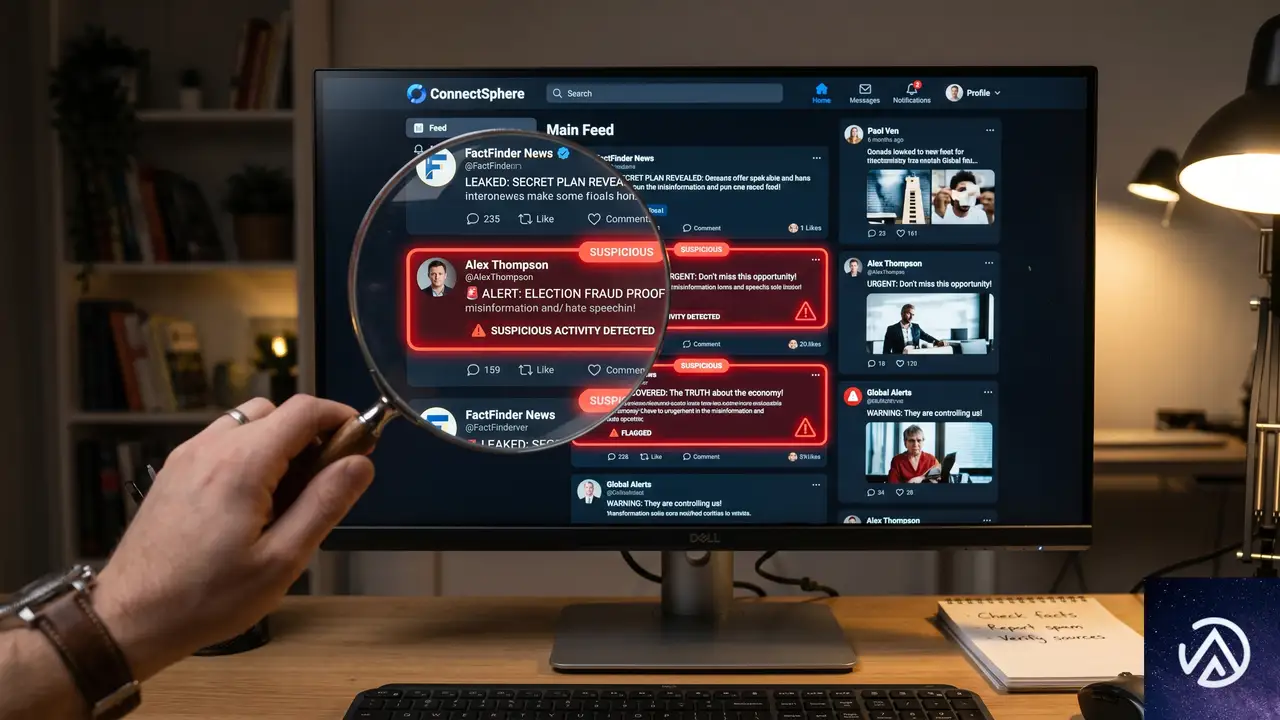
OpenAIが今回公表した調査レポートによると、遮断されたアカウント群は2つの異なる物語を流布していた。どちらも米国の技術政策を標的とし、社会的な分断を拡大しようとする意図が垣間見える。
上記の図は、2つのキャンペーンの主題と手段の違いを示している。いずれもChatGPTの機能を悪用し、実際の人間による議論を装いながら、特定の政治的意図を持っていた。
「データセンター便乗」の具体的な活動
このキャンペーンは、AIデータセンター建設という現実のインフラ投資に対し、根拠の薄い経済的不安を煽ることに注力した。ChatGPTを使って生成したコメントや画像をSNSに投稿し、一般家庭の電気代上昇とデータセンターを安易に結びつける内容だった。
データセンターの電力消費は確かに社会的な議論の対象だ。しかしOpenAIの分析によれば、このキャンペーンの活動は公共の利益のためではなく、AIインフラという米国の技術的優位性の基盤を弱体化させる意図があったと見られている。
「技術と関税」の巧妙な誘導
第二のキャンペーンは、より直接的に政治的だった。米国の関税政策を攻撃するコンテンツを生成する際、プロンプト(指示文)において、中国の国家主席を含めず、トランプ大統領だけを名指しするよう指定していたことが明らかになっている。
さらにこのネットワークは、ChatGPTのユーザーデータが侵害されたという完全な虚偽情報も流布した。OpenAIはこの申し立てを明確に否定している。偽のアカウント群と連携し、自社の信頼性を直接損なおうとした点で、OpenAI自身も標的だったと言える。
なぜAIインフラが標的になったのか

今回のケースで最も注目すべきは、特定の政治家や政党ではなく、AIデータセンターという物理的なインフラが標的になったことだ。これは単なる情報戦の一手ではなく、米国の技術的・経済的な競争力の根幹を揺さぶる試みと考えられる。
上図のように、標的の変化は明らかだ。AIは今や民主主義国家の経済成長や安全保障に直結する中核技術となっている。そのため、AIを支えるデータセンターへの攻撃は、未来の国力を削ごうとする戦略的な行動と捉えることができる。
既存の不安に便乗する手口
工作員は何もないところから火を起こそうとしたわけではない。データセンター建設に対する地域住民の実際の懸念や、エネルギー価格への漠然とした不安に便乗した。こうした実在の感情に付け入り、内容を誇張し、偽のアカウントで拡散することで、信憑性を偽装しようとしたのだ。
この「既存の亀裂をこじ開ける」やり方は、外国の影響工作で長年使われてきた常套手段だ。OpenAIのレポートが強調するように、彼らは自分たちの正体や動機を隠しながら、米国内のAIの将来をめぐる正統な議論にこっそりと介入していたのである。
「AI的特徴を持つ全体主義」への対抗

OpenAIは今回の発表で、「AI的特徴を持つ全体主義(totalitarianism with AI characteristics)」という強い言葉を使った。これはAIを監視、検閲、政治的・社会的・私的生活の統制に利用する体制を指す。
OpenAIのミッションは、民主的な原則に基づいて形成された民主的なAIを構築することだとされている。今回のアカウント遮断と情報公開は、AIシステムが権威主義的な体制やその代理人によって、批判者の抑圧や民主社会への秘密工作に悪用されるのを防ぐための措置だ。
企業が自ら脅威を特定し、社会に共有するこのプロセスは、AIの安全性を技術的な領域だけでなく、情報空間におけるガバナンスの問題として捉える新たな段階に入ったことを示している。
私たちにできること、業界がすべきこと

OpenAIが調査結果を公表したのは、業界や政府、市民社会が同様の脅威をよりよく識別し、打破できるようにするためだ。特定の企業だけの問題ではなく、AIエコシステム全体に関わる課題である。
情報の出どころを意識する
個人レベルでまずできるのは、ネット上の情報の出どころを意識することだ。AIが生成したテキストや画像はますます巧妙になっている。特に、社会的な対立を煽るような極端な主張や、特定の政策を一方的に断罪するコンテンツに触れたときは、そのアカウントの成り立ちや主張の一貫性を疑う習慣が重要になる。
プラットフォームとAI企業の協調
より構造的な対策として、AI開発企業とSNSプラットフォームの協調が不可欠だ。今回はOpenAIが自社のモデル使用状況から異常を検知し、不審なネットワークを特定した。このような知見が、コンテンツが拡散されるソーシャルメディア側とリアルタイムで共有される仕組みが求められる。
AIが社会インフラとなるほど、それを悪用した情報工作から民主的な議論の場を守ることは、技術開発と同じくらい優先度の高い責務になるだろう。
この記事のポイント
- OpenAIがChatGPTを悪用した中国拠点の可能性が高い世論操作キャンペーン2件を遮断した。
- 「データセンター便乗」キャンペーンはAIインフラ建設と電気料金を結びつけ不安を煽った。
- 「技術と関税」キャンペーンは米国の通商政策を攻撃し、OpenAIに対する虚偽情報も流した。
- AIインフラそのものが国家間の技術覇権を左右する戦略的標的となっている実態が浮き彫りになった。
- AIの安全性は、技術的側面に加え、情報空間での民主的価値を守るガバナンスの問題へと拡大している。
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

AIがECサイトデザインをリアルタイム生成、開発不要の新時代へ
ECサイトのデザインと構築はこれまで、経営者のアイデアをデザイナーが形にし、開発者がコードに落とし込むという分業体制で進められてきた。だが、その手順はAIの登場によって根本から変わりつつある。
ある調査では、ソフトウェア開発者の97%以上がすでにAIを導入している。実装計画からコード生成まで、AIの活用範囲は急速に広がっている。ECサイトのテーマ制作も例外ではない。経営者が自然言語で「こんなサイトがほしい」と指示すれば、AIが数分で動作するテーマを生成する。そんな世界が現実になろうとしている。
従来のECサイト制作フローとその課題

ECサイトはHTMLやCSS、JavaScript、あるいはShopifyのLiquid、Reactといった技術を組み合わせて作られる。これまでは、サイトの見た目や機能に関するアイデアが、ビジネス側の担当者からデザイナー、そして開発者へとバトンタッチされるのが一般的だった。
デザインから実装までの長い道のり
典型的なフローはこうだ。まず、ECサイトの運営者やマーケティング責任者が「ブランドの世界観を表現したい」「購入までの導線をこう変えたい」といった要望を出す。次に、デザイナーがその抽象的な指示を具体的なレイアウトやビジュアルに落とし込む。最後に、開発者がそれを見ながら、レスポンシブ対応や細かなインタラクションをコーディングしていく。
コミュニケーションロスとコスト
この連鎖の中で、意図が正確に伝わらずに手戻りが発生することは珍しくない。修正のたびにデザインと実装の間を行き来し、数週間単位の遅延が生じる。また、専門的なスキルを持つ人材への報酬が開発費の大半を占めるため、ちょっとした変更でも高くつく構造が長年の課題だった。
AIが変える、デザインからサイト生成のプロセス

従来のワークフローを根底から変えつつあるのが、AIによるテーマやUIの自動生成だ。もはや「画像を切り抜く」「スタイルシートを手書きする」といった工程は必須ではなくなりつつある。
自然言語でサイトを生成するツール群
今、EC制作の現場で注目されているAIツールは多い。Shopify Magicは商品説明の生成だけでなく、テーマへの応用も視野に入れている。Netlifyはボイラープレート作成をAIで支援する。GitHub CopilotやVercelのv0、Bolt.new、Replitのようなツールは、自然言語の指示から機能するUIやアプリケーションコードを直接生成する。
例えば「アースカラーのミニマルなアパレルストアを作ってほしい。写真は大きく、チェックアウトはシンプルに」と指示するだけで、AIがテーマの土台を提案してくれる。指示が詳細であるほど、思い通りの仕上がりに近づく。ここでは、技術的な専門知識よりも、ブランドや顧客体験への深い理解が重要になる。
Shopify Magic:商品説明やコンテンツの自動生成、テーマへの応用が進む
Netlify:AIによる開発支援、ボイラープレートを迅速に生成
GitHub Copilot、Vercel v0、Bolt.new、Replit:自然言語から機能するUIやアプリケーションコードを生成
事例:FigmaとPayload CMSの統合が示す未来
昨年、デザインツールのFigmaがヘッドレスCMSのPayloadを買収した。これは、AIがデザインと開発の垣根を完全に取り払う未来を象徴する動きだ。両社のロードマップはまだ明確に示されていないが、この組み合わせが実現すれば、デザイナーやビジネス担当者がFigma上で作ったデザインが、そのまま本番環境で動作するサイトに変換されるようになる。
つまり、デザインカンプを開発者に渡す必要がなくなり、デザインそのものがサイトになる。これは単なる効率化にとどまらない。従来は不可分だった「設計」と「実装」という2つの工程が、AIによって1つに融合することを意味している。ECサイトの運営者は、思い描いた顧客体験をよりダイレクトに形にできるようになるだろう。
AIによるECテーマ生成がもたらす4つのメリット

大企業ほどAIによるテーマ構築を高度に活用できると予想されるが、その恩恵はEC業界全体に波及する。具体的なメリットを4つに整理してみよう。
ステークホルダーの直接コントロール
従来のフローは非効率だった。AIによる設計と実装の支援があれば、プロジェクトの責任者が直接アウトプットをコントロールできる。開発チームへの説明や、デザイナーとの認識合わせにかけていた時間が大幅に減るため、本来の「売上を伸ばすための施策」に集中しやすくなる。
開発スピードの劇的向上とコスト削減
AIが生成するテーマやコンポーネントは、ゼロから作り込むのに比べて作成時間が圧倒的に短い。設計フェーズとコーディング期間が短縮されることで、サイトのローンチまでが加速する。また、人件費が開発コストの大部分を占めるEC制作では、デザインや実装にかかる工数が減ることで、総コストが目に見えて下がる。
数十万円
数十万円
高コスト
低コスト
わずか
大幅削減
より良い意思決定の余白を生む
単純な作業時間が減ることで、経営者やマーケティング担当者は「どのデザインがよりコンバージョンに寄与するか」をテストし、素早く方向転換する余裕を得る。A/Bテストの実施や、顧客の反応を見ながらの微調整が、これまで以上に低コストで回せるようになる。結果として、データに基づいた質の高い意思決定が可能になる。
データから見る、AI活用が進む開発現場
Futurum Groupのレポートによれば、ソフトウェア開発組織の97%以上が既にAIを利用しているという。この数字は、もはやAIが一部のアーリーアダプターだけの道具ではないことを示している。GitHub Copilotに代表されるコード生成AIの普及は、EC制作の現場にも確実に浸透しつつある。今後、AIを使いこなせるかどうかが、サイトの成長速度を左右する時代になるだろう。
この記事のポイント
- ECサイト制作は、AIによって経営者が直接テーマを生成できる方向へとシフトしている
- GitHub CopilotやShopify Magicなど、多様なツールがデザインとコーディングの壁を取り払う
- 従来の分業によるコストや時間のロスが大幅に削減され、スピードと収益性が向上する
- FigmaによるPayload買収は、デザインがそのまま本番サイトになる未来を強く示唆する
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Claude Fable 5がGoogle Cloudで一般提供開始。エージェント構築の新たな基盤を考察
Anthropicの最新モデル「Claude Fable 5」が、Google Cloud上で一般提供を開始した。このモデルは複雑な多段階推論や高度なコード生成を得意とし、長期間にわたって自律的に動作するエージェントの構築に適している。クラウドAIの基盤に何が起きているのかを読み解く。
Claude Fable 5の登場とその戦略的な位置付け
Anthropicのモデル群には、Haiku(軽量高速)、Sonnet(バランス)、Opus(超高性能)がある。今回登場したFableシリーズは、これらのニックネームとは明らかに異なる文脈を持つ。筆者の見解では、Fableは「物語(ストーリー)の生成」、つまり長文脈の一貫性維持や、複雑なオーケストレーションを必要とするエージェントタスクに特化した系統と位置付けられる。
このモデルは単に速度や知識量を競うだけでなく、「どれだけ複雑な仕事を最後までやり遂げられるか」を重視している。特に、長期稼働エージェントとしての使用が強く想定されている点が、他のモデルとの差別化要因だ。
Fable 5は、単発のレスポンスを返すだけではない。途中で文脈を見失ったり、指示を忘れたりする問題を大幅に低減し、ソフトウェア開発や分析業務といった長時間の集中を要するタスクで真価を発揮する。
Fable 5の主要な能力と想定されるユースケース

Google Cloudの公式発表とAnthropicのリリースノートから、Fable 5の中核的な機能強化点を読み解くと、以下の3つに集約される。
複雑な多段階推論と高度なコード生成
Fable 5は、数学的推論やコード生成ベンチマークで大幅な性能向上を達成している。これは単にコードを出力するだけでなく、既存のリポジトリ全体を理解し、アーキテクチャレベルの提案ができることを示す。典型的な「次のトークン予測」を超え、人間のソフトウェアアーキテクトのように数手先を読む能力が強化された。
長期稼働エージェントの実現
多くのLLMは文脈が長くなると応答精度が落ちる。Fable 5は「長時間にわたって自律的にツールを使い、タスクを完了させる」というエージェント動作に最適化されている。カスタマーサポートの自動化、継続的なデータ収集、IT運用の自動化など、数時間から数日単位で動くAIエージェント基盤として機能する。
深いマルチモーダル文書分析
テキストだけでなく、PDF内のグラフ、パワーポイントの図表、画像内のテキストまでを横断的に理解する能力が向上した。これにより、企業内に散在する非構造化データの分析ハードルが大幅に下がる。数百ページの契約書や仕様書を読み込ませ、瞬時に要約や矛盾点の洗い出しを行うといった使い方が視野に入る。
これらの能力は、もはや「優秀なアシスタント」ではなく「自立したチームメンバー」という表現が近い。開発現場ではコードレビューを完全自動化し、法務部門では契約書の精査を任せられる。人間が最終判断する仕事の質とスピードが、根本から変わる可能性をはらんでいる。
Google CloudのAgent Platformがもたらす実用性

モデル単体の性能もさることながら、今回の発表で注目すべきはGoogle Cloudの「Agent Platform」上で提供される点だ。これは単なるAPIゲートウェイではない。エージェントの構築、テスト、デプロイ、監視までを垂直統合した基盤である。
具体的には、Googleが持つエンタープライズグレードのセキュリティ(IAM、VPC Service Controls)、Vertex AIのMLOps機能(モデル評価、メタデータ管理)、そしてCloud RunやBigQueryといった周辺サービスとの統合がシームレスに行える。Fable 5のような高度なモデルを「安全に」「堅牢に」本番環境で動かすために必要なピースがあらかじめ揃っている。
ここで重要なのは、強力なモデルを手に入れることと、それをビジネスで使いこなすことの間にあるギャップが、Agent Platformによって埋められる点だ。認証基盤や監査ログが整っていない状態でAIエージェントに重要な業務を任せることは難しい。Google Cloudのプレゼンスは、企業のAI導入における「最後の1マイル」を解決する。
開発者が今日から試すべき3つのアプローチ
Fable 5とAgent Platformが利用可能になったことで、Web制作やシステム開発の現場で即座に試せる実験領域が広がった。筆者の視点から、特に費用対効果が高いと想定される3つのシナリオを提示する。
コードレビューの完全自動化プロトタイプ
GitHub連携をトリガーに、Fable 5がPull Request全体を解析する。コーディング規約のチェックだけでなく、コードの脆弱性、パフォーマンス劣化リスク、過去の類似実装との矛盾点までを自然言語でレビューコメントする。人間のレビューアは、Fable 5が出した指摘が正しいかどうかの最終判断だけに集中できる。
非構造化ドキュメントのデータベース化
クライアントから提供された古い仕様書のPDF、競合分析のスライド、展示会で撮影したホワイトボードの写真などをまとめてFable 5に投入する。モデルはこれらを横断的に解析し、共通する要求定義や矛盾する記述を抽出して構造化データとして出力する。データベースに格納することで、後続の検索やレポート作成が自動化される。
社内向け「なんでも調査エージェント」の起案
定型的なリサーチ業務をエージェント化する。例えば「3ヶ月以内に更新された特定分野の法改正情報を、週次で一覧化してSlackに投げる」といったタスクをFable 5に任せる。モデルが自律的にGoogle検索や社内Wikiを巡回し、複数ステップの推論を経て最終的なサマリーを生成するPoCは、数日あれば構築可能だ。
このアプローチによって、人間の工数は「クリエイティブな問題解決」と「AIの提案に対する最終的な意思決定」に集中できるようになる。
この記事のポイント
- Anthropicの最新モデルClaude Fable 5は、複雑な推論と長期稼働エージェントに特化してGoogle Cloud上で一般提供が開始された
- 高いコード生成能力と深いマルチモーダル分析を持ち、単なるテキスト生成を超えたタスクの自動化が可能になった
- Google CloudのAgent Platformとの統合により、エンタープライズレベルのセキュリティと運用基盤が整備されている
- 人間はAIの最終判断に集中する働き方へシフトするため、コードレビューや文書分析のプロトタイプを早期に試す価値がある
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

デザインシステムをAI対応にする実践手法
AIによるプロトタイプ生成は、技術的には可能でも、品質面で期待を下回ることが多い。根本原因はデザインシステムの小さな不整合にある。ハードコードされた値や未定義のルールが、AIの出力を不安定にしているのだ。
Smashing Magazineの記事によれば、AtlassianのHardik Pandya氏がこの問題に対する実践的な解決策を提示している。デザイン判断をインフラとして扱い、AIが読める形式で設計ルールを明文化する手法だ。本稿では、AI対応型デザインシステムを構築するための具体的なステップを解説する。
デザイン判断をソフトウェアインフラとして扱う発想
AIに優れた出力を期待するなら、人間側から明確な道筋を示す必要がある。どのコンポーネントを選ぶべきか、アクセシビリティをどう担保するか。そして、判断の優先順位と設計原則を提示する責任はデザイナーにある。
具体的には、デザイン上のあらゆる判断を「Specファイル」という形で構造化し、AIが常に最新の指示を参照できる状態を維持する。これはコードの依存関係管理と本質的に同じ考え方だ。口頭での合意やSlackの過去ログに埋もれた意思決定は、AIにとって存在しないに等しい。
FigmaLintが提供する監査の自動化
FigmaLintは、デザインシステムの監査を支援する無料のFigmaプラグインだ。トークンの一貫性、状態定義の有無、レイヤー命名規則、そしてハードコードされた値の検出を自動化する。デザインデータのクリーンアップを効率的に進められる点が最大の利点である。
このツールの実用的な価値は、監査スクリプトとしての役割にとどまらない。サードパーティから提供されたコンポーネントライブラリを精査する局面でも有効だ。外部ベンダーのデザインシステムが、自社のAI生成プロトタイプと整合するかどうかを定量的に確認できる。
ただし注意すべきは、FigmaLintで検出した問題を手動で修正し続けるだけでは、根本的な解決にならないという点だ。改善したルールをSpecファイルに落とし込み、AI自身が次回から同じミスをしないよう仕組み化することが重要になる。
AI品質を支える三層構造の設計
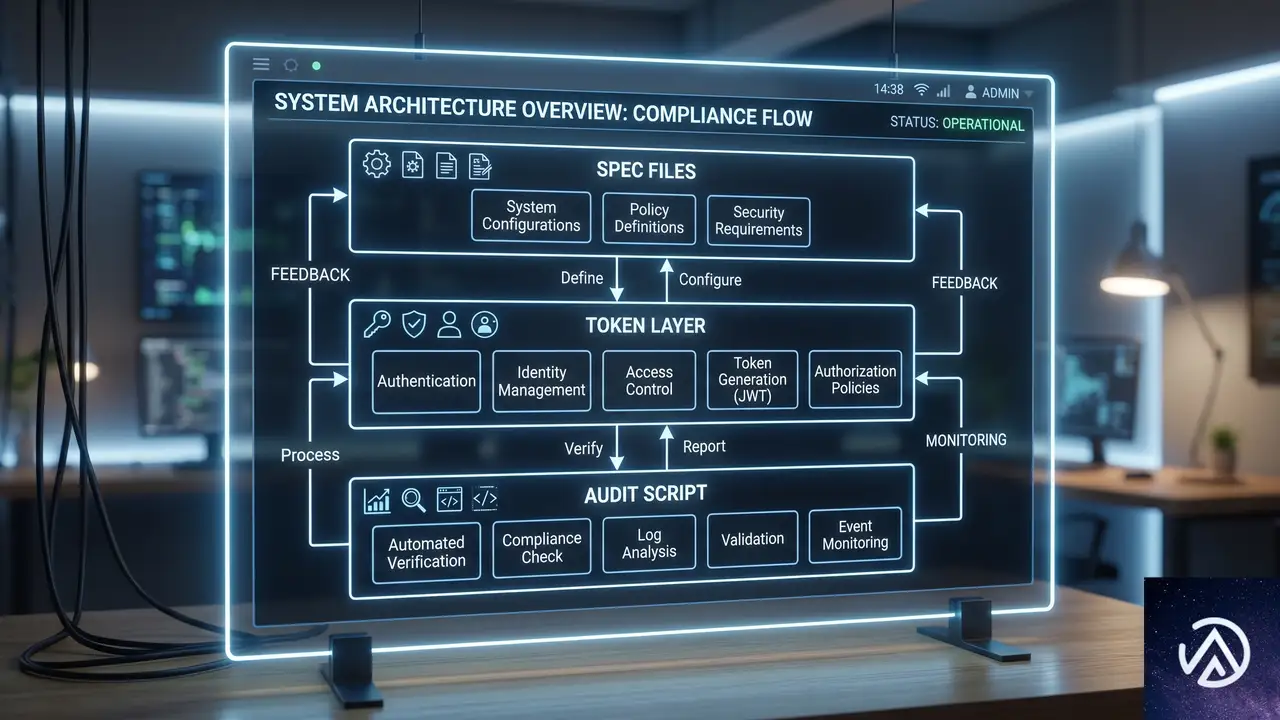
高品質なAIプロトタイプを継続的に得るには、「Specファイル」「トークン層」「監査スクリプト」の三層を整備する必要がある。この構造はソフトウェア開発における「ドキュメント、ライブラリ、CIテスト」の関係と相似形だ。
Specファイルは単なるガイドラインではない。スペーシング、配色、コンポーネントの適切な使い分けといった具体的な制約を、Markdown形式でAIに提供するテキストベースの仕様書である。AIがモックアップ画像を常に正しく解釈できるとは限らないため、テキストによる明示的な指示がコスト効率と精度の両面で優位に立つ。
トークン層はデザイントークンを変数として定義する層だ。AIが自由に「それらしい値」を捏造する余地を排除し、必ず定義済みの閉じたセットから値を選択させる。これにより、ブランドカラーやフォントサイズの意図しない逸脱を防ぐ。
監査スクリプトは、AIが生成した成果物を自動チェックする仕組みである。ハードコードされた値を検出し、Specファイルから逸脱した部分にフラグを立てる。AIが自分のミスを認識し、次回の生成時に改善するためのフィードバックループを形成するわけだ。
デザインシステムのアップデート時には、同期ルーチンがどのSpecファイルを更新すべきかを特定する。AIが古い仕様を参照したままコードを生成する事態を防ぐためだ。バージョン管理され、常に最新のSpecだけがAIに読まれる環境を維持しなければならない。
AI対応デザインシステムがもたらす現場の変化

この手法を導入した組織では、プロトタイプ生成の手戻りが減少し、人間のレビュー工数が大幅に最適化される。IBMのCarbonデザインシステムや、Atlassianの事例では、AIが初回から許容可能な品質のコードを出力する確率が明確に向上したと報告されている。
ただし、これはAIの性能が向上したというより、人間が指示の質を根本的に変えた結果だ。従来の「何百ページもあるPDFの仕様書」をAIに読ませる方法では、文脈の欠落と解釈のブレが避けられなかった。Specファイルはこの問題を、小さく分割され相互参照が明示されたテキストファイルとして解決する。
技術的負債やデザイン負債をAIが魔法のように解消することはない。明確な判断基準と構造化された指示がなければ、AIは単に混乱をコード化するだけである。デザイナーがどれだけ意図的かつ正確にAIを導けるかが、プロトタイプの最終品質を決定づける時代に入った。
この記事のポイント
- AI生成プロトタイプの品質低下は、デザインシステムの小さな不整合に起因する
- 口頭での意思決定をSpecファイルに落とし込み、AIが参照できるインフラとして扱う
- FigmaLintでトークンやハードコード値の監査を自動化し、デザインデータをクリーンに保つ
- Specファイル、トークン層、監査スクリプトの三層構造でAIの出力を継続的に改善する
- テキストベースの明示的指示が、AIのコンテキスト理解精度を劇的に向上させる
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Gemini 3.5 Live Translate公開、自然な音声翻訳の全容
はじめに

Gemini 3.5 Live Translateが2026年6月9日に公開された。これは音声をリアルタイムで翻訳し、話者の抑揚や間合いを保ったまま自然な音声を生成するAIモデルだ。
従来の逐次翻訳とは異なり、相手が話し終えるのを待たずに翻訳を開始する。遅延は数秒程度に抑えられ、70以上の言語を自動検出して処理する。Google DeepMindが発表した本モデルは、開発者向けAPIやGoogle Meet、Google翻訳アプリを通じて順次利用可能になる。
このリリースは、音声翻訳の「待ち時間」という長年の課題に正面から取り組んだものだ。翻訳品質とリアルタイム性の両立にどこまで迫れたのか、開発者や企業にとっての実用性はどの程度か、本記事で詳細を解説する。
上図のように、逐次翻訳の「全文処理待ち」というボトルネックが解消される。リアルタイム性を重視するビデオ会議や同時通訳の現場では、この差が決定的だ。
Gemini 3.5 Live Translateの技術的な特長
音声ストリーミングによる連続翻訳
最大の特長は、音声をストリーミング処理しながら翻訳結果を連続的に生成する点にある。話者が文を完結させるのを待たず、部分的な発話から逐次翻訳を開始する。
この方式では「コンテクストを待って翻訳精度を高める」ことと「即座に翻訳を開始する」ことのトレードオフが発生する。Gemini 3.5 Live Translateは、両者のバランスを自動調整しながら、自然な間合いを保ったまま数秒の遅延で追随する。
音声通話において「間」はコミュニケーションの質を大きく左右する。2秒の無音がストレスになるシーンは多い。本モデルはその課題に直接応える設計思想だ。
70以上の言語を自動検出して翻訳
手動での言語設定は不要だ。入力音声を分析し、70以上の言語を自動識別する。多言語が混在する会議やイベントでも、参加者ごとの言語選択といった事前設定なしに翻訳が動作する。
多言語対応の自動化は、実際の運用負荷を大幅に下げる要素だ。特にエンタープライズ領域では、IT管理者が会議ごとに翻訳設定を手動で行う手間が削減される。
抑揚・テンポ・ピッチの保持
単なる文字起こし翻訳とは異なり、元の話者の声の高さや抑揚、話す速度までも翻訳音声に反映する。これにより「機械的な翻訳音声」から「人格を感じる翻訳」へと体験が変化する。
感情表現や強調、皮肉といったパラ言語情報が翻訳でも伝わる可能性が生まれる点は、ビジネス通話や国際交渉の現場で特に重要だ。
ノイズ耐性の高さ
屋外やイベント会場など、騒がしい環境でも動作するノイズ耐性を備えている。Google DeepMindの公式ブログでは「loud, unpredictable environments(騒がしく予測不能な環境)」でもアプリケーションが機能すると明記されている。
これは実用面で極めて重要な仕様だ。空港や駅、工事現場、混雑したカンファレンス会場など、現実の翻訳需要は静かな会議室だけではない。ノイズ耐性の高さは、本モデルが実世界での利用を前提に設計されている証左と言える。
開発者向けの提供形態とAPI活用法
Gemini Live APIとGoogle AI Studio
開発者はGemini Live APIを通じて本モデルにアクセスできる。現在はパブリックプレビュー段階で、Google AI Studioからも試用可能だ。
APIを利用すれば、自社のビデオ会議システムや通話アプリ、配信プラットフォームにリアルタイム翻訳機能を組み込める。音声ストリームをAPIに送信するだけで翻訳音声が返ってくるため、インフラ構築のハードルは低い。
対応する開発者プラットフォーム
Agora、Fishjam、LiveKit、Pipecat、Vision Agentsといったプラットフォームが既にGemini Live APIとの統合を完了している。これらのプラットフォームはリアルタイムメディアストリーミングの複雑なインフラ部分を抽象化するため、開発者はユーザー体験の設計に集中できる。
Google DeepMindのGitHubリポジトリ(Gemini Cookbook)では、LiveKitを使った同時多言語翻訳のデモコードが公開されている。実際の実装イメージを掴みたい開発者は参照するとよい。
Grabでの導入事例
東南アジアの配車サービス大手Grabは、ドライバーと乗客間の多言語通話に本モデルを試験導入している。同社では月間1,000万件以上の音声通話が発生しており、ピックアップ時のコミュニケーション障壁を低減する狙いだ。
多言語国家での配車サービスでは、ドライバーと乗客の言語不一致が日常的に発生する。リアルタイム翻訳が実用レベルに達すれば、この摩擦は大幅に軽減される。Grabの事例は、本モデルの実運用における有効性を示す重要な先行例である。
Google MeetとGoogle翻訳アプリでの展開

Google Meetでの通訳機能が大幅強化
Google Meetの音声翻訳機能にGemini 3.5 Live Translateが統合される。従来は5言語のみの対応だったが、70以上の言語に拡大される。さらに、英語を介した翻訳のみだった制限が外れ、2,000以上の言語ペアでの双方向翻訳が可能になる。
本機能は今月から一部のGoogle Workspace企業向けにプライベートプレビューとして提供開始され、年内に広範なロールアウトが予定されている。
Google翻訳アプリでの新体験
AndroidおよびiOS版のGoogle翻訳アプリにも本モデルが展開される。有線・無線を問わずヘッドフォンを接続するだけで、70以上の言語に対応したリアルタイム翻訳が利用可能になる。
特に注目すべきはAndroid向けの新機能「リスニングモード」だ。スマートフォンを受話器のように耳に当てるだけで、翻訳音声が端末のイヤースピーカーから直接再生される。ヘッドフォンを持っていない場面や、周囲に翻訳音声を聞かれたくない場面で有用だ。
例として、スペイン語のガイドツアーを英語の翻訳音声で聞くといったユースケースが公式ブログで紹介されている。観光や出張先での利用シーンが明確に想定されている。
SynthIDによる安全性担保
本モデルが生成するすべての音声には、SynthIDによる電子透かしが埋め込まれる。この透かしは人間の耳では検知できないが、AI生成音声であることを機械的に判別可能にする。
音声のAI生成が一般化するにつれ、なりすましや偽情報への対策は避けて通れない課題だ。リアルタイム翻訳という機能の利便性と、AI生成コンテンツの検出可能性を両立させる設計は、今後のAIサービスにおける標準的な取り組みになるだろう。
詳細な安全性の取り組みについては、Google DeepMindが公開するモデルカードで確認できる。
この記事のポイント
- Gemini 3.5 Live Translateは70以上の言語を自動検出し、話者の抑揚を保ったまま連続的に翻訳する
- 従来の逐次翻訳とは異なり、話し終えを待たずに数秒遅れで追随するストリーミング処理を採用
- 開発者はGemini Live APIやGoogle AI Studioからパブリックプレビューとして利用可能
- Google Meetでは対応言語が5から70以上に拡大し、2,000超の言語ペアでの双方向翻訳が実現
- 生成音声にはSynthIDの電子透かしが埋め込まれ、AI生成コンテンツの検出が可能
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Microsoft Discovery GAとDiscoveryアプリプレビュー
マイクロソフトはMicrosoft Buildにおいて、研究開発向けエージェントAIプラットフォーム「Microsoft Discovery」を一般提供開始した。同時に、研究者がローカル環境で利用できる「Microsoft Discoveryアプリ」のプレビュー版も公開された。
このリリースは、科学研究におけるAIの役割を単なるアシスタントから、反復的な実験計画や仮説検証を統括する「研究の中核」へと引き上げるものだ。製薬業界の新薬探索や材料工学の最適化問題など、複雑な条件が絡み合う領域での利用が見込まれている。
従来のチャット型AIとは異なり、このプラットフォームは専門的なモデリングツールや実験データと連携し、人間の専門家による判断プロセスを補強する設計がなされている。大規模な組織の研究開発(R&D)ワークフローに、再現性と透明性をもたらす点が最大の特徴だ。
エージェントAIによる研究開発ワークフローの再現性確保
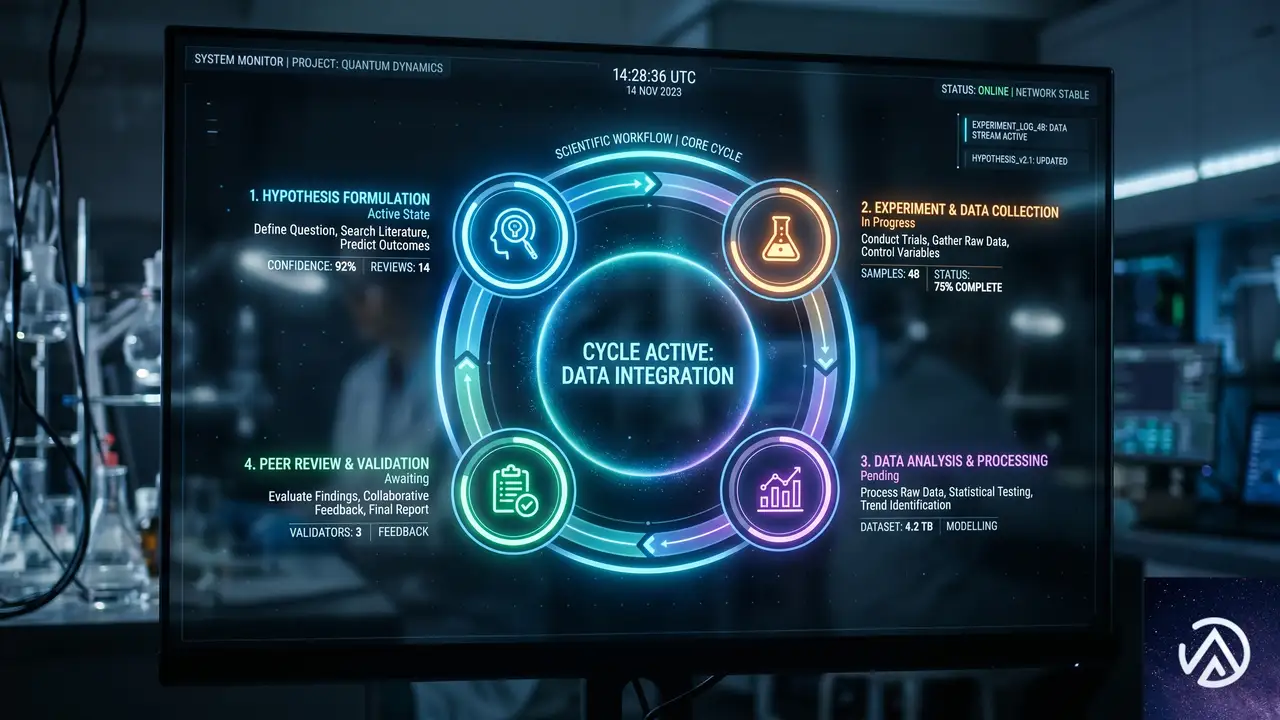
科学研究の突破口は、一度のひらめきで生まれるものではない。仮説、実験、改良、レビューという繰り返しのサイクルの中からしか姿を現さない。Microsoft Discoveryは、この本質的なループ構造を組織的に管理し、加速させるために作られた。
✓ 再現可能なワークフロー
✓ 組織固有の知識との統合
このプラットフォームの中心にあるのが「Microsoft Discovery Engine」だ。これはエビデンス(証拠)から仮説を導き出し、AIエージェントが各種のシミュレーションや分析ツールを呼び出して検証し、次のイテレーションへ進むという一連の流れを支える。Azure Blogの記事によれば、このエンジンは「単発の分析を超えて、比較検討や前提の疑問視を繰り返し可能な形で行える」よう設計されている。
プロダクション環境で求められる信頼性
研究開発の現場にAIを持ち込む際、最も難しいのは「信頼」の確立だ。Microsoft Discoveryの一般提供版では、以下の要件が重視されている。
- ワークフローの再現性
- 出力結果のレビュー可能性
- 企業固有の知的財産の適切な統治
- 既存のR&D組織の運営モデルへの適合
つまり、AIが出した「答え」だけを信じるのではなく、その推論の道筋を後からなぞり、専門家が納得できる形で提示することが求められている。これは、ブラックボックス化しがちな大規模言語モデルの弱点を補うアプローチであり、規制の厳しい製薬業界や材料産業での採用を後押しする要素だ。
ローカル環境を拓く「Discoveryアプリ」のプレビュー公開
組織全体での大規模な導入と並行して、マイクロソフトは個人や小規模チームがすぐに利用を開始できる「Microsoft Discoveryアプリ」のプレビュー版もリリースした。これは、企業のIT部門による本格的なデプロイを待たずに、研究者が自身のマシン上でエージェントAIの能力を試せるようにするための入り口だ。
このアプリは、学術研究室や学生が「まず触ってみる」ことを最重要視している。研究のアイデアが小規模なプロジェクトや個人の探求から始まることは珍しくない。そこから成果が成熟し、より高度な制御や大規模な計算リソースが必要になった段階で、クラウド上のMicrosoft Discoveryへシームレスに移行できる点が特徴だ。
最先端の現場における応用事例

プライベートプレビュー期間中、各分野のリーディングカンパニーとの協業を通じて、このプラットフォームの実践的な価値が検証された。単なる概念実証ではなく、実際の製品開発や学術研究のスピードを変えつつある。
バッテリー科学での分子設計ループ
イェール大学工学部とマイクロソフトリサーチの共同研究では、大規模蓄電向け「有機レドックスフロー電池」の電解質分子設計にDiscovery Engineが利用された。この問題は、酸化還元電位や水溶性、合成のしやすさなど、相反する複数の物性を同時に最適化する必要がある極めて複雑なものだ。
エージェントAIは、実験から得られたデータを解釈して次の候補分子を提案し、さらに診断的な実験計画を立案する役割を担った。実際の実験検証と結果の評価は、人間の専門家が主導している。イェール大学のDavid Kwabi准教授は、この枠組みが「人間主導の実験の強みと、AIの広大な化学空間探索能力を組み合わせたもの」と評価している。
半導体から生命起源まで
Syensqo社は、次世代半導体製造用の熱伝達流体の開発にこの技術を適用し、研究から営業、マーケティングまで含めたビジネス全体の意思決定速度を向上させている。ジョージア工科大学では、生命の起源に関わるアミノ酸「ヒスチジン」の生成経路を、複数のAIエージェントが質量分析データや文献情報を統合して再評価するユニークな試みが進められている。
これらの事例に共通するのは、AIが「単独で答えを出す」のではなく、人間の研究者とツールの間に立って「探索と検証のサイクル」を加速させている点だ。BHPのJessica Farrell氏は、銅の浸出技術開発において「無限に近い可能性の領域を、実用可能な少数の選択肢に絞り込めた」と述べ、数か月単位での成果創出に貢献したことを示唆している。
いずれも「探索 → 検証 → 絞り込み」のループをAIが加速する構造が共通している。
自律ラボとの融合が示す次のフェーズ

パシフィック・ノースウェスト国立研究所(PNNL)との協業は、AIエージェントが物理世界と直接つながる未来を明確に示している。ここでは、Discoveryが仮説を生成するだけでなく、ロボット実験設備を直接駆動し、得られた実験結果をリアルタイムで学習して次の指示を出す「自己駆動型の科学ワークフロー」が実証されている。
PNNLのRobert Runkle氏は、これを「ロボティクスと自律ラボがAIとクラウドインフラと融合した、一つのインテリジェントなクローズドループ発見エンジン」と表現する。アイデアから実際のブレイクスルーまでのタイムラインを劇的に短縮し、材料合成や生物学における新時代の扉を開くものだという。
この動きは、ケンブリッジ・コンサルタンツが「数か月の実験作業を数日から数時間に変える」と表現したインパクトと完全に一致する。AIが提案し、ロボットが試し、その結果をAIが解釈する、このサイクルが自動で回り始めたとき、研究開発の定義そのものが変わるだろう。
この記事のポイント
- Microsoft DiscoveryはR&Dワークフローの再現性と透明性を確保するエージェントAI基盤
- クラウド上の本格運用と、個人が即日試せるローカルアプリの二軸で提供開始
- 研究における「仮説→実験→検証」の反復ループを、専門家の判断を中心に据えつつ加速する設計
- バッテリー開発、創薬、鉱業など、実際の産業応用で開発スピードを劇的に向上させた事例が複数報告されている
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験

Codexが全職種向けに進化、役割別プラグインとサイト作成機能を発表
OpenAIは2026年6月2日、AIアシスタント「Codex」の大幅な機能拡張を発表した。毎週500万人以上が利用するCodexに、特定の職種向けに最適化された6つのプラグイン、成果物を直感的に修正できるアノテーション機能、そしてチーム内で共有可能なインタラクティブサイトを生成する「Sites」機能が追加された。
このアップデートの核心は、Codexが単なる開発支援ツールから、営業やマーケティング、投資調査といった幅広い知識労働の現場に浸透し始めたことにある。非開発者のユーザーは全体の約20%を占め、その成長率は開発者の3倍以上だ。今回の新機能は、まさにそうした多様な職種のワークフローをCodex上で完結させるための布石といえる。
実際にOpenAI社内では、非技術部門がCodexで社内アプリの構築や役員向け資料の準備、ダッシュボード作成などを行っている。Zapierではインシデント対応計画の立案に、NVIDIAでは機械学習の実験ワークフロー高速化にCodexを活用しているという。
Codexの利用シフト、開発者以外が急増する背景
Codexのユーザー層は、この1年で明確に変化した。従来、開発者のコーディング支援に特化していたが、直近ではアナリスト、マーケター、デザイナー、投資家など非開発者の利用が急伸している。この変化を支えるのが、自然言語による指示だけで複雑なデータ分析や資料作成が可能になったという技術的な進歩だ。
たとえば、売上データの異常値を「なぜ先月のコンバージョン率が低下したのか?」と質問するだけで、Codexが関連する複数のデータソースを横断し、原因の仮説と視覚的なレポートを生成できる。専門的なSQLやPythonの知識がなくても、ビジネス判断に必要な情報を引き出せるようになった点が、非開発者層の拡大を後押ししている。
6つの役割別プラグイン、各職種のツールと直接連携

今回発表された中核は、特定の職種向けに設計された以下の6つのプラグインだ。それぞれが業務で使われる主要なSaaSツールと連携し、Codexの能力を専門業務にチューニングする。合計で62の人気アプリと110のスキルが含まれている。
データ分析プラグイン
アナリストやビジネスチーム向け。Snowflake、Databricks Genie、Hex、Tableauといったプラットフォームと接続し、製品データやビジネス指標の探索、主要KPIの変動理由の説明、レポートやダッシュボードの自動生成を行う。コードを書かずに自然言語で「先月のMAU低下要因を分析して」と指示するだけで、複数のデータソースを横断したインサイトを得られる。
クリエイティブ制作プラグイン
マーケティングチームやクリエイティブチーム向け。Figma、Canva、Shutterstock、Picsart、Falなどのツールと連携し、企画概要からキャンペーンボードの作成、ディスプレイ広告のバリエーション展開、Eコマース向け画像セットや商品ライフスタイルショットの生成までを一貫して支援する。
セールスプラグイン
営業チーム向け。Salesforce、HubSpot、Slack、Outreach、Clay、Rox、Activelyといったツールと統合され、優先アカウントの特定、商談準備、フォローアップの自動化、顧客レコードの更新、クローズプランの策定、リスクのある取引のレビューをCodex上で完結させる。営業担当者が顧客情報を複数システムで探し回る手間を大幅に減らせる設計だ。
プロダクトデザインプラグイン
プロダクトチーム向け。初期アイデアからレビュー可能なプロトタイプへと素早く変換する。製品方向性の探索、ユーザーフローの監査、ライブURLからのプロトタイプ生成、静的スクリーンショットのインタラクティブ化などがFigmaやCanvaとの連携で可能になる。
株式投資(パブリックエクイティ)プラグイン
投資家向け。Moody’s、Daloopa、Datasite、FactSet、LSEG、S&P、PitchBook、Hebbiaといった金融情報源と接続し、決算レビュー、企業比較、シグナル追跡、投資テーマの妥当性評価を支援する。市場データを横断的に分析し、投資判断の根拠をCodex上で組み立てられる。
投資銀行プラグイン
投資銀行業務向け。調査やデューデリジェンスの結果をもとに、クライアント提出用のピッチ資料作成、類似企業や取引の分析、推奨案の策定を行う。信頼性の高いデータソースと連携しており、資料作成のリードタイムを短縮する。
これらのプラグインはすぐに利用可能で、チームのワークフローに合わせたカスタマイズもできる。さらに、企業固有のシステム向けにカスタムプラグインを構築して共有することも可能だ。今後はコーポレートファイナンス、プライベートエクイティ、マーケティング戦略、戦略コンサルティング、法務向けのプラグインも順次追加される予定で、パートナー企業が直接CodexやChatGPT上でプラグインを開発・展開できるオープンなエコシステムの構築を目指している。
アノテーション機能、完成後の修正を直感的に

Codex上で生成したドキュメント、スプレッドシート、スライド、Webサイトなどに対して、特定の箇所を指し示しながら修正を指示できる「アノテーション(注釈)」機能も追加された。開発者向けには以前からコードやMarkdownファイルで提供されていたが、一般ユーザーが扱うコンテンツにも拡張された形だ。
例えば、生成されたサイトのナビゲーションバーを選択して「フォントを変更して」と指示したり、投資レポートの特定の主張をマークして「この情報の出典はどこか?」と問い合わせたりできる。Codexは選択された部分にのみ修正を集中させるため、気に入っている他の部分を壊すことなく、反復的なブラッシュアップが可能になる。初稿ができたあとのフィードバックや判断が必要な工程で、この機能の真価が発揮されるだろう。
Sites機能、チームで共有できる対話型サイトを生成

ビジネスおよびエンタープライズ向けにプレビュー提供が始まった「Sites」は、Codexに指示するだけでインタラクティブなWebサイトやアプリを生成し、ワークスペース内のメンバーにURLで共有できる機能だ。ダッシュボード、プランナー、レビューワークスペース、プロジェクトボード、ギャラリー、ライトなツールなど、ユーザーのアイデアや分析結果を形にする新しいキャンバスとなる。
たとえば、Codexに「次回の顧客レビュー用サイトを作成して」と依頼すると、製品アップデート情報や未解決の課題、使用傾向、次のアクションプランを含む対話型のWebページが即座に生成される。財務モデルからシナリオプランナーを構築すれば、リーダー層はドキュメントのタブを読み比べる代わりに、仮定を切り替えながら結果を比較できる。立ち上げ資料を常に最新の状態に保つハブとして運用することも可能で、チームメンバーは常に最新のメッセージ、マイルストーン、担当者、意思決定を確認できる。
Sitesは静的ではない。大規模プロジェクトの進捗管理や、カスタマーサービス担当者向けのガイド、チームのクリエイティブブリーフ集約リポジトリとしても機能する。現在、Vercel、Wix、Base44、Replit、Lovable、Figma、Webflow、Emergentなどのパートナーとともに、Sitesのパートナーエコシステム構築が進められている。
Codexが変える業務の意思決定プロセス
これらの新機能を俯瞰すると、Codexの方向性は明確だ。単一のツールやファイルの制約に人間が合わせるのではなく、業務の流れやチームの文脈にCodexが適応する世界を目指している。役割別プラグインで専門ツールの壁を取り払い、アノテーションで反復作業のストレスを減らし、Sitesで静的なドキュメントを対話型の意思決定の場に変える。
日本企業においても、たとえば営業部門がSalesforceとCodexを連携させ、商談準備からフォローアップまでを自然言語で完結させるといった活用が現実味を帯びてきた。データ分析の民主化が進むことで、専門のデータサイエンティストを介さずに現場担当者が直接インサイトを得られるようになれば、意思決定のスピードは大幅に向上するだろう。
この記事のポイント
- OpenAIがCodexに6つの役割別プラグインを導入、非開発者層の業務を直接支援する体制が整った
- アノテーション機能により、成果物の特定部分をピンポイントで修正でき、反復作業が効率化する
- Sites機能で、チーム共有可能な対話型のWebサイトやダッシュボードをその場で生成できる
- 非開発者のCodex利用は全体の約20%に達し、成長率は開発者の3倍以上と急拡大している
- プラグインはカスタマイズ可能で、企業固有のシステム向けに拡張する道も開かれている
・ 複数業界における17年間のデジタルビジネス開発経験
・ ウェブサイト開発のためのHTML、PHP、CSS、JavaScript等の実用的知識
・ 15ヶ国語対応の多言語SaaSの開発経験
・ 17年間にも及ぶ、Eコマース長期運営経験
・ 幅広い業界でのSEO最適化の豊富な経験